Подборка интересных мероприятий на неделю в Москве |
|
Метки: author rvnikita хакатоны учебный процесс в it мероприятие мероприятия конференции митап митапы конференция хакатон маркетинг аналитика it |
[Перевод] Как эффективно работать с рекламным форматом Playable ads: пять типичных ошибок |



|
|
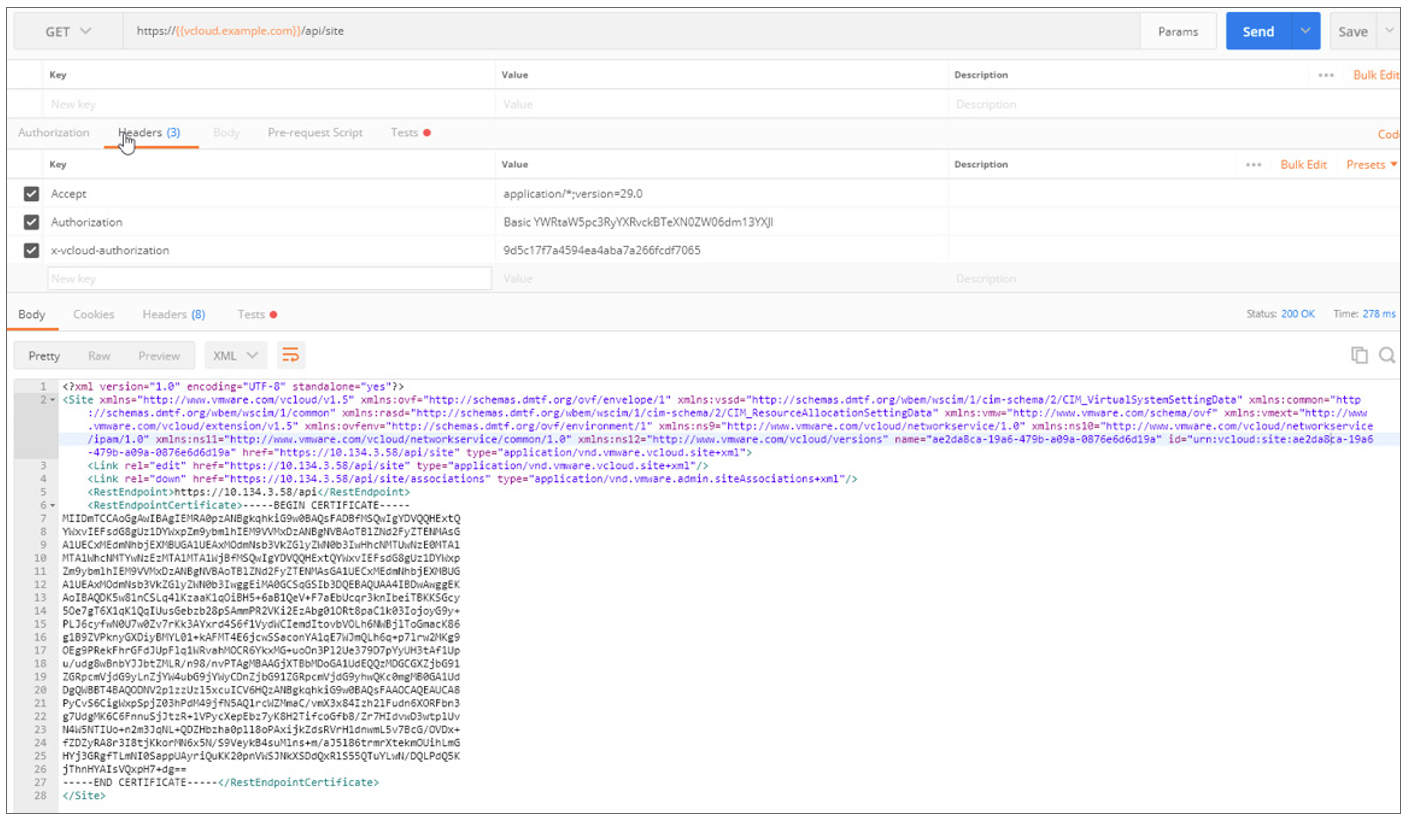
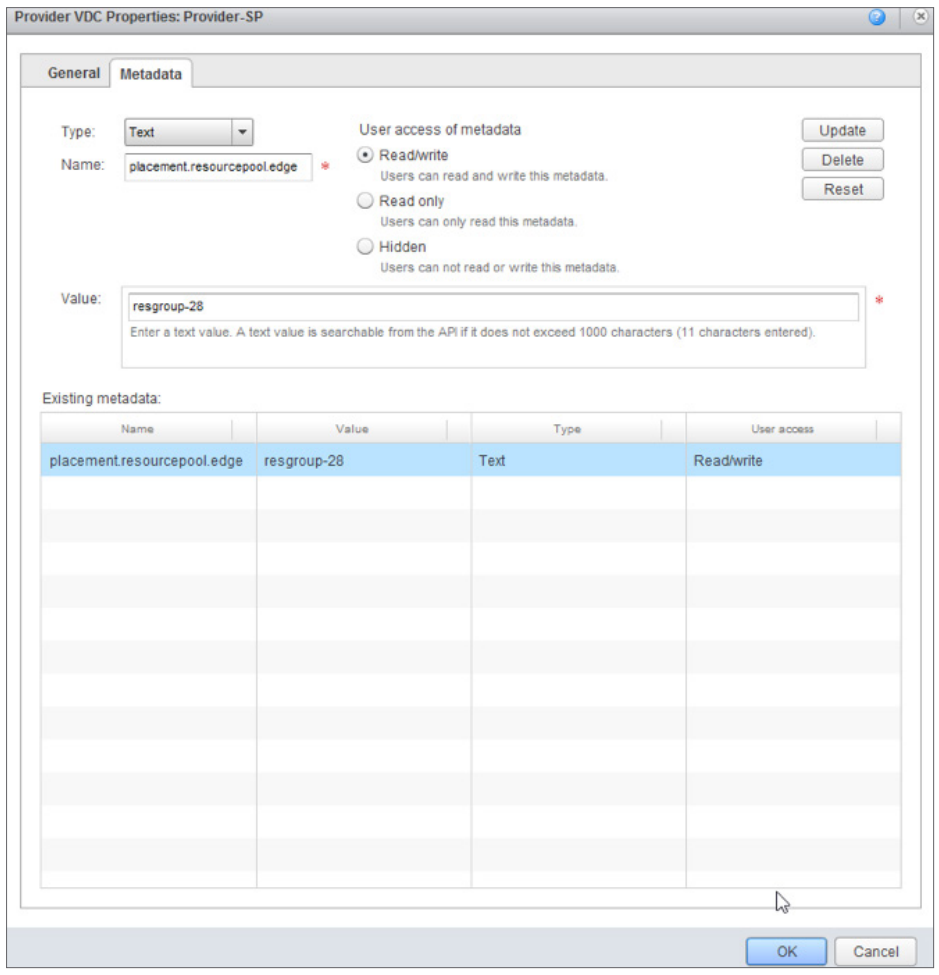
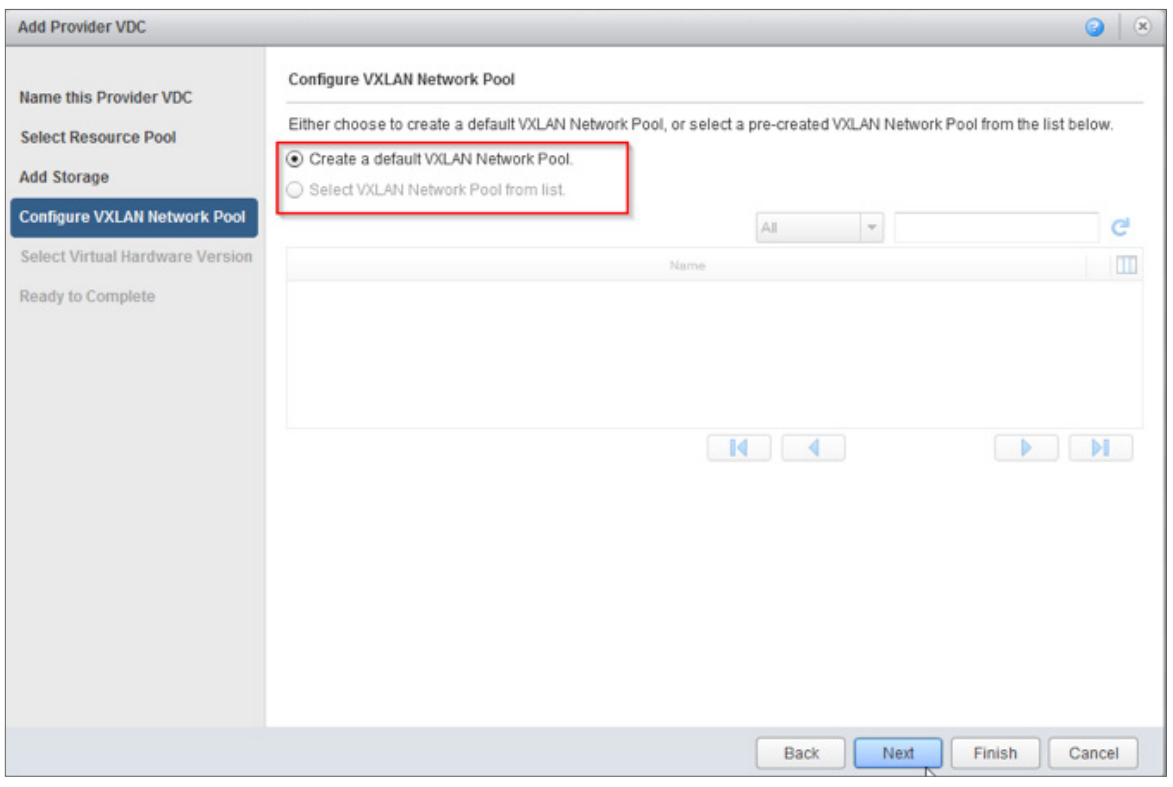
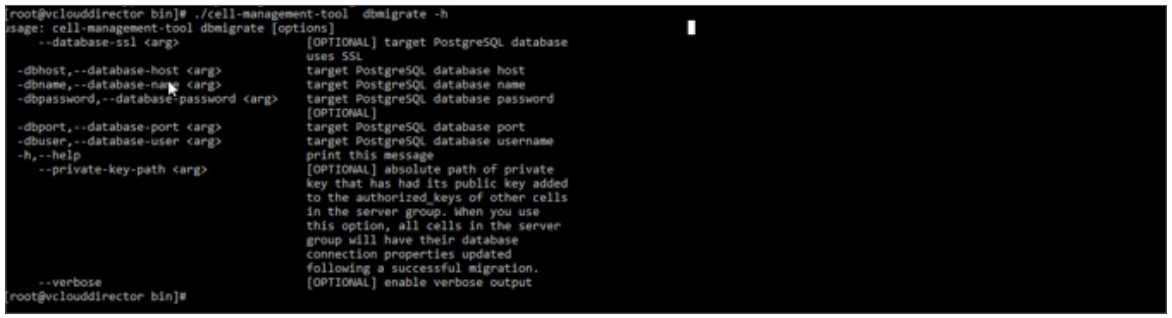
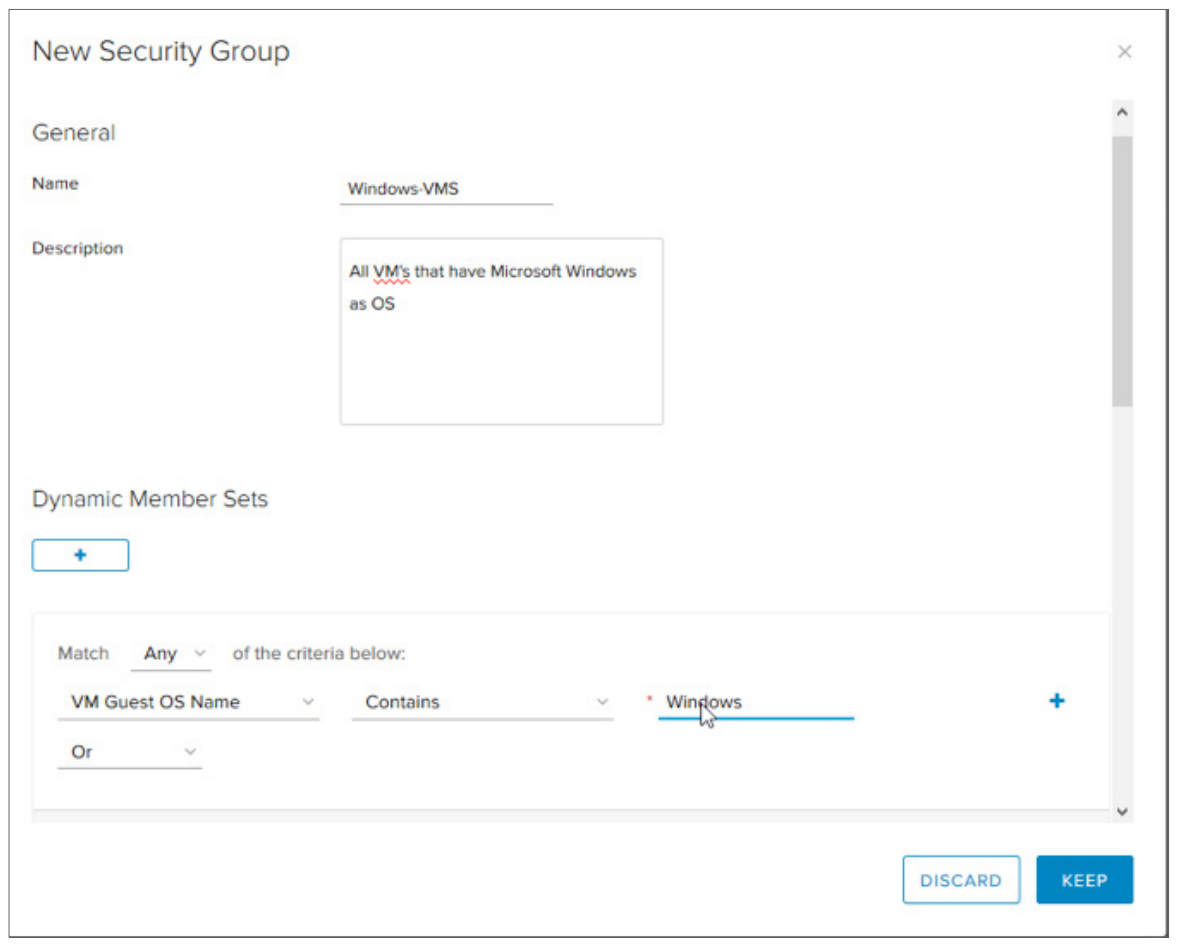
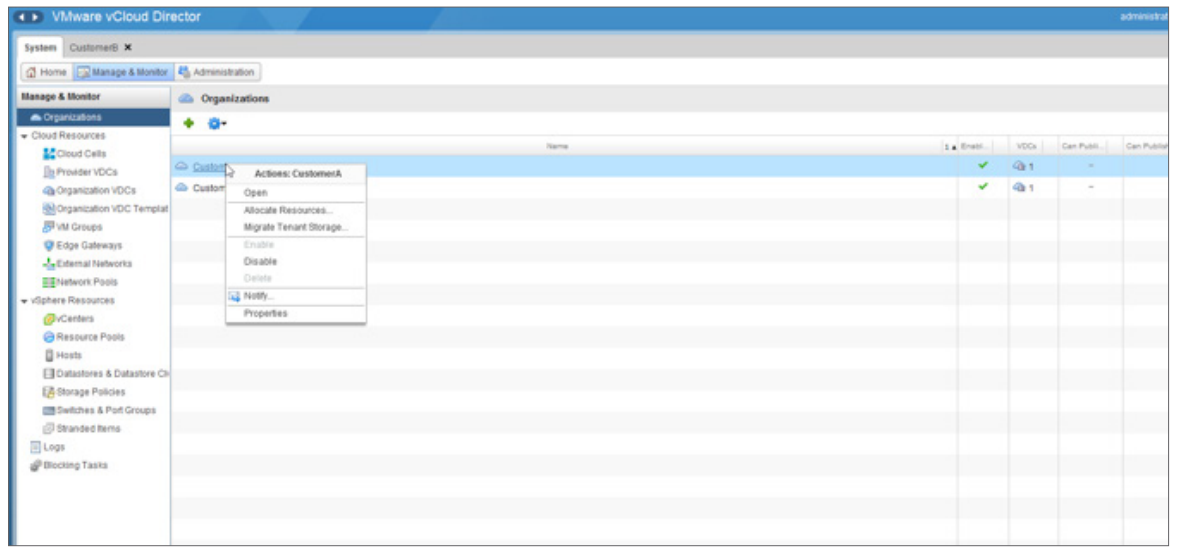
VMware vCloud Director. Что нового в версии 9.0? |






|
|
[Перевод] [Перевод] Переосмысление drag&drop |
react-beautiful-dndreact-beautiful-dnd, которая делает перетаскивание (drag&drop) внутри списков в вебе красивыми, естественными и доступными. react-beautiful-dnd заключается в осязании (physicality): хочется, чтобы у пользователей было ощущение будто они передвигают физические объекты. Это лучше всего продемонстрировать контрастными примерами — поэтому давайте рассмотрим некоторые стандартные принципы использования этой техники, и посмотрим как можно их улучшить.
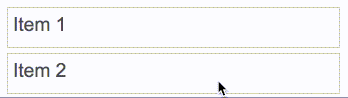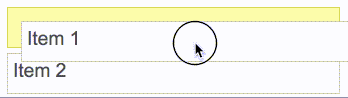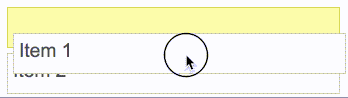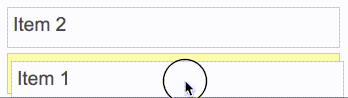

react-beautiful-dnd действия перетаскиваемых элементов основаны на центре притяжения — независимо от того, откуда пользователь берет элемент. К действиям перетаскиваемых объектов применимы те же правила, что и к набору гирь. Ниже приведены некоторые правила, которые используются даже с подвижными элементами при естественном перетаскивании:react-beautiful-dnd поддерживает возможность осуществлять функцию перетаскивания с помощью одной лишь клавиатуры. Это позволяет пользователям получить опыт использования этой функции еще и с клавиатуры и открывает возможность узнать об этой функции тем, кто был с ней ранее не знаком.React-beautiful-dnd усердно работает, чтобы избежать периодов отсутствия интерактивности настолько, насколько это возможно. Пользователь должен иметь ощущение, что он контролирует интерфейс, а не ждет пока закончится анимация, прежде чем он сможет продолжить взаимодействие с интерфейсом. react-motion). Это приводит к тому, что когда элемент падает он кажется более весомым и ощутимым.
React-beautiful-dnd упорно трудится, чтобы убедиться, что он не влияет на обычные вкладки потока документов. Например, если вы добавляете теги привязки, то пользователь по-прежнему сможет перейти непосредственно к привязке, а не к элементу, к которому осуществляли привязку. Мы добавляем tab-index к определяемым элементам, чтобы убедиться, что даже если вы не добавляете что-либо к тому, что обычно является интерактивным элементом, (например, div), то пользователь все равно сможет получить доступ к нему с помощью своей клавиатуры, чтобы перетащить его куда-либо.react-dnd. Она проделывает невероятную работу по обеспечению огромным набором примитивов функции перетаскивания, которые особенно хорошо работают с HTML5, несмотря на то что HTML5 мало с чем совместим. React-beautiful-dnd это абстракция высокого уровня, построенная специально для вертикальных и горизонтальных списков. С таким подмножеством функциональности react-beautiful-dnd предлагает действенный, красивый и естественный опыт использования функции перетаскивания. Однако, react-beautiful-dnd не обеспечивает широтой возможностей, предоставляемых react-dnd. Таким образом, эта библиотека может быть не для вас, все зависит от того в каких целях вы собираетесь её использовать.React-beautiful-dnd спроектирована быть чрезвычайно производительной — это часть её ДНК. Она основана на предыдущих исследованиях производительности реакции, которые можно прочитать здесь и здесь. React-beautiful-dnd предназначена для выполнения минимального количества исполнений, необходимых для каждой задачи. react-redux, reselect и memoize-one.requestAnimationFrame - благодаря raf-schdmemoize-one
React-beautiful-dnd использует несколько различных стратегий тестирования, в том числе модульное тестирование, тестирование производительности и интеграционное тестирование. Проверка различных аспектов системы способствует повышению ее качества и стабильности.flowtype для повышения внутренней согласованности и устойчивости кода. Она также предоставляет историю документации разработчика о том, как работает API.react-beautiful-dnd. Для получения дополнительной информации и примеров перейдите в архив.react-beautiful-dnd была невероятной! Большое спасибо. Мы уже добавили некоторые новые функции, такие как перемещение по-горизонтали.
react-beautiful-dnd работать на мобильных и планшетных устройствах). Это всегда было в планах и мы уже очень скоро начнем над этим работать! Библиотека еще совсем новая.react-beautiful-dnd. Я написал блог. “Естественное движение клавиатуры между списками", в котором говорится о том, как мы пришли к тому, чтобы создать это обновление таким образом, чтобы оно ощущалось естественным.
|
Метки: author MagisterLudi интерфейсы веб-дизайн usability блог компании edison дизайн react ui frontend development javascript ux edisonsoftware |
Разбираем WeChat — второй по популярности мессенджер в мире |

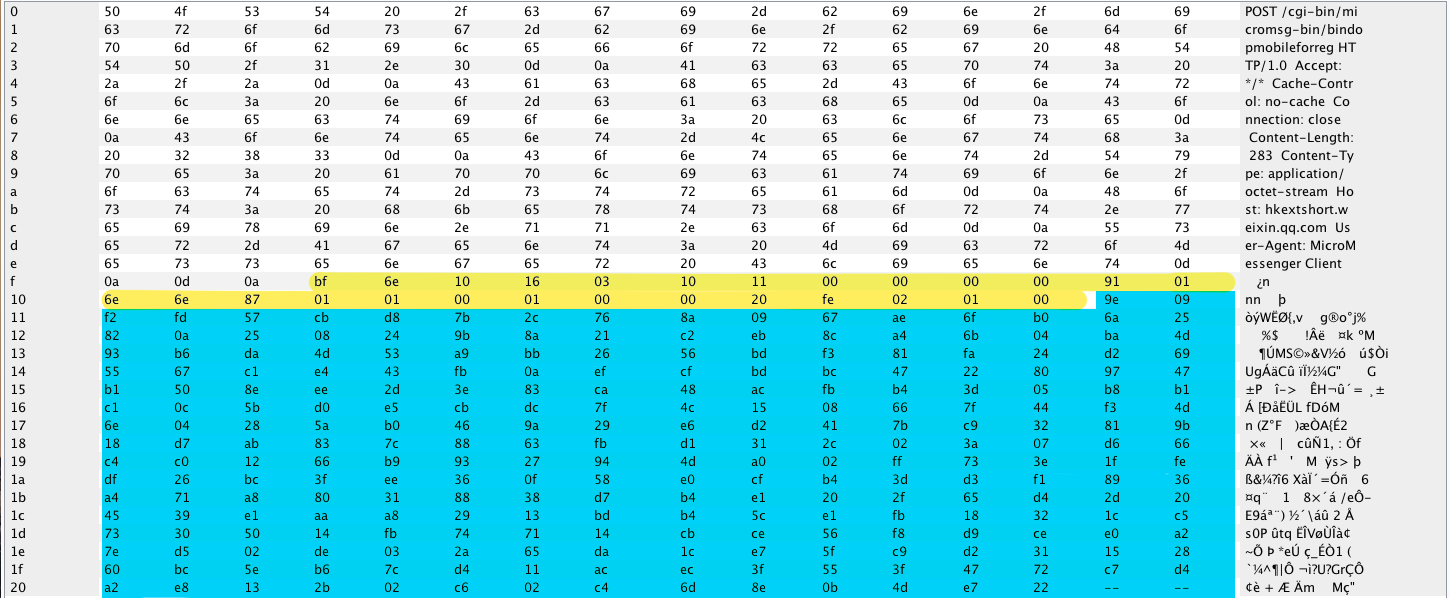
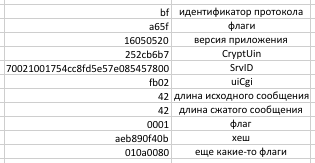

private static void Write7BitEncodedInt(BinaryWriter store, int value)
{
Debug.Assert(store != null);
// Write out an int 7 bits at a time. The high bit of the byte,
// when on, tells reader to continue reading more bytes.
uint v = (uint)value; // support negative numbers
while (v >= 0x80)
{
store.Write((byte)(v | 0x80));
v >>= 7;
}
store.Write((byte)v);
}|
Метки: author Sqwony блог компании бринго reverse engineering криптография информационная безопасность мессенджеры messengers |
[Перевод] Три карьерных пути в IT: основатель, руководитель или наёмный работник |
|
Метки: author m1rko развитие стартапа карьера в it-индустрии стартап основатель руководитель наемный сотрудник карьера |
Аналитика Solar JSOC: как атакуют российские компании |
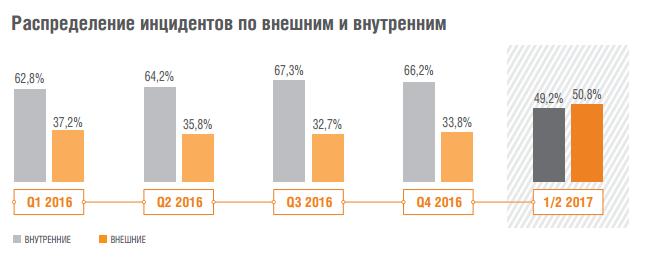


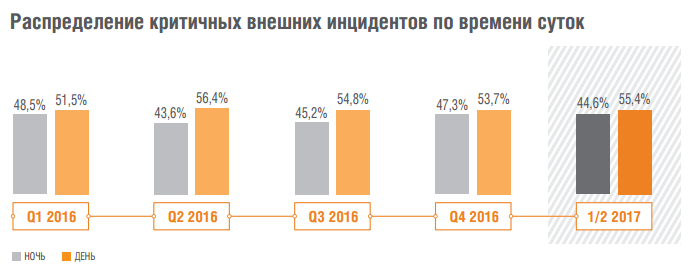
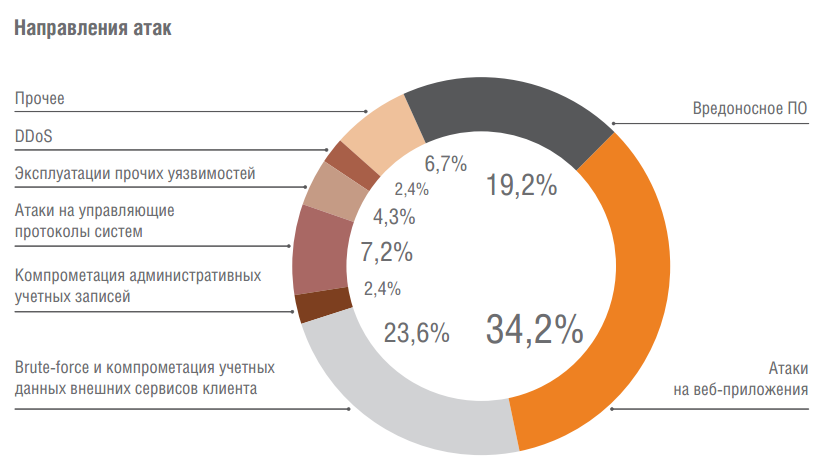
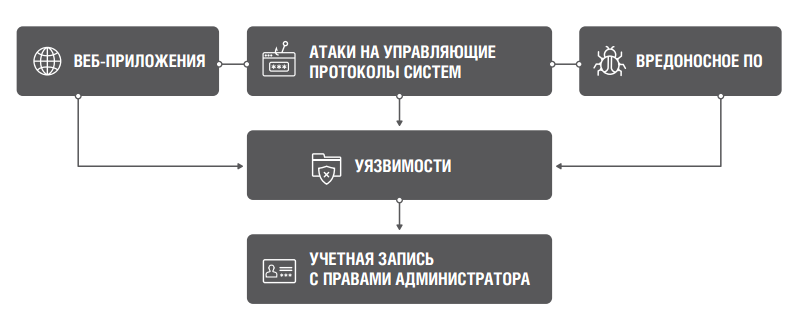
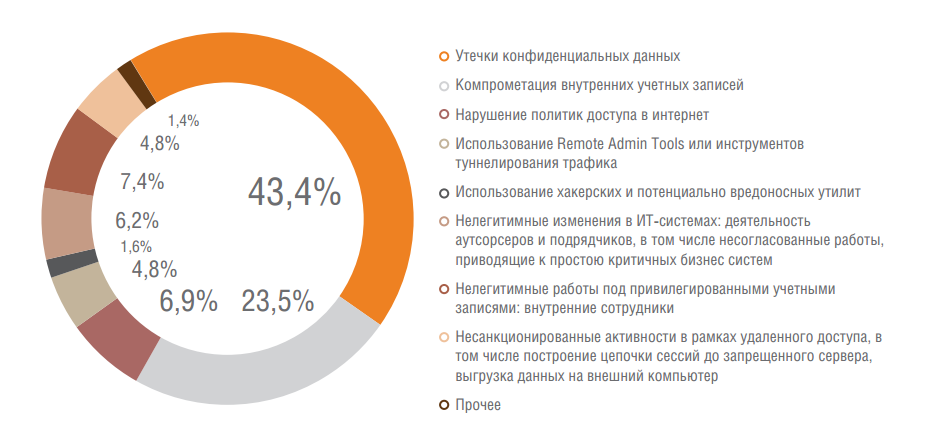
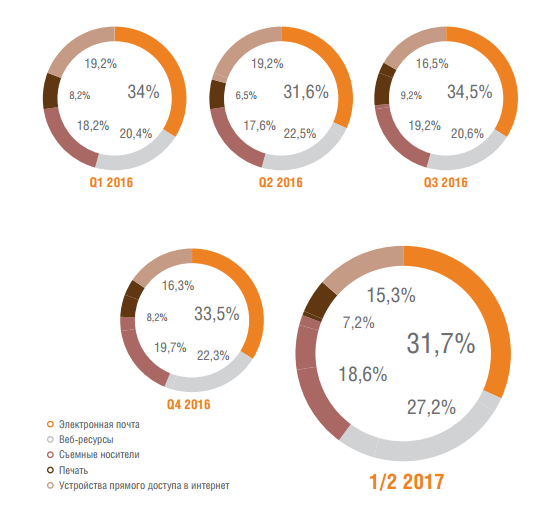

|
|
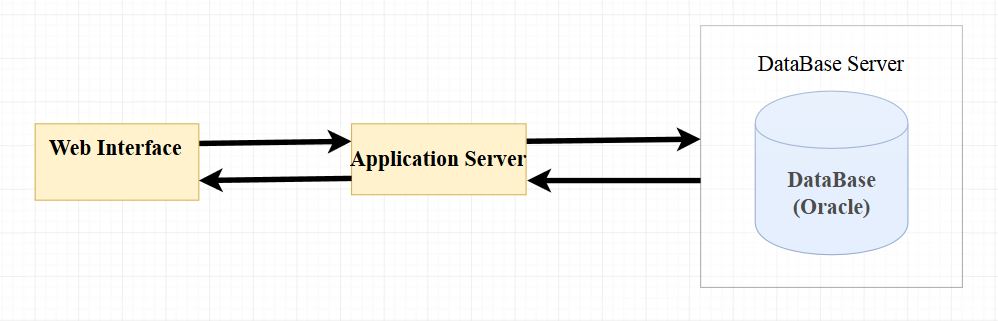
Отладка PL/SQL кода для внешней сессии БД |
create or replace procedure checkout_with_pipe_and_alert(p_cycle_size in number) is
c_method_error constant number := -20000;
c_method_error_message constant varchar2(4000) := 'Cycle size should be > 0';
l_power_value number;
l_i_value number := 1;
l_pipe pls_integer;
begin
if p_cycle_size > 0 then
for i in 1 .. p_cycle_size
loop
l_power_value := power(i, 2);
l_i_value := l_i_value * i;
--Send pipe info
l_pipe := dbms_pipe.create_pipe(pipename => 'pipe');
dbms_pipe.pack_message(i || '.l_power_value:=' || l_power_value || ' l_i_value=' || l_i_value);
l_pipe := dbms_pipe.send_message(pipename => 'pipe');
--Send alert info
dbms_alert.register('alert');
dbms_alert.signal(name => 'alert',
message => i || '.l_power_value:=' || l_power_value || ' l_i_value=' || l_i_value);
dbms_alert.remove(name => 'alert');
end loop;
else
raise_application_error(c_method_error, c_method_error_message);
end if;
end checkout_with_pipe_and_alert;


begin
checkout_with_pipe_and_alert(5);
end;

|
Метки: author ympukhov отладка oracle pl/sql developer oracle pl/sql |
[Перевод] Что последует за вебом? |
 В первой части я утверждал, что пришло время подумать, как заменить современную веб-платформу для приложений. Причина — её низкая производительность и в принципе нерешаемые проблемы безопасности.
В первой части я утверждал, что пришло время подумать, как заменить современную веб-платформу для приложений. Причина — её низкая производительность и в принципе нерешаемые проблемы безопасности.
Со временем многие технологии сошлись на концепции источника как на удобной единице изоляции. Однако многие из ныне используемых технологий, такие как куки [RFC6265], созданы раньше, чем современная концепция источника в вебе. У этих технологий часто другие единицы изоляции, что ведёт к уязвимостям.

enum SortBy {
Featured,
Relevance,
PriceLowToHigh,
PriceHighToLow,
Reviews
}
@PermazenType
class AmazonSearch(
val query: String,
val sortBy: SortBy?
) : LinkPacket@PermazenType. Что это значит?Permazen — совершенно новый подход к стойкому программированию. Вместо того, чтобы начинать разработку со стороны технологии хранения, он начинает со стороны языка программирования, задавая простой вопрос: «Какие проблемы присущи стойкому программированию, независимо от языка программирования или технологии СУБД, и как их можно решить на уровне языка наиболее простым, самым корректным и самым естественным с точки зрения языка способом?»
Any), среда выполнения может попробовать определить, какими должны быть исходные типы, и транслировать эту информацию обратно в IDE. Затем она может предложить замену на лучшие аннотации типов. Если разработчик сталкивается с ошибками приведения типа во время работы программы, то IDE может предложить снова ослабить ограничение.|
|
[Перевод] Симуляция физического мира |

|
|
В абзаце всё должно быть прекрасно |
|
Метки: author pantlmn типографика веб-дизайн абзац пробел пробелы latex indesign |
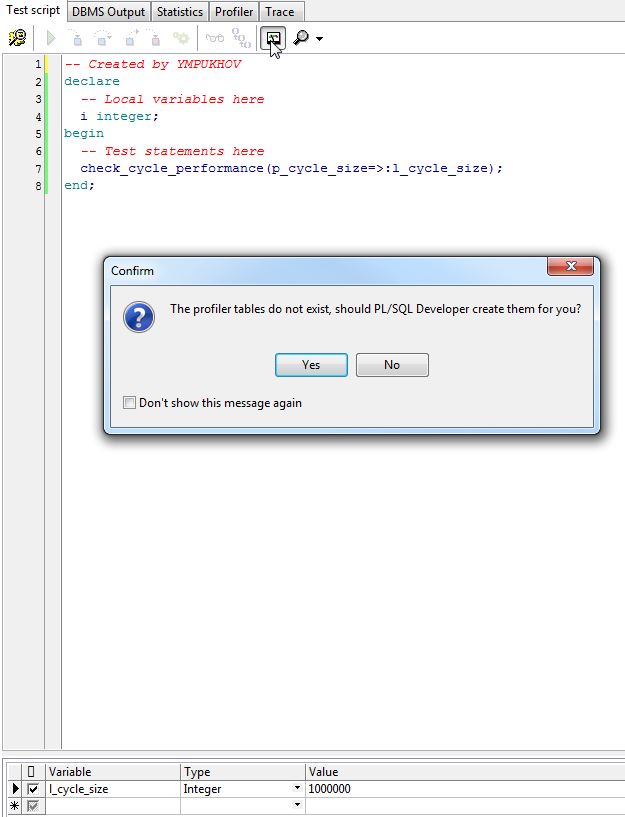
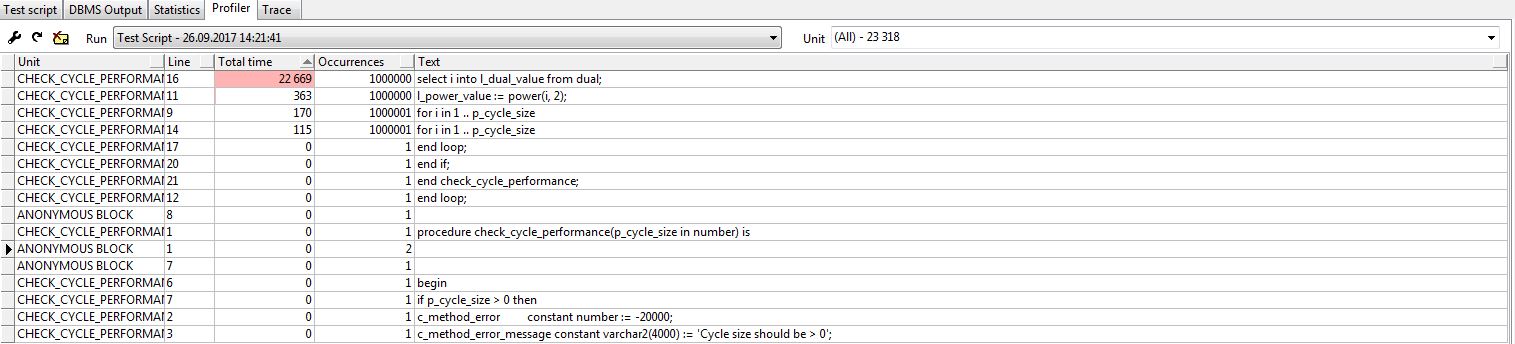
Профилирование PL/SQL кода при помощи IDE PL/SQL Developer |
create or replace procedure check_cycle_performance(p_cycle_size in number) is
c_method_error constant number := -20000;
c_method_error_message constant varchar2(4000) := 'Cycle size should be > 0';
l_power_value number;
l_dual_value number;
begin
if p_cycle_size > 0 then
--Cycle with power calculation
for i in 1 .. p_cycle_size
loop
l_power_value := power(i, 2);
end loop;
--Cycle with switching context(sql-pl/sql)
for i in 1 .. p_cycle_size
loop
select i into l_dual_value from dual;
end loop;
else
raise_application_error(c_method_error, c_method_error_message);
end if;
end check_cycle_performance;
|
Метки: author ympukhov программирование высокая производительность oracle oracle pl/sql профилирование pl/sql developer |
Про интервальные индексы |

create table reservations(during tsrange);
insert into reservations(during) values
('[2016-12-30, 2017-01-09)'),
('[2017-02-23, 2017-02-27)'),
('[2017-04-29, 2017-05-02)');
create index on reservations using gist(during);
select * from reservations where during && '[2017-01-01, 2017-04-01)';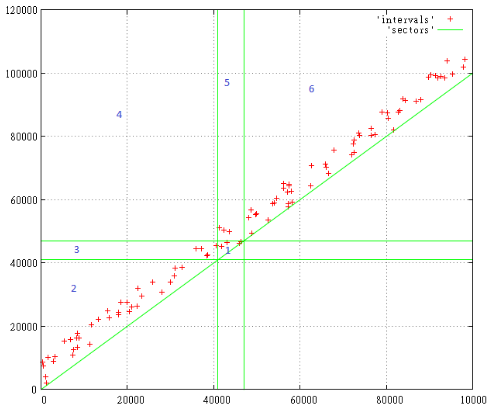
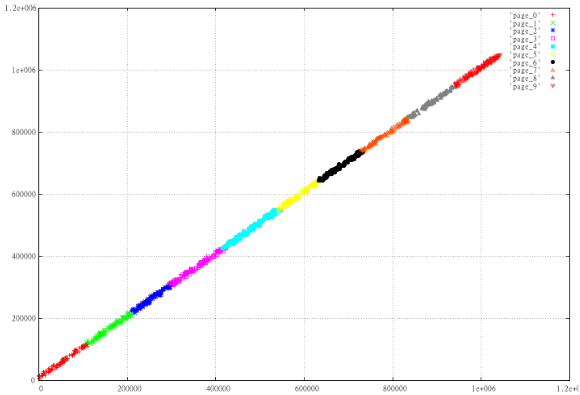
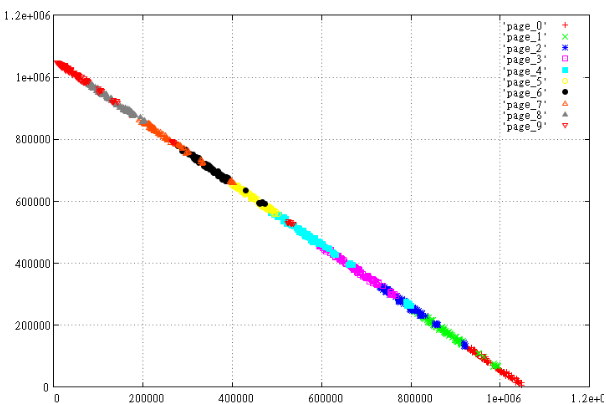
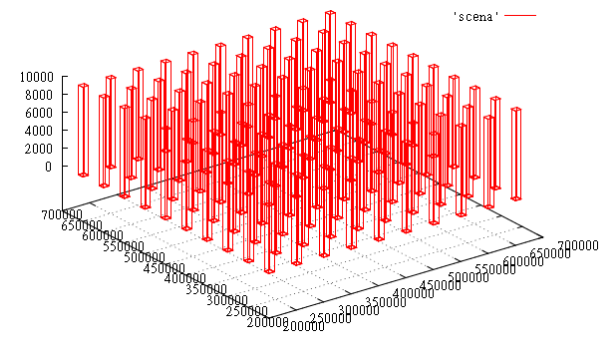
create table test_points_8d (p integer[8]);
COPY test_points_8d from '/home/.../data.csv';
create index zcurve_test_points_8d on test_points_8d (zcurve_num_from_8coords (p[1], p[2], p[3], p[4], p[5], p[6], p[7], p[8]));{210000,200000,210000,200000,0,0,0,0}
{210000,200000,210000,200000,10,0,1,1}
{210000,200000,210000,200000,20,0,2,2}
{210000,200000,210000,200000,30,0,3,3}
{210000,200000,210000,200000,40,0,4,4}
{210000,200000,210000,200000,50,0,5,5}
{210000,200000,210000,200000,60,0,6,6}
{210000,200000,210000,200000,70,0,7,7}
{210000,200000,210000,200000,80,0,8,8}
{210000,200000,210000,200000,90,0,9,9}
...select c, t_row from (select c, (select p from test_points_8d t where c = t.ctid) t_row
from zcurve_8d_lookup_tidonly('zcurve_test_points_8d',
200000,0,200000,0,100,0,10,0,
1000000,300000,1000000,300000,1000000,1000,1000000,11
) as c) x; c | t_row
-------------+-------------------------------------------
(0,11) | {210000,200000,210000,200000,100,0,10,10}
(0,12) | {210000,200000,210000,200000,110,0,11,11}
(103092,87) | {260000,250000,210000,200000,100,0,10,10}
(103092,88) | {260000,250000,210000,200000,110,0,11,11}
(10309,38) | {210000,200000,260000,250000,100,0,10,10}
(10309,39) | {210000,200000,260000,250000,110,0,11,11}
(113402,17) | {260000,250000,260000,250000,100,0,10,10}
(113402,18) | {260000,250000,260000,250000,110,0,11,11}
(206185,66) | {310000,300000,210000,200000,100,0,10,10}
(206185,67) | {310000,300000,210000,200000,110,0,11,11}
(216494,93) | {310000,300000,260000,250000,100,0,10,10}
(216494,94) | {310000,300000,260000,250000,110,0,11,11}
(20618,65) | {210000,200000,310000,300000,100,0,10,10}
(20618,66) | {210000,200000,310000,300000,110,0,11,11}
(123711,44) | {260000,250000,310000,300000,100,0,10,10}
(123711,45) | {260000,250000,310000,300000,110,0,11,11}
(226804,23) | {310000,300000,310000,300000,100,0,10,10}
(226804,24) | {310000,300000,310000,300000,110,0,11,11}
(18 rows)EXPLAIN (ANALYZE,BUFFERS) select c, t_row from (select c, (select p from test_points_8d t where c = t.ctid) t_row
from zcurve_8d_lookup_tidonly('zcurve_test_points_8d',
200000,0,200000,0,0,0,10,0,
1000000,300000,1000000,300000,1000000,1000,1000000,11) as c) x;

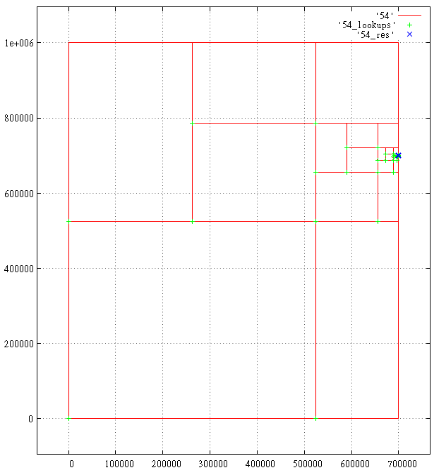

|
Метки: author zzeng алгоритмы postgresql open source spatial index r-tree zorder субд rdbms |
Смарт контракты Ethereum: что делать при ошибке в смартконтракте или техники миграции |

contract ERC20base {
uint public totalSupply;
function balanceOf(address _who) public constant returns(uint);
}contract NewContract {
uint public totalSupply;
mapping (address => uint) balanceOf;
function NewContract(address _migrationSource, address [] _holders) public {
for(uint i=0; i<_holders.length; ++i) {
uint balance = ERC20base(_migrationSource).balanceOf(_holders[i]);
balanceOf[_holders[i]] = balance;
totalSupply += balance;
}
require(totalSupply == ERC20base(_migrationSource).totalSupply());
}
}contract NewContract {
uint public totalSupply;
mapping (address => uint) balanceOf;
address public migrationSource;
address public owner;
function NewContract(address _migrationSource) public {
migrationSource = _migrationSource;
owner = msg.sender;
}
function migrate(address [] _holders) public
require(msg.sender == owner);
for(uint i=0; i<_holders.length; ++i) {
uint balance = ERC20base(_migrationSource).balanceOf(_holders[i]);
balanceOf[_holders[i]] = balance;
totalSupply += balance;
}
}
} address [] public holders; mapping (address => bool) public isHolder;
address [] public holders;
….
if (isHolder[_who] != true) {
holders[holders.length++] = _who;
isHolder[_who] = true;
}contract MigrationAgent {
function migrateFrom(address _from, uint256 _value);
}contract TokenMigration is Token {
address public migrationAgent;
// Migrate tokens to the new token contract
function migrate() external {
require(migrationAgent != 0);
uint value = balanceOf[msg.sender];
balanceOf[msg.sender] -= value;
totalSupply -= value;
MigrationAgent(migrationAgent).migrateFrom(msg.sender, value);
}
function setMigrationAgent(address _agent) external {
require(msg.sender == owner && migrationAgent == 0);
migrationAgent = _agent;
}
}contract NewContact is MigrationAgent {
uint256 public totalSupply;
mapping (address => uint256) public balanceOf;
address public migrationHost;
function NewContract(address _migrationHost) {
migrationHost = _migrationHost;
}
function migrateFrom(address _from, uint256 _value) public {
require(migrationHost == msg.sender);
require(balanceOf[_from] + _value > balanceOf[_from]); // overflow?
balanceOf[_from] += _value;
totalSupply += _value;
}
}function () payable {
if (state = State.Migration) {
migrate();
} else { … }
}|
Метки: author isvirin solidity блокчейн смартконтракт ethereum миграция |
Сказка о хорошо выстроенных бизнес-процессах, или как одна проблема хакнула идеально работающую систему разработки |
|
Метки: author NickPasko управление разработкой управление проектами управление продуктом agile разработка программного обеспечения бизнес-процессы scrum инженеры шутят |
Дайджест свежих материалов из мира фронтенда за последнюю неделю №282 (25 сентября — 1 октября 2017) |
|
|
Электронные документы в российских судах, как критерий электронной зрелости России |
|
Метки: author akolesov ecm/ сэд электронные документы суд |
[Перевод] ggplot2: как легко совместить несколько графиков в одном, часть 3 |
ggdensity() [в ggpubr]desc_statby() [в ggpubr]ggtexttable() [в ggpubr]ggparagraph() [в ggpubr]ggarrange() [в ggpubr].# График плотности "Sepal.Length"
#::::::::::::::::::::::::::::::::::::::
density.p <- ggdensity(iris, x = "Sepal.Length",
fill = "Species", palette = "jco")
# Вывести сводную таблицу Sepal.Length
#::::::::::::::::::::::::::::::::::::::
# Вычислить описательные статистики по группам
stable <- desc_statby(iris, measure.var = "Sepal.Length",
grps = "Species")
stable <- stable[, c("Species", "length", "mean", "sd")]
# График со сводной таблицей, тема "medium orange" (средний оранжевый)
stable.p <- ggtexttable(stable, rows = NULL,
theme = ttheme("mOrange"))
# Вывести текст
#::::::::::::::::::::::::::::::::::::::
text <- paste("iris data set gives the measurements in cm",
"of the variables sepal length and width",
"and petal length and width, respectively,",
"for 50 flowers from each of 3 species of iris.",
"The species are Iris setosa, versicolor, and virginica.", sep = " ")
text.p <- ggparagraph(text = text, face = "italic", size = 11, color = "black")
# Разместить графики на странице
ggarrange(density.p, stable.p, text.p,
ncol = 1, nrow = 3,
heights = c(1, 0.5, 0.3))
annotation_custom() [в ggplot2]. Упрощенный формат:annotation_custom(grob, xmin, xmax, ymin, ymax)density.p + annotation_custom(ggplotGrob(stable.p),
xmin = 5.5, ymin = 0.7,
xmax = 8)
ggscatter() [ggpubr].ggboxplot() [ggpubr].ggplotGrob() [ggplot2].annotation_custom() [ggplot2].# Диаграмма разброса по группам ("Species")
#::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
sp <- ggscatter(iris, x = "Sepal.Length", y = "Sepal.Width",
color = "Species", palette = "jco",
size = 3, alpha = 0.6)
# Диаграммы рассеивания переменных x/y
#::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
# Диаграмма рассеивания переменной x
xbp <- ggboxplot(iris$Sepal.Length, width = 0.3, fill = "lightgray") +
rotate() +
theme_transparent()
# Диаграмма рассеивания переменной у
ybp <- ggboxplot(iris$Sepal.Width, width = 0.3, fill = "lightgray") +
theme_transparent()
# Создать внешние графические объекты
# под названием “grob” в терминологии Grid
xbp_grob <- ggplotGrob(xbp)
ybp_grob <- ggplotGrob(ybp)
# Поместить диаграммы рассеивания в диаграмму разброса
#::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
xmin <- min(iris$Sepal.Length); xmax <- max(iris$Sepal.Length)
ymin <- min(iris$Sepal.Width); ymax <- max(iris$Sepal.Width)
yoffset <- (1/15)*ymax; xoffset <- (1/15)*xmax
# Вставить xbp_grob внутрь диаграммы разброса
sp + annotation_custom(grob = xbp_grob, xmin = xmin, xmax = xmax,
ymin = ymin-yoffset, ymax = ymin+yoffset) +
# Вставить ybp_grob внутрь диаграммы разброса
annotation_custom(grob = ybp_grob,
xmin = xmin-xoffset, xmax = xmin+xoffset,
ymin = ymin, ymax = ymax)
readJPEG() [в пакете jpeg], или функцию readPNG() [в пакете png] в зависимости от формата фоновой картинки.install.packages(“png”).# Импорт картинки
img.file <- system.file(file.path("images", "background-image.png"),
package = "ggpubr")
img <- png::readPNG(img.file)background_image() [в ggpubr].library(ggplot2)
library(ggpubr)
ggplot(iris, aes(Species, Sepal.Length))+
background_image(img)+
geom_boxplot(aes(fill = Species), color = "white")+
fill_palette("jco")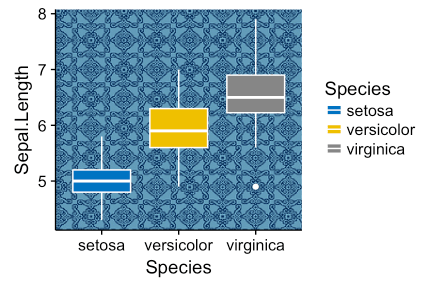
library(ggplot2)
library(ggpubr)
ggplot(iris, aes(Species, Sepal.Length))+
background_image(img)+
geom_boxplot(aes(fill = Species), color = "white", alpha = 0.5)+
fill_palette("jco")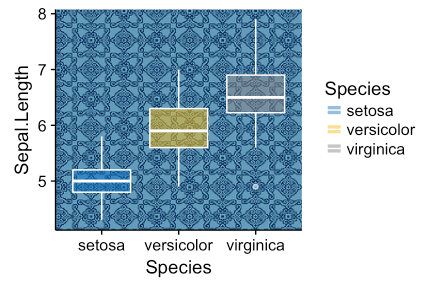
mypngfile <- download.file("https://upload.wikimedia.org/wikipedia/commons/thumb/e/e4/France_Flag_Map.svg/612px-France_Flag_Map.svg.png",
destfile = "france.png", mode = 'wb')
img <- png::readPNG('france.png')
ggplot(iris, aes(x = Sepal.Length, y = Sepal.Width)) +
background_image(img)+
geom_point(aes(color = Species), alpha = 0.6, size = 5)+
color_palette("jco")+
theme(legend.position = "top")
ggarrange() [в ggpubr] предоставляет удобное решение, чтобы расположить несколько ggplot-ов на нескольких страницах. После задания аргументов nrow и ncol функция ggarrange() автоматически рассчитывает количество страниц, которое потребуется, чтобы разместить все графики. Она возвращает список упорядоченных ggplot-ов.multi.page <- ggarrange(bxp, dp, bp, sp,
nrow = 1, ncol = 2)multi.page[[1]] # Вывести страницу 1
multi.page[[2]] # Вывести страницу 2ggexport() [в ggpubr]:ggexport(multi.page, filename = "multi.page.ggplot2.pdf")marrangeGrob() [в gridExtra].library(gridExtra)
res <- marrangeGrob(list(bxp, dp, bp, sp), nrow = 1, ncol = 2)
# Экспорт в pdf-файл
ggexport(res, filename = "multi.page.ggplot2.pdf")
# Интерактивный вывод
resp1 <- ggarrange(sp, bp + font("x.text", size = 9),
ncol = 1, nrow = 2)
p2 <- ggarrange(density.p, stable.p, text.p,
ncol = 1, nrow = 3,
heights = c(1, 0.5, 0.3))
ggarrange(p1, p2, ncol = 2, nrow = 1)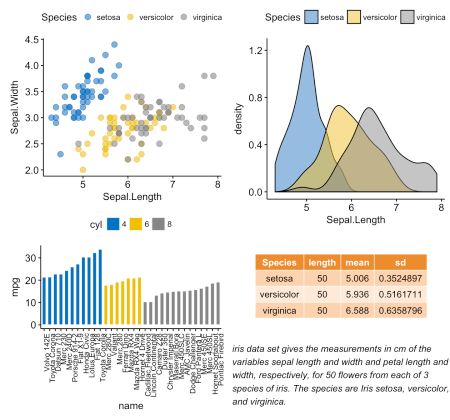
ggexport() [в ggpubr].plots <- ggboxplot(iris, x = "Species",
y = c("Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width"),
color = "Species", palette = "jco"
)
plots[[1]] # Вывести первый график
plots[[2]] # Вывести второй график и т.д.ggexport(plotlist = plots, filename = "test.pdf")ggexport(plotlist = plots, filename = "test.pdf",
nrow = 2, ncol = 1)|
Метки: author qc-enior визуализация данных визуализация ggplot2 |
Классический 2д квест или как прошли наши два года разработки. Часть 3 |


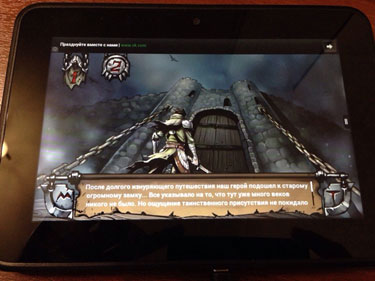
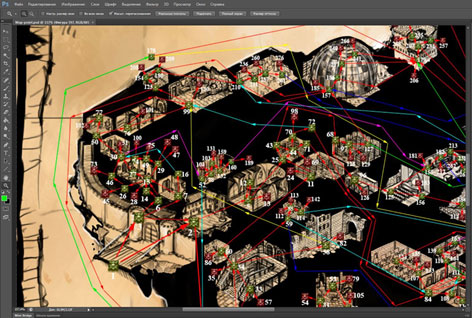
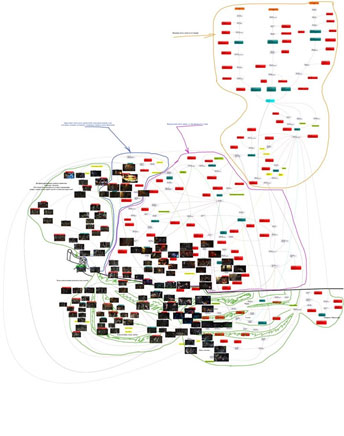

|
Метки: author MaikShamrock разработка под android разработка игр программирование libgdx corona sdk разработка игр под android программирование игр |
Liquibase: пример автоматизированного наката изменений на реляционную БД |
Статья будет интересна тем, кто хоть раз задумывался о вопросе наката изменений (патча) на реляционную БД. Статья не будет интересна тем, кто уже освоил и использует Liquibase. Главной целью данной статьи является указание ссылки на репозиторий с примером использования. В качестве примера я выбрал накат sample-схемы HR на БД Oracle (список всех поддерживаемых БД) — любой желающий может скачать себе репозиторий и поиграться в домашних условиях. Желание продемонстрировать пример вызвано обсуждением этого вопроса на ресурсе sql.ru.
Что такое Liquibase, можно узнать на официальном сайте продукта. Хочется отметить пару хороших статей и на этом ресурсе:
Управление миграциями БД с Liquibase
Использование Liquibase без головной боли. 10 советов из опыта реальной разработки
Мой выбор остановился на этом инструменте, так как:
1) Инструмент отслеживает, какие changeset-ы уже были применены к данному экземпляру БД и накатывает только те, которые еще не накатывались и какие нужно еще донакатить. Если в процессе наката применение какого-либо изменения упало с ошибкой, то, после устранения причины вы перезапускаете накат и Liquibase продолжает выполнение с того changeset-а, на котором остановился.
2) Возможность выставить changeset-у атрибуты runOnChange и runAlways существенно упрощает управление изменениями, в частности, recreatable-объектов.
3) Свойство context позволяет выполнять/не выполнять changeset-ы в зависимости от текущего окружения (например, не запускать юнит-тесты на проде).
Это был не полный список фич.
Он здесь. В нем приведены "hard" (таблицы, индексы, ограничения целостности) и "soft" (триггеры, процедуры, представления) объекты, changeset-ы с тегами sql и sqlFile, c атрибутами runOnChange и runAlways и без.
Ввиду отсутствия необходимости в репозитории нет таких полезных фич/шагов, которые я обычно использую в своих проектах:
|
Метки: author akk0rd87 sql postgresql oracle microsoft sql server database migrations database tools liquibase |






