Участникам чемпионата RAIF стали доступны бизнес-данные «М.Видео» |

|
Метки: author JetHabr машинное обучение анализ и проектирование систем алгоритмы блог компании инфосистемы джет raif чемпионат искусственный интеллект |
Итоги второго хакатона по ReactOS: мы переходим на GitHub |

First pic coming from #ReactOSHackfest ! Coding hard... #development #opensource pic.twitter.com/HoLr2q3x5W
— ReactOS (@reactos) August 14, 2017
|
|
[Из песочницы] Кому из айтишников на Руси жить хорошо (а кому будет еще лучше) |

|
|
CIS Benchmarks: лучшие практики и рекомендации по информационной безопасности |
|
Метки: author LukaSafonov информационная безопасность блог компании pentestit cis benchmarks |
Hacktoberfest Open Hack Day в Avito — анонс |
Hacktoberfest близко. Как перестать бояться и начать контрибьютить? С кем обсудить самые полезные открытые проекты? Если вы любите опенсорс так же, как и мы, то приходите в гости в наш московский офис 7 октября. Будет кодовикторина, общение с нашими ведущими разработчиками, много опенсорса, свободный микрофон для рассказов о проектах и Hack Time в отличной компании. Под катом — подробности про мероприятие и темы, которые мы обсудим.

Happy Hacktoberfest!
Читать дальше ->|
Метки: author rafinirovannoe разработка мобильных приложений разработка веб-сайтов open source github блог компании avito hacktoberfest event avito |
[Перевод] Node.js и переход с PHP на JavaScript |

|
Метки: author ru_vds разработка веб-сайтов php node.js javascript блог компании ruvds.com разработка |
Необразованная молодёжь. Ответ преподавателя-совместителя |
30 сентября пользователь aleshqqa1337 опубликовал искренний и, в целом, правильный пост Необразованная молодёжь. Я понял, что не могу не ответить. Писал комментарий, писал… И в итоге решил написать пост.
Кратко о себе (это важно): работаю программистом-исследователем в сфере ИБ. Сейчас в крупной российской компании, до этого в двух банках, ещё до этого в небольшой инновационной ИБ компании. Преподаю в МГТУ им.Баумана более 3-х лет… И тоже много что насмотрелся.
Тем не менее "угол зрения" aleshqqa1337 на мой взгляд немного не правильный. Это статья написана не для критики, а скорее для того чтобы дополнить картину того, что в целом происходит с техническим образованием в России.
|
Метки: author PavelMSTU учебный процесс в it исследования и прогнозы в it обучение обучение программистов молодые специалисты вуз колледжи |
Интернет-аукционы, API и конкретный пример, как на этом могут заработать сторонние разработчики |

|
|
Онлайн-консультанты: тест-обзор 7 популярных систем. Что вы получите, если откинуть рекламу? |

|
|
Лекции по криптографии, блокчейну и вообще |

|
Метки: author EmercoinBlog блог компании emercoin блокчейн криптография криптоанализ лекция стрим анонс эфириум биткоин майнинг эмеркоин консенсус |
[Из песочницы] Разработка первой игры. Впечатления и работа над ошибками. Часть 1 |

|
Метки: author Danil_ka88 разработка игр unity3d unity игры steam |
Next billion users: кто эти люди и как они повлияют на мировую экономику |

|
Метки: author timurgaliev стандарты связи сетевые технологии it- инфраструктура блог компании unolabo gig economy рынок труда next billion users безработица |
[Из песочницы] [CppCon 2017] Herb Sutter: Метапрограммирование и кодогенерация в C++ |
Продолжаю серию публикаций Fil по CppCon 2017. В докладе представлены ранние наработки по добавлению рефлексии и кодогенерации в C++, а также по метаклассам, которые позволят генерировать части классов C++. В стандарт эти новшества попадут не ранее, чем в C++23.
Читать дальше ->|
|
[CppCon 2017] Ларс Кнолл: C++ фреймворк Qt: История, Настоящее и Будущее |
Содержание цикла обзора выступлений CppCon 2017:
Обзор выступления Ларса Кнолла (Lars Knoll), являющегося техническим директором Qt Company. Не ждите от этого выступления слишком многого. В квадратных скобках курсивом мои примечания.
|
Метки: author Fil qt c++ cppcon qml qt quick |
[Перевод] Вышел GitLab 10.0: Авто-DevOps и групповые доски задач |
Вышел GitLab 10.0 с Авто-DevOps, групповыми досками задач, новой навигацией и множеством других фич.

От формулировки идеи — до запуска и мониторинга на производстве. DevOps задаёт культуру и окружение, в которых разработка, тестирование и выпуск ПО происходят быстрее, чаще и надёжнее.
|
|
Текстовая трансляция со дня открытых дверей Лаборатории Касперского – Open Day 2017 |

|
Метки: author Kaspersky_Lab разработка для интернета вещей информационная безопасность блог компании «лаборатория касперского» кибер |
[Из песочницы] t1ha |
Чуть менее чем самая быстрая, переносимая, 64-битная хэш-функция, с достойным качеством.
Да, вжух и в дамки, примерно так. Читаем дальше?
Опустим определение хэш-функций вместе с детальным перечислением свойств и требований для их криптографического применения, предполагая что читатель либо владеет необходимым минимумов знаний, либо восполнит их. Также условимся, что здесь и далее мы подразумеваем некриптографические (криптографически не стойкие) хэш-функции, если явно не указывается иное.
Хэширование применяется в массе алгоритмов, при этом практически всегда требуется максимально эффективная (быстрая) обработка данных, одновременно с соблюдением некоторого минимального уровня качества хеширования. Причём под «качеством», прежде всего, понимается «условная случайность» (стохастичность) результата относительно исходных данных. Несколько реже предъявляются дополнительные требования: устойчивость к преднамеренной генерации коллизий или необратимость.
Для стройности изложения необходимо определить понятия «качества» хэш-функции и остальные требования чуть более детально:
Опуская цитирование доказательств и прочие выкладки можно констатировать:
Так вот, можно сказать, что t1ha появилась в результате поиска компромисса между качеством и скоростью, одновременно с учетом возможностей современных процессоров и уже найденных способов (арифметико-логических комбинаций) перемешивания и распространения зависимостей (лавинного эффекта).
Базовый вариант t1ha является (самой) быстрой переносимой хэш-функцией для построения хэш-таблиц и других родственных применений. Поэтому базовый вариант t1ha ориентирован на 64-битные little-endian архитектуры, принимает 64-битное подсаливающее значение (seed) и выдает 64-битный результат, который включает усиление длиной ключа и seed-ом. Стоит отметить, t1ha намеренно сконструирована так, чтобы возвращать 0 при нулевых входных данных (ключ нулевого размера и нулевой seed).
Оценить качество хэш-функции во всех аспектах достаточно сложно. Можно идти аналитическим путем, либо проводить различные статистические испытания. К сожалению, аналитический подход малоэффективен для оценки хэш-функций с компромиссом между качеством и скоростью. Причем сравнительная аналитическая оценка таких функций стремиться к субъективной.
Напротив, для статистических испытаний легко получить прозрачные количественные оценки. При этом есть хорошо зарекомендовавшие себя тестовые пакеты, например SMHasher. Для t1ha результаты просты — все варианты t1ha проходят все тесты без каких-либо замечаний. С другой стороны, не следует считать, что у t1ha есть какие-либо свойства сверх тех, что необходимы для целевого применения (построение хэш-таблиц).
Читатели наверняка оценили бы тщательный и глубокий анализ качественности и/или стойкости t1ha. Однако, исходя из целевых областей применения t1ha это представляется излишним. Проще говоря, нам была важнее скорость, в том числе для коротких ключей. Поэтому много-раундовое перемешивание не рассматривалось. Представляемый вариант t1ha экономит на спичках тактах и выдает 64-битный результат — практически бессмысленно измерять найденный компромисс иначе как статистически, а эти результаты просто хороши.
Мы просто берем пример в statistical prove с коллег из Google ;)
Стоит пояснить наличие в заголовке словосочетания «самая быстрая». Действительно, крайне маловероятно, что существует хэш-функция, которая будет полезной и одновременно самой быстрой на всех платформах/архитектурах. На разных процессорах доступны разные наборы инструкций, а схожие инструкции выполняются с разной эффективностью. Очевидно, что «всеобщая самая быстрая» функция, скорее всего, не может быть создана. Однако, представляется допустимым использовать «самая быстрая» для функции, которая является переносимой и одновременно самой быстрой как минимум на самой распространенной платформе (x86_64), при этом имея мало шансов проиграть на любом современном процессоре с достойным оптимизирующим компилятором.
В состав исходных текстов проекта входить тест, который проверяет как корректность результата, так и замеряет скорость работы каждого реализованного варианта. При этом на x86, в зависимости от возможностей процессора (и компилятора) могут проверяться дополнительные варианты функций, а замеры производится в тактах процессора.
Кроме этого, на сайте проекта приведены таблицы с результатам замеров производительности посредством доработанной версии SMHasher от Reini Urban. Соответственно, все цифры можно перепроверить и/или получить результаты на конкретном процессоре при использовании конкретного компилятора.
Здесь же можно привести сопоставление с некоторыми ближайшими конкурентами t1ha.
Хэширование коротких ключей (среднее для 1..31 байта).
Смотрим на правую колонку «Cycles/Hash» (чем меньше значение, тем быстрее):
| Function | MiB/Second | Cycles/Hash |
|---|---|---|
| t1ha | 12228.80 | 35.55 |
| FastHash64 | 5578.06 | 43.42 |
| CityHash64 | 11041.72 | 51.77 |
| xxHash64 | 11123.15 | 56.17 |
| MetroHash | 11808.92 | 46.33 |
Хэширование длинных ключей (256 Кб).
Смотрим на среднюю колонку «MiB/Second» (чем больше значение, тем быстрее):
| Function | MiB/Second | Cycles/Hash |
|---|---|---|
| t1ha | 12228.80 | 35.55 |
| FarmHash64 | 12145.36 | 60.12 |
| CityHash64 | 11041.72 | 51.77 |
| xxHash64 | 11123.15 | 56.17 |
| Spooky64 | 11820.20 | 60.39 |
Разработка t1ha преследовала сугубо практические цели. Первой такой целью было получение быстрой переносимой и достаточно качественной функции для построения хеш-таблиц.
Затем потребовалась максимально быстрый вариант хэш-функции, который давал-бы сравнимый по качеству результат, но был максимально адаптирован на целевую платформу. Например, базовый вариант t1ha работает с little-endian порядком байт, из-за чего на big-endian архитектурах требуется конвертация с неизбежной потерей производительности. Так почему-бы не избавиться от лишних операций на конкретной целевой платформе? Таким же образом было добавлено ещё несколько вариантов:
Чуть позже стало понятно что потребуются ещё варианты, сконструированные для различных применений, включая разную разрядность результата, требования к качеству и стойкости. Такое многообразие потребовало наведения порядка. Что выразилось в смене схемы именования, в которой цифровой суффикс обозначает «уровень» функции:
t1ha0() — максимально быстрый вариант для текущего процессора.t1ha1() — базовый переносимый 64-битный вариант t1ha.t1ha2() — переносимый 64-битный вариант с чуть большей заботой о качестве.t1ha3() — быстрый переносимый 128-битный вариант для получения отпечатков.В этой схеме предполагается, что t1ha0() является диспетчером, который реализует перенаправление в зависимости от платформы и возможностей текущего процессора. Кроме этого, не исключается использование суффиксов «_le» и «_be» для явного выбора между little-endian и big-endian вариантами. Таким образом, под «вывеской» t1ha сейчас находиться несколько хеш-функций и это семейство будет пополняться, в том числе с прицелом на отечественный E2K «Эльбрус».
Представление о текущем наборе функций и их свойствах можно получить из вывода теста. Стоит лишь отметить, что все функции проходят все тесты SMHasher, а производительность вариантов AES-NI сильно варьируется в зависимости от модели процессора:
Simple bench for x86 (large keys, 262144 bytes):
t1ha1_64le: 47151 ticks, 0.1799 clk/byte, 16.679 Gb/s @3GHz
t1ha1_64be: 61602 ticks, 0.2350 clk/byte, 12.766 Gb/s @3GHz
t1ha0_32le: 94101 ticks, 0.3590 clk/byte, 8.357 Gb/s @3GHz
t1ha0_32be: 99804 ticks, 0.3807 clk/byte, 7.880 Gb/s @3GHz
Simple bench for x86 (small keys, 31 bytes):
t1ha1_64le: 39 ticks, 1.2581 clk/byte, 2.385 Gb/s @3GHz
t1ha1_64be: 42 ticks, 1.3548 clk/byte, 2.214 Gb/s @3GHz
t1ha0_32le: 51 ticks, 1.6452 clk/byte, 1.824 Gb/s @3GHz
t1ha0_32be: 54 ticks, 1.7419 clk/byte, 1.722 Gb/s @3GHz
Simple bench for AES-NI (medium keys, 127 bytes):
t1ha0_ia32aes_noavx: 72 ticks, 0.5669 clk/byte, 5.292 Gb/s @3GHz
t1ha0_ia32aes_avx: 78 ticks, 0.6142 clk/byte, 4.885 Gb/s @3GHz
t1ha0_ia32aes_avx2: 78 ticks, 0.6142 clk/byte, 4.885 Gb/s @3GHz
Simple bench for AES-NI (large keys, 262144 bytes):
t1ha0_ia32aes_noavx: 38607 ticks, 0.1473 clk/byte, 20.370 Gb/s @3GHz
t1ha0_ia32aes_avx: 38595 ticks, 0.1472 clk/byte, 20.377 Gb/s @3GHz
t1ha0_ia32aes_avx2: 19881 ticks, 0.0758 clk/byte, 39.557 Gb/s @3GHzЕсли говорить чуть более детально, то t1ha построена по схеме Меркла-Дамгарда (в варианте «wipe-pipe») с упрочнением от размера данных и подсаливающего значения. Внутри основного сжимающего цикла используется 256-битное состояние, с аналогичным размером входного блока. Причем для каждого операнда данных реализуется две точки инъекции с перекрестным опылением. По завершению сжимающего цикла выполняется сжатие 256-битного состояния до 128 бит.
При выполнении описанных действий используются 64-битные операции, комбинирующие миксеры ARX (Add-Rotate-Xor) и MUX/MRX (Mul-Rotate-Xor). Немаловажно, что все эти вычисления выстроены так, чтобы обеспечить возможность параллельного выполнения большинства операция и плотной укладки u-ops как в конвейер, так и в исполняющие устройства x86_64. За счет этого достигается достаточно хорошее качество при практически предельной скорости хэширования длинных ключей.
Стоит отметить, что сжимающий цикл запускается только для блоков достаточного размера. Если же данных меньше, то промежуточное 128-битное состояние будет состоять только из размера ключа и подсаливающего значения.
Далее, оставшийся хвост данных порциями по 64 бита подмешивается попеременно к половинам 128-битного состояния. В заключении выполняется перемешивание состояния одновременно со сжатием до 64-битного результата. Немаловажной особенностью t1ha здесь является использование миксера на базе широкого умножения (128-битное произведение двух 64-битных множителей). Это позволяет реализовать качественно перемешивание с хорошим лавинным эффектом за меньшее количество операций. Несмотря на то, что широкое умножение относительно дорогая операция, меньшее количество операций позволяет t1ha обрабатывать короткие ключи за рекордно малое количество тактов процессора.
Следует отметить, что используемый миксер на основе широкого умножения и исключающего ИЛИ не идеален. Несмотря на то, что t1ha проходит все тесты SMHasher, у автора есть представление о последствиях неинъективности. Тем не менее, результирующее качество представляется рационально-достаточным, а в планах развития линейки t1ha уже отражено намерение предоставить чуть более качественный вариант.
Спасибо за внимание. Всем добра.
|
Метки: author yleo совершенный код системное программирование ненормальное программирование высокая производительность t1ha hash function hash cityhash |
Методы приближенного поиска ближайших соседей |
Довольно часто программисты и специалисты из области data science сталкиваются с задачей поиска похожих профилей пользователей или подбора схожей музыки. Решения могут сводиться к преобразованию объектов в векторную форму и поиску ближайших.
Мы тоже столкнулись с необходимостью поиска ближайших соседей в задаче распознавания лиц. Там мы формируем векторные представления лиц при помощи нейросети и ищем ближайшие векторы уже известных людей. Изначально для поиска мы выбрали Annoy, как хорошо известный и проверенный алгоритм, используемый в том числе в Spotify. Но быстро поняли, что с его аппетитами по памяти мы либо не вмещаемся в RAM, либо сильно теряем в точности. Это привело к небольшому исследованию. О результатах которого пойдет речь ниже.
Чтобы разбавить теорию практикой, в статье будет немного кода, где мы ищем ближайших соседей для слов. Получим их векторные представления, используя популярный word2vec. Этот алгоритм выдает близкие векторы для семантически похожих слов. В word2vec CBOW векторные представления получаются как побочный продукт обучения небольшой нейросети, которая предсказывает слово по его окружению. Любопытно, что с векторами можно проворачивать арифметические операции наподобие king + (woman – man) = queen.
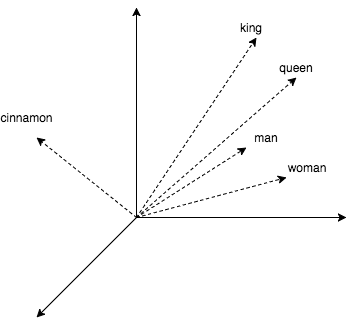
Посмотрим, как с этим работать в коде.
model = gensim.models.KeyedVectors.load_word2vec_format('./GoogleNews-vectors-negative300.bin', binary=True)
start = time.time()
pprint.pprint(model.wv.most_similar(positive=['king']))
print('time:', time.time() - start)
print('king + (woman - man) = ', model.wv.most_similar(positive=['woman', 'king'], negative=['man'])[0])
print('Japan + (Moscow - Russia) = ', model.wv.most_similar(positive=['Moscow', 'Japan'], negative=['Russia'])[0])Получаем:
[(u'kings', 0.7138045430183411),
(u'queen', 0.6510956883430481),
(u'monarch', 0.6413194537162781),
(u'crown_prince', 0.6204219460487366),
(u'prince', 0.6159993410110474),
(u'sultan', 0.5864823460578918),
(u'ruler', 0.5797567367553711),
(u'princes', 0.5646552443504333),
(u'Prince_Paras', 0.5432944297790527),
(u'throne', 0.5422105193138123)]
time: 0.236690998077
king + (woman - man) = (u'queen', 0.7118192911148071)
Japan + (Moscow - Russia) = (u'Tokyo', 0.8696038722991943)В примере выше использовалась библиотека для работы с текстом gensim и word2vec модель (1,5 Гбайт) от Google, которая насчитывает 3 миллиона слов и коротких фраз. В выводе кода видно, что к королю близки королевы, монархи и принцы. Также мы убедились, что арифметика с векторами работает. Однако четверть секунды на один запрос — не очень привлекательно, а ведь в gensim сравнительно хорошая реализация bruteforce-поиска (с подсчетом расстояний до всех известных объектов). Далее мы рассмотрим методы, позволяющие сократить это время в сотни раз лишь с небольшими потерями в точности.
Но начнем с простой идеи: попробуем сузить пространство поиска, разделив его плоскостью на две половины. А во время поиска будем считать расстояния только до тех соседей, которые оказались по ту же сторону от плоскости, что и запрос.
nbrs = NearestNeighbors(algorithm='brute', metric='cosine')
nbrs.fit(model.wv.syn0norm)
king_vec = model.wv['king'][np.newaxis, :]
# замерим скорость поиска сосдей к королю без разделения пространства и заодно выведем результат
start = time.time()
idxs = nbrs.kneighbors(king_vec, return_distance=False, n_neighbors=10)[0]
print('full search time:', time.time() - start)
print([model.wv.index2word[idx] for idx in idxs])
# выберем 2 случайных вектора и получем коэффициенты задающие плоскость между ними
vec1_idx = random.randint(0, model.wv.syn0norm.shape[0])
vec2_idx = random.randint(0, model.wv.syn0norm.shape[0])
plane = model.wv.syn0norm[vec1_idx] - model.wv.syn0norm[vec2_idx]
# в результате следующего умножения матрица-вектор, мы получим вектор.
# Знаки элементов этого вектора указывают с какой стороны разделяющей плоскости оказалось слово
scalar = model.wv.syn0norm.dot(np.transpose(plane))
# определим с какой стороны плоскости запрос и подготовим бинарную маску для выборки векторов по ту же сторону плоскости
if king_vec.dot(plane) > 0:
mask = scalar > 0
else:
mask = scalar < 0
print('elements in mask:', mask.sum())
half_nbrs = NearestNeighbors(algorithm='brute', metric='cosine')
half_nbrs.fit(model.wv.syn0norm[mask])
half_index2word = list(compress(model.wv.index2word, mask))
start = time.time()
idxs = half_nbrs.kneighbors(king_vec, return_distance=False, n_neighbors=10)[0]
print('half search time:', time.time() - start)
print([half_index2word[idx] for idx in idxs])Получаем:
full search time: 20.3163180351
[u'king', u'kings', u'queen', u'monarch', u'crown_prince', u'prince', u'sultan', u'ruler', u'princes', u'Prince_Paras']
elements in mask: 1961204
half search time: 9.15824007988
[u'king', u'kings', u'queen', u'monarch', u'crown_prince', u'prince', u'sultan', u'ruler', u'princes', u'Prince_Paras']Так мы сократили вычисления вдвое, потеряв в точности только рядом с плоскостью. В кое-каких алгоритмах, которые мы рассмотрим дальше, используются похожие трюки.

В 2013 году был опубликован один из лучших алгоритмов поиска ближайших соседей Navigable Small World (NSW). В 2016-м появился его наследник Hierarchical Navigable Small World (HNSW).
Начнем с родительского алгоритма NSW. Он основан на графе «мир тесен». Эти графы имеют любопытную и полезную нам особенность: пара вершин с большой вероятностью не смежна, но они достижимы за сравнительно небольшое число шагов ( в среднем). Такие графы встречаются довольно часто. К примеру, нейронные сети мозга, группы в социальных сетях и семантическая сеть WordNet — это графы SW. В нашем случае вершинами являются векторы, а ребра соединяют их с ближайшими. В графе также представлены ребра, соединяющие вершины на большом расстоянии.
Для поиска соседей мы обходим граф в поисках вершин с минимальным расстоянием до запроса. Начинаем со случайной вершины, считаем расстояние от непосещенных вершин «друзей» (вершин, соединенных с текущей ребром) до запроса и переходим в вершину с наименьшим расстоянием. Длинные ребра придают графу свойства тесного мира и позволяют быстро перемещаться в область близких к запросу объектов, а короткие — жадно искать ближайших соседей.

По мере обхода графа обновляем небольшой список ближайших соседей и останавливаемся, если на очередной итерации список не обновился.
K-NNSearch(object q, integer: m, k)
1 TreeSet [object] tempRes, candidates, visitedSet, result
2 for (i<-0; i < m; i++) do:
3 put random entry point in candidates
4 tempRes<-null
5 repeat:
6 get element c closest from candidates to q
7 remove c from candidates
8 //check stop condition:
9 if c is further than k-th element from result
10 than break repeat
11 //update list of candidates:
12 for every element e from friends of c do:
13 if e is not in visitedSet than
14 add e to visitedSet, candidates, tempRes
15
16 end repeat
17 //aggregate the results:
18 add objects from tempRes to result
19 end for
20 return best k elements from resultindex = nmslib.init(space='cosinesimil', method='sw-graph')
nmslib.addDataPointBatch(index, np.arange(model.wv.syn0.shape[0], dtype=np.int32), model.wv.syn0)
index.createIndex({}, print_progress=True)
start = time.time()
items = nmslib.knnQuery(index, 10, king_vec.tolist())
print(time.time() - start)
print([model.wv.index2word[idx] for idx in items])Получаем:
0.000545024871826
[u'king', u'kings', u'queen', u'monarch', u'crown_prince', u'prince', u'sultan', u'ruler', u'princes', u'royal']Рассмотрим развитие описанной выше идеи в алгоритме Hierarchical Navigable Small World (HNSW). Он во многом схож с NSW, однако теперь мы имеем дело с иерархией графов: на нулевом слое представлены все объекты, а по мере увеличения слоя — все меньшая и меньшая их подвыборка. При этом все объекты на слое есть и на слое .

При поиске старт происходит со случайной вершины в графе верхнего слоя, там мы быстро находим близкие к запросу вершины (кандидаты) и возобновляем поиск с них на предыдущем слое.
SearchAtLayer (object q, Set[object] enterPoints, integer: M, ef, layer)
1 Set [object] visitedSet
2 priority_queue [object] candidates (closer - first), result (further - first)
3 candidates, visitedSet, result <- enterPoints
7
4 repeat:
5 object c =candidates.top()
6 candidates.pop()
7 //check stop condition:
8 if d(c,q)>d(result.top(),q) do:
9 break
10 //update list of candidates:
11 for_each object e from c.friends(layer) do:
12 if e is not in visitedSet do:
13 add e to visitedSet
14 if d(e, q)< d(result.top(),q) or result.size()ef do:
17 result.pop()
18 return best k elements from result
K-NNSearch (object query, integer: ef)
1 Set [object] tempRes, enterPoints=[enterpoint]
2 for i=maxLayer downto 1 do:
3 tempRes=SearchAtLayer (query, enterPoints, M, 1, i)
4 enterPoints =closest elements from tempRes
5 tempRes=SearchAtLayer (query, enterPoints, M, ef, 0)
6 return best K of tempRes + Алгоритм просто понять
+ Он показывает state-of-the-art результаты
+ Существует эффективная реализация в библиотеке nmslib
+ Небольшие дополнительные расходы памяти на хранение ребер графа
– Алгоритм не поддерживает сжатие векторных представлений, которое мы рассмотрим далее
index = nmslib.init(space='cosinesimil', method='hnsw')
nmslib.addDataPointBatch(index, np.arange(model.wv.syn0.shape[0], dtype=np.int32), model.wv.syn0)
index.createIndex({}, print_progress=True)
start = time.time()
items = nmslib.knnQuery(index, 10, king_vec.tolist())
print(time.time() - start)
print([model.wv.index2word[idx] for idx in items])Получаем:
0.000469923019409
[u'king', u'kings', u'queen', u'monarch', u'crown_prince', u'prince', u'sultan', u'ruler', u'princes', u'Prince_Paras']В марте 2017 года Facebook представила свое решение для ANN — библиотеку FAISS. Она объединяет множество методов и алгоритмов. В алгоритме, который мы рассмотрим ниже, расстояния до групп векторов будут приближаться расстоянием до опорной точки рядом с ними. Так мы можем выяснить расстояния от запроса до небольшого количества опорных точек, а затем полным перебором посчитать расстояния до векторов, принадлежащих опорной точке, которая ближе остальных к запросу. Разберем этот алгоритм по частям.
Рассмотрим подробнее следующую идею: расстояния до групп векторов можно приблизить расстояниями до опорных точек рядом с ними. Опорные точки делят пространство на области. Для поиска опорных точек в FAISS используется широко известный алгоритм кластеризации k-means, векторам сопоставляются полученные центроиды.
(0.1, 0.2) -> 1 (0.5, -0.2) -> 2 (0.1, 0.1) -> 1 (0.6, -0.1) -> 2
Векторы коллекции аппроксимируются своими центроидами , где и — множество центроидов. Тогда расстояние от запроса до может быть приближено . Такой способ вычисления дистанции называют асимметричным. Простыми словами: мы разбили пространство на области и сказали, что расстояние от запроса до группы векторов, попавших в одну область, приблизительно равно расстоянию до центроида, образующего эту область.

Эффективно хранить и быстро получать векторы, принадлежащие центроиду, помогает простой трюк под названием inverted file.
В IVF мы инвертируем присвоение. Теперь центроидам сопоставляются списки векторов.
1 -> [(0.1, 0.2), (0.1, 0.1)] 2 -> [(0.5, -0.2), (0.6, -0.1)]
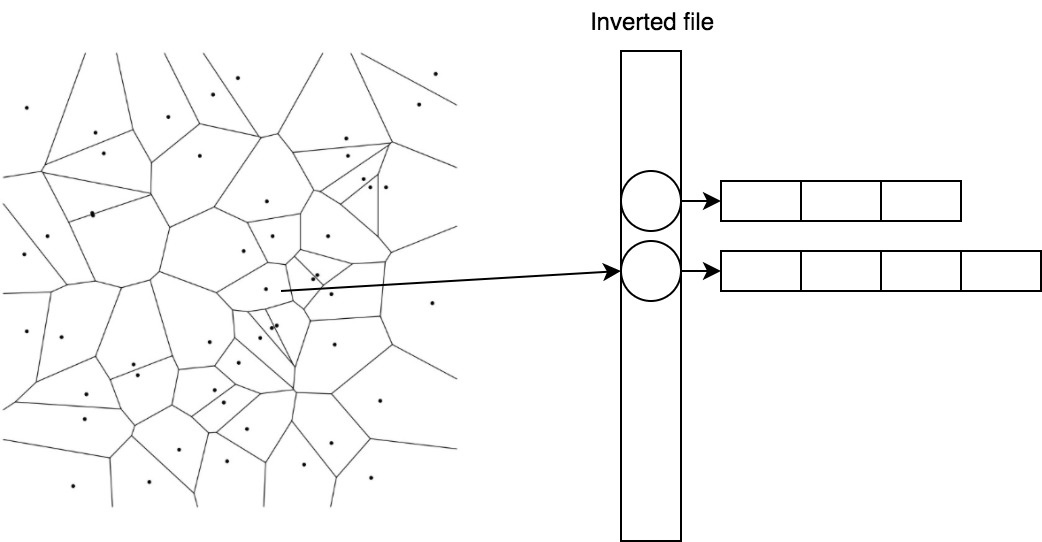
Так мы можем быстро находить кандидатов, посчитав расстояния до центроидов, а затем брать уже готовый список для ближайшего.
Последняя составляющая, которой мы коснемся в статье, называется product quantizer. Она обеспечивает сжатие векторов с потерями и применяется, когда векторные представления не влезают в память. Предположим, что наши векторы имеют размерность 128 и мы хотим кодировать их 64 битами (всего 0,5 бита на компоненту), тогда нам придется заниматься квантованием с количеством центроидов, равным . Это нетривиальная задача , которая также требует огромной обучающей выборки.
Упростим задачу, разбив вектор на частей , и по традиции найдем 256 центроидов для каждой из частей. То есть вектор можно переписать как набор индексов центроидов — например , а занимает это хозяйство байт.
Такой вид кодирования будем применять к остаточным векторам , , и тогда
А теперь соберем все это в одной схеме.

Для запроса находим ближайших центроидов, собираем списки векторов, соответствующих этим центроидам, и считаем до них расстояния, используя остаточные векторы, а затем выбираем ближайших.
import faiss
index = faiss.index_factory(model.wv.syn0norm.shape[1], 'IVF16384,Flat')
index.verbose = True
train = model.wv.syn0norm[np.random.binomial(1, 1./3, size=model.wv.syn0norm.shape[0]).astype(bool)]
index.train(train)
index.add(model.wv.syn0norm)
index.nprobe = 100
start = time.time()
distances, items = index.search(king_vec, 10)
print(time.time() - start)
print([model.wv.index2word[idx] for idx in items[0]])Получаем:
0.0048999786377
[u'king', u'kings', u'queen', u'monarch', u'crown_prince', u'prince', u'sultan', u'ruler', u'princes', u'Prince_Paras']+ Поддержка сжатия
+ Малые накладные расходы на хранение центроидов
+ Возможность вычислений на GPU*
– В пять раз медленнее HNSW на CPU
* Мы не смогли быстро завести GPU-реализацию из коробки и решили не тратить время на это.
Идея деления пространства плоскостями хорошо реализована в Annoy. Алгоритм прекрасно описан автором в блоге, рекомендую прочесть, если хотите разобраться в деталях. Я попробую коротко изложить суть. В алгоритме мы рекурсивно делим пространство плоскостями, образуя бинарное дерево. В каждом узле дерева хранится вектор, задающий текущую плоскость. При поиске мы начинаем с корня и выбираем дочернюю ноду на основе положения запроса относительно плоскости. Так мы спускаемся к листовым элементам дерева, в которых хранятся векторы, оказавшиеся по одну сторону группы плоскостей (это небольшой кусочек пространства), они с высокой вероятностью окажутся искомыми ближайшими соседями. Посмотрим на достоинства и недостатки Annoy по сравнению с другими алгоритмами.
+ Алгоритм просто понять
– Он требует много памяти
– Проигрывает в скорости работы
У каждого из алгоритмов есть набор параметров, будь то максимальное количество друзей для вершины (в NSW, HNSW) или количество центроидов (в FAISS). Эти параметры влияют на объем потребляемой памяти, качество и скорость поиска. Автор Annoy реализовал тесты для группы ANN алгоритмов в репозитории ann-benchmarks на разных параметрах. В них оценивается точность поиска десяти ближайших соседей в датасетах, полученных при помощи алгоритмов GloVe и SIFT.
GloVe — это еще один способ получить векторные представления слов, он превосходит word2vec по всем показателям при обучении на корпусе одного размера. Датасет составлен из 1,2 миллиона векторных представлений слов, обученных на 2 миллиардах твитов. SIFT — старый алгоритм получения ключевых точек изображения и их векторных представлений, устойчивых к трансформациям. Он использовался для распознавания объектов, и важной частью этого распознавания был поиск похожих векторных представлений. Есть несколько вариаций датасетов, нас интересует SIFT 1M, содержащий миллион векторов.
Ниже приведу графики, отражающие взаимосвязь скорости работы алгоритмов и точности поиска десяти ближайших соседей. Алгоритмы представлены группами точек, каждая из точек — это запуск теста на наборе параметров.
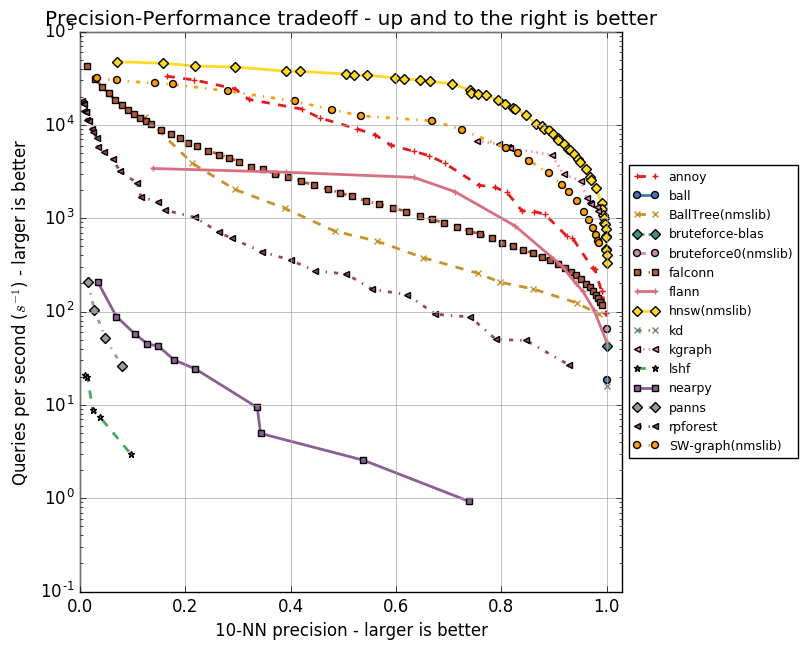
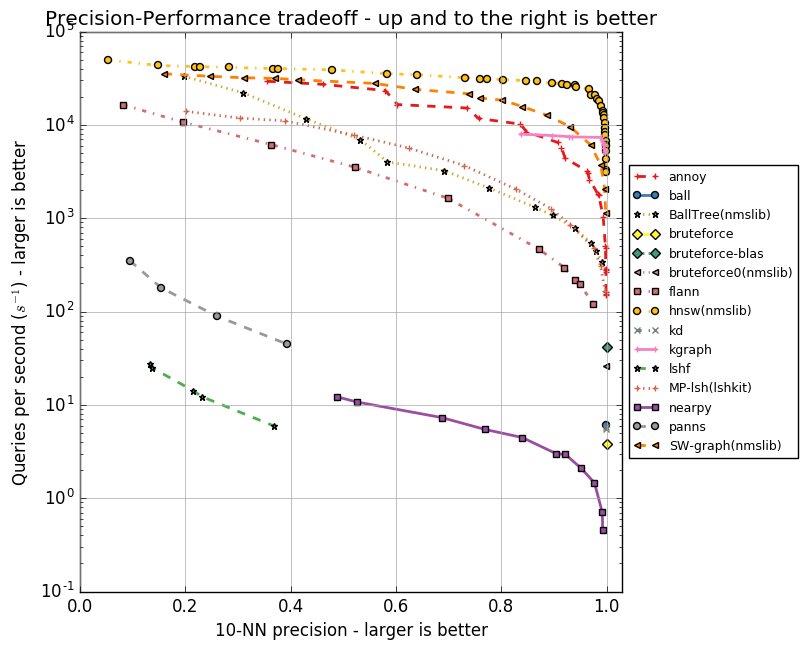
Видно, что HNSW уверенно лидирует. Однако на графиках нет FAISS. Facebook самостоятельно сравнил HNSW и FAISS в разных конфигурациях, результаты приведены в таблице.
| Method | search time | 1-R@1 | index size | index build time |
|---|---|---|---|---|
| Flat-CPU | 9.100 s | 1.0000 | 512 MB | 0 s |
| nmslib (hnsw) | 0.081 s | 0.8195 | 512 + 796 MB | 173 s |
| IVF16384,Flat | 0.538 s | 0.8980 | 512 + 8 MB | 240 s |
| IVF16384,Flat (Titan X) | 0.059 s | 0.8145 | 512 + 8 MB | 5 s |
| Flat-GPU (Titan X) | 0.753 s | 0.9935 | 512 MB | 0 s |
В таблице методы FAISS без сжатия, в частности IVF16384,Flat. Значит, используется IVFADC c 16 384 центроидами. Расходы памяти указаны для случая с миллионом векторов размерности 128 в float32. HNSW в пять раз быстрее при вычислениях на CPU, но на хранение ребер графа () требуется больше памяти, чем на центроиды ().
Мы рассмотрели ряд алгоритмов, применяемых для быстрого поиска ближайших соседей. Annoy проиграл и по памяти, и по скорости работы, но идея хороша и может помочь в решении смежных задач. Например, удобный для чистки датасета алгоритм поиска аномалий isolation forest очень похож по своей задумке. FAISS — отличное решение при ограничениях по памяти, с ним вполне можно уложить миллиард векторных представлений в 60 Гбайт RAM, используя IVF16384, PQ64. Однако если память не узкое место, то стоит выбрать HNSW.
P. S. Самыми интересными оказались публикации об алгоритмах в FAISS. Там, к примеру, можно прочесть об оптимизации под GPU, об улучшенном методе квантования (Optimized Product Quantization) и о более хитром способе построении индекса (inverted multi-index).
P. P. S. Для себя мы выбрали HNSW.
|
Метки: author Chetter2 машинное обучение алгоритмы блог компании mail.ru group knn aknn |
[Перевод] Новшества серверного рендеринга в React 16 |

renderToString для преобразования корневого компонента в строку, которую затем записывают в ответ сервера:// используем Express
import { renderToString } from "react-dom/server"
import MyPage from "./MyPage"
app.get("/", (req, res) => {
res.write("");
res.write("");
res.write(renderToString(render(). Тот же метод используют и в приложениях, выполняющих рендеринг на клиенте без участия сервера:import { render } from "react-dom"
import MyPage from "./MyPage"
render(
render() для ситуаций, когда рендеринг выполняются полностью на клиенте, и метод hydrate() для случаев, когда рендеринг на клиенте основан на результатах серверного рендеринга. Благодаря обратной совместимости новой версии React, render() будет работать и в том случае, если ему передать то, что пришло с сервера. Однако, эти вызовы следует заменить вызовами hydrate() для того, чтобы система перестала выдавать предупреждения, и для того, чтобы подготовить код к React 17. При таком подходе код, показанный выше, изменился бы так:import { hydrate } from "react-dom"
import MyPage from "./MyPage"
hydrate(render() должен всегда возвращать единственный элемент React. Однако, в React 16 рендеринг на стороне клиента позволяет компонентам, кроме того, возвращать из метода render() строку, число, или массив элементов. Естественно, это касается и SSR.class MyArrayComponent extends React.Component {
render() {
return [
first element,
second element
];
}
}
class MyStringComponent extends React.Component {
render() {
return "hey there";
}
}
class MyNumberComponent extends React.Component {
render() {
return 2;
}
}renderToString:res.write(renderToString([
first element,
second element
]));
// Не вполне ясно, зачем так делать, но это работает!
res.write(renderToString("hey there"));
res.write(renderToString(2));div и span, которые просто добавлялись к вашему дереву компонентов React, что ведёт к общему уменьшению размеров HTML-документов.data-reactid, значение которого представляет собой монотонно возрастающие ID, и текстовые узлы иногда окружены комментариями с react-text и ID. Для того, чтобы это увидеть, рассмотрим следующий фрагмент кода:renderToString(
This is some server-generated HTML.
);
This is some
server-generated
HTML.
This is some server-generated HTML.
ReactDom.render() выполняет посимвольное сравнение с серверной разметкой. Если по какой-либо причине будет обнаружено несовпадение, React выдаёт предупреждение в режиме разработки и заменяет всё дерево разметки, сгенерированной на сервере, на HTML, который был сгенерирован на клиенте.ReactDom.render() / hydrate(), не исправляет несовпадающие HTML-атрибуты, сгенерированные SSR. Эта оптимизация производительности означает, что вам понадобится внимательнее относиться к исправлению несовпадений разметки, приводящих к предупреждениям, которые вы видите в режиме development.production. Это так из-за того, что в React есть множество замечательных предупреждений и подсказок для разработчика. Каждое из этих предупреждений выглядит примерно так:if (process.env.NODE_ENV !== "production") {
// что-то тут проверить и выдать полезное
// предупреждение для разработчика.
}process.env — это не обычный объект JavaScript, и обращение к нему — операция затратная. В итоге, даже если значение NODE_ENV установлено в production, частая проверка переменной окружения ощутимо замедляет серверный рендеринг.process.env, используя что-то вроде Environment Plugin в Webpack, или плагин transform-inline-environment-variables для Babel. По опыту знаю, что многие не компилируют свой серверный код, что, в результате, значительно ухудшает производительность SSR.process.env.NODE_ENV в самом начале кода React 16, в итоге компилировать SSR-код для улучшения производительности больше не нужно. Сразу после установки, без дополнительных манипуляций, мы получаем отличную производительность.NODE_ENV была установлена в значение production, когда вы используете SSR в продакшне.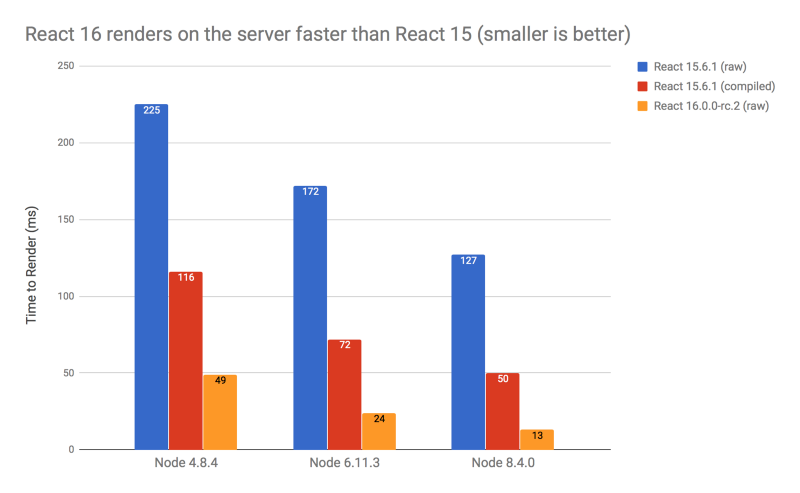
process.env были устранены благодаря компиляции, наблюдается рост производительности примерно в 2.4 раза в Node 4, в 3 раза — в Node 6, и замечательный рост в 3.8 раза в Node 8.4. Если сравнить React 16 и React 15 без компиляции последнего, результаты на последней версии Node будут просто потрясающими.renderToString. В результате, на сервере проводилось много ненужной работы.render, обработка которых занимает много циклов процессора, React 16 ничего не сможет сделать для того, чтобы их ускорить. Поэтому, хотя я и ожидаю увидеть ускорение серверного рендеринга при переходе на React 16, я не жду, скажем, трёхкратного роста производительности в реальных приложениях. По непроверенным данным, при использовании React 16 в реальном проекте, удалось достичь роста производительности примерно в 1.3 раза. Лучший способ понять, как React 16 отразится на производительности вашего приложения — попробовать его самостоятельно.react-dom/server: renderToNodeStream или renderToStaticNodeStream, которые соответствуют методам renderToString и renderToStaticMarkup. Вместо возврата строки эти методы возвращают объект Readable. Такие объекты используются в модели работы с потоками Node для сущностей, генерирующих данные.Readable из методов renderToNodeStream или renderToStaticNodeStream, он находится в режиме приостановки, то есть, рендеринг в этот момент ещё не начинался. Рендеринг начнётся только в том случае, если вызвать read, или, более вероятно, подключить поток Readable с помощью pipe к потоку Writable. Большинство веб-фреймворков Node имеют объект ответа, который унаследован от Writable, поэтому обычно можно просто перенаправить Readable в ответ.// используем Express
import { renderToNodeStream } from "react-dom/server"
import MyPage from "./MyPage"
app.get("/", (req, res) => {
res.write("");
res.write("");
const stream = renderToNodeStream({ end: false } для того, чтобы сообщить потоку о том, что он не должен автоматически завершать ответ при завершении рендеринга. Это позволяет нам закончить оформление тела HTML-документа, и, как только поток будет полностью записан в ответ, завершить ответ самостоятельно.|
Метки: author ru_vds разработка веб-сайтов reactjs javascript блог компании ruvds.com react разработка |
Команда Университета ИТМО вышла в финал Всемирной олимпиады роботов |
|
Метки: author itmo разработка робототехники блог компании университет итмо университет итмо wro 2017 робототехника |






