Паттерны проектирования в автоматизации тестирования |
«Нельзя просто так взять и написать классный тест. Один тест написать можно, но сделать, так чтобы по мере того, как количество этих классных тестов росло, как количество людей, которые пишут эти классные тесты, и вы не теряли ни в скорости, ни во времени...»

























|
Метки: author sinnerspinner тестирование веб-сервисов блог компании jug.ru group тестирование паттерны |
[Из песочницы] Когда переменная bool не true и не false одновременно |
bool *t = new bool[X][Y];
// много строк
switch (t[M][N])
{
case true:
// много строк
break;
case false:
// много строк
break;
default:
// много строк
break;
}
#include
using namespace std;
int main() {
bool *t = new bool[1];
switch (t[0])
{
case true:
cout << "true\n";
break;
case false:
cout << "false\n";
break;
default:
cout << "superposition\n";
break;
}
if(t[0] == true) {
cout << "true\n";
} else if(t[0] == false) {
cout << "false\n";
} else {
cout << "superposition\n";
}
if(t[0]) {
cout << "true\n";
} else if(!t[0]) {
cout << "false\n";
} else {
cout << "superposition\n";
}
delete[] t;
return 0;
}
char a = t[0];
t[0] = a;
bool a = t[0];
t[0] = a;
|
Метки: author alsoijw ненормальное программирование c++ |
[Перевод] Эргономика текста: Пользователь социальных сетей видит около 54 000 слов в день |



 = Этот отрывок не имеет никакого смысла
= Этот отрывок не имеет никакого смысла = Этот отрывок был познавательным
= Этот отрывок был познавательным = Этот отрывок был пугающим
= Этот отрывок был пугающим = О, этот отрывок был настолько ужасным, что у меня болит сердечко
= О, этот отрывок был настолько ужасным, что у меня болит сердечко
|
Метки: author MagisterLudi интерфейсы дизайн мобильных приложений веб-дизайн usability блог компании edison дизайн слов разработка дизайн |
Mars Information Services: добро пожаловать в Марс |



|
|
Переводим интерфейсы на полсотни языков. Sketch |

Герои сериала «Шерлок»
Привет! Я Алексей Тимин, инженер из команды локализации Badoo. В этом посте я расскажу вам о том, как мы помогаем переводчикам в их нелёгком труде, и о новом Open Source-решении, позволяющем генерировать скриншоты дизайна, подготовленного в Sketch, для разных языков.
Если вы создаёте дизайны для мультиязычных проектов или работаете в компании, разрабатывающей такие проекты, то информация будет вам полезной.
В команде локализации Badoo всего лишь два разработчика, но мы держимся и создаём очень интересные инструменты:
Перечисленные инструменты призваны помочь в процессе локализации сайта Badoo, двух мобильных приложений Badoo (для Android и iOS), а также партнёрских приложений Chappy, Bumble, Huggle, Hot or Not на 47 языков. Это огромный фронт работ.
Наши переводчики работают с лексемами (так мы называем неделимую единицу перевода: слово или предложение). Для каждой лексемы подбирается формулировка оптимальной длины, чтобы обеспечить корректное отображение приложения на экранах пользователей. Иногда перевод должен быть не только корректным, но и привлекательным (например, для маркетинговых нужд).
Процесс перевода выглядит так:
Как видно, переводчики вынуждены ждать прототип приложения от программистов. Или, если произошли изменения в переводах, им необходимо попросить разработчиков собрать заново тестовую версию, чтобы проверить отображение. Но у нас зародилась идея максимально ограничить участие программистов в процессе перевода и ускорить подготовку релиза.
По нашей задумке, процесс должен выглядеть так:
Чтобы вам было проще представить проблему, привожу схемы процесса до и после. Красным на первой схеме выделен оптимизируемый участок:

Наши дизайнеры работают в графическом редакторе Sketch. Мы выяснили, что идущая вместе с ним утилита sketch-tool умеет генерировать скриншоты, а это значит, при добавлении перевода есть возможность сразу показывать скриншот переводчику! Но возник вопрос: как заменить исходные тексты в дизайне, чтобы получить локализованный скриншот?
В перерывах между вечеринками мы обсуждали возможные варианты реализации идеи. И выход был найден.
Давайте разберёмся, как устроен .sketch-файл изнутри.
В 43-й версии Sketch разработчики стали использовать новый формат .sketch-файла для «лучшей интеграции со сторонними сервисами».
Логически в подготовленном в Sketch дизайне выделяются Pages, Artboards и графические элементы. Каждой сущности – Pages, Artboards и графическим элементам – один раз (в момент создания) присваивается уникальный идентификатор (UUID), который впоследствии не меняется.
Схематично связи между сущностями можно изобразить так:

Смотрите картинку ниже, чтобы понять, что есть что в интерфейсе Sketch: iPhone SE и iPhone 7 – две из возможных Artboards, a Page 1 – это одна из возможных Pages.

Сохранённый в .sketch-файл дизайн представляет собой ZIP-архив, внутри которого находятся директории с PNG- и JSON-файлами. Выглядит просто?
Если мы разархивируем .sketch-файл, то дерево директорий получится примерно таким:
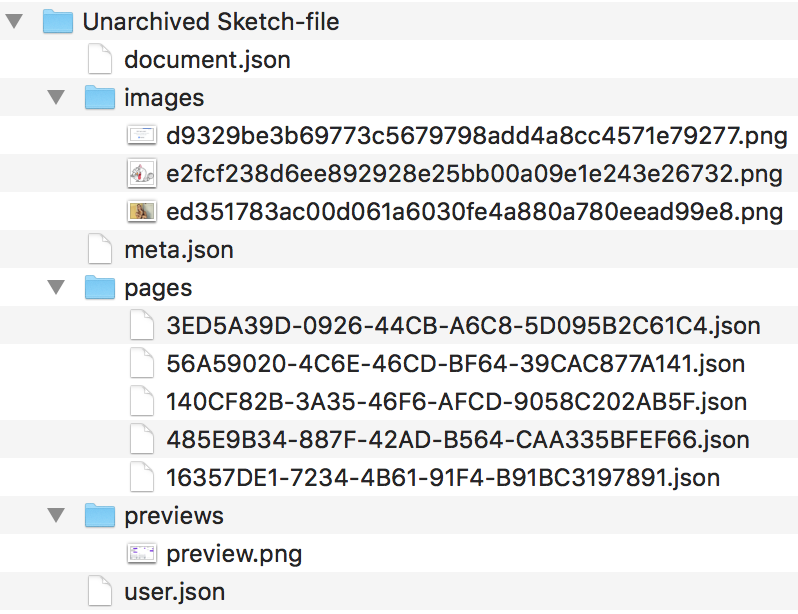
Информация о каждой Page и связанных объектах Artboard хранится в pages/*.json. Именем файла служит UUID объекта Page, каждому объекту Page соответствует один файл.
Мы можем запросто открыть любой pages/*.json и отредактировать, например, название одного из Artboards. Чтобы определить конкретный файл для редактирования, запускаем:
$ grep -l ‘iPhone 7’ pages/* И если изменить название – не проблема, то изменить, допустим, текст «Нажми меня» на кнопке уже сложнее. После блуждания по форумам и безрезультатных поисков подходящей библиотеки мы поняли, что многие другие люди тоже ищут решение.
…смерть его на конце иглы, та игла в яйце, то яйцо в утке, та утка в зайце, тот заяц в сундуке, а сундук стоит на высоком дубу...
«Царевна-лягушка»
Текст на кнопке упакован в бинарный plist, закодированный в строку Base64, являющуюся значением атрибута сериализованного JS-объекта, находящегося в одном из файлов, сжатых ZIP-ом.
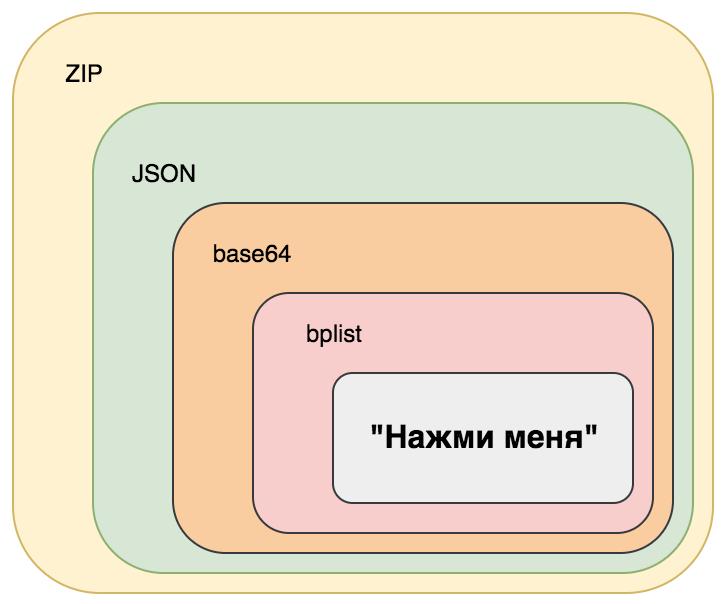
Не будем касаться вопросов разархивирования и чтения JSON из файлов, но стоит сказать о формате Property Lists (bplist на схеме выше). Чтобы модифицировать текст «Нажми меня», можно использовать утилиту plutil. Она позволяет вставить новое и удалить старое значение некоего свойства, а ещё с её помощью можно преобразовать plist из бинарного вида в XML и обратно. XML – удобный формат, для работы с ним существует множество инструментов. Также возможен экспорт в JSON, но, во-первых, при этом происходит потеря типов данных, а во-вторых, не всегда plist может быть сконвертирован в JSON. Например, с plist-ом из .sketch-файла экспорт в JSON не сработал.
Итак, мы разобрались с внутренним представлением и наконец переходим к вариантам реализации нашей задумки.
Мы пытались рассказать переводчикам про JSON, Base64 и bplist, научить их самостоятельно заменять тексты переводами и делать скриншоты. Но когда им показали консольную команду экспорта превью
$ sketchtool export artboards --items='42C53146-F9BF-4EEE-A4F8-BB489F0A3CDA,BF38A95A-F0CD-452E-BE26-E346EBD349CE' --formats=png --save-for-web example_design.sketchпоняли, что этот вариант не годится.
(Шутка, ничего переводчикам мы не рассказывали, а сразу перешли ко второму варианту).
Переводчики не должны думать о технических вопросах. Просто нужно, чтобы при сохранении перевода им был предоставлен скриншот.
Для этого мы решили разработать сервис, минимальным функционалом которого стало бы:
Проект получил название Sketch Modifier и был опубликован на GitHub.
Чтобы начать использовать Sketch Modifier, нужно установить Node.js. на macOS (где конечно уже должен быть установлен Sketch https://www.sketchapp.com/). Да, Sketch есть только под macOS. Но если ваш дизайнер работает в Sketch, то как минимум один Mac у вас есть.
Рассмотрим процесс работы со Sketch Modifier по шагам.
Находите компьютер под управлением macOS. Скачиваете и устанавливаете на него Node.js, что совсем просто.
Далее скачиваете архив или клонируете репозиторий с GitHub командой
$ git clone https://github.com/AlexTimin/sketch-modifier.gitПереходите в директорию проекта
$ cd sketch-modifierУстанавливаете зависимости с помощью npm:
$ npm installИ, наконец, запускаете сервер
$ ./bin/wwwВсё, теперь по адресу http://localhost:3000 у вас должен отзываться сервер. Можете перейти по этому адресу в браузере и проверить.
.sketch-файла и определение исходных текстовДля примера возьмем example_design.sketch и загрузим его в систему. Для этого нужно отправить запрос из директории, в которую вы сохранили example_design.sketch:
$ curl -F 'data=@example_design.sketch' http://localhost:3000/add-sketch/.sketch-файлу будет присвоен UUID. В ответ вы получите JSON следующего вида:
{
"8a2009c5-36ca-4328-87d6-16aa0c2e2800": { // присвоенный example_design.sketch UUID, у вас он будет другой
"5A0F429A-C974-460A-9482-93AED7456850": { // Page 1 UUID
"C1C29749-B967-494D-8D7E-A484EAB37534": { // iPhone SE Artboard UUID
"E335D359-9DF3-4DCC-8B79-E77E38824714": "Нажми меня" // UUID текста на кнопке
}
… // информация по другим Artboards
}
… // информация по другим Pages
}
}Можете сохранить эти данные себе в базу, отправить в /dev/null или сделать ещё что-нибудь интересное. Но мы сохраняем их в базу.
Чтобы заменить текст, нужно отправить запрос на адрес http://localhost:3000/generate-preview/ с указанием параметров screens и textReplaces. Список необходимых команд будет ниже, а пока разберёмся со структурой параметров запроса.
В параметре screens мы указываем список UUID тех Artboards, скриншоты которых хотим получить. Значение параметра имеет такую структуру:
{
Example Design UUID: [ // example_design.sketch
Artboard UUID, // iPhone SE
...
]
}В textReplaces мы указываем UUID текстовых элементов и новый текст. Значение параметра имеет такую структуру:
{
Text UUID: "новый текст, перевод",
...
}Итак, формируем запрос для генерации скриншота. Заменим текст «Нажми меня» на «Start the party!», например. Для этого нам понадобится файл generate-preview-request-data, в котором мы укажем значения параметров запроса.
Содержимое файла generate-preview-request-data:
textReplaces={
"E335D359-9DF3-4DCC-8B79-E77E38824714": "Start the party!"
}&screens={
"8a2009c5-36ca-4328-87d6-16aa0c2e2800" : [
"C1C29749-B967-494D-8D7E-A484EAB37534"
]
}Выполняем команду из директории, в которую вы сохранили файл generate-preview-request-data.
$ curl -X POST -d "@generate-preview-request-data" http://localhost:3000/generate-preview/В ответ вы получите скриншоты в Base64. Структура ответа будет такая:
{
"C1C29749-B967-494D-8D7E-A484EAB37534": "data:image/7HYUIY786GFFDASeY+...;base64",
...
}Наверное, вы догадались, что ключом в структуре ответа является UUID запрошенного скриншота, а в значении записано представление скриншота (напомню, мы запрашивали скриншот для iPhone SE) в Base64.
Если вы сохраните, допустим, в example.html следующий код с подставленным Base64-представлением картинки
а потом откроете example.html в браузере, то увидите переведённый скриншот:
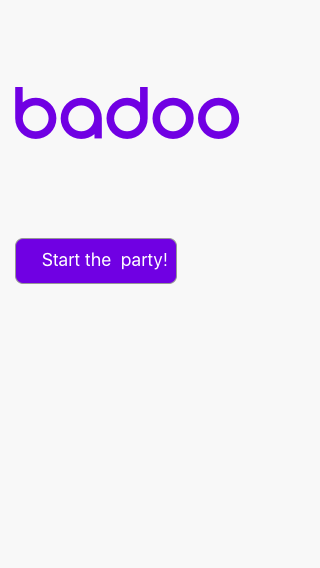
C помощью Sketch Modifier вы можете делать скриншоты до локализации, в процессе и после локализации, что очень важно. Вы будете видеть, как ведёт себя дизайн при использовании реальных текстов, и понимать, что нужно доработать.
Мы настраиваем работу со Sketch Modifier таким образом, что дизайн загружается один раз, а скриншоты генерируются при сохранении переводов. Переводчики будут сразу видеть, умещаются ли выбранные формулировки переводов в заданных областях. А значит, о проблемах будет известно заранее.
Исходный код реализации находится на GitHub.
Пользуйтесь, советуйте способы усовершенствования, пишите отзывы.
|
Метки: author aatimin программирование open source node.js javascript блог компании badoo sketch интерфейсы nodejs |
Странный символ и горячие анонсы первых дней Microsoft Ignite |

 Антон Мосягин — системный инженер в Rambler&Co, ведёт канал в Telegram с заметками для ITpro и свой блог.
Антон Мосягин — системный инженер в Rambler&Co, ведёт канал в Telegram с заметками для ITpro и свой блог.|
Метки: author Schvepsss машинное обучение microsoft azure блог компании microsoft microsoft microsoft ignite 2017 квантовые компьютеры azure |
[Перевод] Пора убить веб |

«Представители Microsoft и агентств безопасности США провели пресс-конференцию, где инструктировали пользователей скачать патч с сайта Microsoft и назвали „гражданским долгом” скачивание этого патча. CNN и другие новостные издания после распространения Code Red предупредили пользователей о необходимости установить патчи на свои системы».

Для исправления вы можете сделать несколько изменений. Любое из этих изменений предотвратит ныне возможные атаки, но если добавить несколько уровней защиты («глубокая защита»), вы защититесь от того, что какой-то из уровней не сработает в случае уязвимостей в браузере, которые найдут в будущем. Во-первых, используйте токен XSRF, как обсуждалось ранее, это гарантирует, что результаты JSON с конфиденциальными данными возвращаются только для ваших страниц. Во-вторых, ваши страницы ответа JSON должны поддерживать только запросы POST, чтобы предотвратить загрузку скрипта через тег |
|
Чем отличается проектирование станции метро от проектирования коттеджа |
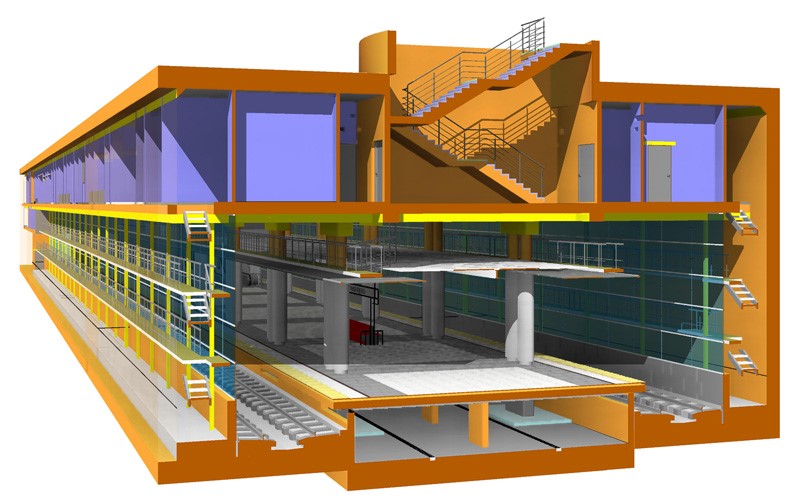


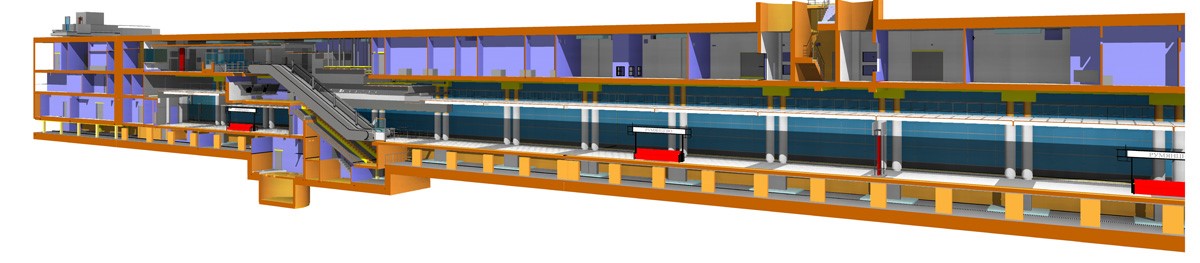










|
Метки: author RomanStepan управление проектами блог компании крок bim проектирование метро |
Из маркетолога в тестировщицу ПО — смена профессии после 40? Почему бы и нет |



|
|
Стартапы из России: дайджест Университета ИТМО |
 Мастерская-лаборатория ФабЛаб — подразделение Технопарка
Мастерская-лаборатория ФабЛаб — подразделение ТехнопаркаПоэтому мы решили создать инструмент, который позволит визуально представлять семантические данные в виде интерактивных графов.
— Дмитрий Павлов, в интервью порталу ITMO.NEWS

Люди, которые смотрят отснятый тобой материал, буквально встают на твое место. Они получают возможность поворачивать голову и смотреть на то, что ты видел сам, на что ты даже, возможно, не обратил внимания.
— Александр Морено, технический директор проекта, в интервью порталу ITMO.NEWS
В организме человека есть белки, которые ответственны за блокирование боли, например, некоторые виды эндорфинов. Когда организм ослаблен, он не может выработать этот белок в достаточном количестве. Если же ввести в организм ДНК, которая кодирует эндорфин, то его выработка увеличится, и человек перестанет чувствовать боль. Таким образом, мы не вводим в организм химическое вещество, тем более, из морфинного или опиоидного ряда.
— Илья Духовлинов, создатель компании «АТГ Сервис Ген» [источник]
|
Метки: author itmo развитие стартапа бизнес-модели блог компании университет итмо университет итмо стартапы дайджест |
Как я участвовал в bug bounty от Xiaomi и что мне за это было |

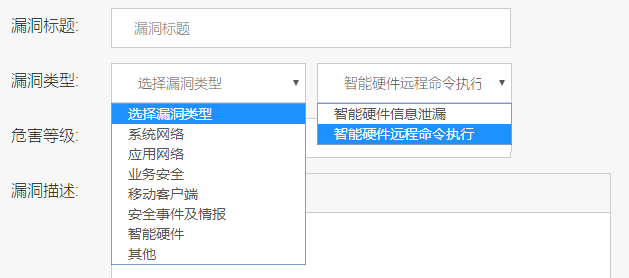



|
|
Атакуем DHCP часть 2. DHCP + WiFi = MiTM |

В данной статье я расскажу про еще один способ осуществления MiTM в WiFi сети, не самый простой, но работающий. Прежде чем читать эту статью настоятельно рекомендую ознакомиться с первой частью, в которой я попытался объяснить принцип работы протокола DHCP и как с его помощью атаковать клиентов и сервер.
Как и всегда для осуществления данной атаки есть пару ограничений:
И так как же это работает? Атака разделяется на несколько этапов:
Разберемся в этой схеме поподробнее.
Подключаемся к атакуемой WiFi сети и производим атаку DHCP Starvation с целью переполнить пул свободных IP-адресов.
Как это работает:
Формируем и отправляем широковещательный DHCPDISCOVER-запрос, при этом представляемся как DHCP relay agent. В поле giaddr (Relay agent IP) указываем свой IP-адрес 192.168.1.172, в поле chaddr (Client MAC address) — рандомный MAC 00:01:96:E5:26:FC, при этом на канальном уровне в SRC MAC выставляем свой MAC-адрес: 84:16:F9:1B:CF:F0.
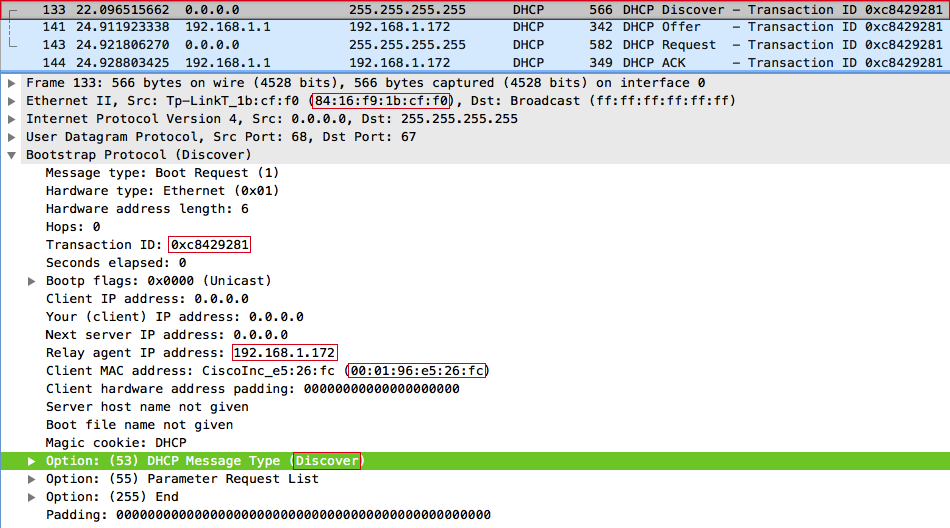
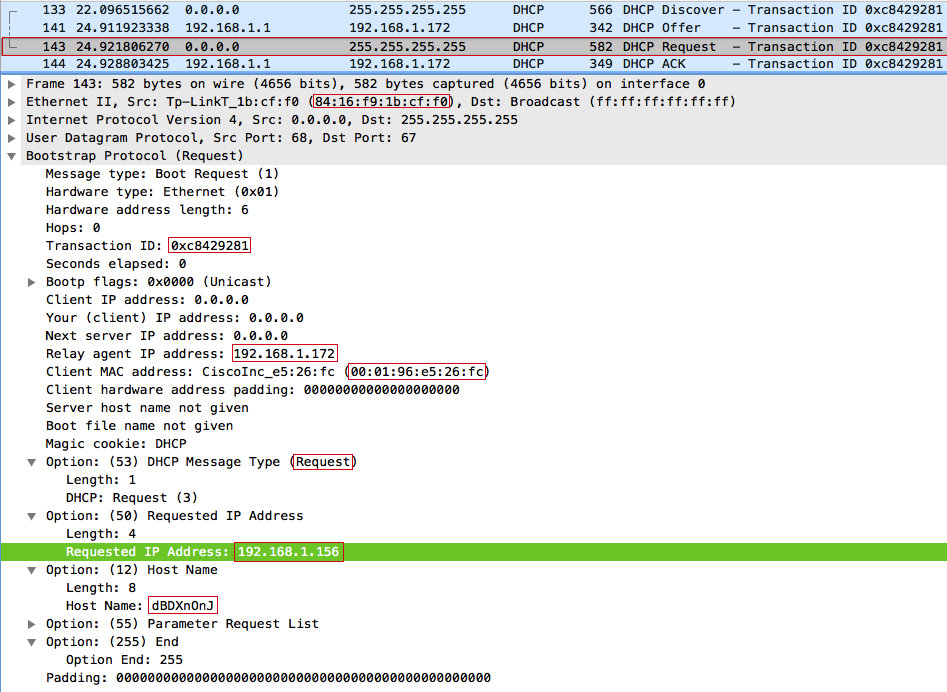
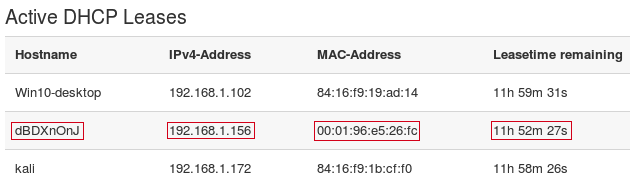
Сервер отвечает сообщением DHCPOFFER агенту ретрансляции (нам), и предлагает клиенту с MAC-адресом 00:01:96:E5:26:FC IP-адрес 192.168.1.156
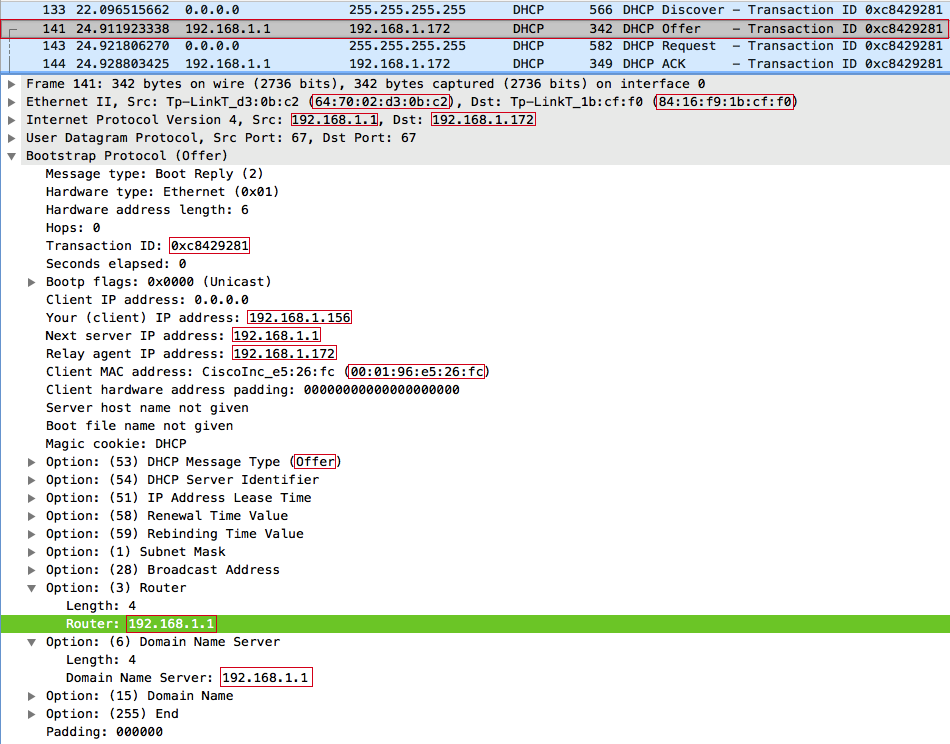
После получения DHCPOFFER, отправляем широковещательный DHCPREQUEST-запрос, при этом в DHCP-опции с кодом 50 (Requested IP address) выставляем предложений клиенту IP-адрес 192.168.1.156, в опции с кодом 12 (Host Name Option) — рандомную строку dBDXnOnJ. Важно: значения полей xid (Transaction ID) и chaddr (Client MAC address) в DHCPREQUEST и DHCPDISCOVER должны быть одинаковыми, иначе сервер отбросит запрос, ведь это будет выглядеть, как другая транзакция от того же клиента, либо другой клиент с той же транзакцией.
Следующим шагом производим Wi-Fi Deauth. Работает эта схема примерно так:

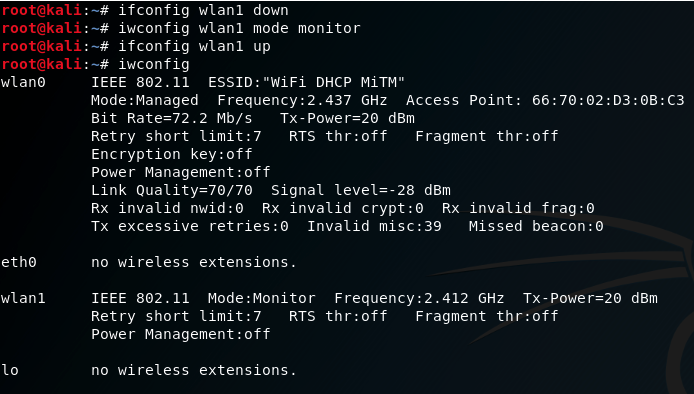
Переводим свободный беспроводной интерфейс в режим мониторинга:
Отправляем deauth пакеты с целью отсоединить атакуемого клиента 84:16:F9:19:AD:14 WiFi сети ESSID: WiFi DHCP MiTM:

После того как клиент 84:16:F9:19:AD:14 отсоединился от точки доступа, вероятнее всего, он заново попробует подключиться к WiFi сети WiFi DHCP MiTM и получить IP-адрес по DHCP. Так как ранее он уже подключались этой сети, то будет отравлять только широковещательный DHCPREQUEST.
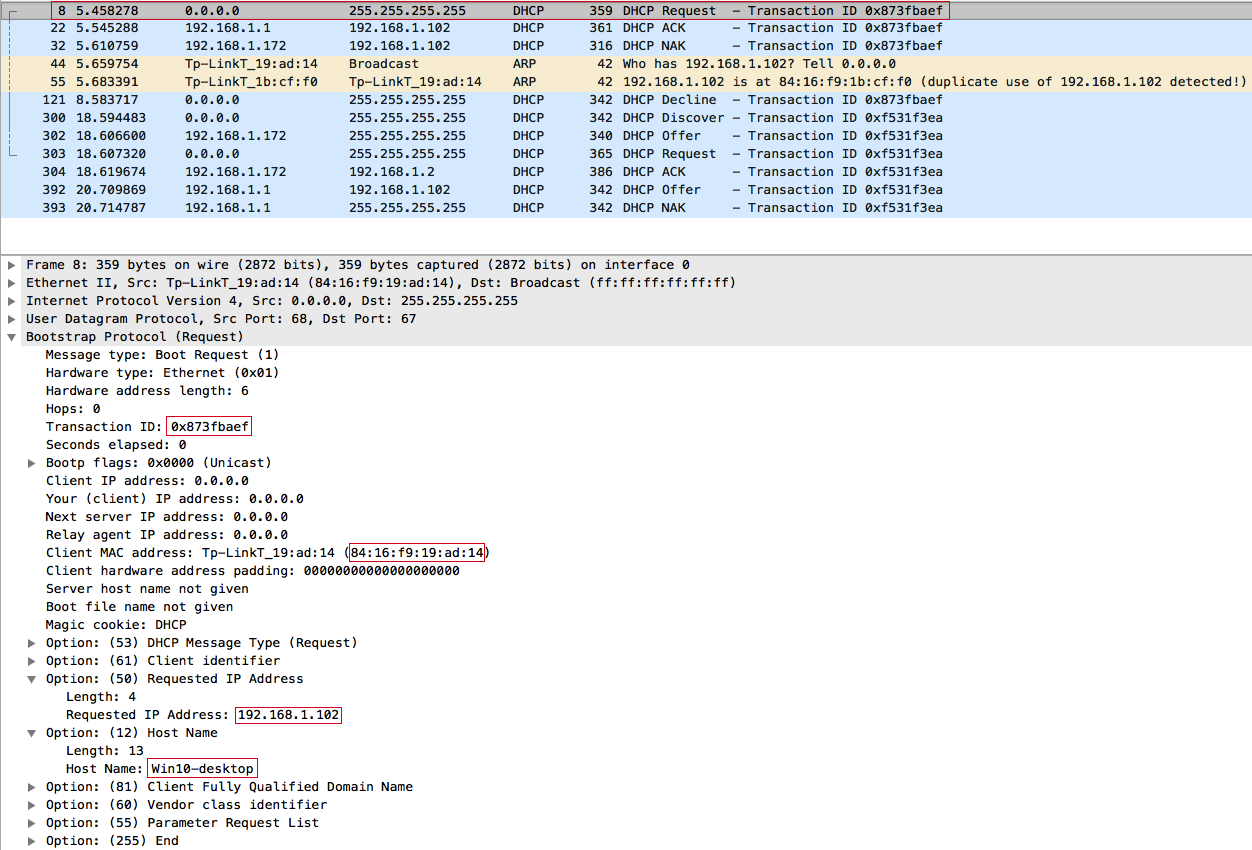
Мы перехватываем запрос клиента, но ответить быстрее точки доступа мы, само собой, не успеем. Поэтому клиент получает IP-адрес от DHCP-сервера, полученный ранее: 192.168.1.102. Далее клиент с помощью протокола ARP пытается обнаружить конфликт IP-адресов в сети:
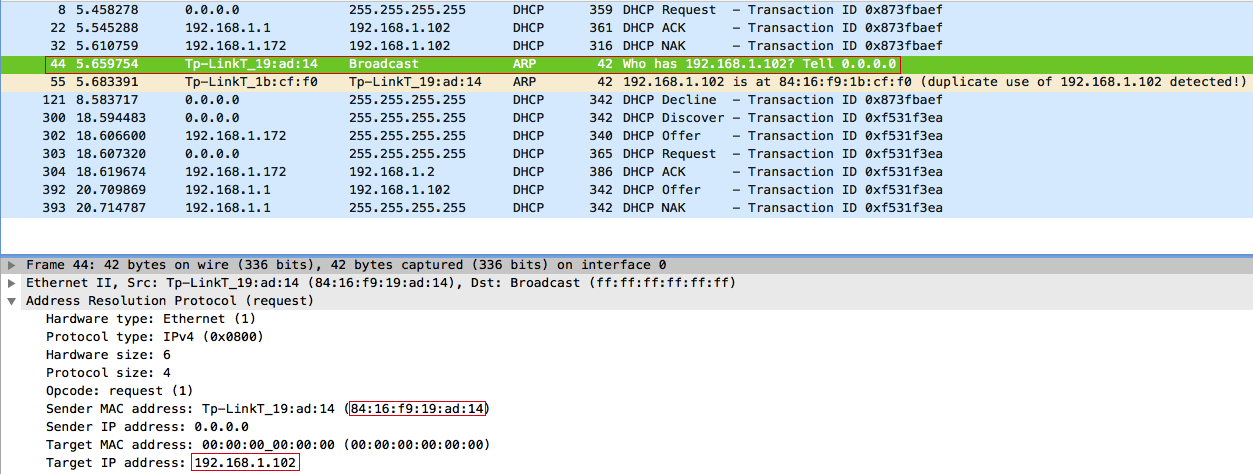
Естественно, такой запрос широковещательный, поэтому мы можем перехватить и ответить на него:
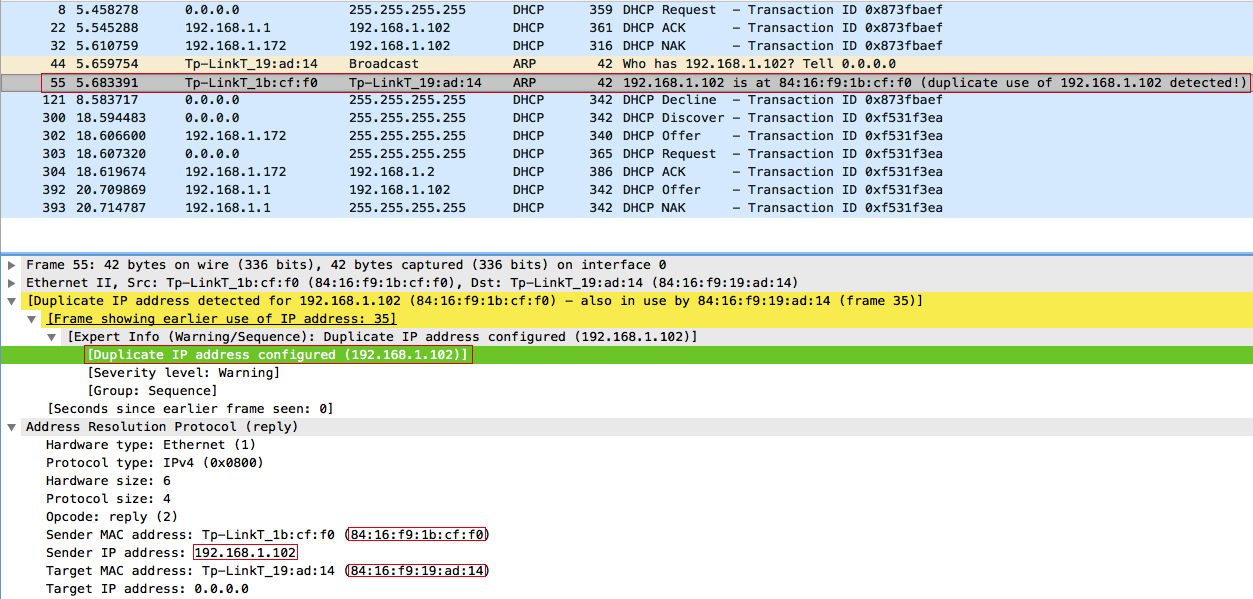
После чего клиент фиксирует конфликт IP-адресов и отправляет широковещательное сообщение отказа DHCP — DHCPDECLINE:
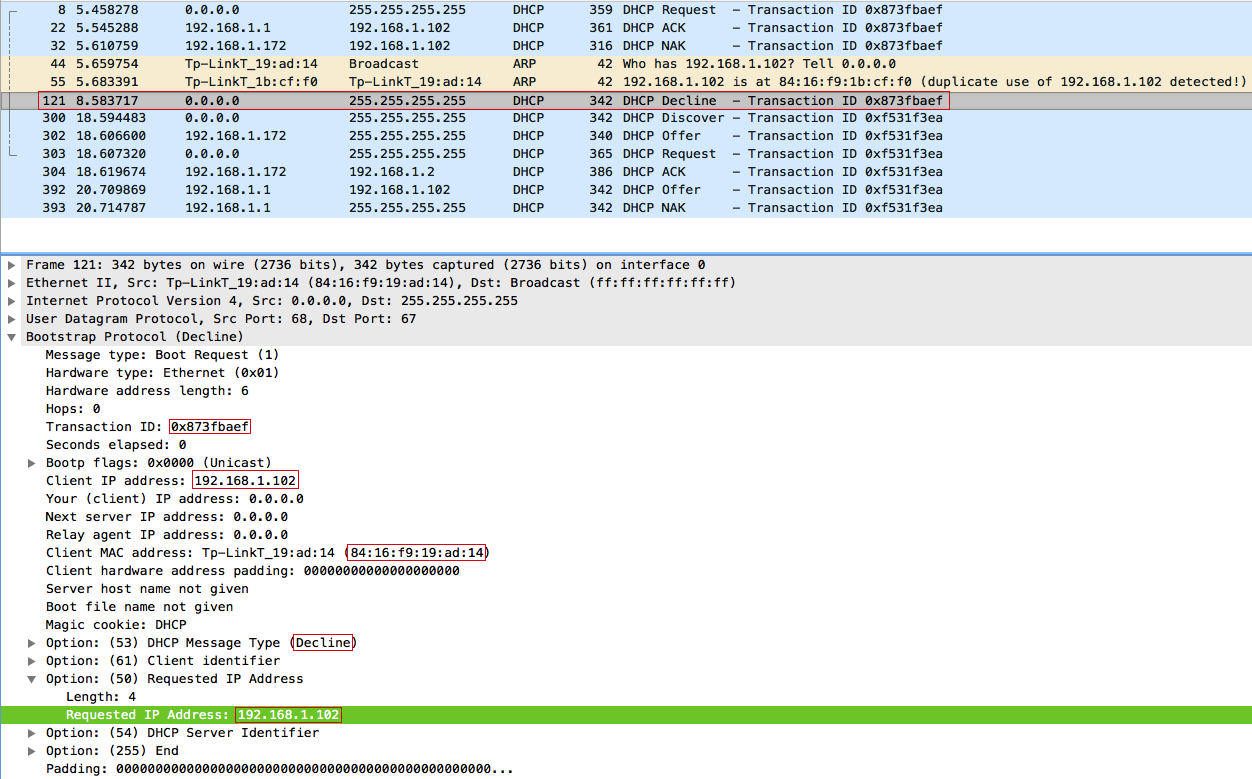
И так, последний этап атаки. После отправки DHCPDECLINE клиент с самого начала проходит процедуру получения IP-адреса, а именно отправляет широковещательный DHCPDISCOVER. Легитимный DHCP-сервер не может ответить на этот запрос, так как пул свободных IP-адресов переполнен после проведения атаки DHCP starvation и поэтому заметно тормозит, зато на DHCPDISCOVER можем ответить мы — 192.168.1.172.
Клиент 84:16:F9:19:AD:14 (Win10-desktop) отправляет широковещательный DHCPDISCOVER:

Отвечаем DHCPOFFER:
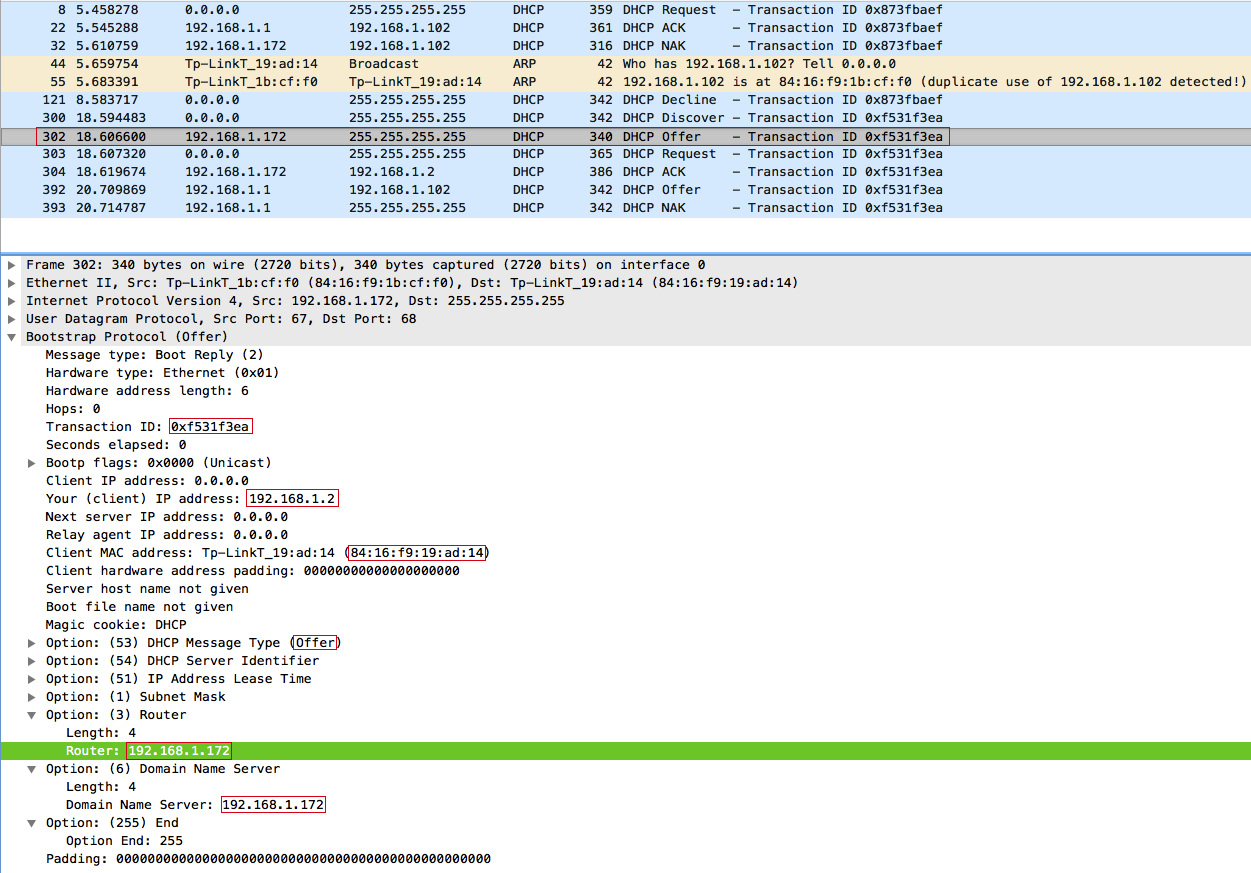
В DHCPOFFER мы предложили клиенту IP-адрес 192.168.1.2. Клиент получив данное предложение только от нас отправляет DHCPREQUEST, выставляя при этом в requested ip значение 192.168.1.2.
Клиент 84:16:F9:19:AD:14 (Win10-desktop) отправляет широковещательный DHCPREQUEST:
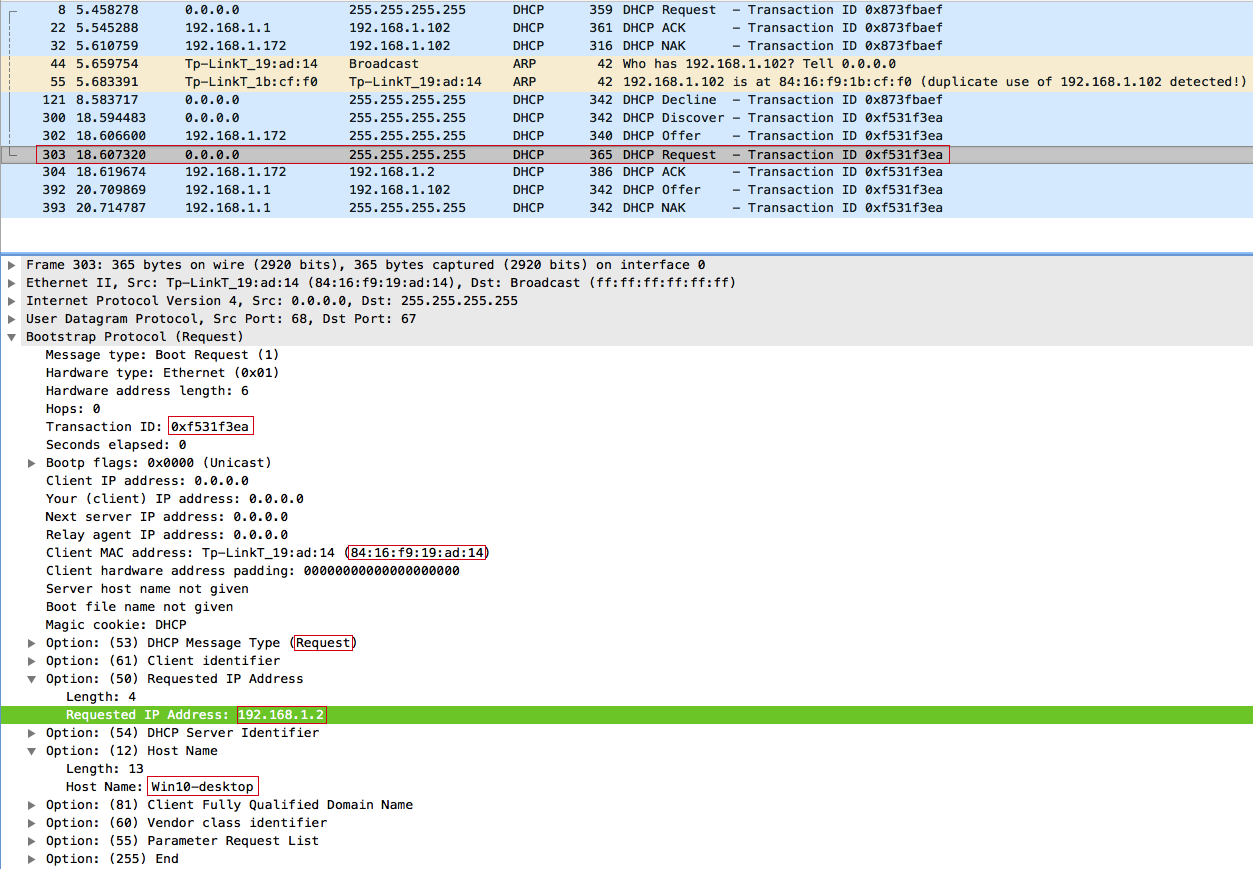
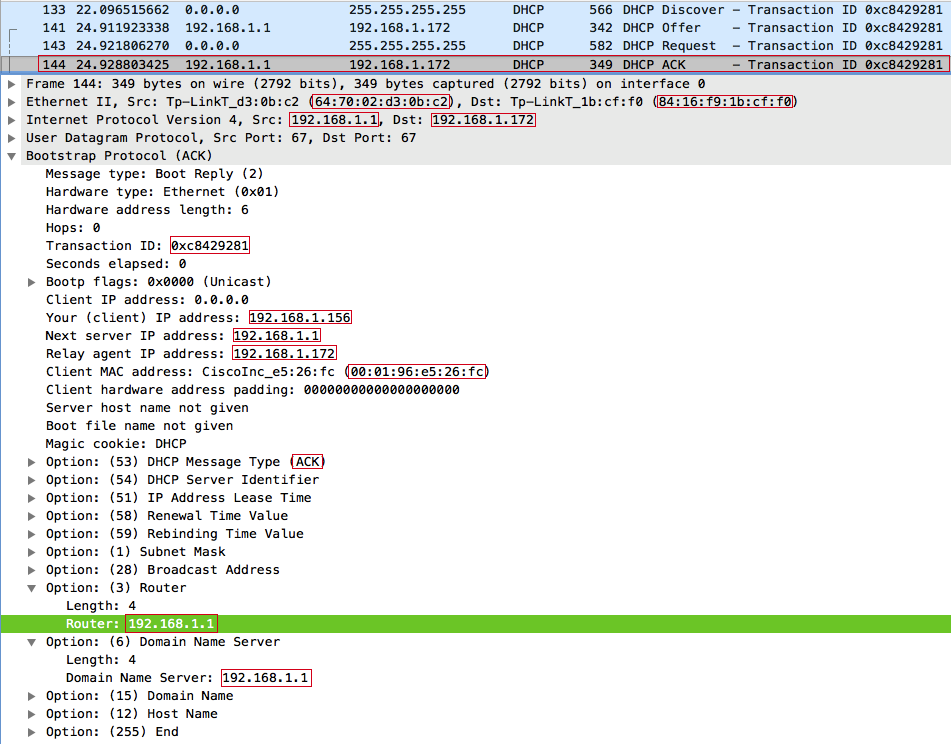
Отвечаем DHCPACK:
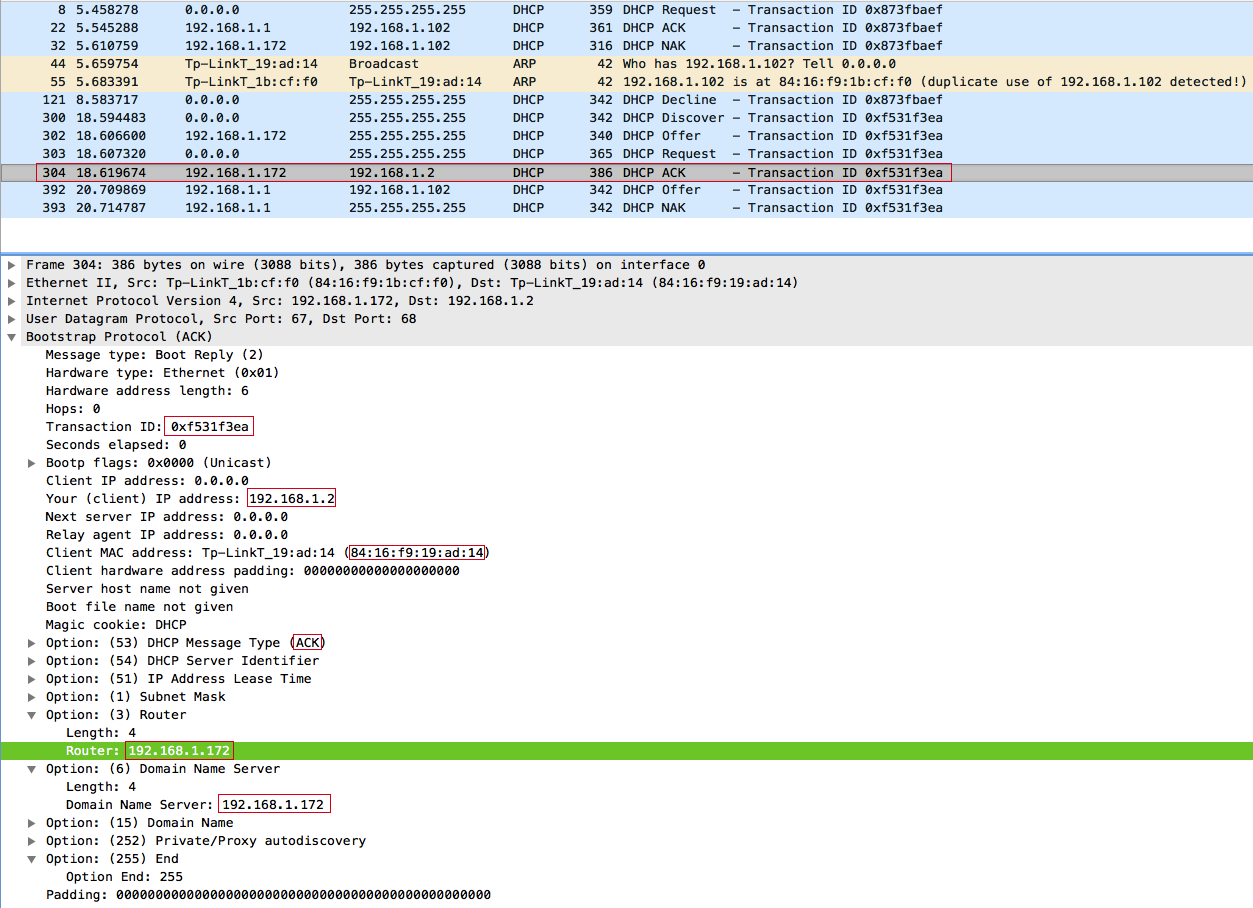
Клиент принимает наш DHCPACK и в качестве шлюза по умолчанию и DNS-сервера выставляет наш IP-адрес: 192.168.1.172, а DHCPNAK от точки доступа присланный на 2 секунды позже просто проигнорирует.
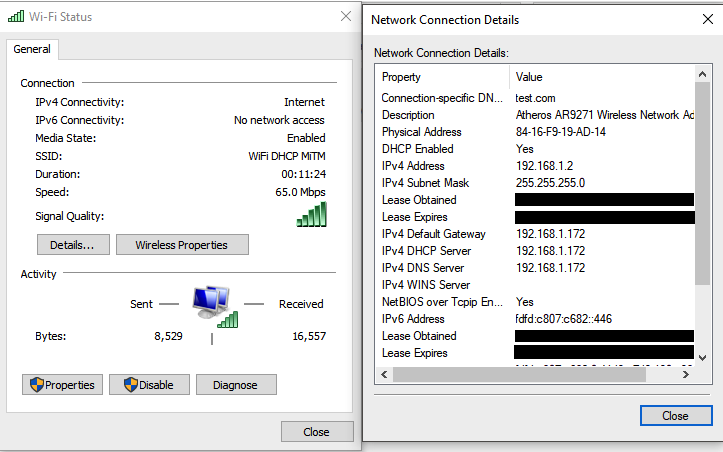
Вопрос: Почему точка доступа прислала DHCPOFFER и DHCPNAK на 2-е секунды позже, да еще и предложила тот же IP-адрес 192.168.1.102, ведь клиент отказался от него?
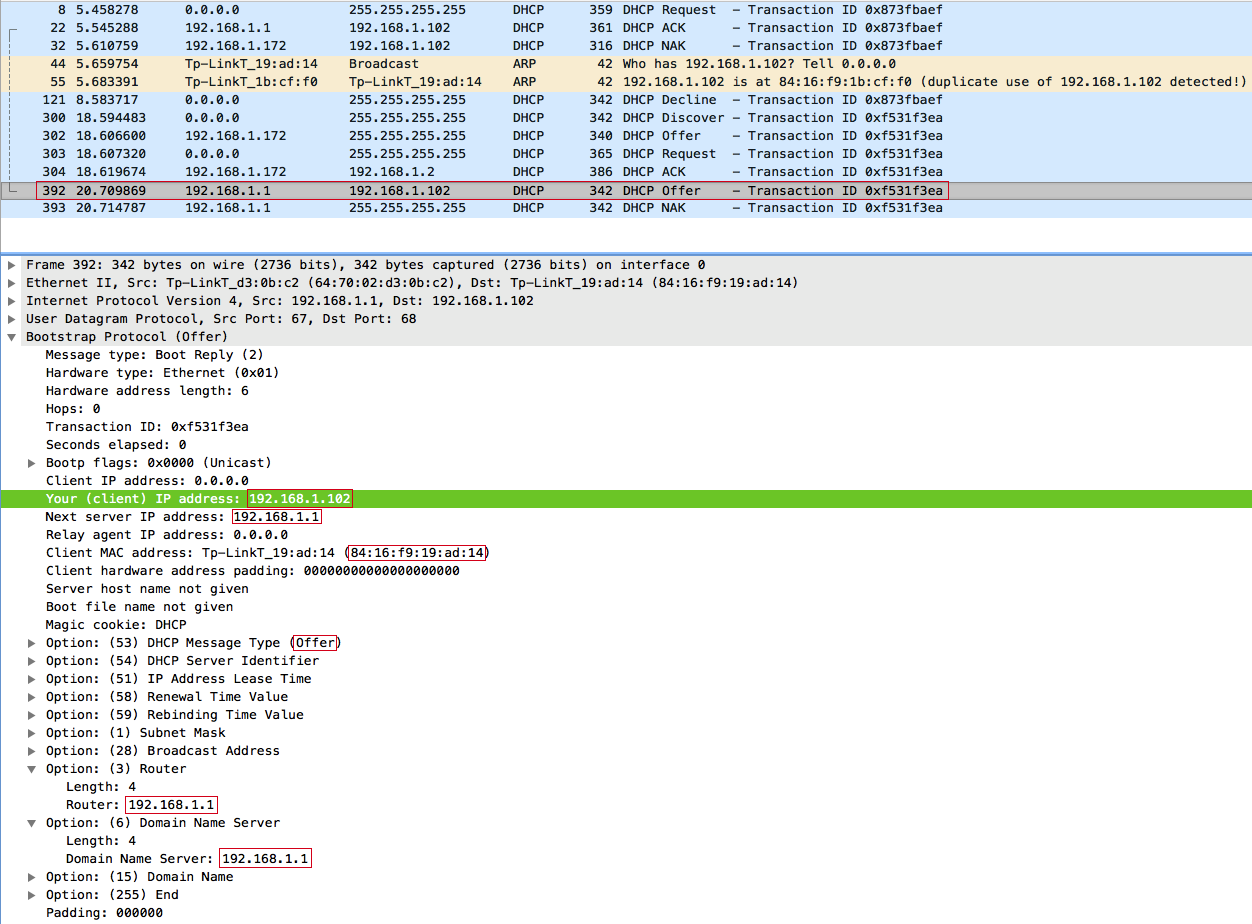
Чтобы ответить на данный вопрос немного изменим фильтр в WireShark и посмотрим ARP запросы от точки доступа:
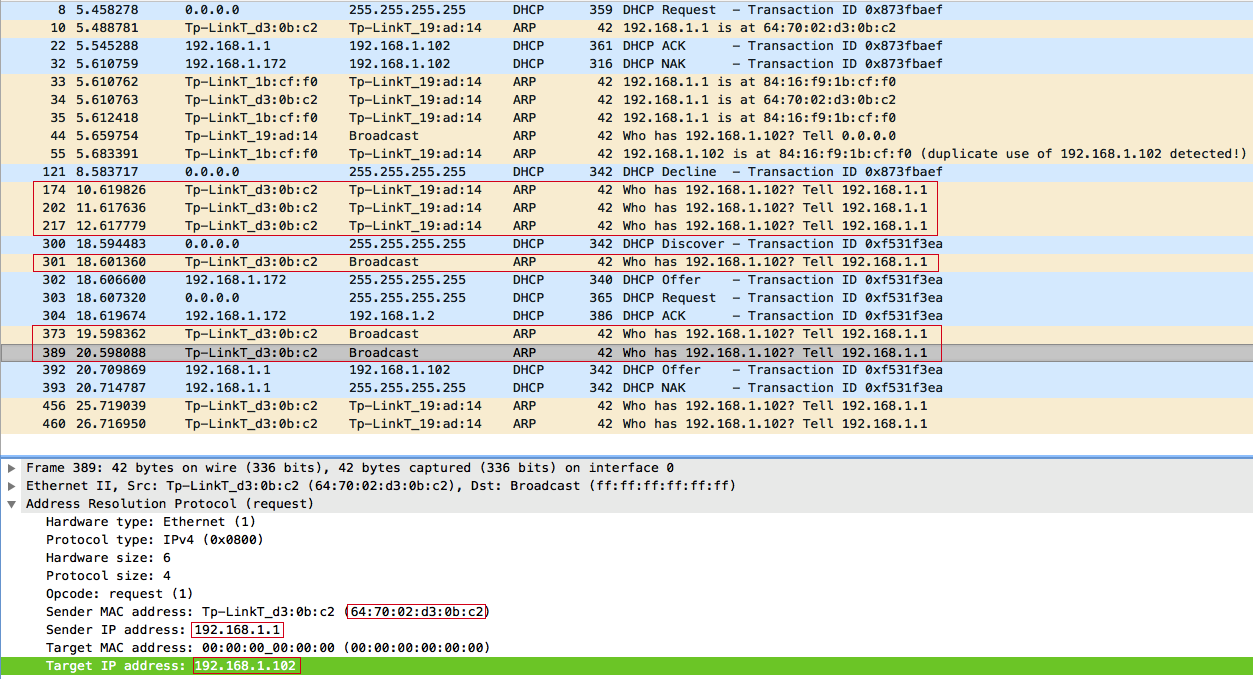
Ответ: После проведения атаки DHCP Starvation у DHCP-сервера не оказалось свободных IP-адресов, кроме того, от которого отказался один из клиентов: 192.168.1.102. Поэтому, получив DHCPDISCOVER-запрос, DHCP-сервер в течении 2-ух секунд отправляет три ARP-запроса, чтобы узнать кто использует IP-адрес: 192.168.1.102, и после того, как сервер убедился что данный IP-адрес свободен, поскольку никто не ответил, выдает его клиенту. Но уже слишком поздно злоумышленник успел ответить быстрее.
Таким образом, мы можем выставлять любые сетевые параметры, а именно: шлюз по умолчанию, DNS сервер и другие — любому подключенному или новому клиенту в атакуемой WiFi сети, при условии, что мы к ней уже подключены и можем прослушивать широковещательный трафик.
Видео проведения атаки на MacOS Siera и Windows 10:
|
Метки: author vladimir-ivanov сетевые технологии беспроводные технологии dhcp wifi mitm |
DPI-дайджест: Закон и порядок, ИБ и виртуализация |
 / Flickr / Pascal / PD
/ Flickr / Pascal / PD5 проблем NFV
VPLS для доступа к ЦОД
Сетевые платы Bypass – отказоустойчивость в сетях с DPI
Конвергенция и унификация – несколько задач на одном устройстве
Этапы проведения кибератак
Что нужно, чтобы стать инженером по ИТ-безопасности
VPN – типы подключения и проверка безопасности
Шифрованный трафик может быть классифицирован
Как безопасно обмениваться паролями в вашей сети
 / Flickr / Pascal / PD
/ Flickr / Pascal / PDФильтрация URL в рамках закона
Оповещение населения о ЧС – новая обязанность интернет-провайдера
Типовой план внедрения СОРМ-3
Что будет с интернет-провайдерами после 1 июля 2018 года
Вебинар «СОРМ-3 и фильтрация трафика»
VAS Experts на ASIA 2017 GCCM в Сингапуре
Интервью с Максимом Хижинским – C++ разработчиком системы DPI
|
Метки: author VASExperts информационная безопасность блог компании vas experts vas experts dpi bypass скат dpi |
Зачем в 2017 году писать свой движок для мобильных игр? |

|
Метки: author anz разработка игр движок мобильные игры |
Как мы делали дизайн для Биткоина |



















|
Метки: author Logomachine графический дизайн блог компании логомашина логомашина логотип биткоин дизайн |
Зачем бизнесу игры и при чем тут ЕРАМ |


|
Метки: author AliceMir разработка игр блог компании epam игры epam геймдев игры в бизнесе |
[Перевод] PowerShell для ИТ-безопасности. Часть IV: платформа безопасности с использованием скриптов |

1. Register-WmiEvent -Query "SELECT * FROM __InstanceModificationEvent WITHIN 5 WHERE TargetInstance ISA 'CIM_DataFile' and TargetInstance.Path = '\\Users\\bob\' and targetInstance.Drive = 'C:' and (targetInstance.Extension = 'doc' or targetInstance.Extension = 'txt)' and targetInstance.LastAccessed > '$($cur)' " -sourceIdentifier "Accessor" -Action $action1. Register-EngineEvent -SourceIdentifier Delta -Forward
2. While ($true) {
3. $args=Wait-Event -SourceIdentifier Access # wait on internal file event
4. Remove-Event -SourceIdentifier Access
5. if ($args.MessageData -eq "Access") {
6. #do some plain access processing
7. New-Event -SourceIdentifier Delta -EventArguments $args.SourceArgs -MessageData $args.MessageData #send event to classifier via forwarding
8. }
9. elseif ($args.MessageData -eq "Burst") {
10. #do some burst processing
11. New-Event -SourceIdentifier Delta -EventArguments $args.SourceArgs -MessageData $args.MessageData #send event to classifier via forwarding
12. }
13. }1. Register-EngineEvent -SourceIdentifier Delta -Action {
2.
3. Remove-Event -SourceIdentifier Delta
4. if($event.MessageData -eq "Access") {
5. $filename = $args[0] #got file!
6. Lock-Object $deltafile.SyncRoot{ $deltafile[$filename]=1} #lock&load
7. }
8. elseif ($event.Messagedata -eq "Burst") {
9. #do something
10. }
11.
12. }1. Import-Module -Name .\pslock.psm1 -Verbose
2. function updatecnts {
3. Param (
4. [parameter(position=1)]
5. $match,
6. [parameter(position=2)]
7. $obj
8. )
9.
10. for($j=0; $j -lt $match.Count;$j=$j+2) {
11. switch -wildcard ($match[$j]) {
12. 'Top*' { $obj| Add-Member -Force -type NoteProperty -Name Secret -Value $match[$j+1] }
13. 'Sens*' { $obj| Add-Member -Force -type NoteProperty -Name Sensitive -Value $match[$j+1] }
14. 'Numb*' { $obj| Add-Member -Force -type NoteProperty -Name Numbers -Value $match[$j+1] }
15. }
16.
17. }
18.
19. return $obj
20. }
21.
22. $scan = {
23. $name=$args[0]
24. function scan {
25. Param (
26. [parameter(position=1)]
27. [string] $Name
28. )
29. $classify =@{"Top Secret"=[regex]'[tT]op [sS]ecret'; "Sensitive"=[regex]'([Cc]onfidential)|([sS]nowflake)'; "Numbers"=[regex]'[0-9]{3}-[0-9]{2}-[0-9]{3}' }
30.
31. $data = Get-Content $Name
32.
33. $cnts= @()
34.
35. if($data.Length -eq 0) { return $cnts}
36.
37. foreach ($key in $classify.Keys) {
38.
39. $m=$classify[$key].matches($data)
40.
41. if($m.Count -gt 0) {
42. $cnts+= @($key,$m.Count)
43. }
44. }
45. $cnts
46. }
47. scan $name
48. }
49.
50.
51. $outarray = @() #where I keep classification stats
52. $deltafile = [hashtable]::Synchronized(@{}) #hold file events for master loop
53.
54. $list=Get-WmiObject -Query "SELECT * From CIM_DataFile where Path = '\\Users\\bob\' and Drive = 'C:' and (Extension = 'txt' or Extension = 'doc' or Extension = 'rtf')"
55.
56.
57. #long list --let's multithread
58.
59. #runspace
60. $RunspacePool = [RunspaceFactory]::CreateRunspacePool(1,5)
61. $RunspacePool.Open()
62. $Tasks = @()
63.
64.
65. foreach ($item in $list) {
66.
67. $Task = [powershell]::Create().AddScript($scan).AddArgument($item.Name)
68. $Task.RunspacePool = $RunspacePool
69.
70. $status= $Task.BeginInvoke()
71. $Tasks += @($status,$Task,$item.Name)
72. }
73.
74.
75. Register-EngineEvent -SourceIdentifier Delta -Action {
76.
77. Remove-Event -SourceIdentifier Delta
78. if($event.MessageData -eq "Access") {
79. $filename = $args[0] #got file
80. Lock-Object $deltafile.SyncRoot{ $deltafile[$filename]=1} #lock& load
81. }
82. elseif ($event.Messagedata -eq "Burst") {
83. #do something
84. }
85. }
86.
87. while ($Tasks.isCompleted -contains $false){
88.
89. }
90.
91. #check results of tasks
92. for ($i=0; $i -lt $Tasks.Count; $i=$i+3){
93. $match=$Tasks[$i+1].EndInvoke($Tasks[$i])
94.
95.
96. if ($match.Count -gt 0) { # update clasafication array
97. $obj = New-Object System.Object
98. $obj | Add-Member -type NoteProperty -Name File -Value $Tasks[$i+2]
99. #defaults
100. $obj| Add-Member -type NoteProperty -Name Secret -Value 0
101. $obj| Add-Member -type NoteProperty -Name Sensitive -Value 0
102. $obj| Add-Member -type NoteProperty -Name Numbers -Value 0
103.
104. $obj=updatecnts $match $obj
105. $outarray += $obj
106. }
107. $Tasks[$i+1].Dispose()
108.
109. }
110.
111. $outarray | Out-GridView -Title "Content Classification" #display
112.
113. #run event handler as a separate job
114. Start-Job -Name EventHandler -ScriptBlock({C:\Users\bob\Documents\evhandler.ps1}) #run event handler in background
115.
116.
117. while ($true) { #the master executive loop
118.
119.
120. Start-Sleep -seconds 10
121. Lock-Object $deltafile.SyncRoot { #lock and iterate through synchronized list
122. foreach ($key in $deltafile.Keys) {
123.
124. $filename=$key
125.
126. if($deltafile[$key] -eq 0) { continue} #nothing new
127.
128. $deltafile[$key]=0
129. $match = & $scan $filename #run scriptblock
130. #incremental part
131.
132. $found=$false
133. $class=$false
134. if($match.Count -gt 0)
135. {$class =$true} #found sensitive data
136. if($outarray.File -contains $filename)
137. {$found = $true} #already in the array
138. if (!$found -and !$class){continue}
139.
140. #let's add/update
141. if (!$found) {
142.
143. $obj = New-Object System.Object
144. $obj | Add-Member -type NoteProperty -Name File -Value $Tasks[$i+2]
145. #defaults
146. $obj| Add-Member -type NoteProperty -Name Secret -Value 0
147. $obj| Add-Member -type NoteProperty -Name Sensitive -Value 0
148. $obj| Add-Member -type NoteProperty -Name Numbers -Value 0
149.
150. $obj=updatecnts $match $obj
151.
152. }
153. else {
154. $outarray|? {$_.File -eq $filename} | % { updatecnts $match $_}
155. }
156. $outarray | Out-GridView -Title "Content Classification ( $(get-date -format M/d/yy:HH:MM) )"
157.
158. } #foreach
159.
160. } #lock
161. }#while
162.
163. Write-Host "Done!"|
Метки: author Alexandra_Varonis информационная безопасность big data блог компании varonis systems varonis powershell хранение данных |
Числа — расшифровка доклада Дагласа Крокфорда с HolyJS 2017 Piter |

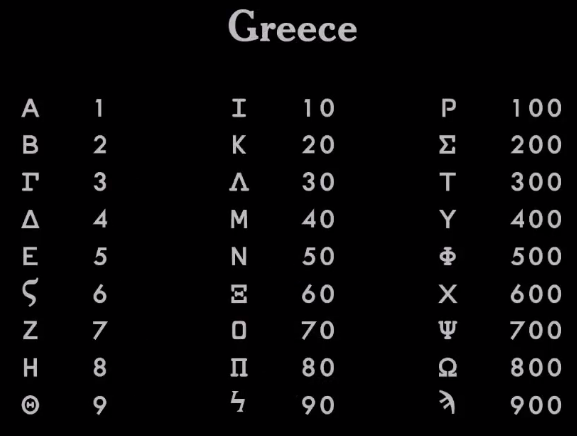

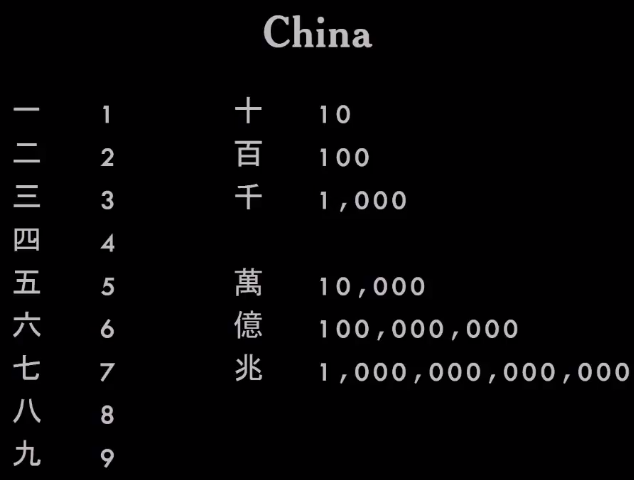








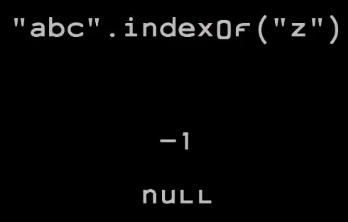
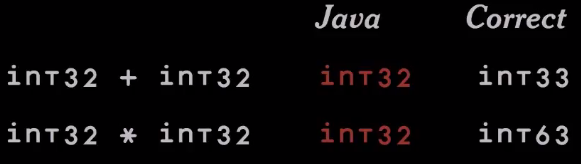

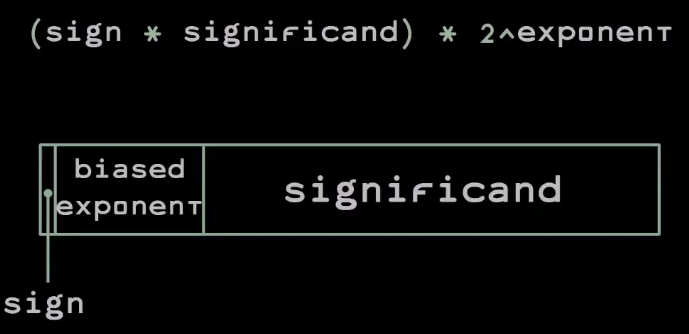
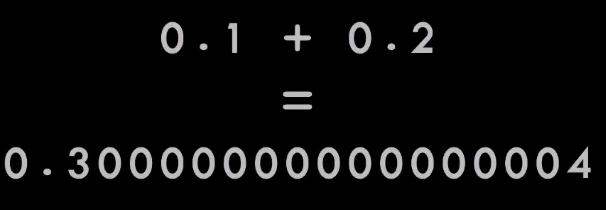
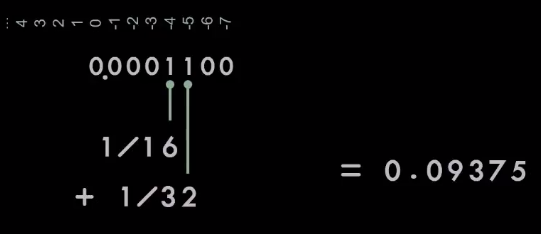




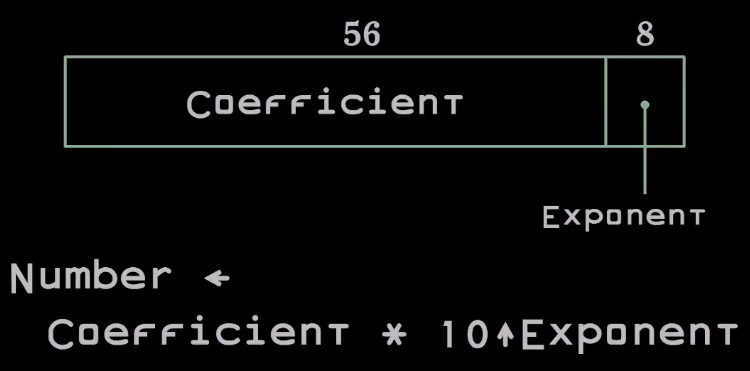





|
Метки: author ARG89 программирование математика javascript it- стандарты блог компании jug.ru group системы счисления |
Числа — расшифровка доклада Дагласа Крокфорда с HolyJS 2017 Piter |
|
Метки: author ARG89 программирование математика javascript it- стандарты блог компании jug.ru group системы счисления |
11 инструментов повышения личной продуктивности, которые помогут вам не профакапить дедлайн |












|
Метки: author SmirkinDA управление разработкой управление проектами управление продуктом управление персоналом блог компании parallels deadline time management it runer parallels |






