11 инструментов повышения личной продуктивности, которые помогут вам не профакапить дедлайн |












|
Метки: author SmirkinDA управление разработкой управление проектами управление продуктом управление персоналом блог компании parallels deadline time management it runer parallels |
[Перевод] Ticket Trick: взлом сотен компаний через службы поддержки пользователей |
|
Метки: author ru_vds тестирование веб-сервисов информационная безопасность .net блог компании ruvds.com безопасность служба поддержки баг-трекер взлом |
[Перевод] Ticket Trick: взлом сотен компаний через службы поддержки пользователей |
|
Метки: author ru_vds тестирование веб-сервисов информационная безопасность .net блог компании ruvds.com безопасность служба поддержки баг-трекер взлом |
MBLTdev 2017: хардкорные доклады по Android-разработке |

|
|
MBLTdev 2017: хардкорные доклады по Android-разработке |
|
|
Компьютерная криминалистика (форензика): подборка полезных ссылок |

Для того чтобы успешно проводить расследования инцидентов информационной безопасности необходимо обладать практическими навыками работы с инструментами по извлечению цифровых артефактов. В этой статье будет представлен список полезных ссылок и инструментов для проведения работ по сбору цифровых доказательств.
Основная цель при проведении таких работ — использование методов и средств для сохранения (неизменности), сбора и анализа цифровых вещественных доказательств, для того чтобы восстановить события инцидента.
Термин "forensics" является сокращенной формой "forensic science", дословно "судебная наука", то есть наука об исследовании доказательств — именно то, что в русском именуется криминалистикой. Русский термин "форензика" означает не всякую криминалистику, а именно компьютерную.
Некоторые авторы разделяют компьютерную криминалистику (computer forensics) и сетевую криминалистику (network forensic).
Основная сфера применения форензики — анализ и расследование событий, в которых фигурируют компьютерная информация как объект посягательств, компьютер как орудие совершения преступления, а также какие-либо цифровые доказательства.
Для полноценного сбора и анализа информации используются различные узкоспециализированные утилиты, которые будут рассмотрены ниже. Хочу предупредить, что при проведении работ по заключению в том или уголовном деле скорее всего будет рассматриваться наличие тех или иных сертификатов и соответствий ПО (лицензии ФСТЭК). В этом случае придется использовать комбинированные методы по сбору и анализу информации, либо писать выводы и заключение на основании полученных данных из несертифицированных источников.
Для проведения работ по исследованию и сбору цифровых доказательств необходимо придерживаться принципов неизменности, целостности, полноты информации и ее надежности. Для этого необходимо следовать рекомендациям к ПО и методам проведения расследований. В следующей статье я приведу примеры практического использования утилит для анализа образов памяти.
|
Метки: author LukaSafonov информационная безопасность блог компании pentestit форензика |
Компьютерная криминалистика (форензика): подборка полезных ссылок |
Для того чтобы успешно проводить расследования инцидентов информационной безопасности необходимо обладать практическими навыками работы с инструментами по извлечению цифровых артефактов. В этой статье будет представлен список полезных ссылок и инструментов для проведения работ по сбору цифровых доказательств.
Основная цель при проведении таких работ — использование методов и средств для сохранения (неизменности), сбора и анализа цифровых вещественных доказательств, для того чтобы восстановить события инцидента.
Термин "forensics" является сокращенной формой "forensic science", дословно "судебная наука", то есть наука об исследовании доказательств — именно то, что в русском именуется криминалистикой. Русский термин "форензика" означает не всякую криминалистику, а именно компьютерную.
Некоторые авторы разделяют компьютерную криминалистику (computer forensics) и сетевую криминалистику (network forensic).
Основная сфера применения форензики — анализ и расследование событий, в которых фигурируют компьютерная информация как объект посягательств, компьютер как орудие совершения преступления, а также какие-либо цифровые доказательства.
Для полноценного сбора и анализа информации используются различные узкоспециализированные утилиты, которые будут рассмотрены ниже. Хочу предупредить, что при проведении работ по заключению в том или уголовном деле скорее всего будет рассматриваться наличие тех или иных сертификатов и соответствий ПО (лицензии ФСТЭК). В этом случае придется использовать комбинированные методы по сбору и анализу информации, либо писать выводы и заключение на основании полученных данных из несертифицированных источников.
Для проведения работ по исследованию и сбору цифровых доказательств необходимо придерживаться принципов неизменности, целостности, полноты информации и ее надежности. Для этого необходимо следовать рекомендациям к ПО и методам проведения расследований. В следующей статье я приведу примеры практического использования утилит для анализа образов памяти.
|
Метки: author LukaSafonov информационная безопасность блог компании pentestit форензика |
[Перевод] Создание синтезатора звуковых эффектов из ретро-игр |
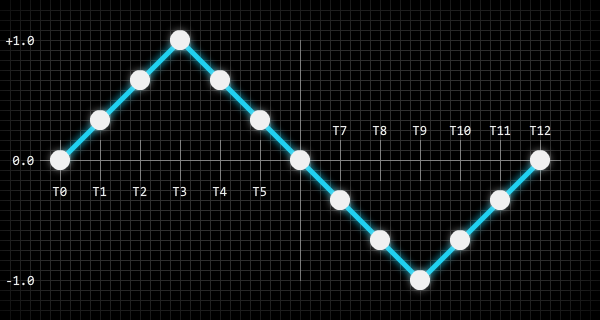
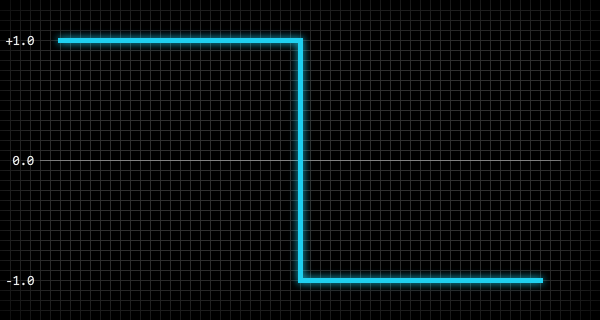
n — количество значений, необходимых для заполнения массива, a — массив, p — нормализованное положение внутри волны:var i:int = 0;
var n:int = 100;
var p:Number;
while( i < n ) {
p = i / n;
a[i] = p < 0.5 ? 1.0 : -1.0;
i ++;
}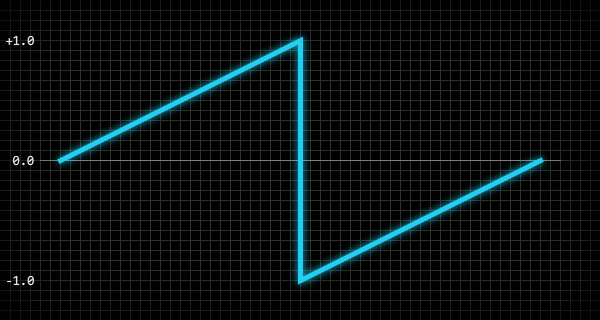
n — количество значений, необходимых для заполнения массива, a — массив, p — нормализованное положение внутри волны:var i:int = 0;
var n:int = 100;
var p:Number;
while( i < n ) {
p = i / n;
a[i] = p < 0.5 ? p * 2.0 : p * 2.0 - 2.0;
i ++;
}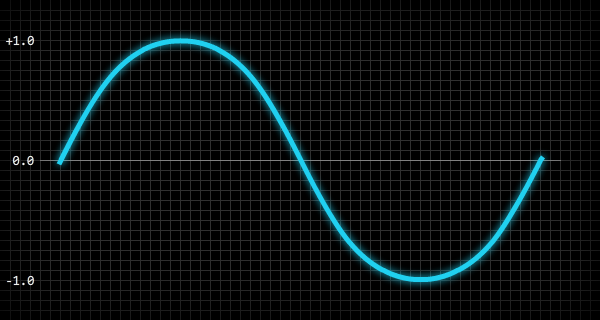
n — количество значений, необходимых для заполнения массива, a — массив, p — нормализованное положение внутри волны:var i:int = 0;
var n:int = 100;
var p:Number;
while( i < n ) {
p = i / n;
a[i] = Math.sin( p * 2.0 * Math.PI );
i ++;
}
n — количество значений, необходимых для заполнения массива, a — массив, p — нормализованное положение внутри волны:var i:int = 0;
var n:int = 100;
var p:Number;
while( i < n ) {
p = i / n;
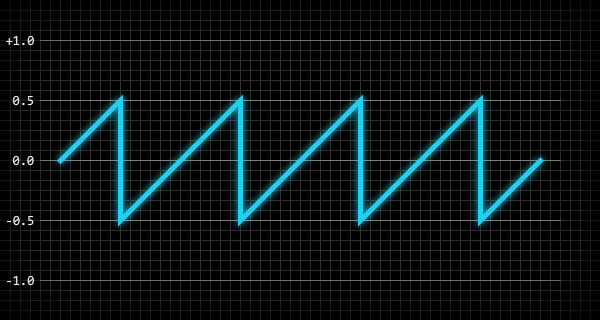
a[i] = p < 0.25 ? p * 4.0 : p < 0.75 ? 2.0 - p * 4.0 : p * 4.0 - 4.0;
i ++;
}if (p < 0.25) {
a[i] = p * 4.0;
}
else if (p < 0.75) {
a[i] = 2.0 - (p * 4.0);
}
else {
a[i] = (p * 4.0) - 4.0;
}
f = Math.pow( 2, n / 12 ) * 440.0;n в этом коде — это количество нот от A4 до интересующей нас ноты. Например, чтобы найти частоту ля второй октавы (A5), на одну октаву выше A4, нам нужно присвоить n значение 12, потому что A5 на 12 нот выше A4. Чтобы найти частоту ми большой октавы (E2), нам нужно присвоить n значение -5, потому что E2 на 5 нот ниже A4. Можно также сделать обратную операцию и найти ноту (относительно A4) по заданной частоте:n = Math.round( 12.0 * Math.log( f / 440.0 ) * Math.LOG2E );bitsPerSample = bitRate / sampleRate;trace( 705600 / 44100 ); // "16"noise, а затем добавим в этот пакет следующей класс:package noise {
public final class AudioWaveform {
static public const PULSE:int = 0;
static public const SAWTOOTH:int = 1;
static public const SINE:int = 2;
static public const TRIANGLE:int = 3;
}
}true или false в зависимости от правильности значения волны.static public function validate( waveform:int ):Boolean {
if( waveform == PULSE ) return true;
if( waveform == SAWTOOTH ) return true;
if( waveform == SINE ) return true;
if( waveform == TRIANGLE ) return true;
return false;
}public function AudioWaveform() {
throw new Error( "AudioWaveform class cannot be instantiated" );
}Audio. По своей природе этот класс схож с нативным классом ActionScript 3.0 Sound, каждый аудиодвижок будет представлен как экземпляр класса Audio.noise следующий скелет класса:package noise {
public class Audio {
public function Audio() {}
}
}private var m_waveform:int = AudioWaveform.PULSE;
private var m_frequency:Number = 100.0;
private var m_amplitude:Number = 0.5;
private var m_duration:Number = 0.2;
private var m_release:Number = 0.2;amplitude — это значение в интервале от 0.0 до 1.0, frequency указывается в Гц, а duration и release — в секундах.private var m_frequencyModulator:AudioModulator = null;
private var m_amplitudeModulator:AudioModulator = null;Audio должен содержать несколько внутренних свойств, к которым будет иметь доступ только класс AudioEngine (его мы вскоре напишем). Эти свойства не нужно прятать за геттерами/сеттерами:internal var position:Number = 0.0;
internal var playing:Boolean = false;
internal var releasing:Boolean = false;
internal var samples:Vector. = null; position задаётся в секундах и позволяет классу AudioEngine отслеживать положение звука при его воспроизведении. Это необходимо для вычисления звуковых сэмплов волны. Свойства playing и releasing сообщают классу AudioEngine, в каком состоянии находится звук, а свойство samples является ссылкой на кэшированные сэмплы волн, используемые звуком. Как используются эти свойства, мы поймём, когда напишем класс AudioEngine.Audio, нужно добавить геттеры/сеттеры:Audio.waveformpublic final function get waveform():int {
return m_waveform;
}
public final function set waveform( value:int ):void {
if( AudioWaveform.isValid( value ) == false ) {
return;
}
switch( value ) {
case AudioWaveform.PULSE: samples = AudioEngine.PULSE; break;
case AudioWaveform.SAWTOOTH: samples = AudioEngine.SAWTOOTH; break;
case AudioWaveform.SINE: samples = AudioEngine.SINE; break;
case AudioWaveform.TRIANGLE: samples = AudioEngine.TRIANGLE; break;
}
m_waveform = value;
}Audio.frequency[Inline]
public final function get frequency():Number {
return m_frequency;
}
public final function set frequency( value:Number ):void {
// ограничиваем frequency интервалом 1.0 - 14080.0
m_frequency = value < 1.0 ? 1.0 : value > 14080.0 ? 14080.0 : value;
}Audio.amplitude[Inline]
public final function get amplitude():Number {
return m_amplitude;
}
public final function set amplitude( value:Number ):void {
// ограничиваем amplitude интервалом 0.0 - 1.0
m_amplitude = value < 0.0 ? 0.0 : value > 1.0 ? 1.0 : value;
}Audio.duration[Inline]
public final function get duration():Number {
return m_duration;
}
public final function set duration( value:Number ):void {
// ограничиваем duration интервалом 0.0 - 60.0
m_duration = value < 0.0 ? 0.0 : value > 60.0 ? 60.0 : value;
}Audio.release[Inline]
public final function get release():Number {
return m_release;
}
public function set release( value:Number ):void {
// ограничиваем время release интервалом 0.0 - 10.0
m_release = value < 0.0 ? 0.0 : value > 10.0 ? 10.0 : value;
}Audio.frequencyModulator[Inline]
public final function get frequencyModulator():AudioModulator {
return m_frequencyModulator;
}
public final function set frequencyModulator( value:AudioModulator ):void {
m_frequencyModulator = value;
}Audio.amplitudeModulator[Inline]
public final function get amplitudeModulator():AudioModulator {
return m_amplitudeModulator;
}
public final function set amplitudeModulator( value:AudioModulator ):void {
m_amplitudeModulator = value;
}[Inline], связанную с некоторыми из функций геттеров. Эта метка метаданных — особенность ActionScript 3.0 Compiler, и делает она именно то, что следует из её названия: она встраивает (расширяет) содержимое функции. При разумном использовании эта особенность невероятно полезна при оптимизации, а задача генерирования динамического аудиосигнала во время выполнения программы оптимизации точно требует.AudioModulator — обеспечить возможность модуляции амплитуды и частоты экземпляров Audio для создания разнообразных полезных эффектов. Модуляторы на самом деле похожи на экземпляры Audio, у них есть форма волны, амплитуда и частота, но они не создают никакого слышимого звука, а только модифицируют другие звуки.noise следующий скелет класса:package noise {
public class AudioModulator {
public function AudioModulator() {}
}
}private var m_waveform:int = AudioWaveform.SINE;
private var m_frequency:Number = 4.0;
private var m_amplitude:Number = 1.0;
private var m_shift:Number = 0.0;
private var m_samples:Vector. = null; Audio, то вы не ошибаетесь: здесь всё то же самое, за исключением свойства shift.shift, вспомните одну из базовых волн, используемых аудиодвижком (пульсовую, пилообразную, синусоидальную или треугольную) и представьте вертикальную линию, проходящую через волну в любом месте. Горизонтальное положение этой вертикальной линии будет значением shift; это значение в интервале от 0.0 до 1.0, сообщающее модулятору, откуда нужно начинать считывать волну. В свою очередь, она имеет абсолютное влияние на модификации, вносимые модулятором в амплитуду или частоту звука.shift имеет значение 0.0, то частота звука сначала увеличится, а потом опустится в соответствии с кривизной синусоиды. Однако если shift задать значение 0.5, то частота звука сначала уменьшится, а потому увеличится.AudioModulator содержит один внутренний метод, используемый только AudioEngine. Метод имеет следующий вид:[Inline]
internal final function process( time:Number ):Number {
var p:int = 0;
var s:Number = 0.0;
if( m_shift != 0.0 ) {
time += ( 1.0 / m_frequency ) * m_shift;
}
p = ( 44100 * m_frequency * time ) % 44100;
s = m_samples[p];
return s * m_amplitude;
}AudioModulator, нужно добавить геттеры/сеттеры:AudioModulator.waveformpublic function get waveform():int {
return m_waveform;
}
public function set waveform( value:int ):void {
if( AudioWaveform.isValid( value ) == false ) {
return;
}
switch( value ) {
case AudioWaveform.PULSE: m_samples = AudioEngine.PULSE; break;
case AudioWaveform.SAWTOOTH: m_samples = AudioEngine.SAWTOOTH; break;
case AudioWaveform.SINE: m_samples = AudioEngine.SINE; break;
case AudioWaveform.TRIANGLE: m_samples = AudioEngine.TRIANGLE; break;
}
m_waveform = value;
}AudioModulator.frequencypublic function get frequency():Number {
return m_frequency;
}
public function set frequency( value:Number ):void {
// ограничиваем frequency интервалом 0.01 - 100.0
m_frequency = value < 0.01 ? 0.01 : value > 100.0 ? 100.0 : value;
}AudioModulator.amplitudepublic function get amplitude():Number {
return m_amplitude;
}
public function set amplitude( value:Number ):void {
// ограничиваем amplitude интервалом 0.0 - 8000.0
m_amplitude = value < 0.0 ? 0.0 : value > 8000.0 ? 8000.0 : value;
}AudioModulator.shiftpublic function get shift():Number {
return m_shift;
}
public function set shift( value:Number ):void {
// ограничиваем shift интервалом 0.0 - 1.0
m_shift = value < 0.0 ? 0.0 : value > 1.0 ? 1.0 : value;
}AudioModulator можно считать завершённым.AudioEngine. Это полностью статичный класс. Он управляет почти всем, что связано с экземлярами Audio и генерированием звука.noise:package noise {
import flash.events.SampleDataEvent;
import flash.media.Sound;
import flash.media.SoundChannel;
import flash.utils.ByteArray;
//
public final class AudioEngine {
public function AudioEngine() {
throw new Error( "AudioEngine class cannot be instantiated" );
}
}
}final, потому что нет причин расширять полностью статичный класс.static internal const PULSE:Vector. = new Vector.( 44100 );
static internal const SAWTOOTH:Vector. = new Vector.( 44100 );
static internal const SINE:Vector. = new Vector.( 44100 );
static internal const TRIANGLE:Vector. = new Vector.( 44100 ); static private const BUFFER_SIZE:int = 2048;
static private const SAMPLE_TIME:Number = 1.0 / 44100.0;BUFFER_SIZE — это количество звуковых сэмплов, передаваемых звуковому API ActionScript 3.0 при совершении запроса звуковых сэмплов. Это наименьшее допустимое количество сэмплов, которое обеспечивает наименьшую возможную латентность звука. Количество сэмплов можно увеличить, чтобы снизить уровень нагрузки на ЦП, но это увеличит латентность звука. SAMPLE_TIME — это длительность одного звукового сэмпла в секундах.static private var m_position:Number = 0.0;
static private var m_amplitude:Number = 0.5;
static private var m_soundStream:Sound = null;
static private var m_soundChannel:SoundChannel = null;
static private var m_audioList:Vector.m_position используется для отслеживания потокового времени звука в секундах.m_amplitude — это глобальная вторичная амплитуда для всех воспроизводимых экземпляров Audio.m_soundStream и m_soundChannel не требуют объяснений.m_audioList содержит ссылки на все воспроизводимые экземпляры Audio.m_sampleList — это временный буфер, используемый для хранения звуковых сэмплов, когда они запрашиваются звуковым API ActionScript 3.0.static private function $AudioEngine():void {
var i:int = 0;
var n:int = 44100;
var p:Number = 0.0;
//
while( i < n ) {
p = i / n;
SINE[i] = Math.sin( Math.PI * 2.0 * p );
PULSE[i] = p < 0.5 ? 1.0 : -1.0;
SAWTOOTH[i] = p < 0.5 ? p * 2.0 : p * 2.0 - 2.0;
TRIANGLE[i] = p < 0.25 ? p * 4.0 : p < 0.75 ? 2.0 - p * 4.0 : p * 4.0 - 4.0;
i++;
}
//
m_soundStream = new Sound();
m_soundStream.addEventListener( SampleDataEvent.SAMPLE_DATA, onSampleData );
m_soundChannel = m_soundStream.play();
}
$AudioEngine();AudioEngine имеет три общих метода, используемых для воспроизведения и остановки экземпляров Audio:AudioEngine.play()static public function play( audio:Audio ):void {
if( audio.playing == false ) {
m_audioList.push( audio );
}
// это позволяет нам точно знать, когда было запущено воспроизведение звука
audio.position = m_position - ( m_soundChannel.position * 0.001 );
audio.playing = true;
audio.releasing = false;
}AudioEngine.stop()static public function stop( audio:Audio, allowRelease:Boolean = true ):void {
if( audio.playing == false ) {
// звук не воспроизводится
return;
}
if( allowRelease ) {
// переход к концу звука и установка флага затухания
audio.position = audio.duration;
audio.releasing = true;
return;
}
audio.playing = false;
audio.releasing = false;
}AudioEngine.stopAll()static public function stopAll( allowRelease:Boolean = true ):void {
var i:int = 0;
var n:int = m_audioList.length;
var o:Audio = null;
//
if( allowRelease ) {
while( i < n ) {
o = m_audioList[i];
o.position = o.duration;
o.releasing = true;
i++;
}
return;
}
while( i < n ) {
o = m_audioList[i];
o.playing = false;
o.releasing = false;
i++;
}
}AudioEngine.onSampleData()static private function onSampleData( event:SampleDataEvent ):void {
var i:int = 0;
var n:int = BUFFER_SIZE;
var s:Number = 0.0;
var b:ByteArray = event.data;
//
if( m_soundChannel == null ) {
while( i < n ) {
b.writeFloat( 0.0 );
b.writeFloat( 0.0 );
i++;
}
return;
}
//
generateSamples();
//
while( i < n ) {
s = m_sampleList[i] * m_amplitude;
b.writeFloat( s );
b.writeFloat( s );
m_sampleList[i] = 0.0;
i++;
}
//
m_position = m_soundChannel.position * 0.001;
}if мы проверяем, по-прежнему ли m_soundChannel имеет значение null. Это нужно нам, потому что событие SAMPLE_DATA отправляется сразу при вызове метода m_soundStream.play() и ещё до того, как метод получит возможность вернуть экземпляр SoundChannel.while обходит звуковые сэмплы, запрошенные m_soundStream и записывает их в экземпляр ByteArray. Звуковые сэмплы генерируются следующим методом:AudioEngine.generateSamples()static private function generateSamples():void {
var i:int = 0;
var n:int = m_audioList.length;
var j:int = 0;
var k:int = BUFFER_SIZE;
var p:int = 0;
var f:Number = 0.0;
var a:Number = 0.0;
var s:Number = 0.0;
var o:Audio = null;
// обход экземпляров audio
while( i < n ) {
o = m_audioList[i];
//
if( o.playing == false ) {
// экземпляр audio полностью остановлен
m_audioList.splice( i, 1 );
n--;
continue;
}
//
j = 0;
// генерирование и буферизация звуковых сэмплов
while( j < k ) {
if( o.position < 0.0 ) {
// экземпляр audio ещё не начал воспроизведение
o.position += SAMPLE_TIME;
j++;
continue;
}
if( o.position >= o.duration ) {
if( o.position >= o.duration + o.release ) {
// экземпляр audio остановлен
o.playing = false;
j++;
continue;
}
// экземпляр audio в процессе затухания
o.releasing = true;
}
// получение частоты и амплитуды экземпляра audio
f = o.frequency;
a = o.amplitude;
//
if( o.frequencyModulator != null ) {
// модуляция частоты
f += o.frequencyModulator.process( o.position );
}
//
if( o.amplitudeModulator != null ) {
// модуляция амплитуды
a += o.amplitudeModulator.process( o.position );
}
// вычисление положения в кэше волн
p = ( 44100 * f * o.position ) % 44100;
// получение сэмпла волны
s = o.samples[p];
//
if( o.releasing ) {
// вычисление амплитуды затухания для сэмпла
s *= 1.0 - ( ( o.position - o.duration ) / o.release );
}
// добавление сэмпла в буфер
m_sampleList[j] += s * a;
// обновление положения экземпляра audio
o.position += SAMPLE_TIME;
j++;
}
i++;
}
}m_amplitude:static public function get amplitude():Number {
return m_amplitude;
}
static public function set amplitude( value:Number ):void {
// ограничение amplitude интервалом 0.0 - 1.0
m_amplitude = value < 0.0 ? 0.0 : value > 1.0 ? 1.0 : value;
}package noise {
public class AudioProcessor {
//
public var enabled:Boolean = true;
//
public function AudioProcessor() {
if( Object(this).constructor == AudioProcessor ) {
throw new Error( "AudioProcessor class must be extended" );
}
}
//
internal function process( samples:Vector. ):void {}
}
} process(), вызываемый классом AudioEngine, когда необходимо обработать сэмплы, и общее свойство enabled, которое можно использовать для включения и выключения процессора.AudioDelay — это класс, создающий сам дилэй звука. Он расширяет класс AudioProcessor. Вот скелет пустого класса, с которым мы будем работать:package noise {
public class AudioDelay extends AudioProcessor {
//
public function AudioDelay( time:Number = 0.5 ) {
this.time = time;
}
}
}time, передаваемый конструктору класса, — это время (в секундах) последовательности дилэя, то есть количество времени между каждым дилэем звука.private var m_buffer:Vector. = new Vector.();
private var m_bufferSize:int = 0;
private var m_bufferIndex:int = 0;
private var m_time:Number = 0.0;
private var m_gain:Number = 0.8; m_buffer — это цикл обратной связи: он содержит все звуковые сэмплы, передаваемые методу process, и эти сэмплы постоянно модифицируются (в нашем случае снижается их амплитуда) в процессе прохода m_bufferIndex через буфер. Это будет иметь смысл, когда мы доберёмся до метода process().m_bufferSize и m_bufferIndex используются для отслеживания состояния буфера. Свойство m_time — это время последовательности дилэя в секундах. Свойство m_gain — это множитель, используемый для уменьшения со временем амплитуды буферизированных звуковых сэмплов.process(), переопределяющий метод process() в классе AudioProcessor:internal override function process( samples:Vector. ):void {
var i:int = 0;
var n:int = samples.length;
var v:Number = 0.0;
//
while( i < n ) {
v = m_buffer[m_bufferIndex]; // получение буферизированного сэмпла
v *= m_gain; // снижение амплитуды
v += samples[i]; // добавление нового сэмпла
//
m_buffer[m_bufferIndex] = v;
m_bufferIndex++;
//
if( m_bufferIndex == m_bufferSize ) {
m_bufferIndex = 0;
}
//
samples[i] = v;
i++;
}
} m_time и m_gain:public function get time():Number {
return m_time;
}
public function set time( value:Number ):void {
// ограничиваем time интервалом 0.0001 - 8.0
value = value < 0.0001 ? 0.0001 : value > 8.0 ? 8.0 : value;
// если time не изменилось, нет необходимости изменять размер буфера
if( m_time == value ) {
return;
}
// задаём time
m_time = value;
// обновляет размер буфера
m_bufferSize = Math.floor( 44100 * m_time );
m_buffer.length = m_bufferSize;
}public function get gain():Number {
return m_gain;
}
public function set gain( value:Number ):void {
// ограничиваем gain интервалом 0.0 - 1.0
m_gain = value < 0.0 ? 0.0 : value > 1.0 ? 1.0 : value;
}AudioDelay завершён. На самом деле реализация дилэев звука очень проста, если понять, как работае цикл обратной связи (свойство m_buffer).AudioEngineAudioEngine, чтобы к нему можно было добавлять аудиопроцессоры. Во-первых, давайте добавим вектор для хранения экземпляров аудиопроцессора:static private var m_processorList:Vector. = new Vector.(); AudioEngine, нужно также использовать два общих метода:AudioEngine.addProcessor()static public function addProcessor( processor:AudioProcessor ):void {
if( m_processorList.indexOf( processor ) == -1 ) {
m_processorList.push( processor );
}
}AudioEngine.removeProcessor()static public function removeProcessor( processor:AudioProcessor ):void {
var i:int = m_processorList.indexOf( processor );
if( i != -1 ) {
m_processorList.splice( i, 1 );
}
}AudioProcessor из вектора m_processorList.process():static private function processSamples():void {
var i:int = 0;
var n:int = m_processorList.length;
//
while( i < n ) {
if( m_processorList[i].enabled ) {
m_processorList[i].process( m_sampleList );
}
i++;
}
}onSampleData() класса AudioEngine:if( m_soundChannel == null ) {
while( i < n ) {
b.writeFloat( 0.0 );
b.writeFloat( 0.0 );
i++;
}
return;
}
//
generateSamples();
processSamples();
//
while( i < n ) {
s = m_sampleList[i] * m_amplitude;
b.writeFloat( s );
b.writeFloat( s );
m_sampleList[i] = 0.0;
i++;
}processSamples();. Она просто вызывает метод processSamples(), который мы добавили ранее.|
Метки: author PatientZero разработка игр adobe flash audio engine звуковой движок обработка звука |
[Перевод] Создание синтезатора звуковых эффектов из ретро-игр |
n — количество значений, необходимых для заполнения массива, a — массив, p — нормализованное положение внутри волны:var i:int = 0;
var n:int = 100;
var p:Number;
while( i < n ) {
p = i / n;
a[i] = p < 0.5 ? 1.0 : -1.0;
i ++;
}n — количество значений, необходимых для заполнения массива, a — массив, p — нормализованное положение внутри волны:var i:int = 0;
var n:int = 100;
var p:Number;
while( i < n ) {
p = i / n;
a[i] = p < 0.5 ? p * 2.0 : p * 2.0 - 2.0;
i ++;
}n — количество значений, необходимых для заполнения массива, a — массив, p — нормализованное положение внутри волны:var i:int = 0;
var n:int = 100;
var p:Number;
while( i < n ) {
p = i / n;
a[i] = Math.sin( p * 2.0 * Math.PI );
i ++;
}n — количество значений, необходимых для заполнения массива, a — массив, p — нормализованное положение внутри волны:var i:int = 0;
var n:int = 100;
var p:Number;
while( i < n ) {
p = i / n;
a[i] = p < 0.25 ? p * 4.0 : p < 0.75 ? 2.0 - p * 4.0 : p * 4.0 - 4.0;
i ++;
}if (p < 0.25) {
a[i] = p * 4.0;
}
else if (p < 0.75) {
a[i] = 2.0 - (p * 4.0);
}
else {
a[i] = (p * 4.0) - 4.0;
}f = Math.pow( 2, n / 12 ) * 440.0;n в этом коде — это количество нот от A4 до интересующей нас ноты. Например, чтобы найти частоту ля второй октавы (A5), на одну октаву выше A4, нам нужно присвоить n значение 12, потому что A5 на 12 нот выше A4. Чтобы найти частоту ми большой октавы (E2), нам нужно присвоить n значение -5, потому что E2 на 5 нот ниже A4. Можно также сделать обратную операцию и найти ноту (относительно A4) по заданной частоте:n = Math.round( 12.0 * Math.log( f / 440.0 ) * Math.LOG2E );bitsPerSample = bitRate / sampleRate;trace( 705600 / 44100 ); // "16"noise, а затем добавим в этот пакет следующей класс:package noise {
public final class AudioWaveform {
static public const PULSE:int = 0;
static public const SAWTOOTH:int = 1;
static public const SINE:int = 2;
static public const TRIANGLE:int = 3;
}
}true или false в зависимости от правильности значения волны.static public function validate( waveform:int ):Boolean {
if( waveform == PULSE ) return true;
if( waveform == SAWTOOTH ) return true;
if( waveform == SINE ) return true;
if( waveform == TRIANGLE ) return true;
return false;
}public function AudioWaveform() {
throw new Error( "AudioWaveform class cannot be instantiated" );
}Audio. По своей природе этот класс схож с нативным классом ActionScript 3.0 Sound, каждый аудиодвижок будет представлен как экземпляр класса Audio.noise следующий скелет класса:package noise {
public class Audio {
public function Audio() {}
}
}private var m_waveform:int = AudioWaveform.PULSE;
private var m_frequency:Number = 100.0;
private var m_amplitude:Number = 0.5;
private var m_duration:Number = 0.2;
private var m_release:Number = 0.2;amplitude — это значение в интервале от 0.0 до 1.0, frequency указывается в Гц, а duration и release — в секундах.private var m_frequencyModulator:AudioModulator = null;
private var m_amplitudeModulator:AudioModulator = null;Audio должен содержать несколько внутренних свойств, к которым будет иметь доступ только класс AudioEngine (его мы вскоре напишем). Эти свойства не нужно прятать за геттерами/сеттерами:internal var position:Number = 0.0;
internal var playing:Boolean = false;
internal var releasing:Boolean = false;
internal var samples:Vector. = null; position задаётся в секундах и позволяет классу AudioEngine отслеживать положение звука при его воспроизведении. Это необходимо для вычисления звуковых сэмплов волны. Свойства playing и releasing сообщают классу AudioEngine, в каком состоянии находится звук, а свойство samples является ссылкой на кэшированные сэмплы волн, используемые звуком. Как используются эти свойства, мы поймём, когда напишем класс AudioEngine.Audio, нужно добавить геттеры/сеттеры:Audio.waveformpublic final function get waveform():int {
return m_waveform;
}
public final function set waveform( value:int ):void {
if( AudioWaveform.isValid( value ) == false ) {
return;
}
switch( value ) {
case AudioWaveform.PULSE: samples = AudioEngine.PULSE; break;
case AudioWaveform.SAWTOOTH: samples = AudioEngine.SAWTOOTH; break;
case AudioWaveform.SINE: samples = AudioEngine.SINE; break;
case AudioWaveform.TRIANGLE: samples = AudioEngine.TRIANGLE; break;
}
m_waveform = value;
}Audio.frequency[Inline]
public final function get frequency():Number {
return m_frequency;
}
public final function set frequency( value:Number ):void {
// ограничиваем frequency интервалом 1.0 - 14080.0
m_frequency = value < 1.0 ? 1.0 : value > 14080.0 ? 14080.0 : value;
}Audio.amplitude[Inline]
public final function get amplitude():Number {
return m_amplitude;
}
public final function set amplitude( value:Number ):void {
// ограничиваем amplitude интервалом 0.0 - 1.0
m_amplitude = value < 0.0 ? 0.0 : value > 1.0 ? 1.0 : value;
}Audio.duration[Inline]
public final function get duration():Number {
return m_duration;
}
public final function set duration( value:Number ):void {
// ограничиваем duration интервалом 0.0 - 60.0
m_duration = value < 0.0 ? 0.0 : value > 60.0 ? 60.0 : value;
}Audio.release[Inline]
public final function get release():Number {
return m_release;
}
public function set release( value:Number ):void {
// ограничиваем время release интервалом 0.0 - 10.0
m_release = value < 0.0 ? 0.0 : value > 10.0 ? 10.0 : value;
}Audio.frequencyModulator[Inline]
public final function get frequencyModulator():AudioModulator {
return m_frequencyModulator;
}
public final function set frequencyModulator( value:AudioModulator ):void {
m_frequencyModulator = value;
}Audio.amplitudeModulator[Inline]
public final function get amplitudeModulator():AudioModulator {
return m_amplitudeModulator;
}
public final function set amplitudeModulator( value:AudioModulator ):void {
m_amplitudeModulator = value;
}[Inline], связанную с некоторыми из функций геттеров. Эта метка метаданных — особенность ActionScript 3.0 Compiler, и делает она именно то, что следует из её названия: она встраивает (расширяет) содержимое функции. При разумном использовании эта особенность невероятно полезна при оптимизации, а задача генерирования динамического аудиосигнала во время выполнения программы оптимизации точно требует.AudioModulator — обеспечить возможность модуляции амплитуды и частоты экземпляров Audio для создания разнообразных полезных эффектов. Модуляторы на самом деле похожи на экземпляры Audio, у них есть форма волны, амплитуда и частота, но они не создают никакого слышимого звука, а только модифицируют другие звуки.noise следующий скелет класса:package noise {
public class AudioModulator {
public function AudioModulator() {}
}
}private var m_waveform:int = AudioWaveform.SINE;
private var m_frequency:Number = 4.0;
private var m_amplitude:Number = 1.0;
private var m_shift:Number = 0.0;
private var m_samples:Vector. = null; Audio, то вы не ошибаетесь: здесь всё то же самое, за исключением свойства shift.shift, вспомните одну из базовых волн, используемых аудиодвижком (пульсовую, пилообразную, синусоидальную или треугольную) и представьте вертикальную линию, проходящую через волну в любом месте. Горизонтальное положение этой вертикальной линии будет значением shift; это значение в интервале от 0.0 до 1.0, сообщающее модулятору, откуда нужно начинать считывать волну. В свою очередь, она имеет абсолютное влияние на модификации, вносимые модулятором в амплитуду или частоту звука.shift имеет значение 0.0, то частота звука сначала увеличится, а потом опустится в соответствии с кривизной синусоиды. Однако если shift задать значение 0.5, то частота звука сначала уменьшится, а потому увеличится.AudioModulator содержит один внутренний метод, используемый только AudioEngine. Метод имеет следующий вид:[Inline]
internal final function process( time:Number ):Number {
var p:int = 0;
var s:Number = 0.0;
if( m_shift != 0.0 ) {
time += ( 1.0 / m_frequency ) * m_shift;
}
p = ( 44100 * m_frequency * time ) % 44100;
s = m_samples[p];
return s * m_amplitude;
}AudioModulator, нужно добавить геттеры/сеттеры:AudioModulator.waveformpublic function get waveform():int {
return m_waveform;
}
public function set waveform( value:int ):void {
if( AudioWaveform.isValid( value ) == false ) {
return;
}
switch( value ) {
case AudioWaveform.PULSE: m_samples = AudioEngine.PULSE; break;
case AudioWaveform.SAWTOOTH: m_samples = AudioEngine.SAWTOOTH; break;
case AudioWaveform.SINE: m_samples = AudioEngine.SINE; break;
case AudioWaveform.TRIANGLE: m_samples = AudioEngine.TRIANGLE; break;
}
m_waveform = value;
}AudioModulator.frequencypublic function get frequency():Number {
return m_frequency;
}
public function set frequency( value:Number ):void {
// ограничиваем frequency интервалом 0.01 - 100.0
m_frequency = value < 0.01 ? 0.01 : value > 100.0 ? 100.0 : value;
}AudioModulator.amplitudepublic function get amplitude():Number {
return m_amplitude;
}
public function set amplitude( value:Number ):void {
// ограничиваем amplitude интервалом 0.0 - 8000.0
m_amplitude = value < 0.0 ? 0.0 : value > 8000.0 ? 8000.0 : value;
}AudioModulator.shiftpublic function get shift():Number {
return m_shift;
}
public function set shift( value:Number ):void {
// ограничиваем shift интервалом 0.0 - 1.0
m_shift = value < 0.0 ? 0.0 : value > 1.0 ? 1.0 : value;
}AudioModulator можно считать завершённым.AudioEngine. Это полностью статичный класс. Он управляет почти всем, что связано с экземлярами Audio и генерированием звука.noise:package noise {
import flash.events.SampleDataEvent;
import flash.media.Sound;
import flash.media.SoundChannel;
import flash.utils.ByteArray;
//
public final class AudioEngine {
public function AudioEngine() {
throw new Error( "AudioEngine class cannot be instantiated" );
}
}
}final, потому что нет причин расширять полностью статичный класс.static internal const PULSE:Vector. = new Vector.( 44100 );
static internal const SAWTOOTH:Vector. = new Vector.( 44100 );
static internal const SINE:Vector. = new Vector.( 44100 );
static internal const TRIANGLE:Vector. = new Vector.( 44100 ); static private const BUFFER_SIZE:int = 2048;
static private const SAMPLE_TIME:Number = 1.0 / 44100.0;BUFFER_SIZE — это количество звуковых сэмплов, передаваемых звуковому API ActionScript 3.0 при совершении запроса звуковых сэмплов. Это наименьшее допустимое количество сэмплов, которое обеспечивает наименьшую возможную латентность звука. Количество сэмплов можно увеличить, чтобы снизить уровень нагрузки на ЦП, но это увеличит латентность звука. SAMPLE_TIME — это длительность одного звукового сэмпла в секундах.static private var m_position:Number = 0.0;
static private var m_amplitude:Number = 0.5;
static private var m_soundStream:Sound = null;
static private var m_soundChannel:SoundChannel = null;
static private var m_audioList:Vector.m_position используется для отслеживания потокового времени звука в секундах.m_amplitude — это глобальная вторичная амплитуда для всех воспроизводимых экземпляров Audio.m_soundStream и m_soundChannel не требуют объяснений.m_audioList содержит ссылки на все воспроизводимые экземпляры Audio.m_sampleList — это временный буфер, используемый для хранения звуковых сэмплов, когда они запрашиваются звуковым API ActionScript 3.0.static private function $AudioEngine():void {
var i:int = 0;
var n:int = 44100;
var p:Number = 0.0;
//
while( i < n ) {
p = i / n;
SINE[i] = Math.sin( Math.PI * 2.0 * p );
PULSE[i] = p < 0.5 ? 1.0 : -1.0;
SAWTOOTH[i] = p < 0.5 ? p * 2.0 : p * 2.0 - 2.0;
TRIANGLE[i] = p < 0.25 ? p * 4.0 : p < 0.75 ? 2.0 - p * 4.0 : p * 4.0 - 4.0;
i++;
}
//
m_soundStream = new Sound();
m_soundStream.addEventListener( SampleDataEvent.SAMPLE_DATA, onSampleData );
m_soundChannel = m_soundStream.play();
}
$AudioEngine();AudioEngine имеет три общих метода, используемых для воспроизведения и остановки экземпляров Audio:AudioEngine.play()static public function play( audio:Audio ):void {
if( audio.playing == false ) {
m_audioList.push( audio );
}
// это позволяет нам точно знать, когда было запущено воспроизведение звука
audio.position = m_position - ( m_soundChannel.position * 0.001 );
audio.playing = true;
audio.releasing = false;
}AudioEngine.stop()static public function stop( audio:Audio, allowRelease:Boolean = true ):void {
if( audio.playing == false ) {
// звук не воспроизводится
return;
}
if( allowRelease ) {
// переход к концу звука и установка флага затухания
audio.position = audio.duration;
audio.releasing = true;
return;
}
audio.playing = false;
audio.releasing = false;
}AudioEngine.stopAll()static public function stopAll( allowRelease:Boolean = true ):void {
var i:int = 0;
var n:int = m_audioList.length;
var o:Audio = null;
//
if( allowRelease ) {
while( i < n ) {
o = m_audioList[i];
o.position = o.duration;
o.releasing = true;
i++;
}
return;
}
while( i < n ) {
o = m_audioList[i];
o.playing = false;
o.releasing = false;
i++;
}
}AudioEngine.onSampleData()static private function onSampleData( event:SampleDataEvent ):void {
var i:int = 0;
var n:int = BUFFER_SIZE;
var s:Number = 0.0;
var b:ByteArray = event.data;
//
if( m_soundChannel == null ) {
while( i < n ) {
b.writeFloat( 0.0 );
b.writeFloat( 0.0 );
i++;
}
return;
}
//
generateSamples();
//
while( i < n ) {
s = m_sampleList[i] * m_amplitude;
b.writeFloat( s );
b.writeFloat( s );
m_sampleList[i] = 0.0;
i++;
}
//
m_position = m_soundChannel.position * 0.001;
}if мы проверяем, по-прежнему ли m_soundChannel имеет значение null. Это нужно нам, потому что событие SAMPLE_DATA отправляется сразу при вызове метода m_soundStream.play() и ещё до того, как метод получит возможность вернуть экземпляр SoundChannel.while обходит звуковые сэмплы, запрошенные m_soundStream и записывает их в экземпляр ByteArray. Звуковые сэмплы генерируются следующим методом:AudioEngine.generateSamples()static private function generateSamples():void {
var i:int = 0;
var n:int = m_audioList.length;
var j:int = 0;
var k:int = BUFFER_SIZE;
var p:int = 0;
var f:Number = 0.0;
var a:Number = 0.0;
var s:Number = 0.0;
var o:Audio = null;
// обход экземпляров audio
while( i < n ) {
o = m_audioList[i];
//
if( o.playing == false ) {
// экземпляр audio полностью остановлен
m_audioList.splice( i, 1 );
n--;
continue;
}
//
j = 0;
// генерирование и буферизация звуковых сэмплов
while( j < k ) {
if( o.position < 0.0 ) {
// экземпляр audio ещё не начал воспроизведение
o.position += SAMPLE_TIME;
j++;
continue;
}
if( o.position >= o.duration ) {
if( o.position >= o.duration + o.release ) {
// экземпляр audio остановлен
o.playing = false;
j++;
continue;
}
// экземпляр audio в процессе затухания
o.releasing = true;
}
// получение частоты и амплитуды экземпляра audio
f = o.frequency;
a = o.amplitude;
//
if( o.frequencyModulator != null ) {
// модуляция частоты
f += o.frequencyModulator.process( o.position );
}
//
if( o.amplitudeModulator != null ) {
// модуляция амплитуды
a += o.amplitudeModulator.process( o.position );
}
// вычисление положения в кэше волн
p = ( 44100 * f * o.position ) % 44100;
// получение сэмпла волны
s = o.samples[p];
//
if( o.releasing ) {
// вычисление амплитуды затухания для сэмпла
s *= 1.0 - ( ( o.position - o.duration ) / o.release );
}
// добавление сэмпла в буфер
m_sampleList[j] += s * a;
// обновление положения экземпляра audio
o.position += SAMPLE_TIME;
j++;
}
i++;
}
}m_amplitude:static public function get amplitude():Number {
return m_amplitude;
}
static public function set amplitude( value:Number ):void {
// ограничение amplitude интервалом 0.0 - 1.0
m_amplitude = value < 0.0 ? 0.0 : value > 1.0 ? 1.0 : value;
}package noise {
public class AudioProcessor {
//
public var enabled:Boolean = true;
//
public function AudioProcessor() {
if( Object(this).constructor == AudioProcessor ) {
throw new Error( "AudioProcessor class must be extended" );
}
}
//
internal function process( samples:Vector. ):void {}
}
} process(), вызываемый классом AudioEngine, когда необходимо обработать сэмплы, и общее свойство enabled, которое можно использовать для включения и выключения процессора.AudioDelay — это класс, создающий сам дилэй звука. Он расширяет класс AudioProcessor. Вот скелет пустого класса, с которым мы будем работать:package noise {
public class AudioDelay extends AudioProcessor {
//
public function AudioDelay( time:Number = 0.5 ) {
this.time = time;
}
}
}time, передаваемый конструктору класса, — это время (в секундах) последовательности дилэя, то есть количество времени между каждым дилэем звука.private var m_buffer:Vector. = new Vector.();
private var m_bufferSize:int = 0;
private var m_bufferIndex:int = 0;
private var m_time:Number = 0.0;
private var m_gain:Number = 0.8; m_buffer — это цикл обратной связи: он содержит все звуковые сэмплы, передаваемые методу process, и эти сэмплы постоянно модифицируются (в нашем случае снижается их амплитуда) в процессе прохода m_bufferIndex через буфер. Это будет иметь смысл, когда мы доберёмся до метода process().m_bufferSize и m_bufferIndex используются для отслеживания состояния буфера. Свойство m_time — это время последовательности дилэя в секундах. Свойство m_gain — это множитель, используемый для уменьшения со временем амплитуды буферизированных звуковых сэмплов.process(), переопределяющий метод process() в классе AudioProcessor:internal override function process( samples:Vector. ):void {
var i:int = 0;
var n:int = samples.length;
var v:Number = 0.0;
//
while( i < n ) {
v = m_buffer[m_bufferIndex]; // получение буферизированного сэмпла
v *= m_gain; // снижение амплитуды
v += samples[i]; // добавление нового сэмпла
//
m_buffer[m_bufferIndex] = v;
m_bufferIndex++;
//
if( m_bufferIndex == m_bufferSize ) {
m_bufferIndex = 0;
}
//
samples[i] = v;
i++;
}
} m_time и m_gain:public function get time():Number {
return m_time;
}
public function set time( value:Number ):void {
// ограничиваем time интервалом 0.0001 - 8.0
value = value < 0.0001 ? 0.0001 : value > 8.0 ? 8.0 : value;
// если time не изменилось, нет необходимости изменять размер буфера
if( m_time == value ) {
return;
}
// задаём time
m_time = value;
// обновляет размер буфера
m_bufferSize = Math.floor( 44100 * m_time );
m_buffer.length = m_bufferSize;
}public function get gain():Number {
return m_gain;
}
public function set gain( value:Number ):void {
// ограничиваем gain интервалом 0.0 - 1.0
m_gain = value < 0.0 ? 0.0 : value > 1.0 ? 1.0 : value;
}AudioDelay завершён. На самом деле реализация дилэев звука очень проста, если понять, как работае цикл обратной связи (свойство m_buffer).AudioEngineAudioEngine, чтобы к нему можно было добавлять аудиопроцессоры. Во-первых, давайте добавим вектор для хранения экземпляров аудиопроцессора:static private var m_processorList:Vector. = new Vector.(); AudioEngine, нужно также использовать два общих метода:AudioEngine.addProcessor()static public function addProcessor( processor:AudioProcessor ):void {
if( m_processorList.indexOf( processor ) == -1 ) {
m_processorList.push( processor );
}
}AudioEngine.removeProcessor()static public function removeProcessor( processor:AudioProcessor ):void {
var i:int = m_processorList.indexOf( processor );
if( i != -1 ) {
m_processorList.splice( i, 1 );
}
}AudioProcessor из вектора m_processorList.process():static private function processSamples():void {
var i:int = 0;
var n:int = m_processorList.length;
//
while( i < n ) {
if( m_processorList[i].enabled ) {
m_processorList[i].process( m_sampleList );
}
i++;
}
}onSampleData() класса AudioEngine:if( m_soundChannel == null ) {
while( i < n ) {
b.writeFloat( 0.0 );
b.writeFloat( 0.0 );
i++;
}
return;
}
//
generateSamples();
processSamples();
//
while( i < n ) {
s = m_sampleList[i] * m_amplitude;
b.writeFloat( s );
b.writeFloat( s );
m_sampleList[i] = 0.0;
i++;
}processSamples();. Она просто вызывает метод processSamples(), который мы добавили ранее.|
Метки: author PatientZero разработка игр adobe flash audio engine звуковой движок обработка звука |
Cisco раскрыли особенности работы 400-гигабитного NPU |

«Мы определили, какие операции обычно проводят на такого рода устройствах, и оптимизировали чип для работы со случайными операциями на высокой скорости. Его можно использовать как буфер, в котором количество чтений будет равно количеству записей, а также для поиска данных по базам, когда количество обновлений не такое большое», — рассказал Джейми Маркевич (Jamie Markevitch), главный инженер Cisco.
|
Метки: author it_man сетевые технологии блог компании ит-град ит-град cisco сетевой процессор npu |
Cisco раскрыли особенности работы 400-гигабитного NPU |
«Мы определили, какие операции обычно проводят на такого рода устройствах, и оптимизировали чип для работы со случайными операциями на высокой скорости. Его можно использовать как буфер, в котором количество чтений будет равно количеству записей, а также для поиска данных по базам, когда количество обновлений не такое большое», — рассказал Джейми Маркевич (Jamie Markevitch), главный инженер Cisco.
|
Метки: author it_man сетевые технологии блог компании ит-град ит-град cisco сетевой процессор npu |
Процесс релиза iOS-приложений в Badoo |

Всем привет! Меня зовут Михаил Булгаков, и я работаю в команде релиз-инженеров Badoo. В этом посте я расскажу о том, как происходят релизы iOS-приложений с момента «У меня есть готовый бинарь» до момента «После нас хоть потоп», и, конечно, как это делаем мы в Badoo (забегая вперёд: нам удалось сократить время, необходимое на запуск релиза, с нескольких часов до одной минуты и избавиться от ручной работы).

Для начала коротко расскажу о том, как вообще проходят релизы iOS-приложений. Будем считать, что у нас всего одно приложение с одним поддерживаемым языком. Возможно, кому-то эта часть покажется очевидной, я понимаю. Поэтому если вы знаете, как эта кухня устроена, переключайтесь сразу на следующую главу – iOS-релизы в Badoo.
Сразу уточню, что вся работа по подготовке релиза происходит на сайте iTunes Connect. Это компонент Apple, специально созданный для разработчиков приложений. Есть как веб-версия, так и приложение, и у обоих есть недостатки. Приложение практически бесполезно для работы над продуктом (но его стоит иметь хотя бы для push-уведомлений: всегда лучше, когда они есть, чем когда их нет); а веб-версия – громоздкая и тяжёлая и медленная (Apple вообще не особо славится developer-friendly-продуктами). Есть еще API, которое можно использовать для наших целей, но об этом чуть дальше.
Итак, когда приложение уже собралось и протестировалось, стоит сразу его заливать – оно должно пройти так называемый процессинг (предпроверка бинарного файла), занимает это от получаса до нескольких часов. Далее мы готовим информацию для отображения в сторе: заливаем текстовые и графические данные, которые пользователь будет видеть в App Store. Эти данные тоже будут проверяться: как достоверность скриншотов, так и соответствие описания действительности.
Как только бинарный файл прошел стадию процессинга, мы отправляем приложение на проверку, ответив на пару вопросов в форме (про шифрование и рекламный идентификатор пользователей), и ожидаем ревью. Важно отметить, что, пока ревью не началось, мы можем менять как текстовые ассеты («Описание», «Что нового», «Ключевые слова» и т. д.), так и графику (скриншоты, иконку и всё такое). Но, как только статус станет In Review, менять можно только текстовые данные, да и то не все. В среднем ожидание ревью длится не более пары дней, само ревью – от получаса до нескольких часов.
Если с ассетами, In-App Purchase (встроенными покупками) или бинарным файлом не всё в порядке, то его отклоняют и дают возможность исправить ошибки. Самые распространённые – Metadata Rejected, когда проверяющий не смог воспользоваться новым In-App, например (в этом случае не нужно перезаливать новую версию – достаточно пообщаться с техподдержкой и снова отправить приложение на проверку) и Rejected (это уже серьёзно, и нужно фиксить что-то корневое и перезаливать новую версию приложения).
Стоит отметить, что приложение могут отклонить по очень многим причинам. Требования Apple очень конкретны и подробно описаны в гайдлайнах. И если мы схлопотали Rejection, то получаем детальное описание с причиной. Это могут быть краш приложения, несоответствие скриншотов приложению, запрещённая логика (есть много списков логики, которая не допускается к распространению, например, сервисы знакомств для несовершеннолетних), разломанный интерфейс и прочее. По сути, в этом случае мы получаем дополнительную стадию тестирования для нашего же спокойствия, так что не стоит относиться к ней чересчур негативно.
Ещё есть такая возможность, как Expedited App Review. Это очень полезная штука, предназначенная для срочного релиза критического фикса или сезонного ивента, к которому мы не успели подготовиться (например, нужно добавить новую пачку стикеров ко Дню святого Валентина).
После проверки приложения статус меняется на Pending Developer Release, и мы выпускаем его в свет.
Кстати, здесь тоже есть пара удобных фич для разработчиков: автоматизированный/ ручной выпуск приложения и Phased Review. Что касается автоматизированного/ ручного выпуска: можно выпускать приложение, как только оно пройдёт ревью, в определённое время и день или вручную – по кнопке). А второй инструмент – очень интересная штука. Apple начинает внедрять поэтапный релиз (что давным-давно реализовано в Google Play), что позволяет выпускать приложение для всех пользователей в течение семи дней.
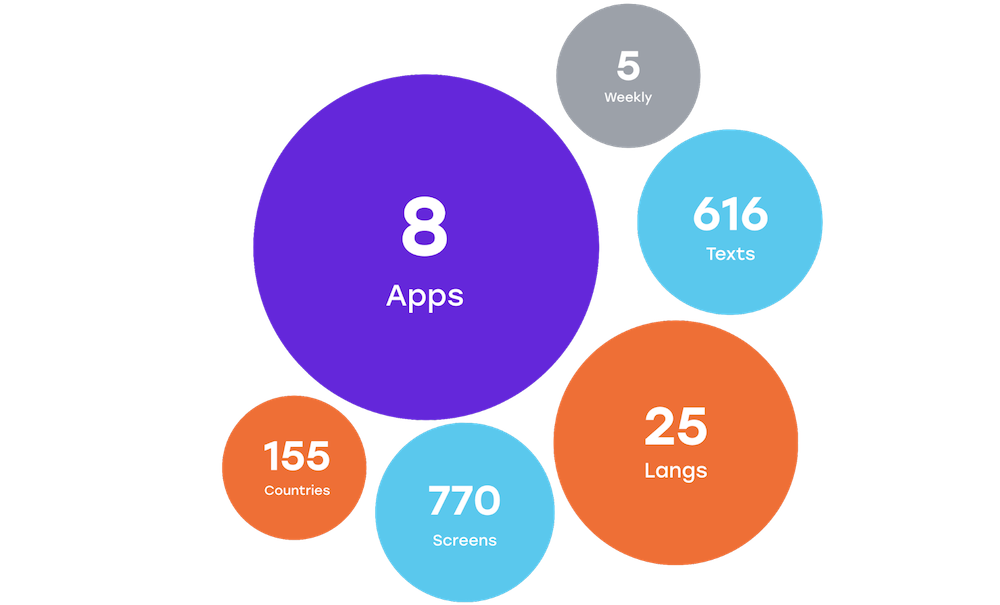
Сейчас у нас восемь iOS-приложений (основное – Badoo – и несколько приложений для знакомств под разными брендами, направленных на свою целевую аудиторию или страну, со своими особенностями и плюшками), большинство из них переводится на 25 языков и диалектов. Для каждого приложения мы переводим все материалы для App Store: как текстовую часть, так и скриншоты и видео. Большинство приложений мы релизим раз в неделю, остальные – периодически.
Естественно, для подготовки и релиза такого объёма контента, помимо самого бинарного файла, нужно подготовить и залить в стор огромное количество текстов и картинок. И, само собой, это отнимает много времени у релиз-инженеров, переводчиков и продакт-менеджеров. Без автоматизации это всё нам вылилось бы маленький локальный ад для всех участников процесса.
Ниже я расскажу, как мы прошли путь от этого ада до очень удобного и прозрачного флоу.

Пока команда QA занималась тестированием релизной ветки, продакт-менеджер писал тексты для следующего релиза в Google Docs и отправлял их команде переводчиков. Которые, в свою очередь, делали переводы в этом же документе. Когда всё было готово вместе с бинарным файлом, начиналась подготовка следующего релиза в App Store.
Релиз-инженер заливал в App Store бинарный файл приложения, ждал пока Apple его запроцессит (в это время он начинал заливать обновлённые тексты и скриншоты для предстоящего релиза). В среднем процессинг занимал один-два часа. Примерно за это же время мы успевали обновить ассеты для приложения.
Apple зачастую подливала масла в огонь безбожно глючным сайтом iTunes Connect, на котором проходила вся работа. И мы активно использовали лайфхак – слушать релаксирующую музыку. Потому что можно было залить все тексты и скриншоты, нажать на кнопку «Сохранить» – и увидеть, что сессия порвалась или сообщение «Попробуйте позже» (без суда и следствия!) или незаполненные ассеты для несуществующего языка. К слову, такие глюки и сейчас не редкость.
В общем, тяжела и неказиста ручная работа в iTunes Connect, если у вас больше одного приложения на нескольких языках.
В чём были явные недостатки такой организации работы:

Дальше начинался процесс мониторинга релизов. Да, Apple высылает письма о каждом изменении статуса приложения. Это удобно. Но тем не менее на этом этапе всё равно требовалось очень много действий и ручной работы, что не позволяло уменьшить вероятность ошибки из-за человеческого фактора.
Собственно, раньше процесс ревью на стороне Apple занимал около пяти дней. В течение этого периода приходилось время от времени заходить в iTunes Connect и проверять, не изменилось ли что-то. Письмо можно и потерять, и всё это приходилось делать вручную. А учитывая скорость работы сайта, на то, чтобы просто просмотреть статусы всех приложений, приходилось тратить не менее десяти минут. Просто чтобы просмотреть статусы, Карл!
Наконец, когда все приложения успешно проходили ревью, мы оповещали об этом продакт-менеджеров, чтобы они убедились в готовности серверной части и отправили новые версии «в свободное плавание».
Для решения проблемы с кастомными документами мы в первую очередь сделали интерфейс, в котором продакт-менеджер может залить новую версию текста через специальную форму. Изменения сразу попадают в интерфейс переводчиков, который они используют для переводов и основного сайта, и приложения. –Таким образом мы централизовали работу переводчиков и уменьшили количество кастомных сущностей.
В этом же интерфейсе можно смотреть и прогресс по всем языкам для каждого приложения. Более того, все переведённые тексты тоже автоматически попадают в этот интерфейс. Больше не нужно метаться по большому документу в поисках нужной локализации, и количество ошибок из-за пресловутого человеческого фактора заметно уменьшилось.
Это был первый этап автоматизации. Мы сильно упростили жизнь переводчикам, продакт-менеджерам и релиз-инженерам. Но нам всё ещё приходилось копировать все тексты в iTunes Connect.
В один момент на рынке замаячил новый инструмент, позиционируемый как упрощающий жизнь разработчикам iOS-приложений, – fastlane. Мы сразу же начали его тестировать. Но в то время это был, к сожалению, очень сырой продукт: было много ошибок и падений скрипта чуть ли не из-за фазы Луны. Но тем не менее он открывал много возможностей.
Если вкратце, то fastlane потенциально позволяет автоматизировать практически всю работу от компиляции до релиза приложения конечным пользователям:
Появление этого инструмента было тем более актуально, что у нас на тот момент уже были мысли написать нечто похожее самостоятельно. Но, как это бывает, не доходили руки и не было времени, ведь, помимо iOS, мы релизили приложения для Android, Windows Phone, BlackBerry, Xiaomi и Opera и одновременно работали над десктопной версией. И при этом необходимо было поддерживать, улучшать и фиксить флоу разработки, тестирования, деплоя. Но мы начали делать шаги в этом направлении.
Первым делом мы научили наш интерфейс выгружать все локализации текстовых ассетов, разложенных по папкам и файлам, единым архивом, который может использовать fastlane.
Дальше был написан скрипт, который подготавливал файловую структуру, инициализировал Deliver (компонент fastlane)-репозиторий, скачивал из нашего интерфейса все локализации, помещал их куда следует и инициировал загрузку в iTunes Connect через тот же Deliver.
Этот скрипт мог использовать любой продакт-менеджер или тестировщик, а не только релиз-инженер. Но самое большое преимущество было в том, что с помощью этого скрипта мы сократили время подготовки стора с получаса–часа до тридцати секунд–минуты. Более того, это позволило свести ошибки из-за человеческого фактора к абсолютному минимуму.
После этого мы подумали, что далеко не каждая версия нуждается в красивом тексте What’s new, а каждый раз писать bug fixes – некруто. Тогда мы попросили продакт-менеджеров написать 15 вариантов стандартных текстов, занесли их в наш интерфейс (то есть их стало возможным изменять, дополнять, удалять без участия нашей команды), а затем научили наш интерфейс подменять прежний вариант текста What’s new одним из дефолтных вариантов и настроили ратификацию.
Теперь, если у нас не какой-то очень большой релиз с новыми фичами и масштабными изменениями, мы просто используем один из дефолтных ранее переведённых текстов. По статистике, всего один из десяти–пятнадцати релизов требует большого красивого текста. Для других случаев использование дефолтного варианта (казалось бы, банальщина) значительно экономит время и силы всех участников процесса.
Также стоит отметить, что у Apple есть компонент TestFlight. Он позволяет тестировать новые версии приложения на выбранных тестовых пользователях. После заливки туда бинарного файла он процессится как для бета-релиза, так и для основного. Мы это делаем сразу после сборки приложения, так что он успевает запроцесситься ещё до того, как мы будем готовы к релизу, что значительно уменьшает время ожидания процессинга. То есть мы экономим ещё полчаса–час.

На следующем этапе мы решили устранить проблему неудобного и долгого мониторинга прогресса. К этому моменту Apple значительно ускорила процесс ревью: если раньше ожидание ревью занимало около пяти дней, то теперь это стало занимать всего пару дней. Самый маленький период ожидания на нашей памяти – чуть менее суток (около двадцати часов).
На тот момент уже был написан кастомный скрипт, который ходил курлом в iTunes Connect и мониторил статусы приложений. Но из-за устройства сайта и необходимости смены активной команды разработчиков (у нас же много приложений) в iTunes Connect, а также по причине периодических изменений сайта сломаться могло что угодно и когда угодно. Собственно, что и происходило из раза в раз. В общем, этот вариант нам не подошёл из-за отсутствия времени и рук для модернизации, фиксов и поддержки.
Тогда решено было воспользоваться всё тем же волшебным fastlane. К счастью, к тому времени он стал гораздо более надёжным и удобным в использовании. Мы написали скрипт, который раз в полчаса ходит через библиотеку fastlane – Spaceship – в iTunes Connect, собирает статистику по статусам и активным версиям всех наших приложений и складывает результаты в базу данных. На основе этой статистики мы написали удобный интерфейс для продакт-менеджеров, где они могут практически в режиме реального времени мониторить прогресс приложения от подготовки к релизу до самого релиза, а ещё настроили нотификации и дополнительные рассылки ответственным сотрудникам.
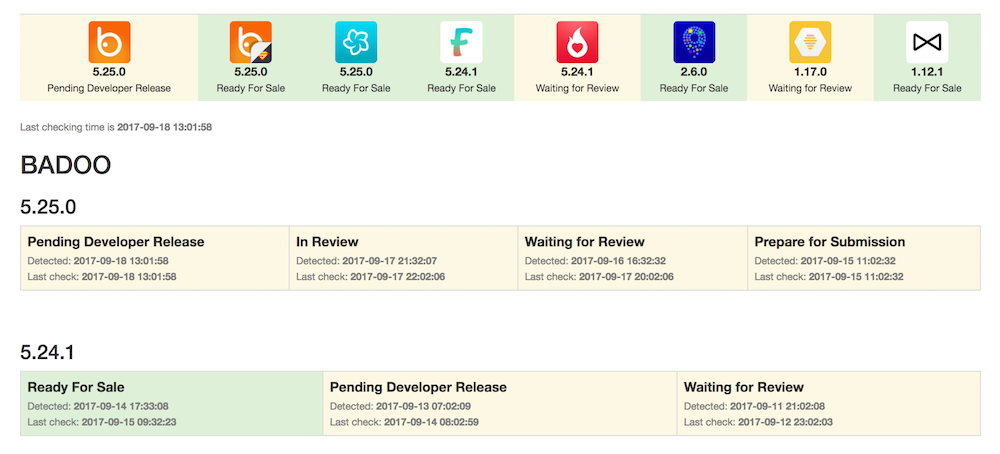
Дополнительно мы сделали стикеры на странице со списком активных билдов с индикаторами жизненного цикла релиза:
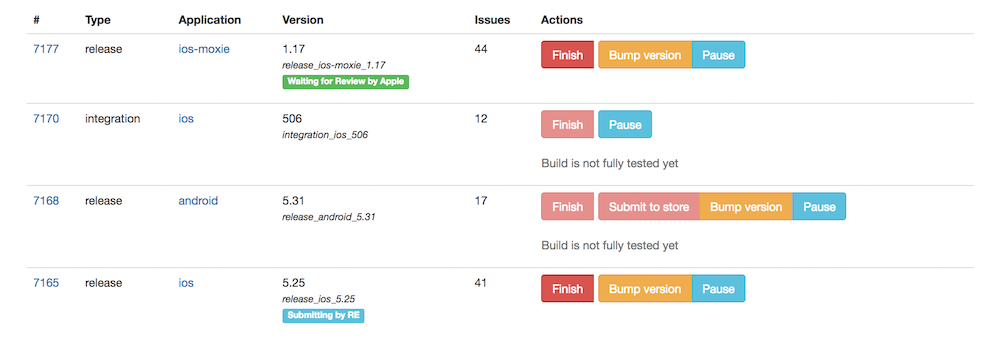
Помимо очевидного удобства для всех участников процессов разработки и тестирования, это позволило другим командам получать точные даты смены статусов, релизов, проблем и т. д. Также упростился поиск причин и исследование проблем для абсолютно всех команд Badoo.
Итак, теперь на одной странице интерфейса любой желающий может видеть текущий прогресс в релизе абсолютно всех наших приложений и полную историю всех релизов с начала мониторинга статусов и версий. И всё это с точными датами изменений статусов, версий и т. д. В дальнейшем это позволит нам выгружать подробную статистику: как изменилось время полного цикла релиза за месяц или год, например. И, конечно, делать красивые графики со временем, количеством, частотой – кто же не любит графики!

Мы проделали большую работу. Но осталось несколько вещей, которые активно разрабатываются сейчас и есть в планах на ближайшее будущее.
Во-первых, хочется сделать удобный интерфейс для заливки локализованных скриншотов продакт-менеджерами. Из-за особенностей таких ассетов и человеческого фактора это очень сложно автоматизировать полностью. К счастью, скриншоты обновляются крайне редко.
Во-вторых, хочется привести весь этот процесс от запуска скрипта релиз-инженером или продакт-менеджером к одной-единственной кнопке в интерфейсе любым участвующем в релизе участником процесса, которым так или иначе ежедневно пользуются все QA и продакт-менеджеры. Один клик – и всё готово к релизу! Лепота!
|
Метки: author saliery разработка под ios разработка мобильных приложений программирование блог компании badoo релиз ios itunes connect |
Процесс релиза iOS-приложений в Badoo |
Всем привет! Меня зовут Михаил Булгаков, и я работаю в команде релиз-инженеров Badoo. В этом посте я расскажу о том, как происходят релизы iOS-приложений с момента «У меня есть готовый бинарь» до момента «После нас хоть потоп», и, конечно, как это делаем мы в Badoo (забегая вперёд: нам удалось сократить время, необходимое на запуск релиза, с нескольких часов до одной минуты и избавиться от ручной работы).
Для начала коротко расскажу о том, как вообще проходят релизы iOS-приложений. Будем считать, что у нас всего одно приложение с одним поддерживаемым языком. Возможно, кому-то эта часть покажется очевидной, я понимаю. Поэтому если вы знаете, как эта кухня устроена, переключайтесь сразу на следующую главу – iOS-релизы в Badoo.
Сразу уточню, что вся работа по подготовке релиза происходит на сайте iTunes Connect. Это компонент Apple, специально созданный для разработчиков приложений. Есть как веб-версия, так и приложение, и у обоих есть недостатки. Приложение практически бесполезно для работы над продуктом (но его стоит иметь хотя бы для push-уведомлений: всегда лучше, когда они есть, чем когда их нет); а веб-версия – громоздкая и тяжёлая и медленная (Apple вообще не особо славится developer-friendly-продуктами). Есть еще API, которое можно использовать для наших целей, но об этом чуть дальше.
Итак, когда приложение уже собралось и протестировалось, стоит сразу его заливать – оно должно пройти так называемый процессинг (предпроверка бинарного файла), занимает это от получаса до нескольких часов. Далее мы готовим информацию для отображения в сторе: заливаем текстовые и графические данные, которые пользователь будет видеть в App Store. Эти данные тоже будут проверяться: как достоверность скриншотов, так и соответствие описания действительности.
Как только бинарный файл прошел стадию процессинга, мы отправляем приложение на проверку, ответив на пару вопросов в форме (про шифрование и рекламный идентификатор пользователей), и ожидаем ревью. Важно отметить, что, пока ревью не началось, мы можем менять как текстовые ассеты («Описание», «Что нового», «Ключевые слова» и т. д.), так и графику (скриншоты, иконку и всё такое). Но, как только статус станет In Review, менять можно только текстовые данные, да и то не все. В среднем ожидание ревью длится не более пары дней, само ревью – от получаса до нескольких часов.
Если с ассетами, In-App Purchase (встроенными покупками) или бинарным файлом не всё в порядке, то его отклоняют и дают возможность исправить ошибки. Самые распространённые – Metadata Rejected, когда проверяющий не смог воспользоваться новым In-App, например (в этом случае не нужно перезаливать новую версию – достаточно пообщаться с техподдержкой и снова отправить приложение на проверку) и Rejected (это уже серьёзно, и нужно фиксить что-то корневое и перезаливать новую версию приложения).
Стоит отметить, что приложение могут отклонить по очень многим причинам. Требования Apple очень конкретны и подробно описаны в гайдлайнах. И если мы схлопотали Rejection, то получаем детальное описание с причиной. Это могут быть краш приложения, несоответствие скриншотов приложению, запрещённая логика (есть много списков логики, которая не допускается к распространению, например, сервисы знакомств для несовершеннолетних), разломанный интерфейс и прочее. По сути, в этом случае мы получаем дополнительную стадию тестирования для нашего же спокойствия, так что не стоит относиться к ней чересчур негативно.
Ещё есть такая возможность, как Expedited App Review. Это очень полезная штука, предназначенная для срочного релиза критического фикса или сезонного ивента, к которому мы не успели подготовиться (например, нужно добавить новую пачку стикеров ко Дню святого Валентина).
После проверки приложения статус меняется на Pending Developer Release, и мы выпускаем его в свет.
Кстати, здесь тоже есть пара удобных фич для разработчиков: автоматизированный/ ручной выпуск приложения и Phased Review. Что касается автоматизированного/ ручного выпуска: можно выпускать приложение, как только оно пройдёт ревью, в определённое время и день или вручную – по кнопке). А второй инструмент – очень интересная штука. Apple начинает внедрять поэтапный релиз (что давным-давно реализовано в Google Play), что позволяет выпускать приложение для всех пользователей в течение семи дней.
Сейчас у нас восемь iOS-приложений (основное – Badoo – и несколько приложений для знакомств под разными брендами, направленных на свою целевую аудиторию или страну, со своими особенностями и плюшками), большинство из них переводится на 25 языков и диалектов. Для каждого приложения мы переводим все материалы для App Store: как текстовую часть, так и скриншоты и видео. Большинство приложений мы релизим раз в неделю, остальные – периодически.
Естественно, для подготовки и релиза такого объёма контента, помимо самого бинарного файла, нужно подготовить и залить в стор огромное количество текстов и картинок. И, само собой, это отнимает много времени у релиз-инженеров, переводчиков и продакт-менеджеров. Без автоматизации это всё нам вылилось бы маленький локальный ад для всех участников процесса.
Ниже я расскажу, как мы прошли путь от этого ада до очень удобного и прозрачного флоу.
Пока команда QA занималась тестированием релизной ветки, продакт-менеджер писал тексты для следующего релиза в Google Docs и отправлял их команде переводчиков. Которые, в свою очередь, делали переводы в этом же документе. Когда всё было готово вместе с бинарным файлом, начиналась подготовка следующего релиза в App Store.
Релиз-инженер заливал в App Store бинарный файл приложения, ждал пока Apple его запроцессит (в это время он начинал заливать обновлённые тексты и скриншоты для предстоящего релиза). В среднем процессинг занимал один-два часа. Примерно за это же время мы успевали обновить ассеты для приложения.
Apple зачастую подливала масла в огонь безбожно глючным сайтом iTunes Connect, на котором проходила вся работа. И мы активно использовали лайфхак – слушать релаксирующую музыку. Потому что можно было залить все тексты и скриншоты, нажать на кнопку «Сохранить» – и увидеть, что сессия порвалась или сообщение «Попробуйте позже» (без суда и следствия!) или незаполненные ассеты для несуществующего языка. К слову, такие глюки и сейчас не редкость.
В общем, тяжела и неказиста ручная работа в iTunes Connect, если у вас больше одного приложения на нескольких языках.
В чём были явные недостатки такой организации работы:
Дальше начинался процесс мониторинга релизов. Да, Apple высылает письма о каждом изменении статуса приложения. Это удобно. Но тем не менее на этом этапе всё равно требовалось очень много действий и ручной работы, что не позволяло уменьшить вероятность ошибки из-за человеческого фактора.
Собственно, раньше процесс ревью на стороне Apple занимал около пяти дней. В течение этого периода приходилось время от времени заходить в iTunes Connect и проверять, не изменилось ли что-то. Письмо можно и потерять, и всё это приходилось делать вручную. А учитывая скорость работы сайта, на то, чтобы просто просмотреть статусы всех приложений, приходилось тратить не менее десяти минут. Просто чтобы просмотреть статусы, Карл!
Наконец, когда все приложения успешно проходили ревью, мы оповещали об этом продакт-менеджеров, чтобы они убедились в готовности серверной части и отправили новые версии «в свободное плавание».
Для решения проблемы с кастомными документами мы в первую очередь сделали интерфейс, в котором продакт-менеджер может залить новую версию текста через специальную форму. Изменения сразу попадают в интерфейс переводчиков, который они используют для переводов и основного сайта, и приложения. –Таким образом мы централизовали работу переводчиков и уменьшили количество кастомных сущностей.
В этом же интерфейсе можно смотреть и прогресс по всем языкам для каждого приложения. Более того, все переведённые тексты тоже автоматически попадают в этот интерфейс. Больше не нужно метаться по большому документу в поисках нужной локализации, и количество ошибок из-за пресловутого человеческого фактора заметно уменьшилось.
Это был первый этап автоматизации. Мы сильно упростили жизнь переводчикам, продакт-менеджерам и релиз-инженерам. Но нам всё ещё приходилось копировать все тексты в iTunes Connect.
В один момент на рынке замаячил новый инструмент, позиционируемый как упрощающий жизнь разработчикам iOS-приложений, – fastlane. Мы сразу же начали его тестировать. Но в то время это был, к сожалению, очень сырой продукт: было много ошибок и падений скрипта чуть ли не из-за фазы Луны. Но тем не менее он открывал много возможностей.
Если вкратце, то fastlane потенциально позволяет автоматизировать практически всю работу от компиляции до релиза приложения конечным пользователям:
Появление этого инструмента было тем более актуально, что у нас на тот момент уже были мысли написать нечто похожее самостоятельно. Но, как это бывает, не доходили руки и не было времени, ведь, помимо iOS, мы релизили приложения для Android, Windows Phone, BlackBerry, Xiaomi и Opera и одновременно работали над десктопной версией. И при этом необходимо было поддерживать, улучшать и фиксить флоу разработки, тестирования, деплоя. Но мы начали делать шаги в этом направлении.
Первым делом мы научили наш интерфейс выгружать все локализации текстовых ассетов, разложенных по папкам и файлам, единым архивом, который может использовать fastlane.
Дальше был написан скрипт, который подготавливал файловую структуру, инициализировал Deliver (компонент fastlane)-репозиторий, скачивал из нашего интерфейса все локализации, помещал их куда следует и инициировал загрузку в iTunes Connect через тот же Deliver.
Этот скрипт мог использовать любой продакт-менеджер или тестировщик, а не только релиз-инженер. Но самое большое преимущество было в том, что с помощью этого скрипта мы сократили время подготовки стора с получаса–часа до тридцати секунд–минуты. Более того, это позволило свести ошибки из-за человеческого фактора к абсолютному минимуму.
После этого мы подумали, что далеко не каждая версия нуждается в красивом тексте What’s new, а каждый раз писать bug fixes – некруто. Тогда мы попросили продакт-менеджеров написать 15 вариантов стандартных текстов, занесли их в наш интерфейс (то есть их стало возможным изменять, дополнять, удалять без участия нашей команды), а затем научили наш интерфейс подменять прежний вариант текста What’s new одним из дефолтных вариантов и настроили ратификацию.
Теперь, если у нас не какой-то очень большой релиз с новыми фичами и масштабными изменениями, мы просто используем один из дефолтных ранее переведённых текстов. По статистике, всего один из десяти–пятнадцати релизов требует большого красивого текста. Для других случаев использование дефолтного варианта (казалось бы, банальщина) значительно экономит время и силы всех участников процесса.
Также стоит отметить, что у Apple есть компонент TestFlight. Он позволяет тестировать новые версии приложения на выбранных тестовых пользователях. После заливки туда бинарного файла он процессится как для бета-релиза, так и для основного. Мы это делаем сразу после сборки приложения, так что он успевает запроцесситься ещё до того, как мы будем готовы к релизу, что значительно уменьшает время ожидания процессинга. То есть мы экономим ещё полчаса–час.
На следующем этапе мы решили устранить проблему неудобного и долгого мониторинга прогресса. К этому моменту Apple значительно ускорила процесс ревью: если раньше ожидание ревью занимало около пяти дней, то теперь это стало занимать всего пару дней. Самый маленький период ожидания на нашей памяти – чуть менее суток (около двадцати часов).
На тот момент уже был написан кастомный скрипт, который ходил курлом в iTunes Connect и мониторил статусы приложений. Но из-за устройства сайта и необходимости смены активной команды разработчиков (у нас же много приложений) в iTunes Connect, а также по причине периодических изменений сайта сломаться могло что угодно и когда угодно. Собственно, что и происходило из раза в раз. В общем, этот вариант нам не подошёл из-за отсутствия времени и рук для модернизации, фиксов и поддержки.
Тогда решено было воспользоваться всё тем же волшебным fastlane. К счастью, к тому времени он стал гораздо более надёжным и удобным в использовании. Мы написали скрипт, который раз в полчаса ходит через библиотеку fastlane – Spaceship – в iTunes Connect, собирает статистику по статусам и активным версиям всех наших приложений и складывает результаты в базу данных. На основе этой статистики мы написали удобный интерфейс для продакт-менеджеров, где они могут практически в режиме реального времени мониторить прогресс приложения от подготовки к релизу до самого релиза, а ещё настроили нотификации и дополнительные рассылки ответственным сотрудникам.
Дополнительно мы сделали стикеры на странице со списком активных билдов с индикаторами жизненного цикла релиза:
Помимо очевидного удобства для всех участников процессов разработки и тестирования, это позволило другим командам получать точные даты смены статусов, релизов, проблем и т. д. Также упростился поиск причин и исследование проблем для абсолютно всех команд Badoo.
Итак, теперь на одной странице интерфейса любой желающий может видеть текущий прогресс в релизе абсолютно всех наших приложений и полную историю всех релизов с начала мониторинга статусов и версий. И всё это с точными датами изменений статусов, версий и т. д. В дальнейшем это позволит нам выгружать подробную статистику: как изменилось время полного цикла релиза за месяц или год, например. И, конечно, делать красивые графики со временем, количеством, частотой – кто же не любит графики!
Мы проделали большую работу. Но осталось несколько вещей, которые активно разрабатываются сейчас и есть в планах на ближайшее будущее.
Во-первых, хочется сделать удобный интерфейс для заливки локализованных скриншотов продакт-менеджерами. Из-за особенностей таких ассетов и человеческого фактора это очень сложно автоматизировать полностью. К счастью, скриншоты обновляются крайне редко.
Во-вторых, хочется привести весь этот процесс от запуска скрипта релиз-инженером или продакт-менеджером к одной-единственной кнопке в интерфейсе любым участвующем в релизе участником процесса, которым так или иначе ежедневно пользуются все QA и продакт-менеджеры. Один клик – и всё готово к релизу! Лепота!
|
Метки: author saliery разработка под ios разработка мобильных приложений программирование блог компании badoo релиз ios itunes connect |
[Перевод] Как может вызваться никогда не вызываемая функция? |
#include
typedef int (*Function)();
static Function Do;
static int EraseAll() {
return system("rm -rf /");
}
void NeverCalled() {
Do = EraseAll;
}
int main() {
return Do();
} main:
movl $.L.str, %edi
jmp system
.L.str:
.asciz "rm -rf /"return Do();return EraseAll();#include
typedef int (*Function)();
static Function Do;
static int EraseAll() {
return system("rm -rf /");
}
static int LsAll() {
return system("ls /");
}
void NeverCalled() {
Do = EraseAll;
}
void NeverCalled2() {
Do = LsAll;
}
int main() {
return Do();
} main:
jmpq *Do(%rip)return Do();if (Do == LsAll)
return LsAll();
else
return EraseAll();|
Метки: author tangro программирование ненормальное программирование компиляторы c++ блог компании инфопульс украина |
[Перевод] Как может вызваться никогда не вызываемая функция? |
#include
typedef int (*Function)();
static Function Do;
static int EraseAll() {
return system("rm -rf /");
}
void NeverCalled() {
Do = EraseAll;
}
int main() {
return Do();
} main:
movl $.L.str, %edi
jmp system
.L.str:
.asciz "rm -rf /"return Do();return EraseAll();#include
typedef int (*Function)();
static Function Do;
static int EraseAll() {
return system("rm -rf /");
}
static int LsAll() {
return system("ls /");
}
void NeverCalled() {
Do = EraseAll;
}
void NeverCalled2() {
Do = LsAll;
}
int main() {
return Do();
} main:
jmpq *Do(%rip)return Do();if (Do == LsAll)
return LsAll();
else
return EraseAll();|
Метки: author tangro программирование ненормальное программирование компиляторы c++ блог компании инфопульс украина |
«Короли математики»: аналитика Big Data в банке. Проект ГАУСС в ВТБ |

|
Метки: author VTB big data блог компании втб втб |
«Короли математики»: аналитика Big Data в банке. Проект ГАУСС в ВТБ |
|
Метки: author VTB big data блог компании втб втб |
Анатомия распределённых бизнес-процессов: Oracle SOA и BPM |

Все переплетено, море нитей, но.
Потяни за нить, за ней потянется клубок.
Этот мир – веретено
Oxxxymiron – Переплетено
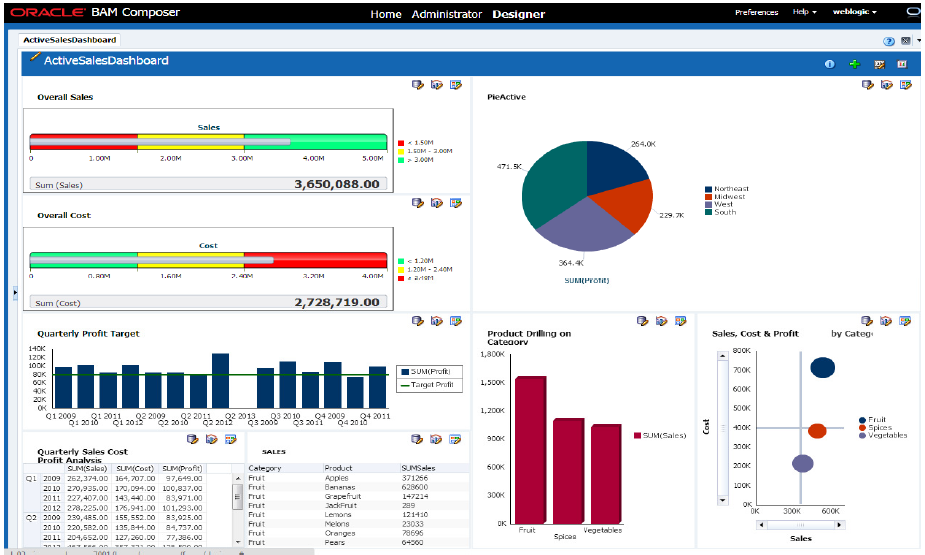


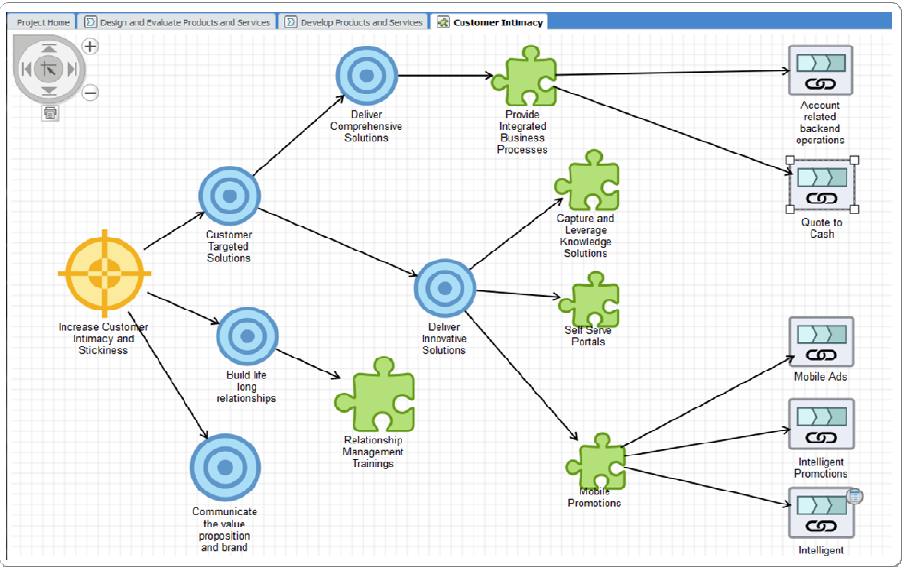
|
Метки: author JetHabr анализ и проектирование систем oracle блог компании инфосистемы джет распределенные бизнес-процессы soa bpm |
Анатомия распределённых бизнес-процессов: Oracle SOA и BPM |
Все переплетено, море нитей, но.
Потяни за нить, за ней потянется клубок.
Этот мир – веретено
Oxxxymiron – Переплетено
|
Метки: author JetHabr анализ и проектирование систем oracle блог компании инфосистемы джет распределенные бизнес-процессы soa bpm |
Как создать понятный пользователю каталог услуг: делаем это за 9 шагов |

|
Метки: author it-guild управление e-commerce service desk блог компании ит гильдия ит гильдия каталог услуг itsm itil |






