Eggs Datacenter: как Emercoin позволил реализовать идею распределённого дата-центра на блокчейне |

Блокчейн — это и база хранения информации, и гарант её неизменности. Одним из вариантов применения блокчейна стала запись и хранение в нем важной информации в виде параметров «имя-значение» (NVS). Реализованное в блокчейне Emercoin, это решение позволяет локально сохранять данные публичных SSH-ключей, SSL-сертификатов и DNS-записей, не доверяя конкретному центру. Блокчейн Emercoin позволяет базирующимся на нём проектам быть и децентрализованными, и защищеннёми одновременно. Такова сила криптографии.


|
Метки: author EmercoinBlog хранилища данных хранение данных хостинг it- инфраструктура блог компании emercoin emercoin eggs datacenter egs ico |
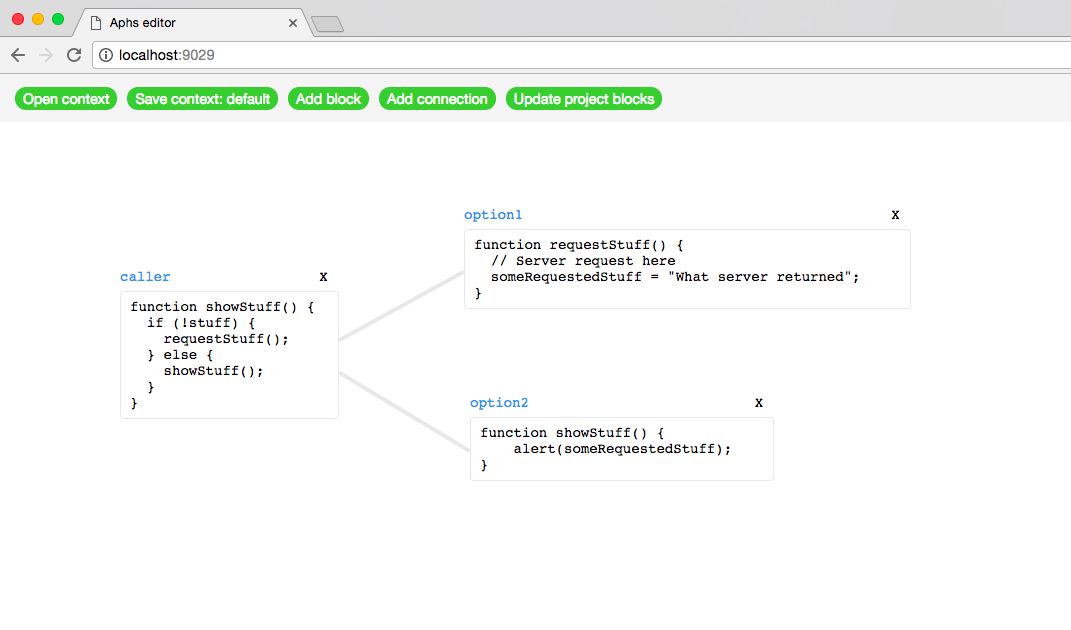
Ускоряем разработку с помощью интерактивных блоксхем |
|
|
Ускоряем разработку с помощью интерактивных блоксхем |
|
|
Machine Learning: State of the art |

 Знакомьтесь: Иван Ямщиков. Получил PhD по прикладной математике в Бранденбургском Технологическом университете (Котбус, Германия). В данный момент — научный сотрудник Института Макса Планка (Лейпциг, Германия) и аналитик/консультант Яндекса.
Знакомьтесь: Иван Ямщиков. Получил PhD по прикладной математике в Бранденбургском Технологическом университете (Котбус, Германия). В данный момент — научный сотрудник Института Макса Планка (Лейпциг, Германия) и аналитик/консультант Яндекса.
|
Метки: author varagian машинное обучение алгоритмы блог компании jug.ru group искусственный интеллект нейронная оборона музыка |
[Перевод] Профилирование сборки проекта |
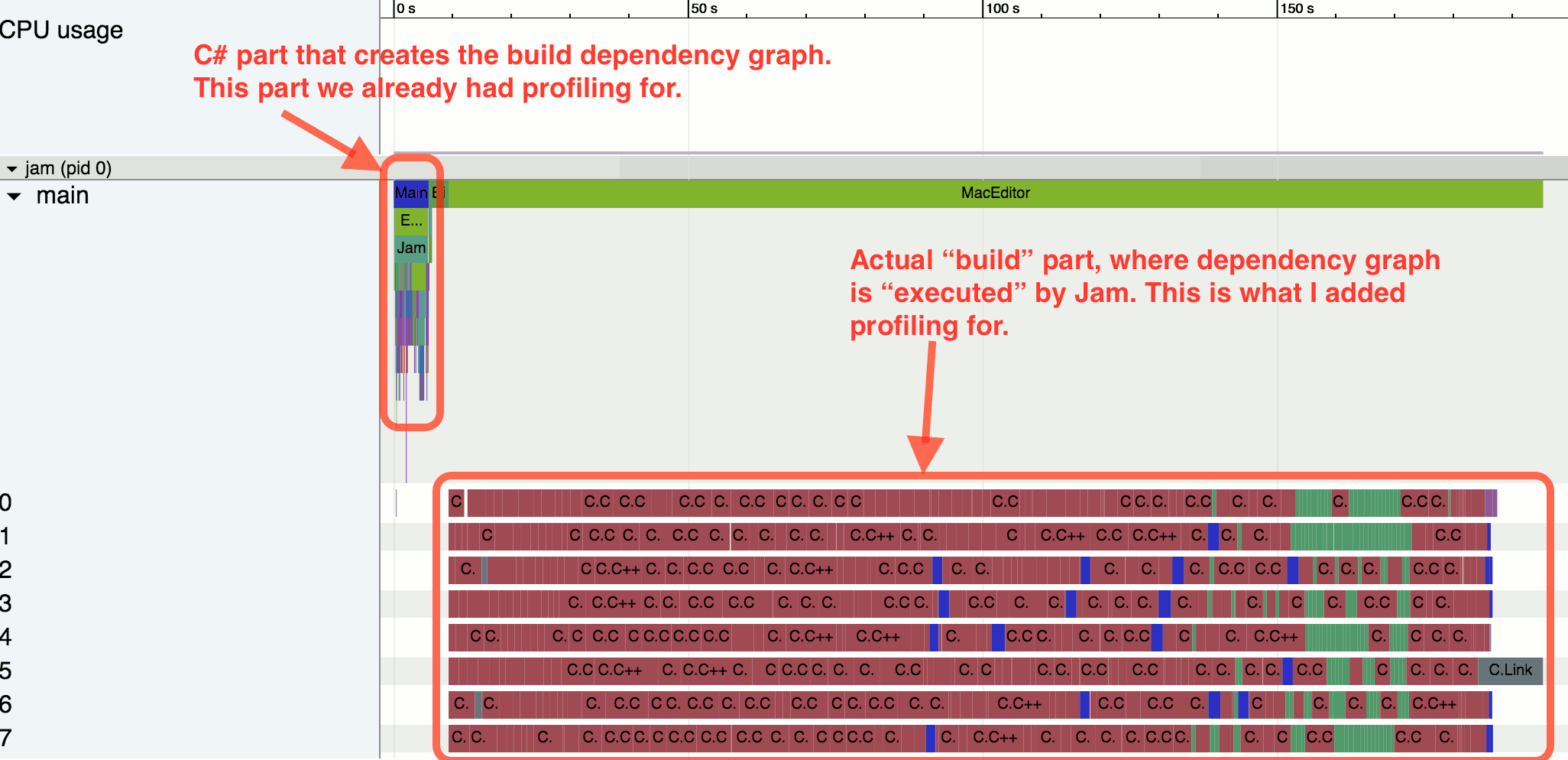

|
Метки: author tangro системы сборки отладка визуализация данных c++ блог компании инфопульс украина профилирование |
[Перевод] Kali Linux: мониторинг и логирование |
|
Метки: author ru_vds системное администрирование серверное администрирование настройка linux блог компании ruvds.com администрирование linux безопасность мониторинг логирование |
Визуализация результатов выборов в Москве на карте в Jupyter Notebook |
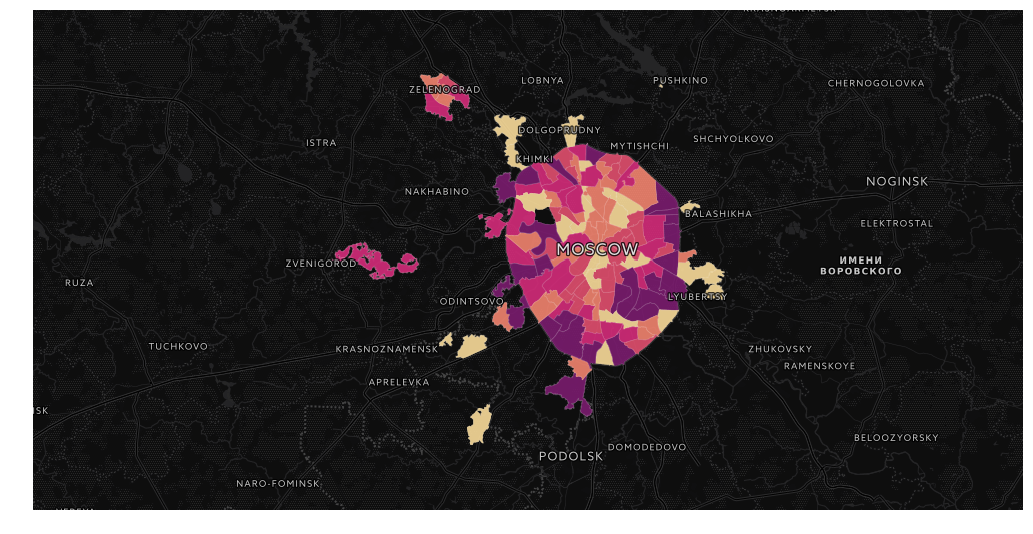
Всем привет!
Сегодня мы поговорим о визуализации геоданных. Имея на руках статистику, явно имеющую пространственную привязку, всегда хочется сделать красивую карту. Желательно, с навигацией да инфоокнами В тетрадках. И, конечно же, чтоб потом можно было показать всему интернету свои успехи в визуализации!
В качестве примера возьмем недавно отгремевшие муниципальные выборы в Москве. Сами данные можно взять с сайта мосгоризбиркома, в можно просто забрать датасеты с https://gudkov.ru/. Там даже есть какая-никакая визуализация, но мы пойдем глубже. Итак, что же у нас в итоге должно получиться?
Потратив некоторое время на написание парсера сайта Избиркома, я получил нужные мне данные. Итак, начнем с импортов.
import pandas as pd
import numpy as np
import os
import pickleЯ работаю в jupyter notebook на Linux-машине. Если вы захотите использовать мой код на Windows машине, то обращайте внимание на написание путей, а также на важные отступления в тексте.
Обычно я использую отдельную папку для проекта, поэтому для простоты задаю текущую директорию:
os.chdir('/data01/jupyter/notebooks/habr/ods_votes/')Дальше нам трубуется забрать данные с самого сайта Избиркома. Для разбора данных я написал отдельный парсер. Весь процесс занимает 10-15 минут. Забрать его можно из репозитория.
Я решил создать большой словарь с датафреймами внутри. Для превращения html-страниц в датафреймы я использовал read_html, эмпирически подбирал нужные датафрейс, а после этого делал небольшую обработку, выкидывая лишнее и добавляя недостающее. Предварительно я уже обработал данные по партиям. Изначально они были не особо читаемы. К тому же, встречается разное написание одних и тех же партий (забавно, но в некоторых случаях это не разное написание, а реально разные партии).
Непосредственно сборка справочника. Что здесь происходит:
В репозитории этой статьи лежат уже готовые данные. Их мы и будем использовать.
import glob
# забираем справочник сокращений для партий
with open('tmp/party_aliases.pkl', 'rb') as f:
party_aliases = pickle.load(f)
votes = {}
# забираем список округов и мунициальных образований
votes['atd'] = pd.read_csv('tmp/atd.csv', index_col=0, sep=';')
votes['data'] = {}
# идем по мунициальным образованиям и собираем статистику ТИК
for v in votes['atd']['municipal'].values:
votes['data']
# забираем статистику по кандидатам
candidates = glob.glob('tmp/data_{}_candidates.csv'.format(v))[0]
votes['data'][v]['candidates'] = pd.read_csv(candidates, index_col=0, sep=';')
votes['data'][v]['votes'] = {}
# теперь по каждому ОИК собираем его статистику
# статистика по УИК
okrug_stats_list = glob.glob('tmp/data_{}*_okrug_stats.csv'.format(v))
for okrug_stats in okrug_stats_list:
okrug = int(okrug_stats.split('_')[2])
try:
votes['data'][v]['votes'][okrug]
except:
votes['data'][v]['votes'][okrug] = {}
votes['data'][v]['votes'][okrug]['okrug_stats'] = pd.read_csv(okrug_stats, index_col=0, sep=';')
# статистика по кандидатам
candidates_stats_list = glob.glob('tmp/data_{}*_candidates_stats.csv'.format(v))
for candidates_stats in candidates_stats_list:
okrug = int(candidates_stats.split('_')[2])
votes['data'][v]['votes'][okrug]['candidates_stats'] = pd.read_csv(candidates_stats, index_col=0, sep=';')
# теперь собираем статистику в удобной нам форме
data = []
# пройдемся по муниципальным округам
for okrug in list(votes['data'].keys()):
#чистим данные
candidates = votes['data'][okrug]['candidates'].replace(to_replace={'party':party_aliases})
group_parties = candidates[['party','elected']].groupby('party').count()
# создаем общую статистику по избирателям
stats = np.zeros(shape=(12))
for oik in votes['data'][okrug]['votes'].keys():
stat = votes['data'][okrug]['votes'][oik]['okrug_stats'].iloc[:,1]
stats += stat
# создаем статистику по партиям
# количество мест
sum_parties = group_parties.sum().values[0]
# количество полученных мест
data_parties = candidates[['party','elected']].groupby('party').count().reset_index()
# процент полученных мест
data_parties['percent'] = data_parties['elected']/sum_parties*100
# собираем итоговую таблицу по округу
tops = data_parties.sort_values('elected', ascending=False)
c = pd.DataFrame({'okrug':okrug}, index=[0])
c['top1'], c['top1_elected'], c['top1_percent'] = tops.iloc[0,:3]
c['top2'], c['top2_elected'], c['top2_percent'] = tops.iloc[1,:3]
c['top3'], c['top3_elected'], c['top3_percent'] = tops.iloc[2,:3]
c['voters_oa'], c['state_rec'], c['state_given'], c['state_anticip'], c['state_out'], c['state_fired'], c['state_box'], c['state_move'], c['state_error'], c['state_right'], c['state_lost'] , c['state_unacc'] = stats
c['voters_percent'] = (c['state_rec'] - c['state_fired'])/c['voters_oa']*100
c['total'] = sum_parties
c['full'] = (c['top1_elected']== sum_parties)
# добавляем полученный датафрейм в список
data.append(c)
# создаем итоговый датафрейм
winners = pd.concat(data,axis=0)Мы получили датафрейм со статистикой явки, бюллютеней (от количества выданных до количества испорченных), распределением мест между партиями.
Можно приступать к визуализации!
Для работы с геоданными мы будем использовать библиотеку geopandas. Что такое geopandas? Это расширение функциональности pandas географическими абстракциями (унаследованными из Shapely), которые позволяют нам проводит аналитические географические операции с геоданными: выборки, оверлей, аггрегация (как, например, в PostGIS для Postgresql).
Напомню, что существует три базовых типа геометрии — точка, линия (а точнее, полилиния, так как состоит из соединенных отрезков) и полигон. У всех у них бывает вариант мульти-(Multi), где геометрия представляет собой объединение отдельных географических образований в один. Например, выход метро может быть точкой, но несколько выходов, объединенных в сущность "станция", уже являются мультиточкой.
Следует обратить внимание, что geopandas неохотно ставится через pip в стандартной установке Python в среде Windows. Проблема, как обычно, в зависимостях. Geopandas опирается на абстракции библиотеки fiona, у которой нет официальных сборок под Windows. Идеально использовать среду Linux, например, в docker-контейнере. Кроме того, в Windows можно использовать менеджер conda, он все зависимости подтягивает из своих репозиториев.
C геометрией муниципальных образований все достаточно просто. Их можно легко забрать из OpenStreetMap (подробнее тут) или, например, из выгрузок NextGIS. Я использую уже готовые шейпы.
Итак, начнем! Выполняем нужные импорты, активируем графики matplotlib...
import geopandas as gpd
%matplotlib inline
mo_gdf = gpd.read_file('atd/mo.shp')
mo_gdf.head()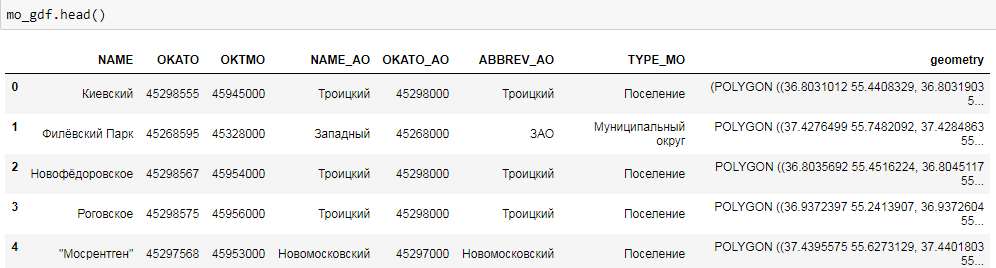
Как видите, это привычный DataFrame. Поле geometry — представление географических объектов (в данном случае — полигонов) в виде WKT, well known text (подробнее — https://en.wikipedia.org/wiki/Well-known_text). Можно довольно просто построить карту наших объектов.
mo_gdf.plot()
Угадывается Москва! Правда, не совсем привычно выглядит. Причина в проекции карты. На Хабре уже есть отличный ликбез по ним.
Итак, представим наши данные в более привычной проекции Web Mercator (исходную проекцию можно легко получить по параметру crs). Окрасим полигоны по названию Административного округа. Ширину линий выставим 0,5. Метод окраски cmap использует стандартные значения matplotlib (если вы, как и я, не помните их наизусть, то вот шпаргалка). Чтобы увидеть легенду карты, задаем параметр legend. Ну а figsize отвечает за размер нашей карты.
mo_gdf_wm = mo_gdf.to_crs({'init' :'epsg:3857'}) #непосредственно преобразование проекции
mo_gdf_wm.plot(column = 'ABBREV_AO', linewidth=0.5, cmap='plasma', legend=True, figsize=[15,15])
Можно построить карту и по типу муниципального образования:
mo_gdf_wm.plot(column = 'TYPE_MO', linewidth=0.5, cmap='plasma', legend=True, figsize=[15,15])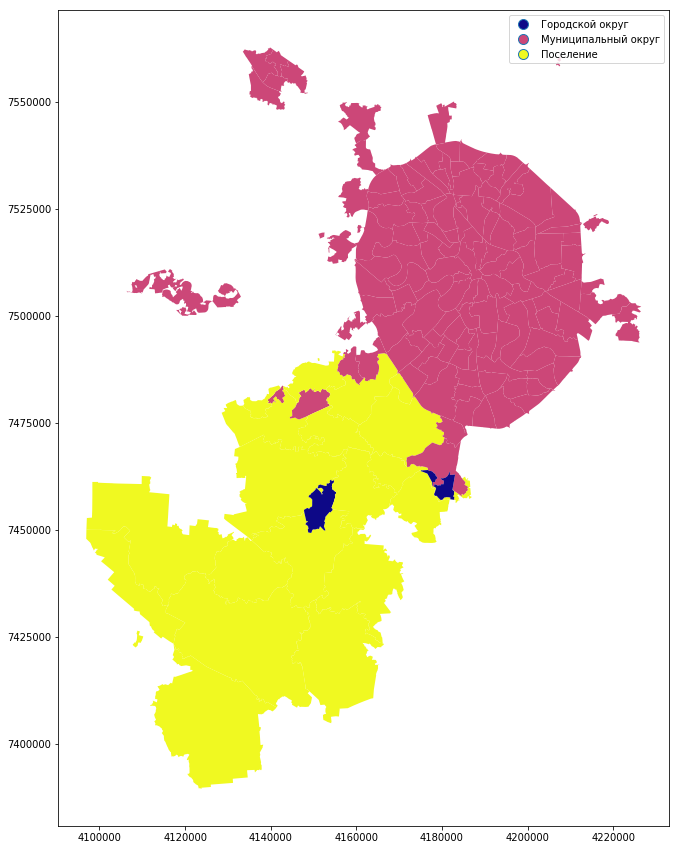
Итак, построим карту статистики по муниципальным округам. Ранее мы уже создали датафрейм winners.
Нам необходимо соединить наш датафрейм с геодатафреймом для создания карты. Немного причешем названия мунициальных округов, чтобы соединение произошло без сюрпризов.
winners['municipal_low'] = winners['okrug'].str.lower()
winners['municipal_low'] = winners['municipal_low'].str.replace('ё', 'е')
mo_gdf_wm['name_low'] = mo_gdf_wm['NAME'].str.lower()
mo_gdf_wm['name_low'] = mo_gdf_wm['name_low'].str.replace('ё', 'е')
full_gdf = winners.merge(mo_gdf_wm[['geometry', 'name_low']], left_on='municipal_low', right_on='name_low', how='left')
full_gdf = gpd.GeoDataFrame(full_gdf)Построим простую категориальная карту, где от зеленого к синему распределены партии-победители. В районе Щукино в этом году и правда не было выборов.
full_gdf.plot(column = 'top1', linewidth=0, cmap='GnBu', legend=True, figsize=[15,15])
Явка:
full_gdf.plot(column = 'voters_percent', linewidth=0, cmap='BuPu', legend=True, figsize=[15,15])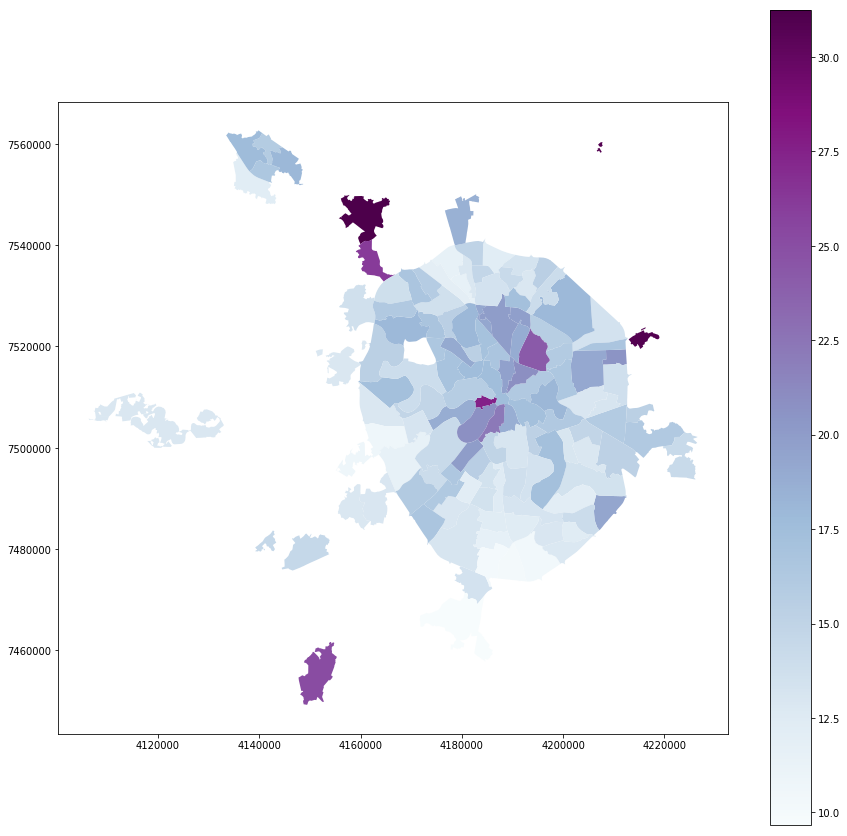
Жители:
full_gdf.plot(column = 'voters_oa', linewidth=0, cmap='YlOrRd', legend=True, figsize=[15,15])
Отлично! У нас получилась симпатичная визуализация. Но хочется и базовую карту, и навигацию! На помощь нам придет библиотека cartoframes.
Одним из самых удобных инструментов для визуализации геоданных является Carto. Для работы с этим сервисом существуюет библиотеке cartoframes, которая позволяет работать с функциями сервиса прямо из тетрадок Jupyter.
Библиотека cartoframes требует внимательного обращения под Windows в силу особенностей разработки (например, при заливке датасета библиотека пытается использовать стиль папок linux, что приводит к печальным последствиям). С кириллическими данными можно легко отстрелить себе ногу (кодировка cp1251 может быть превращена в кракозябры). Лучше ее использовать или в docker-контейнере, или на полноценном Linux. Ставится библиотека только через pip. В windows ее можно успешно установить, предварительно поставив geopandas через conda (или поставив все зависимости руками).
Cartoframes работает с проекцией WGS84. В нее и перепроецируем наш датасет. После соединения двух датафреймов может теряться информация о проекции. Зададим ее заново и перепроецируем.
full_gdf.crs = ({'init' :'epsg:3857'})
full_gdf = full_gdf.to_crs({'init' :'epsg:4326'})Делаем нужные импорты...
import cartoframes
import json
import warnings
warnings.filterwarnings("ignore")Добавляем данные от аккаунта Carto:
USERNAME = 'ваш пользователь Carto'
APIKEY = 'ваш ключ API'И, наконец, подключаемся к Carto и заливаем наш датасет:
cc = cartoframes.CartoContext(api_key=APIKEY, base_url='https://{}.carto.com/'.format(USERNAME))
cc.write(full_gdf, encode_geom=True, table_name='mo_votes', overwrite=True)Датасет можно выгрузить с Carto обратно. Но полноценный геодатафрейм пока только в проекте. Правда, можно с помощью gdal и shapely сконвертировать бинарное представление геометрии PostGIS снова в WKT.
Особенностью работы плагина является приведением типов. Увы, в текущей версии датафрейм заливается в таблицу с назначением типа str для каждого столбца. Об этом надо помнить при работе с картами.
Наконец, карта! Разукрасим данные, положим на базовую карту и включим навигацию. Подсмотреть схемы окрашивания можно здесь.
Для нормальной работы с разбиением классов напишем запрос с приведением типов. Синтаксис PostgreSQL
query_layer = 'select cartodb_id, the_geom, the_geom_webmercator, voters_oa::integer, voters_percent::float, state_out::float from mo_votes'Итак, явка:
from cartoframes import Layer, BaseMap, styling, QueryLayer
l = QueryLayer(query_layer, color={'column': 'voters_percent', 'scheme': styling.darkMint(bins=7)})
map = cc.map(layers=[BaseMap(source='light', labels='front'), l], size=(990, 500), interactive=False)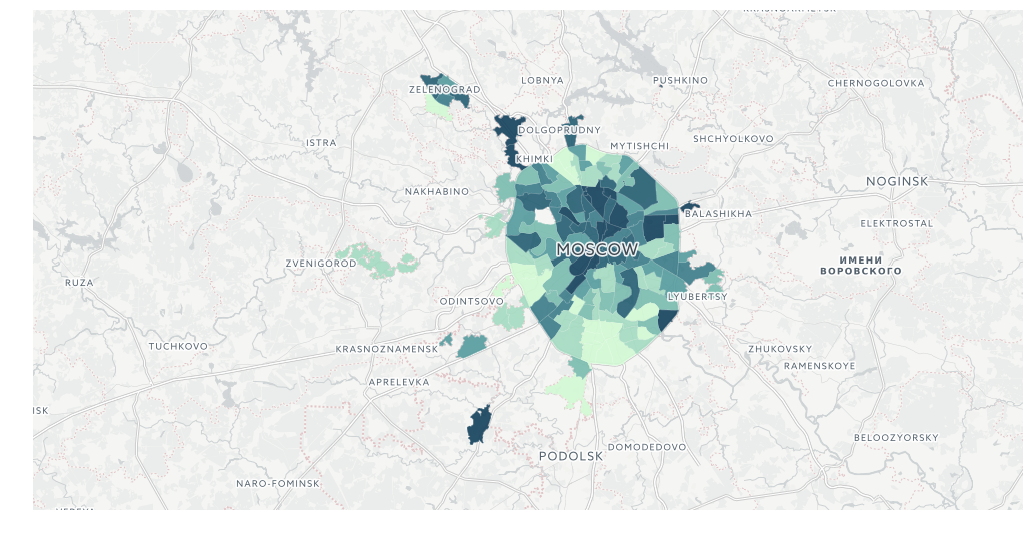
Количество жителей
l = QueryLayer(query_layer, color={'column': 'voters_oa', 'scheme': styling.burg(bins=7)})
map = cc.map(layers=[BaseMap(source='light', labels='front'), l], size=(990, 500), interactive=False)
И, например, надомное голосование
l = QueryLayer(query_layer, color={'column': 'state_out', 'scheme': styling.sunsetDark(bins=5)})
map = cc.map(layers=[BaseMap(source='light', labels='front'), l], size=(990, 500), interactive=False)
Следует заметить, что в данный момент cartoframes не позволяет встроить инфоокна прямо в окно тетрадки, показывать легенду, а также публиковать карты на Carto. Но эти опции в процессе имплементации.
А теперь попробуем более сложный, но весьма гибкий способ встраивания карт в Jupyter Notebook...
Итак, нам хотелось бы получить не только навигацию, но и инфоокна на карте. А еще получить возможность публикации визуализации на своем сервере или на github. Нам поможет folium.
Библиотека folium — довольно специфичная штука. Она представляет собой python-обертку вокруг JS-библиотеки Leaflet, которая как раз и отвечает за картографическую визуализацию. Следующие манипуляции выглядят не очень pythonic, но не пугайтесь, я все поясню.
import foliumПростая визуализация наподобие Carto делается достаточно просто.
Что происходит?
Цветовая шкала основывается на библиотеке Color Brewer. Я крайне рекомендую при работе с картами пользоваться ей.
m = folium.Map(location=[55.764414, 37.647859])
m.choropleth(
geo_data=full_gdf[['okrug', 'geometry']].to_json(),
name='choropleth',
data=full_gdf[['okrug', 'voters_oa']],
key_on='feature.properties.okrug',
columns=['okrug', 'voters_oa'],
fill_color='YlGnBu',
line_weight=1,
fill_opacity=0.7,
line_opacity=0.2,
legend_name='type',
highlight = True
)
m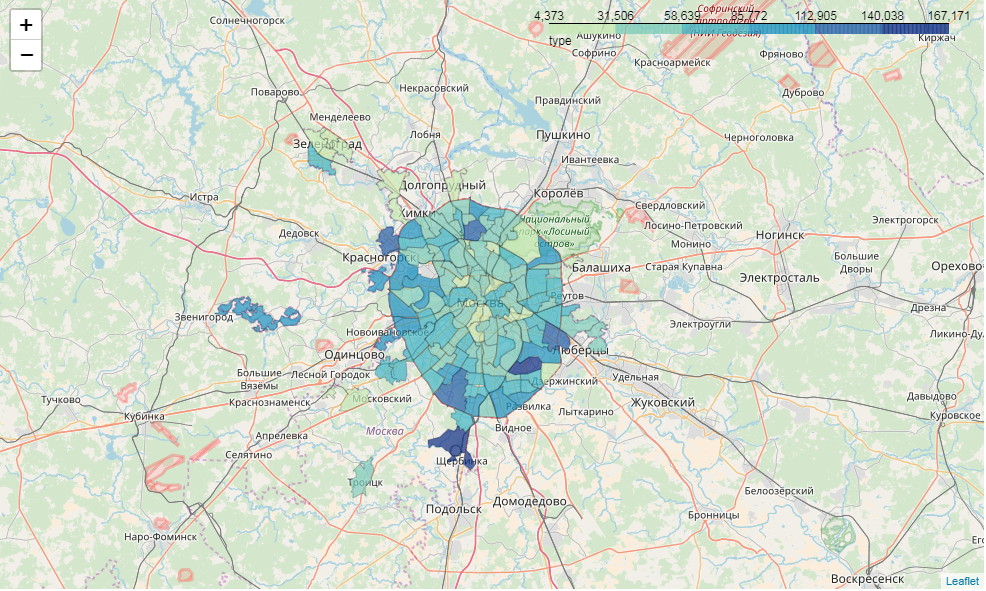
Итак, у нас получилась интерактивная картограмма. Но хотелось бы и инфоокон...
Здесь нам придется немного хакнуть библиотеку. У нас есть партии-победители в каждом ТИК. Для каждой из них мы определим базовый цвет. Но не в каждом округе победа партии означает 100% голосов. К каждому базовому цвету мы определим 3 градации: абсолютная власть (100%), контрольный пакет (>50%) и кооперация (<50%). Напишем функцию определения цвета:
def party_color(feature):
party = feature['properties']['top1']
percent = feature['properties']['top1_percent']
if party == 'Единая Россия':
if percent == 100:
color = '#969696'
elif 50 < percent < 100:
color = '#bdbdbd'
else:
color = '#d9d9d9'
elif party == 'Яблоко':
if percent == 100:
color = '#78c679'
elif 50 < percent < 100:
color = '#addd8e'
else:
color = '#d9f0a3'
elif party == 'КПРФ':
if percent == 100:
color = '#ef3b2c'
elif 50 < percent < 100:
color = '#fb6a4a'
else:
color = '#fc9272'
elif party == 'Справедливая Россия':
if percent == 100:
color = '#2171b5'
elif 50 < percent < 100:
color = '#4292c6'
else:
color = '#6baed6'
elif party == 'Самовыдвижение':
if percent == 100:
color = '#ec7014'
elif 50 < percent < 100:
color = '#fe9929'
else:
color = '#fec44f'
return {"fillColor":color, "fillOpacity":0.8,"opacity":0}Теперь напишем функцию формирования html для инфоокна:
def popup_html(feature):
html = ' Распределение мест в ТИК {}
'.format(feature['properties']['okrug'])
for p in ['top1', 'top2', 'top3']:
if feature['properties'][p + '_elected'] > 0:
html += '
{}: {} мест'.format(feature['properties'][p], feature['properties'][p + '_elected'])
return htmlНаконец, мы конвертируем каждый объект датафрейма в geojson и добавляем его к карте, привязывая к каждому стиль, поведение при наведении и инфоокно
m = folium.Map(location=[55.764414, 37.647859], zoom_start=9)
for mo in json.loads(full_gdf.to_json())['features']:
gj = folium.GeoJson(data=mo, style_function = party_color, control=False, highlight_function=lambda x:{"fillOpacity":1, "opacity":1}, smooth_factor=0)
folium.Popup(popup_html(mo)).add_to(gj)
gj.add_to(m)
m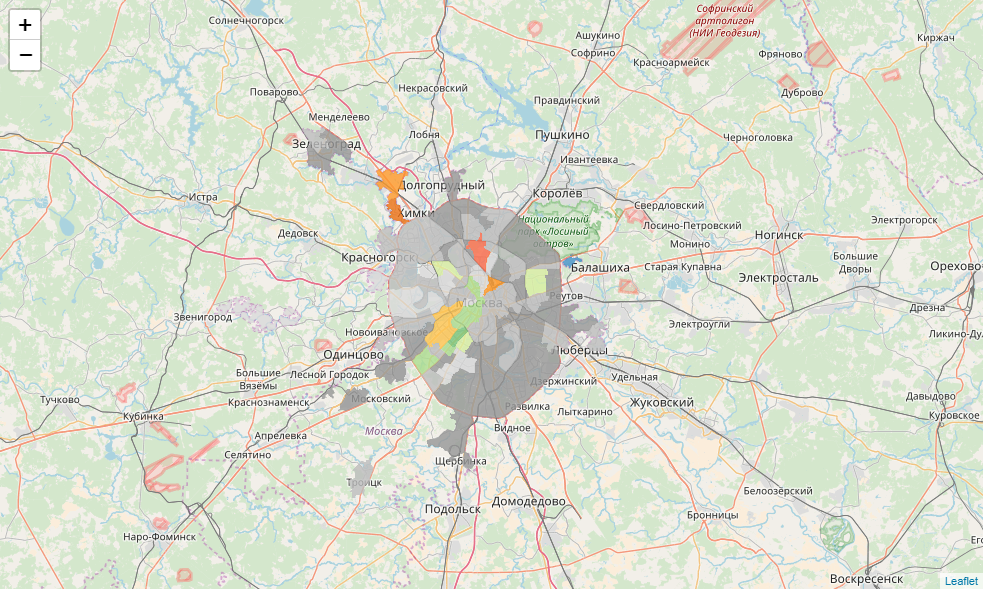
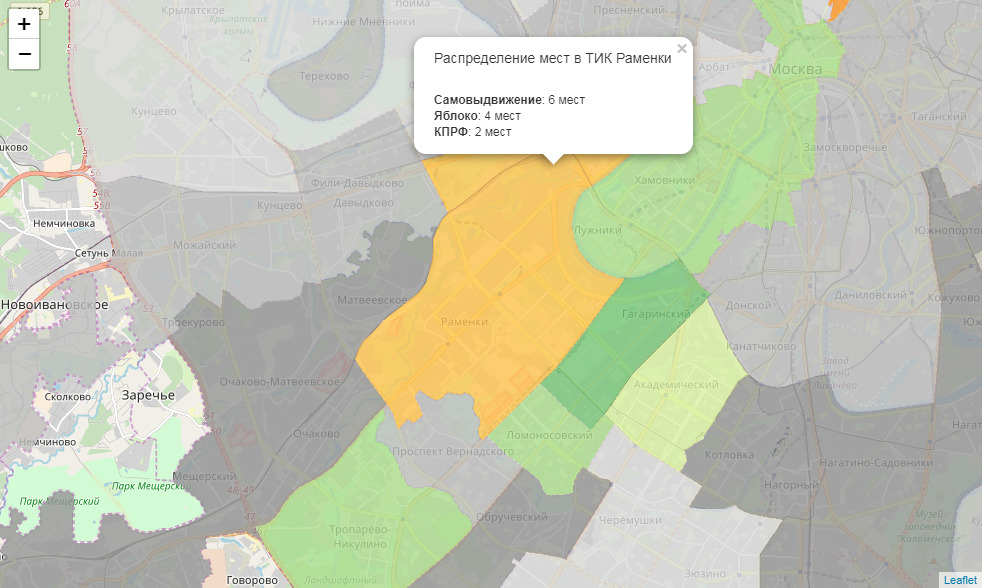
Наконец, мы сохраняем нашу карту. Ее можно опубликовать, например, на Github:
m.save('tmp/map.html')С помощью простых инструментов визуализации геоданных можно найти бесконечный простор для инсайтов. А немного поработав над данными и визуализацией, можно успешно опубликовать ваши инсайты на Carto или на github. Репозиторий этот статьи: https://github.com/fall-out-bug/izbirkom_viz.
Поздравляю, теперь вы политолог!

Вы научились анализировать результаты выборов. Поделитесь инсайтами в коментах!
|
Метки: author fall_out_bug геоинформационные сервисы визуализация данных python data mining блог компании open data science jupyter notebook картография картограмма visualization |
HR-робот обзванивает тысячи людей одновременно: рассказываем, как |
 Хабр, привет. Период отпусков закончился, так что вливаемся в работу. Мы работаем и пишем, вы — читаете и тоже работаете (надеемся, и с нашей помощью тоже). Сегодня хотим поделиться еще одним кейсом – расскажем о нашем сотрудничестве с Роботом Верой. Эта компания помогает подбирать персонал для тех, кому нужны новые кадры. Частичная (и эффективная) автоматизация процесса рекрутинга не отменяет того, что нужно много звонить. Здесь на помощь Вере приходим мы – на Voximplant компания автоматизирует телефонный дозвон кандидатам.
Хабр, привет. Период отпусков закончился, так что вливаемся в работу. Мы работаем и пишем, вы — читаете и тоже работаете (надеемся, и с нашей помощью тоже). Сегодня хотим поделиться еще одним кейсом – расскажем о нашем сотрудничестве с Роботом Верой. Эта компания помогает подбирать персонал для тех, кому нужны новые кадры. Частичная (и эффективная) автоматизация процесса рекрутинга не отменяет того, что нужно много звонить. Здесь на помощь Вере приходим мы – на Voximplant компания автоматизирует телефонный дозвон кандидатам.|
Метки: author glagoleva разработка мобильных приложений разработка веб-сайтов программирование javascript блог компании voximplant робозвонок |
Как чат-боты помогают выстраивать омниканальный опыт |
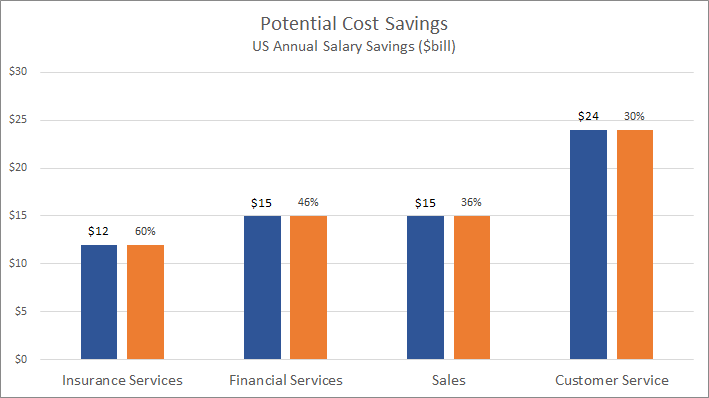
|
Метки: author LiveTex повышение конверсии монетизация веб-сервисов интернет-маркетинг чат-боты омниканальность клиентский опыт |
Comodo Group сообщают о четырехкратном увеличении числа киберугроз |


|
Метки: author VASExperts машинное обучение информационная безопасность блог компании vas experts vas experts киберугрозы |
Почта России: страшно ли жить после Страшнова? |

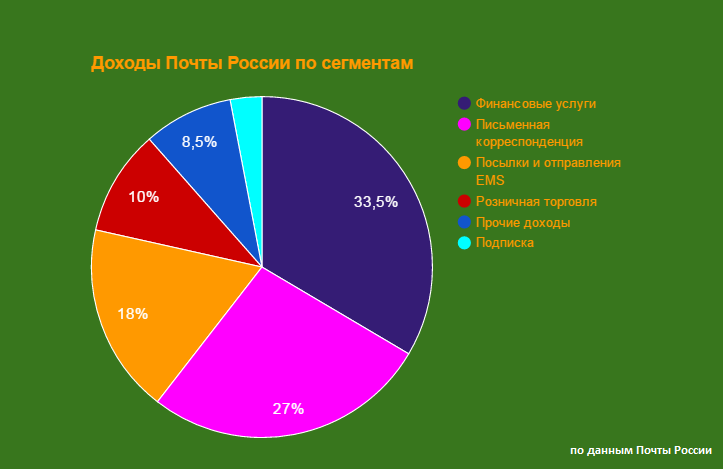

|
|
Переход с ASP.NET к ASP.NET Core 2.0 |
Эта статья является переводом справочного руководства по переносу приложений из ASP.NET в ASP.NET Core 2.0. Ссылка на оригинал
В силу некоторых причин, у нас возникла необходимость перейти с ASP.NET в ASP.NET Core 1.1., о том, как это у нас получилось, читайте тут.
• .NET Core 2.0.0 SDK или более поздняя версия.
Для работы с ASP.NET Core 2.0 проектом, разработчику предстоит сделать выбор – использовать .NET Core, .NET Framework или использовать сразу оба варианта. В качестве дополнительной информации можно использовать руководство Choosing between .NET Core and .NET Framework for server apps (вкратце можно сказать что .NET core является кроссплатформенной библиотекой, в отличие от .NET Framework) для того чтобы понять, какой Фреймворк для вас окажется наиболее предпочтительным.
После выбора нужного Фреймворка в проекте необходимо указать ссылки на пакеты NuGet.
Использование .NET Core позволяет устранить многочисленные явные ссылки на пакеты, благодаря объединенному пакету (мета пакету) ASP.NET Core 2.0. Так выглядит установка мета пакета Microsoft.AspNetCore.All в проект:
Структура файла проекта .csproj была упрощена в ASP.NET Core. Вот некоторые значительные изменения:
• Явное указание файлов является необязательным для добавления их в проект. Таким образом, уменьшается риск конфликтов в процессе слияния XML, если над проектом работает большая команда
• Больше нет GUID ссылок на другие проекты, что улучшает читаемость
• Файл можно редактировать без его выгрузки из Visual Studio:
Точкой входа для ASP.NET приложений является Global.asax файл. Такие задачи, как конфигурация маршрута и регистрация фильтров и областей, обрабатываются в файле Global.asax
public class MvcApplication : System.Web.HttpApplication
{
protected void Application_Start()
{
AreaRegistration.RegisterAllAreas();
FilterConfig.RegisterGlobalFilters(GlobalFilters.Filters);
RouteConfig.RegisterRoutes(RouteTable.Routes);
BundleConfig.RegisterBundles(BundleTable.Bundles);
}
}Этот подход тесно связывает приложение и сервер, на котором развернуто приложение. Для уменьшения связности был представлен OWIN как средство, обеспечивающее более правильный путь совместного использования нескольких фреймворков вместе.
OWIN позволяет добавить в конвейер запроса только необходимые модули. Среда выполнения использует Startup для конфигурации сервисов и конвейера запросов.
Startupрегистрирует набор промежуточных сервисов (middleware) вместе с приложением. Для каждого запроса приложение вызывает поочередно каждый из набора промежуточных сервисов, имеющих указатель на первый элемент связанного списка обработчиков.
Каждый компонент промежуточного сервиса может добавить один или несколько обработчиков в конвейер обработки запросов. Это происходит с помощью возврата ссылки на обработчик, который находится в начале списка.
И обработчик, закончив свою работу, вызывает следующий обработчик из очереди.
В ASP.NET Core, точкой входа в приложении является класс Startup, с помощью которого мы нивелируем зависимость от Global.asax.
Если изначально был выбран .NET Framework то при помощи OWIN мы можем сконфигурировать конвейер запросов как в следующем примере:
using Owin;
using System.Web.Http;
namespace WebApi
{
// Заметка: По умолчанию все запросы проходят через этот конвейер OWIN. В качестве альтернативы вы можете отключить это, добавив appSetting owin: AutomaticAppStartup со значением «false».
// При отключении вы все равно можете использовать приложения OWIN для прослушивания определенных маршрутов, добавив маршруты в файл global.asax с помощью MapOwinPath или расширений MapOwinRoute на RouteTable.Routes
public class Startup
{
// Вызывается один раз при запуске для настройки вашего приложения.
public void Configuration(IAppBuilder builder)
{
HttpConfiguration config = new HttpConfiguration();
//Здесь настраиваем маршруты по умолчанию,
config.Routes.MapHttpRoute("Default", "{controller}/{customerID}", new { controller = "Customer", customerID = RouteParameter.Optional });
//Указываем на то что в качестве файла конфигурации мы будем использовать xml вместо json
config.Formatters.XmlFormatter.UseXmlSerializer = true;
config.Formatters.Remove(config.Formatters.JsonFormatter);
// config.Formatters.JsonFormatter.UseDataContractJsonSerializer = true;
builder.UseWebApi(config);
}
}
}Также при необходимости здесь мы можем добавить другие промежуточные сервисы в этот конвейер (загрузка сервисов, настройки конфигурации, статические файлы и т.д.).
Что касается версии фреймворка .NET Core, то здесь используется подобный подход, но не без использования OWIN для определения точки входа. В качестве альтернативы используется метод Main в Program.cs (по аналогии с консольными приложениям), где и происходит загрузка Startup:
using Microsoft.AspNetCore;
using Microsoft.AspNetCore.Hosting;
namespace WebApplication2
{
public class Program
{
public static void Main(string[] args)
{
BuildWebHost(args).Run();
}
public static IWebHost BuildWebHost(string[] args) =>
WebHost.CreateDefaultBuilder(args)
.UseStartup()
.Build();
}
} Startup должен включать метод Configure. В Configure определяется, какие сервисы будут использоваться в конвейере запроса. В следующем примере (взятом из стандартного шаблона web-сайта), несколько методов расширения используются для настройки конвейера с поддержкой:
• BrowserLink
• Error pages
• Static files
• ASP.NET Core MVC
• Identity
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory)
{
loggerFactory.AddConsole(Configuration.GetSection("Logging"));
loggerFactory.AddDebug();
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
app.UseDatabaseErrorPage();
app.UseBrowserLink();
}
else
{
app.UseExceptionHandler("/Home/Error");
}
app.UseStaticFiles();
app.UseIdentity();
app.UseMvc(routes =>
{
routes.MapRoute(
name: "default",
template: "{controller=Home}/{action=Index}/{id?}");
});
}В итоге мы имеем разделение среды выполнения и приложения, что дает нам возможность осуществить переход на другую платформу в будущем.
Заметка: Для более глубокого понимания ASP.NET Core Startup и Middleware, можно изучить Startup in ASP.NET Core
ASP.NET поддерживает сохранение настроек. Например, это настройки, которые используются средой выполнения, где было развернуто приложение. Сам подход заключался в том, что для хранение пользовательских key-value пар использовалась секция
Приложение получало доступ к этим настройкам с помощью коллекции ConfigurationManager.AppSettings из пространства имен System.Configuration :
string userName = System.Web.Configuration.ConfigurationManager.AppSettings["UserName"];
string password = System.Web.Configuration.ConfigurationManager.AppSettings["Password"];В ASP.NET Core мы можем хранить конфигурационные данные для приложения в любом файле и загружать их с помощью сервисов на начальном этапе загрузки.
Файл, используемый по умолчанию в новом шаблонном проекте appsettings.json:
{
"Logging": {
"IncludeScopes": false,
"LogLevel": {
"Default": "Debug",
"System": "Information",
"Microsoft": "Information"
}
},
// Здесь можно указать настраиваемые параметры конфигурации. Поскольку это JSON, все представлено в виде пар символов: значение
// Как назвать раздел, определяет сам разработчик
"AppConfiguration": {
"UserName": "UserName",
"Password": "Password"
}
}Загрузка этого файла в экземпляр IConfiguration для приложения происходит в Startup.cs:
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }А вот так приложение использует Configuration для получения этих настроек:
string userName = Configuration.GetSection("AppConfiguration")["UserName"];
string password = Configuration.GetSection("AppConfiguration")["Password"];Есть другие способы, основанные на данном подходе, которые позволяют сделать процесс более надежным, например Dependency Injection (DI).
Подход DI обеспечивает доступ к строго типизированному набору объектов конфигурации.
// Предположим, AppConfiguration - это класс, который представляет строго типизированную версию раздела AppConfiguration
services.Configure(Configuration.GetSection("AppConfiguration")); Заметка: Для более глубокого понимания конфигураций ASP.NET Core, можно ознакомится с Configuration in ASP.NET Core.
Важной целью при создании больших масштабируемых приложений является ослабление связи между компонентами и сервисами. Dependency Injection – распространенная техника для решения данной проблемы и ее реализация является встроенным в ASP.NET Core компонентом.
В приложениях ASP.NET разработчики использовали сторонние библиотеки для внедрения Injection Dependency. Примером такой библиотеки является Unity .
Пример настройки Dependency Injection с Unity — это реализация UnityContainer, обернутая в IDependencyResolver:
using Microsoft.Practices.Unity;
using System;
using System.Collections.Generic;
using System.Web.Http.Dependencies;
public class UnityResolver : IDependencyResolver
{
protected IUnityContainer container;
public UnityResolver(IUnityContainer container)
{
if (container == null)
{
throw new ArgumentNullException("container");
}
this.container = container;
}
public object GetService(Type serviceType)
{
try
{
return container.Resolve(serviceType);
}
catch (ResolutionFailedException)
{
return null;
}
}
public IEnumerable GetServices(Type serviceType)
{
try
{
return container.ResolveAll(serviceType);
}
catch (ResolutionFailedException)
{
return new List();
}
}
public IDependencyScope BeginScope()
{
var child = container.CreateChildContainer();
return new UnityResolver(child);
}
public void Dispose()
{
Dispose(true);
}
protected virtual void Dispose(bool disposing)
{
container.Dispose();
}
}Создаем экземпляр своего UnityContainer, регистрируем свою службу и устанавливаем разрешение зависимости для HttpConfiguration в новый экземпляр UnityResolver для нашего контейнера:
public static void Register(HttpConfiguration config)
{
var container = new UnityContainer();
container.RegisterType(new HierarchicalLifetimeManager());
config.DependencyResolver = new UnityResolver(container);
// Опустим остальную часть реализации
}Далее производим инъекцию IProductRepository там, где это необходимо:
public class ProductsController : ApiController
{
private IProductRepository _repository;
public ProductsController(IProductRepository repository)
{
_repository = repository;
}
}Поскольку Dependency Injection является частью ядра ASP.NET Core, мы можем добавить свой сервис в метод ConfigureServices внутри Startup.cs:
public void ConfigureServices(IServiceCollection services)
{
//Добавляем сервис приложения
services.AddTransient();
}И далее инъекцию репозитория можно осуществить в любом месте, как и в случае с Unity.
Заметка: Подробности можно посмотреть в Dependency Injection in ASP.NET Core
Важной частью веб-разработки является возможность обслуживания статики. Самые распространенные примеры статики — это HTML, CSS, JavaScript и картинки.
Эти файлы нужно сохранять в общей папке приложения (или например в CDN) чтобы в дальнейшем они были доступны по ссылке. В ASP.NET Core был изменен подход для работы с статикой.
В ASP.NET статика хранится в разных каталогах.
А в ASP.NET Core статические файлы по умолчанию хранятся в «web root» (/ wwwroot). И доступ к этим файлам осуществляется с помощью метода расширения UseStaticFiles из Startup.Configure:
public void Configure(IApplicationBuilder app)
{
app.UseStaticFiles();
}К примеру, изображения находящееся в папке wwwroot/images будет доступно из браузера по адресу http:///images/.
Заметка: Если был выбран .NET Framework, то дополнительно нужно будет установить NuGet пакет Microsoft.AspNetCore.StaticFiles.
Заметка: Для более подробной ссылки на обслуживание статических файлов в ядре ASP.NET см. Introduction to working with static files in ASP.NET Core.
|
Метки: author Wellsoft c# asp .net asp.net .net core |
Переход с ASP.NET к ASP.NET Core 2.0 |
Эта статья является переводом справочного руководства по переносу приложений из ASP.NET в ASP.NET Core 2.0. Ссылка на оригинал
В силу некоторых причин, у нас возникла необходимость перейти с ASP.NET в ASP.NET Core 1.1., о том, как это у нас получилось, читайте тут.
• .NET Core 2.0.0 SDK или более поздняя версия.
Для работы с ASP.NET Core 2.0 проектом, разработчику предстоит сделать выбор – использовать .NET Core, .NET Framework или использовать сразу оба варианта. В качестве дополнительной информации можно использовать руководство Choosing between .NET Core and .NET Framework for server apps (вкратце можно сказать что .NET core является кроссплатформенной библиотекой, в отличие от .NET Framework) для того чтобы понять, какой Фреймворк для вас окажется наиболее предпочтительным.
После выбора нужного Фреймворка в проекте необходимо указать ссылки на пакеты NuGet.
Использование .NET Core позволяет устранить многочисленные явные ссылки на пакеты, благодаря объединенному пакету (мета пакету) ASP.NET Core 2.0. Так выглядит установка мета пакета Microsoft.AspNetCore.All в проект:
Структура файла проекта .csproj была упрощена в ASP.NET Core. Вот некоторые значительные изменения:
• Явное указание файлов является необязательным для добавления их в проект. Таким образом, уменьшается риск конфликтов в процессе слияния XML, если над проектом работает большая команда
• Больше нет GUID ссылок на другие проекты, что улучшает читаемость
• Файл можно редактировать без его выгрузки из Visual Studio:
Точкой входа для ASP.NET приложений является Global.asax файл. Такие задачи, как конфигурация маршрута и регистрация фильтров и областей, обрабатываются в файле Global.asax
public class MvcApplication : System.Web.HttpApplication
{
protected void Application_Start()
{
AreaRegistration.RegisterAllAreas();
FilterConfig.RegisterGlobalFilters(GlobalFilters.Filters);
RouteConfig.RegisterRoutes(RouteTable.Routes);
BundleConfig.RegisterBundles(BundleTable.Bundles);
}
}Этот подход тесно связывает приложение и сервер, на котором развернуто приложение. Для уменьшения связности был представлен OWIN как средство, обеспечивающее более правильный путь совместного использования нескольких фреймворков вместе.
OWIN позволяет добавить в конвейер запроса только необходимые модули. Среда выполнения использует Startup для конфигурации сервисов и конвейера запросов.
Startupрегистрирует набор промежуточных сервисов (middleware) вместе с приложением. Для каждого запроса приложение вызывает поочередно каждый из набора промежуточных сервисов, имеющих указатель на первый элемент связанного списка обработчиков.
Каждый компонент промежуточного сервиса может добавить один или несколько обработчиков в конвейер обработки запросов. Это происходит с помощью возврата ссылки на обработчик, который находится в начале списка.
И обработчик, закончив свою работу, вызывает следующий обработчик из очереди.
В ASP.NET Core, точкой входа в приложении является класс Startup, с помощью которого мы нивелируем зависимость от Global.asax.
Если изначально был выбран .NET Framework то при помощи OWIN мы можем сконфигурировать конвейер запросов как в следующем примере:
using Owin;
using System.Web.Http;
namespace WebApi
{
// Заметка: По умолчанию все запросы проходят через этот конвейер OWIN. В качестве альтернативы вы можете отключить это, добавив appSetting owin: AutomaticAppStartup со значением «false».
// При отключении вы все равно можете использовать приложения OWIN для прослушивания определенных маршрутов, добавив маршруты в файл global.asax с помощью MapOwinPath или расширений MapOwinRoute на RouteTable.Routes
public class Startup
{
// Вызывается один раз при запуске для настройки вашего приложения.
public void Configuration(IAppBuilder builder)
{
HttpConfiguration config = new HttpConfiguration();
//Здесь настраиваем маршруты по умолчанию,
config.Routes.MapHttpRoute("Default", "{controller}/{customerID}", new { controller = "Customer", customerID = RouteParameter.Optional });
//Указываем на то что в качестве файла конфигурации мы будем использовать xml вместо json
config.Formatters.XmlFormatter.UseXmlSerializer = true;
config.Formatters.Remove(config.Formatters.JsonFormatter);
// config.Formatters.JsonFormatter.UseDataContractJsonSerializer = true;
builder.UseWebApi(config);
}
}
}Также при необходимости здесь мы можем добавить другие промежуточные сервисы в этот конвейер (загрузка сервисов, настройки конфигурации, статические файлы и т.д.).
Что касается версии фреймворка .NET Core, то здесь используется подобный подход, но не без использования OWIN для определения точки входа. В качестве альтернативы используется метод Main в Program.cs (по аналогии с консольными приложениям), где и происходит загрузка Startup:
using Microsoft.AspNetCore;
using Microsoft.AspNetCore.Hosting;
namespace WebApplication2
{
public class Program
{
public static void Main(string[] args)
{
BuildWebHost(args).Run();
}
public static IWebHost BuildWebHost(string[] args) =>
WebHost.CreateDefaultBuilder(args)
.UseStartup()
.Build();
}
} Startup должен включать метод Configure. В Configure определяется, какие сервисы будут использоваться в конвейере запроса. В следующем примере (взятом из стандартного шаблона web-сайта), несколько методов расширения используются для настройки конвейера с поддержкой:
• BrowserLink
• Error pages
• Static files
• ASP.NET Core MVC
• Identity
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory)
{
loggerFactory.AddConsole(Configuration.GetSection("Logging"));
loggerFactory.AddDebug();
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
app.UseDatabaseErrorPage();
app.UseBrowserLink();
}
else
{
app.UseExceptionHandler("/Home/Error");
}
app.UseStaticFiles();
app.UseIdentity();
app.UseMvc(routes =>
{
routes.MapRoute(
name: "default",
template: "{controller=Home}/{action=Index}/{id?}");
});
}В итоге мы имеем разделение среды выполнения и приложения, что дает нам возможность осуществить переход на другую платформу в будущем.
Заметка: Для более глубокого понимания ASP.NET Core Startup и Middleware, можно изучить Startup in ASP.NET Core
ASP.NET поддерживает сохранение настроек. Например, это настройки, которые используются средой выполнения, где было развернуто приложение. Сам подход заключался в том, что для хранение пользовательских key-value пар использовалась секция
Приложение получало доступ к этим настройкам с помощью коллекции ConfigurationManager.AppSettings из пространства имен System.Configuration :
string userName = System.Web.Configuration.ConfigurationManager.AppSettings["UserName"];
string password = System.Web.Configuration.ConfigurationManager.AppSettings["Password"];В ASP.NET Core мы можем хранить конфигурационные данные для приложения в любом файле и загружать их с помощью сервисов на начальном этапе загрузки.
Файл, используемый по умолчанию в новом шаблонном проекте appsettings.json:
{
"Logging": {
"IncludeScopes": false,
"LogLevel": {
"Default": "Debug",
"System": "Information",
"Microsoft": "Information"
}
},
// Здесь можно указать настраиваемые параметры конфигурации. Поскольку это JSON, все представлено в виде пар символов: значение
// Как назвать раздел, определяет сам разработчик
"AppConfiguration": {
"UserName": "UserName",
"Password": "Password"
}
}Загрузка этого файла в экземпляр IConfiguration для приложения происходит в Startup.cs:
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }А вот так приложение использует Configuration для получения этих настроек:
string userName = Configuration.GetSection("AppConfiguration")["UserName"];
string password = Configuration.GetSection("AppConfiguration")["Password"];Есть другие способы, основанные на данном подходе, которые позволяют сделать процесс более надежным, например Dependency Injection (DI).
Подход DI обеспечивает доступ к строго типизированному набору объектов конфигурации.
// Предположим, AppConfiguration - это класс, который представляет строго типизированную версию раздела AppConfiguration
services.Configure(Configuration.GetSection("AppConfiguration")); Заметка: Для более глубокого понимания конфигураций ASP.NET Core, можно ознакомится с Configuration in ASP.NET Core.
Важной целью при создании больших масштабируемых приложений является ослабление связи между компонентами и сервисами. Dependency Injection – распространенная техника для решения данной проблемы и ее реализация является встроенным в ASP.NET Core компонентом.
В приложениях ASP.NET разработчики использовали сторонние библиотеки для внедрения Injection Dependency. Примером такой библиотеки является Unity .
Пример настройки Dependency Injection с Unity — это реализация UnityContainer, обернутая в IDependencyResolver:
using Microsoft.Practices.Unity;
using System;
using System.Collections.Generic;
using System.Web.Http.Dependencies;
public class UnityResolver : IDependencyResolver
{
protected IUnityContainer container;
public UnityResolver(IUnityContainer container)
{
if (container == null)
{
throw new ArgumentNullException("container");
}
this.container = container;
}
public object GetService(Type serviceType)
{
try
{
return container.Resolve(serviceType);
}
catch (ResolutionFailedException)
{
return null;
}
}
public IEnumerable GetServices(Type serviceType)
{
try
{
return container.ResolveAll(serviceType);
}
catch (ResolutionFailedException)
{
return new List();
}
}
public IDependencyScope BeginScope()
{
var child = container.CreateChildContainer();
return new UnityResolver(child);
}
public void Dispose()
{
Dispose(true);
}
protected virtual void Dispose(bool disposing)
{
container.Dispose();
}
}Создаем экземпляр своего UnityContainer, регистрируем свою службу и устанавливаем разрешение зависимости для HttpConfiguration в новый экземпляр UnityResolver для нашего контейнера:
public static void Register(HttpConfiguration config)
{
var container = new UnityContainer();
container.RegisterType(new HierarchicalLifetimeManager());
config.DependencyResolver = new UnityResolver(container);
// Опустим остальную часть реализации
}Далее производим инъекцию IProductRepository там, где это необходимо:
public class ProductsController : ApiController
{
private IProductRepository _repository;
public ProductsController(IProductRepository repository)
{
_repository = repository;
}
}Поскольку Dependency Injection является частью ядра ASP.NET Core, мы можем добавить свой сервис в метод ConfigureServices внутри Startup.cs:
public void ConfigureServices(IServiceCollection services)
{
//Добавляем сервис приложения
services.AddTransient();
}И далее инъекцию репозитория можно осуществить в любом месте, как и в случае с Unity.
Заметка: Подробности можно посмотреть в Dependency Injection in ASP.NET Core
Важной частью веб-разработки является возможность обслуживания статики. Самые распространенные примеры статики — это HTML, CSS, JavaScript и картинки.
Эти файлы нужно сохранять в общей папке приложения (или например в CDN) чтобы в дальнейшем они были доступны по ссылке. В ASP.NET Core был изменен подход для работы с статикой.
В ASP.NET статика хранится в разных каталогах.
А в ASP.NET Core статические файлы по умолчанию хранятся в «web root» (/ wwwroot). И доступ к этим файлам осуществляется с помощью метода расширения UseStaticFiles из Startup.Configure:
public void Configure(IApplicationBuilder app)
{
app.UseStaticFiles();
}К примеру, изображения находящееся в папке wwwroot/images будет доступно из браузера по адресу http:///images/.
Заметка: Если был выбран .NET Framework, то дополнительно нужно будет установить NuGet пакет Microsoft.AspNetCore.StaticFiles.
Заметка: Для более подробной ссылки на обслуживание статических файлов в ядре ASP.NET см. Introduction to working with static files in ASP.NET Core.
|
Метки: author Wellsoft c# asp .net asp.net .net core |
[Перевод] Развертывание кода ES2015+ в продакшн сегодня |

script type="module".script type="module" как о способе загрузки модулей ES (и, конечно же, это так), но script type="module" также имеет более быстрый и практичный вариант использования — загружает обычные файлы JavaScript с функциями ES2015+, зная, что браузер может справиться с ними!script type="module" также поддерживает большинство функций ES2015+, которые вы знаете и любите. Например:script type="module", также поддерживает async/awaitscript type="module", также поддерживает классы.script type="module", также поддерживает стрелочные функции.script type="module", также поддерживает fetch, Promises, Map, Set, и многое другое!script type="module". К счастью, если вы в настоящее время генерируете ES5-версию своего кода, вы уже сделали эту работу. Все, что вам теперь нужно — создать версию ES2015+!babel-preset-env (что должны), то второй шаг будет очень прост. Все, что вам нужно сделать, это изменить список браузеров только на те, которые поддерживают script type="module", и Babel автоматически не будет делать ненужные преобразования../path/to/main.js, тогда конфигурация вашей текущей версии ES5 может иметь следующий вид (обратите внимание, так как это ES5, я называю набор (bundle) main-legacy):module.exports = {
entry: {
'main-legacy': './path/to/main.js',
},
output: {
filename: '[name].js',
path: path.resolve(__dirname, 'public'),
},
module: {
rules: [{
test: /\.js$/,
use: {
loader: 'babel-loader',
options: {
presets: [
['env', {
modules: false,
useBuiltIns: true,
targets: {
browsers: [
'> 1%',
'last 2 versions',
'Firefox ESR',
],
},
}],
],
},
},
}],
},
};
script type="module". Вот как это может выглядеть:module.exports = {
entry: {
'main': './path/to/main.js',
},
output: {
filename: '[name].js',
path: path.resolve(__dirname, 'public'),
},
module: {
rules: [{
test: /\.js$/,
use: {
loader: 'babel-loader',
options: {
presets: [
['env', {
modules: false,
useBuiltIns: true,
targets: {
browsers: [
'Chrome >= 60',
'Safari >= 10.1',
'iOS >= 10.3',
'Firefox >= 54',
'Edge >= 15',
],
},
}],
],
},
},
}],
},
};
main.js (ES2015+ синтаксис)main-legacy.js (ES5 синтаксис)script type="module" и script nomodule:
nomodule, но вы можете решить это, встроив JavaScript-сниппет в ваш HTML до использования любых тегов script nomodule. (Примечание: это было исправлено в Safari 11).script defer. Это означает, что они не выполняются до тех пор, пока документ не будет распарсен. Если какую-то часть вашего кода нужно запустить раньше, лучше разбить этот код и загрузить его отдельно.var) и функций (function) отлично от обычных сценариев. Например, к var foo = 'bar' и function foo() {…} в скрипте можно получить доступ через window.foo, но в модуле это не будет работать. Убедитесь, что в своем коде вы не зависите от такого поведения.| Версия | Размер (minified) | Размер (minified + gzipped) |
|---|---|---|
| ES2015+ (main.js) | 80K | 21K |
| ES5 (main-legacy.js) | 175K | 43K |
| Версия | Parse/eval time (по отдельности) | Parse/eval time (среднее) |
|---|---|---|
| ES2015+ (main.js) | 184ms, 164ms, 166ms | 172ms |
| ES5 (main-legacy.js) | 389ms, 351ms, 360ms | 367ms |
node_modules не транспилировался. Однако, если модули опубликованы с исходным кодом ES2015+, возникает проблема. К счастью, она легко исправима. Вам просто нужно удалить исключение node_modules из конфигурации сборки:rules: [
{
test: /\.js$/,
exclude: /node_modules/, // удалите эту строку
use: {
loader: 'babel-loader',
options: {
presets: ['env']
}
}
}
]
node_modules, в дополнение к локальным зависимостям, это замедлит скорость сборки. К счастью, эту проблему можно отчасти решить на уровне инструментария с постоянным локальным кэшированием.script type="module" предназначен для загрузки модулей ES (и их зависимостей) в браузере, его не нужно использовать только для этой цели.script type="module" будет успешно загружать единственный файл Javascript, и это даст разработчикам столь необходимое средство для условной загрузки современного функционала в тех браузерах, которые могут его поддерживать.nomodule, дает нам возможность использовать код ES2015+ в продакшн, и наконец-то мы можем прекратить отправку транспилированного кода в браузеры, которые в нем не нуждаются.|
Метки: author ollazarev разработка веб-сайтов высокая производительность javascript production perfomance optimization es6 webpack |
[Перевод] Развертывание кода ES2015+ в продакшн сегодня |
script type="module".script type="module" как о способе загрузки модулей ES (и, конечно же, это так), но script type="module" также имеет более быстрый и практичный вариант использования — загружает обычные файлы JavaScript с функциями ES2015+, зная, что браузер может справиться с ними!script type="module" также поддерживает большинство функций ES2015+, которые вы знаете и любите. Например:script type="module", также поддерживает async/awaitscript type="module", также поддерживает классы.script type="module", также поддерживает стрелочные функции.script type="module", также поддерживает fetch, Promises, Map, Set, и многое другое!script type="module". К счастью, если вы в настоящее время генерируете ES5-версию своего кода, вы уже сделали эту работу. Все, что вам теперь нужно — создать версию ES2015+!babel-preset-env (что должны), то второй шаг будет очень прост. Все, что вам нужно сделать, это изменить список браузеров только на те, которые поддерживают script type="module", и Babel автоматически не будет делать ненужные преобразования../path/to/main.js, тогда конфигурация вашей текущей версии ES5 может иметь следующий вид (обратите внимание, так как это ES5, я называю набор (bundle) main-legacy):module.exports = {
entry: {
'main-legacy': './path/to/main.js',
},
output: {
filename: '[name].js',
path: path.resolve(__dirname, 'public'),
},
module: {
rules: [{
test: /\.js$/,
use: {
loader: 'babel-loader',
options: {
presets: [
['env', {
modules: false,
useBuiltIns: true,
targets: {
browsers: [
'> 1%',
'last 2 versions',
'Firefox ESR',
],
},
}],
],
},
},
}],
},
};
script type="module". Вот как это может выглядеть:module.exports = {
entry: {
'main': './path/to/main.js',
},
output: {
filename: '[name].js',
path: path.resolve(__dirname, 'public'),
},
module: {
rules: [{
test: /\.js$/,
use: {
loader: 'babel-loader',
options: {
presets: [
['env', {
modules: false,
useBuiltIns: true,
targets: {
browsers: [
'Chrome >= 60',
'Safari >= 10.1',
'iOS >= 10.3',
'Firefox >= 54',
'Edge >= 15',
],
},
}],
],
},
},
}],
},
};
main.js (ES2015+ синтаксис)main-legacy.js (ES5 синтаксис)script type="module" и script nomodule:
nomodule, но вы можете решить это, встроив JavaScript-сниппет в ваш HTML до использования любых тегов script nomodule. (Примечание: это было исправлено в Safari 11).script defer. Это означает, что они не выполняются до тех пор, пока документ не будет распарсен. Если какую-то часть вашего кода нужно запустить раньше, лучше разбить этот код и загрузить его отдельно.var) и функций (function) отлично от обычных сценариев. Например, к var foo = 'bar' и function foo() {…} в скрипте можно получить доступ через window.foo, но в модуле это не будет работать. Убедитесь, что в своем коде вы не зависите от такого поведения.| Версия | Размер (minified) | Размер (minified + gzipped) |
|---|---|---|
| ES2015+ (main.js) | 80K | 21K |
| ES5 (main-legacy.js) | 175K | 43K |
| Версия | Parse/eval time (по отдельности) | Parse/eval time (среднее) |
|---|---|---|
| ES2015+ (main.js) | 184ms, 164ms, 166ms | 172ms |
| ES5 (main-legacy.js) | 389ms, 351ms, 360ms | 367ms |
node_modules не транспилировался. Однако, если модули опубликованы с исходным кодом ES2015+, возникает проблема. К счастью, она легко исправима. Вам просто нужно удалить исключение node_modules из конфигурации сборки:rules: [
{
test: /\.js$/,
exclude: /node_modules/, // удалите эту строку
use: {
loader: 'babel-loader',
options: {
presets: ['env']
}
}
}
]
node_modules, в дополнение к локальным зависимостям, это замедлит скорость сборки. К счастью, эту проблему можно отчасти решить на уровне инструментария с постоянным локальным кэшированием.script type="module" предназначен для загрузки модулей ES (и их зависимостей) в браузере, его не нужно использовать только для этой цели.script type="module" будет успешно загружать единственный файл Javascript, и это даст разработчикам столь необходимое средство для условной загрузки современного функционала в тех браузерах, которые могут его поддерживать.nomodule, дает нам возможность использовать код ES2015+ в продакшн, и наконец-то мы можем прекратить отправку транспилированного кода в браузеры, которые в нем не нуждаются.|
Метки: author ollazarev разработка веб-сайтов высокая производительность javascript production perfomance optimization es6 webpack |
[recovery mode] Быстрый пул для php+websocket без прослойки nodejs на основе lua+nginx |

lua_package_path "/home/username/lib/lua/lib/?.lua;;";
server {
# магия, которая держит вебсокет открытым столько, сколько нам надо внутри nginx
location ~ ^/ws/?(.*)$ {
default_type 'plain/text';
# всё что надо здесь для веб сокета - это включить луа, который будет его хендлить
content_by_lua_file /home/username/www/wsexample.local/ws.lua;
}
# а это магия, которая отдаёт ответы от php
# я шлю только POST запросы, чтобы нормально передать json payload
location ~ ^/lua_fastcgi_connection(/?.*)$ {
internal; # видно только подзапросам внутри nginx
fastcgi_pass_request_body on;
fastcgi_pass_request_headers off;
# never never use it for lua handler
#include snippets/fastcgi-php.conf;
fastcgi_param QUERY_STRING $query_string;
fastcgi_param REQUEST_METHOD "POST"; # $request_method;
fastcgi_param CONTENT_TYPE "application/x-www-form-urlencoded"; #вместо $content_type;
fastcgi_param CONTENT_LENGTH $content_length;
fastcgi_param DOCUMENT_URI "$1"; # вместо $document_uri
fastcgi_param DOCUMENT_ROOT $document_root;
fastcgi_param SERVER_PROTOCOL $server_protocol;
fastcgi_param REQUEST_SCHEME $scheme;
fastcgi_param HTTPS $https if_not_empty;
fastcgi_param GATEWAY_INTERFACE CGI/1.1;
fastcgi_param SERVER_SOFTWARE nginx/$nginx_version;
fastcgi_param REMOTE_ADDR $remote_addr;
fastcgi_param REMOTE_PORT $remote_port;
fastcgi_param SERVER_ADDR $server_addr;
fastcgi_param SERVER_PORT $server_port;
fastcgi_param SERVER_NAME $server_name;
fastcgi_param SCRIPT_FILENAME "$document_root/mywebsockethandler.php";
fastcgi_param SCRIPT_NAME "/mywebsockethandler.php";
fastcgi_param REQUEST_URI "$1"; # здесь вообще может быть что угодно. А можно передать параметр из lua чтобы сделать какой-нибудь роутинг внутри php обработчика.
fastcgi_pass unix:/var/run/php/php7.1-fpm.sock;
fastcgi_keep_conn on;
}
local server = require "resty.websocket.server"
local wb, err = server:new{
-- timeout = 5000, -- in milliseconds -- не надо нам таймаут
max_payload_len = 65535,
}
if not wb then
ngx.log(ngx.ERR, "failed to new websocket: ", err)
return ngx.exit(444)
end
while true do
local data, typ, err = wb:recv_frame()
if wb.fatal then return
elseif not data then
ngx.log(ngx.DEBUG, "Sending Websocket ping")
wb:send_ping()
elseif typ == "close" then
-- send a close frame back:
local bytes, err = wb:send_close(1000, "enough, enough!")
if not bytes then
ngx.log(ngx.ERR, "failed to send the close frame: ", err)
return
end
local code = err
ngx.log(ngx.INFO, "closing with status code ", code, " and message ", data)
break;
elseif typ == "ping" then
-- send a pong frame back:
local bytes, err = wb:send_pong(data)
if not bytes then
ngx.log(ngx.ERR, "failed to send frame: ", err)
return
end
elseif typ == "pong" then
-- just discard the incoming pong frame
elseif data then
-- здесь в пути передаётся реальный uri, а json payload уходит в body
local res = ngx.location.capture("/lua-fastcgi-forward"..ngx.var.request_uri,{method=ngx.HTTP_POST,body=data})
if wb == nil then
ngx.log(ngx.ERR, "WebSocket instaince is NIL");
return ngx.exit(444)
end
wb:send_text(res.body)
else
ngx.log(ngx.INFO, "received a frame of type ", typ, " and payload ", data)
end
end
|
Метки: author romy4 высокая производительность php lua fastcgi websockets nginx highload nodejs lua-nginx-module |
[recovery mode] Быстрый пул для php+websocket без прослойки nodejs на основе lua+nginx |
lua_package_path "/home/username/lib/lua/lib/?.lua;;";
server {
# магия, которая держит вебсокет открытым столько, сколько нам надо внутри nginx
location ~ ^/ws/?(.*)$ {
default_type 'plain/text';
# всё что надо здесь для веб сокета - это включить луа, который будет его хендлить
content_by_lua_file /home/username/www/wsexample.local/ws.lua;
}
# а это магия, которая отдаёт ответы от php
# я шлю только POST запросы, чтобы нормально передать json payload
location ~ ^/lua_fastcgi_connection(/?.*)$ {
internal; # видно только подзапросам внутри nginx
fastcgi_pass_request_body on;
fastcgi_pass_request_headers off;
# never never use it for lua handler
#include snippets/fastcgi-php.conf;
fastcgi_param QUERY_STRING $query_string;
fastcgi_param REQUEST_METHOD "POST"; # $request_method;
fastcgi_param CONTENT_TYPE "application/x-www-form-urlencoded"; #вместо $content_type;
fastcgi_param CONTENT_LENGTH $content_length;
fastcgi_param DOCUMENT_URI "$1"; # вместо $document_uri
fastcgi_param DOCUMENT_ROOT $document_root;
fastcgi_param SERVER_PROTOCOL $server_protocol;
fastcgi_param REQUEST_SCHEME $scheme;
fastcgi_param HTTPS $https if_not_empty;
fastcgi_param GATEWAY_INTERFACE CGI/1.1;
fastcgi_param SERVER_SOFTWARE nginx/$nginx_version;
fastcgi_param REMOTE_ADDR $remote_addr;
fastcgi_param REMOTE_PORT $remote_port;
fastcgi_param SERVER_ADDR $server_addr;
fastcgi_param SERVER_PORT $server_port;
fastcgi_param SERVER_NAME $server_name;
fastcgi_param SCRIPT_FILENAME "$document_root/mywebsockethandler.php";
fastcgi_param SCRIPT_NAME "/mywebsockethandler.php";
fastcgi_param REQUEST_URI "$1"; # здесь вообще может быть что угодно. А можно передать параметр из lua чтобы сделать какой-нибудь роутинг внутри php обработчика.
fastcgi_pass unix:/var/run/php/php7.1-fpm.sock;
fastcgi_keep_conn on;
}
local server = require "resty.websocket.server"
local wb, err = server:new{
-- timeout = 5000, -- in milliseconds -- не надо нам таймаут
max_payload_len = 65535,
}
if not wb then
ngx.log(ngx.ERR, "failed to new websocket: ", err)
return ngx.exit(444)
end
while true do
local data, typ, err = wb:recv_frame()
if wb.fatal then return
elseif not data then
ngx.log(ngx.DEBUG, "Sending Websocket ping")
wb:send_ping()
elseif typ == "close" then
-- send a close frame back:
local bytes, err = wb:send_close(1000, "enough, enough!")
if not bytes then
ngx.log(ngx.ERR, "failed to send the close frame: ", err)
return
end
local code = err
ngx.log(ngx.INFO, "closing with status code ", code, " and message ", data)
break;
elseif typ == "ping" then
-- send a pong frame back:
local bytes, err = wb:send_pong(data)
if not bytes then
ngx.log(ngx.ERR, "failed to send frame: ", err)
return
end
elseif typ == "pong" then
-- just discard the incoming pong frame
elseif data then
-- здесь в пути передаётся реальный uri, а json payload уходит в body
local res = ngx.location.capture("/lua-fastcgi-forward"..ngx.var.request_uri,{method=ngx.HTTP_POST,body=data})
if wb == nil then
ngx.log(ngx.ERR, "WebSocket instaince is NIL");
return ngx.exit(444)
end
wb:send_text(res.body)
else
ngx.log(ngx.INFO, "received a frame of type ", typ, " and payload ", data)
end
end
|
Метки: author romy4 высокая производительность php lua fastcgi websockets nginx highload nodejs lua-nginx-module |
Квантовый компьютер IBM научили моделировать сложные химические элементы |


|
Метки: author it_man высокая производительность блог компании ит-град ит-град ibm квантовый компьютер |
Квантовый компьютер IBM научили моделировать сложные химические элементы |
|
Метки: author it_man высокая производительность блог компании ит-град ит-град ibm квантовый компьютер |
iOS+Kotlin. Что можно сделать сейчас |

@ExportObjCClass
class KotlinViewController : UIViewController {
constructor(aDecoder: NSCoder) : super(aDecoder)
override fun initWithCoder(aDecoder: NSCoder) = initBy(KotlinViewController(aDecoder))
@ObjCOutlet
lateinit var label: UILabel
@ObjCOutlet
lateinit var textField: UITextField
@ObjCOutlet
lateinit var button: UIButton
@ObjCAction
fun buttonPressed() {
label.text = "Konan says: 'Hello, ${textField.text}!'"
}
}|
Метки: author adev_one разработка под ios разработка под android kotlin android development ios development android ios |






