Codota: использование ИИ для улучшение кода |

|
Метки: author velkonost программирование java codota парное программирование искусственный интеллект |
[Перевод] Законы Авери для надёжности Wi-Fi |
| Замена маршрутизатора: Производитель A: 10% сломано Производитель B: 10% сломано P(одновременно A и B сломаны): 10% x 10% = 1% Замена маршрутизатора (или прошивки) почти всегда решает проблему. |
Добавление усилителя Wi-Fi: Маршрутизатор A: 90% работает Маршрутизатор B: 90% работает P(одновременно A и B работают): 90% x 90% = 81% Дополнительный маршрутизатор почти всегда ухудшает ситуацию. |
|
Метки: author m1rko стандарты связи сетевые технологии децентрализованные сети беспроводные технологии openwrt tomato wi-fi lte mesh распределенные системы |
Конкурс по программированию: JSDash (промежуточные результаты 3) |
|
|
О чем всегда стоит помнить при локализации веб-сайта, чтобы потом не было стыдно |








|
|
[Из песочницы] Разработка интерфейса приложения для пожизненного использования на примере мобильного дневника диабета |
|
Метки: author VolkoIvan интерфейсы дизайн мобильных приложений usability ios android разработка мобильных приложений ui/ux диабет |
Как угодить кинозрителю и не потерять деньги: составляем план закупок при помощи ML |
|
|
Как С# разработчику перейти на Unity |

|
Метки: author Plarium учебный процесс в it блог компании plarium unity c# .net programming gamedev игры разработка обучение геймдев |
DevOps не проблема технологий. DevOps — это проблема бизнеса. (перевод) |






|
Метки: author Tully системное администрирование серверное администрирование devops блог компании отус otus.ru otus business |
[Из песочницы] Пишем (недо)интерпретатор на Haskell с помощью alex и happy |
let a = 2 in a*2
4
let a = 8 in (let b = a - 1 in a*b)
56
$ sudo apt-get install alex{
module Lex where
}
%wrapper "basic"
$digit = 0-9
$alpha = [a-zA-Z]
tokens :-
$white ;
let { \s -> TLet }
in { \s -> TIn }
$digit+ { \s -> TNum (read s)}
[\=\+\-\*\/\(\)] { \s -> TSym (head s)}
$alpha [$alpha $digit \_ ']* { \s -> TVar s}
{
data Token = TLet | TIn | TNum Int | TSym Char | TVar String deriving (Eq, Show)
}
$ alex Lex.x$ sudo apt-get install happy{
module Synt where
import Lex
}
%name synt
%tokentype { Token }
%error { parseError }
%token
let { TLet }
in { TIn }
num { TNum $$ }
var { TVar $$ }
'=' { TSym '=' }
'+' { TSym '+' }
'-' { TSym '-' }
'*' { TSym '*' }
'/' { TSym '/' }
'(' { TSym '(' }
')' { TSym ')' }
%%
Exp:
let var '=' Exp in Exp { Let $2 $4 $6 }
| Exp1 { Exp1 $1 }
Exp1:
Exp1 '+' Term { Plus $1 $3 }
| Exp1 '-' Term { Minus $1 $3 }
| Term { Term $1 }
Term:
Term '*' Factor { Mul $1 $3 }
| Term '/' Factor { Div $1 $3 }
| Factor { Factor $1 }
Factor:
num { Num $1 }
| var { Var $1 }
| '(' Exp ')' { Brack $2 }
{
parseError :: [Token] -> a
parseError _ = error "Parse error"
data Exp = Let String Exp Exp | Exp1 Exp1 deriving (Show)
data Exp1 = Plus Exp1 Term | Minus Exp1 Term | Term Term deriving (Show)
data Term = Mul Term Factor | Div Term Factor | Factor Factor deriving (Show)
data Factor = Num Int | Var String | Brack Exp deriving (Show)
}
$ happy Synt.ymodule Main where
import qualified Data.Map as M
import Lex
import Synt
newtype Context = Context {getContext :: M.Map String Int} deriving (Show)
pull :: Maybe a -> a
pull (Just m) = m
pull Nothing = error "Undefined variable"
createContext :: Context
createContext = Context {getContext = M.empty}
getValue :: Context -> String -> Maybe Int
getValue ctx name = M.lookup name $ getContext ctx
solveExp :: Context -> Exp -> Maybe Int
solveExp ctx exp = case exp of (Let name expl rexp) -> solveExp newCtx rexp where newCtx = Context {getContext = M.insert name (pull (solveExp ctx expl)) (getContext ctx)}
(Exp1 exp1) -> solveExp1 ctx exp1
solveExp1 :: Context -> Exp1 -> Maybe Int
solveExp1 ctx exp1 = case exp1 of (Plus lexp1 rterm) -> (+) <$> (solveExp1 ctx lexp1) <*> (solveTerm ctx rterm)
(Minus lexp1 rterm) -> (-) <$> (solveExp1 ctx lexp1) <*> (solveTerm ctx rterm)
(Term term) -> solveTerm ctx term
solveTerm :: Context -> Term -> Maybe Int
solveTerm ctx term = case term of (Mul lterm rfactor) -> (*) <$> (solveTerm ctx lterm) <*> (solveFactor ctx rfactor)
(Div lterm rfactor) -> (div) <$> (solveTerm ctx lterm) <*> (solveFactor ctx rfactor)
(Factor factor) -> solveFactor ctx factor
solveFactor :: Context -> Factor -> Maybe Int
solveFactor ctx factor = case factor of (Num n) -> (Just n)
(Var s) -> getValue ctx s
(Brack exp) -> solveExp ctx exp
main = do
s <- getContents
mapM putStrLn $ (map (show . pull . (solveExp createContext) . synt . alexScanTokens) . lines) s
8let res = Exp (Exp1 (Term (Num 8)))((solveFactor ctx) <- (solveTerm ctx) <- (solveExp1 ctx) <- (solveExp ctx)) res|
Метки: author s2002kir haskell alex happy |
[Перевод] Почему я до сих пор использую Vim? |
#include
int main() {
printf("Hello, world!\n");
}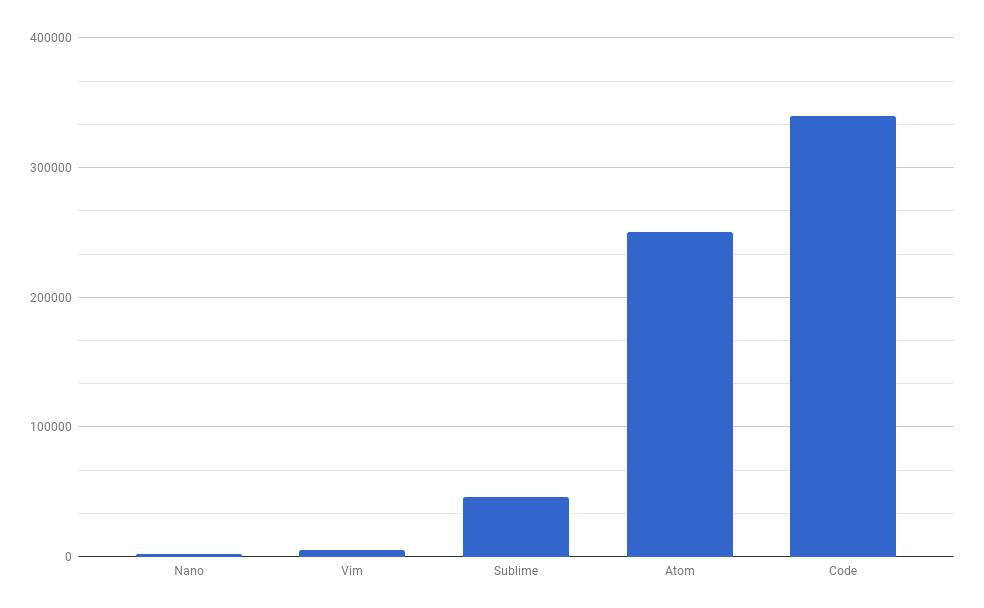 Редактору Code для открытия 60-байтного кода потребуется 349 мегабайт! Atom потребуется 256 мегабайт. А вот Vim нуждается всего в 5 мегабайтах.
Редактору Code для открытия 60-байтного кода потребуется 349 мегабайт! Atom потребуется 256 мегабайт. А вот Vim нуждается всего в 5 мегабайтах. Время запуска
Время запуска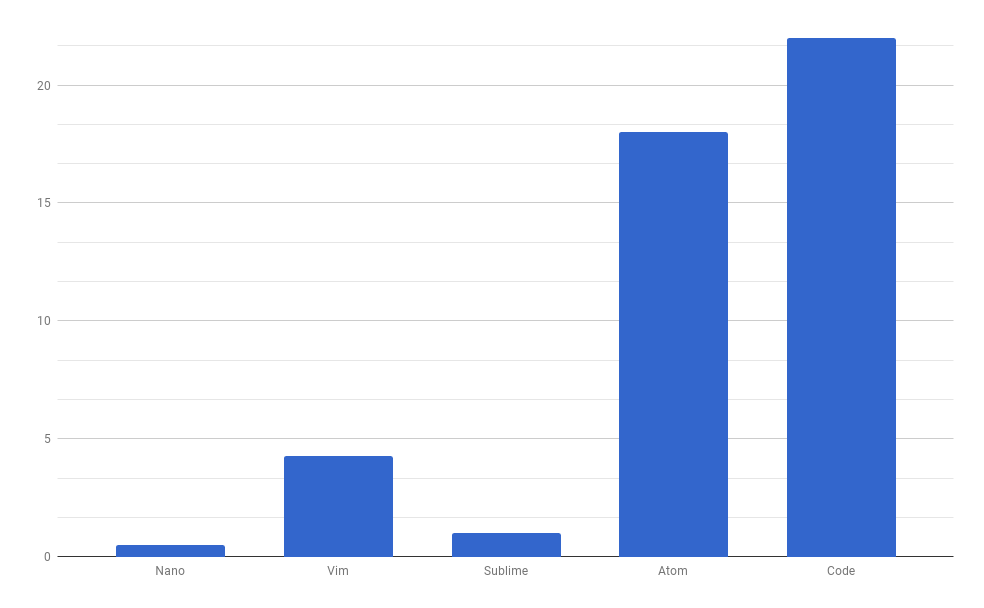 Выполнение поиска и замена 100 000 слов, в том же XML файле показали достаточно неожиданные результаты. Nano и Atom потерпели неудачу, так как для выполнения задачи потребуется почти 10 минут. Atom завис несколько раз, перед тем как получить результат. Code выполнил задачу за 80 секунд, Sublime за 6 секунд. Vim справился за 4 секунды.
Выполнение поиска и замена 100 000 слов, в том же XML файле показали достаточно неожиданные результаты. Nano и Atom потерпели неудачу, так как для выполнения задачи потребуется почти 10 минут. Atom завис несколько раз, перед тем как получить результат. Code выполнил задачу за 80 секунд, Sublime за 6 секунд. Vim справился за 4 секунды. Печально смотреть на то, когда редактор потребляет всю вычислительную мощность и память, которые доступны на «современном» дорогостоящем ноутбуке.
Печально смотреть на то, когда редактор потребляет всю вычислительную мощность и память, которые доступны на «современном» дорогостоящем ноутбуке.Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Arturo01 vim |
[Из песочницы] Исследование соответствия интернет-магазинов закону 152 ФЗ «О персональных данных» |




|
Метки: author dimchic4444 законодательство и it-бизнес интернет 152- фз 152 персональные данные |
Как я написал мобильное приложение на react-native |
render() {
return (
{ myText.join(', ') }
}
/>
{this.props.children}
);
}
const styles = StyleSheet.create({
default: {
fontSize: PixelRatio.getPixelSizeForLayoutSize(7),
color: 'rgba(0, 0, 0, 0.60)'
},
suggestUser: {
height: PixelRatio.getPixelSizeForLayoutSize(100),
backgroundColor: '#FFF',
shadowColor: '#000',
shadowOffset: {
height: -5
},
shadowRadius: 5,
shadowOpacity: 0.5
}
};

|
Метки: author doochik reactjs javascript react react-native |
UI-тесты для iOS: почему нужно поверить в дружбу QA и разработки, но не обольщаться |

- (void)testIsNewFeaturedSetForContentArrayFalse {
FNContentFeedDataSource *feedDataSource = [FNContentFeedDataSource new];
NSMutableArray *insertArray = [NSMutableArray arrayWithArray:[self baseContentArray]];
feedDataSource.currentSessionCID = @"0";
BOOL result = [feedDataSource isNewFeaturedSetForContentArray:insertArray];
XCTAssertFalse(result, @"cid check assert");
feedDataSource.currentSessionCID = @"777";
result = [feedDataSource isNewFeaturedSetForContentArray:insertArray];
XCTAssertTrue(result, @"cid check assert");
}
- (void)testAllAnalyticParametersClasses {
NSArray *parameterClasses = [FNTestUtils classesForClassesOfType:[FNAnalyticParameter class]];
for (Class parameterClass in parameterClasses) {
FNAnalyticParameter *parameter = [parameterClass value:@"TEST_VALUE"];
XCTAssertNotNil(((FNAnalyticParameter *)parameter).key);
XCTAssertNotNil(((FNAnalyticParameter *)parameter).dictionary);
}
}




xcrun simctl uninstall booted ${PRODUCT_BUNDLE_IDENTIFIER}app = [[XCUIApplication alloc] init];
app.launchEnvironment = @{
testEnviromentUserToken : @"",
testEnviromentDeviceID : @"",
testEnviromentCountry : @""
};
app.launchArguments = @[testArgumentNotClearStart];
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions
NSProcessInfo *processInfo = [NSProcessInfo processInfo];
[FNTestAPIEnviromentHandler handleArguments:processInfo.arguments
enviroment:processInfo.environment];
@implementation UIButton (TestApi)
- (NSString *)accessibilityValue {
NSMutableDictionary *result = [NSMutableDictionary new];
UIColor *titleColor = [self titleColorForState:UIControlStateNormal];
CGColorRef cgColor = titleColor.CGColor;
CIColor *ciColor = [CIColor colorWithCGColor:cgColor];
NSString *colorString = ciColor.stringRepresentation;
if (titleColor) {
[result setObject:colorString forKey:testKeyTextColor];
}
return [FNTestAPIParametersParser encodeDictionary:result];
}
@end
XCUIElement *button = app.buttons[@"FeedSmile"];
NSData *stringData = [button.value dataUsingEncoding:NSUTF8StringEncoding];
NSError *error;
NSDictionary *dictionary = [NSJSONSerialization JSONObjectWithData:stringData options:0 error:&error];
- (void)testExample {
XCUIElement *feedElement = app.otherElements[@"FeedContentItem"];
XCTAssertNotNil(feedElement);
XCUIElement *button = app.buttons[@"FeedSmile"];
[button tap];
[[[[XCUIApplication alloc] init].otherElements[@"FeedContentItem"].scrollViews childrenMatchingType:XCUIElementTypeImage].element tap];
NSDictionary *result = [FNTestAPIParametersParser decodeString:button.value];
CIColor *color = [CIColor colorWithString:result[testKeyTextColor]];
XCTAssertFalse(color.red - 1.f < FLT_EPSILON &&
color.green - 0.76f < FLT_EPSILON &&
color.blue - 0.29f < FLT_EPSILON,
@"Color not valid");
XCUIElement *feed = app.scrollViews[@"FeedContentFeed"];
[feed swipeLeft];
[feed swipeLeft];
[feed swipeLeft];
}

|
|
Не думай о минутах свысока |

| Модель |
Инфраструктура |
Масштабируемость |
Для чего лучше всего подходит |
Ценообразование |
| VPS |
Физический сервер, используемый ограниченным числом пользователей. Общая среда. |
Масштабируется «вручную» посредством запроса к провайдеру. |
Сайты с предсказуемым трафиком |
Оплачиваются прописанный в договоре ресурсы, ежемесячно или ежегодно. Требуются контракты. |
| Выделенный сервер |
Физический сервер, используемый одним клиентом / пользователем. Изолированная среда. |
Не модернизируется. Если пользователь нуждается в увеличении ресурсов, нужно получить другой пакет, определенный поставщиком, даже если он не оптимален для ваших нужд. |
Высоконагруженные веб-приложения |
Оплачиваются необходимые ресурсы — ежемесячно или ежегодно. Требуются контракты. |
| Облачный сервер |
Распределенные ресурсы на нескольких физических серверах. Изолированная виртуальная среда. |
Быстрое самостоятельное администрирование и развертывание (несколько кликов), масштабирование за несколько секунд, нулевые простои. |
Широкий спектр задач |
Оплачиваются ресурсы, которые самом деле используются. Оплата обычно почасовая. Не требуется контрактов. |

| Тип ресурса/услуги |
Цена в рублях |
Тарификация |
| Установочный платеж |
30 |
единоразово |
| 1 МГГц |
0,000008 |
поминутно |
| 1 Мб RAM |
0,000006 |
поминутно |
| 1 Мб, прочитанный с диска |
0,002 |
поминутно |
| 1 Мб, записанный на диск |
0,003 |
поминутно |
| 1 Мб, HDD |
0,00000007 |
поминутно |
| 1 Мб, SSD |
0,00000025 |
поминутно |
| 1 IOPS |
0,001 |
поминутно |
| 1 Мб исходящего трафика |
0,001 |
поминутно |
| 1 Мб входящего трафика |
0,001 |
поминутно |
| 1 Мб исходящего защищенного от DDOS трафика |
0,001 |
поминутно |
| 1 Мб входящего защищенного от DDOS трафика |
0,0035 |
поминутно |
| 1 IPv4 адрес |
0,0025 |
поминутно |

|
Метки: author ru_vds хранилища данных хостинг it- инфраструктура блог компании ruvds.com ruvds vps |
[Из песочницы] Основные ошибки accessability при разработке сайта |
| Роль | Заменяющий тег | Представление скринридером |
|---|---|---|
| banner | Банер ориентир | |
| navigation | Навигация ориентир | |
| main | Основной ориентир | |
| complementary | Добавочный ориентир | |
| contentinfo | Информация о содержимом ориентир | |
| search | - | Поиск ориентир |
|
Метки: author maniyax разработка веб-сайтов html accessability |
Dagaz: Шажки |
 — Давненько не брал я в руки шашек!
— Давненько не брал я в руки шашек! var priors = [];
_.chain(_.keys(this.pieces))
.filter(function(pos)
{ return Dagaz.Model.sharedPieces ||
Dagaz.Model.isFriend(this.pieces[pos], this.player);
}, this)
.each(function(pos) {
var piece = this.pieces[pos];
_.chain(design.pieces[piece.type])
.filter(function(move) { return (move.type == 0); })
.each(function(move) {
var g = Dagaz.Model.createGen(move.template, move.params, this.game.design);
g.init(this, pos);
addPrior(priors, move.mode, g);
}, this);
}, this);
...
for (var i = 0; i <= design.modes.length; i++) {
var f = false;
if (!_.isUndefined(priors[i])) {
while (priors[i].length > 0) {
var g = priors[i].pop();
g.generate();
if (g.completed && !g.move.isPass()) {
if (cont && (g.moveType == 0)) {
CompleteMove(this, g);
}
f = true;
}
}
}
if (f) break;
if (i >= design.modes.length) break;
}

ZrfMoveGenerator.prototype.isCaptured = function(pos, level) {
if (this.parent) {
return this.parent.isCaptured(pos, level);
}
if (_.isUndefined(this.captured)) {
this.captured = [];
}
if (this.captured[pos] && (this.captured[pos] < level)) return true;
_.each(Dagaz.Model.getDesign().allPositions(), function(p) {
if (this.captured[p] && (this.captured[p] >= level)) {
delete this.captured[p];
}
}, this);
this.captured[pos] = level;
return false;
}
ZrfMoveGenerator.prototype.capturePiece = function(pos) {
if (Dagaz.Model.deferredStrike) {
if (this.isCaptured(pos, this.level)) return false;
}
this.move.capturePiece(pos, this.level);
if (!Dagaz.Model.deferredStrike) {
this.setPiece(pos, null);
}
return true;
}
_.chain(move.actions)
.filter(function(action) {
return (action[0] !== null) && (action[1] === null);
})
.each(function(action) {
action[3] = mx;
});
var actions = [];
_.each(move.actions, function(action) {
var pn = action[3];
if ((action[0] !== null) && (action[1] === null)) {
pn = mx;
}
actions.push([ action[0], action[1], action[2], pn ]);
});
move.actions = actions;

if (_.chain(board.moves)
.filter(function(move) {
return _.isUndefined(move.failed);
})
.filter(function(move) {
return move.actions.length > 1;
})
.filter(function(move) {
...
- }).value().length > 1) {
+ }).value().length >= 1) {
_.chain(board.moves)
.filter(function(move) {
return move.actions.length == 1;
})
.each(function(move) {
move.failed = true;
});
}
|
Метки: author GlukKazan разработка игр javascript шашки checkers fanorona dagaz |
Материализуем результаты поиска, или как мы освободили 25 процессорных ядер |
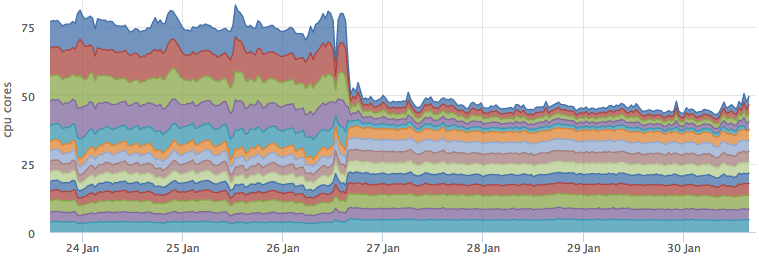
Не так давно мы решали задачу оптимизации потребления ресурсов нашего кластера elasticsearch. Неосилив настроить сам эластик, мы сделали что-то типа кэша результатов поиска, использовав при этом подход называемый "обратным" поиском или перколятором. Под катом рассказ про то, как мы работаем с метаданными метрик и собственно перколятор.
Цель сервиса мониторинга, который мы разрабытываем — показывать причины проблем, для этого мы снимаем очень много подробных метрик про разные подсистемы инфраструктуры клиентов.
С одной стороны мы решаем задачу записи большого количества метрик с тысяч хостов, с другой стороны метрики не лежат мертвым грузом в нашем хранилище, а постоянно читаются:
Когда мы начинали разработку okmeter (в тот момент еще не было публичных версий influxdb, prometheus), нам было сразу понятно, что метрики не должны быть "плоскими". В нашем случае идентификатор метрики это словарь ключ-значение (у нас он исторически называется label_set):
{
"name": "nginx.requests.rate",
"status": "403",
"source_hostname": "front3",
"file": "/var/log/access.log",
"cache_status": "MISS",
"url": "/order"
}Для каждой такой метрики у нас есть значения, привязанные к определенным моментам времени (временной ряд).
На основе хэша от label_set для каждой метрики рассчитывается строковый ключ, по которому мы идентифицируем метрики в хранилище. И тут мы разделяем задачу хранения значений метрик по ключу от задачи хранения и обработки метаинформации о метриках:

Хранилище значений метрик мы в этой статье рассматривать не будем, а о метаданных поговорим более детально.
Метаинформация метрики это собственно ключ, label_set, время создания, время обновления и еще несколько служебных полей.
Эту информацию мы храним в кассандре и можем ее получать по ключу метрики. В дополнении к основному хранилищу метаданных у нас есть индекс в elasticsearch, который по некоторому поисковому запросу пользователя возвращает набор ключей метрик.
Когда от агента, установленного на сервере клиента, приходит пачка метрик, на сервере для каждой метрики происходит примерно следующее:
Вычисляем metric_key, проверяем, есть ли эта метрика в хранилище метаинформации (C*)
Регистрируем новую, если нужно (записали в C* и ES)
Поднимаем updated_ts и вычисляем, пора ли его обновить (обновляется раз в 12 часов, ради снижения нагрузки на индексацию в ES)
Если пора – обновляем updated_ts в C* и ES
У нас есть 2 основных источника запросов на чтение метрик: запросы пользователей на отрисовку графиков и система проверки триггеров. Такие запросы представляют собой некие выражения на нашем dsl:
top(5, sum_by(url, metric(name=“nginx.requests.rate”, status=“5*”)))Это выражение содержит:
"Селектор" метрик (аргументы функции metric()), который является поисковым запросом для выбора всех метрик, интересных пользователю. В данном случае мы выбираем все метрики с именем "nginx.requests.rate" и меткой status, имеющей префикс на "5" (хотим посчитать все http-5xx ошибки)
При этом всегда наш запрос работает в каком-то интервале времени: [since_ts=X, to_ts=Y]
Селектор метрик преобразуется в примерно такой запрос к elasticsearch (валидный json запроса сильно многословнее):
{"name": “nginx.requests.rate”, "status_prefix": "5", "created_lt": "Y", "updated_gt": "X+12h"}Получили N (часто тысячи) ключей
Идем в C* получать label_sets по ключам
Идем в metric_storage получать данные по ключам
В данный момент наше облако обрабатывает чуть больше 100 тысяч метрик в секунду на запись. Посковых запросов в среднем около 350 rps (90% из них от триггеров). Каждый поисковый запрос идет по 1-3 индексам ES, каждый индекс ~100млн документов (~30GB).
При этом потребление CPU эластиком не оставит равнодушным любого, кто считает деньги, потраченные на хостинг :)
Мы пытались крутить настроки elasticsearch, ожидая, что встроенный query cache как раз создан для нашего случая повторяющихся запросов. Была попытка смоделировать индекс, в который для некоторых запросов не приходят никакие обновления, чтобы исключить инвалидацию кэша для этих запросов.
Но к сожалению все наши упражнения не дали ни снижения потребляемых ресурсов, ни снижения времени ответа эластика.
Мы решили сделать внешний по отношению к ES кэш результатов поиска и сформулировали к нему такие требования:
Поиск всегда идет по интервалу времени
Метрики, которые перестали приходить, должны уходить из кэша
При таких требованиях просто кэшировать ответ ES можно лишь на 1 минуту, при этом понятно, что hit rate будет никакой. В итоге мы пришли к тому, что будем делать не совсем кэш, а что-то вроде материлизованного представления с результатами поиска по каждому известному нам поисковому запросу.
Идея заключалась в том, что при каждой записи метрики мы будем проверять, какому известному поисковому запросу она соответствует. В случае совпадения, метрика записывается в наш кэш.
Такой подход называется "перспективным поиском", он же "обратный поиск", он же "перколятор".
Насколько я понял, термин "перколяция" здесь употребляется из-за схожести процесса, мы как-бы проверяем "протекание" документа через множество поисковых запросов.
В задаче обычного поиска у нас есть документы, мы строим из них индекс, в котором (сильно упрощенно) каждому "слову" соответствует список документов, в котором это слово встречается.

В случае перколяции у нас есть заранее известные поисковые запросы, а каждый документ является поисковым запросом:
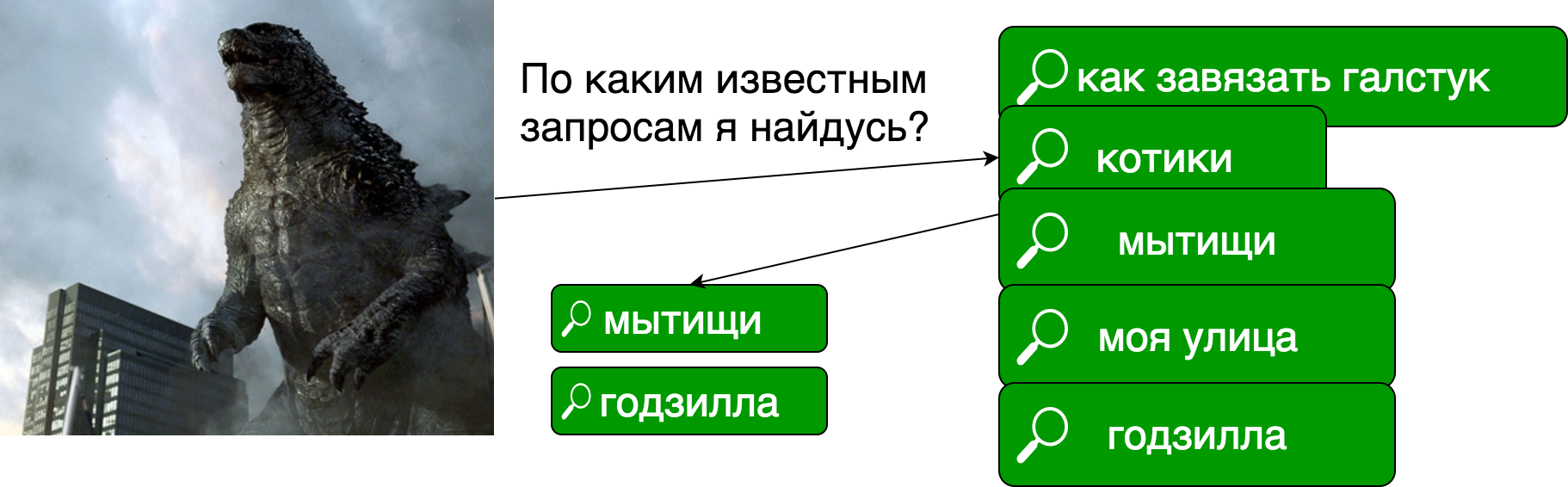
Реализации перколятора:
Мы рассматривали только elasticsearch, там перколятор представляет из себя специальный тип индекса, в котором мы описываем структуру наших будущих документов: какие будут поля у документа и их типы (mapping). Дальше в этот индекс мы сохраняем наши запросы, после чего ищем, подавая на вход документы.
Внутри ES при каждом запросе перколяции создается временный индекс в памяти, состоящий только из одного документа, который мы подали на вход. Из всех сохраненных запросов отбрасываются те, которые заведомо не подходят документу по набору полей. После чего для каждого оставшегося запроса-кандидата выполняется поиск по нашему временному индексу.
На нашем простеньком бенчмарке мы получили 2-10ms на проверке 1 документа на соответствие 1 запросу в перколяторе. При нашем потоке документов, это будет очень накладно. К тому же мы так и не научились "готовить" elasticsearch:)
Вернемся к нашим метрикам. Как я говорил выше, наш документ — это словарь ключ-значение. Наш поисковый запрос — поиск по точному или префиксному совпадению полей. То есть как таковой полнотекстовый поиск нам не требуется.
Мы решили попробовать сделать "наивную" реализацию перколятора, то есть в лоб проверять соответствие каждой метрики всем известным запросам. У нас есть поток записи ~100 тысяч метрик в секунду, каждую метрику нужно проверить на соответствие ~100 запросам.
Бенчмарк одной проверки (данный кусок нашего кода работает на golang, на нем и писали прототип) показал ~300ns. Так как это полностью cpu bound задача, имеем право суммировать время, получаем:
100k * 100 = 10M проверок в секунду
10M * 300ns = 3 секунды в секуду = 3 процессорных ядра
Логика работы нашего кэша получилась примерно такой:

В процесс записи метрик добавились дополнительные этапы:
Стоит отметить, что после того, как мы регистрируем новый запрос, кэш для него валиден не сразу. Мы должны дождаться окончания запросов на запись, которые уже начались и не видели новый запрос в списке известных. Поэтому мы отодвигаем время инициализации кэша на величину таймаута запроса на запись метрик.
Кэш мы храним в кассандре, результаты для каждого запроса побиты на куски по времени (каждый кусок 24 часа). Это сделано для того, чтобы обеспечить вымывание из результатов метрики, которые перестали приходить.
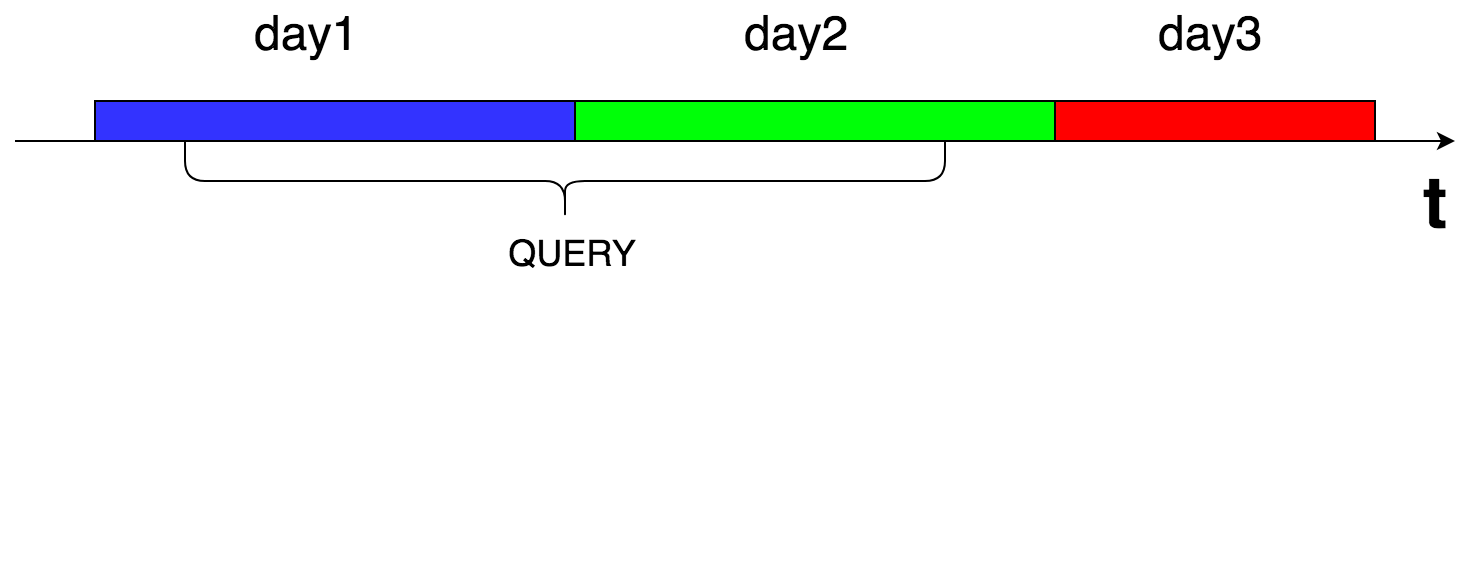
При запросе мы вычитываем все суточные куски, попадающие в интересующий нас интервал времени и объединяем результаты в памяти.
Значением является словарь ключ метрик и json представление label_set. Таким образом, если мы используем результаты из кэша, нам не нужно дополнительно идти в кассандру еще и за метаданными метрики по ключу, как мы делали это после получения результатов из ES.
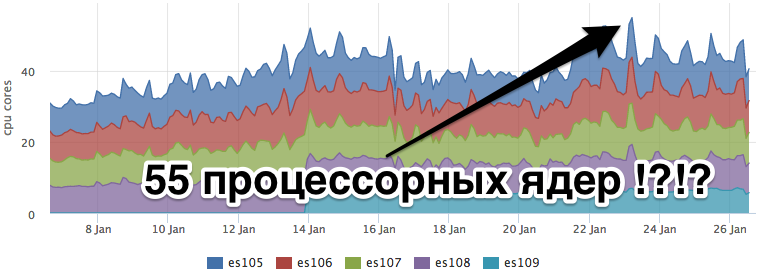
После того, как мы выкатили кэш в бой и он стал валиден для большинства запросов, нагрузка на ES сильно упала:
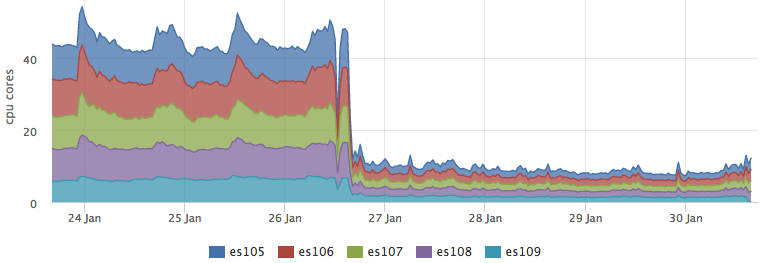
При этом потребление ресурсов кассандрой никак не изменилось:
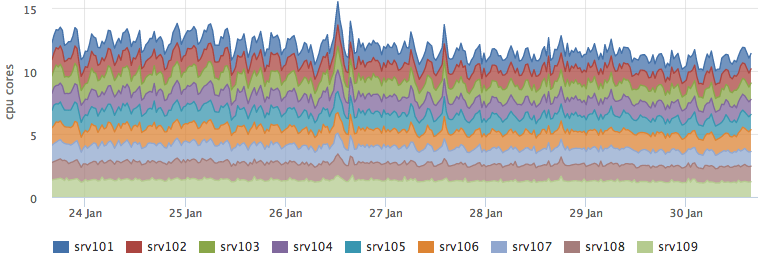
А бэкенд, который выполняет перколяцию вырос как раз на прогнозируемые ~3 ядра:
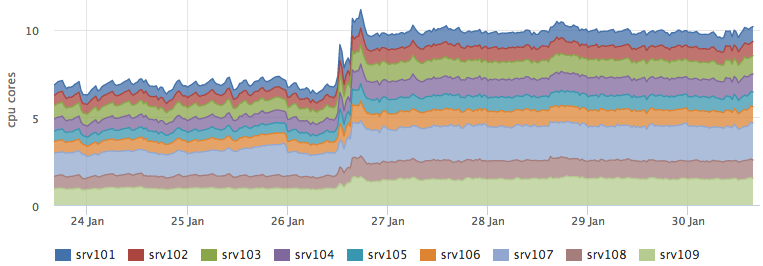
Как бонус мы получили хорошую оптимизацию по latency, взять из кэша результаты оказалось в ~5 раз быстрее, чем сходить в ES и потом достать метаинформацию из C*:
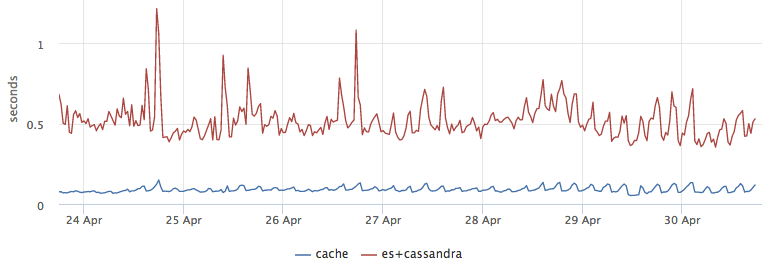
Чтобы убедиться, что мы нигде не накосячили с логикой работы кэша, первые несколько дней поиск шел одновременно и по ES и по кэшу, при этом мы сравнивали результаты и писали соответствующую метрику. После переключения нагрузки на кэш, мы не стали выпиливать логику валидации кэша и делаем спекулятивные запросы в ES для 1% запросов. Эти же запросы являюся ещё и "грелкой" для ES, в противном случае без нагрузки индексы могут не попасть в page cache и запросы пользователей будут тупить.
Мы пытались не делать внешний кэш, а заставить ES использовать внутренний. Но пришлось заниматься велосипедостроением. Но есть и плюс: мы будем навешивать дополнительную логику на перколятор.
По результатам мы неплохо ужались по железкам, при этом наш самодельный перколятор достаточно хорошо масштабируется. Это для нас достаточно важно, так как мы быстро растем как по количеству клиентов, так и по количеству метрик с каждого клиентского сервера.
|
Метки: author NikolaySivko программирование поисковые технологии высокая производительность блог компании okmeter.io percolator monitoring elasticsearch search |
Релиз YouTrack 2017.3: автоматизация рабочих процессов на JavaScript, улучшенная поддержка Kanban и многое другое |

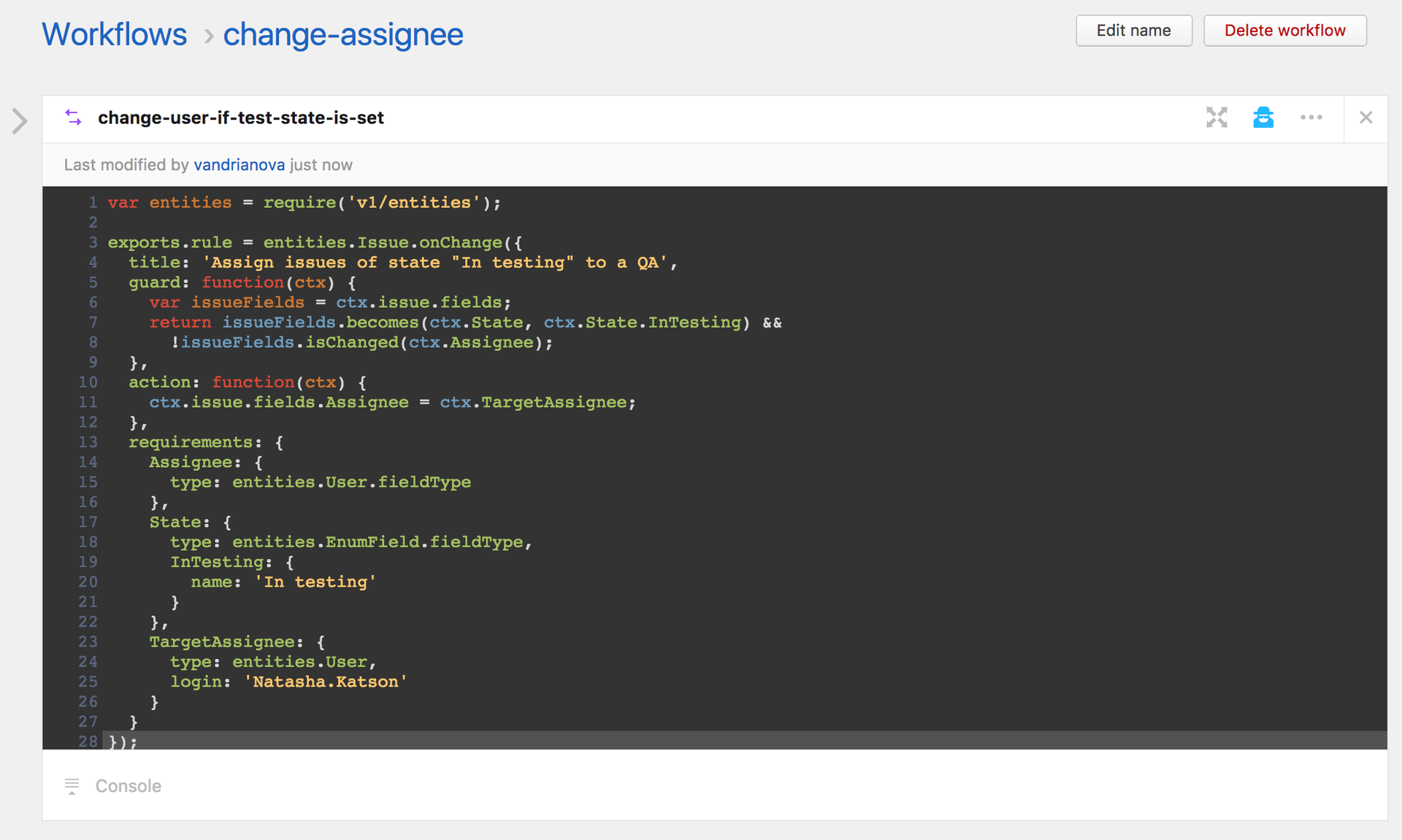





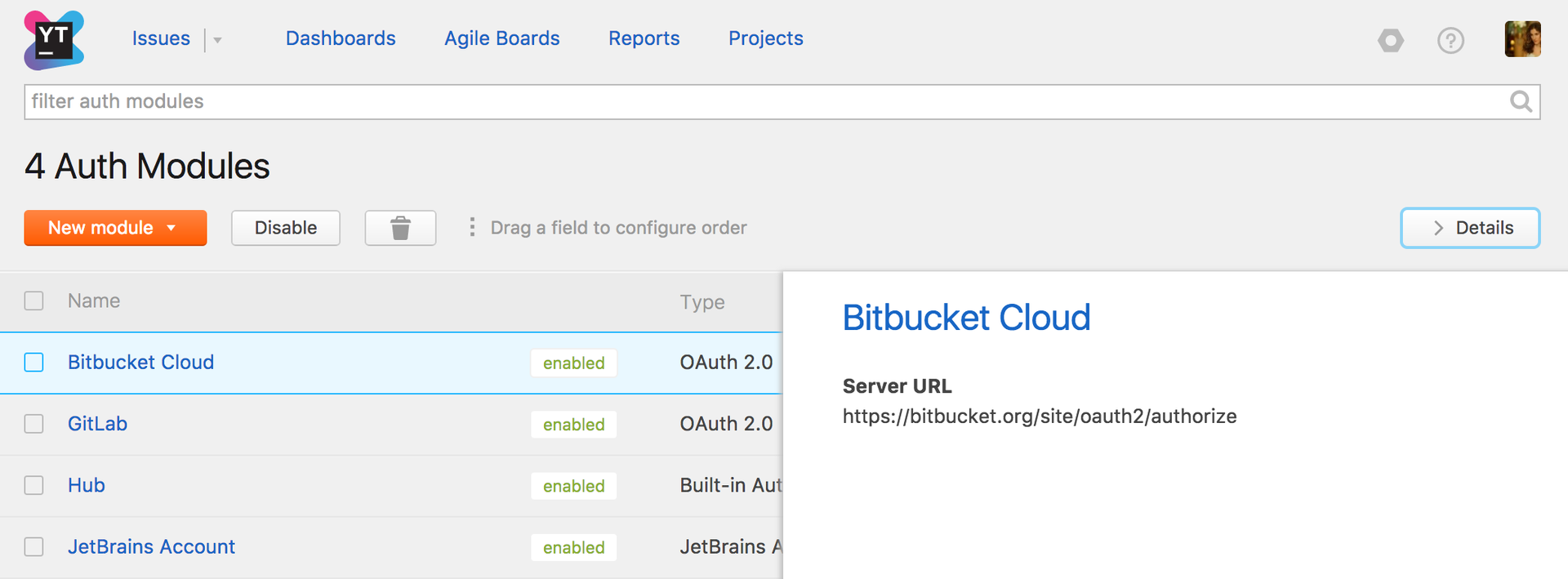
|
Метки: author nkatson блог компании jetbrains youtrack issue tracking issue tracker jetbrains agile kanban scrum scrum board team work |
Стартап дня (июль 2017-го) |

Продолжая серию дайджестов «Стартап дня», сегодня я представляю самые интересные проекты за июль. Если хотите ознакомиться с остальными, то прошу в мой блог. Записи доступны в Facebook, ICQ и Телеграм.
Лет восемь назад таких проектов было много, но, кажется, качества продукта никому не хватило, все умерли. Может быть, сейчас пришло время и теперь получится. Twiggle продает e-commerce-сервисам технологию интеллектуального поиска по товарам с пониманием естественного языка.

В качестве демонстрационного примера они используют запрос “Open back button dress for a wedding under 200 not blue” — попробуйте вбить его аналог в любую Ламоду, в лучшем случае как раз синие платья в выдаче и окажутся. Или, например, “under 200” — самый тупой консультант в магазине отлично поймет, что это про цену, но какой-либо интернет-магазин — нет. Даже Амазон не понимает! Запрос “tv under 200 dollars” там легко выпадает в предложениях, он популярен, живые люди хотят так искать, но посмотрите, что в ответ находит «магазин всего».
У Twiggle в демонстрациях, разумеется, всё работает. И “not blue”, и “under 200”, и “dress shirt” с “without” в других хитрых примерах — всё это стартап понимает корректно, и результаты выдачи соответствуют человеческим ожиданиям. Посмотреть на проект в реальной жизни, а не в презентациях пока, к сожалению, нельзя — никто ещё не внедрил полностью, хотя «у некоторых клиентов уже идут A/B-тесты».
Технически Twiggle работает как SaaS, предоставляя партнерам по сути два метода API: «загрузить базу» и «получить результаты поиска». Интеграция, соответственно, несложная, дизайн менять не надо, использовать легко. Русский язык, к сожалению, не поддерживается, в местные проекты чудо-оружие внедрить не получится, но можно попробовать отечественный аналог — Детектум

Cardlytics элегантно торгует банковской тайной. Ведь, в самом деле, любой банк знает про своих клиентов столько, что никакому поисковику не снилось, и хочется им рекламу таргетированную продавать. Cardlytics реализует один из возможных сценариев.
Часть софта стартапа устанавливается внутри периметра банка, имеет доступ ко всем транзакциям, и на основе этих данных как-то сегментирует пользователей. При начале рекламной кампании, нацеленной, например, на богатых любителей пивных ресторанов, отобранные клиенты передаются в систему самого банка, а та рассылает SMS или другие оповещения о супер-скидке и повышенном кеш-беке. Ничего не подозревающий человек радуется удачному подарку («надо же, как угадали») и отправляется знакомиться с новым заведением. Cardlytics и банк получают свою комиссию, а банк ещё и дополнительную лояльность счастливого клиента.
Персональные данные при этом защищены на двух уровнях. Истинные имена пользователей можно и не передавать в Cardlytics, ему достаточно обмениваться с банком совершенно условными идентификаторами. Кроме того, часть софта, расположенная в периметре, в периметре же и должна хранить всё, что накопила, наружу ей надо отправлять только общую статистику.
Теоретически, всё, что делает Cardlytics, может делать и сам банк: Умные Алгоритмы на BigData там весьма условны, имея доступ к тратам по карте можно использовать и прямолинейные фильтры. На практике у маленьких банков нет ни ресурсов на разработку, ни возможностей достучаться до больших рекламодателей, а стартап дает им единую точку входа.
Сейчас с Cardlytics работает 1500 американских банков, вместе они видят порядка 10 % всех американских трат по картам и чекам. Для сравнения, в России такая доля соответствовала бы позиции номер два после Сбербанка. Объёмы инвестиций соответствуют масштабам: за почти 10 лет жизни компания «освоила» 180 миллионов долларов — попробуйте дешевле подключить к своей платформе 1500 мелких банков. Серьезная выручка пошла только в самое последнее время: 80 миллионов за 2016-й год при быстром росте.

Новый гаджет для забывчивых хипстеров предлагает стартап Tile. Он продает небольшие электронные карточки с Bluetooth-чипом, которые пользователи кладут в кошелек, вешают на брелок с ключами, прикрепляют к ошейнику собаки или как-то иначе соединяют с тем, что они боятся потерять. Теперь, если страхи сбудутся, достаточно нажать кнопку в мобильном приложении, Tile зазвенит и вещь найдется. Маленький wow-эффект от дизайнеров продукта: если вдруг потеряется телефон, то всё работает совершенно симметрично — нажать кнопку надо на Tile и зазвенит уже смартфон.
Такой подход отлично работает, если ключи завалились куда-то в пределах квартиры. Но когда они вылетели из кармана где-нибудь в дороге, Bluetooth, скорее всего, не добьет. На этот случай Tile предлагает два механизма. Приложение умеет показывать точку на карте, в которой у него в последний раз получилось связаться с карточкой. Если это, скажем, работа или любимое кафе, то проблема с большой вероятностью решена. Если же кошелек выпал в автобусе и географическая координата этого места совершенно бессмысленна, то в бой вступает сообщество. Когда карточка теряет из «виду» хозяйский телефон, она начинает посылать сигнал SOS для всех. Любой оказавшийся рядом с пропажей смартфон с приложением Tile получит сигнал и переправит его в облако, откуда информация о перемещениях вещи отправится уже её хозяину. Стопроцентной гарантии, конечно, никто не дает, но шансы на счастливый конец истории есть.
Стоит одна карточка двадцать пять баксов, при покупке одновременно нескольких можно получить существенную скидку. Батарейка служит год, после этого срока компания предлагает за доплату обменять карточки на новые — по сути, скрытая подписная модель с годовым контрактом, не очень понимаю, почему она не оформляется явно. Сейчас стартап вышел на оборот в 100 миллионов долларов в год, а за всю историю продал 10 миллионов устройств, из них больше половины за последние 12 месяцев. Примерно так же растут и инвестиции: из полученных 59 миллионов 25 пришли в этом мае.

Американский LevelUp предлагает пользователям киоски предзаказа — как в McDonalds, только через приложение, а не в железном ящике. Офисный сотрудник спускается на обед, в лифте вводит заказ в соседней забегаловке, и к тому моменту, как он подойдет, еда на вынос уже будет его ждать. Пользователю не надо терять время, ресторану не надо платить кассиру, стартап собирает свои $69 в месяц за подписку, довольны даже другие, менее продвинутые, гости — очередь-то стала короче.
Одна эта функция и подписка на неё — это уже большой бизнес, LevelUp говорит о 300 тысячах подключенных точек. Оценивать выручку умножением их на $69 и на 12, конечно, нельзя, у сетей огромные скидки, но денег всё равно много. И подписка — это не всё, другой источник дохода — реклама и продвижение. Человек запускает приложение, когда идет куда-то за едой, причем его местоположение известно — идеальный момент для рекламы какого-нибудь нового бургера от кафешки неподалеку.
Самый неоднозначный путь монетизации — CRM-возможности. Заказы и платежи проходят исключительно через LevelUp, и в заведение общепита они приходят уже деперсонифицированными. Знаниями о привычках пользователей стартап и торгует. Кафе может сегментировать своих гостей, делать им спецпредложения и даже отправлять пуши.
Интересно, что продукт молодой, а стартап очень старый, но раньше он занимался совсем другим — делал эдакий Appe Pay через QR-коды. Свою бизнес-модель LevelUp изменил примерно год назад, но во всех статьях в прессе, и даже в собственном разделе Help описывается ещё старый вариант. Если считать с момента пивота, то инвестиций получено 42 миллиона долларов, 37 из них совсем недавно.

Иногда стартапом может быть и просто страница в социальной сети. У российского стартапа Meet For Charity нет никакой IT-платформы, но это не мешает ему добиваться успехов.
Идея проекта очень проста — это регулярный благотворительный аукцион за право встретиться с интересной личностью. Каждый день объявляется новый гость («лот»), и подписчики страницы прямо в комментариях делают свои ставки — кто какую сумму готов заплатить за возможность пообщаться с этим человеком. После окончания торгов победитель перечисляет свою ставку благотворительному фонду, а тот делится с Meet For Charity 15 % комиссии. В результате в выигрыше абсолютно все: мир получает больше добра, стартап зарабатывает деньги, а кто-то получает важную для себя встречу.
Гости «в лотах» бывают самые разные: бизнесмены, шоу-звезды, спортсмены. В момент написания оригинального поста «разыгрывался» Кортнев из «Несчастного случая», а рекордную сумму в 1,2 миллиона рублей выручили два месяца назад за обед с Дмитрием Гришиным. Для сравнения, ставкой в 20-25 тысяч долларов заканчивались аналогичные аукционы за встречу с Уорреном Баффеттом в начале двухтысячных.
Текущая средняя финальная цена лота — 90 000 рублей (год назад была 20 000), 15 % комиссии дали за прошедшие полгода больше полутора миллионов выручки, при практически нулевых расходах и органическом росте. На рост неорганический основатели ищут инвестиции — хотят уйти от страницы на Facebook к мобильному приложению и выйти со своей моделью в другие страны. Мне кажется, надо как минимум пожелать им удачи!
|
Метки: author gornal развитие стартапа венчурные инвестиции бизнес-модели блог компании mail.ru group стартапы стартапдня startups |
Как искусственный интеллект может спасти email |



|
Метки: author Marger1 повышение конверсии интернет-маркетинг веб-аналитика email машинное обучение искусственный интеллект коммуникации |






