[recovery mode] Clonezilla жив |




|
Метки: author mikhaylovns системное администрирование настройка linux восстановление данных clonezilla dd-wrt dlink cloning imaging rescue system |
Еще один breakpad сервер. Часть 1 |

В прошлом квартале делали MVP сервиса по обработке крешей. Аналог Socorro от Mozilla, но с учетом своих требований. Код сервиса будет выкладываться на GitHub по мере рефакторинга. Утилиты, о которых пойдет речь в этой статье, доступны тут.
У нас были следующие требования:
Содержание:
В составе breakpad есть утилита извлекающая файлы символов из elf/pdb. Вот описание формата файла. Это текстовый файл, но нас интересует первая строка имеет формат MODULE operatingsystem architecture id name, у нас она выглядит так:
MODULE windows x86 9E8FC13F1B3F448B89FF7C940AC054A21 IQ Option.pdb
MODULE Linux x86_64 4FC3EB040E16C7C75481BC5AA03EC8F50 IQOption
MODULE mac x86_64 B25BF49C9270383E8DE34560730689030 IQOptionДалее эти файлы следует расположить в особом порядке: base_dir/name/id/name.sym, выглядит это так:
base_dir/IQ Option/9E8FC13F1B3F448B89FF7C940AC054A21/IQ Option.sym
base_dir/IQOption/4FC3EB040E16C7C75481BC5AA03EC8F50/IQOption.sym
base_dir/IQOption/B25BF49C9270383E8DE34560730689030/IQOption.symДля получения отчета о падения можно воспользоваться утилитой minidump_stackwalk из поставки breakpad:
$ minidump_stackwalk path_to_crash base_dirДанная утилита может выводить как в человеко читаемым виде так и в machine-readable формате.
Но это не очень удобно. В Mozilla Socorro входит утилита stackwalker которая выдает json(пример на crash-stats.mozilla.com)
Ловить падения можно через глобальный обработчик window.onerror. В зависимости от браузера, сообщения будут отличаться:
Uncaught abort() at Error
at jsStackTrace (http://localhost/traderoom/glengine.js?v=1485951440.84:1258:13)
at Object.abort (http://localhost/traderoom/glengine.js?v=1485951440.84:776417:44)
at _abort (http://localhost/traderoom/glengine.js?v=1485951440.84:9914:22)
at _free (http://localhost/traderoom/glengine.js?v=1485951440.84:232487:38)
at __ZN2F28ViewMain13setFullscreenEb (http://localhost/traderoom/glengine.js?v=1485951440.84:533436:2)
at Array.__ZNSt3__210__function6__funcIZN2F28ViewMainC1EvE4__13NS_9allocatorIS4_EEFbPNS2_9UIElementEEEclEOS8_ (http://localhost/traderoom/glengine.js?v=1485951440.84:658644:2)
at __ZNKSt3__28functionIFllEEclEl (http://localhost/traderoom/glengine.js?v=1485951440.84:673406:75)
at __ZNK2F26detail23multicast_function_baseIFbPNS_9UIElementEENS_24multicast_result_reducerIFbRKNSt3__26vectorIbNS6_9allocatorIbEEEEEXadL_ZNS_10atLeastOneESC_EEEEiLin1EEclERKS3_ (http://localhost/traderoom/glengine.js?v=1485951440.84:476310:12)
at __ZN2F29UIElement14processTouchUpERKNS_6vec2_tIfEE (http://localhost/traderoom/glengine.js?v=1485951440.84:471241:9)
If this abort() is unexpected, build with -s ASSERTIONS=1 which can give more information.uncaught exception: abort() at jsStackTrace@http://localhost/traderoom/glengine.js?v=1485951440.84:1258:13
stackTrace@http://localhost/traderoom/glengine.js?v=1485951440.84:1275:12
abort@http://localhost/traderoom/glengine.js?v=1485951440.84:776417:44
_abort@http://localhost/traderoom/glengine.js?v=1485951440.84:9914:7
_free@http://localhost/traderoom/glengine.js?v=1485951440.84:232487:38
__ZN2F28ViewMain13setFullscreenEb@http://localhost/traderoom/glengine.js?v=1485951440.84:533436:2
__ZNSt3__210__function6__funcIZN2F28ViewMainC1EvE4__13NS_9allocatorIS4_EEFbPNS2_9UIElementEEEclEOS8_@http://localhost/traderoom/glengine.js?v=1485951440.84:658644:2
__ZNKSt3__28functionIFllEEclEl@http://localhost/traderoom/glengine.js?v=1485951440.84:673406:9
__ZNK2F26detail23multicast_function_baseIFbPNS_9UIElementEENS_24multicast_result_reducerIFbRKNSt3__26vectorIbNS6_9allocatorIbEEEEEXadL_ZNS_10atLeastOneESC_EEEEiLin1EEclERKS3_@http://localhost/traderoom/glengine.js?v=1485951440.84:476310:12
__ZN2F29UIElement14processTouchUpERKNS_6vec2_tIfEE@http://localhost/traderoom/glengine.js?v=1485951440.84:471241:9
__ZN2F29UIElement17processTouchEventERNSt3__26vectorINS1_4pairIPS0_NS_6vec2_tIfEEEENS1_9allocatorIS7_EEEEjNS_15UI_TOUCH_ACTIONE@http://localhost/traderoom/glengine.js?v=1485951440.84:468018:35
__ZN2F29UIElement5touchEffNS_15UI_TOUCH_ACTIONEj@http://localhost/traderoom/glengine.js?v=1485951440.84:598797:8
__ZN2F213MVApplication5touchEffNS_15UI_TOUCH_ACTIONEj@http://localhost/traderoom/ at stackTrace (http://localhost/traderoom/glengine.js?v=1485951440.84:1275:12)
glengine.js?v=1485951440.84:360629:11
__ZN2F27UIInput7processEj@http://localhost/traderoom/glengine.js?v=1485951440.84:273450:6
__Z14on_mouse_eventiPK20EmscriptenMouseEventPv@http://localhost/traderoom/glengine.js?v=1485951440.84:446769:5
dynCall_iiii@http://localhost/traderoom/glengine.js?v=1485951440.84:767912:9
dynCall@http://localhost/traderoom/glengine.js?v=1485951440.84:501:14
handlerFunc@http://localhost/traderoom/glengine.js?v=1485951440.84:2526:30
jsEventHandler@http://localhost/traderoom/glengine.js?v=1485951440.84:2429:11
If this abort() is unexpected, build with -s ASSERTIONS=1 which can give more information.Такое сообщение создаются если при компиляции использовать ключ -g. На нашем проекте размер выходного asm.js кода раза в 3 больше. Поэтому у нас используется --emit-symbol-map.
На выходе получаем файл с символами в простом формате key:value:
$cc:__ZNSt3__210__function6__funcIZN2F28ViewMain17animateLeftPannelEbE4__36NS_9allocatorIS4_EEFvvEEclEv
f8d:__ZNKSt3__210__function6__funcIZN2F218MVMessageQueueImpl4sendINS2_26EventSocialProfileReceivedEJiEEEvDpRKT0_EUlvE_NS_9allocatorISA_EEFvvEE7__cloneEPNS0_6__baseISD_EE
Z1:__ZN2F211recognizers24UIPinchGestureRecognizer6updateEPNS_9UIElementERKNS_6vec2_tIfEEjа сообщения теперь имеют вид:
Uncaught abort() at Error
at jsStackTrace (http://10.10.1.247:8080/main.js:1:17947)
at stackTrace (http://10.10.1.247:8080/main.js:1:18118)
at Object.abort (http://10.10.1.247:8080/main.js:12:6480)
at _abort (http://10.10.1.247:8080/main.js:1:37453)
at Eb (http://10.10.1.247:8080/main.js:5:22979)
at Xc (http://10.10.1.247:8080/main.js:5:53767)
at rc (http://10.10.1.247:8080/main.js:5:47782)
at Array.$c (http://10.10.1.247:8080/main.js:5:54228)
at Pc (http://10.10.1.247:8080/main.js:5:52663)
at Array.Wb (http://10.10.1.247:8080/main.js:5:40899)
If this abort() is unexpected, build with -s ASSERTIONS=1 which can give more information.Для получения получения стека вызовов была написана вспомогательная утилита:
#include Утилита использует demangle, для преобразования:
_ZN2F211recognizers24UIPinchGestureRecognizer6updateEPNS_9UIElementERKNS_6vec2_tIfEEjв
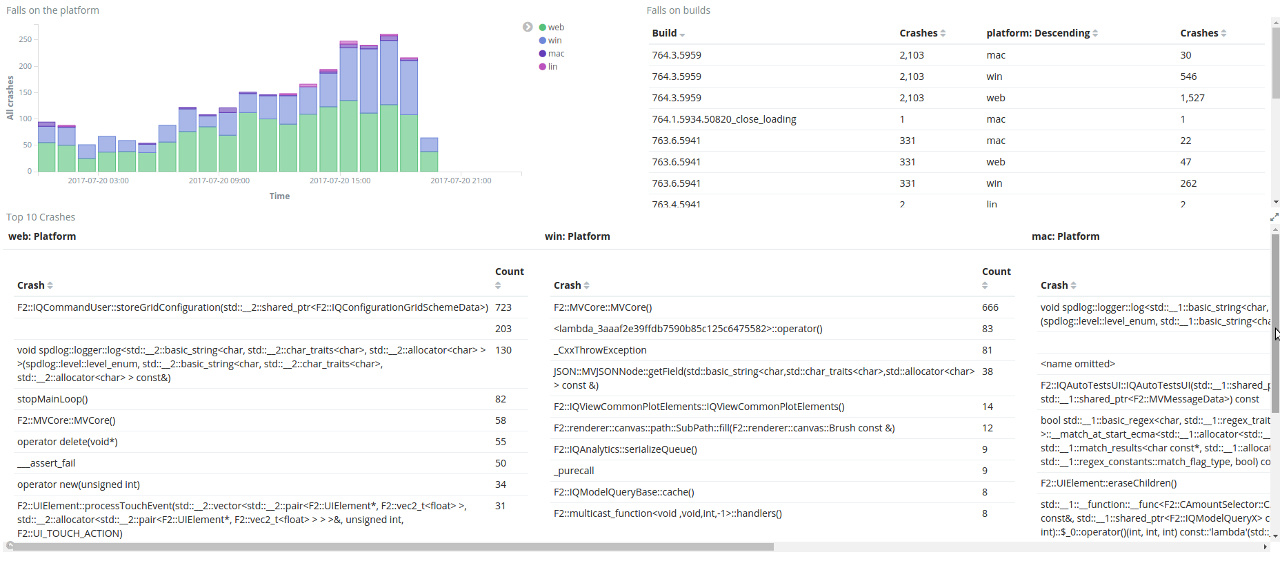
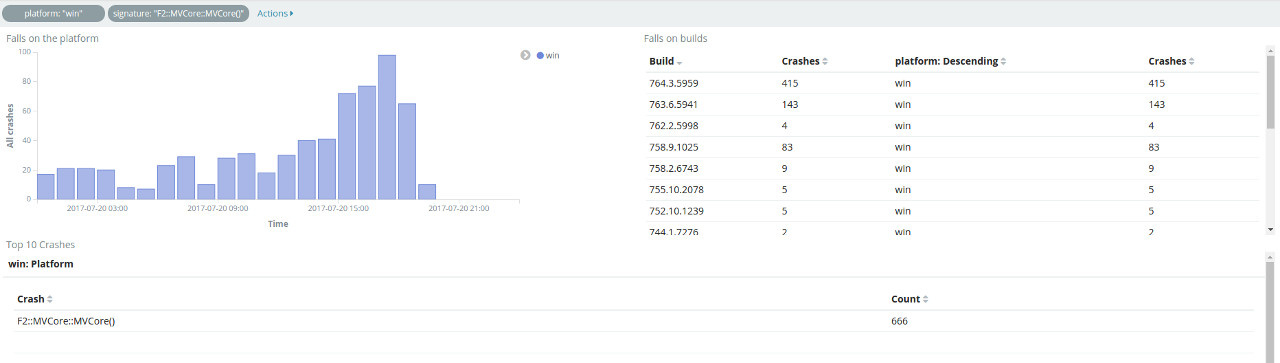
F2::recognizers::UIPinchGestureRecognizer::update(F2::UIElement*, F2::vec2_t const&, unsigned int) Отчеты о падении складываем в Elasticsearch, поэтому на первое время используем Kibana, как средство визуализации и анализа содержимого эластика.
При использовании кибаны получаем из коробки:
Дашборды группируют креши по платформе, билду, сигнатуре. Система фильтров позволяет узнать:
Примененные фильтры можно перенести на вкладку discover, где можно посмотреть подробности падения. Как оказалось кибана имеет модульную структуру, что позволяет расширять её возможности. Был написан простой плагин, добавляющий рендер отчета, что намного удобней стандартного Table и JSon.

|
Метки: author RPG18 отладка c++ breakpad emscripten |
[Перевод] Куда уйти из IT: 3 сферы, которые нуждаются в технических специалистах |




|
Метки: author ksusha_icc исследования и прогнозы в it блог компании icanchoose.ru карьера выбор карьеры карьера в it начало карьеры |
«Познай самого себя»: social media mining-проекты в Университете ИТМО |
 / Фотография perzon seo CC-BY
/ Фотография perzon seo CC-BYЗа экстремальные ситуации, помимо драк, также считались использование пиротехники, бросание предметов на трибуны и поле стадиона, демонстрация оскорбительных баннеров, скандирование нетолерантных кричалок и другое. Мы рассматривали матчи [ФК «Зенит»] в период с 2013 по 2015 годы. Получилось около десяти игр, после чего мы брали и другие команды.
Всего матчей с драками было немного, но, когда мы стали работать с официальной статистикой Российского футбольного союза и смотрели не только драки, но и на иные события, которые могут угрожать здоровью и состоянию болельщиков, [выяснилось, что] за три сезона из 700 матчей с экстремальными событиями на трибунах прошло около половины игр.
– Василий Бойчук, инженер НИИ НКТ

|
Метки: author itmo разработка под e-commerce блог компании университет итмо университет итмо social media mining анализ данных |
[Перевод] Полезные команды и советы при работе с Kubernetes через консольную утилиту kubectl |

kubectl. Не забудьте также посмотреть на cheat sheet в секции официальной документации Kubernetes!kubectl есть отличное встроенное автодополнение для bash и zsh, что значительно упрощает работу с командами, флагами и объектами вроде пространств имён и названий подов. В документации есть готовые инструкции по его включению. А GIF-анимация ниже показывает, как автодополнение работает:
# Подключить код автодополнения для текущего сеанса в Bash
source <(kubectl completion bash)
# … или добавить код автодополнения в файл и подключить его к .bashrc
mkdir ~/.kube
kubectl completion bash > ~/.kube/completion.bash.inc
printf "\n# Kubectl shell completion\nsource '$HOME/.kube/completion.bash.inc'\n" >> $HOME/.bashrc
source $HOME/.bashrc
# Альтернатива — подключить код автодополнения для текущего сеанса в Zsh
source <(kubectl completion zsh)KUBECONFIGcontext), указывающего на параметры, которые kubectl будет использовать для поиска конкретного, целевого кластера. Но добиться нужного результата с контекстами бывает сложно. Чтобы упростить себе жизнь, воспользуйтесь переменной окружения KUBECONFIG — она позволяет указать на конфигурационные файлы, которые используются при слиянии. Подробнее о KUBECONFIG можно прочитать в официальной документации.$ kubectl config view --minify > cluster1-configapiVersion: v1
clusters:
- cluster:
certificate-authority: cluster1_ca.crt
server: https://cluster1
name: cluster1
contexts:
- context:
cluster: cluster1
user: cluster1
name: cluster1
current-context: cluster1
kind: Config
preferences: {}
users:
- name: cluster1
user:
client-certificate: cluster1_apiserver.crt
client-key: cluster1_apiserver.key$ cat cluster2-configapiVersion: v1
clusters:
- cluster:
certificate-authority: cluster2_ca.crt
server: https://cluster2
name: cluster2
contexts:
- context:
cluster: cluster2
user: cluster2
name: cluster2
current-context: cluster2
kind: Config
preferences: {}
users:
- name: cluster2
user:
client-certificate: cluster2_apiserver.crt
client-key: cluster2_apiserver.keyKUBECONFIG. Преимуществом такого слияния станет возможность динамически переключаться между контекстами. Контекст — это «сопоставление» (map), включающее в себя описания кластера и пользователя, а также название, с помощью которого на конфигурацию можно ссылаться для аутентификации кластера и взаимодействия с ним. Флаг --kubeconfig позволяет посмотреть на контекст для каждого файла:$ kubectl --kubeconfig=cluster1-config config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* cluster1 cluster1 cluster1
$ kubectl --kubeconfig=cluster2-config config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* cluster2 cluster2 cluster2KUBECONFIG показывает оба контекста. Для сохранения текущего контекста создайте новый пустой файл с названием cluster-merge:$ export KUBECONFIG=cluster-merge:cluster-config:cluster2-config
dcooley@lynx ~
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* cluster1 cluster1 cluster1
cluster2 cluster2 cluster2KUBECONFIG, загружается в строгом порядке. Поэтому контекст, который выбирается, соответствует указанному как current-context в первом конфиге. Изменение контекста на cluster2 смещает знак текущего (*) к этому контексту в списке, и команды kubectl начинают применяться к этому (второму) контексту:$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* cluster1 cluster1 cluster1
cluster2 cluster2 cluster2
$ kubectl config use-context cluster2
Switched to context "cluster2".
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
cluster1 cluster1 cluster1
* cluster2 cluster2 cluster2
$ cat cluster-mergeapiVersion: v1
clusters: []
contexts: []
current-context: cluster2
kind: Config
preferences: {}
users: []current-context. Использовать контексты Kubernetes и осуществлять их слияние можно разными способами. Например, вы можете создать контекст (cluster1_kube-system), который будет определять пространство имён (kube-system) для всех исполняемых команд kubectl:$ kubectl config set-context cluster1_kube-system --cluster=cluster1 --namespace=kube-system --user=cluster1
Context "cluster1_kube-system" set.
$ cat cluster-mergeapiVersion: v1
clusters: []
contexts:
- context:
cluster: cluster1
namespace: kube-system
user: cluster1
name: cluster1_kube-system
current-context: cluster2
kind: Config
preferences: {}
users: []$ kubectl config use-context cluster1_kube-system
Switched to context "cluster1_kube-system".
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
default-http-backend-fwx3g 1/1 Running 0 28m
kube-addon-manager-cluster 1/1 Running 0 28m
kube-dns-268032401-snq3h 3/3 Running 0 28m
kubernetes-dashboard-b0thj 1/1 Running 0 28m
nginx-ingress-controller-b15xz 1/1 Running 0 28mswagger.json:$ kubectl proxy
$ curl -O 127.0.0.1:8001/swagger.jsonhttp://localhost:8001/api/ и посмотреть на имеющиеся в Kubernetes API пути.swagger.json — это документ в формате JSON, можно его просмотреть с помощью jq. Утилита jq — лёгкий обработчик JSON-файлов, позволяющий выполнять сравнения и другие операции. Подробнее читайте здесь.swagger.json поможет понять Kubernetes API. Это сложный API, функции в котором разбиты на группы, что затрудняет его восприятие:$ cat swagger.json | jq '.paths | keys[]'
"/api/"
"/api/v1/"
"/api/v1/configmaps"
"/api/v1/endpoints"
"/api/v1/events"
"/api/v1/namespaces"
"/api/v1/nodes"
"/api/v1/persistentvolumeclaims"
"/api/v1/persistentvolumes"
"/api/v1/pods"
"/api/v1/podtemplates"
"/api/v1/replicationcontrollers"
"/api/v1/resourcequotas"
"/api/v1/secrets"
"/api/v1/serviceaccounts"
"/api/v1/services"
"/apis/"
"/apis/apps/"
"/apis/apps/v1beta1/"
"/apis/apps/v1beta1/statefulsets"
"/apis/autoscaling/"
"/apis/batch/"
"/apis/certificates.k8s.io/"
"/apis/extensions/"
"/apis/extensions/v1beta1/"
"/apis/extensions/v1beta1/daemonsets"
"/apis/extensions/v1beta1/deployments"
"/apis/extensions/v1beta1/horizontalpodautoscalers"
"/apis/extensions/v1beta1/ingresses"
"/apis/extensions/v1beta1/jobs"
"/apis/extensions/v1beta1/networkpolicies"
"/apis/extensions/v1beta1/replicasets"
"/apis/extensions/v1beta1/thirdpartyresources"
"/apis/policy/"
"/apis/policy/v1beta1/poddisruptionbudgets"
"/apis/rbac.authorization.k8s.io/"
"/apis/storage.k8s.io/"
"/logs/"
"/version/"$ kubectl api-versions
apps/v1beta1
authentication.k8s.io/v1beta1
authorization.k8s.io/v1beta1
autoscaling/v1
batch/v1
batch/v2alpha1
certificates.k8s.io/v1alpha1
coreos.com/v1
etcd.coreos.com/v1beta1
extensions/v1beta1
oidc.coreos.com/v1
policy/v1beta1
rbac.authorization.k8s.io/v1alpha1
storage.k8s.io/v1beta1
v1kubectl explain помогает лучше понять, что делают разные компоненты API:$ kubectl explain
You must specify the type of resource to explain. Valid resource types include:
* all
* certificatesigningrequests (aka 'csr')
* clusters (valid only for federation apiservers)
* clusterrolebindings
* clusterroles
* componentstatuses (aka 'cs')
* configmaps (aka 'cm')
* daemonsets (aka 'ds')
* deployments (aka 'deploy')
* endpoints (aka 'ep')
* events (aka 'ev')
* horizontalpodautoscalers (aka 'hpa')
* ingresses (aka 'ing')
* jobs
* limitranges (aka 'limits')
* namespaces (aka 'ns')
* networkpolicies
* nodes (aka 'no')
* persistentvolumeclaims (aka 'pvc')
* persistentvolumes (aka 'pv')
* pods (aka 'po')
* poddisruptionbudgets (aka 'pdb')
* podsecuritypolicies (aka 'psp')
* podtemplates
* replicasets (aka 'rs')
* replicationcontrollers (aka 'rc')
* resourcequotas (aka 'quota')
* rolebindings
* roles
* secrets
* serviceaccounts (aka 'sa')
* services (aka 'svc')
* statefulsets
* storageclasses
* thirdpartyresources
error: Required resource not specified.
See 'kubectl explain -h' for help and examples.kubectl explain deploy. Команда explain работает с разными уровнями вложенности, что позволяет вам также ссылаться на зависимые объекты:$ kubectl explain deploy.spec.template.spec.containers.livenessProbe.exec
RESOURCE: exec
DESCRIPTION:
One and only one of the following should be specified. Exec specifies the
action to take.
ExecAction describes a "run in container" action.
FIELDS:
command <[]string>
Command is the command line to execute inside the container, the working
directory for the command is root ('/') in the container's filesystem. The
command is simply exec'd, it is not run inside a shell, so traditional shell
instructions ('|', etc) won't work. To use a shell, you need to explicitly
call out to that shell. Exit status of 0 is treated as live/healthy and
non-zero is unhealthy.kubectljsonpath. Например, можно выполнить kubectl get pods --all-namespaces -o json, чтобы увидеть весь вывод, из которого мы можем потом отфильтровать нужные данные для примера с сортировкой подов по времени (см. ниже).$ kubectl run shop --replicas=2 --image quay.io/coreos/example-app:v1.0 --port 80 --exposejsonpath. Более подробную информацию по нему можно получить из официальной документации.$ kubectl get pods --all-namespaces --sort-by='.metadata.creationTimestamp' -o jsonpath='{range .items[]}{.metadata.name}, {.metadata.creationTimestamp}{"\n"}{end}'your-namespace) и свой запрос на наличие лейбла, который поможет найти нужные поды, и получите логи этих подов. Если под не единственный, логи будут получены из всех подов параллельно:$ ns='' label='=' kubectl get pods -n $ns -l $label -o jsonpath='{range .items[]}{.metadata.name}{"\n"}{end}' | xargs -I {} kubectl -n $ns logs {} your-namespace) и свой запрос на наличие лейбла, который поможет найти нужные поды, и подключитесь к нему по имени (к первому из найденных подов). Замените 8080 на нужный порт пода:$ ns='' label='=' kubectl -n $ns get pod -l $label -o jsonpath='{.items[1].metadata.name}' | xargs -I{} kubectl -n $ns port-forward {} 8080:80 kubectljq и JSON-вывода kubectl позволяет делать сложные запросы, такие как фильтрация всех ресурсов по времени их создания.$ kubectl get pods --all-namespaces -o json | jq '.items[] | .spec.nodeName' -r | sort | uniq -ckubectl explain deployment.spec.selector.$ kubectl get nodes -l 'master' or kubectl get nodes -l '!master'--show-labels для любого объекта Kubernetes:$ kubectl get nodes --all-namespaces --show-labels$ kubectl get pods --all-namespaces -o json | jq '.items | map({podName: .metadata.name, nodeName: .spec.nodeName}) | group_by(.nodeName) | map({nodeName: .[0].nodeName, pods: map(.podName)})'$ kubectl get nodes -o jsonpath='{range .items[]}{.metadata.name} {.status.addresses[?(@.type=="ExternalIP")].address}{"\n"}{end}'|
Метки: author shurup системное администрирование devops *nix блог компании флант kubernetes kubectl bash |
[recovery mode] Маршрутизация входящих вызовов в 3CX в зависимости от времени суток |
В этой статье мы покажем, как создавать голосовое приложение 3CX Call Flow Designer, которое маршрутизирует входящие вызовы с 3CX в зависимости от времени суток.
Такая функция весьма востребована, если нужно сообщать звонящим разные приветственные сообщения в зависимости от времени суток, либо направлять абонентов в Очереди обслуживания на разных языках, в зависимости от времени звонка.
Это простое приложение поможет вам освоиться в среде разработки и получить базовые навыки использования CFD.
Обратите внимание — утилита 3CX CFD бесплатно доступна для пользователей 3CX Phone System Pro.
Для вашего удобства, 3CX включила это приложение в набор демо-приложений CFD. Вы можете открыть и изучить его более детально. Готовый рабочий проект приложения размещается в папке Documents\3CX Call Flow Designer Demos при установке CFD.
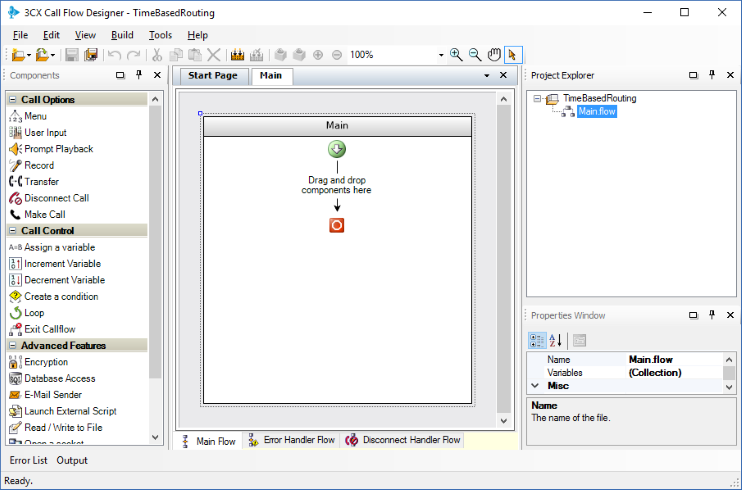
Чтобы добавить компонент:

Создав условия для ветвлении, добавим в каждое ветвление компонент Transfer. Таким образом, при “срабатывании” условия, вызов будет переводиться на соответствующий добавочный номер.
Для этого перетащите компонент Transfer в каждое из ветвлений. Настройте каждый компонент для перевода вызова на разный добавочный номер. Для этого кликните на компоненте и установите свойство Destination на добавочные номера 101, 102, 103 и 104, соответственно.

Свойство Destination — это выражение, поэтому, если вы указываете здесь константу, она должна быть взята в скобки. Обратите внимание, что в Destination можно указывать и переменные, и вычисляемые выражения.

Голосовое приложение готово! Теперь его следует скомпилировать и загрузить на сервер 3CX. Для этого:

Вы можете проверить работу приложения, позвонив на добавочный номер Очереди, либо направив на эту Очередь вызовы с внешних транков.
|
|
Квантовый протокол распределения ключей BB84 |
|
Метки: author vlsergey криптография квантовая криптография bb84 учебник |
Тестирование БД мобильного Delphi-приложения |
|
Метки: author SergeyPyankov тестирование мобильных приложений firebird/interbase delphi dunitx iblite firemonkey |
Дайджест свежих материалов из мира фронтенда за последнюю неделю №272 (17 — 23 июля 2017) |

| Веб-разработка |
| CSS |
| Javascript |
| Браузеры |
| Занимательное |
 Веб-разработка
Веб-разработка Разбираемся с Shadow DOM Измерение веб производительности; это довольно просто на самом деле Размышления по поводу HTTP/2 и бандлинга О нюансах использования Inline SVG на продакшене. Продолжение популярной статьи двухлетней давности
Разбираемся с Shadow DOM Измерение веб производительности; это довольно просто на самом деле Размышления по поводу HTTP/2 и бандлинга О нюансах использования Inline SVG на продакшене. Продолжение популярной статьи двухлетней давности HTML Шорты: Как прятать. display: none или visibility: hidden?
HTML Шорты: Как прятать. display: none или visibility: hidden? Подкаст «Frontend Weekend» FW #12: Ведущий «Пятиминутки React» про подкастинг и фреймворки Подкаст «Пятиминутка React» #26: Preact Rocks! Подкаст «Фронтёрки» #8: Шебанов, зависимые типы, ВК Подкаст «Фронтенд Юность» #10: Как убивали JavaScript!
Подкаст «Frontend Weekend» FW #12: Ведущий «Пятиминутки React» про подкастинг и фреймворки Подкаст «Пятиминутка React» #26: Preact Rocks! Подкаст «Фронтёрки» #8: Шебанов, зависимые типы, ВК Подкаст «Фронтенд Юность» #10: Как убивали JavaScript!
 Как сделать Progressive Web Apps: руководство новичка Комьюнити выбрало официальный неофициальный логотип для Progressive Web Apps Подробное руководство для новичков по PWA
Как сделать Progressive Web Apps: руководство новичка Комьюнити выбрало официальный неофициальный логотип для Progressive Web Apps Подробное руководство для новичков по PWA  Gulp и верстка простой AMP страницы, стрим Юрия Артюха ALL YOUR HTML #8 Как использовать AMP в WordPress Как Accelerated Mobile Pages (AMP) могут улучшить вам SEO WebStorm 2017.2 – что нового в поддержке JavaScript, TypeScript, Angular и Sass и работе с ESLint, Karma и Mocha npm link на стероидах Как использовать Polymer Webpack
Gulp и верстка простой AMP страницы, стрим Юрия Артюха ALL YOUR HTML #8 Как использовать AMP в WordPress Как Accelerated Mobile Pages (AMP) могут улучшить вам SEO WebStorm 2017.2 – что нового в поддержке JavaScript, TypeScript, Angular и Sass и работе с ESLint, Karma и Mocha npm link на стероидах Как использовать Polymer Webpack 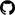 bundle-buddy — инструмент, который поможет найти дубликаты в ваших бандлах Создание прогрессивного веб-приложения «Тренды Git»: Концепты и Service Workers, Кеширование и Оффлайн Создание графики на HTML Canvas: новый бесплатный курс на egghead.io Из грязи в князи, создание WebVR интерактива с помощью Babylon.js для всех платформ Создание вращающейся 3D карусели на CSS и JavaScript GreenSock для новичков (часть 2): GSAP’s Timeline
bundle-buddy — инструмент, который поможет найти дубликаты в ваших бандлах Создание прогрессивного веб-приложения «Тренды Git»: Концепты и Service Workers, Кеширование и Оффлайн Создание графики на HTML Canvas: новый бесплатный курс на egghead.io Из грязи в князи, создание WebVR интерактива с помощью Babylon.js для всех платформ Создание вращающейся 3D карусели на CSS и JavaScript GreenSock для новичков (часть 2): GSAP’s Timeline Слайдер изображений на CSS с использованием шаблонов SVG Адаптивный анимированный дом на CSS LEGO Loader (SVG анимация)
Слайдер изображений на CSS с использованием шаблонов SVG Адаптивный анимированный дом на CSS LEGO Loader (SVG анимация) CSS CSS — это не чёрная магия Как создать эффект матового стекла на чистом CSS? Let's Get Critical: минимизация блокирующего рендер CSS с помощью Webpack Использование CSS для определения и подсчета простых чисел Отключаем возможность зума в Google Maps iframe 4 техники для задания отзывчивых размеров шрифта с помощью RFS: миксин, автоматизирующий использование отзывчивой типографики Что для веб-разработчиков означают вариабельные шрифты? Коллекция интересных фактов о CSS Grid Layout Слайдшоу на CSS Grid Layout Rachel Andrew о причинах возникновения спецификации гридов и о проблемах, которые они решают display:contents — это не CSS Grid Layout subgrid
CSS CSS — это не чёрная магия Как создать эффект матового стекла на чистом CSS? Let's Get Critical: минимизация блокирующего рендер CSS с помощью Webpack Использование CSS для определения и подсчета простых чисел Отключаем возможность зума в Google Maps iframe 4 техники для задания отзывчивых размеров шрифта с помощью RFS: миксин, автоматизирующий использование отзывчивой типографики Что для веб-разработчиков означают вариабельные шрифты? Коллекция интересных фактов о CSS Grid Layout Слайдшоу на CSS Grid Layout Rachel Andrew о причинах возникновения спецификации гридов и о проблемах, которые они решают display:contents — это не CSS Grid Layout subgrid JavaScript Дели — сокращай, или как мы делали мобильный 2ГИС Онлайн Состояние JavaScript в 2017. Ежегодный глобальный опрос Десять вещей, которые серьезный JavaScript разработчик должен изучить Скрытые сообщения в именах свойств в JavaScript Современный стек разработки фронтенда. Статья на linux.com о революции в JS разработке за последние несколько лет 6 нативных методов манипуляции DOM, вдохновленные jQuery Инструменты Javascript для end-to-end тестирования веб приложений Состояние интернационализации в JavaScript Angular vs React vs Vue
JavaScript Дели — сокращай, или как мы делали мобильный 2ГИС Онлайн Состояние JavaScript в 2017. Ежегодный глобальный опрос Десять вещей, которые серьезный JavaScript разработчик должен изучить Скрытые сообщения в именах свойств в JavaScript Современный стек разработки фронтенда. Статья на linux.com о революции в JS разработке за последние несколько лет 6 нативных методов манипуляции DOM, вдохновленные jQuery Инструменты Javascript для end-to-end тестирования веб приложений Состояние интернационализации в JavaScript Angular vs React vs Vue VueJS: CSSSR Live: Мастер-класс по Vue.js. Приглашенный спикер Борис Окунский проводит двухчасовой мастер-класс для разработчиков CSSSR CSSSR Pair Coding #1: Делаем учебный проект «Каталог фильмов» на Vue.js Начинаем работать с Vue.js Flue. Еще одна flux библиотека Как (безопасно) использовать jQuery плагины с Vue.js История нашей прогрессивной миграции с Backbone на Vue.js Как работать с Computed Properties в VueJS? Как использовать вотчеры Vue.js для асинхронных обновлений? Vue.js API в терминале Vue.js: прогрессивный Javascript фреймворк. Доклад Vito Huang на Bristol JS в июне 2017
VueJS: CSSSR Live: Мастер-класс по Vue.js. Приглашенный спикер Борис Окунский проводит двухчасовой мастер-класс для разработчиков CSSSR CSSSR Pair Coding #1: Делаем учебный проект «Каталог фильмов» на Vue.js Начинаем работать с Vue.js Flue. Еще одна flux библиотека Как (безопасно) использовать jQuery плагины с Vue.js История нашей прогрессивной миграции с Backbone на Vue.js Как работать с Computed Properties в VueJS? Как использовать вотчеры Vue.js для асинхронных обновлений? Vue.js API в терминале Vue.js: прогрессивный Javascript фреймворк. Доклад Vito Huang на Bristol JS в июне 2017 React: В чём сила Redux? Восемь вещей, которые необходимо изучить в React перед использованием Redux React Starter Kit: быстрый стартовый шаблон, состоящий из React.js, Babel, PostCSS, Webpack Введение в Hoodie и React Как создать клон Reddit с использованием React и Firebase Как использовать React, ES6, Yarn и Webpack для создания WordPress плагина Как изучать React: план из пяти шагов
React: В чём сила Redux? Восемь вещей, которые необходимо изучить в React перед использованием Redux React Starter Kit: быстрый стартовый шаблон, состоящий из React.js, Babel, PostCSS, Webpack Введение в Hoodie и React Как создать клон Reddit с использованием React и Firebase Как использовать React, ES6, Yarn и Webpack для создания WordPress плагина Как изучать React: план из пяти шагов Angular: Angular 4 — Third Party API’s Lazy loading: разделение кода NgModules с Webpack Совмещаем формы Angular с @ngrx/store Popmotion — маленький кроссплатформенный JavaScript движок для работы с анимацией RE:DOM — маленькая библиотека, добавляющая хелперы для создания DOM элементов и поддержки синхронизации с данными. mesh — визуализация данных и редактирование кода JavaScript в табличном интерфейсе wade — очень быстрая библиотека для поиска GPU.JS — JavaScript, ускоренный GPU tiza — стилизация вывода данных в консоль
Angular: Angular 4 — Third Party API’s Lazy loading: разделение кода NgModules с Webpack Совмещаем формы Angular с @ngrx/store Popmotion — маленький кроссплатформенный JavaScript движок для работы с анимацией RE:DOM — маленькая библиотека, добавляющая хелперы для создания DOM элементов и поддержки синхронизации с данными. mesh — визуализация данных и редактирование кода JavaScript в табличном интерфейсе wade — очень быстрая библиотека для поиска GPU.JS — JavaScript, ускоренный GPU tiza — стилизация вывода данных в консоль  Пересмотр рыночной доли Firefox. Почему создание лучшего браузера не приводит к росту популярности Новый Firefox и огромное количество табов Превью Storage API в Firefox Nightly
Пересмотр рыночной доли Firefox. Почему создание лучшего браузера не приводит к росту популярности Новый Firefox и огромное количество табов Превью Storage API в Firefox Nightly Занимательное
ЗанимательноеПросим прощения за возможные опечатки или неработающие/дублирующиеся ссылки. Если вы заметили проблему — напишите пожалуйста в личку, мы стараемся оперативно их исправлять.
|
|
[Из песочницы] Будь в курсе |


import websocketdef get_streaming_server_key(token):
request_url = "https://api.vk.com/method/streaming.getServerUrl?access_token={}&v=5.64".format(token)
r = requests.get(request_url)
data = r.json()
return {"server":data["response"]["endpoint"],"key":data["response"]["key"]}
def listen_stream():
websocket.enableTrace(True)
ws = websocket.WebSocketApp("wss://{}/stream?key={} ".format(stream["server"], stream["key"]),
on_message=on_message,
on_error=on_error,
on_close=on_close)
ws.on_open = on_open
ws.run_forever()
def on_message(ws, message):
print(">>>> receive message:", message)
def on_error(ws, error):
print(">>>> error thead:",error)
def on_close(ws):
print(">>>> close thead")
def on_open(ws):
print(">>>> open thead")
stream = get_streaming_server_key(my_servise_token)
listen_stream()
— request header — GET /stream?key=e6290ba04916a314c398c331f60224d012fabeb1 HTTP/1.1
Upgrade: websocket
Connection: Upgrade
Host: streaming.vk.com
Origin: streaming.vk.com
Sec-WebSocket-Key: vG40A5bwbPaVBS+DLBOyog==
Sec-WebSocket-Version: 13
— — response header — HTTP/1.1 101 Switching Protocols
Server: Apache
Date: Thu, 20 Jul 2017 22:06:55 GMT
Connection: upgrade
Upgrade: websocket
Sec-WebSocket-Accept: QRJNqD8K7vWNMcQesYKo64q8MfA=
— >>>> open thead
send: b"\x8a\x80d')\x90"
send: b'\x8a\x80\xfcmp\xe6'
send: b'\x8a\x80s\x9f6{'
send: b'\x8a\x80\xc9\xfa.\xd4'
send: b'\x8a\x80fU<\xed'
send: b'\x8a\x80\xc6Ji\x19'
send: b'\x8a\x80\xd2D\x08!'
def set_my_rules(value):
rule_params = {"rule":{"value":value,"tag":'tag_'+str(random.randint(11111, 99999))}}
headers = {'content-type': 'application/json'}
r = requests.post("https://{}/rules?key={}".format(stream["server"], stream["key"]), data=json.dumps(rule_params), headers=headers)
data = r.json()
return data['code'] == 200
def get_my_rules():
r = requests.get("https://{}/rules?key={}".format(stream["server"], stream["key"]))
data = r.json()
if data['code'] != 200:
return False
return data['rules']
def del_my_rules(tag):
headers = {'content-type': 'application/json'}
rule_params = {"tag":tag}
r = requests.delete("https://{}/rules?key={}".format(stream["server"], stream["key"]), data=json.dumps(rule_params), headers=headers)
data = r.json()
return data['code'] == 200stream = get_streaming_server_key(my_servise_token)
set_my_rules('кот')
listen_stream()send: b'\x8a\x80\xc9\xfa.\xd4'
send: b'\x8a\x80fU<\xed'
send: b'\x8a\x80\xc6Ji\x19'
send: b'\x8a\x80\xd2D\x08!'
{«code»:100,«event»:{«event_type»:«post»,«event_id»:{«post_owner_id»:-35708825,«post_id»:4560},«event_url»:«vk.com/wall-35708825_4560»,«text»:«vk.com/small.dolly
Пропал кот. В г.Электросталь на улице Загонова в районе 16 школы. Молодой мальчик, 2 года кастрирован. Обычного серого окраса с полосками. На подбородке и грудке белое пятно. Кот крупный около 7 кг. Пропал 27 июня. Если кто-то его видел пожалуйста сообщите 89250506596 или 89251527466. Мы его очень любим и хотим чтобы он вернулся домой»,«creation_time»:1498942995,«tags»:[«test_cats»],«author»:{«id»:-35708825}}} — наша новсть
import telebot
TELEGRAM_API_TOKEN = '3277332...' # токен выдаваемый при создании бота
bot = telebot.TeleBot(TELEGRAM_API_TOKEN)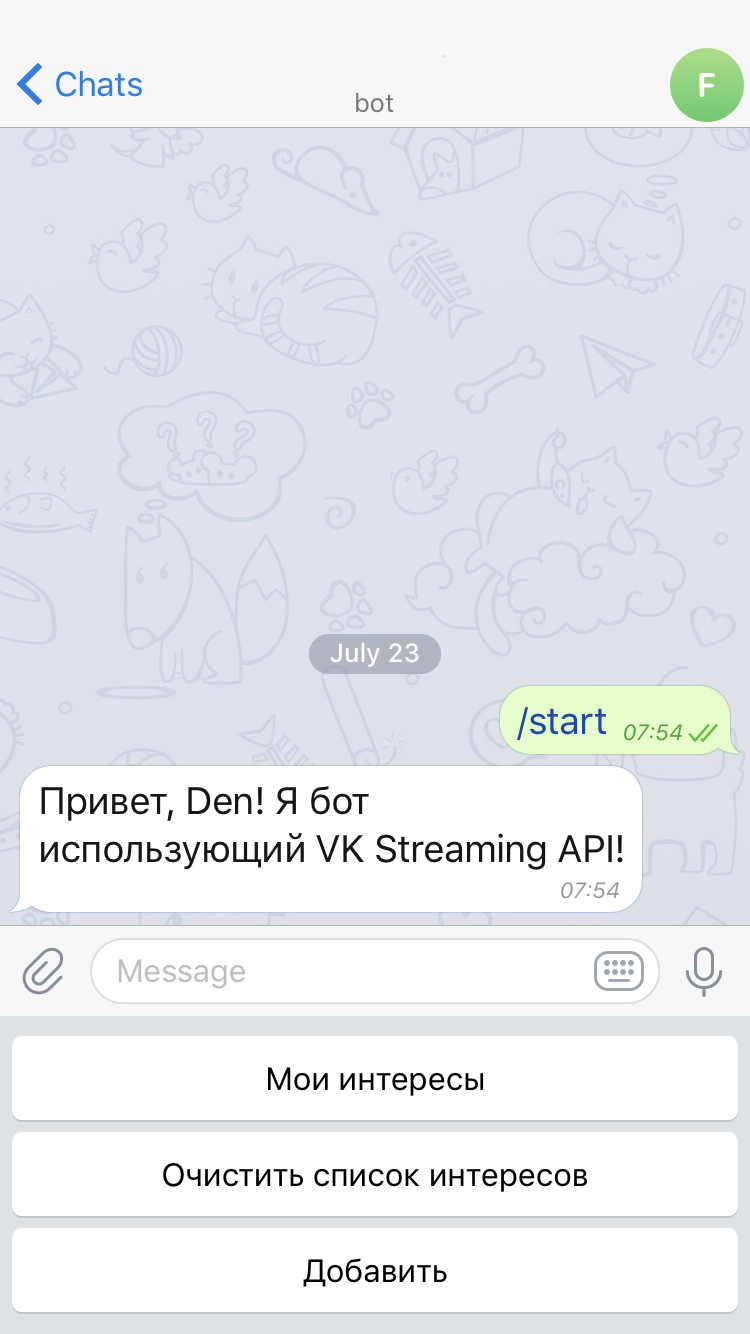
def _send(msg):
markup = types.ReplyKeyboardMarkup(row_width=1, resize_keyboard=True)
markup.add('Мои интересы', 'Очистить список интересов', 'Добавить')
msg = bot.send_message(chatID, msg, reply_markup=markup) # шлем текст с вариантами ответа
bot.register_next_step_handler(msg, process_step) # устанавливаем обработчик для наших ответов
# обработчик для 'help', 'start'
@bot.message_handler(commands=['help', 'start'])
def send_welcome(message):
global chatID
chatID = message.chat.id
hello_test = 'Привет, %s! Я бот использующий VK Streaming API!' % message.from_user.first_name
_send(hello_test)
# обработчик для наших ответов
def process_step(message):
if message.text == 'Мои интересы':
_send(get_rules_list())
if message.text == 'Очистить список интересов':
_send(clear_rules_list())
if message.text == 'Добавить':
msg = bot.send_message(chatID, "Что добавить?")
bot.register_next_step_handler(msg, add_rule_handler)
if message.text == 'Добавить':
msg = bot.send_message(chatID, "Что добавить?")
bot.register_next_step_handler(msg, add_rule_handler)
.....
def add_rule_handler(message):
new_rule = set_my_rules(message.text)
if new_rule:
_send("Successful")
else:
logging.debug("Error add rules")
_send("Error")def get_rules_list():
rules = get_my_rules()
if rules:
return "\n".join([str(rule['value']) for rule in rules])
else:
logging.debug("Error get rules list")
return 'Error'def clear_rules_list():
rules = get_my_rules()
if rules:
for rule in rules:
del_my_rules(rule['tag'])
return "Successful"
else:
logging.debug("Error clear rules list")
return 'Error'def on_message(ws, message):
print(">>>> receive message:", message)
message = json.loads(message)
if not message['code']:
return
if not message['event']['event_type'] or message['event']['event_type'] != 'post':
return # выходим, если запись не отдельный пост
post = message['event']['event_type'] +"\n"+message['event']['text'].replace("
", "\n") +"\n\n"+ message['event']['event_url']
_send_post(post)def listen_stream():
websocket.enableTrace(True)
ws = websocket.WebSocketApp("wss://{}/stream?key={} ".format(stream["server"], stream["key"]),
on_message=on_message,
on_error=on_error,
on_close=on_close)
ws.on_open = on_open
#ws.run_forever()
wst = threading.Thread(target=ws.run_forever)
wst.daemon = True
wst.start()if __name__ == '__main__':
try:
chatID = 0
stream = get_streaming_server_key(my_servise_token)
listen_stream()
bot.polling(none_stop=True)
except Exception as e:
logging.exception("error start")
|
Метки: author WSN3 программирование вконтакте api python telegram vk api |
[Перевод] Как объяснить дизайн четырехлетним? |





|
Метки: author Logomachine работа с векторной графикой графический дизайн блог компании логомашина дизайн типографика просто о сложном |
Дайджест интересных материалов для мобильного разработчика #213 (17 — 23 июля) |

 |
Локализацию можно автоматизировать: опыт использования Lokalise в боевых условиях |
 |
Дизайн для пальцев, касаний и людей |
 iOS
iOS Будущее игр в App Store Симулятор iOS на стероидах: Tips & Tricks Журнал по машинному обучению от Apple
Будущее игр в App Store Симулятор iOS на стероидах: Tips & Tricks Журнал по машинному обучению от Apple SBCardPopup: UIViewController или UIView в виде попапа ARuler: измерение расстояний в ARKit
SBCardPopup: UIViewController или UIView в виде попапа ARuler: измерение расстояний в ARKit Android Retrofit c RxJava и Gson Песочница Dagger 2 Продвинутое руководство по Dagger 2 Как уменьшить размер APK Создание адаптивных иконок для Android O Миграция с Room Анатомия RxJava Взгляд на MVI через колоду карт Kotlin для сердитых Java-разработчиков Архитектурные компоненты: ViewModel FaceDetector: определение лиц на фотографиях Orin: открытый музыкальный плеер Lush Player: плеер для Lush TV
Android Retrofit c RxJava и Gson Песочница Dagger 2 Продвинутое руководство по Dagger 2 Как уменьшить размер APK Создание адаптивных иконок для Android O Миграция с Room Анатомия RxJava Взгляд на MVI через колоду карт Kotlin для сердитых Java-разработчиков Архитектурные компоненты: ViewModel FaceDetector: определение лиц на фотографиях Orin: открытый музыкальный плеер Lush Player: плеер для Lush TV Windows
Windows Разработка 3 шага, чтобы протестировать идею вашего стартапа Мощь минимализма в UI Уведомления через Firebase 5 способов разработки WebGL приложений Руководство по созданию RESTful API для вашего мобильного приложения 7 сервисов пользовательского тестирования Основы A/B-тестирования от Duolingo
Разработка 3 шага, чтобы протестировать идею вашего стартапа Мощь минимализма в UI Уведомления через Firebase 5 способов разработки WebGL приложений Руководство по созданию RESTful API для вашего мобильного приложения 7 сервисов пользовательского тестирования Основы A/B-тестирования от Duolingo Аналитика, маркетинг и монетизация 7 самых важных метрик для вашего приложения Как Kip получил 1.5 млн пользователей и 500К дохода за год
Аналитика, маркетинг и монетизация 7 самых важных метрик для вашего приложения Как Kip получил 1.5 млн пользователей и 500К дохода за год Устройства, IoT, AI
Устройства, IoT, AI|
|
[Перевод] Правда ли, что люди пишут безумный код с перекрывающимися побочными эффектами, сохраняя при этом невозмутимость? |
Порядок вычисления выражений определяется конкретной реализацией, за исключением случаев, когда язык гарантирует определенный порядок вычислений. Если же в дополнение к результату вычисление выражения вызывает изменения в среде выполнения, то говорят, что данное выражение имеет побочные эффекты.
MSDN
a -= a *= a;
p[x++] = ++x;
Да кто вообще пишет такой код с невозмутимым видом? Одно дело, когда такое пишешь, пытаясь победить в «Международном Конкурсе запутывания кода на Си» (IOCCC, International Obfuscated C Code Contest), или если хочешь написать головоломку — но в обоих случаях понимаешь, что ты занимаешься чем-то нестандартным. Что, реально есть кто-то, кто пишет a -= a *= a и p[x++] = ++x; и думает про себя «Чёрт возьми, да я пишу действительно классный код!»На что Эрик Липперт отвечает мне: «Да, такие люди определенно встречаются». В качестве примера он привел одну успешную книгу популярного автора, который свято верил в то, что чем короче код, тем быстрее он работает. Так вот, представьте себе — продажи этой книги составляют уже свыше 4 миллионов копий и продолжают расти. Автор этой книги постарался впихнуть в каждое выражение несколько побочных эффектов сразу, плотно усеяв их условными тернарными операторами; всё дело в том, что он искренне верил в то, что скорость выполнения программы пропорциональна количеству использованных в ней точек с запятыми — и что каждый раз, когда программист объявляет новую переменную, Бог убивает щеночка.
total_cost = p->base_price + p->calculate_tax();|
Метки: author HotWaterMusic совершенный код программирование raymond chen побочные эффекты с# c++ |
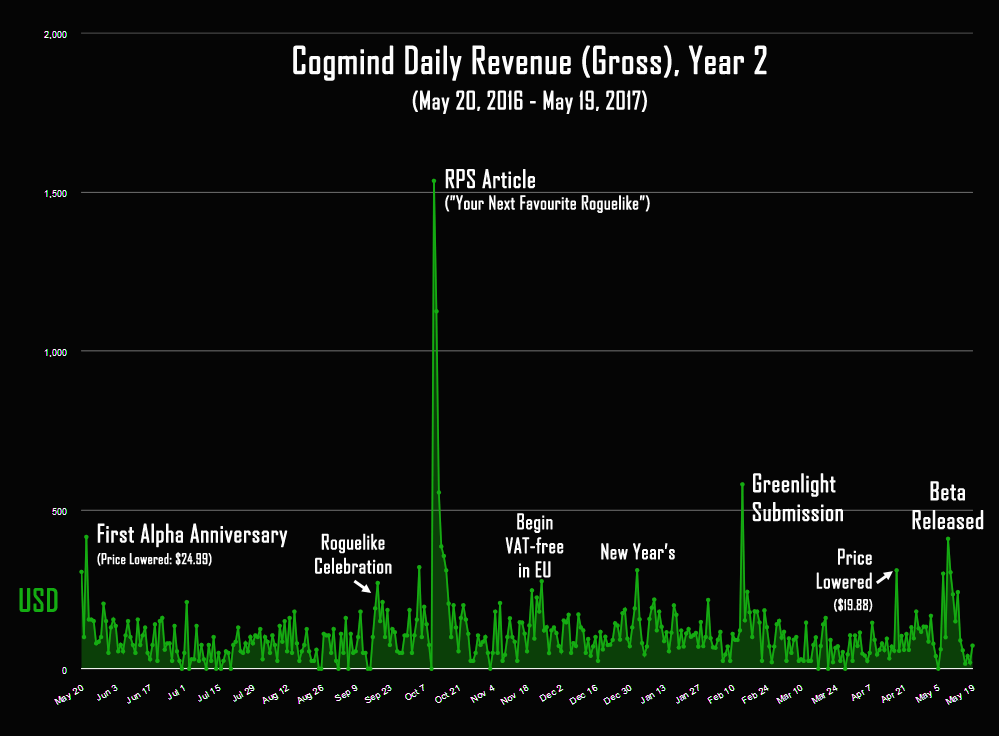
[Перевод] Торгуем ASCII: результаты продаж традиционной Roguelike в раннем доступе |




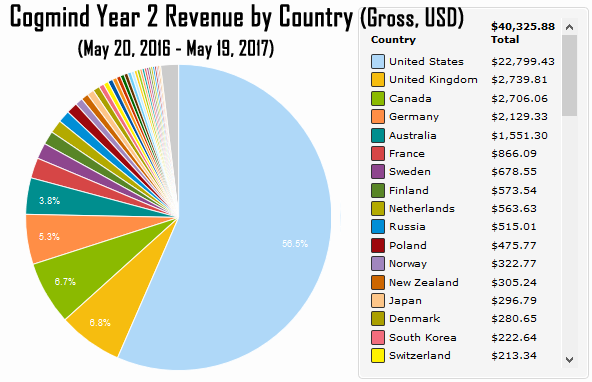


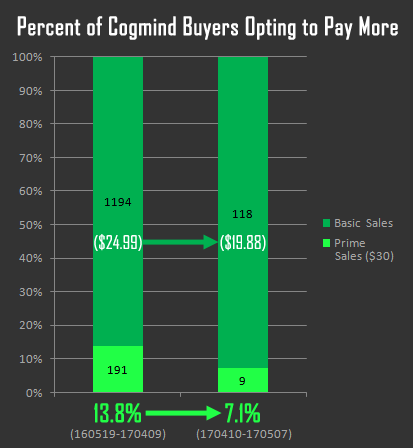
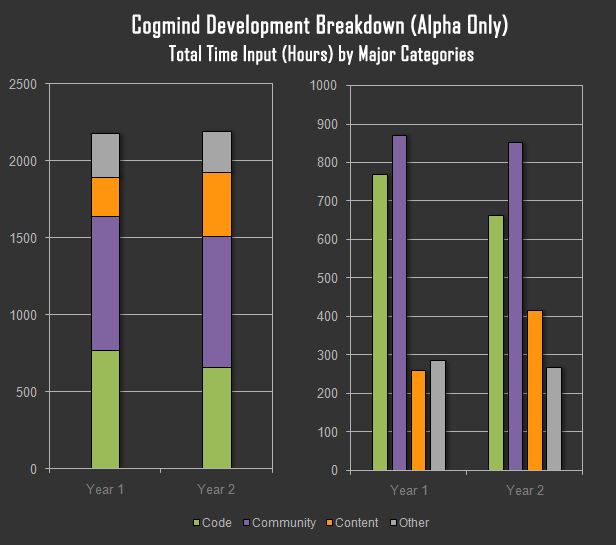
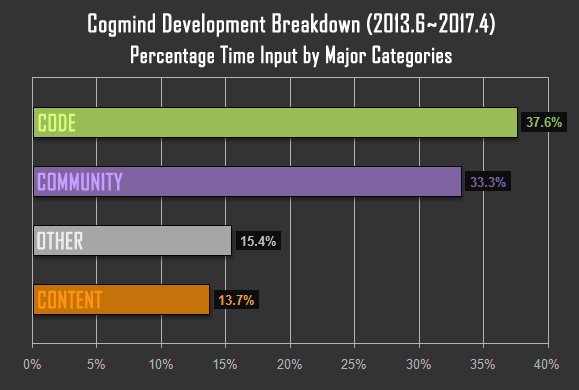
|
Метки: author PatientZero продвижение игр повышение конверсии интернет-маркетинг продажи cogmind steam greenlight ранний доступ early access |
learnopengl. Урок 2.2 — Основы освещения |
|
Метки: author 0xEEd разработка игр программирование c++ opengl 3 glsl перевод |
Orchid CMS — ещё одна CMS на Laravel |
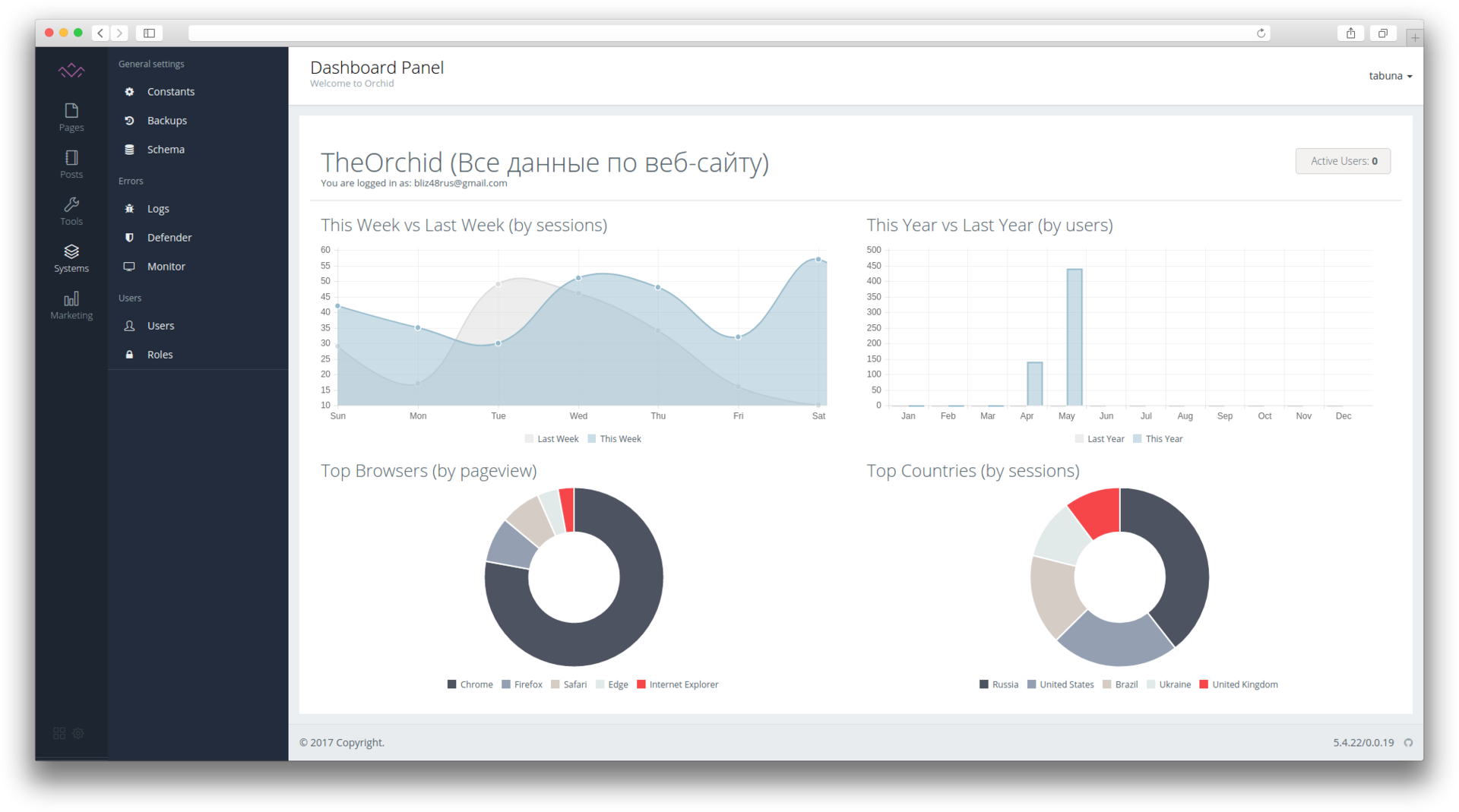
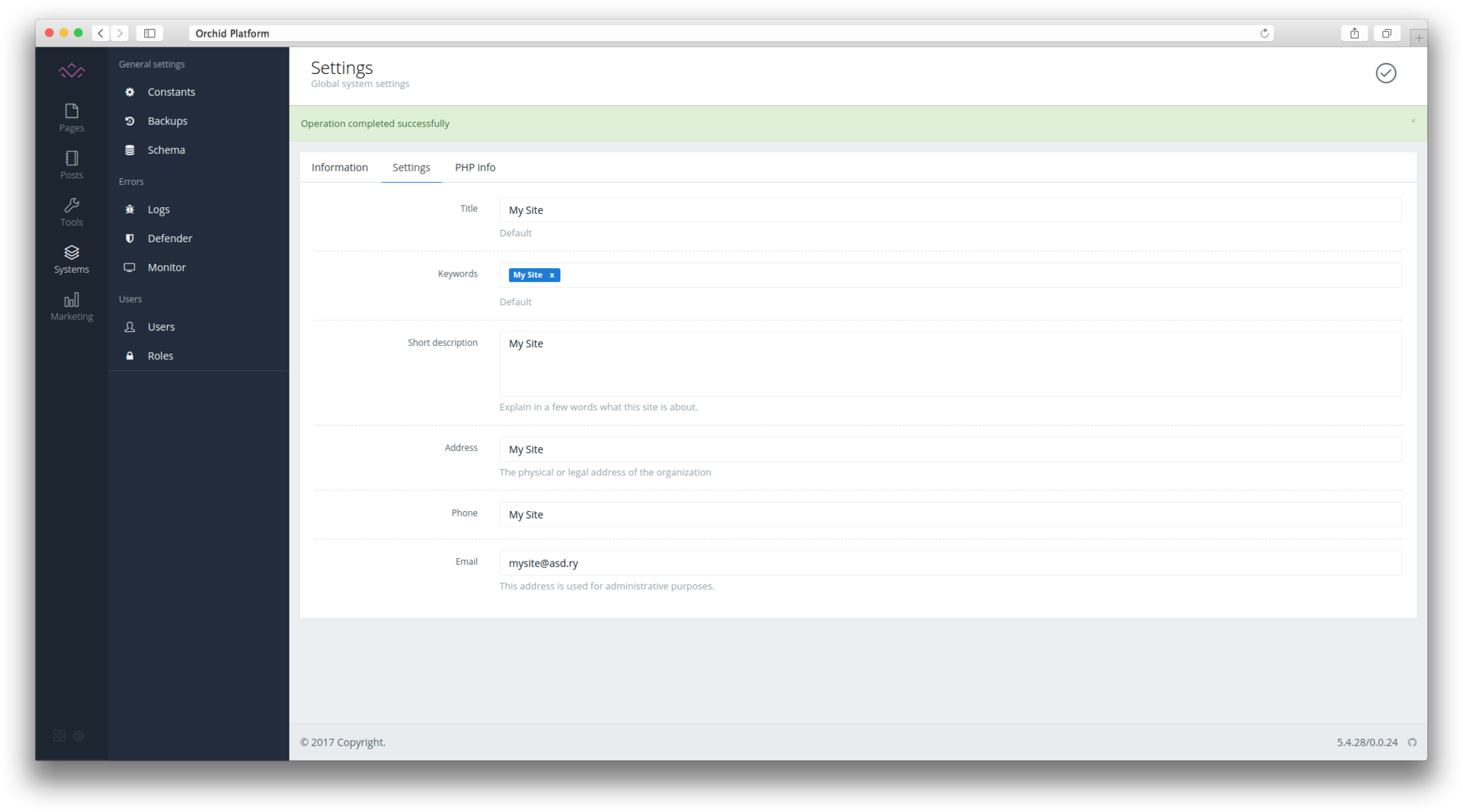
namespace DummyNamespace;
use Orchid\Behaviors\Many;
class DummyClass extends Many
{
/**
* @var string
*/
public $name = '';
/**
* @var string
*/
public $slug = '';
/**
* @var string
*/
public $icon = '';
/**
* Slug url /news/{name}.
* @var string
*/
public $slugFields = '';
/**
* Rules Validation.
* @return array
*/
public function rules()
{
return [];
}
/**
* @return array
*/
public function fields()
{
return [];
}
/**
* Grid View for post type.
*/
public function grid()
{
return [];
}
/**
* @return array
*/
public function modules()
{
return [];
}
}
'types' => [
App\Core\Behaviors\Many\DemoPost::class,
],
'fields' => [
'textarea' => Orchid\Fields\TextAreaField::class,
'input' => Orchid\Fields\InputField::class,
'tags' => Orchid\Fields\TagsField::class,
'robot' => Orchid\Fields\RobotField::class,
'place' => Orchid\Fields\PlaceField::class,
'datetime' => Orchid\Fields\DateTimerField::class,
'checkbox' => Orchid\Fields\CheckBoxField::class,
'path' => Orchid\Fields\PathField::class,
'code' => Orchid\Fields\CodeField::class,
'wysiwyg' => \Orchid\Fields\SummernoteField::class,
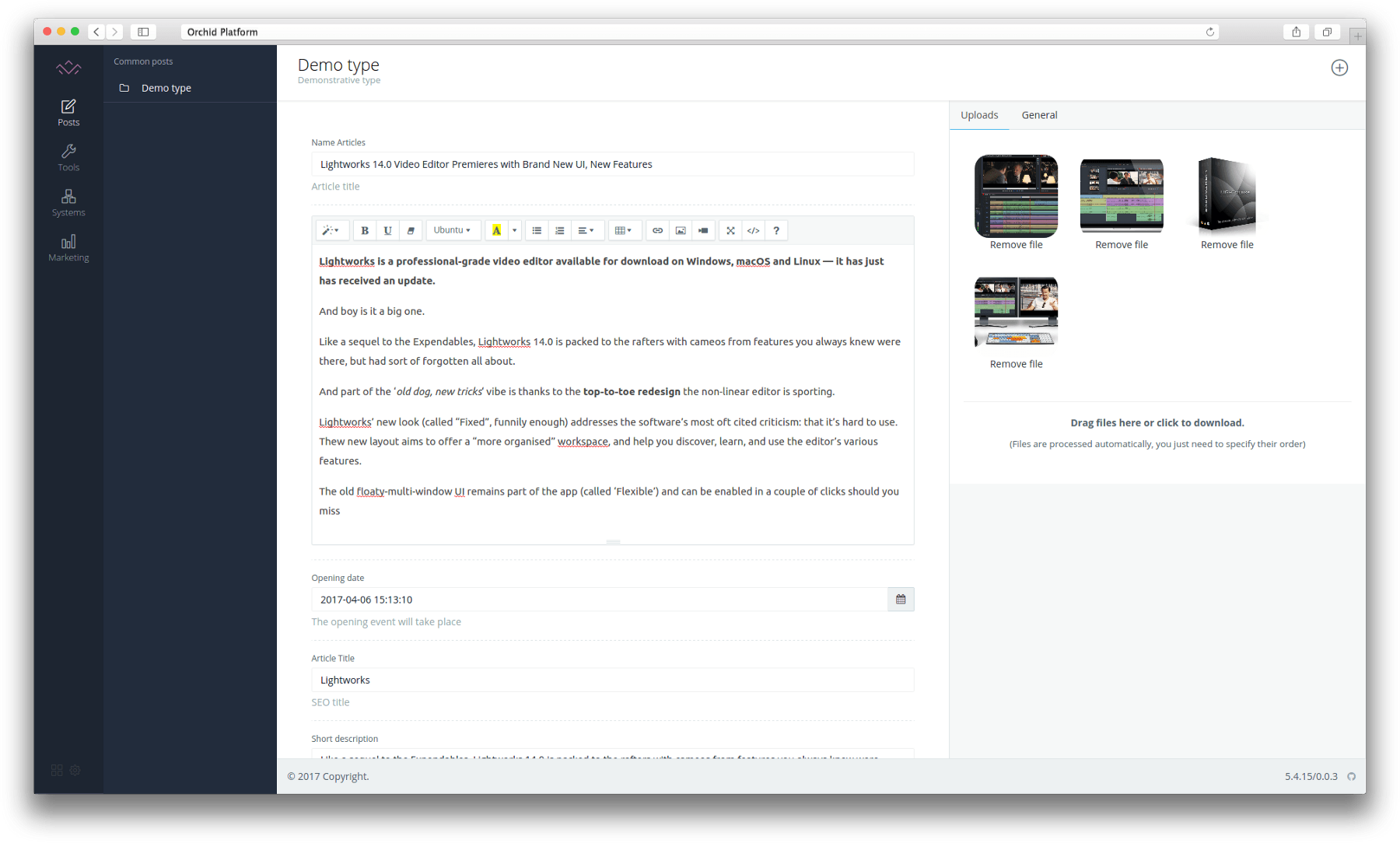
],
|
Метки: author tatu wordpress php laravel cms второй битрикс все равно их никто не читает |
Интеграция Apache CloudStack со сторонними системами. Подписка на события с помощью Apache Kafka |

В данной статье рассматривается подход к интеграции Apache CloudStack (ACS) со сторонними системами посредством экспорта событий в брокер очередей сообщений Apache Kafka.
В современном мире полноценное оказание услуг без интеграции продуктов практически невозможно. В случае сетевых и облачных сервисов, важной является интеграция с биллинговыми системами, системами мониторинга доступности, службами клиентского сервиса и прочими инфраструктурыми и бизнес-ориентирванными компонентами. При этом, продукт, обычно, интегрируется со сторонними системами способами, изображенными на следующей картинке:

Таким образом, продукт предоставляет сторонним сервисам API, который они могут использовать для взаимодействия с продуктом, и поддерживает механизм расширения, который позволяет продукту взаимодействовать с внешними системами через их API.
В разрезе ACS данные функции реализуются следующими возможностями:
Итак, ACS предоставляет нам все необходимые способы взаимодействия. В рамках статьи освещается третий способ взаимодействия — Экспорт событий. Вариантов, когда такой способ взаимодействия является полезным достаточно много, приведем несколько примеров:
Вообще, в условиях отсутствия подсистемы уведомления сторонних систем о событиях внутри продукта, существует единственный способ решения такого класса задач — периодический опрос API. Само собой, что способ рабочий, но редко может считаться эффективным.
ACS позволяет экспортировать события в брокеры очередей сообщений двумя способами — с применением протокола AMPQ в RabbitMQ и по протоколу Apache Kafka в Apache Kafka, соответственно. Мы широко используем в своей практике Apache Kafka, поэтому в данной статье рассмотрим как подключить к серверу ACS экспорт событий в эту систему.
При реализации подобных механизмов разработчики часто выбирают между двумя опциями — экспорт событий в брокеры очередей сообщений или явный вызов API сторонних систем. На наш взгляд, подход с экспортом в брокеры является крайне выгодным, и значительно превосходит по своей гибкости явный вызов API (например, REST с некоторым определенным протоколом). Связано это со следующими свойствами брокеров очередей сообщений:
Данных свойств весьма сложно добиться в случае с непосредственным вызовом обрабатывающего кода сторонних систем без ущерба стабильности вызывающей подсистемы продукта. К примеру, представим, что при создании аккаунта требуется отправить SMS с уведомлением. В случае непосредственного вызова кода отправки возможны следующие классы ошибок:
Единственным преимуществом данного подхода может считаться то, что время между экспортом события и обработкой события сторонней системой может быть меньше, чем в случае экспорта данного события в брокер очередей сообщений, однако требуется обеспечить определенные гарантии по времени и надежности обработки как на стороне вызывающей подсистемы продукта, так и на стороне вызываемой системы.
В том же случае, когда используется экспорт событий в брокер очередей сообщений, который настроен правильным образом (реплицируемая среда), данные проблемы не будут возникать, кроме того, код, обрабатывающий события из очереди брокера сообщений и вызывающий API сторонней системы, может разрабатываться и развертываться, исходя из усредненного ожидания к интенсивности потока событий, без необходимости обеспечения гарантий пиковой обработки.
Обратная сторона использования брокера сообщений — необходимость настройки данного сервиса и наличие опыта его администрирования и решения проблем. Хотя, Apache Kafka является весьма беcпроблемным сервисом, все же, рекомендуется посвятить время его настройке, моделированию аварийных ситуаций и разработке ответных мер.
В рамках настоящего руководства не уделяется внимание как настроить Apache Kafka для использования в "боевой" среде. Этому посвящено немало профильных руководств. Мы же уделим основное внимание тому, каким образом подключить Kafka к ACS и протестировать экспорт событий.
Для развертывания Kafka будем использовать Docker-контейнер spotify/kafka, который включает в себя все необходимые компоненты (Apache Zookeeper и Kafka) и поэтому отлично подходит для целей разработки.
Установка Docker (из официального гайда для установки в CentOS 7) выполняется элементарно:
# yum install -y yum-utils device-mapper-persistent-data lvm2
# yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# yum makecache fast
# yum install docker-ceРазвернем контейнер с Apache Kafka:
# docker run -d -p 2181:2181 -p 9092:9092 --env ADVERTISED_HOST=10.0.0.66 --env ADVERTISED_PORT=9092 spotify/kafka
c660741b512aТаким образом, Kafka будет доступен по адресу 10.0.0.66:9092, а Apache Zookeeper по адресу 10.0.0.66:2181.
Протестировать Kafka и Zookeeper можно следующим образом:
Создадим и запишем в топик "cs" строку "test":
# docker exec -i -t c660741b512a bash -c "echo 'test' | /opt/kafka_2.11-0.10.1.0/bin/kafka-console-producer.sh --broker-list 10.0.0.66:9092 --topic cs"
[2017-07-23 08:48:11,222] WARN Error while fetching metadata with correlation id 0 : {cs=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)Прочитаем ее же:
# docker exec -i -t c660741b512a /opt/kafka_2.11-0.10.1.0/bin/kafka-console-consumer.sh --bootstrap-server=10.0.0.66:9092 --topic cs --offset=earliest --partition=0
test
^CProcessed a total of 1 messagesЕсли все произошло так, как отображено на врезках кода выше, значит Kafka исправно функционирует.
Следующим шагом настроим экспорт событий в ACS (оригинал документации здесь). Создадим файл настроек (/etc/cloudstack/management/kafka.producer.properties) для продюсера Kafka, который использоваться ACS со следующим содержимым:
bootstrap.servers=10.0.0.66:9092
acks=all
topic=cs
retries=1Детальное описание настроек Kafka можно найти на странице официальной документации.
При использовании реплицируемого кластера Kafka в строке bootstrap.servers необходимо указать все известные серверы.
Создадим каталог для java bean, активирующего экспорт событий в Kafka:
# mkdir -p /etc/cloudstack/management/META-INF/cloudstack/coreИ сам файл конфигурации для bean-a (/etc/cloudstack/management/META-INF/cloudstack/core/spring-event-bus-context.xml) со следующим содержимым:
Перезагрузим управляющий сервер ACS:
# systemctl restart cloudstack-managementЭкспортируемые события теперь попадают в топик cs, при этом имеют формат JSON, пример событий отображен далее (отформатирован для удобства):
{
"Role":"e767a39b-6b93-11e7-81e3-06565200012c",
"Account":"54d5f55c-5311-48db-bbb8-c44c5175cb2a",
"eventDateTime":"2017-07-23 14:09:08 +0700",
"entityuuid":"54d5f55c-5311-48db-bbb8-c44c5175cb2a",
"description":"Successfully completed creating Account. Account Name: null, Domain Id:1",
"event":"ACCOUNT.CREATE",
"Domain":"8a90b067-6b93-11e7-81e3-06565200012c",
"user":"f484a624-6b93-11e7-81e3-06565200012c",
"account":"f4849ae2-6b93-11e7-81e3-06565200012c",
"entity":"com.cloud.user.Account","status":"Completed"
}
{
"Role":"e767a39b-6b93-11e7-81e3-06565200012c",
"Account":"54d5f55c-5311-48db-bbb8-c44c5175cb2a",
"eventDateTime":"2017-07-23 14:09:08 +0700",
"entityuuid":"4de64270-7bd7-4932-811a-c7ca7916cd2d",
"description":"Successfully completed creating User. Account Name: null, DomainId:1",
"event":"USER.CREATE",
"Domain":"8a90b067-6b93-11e7-81e3-06565200012c",
"user":"f484a624-6b93-11e7-81e3-06565200012c",
"account":"f4849ae2-6b93-11e7-81e3-06565200012c",
"entity":"com.cloud.user.User","status":"Completed"
}
{
"eventDateTime":"2017-07-23 14:14:13 +0700",
"entityuuid":"0f8ffffa-ae04-4d03-902a-d80ef0223b7b",
"description":"Successfully completed creating User. UserName: test2, FirstName :test2, LastName: test2",
"event":"USER.CREATE",
"Domain":"8a90b067-6b93-11e7-81e3-06565200012c",
"user":"f484a624-6b93-11e7-81e3-06565200012c",
"account":"f4849ae2-6b93-11e7-81e3-06565200012c",
"entity":"com.cloud.user.User","status":"Completed"
}Первое событие — создание аккаунта, остальные два — создание пользователей в рамках аккаунта. Для проверки поступления событий в Kafka легче всего воспользоваться уже известным нам способом:
# docker exec -i -t c660741b512a \
/opt/kafka_2.11-0.10.1.0/bin/kafka-console-consumer.sh --bootstrap-server=10.0.0.66:9092 --topic cs --offset=earliest --partition=0Если события поступают, то дальше можно начинать разрабатывать интеграционные приложения с помощью любых языков программирования, для которых существует интерфейс потребителя для Apache Kafka. Вся настройка занимает 15-20 минут и не представляет никакой сложности даже для новичка.
В случае настройки экспорта событий для "боевой" среды необходимо помнить о следующем:
/etc/cloudstack/management/kafka.producer.properties должны быть подобраны с учетом требуемого уровня надежности доставки событий.Возможно, что статья не является слишком ценной, тем более, что в документации "вроде как все написано", однако, когда я решил ее написать я руководствовался следующими соображениями:
Надеюсь, что читатели найдут материал интересным и полезным для себя.
|
|
Поднимаем Linux на MIPSfpga и ПЛИС Altera |

Предоставленная Imagination Technologies документация на MIPSfpga очень хорошо и подробно описывает развертывание Linux. Но используемая при этом система на кристалле построена с помощью Xilinx-специфических периферийных модулей. Потому ее повторение на отладочной плате с ПЛИС Altera в исходном виде представляется невозможным. Решением является система на кристалле MIPSfpga-plus с ее платформонезависимой периферией. О том, как запустить на ней Linux, читайте в этой статье.
Сразу отметим, что получаемой в результате описанных ниже действий конфигурации пока что далеко от идеала. На данный момент не поддерживается загрузка с внешнего носителя, а в числе поддерживаемых устройств можно упомянуть только UART и GPIO. Поэтому фронт дальнейшей работы по развитию системы MIPSfpga-plus представляется очень широким.
Далее предполагается, что читатель:
В описываемом случае используется следующая конфигурация:
В случае, если вы планируете серьезно и глубоко погрузиться в магию ядра Linux, настойчиво рекомендуется ознакомится с материалами [L7], в частности, с презентациями [L8] и [L9].
Если все перечисленные требования выполнены, начнем!
в настройках MIPSfpga-plus (файл mfp_ahb_lite_matrix_config.vh) должны быть включены периферийные модули работы с SDRAM и UART, а также отладка через MPSSE — если используется механизм отладки, описанный в [L4]:
`define MFP_USE_SDRAM_MEMORY
`define MFP_USE_DUPLEX_UART
`define MFP_USE_MPSSE_DEBUGGERПредполагается, что дальнейшие действия выполняются на машине под управлением Linux.
обновить список доступных для системы пакетов:
sudo apt-get updateустановить утилиты и библиотеки, необходимые для конфигурирования и сборки:
sudo apt-get install -y build-essential git libncurses5-dev bc unzipсоздать каталог, в котором будет идти вся дальнейшая работа и перейти в него:
mkdir ~/mipsfpga
cd ~/mipsfpgaвыполнить загрузку toolchain с сайта Imagination Technologies:
wget http://codescape-mips-sdk.imgtec.com/components/toolchain/2016.05-06/Codescape.GNU.Tools.Package.2016.05-06.for.MIPS.MTI.Linux.CentOS-5.x86_64.tar.gzсоздать каталог и развернуть в нем скачанный пакет:
mkdir ~/mipsfpga/toolchain
tar -xvf Codescape.GNU.Tools.Package.2016.05-06.for.MIPS.MTI.Linux.CentOS-5.x86_64.tar.gz -C ~/mipsfpga/toolchainжелательно (но не обязательно) прописать путь к развернутым исполняемым файлам в переменную $PATH, это упростит работу с ними. Например, в ~/.profile
pathadd() {
if [ -d "$1" ] && [[ ":$PATH:" != *":$1:"* ]]; then
PATH="$1${PATH:+":$PATH"}"
fi
}
pathadd "$HOME/bin"
pathadd "$HOME/.local/bin"
pathadd "$HOME/mipsfpga/toolchain/mips-mti-linux-gnu/2016.05-06/bin"получаем ядро Linux:
git clone git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git kernelполучаем buildroot, с помощью которого будет сформирован RAM-образа файловой системы:
git clone git://git.buildroot.net/buildrootсоздаем каталог для патчей buildroot и Linux, необходимых для развертывания на MIPSfpga-plus:
mkdir patchesскачиваем патчи [L10], сохраняем их в только что созданном каталоге;
переходим в каталог с buildroot и откатываемся на версию 2017.05.1 (коммит f3d8beeb3694):
cd buildroot
git checkout 2017.05.1применяем патч к buildroot:
git apply ../patches/MIPSfpga_buildroot.patchвыполняем конфигурирование buildroot:
make xilfpga_static_defconfigпри необходимости вносим изменения в конфигурацию:
make menuconfigзапускаем сборку RAM-образа файловой системы и идем пить вкусный кофе (чай, пиво или кто что любит), т.к. процесс это весьма продолжительный:
make
переходим в каталог с ядром Linux и проверяем, что RAM-образа файловой системы находится по ожидаемому нами пути (в дальнейшем нам необходимо будет указать его в конфигурации ядра):
cd ../kernel/
ls -l ../buildroot/output/images/rootfs.cpioоткатываемся на версию v4.12.1 (коммит cb6621858813), т.к. именно от нее сформирован патч:
git checkout v4.12.1применяем патч:
git apply ../patches/MIPSfpga_linux.patchприменяем базовую конфигурацию ядра MIPSfpga:
make ARCH=mips xilfpga_de10lite_defconfigзапускаем редактор конфигурации:
make ARCH=mips menuconfig
make ARCH=mips CROSS_COMPILE=~/mipsfpga/toolchain/mips-mti-linux-gnu/2016.05-06/bin/mips-mti-linux-gnu-на Linux-компьютере, где мы выполняли сборку, запускаем gdb из состава MIPS toolchain. Предполагается, что мы находимся в каталоге с собранным ядром:
mips-mti-linux-gnu-gdb ./vmlinuxДальнейшие действия выполняются в консоли gdb.
подключаемся к OpenOCD, который запущен на машине с аппаратным отладчиком:
(gdb) target remote 192.168.Х.Х:3333выполняем сброс системы MIPSfpga:
(gdb) mo reset haltсообщаем отладчику, что наша система Little Endian:
(gdb) set endian littleзапускаем ядро на выполнение:
(gdb) continueLinux version 4.12.1+ (stas@ubuntu) (gcc version 4.9.2 (Codescape GNU Tools 2016.05-06 for MIPS MTI Linux) ) #1 Sat Jul 22 14:35:05 MSK 2017
CPU0 revision is: 00019e60 (MIPS M14KEc)
MIPS: machine is terasic,de10lite
Determined physical RAM map:
memory: 04000000 @ 00000000 (usable)
Initrd not found or empty - disabling initrd
Primary instruction cache 4kB, VIPT, 2-way, linesize 16 bytes.
Primary data cache 4kB, 2-way, VIPT, no aliases, linesize 16 bytes
Zone ranges:
Normal [mem 0x0000000000000000-0x0000000003ffffff]
Movable zone start for each node
Early memory node ranges
node 0: [mem 0x0000000000000000-0x0000000003ffffff]
Initmem setup node 0 [mem 0x0000000000000000-0x0000000003ffffff]
Built 1 zonelists in Zone order, mobility grouping on. Total pages: 16256
Kernel command line: console=ttyS0,115200
PID hash table entries: 256 (order: -2, 1024 bytes)
Dentry cache hash table entries: 8192 (order: 3, 32768 bytes)
Inode-cache hash table entries: 4096 (order: 2, 16384 bytes)
Memory: 60512K/65536K available (1830K kernel code, 99K rwdata, 320K rodata, 944K init, 185K bss, 5024K reserved, 0K cma-reserved)
NR_IRQS:8
clocksource: MIPS: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 38225208935 ns
sched_clock: 32 bits at 50MHz, resolution 20ns, wraps every 42949672950ns
Console: colour dummy device 80x25
Calibrating delay loop... 10.81 BogoMIPS (lpj=21632)
pid_max: default: 32768 minimum: 301
Mount-cache hash table entries: 1024 (order: 0, 4096 bytes)
Mountpoint-cache hash table entries: 1024 (order: 0, 4096 bytes)
devtmpfs: initialized
clocksource: jiffies: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 7645041785100000 ns
futex hash table entries: 256 (order: -1, 3072 bytes)
clocksource: Switched to clocksource MIPS
random: fast init done
workingset: timestamp_bits=30 max_order=14 bucket_order=0
Serial: 8250/16550 driver, 4 ports, IRQ sharing disabled
console [ttyS0] disabled
b0400000.serial: ttyS0 at MMIO 0xb0401000 (irq = 0, base_baud = 3125000) is a 16550A
console [ttyS0] enabled
Freeing unused kernel memory: 944K
This architecture does not have kernel memory protection.
mount: mounting devpts on /dev/pts failed: No such device
mount: mounting tmpfs on /dev/shm failed: Invalid argument
mount: mounting tmpfs on /tmp failed: Invalid argument
mount: mounting tmpfs on /run failed: Invalid argument
Starting logging: OK
Initializing random number generator... done.
Starting network: ip: socket: Function not implemented
ip: socket: Function not implemented
FAIL
Welcome to MIPSfpga
mipsfpga login:Воспользуемся возможностями Linux для того, чтобы поуправлять той периферией, которая нам доступна (на момент написания статьи это GPIO, правда не в полном объеме):
проверяем, что драйвер GPIO загружен и устройство доступно:
ls /sys/class/gpio/
export gpiochip480 unexportдля того, чтобы определить доступный диапазон выводов (в текущей конфигурации подключены светодиоды на плате), монтируем debugfs и с ее помощью получаем необходимую информацию:
mount -t debugfs none /sys/kernel/debug
cat /sys/kernel/debug/gpio
gpiochip0: GPIOs 480-511, parent: platform/bf800000.gpio, bf800000.gpio:активируем LED0 (в текущем случае это gpio480):
echo 480 > /sys/class/gpio/exportпереводим его в режим вывода:
echo out > /sys/class/gpio/gpio480/directionпереводим его в высокий уровень:
echo 1 > /sys/class/gpio/gpio480/valueОписанная конфигурация — это, по сути, только начало портирования Linux на систему MIPSfpga-plus. К числу работ, которые необходимо выполнить, чтобы система могла нормально использоваться для практических задач, можно отнести:
Автор выражает благодарность коллективу переводчиков учебника Дэвида Харриса и Сары Харрис «Цифровая схемотехника и архитектура компьютера» [L1], компании Imagination Technologies за академическую лицензию на современное процессорное ядро и образовательные материалы, а также персонально Юрию Панчулу YuriPanchul за его работу по популяризации MIPSfpga.
[L1] — Цифровая схемотехника и архитектура компьютера
[L2] — Как начать работать с MIPSfpga;
[L3] — Проект MIPSfpga-plus на github;
[L4] — MIPSfpga и внутрисхемная отладка;
[L5] — MIPSfpga и SDRAM. Часть 1;
[L6] — MIPSfpga и UART;
[L7] — Free Electrons. Free training materials and conference presentations;
[L8] — Free Electrons. Embedded Linux system development course;
[L9] — Free Electrons. Linux kernel and driver development course;
[L10] — Патчи для buildroot и Linux, необходимые для развертывания на MIPSfpga-plus.
|
Метки: author SparF системное программирование программирование микроконтроллеров анализ и проектирование систем fpga verilog mips mipsfpga mips microaptiv up soc |
[Из песочницы] Релизный цикл для Infrastructure as Code |
|
Метки: author axmetishe it- инфраструктура devops *nix linux saltstack jenkins sonatype nexus kitchen-ci serverspec |
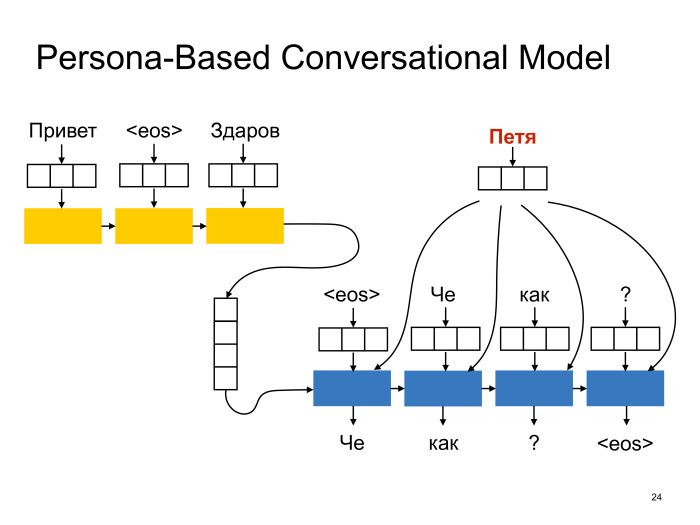
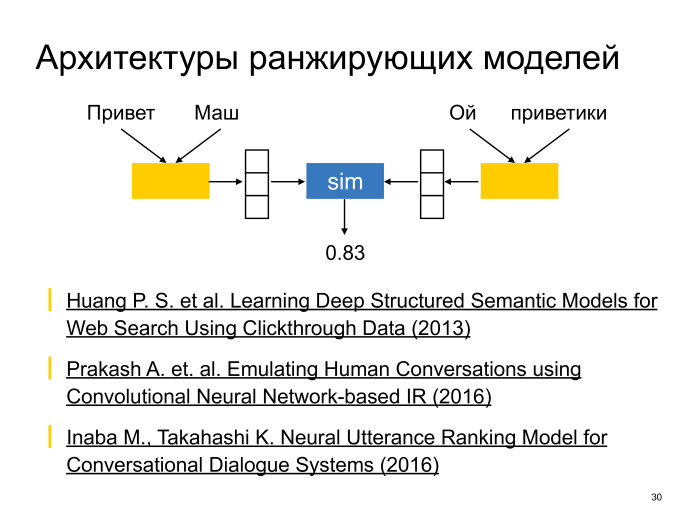
Neural conversational models: как научить нейронную сеть светской беседе. Лекция в Яндексе |







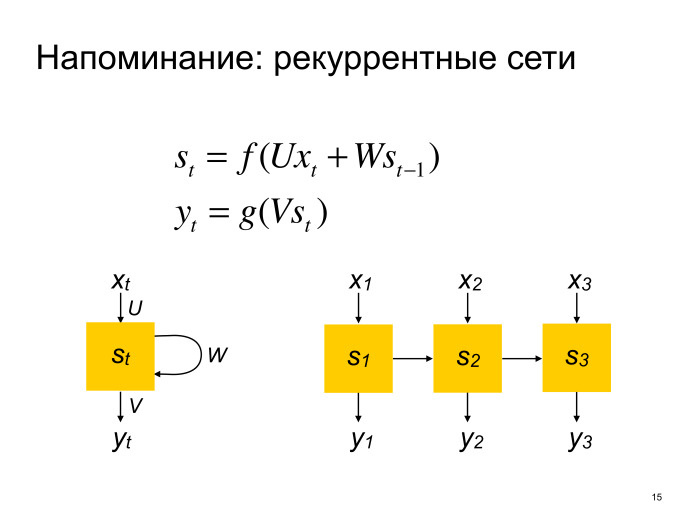










|
Метки: author Leono машинное обучение блог компании яндекс диалоговые системы ассистент нейронные сети рекуррентная нейронная сеть естественный язык conversation deep learning |






