Результаты первого тура CTFzone |

|
Метки: author vadimmaslikhin информационная безопасность ctf блог компании bi.zone zeronights2017 ctfzone results bi.zone |
[Из песочницы] Обзор-рейтинг провайдеров виртуальных серверов Windows: 2017 |

| Вычислительная подсистема: Linpack |
|
| Объём задачи |
10000 |
| Объём памяти |
772 МБ |
| Время испытания |
5 часов |
| Режим |
64-bit |
| Число потоков |
Равняется количеству ядер |
| Данные |
4 КБ |
| Дисковая подсистема: CrystalDiskMark |
|
| Размер файла |
1 ГБ |
| Количество проверок |
5 |
| Дисковая подсистема |
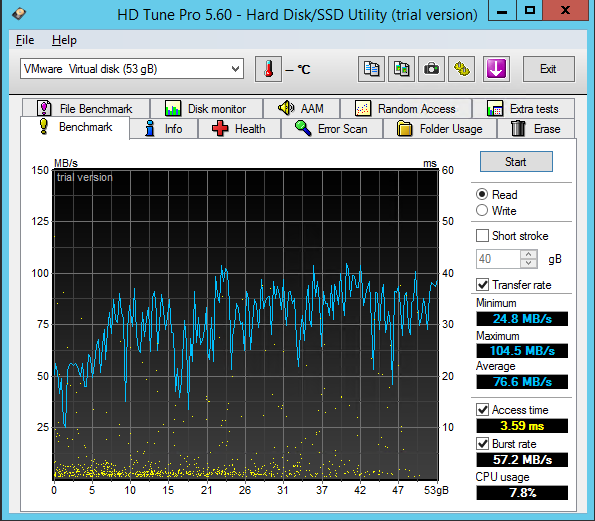
HD Tune Pro |
| Benchmark |
Чтение |
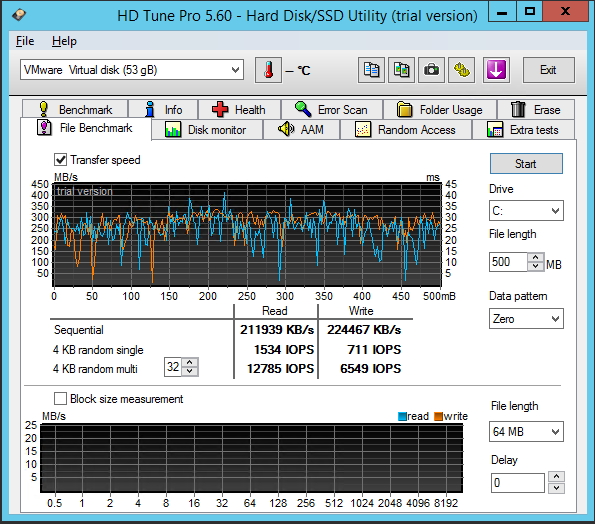
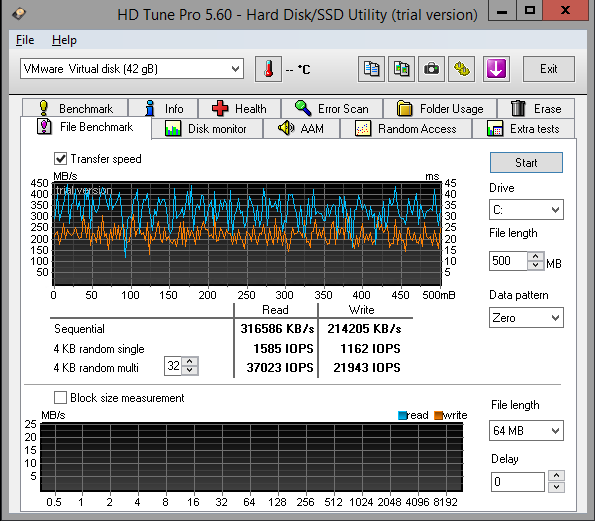
| File Benchmark |
Размер файла 500 МБ Шаблон: заполнение нулями |
| Пропускная способность доступа в сеть Интернет |
|
| Москва |
Билайн |
| Краснодар |
РТ (Ростелеком) |
| Екатеринбург |
РТ |
| Иркутск |
РТ |
| Владивосток |
РТ |
| Франкфурт |
Leaseweb |
| Наименование |
Баллы |
Описание |
| Дата-центр |
0.6 |
|
| Информация о ДЦ |
0.2 |
Информация о том, где размещается оборудование |
| Информация об инженерных подсистемах |
0.2 |
Данные об уровне инженерных подсистемах ДЦ |
| Сертификация TIER |
0.2 |
Есть ли подтверждение о сертификации TIER по uptime institute / IBM и подобных организаций |
| Информация об оборудовании |
0.3 |
|
| Серверное оборудование |
0.1 |
Какое оборудование используется и какие вычислители задействованы в кластере |
| Система хранения данных |
0.1 |
Используются ли СХД или SDS решения |
| Сетевое оборудование |
0.1 |
Используемое сетевое оборудование |
| Информация о юр.лице |
0.3 |
|
| Контактные данные |
0.1 |
Контактные данные технической поддержки и наличие номера телефона для обращений в поддержку |
| Адрес юр.лица |
0.1 |
Контактные данные и адрес юридического лица, которое предоставляет хостинг услуги |
| Реквизиты компании |
0.1 |
Реквизиты юридического лица |
| Информация о платформе виртуализации |
0.1 |
|
| Договор оферты |
0.2 |
|
| Договор оферты |
0.1 |
Доступ к договору оферты без прохождения регистрации |
| SLA |
0.3 |
Доступ к SLA без прохождения регистрации |
| Тестирование сервиса |
||
| Вычислительная подсистема |
0.4 |
|
| Соответствие заявленной частоты и выделенной частоты процессора |
0.2 |
Соответствие выделенной частоты и процессора согласно описанию тарифа |
| Стабильность вычислительной подсистемы |
0.2 |
Стабильность вычислительной подсистемы без заметных провисов в производительности |
| Недокументированное ограничение вычислительной подсистемы |
-0.3 |
Наличие ограничений на использование CPU, которое не документировано в договоре. Параметр добавлен после выставления ограничений на ресурсы одним из провайдеров |
| Дисковая подсистема |
0.8 |
|
| Стабильность дисковой подсистемы |
0.2 |
Стабильность дисковой подсистемы с низкой задержкой и без заметных провисов в производительности |
| Высокоскоростная дисковая подсистема |
0.2 |
Высокая скорость дисковой подсистемы на уровне SSD (Seq.R 400 / Seq.W 300), HDD (Seq.R 100 / Seq.W 100) |
| Высокая доступность данных |
0.2 |
В случае падения сервера данные будут доступны |
| Отказоустойчивость дискового хранения |
0.2 |
|
| Сетевое соединение |
0.5 |
|
| Стабильность сетевого соединения |
0.2 |
Стабильное сетевое подключение без обрывов и зависаний |
| Низкие задержки по России |
0.1 |
Субъективный параметр основываясь на текущих наших средних показателях PRTG |
| Высокая скорость доступа по России (более 20 мбит/с) |
0.2 |
|
| Дополнительные услуги |
1 |
|
| Базовая техническая поддержка |
0.2 |
Наличие бесплатной базовой технической поддержки (не включая конфигурирование сервисов) |
| Расширенная техническая поддержка |
0.2 |
Наличие расширенной технической поддержки (включая конфигурирование сервисов) |
| Бесплатная лицензия Windows Server |
0.2 |
Бесплатное предоставление Windows Server по программе SPLA |
| Лицензия ПО | 0.1 | Возможен заказ дополнительных лицензий |
| Гибкое расширение ресурсов | 0.3 | Создание произвольной конфигурации виртуального сервера с возможностью расширения ресурсов |

| Местоположение |
Download (Mbps) |
Upload (Mbps) |
Ping (ms) |
| Москва (Beeline) |
96.46 |
90.55 |
19 |
| Краснодар (Rostelecom) |
96.25 |
78.56 |
29 |
| Екатеринбург (Rostelecom) |
96.36 |
69.19 |
47 |
| Иркутск (Rostelecom) |
95.55 |
48.08 |
82 |
| Владивосток (Rostelecom) |
88.31 |
26.26 |
133 |
| Франкфурт (Leaseweb) |
96.23 |
75.11 |
42 |


| Местоположение |
Download (Mbps) |
Upload (Mbps) |
Ping (ms) |
| Москва (Beeline) |
204.83 |
269.13 |
2 |
| Краснодар (Rostelecom) |
191.81 |
232.82 |
107 |
| Екатеринбург (Rostelecom) |
122.68 |
177.04 |
181 |
| Иркутск (Rostelecom) |
120.90 |
106.89 |
74 |
| Владивосток (Rostelecom) |
104.41 |
34.33 |
161 |
| Франкфурт (Leaseweb) |
143.03 |
181.90 |
65 |

| Местоположение |
Download (Mbps) |
Upload (Mbps) |
Ping (ms) |
| Москва (Beeline) |
126.43 |
17.66 |
45 |
| Краснодар (Rostelecom) |
103.5 |
20.34 |
93 |
| Екатеринбург (Rostelecom) |
114.95 |
18.26 |
127 |
| Иркутск (Rostelecom) |
53.78 |
19.96 |
110 |
| Владивосток (Rostelecom) |
48.68 |
17.33 |
190 |
| Франкфурт (Leaseweb) |
193.87 |
20.31 |
15 |

| Местоположение |
Download (Mbps) |
Upload (Mbps) |
Ping (ms) |
| Москва (Beeline) |
19.72 |
19.78 |
13 |
| Краснодар (Rostelecom) |
19.71 |
19.64 |
78 |
| Екатеринбург (Rostelecom) |
19.64 |
16.55 |
41 |
| Иркутск (Rostelecom) |
19.76 |
16.16 |
72 |
| Владивосток (Rostelecom) |
19.6 |
12.65 |
135 |
| Франкфурт (Leaseweb) |
19.75 |
15.62 |
48 |


| Местоположение |
Download (Mbps) |
Upload (Mbps) |
Ping (ms) |
| Москва (Beeline) |
9.6 |
9.47 |
2 |
| Краснодар (Rostelecom) |
9.58 |
9.6 |
23 |
| Екатеринбург (Rostelecom) |
9.58 |
9.46 |
29 |
| Иркутск (Rostelecom) |
9.61 |
9.28 |
64 |
| Владивосток (Rostelecom) |
9.61 |
8.45 |
115 |
| Франкфурт (Leaseweb) |
9.58 |
9.44 |
49 |
| Местоположение |
Download (Mbps) |
Upload (Mbps) |
Ping (ms) |
| Москва (Beeline) |
87.9 |
83.6 |
3 |
| Краснодар (Rostelecom) |
89.4 |
31.3 |
17 |
| Екатеринбург (Rostelecom) |
97.4 |
89.1 |
29 |
| Иркутск (Rostelecom) |
76.1 |
59.7 |
64 |
| Владивосток (Rostelecom) |
91.3 |
45.1 |
107 |
| Франкфурт (Leaseweb) |
98 |
91.7 |
43 |
| Наименование |
Баллы |
incloud.ru |
ihc.ru |
infobox.ru |
1cloud.ru |
cloudlite.ru |
mclouds.ru |
| Дата-центр |
0.6 |
0.1 |
0.5 |
0.3 |
0.6 |
0.1 |
0.6 |
| Информация о ДЦ |
0.2 |
0 |
0.2 |
0.1 |
0.2 |
0.1 |
0.2 |
| Информация об инженерных подсистемах |
0.2 |
0.1 |
0.1 |
0.2 |
0.2 |
0.2 |
0.2 |
| Сертификация TIER |
0.2 |
0 |
0.2 |
0 |
0.2 |
0.2 |
0.2 |
| Информация об оборудовании |
0.3 |
0.3 |
0 |
0 |
0.3 |
0.3 |
0.2 |
| Серверное оборудование |
0.1 |
0.1 |
0 |
0 |
0.1 |
0.1 |
0.1 |
| Система хранения данных |
0.1 |
0.1 |
0 |
0 |
0.1 |
0.1 |
0.0 |
| Сетевое оборудование |
0.1 |
0.1 |
0 |
0 |
0.1 |
0.1 |
0.1 |
| Информация о юр.лице |
0.3 |
0 |
0.3 |
0.3 |
0.3 |
0.2 |
0.2 |
| Контактные данные |
0.1 |
0 |
0.1 |
0.1 |
0.1 |
0.1 |
0.1 |
| Адрес юр.лица |
0.1 |
0 |
0.1 |
0.1 |
0.1 |
0.1 |
0.1 |
| Реквизиты компании |
0.1 |
0 |
0.1 |
0.1 |
0.1 |
0 |
0 |
| Информация о платформе виртуализации |
0.1 |
0.1 |
0.1 |
0.1 |
0.1 |
0.1 |
0.1 |
| Договор оферты |
0.4 |
0.1 |
0.1 |
0.1 |
0.4 |
0.4 |
0.4 |
| Договор оферты |
0.1 |
0.1 |
0.1 |
0.1 |
0.1 |
0.1 |
0.1 |
| SLA |
0.3 |
0 |
0 |
0 |
0.3 |
0.3 |
0.3 |
| Тестирование сервиса |
|||||||
| Вычислительная подсистема |
0.4 |
0.2 |
0.2 |
0.2 |
-0.1 |
0.4 |
0.4 |
| Соответствие заявленной частоты и выделенной частоты процессора |
0.2 |
0 |
0 |
0.2 |
0.2 |
0.2 |
0.2 |
| Стабильность вычислительной подсистемы |
0.2 |
0.2 |
0.2 |
0 |
0 |
0.2 |
0.2 |
| Недокументированное ограничение вычислительной подсистемы * во время тестирования ограничения не были выявлены |
-0.3 |
0* |
0* |
0* |
-0.3 |
0* |
0* |
| Дисковая подсистема |
0.8 |
0.6 |
0.5 |
0.3 |
0.8 |
0.6 |
0.6 |
| Стабильность дисковой подсистемы |
0.2 |
0.2 |
0.2 |
0.1 |
0.2 |
0.2 |
0.2 |
| Высокоскоростная дисковая подсистема |
0.2 |
0 |
0.2 |
0.2 |
0.2 |
0.2 |
0.2 |
| Высокая доступность данных |
0.2 |
0.2 |
0 |
0 |
0.2 |
0.2 |
0.1 |
| Отказоустойчивость дискового хранения |
0.2 |
0.2 |
0.1 |
0.1 |
0.2 |
0.2 |
0.1 |
| Сетевое соединение |
0.5 |
0.5 |
0.4 |
0.4 |
0.3 |
0.3 |
0.5 |
| Стабильность сетевого соединения |
0.2 |
0.2 |
0.2 |
0.2 |
0.2 |
0.2 |
0.2 |
| Низкие задержки по России |
0.1 |
0.1 |
0 |
0 |
0 |
0.1 |
0.1 |
| Высокая скорость доступа по России (более 20 мбит/с) |
0.2 |
0.2 |
0.2 |
0.2 |
0.1 |
0 |
0.2 |
| Дополнительные услуги |
1 |
0.8 |
0.5 |
0.5 |
0.6 |
0.8 |
0.7 |
| Базовая техническая поддержка |
0.2 |
0.2 |
0.2 |
0 |
0 |
0.2 |
0.2 |
| Расширенная техническая поддержка |
0.2 |
0 |
0 |
0.2 |
0 |
0 |
0 |
| Бесплатная лицензия Windows Server |
0.2 |
0.2 |
0.2 |
0.2 |
0.2 |
0.2 |
0.2 |
| Лицензия ПО |
0.1 |
0.1 |
0.1 |
0.1 |
0.1 |
0.1 |
0 |
| Гибкое расширение ресурсов |
0.3 |
0.3 |
0 |
0 |
0.3 |
0.3 |
0.3 |
| Итого |
3,4 |
1,9 |
2,1 |
1,7 |
2,7 |
2,8 |
3 |
| |
incloud.ru |
ihc.ru |
infobox.ru |
1cloud.ru |
cloudlite.ru |
mclouds.ru |
| CPU GHz заявленная |
— | 2 |
— | 2 |
2.2 |
2.6 |
| CPU GHz выделенная |
1.597 |
1.286 |
2.414 |
2.082 |
2.147 |
2.592 |
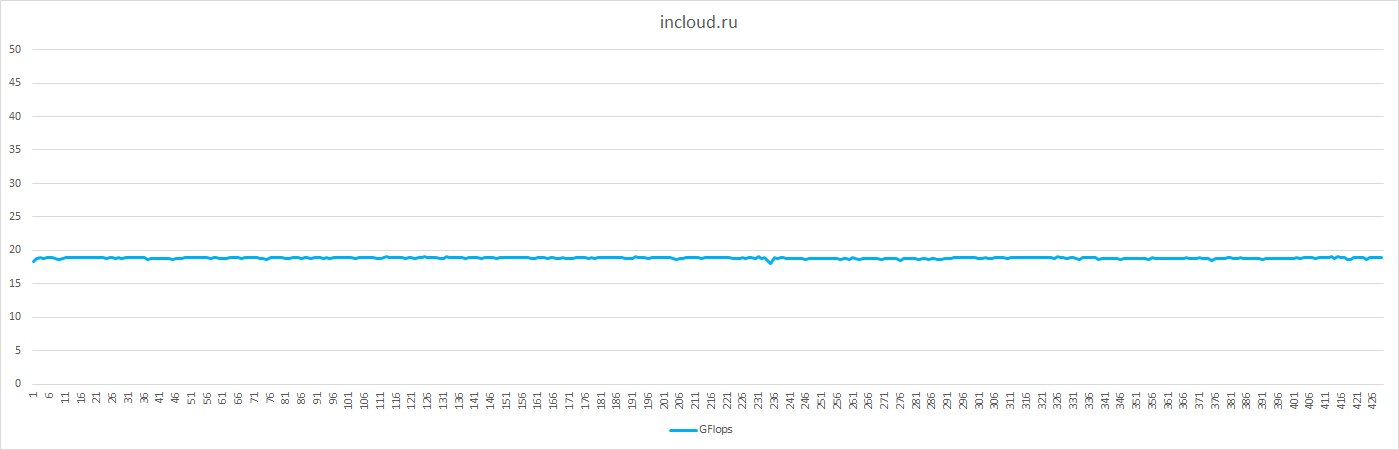
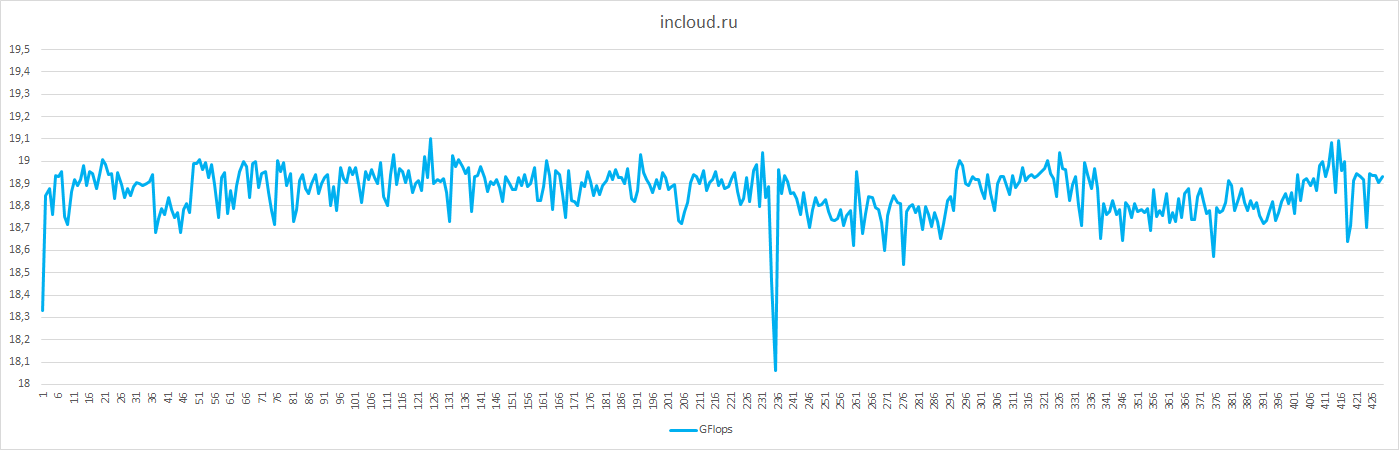
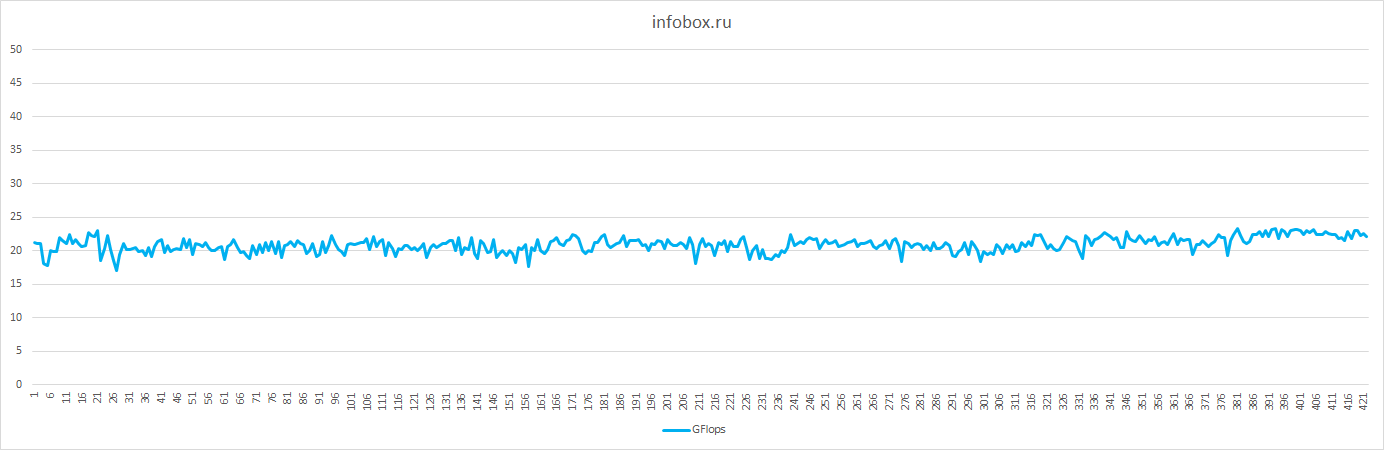
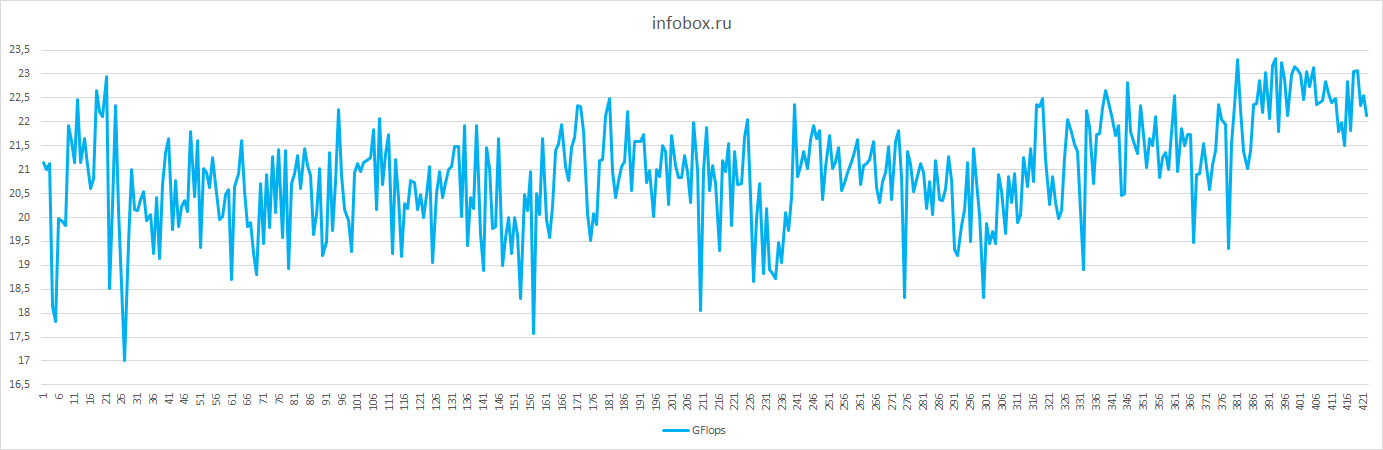
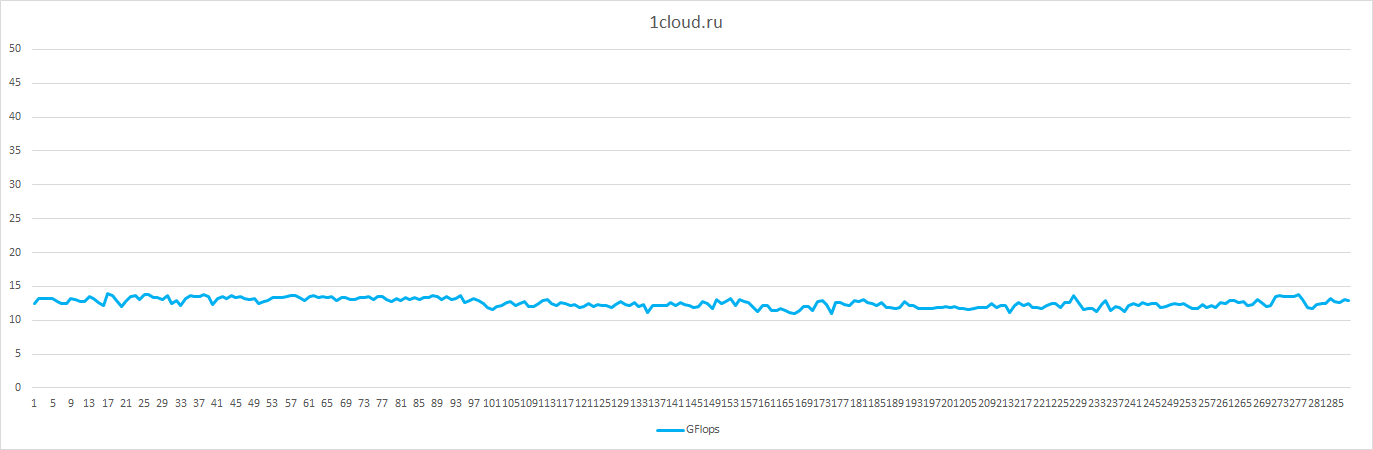
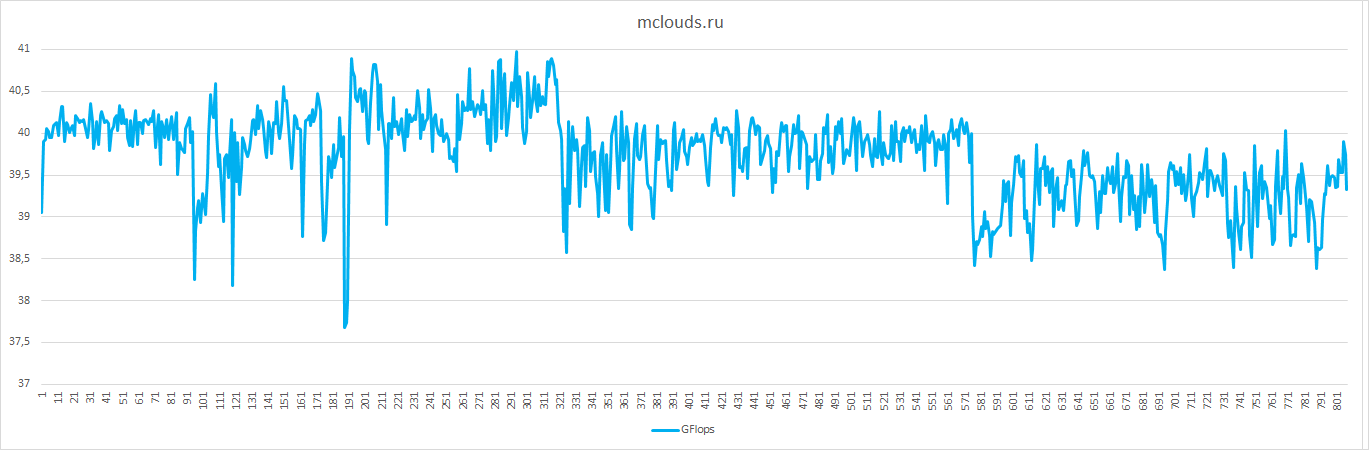
| Ср.знач. GFlops |
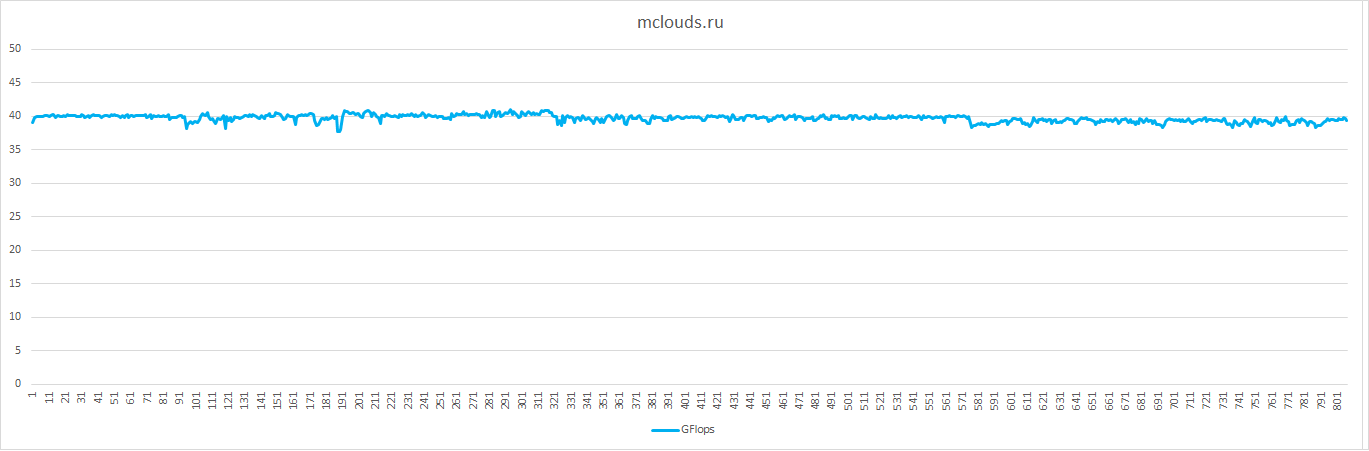
18.86 |
4.79 |
20.91 |
12.57 |
27.7 |
39.74 |
| Отклонение от ср.знач. в % |
6 |
2 |
19 |
16 |
5 |
9 |
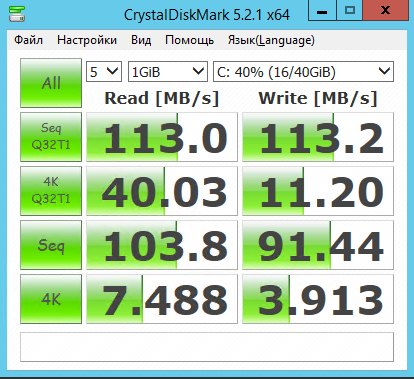
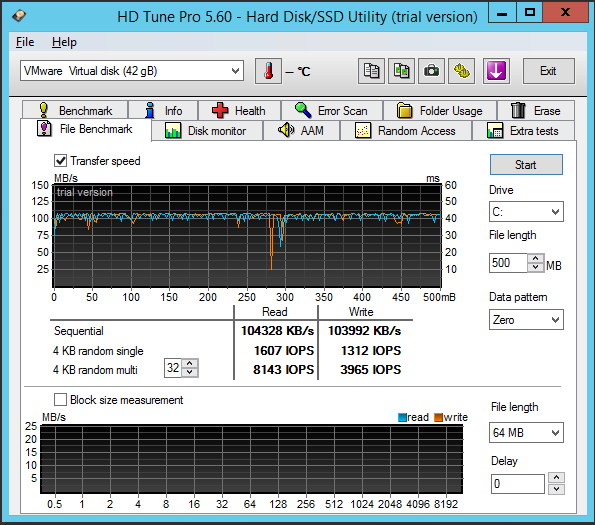
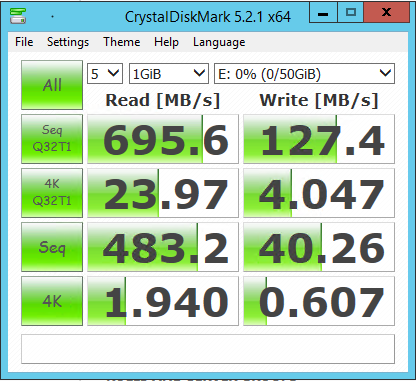
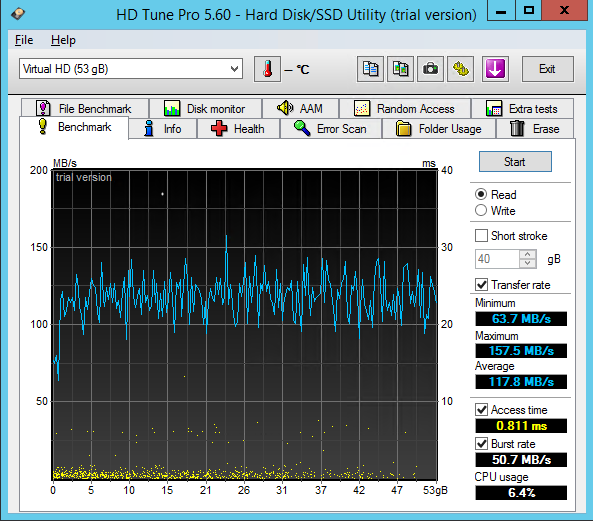
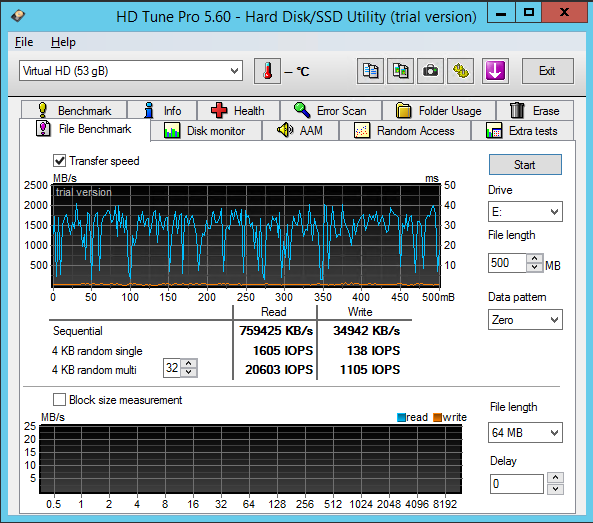
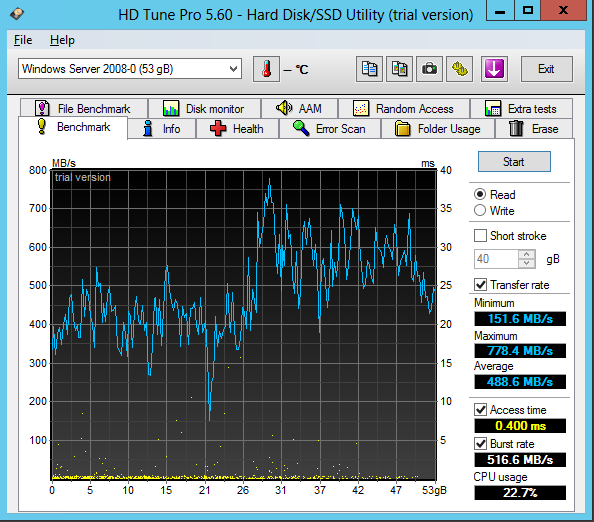
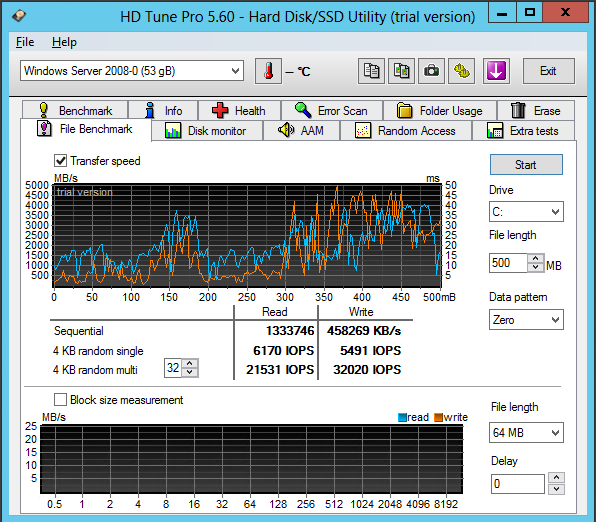
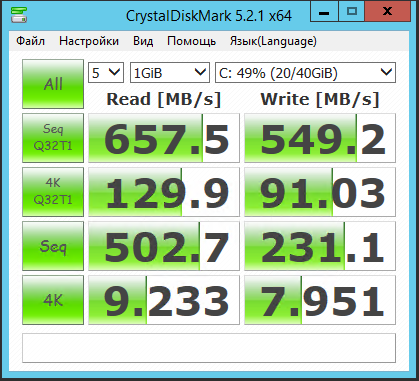
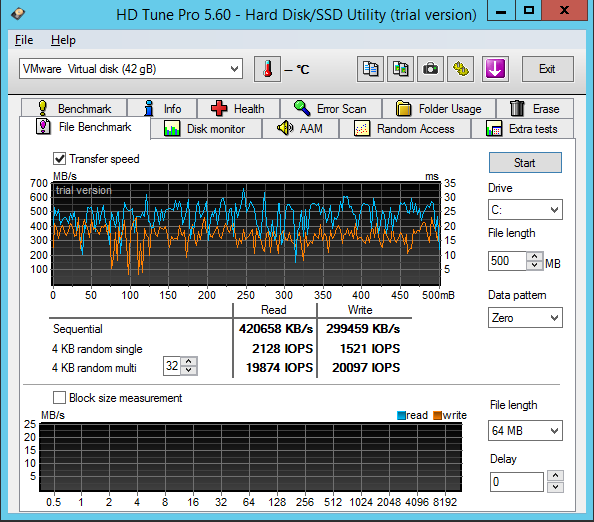
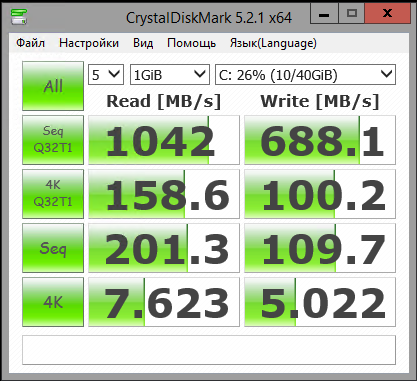
| Seq.R Q32T1 (MB/s) |
113 (SSD) |
695.6 (HDD) |
1402 (SSD) |
657.5 (SSD) |
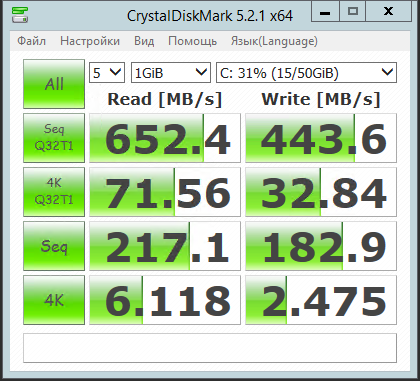
652.4 (HDD) |
1042 (SSD) |
| Seq.W Q32T1 (MB/S) |
113.2 (SSD) |
127.4 (HDD) |
1300 (SSD) |
549.2 (SSD) |
443.6 (HDD) |
688.1 (SSD) |
| 4 KB Random Read (IOPS) |
8143 |
20603 |
21531 |
19874 |
12785 |
37023 |
| 4 KB Random Write (IOPS) |
3965 |
1105 |
32020 |
20097 |
6549 |
21943 |
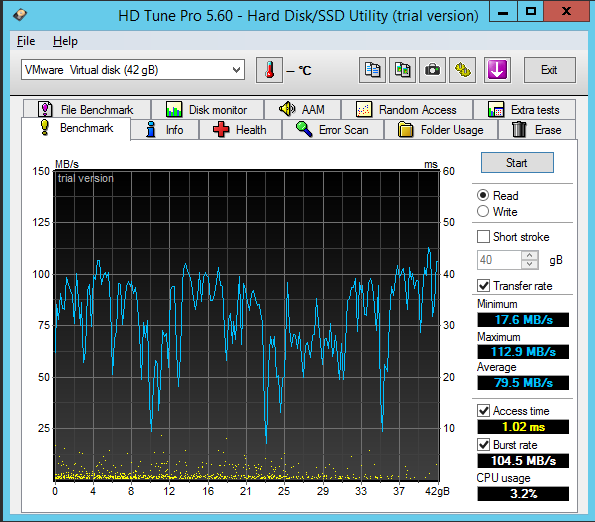
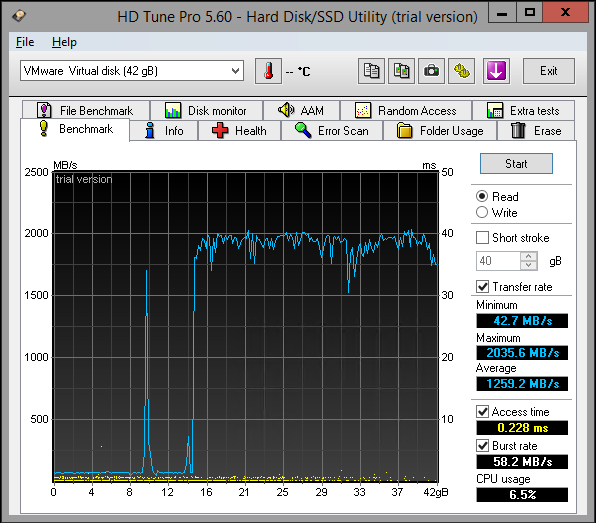
| Access time (ms) |
0.287 |
0.811 |
0.400 |
1.02 |
3.59 |
0.228 |
|
Метки: author igored хостинг серверное администрирование it- инфраструктура windows vps vps vds виртуальный сервер хостинг-провайдеры |
Британские спутниковые снимки 2: Как все было на самом деле |

— There is likely to be a change to the terms and conditions relating to the datasciencechallenge.org. The original conditions were set by the company who are running the challenge for us (based on legal grounds) but following feedback they have/will be changed. Please don't let it put you off participating.







Please send the following information to general@datasciencechallenge.org:
Full name
Nationality
Telephone contact details
Whether you would be happy to provide an interview for the winner announcements
Passport details (scan/photo of details page with photo)
Proof of address (eg. scan/photo of a utility bill)
Bank account details (IBAN, Account Number and Sort Code)
…
I'm sorry to say that due to your Russian citizenship you do not meet Clause 2.3b because Russia has a score below 37. As a result the company running the challenges is unable to award you any prize money as you do not meet the criteria that they need to follow due to their legal obligations in the UK.
…

|
|
Инструменты для прототипирования на Mac: сопоставительная характеристика |






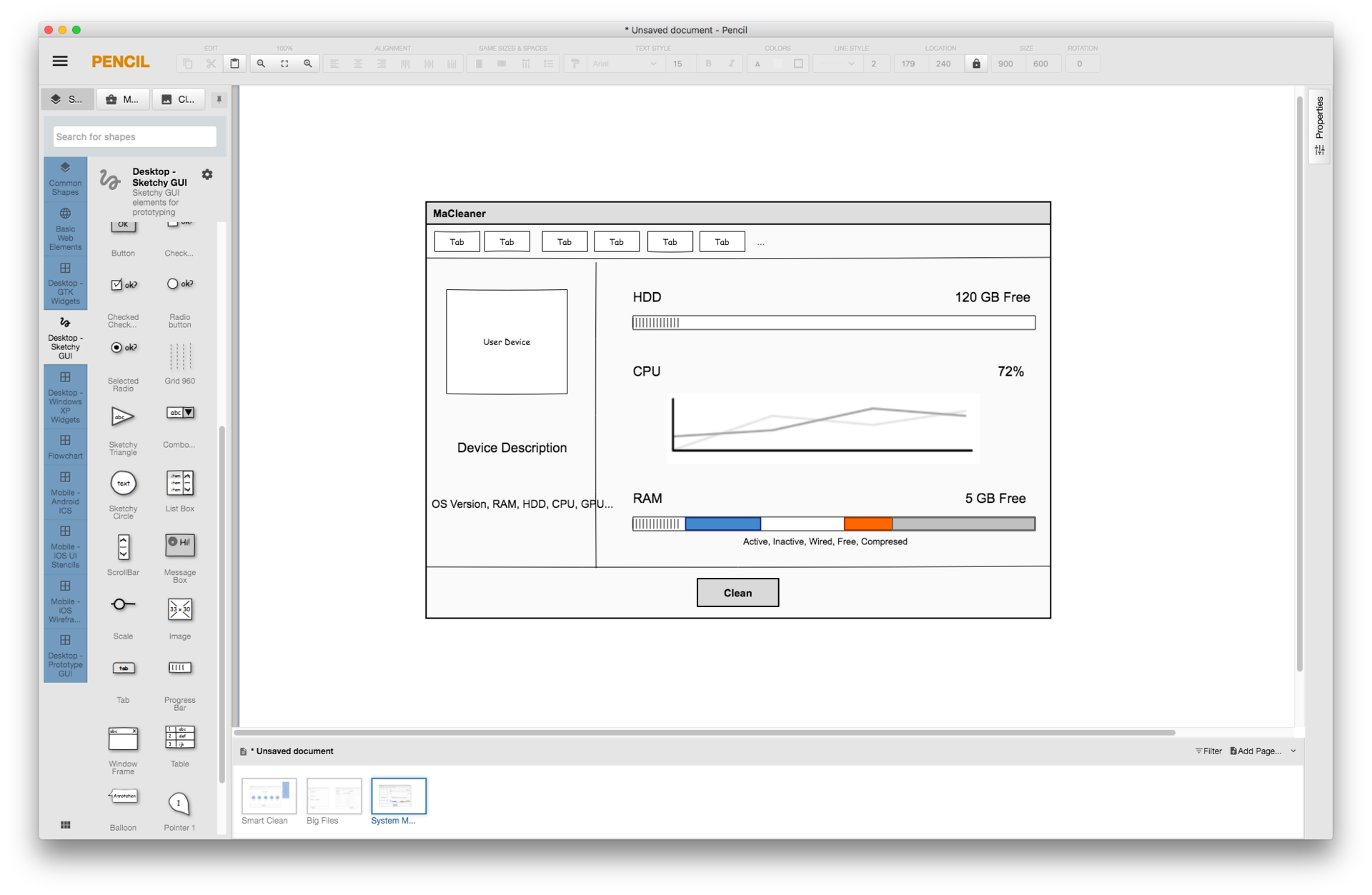




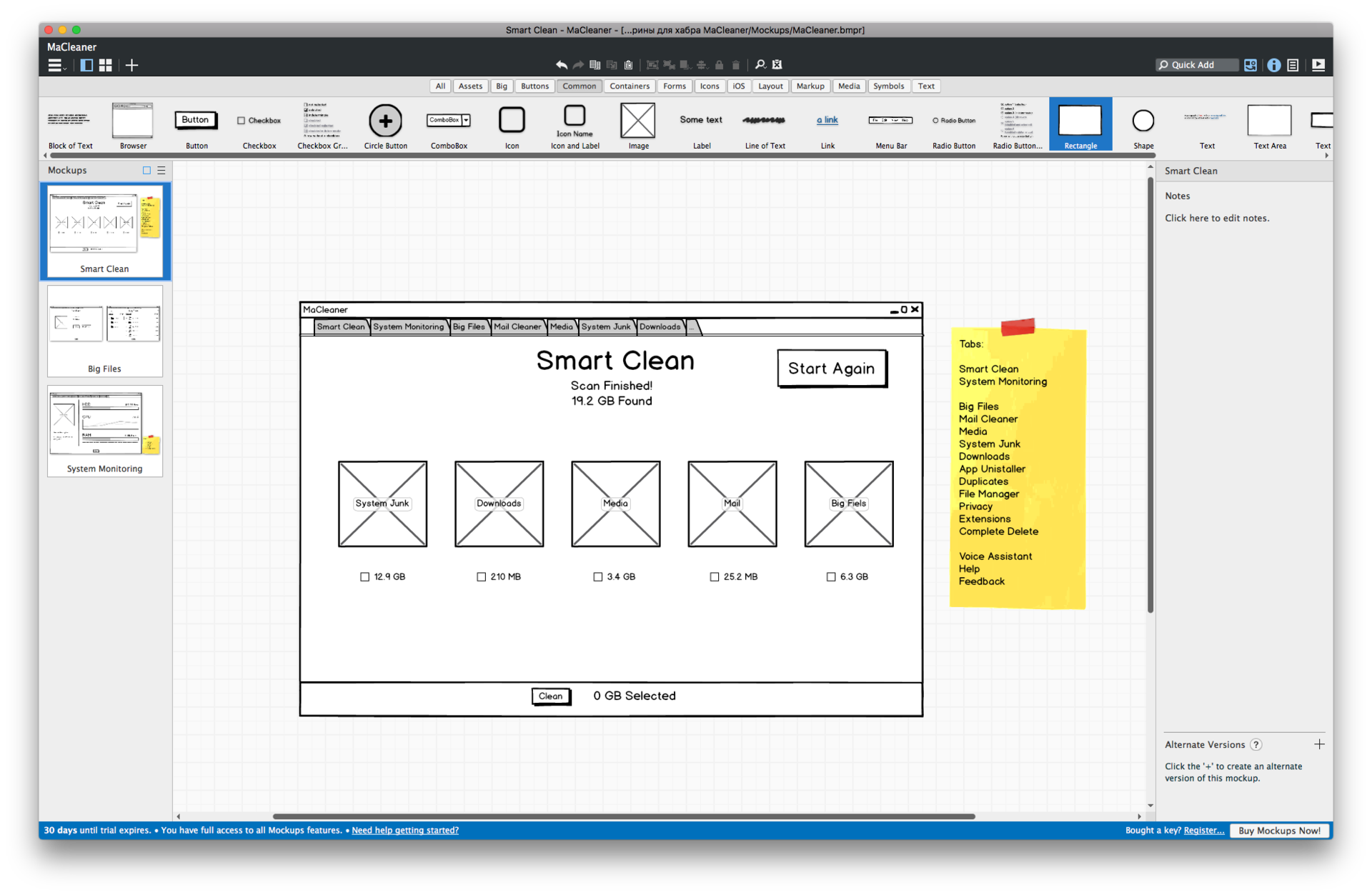



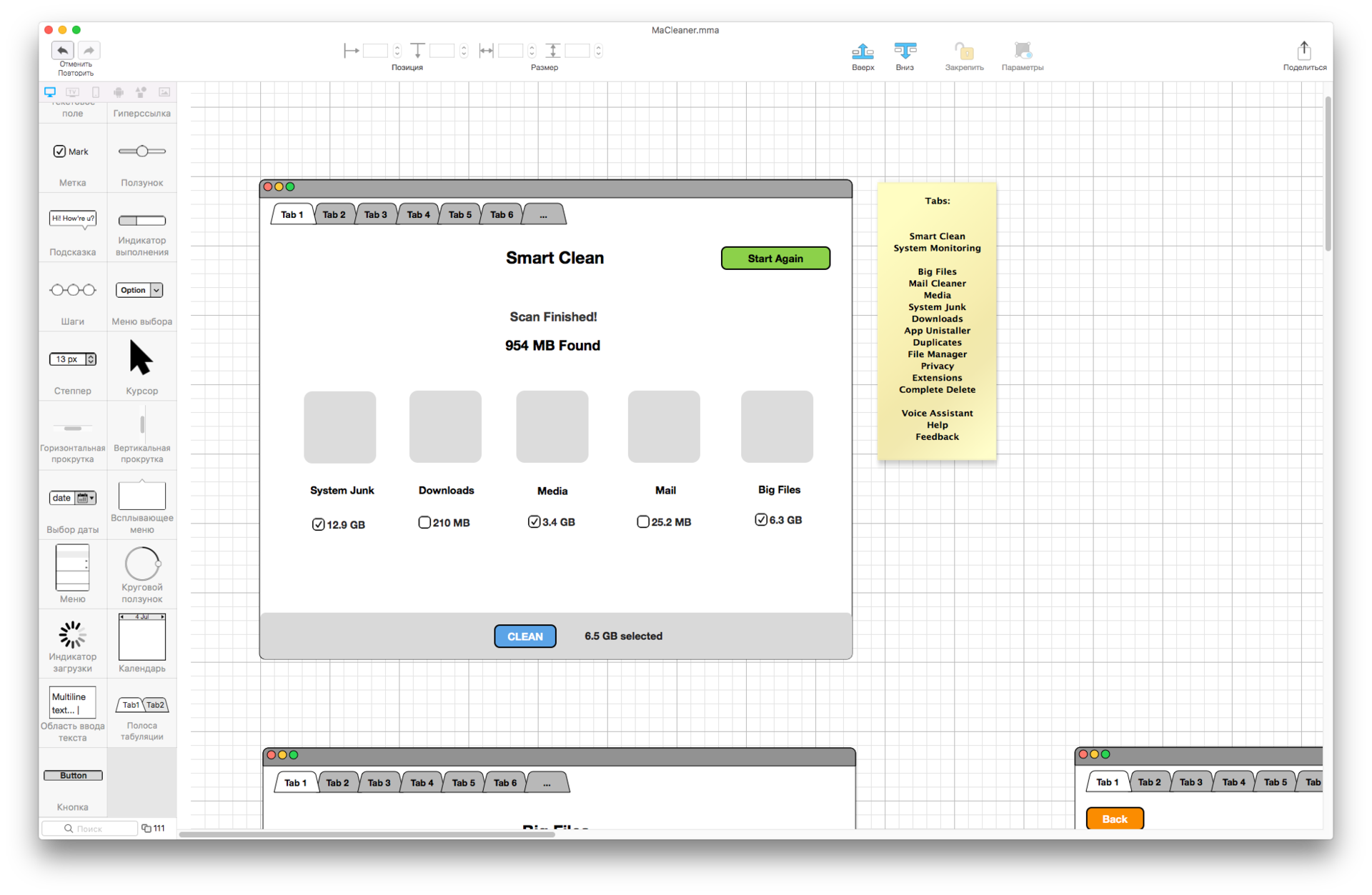



|
Метки: author EverydayTools прототипирование блог компании everyday tools прототипы прототипирование интерфейсов макеты мокапы |
Безопасность в эпоху интернета вещей: истории взломов видеонянь, кардиостимуляторов и суперкаров |
|
|
[Перевод] В чём сила Redux? |

Это перевод статьи "What’s So Great About Redux?" (автор Justin Falcone), которая мне показалась весьма приятной и интересной для прочтения, enjoy!
Redux мастерски справляется со сложными взаимодействиями состояний, которые трудно передать с помощью состояния компонента React. По сути, это система передачи сообщений, которая встречается и в объектно-ориентированном программировании, но она не встроена непосредственно в язык, а реализована в виде библиотеки. Подобно ООП, Redux переводит контроль от вызывающего объекта к получателю — интерфейс не управляет состоянием напрямую, а передает ему сообщение для обработки.
В этом плане хранилище в Redux — это объект, редюсеры — это обработчики методов, а действия — это сообщения. Вызов store.dispatch({ type:"foo", payload:"bar" }) равносилен store.send(:foo, "bar") в Ruby. Middleware используется почти таким же образом, как в аспектно-ориентированном программировании (например, before_action в Rails), а с помощью connect в react-redux осуществляется внедрение зависимости.
Какие преимущества даёт такой подход?
method_missing.Но все эти случаи особые. Что же насчёт более простых сценариев?
Как раз здесь у нас проблемы.
Однако главный подвох состоит в том, что после такой долгой работы над бойлерплейтами для простых случаев вообще забываешь, что для сложных случаев есть решения и получше. Столкнувшись с хитроумным переходом состояний в итоге отправляешь десяток разных actions которые просто устанавливают новые значения. Копируешь и вставляешь варианты switch из одного редюсера в другой, а не абстрагируешь их в виде функций, которые можно использовать отовсюду.
Легко списать всё это на человеческий фактор: не осилил документацию, или "мастер глуп — нож туп" — но такие проблемы встречаются подозрительно часто. Не в ноже ли проблема, если он туп для большинства мастеров?
Получается, лучше сторониться Redux в обычных случаях и приберечь его для особенных?
Как раз такой совет вам даст команда Redux — и я говорю то же самое своим коллегам: не беритесь за него до тех пор, пока setState не начнёт совсем выходить из-под контроля. Но даже я сам не следую собственным правилам, потому что всегда можно найти повод использовать Redux. Может быть, у вас есть много actions вроде set_$foo, при этом с каждым присвоением значения обновляется URL или сбрасывается ещё какое-нибудь промежуточное значение. Может, у вас установлено чёткое однозначное соответствие между состоянием и пользовательским интерфейсом, но вам требуется логирование или отмена действий.
На самом деле, я не знаю, как правильно писать на Redux, и тем более как этому учить. В каждом приложении, над которым я работал, полно таких антипаттернов из Redux — или я сам не мог найти лучшего решения, или у меня не получилось убедить коллег что-то изменить. Если, можно сказать, эксперт по Redux пишет посредственный код, то что и говорить о новичке. Я просто пытаюсь уравновесить популярный подход использования Redux для всего подряд, и надеюсь, что каждый выработает собственное понимание Redux.
Что же делать в таком случае?
К счастью, Redux достаточно гибкий, чтобы подключить к нему сторонние библиотеки для работы с простыми вещами — тaкие, как Jumpstart (https://github.com/jumpsuit/jumpstate). Поясню: я не считаю, что Redux нельзя использовать для низкоуровневых задач. Просто если работа над ними отдаётся сторонним библиотекам, это усложняет понимание, и по закону тривиальности время тратится на мелочи, потому что каждому пользователю в итоге приходится строить собственный фреймворк по частям.
Некоторым такое по душе.
И я в их числе! Но это относится далеко не ко всем. Я большой поклонник Redux и использую его почти во всех проектах, но мне также нравится пробовать новые конфигурации webpack. Я не типичный пример пользователя. Создание собственных абстракций на основе Redux даёт мне новые возможности, но что могут дать абстракции, написанные каким-нибудь Senior-инженером, который не оставил никакой документации и уволился полгода назад?
Вполне возможно, что вы и не встретитесь со сложными проблемами, которые так хорошо решает Redux, особенно если вы новичок (junior) в команде, где такими заданиями занимаются старшие коллеги. Тогда вы представляете себе Redux как такую странную библиотеку, с которой всё переписывают по три раза. Redux достаточно прост, чтобы работать с ним машинально, без глубокого понимания, но радости и выгоды от этого мало.
Так я возвращаюсь к вопросу, который задал ранее: если большинство использует инструмент неправильно, не в нём ли вся проблема? Качественный инструмент не просто полезен и долговечен — с ним ещё и приятно работать. Использовать его правильно удобнее всего. Такой инструмент делается не только для работы, но и для человека. Качество инструмента — это отражение заботы его создателя о мастере, который будет им пользоваться.
А как мы заботимся о мастерах? Почему мы утверждаем, что они всё делают не так, вместо того, чтобы поработать над удобством инструмента?
В функциональном программировании есть похожее явление, которое я называю «Проклятием урока о монадах»: объяснить, как работают монады, проще простого, а вот рассказать, в чём их польза, на удивление трудно.
Ты серьёзно собираешься объяснять монады посреди поста?
Монады — это распространённая в Haskell абстракция, которая используется для самых разных вычислений, например, при работе со списками или обработке ошибок, состояний, времени или ввода/вывода. Синтаксический сахар в виде do-нотации позволяет представлять последовательности операций над монадами в форме, похожей на императивный код, примерно как генераторы в JavaScript, которые делают асинхронный код похожим на синхронный.
Первая проблема состоит в том, что не совсем правильно описывать монады с точки зрения их применения. Монады появились в Haskell для работы с побочными эффектами и последовательным вычислением, но в абстрактном смысле они не имеют с этим ничего общего: они просто представляют из себя набор правил взаимодействия двух функций, и в них не заложено никакого особого смысла. Похожим образом ассоциативность применима к арифметике, операциям над множествами, объединению списков и null propagation, но существует независимо от них.
Вторая проблема — это многословность, а значит, как минимум, визуальная сложность монад по сравнению с императивным подходом. Четко определенные опциональные типы вроде Maybe более безопасны, чем поиск подводных камней в виде null, но код с ними длиннее и несуразнее. Обработка ошибок с помощью типа Either выглядит понятнее, чем код, в котором где угодно может быть брошено исключение, но, согласимся, код с исключениями намного лаконичнее, чем постоянный возврат значений с Either. Что касается побочных эффектов в состоянии, вводе/выводе и т.д., то они и вовсе тривиальны в императивных языках. Любители функционального программирования (я в их числе) возразили бы, что работать с побочными эффектами в функциональных языках очень легко, но вряд ли кого-то получится убедить, что какое бы то ни было программирование — это легко.
Польза по-настоящему заметна, если посмотреть на эти примеры широким взглядом: oни не просто следуют законам монад — это одни и те же законы. Набор операций, который работает в одном случае, может работать и в остальных. Превратить пару списков в список пар — это условно то же самое, что объединить пару объектов Promise в один, который возвращает кортеж с результатами.
Так к чему же всё это?
Дело в том, что с Redux такая же проблема — ему трудно обучать не потому, что он сложный, а как раз потому, что он простой. Понимание заключается скорее не в знании, а в доверии основному принципу, благодаря которому можно прийти ко всему остальному путём индукции.
Этим пониманием нелегко поделиться, потому что основные принципы сводятся к банальным аксиомам («избегайте побочных эффектов») или настолько абстрактны, что почти теряют смысл ((prevState, action) => nextState). Конкретные примеры не помогают: они только демонстрируют многословность Redux, но не показывают его выразительность.
Достигнув просвещения, многие из нас сразу же забывают о том, как к нему пришли. Мы уже не помним, что наше «просвещение» — это результат многократных ошибок и заблуждений.
И что ты предлагаешь?
Я хочу, чтобы мы осознали, что у нас есть проблема. Redux простой, но не лёгкий. Это оправданное решение разработчиков, но в то же время и компромисс. Многим людям пригодился бы инструмент, который бы частично пожертвовал простотой механизма в пользу простоты использования. Но в сообществе зачастую даже не признают, что какой-то компромисс вообще был сделан.
По-моему, интересно сравнивать React и Redux: хоть React и гораздо сложнее Redux и его API намного шире, как ни странно, его легче изучать и использовать. Всё, что действительно необходимо в API React, — это функции React.createElement и ReactDOM.render , а с состоянием, жизненным циклом компонентов и даже с событиями DOM можно справиться по-другому. Включение всех этих функций в React сделало его сложнее, но при этом и лучше.
"Атомарное состояние" — это абстрактная идея, и оно приносит практическую пользу только после того, как вы в нем разберётесь. С другой стороны, в React метод компонента setState управляет атомарностью состояния за вас, даже если вы не понимаете, как оно работает. Такое решение не идеально — было бы эффективнее отказаться от состояния вообще, или в обязательном порядке обновлять его при каждом изменении. Ещё этот метод может преподнести неприятные сюрпризы, если вызвать его асинхронно, но всё же setState намного полезнее для React в качестве рабочего метода, а не просто теоретического понятия.
И команда разработчиков Redux, и сообщество его пользователей активно выступают против расширения API, но склеивать десятки маленьких библиотек, как это делается сейчас, — утомительное занятие даже для экспертов и тёмный лес для новичков. Если Redux не сможет вырасти до уровня встроенной поддержки простых случаев, ему потребуется фреймворк-«спаситель», который займёт эту нишу. Jumpsuit мог бы стать неплохим кандидатом — он воплощает идеи действий и состояния в виде конкретных функций, при этом сохраняя характер отношений «многие ко многим». Но выбор спасителя не так важен, как сам факт спасения.
Вся ирония в том, что смысл существования Redux — это «Developer Experience»: Дэн разработал Redux, чтобы изучить и воспроизвести time-travel debugger как в Elm. Однако, по мере того, как идея приобретала собственную форму и превращалась, по факту, в объектно-ориентированную среду экосистемы React, удобство «DX» отошло на второй план и уступило гибкости конфигурации. Это вызвало расцвет экосистемы Redux, но там, где должен быть удобный фреймворк с активной поддержкой, пока зияет пустота. Готовы ли мы, сообщество Redux, заполнить её?
|
Метки: author PQR reactjs javascript react redux |
Мониторинг работы производства веб-студии |

|
Метки: author vasyay управление разработкой управление проектами управление персоналом блог компании webcanape веб-студия мониторинг kpi webcanape |
Фотографируем объекты в C#: хроника и сопоставление снимков, реконструкция состояния по снимку |





private void Edit(T sourceEntry, bool useCopy, bool showChanges, ReplicationProfile replicationProfile)
{
var cache = new ReconstructionCache();
var sourceSnapshot = sourceEntry.CreateSnapshot(cache, replicationProfile);
var editableEntry = useCopy ? sourceSnapshot.ReplicateGraph() : sourceEntry;
if (GetView(editableEntry).ShowDialog() == true)
{
var resultSnapshot = editableEntry.CreateSnapshot(null, replicationProfile);
var changes = sourceSnapshot.Juxtapose(resultSnapshot)
.Where(j => j.State != Etalon.State.Identical);
if (changes.Any())
{
MessageBox.Show(showChanges
? changes.Aggregate("", (x, y) => x + y + Environment.NewLine)
: "Any changes has been detected!");
UpdateSourceData(editableEntry);
UpdateUserInterface();
}
else MessageBox.Show("There are no any changes.");
}
else if (!useCopy) sourceSnapshot.ReconstructGraph(cache);
} public class Person : INotifyPropertyChanged
{
private int _id;
private string _name;
private string _birthday;
private string _phone;
private string _mail;
public event PropertyChangedEventHandler PropertyChanged = (o, e) => { };
private void Set(ref T target, T value, [CallerMemberName]string caller = "")
{
if (Equals(target, value)) return;
target = value;
PropertyChanged(this, new PropertyChangedEventArgs(caller));
}
public int Id
{
get => _id;
set => Set(ref _id, value);
}
public string Name
{
get => _name;
set => Set(ref _name, value);
}
public string Birthday
{
get => _birthday;
set => Set(ref _birthday, value);
}
public string Phone
{
get => _phone;
set => Set(ref _phone, value);
}
public string Mail
{
get => _mail;
set => Set(ref _mail, value);
}
} private static readonly ReplicationProfile PersonRepicationProfile = new ReplicationProfile
{
MemberProviders = new List
{
new CoreMemberProviderForKeyValuePair(),
new CoreMemberProvider(BindingFlags.Public | BindingFlags.Instance, Member.CanReadWrite),
}
}; var cache = new ReconstructionCache();
var sourceSnapshot = sourceEntry.CreateSnapshot(cache, replicationProfile);
...
var resultSnapshot = editableEntry.CreateSnapshot(null, replicationProfile); var changes = sourceSnapshot.Juxtapose(resultSnapshot)
.Where(j => j.State != Etalon.State.Identical); var editableEntry = useCopy ? sourceSnapshot.ReplicateGraph() : sourceEntry; var cache = new ReconstructionCache();
var sourceSnapshot = sourceEntry.CreateSnapshot(cache, replicationProfile);
...
else if (!useCopy) sourceSnapshot.ReconstructGraph(cache);|
|
Многоярусный бэкап PostgreSQL с помощью Barman и синхронного переноса журналов транзакций |

В Яндекс.Деньгах хранится масса важной для комфортной работы пользователя информации. Настройки профилей и подписки на штрафы тоже нужно бэкапить, чем и занимается у нас связка из Barman Backup & Recovery for PostgreSQL и pg_receivexlog.
В статье расскажу о том, почему архитектура стала такой, какой стала, а также расскажу, как реализовать подобный сценарий для вашей базы PostgreSQL.
До описываемых в статье изменений бэкап платежной системы снимался с мастер-базы в одном из наших дата-центров (ДЦ). Вообще, платежная система состоит из множества отдельных сервисов, баз и приложений. Все это добро резервируется сообразно важности данных. Так как статья более практическая, рассмотрю в качестве примера одну из множества СУБД без повышенных требований к безопасности – в ней хранятся настройки пользовательских профилей, история переводов, предпочтения по аутентификации и прочее.
В качестве инструмента резервного копирования у нас в эксплуатации любят Barman, гибкий и стабильный продукт. Кроме того, его делают люди, участвующие в разработке нашего любимого PostgreSQL.
Проблема резервного копирования только с активных узлов в том, что если мастер переключали на второй ДЦ (где резервных копий не было), то бэкап-сервер первого ДЦ медленно и долго собирал копии с нового мастера по сети. И потенциальные потери самых последних транзакций при восстановлении стали вызывать все больше опасений по мере роста числа пользователей.
Итого, будем решать следующие задачи:
Обеспечение доступности резервных копий при отказе ДЦ или бэкап-сервера.
Масштаб нашей задачи составляли 20 серверов PostgreSQL 9.5 (10 мастеров и 10 слейвов), обслуживающих 36 баз данных суммарным объемом около 3 ТБ. Но описываемый сценарий подойдет и для пары серверов с критичными БД.
С версии 2.1 в Barman Backup & Recovery появилась возможность записывать поток транзакций не только с мастера, но и со слейв-серверов (реплик).
Общая схема нового решения представлена ниже, она довольно незамысловата:
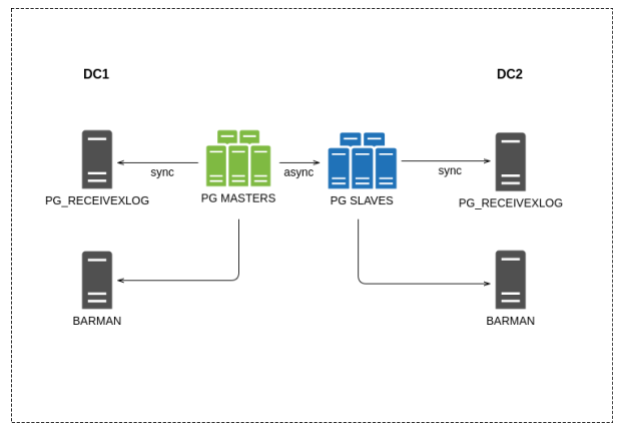
По одному серверу резервного копирования в каждом ДЦ, конфигурация у них общая (один из плюсов Barman).
Процесс конфигурации выглядит следующим образом:
1. Подключаемся к серверу БД и с помощью пакетного менеджера устанавливаем postgresql-9.5-pgespresso – расширение для интеграции Barman Backup & Recovery c PostgreSQL.
Все команды приводятся для Ubuntu, для других дистрибутивов могут быть отличия:
apt-get install postgresql-9.5-pgespresso2. Устанавливаем расширение pg_espresso в PostgreSQL:
postgres@db1:5432 (postgres) # CREATE EXTENSION pgespresso3. Теперь на сервере с Barman нужно создать файл, описывающий настройки резервного копирования для сервера db1 – db1.conf в каталоге /etc/barman.d/ со следующим содержимым:
[db1]
ssh_command = ssh postgres@db1
conninfo = host=pgdb1 user=postgres port=5432
backup_options = concurrent_backup ; позволяет выполнять бэкап с реплики при наличии расширения pg_espresso
archiver = off ; выключаем доставку логов через archive_command
streaming_archiver = on ; включаем доставку логов через механизм репликации
slot_name = barman ; имя слота репликации4. Далее нужно создать слот репликации, чтобы гарантировать, что мастер не удалит журналы транзакций, которые еще не были получены репликой:
$ barman receive-wal --create-slot db15. И проверить, что Barman видит сервер и забирает с него журналы транзакций:
$ barman check db1Если все команды выполнены правильно, то в результате выполнения команды проверки должно получиться нечто похожее:
Server db1:
PostgreSQL: OK
superuser: OK
PostgreSQL streaming: OK
wal_level: OK
replication slot: OK
directories: OK
retention policy settings: OK
backup maximum age: OK (no last_backup_maximum_age provided)
compression settings: OK
failed backups: OK (there are 0 failed backups)
minimum redundancy requirements: OK (have 7 backups, expected at least 7)
ssh: OK (PostgreSQL server)
pgespresso extension: OK
pg_receivexlog: OK
pg_receivexlog compatible: OK
receive-wal running: OK
archiver errors: OKТеперь Barman будет забирать журналы и делать бэкапы с реплик. В бэкап попадают все базы PostgreSQL c профилями пользователей, историей платежей, подписками на штрафы, настройками аутентификации и т.п.
Напомню, что нулевое RPO при восстановлении нам очень важно, поэтому решили подстраховать Barman дополнительным механизмом – pg_receivexlog. Этот процесс находится на отдельном сервере – не на сервере с базой данных – и непрерывно переносит копии журналов транзакций из мастер-ноды в отдельное хранилище журналов транзакций, доступное для реплики. И так для каждого ДЦ отдельно.
Особенность механизма в том, что СУБД не подтвердит приложению запись данных в базу, пока не получит подтверждение от pg_receivexlog об успешном копировании транзакции.
Без этого сохранялась бы вероятность следующего сценария:
Допустим, Иннокентий платит 100 рублей за сотовую связь, операция успешно проводится нашей платежной системой (ПС).
Сразу после проведения в бэкенде происходит авария, и мы откатываем бэкап, включая журналы транзакций.
Получается, что ПС знает о проведении платежа, деньги не потеряны, но саму операцию в истории не посмотреть. Конечно, это неудобно и обескураживает. Операцию пришлось бы в ручном режиме вносить через службу поддержки.
Теперь как настроить чудо механизм синхронного переноса логов:
1. Создаем слот для сборщика логов:
pg_receivexlog --create-slot -S pgreceiver --if-not-exists -h db12. Запускаем службы сбора логов с сервера PostgreSQL:
pg_receivexlog -S pgreceiver -d "host=db1 user=postgres application_name=logreceiver" -D /var/lib/postgresql/log/db1/ --verbose --synchronous*-S: используемый слот репликации. Должен быть создан на первом шаге;*
*-d: строка подключения к базе;*
*-D: каталог, куда будут сохраняться журналы;*
*—synchronous: записывать данные в синхронном режиме;*3. После запуска pg_receivexlog будет пытаться в синхронном режиме сохранять журналы транзакций в каталог. Таких сборщиков может быть несколько, по одному на сервер PostreSQL. Но чтобы синхронный режим заработал, нужно в настройках СУБД на мастер-ноде указать параметр в конфигурации PostgreSQL:
synchronous_standby_names = 'logreceiver, standby'4. Но чтобы при отказе сервера со сборщиком логов мастер-нода могла продолжать обработку пользовательских транзакций, вторым сервером лучше указать реплику. На реплике в recovery.conf нужно указать, откуда брать журналы транзакций в случае недоступности мастер-ноды:
restore_command = 'scp postgres@logreceiver:/var/lib/postgresql/log/db1/%f* %p'Конечно, при выходе из строя сервера сбора логов скорость работы всей системы немного снизится, потому что вместо синхронной отправки журналов на сборщик логов в том же ДЦ, что и мастер, придется отправлять их с подтверждением в другой ДЦ. Тем не менее стабильность важнее.
В качестве резюме приведу немного конкретики о времени и объеме бэкапов по описанной в статье схеме. Полный бэкап упомянутых серверов снимается в Яндекс.Деньгах ежедневно и весит около 2 ТБ, на обработку которых бэкап-серверу нужно 5-10 часов. Кроме того, выполняется постоянный бэкап журналов транзакций с помощью перемещения их файлов в хранилище.
|
Метки: author dimskiy системное администрирование резервное копирование администрирование баз данных it- инфраструктура блог компании яндекс.деньги barman postgresql бэкап |
Необходимость регулирования интернета вещей |



|
|
Без заголовка |

Все мы в качестве сниффера обычно используем готовые программы. Однако, можно обойтись и встроенными средствами Windows с помощью PowerShell. Помимо изобретения велосипеда «потому что можем», скрипты пригодятся в сценариях автоматизированного анализа трафика.
До изобретения велосипеда немного расскажу (или напомню) о готовых продуктах, предназначенных для перехвата сетевого трафика и последующего анализа. Вот основные программы, занимающиеся анализом трафика.
Tcpdump. Консольный и довольно известный сниффер для UNIX-систем.
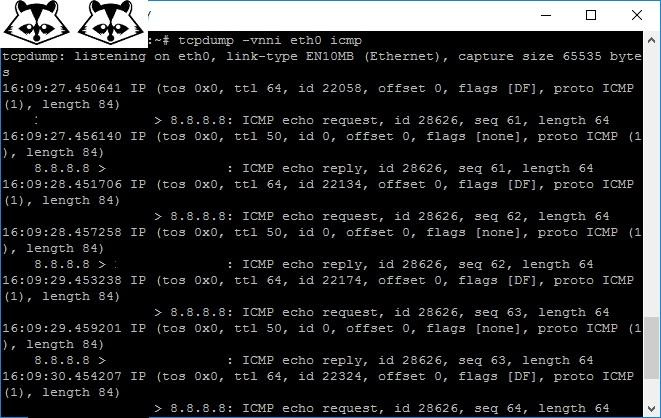
Пингуем 8.8.8.8 и любуемся выводом tcpdump.
Wireshark. Пожалуй, сегодня это один из самых известных кроссплатформенных снифферов с GUI. Для расширения возможностей можно использовать скриптовый язык LUA. Также программой удобно анализировать трафик, захваченный на других устройствах в различных форматах.
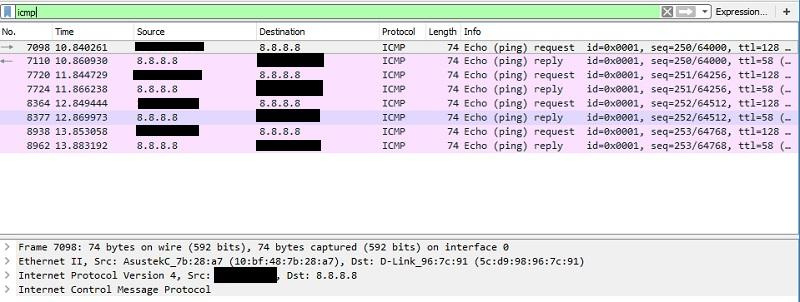
Продолжаем пинговать 8.8.8.8, но смотрим уже с помощью Wireshark.
Microsoft Message Analyzer (в прошлом Microsoft Network Monitor). Помимо функций сниффера, может анализировать сообщения программ и устройств, системные события.
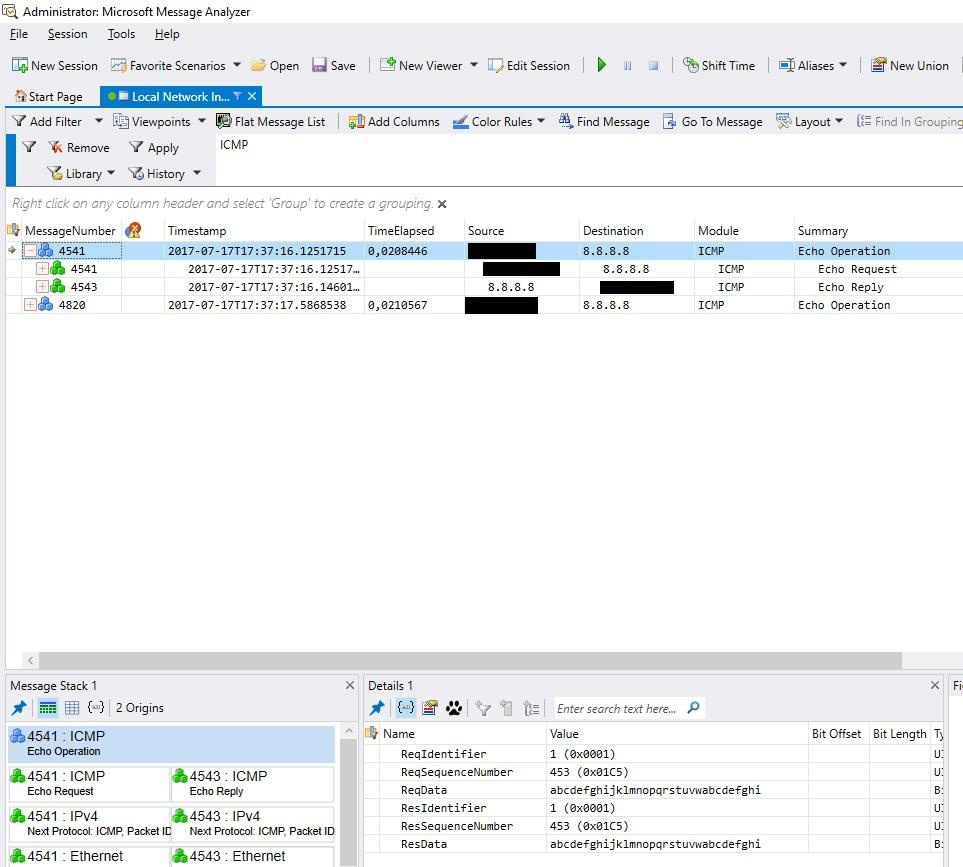
Возможностей много, поэтому и интерфейс громоздкий.
Наконец, WinDump. Аналог tcpdump, но для Windows.
Отдельно отмечу снифферы на сетевом оборудовании. Ведь куда удобнее смотреть трафик сразу на пограничном маршрутизаторе или коммутаторе, чем топать к проблемному компьютеру:
В маршрутизаторах Mikrotik сниффер стоит искать в Tools - Packet Sniffer.
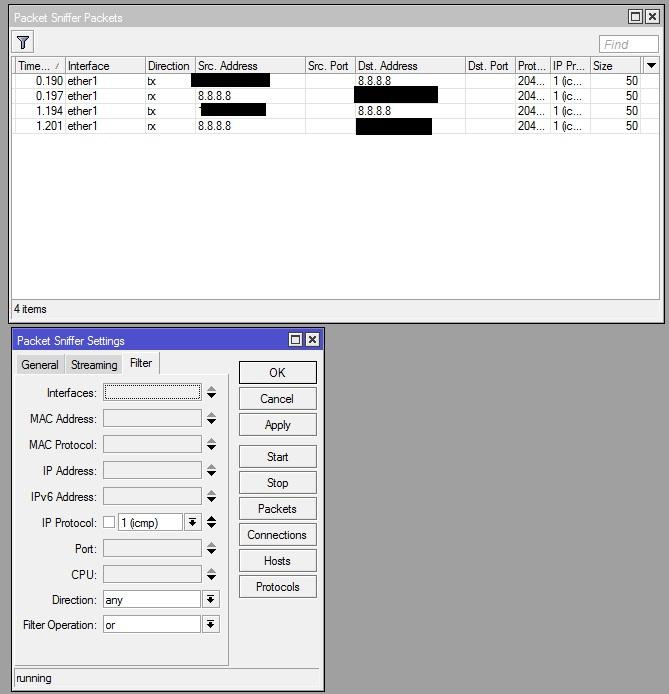
Сниффер на Микротике.
Любопытной возможностью является настройка потока (Streaming), позволяющая отправлять трафик с роутера прямо на компьютер с запущенным Wireshark.
К сожалению, через GUI пакеты не посмотреть, но можно скачать дамп трафика в формате .cap и открывать привычным анализатором Wireshark или Microsoft Message Analyzer.
А теперь представим, что сниффер почему-то вот прямо сейчас не скачать, а инструмент нужен - приступим к упражнениям с PowerShell.
Первая версия этого средства автоматизации вышла больше 10 лет назад, поэтому прописные истины синтаксиса повторять не буду. Но если нужна памятка - рекомендую начать с официального сайта Microsoft, где заодно есть галерея готовых скриптов.
Ловить пакеты будем из командной строки с использованием набора командлетов NetEventPacketCapture в Windows 8.1/2012R2. Для примера представим, что на компьютере с именем REIKO пользователь работает в терминальной сессии - подглядим за его работой при помощи PowerShell.
Для начала создадим подключение к компьютеру пользователя:
$Cim = New-CimSession -ComputerName 'REIKO'После этого создадим сессию обработчика событий:
New-NetEventSession -Name "Session01" -CimSession $Cim -LocalFilePath "C:\Windows\Temp\Trace.etl" -CaptureMode SaveToFileИ добавим поставщика событий:
Add-NetEventProvider -CimSession $Cim -Name 'Microsoft-Windows-TCPIP' -SessionName "Session01"Посмотреть всех возможных поставщиков можно командой logman query providers.
После чего осталось запустить трассировку:
Start-NetEventSession -Name "Session01" -CimSession $CimДля остановки достаточно в той же команде заменить Start на Stop.
Результаты можно посмотреть следующей командой:
Get-WinEvent -Path "\\REIKO\C$\Windows\Temp\Trace.etl" -Oldest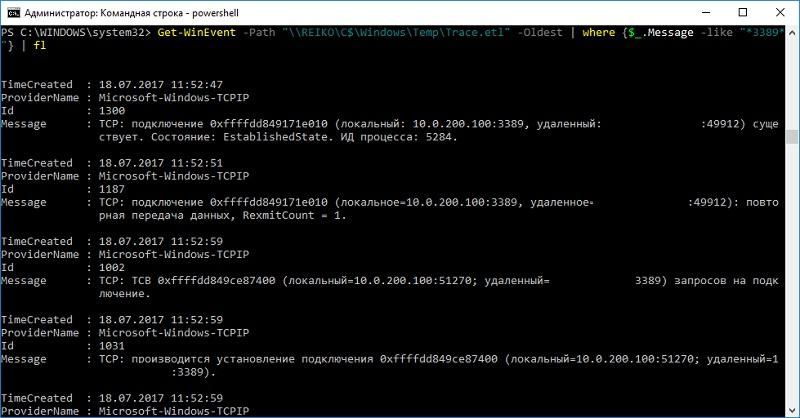
По результатам трассировки видно, что с компьютера не только работают на терминальном сервере, но и на самом компьютере кто-то сидит в локальной терминальной сессии.
Для автоматизации процессов такой трассировки (привет коллегам из ИБ) системный администратор Dan Franciscus написал скрипт Invoke-PSTrace.
#requires -Modules NetEventPacketCapture
function Invoke-PSTrace {
[OutputType([System.Diagnostics.Eventing.Reader.EventLogRecord])]
[CmdletBinding()]
param(
[Parameter(Mandatory=$true)]
[string]$ComputerName,
[switch]$OpenWithMessageAnalyzer,
[pscredential]$Credential
)
DynamicParam
{
$ParameterName = 'ETWProvider'
$RuntimeParameterDictionary = New-Object System.Management.Automation.RuntimeDefinedParameterDictionary
$AttributeCollection = New-Object System.Collections.ObjectModel.Collection[System.Attribute]
$ParameterAttribute = New-Object System.Management.Automation.ParameterAttribute
$ParameterAttribute.Mandatory = $true
$AttributeCollection.Add($ParameterAttribute)
$arrSet = logman query providers | Foreach-Object {$_.split('{')[0].trimend()} | Select-Object -Skip 3 | Select-Object -SkipLast 2
$ValidateSetAttribute = New-Object System.Management.Automation.ValidateSetAttribute($arrSet)
$AttributeCollection.Add($ValidateSetAttribute)
$RuntimeParameter = New-Object System.Management.Automation.RuntimeDefinedParameter($ParameterName, [string], $AttributeCollection)
$RuntimeParameterDictionary.Add($ParameterName, $RuntimeParameter)
return $RuntimeParameterDictionary
}
begin
{
$ETWProvider = $PsBoundParameters[$ParameterName]
}
process
{
#Remove any existing sessions
Get-CimSession -ComputerName $ComputerName -ErrorAction SilentlyContinue | Remove-CimSession -Confirm:$False
Get-NetEventSession -Name "Session1" -ErrorAction SilentlyContinue | Remove-NetEventSession -Confirm:$False
Remove-Item -Path "C:\Windows\Temp\$ComputerName-Trace.etl" -Force -Confirm:$False -ErrorAction SilentlyContinue
#Create new session
try
{
$Cim = New-CimSession -ComputerName $ComputerName -Credential $Credential -ErrorAction Stop
New-NetEventSession -Name "Session1" -CimSession $Cim -LocalFilePath "C:\Windows\Temp\$ComputerName-Trace.etl" -ErrorAction Stop -CaptureMode SaveToFile | Out-Null
}
catch
{
Write-Error $_
Break
}
Add-NetEventProvider -CimSession $Cim -Name $ETWProvider -SessionName "Session1" | Out-Null
Start-NetEventSession -Name "Session1" -CimSession $Cim | Out-Null
if (Get-NetEventSession -CimSession $Cim)
{
Read-Host 'Press enter to stop trace' | Out-Null
}
Stop-NetEventSession -Name 'Session1' -CimSession $Cim
Remove-NetEventProvider -Name $ETWProvider -CimSession $Cim
Remove-NetEventSession -Name 'Session1' -CimSession $Cim
Remove-CimSession -CimSession $Cim -Confirm:$False
if ($ComputerName -ne 'LocalHost')
{
Copy-Item -Path "\\$ComputerName\C$\Windows\Temp\$ComputerName-trace.etl" -Destination 'C:\Windows\Temp' -Force
}
Get-CimSession -ComputerName $ComputerName -ErrorAction SilentlyContinue | Remove-CimSession -Confirm:$False
if ($OpenWithMessageAnalyzer)
{
Start-Process -FilePath 'C:\Program Files\Microsoft Message Analyzer\MessageAnalyzer.exe' -ArgumentList "C:\Windows\Temp\$ComputerName-trace.etl"
}
else
{
Get-WinEvent -Path "C:\Windows\Temp\$ComputerName-trace.etl" -Oldest
}
}
}При запуске скрипта можно задать имя удаленной машины, поставщика событий, а при необходимости открыть трассировку в Microsoft Message Analyzer.
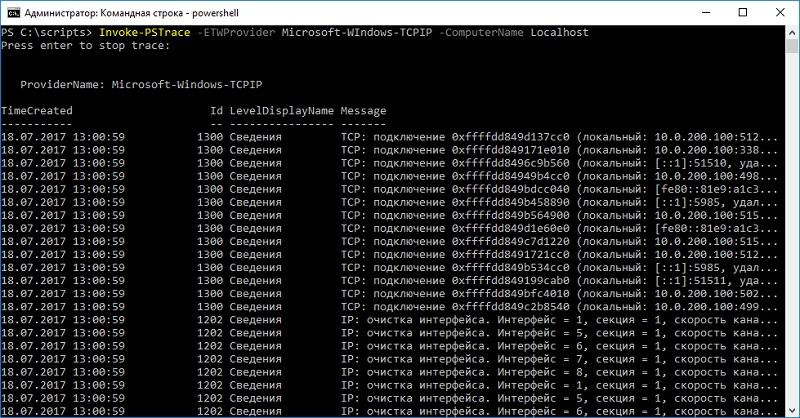
Пример работы скрипта.
Поскольку в PowerShell можно использовать инструментарий .NET, еще до появления набора командлетов NetEventPacketCapture в сообществе появился скрипт сниффера Get-Packet. Ознакомиться с одним из вариантов доработанного скрипта можно в блоге у автора, я же приведу пример его работы.
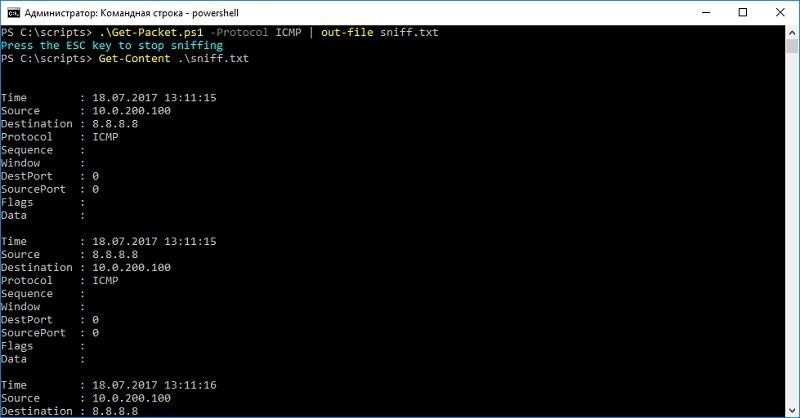
Пингуем и смотрим трафик скриптом PowerShell.
Из-за использования методов .NET работает значительно быстрее командлетов, но создать его «на коленке» и без доступа к интернету будет непросто. Тем не менее это неплохая альтернатива проприетарным программам.
Если вы также любите батники, как их люблю я, то можете заинтересоваться трассировкой без всяких PowerShell, средствами привычного netsh.exe. Помимо создания можно ещё и сконвертировать файл трассировки из формата .etl в удобные форматы вроде .txt и .html.
@echo off
rem запускаем трассировку
netsh trace start InternetClient provider=Microsoft-Windows-TCPIP level=5 tracefile=trace.etl > nul
rem ждем 5 секунд
timeout 5 > nul
rem останавливаем трассировку
netsh trace stop > nul
rem конвертируем файл .etl в удобный .txt, чтоб не открывать Microsoft Message Analyzer
netsh trace convert input=trace.etl output=trace.txt dump=txt > nul
rem посмотрим, кто у нас занимается RDP
type trace.txt | findstr "3389"
rem убираем временные файлы
del trace*
Результат работы скрипта.
Подробнее с синтаксисом netsh для сбора трассировки можно ознакомится в документации Microsoft.
С CMD самое большое неудобство в том, что без дополнительных утилит не так просто выполнить запуск скрипта, поэтому PsExec.exe или команду WMIC стоит держать под рукой:
wmic /user:"username" /password:"password" /node:"computer" process call create "sniffer.bat > log.txt"В качестве «домашнего задания» предлагаю читателям запустить сбор трассировки на файловом сервере или сервере печати с помощью поставщика событий Microsoft-Windows-SMBServer. Особенно интересные результаты выходят, если с сервером работают как клиенты SMB v1, так и SMB v2 и старше.
|
Метки: author Tri-Edge системное администрирование серверное администрирование powershell блог компании сервер молл скрипты снифферы |
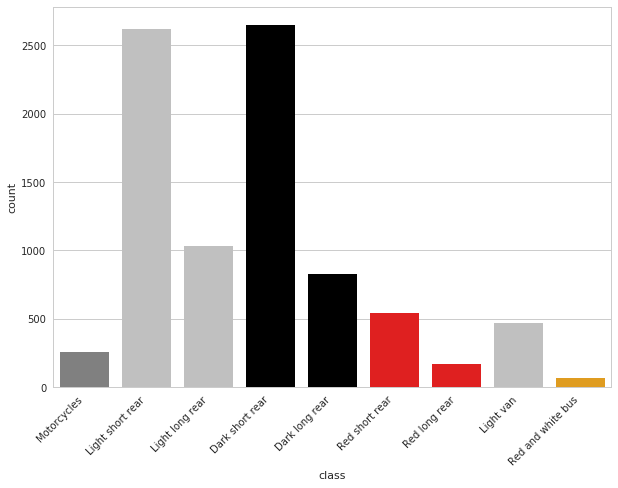
Отчёт Центра мониторинга информационной безопасности за II квартал 2017 года |
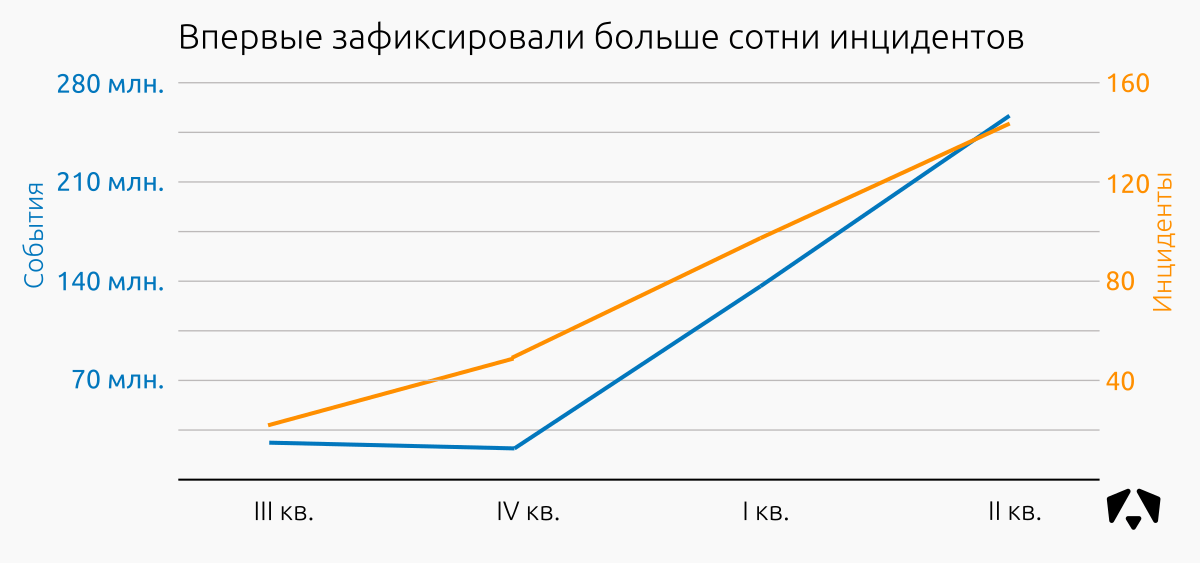
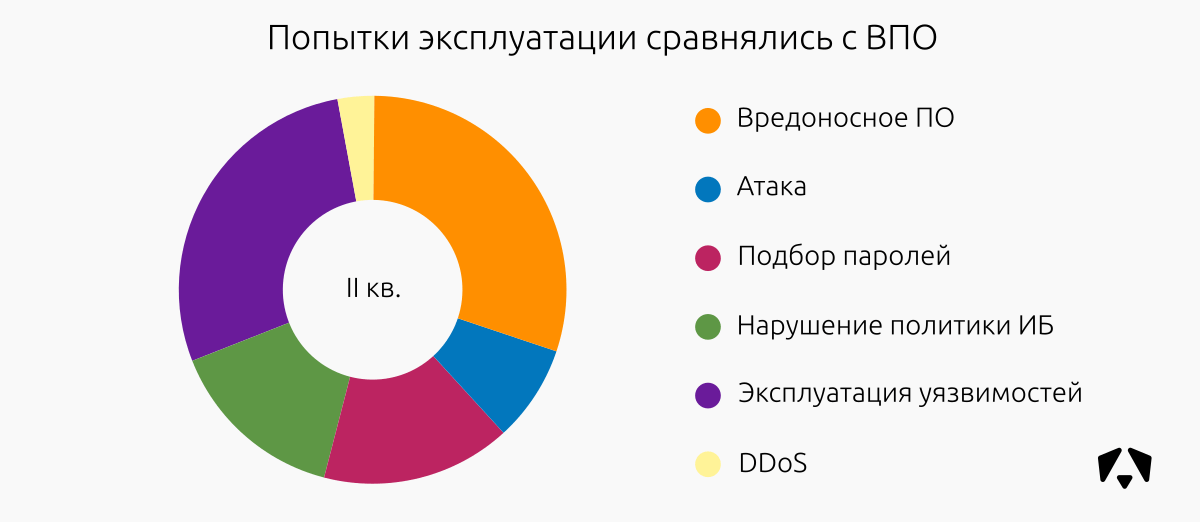
| Класс инцидента |
Высокая критичность |
Средняя критичность |
Низкая критичность |
Всего инцидентов |
Доля инцидентов |
|---|---|---|---|---|---|
| Вредоносное ПО |
8 |
21 |
14 |
43 |
30% |
| Атака |
4 |
5 |
3 |
12 |
8% |
| Подбор паролей |
11 |
8 |
4 |
23 |
16% |
| Нарушение политики ИБ |
2 |
6 |
13 |
21 |
15% |
| Эксплуатация уязвимостей |
12 |
21 |
7 |
40 |
28% |
| DDoS |
3 |
2 |
5 |
3% |
|
| Всего: |
40 |
63 |
41 |
144 |
100,0% |
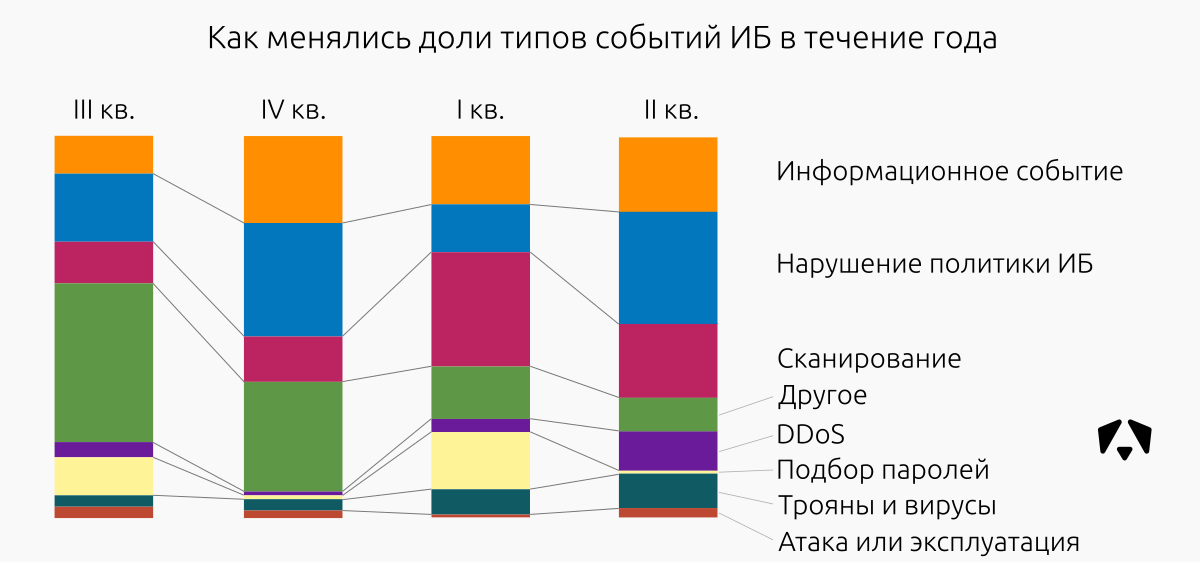
| Доля инцидентов, % | ||||
|---|---|---|---|---|
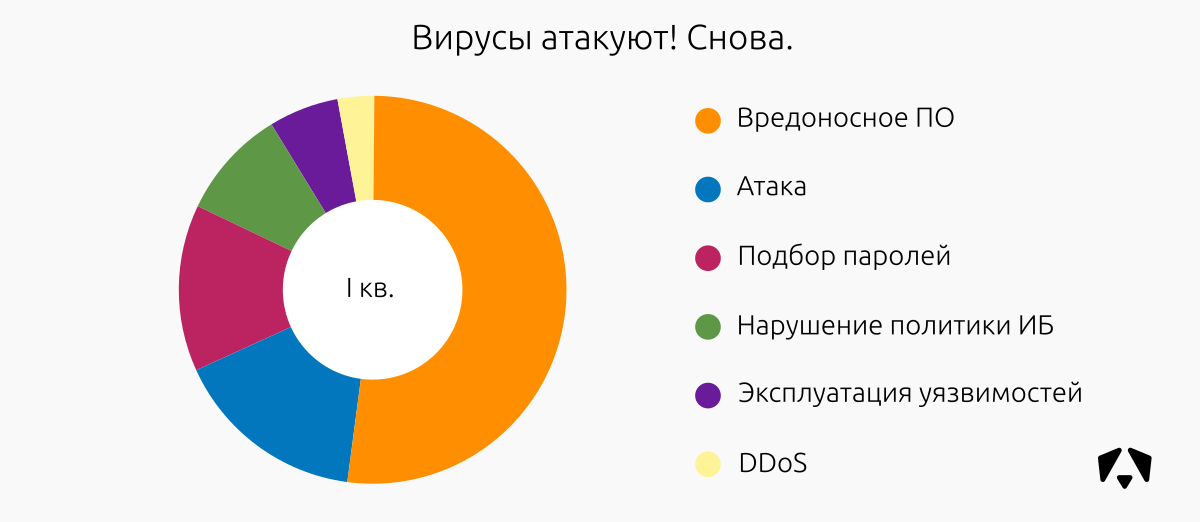
| Класс инцидента | III кв. 2016 | IV кв. 2016 | I кв. 2017 | II кв. 2017 |
| Вредоносное ПО | 42,8 | 51 | 52 | 30 |
| DDoS | 14,3 | 1,9 | 3 | 3 |
| Нарушение политики ИБ | 14,3 | 13,2 | 9 | 15 |
| Подбор паролей | 23,8 | 13,2 | 14 | 16 |
| Атака | 11,3 | 16 | 8 | |
| Эксплуатация уязвимостей | 4,8 | 9,4 | 6 | 28 |
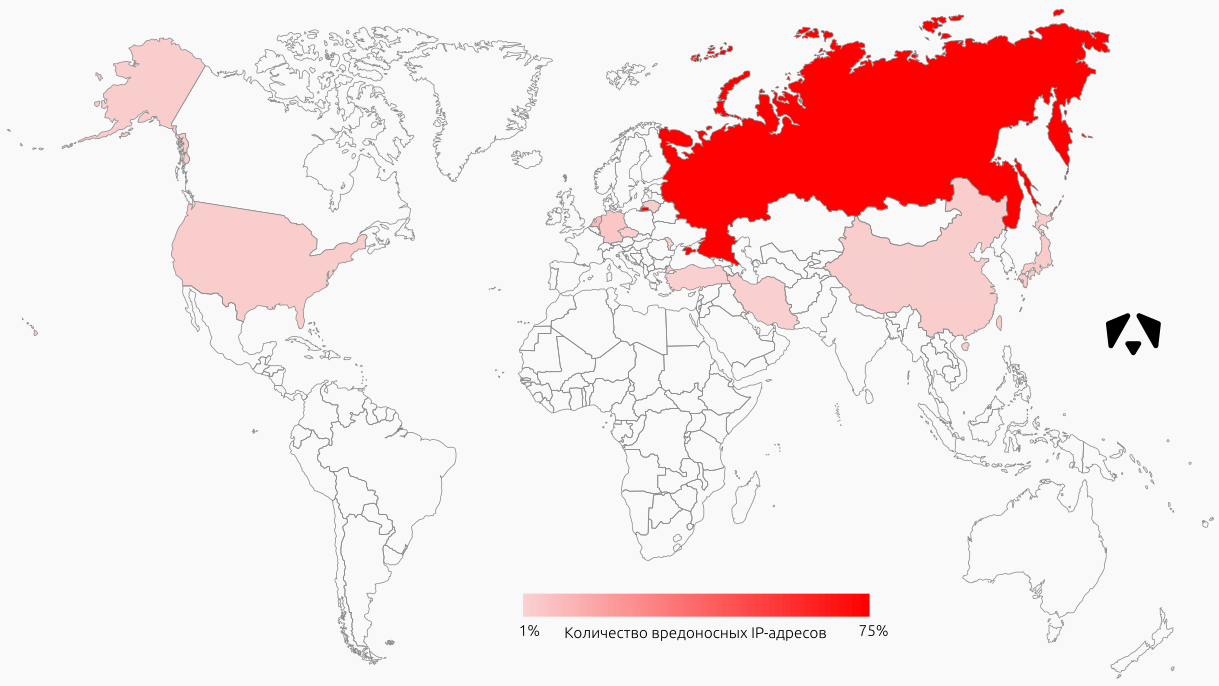
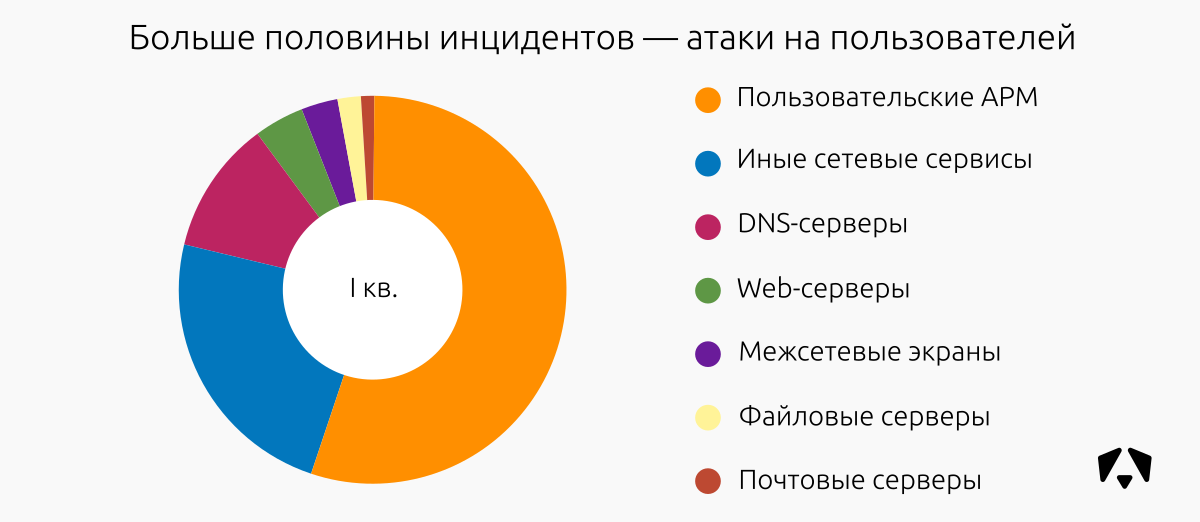
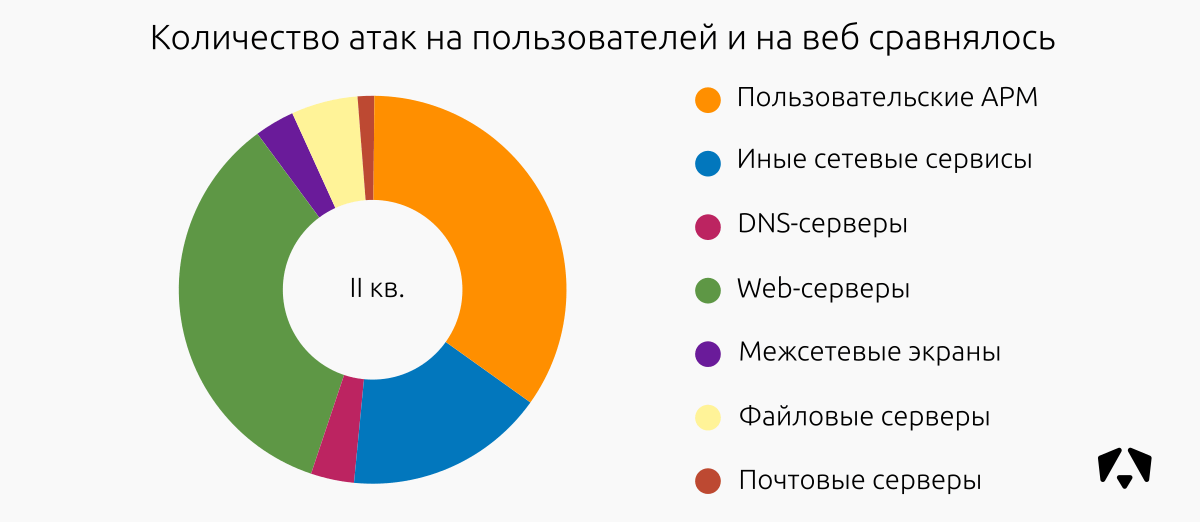
| Угроза | Техника воздействия |
|---|---|
| Подбор паролей | Попытки подбора аутентификационной информации для доступа к сервисам и ресурсам контролируемых организаций — RDP, SSH, SMB, DB, Web. |
| Нарушение политик ИБ | Нарушение пользователями/администраторами контролируемых ресурсов требований политик ИБ в части использования устаревших версий или недоверенного ПО. Данное ПО может быть использовано злоумышленником для атаки путём эксплуатации уязвимости. Также использование ресурсов компании для получения собственной выгоды (майнинг bitcoin/ethereum). Использование торрент-трекеров. |
| Вредоносное ПО | Заражение конечной системы, распространение вируса по локальной сети, отключение/блокировка служб, препятствующих распространению вируса, попытки проведения иных атак внутри сети для получения критичной информации и передачи на командные серверы. |
| Попытки эксплуатации уязвимостей | Использование недостатков в системе для нарушения КЦД и воздействие на правильную работу системы. Уязвимость может быть результатом ошибок программирования, недостатков, допущенных при проектировании системы, ошибки конфигурации, отсутствия обновлений. Некоторые уязвимости известны только теоретически, другие же активно используются и имеют известные эксплойты. |
|
|
[Перевод] Дизайн для пальцев, касаний и людей |











|
Метки: author NIX_Solutions интерфейсы дизайн мобильных приложений usability блог компании nix solutions дизайн интерфейс мобильное приложение |
Первенцы МЕГА Accelerator: год свободного полета |




|
Метки: author MEGA_Accelerator управление проектами управление e-commerce развитие стартапа бизнес-модели блог компании мега accelerator акселератор мега проект ритейл инновации |
Как подсознательно побудить сотрудников соблюдать дедлайны проекта |








|
Метки: author stannislav управление проектами управление продуктом agile дедлайны советы и рекомендации управление продуктами |
Как мы добавили RAM в серверы HPE |


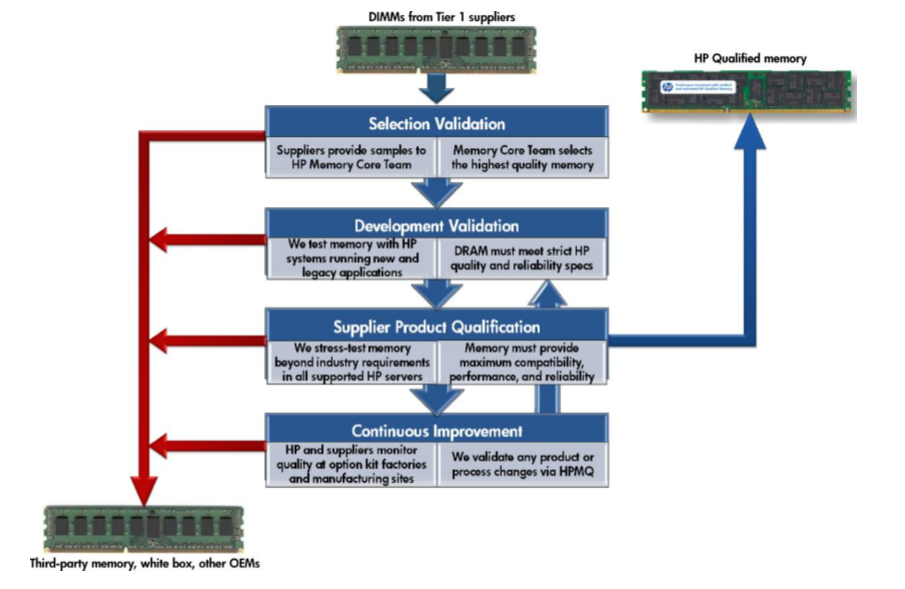
HP-validated memory is tested so that it does not get too hot and forget your data. HP-validated memory is tested so that it does not cause the system to shut-down due to power overload.

|
|
[Перевод] XBRL: просто о сложном - Глава 3. Анатомия таксономии |
Эта глава с названием как у песни рок-группы 60-х годов описывает структуру таксономии XBRL. Больше внимания уделяется тому, что можно сделать с помощью таксономий, и меньше - тому, как это делается с технической точки зрения. Мы оставим этот уровень детализации для другой главы.
Начнем вот с чего: то, что мы называем таксономией, на самом деле представляет собой, как правило, целый набор связанных документов, называемых Связанным комплексом таксономий (Discoverable Taxonomy Set), для краткости - DTS.
Отправной точкой DTS является Схема таксономии. Это документ, на который ссылается отчет XBRL. Эта схема таксономии может ссылаться на другие документы, которые в свою очередь могут также ссылаться на другие документы и т.д.
Чтение DTS подразумевает переход по всем ссылкам до тех пор, пока не будут прочитаны все из связанных документов.
Таксономия может ссылаться на два типа документов:
Схематически это можно изобразить следующим образом:
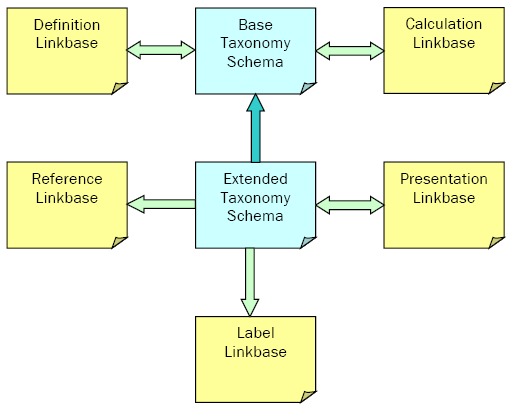
Обратите внимание, что некоторые базы ссылок (Reference и Label) являются однонаправленными, т.е. ссылка ведет от таксономии к ресурсам базы ссылок. Другие базы ссылок (Definition, Calculation и Presentation) являются двунаправленными. Ссылки указывают от одной части таксономии к другой части.
Если необходимо, таксономия также ссылается на схему отчета XBRL «xbrl-instance-2003-12-31.xsd» (или, правильней сказать, импортирует ее) - она содержит базовые элементы, необходимые для определения всех концептов.
Это примеры технических подробностей, которые я буду игнорировать для большей части этой книги. Я просто предполагаю, что, например, схема таксономии существует в некотором контексте (в данном случае это схема отчета XBRL), и фокусируюсь на более функциональных аспектах XBRL.
Остальная часть этой главы будет описывать каждый тип документа более подробно.
Ядро таксономии – это ее схема, которая является обязательным документом. Эта схема, о которой мы все это время говорим, на самом деле представляет собой документ XML Schema (стандарт W3C, позволяющий определять структуру XML-документов). Спецификация XBRL использует XML Schema в качестве базового языка для описания таксономий. Поверх этого базового языка она определяет набор специфичных для XBRL дополнений и ограничений.
В рамках схемы таксономии можно:
Спецификация XBRL содержит ряд требований и рекомендаций по определению концептов:
Это означает, что каждый концепт должен иметь атрибут substitution group со значениемxbrli:itemилиxbrli:tuple
XML Schema предоставляет несколько способов улучшить определение концептов:
Кроме того, XBRL определяет для концептов атрибуты periodType и balance:
periodType необходим для item-концептов (xbrli:item). Он позволяет отделить концепты, измеряемые по состоянию на определенную дату, от концептов, измеряемых за период времени;В отчете XBRL факты указываются в определенном контексте. АтрибутperiodTypeконцепта, по которому передается факт, должен соответствовать типу периода в контексте факта.
balance, указывающий, определяет ли концепт дебетовое либо кредитовое значение. Это очень удобно для концептов бухгалтерского учета, как напр. активы, обязательства, доходы и расходы.Концепты могут быть расширены, образуя струкрутированное дерево концептов. Примером может служить концепт «менеджер», который расширяется на «менеджер бизнес-единицы» и «менеджер подразделения».
Поскольку в отчете XBRL могут быть указаны только факты по не абстрактным концептам, можно предотвратить передачу излишних фактов. В приведенном выше примере можно разрешать передачу фактов по концептам «менеджер бизнес-единицы» и «менеджер подразделения», но не по концепту «менеджер». Это возможно определением концепта «менеджер» как абстрактного.
Для всех item-концептов должен быть указан тип передаваемых данных. Доступные типы данных определяются стандартом XML Schema и спецификацией XBRL.
XML Schema включает в себя следующие типы: логический (boolean), текстовый (text), десятичный (decimal), дата (date), части дат и т.д. (полный список можно найти в разделе 5.1.1.3 спецификации XBRL).
Примечание: для каждого типа из XML Schema имеется соответствующее определение типа XBRL.
Спецификация XBRL добавляет следующие типы данных:
Схема таксономии может содержать, и как правило содержит ссылки на Базы ссылок, предоставляющие дополнительную информацию о концептах таксономии.
Ссылка может указывать на определенный вид Базы ссылок путем определения роли. Спецификация XBRL допускает следующие роли:
Примечание: Для сносок не создается отдельных баз ссылок. Эта роль используется только в пределах отчета XBRL.
Также, возможно определить пользовательские роли, что является еще одним примером расширяемости XBRL.
Чтобы еще больше ограничить использование базы ссылок, можно определить тип фактов, на который могут указывать типы ссылок в базе.
Для идентификации различных типов связей внутри баз ссылок используются роли. Спецификация XBRL определяет одну базовую роль, чтобы гарантировать, что роль есть у всех ссылок. Тем не менее, автор таксономии или базы ссылок обычно определяет свои дополнительные роли. Они используются для группировки ссылок в так называемые базовые наборы (base sets). Такая сегментация может быть полезна, например, для определения различных разделов отчета при использовании презентационной базы ссылок. В базе вычислений они необходимы для всех вычислений кроме самых примитивных, чтобы предотвратить ошибки из-за смешивания связей.
Связи, которые определяются дугами, типизируются ролями дуг (arcroles). Основные дуги, такие как «concept-label» или «summation-item» предопределены спецификацией XBRL. Также, возможно определить собственные дуги. Но используется это обычно для технических целей, напр. для определения новых связей в расширении спецификации XBRL. Примером этого могут служить дуги, определенные в спецификации XBRL Dimensions, о которой мы поговорим в Главе 5.
Вернемся к примеру «таксономии»:
Здесь мы можем приблизительно определить следующие концепты:
Имя Тип nr_employees_total non-negative integer item nr_employees_male non-negative integer item nr_employees_female non-negative integer item nr_employees_age_up_to_20 non-negative integer item nr_employees_age_21_to_40 non-negative integer item nr_employees_age_41_and_up non-negative integer item
Мы рассмотрим эти концепты в следующем разделе про базы ссылок.
Определенные в схеме таксономии концепты являются минимально необходимыми строительными блоками таксономии. Они содержат точные данные о том, какие факты могут быть переданы в составе отчета XBRL.
Базы ссылок расширяют это определение следующим образом:
Давайте сначала рассмотрим некоторые возможные базы ссылок для «таксономии» из нашего примера, чтобы понять, что они из себя представляют.
Примечание: Приведенные здесь «базы ссылок» не являются полными или корректными. Они приведены просто для иллюстрации.
База ссылок ярлыков (label linkbase)
База ссылок ярлыков может присвоить русский ярлык каждому используемому в форме концепту:
Концепт Ярлык nr_employees_total Всего nr_employees_male Мужчины nr_employees_female Женщины
Другая база ссылок ярлыков может использоваться для присвоения английских ярлыков концептам:
Концепт Ярлык nr_employees_total Total nr_employees_male Men nr_employees_female Women
Примечание: Этот пример базы ссылок ярлыков не совсем корректен. Мы вернемся к нему позже.
База ссылок определений (definition linkbase)
Определения концептов предоставляют различного рода информацию. Например, о том, что определенный концепт требует обязательного наличия другого концепта:
Концепт Требует nr_employees_male nr_employees_female nr_employees_female nr_employees_male
Если вы указываете факт по количеству мужчин, вы также должны указать факт по количеству женщин, и наоборот.
Если бы был определен концепт nr_employees, база ссылок определений могла бы указать, что он является аналогом всех nr_employees… концептов:
Концепт Псевдоним nr_employees nr_employees_total nr_employees nr_employees_male nr_employees nr_employees_female
База ссылок вычислений (calculation linkbase)
C помощью вычисления можно задавать такие правила:
- nr_employees_male + nr_employees_female = nr_employees_total
Такое правило автоматически отловило бы арифметическую ошибку в заполненной форме.
База ссылок на ресурсы (reference linkbase)
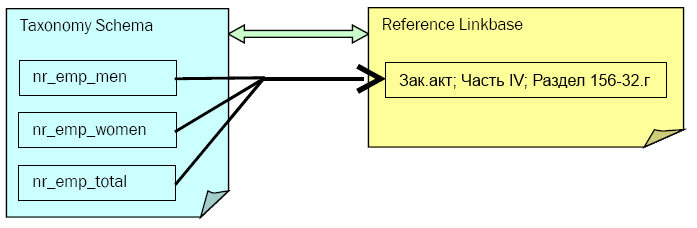
Предположим, что таксономия описывает отчет, требуемый законодательством. Полное описание того, что именно требуется предоставить, детально указано в законодательном акте, напр. как именно отчитываться по сотрудникам с частичной занятостью. База ссылок на ресурсы позволяет связать концепт с соответствующим ему разделом законодательного акта:
Концепт Ресурс nr_employees_total Законодательный акт; Часть IV; Раздел 156-32.г nr_employees_male Законодательный акт; Часть IV; Раздел 156-32.г nr_employees_female Законодательный акт; Часть IV; Раздел 156-32.г
Примечание: Это можно выразить и связью «многие-к-одному», рассмотрим это далее.
База ссылок на презентаций (presentation linkbase)
Презентации описывают, как концепты могут быть иерархически представлены в отчетной форме. Наш пример мог бы иметь следующую иерархию:
Концепт Нижний уровень иерархии nr_employees_total nr_employees_male nr_employees_total nr_employees_female
Когда вы начнете углубляться в базы ссылок, вы увидите, что они обладают множеством общих характеристик. Рассмотрим некоторые из них.
Все базы ссылок используют дуги для описания взаимосвязей между концептами и их ресурсами или между разными концептами. Дуга представляет собой двустороннюю направленную связь, т.е. она указывает от одной стороны к другой. Каждая из сторон может состоять из одного или нескольких концептов или ресурсов.
В нашем примере базы ссылок на ресурсы мы можем использовать дугу вида «многие-к-одному», чтобы связать все три концепта одной ссылкой:
Атрибуты дугиfromиtoмогут быть ресурсами, включенными в расширенную ссылку (extended link), или локаторами (locators) в расширенной ссылке, которые указывают на концепты или ресурсы в других документах.
Локатор указывает на концепт или ресурс с помощью атрибутаhref, который может содержатьidконцепта или выражение стандарта XPointer.
Когда таксономия расширяется, может потребоваться изменить существующие взаимосвязи между концептами. Для этого существует два механизма – запрет (prohibiting) и переопределение (overriding).
Дуга может иметь атрибут «приоритет». Когда у нескольких дуг случается «конфликт», преобладает та, что имеет наивысший приоритет, фактически переопределяя остальные дуги.
Если существующая дуга больше недействительна, можно добавить запрещающую дугу в свою базу ссылок с более высоким приоритетом, чем существующая. Запрещающей дугой является та, у которой необязательный атрибут use имеет значение prohibit.
При применении правил запрета и переопределения «базовая» сеть взаимосвязей изменяется расширениями. С использованием приоритета могут быть добавлены новые взаимосвязи, удалены существующие, либо существующие заменены новыми.
Спецификация XBRL указывает, что правила применяются к эквивалентным отношениям, и точно определяет, когда отношения эквивалентны на основе атрибутов дуг и сторон «от» и «к».
Дуги образуют сеть взаимосвязей. Сеть может становиться очень сложной. Циклы внутри сети возникают, когда есть два или более путей от одного узла к другому. Таксономия должна указывать, какие из циклов разрешены:
Примечание: Путь состоит из набора дуг между узлами. Путь может быть коротким (одна дуга между двумя узлами) или длинным (сотни дуг между сотнями узлов).
Каждая ссылка в базе ссылок может иметь одну из нескольких ролей. Роль определяет использование ссылки. Доступные роли зависят от типа базы ссылок, они описаны в следующем разделе.
Как было сказано ранее, спецификация XBRL предоставляет набор ролей «общего назначения» для каждого типа базы ссылок. Вместо них возможно определить свои, более специфичные роли.
Роли могут быть использованы в ресурсах и в дугах между ними.
Хотя разные базы ссылок выглядят очень похожими по структуре, в них есть и различия. В этом разделе описываются характеристики, специфичные для каждого из типов баз ссылок.
Ярлыки предоставляют человекочитаемый текст на определенном языке. Каждый ресурс должен идентифицировать используемый в ярлыке язык.
Ярлыки могут иметь следующие роли:
label (роль по умолчанию) – используется для стандартных ярлыков;terseLabel – используется для сокращенных ярлыков, где часть описания опущена;verboseLabel – используется для расширенных меток, подробно описывающих концепт;positiveLabel, positiveTerseLabel и positiveVerboseLabel – стандартный, сокращенный и расширенный ярлыки, используемые для положительного значения факта;negativeLabel, negativeTerseLabel и negativeVerboseLabel – стандартный, сокращенный и расширенный ярлыки, используемые для отрицательного значения факта;zeroLabel, zeroTerseLabel и zeroVerboseLabel – стандартный, сокращенный и расширенный ярлыки, используемые для нулевого значения факта;totalLabel – используется для ярлыков концептов, определяющих итоговые значения;periodStartLabel и periodEndLabel – используются для ярлыков концептов, определяющих факты, ассоциированные с началом или окончанием периода;documentation – для ярлыков, предоставляющих документацию по концепту;definitionGuidance, disclosureGuidance, presentationGuidance, measurementGuidance, commentaryGuidance и exampleGuidance – для ярлыков, которые дают пояснения по таким аспектам концепта как определение, способ измерения или пример заполнения.Дуга ярлыков имеет роль «concept-label», которая означает, что она всегда указывает от концепта к ярлыку. Поэтому дуги ярлыков никогда не образуют циклических связей между концептами.
Учитывая все вышесказанное, теперь мы можем более точно определить базу ссылок ярлыков из нашего примера:
Концепт Язык Роль Ярлык nr_employees_total ru totalLabel Всего nr_employees_male ru terseLabel Мужчины nr_employees_female ru terseLabel Женщины nr_employees_total en totalLabel Total nr_employees_male en terseLabel Men nr_employees_female en terseLabel Women
Ссылки дают возможность связать определения концептов с положениями, опубликованными в деловой, финансовой и бухгалтерской литературе. Элемент должен предоставлять только ту информацию, которая необходима для идентификации и поиска соответствующей публикации. Он никогда не должен содержать текст самой публикации.
Ссылки могут состоять из частей (part), напр. «Законодательный акт; Часть IV; Раздел 156-32.г». В спецификации XBRL элемент part является абстрактным, поскольку способ разделения публикации на части варьируется для каждой публикации / юрисдикции.
Ссылки могут иметь следующие роли:
reference (значение по умолчанию) – используется для стандартного ресурса концепта;definitionRef – используется для ссылки на точное определение концепта;disclosureRef, mandatoryDisclosureRef и recommendedDisclosureRef – используются для ссылки на объяснения требований к раскрытию;unspecifiedDisclosureRef – используется для ссылки на объяснения не указанных требований к раскрытию, таких как общая практика, полнота и структура;presentationRef – используется для ссылки на объяснение презентации концепта;measurementRef – используется для ссылки на метод измерения значения концепта;commentaryRef – используется для ссылки на любой комментарий общего плана к концепту;exampleRef – используется для ссылки на документацию, иллюстрирующую использование концепта с помощью примера.Дуга ресурсов имеет роль «concept-reference», которая означает, что она всегда указывает от концепта к ресурсу. Поэтому дуги ресурсов никогда не образуют циклических связей между концептами.
Дуги презентаций имеют роль «parent-child», что позволяет определять иерархическую структуру концептов. И parent-, и child-сторона связи должна указывать на концепт.
Когда нет концепта, который мог бы естественным образом выступать в качестве корня иерархии презентации, вместо него можно использовать абстрактный концепт, специально определенный для этой цели.
Дуга может иметь атрибут preferredLabel, который идентифицирует предпочтительную роль метки для указания на child-концепте презентации. Это особенно полезно, когда концепт используется несколько раз по-разному в DTS. Каждая связь в презентации может указывать на отдельную метку (в соответствии с ее ролью) для использования по этому концепту.
Для определения порядка следования концептов в презентации может использоваться атрибут дуги order.
Дуги вычислений имеют роль «summation-item», представляющую суммирующие взаимосвязи между концептами (вычитание в этом случае обеспечивается суммированием концепта, умноженного на -1, см.далее). Связь указывает от суммирующего концепта к нескольким суммируемым концептам. Дуга вычислений может соединять только item-концепты.
Вычисления возможны только по концептам, эквивалентным по контексту и единице измерения.
Примечание: Отношения, заданные кортежами, также играют роль в вычислениях. Например, невозможно выполнять суммирование по элементам дублирующихся кортежей.
Дуга вычисления имеет атрибут weight, который используется как коэффициент умножения для суммируемого значения. Это позволяет осуществлять более сложные вычисления, чем простое сложение. В момент умножения выполняется необходимое округление.
В DTS учитывается полная совокупность вычислений. Все вычисления с одной и той же ролью по одному и тому же концепту будут выполнены в полном объёме. Если в одном отчете присутствует несколько детализаций одного и того же значения, каждое из его вычислений должно иметь свою собственную роль. В противном случае все вычисления будут суммированы вместе, что приведет к задвоению, затроению и т.д. результирующего значения.
Отчет XBRL считается корректным относительно базы ссылок вычислений, если все вычисления в пределах этого отчета согласованы. Это позволяет выполнять автоматическую проверку вычислений.
Возможности, предоставляемые базой ссылок вычислений, достаточно ограничены.
Можно выполнять более сложные вычисления, чем простое сложение, но это непросто, и даже в этом случае ограничения являются довольно серьезными. Например, невозможно вычислить разницу между фактами по одному и тому же концепту, но в разных контекстах, скажем, на начало и на конец периода.
В настоящее время разрабатывается еще одна база ссылок – формулы (formula linkbase). Она станет доступна для использования в ближайшее время и обеспечит более широкие функциональные возможности для определения формул расчета.
Дуга определений может иметь следующие роли, обозначающие разные виды взаимосвязей:
general-specialessence-aliassimilar-tuplesessence-alias для item-концептов – она идентифицирует кортежи с эквивалентными определениями. Примером может служить почтовый адрес, который может отражаться в разных форматах, но содержать эквивалентные данные.requires-element|
Метки: author r_udaltsov it- стандарты xbrl финансы отчетность цб рф |
Microsoft Bot Framework на Linux под Node.JS |
curl -sL https://deb.nodesource.com/setup_8.x | sudo -E bash -
sudo apt-get install -y nodejs
sudo apt-get install -y build-essentialarchbotframework-emulator-3.5.29-x86_64.AppImageCtrl-`. Набираем команду для создания нового проекта:npm initEnter потом yes. Теперь устанавливаем 2 пакета node.js: botbuilder и restify командами:npm install --save botbuilder
npm install --save restifyvar restify = require('restify');
var builder = require('botbuilder');
// Setup Restify Server
var server = restify.createServer();
server.listen(process.env.port || process.env.PORT || 3978, function () {
console.log('%s listening to %s', server.name, server.url);
});
// Create chat connector for communicating with the Bot Framework Service
var connector = new builder.ChatConnector({
appId: process.env.MICROSOFT_APP_ID,
appPassword: process.env.MICROSOFT_APP_PASSWORD
});
// Listen for messages from users
server.post('/api/messages', connector.listen());
// Receive messages from the user and respond by echoing each message back (prefixed with 'You said:')
var bot = new builder.UniversalBot(connector, function (session) {
session.send("You said: %s", session.message.text);
});
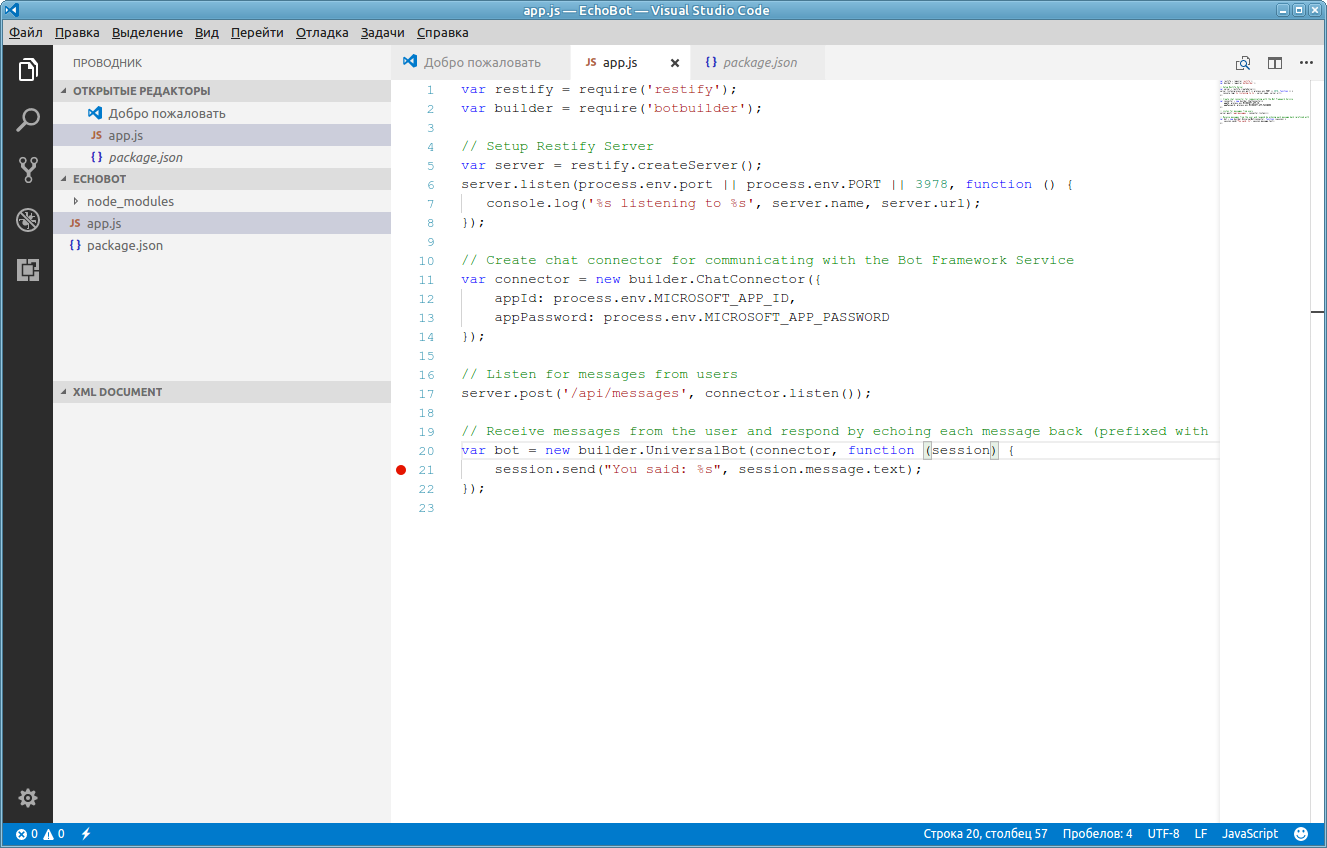
node app.jsF5. Для установки точки останова подводим курсор к нужной строке и нажимаем — F9. После запуска бота возвращаемся в эмулятор, подсоединяемся к адресу http://127.0.0.1:3978/api/messages и набираем: Hi и видим ответ нашего бота:
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Tantrido разработка под linux visual studio node.js microsoft bot framework npm visual studio code .net core c# |
Байки из Lab’а |

 Прямой предок нашего основного защитного решения для домашних пользователей — программа AVP, которую Евгений Валентинович делал задолго до создания компании. Программа уже давно не выпускается, но нам до сих пор периодически задают вопрос, почему Antivirus Toolkit Pro сокращался как AVP, а не ATP (как это было бы логично).
Прямой предок нашего основного защитного решения для домашних пользователей — программа AVP, которую Евгений Валентинович делал задолго до создания компании. Программа уже давно не выпускается, но нам до сих пор периодически задают вопрос, почему Antivirus Toolkit Pro сокращался как AVP, а не ATP (как это было бы логично).  До сих пор одна из первых ассоциаций с нашими защитными продуктами — визг свиньи, которым «Антивирус Касперского» оповещал о найденной угрозе. Интернет тогда был медленный, поэтому оставить компьютер включенным на всю ночь было совершенно нормально. И вот лежишь ты, на часах 4.00 ночи, и тут из колонок визг. Да и днем внезапное «уи-и-и-и-и» вполне могло заставить заикаться. Сразу после релиза нам стали приходить гневные письма с требованиями убрать визг. И мы его убрали. К слову, в 8-й версии продукта он был выключен по дефолту, а с 13-й был убран совсем.
До сих пор одна из первых ассоциаций с нашими защитными продуктами — визг свиньи, которым «Антивирус Касперского» оповещал о найденной угрозе. Интернет тогда был медленный, поэтому оставить компьютер включенным на всю ночь было совершенно нормально. И вот лежишь ты, на часах 4.00 ночи, и тут из колонок визг. Да и днем внезапное «уи-и-и-и-и» вполне могло заставить заикаться. Сразу после релиза нам стали приходить гневные письма с требованиями убрать визг. И мы его убрали. К слову, в 8-й версии продукта он был выключен по дефолту, а с 13-й был убран совсем.  В 2016 году Евгений Валентинович встречался с Папой Римским. В силу ряда причин в качестве подарка понтифику он решил привезти такую полезную вещь, как арифмометр. Рассматривались несколько моделей. Одна из них была привезена в офис накануне поездки, и внезапно выяснилось, что на этой вычислительной машине никто не работал последние полвека как минимум. Что делать? Техсаппорт такое не поддерживает. Вспомнили, что в административно-хозяйственном управлении есть машинное масло для дверей.
В 2016 году Евгений Валентинович встречался с Папой Римским. В силу ряда причин в качестве подарка понтифику он решил привезти такую полезную вещь, как арифмометр. Рассматривались несколько моделей. Одна из них была привезена в офис накануне поездки, и внезапно выяснилось, что на этой вычислительной машине никто не работал последние полвека как минимум. Что делать? Техсаппорт такое не поддерживает. Вспомнили, что в административно-хозяйственном управлении есть машинное масло для дверей.  Последние несколько лет мы серьезно занимаемся промышленной кибербезопасностью. Для того чтобы наглядно продемонстрировать уязвимость промышленных контроллеров, мы собираем стенды — модели гипотетических технологических процессов, построенные на самом настоящем промышленном оборудовании. Обычно мы возим их на тематические конференции и выставки. На самом деле мы перепробовали несколько вариантов. И знаете, какой из них оказался наиболее наглядным?
Последние несколько лет мы серьезно занимаемся промышленной кибербезопасностью. Для того чтобы наглядно продемонстрировать уязвимость промышленных контроллеров, мы собираем стенды — модели гипотетических технологических процессов, построенные на самом настоящем промышленном оборудовании. Обычно мы возим их на тематические конференции и выставки. На самом деле мы перепробовали несколько вариантов. И знаете, какой из них оказался наиболее наглядным? |
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» kaspersky lab fun anniversary |
[Перевод] Копируем человеческий мозг: операция «Свертка» |
Чему уже научились сверточные искусственные нейронные сети (ИНС) и как они устроены?
Такие статьи принято начинать с экскурса в историю, дабы описать кто придумал первые ИНС, как они устроены и налить прочую, бесполезную, по большей части, воду. Скучно. Опустим это. Скорее всего вы представляете, хотя бы образно, как устроены простейшие ИНС. Давайте договоримся рассматривать классические нейронные сети (типа перцептрона), в которых есть только нейроны и связи, как черный ящик, у которого есть вход и выход, и который можно натренировать воспроизводить результат некой функции. Нам не важна архитектура этого ящика, она может быть очень разной для разных случаев. Задачи, которые они решают — это регрессия и классификация.
Что же такого произошло в последние годы, что вызвало бурное развитие ИНС?
Ответ очевиден — это технический прогресс и доступность вычислительных мощностей.
Приведу простой и очень наглядный пример:
2002:

Earth Simulator – один из самых быстрых в мире вычислительных комплексов. Он был построен в 2002 году. До 2004 года эта машина оставалась самым мощным вычислительным устройством в мире.
Стоимость: $350.000.000.
Площадь: четыре теннисных корта,
Производительность: 35600 гигафлопс.
2015:

NVIDIA Tesla M40/M4: GPU для нейронных сетей
Стоимость: $5000
Площадь: помещается в карман,
Производительность: До 2,2 Терафлопс производительности в операциях с одинарной точностью с NVIDIA GPU Boost
Итогом такого бурного роста производительности стала общедоступность ресурсоемких математических операций, что позволило испытать давно зародившиеся теории на практике.
Одной из ресурсоемких в реализации теорий, а точнее методом, который требует очень больших мощностей, является операция свертки.
Что же это такое?
Попробуем разложить всё по полочкам:
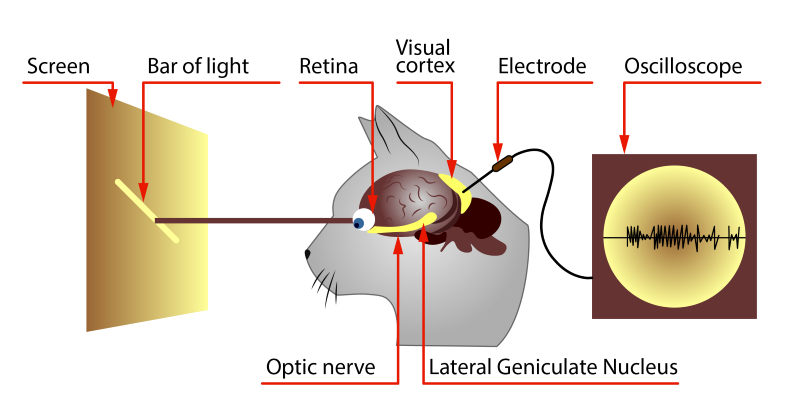
Экспериментируя на животных, David Hubel и Torsten Wiesel выяснили, что одинаковые фрагменты изображения, простейшие формы, активируют одинаковые участки мозга. Другими словами, когда котик видит кружочек, то у него активируется зона “А”, когда квадратик, то “Б”. И это сподвигло ученых написать работу, в которой они изложили свои идеи по принципам работы зрения, а затем они это подтвердили опытами:
Вывод был примерно такой:
В мозгу животных существует область нейронов, которая реагирует на наличие определенной особенности у изображения. Т.е. перед тем как изображение попадает в глубины мозга, оно проходит так называемый фича-экстрактор.

Графические редакторы давно используют математику для изменения стиля изображения, но как оказалось, те же самые принципы можно применить и в области распознавания образов.
Если мы рассмотрим картинку как двумерный массив точек, каждую точку — как набор значений RGB, а каждое значение — это просто 8-ми битовое число, то получим вполне себе классическую матрицу. Теперь возьмем и придумаем свою, назовем её Kernel, матрицу, и будет она такой:

Попробуем пройтись по всем позициям, от начала и до конца матрицы изображения и перемножить наш Kernel на участок с таким же размером, а результаты сформируют выходную матрицу.
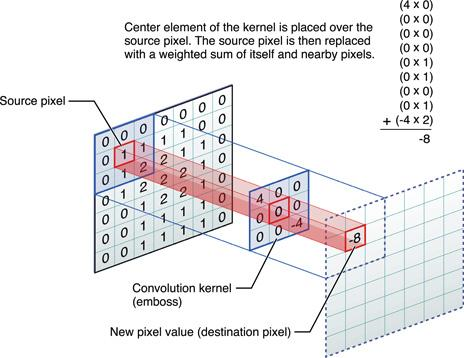
Вот что мы получим:

Взглянув на секцию Edge Detection мы увидим, что результатом являются грани, т.е. мы легко можем подобрать такие Kernel, которые на выходе будут определять линии и дуги разной направленности. И это именно то что нам нужно — фичи изображения первого уровня. Соответственно, можно предположить, что применив те же действия еще раз, мы получим комбинации фич первого уровня — фичи второго уровня (кривые, окружности и т.п.) и это можно было бы повторять очень много раз, если бы мы не были ограничены в ресурсах.
Вот пример наборов Kernel матриц:


А вот так выглядит фича-экстрактор от слоя к слою. На пятом слое уже формируются очень сложные фичи, например глаза, образы животных и прочего вида объекты, на которые и натренирован экстрактор.

Сначала разработчики пытались сами подобрать Kernel, но вскоре выяснилось, что его можно получить обучением, и это намного эффективнее.
Поняв, как работают мозги котов и как применить математический аппарат, мы решили создать свой фича-экстрактор! Но… подумав сколько фич нужно извлекать, сколько уровней извлечения нам надо и, прикинув, что для нахождения сложных образов мы должны анализировать сочетания фич “каждая с каждой” мы поняли, что памяти для хранения этого всего нам точно не хватит.
На помощь вновь пришли математики и придумали операцию объединения (pooling).
Суть ее проста — если в определенной области присутствует фича высокого уровня, то можно откинуть другие.

Такая операция не только помогает экономить память, но и избавляет от мусора и шумов на изображении.
На практике чередуют слои свертки и объединения несколько раз.
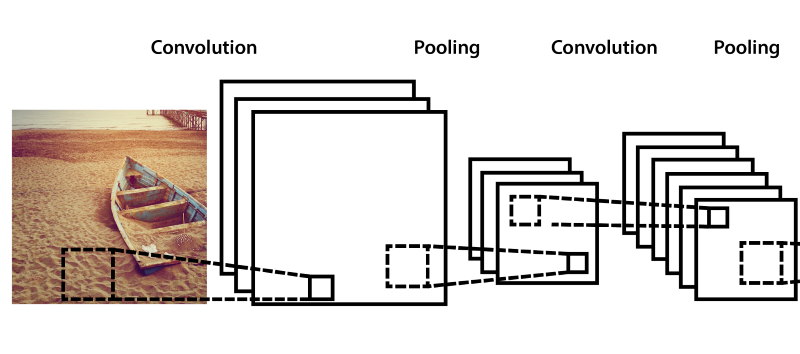
Применив всё, что описано выше, можно получить вполне рабочую архитектуру фиче-экстрактора, не хуже, чем у кошки в голове, более того, в настоящее время точность распознавания компьютерного зрения достигает в отдельных случаях >98%, а, как подсчитали ученые, точность распознавания образа человеком составляет в среднем 97%. Будущее пришло, Скайнет наступает!
Вот примеры нескольких схем реальных фича-экстракторов:
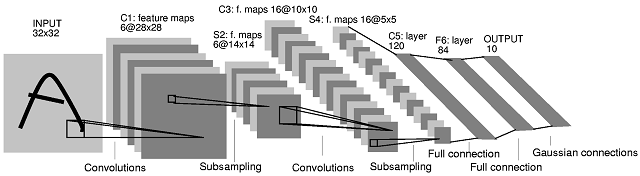

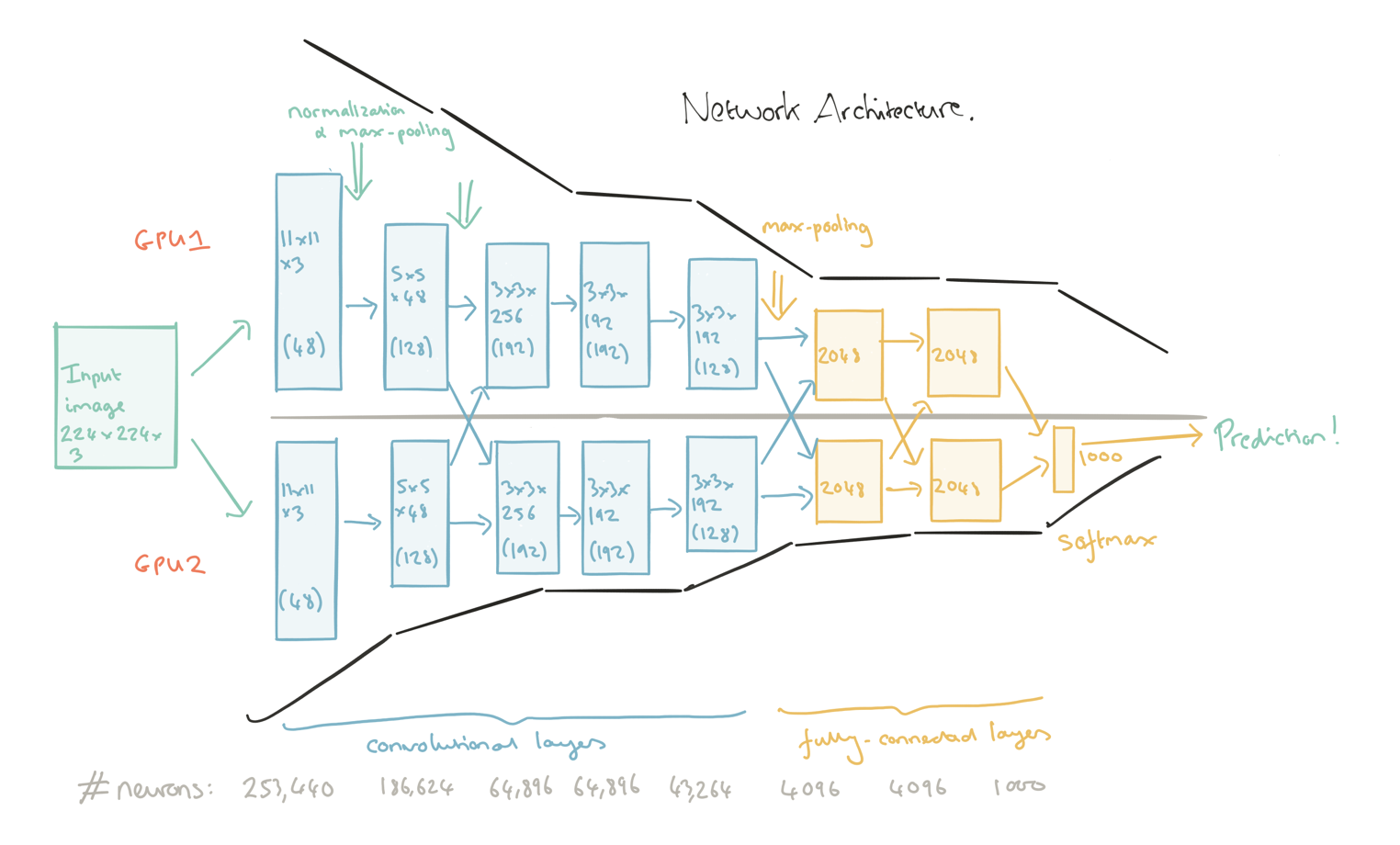
Как вы видите, на каждой схеме в конце присутствуют еще 2-3 слоя нейронов. Они не являются частью экстрактора, они — наш черный ящик из предисловия. Только вот на вход ящика при распознавании, подаются не просто цвета пикселей, как в простейших сетях, а факт наличия сложной фичи, на которую тренировали экстрактор. Ну вам же тоже проще определить что перед вами, например, лицо человека, если вы видите нос, глаза, уши, волосы, чем если бы вам назвали по отдельности цвет каждого пикселя?
Это видео просто шикарно демонстрирует как работают фича-экстракторы:
Свободная программная библиотека для машинного обучения.
Практически всё, что делает сервисы Google такими умными использует эту библиотеку.
Пример того, что дает Inception-v3 (классификатор изображений от Google, построенный на Tensorflow) и натренированный на ImageNet наборе изображений:

Компания Microsoft пошла другой дорогой, она предоставляет готовые API, как за деньги, так и бесплатно, с целью ознакомления, но лимитируя количество запросов. API — очень обширные, решают десятки задач. Это всё можно попробовать прямо на их сайте.
Можно, конечно, использовать MSCT так же как и TF, там даже синтаксис и идея очень похожи, оба описывают графы с заглушками, но ведь зачем тратить время, когда можно использовать уже обученные модели?
Открытая библиотека, фрэймворк на котором можно построить любые архитектуры. До недавнего времени был самым популярным. Существует множество готовых (натренированных) бесплатных моделей сетей на этом фрэймворке.
Яркий пример применения Caffe:
Rober Bond, используя натренированную на распознавание котов сеть, соорудил автоматизированную прогонялку котов с его газона, которая при обнаружении кота на видео, поливает его водой.

Существует еще много разных, популярных в свое время библиотек, оберток, надстроек: BidMach, Brainstorm, Kaldi, MatConvNet, MaxDNN, Deeplearning4j, Keras, Lasagne(Theano), Leaf, но лидером считается Tensorflow, в силу своего бурного роста за последние два года.
В конце статьи хочу поделиться некоторыми яркими примерами использования сверточных сетей:
| Область применения | Коментарии | Ссылки |
|---|---|---|
| Распознавание рукописного текста | Точность человека — 97.5% CNN — 99.8% | Визуализация образов натренированной сети в TF, JS интерактивная визуализация работы свертки, MNIST |
| Компьютерное зрение | CNN распознает не только простые объекты на фото, но и эмоции, действия, а еще анализирует видео для автопилотов (семантическая сегментация). | Эмоции, Семантическая сегментация, Skype Caption бот, Google Image поиск |
| 3D реконструкция | Создание 3D моделей по видео | Deep stereo |
| Развлечение | Стилизация и генерация картинок | Deep dream, Deep style, Перенос стиля на видео, Генерация лиц, Генерация различных объектов |
| Фото | Улучшение качества, оцветнение | Face Hallucination, Colorizing |
| Медицина | Создание лекарств | |
| Безопасность | Обнаружение аномального поведения (Свертка + Реккурентрость) | Пример 1, 2, 3 |
| Игры | В итоге сеть играет круче профессионала, выбивая дырку и специально загоняя туда шар. | Atari Breakout |
|
Метки: author verych машинное обучение нейронные сети компьютерное зрение сверточная нейросеть |