[Из песочницы] Runtime перекраска приложения |
|
Метки: author DeFract разработка под android android development |
«Необходимость возникает с обеих сторон»: программный комитет DevOops о конференции и о DevOps |

 Барух Садогурский: По-моему, что такое DevOps, все уже давно определились.
Барух Садогурский: По-моему, что такое DevOps, все уже давно определились.  Александр Тарасов: А по-моему, немного по-разному воспринимают до сих пор. У нас всех разный бэкграунд, и все мы видим разное. Как и с любым словом, которое является довольно большим обобщением. Безусловно, у людей есть общее понимание, но в деталях оно порой очень сильно разнится, а уж способов имплементации этой идеи на реальном ландшафте вообще зоопарк.
Александр Тарасов: А по-моему, немного по-разному воспринимают до сих пор. У нас всех разный бэкграунд, и все мы видим разное. Как и с любым словом, которое является довольно большим обобщением. Безусловно, у людей есть общее понимание, но в деталях оно порой очень сильно разнится, а уж способов имплементации этой идеи на реальном ландшафте вообще зоопарк. 
 Олег Анастасьев: А я вот в корне не соглашусь с Барухом, должна же быть интрига! Я скажу, что скорее наоборот: это движение идёт от программистов. Потому что админы до возникновения этого термина традиционно выполняли какие-то ручные процедуры, у них были свои процессы, свои инструкции, они их вручную или полускриптами решали. А программистам надоедает выполнять команды на машинах через админа, получается такой испорченный телефон: когда админ доходит до границы своей компетенции по поводу какого-то продукта, начинает программиста спрашивать. Программист сам не знает, что делать, и начинает командовать: ну посмотри, что в этой директории, а даты какие, а вот то что показывает, а это…
Олег Анастасьев: А я вот в корне не соглашусь с Барухом, должна же быть интрига! Я скажу, что скорее наоборот: это движение идёт от программистов. Потому что админы до возникновения этого термина традиционно выполняли какие-то ручные процедуры, у них были свои процессы, свои инструкции, они их вручную или полускриптами решали. А программистам надоедает выполнять команды на машинах через админа, получается такой испорченный телефон: когда админ доходит до границы своей компетенции по поводу какого-то продукта, начинает программиста спрашивать. Программист сам не знает, что делать, и начинает командовать: ну посмотри, что в этой директории, а даты какие, а вот то что показывает, а это…  Алексей Акопян: Мне хочется добавить вот что. По-моему, важно, что в последнее время стало много сервисов, идущих на смену продуктам. Традиционно большую часть софтверного бизнеса составляли коробочные продукты, которые команда писала, затем отдавала в энном количестве заказчикам, они должны были где-то у себя разворачивать. Соответственно, нужны были инструкции, потому что админы сидели в первую очередь на стороне заказчика. А сейчас индустрия довольно сильно эволюционирует в сторону публичных сервисов (да и внутренних тоже). Соответственно, мы чаще сталкиваемся с тем, что есть сервис, с которым пользователи взаимодействуют зачастую через единственный размазанный в каком-нибудь облаке деплоймент, который надо поддерживать. И это, на мой взгляд, дало очень большой толчок всей идеологии девопса: совместное владение не кодом, а именно работающим сервисом.
Алексей Акопян: Мне хочется добавить вот что. По-моему, важно, что в последнее время стало много сервисов, идущих на смену продуктам. Традиционно большую часть софтверного бизнеса составляли коробочные продукты, которые команда писала, затем отдавала в энном количестве заказчикам, они должны были где-то у себя разворачивать. Соответственно, нужны были инструкции, потому что админы сидели в первую очередь на стороне заказчика. А сейчас индустрия довольно сильно эволюционирует в сторону публичных сервисов (да и внутренних тоже). Соответственно, мы чаще сталкиваемся с тем, что есть сервис, с которым пользователи взаимодействуют зачастую через единственный размазанный в каком-нибудь облаке деплоймент, который надо поддерживать. И это, на мой взгляд, дало очень большой толчок всей идеологии девопса: совместное владение не кодом, а именно работающим сервисом. Кирилл Толкачёв: Ещё на других конференциях бывают доклады, которые можно назвать BizOps. Условно, я как начальник большой компании рассказываю про плюсы внедрения девопса в своей компании с цифрами, объясняющими формулу успеха. Слушайте, а мы вот такое хотим?
Кирилл Толкачёв: Ещё на других конференциях бывают доклады, которые можно назвать BizOps. Условно, я как начальник большой компании рассказываю про плюсы внедрения девопса в своей компании с цифрами, объясняющими формулу успеха. Слушайте, а мы вот такое хотим?|
Метки: author phillennium системное администрирование облачные вычисления it- инфраструктура devops блог компании jug.ru group devoops |
Печать на произвольном размере бумаги в Linux |
|
Метки: author LinuxComp разработка под linux pdf open source printing libreoffice печать размер бумага cups ppd postscript kde bug |
ФИАС умер, да здравствует… да здравствует… да не понятно что пока |
|
Метки: author MaximKovalev читальный зал фиас кладр e-commerce логистика |
[Из песочницы] Как рекламная сеть Vungle пытается усложнить жизнь своим клиентам |







#pragma strict
import System;
class MainMainVungle{
var mvungle: MainVungle;
}
class MainVungle {
var vungle: Vungle[];
}
class Vungle {
var date: String;
var impressions: int;
var views: int;
var completes: int;
var clicks: int;
var revenue: float;
var eCPM: float;
var geo_eCPMs: VunlgeCounty[];
}
class VunlgeCounty {
var country: String;
var views: int;
var clicks: int;
var revenue: float;
var eCPM: float;
}
var apps: String[];
private var url: String = "https://ssl.vungle.com/api/applications/{0}?key=[ВАШ КЛЮЧ API]&start={1}&end={2}&geo=all";
private var templateJson: String = '{"vungle":';
var startDate = "2016-09-27";
var mmvungle: MainMainVungle[];
var revenue: float;
function Start () {
var cTime: Date = System.DateTime.Now;
var i: int;
for (i = 0; i< apps.Length; i++){
var cUrl = String.Format(url, apps[i], startDate, cTime.Year+"-"+StringTime(cTime.Month)+"-"+StringTime(cTime.Day));
var www : WWW = new WWW(cUrl);
yield www;
var json: String = templateJson+ www.text+"}";
mmvungle[i].mvungle = JsonUtility.FromJson(json, MainVungle);
Debug.Log("Loading "+apps[i]);
}
for (i = 0; i< mmvungle.Length; i++){
for (var v: int = 0; v< mmvungle[i].mvungle.vungle.Length; v++){
revenue+=mmvungle[i].mvungle.vungle
}
}
Debug.Log("Revenue: "+revenue);
}
function StringTime(v: int){
if (v < 10){return "0"+v;}
else {return ""+v;}
}
|
Метки: author varlamov5264 монетизация игр реклама в приложениях vungle видеореклама монетизация приложений |
[Перевод] Сети Docker изнутри: связь между контейнерами в Docker Swarm и Overlay-сети |
В предыдущей статье я рассказал, как Docker использует виртуальные интерфейсы Linux и bridge-интерфейсы, чтобы установить связь между контейнерами по bridge-сетям. В этот раз я расскажу, как Docker использует технологию vxlan, чтобы создавать overlay-сети, которые используются в swarm-кластерах, а также где можно посмотреть и проинспектировать эту конфигурацию. Также я расскажу, как различные типы сетей решают разные задачи связи для контейнеров, которые запущены в swarm-кластерах.
Я предполагаю, что читатели уже знают, как разворачивать swarm-кластеры и запускать сервисы в Docker Swarm. Также в конце статьи я приведу несколько ссылок на полезные ресурсы, с помощью которых можно будет изучить предмет в деталях и вникнуть в контекст обсуждаемых здесь тем. Опять же, буду ждать ваших мнений в комментариях.
Overlay-сети используются в контексте кластеров (Docker Swarm), где виртуальная сеть, которую используют контейнеры, связывает несколько физических хостов, на которых запущен Docker. Когда вы запускаете контейнер на swarm-кластере (как часть сервиса), множество сетей присоединяется по умолчанию, и каждая из них соответствует разным требованиям связи.
Например, у меня есть 3 ноды docker swarm кластера:

Для начала я создам overlay-сеть под названием my-overlay-network:

Затем запущу сервис с контейнером, на котором запущен простой веб-сервер, который смотрит портом 8080 во внешний мир. Этот сервис будет иметь 3 реплики, и я отмечу, что он связан только с одной сетью (my-overlay-network):

Если затем вывести список всех интерфейсов, доступных любому запущенному контейнеру, то их будет 3. В то же время, если запустить контейнер на одном хосте, то можно ожидать только 1 интерфейс:
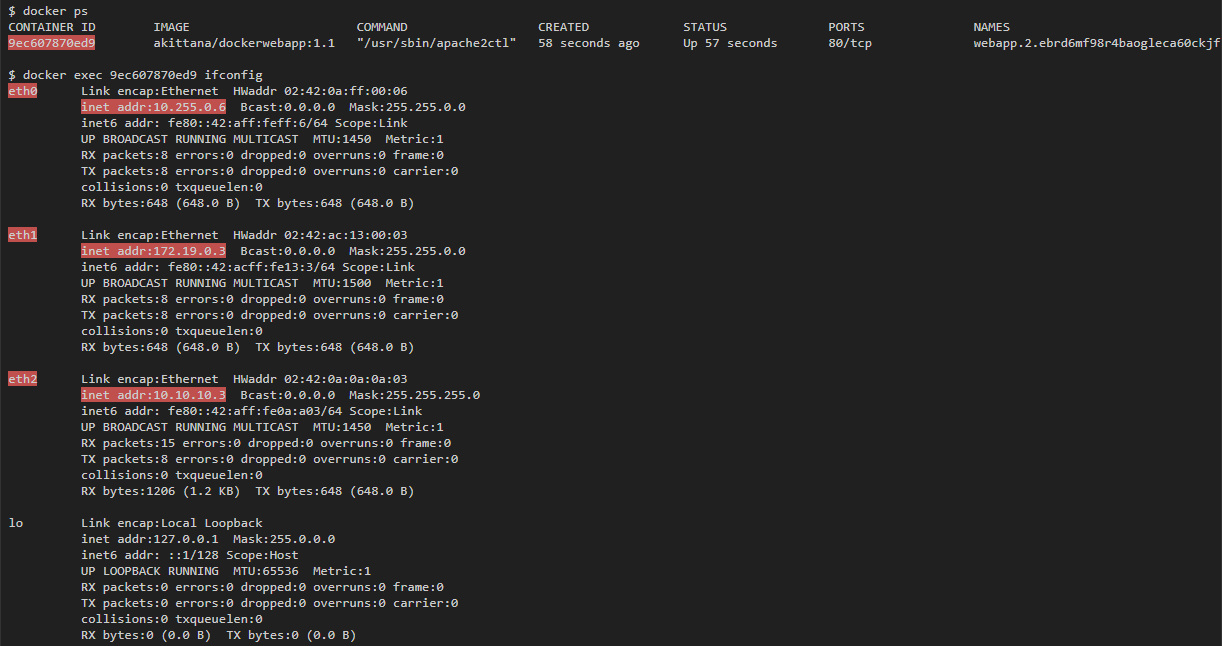
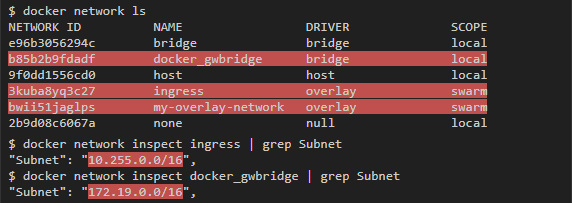
Контейнер связан с my-overlay-network через eth2, что можно понять по IP-адресу. eth0 и eth1 связаны с другими сетями. Если запустить docker network ls, то можно увидеть 2 дополнительные сети, которые добавились: docker_gwbridge и ingress, а по адресам подсетей можно понять, что они привязаны к eth0 и eth1:
Overlay-сеть создает подсеть, которую могут использовать контейнеры в разных хостах swarm-кластера. Контейнеры на разных физических хостах могут обмениваться данными по overlay-сети (если все они прикреплены к одной сети).
Например, для веб-приложения, которое мы запустили, можно увидеть по одному контейнеру на каждом хосте в swarm-кластере:

Я могу получить overlay IP-адрес для каждого контейнера при помощи команды ifconfig eth2 (eth2 — это интерфейс, присоединенный к overlay-сети).
На swarm01:

Потом с контейнера на swarm02 у меня должна быть возможность пингануть 10.10.10.5 (IP контейнера на swarm01):

Overlay-сеть использует технологию vxlan, которая инкапсулирует layer 2 фреймы в layer 4 пакеты (UDP/IP). При помощи этого действия Docker создает виртуальные сети поверх существующих связей между хостами, которые могут оказаться внутри одной подсети. Любые точки, которые являются частью этой виртуальной сети, выглядят друг для друга так, будто они связаны поверх свича и не заботятся об устройстве основной физической сети.
Чтобы увидеть этот процесс в действии, можно сделать захват трафика на хостах, которые являются частью overlay-сети. В последнем примере захват трафика на swarm01 или swarm02 выявит icmp-трафик между контейнерами, которые на них запущены (vxlan использует udp port 4789):

В этом примере в пакетах можно видеть два слоя. Первый — это туннельный трафик udp vxlan между хостами по порту 4789, а внутри можно увидеть второй — icmp трафик с IP-адресами контейнера.
Захват трафика в этом примере показал, что если ты видишь трафик между хостами, то увидишь и трафик внутри контейнеров, проходящий по overlay-сети. Именно поэтому в Docker есть опция шифроования. Можно запустить автоматическое IPSec-шифрование vxlan-туннелей, просто добавив --opt encrypted при создании сети.
Если запустить такой же тест, но с использованием зашифрованной overlay-сети, то можно увидеть только зашифрованные пакеты между хостами:
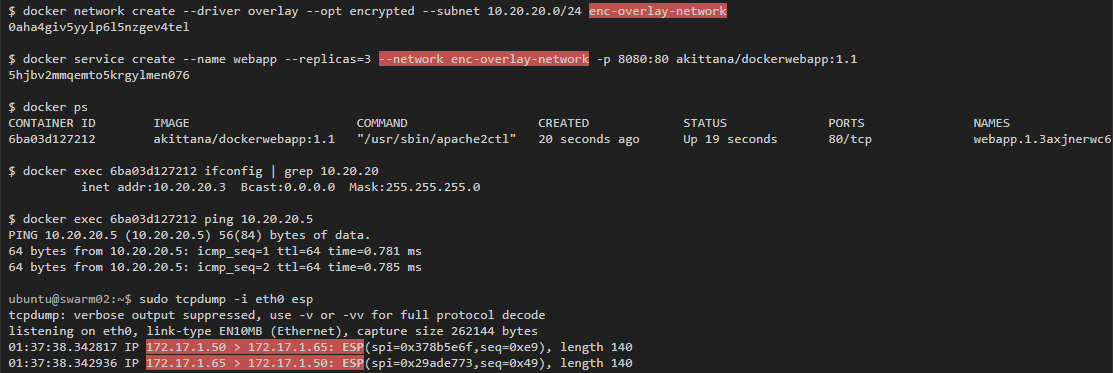
Как и bridge-сети, Docker создает bridge-интерфейс для каждой overlay-сети, который соединяет виртуальные туннельные интерфейсы, выполняющие vxlan туннельную связь между хостами. Впрочем, эти туннельные интерфейсы (bridge и vxlan) создаются не напрямую на туннельном хосте. Они находятся в разных контейнерах, которые Docker запускает для каждой создаваемой overlay-сети.
Чтобы действительно проинспектировать эти интерфейсы, надо использовать nsenter для запуска команд внутри сети контейнера, который управляет туннелями и виртуальными интерфейсами. Эту команду надо запустить на хостах с контейнерами, которые участвуют в overlay-сети.
Также надо отредактировать /etc/systemd/system/multi-user.target.wants/docker.service на хосте и закомментировать MountFlags=slave по инструкции из этого обсуждения.

Наконец, если запустить захват трафика на veth-интерфейсе, то мы увидим трафик, который покидает контейнер, но до того, как он будет направлен в vxlan туннель (упомянутый выше пинг все еще работает):

Вторая сеть, к которой были присоединены контейнеры, — это сеть ingress. Это overlay-сеть, но она устанавливается по умолчанию сразу после запуска swarm-кластера. Эта сеть отвечает за связи, которые устанавливаются с контейнерами со стороны внешнего мира. Также именно в ней происходит балансировка нагрузки, которую предоставляет swarm-кластер.
Балансировку нагрузки выполняет IPVS в контейнере, который Docker swarm запускает по умолчанию. Можно увидеть, что этот контейнер прикреплен к ingress-сети (я использовал тот же веб-сервис, что и раньше: он раскрывает порт 8080, который прикрепляется к порту 80 в контейнерах):
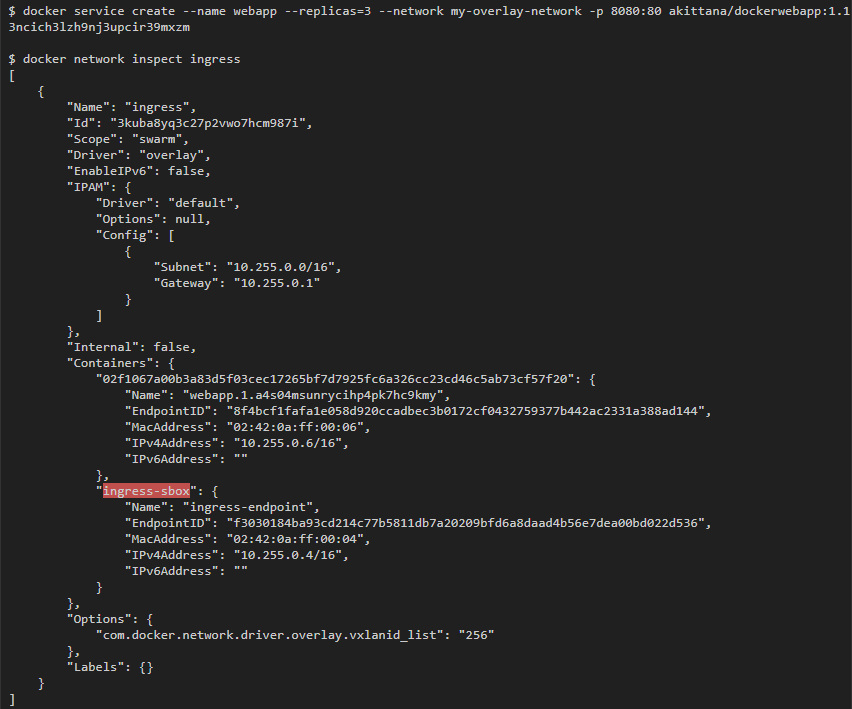
Для начала, взглянем на хост — на любой хост, который участвует в swarm-кластере:
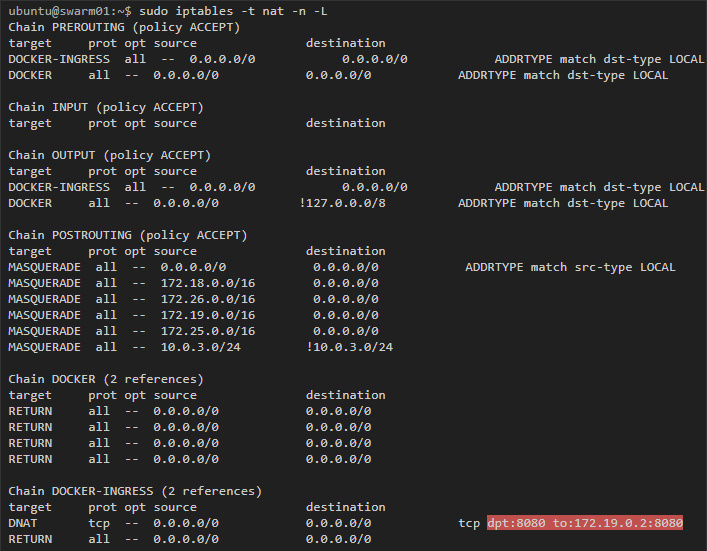
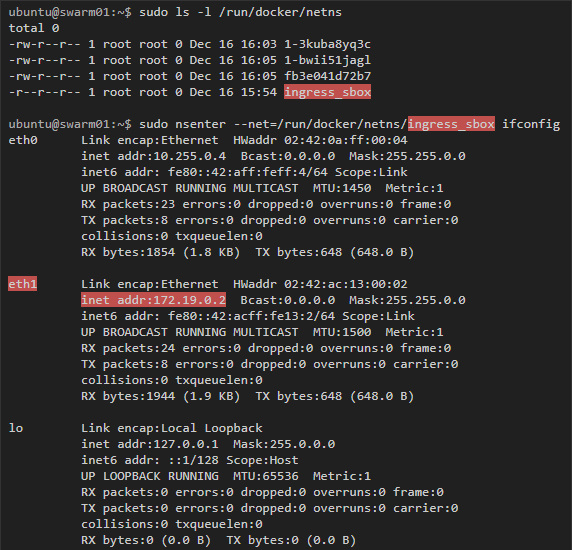
Здесь мы видим правило, по которому трафик, предназначенный для порта 8080, перенаправляется по адресу 172.19.0.2. Этот адрес принадлежит контейнеру ingress-sbox, если проинспектировать его интерфейсы, то мы получим слещующее:
Docker использует mangle-правила iptables, чтобы назначить определенный номер пакетам для порта 8080. IPVS будет использовать этот номер, чтобы балансировать нагрузку в подходящие контейнеры:
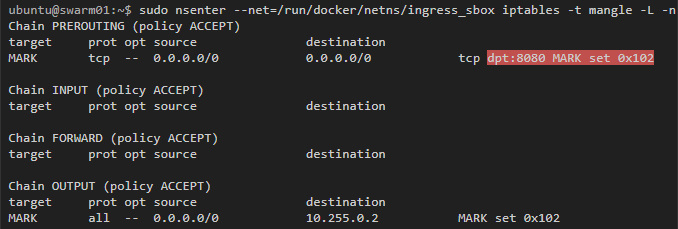
Как Docker swarm использует iptables и IPVS для балансировки нагрузки контейнеров, можно более детально изучить по видеоролику Deep Dive into Docker 1.12 Networking.
Наконец, поговорим о сети docker_gwbridge. Это bridge-сеть с соответствующим интерфейсом под названием docker_gwbridge, который создается на каждом хосте swarm-кластера. Сеть docker_gwbridge соединяет трафик из контейнеров swarm-кластера с внешним миром. Например, такой трафик получится, если мы направим запрос в Google.
Не буду вдаваться в подробности, поскольку bridge-сети я уже в деталях рассмотрел в предыдущей статье.
Контейнер, запущенный на swarm-кластере, по умолчанию может быть соединён с тремя и более сетями. Первая сеть, docker_gwbridge, позволяет контейнерам поддерживать связь с внешним миром. Сеть ingress нужна только для того, чтобы устанавливать входящие соединения из внешнего мира. И, наконец, сети overlay: их создает сам пользователь и их можно прикрепить к контейнерам. Эти сети служат общей подсетью для контейнеров единой сети, в которой они могут обмениваться данными напрямую (даже если они запущены на разных физических хостах).
Также существуют пространства разных сетей, которые создаются по умолчанию на swarm-кластере. Эти пространства помогают управлять vxlan-туннелями для overlay-сетей и правилами балансировки нагрузки для входящих связей.
|
Метки: author r-moiseev системное администрирование сетевые технологии devops docker docker swarm overlay iptables |
TamTam: как мы делали новый мессенджер |
|
Метки: author Digal системы обмена сообщениями разработка мобильных приложений анализ и проектирование систем блог компании mail.ru group mail.ru tamtam мессенджер |
[Из песочницы] Вынос локального сервера в сеть с помощью другого внешнего сервера |
apt install pptpdlocalip 10.0.0.1
remoteip 10.0.0.100-200# client server secret IP addresses
orange pptpd pass123 10.0.0.100
ms-dns 8.8.8.8
ms-dns 8.8.4.4service pptpd restartnet.ipv4.ip_forward = 1~$ ifconfig
ens3 Link encap:Ethernet HWaddr 52:54:00:f8:0c:4a
inet addr:31.148.99.234 Bcast:31.148.99.255 Mask:255.255.255.0
inet6 addr: fe80::5054:ff:fef8:c4a/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:8808733 errors:0 dropped:0 overruns:0 frame:0
TX packets:3300625 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:3511383831 (3.5 GB) TX bytes:3245380453 (3.2 GB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:216 errors:0 dropped:0 overruns:0 frame:0
TX packets:216 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:16618 (16.6 KB) TX bytes:16618 (16.6 KB)
iptables -t nat -A POSTROUTING -o ens3 -j MASQUERADE && iptables-saveiptables --table nat --append POSTROUTING --out-interface ppp0 -j MASQUERADE
iptables -I INPUT -s 10.0.0.0/8 -i ppp0 -j ACCEPT
iptables --append FORWARD --in-interface ens3 -j ACCEPT
apt install pptp-linuxpty "pptp 31.148.99.234 --nolaunchpppd"
name orange
password pass123
remotename PPTP
require-mppe-128
lock
noauth
nobsdcomp
nodeflate
defaultroute
replacedefaultroute
mtu 1400
persist
maxfail 0
lcp-echo-interval 20
lcp-echo-failure 3
pon pptpserver~$ ifconfig ppp0
ppp0 Link encap:Point-to-Point Protocol
inet addr:10.0.0.100 P-t-P:10.0.0.1 Mask:255.255.255.255
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1496 Metric:1
RX packets:1075 errors:0 dropped:0 overruns:0 frame:0
TX packets:959 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:3
RX bytes:154176 (154.1 KB) TX bytes:194499 (194.4 KB)
~$ ping 10.0.0.100
PING 10.0.0.100 (10.0.0.100) 56(84) bytes of data.
64 bytes from 10.0.0.100: icmp_seq=1 ttl=64 time=8.91 ms
64 bytes from 10.0.0.100: icmp_seq=2 ttl=64 time=8.80 ms
64 bytes from 10.0.0.100: icmp_seq=3 ttl=64 time=8.93 ms
64 bytes from 10.0.0.100: icmp_seq=4 ttl=64 time=9.00 ms
iptables -t nat -A PREROUTING -p tcp -d 31.148.99.234 --dport 80 -j DNAT --to-destination 10.0.0.100:80
iptables -A FORWARD -i ppp0 -d 10.0.0.100 -p tcp --dport 80 -j ACCEPT
iptables -t nat -A PREROUTING -p tcp -d 31.148.99.234 --dport 443 -j DNAT --to-destination 10.0.0.100:443
iptables -A FORWARD -i ppp0 -d 10.0.0.100 -p tcp --dport 443 -j ACCEPT
#!/bin/sh
while [ 0 ]
do
if ifconfig ppp0>>/dev/null
then
sleep 7
else
pon pptpserver
if $?
then
echo $(date) Connected
else
echo $(date) Connection error
fi
fi
sleep 3
done/root/scripts/ppp.shchmod +x /root/scripts/ppp.sh|
Метки: author Trofen сетевые технологии серверное администрирование настройка linux orange pi nat iptables linux vpn pptp |
Разработка для Sailfish OS: Работа c календарем и списком контактов |
...
# Runtime dependencies which are not automatically detected
Requires:
- sailfishsilica-qt5 >= 0.10.9
- nemo-qml-plugin-contacts-qt5
...
import org.nemomobile.contacts 1.0
PeopleModel {
id: peopleModel
filterType: PeopleModel.FilterAll
requiredProperty: PeopleModel.PhoneNumberRequired
}
SilicaListView {
anchors.fill: parent
header: PageHeader {title: qsTr("Contacts")}
model: peopleModel
delegate: ListItem {
width: parent.width
Column {
width: parent.width
Label {text: firstName + " " + lastName}
Label {text: qsTr("Phone numbers: ") + phoneNumbers.join(", ")}
}
}
}
AgendaModel {
id: agendaModel
startDate: new Date()
endDate: new Date(2018, 0)
}
Calendar.createNewEvent();
Calendar.createModification(event);
Calendar.remove(event.uniqueId);
...
# Runtime dependencies which are not automatically detected
Requires:
- sailfishsilica-qt5 >= 0.10.9
- nemo-qml-plugin-calendar-qt5
...
import org.nemomobile.calendar 1.0
AgendaModel {
id: agendaModel
startDate: new Date()
endDate: new Date(2018, 0)
}
SilicaListView {
anchors.fill: parent
header: PageHeader { title: qsTr("Calendar events") }
model: agendaModel
delegate: ListItem {
width: parent.width
contentHeight: column.height
Column {
id: column;
width: parent.width
Label { text: eventDateTimeToString(event) }
Label { text: event.displayLabel }
Label { text: qsTr("Location: ") + event.location }
}
}
}
function eventDateTimeToString(event) {
return Qt.formatTime(event.startTime, "HH:mm") + " – "
+ Qt.formatTime(event.endTime, "HH:mm") + "\t"
+ Qt.formatDate(event.startTime, Qt.SystemLocaleShortDate);
}

Dialog {
property var eventModification
SilicaFlickable {
// Компоненты ValueButton для установки даты, времени начала и времени конца события.
TextField {
id: eventLabelTextField
label: qsTr("Event")
text: eventModification.displayLabel
}
// Компонент TextField с id=locationTextField для установки места проведения мероприятия.
}
onAccepted: {
eventModification.displayLabel = eventLabelTextField.text;
eventModification.location = locationTextField.text;
eventModification.save();
}
}

PullDownMenu {
MenuItem {
text: "Add new event"
onClicked: pageStack.push(Qt.resolvedUrl("EditEventDialog.qml"),
{eventModification: Calendar.createNewEvent()})
}
}

SilicaListView {
// ...
model: agendaModel
delegate: ListItem {
// ...
menu: ContextMenu {
MenuItem {
text: "Edit"
onClicked: pageStack.push(Qt.resolvedUrl("EditEventDialog.qml"),
{eventMod: Calendar.createModification(event)})
}
}
}
}
MenuItem {
text: qsTr("Delete")
onClicked: Calendar.remove(event.uniqueId)
}

|
Метки: author FRUCT разработка мобильных приложений qt sailfish os qml контакты календарь события |
Команда веб-энтузиастов представила P2P-браузер Beaker |
 / Flickr / hackNY.org / CC
/ Flickr / hackNY.org / CCПри отправке содержимого используется протокол Dat (Distributed Dataset Synchronization and Versioning), специально разработанный для передачи данных в рамках распределенной сети.
|
Метки: author 1cloud разработка веб-сайтов блог компании 1cloud.ru 1cloud p2p beaker dat |
[Перевод - recovery mode ] Почему мы выбрали TypeScript: история разработчиков из Reddit |
 Примерно полгода назад CEO Reddit Стив сообщил о том, что мы перепроектируем сайт. Главный вопрос тут — как именно мы этим занимаемся. В наше время фронтенд-разработка очень сильно отличается от того, что было во времена, когда Reddit появился на свет. Сейчас имеется огромный выбор вариантов для каждой подсистемы веб-приложения. Как рендерить страницы? Как стилизовать контент? Как хранить и обслуживать картинки и видеофайлы? Как писать код? В современных условиях ни на один из этих вопросов нет готового ответа.
Примерно полгода назад CEO Reddit Стив сообщил о том, что мы перепроектируем сайт. Главный вопрос тут — как именно мы этим занимаемся. В наше время фронтенд-разработка очень сильно отличается от того, что было во времена, когда Reddit появился на свет. Сейчас имеется огромный выбор вариантов для каждой подсистемы веб-приложения. Как рендерить страницы? Как стилизовать контент? Как хранить и обслуживать картинки и видеофайлы? Как писать код? В современных условиях ни на один из этих вопросов нет готового ответа. enum VoteDirection {
upvoted = 1,
notvoted = 0,
downvoted = -1,
};
const voteState: VoteDirection = VoteDirection.upvoted;const voteDirections = {
upvoted: 1,
notvoted: 0,
downvoted: -1,
};
type VoteDirection = $Keys;
const voteState: VoteDirection = voteDirections.upvoted; NULL. В TypeScript 2.x была добавлена поддержка типов, в которых не допускается NULL, однако, эту возможность нужно включать самостоятельно. Кроме того, Flow лучше выводит типы, в то время как TypeScript часто обращается к типу any. NULL и вывода типов, Flow лучше в вопросах ковариантности и контравариантности (вот материал на эту тему). Одна из типичных проблемных ситуаций здесь — работа с типизированными массивами. По умолчанию массивы во Flow инвариантны. Это означает, что следующая конструкция во Flow вызовет ошибку:class Animal {}
class Bird extends Animal {}
const foo: Array = [];
foo.push(new Animal());
/*
foo.push(new A);
^ A. This type is incompatible with
const foo: Array = [];
^ B
*/ class Animal {}
class Bird extends Animal {}
const foo: Array = [];
foo.push(new Animal()); // в typescript всё нормально |
Метки: author ru_vds разработка веб-сайтов javascript блог компании ruvds.com typescript веб-разработка |
[Из песочницы] Найдена новая версия программы. Устанавливаем? |
|
Метки: author drno-reg исследования и прогнозы в it apache tomcat apache hadoop intellij idea cisco vpn |
Спускаемся с небес: давайте просто посчитаем? |


|
|
Как и зачем скрывать телефонные номера |

|
Метки: author akvakh разработка веб-сайтов программирование javascript блог компании voximplant phone number masking |
[Перевод] XBRL: просто о сложном - Глава 4. Отчет XBRL |
В этой главе мы рассмотрим отчеты XBRL. Как и прежде, основное внимание уделяем тому, что можно сделать, а не как это делается.
Отчет (instance document) содержит факты и ссылается на таксономию для придания фактам смысла:
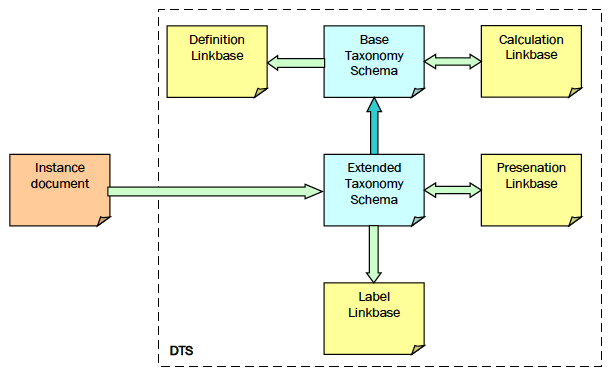
Факты могут быть простыми (item) или составными (кортеж, tuple). Все простые факты в отчете имеют контекст, напр. финансовый год или начало отчетного периода. Все используемые контексты содержатся в самом отчете.
Схематически состав отчета можно изобразить следующим образом:
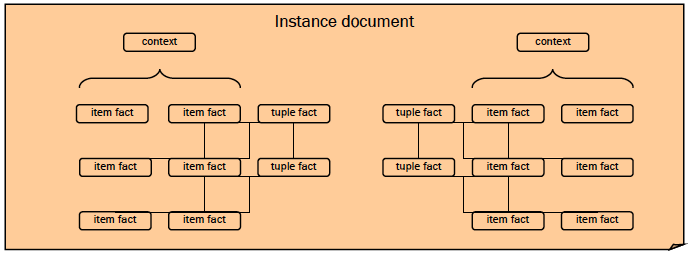
В следующих разделах мы более подробно рассмотрим составные части отчета.
xbrlОтчет содержит различные виды данных:
Общим контейнером для всех составных частей отчета является обязательный элемент xbrl.
Отчет может содержать некоторые ссылки на внешние ресурсы.
Факты в отчете представляют собой бесполезные данные без таксономии, придающей им смысл. Каждый отчет должен ссылаться хотя бы на одну таксономию. Ссылка должна указывать на схему таксономии.
Автор отчета может добавлять в него ссылки на базы ссылок, которые вместе таксономией (или таксономиями) становятся частью DTS (связанный комплекс таксономий, мы обсуждали его ранее). Примерами могут служить дополнительные определения или ссылки на концепты, свои версии презентаций или меток. Способ указания ссылки в отчете идентичен таковому в таксономии.
Отчет может содержать сноски к фактам. Если для них используются собственные роли или роли дуг, на них также должна быть ссылка.
Чтобы можно было понять приведенные в отчете факты, у них должен быть контекст. Представленный в XBRL контекст должен содержать составителя отчета, отчетный период и, при необходимости, сценарий. Контекст должен иметь атрибут id, который используется для ссылки на него из элементов отчета.
Компания, государственное ведомство или физическое лицо, составляющее отчет; описывается в контексте атрибутом entity.
Составитель отчета должен иметь уникальный идентификатор, однозначно его определяющий. Это обеспечивается определением схемы и токена, который является корректным идентификатором в пространстве имен, на которое ссылается схема. Примером могут служить биржевые тикеры.
Опционально, составитель отчетности может также иметь элемент segment для дополнительной детализации, напр. бизнес-единица внутри крупной компании или территориальное подразделение государственной организации. В спецификации не дается каких-либо указаний относительно того, как именно следует использовать этот элемент – это любое XML-выражение, не использующее синтаксис XBRL.
Период может быть двух типов – на дату (instant) и собственно за период (duration). Во втором случае можно либо явно задать начало и окончание периода, либо указать за все время (forever).
Примечание: Дата окончания всегда следует после даты начала. Если дата указывается без времени, то автоматически устанавливается полночь. Для начала периода это будет начало указанного дня, а для окончания периода – конец указанного дня (но технически это будет полночь следующего дня).
Отчет может опционально определять в контексте сценарий, указывающий тип отчетных данных, напр. плановые, фактические, или исправленные. Сценарий описывает обстоятельства расчета отчетных данных.
В спецификации не дается каких-либо указаний относительно того, как именно следует использовать этот элемент – это любое XML-выражение, не использующее синтаксис XBRL.
Числовые значения должны иметь единицу измерения, которая предоставляет возможность их интерпретировать. Каждая используемая в отчете единица измерения должна быть определена отдельным элементом внутри корневого элемента xbrl.
Единица измерения содержит отдельную единицу, произведение, либо отношение единиц, напр. RUB, килограмм или квадратный метр.
У каждой единицы измерения должен быть указан атрибут id, используемый для обращения к ней в пределах отчета.
Факт (item) – это отдельное значение, которое передается в качестве отчетных данных. Факт не может содержать в себе другие факты, для таких случаев используются кортежи фактов (см. далее).
Значение факта может быть либо числовым, либо нечисловым. Помимо самого значения, в факте также содержатся дополнительные данные.
Каждый факт в отчете должен ссылаться на контекст путем указания его id. Тип отчетного периода, используемого при расчете факта, должен совпадать с типом отчетного периода в контексте:
startDate (начало периода) и endDate (окончание периода), либо иметь значение forever (за все время).Числовые факты должны ссылаться на единицу измерения путем указания ее id.
Числовые факты должны содержать либо точность (precision), либо количество десятичных знаков (decimals). Это важно при сравнении значений, а также при выполнении расчетов, особенно при округлении и усечении.
Атрибут precision указывает количество значимых знаков факта (до десятичного разделителя). Атрибут decimals указывает точность значения в количестве знаков после десятичного разделителя. Эти атрибуты являются взаимоисключающими, т.е. недопустимо использовать оба из них в одном факте.
Атрибутprecisionопределяется автоматически при наличии атрибутаdecimals. Спецификация XBRL дает точные правила такого определения. Также, она приводит примеры того, как читать эти атрибуты.
Большинство фактов существуют независимо друг от друга. Они определяются отдельными элементами под корневым элементом xbrl. Когда смысл фактов раскрывается только с учетом их взаимосвязи, для объединения фактов в связанные множества используются кортежи. Примером может служить имя и должность менеджера.
Кортежи объединяют факты, при этом в качестве элементов кортежа могут использоваться как факты, так и другие кортежи. Сам по себе кортеж не может ссылаться на контекст или единицу измерения. Также, он не может иметь атрибутов тип периода (periodType) и баланс (balance).
Факты передаются независимо, кортежи позволяют собирать факты в связанную структуру. Другие, менее структурированные связи между фактами и дополнительными данными к ним, можно определить с помощью сносок.
Сноски (footnotes) – это дополнительные данные к фактам и ссылки на них, которые существуют только в пределах отчета. Для ссылок на сноски используется роль footnotes. Сама сноска содержит текст и должна иметь метку языка.
Для сравнения фактов или кортежей фактов могут иметь значение несколько форм равенства:
Спецификация XBRL содержит большую таблицу, которая точно определяет, как каждая форма равенства должна применяться к различным типам аргументов, таким как узлы, атрибуты, составители отчета и т.д.
|
Метки: author r_udaltsov it- стандарты xbrl финансы отчетность цб рф |
Точное вычисление средних и ковариаций методом Уэлфорда |
Метод Уэлфорда — простой и эффективный способ для вычисления средних, дисперсий, ковариаций и других статистик. Этот метод обладает целым рядом прекрасных свойств:
Оригинальная статья Уэлфорда была опубликована в 1962 году. Тем не менее, нельзя сказать, что алгоритм сколь-нибудь широко известен в настоящее время. А уж найти математическое доказательство его корректности или экспериментальные сравнения с другими методами и вовсе нетривиально.
Настоящая статья пытается заполнить эти пробелы.

В первые месяцы своей деятельности в качестве разработчика я занимался созданием метода машинного обучения, в котором градиентному бустингу подвергались деревья решений с линейными регрессионными моделями в листьях. Такой алгоритм был выбран отчасти в пику модной тогда и победившей сегодня концепции строить огромные композиции очень простых алгоритмов: хотелось, напротив, строить небольшие композиции достаточно сложных моделей.
Сама эта тема оказалась настолько для меня интересной, что я потом даже диссертацию про это написал. Для построения модели из нескольких сотен деревьев приходится решать задачу линейной регрессии десятки тысяч раз, и оказалось сложным достичь хорошего качества во всех случаях, ведь данные для этих моделей весьма разнообразны, и проблемы мультиколлинеарности, регуляризации и вычислительной точности встают в полный рост. А ведь достаточно одной плохой модели в одном листе одного дерева для того, чтобы вся композиция оказалась совершенно непригодной.
В процессе решения проблем, связанных с автоматическим построением огромного количества линейных моделей, мне удалось узнать некоторое количество фактов, которые пригодились мне в дальнейшем в самых разных ситуациях, в том числе не связанных с собственно задачей линейной регрессии. Теперь хочется рассказать о некоторых из этих фактов, и для начала я решил рассказать о методе Уэлфорда.
У статьи следующая структура. В пункте 1 мы рассмотрим простейшую задачу вычисления среднего, на примере которой поймём, что эта задача не так уж и проста, как это кажется на первый взгляд. Пункт 2 вводит используемые в данной статье обозначения, которые пригодятся в разделах 3 и 4, посвящённых выводу формул метода Уэлфорда для, соответственно, вычисления взвешенных средних и взвешенных ковариаций. Если вам неинтересны технические подробности вывода формул, вы можете пропустить эти разделы. Пункт 5 содержит результаты экспериментального сравнения методов, а в заключении находится пример реализации алгоритмов на языке С++.
Модельный код для сравнения методов вычисления ковариации находится в моём проекте на github. Более сложный код, в котором метод Уэлфорда применяется для решения задачи линейной регрессии, находится в другом проекте, речь о котором пойдёт в следующих статьях.
Начну c классического примера. Пусть есть простой класс, вычисляющий среднее для набора чисел:
class TDummyMeanCalculator {
private:
float SumValues = 0.;
size_t CountValues = 0;
public:
void Add(const float value) {
++CountValues;
SumValues += value;
}
double Mean() const {
return CountValues ? SumValues / CountValues : 0.;
}
};Попробуем применить его на практике следующим способом:
int main() {
size_t n;
while (std::cin >> n) {
TDummyMeanCalculator meanCalculator;
for (size_t i = 0; i < n; ++i) {
meanCalculator.Add(1e-3);
}
std::cout << meanCalculator.Mean() << std::endl;
}
return 0;
}Что же выведет программа?
| Ввод | Вывод |
|---|---|
| 10000 | 0.001000040 |
| 1000000 | 0.000991142 |
| 100000000 | 0.000327680 |
| 200000000 | 0.000163840 |
| 300000000 | 0.000109227 |
Начиная с некоторого момента, сумма перестаёт меняться после прибавления очередного слагаемого: это происходит, когда SumValues оказывается равным 32768, т.к. для представления результата суммирования типу float просто не хватает разрядности.
Из этой ситуации есть несколько выходов:
float на double.Не так просто найти данные, на которых плохо работает решение с использованием double. Тем не менее, такие данные встречаются, особенно в более сложных задачах. Также неприятно, что использование double увеличивает затраты памяти: иногда требуется хранить большое количество средних одновременно.
Методы Кэхэна и другие сложные способы суммирования по-своему хороши, но в дальнейшем мы увидим, что метод Уэлфорда всё же работает лучше, и, кроме того, он удивительно прост в реализации. Действительно, давайте посмотрим на соответствующий код:
class TWelfordMeanCalculator {
private:
float MeanValues = 0.;
size_t CountValues = 0;
public:
void Add(const float value) {
++CountValues;
MeanValues += (value - MeanValues) / CountValues;
}
double Mean() const {
return MeanValues;
}
};К вопросу о корректности этого кода мы вернёмся в дальнейшем. Пока же заметим, что реализация выглядит достаточно простой, а на тех данных, что используются в нашей программе, еще и работает с идеальной точностью. Это происходит из-за того, что разность value - MeanValues на первой итерации в точности равна среднему, а на последующих итерациях равна нулю.
Этот пример иллюстрирует основное достоинство метода Уэлфорда: все участвующие в арифметических операциях величины оказываются "сравнимы" по величине, что, как известно, способствует хорошей точности вычислений.
| Ввод | Вывод |
|---|---|
| 10000 | 0.001 |
| 1000000 | 0.001 |
| 100000000 | 0.001 |
| 200000000 | 0.001 |
| 300000000 | 0.001 |
В этой статье мы рассмотрим применение метода Уэлфорда к ещё одной задаче — задаче вычисления ковариации. Кроме того, мы проведём сравнение различных алгоритмов и получим математические доказательства корректности метода.
Вывод формулы часто можно сделать очень простым и понятным, если выбрать правильные обозначения. Попробуем и мы. Будем считать, что заданы две последовательности вещественных чисел: и , и последовательность соответствующих им весов :
Поскольку мы хотим вычислять средние и ковариации, нам понадобятся обозначения для взвешенных сумм и сумм произведений. Попытаемся описать их единообразно:
Тогда, например, — это сумма весов первых элементов, — это взвешенная сумма первых чисел первой последовательности, а — сумма взвешенных произведений:
Также понадобятся средние взвешенные величины:
Наконец, введём обозначения для ненормированных "разбросов" и нормированных ковариаций :
Докажем взвешенный аналог формулы, использованной нами выше для вычисления среднего по методу Уэлфорда. Рассмотрим разность :
В частности, если все веса равняются единице, получим, что
Кстати, формулы для "взвешенного" случая позволяют легко реализовывать операции, отличные от добавления ровно одного очередного числа. Например, удаление числа из множества, по которому вычисляется среднее — это то же, что добавление числа с весом . Добавление сразу нескольких чисел — то же, что добавление одного из среднего с весом, равным количеству этих чисел, и так далее.
Покажем, что и для взвешенной задачи верна классическая формула для вычисления ковариации. Сейчас для простоты будем работать с ненормированными величинами.
Отсюда уже легко видеть, что
Эта формула чрезвычайно удобна, в том числе и для онлайн-алгоритма, однако, если величины и окажутся близкими и при этом большими по абсолютному значению, её использование приведёт к существенным вычислительным погрешностям.
Давайте попробуем вывести рекуррентную формулу для , в каком-то смысле аналогичную формуле Уэлфорда для средних. Итак:
Рассмотрим последнее слагаемое:
Подставим получившееся в выражение для :
Код, реализующий вычисления по этой формуле, при отсутствии весов выглядит очень просто. Необходимо обновлять две средних величины, а также сумму произведений:
double WelfordCovariation(const std::vector& x, const std::vector& y) {
double sumProducts = 0.;
double xMean = 0.;
double yMean = 0.;
for (size_t i = 0; i < x.size(); ++i) {
xMean += (x[i] - xMean) / (i + 1);
sumProducts += (x[i] - xMean) * (y[i] - yMean);
yMean += (y[i] - yMean) / (i + 1);
}
return sumProducts / x.size();
} Также интересным является вопрос об обновлении величины собственно ковариации, т.е. нормированной величины:
Рассмотрим первое слагаемое:
Вернёмся теперь к рассмотрению :
Это можно переписать, например, так:
Получилась формула, действительно обладающая удивительным сходством с формулой для обновления среднего!
Я написал небольшую программу, в которой реализуются три способа вычисления ковариации:
Данные в задаче формируются следующим образом: выбираются два числа, и — средние двух выборок. Затем выбираются еще два числа, и — соответственно, отклонения. На вход алгоритмам подаются последовательности чисел вида
причём знаки при отклонениях меняются на каждой итерации, так, чтобы истинная ковариация вычислялась следующим образом:
Истинная ковариация константна и не зависит от числа слагаемых, поэтому мы можем вычислять относительную погрешность вычисления для каждого метода на каждой итерации. Так, в текущей реализации , а средние принимают значения 100000 и 1000000.
На первом графике изображена зависимость величины относительной погрешности при использовании наивного метода для среднего, равного 100 тысячам. Этот график демонстрирует несостоятельность наивного метода: начиная с какого-то момента погрешность начинает быстро расти, достигая совершенно неприемлемых величин. На тех же данных методы Кэхэна и Уэлфорда не допускают существенных ошибок.

Второй график построен для метода Кэхэна при среднем, равном одному миллиону. Ошибка не растёт с увеличением количества слагаемых, но, хотя она и существенно ниже, чем ошибка "наивного" метода, всё равно она слишком велика для практических применений.
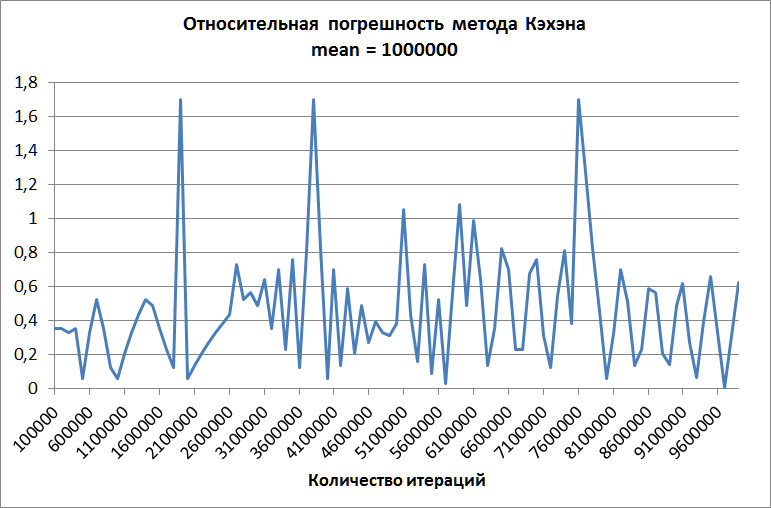
Метод Уэлфорда, в свою очередь, и на этих данных демонстрирует идеальную точность!
В этой статье мы сравнили несколько способов вычисления ковариации и убедились в том, что метод Уэлфорда даёт наилучшие результаты. Для того, чтобы использовать его на практике, достаточно запомнить лишь две следующие реализации:
class TWelfordMeanCalculator {
private:
double Mean = 0.;
size_t Count = 0;
public:
void Add(const float value) {
++Count;
Mean += (value - Mean) / Count;
}
double GetMean() const {
return Mean;
}
};
class TWelfordCovariationCalculator {
private:
size_t Count = 0;
double MeanX = 0.;
double MeanY = 0.;
double SumProducts = 0.;
public:
void Add(const double x, const double y) {
++Count;
MeanX += (x - MeanX) / Count;
SumProducts += (x - MeanX) * (y - MeanY);
MeanY += (y - MeanY) / Count;
}
double Covariation() const {
return SumProducts / Count;
}
};Использование этих методов может сэкономить много времени и сил в ситуациях, когда данные устроены достаточно "неудачно". Натолкнуться на проблемы с точностью вычислений можно в сколь угодно неожиданных ситуациях, даже при реализации одномерного алгоритма kMeans.
В следующей статье мы рассмотрим применение рассмотренных методов в задаче восстановления линейной регрессии, поговорим о скорости вычислений и о том, как справляются с "плохими" данными распространённые реализации методов машинного обучения.
|
Метки: author ashagraev программирование машинное обучение математика алгоритмы вычислительная математика численные методы метод уэлфорда |
Поиск по документации InterSystems с помощью технологий iKnow и iFind |

Intersystems iKnow это средство анализа неструктурированных данных, предоставляющее доступ к данным путем индексирования содержащихся в тексте предложений и сущностей. Для начала анализа, необходимо создать домен — хранилище неструктурированных данных, и загрузить в него текст. Процесс создания домена хорошо описан здесь и здесь. Об основных способах использования iKnow написано тут, также я рекомендовал бы вам эту статью.
Технология iFind это модуль СУБД Cach'e для выполнения операций полнотекстового поиска по данным классов Cach'e. iFind использует многие функции iKnow для обеспечения интеллектуального текстового поиска. Чтобы использовать iFind в запросах, необходимо описать в классе Cach'e специальный iFind индекс.
Существует три вида индексов iFind, каждый вид индекса предоставляет все функции предыдущего вида, плюс дополнительные функции:
XData Install [ XMLNamespace = INSTALLER ]
{
// Указываем название области
// Проверяем существует ли такая область
// Создаем область
}
Домен, который нужен нам для работы iKnow, строится по таблице содержащей документацию. Так как источником данных является таблица, будем использовать SQL.Lister. Поле content содержит текст документации, значит укажем его как поле данных. Остальные поля укажем в метаданных.
ClassMethod Domain(ByRef pVars, pLogLevel As %String, tInstaller As %Installer.Installer) As %Status
{
#Include %IKInclude
#Include %IKPublic
set ns = $Namespace
znspace "DOCSEARCH"
// Создание домена или открытие если он существует
set dname="DocSearch"
if (##class(%iKnow.Domain).Exists(dname)=1){
write "The ",dname," domain already exists",!
zn ns
quit
}
else {
write "The ",dname," domain does not exist",!
set domoref=##class(%iKnow.Domain).%New(dname)
do domoref.%Save()
}
set domId=domoref.Id
// Lister используется для поиска источников, соответствующих записям в результатах запроса
set flister=##class(%iKnow.Source.SQL.Lister).%New(domId)
set myloader=##class(%iKnow.Source.Loader).%New(domId)
// Построение запроса
set myquery="SELECT id, docKey, title, bookKey, bookTitle, content, textKey FROM SQLUser.DocBook"
set idfld="id"
set grpfld="id"
// Указываем поля данных и метаданных
set dataflds=$LB("content")
set metaflds=$LB("docKey", "title", "bookKey", "bookTitle", "textKey")
//Занесем все данные в Lister
set stat=flister.AddListToBatch(myquery,idfld,grpfld,dataflds,metaflds)
if stat '= 1 {write "The lister failed: ",$System.Status.DisplayError(stat) quit }
//Запускаем процесс анализа
set stat=myloader.ProcessBatch()
if stat '= 1 {
quit
}
set numSrcD=##class(%iKnow.Queries.SourceQAPI).GetCountByDomain(domId)
write "Done",!
write "Domain cointains ",numSrcD," source(s)",!
zn ns
quit
}
Для поиска по документации мы используем индекс %iFind.Index.Analytic:
Index contentInd On (content) As %iFind.Index.Analytic(LANGUAGE = "en", LOWER = 1, RANKERCLASS = "%iFind.Rank.Analytic");После добавления и построения такого индекса, его можно использовать, например в SQL запросах. Общий синтаксис использования iFind в SQL:
SELECT * FROM TABLE WHERE %ID %FIND search_index(indexname,'search_items',search_option)После создания индекса %iFind.Index.Analytic с такими параметрами генерируются несколько SQL процедур вида — [Название таблицы]_[Название индекса]Название процедуры
SELECT DocBook_contentIndRank(%ID, ‘SearchString’, ‘SearchOption’) Rank FROM DocBook WHERE %ID %FIND search_index(contentInd,‘SearchString’, ‘SearchOption’)SELECT DocBook_contentIndHighlight(%ID, ‘SearchString’, ‘SearchOption’,’Tags’) Text FROM DocBook WHERE %ID %FIND search_index(contentInd,‘SearchString’, ‘SearchOption’)Когда вы вводите текст в строке поиска, предлагаются возможные варианты запросов, чтобы помочь быстрее найти нужную информацию. Эти подсказки создаются на основе того слова(или начальной части слова, если ввод слова не закончен) которое вы ввели и пользователю демонстрируются десять наиболее похожих слов или словосочетаний.
Происходит этот процесс с помощью iKnow, метода %iKnow.Queries.Entity.GetSimilar
Технология iFind поддерживает нечеткий поиск, для нахождения слов, почти соответствующих строке поиска. Реализуется с помощью сравнения расстояния Левенштейна между двумя словами. Расстояние Левенштейна — это минимальное количество односимвольных изменений (вставки, удаления или замены), необходимые для изменения одного слова в другое. Может быть использовано для исправления опечаток, небольших вариаций в письменной форме, различных грамматических форм (единственное и множественное число).
В SQL запросах iFind, за использование нечеткого поиска отвечает параметр search_option.
Значение search_option = 3, означает расстояния Левенштейна равное двум.
Для задания расстояния Левенштейна равное n, следует указать значение search_option = ‘3:n’
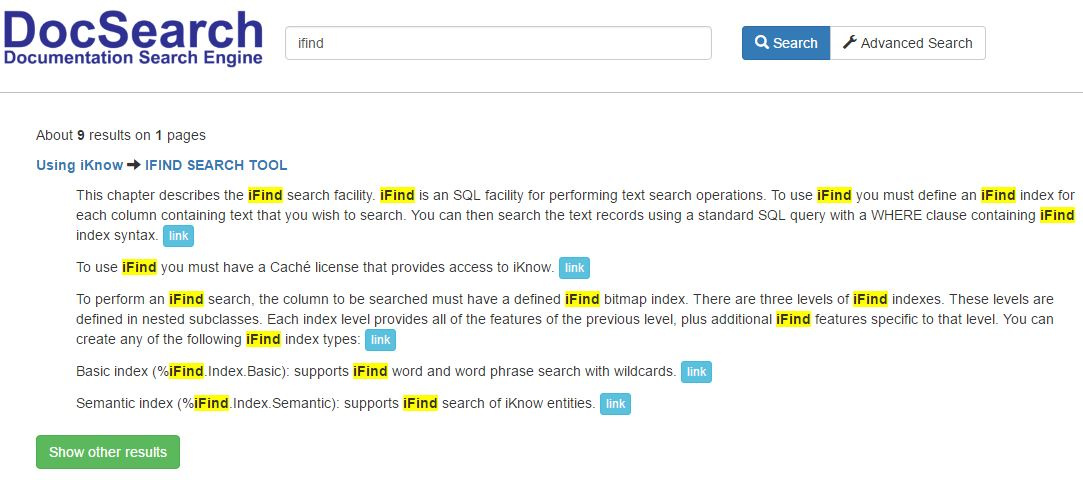
В поиске по документации используется расстояния Левенштейна равное единице, продемонстрируем как это работает:
Наберем в поиске слово ifind:
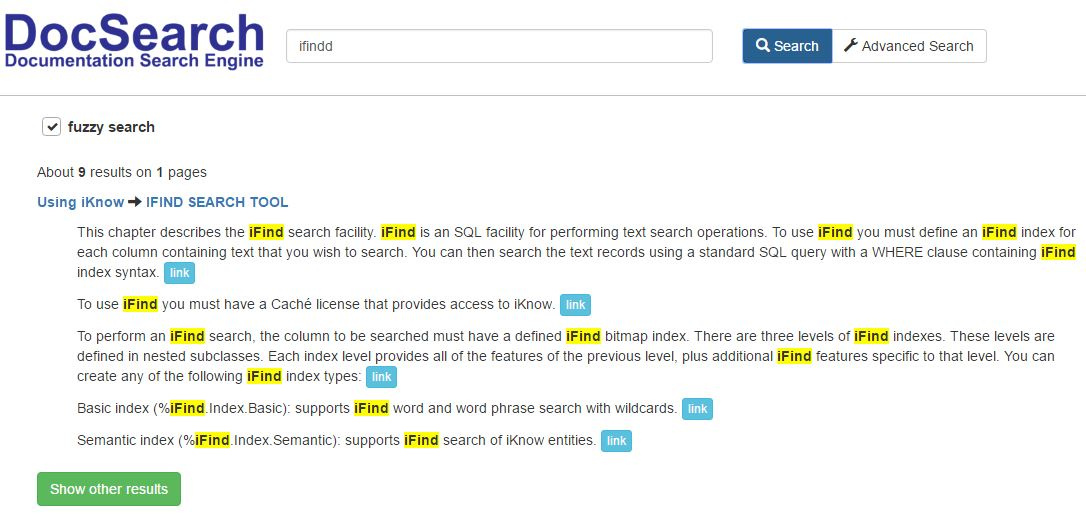
Попробуем произвести нечеткий поиск, например слово с опечаткой — ifindd. Как мы видим поиск исправил опечатку и нашел нужные статьи.
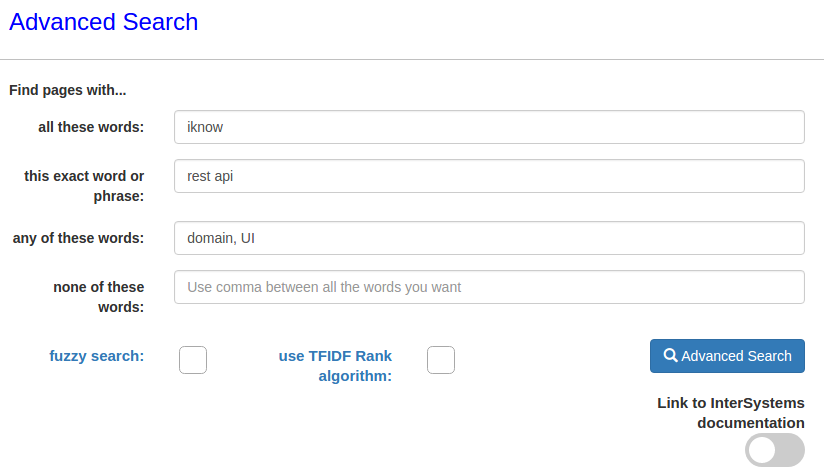
Благодаря тому, что iFind поддерживает сложные запросы с применением скобок и операторов AND OR NOT, мы реализовали расширенный поиск. В поиске можно указать: слово, словосочетания, любое из нескольких слов, либо не содержащие некоторые слова. Поля можно заполнять как одно или несколько, так и все сразу.
Например, найдем статьи содержащие слово iknow, словосочетание rest api и содержащие любое из слов domain или UI.
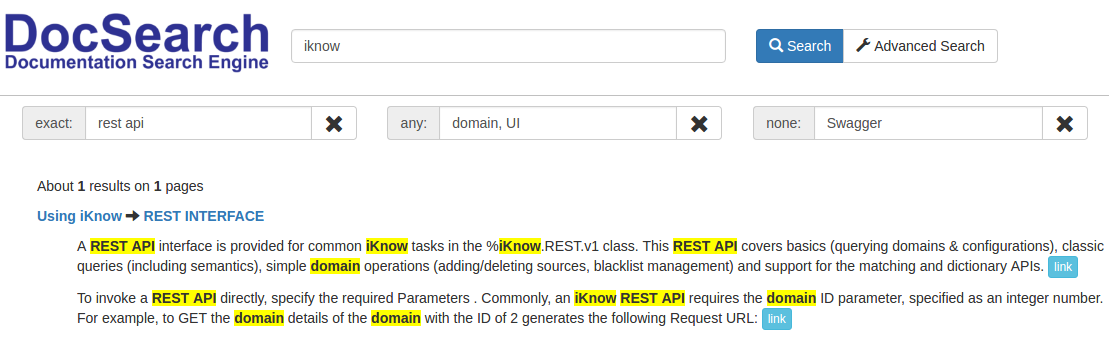
Видим, что таких статей две:
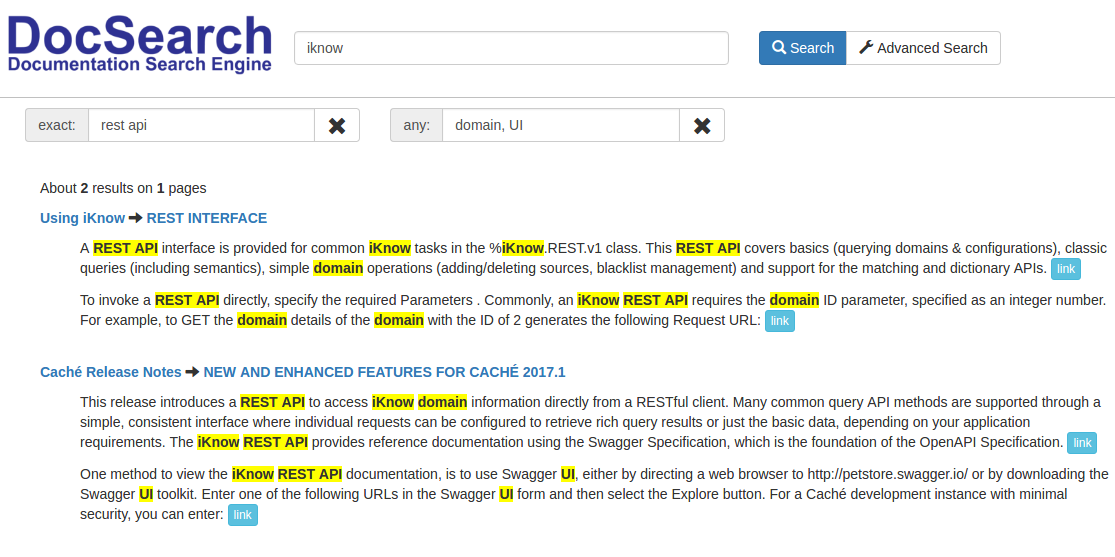
Заметим, что во второй статье упоминается Swagger UI, можно добавить в запрос, поиск статьей, не содержащих слово Swagger
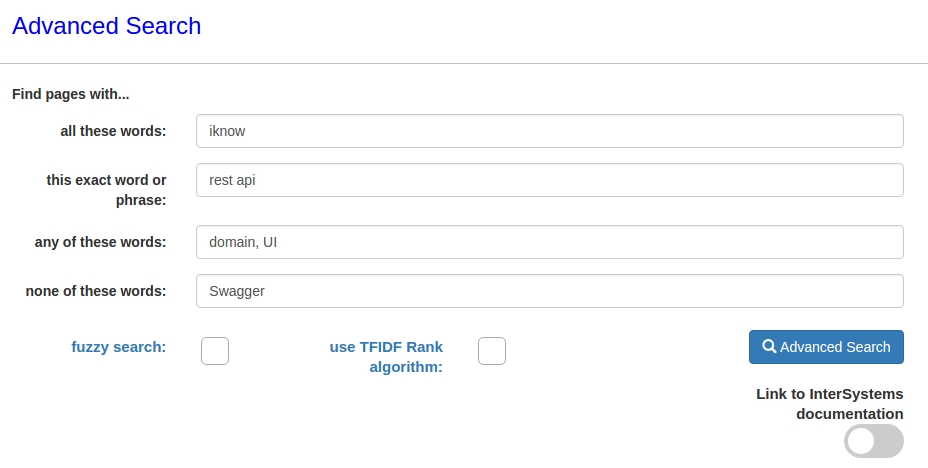
В итоге найдена только одна статья:
Как уже говорилось выше, использование iFind индекса, создает процедуру DocBook_contentIndHighlight. Используя:
SELECT DocBook_contentIndHighlight(%ID, 'search_items', '0', '', 0) Text FROM DocBookПолучаем искомый текст обрамленный в тег
Это позволяет на фронтенде визуально выделять результаты поиска.

iFind поддерживает возможность ранжирования результатов по алгоритму TF-IDF. Мера TF-IDF часто используется в задачах анализа текстов и информационного поиска, например, как один из критериев релевантности документа поисковому запросу.
В результате SQL запроса, поле Rank будет содержать вес слова, который пропорционален количеству употребления этого слова в статье, и обратно пропорционален частоте употребления слова в других статьях.
SELECT DocBook_contentIndRank(%ID, ‘SearchString’, ‘SearchOption’) Rank FROM DocBook WHERE %ID %FIND search_index(contentInd,‘SearchString’, ‘SearchOption’)После установки, в официальный поиск по документации добавляется кнопка “Search using iFind”.

Если заполнено поле Search words, то после нажатия на “Search using iFind”, будет выполнен переход на страницу с результатами поиска для введенного запроса.
do ##class(Docsearch.Installer).setup(.pVars)|
Метки: author ereminkostya разработка веб-сайтов программирование data mining блог компании intersystems intersystems intersystems cache iknow ifind |
[Перевод] Создание шейдера дыма на GLSL |

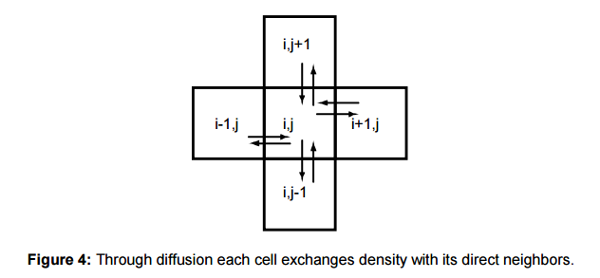

100. Вы видите, как каждая ячейка постепенно передаёт своё значение соседним. Проще всего это увидеть, нажав Next для просмотра отдельных кадров. Переключите Display Mode, чтобы увидеть, как это будет выглядеть, когда этим числам соответствуют значения цвета.//W = количество столбцов в сетке
//H = количество строк
//f = коэффициент распределения/рассеивания
//Сначала мы копируем сетку в newGrid, чтобы не изменять сетку, потому что выполняем считывание из неё
for(var r=1; rcode>f — коэффициент меньше 1. Мы умножаем текущее значение ячейки на 4, чтобы оно рассеивалось от высоких к низким значениям.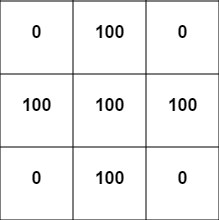
[1,1] в сетке) и применим указанное выше уравнение рассеивания. Допустим, что f равен 0.1:0.1 * (100+100+100+100-4*100) = 0.1 * (400-400) = 00):0.1 * (100+100+0+0-4*0) = 0.1 * (200) = 20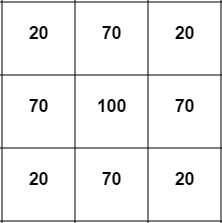
0.1 * (70+70+70+70-4*100) = 0.1 * (280 - 400) = -12uniform vec2 res;
void main() {
vec2 pixel = gl_FragCoord.xy / res.xy;
gl_FragColor = vec4(0.0,0.0,0.0,1.0);
}res и pixel сообщают нам координаты текущего пикселя. Мы передаём размеры экрана в res как uniform-переменную. (Пока мы их не используем, но скоро они пригодятся.)Наша общая техника заключается в том, что каждый пиксель каждый кадр теряет часть своего значения цвета и передаёт его соседним пикселям.
Каждый пиксель должен получить немного цвета своих соседей и потерять немного своего.
uniform vec2 res;
uniform sampler2D texture;
void main() {
vec2 pixel = gl_FragCoord.xy / res.xy;
gl_FragColor = texture2D( tex, pixel );// Это цвет текущего пикселя
gl_FragColor.r += 0.01;// Инкремент красного компонента
}0.01. Вместо этого мы получим статичное изображение, в котором все пиксели стали всего немного краснее, чем в начале. Красный компонент каждого пикселя увеличится только один раз, несмотря на то, что шейдер выполняется каждый кадр.
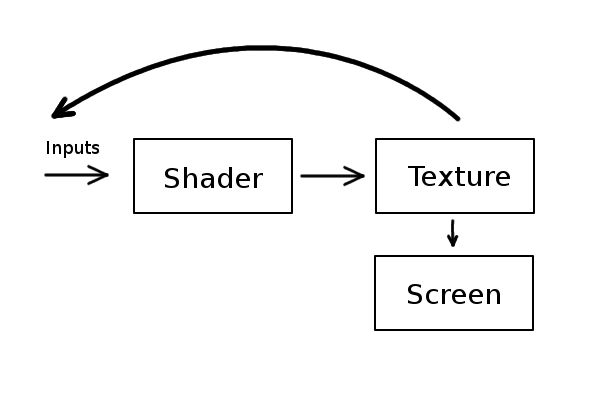
uniform vec2 res; // Ширина и высота экрана
uniform sampler2D bufferTexture; // Входная текстура
void main() {
vec2 pixel = gl_FragCoord.xy / res.xy;
gl_FragColor = texture2D( bufferTexture, pixel );
}gl_FragColor.r += 0.01;gl_FragColor.r += pixel.x; в примере с буфером кадра, в отличие от первоначального примера? Подумайте немного, почему отличаются результаты, и почему они именно такие.// Получаем расстояние от этого пикселя до центра экрана
float dist = distance(gl_FragCoord.xy, res.xy/2.0);
if(dist < 15.0){ // Создаём круг радиусом 15 пикселей
gl_FragColor.rgb = vec3(1.0);
}// Получаем расстояние от этого пикселя до центра экрана
float dist = distance(gl_FragCoord.xy, res.xy/2.0);
if(dist < 15.0){ // Создаём круг радиусом 15 пикселей
gl_FragColor.rgb += 0.01;
}// Ширина и высота экрана
uniform vec2 res;
// Входная текстура
uniform sampler2D bufferTexture;
// x,y - это положение. z - это сила/плотность
uniform vec3 smokeSource;
void main() {
vec2 pixel = gl_FragCoord.xy / res.xy;
gl_FragColor = texture2D( bufferTexture, pixel );
// Получаем расстояние от текущего пикселя до источника дыма
float dist = distance(smokeSource.xy,gl_FragCoord.xy);
// Создаём дым, когда нажата клавиша мыши
if(smokeSource.z > 0.0 && dist < 15.0){
gl_FragColor.rgb += smokeSource.z;
}
}// Рассеивание дыма
float xPixel = 1.0/res.x; // Размер единичного пикселя
float yPixel = 1.0/res.y;
vec4 rightColor = texture2D(bufferTexture,vec2(pixel.x+xPixel,pixel.y));
vec4 leftColor = texture2D(bufferTexture,vec2(pixel.x-xPixel,pixel.y));
vec4 upColor = texture2D(bufferTexture,vec2(pixel.x,pixel.y+yPixel));
vec4 downColor = texture2D(bufferTexture,vec2(pixel.x,pixel.y-yPixel));
// Уравнение рассеивания
gl_FragColor.rgb +=
14.0 * 0.016 *
(
leftColor.rgb +
rightColor.rgb +
downColor.rgb +
upColor.rgb -
4.0 * gl_FragColor.rgb
);f остаётся прежним. В этом случае у нас есть временной шаг (0.016, то есть 1/60, потому что программа выполняется с частотой 60 fps), и я подбирал разные числа, пока не остановился на значении 14, которое хорошо выглядит. Вот результат:float factor = 14.0 * 0.016 * (leftColor.r + rightColor.r + downColor.r + upColor.r - 4.0 * gl_FragColor.r);
// Нам нужно учитывать низкую точность текселов
float minimum = 0.003;
if (factor >= -minimum && factor < 0.0) factor = -minimum;
gl_FragColor.rgb += factor;r вместо rgb, потому что легче работать с отдельными числами и потому, что все компоненты всё равно имеют одинаковые значения (так как дым белый).0.003, при котором программа не останавливается. Меня беспокоит только коэффициент при отрицательном значении, чтобы гарантировать его постоянное уменьшение. Добавив это исправление, мы получим следующее:// Уравнение рассеивания
float factor = 8.0 * 0.016 *
(
leftColor.r +
rightColor.r +
downColor.r * 3.0 +
upColor.r -
6.0 * gl_FragColor.r
);6.0 на 5.0 и посмотрите, что получится). Очевидно, что это происходит из-за того, что ячейки получают больше, чем теряют.diffuse_advanced().0:// Обрабатываем нижнюю границу
// Эти строки нужно выполнять до функции рассеивания
if(pixel.y <= yPixel){
downColor.rgb = vec3(0.0);
}0. (Сетка в демо для ЦП выходит за границы во всех направлениях на одну строку и один столбец, то есть мы никогда не видим границ)
|
Метки: author PatientZero разработка игр обработка изображений webgl шейдеры opengl glsl |
Анонс RamblerFront& #2 |

В коде начинающих программистов обычно много ошибок. Постепенно мы набираемся опыта, код становится надежнее, покрывается тестами, и нам кажется, что ошибки в нашем коде практически исключены. Но фронтенд — это неконтролируемая среда и произойти может что угодно. Небольшой доклад о том, как начать использовать ошибки в свою пользу.
Павел расскажет про способы тестирования верстки и сам Galen Framework — что это и как работает, опыт использования на проекте, его плюсы и минусы, а также небольшое сравнение с BackstopJS.
Михаил расскажет об оптимизации изоморфного react-приложения на примере обновленного сайта rambler.ru. Также разберем assets, конфигурацию Webpack и Server Side Rendering.

|
Метки: author SanDark7 reactjs javascript html css блог компании rambler co frontend react redux galen framework |
КОГДА В РОССИИ ЖДАТЬ 5G |
|
Метки: author info_habr тестирование it-систем разработка систем связи блог компании мтс мтс 5g lte 4g передача данных |






