InnoDB cluster — оно работает, и вроде бы именно так, как обещали |
Я занимаюсь АТСками. И как-то так сложилась, что с самого первого заказа от меня хотели отказоустойчивости. Одним из ключевых компонентов современной АТС (как и любой информационной системы, наверное) является БД, где хранятся как данные о текущем состоянии системы, так и всякие конфигурационные параметры. Естественно, падение БД приводит к поломке всей системы. Начиналось все с MASTER-MASTER репликации в MySQL (исключительно для оперативности переключения), потом были эксперименты с MySQL over DRBD. Все это жило в pacemaker/corosync инфраструктуре. Там ездили IP-адреса, шлюзы и прочая лабудень. Со временем оно даже стало работать как-то более-менее устойчиво. Но тут мне попалась пара серверов, на которых DRBD сделать было нельзя, в MASTER-MASTER я разочаровался довольно давно (постоянно она у меня ломается, такая репликация), а без отказоустойчивой БД терялся весь смысл решения. На глаза мне попалось название InnoDB cluster и я решил: "была-не-была". Что из этого получилось — смотрите под катом.
Я все делаю на Debian Jessie. В других системах отличия будут, но не очень существенные.
Нам понадобятся:
Скачиваем (это можно сделать только вручную, пройдя регистрацию на сайте Оракла) и устанавливаем файл репозитория, обновляем наш кэш, устанавливаем MySQL Router (интересный зверь, познакомимся ниже) и MySQL Client:
dpkg -i mysql-apt-config_0.8.6-1_all.deb
apt-get update
apt-get install mysql-router
apt-get install mysql-clientРаспаковываем и раскладываем по местам MySQL Shell из архива. Двигаемся дальше, ставим сервер:
apt-get install mysql-serverТут устанавливаем ВСЕ предложенные компоненты (обратите внимание, третий компонент в списке по-умолчанию не выбран, а он понадобится). И останавливаем запущенный сразу ретивым установщиком сервер:
systemctl stop mysqlДалее, идем в
/etc/mysql/mysql.conf.d/mysqld.cnf и пишем туда что-то типа:
[mysqld]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
log-error = /var/log/mysql/error.log
bind-address = 0.0.0.0
port = 3300
symbolic-links=0
# Replication part
server_id=3
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
binlog_checksum=NONE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW
# Group replication part
transaction_write_set_extraction=XXHASH64
loose-group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
loose-group_replication_start_on_boot=off
loose-group_replication_local_address= "1.1.1.1:33061"
loose-group_replication_group_seeds= "1.1.1.1:33061,1.1.1.2:33061,1.1.1.3:33061"
loose-group_replication_bootstrap_group= off
Здесь уже надо остановиться подробнее.
Первая опция, заслуживающая нашего внимания — port Рекомендую её значение устанавливать отличным от 3306. Почему — станет понятно ниже (на 3306 мы повесим кое-что другое)
Следующая: server_id. Для каждого сервера mysql в кластере это значение должно быть уникальным.
Опция, которая съела пару часов моего времени — безобидная (казалось бы) group_replication_local_address. Эта опция говорит о том, на каком адресе/порту слушать обращения за репликами с локальной БД. Алгоритм, по которому MySQL определяет, является ли указанный в этом поле IP-адрес локальным, мне угадать не удалось. На машине с 2-мя активными интерфейсами и тремя IP-адресами, подвешенными на эти интерфейсы только один адрес устроил MySQL.
И последняя: group_replication_group_seeds — в ней перечисляются сокеты, на которые необходимо обращаться (в указанном порядке) с попытками заказать реплики актуальных данных при подключении.
За подробностями можно обратиться на страничку с официальной документацией по GROUP REPLICATION
Итак, развернув на машине MySQL и настроив его таким образом двигаемся дальше. Удаляем все содержимое /var/lib/mysql Я серьезно. Взяли себя в руки, пошли и удалили. Если там лежит что-то, что дорого Вам как память — сделайте предварительно бэкап. Можно. Запускаем mysql:
systemctl start mysqlВ общем-то, все подготовительные манипуляции завершены. Описанную процедуру надо будет повторить на всех серверах, которые планируется объединять в кластер.
Теперь особенности для первого сервера. Для начала объявляем root:
mysql
> create user 'root'@'%' identified by 'ochen-strashniy-parol';
> grant all to 'root'@'%' on *.* with grant option;
> flush privileges;
> \qЯ знаю, знаю, знаю… Несекьюрно. Но, поверьте, указанному в документации набору привилегий верить нельзя (проверял: не работает), и подключиться с локалхоста тоже не выйдет. Более точный вариант с выделением отдельного пользователя в следующий раз, как будет "час та натхнення".
Потом подгружаем модуль X. Честно-честно, именно так его и зовут:
mysqlsh --classic --dba enableXProtocolИ в этот момент модные брюки превращаются… превращаются… превращаются в элегантные шорты. То бишь, MySQL уже не совсем SQL, а вовсе даже Document Store
Но нас это никак не расстраивает, поэтому двигаемся дальше:
mysqlshТеперь мы можем общаться с MySQL на JavaScript. Для начала подключимся к нашему серверу:
\c root@1.1.1.1:3300Введем пароль и проверим, все ли в порядке с нашим сервером, подходит ли его конфигурация для кластеризации:
dba.checkInstanceConfiguration('root@1.1.1.1:3300')Если все сделано по инструкции, то вопросов быть не должно. Если вопросы есть — исправляем, дока вам в помощь. В принципе, там даже есть возможность сгенерировать конфигурацию самостоятельно:
dba.configureLocalInstance('localhost:3300', {password:'somePwd', mycnfPath:'some path'})Однако, у меня этот вариант сходу не заработал, потребовались допиливания напильником конфига до состояния, указанного в начале заметки. Естественно, что после каждого перепиливания конфига, сервер надо перезапускать. Например, при помощи systemctl restart mysq. Ну или как вам больше нравится…
Создаем кластер (предполагаю, что вы все еще в mysqlsh и сессия не обрывалась):
var cl = dba.createCluster('moyCluster')Ну и добавляем в него только что настроенный сервер:
cl.addInstance('root@1.1.1.1:3300')Начиная с этого момента рекомендую на какой-нибудь отдельной консоли держать
tail -f /var/log/mysql/error.logи при появлении любых ошибок туда поглядывать. Вывод у mysqlsh не очень информативный, а в логе есть все необходимое. В доке говорят, что можно увеличить уровень дебага вывода, но я не пробовал.
Если ошибок до данного момента не наблюдалось, то у нас есть кластер из одной машины.
Последняя манипуляция на данном сервере:
mysqldump --all-databases --triggers --routines --events > dump.sqlТеперь займемся остальными. Для этого на всех машинах повторяем манипуляции, описанные от начал статьи и до
systemctl start mysqlНе забываем поправить значения server_id и group_replication_local_address. После этого:
mysql
> reset master;
mysql < dump.sqlДа-да, заливаем в машину дамп с работающего в кластере сервера. Теперь с локальной машины (той, на которой крутится инстанс mysql-server`а, который мы будем подключать к кластеру) делаем:
mysql
> set GLOBAL group_replication_allow_local_disjoint_gtids_join=ON;
mysqlsh
> dba.checkInstanceConfiguration('root@1.1.1.2:3300')
> \c root@1.1.1.1:3300
> var cl = getCluster('moyCluster')
> cl.addInstance('root@1.1.1.2:3300',{ipWhitelist: '1.1.1.0/24, 127.0.0.1/8'})Если мы ничего не перепутали, то в этот момент у нас в кластере уже две машины. Аналогично добавляем третью.
В данный момент у нас есть кластер, который сам за собой присматривает, выбирает мастера и реплицируется на слэйвы. К каждому серверу можно обратиться на его порт 3300 и, если вы обратитесь к мастеру, то вы сможете читать и писать, а если к слейву — то только читать. Выяснить, мастером является сервер или слейвом можно из вывода cluster.status(). Но это еще не очень удобно. Хотелось бы обращаться всегда в одно и то же место, на один и тот же ip/port и не зависеть от внутреннего состояния кластера. Для этого используем MySQL Router Прямо в доке есть пример его начального конфигурирования, который делает почти все, что нам нужно. Изменим его немного:
mysqlrouter --bootstrap 1.1.1.1:3300 --user mysqlrouterТеперь идем в /etc/mysqlrouter/mysqlrouter.conf и исправляем там порты как-нибудь так:
[routing:moyCluster_default_rw]
...
bind_port=3306
...
[routing:moyCluster_default_ro]
...
bind_port=3307
...После этого можно делать
systemctl start mysqlrouterИ теперь у вас на порту 3306 отвечает обычный mysql с поддержкой чтения/записи вне зависимости от того, какая из машин кластера сейчас мастером, а какая слейвом. На 3307 — всегда read-only. Количество экземпляров mysqlrouter никак не ограничено, вы можете на каждой клиентской машине запустить свой экземпляр и повесить его на внутренний интерфейс 127.0.0.1:3306. mysqlrouter сам отслеживает изменения в кластере (как добавления, так и пропадания нод в нем) и актуализирует маршрутизацию. Происходит это раз в пять минут (если верить логам). Если в этом промежутке возникает обращение которое не может быть обработано (нода выпала или была целенаправленно выведена из кластера), то роутер дает отказ в исполнении транзакции и перечитывает состояние кластера во внеочередном порядке.
Кстати, если по какой-то причине нода отвалилась от кластера, её можно вернуть в семью командой
mysqlsh
> \c root@
> var cl = dba.getCluster('moyCluster')
> cl.rejoinInstance('root@ip:port-отвалившейся_ноды')Спасибо, что дочитали. Надеюсь, что это будет полезно. Если заметите в тексте неточности — пишите в комментарии, писал на горячую, но по памяти, так что мог напутать.
|
Метки: author Borikinternet хранилища данных администрирование баз данных mysql clusterization базы данных innodb |
Константин Кривопустов и Алексей Стукалов о CUBA Platform на jug.msk.ru |





|
Метки: author dbelob java блог компании jug.ru group jug jug.msk.ru cuba haulmont |
Proxmox 5 и частичная запись в блочных устройствах эффективного хранения Ceph |
|
|
Как запутать аналитика. Часть третья. Глаголы и числителные |
|
Метки: author maxstroy семантика проектирование и рефакторинг анализ и проектирование систем it- стандарты моделирование предметной области аналитика |
Книга «Машинное обучение» |
 Привет, Хаброжители к нам из типография наконец-то пришла новинка от Хенрика Бринка, Джозефа Ричардса и Марка Февероволофа.
Привет, Хаброжители к нам из типография наконец-то пришла новинка от Хенрика Бринка, Джозефа Ричардса и Марка Февероволофа.|
Метки: author ph_piter профессиональная литература машинное обучение блог компании издательский дом «питер» книги |
Кто владеет данными, генерируемыми устройствами из интернета вещей? |




|
|
Big Data в Райффайзенбанке |


|
Метки: author msetkin big data блог компании райффайзенбанк hadoop hortonworks spark data lake |
Бэкап скриптами в облако Google Cloud Platform (GCP) за пять минут |
gcloud initgsutil -m rsync -r -d -e -C file://c:\bak gs://bakwinImport-Module GoogleCloud$folder = "C:\Bak"
$bucket = "gs:\backupwin"$date = Get-date -format dd.MM.yyyy
$bucket = $bucket + "\" + $date
mkdir $bucketcd $folder
$files = Get-ChildItem -Recurse -Attributes !Directory
$data = @()
foreach ($file in $files) {
$objectPath = $file | Resolve-Path -Relative
$data += @{file = $file; objectPath = $objectPath} #
}
cd $bucket
foreach($element in $data) {
Write-Host $element.objectPath
New-Item -ItemType File -Path $element.objectPath
}|
|
Опыт создания реалтайм видео-секвенсора на iOS |
Привет, меня зовут Антон и я iOS-разработчик в Rosberry. Не так давно мне довелось работать над проектом Hype Type и решить несколько интересных задач по работе с видео, текстом и анимациями. В этой статье я расскажу о подводных камнях и возможных путях их обхода при написании реалтайм видео-секвенсора на iOS.
Hype Type позволяет пользователю записать несколько коротких отрывков видео и/или фотографий общей длительностью до 15 секунд, добавить к полученному ролику текст и применить к нему одну из анимаций на выбор.

Основная особенность работы с видео в данном случае состоит в том, что у юзера должна быть возможность управлять отрывками видео независимо друг от друга: изменять скорость воспроизведения, делать реверс, флип и (возможно в будущих версиях) на лету менять отрывки местами.

“Почему бы не использовать AVMutableComposition?” — можете спросить вы, и, в большинстве
случаев, будете правы — это действительно достаточно удобный системный видео-секвенсор, но, увы, у него есть ограничения, которые не позволили нам его использовать. В первую очередь, это невозможность изменения и добавления треков на лету — чтобы получить измененный видеопоток потребуется пересоздавать AVPlayerItem и переинициализировать AVPlayer. Также в AVMutableComposition далеко не идеальна работа с изображениями — для того, чтобы добавить в таймлайн статичное изображение, придется использовать AVVideoCompositionCoreAnimationTool, который добавит изрядное количество оверхеда и значительно замедлит рендер.
Недолгий поиск по просторам интернета не выявил никаких других более-менее подходящих под задачу решений, поэтому было решено написать свой секвенсор.
Для начала — немного о структуре render pipeline в проекте. Сразу скажу, я не буду слишком вдаваться в детали и буду считать что вы уже более-менее знакомы с этой темой, иначе этот материал разрастется до невероятных масштабов. Если же вы новичок — советую обратить внимание на достаточно известный фреймворк GPUImage (Obj-C, Swift) — это отличная стартовая точка для того, чтобы на наглядном примере разобраться в OpenGLES.
View, которая занимается отрисовкой полученного видео на экране по таймеру (CADisplayLink), запрашивает кадры у секвенсора. Так как приложение работает преимущественно с видео, то логичнее всего использовать YCbCr colorspace и передавать каждый кадр как CVPixelBufferRef. После получения кадра создаются luminance и chrominance текстуры, которые передаются в shader program. На выходе получается RGB изображения, которое и видит пользователь. Refresh loop в данном случае будет выглядеть примерно так:
- (void)onDisplayRefresh:(CADisplayLink *)sender {
// advance position of sequencer
[self.source advanceBy:sender.duration];
// check for new pixel buffer
if ([self.source hasNewPixelBuffer]) {
// get one
PixelBuffer *pixelBuffer = [self.source nextPixelBuffer];
// dispatch to gl processing queue
[self.context performAsync:^{
// prepare textures
self.luminanceTexture = [self.context.textureCache textureWithPixelBuffer:pixelBuffer planeIndex:0 glFormat:GL_LUMINANCE];
self.chrominanceTexture = [self.context.textureCache textureWithPixelBuffer:pixelBuffer planeIndex:1 glFormat:GL_LUMINANCE_ALPHA];
// prepare shader program, uniforms, etc
self.program.orientation = pixelBuffer.orientation;
// ...
// signal to draw
[self setNeedsRedraw];
}];
}
if ([self.source isFinished]) {
// rewind if needed
[self.source rewind];
}
}
// ...
- (void)draw {
[self.context performSync:^{
// bind textures
[self.luminanceTexture bind];
[self.chrominanceTexture bind];
// use shader program
[self.program use];
// unbind textures
[self.luminanceTexture unbind];
[self.chrominanceTexture unbind];
}];
}Практически все здесь построено на обертках (для CVPixelBufferRef, CVOpenGLESTexture и т.д.), что позволяет вынести основную low-level логику в отдельный слой и значительно упростить базовые моменты работы с OpenGL. Конечно, у этого есть свои минусы (в основном — небольшая потеря производительности и меньшая гибкость), однако они не столь критичны. Что стоит пояcнить: self.context — достаточно простая обертка над EAGLContext, облегчающая работу с CVOpenGLESTextureCache и многопоточными обращениями к OpenGL. self.source — секвенсор, который решает, какой кадр из какого трека отдать во view.
Теперь о том, как организовано получение кадров для рендеринга. Так как секвенсор должен работать как с видео, так и картинками, логичнее всего закрыть все общим протоколом. Таким образом, задача секвенсора сведется к тому, чтобы следить за playhead и, в зависимости от ее позиции, отдавать новый кадр из соответствующего трека.
@protocol MovieSourceProtocol
// start & stop reading methods
- (void)startReading;
- (void)cancelReading;
// methods for getting frame rate & current offset
- (float)frameRate;
- (float)offset;
// method to check if we already read everything...
- (BOOL)isFinished;
// ...and to rewind source if we did
- (void)rewind;
// method for scrubbing
- (void)seekToOffset:(CGFloat)offset;
// method for reading frames
- (PixelBuffer *)nextPixelBuffer;
@end Логика того, как получать кадры, ложится на объекты, реализующие MovieSourceProtocol. Такая схема позволяет сделать систему универсальной и расширяемой, так как единственным отличием в обработке изображений и видео будет только способ получения кадров.
Таким образом, VideoSequencer становится совсем простым, и главной сложностью остается определение текущего трека и приведение всех треков к единому frame rate.
- (PixelBuffer *)nextPixelBuffer {
// get current track
VideoSequencerTrack *track = [self trackForPosition:self.position];
// get track source
id source = track.source; // Here's our source
// get pixel buffer
return [source nextPixelBuffer];
} VideoSequencerTrack здесь — обертка над объектом, реализующим MovieSourceProtocol, содержащая различную метадату.
@interface FCCGLVideoSequencerTrack : NSObject
- (id) initWithSource:(id)source;
@property (nonatomic, assign) BOOL editable;
// ... and other metadata
@end Теперь перейдем непосредственно к получению кадров. Рассмотрим простейший случай — отображение одной картинки. Получить ее возможно либо с камеры, и тогда мы сразу можем получить CVPixelBufferRef в формате YCbCr, который достаточно просто скопировать (почему это важно, я объясню чуть позже) и отдавать по запросу; либо из медиа-библиотеки — в этом случае придется немного извернуться и вручную конвертировать изображение в нужный формат. Операцию конвертирования из RGB в YCbCr можно было вынести на GPU, однако на современных девайсах и CPU справляется с этой задачей достаточно быстро, особенно учитывая тот факт, что приложение дополнительно кропает и сжимает изображение перед тем, как его использовать. В остальном же все достаточно просто, все что нужно делать — отдавать один и тот же кадр в течение отведенного промежутка времени.
@implementation ImageSource
// init with pixel buffer from camera
- (id)initWithPixelBuffer:(PixelBuffer *)pixelBuffer orientation:(AVCaptureVideoOrientation)orientation duration:(NSTimeInterval)duration {
if (self = [super init]) {
self.orientation = orientation;
self.pixelBuffer = [pixelBuffer copy];
self.duration = duration;
}
return self;
}
// init with UIImage
- (id)initWithImage:(UIImage *)image duration:(NSTimeInterval)duration {
if (self = [super init]) {
self.duration = duration;
self.orientation = AVCaptureVideoOrientationPortrait;
// prepare empty pixel buffer
self.pixelBuffer = [[PixelBuffer alloc] initWithSize:image.size pixelFormat:kCVPixelFormatType_420YpCbCr8BiPlanarFullRange];
// get base addresses of image planes
uint8_t *yBaseAddress = self.pixelBuffer.yPlane.baseAddress;
size_t yPitch = self.pixelBuffer.yPlane.bytesPerRow;
uint8_t *uvBaseAddress = self.pixelBuffer.uvPlane.baseAddress;
size_t uvPitch = self.pixelBuffer.uvPlane.bytesPerRow;
// get image data
CFDataRef pixelData = CGDataProviderCopyData(CGImageGetDataProvider(image.CGImage));
uint8_t *data = (uint8_t *)CFDataGetBytePtr(pixelData);
uint32_t imageWidth = image.size.width;
uint32_t imageHeight = image.size.height;
// do the magic (convert from RGB to YCbCr)
for (int y = 0; y < imageHeight; ++y) {
uint8_t *rgbBufferLine = &data[y * imageWidth * 4];
uint8_t *yBufferLine = &yBaseAddress[y * yPitch];
uint8_t *cbCrBufferLine = &uvBaseAddress[(y >> 1) * uvPitch];
for (int x = 0; x < imageWidth; ++x) {
uint8_t *rgbOutput = &rgbBufferLine[x * 4];
int16_t red = rgbOutput[0];
int16_t green = rgbOutput[1];
int16_t blue = rgbOutput[2];
int16_t y = 0.299 * red + 0.587 * green + 0.114 * blue;
int16_t u = -0.147 * red - 0.289 * green + 0.436 * blue;
int16_t v = 0.615 * red - 0.515 * green - 0.1 * blue;
yBufferLine[x] = CLAMP(y, 0, 255);
cbCrBufferLine[x & ~1] = CLAMP(u + 128, 0, 255);
cbCrBufferLine[x | 1] = CLAMP(v + 128, 0, 255);
}
}
CFRelease(pixelData);
}
return self;
}
// ...
- (BOOL)isFinished {
return (self.offset > self.duration);
}
- (void)rewind {
self.offset = 0.0;
}
- (PixelBuffer *)nextPixelBuffer {
if ([self isFinished]) {
return nil;
}
return self.pixelBuffer;
}
// ...А теперь добавим видео. Для этого было решено использовать AVPlayer — в основном из-за того, что он имеет достаточно удобное API для получения кадров и полностью берет на себя работу со звуком. В общем, звучит достаточно просто, но есть и некоторые моменты, на которые стоит обратить внимание.
Начнем с очевидного:
- (void)setURL:(NSURL *)url withCompletion:(void(^)(BOOL success))completion {
self.setupCompletion = completion;
// prepare asset
self.asset = [[AVURLAsset alloc] initWithURL:url options:@{
AVURLAssetPreferPreciseDurationAndTimingKey : @(YES),
}];
// load asset tracks
__weak VideoSource *weakSelf = self;
[self.asset loadValuesAsynchronouslyForKeys:@[@"tracks"] completionHandler:^{
// prepare player item
weakSelf.playerItem = [AVPlayerItem playerItemWithAsset:weakSelf.asset];
[weakSelf.playerItem addObserver:weakSelf forKeyPath:@"status" options:NSKeyValueObservingOptionNew context:nil];
}];
}
- (void)observeValueForKeyPath:(NSString *)keyPath ofObject:(id)object change:(NSDictionary *)change context:(void *)context {
if(self.playerItem.status == AVPlayerItemStatusReadyToPlay) {
// ready to play, prepare output
NSDictionary *outputSettings = @{
(id)kCVPixelBufferPixelFormatTypeKey: @(kCVPixelFormatType_420YpCbCr8BiPlanarFullRange),
(id)kCVPixelBufferOpenGLESCompatibilityKey: @(YES),
(id)kCVPixelBufferOpenGLCompatibilityKey: @(YES),
(id)kCVPixelBufferIOSurfacePropertiesKey: @{
@"IOSurfaceOpenGLESFBOCompatibility": @(YES),
@"IOSurfaceOpenGLESTextureCompatibility": @(YES),
},
};
self.videoOutput = [[AVPlayerItemVideoOutput alloc] initWithPixelBufferAttributes:outputSettings];
[self.playerItem addOutput:self.videoOutput];
if (self.setupCompletion) {
self.setupCompletion();
}
};
}
// ...
- (void) rewind {
[self seekToOffset:0.0];
}
- (void)seekToOffset:(CGFloat)offset {
[self.playerItem seekToTime:[self timeForOffset:offset] toleranceBefore:kCMTimeZero toleranceAfter:kCMTimeZero];
}
- (PixelBuffer *)nextPixelBuffer {
// check for new pixel buffer...
CMTime time = self.playerItem.currentTime;
if(![self.videoOutput hasNewPixelBufferForItemTime:time]) {
return nil;
}
// ... and grab it if there is one
CVPixelBufferRef bufferRef = [self.videoOutput copyPixelBufferForItemTime:time itemTimeForDisplay:nil];
if (!bufferRef) {
return nil;
}
PixelBuffer *pixelBuffer = [[FCCGLPixelBuffer alloc] initWithPixelBuffer:bufferRef];
CVBufferRelease(bufferRef);
return pixelBuffer;
}Создаем AVURLAsset, подгружаем информацию о треках, создаем AVPlayerItem, дожидаемся нотификации о том, что он готов к воспроизведению и создаем AVPlayerItemVideoOutput с подходящими для рендера параметрами — все по-прежнему достаточно просто.
Однако тут же кроется и первая проблема — seekToTime работает недостаточно быстро, и при loop’е есть заметные задержки. Если же не изменять параметры toleranceBefore и toleranceAfter, то это мало что меняет, за исключением того, что, кроме задержки, добавляется еще и неточность позиционирования. Это ограничение системы и полностью его не решить, но можно обойти, для чего достаточно готовить 2 AVPlayerItem’a и использовать их по очереди — как только один из них заканчивает воспроизведение, тут же начинает играть другой, в то время как первый перематывается на начало. И так по кругу.
Еще одна неприятная, но решаемая проблема — AVFoundation как следует (seamless & smooth) поддерживает изменение скорости воспроизведения и reverse далеко не для всех типов файлов, и, если в случае с записи с камеры выходной формат мы контролируем, то в случае, если пользователь загружает видео из медиа-библиотеки, такой роскоши у нас нет. Заставлять пользователей ждать, пока видео сконвертируется — выход плохой, тем более далеко не факт, что они будут использовать эти настройки, поэтому было решено делать это в бэкграунде и незаметно подменять оригинальное видео на сконвертированное.
- (void)processAndReplace:(NSURL *)inputURL outputURL:(NSURL *)outputURL {
[[NSFileManager defaultManager] removeItemAtURL:outputURL error:nil];
// prepare reader
MovieReader *reader = [[MovieReader alloc] initWithInputURL:inputURL];
reader.timeRange = self.timeRange;
// prepare writer
MovieWriter *writer = [[FCCGLMovieWriter alloc] initWithOutputURL:outputURL];
writer.videoSettings = @{
AVVideoCodecKey: AVVideoCodecH264,
AVVideoWidthKey: @(1280.0),
AVVideoHeightKey: @(720.0),
};
writer.audioSettings = @{
AVFormatIDKey: @(kAudioFormatMPEG4AAC),
AVNumberOfChannelsKey: @(1),
AVSampleRateKey: @(44100),
AVEncoderBitRateStrategyKey: AVAudioBitRateStrategy_Variable,
AVEncoderAudioQualityForVBRKey: @(90),
};
// fire up reencoding
MovieProcessor *processor = [[MovieProcessor alloc] initWithReader:reader writer:writer];
processor.processingSize = (CGSize){
.width = 1280.0,
.height = 720.0
};
__weak FCCGLMovieStreamer *weakSelf = self;
[processor processWithProgressBlock:nil andCompletion:^(NSError *error) {
if(!error) {
weakSelf.replacementURL = outputURL;
}
}];
}MovieProcessor здесь — сервис, который получает кадры и аудио сэмплы от reader’а и отдает их writer’у. (На самом деле он также умеет и обрабатывать полученные от reader’а кадры на GPU, но это используется только при рендере всего проекта, для того, чтобы наложить на готовое видео кадры анимации)
А что, если юзер захочет добавить в проект сразу 10-15 видеоклипов? Так как приложение не должно ограничивать пользователя в количестве клипов, которые он может использовать в приложении, нужно предусмотреть этот сценарий.
Если готовить каждый отрывок к воспроизведению по мере надобности, возникнут слишком заметные задержки. Подготавливать к воспроизведению все клипы сразу тоже не получится — из-за ограничения iOS на количество h264 декодеров, работающих одновременно. Выход из этой ситуации, разумеется, есть и он достаточно прост — готовить заранее пару треков, которые будут проигрываться следующими, “очищая” те, которые использовать в ближайшее время не планируется.
- (void) cleanupTrackSourcesIfNeeded {
const NSUInteger cleanupDelta = 1;
NSUInteger trackCount = [self.tracks count];
NSUInteger currentIndex = [self.tracks indexOfObject:self.currentTrack];
if (currentIndex == NSNotFound) {
currentIndex = 0;
}
NSUInteger index = 0;
for (FCCGLVideoSequencerTrack *track in self.tracks) {
NSUInteger currentDelta = MAX(currentIndex, index) - MIN(currentIndex, index);
currentDelta = MIN(currentDelta, index + (trackCount - currentIndex - 1));
if (currentDelta > cleanupDelta) {
track.playheadPosition = 0.0;
[track.source cancelReading];
[track.source cleanup];
}
else {
[track.source startReading];
}
++index;
}
}Таким нехитрым способом удалось добиться непрерывного воспроизведения и loop’а. Да, при scrubbing’е неизбежно будет небольшой лаг, но это не столь критично.
Напоследок расскажу немного о подводных камнях, которые могут встретиться при решении подобных задач.
Первое — если вы работаете с pixel buffers, полученными с камеры девайса — либо сразу освобождайте их, либо копируйте, если хотите использовать их позже. В противном случае видеопоток зафризится — я не нашел упоминаний об этом ограничении в документации, но, по-видимому, система трекает pixel buffers, которые отдает и просто не будет отдавать вам новые, пока старые висят в памяти.
Второе — многопоточность при работе с OpenGL. Сам по себе OpenGL с ней не очень и дружит, однако это можно обойти, используя разные EAGLContext, находящиеся в одной EAGLSharegroup, что позволит быстро и просто разделить логику отрисовки того, что пользователь увидит на экране, и различные фоновые процессы (обработку видео, рендер и т.п.).
|
Метки: author Narayan разработка под ios разработка мобильных приложений objective c obj-c ios видео секвенсор |
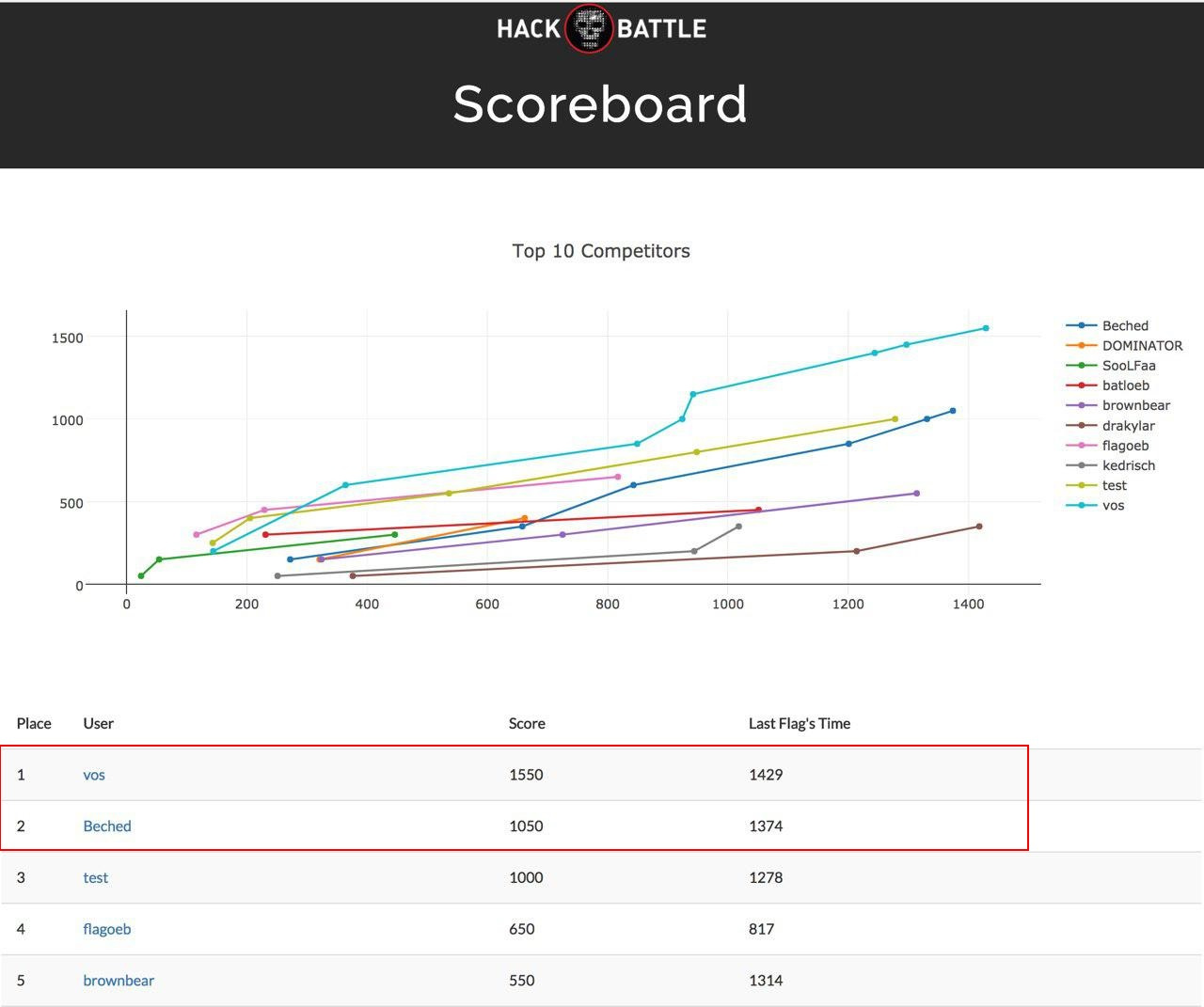
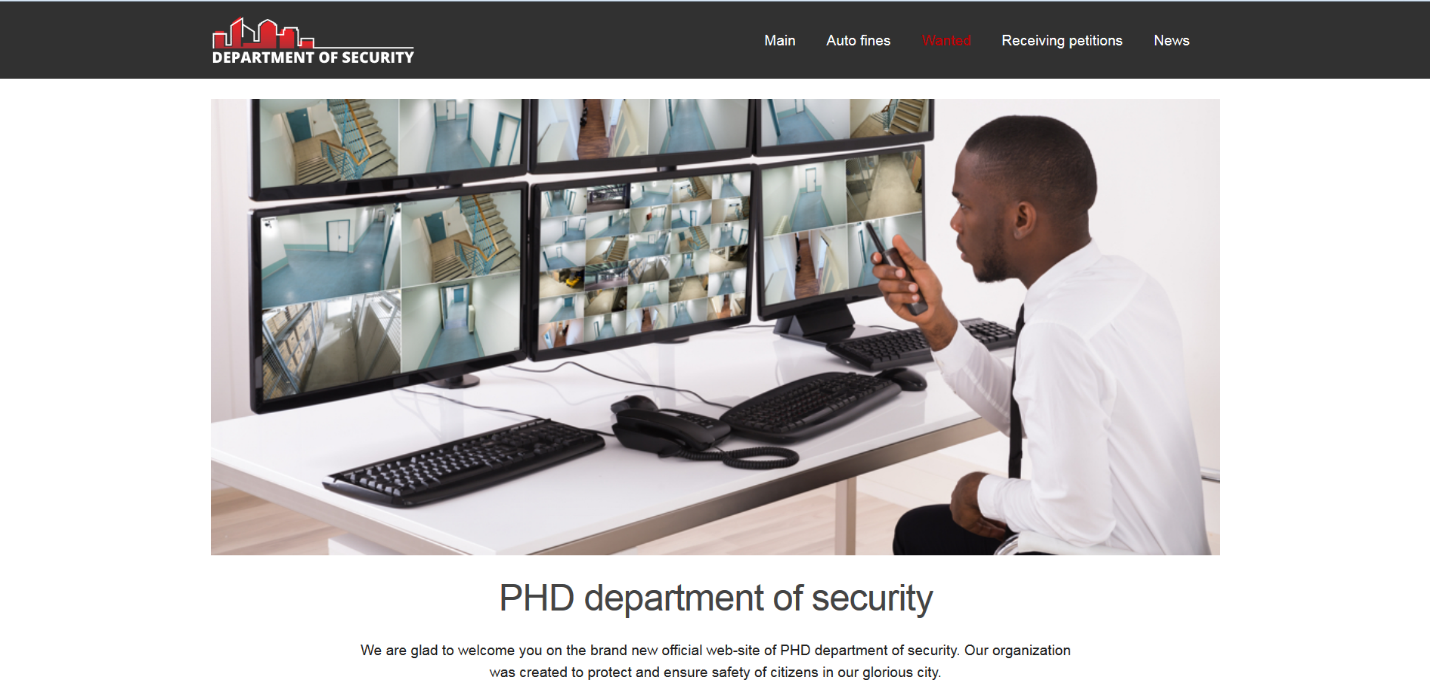
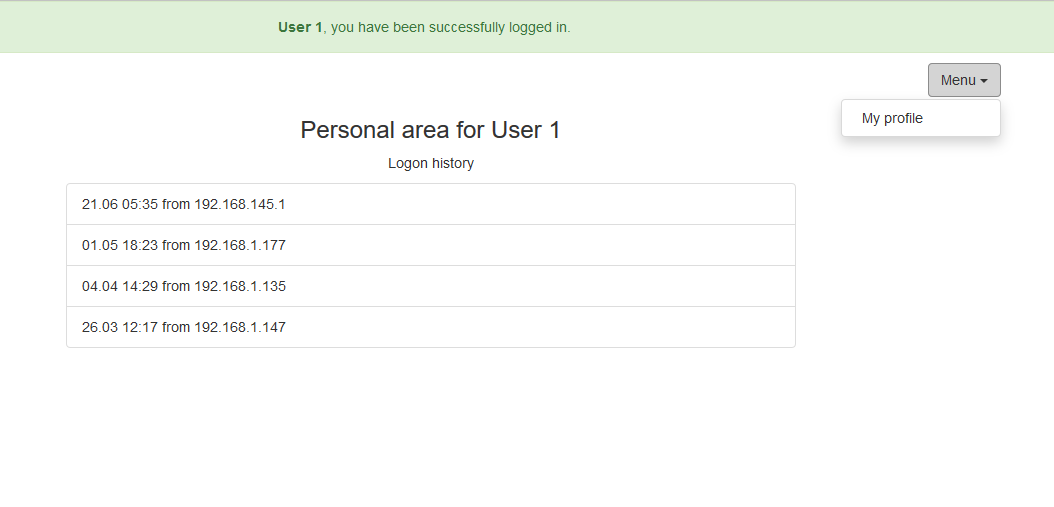
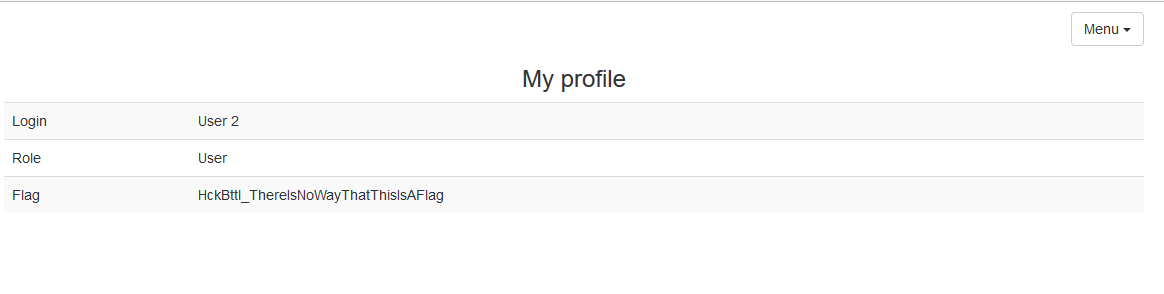
PHDays HackBattle: ломаем один на один |





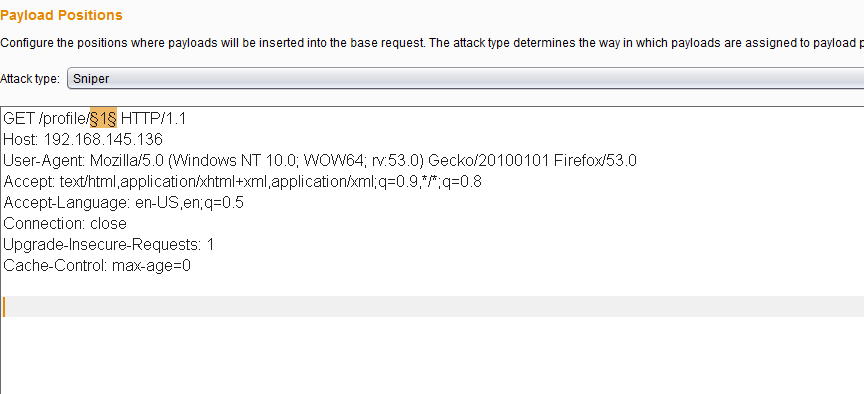
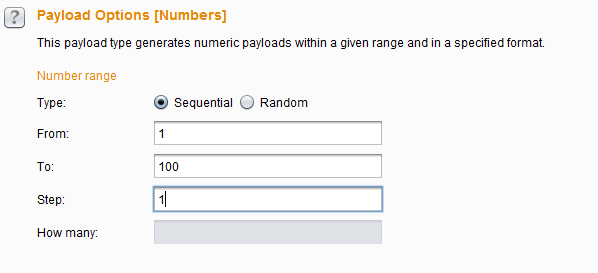
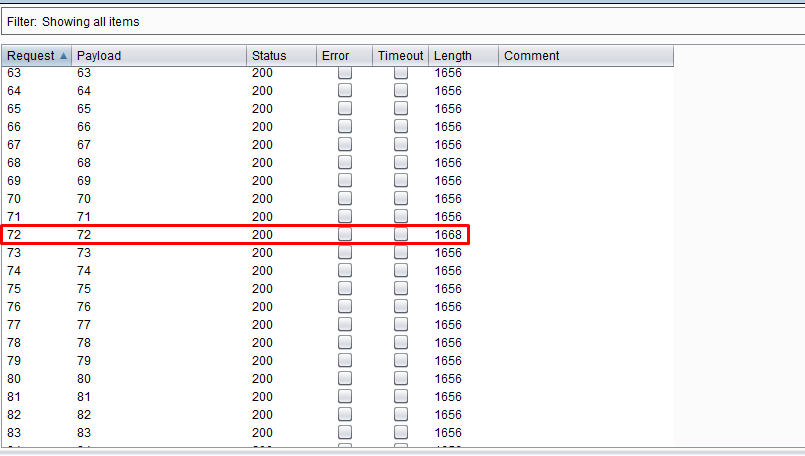

|
Метки: author ptsecurity информационная безопасность блог компании positive technologies phdays конкурс hackbattle |
Датацентр ВКонтакте |


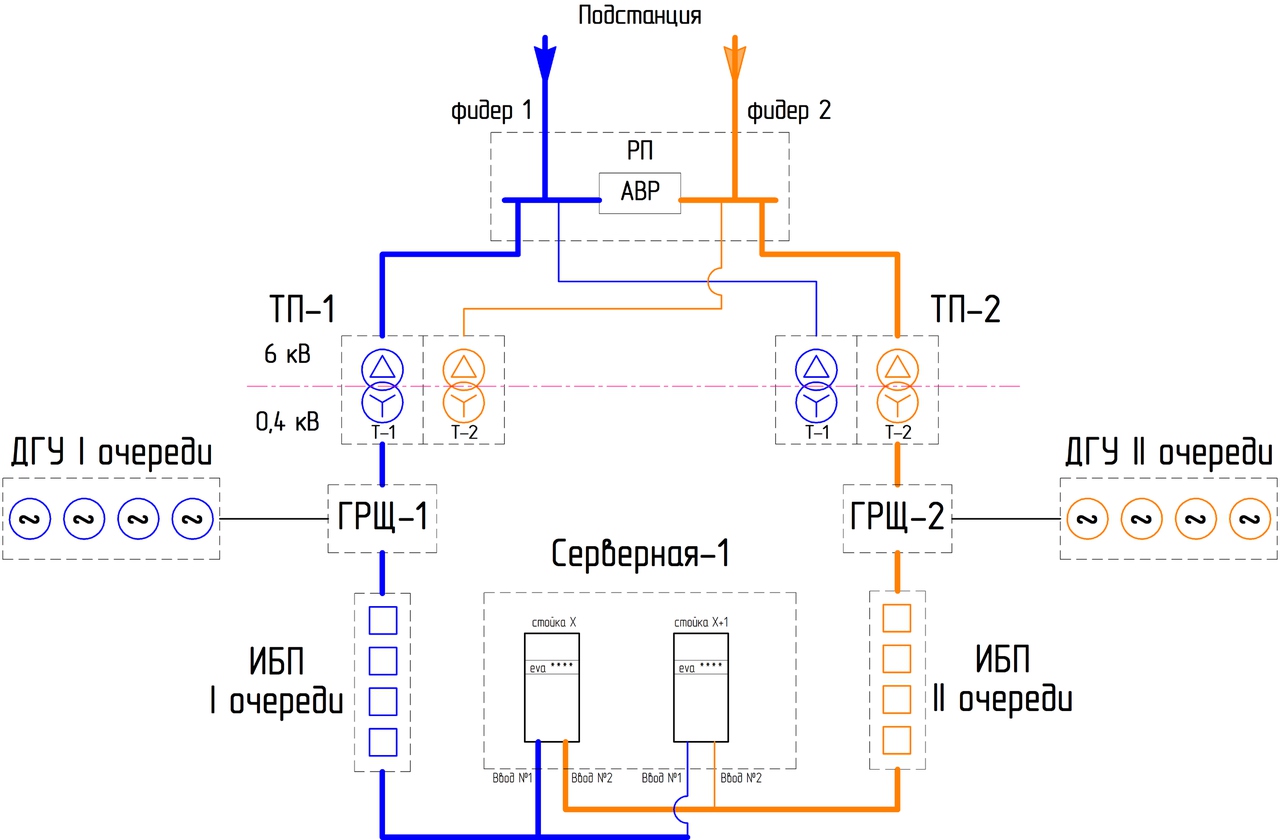




















|
Метки: author kyur хранение данных сетевые технологии it- инфраструктура блог компании вконтакте вконтакте датацентр цод |
[Из песочницы] Главная проблема CG в России и первый шаг на пути её решения |

|
Метки: author eugeneberlin cgi ( графика) cg cgi vfx freelance выставка зарплаты работа |
Новый пак стикеров Otus coding Owl |

|
Метки: author Tully программирование блог компании отус otus.ru telegram стикеры |
[recovery mode] Программирование и боевое искусство: что общего? |





|
Метки: author Volgafe87 разработка игр программирование блог компании epam coding dojo додзе codenjoy coding epam |
Вырастаем над проблемами Python |
|
Метки: author dkliminsky python блог компании avito конференции avito |
[Из песочницы] Переписываем домашний проект на микросервисы (Java, Spring Boot, Gradle) |
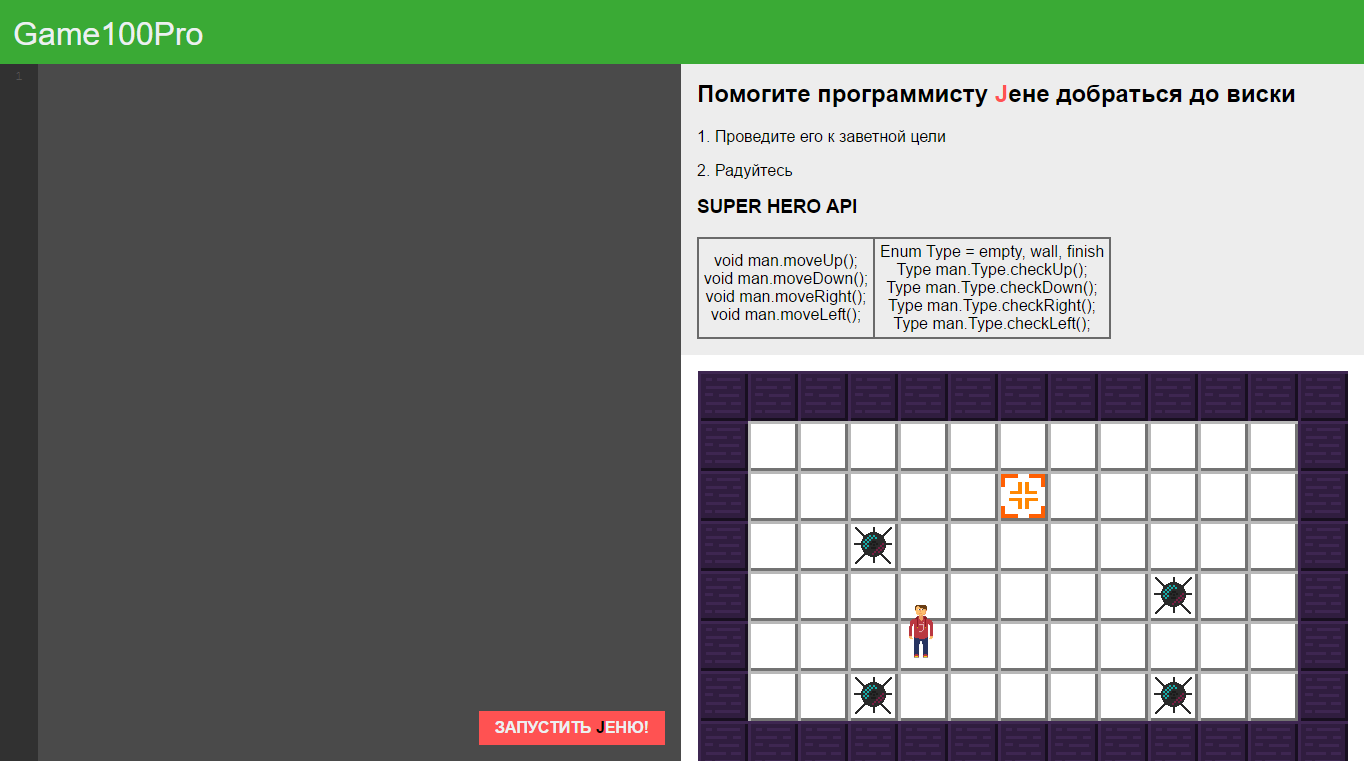
Последние годы стала очень популярна тема микросервисов. Я не попадал на проекты с микросервисами, поэтому мне, естественно, захотелось ближе познакомиться с такой концепцией архитектуры.
Ранее у меня был домашний проект (хотя скорее даже его прототип), который было решено переписать на микросервисы. Проект представлял собой попытку сделать обучающую Java игру. То есть у игрока есть поле, на этом поле он может управлять каким-то юнитом с помощью кода. Пишет код, отправляет на сервер, там он выполняется и возвращает результат, который отображается пользователю.
Всё это было реализовано в виде прототипа — были пользователи, один урок и одна задача для него, возможность отправить код, который компилировался и исполнялся. Кое-какой фронтенд, но в статье о нём речи не будет. Технологии — Spring Boot, Spring Data, Gradle.
В статье будет реализован такой же прототип, но уже на микросервисах. Реализация будет наиболее простым путём (точнее наиболее простым, из известных мне). Реализация будет доступна любому, кто знаком со Spring.
В процессе изучения информации я нашёл хорошую статью, где аналогично разбивали некий небольшой монолит на микросервисы. Но там всё делалось на основе Spring Cloud, что безусловно правильнее, но мне хотелось сначала написать велосипед, чтобы потом на практике понимать от каких проблем лечат данные решения. Из данной статьи я использовал только Zuul.
О том, что такое микросервисы писали много раз, например тут. Вкратце: вместо одного большого приложения, у нас много маленьких, у которых очень узкая область ответственности и которые общаются друг с другом.
Первый этап, это нужно разбить логику на ряд микросервисов:
user-service: сервис с пользователями (создание, просмотр, возможно авторизация)lesson-service: сервис с уроками (создание, просмотр уроков и задач)result-service: сервис с ответами (отправка выполненных задач, хранение результатов)task-executor-service: сервис исполнения кода (компиляция и исполнение задач)На этом этапе появляется мысль, что со всем этим зоопарком нужно как-то общаться фронтенду и отдельным микросервисам. Кажется неудобным, если все будут знать API и адреса друг друга.
Отсюда появляется ещё один сервис — gateway-service — общая точка входа.
Схема проекта будет выглядеть так:

Поскольку я иду по самому простому пути, первой мыслью было сделать просто по контроллеру для каждого микросервиса, в которых будет перенаправление всех запросов по нужным адресам с помощью RestTemplate. Но, немного погуглив, я нашёл Zuul. У него есть интеграция со Spring Boot и конфигурация выходит крайне простой.
build.gradle сервиса выглядит так:
plugins {
id 'java'
id 'war'
}
apply plugin: 'spring-boot'
springBoot {
mainClass 'gateway.App'
}
dependencies {
compile('org.springframework.cloud:spring-cloud-starter-zuul:1.2.0.RELEASE')
compile('org.springframework.boot:spring-boot-starter-web')
}А весь код микросервиса состоит из одного класса, App.java:
@SpringBootApplication
@EnableZuulProxy
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
}Это включает ZuulProxy. Маршрутизация описывается в конфиге, у меня это application.properties:
zuul.routes.lesson-service.url=http://localhost:8081
zuul.routes.user-service.url=http://localhost:8082
zuul.routes.task-executor-service.url=http://localhost:8083
zuul.routes.result-service.url=http://localhost:8084
zuul.prefix=/servicesТаким образом, запросы на /services/lesson-service/... будут направляться на http://localhost:8081/... и т.д. Получается очень удобное и простое решение для точки входа.
Zuul имеет много других различных фич типа фильтров, но нам от него больше ничего и не нужно.
Фронтенд так же, как мне кажется, в нашем случае должен отдаваться клиенту отсюда. Кладём всё что нужно в gateway-service/src/main/webapp/... и всё.
Остальные сервисы будут сильно похожи друг на друга и их реализация мало чем отличается от привычного подхода. Но тут есть несколько моментов:
Каждый микросервис теперь может сам решать как ему хранить данные. Традиционным преимуществом микросервисов является как раз свобода выбора технологий независимо от других частей приложения.
Можно для каждого использовать новый тип базы данных. Но у меня просто появились три MySQL базы данных вместо одной, для user-service, lesson-service и answer-service. A task-executor-service должен хранить некий код задач, в который вставляется пользовательский код для выполнения задачи. Это будет храниться без БД, просто в виде файлов.
В момент разделения схемы на три базы у меня с непривычки возник вопрос — а как же внешние ключи, целостность данных на уровне бд и всё такое. Как оказалось никак. Точнее — всё на уровне бизнес-логики.
В момент, когда мы начинаем реализовывать первый микросервис, возникает вопрос как запрашивать данные у другого. Понятно, что такой функционал нужен во всех сервисах, а значит нужно что-то типа библиотеки.
Создаём новый модуль в проекте, назовём его service-client. В нём будут, во-первых, классы для взаимодействия с сервисами, во-вторых общие классы для передачи данных. То есть у каждого сервиса есть свои какие-то Entity, соответствующие внутренней логике или схеме БД, но наружу они должны отдавать только экземпляры объектов из общей библиотеки.
Для классов-клиентов пишем абстрактный класс Client:
abstract class Client {
private final RestTemplate rest;
private final String serviceFullPath;
private final static String GATEWAY_PATH = "http://localhost:8080/services";
Client(final String servicePath) {
this.rest = new RestTemplate(Collections.singletonList(new MappingJackson2HttpMessageConverter()));
this.serviceFullPath = GATEWAY_PATH + servicePath;
}
protected T get(final String path, final Class type) {
return rest.getForObject(serviceFullPath + path, type);
}
protected T post(final String path, final E object, final Class type) {
return rest.postForObject(serviceFullPath + path, object, type);
}
} GATEWAY_PATH — лучше задавать из конфига или ещё как-то, а не хардкодить в этом классе.
И пример наследования этого класса для lesson-service:
public class TaskClient extends Client {
private static final String SERVICE_PATH = "/lesson-service/task/";
public TaskClient() {
super(SERVICE_PATH);
}
public Task get(final Long id) {
return get(id.toString(), TaskResult.class).getData();
}
public List getList() {
return get("", TaskListResult.class).getData();
}
public List getListByLesson(final Long lessonId) {
return get("/getByLesson/" + lessonId, TaskListResult.class).getData();
}
public Task add(final TaskCreation taskCreation) {
return post( "/add", taskCreation, TaskResult.class).getData();
}
} Тут может возникнуть вопрос, что за Result и почему мы возвращаем результат от getData() для него. Каждый контроллер возвращает не просто некий запрашиваемый объект в json, а ещё и дополнительную мета-информацию, которая в дальнейшем может быть полезна, поэтому при переписывании в микросервисы я не убрал это. То есть возвращается объект класса Result, где T это сам запрашиваемый объект:
@Data
public class Result {
public String message;
public T data;
public static Result success(final T data) {
return new Result<>(null, data);
}
public static Result error(final String message) {
return new Result<>(message, null);
}
public static Result run(final Supplier function ) {
final T result = function.get();
return Result.success(result);
}
} Тут нет метода getData(), хотя ранее в коде он используется. Всё это благодаря аннотации @Data от lombok, который я активно использовал.Result удобен тем, что далее можно легко добавлять некую мета-информацию (например время выполнения запроса), и как-то её использовать.
Теперь, чтобы использовать написанный нами код в других модулях, достаточно добавить зависимость (compile project(':service-client') в блок dependencies) и создать такой бин. Вот так выглядит конфигурация result-service:
@SpringBootApplication(scanBasePackages = "result")
@EnableJpaRepositories("result.repository")
@Configuration
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
@Bean
public UserClient getUserClient() {
return new UserClient();
}
@Bean
public TaskClient getTaskClient() {
return new TaskClient();
}
@Bean
public ExecutorClient getTaskExecutor() {
return new ExecutorClient();
}
}Его контроллер:
@RestController
@RequestMapping
public class ResultController {
@Autowired
private ResultService service;
@RequestMapping(value = "/submit", method = RequestMethod.POST)
public Result submit(@RequestBody final SubmitRequest submit){
return run(() -> service.submit(submit));
}
@RequestMapping(value = "/getByTask/{id}", method = RequestMethod.GET)
public Result> getByTask(@PathVariable final Long id) {
return run(() -> service.getByTask(id));
}
} Видно, что везде контроллер возвращает некий Result. И фрагмент сервиса:
@Service
@Transactional
public class ResultService {
@Autowired
private AnswerRepository answerRepository;
@Autowired
private TaskClient taskClient;
@Autowired
private ExecutorClient executorClient;
public TaskResult submit(final SubmitRequest submit) {
val task = taskClient.get(submit.getTaskId());
if (task == null)
throw new RuntimeException("Invalid task id");
val result = executorClient.submit(submit);
val answerEntity = new AnswerEntity();
answerEntity.setAnswer(submit.getCode());
answerEntity.setTaskId(task.getId());
answerEntity.setUserId(1L);
answerEntity.setCorrect(result.getStatus() == TaskResult.Status.SUCCESS);
answerRepository.save(answerEntity);
return result;
}
...answerEntity.setUserId(1L) — пока тут просто константа, ибо пока что совершенно непонятно как делать авторизацию.
В целом основную часть сделали, по образцу реализуем все остальные сервисы и всё должно работать. Но остаётся ещё разобраться с пользователями и их авторизацией. Это оказалось самой сложной частью для меня.
Раньше, до разбивки на микросервисы, авторизация была стандартная — по логину и паролю пользователь авторизировался в пределах контекста приложения.
Теперь задача расширяется, и каждый из сервисов должен понимать, авторизован ли пользователь, по которому пришёл к сервису запрос. И это при том, что запросы приходят не только непосредственно от пользователя, но и от других сервисов.
Первоначальный поиск привёл меня на разнообразные статьи, показывающие как шарить сессии с помощью Redis, но прочитанное мною показалось слишком сложным для hello-world домашнего проекта. Через некоторое время, вернувшись к вопросу, я уже нашёл информацию о JWT — JSON Web Token. Кстати, повторяя попытки поиска при написании этой статьи, я уже сразу натыкался на JWT.
Идея проста — вместо куков, на которых обычно держится авторизация, авторизирующий сервис будет выдавать некий токен, который в себя включает данные о пользователе, время выдачи и прочую нужную вам информацию. Затем, при любом обращении к сервисам, клиент должен передавать этот токен в заголовке (или как-либо ещё, как удобнее). Каждый сервис умеет его расшифровывать и понимать что это за пользователь, и ему не нужно лезть в базу и всё такое.
Тут возникает множество проблем, например как отзывать токен. Появляются идеи с несколькими токенами (длительного действия и короткого, второй используем для обычных запросов, первый для получения нового токена второго типа и как раз первый можно отозвать и для его проверки нужно лезть в БД).
На эту тему написано много статей, например эта, а также уже есть готовые библиотеки для использования.
Но у нас hello-world проект, поэтому нам не нужна серьёзная и совсем правильная авторизация, а нужно что-то, что можно быстро реализовать, но что тем не менее будет работать достаточно хорошо.
Итак, немного почитав интернеты, например эту статью, решаем что токен будет всего один и его будет выдавать user-service. Добавляем зависимости:
compile('org.springframework.boot:spring-boot-starter-security')
compile('io.jsonwebtoken:jjwt:0.7.0')Второе необходимо как раз для генерации самого токена. Токен генерируем следующим образом на запрос с верным логином и паролем:
private String getToken(final UserEntity user) {
final Map tokenData = new HashMap<>();
tokenData.put(TokenData.ID.getValue(), user.getId());
tokenData.put(TokenData.LOGIN.getValue(), user.getLogin());
tokenData.put(TokenData.GROUP.getValue(), user.getGroup());
tokenData.put(TokenData.CREATE_DATE.getValue(), new Date().getTime());
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.DATE, tokenDaysAlive);
tokenData.put(TokenData.EXPIRATION_DATE.getValue(), calendar.getTime());
JwtBuilder jwtBuilder = Jwts.builder();
jwtBuilder.setExpiration(calendar.getTime());
jwtBuilder.setClaims(tokenData);
return jwtBuilder.signWith(SignatureAlgorithm.HS512, key).compact();
}key тут это секретный ключ токена, который должны знать все сервисы для декодирования токена. Мне не понравилось, что его нужно писать в конфиг каждого сервиса, но другие варианты сложнее.
Далее нам нужно написать фильтр, который при каждом запросе будет проверять токен и авторизировать если всё ок. Но фильтр уже будет не в user-service, а в service-client, т.к. это общий код для всех сервисов.
Сам фильтр:
public class TokenAuthenticationFilter extends GenericFilterBean {
private final TokenService tokenService;
public TokenAuthenticationFilter(final TokenService tokenService) {
this.tokenService = tokenService;
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
final String token = ((HttpServletRequest) request).getHeader(TokenData.TOKEN.getValue());
if (token == null) {
chain.doFilter(request, response);
return;
}
final TokenAuthentication authentication = tokenService.parseAndCheckToken(token);
SecurityContextHolder.getContext().setAuthentication(authentication);
chain.doFilter(request, response);
}
}Если token не прислали — не делаем ничего, иначе пытаемся авторизировать клиента. Проверка авторизации осуществляется уже не нами, а дальше в другом (стандартном) фильтре от spring security. TokenService, где происходит непосредственная проверка токена:
public class TokenService {
private String key;
public void setKey(String key) {
this.key = key;
}
public TokenAuthentication parseAndCheckToken(final String token) {
DefaultClaims claims;
try {
claims = (DefaultClaims) Jwts.parser().setSigningKey(key).parse(token).getBody();
} catch (Exception ex) {
throw new AuthenticationServiceException("Token corrupted");
}
if (claims.get(TokenData.EXPIRATION_DATE.getValue(), Long.class) == null) {
throw new AuthenticationServiceException("Invalid token");
}
Date expiredDate = new Date(claims.get(TokenData.EXPIRATION_DATE.getValue(), Long.class));
if (!expiredDate.after(new Date())) {
throw new AuthenticationServiceException("Token expired date error");
}
Long id = claims.get(TokenData.ID.getValue(), Number.class).longValue();
String login = claims.get(TokenData.LOGIN.getValue(), String.class);
String group = claims.get(TokenData.GROUP.getValue(), String.class);
TokenUser user = new TokenUser(id, login, group);
return new TokenAuthentication(token, true, user);
}
}TokenData это enum для удобства, из которого можно взять строковые представления полей. Ещё тут есть два класса — TokenUser (это класс с тремя полями) и TokenAuthentication:
public class TokenAuthentication implements Authentication {
private String token;
private Collection|
Метки: author z17 java spring microservices spring boot gradle велосипедостроение jwt spring security |
[Перевод] Рефакторинг кода в обеденный перерыв: знакомство с сodemod-скриптами |

Думаю, что рефакторинг проекта – тема, близкая каждому разработчику. Зачастую мы сталкиваемся с проблемами, когда нам перестает хватать средств IDE и регулярных выражений, и тогда на помощь приходят средства вроде тех, что описаны в этом посте. Codemod скрипты – это очень мощный инструмент. После его освоения станет ясно, что ваш рефакторинг уже никогда уже не будет прежним. Поэтому я перевел этот пост для нашего хабраблога. Желаю приятного прочтения.
Сопровождение кодовой базы может обернуться головной болью для любого разработчика, особенно когда дело касается JavaScript. В условиях постоянно меняющихся стандартов, синтаксиса и критических изменений сторонних пакетов поддерживать такой код очень непросто.
За последние годы JavaScript изменился до неузнаваемости. Развитие этого языка привело к тому, что была изменена даже простейшая задача по объявлению переменных. В ES6 появились let и const, стрелочные функции и множество других новшеств, каждое из которых приносит пользу разработчикам.
При создании и поддержке в рабочем состоянии кода, призванного выдерживать проверку временем, растёт нагрузка на разработчиков. Из этого поста вы узнаете, как можно автоматизировать задачи по широкомасштабному рефакторингу кода с использованием Codemod-скриптов и инструмента jscodeshift, что позволит вам, например, легко обновлять свой код для использования новых возможностей языка.
Codemod – это инструмент, разработанный Facebook для рефакторинга больших кодовых баз. Он позволяет разработчику реорганизовать большой объём кода за небольшой промежуток времени. Для небольших задач по рефакторингу вроде переименования класса или переменной разработчик использует IDE, такие изменения обычно затрагивают только один файл. Следующим инструментом для рефакторинга является глобальный поиск и замена. Часто он может работать с использованием сложных регулярных выражений. Но такой метод подходит не для всех случаев.
Codemod написан на Python, он принимает ряд параметров, включая выражения для поиска и замены.
codemod -m -d /code/myAwesomeSite/pages --extensions php,html \
'(.*?)' \
'\2'В приведённом примере мы заменяем на с использованием встроенного стиля для указания цвета. Первые два параметра – это флаги, указывающие на необходимость поиска нескольких совпадений (-m), и каталог для начала обработки (-d /code/myAwesomeSite/pages). Мы также можем ограничить обрабатываемые расширения (-extensions php, html). Затем мы предоставляем выражения для поиска и замены. Если выражение для замены не указано, будет предложено ввести его во время выполнения. Инструмент работает нормально, но он очень похож на существующие инструменты для поиска и замены с использованием регулярных выражений.
jscodeshift следующий в наборе инструментов для рефакторинга. Он также разработан Facebook и предназначен для обработки нескольких файлов Codemod-скриптом. Будучи модулем Node.js, jscodeshift предоставляет простой и удобный API, а «под капотом» использует Recast, являющийся инструментом преобразования AST-to-AST (Abstract Syntax Tree).
Recast – это модуль Node.js, который предоставляет интерфейс для парсинга и перегенерации JavaScript-кода. Он может анализировать код в виде строки и генерировать из него объекты, соответствующие структуре AST. Это позволяет разработчикам проверять код для таких шаблонов, как, например, объявление функций.
var recast = require("recast");
var code = [
"function add(a, b) {",
" return a + b",
"}"
].join("\n");
var ast = recast.parse(code);
console.log(ast);
//output
{
"program": {
"type": "Program",
"body": [
{
"type": "FunctionDeclaration",
"id": {
"type": "Identifier",
"name": "add",
"loc": {
"start": {
"line": 1,
"column": 9
},
"end": {
"line": 1,
"column": 12
},
"lines": {},
"indent": 0
}
},
........... Как видно из примера, мы передаём строку кода с функцией, которая складывает два числа. Когда мы парсим строку и распечатываем получившийся объект, то можем видеть AST: видим FunctionDeclaration, имя функции и т. д. Так как это просто JavaScript-объект, то мы можем изменить его как угодно. Затем можно вызвать функцию print для возврата обновлённой строки кода.
Как упоминалось ранее, Recast строит AST из строки кода. AST – это древовидное представление абстрактного синтаксиса исходного кода. Каждый узел дерева представляет собой конструкцию в исходном коде. ASTExplorer – это онлайн-инструмент, который поможет разобрать и понять дерево вашего кода.
С помощью ASTExplorer можно просмотреть AST простого примера кода. Объявим константу с именем foo и присвоим ей строковое значение ‘bar’.
const foo = 'bar';Это соответствует такому AST:

В массиве body есть ветвь VariableDeclaration, которая содержит нашу константу. Все VariableDeclarations имеют атрибут id, который содержит важную информацию (имя и т. д.). Если бы мы создавали Codemod-скрипт для переименования всех экземпляров foo, то использовали бы этот атрибут и перебирали бы все экземпляры, чтобы изменить имя.
Используя инструменты и приёмы, рассмотренные выше, мы можем воспользоваться всеми преимуществами jscodeshift. Поскольку, как мы знаем, он является модулем Node.js, можно установить его для проекта или глобально.
npm install -g jscodeshiftПосле установки мы можем использовать имеющиеся Codemod-скрипты совместно с jscodeshift. Нужно предоставить некоторые параметры, которые укажут jscodeshift, чего мы хотим достичь. Базовый синтаксис – это вызов jscodeshift с указанием пути к файлу или файлам, которые требуется преобразовать. Важным параметром является местоположение скрипта преобразования (-t): это может быть локальный файл или URL-адрес файла Codemod-скрипта. По умолчанию jscodeshift ищет скрипт преобразования в файле transform.js в текущем каталоге.
Другими полезными параметрами являются пробный прогон (-d), который будет применять преобразование, но не станет обновлять файлы, и параметр -v, который выведет всю информацию о процессе преобразования. Скрипты преобразования – это Codemod-скрипты, простые модули JavaScript, которые экспортируют функцию. Эта функция принимает следующие параметры:
Параметр fileInfo хранит всю информацию о текущем файле, включая путь и источник. Параметр api – это объект, который обеспечивает доступ к вспомогательным функциям jscodeshift, таким как findVariableDeclarators и renameTo. Наконец, параметр – это опции, которые позволяют передавать параметры из командной строки в Codemod. Например, если мы хотим добавить версию кода ко всем файлам, то можем передать её через параметры командной строки jscodeshift -t myTransforms fileA fileB --codeVersion = 1.2. В этом случае параметр options будет содержать {codeVersion: '1.2'}.
Внутри функции, которую мы экспортируем, нужно вернуть преобразованный код в виде строки. Например, если у нас есть строка кода const foo = 'bar', и мы хотим преобразовать её, заменив const foo на const bar, наш код будет выглядеть так:
export default function transformer(file, api) {
const j = api.jscodeshift;
return j(file.source)
.find(j.Identifier)
.forEach(path => {
j(path).replaceWith(
j.identifier('bar')
);
})
.toSource();
}Здесь мы объединяем ряд функций в цепочку вызовов и в конце вызываем toSource() для генерации преобразованной строки кода.
При возврате кода необходимо соблюдать некоторые правила. Возврат строки, отличной от входящей, считается успешным преобразованием. Если же строка такая же, как на входе, то преобразование считается неудачным, и, если ничего не будет возвращено, значит, оно не понадобилось. jscodeshift использует эти результаты при обработке статистики по преобразованиям.
В большинстве случаев разработчикам не нужно писать собственный код – многие типовые действия по рефакторингу уже были превращены в Codemod-скрипты. Например, js-codemod no-vars, который преобразуют все экземпляры var в let или const в зависимости от использования переменной (в let – если переменная будет изменена позже, в const – если переменная никогда не будет изменена).
js-codemod template-literals заменяют конкатенацию строк шаблонными строками, например:
const sayHello = 'Hi my name is ' + name;
//after transform
const sayHello = `Hi my name is ${name}`;Мы можем взять Codemod-скрипт no-vars, упомянутый выше, и разбить код, чтобы увидеть, как работает сложный Codemod-скрипт.
const updatedAnything = root.find(j.VariableDeclaration).filter(
dec => dec.value.kind === 'var'
).filter(declaration => {
return declaration.value.declarations.every(declarator => {
return !isTruelyVar(declaration, declarator);
});
}).forEach(declaration => {
const forLoopWithoutInit = isForLoopDeclarationWithoutInit(declaration);
if (
declaration.value.declarations.some(declarator => {
return (!declarator.init && !forLoopWithoutInit) || isMutated(declaration, declarator);
})
) {
declaration.value.kind = 'let';
} else {
declaration.value.kind = 'const';
}
}).size() !== 0;
return updatedAnything ? root.toSource() : null;Этот код является ядром скрипта no-vars. Во-первых, фильтр запускается на всех переменных VariableDeclaration, включая var, let и const, а возвращает только объявления var, которые передаются во второй фильтр, вызывающий пользовательскую функцию isTruelyVar. Она используется для определения характера var (например, var внутри замыкания, или объявляется дважды, или объявление функции, которое может быть поднято) и покажет, безопасно ли делать преобразование этой var. Каждая var, которую возвращает фильтр isTruelyVar, обрабатывается в цикле foreach.
Внутри цикла выполняется проверка, находится ли var внутри цикла, например:
for(var i = 0; i < 10; i++) {
doSomething();
}Чтобы определить, находится ли var внутри цикла, можно проверить родительский тип.
const isForLoopDeclarationWithoutInit = declaration => {
const parentType = declaration.parentPath.value.type;
return parentType === 'ForOfStatement' || parentType === 'ForInStatement';
};Если var находится внутри цикла и не меняется, то её можно заменить на const. Проверка может быть выполнена путём фильтрации по узлам var AssignmentExpression и UpdateExpression. AssignmentExpression покажет, где и когда var была инициализирована, например:
var foo = 'bar';
UpdateExpression покажет, где и когда var была обновлена, например:
var foo = 'bar';
foo = 'Foo Bar'; //UpdatedЕсли var находится внутри цикла с изменением, используется let, поскольку она может меняться после создания экземпляра. Последняя строка в скрипте проверяет, было ли что-нибудь изменено, и, если ответ положительный, возвращается новый исходный код для файла. В противном случае возвращается null, сообщающий, что обработка данных не выполнялась. Полный код для этого Codemod-скрипта можно найти здесь.
Команда Facebook также добавила несколько Codemod-скриптов для обновления синтаксиса React и обработки изменений в React API. Например, react-codemod sort-comp, который сортирует методы жизненного цикла React для соответствия правилу ESlint sort-comp.
Последним популярным Codemod-скриптом React является React-PropTypes-to-prop-types, помогающий справиться с недавним изменением React, в результате которого разработчикам требуется установить prop-types для продолжения использования PropTypes в компонентах React версии 16. Это отличный пример использования Codemod-скриптов. Метод использования PropTypes не увековечен в камне.
Верны все следующие примеры.
Импортируем React и получаем доступ к PropTypes из импорта по умолчанию:
import React from 'react';
class HelloWorld extends React.Component {
static propTypes = {
name: React.PropTypes.string,
}
.....Импортируем React и делаем именованный импорт для PropTypes:
import React, { PropTypes, Component } from 'react';
class HelloWorld extends Component {
static propTypes = {
name: PropTypes.string,
}
.....И еще один вариант для для stateless компонента:
import React, { PropTypes } from 'react';
const HelloWorld = ({name}) => {
.....
}
HelloWorld.propTypes = {
name: PropTypes.string
};Наличие трёх способов реализации одного и того же решения затрудняет применение регулярного выражения для поиска и замены. Если бы в нашем коде были все три варианта, мы могли бы легко перейти к новому паттерну PropTypes, выполнив:
jscodeshift src/ -t transforms/proptypes.jsВ этом примере мы взяли PropTypes Codemod-скрипт из репозитория react-codemod и добавили его в каталог transforms в нашем проекте. Скрипт добавит import PropTypes from 'prop-types'; для каждого файла и заменит все React.PropTypes на PropTypes.
Facebook начал внедрять поддержку кода, позволяя разработчикам адаптироваться под её постоянно меняющиеся API и практические подходы работы с кодом. Javascript Fatigue стала большой проблемой, и, как мы увидели, инструменты, помогающие в процессе обновления существующего кода, во многом способствуют её решению.
В мире серверной разработки программисты регулярно создают сценарии миграции для поддержания баз данных в актуальном состоянии и обеспечения осведомлённости пользователей об их последних версиях. Создатели JavaScript-библиотек могли бы предоставлять Codemod-скрипты в качестве таких сценариев миграции, чтобы при выпуске новых версий с критическими изменениями можно было легко обработать свой код для обновления.
Наличие Codemod-скрипта, запускаемого автоматически при установке или обновлении, может ускорить процесс и повысить доверие потребителей. Кроме того, включение такого скрипта в процесс выпуска релизов не только было бы полезно для потребителей, но и уменьшило бы расходы на сопровождающие обновления примеры и руководства.
В этом посту мы рассмотрели природу Cdemod-скриптов и jscodeshift и то, как быстро они могут обновлять сложный код. Начав с Codemod и перейдя к таким инструментам, как ASTExplorer и jscodeshift, можно научиться создавать Codemod-скрипты в соответствии со своими потребностями. А наличие широкого спектра готовых модулей позволяет разработчикам активно продвигать технологию в массы.
Примечание переводчика: на эту тему было интересное выступление на JSConfEU.
|
Метки: author alxgutnikov регулярные выражения проектирование и рефакторинг javascript блог компании badoo react рефакторинг |
5 бесплатных ассетов для Unity3D, которые облегчат процесс разработки |







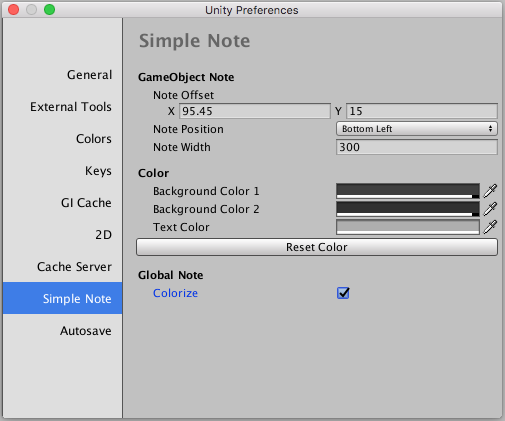

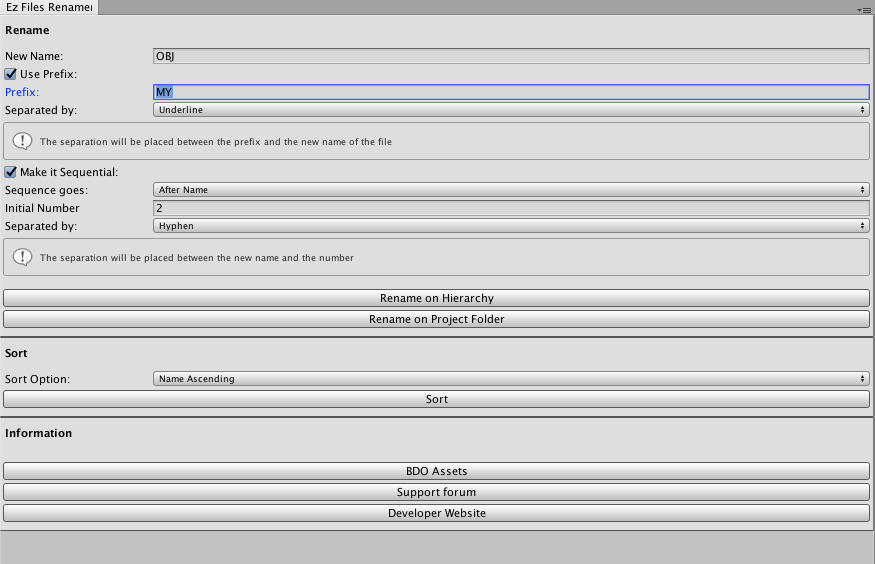
|
Метки: author nanton разработка мобильных приложений разработка игр unity3d блог компании everyday tools unity unity asset store asset store assets ассеты |
[Перевод] Чтобы ваша культура вмещала всех, попробуйте работать меньше |
|
Метки: author j_wayne управление разработкой управление проектами управление персоналом перевод разнообразие разработка программного обеспечения персонал |






