Атмосфера в компании InfoWatch |





































|
Метки: author InfoWatch блог компании infowatch infowatch офис верейская плаза |
[Перевод] ArrayBuffer и SharedArrayBuffer в JavaScript, часть 1: краткий курс по управлению памятью |













|
Метки: author ru_vds javascript блог компании ruvds.com программирование управление памятью |
Усатый стрелок из двадцати трёх полигонов |
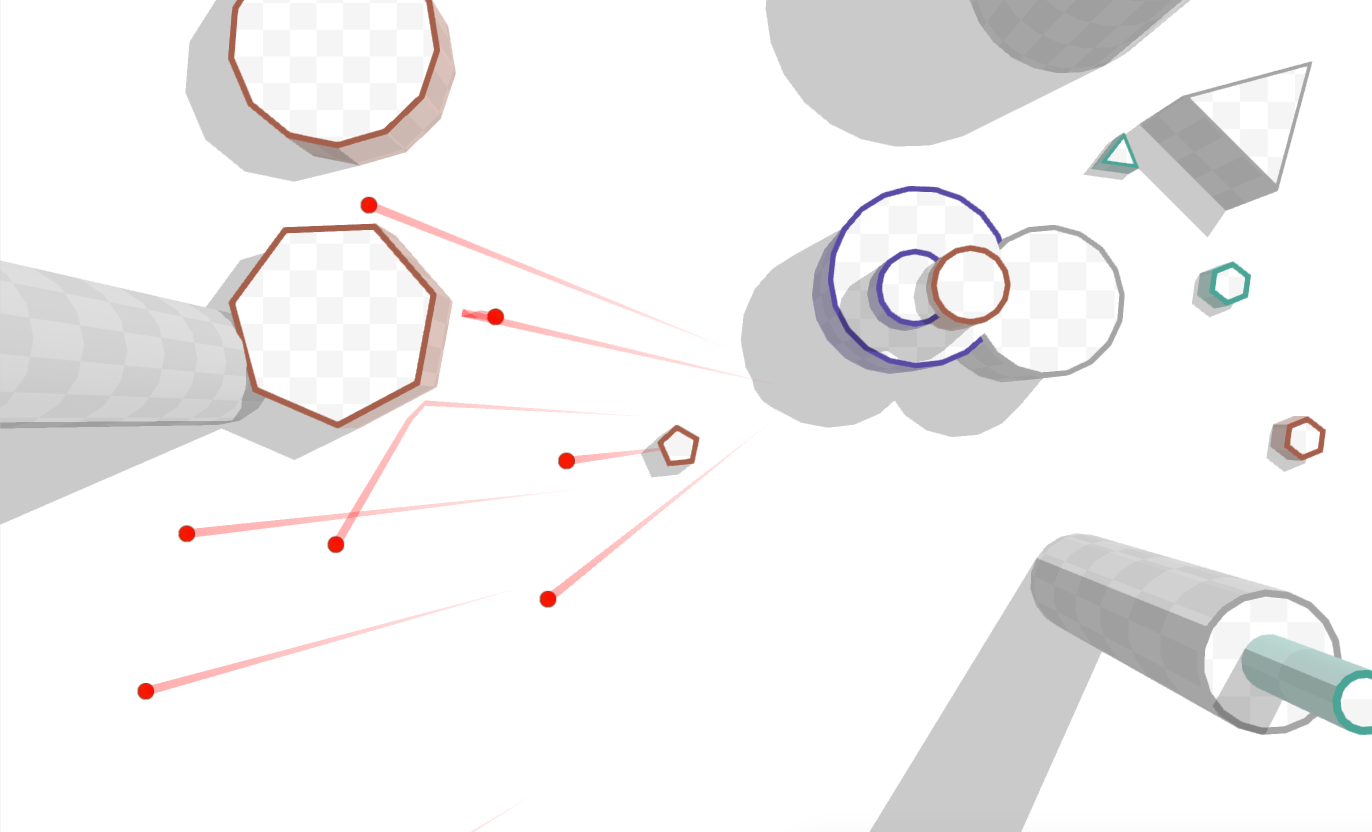
А давайте отвлечёмся немного и напишем игру в google play? И не такую огромную и неподъёмную фигню, про которую я обычно пишу статьи, а что-нибудь простое и милое сердцу?
На самом деле, всё очень просто: я наконец-то зарегистрировал аккаунт разработчика и очень хочу его опробовать. На момент написания этих строк у меня нет ни одного написанного класса и ни одного нарисованного пикселя. По сути, эта статья — самый настоящий devlog.
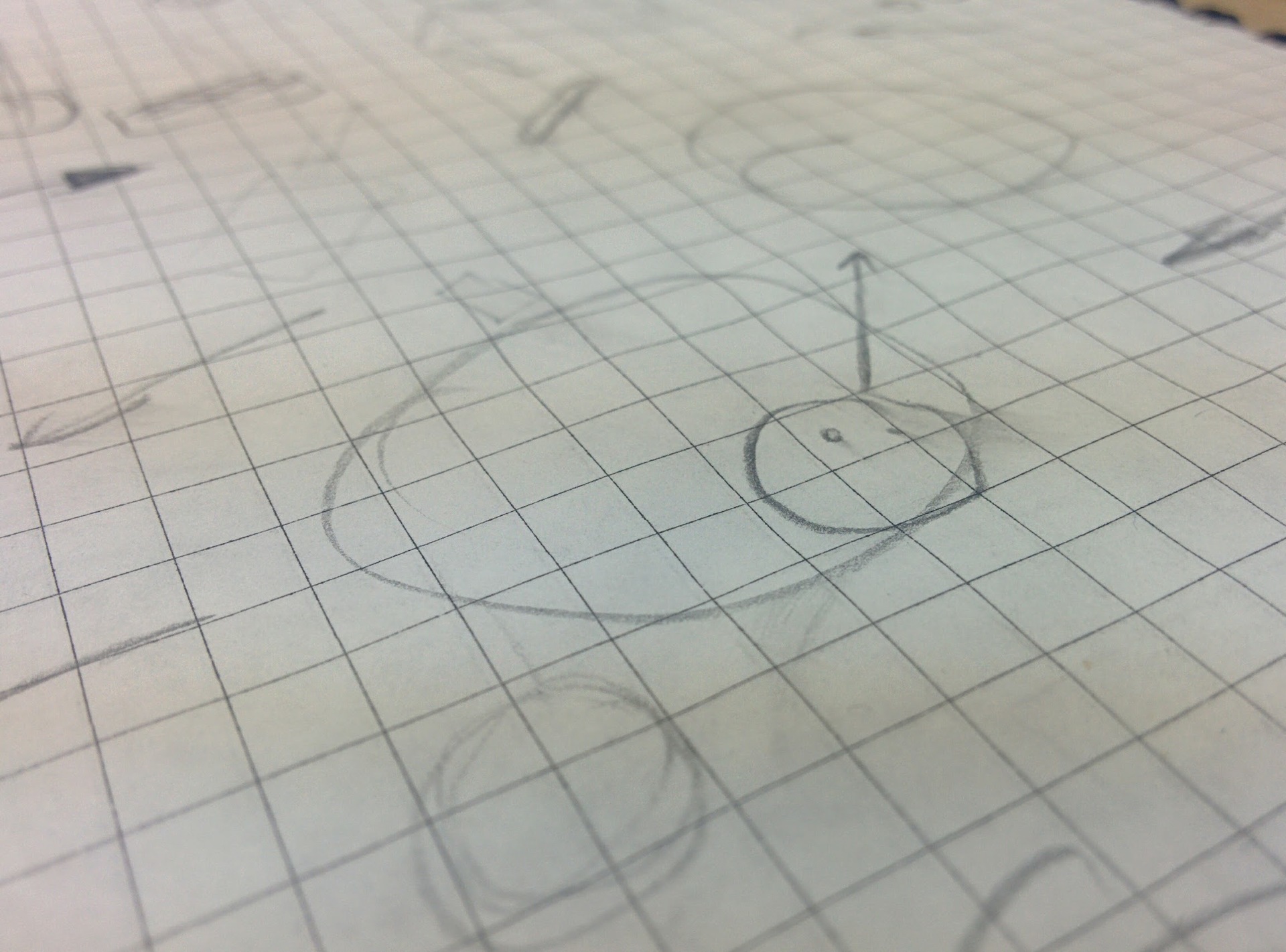
Первые каляки-маляки.
Видите этот кружочек на бумаге? С него и начнём. Мне кажется, любую игру (да ладно, любое произведение) можно начать с подобной окружности. Чем он станет через несколько секунд? Колесом? Шляпой? Планетой? Рисую каракули, пытаюсь представить, что этот кружок означает. Шляпу!
Некий суровый дядя ходит по дорогам, а мы смотрим на него сверху. Суровый — потому что с пистолетом и стрелять умеет. Топает себе по городу, дует в усы, пускает пули в бандитов.
Эта заготовка — просто образ, который давно крутится в голове. Вот только делать игру на подобии Crimsonland делать решительно не хочется. И gui с двумя джойстиками я всегда недолюбливал. Обрезаем бритвой Оккама всё лишнее и получаем на выходе такую концепцию:
Уровень: небольшой городок с домами, ящиками и бочками.
Персонажи: главный герой (стрелок), бандиты и прохожие.
Игра стоит на паузе и ждёт действия игрока. Игрок делает свайп в любом направлении. В этот момент:
1. Время в игре начинает идти;
2. Главный герой стреляет в указанном игроком направлении;
3. Главный герой начинает двигаться в указанном направлении.
Проходит половина секунды и время в игре снова останавливается. Игроку нужно победить всех бандитов, ранив как можно меньше прохожих.
Это сочетание автоматической стрельбы и остановки времени мне очень приглянулось:
Постепенно идея визуализируется и обрастает деталями. Отметаю одну за другой, хватит на сегодня.
Todo: сделать крохотный прототип и проверить, насколько фаново будет двигаться/стрелять с остановкой времени.
Спасибо Unity3D, прототипирование на нём очень простое.
Добавляю пару стен с BoxCollider2D, круглые спрайты с RigidBody2D и CircleCollider2D (игрок, прохожие и бандиты). Пули — тот же спрайт, только маленький, красный, с RigidBody2D, CircleCollider2D и TrailRenderer для траектории полёта.
Управление временем делаю через свой класс Clock, все прочие классы (игрок, пуля и тд) используют дельту времени из него, а не Time.DeltaTime.
using UnityEngine;
using System.Collections;
public class Clock : MonoBehaviour {
[SerializeField, Range(0, 2)] float stepDuration;
[SerializeField] AnimationCurve stepCurve;
float time = -1;
float timeRatio = 0;
float defaultFixedDeltaTime = 0;
static Clock instance;
public static Clock Instance { get { return instance; } }
void Start() {
instance = this;
defaultFixedDeltaTime = Time.fixedDeltaTime;
}
void OnDestroy() {
if (instance == this)
instance = null;
}
public bool Paused {
get { return time < 0; }
}
public float DeltaTime {
get { return
timeRatio * Time.deltaTime; }
}
public float FixedDeltaTime {
get { return
timeRatio * Time.fixedDeltaTime; }
}
public void Play() {
if (!Paused)
return;
time = 0;
timeRatio = Mathf.Max(0, stepCurve.Evaluate(0));
UpdatePhysicSpeed();
}
public void Update() {
if (Paused)
return;
time = Mathf.Min(time + Time.unscaledDeltaTime, stepDuration);
if (time >= stepDuration) {
timeRatio = 0;
time = -1;
UpdatePhysicSpeed();
return;
}
timeRatio = Mathf.Max(0, stepCurve.Evaluate(time / stepDuration));
UpdatePhysicSpeed();
}
void UpdatePhysicSpeed() {
Time.timeScale = timeRatio;
Time.fixedDeltaTime = defaultFixedDeltaTime * timeRatio;
}
}Самый базовый прототип готов через полтора часа, полно багов:
Но даже в этом варианте уже интересно двигаться и стрелять. Выглядит первый прототип, конечно, совершенно непрезентабельно:
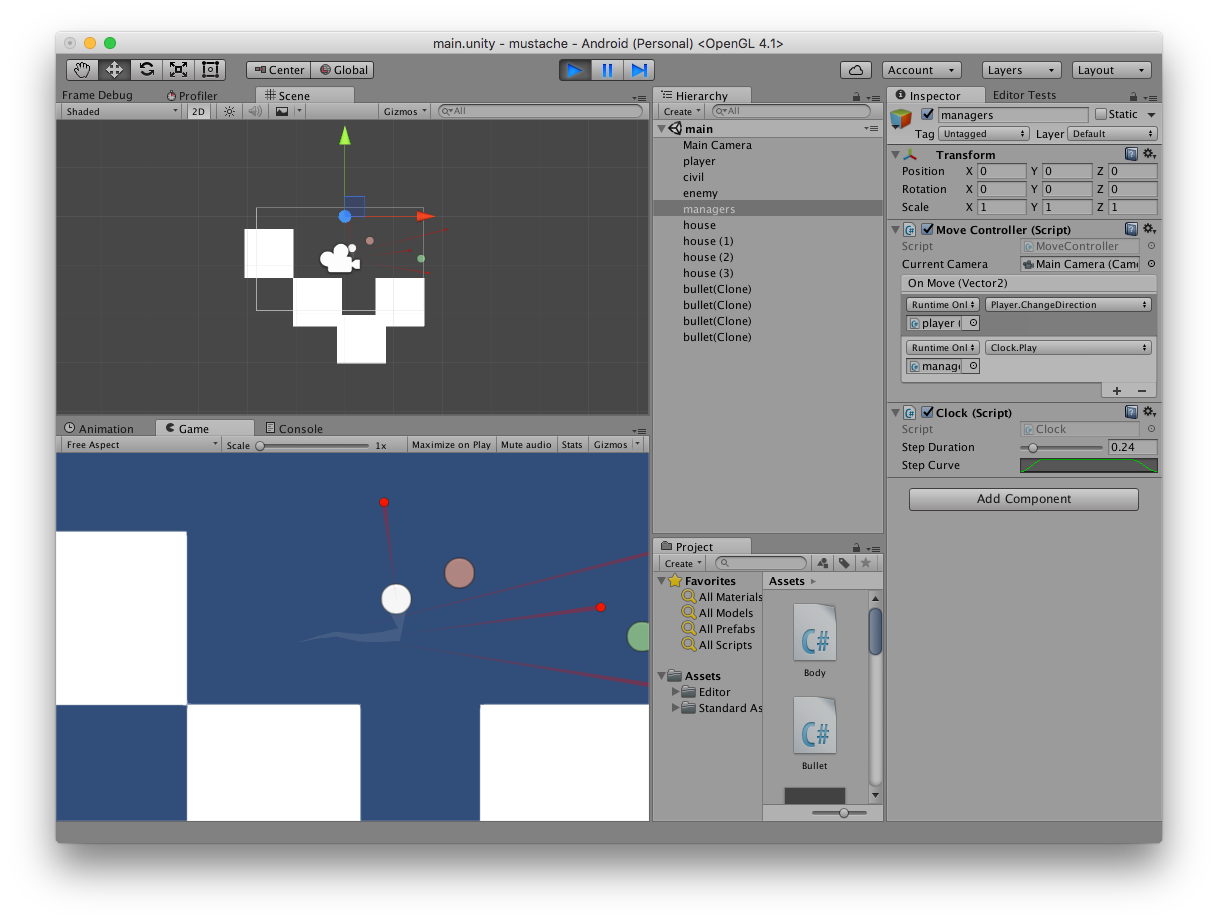
Первый играбельный прототип
Но уже появляются таски на следующий день:
Фишки:
Фиксы:
Todo: сделать тестовый обучающий уровень с придуманными фишками.
Пока шёл по улице, придумал план тестового уровня:
Закидываю объекты на сцену, перекрашиваю отражающие стены в жёлтый. Получается что-то такое:
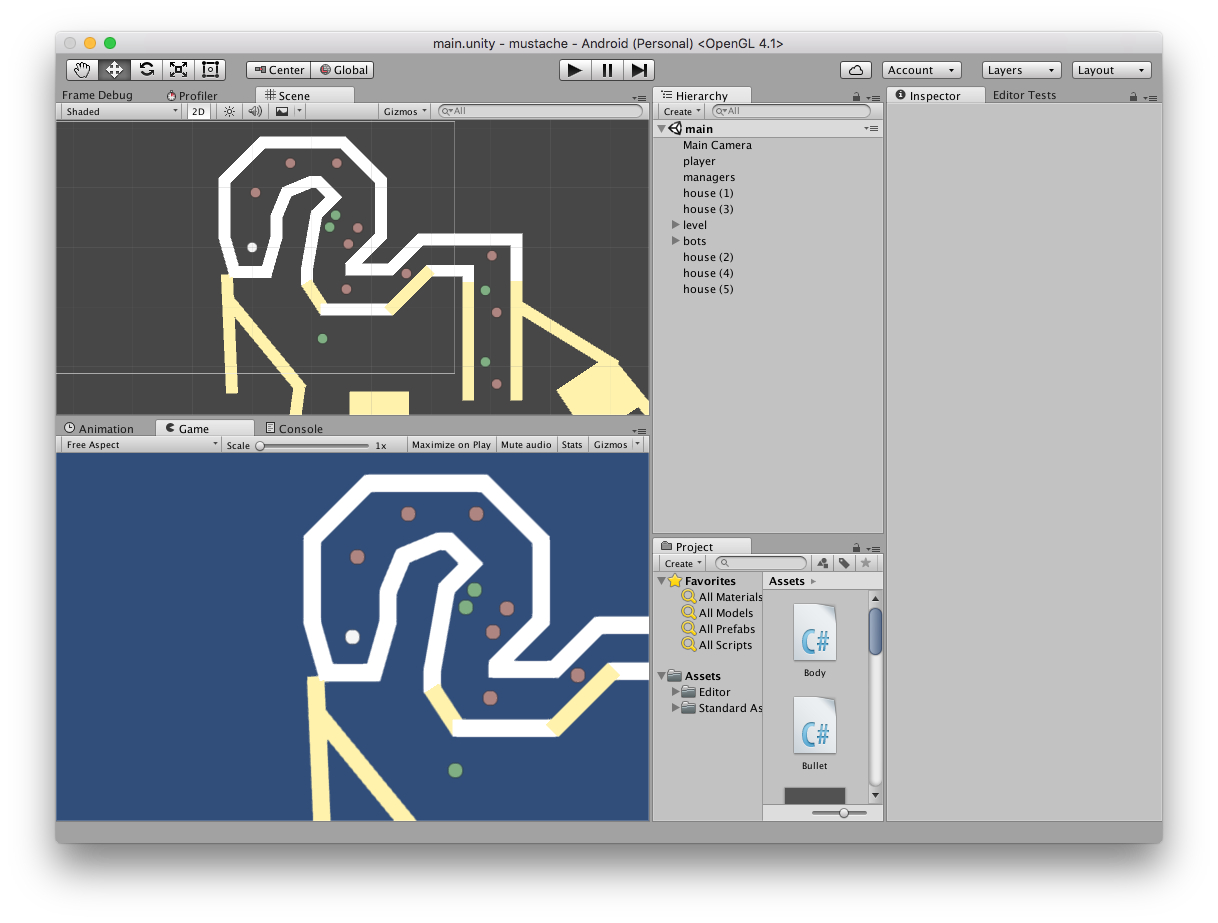
Вид обучающего уровня
Делаю отражающие стены через отдельный слой, код столкновения пули с препятствием становится таким:
void OnCollisionEnter2D(Collision2D coll) {
int layer = 1 << coll.gameObject.layer;
if (layer == wall.value)
Destroy(gameObject);
else if (layer == human.value) {
Destroy(gameObject);
var humanBody = coll.gameObject.GetComponent();
if (humanBody != null)
humanBody.Kill();
return;
} else if (layer == wallMirror.value) {
Vector2 normal = Vector2.zero;
foreach (var contact in coll.contacts)
normal += contact.normal;
direction = Vector2.Reflect(direction, normal);
}
} Исправляю баги, добавляю придуманные за прошлый день фишки.
Переделываю класс Clock: раньше ход длился stepDuration реальных секунд, а коэффициент скорости времени определялся кривой stepCurve. Кривая нужна для плавного старта и завершения хода.
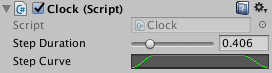
Старые настройки в Clock.cs
Вот только если изменить длительность хода, изменится и длительность начала/конца (где значение ординаты на кривой не равно 1). И при слишком небольшой длительности хода "включение" времени кажется слишком резким, а при длительности порядка секунды — слишком медленным (т.к. кривая "растягивается" на всё время хода). Добавляю отдельные кривые для начала и конца хода, а также длительности начала/конца.
Добавляю камеру, которая следит за игроком и визуализацию траектории игрока.
Молча показываю прототип нескольким знакомым, не объясняя ни цель, не управление. Все смогли разобраться с управлением, но есть и проблемы, которых я не замечал. Для себя записал выводы playtest'а:
Прототип готов настолько, что можно показать геймплей!
Todo: определиться с сеттингом, графикой.
Моим первым "боссом" оказался именно этот этап, вот уж не думал.
Планировал я следующее: прошерстить интернет на тему популярных игровых сеттингов, поискать референсы и арт для вдохновения, и начать рисовать уровни в пиксельарте.
После некоторого гугления решил остановиться на антураже викторианской Англии. Папоротники, культ смерти, мрачные доки. Дерево, металл, пар и масло.
Пробую нарисовать первые спрайты и обнаруживаю проблему. Все объекты в игре могут вращаться. А пиксели, как известно, нет.
Отрисовать по 360 вариантов каждого спрайта, очевидно, не вариант. К счастью, сейчас возникла мода не "нечестный пиксельарт", когда спрайты свободно вращаются вокруг своей оси. В этом случае нужно что-то делать с лесенками алиасинга, которые неизбежно появятся, высунут хищные угловатые мордочки и будут мелькать тут и там. Можно смириться и сказать: "Это и есть мой стиль!", как сделали создатели Hotline miami (и ведь получилось!). Можно подключить антиалиасинг: "Да здравствует мыло душистое!".
Во всяком случае, у меня так и получилось: либо алиасинг и лесенки, либо нечёткие грани после антиалиасинга.

Тестовый пиксельарт
Отметаю пиксельарт (прости, друг!) и упрощаю, упрощаю!
Todo: выбрать подходящий визуальный стиль.
Город из бумаги! Похожий немного на Wildfire worlds, только ещё проще. Благородные белые грани шершавой бумаги, пятна краски на полу, вот такие персонажи в смешных шляпах:

Цилиндрический чел
По правде говоря, с 3д в геймдеве я никогда не работал, а 3д редакторы открывал последний раз несколько лет назад. Но знаю, что многое решается освещением и тенями. Особенно, если текстура — белая бумага, где толком не скроешь недостатки плохого света.
Трачу вечер на моделирование первого объекта: пакета молока. Разбираюсь со стандартными шейдерами, освещением.
Вывод простой: не потяну. Я трачу очень много времени на моделлинг и не могу получить красивую картинку стандартными средствами. Запекание освещения помогает, но я хотел сделать небольшую игрушку с множеством уровней, так что запекание в пролёте. Похоже, босс ещё не побеждён...
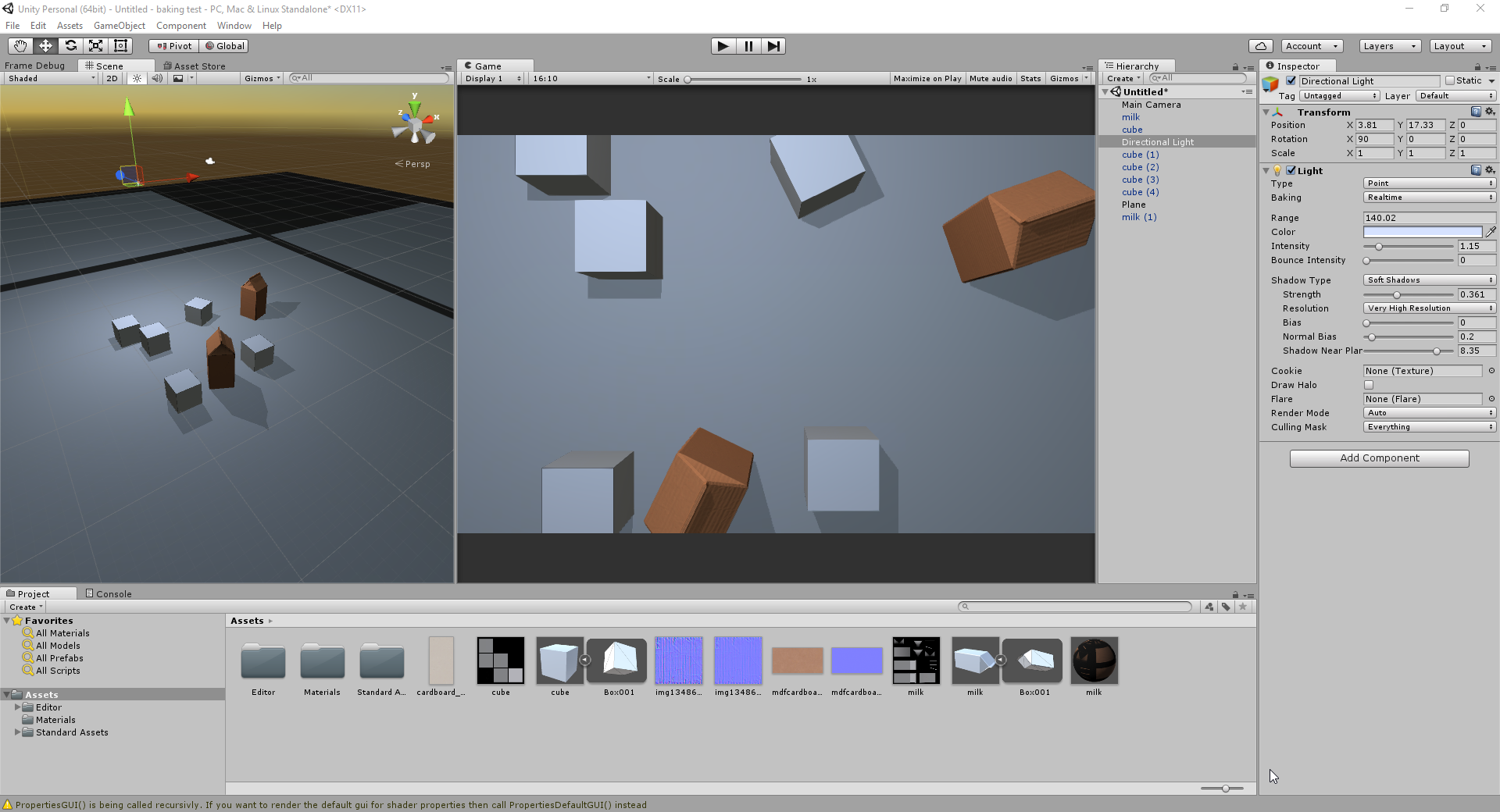
Пакет молока с простым освещением
Вспоминаю свои сильные и слабые стороны. Обычно, если я не могу нарисовать какой-нибудь арт для своего проекта, я пишу скрипт, который сделает это за меня. Чем 3д хуже? Итак, процедурная генерация! Базовые примитивы, фактически, low poly. Яркие, контрастные цвета, визуально кодирующие геймплейные различия.
Нужно определиться, какие примитивы мне понадобятся для создания уровней. Цилиндры и кубы, возможно, пятиугольники… Хм, это ведь все можно генерировать одним кодом. За работу!
Todo: реализовать простую генерацию примитивов.
Пока для уровня будет достаточно правильных многоугольников. Для начала я решил попробовать в 2д, перевёл камеру в ортогональный режим и создал элементы из двух кусочков:
Если использовать константный радиус кольца для всех многоугольников, получатся вот такие разномастные контуры:
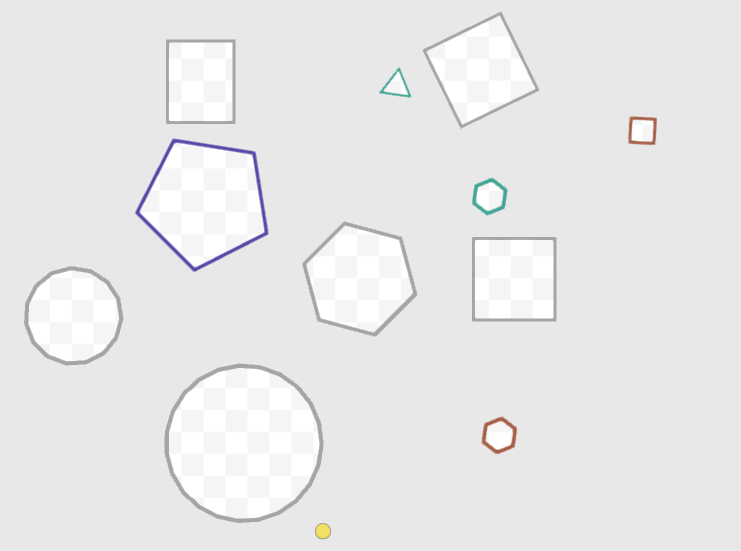
Контуры разной толщины
Дело в том, что нужно получить одинаковое расстояние между сторонами внешней и внутренней части "кольца", а я работаю с углами, а не сторонами. Чем меньше углов в многоугольнике, тем сильнее будут различаться радиусы описанной и вписанной окружности и, соответственно, сильнее будут различаться расстояния между сторонами и расстояния между углами.
— решает проблему.
Теперь чем меньше углов, тем шире будет контур:

Контуры одинаковой толщины
Немножко стенсильной магии, чтобы не было видно колец внутри других многоугольников и получаем такого зайку:

Зайка
И тут завертелось!
Добавил стандартную клеточную текстуру на тело, подобрал цвета и наконец не удержался и подключил мои любимые тени (о них я уже как-то писал).

Просто и аккуратно.
Делюсь скрином с девушкой и получаю резонный фидбек: тень, падающая с высокого объекта на более низкий имеет искажения, изломы. Согласен, я постоянно такое вижу в реальном мире. Пробую нарисовать на бумаге и понять, как должны эти искажения выглядеть. И тут понимаю: какие искажения, если камера — ортогональная?

Слева тени при перспективной камере, справа при ортогональной
Получается, мои красивые тени только подчёркивают плоский вид карты. Время возвращаться в 3D.
Честно говоря, процедурная генерация в 3D для меня совершенно новый опыт. С другой стороны, он ничем не должен отличаться от 2D.
Для начала определился с настройками конкретного многоугольника:
И с общими настройками, которые будут одинаковы для одного типа игровых объектов:
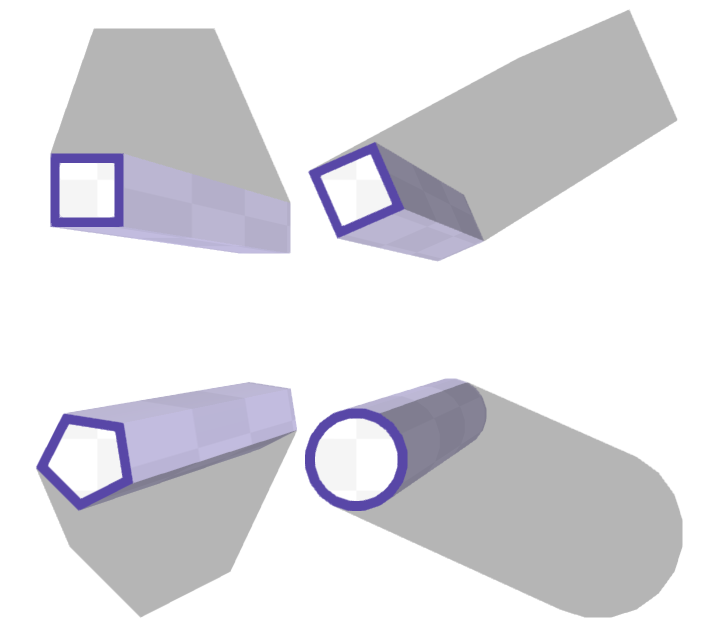
Теперь самое время создавать эти многоугольники. Я разбил каждый на 3 меша:
Нижнее основание нет смысла генерировать, т.к. объекты не могут поворачиваться по осям x или y, а камера всегда находится над картой.
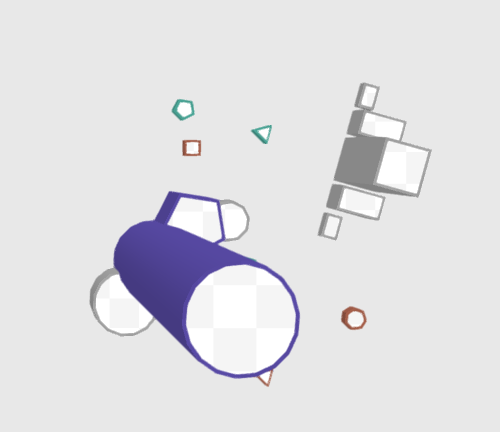
Получаем вот такие многоугольники
Время для оптимизаций:
Во первых, я постоянно рассчитываю единичные вектора, повёрнутые на определённые углы.
Заводим класс AnglesCache с одним публичным методом:
namespace ObstacleGenerators {
public class AnglesCache {
public Vector3[] GetAngles(int sides);
}
}Далее, кеширую все 3 типа мешей, в качестве ключей использую значимые параметры (количество сторон, цвет, круг ли это и т.д.). Цвет сохраняю в вершины, это позволит использовать для мешей один материал и, как следствие, динамический батчинг.
Правда теперь возникла проблема с границами и стенсилом: раньше я объединял границы с помощью стенсила, теперь, когда появился объём, этот подход даёт плохие результаты:
Границы более высоких цилиндров не рисуются, т.к. под ними отрисованы основания низких цилиндров
Перестаю пользоваться стенсил буфером. Теперь все границы обязательно отрисовываются:

Без стенсил буфера
И наконец, меняю в шейдере границ настройки ZTest с On (LEqual) на Less. Теперь границы не будут рисоваться поверх оснований цилиндров с такой же высотой. В результате получаю аккуратное объединение границ, которое корректно работает с объектами разной высоты:

Объединение границ через настройки ZTest'а
Наконец, последние штрихи:
Освещение, сглаживание, шейдеры и мировые uv координаты. (Освещение выкручено посильнее для наглядности)
Последний штрих — генерируем для многоугольников PolygonCollider2D нужной формы.
Итого: трёхмерные многоугольники с физикой и аккуратным lowpoly стилем.
Todo: тени.
Конечно, теперь прежние двумерные тени не подойдут:
Плоские тени выглядят странно, т.к. не учитывают объёмность объекта
А должны они выглядеть примерно вот так:

Более реалистичные тени
"Ну в в чём проблема?" — Спросите вы. "В Unity3D есть отличные тени!".
Действительно, есть. Вот только для построения теней используется алгоритм Shadow mapping. В двух словах: Если мы посмотрим на сцену из источника света, то все объекты, которые нам видны — освещены, а те, которые чем-то закрыты — в тени. Мы можем создать теневую карту, расположив камеру в координатах источника света и отрендерив сцену (в z-buffer'е окажутся данные расстоянии до источника света). Проблема в перспективном искажении. Чем дальше объекты от источника света, тем больше экранных пикселей соответствует текселям из теневой карты.
Т.е. тени не "pixel perfect", это не их фишка, куда важнее, что они очень быстрые. Обычно в искажениях нет проблемы, так как тени накладываются на сложные объекты с текстурой, в результате небольшая потеря качества не заметна. Но у меня очень светлые текстуры, очень мало полигонов, поэтому низкое качество теней прекрасно видно.
Впрочем, есть неплохое решение. Называется алгоритм "Shadow volume" и он очень похож на те двумерные тени, что я делал в прошлых статьях.
Пусть у нас есть некий меш, который должен отбрасывать тени от источника света.
Получается, что если мы 1 раз "вошли" в тень (пересекли front треугольник) и один — "вышли" (пересекли back треугольник) — значение в стенсиле будет равно и пиксель освещён. Если же мы вошли в тень большее количество раз, чем вышли (когда, перед между front и back находится какой-то треугольник, который отрисовался и записал данные в z-buffer) — пиксель в тени и его освещать не нужно.
Итак, нужно получить теневые меши от объектов, пройтись шейдером, добавив в стенсил нужные данные, а затем, отрисовать тень там, где в стенсиле ненулевое значение. Звучит как задача, решаемая на шейдерах!
Todo: генерация теней на шейдерах.
Геометрический шейдер я использовать не стал, не хочется терять часть девайсов из-за того, что версия GL старая. Соответственно, все потенциальные грани придётся запекать заранее для каждого многоугольника.
Пусть есть цилиндр с 32 углами. Каждая грань превращается в два треугольника и 4 вершины, итого:
Всего граней — 32 боковых, и 32 на каждом из двух оснований, 96 в сумме.
Значит, 96*2 = 192 треугольника и 384 вершины на цилиндр. Довольно много.
На самом деле, ещё больше: изначально мы не знаем, какая из боковых граней будет переходом из света в тень (front), а какая — из тени в свет (back). Поэтому для каждой боковой грани приходится делать не 2 треугольника, а 4 (2 из них с противоположным направлением нормали), чтобы позже можно было корректно отсечь нужные с помощью Cull Back или Cull Front.
Поэтому 32 * 4 = 128 граней, 256 треугольников и 512 вершин. Действительно много.
Создать нужный меш довольно просто, не буду акцентировать на этом внимание.
А вот шейдер получается очень любопытный.
Судите сами: нам не нужно отрисовывать все грани, только силуэтные (те, которые разделяют свет и тень). Значит, нам нужно для каждой вершины в вершинном шейдере:
Для всех этих расчётов приходиться хранить большое количество данных в вершине:
координаты (или смещение) до предыдущей и следующей вершин, флаг — нужно ли смещать текущую вершину.
Представьте себе, работает!
Однако, этот способ создания теней содержит столько фатальных недостатков, что грустно становится:
Большое количество вершин оказалось неприятным следствием выбранного метода, но сломаный батчинг забил последний гвоздь: 100-200 draw call'ов на тени для мобильного устройства — неприемлемый результат. Судя по всему, придётся переводить расчёты теней на CPU. Однако, так ли это плохо, как кажется? :)
Todo: перенести генерацию теней на CPU.
Начну с решения в лоб.
Для каждой вершины:
1.1. Получить уравнение прямой проходящей через текущую и предыдущую вершину;
1.2. Проверить с одной ли стороны находятся центр многоугольника и источник света;
1.3. Взять результаты для предыдущей вершины и сравнить с текущей;
1.4. Если предыдущая грань освещена, а текущая — нет, сохранить вершину как силуэтную (lightToShadowIndex);
1.5.1 Если предыдущая грань в тени, а текущая на свету, сохранить вершину как силуэтную (shadowToLightIndex);
Верхнее основание цилиндра:
2.1. Для каждой грани от вершины lightToShadowIndex до вершины shadowToLightIndex добавить в список полигонов тени 2 треугольника (помните, каждую грань мы превращаем в 4х-угольник, где 2 вершины лежат на цилиндре, а 2 — вытягиваются, создавая тень);
Нижнее основание цилиндра:
3.1 Для каждой грани от вершины shadowToLightIndex до вершины lightToShadowIndex добавить в список полигонов тени 2 треугольника;
Парочка замечаний:
Если источник находится над цилиндром, боковых силуэтных граней не будет вовсе (зато будет целая тень от верхнего основания).
Стоит ввести ограничения на положение источника света: если он окажется внутри цилиндра, тени станут некорректными.
Алгоритм работает, пришло время для оптимизаций. На данный момент, чтобы обеспечить 60fps при 10 объектах, нужно рассчитать 600 мешей за секунду. (Если не впечатлило — 6к за 10 секунд).
Todo: Оптимизация теней, 60fps с включёнными тенями на моём nexus 5.
Удаляю лишнее:
Самое очевидное — большинство цилиндров стоит на полу, а источник света всегда над полом. Перестаю генерировать тень от нижнего основания, если объект не висит в воздухе.
Меньше тригонометрии:
Избавляюсь от вездесущих синусов и косинусов. Воспользуюсь классом AnglesCache, описанным выше. Для любознательных вот его полный код:
using UnityEngine;
using System.Collections.Generic;
namespace ObstacleGenerators {
public class AnglesCache {
List cache;
const int MAX_CACHE_SIZE = 100;
public AnglesCache () {
cache = new List(MAX_CACHE_SIZE);
for (int i = 0; i < MAX_CACHE_SIZE; ++i)
cache.Add(null);
}
public Vector2[] GetAngles(int sides) {
if (sides < 0)
return null;
if (sides > MAX_CACHE_SIZE)
return GenerateAngles(sides);
if (cache[sides] == null)
cache[sides] = GenerateAngles(sides);
return cache[sides];
}
public float AngleOffset {
get { return Mathf.PI * 0.25f; }
}
Vector2[] GenerateAngles(int sides) {
var result = new Vector2[sides];
float deltaAngle = 360.0f / sides;
float firstAngle = AngleOffset;
var matrix = Matrix4x4.TRS(Vector2.zero, Quaternion.Euler(0, 0, deltaAngle), Vector2.one);
var direction = new Vector2(Mathf.Cos(firstAngle), Mathf.Sin(firstAngle));
for (int i = 0; i < sides; ++i) {
result[i] = direction;
direction = matrix.MultiplyPoint3x4(direction);
}
return result;
}
}
}Расширяю кеш:
Кеширую коэффициенты прямых (для расчёта освещённости граней). Теперь для поиска силуэтных граней достаточно получить позицию источника света в локальных координатах многоугольника, а затем пройтись по предрасcчитанному массиву прямых.
Убираю медленные операции:
Вместо использования Transform.TransformPoint в циклах использую матрицу transform.localToWorldMatrix и MultiplyPoint3x4.
Избавляюсь от неявных преобразований из Vector3 в Vector2 (куда дешевле кешировать трёхмерные вектора, чем делать каст внутри циклов), в большинстве случаев напрямую присваиваю компоненты вектора, а не сами вектора:
Vector2 v2;
Vector3 v3;
// присвоение компонент куда быстрее,
v2.x = v3.x;
v2.y = v3.y;
// чем вызов функции
v2.Set(v3.x, v3.y);
// и в разы быстрее, чем неявный каст
v2 = v3;Вообще, следите за операциями с векторами, они создают очень много новых структур, это бьёт по производительности.
Оптимизирую поиск граней:
Ещё одна крупная оптимизация. Очень много времени тратится на поиск силуэтных граней, однако, чаще всего тень рассчитывается для очень простой конфигурации:
По сути, правильный многоугольник — аппроксимация для окружности. А рассчитать силуэтные точки на грани — элементарно.
Алгоритм прост:
direction = lightPosition - obstacleCenter;firstAngle = directionAngle - deltaAngle;
secondAngle = directionAngle + deltaAngle;fromLightToShadow = Mathf.FloorToInt(firstAngle / pi2 * edges + edges) % edges;
fromShadowToLight = Mathf.FloorToInt(secondAngle / pi2 * edges + edges) % edges;if (linesCache[fromLightToShadow].HalfPlainSign(lightPosition) < 0)
fromLightToShadow = (fromLightToShadow + 1) % edges;
if (linesCache[fromShadowToLight].HalfPlainSign(lightPosition) >= 0)
fromShadowToLight = (fromShadowToLight + 1) % edges;В результате получаем индексы силуэтных вершин. Из тяжёлых операций — несколько тригонометрических преобразований (Acos, Atan2) и расчёт длины вектора. Зато — ни одного цикла. Куда понятнее станет, если посмотреть видео. Обратите внимание, что правильная силуэтная вершина не всегда ближайшая к силуэтной точке на описанной окружности:
Работа алгоритма быстрого поиска силуэтных вершин.
bool CanUseFastSilhouette(Vector2 lightPosition) {
if (size.x != size.y || edgesList != null)
return false;
return (lightPosition - (Vector2)transform.position).sqrMagnitude > size.x * size.x;
}
bool FindSilhouetteEdges(Vector2 lightPosition, Vector3[] angles, out int fromLightToShadow, out int fromShadowToLight) {
if (CanUseFastSilhouette(lightPosition))
return FindSilhouetteEdgesFast(lightPosition, angles, out fromLightToShadow, out fromShadowToLight);
return FindSilhouetteEdges(lightPosition, out fromLightToShadow, out fromShadowToLight);
}
bool FindSilhouetteEdgesFast(Vector2 lightPosition, Vector3[] angles, out int fromLightToShadow, out int fromShadowToLight) {
Vector2 center = transform.position;
float radius = size.x;
Vector2 delta = center - lightPosition;
float deltaMagnitude = delta.magnitude;
float sin = radius / deltaMagnitude;
Vector2 direction = delta / deltaMagnitude;
float pi2 = Mathf.PI * 2.0f;
float directionAngle = Mathf.Atan2(-direction.y, -direction.x) - anglesCache.AngleOffset - transform.rotation.eulerAngles.z * Mathf.Deg2Rad;
float deltaAngle = Mathf.Acos(sin);
float firstAngle = ((directionAngle - deltaAngle) % pi2 + pi2) % pi2;
float secondAngle = ((directionAngle + deltaAngle) % pi2 + pi2) % pi2;
fromLightToShadow = Mathf.RoundToInt(firstAngle / pi2 * edges - 1 + edges) % edges;
fromShadowToLight = Mathf.RoundToInt(secondAngle / pi2 * edges - 1 + edges) % edges;
return true;
}Оптимизирую меш:
Так как теперь все расчёты происходят на cpu, можно использовать общие точки для смежных граней. Так, например, для цилиндра с 32мя гранями и далёким источником света, когда освещена половина цилиндра, получаю 42 вершины и 36 треугольников (сравните с 512 вершинами и 256 треугольниками при расчётах на gpu).
Сокращаю количество вызовов:
Если силуэтные грани не изменились, не нужно и перерассчитывать меш. А они довольно часто остаются неизменными — при небольших перемещениях источника света или многоугольника меняется только направление "вытягивания" тени. Сравниваю индексы силуэтных граней с их предыдущим значением и не рассчитываю тень, если в этом нет необходимости.
Ещё сильнее сокращаю количество вызовов:
Если не изменились x и y координаты у источника света (высота света не повлияет на силуэтные грани) и позиция многоугольника — не расcчитываем вообще ничего, даже силуэтные грани.
Рассчитываю bounding box:
Стандартный Mesh.RecalculateBounds для тени не подойдёт — ведь она вытягивается искусственно в шейдере. Попробую рассчитать AABB для тени самостоятельно.
Очередной нумерованный список:
На самом деле, нижние точки не рассчитываются для многоугольников, стоящих на земле.

Вид сверху (только нижние точки)
Вид сбоку (только нижние точки)

Bounding box приподнятых над землёй (нижние точки тоже рассчитываются) многоугольников
Теперь те тени, которые не попадают на экран, будут отсекаться.
Я планировал написать про сам рендеринг теней, но у меня кончились кружочки, обозначающие разделы. :)
Судя по ощущениям, скорость написания статьи примерно в полтора раза медленнее, чем написание проекта, поэтому материала для следующей части накопилось достаточно. Однако, я не буду спойлерить, лучше подведу итоги:
Несколько выводов по процессу разработки:
Спасибо за внимание, встретимся в комментариях и следующей статье! :)
|
Метки: author nightrain912 разработка под android разработка игр unity3d c# lowpoly shadows procedural generation shadow volumes |
UNIGINE С++ School: бесплатный онлайн-курс для продвинутых |

Магия оптимизации, которую Шодан показал в первом задании, выглядела впечатляюще. Узнал, в каких местах можно обогнать std и что это делается малой кровью. В первый раз услышал об устройстве hash-таблиц. Узнал, как бенчмаркать свой код, чтобы компилятор всё не соптимизировал. Не смотреть информацию в книгах/статьях, а проверять самому, потому что время идёт, многое меняется и то, что раньше работало медленно, сейчас может быть реализовано достаточно быстро.
Очень много нового, причём, в тех областях, которые считал давно проясненными и закрытыми для экспериментов.
— Об особенностях использования STL. Ещё раз покопался в его внутреннем устройстве, с более критическим подходом. С вопросом «А что в нём плохо?».
— Много новых фишек про оптимизацию программ. Часть из них слышал — но «мимо», не применял. Как все эти бесконечные закладки в браузере из серии «будет время — разберусь».
— Некоторые вещи были для меня совсем новые. Trie-tree, например. Даже не слышал о такой штуке. Не так, чтобы это перевернуло вселенную вверх ногами, но рассказано это было понятно, и наверняка пригодится.
Что узнал нового? Что STL действительно можно уделать на порядок, и это проще чем кажется. Что для внятной оптимизации нужно знать намного больше чем мне известно сейчас.
Что узнал? На самом деле, много. Понял насколько крут и на самом деле «разноуровнев» C++. Тематические штуковины (например размытый ключ деревьев на примере). Ссылки, подобранные уже в скайпе. Например про битхаки в духе nonbranching code.
Никогда не пробовал замерять собственно скорость работы STL контейнеров, и думал что он и так норм. В процессе курса я был вынужден этим заняться и своими руками получил нужные мне результаты на собственном железе. Кое-какие взгляды на STL поменялись.
Оценил inplacement new подход к инициализации объектов и malloc для аллокации памяти. Раньше всегда пользовался new, но, видимо, просто не вставало нужды что-то оптимизировать до такой степени.
Узнал про Bloom filter, экзотические и композитные структуры данных. Маленькие трюки, типа компактной укладки сложных структур в линейный массив. Привёл в порядок голову и систематизировал знания. Была пара моментов, когда думал что знаешь как оно работает, а потом случалось озарение. Сборка собственного велосипеда оказалась не таким очевидным делом.
|
Метки: author Beatrix программирование c++ блог компании unigine unigine обучение программированию обучение онлайн |
Построение информационных ландшафтов с использованием сервисных шин |
|
Метки: author AXELOT-IT системы обмена сообщениями интеграционный ландшафт интеграция приложений маршрутная схема потоковая схема интеграционная модель схемы трансформации данных |
[recovery mode] Правила жизни UX-проектировщика |
«Данные сами по себе не имеют никакого смысла, они собираются и анализируются с определенной целью. И аналитика без последующего проектирования тоже бессмысленна — так же, как проектирование, которое происходит без подтверждения данными: в итоге оно делается в стол».
«Ошибки всегда случаются, и это ещё не говорит о неправильности подхода к работе в целом».
«Должно быть отчетливое желание приносить пользу — равнодушие разрушает весь процесс создания продукта».
|
Метки: author netologyru интерфейсы usability блог компании нетология ux ui проектирование интерфейсов интерфейс дизайн |
[recovery mode] Solid12 — версия IEM-платформы Ultimate для бесплатной PostgreSQL |
|
Метки: author Rupper erp- системы crm- блог компании ultima erp iem- iem oracle database postgresql |
Технологические тенденции и актуальные решения SDN для ЦОД |




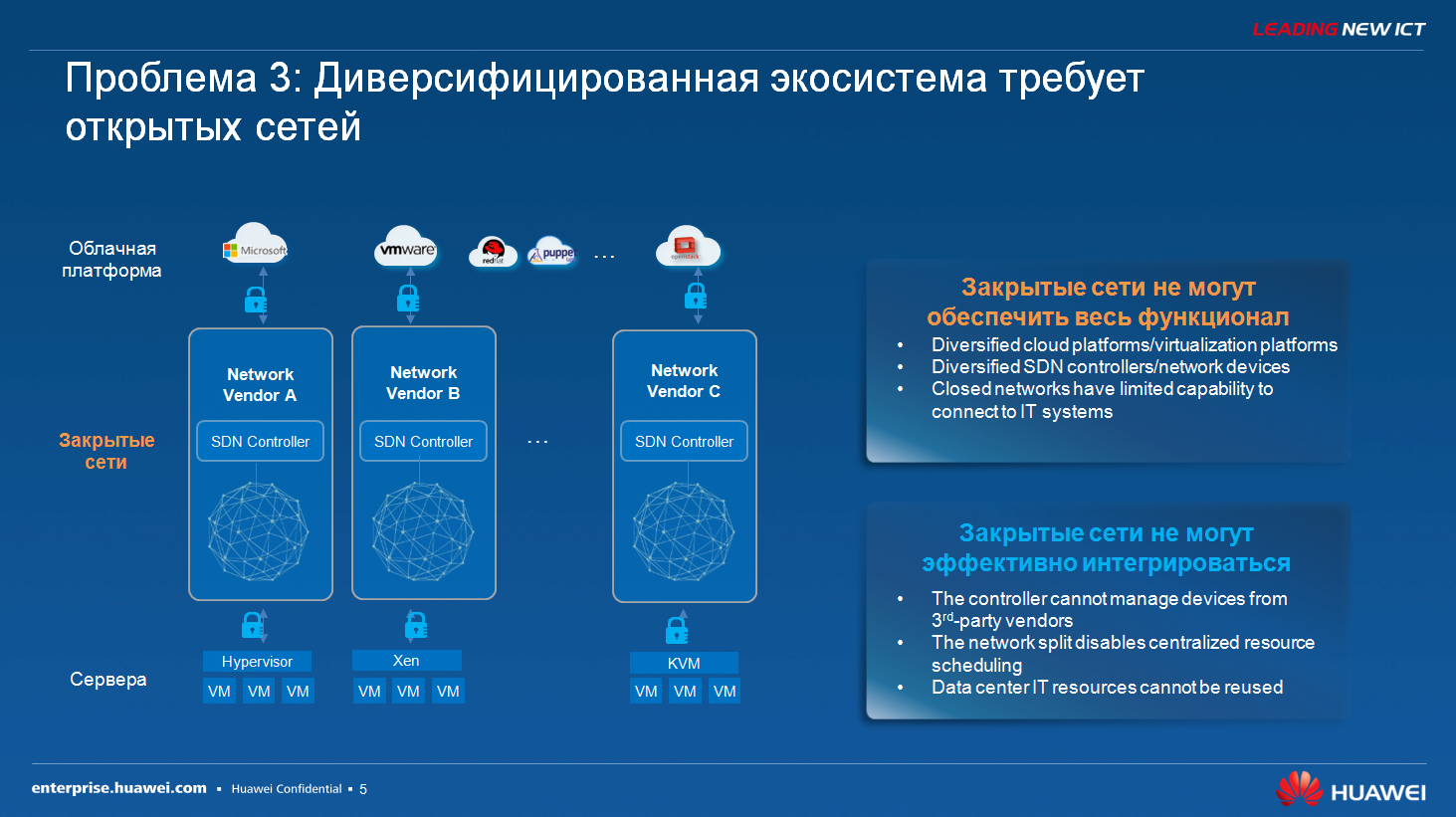
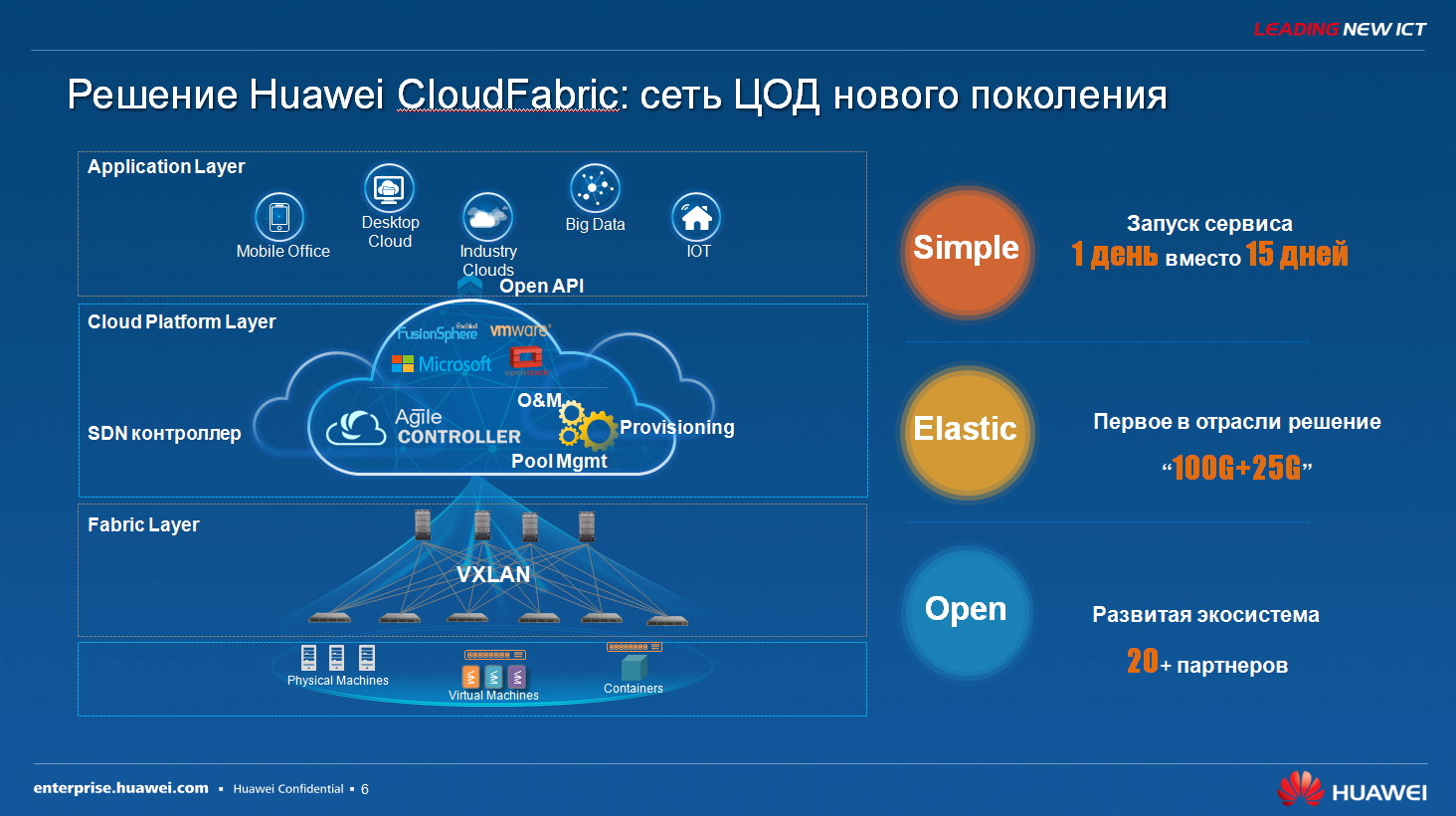
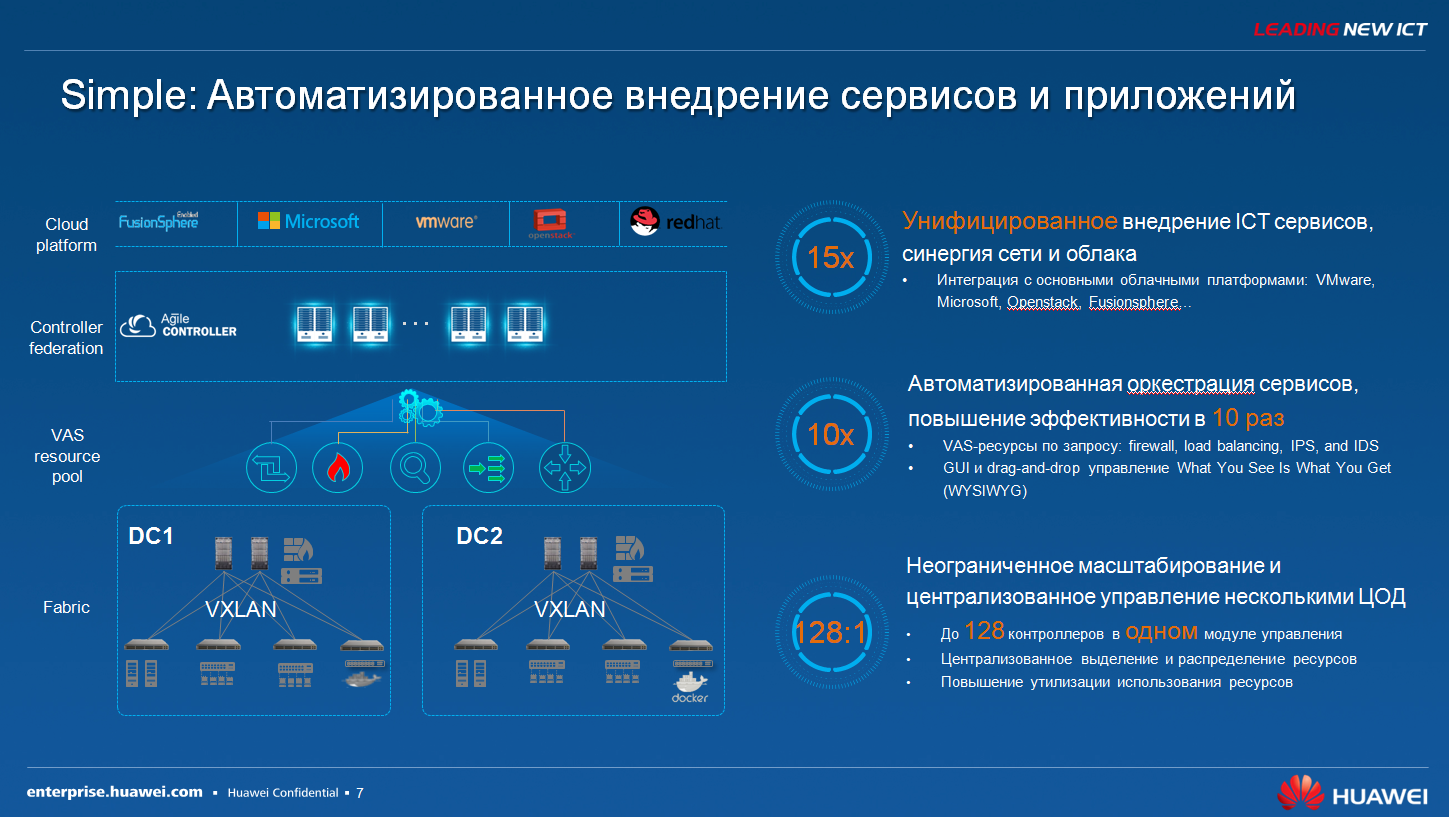

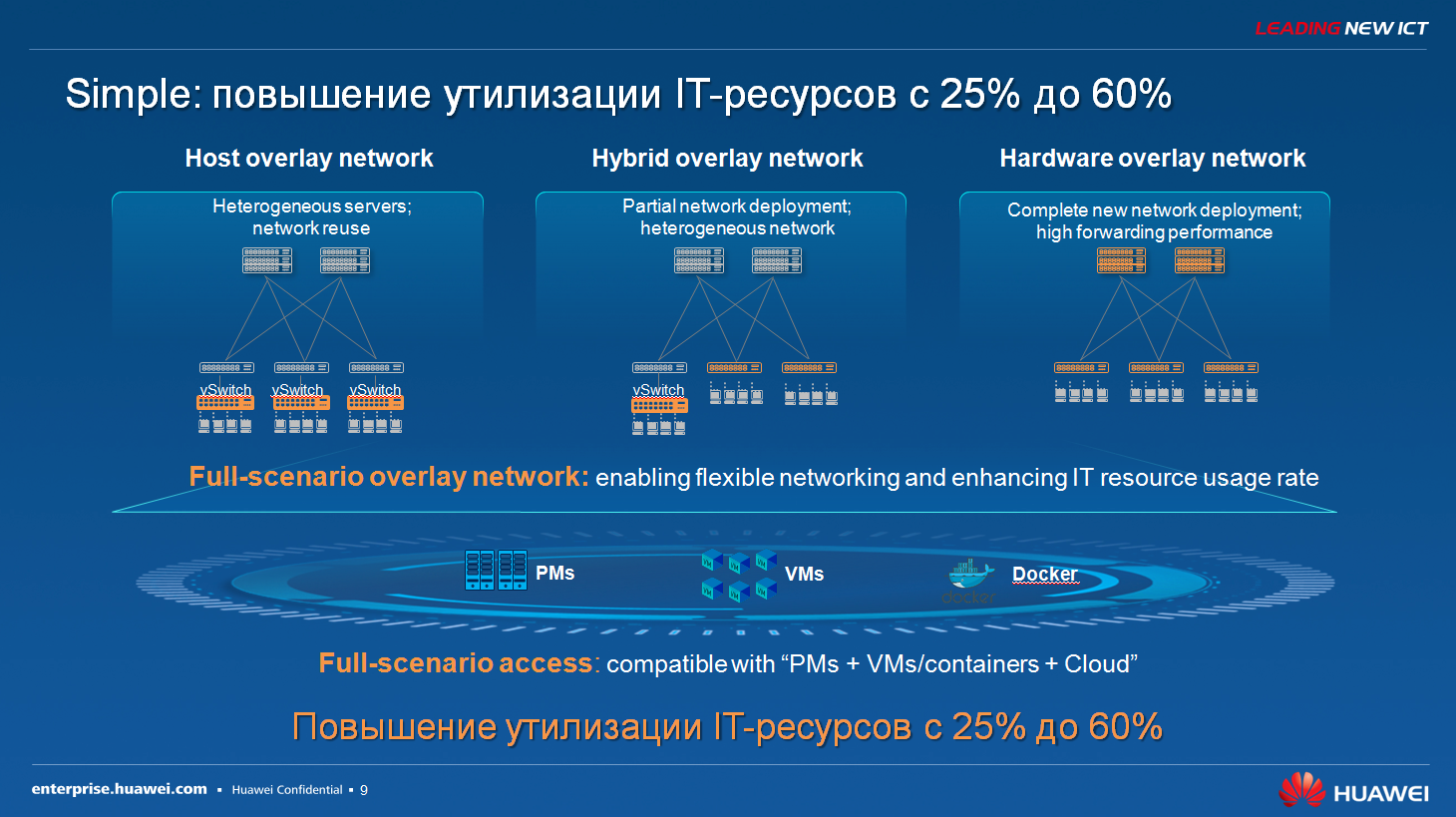


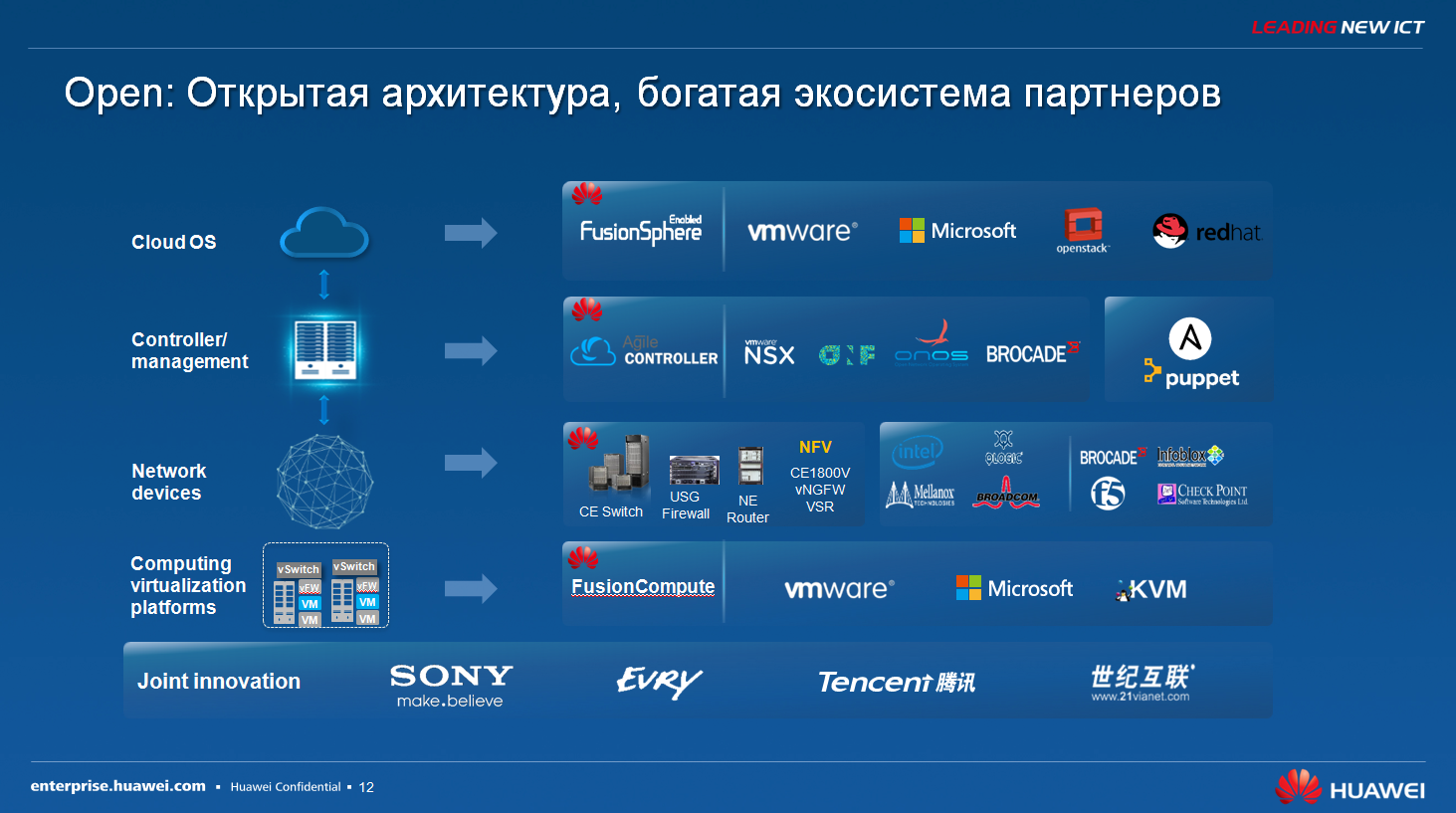


|
Метки: author ru_vds хранилища данных хранение данных хостинг it- инфраструктура блог компании ruvds.com ruvds sdn цод huawei |
Программа PYCON RUSSIA готова: 25 докладов от спикеров из Disney, Facebook, Spotify, PyPy, Тинькофф Банк, Яндекс |

 Inside the Hat: Python @ Walt Disney Animation Studios
Inside the Hat: Python @ Walt Disney Animation Studios Gradual Typing of Production Applications
Gradual Typing of Production Applications Why is Python slow?
Why is Python slow? Elegant Solutions for Everyday Python Problems
Elegant Solutions for Everyday Python Problems Tales of Tunes on Tubes: Python in Spotify's Infrastructure
Tales of Tunes on Tubes: Python in Spotify's Infrastructure Мастер-класс «Распознавание речи на Python без PhD»
Мастер-класс «Распознавание речи на Python без PhD» Python на острие бритвы: PyPy project
Python на острие бритвы: PyPy project Отладка в Python 3.6: быстрее, выше, сильнее
Отладка в Python 3.6: быстрее, выше, сильнее Scrapy internals
Scrapy internals Python of Things
Python of Things Что может Python на микроконтроллерах
Что может Python на микроконтроллерах Тотальный контроль производительности
Тотальный контроль производительности Write once run anywhere — почём опиум для народа?
Write once run anywhere — почём опиум для народа? Микросервисы наносят ответный удар!
Микросервисы наносят ответный удар! PyWat. А хорошо ли вы знаете Python?
PyWat. А хорошо ли вы знаете Python? Детские болезни live-чата
Детские болезни live-чата Amazing AppEngine
Amazing AppEngine How I Learned to Stop Worrying and Love the BFG: нагрузочное тестирование со вкусом питона
How I Learned to Stop Worrying and Love the BFG: нагрузочное тестирование со вкусом питона Что такое serverless-архитектура и как с ней жить?
Что такое serverless-архитектура и как с ней жить? Как написать свой debugger
Как написать свой debugger (Без)опасный Python
(Без)опасный Python Про аналитику и серебряные пули
Про аналитику и серебряные пули Gevent — быть или не быть?
Gevent — быть или не быть?  Gensim — тематическое моделирование для людей
Gensim — тематическое моделирование для людей Память и Python. Что надо знать для счастья?
Память и Python. Что надо знать для счастья?



|
Метки: author shulyndina разработка веб-сайтов программирование python django блог компании it-people конференция |
[Перевод] Как улучшить legacy-код |
|
Метки: author m1rko тестирование it-систем проектирование и рефакторинг legacy code рефакторинг |
[Из песочницы] Виртуальная реальность на геймдев-конференции White Nights |



|
Метки: author Agorov разработка под ar и vr vr virtual reality gamedev виртуальная реальность разработка игр игровая индустрия геймдев white nights |
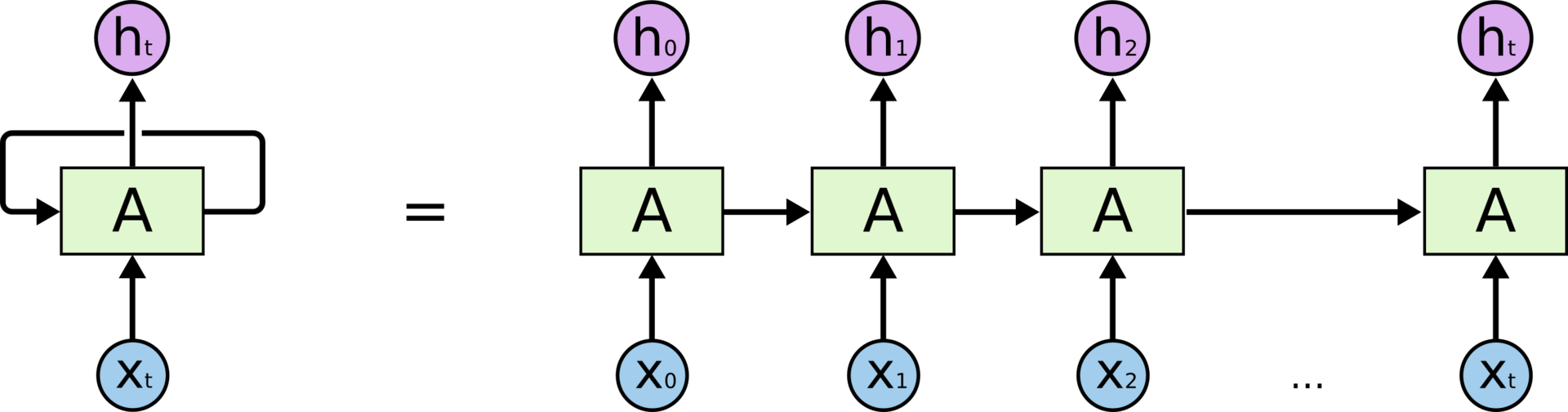
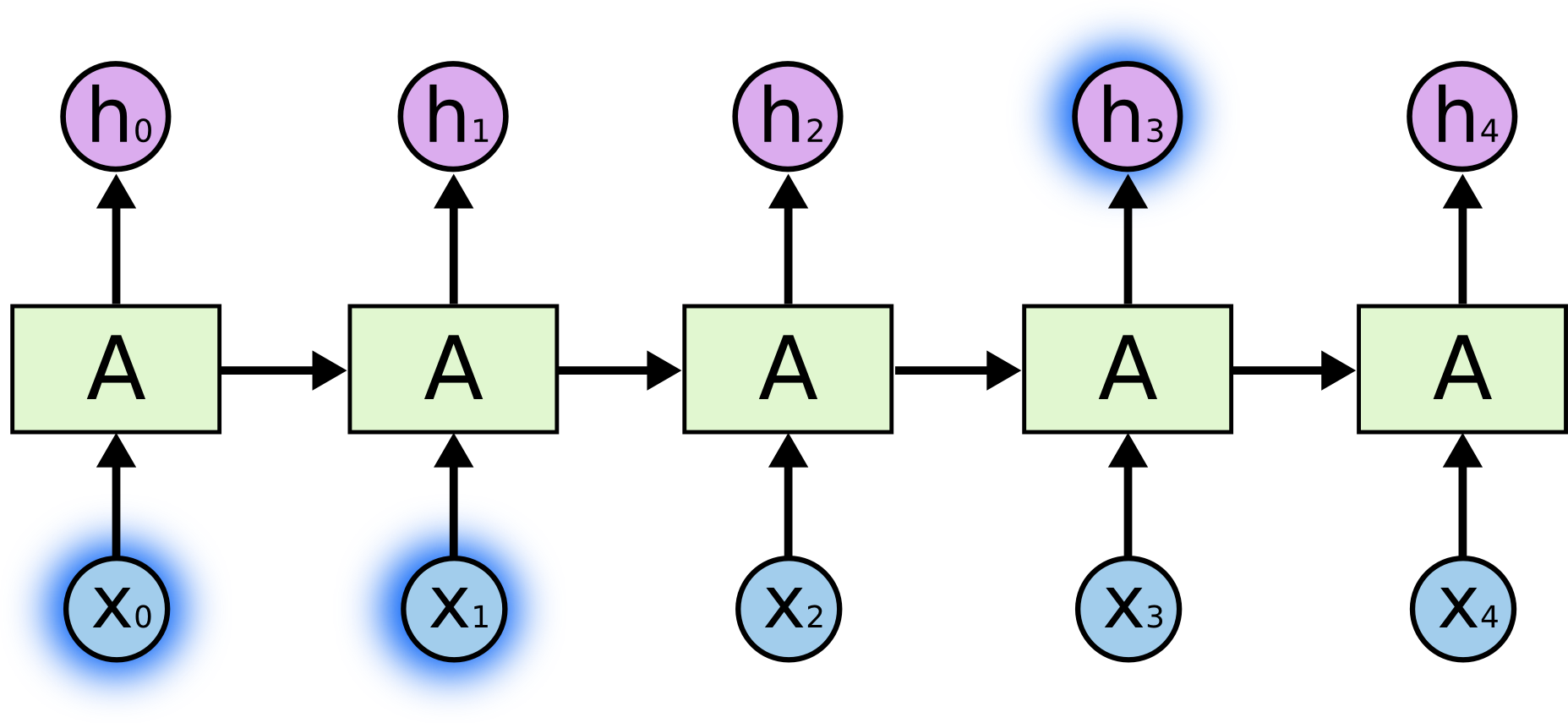
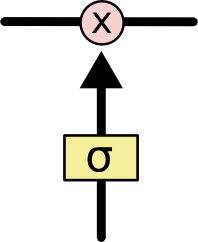
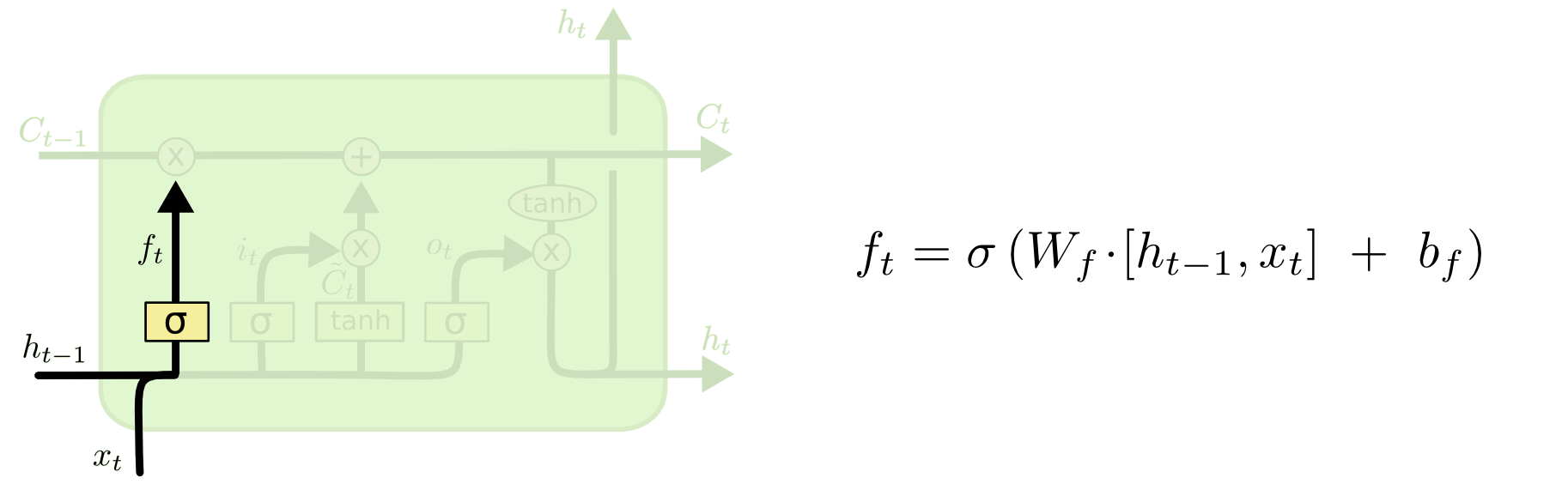
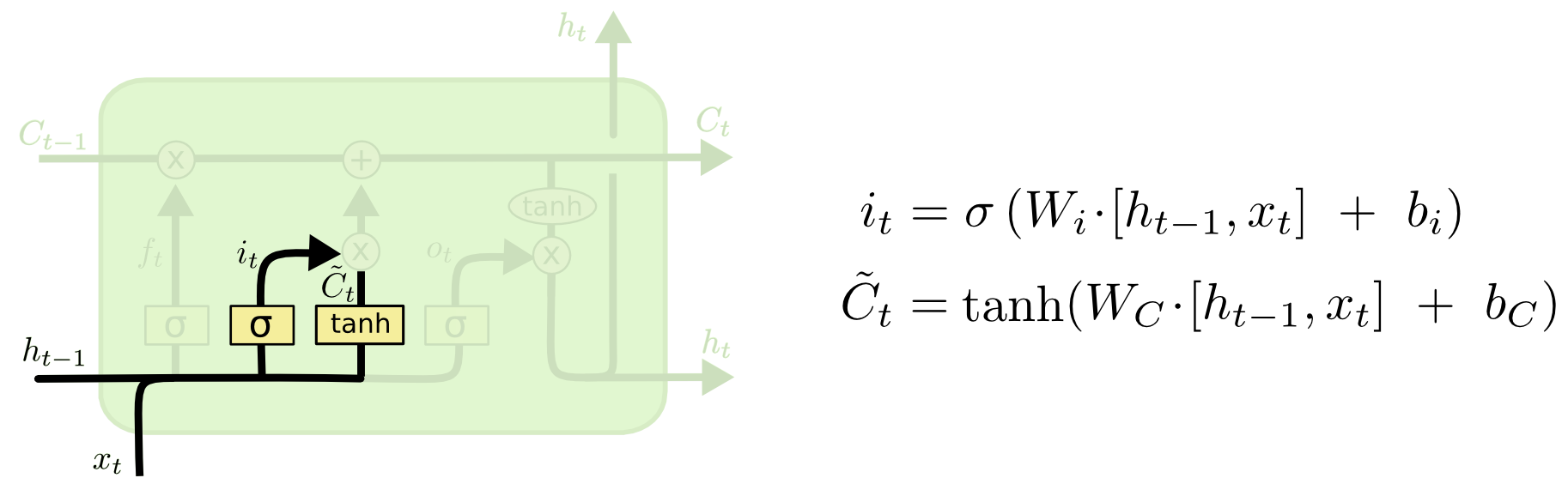
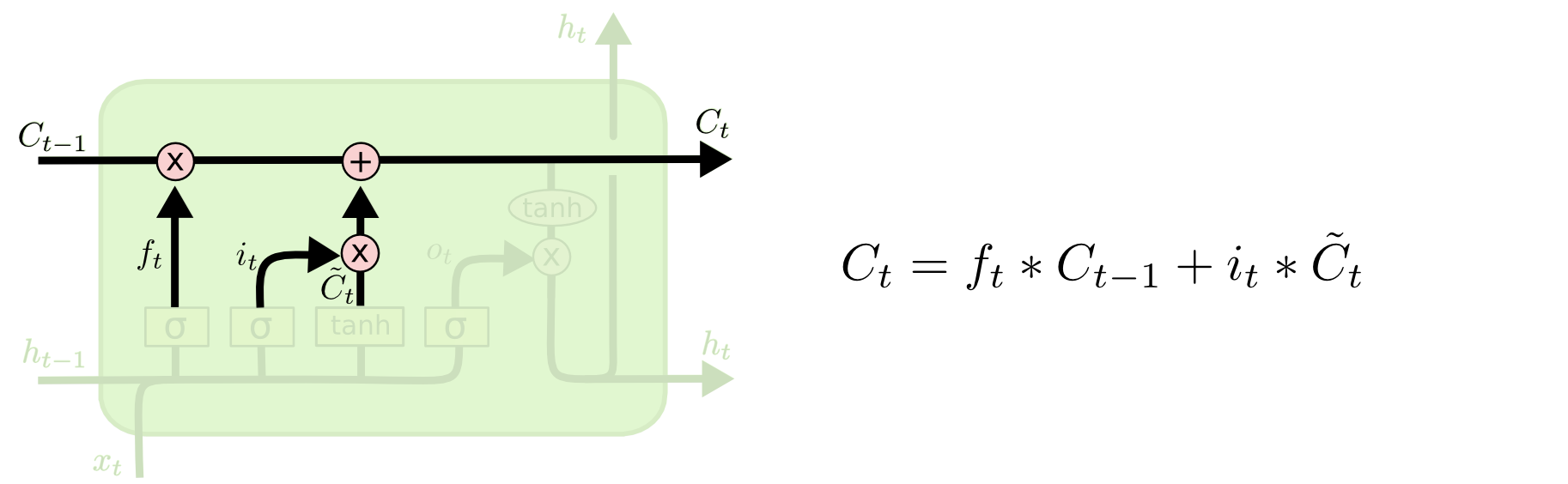
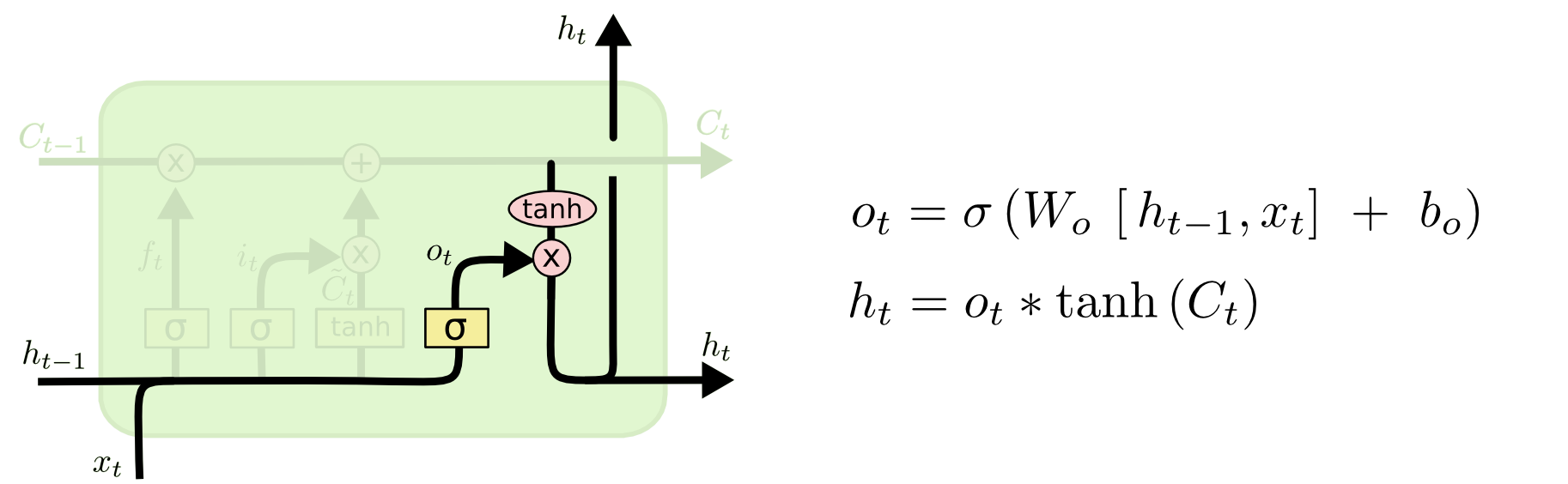
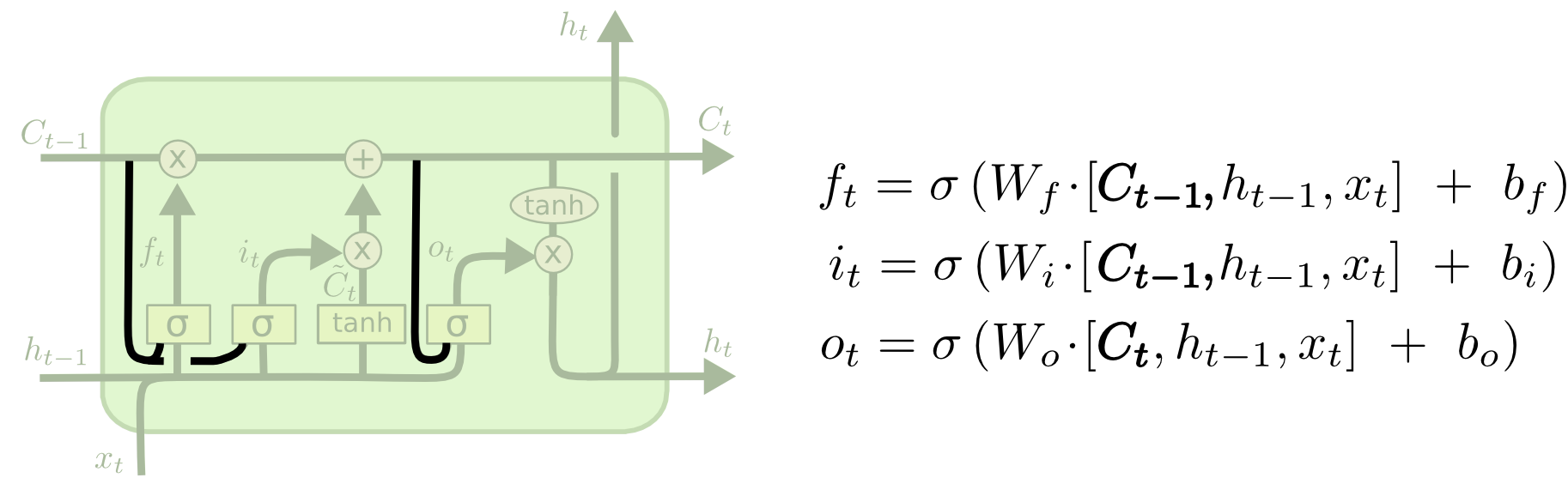
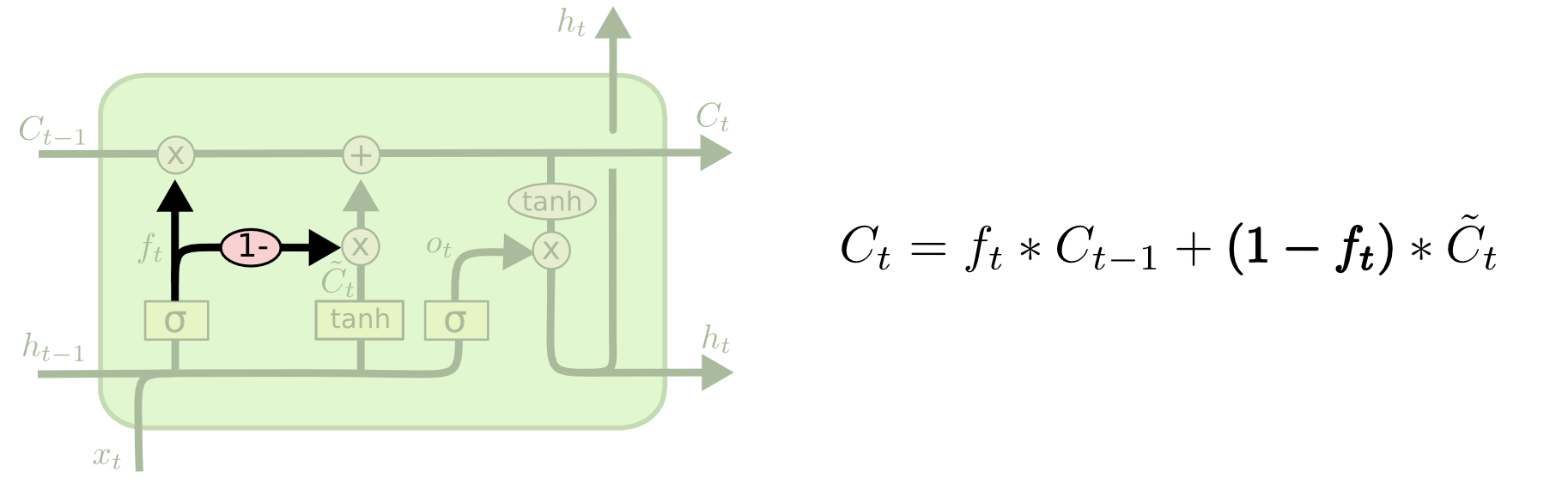
[Перевод] LSTM – сети долгой краткосрочной памяти |

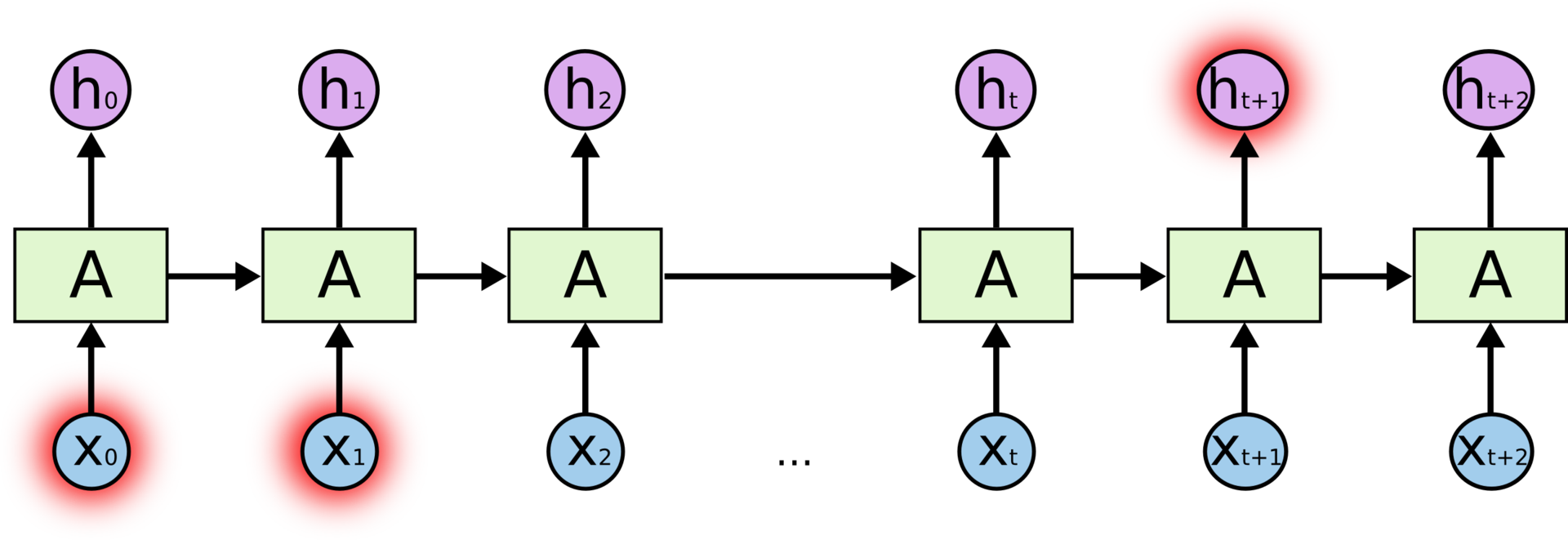
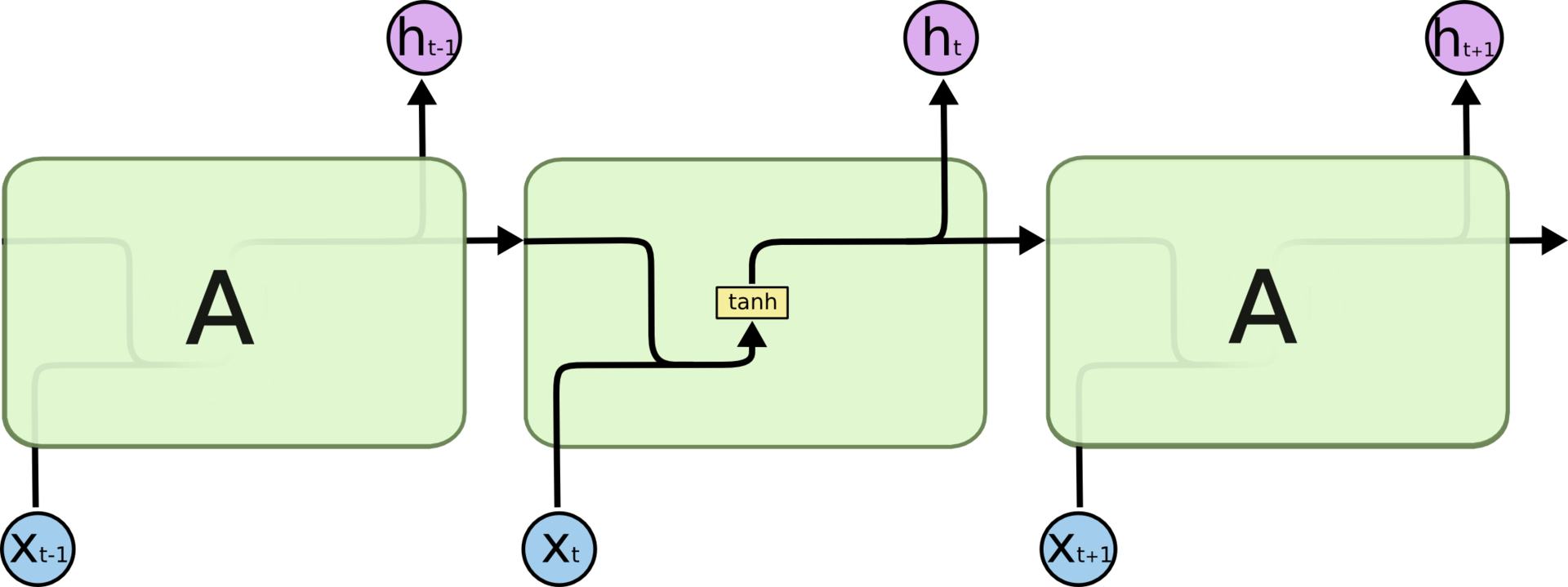
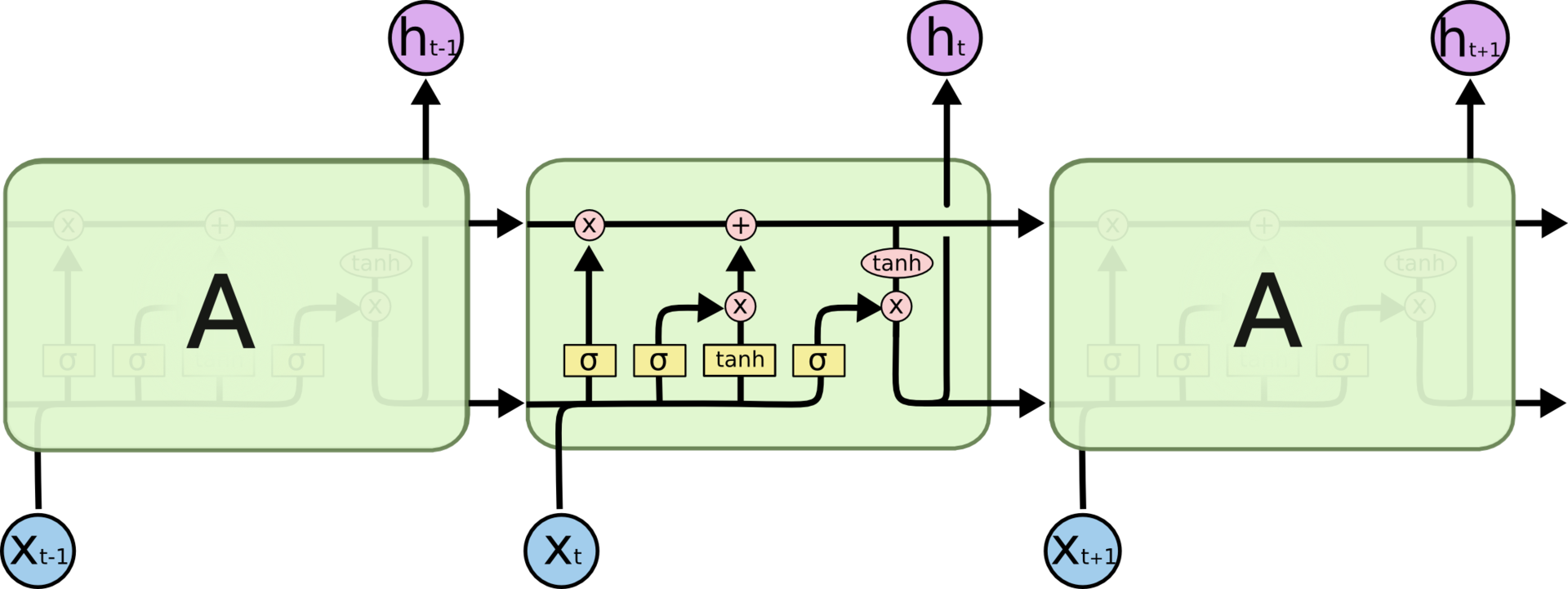

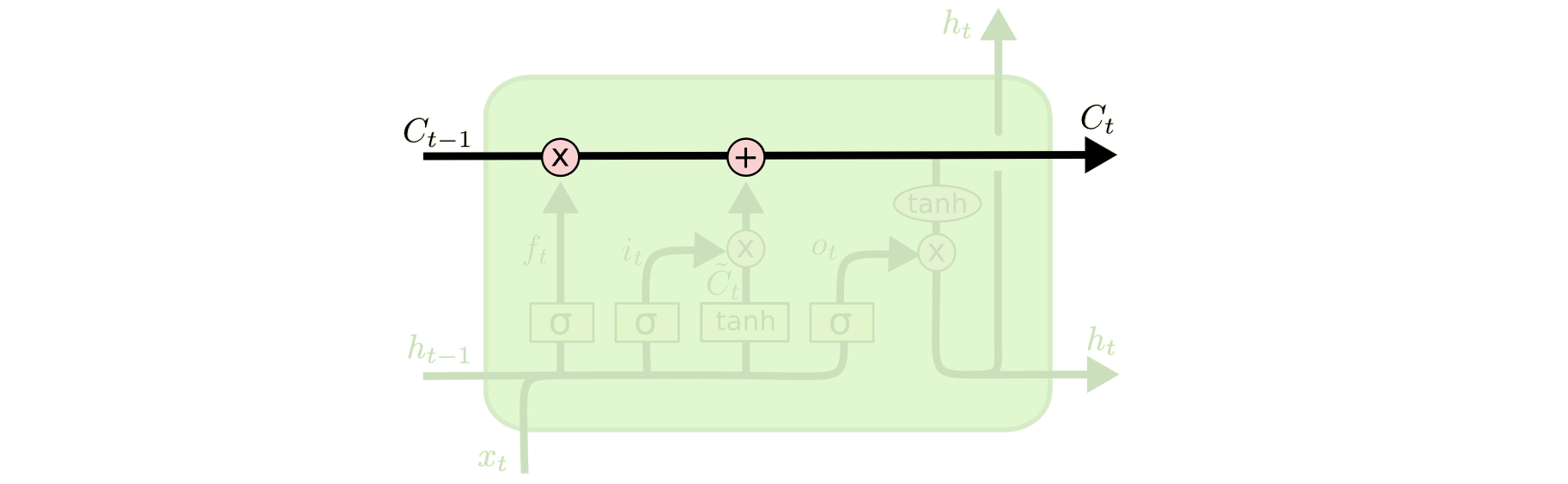

О, а приходите к нам работать? :)wunderfund.io — молодой фонд, который занимается высокочастотной алготорговлей. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Присоединяйтесь к нашей команде: wunderfund.io
|
Метки: author wunder_editor машинное обучение алгоритмы блог компании wunder fund lstm rnn neural networks machine learning wunderfund wunder fund |
[Перевод] Жизнь Oracle I/O: трассировка логического и физического ввода-вывода с помощью SystemTap |
|
Метки: author rdruzyagin sql oracle блог компании pg day'17 russia systemap profiling tracing linux kernel i/o |
Самодостаточные контроллы на Xamarin.Forms: «Переиспользуй код на максимум!». Часть 2 |

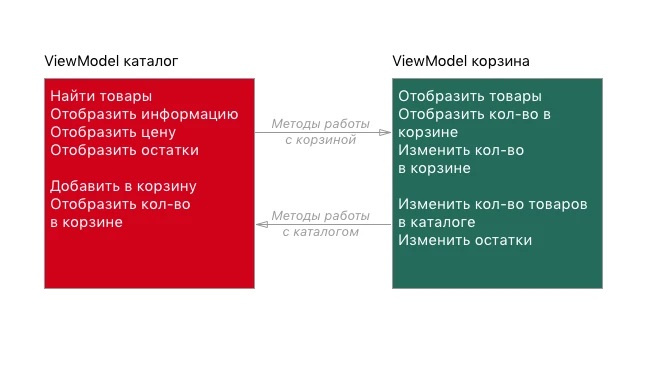
public event Action OnProductAddedSuccessfully;
public event Action OnProductAddedFailure;
public void StartAddingProduct(string sku)
{
var newProduct = new BasketProduct() { Sku = sku, State = Enums.RequestState.InProgress };
//сохраняем локально новый экземпляр возможного продукта в корзине
_products.Add(newProduct);
//обращаемся к хранилищу корзины, получаем билет, в котором выполняется запрос...
var tiket = _basketRepository.AddToBasket(sku);
tiket.OnSuccess += (response) =>
{
//результат содержит поле, которое указывает на то удалось ли добавить товар в корзину
if(response.Data.Succseeded != null && response.Data.Succseeded.Value)
{
//каждый товар в корзине должен содержать свой собственный идентификатор, который тоже приходит в ответе (positionId)
newProduct.PositionId = response.Data.PositionId;
newProduct.State = Enums.RequestState.Succseeded;
//оповещаем подписчиков (контроллы), что товар добавлен успешно
OnProductAddedSuccessfully?.Invoke(newProduct.Sku, newProduct.PositionId);
}
else
{
//оповещаем подписчиков, что товар не удалось добавить
OnProductAddedFailure?.Invoke(sku);
newProduct.State = Enums.RequestState.Failed;
}
};
//дополнительный запрос на то, чтоб конкретизировать цену (необходимо при подсчете общей стоимости корзины)
var priceTicket = _catalogRepository.GetPriceTicket(sku);
priceTicket.OnSuccess += (response) =>
{
if(response.Data != null){
//обновляем данные о цене
newProduct.Price = response.Data.Price;
}
};
} public int? TotalCount
{
get
{
return _basketService.TotalCount;
}
}
public int? TotalPrice
{
get
{
return _basketService.TotalPrice;
}
}
void _basketService_OnProductAddedSuccessfully(string sku, string positionId)
{
var product = Products.ToList().FirstOrDefault(x => x.Sku == sku);
product.CountInBasket++;
product.IsAddingInProfress = false;
product.PositionIds.Add(positionId);
//Рейз происходит не в сеттере поля, а именно в тот момент, когда в корзине действительно что-то поменялось
RaizePropertyChanged(nameof(TotalCount), nameof(TotalPrice));
}


|
|
Технологии и «не-IT»: как и зачем S/4HANA применяется в оптовой торговле |
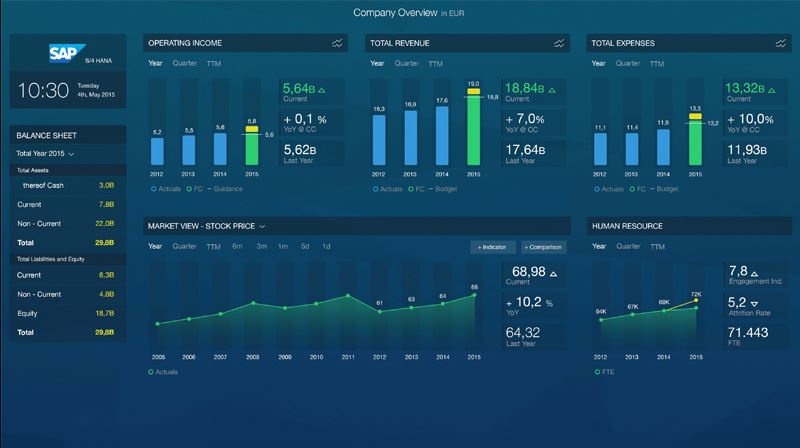


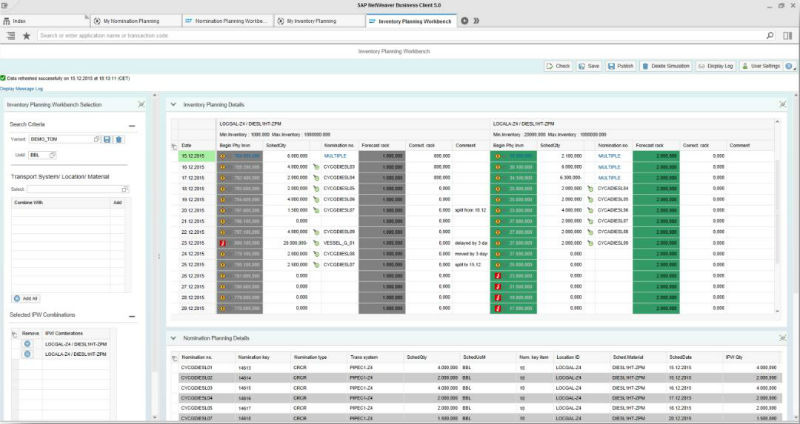
|
Метки: author pilot-retail it- инфраструктура блог компании пилот анализ sap sap hana s/4hana ритейл аналитика |
Два года с Dart: о том, как мы пишем на языке, который ежегодно «хоронят» (часть 2) |



|
|
Анонс DotNext 2017 Moscow: двойная порция .NET |





|
Метки: author phillennium .net блог компании jug.ru group конференция dotnext c# f# андрей акиньшин sasha goldshtein |
Обзор анимации с codepen для страниц загрузки сайта |

Программисты проверяют идеи для сайтов на площадках: codepen, jsbin, jsfiddle, cssdesk. Потому что там они мгновенно видят результат написанного кода и могут показать его другим.
Codepen — одна из самых популярных. Там более 500 тыс. готовых решений. Из них половина — хлам: неэффективный код, не работают на планшетах и телефонах, не поддерживают все популярные браузеры. Надо потратить много часов на поиск идеи, которую можно использовать на своем сайте.
Я решил делать подборки полезных решений с codepen. Первую уже выпускал на хабре «Обзор многоуровневых меню». Теперь вторая — «Обзор анимации для страниц загрузки сайта».
Подборку разделил на 3 статьи.
Решения с codepen я пропустил через 3 критерия:
Я выбрал 1440 решений codepen по запросу «Preloader». Пропустил их через первый и второй фильтр. Из 1440 осталось 465. В каждой статье проанализирую по 155 идей.
Если идею нельзя использовать в реальном проекте, она не работает в 2-3 браузерах, на планшете или телефоне и в ней используются медленный код — я её выкидываю. Поэтому из первых 155 дожило только 83.
P.S. Если хотите помочь в анализе оставшихся 310 идей для preloader-страниц, то напишите мне личным сообщением. У меня не хватает времени быстро их обработать из-за работы над Gefest IDE. А вместе мы сделаем это быстрее. Вклад каждого будет описан в статьях.

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Не достаточно эффективное решение из-за "> div > div".
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Интересное решение, но неэффективное — из-за анимации css-свойства box-shadow.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В Safari (mac) не работает.
Использует технологии:

Простой код, но не достаточно эффективное решение из-за анимации css-свойств margin и box-shadow.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение и простой код.
Сайт библиотеки.
Работает в браузерах:
В IE и Firefox не работает.
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В Android 3.3+ не работает
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Простое и эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В Android 3.3+ не работает.
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Некоторые решения эффективные, а некоторые — нет из-за анимации css-свойств: margin, border, text-shadow, border-radius, height, width и right.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В Firefox не работает.
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Простое и эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Неэффективное из-за box-shadow, но красивое.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Решение красивое, но неэффективное из-за css-свойства height.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В IE не работает.
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:
")
Часть решений эффективны, а часть — нет из-за анимации css-свойств: width, left, right и top.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Часть решений эффективны, а часть — нет из-за анимации css-свойств: height, border-radius, border, left и margin.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Не которые решения не эффективны из-за анимации css-свойств: left, right, width, box-shadow и height.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Неэффективное, но интересное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Чистый код, но неэффективное решение из-за анимации css-свойства width.
Сайт библиотеки.
Работает в браузерах:
В Windows phone 8+ не работает.
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Не достаточно эффективное решение из-за анимации css-свойства left.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В IE и Firefox не работает.
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Интересное решение, но неэффективное из-за анимации css-свойств: border-radius, left и top.
Сайт библиотеки.
Работает в браузерах:
В Android 3.3+ не работает.
Использует технологии:

Решение эффективное. Js-код выполняется только при открытии: определяет расположение и скорость анимаци шариков.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Не достаточно эффективное решение из-за анимации css-свойств: left и padding.
Сайт библиотеки.
Работает в браузерах:
В IE и Windows phone не работает.
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение, но требует подключать тяжелый скрипт Tween max.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение, но требует подключать тяжелые скрипты: Tween max и CSSRulePlugin.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение. При помощи GreenSock Animation Platform происходит анимация svg объектов.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение. При помощи GreenSock Animation Platform происходит анимация svg объектов.
Сайт библиотеки.
Работает в браузерах:
В Windows phone не работает
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В iOS не работает.
Использует технологии:

Решение не достаточно эффективное. Начальный перебор элементов svg объекта сделан плохо.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В IE и Windows phone не работает, потому что они не поддерживают SVG.
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В IE и Windows phone не работает, потому что они не поддерживают SVG.
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В Windows phone не работает, потому что не поддерживает SVG.
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В IE и Windows phone не работает, потому что они не поддерживают SVG.
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В IE и Windows phone не работает, потому что они не поддерживают SVG.
Использует технологии:

Не достаточно эффективное решение из-за анимации css-своства height.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В Safari (mac) не работает.
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В IE и Windows phone не работает.
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В IE и Windows phone не работает.
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
Использует технологии:

Эффективное решение.
Сайт библиотеки.
Работает в браузерах:
В iOS8+ не работает.
Использует технологии:
|
Метки: author Teadon разработка веб-сайтов javascript html css подборка css3 web- разработка веб-дизайн codepen |
[Перевод] Взлом Age of Mythology: отключение тумана войны |





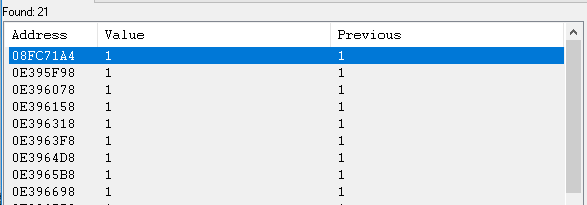

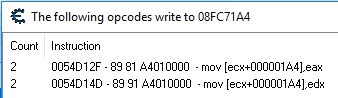

.text:0054B670 mov eax, large fs:0
.text:0054B676 push 0FFFFFFFFh
.text:0054B678 push offset SEH_54B670
.text:0054B67D push eax
.text:0054B67E mov large fs:0, esp
.text:0054B685 sub esp, 8
.text:0054B688 push esi
.text:0054B689 mov esi, ecx
.text:0054B68B mov eax, [esi+148h]
.text:0054B691 push edi
.text:0054B692 mov edi, [esi]
.text:0054B694 push eax
.text:0054B695 push esi
.text:0054B696 lea ecx, [esp+24h+var_10]
.text:0054B69A call sub_4D7470
.text:0054B69F mov ecx, [eax]
.text:0054B6A1 push ecx
.text:0054B6A2 push 1
.text:0054B6A4 mov ecx, esi
.text:0054B6A6 call dword ptr [edi+54h]
.text:0054B6A9 cmp [esp+1Ch+arg_0], 0Dh
.text:0054B6AE jnz loc_54B769
.text:0054B6B4 lea edi, [esi+154h]
......
.text:0054BF98 push 0Ch
.text:0054BF9A call dword ptr [eax+0CCh]
.text:0054BFA0
.text:0054BFA0 loc_54BFA0: ; CODE XREF: sub_54BF80+Fj
.text:0054BFA0 ; sub_54BF80+14j
.text:0054BFA0 mov ecx, [esp+0Ch+arg_8]
.text:0054BFA4 push ecx
.text:0054BFA5 push edi
.text:0054BFA6 push ebx
.text:0054BFA7 mov ecx, esi
.text:0054BFA9 call sub_4D4EF0
.text:0054BFAE pop edi
......
.text:004D504C cmp esi, dword_A9D068
.text:004D5052 jz short loc_4D5087
.text:004D5054 push esi
.text:004D5055 call sub_424750
.text:004D505A mov edi, eax
.text:004D505C add esp, 4
.text:004D505F test edi, edi
.text:004D5061 jz short loc_4D5070
.text:004D5063 push esi
.text:004D5064 call sub_4D58B0
.text:004D5069 add esp, 4
.text:004D506C test edi, edi
.text:004D506E jnz short loc_4D5079
.text:004D5070
.text:004D5070 loc_4D5070: ; CODE XREF: sub_4D4EF0+171j
.text:004D5070 pop edi
.text:004D5071 pop esi
.text:004D5072 pop ebp
.text:004D5073 xor al, al
.text:004D5075 pop ebx
.text:004D5076 retn 0Ch
.text:004D5079 ; ---------------------------------------------------------------------------
.text:004D5079
.text:004D5079 loc_4D5079: ; CODE XREF: sub_4D4EF0+17Ej
.text:004D5079 mov eax, [esp+10h+arg_4]
.text:004D507D mov edx, [edi]
.text:004D507F push ebp
.text:004D5080 push eax
.text:004D5081 push ebx
.text:004D5082 mov ecx, edi
.text:004D5084 call dword ptr [edx+54h]
.text:004D5087
.text:004D5087 loc_4D5087: ; CODE XREF: sub_4D4EF0+157j
.text:004D5087 ; sub_4D4EF0+162j
.text:004D5087 pop edi
....text:004D4EF0 push ebx
.text:004D4EF1 mov ebx, [esp+4+arg_0]
.text:004D4EF5 push ebp
.text:004D4EF6 mov ebp, [esp+8+arg_8]
.text:004D4EFA push esi
.text:004D4EFB mov esi, ecx
.text:004D4EFD mov ecx, [esi+0B8h]
....text:004D0C70 mov ecx, [ecx+14Ch]
.text:004D0C76 test ecx, ecx
.text:004D0C78 jz short loc_4D0C91
.text:004D0C7A mov edx, [esp+arg_8]
.text:004D0C7E mov eax, [ecx]
.text:004D0C80 push edx
.text:004D0C81 mov edx, [esp+4+arg_4]
.text:004D0C85 push edx
.text:004D0C86 mov edx, [esp+8+arg_0]
.text:004D0C8A push edx
.text:004D0C8B call dword ptr [eax+30h]
.text:004D0C8E retn 0Ch
.text:004D0C91 ; ---------------------------------------------------------------------------
.text:004D0C91
.text:004D0C91 loc_4D0C91: ; CODE XREF: sub_4D0C70+8j
.text:004D0C91 xor al, al
.text:004D0C93 retn 0Ch
.text:004D0C93 sub_4D0C70 endp.text:004680D0 push 0FFFFFFFFh
.text:004680D2 push offset SEH_4680D0
.text:004680D7 mov eax, large fs:0
.text:004680DD push eax
.text:004680DE mov large fs:0, esp
.text:004680E5 sub esp, 0F8h
.text:004680EB mov eax, [esp+104h+arg_8]
.text:004680F2 push ebx
.text:004680F3 push ebp
.text:004680F4 push esi
.text:004680F5 mov esi, [esp+110h+arg_0]
.text:004680FC push edi
.text:004680FD mov ebp, ecx
.text:004680FF mov ecx, [esp+114h+arg_4]
.text:00468106 push eax
.text:00468107 push ecx
.text:00468108 push esi
.text:00468109 mov ecx, ebp
.text:0046810B mov [esp+120h+var_F0], ebp
.text:0046810F call sub_4718B0
.text:00468114 test al, al
...
.text:00471DB4 loc_471DB4: ; CODE XREF: sub_4718B0+4FDj
.text:00471DB4 ; DATA XREF: .text:off_471FA0o
.text:00471DB4 push edi ; jumptable 00471DAD case 4
.text:00471DB5 call sub_54E7D0
.text:00471DBA mov esi, eax
.text:00471DBC add esp, 4
.text:00471DBF test esi, esi
.text:00471DC1 jz loc_471F5F ; jumptable 00471DAD case 3
.text:00471DC7 push edi
.text:00471DC8 call sub_4D58B0
.text:00471DCD add esp, 4
.text:00471DD0 test esi, esi
.text:00471DD2 jz loc_471F5F ; jumptable 00471DAD case 3
.text:00471DD8 mov edx, [esi+1A4h]
.text:00471DDE mov ecx, [esp+50h+var_40]
.text:00471DE2 cmp edx, ebx
.text:00471DE4 setz al
.text:00471DE7 push eax
.text:00471DE8 call sub_58EA10
.text:00471DED mov al, 1
.text:00471DEF jmp loc_471F65
....text:0058EA10 sub_58EA10 proc near ; CODE XREF: sub_4718B0+538p
.text:0058EA10 ; sub_58DF30+919p ...
.text:0058EA10
.text:0058EA10 arg_0 = dword ptr 4
.text:0058EA10
.text:0058EA10 push ebx
.text:0058EA11 mov ebx, [esp+4+arg_0]
.text:0058EA15 mov [ecx+53h], bl
.text:0058EA18 mov eax, dword_A9D244
.text:0058EA1D mov ecx, [eax+140h]
.text:0058EA23 test ecx, ecx
.text:0058EA25 jz short loc_58EA43
.text:0058EA27 push 1
.text:0058EA29 push ebx
.text:0058EA2A call sub_5316B0
.text:0058EA2F mov ecx, dword_A9D244
.text:0058EA35 mov ecx, [ecx+140h]
.text:0058EA3B push 1
.text:0058EA3D push ebx
.text:0058EA3E call sub_5316D0
.text:0058EA43
.text:0058EA43 loc_58EA43: ; CODE XREF: sub_58EA10+15j
.text:0058EA43 pop ebx
.text:0058EA44 retn 4
.text:0058EA44 sub_58EA10 endp
.text:005316B0 ; =============== S U B R O U T I N E =======================================
.text:005316B0
.text:005316B0
.text:005316B0 public sub_5316B0
.text:005316B0 sub_5316B0 proc near ; CODE XREF: sub_442070+1684p
.text:005316B0 ; sub_4C91E0+14Cp ...
.text:005316B0
.text:005316B0 arg_0 = byte ptr 4
.text:005316B0 arg_4 = dword ptr 8
.text:005316B0
.text:005316B0 mov edx, [esp+arg_4]
.text:005316B4 mov al, [esp+arg_0]
.text:005316B8 push edx
.text:005316B9 push 1
.text:005316BB mov [ecx+40Eh], al
.text:005316C1 call sub_5316F0
.text:005316C6 retn 8
.text:005316C6 sub_5316B0 endp
.text:005316C6
.text:005316C6 ; ---------------------------------------------------------------------------
.text:005316C9 align 10h
.text:005316D0
.text:005316D0 ; =============== S U B R O U T I N E =======================================
.text:005316D0
.text:005316D0
.text:005316D0 sub_5316D0 proc near ; CODE XREF: sub_442070+1698p
.text:005316D0 ; sub_4C91E0+137p ...
.text:005316D0
.text:005316D0 arg_0 = byte ptr 4
.text:005316D0 arg_4 = dword ptr 8
.text:005316D0
.text:005316D0 mov edx, [esp+arg_4]
.text:005316D4 mov al, [esp+arg_0]
.text:005316D8 push edx
.text:005316D9 push 1
.text:005316DB mov [ecx+40Fh], al
.text:005316E1 call sub_5316F0
.text:005316E6 retn 8
.text:005316E6 sub_5316D0 endp#include
struct DummyObj
{
char Junk[0x53];
};
DummyObj dummy = { 0 };
using pToggleMapFnc = void (__thiscall *)(void *pDummyObj, bool bHideAll);
int APIENTRY DllMain(HMODULE hModule, DWORD dwReason, LPVOID lpReserved)
{
switch (dwReason)
{
case DLL_PROCESS_ATTACH:
{
(void)DisableThreadLibraryCalls(hModule);
pToggleMapFnc ToggleMap = (pToggleMapFnc)0x0058EA10;
while (!GetAsyncKeyState('0'))
{
if (GetAsyncKeyState('7'))
{
ToggleMap(&dummy, true);
}
else if (GetAsyncKeyState('8'))
{
ToggleMap(&dummy, false);
}
Sleep(10);
}
break;
}
case DLL_PROCESS_DETACH:
case DLL_THREAD_ATTACH:
case DLL_THREAD_DETACH:
break;
}
return TRUE;
}


...
.text:008B2B76 loc_8B2B76: ; CODE XREF: sub_8AE4A0+46CDj
.text:008B2B76 mov ecx, esi
.text:008B2B78 call sub_59C270
.text:008B2B7D push 1
.text:008B2B7F push offset loc_8AAEE0
.text:008B2B84 push offset aTrsetfogandbla ; "trSetFogAndBlackmap"
.text:008B2B89 mov ecx, esi
.text:008B2B8B call sub_59BE80
.text:008B2B90 test al, al
.text:008B2B92 jnz short loc_8B2BAE
.text:008B2B94 push offset aTrsetfogandbla ; "trSetFogAndBlackmap"
.text:008B2B99 push offset aSyscallConfigE ; "Syscall config error - Unable to add th"...
.text:008B2B9E push esi ; int
.text:008B2B9F call sub_59DBC0
....text:008AAEE0 loc_8AAEE0: ; DATA XREF: sub_8AE4A0+46DFo
.text:008AAEE0 mov eax, dword_A9D244
.text:008AAEE5 mov ecx, [eax+140h]
.text:008AAEEB test ecx, ecx
.text:008AAEED jz short locret_8AAF13
.text:008AAEEF mov edx, [esp+4]
.text:008AAEF3 push 0
.text:008AAEF5 push edx
.text:008AAEF6 call sub_5316B0
.text:008AAEFB mov eax, [esp+8]
.text:008AAEFF mov ecx, dword_A9D244
.text:008AAF05 mov ecx, [ecx+140h]
.text:008AAF0B push 0
.text:008AAF0D push eax
.text:008AAF0E call sub_5316D0
.text:008AAF13
.text:008AAF13 locret_8AAF13: ; CODE XREF: .text:008AAEEDj
.text:008AAF13 retn#include
using pToggleMapFnc = void (__cdecl *)(bool bEnableBlackOverlay, bool bEnableFogOfWar);
int APIENTRY DllMain(HMODULE hModule, DWORD dwReason, LPVOID lpReserved)
{
switch (dwReason)
{
case DLL_PROCESS_ATTACH:
{
(void)DisableThreadLibraryCalls(hModule);
pToggleMapFnc ToggleMap = (pToggleMapFnc)0x008AAEE0;
while (!GetAsyncKeyState('0'))
{
if (GetAsyncKeyState('6'))
{
ToggleMap(true, true);
}
else if (GetAsyncKeyState('7'))
{
ToggleMap(true, false);
}
else if (GetAsyncKeyState('8'))
{
ToggleMap(false, true);
}
else if (GetAsyncKeyState('9'))
{
ToggleMap(false, false);
}
Sleep(10);
}
break;
}
case DLL_PROCESS_DETACH:
case DLL_THREAD_ATTACH:
case DLL_THREAD_DETACH:
break;
}
return TRUE;
}
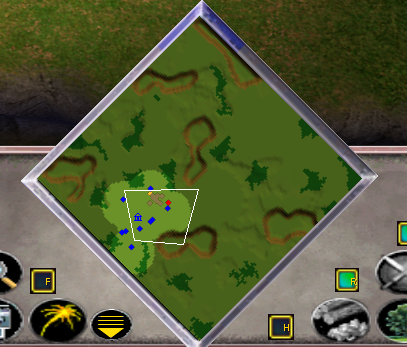
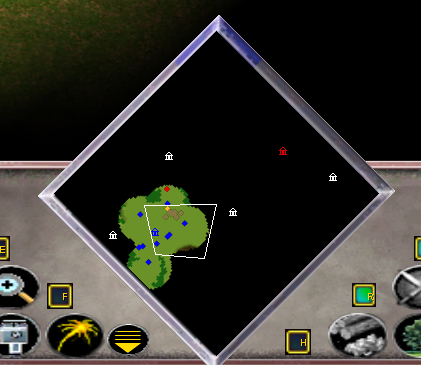
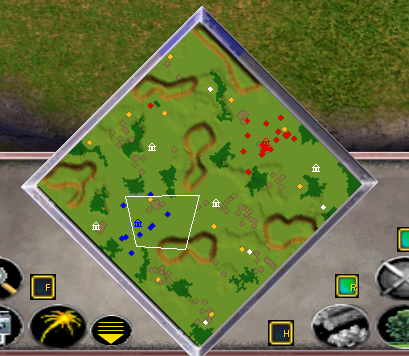
|
Метки: author PatientZero реверс-инжиниринг разработка игр обратная разработка cheat engine ida туман войны взлом игр |
A fistful of relays. Часть 4. Система команд или что можно уместить в 8 машинных инструкций? |
1cccLddd iiiiiiii 01bbbddd ixxxryyy - бинарные операции ADD, ADC, SUB, SBC, AND, OR, XOR
01111ddd -xxxruu0 - унарные операции NOT, SHR, ROR, RCR
ADD A, A, A
ADC A, A, 0



1000 0001 0000 0001 00: movi B, 1
0100 1010 0001 1000 01: add C, B, A
0001 1000 0001 0000 02: mov A, B
0001 1001 0010 0000 03: mov B, C
1000 0111 0000 0001 04: jmp 01
|
Метки: author Dovgaluk системное программирование программирование микроконтроллеров ненормальное программирование assembler реле странные компьютеры |






