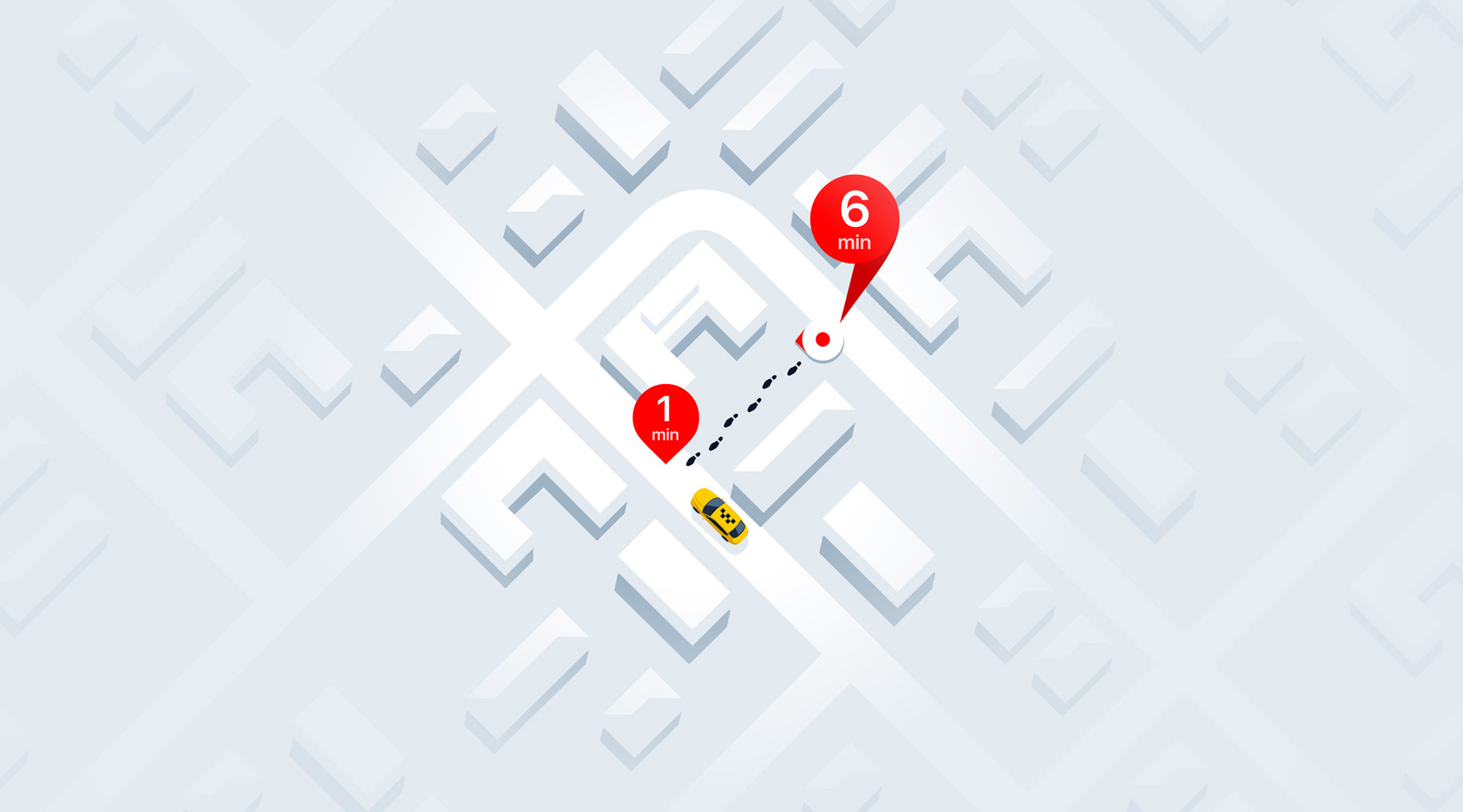
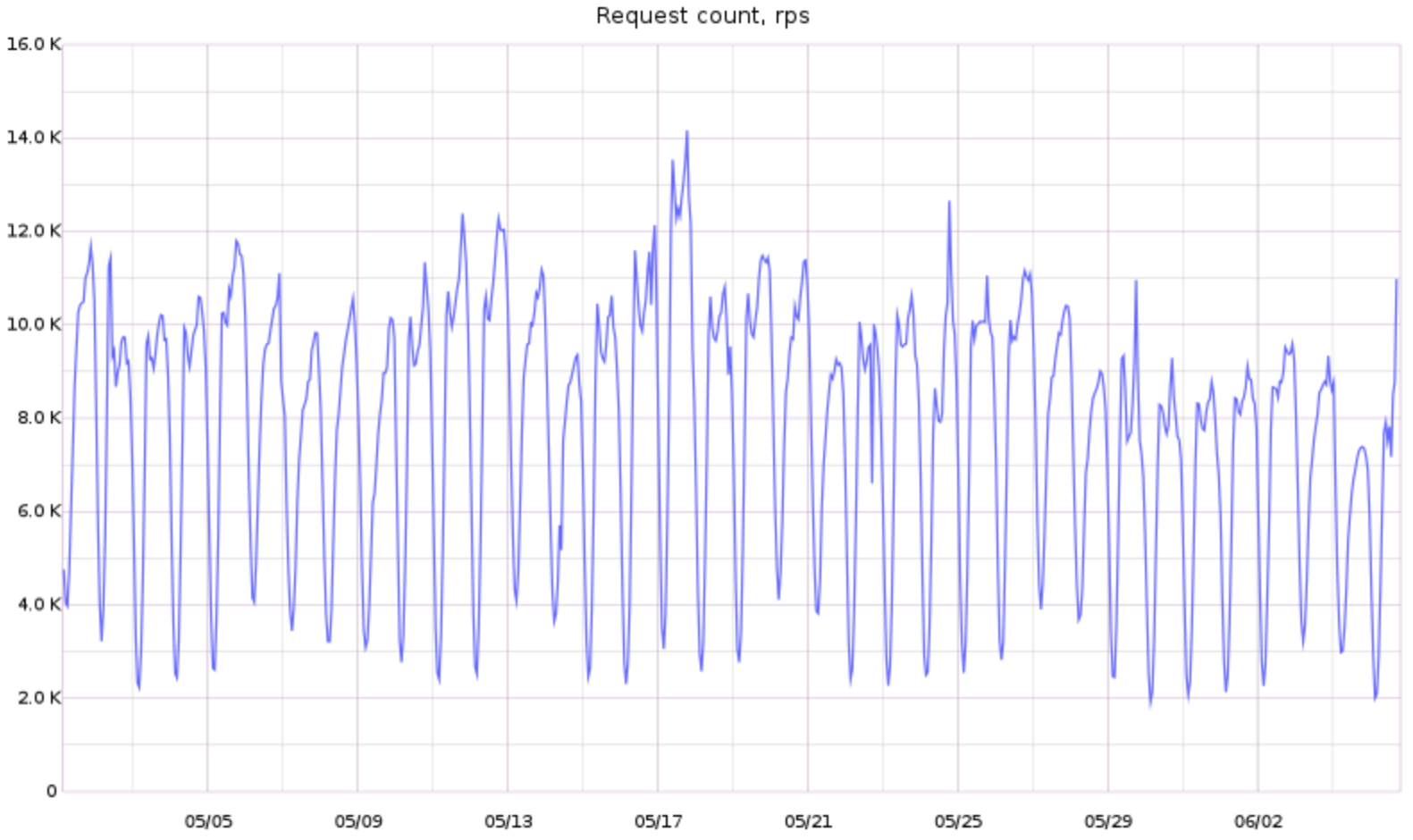
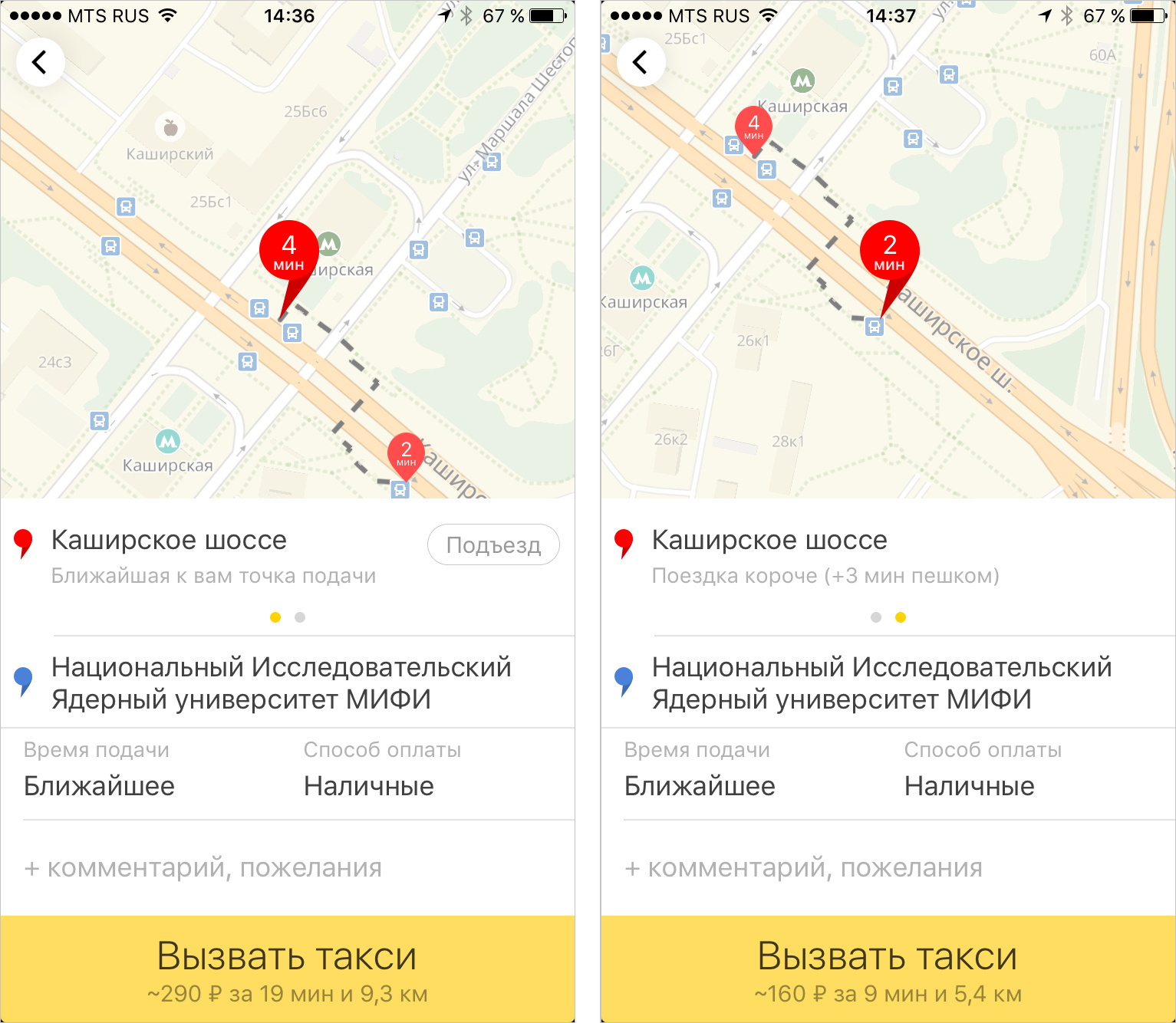
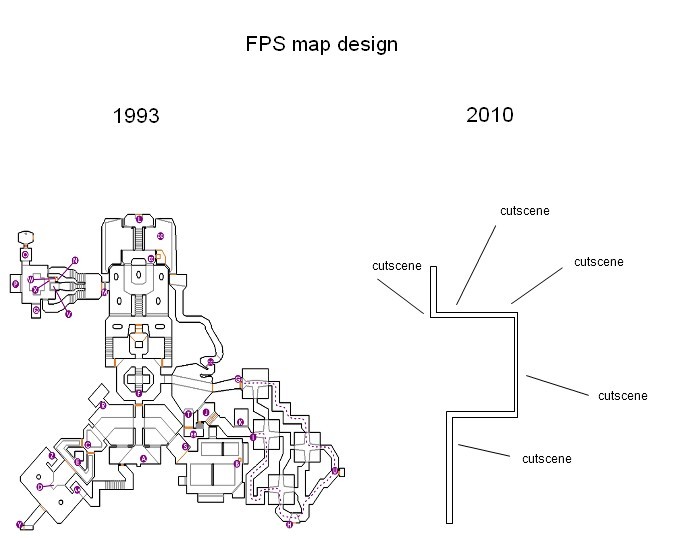
Как технологии Яндекс.Такси приближают будущее личного и общественного транспорта |
|
|
[Перевод] Dropout — метод решения проблемы переобучения в нейронных сетях |
|
Метки: author wunder_editor машинное обучение алгоритмы big data блог компании wunder fund dropout deep learning overfitting neural networks wunderfund wunder fund |
Топ 15 бесплатных Unity ассетов для начинающего 2D разработчика |


|
Метки: author TimTim разработка игр unity3d блог компании everyday tools unity unity asste store asset store ассеты |
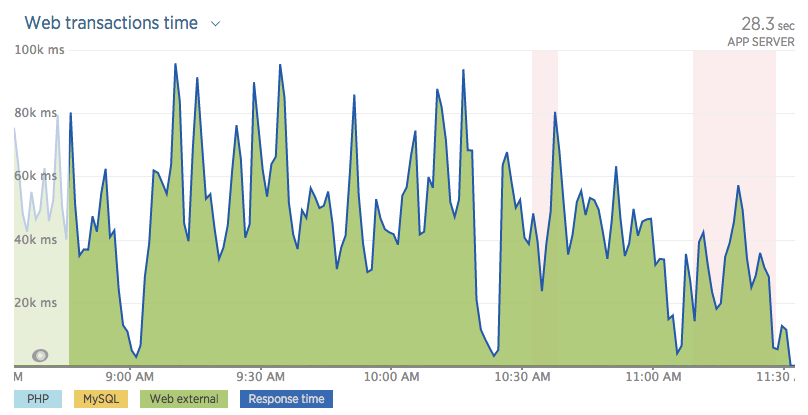
[Из песочницы] Создание быстрых и более оптимизированных сайтов на WordPress |

define('DISALLOW_FILE_EDIT', true);define('DISALLOW_FILE_MODS', true);


src="example.js" asyncsrc="example.js" defer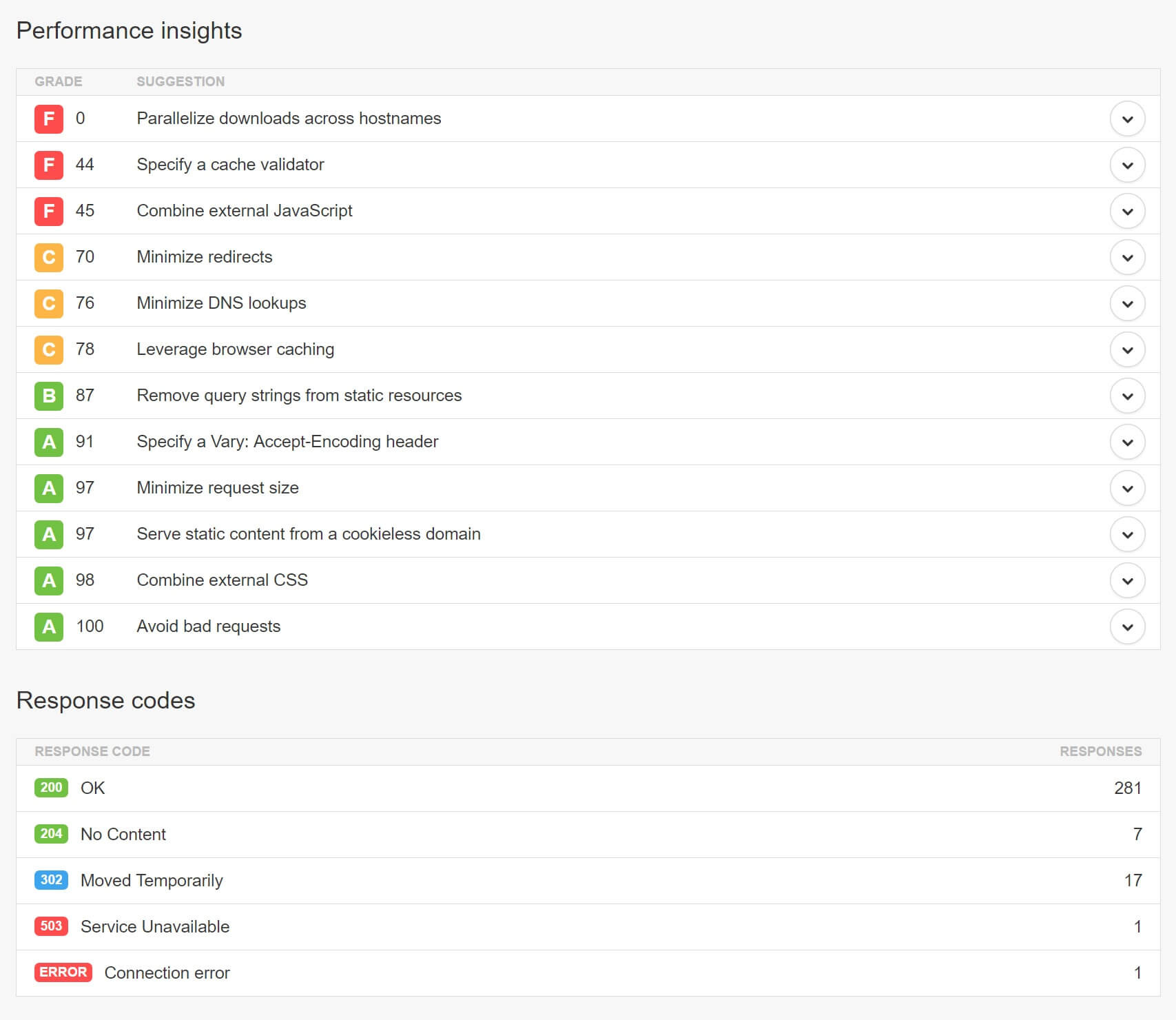
ALTER TABLE wp_comments ENGINE=InnoDB;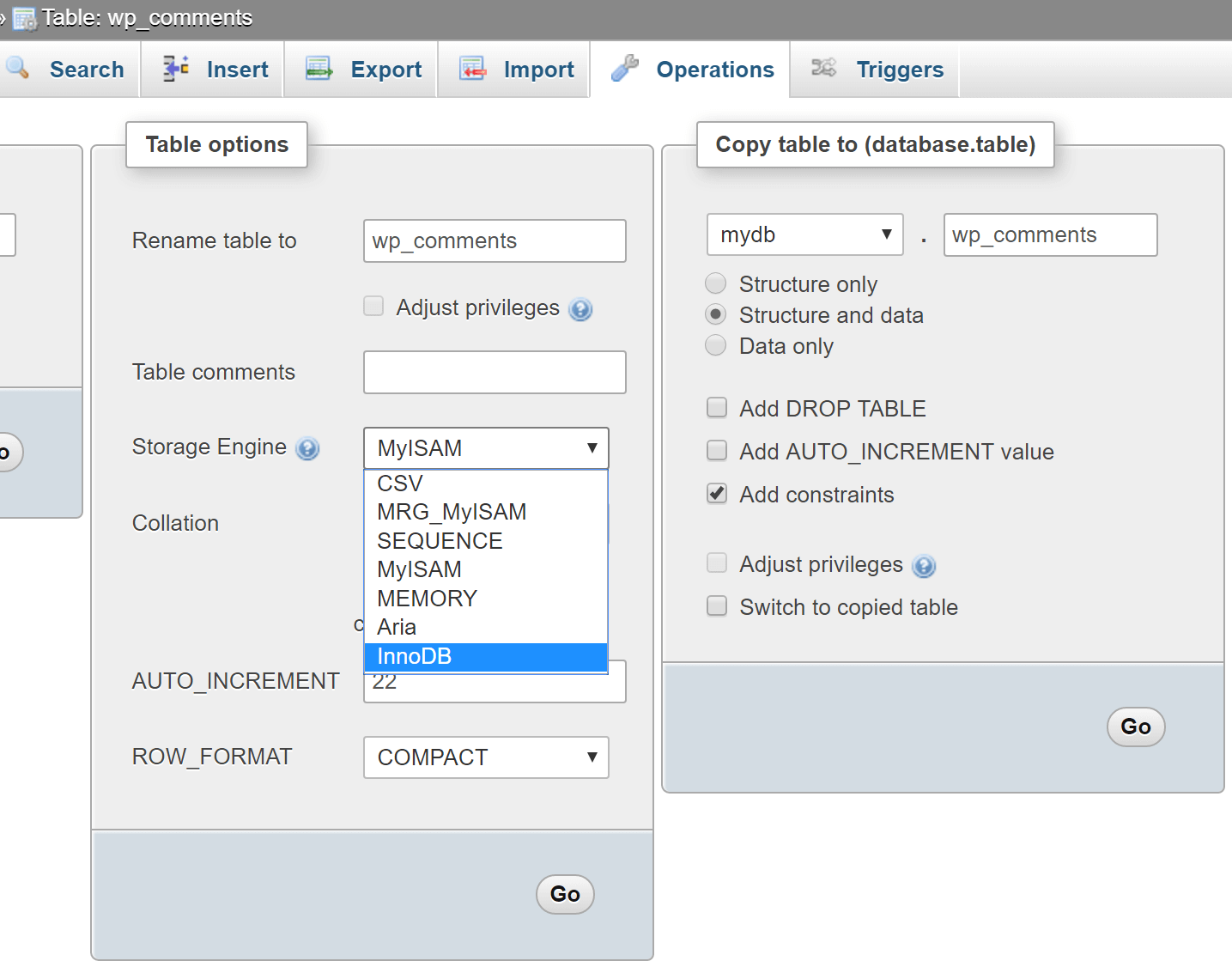
define('WP_POST_REVISIONS', false );define('WP_POST_REVISIONS', 3);DELETE FROM wp_posts WHERE post_type = "revision";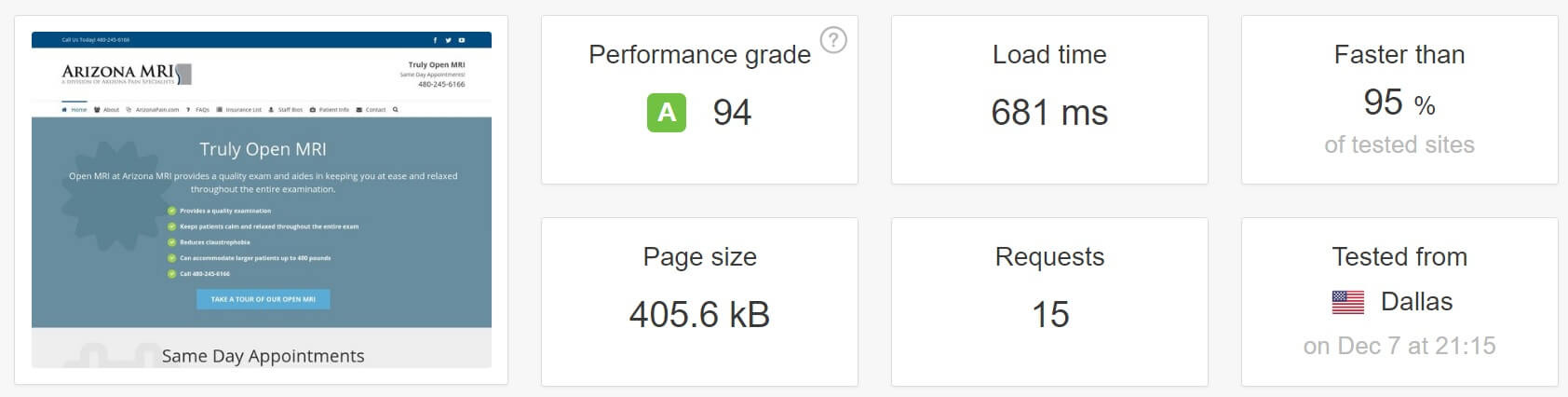
define( 'WP_DEBUG_LOG', true );define( 'WP_DEBUG_DISPLAY', true );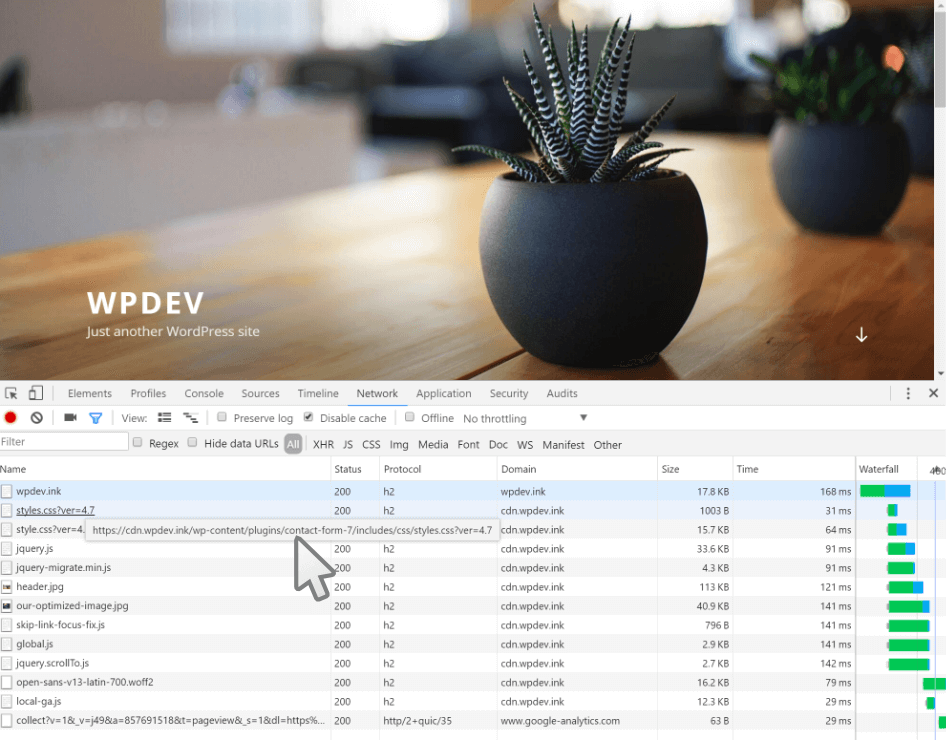
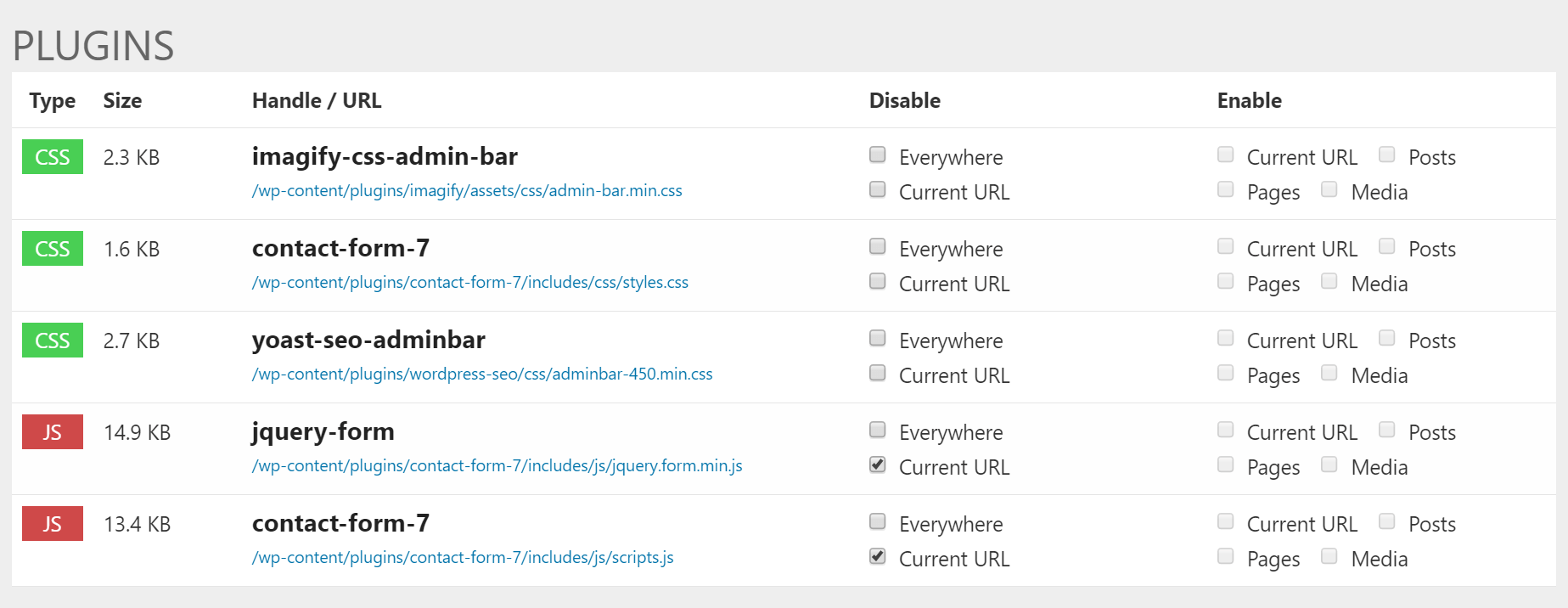
|
Метки: author ScarletFlash высокая производительность wordpress перевод оптимизация mysql css javascript хостинг |
gdb-дуэль — списки, деревья и хэш таблицы против командной строки |

duel в gdb на каком-то древнем IRIX-е, лет пятнадцать назад. Это была невероятно крутая штука для просмотра разных связанных списков, массивов структур, и прочих подобных конструкций. Помечтал, мол, если б в Линуксе такая была, и забыл. Лет десять назад вспомнил, погуглил — оказалось, что DUEL, это вообще-то патч 93-го года для gdb 4.6, а вовсе не что-то уникальное в IRIX. Только автор по идейным соображениям выпустил его как public domain, а gdb-шники были тоже идейные и хотели GPL, так что попасть в upstream этому патчу не грозило. Я портировал его на тогдашний gdb 6.6.2, отдал в gentoo и до выхода 7-го gdb наслаждался жизнью. Потом duel из gentoo выкинули, портировать на новый gdb было сложно, никто не взялся. А недавно я его попробовал оживить. Только вместо патча (надо собирать вместе с gdb из исходников, использует всякие внутренние gdb-шные функции) я его написал с нуля на питоне. Теперь Duel.py (так называется новая реализация Duel-а) грузится в gdb на лету, и, надеюсь, Python API не будет меняться от версии к версии так, как недокументированные gdb-шные потроха. Итак, встречайте: DUEL — высокоуровневый язык анализа данных для gdb.(gdb) dl table_list-->next_local->table_name
tables->table_name = 0x7fffc40126b8 "t2"
tables->next_local->table_name = 0x7fffc4012d18 "t1"
tables-->next_local[[2]]->table_name = 0x7fffc4013388 "t1"
TABLE_LIST и для каждого элемента списка выводит TABLE_LIST::table_name.(gdb) dl longopts[0..].name @0
longopts[0].name = "help"
longopts[1].name = "allow-suspicious-udfs"
longopts[2].name = "ansi"
<... cut ...>
longopts[403].name = "session_track_schema"
longopts[404].name = "session_track_transaction_info"
longopts[405].name = "session_track_state_change"
name == 0. А можно просто посчитать, сколько их:(gdb) dl #/longopts[0..].name @0
#/longopts[0..].name@0 = 406
(gdb) dl 1..4
1 = 1
2 = 2
3 = 3
4 = 4
(gdb) dl my_long_options[1..4].(name,def_value)
my_long_options[1].(name) = "allow-suspicious-udfs"
my_long_options[1].(def_value) = 0
my_long_options[2].(name) = "ansi"
my_long_options[2].(def_value) = 0
my_long_options[3].(name) = "autocommit"
my_long_options[3].(def_value) = 1
my_long_options[4].(name) = "bind-address"
my_long_options[4].(def_value) = 0
..20, то диапазон начнется с нуля и в нем будет 20 значений, так же, как если бы было написано 0..19. Если же указать только начало, то получится открытый диапазон! Чтобы duel не продолжал генерировать числа до тепловой смерти вселенной (или до переполнения счетчика, смотря что случится раньше), вместе с открытым диапазоном обычно используют оператор остановки по условию, @.x@y, выражение x будет генерировать значения до тех пор, пока y ложно. Например,(gdb) dl arr[0..]@(count > 10)
arr[] до тех пор, пока arr[i].count будет не больше десяти.(gdb) dl str[0..]@0
'\0'. Более практичный пример — вывести все опции командной строки из argv:(gdb) dl argv[0..]@0
argv[0] = "./mysqld"
argv[1] = "--log-output=file"
argv[2] = "--gdb"
argv[3] = "--core-file"
(gdb) dl argv[..argc]
argv[0] = "./mysqld"
argv[1] = "--log-output=file"
argv[2] = "--gdb"
argv[3] = "--core-file"
a-->b порождает множество значений a, a->b, a->b->b, и так далее, пока не уткнется в NULL. Я уже приводил пример, как таким образом можно пройтись по односвязному списку. Но это точно так же работает и для деревьев, например:(gdb) dl tree-->(left,right)->info
(gdb) dl i:=5
i = 5
(gdb) dl i+6
i+6 = 11
(gdb) dl {i}+6
5+6 = 11
(gdb) dl {i+6}
11 = 11
(gdb) dl if (my_long_options[i:=1..20].name[0] == 'd') my_long_options[i].name
if(my_long_options[i].name[0] == 'd') my_long_options[i].name = "debug-abort-slave-event-count"
if(my_long_options[i].name[0] == 'd') my_long_options[i].name = "debug-assert-on-error"
if(my_long_options[i].name[0] == 'd') my_long_options[i].name = "debug-assert-if-crashed-table"
if(my_long_options[i].name[0] == 'd') my_long_options[i].name = "debug-disconnect-slave-event-count"
if(my_long_options[i].name[0] == 'd') my_long_options[i].name = "debug-exit-info"
(gdb) dl if (my_long_options[i:=1..20].name[0] == 'd') my_long_options[{i}].name
if(my_long_options[i].name[0] == 'd') my_long_options[16].name = "debug-abort-slave-event-count"
if(my_long_options[i].name[0] == 'd') my_long_options[17].name = "debug-assert-on-error"
if(my_long_options[i].name[0] == 'd') my_long_options[18].name = "debug-assert-if-crashed-table"
if(my_long_options[i].name[0] == 'd') my_long_options[19].name = "debug-disconnect-slave-event-count"
if(my_long_options[i].name[0] == 'd') my_long_options[20].name = "debug-exit-info"
|
Метки: author petropavel отладка c++ gdb |
Бизнес на данных: стероиды для компании |


Сравнительно недавно с нами произошла история, когда наша CRM-система нас же самих и выручила — всё потому, что менеджеры записывают в неё каждую мелочь, а в карточке хранятся документы, история переписки и записи переговоров. Дело было так: пользователь на публичном ресурсе обвинил нас в том, что наш продукт сырой и часть функциональности работала не так, как это ожидалось. Выпад с его точки зрения был красивым. Однако мы подняли информацию и нашли в его карточке клиента много опровержений его словам, а также гарантийное письмо, в котором он отказывался от претензий к продукту, который настоятельно купил в бета-версии. Нападение было отбито. Вообще, когда все данные и транзакции записаны, компанию максимально сложно опорочить лживыми сведениями — на вашей стороне будут факты.




|
Метки: author Axelus управление проектами управление продажами erp- системы crm- блог компании regionsoft developer studio crm аналитика анализ данных regionsoft |
Своя CRM система за 3 часа в Гугл-таблицах |



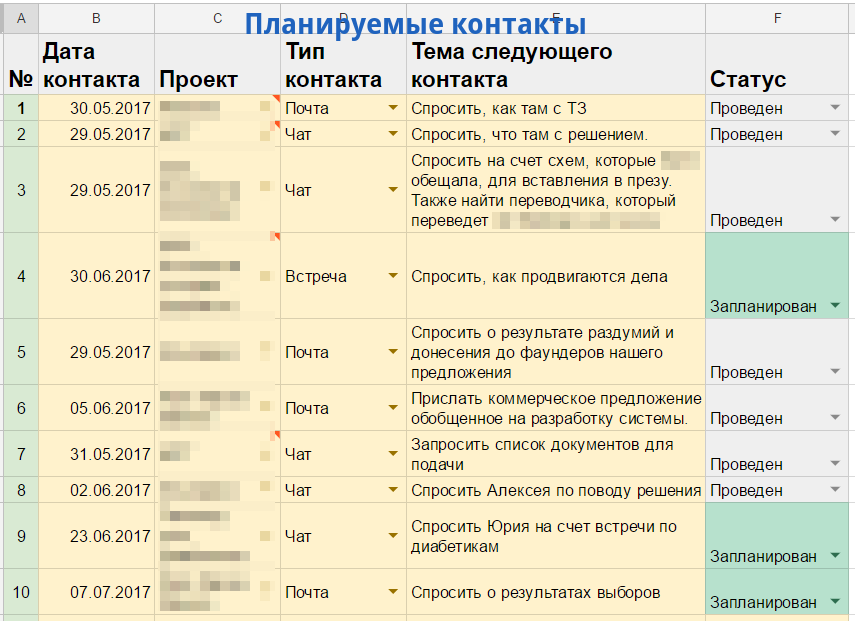
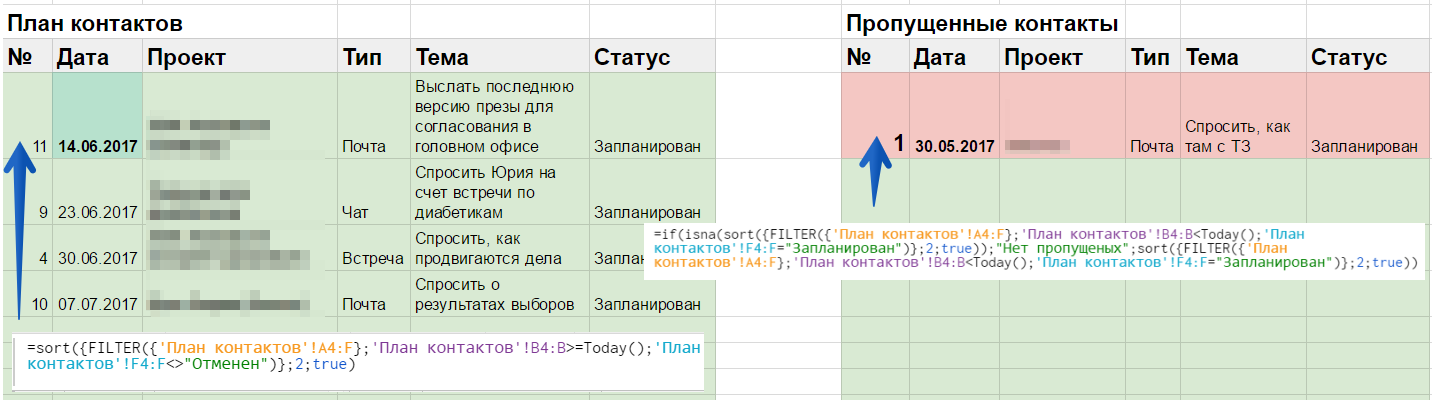
|
Метки: author pkondaurov crm- системы #crm # гуглдок #самсебеинтегратор |
Что угрожает информационной безопасности или обзор форума PHDays VII 2017 в Москве |

|
Метки: author inforion_ru исследования и прогнозы в it блог компании инфорион phdays 2017 информационная безопасность хакерство защита данных защита информации |
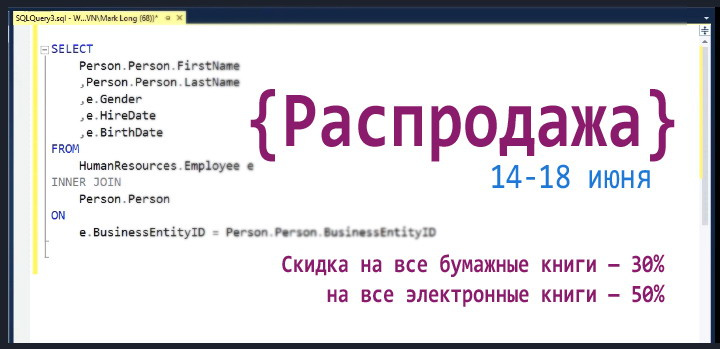
Издательство Питер. Летняя распродажа |

|
Метки: author ph_piter профессиональная литература блог компании издательский дом «питер» книги |
Microsoft на CodeFest 2017 — отчёт, слайды и видео докладов |
 Джеффри Рихтер, Partner Software Engineer, Microsoft/WintellectО Джеффри все сказано в Википедии. Сейчас он работает в команде Microsoft Azure Hyper-Scale и активно занимается Service Fabric. В докладе Джеффри рассказал про важные пункты и нюансы, которые необходимо учитывать при проектировании распределённых облачных приложений. Must see для архитекторов.
Джеффри Рихтер, Partner Software Engineer, Microsoft/WintellectО Джеффри все сказано в Википедии. Сейчас он работает в команде Microsoft Azure Hyper-Scale и активно занимается Service Fabric. В докладе Джеффри рассказал про важные пункты и нюансы, которые необходимо учитывать при проектировании распределённых облачных приложений. Must see для архитекторов. Рафаэль Риальди много лет как Microsoft Most Valuable Professional, автор книг и популяризатор технологий. По разработке на С++, архитектуре программных систем, IoT — к нему. Рафаэль в этот раз рассказал несколько прекрасных докладов про .NET Core — один про использование с NodeJS, второй про поддержку .NET Core в Visual Studio 2017.
Рафаэль Риальди много лет как Microsoft Most Valuable Professional, автор книг и популяризатор технологий. По разработке на С++, архитектуре программных систем, IoT — к нему. Рафаэль в этот раз рассказал несколько прекрасных докладов про .NET Core — один про использование с NodeJS, второй про поддержку .NET Core в Visual Studio 2017.  Андрей Беленко работает в Microsoft на должности Senior Program Manager. Работает с мобильными платформами и безопасностью. Доклад от представителя Microsoft по безопасности мобильных приложений с акцентом на iOS был тепло встречен аудиторией. :)
Андрей Беленко работает в Microsoft на должности Senior Program Manager. Работает с мобильными платформами и безопасностью. Доклад от представителя Microsoft по безопасности мобильных приложений с акцентом на iOS был тепло встречен аудиторией. :)  Александр Белоцерковский, автор сей статьи, работает в Microsoft в России на должности технологического евангелиста. Разрабатывает на .NET, работает с Microsoft Azure с почти ее запуска и любит людей. В этот раз рассказал про свой pet project, который помогал разрабатывать своим американским коллегам как коммьюнити-проект.
Александр Белоцерковский, автор сей статьи, работает в Microsoft в России на должности технологического евангелиста. Разрабатывает на .NET, работает с Microsoft Azure с почти ее запуска и любит людей. В этот раз рассказал про свой pet project, который помогал разрабатывать своим американским коллегам как коммьюнити-проект. Сергей Звягин, ведущий разработчик в DevExpress. Фронтендер с прошлым бэкендера. Любит виртуальную реальность, и популяризирует её в России, а также является хабом, распределяющим официальные пряники DevExpress. В докладе Сергей рассказал про различные устройства VR/AR, разные проекты — успешные, не очень и те, которые так и остались красивой идеей. Был продемонстрирован Hololens, даны рекомендации.
Сергей Звягин, ведущий разработчик в DevExpress. Фронтендер с прошлым бэкендера. Любит виртуальную реальность, и популяризирует её в России, а также является хабом, распределяющим официальные пряники DevExpress. В докладе Сергей рассказал про различные устройства VR/AR, разные проекты — успешные, не очень и те, которые так и остались красивой идеей. Был продемонстрирован Hololens, даны рекомендации.  Дон Вибьер, еще один коллега из DevExpress, технологический евангелист из Microsoft Most Valuable Professional. Хардкорный разработчик и прекрасный собеседник — надеюсь, что он снова приедет на CodeFest в следующем году.
Дон Вибьер, еще один коллега из DevExpress, технологический евангелист из Microsoft Most Valuable Professional. Хардкорный разработчик и прекрасный собеседник — надеюсь, что он снова приедет на CodeFest в следующем году. Мет Атамель, Developer Advocate в Google.
Мет Атамель, Developer Advocate в Google. Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author ahriman microsoft azure .net блог компании microsoft microsoft azure google kubernetes architecture ios security codefest codefest 2017 |
В чем особенности работы дисков в NAS: экспресс-тест HDD WD Red |
|
Метки: author megapost хранение данных системное администрирование hdd western digital nas |
Пишем простой драйвер под Windows для блокировки USB-устройств |
for ( ULONG i = 0; i <= IRP_MJ_MAXIMUM_FUNCTION; i++ ) {
DriverObject->MajorFunction[i] = DispatchCommon;
}
DriverObject->MajorFunction[IRP_MJ_CREATE] = DispatchCreate;
DriverObject->MajorFunction[IRP_MJ_CLOSE] = DispatchClose;
DriverObject->MajorFunction[IRP_MJ_READ] = DispatchRead;
DriverObject->MajorFunction[IRP_MJ_WRITE] = DispatchWrite;
DriverObject->MajorFunction[IRP_MJ_CLEANUP] = DispatchCleanup;
DriverObject->MajorFunction[IRP_MJ_PNP] = DispatchPnp;
DriverObject->DriverUnload = DriverUnload;
DriverObject->DriverExtension->AddDevice = DispatchAddDevice; NTSTATUS DriverEntry( PDRIVER_OBJECT DriverObject, PUNICODE_STRING RegistryPath ); NTSTATUS Dispatch( PDEVICE_OBJECT DeviceObject, PIRP Irp ); 

NTSTATUS DispatchAddDevice(
PDRIVER_OBJECT DriverObject,
PDEVICE_OBJECT PhysicalDeviceObject
); 
NTSTATUS UsbCreateAndAttachFilter(
PDEVICE_OBJECT PhysicalDeviceObject,
bool UpperFilter
) {
SUSBDevice* USBDevice;
PDEVICE_OBJECT USBDeviceObject = nullptr;
ULONG Flags;
NTSTATUS Status = STATUS_SUCCESS;
PAGED_CODE();
for ( ;; ) {
// если нижний фильтр уже прикреплен, тогда здесь больше делать нечего
if ( !UpperFilter ) {
USBDeviceObject = PhysicalDeviceObject;
while ( USBDeviceObject->AttachedDevice ) {
if ( USBDeviceObject->DriverObject == g_DriverObject ) {
return STATUS_SUCCESS;
}
USBDeviceObject = USBDeviceObject->AttachedDevice;
}
}
// создаем фильтр
Status = IoCreateDevice(
g_DriverObject,
sizeof( SUSBDevice ),
nullptr,
PhysicalDeviceObject->DeviceType,
PhysicalDeviceObject->Characteristics,
false,
&USBDeviceObject
);
if ( !NT_SUCCESS( Status ) ) {
break;
}
// инициализируем флаги созданного устройства, копируем их из объекта к
// которому прикрепились
Flags = PhysicalDeviceObject->Flags &
(DO_BUFFERED_IO | DO_DIRECT_IO | DO_POWER_PAGABLE);
USBDeviceObject->Flags |= Flags;
// получаем указатель на нашу структуру
USBDevice = (SUSBDevice*)USBDeviceObject->DeviceExtension;
// инициализируем деструктор
USBDevice->DeleteDevice = DetachAndDeleteDevice;
// инициализируем обработчики
for ( ULONG i = 0; i <= IRP_MJ_MAXIMUM_FUNCTION; i++ ) {
USBDevice->MajorFunction[i] = UsbDispatchCommon;
}
USBDevice->MajorFunction[IRP_MJ_PNP] = UsbDispatchPnp;
USBDevice->MajorFunction[IRP_MJ_POWER] = UsbDispatchPower;
// инициализируем семафор удаления устройства
IoInitializeRemoveLock(
&USBDevice->Lock,
USBDEVICE_REMOVE_LOCK_TAG,
0,
0
);
// заполняем структуру
USBDevice->SelfDevice = USBDeviceObject;
USBDevice->BaseDevice = PhysicalDeviceObject;
USBDevice->UpperFilter = UpperFilter;
// инициализируем paging семафор
USBDevice->PagingCount = 0;
KeInitializeEvent( &USBDevice->PagingLock, SynchronizationEvent, true );
// прикрепляем устройство к PDO
USBDevice->LowerDevice = IoAttachDeviceToDeviceStack(
USBDeviceObject,
PhysicalDeviceObject
);
if ( !USBDevice->LowerDevice ) {
Status = STATUS_NO_SUCH_DEVICE;
break;
}
break;
}
// в зависимости от результата делаем
if ( !NT_SUCCESS( Status ) ) {
// отчистку
if ( USBDeviceObject ) {
IoDeleteDevice( USBDeviceObject );
}
} else {
// или сбрасываем флаг инициализации
USBDeviceObject->Flags &= ~DO_DEVICE_INITIALIZING;
}
return Status;
}
static NTSTATUS DispatchAddDevice(
PDRIVER_OBJECT DriverObject,
PDEVICE_OBJECT PhysicalDeviceObject
) {
UNREFERENCED_PARAMETER( DriverObject );
return UsbCreateAndAttachFilter( PhysicalDeviceObject, true );
}static NTSTATUS UsbDispatchPnpStartDevice( SUSBDevice* USBDevice, PIRP Irp ) {
bool HubOrComposite;
NTSTATUS Status;
PAGED_CODE();
for ( ;; ) {
// проверить, позволено ли устройству работать, также обновить
// информацию об устройстве, является ли оно хабом или композитным
Status = UsbIsDeviceAllowedToWork( &HubOrComposite, USBDevice );
if ( !NT_SUCCESS( Status ) ) {
break;
}
USBDevice->HubOrComposite = HubOrComposite;
// продвинуть запрос
Status = ForwardIrpSynchronously( USBDevice->LowerDevice, Irp );
if ( !NT_SUCCESS( Status ) ) {
break;
}
break;
}
// завершаем запрос
Irp->IoStatus.Status = Status;
IoCompleteRequest( Irp, IO_NO_INCREMENT );
// и освобождаем устройство
IoReleaseRemoveLock( &USBDevice->Lock, Irp );
return Status;
}|
Метки: author anatolymik системное программирование информационная безопасность open source блог компании аладдин р.д. windows usb- устройства блокировка github |
[Перевод] RESTForms — REST API для ваших классов InterSystems Cach'e |
В этой статье я хотел бы представить проект RESTForms — универсальный REST API бэкэнд для современных веб-приложений.
Идея проекта проста — после написания нескольких REST API стало понятно, что, как правило, REST API состоит из двух частей:
И, хотя вам придется писать свою собственную бизнес-логику, RESTForms предоставляет все необходимое для работы с хранимыми данными из коробки.
Этот проект разработан как бэкэнд для JS веб-приложений, поэтому JS сразу может начинать работу с RESTForms, не требуется преобразования форматов данных и т.п.
Что уже можно делать с RESTForms:
Далее представлена таблица доступных методов API, которая демонстрирует то, что Вы можете сделать через RESTForms.
| URL | Описание |
|---|---|
| test | Тестовый метод |
| form/info | Список классов |
| form/info/all | Метаинформация всех классов |
| form/info/:class | Метаинформация одного класса |
| form/field/:class | Добавить свойство в класс |
| form/field/:class | Изменить свойство |
| form/field/:class/:property | Удалить свойство |
| form/object/:class/:id | Получить объект |
| form/object/:class/:id/:property | Получить свойство объекта |
| form/object/:class | Создать объект |
| form/object/:class/:id | Обновить объект из динамического объекта |
| form/object/:class | Обновить объект из объекта класса |
| form/object/:class/:id | Удалить объект |
| form/objects/:class/:query | Выполнить SQL запрос |
| form/objects/:class/custom/:query | Выполнить пользовательский SQL запрос |
/forms с классом брокером Form.REST.Main{"Status": "OK"}, возможно, будет запрошен пароль).do ##class(Form.Util.Init).populateTestForms()Cписок объектов класса:
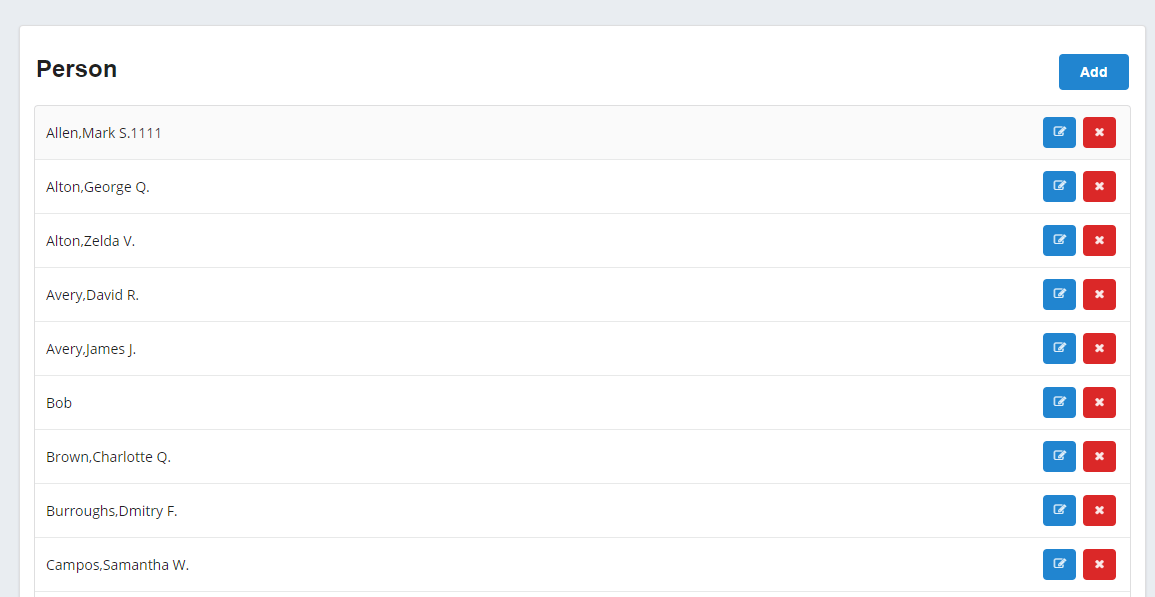
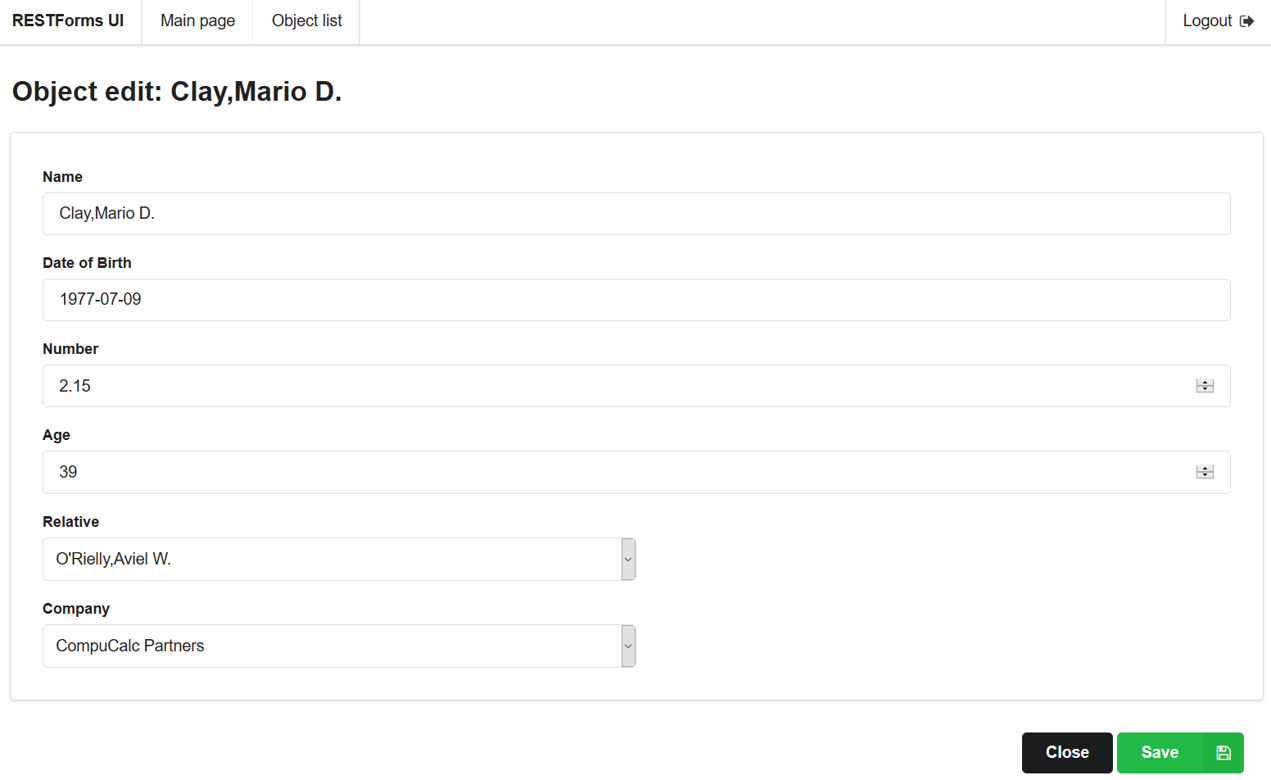
И объект класса:
Во-первых, вы хотите знать, какие классы доступны. Чтобы получить эту информацию, вызовите:
http://localhost:57772/forms/form/infoВы получите в ответ что-то вроде этого:
[
{ "name":"Company", "class":"Form.Test.Company" },
{ "name":"Person", "class":"Form.Test.Person" },
{ "name":"Simple form", "class":"Form.Test.Simple" }
]На данный момент с RESTForms поставляются 3 тестовых класса. Давайте посмотрим метаданные для формы Person (класс Form.Test.Person). Чтобы получить эти данные, нужно вызвать:
http://localhost:57772/forms/form/info/Form.Test.Person{
"name":"Person",
"class":"Form.Test.Person",
"displayProperty":"name",
"objpermissions":"CRUD",
"fields":[
{
"name":"name",
"type":"%Library.String",
"collection":"",
"displayName":"Name",
"required":0,
"category":"datatype"
},
{
"name":"dob",
"type":"%Library.Date",
"collection":"",
"displayName":"Date of Birth",
"required":0,
"category":"datatype"
},
{
"name":"ts",
"type":"%Library.TimeStamp",
"collection":"",
"displayName":"Timestamp",
"required":0,
"category":"datatype"
},
{
"name":"num",
"type":"%Library.Numeric",
"collection":"",
"displayName":"Number",
"required":0,
"category":"datatype"
},
{
"name":"аge",
"type":"%Library.Integer",
"collection":"",
"displayName":"Age",
"required":0,
"category":"datatype"
},
{
"name":"relative",
"type":"Form.Test.Person",
"collection":"",
"displayName":"Relative",
"required":0,
"category":"form"
},
{
"name":"Home",
"type":"Form.Test.Address",
"collection":"",
"displayName":"House",
"required":0,
"category":"serial"
},
{
"name":"company",
"type":"Form.Test.Company",
"collection":"",
"displayName":"Company",
"required":0,
"category":"form"
}
]
}Что все это значит?
Метаданные класса:
Метаданные свойств:
/// Test form: Person
Class Form.Test.Person Extends (%Persistent, Form.Adaptor)
{
/// Отображаемое имя формы
Parameter FORMNAME = "Person";
/// Разрешения
/// Объекты этого класса могут быть Созданы (C), Получены (R), Изменены (U), и удалены (D)
Parameter OBJPERMISSIONS As %String = "CRUD";
/// Свойство "имени" объекта
Parameter DISPLAYPROPERTY As %String = "name";
/// Свойство сортировки по-умолчанию
Parameter FORMORDERBY As %String = "dob";
/// Имя
Property name As %String(DISPLAYNAME = "Name");
/// Дата рождения
Property dob As %Date(DISPLAYNAME = "Date of Birth");
/// Число
Property num As %Numeric(DISPLAYNAME = "Number") [ InitialExpression = "2.15" ];
/// Возраст, вычисляется автоматически
Property аge As %Integer(DISPLAYNAME = "Age") [ Calculated, SqlComputeCode = { set {*}=##class(Form.Test.Person).currentAge({dob})}, SqlComputed, SqlComputeOnChange = dob ];
/// Вычисление возраста
ClassMethod currentAge(date As %Date = "") As %Integer [ CodeMode = expression ]
{
$Select(date="":"",1:($ZD($H,8)-$ZD(date,8)\10000))
}
/// Родственник - ссылка на другой объект класса Form.Test.Person
Property relative As Form.Test.Person(DISPLAYNAME = "Relative");
/// Адрес
Property Home As Form.Test.Address(DISPLAYNAME = "House");
/// Ссылка на компания, в которой человек работает
/// http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GOBJ_relationships
Relationship company As Form.Test.Company(DISPLAYNAME = "Company") [ Cardinality = one, Inverse = employees ];
}Чтобы сделать хранимый класс доступным для RESTForms, надо:
FORMNAME со значением – имя классаOBJPERMISSIONS – что можно делать с объектами класса (CRUD)DISPLAYPROPERTY – имя свойства, используемое для отображения имени объектаFORMORDERBY – свойство по умолчанию для сортировки по запросам с использованием RESTFormsПосле того как мы сгенерировали некоторые тестовые данные (см. Установку, шаг 4), давайте получим Person с идентификатором 1. Чтобы получить объект, вызовем:
http://localhost:57772/forms/form/object/Form.Test.Person/1И получим ответ:
{
"_class":"Form.Test.Person",
"_id":1,
"name":"Klingman,Rhonda H.",
"dob":"1996-10-18",
"ts":"2016-09-20T10:51:31.375Z",
"num":2.15,
"аge":20,
"relative":null,
"Home":{
"_class":"Form.Test.Address",
"House":430,
"Street":"5337 Second Place",
"City":"Jackson"
},
"company":{
"_class":"Form.Test.Company",
"_id":60,
"name":"XenaSys.com",
"employees":[
null
]
}
}Чтобы изменить объект (в частности, свойство num), вызовем:
PUT http://localhost:57772/forms/form/object/Form.Test.PersonС телом:
{
"_class":"Form.Test.Person",
"_id":1,
"num":3.15
}Обратите внимание на то, что для улучшения скорости, только _class, _id и измененные свойства должны быть в теле запроса.
Теперь, давайте создадим новый объект. Вызовем:
POST http://localhost:57772/forms/form/object/Form.Test.PersonС телом:
{
"_class":"Form.Test.Person",
"name":"Test person",
"dob":"2000-01-18",
"ts":"2016-09-20T10:51:31.375Z",
"num":2.15,
"company":{ "_class":"Form.Test.Company", "_id":1 }
}Если создание объекта завершилось успешно, RESTForms вернёт идентификатор:
{"Id": "101"}В противном случае, будет возвращена ошибка в формате JSON. Обратите внимание на то, что на персистентные свойства необходимо ссылаться через свойства _class и _id.
Вы можете попробовать RESTForms онлайн здесь (пользователь: Demo, пароль: Demo).
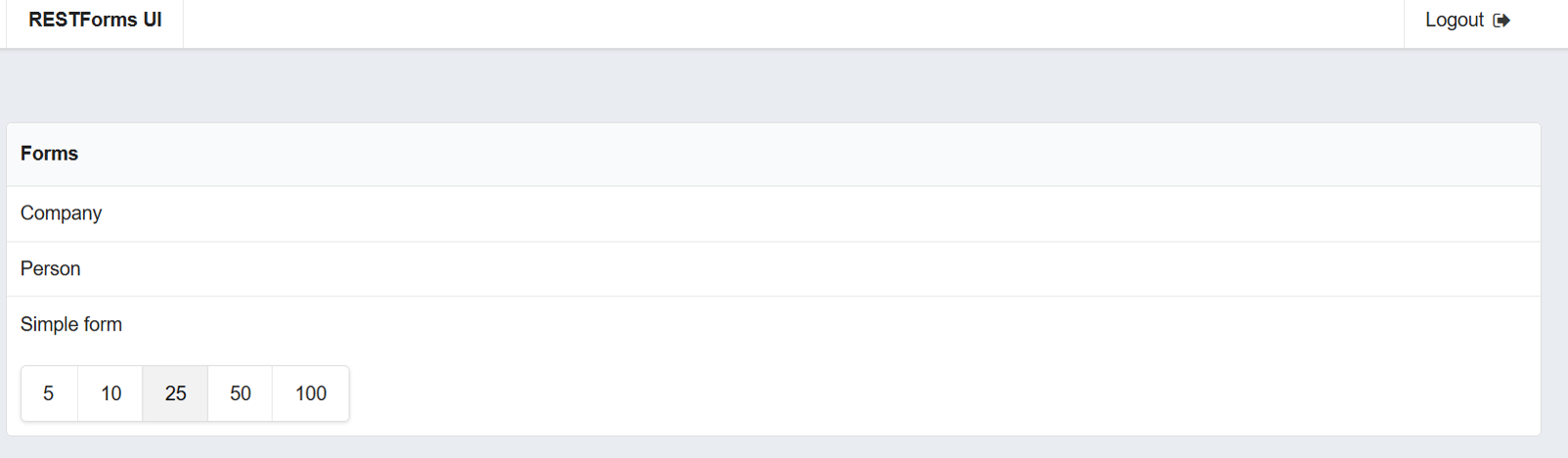
Кроме того, есть приложение RESTFormsUI — редактор для данных RESTForms. Демо стенд доступен здесь (пользователь: Demo, пароль: Demo). Скриншот списка классов:
RESTForms выполняет почти всю работу, требуемую от REST API в отношении хранимых классов.
В этой статье я только начал говорить о функциональных возможностях RESTForms. В следующей я бы хотел рассказать о некоторых дополнительных функциях, а именно о запросах, которые позволяют клиенту безопасно получать наборы данных без риска SQL-инъекций.
|
Метки: author eduard93 блог компании intersystems intersystems cache intersystems rest api rest web |
[Перевод] Если вы это читаете, то работа у вас наверняка не тяжелая |

Из комментариев к статье:
«Мне это напомнило прочитанный где-то хороший совет на случай, когда в не самом важном разговоре повисла пауза.
1. Спросите, чем человек занимается.
2. Затем (неважно, что вам ответили) скажите: «Тяжело вам, наверное!»
Собеседник сразу приободряется и продолжает болтать».
|
Метки: author alconost управление разработкой управление проектами управление персоналом карьера в it-индустрии блог компании alconost alconost джейсон фрайд работа тяжелая работа |
[Перевод] От чего зависит интересность геймплея? |



«Но потом, примерно 350 миллионов лет назад, в девонский период, такие животные, как тиктаалик, начали совершать первые пробные набеги на сушу. С точки зрения восприятия это был совершенно новый мир. Мы можем видеть объекты примерно в десять тысяч раз лучше. Поэтому просто высунув глаза из воды, наши предки попали из мутного тумана прежней среды в чётко видимый мир, где они могли обозревать окружение с достаточно значительного расстояния.
Это поставило таких первых членов клуба „чётко видящих“ в очень интересное положение с точки зрения эволюционных перспектив. Подумайте о первом животном, получившем любую мутацию, отделяющую его сенсорные входящие сигналы от моторных реакций (до этого момента их мгновенная связь была необходима, ведь реактивность требовалась, чтобы не стать чьим-то обедом). На этом этапе они потенциально могли обозревать несколько возможных вариантов будущего и выбирать тот, который с наибольшей вероятностью приведёт к успеху. Например, вместо того, чтобы рвануть напрямик к газели, рискуя раскрыть своё расположение слишком рано, можно медленно прокрасться вдоль линии кустов (зная, что ваш будущий ужин тоже видит в десять тысяч раз лучше, чем его живший в воде предок), пока не подберётесь поближе».

«Потрясающе, как эти незащищённые куски вкусного белка выжили в условиях миллионов лет постоянной угрозы. У них, кстати, самые большие из всех известных видов глаза (у крупнейших глубоководных видов размер достигает диаметра баскетбольного мяча). Очевидно, они используют их для распознавания очень отдалённых силуэтов китов (их величайших врагов), в отражённом от поверхности свете.
Теория развивает идею о том, что преимущество планирования пропорционально пределу, в котором существо может ощущать, к расстоянию движения во время реакции. Теория определяет период нашего эволюционного прошлого, в который происходило масштабное изменение такого соотношения, и предполагает, что такое изменение стало важным фактором развития способности планирования. Интересно, что осьминоги и брызгуны обычно перед выполнением своих действий неподвижны. Это максимально усиливает их относительно небольшую область сенсорного восприятия. Иными словами, для животных, попавших в капкан тумана воды, благодаря планированию существуют другие способы увеличения области восприятия относительно к расстоянию их перемещения».

«Это простое, логичное управление в сочетании с очень предсказуемой физикой (чёткой для мира Mario) позволяют игрокам строить правильные предположения о том, что случится при их действиях. Сложность монстров и окружений увеличивается, но новые и специальные элементы вводятся постепенно, и обычно построены на уже имеющемся принципе взаимодействия. Это делает игровые ситуации чётко выраженными – игрокам очень просто планировать действия. Если игроки видят высокий выступ, вставшего на пути монстра или сундук под водой, они начинают думать о том, что с ними делать.
Это позволяет игрокам поучаствовать в довольно изощрённом процессе планирования. Их знакомят (обычно косвенно) с тем, как работает мир, как они могут двигаться и взаимодействовать с миром, какие препятствия они должны преодолеть. Потом, часто подсознательно, они изменяют план, чтобы попасть туда, куда хотят. В процессе игры игроки создают тысячи таких мелких планов, часть из которых работает, а некоторые — нет. Важно то, что когда план терпит неудачу, игроки понимают, почему это произошло. Мир настолько целостен, что сразу же становится очевидно, почему план не сработал».


|
Метки: author PatientZero разработка игр дизайн игр геймплей |
[recovery mode] Работа с сервером с помощью Alamofire на Swift |

Сразу хочу сказать, данная статья предназначена прежде всего для новичков. Здесь не будет best practice, создание сервисов, репозиториев и прочей оптимизации кода. Расскажу про основы работы с запросами и покажу применение на примерах.
Итак, у нас возникла необходимость обрабатывать данные с сервера. Данная задача присутствует почти во всех мобильных приложениях.
Существует нативный инструмент для этого — URLSession, но работать с ним немного сложнее, чем хотелось бы. Для облегчения этого процесса существует framework Alamofire — это обвертка над URLSession, которая сильно упрощает жизнь при работе с сервером.
Воспользуемся CocoaPods т.к. с ним очень легко и быстро работать.
Добавим в Podfile:
pod 'Alamofire'Для использования Alamofire версии 4+ необходимы следующие требования:
Так же нам необходимо добавить use_frameworks!.
Так будет выглядеть минимальный Podfile:
platform :ios, '9.0'
use_frameworks!
target 'Networking' do
pod 'Alamofire'
endПо умолчанию в приложении закрыт доступ к HTTP соединениям, доступны только HTTPS. Но пока еще очень много сайтов не перешли на https.
Мы будем работать с сервером http://jsonplaceholder.typicode.com, а он работает по http. Поэтому нам надо открыть доступ для него.
Для тренировки мы откроем доступ для всех сайтов. Открытие для одного сайта в данной статье не буду рассматривать.
Открываем Info.plist и добавляем в него App Transport Security Settings и внутрь этого параметра необходимо добавить Allow Arbitrary Loads, со значением YES.
Выглядеть это должно следующим образом:

Или вот Source code, который необходимо добавить:
правой кнопкой мыши на Info.plist -> Open as -> Source code
NSAppTransportSecurity
NSAllowsArbitraryLoads
Открываем проект.
Не забудьте, что нам нужно открыть Networking.xcworkspace, а не Networking.xcodeproj, который создался после pod install
Открываем файл ViewController.swift и заменяем его код на следующий:
import UIKit
import Alamofire
class ViewController: UIViewController {
override func viewDidLoad() {
super.viewDidLoad()
request("http://jsonplaceholder.typicode.com/posts").responseJSON { response in
print(response)
}
print("viewDidLoad ended")
}
}Запускайте проект.
В консоли выведится:
viewDidLoad ended
SUCCESS: (
{
body = "quia et suscipit\nsuscipit recusandae consequuntur expedita et cum\nreprehenderit molestiae ut ut quas totam\nnostrum rerum est autem sunt rem eveniet architecto";
id = 1;
title = "sunt aut facere repellat provident occaecati excepturi optio reprehenderit";
userId = 1;
},
...Поздравляю! Вы сделали первый запрос на сервер и получили от него ответ с результатом.
Нам необходимо получить доступ к новым функция, т.к. это не наши файлы, а отдельная библиотека:
import Alamofire
Собственно сам метод запроса:
request
Далее первым параметром передается URL, по которому будет производится запрос:
"http://jsonplaceholder.typicode.com/posts"
Метод responseJSON говорит о том, что ответ от сервера нам нужен в JSON формате.
Далее в клоужере мы получаем ответ от сервера и выводим его в консоль:
{ response in
print(response)
}Важно заметить, что код в этом клоужере происходит асинхронно и выполнится после выхода из viewDidLoad, тем самым строка viewDidLoad ended в консоль выводится раньше.
На самом деле мы сделали GET запрос, но нигде этого не указывали. Начиная с Alamofire 4 по умолчанию выполняется GET запрос. Мы может его явно указать, заменив соответствующий код на следующий:
request("http://jsonplaceholder.typicode.com/posts", method: .get)Как Вы уже поняли в параметре method: передается метод запроса и от него зависит, как мы будем общаться с сервером. Чаще всего мы будем:
данные с сервера.
Подробнее про эти и другие методы HTTP можете почитать на википедии:
Функция request — глобальная функция, поэтому мы можем ее вызывать через Alamofire.request или просто request.
Так выглядит полный запрос со всеми параметрами:
request(URLConvertible, method: HTTPMethod, parameters: Parameters?, encoding: ParameterEncoding, headers: HTTPHeaders?)Рассмотрим подробнее:
Первым параметром является путь запросу и он принимает URLConvertible. (Ваш КЭП)
Если мы посмотрим на его реализацию, то увидим, что это протокол с одной функцией:
public protocol URLConvertible {
func asURL() throws -> URL
}и он уже реализован для следующих типов данных:
В связи с этим мы можем передавать любой из выше перечисленных типов в качестве параметра или создать свой собственный тип данных с реализацией данного протокола.
Это enum, со всеми возможными типами запросов:
public enum HTTPMethod: String {
case options = "OPTIONS"
case get = "GET"
case head = "HEAD"
case post = "POST"
case put = "PUT"
case patch = "PATCH"
case delete = "DELETE"
case trace = "TRACE"
case connect = "CONNECT"
}Как мы уже выяснили: по умолчанию .get
Тут ничего сложного, идем дальше.
Это простой Dictionary:
public typealias Parameters = [String: Any]Через параметры мы будем передавать данные на сервер (например, для изменения или создания объектов).
Это тоже протокол с одной функцией:
public protocol ParameterEncoding {
func encode(_ urlRequest: URLRequestConvertible, with parameters: Parameters?) throws -> URLRequest
}Он необходим для определения в каком виде нам закодировать наши параметры. Разные серверы и запросы требуют определенной кодировки.
Этот протокол реализуют:
По умолчанию у нас URLEncoding.default.
В основном этот параметр не используется, но иногда бывает нужен, в частности JSONEncoding.default для кодировки в JSON формате и PropertyListEncoding.default в XML.
Я заметил, что Int не отправляется без JSONEncoding.default, но возможно это было в Alamofire 3, а может из-за сервера. Просто имейте это ввиду.
Это также Dictionary, но другой типизации:
public typealias HTTPHeaders = [String: String]Headers(заголовки) нам будут необходимы в основном для авторизации.
Подробнее про заголовки на википедии:
На выходе мы получаем объект типа DataRequest — сам запрос. Его мы можем сохранить, передать, как параметр в другую функцию при необходимости, донастроить и отправить. Об этом далее.
Ответ от сервера может прийти, как с результатом, так и с ошибкой. Для того, чтобы их различать у ответа есть такие параметры, как statusCode и contentType.
Вот эти параметры мы можем проверять вручную, а можем настроить запрос, так что он нам сразу будет говорить, ответ пришел с ошибкой или с результатом.
Если мы не настраивали валидацию, то в
responseJSON.response?.statusCode
у нас будет статус код ответа, а в
responseJSON.result.value
будет результат, если ответ пришел без ошибки, и в
responseJSON.result.error
если с ошибкой.
request("http://jsonplaceholder.typicode.com/posts").responseJSON { responseJSON in
guard let statusCode = responseJSON.response?.statusCode else { return }
print("statusCode: ", statusCode)
if (200..<300).contains(statusCode) {
let value = responseJSON.result.value
print("value: ", value ?? "nil")
} else {
print("error")
}
}Подробнее про коды состояний на википедии:
Для этого у DataRequest есть 4 метода:
Рассмотрим только последний, потому что его нам будет хватать для 95% запросов.
Взглянем на его реализацию:
public func validate() -> Self {
return validate(statusCode: self.acceptableStatusCodes).validate(contentType: self.acceptableContentTypes)
}Видим, что он состоит из двух других валидаций:
self.acceptableStatusCodes — возвращает массив статус кодов(Int) из range 200..<300self.acceptableContentTypes — возвращает массив допустимых хедеров(String)У DataResponse есть параметр result, который может сказать нам, пришел ответ с ошибкой или с результатом.
Итак, применим валидацию для запроса:
request("http://jsonplaceholder.typicode.com/posts").validate().responseJSON { responseJSON in
switch responseJSON.result {
case .success(let value):
print(value)
case .failure(let error):
print(error)
}
}Если у нас не будет вылидации запроса (validate()), то result всегда будет равен .success, за исключением ошибки из-за отсутствия интернета.
Можно обрабатывать ответ обоими способами, но я настоятельно рекомендую пользоваться настройкой валидации запроса — будет меньше ошибок!
Ответ от сервера чаще всего бывает в виде одного объекта или массива объектов.
Если мы посмотрим на тип результата ответа, то увидим тип Any. Чтобы из него что-то достать — нам надо его привести к нужному формату.
В логах мы замечали, что у нас приходит массив Dictionary, поэтому к нему и будем приводить:
request("http://jsonplaceholder.typicode.com/posts").responseJSON { responseJSON in
switch responseJSON.result {
case .success(let value):
print("value", value)
guard let jsonArray = responseJSON.result.value as? [[String: Any]] else { return }
print("array: ", jsonArray)
print("1 object: ", jsonArray[0])
print("id: ", jsonArray[0]["id"]!)
case .failure(let error):
print(error)
}
}После этого, как показано выше, мы можем делать что угодно, например, создать объект и сохранить его, чтобы потом было удобнее работать с данными.
В отдельном файле создадим структуру Post:
struct Post {
var id: Int
var title: String
var body: String
var userId: Int
}Так будет выглядеть парсинг в массив объектов:
request("http://jsonplaceholder.typicode.com/posts").responseJSON { responseJSON in
switch responseJSON.result {
case .success(let value):
guard let jsonArray = value as? Array<[String: Any]> else { return }
var posts: [Post] = []
for jsonObject in jsonArray {
guard
let id = jsonObject["id"] as? Int,
let title = jsonObject["title"] as? String,
let body = jsonObject["body"] as? String,
let userId = jsonObject["userId"] as? Int
else {
return
}
let post = Post(id: id, title: title, body: body, userId: userId)
posts.append(post)
}
print(posts)
case .failure(let error):
print(error)
}
}Парсинг объекта внутри запроса выглядит очень плохо + нам придется всегда копировать эти строки для каждого запроса. Чтобы от этого избавиться создадим конструктор init?(json: [String: Any]):
init?(json: [String: Any]) {
guard
let id = json["id"] as? Int,
let title = json["title"] as? String,
let body = json["body"] as? String,
let userId = json["userId"] as? Int
else {
return nil
}
self.id = id
self.title = title
self.body = body
self.userId = userId
}Он может вернуть nil, если сервер нам что-то не вернул
И тогда метод запроса выглядит на много понятнее и приятнее:
request("http://jsonplaceholder.typicode.com/posts").responseJSON { responseJSON in
switch responseJSON.result {
case .success(let value):
guard let jsonArray = value as? Array<[String: Any]> else { return }
var posts: [Post] = []
for jsonObject in jsonArray {
guard let post = Post(json: jsonObject) else { return }
posts.append(post)
}
print(posts)
case .failure(let error):
print(error)
}
}Пойдем еще дальше и в Post добавим метод обработки массива:
static func getArray(from jsonArray: Any) -> [Post]? {
guard let jsonArray = jsonArray as? Array<[String: Any]> else { return nil }
var posts: [Post] = []
for jsonObject in jsonArray {
if let post = Post(json: jsonObject) {
posts.append(post)
}
}
return posts
}Тогда метод запроса примет следующий вид:
request("http://jsonplaceholder.typicode.com/posts").responseJSON { responseJSON in
switch responseJSON.result {
case .success(let value):
guard let posts = Post.getArray(from: value) else { return }
print(posts)
case .failure(let error):
print(error)
}
}Конечный вариант файла Post.swift:
import Foundation
struct Post {
var id: Int
var title: String
var body: String
var userId: Int
init?(json: [String: Any]) {
guard
let id = json["id"] as? Int,
let title = json["title"] as? String,
let body = json["body"] as? String,
let userId = json["userId"] as? Int
else {
return nil
}
self.id = id
self.title = title
self.body = body
self.userId = userId
}
static func getArray(from jsonArray: Any) -> [Post]? {
guard let jsonArray = jsonArray as? Array<[String: Any]> else { return nil }
var posts: [Post] = []
for jsonObject in jsonArray {
if let post = Post(json: jsonObject) {
posts.append(post)
}
}
return posts
}
}Для тех кто уже разобрался в работе с flatMap, то функцию getArray можно написать так:
static func getArray(from jsonArray: Any) -> [Post]? {
guard let jsonArray = jsonArray as? Array<[String: Any]> else { return nil }
return jsonArray.flatMap { Post(json: $0) }
}Как отправлять запрос и получать ответ в виде JSON с помощью responseJSON мы научились. Теперь разберем в каком еще виде можем получить ответ.
Ответ нам придет в виде Data. Зачастую так приходят картинки, но даже наш предыдущий запрос мы можем получть в виде Data:
request("http://jsonplaceholder.typicode.com/posts").responseData { responseData in
switch responseData.result {
case .success(let value):
guard let string = String(data: value, encoding: .utf8) else { return }
print(string)
case .failure(let error):
print(error)
}
}В примере мы получает ответ и преобразовываем его в строку. Из нее неудобно получать данные, как из Dictionary, но есть парсеры, которые сделают из стоки объект.
Здесь все просто. Ответ придет в виде JSON строки. По факту он делает, то, что мы написали выше в responseData:
request("http://jsonplaceholder.typicode.com/posts").responseString { responseString in
switch responseString.result {
case .success(let value):
print(value)
case .failure(let error):
print(error)
}
}Можно сказать это базовый метод. Он никак не обрабатывает данные от сервера, выдает их в том виде, в каком они пришли. У него нету свойства result и поэтому конструкция вида switch response.result здесь не сработает. Все придется делать вручную. Он нам редко понадобится, но знать о нем надо.
request("http://jsonplaceholder.typicode.com/posts").response { response in
guard
let data = response.data,
let string = String(data: data, encoding: .utf8)
else { return }
print(string)
}Выведется строка, если ответ пришел без ошибки.
Существует еще метод .responsePropertyList. Он нужен для получения распарсенного plist файла. Я им еще не пользовался и не нашел тестого сервера, чтобы привести пример. Просто знайте, что он есть или можете сами с ним разобраться по аналогии с другими.
Иногда мы можем получать большой ответ от сервера, например, когда скачиваем фотографию, и нам необходимо отображать прогресс загрузки. Для этого у request есть метод downloadProgress:
Вместо https://s-media-cache-ak0.pinimg.com/originals/ef/6f/8a/ef6f8ac3c1d9038cad7f072261ffc841.jpg можете вставить любую ссылку на фотографию. Желательно большую, чтобы запрос не выполнился моментально и вы увидели сам процесс.request("https://s-media-cache-ak0.pinimg.com/originals/ef/6f/8a/ef6f8ac3c1d9038cad7f072261ffc841.jpg")
.validate()
.downloadProgress { progress in
print("totalUnitCount:\n", progress.totalUnitCount)
print("completedUnitCount:\n", progress.completedUnitCount)
print("fractionCompleted:\n", progress.fractionCompleted)
print("localizedDescription:\n", progress.localizedDescription)
print("---------------------------------------------")
}
.response { response in
guard
let data = response.data,
let image = UIImage(data: data)
else { return }
print(image)
}Класс Progress — это класс стандартной библиотеки.В логах будет выводиться прогресс в виде блоков:
totalUnitCount:
2113789
completedUnitCount:
2096902
fractionCompleted:
0.992011028536907
localizedDescription:
99% completedМы можем поделить completedUnitCount на totalUnitCount и получим число от 0 до 1, которое будет использоваться в UIProgressView, но за нас это уже сделали в свойстве fractionCompleted.
Чтобы увидеть саму картинку, поставьте breakpoint на строку с print(image) и нажмите на Quick Look (кнопка с глазом) в дебаг панели:

Самое простое создание объекта на сервере выглядит так:
let params: [String: Any] = [
"title": "new post",
"body": "some news",
"userId": 10
]
request("http://jsonplaceholder.typicode.com/posts", method: .post, parameters: params).validate().responseJSON { responseJSON in
switch responseJSON.result {
case .success(let value):
guard
let jsonObject = value as? [String: Any],
let post = Post(json: jsonObject)
else { return }
print(post)
case .failure(let error):
print(error)
}
}id не передаем т.к. сервер должен сам его назначить. А вообще для создания каждого объекта в документации должны прописываться необходимые параметры.
При обновлении объекта, его id зачастую прописывается не в параметре, а в пути запроса (~/posts/1):
let params: [String: Any] = [
"title": "new post",
"body": "some news",
"userId": 10
]
request("http://jsonplaceholder.typicode.com/posts/1", method: .put, parameters: params).validate().responseJSON { responseJSON in
switch responseJSON.result {
case .success(let value):
guard
let jsonObject = value as? [String: Any],
let post = Post(json: jsonObject)
else { return }
print(post)
case .failure(let error):
print(error)
}
}Конечно, могут сделать и через параметр, но это будет не по REST. Подробнее про REST в статье на хабре:
Так выглядит загрузка фотографии на сервер:
let image = UIImage(named: "some_photo")!
let data = UIImagePNGRepresentation(image)!
let httpHeaders = ["Authorization": "Basic YWNjXzE4MTM2ZmRhOW*****A=="]
upload(multipartFormData: { multipartFormData in
multipartFormData.append(data, withName: "imagefile", fileName: "image.jpg", mimeType: "image/jpeg")
}, to: "https://api.imagga.com/v1/content", headers: httpHeaders, encodingCompletion: { encodingResult in
switch encodingResult {
case .success(let uploadRequest, let streamingFromDisk, let streamFileURL):
print(uploadRequest)
print(streamingFromDisk)
print(streamFileURL ?? "streamFileURL is NIL")
uploadRequest.validate().responseJSON() { responseJSON in
switch responseJSON.result {
case .success(let value):
print(value)
case .failure(let error):
print(error)
}
}
case .failure(let error):
print(error)
}
})Ужасно не правда ли?
Давайте разберем, что за что отвечает.
Я закинул фотографию с именем some_photo в Assets.xcassets
Создаем объект картинки и преобразуем ее в Data:
let image = UIImage(named: "some_photo")!
let data = UIImagePNGRepresentation(image)!Создаем словарь для передачи токена авторизации:
let httpHeaders = ["Authorization": "Basic YWNjXzE4MTM2ZmRhOW*****A=="]Это необходимо т.к. сервис www.imagga.com требует авторизацию, чтобы залить картинку.
Чтобы получить свой токен, вам необходимо всего лишь зарегистрироваться на их сайте и скопировать его из своего профиля по ссылке: https://imagga.com/profile/dashboard
До этого мы использовали метод request. Сдесь же используется метод upload. Первым параметром идет клоужер для присоединения нашей картинки:
upload(multipartFormData: { multipartFormData in
multipartFormData.append(data, withName: "imagefile", fileName: "image.jpg", mimeType: "image/jpeg")
}Следующими параметрами идут URL и headers:
to: "https://api.imagga.com/v1/content", headers: httpHeadersДальше идет клоужер с закодированным запросом:
encodingCompletion: { encodingResult in
switch encodingResult {
case .success(let uploadRequest, let streamingFromDisk, let streamFileURL):
print(uploadRequest)
print(streamingFromDisk)
print(streamFileURL ?? "streamFileURL is NIL")
...
case .failure(let error):
print(error)
}
})Из него мы можем получить запрос (uploadRequest), и две переменные необходимые для потока(stream) файлов.
Про потоки говорить не буду, достаточно редкая штука. Пока вы просто увидите, что эти две переменные равны false и nil соответственно.
Дальше мы должны отправить запрос в привычной для нас форме:
uploadRequest.validate().responseJSON() { responseJSON in
switch responseJSON.result {
case .success(let value):
print(value)
case .failure(let error):
print(error)
}
}Когда вы получите свой токен, вставите свою фотографию и выполните запрос, то результат будет следующим:
{
status = success;
uploaded = (
{
filename = "image.jpg";
id = 83800f331a7f97e41e0f0b70bf7847bd;
}
);
}filename может не отличаться, а id будут.
Мы познакомились с фреймворком Alamofire, разобрались с методом request, отправкой запросов, обработкой ответа, парснгом положительного ответа, получением информации о прогрессе запроса. Сделали несколько простых запросов и научились загружать фотографии на сервер с авторизацией.
|
Метки: author bonyadmitr разработка под ios разработка мобильных приложений swift alamofire ios ios development |
Внимание, Хабрахабр: IBM открывает бесплатный доступ к большому количеству своих ресурсов |


|
Метки: author ibm программирование высокая производительность блог компании ibm разработка ibm ресурсы ibm обучение наука |
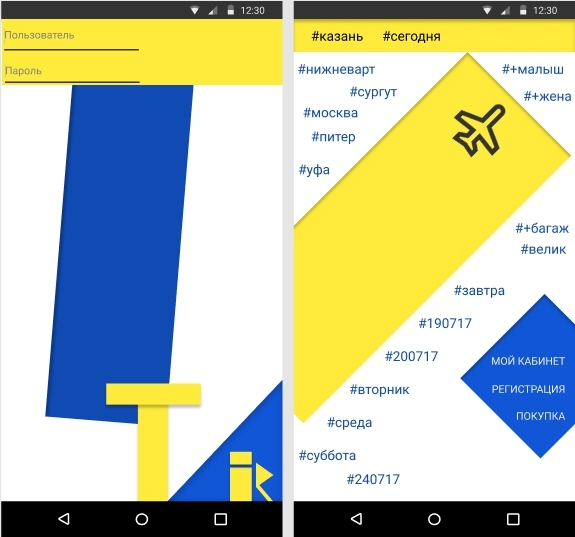
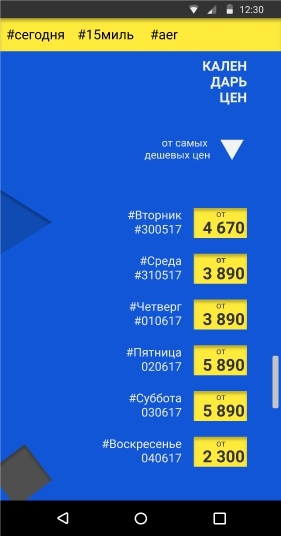
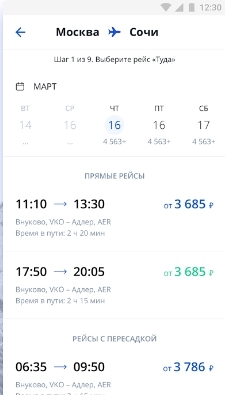
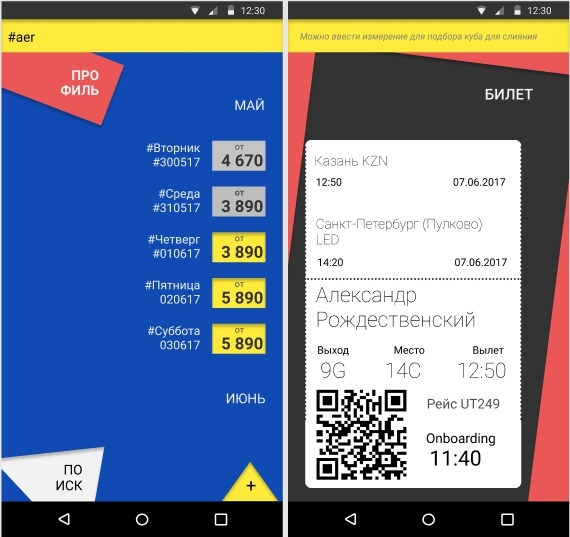
Дизайн как всемирный язык 21 века |





|
Метки: author sanemerov интерфейсы дизайн мобильных приложений веб-дизайн usability accessibility ux design mobile apps user experience guidelines супрематизм |
Microsoft MVP – путь просветленного самурая |
|
Метки: author megapost карьера в it-индустрии mvp microsoft |
[Перевод] Адаптация Xamarin.Forms к разработке корпоративных и B2E приложений |
Немного об авторе:
Adam Pedley (Microsoft MVP, Xamarin MVP, Xamarin Certified Developer)
Корпоративные или Business to Employee (B2E) мобильные приложения могут сильно отличаться от их B2C-аналогов. B2C приложения, как правило, сосредоточены на небольшом количестве экранов для основного использования, а дополнительные экраны используются не так часто, там, где необходимо выполнять вспомогательные функции.
B2E приложения сосредоточены, обычно, на функциях для записи или доступа к данным для повседневной работы. Многие из них заменяют рукописные записи на цифровые, которые автоматически синхронизируются с основной базой данных. Тот факт, что эти пользователи являются сотрудниками крупных компаний, и использую приложение как того требует их работа, приводит к ряду различий с которыми вам приходится иметь дело, не только в коде, а и в окружающих его процессах.
Я предполагаю, что большинство из вас уже слышали о MVVM и Dependency Injection. Я рекомендовал бы это для любой разработки на Xamarin.Forms, не только корпоративной. Использование MVVM с Dependency Injection, поможет вам создать качественное приложение на Xamarin.Forms. Как спроектировать архитектуру вашего приложения, если оно будет иметь очень большую кодовую базу — это еще одна история, но в этой статье она рассмотрена не будет.
Но, когда мы имеем дело с корпоративной разработкой, существуют дополнительные соображения, которые вам нужно выполнить.
Если вы используете один API, то вы его контролируете, вам повезло. К сожалению, так не всегда происходит в корпоративных приложениях. У вас может быть небольшое количество API, которые вы не контролируете, и они могут меняться в течении жизни вашего приложения, особенно если вы имеете дело с плохо реализованными API.
Чтобы противостоять этому, я всегда создаю сервис для своих репозиториев на общем уровне. Класс репозитория — это просто код, который соединяется с API и передает/извлекает данные между ними.
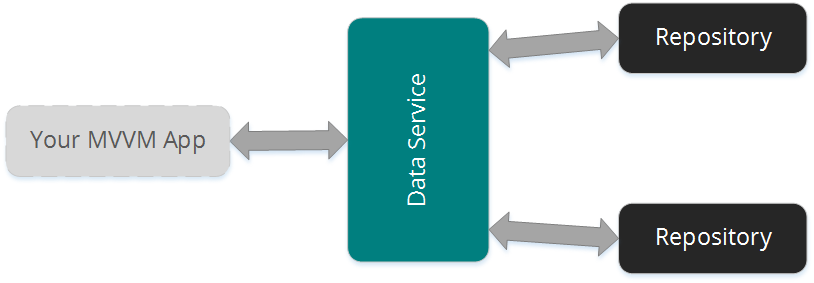
Это защищает ваше приложение от изменений API и удаляет его как зависимость при модульном тестировании.
Из-за большого количества страниц, многошаговых форм и, возможно, доступ по ролям, навигация может усложниться. Варианты навигации, с которыми вы можете столкнуться:
Эти варианты навигации являются достаточно сложными и не входят в стандартную поставку распространенных MVVM фреймворков, за исключением Exrin. Это одна из главных причин, по которой Exrin был создан.
Системы безопасности корпоративного класса, на самом деле, не более безопастны чем и стандартная система безопасности, обычно они сложнее, а следовательно повышается риск неправильной реализации. Вы можете обратиться к Citrix, Microsoft Online или Azure Active Directory. Если вам повезет, у вас будет хороший OAuth API.
Безопасность становится более важной, когда хранятся конфиденциальные данные, например записи пациентов. Правила, которые я использую при работе с конфиденциальной информацией:
Ключ шифрования должен быть сгенерирован мобильным приложением во время выполнения, а затем безопасно сохранен, например в KeyChain или KeyStore.
Убедитесь, что вы также следуете отраслевым стандартам, таким как OWASP Mobile Security Testing Guide.
B2C приложения в основном имеют роскошь говорить — «Вы должны быть подключены к Интернету», при использовании приложения. B2E приложения не всегда имеют такую возможность, например в шахтах или пробелы Wi-Fi зон в больших зданиях. Это означает, что вам потребуется какое-то автономное хранилище. В этом случае, чтобы избежать осложнений, лучше всего всегда запускать приложение из базы данных с помощью службы синхронизации, чтобы обеспечить подключение к API.
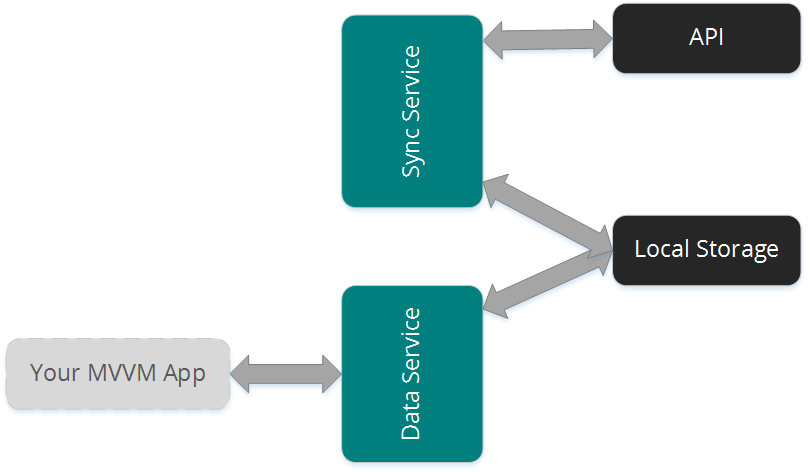
DevOps устанавливает набор процессов для взаимодействия между специалистами по разработке и информационно-технологическому обслуживанию. Это похоже на Agile и Continuous Delivery, но добавляет дополнительное освещение специалистов по управлению и ИТ-обслуживанию, которые обычно исключены из цикла рабработки. DevOps это не то, что вы найдете в небольшой компании, но сможете найти на уровне предприятия.
Как DevOps связан с разработкой на Xamarin.Forms? По сути, никак, но есть вещи которые могут сделать вашу жизнь проще.
Перед обсуждением аналитики, я хотел бы обратить внимание на ее важность. Убедитесь, что ожидаемые результаты можно связать с определенной метрикой.
Например, если цель была простой, сэкономить время сотрудников. Во-первых необходимо установить базовый уровень, который определяет бизнес в данный момент. Если заполнение бумажной формы займет приблизительно 2 минуты, и еще 2 минуты для чего-то, чтобы скопировать в систему и возможно еще 2 минуты, чтобы исправить какие-то ошибки, в среднем это занимает 6 минут. Убедитесь, что вы измеряете время, необходимое, чтобы заполнить форму в мобильном приложении, и как часто это делается. Тогда у вас будет точная метрика сэкономленного времени сотрудника. Далее бизнес может связать это с внутренней оценкой того, сколько будет стоит время сотрудника.
Когда вы являетесь крупной компанией, у вас уже должен быть MDM-набор, чтобы управлять всеми мобильными устройствами своих сотрудников. К сожалению, эти системы иногда не имеют API, который может подключиться к вашему автоматизированному процессу сборки. Я рекомендую использовать HockeyApp или Mobile Center, чтобы обеспечить тестирование и UAT возможности, затем ручное развертывание в MDM, когда будете готовы к выходу в продакшн.
Некоторые основные отличия в корпоративных приложениях, которые необходимо учитывать:
|
Метки: author wcoder разработка мобильных приложений xamarin.forms b2e корпоративная разработка архитектура приложений безопасность devops аналитика советы и рекомендации |






