Курсы Computer Science клуба, весна 2017, часть вторая |





|
Метки: author avsmal машинное обучение математика алгоритмы блог компании спбау экспандеры теория графов машинный перевод коммуникационная сложность потоки теория сложности |
Вебинар Linux on Azure и подборка материалов Open Source & Microsoft |

1. Linux в Azure – обзорВ этом модуле рассмотрены основы облачной платформы Azure. Основное внимание сосредоточено на сервисе виртуальных машин, а именно — на запуске Linux виртуальных машин в облаке Azure.
2. Сетевое взаимодействие виртуальных машин Linux в AzureВ этом модуле рассмотрены основные моменты сетевого взаимодействия в Azure, а именно — создание нескольких виртуальных машин для обслуживания веб сайта, горизонтальное масштабирование и так далее.
3. Управление Linux VM в облаке Azure ч.1: Azure Management PortalВ этом модуле рассмотрены основные принципы работы с порталом Azure. Портал Azure — это веб приложение, следовательно, работать с ним можно практически с любого устройства.
4. Управление Linux VM в облаке Azure ч.2: Azure PowershellВ этом модуле рассмотрены команды PowerShell для работы с Azure. В модуле показано как можно установить себе команды PowerShell для работы с Azure и как подключить их к своей Azure подписке.
5. Управление Linux VM в облаке Azure ч.3: Azure Command Line interfaceВ этом модуле рассмотрены основные принципы работы с утилитами командной строки для Azure. В модуле показано как можно установить себе утилиты командной строки и как подключить их к Azure.
6. Управление Linux VM в облаке Azure ч.4: Инструменты Cerebrata ToolsВ этом модуле рассмотрены такие утилиты компании Cerebrata, как Azure Explorer, Azure PowerShell и Azure Management Studio. Все эти инструменты позволяют нам намного комфортнее работать с Azure.
7. Хранение данных в Azure - диски и распределенные файловые системыВ этом модуле рассмотрены все доступные возможности хранения данных Linux виртуальных машин в облаке Azure (Blob хранилище, Azure диски, распределенная файловая система GlusterFS в Azure и так далее).
1. Типы кластеров, кластер балансировки нагрузкиВ начале рассматриваются различные типы Linux-кластеров, подходы к их построению и задачи, которые они решают. Обзорно рассматривается архитектура Linux-кластера балансировки нагрузки.
2. Отказоустойчивый и вычислительный кластерыТеория, вторая часть: отказоустойчивый и вычислительный кластеры. Подробнее об устройстве кластера отказоустойчивости и вычислительного кластера.
3. Настройка кластера отказоустойчивости в облакеПример создания кластера отказоустойчивости в IaaS-облаке Azure. Отказоустойчивое хранилище DRBD. Прикладное программное обеспечение: MySQL-сервер.
4. Настройка доступа к кластеру снаружи облака, настройка STONITHВ этой части подробно показано, как выполнить проверку работоспособности кластера в различных режимах; настройку множественного endpoint; настройку STONITH и проверку правильности его работы.
|
Метки: author ahriman microsoft azure блог компании microsoft azure open source and microsoft linux |
Как учится и отвечает на вопросы когнитивная система IBM Watson. Часть 1 |

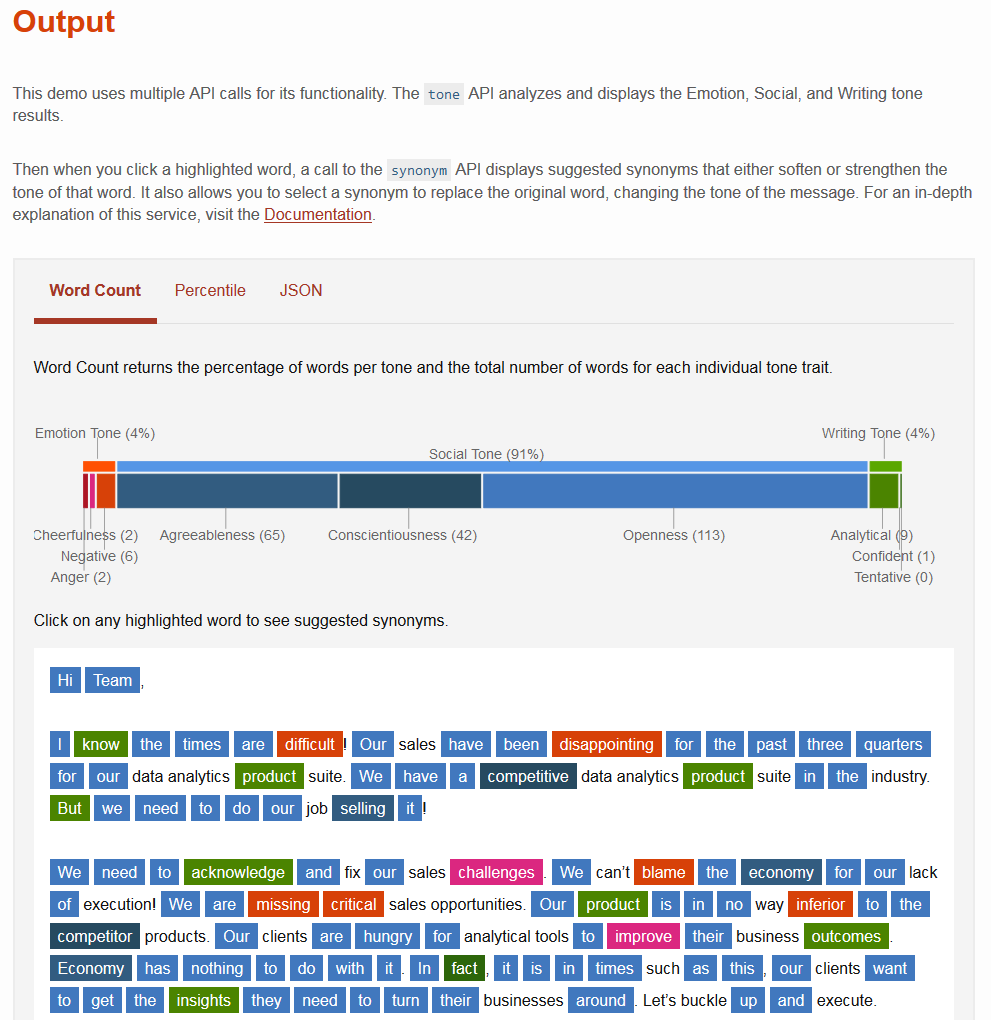
|
Метки: author ibm машинное обучение высокая производительность блог компании ibm watson облачные сервисы ibm когнитивные системы глубокое обучение |
[Перевод] 11 вещей которые я узнал, читая спецификацию flexbox |
Я всегда считал, что с flexbox довольно легко работать — глоток свежего воздуха после стольких лет float'ов и clearfix'ов.
Правда недавно я обнаружил что борюсь с ним; что-то растягивалось, когда я не думал, что оно должно тянуться. Я поправил здесь, другой элемент сжался. Я починил это, что-то другое ушло за экран. Что во имя Джорджа Буша происходит?
В конце концов, все заработало, но солнце село, а мой процесс был привычной игрой с CSS. Или… как называется та игра, где надо ударить крота, а затем другой крот выпрыгивает и надо ударить и его тоже?
Как бы там ни было, я решил что пора вести себя как взрослый разработчик и выучить flexbox должным образом. Но вместо того, чтобы прочитать 10 очередных блог-постов, я решил отправиться прямиком к исходнику и прочитать The CSS Flexible Box Layout Module Level 1 Spec
Вот хорошие отрывки.
Я думал, что если, например, ты хочешь заголовок с логотипом и названием сайта слева, а кнопкой логина справа...

… тебе следует дать названию flex: 1, чтобы прижать остальные элементы к другому концу строки.
Вот почему flexbox — Очень Хорошая Вещь. Простые вещи такие простые.
Но возможно, по какой-то причине, ты не хочешь тянуть элемент только для того чтобы прижать другой элемент вправо. Может, потому что у элемента есть подчеркивание, изображение или какая-либо третья причина, которую я не могу придумать.
Отличные новости! Вместо этого, ты можешь сказать прямо: «прижми этот элемент вправо», определив margin-left: auto на нужном элементе. Думай об этом как о float: right.
Например, если элемент слева является изображением:

Мне не нужно применять flex к изображению, мне не нужно применять space-between к flex-контейнеру, я просто установлю margin-left: auto на кнопке «Войти» («Sign in»):
.header {
display: flex;
}
.header .logo {
/* nothing needed! */
}
.header .sign-in {
margin-left: auto;
}Тебе может показаться это некоторым хаком, но нет, это прямо там в обзоре спецификации как способ прижать flex-элемент в конец flexbox'а. У способа даже есть своя глава: "Выравнивание с авто margin'ами".
О, мне также следует здесь упомянуть, что я предполагаю flex-direction: row везде в этом блог-посте, но все применимо также и к row-reverse или column или column-reverse.
Возможно, ты думаешь, что несложно заставить все flex-элементы внутри flex-контейнера сжиматься, для того чтобы уместить контент. Наверняка, если ты укажешь flex-shrink: 1 на элементах, они так и будут себя вести, правда?
Может, пример.
Скажем, у тебя есть часть DOM, которая отображает книгу на продажу и кнопку чтобы ее купить.

Ты разместил все с помощью flexbox и все хорошо.
.book {
display: flex;
}
.book .description {
font-size: 30px;
}
.book .buy {
margin-left: auto;
width: 80px;
text-align: center;
align-self: center;
}(Поскольку ты хочешь кнопку «Купить» справа — даже для очень коротких названий — ты, будучи умным, указал margin-left: auto)
Название книги довольно длинное, поэтому оно использует столько пространства сколько может и затем переходит на следующую строку. Ты счастлив, жизнь прекрасна. Ты блаженно отправляешь свой код в продакшн, с уверенностью, что он выдержит все.
И потом получаешь неприятный сюрприз. Совсем не хорошего рода.
Некий маппет, много о себе возомнивший, написал книгу с длинным словом в названии.

Все сломано!
Если красная граница обозначает ширину смартфона, и ты скрываешь переполнение (overflow: hidden), ты только что потерял свою кнопку «Купить». Твой коэффициент конверсии — как и эго бедного автора — будет страдать.
(Примечание: к счастью, там где я работаю, есть хорошая QA команда, которая наполнила нашу базу данных разнородным текстом, наподобие такого. В частности, именно эта проблема побудила меня прочитать спецификацию.)
Оказывается, такое поведение происходит из-за того, что min-width элемента описания изначально установлена в auto, что в данном случае равняется ширине слова Electroencephalographically (электроэнцелографически). Flex-элементу буквально не разрешается быть уже чем это слово.
Решение? Переопределить эту проблемную минимальную ширину min-width: auto установив min-width: 0, указывая flexbox'у, что этот элемент может быть уже, чем содержимое внутри него.
Теперь за управление текстом внутри элемента отвечаешь ты. Я предлагаю перенести слово. Таким образом, твой CSS будет выглядеть так:
.book {
display: flex;
}
.book .description {
font-size: 30px;
min-width: 0;
word-wrap: break-word;
}
.book .buy {
margin-left: auto;
width: 80px;
text-align: center;
align-self: center;
}Результат будет таким:

Опять же, min-width: 0 не какой-то хак для обхода нелепости, это предлагаемое поведение прямо в спецификации.
В следующей секции, я вернусь к тому, что кнопка «Купить» совсем не 80 пикселей по ширине, как я довольно ясно ей сказал.
Как вы возможно знаете, свойство flex является краткой записью flex-grow, flex-shrink и flex-basis.
Должен признать, я потратил энное количество минут, гадая-проверяя различные значения для этой тройки, когда пытался заставить элементы тянуться так, как надо мне.
Что я не знал до сей поры, это то, что, в общем случае, я хочу одну из трех комбинаций:
Надеюсь, что ты пока не на максимальном изумлении — сейчас станет еще поразительнее.
Видишь ли, Бригада Flexbox'а (мне нравится думать, что команда flexbox'а носит кожаные куртки с этой надписью сзади — доступны мужские и женские размеры). Где там было это предложение? Ах да, Бригада Flexbox'а знала, что я хочу эти три комбинации свойств в большинстве случаев. Поэтому они дали им ключевые слова специально для меня.
Первый случай — это значение initial так что ключевое слово не нужно. Для второго случая используется flex: auto, и flex: none замечательно простое решение чтобы элемент не тянулся совсем.
Кто бы мог подуть! (Who woulda thunk it — игра слов, прим. переводчика)
Это как если бы было box-shadow: garish, что по умолчанию равнялось 2px 2px 4px hotpink потому что считалось «полезным значением по умолчанию».
Вернемся к невероятно уродливому книжному примеру. Чтобы сделать ту кнопку «Купить» постоянно толстой для нажатия пальцем...

… мне всего лишь надо задать на ней flex: none:
.book {
display: flex;
}
.book .description {
font-size: 30px;
min-width: 0;
word-wrap: break-word;
}
.book .buy {
margin-left: auto;
flex: none;
width: 80px;
text-align: center;
align-self: center;
}(Да, я мог бы указать flex: 0 0 80px; и сэкономить строку CSS. Но есть что-то особенное в том, как ясно flex: none демонстрирует намерение кода. Это хорошо для Будущего Дэвида который забудет как это все работает.)
По правде говоря, я узнал, что есть такая вещь как display: inline-flex несколько месяцев назад. И то, что она создаст инлайновый flex-контейнер, вместо блочного.
Но по моей оценке, 28% людей еще не знали этого, так что… теперь знайте, нижние 28%.
Возможно это то, что я знал наполовину, но я уверен, что в какой-то момент, когда пытался задать правильное выравнивание, я мог испробовать vertical-align: middle и пожать плечами, когда это не сработало.
Теперь я знаю наверняка, прямо из спецификации, что "вертикальное выравнивание не влияет на flex-элемент" (так же как и float, замечу).
Это не просто уровня «лучшая практика», это уровня «совет-от-бабушки», так что просто делай что говорят и не задавай вопросов.
«Авторам следует полностью избегать использования процентов в padding'ах или margin'ах на flex-элементах» — с любовью, спецификация flexbox.
За этим следует моя самая любимая цитата из всех, когда-либо существовавших, спецификаций:
Заметка: это разночтение отстой, но оно в точности отражает текущее состояние мира (нет консенсуса среди реализаций, и нет консенсуса внутри CSSWG)...
Осторожно! Бомбардировка честностью продолжается.
Возможно, ты уже знаешь, что margin'ы иногда объединяются вместе. Ты также можешь знать, что margin'ы не объединяются вместе в некоторых других случаях.
И теперь мы все знаем, что margin'ы соседних flex-элементов никогда не объединяются.
Я не уверен, что мне есть дело до этого. Но я чувствую, что в один день, может быть, это пригодится. Это в точности та же причина, по которой я держу бутылку лимонного сока в холодильнике.
Однажды в моем доме будет другой человек, который скажет типа «эй, у тебя есть лимонный сок?», а я типа «конечно, в холодильнике», а он «спасибо, приятель. Эй, а надо ли мне указывать position если я хочу задать z-index на flex-элементе?», и тут я такой «не братан, не для flex-элементов».
Когда твои требования перерастут ключевые слова initial, auto и none, все станет немного сложнее, и теперь, когда я понял flex-basis, забавно, знаешь, я не могу придумать как закончить это предложение. Оставь комментарий, если у тебя есть идеи.
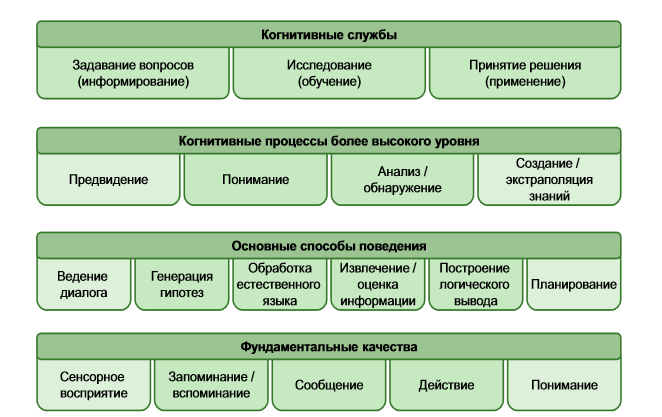
Если у тебя есть три flex-элемента с flex-значениями 3, 3, 4, тогда они гарантированно займут 30%, 30% и 40% доступного пространства, независимо от их содержимого, если их flex-basis равен 0. И только если он равен нулю.
Тем не менее, если ты хочешь чтобы flex вел себя в более дружественной, предсказуемой манере, используй flex-basis: auto. В этом случае flexbox примет твои flex-значения во внимание, но также учтет и другие факторы, подумает немного, и подберет ширины, подходящие по его мнению тебе.
Взгляни на эту четкую диаграмму из спецификации:
Я уверен, что это упомянуто по меньшей мере в одном из блог-постов про flex, которые я читал, но по какой-то причине, не проникся пока не увидел эту картинку в спецификации (schmick pick in the spec)(тройная рифма если ты из Новой Зеландии).
Когда я хотел выравнять flex-элементы по вертикали, я всегда использовал align-items: center. Но также как с vertical-align, у тебя есть возможность установить значение в baseline, что может быть более подходящим если у твоих элементов различный размер шрифта, а ты хочешь выравнять их базу.
Возможно очевидно, align-self: baseline тоже работает.
Сколько бы раз я не читал следующий параграф, я остался неспособным его понять...
Размер содержимого — это минимальный размер содержимого на основной оси, зажатый, если он имеет соотношение сторон, с помощью любых определенных минимальных и максимальных свойств кросс-размера, преобразованных через соотношение сторон, а затем дополнительно зажатых с помощью свойства максимального основного размера, если это определено.
The content size is the min-content size in the main axis, clamped, if it has an aspect ratio, by any definite min and max cross size properties converted through the aspect ratio, and then further clamped by the max main size property if that is definite.
Слова проходят через мои отверстия, преобразуются в электрические импульсы, путешествующие по моему оптическому нерву, и прибывают как раз вовремя, чтобы увидеть как мой мозг выбегает через черный ход в клубе дыма.
Как будто Минни Маус и Мэд Макс завели ребенка семь лет назад, и теперь он, будучи пьяным с мятного шнапса, оскорбляет всех в пределах слышимости словами, которые он узнал когда Мамочка и Папочка ругались.
Леди и Джентльмены, мы начали наш спуск в чепуху, что значит пришло время подвести итоги (или перестань читать, если ты здесь для изучения нового).
Самое интересное из того, что я узнал, читая спецификацию, это то, насколько неполным было мое понимание, несмотря на полдюжины блог-постов которые я прочитал, и на то, насколько относительно простым является flexbox. Оказывается, что «опыт» — это не просто занятие одним и тем же из года в год.
С удовольствием могу отметить, что время, потраченное мной на чтение, уже окупилось. Я прошелся по старому коду, выставил авто margin'ы, flex-значения в краткой записи auto или none, и задал минимальную ширину в ноль там, где это было нужно.
Я лучше отношусь к этому коду теперь, зная что я делаю это должным образом.
Еще я узнал, что несмотря на то, что спецификация — местами — перенасыщена и предназначена для вендоров как я и думал, все же содержит много дружественных слов и примеров. В ней даже выделены части которые скромные веб-разработчики могут пропустить.
Однако это спорный вопрос, потому что я рассказал тебе про все хорошие отрывки, так что тебе не нужно утруждать себя ее чтением.
Теперь, если позволите, мне надо идти и прочитать все остальные CSS спецификации.
P.S. Я крайне рекомендую прочитать следующий список всех flexbox багов по браузерам:
github.com/philipwalton/flexbugs
От переводчика: это мой первый опыт перевода зарубежных публикаций, если есть замечания/предложения/ремарки по качеству перевода или по содержимому, пишите в комментариях.
Оригинальный пост здесь: hackernoon.com/11-things-i-learned-reading-the-flexbox-spec-5f0c799c776b
|
Метки: author Checkmatez разработка веб-сайтов браузеры html css flexbox layout specification |
Инвентаризация SCCM |

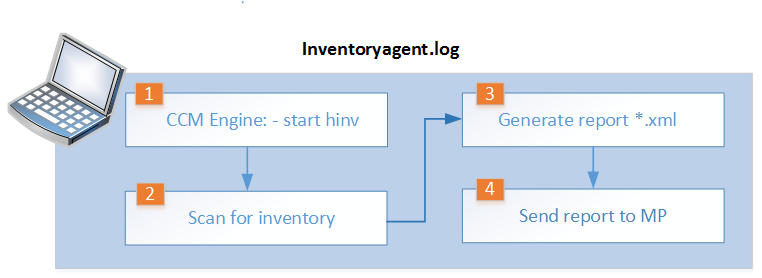
Inventory: Opening store for action {00000000-0000-0000-0000-000000000001}…
Inventory: Action=Hardware, ReportType=Delta, MajorVersion=1, MinorVersion=5
……
|
Метки: author Schvepsss it- инфраструктура блог компании microsoft microsoft инвентаризация configmgr system center configuration manager |
[recovery mode] Оценка качества алгоритмов распознавания лиц |



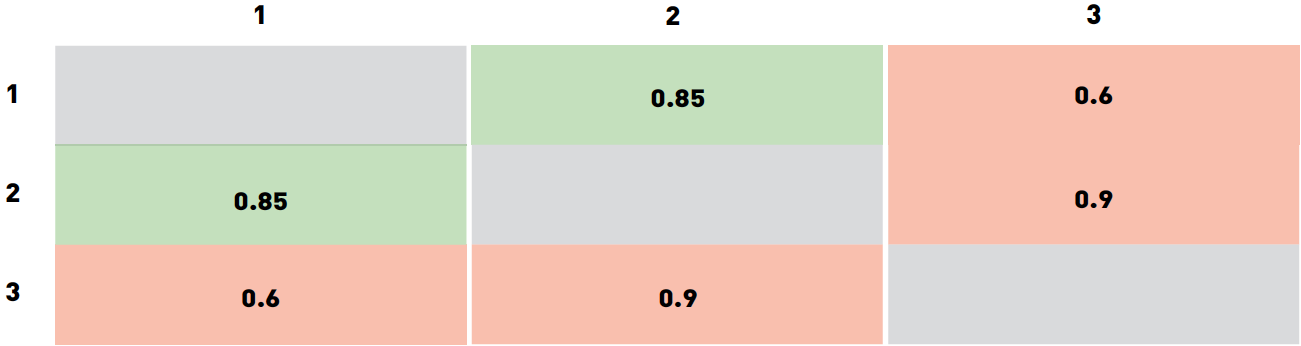



|
Метки: author dadalotta обработка изображений машинное обучение алгоритмы big data блог компании ntechlab распознавание лиц тестирование алгоритмов |
Git: много хуков полезных и разных |
cd /opt/repo-dev/example-repo/ && git remote add prod /opt/repo-remote.gittouch /opt/repo-remote.git/hooks/post-update && chmod +x /opt/repo-remote.git/hooks/post-update#!/bin/bash
cd /opt/repo-remote.git
/usr/bin/git --work-tree=/opt/repo/example-repo/ checkout -f origin/test
cd /opt/repo/example-repo/
/usr/bin/npm install
/usr/local/bin/pm2 restart all
git fetch origin && git reset --hard -f origin/testgit push prod test|
Метки: author akrymets devops git continuous deployment continuous integration hooks |
Перспективы трудоустройства для Java-программистов |
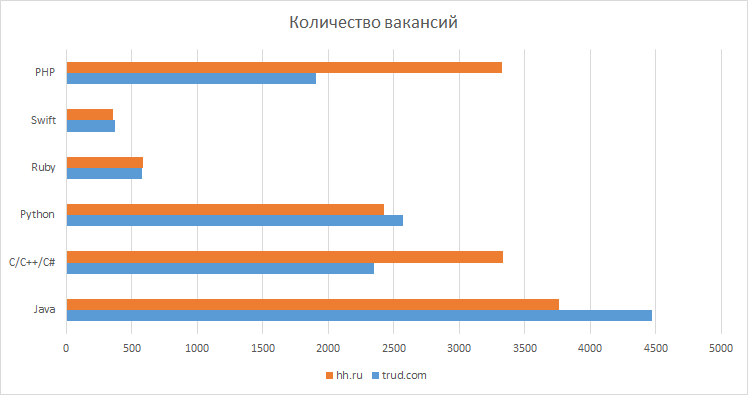

|
Метки: author Dmitry21 программирование java блог компании отус otus otus.ru |
[Перевод] SQL101: Почему восстановление из резервной копии медленнее, чем ее создание |
|
Метки: author minamoto microsoft sql server sql server администрирование баз данных резервные копии восстановление backup restore |
IT — проект со школьниками: несколько рекомендаций |

|
Метки: author ESolovey учебный процесс в it обучение проект it |
[Из песочницы] Портирование MIPSfpga на другие платы и интеграция периферии в систему. Часть 1 |







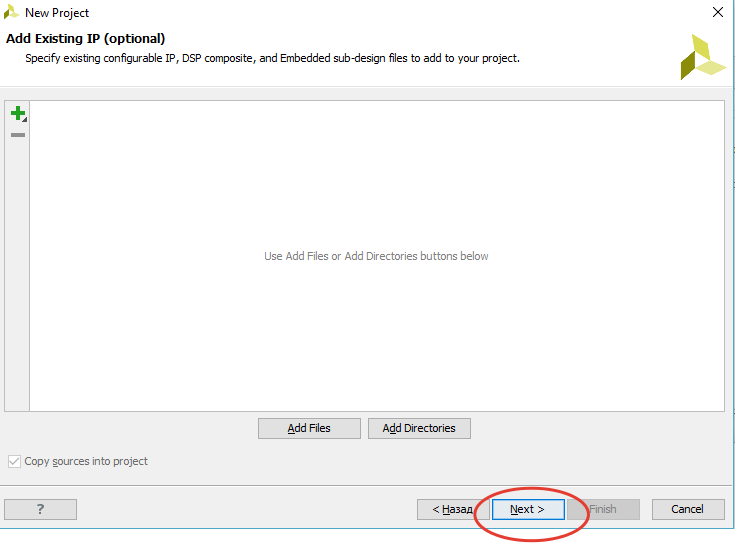
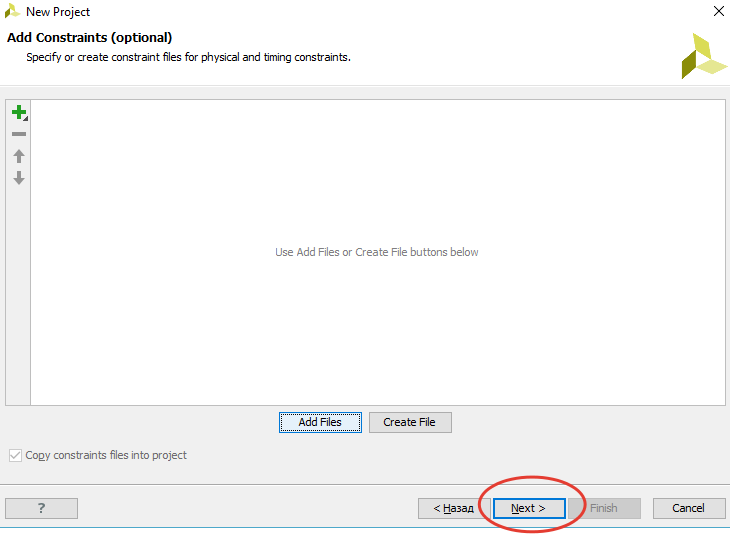

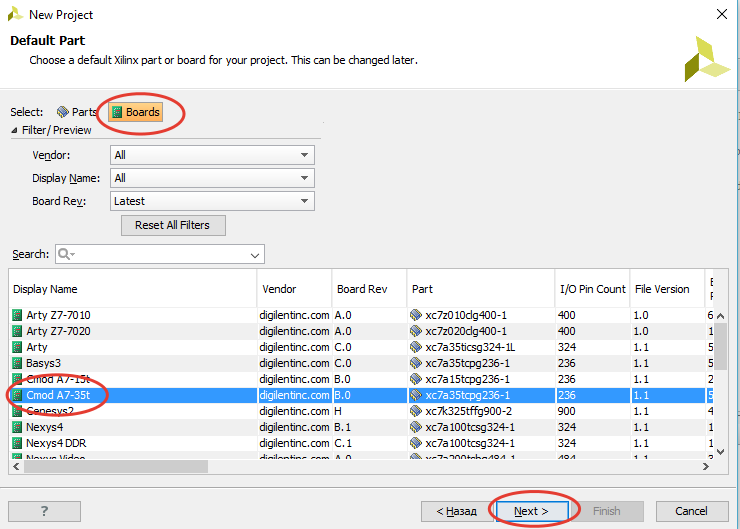




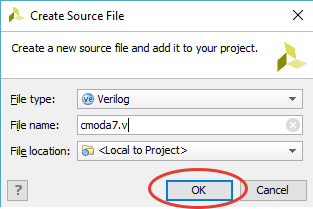

`include "mfp_ahb_lite_matrix_config.vh"
module cmoda7
(
input i_clk,
input i_btn0,
input i_btn1,
input RsRx,
output [ 6:0] seg,
output dp,
output [ 3:0] an,
output led0_r,
output led0_g,
output led0_b,
inout [ 7:0] JA
);
wire clock;
wire reset = i_btn0;
wire display_clock;
wire [7:0] anodes;
wire [`MFP_N_BUTTONS - 1:0] IO_Buttons;
wire [`MFP_7_SEGMENT_HEX_WIDTH - 1:0] IO_7_SegmentHEX;
assign IO_Buttons = { { `MFP_N_BUTTONS - 2 { 1'b0 } } , i_btn0, i_btn1 };
mfp_system mfp_system
(
.SI_ClkIn ( clock ),
.SI_Reset ( reset ),
.HADDR ( ),
.HRDATA ( ),
.HWDATA ( ),
.HWRITE ( ),
.EJ_TRST_N_probe ( ),
.EJ_TDI ( ),
.EJ_TDO ( ),
.EJ_TMS ( ),
.EJ_TCK ( ),
.SI_ColdReset ( ),
.EJ_DINT ( 1'b0 ),
.IO_Switches ( ),
.IO_Buttons ( IO_Buttons ),
.IO_RedLEDs ( ),
.IO_GreenLEDs ( ),
.IO_7_SegmentHEX ( IO_7_SegmentHEX ),
`ifdef MFP_DEMO_LIGHT_SENSOR
.SPI_CS ( JA [0] ),
.SPI_SCK ( JA [3] ),
.SPI_SDO ( JA [2] ),
`endif
.UART_RX ( RsRx ),
.UART_TX ( )
);
`ifdef MFP_DEMO_LIGHT_SENSOR
assign JA [1] = 1'b0;
`endifmfp_multi_digit_display multi_digit_display
(
.clock ( display_clock ),
.resetn ( ~ reset ),
.number ( IO_7_SegmentHEX ),
.seven_segments ( seg ),
.dot ( dp ),
.anodes ( an )
);module mfp_single_digit_seven_segment_display
(
input [3:0] digit,
output reg [6:0] seven_segments
);
always @*
case (digit)
'h0: seven_segments = 'b1000000; // a b c d e f g
'h1: seven_segments = 'b1111001;
'h2: seven_segments = 'b0100100; // --a--
'h3: seven_segments = 'b0110000; // | |
'h4: seven_segments = 'b0011001; // f b
'h5: seven_segments = 'b0010010; // | |
'h6: seven_segments = 'b0000010; // --g--
'h7: seven_segments = 'b1111000; // | |
'h8: seven_segments = 'b0000000; // e c
'h9: seven_segments = 'b0011000; // | |
'ha: seven_segments = 'b0001000; // --d--
'hb: seven_segments = 'b0000011;
'hc: seven_segments = 'b1000110;
'hd: seven_segments = 'b0100001;
'he: seven_segments = 'b0000110;
'hf: seven_segments = 'b0001110;
endcase
endmodule
//--------------------------------------------------------------------
module mfp_multi_digit_display
(
input clock,
input resetn,
input [31:0] number,
output reg [ 6:0] seven_segments,
output reg dot,
output reg [ 7:0] anodes
);
function [6:0] bcd_to_seg (input [3:0] bcd);
case (bcd)
'h0: bcd_to_seg = 'b1000000; // a b c d e f g
'h1: bcd_to_seg = 'b1111001;
'h2: bcd_to_seg = 'b0100100; // --a--
'h3: bcd_to_seg = 'b0110000; // | |
'h4: bcd_to_seg = 'b0011001; // f b
'h5: bcd_to_seg = 'b0010010; // | |
'h6: bcd_to_seg = 'b0000010; // --g--
'h7: bcd_to_seg = 'b1111000; // | |
'h8: bcd_to_seg = 'b0000000; // e c
'h9: bcd_to_seg = 'b0010000; // | |
'ha: bcd_to_seg = 'b0001000; // --d--
'hb: bcd_to_seg = 'b0000011;
'hc: bcd_to_seg = 'b1000110;
'hd: bcd_to_seg = 'b0100001;
'he: bcd_to_seg = 'b0000110;
'hf: bcd_to_seg = 'b0001110;
endcase
endfunction
reg [2:0] i;
always @ (posedge clock or negedge resetn)
begin
if (! resetn)
begin
seven_segments <= bcd_to_seg (0);
dot <= 0;
anodes <= 8'b00000001;
i <= 0;
end
else
begin
seven_segments <= bcd_to_seg (number [i * 4 +: 4]);
dot <= 0;
anodes <= (1 << i);
i <= i + 1;
end
end
endmodule
mfp_clock_divider_50_MHz_to_763_Hz mfp_clock_divider_50_MHz_to_763_Hz
(clock, display_clock);
module mfp_clock_divider_50_MHz_to_763_Hz
(
input clki,
output clko
);
mfp_clock_divider
# (.DIV_POW_SLOWEST (16))
mfp_clock_divider
(
.clki ( clki ),
.sel_lo ( 1'b1 ),
.sel_mid ( 1'b0 ),
.clko ( clko )
);
endmodule




assign led0_r = 1'b1;
assign led0_g = 1'b1;
assign led0_b = 1'b1;endmodule
`define H_RAM_RESET_ADDR_WIDTH 13 `define H_RAM_ADDR_WIDTH 14

## Clock signal 12 MHz
set_property -dict {PACKAGE_PIN L17 IOSTANDARD LVCMOS33} [get_ports i_clk]
create_clock -period 83.330 -name sys_clk_pin -waveform {0.000 41.660} -add [get_ports i_clk]
## Buttons
set_property -dict {PACKAGE_PIN A18 IOSTANDARD LVCMOS33} [get_ports i_btn0]
set_property -dict {PACKAGE_PIN B18 IOSTANDARD LVCMOS33} [get_ports i_btn1]
## LEDs
set_property -dict {PACKAGE_PIN B17 IOSTANDARD LVCMOS33} [get_ports led0_b]
set_property -dict {PACKAGE_PIN B16 IOSTANDARD LVCMOS33} [get_ports led0_g]
set_property -dict {PACKAGE_PIN C17 IOSTANDARD LVCMOS33} [get_ports led0_r]
## Pmod Header JA
set_property -dict {PACKAGE_PIN G17 IOSTANDARD LVCMOS33} [get_ports {JA[0]}]
set_property -dict {PACKAGE_PIN G19 IOSTANDARD LVCMOS33} [get_ports {JA[1]}]
set_property -dict {PACKAGE_PIN N18 IOSTANDARD LVCMOS33} [get_ports {JA[2]}]
set_property -dict {PACKAGE_PIN L18 IOSTANDARD LVCMOS33} [get_ports {JA[3]}]
set_property -dict {PACKAGE_PIN H17 IOSTANDARD LVCMOS33} [get_ports {JA[4]}]
set_property -dict {PACKAGE_PIN H19 IOSTANDARD LVCMOS33} [get_ports {JA[5]}]
set_property -dict {PACKAGE_PIN J19 IOSTANDARD LVCMOS33} [get_ports {JA[6]}]
set_property -dict {PACKAGE_PIN K18 IOSTANDARD LVCMOS33} [get_ports {JA[7]}]
## GPIO Pins 1 - 6 7_segment_ind
set_property -dict {PACKAGE_PIN M3 IOSTANDARD LVCMOS33} [get_ports {seg[1]}]
set_property -dict {PACKAGE_PIN L3 IOSTANDARD LVCMOS33} [get_ports {an[1]} ]
set_property -dict {PACKAGE_PIN A16 IOSTANDARD LVCMOS33}[get_ports {an[2]} ]
set_property -dict {PACKAGE_PIN K3 IOSTANDARD LVCMOS33} [get_ports {seg[5]}]
set_property -dict {PACKAGE_PIN C15 IOSTANDARD LVCMOS33}[get_ports {seg[0]}]
set_property -dict {PACKAGE_PIN H1 IOSTANDARD LVCMOS33} [get_ports {an[3]} ]
## GPIO Pins 43 - 48 7_segment_ind
set_property -dict {PACKAGE_PIN U3 IOSTANDARD LVCMOS33} [get_ports {seg[3]}]
set_property -dict {PACKAGE_PIN W6 IOSTANDARD LVCMOS33} [get_ports {seg[4]}]
set_property -dict {PACKAGE_PIN U7 IOSTANDARD LVCMOS33} [get_ports dp ]
set_property -dict {PACKAGE_PIN W7 IOSTANDARD LVCMOS33} [get_ports {seg[2]}]
set_property -dict {PACKAGE_PIN U8 IOSTANDARD LVCMOS33} [get_ports {seg[6]}]
set_property -dict {PACKAGE_PIN V8 IOSTANDARD LVCMOS33} [get_ports {an[0]} ]
## UART
#set_property -dict { PACKAGE_PIN J18 IOSTANDARD LVCMOS33 } [get_ports { uart_rxd_out }]; #IO_L7N_T1_D10_14 Sch=uart_rxd_out
set_property -dict {PACKAGE_PIN J17 IOSTANDARD LVCMOS33} [get_ports RsRx]
set_property -dict {PACKAGE_PIN L17 IOSTANDARD LVCMOS33} [get_ports i_clk]
create_clock -period 83.330 -name sys_clk_pin -waveform {0.000 41.660} -add [get_ports i_clk]# I/O virtual clock
create_clock -period 83.330 -name "clk_virt"
# tsu/th constraints
set_input_delay -clock "clk_virt" -min -add_delay 0.000 [get_ports i_btn0]
set_input_delay -clock "clk_virt" -max -add_delay 10.000 [get_ports i_btn0]
set_input_delay -clock "clk_virt" -min -add_delay 0.000 [get_ports i_btn1]
set_input_delay -clock "clk_virt" -max -add_delay 10.000 [get_ports i_btn1]
set_input_delay -clock "clk_virt" -min -add_delay 0.000 [get_ports led0_b]
set_input_delay -clock "clk_virt" -max -add_delay 10.000 [get_ports led0_b]
set_input_delay -clock "clk_virt" -min -add_delay 0.000 [get_ports led0_g]
set_input_delay -clock "clk_virt" -max -add_delay 10.000 [get_ports led0_g]
set_input_delay -clock "clk_virt" -min -add_delay 0.000 [get_ports led0_r]
set_input_delay -clock "clk_virt" -max -add_delay 10.000 [get_ports led0_r]
## PMOD ALS
set_output_delay -clock "clk_virt" -min -add_delay 0.000 [get_ports {JA[0]}]
set_output_delay -clock "clk_virt" -max -add_delay 10.000 [get_ports {JA[0]}]
set_output_delay -clock "clk_virt" -min -add_delay 0.000 [get_ports {JA[1]}]
set_output_delay -clock "clk_virt" -max -add_delay 10.000 [get_ports {JA[1]}]
set_input_delay -clock "clk_virt" -min -add_delay 0.000 [get_ports {JA[2]}]
set_input_delay -clock "clk_virt" -max -add_delay 10.000 [get_ports {JA[2]}]
set_output_delay -clock "clk_virt" -min -add_delay 0.000 [get_ports {JA[3]}]
set_output_delay -clock "clk_virt" -max -add_delay 10.000 [get_ports {JA[3]}]
set_input_delay -clock "clk_virt" -min -add_delay 0.000 [get_ports {seg[]}]
set_input_delay -clock "clk_virt" -max -add_delay 10.000 [get_ports {seg[]}]
set_input_delay -clock "clk_virt" -min -add_delay 0.000 [get_ports {an[]}]
set_input_delay -clock "clk_virt" -max -add_delay 10.000 [get_ports {an[]}]
set_input_delay -clock "clk_virt" -min -add_delay 0.000 [get_ports dp]
set_input_delay -clock "clk_virt" -max -add_delay 10.000 [get_ports dp]
set_output_delay -clock "clk_virt" -min -add_delay 0.000 [get_ports RsRx]
set_output_delay -clock "clk_virt" -max -add_delay 10.000 [get_ports RsRx]`define MFP_DEMO_LIGHT_SENSOR
module mfp_pmod_als_spi_receiver
(
input clock,
input reset_n,
output cs,
output sck,
input sdo,
output reg [15:0] value
);
reg [21:0] cnt;
reg [15:0] shift;
always @ (posedge clock or negedge reset_n)
begin
if (! reset_n)
cnt <= 22'b100;
else
cnt <= cnt + 22'b1;
end
assign sck = ~ cnt [3];
assign cs = cnt [8];
wire sample_bit = ( cs == 1'b0 && cnt [3:0] == 4'b1111 );
wire value_done = ( cnt [21:0] == 22'b0 );
always @ (posedge clock or negedge reset_n)
begin
if (! reset_n)
begin
shift <= 16'h0000;
value <= 16'h0000;
end
else if (sample_bit)
begin
shift <= (shift << 1) | sdo;
end
else if (value_done)
begin
value <= shift;
end
end
endmodule


## Pmod Header JA
set_property -dict {PACKAGE_PIN G17 IOSTANDARD LVCMOS33} [get_ports {JA[0]}]
...
set_property -dict {PACKAGE_PIN K18 IOSTANDARD LVCMOS33} [get_ports {JA[7]}]


#define MFP_LIGHT_SENSOR_ADDR 0xBF800014
и
#define MFP_LIGHT_SENSOR (* (volatile unsigned *) MFP_LIGHT_SENSOR_ADDR )
#include "mfp_memory_mapped_registers.h"
int main ()
{
int n = 0;
for (;;)
{
MFP_7_SEGMENT_HEX = MFP_LIGHT_SENSOR;
}
return 0;
}
02_compile_and_link08_generate_motorola_s_record_file11_check_which_com_port_is_usedset a=7
mode com%a% baud=115200 parity=n data=8 stop=1 to=off xon=off odsr=off octs=off dtr=off rts=off idsr=off type program.rec >\.\COM%a%12_upload_to_the_board_using_uart|
|
Ко-маркетинг как способ монетизации мобильных приложений |

|
|
Много бессмысленных переписок |

На беседе по итогам испытательного срока моя новая сотрудника сказала, что все ей понятно и нравится, кроме одного: слишком много переписки. «Ведь куда проще, — сказала она, — подойти к человеку и обсудить вопрос голосом». Это ее первая большая компания.

Один хорошо знакомый мне проектный менеджер начинает свое утро со звонков заказчикам и попутно их комментирует: «Вот, а этот товарищ только по телефону со всеми разговаривает. И потом: упс, я этого не говорил! И он прав: то, что не написано, не существует!».

|
Метки: author MarinaPronina управление персоналом блог компании icl services вовлеченность коммуникация |
WebVR: второе рождение виртуальной реальности |

 Мартин Сплитт — инженер по ПО по фронт- и бэкенду в Archilogic. Евангелист и активный участник развития ПО с открытым кодом. Верит в веб-платформы и работает с самыми современными технологиями, направленными на развитие веба.
Мартин Сплитт — инженер по ПО по фронт- и бэкенду в Archilogic. Евангелист и активный участник развития ПО с открытым кодом. Верит в веб-платформы и работает с самыми современными технологиями, направленными на развитие веба. Денис Радин — фронтенд-инженер, разрабатывающий «встроенный» JavaScript в Liberty Global. Энтузиаст компьютерной графики и оптимизации быстродействия веб-приложений. Организатор AmsterdamJS и React Amsterdam. Ведет блог PixelsCommander.com.
Денис Радин — фронтенд-инженер, разрабатывающий «встроенный» JavaScript в Liberty Global. Энтузиаст компьютерной графики и оптимизации быстродействия веб-приложений. Организатор AmsterdamJS и React Amsterdam. Ведет блог PixelsCommander.com.


|
Метки: author MaxJoint разработка под ar и vr визуализация данных блог компании jug.ru group vr виртуальная реальность технологии |
Ещё раз о хранении логов в Zabbix |




evtsys -i -h -p -f 17 -t


[eventlog]
type = "UdpInput"
address = ":10514"
decoder = "syslog-decoder"
[syslog-decoder]
type = "MultiDecoder"
subs = ["rsyslog-decoder", "events-decoder"]
cascade_strategy = "all"
#log_sub_errors = true
[events-decoder]
type = "MultiDecoder"
subs = ["event-4624-decoder", "event-4625-decoder", "event-4724-decoder", "event-4738-decoder", "event-4740-decoder"]
cascade_strategy = "first-wins"
#log_sub_errors = true
[rsyslog-decoder]
type = "SandboxDecoder"
filename = "lua_decoders/rsyslog.lua"
[rsyslog-decoder.config]
type = "RSYSLOG_TraditionalForwardFormat"
template = '%TIMESTAMP% %HOSTNAME% %HOSTNAME% %syslogtag:1:32%%msg:::sp-if-no-1st-sp%%msg%'
tz = "Europe/Moscow"
[event-4624-decoder]
type = "PayloadRegexDecoder"
match_regex = '^(?P4624):(?:[^:]+:){10}\s(?P[^\s]+)[^:]+:\s(?P[^\s]+)(?:[^:]+:){8}\s(?P[^\s]+)'
[event-4624-decoder.message_fields]
Type = "windows.eventlog"
Key = 'eventlog.%EventID%'
Value = 'Успешный вход пользователя %Domain%\%Account% с адреса %IP%.'
[ZabbixEncoder]
type = "SandboxEncoder"
filename = "lua_encoders/zabbix_trapper.lua"
[event-out-zabbix]
type = "TcpOutput"
message_matcher = "Type == 'windows.eventlog'"
address = "127.0.0.1:10051"
encoder = "ZabbixEncoder"
reconnect_after = 1
[event-out-file]
type = "FileOutput"
message_matcher = "Type == 'windows.eventlog'"
path = "/tmp/events.log"
perm = "666"
flush_count = 100
flush_operator = "OR"
encoder = "RstEncoder"
require "os"
require "string"
require "table"
-- Библиотека JSON.
-- https://www.kyne.com.au/~mark/software/lua-cjson.php
local cjson = require("cjson")
function process_message()
-- Название хоста в Zabbix.
local host = read_message("Hostname")
-- Ключ элемента данных.
local key = read_message("Fields[Key]")
-- Значение элемента данных.
local value = read_message("Fields[Value]")
-- Начинаем собирать JSON-сообщение.
local message = {}
-- Отрезаем паразитное двоеточие, которое у нас осталось со времён парсинга syslog сообщения.
message["host"] = string.sub(host, 1, -2)
message["key"] = key
message["value"] = value
local buffer = {message}
local zabbix_message = {}
zabbix_message["request"] = "sender data"
zabbix_message["data"] = buffer
-- Создаём новый payload в сообщении, который состоит из подготовленного массива с данными, закодированного в JSON.
inject_payload("json", "Payload", cjson.encode(zabbix_message))
return 0
end
3.0
2016-10-01T13:30:30Z
Шаблоны безопасности
Template Windows Users Audit
Template Windows Users Audit
Шаблон, обеспечивающий контрольдействий пользователей, путем анализа журнала безопасности системы.
Шаблоны безопасности
Группы пользователей
Пользователи
-
Журнал аудита очищен.
2
0
eventlog.1102
0
1
0
0
2
0
0
0
0
1
0
Возникает при очистке пользователем журнала аудита.
0
Пользователи
-
Успешный вход пользователя в систему.
2
0
eventlog.4624
0
1
0
0
2
0
0
0
0
1
0
Возникает при успешном входе пользователя или службы в систему.
0
Пользователи
-
Учётной записи не удалось выполнить вход в систему.
2
0
eventlog.4625
0
1
0
0
2
0
0
0
0
1
0
Возникает при проблемах со входом пользователя или службы в систему.
0
Пользователи
-
Создана учётная запись пользователя.
2
0
eventlog.4720
0
1
0
0
2
0
0
0
0
1
0
Возникает при создании новой учетной записи.
0
Пользователи
-
Попытка сбросить пароль учётной записи.
2
0
eventlog.4724
0
1
0
0
2
0
0
0
0
1
0
Возникает при попытке сбросить пароль учетной записи.
0
Пользователи
-
Отключена учётная запись пользователя.
2
0
eventlog.4725
0
1
0
0
2
0
0
0
0
1
0
Возникает при отключении учетной записи пользователя.
0
Пользователи
-
Удалена учётная запись пользователя.
2
0
eventlog.4726
0
1
0
0
2
0
0
0
0
1
0
Возникает при удалении учетной записи пользователя.
0
Пользователи
-
Создана защищённая локальная группа безопасности.
2
0
eventlog.4731
0
1
0
0
2
0
0
0
0
1
0
Возникает при создании локальной группы безопасности.
0
Группы пользователей
-
Добавлен участник в защищённую локальную группу.
2
0
eventlog.4732
0
1
0
0
2
0
0
0
0
1
0
Возникает при добавлении участника в локальную группу безопасности.
0
Группы пользователей
-
Удален участник из защищённой локальной группы.
2
0
eventlog.4733
0
1
0
0
2
0
0
0
0
1
0
Возникает при удалении участника из локальной группы безопасности.
0
Группы пользователей
-
Удалена защищённая локальная группа безопасности.
2
0
eventlog.4734
0
1
0
0
2
0
0
0
0
1
0
Возникает при удалении защищенной локальной группы безопасности.
0
Группы пользователей
-
Изменена защищённая локальная группа безопасности.
2
0
eventlog.4735
0
1
0
0
2
0
0
0
0
1
0
Возникает при изменении защищенной локальной группы безопасности.
0
Группы пользователей
-
Изменена учётная запись пользователя.
2
0
eventlog.4738
0
1
0
0
2
0
0
0
0
1
0
Возникает при изменении свойств учетной записи пользователя.
0
Пользователи
-
Заблокирована учётная запись пользователя.
2
0
eventlog.4740
0
1
0
0
2
0
0
0
0
1
0
Возникает при блокировке учетной записи пользователя.
0
Пользователи
-
Изменено имя учётной записи.
2
0
eventlog.4781
0
1
0
0
2
0
0
0
0
1
0
Возникает при изменении имени учетной записи пользователя.
0
Пользователи
{Template Windows Users Audit:eventlog.4732.nodata(120)}=0
{HOST.NAME}: Добавлен участник в защищённую локальную группу.
0
4
{HOST.NAME}: Добавлен участник в защищённую локальную группу.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.1102.nodata(120)}=0
{HOST.NAME}: Журнал аудита очищен.
0
4
{HOST.NAME}: Журнал аудита очищен.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4740.nodata(120)}=0
{HOST.NAME}: Заблокирована учётная запись пользователя.
0
3
{HOST.NAME}: Заблокирована учётная запись пользователя.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4735.nodata(120)}=0
{HOST.NAME}: Изменена защищённая локальная группа безопасности.
0
4
{HOST.NAME}: Изменена защищённая локальная группа безопасности.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4738.nodata(120)}=0
{HOST.NAME}: Изменена учётная запись пользователя.
0
4
{HOST.NAME}: Изменена учётная запись пользователя.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4781.nodata(120)}=0
{HOST.NAME}: Изменено имя учётной записи.
0
4
{HOST.NAME}: Изменено имя учётной записи.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4725.nodata(120)}=0
{HOST.NAME}: Отключена учётная запись пользователя.
0
4
{HOST.NAME}: Отключена учётная запись пользователя.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4724.nodata(120)}=0
{HOST.NAME}: Попытка сбросить пароль учётной записи.
0
4
{HOST.NAME}: Попытка сбросить пароль учётной записи.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4731.nodata(120)}=0
{HOST.NAME}: Создана защищённая локальная группа безопасности.
0
4
{HOST.NAME}: Создана защищённая локальная группа безопасности.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4720.nodata(120)}=0
{HOST.NAME}: Создана учётная запись пользователя.
0
4
{HOST.NAME}: Создана учётная запись пользователя.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4734.nodata(120)}=0
{HOST.NAME}: Удалена защищённая локальная группа безопасности.
0
3
{HOST.NAME}: Удалена защищённая локальная группа безопасности.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4726.nodata(120)}=0
{HOST.NAME}: Удалена учётная запись пользователя.
0
3
{HOST.NAME}: Удалена учётная запись пользователя.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4733.nodata(120)}=0
{HOST.NAME}: Удален участник из защищённой локальной группы.
0
3
{HOST.NAME}: Удален участник из защищённой локальной группы.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4624.nodata(10)}=0
{HOST.NAME}: Успешный вход пользователя в систему.
0
1
{HOST.NAME}: Успешный вход пользователя в систему.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4625.nodata(120)}=0
{HOST.NAME}: Учётной записи не удалось выполнить вход в систему.
0
2
{HOST.NAME}: Учётной записи не удалось выполнить вход в систему.
{ITEM.LASTVALUE}
0


|
Метки: author binfini системное администрирование серверное администрирование it- инфраструктура блог компании business infinity group zabbix monitoring logs sql heka |
Intel представила 18-ядерный Core i9 Extreme из линейки Core X |
 / фото Chris Isherwood CC
/ фото Chris Isherwood CC|
Метки: author it_man высокая производительность блог компании ит-град ит-град core i9 intel |
[Перевод] Node.js и cote: простая и удобная разработка микросервисов |
|
Метки: author ru_vds разработка веб-сайтов node.js javascript блог компании ruvds.com микросервисы разработка cote |
[Перевод] Chrome победил |
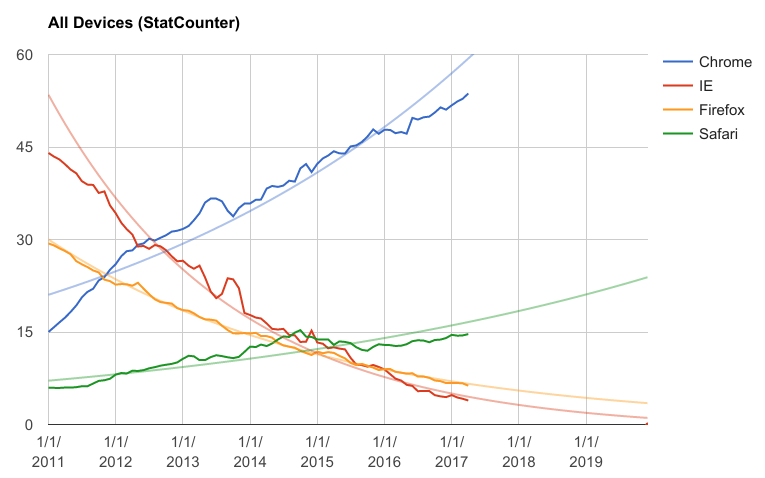

|
Метки: author m1rko браузеры chrome firefox firefox os |
Ещё раз о хранении логов в Zabbix |
evtsys -i -h -p -f 17 -t
[eventlog]
type = "UdpInput"
address = ":10514"
decoder = "syslog-decoder"
[syslog-decoder]
type = "MultiDecoder"
subs = ["rsyslog-decoder", "events-decoder"]
cascade_strategy = "all"
#log_sub_errors = true
[events-decoder]
type = "MultiDecoder"
subs = ["event-4624-decoder", "event-4625-decoder", "event-4724-decoder", "event-4738-decoder", "event-4740-decoder"]
cascade_strategy = "first-wins"
#log_sub_errors = true
[rsyslog-decoder]
type = "SandboxDecoder"
filename = "lua_decoders/rsyslog.lua"
[rsyslog-decoder.config]
type = "RSYSLOG_TraditionalForwardFormat"
template = '%TIMESTAMP% %HOSTNAME% %HOSTNAME% %syslogtag:1:32%%msg:::sp-if-no-1st-sp%%msg%'
tz = "Europe/Moscow"
[event-4624-decoder]
type = "PayloadRegexDecoder"
match_regex = '^(?P4624):(?:[^:]+:){10}\s(?P[^\s]+)[^:]+:\s(?P[^\s]+)(?:[^:]+:){8}\s(?P[^\s]+)'
[event-4624-decoder.message_fields]
Type = "windows.eventlog"
Key = 'eventlog.%EventID%'
Value = 'Успешный вход пользователя %Domain%\%Account% с адреса %IP%.'
[ZabbixEncoder]
type = "SandboxEncoder"
filename = "lua_encoders/zabbix_trapper.lua"
[event-out-zabbix]
type = "TcpOutput"
message_matcher = "Type == 'windows.eventlog'"
address = "127.0.0.1:10051"
encoder = "ZabbixEncoder"
reconnect_after = 1
[event-out-file]
type = "FileOutput"
message_matcher = "Type == 'windows.eventlog'"
path = "/tmp/events.log"
perm = "666"
flush_count = 100
flush_operator = "OR"
encoder = "RstEncoder"
require "os"
require "string"
require "table"
-- Библиотека JSON.
-- https://www.kyne.com.au/~mark/software/lua-cjson.php
local cjson = require("cjson")
function process_message()
-- Название хоста в Zabbix.
local host = read_message("Hostname")
-- Ключ элемента данных.
local key = read_message("Fields[Key]")
-- Значение элемента данных.
local value = read_message("Fields[Value]")
-- Начинаем собирать JSON-сообщение.
local message = {}
-- Отрезаем паразитное двоеточие, которое у нас осталось со времён парсинга syslog сообщения.
message["host"] = string.sub(host, 1, -2)
message["key"] = key
message["value"] = value
local buffer = {message}
local zabbix_message = {}
zabbix_message["request"] = "sender data"
zabbix_message["data"] = buffer
-- Создаём новый payload в сообщении, который состоит из подготовленного массива с данными, закодированного в JSON.
inject_payload("json", "Payload", cjson.encode(zabbix_message))
return 0
end
3.0
2016-10-01T13:30:30Z
Шаблоны безопасности
Template Windows Users Audit
Template Windows Users Audit
Шаблон, обеспечивающий контрольдействий пользователей, путем анализа журнала безопасности системы.
Шаблоны безопасности
Группы пользователей
Пользователи
-
Журнал аудита очищен.
2
0
eventlog.1102
0
1
0
0
2
0
0
0
0
1
0
Возникает при очистке пользователем журнала аудита.
0
Пользователи
-
Успешный вход пользователя в систему.
2
0
eventlog.4624
0
1
0
0
2
0
0
0
0
1
0
Возникает при успешном входе пользователя или службы в систему.
0
Пользователи
-
Учётной записи не удалось выполнить вход в систему.
2
0
eventlog.4625
0
1
0
0
2
0
0
0
0
1
0
Возникает при проблемах со входом пользователя или службы в систему.
0
Пользователи
-
Создана учётная запись пользователя.
2
0
eventlog.4720
0
1
0
0
2
0
0
0
0
1
0
Возникает при создании новой учетной записи.
0
Пользователи
-
Попытка сбросить пароль учётной записи.
2
0
eventlog.4724
0
1
0
0
2
0
0
0
0
1
0
Возникает при попытке сбросить пароль учетной записи.
0
Пользователи
-
Отключена учётная запись пользователя.
2
0
eventlog.4725
0
1
0
0
2
0
0
0
0
1
0
Возникает при отключении учетной записи пользователя.
0
Пользователи
-
Удалена учётная запись пользователя.
2
0
eventlog.4726
0
1
0
0
2
0
0
0
0
1
0
Возникает при удалении учетной записи пользователя.
0
Пользователи
-
Создана защищённая локальная группа безопасности.
2
0
eventlog.4731
0
1
0
0
2
0
0
0
0
1
0
Возникает при создании локальной группы безопасности.
0
Группы пользователей
-
Добавлен участник в защищённую локальную группу.
2
0
eventlog.4732
0
1
0
0
2
0
0
0
0
1
0
Возникает при добавлении участника в локальную группу безопасности.
0
Группы пользователей
-
Удален участник из защищённой локальной группы.
2
0
eventlog.4733
0
1
0
0
2
0
0
0
0
1
0
Возникает при удалении участника из локальной группы безопасности.
0
Группы пользователей
-
Удалена защищённая локальная группа безопасности.
2
0
eventlog.4734
0
1
0
0
2
0
0
0
0
1
0
Возникает при удалении защищенной локальной группы безопасности.
0
Группы пользователей
-
Изменена защищённая локальная группа безопасности.
2
0
eventlog.4735
0
1
0
0
2
0
0
0
0
1
0
Возникает при изменении защищенной локальной группы безопасности.
0
Группы пользователей
-
Изменена учётная запись пользователя.
2
0
eventlog.4738
0
1
0
0
2
0
0
0
0
1
0
Возникает при изменении свойств учетной записи пользователя.
0
Пользователи
-
Заблокирована учётная запись пользователя.
2
0
eventlog.4740
0
1
0
0
2
0
0
0
0
1
0
Возникает при блокировке учетной записи пользователя.
0
Пользователи
-
Изменено имя учётной записи.
2
0
eventlog.4781
0
1
0
0
2
0
0
0
0
1
0
Возникает при изменении имени учетной записи пользователя.
0
Пользователи
{Template Windows Users Audit:eventlog.4732.nodata(120)}=0
{HOST.NAME}: Добавлен участник в защищённую локальную группу.
0
4
{HOST.NAME}: Добавлен участник в защищённую локальную группу.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.1102.nodata(120)}=0
{HOST.NAME}: Журнал аудита очищен.
0
4
{HOST.NAME}: Журнал аудита очищен.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4740.nodata(120)}=0
{HOST.NAME}: Заблокирована учётная запись пользователя.
0
3
{HOST.NAME}: Заблокирована учётная запись пользователя.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4735.nodata(120)}=0
{HOST.NAME}: Изменена защищённая локальная группа безопасности.
0
4
{HOST.NAME}: Изменена защищённая локальная группа безопасности.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4738.nodata(120)}=0
{HOST.NAME}: Изменена учётная запись пользователя.
0
4
{HOST.NAME}: Изменена учётная запись пользователя.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4781.nodata(120)}=0
{HOST.NAME}: Изменено имя учётной записи.
0
4
{HOST.NAME}: Изменено имя учётной записи.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4725.nodata(120)}=0
{HOST.NAME}: Отключена учётная запись пользователя.
0
4
{HOST.NAME}: Отключена учётная запись пользователя.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4724.nodata(120)}=0
{HOST.NAME}: Попытка сбросить пароль учётной записи.
0
4
{HOST.NAME}: Попытка сбросить пароль учётной записи.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4731.nodata(120)}=0
{HOST.NAME}: Создана защищённая локальная группа безопасности.
0
4
{HOST.NAME}: Создана защищённая локальная группа безопасности.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4720.nodata(120)}=0
{HOST.NAME}: Создана учётная запись пользователя.
0
4
{HOST.NAME}: Создана учётная запись пользователя.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4734.nodata(120)}=0
{HOST.NAME}: Удалена защищённая локальная группа безопасности.
0
3
{HOST.NAME}: Удалена защищённая локальная группа безопасности.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4726.nodata(120)}=0
{HOST.NAME}: Удалена учётная запись пользователя.
0
3
{HOST.NAME}: Удалена учётная запись пользователя.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4733.nodata(120)}=0
{HOST.NAME}: Удален участник из защищённой локальной группы.
0
3
{HOST.NAME}: Удален участник из защищённой локальной группы.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4624.nodata(10)}=0
{HOST.NAME}: Успешный вход пользователя в систему.
0
1
{HOST.NAME}: Успешный вход пользователя в систему.
{ITEM.LASTVALUE}
0
{Template Windows Users Audit:eventlog.4625.nodata(120)}=0
{HOST.NAME}: Учётной записи не удалось выполнить вход в систему.
0
2
{HOST.NAME}: Учётной записи не удалось выполнить вход в систему.
{ITEM.LASTVALUE}
0
|
Метки: author binfini системное администрирование серверное администрирование it- инфраструктура zabbix monitoring logs sql heka |
[Из песочницы] Создаем свой Angular 2 |

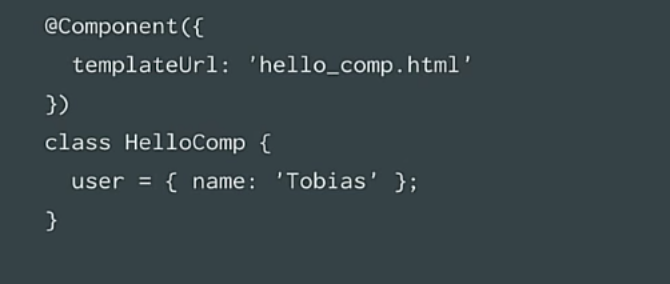
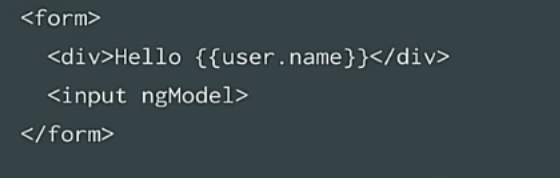




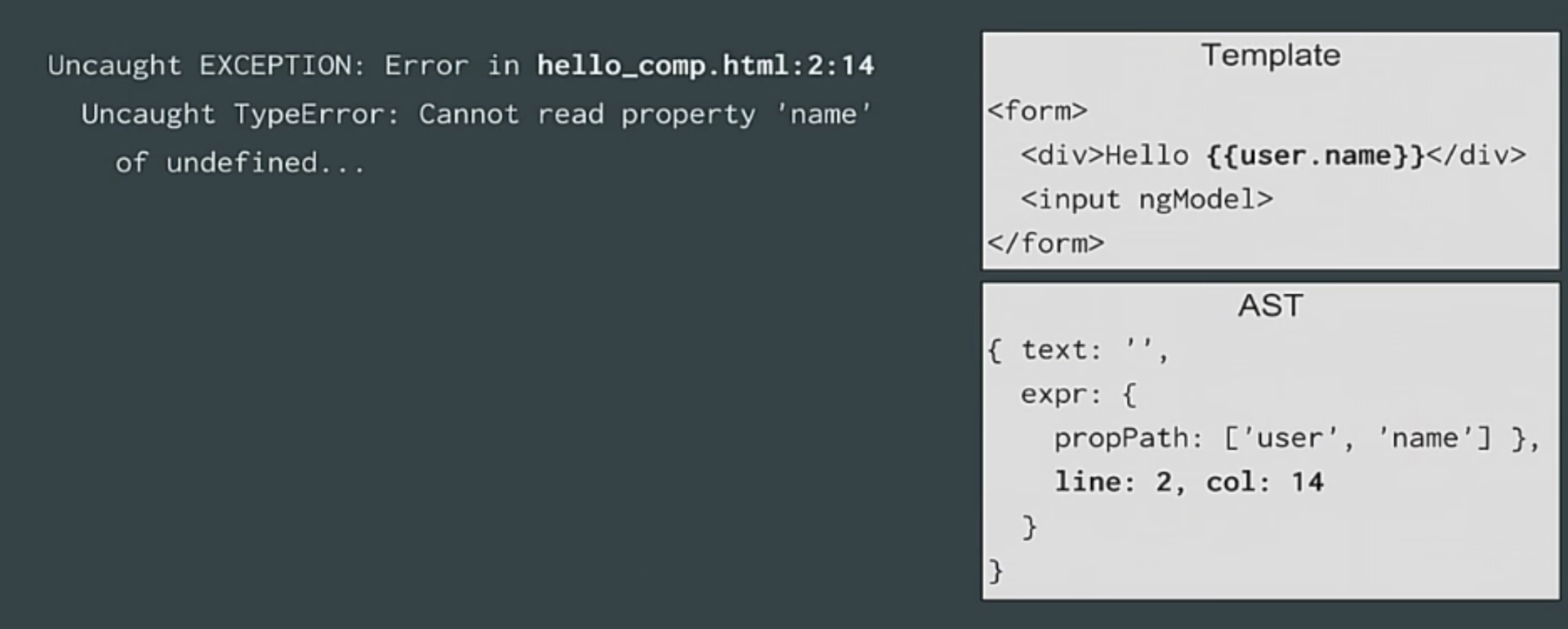



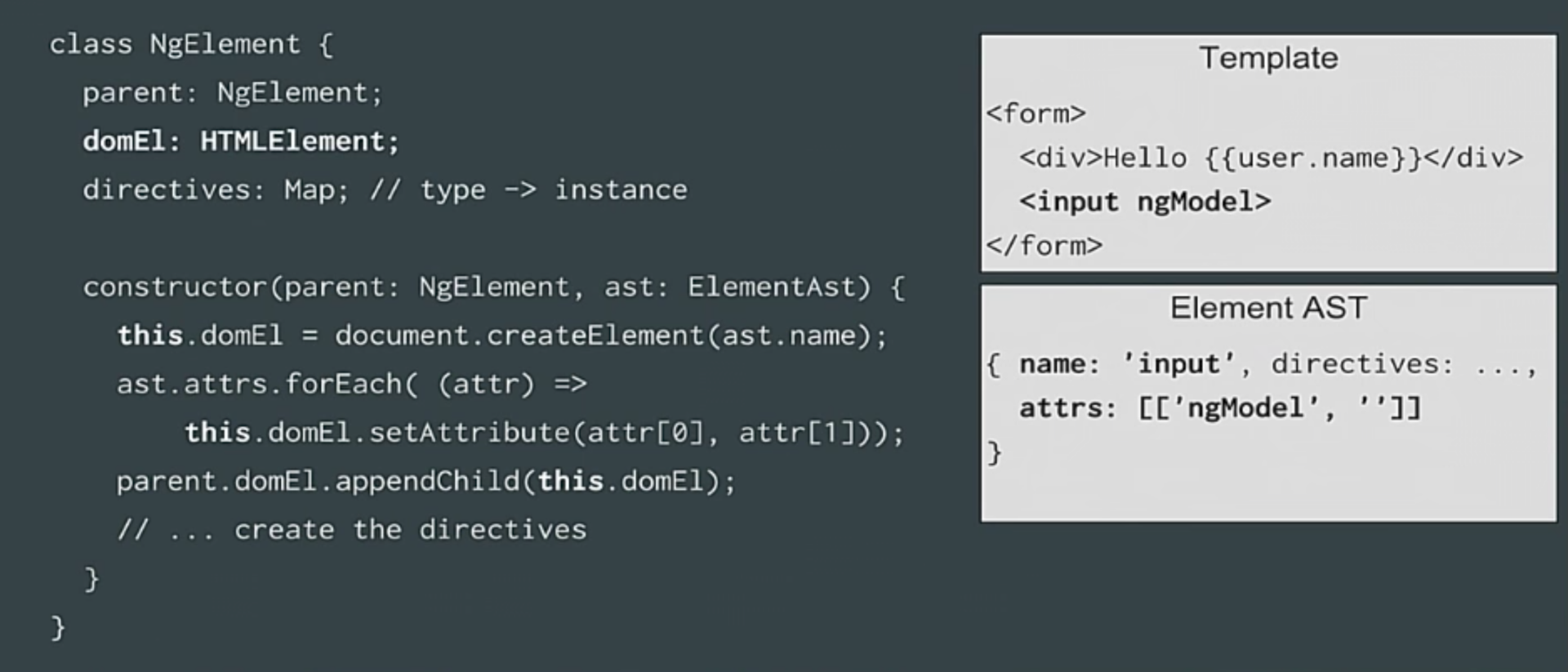
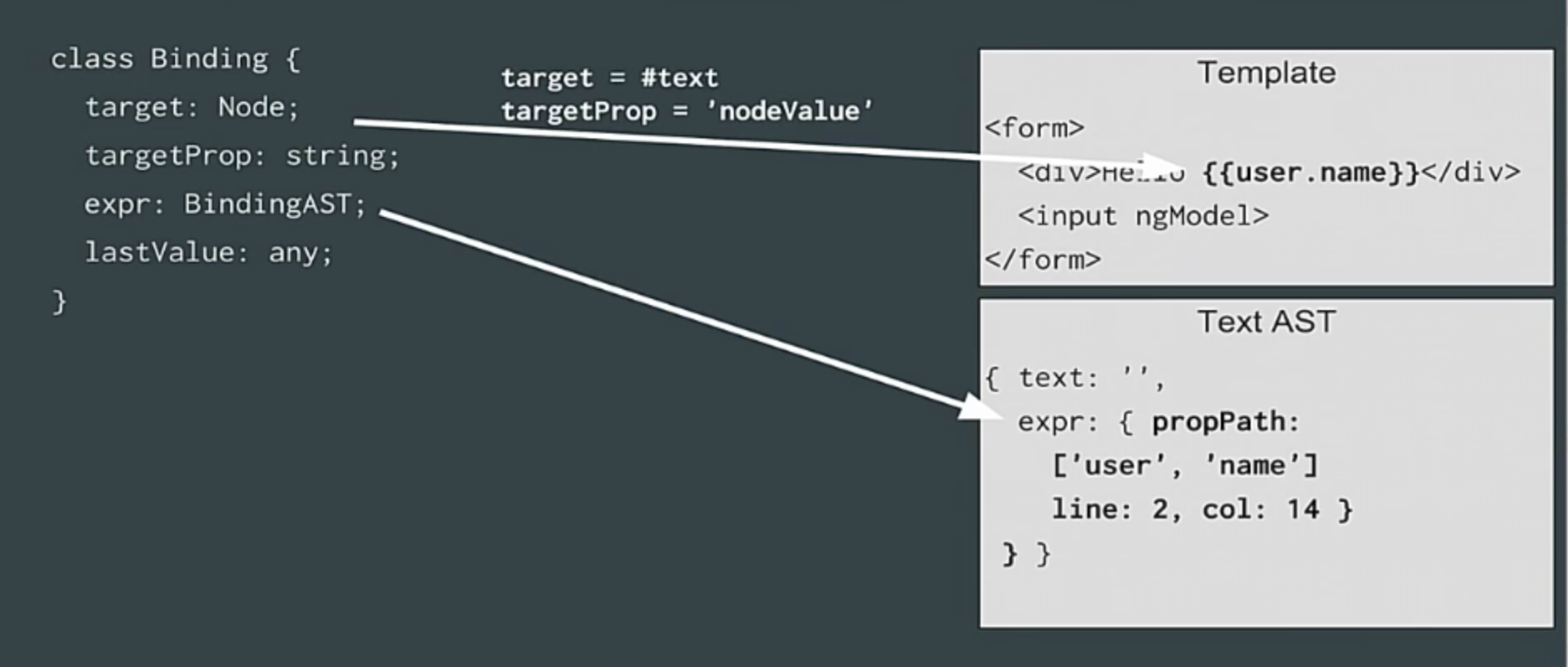

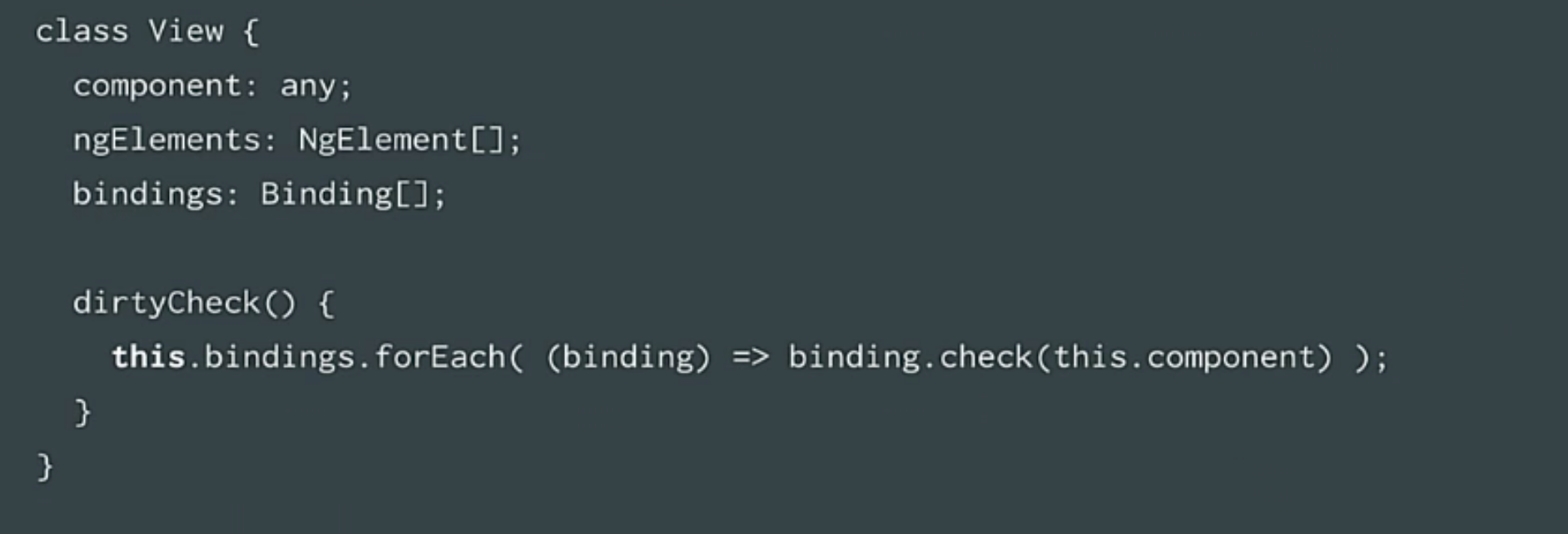


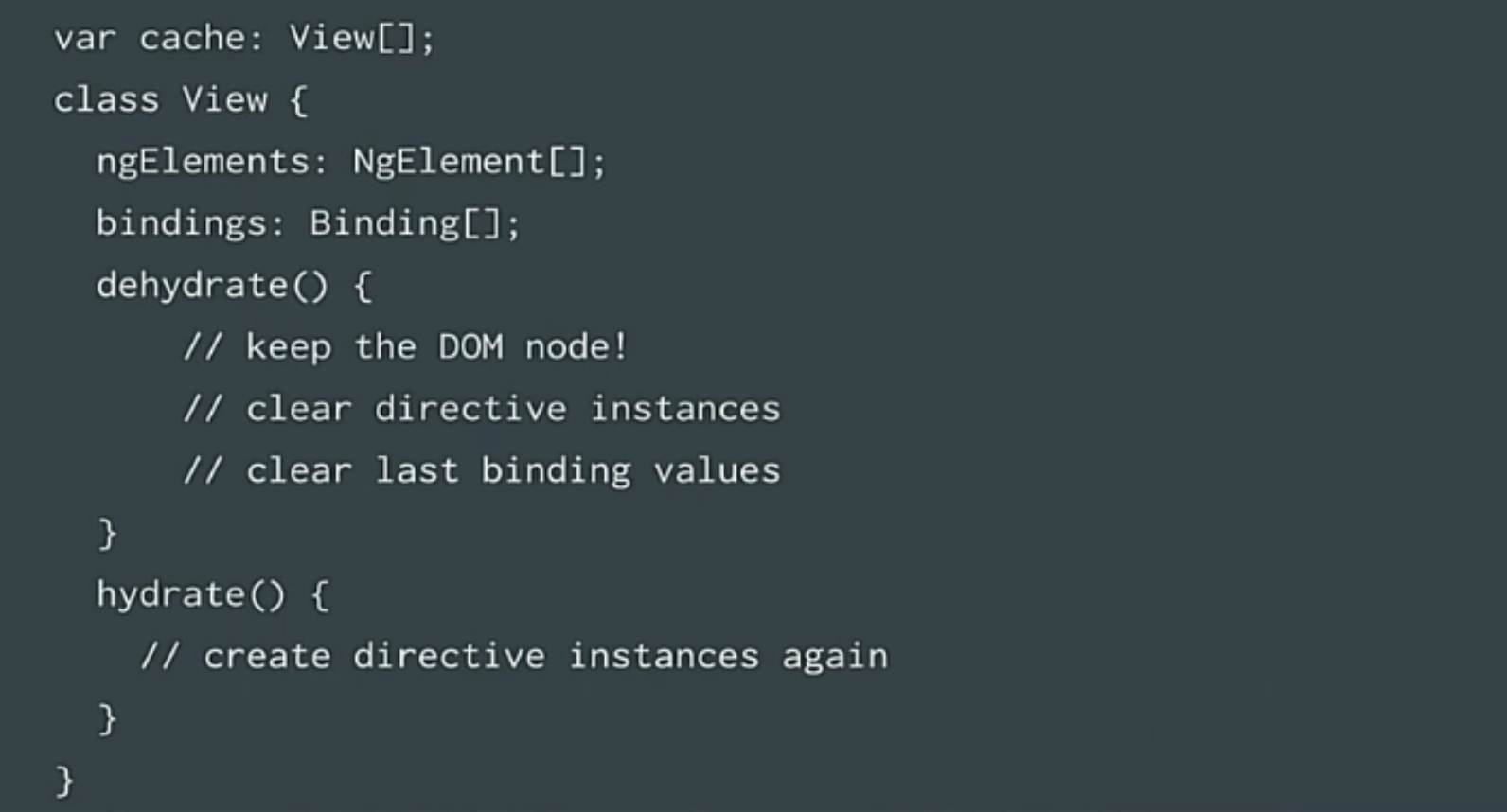
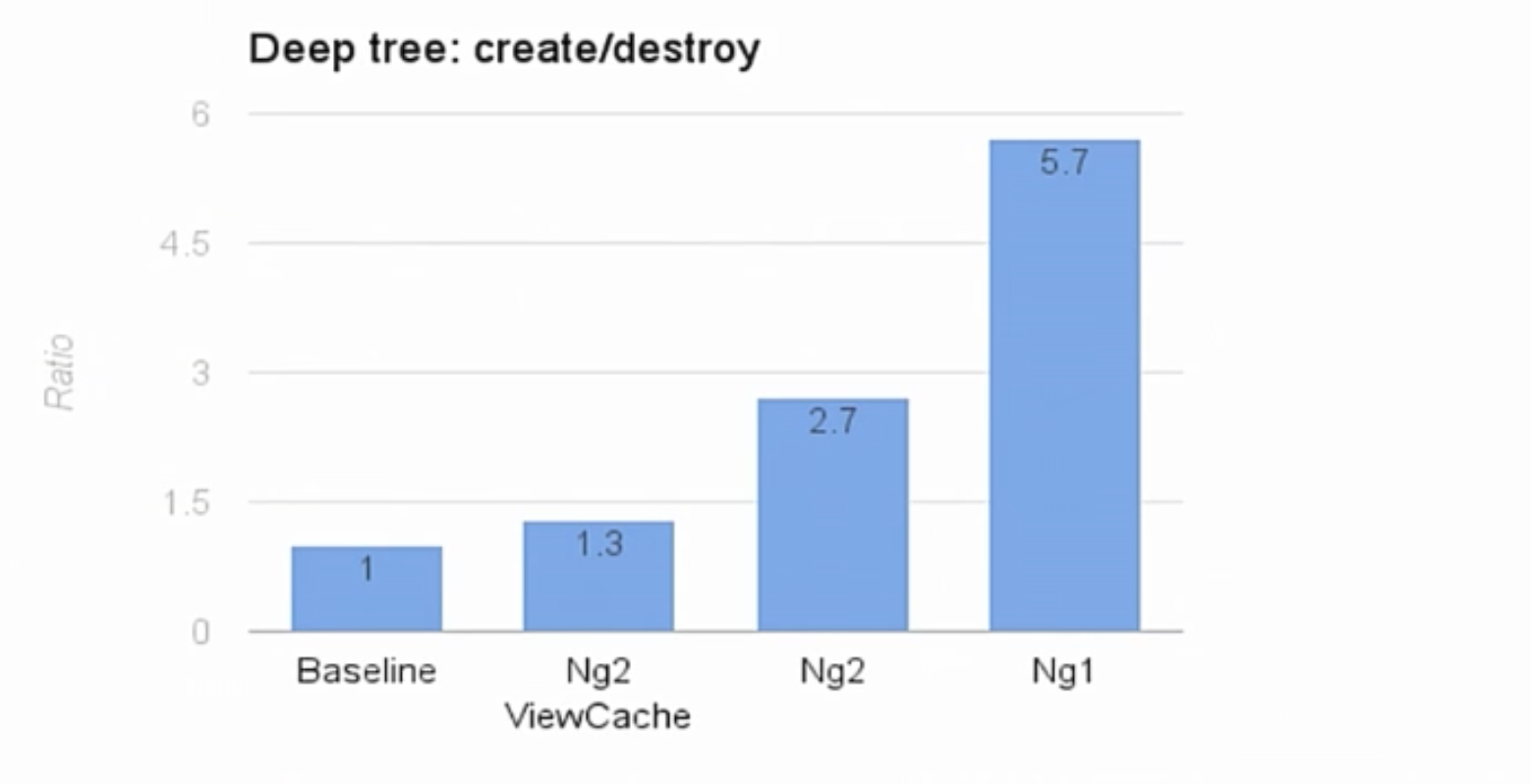
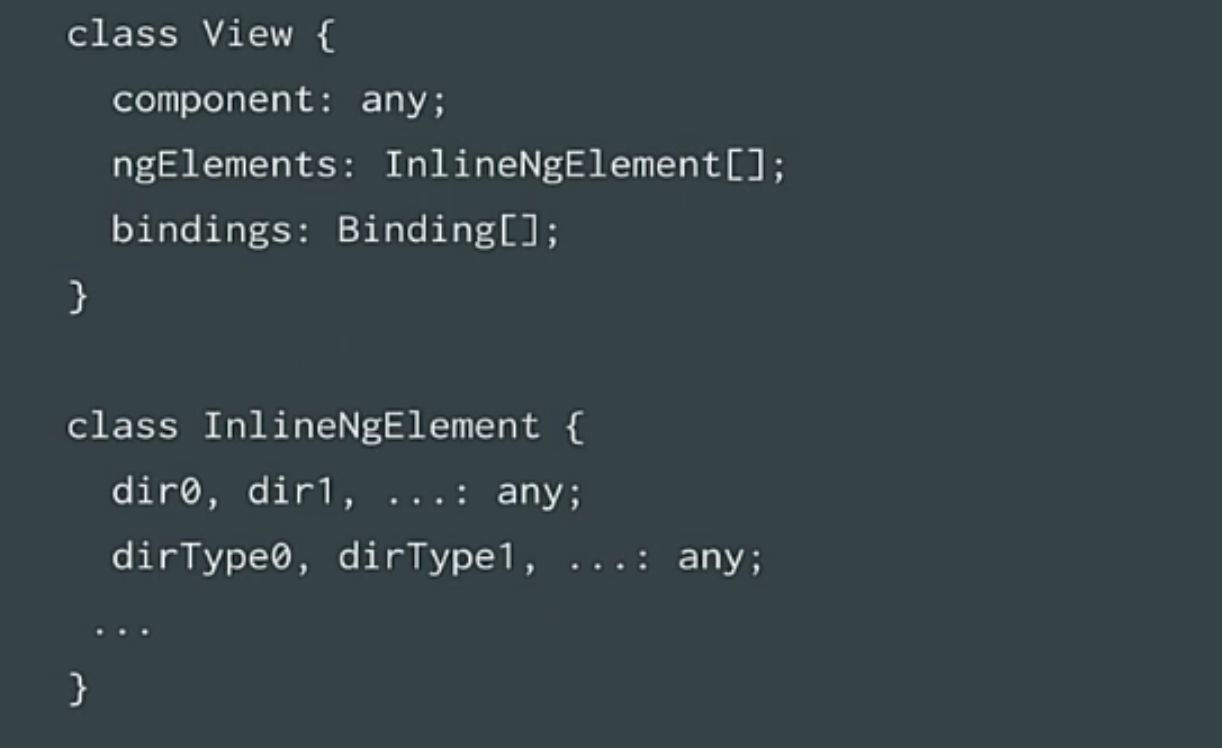
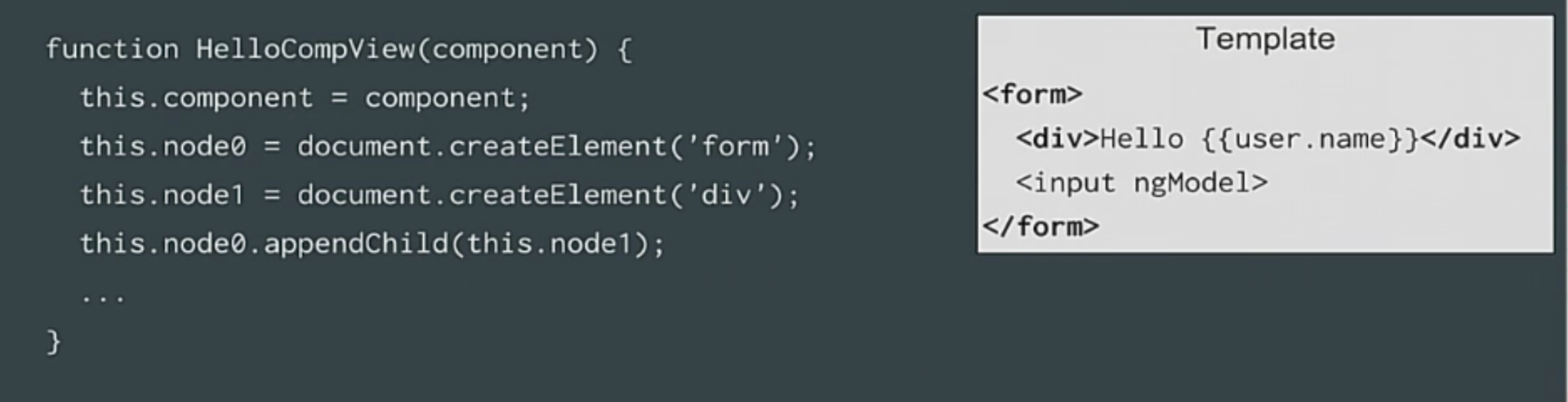
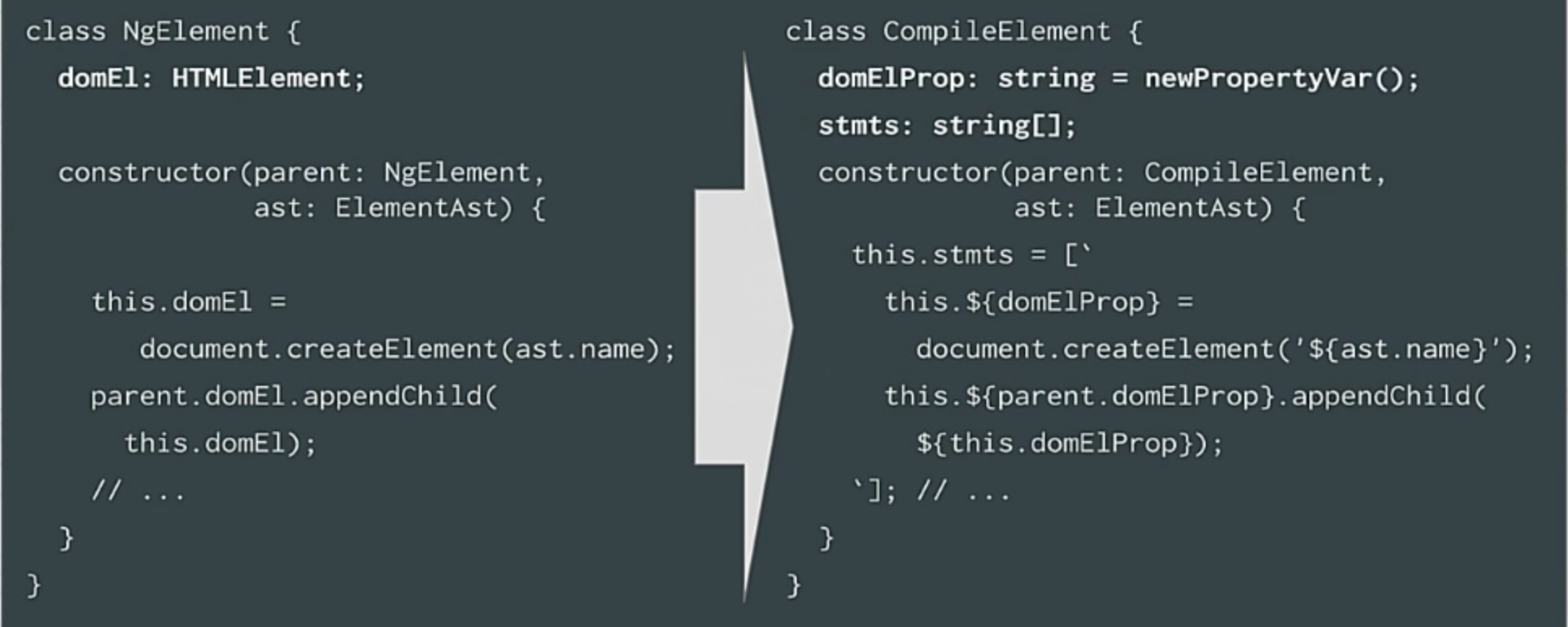
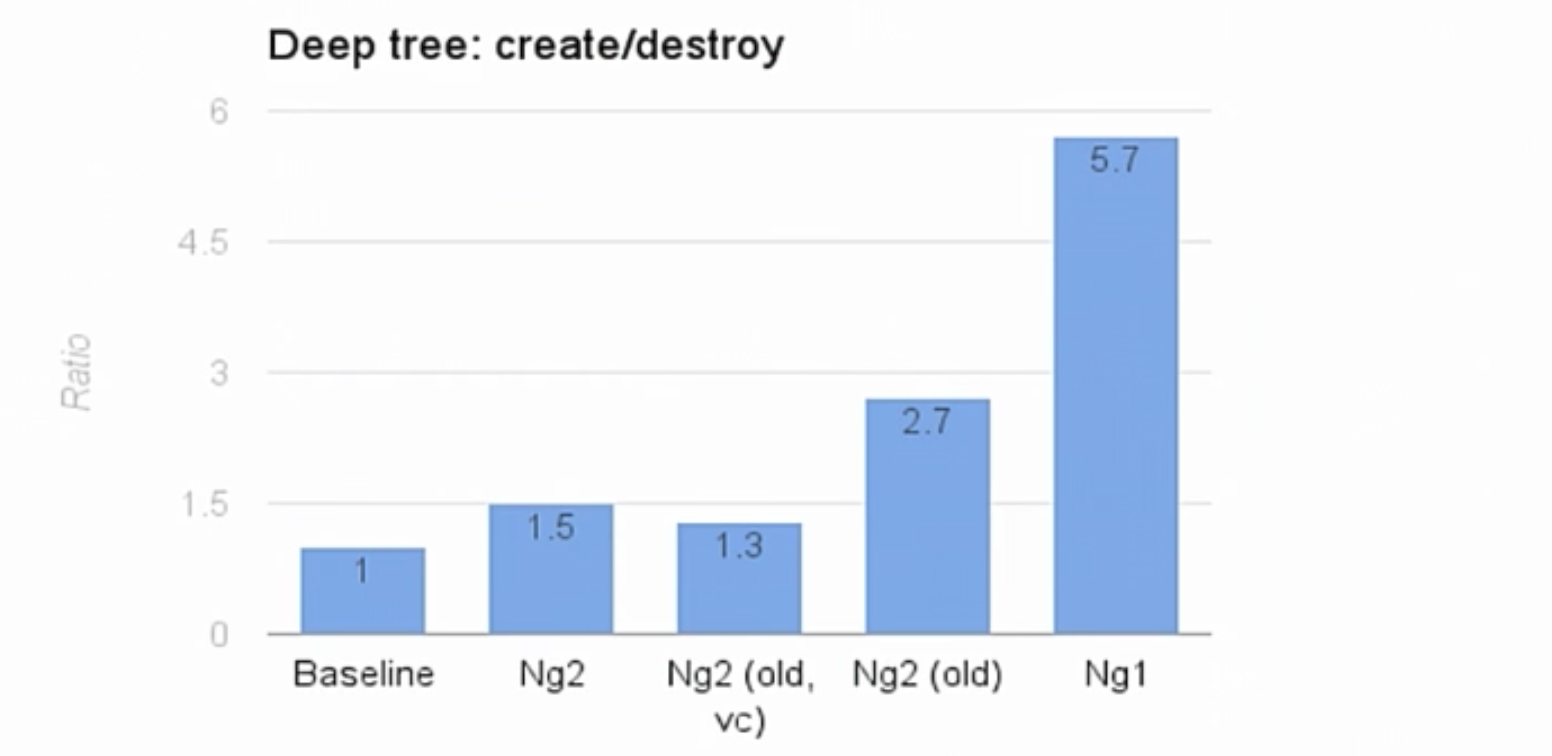
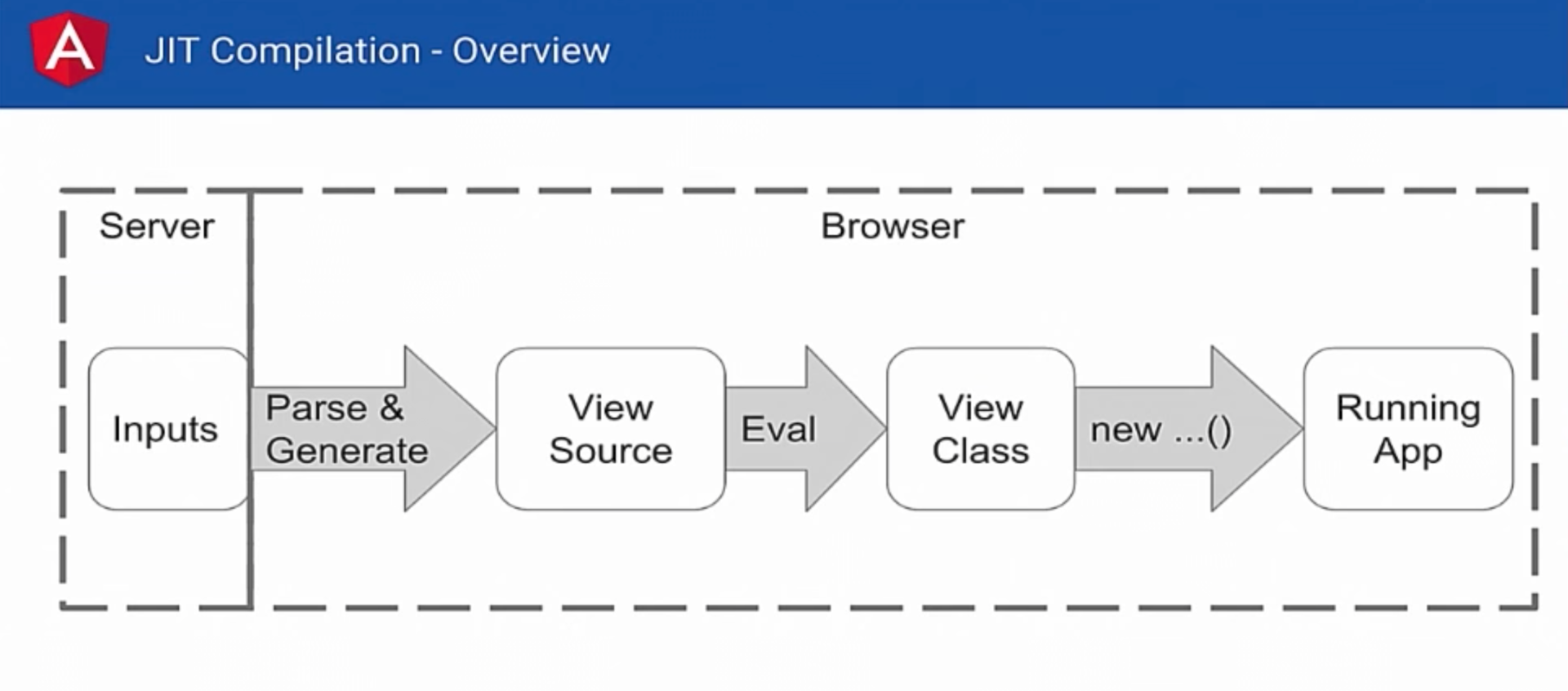

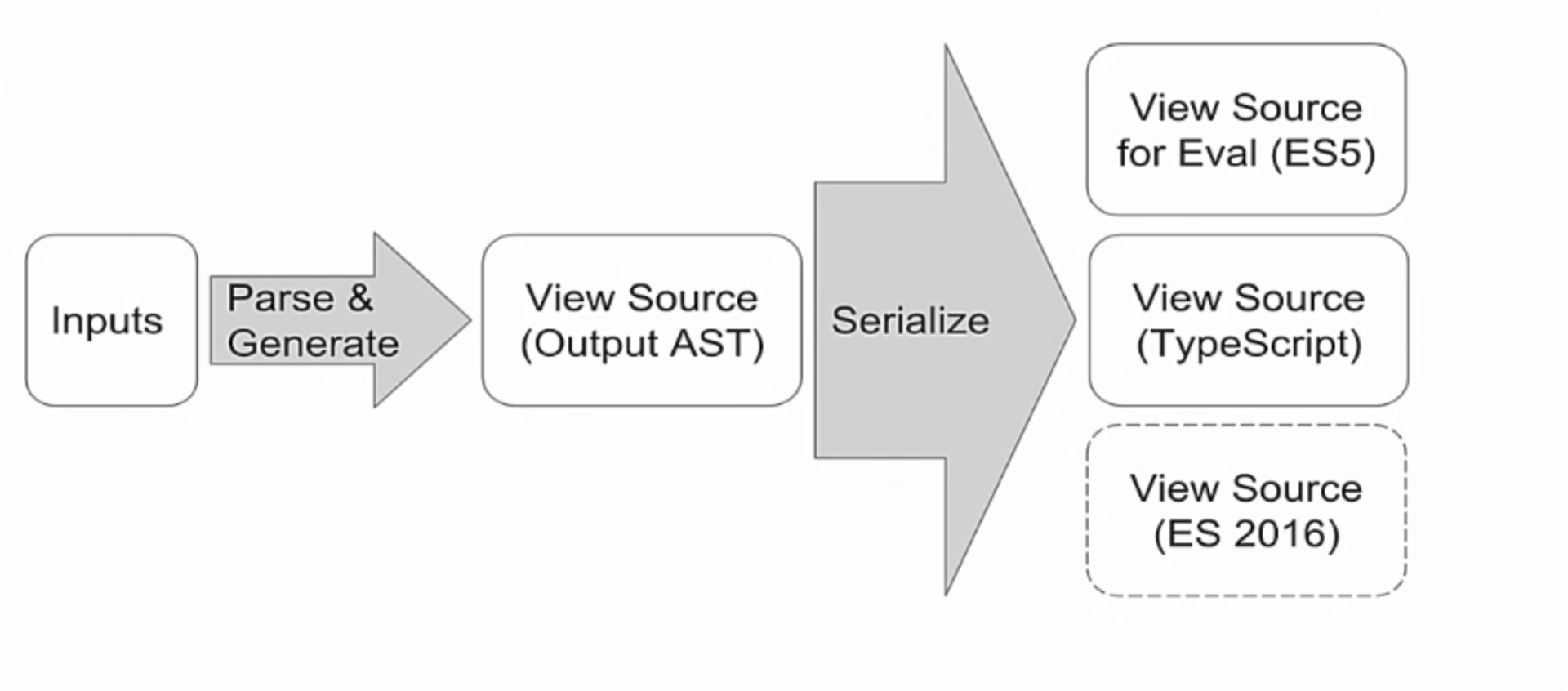

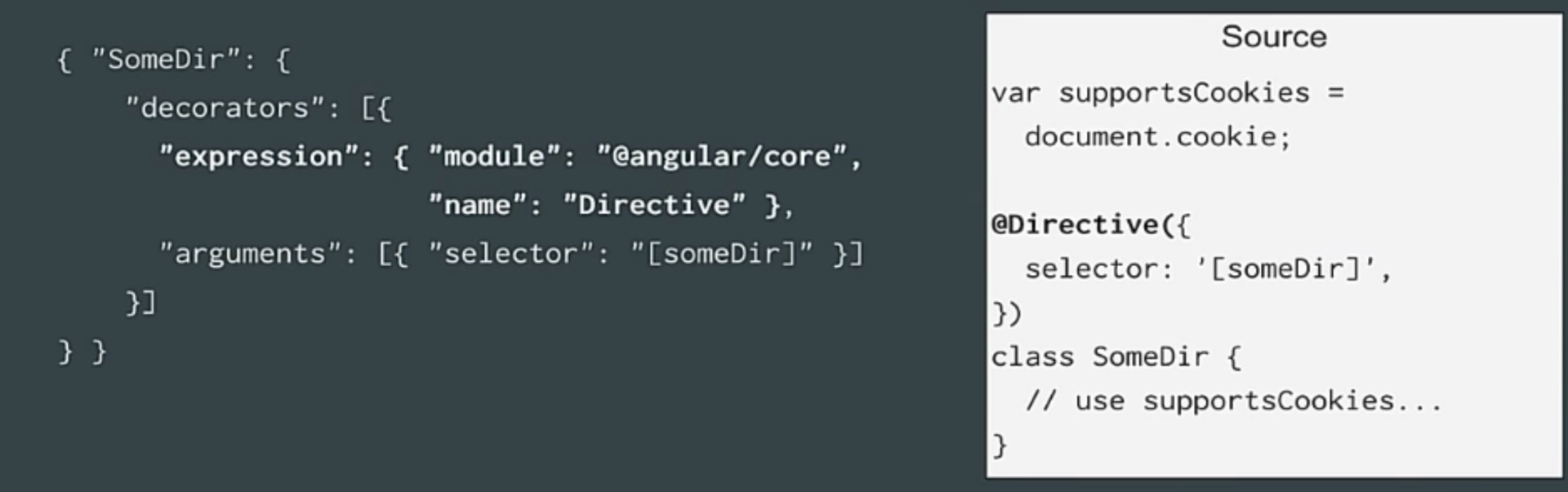
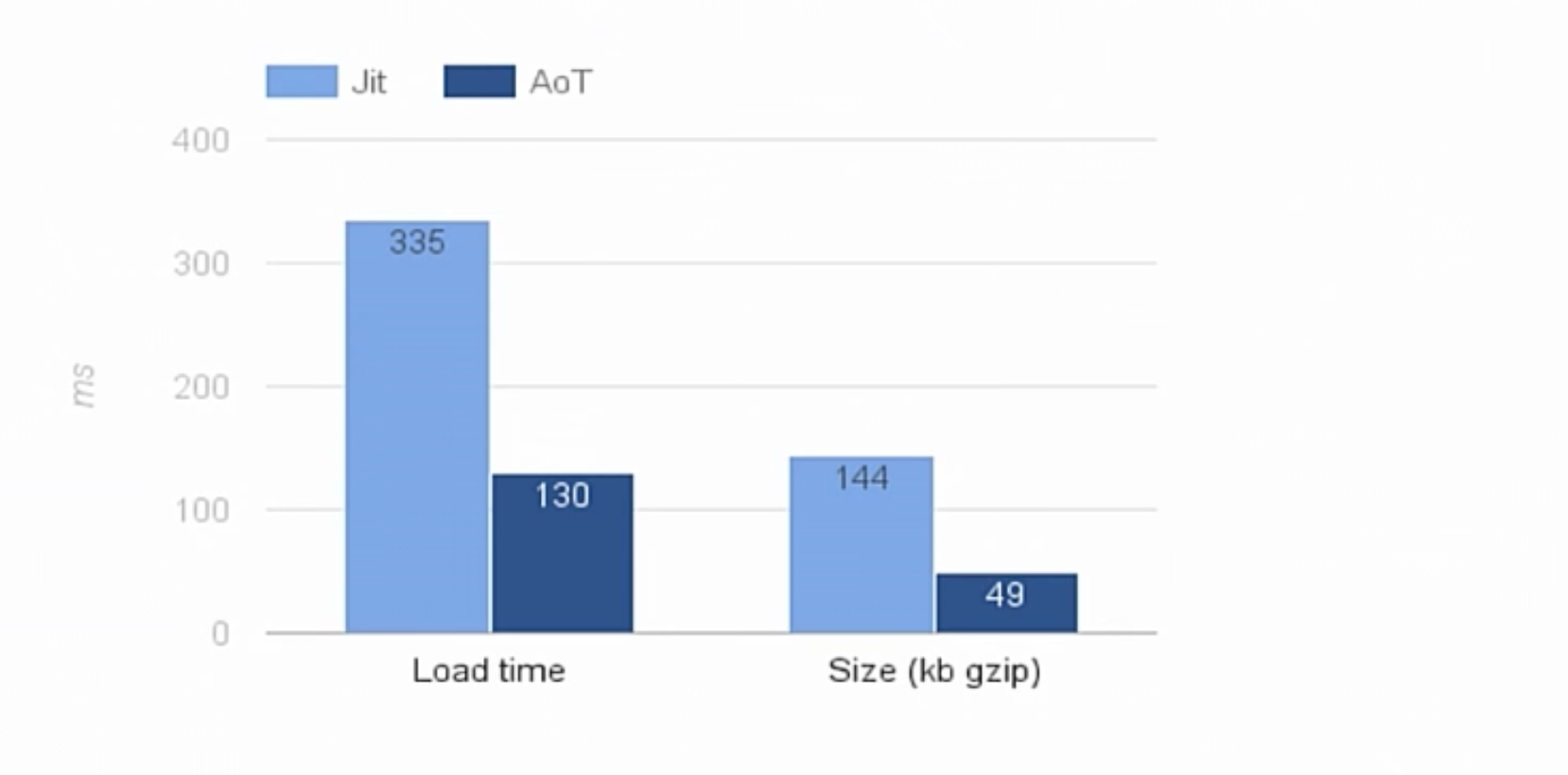
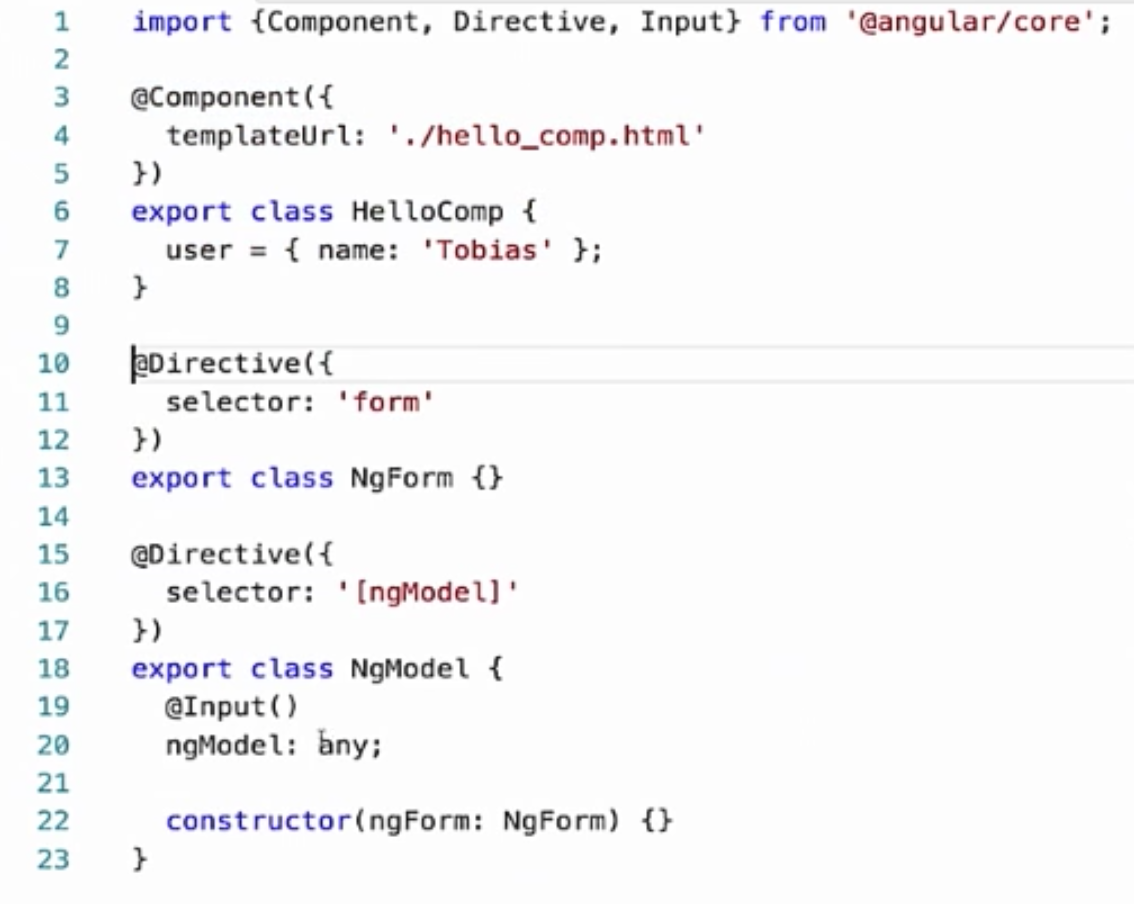

|
Метки: author zhartole javascript angularjs |






