[Из песочницы] Определение номера пользователя Telegram с помощью брутфорса в адресной книге |

|
Метки: author nusitocu информационная безопасность telegram |
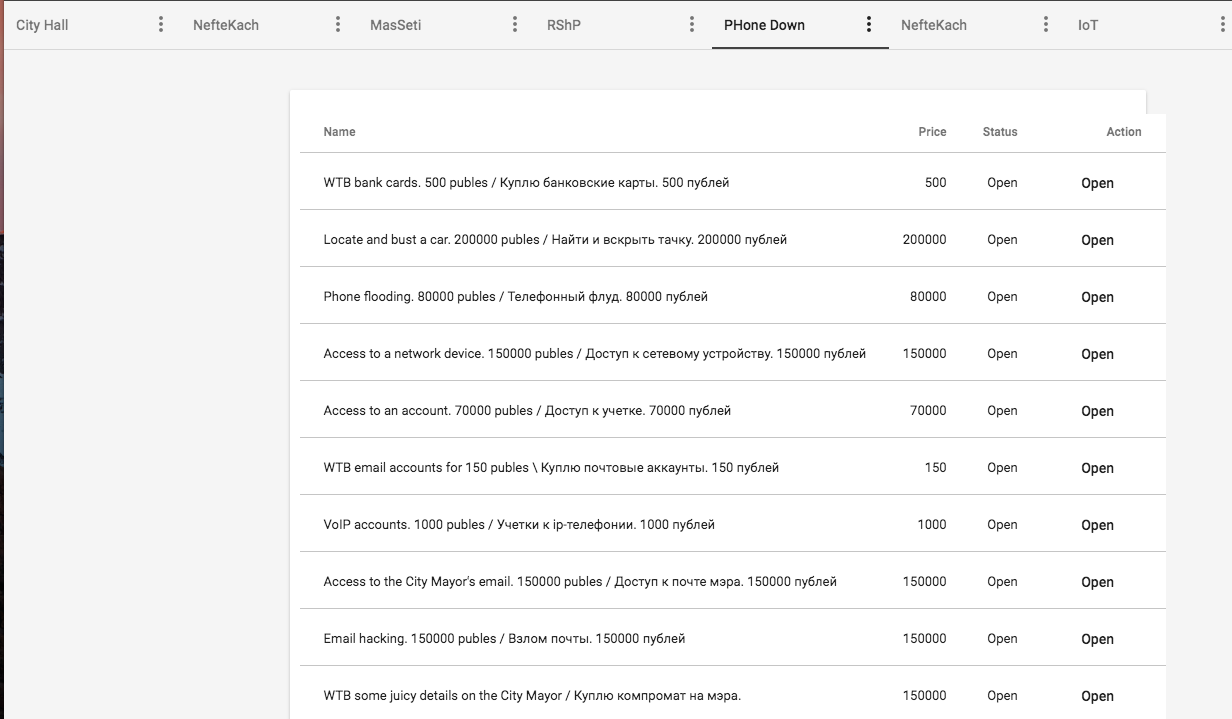
«Противостояние» PHDays VII: Новичкам везет или Грабим банки, ломаем GSM-ы |






|
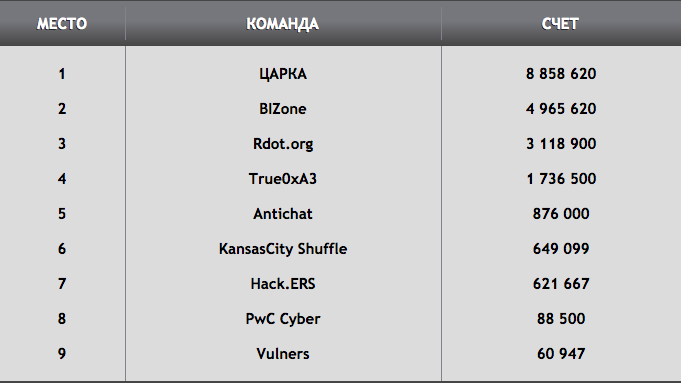
Метки: author NFM информационная безопасность царка phdays казахстан |
Машинное обучение — магия или наука? |


















|
Метки: author SAP машинное обучение блог компании sap sap нейронные сети |
Прав ли был Gartner, прогнозируя смену подхода к обеспечению ИБ? |


|
Метки: author PandaSecurityRus системное администрирование антивирусная защита блог компании panda security в россии информационная безопасность panda adaptive defense 360 защита информации |
Фишинг «своими руками». Опыт компании «Актив», часть вторая |

В первой статье я рассказал о теории вопроса, теперь же от теории перейдем к практике. Итак, мы успешно установили систему, настроили ее и готовы приступить к «фишингу» на собственных сотрудниках :)
План у нас достаточно простой.
На первом этапе мы рассылаем несколько разных писем по всем сотрудникам. Рассылки выбираем персонифицированные (спирфишинг). Ссылка в рассылке ведет через пустую страницу (которая нужна для анализа переходов) на оригинальную страницу сервиса. Первый этап посвящен по сути чистому эксперименту с целью определения всей глубины проблемы. После первого письма мы официально объявляем всем сотрудникам, что письма рассылали мы и направляем всех на страницу с обучением по борьбе с фишингом.
Через неделю проводим второй этап, похожий на первый (письма с новым содержанием), но ссылка в письмах уже напрямую ведет на нашу страницу обучения. Третий этап — контрольный. По итогам проводим сравнение и видим динамику переходов по ссылке и обращений в ИТ-отдел. С теми, кто продолжает «попадаться», проводим индивидуальную работу. План в целом был выполнен и признан успешным, но жизнь внесла в него коррективы.
В нашей компании, как и во многих, зарплата перечисляется на карты. Карты Сбербанка занимают лидирующие позиции. Почему бы не начать фишинг с проверки «Сбербанком», подумали мы, и сделали первый шаблон писем, который выглядел следующим образом (к слову, этот и все остальные шаблоны, мы не придумали сами, а нашли его в интернете). И вот наступил день «X», и сотрудники получи подобное письмо.

По ссылке мы сделали очень простую страницу:
Как видно из кода страницы, происходил редирект на настоящий сайт «Сбербанка». Нам был важен лишь сам факт перехода.
Сбербанк — это хорошо, но одного его для первой рассылки нам показалось недостаточно. Что же еще будет интересно сразу всем сотрудникам компании? Госуслуги. Они все больше и больше входят в нашу жизнь и множество людей ими пользуются, соответственно, это вполне достойный объект для рассылки. Побродив по просторам сити, подвернулся и интересный спам-шаблон:

Ссылка снова была пустая, страница во многом аналогичная сбербанковской, но ссылающаяся на другой ресурс.
Итак, мы запустили рассылку. Первый час-два была тишина: кто-то переходил по ссылке, кто-то не переходил. Затем в ИТ-отделе стали раздаваться звонки. Стоит пояснить, что сотрудники у нас в компании достаточно продвинутые. Рядовой менеджер у нас должен знать, что такое PKI и с чем его едят. Поэтому самое мягкое, что мы получали по телефону или в jira были сообщения вида «Какой-то странный спам к нам пришел. Подкрутите спам-фильтры». Ближе к обеду пришли на работу программисты, и они заинтересовались нашими письма. Довольно быстро был обнаружен наш сервер рассылки, и вот тут началась небольшая паника — нас что взломали? Пришлось провести небольшую разъяснительную работу с рядом руководителей и погасить панику, но сарафанное радио было уже не остановить. На этом этапе мы поняли, что допустили одну ошибку.
Не стоит использовать для размещения системы внутрисетевые ресурсы. Даже, если вы управляете днс, можно просто пропинговать ваш домен и понять, что он находится внутри сети. Арендуйте виртуальную машину во вне сети и настройте днс на него, или купите несколько доменов для полной чистоты эксперимента.
Начиная со второго этапа, мы уже исправились. Подобной проблемы у нас больше не возникало.
Отдельной истории заслуживает реакция бухгалтерии. Бухгалтерия принимает участие в выплате зарплаты сотрудникам, и получив наши «письма счастья от Сбербанка», не могла не отреагировать. Сделала она это бурно и прекрасно. Лучшей реакции при реальном «фишинге» нельзя и представить! Бухгалтерия сделала три вещи. Во-первых, позвонили в Сбербанка и уточнили подлинность писем. В Сбербанке объяснили, что это фишинг, не нужно ничего скачивать и переходить по ссылкам. Во-вторых, сотрудники бухгалтерии сообщили в ИТ -отдел об инциденте с спам-рассылкой. И самое ценное, бухгалтерия предупредила всех сотрудников компании об опасности полученных писем.
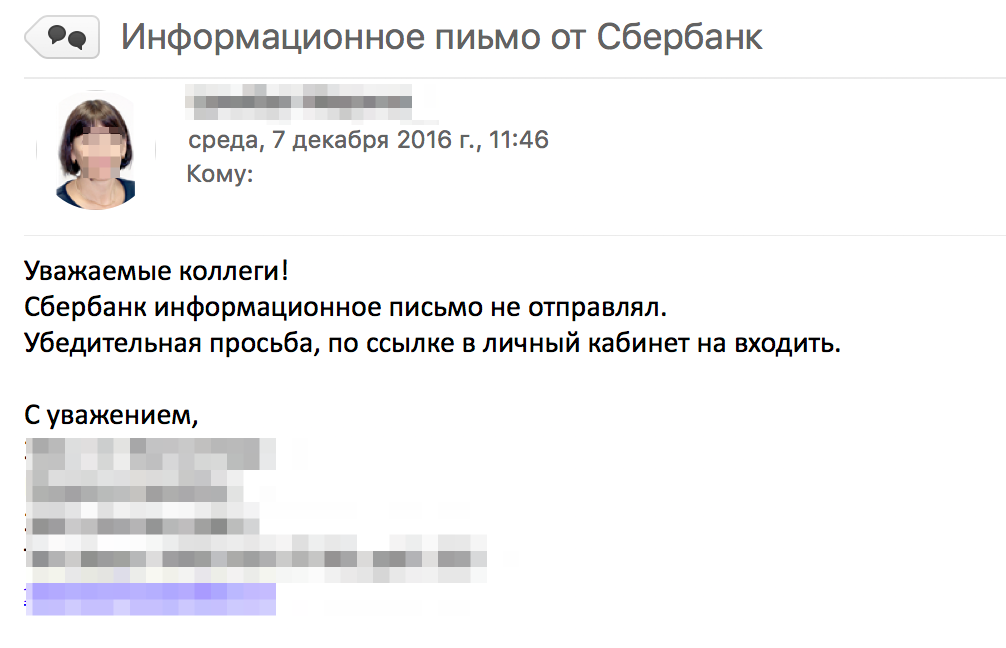
Еще раз напомню, что это была не постановочная, а реальная реакция сотрудников компании. Кроме руководства компании, о запланированных письмах никто не знал. На первом этапе нам важно было понять, как поведет себя компания в условиях фишинговый атаки. Проведя последующие разбор и анализ ситуации, мы поняли, что частично подобная бурная реакция была спровоцированная нашей второй ошибкой:
Не стоит производить рассылку всем и сразу. Подобные рассылки вызывают быстрый эффект сарафанного радио и на первом этапе могут исказить реальную проблему. Нужно разделить сотрудников по группам так, чтобы сотрудники с одной и той же рассылкой находились далеко друг от другу и не могли быстро обменяться подозрениями. Рассылки стоит квантовать и избегать массовой рассылки в одно время.
Сотрудники пользуются социальными сетями, и мы одновременно мониторили их реакцию на этих ресурсах.
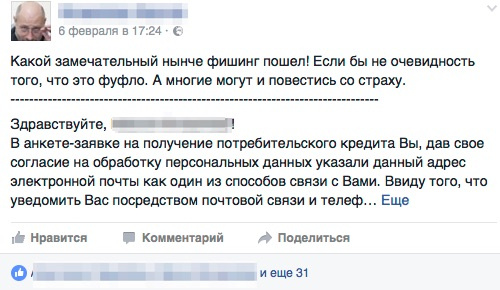
Посты вызывали интересные дискуссии (следует учесть, что «тусовка» наших сотрудников весьма «ибэшная»).

Обсуждались интересные теории получения базы почтовых адресов.

Для обучения сотрудников была создана специальная страница, где на простых примерах объяснялось, как можно понять, что письмо является фишингом. Приведу здесь небольшой пример из страницы, а уже в конце статьи в архиве приложу ее полный вариант.
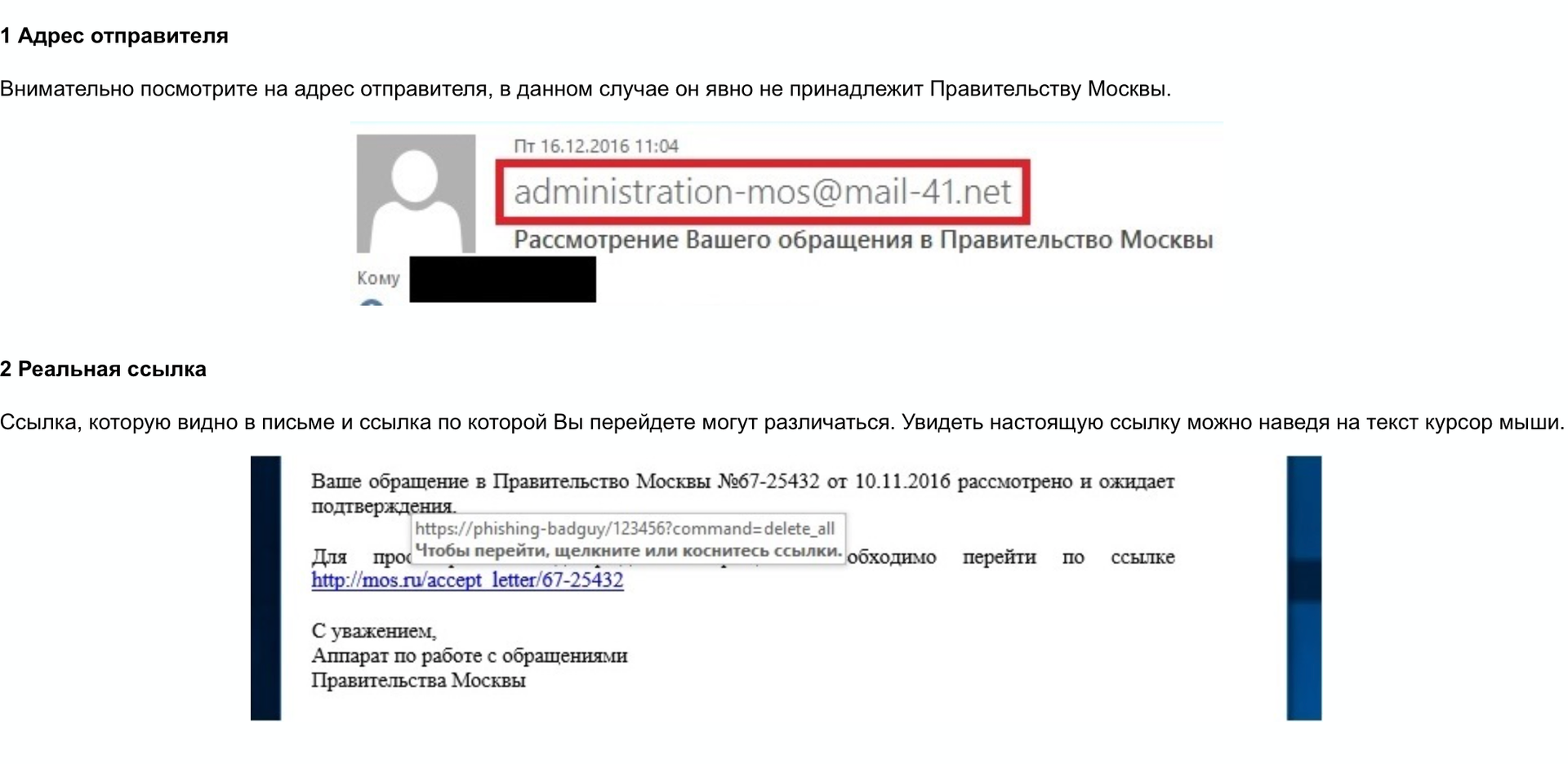
Второй этап происходил уже достаточно спокойно. Ни бурного обсуждения, ни конспиративных теорий не было. Те, кто переходили по ссылке, попадали на нашу страницу обучения и понимали, что это «ИТ-отдел снова запустил проверку». Интересней была реакция на контрольный этап проверки без страниц обучения. Ее можно охарактеризовать следующим тикетом:
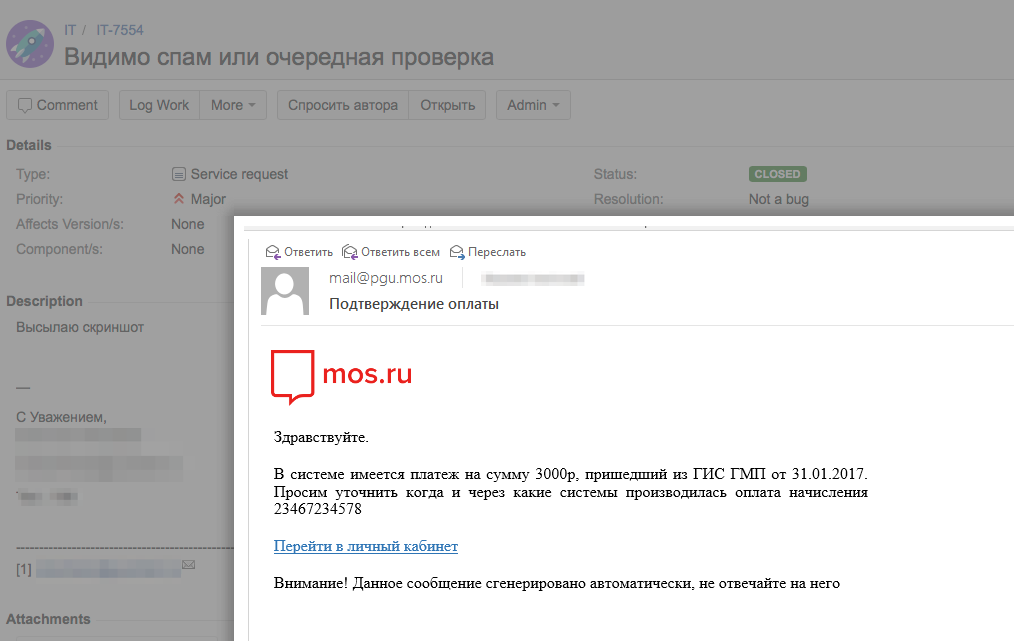
Все больше и больше сотрудников реагировали так, как нам было нужно.
Чего же нам в итоге удалось достичь:
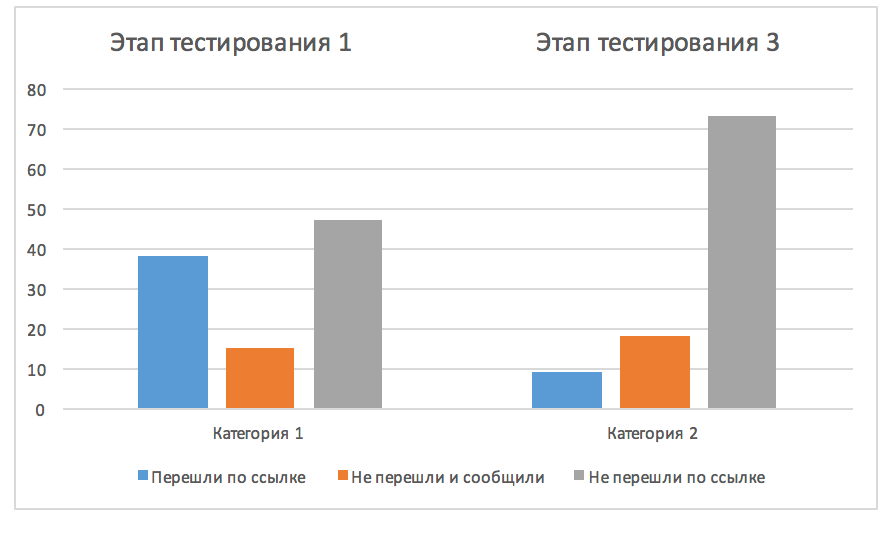
Самое важное – мы научили сотрудников не переходить по подозрительным ссылкам. С 39% на первом этапе нам удалось снизить число перешедших до 9%. Т.е. периметр возможной атаки был уменьшен в 4 раза. Увеличилось число людей, которые стали не просто игнорировать фишинговые письма, но стали сообщать о них. Стоит отдельно заметить, что система фиксирует конкретных лиц, и с оставшимися 9% уже вполне можно работать персонально, что мы успешно и делаем.
хочу привести еще несколько писем и приложить ссылки на архивы с образцами фишинг-писем и обучающую страницу.

Данное письмо имело определенный «успех» на контрольном этапе.
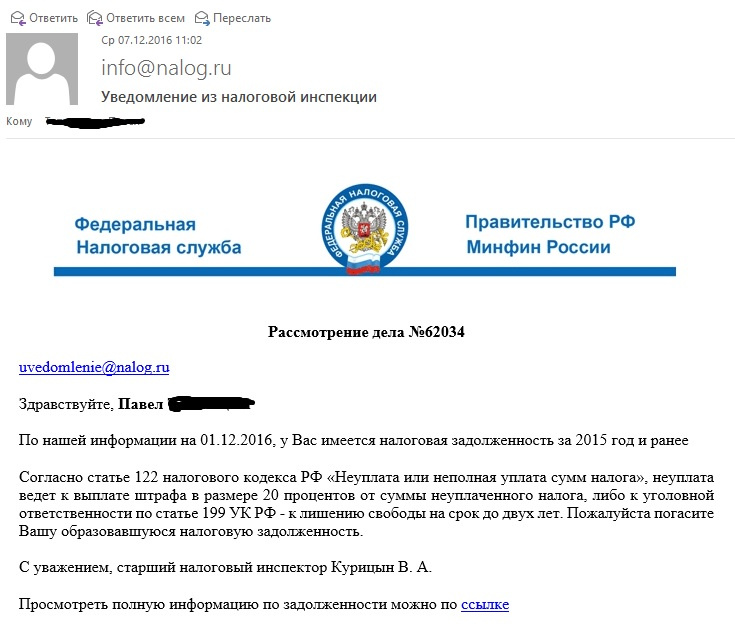
В сезон сдачи отчётностей письма из налоговой очень актуальны.
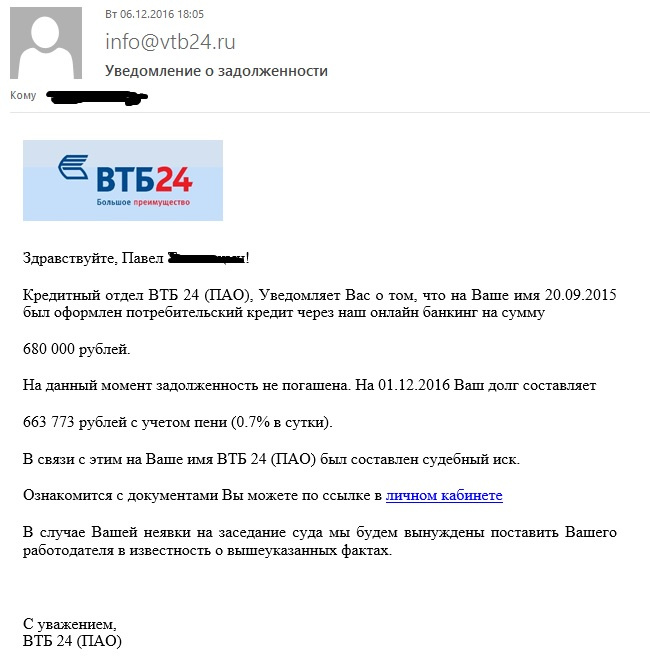
Банки в фишинге никогда не теряют актуальности.
Как и обещал, прикладываю два архива:
Занимайтесь обучением сотрудников компании. Устраивайте разнообразные проверки. Причем делайте это не разово, а организуйте проверки на регулярной основе. Одного раза людям может быть недостаточно. Если это не сделаете вы, это сделает злоумышленник и атака может быть успешной.
|
Метки: author shriek тестирование it-систем информационная безопасность open source блог компании «актив» спам фишинг социальная инженерия обучение |
Сколько технологий нужно Яндексу, чтобы поиск находил свежие документы почти моментально |
За последний год Яндекс добился значительного прогресса в качестве поиска для запросов, требующих наличия в выдаче актуальных документов. Теперь популярные документы в большинстве своём попадают в результаты поиска по релевантным запросам практически сразу после публикации.

Добиться этого непросто, ведь добавление только что созданных документов в поисковые выдачи, как правило, противоречит другим важным пользовательским метрикам: релевантности, авторитетности и т.д. Сегодня мы решили впервые рассказать о базовых технологиях, позволяющих с пользой подмешивать свежие документы в Поиск.
Интерес к любому событию в течение нескольких дней угасает практически до нуля, если, конечно, это событие не получает какого-либо дальнейшего развития. Мы проводили исследование, из которого и родилось это утверждение: оказывается, в среднем 73% пользователей интересуется событием непосредственно в день, когда оно произошло, и только 3% читателей приходит на ресурсы спустя трое суток и более после публикации. С момента проведения этого исследования прошло уже много лет, но в целом ситуация не изменилась. И даже статьи на habrahabr.ru получают наибольшее количество поисковых переходов в первые несколько суток своего существования.
Своевременно продемонстрированная свежесть – важная характеристика не только для веб-поиска. Свежесть нужна также и в поиске по картинкам и видео, поисковых подсказках; разумеется, в новостных агрегаторах и СМИ. Да что уж там: даже в кинотеатр мы в большинстве ситуаций идём на новый фильм, а не на давно вышедший!
Важность освежения поисковой выдачи для поисковой системы сложно переоценить. Для того, чтобы добиться хорошей свежести, нужно решить множество задач: построить контент-систему, которая находит и добавляет в индекс новые документы в реальном времени, научиться предсказывать, каким пользователям по каким запросам необходимо показывать свежие документы, определить лучшие из этих документов. Конечно, все эти задачи решаются с использованием методов машинного обучения.
Данная статья описывает некоторые из наших подходов к решению указанных проблем. А восьмого июня в нашем офисе состоится встреча Яндекс изнутри, на которой в том числе состоится и доклад про свежесть. Мы рассмотрим самую сложную из возникающих задач — задачу ускорения реакции на происходящие события. Записаться на мероприятие можно по этой ссылке.
В той или иной мере свежесть необходима в 10-20% запросов, которые пользователи задают в Яндекс.
Прежде всего, это «событийные» запросы. Когда в мире что-то происходит, пользователи приходят в Поиск, чтобы узнать подробности события. Разные события достаточно сильно отличаются друг от друга как с точки зрения пользовательского интереса, так и с точки зрения необходимой разработки.
Рассмотрим для примера график количества кликов на свежие документы во время проведения выборов в сентябре 2016 года:
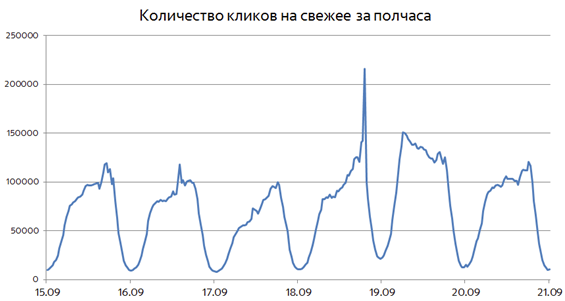
Хорошо видно, как в день выборов потребность в свежем постепенно нарастала, пока не достигла своего пика в 22:00. На следующий день повышенный интерес к свежему сохранялся, но уже через сутки вернулся примерно к обычным значениям. Другими словами, интерес к событию меняется с течением времени. Поэтому первая идея, полезная для определения потребности в свежем – «если какие-то запросы вдруг начинают задавать чаще, наверное, что-то произошло, и пользователям стоит показать свежие документы». Рассмотренная ситуация интересна и ещё по одной причине: интерес к свежему был прогнозируем заранее, т.к. дата выборов была известна задолго до их проведения.
Бывает так, что события сильно растянуты во времени. Примером такого события является Олимпиада 2016 года: в течение всех соревнований пользователи практически в два раза чаще потребляли свежие документы, чем это происходит в обычные дни:
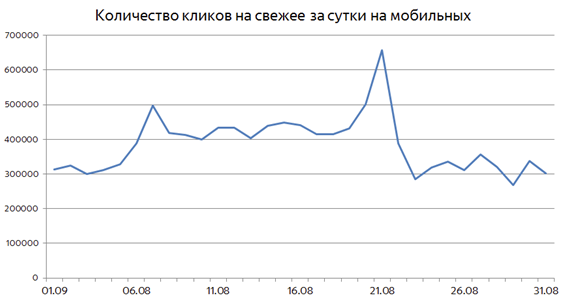
В таких ситуациях уже не получается детектировать интерес к свежести, исходя из резкого всплеска частотности запросов определённой тематики. Здесь на помощь может придти другой метод: если пользователям действительно нужна свежесть по каким-то запросам, возможно, она им понадобится и в ближайшем будущем.
Совсем иначе выглядит ситуация, когда происходит что-то неожиданное. Неожиданные резонансные события обычно не связаны ни с чем хорошим, поэтому просто посмотрим на графики без привязки к датам и конкретным происшествиям:
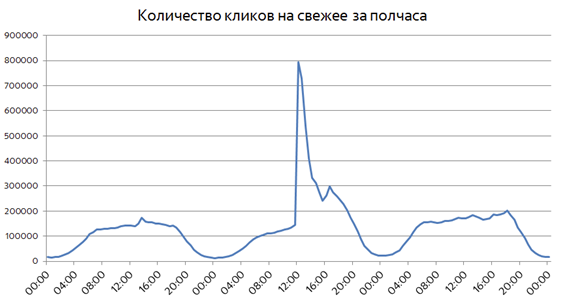
Уже в первые полчаса после произошедшего пользовательский интерес к свежему вырастает почти на порядок. Доля свежих запросов среди всех запросов в Поиск в такие моменты может увеличиваться до 25%. Неожиданные события хорошо детектируются резким всплеском пользовательского интереса, но такие всплески нужно определять в течение считанных минут после возникновения. Мы уже рассказывали о технологии Real Time MapReduce, которая позволяет Яндексу обрабатывать поисковые логи и доставлять результаты вычислений в Поиск в реальном времени.
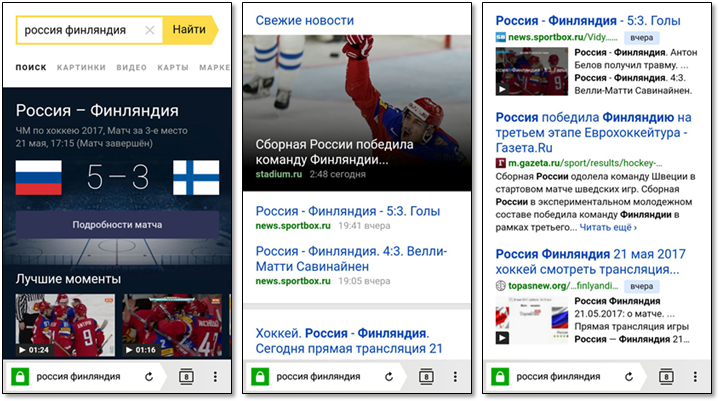
Сейчас мы поговорим о том, как свежие результаты представляются в поисковой выдаче. Рассмотрим запрос «россия финляндия», заданный 22 мая 2017 года. Этот запрос показателен, потому что при ответе на него Поиск демонстрирует практически все функциональные элементы, связанные с отработкой свежих запросов.
Поскольку спортивные запросы составляют значительную долю свежих запросов, мы специальным образом представляем информацию о спортивных матчах. Пользователь может узнать дату и время начала матча, счёт; иногда мы знаем ссылку на прямую трансляцию или видео интересных моментов.
Мы специальным образом группируем результаты из новостных источников, добиваясь большей аттрактивности.
Для остальных случаев мы ограничиваемся стандартными поисковыми сниппетами, к которым добавляем цветную плашки с возрастом документа. Иногда мы знаем, что документ содержит видео, и добавляем в сниппет его превью.
Свежие документы подмешиваются в выдачу по модели wide pFound. Эта модель в своё время была предложена для задачи разнообразия поисковой выдачи, вы можете посмотреть соответствующий доклад yafinder на YaC'2011, посвященный этому: https://events.yandex.ru/lib/talks/12/. Оказалось, что модель подходит для более широкого круга задач, в частности, для подмешивания свежих результатов.
В этой модели мы предполагаем, что пользователь, задавая конкретный поисковый запрос, имеет в виду один из интентов (интересов, тематик,...). Например, задавая запрос «ягуар», пользователь может иметь в виду автомобиль, напиток или животное. Запрос «котики» может предполагать потребность в соответствующих картинках, видео или же просто статьях. Запрос «евровидение» в определённые моменты наверняка требует самых актуальных (свежих!) новостей о ходе конкурса или подготовки к нему, в другие более вероятной потребностью представляется страница Википедии со списком победителей прошлых лет. Среди интентов нужно особо выделить специальный интент, который у нас обозначается – это интент «всё остальное», который соответствует обычной органической выдаче.
Задача поисковой системы заключается в том, чтобы подобрать для каждого пользователя и его запроса набор подходящих интентов, а затем правильным образом составить из релевантных этим интентам документов выдачу. В модели wide pFound мы считаем, что каждому из интентов соответствует некоторый вес, обозначающий вероятность пользовательского интереса именно к этому интенту, а для каждого документа на выдаче известен вектор его релевантностей для всех рассматриваемых интентов. Тогда для каждого интента можно расчитать метрику pFound – вероятность того, что наша выдача отвечает на запрос пользователя, если он имел в виду именно этот интент. Wide pFound – метрика, равная сумме взвешенных весами интентов pFound'ов по каждому из интентов:
где — вероятность найти релевантный документ в выдаче, если пользователь имел в виду -й интент.
Пусть, например, по некоторому запросу вес интента свежести равен 0.9, а релевантности документов соответствуют следующей таблице.
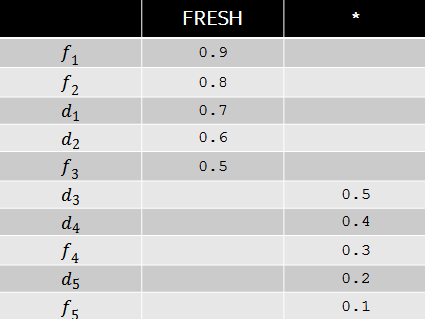
Тогда оптимальной с точки зрения wide pFound будет перестановка документов, изображенная в таблице ниже. Несмотря на то, что релевантности свежих документов в данном случае больше, с точки зрения разнообразия выгодно поставить на третью и четвертую позиции обычные документы, т.к. свежий интент уже в высокой степени удовлетворены первыми двумя результатами. Как мы видим, модель wide pFound представляет некоторый подход к формированию поисковой выдачи из разнородных источников, при этом задача сводится к определению весов интентов и релевантностей документов этим интентам.
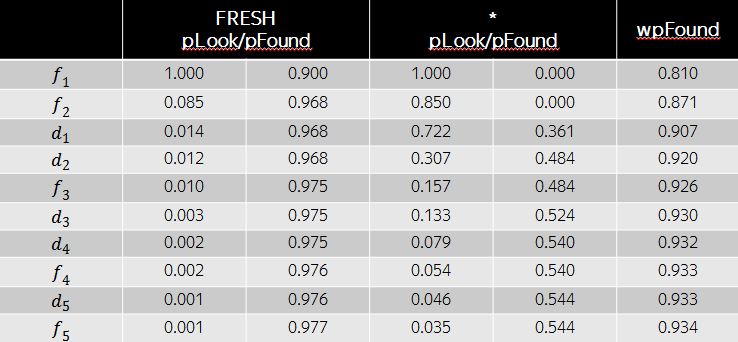
Исторически в Свежести мы называем задачу определения веса свежего интента задачей детекции свежего. Вторая задача – стандартная задача ранжирования документов, в нашем случае – свежих.
Множество документов, предназначенных для свежего ранжирования, меняется с каждой минутой: появляются новые документы, исчезают старые. Из-за этого возникают сложности с использованием оценок, полученных в прошлом, т.к. и факторы, и оценки документов меняются с течением времени. Например, в 12:00 новость о том, что где-то произошел пожар, может быть релевантной, а в 14:00 уже нет, поскольку пожар к этому времени уже локализован. Поэтому, чтобы оценить релевантность свежей выдачи в 14:00, не удастся обойтись оценкой лишь новых документов: придется пересмотреть релевантности абсолютно всех свежих документов на выдаче.
Из-за этого оказывается сложным иметь большой актуальный оценённый набор размеченных пар «запрос – документ» в свежем ранжировании. Прорыва в качестве свежего ранжирования удалось добиться, когда мы научились использовать для обучения дополнительные источники информации. Главный из них – это пользовательский сигнал, клики на поисковых выдачах.
В большинстве случаев свежие документы не показываются на первой позиции в выдаче, поэтому даже обучить простейший классификатор, предсказывающий кликабельность свежего документа на первой позиции, не так-то просто. Сравнивать между собой соседние свежие документы тоже не получается: между первым и вторым документами из свежести может распологаться произвольно большое количество документов из других источников. Поэтому многие подходы, используемые для обучения по кликам в традиционном ранжировании, совершенно не работают для свежести. Мы используем другие способы.

Представим себе выдачу, содержащую четыре обычных документа и три свежих, причем клики пришлись на первый свежий и последний обычный документы.
Можно предположить, что документ предпочтительнее, чем документы и , а вот сравнить и между собой уже достаточно сложно. Но, например, можно считать, что всё-таки лучше, т.к. текущая формула ранжирования предпочитает именно его.
Поэтому можно сформировать выборку несколькими различными способами:
Конечно, можно придумать и другие способы формирования обучающих выборок. Это творческий и очень увлекательный процесс.
Рассмотрим две схемы обучения детекции свежего по кликам, которыми мы пользовались в разное время. Каждая из этих схем решает задачу так называемых контекстных многоруких бандитов. Контекстом в данном случае являются факторы, вычисляемые по пользовательскому запросу. Среди относящихся к свежести имело бы смысл упомянуть несколько: «контрастность» запроса (например, отношение частоты запроса за последние сутки к его частоте за последнюю неделю), количество новостей, написанных за последнее время на эту тему, CTR свежести по запросу и так далее.
Кликовую информацию можно собирать несколькими способами. Например, можно использовать клики пользователей по всем свежим документам: если произошел клик по свежему, то необходимо подкрепить предсказание детектора, т.к. срабатывание было уместно. Это весьма привлекательный способ, но при практическом применении он сталкивается с рядом трудностей. Выборка оказывается сильно смещена в сторону срабатываний текущей формулы, а в некоторых случаях очень сложно понять, какой должна быть величина подкрепления. Скажем, если свежесть была показана низко, а кликов не было, то это может быть свидетельством как отсутствия интереса к свежему (и в этом случае необходимо уменьшать вес интента), так и слишком низкой позиции (и в этом случае вес интента необходимо увеличивать).
Можно использовать специальный эксперимент, в котором свежесть показывается на «случайных» позициях. Интент свежести – число от нуля до единицы, которое можно выбирать из небольшого набора — скажем, чисел, кратных 0.05. Тогда задача сводится к выбору одного из 21 различных значений. Это и есть задача о многоруких бандитах. Откликом на наш выбор будет некоторое поведение пользователя на выдаче – например, клик на какой-либо результат, а задача машинного обучения будет формулироваться в терминах выбора величины интента свежести, для которой вероятность этого отлика максимальна. Этот способ дает очень хорошие результаты, но у него есть один значительный недостаток: сама процедура сбора кликового сигнала очень сильно ухудшает выдачу для пользователей, т.к. большинство показов свежего оказываются нерелевантны.
Если же уже имеется некоторая формула детекции свежести – подобранная по асессорским оценкам или же методом, описанным выше, — то ее значение можно изменять на небольшую случайную величину, а затем предсказывать оптимальное значение изменения её предсказания так же, как это делалось выше. Если говорить точнее, то положим, что на текущем запросе формула предсказывает вес интента . Прибавим к этому весу небольшую случайную добавку: , где – величина из небольшого дискретного множества значений. Например, . Тогда можно обучить формулу , которая будет предсказывать оптимальную величину добавки, а в качестве новой формулы использовать сумму двух: .
Этот способ позволяет модифицировать значения текущих формул детекции свежести и постоянно вносить в них улучшения. Он практически не портит выдачу для пользователей, но позволяет за несколько шагов вносить существенные изменения в предсказания наших формул.
Наконец, хотелось бы на примере нескольких событий рассказать о показателях, при помощи которых мы понимаем, что Свежесть работает хорошо.
Начать хотелось бы с графика общей актуальности результатов поиска. Этот график строится компанией "Ашманов и партнёры", так что можно не сомневаться в его объективности:
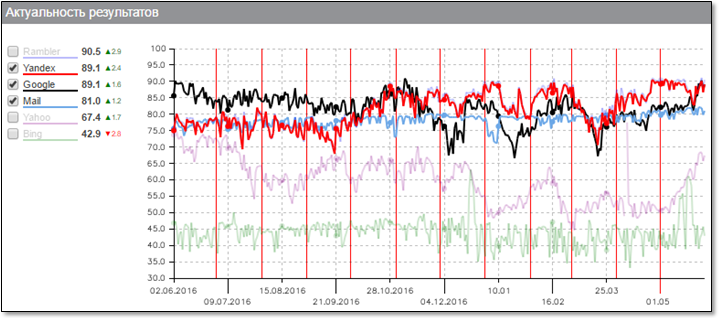
Здесь хорошо виден прогресс Яндекса (красная линия) в скорости индексации документов, который был достигнут в течение последнего года. Наш робот действительно способен за считанные минуты узнать о появлении нового документа и доставить его до поискового индекса Свежести с тем, чтобы он был показан пользователям по релевантным запросам.
Рассмотрим для примера новость о квалификации сборной Бразилии на ЧМ-2018. Документ появился на сайте издательства в 10:56, и уже в 10:58 мы впервые показали его на выдаче пользователю, а вплоть до 11:00 он был показан еще порядка двадцати раз по релевантным запросам. По этой схеме можно построить и общую метрику, а не только изучать конкретные документы. Возьмём, например, все достаточно популярные документы (которые показывались на выдачах хотя бы 1000 раз в день) и посмотрим на медианное время между их публикацией и первым показом на выдаче.
Если нарисовать этот график за последний год, можно увидеть, что эта величина уменьшилась с четырёх минут до примерно двух. Это и означает, что свежие документы сейчас становятся доступными для пользователей практически моментально.
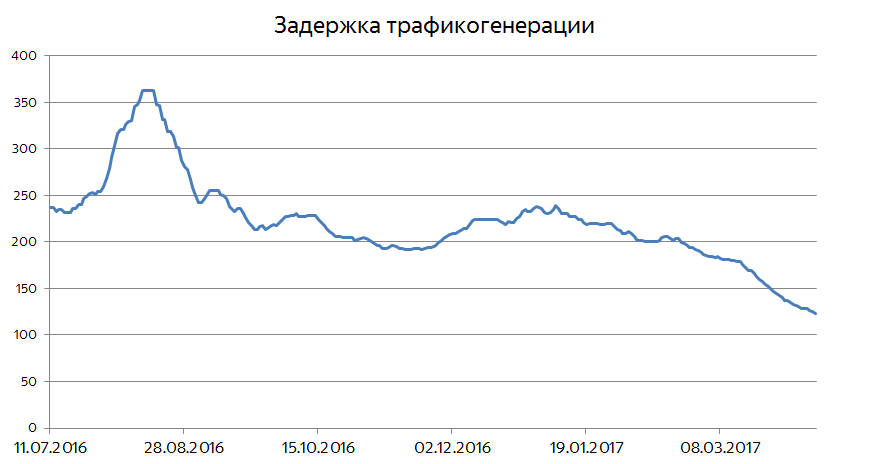
Когда происходит какое-нибудь достаточно крупное событие, важно сразу начать отвечать пользователям на соответствующие запросы максимально актуальными документами. Иногда это видно на глобальных графиках возраста свежих документов на выдачах. Мы постоянно следим за тем, какая доля показанных документов имеет возраст меньше 10 минут, получаса, часа, двух часов и так далее. За счет того, что интерес к событиям всё-таки растянут во времени, доля такого рода документов редко превышает 50%. Но бывают случаи, когда графики ведут себя так:
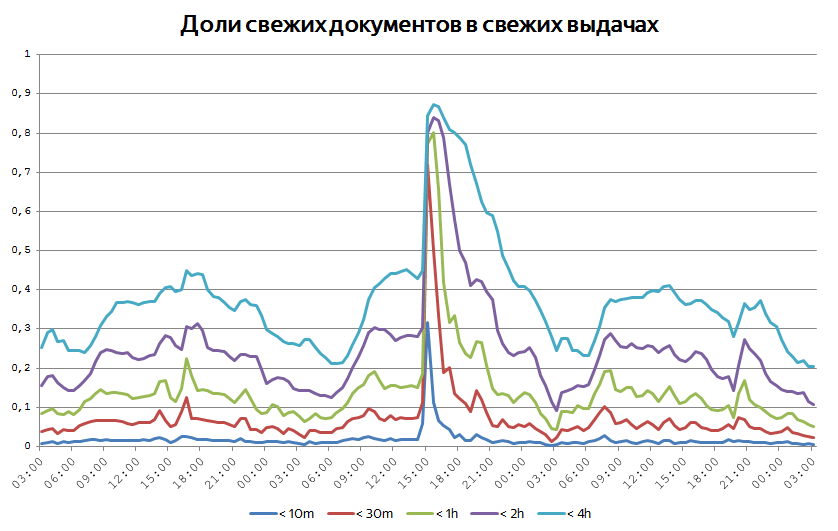
Когда в мире происходит какое-то значительное событие, оно порождает всплеск публикаций и поисковой активности, и тогда чрезвычайно свежие документы начинают превалировать.
Мы рассмотрели некоторые аспекты формирования поисковой выдачи в ситуациях, когда пользователю необходима максимально актуальная информация по запросу. Конечно, за рамками нашего рассмотрения осталось большое количество вопросов, таких, например, как качество быстрого обхода и робота, антиспам, авторитетность, дизайн и так далее. Мы обсудили лишь свежесть в веб-поиске и оставили за рамками рассмотрения другие сервисы, также испытывающие потребность в свежем: картинки, видео, поисковые подсказки, голосовой поиск и так далее. Часть из этих тем будет затронута на уже анонсированной встрече "Яндекс изнутри", а другие, я надеюсь, мы обсудим в будущих статьях.
Stay tuned!
|
Метки: author ashagraev поисковые технологии машинное обучение блог компании яндекс яндекс поиск свежесть выдачи |
Жизнь: перезагрузка. Репортаж с отборов в Университет Иннополис |
|
Метки: author megapost учебный процесс в it иннополис университет иннополис |
«Готовимся к переходу на Angular 4»: Tinkoff.ru о JS-разработке |
 — Вводный вопрос: над чем вы работаете в компании?
— Вводный вопрос: над чем вы работаете в компании? — Tinkoff.ru очень нетипичный банк — а как эта необычность сказывается на JS-разработке, в чём оказывается ваша специфика?
— Tinkoff.ru очень нетипичный банк — а как эта необычность сказывается на JS-разработке, в чём оказывается ваша специфика?|
Метки: author phillennium javascript блог компании jug.ru group tinkoff.ru holyjs angular angularjs rxjs redux flux |
Стартапы и ненормальное программирование. TBD |
|
Метки: author ARG89 open source javascript блог компании jug.ru group стартап разработка фриланс |
[Перевод] Как поменьше беспокоиться о собственной бездарности |

|
|
Исчезающая граница между корпоративными и личными учетными записями |

|
Метки: author GemaltoRussia блог компании gemalto russia безопасность аутентификация учетные записи |
ONTAP 9.2: новый функционал |
|
Метки: author bbk системное администрирование san ontap 9 ontap ontap select netapp fas fas aff netapp aff metrocluster |
Наука о нейронных сетях. Прямой эфир |

- Современный браузер (Microsoft Edge, Internet Explorer, Safari).
- Средство подключения к удаленному рабочему столу Windows (Remote Desktop), способное подключаться к виртуальным машинам в Microsoft Azure (для Mac OS).
- Основная часть интенсива будет проходить в браузере с использованием Azure Notebooks или в удаленной виртуальной машине в облаке Microsoft Azure.
- Чтобы избежать проблем, попробуйте заранее открыть какие-нибудь из Azure Notebooks отсюда.
- Также понадобится Microsoft Account – если у вас его нет, создайте себе новый почтовый ящик на Outlook.com.
- Мы также рекомендуем заранее создать новый почтовый ящик для экспериментов, если у вас нет подписки Microsoft Azure, и вы планируете использовать триальную подписку, которую мы предоставим на мероприятии.
- Дмитрий Сошников, Эксперт по стратегическим технологиям, Microsoft
- Михаил Бурцев, Заведующий лабораторией нейронных систем, МФТИ
- Михаил Козлов, Руководитель отдела разработки, ГК ПИК
- Андрей Устюжанин, Заведующий лабораторией факультета компьютерных наук, НИУ ВШЭ
10:00 — 11:00 Открытие мероприятия, пленарный доклад
11:00 — 11:30 Перерыв
11:30 — 13:00 Практическое введение в нейронные сети и глубокое обучение. Часть 1
13:30 — 14:30 Перерыв
14:30 — 16:30 Практическое введение в нейронные сети и глубокое обучение. Часть 2
16:30 — 17:00 Перерыв
17:00 — 19:00 Практическое введение в нейронные сети и глубокое обучение. Часть 3
19:00 — 19:30 Закрытие мероприятия
|
Метки: author Schvepsss машинное обучение big data блог компании microsoft microsoft нейронные сети глубокое обучение azure notebooks cntk |
Самые интересные доклады с конференции Analyst Days 2017 |
 В апреле наши коллеги побывали на международной конференции по системному и бизнес-анализу Analyst Days 2017, проходившей в Москве. Под катом — впечатления от самых интересных, на наш взгляд, докладов этой конференции.
В апреле наши коллеги побывали на международной конференции по системному и бизнес-анализу Analyst Days 2017, проходившей в Москве. Под катом — впечатления от самых интересных, на наш взгляд, докладов этой конференции.








|
Метки: author NIX_Solutions тестирование веб-сервисов тестирование it-систем анализ и проектирование систем блог компании nix solutions analyst days |
[Перевод] GitHub переходит на GraphQL |

22 мая компания GitHub объявила, что следующая версия их API будет использовать разработанную Facebook технологию под названием GraphQL.
В итоге GraphQL может прийти на смену самому популярному на сегодняшний день типу API — REST API.
В документации к новой версии API GitHub говорится:
«В 4 версии API GitHub движется к GraphQL, поскольку эта технология обеспечивает гораздо большую гибкость для интеграторов. Возможность точно определить необходимые вам данные (и только те, которые необходимы) — это большое преимущество по сравнению с REST API v3».
«GraphQL позволяет переосмыслить создание и использование API. Вместо выполнения нескольких REST-запросов для получения интересующих данных вы в большинстве случаев можете сделать лишь один вызов».
О GraphQL мы уже написали достаточно много и планируем создать несколько уроков, посвященных этой технологии.
Что почитать о GraphQL:
Ссылки:
|
Метки: author olemskoi разработка веб-сайтов github api блог компании southbridge graphql rest facebook |
[recovery mode] Психология тестирования (конечно же, не исчерпывающая). Личный перевод из книги «Искусство тестирования» Г. Майерса |
|
Метки: author RockMachine тестирование it-систем тестирование психология терминология дефиниция метафизика трансценденция |
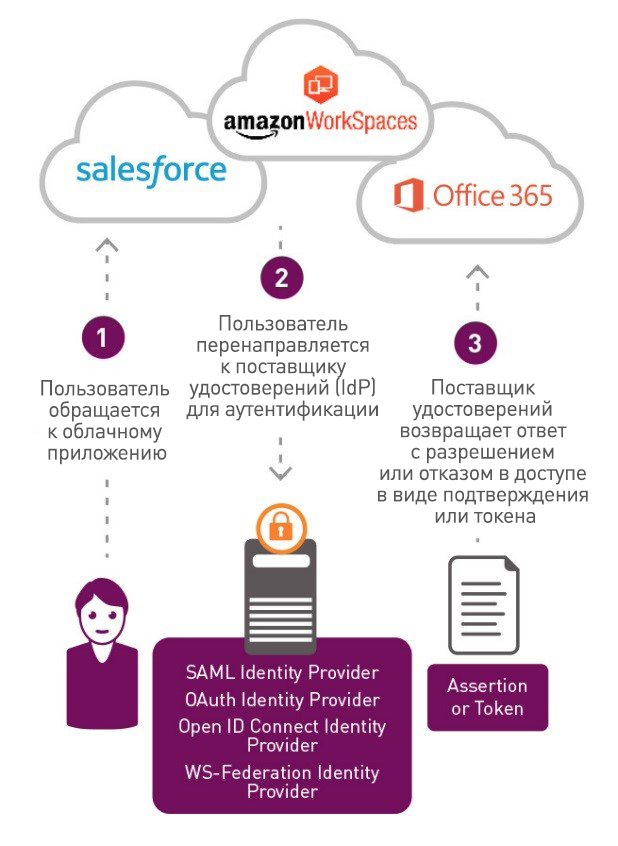
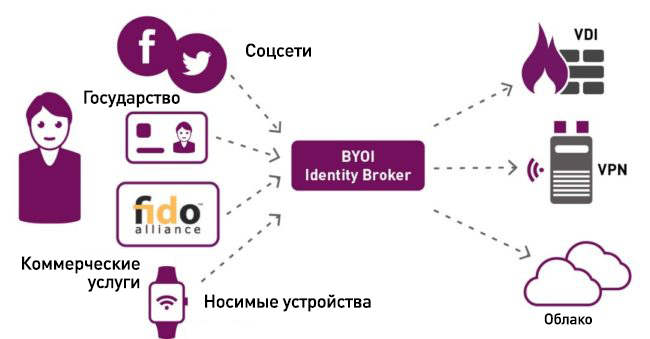
[Перевод - recovery mode ] Identity-as-a-Service (IDaaS). Что это? |

|
Метки: author mclouds облачные вычисления блог компании mclouds.ru cloud computing idaas |
[Перевод] Доклад Мари Микер с Code Conference: главное |

|
Метки: author lera_alfimova конференции интернет-маркетинг веб-аналитика блог компании appodeal конференция аналитика |
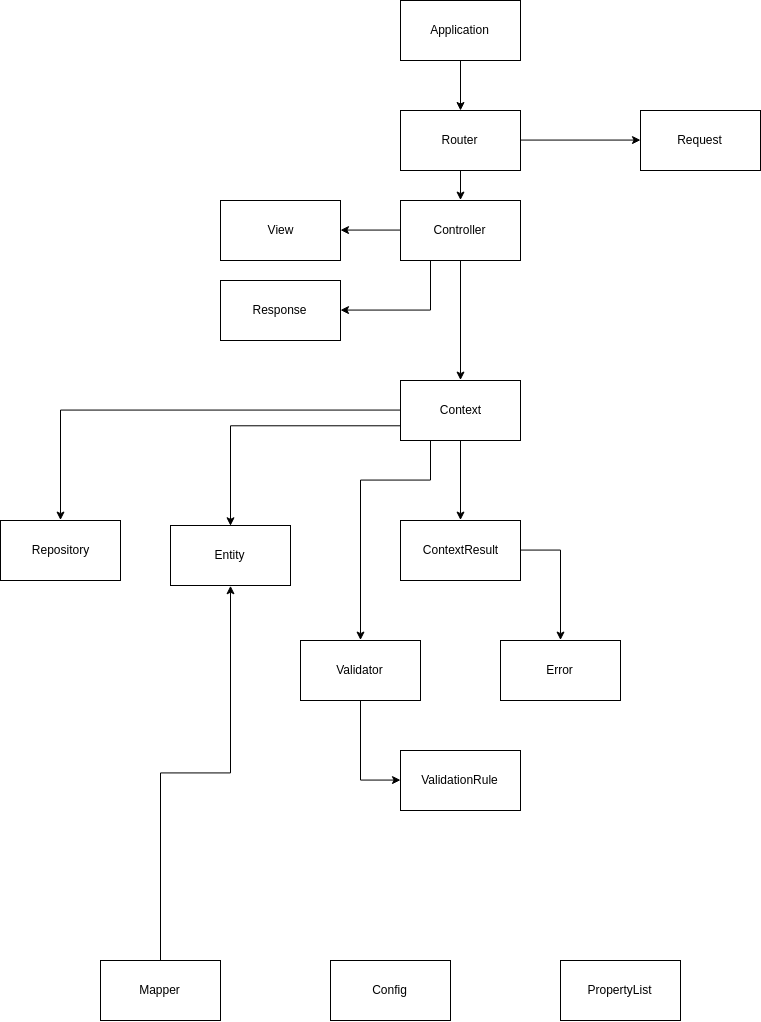
Решение проблем организации бизнес-логики в PHP или как пойти своим путем |


abstract class Entity
{
protected $_privateGetList = [];
protected $_privateSetList = [ 'ctime', 'utime'];
protected $id = 0;
protected $ctime;
protected $utime;
public function getId()
{
return $this->id;
}
public function setId( $id)
{
$this->id = $this->id == 0? $id: $this->id;
}
public function getCtime()
{
return $this->ctime;
}
public function getUtime()
{
return $this->utime;
}
public function __call( $name, $arguments)
{
if( strpos( $name, "get" ) === 0)
{
$attrName = substr( $name, 3);
$attrName = preg_replace_callback( "/(^[A-Z])/", create_function( '$matches', 'return strtolower($matches[0]);'), $attrName);
$attrName = preg_replace_callback( "/([A-Z])/", create_function( '$matches', 'return '_'.strtolower($matches[0]);'), $attrName);
if( !in_array( $attrName, $this->_privateGetList))
return $this->$attrName;
}
if( strpos( $name, "set" ) === 0)
{
$attrName = substr( $name, 3);
$attrName = preg_replace_callback( "/(^[A-Z])/", create_function( '$matches', 'return strtolower($matches[0]);'), $attrName);
$attrName = preg_replace_callback( "/([A-Z])/", create_function( '$matches', 'return '_'.strtolower($matches[0]);'), $attrName);
if( !in_array( $attrName, $this->_privateSetList))
$this->$attrName = $arguments[0];
}
}
public function get( $name)
{
if( !in_array( $name, $this->_privateGetList))
return $this->$name;
}
public function set( $name, $value)
{
if( !in_array( $name, $this->_privateSetList))
$this->$name = $value;
}
static public function name()
{
return get_called_class();
}
}
abstract class Context
{
protected $_property_list = null;
function __construct( \foci\utils\PropertyList $property_list)
{
$this->_property_list = $property_list;
}
abstract public function execute();
static public function name()
{
return get_called_class();
}
}
class Repository
{
function add( \foci\model\Entity &$entity)
{
$result = $this->_mapper->insert( $entity);
return $result;
}
function update( \foci\model\Entity &$entity)
{
$result = $this->_mapper->update( $entity);
return $result;
}
function delete( \foci\model\Entity &$entity)
{
$result = $this->_mapper->deleteById( $entity->getId());
return $result;
}
}
|
Метки: author xanm анализ и проектирование систем php ddd |
Доклад Мари Микер с Code Conference: главное |
|
Метки: author lera_alfimova конференции интернет-маркетинг веб-аналитика конференция аналитика высокие технологии маркетинг силиконовая долина |






