Как мы улучшали TFS |
Ранее, когда у нас не было своего корпоративного блога, я писал о том, как мы используем Microsoft TFS (Visual Studio Team Servives on Premises) для управления жизненным циклом разработки ПО и для автоматизации тестирования. В частности мы собрали большой набор автотестов по разным системам в один пакет, который запускаем каждый день. Подробнее об этом я рассказывал на конференции DevOpsDaysMoscow ( презентация, видео выступления )В ходе внедрения мы столкнулись с несколькими проблемами:
Сборки из дженкинса не публикуют результаты тестов в VSTS
все эти проблемы были успешно решены с помощью собственных расширений VSTS:
Доработка стандартной задачи запуска Jenkins job
Подробнее о проблемах и как мы искали решения — в моей прошлой статье. А сегодня я хочу рассказать о том как делать эти расширения и как мы можем помочь разработчикам расширений.
Практически с самого начала мы поняли, что самый простой способ решить наши проблемы — это собственные задачи (tasks) или шаги сборки в TFS. Задачи можно писать либо на powershell, либо на typescript. Мы выбрали typescript, и вот почему — фактически это javascript, но с поддержкой типизации. О преимуществах typescript и его использовании существует множество статей, в том числе и на хабре. Для нас же основными преимуществами было следующее:
Для работы c TFS Microsoft создала и опубликовала 2 npm модуля, что опять же избавило от необходимости изобретать велосипед.
Также большой помощью оказалось то, что многие задачи от Microsoft написаны и typescript и опубликованы под открытой лицензией. Кроме того, что это позволяет использовать их как примеры, это дало возможность сделать собственный форк этого репозитория и сделать свой "бутсрап" набор для быстрого создания задач и автоматизации сборки и упаковки расширений.
Что представляет собой задача для VSTS? Это набор обязательных компонентов:
иконка задачи
Определение задачи содержит несколько блоков.
{
"id": "b5525419-bae1-44de-a479-d6de6a3ccb2f",
"name": "TestTask",
"friendlyName": "TestTask",
"description": "TestTask",
"helpMarkDown": "",
"category": "Build",
"author": "authorName",
"version": {
"Major": 1,
"Minor": 0,
"Patch": 0
},
"instanceNameFormat": "TestTask $(testparam)"
}В этом блоке описывается уникальный id задачи, ее имя, категория и версия. При создании задачи необходимо указывать все эти поля. Поле instanceNameFormat определяет как будет выглядеть имя задачи в сборке VSTS по умолчанию. В нем могут быть указаны параметры из блока параметров в виде $(имя параметра)
В блоке параметров указываются входные параметры задачи, их имена, описания и типы. Параметры могут группироваться для удобства представления на странице настройки задачи. Ниже блок параметром задачи AutoDefects:
{
"groups": [
{
"name": "authentication",
"displayName": "Authentication",
"isExpanded": false
}
],
"inputs": [
{
"name": "Assignees",
"type": "filePath",
"label": "Assignees list file",
"defaultValue": "assignees.json",
"required": false,
"helpMarkDown": "Bug assignees list in json format. Format: {\"testrunname\":\"username\"}"
},
{
"name": "authtype",
"type": "pickList",
"label": "Authentication type",
"defaultValue": "oauth",
"required": false,
"helpMarkDown": "Authentication type to access the tfs rest api",
"options": {
"oauth": "OAuth",
"NTLM": "NTLM",
"Basic": "Basic"
},
"groupName" : "authentication"
},
{
"name": "Username",
"type": "string",
"label": "Username",
"defaultValue": "",
"required": false,
"helpMarkDown": "Username to access tfs rest api (NTLM and Basic types)",
"groupName" : "authentication",
"visibilityRule" : "authtype != OAuth"
},
{
"name": "Password",
"type": "string",
"label": "Password",
"defaultValue": "",
"required": false,
"helpMarkDown": "Password to access tfs rest api (NTLM and Basic types)",
"groupName" : "authentication",
"visibilityRule" : "authtype != OAuth"
}
]
}Параметры, определяющие схему аутентификации вынесены в отдельную группу, которая свернута по умолчанию.
В качестве типов параметров чаще всего используются:
содержит ссылку на главный исполняемый файл задачи
{
"execution": {
"Node": {
"target": "testtask.ts"
}
}
}{
"messages": {
"taskSucceeded": "All done",
"taskFailed": "Task Failed"
}
}
содержит набор локализованных строк для протоколирования работы задачи в лог файле сборки. Используется реже, чем блоки выше. Сообщения для текущих локальных настроек можно получить вызовом task.loc("messagename");
Главный исполняемый файл — это скрипт, который выполняет VSTS при старте задачи. Как минимум должен содержать код для импорта необходимых модулей для работы задачи и обработку ошибок. Например:
import tl = require('vsts-task-lib/task');
import trm = require('vsts-task-lib/toolrunner');
import path = require('path');
import fs = require('fs');
import Q = require("q");
import * as vm from 'vso-node-api';
import * as bi from 'vso-node-api/interfaces/BuildInterfaces';
import * as ci from 'vso-node-api/interfaces/CoreInterfaces';
import * as ti from 'vso-node-api/interfaces/TestInterfaces';
import * as wi from 'vso-node-api/interfaces/WorkItemTrackingInterfaces';
async function run() {
tl.setResourcePath(path.join(__dirname, 'task.json'));
let projId = tl.getVariable("System.TeamProjectId");
try {
} catch(err) {
console.log(err);
console.log(err.stack);
throw err;
}
}
run()
.then(r => tl.setResult(tl.TaskResult.Succeeded,tl.loc("taskSucceeded")))
.catch(r => tl.setResult(tl.TaskResult.Failed,tl.loc("taskFailed")))
Как видно задача представляет собой набор стандартных компонентов, которые мало меняются от задачи к задаче. Поэтому, когда я создавал третью задачу, появилась идея автоматизировать создание задач. Так появился наш "бутстрап", который значительно облегчает жизнь разработику расширений для VSTS.
Что нужно сделать когда создаешь задачу для VSTS, кроме собственно написание кода самой задачи? Шаги обычно одни и те же:
Все эти шаги могут быть автоматизированы для ускорения разработки и устранения ненужного ручного труда. Для автоматизации этих шагов и можно применять наш "бутстрап". Схема работы нашего сборщика аналогична сборщику задач от Microsoft — задачи для сборки перечисляются в файле make-options.json в корне проекта:
{
"tasks": [
"AutoDefects",
"ChainBuildsAwaiter",
"ChainBuildsStarter",
"TestTask"
],
...
}для создания расширений Вам понадобятся следущее ПО:
npm install -g typescriptnpm install -g gulpnpm install -g tfx-cliЗадача TaskName создается командой:
gulp generate –-name TaskName
В результае выполениея команды происходит следующее:
Скелетные файлы содержат минимально необходимый набор данных и кода.
Сборка задач проекта осуществляется комадной gulp
При этом для всех задач, перечисленных в make-options.json происходит следующее:
Упаковка задач осуществляется командой gulp mkext [--all] [--exts ext1,ext2]
По умолчанию каждая задача упаковывается в отдельный vsix файл, если указан параметр --all, то все задачи собираются в один большой vsix файл.
По умолчанию упаковываются все задачи, перечисленные в make-options.json, если указан параметр --exts, то упаковываются только перечисленные в параметре расширения.
Бутстрап опубликован на GitHub — форки, feature requests, pull requests приветствуются.
Очень надеюсь, что эта статья вызовет интерес к Miscosoft VSTS, который на мой взгляд является отличным инструментом групповой работы не только для больших компаний, но и для небольших гибких команд.
Константин Нерадовский,
начальник отдела автоматизации тестирования,
банк "Открытие"
|
Метки: author Otkritie тестирование мобильных приложений тестирование it-систем microsoft sql server microsoft access блог компании открытие tfs microsoft microsoft tfs |
[Из песочницы] Оптимизация загрузки в задаче «Остатки на складах» с помощью секционирования в SQL Server |
create table dbo.Turnover
(
id int identity primary key,
dt datetime not null,
ProductID int not null,
StorehouseID int not null,
Operation smallint not null check (Operation in (-1,1)), -- +1 приход на склад, -1 расход со склада
Quantity numeric(20,2) not null,
Cost money not null
)Dt — Дата время поступления/списания на/со склада.
ProductID — Продукт
StorehouseID — склад
Operation — 2 значения приход или расход
Quantity — количество продукта на складе. Может быть вещественным если продукт не в штуках, а, например, в килограммах.
Cost — стоимость партии продукта.
if object_id('dbo.Turnover','U') is not null drop table dbo.Turnover;
go
with times as
(
select 1 id
union all
select id+1
from times
where id < 10*365*24*60 -- 10 лет * 365 дней * 24 часа * 60 минут = столько минут в 10 лет
)
, storehouse as
(
select 1 id
union all
select id+1
from storehouse
where id < 100 -- количество складов
)
select
identity(int,1,1) id,
dateadd(minute, t.id, convert(datetime,'20060101',120)) dt,
1+abs(convert(int,convert(binary(4),newid()))%1000) ProductID, -- 1000 - количество разных продуктов
s.id StorehouseID,
case when abs(convert(int,convert(binary(4),newid()))%3) in (0,1) then 1 else -1 end Operation, -- какой то приход и расход, из случайных сделаем из 3х вариантов 2 приход 1 расход
1+abs(convert(int,convert(binary(4),newid()))%100) Quantity
into dbo.Turnover
from times t cross join storehouse s
option(maxrecursion 0);
go
--- 15 min
alter table dbo.Turnover alter column id int not null
go
alter table dbo.Turnover add constraint pk_turnover primary key (id) with(data_compression=page)
go
-- 6 minselect top(1000)
convert(datetime,convert(varchar(13),dt,120)+':00',120) as dt, -- округляем до часа
ProductID,
StorehouseID,
sum(Operation*Quantity) as Quantity
from dbo.Turnover
group by
convert(datetime,convert(varchar(13),dt,120)+':00',120),
ProductID,
StorehouseID
Стоимость запроса — 12406
(строк обработано: 1000)
Время работы SQL Server:
Время ЦП = 2096594 мс, затраченное время = 321797 мс.
select top(1000)
convert(datetime,convert(varchar(13),dt,120)+':00',120) as dt, -- округляем до часа
ProductID,
StorehouseID,
sum(Operation*Quantity) as Quantity,
sum(sum(Operation*Quantity)) over
(
partition by StorehouseID, ProductID
order by convert(datetime,convert(varchar(13),dt,120)+':00',120)
) as Balance
from dbo.Turnover
group by
convert(datetime,convert(varchar(13),dt,120)+':00',120),
ProductID,
StorehouseID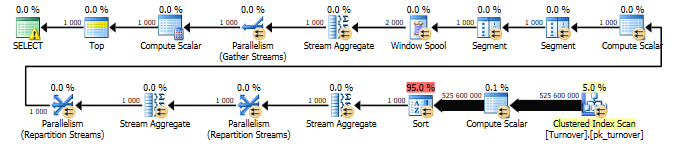
Стоимость запроса — 19329
(строк обработано: 1000)
Время работы SQL Server:
Время ЦП = 2413155 мс, затраченное время = 344631 мс.
create view dbo.TurnoverHour
with schemabinding as
select
convert(datetime,convert(varchar(13),dt,120)+':00',120) as dt, -- округляем до часа
ProductID,
StorehouseID,
sum(isnull(Operation*Quantity,0)) as Quantity,
count_big(*) qty
from dbo.Turnover
group by
convert(datetime,convert(varchar(13),dt,120)+':00',120),
ProductID,
StorehouseID
gocreate unique clustered index uix_TurnoverHour on dbo.TurnoverHour (StorehouseID, ProductID, dt)select top(1000)
convert(datetime,convert(varchar(13),dt,120)+':00',120) as dt, -- округляем до часа
ProductID,
StorehouseID,
sum(isnull(Operation*Quantity,0)) as Quantity
from dbo.Turnover
group by
convert(datetime,convert(varchar(13),dt,120)+':00',120),
ProductID,
StorehouseID
select top(1000)
convert(datetime,convert(varchar(13),dt,120)+':00',120) as dt, -- округляем до часа
ProductID,
StorehouseID,
sum(isnull(Operation*Quantity,0)) as Quantity,
sum(sum(isnull(Operation*Quantity,0))) over
(
partition by StorehouseID, ProductID
order by convert(datetime,convert(varchar(13),dt,120)+':00',120)
) as Balance
from dbo.Turnover
group by
convert(datetime,convert(varchar(13),dt,120)+':00',120),
ProductID,
StorehouseID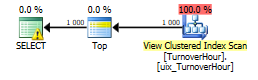 Стоимость 0.008
Стоимость 0.008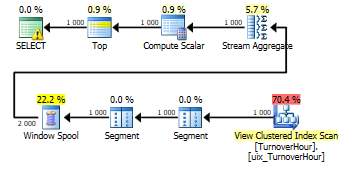 Стоимость 0.01
Стоимость 0.01Время работы SQL Server:
Время ЦП = 31 мс, затраченное время = 116 мс.
(строк обработано: 1000)
Время работы SQL Server:
Время ЦП = 0 мс, затраченное время = 151 мс.
set dateformat ymd;
declare
@start datetime = '2015-01-02',
@finish datetime = '2015-01-03'
select *
from
(
select
dt,
StorehouseID,
ProductId,
Quantity,
sum(Quantity) over
(
partition by StorehouseID, ProductID
order by dt
) as Balance
from dbo.TurnoverHour with(noexpand)
where dt <= @finish
) as tmp
where dt >= @start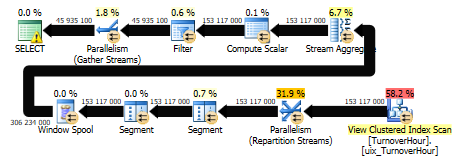
create index ix_dt on dbo.TurnoverHour (dt) include (Quantity) with(data_compression=page); --7 min
И наш запрос будет вида:
set dateformat ymd;
declare
@start datetime = '2015-01-02',
@finish datetime = '2015-01-03'
declare
@start_month datetime = convert(datetime,convert(varchar(9),@start,120)+'1',120)
select *
from
(
select
dt,
StorehouseID,
ProductId,
Quantity,
sum(Quantity) over
(
partition by StorehouseID, ProductID
order by dt
) as Balance
from dbo.TurnoverHour with(noexpand)
where dt between @start_month and @finish
) as tmp
where dt >= @start
order by StorehouseID, ProductID, dtset dateformat ymd;
declare
@start datetime = '2015-01-02',
@finish datetime = '2015-01-03'
declare
@start_month datetime = convert(datetime,convert(varchar(9),@start,120)+'1',120)
select *
from
(
select
dt,
StorehouseID,
ProductId,
Quantity,
sum(Quantity) over
(
partition by StorehouseID, ProductID
order by dt
) as Balance
from dbo.TurnoverHour with(noexpand)
where dt between @start_month and @finish
) as tmp
where dt >= @start
order by StorehouseID, ProductID, dt
select *
from
(
select
dt,
StorehouseID,
ProductId,
Quantity,
sum(Quantity) over
(
partition by StorehouseID, ProductID
order by dt
) as Balance
from dbo.TurnoverHour with(noexpand,index=ix_dt)
where dt between @start_month and @finish
) as tmp
where dt >= @start
order by StorehouseID, ProductID, dtВремя работы SQL Server:
Время ЦП = 33860 мс, затраченное время = 24247 мс.
(строк обработано: 145608)
(строк обработано: 1)
Время работы SQL Server:
Время ЦП = 6374 мс, затраченное время = 1718 мс.
Время синтаксического анализа и компиляции SQL Server:
время ЦП = 0 мс, истекшее время = 0 мс.

drop index ix_dt on dbo.TurnoverHour;
drop index uix_TurnoverHour on dbo.TurnoverHour;set dateformat ymd;
create partition function pf_TurnoverHour(datetime) as range right for values (
'2006-01-01', '2006-02-01', '2006-03-01', '2006-04-01', '2006-05-01', '2006-06-01', '2006-07-01', '2006-08-01', '2006-09-01', '2006-10-01', '2006-11-01', '2006-12-01',
'2007-01-01', '2007-02-01', '2007-03-01', '2007-04-01', '2007-05-01', '2007-06-01', '2007-07-01', '2007-08-01', '2007-09-01', '2007-10-01', '2007-11-01', '2007-12-01',
'2008-01-01', '2008-02-01', '2008-03-01', '2008-04-01', '2008-05-01', '2008-06-01', '2008-07-01', '2008-08-01', '2008-09-01', '2008-10-01', '2008-11-01', '2008-12-01',
'2009-01-01', '2009-02-01', '2009-03-01', '2009-04-01', '2009-05-01', '2009-06-01', '2009-07-01', '2009-08-01', '2009-09-01', '2009-10-01', '2009-11-01', '2009-12-01',
'2010-01-01', '2010-02-01', '2010-03-01', '2010-04-01', '2010-05-01', '2010-06-01', '2010-07-01', '2010-08-01', '2010-09-01', '2010-10-01', '2010-11-01', '2010-12-01',
'2011-01-01', '2011-02-01', '2011-03-01', '2011-04-01', '2011-05-01', '2011-06-01', '2011-07-01', '2011-08-01', '2011-09-01', '2011-10-01', '2011-11-01', '2011-12-01',
'2012-01-01', '2012-02-01', '2012-03-01', '2012-04-01', '2012-05-01', '2012-06-01', '2012-07-01', '2012-08-01', '2012-09-01', '2012-10-01', '2012-11-01', '2012-12-01',
'2013-01-01', '2013-02-01', '2013-03-01', '2013-04-01', '2013-05-01', '2013-06-01', '2013-07-01', '2013-08-01', '2013-09-01', '2013-10-01', '2013-11-01', '2013-12-01',
'2014-01-01', '2014-02-01', '2014-03-01', '2014-04-01', '2014-05-01', '2014-06-01', '2014-07-01', '2014-08-01', '2014-09-01', '2014-10-01', '2014-11-01', '2014-12-01',
'2015-01-01', '2015-02-01', '2015-03-01', '2015-04-01', '2015-05-01', '2015-06-01', '2015-07-01', '2015-08-01', '2015-09-01', '2015-10-01', '2015-11-01', '2015-12-01',
'2016-01-01', '2016-02-01', '2016-03-01', '2016-04-01', '2016-05-01', '2016-06-01', '2016-07-01', '2016-08-01', '2016-09-01', '2016-10-01', '2016-11-01', '2016-12-01',
'2017-01-01', '2017-02-01', '2017-03-01', '2017-04-01', '2017-05-01', '2017-06-01', '2017-07-01', '2017-08-01', '2017-09-01', '2017-10-01', '2017-11-01', '2017-12-01',
'2018-01-01', '2018-02-01', '2018-03-01', '2018-04-01', '2018-05-01', '2018-06-01', '2018-07-01', '2018-08-01', '2018-09-01', '2018-10-01', '2018-11-01', '2018-12-01',
'2019-01-01', '2019-02-01', '2019-03-01', '2019-04-01', '2019-05-01', '2019-06-01', '2019-07-01', '2019-08-01', '2019-09-01', '2019-10-01', '2019-11-01', '2019-12-01');
go
create partition scheme ps_TurnoverHour as partition pf_TurnoverHour all to ([primary]);
go
Ну и уже известный нам кластерный индекс только в созданной схеме секционирования:
create unique clustered index uix_TurnoverHour on dbo.TurnoverHour (StorehouseID, ProductID, dt) with (data_compression=page) on ps_TurnoverHour(dt); --- 19 min
И теперь посмотрим, что у нас получилось. Сам запрос:
set dateformat ymd;
declare
@start datetime = '2015-01-02',
@finish datetime = '2015-01-03'
declare
@start_month datetime = convert(datetime,convert(varchar(9),@start,120)+'1',120)
select *
from
(
select
dt,
StorehouseID,
ProductId,
Quantity,
sum(Quantity) over
(
partition by StorehouseID, ProductID
order by dt
) as Balance
from dbo.TurnoverHour with(noexpand)
where dt between @start_month and @finish
) as tmp
where dt >= @start
order by StorehouseID, ProductID, dt
option(recompile);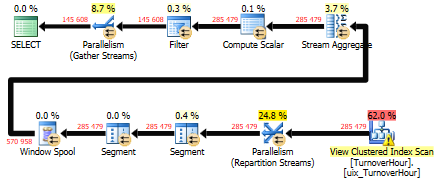
Время работы SQL Server:
Время ЦП = 7860 мс, затраченное время = 1725 мс.
Время синтаксического анализа и компиляции SQL Server:
время ЦП = 0 мс, истекшее время = 0 мс.
Стоимость плана запроса = 9.4
|
Метки: author abkurenkov microsoft sql server sql server материализованные представления секционированные таблицы остатки на складах |
[Перевод] Must-Have: 20 игровых ассетов для дизайнера и художника |





















|
|
Kotlin, компиляция в байткод и производительность (часть 2) |
//Kotlin
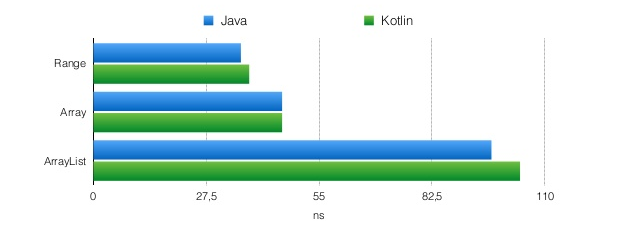
fun rangeLoop() {
for (i in 1..10) {
println(i)
}
}
//Java
public static final void rangeLoop() {
int i = 1;
byte var1 = 10;
if(i <= var1) {
while(true) {
System.out.println(i);
if(i == var1) {
break;
}
++i;
}
}
}
//Kotlin
fun arrayLoop(x: Array) {
for (s in x) {
println(s)
}
}
//Java
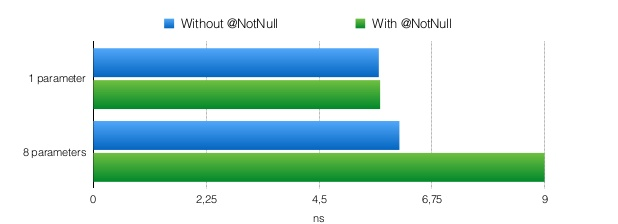
public static final void arrayLoop(@NotNull String[] x) {
Intrinsics.checkParameterIsNotNull(x, "x");
for(int var2 = 0; var2 < x.length; ++var2) {
String s = x[var2];
System.out.println(s);
}
}
//Kotlin
fun listLoop(x: List) {
for (s in x) {
println(s)
}
}
//Java
public static final void listLoop(@NotNull List x) {
Intrinsics.checkParameterIsNotNull(x, "x");
Iterator var2 = x.iterator();
while(var2.hasNext()) {
String s = (String)var2.next();
System.out.println(s);
}
}
/Kotlin
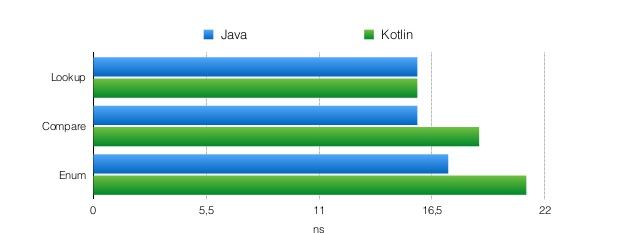
fun tableWhen(x: Int): String = when(x) {
0 -> "zero"
1 -> "one"
else -> "many"
}
//Java
public static final String tableWhen(int x) {
String var10000;
switch(x) {
case 0:
var10000 = "zero";
break;
case 1:
var10000 = "one";
break;
default:
var10000 = "many";
}
return var10000;
}
//Kotlin
val ZERO = 1
val ONE = 1
fun constWhen(x: Int): String = when(x) {
ZERO -> "zero"
ONE -> "one"
else -> "many"
}
//Java
public static final String constWhen(int x) {
return x == ZERO?"zero":(x == ONE?"one":"many");
}
//Kotlin (файл When3.kt)
enum class NumberValue {
ZERO, ONE, MANY
}
fun enumWhen(x: NumberValue): String = when(x) {
NumberValue.ZERO -> "zero"
NumberValue.ONE -> "one"
NumberValue.MANY -> "many"
}
//Java
public final class When3Kt$WhenMappings {
// $FF: synthetic field
public static final int[] $EnumSwitchMapping$0 = new int[NumberValue.values().length];
static {
$EnumSwitchMapping$0[NumberValue.ZERO.ordinal()] = 1;
$EnumSwitchMapping$0[NumberValue.ONE.ordinal()] = 2;
$EnumSwitchMapping$0[NumberValue.MANY.ordinal()] = 3;
}
}
public static final String enumWhen(@NotNull NumberValue x) {
Intrinsics.checkParameterIsNotNull(x, "x");
String var10000;
switch(When3Kt$WhenMappings.$EnumSwitchMapping$0[x.ordinal()]) {
case 1:
var10000 = "zero";
break;
case 2:
var10000 = "one";
break;
case 3:
var10000 = "many";
break;
default:
throw new NoWhenBranchMatchedException();
}
return var10000;
}
//Kotlin
package examples
interface Base {
fun print()
}
class BaseImpl(val x: Int) : Base {
override fun print() { print(x) }
}
class Derived(b: Base) : Base by b {
fun anotherMethod(): Unit {}
}
public final class Derived implements Base {
private final Base $$delegate_0;
public Derived(@NotNull Base b) {
Intrinsics.checkParameterIsNotNull(b, "b");
super();
this.$$delegate_0 = b;
}
public void print() {
this.$$delegate_0.print();
}
public final void anotherMethod() {
}
}
//Kotlin
class DeleteExample {
val name: String by Delegate()
}
public final class DeleteExample {
@NotNull
private final Delegate name$delegate = new Delegate();
static final KProperty[] $$delegatedProperties = new KProperty[]{(KProperty)Reflection.property1(new PropertyReference1Impl(Reflection.getOrCreateKotlinClass(DeleteExample.class), "name", "getName()Ljava/lang/String;"))};
@NotNull
public final String getName() {
return this.name$delegate.getValue(this, $$delegatedProperties[0]);
}
}
//Kotlin
object ObjectExample {
fun objectFun(): Int {
return 1
}
}
public final class ObjectExample {
public static final ObjectExample INSTANCE;
public final int objectFun() {
return 1;
}
private ObjectExample() {
INSTANCE = (ObjectExample)this;
}
static {
new ObjectExample();
}
}
//Kotlin
val value = ObjectExample.objectFun()
//Java
int value = ObjectExample.INSTANCE.objectFun();
//Kotlin
class ClassWithCompanion {
val name: String = "Kurt"
companion object {
fun companionFun(): Int = 5
}
}
//method call
ClassWithCompanion.companionFun()
//Java
public final class ClassWithCompanion {
@NotNull
private final String name = "Kurt";
public static final ClassWithCompanion.Companion Companion = new ClassWithCompanion.Companion((DefaultConstructorMarker)null);
@NotNull
public final String getName() {
return this.name;
}
public static final class Companion {
public final int companionFun() {
return 5;
}
private Companion() {
}
public Companion(DefaultConstructorMarker $constructor_marker) {
this();
}
}
}
//вызов функции
ClassWithCompanion.Companion.companionFun();
//Kotlin
object ObjectWithStatic {
@JvmStatic
fun staticFun(): Int {
return 5
}
}
public final class ObjectWithStatic {
public static final ObjectWithStatic INSTANCE;
@JvmStatic
public static final int staticFun() {
return 5;
}
private ObjectWithStatic() {
INSTANCE = (ObjectWithStatic)this;
}
static {
new ObjectWithStatic();
}
}
class ClassWithCompanionStatic {
val name: String = "Kurt"
companion object {
@JvmStatic
fun companionFun(): Int = 5
}
}
public final class ClassWithCompanionStatic {
@NotNull
private final String name = "Kurt";
public static final ClassWithCompanionStatic.Companion Companion = new ClassWithCompanionStatic.Companion((DefaultConstructorMarker)null);
@NotNull
public final String getName() {
return this.name;
}
@JvmStatic
public static final int companionFun() {
return Companion.companionFun();
}
public static final class Companion {
@JvmStatic
public final int companionFun() {
return 5;
}
private Companion() {
}
// $FF: synthetic method
public Companion(DefaultConstructorMarker $constructor_marker) {
this();
}
}
}
//Kotlin
class LateinitExample {
lateinit var lateinitValue: String
}
//Java
public final class LateinitExample {
@NotNull
public String lateinitValue;
@NotNull
public final String getLateinitValue() {
String var10000 = this.lateinitValue;
if(this.lateinitValue == null) {
Intrinsics.throwUninitializedPropertyAccessException("lateinitValue");
}
return var10000;
}
public final void setLateinitValue(@NotNull String var1) {
Intrinsics.checkParameterIsNotNull(var1, "");
this.lateinitValue = var1;
}
}
//Kotlin
suspend fun asyncFun(x: Int): Int {
return x * 3
}
//Java
public static final Object asyncFun(int x, @NotNull Continuation $continuation) {
Intrinsics.checkParameterIsNotNull($continuation, "$continuation");
return Integer.valueOf(x * 3);
}
interface Continuation {
val context: CoroutineContext
fun resume(value: T)
fun resumeWithException(exception: Throwable)
}
val a = a()
val y = foo(a).await() // точка прерывания #1
b()
val z = bar(a, y).await() // точка прерывания #2
c(z)
class extends CoroutineImpl<...> implements Continuation {
// текущее состояние машины состояний
int label = 0
// локальные переменные корутин
A a = null
Y y = null
void resume(Object data) {
if (label == 0) goto L0
if (label == 1) goto L1
if (label == 2) goto L2
else throw IllegalStateException()
L0:
a = a()
label = 1
data = foo(a).await(this) // 'this' передается как continuation
if (data == COROUTINE_SUSPENDED) return // возвращение, если await прервал выполнение
L1:
// внешний код возвращает выполнение корутины, передавая результат как data
y = (Y) data
b()
label = 2
data = bar(a, y).await(this) // 'this' передается как continuation
if (data == COROUTINE_SUSPENDED) return // возвращение, если await прервал выполнение
L2:
// внешний код возвращает выполнение корутины передавая результат как data
Z z = (Z) data
c(z)
label = -1 // Не допускается больше никаких шагов
return
}
}
|
Метки: author nerumb программирование компиляторы kotlin java блог компании инфорион разработка байткод |
Kotlin, компиляция в байткод и производительность (часть 1) |

@Metadata(
mv = {1, 1, 6},
bv = {1, 0, 1},
k = 1,
d1 = {"\u0000\u0014\n\u0002\u0018\u0002\n\u0002\u0010\u0000\n\u0002\b\u0002\n\u0002\u0010\b\n\u0002\b\u0003\u0018\u00002\u00020\u0001B\u0005c\u0006\u0002\u0010\u0002R\u0014\u0010\u0003\u001a\u00020\u0004X\u0086Dc\u0006\b\n\u0000\u001a\u0004\b\u0005\u0010\u0006"\u0006\u0007"},
d2 = {"LSimpleKotlinClass;", "", "()V", "test", "", "getTest", "()I", "production sources for module KotlinTest_main"}
)
Она содержит всю ту информацию, которая существует в языке Kotlin, и которую невозможно представить на уровне Java байткода. Например информацию о свойствах, nullable типов и т.п. С этой информацией не нужно работать напрямую, но с ней работает компилятор, и к ней можно получить доступ используя Reflection API. Формат метадаты это на самом деле Protobuf cо своими декларациями.
Дмитрий Жемеров
//Kotlin, файл Example1.kt
fun foo() { }
//Java
public final class Example1Kt {
public static final void foo() {
}
}
//Kotlin
@file:JvmName("Utils")
fun foo() { }
//Java
public final class Utils {
public static final void foo() {
}
}
//Kotlin
class A(val x: Int, val y: Long) {}
//Java
public final class A {
private final int x;
private final long y;
public final int getX() {
return this.x;
}
public final long getY() {
return this.y;
}
public A(int x, long y) {
this.x = x;
this.y = y;
}
}
//Kotlin
data class B(val x: Int, val y: Long) { }
//Java
public final class B {
// --- аналогично примеру 2
public final int component1() {
return this.x;
}
public final long component2() {
return this.y;
}
@NotNull
public final B copy(int x, long y) {
return new B(x, y);
}
public String toString() {
return "B(x=" + this.x + ", y=" + this.y + ")";
}
public int hashCode() {
return this.x * 31 + (int)(this.y ^ this.y >>> 32);
}
public boolean equals(Object var1) {
if(this != var1) {
if(var1 instanceof B) {
B var2 = (B)var1;
if(this.x == var2.x && this.y == var2.y) {
return true;
}
}
return false;
} else {
return true;
}
}
//Kotlin
class C {
var x: String? = null
}
//Java
import org.jetbrains.annotations.Nullable;
public final class C {
@Nullable
private String x;
@Nullable
public final String getX() {
return this.x;
}
public final void setX(@Nullable String var1) {
this.x = var1;
}
}
//Kotlin
class C {
@JvmField var x: String? = null
}
//Java
public final class C {
@JvmField
@Nullable
public String x;
}
//Kotlin
class E {
fun x(s: String) {
println(s)
}
private fun y(s: String) {
println(s)
}
}
//Java
import kotlin.jvm.internal.Intrinsics;
public final class E {
public final void x(@NotNull String s) {
Intrinsics.checkParameterIsNotNull(s, "s");
System.out.println(s);
}
private final void y(String s) {
System.out.println(s);
}
}
//Kotlin (файл Example6.kt)
class T(val i: Int)
fun T.foo(): Int {
return i
}
fun useFoo() {
T(1).foo()
}
//Java
public final class Example6Kt {
public static final int foo(@NotNull T $receiver) {
Intrinsics.checkParameterIsNotNull($receiver, "$receiver");
return $receiver.getI();
}
public static final void useFoo() {
foo(new T(1));
}
}
//Kotlin
interface I {
fun foo(): Int {
return 42
}
}
class D : I { }
public interface I {
int foo();
public static final class DefaultImpls {
public static int foo(I $this) {
return 42;
}
}
}
public final class D implements I {
public int foo() {
return I.DefaultImpls.foo(this);
}
}
//Kotlin (файл Example8.kt)
fun first(x: Int = 11, y: Long = 22) {
println(x)
println(y)
}
fun second() {
first()
}
//Java
public final class Example8Kt {
public static final void first(int x, long y) {
System.out.println(x);
System.out.println(y);
}
public static void first$default(int var0, long var1, int mask, Object var4) {
if((mask & 1) != 0) {
var0 = 11;
}
if((mask & 2) != 0) {
var1 = 22L;
}
first(var0, var1);
}
public static final void second() {
first$default(0, 0L, 3, (Object)null);
}
}

//Kotlin
@JvmOverloads
fun first(x: Int = 11, y: Long = 22) {
println(x)
println(y)
}
//Java
public final class Example8Kt {
//-- методы first, second, first$default из предыдущего примера
@JvmOverloads
public static final void first(int x) {
first$default(x, 0L, 2, (Object)null);
}
@JvmOverloads
public static final void first() {
first$default(0, 0L, 3, (Object)null);
}
}
//Kotlin (файл Lambda1.kt)
fun runLambda(x: ()-> T): T = x()
//Java
public final class Lambda1Kt {
public static final Object runLambda(@NotNull Function0 x) {
Intrinsics.checkParameterIsNotNull(x, "x");
return x.invoke();
}
}
//Kotlin (файл Lambda2.kt)
var value = 0
fun noncapLambda(): Int = runLambda { value }
//Java
final class Lambda2Kt$noncapLambda$1 extends Lambda implements Function0 {
public static final Lambda2Kt$noncapLambda$1 INSTANCE = new Lambda2Kt$noncapLambda$1()
public final int invoke() {
return Lambda2Kt.getValue();
}
}
public final class Lambda2Kt {
private static int value;
public static final int getValue() {
return value;
}
public static final void setValue(int var0) {
value = var0;
}
public static final int noncapLambda() {
return ((Number)Lambda1Kt.runLambda(Lambda2Kt$noncapLambda$1.INSTANCE)).intValue();
}
}
//Kotlin (файл Lambda3.kt)
fun capturingLambda(v: Int): Int = runLambda { v }
//Java
public static final int capturingLambda(int v) {
return ((Number)Lambda1Kt.runLambda((Function0)(new Function0() {
public Object invoke() {
return Integer.valueOf(this.invoke());
}
public final int invoke() {
return v;
}
}))).intValue();
}
//Kotlin (файл Lambda4.kt)
fun mutatingLambda(): Int {
var x = 0
runLambda { x++ }
return x
}
public final class Lambda4Kt {
public static final int mutatingLambda() {
final IntRef x = new IntRef();
x.element = 0;
Lambda1Kt.runLambda((Function0)(new Function0() {
public Object invoke() {
return Integer.valueOf(this.invoke());
}
public final int invoke() {
int var1 = x.element++;
return var1;
}
}));
return x.element;
}
}

//Kotin (файл Lambda5.kt)
fun inlineLambda(x: Int): Int = run { x }
//run это функция из стандартной библиотеки:
public inline fun run(block: () -> R): R = block()
//Java
public final class Lambda5Kt {
public static final int inlineLambda(int x) {
return x;
}
}
|
Метки: author nerumb программирование компиляторы kotlin java блог компании инфорион разработка байткод |
Выпуск#3: ITренировка — актуальные вопросы и задачи от ведущих компаний |
Given an arraynums, write a function to move all0's to the end of it while maintaining the relative order of the non-zero elements.
For example, givennums = [0, 1, 0, 3, 12], after calling your function,numsshould be[1, 3, 12, 0, 0].
Note:
You must do this in-place without making a copy of the array.
Minimize the total number of operations.
Given an array nums and a target value k, find the maximum length of a subarray that sums to k. If there isn't one, return 0 instead.
Note:
The sum of the entire nums array is guaranteed to fit within the 32-bit signed integer range.
Example 1:
Givennums = [1, -1, 5, -2, 3], k = 3,
return4. (because the subarray[1, -1, 5, -2] sumsto3and is the longest)
Example 2:
Givennums = [-2, -1, 2, 1], k = 1,
return 2. (because the subarray[-1, 2] sumsto1and is the longest)
Follow Up:
Can you do it in O(n) time?
Remove the minimum number of invalid parentheses in order to make the input string valid. Return all possible results.
Note: The input string may contain letters other than the parentheses ( and ).
Examples:
"()())()" -> ["()()()", "(())()"]
"(a)())()" -> ["(a)()()", "(a())()"]
")(" -> [""]
|
Метки: author SpiceIT программирование занимательные задачки блог компании spice it recruitment facebook spiceit it ренировка собеседование |
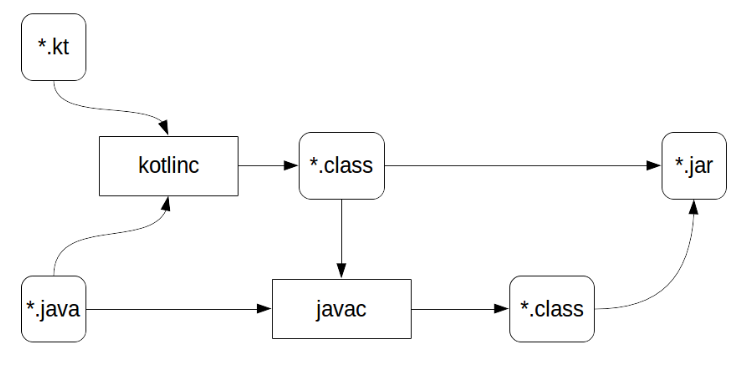
Свой скриптовый движок для игр средствами С++ и Lua (часть — 1) |
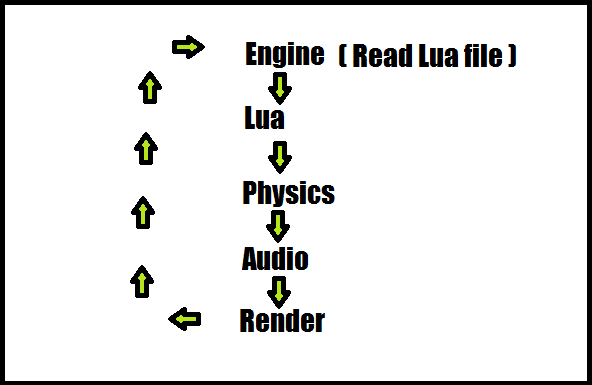
int main()
{
return 0;
}

int main(int argc, char * argv[])
{
return 0;
}
#include
#include
#pragma comment(lib,"lua53") // на момент написания статьи версия Lua 5.3.
using namespace std;
class Lua
{
private:
lua_State * lua_state;
public:
void Init() // инициализируем и подключаем модули.
{
lua_state = luaL_newstate();
static const luaL_Reg lualibs[] =
{
{ "base", luaopen_base },
{ "io", luaopen_io },
{ "os",luaopen_os },
{ "math",luaopen_math },
{ "table",luaopen_table },
{ "string",luaopen_string },
{ "package",luaopen_package },
{ NULL, NULL }
};
for (const luaL_Reg *lib = lualibs; lib->func != NULL; lib++)
{
luaL_requiref(lua_state, lib->name, lib->func, 1);
lua_settop(lua_state, 0);
}
}
void Open(const char*filename) // открываем файл с кодом (main.lua)
{
luaL_openlibs(lua_state);
if (luaL_dofile(lua_state, filename))
{
const char*error = lua_tostring(lua_state, -1);
}
}
void Close() // закрываем
{
lua_close(lua_state);
}
void Reg_int(int value, char*name)
{
lua_pushinteger(lua_state, value);
lua_setglobal(lua_state, name);
}
void Reg_double(double value, char*name)
{
lua_pushnumber(lua_state, value);
lua_setglobal(lua_state, name);
}
void Reg_bool(bool value, char*name)
{
lua_pushboolean(lua_state, value);
lua_setglobal(lua_state, name);
}
void Reg_string(char*value, char*name)
{
lua_pushstring(lua_state, value);
lua_setglobal(lua_state, name);
}
void Reg_function(lua_CFunction value, const char*name)
{
lua_pushcfunction(lua_state, value);
lua_setglobal(lua_state, name);
}
int Get_int(int index)
{
return (int)lua_tointeger(lua_state, index);
}
double Get_double(int index)
{
return lua_tonumber(lua_state, index);
}
char* Get_string(int index)
{
return (char*)lua_tostring(lua_state, index);
}
bool Get_bool(int index)
{
return lua_toboolean(lua_state, index);
}
void Return_int(int value)
{
lua_pushinteger(lua_state, value);
}
void Return_double(double value)
{
lua_pushnumber(lua_state, value);
}
void Return_string(char*value)
{
lua_pushstring(lua_state, value);
}
void Return_bool(int value)
{
lua_pushboolean(lua_state, value);
}
int Call_load() // вызываем при старте
{
lua_getglobal(lua_state, "Load");
lua_call(lua_state, 0, 1);
return 0;
}
int Call_update() // вызываем пока работает приложения
{
lua_getglobal(lua_state, "Update");
lua_call(lua_state, 0, 1);
return 0;
}
int Call_draw()
{
lua_getglobal(lua_state, "Draw"); // вызываем после "Update"
lua_call(lua_state, 0, 1);
return 0;
}
};
Lua lua;// lua экземпляр
include "Engiine.h"
int main(int argc, char * argv[])
{
lua.Init();
lua.Open("main.lua");
lua.Call_load();
lua.Close();
return 0;
}
function Load()
print("Lua inited!")
end
function Update()
end
function Draw()
end
|
Метки: author Wolf_Black lua c++ engine gamedev |
Простейшее ММО на Phaser и Node.js |

var express = require('express'); //подключаем экспресс
var app = require('express')();
var http = require('http').Server(app);
var io = require('socket.io')(http); //подключаем socket.IO
var port = process.env.PORT || 3000; //указываем порт на котором у нас будет работать игра
var players = {}; //переменная со всеми игроками
/* При открытии страницы, открываем новое подключение для обмена сокетами*/
io.on("connection", function(socket) {
console.log('an user connected ' + socket.id); //выводим в консоль node.js инфу о том, что подключился новый пользователь
players[socket.id] = {
"x": Math.floor(Math.random(1) * 2000),
"y": Math.floor(Math.random(1) * 2000),
"live": true,
}; //генерирует параметры нового игрока
io.sockets.emit('add_player', JSON.stringify({
"id": socket.id,
"player": players[socket.id]
})); //создаем нового игрока на клиенте
socket.emit('add_players', JSON.stringify(players));// создаем нового игрока на клиенте(если игроков более одного)
socket.on('player_rotation', function(data) {
io.sockets.emit('player_rotation_update', JSON.stringify({
"id": socket.id,
"value": data
}));
}); // пакет получающий данные о направлении игрока и отправляющий их на клиент для синхронного отображения для всех пользователей
socket.on('player_move', function(data) {
data = JSON.parse(data); //получаем данные какая кнопка нажата
data.x = 0; //создаем новое свойство объекта x и заодно сбрасываем его до нуля, при каждом обновлении сокета
data.y = 0; // аналогично предыдущему, только ось y
/*передаем различные параметры в зависимости от нажатой кнопки*/
switch (data.character) {
case "W":
data.y = -5;
players[data.id].y -= 5;
break;
case "S":
data.y = 5;
players[data.id].y += 5;
break;
case "A":
data.x = -5;
players[data.id].x -= 5;
break;
case "D":
data.x = 5;
players[data.id].x += 5;
break;
}
io.sockets.emit('player_position_update', JSON.stringify(data)); //отправляем данные на клиент
});
socket.on('shots_fired', function(id) { //получаем id стреляющего
io.sockets.emit("player_fire_add", id); //отправляем на клиент вызов функции выстрелов от конкретного пользователся
});
socket.on('player_killed', function (victimId) { //функция при попадания пули в игрока
io.sockets.emit('clean_dead_player', victimId); //чистим поле от проигравших
players[victimId].live = false; //заканчиваем выполнение ряда функций для проигравшего игрока
io.sockets.connected[victimId].emit('gameOver', 'Game Over'); //выводим пользователю в которого попали информацию о проиграше
});
socket.on('disconnect', function() { //убираем с поля отсоединившихся игроков
console.log("an user disconnected " + socket.id);
delete players[socket.id];
io.sockets.emit('player_disconnect', socket.id);
});
});
app.use("/", express.static(__dirname + "/public")); //пути к файлам клиента
app.get("/", function(req, res) {
res.sendFile(__dirname + "/public/index.html"); // главная страница
});
http.listen(port, function() {
console.log('listening on *:' + port); // запуск сервера
});
var width = window.innerWidth; //получаем ширину монитора
var height = window.innerHeight; //получаем высоту монитора
var game = new Phaser.Game(width, height, Phaser.CANVAS, 'phaser-example', { preload: preload, create: create, update: update, render: render }); //создаем игровое поле с высотой и шириной экрана пользователя;
/*инициализируем все наши переменные */
var player;
var socket, players = {};
var map;
var map_size = 2000; //размер карты
var style = { font: "80px Arial", fill: "white" }; //стили для надписи "Game Over"
var text;
var bullets;
var fireRate = 100;
var nextFire = 0;
var balls;
var ball;
var player_speed = 400; //скорость движения игрока
var live;
var moveBullets;
/*предзагружаем графические элементы*/
function preload() {
game.load.image('unit', 'img/unit.png');
game.load.image('bullet', 'img/bullet.png');
game.load.image('killer', 'img/killers.png');
game.load.image('map', 'img/grid.png');
}
function create() {
socket = io.connect(window.location.host); //подключаем сокеты
game.physics.startSystem(Phaser.Physics.ARCADE);
game.time.advancedTiming = true;
game.time.desiredFps = 60;
game.time.slowMotion = 0;
bg = game.add.tileSprite(0, 0, map_size, map_size, 'map'); //спрайт карты
game.world.setBounds(0, 0, map_size, map_size); //размеры карты
game.stage.backgroundColor = "#242424"; //цвет фона
socket.on("add_players", function(data) {
data = JSON.parse(data);
for (let playerId in data) {
if (players[playerId] == null && data[playerId].live) {
addPlayer(playerId, data[playerId].x, data[playerId].y, data[playerId].name);
}
}
live = true;
}); //создаем игроков
socket.on("add_player", function(data) {
data = JSON.parse(data);
if (data.player.live) {
addPlayer(data.id, data.player.x, data.player.y, data.player.name);
}
}); //создаем игрока
socket.on("player_rotation_update", function(data) {
data = JSON.parse(data);
players[data.id].player.rotation = data.value;
}); //вращение вокруг своей оси, ориентируясь на курсор
socket.on("player_position_update", function(data) {
data = JSON.parse(data);
players[socket.id].player.body.velocity.x = 0;
players[socket.id].player.body.velocity.y = 0;
players[data.id].player.x += data.x;
players[data.id].player.y += data.y;
}); //обновляем положение игроков
socket.on('player_fire_add', function(id) {
players[id].weapon.fire();
}); //исполняем выстрелы
game.input.onDown.add(function() {
socket.emit("shots_fired", socket.id);
}); //вызываем выстрелы
socket.on('clean_dead_player', function(victimId) {
if (victimId == socket.id) {
live = false;
}
socket.on("gameOver", function(data){
text = game.add.text(width / 2, height / 2, data, { font: "32px Arial", fill: "#ffffff", align: "center" });
text.fixedToCamera = true;
text.anchor.setTo(.5, .5);
});
players[victimId].player.kill();
}); //чистим поле от игроков в которых попали и выводим им текст о проигрыш
socket.on('player_disconnect', function(id) {
players[id].player.kill();
}); //чистим поле от отключившихся игроков
keybord = game.input.keyboard.createCursorKeys(); //инициализируем клавиатуру
}
function update() {
if (live == true) {
players[socket.id].player.rotation = game.physics.arcade.angleToPointer(players[socket.id].player); //вращаем игрока в сторону курсора
socket.emit("player_rotation", players[socket.id].player.rotation); //отправляем на сервер данные о вращени
setCollisions(); //функция вызывающаяся при столкновении пули с игроком
characterController(); //управление игроком
}
}
function bulletHitHandler(player, bullet) {
socket.emit("player_killed", player.id);
bullet.destroy(); // убираем пулю с поля, после попадания
} //функция при столкновении пули с игроком
function setCollisions() {
for (let x in players) {
for (let y in players) {
if (x != y) {
game.physics.arcade.collide(players[x].weapon.bullets, players[y].player, bulletHitHandler, null, this);
}
}
}
} //Проверка столкновения игрока с пулей
function sendPosition(character) {
socket.emit("player_move", JSON.stringify({
"id": socket.id,
"character": character
}));
} //отправляем инфу о том, куда игрок двинулся на сервер
function characterController() {
if (game.input.keyboard.isDown(Phaser.Keyboard.A) || keybord.left.isDown) {
//players[socket.id].player.x -= 5;
sendPosition("A");
}
if (game.input.keyboard.isDown(Phaser.Keyboard.D) || keybord.right.isDown) {
//players[socket.id].player.x += 5;
sendPosition("D");
}
if (game.input.keyboard.isDown(Phaser.Keyboard.W) || keybord.up.isDown) {
//players[socket.id].player.y -= 5;
sendPosition("W");
}
if (game.input.keyboard.isDown(Phaser.Keyboard.S) || keybord.down.isDown) {
//players[socket.id].player.y += 5;
sendPosition("S");
}
} //управление
function render() {
game.debug.cameraInfo(game.camera, 32, 32);
}
function addPlayer(playerId, x, y) {
player = game.add.sprite(x, y, "unit");
game.physics.arcade.enable(player);
player.smoothed = false;
player.anchor.setTo(0.5, 0.5);
player.scale.set(.8);
player.body.collideWorldBounds = true; //границы страницы
player.id = playerId;
let weapon = game.add.weapon(30, 'bullet'); //подключаем возможность выстрелов
weapon.bulletKillType = Phaser.Weapon.KILL_WORLD_BOUNDS;
weapon.bulletSpeed = 600; //скорость выстрелов
weapon.fireRate = 100;
weapon.trackSprite(player, 0, 0, true);
players[playerId] = { player, weapon };
game.camera.follow(players[socket.id].player, ); //слежение за игроком который открыл страницу
} //создаем игрока и даем ему ствол :)
|
Метки: author Dmitriy_Rudenko разработка игр node.js javascript phaser.js socket.io express mmo real-time |
Flashcache — дёшево и сердито или альтернатива HW RAID 10 SAS |
| Параметр | raid10 sas | SSD | MD | flashcache write back |
|---|---|---|---|---|
| глубина очереди | 32 | 32 | 32 | 32 |
| IOPSread | 1 401 | 51 460 | 598 | 6 124 |
| IOPSwrite | 999 | 23 082 | 230 | 3 205 |
| скорость чтения | 5 607 Kb/s | 205 842 Kb/s | 2 393 Kb/s | 24 496 Kb/s |
| скорость записи | 3 998 Kb/s | 92 329 Kb/s | 922 Kb/s | 12 823 Kb/s |
| RAID 10 SAS | примерные цены за март 2013 г. |
|---|---|
| SAS 600 Гб, 4 шт. | 7714 руб. x 4 |
| аппаратный контроллер + батарейка | 8600 руб. + 4500 руб. |
| кабель | 850 руб. |
| = 44806 руб. или 1493 $ ( при курсе 1$=30 руб.) | |
| — стоимость 1 Тб места на родительском сервере |
| SATA HDD + SSD | цены на май 2017 г. |
|---|---|
| SATA HDD 4 Тб, 2 шт. | 12 000 руб. x 2 |
| SSD | 17 100 руб. |
| = 41 100 руб. или 685 $ ( при курсе 1$=60 руб.) |
|
|
Открытая трансляция из главного зала конференции HolyJS 2017 Piter: Douglas Crockford, Lea Verou и еще кое-кто |
 10:30-11:30 Алексей Золотых — ES2017 vs Typescript vs Dart. Сравниваем без эмоций
10:30-11:30 Алексей Золотых — ES2017 vs Typescript vs Dart. Сравниваем без эмоций 12:00-13:00 Douglas Crockford — Goto There and Back Again
12:00-13:00 Douglas Crockford — Goto There and Back Again  13:30-14:30 Anjana Vakil — Functional Programming in JS: What? Why? How?
13:30-14:30 Anjana Vakil — Functional Programming in JS: What? Why? How? 15:15-16:15 Алексей Иванов — Внутреннее устройство бандла webpack
15:15-16:15 Алексей Иванов — Внутреннее устройство бандла webpack 16:45-17:45 Владимир Гриненко — Зависимости в компонентном вебе, сделанные правильно
16:45-17:45 Владимир Гриненко — Зависимости в компонентном вебе, сделанные правильно 18:15-19:15 Lea Verou — JS UX: Writing code for humans
18:15-19:15 Lea Verou — JS UX: Writing code for humans 
|
Метки: author osma программирование javascript блог компании jug.ru group javascript framework конференция holyjs трансляция трансляция видео |
Визуальный редактор писем на React+Redux. Обзор, пример использования и расширения |
Всем привет! Не так давно мне поступила задача встроить визуальный редактор email в наш сервис внутренней рассылки, ибо людям надоело набирать html руками и компоновать валидные шаблоны для писем. Побродив по интернету, я нашёл 2 редактора, которые, как мне тогда казалось, прекрасно подойдут для этих целей. Ссылки на них приведу в конце топика. Изучив их более внимательно (EmailEditor написан с использованием jQuery, который я в своё время неплохо изучил, а Mosaico был на KnockoutJS, с ним я знаком лишь поверхностно), я остановился на EmailEditor, и снова окунулся в то дерьмо из которого год назад так успешно выбрался с помощью Angular и Ionic, а именно — файлы по 2-3к строк, повсеместное и рандомное изменение DOM различными способами из различных мест и т.д., ну вы меня понимаете).
Потратив больше месяца на попытки пофиксить все баги, запилить нужные нам для рассылки строительные блоки и прочее, я сдался… Решил попробовать Mosaico и даже начал активно изучать Knockout, но проблема в том, что этот монстр (я про Mosaico) был настолько сложно написан, что EmailEditor показался не таким уж и плохим. Плюс ко всему, а точнее минус, у Mosaico практически нет вменяемой документации и если в первом я интуитивно понимал как всё работает и как создать свои блоки, то тут никакая интуиция мне не помогла. Возможно, просто не хватило мозга, терпения и желания разбираться, не знаю, просто гляньте на досуге исходники этих редакторов… А сроки поджимали...
спросил я себя, и сам же себе ответил "Конечно же, изобретать велосипед! С золотой цепью и малиновыми колёсами!". Так получилось, что как раз в этот момент для одного из своих pet-projects мне нужно было приступить к изучению популярного на сегодняшний день React+Redux подхода к построению веб приложений. Прочитав про Redux, меня осенило! Вот же оно! Состояние приложения в одном месте — это ли не лучший вариант, чтобы строить архитектуру, в которой будет меняться JSON представление шаблона письма! И я начал писать… После пары недель бессонных ночей, начальству был презентован прототип и решено попробовать внедрить мой редактор. По репозиторию может быть заметно, что в самом начале мне трудно было определиться со структурой шаблона и принципами работы, но по мере изучения, пробуя разные подходы, решил не усложнять и таки пришёл к тому, что есть сейчас, а именно:
Вот и весь store.
C чего бы начать… Здесь и далее я предполагаю что у вас установлены NodeJS, npm, и, желательно, MongoDB, а также, что у вас есть небольшой опыт работы как с ними, так и с React+Redux стеком. Запуск live development простой, поскольку проект пишется с использованием create-react-app. Так что, после того как скопируете репозиторий, просто выполните:
npm install
npm start
в папке проекта и в вашем браузере откроется адрес http://localhost:3000, где вы увидите примерно такую картину:

Из доступных локалей пока поддерживаются только en и ru, загрузка происходит напрямую из JSON файла в папке translations и, к сожалению, я пока не написал проверку того, доступна ли пользовательская локаль, чтобы подставить по дефолту, но это мелочи, это потом… Точка входа приложения — index.js в корне src/, там задаётся первоначальный store, и диспатчатся три action'а, чтобы загрузить локаль, список блоков и шаблон взятый по ID из вашего хранилища, либо, если ID не указан, — шаблон по умолчанию. Поскольку первоначально происходит запуск без каких-либо параметров, всё будет загружено из локальных файлов, настройка сервера на данном этапе не требуется (но понадобится для методов сохранения\загрузки шаблона, загрузки изображения и отправки тестового письма).
Интерфейс до жути простой — слева панель настроек и блоков, по центру — шаблон письма, по бокам от шаблона — кнопки. Блоки можно перетаскивать на шаблон (они добавляются как бы поверх целевого блока, смещая всё вниз), при наведении на целевой блок он меняет цвет. Тут я думаю о том, чтобы реализовать "фантомный блок", как в некоторых других редакторах, но это не приоритетная задача. При клике на блок активируется вкладка, в которой содержатся настройки для выделенного блока, и этот блок подсвечивается, а также появляется кнопка удаления блока, что видно на скриншоте:

Ну а если выбрать вкладку общих настроек, вы увидите набор настроек, которые будут применяться ко всем блокам, кроме тех, у которых стоит флаг Custom style. Также там есть возможность задать фон контейнера шаблона:

Клики на кнопках позволяют сохранить шаблон (вас попросят задать имя шаблона, но это легко выпиливается), отправить тестовое письмо и удалить блок (в планах также реализовать Undo\Redo функционал, сейчас читаю об этом)
Вы также можете запустить и поиграться с NodeJS сервером (он в папке server_nodejs), предварительно скопировав туда папку build которая появится если вы сделаете npm run build в основной папке проекта (не забудьте выполнить npm install в обеих папках!). Что умеет сервер: сохраняет\выдаёт шаблон(?id=ваш_id) и загружает изображения, а также говорит 'OK' при отправке тестового письма =). Думаю, разобраться не составит труда, структура проекта довольно простая, я вообще не люблю усложнять… Точка входа — app.js, в папке app есть Controller — там всё поведение, Router — прописаны пути и связаны с контроллером, и TemplateModel — ORM для шаблона.
В папке src/components есть подпапки blocks и options в которых лежат шаблоны блоков и настроек этих блоков.
import React from 'react';
const BlockHr = ({ blockOptions }) => {
return (
);
};
export default BlockHr;import React from 'react';
const OptionsHr = ({ block, language, onPropChange }) => {
return (
);
};
export default OptionsHr;также в папке src/components есть файл Block.js, в котором подключены все блоки из blocks и switch...case, в котором по block_type (который я упоминал выше) определяется какой вариант блока будет возвращён.
Такой же принцип и в файле Options.js для настроек. И вот от этой архитектуры мне хотелось бы уйти как можно скорее (может у кого-то есть мысли в какую сторону осуществить переход?). В файле BlockList.js содержится шаблон письма, в котором видно, как всё устроено — в цикле строятся tr>td элементы, и td в данном случае является контейнером внутри которого уже размещается блок с элементами. Тут же подхватываются и настройки контейнера (стили из block.options.container), а также реализована DnD логика. В настройке тоже всё достаточно прозрачно, на инпуты навешаны обработчики onChange, внутри которых вызывается onPropChange(prop, value, container?, element_index) с параметрами ('свойство для изменения, например, color', новое значение свойства, элемент для изменения (контейнер — true, элемент — false), индекс элемента). В принципе это основная идея и больше рассказывать нечего =). На mindmap'е я постарался схематично изобразить работу этого конвейера:

P.S. В репозитории две ветки — master и react_email_editor_wordpress. В принципе особых отличий нет, различия в файлах sagas/api.js (у WP свой подход к AJAX), блоках типа feedback и social (там пути к картинкам другие… WP жеж). Редактор у нас интегрирован в WP и на данный момент тестируется.
Очень просто! Ну мне так кажется, потому что я с этим работал плотно и каждодневно…
Начну с выбора типа блока. Бродя по интернету, я наткнулся на один симпатичный шаблон:
Мне понравился блок с тремя пиктограммами WEBSITES, SERVICES, SEO. Что-ж, попробую рассказать как же реализовать такой блок. Для начала давайте определимся с составом блока. Я вижу тут 6 элементов: 3 картинки и 3 текстовых элемента, ну а вы можете впоследствии запрограммировать своё видение этого блока. Поскольку я старался сделать как можно более гибкую настройку, вы вольны придумать практически любую компоновку (например 3 элемента картинка-текст), и это будет вполне реально осуществить. Довольно слов, go кодить!
Откройте файл public/components.json и добавьте следующий JSON:
...тут предыдущие блоки...
{
"preview": "images/3_icons.png",
"block": {
"block_type": "3_icons",
"options": {
"container": {
"padding": "0 50px",
"color": "#333333",
"fontSize": "20px",
"customStyle": false,
"backgroundColor": "#F7F8FA"
},
"elements": [{
"source": "https://images.vexels.com/media/users/3/136010/isolated/preview/e7e28c15388e5196611aa2d7b7056165-ghost-skull-circle-icon-by-vexels.png"
},
{
"source": "http://www.1pengguna.com/1pengguna/uploads/images/tipimgdemo/kesihatan.gif"
},
{
"source": "https://upload.wikimedia.org/wikipedia/commons/thumb/5/56/Circle-icons-cloud.svg/2000px-Circle-icons-cloud.svg.png"
},
{
"text": "DEADS",
"textAlign": "center"
},
{
"text": "LOVES",
"textAlign": "center"
},
{
"text": "CLOUDS",
"textAlign": "center"
}]
}
}
},
...тут следующие блоки...Таким образом, мы определили блок типа 3_icons с превью images/3_icons.png, контейнером и шестью элементами. У них уже есть какая-то базовая настройка стилей, чтобы при добавлении смотрелось более-менее прилично. Ок, далее открываем GIMP (если установлен) и в нём открываем файл preview_template.xcf, который лежит в корне проекта. Эту заготовку я сделал для того, чтобы клепать превью блоков. Путём нехитрых манипуляций (Cut\Paste\Colorize) из исходного изображения шаблона получим превью для будущего блока:

Сохраните его в папку src/images (или public/images, а лучше в оба места) и обновите страницу с редактором. Вы увидите, что новый блок добавился на позицию, на которой вы его вставили в components.json

Теперь создадим шаблон блока. Добавьте новый файл Block3Icons.js в папку src/components/blocks:
import React from 'react';
const Block3Icons = ({ blockOptions, onPropChange }) => {
const alt="cool image";
return (



{blockOptions.elements[3].text}
{blockOptions.elements[4].text}
{blockOptions.elements[5].text}
);
};
export default Block3Icons;Как видно, блок простейший — 2 строки 3 столбца. Из настроек для элементов я пока сделал доступными только source для элементов изображений и text для текстовых элементов, стили контейнера применяются в файле BlockList.js, о котором я упоминал выше по тексту.
Пора создать настройку блока. Добавьте новый файл Options3Icons.js в папке src/components/options:
import React from 'react';
const Options3Icons = ({ block, language, onFileChange, onPropChange }) => {
let textIndex = 3;
let imageIndex = 0;
return (
);
};
export default Options3Icons;Отлично! Почти готово! Надеюсь, в том, что мы тут уже создали, вы хоть немного ориентируетесь? В блоке всё тупо (потому что он dumb component, т.е. рендерится только на основе своих props). В настройках каждому элементу ввода (checkbox, input, etc...) сопоставлен обработчик, в котором вызывается onPropChange для свойств (про это я тоже упоминал выше). На основе этих свойств блок динамически отрисовывается заново. Всё просто. Давайте теперь применим результаты трудов и посмотрим, наконец, работает ли это всё вообще =).
Для этого надо добавить в файл src/components/Block.js импорт нового блока и условие для его возвращения:
//...тут другие import'ы...
import Block3Icons from './blocks/Block3Icons';
//...тут тоже...
//...тут другие case'ы...
case '3_icons':
return Почти то же самое проделайте в файле src/containers/Options.js
//...тут другие import'ы...
import Options3Icons from '../components/options/Options3Icons';
//...тут тоже...
//...тут другие case'ы...
case '3_icons':
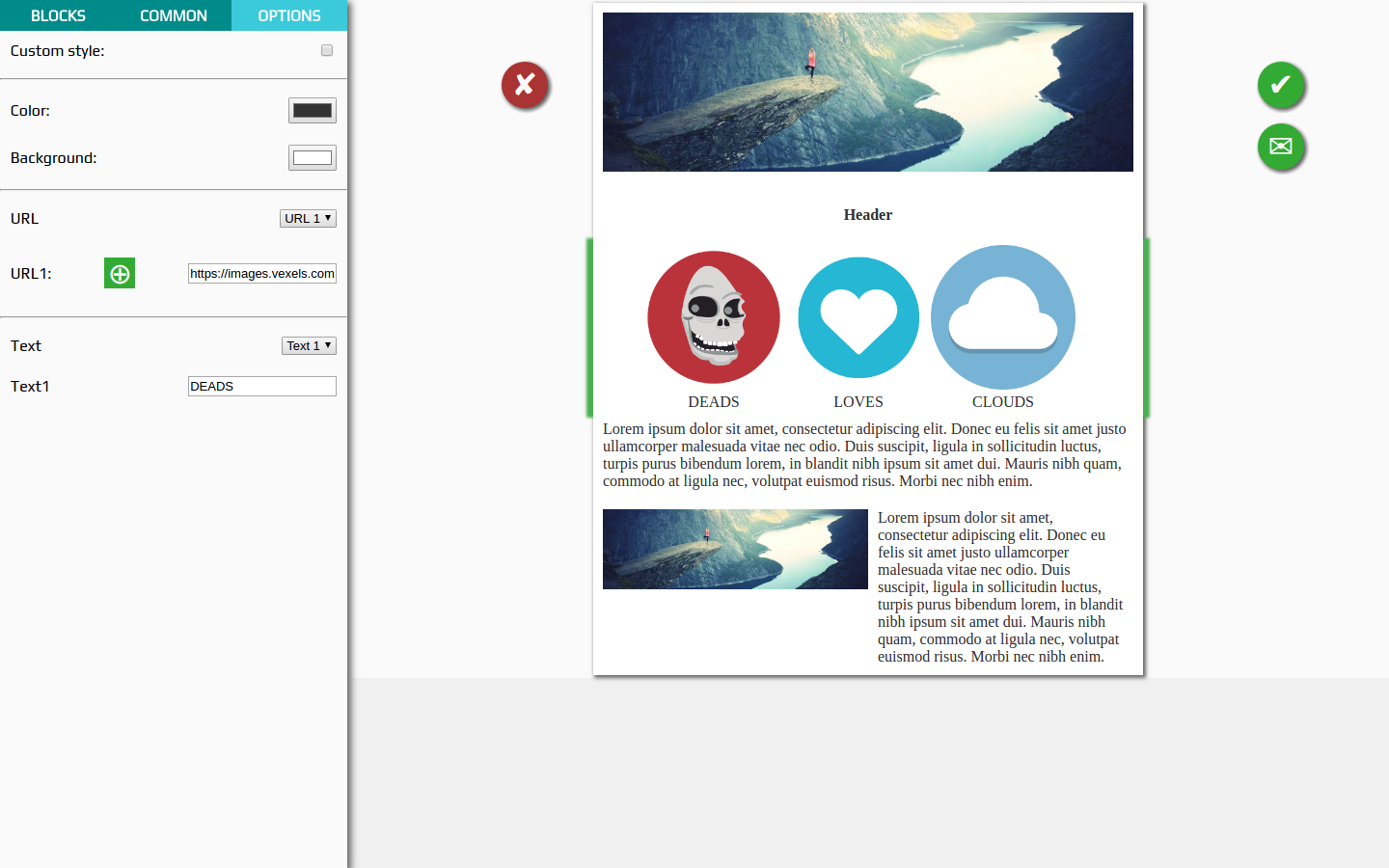
return Теперь сохраняем все файлы, и, если вы ранее запускали npm start в корне проекта, у вас должно всё скомпилироваться без ошибок. Перетащите ваш новый блок на шаблон, выделите его и поиграйтесь с его настройками. Вот пример, как это выглядит у меня:
Я старался сделать редактор как можно более простым в использовании и достаточно удобным в плане интерфейса, а вышло ли у меня это или нет — решать конечно же вам. На мой взгляд получился редактор с низким порогом входа в плане внедрения и расширения компонентной базы в противовес Mosaico. Также у него гораздо более прозрачная (опять же по сравнению с Mosaico) и менее забагованная (по сравнению с EmailEditor'ом) реализация, которая легко настраивается, расширяется и переписывается под свои нужды буквально за часы (реже — дни).
В планах продолжить вести работу над следующими пунктами:
Буду рад помощи, советам, критике, любому фидбеку. На основе этого решу продолжать ли заниматься проектом =).
На этом пока всё… Спасибо за внимание! В дальнейшем буду писать только об очень крупных изменениях, если, конечно, проект окажется кому-нибудь полезен.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author m0sk1t верстка писем reactjs node.js javascript почто-велик на react'ивном топливе js react redux email потеря волос на заднице |
[Перевод] Не слишком ли много текста в вашей игре? |

«Слишком длинно. Вырежьте половину».
«Какую половину?»
«Ту, которая лишняя».
Их звёздные полтора часа



|
Метки: author PatientZero разработка игр storytelling сюжет тексты |
Чат своими руками |
|
Метки: author SSul разработка под ios разработка мобильных приложений блог компании simbirsoft ios development ios разработка чаты uikit uicollectionview xmpp |
StringBuffer, и как тяжело избавиться от наследия старого кода |
StringBuilder. Более легковесная и разумная альтернатива StringBuffer. Вот, что говорит официальная документация по StringBuffer:Этот класс дополнен аналогичным классом предназначенным для использования в одном потоке — StringBuilder. В общем случае нужно отдавать предпочтение классу StringBuilder, так как он поддерживает все те же операции, что и этот (StringBuffer), но быстрее, так как не выполняет никаких синхронизаций.
synchronized в StringBuffer вообще никогда не было хорошей идеей. Основная проблема в том, что одной операции никогда не достаточно. Одиночная конкатенация .append(x) бесполезная без других операций, таких как .append(y) и .toString(). В то время, когда каждый конкретный метод потокобезопасный, вы не можете сделать несколько вызовов без конкуренции между потоками. Ваша единственная опция — внешняя синхронизация.public class Main {
public static void main(String... args) {
System.out.println("Hello " + "world");
}
}
public class Main {
public static void main(String[] args) throws IOException {
System.out.println("Waiting");
System.in.read();
}
}jmap -histo {pid} | grep StringBuffer 18: 129 3096 java.lang.StringBufferStringBuffer которые создала Java 8 Update 121. Это меньше, чем в прошлый раз, когда я проверял, но всё равно, немножко удивительно.public class Main {
public static void main(String[] args) throws IOException {
IntStream.range(0, 4).forEach(System.out::println);
System.out.println("Waiting");
System.in.read();
}
}jmap опять и что мы видим? 17: 545 13080 java.lang.StringBufferTotal 35486 4027224StringBuffer в 9-ке.StringBuffer. Не забываем про Vector, Hashtable и прочие приятности.
|
Метки: author doom369 java stringbuffer stringbuilder legacy жизнь-боль |
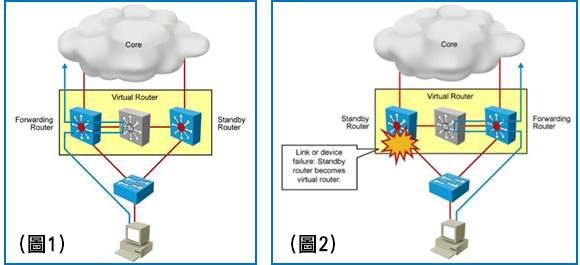
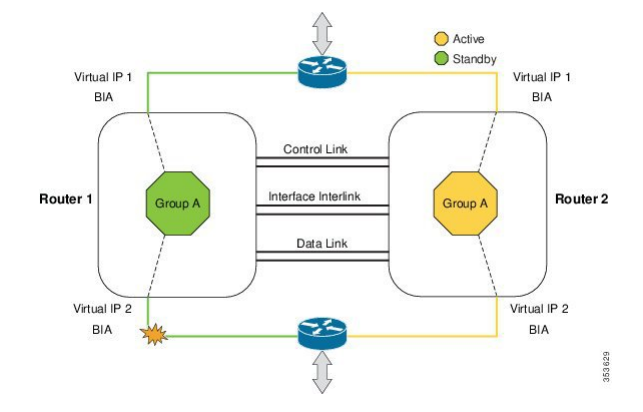
Cisco CSR 1000v: Надёжность – залог успеха. Часть 2 |


|
|
HexRaysPyTools: декомпилируй с удовольствием |

В этой статье я собираюсь рассказать о плагине для IDA Pro, который написал прошлым летом еще находясь на стажировке в нашей кампании. В итоге, плагин был представлен на ZeroNights 2016 (Слайды) и, с тех пор, в нём было исправлено несколько багов и добавлены новые фичи. Хотя на GitHub я постарался описать его как можно подробнее, обычно коллеги и знакомые начинают пользоваться им только после проведения небольшого воркшопа. Кроме того там опущены некоторые детали внутренней работы, которые позволили бы лучше понять и использовать возможности плагина. Поэтому хотелось бы попытаться на примере объяснить как с ним работать, а также описать некоторые проблемы и тонкости.
HexRaysPyTools, как можно догадаться из названия, направлен на улучшение работы декомпилятора Hex-Rays Decompiler. Декомпилятор, создавая псевдо-С код, существенно облегчает работу ревёрсера. Основым его достоинством, выделяющим на фоне других подобных инструментов, является возможность трансформировать код, приводя его к удобному и понятному виду, в отличие от ассемблерного кода, который, даже при самом лучшем сопровождении, требует некоторой доли внимания и сосредоточенности для понимания его работы. У Hex-Rays Decompiler, как и самой IDA Pro, есть API, позволяющий писать расширения и выходить за рамки стандартного функционала. И хотя API очень широк и, в теории, позволяет удовлетворить самые изысканные потребности разработчика дополнений, он страдает несколькими существенными недостатками, а именно:
idaapi содержит новые методы наткнуться на которые получилось чисто случайно.idaapi в абстрактное синтаксическое дерево (оно всегда строится, когда происходит декомпиляция и в нём можно изменять объекты или вставлять свои)Чтобы разобраться во всем этом, помогали рабочие примеры, собранные в интернете (что-то интересное нашлось даже в китайском сегменте). Так что теперь, если кто-то захочет создать что-то своё для декомпилятора, то можно обратиться еще и к исходным кодам моего плагина.
Перейдем к описанию плагина. В HexRaysPyTools можно выделить две отдельные категории — это помощь по трансформации дефолтного вывода Hex-Rays Decompiler к удобному виду и реконструкция структур и классов.
Изначально, после запуска декомпилятора клавишей F5, IDA Pro выдаёт не очень понятый код, состоящий преимущественно из стандартных типов и имён переменных. И несмотря на то, что местами она пытается угадать типы, создать массивы или назвать эти переменные (которым повезло оказаться аргументами у стандартных функций) получается у неё это не очень. В целом это работа ревёрсера привести к адекватному виду декомпилированный код. К сожалению, есть вещи, которые невозможно сделать не прибегая к IDA SDK. Например, отрицательные обращения к полям структур, которые всегда выглядят безобразно (порой превращаясь в массивы с отрицательными индексами), а также длинные условные вложения, тянущиеся из левого верхнего угла в правый нижний. Кроме этого очень не хватает горячих клавиш и опций для более быстрой трансформации кода. По мере получения информации в процессе анализа программы приходится изменять сигнатуры функций, переименовывать переменные и изменять типы. Всё это требует большого количества манипуляций мышкой и копирований-вставок. Перейдем к описанию того, что предлагает плагин, для решения этих проблем.
Очень часто встречаются при реверсинге драйверов или ядра Windows или модулей ядра Linux. Например, несколько разных структур могут быть расположены в двусвязном списке с использованием структуры LIST_ENTRY. При этом у каждой структуры обращение к этому двусвязному списку может производиться из произвольного поля.
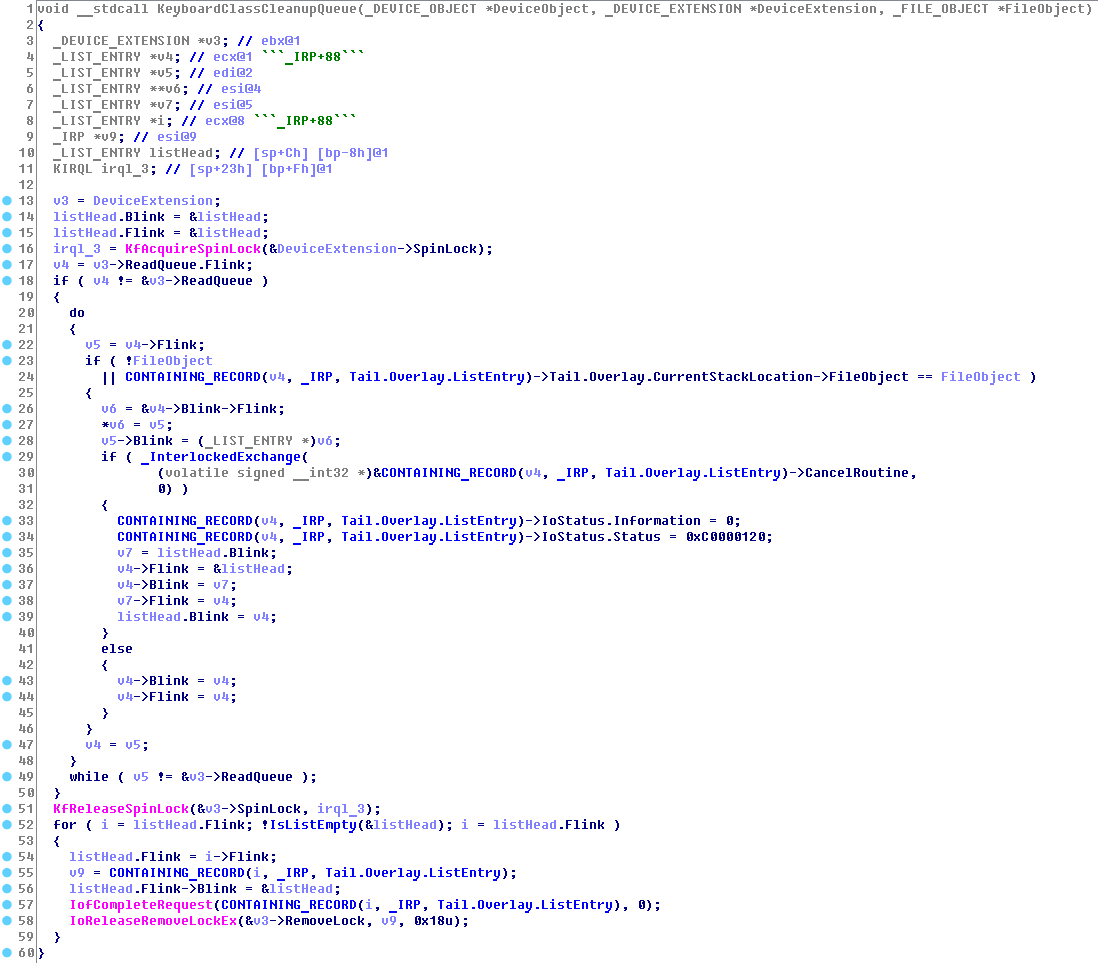
В результате, когда мы смотрим на то, что получается в IDA Pro, видим следующую картину:

Такой вывод будет всякий раз, когда в исходных кодах программ используются макросы CONTIAINING_RECORD (windows) и container_of (linux). Эти макросы возвращают указатель на начало структуры по её типу, адресу и названию поля. И именно их плагин позволяет вставлять в дизассемблер. Вот как выглядит пример после его применения:
Еще с отрицательными смещениями можно встретиться при множественном наследовании, но это довольно изысканный пример и надо еще постараться встретить его в своей практике.
Для того, чтобы вставить макрос в дизассемблер, нужно чтобы подходящая в данном контексте структуры существовала в Local Types или в одной из библиотек в Types Library (их может быть несколько). Мы кликаем по вложенной структуре правой кнопкой и выбираем Select Containing Structure. Далее выбираем где искать структуру — либо в Local Types, либо в Types Library и плагин составляет список подходящих структур. Для этого он анализирует как указанная переменная используется в коде и определяет минимальную и максимальную границы, по которым может находиться поле типа этой переменной. Затем используя эти сведения проходит по всем структурам отбирая те из них, которые содержат поле и у него все в порядке с границей. При поиске плагин смотрит вложенные структуры и объединения на любую глубину.
В примере выше у exe-файла есть символы, поэтому список подходящих структур получился довольно большой:
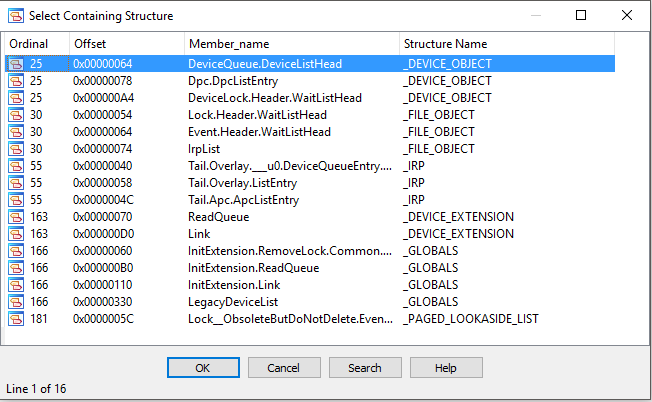
Помимо этого, существует ситуация, когда плагин автоматически может вставить макрос. Дело в том, что, когда есть явное присвоение указателя, IDA Pro догадывается (иногда неправильно) его вставить, но она не распространяет его дальше в коде.
Без плагина:

С плагином:

Пожалуй, лучше всего показать искусственный пример. Без плагина:

С плагином:

Подобное изменение будет произведено автоматически, если установлен плагин. Хотелось бы, чтобы можно было накладывать и вручную, но увы то, что выдаёт декомпилятор очень нестабильно в плане сохранения вносимых изменений в синтаксическое дерево.
Идея в том, чтобы называть переменную или аргумент приходилось не более одного раза, а дальше все переименования совершались горячими клавишами или двумя кликами.
Часто IDA Pro создаёт дублированные переменные. Можно было бы, используя стандартную опцию "map to another variable", избавиться от них. Но это не всегда удобно при отладке, может быть ошибочно и к тому же невозможно откатить не пересоздавая функцию заново.
Перебросить можно имя с одной переменной на другую, при этом добавляется символ "_":
До:
После:

Можно переименовать аргумент у функции, заставив её взять имя переменной (при этом лишние символы подчёркивания уберутся). Либо наоборот, переменной присвоить имя аргумента функции.
Существует множество ситуаций, когда есть взаимодействие между двумя некоторыми сущностями с разными типами и нам нужно перенести тип одной сущности на другую. Под сущностями понимаются локальные, глобальные переменные, аргументы, функции, поля структур (с обращением по ссылке и без) и возвращаемые значения функции. Плагин позволяет это быстро произвести. Сложно показать это картинкой, рекомендую каждый раз, когда нужно перенести тип одной сущности на другую, кликнуть правой кнопкой мыши по ней и посмотреть на опции. В большинстве случаев там появится "Recast ..." (а если не появится, то можно написать мне, и я попробую её добавить).
Помимо этого, добавляются следующие опции:
sizeof(Structure)). Удобно для поиска структуры подходящего размера по числу байт, указанных оператору new или функции malloc.Одной из самых сложных и энергозатратных задач ревёрс-инжиниринга является понимание работы и реконструкция структур и классов. HexRaysPyTools выступает помощником в этом процессе. В чём собственно проблема? Средствами по умолчанию можно только залить уже готовое объявление структуры, поэтому приходится ползать по коду пытаясь насобирать сведения о полях, вручную высчитывать смещения и записывать куда-то всю информацию (например, в блокнот). Но, если у нас размеры классов исчисляются сотнями байт и, в придачу, имеют множество методов и несколько виртуальных таблиц, то всё становится гораздо сложнее.
Рассмотрим на примере, как помогает в данном случае плагин. Когда-то (исключительно ради самообразования :D) я делал бота для онлайн игрушки и наткнулся на защиту, шифрующую пакеты, не позволявшую модифицировать код в памяти и мешающую хукать вызов шифрующей функции (которая была жестко обфусцирована). Для того чтобы обойти её нужно было распарсить класс, отвечающий за обмен данными между клиентом и сервером и научиться, используя его, вызывать отправку пакетов и считывать полученные, расшифрованные пакеты за несколько вызовов от функций защиты. Тогда для меня это было непростой задачей, но с плагином всё делается довольно просто.
Вот так выглядит метод принимающий пакеты. this и v1 являются указателями на объект класса, gepard_1 — это функция, заменяющая recv

Если заглянуть внутрь функций sub_41AF50 и sub_41AFF0, то можно увидеть довольно много кода, обращающегося к разным полям. И даже — это только часть функционала ответственного за создание и отправку пакетов, поэтому разобраться в назначении полей может оказаться непросто. Плагин помогает автоматически проанализировать большое количество кода, и из собранной информации составить некий каркас структуры, которая в дальнейшем анализе может быть изменена исследователем и использована для автоматического сознания нового типа. Для начала надо открыть Structure Builder через Edit->Plugins->HexRaysPyTools. Это окошко будет содержать собранную информацию, предоставлять возможность для редактирования имен полей и разрешения конфликтов, а также просмотра виртуальных таблиц и сканирования виртуальных функций.
Есть 3 возможных способа собирать информацию о полях.
1) Можно кликнуть правой кнопкой по переменной и, нажав Scan Variable, запустить сканирование в пределах одной функции. При сканировании будет рассматриваться то, как происходит обращение к переменной и, если оно под падает под паттерн обращения к полю, то такая информацию будет запомнена. Если другой переменной присваивается значение первой (причем их типы не обязательно должны совпадать), то она так же подключается к сканированию (и отключается, если ей будет присвоено новое значение). Вот какой результат будет, если применить этот метод к переменной this в функции выше:

Хотя мы запускали сканирование для переменной this, информация о v1 также была собрана.
Жёлтым отмечены разного рода обращения к полям и нужно выбрать какой вариант более подходящий, отключив все остальные. До тех пор, пока есть конфликты, создать финальную структуру будет нельзя. Красный — это смещение начиная с которого производится сканирование. Его можно сдвинуть с помощью кнопки Origin для того чтобы просканировать потенциальную подструктуру. Например, можно зайти в функцию sub_41AF50 и сдвинув указатель собрать немного новой информации:
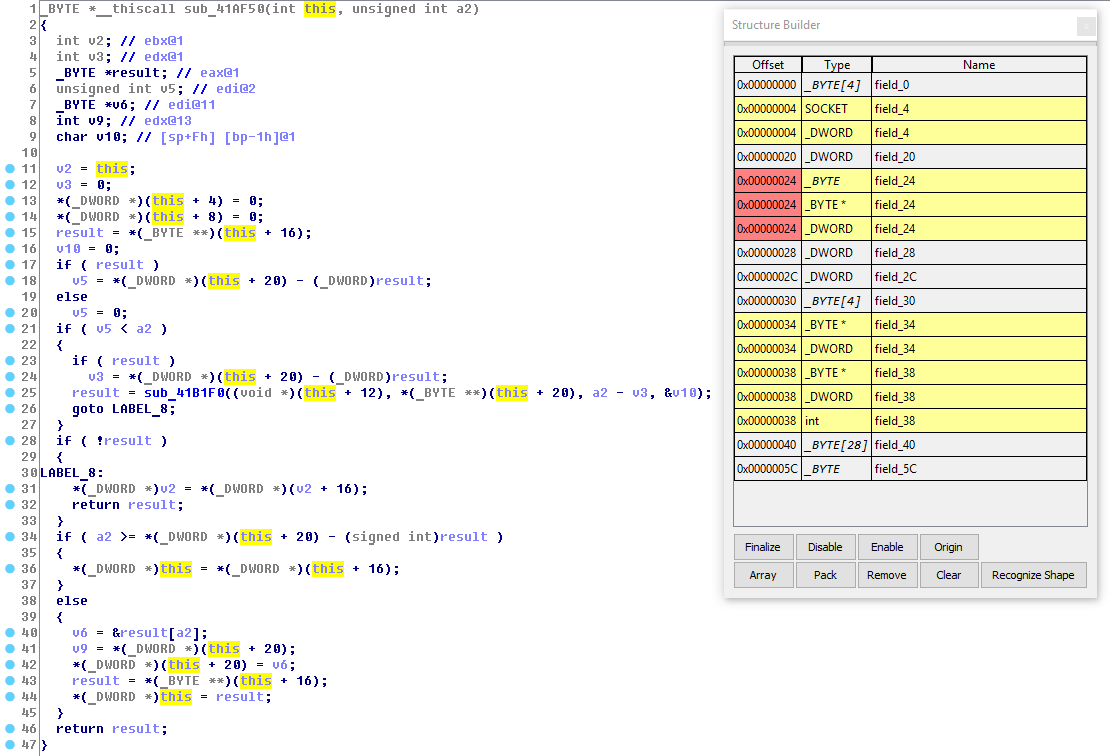
Если дважды кликнуть по столбцу Offset интересующего поля, то можно увидеть список всех обращений к этому полю и быстро переместиться в дизассемблере к месту обращения. Поэтому есть смысл как можно сильнее покрывать сканированиями все места использования восстанавливаемой структуры. Больше информации о полях — проще разобраться что зачем нужно. Сканировать каждую переменную может быть весьма утомительно, т.к. указатель на структуру может путешествовать по большому количеству функций, поэтому есть другой способ сбора информации.
2) Кликнув правой кнопкой по переменной, можно выбрать опции "Deep Scan Variable". Основной процесс сканирования будет такой же как и у первого способа, только теперь, если указатель на структуру будет передаваться как аргумент функции, то будет запущенно рекурсивное сканирование этого аргумента. Warning! Здесь есть одна проблема — декомпилятор не всегда распознает правильно аргументы функции, которую он еще не декомпилировал, поэтому приходится рекурсивно заходить и декомпилировать каждую функцию, которая потенциально может содержать указатель на нашу структуру как аргумент. Этот процесс запускается автоматически и случается только один раз за сессию для каждой функции. Поэтому первые процессы глубокого сканирования могут занять некоторое время (порядка пары минут)
Переместившись несколько раз вверх по цепочке вызов, можно найти место, где создается структура:
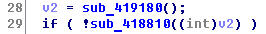
Запустив здесь сканирование получаем следующее:

3) Начинать сканировать лучше всего там, где структура впервые возникает, чтобы максимально покрыть её использование в коде. Плагин предоставляет возможность просканировать все переменные, которым присваивается результат, возвращаемый конструктором.
Если зайти в функции sub_419890, которая впервые возвращает указатель на структуру, то можно увидеть, что используется паттерн одиночка:
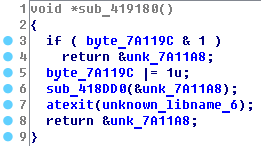
Количество вызовов этой функции очень велико:
Сканировать каждую переменную было бы утомительно, поэтому есть возможность запустить сканер для всех сразу, кликнув по заголовку функции и выбрав опцию "Deep Scan Returned Variables"
Вот результат применения на моём примере:

Можно заметить, что нашлась информация об обращении к полям 0x8 — 0x14. Так же нашлись виртуальные таблицы — они отображены жирным шрифтом и, дважды кликнув по ним, можно увидеть список виртуальных функций (а заодно и просканировать их как по одной, так и все сразу)
Теперь можно разбираться с устройством структуры. Напомню, что кликнув по офсету можно увидеть все обращения к полям.
Вот, что получилось у меня после непродолжительного анализа:
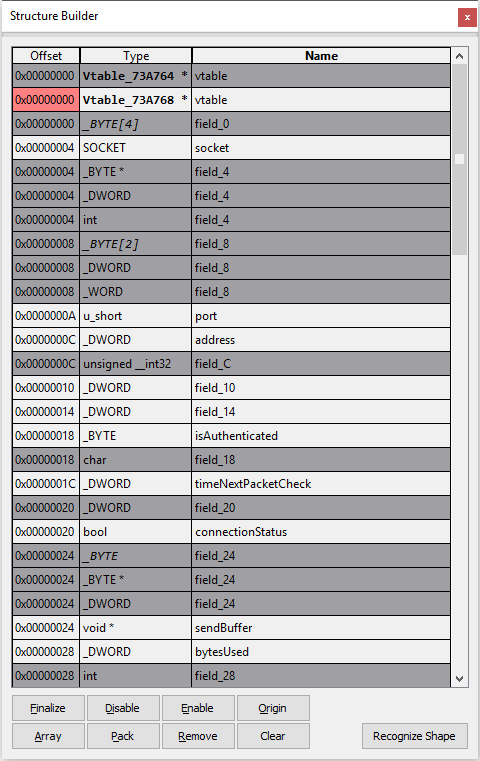
Подготовка создания структуры завершена. Теперь можно кликнуть "Finalize" и, внеся последние изменения, закончить её создание:
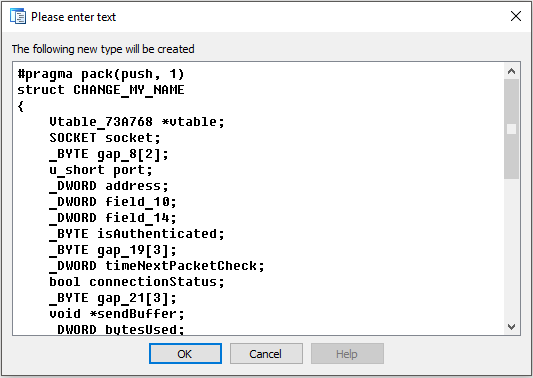
Далее, везде, куда протянул свои руки сканнер, переменным, которые являлись указателем на эту структуру будет применён её новосозданный тип. Вот как преобразится функция отправки пакетов:

Помимо представленного, в Structure Builder можно создать или попытаться угадать подструктуры, выделив необходимое количество полей и нажав Pack или Recognize Shape соответственно. При поиске подходящей структуры учитываются типы полей — они должны точно совпадать, за исключением базовых типов (char — BYTE, int — DWORD — int *) считающихся одинаковыми.
Для уже созданных классов (структур с виртуальными таблицами), в плагине есть возможность более удобной работы с ними. По пути View-> Open Subviews-> Classes можно открыть следующее окошко:

Здесь можно:
И еще, хотелось бы лишний раз напомнить, что при работе с классами очень удобно использовать плагин ClassInformer. Если в файле есть RTTI информация, то это поможет восстановить иерархия классов, а мой плагин возьмёт имена виртуальных таблиц, что поможет получить близкие к оригиналу имена классов.
Надеюсь эта статья поможет разобраться как пользоваться плагином. Найти его и сообщить о багах можно по адресу — https://github.com/igogo-x86/HexRaysPyTools. Также жду feature requests.
|
Метки: author igogo_x86 реверс-инжиниринг информационная безопасность блог компании «digital security» ida python |
Динамический Angular или манипулируй правильно |
|
Метки: author KyKyPy3uK разработка веб-сайтов angularjs блог компании infowatch angular 4 angular модальные окна |
[Перевод] Да, Python медленный, но меня это не волнует |

Оптимизируйте использование своих самых дорогих ресурсов.Исторически самым дорогим было процессорное время. Именно к этому подводят при изучению информатики, фокусируясь на эффективности различных алгоритмов. Увы, это уже не так — железо сейчас дёшево как никогда, а вслед за ним и время выполнения становится всё дешевле. Самым дорогим же становится время сотрудника, то есть вас. Гораздо важнее решить задачу, нежели ускорить выполнение программы. Повторюсь для тех, кто просто пролистывает статью:
Гораздо важнее решить задачу, нежели ускорить выполнение программы.

Единственный способ выжить в бизнесе — развиваться быстрее, чем конкуренты.
 Крупные компании, такие как Amazon, Google или Netflix, понимают важность быстрого развития. Они специально строят свой бизнес так, чтобы быстро вводить инновации. Микросервисы помогают им в этом. Эта статья не имеет никакого отношения к тому, следует ли вам строить на них свою архитектуру, но, по крайней мере, согласитесь с тем, что Amazon и Google должны их использовать. Микросервисы медленны по своей сути. Сама их концепция заключается в том, чтобы использовать сетевые вызовы. Иными словами, вместо вызова функции вы отправляетесь гулять по сети. Что может быть хуже с точки зрения производительности?! Сетевые вызовы очень медленны по сравнению с тактами процессора. Однако, большие компании по-прежнему предпочитают строить архитектуру на основе микросервисов. Я действительно не знаю, что может быть медленнее. Самый большой минус такого подхода — производительность, в то время как плюсом будет время выхода на рынок. Создавая команды вокруг небольших проектов и кодовых баз, компания может проводить итерации и вводить инновации намного быстрее. Мы видим, что даже очень крупные компании заботятся о времени выхода на рынок, а не только стартапы.
Крупные компании, такие как Amazon, Google или Netflix, понимают важность быстрого развития. Они специально строят свой бизнес так, чтобы быстро вводить инновации. Микросервисы помогают им в этом. Эта статья не имеет никакого отношения к тому, следует ли вам строить на них свою архитектуру, но, по крайней мере, согласитесь с тем, что Amazon и Google должны их использовать. Микросервисы медленны по своей сути. Сама их концепция заключается в том, чтобы использовать сетевые вызовы. Иными словами, вместо вызова функции вы отправляетесь гулять по сети. Что может быть хуже с точки зрения производительности?! Сетевые вызовы очень медленны по сравнению с тактами процессора. Однако, большие компании по-прежнему предпочитают строить архитектуру на основе микросервисов. Я действительно не знаю, что может быть медленнее. Самый большой минус такого подхода — производительность, в то время как плюсом будет время выхода на рынок. Создавая команды вокруг небольших проектов и кодовых баз, компания может проводить итерации и вводить инновации намного быстрее. Мы видим, что даже очень крупные компании заботятся о времени выхода на рынок, а не только стартапы.Решение использовать интерпретируемый язык программирования в высокопроизводительных приложениях может быть парадоксальным, но мы столкнулись с тем, что CPU редко когда является сдерживающим фактором; выразительность языка означает, что большинство программ невелики и большую часть времени тратят на ввод-вывод, а не на собственный код. Более того, гибкость интерпретируемой реализации была полезной, как в простоте экспериментов на лингвистическом уровне, так и в предоставлении нам возможности исследовать способы распределения вычислений на многих машинах.
CPU редко когда является сдерживающим фактором.

Python, в целом, наиболее краток, даже в сравнении с функциональными языками (в среднем в 1,2-1,6 раза короче).
import __hello__Любые улучшения, сделанные где-либо помимо узкого места, являются иллюзией. — Джин Ким.
Преждевременная оптимизация — корень всех зол.Если быть точным, то более полная цитата:
Мы должны забыть об эффективности, скажем, на 97% времени: преждевременная оптимизация — корень всех зол. Однако мы не должны упускать наши возможности в этих критических 3%.


|
Метки: author TyVik программирование python сравнение производительности продуктивность работы почему не любят python |
[Перевод] Вышел GitLab 9.2: Несколько исполнителей задачи, конвейеры по расписанию, локализация, альфа-версия аварийного восстанов |

GitLab спроектирован таким образом, что каждый участник проекта может вносить свой вклад, независимо от размера команды и местонахождения ее участников.
Зачастую в процессе разработки продукта несколько человек работают над одной задачей: например, разработчики фронтэнда и бэкэнда, дизайнер интерфейса, тестировщик и менеджер продукта. С выходом GitLab 9.2 все они могут быть назначены исполнителями одной задачи, что упрощает процесс совместной разработки и позволяет наглядно отображать их общую область ответственности.
Также в версии 9.2 положено начало процесса локализации GitLab: аналитика цикла разработки (Cycle Analytics) теперь доступна на испанском и немецком языках. Локализация GitLab будет продолжена в последующих релизах, чтобы каждый мог вносить свой вклад независимо от родного языка.
Кроме того, разработчики получили больше контроля над временем выполнения конвейеров CI/CD. Теперь можно составлять расписание выполнения конвейеров, что позволяет автоматизировать периодические задачи, такие как ночные сборки, профилактика или подтверждение внешних зависимостей.

Dosuken добавил дополнительные параметры поиска в интерфейс конвейеров. Это нововведение открывает множество возможностей: например, теперь можно с легкостью сформировать запрос на последний конвейер определенной ветки. Также Dosuken внес существенный вклад в прошлый релиз — он заложил основы выполнения конвейеров по расписанию. Спасибо, Dosuken!
При работе с GitLab нередко появляются задачи, которые требуют совместных усилий сразу нескольких человек. Ранее в таких ситуациях было сложно понять, на кого назначена задача; это было особенно актуально для организаций, в которых исполнители не контактируют друг с другом ежедневно. С выходом GitLab 9.2 становится возможным назначить исполнителями одной задачи столько пользователей, сколько необходимо. Все они будут обладать равным уровнем ответственности и получать те же оповещения, что и в предыдущих версиях. Все исполнители отображаются в списке задач и досках задач, каждый из них может отслеживать свою связь с задачами на своей панели управления.
Обратите внимание: в связи с этими изменениями параметр API задач assignee_id устарел, вместо него нужно использовать assignee_ids. Также, вместо объекта JSON assignee нужно использовать assignees.

Больше информации в нашей документации
Hola Mundo, Hallo Welt! Мы рады сообщить, что, начиная с данного релиза, мы приступаем к работе над локализацией GitLab. Будем рады вашей поддержке в этом начинании!
В версию 9.2 добавлены инструментарий и инфраструктура для перевода GitLab на любой язык мира. Пока что в тестовых целях мы перевели только одну страницу (Cycle Analytics) на испанский и немецкий. В следующих версиях мы будем переводить новые страницы, а также добавлять другие языки. Если вы хотите помочь нам в этом — обратитесь к инструкции.
Для смены языка GitLab нажмите на свою иконку в правом верхнем углу экрана и зайдите в настройки (Settings).
Больше информации об аналитике цикла разработки в нашей документации

В большинстве проектов конвейеры CI/CD запускаются для каждого нового коммита — таким образом, все изменения в коде проходят сборку, тестирование и развертывание. Однако, существуют ситуации, в которых требуется запуск конвейера по определенному расписанию.
С выходом GitLab 9.2 становится возможным настроить запуск конвейеров тогда, когда нужно, и так часто, как нужно. Ежедневный и еженедельный запуск конвейеров, проверка внешних зависимостей или просто профилактические запуски — теперь все это можно легко настроить.
Данная функциональность полностью заменяет альфа-версию интерфейса для триггеров конвейеров по расписанию.
Больше информации о планировании запуска конвейеров в нашей документации

Мы хотим, чтобы GitLab был как можно лучшим инструментом для нативной облачной разработки. Для этого важно, чтобы вы могли легко начать работу с Kubernetes. Поэтому мы с радостью сообщаем, что с версией 9.2 выходят официальные Helm-чарты GitLab.
Helm — это инструмент управления пакетами, который позволяет проводить развертывание, апгрейд и настройку приложений в кластерах Kubernetes. GitLab и Kubernetes прекрасно взаимодействуют друг с другом: все идеи, представленные в нашем видео Idea to Production, такие как автоматизация масштабирования CI и развертывания в ваши кластеры, легко реализуются с минимумом дополнительной настройки.
Больше информации об установке GitLab при помощи Helm-чартов в нашей документации

В большинстве случаев нелегко отследить влияние определенного мержа на производительность системы. Зачастую, за данные о производительности отвечает отдельный инструмент, к которому у команды разработчиков даже нет доступа. Мы хотим, чтобы у разработчиков была возможность получать эти данные для каждого изменения, которое они вносят. Интеграция с Prometheus является большим шагом к достижению этой цели.
Начиная с GitLab 9.2 изменения в потреблении памяти после развертывания отображаются прямо в мерж-реквесте. Теперь разработчики могут отслеживать изменения в производительности, не отвлекаясь от привычного процесса работы. В последующих релизах мы планируем добавить другие метрики производительности.
Больше информации об отслеживании воздействия мерж-реквестов на потребление памяти в нашей документации

Начиная с версии 9.0, в GitLab Geo входит альфа-версия аварийного восстановления. Мы стремимся улучшать ее с каждым новым релизом, и GitLab 9.2 не стал исключением. В новой версии мы сделали аварийное восстановление более удобным: смысл элементов управления стал более очевидным, а отчеты о процессе репликации — более подробными.
Также улучшился механизм репликации репозиториев: теперь повторная синхронизация для репозиториев, поврежденных из-за ошибок синхронизации, происходит автоматически. Кроме того, при обновлении основной базы данных происходит ее автоматическая синхронизация со вторичными базами.
Больше информации о GItLab Geo в нашей документации

Поскольку страница задачи является основным местом совместной работы, ее содержимое постоянно меняется. Начиная с версии GitLab 9.2, название и описание задач обновляются автоматически, без обновления страницы. Так что теперь для того, чтобы постоянно видеть последнюю версию задачи, достаточно просто держать ее вкладку открытой. Даже название вкладки в браузере обновляется автоматически.
Кроме того, при редактировании описания задачи добавляется системная заметка, благодаря чему можно просмотреть полную историю изменений задачи просто пролистав ее комментарии. Эти изменения затронули и комментарии — они таким же образом автоматически обновляются при их редактировании.
Больше информации по задачам в нашей документации

Теперь вы сможете одним кликом удалять фильтры в строке поиска задач и мерж-реквестов.
Также мы изменили стиль ярлыков в строке поиска: теперь они соотносятся по цвету с остальными ярлыками по всему приложению.
Подробности о поиске задач и мерж-реквестов

Мы добавляем больше возможностей расширенного поиска за счет интеграции с Elasticsearch. Если вы настроили Elasticsearch, вы можете искать точные фразы (в двойных кавычках) или неупорядоченный набор ключевых слов, по совпадению части слова или использовать другие возможности поискового синтаксиса. (Заметьте, что это относится к строке поиска в правом верхнем углу на любой странице GitLab, но не к поиску в списках задач и мерж-реквестов.)
Также благодаря Elasticsearch стал возможным глобальный поиск по всем вики в вашем инстансе.
Узнайте больше о расширенном поиске с помощью Elasticsearch

В каждой итерации GitLab мы стараемся сделать путь от идеи к производству более быстрым и легким.
Эта новая маленькая фича позволит вам создать мерж-реквест прямо со страницы задачи, а необходимую для этого ветку GitLab создаст автоматически. Это особенно полезно, когда вам нужно сделать небольшой коммит прямо из интерфейса GitLab.

О том, как создать мерж-реквест из задачи
В сниппетах (даже в личных) часто происходит совместная работа. В этом обновлении появятся треды комментариев для каждого личного сниппета — так же, как и для сниппетов проекта.
Дополнительно о сниппетах можно прочитать в нашей документации
При просмотре файлов GitLab многие файлы, например, SVG & Markdown, отображаются в отрендеренной форме. На странице просмотра файла появился удобный маленький переключатель между режимами просмотра исходного кода и отрендеренного файла.

В GitLab 9.1 мы запустили поддержку установки GitLab на GCE через Terraform компании Hashicorp. В версии 9.2 мы также добавляем возможность разворачивать GitLab Runner, дополнив этим принцип «от идеи к производству».
Репозиторий с конфигурацией Terraform для GitLab
Артефактом может быть любой файл; вы можете добраться до этого файла с помощью поиска по архиву прямо в пользовательском интерфейсе. GitLab 9.2 расширил возможности этого поиска: теперь у файлов PDF, картинок, видео и других форматов будет предпросмотр прямо в поиске артефактов заданий — их больше не нужно скачивать.

Больше информации о поиске артефактов заданий в нашей документации
В GitLab есть несколько путей до конкретных фич. После введения вложенных групп эти фичи могли стать недоступными для тех проектов или групп, названия которых конфликтуют с этими путями. Например, для проекта под названием 'badges' бэйджи (badges) статусов сборки или покрытия стали недоступны.
Чтобы избежать таких недоразумений, мы убрали возможность создавать проекты или группы с названиями, которые могут конфликтовать с существующими маршрутами GitLab.
Если у вас были проекты или группы с названиями одного из таких путей, они автоматически переименуются при обновлении. Проект с названием badges будет называться badges0.
Учтите, что настройки git remote нужно будет обновить вручную, например, так:
git remote set-url origin git@gitlab.com:the-updated-path/the-updated-name.gitПолный список зарезервированных слов вы можете посмотреть в файле dynamic_path_validator.rb. Список существующих проектов и групп, которых в этом релизе затронуло автоматическое переименование, можно найти в миграции, которая их переименовала.
Подробности о создании подгрупп
Начиная с GitLab 9.2 исходные ветки в мерж-реквестах по умолчанию удаляются. Если вы хотите сохранить ветку даже после мержа, вам нужно отключить опцию в виджете мерж-реквеста до его принятия.

Может так случиться, что кто-то (случайно или умышленно) использует в .gitlab-ci.yml один и тот же путь для ключевых слов cache (кэш) and artifacts (артефакты), что может вызвать ситуацию, когда залежавшийся кэш может случайно перезаписать артефакты, которые используются в конвейере.
С этого релиза артефакты можно восстанавливать после кэширования — чтобы убедиться, что они сохранятся и будут доступны даже в критической ситуации.
GitLab 9.2 включает Mattermost 3.9, альтернативу Slack с открытым исходным кодом. В этом релизе мы добавили в нее новый каталог интеграций и поддержку польского языка, дополнили десктопные приложения проверкой орфографии и добавили еще много полезного.
Версия включает обновления безопасности. Рекомендуем обновиться.
Реестр контейнеров GitLab (GitLab Container Registry) обновился с версии 2.4 до версии 2.6.1.
Интерфейс мерж-реквестов позволяет выбирать отдельных ревьюеров, которые смогут принять (подтвердить) этот реквест. На выбор предлагаются только участники проекта, а также группы, к которой принадлежит проект (parent group), и группы, которым предоставлен доступ к проекту (project share). Поэтому вы сможете легко найти нужных пользователей.
Подробнее о настройке ревьюеров мерж-реквестов
В этом релизе появилась возможность ссылаться на устаревший дифф прямо из треда обсуждения мерж-реквеста. Это позволит быстро обращаться к содержимому старых коммитов в процессе разработки, совместной работы и ревью. Вы даже сможете оставлять комментарии в тех устаревших диффах.


Если производительность продукта поменялась, то первый вопрос — менялось ли рабочее окружение? GitLab 9.2 теперь быстро отвечает на этот вопрос, отображая все развертывания в окружении прямо на доске мониторинга. Это позволяет сразу видеть зависимость между изменениями в производительности и новой версией приложения (и все это не покидая GitLab).

Документация о мониторинге окружения
Для ручных действий теперь требуются те же права доступа, что и на запись в репозиторий, что позволит контролировать, кто может их совершать. Например, теперь можно оставить право на ручной запуск задачи по развертыванию кода из стабильной ветки на production только для пользователей, имеющих право на коммит в эту ветку.
Это очень важная часть в списке улучшений системы безопасности, которые мы добавляем в GitLab для защиты развертывания в ваших проектах. Подробности можно прочитать в этой задаче.
Когда вы совершаете коммит новой части кода в проект с continuous integration (CI), обычно вы ожидаете увидеть отметку, которая обозначает, что конвейер выполнен успешно, и все сработало так, как было задумано. В случае, если что-то пошло не так, нужно как можно быстрее узнать подробности. Но многочисленные переходы по каждому из этапов и заданий не очень вдохновляют, особенно если конвейер сложный.
В GitLab 9.2 на странице информации о конвейере (в разделе Pipelines выбрать конкретный конвейер) появилась вкладка Failed Jobs. На ней можно посмотреть логи всех проваленных заданий и оценить общую картину выполнения конвейера.

Подробные release notes и инструкции по обновлению/установке можно прочитать в оригинальном англоязычном посте: https://about.gitlab.com/2017/05/22/gitlab-9-2-released/
Перевод с английского выполнен переводческой артелью «Надмозг и партнеры», http://nadmosq.ru. Над переводом работали nick_volynkin, rishavant и sgnl_05 .
|
|
[Перевод] Именованные кортежи. Пишем код на Python чище |
В стандартной библиотеке питона содержится специализированный тип "namedtuple", который, кажется, не получает того внимания, которое он заслуживает. Это одна из прекрасных фич в питоне, которая скрыта с первого взгляда.

Именованные кортежи могут быть отличной альтернативой определению классов и они имеют некоторые другие интересные особенности, которые я хочу показать вам в этой статье.
Так что же такое именованный кортеж и что делает его таким специализированным? Хороший способ поразмышлять над этим — рассмотреть именованные кортежи как расширение над обычными кортежами.
Кортежи в питоне представляют собой простую структуру данных для группировки произвольных объектов. Кортежи являются неизменяемыми — они не могут быть изменены после их создания.
>>> tup = ('hello', object(), 42)
>>> tup
('hello', , 42)
>>> tup[2]
42
>>> tup[2] = 23
TypeError: "'tuple' object does not support item assignment"Обратная сторона кортежей — это то, что мы можем получать данные из них используя только числовые индексы. Вы не можете дать имена отдельным элементам сохранённым в кортеже. Это может повлиять на читаемость кода.
Также, кортеж всегда является узкоспециализированной структурой. Тяжело обеспечить, что бы два кортежа имели одни и те же номера полей и одни и те же свойства сохранённые в них. Это делает их лёгкими для знакомства со “slip-of-the-mind” багами, где легко перепутать порядок полей.
Цель именованных кортежей — решить эти две проблемы.
Прежде всего, именованные кортежи являются неизменяемыми подобно обычным кортежам. Вы не можете изменять их после того, как вы что-то поместили в них.
Кроме этого, именованные кортежи это, эм..., именованные кортежи. Каждый объект сохраненный в них может быть доступен через уникальный, удобный для чтения человеком, идентификатор. Это освобождает вас от запоминания целочисленных индексов или выдумывания обходных путей типо определения целочисленных констант как мнемоник для ваших индексов.
Вот как выглядит именованный кортеж:
>>> from collections import namedtuple
>>> Car = namedtuple('Car' , 'color mileage')Чтобы использовать именованный кортеж, вам нужно импортировать модуль collections. Именованные кортежи были добавлены в стандартную библиотеку в Python 2.6. В примере выше мы определили простой тип данных "Car" с двумя полями: "color" и "mileage".
Вы можете найти синтакс немного странным здесь. Почему мы передаём поля как строку закодированную с "color mileage"?
Ответ в том, что функция фабрики именованных кортежей вызывает метод split() на строки с именами полей. Таким образом, это, действительно, просто сокращение, что бы сказать следующее:
>>> 'color mileage'.split()
['color', 'mileage']
>>> Car = namedtuple('Car', ['color', 'mileage'])Конечно, вы также можете передать список со строками имён полей напрямую, если вы предпочитаете такой стиль. Преимущество использования списка в том, что в этом случае легко переформатировать этот код, если вам понадобится разделить его на несколько линий:
>>> Car = namedtuple('Car', [
... 'color',
... 'mileage',
... ])Как бы вы ни решили, сейчас вы можете создать новые объекты "car" через фабричную функцию Car. Поведение будет такое же, как если бы вы решили определить класс Car вручную и дать ему конструктор принимающий значения "color" и "mileage":
>>> my_car = Car('red', 3812.4)
>>> my_car.color
'red'
>>> my_car.mileage
3812.4Распаковка кортежей и оператор '*' для распаковки аргументов функций также работают как ожидается:
>>> color, mileage = my_car
>>> print(color, mileage)
red 3812.4
>>> print(*my_car)
red 3812.4Несмотря на доступ к значениям сохранённым в именованном кортеже через их идентификатор, вы всё ещё можете обращаться к ним через их индекс. Это свойство именованных кортежей может быть использовано для их распаковки в обычный кортеж:
>>> my_car[0]
'red'
>>> tuple(my_car)
('red', 3812.4)Вы даже можете получить красивое строковое отображение объектов бесплатно, что сэкономит вам время и спасёт от избыточности:
>>> my_car
Car(color='red' , mileage=3812.4)Именованные кортежи, как и обычные кортежи, являются неизменяемыми. Когда вы попытаетесь перезаписать одно из их полей, вы получите исключение AttributeError:
>>> my_car.color = 'blue'
AttributeError: "can't set attribute"Объекты именованных кортежей внутренне реализуются в питоне как обычные классы. Когда дело доходит до использованию памяти, то они так же "лучше", чем обычные классы и просто так же эффективны в использовании памяти как и обычные кортежи.
Хороший путь судить о них — считать, что именованные кортежи являются краткой формой для создания вручную эффективно работающего с памятью неизменяемого класса.
Поскольку именованные кортежи построены на обычных классах, то вы можете добавить методы в класс, унаследованный от именованного кортежа.
>>> Car = namedtuple('Car', 'color mileage')
>>> class MyCarWithMethods(Car):
... def hexcolor(self):
... if self.color == 'red':
... return '#ff0000'
... else:
... return '#000000'Сейчас мы можем создать объекты MyCarWithMethods и вызвать их метод hexcolor() так, как ожидалось:
>>> c = MyCarWithMethods('red', 1234)
>>> c.hexcolor()
'#ff0000'Однако, это может быть немного неуклюже. Это может быть стоящим, если вы хотите получить класс с неизменяемыми свойствами. Но вы легко можете прострелить себе ногу в таком случае.
Например, добавление нового неизменяемого поля является каверзной операцией из-за того как именованные кортежи устроены внутри. Более простой путь создания иерархии именованных кортежей — использование свойства ._fields базового кортежа:
>>> Car = namedtuple('Car', 'color mileage')
>>> ElectricCar = namedtuple(
... 'ElectricCar', Car._fields + ('charge',))Это даёт желаемый результат:
>>> ElectricCar('red', 1234, 45.0)
ElectricCar(color='red', mileage=1234, charge=45.0)Кроме свойства _fields каждый экземпляр именованного кортежа также предоставляет ещё несколько вспомогательных методов, которые вы можете найти полезными. Все их имена начинаются со знака подчёркивания, который говорит нам, что метод или свойство "приватное" и не является частью устоявшегося интерфейса класса или модуля.
Что касается именованных кортежей, то соглашение об именах начинающихся со знака подчёркивания здесь имеет другое значение: эти вспомогательные методы и свойства являются частью открытого интерфейса именованных кортежей. Символ подчёркивания в этих именах был использован для того, чтобы избежать коллизий имён с полями кортежа, определёнными пользователем. Так что, не стесняйтесь использовать их, если они вам понадобятся!
Я хочу показать вам несколько сценариев где вспомогательные методы именованного кортежа могут пригодиться. Давайте начнём с метода _asdict(). Он возвращает содержимое именованного кортежа в виде словаря:
>>> my_car._asdict()
OrderedDict([('color', 'red'), ('mileage', 3812.4)])Это очень здорово для избегания опечаток при создании JSON, например:
>>> json.dumps(my_car._asdict())
'{"color": "red", "mileage": 3812.4}'Другой полезный помощник — функция _replace(). Она создаёт поверхностную(shallow) копию кортежа и разрешает вам выборочно заменять некоторые поля:
>>> my_car._replace(color='blue')
Car(color='blue', mileage=3812.4)И, наконец, метод класса _make() может быть использован чтобы создать новый экземпляр именованного кортежа из последовательности:
>>> Car._make(['red', 999])
Car(color='red', mileage=999)Именованные кортежи могут быть простым способом для построения вашего кода, делая его более читаемым и обеспечивая лучшее структурирование ваших данных.
Я нахожу, например, что путь от узкоспециализированных структур данных с жёстко заданным форматом, таких как словари к именованным кортежам помогает мне выражать мои намерения более чисто. Часто когда я пытаюсь это рефакторить, то я магически достигаю лучших решений проблем, с которыми я сталкиваюсь.
Использование именованных кортежей вместо неструктурированных кортежей и словарей может также сделать жизнь моих коворкеров легче, потому что эти структуры данных помогают создавать данные понятным, самодокументирующимся(в достаточной степени) образом.
С другой стороны, я стараюсь не использовать именованные кортежи ради их пользы, если они не помогают мне писать чище, читабельнее и не делают код более лёгким в сопровождении. Слишком много хороших вещей может оказаться плохой вещью.
Однако, если вы используете их с осторожностью, то именованные кортежи, без сомнения, могут сделать ваш код на Python лучше и более выразительным.
|
Метки: author kvothe программирование python namedtuple |






