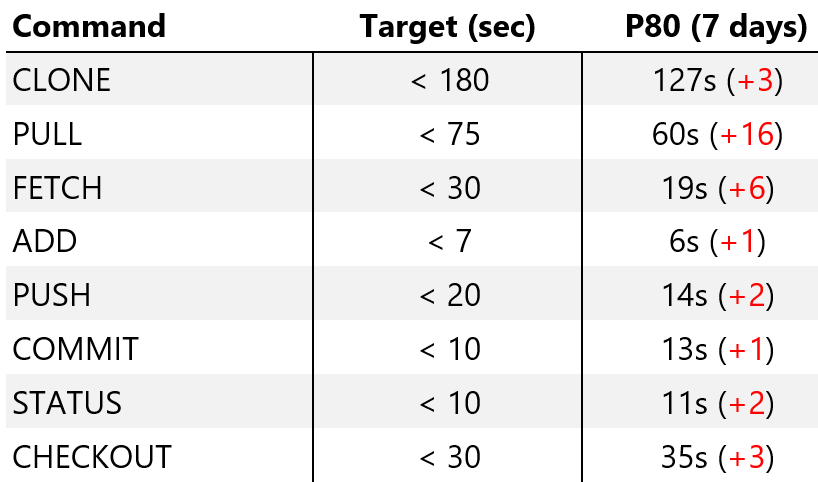
[Перевод] Самый большой репозиторий Git на свете |



|
Метки: author nanton github git блог компании everyday tools microsoft gvfs |
[Из песочницы] Реактивная обработка стрима логов с RxJava — Часть 1 |
Reactive log stream processing with RxJava — Part l
В предыдущем посте автор рассматривал случаи использования ELK стека и сбора логов.
С учетом движения в сторону микросервисов и контейнеризации приложений, централизованная обработка логов и их хранение становится де-факто стандартом.
Может быть, нам стоит попробовать сделать следующий шаг и более активно использовать полученную информацию для того, чтобы находить причины ряда проблем задолго до их появления.*
Сноска — стримы и потоки данных в данном переводе являются взаимозаменяемыми словами. Также слово лог может означать журнал, хотя в большинстве случаев в тексте мы используем иное значение
Если бы мы рассматривали лог событий как поток данных того, что происходит в реальном времени в вашей системе, было бы очень интересно анализировать в реальном времени данные и все возможные варианты их использования, к примеру, обнаружить мошенническое поведение, с помощью агрегирования различных потоков информации непосредственно во время "атаки", и сразу же заблокировать атакующего вместо того, чтобы "традиционно" собирать лог данных и заниматься расследованием уже после возникновения инцидента.
Или другой пример, мы можем отфильтровать (filter) только те события, которые соответствуют определенному типу событий, сгруппировать (group by) их по общему ключу как userID и вычислить общее количество во временном окне, получив количество событий данного типа, которые пользователь совершает в определенный период времени.
failedLogStream()
.window(5,TimeUnit.SECONDS)
.flatMap(window ->
window
.groupBy(propertyStringValue("remoteIP"))
.flatMap(grouped -> grouped
.count()
.map( failedLoginsCount -> {
final String remoteIp = grouped.getKey();
return new Pair<>(remoteIp, failedLoginsCount);
}))
)
.filter(pair -> pair.get > 10)
.forEach(System.out::println); Мы можем инициировать запросы и в других системах и работать с их ответами как с потоками данных, на которые мы можем подписаться и применить несколько привычных операторов для работы со стримами (потоками данных), которые представлены во фреймворках reactive streams (реактивных стримов).
Хорошо бы разобрать, что такое реактивное программирование стримов, для этого нам нет необходимости разворачивать что-то большое, такое как Kafka Streams Spark or Flink.
Реактивное программирование — это неблокирующие приложения, управляемые событиями, которые масштабируются даже при небольшом числе потоков с противодействием нагрузке (механизм обратной связи, при котором количество данных от производителей не превышает число данных принимаемых потребителями).
Самой большой темой, которую принесет Spring5, будет поддержка Реактивного программирования. Новый модуль spring-web-reactive — фреймворк, похожий на spring-web-mvc, который позволит отдавать асинхронные (неблокирующие) ответы для REST сервисов и реактивный веб-клиент, из чего следует возможность применения данного решение для микросервисной архитектуры. Концепция реактивных стримов не специфична для Spring, поскольку существует общая спецификация reactive-streams-jvm, согласованная большинством реактивных фреймворков (пока для нее, может быть, и не существует идентичного наименования, но концепция должна быть достаточно простой, чтобы стать заменой фреймворкам).
Исторически модель реактивные потоки была представлена Rx.NET, а затем при помощи Netflix портирована на java, получив название RxJava. В то же время концепция был также успешно реализована и в других языках, под названием Реактивные расширения (Reactive EXtensions). С тех пор компании движутся в том же направлении, что и спецификация реактивных стримов. Сейчас RxJava, поскольку он был первопроходцем, нуждается в значительном рефакторинге(переписании кода) — соответственно, версия 2.х лучше соответствует спецификации, и, пока Spring reactor еще новичок, компании не составит труда переписать реализацию согласно спецификации. Рекомендуем прочитать больше о том как они взаимосвязаны.
Doug Lea сообщил, что хочет включить реактивные потоки в состав объекта java.util.concurrent.Flow, а это значит, что реактивные стримы будут поставляться в составе Java 9.
Также другим модным словом сейчас является микросервисная архитектура с обязательной возможностью делать запросы на множество разных сервисов. В идеале, лучше всего выполнять неблокирующие запросы, не ожидая для выполнения следующего запроса получение ответа целиком. Подумайте, вместо того чтобы ждать момента, когда какой-нибудь сервис вернет вам большой список результатов, возможно, стоит в то же время при получении первого фрагмента отправлять новый запрос в другую систему.

Если рассматривать ответ от удаленного запрос как Stream (Стрим-поток данных), подписка на который запускает action (действие) при получении ответа, то вместо блокировки потока, ожидающего свой ответ, мы можем воспользоваться меньшим числом потоков в целом, что, в свою очередь, уменьшит затраты ресурсов (к примеру, процессорное время для переключения контекста между потоками и памяти для каждого стека потоков).
Таким образом, использование реактивного программирования позволит нам на стандартном железе обработать больше логов событий, чем обычно.
Пример: сервису, такому как Gmail, нужно отображать пользовательские почтовые сообщения (emails). Тем не менее, emails, в свою очередь, могут иметь множество людей в копии (CC). Было бы прикольно отобразить фотографию для тех пользователей, которые находятся в твоих контактах, что означает вызов REST — ContactService.
Получится вот так:
Future> emailsFuture = mailstoreService.getUnreadEmails();
List emails = emailsFuture.get(); //блокировка текущего потока
//возможно долгое ожидание, пока не будет получен полный список данных
//можно ли запустить следующий процесс, как только первый фрагмент будет получен?
Future> contacts = getContactsForEmails(emails);
for(Mail mail : emails) {
streamRenderEmails(mail, contacts); //push(отправить) emails клиенту
} Частично проблема была решена с приходом поддержки реактивного программирования в Java 8 с CompletableFuture (со своими thenCompose, thenCombine, thenAccept и еще 50 методами, хотя это не отменяет того факта, что нужно помнить все, что они делают, а это никак не помогает в прочтении кода).
CompletableFuture> emailsFuture = mailstoreService.getUnreadEmails();
CompletableFuture> emailsFuture
.thenCompose(emails -> getContactsForEmails(emails)) //нам все еще нужно ожидать List
.thenAccept(emailsContactsPair -> streamRenderEmails(emailsContactsPair.getKey(), emailsContactsPair.getValue())) Мы можем переключиться на Iterator вместо List-а, и в тоже время не существует методов, говорящих выполнить какое-либо действие при появлении новых значений. В SQL есть такая возможность, к примеру, ResultSet (в котором вы можете выполнить rs.next()) вместо загрузки всех данных в память.
public interface Iterator {
/**
* Возвращает {@code true}, если в итерации больше элементов.
*/
boolean hasNext();
/**
* Возвращает следующий элемент итерации.
*/
E next();
} Но нам все еще нужно постоянно спрашивать "а у тебя есть новое значение?"
Iterable emails = mailstoreService.getUnreadEmails();
Iterator emailsIt = emails.iterator();
while(emailsIt.hasNext()) {
Mail mail = emailsIt.next(); //неблокирующее действие все равно тратит много процессорного времени на получение новых значений
if(mail != null) {
....
}
} Что нам нужно, так это реактивный итератор, такой тип данных, который сможет подписаться и выполнить действие, как только получено новое значение. Именно здесь начинается reactive stream programming (реактивное программирование стримов).
Stream по-простому это последовательность упорядоченных во времени событий (событиеX происходит после событияY, так что события не конкурируют между собой).
Stream смоделирован так, что выпускает 0..N событий и одну из двух терминальных операций:
Мы можем описать это визуально с помощью 'marble diagrams'.

Таким образом мы можем представить, что Stream-ом является все, а не только лог событий. Даже единичное значение может быть выражено как Стрим, выпускающий значение, за которым следует событие о завершении.
Бесконечный стрим — стрим, который выпускает события, но без единого терминального события(завершения | ошибки).
RxJava определяет Observable (Наблюдаемый) тип данных для моделирования Stream-а событий типа . В Spring Reactor-е он равен типу Flux.
Observable представляет собой stream температур, взятых с различными интервалами.
Observable представляет собой stream продуктов, купленных в нашем веб магазине.
Observable представляет собой одного пользователя (User), вернувшегося по запросу к БД.
public Observable findByUserId(String userId) {...}
//пусть будет Single для большей наглядности
public Single findByUserId(String userId) {...} Но Observable это просто тип данных, поэтому, как и в случае с шаблоном проектирования Publish/Subscriber (Публикации/Подписчика), нам нужен Subscriber(Подписчик) чтобы обработать 3 типа событий
Observable cartItemsStream = ...;
Subscriber subscriber = new Subscriber() {
@Override
public void onNext(CartItem cartItem) {
System.out.println("Cart Item added " + cartItem);
}
@Override
public void onCompleted() {
}
@Override
public void onError(Throwable e) {
e.printStackTrace();
}
};
cartItemsStream.subscribe(subscriber); Но это просто часть Stream-a, а до сих пор мы не применяли ничего необычного, только классический шаблон проектирования Observer (Наблюдатель).
Reactive (Реактивная) же часть означает, что мы можем определить некоторые Function (операторы — функции), которые будут выполнены, когда stream запустит событие.
Это значит, что будет создан другой stream (стримы immutable), на который мы можем подписать другой оператор и т.д.
Observable filteredCartStream = cartStream.filter(new Func1() {
@Override
public Boolean call(CartItem cartItem) {
return cartItem.isLaptop();
}
});
Observable laptopCartItemsPriceStream = filteredCartStream.map(new Func1() {
@Override
public Long call(CartItem cartItem) {
try {
return priceService.getPrice(cartItem.getId());
} catch(PriceServiceException e) {
thrown new RuntimeException(e);
}
}
}); Поскольку операторы (методы) класса Observable (filter, map, groupBy,...) возвращают Observable, это значит, что мы можем использовать цепочку из операторов, чтобы объединить их с лямбда синтаксисом и написать что-нибудь красивое.
Observable priceStream = cartStream
.filter((cartItem) -> cartItem.isLaptop()).
.map((laptop) -> {
try {
return priceService.getPrice(cartItem.getId());
} catch(PriceServiceException e) {
thrown new RuntimeException(e);
}
}); Обратите внимание, что выше, когда создается priceStream, ничего не происходит — priceService.getPrice() не вызывается, пока нет элемента, проходящего по цепочке операторов. Это означает, что мы создали через rx-оператор подобие плана, как управляемые данные будут спускаться вниз по цепочке(подписание регистрируется).
Когда просят объяснить реактивное программирование, обычно в шутку дают пример с Excel листами, где в колонках написаны формулы, вызываемые при обновлении ячейки, что, в свою очередь, обновляет другую ячейку, которая, в свою очередь, обновляет другую и так далее по цепочке.
Прямо как rx-operator, который ничего не делает, эти формулы просто управляют данными и каждая из них получает свой шанс сделать что-то до того момента, как данные спустились вниз по цепочке.
Чтобы лучше понимать, как события путешествуют вместе с цепочкой операторов, я нашел полезную аналогию, в примере с переездом из одного дома в другой, грузчики выступают в роли операторов, вместе с которым перемещаются вещи из вашего дома — так это изобразил Томас Нильд.
Его пример с кодом:
Observable- mover1 = Observable.create(s -> {
while (house.hasItems()) {
s.onNext(house.getItem());
}
s.onCompleted();
});
Observable
- mover2 = mover1.map(item -> putInBox(item));
Subscription mover3 = mover2.subscribe(box -> putInTruck(box),
() -> closeTruck()); //это сработает на событие OnCompleted()

"Грузчик 1 с одной стороны источник Observable. Он создает выбросы за счет того, что выносит вещи из дома. Он вызывает Грузчика 2 с методом onNext(), который выполняет map() операцию. Когда его метод onNext() вызван, он берет вещь и перекладывает в коробку. Затем он вызывает Грузчика 3, конечного Subscriber(подписчика), с методом onNext(), который грузит коробку в машину."
Магия RxJava — это большой набор доступных операторов, ваша же работа заключается в комбинировании их всех вместе для управления течением данных.

Множество Stream операторов помогают составить словарь терминов для обозначения действий, производимых со стримами, которые могут быть реализованы в популярных языках (RxJava, RxJS, Rx.NET, etc) из числа ReactiveX framework (Реактивных расширений).
Эти понятия надо знать даже при использовании различных фреймворков для работы с реактивными стримами, таких как Spring Reactor (в надежде на наличие неких операторов, общих для этих фреймворков).
Пока что мы видели только простые операторы, такие как фильтрация:
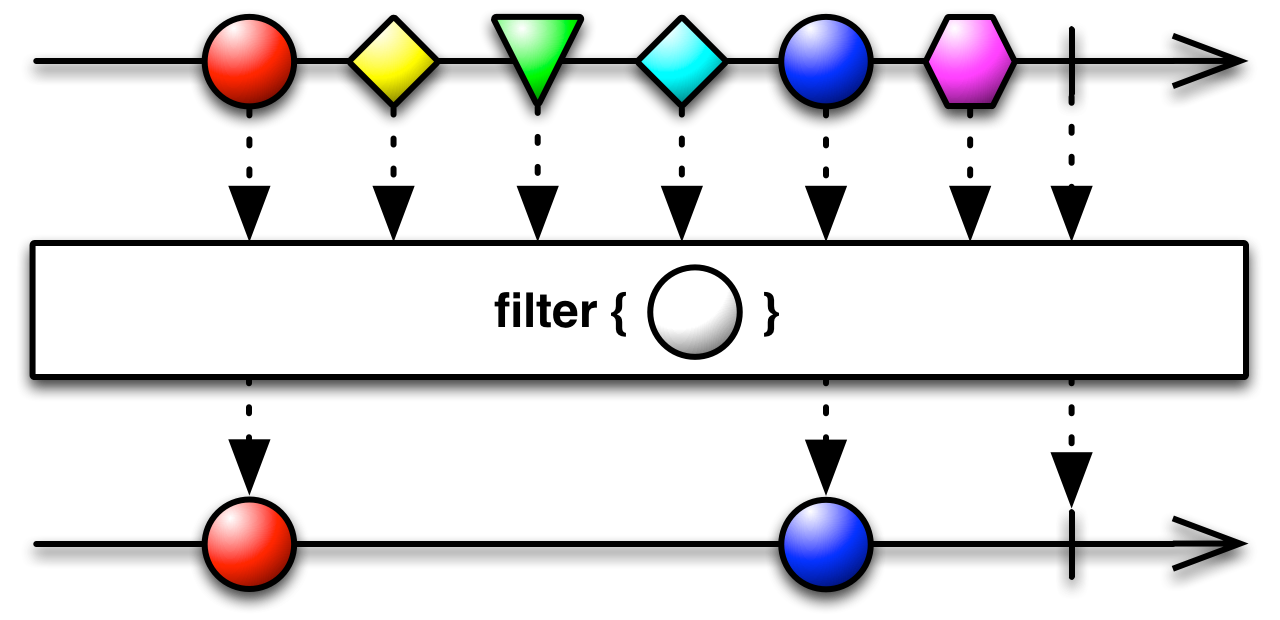
Которые только пропускают элементы, попадающие под условие фильтра (один грузчик перенесет только те вещи, которые стоят меньше 100$, вместо того, чтобы передать сразу все другому грузчику)
Однако есть операторы, которые могут разбить стрим на множество отдельных стримов — Observable>(Стрим стримов) — это такие операторы, как groupBy

Observable values = Observable.just(1,4,5,7,8,9,10);
Observable> oddEvenStream = values.groupBy((number) -> number % 2 == 0 ? "odd":"even");
Observable remergedStream = Observable.concat(oddEvenStream);
remergedStream.subscribe(number -> System.out.print(number +" ")); //Выводит
//1 5 7 9 4 8 10 и достаточно простой оператор concat, который снова из четных и нечетных стримов создает один-единственный стрим, и устанавливает на него подписку.
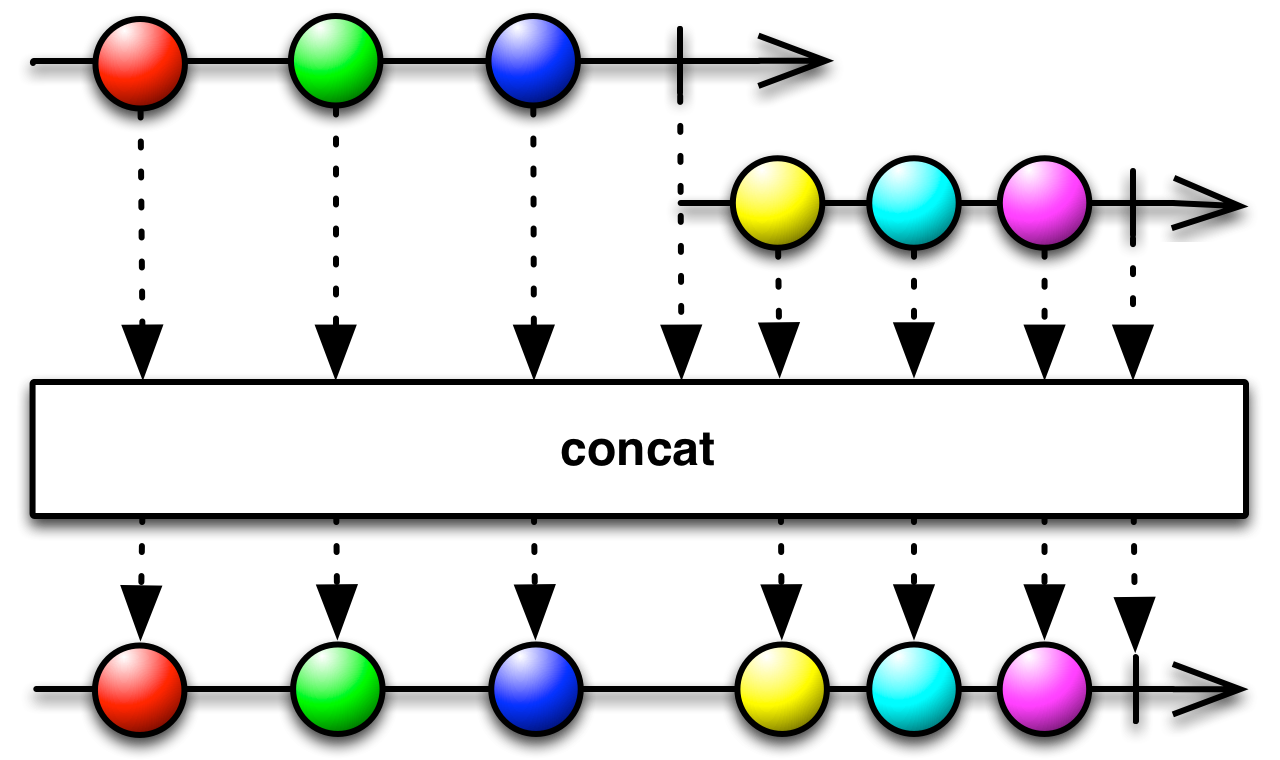
Мы видим, что оператор concat ожидает завершения стрима перед тем, как добавить еще один, снова создавая один стрим. Таким образом, нечетные числа отображаются первыми.
Также у нас есть возможность скомбинировать вместе множество stream-ов, как, например, это делает zip оператор

Zip назван так не потому, что он работает как архиватор, но скорее из-за то, что он, как молния (на куртке), комбинирует события из двух stream-ов.

Он берет одно событие из одного stream-а и соединяет с событием из другого (делая пару). Как только это выполнено, он применяет оператор склеивания, перед тем, как спуститься дальше по цепочке.
PS: это работает и для большего количества stream-ов.
Так что, даже если один stream выпускает события быстрее, то дальше слушатель увидит только скомбинированное событие, которое выпустится из более медленного stream-а.
Иметь возможность "ждать" ответа от множества удаленных вызовов, которые мы получаем от stream-ов, на самом деле очень полезно.
С другой стороны, оператор combineLatest не ожидает выпуска пары событий, но вместо этого, использует последние выпущенные события из более медленного stream-а, до применения функции склейки и передачи его дальше по цепочки.
Давайте рассмотрим несколько примеров, как на самом деле создают Observables. Наиболее длинный вариант создания:
log("Before create Observable");
Observable someIntStream = Observable
.create(new ObservableOnSubscribe() {
@Override
public void subscribe(ObservableEmitter emitter) throws Exception {
log("Create");
emitter.onNext(3);
emitter.onNext(4);
emitter.onNext(5);
emitter.onComplete();
log("Completed");
}
});
log("After create Observable");
log("Subscribing 1st");
someIntStream.subscribe((val) -> LOGGER.info("received " + val));
//мы можем опустить реализацию
//другие методы(for onError and onComplete) если мы ее хотим сделать, что-то особенное
log("Subscribing 2nd");
someIntStream.subscribe((val) -> LOGGER.info("received " + val)); События посылаются подписчику, как только тот подписался.
Не то, что мы пользуемся такой конструкцией, просто мы передали новый объект ObservableOnSubscribe, который демонстрирует, что делать, когда на него кто-нибудь подписывается.
Пока мы не подписались на Observable, выходных данных нет и ничего не происходит, данные не движутся.
Когда кто-то подписывается, вызывается метод call() и 3 сообщения проталкиваются вниз по цепочке, следом за ними идет сигнал, что stream завершился.
Выше мы дважды подписались, код внутри метода call(...) также будет вызван дважды. Так что он эффективно переотправляет те же значения, как только кто-нибудь еще подпишется и тогда получит следующие значения на вывод:
mainThread: Before create Observable
mainThread: After create Observable
mainThread: Subscribing 1st
mainThread: Create
mainThread: received 3
mainThread: received 4
mainThread: received 5
mainThread: Completed
mainThread: Subscribing 2nd
mainThread: Create
mainThread: received 3
mainThread: received 4
mainThread: received 5
mainThread: Completed Важно заметить, что rx операторы не обязательно означают многопоточность. RxJava не внедряет конкурентность по умолчанию между Observable и Subscriber. Поэтому все вызовы происходят на "главном" потоке.
Такой тип Observable, которые начинают распространение, когда кто-нибудь подписан называются cold observables(холодные наблюдатели). Другой вид — hot observables(горячие наблюдатели), они могут выпускать события, даже когда никто не подписан на них.
Cold Observables начинают распространять события только когда кто-то подписывается. Каждый подписчик получает одни и те же события. Например, как CD на котором играют одни и те же песни для того, кто включил cd в плеер послушать. Hot Observables события распространяются даже когда на них еще никто не подписался. Как радиостанция которая проигрывает песни через радиовещание, даже когда никто его не включал. И так же, как при включении радиоприемника, ты пропускаешь предшествующие события. Hot observable моделирует события, распространением которых вы не можете управлять. Примерно как в случае записи событий в журнал (лог событий).Subjects это такой специальный вид Observable, который также является Observer (как Subscriber — который решает, что он может протолкнуть данные (вызовом onNext()) до них) и сделает реализацию горячих Observables проще. Также существует множество реализаций, подобных ReplaySubject, которые сохраняют выделенные события в буфере и воспроизводят их по подписке (конечно, можно указать размер буфера, чтобы предотвратить ошибку OutOfMemory), пока PublishSubject только пропускает события, которые случились после подписания.
И конечно, существует множество статических методов для создания Observables и из других источников.
Observable.just("This", "is", "something")
Observable.from(Iterable collection)
Observable.from(Future future) - передает значение после того, как `future` выполнится По традиции, работая со стеком ELK, мы используем ElasticSearch чтобы запросить данные по логу событий, так что можно сказать, что они в опрашивающем стиле 'pull-based'.
Можем ли вместо этого иметь push-based, где мы собираемся информировать 'незамедлительно' при появлении события в журнале, чтобы дальше уменьшить время реагирования на событие, с того момента как оно произошло и до того как мы начнем его обрабатывать.
Одним из множества возможных решение может стать RabbitMq, как бывалое в сражениях решение с очень хорошей репутацией за его производительность, за его возможность обработки огромного числа сообщений. Несмотря на это Logstash уже поддерживает плагин для RabbitMQ (также есть еще один плагин для FluentD) так что мы можем с легкостью интегрировать его в наш существующий ELK стек и записывать логи в ElasticSearch и RabbitMQ.
Возможно вы помните, что Logstash может вести себя как контроллер, и выбирать как ему работать, и куда отправлять/сохранять логируемые событий. Это значит что мы можем отфильтровать те события, которые хотим обработать или указать куда их послать, например, в другие RabbitMQ очереди.
Существует даже возможность напрямую отправлять данные в RabbitMQ через Logback Appender, если вам захочется опустить использование Logstash.
К слову сказать: Пока так называемый AmqpAppender, является скорее специфичной реализацией RabbitMQ AMQP (с версией протокола AMQP 0-9-1, 0-9).
ActiveMQ для примера (пока тоже поддерживает AMQP connector) кажется реализует протокол версии AMQP 1.0, пока spring-amqp библиотека с протоколом версий 0-9-1, 0-9, которые совсем отличаются от 1.0), так что вы может столкнетесь с ошибками по типу 'org.apache.activemq.transport.amqp.AmqpProtocolException: Connection from client using unsupported AMQP attempted'
Однако наше решение было чтобы использовать logstash-logback-encoder и отправлять отформатированный JSON с журналом событий в Logstash. Мы перенаправим logstash вывод на точку обмена RabbitMQ (exchange).
Мы будем использовать docker-compose, чтобы запустить кластер logstash-rabbitmq
Вы можете склонировать репозиторий
docker-compose -f docker-compose-rabbitmq.yml up
и затем вы можете использовать
./event-generate.sh
чтобы сгенерировать некоторое число случайных событий которые будут отправлены на logstash.
Для того, чтобы определить, куда отправлять данные, используйте файл настроек logstash. Мы используем rabbitmq-output-plugin, как ссылку:
output {
rabbitmq {
exchange => logstash
exchange_type => direct
host => rabbitmq
key => my_app
}
}RabbitMQ это не классический JMS сервер, вместо этого он использует AMQP протокол, который имеет весьма отличную от остальных концепцию для очередей.
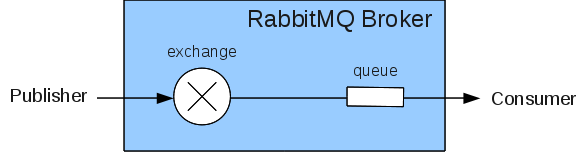
Издатель отправляет сообщения на именованную точку обмена (exchange) и потребитель забирает сообщения из очереди.
У сообщения есть стандартный заголовок 'routing-key', который используется в процессе называемом ассоциативным привязкой, чтобы связать обмен сообщениями в очереди. Очереди могут фильтровать какие сообщения они получают через ключ привязки, и к тому же можно использовать подставленные знаки в привязке как эти 'logstash.'
Для более подробного объяснения AMQP вы можете прочитать здесь и тут. Так мы настроили Spring соединение c RabbitMq
@Bean
ConnectionFactory connectionFactory() {
return new CachingConnectionFactory(host, port);
}
@Bean
RabbitAdmin rabbitAdmin() {
RabbitAdmin rabbitAdmin = new RabbitAdmin(connectionFactory());
rabbitAdmin.declareQueue(queue());
rabbitAdmin.declareBinding(bindQueueFromExchange(queue(), exchange()));
return rabbitAdmin;
}
@Bean
SimpleMessageListenerContainer container(ConnectionFactory connectionFactory, MessageListenerAdapter listenerAdapter) {
SimpleMessageListenerContainer container = new SimpleMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
container.setQueueNames(queueName);
container.setMessageListener(listenerAdapter);
return container;
}
@Bean
Queue queue() {
return new Queue(queueName, false);
}
DirectExchange exchange() {
return new DirectExchange("logstash");
}
private Binding bindQueueFromExchange(Queue queue, DirectExchange exchange) {
return BindingBuilder.bind(queue).to(exchange).with("my_app");
}
@Bean
MessageListenerAdapter listenerAdapter(Receiver receiver) {
MessageListenerAdapter messageListenerAdapter = new MessageListenerAdapter(receiver,
new MessageConverter() {
public Message toMessage(Object o, MessageProperties messageProperties)
throws MessageConversionException {
throw new RuntimeException("Unsupported");
}
public String fromMessage(Message message) throws MessageConversionException {
try {
return new String(message.getBody(), "UTF-8");
} catch (UnsupportedEncodingException e) {
throw new RuntimeException("UnsupportedEncodingException");
}
}
});
messageListenerAdapter.setDefaultListenerMethod("receive"); //the method in our Receiver class
return messageListenerAdapter;
}
@Bean
Receiver receiver() {
return new Receiver();
}Мы определили очередь и связываем с сервисом обмена 'logstash', чтобы принять сообщения с ключем маршрутизации 'my_app'. MessageListenerAdapter выше определяет, что метод 'receive' должен быть вызван на бине Receiver каждый раз, когда новое сообщение приходит из очереди.
Поскольку мы ожидаем непрерывный поток в лог событий, мы не имеем над ним контроль, мы можем подумать об использовании hot observable, которые распространяют события всем подписчикам после того, как они подписались, так что мы используем для работы PublishSubject.
public class Receiver {
private PublishSubject publishSubject = PublishSubject.create();
public Receiver() {
}
/**
* Method invoked by Spring whenever a new message arrives
* @param message amqp message
*/
public void receive(Object message) {
log.info("Received remote message {}", message);
JsonElement remoteJsonElement = gson.fromJson ((String) message, JsonElement.class);
JsonObject jsonObj = remoteJsonElement.getAsJsonObject();
publishSubject.onNext(jsonObj);
}
public PublishSubject getPublishSubject() {
return publishSubject;
}
} Мы должны знать, что событие SimpleMessageListenerContainer поддерживает наличие более одного потока, который потребляет из очереди (и пропускает события вниз по цепочки). Однако контракт Observable говорит, что мы не можем выделять события конкурентно (вызовы onNext,onComplete, onError должны быть сериализованы):
// ТАК ДЕЛАТЬ НЕ НАДО
Observable.create(s -> {
// Thread A
new Thread(() -> {
s.onNext("one");
s.onNext("two");
}).start();
// Thread B
new Thread(() -> {
s.onNext("three");
s.onNext("four");
}).start();
});
// ТАК ДЕЛАТЬ НЕ НАДО
//ДЕЛАЙТЕ ТАК
Observable obs1 = Observable.create(s -> {
// Thread A
new Thread(() -> {
s.onNext("one");
s.onNext("two");
}).start();
});
Observable obs2 = Observable.create(s -> {
// Thread B
new Thread(() -> {
s.onNext("three");
s.onNext("four");
}).start();
});
Observable c = Observable.merge(obs1, obs2); Мы можем обойти эту проблему вызывая Observable.serialize() или Subject.toSerialized(), но мы остаемся со значение по умолчанию 1 Thread в ListenerContainer, нет необходимости делать это. Еще вы должны быть в курсе того, что если вы планируете использовать Subjects как шину событий, распространяющихся на несколько потоков. Прочитайте подробное объяснение.
А сейчас вы можете взглянуть на код и репозиторий, как продолжение этого длинного поста Part II (Части 2) или перейдите на Rx Playground там вы найдете больше примеров.
|
Метки: author isatimur java elk rxjava |
Microsoft внедрит ДНК-хранилище в одном из своих ЦОД |
 / фото igemhq CC
/ фото igemhq CC|
Метки: author it_man хранение данных блог компании ит-град ит-град днк microsoft |
Пятое поколение СХД HPE MSA: удвоенная производительность за ту же цену |

|
Метки: author beibaraban хранение данных it- инфраструктура блог компании hewlett packard enterprise msa storage схд hpe hewlett packard enterprise |
Сравнение Эльбрус-4С и Эльбрус-8С в нескольких задачах машинного зрения |
|
|
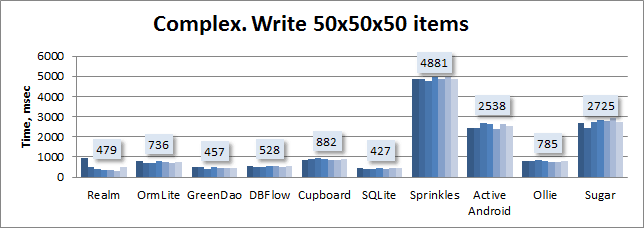
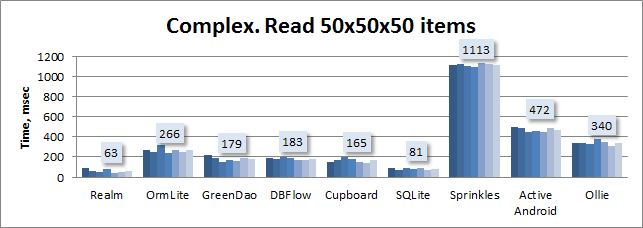
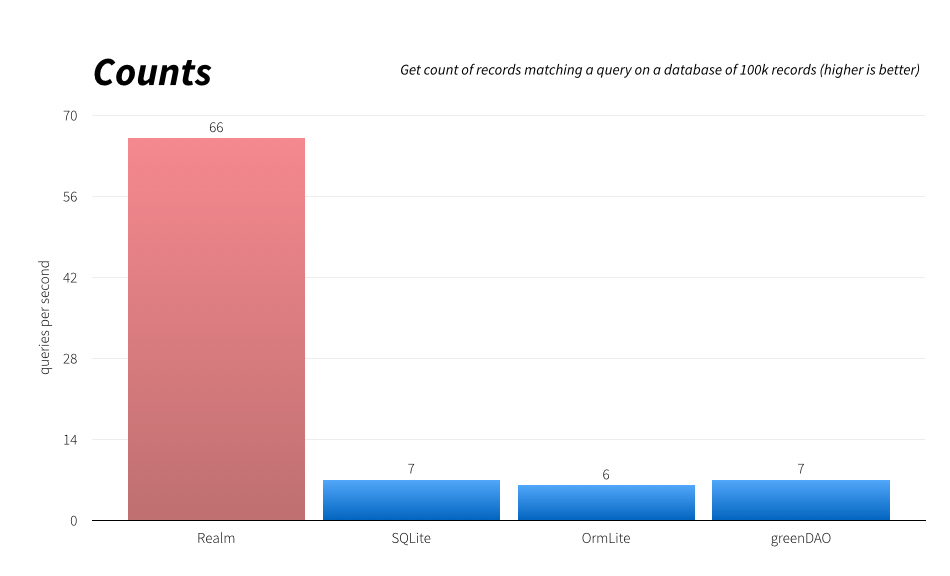
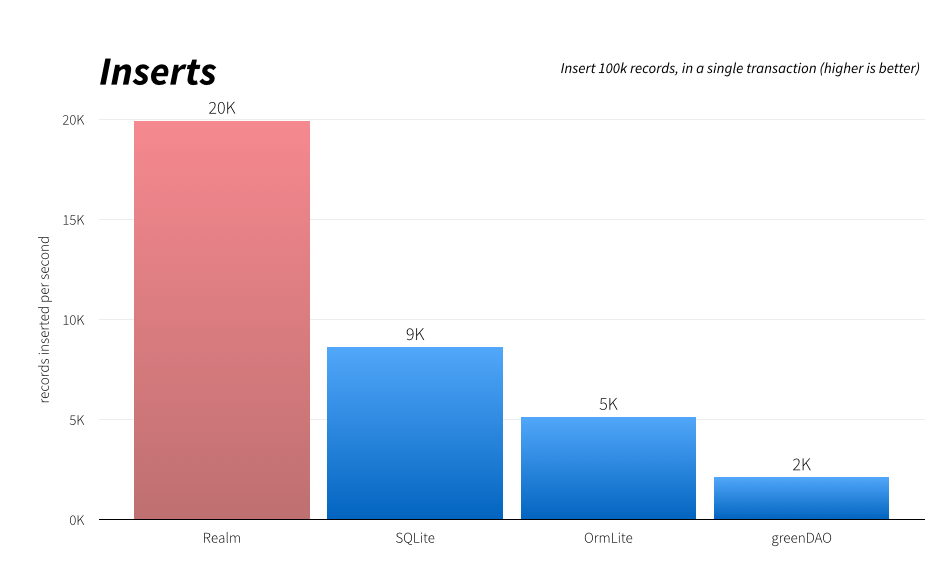
Реалистичный Realm. 1 год опыта |

classpath "io.realm:realm-gradle-plugin:0.89.1" The Realm Mobile Platform is a next-generation data layer for applications. Realm is reactive, concurrent, and lightweight, allowing you to work with live, native objects.
build.gradle (Project level)
classpath "io.realm:realm-gradle-plugin:3.3.0"
build.gradle (App level)
apply plugin: 'realm-android'Realm.init(this)
val config = RealmConfiguration.Builder()
.build()
Realm.setDefaultConfiguration(config)
val realm = Realm.getDefaultInstance()
realm.executeTransaction { realm ->
val dataObject = realm.createObject(DataObject::class.java)
dataObject.name = "A"
dataObject.id = 1
}
val dataObject = realm.where(DataObject::class.java).equalTo("id", 1).findFirst()
dataObject.name // => A
realm.executeTransaction { realm ->
val dataObjectTransaction = realm.where(DataObject::class.java).equalTo("id", 1).findFirst()
dataObjectTransaction.name = "B"
}
dataObject.name // => B
fun getFirstObject(realm: Realm, id: Long): DataObject? {
return realm.where(DataObject::class.java).equalTo("id", id).findFirst()
}val firstObject = realm.where(DataObject::class.java).findFirstAsync()
log(firstObject.id)fun getObjectObservable(realm: Realm, id: Long): Observable {
return realm.where(DataObject::class.java).findFirstAsync().asObservable()
}
fun findFirstDataObject(id: Long, realm: Realm) : DataObject
= realm.where(DataObject::class.java).equalTo("id", id).findFirst() Person p = realm.where(Person.class).findFirst();
p.addChangeListener(new RealmObjectChangeListener() {
@Override
public void onChange(Person person, ObjectChangeSet changeSet) {
if (changeSet.isDeleted()) {
hide(); // Object was deleted
} else {
// Use information about which fields changed to only update part of the UI
if (changeSet.isFieldChanged("name")) {
updateName(person.getName());
}
}
}
});
private final OrderedRealmCollectionChangeListener> changeListener = new OrderedRealmCollectionChangeListener() {
@Override
public void onChange(RealmResults collection, OrderedCollectionChangeSet changeSet) {
// `null` means the async query returns the first time.
if (changeSet == null) {
notifyDataSetChanged();
return;
}
// For deletions, the adapter has to be notified in reverse order.
OrderedCollectionChangeSet.Range[] deletions = changeSet.getDeletionRanges();
for (int i = deletions.length - 1; i >= 0; i--) {
OrderedCollectionChangeSet.Range range = deletions[i];
notifyItemRangeRemoved(range.startIndex, range.length);
}
OrderedCollectionChangeSet.Range[] insertions = changeSet.getInsertionRanges();
for (OrderedCollectionChangeSet.Range range : insertions) {
notifyItemRangeInserted(range.startIndex, range.length);
}
OrderedCollectionChangeSet.Range[] modifications = changeSet.getChangeRanges();
for (OrderedCollectionChangeSet.Range range : modifications) {
notifyItemRangeChanged(range.startIndex, range.length);
}
}
};
val user = database.getUser(1)
button.setOnClickListener { user.name = "Test" }val user = database.getUser(1)
button.setOnClickListener { database.setUserName(user, "Test") }fun syncTransaction() {
Realm.getDefaultInstance().use {
it.executeTransaction {
val dataObject = DataObject()
it.insertOrUpdate(dataObject)
}
}
}Realm.getDefaultInstance().use {
it.executeTransactionAsync({
it.insertOrUpdate(DataObject(0))
}, {
log("OnSuccess")
}, {
log("onError")
it.printStackTrace()
})
}val realm = Realm.getDefaultInstance()
val parent = realm.where(Parent::class.java).findFirst()
val children = Children()
// parent.setChildren(children) <-- Error
val childrenRealm = realm.copyToRealmOrUpdate(children)
parent.setChildren(childrenRealm) /// Ok// Thread pool for all async operations (Query & transaction)
static final RealmThreadPoolExecutor asyncTaskExecutor = RealmThreadPoolExecutor.newDefaultExecutor();Realm.getDefaultInstance().use { // it = realm instance}// Use doOnUnsubscribe
val realm = Realm.getDefaultInstance()
realm.where(DataObject::class.java).findAllSorted("id").asObservable().doOnUnsubscribe { realm.close() }
// Use Observable.using
Observable.using(Realm.getDefaultInstance(), realm -> realm.where(DataObject::class.java).equalTo("id", id)
.findFirstAsync()
.asObservable()
.filter(realmObject -> realmObject.isLoaded())
.cast(DataObject::class.java), Realm::close);fun getObjectObservable(realm: Realm, id: Long): Observable {
return realm.where(DataObject::class.java).equalTo("id", id).findFirstAsync()
.asObservable().filter({ it?.isLoaded }).filter { it?.isValid }
}“Управление параллельным доступом с помощью многоверсионности (англ. MVCC — MultiVersion Concurrency Control) — один из механизмов обеспечения параллельного доступа к БД, заключающийся в предоставлении каждому пользователю так называемого «снимка» БД, обладающего тем свойством, что вносимые пользователем изменения в БД невидимы другим пользователям до момента фиксации транзакции. Этот способ управления позволяет добиться того, что пишущие транзакции не блокируют читающих, и читающие транзакции не блокируют пишущих.”

|
Метки: author andrey7mel разработка под android разработка мобильных приложений android android development android database realm |
Unit-тесты: что, как и когда тестировать? |

 Marc Philipp – один из основных разработчиков фреймворка JUnit 5 – инструмента для Java-тестировщиков. В данный момент работает в качестве инженера в немецкой компании LogMeIn над облачными SaaS-решениями.
Marc Philipp – один из основных разработчиков фреймворка JUnit 5 – инструмента для Java-тестировщиков. В данный момент работает в качестве инженера в немецкой компании LogMeIn над облачными SaaS-решениями. Всеволод Брекелов — Senior QA Engineer в компании Grid Dynamics, более 5 лет занимается тестированием, имеет опыт построения автоматизации тестирования с нуля.
Всеволод Брекелов — Senior QA Engineer в компании Grid Dynamics, более 5 лет занимается тестированием, имеет опыт построения автоматизации тестирования с нуля. |
Метки: author sinnerspinner тестирование it-систем tdd блог компании jug.ru group тестирование гейзенбаг unit testing |
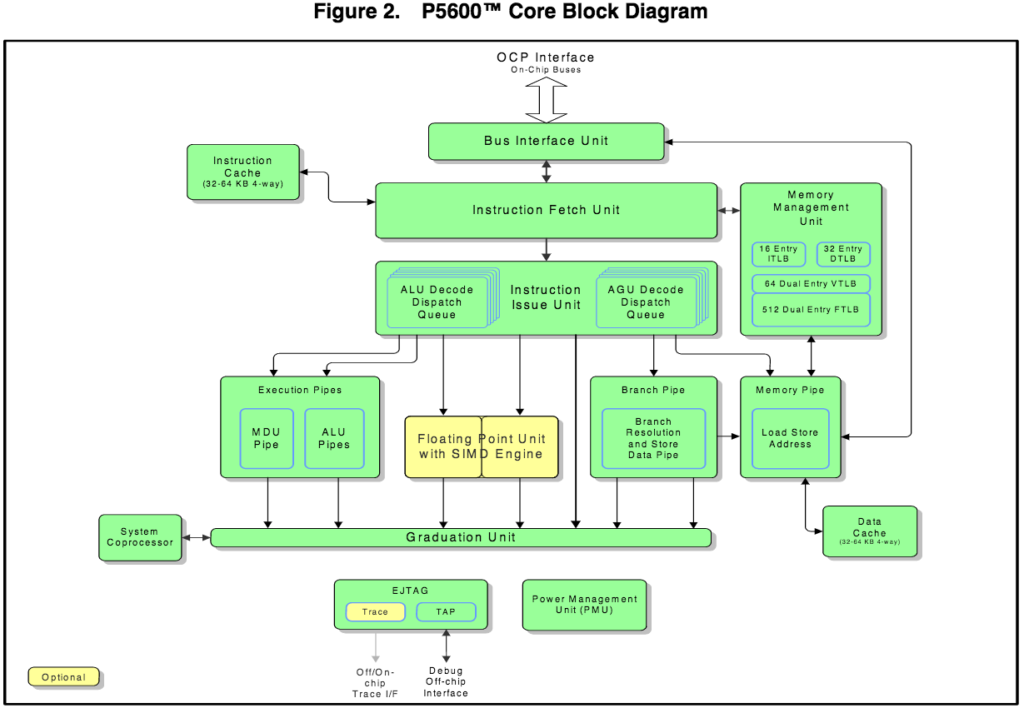
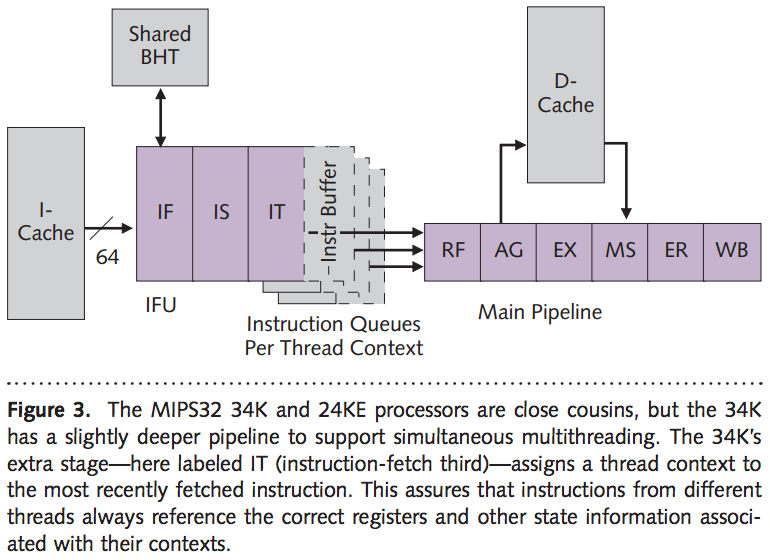
Чип для умных камер ELISE — одно из самых высокотехнологичных изделий России 2017 года. Плата для разработчиков и камера |










|
|
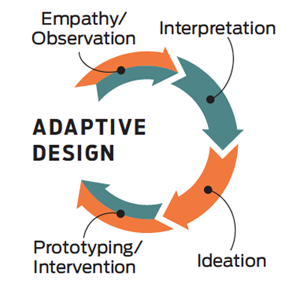
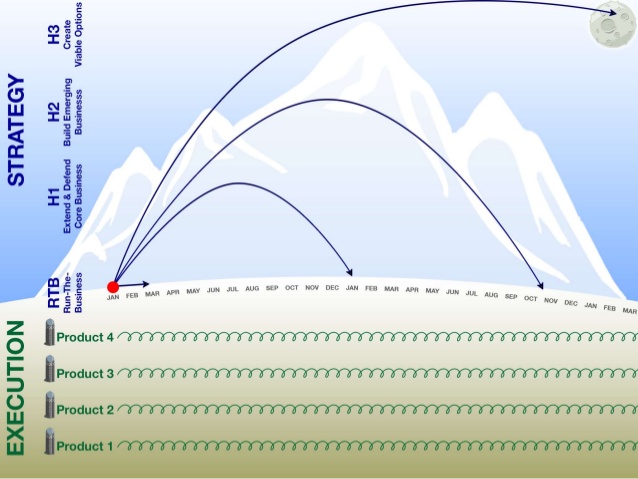
UX-стратегия. Часть 6 — Внедрение |








| Ценность | сейчас | через год |
|---|---|---|
| Качество продукта | терпимо | критично |
| Скорость выхода на рынок | критично | терпимо |
| Снижение рисков при выходе на рынок | терпимо | терпимо |
| Увеличение аудитории и прибыли продукта | критично | терпимо |
| Усиление бренда | не важно | терпимо |
| Найм и развитие дизайнеров | терпимо | терпимо |
| Осознание ценности дизайна | терпимо | терпимо |
| Проблема или идея |
|---|
| Общая дизайн-грамотность: Тренинг для менеджеров и разработчиков |
| Медиа-кит по рекламным форматам |
| Описать интерфейсный долг |
| База знаний по трендам |
| Участие дизайнеров в продуктовых планёрках |
| Формат хакатонов |
| Именование файлов |
| Генератор иконок в SVG |
| Бенчмарки: Наши продукты и конкуренты |
| Проблема или идея |
|---|
| Переделать предупреждение про регион |
| Перенести шаринг из левой колонки |
| Заменить пояс новостей на более ёмкий и простой |
| Оптимизировать врез киноафиши на главной |
| Убрать новости из истории просмотра |
| Улучшение интерфейсных текстов |
| Обменный пояс не на своём месте |
| Тянуть блок фильма до конца |
| Убрать ALL CAPS |
| Проблема или идея | Ценность | Уровень | Сложность |
|---|---|---|---|
| Общая дизайн-грамотность: Тренинг для менеджеров и разработчиков | качество риски бренд |
С | квартал |
| Медиа-кит по рекламным форматам | качество скорость рост |
Т | месяц |
| Описать интерфейсный долг | качество риски рост |
Т | месяц |
| База знаний по трендам | риски рост |
С | месяц |
| Участие дизайнеров в продуктовых планёрках | скорость риски рост |
Т | месяц |
| Формат хакатонов | скорость рост бренд |
Т | неделя |
| Именование файлов | качество скорость |
О | неделя |
| Генератор иконок в SVG | качество скорость |
О | квартал |
| Бенчмарки: Наши продукты и конкуренты | качество рост |
С | квартал |
| Проблема или идея | Метрики | Пользователей затронуто, тыс. | % | Сложность |
|---|---|---|---|---|
| Переделать предупреждение про регион | отношение | 4 000 | 20% | неделя |
| Перенести шаринг из левой колонки | качество | 20 000 | 100% | месяц |
| Заменить пояс новостей на более ёмкий и простой | деньги качество |
4 000 | 20% | неделя |
| Оптимизировать врез киноафиши на главной | деньги качество |
2 000 | 10% | неделя |
| Убрать новости из истории просмотра | деньги качество |
1 000 | 5% | неделя |
| Улучшение интерфейсных текстов | качество | 20 000 | 100% | неделя |
| Обменный пояс не на своём месте | деньги | 4 000 | 20% | день |
| Тянуть блок фильма до конца | качество | — | — | месяц |
| Убрать ALL CAPS | качество | — | — | день |





|
Метки: author jvetrau интерфейсы веб-дизайн usability ux ux- стратегия дизайн-стратегия пользовательские интерфейсы дизайн-менеджмент продуктовый дизайн |
Играем с эмоциями: Microsoft Cognitive Services + Unity |


private IEnumerator CheckEmotions()
{
EmotionService emoServ = new EmotionService(SubscriptionKeys.Instance.EmotionsApiKey);
while (true)
{
yield return new WaitForEndOfFrame();
yield return emoServ.GetEmoInfoCoroutine(_WebCam.Screenshot);
var emotions = emoServ.LastEmotions;
if (emotions != null)
{
_MaxEmotionValue.text = GetMaxEmotionOnScreenshot(emotions);
}
yield return new WaitForSeconds(DELAY);
}
}private IEnumerator CreateRecognizeRequestAndSaveResponseCoroutine(
string contentHeader,
byte[] data)
{
Dictionary headers = new Dictionary();
headers.Add(Constants.SUB_KEY_HEADER, _SubscriptionKey);
headers.Add(Constants.CONTENT_TYPE_HEADER, contentHeader);
WWW request = new WWW(_RecognizeRequestUrl, data, headers);
yield return new WaitUntil(() => request.isDone);
ParseEmotionsFromJson(request.text);
}private void CreateRecognizeRequest()
{
Clear();
_Thread = new Thread(Run);
_Thread.Start();
}
private void Run()
{
WebHeaderCollection headers = new WebHeaderCollection();
headers.Add(Constants.SUB_KEY_HEADER, _SubscriptionKey);
var request = HttpWebRequest.Create(_RecognizeRequestUrl);
request.ContentType = _ContentHeader;
request.Headers = headers;
request.ContentLength = _Data.Length;
request.Method = WebRequestMethods.Http.Post;
var dataStream = request.GetRequestStream();
dataStream.Write(_Data, 0, _Data.Length);
dataStream.Close();
var response = request.GetResponse();
dataStream = response.GetResponseStream();
StreamReader reader = new StreamReader(dataStream);
string responseString = reader.ReadToEnd();
reader.Close();
dataStream.Close();
response.Close();
Debug.Log(responseString);
if (!TryParseEmotionsFromJson(responseString))
{
Run();
}
else
{
_IsDataReady = true;
}
} Дядиченко Григорий — ведущий Unity разработчик в VRTech. Организатор Unity Moscow Meetup. Увлекается алгоритмами на графах, разработкой игр и всем, что связано с компьютерной графикой.
Дядиченко Григорий — ведущий Unity разработчик в VRTech. Организатор Unity Moscow Meetup. Увлекается алгоритмами на графах, разработкой игр и всем, что связано с компьютерной графикой.
|
Метки: author shwars unity3d блог компании microsoft cognitive services faceapi emotion api |
Удаленное подключение к защищаемым компьютерам из корпоративного антивируса |




 — модуль включен
— модуль включен — модуль выключен
— модуль выключен












|
|
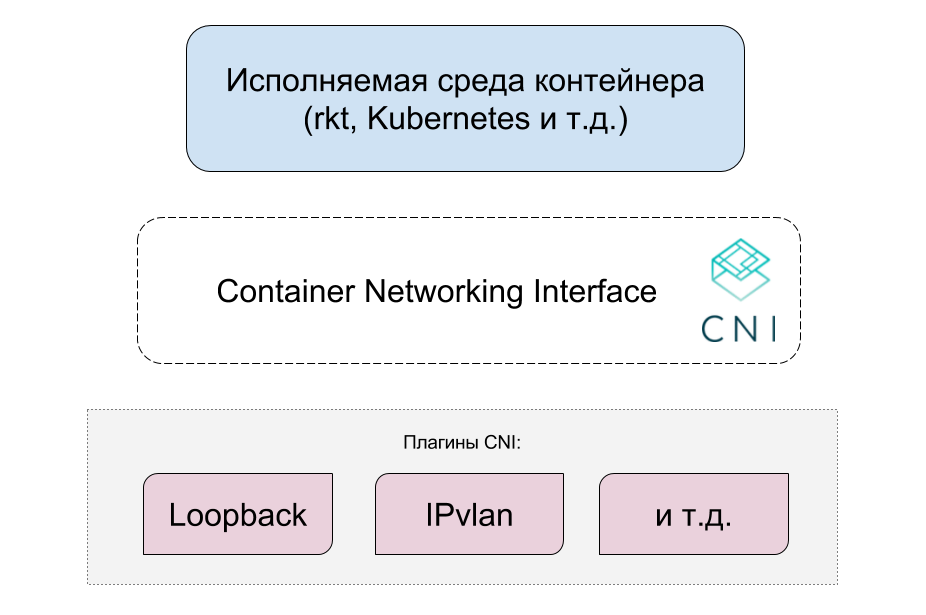
Container Networking Interface (CNI) — сетевой интерфейс и стандарт для Linux-контейнеров |

CNI ближе к Kubernetes с философской точки зрения. Он гораздо проще CNM, не требует демонов и его кроссплатформенность по меньшей правдоподобна (исполняемая среда контейнеров CoreOS rkt поддерживает его) [… а Kubernetes стремится поддерживать разные реализации контейнеров — прим. перев.]. Быть кроссплатформенным означает возможность использования сетевых конфигураций, которые будут одинаково работать в разных исполняемых средах (т.е. Docker, Rocket, Hyper). Этот подход следует философии UNIX делать одну вещь хорошо.

{
"cniVersion": "0.3.1",
"name": "dbnet",
"type": "bridge",
"bridge": "cni0",
"ipam": {
"type": "host-local",
"subnet": "10.1.0.0/16",
"gateway": "10.1.0.1"
},
"dns": {
"nameservers": [ "10.1.0.1" ]
}
}
./build.sh (или скачать уже бинарную сборку), после чего — воспользоваться исполняемым файлом плагина (например, ./bin/bridge), передав ему необходимые для функционирования аргументы через переменные окружения CNI_*, а сетевую конфигурацию — прямо JSON-данными через STDIN (так предусмотрено в спецификации CNI).$ cat > mybridge.conf <<"EOF"
{
"cniVersion": "0.2.0",
"name": "mybridge",
"type": "bridge",
"bridge": "cni_bridge0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "10.15.20.0/24",
"routes": [
{ "dst": "0.0.0.0/0" },
{ "dst": "1.1.1.1/32", "gw":"10.15.20.1"}
]
}
}
EOF
$ sudo ip netns add 1234567890
$ sudo CNI_COMMAND=ADD CNI_CONTAINERID=1234567890 \
CNI_NETNS=/var/run/netns/1234567890 CNI_IFNAME=eth12 \
CNI_PATH=`pwd` ./bridge 64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:8 errors:0 dropped:0 overruns:0 frame:0
TX packets:8 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:536 (536.0 B) TX bytes:648 (648.0 B)
…
|
|
Postgres и Пустота |
Только что натолкнулся на возможность Postgresql, показавшуюся мне забавной.
Для кого "боян" — респект вам, я несколько лет работаю с Postgres и до сих пор не натыкался на такую штуку.
select; без указания полей, таблицы и условий возвращает одну строку.
Но у этой строки нет полей:
=> select;
--
(1 row)Для сравнения:
=> select null;
?column?
----------
(1 row)
=> select null where 0=1;
?column?
----------
(0 rows)А сможем ли мы создать таблицу из такого "пустого" запроса? Таблицу без полей.
Да пожалуйста:
=> create table t as select;
SELECT 1
=> \d+ t
Table "t"
Column | Type | Modifiers | Storage | Stats target | Description
--------+------+-----------+---------+--------------+-------------
=> select * from t;
--
(1 row)А можем ли мы в неё вставить?
Легко:
=> insert into t select;
INSERT 0 1
=> insert into t select;
INSERT 0 1
=> select * from t;
--
(3 rows)
=> select count(*) from t;
count
-------
3ЕЩЕ!
=> insert into t select from generate_series(1,1000000);
INSERT 0 1000000Интересно, будет ли Postgresql сканировать такую таблицу?
=> explain analyze select * from t;
QUERY PLAN
------------------------------------------------------------------------------------------------------------
Seq Scan on t (cost=0.00..13438.67 rows=1000167 width=0) (actual time=0.018..96.389 rows=1000003 loops=1)
Planning time: 0.024 ms
Execution time: 134.654 ms
(3 rows)Да, честно сканирует. Больше 100 ms — вполне себе заметное время.
Ну и чтобы убедиться, что всё по честному, посмотрим сколько места занимает наша супер-полезная таблица:
=> select pg_size_pretty(pg_total_relation_size('t'));
pg_size_pretty
----------------
27 MB
(1 row)То есть таблица есть, занимает место на диске, в блоках хранятся разные служебные данные, ну а то, что в ней нет полей — бывает, дело житейское!
=> select t.xmin, t.ctid from t limit 10;
xmin | ctid
---------+--------
1029645 | (0,1)
1029647 | (0,2)
1029648 | (0,3)
1029649 | (0,4)
1029649 | (0,5)
1029649 | (0,6)
1029649 | (0,7)
1029649 | (0,8)
1029649 | (0,9)
1029649 | (0,10)
(10 rows)Я не придумал, зачем может понадобиться такая таблица. Но возможность есть, и это хорошо!
|
Метки: author CPro ненормальное программирование postgresql пустота |
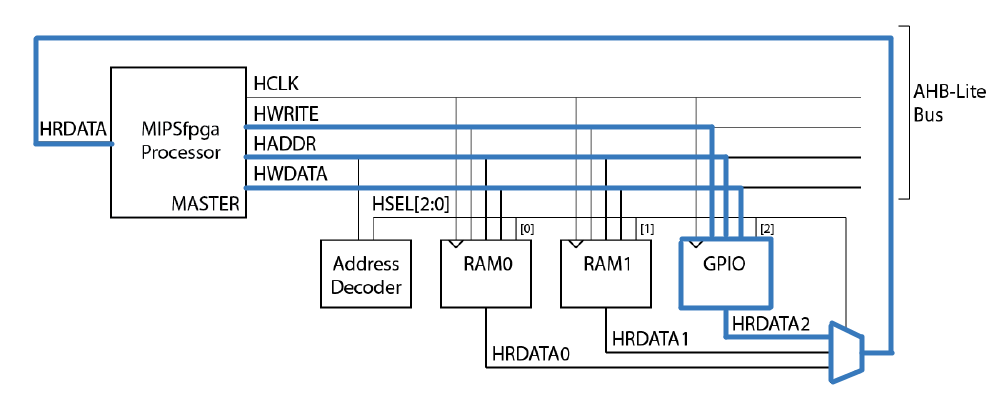
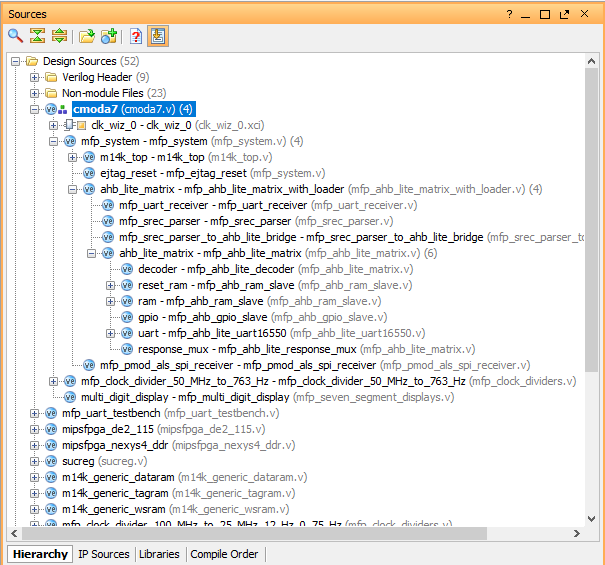
Портирование MIPSfpga на другие платы и интеграция периферии в систему. Часть 3 |
|
|
Портирование MIPSfpga на другие платы и интеграция периферии в систему. Часть 2 |


| Пин | Сигнал | Назначение | Пин | Сигнал | Назначение |
|---|---|---|---|---|---|
| 1 | Col4 | 4 колонка | 7 | ROW4 | 4 ряд |
| 2 | Col3 | 3 колонка | 8 | ROW3 | 3 ряд |
| 3 | Col2 | 2 колонка | 9 | ROW2 | 2 ряд |
| 4 | Col1 | 1 колонка | 10 | ROW1 | 1 ряд |
| 5 | GND | контакт земли | 11 | GND | контакт земли |
| 6 | GND | контакт питания | 12 | VCC | контакт питания |

module kypd_decoder(
input i_clk,
input i_rst_n,
input [3:0] i_row,
output reg [3:0] o_col,
output reg [3:0] o_number
);
reg [19:0] counter;
reg [3:0] col;
reg [3:0] row;
// row col
parameter ZERO = 8'b11100111,
ONE = 8'b01110111,
TWO = 8'b01111011,
THREE = 8'b01111101,
FOUR = 8'b10110111,
FIVE = 8'b10111011,
SIX = 8'b10111101,
SEVEN = 8'b11010111,
EIGHT = 8'b11011011,
NINE = 8'b11011101,
A = 8'b01111110,
B = 8'b10111110,
C = 8'b11011110,
D = 8'b11101110,
E = 8'b11101101,
F = 8'b11101011;
always @(posedge i_clk or negedge i_rst_n)
if (i_rst_n == 0)
counter <= 20'b0;
else
counter <= counter + 1'b1;
always @(posedge i_clk or negedge i_rst_n)
if (i_rst_n == 1'b0) begin
o_col <= 4'b1110;
col <= 4'b1110;
row <= 4'b1111;
end else if (!counter) begin
o_col <= {o_col [0], o_col [3:1]};
col <= o_col;
row <= i_row;
end
always @(posedge i_clk or negedge i_rst_n)
if (i_rst_n == 0)
o_number <= 4'b0;
else
case ({row, col})
ZERO: o_number <= 4'h0;
ONE: o_number <= 4'h1;
TWO: o_number <= 4'h2;
THREE: o_number <= 4'h3;
FOUR: o_number <= 4'h4;
FIVE: o_number <= 4'h5;
SIX: o_number <= 4'h6;
SEVEN: o_number <= 4'h7;
EIGHT: o_number <= 4'h8;
NINE: o_number <= 4'h9;
A: o_number <= 4'hA;
B: o_number <= 4'hB;
C: o_number <= 4'hC;
D: o_number <= 4'hD;
E: o_number <= 4'hE;
F: o_number <= 4'hF;
endcase
endmodule
//`define MFP_DEMO_LIGHT_SENSOR`define MFP_PMOD_KYPD`ifdef MFP_DEMO_LIGHT_SENSOR`ifdef MFP_PMOD_KYPD
kypd_decoder kypd_decoder
(
.i_clk ( SI_ClkIn ),
.i_rst_n ( KEY_0 ),
.o_col ( KYPD_DATA [3:0] ),
.i_row ( KYPD_DATA [7:4] ),
.o_number ( KYPD_OUT )
);
`endif`ifdef MFP_PMOD_KYPD
.KYPD_OUT ( KYPD_OUT ),
`endif`ifdef MFP_PMOD_KYPD
wire [3:0] KYPD_OUT;
`endif`ifdef MFP_PMOD_KYPD
input [3:0] KYPD_OUT,
`endif`ifdef MFP_PMOD_KYPD
.KYPD_OUT ( KYPD_OUT ),
`endif`ifdef MFP_PMOD_KYPD
input [3:0] KYPD_OUT,
`endif`ifdef MFP_PMOD_KYPD
.KYPD_OUT ( KYPD_OUT ),
`endif`ifdef MFP_PMOD_KYPD
input [3:0] KYPD_OUT,
`endif`ifdef MFP_PMOD_KYPD
`MFP_PMOD_KYPD_IONUM : HRDATA <= { 28'b0, KYPD_OUT };
`endif`ifdef MFP_PMOD_KYPD
`define MFP_PMOD_KYPD_ADDR 32'h1f800018
`endif`ifdef MFP_PMOD_KYPD
`define MFP_PMOD_KYPD_IONUM 4'h6
`endif `ifdef MFP_PMOD_KYPD
inout [7:0] KYPD_DATA,
input KEY_0,
`endif `ifdef MFP_PMOD_KYPD
.KYPD_DATA ( JA ),
.KEY_0 ( ~ i_btn1 ),
`endifmodule cmoda7
(
...
...
...
inout [ 7:0] JA
);
## Pmod Header JA
set_property -dict {PACKAGE_PIN G17 IOSTANDARD LVCMOS33} [get_ports {JA[0]}]
set_property -dict {PACKAGE_PIN G19 IOSTANDARD LVCMOS33} [get_ports {JA[1]}]
set_property -dict {PACKAGE_PIN N18 IOSTANDARD LVCMOS33} [get_ports {JA[2]}]
set_property -dict {PACKAGE_PIN L18 IOSTANDARD LVCMOS33} [get_ports {JA[3]}]
set_property -dict {PACKAGE_PIN H17 IOSTANDARD LVCMOS33} [get_ports {JA[4]}]
set_property -dict {PACKAGE_PIN H19 IOSTANDARD LVCMOS33} [get_ports {JA[5]}]
set_property -dict {PACKAGE_PIN J19 IOSTANDARD LVCMOS33} [get_ports {JA[6]}]
set_property -dict {PACKAGE_PIN K18 IOSTANDARD LVCMOS33} [get_ports {JA[7]}]
//`define MFP_DEMO_LIGHT_SENSOR`ifdef MFP_DEMO_LIGHT_SENSOR
...
`endif #define MFP_PMOD_KYPD_ADDR 0xBF800018
и
#define MFP_PMOD_KYPD (* (volatile unsigned *) MFP_PMOD_KYPD_ADDR )
#include "mfp_memory_mapped_registers.h"
int main ()
{
int n = 0;
for (;;)
{
MFP_7_SEGMENT_HEX = MFP_PMOD_KYPD;
}
return 0;
}
02_compile_and_link
08_generate_motorola_s_record_file11_check_which_com_port_is_usedset a=7
mode com%a% baud=115200 parity=n data=8 stop=1 to=off xon=off odsr=off octs=off dtr=off rts=off idsr=off type program.rec >\.\COM%a%12_upload_to_the_board_using_uart|
|
[Перевод] Что нового нас ждет в Swift 4? |
|
Метки: author JiLiZART разработка под ios разработка мобильных приложений программирование swift swift 4 никто не читает теги с правками в личку |
[Перевод] Ruby on Rails соглашение. Часть 3 |

class Project < ApplicationRecord
belongs_to :account
has_many :participants, class_name: 'Person'
validates_presence_of :name
end
class CreateAccounts < ActiveRecord::Migration
def change
create_table :accounts do |t|
t.integer :queenbee_id
t.timestamps
end
end
end
if people.include? person
…
if person.in? people
|
Метки: author dmitriy-strukov ruby on rails ruby dhh |
DevOps на сервисах Amazon AWS |





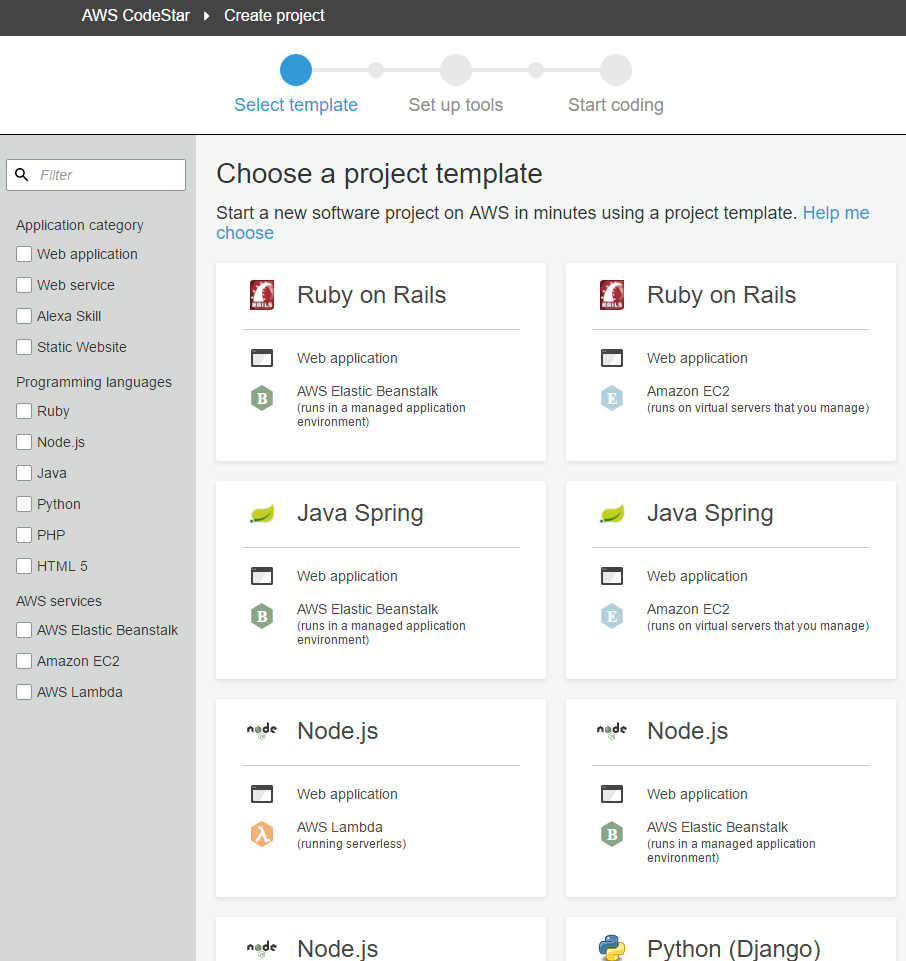
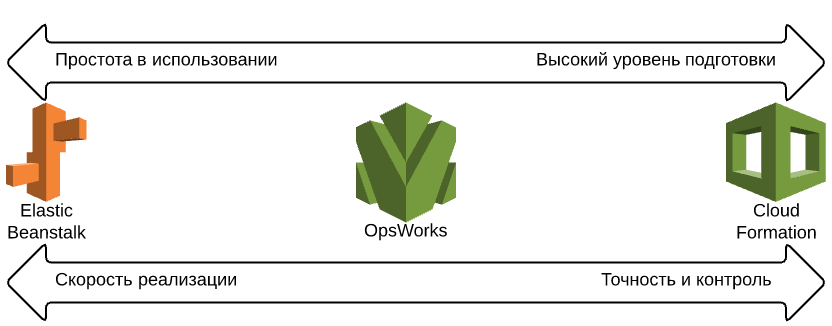

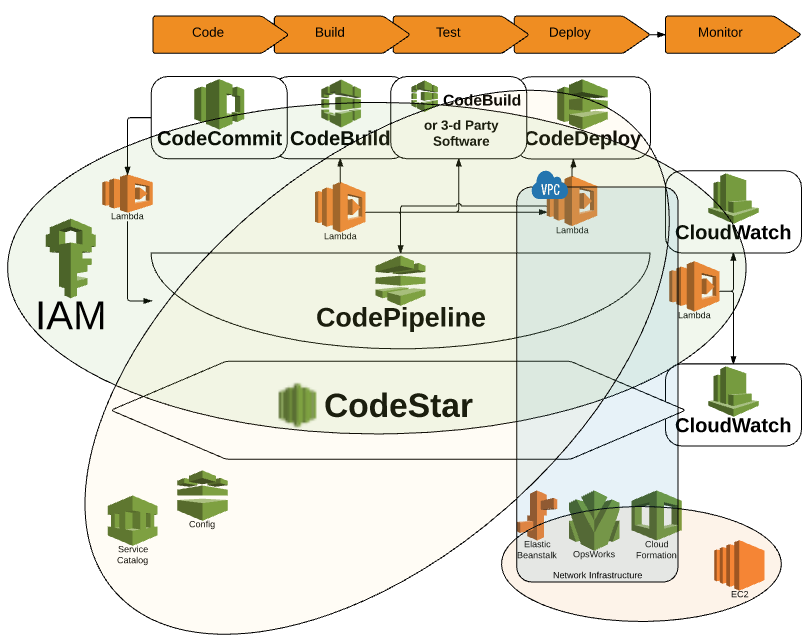
|
Метки: author apple_rom amazon web services devops aws |
Никита Липский и Дмитрий Чуйко об AOT в Java на jug.msk.ru |





|
Метки: author dbelob java блог компании jug.ru group jug jug.msk.ru aot excelsior oracle |






