Tizen: подводим итоги |
 Наша команда написала три заметки, связанные с анализом кода операционной системы Tizen. Операционная система содержит много кода и поэтому является благодатной почвой для написания различных статей. Думаю, что к Tizen мы ещё вернёмся в будущем, но сейчас нас ждут другие интересные проекты. Поэтому я подведу некоторые итоги проделанной работы и отвечу на ряд вопросов, возникших после опубликованных ранее статей.
Наша команда написала три заметки, связанные с анализом кода операционной системы Tizen. Операционная система содержит много кода и поэтому является благодатной почвой для написания различных статей. Думаю, что к Tizen мы ещё вернёмся в будущем, но сейчас нас ждут другие интересные проекты. Поэтому я подведу некоторые итоги проделанной работы и отвечу на ряд вопросов, возникших после опубликованных ранее статей.

class BookmarkItem
{
public:
BookmarkItem();
BookmarkItem(
const std::string& url,
const std::string& title,
const std::string& note,
unsigned int dir = 0,
unsigned int id = 0
);
virtual ~BookmarkItem();
void setAddress(const std::string & url) { m_url = url; };
std::string getAddress() const { return m_url; };
void setTitle(const std::string & title) { m_title = title; };
std::string getTitle() const { return m_title; };
void setNote(const std::string& note){m_note = note;};
std::string getNote() const { return m_note;};
void setId(int id) { m_saved_id = id; };
unsigned int getId() const { return m_saved_id; };
....
....
bool is_folder(void) const { return m_is_folder; }
bool is_editable(void) const { return m_is_editable; }
void set_folder_flag(bool flag) { m_is_folder = flag; }
void set_editable_flag(bool flag) { m_is_editable = flag; }
private:
unsigned int m_saved_id;
std::string m_url;
std::string m_title;
std::string m_note;
std::shared_ptr m_thumbnail;
std::shared_ptr m_favicon;
unsigned int m_directory;
std::vector m_tags;
bool m_is_folder;
bool m_is_editable;
}; BookmarkItem::BookmarkItem()
: m_saved_id(0)
, m_url()
, m_title()
, m_note()
, m_thumbnail(std::make_shared<.....>())
, m_favicon(std::make_shared<.....>())
, m_directory(0)
, m_is_folder(false)
, m_is_editable(true)
{
}
BookmarkItem::BookmarkItem(
const std::string& url,
const std::string& title,
const std::string& note,
unsigned int dir,
unsigned int id
)
: m_saved_id(id)
, m_url(url)
, m_title(title)
, m_note(note)
, m_directory(dir)
{
}
int **PtrArray = (int **)malloc(Count * size_of(int));int **PtrArray = (int **)malloc(Count * size_of(int *));*string = (char*)malloc(real_string_len * sizeof(char));int malloc(int x);
|
|
Skype-бот с человеческим лицом (на Microsoft Bot Framework V3 и Slack API) |

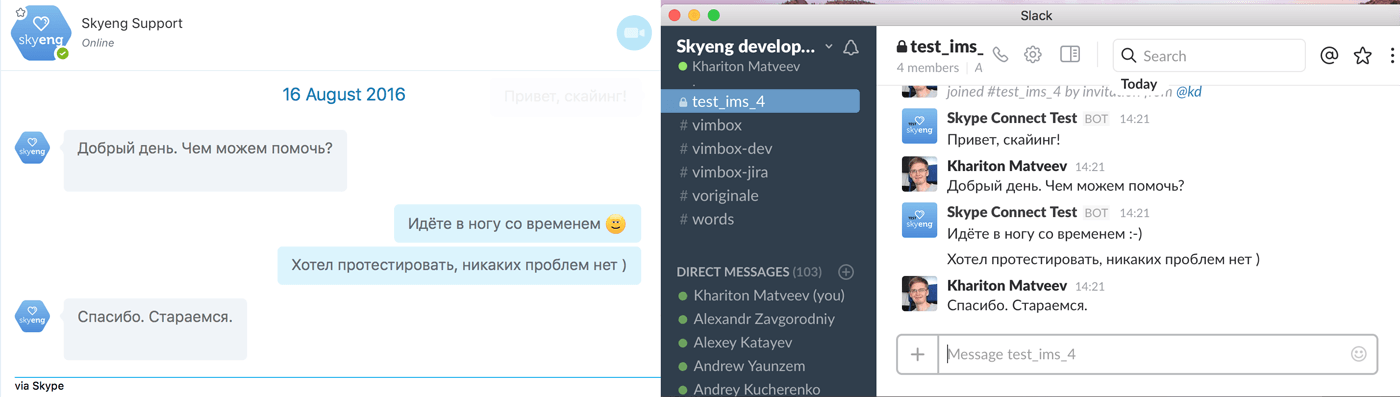




bot.send(
'8:skype.username',
'message from bot to user',
true, // escape
(error) => console.log(error)
);bot.send(
new builder.Message()
.address({
channelId: "skype",
user: {
id: "29:some-long-hash-here",
name: "User Display Name"
},
bot: {
id: "28:bot-uuid",
name: "Bot Name"
},
serviceUrl: "https://skype.botframework.com",
useAuth: true
})
.text('Message from bot to user'),
(err) => console.log(err)
);bot.on('personalMessage', (bot, data) => {
console.log('Got message from user');
});bot.dialog("/", [
(session) => {
console.log("Got message from bot", session.message);
}
]);


|
Метки: author Ontaelio системы обмена сообщениями node.js блог компании skyeng бот для скайпа microsoft bot framework slack api rabbitmq клиентский сервис |
Добавляем эффект нажатия в Xamarin.Forms |
Xamarin.Forms набирает обороты и к, сожалению, из коробки доступно совсем мало возможностей, все неоходимо добавлять через Dependency service или рендереры. На этой волне стало очень много различных библиотек, добавляющих зачастую базовый функционал.
Мое решение не исключение.
У меня стояла задача сделать небольшое расширение, позволяющее добавить эффект нажатия на почти любой элемент для iOS и Android.
Изначально у меня мысль создать контейнер с эффектом нажатия и в него уже добавлять необходимые элементы. От этой идеи пришлось отказаться в виду дополнительной вложенности и некорректности выделения. То есть, положив в этот контейнер не прямоугольный элемент по типу CircularImage или Frame я получил бы выделение за пределами закругленной области.
Переписывать и расширять все контролы было бы глупо, поэтому я решил добавить статическое расширение.
Для Android 5+ очевидно, надо использовать Ripple effect. Но для iOS и Android <5 это решение будет выглядеть неуместно. Для этих платформ я решил реализовать цветное анимированное выделение, срабатываемое при касании.
Для начала в PCL проекте был создан статический класс TouchEffect с двумя BindableProperty:
Первое отвечает за активность расширения для элемента, соответсвенно второе за цвет эффекта.
Необходимо определить переменную, которая идентифицирует нужно использовать Ripple effect или нет в зависимости от версии Android:
public bool EnableRipple => Build.VERSION.SdkInt >= BuildVersionCodes.Lollipop;Для реализация стандартных волн для андроида довольно проста:
private void AddRipple()
{
if (Element is Layout)
{
_rippleOverlay = new FrameLayout(Container.Context)
{
LayoutParameters = new ViewGroup.LayoutParams(-1, -1)
};
_rippleListener = new ContainerOnLayoutChangeListener(_rippleOverlay);
_view.AddOnLayoutChangeListener(_rippleListener);
((ViewGroup)_view).AddView(_rippleOverlay);
_rippleOverlay.BringToFront();
_rippleOverlay.Foreground = CreateRipple(Color.Accent.ToAndroid());
}
else
{
_orgDrawable = _view.Background;
_view.Background = CreateRipple(Color.Accent.ToAndroid());
}
_ripple.SetColor(GetPressedColorSelector(_color));
}
private void RemoveRipple()
{
if (Element is Layout)
{
var viewgrp = (ViewGroup)_view;
viewgrp?.RemoveOnLayoutChangeListener(_rippleListener);
viewgrp?.RemoveView(_rippleOverlay);
_rippleListener?.Dispose();
_rippleListener = null;
_rippleOverlay?.Dispose();
_rippleOverlay = null;
}
else
{
_view.Background = _orgDrawable;
_orgDrawable?.Dispose();
_orgDrawable = null;
}
_ripple?.Dispose();
_ripple = null;
}
private RippleDrawable CreateRipple(Android.Graphics.Color color)
{
if (Element is Layout)
{
var mask = new ColorDrawable(Android.Graphics.Color.White);
return _ripple = new RippleDrawable(GetPressedColorSelector(color), null, mask);
}
var back = _view.Background;
if (back == null)
{
var mask = new ColorDrawable(Android.Graphics.Color.White);
return _ripple = new RippleDrawable(GetPressedColorSelector(color), null, mask);
}
else if (back is RippleDrawable)
{
_ripple = (RippleDrawable) back.GetConstantState().NewDrawable();
_ripple.SetColor(GetPressedColorSelector(color));
return _ripple;
}
else
{
return _ripple = new RippleDrawable(GetPressedColorSelector(color), back, null);
}
}У контрола берется задний фон и на него добавляется эффект.
Для более старых версий андроида я решил добавлять FrameLayout поверх элемента с анимацией Alpha канала заднего фона.
К событию Touch элемента подписывается этот метод:
private void OnTouch(object sender, View.TouchEventArgs args)
{
switch (args.Event.Action)
{
case MotionEventActions.Down:
Container.RemoveView(_layer);
Container.AddView(_layer);
_layer.Top = 0;
_layer.Left = 0;
_layer.Right = _view.Width;
_layer.Bottom = _view.Height;
_layer.BringToFront();
TapAnimation(250, 0, 65, false);
break;
case MotionEventActions.Up:
case MotionEventActions.Cancel:
TapAnimation(250, 65, 0);
break;
}
}Который при нажатии добавляет в контейнер новый лэйаут с анимацией A-канала с 0 до 65, а при отпускании анимирует обратно от 65 до 0 и удаляет из контейнера.
Потом, в методе OnAttached определяем, что делать, создавать Ripple effect или подписываться на Touch:
if (EnableRipple)
AddRipple();
else
_view.Touch += OnTouch;Для iOS подход схож с предыдущим шагом, добавляется UIView поверх основного элемента при нажатии и так же анимируется A-канал. Для этого создаются UITapGestureRecognizer и UILongPressGestureRecognizer и добавляются к элементу:
_tapGesture = new UITapGestureRecognizer(async (obj) => {
await TapAnimation(0.3, _alpha, 0);
});
_longTapGesture = new UILongPressGestureRecognizer(async (obj) => {
switch (obj.State)
{
case UIGestureRecognizerState.Began:
await TapAnimation(0.5, 0, _alpha, false);
break;
case UIGestureRecognizerState.Ended:
case UIGestureRecognizerState.Cancelled:
case UIGestureRecognizerState.Failed:
await TapAnimation(0.5, _alpha);
break;
}
});
_view.AddGestureRecognizer(_longTapGesture);
_view.AddGestureRecognizer(_tapGesture);При долгом нажатии задается другое время анимации и, в отличие от простого нажатия, элемент удаляется только после отпускания пальца.
Собственно все.
XAML:
| iOS | Android API >=21 | Android API < 21 |
|---|---|---|
 |
 |
 |
Я привел основую идею реализации эффекта касания, весь код, а так же Nuget пакеты доступны на GitHub.
P.S. Опыт у меня в нативной разработке небольшой, буду рад советам, что можно улучшить/доработать.
P.P.S Habrastorage немного коряво преобразовал gif'ки.
|
Метки: author mrxten разработка мобильных приложений c# .net xamarin xamarin.forms effects |
Случайный лес vs нейросети: кто лучше справится с задачей распознавания аудио |
 / Фотография justin lincoln / CC-BY
/ Фотография justin lincoln / CC-BYХарактеристики голоса, которые мы будем использовать


import csv, os
import numpy as np
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import GroupKFold
# read data
with open('data.csv', 'r')as c:
r = csv.reader(c, delimiter=',')
header = r.next()
data = []
for row in r:
data.append(row)
data = np.array(data)
# preprocess
genders = data[:, 0].astype(int)
speakers = data[:, 1].astype(int)
filenames = data[:, 2]
times = data[:, 3].astype(float)
pitch = data[:, 4:5].astype(float)
features = data[:, 4:].astype(float)def subject_cross_validation(clf, x, y, subj, folds):
gkf = GroupKFold(n_splits=folds)
scores = []
for train, test in gkf.split(x, y, groups=subj):
clf.fit(x[train], y[train])
scores.append(clf.score(x[test], y[test]))
return np.mean(scores)# classify frames separately
score_frames_pitch = subject_cross_validation(RFC(n_estimators=100), pitch, genders, speakers, 5)
print 'Frames classification on pitch, accuracy:', score_frames_pitch
score_frames_features = subject_cross_validation(RFC(n_estimators=100), features, genders, speakers, 5)
print 'Frames classification on all features, accuracy:', score_frames_featuresdef make_sample(x, y, subj, names, statistics=[np.mean, np.std, np.median, np.min, np.max]):
avx = []
avy = []
avs = []
keys = np.unique(names)
for k in keys:
idx = names == k
v = []
for stat in statistics:
v += stat(x[idx], axis=0).tolist()
avx.append(v)
avy.append(y[idx][0])
avs.append(subj[idx][0])
return np.array(avx), np.array(avy).astype(int), np.array(avs).astype(int)
# average features for each frame
average_features, average_genders, average_speakers = make_sample(features, genders, speakers, filenames)
average_pitch, average_genders, average_speakers = make_sample(pitch, genders, speakers, filenames)# train models on pitch and on all features
score_pitch = subject_cross_validation(RFC(n_estimators=100), average_pitch, average_genders, average_speakers, 5)
print 'Utterance classification on pitch, accuracy:', score_pitch
score_features = subject_cross_validation(RFC(n_estimators=100), average_features, average_genders, average_speakers, 5)
print 'Utterance classification on features, accuracy:', score_features# skip all frames without pitch
filter_idx = pitch[:, 0] > 1
filtered_average_features, filtered_average_genders, filtered_average_speakers = make_sample(features[filter_idx], genders[filter_idx], speakers[filter_idx], filenames[filter_idx])
score_filtered = subject_cross_validation(RFC(n_estimators=100), filtered_average_features, filtered_average_genders, filtered_average_speakers, 5)
print 'Utterance classification an averaged features over filtered frames, accuracy:', score_filtered
|
Метки: author IgorLevin работа со звуком блог компании neurodata lab neurodata lab распознавание аудио нейросети |
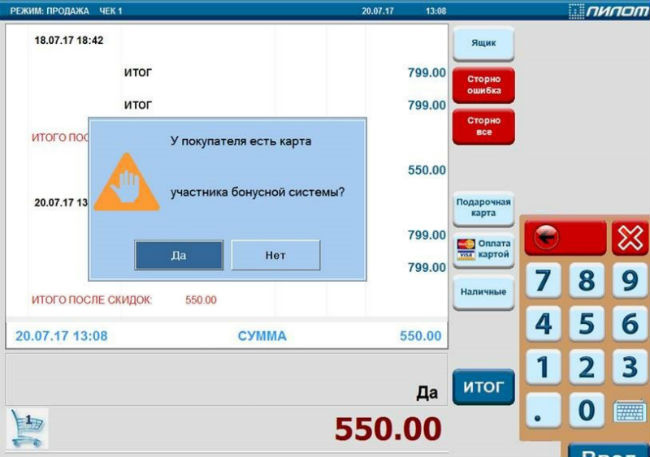
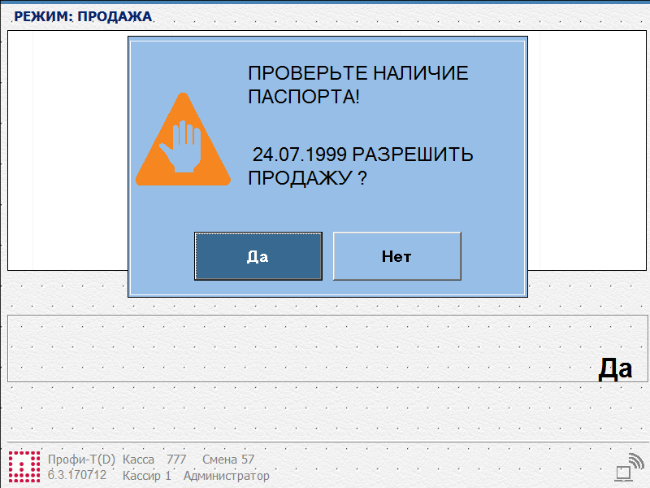
Плюсы автоматизации: как технологии исправляют ошибки сотрудников магазинов |



|
Метки: author pilot-retail it- инфраструктура блог компании пилот ритейл технологии автоматизация |
Опыт использования FPGA платы DE10-Standard и DMA PL330 |




ethaddr=fe:cd:12:34:56:67
ipaddr=10.8.0.97
serverip=10.8.0.36
xfpga=tftpboot 100 socfpga.rbf; fpga load 0 100 $filesize; run bridge_enable_handoff; tftpboot 100 socfpga.dtb
xload=run xfpga; tftpboot 8000 zImage; bootz 8000 – 100>run xload>sopc2dts --input soc_system.sopcinfo --output socfpga.dts --board soc_system_board_info.xml --board hps_clock_info.xml>dtc -I dts -O dtb -o socfpga.dtb socfpga.dts#ifdef CONFIG_OF
static const struct of_device_id fpga_dma_of_match[] = {
{.compatible = "altr,fpga-dma",},
{},
};
MODULE_DEVICE_TABLE(of, fpga_dma_of_match);
#endif
static struct platform_driver fpga_dma_driver = {
.probe = fpga_dma_probe,
.remove = fpga_dma_remove,
.driver = {
.name = "fpga_dma",
.owner = THIS_MODULE,
.of_match_table = of_match_ptr(fpga_dma_of_match),
},
};
static int __init fpga_dma_init(void)
{
return platform_driver_probe(&fpga_dma_driver, fpga_dma_probe);
}fpga_dma: fpga_dma@0x10033000 {
compatible = "altr,fpga-dma";csr_reg = platform_get_resource_byname(pdev, IORESOURCE_MEM, "csr");
data_reg = platform_get_resource_byname(pdev, IORESOURCE_MEM, "data");static int fpga_dma_dma_init(struct fpga_dma_pdata *pdata)
{
struct platform_device *pdev = pdata->pdev;
pdata->txchan = dma_request_slave_channel(&pdev->dev, "tx");
if (pdata->txchan)
dev_dbg(&pdev->dev, "TX channel %s %d selected\n",
dma_chan_name(pdata->txchan), pdata->txchan->chan_id);
else
dev_err(&pdev->dev, "could not get TX dma channel\n");
pdata->rxchan = dma_request_slave_channel(&pdev->dev, "rx");
if (pdata->rxchan)fpga_dma: fpga_dma@0x10033000 {
compatible = "altr,fpga-dma";
reg = <0x00000001 0x00033000 0x00000020>,
<0x00000000 0x00034000 0x00000010>;
reg-names = "csr", "data";
dmas = <&hps_0_dma 0 &hps_0_dma 1>;
dma-names = "rx", "tx";DMAMOV CCR, SB4 SS64 DB4 DS64
DMAMOV SAR, 0x1000
DMAMOV DAR, 0x4000
DMALP 16
DMALD
DMAST
DMALPEND
DMAEND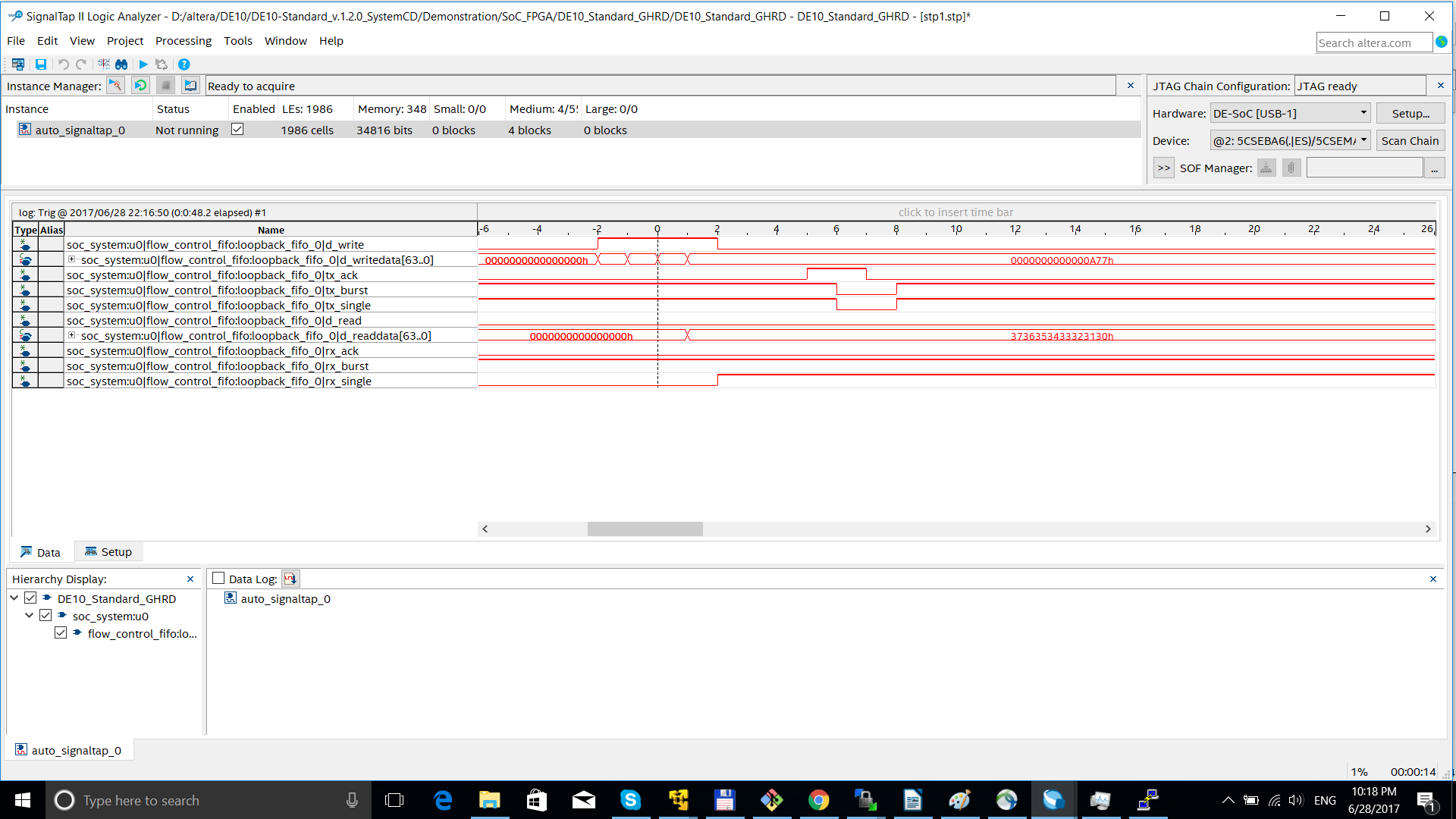
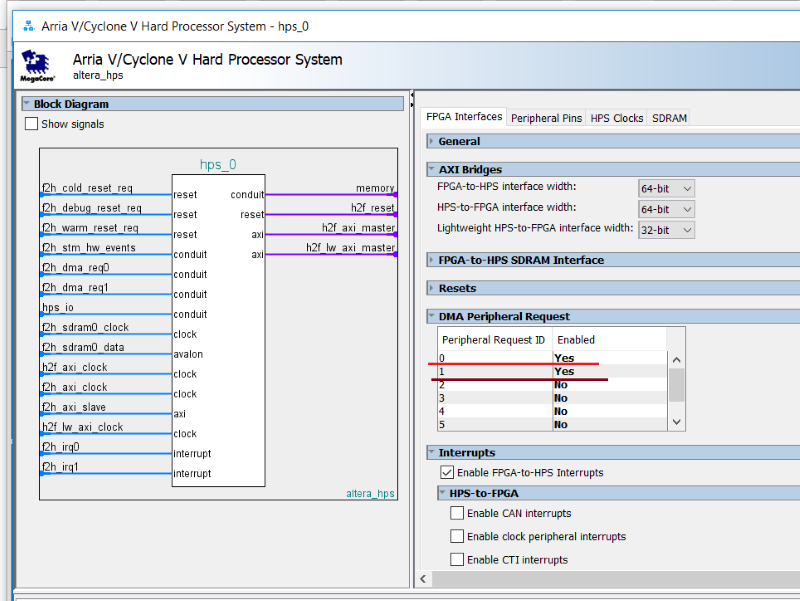
hps_0_dma: dma@0xffe01000 {
compatible = "arm,pl330-16.1", "arm,pl330", "arm,primecell";
reg = <0xffe01000 0x00001000>;
interrupt-parent = <&hps_0_arm_gic_0>;
interrupts = <0 104 4>, <0 105 4>;
clocks = <&l4_main_clk>;

|
Метки: author nckma fpga soc hps cyclone v dma linux kernel |
Как управлять ценообразованием в SAP Business One |
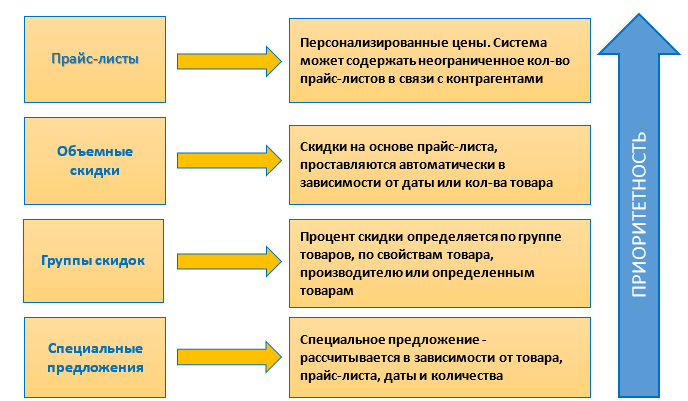
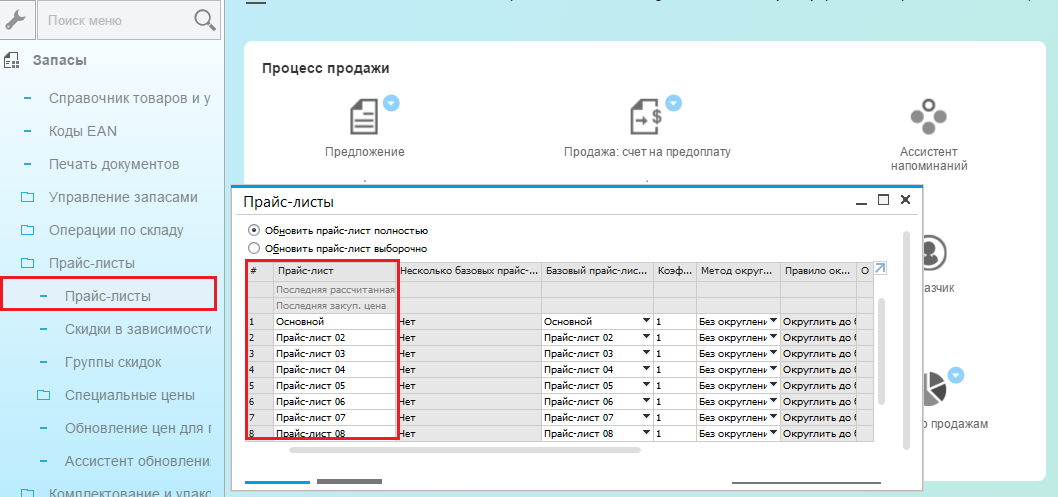
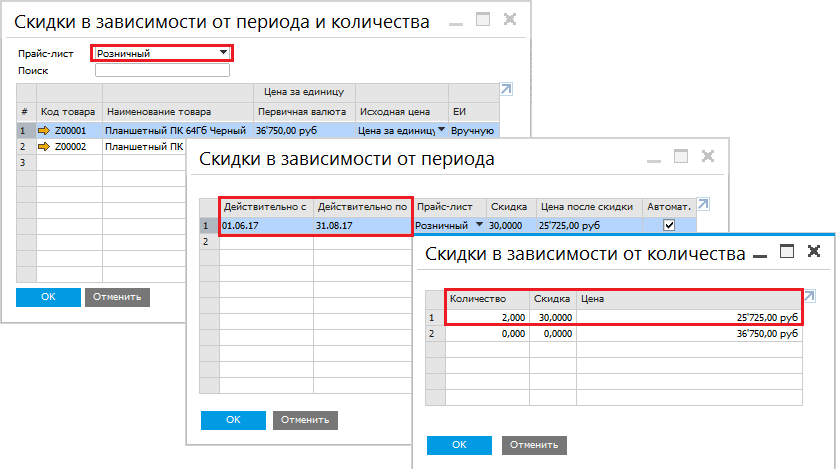
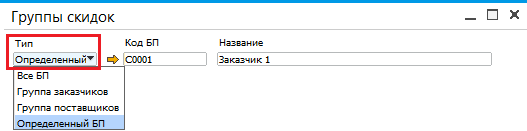
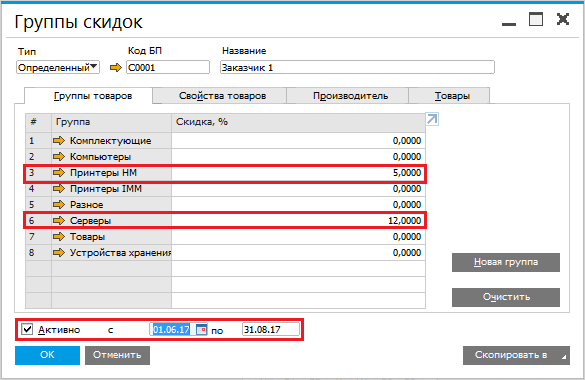
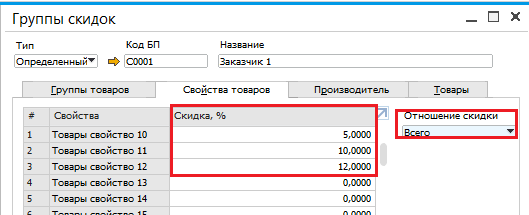
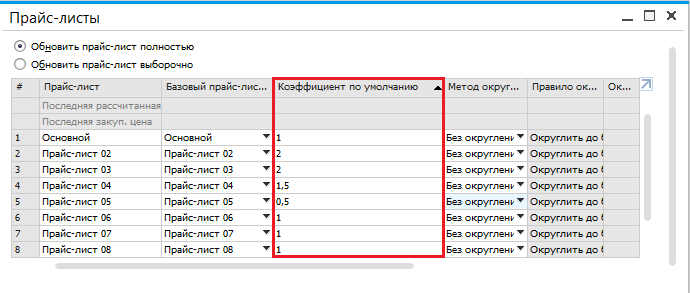 Коэффициенты для расчета прайс-листов
Коэффициенты для расчета прайс-листов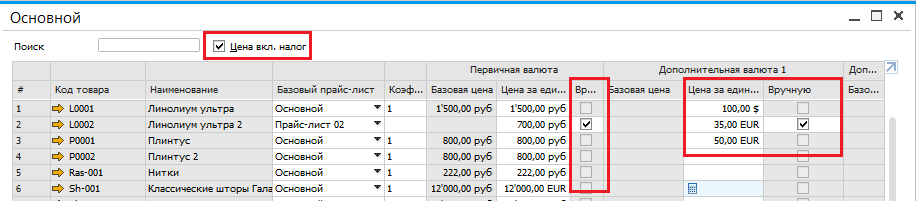
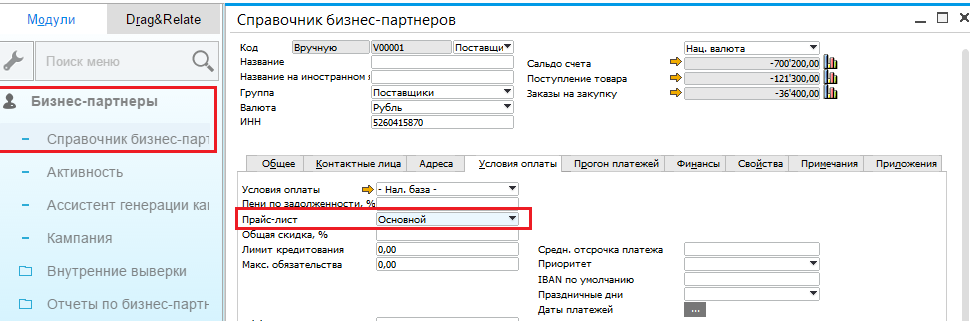
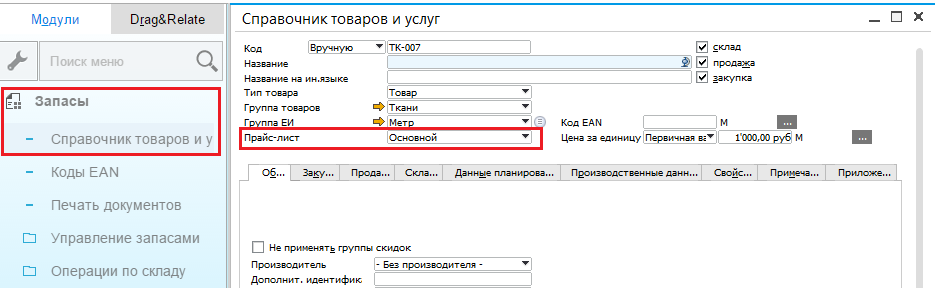
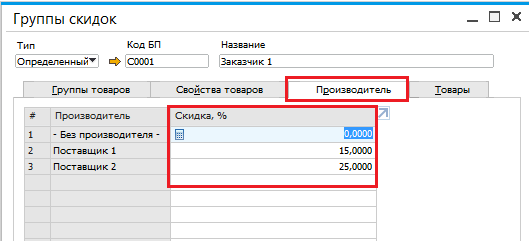
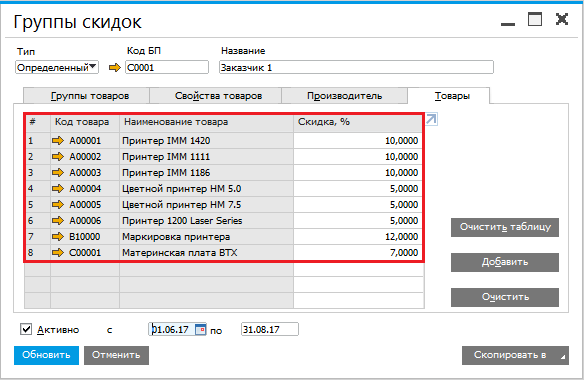
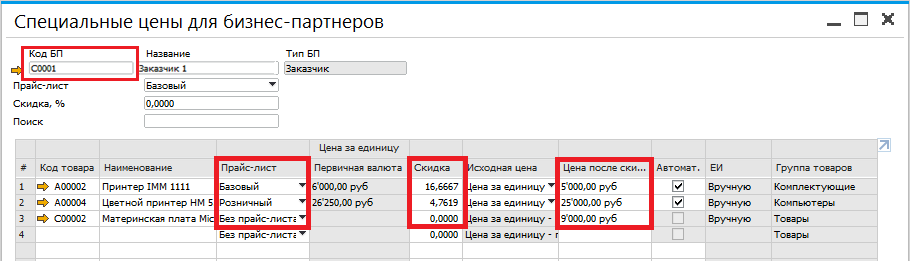
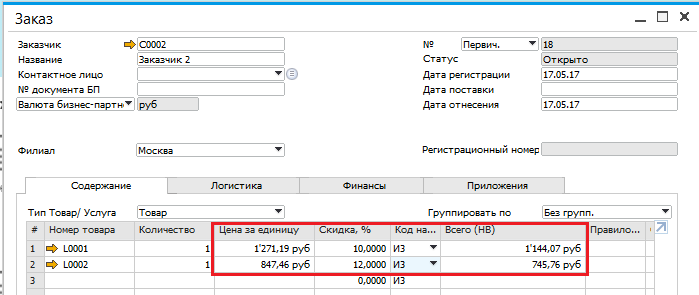
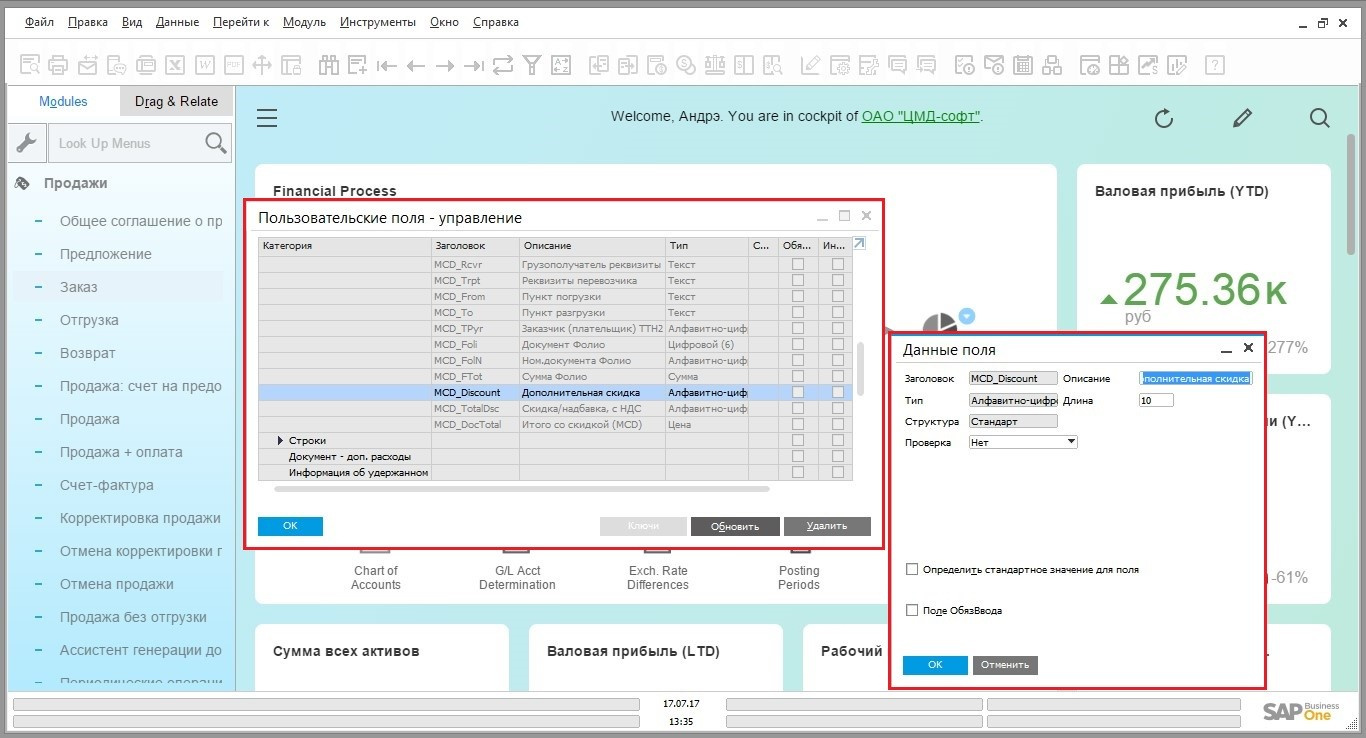
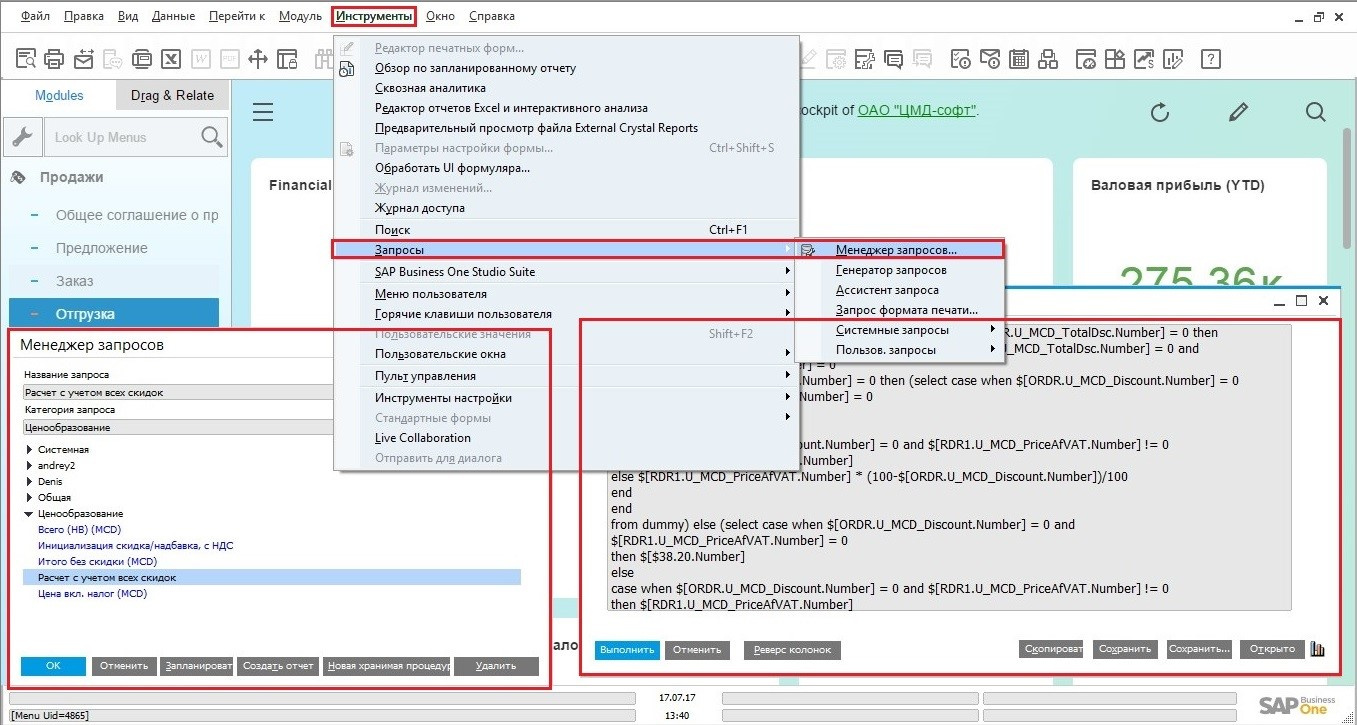
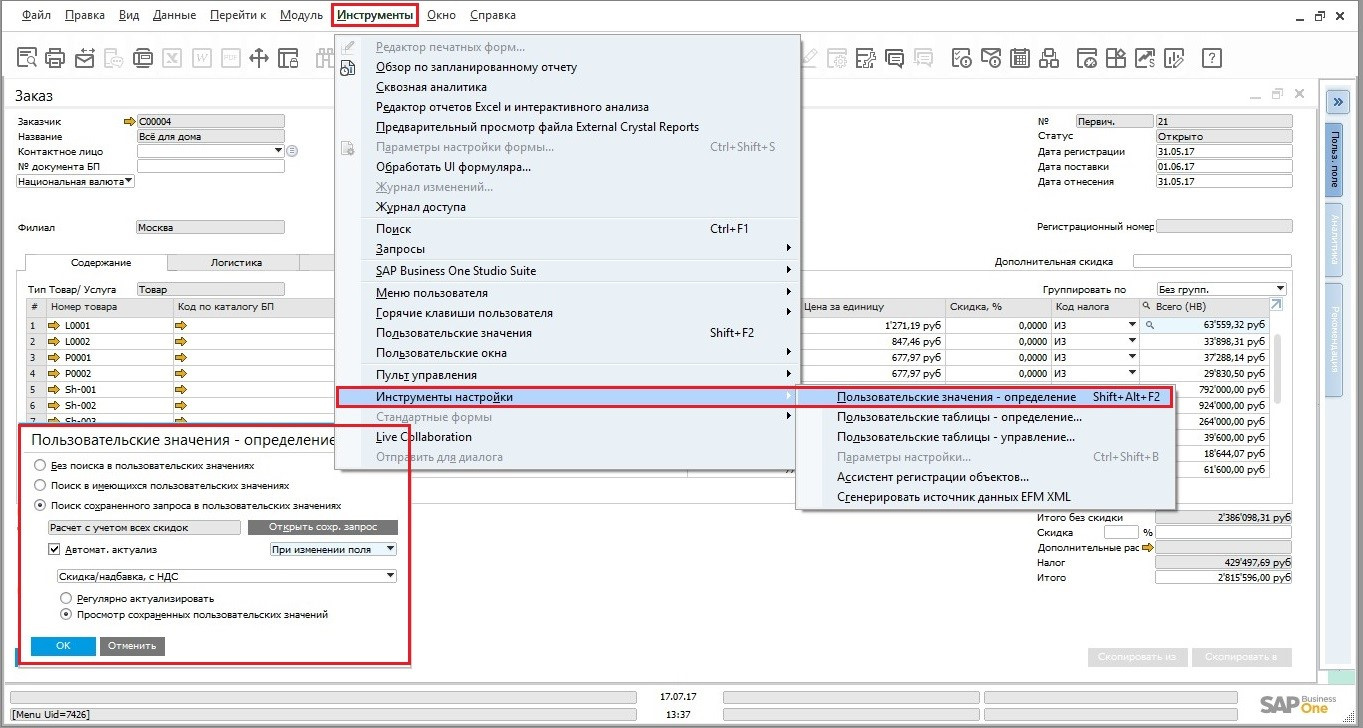
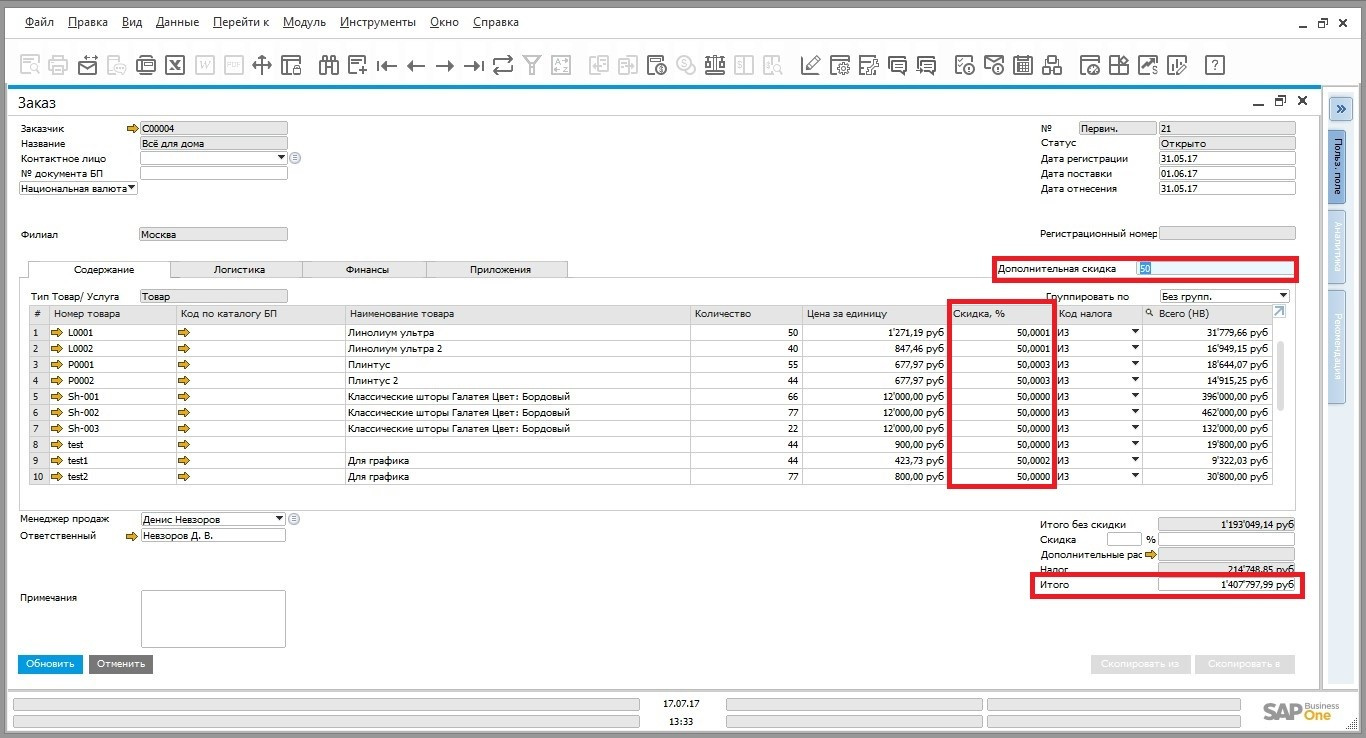
|
Метки: author SAP управление продуктом управление продажами erp- системы блог компании sap sap ценообразование erp smb автоматизация бизнеса sap business one |
Подробно о новой версии Veeam Backup for Microsoft Office 365 и коротко о розыгрыше билетов на VMworld 2017 |
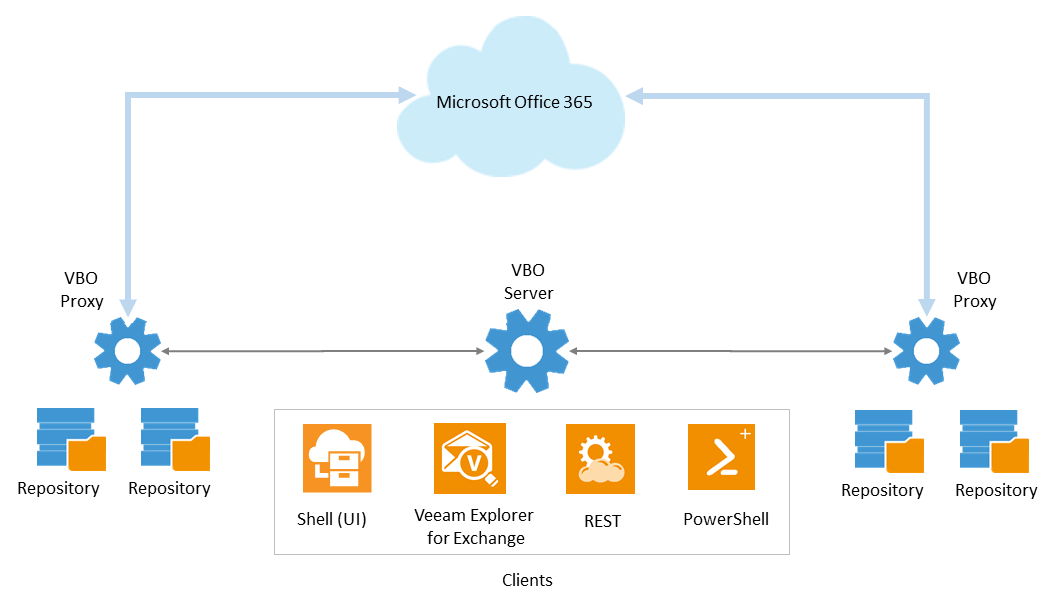









|
Метки: author polarowl резервное копирование облачные вычисления восстановление данных виртуализация блог компании «veeam software» veeam backup office 365 exchange online |
Как мы бесплатно привлекли почти 90% своих пользователей |









|
Метки: author Enmoore повышение конверсии монетизация веб-сервисов монетизация it-систем интернет-маркетинг growth hacking гроус хакинг виджеты |
Новшества главной робототехнической олимпиады России 2017 в официальном видео |
|
Метки: author T-Fazullin хакатоны учебный процесс в it блог компании innopolis university университет иннополис вро2017 робототехника олимпиада устойчивое развитие |
Быстрое удаление пробелов из строк на процессорах ARM — альтернативный анализ |
Оригинал статьи: https://github.com/blu/ascii_pruner
Автор: Мартин Кръстев
Один мой друг обратил мое внимание на интересную статью на habrahabr.ru — русский перевод статьи Дэниела Лемира Быстрое удаление пробелов из строк на процессорах ARM. Эта статья заинтриговала меня по двум причинам: во-первых, кто-то на самом деле потратил время и усилия по поиску оптимального решения общей проблемы на не-x86 архитектуре (ура!), а во-вторых, результаты автор дал в конце статьи немного озадачили меня: порядка 6-ти кратное преимущество для Intel? Автор сделал однозначный вывод, что ARM-у ну очень далеко по соотношению «эффективность на такт» до «большого железа» от Интела в этой простой задаче.
Вызов принят!
Но начнем с самого начала! Автор начал с некого бейзлайна — последовательной реализации, поэтому я тоже решил начать оттуда и двигаться вверх. Давайте назовем этот базис testee00 для пущей тайны:
inline void testee00() {
size_t i = 0, pos = 0;
while (i < 16) {
const char c = input[i++];
output[pos] = c;
pos += (c > 32 ? 1 : 0);
}
}Я запускал testee00 на нескольких процессорах amd64 и одном процессоре arm64, используя разные версии компилятора GCC и Clang, всегда беря за основу лучший результат компиляции. Ниже приведены результаты соотношения такт/символ, рассчитанные perf -e cycles, деленным на количество обработанных символов (в нашем случае — 5 10 ^ 7 16) и усеченные до 4-й цифры после десятичной точки:
| CPU | Compiler & flags | clocks/character |
|---|---|---|
| Intel Xeon E5-2687W (SNB) | g++-4.8 -Ofast | 1.6363 |
| Intel Xeon E3-1270v2 (IVB) | g++-5.1 -Ofast | 1.6186 |
| Intel i7-5820K (HSW) | g++-4.8 -Ofast | 1.5223 |
| AMD Ryzen 7 1700 (Zen) | g++-5.4 -Ofast | 1.4113 |
| Marvell 8040 (Cortex-A72) | g++-5.4 -Ofast | 1.3805 |
Таблица 1. Производительность testee00 на десктоповых ядрах
Интересно, не так ли? Маленький чип телефона (3-Decoder OoO) действительно дает лучшее соотношение такт / символ, чем более крупный настольный чип (в конце этой статьи вы можете увидеть фактические данные статистики).
Итак, давайте перейдем к SIMD. Я не претендую на то, чтобы считаться опытным кодером на NEON, но иногда я заморачиваюсь с ARM SIMD. Я не буду инлайнить подпрограммы SIMD в основную часть этой статьи, чтобы не отпугнуть читателя; Вместо этого весь тестовый код и участвующие тестовые процедуры можно найти в конце этой статьи.
Я взял на себя смелость изменить первоначальную процедуру обрезки SSSE3 Даниэля — на самом деле, я использовал свою версию для теста. Причина? Я не могу просто так взять 2 ^ 16 * 2 ^ 4 = 1 Мбайт таблицы поиска в моем коде — это был бы большой пожиратель кеша для любых сценариев, где мы не просто обрезаем потоки ascii, но вызов подпрограммы облегчает другую работу. Версия LSS-less SSSE3 поставляется с ценой немногочисленных вычислений, но работает только на регистрах, и, как вы увидите, цена за исключение таблицы не является запретительной даже при интенсивных нагрузках на обрезку. Более того, как новая версия SSSE3, так и версия NEON (ASIMD2) используют один и тот же алгоритм, поэтому сравнение является настолько прямым, насколько это возможно физически:
| CPU | Compiler & flags | clocks/character |
|---|---|---|
| Intel Xeon E5-2687W (SNB) | g++-4.8 -Ofast -mssse3 | .4230 |
| Intel Xeon E3-1270v2 (IVB) | g++-5.4 -Ofast -mssse3 | .3774 |
| Marvell 8040 (Cortex-A72) | g++-5.4 -Ofast -mcpu=cortex-a57 | 1.0503 |
Таблица 2. Производительность testee01 на десктопных ядрах
Замечание: Тюнинг микроархитектуры для A57 передается в билд arm64, поскольку планировщик A72 от компилятора явно хуже в этой версии, что касается кода NEON, и A57 является довольно «общим» общим знаменателем ARMv8, когда дело доходит до планирования.
Как вы видите, эффективность в расчете на такта составляет 2x в пользу Sandy Bridge — ядро, которое при том же (или аналогичном) fabnode будет в 4 раза больше по площади A72. Так что все не так уж плохо для телефонных чипов; )
Бонусный материал: тот же тест на малых arm64 and amd64 CP:
| CPU | Compiler & flags | clocks/character, scalar | clocks/character, vector |
|---|---|---|---|
| AMD C60 (Bobcat) | g++-4.8 -Ofast -mssse3 | 3.5751 | 1.8215 |
| MediaTek MT8163 (Cortex-A53) | clang++-3.6 -march=armv8-a -mtune=cortex-a53 -Ofast | 2.6568 | 1.7100 |
Таблица 3. Производительность testee00 на testee01 на entry-level ядрах
Xeon E5-2687W @ 3.10GHz
Scalar version
$ g++-4.8 prune.cpp -Ofast
$ perf stat -e task-clock,cycles,instructions -- ./a.out
alabalanica1234
Performance counter stats for './a.out':
421.886991 task-clock (msec) # 0.998 CPUs utilized
1,309,087,898 cycles # 3.103 GHz
4,603,132,268 instructions # 3.52 insns per cycle
0.422602570 seconds time elapsed
$ echo "scale=4; 1309087898 / (5 * 10^7 * 16)" | bc
1.6363SSSE3 version (batch of 16, misaligned write)
$ g++-4.8 prune.cpp -Ofast -mssse3
$ perf stat -e task-clock,cycles,instructions -- ./a.out
alabalanica1234a
Performance counter stats for './a.out':
109.063426 task-clock (msec) # 0.997 CPUs utilized
338,414,215 cycles # 3.103 GHz
1,052,118,398 instructions # 3.11 insns per cycle
0.109422808 seconds time elapsed
$ echo "scale=4; 338414215 / (5 * 10^7 * 16)" | bc
.4230Xeon E3-1270v2 @ 1.60GHz
Scalar version
$ g++-5 -Ofast prune.cpp
$ perf stat -e task-clock,cycles,instructions -- ./a.out
alabalanica1234
Performance counter stats for './a.out':
810.515709 task-clock (msec) # 0.999 CPUs utilized
1,294,903,960 cycles # 1.598 GHz
4,601,118,631 instructions # 3.55 insns per cycle
0.811646618 seconds time elapsed
$ echo "scale=4; 1294903960 / (5 * 10^7 * 16)" | bc
1.6186SSSE3 version (batch of 16, misaligned write)
$ g++-5 -Ofast prune.cpp -mssse3
$ perf stat -e task-clock,cycles,instructions -- ./a.out
alabalanica1234a
Performance counter stats for './a.out':
188.995814 task-clock (msec) # 0.997 CPUs utilized
301,931,101 cycles # 1.598 GHz
1,050,607,539 instructions # 3.48 insns per cycle
0.189536527 seconds time elapsed
$ echo "scale=4; 301931101 / (5 * 10^7 * 16)" | bc
.3774Intel i7-5820K
Scalar version
$ g++-4.8 -Ofast prune.cpp
$ perf stat -e task-clock,cycles,instructions -- ./a.out
alabalanica1234
Performance counter stats for './a.out':
339.202545 task-clock (msec) # 0.997 CPUs utilized
1,204,872,493 cycles # 3.552 GHz
4,602,943,398 instructions # 3.82 insn per cycle
0.340089829 seconds time elapsed
$ echo "scale=4; 1204872493 / (5 * 10^7 * 16)" | bc
1.5060AMD Ryzen 7 1700
Scalar version
$ perf stat -e task-clock,cycles,instructions -- ./a.out
alabalanica1234
Performance counter stats for './a.out':
356,169901 task-clock:u (msec) # 0,999 CPUs utilized
1129098820 cycles:u # 3,170 GHz
4602126161 instructions:u # 4,08 insn per cycle
0,356353748 seconds time elapsed
$ echo "scale=4; 1129098820 / (5 * 10^7 * 16)" | bc
1.4113Marvell ARMADA 8040 (Cortex-A72) @ 1.30GHz
Scalar version
$ g++-5 prune.cpp -Ofast
$ perf stat -e task-clock,cycles,instructions -- ./a.out
alabalanica1234
Performance counter stats for './a.out':
849.549040 task-clock (msec) # 0.999 CPUs utilized
1,104,405,671 cycles # 1.300 GHz
3,251,212,918 instructions # 2.94 insns per cycle
0.850107930 seconds time elapsed
$ echo "scale=4; 1104405671 / (5 * 10^7 * 16)" | bc
1.3805ASIMD2 version (batch of 16, misaligned write)
$ g++-5 prune.cpp -Ofast -mcpu=cortex-a57 -mtune=cortex-a57
$ perf stat -e task-clock,cycles,instructions -- ./a.out
alabalanica1234
Performance counter stats for './a.out':
646.394560 task-clock (msec) # 0.999 CPUs utilized
840,305,966 cycles # 1.300 GHz
801,000,092 instructions # 0.95 insns per cycle
0.646946289 seconds time elapsed
$ echo "scale=4; 840305966 / (5 * 10^7 * 16)" | bc
1.0503ASIMD2 version (batch of 32, misaligned write)
$ clang++-3.7 prune.cpp -Ofast -mcpu=cortex-a57 -mtune=cortex-a57
$ perf stat -e task-clock,cycles,instructions -- ./a.out
alabalanica1234
Performance counter stats for './a.out':
1140.643640 task-clock (msec) # 0.999 CPUs utilized
1,482,826,308 cycles # 1.300 GHz
1,504,011,807 instructions # 1.01 insns per cycle
1.141241760 seconds time elapsed
$ echo "scale=4; 1482826308 / (5 * 10^7 * 32)" | bc
.9267AMD C60 (Bobcat) @ 1.333GHz
Scalar version
$ g++-4.8 prune.cpp -Ofast
$ perf stat -e task-clock,cycles,instructions -- ./a.out
alabalanica1234
Performance counter stats for './a.out':
2208.190651 task-clock (msec) # 0.997 CPUs utilized
2,860,081,604 cycles # 1.295 GHz
4,602,968,860 instructions # 1.61 insns per cycle
2.214173331 seconds time elapsed
$ echo "scale=4; 2860081604 / (5 * 10^7 * 16)" | bc
3.5751SSSE3 version (batch of 16, misaligned write)
$ clang++-3.5 prune.cpp -Ofast -mssse3
$ perf stat -e task-clock,cycles,instructions -- ./a.out
alabalanica1234a
Performance counter stats for './a.out':
1098.519499 task-clock (msec) # 0.998 CPUs utilized
1,457,266,396 cycles # 1.327 GHz
1,053,073,591 instructions # 0.72 insns per cycle
1.101240320 seconds time elapsed
$ echo "scale=4; 1457266396 / (5 * 10^7 * 16)" | bc
1.8215MediaTek MT8163 (Cortex-A53) @ 1.50GHz (sans perf)
Scalar version
$ ../clang+llvm-3.6.2-aarch64-linux-gnu/bin/clang++ prune.cpp -march=armv8-a -mtune=cortex-a53 -Ofast
$ time ./a.out
alabalanica1234
real 0m1.417s
user 0m1.410s
sys 0m0.000s
$ echo "scale=4; 1.417 * 1.5 * 10^9 / (5 * 10^7 * 16)" | bc
2.6568ASIMD2 version (batch of 16, misaligned write)
$ ../clang+llvm-3.6.2-aarch64-linux-gnu/bin/clang++ prune.cpp -march=armv8-a -mtune=cortex-a53 -Ofast
$ time ./a.out
alabalanica1234
real 0m0.912s
user 0m0.900s
sys 0m0.000s
$ echo "scale=4; 0.912 * 1.5 * 10^9 / (5 * 10^7 * 16)" | bc
1.7100Мартин Кръстев.
Перевод: Дмитрий Александров
|
Метки: author advbg программирование высокая производительность алгоритмы assembler перевод с английского перевод |
[Перевод] Анализ исходного кода Doom 3 |
|
Метки: author PatientZero реверс-инжиниринг разработка игр c++ doom 3 игровые движки обратная разработка открытый исходный код id software |
[Из песочницы] Простой трекер семейного бюджета с помощью AWS SES, Lambda и DynamoDB (и Route53) |

У меня всегда были сложности точно следовать бюджету, особенно сейчас, когда все покупки проходят по кредитной карте. Причина проста — перед глазами нет пачки денег, которая постепенно сокращается, и в какой-то момент ты понимаешь, что тратить больше нечего. Если большая часть покупок оплачивается кредитной картой, то единственный способ узнать, сколько cредств осталось или сколько потрачено, это зайти в Интернет-банк или мобильный банк, или же использовать финансовые агрегаторы, например Mint, в которые тоже надо заходить и проверять баланс. Это возможно, но на это требуется дисциплина, а когда с той же карточки платишь не только ты, то установить её сложно.
Я подумал, что меня устроит вариант, если каждый день мне будет приходить уведомление о том, сколько денег у меня ещё осталось в этом месяце. То есть я бы устанавливал бюджет на месяц, и что-то бы считало мои траты и каждый день посылало отчёт о состоянии бюджета.
Самый очевидный вариант это использовать API банка или ходить в его Интернет-банк программно каким-нибудь headless-браузром. К сожалению, доступ к API моего банка платный, а ходить в Интернет-банк проблемно из-за двухфакторной авторизации. Однако, есть ещё один вариант. Почти все банки сегодня присылают оповещения на каждую транзакцию, информируя когда, сколько и в каком месте была совершена транзакция. Именно та информация, которая нужна для ведения бюджета. Осталось придумать, как её обрабатывать.
Мой банк может отправлять оповещения на мобильный телефон и на электронную почту. Вариант с мобильным телефоном не рассматривался ввиду сложности обработки смс-сообщений. Вариант с электронной почтой же выглядит очень заманчиво, программную обработку электронный писем можно было сделать и десятки лет назад. Но сейчас у меня дома только не всегда включённый ноутбук, а значит автоматизировать бюджет мы будем где-то в облаке, например, AWS.
В AWS есть множество сервисов, но нам нужно всего три: чтобы получать и отправлять электронные письма — SES, чтобы их обрабатывать — Lambda, и чтобы хранить результат DynamoDB. Плюс ещё пара вспомогательных для связки — SNS, Kinesis, CloudWatch. Это не единственный вариант обработки сообщений: вместо Lambda можно использовать EC2, вместо DynamoDB хранить данные можно в RDS (MySQL, PostgreSQL, Oracle, …), а можно и вообще написать простенький скрипт на своём маленьком сервере на перле и BerkleyDB.
Как выглядит вся обработка в общем? Приходит письмо о транзакции, мы записываем дату, сумму и место платежа в БД, и раз в день отправляем письмо с остатком для данного месяца. Вся архитектура чуть сложнее и выглядит следующим образом:
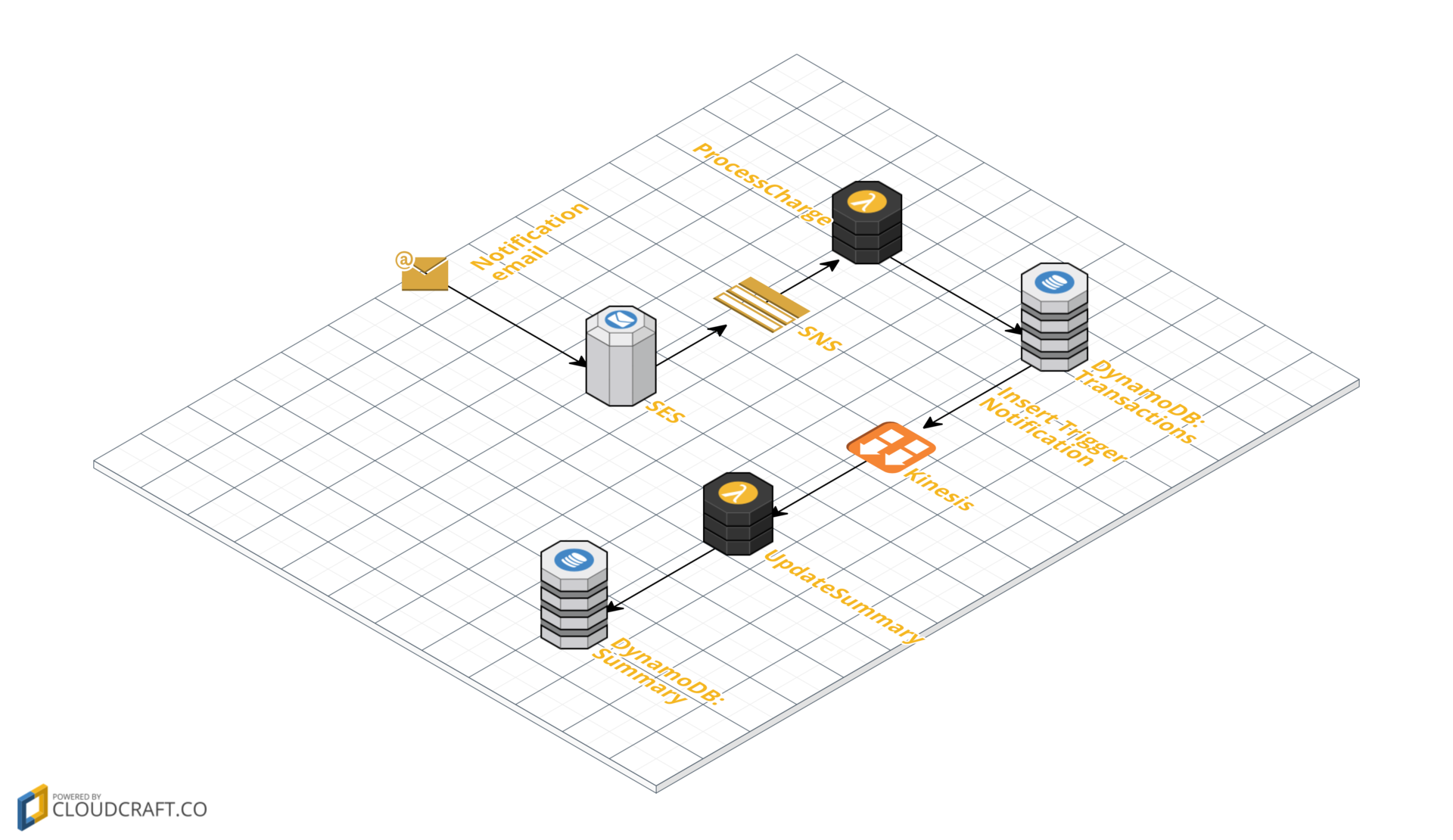
Рассмотрим эти шаги более подробно.
Simple Email Service, он же SES, это сервис для приёма и отправки писем. При получении письма можно указать, какое действие должно быть выполнено: сохранить письмо в S3, вызвать Lambda-функцию, послать письмо в SNS и другие. Для получения писем необходимо привязать свой домен, а именно указать SES сервера в MX записи домена. Своего домена у меня на тот момент не было, и я решил, что это хороший повод его зарегистрировать, воспользовавшись ещё одним AWS сервисом Route 53. Захостил я его тоже там же, в Route 53.
При привязки домена к SES требуется его проверка. Для этого SES просит добавить некоторые записи в DNS зону (MX и TXT), а затем проверяет их наличие. Если домен хостится в Route 53, то всё это делается автоматически. Когда домен проверен, можно переходить к настройке правил для получения почты. Моё единственное правило очень простое: все письма, приходящие на адрес ccalert@ нашего домена, отправлять в SNS топик ccalerts:
aws> ses describe-receipt-rule --rule-set-name "ccalerts" --rule-name "ccalert"
{
"Rule": {
"Name": "ccalert",
"Recipients": [
"ccalert@=censored=”
],
"Enabled": true,
"ScanEnabled": true,
"Actions": [
{
"SNSAction": {
"TopicArn": "arn:aws:sns:us-west-2:=censored=:ccalerts",
"Encoding": "UTF-8"
}
}
],
"TlsPolicy": "Optional"
}
}Когда новое письмо публикуется в SNS-топик, вызывается Lambda-функция ProcessCharge. Ей нужно сделать два действия — распарсить письмо и сохранить данные в БД.
from __future__ import print_function
import json
import re
import uuid
from datetime import datetime
import boto3
def lambda_handler(event, context):
message = json.loads(event['Records'][0]['Sns']['Message'])
print("Processing email {}".format(message['mail']))
content = message['content']
trn = parse_content(content)
if trn is not None:
print("Transaction: %s" % trn)
process_transaction(trn)За парсинг отвечает метод parse_content():
def parse_content(content):
content = content.replace("=\r\n", "")
match = re.search(r'A charge of \(\$USD\) (\d+\.\d+) at (.+?) has been authorized on (\d+/\d+/\d+ \d+:\d+:\d+ \S{2} \S+?)\.', content, re.M)
if match:
print("Matched %s" % match.group(0))
date = match.group(3)
# replace time zone with hour offset because Python can't parse it
date = date.replace("EDT", "-0400")
date = date.replace("EST", "-0500")
dt = datetime.strptime(date, "%m/%d/%Y %I:%M:%S %p %z")
return {'billed': match.group(1), 'merchant': match.group(2), 'datetime': dt.isoformat()}
else:
print("Didn't match")
return NoneВ нём мы убираем ненужные символы и с помощью регулярного выражения проверяем, содержит ли письмо информацию о транзакции, и если содержит, разбиваем её на части. Искомый текст выглядит следующим образом:
A charge of ($USD) 100.00 at Amazon.com has been authorized on 07/19/2017 1:55:52 PM EDT.
К сожалению, стандартная библиотека Питона знает мало часовых поясов, и EDT (Eastern Daylight Time) не среди них. Поэтому мы заменяем EDT на числовое обозначение -0400, и делаем такое же для основного часового пояса, EST. После этого мы можем распарсить дату и время транзакции, и преобразовать его в стандартный формат ISO 8601, поддерживаемый DynamoDB.
Метод возвращает хэш-таблицу с суммой транзакции, названием магазина и датой со временем. Эти данные передаются в метод process_transaction:
def process_transaction(trn):
ddb = boto3.client('dynamodb')
trn_id = uuid.uuid4().hex
ddb.put_item(
TableName='Transactions',
Item={
'id': {'S': trn_id},
'datetime': {'S': trn['datetime']},
'merchant': {'S': trn['merchant']},
'billed': {'N': trn['billed']}
})В нём мы сохраняем данные в таблицу Transactions, генерируя уникальный идентификатор транзакции.
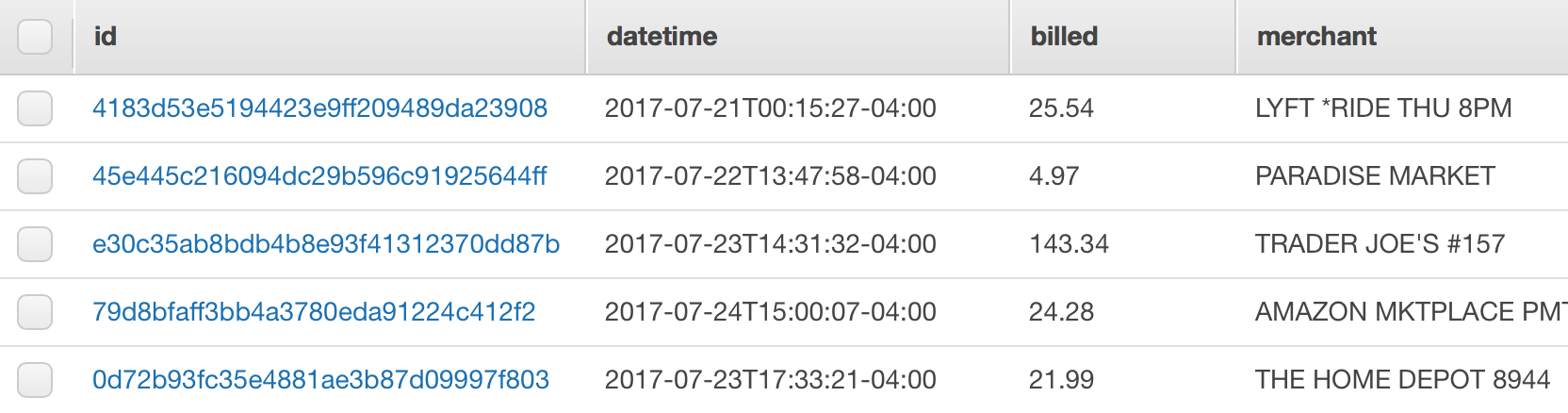
Я бы хотел остановиться здесь подробнее, а именно на моменте как отслеживается состояние бюджета. Определим для себя несколько значений:
В любой момент времени мы хотим знать все эти значения. Это можно сделать двумя способами:
Оба подхода имеют плюсы и минусы, и выбор сильно зависит от требований и ограничений системы. Первый подход хорош тем, что он не денормализует данные, храня отдельно сумму транзакций. С другой стороны, с ним сумму надо считать при каждом запросе. Для моих объёмов это не будет проблемой, но в моём случае у меня есть ограничение, вызванное DynamoDB. Чтобы посчитать сумму N транзакций, надо прочитать N записей, а значит потратить N read capacity units. Очевидно, это не очень масштабируемое решение, которое будет вызывать сложности (или высокую стоимость) даже при нескольких десятках транзакций.
При использовании второго подхода, total обновляется после каждой транзакции и всегда актуально, что позволяет избежать суммирования всех транзакций. Мне этот подход показался более рациональным в моём случае. Реализовать его, опять же, можно по-разному:
Обновление в триггере более практично, в том числе с точки зрения многопоточности, поэтому я создал Lambda-функцию UpdateSummary:
from __future__ import print_function
from datetime import datetime
import boto3
def lambda_handler(event, context):
for record in event['Records']:
if record['eventName'] != 'INSERT':
print("Unsupported event {}".format(record))
return
trn = record['dynamodb']['NewImage']
print(trn)
process_transaction(trn)Нас интересуют только события о добавлении элементов в таблицу, все остальные игнорируются.
def process_transaction(trn):
period = get_period(trn)
if period is None:
return
billed = trn['billed']['N']
# update total for current period
update_total(period, billed)
print("Transaction processed")В process_transaction() мы вычисляем период, в виде год-месяц, к которому относится транзакция, и вызываем метод обновления total.
def get_period(trn):
try:
# python cannot parse -04:00, it needs -0400
dt = trn['datetime']['S'].replace("-04:00", "-0400")
dt = dt.replace("-05:00", "-0500")
dt = dt.replace("-07:00", "-0700")
dt = datetime.strptime(dt, "%Y-%m-%dT%H:%M:%S%z")
return dt.strftime("%Y-%m")
except ValueError as err:
print("Cannot parse date {}: {}".format(trn['datetime']['S'], err))
return NoneЭтот код весьма далёк от совершенства, и в этом сыграла роль интересная особенность Питона, что он не может распарсить дату/время с часовым поясом в формате -HH:MM, который соответствует стандарту ISO 8601, и которую сам же Питон и сгенерировал (код выше, в методе parse_content()). Поэтому нужные мне часовые пояса я просто заменяю на понимаемый им формат -HHMM. Можно было воспользоваться сторонней библиотекой и сделать это более красиво, оставлю это на будущее. Возможно, ещё сказывается моё плохое знание Питона — этот проект мой первый опыт разработки на нём.
Обновление total:
def update_total(period, billed):
ddb = boto3.client('dynamodb')
response = load_summary(ddb, period)
print("Summary: {}".format(response))
if 'Item' not in response:
create_summary(ddb, period, billed)
else:
total = response['Item']['total']['N']
update_summary(ddb, period, total, billed)В этом методе мы загружаем сводку (Summary) за текущий период с помощью метода load_summary(), total в котором нам надо обновить. Если сводки ещё не существует, мы создаём её в методе create_summary(), если существует, обновляем в update_summary().
def load_summary(ddb, period):
print("Loading summary for period {}".format(period))
return ddb.get_item(
TableName = 'Summary',
Key = {
'period': {'S': period}
},
ConsistentRead = True
)Так как обновление сводки может производиться из нескольких потоков, мы используем консистентное чтение, которое дороже, но гарантирует, что мы получим последнее записанное значение.
def create_summary(ddb, period, total):
print("Creating summary for period {} with total {}".format(period, total))
ddb.put_item(
TableName = 'Summary',
Item = {
'period': {'S': period},
'total': {'N': total},
'budget': {'N': "0"}
},
ConditionExpression = 'attribute_not_exists(period)'
)При создании новой сводки, по той же причине возможной записи из нескольких потоков, используется условная запись, ConditionExpression = 'attribute_not_exists(period)', которая сохранит новую сводку только в случае, если она не существует. Таким образом, если кто-то успел создать сводку в промежутке, когда мы попробовали её загрузить в load_summary() и её не было, и когда мы попытались её создать в create_summary(), наш вызов put_item() завершится исключением и вся Lambda-функция будет перезапущена.
def update_summary(ddb, period, total, billed):
print("Updating summary for period {} with total {} for billed {}".format(period, total, billed))
ddb.update_item(
TableName = 'Summary',
Key = {
'period': {'S': period}
},
UpdateExpression = 'SET #total = #total + :billed',
ConditionExpression = '#total = :total',
ExpressionAttributeValues = {
':billed': {'N': billed},
':total': {'N': total}
},
# total is a reserved word so we create an alias #total to use it in expression
ExpressionAttributeNames = {
'#total': 'total'
}
)Обновления значения total в сводке производится внутри DynamoDB:
UpdateExpression = 'SET #total = #total + :billed'
Скорее всего, этого достаточно для безопасного обновления, однако я решил поступить консервативно и добавил условие, что запись должна произойти, только если сводку не успели обновить в другом потоке, и она до сих пор содержит значение, которое есть у нас:
ConditionExpression = '#total = :total',
Так как total является ключевым словом для DynamoDB, чтобы использовать его в выражениях DynamoDB надо создать синоним:
ExpressionAttributeNames = {
'#total': 'total'
}
На этом процесс обработки транзакций и обновления бюджета завершён:
| period | budget | total |
|---|---|---|
| 2017-07 | 1000 | 500 |
Последняя часть системы — уведомление о состояние бюджета. Как я писал в самом начале, мне достаточно получать уведомление раз в день, что я и реализовал. Однако ничего не мешает уведомлять после каждой транзакции, или после каких-то пороговых значений расходов / остатка. Архитектура отправки электронного письма с уведомлением достаточно проста и выглядит так:
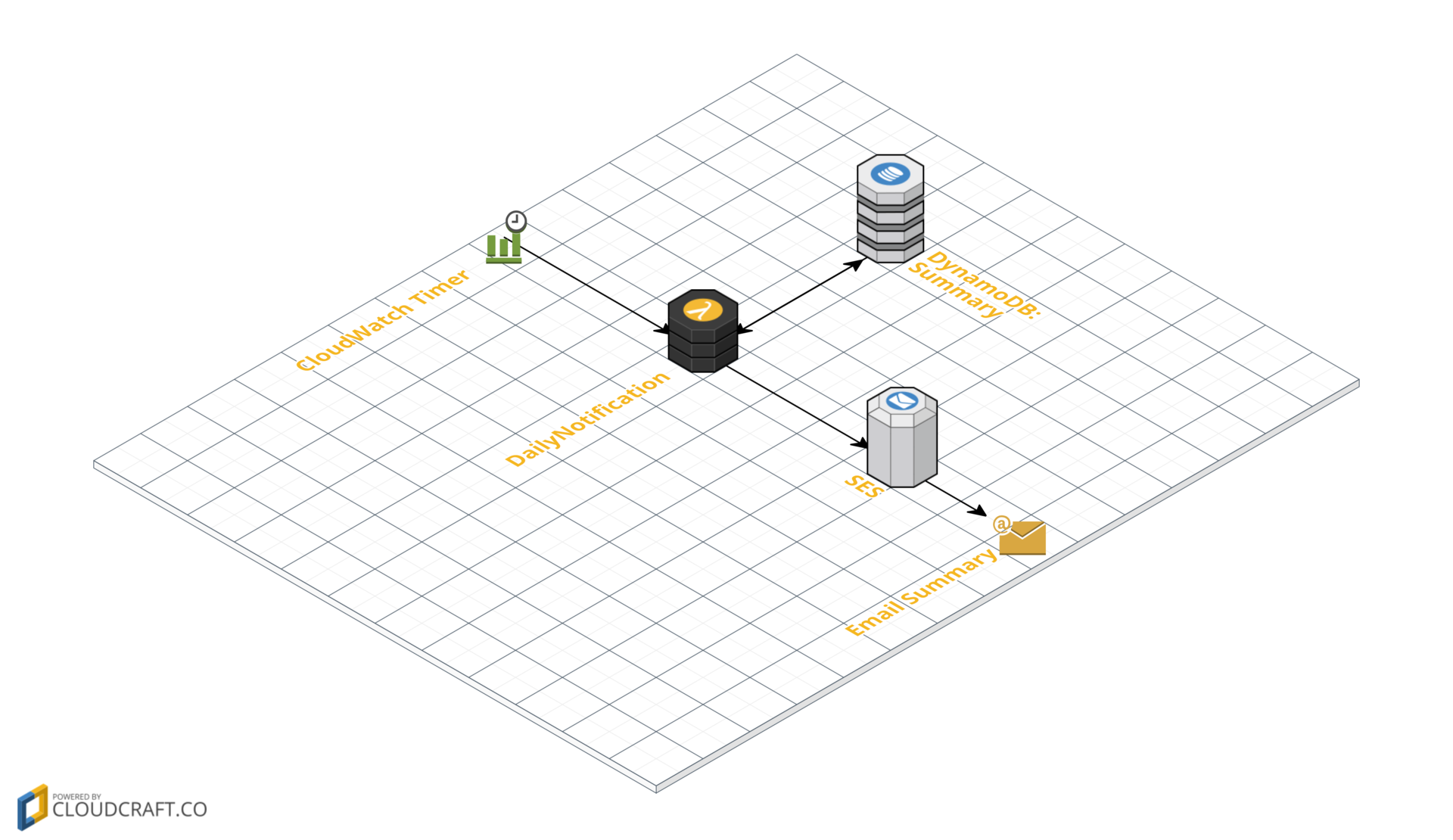
from __future__ import print_function
from datetime import date
import boto3
def lambda_handler(event, context):
ddb = boto3.client('dynamodb')
current_date = date.today()
print("Preparing daily notification for {}".format(current_date.isoformat()))
period = current_date.strftime("%Y-%m")
response = load_summary(ddb, period)
print("Summary: {}".format(response))
if 'Item' not in response:
print("No summary available for period {}".format(period))
return
summary = response['Item']
total = summary['total']['N']
budget = summary['budget']['N']
send_email(total, budget)
def load_summary(ddb, period):
print("Loading summary for period {}".format(period))
return ddb.get_item(
TableName = 'Summary',
Key = {
'period': {'S': period}
},
ConsistentRead = True
)Сперва мы пытаемся загрузить сводку для текущего периода, и если её нет, то заканчиваем работу. Если есть — готовим и отправляем письмо:
def send_email(total, budget):
sender = "Our Budget <ccalert@==censored==>"
recipients = [“==censored==“]
charset = "UTF-8"
available = float(budget) - float(total)
today = date.today().strftime("%Y-%m-%d")
message = '''
As of {0}, available funds are ${1:.2f}. This month budget is ${2:.2f}, spendings so far totals ${3:.2f}.
More details coming soon!'''
subject = "How are we doing?"
textbody = message.format(today, float(available), float(budget), float(total))
print("Sending email: {}".format(textbody))
client = boto3.client('ses', region_name = 'us-west-2')
try:
response = client.send_email(
Destination = {
'ToAddresses': recipients
},
Message = {
'Body': {
'Text': {
'Charset': charset,
'Data': textbody,
},
},
'Subject': {
'Charset': charset,
'Data': subject,
},
},
Source = sender,
)
# Display an error if something goes wrong.
except Exception as e:
print("Couldn't send email: {}".format(e))
else:
print("Email sent!")На этом всё. Сейчас, после каждой транзакции, пришедшее письмо обрабатывается и обновляется бюджет, и раз в день посылается письмо с уведомлением о состоянии бюджета. У меня ещё есть планы по добавлению функциональности, например, классификация расходов по категориям, и включение списка последних транзакций в уведомление, если получится что-то стоящее — поделюсь в другой статье. Если есть какие-то вопросы, комментарии или правки — жду в комментариях.
|
Метки: author kazaand программирование nosql amazon web services aws aws lambda dynamodb aws ses бюджет |
БИТ-пикник глоток лета и полезной информации |
















|
Метки: author KorP хранение данных системное администрирование сетевые технологии серверное администрирование it- инфраструктура hpe aruba simplivity 3par nimble |
История с хэппи-эндом: интеграция «Битрикс24» с Asterisk |






|
Метки: author 1cbitrix asterisk с-битрикс блог компании 1с-битрикс интеграция телефония |
Настройка push-нотификаций для своего сервиса |

https://pushall.ru/channels/host-tracker/callback.php?uid=47920&key=0cfd2f05b7442aeb988a326f7adadb06

|
|
[Перевод] Дядя Боб Мартин: «Вези меня в Торонто, HAL» |
if-выражений, сравнивающих взвешенные значения при помощи сложного ассоциативного дерева, дал конечный, определенный результат. То есть, безусловно, существовала причина. Веская причина.if-выражений, сравнивая все аккуратно взвешенные значения, и наконец, отвечает: «Причина была в том, что Торонто».
|
Метки: author j_wayne исследования и прогнозы в it беспилотные автомобили прогнозы опасения uncle bob martin перевод ibm watson искуственный интеллект |
Мама хочет внуков! Или где может пригодиться телемедицина |

Предыстория: на данный момент любая медицинская деятельность может осуществляться только очно, с использованием имеющихся протоколов обследований, документация — в бумажном виде. Если используется компьютер с электронными картами — все равно печатать и подшивать. Консультации врача по телефону, сервису Яндекс.Здоровье и проч. — не являются медицинской деятельностью со всеми вытекающими. Поэтому посещение врача или его приезд домой единственный вариант получить врачебную помощь и консультацию законным путем.


|
Метки: author YuliyaCl читальный зал гаджеты телемедицина медтех беременность мониторинг здоровье |
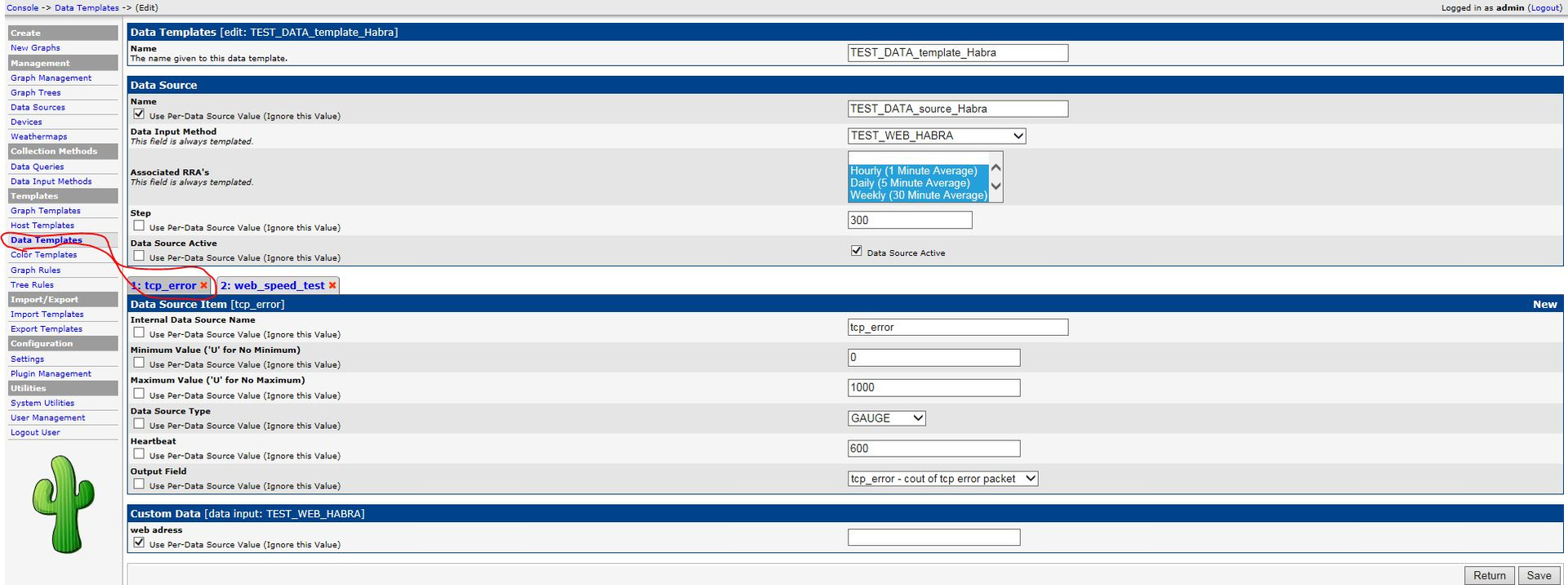
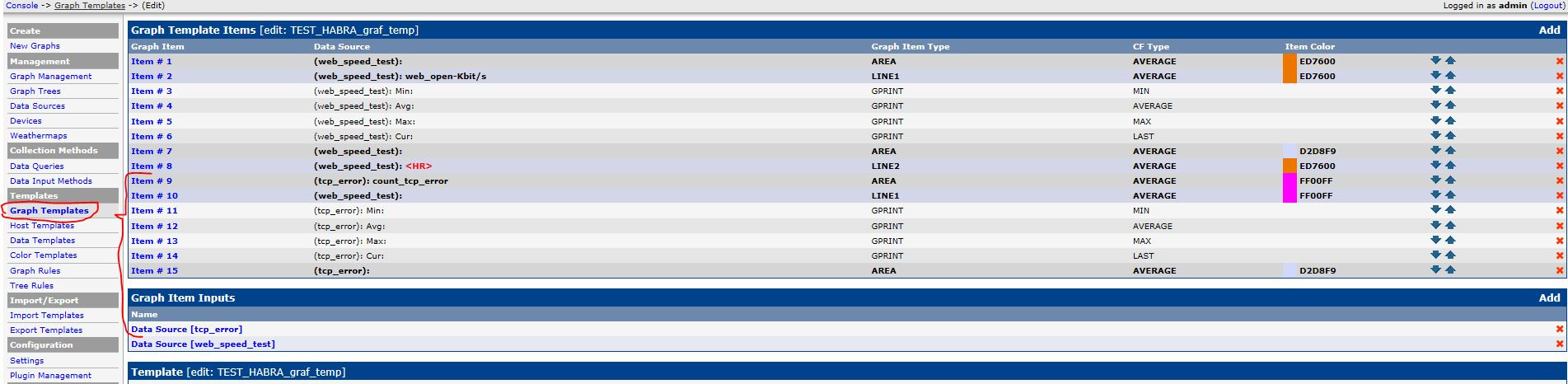
Автоматизация IP-сети. Часть3 – Мониторинг TCP аномалий |
 В предыдущей статье рассмотрен мониторинг скорости открытия Веб ресурсов. В качестве параллельного процесса при измерении скорости, для более глубокого понимания возможных причин низкой скорости открытия Веб страниц, было бы интересно провести измерение TCP аномалий. Эту задачу попробуем решить в этой статье.
В предыдущей статье рассмотрен мониторинг скорости открытия Веб ресурсов. В качестве параллельного процесса при измерении скорости, для более глубокого понимания возможных причин низкой скорости открытия Веб страниц, было бы интересно провести измерение TCP аномалий. Эту задачу попробуем решить в этой статье.tshark -i bce0 -t ad -qz io,stat,5,"(ip.addr==1.1.1.1) && tcp","COUNT(tcp.analysis.retransmission)(ip.addr==1.1.1.1) && tcp.analysis.retransmission","COUNT(tcp.analysis.duplicate_ack)(ip.addr==1.1.1.1) && tcp.analysis.duplicate_ack","COUNT(tcp.analysis.lost_segment)(ip.addr==1.1.1.1) && tcp.analysis.lost_segment","COUNT(tcp.analysis.fast_retransmission)(ip.addr==1.1.1.1) && tcp.analysis.fast_retransmission","COUNT(tcp.analysis.lost_segment)(ip.addr==1.1.1.1) && tcp.analysis.ack_lost_segment")======================================================================================================
| IO Statistics |
| |
| Duration: 5. 40977 secs |
| Interval: 5 secs |
| |
| Col 1: (ip.addr==1.1.1.1) && tcp |
| 2: COUNT(tcp.analysis.retransmission)(ip.addr==1.1.1.1) && tcp.analysis.retransmission |
| 3: COUNT(tcp.analysis.duplicate_ack)(ip.addr==1.1.1.1) && tcp.analysis.duplicate_ack |
| 4: COUNT(tcp.analysis.lost_segment)(ip.addr==1.1.1.1) && tcp.analysis.lost_segment |
| 5: COUNT(tcp.analysis.fast_retransmission)(ip.addr==1.1.1.1) && |
| tcp.analysis.fast_retransmission |
| 6: COUNT(tcp.analysis.lost_segment)(ip.addr==1.1.1.1) && tcp.analysis.ack_lost_segment |
|----------------------------------------------------------------------------------------------------|
| |1 |2 |3 |4 |5 |6 | |
| Date and time | Frames | Bytes | COUNT | COUNT | COUNT | COUNT | COUNT | |
|-------------------------------------------------------------------------------| |
| 2017-07-10 15:00:45 | 507 | 481496 | 1 | 0 | 2 | 0 | 0 | |
| 2017-07-10 15:00:50 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
======================================================================================================#!/usr/bin/env python
# -*- coding: utf-8 -*-
import datetime
import re
import os
import subprocess
import argparse
import time
import signal
parser = argparse.ArgumentParser()
parser.add_argument("-h_page", "--hostname_page", dest = "hostname_page")
args = parser.parse_args()
curent_time=str(datetime.datetime.now().strftime("%Y-%m-%d_%H:%M:%S_"))
pid=os.getpid()
##########start Table parser###############
def parser_tshark_output(open_time, parser_file):
table_data = {'date':[],'1 frame':[],'2 frame':[],'retr':[],'dup_ack':[],'lost_seg':[],'fast_retr':[],'ack_lost_seg':[]}
lines = open(parser_file, 'r').readlines()
lookup = 'tcp.analysis.ack_lost_segment '
number = 0
for num in lines:
if lookup in num:
number+=lines.index(num)
try:
del (lines[-1])
except:
pass
L=open("/usr/TEST/TMP_FILES/test_tshark_temp_"+str(os.getpid())+".txt", 'w')
L.writelines(lines)
L.close()
with open("/usr/TEST/TMP_FILES/test_tshark_temp_"+str(os.getpid())+".txt", 'r') as table:
if number != 0:
for _ in range(int(number+5)):
next(table) #skip header
for row in table:
row=row.strip('\n').split('|')
values = [r.strip() for r in row if r != '']
table_data['date'].append(values[0])
table_data['1 frame'].append(int(values[1]))
table_data['2 frame'].append(int(values[2]))
table_data['retr'].append(int(values[3]))
table_data['dup_ack'].append(int(values[4]))
table_data['lost_seg'].append(int(values[5]))
table_data['fast_retr'].append(int(values[6]))
table_data['ack_lost_seg'].append(int(values[7]))
else:
pass
if number !=0:
frames=sum(table_data['2 frame'])
print ('start-frames_' + str.format("{0:.2f}", frames)+'_end-frames')
tcp_errors=sum(table_data['retr'])+sum(table_data['dup_ack'])++sum(table_data['fast_retr'])+sum(table_data['ack_lost_seg'])
print ('start-tcp_errors_' + str(tcp_errors)+'_end-tcp_errors')
if open_time != 'open_error' and frames != 0:
k=tcp_errors
else:
k= 'no data'
else:
k= 'no data'
os.remove("/usr/TEST/TMP_FILES/test_tshark_temp_"+str(os.getpid())+".txt")
return (k)
###########end table parser###############
###########start tshark part 1###########
resault_temp=subprocess.Popen(['nslookup '+str(args.hostname_page)], bufsize=0, shell=True, stdout = subprocess.PIPE, stderr=subprocess.PIPE)
data=resault_temp.communicate()
ip_adr_temp=re.findall(r'(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})', str(re.findall(r'Address: (\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})', str(data))))
if ip_adr_temp != []:
pass
else:
ip_adr_temp = ['1.1.1.1']
ip_adr=''
for z in ip_adr_temp:
if len(ip_adr_temp)-ip_adr_temp.index(z)==1:
ip_adr+='ip.addr=='+str(z)+')'
else:
ip_adr+='ip.addr=='+str(z)+' or '
ftcp=open('/usr/TEST/TMP_FILES/1tshark_temp'+curent_time+str(pid)+'.txt', 'w')
tcp=subprocess.Popen(['timeout 180 tshark -i bce0 -t ad -qz io,stat,5,"('+str(ip_adr)+' && tcp","COUNT(tcp.analysis.retransmission)('+str(ip_adr)+' && tcp.analysis.retransmission","COUNT(tcp.analysis.duplicate_ack)('\
+str(ip_adr)+' && tcp.analysis.duplicate_ack","COUNT(tcp.analysis.lost_segment)('+str(ip_adr)+' && tcp.analysis.lost_segment","COUNT(tcp.analysis.fast_retransmission)('+str(ip_adr)+\
' && tcp.analysis.fast_retransmission","COUNT(tcp.analysis.lost_segment)('+str(ip_adr)+' && tcp.analysis.ack_lost_segment"']\
, bufsize=0, shell=True, stdout=(ftcp))#stdout = subprocess.PIPE, stderr=subprocess.PIPE)
time.sleep(2)
############start wget ################
fweb=open('/usr/TEST/TMP_FILES/web_temp'+curent_time+str(pid)+'.txt', 'w')
web=subprocess.call(["timeout 120 wget -E -H -p -Q300K --user-agent=Mozilla --no-cache --no-cookies --delete-after --timeout=15 --tries=2 "+args.hostname_page+" 2>&1 | grep '\([0-9.]\+ [KM]B/s\)'"], bufsize=0, shell=True, stdout=(fweb))
fweb.close()
fweb=open('/usr/TEST/TMP_FILES/web_temp'+curent_time+str(pid)+'.txt', 'r')
data=fweb.read()
os.remove('/usr/TEST/TMP_FILES/web_temp'+curent_time+str(pid)+'.txt')
speed_temp=re.findall(r's \((.*?)B/s', str(data))#[KM]B/s', str(data)))
speed_temp_si=re.findall(r's \((.*?) [KM]B/s', str(data))
try:
if re.findall(r'M', str(speed_temp))==[] and re.findall(r'K', str(speed_temp))==[]:
speed_="{0:.3f}".format(float(speed_temp_si[0])*0.001*8)
elif re.findall(r'M', str(speed_temp))!=[]:
speed_="{0:.3f}".format(float(speed_temp_si[0])*1000*8)
elif re.findall(r'K', str(speed_temp))!=[]:
speed_="{0:.3f}".format(float(speed_temp_si[0])*1*8)
except:
speed_='no_data'
##############stop wget##############
##############start tshark part2#######
os.kill(tcp.pid, signal.SIGINT)
ftcp.close()
time.sleep(0.3)
tcp_error=parser_tshark_output('1', '/usr/TEST/TMP_FILES/1tshark_temp'+curent_time+str(pid)+'.txt')
os.remove('/usr/TEST/TMP_FILES/1tshark_temp'+curent_time+str(pid)+'.txt')
#########resault to DB###########
print ('web_speed_test:'+str(speed_)+' tcp_error:'+str(tcp_error))
$python3.3 web_open.py -h_page habrahabr.ru
web_speed_test:10960.000 tcp_error:2.0


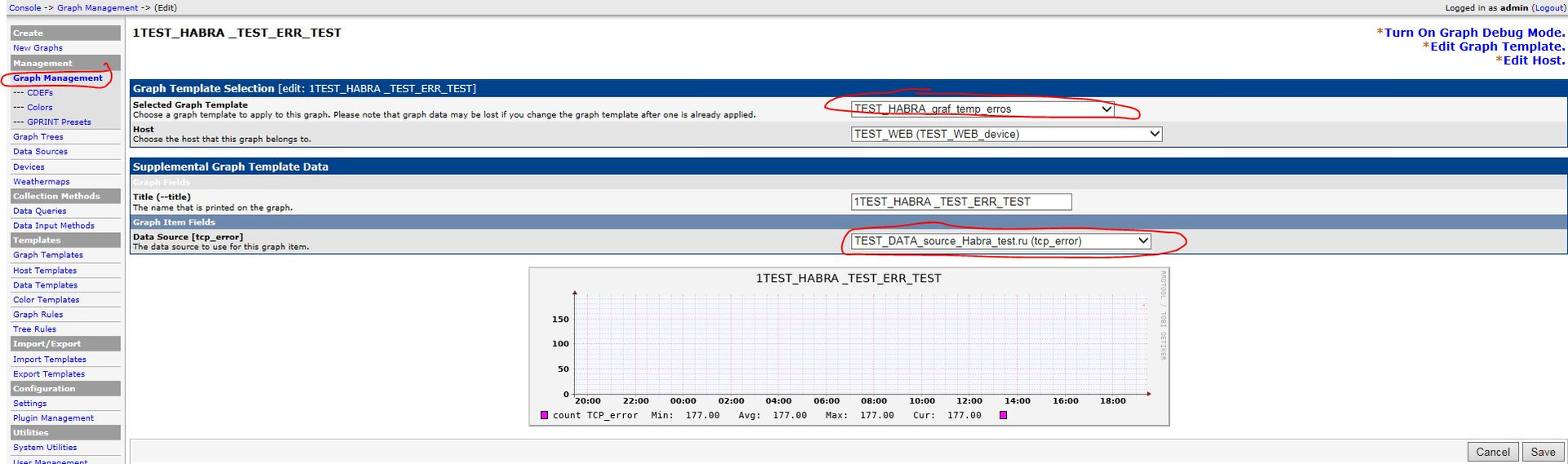
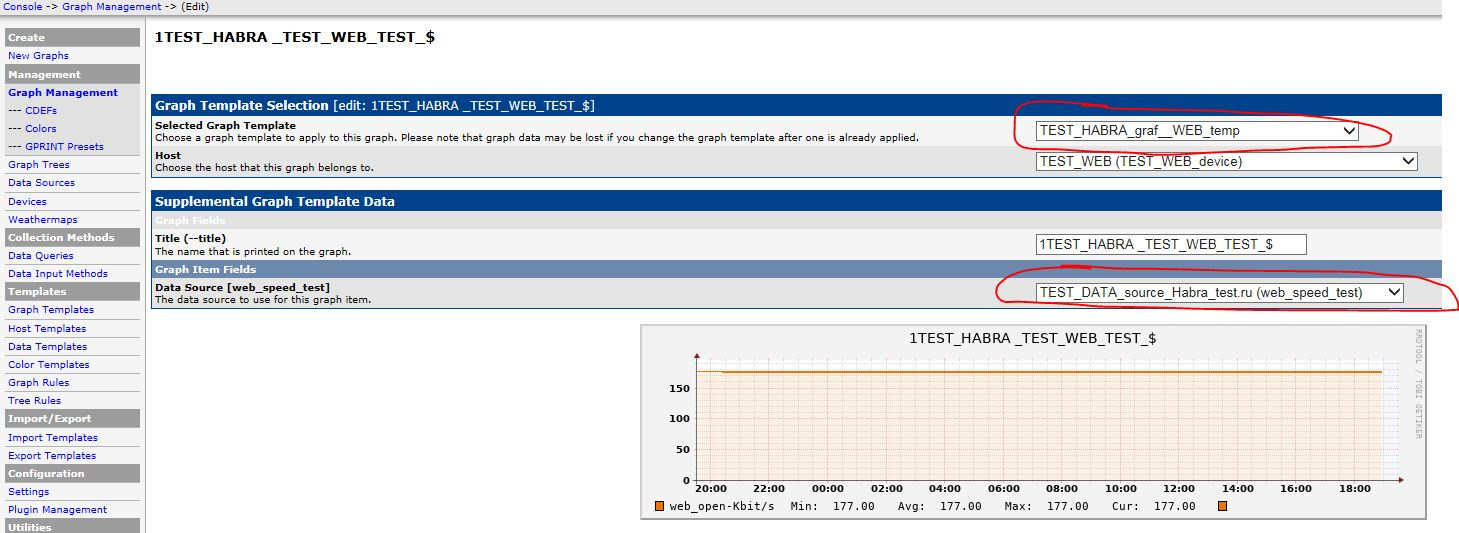

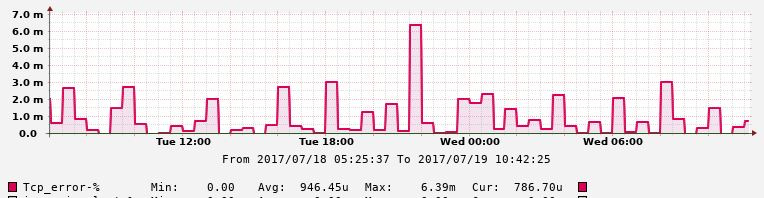
|
Метки: author Lost63 визуализация данных python python3 мониторинг сайта сетевые технологии tshark ip tcp |






