[Перевод] Данные: красивые и ужасные |






|
Метки: author Cloud4Y открытые данные визуализация данных data mining big data блог компании cloud4y анализ данных красота |
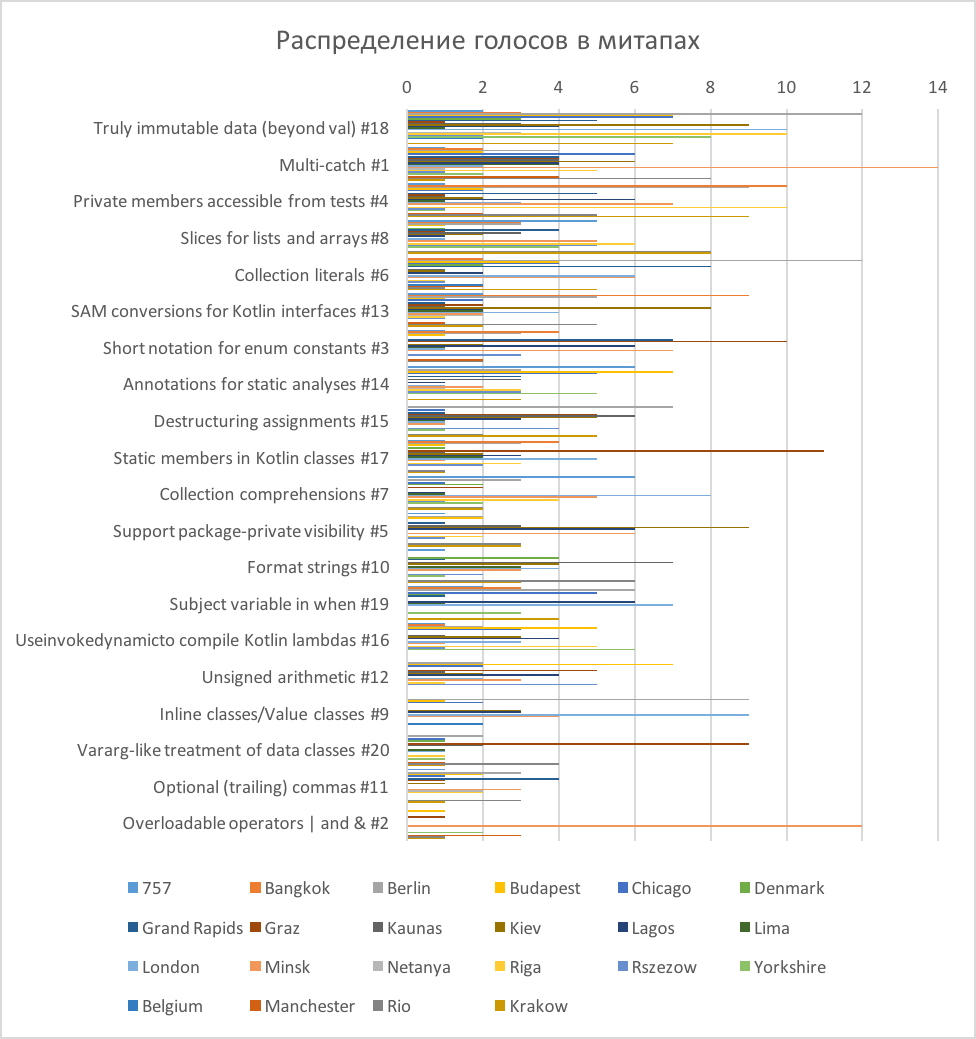
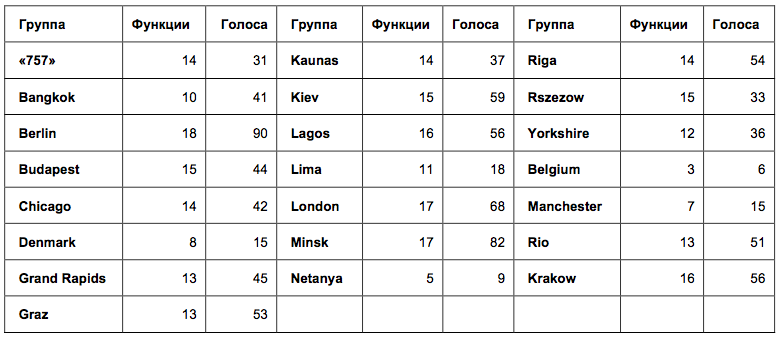
Неожиданные результаты опросов Kotlin: маленькое расследование |


Насчет этого эффекта есть интересный пример из социальной психологии.
Несмотря на традиционные представления, научные исследования показывают, что различия между группами (между мужчинами и женщинами) часто оказываются менее существенными, чем различия внутри гендерных групп (например, только между женщинами).
Так, в разных странах проводились исследования математических способностей у мальчиков и девочек. В части стран лучше успевали мальчики, в других странах – девочки. Везде различия были статистически значимыми. И если бы мы знали только об одном таком исследовании, это бы могло сформировать наше представление о математических способностях мужчин и женщин. Но ученые провели мета-исследование и проверили разбросы внутри групп. В большинстве стран различия между мальчиками и девочками оказались меньше, чем различия внутри групп мальчиков и девочек (D. Baker, D. Jones, 1993).
Часто группы, которые нам кажутся очевидно разными, внутри имеют даже больший разброс. Особенно интересно узнавать про такие исследования внутри расовых групп (Zuckerman, 1990).
Поведение окружающих, действительно, оказывает влияние на взрослых здравомыслящих людей. Это описывают многие эксперименты конформности. Но бывают случаи, когда не только групповое давление, но и просто модель поведения других людей меняет действия человека.
В эксперименте С. Милгрэма на оживленной улице Нью-Йорка сообщники экспериментатора останавливались и начинали смотреть в одну точку, подняв головы. Оказалось, что число присоединившихся к ним прохожих росло по мере увеличения группы. Обычные люди тоже останавливались и начинали смотреть вверх, не зная, куда смотрят остальные. Эксперимент проводился с разным количеством сообщников. Чем больше их было (от 1 до 5), тем больше подражателей они привлекали. Но после того, как размер группы сообщников превышал 5 человек, рост подражателей останавливался. Группа становилась больше, но подражателей больше не становилось.
В других исследованиях – Герарда (1968) и Розенберга (1961) – также было показано, что увеличение группы сверх 5 человек приводит к снижению конформности.
«Эффект привязки» был описан в одном из исследований Д. Канемана. Если одну группу испытуемых спросить: «Дожил ли Ганди до 114 лет? В каком возрасте он умер?», а другую: «Дожил ли Ганди до 35 лет? В каком возрасте он умер?», то первая группа оценит жизнь Ганди как гораздо более долгую, чем вторая.
Чаще всего эффект привязки используется в торговле, когда пишется самая низкая цена в группе товаров без уточнения, что остальные товары стоят дороже (рис. 7). Или, наоборот, когда вначале выставляются самые дорогие товары, чтобы скидки на остальные товары воспринимались более существенными.
Рисунок 7. Эффект привязки часто используют в магазинах одежды, указывая над стойкой самую низкую цену, или самую большую скидку, соответствующую, однако, не всем вещам, висящим на стойке.
Интересно, в исследованиях было доказано, что эффект привязки продолжает действовать, даже если человек знает о нем.
|
|
Enjoy! Сервер аутентификации Isolate в Open Source |

[~]$ s .
myproject
------
10001 | 11.22.22.22 | aws-main-prod
10002 | 11.33.33.33 | aws-dev
10003 | 11.44.44.44 | vs-ci
------
Total: 3
[~]$[~]$ g myproject aws-dev
Warning: Permanently added 3.3.3.100 (RSA) to the list of known hosts.
Warning: Permanently added 10.10.10.12 (RSA) to the list of known hosts.
[root@dev ~]$[isolate ~]$ g 45.32.44.87 --user support --port 2232 --nosudo
Warning: Permanently added 45.32.44.87 (RSA) to the list of known hosts.$ sudo -l
(auth) NOPASSWD: /opt/auth/wrappers/ssh.py
$ sudo /opt/auth/wrappers/ssh.py -h
usage: ssh-wrapper [-h] [--user USER] [--port PORT] [--nosudo]
[--config CONFIG] [--debug] [--proxy-host PROXY_HOST]
[--proxy-user PROXY_USER] [--proxy-port PROXY_PORT]
[--proxy-id PROXY_ID]
hostname
positional arguments:
hostname server address (allowed FQDN,[a-z-],ip6,ip4)
optional arguments:
-h, --help show this help message and exit
--user USER set target username
--port PORT set target port
--nosudo run connection without sudo terminating command
--debug
--proxy-host PROXY_HOST
--proxy-user PROXY_USER
--proxy-port PROXY_PORT
--proxy-id PROXY_ID just for pretty logs
------s () {
if [[ $# -eq 0 ]] ; then
echo -e "\\n Usage: s \\n";
return
elif [[ $# -gt 0 ]] ; then
"${ISOLATE_HELPER}" search "${@}";
fi
} $ g rogairoga nyc-prod-1$ g rogairoga 192.168.1.1$ g rogairoga 192.168.22.22 --port 23 --user support --nosudo$ g 12345|
Метки: author eapotapov системное администрирование серверное администрирование блог компании itsumma otp ssh logging security management |
Сервер VESNIN: первые тесты дисковой подсистемы |


[global]
ioengine=libaio
direct=1
group_reporting=1
bs=4k
iodepth=16
rw=randread
[ /dev/nvme1n1 P60713012839 MTFDHAL2T4MCF-1AN1ZABYY]
stonewall
numjobs=1
filename=/dev/nvme1n1
# numactl --physcpubind=0 ../fio/fio workload.fio
/dev/nvme1n1 P60713012839 MTFDHAL2T4MCF-1AN1ZABYY: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=16
fio-2.21-89-gb034
time 3233 cycles_start=1115105806326
Starting 1 process
Jobs: 1 (f=1): [r(1)][13.7%][r=519MiB/s,w=0KiB/s][r=133k,w=0 IOPS][eta 08m:38s]
fio: terminating on signal 2
Jobs: 1 (f=0): [f(1)][100.0%][r=513MiB/s,w=0KiB/s][r=131k,w=0 IOPS][eta 00m:00s]
/dev/nvme1n1 P60713012839 MTFDHAL2T4MCF-1AN1ZABYY: (groupid=0, jobs=1): err= 0: pid=3235: Fri Jul 7 13:36:21 2017
read: IOPS=133k, BW=519MiB/s (544MB/s)(41.9GiB/82708msec)
slat (nsec): min=2070, max=124385, avg=2801.77, stdev=916.90
clat (usec): min=9, max=921, avg=116.28, stdev=15.85
lat (usec): min=13, max=924, avg=119.38, stdev=15.85
………...
cpu : usr=20.92%, sys=52.63%, ctx=2979188, majf=0, minf=14
Starting 2 processes
Jobs: 2 (f=2): [r(2)][100.0%][r=733MiB/s,w=0KiB/s][r=188k,w=0 IOPS][eta 00m:00s]
/dev/nvme1n1 P60713012839 MTFDHAL2T4MCF-1AN1ZABYY: (g=0): rw=randread, bs=(R)
pid=3391: Sun Jul 9 13:14:02 2017
read: IOPS=188k, BW=733MiB/s (769MB/s)(430GiB/600001msec)
slat (usec): min=2, max=963, avg= 3.23, stdev= 1.82
clat (nsec): min=543, max=4446.1k, avg=165831.65, stdev=24645.35
lat (usec): min=13, max=4465, avg=169.37, stdev=24.65
…………
cpu : usr=13.71%, sys=36.23%, ctx=7072266, majf=0, minf=72
PID COMM D MAJ MIN DISK I/O Kbytes AVGus
3553 fio R 259 1 nvme0n1 633385 2533540 109.25
3554 fio R 259 1 nvme0n1 630130 2520520 109.25
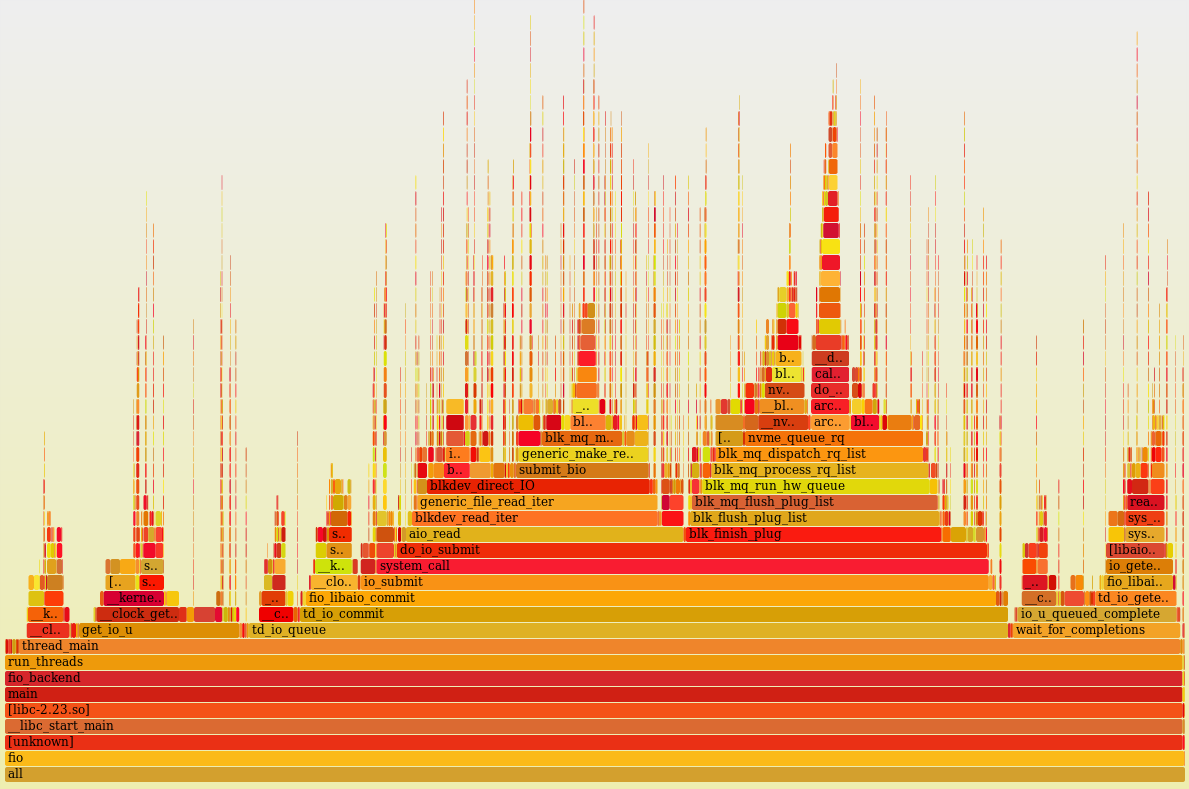
root@vesninl:~# perf stat -C 0
Performance counter stats for 'CPU(s) 0':
2393.117988 cpu-clock (msec) # 1.000 CPUs utilized
7,518 context-switches # 0.003 M/sec
0 cpu-migrations # 0.000 K/sec
0 page-faults # 0.000 K/sec
9,248,790,673 cycles # 3.865 GHz (66.57%)
401,873,580 stalled-cycles-frontend # 4.35% frontend cycles idle (49.90%)
4,639,391,312 stalled-cycles-backend # 50.16% backend cycles idle (50.07%)
6,741,772,234 instructions # 0.73 insn per cycle
# 0.69 stalled cycles per insn (66.78%)
1,242,533,904 branches # 519.211 M/sec (50.10%)
19,620,628 branch-misses # 1.58% of all branches (49.93%)
2.393230155 seconds time elapsed
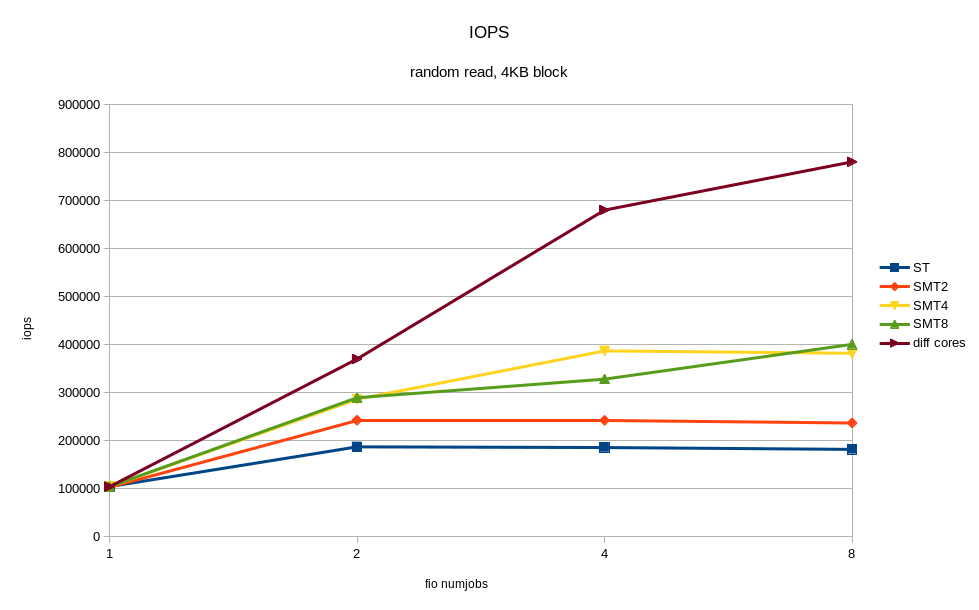
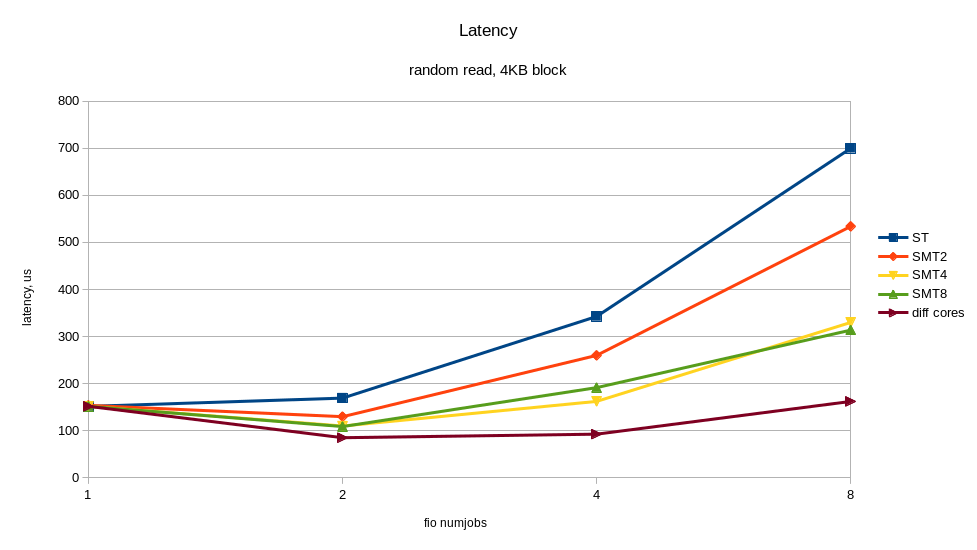
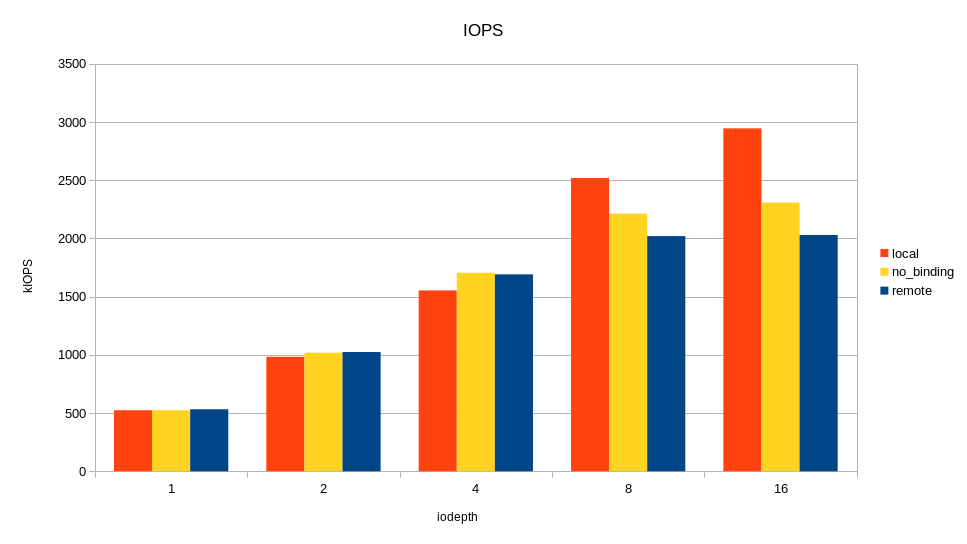
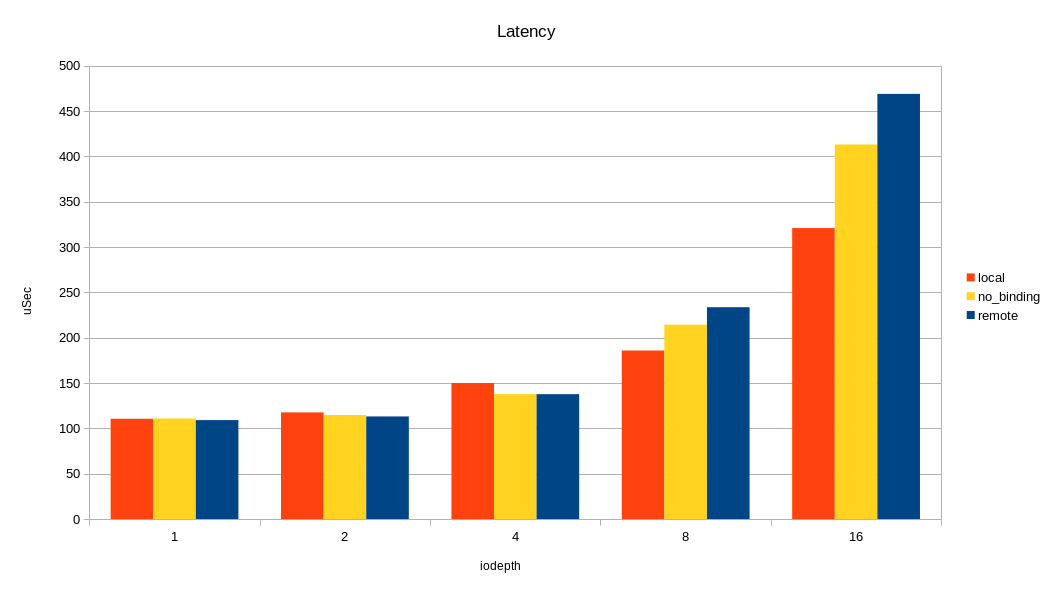
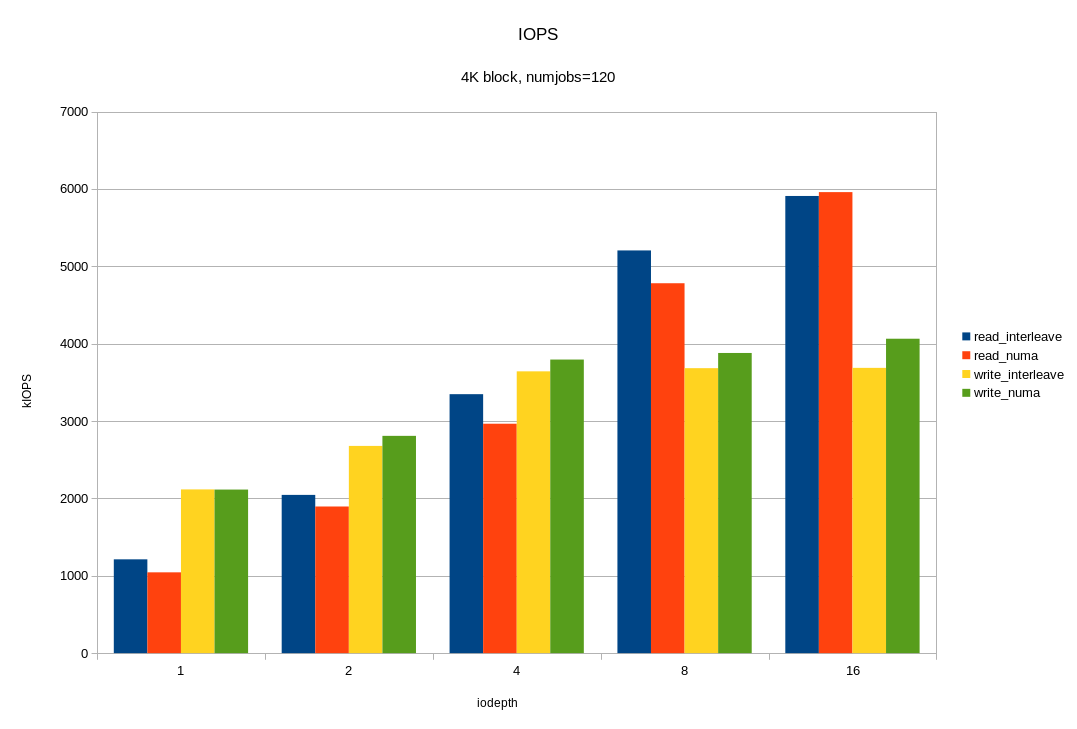
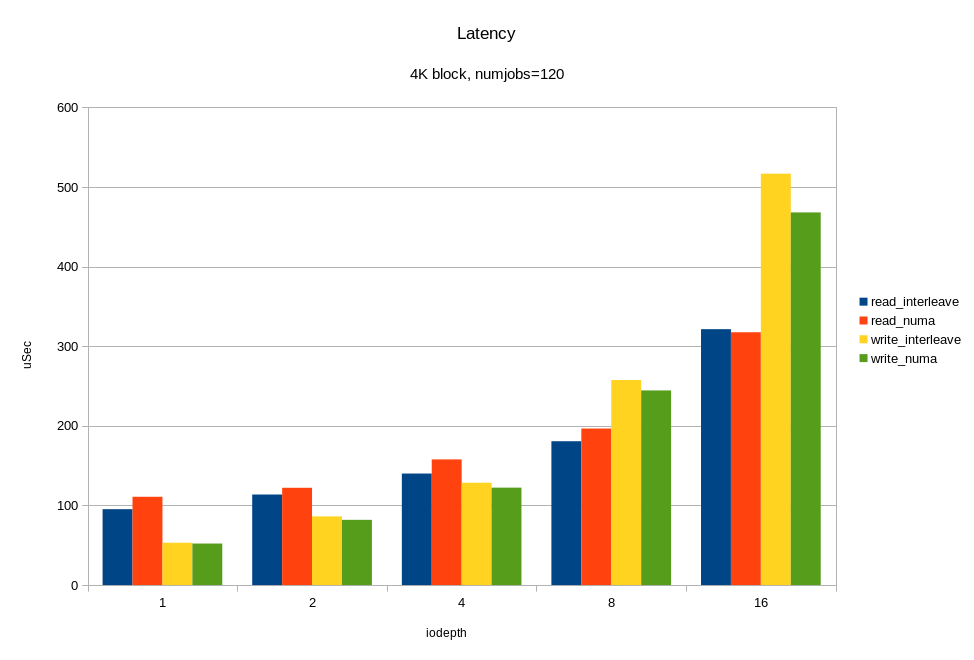
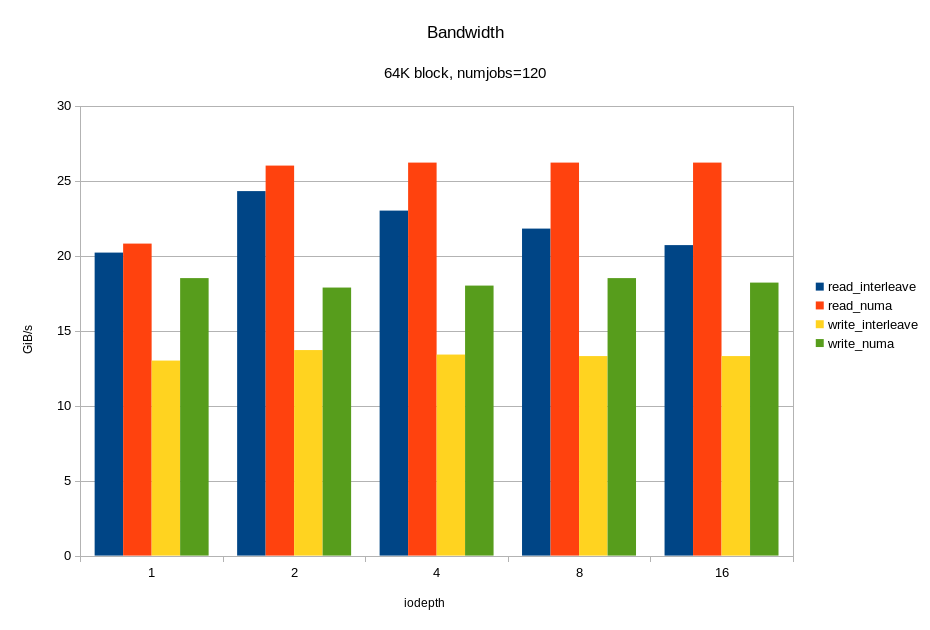
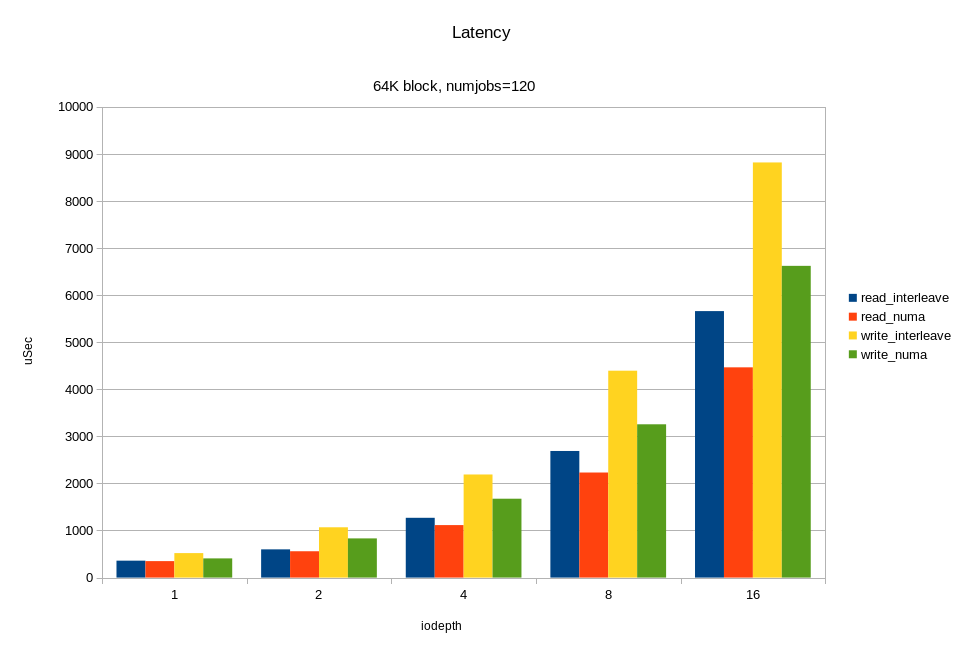
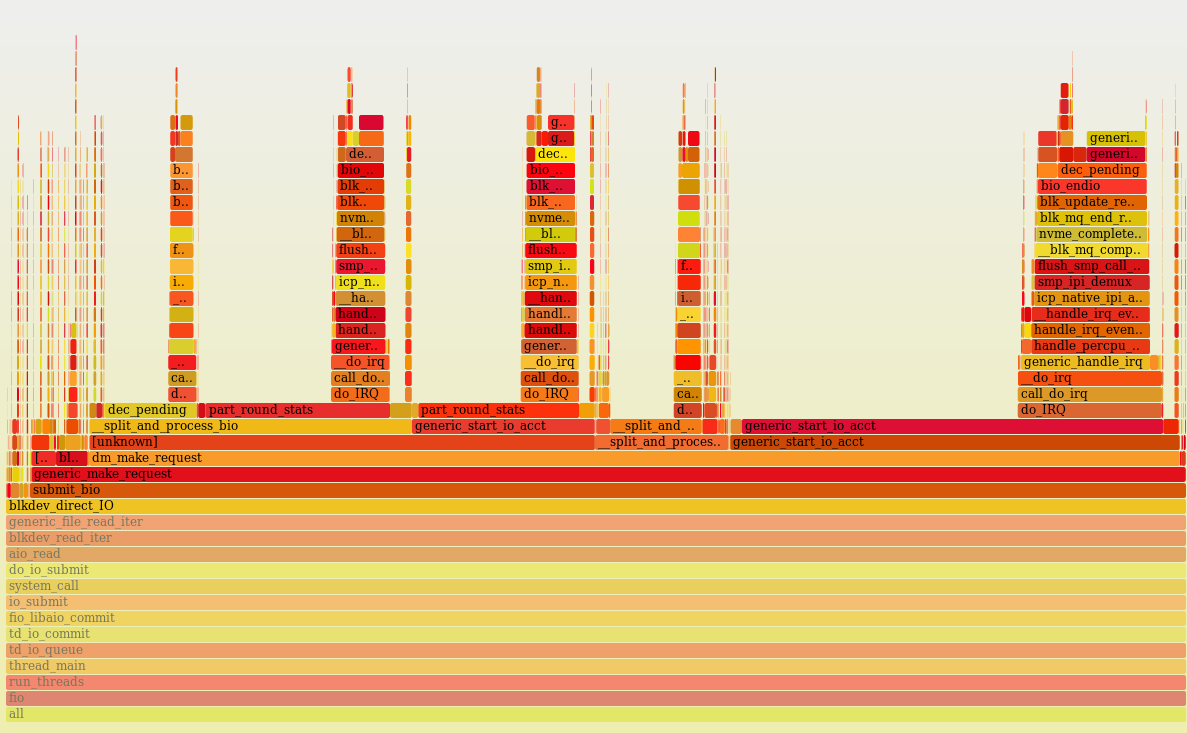
/* flags for preadv2/pwritev2: */
#define RWF_HIPRI 0x00000001 /* high priority request, poll if possible */|
Метки: author kachini анализ и проектирование систем блог компании yadro серверы проектирование openpower in-memory nvme storage latency bandwidth iops |
Planning Poker: как сделать процесс постановки задач максимально прозрачным и четким |

Главная цель оценки сложности не предсказать, когда задача будет готова, а убедиться, что все участники одинаково понимают задачу.
|
Метки: author RetailRocket управление разработкой управление продуктом блог компании retail rocket управление продуктами управление процессами в it планирование разработка |
[Перевод] XBRL: просто о сложном - Глава 5. Открывая новые измерения |
Предыдущие главы показали вам, что такое XBRL, и что с его помощью можно сделать. Как вы уже знаете, он является расширяемым стандартом. В этой главе мы рассмотрим один из расширяющих стандартную спецификацию модулей – XBRL Dimensions (Измерения).
Глава основывается на спецификации XBRL Dimensions версии 1.0 CR от 19.06.2006. На момент написания книги спецификация находится в статусе Candidate Recommendation, но ожидается, что окончательный вариант не принесет никаких значительных сюрпризов.
Что касается самой спецификации XBRL, данная глава подчеркивает некоторые ее важные моменты, необходимые для уверенного базового понимания XBRL Dimensions. Остальные нюансы приведены в полной спецификации.
Обычно, факты в отчетах некоторым образом классифицируются, например:
Две из этих категорий явно определены спецификацией XBRL – период и составитель отчета (компания, департамент, отдел компании). Эти категории всегда присутствуют в контекстах, на которые ссылаются факты отчета.
Желание расширить эти возможности, чтобы позволить авторам таксономии указать свои собственные категории вроде продуктовой линии, пола и т.д., является вполне естественным. Это именно то, что позволяет сделать XBRL Dimensions. В этой спецификации такие категории называются измерениями (dimension).
Как определено в спецификации XBRL, входящие в контекст сценарий и сегмент могут иметь любое валидное XML-содержание. XBRL Dimensions определяет формализованный способ использования таких элементов для добавления новых измерений (категории) в контекст.
Пример, который мы ранее использовали, очень хорошо подходит для иллюстрации:
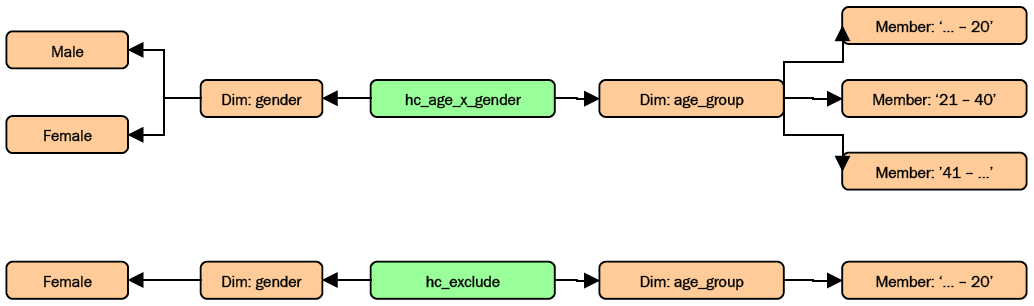
Нам лишь надо определить концепт nr_employees и пару измерений: gender (пол) со значениями {‘men’, ‘women’} и age group (возрастная группа) со значениями {‘...–20’, ‘21–40’, ‘41–…’}.
Отчет содержит набор контекстов для каждого сочетания периода и измерения, и каждому контексту соответствует свой факт:
Контекст Факт 01-01-2015 nr_employees = 35 01-01-2015 + ‘men’ nr_employees = 23 01-01-2015 + ‘women’ nr_employees = 12 01-01-2015 + ‘...–20’ nr_employees = 5 01-01-2015 + ‘21–40’ nr_employees = 23 01-01-2015 + ‘41–…’ nr_employees = 7 31-12-2015 nr_employees = 41 31-12-2015 + ‘men’ nr_employees = 27 31-12-2015 + ‘women’ nr_employees = 15 31-12-2015 + ‘...–20’ nr_employees = 9 31-12-2015 + ‘21–40’ nr_employees = 21 31-12-2015 + ‘41–…’ nr_employees = 11
Спецификация XBRL Dimensions использует ряд понятий, которые кратко представлены здесь и будут более подробно разобраны в следующем разделе.
Спецификация определяет три типа таксономий. Это разделение на три типа – лишь концепция. Можно использовать три отдельные таксономии, но спецификация не требует использования отдельных таксономий для каждого из типов. Комбинировать разные типы в одной таксономии – совершенно нормально. Допустимо даже использовать концепт в качестве первичного концепта в одной взаимосвязи, и в качестве элемента измерения в другой.
В этом разделе рассматривается способ расширения таксономий для применения спецификации XBRL Dimensions. Начну с архитектурной диаграммы, показывающей, как все компоненты связаны между собой.

Следующие подразделы описывают каждый компонент архитектуры более подробно.
DMT определяет измерения как абстрактные item-концепты со значением xbrldt:dimensionItem атрибута substitution group.
Примечание: Атрибуты xbrli:balance, xbrli:periodType и nillable игнорируются.
Измерения могут быть типизированными или явными, как было сказано выше, в каждом из них используется свой способ определения элементов домена.
Определение типизированного домена должно иметь значение атрибута xbrldt:typedDomainRef, которое ссылается на объявление элемента, определяющего домен измерения.
Домен определяется с использованием типов XML Schema:
SimpleType может, к примеру, определить в качестве идентификатора клиента компании значения от 0 до 100 в виде целого числа или строки длиной 5 символов;ComplexType может быть использован для определения адреса, включающего в себя город, улицу, номер дома, индекс и т.д.Домен явного измерения идентифицируется связью dimension-domain от измерения к корню сети связей domain-member между элементами домена. В явном измерении не может содержаться атрибут xbrldt:typedDomainRef.
Элементами домена измерения являются все qname-элементы в сети связей domain-member. Каждый элемент – это определение item-концепта со значением xbrli:item атрибута substitution group (он не может принадлежать к группе xbrldt:hypercubeItem или xbrldt:dimensionItem).
Связи domain-member образуют иерархию элементов. Можно добавлять элементы в иерархию, например, чтобы создать корень вложенной иерархии, который не предназначен для использования в качестве элемента домена. Для этого в булевом атрибуте usable, имеющего по умолчанию значение true, указывается значение false.
У явного измерения может быть указан элемент по умолчанию, это делается с помощью связи dimension-default к элементу домена. Это значение по умолчанию используется в контексте, если не задано ни одного элемента измерения. Само значение по умолчанию в не может быть явно указано в контексте, оно всегда определяется автоматически.
Обратите внимание, что связь dimension-default сама по себе не добавляет элемент в домен и не является эквивалентом связи domain-member.
domain-member и наследование (inheritance)Первичные концепты могут наследовать гиперкубы других первичных концептов путем указания связи domain-member между первичными концептами.
Предположим, у нас есть два первичных концепта, один из которых (item) связан с гиперкубом hc_age, а другой (another item) – связьюdomain-memberс первым концептом:
Так как у первого концепта есть связь с измерением age_group через гиперкуб hc_age, а второй концепт имеет связьdomain-memberс первым концептом – второй концепт наследует измерение age_group.
Гиперкубы определяются в таксономии шаблонов (template taxonomy) путем объединения нуля (гиперкуб может быть пустым) и более измерений.
Объявляющий элемент является абстрактным концептом, который должен иметь значение xbrldt:hypercubeItem атрибута substitution group.
Измерения связываются с гиперкубом дугами с ролью hypercube-dimension. Эти отношения упорядочены значением атрибута order в каждой дуге. Дуги не могут образовывать циклических связей.
При создании таксономии с измерениями вам захочется иметь возможность контролировать, с какими измерениями может быть связан каждый из концептов. Таксономия шаблонов обеспечивает такую возможность путем определения связей между гиперкубами и первичными концептами через связи has-hypercube между первичным концептом и концептом гиперкуба.
Есть два типа связей has-hypercube – all и notAll:
all используется для определения измерений (и элементов измерений), которые разрешены для концепта;notAll используется для определения измерений (и элементов измерений), которые не разрешены.Сочетание этих типов связей позволяет точно контролировать состав измерений и элементов измерений для каждого концепта.
Предположим, у нас есть два гиперкуба:
Первичный концепт со связьюhas-hypercubeтипаallс кубом hc_age_x_gender может иметь все элементы измерений gender и age_group. Если мы добавим к этому концепту связь типаnotAllс гиперкубом hc_exclude, элемент ‘Female’ измерения gender и элемент ‘...–20’ измерения age_group станут ему недоступны.
Связь has-hypercube должна указывать, в какой части контекста должны быть определены измерения – segment или scenario, для этого предназначен атрибут contextElement:
segment используется для измерений, которые определяют часть организационной структуры формирующей отчет компании, напр. отдел, регион и т.д.;scenario используется для измерений, не связанных с организационной структурой компании, таких как возрастная группа, продукт и т.д.Чтобы указать, что концепту доступны только элементы внутри измерений гиперкуба, в необязательном булевом атрибуте closed связи has-hypercube указывается значение true. Этот атрибут применяется только к сегменту сценария в соответствии со значением атрибута contextElement в связи. Значением по умолчанию является false, которое оставляет сегмент или сценарий открытым.
Определенные в XBRL Dimensions взаимосвязи включаются в базы ссылок определений (definition linkbase). В соответствии со спецификацией XBRL, взаимосвязи группируются в сети в соответствии с их ролями. Это называют базовым набором взаимосвязей.
Спецификация XBRL Dimensions расширяет понятие базового набора путем введения атрибута targetRole для таких типов связей как all, notAll, hypercube-dimension, dimension-domain и domain-member. Атрибут targetRole ссылается на другую роль и определяет переход от базы ссылок в одном базовом наборе к базе ссылок в базовом наборе с указанной в атрибуте ролью. Набор таких сгруппированных взаимосвязей называется Набором взаимосвязей измерений, DRS.
Создание DRS может быть полезным и даже необходимым, когда таксономия измерений становится все более сложной. Без DRS вы скорее всего включите элементы в измерения, которым они не принадлежат или добавите измерения не в те гиперкубы. Вы можете запросто получить набор взаимосвязей, которые не имеют никакого смысла или могут даже оказаться противоречивыми и невалидными.
Этот механизм перехода от одной базы ссылок (роли) к другой делает процесс валидации таксономии или отчета намного более сложным, так как взаимосвязи существуют вне границ базовых наборов, как это определено в спецификации XBRL.
Спецификация XBRL Dimensions использует понятие последовательных взаимосвязей (consecutive relationship). Оно означает, что, например, элементы гиперкуба определяются сначала по взаимосвязиhypercube-dimension, а затем для всех найденных измерений – последовательно по каждой из связейdomain-member.
Все последовательные взаимосвязи находятся в пределах одной роли баз ссылок, если не определено значение атрибутаtargetRole. Если же в дуге этот атрибут присутствует, то поиск взаимосвязей переходит в базу ссылок с указанной ролью. Последовательные взаимосвязи в исходной базе ссылок (роли) в этом случае отсутствуют.
Взаимосвязи, которые могут быть объединены как последовательные, ограничены тем, что вы бы логично ожидали – связиhas-hypercube(all,notAll) могут иметьhypercube_dimensionв качестве последовательных взаимосвязей, но неdimension_domainилиdomain_member, так как они пропускают связи.
Как говорилось во введении, измерения используются в сегменте или сценарии контекстов отчета. Выбор между ними производится с помощью атрибута contextElementType связи has-hypercube.
Для типизированных измерений значения указываются как дочерние элементы xbrldi:typedMember внутри сегмента или сценария. Атрибут dimension таких элементов должен ссылаться на определение типизированного измерения. Содержанием typedMember является элемент с типом как у измерения, указанного в атрибуте xbrldt:typedDomainRef. Значением для измерения является значение этого элемента.
Предположим, у нас есть измерение ageDim типа age с целочисленными значениями от 0 до (будем оптимистами) 150. Значение измерения 45 задается как дочерний элемент age внутри, к примеру, сегмента следующим образом:
45
Для явных измерений значения указываются с помощью элементов xbrldi:explicitMember. Атрибут dimension таких элементов должен ссылаться на определение явного измерения. Значением для измерения является содержание этого элемента и оно должно быть qname-элементом одного из явно определенных значений измерения.
Предположим, у нас есть измерение ageGroupDim со следующими явно определенными элементами: ageLessThan20, ageFrom21To40 и age41OrMore. Значение измерения для возрастной группы 21–40 задается дочерним элементом внутри, к примеру, сегмента следующим образом:
d:ageFrom21To40
Спецификация XBRL Dimensions дополняет набор правил валидации из спецификации XBRL.
Факты по первичным концептам должны валидироваться на основании концепта и контекста. Факт автоматически считается валидным по измерениям, если для его концепта не определены связи has-hypercube.
Если в концепте определены связи has-hypercube, указанные ими гиперкубы должны быть валидными по измерениям. Контекст факта должен содержать валидную комбинацию элементов домена или значений для каждого из связанных с ним измерений гиперкуба в пределах как минимум одного базового набора. Если не задано ни одного значения измерения, используется значение измерения по умолчанию (при его наличии). Недопустимо указывать более одного значения измерения.
Обратите внимание, что при определении валидности указанного значения в пределах измерения учитываются такие атрибуты как usable в связях domain-member и closed в связях has-hypercube.
Потребовалось несколько страниц спецификации XBRL Dimensions для описания нормативного определения валидации по измерениям, поэтому реальность чуть более сложна, чем я описал здесь. Тем не менее, приведенные выше простые правила и здравый смысл должны дать вам неплохое понимание того, что же такое валидация по измерениям.
5.3.3. Равенство по измерениям
Спецификация XBRL Dimensions добавляет новый тип равенства к приведенному в спецификации XBRL обширному перечню – d-равенство (d-equal). Два факта считаются d-равными для одного измерения, если они имеют одно и то же значение этого измерения.
|
Метки: author r_udaltsov it- стандарты xbrl финансы отчетность цб рф |
IT-события, которые вы можете посетить до конца лета |




|
Метки: author EverydayTools хакатоны учебный процесс в it блог компании everyday tools курсы курсы повышения квалификации митапы конференции it- образование сообщество |
[Из песочницы] Как ускорить сайт или факторы, влияющие на загрузку сайта |
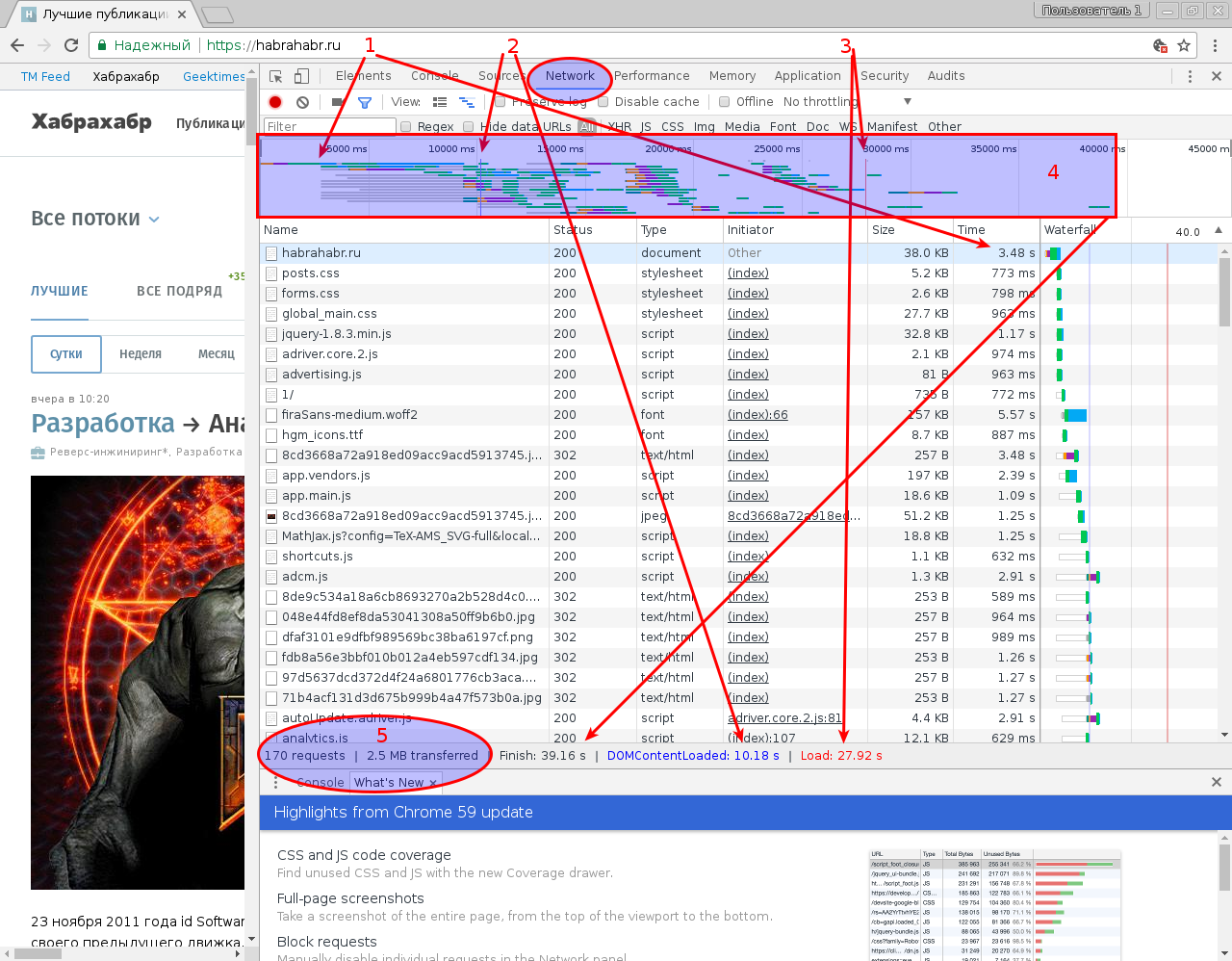
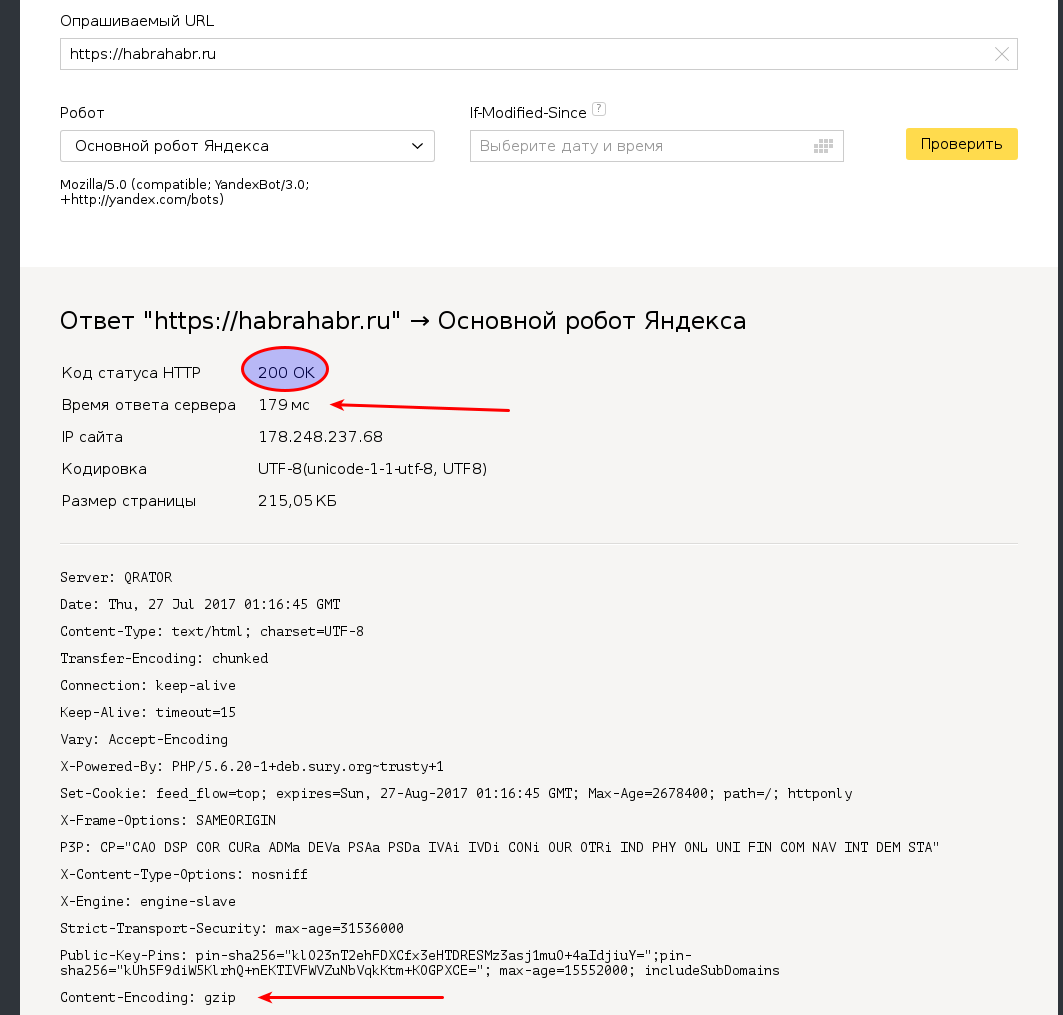
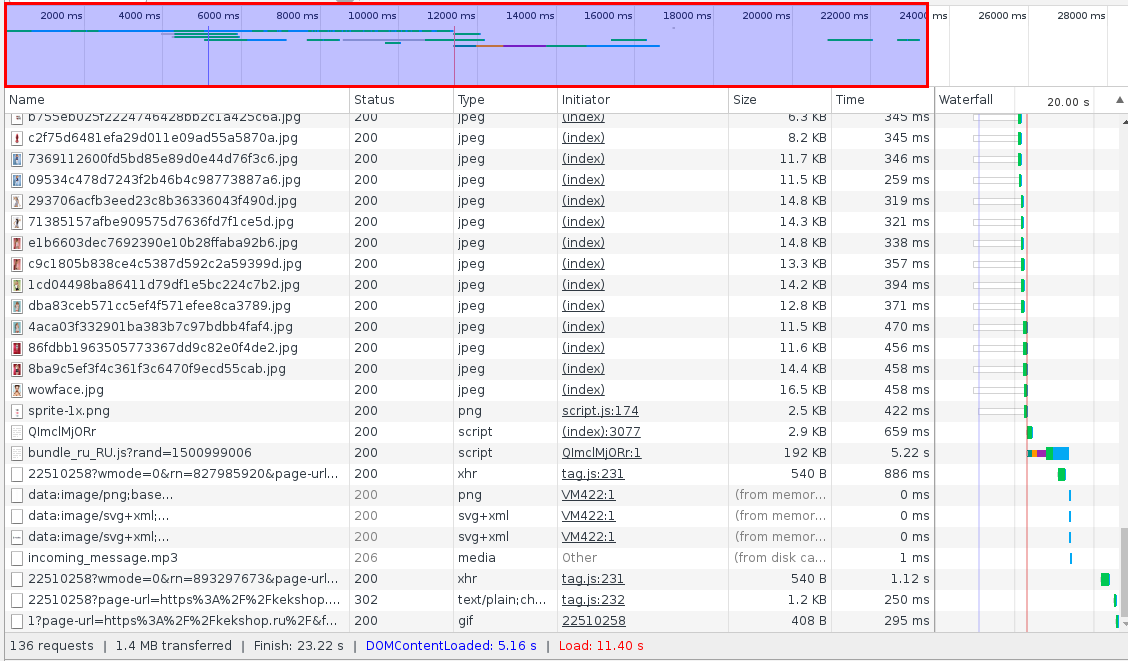
|
Метки: author castomi хостинг серверная оптимизация настройка linux ускорить сайт ускорение сайта ускорение ускорение загрузки ускорение сайтов ускорение страниц |
Неклассическое поступление в вуз |
 / Фотография hackNY.org CC-BY
/ Фотография hackNY.org CC-BYВсе действительно произошло, когда я готовился к ЕГЭ по информатике. Там была задача под номером 27. Смысл в том, что в ней было очень много параметров — х1, х2, х3, х4, х5 и так далее. Надо было пробовать, перебирать.
И мне так надоело это делать, что я просто решил отвлечься и что-нибудь почитать. Наткнулся на статью об уязвимости в Facebook и решил попробовать этот способ на ВК
– Илья Глебов в интервью порталу ITMO.News
Пост Ильи очень быстро попал в топ дня Хабра, а затем и недели, а я, как и многие мои коллеги, регулярно посещаю профильные ресурсы. Поэтому уже на следующий день после публикации мы в телеграм-чате департамента обсуждали как саму запись, так и один из комментариев Ильи, где он, отвечая на вопрос о выборе вуза, перечислял университеты Петербурга, но не упомянул ИТМО.
– Николай Пшеничный, начальник отдела профориентации и работы с талантами Департамента по стратегическим коммуникациям
Знания Ильи в некоторых предметных областях значительно превосходят требования, предъявляемые ребятам его возраста: очевиден интерес к реверс-инженирингу и желание развиваться, в том числе самостоятельно. Рассчитываем, что он выдержит серьезную нагрузку базовых дисциплин в первый год обучения и сможет раскрыть свои таланты в области информационной безопасности.
– Данил Заколдаев

Системный поиск абитуриентов на Хабре невозможен по объективным причинам: хоть и IT-компетенции покорны всем возрастам, но чаще всего самые молодые хабражители, если и участвуют в дискуссиях и публикуют записи, то не акцентируют внимание на том, что ещё учатся в школе […]
Важно понимать, что история поступления Ильи в Университет ИТМО — это совпадение, которое стало возможным благодаря тому, что сотрудники и студенты нашего вуза регулярно читают этот блог. Если хотите, то можно сказать, что пост попал в нужные руки сотрудника Приемной комиссии. Всерьёз рекомендовать такой путь в будущем, возможно, мы бы не стали. Но и не поощрять такие достижения мотивированных школьников тоже нельзя. Как всегда нужно искать золотую средину.
– Николай Пшеничный
|
Метки: author itmo учебный процесс в it блог компании университет итмо университет итмо vk |
Информационные сервисы, роботы и торговый софт: применение API в мире финансов |


|
Метки: author itinvest api блог компании itinvest разработка финансы биржа торговые роботы |
«Google для смысла»: стартап Node представил платформу для семантического профилирования |
 / фото Ryan Van Etten CC
/ фото Ryan Van Etten CCОна выяснила, что результатом более 85% знакомств стали инвестиционные сделки, долговременное сотрудничество и многомиллионные контракты, которые заключили ее коллеги.
|
Метки: author it_man венчурные инвестиции блог компании ит-град ит-град node семантическая платформа |
Без заголовка |



|
Метки: author kudzev разработка под android qt c++ блог компании 2гис гис qml android |
Берегите ваши баллы, или Как противостоять мошенничеству в программах лояльности |

|
Метки: author GemaltoRussia блог компании gemalto russia безопасность безопасность в сети лояльность лояльность клиентов защита информации мошенничество в интернете |
Нестандартная кластеризация, часть 3: приёмы и метрики для кластеризации временных рядов |


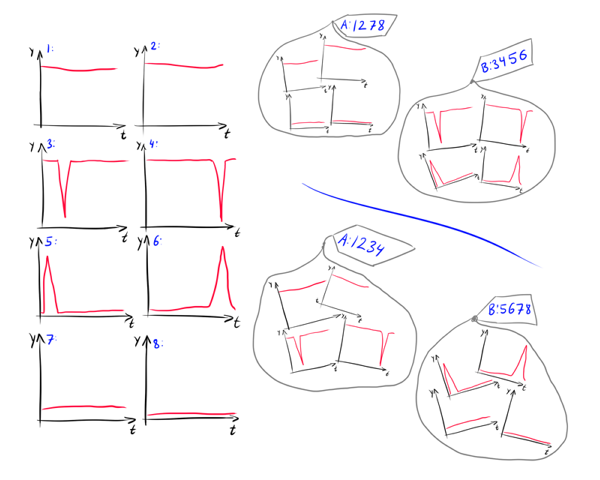



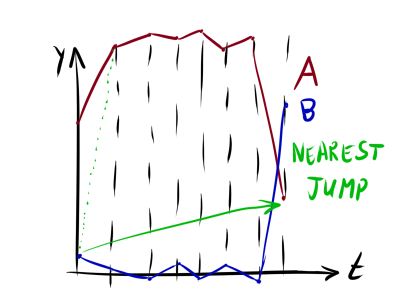
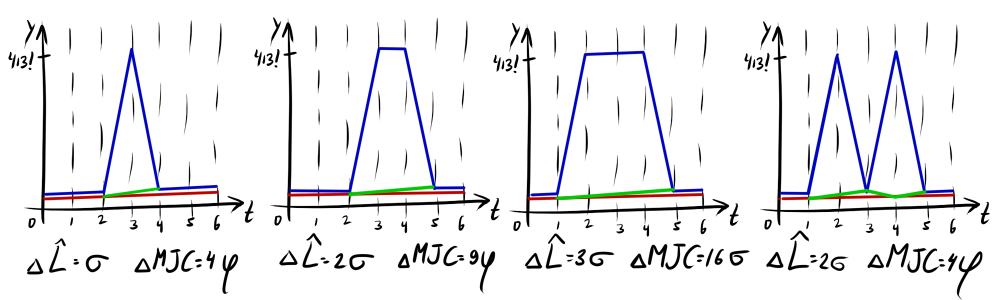
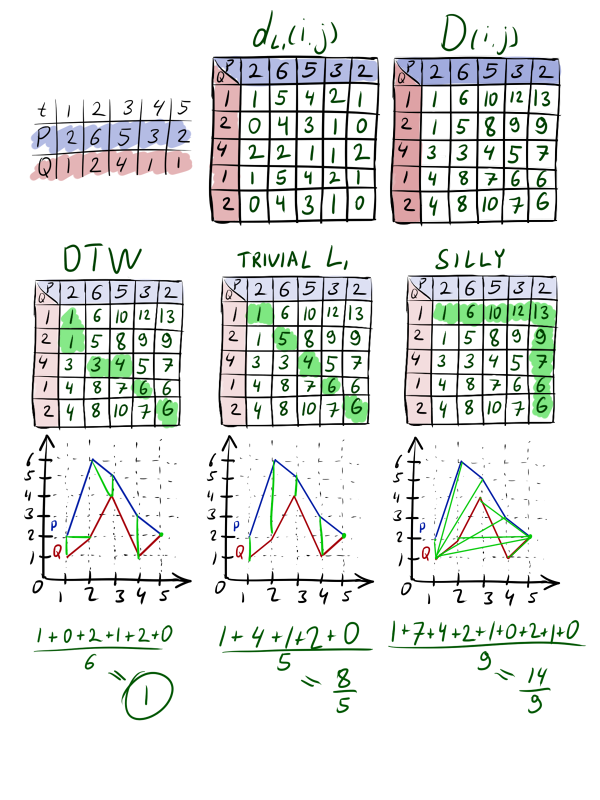


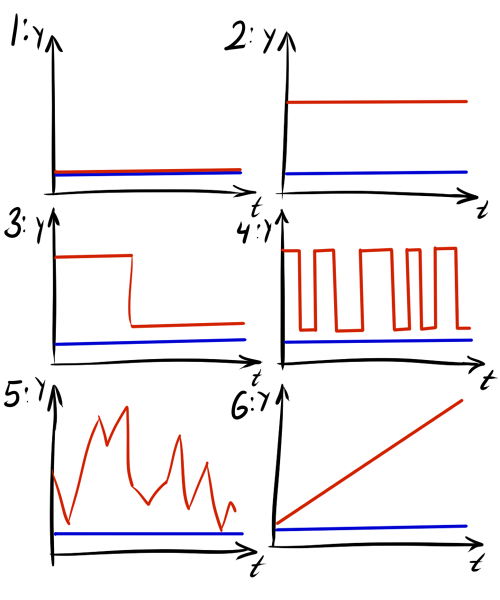
|
Метки: author Siarshai машинное обучение математика data mining cluster clustering graphs time series metrics review |
CASL. Авторизация для JavaScript приложения |
В наше время почти каждое приложение имеет понятие прав доступа и предоставляет различные функции для разных групп пользователей (например, admin, member, subscriber и т.д.). Эти группы обычно называются "роли".
По своему опыту скажу, что логика прав доступа большинства приложений построена вокруг ролей (проверка звучит так: если пользователь имеет эту роль, то он может что-то сделать) и в конечном итоге имеем массивную систему, с множеством сложных проверок, которую трудно поддерживать. Эту проблему можно решить при помощи CASL.
CASL — это библиотека для авторизации в JavaScript, которая заставляет задумываться о том, что пользователь может делать в системе, а не какую роль он имеет (проверка звучит так: если пользователь имеет эту способность, то он может сделай это). Например, в приложении для блогинга пользователь может создавать, редактировать, удалять, просматривать статьи и комментарии. Давайте разделим эти способности между двумя группами пользователей: анонимными пользователями (теми, кто не идентифицировался в системе) и писателями (теми, кто идентифицировался в системе).
Анонимные пользователи могут только читать статьи и комментарии. Писатели могут делать то же самое плюс управлять своими статьями и комментариями (в этом случае "управлять" означает создавать, читать, обновлять и удалять). При помощи CASL это можно записать вот так:
import { AbilityBuilder } from 'casl'
const user = whateverLogicToGetUser()
const ability = AbilityBuidler.define(can => {
can('read', ['Post', 'Comment'])
if (user.isLoggedIn) {
can('create', 'Post')
can('manage', ['Post', 'Comment'], { authorId: user.id })
}
})Таким образом, можно определить, что пользователь может делать не только на основе ролей, но и на базе любых других критериев. Например, мы можем разрешить пользователям модерировать другие комментарии или сообщения основываясь на их репутации, разрешать просмотр содержимого только тем людям, которые подтвердили, что им 18 лет и т.д. При помощи CASL, все это можно описать в одном месте!
Кроме того, для определения условий можно использовать некоторые операторы из языка запросов для MongoDB. Например, можно давать удалять статьи при условии, что у них нет комментариев:
can('delete', 'Post', { 'comments.0': { $exists: false } })Существует 3 метода у экземпляра Ability, которые позволяют проверять права доступа:
import { ForbiddenError } from 'casl'
ability.can('update', 'Post')
ability.cannot('update', 'Post')
try {
ability.throwUnlessCan('update', 'Post')
} catch (error) {
console.log(error instanceof Error) // true
console.log(error instanceof ForbiddenError) // true
}Первый метод вернет false, второй true, а третий выбросит ForbiddenError для анонимного пользователя, так как они не имеют права обновлять статьи. В качестве второго аргумента, эти методы могут принимать экземпляр класса:
const post = new Post({ title: 'What is CASL?' })
ability.can('read', post)В этом случае can ('read', post) возвращает true, потому что в способностях мы определили, что пользователь может читать все статьи. Тип объекта вычисляется на основе constructor.name. Его можно переопределить создав статическое свойство modelName на классе Post, это может понадобится если для продакшн сборки используется минификация имен функций. Также можно написать свою функцию по определению типа объекта и передать ее как опцию в конструктор Ability:
import { Ability } from 'casl'
function subjectName(subject) {
// custom logic to detect subject name, should return string or undefined
}
const ability = new Ability([], { subjectName })Давайте теперь проверим случай, когда пользователь пытается обновить статью другого пользователя (я буду ссылаться на идентификатор другого автора как anotherId и к идентификатору текущего пользователя как myId):
const post = new Post({ title: 'What is CASL?', authorId: 'anotherId' })
ability.can('update', post)В этом случае can('update', post) возвращает false, поскольку мы определили, что пользователь может обновлять только свои собственные статьи. Конечно же, если проверить то же самое на собственной статье то получим true. Подробнее о проверках прав доступа можно посмотреть в разделе Check Abilities в официальной документации.
CASL предоставляет функции, которые позволяют преобразовывать описанные права доступа в запросы к базе данных. Таким образом можно достаточно легко получить все записи из базы, к которым пользователь имеет доступ. На данный момент библиотека поддерживает только MongoDB и предоставляет средства для написания интеграции с другими языками запросов.
Для конвертации прав доступа в Mongo запрос существует toMongoQuery функция:
import { toMongoQuery } from 'casl'
const query = toMongoQuery(ability.rulesFor('read', 'Post'))В этом случае query будет пустым объектом, потому что пользователь может читать все статьи. Давайте проверим, что будет на выходе для операции обновления:
// { $or: [{ authorId: 'myId' }] }
const query = toMongoQuery(ability.rulesFor('update', 'Post'))Теперь query содержит запрос, который должен возвращать только те записи, которые были созданы мной. Все обычные правила проходят через цепочку логического OR, поэтому вы и видите $or оператор в результате запроса.
Также CASL предоставляет плагин под mongoose, который добавляет accessibleBy метод к моделям. Этот метод под капотом вызывает функцию toMongoQuery и передает результат в метод find mongoose-a.
const { mongoosePlugin, AbilityBuilder } = require('casl')
const mongoose = require('mongoose')
mongoose.plugin(mongoosePlugin)
const Post = mongoose.model('Post', mongoose.Schema({
title: String,
author: String,
content: String,
createdAt: Date
}))
// by default it asks for `read` rules and returns mongoose Query, so you can chain it
Post.accessibleBy(ability).where({ createdAt: { $gt: Date.now() - 24 * 3600 } })
// also you can call it on existing query to enforce visibility.
// In this case it returns empty array because rules does not allow to read Posts of `someoneelse` author
Post.find({ author: 'someoneelse' }).accessibleBy(ability, 'update').exec()По умолчанию accessibleBy создаст запрос на базе read прав доступа. Чтобы построить запрос для другого действия, просто передайте его вторым аргументом. Более детально можно посмотреть в разделе Database Integration.
CASL написан на чистом ES6, поэтому его можно использовать для авторизации как на API так и на UI стороне. Дополнительным плюсом является то, что UI может запросить все права доступа с API, и использовать их, чтобы показать или скрыть кнопки или целые секции на странице.
|
Метки: author serjoga node.js javascript authorization isomorphic casl mongoose.js |
[Перевод] Почему хорошие люди покидают крупные IT-компании? |

Если ты хочешь построить корабль, не надо созывать людей,
планировать, делить работу, доставать инструменты.
Надо заразить людей стремлением к бесконечному морю.
Антуан де Сент-Экзюпери
|
|
СХД Infortrend — альтернатива А-брендам. Обзор и тестирование |
 Системы хранения данных все чаще используются в IT-инфраструктуре сегмента малого и среднего бизнеса. Рабочие места мигрируют в виртуальную среду, а для хранения данных уже не достаточно обычной «файловой помойки» в виде старого железа набитого дисками. Поэтому для многих небольших компаний рано или поздно встаёт вопрос выбора Enterprise СХД начального уровня. Задачи перед системой хранения становятся типовые: обеспечить необходимую производительность, отказоустойчивость и совместимость с существующей IT-инфраструктурой. Но, к сожалению, решающим фактором выбора является обоснованность стоимости решения.
Системы хранения данных все чаще используются в IT-инфраструктуре сегмента малого и среднего бизнеса. Рабочие места мигрируют в виртуальную среду, а для хранения данных уже не достаточно обычной «файловой помойки» в виде старого железа набитого дисками. Поэтому для многих небольших компаний рано или поздно встаёт вопрос выбора Enterprise СХД начального уровня. Задачи перед системой хранения становятся типовые: обеспечить необходимую производительность, отказоустойчивость и совместимость с существующей IT-инфраструктурой. Но, к сожалению, решающим фактором выбора является обоснованность стоимости решения.







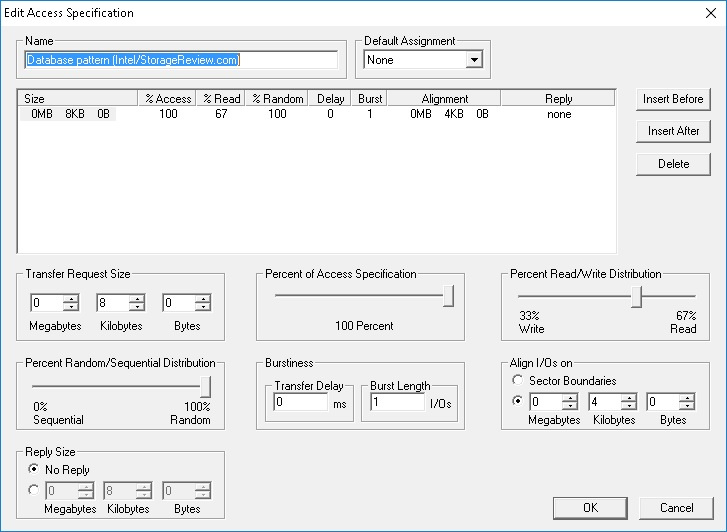
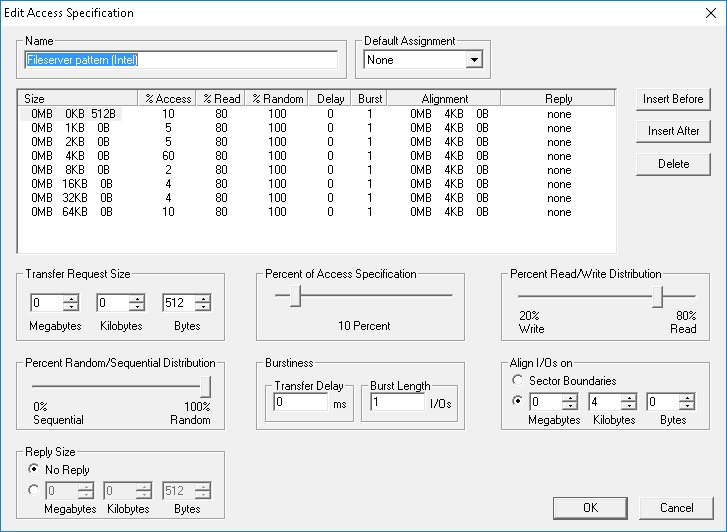
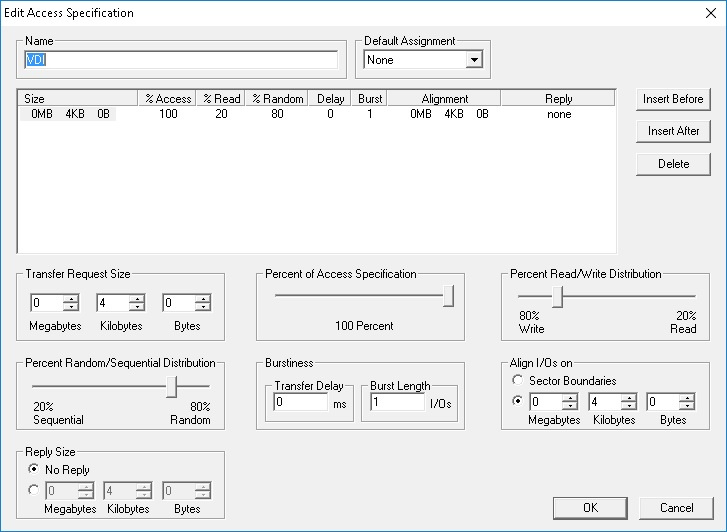
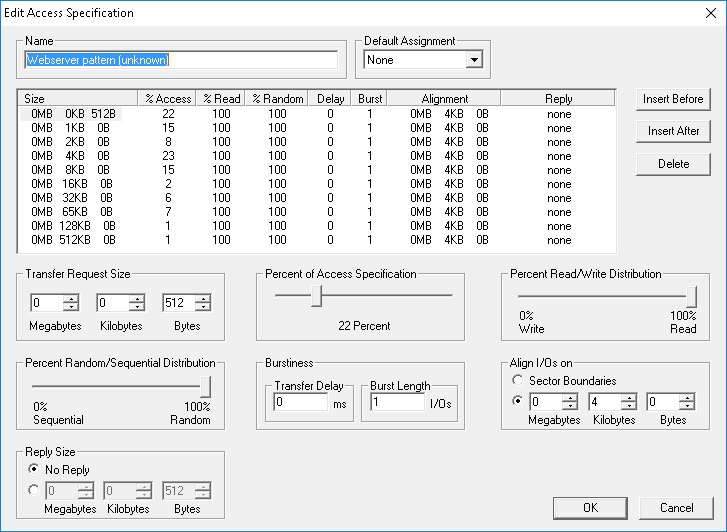
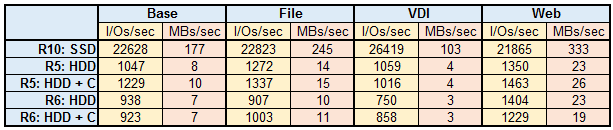
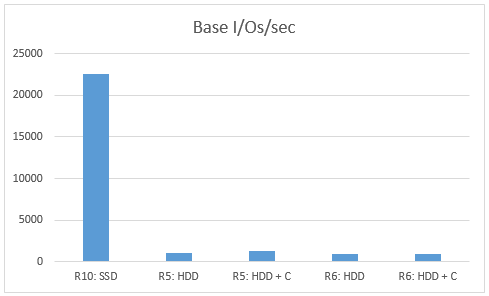


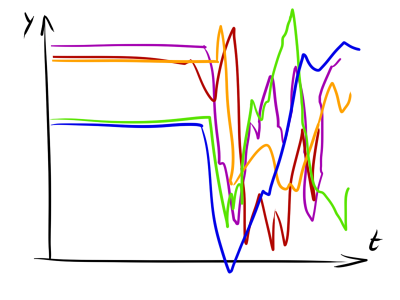
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
|
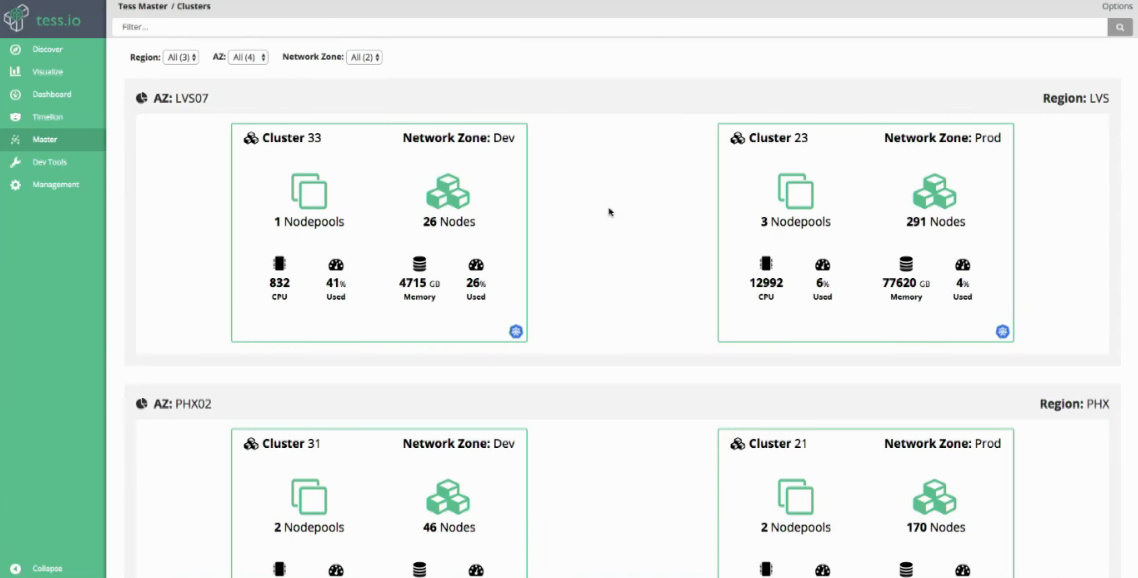
Истории успеха Kubernetes в production. Часть 1: 4200 подов и TessMaster у eBay |


«Мы очень целеустремлённо занимались адаптацией Kubernetes. Команды разработки в eBay любят контейнеры Docker для dev- и test-окружений, а Kubernetes поддерживает работу с Docker и берёт на себя управление им. В дополнение к окружениям dev и test мы начали запускать production-приложения в контейнерах. Каждое приложение представлено набором из контейнеров, реализующих различные компоненты и зависимости. [..] В этом году мы запустили в Kubernetes четыре приложения. Видим огромный потенциал в том, как приложения работают и какая гибкость появляется у разработчиков».



|
|
ICO: основные риски |

Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Menaskop финансы в it исследования и прогнозы в it ico первичное размещение токенов blockchain закон о крипто it- юрист |
[Перевод] Резервное копирование виртуальной машины и скрипты заморозки/оттаивания InterSystems Cach'e |
В этой статье я рассмотрю стратегии резервного копирования Cach'e с использованием систем внешнего резервного копирования и приведу примеры интеграции с решениями на основе снимков состояния виртуальной машины (VM snapshot, снапшот). Большинство решений, с которыми я сталкиваюсь сегодня, развернуты на базе Linux и VMware, поэтому я приведу примеры решений именно с использованием снапшотов VMware.
Список моих статей из серии 'Платформы данных InterSystems и производительность' находится здесь (англ.).
Для лучшего понимания данной статьи вам следует также ознакомиться с руководством по резервному копированию и восстановлению в онлайн-документации Cach'e.
Встроенное горячее резервное копирование (Cach'e online backup) поставляется вместе с Cach'e «из коробки» и предназначено для резервного копирования баз данных Cach'e без остановки системы. Однако существуют и более эффективные решения для резервного копирования, о которых стоит знать в те моменты, когда вы планируете масштабирование крупной системы. Внешнее резервное копирование (External Backup) с использованием технологий создания снимков — рекомендуемое мною решение для резервного копирования систем, в том числе, использующих базы данных Cach'e.
В онлайн документации InterSystems, посвященной внешнему резервному копированию, можно найти все интересующие детали. Отметим лишь ключевой момент:
«Для обеспечения целостности снимка файловой системы Cach'e предоставляет возможности для заморозки (freeze) записи в базы данных в момент создания снимка. Заморозке подвергаются только попытки физической записи в файлы базы данных, что позволяет пользовательским процессам продолжать бесперебойно выполнять обновления базы данных в памяти».
Важно также отметить, что часть процесса создания снимка в виртуализированных системах вызывает небольшую паузу в работе виртуальной машины, которую принято называть замиранием (stun). Обычно замирание длится меньше секунды, поэтому его не замечают пользователи и оно не оказывает воздействия на работу системы, однако в некоторых случаях замирание может длиться и дольше. Если замирание длится дольше, чем таймаут QoS (Quality of service, показатель качества обслуживания) зеркалирования базы данных Cach'e, то резервный узел зеркала решит, что произошел сбой в основной системе, и произведет переключение зеркала. Позже в этой статье я расскажу как можно замерить время замирания на тот случай, если вам нужно будет внести изменения в настройку таймаута QoS для зеркалирования.
Если у вас нет возможности использовать другие средства, остается этот старый добрый способ, который входит в комплект поставки с платформами InterSystems. Учтите, что Cach'e online backup создает резервные копии только для файлов баз данных Cach'e, сохраняя все непустые блоки в базах данных, записывая их последовательно в файл. Cach'e Online Backup поддерживает накопительное (cumulative) и инкрементное (incremental) резервное копирование.
В контексте VMware, Cach'e Online Backup выполняется на гостевой машине. Подобно другим аналогичным решениям, операции, выполняемые Cach'e Online Backup, одинаковы независимо от того, виртуализировано ли приложение или выполняется непосредственно на физическом сервере. Соответственно, копии, полученные Cach'e Online Backup должны быть перемещены на резервный носитель вместе со всеми другими файлами, которыми пользуется ваше приложение. При резервном копировании системы необходимо помнить о каталоге приложения, основном и альтернативном каталогах журнала БД, и любых других каталогах, содержащих файлы, используемые приложением.
Cach'e Online Backup следует рассматривать либо как подход начального уровня для небольших проектов, желающих реализовать недорогое решение для «горячего» резервного копирования баз данных, либо для создания разовых резервных копий. Например, создание подобных копий очень полезно при первоначальной настройке зеркалирования. Однако, поскольку базы данных увеличиваются в размерах и поскольку базы данных Cach'e обычно являются лишь частью клиентского набора данных, внешние резервные копии в сочетании с технологией создания моментальных снимков при использовании сторонних утилит рекомендуются как наилучшее решение с такими преимуществами, как возможность включать в резервную копию файлы, отличных от файлов базы данных, уменьшенное время восстановления, возможность контроля данных в масштабах всей организации и доступность улучшенных инструментов для каталогизации и управления.
Рассмотрим его на примере VMware. Использование VMware для виртуализации добавляет новые функции и возможности для защиты виртуальных машин в целом. Виртуализация решения приводит систему (включая операционную систему) к эффективной инкапсуляции вашего приложения со всеми данными внутри одного файла vmdk (и нескольких других файлов). При необходимости этими файлами можно очень легко манипулировать, и они могут использоваться для быстрого восстановления целой системы. Это сильно отличается от восстановления работоспособности вашего приложения на голом железе, где вы должны восстановить и настроить каждый компонент по отдельности — операционную систему, драйверы, сторонние приложения, СУБД и файлы баз данных и т.д.
VMware vSphere Data Protection (VDP) и другие сторонние решения для резервного копирования виртуальных машин, такие как Veeam или Commvault, используют функции снимков состояния (snapshot) виртуальных машин VMware для создания резервных копий. Ниже приведено краткое объяснение механизма работы снимков VMware. Для получения более подробной информации обратитесь к документации.
Важно помнить, что снимки делаются со всей виртуальной машины и что гостевая операционная система и любые приложения или СУБД не знают о том, что сейчас с них делают снимок. Запомните также следующее:
Сами по себе снимки VMware не являются резервными копиями!
Снимки позволяют использовать ПО для резервного копирования и сделать резервные копии, но они не являются резервными копиями сами по себе.
VDP и другие сторонние решения используют процесс создания снимков состояния VMware в сочетании с каким-либо приложением для управления созданием и, что очень важно, удалением снимков. Вкратце последовательность событий для создания внешней резервной копии с помощью снимков VMware выглядит следующим образом:
Решения для резервного копирования также содержат специальные возможности, как например отслеживание измененных блоков (Changed Block Tracking, CBT), чтобы выполнять инкрементное или накопительное резервное копирование максимально быстро и эффективно (что особо важно для экономии места). Подобные решения обычно также добавляют другие полезные и важные функции, такие как сжатие данных, организация работы по расписанию, восстановление виртуальных машин с другим IP-адресом для проверки целостности, восстановление как всей виртуальной машины, так и отдельных файлов с нее, управление каталогом резервных копий и т.д.
Снимки состояния VMware, которые должным образом не управляются или оставляются висеть длительное время, могут сильно уменьшить свободное место в хранилище (по мере накопления изменений дельта-файлы становятся всё больше и больше), а также замедлить работу виртуальной машины.
Следует очень хорошо подумать, прежде чем делать снимки состояния вручную на основном сервере баз данных. Зачем вы это делаете? Что произойдет, если вы вернетесь в прошлое к тому моменту, когда создавали снимок? Что происходит со всеми транзакциями между созданием снимка и откатом изменений?
Если ваше программное обеспечение резервного копирования создает и удаляет снимки состояния — это абсолютно нормально. Снимок и должен создаваться только на непродолжительное время, а ключевой частью вашей стратегии резервного копирования будет выбор времени копирования когда система минимально загружена, что еще больше снизит влияние на пользователей и общую производительность.
Перед выполнением снимка база данных должна быть стабилизирована (quiesced): все записи в файлы должны быть завершены и файлы баз данных должны быть в корректном состоянии. Cach'e предоставляет методы и API для завершения, а затем замораживания (freeze) записи в базы данных на короткий период создания снимка. Заморозке во время создания снимка подвергаются только попытки физической записи в файлы базы данных, что позволяет пользовательским процессам продолжать выполнять обновления в памяти бесперебойно. После того как снимок был сделан, возможность записи в базу данных восстанавливается, база данных «оттаивает» (thaw), и резервная копия продолжает копироваться на резервный носитель. Время между замораживанием и оттаиванием должно быть небольшим (не более нескольких секунд).
В дополнение к приостановке записи, заморозка Cach'e также приводит к смене файлов журнала и помещению маркера создания резервной копии в журнал. Запись в файл журнала при этом продолжается нормально, пока запись в физическую базу данных заморожена. Если система рухнет в то время, пока записи в физической базе данных будут заморожены, данные будут восстановлены из журнала как обычно при запуске.
Следующая диаграмма показывает замораживание и оттаивание с выполнением снимков для создания резервной копии с корректным файлом базы данных.
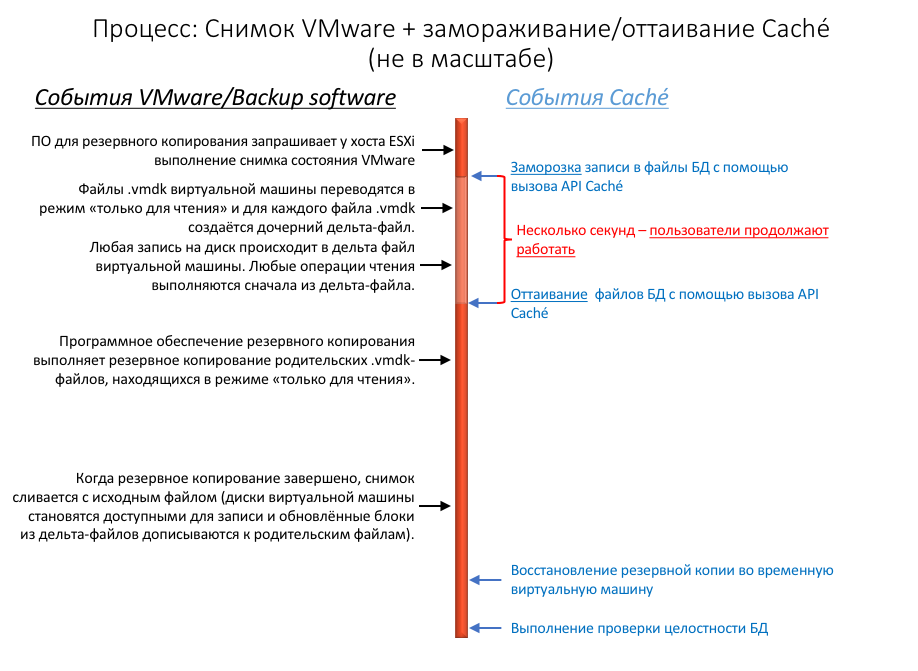
Обратите внимание на короткое время между замораживанием и оттаиванием — это время только на создание снимка, а не время, которое требуется на копирование всего родительского объекта в резервную копию.
vSphere позволяет автоматически вызывать скрипты до и после создания снимка: это и есть те самые моменты, которые называются заморозкой и оттаиванием Cach'e. Примечание: для правильной работы этого функционала ESXi хост запрашивает у гостевой операционной системы заморозку дисков через VMware Tools.
В гостевой операционной системе должны быть установлены Инструменты VMware.
Скрипты должны соблюдать строгие требования к имени и местоположению. Необходимо также назначить корректные права на файлы. Имена скриптов для VMware на Linux:
# /usr/sbin/pre-freeze-script
# /usr/sbin/post-thaw-scriptНиже приведены примеры скриптов замораживания и оттаивания, которые наша команда использует для резервного копирования с помощью Veeam в наших внутренних тестовых лабораториях. Эти скрипты также должны подойти для работы и с использованием других продуктов. Примеры были протестированы и использовались на vSphere 6 и Red Hat 7.
Хотя эти сценарии могут использоваться в качестве примеров и являются иллюстрацией к описываемому методу, вы должны убедиться в их корректности для вашей собственной среды!
Пример скрипта заморозки:
#!/bin/sh
#
# Script called by VMWare immediately prior to snapshot for backup.
# Tested on Red Hat 7.2
#
LOGDIR=/var/log
SNAPLOG=$LOGDIR/snapshot.log
echo >> $SNAPLOG
echo "`date`: Pre freeze script started" >> $SNAPLOG
exit_code=0
# Только для запущенных экземпляров
for INST in `ccontrol qall 2>/dev/null | tail -n +3 | grep '^up' | cut -c5- | awk '{print $1}'`; do
echo "`date`: Attempting to freeze $INST" >> $SNAPLOG
# Detailed instances specific log
LOGFILE=$LOGDIR/$INST-pre_post.log
# Freeze
csession $INST -U '%SYS' "##Class(Backup.General).ExternalFreeze(\"$LOGFILE\",,,,,,1800)" >> $SNAPLOG $
status=$?
case $status in
5) echo "`date`: $INST IS FROZEN" >> $SNAPLOG
;;
3) echo "`date`: $INST FREEZE FAILED" >> $SNAPLOG
logger -p user.err "freeze of $INST failed"
exit_code=1
;;
*) echo "`date`: ERROR: Unknown status code: $status" >> $SNAPLOG
logger -p user.err "ERROR when freezing $INST"
exit_code=1
;;
esac
echo "`date`: Completed freeze of $INST" >> $SNAPLOG
done
echo "`date`: Pre freeze script finished" >> $SNAPLOG
exit $exit_code
Пример скрипта оттаивания:
#!/bin/sh
#
# Script called by VMWare immediately after backup snapshot has been created
# Tested on Red Hat 7.2
#
LOGDIR=/var/log
SNAPLOG=$LOGDIR/snapshot.log
echo >> $SNAPLOG
echo "`date`: Post thaw script started" >> $SNAPLOG
exit_code=0
if [ -d "$LOGDIR" ]; then
# Только для запущенных экземпляров
for INST in `ccontrol qall 2>/dev/null | tail -n +3 | grep '^up' | cut -c5- | awk '{print $1}'`; do
echo "`date`: Attempting to thaw $INST" >> $SNAPLOG
# Detailed instances specific log
LOGFILE=$LOGDIR/$INST-pre_post.log
# Оттаивание
csession $INST -U%SYS "##Class(Backup.General).ExternalThaw(\"$LOGFILE\")" >> $SNAPLOG 2>&1
status=$?
case $status in
5) echo "`date`: $INST IS THAWED" >> $SNAPLOG
csession $INST -U%SYS "##Class(Backup.General).ExternalSetHistory(\"$LOGFILE\")" >> $SNAPLOG$
;;
3) echo "`date`: $INST THAW FAILED" >> $SNAPLOG
logger -p user.err "thaw of $INST failed"
exit_code=1
;;
*) echo "`date`: ERROR: Unknown status code: $status" >> $SNAPLOG
logger -p user.err "ERROR when thawing $INST"
exit_code=1
;;
esac
echo "`date`: Completed thaw of $INST" >> $SNAPLOG
done
fi
echo "`date`: Post thaw script finished" >> $SNAPLOG
exit $exit_code
Не забудьте установить права на файлы:
# sudo chown root.root /usr/sbin/pre-freeze-script /usr/sbin/post-thaw-script
# sudo chmod 0700 /usr/sbin/pre-freeze-script /usr/sbin/post-thaw-scriptЧтобы проверить работу приведенных сценариев, вы можете вручную запустить выполнение снимка на виртуальной машине и проверить что выведет сценарий. На следующем скриншоте показан диалог «Take VM Snapshot» и его опции.

Сбросьте флажок "Snapshot the virtual machine's memory" (Сохранить оперативную память виртуальной машины)
Отметьте флажок "Quiesce guest file system (Needs VMware Tools installed)" (Стабилизировать гостевую файловую систему). Это приведет к приостановке запущенных процессов в гостевой операционной системе и сбросу буферов, чтобы содержимое файловой системы находилось в известном непротиворечивом состоянии при выполнении снимка.
Важно! После теста не забудьте удалить сделанный снимок!
Если флажок стабилизации (quiescing) отмечен и виртуальная машина работает в тот момент, когда делается снимок, для стабилизации файловой системы виртуальной машины будет использоваться VMware Tools. Стабилизация файловой системы представляет собой процесс приведения данных на диске в состояние "готов к резервному копированию". Этот процесс может включать в себя такие операции, как очистка заполненных буферов между кэшем операционной системы в памяти и диском.
Следующий вывод показывает содержимое файла журнала $SNAPLOG, указанного в приведенных выше примерах сценариев замораживания/оттаивания после запуска процедуры резервного копирования, которая в том числе делает выполнение снимка.
Wed Jan 4 16:30:35 EST 2017: Pre freeze script started
Wed Jan 4 16:30:35 EST 2017: Attempting to freeze H20152
Wed Jan 4 16:30:36 EST 2017: H20152 IS FROZEN
Wed Jan 4 16:30:36 EST 2017: Completed freeze of H20152
Wed Jan 4 16:30:36 EST 2017: Pre freeze script finished
Wed Jan 4 16:30:41 EST 2017: Post thaw script started
Wed Jan 4 16:30:41 EST 2017: Attempting to thaw H20152
Wed Jan 4 16:30:42 EST 2017: H20152 IS THAWED
Wed Jan 4 16:30:42 EST 2017: Completed thaw of H20152
Wed Jan 4 16:30:42 EST 2017: Post thaw script finishedНа этом примере видно, что время между замораживанием и оттаиванием составляет 6 секунд (16:30:36 — 16:30:42). В течение этого периода работа пользователей НЕ прерывается. Вам нужно будет собрать статистику с ваших собственных систем, но для информации отметим, что данный пример был запущен во время тестирования производительности приложения на системе без «узких мест» в системе ввода/вывода, в среднем выполнявшей более 2 миллионов операций чтения БД в секунду (Glorefs/sec), 170 000 операций записи БД в секунду (Gloupds/sec) и в среднем 1100 физических операций чтения диска в секунду и 3000 записей за цикл демона записи БД (write daemon cycle).
Помните, что оперативная память не является частью снимка, поэтому при восстановлении резервной копии виртуальная машина будет перезагружена и выполнит процедуры восстановления. Файлы базы данных будут согласованными. Вы не ставите целью «продолжить работу» из резервной копии и просто хотите, чтобы у вас были корректные резервные копии файлов на конкретный момент времени. Вы можете затем выполнить прогон журналов БД и выполнить другие процедуры восстановления, необходимые для восстановления целостности приложения и согласованности транзакций после восстановления файлов.
Для дополнительной защиты данных, смена журнала может также выполняться сама по себе, сопровождаемая резервным копированием или репликацией журнала, например, ежечасно.
Ниже приведено содержимое $LOGFILE из примера заморозки/оттаивания, приведенного выше, в котором показаны подробности журнала для снимка.
01/04/2017 16:30:35: Backup.General.ExternalFreeze: Suspending system
Journal file switched to:
/trak/jnl/jrnpri/h20152/H20152_20170104.011
01/04/2017 16:30:35: Backup.General.ExternalFreeze: Start a journal restore for this backup with journal file: /trak/jnl/jrnpri/h20152/H20152_20170104.011
Journal marker set at
offset 197192 of /trak/jnl/jrnpri/h20152/H20152_20170104.011
01/04/2017 16:30:36: Backup.General.ExternalFreeze: System suspended
01/04/2017 16:30:41: Backup.General.ExternalThaw: Resuming system
01/04/2017 16:30:42: Backup.General.ExternalThaw: System resumedВо время создания снимка виртуальной машины, а также после завершения резервного копирования и удаления снимка виртуальную машину необходимо заморозить на короткий период времени. Это кратковременное замораживание часто называют замиранием (stun). Хорошая статья о замирании виртуальных машин есть здесь. Я изложу некоторые подробности ниже, применительно базам данных Cach'e.
Выдержка из статьи: «Чтобы создать снимок виртуальной машины, виртуальная машина «замирает», чтобы (i) сериализовать состояние устройства на диск и (ii) закрыть текущий работающий диск и создать точку начала снимка… При слиянии дельта-файлов виртуальная машина «замирает», чтобы закрыть диски для записи и перевести их в состояние, подходящее для слияния.»
Время замирания обычно составляет около 100 миллисекунд, однако, при очень высокой активности записи на диск, во время фазы слияния дельта-файлов замирание может длиться до нескольких секунд.
Если виртуальная машина является основным или резервным участником зеркалирования Cach'e, и время замирания больше, чем таймаут QoS для зеркалирования, зеркало может ошибочно сообщить о сбое основной виртуальной машины и инициировать перехват зеркала резервной системой.
Для получения дополнительной информации о параметре QoS при зеркалировании обратитесь к документации. Стратегии, сводящие к минимуму время замирания, включают выбор момента резервного копирования, когда активность базы данных является максимально низкой, а также наличие хорошо настроенной системы хранения.
Как отмечалось выше, при создании снимка есть несколько опций, которые можно указать. Одна из опций позволяет включать сохранение оперативной памяти в снимке. Помните, что сохранение оперативной памяти не требуется для резервного копирования базы данных Cach'e. Если установлен флаг сохранения памяти, дамп внутреннего состояния виртуальной машины будет входить в снимок. Выполнение снимка с памятью занимает гораздо больше времени. Снимки памяти используются для возврата к такому состоянию виртуальной машины, которое было на момент выполнения снимка. Этого НЕ требуется для резервного копирования файлов базы данных.
Когда выполняется снимок оперативной памяти, состояние всей виртуальной машины будет заморожено на неопределенное время.
Как уже отмечалось ранее, для резервных копий флажок «согласованность» (quiesce) должен быть отмечен, чтобы гарантировать целостное и успешное резервное копирование.
Начиная с ESXi 5.0 время замирания регистрируется в файле журнала каждой виртуальной машины (vmware.log) сообщениями, похожими на следующие:
2017-01-04T22:15:58.846Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 38123 usВремя замирания указывается в микросекундах, поэтому в примере выше 38123 us это 38123/1,000,000 секунд или 0.038 секунды.
Чтобы быть уверенным в том, что продолжительность замирания машины находится в допустимых пределах, или если есть подозрение, что длительное время замирания машины вызывает проблемы, вы можете скачать и просмотреть файлы vmware.log из папки этой виртуальной машины. После загрузки вы можете открыть и упорядочить журнал с помощью стандартных команд Linux, которые мы рассмотрим в следующей главе.
Существует несколько способов скачать журналы, в том числе путём создания пакета поддержки (support bundle) VMware через консоль управления vSphere или из командной строки хоста ESXi. Обратитесь к документации VMware за всеми подробностями, а ниже приведен простой способ создания и сбора минимального пакета журналов поддержки, который включает в себя файл vmware.log, позволяющий узнать продолжительность замирания.
Вам понадобится длинное имя каталога, где расположены файлы виртуальной машины. Зайдите по ssh на тот хост ESXi, где запущена виртуальная машина с базой данных и выполните команду vim-cmd vmsvc/getallvms для получения списка vmx файлов и связанных с ними уникальных длинных имён.
Пример длинного имени для базы данных виртуальной машины, упоминающейся в этой статье, будет выглядеть так:
26 vsan-tc2016-db1 [vsanDatastore] e2fe4e58-dbd1-5e79-e3e2-246e9613a6f0/vsan-tc2016-db1.vmx rhel7_64Guest vmx-11Далее выполните команду для сбора файлов журнала:
vm-support -a VirtualMachines:logsКоманда отобразит местоположение созданного пакета поддержки, например:
To see the files collected, check '/vmfs/volumes/datastore1 (3)/esx-esxvsan4.iscinternal.com-2016-12-30--07.19-9235879.tgz'Теперь вы можете забрать файлы с хоста для дальнейшей обработки и анализа по протоколу sftp.
В этом примере после распаковки пакета поддержки вы можете проследовать по путям, соответствующим длинным именам баз данных виртуальных машин. Например, в данном случае:
/vmfs/volumes//e2fe4e58-dbd1-5e79-e3e2-246e9613a6f0. Там вы увидите несколько пронумерованных лог-файлов. Самый последний файл номера не имеет, это vmware.log. Журнал может быть не более 100 КБ, но при этом будет содержать очень много информации. Поскольку мы просто ищем моменты начала и конца замирания, их достаточно легко найти с помощью утилиты grep, например:
$ grep Unstun vmware.log
2017-01-04T21:30:19.662Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 1091706 us
---
2017-01-04T22:15:58.846Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 38123 us
2017-01-04T22:15:59.573Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 298346 us
2017-01-04T22:16:03.672Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 301099 us
2017-01-04T22:16:06.471Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 341616 us
2017-01-04T22:16:24.813Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 264392 us
2017-01-04T22:16:30.921Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 221633 usВ примере мы видим две группы замираний. Первая состоит из момента создания снимков, а вторая — через 45 минут для каждого диска при завершении объединения снимка (например, после того, как программное обеспечение для резервного копирования завершило копирование основного vmx файла). В приведенном выше примере мы можем видеть, что большинство замираний не превосходят секунды, хотя начальное замирание составляет чуть более одной секунды.
Короткое замирание незаметно для конечного пользователя. Тем не менее, системные процессы, такие как, например, зеркалирование Cach'e, постоянно контролируют, является ли база «живой». Если время замирания превышает таймаут QoS для зеркалирования, то узел может быть признан неконтактным и «мертвым», и произойдет обработка аварийной ситуации.
Совет: для обзора всех журналов или поиска неисправностей удобно использовать команду grep чтобы найти все времена замираний и затем отформатировать их с помощью утилиты awk и отсортировать, как в следующем примере:
grep Unstun vmware* | awk '{ printf ("%'"'"'d", $8)} {print " ---" $0}' | sort -nrВы должны регулярно контролировать свою систему во время нормальной работы, чтобы знать и понимать величину времени замирания и то, как она может повлиять на средства обеспечения высокой доступности, например, зеркалирование. Как уже отмечалось ранее, стратегии, направленные на то, чтобы свести к минимуму время замирания, включают запуск резервных копий, когда активность базы данных и хранилища низкая и когда производительность хранилища максимальная. Для постоянного мониторинга журналы могут обрабатываться с помощью VMware Log insight или других инструментов.
Я ещё вернусь к операциям резервного копирования для платформ данных InterSystems в будущих статьях. А теперь если у вас есть комментарии или предложения, основанные на процессах, происходящих в ваших системах, поделитесь ими в комментариях.
Примечание переводчика: поскольку мы работаем с автором в одном офисе, я могу передать ему ваши вопросы и переслать сюда его ответы. Также обсуждение на английском есть в оригинале статьи на InterSystems Developer Community.
|
Метки: author logist резервное копирование виртуализация администрирование баз данных блог компании intersystems cach 'e системный администратор зеркалирование советы и трюки |