Идеальная домашняя сеть или «сам себе злобный перфекционист» |



|
Метки: author Shapelez сетевые технологии беспроводные технологии it- инфраструктура блог компании qrator labs системный администратор домашняя сеть перфекционизм паранойя |
20 правил самых коротких маркетинговых текстов |

|
Метки: author serkon повышение конверсии контент-маркетинг интернет-маркетинг блог компании infobip смс sms a2p маркетинг копирайтинг текст инфобип infobip |
Ужасный рекрутер, ужасный кандидат |



Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
|
Уменьшаем размер приложения: проверенные способы |


UIImage *templateImage = [[UIImage imageNamed:@«Back Chevron»] imageWithRenderingMode:UIImageRenderingModeAlwaysTemplate]; - где UIImageRenderingModeAlwaysTemplate и является шаблонным режимом изображения.
После чего уже в коде выставлять цвет оттенка:
[backButton setTintColor:[UIColor blueColor]]; NSArray *gif=@[@"frame1",@"frame2",@"frame3",@"frame4",@"frame5", @"frame6",@"frame7",@"frame8",@"frame9",@"frame10"];
NSMutableArray *images = [[NSMutableArray alloc] init];
for (int i = 0; i < gif.count; i++)
{
UIImage *image=[UIImage imageNamed:[gif objectAtIndex:i]];
[images addObject:image];
}
imageView.animationImages = images;
imageView.animationDuration = 0.3;
imageView.animationRepeatCount=1;
[imageView startAnimating]; + (UIImage * _Nullable)animatedImageWithAnimatedGIFData:(NSData * _Nonnull)theData;
+ (UIImage * _Nullable)animatedImageWithAnimatedGIFURL:(NSURL * _Nonnull)theURL;CAGradientLayer *gradient=[CAGradientLayer layer];
gradient.frame=animationLabel.bounds;
gradient.colors = @[(id)[UIColor colorWithWhite:1 alpha:1.0].CGColor,
(id)[UIColor clearColor].CGColor];
gradient.startPoint = CGPointMake(0.0, 0.5);
gradient.endPoint = CGPointMake(0.1, 0.5);
animationLabel.layer.mask=gradient;
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(0.99 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{
gradient.colors = @[(id)[UIColor colorWithWhite:1 alpha:1.0].CGColor,
(id)[UIColor colorWithWhite:1 alpha:1.0].CGColor];
});
CABasicAnimation *startPoint=[CABasicAnimation animationWithKeyPath:@"startPoint"];
startPoint.fromValue= [NSValue valueWithCGPoint:CGPointMake(0.0, 0.5)];
startPoint.toValue= [NSValue valueWithCGPoint:CGPointMake(1.0, 0.5)];
startPoint.duration = 0.9;
[startPoint setBeginTime:0.1];
startPoint.removedOnCompletion=NO;
CABasicAnimation *endPoint=[CABasicAnimation animationWithKeyPath:@"endPoint"];
endPoint.fromValue= [NSValue valueWithCGPoint:CGPointMake(0.1, 0.5)];
endPoint.toValue= [NSValue valueWithCGPoint:CGPointMake(1.0, 0.5)];
endPoint.duration = 1.0;
[endPoint setBeginTime:0.0];
endPoint.removedOnCompletion=NO;
CAAnimationGroup *group = [CAAnimationGroup animation];
[group setDuration:1.2];
[group setAnimations:[NSArray arrayWithObjects:startPoint, endPoint, nil]];
[ gradient addAnimation:group forKey:nil];+(void)convertAudio:(NSURL *)url toUrl:(NSURL *)convertedUrl{
AVAudioFile *audioFile = [[AVAudioFile alloc] initForReading:url error:nil];
AVAudioPCMBuffer *buffer = [[AVAudioPCMBuffer alloc] initWithPCMFormat:audioFile.processingFormat frameCapacity:(uint32_t)audioFile.length];
[audioFile readIntoBuffer:buffer error:nil];
NSDictionary *recordSettings = @{
AVFormatIDKey : @(kAudioFormatLinearPCM),
AVSampleRateKey : @(audioFile.processingFormat.sampleRate),
AVNumberOfChannelsKey : @(audioFile.processingFormat.channelCount),
AVEncoderBitDepthHintKey : @16,
AVEncoderAudioQualityKey : @(AVAudioQualityMedium),
AVLinearPCMIsBigEndianKey: @0,
AVLinearPCMIsFloatKey: @0,
};
AVAudioFile *writeAudioFile = [[AVAudioFile alloc] initForWriting:convertedUrl settings:recordSettings error:nil];
[writeAudioFile writeFromBuffer:buffer error:nil];
}
+ (BOOL)unzipFileAtPath:(NSString *)path
toDestination:(NSString *)destination
progressHandler:(void (^)(NSString *entry, unz_file_info zipInfo, long entryNumber, long total))progressHandler
completionHandler:(void (^)(NSString *path, BOOL succeeded, NSError *error))completionHandler;|
|
[Из песочницы] Как крупная курьерская компания персональные данные своих клиентов раздавала |






|
Метки: author iSergios информационная безопасность персональные данные авторизация без паролей хранение информации |
Про Agile, Scrum и командную работу. Как устроены процессы развития продуктов в Альфа-Лаборатории |


|
|
Red Architecture — красная кнопка помощи для сложных и запутанных систем — часть 2 (пример с миллиардом ячеек) |

class v {
// value got from this format string will look like OnCellUpdateForList_List1_Cell_D9
public const string KeyOnCellUpdate = “OnCellUpdateForList_%s_Cell_%s”;
}
class v {
// for instance, OnCellUpdateForList_List1_Cell_D9
public const string KeyOnCellUpdate = “OnCellUpdateForList_%s_Cell_%s”;
private var handlers = new HashMap >();
void h(string Key, HandlerMethod h) {
handlers[Key] += h;
}
void Add(string Key, data d) {
for_each(handler in handlers[Key]) {
handler(Key, d);
}
}
}
class TableCellView {
// List and Address are components of identifier for this cell in system (i.e. GUID consisting of two strings)
private const string List;
private const string Address;
handler void OnEvent(string key, object data) {
string thisCellUpdateKey = string.Format( /* format string */ v.OnCellUpdate, /* arguments for format string */ this.List, this.Address);
if(key == thisCellUpdateKey)
// update content of this cell
this.CellContent = data.Content;
}
// constructor
TableCellView(string list, string address) {
this.List = list;
this.Address = address;
}
// cell appears on user’s screen - register it for receiving events
void OnAppear() {
string thisCellUpdateKey = string.Format( /* format string */ v.OnCellUpdate, /* arguments for format string */ this.List, this.Address);
v.Add(thisCellUpdateKey, OnEvent);
}
// don't forget to "switch off" the cell from receiving events when cell goes out of user's screen
void OnDisappear() {
string thisCellUpdateKey = string.Format( /* format string */ v.OnCellUpdate, /* arguments for format string */ this.List, this.Address);
v.m(thisCellUpdateKey, OnEvent);
}
}
class SomeObjectWorkingWithSocket {
void socket.OnData(data) {
if(data.Action == SocketActions.UpdateCell) {
string cellKey = string.Format( /* format string */ v.OnCellUpdate, /* arguments for format string */ data.List, data.Address);
v.Add(cellKey, data);
// This call for objects which process updates for any of the cells, for instance, caching data objects
v.Add(v.OnCellUpdate, data);
}
}
}

class db {
handler void OnEvent(string key, object data) {
if(key == v.OnUpdateCell)
// cache updates in db
db.Cells.update("content = data.content WHERE list = data.List AND address = data.Address");
}
// constructor
db() {
v.h(v.OnUpdateCell, OnEvent);
}
// destructor
~db() {
v.m(v.OnUdateCell, OnEvent);
}
}
|
|
Что необходимо для качественной Web разработки? |

|
Метки: author Tully тестирование веб-сервисов разработка веб-сайтов python django блог компании отус otus.ru python3 web- разработка программирование образование |
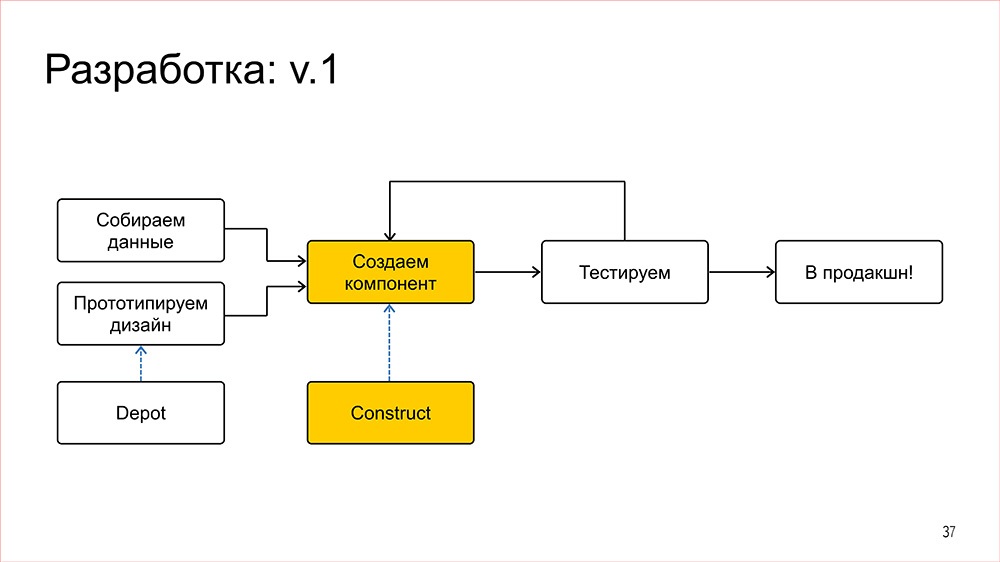
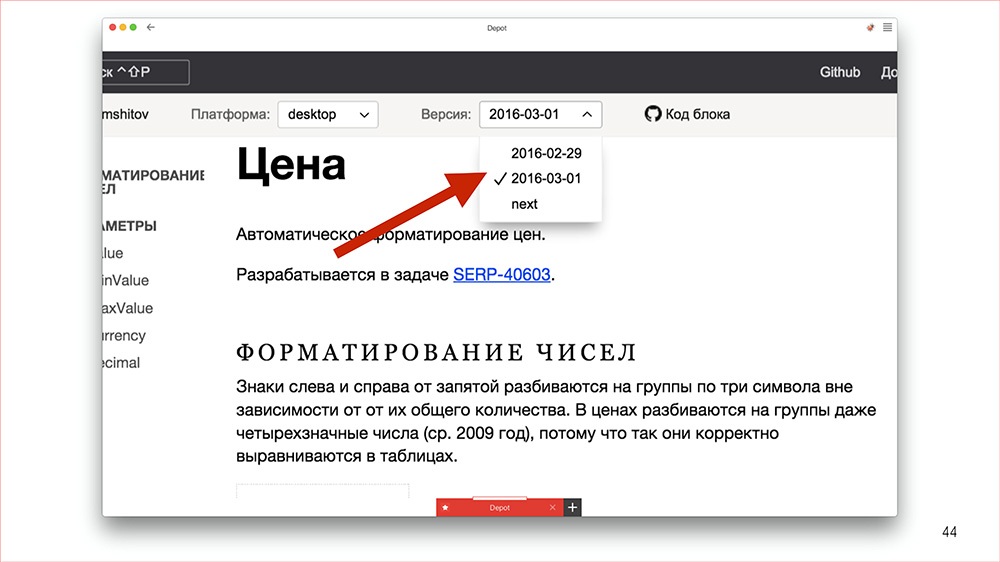
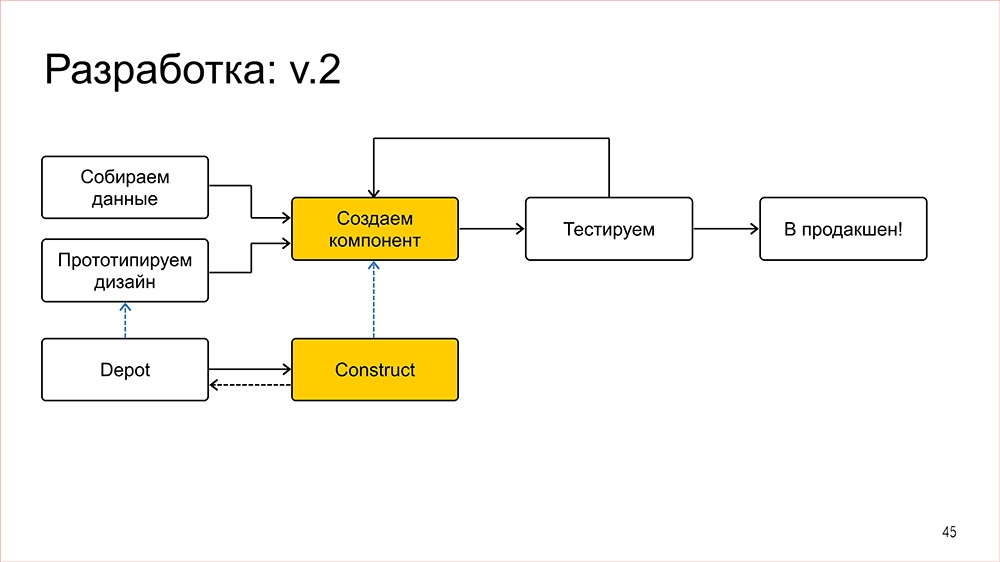
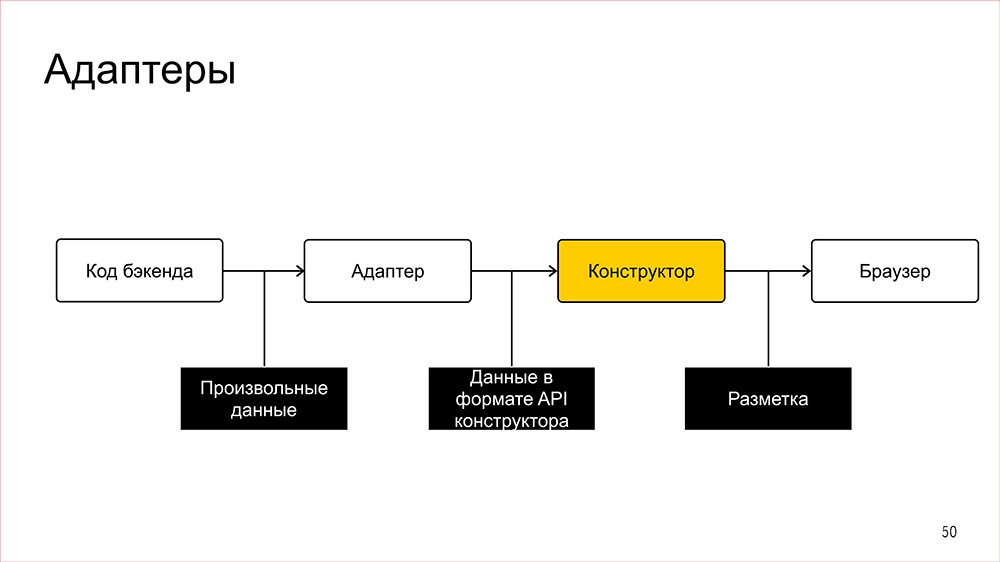
Конструктор |

Дисклеймер: Денис рассказывал об этом в 2016 году, но мы посчитали, что как демонстрация архитектурного подхода сейчас этот доклад актуален даже больше, чем тогда.


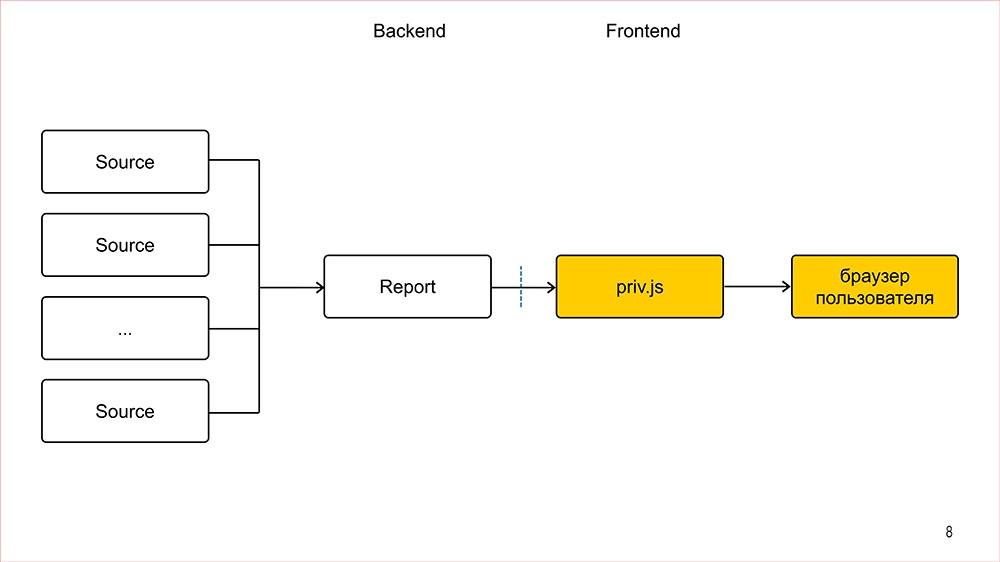





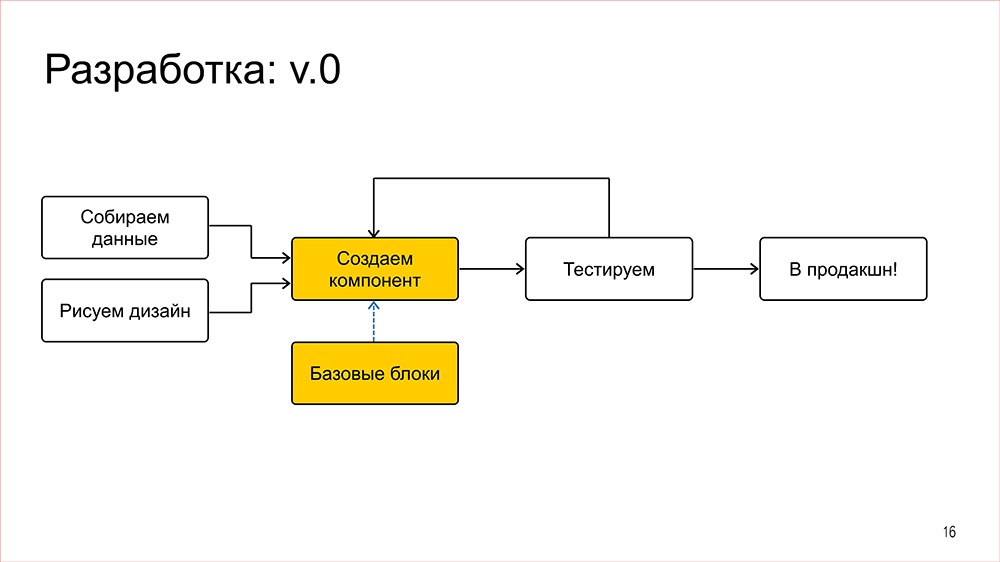
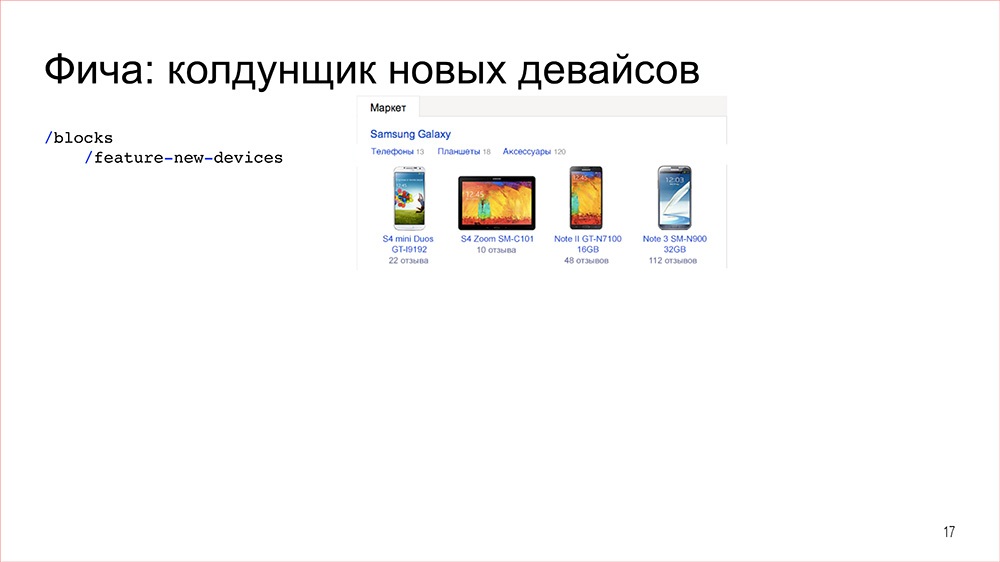

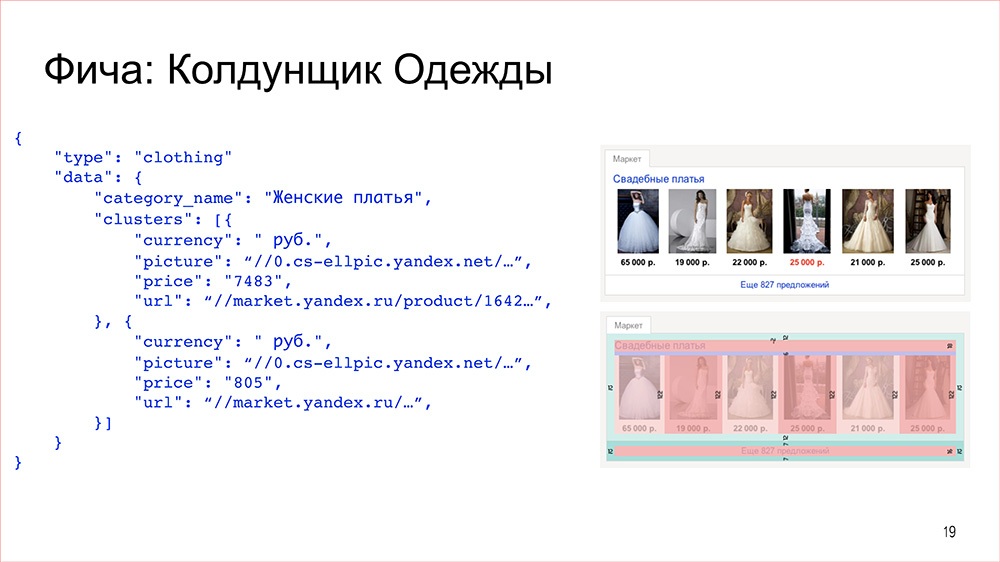
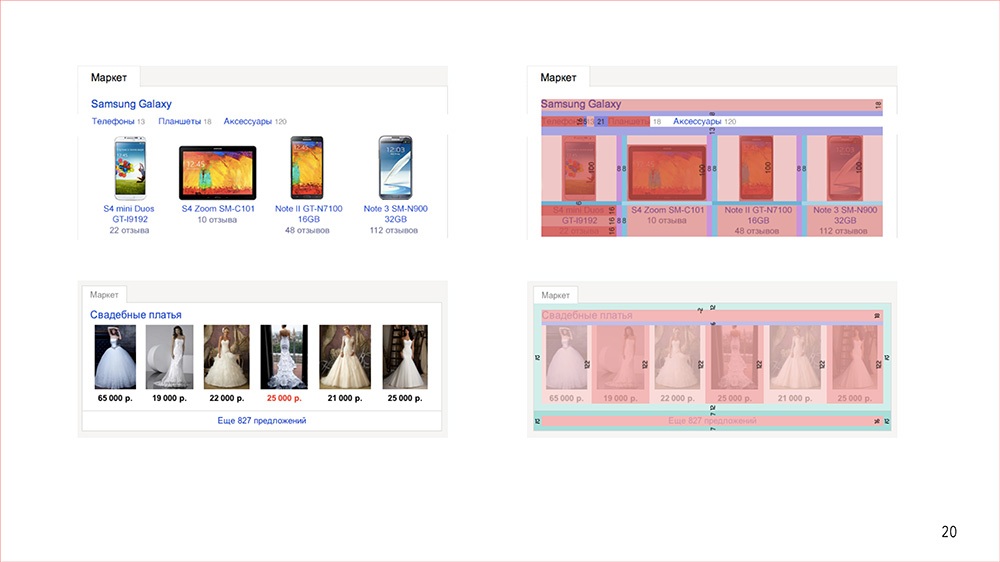


















Кстати, мы выложили в открытый доступ видеозаписи последних двух лет конференции фронтенд-разработчиков Frontend Conf. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.





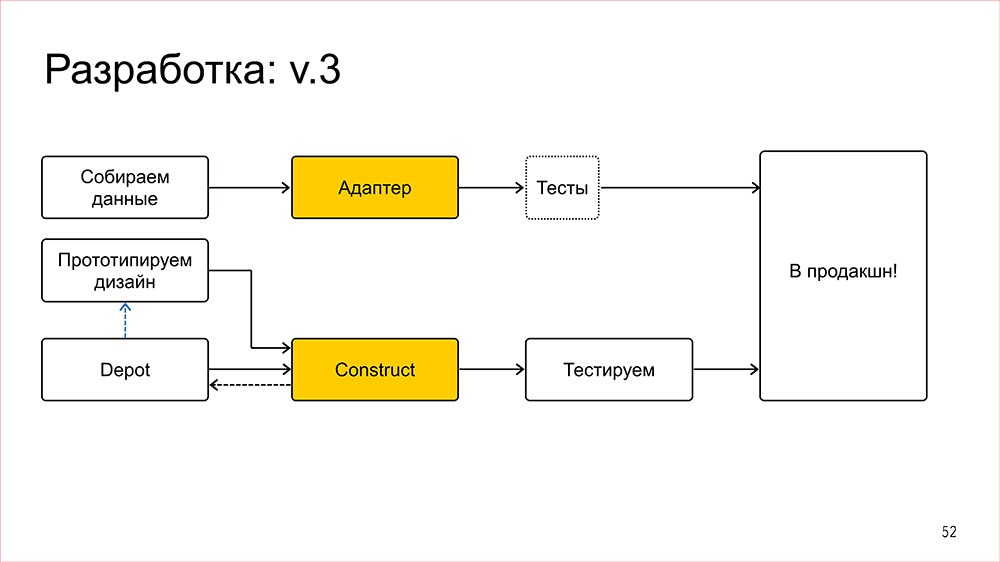






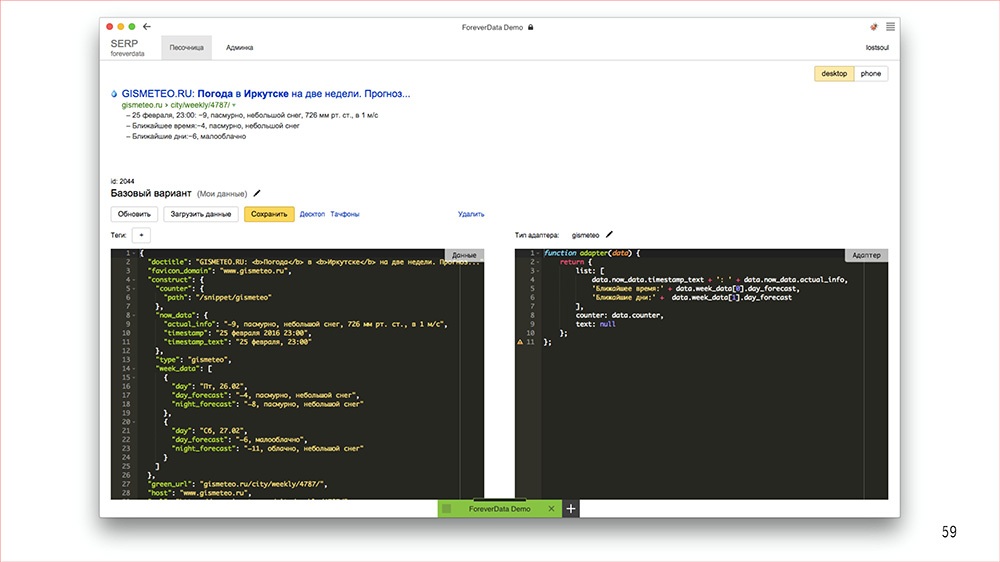

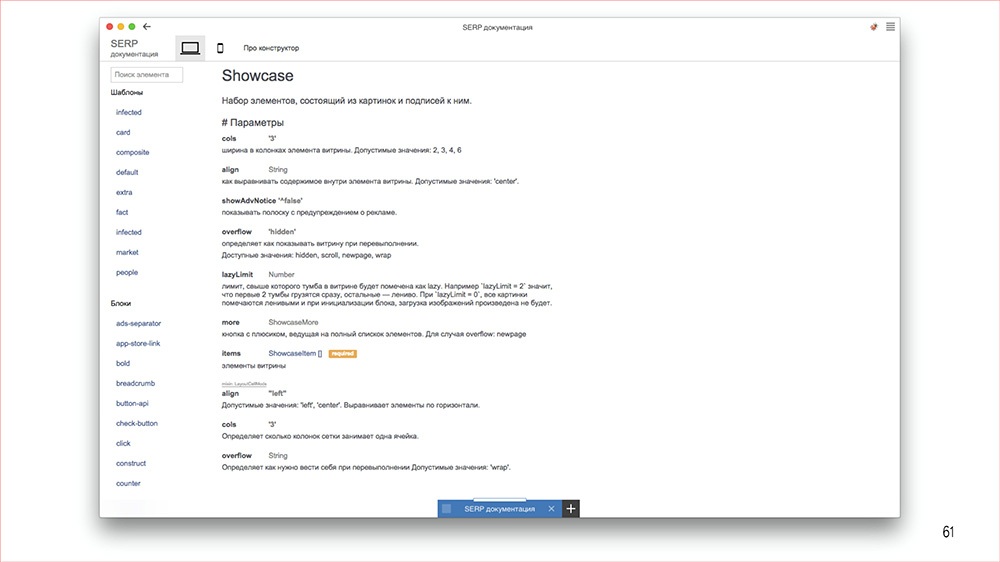


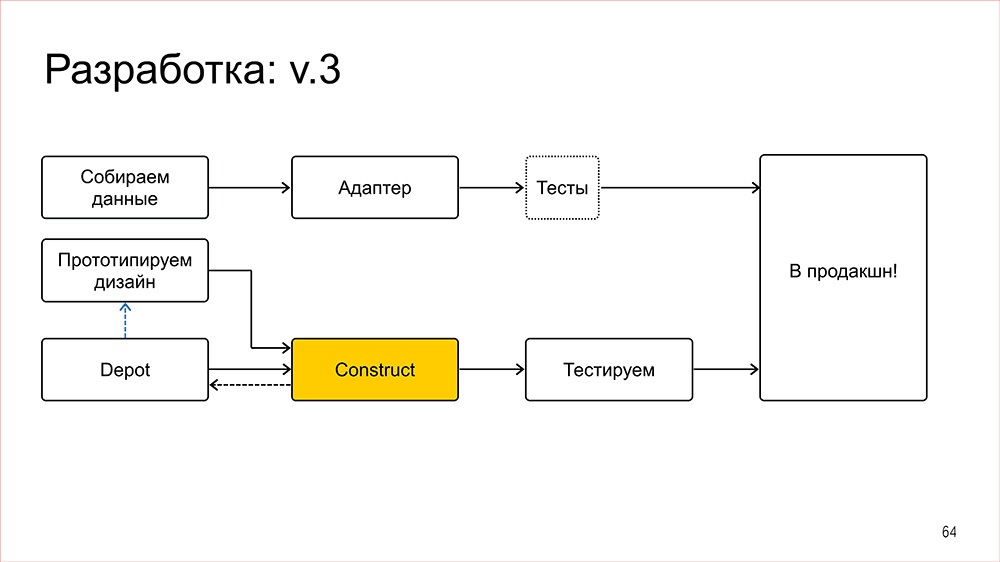


Этот доклад — расшифровка одного из лучших выступлений на профессиональной конференции фронтенд-разработчиков Frontend Conf.
С этого года мы решили выделить секцию "Архитектура фронтенда" в отдельный трек на конференции разработчиков высоконагруженных систем HighLoad++. Мы приглашаем докладчиков и слушателей!
|
|
Yota в России: от безлимита до гибких пакетов |
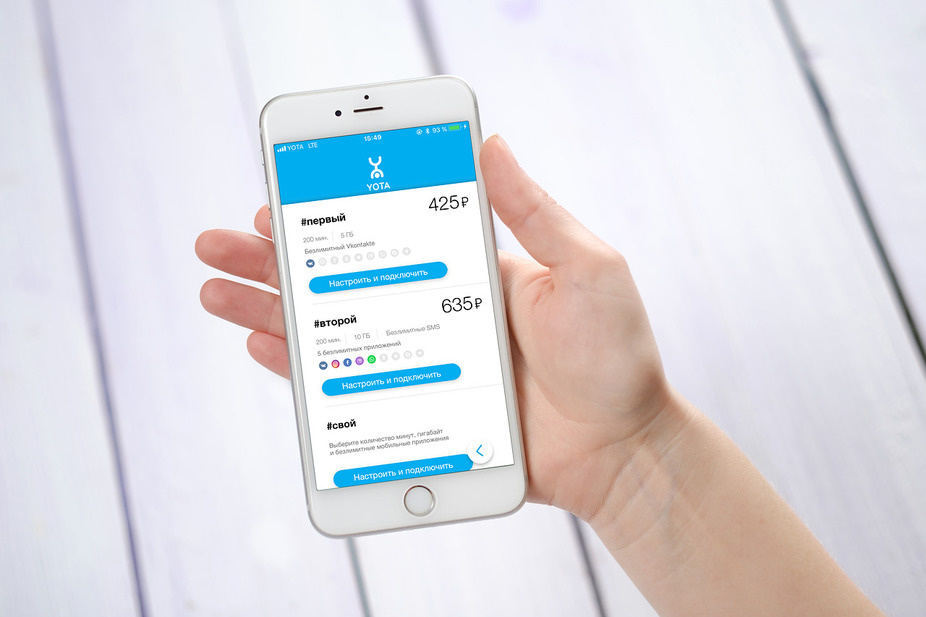

|
Метки: author Yota4All блог компании yota yota новый продукт новая услуга мобильные приложения |
Бюджет на эксплуатацию дата-центра: инструкция по составлению |

В прошлом посте рассказал, что и почему нужно делать самим в эксплуатации дата-центра. Потихоньку буду делиться опытом по каждому аспекту. Начну с бюджетирования.
Во времена руководства службой эксплуатации я на несколько дней, а иногда ночей, выпадал из реальности. Заваривал покрепче чай и погружался с головой в мир цифр и статистики, чтобы эксплуатации дата-центра было на что жить в следующем году. Вот где действительно день год кормит: нужно просчитать и расписать все плановые ТО, замены расходных материалов, а также спрогнозировать все возможные ремонты. Да, и при самой образцовой эксплуатации все когда-нибудь ломается. После нужно выполнить отдельное упражнение – доказать руководству целесообразность всего, что ты написал. Сегодня расскажу, как собрать бюджет так, чтобы прийти к желанному “Согласовано” самой прямой дорогой.
Все затраты на эксплуатацию серверной/дата-центра мы делим на два типа:
Кто-то может включить еще сюда и кадровый (зарплаты людей, отвечающих за эксплуатацию, расходы на их обучение), но я не буду его тут касаться.
Давайте смотреть, как собрать каждый из бюджетов.
Это постоянные затраты на ЗИП, расходники, ремонты и ТО, которые закладываются из года в год.
ШАГ 1. Составляем список инженерных систем и самого главного оборудования.
Покажу на примере дата-центра NORD-4:
Составляя такой список, важно не забыть про:
ШАГ 2. Определяем стоимость и количество расходных материалов и ЗИП по каждой системе.
Если про стоимость деталей понятно – просто запрашиваем у поставщиков или делаем мониторинг предложения на рынке, то с вопросом: “А сколько нам этого надо?” – сложнее. Вот тут нам пригодится статистика по поломкам и ремонтам, о которой я говорю, наверное, на каждом своем семинаре.
Лайфхак для тех, кто упорно отказывается от этой полезной практики: собрать информацию задним числом теоретически можно по счетам/актам от подрядчиков на ремонты и покупку запасных деталей.
Предвижу вопрос: что делать, если серверная и дата-центр новые? Первые год-два можно продержаться на гарантии от поставщика оборудования, но все это время собираем статистику.
Для расчета количества необходимых запчастей я пользуюсь коэффициентами. Вот как их можно получить. Допустим, надо понять, сколько нам потребуется вентиляторов для внешних блоков кондиционеров. Обращаемся к статистике и видим, что за предыдущий год вышло из строя 10 вентиляторов. Всего 100 кондиционеров. Соответственно, нам нужно 0,1 вентилятора на 1 кондиционер.
Вот такая табличка может получиться на выходе по остальным деталям и расходникам системы кондиционирования:
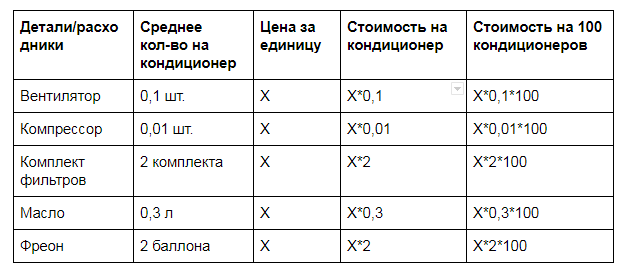
Рассчитав такие коэффициенты для одного года, можно их использовать и для последующих. Мой опыт показывает, что второй год от третьего, третий от четвертого будут отличаться минимально: для последующих годов останется только свериться со статистикой на предмет корректировки коэффициентов, и уже просто подставлять в формулу акутальную стоимость запчасти или расходника. Если в какой-то год коэффициент сильно увеличился, то стоит задуматься о модернизации, но об этом чуть позже.
Есть нетривиальные расходники и запчасти, для которых коэффициенты не очень работают. Например, топливо для ДГУ. С одной стороны, спрогнозировать, сколько раз в следующем году нас подведет Мосэнерго, сложно, с другой – у нас есть такая предсказуемая вещь, как тестирования. Если ДГУ регулярно тестируются, то мы знаем частоту запусков, их длительность. Также мы знаем потребление дизеля и нагрузку. Исходя из этого рассчитываем объемы топлива. Если происходит незапланированное выключение городского питания, то ближайшее тестирование не проводим, так как уже протестировались в реальных условиях.
ШАГ 3. Рассчитываем стоимость работ по каждой системе силами подрядчиков.
Если у нас вариант, когда в договор включено все, в том числе и ремонт оборудования, то просто запрашиваем обновленное КП, проводим тендер или без лишних движений продлеваем договор на следующий год (тут можно попробовать поторговаться с существующими подрядчиками, чтобы они сделали дешевле, или они торгуются с нами, чтобы было дороже :)). В конечном итоге мы получим какую-то фиксированную цену на следующий год. Тут все понятно.
Если в договоре прописаны только ТО, нужно дополнительно рассчитать стоимость ремонтов и аварийных выездов. Тут так же, как и с расходниками и ЗИП: смотрим на статистику по проведенным работам за прошлый год.
Важно учесть, какой у нас договор – с постоплатой или предоплатой, чтобы не промахнуться с месяцем платежа. Допустим, работы по промывке внешних блоков кондиционеров у нас запланированы на апрель, значит с предоплатой это пойдет в марте, а с постоплатой – на май. Для чьей-то бухгалтерии это будут не просто разные кварталы, но разные финансовые года.
ШАГ 4. Сводим все цифры в один excel-файл.
Сначала берем наши расходы на ТО и расписываем их в виде графика по месяцам. К этому добавляем в отдельной вкладке расходы на ремонты и стоимость ЗИП и расходников.
По поводу графика ТО. Рекомендую все работы “размазать” равномерно по календарному году, чтобы несколько работ не приходилось на один месяц. Тогда не придется выкладывать в один месяц сразу кругленькую сумму денег, да и люди, контролирующие работы, не будут перегружены.
Это крупные траты на модернизацию и замену оборудования. Для его составления нам понадобится следующее:
Далее рассчитываем стоимость модернизаций и замен с подрядчиком. Заносим в бюджет.
нам предлагают подумать, как это все умножить на 0,8. Без паники. Место для маневров есть.
Вдумчивое прочтение договора на обслуживание подрядчиком дает большие возможности сэкономить. О премудростях составления таких договоров я уже писал. Добавлю еще немного премудростей. Итак, проверяем:
Не дублируются ли одни и те же работы под разными формулировками.
Можем ли мы какие-то работы, не требующие высокой квалификации, выполнять собственными силами. Например, заменять фильтры кондиционеров.
Нет ли нерелевантных для ваших систем работ. Вот пара случаев из нашей практики: в стандартном договоре значилась проверка уровня масла в компрессоре кондиционеров, а у нас чиллерная схема, где компрессор есть только в чиллере. Проверка пароувлажнителей для всех кондиционеров, хотя у нас было всего два кондиционера с пароувлажнителем.
Нет ли “пустых” проверок оборудования без последующего устранения неисправностей. Предпочтительнее, чтобы формулировки звучали следующим образом: “Проверка и, в случае необходимости, исправление неисправностей”. Поэтому если в договоре значится: “Контроль уровня хладагента и масла», то дополняем: “Контроль уровня хладагента и масла, при необходимости – дозаправка”.
Периодичность ТО. Понятно, что подрядчику чем больше, тем лучше. Не поленитесь проконсультироваться с производителем оборудования, чтобы определиться с оптимальным количеством. Ну и смотрите на свою практику. Мы, например, отказались от ежегодной замены масла для одной из моделей ДГУ, так как масло сливалось абсолютно чистое. После консультации с вендором мы стали менять масло раз в два года. Примерно такая же ситуация у нас была с фильтрами кондиционеров, с которыми мы перешли на замену по мере необходимости, а не каждый раз, когда проводилось ТО.
Хороший способ урезать бюджет – заняться оптимизацией расходов на ЗИП и расходники. Вот тут внимательно: экономить призываю НЕ за счет отказа от закупки ЗИП. Делаем следующее:
Самый энергозатратный, но действенный способ сэкономить – найти и устранить ошибки в эксплуатации, которые регулярно приводят к поломкам, а значит к затратам на ремонты. Аудит инженерных систем поможет выявить неправильную эксплуатацию оборудования, предотвратить будущие поломки. Вот мой топ возможных слабых мест:
Проблемы в эксплуатации могут достаться и по наследству от тех, кто допустил просчеты на этапе проектирования или строительства.
В отличие от предыдущих приемов, аудит поможет не только тратить меньше, но и спасет дата-центр от потенциальных аварий.
Радостно вычеркивая статьи из бюджета, даже и не думайте резать следующие траты.
Тестирование. Если хотите спать спокойно, то боевые учения необходимы. Пусть лучше неисправность в оборудовании или системе (а иногда и в процессе) проявится во всей красе под нашим контролем, чем это случится 31 декабря, когда нужные люди будут водить хороводы вокруг елки.
Тестировать нужно правильно. В моем понимании это – комплексно и регулярно. Даже когда тестируем дизель-генераторы, у нас есть возможность попутно проверить систему бесперебойного энергоснабжения, мониторинг и много чего другого (читайте подробнее тут). Если последние 44 тестирования прошли успешно, это не означает, что 45-е можно отложить или отменить.
Сезонные подготовительные работы. В первую очередь это касается системы холодоснабжения. Перед летним сезоном, самое позднее – в апреле, нужно промыть все внешние блоки и чиллеры, проверить правильность установленного ИТ-оборудования в залах, работоспособность резервных кондиционеров (здесь подробно рассказывал, как подготовить дата-центр к лету).
К зиме готовимся в октябре: сливаем все, что может замерзнуть, проверяем подогрев ДГУ.
Закупка ЗИП. Мой опыт показывает, что подрядчика или своего инженера можно быстро вытащить на площадку ночью, в выходные или праздники, а вот привезти нужную деталь со склада так же быстро сложно. Склады живут по своему графику, не 24х7. А еще там просто может не оказаться нужной детали. Тогда ЗИП придется ждать неделями, если не месяцами.
Необязательно дублировать всю инфраструктуру на складе. Достаточно определить те детали, которые часто приходится менять (опять же смотрим статистику), и те, из-за которых вы можете лишиться резерва или вовсе остаться с неработающим оборудованием/системой. Когда пускаем в дело запасы со склада, сразу же закупаем новые, хотя бухгалтерия будет удивленно спрашивать: “Зачем вам новое, вы же только что поменяли?”
И еще момент: список ЗИП – это не константа. Каждый раз будет ломаться что-то новое, не забывайте добавлять это в список будущих покупок для постоянного хранения на вашем складе.
Если не убедил, то вот вам поучительный случай, после которого мы начали закупать и хранить ЗИП у себя.

Склад с ЗИП для системы холодоснабжения на площадке OST.
И последнее напутствие.
Если составление бюджета – наука, то согласование больше походит на искусство, которым, впрочем, тоже можно овладеть. На защите руководство любит задавать каверзные вопросы, типа: “Почему здесь 150, а не 149 тысяч?” Или: “Зачем тебе так много на вентиляторы?” Если вы, не приходя в сознание, сможете ответить с примерами из статистики, откуда берется каждая цифра, то отобьетесь.
|
Метки: author kshadskiy it- инфраструктура блог компании dataline бюджетирование бюджет дата-центр дата-центры цод цоды эксплуатация цод даталайн dataline |
Читаем, слушаем, используем. Гайд по источникам для саморазвития Android-разработчика |

|
Метки: author YourDestiny разработка под android блог компании avito android kotlin java meetups |
[Перевод] Продвинутая тактика игры в «Сапёр» |


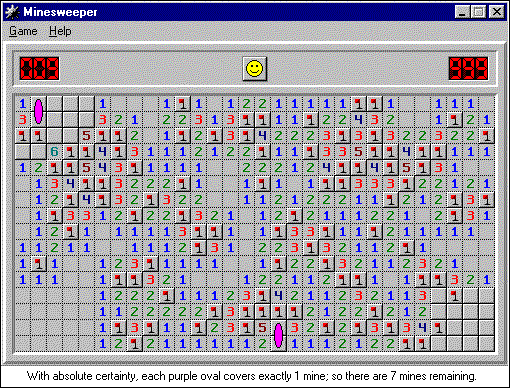
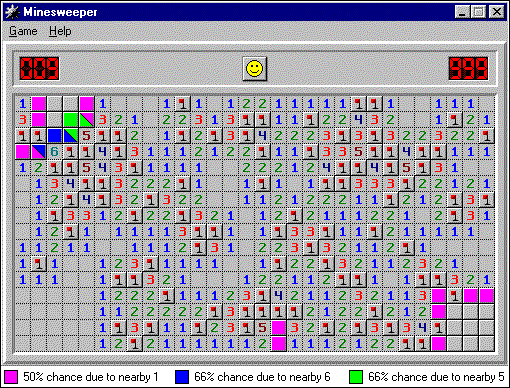
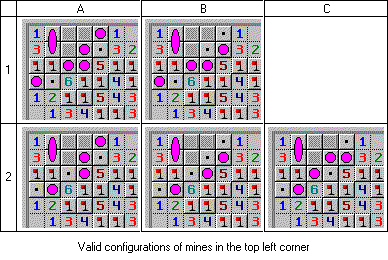
| Вверху слева | Внизу справа | Количество мин | Осталось мин | Закрытые варианты |
|---|---|---|---|---|
| A1 | B | 8 | 0 | 1 |
| B1 | A | 8 | 0 | 1 |
| B1 | B | 7 | 1 | 12 |
| A2 | A | 8 | 0 | 1 |
| A2 | B | 7 | 1 | 12 |
| B2 | A | 7 | 1 | 12 |
| B2 | B | 6 | 2 | 66 |
| C2 | A | 8 | 0 | 1 |
| C2 | B | 7 | 1 | 12 |
| Конфигурация | Варианты | Процент |
|---|---|---|
| A1 | 1 | 1 |
| B1 | 13 | 11 |
| A2 | 13 | 11 |
| B2 | 78 | 66 |
| C2 | 13 | 11 |
| A | 15 | 13 |
| B | 103 | 87 |


|
Метки: author PatientZero читальный зал сапер minesweeper статистика вероятности |
«Пятничный формат»: Как погасить пламя или 8 верных способов загубить разработку |
 / фото Bureau of Land Management CC
/ фото Bureau of Land Management CC


|
Метки: author it_man программирование блог компании ит-град it-grad разработка советы |
Автоматизация CI/CD для Java приложений с помощью Microsoft Visual Studio Team Services |









































|
Метки: author easkero visual studio microsoft azure java блог компании microsoft microsoft microsoft developer devops visual studio team services ci/cd azure cloud |
Настройка аутентификации в Citrix XenDesktop 7.x c использованием смарт-карт JaCarta PKI |
























































|
|
С днем системного администратора |

|
Метки: author n0wi системное администрирование сетевые технологии *nix праздник пиво сисадмин |
[Перевод] «Алекса, пожалуйста, убей меня уже»: разговорные интерфейсы |

Мы в UIS сейчас полным ходом пилим модуль распознавания речи Виртуальной АТС. И потому следим за тем, что думают о развитии разговорных интерфейсов люди, которым есть, что о них сказать. Под катом — перевод свежей статьи Алана Купера, который, как и мы, думает, что главное в технологии — ее потенциал по оптимизации затрат.
Главный технологический парадокс современности: труднее сообщить компьютеру, что нужно сделать, чем компьютеру — сделать это. Сложные задачи относительно легко выполняются с помощью цифровых технологий, но составление инструкций для реализации, учитывающих все нюансы и тонкости этих сложных задач — неизменный вызов для разработчика. Разрешение этого парадокса лежит в основе профессионального проектирования взаимодействия (interaction design).
Некоторые полагают, что трудностей с направлением цифрового разума в нужное русло станут значительно меньше, когда мы усовершенствуем разговорные интерфейсы. То есть, когда мы сможем просто разговаривать с компьютером, взаимодействие с ним станет простым, ясным и понятным. Это мнение бытует десятилетиями и, как пламя от сжигания покрышек в долинах, вовсе не собирается угасать. А по мере того, как софт по распознаванию речи становится все лучше — а он весьма хорош сегодня — токсичное пламя ажиотажа разгорается даже больше.
Наше воображение тяготеет к голливудской картинке непринужденного душевного общения с ловящим каждое наше слово роботом, который почтительно кланяется каждый раз, спеша выполнять наше приказание. Машины представляются нашими чуткими и старательными слугами, реагирующими на вербальные команды. «Организуй обед». «Скажи Джейн, что я опоздаю». «Увеличь продажи на десять процентов». «Убедись, что за мной никто не следит».

Такое видение не только антропоморфно, оно еще и фантастично. Это не просто наделение компьютеров человеческими качествами, это наделение их супер-человеческими качествами. Просто потому что мы способны формировать мысли в своей голове, мы ошибочно полагаем, что кто-то другой может сформировать такую же мысль на основании какого-то шума из нашего рта.
Если ваш компьютер распознает слова, которые вы произносите, не стоит делать из этого скоропалительный вывод, что он понимает, что вы имеете в виду. Ваша супруга, которая прожила с вами 20 лет, только сейчас начинает отдаленно представлять себе, что вы подразумеваете на самом деле, когда что-то говорите. Ваш компьютер, скорее всего, никогда не начнет вас понимать по той простой причине, что вещи, которые вы говорите, в принципе не понимаемы.
Долгая история недопонимания, двусмысленности и провальных коммуникаций людей с людьми должна бы напоминать нам о том, что такое видение основано на том, что нам хочется, а не на том, что на самом деле имеет место быть. Если даже людям так трудно давать вербальные инструкции, то как мы вообще собираемся эффективно давать вербальные инструкции компьютерам?
Множество людей, включая меня, полагают, что этот фантастический мир останется недостижимой химерой.
«Алекса, выключи свет!» — вот тот уровень распознавания речи, которого мы достигли сейчас. Это круто! Это весело! Удиви своих друзей! Это не киллер-фича, но это то, на что способна технология сегодня, так что мы увидим кучу вариантов использования такого рода сценариев в ближайшем будущем. Конечно, неосознанные последствия сырого применения технологии, например, в умном доме с встроенным распознаванием голоса, потрясающе легко предвидеть. «Алекса, выключи свет!» «Не этот свет!» «Нет, в другом месте!» «Алекса, только свет в гараже!» «Нет, Алекса, выключи, а не включи». «Только в гараже». «Черт тебя побери, Алекса!»
Одна из причин того, что разговорные пользовательские интерфейсы искушают нас ложными надеждами — то, что современный софт крайне хорош в распознавании речи. К сожалению, «крайне хорош» — это относительное понятие, которое зависит от того, что вам нужно сделать.
Несколько лет назад один мой хороший приятель с огромным опытом работы в здравоохранении задумал проект, который должен был упростить для врачей решение их старой как мир проблемы с необходимостью делать много записей. Терапевты тратят на это примерно столько же времени, как и на осмотр пациентов, так что проект обладал огромным потенциалом по экономии времени. Мой друг собирался дать врачам возможность просто наговаривать эти записи в микрофон-петличку прямо в процессе прослушивания и прощупывания пациентов. Программа была построена на базе очень функциональной платформы распознавания речи Dragon. Все работало хорошо, за исключением того, что это не работало достаточно хорошо для медицинских целей. Выяснилось, что врачам все равно нужно вычитывать и проверять текст. В программах, где критична полнота реализации задачи, 99,9% успеха означают шанс одной ошибки на тысячу случаев. Когда ставка — человеческая жизнь, это не достаточно хорошо.
Невзирая на историю с врачами, все еще остается немалая ценность голосового распознавания для многих приложений, работающих с вводом данных. Последний iPhone от Apple, например, умеет делать текстовую расшифровку сообщений на голосовую почту. Это замечательно удобный инструмент для экономии времени, потому что — даже несмотря на то, что 20% слов пропущено или искажено — я могу понять суть сообщения без необходимости прослушивать его.
В моей машине — атрибуте реального мира — все происходит немного по-другому. «Позвони Роберту». «Извините, я не понимаю». «Позвони Роберту». «Извините, я не понимаю». «Набери номер Роберта». «Вы имеете в виду Роберта Джонса, 555-543-1298». «Да». «Готова». «Набирай номер». «Набираю номер». И в этот момент я понимаю, что пока был занят этим избыточным проговариванием, я пропустил свой съезд. С точки зрения основного постулата проектирования взаимодействия, любая голосовая команда пользователя должна считаться критически важной, и ровно поэтому большая часть автомобильных систем голосового управления не используется ни разу после того, как машина покидает автосалон.
А теперь представьте себе ту же степень туповатого непонимания и вялого педантичного обструкционизма системы при управлении трактором, линией конвейера, самолетом или ядерной боеголовкой. Такие системы распознавания команд туповаты не случайно. Они должны вести себя подобным образом, чтобы избежать двусмысленности, потому что неопределенность в диалоге человека и машины технически недопустима. К сожалению, включение голоса в это взаимодействие всегда порождает неопределенность, и это, по моим прогнозам, никогда не вылечится.
Мы неизбежно будем использовать все больше и больше разговорных пользовательских интерфейсов в будущем. Не потому что они хорошие или лучше, чем другие технологии проектирования интерфейсов, а потому что они дешевле. Они позволяют использовать софт там, где в ином случае пришлось бы задействовать оператора-человека. Так что развитие этой технологии движет оптимизация затрат, а не рост удобства для пользователя.
Один из моих любимых фильмов — «Разговор» (The Conversation) Фрэнсиса Форда Копполы. Этот мрачноватый бриллиант, на самом деле, очень глубокий и личный фильм великого режиссера, выпущенный в 1974 году сразу после триумфа фильма жизни Копполы, «Крестного отца». В целом, как и любая хорошая детективная история в жанре нуара, это фильм про характеры, маскирующийся под расследование убийства. И, почему я вообще о нем говорю — все в этом фильме (персонажи, сюжет, тема, определение того, кто хороший парень, а кто плохой) завязано на интерпретацию того, как было произнесено одно-единственное слово.
|
Метки: author sophie интерфейсы usability блог компании uis алан купер разговорные интерфейсы голосовое управление распознавание голоса юзабилити интерфейсов тренды |
Тут вам не DevOps: судьба сисадмина в малом бизнесе |








|
Метки: author Axelus системное администрирование it- инфраструктура блог компании regionsoft developer studio день системного администратора сисадмин - это звучит гордо |
День сисадмина: зажги на квесте, закрути баклажан |

|
|






