[Перевод] R и большие данные: использование Replyr |
replyr — сокращение от REmote PLYing of big data for R (удаленная обработка больших данных в R). replyr? Потому что он позволяет применять стандартные рабочие подходы к удаленным данным (базы данных или Spark).data.frame. replyr предоставляет такие возможности:replyr_summary().replyr_union_all().replyr_bind_rows().dplyr::do()): replyr_split(), replyr::gapply().replyr_moveValuesToRows() / replyr_moveValuesToColumns().Spark и sparklyr гораздо легче.replyr — продукт коллективного опыта использования R в прикладных решениях для многих клиентов, сбора обратной связи и исправления недостатков.base::date()
## [1] "Thu Jul 6 15:56:28 2017"
# devtools::install_github('rstudio/sparklyr')
# devtools::install_github('tidyverse/dplyr')
# devtools::install_github('tidyverse/dbplyr')
# install.packages("replyr")
suppressPackageStartupMessages(library("dplyr"))
packageVersion("dplyr")
## [1] '0.7.1.9000'
packageVersion("dbplyr")
## [1] '1.1.0.9000'
library("tidyr")
packageVersion("tidyr")
## [1] '0.6.3'
library("replyr")
packageVersion("replyr")
## [1] '0.4.2'
suppressPackageStartupMessages(library("sparklyr"))
packageVersion("sparklyr")
## [1] '0.5.6.9012'
# больше памяти, чем предполагается в https://github.com/rstudio/sparklyr/issues/783
config <- spark_config()
config[["sparklyr.shell.driver-memory"]] <- "8G"
sc <- sparklyr::spark_connect(version='2.1.0',
hadoop_version = '2.7',
master = "local",
config = config)
summary() и glance(), которые нельзя выполнить на Spark.mtcars_spark <- copy_to(sc, mtcars)
# резюме обработки, а не данных
summary(mtcars_spark)
## Length Class Mode
## src 1 src_spark list
## ops 2 op_base_remote list
packageVersion("broom")
## [1] '0.4.2'
broom::glance(mtcars_spark)
## Error: glance doesn't know how to deal with data of class tbl_sparktbl_sqltbl_lazytbl
replyr_summary работает.replyr_summary(mtcars_spark) %>%
select(-lexmin, -lexmax, -nunique, -index)
## column class nrows nna min max mean sd
## 1 mpg numeric 32 0 10.400 33.900 20.090625 6.0269481
## 2 cyl numeric 32 0 4.000 8.000 6.187500 1.7859216
## 3 disp numeric 32 0 71.100 472.000 230.721875 123.9386938
## 4 hp numeric 32 0 52.000 335.000 146.687500 68.5628685
## 5 drat numeric 32 0 2.760 4.930 3.596563 0.5346787
## 6 wt numeric 32 0 1.513 5.424 3.217250 0.9784574
## 7 qsec numeric 32 0 14.500 22.900 17.848750 1.7869432
## 8 vs numeric 32 0 0.000 1.000 0.437500 0.5040161
## 9 am numeric 32 0 0.000 1.000 0.406250 0.4989909
## 10 gear numeric 32 0 3.000 5.000 3.687500 0.7378041
## 11 carb numeric 32 0 1.000 8.000 2.812500 1.6152000tidyr работает в основном с локальными данными.mtcars2 <- mtcars %>%
mutate(car = row.names(mtcars)) %>%
copy_to(sc, ., 'mtcars2')
# ошибки
mtcars2 %>%
tidyr::gather('fact', 'value')
## Error in UseMethod("gather_"): no applicable method for 'gather_' applied to an object of class "c('tbl_spark', 'tbl_sql', 'tbl_lazy', 'tbl')"
mtcars2 %>%
replyr_moveValuesToRows(nameForNewKeyColumn= 'fact',
nameForNewValueColumn= 'value',
columnsToTakeFrom= colnames(mtcars),
nameForNewClassColumn= 'class') %>%
arrange(car, fact)
## # Source: lazy query [?? x 4]
## # Database: spark_connection
## # Ordered by: car, fact
## car fact value class
##
## 1 AMC Javelin am 0.00 numeric
## 2 AMC Javelin carb 2.00 numeric
## 3 AMC Javelin cyl 8.00 numeric
## 4 AMC Javelin disp 304.00 numeric
## 5 AMC Javelin drat 3.15 numeric
## 6 AMC Javelin gear 3.00 numeric
## 7 AMC Javelin hp 150.00 numeric
## 8 AMC Javelin mpg 15.20 numeric
## 9 AMC Javelin qsec 17.30 numeric
## 10 AMC Javelin vs 0.00 numeric
## # ... with 342 more rowsdplyr bind_rows, union и union_all сейчас неприменимы в Spark. replyr::replyr_union_all() и replyr::replyr_bind_rows() — работоспособная альтернатива.db1 <- copy_to(sc,
data.frame(x=1:2, y=c('a','b'),
stringsAsFactors=FALSE),
name='db1')
db2 <- copy_to(sc,
data.frame(y=c('c','d'), x=3:4,
stringsAsFactors=FALSE),
name='db2')
# Ошибки из-за попытки осуществить операцию над обработчиком, а не данными
bind_rows(list(db1, db2))
## Error in bind_rows_(x, .id): Argument 1 must be a data frame or a named atomic vector, not a tbl_spark/tbl_sql/tbl_lazy/tbl# игнорирует названия столбцов и приводит все данные к строкам
union_all(db1, db2)
## # Source: lazy query [?? x 2]
## # Database: spark_connection
## x y
##
## 1 1 a
## 2 2 b
## 3 3 c
## 4 4 d# игнорирует названия столбцов и приводит все данные к строкам
# скорее всего, также потеряет дублирующиеся строки
union(db1, db2)
## # Source: lazy query [?? x 2]
## # Database: spark_connection
## x y
##
## 1 4 d
## 2 1 a
## 3 3 c
## 4 2 breplyr::replyr_bind_rows может связывать вместе несколько data.frame-ов.replyr_bind_rows(list(db1, db2))
## # Source: table [?? x 2]
## # Database: spark_connection
## x y
##
## 1 1 a
## 2 2 b
## 3 3 c
## 4 4 dSpark).dplyr::do на локальных данныхhelp('do', package='dplyr'):by_cyl <- group_by(mtcars, cyl)
do(by_cyl, head(., 2))
## # A tibble: 6 x 11
## # Groups: cyl [3]
## mpg cyl disp hp drat wt qsec vs am gear carb
##
## 1 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
## 2 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
## 3 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
## 4 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
## 5 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
## 6 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4dplyr::do на Sparkby_cyl <- group_by(mtcars_spark, cyl)
do(by_cyl, head(., 2))
## # A tibble: 3 x 2
## cyl V2
##
## 1 6
## 2 4
## 3 8 replyr разделение/объединениеmtcars_spark %>%
replyr_split('cyl',
partitionMethod = 'extract') %>%
lapply(function(di) head(di, 2)) %>%
replyr_bind_rows()
## # Source: table [?? x 11]
## # Database: spark_connection
## mpg cyl disp hp drat wt qsec vs am gear carb
##
## 1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
## 2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
## 3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
## 4 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
## 5 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
## 6 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4replyr gapplymtcars_spark %>%
gapply('cyl',
partitionMethod = 'extract',
function(di) head(di, 2))
## # Source: table [?? x 11]
## # Database: spark_connection
## mpg cyl disp hp drat wt qsec vs am gear carb
##
## 1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
## 2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
## 3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
## 4 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
## 5 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
## 6 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4replyr::replyr_apply_f_mappedreplyr::replyr_apply_f_mapped(), и работает она следующим образом.wrapr::let()).# внешняя функция с заданными в явном виде названиями столбцов
DecreaseRankColumnByOne <- function(d) {
d$RankColumn <- d$RankColumn - 1
d
}d (в котором не такие, как ожидается, названия столбцов!), мы используем replyr::replyr_apply_f_mapped() для создания нового параметризированного адаптера:# наши данные
d <- data.frame(Sepal_Length = c(5.8,5.7),
Sepal_Width = c(4.0,4.4),
Species = 'setosa',
rank = c(1,2))
# обработчик для ввода параметров
DecreaseRankColumnByOneNamed <- function(d, ColName) {
replyr::replyr_apply_f_mapped(d,
f = DecreaseRankColumnByOne,
nmap = c(RankColumn = ColName),
restrictMapIn = FALSE,
restrictMapOut = FALSE)
}
# использование
dF <- DecreaseRankColumnByOneNamed(d, 'rank')
print(dF)
## Sepal_Length Sepal_Width Species rank
## 1 5.8 4.0 setosa 0
## 2 5.7 4.4 setosa 1replyr::replyr_apply_f_mapped() переименовывает столбцы так, как ожидается в DecreaseRankColumnByOne (соответствие задано в nmap), применяет DecreaseRankColumnByOne и возвращает имена к исходным перед тем, как вернуть результат.Sparklyr связаны с созданием промежуточных или временных таблиц. Это можно делать с помощью dplyr::copy_to() и dplyr::compute(). Эти способы могут быть ресурсоёмкими.replyr есть функции, позволяющие держать процесс под контролем: генераторы временных имен, не изменяющие собственно данные (они также используются внутри самого пакета).print(replyr::makeTempNameGenerator)
## function (prefix, suffix = NULL)
## {
## force(prefix)
## if ((length(prefix) != 1) || (!is.character(prefix))) {
## stop("repyr::makeTempNameGenerator prefix must be a string")
## }
## if (is.null(suffix)) {
## alphabet <- c(letters, toupper(letters), as.character(0:9))
## suffix <- paste(base::sample(alphabet, size = 20, replace = TRUE),
## collapse = "")
## }
## count <- 0
## nameList <- list()
## function(..., peek = FALSE, dumpList = FALSE, remove = NULL) {
## if (length(list(...)) > 0) {
## stop("replyr::makeTempNameGenerator tempname generate unexpected argument")
## }
## if (peek) {
## return(names(nameList))
## }
## if (dumpList) {
## v <- names(nameList)
## nameList <<- list()
## return(v)
## }
## if (!is.null(remove)) {
## victims <- intersect(remove, names(nameList))
## nameList[victims] <<- NULL
## return(victims)
## }
## nm <- paste(prefix, suffix, sprintf("%010d", count),
## sep = "_")
## nameList[[nm]] <<- 1
## count <<- count + 1
## nm
## }
## }
##
## compute после каждого объединения (иначе полученный SQL может стать длинным и трудным для понимания и в поддержке). Код выглядит примерно так:# создание данных для примера
names <- paste('table', 1:5, sep='_')
tables <- lapply(names,
function(ni) {
di <- data.frame(key= 1:3)
di[[paste('val',ni,sep='_')]] <- runif(nrow(di))
copy_to(sc, di, ni)
})
# собственный генератор временных имён
tmpNamGen <- replyr::makeTempNameGenerator('JOINTMP')
# объединение слева таблиц в последовательности
joined <- tables[[1]]
for(i in seq(2,length(tables))) {
ti <- tables[[i]]
if(icode>Sparklyr, а затем очищать временные значения все вместе, когда результаты от них больше не зависят.Spark или БД с помощью R, стоит рассмотреть replyr в дополнение к dplyr и sparklyr.sparklyr::spark_disconnect(sc)
rm(list=ls())
gc()
## used (Mb) gc trigger (Mb) max used (Mb)
## Ncells 821292 43.9 1442291 77.1 1168576 62.5
## Vcells 1364897 10.5 2552219 19.5 1694265 13.0|
Метки: author qc-enior big data dplyr большие данные replyr spark sparklyr |
Взлом казино через умный аквариум и DDoS биржевых брокеров: новые атаки на сферу финансов |


Для того, чтобы минимизировать возможный ущерб как от хакерских атак, так и технических сбоев, брокерские компании разрабатывают различные системы защиты клиентов. О том, как реализована подобная защита в торговой системе ITinvest MatriX можно прочитать по ссылке.
|
Метки: author itinvest информационная безопасность блог компании itinvest взлом ddos iot интернет вещей |
Наведение порядка: в Chrome и Firefox будет прекращено доверие к удостоверяющему центру Symantec |
 Как обычно, до ката нужно привести выжимку: в связи с проблемами в организации работы инфраструктуры, нарушениями при подготовке отчётности и злоупотреблениями, которые привели к выдаче сертификатов уровня EV (Extended Validation) без требуемых проверок, в настоящее время Goolge и Mozilla планируют процесс утраты доверия к сертификатам Symantec.
Как обычно, до ката нужно привести выжимку: в связи с проблемами в организации работы инфраструктуры, нарушениями при подготовке отчётности и злоупотреблениями, которые привели к выдаче сертификатов уровня EV (Extended Validation) без требуемых проверок, в настоящее время Goolge и Mozilla планируют процесс утраты доверия к сертификатам Symantec.Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author dmitry_ch хостинг серверное администрирование администрирование доменных имен symantec ca https допрыгались |
Android Architecture Components в связке с Data Binding |

Не так давно для андроид-разработчиков Google представил новую библиотеку — Android Architecture Components. Она помогает реализовать в приложении архитектуру на основе паттернов MVx (MVP, MVVM etc.). Кроме того, уже давно выпущена другая библиотека от Google — Data Binding Library. Она позволяет прямо в разметке связывать отображение UI-контролов со значениями, содержащимися в объектах. Это важная особенность паттерна MVVM — связывать слой View со слоем ViewModel.
Обе библиотеки направлены на построение архитектуры Android-приложений в MVVM стиле.
Я расскажу, как можно использовать их вместе для создания проекта с архитектурой на основе MVVM.
Паттерн MVVM предполагает разделение архитектуры приложения на 3 слоя:

Основной интерес в статье будет прикован к байндингам. Это связи отображения конкретных параметров View (например, “text” у TextView) с конкретными полями представления ViewModel (например, поле “имя пользователя”). Задаются они в разметке View (в layout), а не в коде. ViewModel, в свою очередь, должна так представлять данные, чтобы их было легко связать байндингами с View.
Сам по себе паттерн MVVM, как и MVP, и MVC, позволяет разделить код на независимые слои. Основное отличие MVVM — в байндингах. То есть, в возможности прямо в разметке связать отображение того, что видно пользователю — слой View, с состоянием приложения — слоем Model. В общем, польза MVVM в том, чтобы не писать лишний код для связывания представления с отображением — за вас это делают байндинги.
Google двигается в сторону поддержки архитектуры на основе паттерна MVVM. Библиотеки Android Architecture Components (далее, AAC) и Data Binding — прямое тому подтверждение. В будущем, скорее всего, этот паттерн будет использоваться на большинстве проектах под Android.
На данный момент проблема в том, что ни AAC, ни Data Binding не предоставляет возможности реализовать MVVM паттерн в полной мере. AAC реализует слой ViewModel, но байндинги надо настраивать вручную в коде. Data Binding, в свою очередь, предоставляет возможность написать байндинги в разметке и привязать их к коду, но слой ViewModel надо реализовывать вручную, чтобы прокидывать обновление состояния приложения через байндинги к View.
В итоге, вроде бы, все уже готово, но разделено на две библиотеки, и чтобы это было действительно похоже на MVVM, нужно просто взять и объединить их.
В общем, что надо для этого сделать:
Сделать это попробуем на примере простого экрана профиля пользователя.
На экране будет три элемента:
Логин будет храниться в SharedPreferences. Пользователь считается авторизованным, если в SharedPreferences записан какой-нибудь логин.
Для простоты не будут использоваться сторонние фреймворки, запросы к сети, а также отображение ошибок.
Начну я со слоя View, чтобы было понятно, что будет видно пользователю на экране. Сразу же размечу нужные мне байндинги без привязки к конкретной ViewModel. Как это все будет работать — станет понятно позже.
Собственно, layout:
Перед реализацией слоя Model надо разобраться с классом LiveData из AAC. Он нам понадобится для нотификации слоя ViewModel об изменениях слоя Model.
LiveData — это класс, объекты которого поставляют данные и их обновления подписчикам. Он представляет собой реализацию паттерна Observer. На LiveData можно подписаться, а сама LiveData реализует внутри то, как она будет вычислять и обновлять данные для подписчиков.
Особенность LiveData в том, что она может быть привязана к объекту жизненного цикла и активироваться, только когда такой объект в состоянии started. Это удобно для обновления слоя View: пока активити или фрагмент в состоянии started, это значит, что у них инициализирован весь UI и им нужны актуальные данные. LiveData реагирует на это и активизируется — рассчитывает актуальное значение и уведомляет подписчиков об обновлении данных.
От слоя Model нам нужна следующая функциональность: методы login(String login), logout() и возможность отслеживать текущий логин авторизованного пользователя на основе LiveData.
Добавим класс ProfileRepository, который будет отвечать за логику авторизации пользователя:
class ProfileRepository(context: Context) {
private val loginKey = "login"
private val preferences = context.getSharedPreferences("prefs", Context.MODE_PRIVATE)
// LiveData, на которую можно подписаться
// и получать обновления логина пользователя
private val innerLoggedInUser = LoggedInUserLiveData()
val loggedInUser: LiveData
get() = innerLoggedInUser
fun login(login: String) {
preferences.edit().putString(loginKey, login).apply()
notifyAboutUpdate(login)
}
fun logout() {
preferences.edit().putString(loginKey, null).apply()
notifyAboutUpdate(null)
}
private fun notifyAboutUpdate(login: String?) {
innerLoggedInUser.update(login)
}
private inner class LoggedInUserLiveData : LiveData() {
// так лучше не делать в конструкторе, а высчитывать текущее значение асинхронно
// при первом вызове метода onActive. Но для примера сойдет
init { value = preferences.getString(loginKey, null) }
// postValue запрашивает обновление на UI-потоке
// используем, так как мы не уверены, с какого потока будет обновлен логин
// для немедленного обновления на UI-потоке можно использовать метод setValue
fun update(login: String?) {
postValue(login)
}
}
}Этот объект разместим в Application, чтобы было проще получить к нему доступ, имея Context:
class AacPlusDbTestApp : Application() {
lateinit var profileRepository: ProfileRepository
private set
override fun onCreate() {
super.onCreate()
profileRepository = ProfileRepository(this)
}
}Перед реализацией слоя ViewModel надо разобраться с основным классом из AAC, использующимся для этого.
ViewModel — это класс, представляющий объекты слоя ViewModel. Объект такого типа может быть создан из любой точки приложения. В этом классе всегда должен быть либо дефолтный конструктор (класс ViewModel), либо конструктор с параметром типа Application (класс AndroidViewModel).
Чтобы запросить ViewModel по типу, нужно вызвать:
mvm = ViewModelProviders.of(fragmentOrActivity).get(MyViewModel::class.java)Либо по ключу:
mvm1 = ViewModelProviders.of(fragmentOrActivity).get("keyVM1", MyViewModel::class.java)
mvm2 = ViewModelProviders.of(fragmentOrActivity).get("keyVM2", MyViewModel::class.java)ViewModel хранятся отдельно для каждой активити и для каждого фрагмента. При первом запросе они создаются и помещаются для хранения в активити или фрагменте. При повторном запросе — возвращается уже созданная ViewModel. Уникальность конкретной ViewModel — это ее тип или строковый ключ + где она хранится.
Создаются ViewModel и AndroidViewModel по умолчанию через рефлексию — вызывается соответствующий конструктор. Так что, при добавлении своих конструкторов, в методе ViewModelProviders.of(...) нужно явно указывать фабрику создания таких объектов.
От ProfileViewModel нам надо следующее:
Создадим ProfileViewModel и свяжем ее с ProfileRepository:
// наследуем от AndroidViewModel, для доступа к ProfileRepository через Application
class ProfileViewModel(application: Application) : AndroidViewModel(application) {
private val profileRepository: ProfileRepository = (application as AacPlusDbTestApp).profileRepository
// класс Transformations — это класс-хэлпер для преобразования данных
// метод map, просто конвертирует данные из одного типа в другой - в данном случае из String? в boolean
val isUserLoggedInLiveData = Transformations.map(profileRepository.loggedInUser) { login -> login != null }
// LiveData чтобы отслеживать логин авторизованного пользователя
val loggedInUserLiveData = profileRepository.loggedInUser
// представляет логин, введенный пользователем с клавиатуры
// TextField - это ObservableField, реализующий интерфейс TextWatcher
// это нужно, чтобы можно было байндиться к text и addTextChangedListener,
// организовав таким образом двустронний байндинг.
// При вводе текста в EditText изменяется ViewModel, при изменении ViewModel — изменяется EditText.
val inputLogin = TextField()
fun loginOrLogout() {
// необходимо получить текущее состояние - авторизован пользователь или нет и решить, что делать
isUserLoggedInLiveData.observeForever(object : Observer {
override fun onChanged(loggedIn: Boolean?) {
if (loggedIn!!) {
profileRepository.logout()
} else if (inputLogin.get() != null) {
// вызываем логин только если пользователь что-то ввел в поле ввода
profileRepository.login(inputLogin.get())
} else {
// по идее, тут можно отобразить ошибку "Введите логин"
}
// при выполнении команды приходится отписываться вручную
isUserLoggedInLiveData.removeObserver(this)
}
})
}
} Теперь при вызове метода loginOrLogout в ProfileRepository будет обновляться LoginLiveData и эти обновления можно будет отображать на слое View, подписавшись на LiveData из ProfileViewModel.
Но LiveData и ViewModel пока что не адаптированы под байндинг, так что использовать этот код еще нельзя.
С доступом к ViewModel из разметки проблем особых нет. Объявляем ее в разметке:
И устанавливаем в активити или фрагменте:
// наследуем от LifecycleActivity, так как это может понадобиться для LiveData.
// LiveData будет активироваться, когда эта активити будет в состоянии started.
class ProfileActivity : LifecycleActivity() {
lateinit private var binding: ActivityProfileBinding
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// инициализируем байндинг
binding = DataBindingUtil.setContentView(this, R.layout.activity_profile)
// устанавливаем ViewModel для байндинга
binding.profileViewModel = ViewModelProviders.of(this).get(ProfileViewModel::class.java)
}
} Адаптировать LiveData я решил на основе класса ObservableField. Он позволяет привязать изменяющееся значение произвольного типа к конкретному свойству view.
В моем примере надо будет прибайндить visibility у view к тому, авторизован пользователь или нет. А также свойство text к логину пользователя.
У ObservableField есть два метода — addOnPropertyChangedCallback и removeOnPropertyChangedCallback. Эти методы вызываются, когда добавляется и удаляется байндинг из view.
По сути, эти методы — те моменты, когда нужно подписываться и отписываться от LiveData:
// наследуем от ObservableField
// имплементируем Observer (подписчик для LiveData) чтобы синхронизировать значения LiveData и ObservableField
class LiveDataField(val source: LiveData) : ObservableField(), Observer {
// отслеживаем количество подписчиков на этот ObservableField
private var observersCount: AtomicInteger = AtomicInteger(0)
override fun addOnPropertyChangedCallback(callback: Observable.OnPropertyChangedCallback) {
super.addOnPropertyChangedCallback(callback)
if (observersCount.incrementAndGet() == 1) {
// подписываемся на LiveData, когда к ObservableField прибайндивается первая view
source.observeForever(this)
}
}
override fun onChanged(value: T?) = set(value)
override fun removeOnPropertyChangedCallback(callback: Observable.OnPropertyChangedCallback) {
super.removeOnPropertyChangedCallback(callback)
if (observersCount.decrementAndGet() == 0) {
// отписываемся от LiveData, когда все view отбайндились от ObservableField
source.removeObserver(this)
}
}
} Для подписки на LiveData я использовал метод observeForever. Он не передает объект жизненного цикла и активирует LiveData независимо от того, в каком состоянии находятся активити или фрагмент, на котором находятся view.
В принципе, из объекта OnPropertyChangedCallback можно достать view, из view — context, context привести к LifecycleActivity и привязать LiveData к этой активити. Тогда можно будет использовать метод observe(lifecycleObject, observer). Тогда LiveData будет активироваться только когда активити, на которой находится view, в состоянии started.
Выглядеть этот хак будет примерно так:
class LifecycleLiveDataField(val source: LiveData) : ObservableField(), Observer {
...
override fun addOnPropertyChangedCallback(callback: Observable.OnPropertyChangedCallback) {
super.addOnPropertyChangedCallback(callback)
try {
// немножко рефлексии, по-другому никак
val callbackListenerField = callback.javaClass.getDeclaredField("mListener")
callbackListenerField.setAccessible(true)
val callbackListener = callbackListenerField.get(callback) as WeakReference
val activity = callbackListener.get()!!.root!!.context as LifecycleActivity
if (observersCount.incrementAndGet() == 1) {
source.observe(activity, this)
}
} catch (bindingThrowable: Throwable) {
Log.e("BINDING", bindingThrowable.message)
}
}
...
} Теперь изменим ProfileViewModel так, чтобы к ней можно было легко прибайндиться:
class ProfileViewModel(application: Application) : AndroidViewModel(application) {
...
// представляет логин авторизованного пользователя или null
val userLogin = LifecycleLiveDataField(loggedInUserLiveData)
// представляет авторизован ли пользователь
val isUserLoggedIn = LifecycleLiveDataField(isUserLoggedInLiveData)
...
}Важно! В процессе тестирования обнаружился один неприятный недостаток в библиотеке Data Binding — прибайнденные view не вызывают метод removeOnPropertyChangedCallback даже когда активити умирает. Это приводит к тому, что слой Model держит ссылки на объекты слоя View через слой ViewModel. В общем, утечка памяти из объектов LiveDataField.
Чтобы этого избежать, можно использовать еще один хак и вручную обнулить все байндинги на onDestroy активити:
class ProfileActivity : LifecycleActivity() {
...
override fun onDestroy() {
super.onDestroy()
// обнуляем поле profileViewModel
binding.profileViewModel = null
// необходимо вручную вызвать обновление байндингов,
// так как автоматическое обновление не работает на этапе onDestroy :(
binding.executePendingBindings()
}
}Кроме того, внимательные читатели могли заметить в разметке класс SafeEditText. В общем, он понадобился, из-за бага в Data Binding Library. Суть в том, что она добавляет в листенер вводимого текста через addTextChangedListener даже если этот листенер null.
Так как на этапе onDestroy я обнуляю модель, то сперва в EditText добавляется null-листенер, а потом обновляется текст, который стал тоже null. В итоге на onDestroy происходил NPE краш при попытке оповестить null-листенер о том, что текст стал null.
В общем, при использовании Data Binding будьте готовы к таким багам — их там довольно много.
В общем, с некоторыми трудностями, хаками и некоторыми разочарованиями, но связать AAC и Data Binding получилось. Скорее всего, в скором времени (года 2?) Google добавит какие-нибудь фичи, чтобы связать их — тот же аналог моей LiveDataField. Пока что AAC в альфе, так что там многое еще может измениться.
Основные проблемы на текущий момент, на мой взгляд, связаны с библиотекой Data Binding — она не подстроена под работу с ViewModel и в ней есть неприятные баги. Это наглядно видно из хаков, которые пришлось использовать в статье.
Во-первых, при байндинге сложно получить активити или фрагмент, чтобы получить LifecycleObject, необходимый для LiveData. Эту проблему можно решить: либо достаем это через рефлексию, либо просто делаем observeForever, который будет держать подписку на LiveData, пока мы вручную не обнулим байндинги на onDestroy.
Во-вторых, Data Binding предполагает, что ObservableField и прочие Observable объекты живут тем же жизненным циклом, что и view. По факты эти объекты — это часть слоя ViewModel, у которой другой жизненный цикл. Например, в AAC этот слой переживает перевороты активити, а Data Binding, не обновляет байндинги после переворота активити — для нее все view умерли, а значит, и все Observable объекты тоже умерли и обновлять ничего нет смысла. Эту проблему можно решить обнулением байндингов вручную на onDestroy. Но это требует лишнего кода и необходимости следить, что все байндинги обнулены.
В-третьих, возникает проблема с объектами слоя View без явного жизненного цикла, например, ViewHolder адаптера для RecyclerView. У них нет четкого вызова onDestroy, так как они переиспользуются. В какой момент обнулять байндинги во ViewHolder — сложно сказать однозначно.
Не сказал бы, что на текущий момент связка этих библиотек выглядит хорошо, хотя использовать ее можно. Стоит ли использовать такой подход с учетом недостатков, описанных выше — решать вам.
Пример из статьи можно посмотреть на гитхабе Touch Instinct.
|
|
[Перевод] Искусственная глупость: искусство намеренных ошибок |

Всё должно быть изложено так просто, как только возможно, но не проще.
— Альберт Эйнштейн



|
Метки: author PatientZero разработка игр искусственный интеллект геймдизайн artificial intelligence playtesting плейтесты |
[Из песочницы] Сравнение* древовидных графов |

MR_ORDER_TREE, имеет следующий вид:order_id |
ID заказа, на котором закреплено дерево |
item_id |
ID элемента в дереве, вместе с order_id формирует первичный ключ и уникален в рамках заказа |
item_ref |
ID элемента в который входит выбранный элемент |
kts_item_id |
ID из справочника деталей и узлов |
item_qty |
Количество |
is_item_buy |
Покупное ли изделие |
item_position |
Номер позиции в сборке |
(item_ref, kts_item_id) уникальны. Кроме покупки, позиции и количества имеются и другие атрибуты конкретного элемента, но речь не о них.MR_ORDER_TREE_PREV.MR_ORDER_TREE_COMP, которая дополнительно будет иметь два столбца:stat |
Столбец для отметки состояния элементов: -1 – дополнительный корневой элемент (об этом ниже) 0 – элемент удален 1 – элемент добавлен 2 – свойства элемента изменились 3 – неизвестное состояние (на случай если что-то пошло не так) 4 – элемент не изменился |
comm |
Комментарий, дающий дополнительные данные по состоянию |
MR_ORDER_TREE_COMP. При этом добавим к ним общий корень, item_id у текущего дерева увеличим на (максимальное значение + 1) item_id дерева с предыдущим состоянием. Все элементы старого дерева будем считать удалением, а все элементы нового вставкой.select nvl(max(item_id), 0) + 1
into v_id
from mr_order_tree_prev t
where t.order_id = p_order_id;
insert into MR_ORDER_TREE_COMP (ORDER_ID, ITEM_ID, KTS_ITEM_ID, ITEM_QTY, IS_ITEM_BUY, IS_ADD_WORK, ITEM_POSITION, N_GROUP, T_LEVEL, STAT, COMM)
values (p_order_id, -1, null, 0, 0, 0, 0, 0, 0, -1, 'Дополнительная голова для расчета');
insert into MR_ORDER_TREE_COMP (ORDER_ID,
ITEM_ID,
ITEM_REF,
KTS_ITEM_ID,
KTS_ITEM_REF,
ITEM_QTY,
IS_ITEM_BUY,
IS_ADD_WORK,
ITEM_POSITION,
N_GROUP,
STAT,
COMM)
select p.order_id,
p.item_id,
nvl(p.item_ref, -1),
p.kts_item_id,
p.kts_item_ref,
p.item_qty,
p.is_item_buy,
p.is_add_work,
p.item_position,
p.n_group,
0,
'удаление'
from mr_order_tree_prev p
where p.order_id = p_order_id;
insert into MR_ORDER_TREE_COMP (ORDER_ID,
ITEM_ID,
ITEM_REF,
KTS_ITEM_ID,
KTS_ITEM_REF,
ITEM_QTY,
IS_ITEM_BUY,
IS_ADD_WORK,
ITEM_POSITION,
N_GROUP,
STAT,
COMM)
select p.order_id,
p.item_id + v_id,
case
when p.item_ref is null
then -1
else p.item_ref + v_id
end,
p.kts_item_id,
p.kts_item_ref,
p.item_qty,
p.is_item_buy,
p.is_add_work,
p.item_position,
p.n_group,
1,
'вставка'
from mr_order_tree p
where p.order_id = p_order_id;
for rec in (select item_id,
level lev
from (select *
from mr_order_tree_comp
where order_id = p_order_id)
connect by prior item_id = item_ref
start with item_id = -1)
loop
update mr_order_tree_comp c
set c.t_level = rec.lev
where c.order_id = p_order_id
and c.item_id = rec.item_id;
end loop;mr_order_tree_comp для пересчитываемого заказа, это понадобится в будущем. Я использовал коллекцию, но думаю, что можно применить и временную таблицу. procedure save_tree_stat(p_order in number)
is
begin
select TREE_BC_STAT_ROW(c.order_id, c.item_id, c.item_ref, c.kts_item_id, c.kts_item_ref)
bulk collect into tree_before_calc
from mr_order_tree_comp c
where c.order_id = p_order;
end save_tree_stat;select max(t_level)
into v_max_lvl
from mr_order_tree_comp
where order_id = p_order_id;kts_item_id с одинаковым item_ref, но состоянием 1 для 0 и 0 для 1. После этого один из них удалять, а входящие элементы перецеплять на оставшийся узел. procedure add_to_rdy (p_item in number,
p_order in number)
is
begin
item_ready_list.extend;
item_ready_list(item_ready_list.last) := tree_rdy_list_row(p_order, p_item);
end add_to_rdy;function item_rdy(p_item in number, p_order in number) return number<>
for i in 1..v_max_lvl
loop
<>
for rh in (select c.*
from mr_order_tree_comp c
where c.order_id = p_order_id
and c.t_level = i)
loop
<>
for rl in (select c.*
from mr_order_tree_comp c
where c.order_id = p_order_id
and c.item_ref = rh.item_id
and c.stat in (0, 1)
order by c.stat)
loop
if (item_rdy(rl.item_id, rl.order_id) = 0) then
if (rl.stat = 0) then
select count(*)
into v_cnt
from mr_order_tree_comp c
where c.order_id = p_order_id
and c.item_ref = rh.item_id
and c.kts_item_id = rl.kts_item_id
and c.stat = 1;
case
when (v_cnt = 1) then
select c.item_id
into v_item
from mr_order_tree_comp c
where c.order_id = p_order_id
and c.item_ref = rh.item_id
and c.kts_item_id = rl.kts_item_id
and c.stat = 1;
update mr_order_tree_comp c
set c.item_ref = v_item
where c.item_ref = rl.item_id
and c.order_id = p_order_id;
update mr_order_tree_comp c
set c.stat = 4
where c.item_id = v_item
and c.order_id = p_order_id;
diff_items(p_order_id, rl.item_id, v_item);
delete mr_order_tree_comp c
where c.item_id = rl.item_id
and c.order_id = p_order_id;
add_to_rdy(rl.item_id, rl.order_id);
add_to_rdy(v_item, rl.order_id);
end case;
end if; (rl.stat = 1) логика аналогична.diff_items. Ситуация, когда найдено более одного элемента, является скорее исключением и говорит о том, что с деревом состава что-то не так.kts_item_id к общему количеству элементов. Если значение данного отношения больше определенного значения, то узлы взаимозаменяемы. Если на текущей итерации цикла у узла есть несколько вариантов замены, то берется вариант с наибольшим «коэффициентом похожести».CASE.when (v_cnt = 0) then
select count(*)
into v_cnt
from mr_order_tree_comp c
where c.order_id = p_order_id
and c.item_ref = rh.item_id
and c.stat = 1
and not exists (select 1
from table(item_ready_list) a
where a.order_id = c.order_id
and a.item_id = c.item_id); if (v_cnt = 1) then
select c.item_id, c.kts_item_id
into v_item, v_kts
from mr_order_tree_comp c
where c.order_id = p_order_id
and c.item_ref = rh.item_id
and c.stat = 1
and not exists (select 1
from table(item_ready_list) a
where a.order_id = c.order_id
and a.item_id = c.item_id); if (is_item_comp(v_item, p_order_id) = is_item_comp(rl.item_id, p_order_id)) then
update mr_order_tree_comp c
set c.item_ref = v_item
where c.item_ref = rl.item_id
and c.order_id = p_order_id;
add_to_rdy(rl.item_id, rl.order_id);
add_to_rdy(v_item, rl.order_id);
end if;
end if;like_degree, значение коэффициента для сравнения содержится в переменной lperc.if (v_cnt > 1) then
begin
select item_id, kts_item_id, max_lperc
into v_item, v_kts, v_perc
from (select c.item_id,
c.kts_item_id,
max(like_degree(rl.item_id, c.item_id, c.order_id)) max_lperc
from mr_order_tree_comp c
where c.order_id = p_order_id
and c.item_ref = rh.item_id
and c.stat = 1
and not exists (select 1
from table(item_ready_list) a
where a.order_id = c.order_id
and a.item_id = c.item_id)
and is_item_comp(c.item_id, p_order_id) = (select is_item_comp(rl.item_id, p_order_id) from dual)
group by c.item_id, c.kts_item_id
order by max_lperc desc)
where rownum < 2;
if (v_perc >= lperc) then
update mr_order_tree_comp c
set c.item_ref = v_item
where c.item_ref = rl.item_id
and c.order_id = p_order_id;
update mr_order_tree_comp c
set c.comm = 'Удаление. Заменилось на ' || kts_pack.item_code(v_kts) || ' (' || to_char(v_perc) || '%)'
where c.item_id = rl.item_id
and c.order_id = p_order_id;
add_to_rdy(rl.item_id, rl.order_id);
add_to_rdy(v_item, rl.order_id);
end if;
end;
end if;
<>
for rs in (select *
from mr_order_tree_comp c
where c.order_id = p_order_id
and c.stat in (0,1))
loop
<>
for rb in (select *
from (select *
from mr_order_tree_comp c
where c.order_id = p_order_id) t
connect by prior t.item_ref = t.item_id
start with t.item_id = rs.item_id)
loop
select count(*)
into v_cnt
from mr_order_tree_comp c
where c.item_ref = rb.item_id
and c.kts_item_id = rs.kts_item_id
and c.stat in (1,0)
and c.stat != rs.stat;
if (v_cnt = 1) then
select c.item_id
into v_item
from mr_order_tree_comp c
where c.item_ref = rb.item_id
and c.kts_item_id = rs.kts_item_id
and c.stat in (1,0)
and c.stat != rs.stat;
if (rs.stat = 0) then
update mr_order_tree_comp c
set c.stat = 4
where c.order_id = p_order_id
and c.item_id = v_item;
diff_items(p_order_id, rs.item_id, v_item);
update mr_order_tree_comp c
set c.item_ref = v_item
where c.order_id = p_order_id
and c.item_ref = rs.item_id;
delete mr_order_tree_comp
where order_id = p_order_id
and item_id = rs.item_id;
end if;
if (rs.stat = 1) then
update mr_order_tree_comp c
set c.stat = 4
where c.order_id = p_order_id
and c.item_id = rs.item_id;
diff_items(p_order_id, rs.item_id, v_item);
update mr_order_tree_comp c
set c.item_ref = rs.item_id
where c.order_id = p_order_id
and c.item_ref = v_item;
delete mr_order_tree_comp
where order_id = p_order_id
and item_id = v_item;
end if;
continue items;
end if;
end loop branch;
end loop items; item_ref. Для этого используется коллекция tree_before_calc, в которую было сохранено начальное состояние дерева mr_order_tree_comp.
|
Метки: author tooteetoo программирование алгоритмы oracle oracle database pl/sql графы деревья |
Security Week 30: Adups снова за свое, как закэшировать некэшируемое, в контейнерах Docker – опасный груз |
 Эта история началась давным-давно, еще в прошлом году, когда исследователи из Kryptowire наткнулись на подозрительный трафик, исходящий из купленного по случаю китайского смартфона. Углубившись в прошивку аппарата, они выяснили, что система OTA-обновлений представляет собой натуральный бэкдор. Ну, и еще немножечко апдейтит прошивку, в свободное от шпионажа за пользователем время.
Эта история началась давным-давно, еще в прошлом году, когда исследователи из Kryptowire наткнулись на подозрительный трафик, исходящий из купленного по случаю китайского смартфона. Углубившись в прошивку аппарата, они выяснили, что система OTA-обновлений представляет собой натуральный бэкдор. Ну, и еще немножечко апдейтит прошивку, в свободное от шпионажа за пользователем время. Исследователь описал механизм атаки следующим образом. Допустим, есть URL — 'www.example.com/personal.php', ссылающийся на контент с важными данными, которые кэшировать не полагается. Хакер вынуждает жертву выполнить запрос 'www.example.com/personal.php/bar.css' (для этого есть масса способов). Сервер на это выдает страницу 'www.example.com/personal.php' с важной информацией жертвы – куки-файлы-то у нее имеются. При этом кэширующий прокси справедливо расценивает 'www.example.com/personal.php/bar.css' как запрос на несуществующий, но подлежащий кэшированию файл bar.css и сохраняет вместо этого содержимое '/personal.php'.
Исследователь описал механизм атаки следующим образом. Допустим, есть URL — 'www.example.com/personal.php', ссылающийся на контент с важными данными, которые кэшировать не полагается. Хакер вынуждает жертву выполнить запрос 'www.example.com/personal.php/bar.css' (для этого есть масса способов). Сервер на это выдает страницу 'www.example.com/personal.php' с важной информацией жертвы – куки-файлы-то у нее имеются. При этом кэширующий прокси справедливо расценивает 'www.example.com/personal.php/bar.css' как запрос на несуществующий, но подлежащий кэшированию файл bar.css и сохраняет вместо этого содержимое '/personal.php'. Для начала надо найти жертву – разработчика, использующего Docker для Windows. Потом следует вынудить его зайти на специальный сайт, где сидит вредоносный JavaScript, который создает на машине жертвы новый контейнер, втягивающий с репозитория вредоносный код. Его устойчивость на машине обеспечивается скриптом, сохраняющим контейнер при шатдауне и запускающим его во время загрузки Docker.
Для начала надо найти жертву – разработчика, использующего Docker для Windows. Потом следует вынудить его зайти на специальный сайт, где сидит вредоносный JavaScript, который создает на машине жертвы новый контейнер, втягивающий с репозитория вредоносный код. Его устойчивость на машине обеспечивается скриптом, сохраняющим контейнер при шатдауне и запускающим его во время загрузки Docker. 
|
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» klsw adups fota docker cloudflare |
JetBrains MPS для интересующихся #2 |
В прошлом посте мы остановились на том, что мы умеем добавлять массив входных погодных данных, а точнее данные "Время + температура", слегка попробовали использовать Behavior и разобрались с концептами.
Пришло время делать что-то полезное, ведь пока все, что мы реализовали, можно было реализовать на любом другом языке, за исключением прикольного синтаксиса.
Первым делом, введем ограничения на время. Сейчас мы ограничим его, чтобы часы были в пределе 0-24, а минуты 0-60, иначе будет выдаваться ошибка компиляции.
Constraints это аспект языка, который отвечает за валидность реализации концепта. В нашем случае нам нужно ограничить property hours и minutes, поэтому мы создаем Constraints аспект концепта Time.
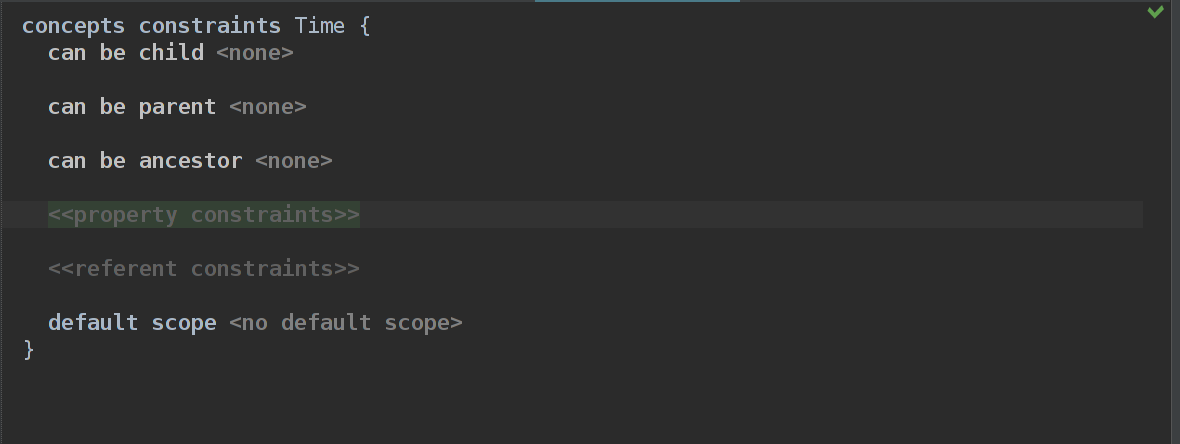
Здесь мы видим 3 пункта, которые отвечают за структуру AST.
can be ancestor: все то же самое, что с parent, но более вложенно: в данном случае мы можем идти как угодно выше по AST, дословно — может ли узел быть предком
Дальше мы можем определить какие то характеристики для properties. Это то, что нам нужно, и пока этого знать вполне достаточно, возиться с областью видимости нам пока не нужно.

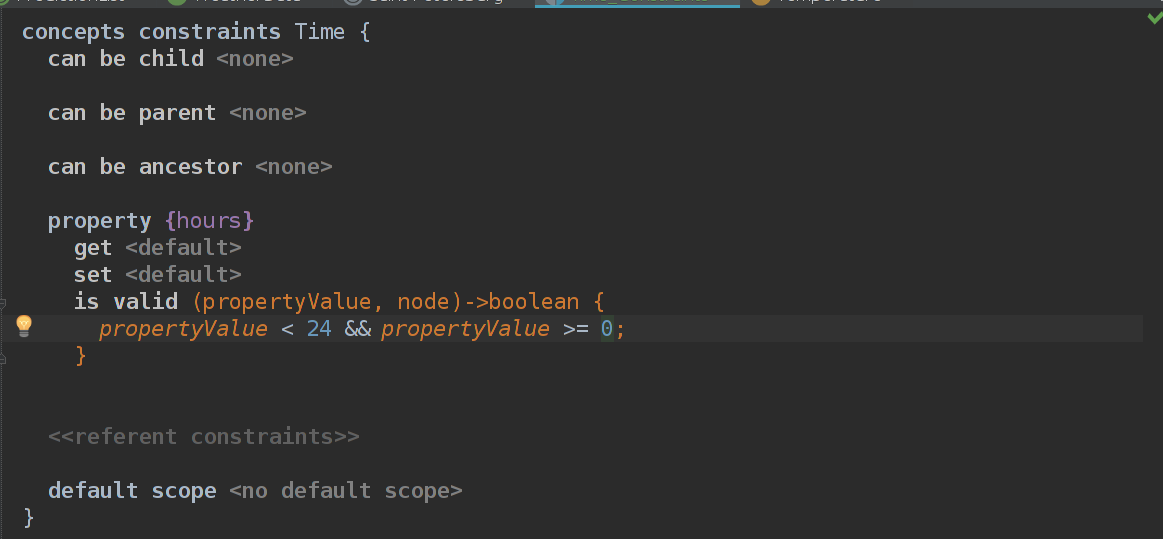
Все, в принципе, просто и понятно: мы можем переопределить геттер и сеттер, но нас интересует is valid. В нем мы на вход получаем propertyValue и текущий node. У нас простое условие, так и пишем, как писали бы на Java.
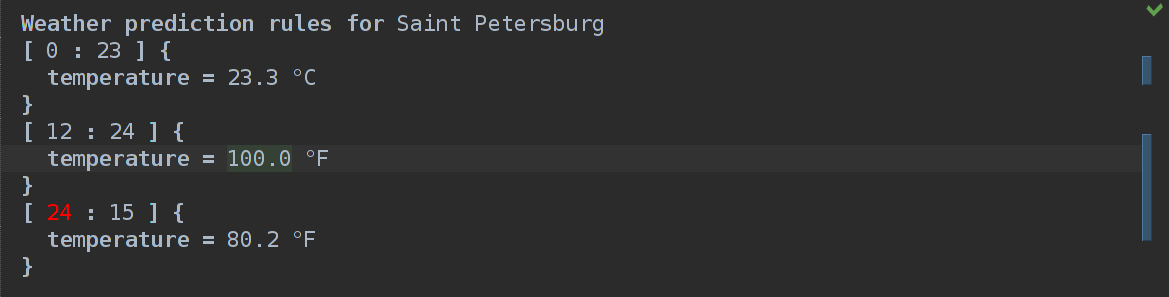
Теперь если мы соберем язык и потыкаем в sandbox, то у нас должно показывать, если значение часа >= 24 или <0.
Написать реализацию для minutes не составит труда Вам самим.
Так, здорово, работает. Теперь стоит попробовать перевести это на Java, ведь не зря же мы это все делали!
Сначала добавляем аспект Generator и называем его main.
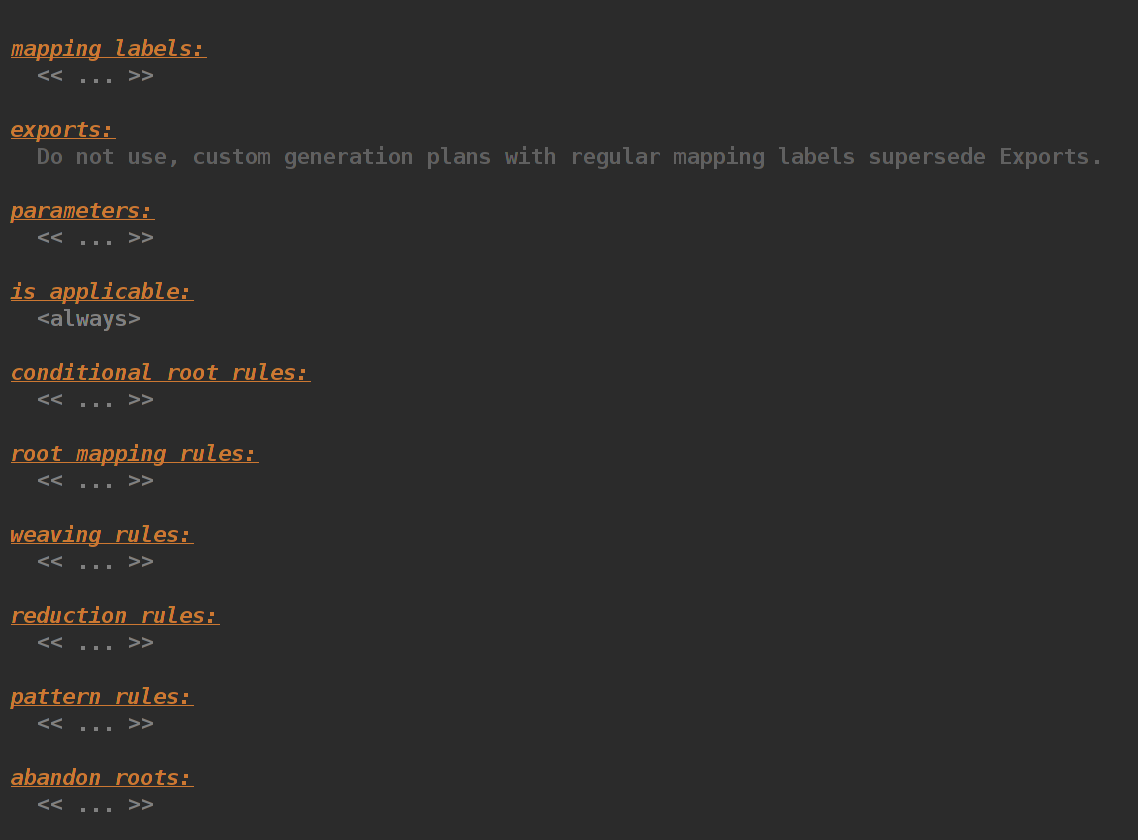
Пустовато, поэтому создадим новый root mapping rule. Выбираем в поле concept наш рутовый концепт PredictionList, а справа от стрелочки — нажимаем Alt + Enter -> New Root Template -> Java class. По логике должно получиться что-то вроде этого:

Если мы откроем map_PredictionList, то у нас будет что-то вроде Java класса с мета информацией над ним.
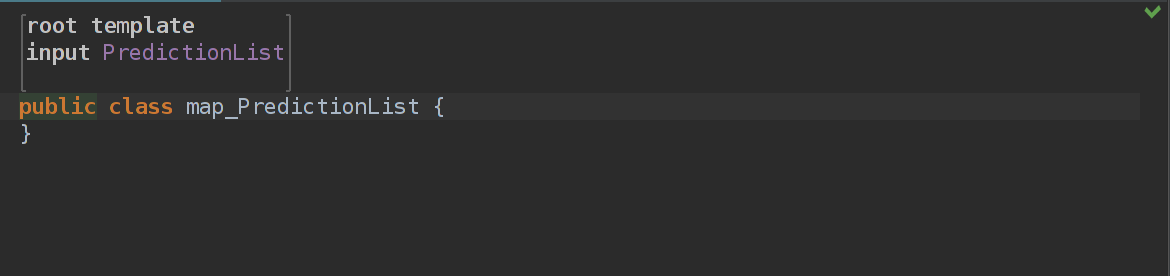
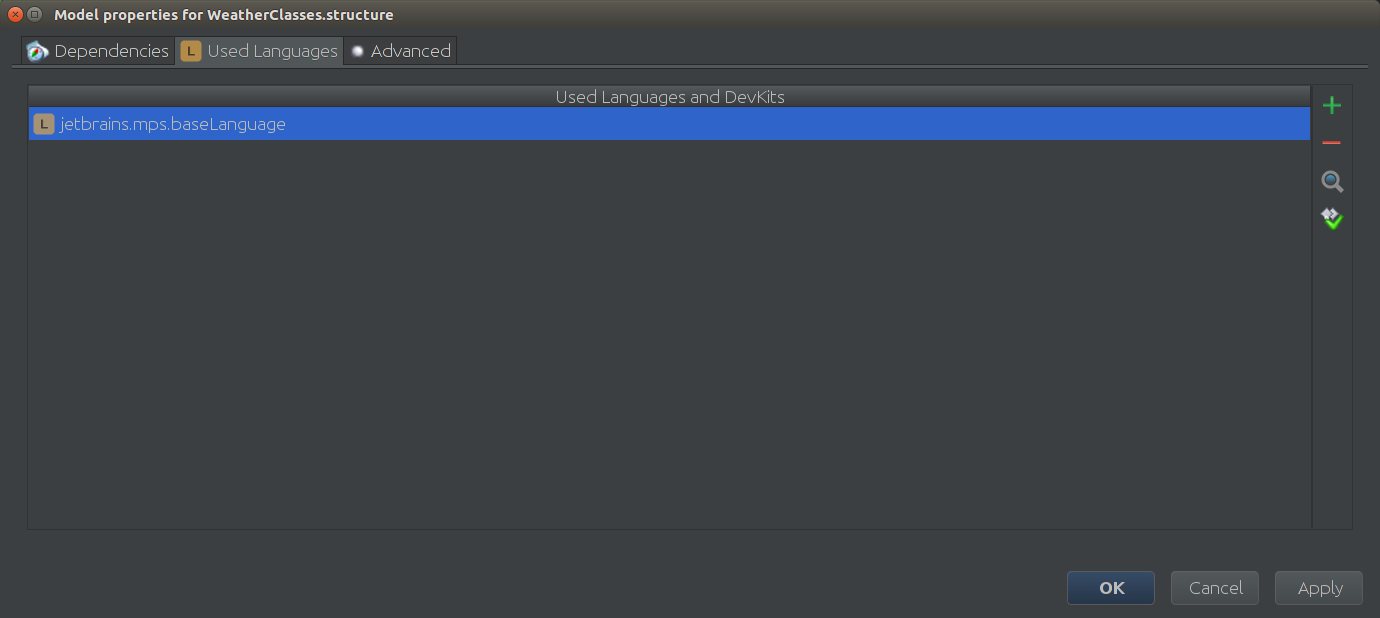
Это наш темплейт, шаблон и вообще самый главный отправной пункт. Но есть один момент: мы же не хотим преобразовывать наш WeatherTimedData в какие то примитивы, верно? Мы хотим чтобы у нас объект класса WeatherTimedData, но тут бамс! У нас же нет такого класса! Так что мы можем написать его вручную. Для этого создадим новый Solution, называем его, как хотим, и самое главное — добавляем в Used Languages jetbrains.mps.baseLanguage, чтобы мы могли написать наши классы.
У меня они получились такие:
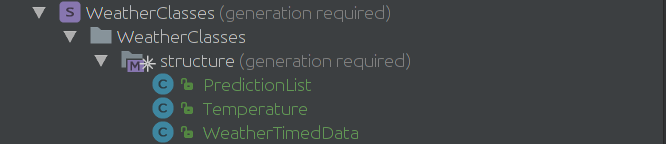
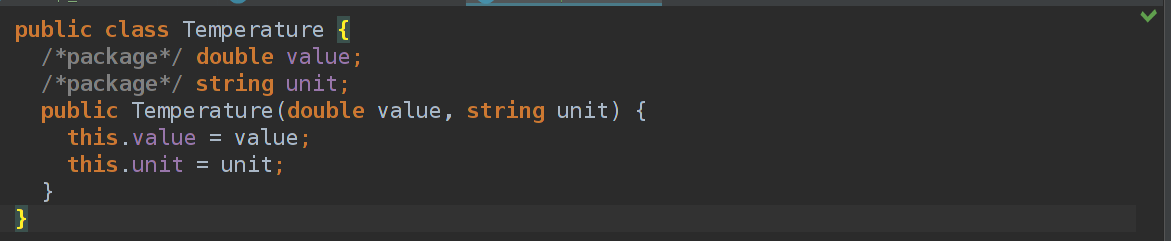
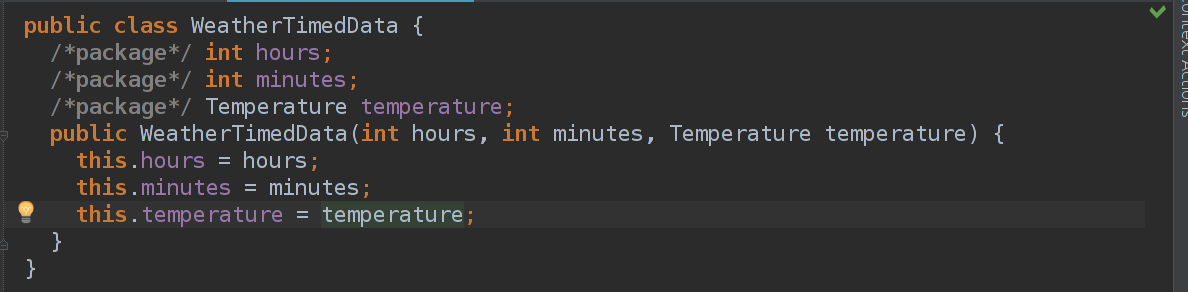

Теперь нужно научиться использовать это в наших генерациях в Java код. Заходим в model properties генератора и добавляем в dependencies WeatherClasses и нажимаем export=true.
Теперь мы можем использовать эти классы в генерации, что мы сейчас и сделаем.
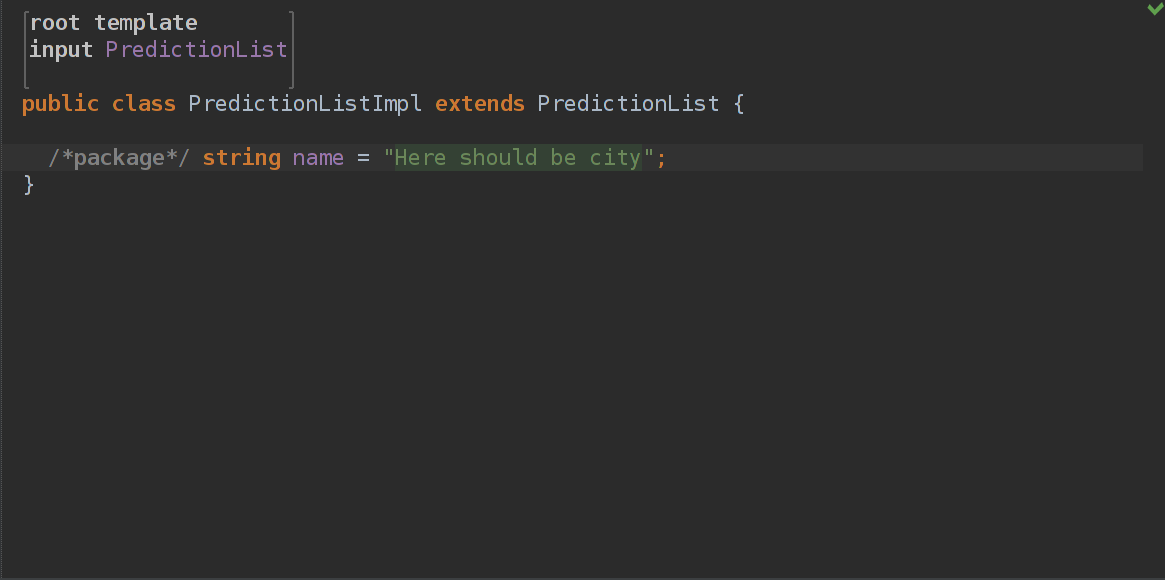
Выглядит как простой класс, но нам нужно добиться того, что name будет иметь значение имени PredictionList. Прогноз погоды для питера — там будет питер. Для Москвы — будет москоу. Нажимаем на строку "Here should be city" и юзаем хоткей Alt + Enter и в выпадающем списке выбираем property macro.
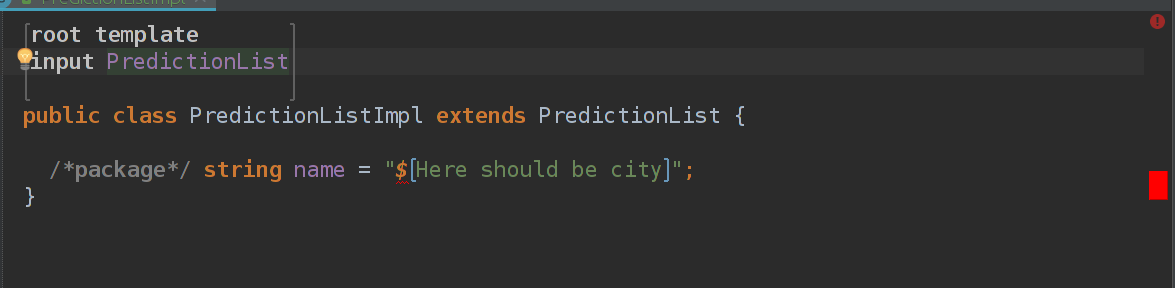
Суть очень простая — нам дается node типа PredictionList и мы должны вернуть строку. Нажимаем на знак доллара, который появился рядом со строкой и редактируем код в инспекторе.

Собираем проект, открываем наш Sandbox solution, где у нас есть только входные погодные данные для Санкт Петербурга, нажимаем ПКМ -> Preview Generated Text, и у нас откроется настоящая Java! Теперь мы можем ее не скринить, а спокойно скидывать копипастом.
package WeatherPrediction.sandbox;
/*Generated by MPS */
import WeatherClasses.structure.PredictionList;
public class PredictionListImpl extends PredictionList {
/*package*/ String name = "Saint Petersburg";
}
Стоит заметить import statement, MPS сгенерировал импорт PredictionList, которые мы писали отдельным Solution. Такие solution можно называть "помогающими", "support solutions". Ну мне лично очень нравится их так называть.
Ну давайте добавим еще реализацию для массива входных данных.
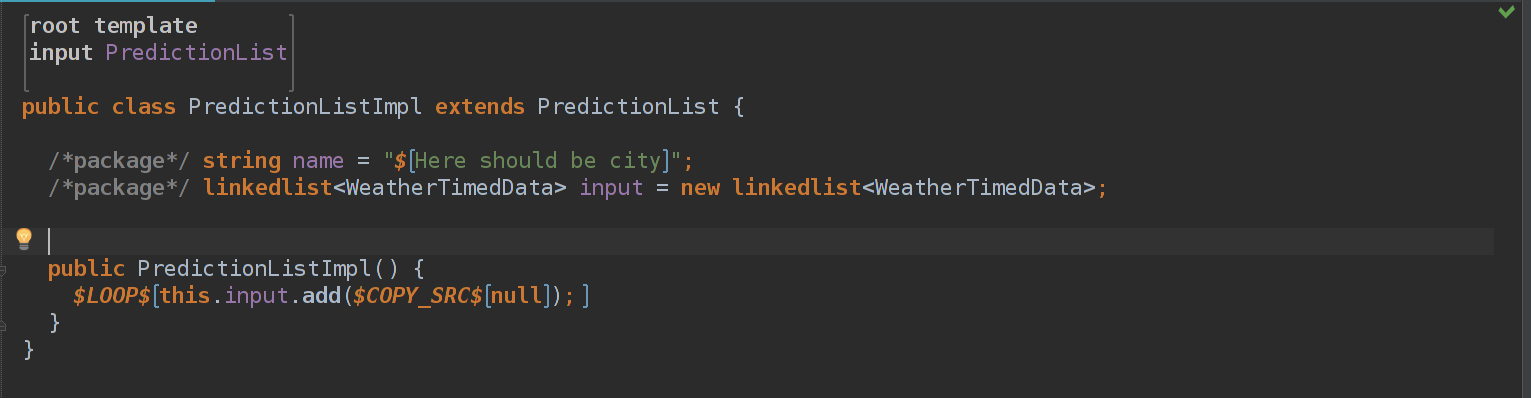
Мы создаем пустой linkedlist(почему бы и нет), в котором мы будем хранить входные данные.
В конструкторе мы используем сразу 2 крутых макроса.
Макрос $LOOP$ делает следующее: он проходит по данной коллекции, и для каждого элемента выполняет что-то. В итоге получается массив сгенерированных данных, которые просто идут друг за другом. В данном случае мы итерируем по node.weatherData.items
Макрос $COPY_SRC$ используется, чтобы получить результат преобразования в другую модель какого-то концепта. В данный момент у нас есть только 1 шаблон: он "главный" и он является шаблоном для PredictionList, и откуда же MPS поймет, что и как делать..?
В такие моменты MPS смотрит в конфигурацию генератора main, а точнее в reduction rules, где у нас сейчас пусто.
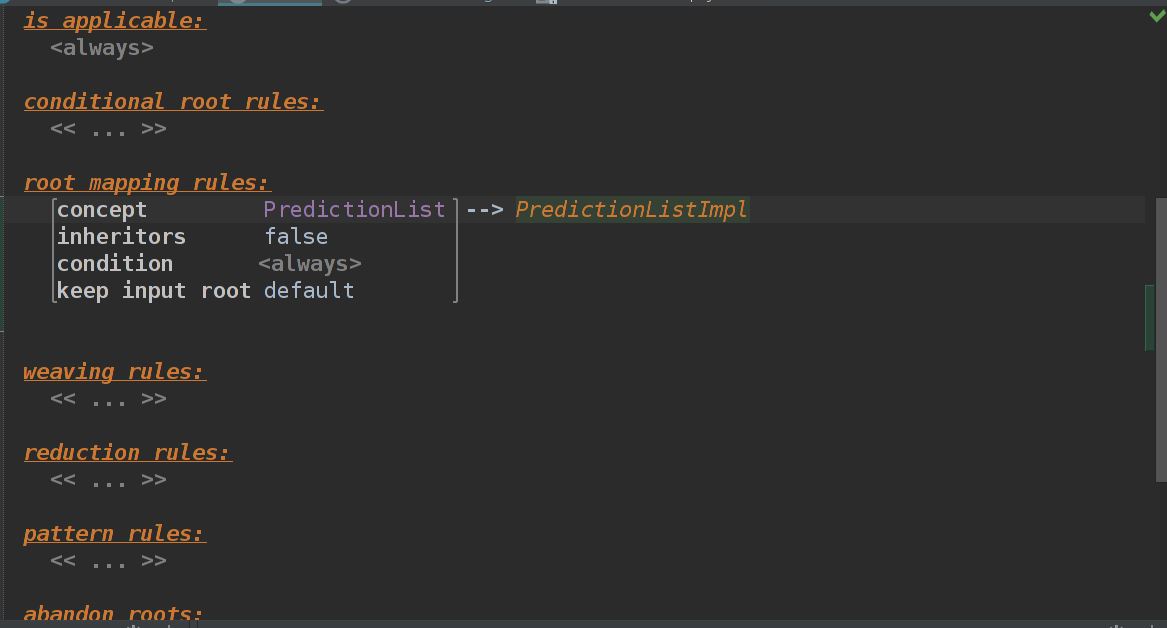
Делаем абсолютно то же самое, что делали с PredictionList.

Переходим в reduce_WeatherTimedData, нажимаем Shift + Space, выбираем Expression. Теперь просто пишем
new WeatherTimedData(0, 0, null)Теперь нужно завернуть этот Expression в TemplateFragment, чье содержимое как раз таки и будет использовано в нашем главном PredictionListImpl.
Выделяем весь expression с помощью хоткея ctrl + w, нажимаем Alt+Enter -> Create Template Fragment.
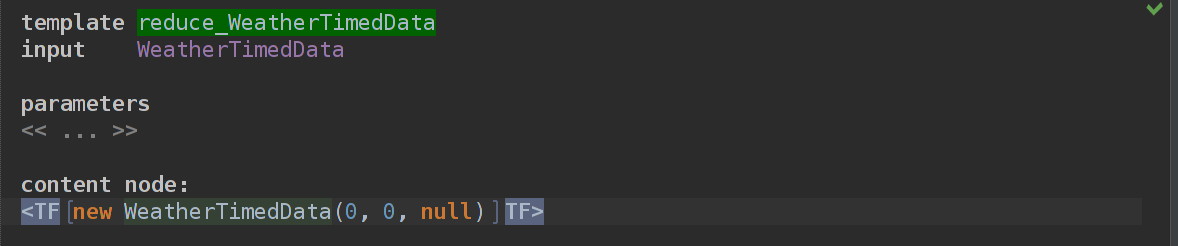
Теперь нам нужно заменить нули на property macro, которые мы уже умеем делать(нажимаем на 0, нажимаем Alt Enter -> Add property macro. В инспекторе пишем
(templateValue, genContext, node, operationContext)->int {
node.time.hours;
}что соотвествует замене 0 на актуальное значение часов. Проделываем то же самое с минутами, а null заменять не будем — мне сейчас лень, но идея та же — мы добавляем reduction rule для концепта Temperature, и вместо property macro используем макрос $COPY_SRC$
После чего заменяем 0 и 0 на property macro, которое мы уже умеем вызывать(Выделяем 0, Alt + Enter ->Add Property Macro -> node.time.minutes).
Собираем язык и идем в Sandbox solution.
Итак, для исходного кода на языке Weather
Weather prediction rules for Saint Petersburg
[ 0 : 23 ] {
temperature = 23.3 °C
}
[ 12 : 24 ] {
temperature = 100.0 °F
}
[ 23 : 33 ] {
temperature = 4.4 °C
} Получается такой Java код:
package WeatherPrediction.sandbox;
/*Generated by MPS */
import WeatherClasses.structure.PredictionList;
import java.util.Deque;
import WeatherClasses.structure.WeatherTimedData;
import jetbrains.mps.internal.collections.runtime.LinkedListSequence;
import java.util.LinkedList;
public class PredictionListImpl extends PredictionList {
/*package*/ String name = "Saint Petersburg";
/*package*/ Deque input = LinkedListSequence.fromLinkedListNew(new LinkedList());
public PredictionListImpl() {
LinkedListSequence.fromLinkedListNew(this.input).addElement(new WeatherTimedData(0, 23, null));
LinkedListSequence.fromLinkedListNew(this.input).addElement(new WeatherTimedData(12, 24, null));
LinkedListSequence.fromLinkedListNew(this.input).addElement(new WeatherTimedData(23, 33, null));
}
} Можно было бы заменить linkedlist на обычный массив, но это было бы сложнее, так как нужно было бы пихать индексы. Можно было бы заменить на ArrayList, но MPS первым посоветовал linkedlist. Можно было бы написать отдельный support-класс для WeatherData, а не добавлять данные в конструкторе, существует много способов сделать генерируемый код лучше. Или хуже. В общем, теперь мы умеем генерить (!)Java код из нашего языка. А вообще, теперь мы можем генерировать Java код для любого другого языка, ведь мы овладели знанием Generator!
Спасибо за внимание.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author enchantinggg программирование java programming jetbrains language design mps |
Инженерные системы малого офиса и вопросы к ним для само (и не само) проверки |
|
Метки: author Scif_yar читальный зал инженерные решения инженерные системы инженерная инфраструктура nag электричество кондиционер кондиционирование |
[Перевод] Как следить за опознанными летающими объектами при помощи Raspberry Pi |
А вы знали, что при помощи Raspberry Pi можно следить за опознанными летающими объектами? Вы можете настроиться на радио-сигналы самолетов на расстоянии до 400 км от вас и отслеживать все рейсы. Для этого вам достаточно найти дешевый USB TV и пару свободных минут.

Изображение: dump1090 — тестирую антенну FlightAware против четвертьволновой гибкой антенны и антенны из банки.
В этой статье вы найдете краткое введение в отслеживание рейсов: обзор софта, аппаратуры и — самое главное — необходимой терминологии и жаргонных выражений. Также я покажу, как Docker и технология контейнеризации помогут управлять софтом в IoT-проектах.
На сайтах типа FlightAware.com можно отслеживать десятки тысяч самолетов при помощи краудсорсинга: задачу выполняют люди по всему миру с помощью своих компьютеров Raspberry Pi (цена вопроса — $35) и дешевых USB TV тюнеров.
Можно следить за рейсами исключительно в личных целях, а можно внести свою маленькую лепту на таких сайтах, как FlightAware.com, FlightRadar24 и PlaneFinder.net и получить взамен детальные показатели — данные радаров и другие ништяки.

Изображение: FlightRadar показывает самолеты в воздушном пространстве Великобритании.
Зачем отслеживать рейсы?
Вот несколько доводов:
И самое главное — это просто веселый проект, который можно провернуть при помощи своего Pi и получить моментальное удовлетворение от каждого кусочка. При этом затраты на него стремятся к нулю.
Если нужен результат, лучше покупайте технику (DVB-T sticks) известных брендов. Представленные выше ссылки — не пиар по партнерке.
На сайте ModMyPi также можно купить весь необходимый набор в одном флаконе.
Итак, наша цель — настроить USB TV тюнер таким образом, чтобы он ловил ADS-B трансляции рейсов в заданном диапазоне. Для начала давайте определимся с некоторыми определениями и терминами из области отслеживания рейсов.
На борту современных самолетов есть автоматические транспондеры, которые собирают информацию с навигационных инструментов и транслируют ее в окружающую среду через ADS-B. Эта информация не зашифрована, так что подхватить ее может любой — что диспетчер, что другой самолет, что владелец Raspberry Pi.
ADS-B (Automatic dependent surveillance-broadcast, автоматическое зависимое наблюдение-вещание) — технология, позволяющая и лётчикам в кабине самолета, и авиадиспетчерам на наземном пункте наблюдать движение воздушных судов с большей точностью, чем это было доступно ранее, и получать аэронавигационную информацию. Источник — Википедия.
TV-тюнер, который нам понадобится, называется DVB-T, что расшифровывается как Digital Video Broadcasting — Terrestrial. Это европейский стандарт эфирного цифрового телевидения. Это устройство также можно использовать как теле-антенну для просмотра любимых ТВ-шоу. Не все устройства DVB-T можно настроить на авиа-сигналы, так что лучше выбирайте что-то из рекомендованного или же тщательно изучите характеристики сами перед покупкой.
Википедия: sub-miniature version A. Такие разъемы меньше коаксиальных и обычно есть у премиальных или целевых DVB-T. У дешевых DVB-T, скорей всего, будет маленький разъем. Пигетйл можно купить на eBay или в любом магазине электроники. Он понадобится, чтобы совмещать любые крупные антенные разъемы — коаксиальные, SMA или RF.

Ключевой компонент для расшифровки сигналов ADS-B — это софт dump1090. Это число означает частоту, на которой мы работаем, а dump — команда, которую он выполняет — расшифровывает и дампит необработанные данные.
Приложение dump1090 — это open-source проект, у которого есть несколько форков благодаря разным людям, которые вносили новые и улучшали старые функции. Выбрать нужный форк может быть довольно затруднительно.
Я воссоздал историю этого приложения по данным с GitHub:
Мы будем использовать Docker для сборки кода, но при желании вы можете точно так же запускать команды отдельно в терминале. Вот несколько причин, почему стоит пользоваться Docker-контейнерами:
У большинства версий dump1090 также есть веб-интерфейс, где можно увидеть самолеты в определенном диапазоне в режиме реального времени.
FlightAware — это один из нескольких сайтов-агрегаторов, которые собирают данные с программы dump1090.При помощи виртуальной визуализации радара вы можете собрать детальную статистику по тем рейсам, которые вы помогли отследить, а также узнать, в каком диапазоне вы работали.
Вот мои результаты, которые я увидел в своем профиле. Я использовал выделенную антенну и тюнер DVB-T с шумоизоляцией.
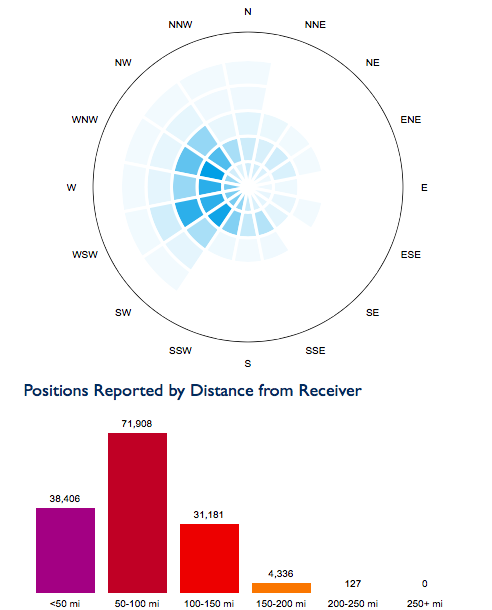
Также вы можете посмотреть мой профиль на FlightAware, чтобы получить больше данных.
MLAT (аббр. мультилатерация) — это технология, при которой можно использовать некоторое количество наземных станций, чтобы отслеживать самолеты, которые не передают данные ADS-B. Можно почитать подробнее в статье на сайте FlightAware.
Она основывается на оценке разности времени прихода сигналов: она должна работать из коробки, и поэтому позволяет вам отслеживать намного больше рейсов, чем вы смогли бы при помощи одного только ADS-B.
$ git clone https://github.com/alexellis/eyes-in-the-skyДобавляем эту строку в /etc/modprobe.d/blacklist.conf:
blacklist dvb_usb_rtl28xxu
Теперь перезагружаемся.

Изображение: тестирую DVB-T от Pimoroni, прикрепленный к Pi Zero и оставленный дома у родственников.
$ cd eyes-in-the-sky/dump1090
$ docker build -t alexellis2/dump1090:malcomrobb . -f Dockerfile.malcolmrobb‘-t’ — устанавливает название образа для дальнейшего использования.
-f — позволяет выбрать Dockerfile с кастомным названием. Также я задал имя для форка mutability.
Docker позволяет вам расшарить свои образы с кем угодно при помощи команды push, которая выгружает их на Docker Hub. Чтобы скачать dump1090 без сборки кода с нуля, выполняем команду:
$ docker pull alexellis2/dump1090:malcolmrobb$ docker rm -f 1090 # remove any old container
$ docker run --privileged -p 8080:8080 -p 30005:30005 -p 30003:30003 --privileged --name 1090 -d alexellis2/dump1090:malcomrobbКоманда docker run отвечает за запуск нашего кода. Чтобы потом код остановить, используйте docker rm -f 1090, а если вы перезагрузили Pi — restart 1090.
При помощи -p Docker определяет, какие порты надо раскрыть из контейнера. Можно запустить две копии кода dump1090, если поменять номер порта и имя контейнера.
При помощи -d контейнер перемещается в фон в качестве демона, так что если вы хотите увидеть консольный вывод, просто напишите ‘docker logs --tail 20 -f 1090’
Пример логов:

Если вы знаете IP-адрес вашего Raspberry Pi, то вы можете открыть его во встроенной странице: http://192.168.0.10:8080/
Чтобы узнать IP-адрес, напишите ifconfig.
Теперь вы сможете залогиниться в ваш Pi из любой точки и увидеть рейсы в вашей местности, а также насколько хороший у вас диапазон в данной локации.
Если вы не хотите запускать контейнер с привилегиями, то вы можете узнать ID устройства USB, а затем заменить --privileged на --device=/dev/bus/usb/001/004, например.
Для своего случая вам следует заменить последние цифры, т.е. 004 в моем примере. Нужные цифры вы можете получить при помощи команды lsusb:
$ lsusb
Bus 001 Device 004: ID 0bda:2838 Realtek Semiconductor Corp. RTL2838 DVB-TЕсть несколько сайтов по отслеживанию рейсов, я начал с FlightAware. Их софт подключается к вашему коду dump1090 и передает данные в их сервера, где вы уже можете сверять статистику и сравнивать свои данные с другими участниками.
Можно установить .deb файл прямо на свой Pi, но я создал отдельный Dockerfile. У него есть два преимущества: можно запустить две и более копий софта и переключаться между версиями без перепрошивки Pi.
Дальше собираем образ при помощи следующей команды или скачиваем образ при помощи docker pull alexellis2/flightaware:3.5.0:
$ cd eyes-in-the-sky/flightaware
$ docker build -t alexellis2/flightaware:3.5.0 .Обратите внимание на точку в конце строки, не пропустите ее.
Теперь регистрируемся на сайте FlightAware.com и задаем имя пользователя и пароль.
Редактируем файл piaware.conf, заменяем следующие поля:
У FlightAware есть классная функция, которая позволяет отслеживать ваш Raspberry Pi по MAC-адресу. К счастью, Docker позволяет подменять MAC-адреса, и поэтому мы можем запустить несколько копий софта. Если вы так делаете, просто поменяйте MAC, чтобы он был уникальным для каждой копии.
Теперь запустим образ и посмотрим логи:
$ cd eyes-in-the-sky/flightaware
$ docker rm -f piaware_1
$ docker run --mac-address 02:42:ac:11:00:01 -v `pwd`/piaware.conf:/etc/piaware.conf --name piaware_1 -d alexellis2/piaware:3.5.0Посмотрите логи и нажмите Control + C в любой момент времени.
$ docker logs --tail 20 -f piaware_1
Ваш Pi появится на сайте через несколько минут.
Какой будет расход электричества?
Pi Zero или 2/3 потребляет 2-3 Ватта во время простоя. Приложение dump1090 задействует процессор Pi, до 50% его мощностей на Zero, поэтому учитывайте, что будет расходоваться дополнительное электричество для нагрузки и USB DVB-T.
Можно ли провернуть операцию с USB-аккумулятора?
Да, в течение ограниченного времени. Аккумулятор, которого мне обычно хватало на 3 дня, ушел за 3 часа, когда я с его помощью отслеживал рейсы.
Можно ли использовать солнечную энергию?
Солнечная энергия, возможно, — не совсем правильное решение. Raspberry Pi не будет надежно работать напрямую от солнечной панели. Вам понадобится сложное оборудование, включая контроллер зарядки, солнечные панели адекватных размеров и батарейки, которых должно хватать на несколько дней.
Лучше подключать Pi через Power over Ethernet с водонепроницаемым корпусом. Вот список необходимых деталей.
Существует ли коробочное решение — образ или ISO?
Можно найти полный образ на SD-карте на сайте FlightAware, но если вы будете строить систему из модульных компонентов, то у вас будет преимущество перед любым другим софтом, разработанным под dump1090.

Изображение: тестирую антенны — антенна из банки, FlightAware, 2x 1090 MHz.
Также вам могут понравиться следующие блоги и статьи о том, что можно сделать с помощью Raspberry Pi и Docker:
|
Метки: author r-moiseev стандарты связи беспроводные технологии devops flightawawre raspberry pi dvb-t mlat ads-b docker dump1090 |
[Из песочницы] Как сдают ISTQB® Foundation Level на русском: шпаргалка по сертификации тестировщика |

|
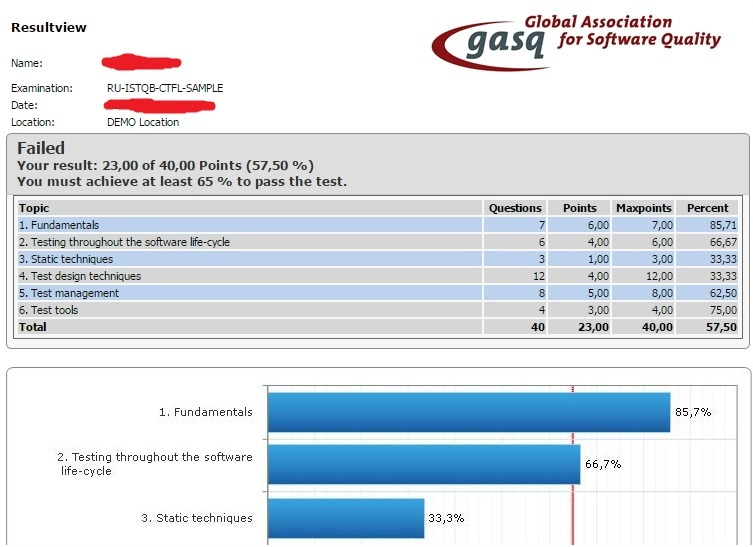
Метки: author Helwig учебный процесс в it istqb qa тестирование сертификация экзамен |
Почему Vue.js — лучший фреймворк для front-end разработки на 2017 год |
{{ message }}
Vue.prototype.$myMethod = function (methodOptions) {
// something logic ...
}
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author rboots javascript vuejs angular react |
[Из песочницы] Реализация выдвижного меню NavigationDrawer при помощи DrawerLayout, с использованием произвольной разметки |
android:clickable="true"
android:background="#FFFFFF"
xmlns:android="http://schemas.android.com/apk/res/android" />
public class NavigationLayout extends RelativeLayout
{
Button ok;
public NavigationLayout(Context context,RelativeLayout parent)
{
super(context);
initView(context,parent);
}
public void initView(final Context context,RelativeLayout parent)
{
// надуваем любой xml файл разметки
View view= LayoutInflater.from(context).inflate(R.layout.view_drawer_layout,parent,true);
ok=(Button)view.findViewById(R.id.ok);
ok.setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
Toast.makeText(context,"Ok",Toast.LENGTH_SHORT).show();
}
});
}
}
public class ParentNavigationActivity extends AppCompatActivity {
NavigationLayout navigationLayout;
RelativeLayout left_drawer;
@Override
public void setContentView(@LayoutRes int layoutResID) {
super.setContentView(layoutResID);
setupMenu();
}
public void setupMenu()
{
left_drawer=(RelativeLayout) findViewById(R.id.left_drawer);
navigationLayout=new NavigationLayout(getApplicationContext(),left_drawer);
left_drawer.addView(navigationLayout);
}
}public class MainActivity extends ParentNavigationActivity {
@Override
protected void onCreate(Bundle savedInstanceState)
{
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_test);
}
}|
|
[Из песочницы] Как уважать время или как стать эффективным тим лидером |









|
Метки: author Exadlive gtd тайм менеджмент it тимлиды и разработчики менеджмент организация времени |
Геймджем для Lua-разработчиков на движках Corona и Defold |

Партнеры и друзья Appodeal, Corona Labs совместно с Defold и DevGAMM Минск, объявляют о старте геймджема #CoronaDefoldJam на базе Lua. Джем пройдет с 28 июля по 30 сентября 2017 на платформе itch.io. Требование к участникам только одно — игры в рамках джема должны быть созданы на Corona или Defold. Если вы никогда не использовали эти движки, не страшно: обе платформы просты для изучения и обладают очень дружелюбными сообществами, которые всегда помогут разобраться. В общем, #CoronaDefoldJam — идеальный повод освоить новые инструменты для создания игр; тем более, что джем поддерживает легендарный Джон Ромеро.

Правила джема разрешают использовать готовые архивы (например, вот этот), однако игра должна быть создана специально для #CoronaDefoldJam. Еще из хороших новостей — джем стартует вместе с Ludum Dare 39 и будет иметь с ним общую тему. Она появится на странице джема 28-29 июля. Itch.io позволит продвигать игры в широком международном кругу разработчиков и любителей indie.
Джем — отличная возможность наконец взяться за разработку игры, о которой вы давно думали. К тому же, организаторы обещают призы:
Подробнее с условиями можно ознакомиться по ссылке.
Все вопросы вы можете задать организаторам через почту: oleg@gamesjam.org, в твиттере с хэштегом #CoronaDefoldJam или в секции “коммьюнити” на itch.io.
|
|
Как «Актив» организовал «электронную переговорку» |
Наша компания постоянно растет во всех смыслах этого слова. В какой-то момент мы почувствовали, что вырос не только штат сотрудников, помещений, но и значительно увеличилось количество проводимых встреч, совещаний, обсуждений и презентаций. И переговорные комнаты стали для нас таким же ограниченным ресурсом, как время, люди и т.д.
Но это только половина проблемы. Как всем известно, ресурсами еще нужно уметь грамотно управлять, чтобы не случалось коллизий. Ситуации, когда во время встречи с партнерами, в переговорную врывается руководитель соседнего подразделения со словами “И эта занята!?”, недопустимы.

Второй момент – когда под рукой нет инструмента (к примеру, Outlook или его web-интерфейса), чтобы забронировать переговорную комнату, но очень нужно «успеть» захватить ценный ресурс. Для осуществления задуманного, необходимо идти на свое рабочее место и с него осуществлять бронирование. Теперь представим, что у вас нет на это времени, выходя из переговорной комнаты с очередной встречи.
Можно конечно придумать еще различные варианты «почему». Для нас уже этих двух моментов было достаточно, чтобы начать исследования в направлении поиска решения проблемы.
Изначально рассматривались стандартные два варианта:
Мы начали с поиска готовых решений, чтобы понять, какие продукты есть на рынке, какой функциональностью обладают и какие проблемы решают.
Мы выделили несколько решений, которые рассматривали как потенциальные для внедрения:
Посмотрев на каждое, проанализировав их функциональность и конечную стоимость, мы решили разработать свой продукт. И не потому, что нас не устроила функциональность. Нас больше не устроила стоимость и невозможность кастомизировать решение под определенные требования.
Было понятно, что нам нужно, мы уже имели перед глазами готовые продукты, следовательно, оставалось только начать «творить”.
Мы выделили основные задачи, которые должен был первично решать продукт:
После проработки задания, макетов интерфейсов и отрисовки необходимой графики, мы приступили к разработке. Нужно оговориться, что для конечного продукта требовалась не только разработка. Необходимо было еще выбрать аппаратную часть. Естественно, мы сразу решили, что конечным устройством у нас будет планшет. Изучив цены и характеристики предлагаемых на рынке планшетов, мы остановили выбор на Lenovo TAB2 A10-30 10.1. По соотношению цена/качество он нас более чем устроил. При этом нужно понимать, что можно на самом деле использовать любое другое устройство, которое устроит по своим техническим, ценовым, имиджевым и другим параметрам. Но и это еще не все. Планшеты нужно еще как-то крепить около переговорных комнат. Мы знали, что для этого используются специализированные кейсы и начали поиск на просторах интернета. Как оказалось, найти подходящий кейс не просто. Не так много предложений есть на рынке, и из имеющихся не так много тех, которые бы могли нам подойти по своему виду. Но как говорится, “вода камень точит”. Кейсы были найдены, планшеты закуплены, разработан продукт, который удовлетворял всем вышеуказанным требованиям.
Саму базу данных на текущем этапе мы используем в очень ограниченном формате. В ней мы храним аккаунт администратора и параметры переговорных комнат. Основным источником данных о расписаниях, списке переговорных комнатах у нас является MS Exchange Server. В дальнейшем за счет реализации промежуточного слоя между Exchange и бэкендом роль БД будет расширяться.
Почему мы хотим реализовать промежуточный слой между бэкендом и Exchange? На самом деле основные задачи, которые мы хотим решить таким образом следующие.
Мы считаем, что не всегда и не у всех в ИТ-инфраструктуре присутствует Exchange-сервер. Поэтому необходимо как минимум абстрагироваться от источника информации (переходим на уровень интерфейсов).
И уже техническая проблема, с которой мы столкнулись – это мягко говоря не мгновенная реакция Exchange на запросы. Нам нужна очередь запросов и промежуточный кеширующий слой, к которому уже непосредственно будут происходить обращения бэкенда, а не напрямую взаимодействуя с Exchange
Работа с конечным устройством (планшетом) начинается с привязки к конкретной переговорной комнате. Для этого реализована простая «админка», в которой выводится список с переговорными комнатами, имеющимися в компании.
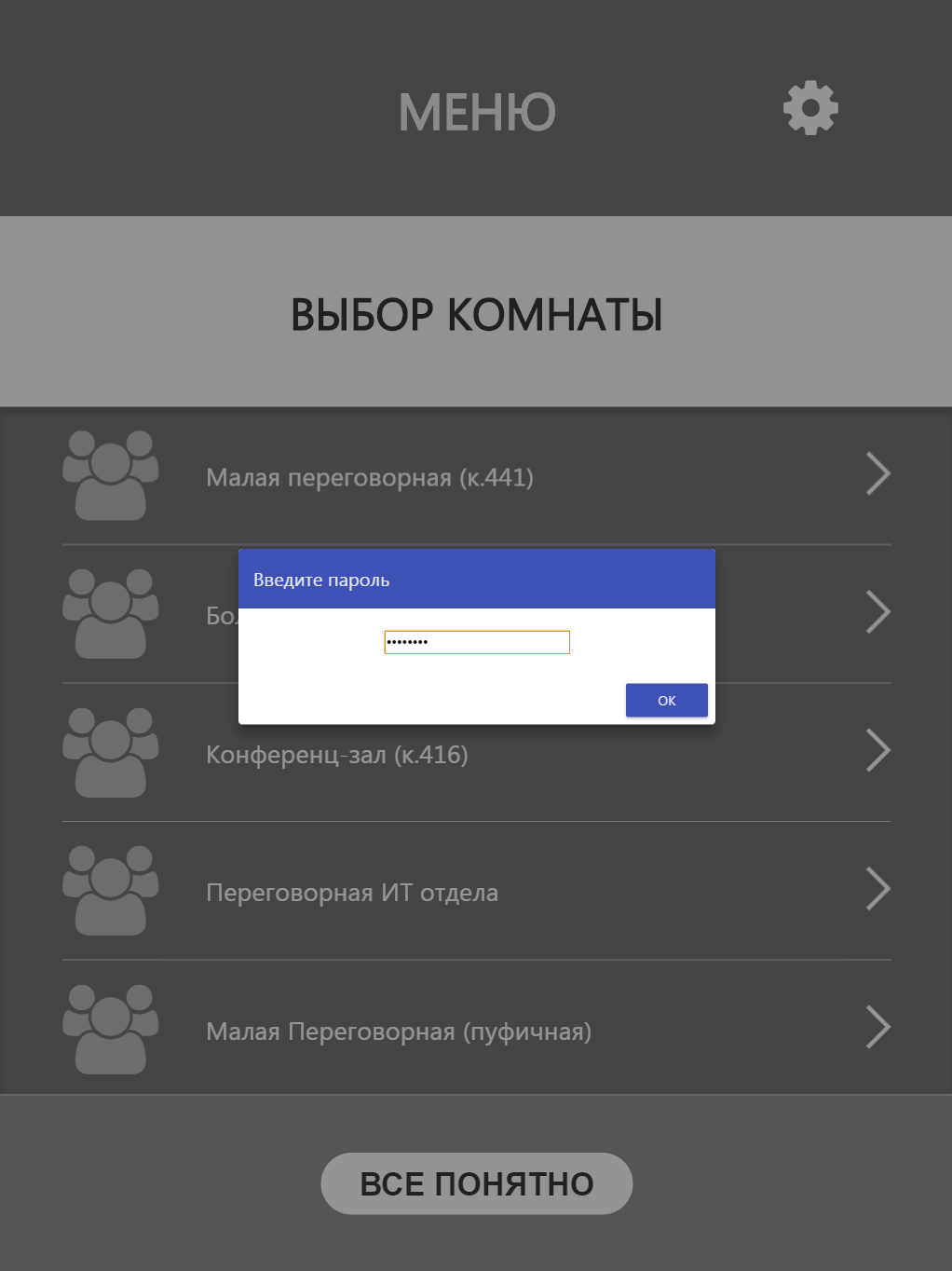
Привязка осуществляется выбором одной из переговорок в данном списке и вводом административного пароля. На этом настройка заканчивается и можно монтировать планшет на стену.
Дополнительной функциональностью является возможность задать параметры переговорной комнаты, такие как:

Данный список расширяем и при необходимости можно без особого труда добавить требуемые пункты. На текущем этапе параметры носят информативный характер, но в дальнейшем будут использоваться в поиске переговорных комнат по заданным характеристикам.
На основном экране представлено название переговорной комнаты, индикация состояния занятости, текущие дата и время. С основного экрана можно перейти в просмотр расписания и бронирования переговорной комнаты, а также просмотреть детальную информацию по переговорке.
На текущий момент мы определили 3 важных статуса занятости переговорной комнаты:
| Переговорная свободна | Переговорная скоро будет занята | Переговорная занята |
|---|---|---|
 |
 |
 |
Если назначение первого и третьего статусов должно быть интуитивно понятно, то второй требует небольших комментариев. Данный статус мы реализовали для того, чтобы у сотрудника была возможность воспользоваться переговорной комнатой прямо сейчас, но предупредить, что у него в распоряжении не более 15 минут (к примеру нужно совершить важный звонок, что бы вокруг не было “фона”).
Более детально остановимся на процессе бронирования. Напомню, что у нас проблема стояла не приглашения на встречу, а именно своевременного бронирования переговорной комнаты.

Мы хотели максимально ускорить и упростить данный процесс, поэтому не стали перегружать интерфейс необходимостью выбора организатора и участников встречи, а также вводом темы (хотя сделать это при необходимости совсем не сложно). В большинстве случаев, проблема с доступностью переговорных комнат ощущается в день ее внезапной надобности. Поэтому мы пошли по пути упрощения — выбрать можно только время начала и продолжительность встречи. Дата всегда считается текущей.

При этом начиная выбирать время начала встречи, у вас будут активироваться или деактивироваться элементы с выбором продолжительности встречи. Логика простая – если промежуток начала и продолжительности не занят, то элемент с заданной продолжительностью становится активным, если какая-либо встреча уже попадает в заданный диапазон, элементы деактивируются.
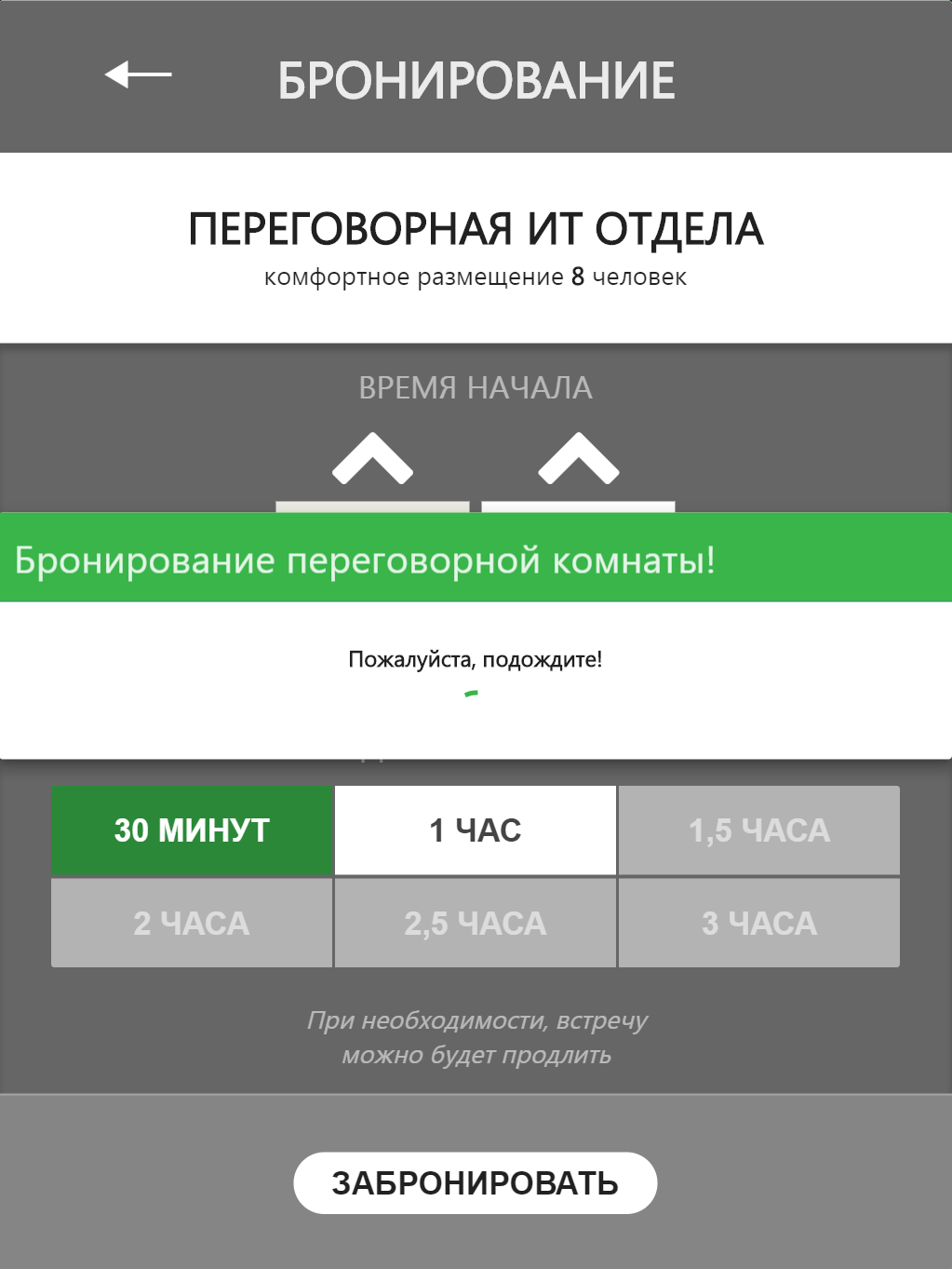
После выбора начала встречи и ее продолжительности можно бронировать. На этом процесс завершен, вы сразу можете увидеть результат произведенных действий, перейдя в просмотр расписания бронирований.
На экране расписания бронирований отображены списком диапазоны занятости и свободы «переговорки».

Как видно, при бронировании посредством сервиса, тема встречи задается как “Экспресс-бронирование”. При клике на не занятый диапазон, мы попадаем в режим бронирования, процесс которого описан выше.
На текущий момент мы закрыли основные свои потребности. Но при этом мы не хотим останавливаться на достигнутом и вынашиваем планы по развитию сервиса. И они касаются не только расширения пользовательской функциональности. Вот не полный список того, что мы планируем реализовать:
Мы всегда стремились сделать жизнь безопаснее и удобнее. При этом мы не только любим и ценим продукты, выложенные в open source, но и сами делам шаги в данном направлении. Реализовав данный продукт, мы сделали еще один шаг в сторону повышения удобства и комфорта, и хотим в дальнейшем делиться нашими наработками и идеями, выложив продукт в публичное использование. Для этого нам бы хотелось получить обратную связь, с предложениями по функциональному развитию и возможно юзабилити, чтобы продукт мог решать больше задач, стоящих перед потенциальными пользователями.
|
Метки: author monnic программирование c# angularjs блог компании «актив» переговорные комнаты |
ICFP Contest 2017 — проверка на прочность для настоящих разработчиков |


|
|
[Перевод] Как работает нейронный машинный перевод? |

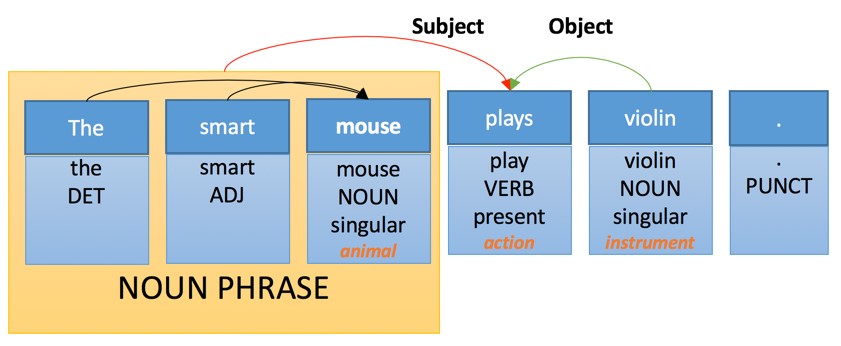

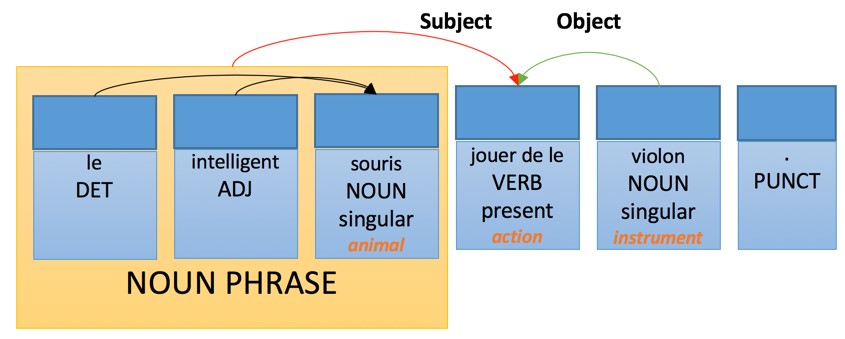
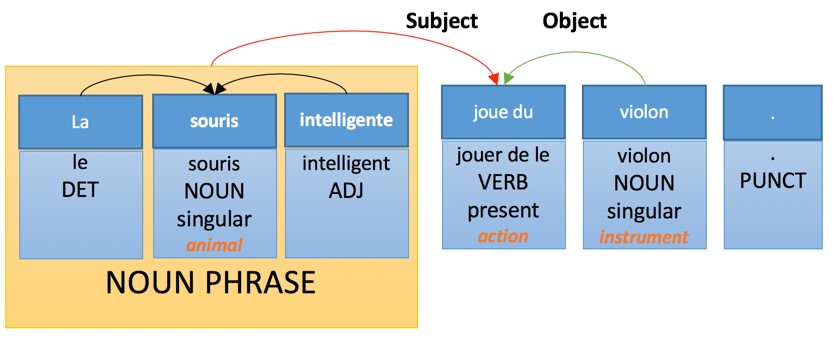
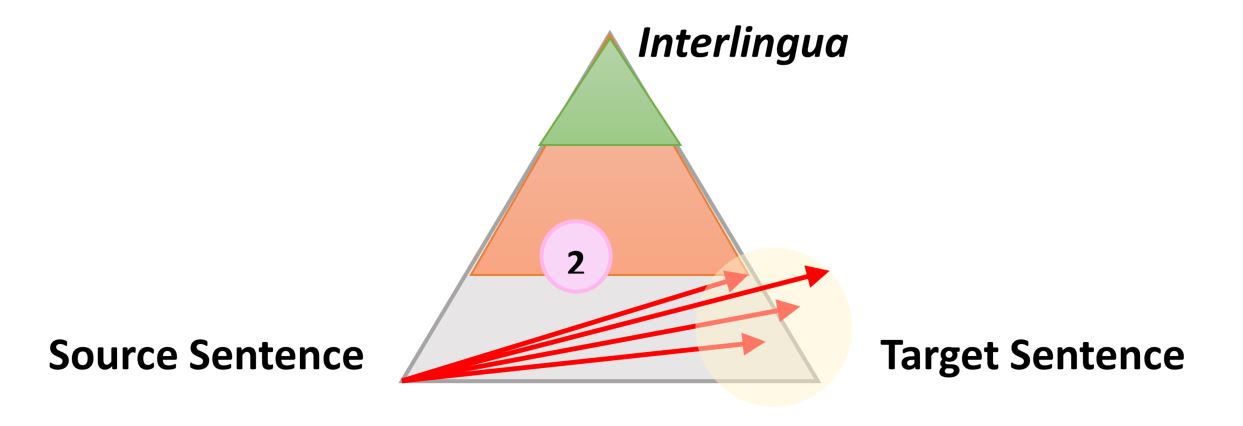
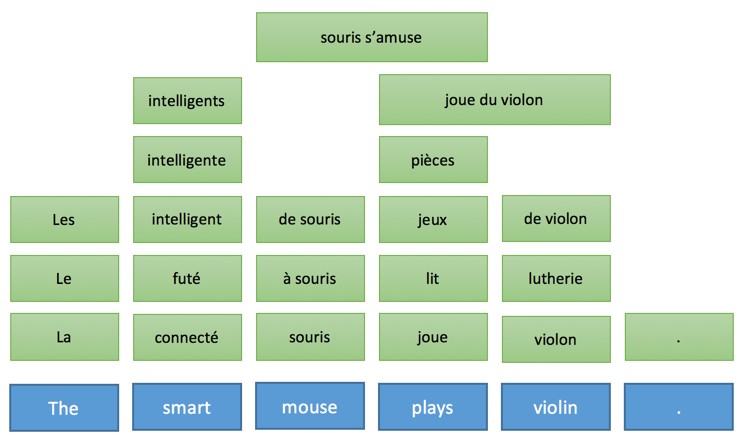
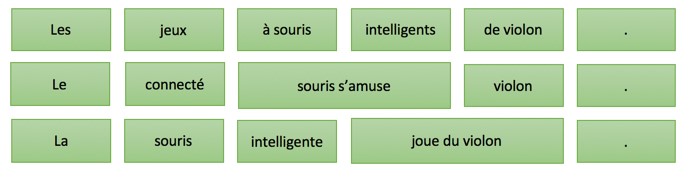

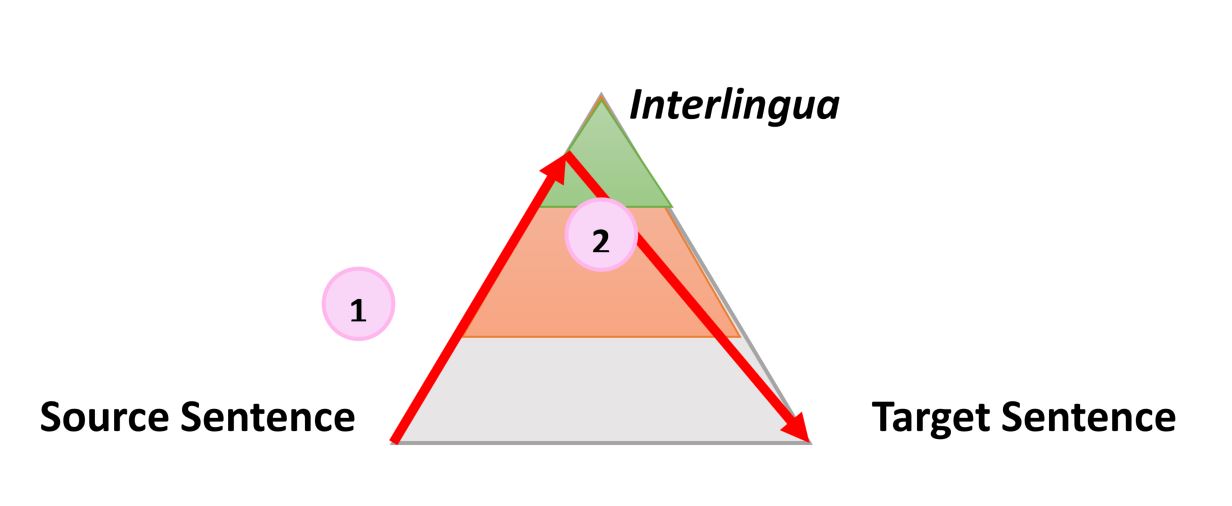
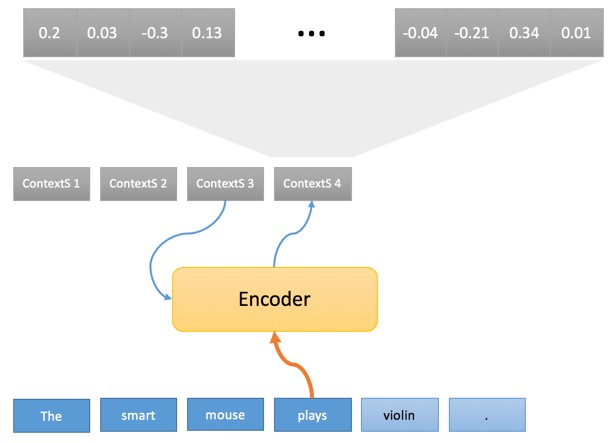
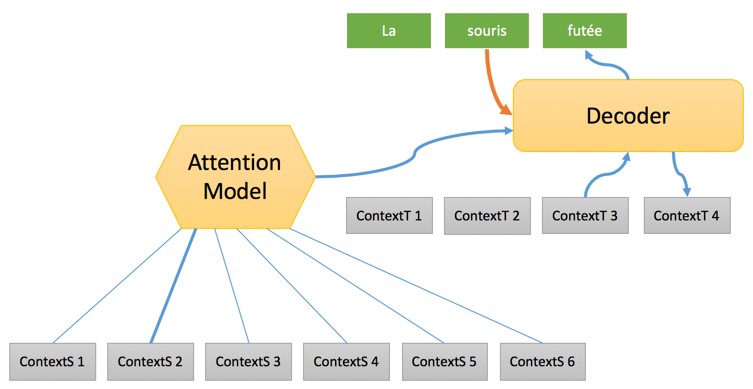

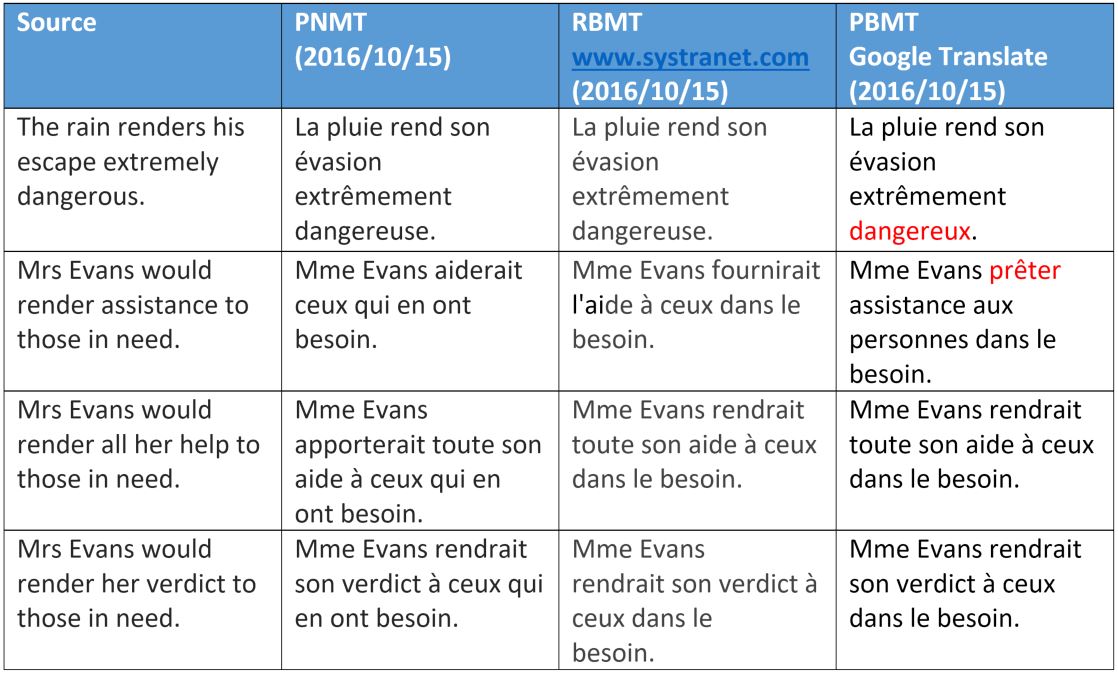

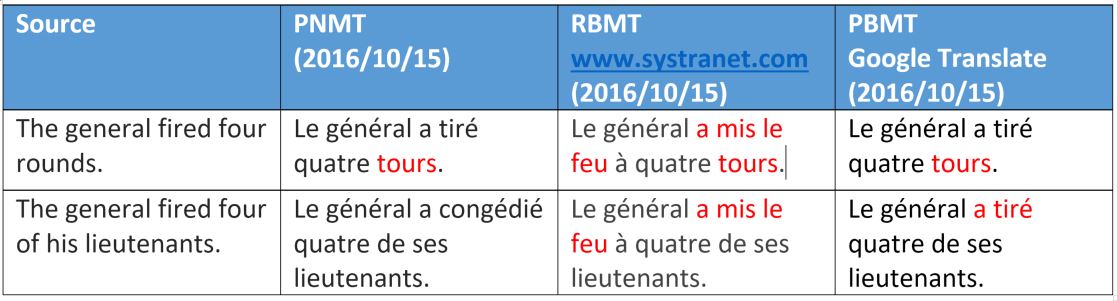

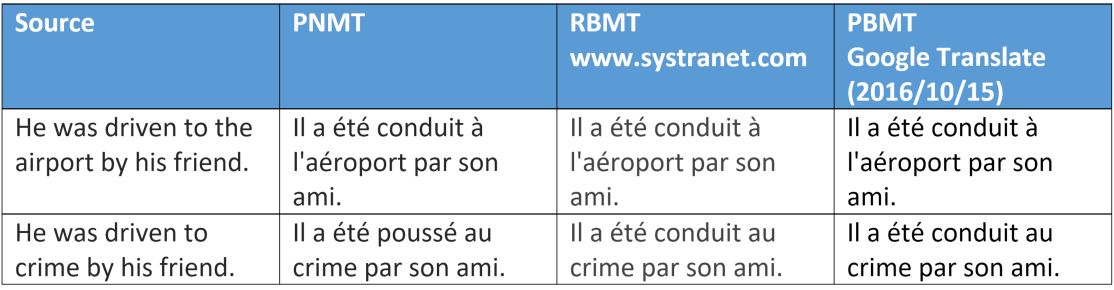
|
|
Cравнение российских операторов предоставляющих облачные услуги |
Я долго ждал и просил автора исследования 2014 года повторить его. Не дождался, несмотря на регулярные просьбы. Видимо, представляя какой титанический труд предстоит, автор эту идею откладывал. Но так совпало, что не только мне, но и моей знакомой для ее компании потребовались облачные услуги, и она предложила мне свою помощь по сбору информации. Так родилась шальная идея повторить статью. Возражений у автора предыдущего обзора не было, поэтому мы принялись за дело, взяв за основу его методику подсчета
В этот раз в обзор вошли 36 компаний, а совместная работа по сбору и анализу информации затянулась аж на 5 месяцев. Конфигурацию мы взяли, опираясь на предыдущее сравнение с поправкой на требования компании моей знакомой.

Итак, запрос мы отправили в следующие компании:
ActiveCloud, AWS (Amazon), Azure (дистрибьютером выступил Comparex)*, b2b.beeline.ru, Clodo, Cloud One, Cloud4Y, CloudLITE **, 1cloud, Croc, DataFort, DataLine, De Novo, DepoCloud, e-Style Telecom, Flops, infoboxcloud.ru, IT Lite, IT-Grad, LanCloud, Linx, M1 Cloud, АЙТеко и MakeCloud***, Oncloud, Orange, Parking, Rackspace, Rentacloud, Selectel, Softline, Корус Консалтинг, Мегафон, Облакотека, Ростелеком О7, РТКОМ.
* Изначально диалог вели с представителями Azure, а для более подробного расчет при предоставлении услуг нас перевели на дистрибьютера Comparex
** CloudLITE интернет-магазин облачных ресурсов от Dataline.
***Айтеко и Makecloud предоставляют услуги одной компании — Сервионика. Параметры облаков у них отличаются. Далее в таблицах отдельно будет Makecloud и Сервионика.
Запрашиваемая конфигурация:
1)Сайт на CentOS. 1CPU, 2Gb RAM, 50Gb;
2) AD, DNS. 1CPU, 2Gb RAM, 50Gb;
3) CRM (ОС Windows). 2CPU, 4Gb RAM, 80Gb;
4) MS Exchange SaaS (с антивирусом и антиспамом). 45 ящиков 1GB;
5) Антивирус на все нужные сервера;
6) Резервное копирование каждый день на все серверы, глубина 14 дней;
7) Файловый сервер. 1CPU, 4Gb RAM, 200Gb;
8) Сервер приложений 3CPU, 5RAM, 40Gb;
9) SQL сервер 4CPU, 8RAM, 140 Gb;
10) Проброс USB ключа 1шт.
11) Терминальный сервер – 2 шт. 6CPU, 13 Gb RAM, 60Gb на каждый. На 45 пользователей;
12) Балансировщик для терминальников. 1CPU, 2Gb RAM, 30Gb;
13) IP ATC (как SaaS) на 45 пользователей;
14) 5 VPN каналов;
15) 15 мегабит гарантированный канал интернет.
Итого необходимо:
CPU (гарантия 100%): 18
RAM (гарантия 100%): 54 Gb
SSD: 710 Gb
MS Windows Server + 45 UserCAL
MS Remote Desktop 45 user
Ящики MS exchange – 45шт по 2 Gb каждый
Антивирус по модели SaaS – 7 шт
Резервное копирование по модели SaaS на все сервера и сервисы. Глубина хранения информации – минимум неделя (14 дней). Частота создания – каждый день.
1C на 20 пользователей/Бухгалтерия Проф
1С сервер лицензия
MS Exchange SaaS (с антивирусом и антиспамом)
Канал 15 мбит
VPN канал – 5 шт
Проброс USB ключа 1шт.
MS SQL лицензия для 1С
IP АТС требования (45 сотрудников, сервер телефонии c записью разговоров).
Мы сократили количество вопросов представителям компании и было задано 17 вопросов:
Выбыли
Как оценивали
При оценке мы обращали внимание на комплексность оказания услуг.
Оценка проводилась на основе количества плюсов, минусов и итоговой стоимости. Как правило, заказчику удобнее всего заказывать услуги и работать с одним исполнителем, поэтому компании, у которых отсутствовали запрашиваемые услуги получали минус.
+ + (супер-отлично – функционал или решение превосходящее запросы/ожидания)
+ (отлично – функционал или решение присутствует и полностью удовлетворяет запросам)
+ — (средне – функционал или решение частично присутствует, существуют ограничения)
- (плохо – функционал или решение полностью отсутствует и не удовлетворяет запросам)
— - (супер-плохо – функционал или решение крайне не удовлетворяет запросам/ожиданиям)
? (информация отсутствует, то есть, вопрос был задан, но ответ не был предоставлен.
Тех, кто выбыл, но ответил на первый запрос, я в сравнительных таблицах пометил желтым маркером.
Коммуникация и скорость реакции
Нами было отправлено 795 писем и получено 668! Всего звонков было 284. Сами представляете, какой это гигантский объем информации. В процессе сбора, я просил свою знакомую, указывать время реакции компаний на ее запросы. Все запросы мы старались направить через сайт. Если с сайта не поступало ответа, то писали письма, если и письма не помогали, что случалось нередко, звонили лично и оставляли запрос.
Под предоставлением коммерческого предложения, подразумеваем расчет по заданным нами ресурсам. Иногда менеджеры компаний высылали пару строчек в письме, где не хватало половины услуг или просто описание тарифов–это мы не засчитывали как первое предоставление КП и просили выслать полное.
| Компания |
Время ответа (реакции) |
Время выставления КП с момента обращения |
| ActiveCloud |
несколько часов + |
через 4 дня + - |
| Azure |
несколько часов + |
через 1 день + |
| Amazon |
4 часа + |
через 3 дня + - |
| b2b.beeline.ru |
через день + |
через 3 недели - - |
| Clodo |
через два дня + - |
не предоставляют windows хостинг |
| Cloud4Y |
несколько часов + |
на следующий день + |
| CloudOne |
несколько часов + |
не предоставили КП - - |
| Croc |
несколько часов + |
через 4 дня + - |
| DataFort |
2 дня + - |
через 6 дней - - |
| DataLine |
несколько часов + |
через 7 дней - - |
| De Novo |
несколько часов + |
через 2 недели - - |
| DepoCloud |
не ответили на запрос - - |
закрывают свой облачный бизнес |
| e-Style Telecom |
несколько минут + |
через 2 дня + |
| infoboxcloud.ru |
несколько минут + |
через 2 дня + |
| IT Lite |
1 день + |
через 6 дней - - |
| IT-Grad |
минута + |
через 1 день + |
| Linx |
через 1 день + |
через 7 дней - - |
| M1 Cloud |
2 часа + |
на следующий день + |
| MakeCloud |
несколько часов + |
через 2 недели - - |
| o7.com |
несколько дней + |
через 3 дня + - |
| Oncloud |
на следующий день + |
через 25 дней - - |
| Orange |
несколько часов + |
КП только после физического обследования - - |
| Parking |
через 2 дня + - |
через 2 дня + |
| Rackspace |
несколько минут + |
через 22 дня - - |
| Rentacloud |
несколько минут + |
через 6 дней - - |
| Selectel |
несколько минут + |
через 5 дней - - |
| Softline |
через 5 часов + |
через день + |
| Корус Консалтинг |
через 5 часов + |
через 2 недели - - |
| Мегафон |
через день + |
предоставляют только АТС - |
| Облакотека |
на следующий день + |
через 5 дней - - |
| РТКОМ (rtcloud) |
через 30 минут + |
через месяц - - |
| Flops |
несколько часов + |
несколько часов + |
| 1cloud |
несколько часов + |
через 5 дней - - |
| cloudlite |
несколько часов + |
сначала написали что отдали в Dataline, после повторного запроса, после повторного запроса через 2 дня + - |
| LanCloud |
в течение минут + |
через день + |
| Сервионика |
несколько часов + |
через 2 недели - - |
Большинство компаний реагировали на запрос в течение нескольких часов, а вот DataFort, Clodo и Parking потребовалось два дня, чтобы ответить. С КП все оказалось сложнее, только 15 компаний уложились в срок от 1 до 4 дней, остальным потребовалось от недели до месяца, чтобы сформировать предложение.
Ответы на вопросы:
Теперь перейдем к ответам на технические вопросы и посмотрим, что за последние годы изменилось у компаний.
| Компания |
Используемые гипервизоры |
Процессоры, сервер |
Какой TIER у ЦОД? |
Какой ДЦ и где? |
| ActiveCloud |
KVM + |
Huawei, и HP – разное оборудование. Процессоры — INTEL Xeon + |
Tier 3 + |
Даталайн в Москве + |
| Azure |
нет информации ? |
нет информации ? |
нет информации ? |
нет информации ? |
| Amazon |
HVM и PV + |
t2 и m4, Intel Xeon + |
TIER III + |
Ирландия и Германия + + |
| b2b.beeline.ru |
VMware ESXi + |
Cisco UCS B200M3 2xE5-2680 v2, 768GB + |
TIA/EIA-942 + |
Два ЦОД, г. Москва, связанные собственными каналами связи, точки присутствия на М9/М10 + + |
| Cloud4Y |
vCloud Director, VMware vSphere 6U2 + |
Blade HP C7000, BL460c G8-G9. Intel Xeon E5-2670, E5-2680v4 + |
TIER-3 + |
2 ЦОД Москва, Санкт-Петербург, |
| Croc |
RedHat KVM, Microsoft Hyper-V, VMware ESXi + |
Dell PowerEdge R720, процессоры Intel Xeon E5-2670 и E5-2690 с частотой 2,6-3 GHz + |
TIER3 + |
2 ЦОД Москва + + |
| DataFort |
VMware ESXi, Microsoft Hyper-V + |
Cisco UCS B200M3 2xE5-2680 v2, 768GB RAM + |
TIER3 + |
1) ул. 8 марта, д. 14, Tier 3 2)ул. Остаповский, д.22 стр. 16 + + |
| DataLine |
VMware и Hyper-V + |
Intel® Xeon® CPU E7-8867 v3 @ 2.50GHz + |
TIER3 + |
Москва + |
| De Novo |
VMWare + |
Cisco UCS + |
ЦОД уровня TIER III по классификации Uptime Institute + |
ДЦ в Киеве + |
| e-Style Telecom |
Hyper-V + |
cpu -E5, сервера HP и Supermicro + |
Tier 3 + |
Дата-центр e-Style Telecom, Москва, ул. Пришвина, д. 8, корпус 1 + |
| infoboxcloud.ru |
Hyper-V Failover Clustering + |
Huawei E9000 + |
Tier III Design + |
Москва, ул. Шарикоподшипниковская, 13 + |
| IT Lite |
Hyper-V + |
SuperMicro с процессорами E5-2630v3 + |
Tier-3 (Stordata), Tier-3+ (Iхcellerate) + |
ДЦ Stordata и ДЦ Ixcelellerate + + |
| IT-Grad |
VMware vSphere 6.0. + |
NetApp, Dell, HP, Cisco и Juniper + |
Tier 3 + |
Москва, Санкт-Петербург + + |
| Linx |
VMware ESXI 5.5 + |
EMC Flex POD (с использованием оборудования Cisco UCS B200) + |
Tier 3 + |
ЦОД Санкт-Петербург + |
| M1 Cloud |
VMware vCloud Director + |
HP + |
Tier 3 + |
ЦОД М1 Москва + |
| MakeCloud |
KVM OpenStack + |
Intel Xeon Processor E5-2620, E5-2660 |
Tier III + |
Дата-центр «ТрастИнфо», Москва + |
| o7.com* |
Hyper-V/Vmware + |
Intel Xeon 2,7 ГГц, серверное оборудование IBM + |
ЦОД соответствует требованиям Tier-III + |
• Москва М10 (Сущевский вал, д.26) |
| Oncloud |
VMWare vSphere + |
HP DL 580G7/G8, Intel E7-4870/ E7-4890v2 + |
Tier 3 + |
Safedata г. Москва и Ixcellerate г. Москва + + |
| Parking |
Hyper-V + |
Hewlett-Packard Enterprise + |
Tier3 + |
В Москве, во Владимире + + |
| Rackspace |
OpenStack + |
Dells and HP + |
Не используют сертификацию TIER3, но имеют SLA 99.999% + |
2 ДЦ в Лондоне + + |
| Rentacloud |
VMware/HyperV + |
Процессоры Intel E5, Сервера Dell, Intel + |
Tier 3 + |
StoreData (Москва) + |
| Selectel |
Openstack KVM + |
Intel Xeon E5-2670v3 или e5-2680v4. Серверы Supermicro + |
Tier 3, но в процессе сертификации + |
Санкт-Петербург + |
| Softline |
VMWare + |
Процессоры Intel, Сервера Cisco + |
TIER 3 + |
ЦОДы на ул. Боровая д 7, на Алтуфьевское ш. д.33Г + + |
| Корус Консалтинг |
VMware vSphere 6.0. + |
NetApp, Dell, HP, Cisco и Juniper + |
Tier 3 + |
Москва, Санкт-Петербург + + |
| Облакотека |
Hyper-V 2012 + |
Supermicro и Dell + |
Tier3 + |
ЦОДы компании Даталайн на Коровинском ш. и Боровой ул + + |
| РТКОМ (rtcloud) |
VMWare + |
HP BL 460C Gen 9 типовой узел: HP, 2 процессора (CPU), 12 ядер на процессор, Intel Xeon E5 2680 v3 – 2.50GHz + |
Соответствие уровню надежности Tier III (сертификат отсутствует) + |
Москва, Новосибирск, Ростов-на-Дону, Красноярск + + |
| Flops |
QEMU/KVM + |
процессоры Xeon e5 2620 и промышленные x86 сервера + |
Tier 3+ + |
ДЦ IXcellerate Moscow One + |
| 1cloud |
Vmware + |
CISCO UCS B200 с процессорами E5 (20 cores, 3.0GHz, 384Gb RAM) + |
Tier III + |
ЦОД SDN Санкт-Петербург, Выборгское шоссе, 503 к. 12 + |
| cloudlite |
Vmware + |
Huawei FusionServer RH5885 V3 на базе процессоров Intel Xeon E7 + |
Tier III + |
Москва, NORD 3 по адресу: улица Боровая д. 7 стр. 10 + |
| LanCloud |
Hyper-V 2012 R2 + AzurePck + |
HP DL380/Huawei RH2288, Xeon E5-26xx V2/V3/V4 – 2,4-2,8 ГГц + |
ЦОД сертификацию Uptime Institute не проходил - |
ЦОД «Агава-Север», г. Долгопрудный, ул. Жуковского, д.3. 4км. от Москвы + |
| Сервионика |
ESXi vCloud Director + |
HP ProLiant BL460c Gen8 |
Tier III + |
Дата-центр «ТрастИнфо», Москва + |
* Ростелеком О7 предлагают два решения на разных гипервизорах. Далее если ответы по платформам отличаются, то они даны в двух строках.
Самой распространенной платформой остается VMWare, однако ряд компаний предлагают и другие платформы, что в некоторых случаях может удешевить решения. Практически все компании имеют ЦОДы уровня TIER 3. А вот Rackspace данную сертификацию не использует, зато уверяет, что уровень доступности даже выше, чем у TIER 3.
| Компания |
Какая СХД? |
Применяется ли штатно технологии |
| ActiveCloud |
Cisco, Huawei + |
нет |
| Azure |
нет информации ? |
нет информации ? |
| Amazon |
gp2 + |
VMware Cloud + |
| b2b.beeline.ru |
EMC VNX5600, HP 3Par 7400 + |
да + |
| Cloud4Y |
СХД SSD AllFlash, дублированные контроллеры. До 1 млн IOPS. + |
да + |
| Croc |
IBM mid-range уровня (4 штуки, 2 на каждый ЦОД) и all-flash массивы Violin Memory + |
Вендорские технологии по HA/DR-решениям не входят в стоимость, но все ресурсы на уровне железа зарезервированы средствами гипервизора KVM.+ |
| DataFort |
EMC VNX5600, HP 3par 7400 + |
да + |
| DataLine |
не предоставили информацию |
да + |
| De Novo |
нет информации ? |
нет информации ? |
| e-Style Telecom |
Своя СХД построенная на ПО Linux + - |
да + |
| infoboxcloud.ru |
Huawei OceanStor 5300 + |
Да, все ВМ в кластере Hyper-V Failover Cluster + |
| IT Lite |
Infortrend ESDS 3024B + |
отказоустойчивость обеспечивается резервным копированием Acronis |
| IT-Grad |
NetApp V6240, V8040 с использованием flash кэширования и SSD дисков. + |
да + |
| Linx |
EMC SCALEIO (с использованием нескольких СХД NettApp DS4246) + |
да + |
| M1 Cloud |
HP 3PAR StoreServ 7400 и NetApp FAS3250 + |
да + |
| MakeCloud |
NetAPP FAS8020 + |
миграция выполняется силами администратора |
| o7.com |
СХД на базе решения Dell, Hitachi, Huawei + |
нет |
| o7.com |
СХД на базе решения Dell, Hitachi, Huawei + |
да, при использовании виртуализации Vmware + |
| Oncloud |
HDS HUS VM/IBM Storwize v7000 + |
да + |
| Parking |
нет информации ? |
да, Hyper-V + |
| Rackspace |
нет информации ? |
нет информации ? |
| Rentacloud |
в основном Netapp + |
да + |
| Selectel |
СХД на базе платформ Supermicro, логически Openstack Ceph + |
При падении физического хоста виртуальные серверы автоматически мигрируют на другие хосты + |
| Softline |
NetApp FAS8040, FAS2552 + |
да + |
| Корус Консалтинг |
NetApp V6240, V8040 с использованием flash кэширования и SSD дисков. + |
Да, High Availability + |
| Облакотека |
СХД Dell + |
да + |
| РТКОМ (rtcloud) |
EMC VNX, HP 3PAR + |
да + |
| Flops |
СХД Ceph + |
При аварии на физической ноде сервер перезапускается на другом гипервизоре в течение нескольких минут + |
| 1cloud |
NetApp V6240 и FAS8040 + |
да + |
| cloudlite |
СХД VMware VSAN + |
да + |
| LanCloud |
HP MSA 2040 SAN, Huawei OceanStore 2600T и, самая мощная: Huawei OceanStore 5500 V3, которая выдаёт до 320 000 IOPS + |
Hyper-V, все машины по умолчанию в кластере High Availability + |
| Сервионика |
HP 3PAR StoreServ 10400 IBM StorWize V7000 IBM XIV + |
да + |
Среди используемых СХД в лидерах решения NetApp, HP 3par и Huawei. Подавляющее большинство компаний указало, что штатно применяет автоматический перезапуск в случае выхода сервера из строя. Здесь особых изменений за прошедшее время не произошло.
| Компания |
Постоплата? |
Гарантия ресурсов CPU, |
Возможность почасового биллинга? |
SLA |
| ActiveCloud |
предоплата - |
гарантированы + |
да, не меняется + |
99,5% + - |
| Azure |
нет информации ? |
нет информации ? |
нет информации ? |
нет информации ? |
| Amazon |
и постоплата и предоплата + |
нет информации ? |
да/не сообщили + |
|
| b2b.beeline.ru |
постоплата + |
99,93% + - |
Лицензии и хранилища — месячная оплата, ресурсы — почасовая. + - |
99,93% + |
| Cloud4Y |
постоплата + |
100% + |
да, не меняется + |
99,95% + |
| Croc |
постоплата + |
100% + |
да, меняется + - |
SLA 99,9 или 8 ч. 45 мин. + |
| DataFort |
постоплата + |
100% + |
да, но ресурсы не гарантированы + - |
99.93% + |
| DataLine |
постоплата + |
уровень доступности 99,982% + - |
да, дороже + - |
99,982% + + |
| De Novo |
постоплата + |
нет информации ? |
Биллинг посуточный - |
99,95% + |
| e-Style Telecom |
предоплата - |
100% + |
нет - |
99,99% + + |
| infoboxcloud.ru |
предоплата - |
RAM гарантированы + - |
помесячная - |
99,982% + + |
| IT Lite |
только предоплата - |
все ресурсы гарантированы + |
нет - |
99,98% + + |
| IT-Grad |
постоплата и предоплата + |
гарантия ресурсов + |
да, увеличится + - |
99,9% + |
| Linx |
постоплата + |
уровень доступности 99,98% + - |
биллинг раз в сутки - |
99,98% + + |
| M1 Cloud |
постоплата + |
100% + |
да, меняется + - |
99,9% + |
| MakeCloud |
предоплата - |
100% + |
нет - |
99,5% + - |
| o7.com |
постоплата + |
гарантированы + |
Начисления происходят по суткам - |
99,9% + |
| Oncloud |
постоплата + |
|
да, не меняется + |
99,5% + - |
| Parking |
предоплата - |
уровень доступности 99,85% + - |
нет - |
99,85% + - |
| Rackspace |
предоплата, постоплата возможна только через месяц работы + - |
нет информации |
да + |
99.99% + + |
| Rentacloud |
Возможны оба варианта + |
гарантированы + |
Нет, только ежемесячный - |
99,9% + |
| Selectel |
предоплата - |
если зарезервированы, то да + - |
почасовой, цена та же + |
99,98% + + |
| Softline |
предоплата, для постоплаты документы для кредитного отдела + - |
99,9%, отображено по SLA + - |
возможен ежедневный по договоренности + - |
99,9% + |
| Корус Консалтинг |
постоплата и предоплата + |
Ресурсы гарантированны, модель Reservation Pool + |
да, увеличится + - |
99,9% + |
| Облакотека |
постоплата + |
100% + |
да, не меняется + |
99,9% + |
| РТКОМ (rtcloud) |
предоплата, при наличии положительного опыта работы возможна постоплата + - |
100% + |
да + |
99,9% + |
| Flops |
работаем на условиях предоплаты, при наличии коммерческой истории мы можем рассмотреть вариант постоплаты + - |
уровень доступности 99,9% + - |
только поминутный + |
99,9% + |
| 1cloud |
Предоплата - |
гарантированы + |
списания каждые 10 мин. + |
99,9% + |
| cloudlite |
оплата ежедневно |
количество доступных ресурсов отображается в личном кабинете |
только для услуги «Виртуальный сервер VDS|VPS + - |
99,95% + |
| LanCloud |
Предоплата - |
RAM, SSD 100% + - |
нет - |
99,9% + |
| Сервионика |
предоплата и постоплата + |
100% + |
почасовая возможна + |
99,982% + + |
Около 50% операторов готовы работать с клиентом на условиях постоплаты, что конечно, очень удобно. С гарантией ресурсов не все однозначно. Ряд компаний ссылался на свой уровень доступности, что не совсем то, что нас интересовало. От уточняющих вопросов уходили, ссылаясь на свой SLA. Оставим это на их совести. Честнее поступили компании LanCloud и infoboxcloud, пояснив, что именно гарантировано. SLA если сравнить в среднем с прошлым обзором, у операторов стал выше. Особенно отличились Rackspace, о которых упоминалось ранее, и e-Style Telecom.
| Компания |
Поддержка 24x7 бесплатна? Что входит? |
Компания работает с НДС? На все услуги в КП распостраняется НДС? |
Сколько телеком операторов используется для отказоустойчивости |
||||
| ActiveCloud |
24/7 бесплатна. Включена круглосуточная техническая поддержка. Максимальный срок реакции 4 часа + |
да + |
до 20 + + |
||||
| Azure |
нет информации ? |
нет - |
нет информации ? |
||||
| Amazon |
Тех. Поддержка платная - |
нет |
нет информации ? |
||||
| b2b.beeline.ru |
да, 24/7.Билайн обеспечивает 1 линию поддержки. SD и тех. службы работают круглосуточно (24х7х365). Так же большинство работ в пулах Заказчиков согласовываются и проводятся в ночное время. |
да + |
Для отказоустойчивости организовано несколько стыков для подключения услуг Интернет и выделенных каналов связи Билайн. + |
||||
| Cloud4Y |
Да, 24/7 бесплатна. Время реакции до 15 минут + |
да + |
4 + |
||||
| Croc |
Да, до уровня гипервизора + |
да + |
4 + |
||||
| DataFort |
да, 24/7 + |
да + |
Если вы работаете в ИТ-сфере, то наверняка сталкиваетесь с проблемами, которые другие люди даже не понимают. Стоит ли говорить о переработках, инцидентах пользователей, людях, которые даже не пытаются понять, чем же вы занимаетесь на работе… не каждый готов разделить ваши головные боли.
Наша команда подготовила вольный пятничный перевод прекрасных комиксов о банальных жизненных ситуациях системных администраторов. А у вас тоже всё так?  Мы в Alloy Software делаем софт для системных администраторов, тестируем его, непрерывно общается с админами и знаем, сколько всего ежечасно сваливается на их инженерные головы. И готовы подписаться под каждой ситуацией — наблюдаем их непрерывно. 1. Пойти на работу, чтобы решить кучу проблем с компьютерами. Вернуться домой, чтобы решить ещё больше таких проблем.  2. Развивается фобия текстовых сообщений. Одно из двух: либо алерт от сервера, либо уведомление о новом тикете.  3. Вроде вы не уборщица, а всегда разгребаете оставленный пользователем ИТ-беспорядок (например, пролитый чай, сок, кефир).  4. Пытаетесь объяснить, почему Интернет и Wi-Fi не одно и то же. 5. Вы научились так быстро ходить по офисным коридорам, чтобы пользователи не успевали вас остановить. 6. Использованные в очередной раз не к месту и неправильно фразы типа «Единая информационная панель», «Облако», «Бигдата», приводят в вас в ярость.  7. Одно слово: вредоносы.  8. Два слова: распутывать провода.  9. Три слова: не могу напечатать.  10. Четыре слова: помоги мне сбросить пароль!  11. Так много ошибок пользователей! 12. Устали просить пользователей выключить и снова включить (но это реально работает!). 13. Мечетесь в агонии, слушая разговоры гуманитариев о технологиях (о которых они просто без понятия). 14. Распугиваете не настолько гикнутых друзей своим техно-жаргоном.  15. Несмотря на непрерывные напоминания, все жестко игнорируют создание тикетов. 16. Зато на вас обрушивается поток телефонных звонков, электронной почты и тикетов, если что-то нужно починить ПРЯМО СЕЙЧАС СРОЧНО ВАЖНО. 17. Отдых и расслабление? Что это вообще? Даже в отпуске на необитаемом острове вы всегда на связи.  БОНУС. Очень мало людей знают о Дне системного администратора SysAdmin Day, который отмечается сегодня, в последнюю пятницу июля.  С Днём системного администратора! Толковых пользователей, успешных обновлений, адекватных боссов. А мы, Alloy Software, продолжаем работать — только для вас!
О проекте
|






