JetBrains MPS для интересующихся #1 |
Спасибо всем за критику в комменте под первым постом, где я хотел попробовать написать про MPS, не затрагивая важные темы, чтобы можно было потом более качественно начать писать по порядку.
В комментариях к 1 посту было следующее высказывание
С этой точки зрения, DSL — это как фреймворк, только с более удобным интерфейсом. Ясное дело, под один проект фреймворк делать никто не будет, за исключением совсем уж монструозных случаев. А сделать его под конкретную предметную область — почему бы и нет?..
В принципе, так оно все и работает. Хорошие языки похожи по сути на хорошие фреймворки: они позволяют писать что-то важное, не заморачиваясь о том, что мы не хотим писать. По ходу повествования я буду периодически обращаться к другим языкам для аналогий и сравнений.
Язык Weather, который мы хотим реализовать, должен выполнять следующую задачу: мы должны уметь лаконично выражать условия (погода сегодня, например) и следствия (погода завтра, послезавтра...).
В языке Weather мы будем делать наши прогнозы отталкиваясь от 1 фактора: от температуры на сегодняшний день(массив объектов время + погодные условия).
const weatherInput = [
{
time: 1501179579253,
temperature: {
unit: "celsius",
value: 23.7
}
},
{
time: 1501185944759,
temperature: {
unit: "fahrenheit",
value: 15.3
}
}
]Думаю сойдет.
Weather prediction rules for Saint Petersburg
data Today:
[21:23]{
temperature = 23.7 °C
}
[23:06]{
temperature = 15.3 °F
}У нас очень простые данные — время + температура в единицах измерения. Создадим абстрактный концепт WeatherTimedData — он нам нужен для хранения времени измерения и самой температуры.
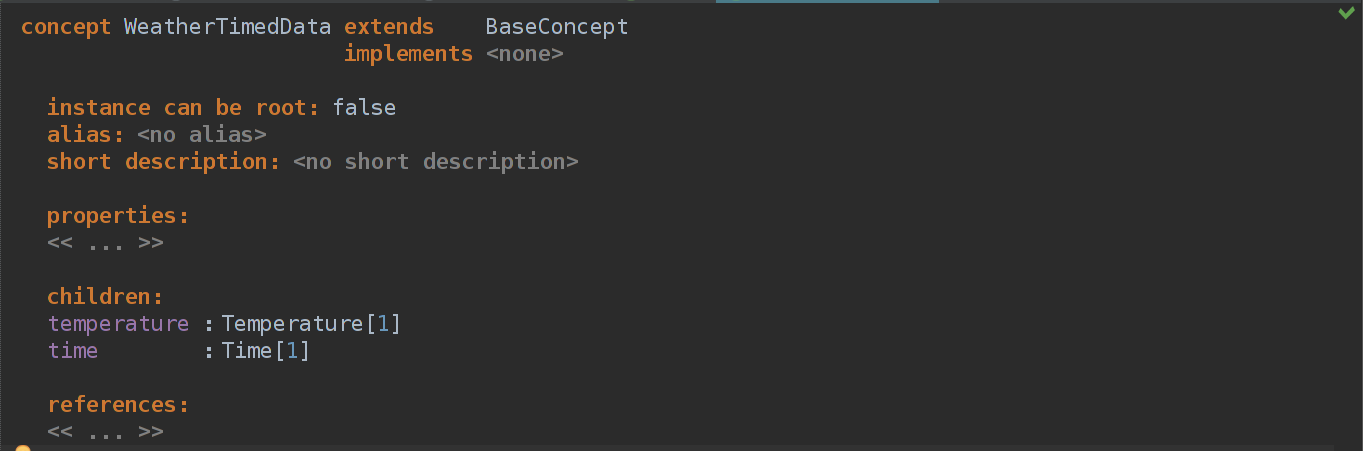
Теперь нужно определить, что такое Temperature и Time.
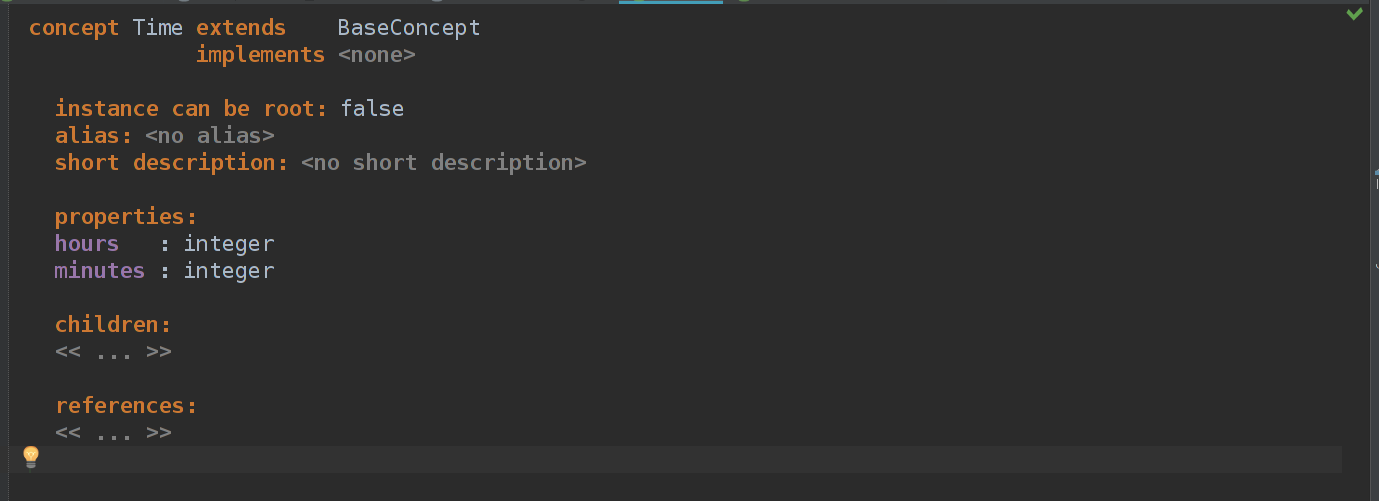
Time реализован очень просто — у нас есть время в часах и минутах, а отображается оно как hh : mm.
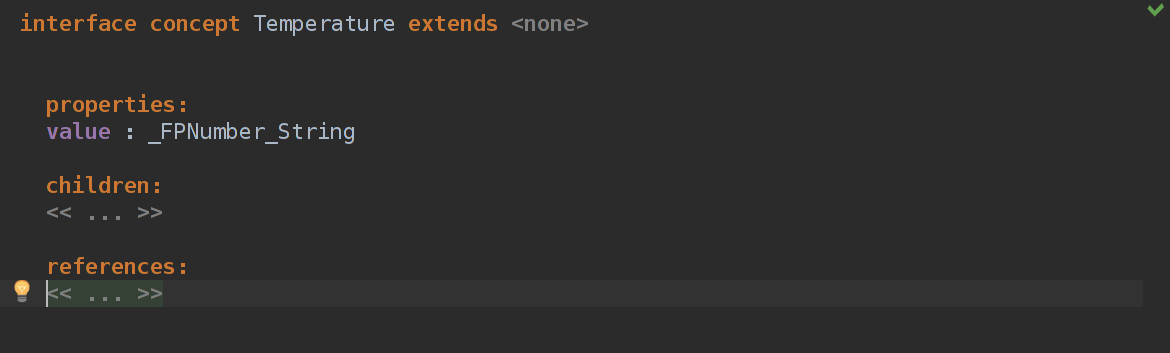
Если с Time все понятно, то с Temperature немного нет. Во-первых — value это какой-то _FPNumber_String. На самом деле это MPS'овский double, так что ничего страшного. Но вопрос — как из интерфейса Temperature сделать реализации температуры в разных единицах измерения, да так чтобы это еще и красиво было? И вообще, что такое интерфейс концепт?
У таких концептов не может быть реализации в AST. То есть, вообще никакой. Только если другой концепт расширяет его, и никак иначе. Делается это, как и в ООП, для того, чтобы обобщить несколько классов под одно общее начало.
Вот как я реализовал отображение в редакторе для Temperature:

Здесь у нас первая ячейка — double значение, величина температуры, а вторая — Read-Only model access. Здесь мы немного отдаляемся от практики и переходим к теории.
В MPS все строится на концептах, если проводить прямую параллель с ООП, то концепты — это классы. Они могут расширять другие концепты, реализовывать интерфейсы, но еще они могут иметь какую-то логику. Например, если мы описываем абстрактный класс температуры, то нужно предусмотреть возможность задания собственных единиц измерения.
abstract class Temperature{
abstract double value;
public abstract String getUnit();
override String toString(){
return value + this.getUnit();
}
}Можно было бы задать unit как переменную, а не писать абстрактный метод, но…
Есть аспект, называется Behavior. Все, что он может делать — добавлять новые методы к концепту. То есть добавить переменную мы не можем, поэтому будем использовать абстрактный метод.
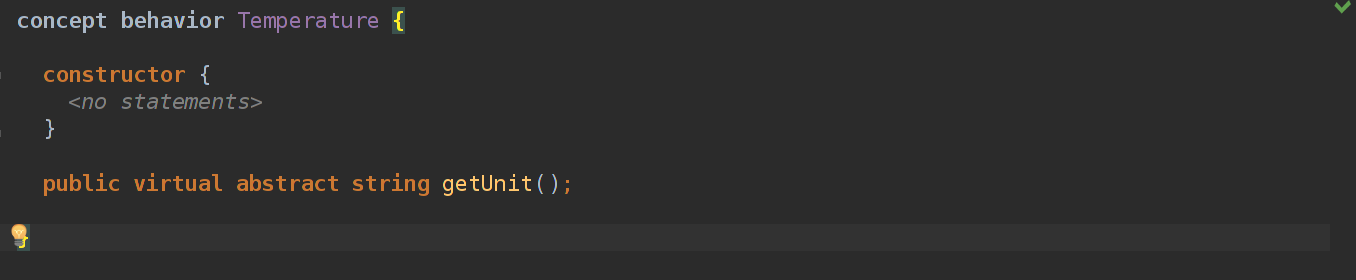
И вот после этого мы можем у каждой реализации концепта Temperature вызывать этот метод. Но где же его вызывать? Как вообще кодить в этом MPS?..
Мы остановились на том, что у нас есть непонятная ячейка в Editor аспекте — ReadOnly model access. Все очень просто — если нужно как-то логически обработать proeprty/children/reference перед тем, как его показывать, и на это не хватает встроенных приколов, то мы можем сами получить нужную строку из контекста редактора и реализации концепта. Если просто — нам дают текущий объект концепта, то есть реализованный, и мы можем из него получить все, что мы там понапихали. В данном случае мы хотим получить единицу измерения, поэтому мы нажимаем на ячейку R/O model access и пишем

Кстати, в любом месте кода вы можете тыкнуть на штучку, что Вас интересует и нажать Ctrl + Shift + Enter и получить информацию о типе этой штучки. Например, если мы нажмем на node в скрине выше и узнаем его тип, то мы получим
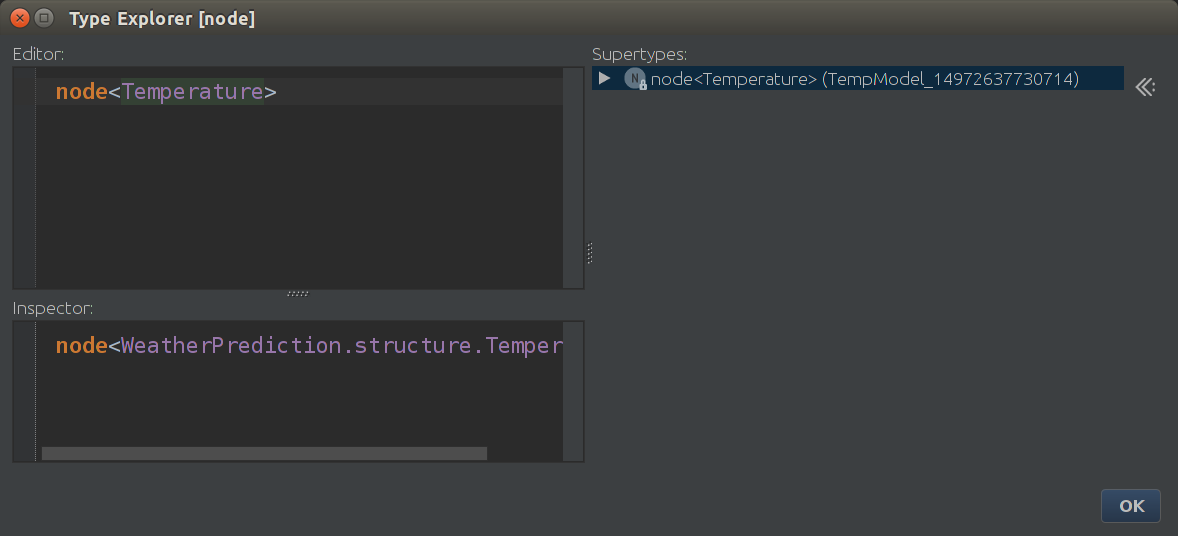
node<Название Концепта> = какая-то реализация концепта
concept<Название Концепта> = класс концепта
Так! Мы уже умеем составлять температуру по значению и единице измерения, но откуда мы возьмем, какая единица измерения нам нужна? Из дочерних реализаций, естественно.
Создаем пустой CelsiusTemperature концепт, расширяем Temperature и создаем для него behavior.
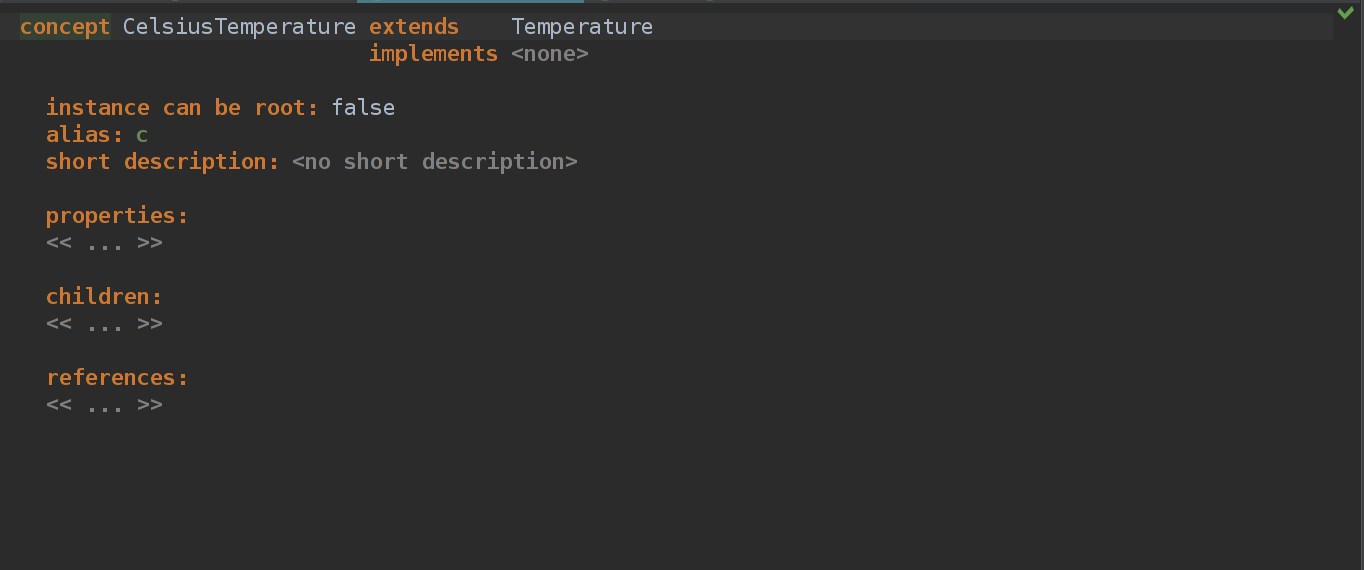
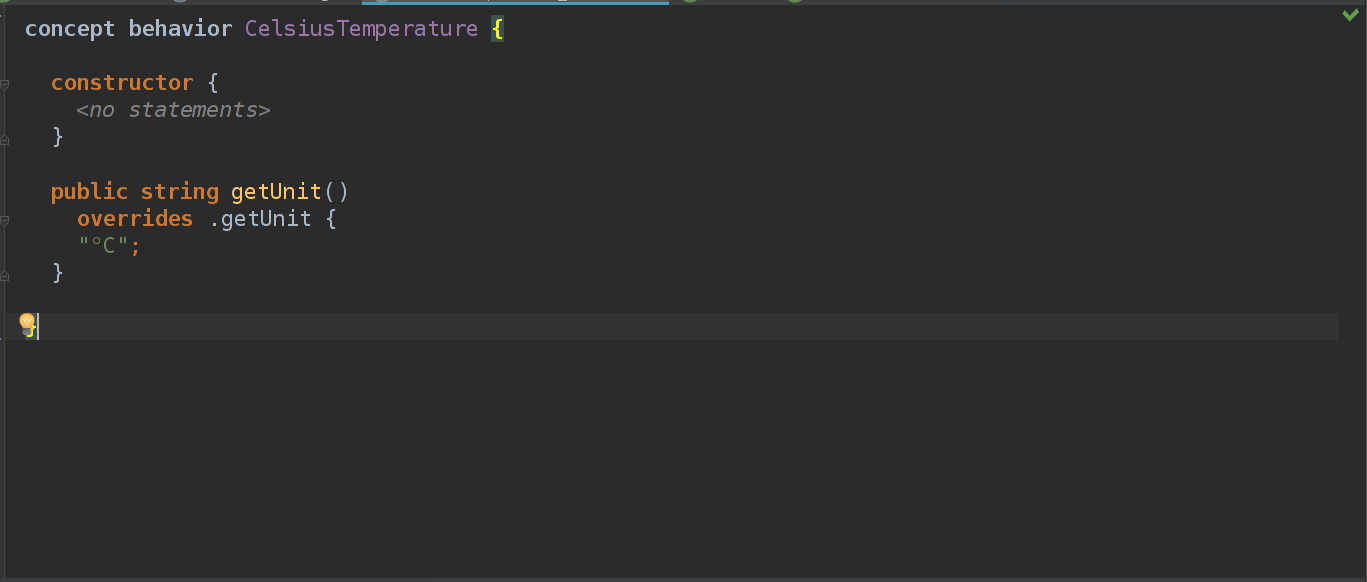
Как видно на последнем скрине, мы переопределяем метод getUnit(он имеется в зоне видимости из-за того, что мы наследовали концепт от Temperature) и возвраещем "°C". Все просто!
Остается только собрать все вместе в WeatherTimedData:
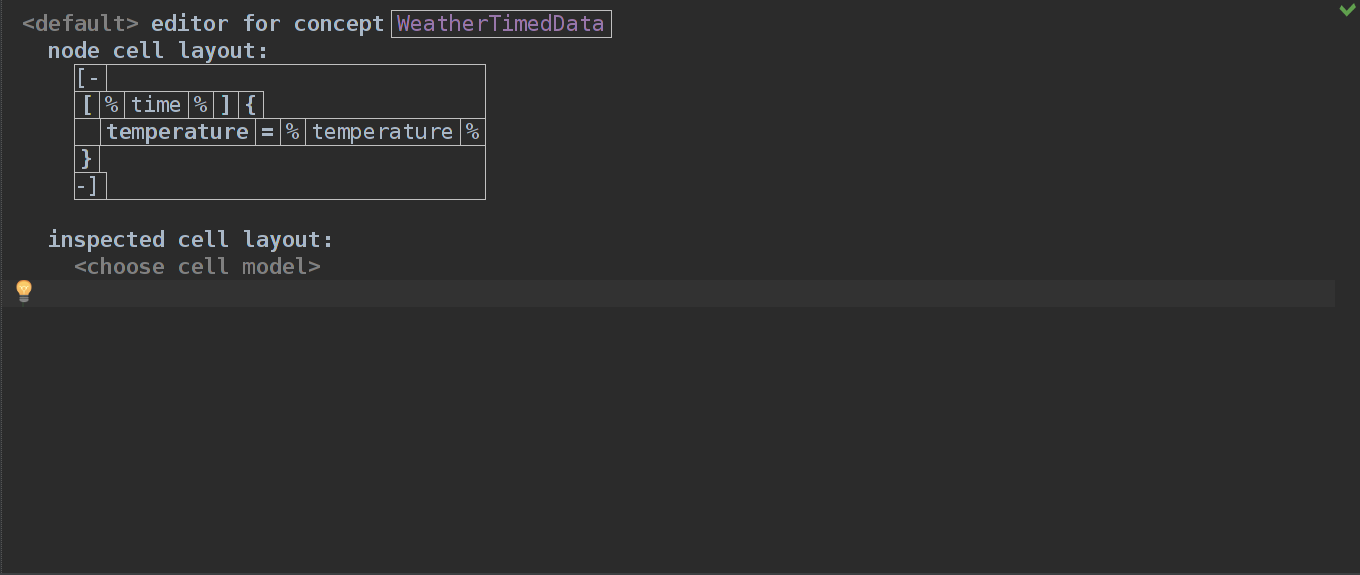
Собираем язык и смотрим на результат:
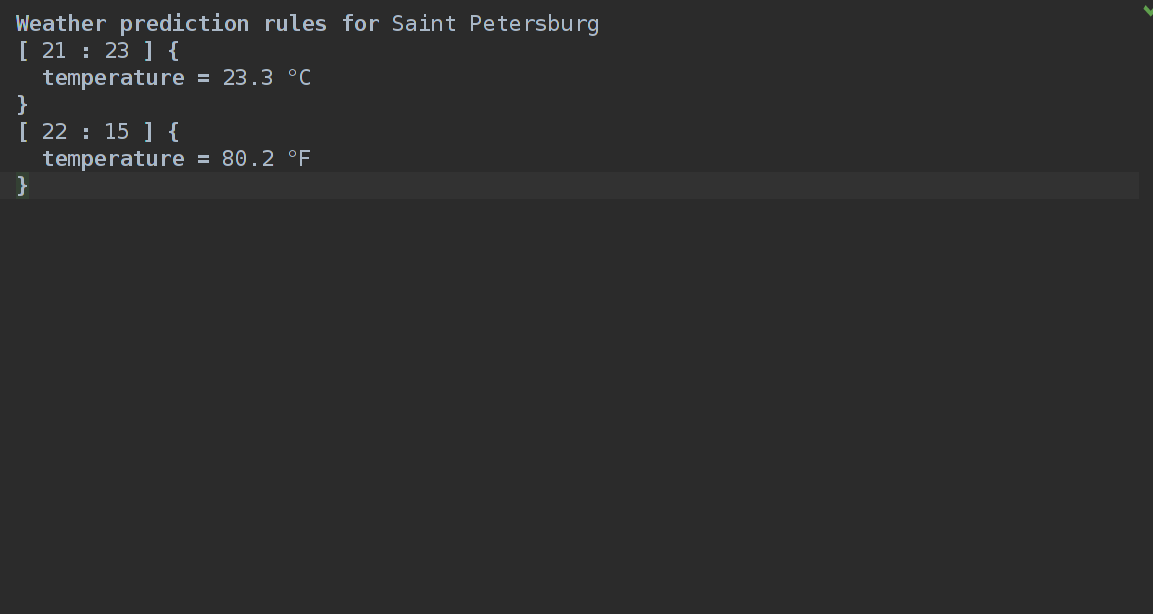
Вроде похоже на правду. Еще, конечно, нет самих предсказаний погоды, нет подсветки, к тому же часы у нас могут быть больше 24 и меньше нуля, минуты тоже не ограничены ничем, кроме размерности integer… В следующем посте ждите разъяснений по новому аспекту — constraints и еще чего-нибудь. А пока — пишите фидбек в комментариях, все как всегда, если вопрос простой — отвечаю там же, если он обширен и скорее как пожелание — то я постараюсь с каждым постом писать все качественнее. Спасибо за внимание!
|
Метки: author enchantinggg программирование java jetbrains mps language design language model javascript |
Перевод книги Appium Essentials. Глава 6 |
| Требования для Android | Требования для iOS |
| Java (версии 7 и выше) | Mac OS (версии 10.7 и выше) |
| Android SDK API, версии 17 и выше | Xcode (версии 4.6.3 и выше; рекомендуется 5.1) |
| Устройство с Android | Профиль iOS [эти и другие непонятные слова объясняются ниже] |
| Браузер Chrome на устройстве | Устройство iOS |
| Eclipse [или Idea] | Приложение SafariLauncher |
| TestNG | ios-webkit-debug-proxy |
| Appium сервер | Java (версии 7 и выше) |
| Клиентская библиотека Appium (у нас все еще Java) | Eclipse [или Idea] |
| Selenium Server и Java-библиотека WebDriver | TestNG |
| Приложение Apk Info app | Selenium Server и Java-библиотека WebDriver |
| Appium сервер | |
| Клиентская библиотека Appium (у нас все еще Java) |
adb devices
adb kill-server
adb start-server
import java.io.File;
import org.openqa.selenium.remote.DesiredCapabilities;
import io.appium.java_client.remote.MobileCapabilityType;
DesiredCapabilities caps = new DesiredCapabilities();
File app=new File("path of the apk");//чтобы определить путь до apk
caps.setCapability(MobileCapabilityType.APP,app);//если приложение уже установлено, эти две опции не нужны
caps.setCapability(MobileCapabilityType.PLATFORM_VERSION, "4.4");//версия Android
caps.setCapability(MobileCapabilityType.PLATFORM_NAME, "Android");//Имя OS
caps.setCapability(MobileCapabilityType.DEVICE_NAME, "Moto X");//здесь указывается имя устройства
caps.setCapability(MobileCapabilityType.APP_PACKAGE, "имя пакета вашего приложения(можете получить его, используя apk info app)");
caps.setCapability(MobileCapabilityType.APP_ACTIVITY, "активити, которую нужно будет запустить (получить так же через apk info app)");
import java.io.File;
import org.openqa.selenium.remote.DesiredCapabilities;
import io.appium.java_client.remote.MobileCapabilityType;
DesiredCapabilities caps = new DesiredCapabilities();
caps.setCapability(MobileCapabilityType.PLATFORM_VERSION, "4.4");//версия Android
caps.setCapability(MobileCapabilityType.PLATFORM_NAME, "Android");//Имя OS
caps.setCapability(MobileCapabilityType.DEVICE_NAME, "Moto X");//здесь указывается имя устройства
caps.setCapability(MobileCapabilityType.BROWSER_NAME, "Chrome"); //чтобы запустить Chrome
import io.appium.java_client.android.AndroidDriver;
import java.net.URL;
AndroidDriver driver = new AndroidDriver (new URL("http://127.0.0.1:4723/wd/hub"), caps);//указываем адрес, где запущен Appium-сервер

brew install ios-webkit-debug-proxyimport java.io.File;
import org.openqa.selenium.remote.DesiredCapabilities;
import io.appium.java_client.remote.MobileCapabilityType;
DesiredCapabilities caps = new DesiredCapabilities();
File app=new File("path of the .app");
caps.setCapability(MobileCapabilityType.APP,app);
caps.setCapability(MobileCapabilityType.PLATFORM_VERSION, "8.1");
caps.setCapability(MobileCapabilityType.PLATFORM_NAME, "iOS");//
caps.setCapability(MobileCapabilityType.DEVICE_NAME, "iPad");//
caps.setCapability("udid","Id реального устройства");//UDID
import java.io.File;
import org.openqa.selenium.remote.DesiredCapabilities;
import io.appium.java_client.remote.MobileCapabilityType;
DesiredCapabilities caps = new DesiredCapabilities();
caps.setCapability(MobileCapabilityType.PLATFORM_VERSION, "8.1");
caps.setCapability(MobileCapabilityType.PLATFORM_NAME, "iOS");
caps.setCapability(MobileCapabilityType.DEVICE_NAME,"iPad");
caps.setCapability("udid","UDID вашего устройства");
caps.setCapability(MobileCapabilityType.BROWSER_NAME,"Safari"); //чтобы запустить Safari
import io.appium.java_client.ios.IOSDriver;
import java.net.URL;
IOSDriver driver = new IOSDriver (new URL("http://127.0.0.1:4723/wd/hub"),caps); //Адрес, где Appium-сервер
import io.appium.java_client.ios.IOSDriver;
import io.appium.java_client.remote.MobileCapabilityType;
import java.io.File;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.remote.DesiredCapabilities;
import org.testng.annotations.AfterClass;
import org.testng.annotations.BeforeClass;
import org.testng.annotations.Test;
public class TestAppIication {
IOSDriver driver;
@BeforeClass //этот метод выполняется перед каждым тестом
public void setUp() throws MalformedURLException{
DesiredCapabilities caps = new DesiredCapabilities();
File app=new File("path of the .app");
caps.setCapability(MobileCapabilityType.APP,app);
caps.setCapability(MobileCapabilityType.PLATFORM_VERSION, "8.1");
caps.setCapability(MobileCapabilityType.PLATFORM_NAME, "iOS");
caps.setCapability(MobileCapabilityType.DEVICE_NAME,"iPad");
caps.setCapability("udid","UDID вашего устройства");
caps.setCapability(MobileCapabilityType.BROWSER_NAME, "Safari");//в случае, если работаем с веб-приложением
driver = new IOSDriver (new URL("http://127.0.0.1:4723/wd/hub"), caps);
driver.manage().timeouts().implicitlyWait(30,TimeUnit.SECONDS);
}
@Test
public void testExample(){
//здесь шаги теста
}
@AfterClass
public void tearDown(){
driver.closeApp();
//driver.quit(); //в случае, если работаем с веб-приложением
}
}
caps.setCapability(MobileCapabilityType.APP_PACKAGE, "com.android.dialer");
caps.setCapability(MobileCapabilityType.APP_ACTIVITY, "com.android.dialer.DialtactsActivity");WebElement dialPad= driver.findElementByAccessibilityId("dial pad"));dialPad.click();for(int n=0;n<10;n++){
driver.findElement(By.name(""+n+"")).click();
}WebElement dial= driver.findElementByAccessibilityId("dial"));dial.click();public class TestAppIication {
AndroidDriver driver;
@BeforeClass
public void setUp() throws MalformedURLException{
DesiredCapabilities caps = new DesiredCapabilities();
caps.setCapability(MobileCapabilityType.PLATFORM_VERSION, "4.4");
caps.setCapability(MobileCapabilityType.PLATFORM_NAME, "Android");
caps.setCapability(MobileCapabilityType.DEVICE_NAME,"Moto X");//I am using Moto X as Real Device
caps.setCapability(MobileCapabilityType.APP_PACKAGE, "com.android.dialer");
caps.setCapability(MobileCapabilityType.APP_ACTIVITY, "com.android.dialer.DailtactsActivity");
driver = new AndroidDriver (new URL("http://127.0.0.1:4723/wd/hub"), caps);
driver.manage().timeouts().implicitlyWait(30,TimeUnit.SECONDS);
}
@Test
public void testExample(){
WebElement dialPad=driver.findElementByAccessibilityId("dial pad");
dialPad.click();
for(int n=0;n<10;n++){
driver.findElement(By.name(""+n+"")).click();
}
WebElement dial=driver.findElementByAccessibilityId("dial");
dial.click();
}
@AfterClass
public void tearDown(){
driver.closeApp();
}
}
File app=new File("/Users/mhans/appium/ios/BmiCalc.app");//You can change it with your app address
caps.setCapability(MobileCapabilityType.APP,app);//To set the app pathWebElement height=driver.findElement(By.xpath("(//UIATextField)[2]"));
WebElement weight=driver.findElement(By.xpath("(//UIATextField)[4]"));
WebElement calculateBMI=driver.findElement(By.name("Calculate BMI"));height.sendKeys("1.82");weight.sendKeys("75");calculateBMI.click();public class TestAppIication {
IOSDriver driver;
@BeforeClass
public void setUp() throws MalformedURLException{
File app=new File("/Users/mhans/appium/ios/BmiCalc.app");//You can change it with your app address
DesiredCapabilities caps = new DesiredCapabilities();
caps.setCapability(MobileCapabilityType.APP,app);
caps.setCapability(MobileCapabilityType.PLATFORM_VERSION, "8.1");
caps.setCapability(MobileCapabilityType.PLATFORM_NAME, "iOS");
caps.setCapability(MobileCapabilityType.DEVICE_NAME,"iPad");
caps.setCapability("udid","Real Device Id ");
driver = new IOSDriver (new URL("http://127.0.0.1:4723/wd/hub"), caps);
driver.manage().timeouts().implicitlyWait(30,TimeUnit.SECONDS);
}
@Test
public void testExample(){
WebElement height=driver.findElement(By.xpath("(//UIATextField)[2]"));
height.sendKeys("1.82");
WebElement weight=driver.findElement(By.xpath("(//UIATextField)[4]"));
weight.sendKeys("75");
WebElement calculateBMI=driver.findElement(By.name("Calculate BMI"));
calculateBMI.click();
}
@AfterClass
public void tearDown(){
driver.closeApp();
}
}

caps.setCapability(MobileCapabilityType.BROWSER_NAME, "Chrome");driver.get("https://www.gmail.com");WebElement username=driver.findElement(By.name("Email"));username.sendKeys("test");WebElement password=driver.findElement(By.name("Passwd"));password.sendKeys("test");WebElement signIn=driver.findElement(By.name("signIn"));signIn.click();public class TestAppIication {
AndroidDriver driver;
@BeforeClass
public void setUp() throws MalformedURLException {
DesiredCapabilities caps = new DesiredCapabilities();
caps.setCapability(MobileCapabilityType.BROWSER_NAME, "Chrome");
caps.setCapability(MobileCapabilityType.PLATFORM_VERSION, "4.4");
caps.setCapability(MobileCapabilityType.PLATFORM_NAME, "Android");
caps.setCapability(MobileCapabilityType.DEVICE_NAME,"Moto X");
driver = new AndroidDriver (new URL("http://127.0.0.1:4723/wd/hub"), caps);
driver.manage().timeouts().implicitlyWait(30,TimeUnit.SECONDS);
}
@Test
public void testExample(){
driver.get("https://www.gmail.com");
WebElement username=driver.findElement(By.name("Email"));
username.sendKeys("test");
WebElement password=driver.findElement(By.name("Passwd"));
password.sendKeys("test");
WebElement signIn=driver.findElement(By.name("signIn"));
signIn.click();
}
@AfterClass
public void tearDown(){
driver.quit();
}
}
caps.setCapability(MobileCapabilityType.BROWSER_NAME, "Safari");driver.get("https://www.google.com");WebElement searchBox=driver.findElement(By.name("q"));searchBox.sendKeys("Appium for mobile automation");ios_webkit_debug_proxy -c 2e5n6f615z66e98c1d07d22ee09658130d345443:27753 –dpublic class TestAppIication {
IOSDriver driver;
@BeforeClass
public void setUp() throws MalformedURLException{
DesiredCapabilities caps = new DesiredCapabilities();
caps.setCapability(MobileCapabilityType.BROWSER_NAME, "Safari");
caps.setCapability(MobileCapabilityType.PLATFORM_VERSION, "8.1");
caps.setCapability(MobileCapabilityType.PLATFORM_NAME, "iOS");
caps.setCapability(MobileCapabilityType.DEVICE_NAME, "iPad");
caps.setCapability("udid","Real Device Identifier");
driver = new IOSDriver (new URL("http://127.0.0.1:4723/wd/hub"), caps);
driver.manage().timeouts().implicitlyWait(30,TimeUnit.SECONDS);
}
@Test
public void testExample(){
driver.get("https://www.google.com");
WebElement searchBox=driver.findElement(By.name("q"));
searchBox.sendKeys("Appium for mobile automation");
}
@AfterClass
public void tearDown(){
driver.quit();
}
}
File app=new File("C:\\Appium_test\\HybridtestApp.apk");// (On window platform)
caps.setCapability(MobileCapabilityType.APP,app);
caps.setCapability(MobileCapabilityType.APP_PACKAGE, "com.example.hybridtestapp");
caps.setCapability(MobileCapabilityType.APP_ACTIVITY, "com.example.hybridtestapp.MainActivity");Set contexts = driver.getContextHandles();
for (String context : contexts) {
System.out.println(context); //выводим список контекстов
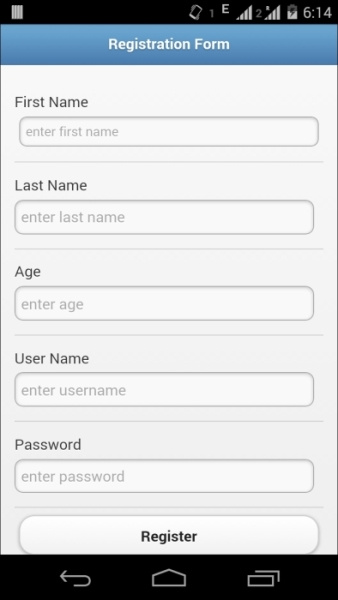
} driver.context("WEBVIEW_com.example.hybridtestapp");driver.context((String) contextNames.toArray()[1]);WebElement firstName=driver.findElement(By.name("fname"));
firstName.sendKeys("test");WebElement lastName=driver.findElement(By.name("lname"));
lastName.sendKeys("test");
WebElement age=driver.findElement(By.name("age"));
age.sendKeys("26");
WebElement username=driver.findElement(By.name("username"));
username.sendKeys("appiumTester");
WebElement password=driver.findElement(By.id("psw"));
password.sendKeys("appium@123");
WebElement registerButton=driver.findElement(By.id("register"));
registerButton.click();
public class TestAppIication {
AndroidDriver driver;
@BeforeClass
public void setUp() throws MalformedURLException{
File app=new File("C:\\Appium_test\\HybridtestApp.apk");
caps.setCapability(MobileCapabilityType.APP,app);
DesiredCapabilities caps = new DesiredCapabilities();
caps.setCapability(MobileCapabilityType.PLATFORM_VERSION, "4.4");
caps.setCapability(MobileCapabilityType.PLATFORM_NAME, "Android");
caps.setCapability(MobileCapabilityType.DEVICE_NAME, "Moto X");
caps.setCapability(MobileCapabilityType.AUTOMATION_NAME, "Appium");//Используйте Selendroid если версия android ниже 4.4
caps.setCapability(MobileCapabilityType.APP_PACKAGE, "com.example.hybridtestapp");
caps.setCapability(MobileCapabilityType.APP_ACTIVITY, "com.example.hybridtestapp.MainActivity");
driver = new AndroidDriver (new URL("http://127.0.0.1:4723/wd/hub"), caps);
driver.manage().timeouts().implicitlyWait(30,TimeUnit.SECONDS);
}
@Test
public void testExample(){
Set contexts = driver.getContextHandles();
for (String context : contexts) {
System.out.println(context);
}
driver.context((String) contexts.toArray()[1]);
WebElement firstName=driver.findElement(By.name("fname"));
firstName.sendKeys("test");
WebElement lastName=driver.findElement(By.name("lname"));
lastName.sendKeys("test");
WebElement age=driver.findElement(By.name("age"));
age.sendKeys("26");
WebElement username=driver.findElement(By.name("username"));
username.sendKeys("appiumTester");
WebElement password=driver.findElement(By.id("psw"));
password.sendKeys("appium@123");
WebElement registerButton=driver.findElement(By.id("register"));
registerButton.click();
}
@AfterClass
public void tearDown(){
driver.closeApp();
}
}
File app=new File("/Users/mhans/appium/ios/WebViewApp.app");
caps.setCapability(MobileCapabilityType.APP,app);WebElement editBox=driver.findElement(By.className("UIATextField"));
editBox.sendKeys("www.google.com");WebElement goButton=driver.findElement(By.name("Go"));
goButton.click();Set contexts = driver.getContextHandles();
for (String context : contexts) {
System.out.println(context);
} driver.context("WEBVIEW_com.example.testapp");driver.context((String) contextNames.toArray()[1]);WebElement images=driver.findElement(By.linkText("Images"));
images.click();ios_webkit_debug_proxy -c :27753 –d public class TestAppIication {
IOSDriver driver;
@BeforeClass
public void setUp() throws MalformedURLException{
DesiredCapabilities caps = new DesiredCapabilities();
File app=new File("/Users/mhans/appium/ios/WebViewApp.app");
caps.setCapability(MobileCapabilityType.APP,app);
caps.setCapability(MobileCapabilityType.PLATFORM_VERSION, "8.1");
caps.setCapability(MobileCapabilityType.PLATFORM_NAME, "iOS");
caps.setCapability(MobileCapabilityType.DEVICE_NAME, "iPad");
caps.setCapability("udid","Real Device Identifier");
driver = new IOSDriver (new URL("http://127.0.0.1:4723/wd/hub"), caps);
driver.manage().timeouts().implicitlyWait(30,TimeUnit.SECONDS);
}
@Test
public void testExample(){
WebElement editBox=driver.findElement(By.className("UIATextField"));
editBox.sendKeys("https://www.google.com");
WebElement goButton=driver.findElement(By.name("Go"));
goButton.click();
Set contexts = driver.getContextHandles();
for (String context : contexts) {
System.out.println(context);
}
driver.context((String) contexts.toArray()[1]);
WebElement images=driver.findElement(By.linkText("Images"));
images.click();
}
@AfterClass
public void tearDown(){
driver.closeApp();
}
}
|
Метки: author EreminD читальный зал appium automation testing тестирование тестирование мобильных приложений java |
Как уязвимость платежной системы раскрывала данные кредитных карт |
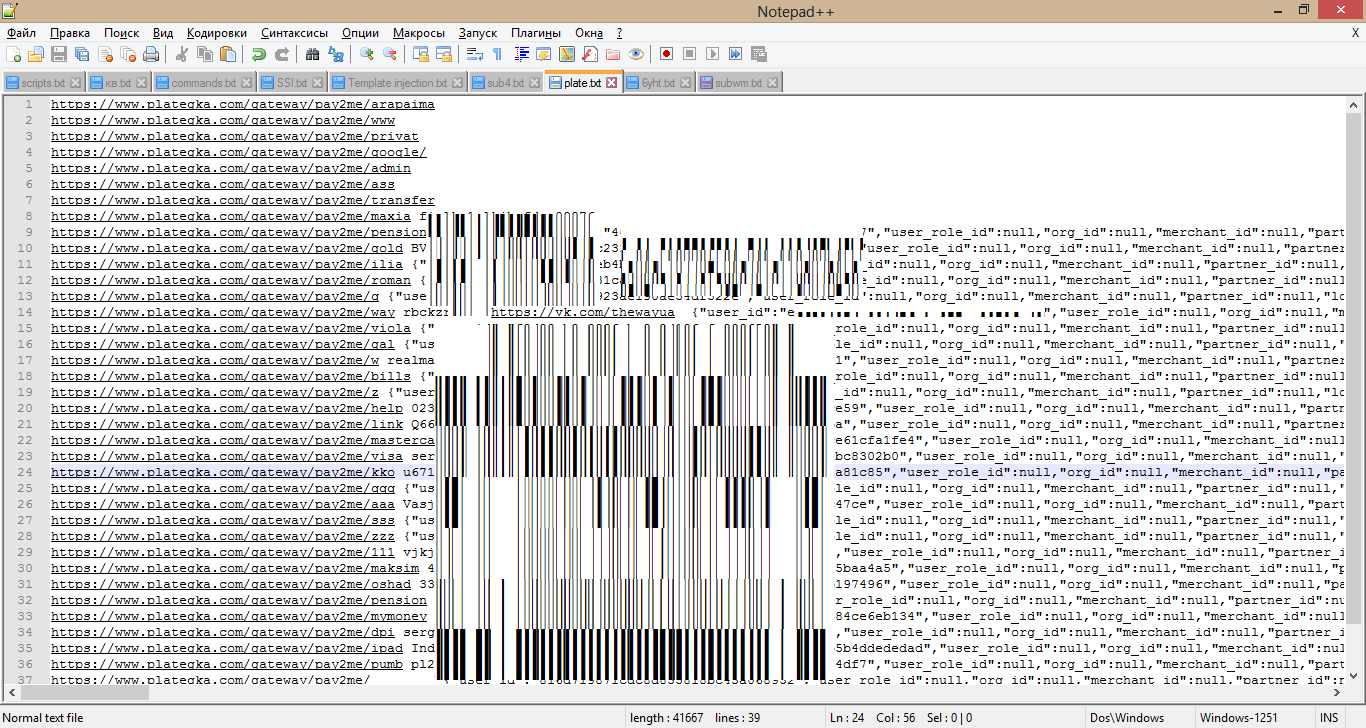
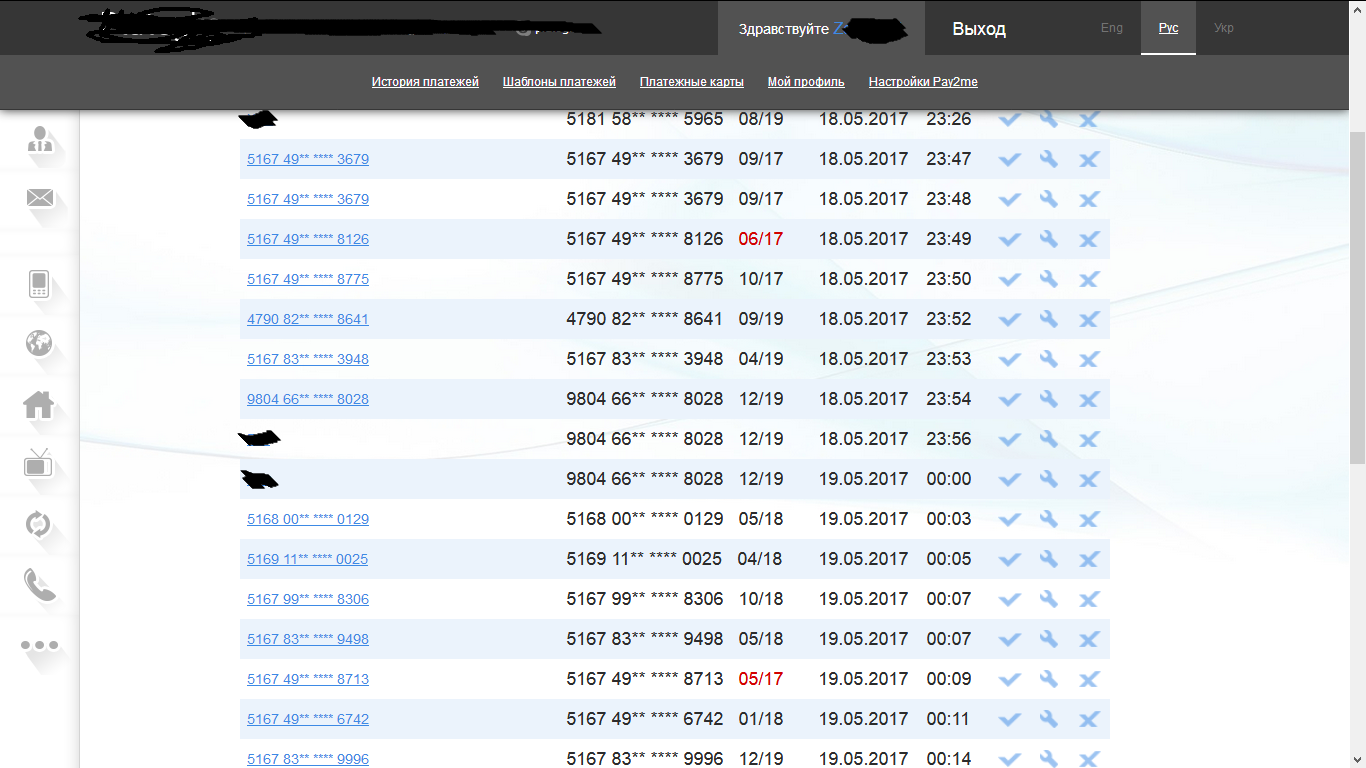
В личном кабинете есть соответствующая вкладка — «Настройки Pay2me». Для создания уникальной ссылки необходимо ввести ее название, 16-значный номер карты и нажать клавишу «Добавить».

{“user_id”:”dd660731660eb4bba1f62e44e7'',”user_role_id”:null,”org_id”:null,”merchant_id”:null,”partner_id”:null,”login”:”berest****”,”passwd”:”f1957496d2f5c7cb3caa73c2e*******”,”first_name”:”\u0418\u043b\u044c\u044f”,”second_name”:”\u0418\u0433\u043e\u0440\u0435\u0432\u0438\u0447'',”last_name”:”\u0412\u044f\u0437\u043c\u0435\u043d\u0442\u0438\u043d\u043e\u0432'',”email”:”berest****@ya.ru”,”phone”:”+38097360'',”key_private”:”inNFD\/aJyC2\/KWsuQ9vAs9FGg6\/\/4YnGjQuHUX7tu0i5GMY7weB3EddH815ytvkaUfS8F0KuxWMgAzDBAKv+Rv6Uzqgtn6qMaHH8N6v5KFWFeeRncGQ6XPQwo4kboNJIf8jidlFj\/Xi8+5BqRM\/cUfDt+P3ODaql5dImLehS36jzBwsQq6NjKZFYVkwhZ1mKbcu4H832JA32mHaHmTLlb\/HAocxg6ws1EDKRyJoNL3S8P”,”key_public”:”/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/+6MXVFgAmowKck8C+Bqoofy6+A2Qx6lREFBM8ENpCZGo6QAkjv2uYcw+JwXzBglqyomyBGp6kCR3G4KwWuFNQG+dNGA+uRC3wCvbHyPPRZKpuNIwM3AFGXdWWs3yZok32NbMkFRRcFa3raJ1QFlk1usJ6D3tnGiSrPL4NM+kB\/S6ezQHZzepScfD”,”secret”:”d7ceeb0a873ad2d29de12c45b******”,”secret_key”:null,”date_created”:”2017-05-11''}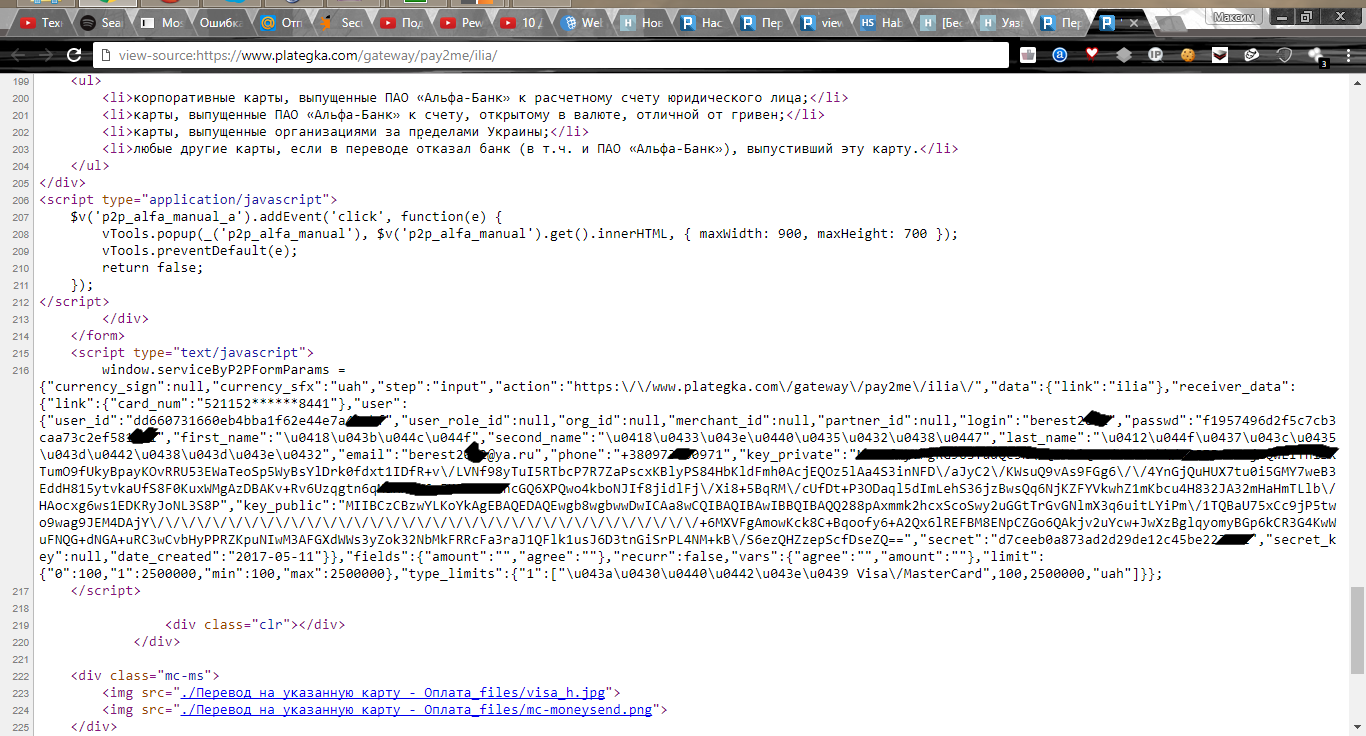


|
|
[Из песочницы] Мониторинг акторов в Akka.Net, но на F# |
type IMetricsTimer =
abstract member Measure : Amount -> unit
abstract member Measure : Amount * Item -> unit
type IMetricsCounter =
abstract member Decrement : unit -> unit
abstract member Decrement : Amount -> unit
abstract member Decrement : Amount * Item -> unit
abstract member Increment : unit -> unit
abstract member Increment : Amount -> unit
abstract member Increment : Amount * Item -> unit
type DecrementCounterCommand =
{ CounterId : CounterId
DecrementAmount : Amount
Item : Item }
type CreateCounterCommand =
{ CounterId : CounterId
Context : ContextName
Name : MetricName
MeasurementUnit : MeasurementUnit
ReportItemPercentages : bool
ReportSetItems : bool
ResetOnReporting : bool }
type MetricsMessage =
| DecrementCounter of DecrementCounterCommand
| IncrementCounter of IncrementCounterCommand
| MarkMeter of MarkMeterCommand
| MeasureTime of MeasureTimeCommand
| CreateCounter of CreateCounterCommand
| CreateMeter of CreateMeterCommand
| CreateTimer of CreateTimerCommand
let private createMeter (evtStream: EventStream) meterId =
{ new IMetricsMeter with
member this.Mark amount =
this.Mark (amount, Item None)
member this.Mark item =
this.Mark (Amount 1L, item)
member this.Mark (amount, item) =
evtStream.Publish <| MarkMeter { MeterId = meterId; Amount = amount; Item = item }
private IMetricsMeter createMeter(EventStream evtStream, MeterId meterId)
{
private class TempClass : IMetricsMeter
{
public void Mark(long amount)
{
Mark(amount, "");
}
public void Mark(string item)
{
Mark(1, item);
}
public void Mark(long amount, string item)
{
evtStream.Publish(new MarkMeter {...});//omitted
}
}
return new TempClass();
}
member this.CreateMeter (name, measureUnit, rateUnit) =
let cmd =
{ MeterId = MeterId (toId name)
Context = context
Name = name
MeasurementUnit = measureUnit
RateUnit = rateUnit }
evtStream.Publish <| CreateMeter cmd
createMeter evtStream cmd.MeterId
type IActorContext with
member x.GetMetricsProducer context =
createAdapter x.System.EventStream context
type public MetricController(metrics: IMetrics) =
inherit ApiController()
[]
[]
member __.GetMetrics() =
__.Ok(metrics.Snapshot.Get())
let createRecorder (metrics: IMetrics) (mailbox: Actor<_>) =
let self = mailbox.Self
let counters = new Dictionary()
let meters = new Dictionary()
let timers = new Dictionary()
//Часть кода для мапинга пропущена...
let handle = function
| DecrementCounter evt ->
match counters.TryGetValue evt.CounterId with
| (false, _) -> ()
| (true, c) ->
let (Amount am) = evt.DecrementAmount
match evt.Item with
| Item (Some i) -> c.Decrement (i, am)
| Item None -> c.Decrement (am)
| CreateMeter cmd ->
match meters.TryGetValue cmd.MeterId with
| (false, _) ->
let (ContextName ctxName) = cmd.Context
let (MetricName name) = cmd.Name
let options = new MeterOptions(
Context = ctxName,
MeasurementUnit = toUnit cmd.MeasurementUnit,
Name = name,
RateUnit = toTimeUnit cmd.RateUnit)
let m = metrics.Provider.Meter.Instance options
meters.Add(cmd.MeterId, m)
| _ -> ()
//Остальные случае в этом match пропущены
subscribe typedefof self mailbox.Context.System.EventStream |> ignore
let rec loop() = actor {
let! msg = mailbox.Receive()
handle msg
return! loop()
}
loop()
type IMetricApiConfig =
abstract member Host: string
abstract member Port: int
type ApiMessage = ReStartApiMessage
let createReader (config: IMetricApiConfig) resolver (mailbox: Actor<_>) =
let startUp (app: IAppBuilder) =
let httpConfig = new HttpConfiguration(DependencyResolver = resolver)
httpConfig.Formatters.JsonFormatter.SerializerSettings.Converters.Add(new MetricDataConverter())
httpConfig.Formatters.JsonFormatter.Indent <- true
httpConfig.MapHttpAttributeRoutes()
httpConfig.EnsureInitialized()
app.UseWebApi(httpConfig) |> ignore
let uri = sprintf "http://%s:%d" config.Host config.Port
let mutable api = {new IDisposable with member this.Dispose() = ()}
let handleMsg (ReStartApiMessage) =
api.Dispose()
api <- WebApp.Start(uri, startUp)
mailbox.Defer api.Dispose
mailbox.Self type Fragment =
| OperationName of string
| OperationDuration of TimeSpan
| TotalDuration of TimeSpan
| ReceivedOn of DateTimeOffset
| MessageType of Type
| Exception of exn
type ILogBuilder =
abstract OnOperationBegin: unit -> unit
abstract OnOperationCompleted: unit -> unit
abstract Set: LogLevel -> unit
abstract Set: Fragment -> unit
abstract Fail: exn -> unit
abstract Supress: unit -> unit
abstract TryGet: Fragment -> Fragment option
type LogBuilder(logger: ILoggingAdapter) =
let logFragments = new Dictionary()
let stopwatch = new Stopwatch()
let mutable logLevel = LogLevel.DebugLevel
interface ILogBuilder with
//Реализация интерфейса
let set fragment =
logFragments.[fragment.GetType()] <- fragment
member x.OnOperationBegin() =
stopwatch.Start()
member this.Fail e =
logLevel <- LogLevel.ErrorLevel
set <| Exception e
member this.OnOperationCompleted() =
stopwatch.Stop()
set <| OperationDuration stopwatch.Elapsed
match tryGet <| ReceivedOn DateTimeOffset.MinValue with
| Some (ReceivedOn date) -> set <| TotalDuration (DateTimeOffset.UtcNow - date)
| _ -> ()
match status with
| Active ->
match (logLevel) with
| LogLevel.DebugLevel -> logger.Debug(message())
| LogLevel.InfoLevel -> logger.Info(message())
| LogLevel.WarningLevel -> logger.Warning(message())
| LogLevel.ErrorLevel -> logger.Error(message())
| x -> failwith(sprintf "Log level %s is not supported" <| string x)
| Supressed -> ()
type Expr<'T,'TLog when 'TLog :> ILogBuilder> = Expression, 'T, 'TLog>>
type Wrap =
static member Handler(e: Expression, 'T, #ILogBuilder>>) = e
let toExprName (expr: Expr<_,_>) =
match expr.Body with
| :? MethodCallExpression as methodCall -> methodCall.Method.Name
| x -> x.ToString()
let loggerActor<'TMsg> (handler: Expr<'TMsg,_>) (mailbox: Actor<'TMsg>) =
let exprName = handler |> toExprName
let metrics = mailbox.Context.GetMetricsProducer (ContextName exprName)
let logger = mailbox.Log.Value
let errorMeter = metrics.CreateMeter (MetricName "Error Rate", Errors)
let instanceCounter = metrics.CreateCounter (MetricName "Instances Counter", Items)
let messagesMeter = metrics.CreateMeter (MetricName "Message Processing Rate", Items)
let operationsTimer = metrics.CreateTimer (MetricName "Operation Durations", Requests, MilliSeconds, MilliSeconds)
instanceCounter.Increment()
mailbox.Defer instanceCounter.Decrement
let completeOperation (msgType: Type) (logger: #ILogBuilder) =
logger.Set (OperationName exprName)
logger.OnOperationCompleted()
match logger.TryGet(OperationDuration TimeSpan.Zero) with
| Some(OperationDuration dur) ->
operationsTimer.Measure(Amount (int64 dur.TotalMilliseconds), Item (Some exprName))
| _ -> ()
messagesMeter.Mark(Item (Some msgType.Name))
let registerExn (msgType: Type) e (logger: #ILogBuilder) =
errorMeter.Mark(Item (Some msgType.Name))
logger.Fail e
let wrapHandler handler mb (logBuilder: unit -> #ILogBuilder) =
let innherHandler mb msg =
let logger = logBuilder()
let msgType = msg.GetType()
logger.Set (MessageType msgType)
try
try
logger.OnOperationBegin()
handler mb msg logger
with
| e -> registerExn msgType e logger; reraise()
finally
completeOperation msgType logger
innherHandler mb
Func wrapHandler(
Func handler,
TMailbox mb,
Func logBuilder)
where TLogBuilder: ILogBuilder
let wrapExpr (expr: Expr<_,_>) mailbox logger =
let action = expr.Compile()
wrapHandler
(fun mb msg log -> action.Invoke(mailbox, msg, log))
mailbox
(fun () -> new LogBuilder(logger))
Action wrapExpr(
Expr expr,
Actor mb,
ILoggingAdapterlogger)
let rec loop() =
actor {
let! msg = mailbox.Receive()
wrapExpr handler mailbox akkaLogger msg
return! loop()
}
loop()
type ActorMessages =
| Wait of int
| Stop
let waitProcess = function
| Wait d -> Async.Sleep d |> Async.RunSynchronously
| Stop -> ()
let spawnWaitWorker() =
loggerActor <| Wrap.Handler(fun mb msg log -> waitProcess msg)
let waitWorker = spawn system "worker-wait" <| spawnWaitWorker()
waitWorker let failOrStopProcess (mailbox: Actor<_>) msg (log: ILogBuilder) =
try
match msg with
| Wait d -> failwith "can't wait!"
| Stop -> mailbox.Context.Stop mailbox.Self
with
| e -> log.Fail e
let spawnFailOrStopWorker() =
loggerActor <| Wrap.Handler(fun mb msg log -> failOrStopProcess mb msg log)
let failOrStopWorker = spawn system "worker-vocal" <| spawnFailOrStopWorker()
failOrStopWorker open Akka.FSharp
open SimpleInjector
open App.Metrics;
open Microsoft.Extensions.DependencyInjection
open SimpleInjector.Integration.WebApi
open System.Reflection
open System
open Metrics.MetricActors
open ExampleActors
let createSystem =
let configStr = System.IO.File.ReadAllText("system.json")
System.create "system-for-metrics" (Configuration.parse(configStr))
let createMetricActors system container =
let dependencyResolver = new SimpleInjectorWebApiDependencyResolver(container)
let apiConfig =
{ new IMetricApiConfig with
member x.Host = "localhost"
member x.Port = 10001 }
let metricsReaderSpawner = createReader apiConfig dependencyResolver
let metricsReader = spawn system "metrics-reader" metricsReaderSpawner
let metricsRecorderSpawner = createRecorder (container.GetInstance())
let metricsRecorder = spawn system "metrics-recorder" metricsRecorderSpawner
()
type Container with
member x.AddMetrics() =
let serviceCollection = new ServiceCollection()
let entryAssemblyName = Assembly.GetEntryAssembly().GetName()
let metricsHostBuilder = serviceCollection.AddMetrics(entryAssemblyName)
serviceCollection.AddLogging() |> ignore
let provider = serviceCollection.BuildServiceProvider()
x.Register(fun () -> provider.GetRequiredService())
[]
let main argv =
let container = new Container()
let system = createSystem
container.RegisterSingleton system
container.AddMetrics()
container.Verify()
createMetricActors system container
let waitWorker1 = spawn system "worker-wait1" <| spawnWaitWorker()
let waitWorker2 = spawn system "worker-wait2" <| spawnWaitWorker()
let waitWorker3 = spawn system "worker-wait3" <| spawnWaitWorker()
let waitWorker4 = spawn system "worker-wait4" <| spawnWaitWorker()
let failWorker = spawn system "worker-fail" <| spawnFailWorker()
let waitOrStopWorker = spawn system "worker-silent" <| spawnWaitOrStopWorker()
let failOrStopWorker = spawn system "worker-vocal" <| spawnFailOrStopWorker()
waitWorker1 ignore
0
{
"Context": "waitProcess",
"Counters": [
{
"Name": "Instances Counter",
"Unit": "items",
"Count": 4
}
],
"Meters": [
{
"Name": "Message Processing Rate",
"Unit": "items",
"Count": 4,
"FifteenMinuteRate": 35.668327519112893,
"FiveMinuteRate": 35.01484385742755,
"Items": [
{
"Count": 4,
"FifteenMinuteRate": 0.0,
"FiveMinuteRate": 0.0,
"Item": "Wait",
"MeanRate": 13.082620551464204,
"OneMinuteRate": 0.0,
"Percent": 100.0
}
],
"MeanRate": 13.082613248856632,
"OneMinuteRate": 31.356094372926623,
"RateUnit": "min"
}
],
"Timers": [
{
"Name": "Operation Durations",
"Unit": "req",
"ActiveSessions": 0,
"Count": 4,
"DurationUnit": "ms",
"Histogram": {
"LastUserValue": "waitProcess",
"LastValue": 8001.0,
"Max": 8001.0,
"MaxUserValue": "waitProcess",
"Mean": 3927.1639786164278,
"Median": 5021.0,
"Min": 1078.0,
"MinUserValue": "waitProcess",
"Percentile75": 8001.0,
"Percentile95": 8001.0,
"Percentile98": 8001.0,
"Percentile99": 8001.0,
"Percentile999": 8001.0,
"SampleSize": 4,
"StdDev": 2932.0567172627871,
"Sum": 15190.0
},
"Rate": {
"FifteenMinuteRate": 0.00059447212531854826,
"FiveMinuteRate": 0.00058358073095712587,
"MeanRate": 0.00021824579927905906,
"OneMinuteRate": 0.00052260157288211038
}
}
]
}
|
Метки: author Szer функциональное программирование c# .net f# |
[Из песочницы] SOAP и REST сервисы с помощью Python-библиотеки Spyne |
from spyne import Application, rpc, ServiceBase, Unicode
from lxml import etree
from spyne.protocol.soap import Soap11
from spyne.protocol.json import JsonDocument
from spyne.server.wsgi import WsgiApplication
from yandex_translate import YandexTranslate
class Soap(ServiceBase):
@rpc(Unicode, _returns=Unicode)
def Insoap(ctx, words):
print(etree.tostring(ctx.in_document))
translate = YandexTranslate('trnsl.1.1.201somesymbols')
tr = translate.translate(words, 'en')
tr_answer = tr['text'][0]
return tr_answer
app = Application([Soap], tns='Translator',
in_protocol=Soap11(validator='lxml'),
out_protocol=Soap11()
application = WsgiApplication(app)
if __name__ == '__main__':
from wsgiref.simple_server import make_server
server = make_server('0.0.0.0', 8000, application)
server.serve_forever()app = Application([Soap], tns='Translator',
in_protocol=JsonDocument(validator='soft'),
out_protocol=JsonDocument())|
Метки: author maxpy разработка под linux python spyne apache httpd wsgi soap rest xml json |
[recovery mode] Призрак локомотива или биржевой рынок через призму корреляций |

 Предварительно заметим, что на сегодняшний день существует значительное количество прогнозных моделей. В некоторых источниках говорится о том, что их число превысило отметку ста. К слову — основная шутка действительности в том, что … чем сложнее модель, тем труднее интерпретация, понимание каждой отдельной компоненты этой самой модели. Подчеркну, что цель данной статьи – ответить на поставленные выше вопросы, а не использовать одну из существующих моделей прогнозирования.
Предварительно заметим, что на сегодняшний день существует значительное количество прогнозных моделей. В некоторых источниках говорится о том, что их число превысило отметку ста. К слову — основная шутка действительности в том, что … чем сложнее модель, тем труднее интерпретация, понимание каждой отдельной компоненты этой самой модели. Подчеркну, что цель данной статьи – ответить на поставленные выше вопросы, а не использовать одну из существующих моделей прогнозирования. # -*- coding: utf-8 -*-
"""
@author: optimusqp
"""
import os
import urllib
import pandas as pd
import time
import codecs
from datetime import datetime, date
from pandas.io.common import EmptyDataError
e='.csv';
p='7';
yf='2017';
yt='2017';
month_start='01';
day_start='01';
month_end='07';
day_end='13';
year_start=yf[2:];
year_end=yt[2:];
mf=(int(month_start.replace('0','')))-1;
mt=(int(month_end.replace('0','')))-1;
df=(int(day_start.replace('0','')));
dt=(int(day_end.replace('0','')));
dtf='1';
tmf='1';
MSOR='1';
mstimever='0'
sep='1';
sep2='1';
datf='5';
at='1';
def quotes_finam_optimusqp(data,year_start,month_start,day_start,year_end,month_end,day_end,e,df,mf,yf,dt,mt,yt,p,dtf,tmf,MSOR,mstimever,sep,sep2,datf,at):
temp_name_file='id,company\n';
incrim=1;
for index, row in data.iterrows():
page = urllib.urlopen('http://export.finam.ru/'+str(row['code'])+'_'+str(year_start)+str(month_start)+str(day_start)+'_'+str(year_end)+str(month_end)+str(day_end)+str(e)+'?market='+str(row['id_exchange_2'])+'&em='+str(row['em'])+'&code='+str(row['code'])+'&apply=0&df='+str(df)+'&mf='+str(mf)+'&yf='+str(yf)+'&from='+str(day_start)+'.'+str(month_start)+'.'+str(yf)+'&dt='+str(dt)+'&mt='+str(mt)+'&yt='+str(yt)+'&to='+str(day_end)+'.'+str(month_end)+'.'+str(yt)+'&p='+str(p)+'&f='+str(row['code'])+'_'+str(year_start)+str(month_start)+str(day_start)+'_'+str(year_end)+str(month_end)+str(day_end)+'&e='+str(e)+'&cn='+str(row['code'])+'&dtf='+str(dtf)+'&tmf='+str(tmf)+'&MSOR='+str(MSOR)+'&mstimever='+str(mstimever)+'&sep='+str(sep)+'&sep2='+str(sep2)+'&datf='+str(datf)+'&at='+str(at))
print('http://export.finam.ru/'+str(row['code'])+'_'+str(year_start)+str(month_start)+str(day_start)+'_'+str(year_end)+str(month_end)+str(day_end)+str(e)+'?market='+str(row['id_exchange_2'])+'&em='+str(row['em'])+'&code='+str(row['code'])+'&apply=0&df='+str(df)+'&mf='+str(mf)+'&yf='+str(yf)+'&from='+str(day_start)+'.'+str(month_start)+'.'+str(yf)+'&dt='+str(dt)+'&mt='+str(mt)+'&yt='+str(yt)+'&to='+str(day_end)+'.'+str(month_end)+'.'+str(yt)+'&p='+str(p)+'&f='+str(row['code'])+'_'+str(year_start)+str(month_start)+str(day_start)+'_'+str(year_end)+str(month_end)+str(day_end)+'&e='+str(e)+'&cn='+str(row['code'])+'&dtf='+str(dtf)+'&tmf='+str(tmf)+'&MSOR='+str(MSOR)+'&mstimever='+str(mstimever)+'&sep='+str(sep)+'&sep2='+str(sep2)+'&datf='+str(datf)+'&at='+str(at))
print('code: '+str(row['code']))
#Формируем перечень файлов в которых будут содержаться котировки.
#Один файл - один торгуемый инструмент
file = codecs.open(str(row['code'])+"_"+"0"+".csv", "w", "utf-8")
content = page.read()
file.write(content)
file.close()
temp_name_file = temp_name_file + (str(incrim) + "," + str(row['code'])+"\n")
incrim+=1
time.sleep(2)
#Формируем файл в котором содержатся code заголовки торгуемых инструментов,
#из расчета одна строка - один заголовок.
write_file = "name_file_data.csv"
with open(write_file, "w") as output:
for line in temp_name_file:
output.write(line)
#Перед запуском quotes_finam_optimusqp в распоряжении должен быть
#файл параметров function_parameters.csv
#___http://optimusqp.ru/articles/articles_1/function_parameters.csv
data_all = pd.read_csv('function_parameters.csv', index_col='id')
#Сузим область нашей выборки до тех инструментов, которые торгуются
#исключительно на id_exchange_2 == 1, т.е. МосБиржа акции
data = data_all[data_all['id_exchange_2']==1]
quotes_finam_optimusqp(data,year_start,month_start,day_start,year_end,month_end,day_end,e,df,mf,yf,dt,mt,yt,p,dtf,tmf,MSOR,mstimever,sep,sep2,datf,at)
#Зачем мы записываем файлы, и потом их считываем тут же?
#Все просто - ради наглядности процесса.
name_file_data = pd.read_csv('name_file_data.csv', index_col='id')
incrim=1;
#Введем показатель how_work_days - он нужен нам затем, чтобы не рассматривать
#неликвидные инструменты, либо инструменты с малой продолжительностью торговли
#на рынке
temp_string_in_file='id,how_work_days\n';
for index, row1 in name_file_data.iterrows():
how_string_in_file = 0
#открываем файл с котировкой по инструменту, в соответствие с имеющейся маской
name_file=row1['company']+"_"+"0"+".csv"
#а существует ли файл котировок? проверка файла на существование
if os.path.exists(name_file):
folder_size = os.path.getsize(name_file)
#если файл котировок имеет нулевой вес - следовательно он пуст, и мы можем его просто удалить
if folder_size>0:
temp_quotes_data=pd.read_csv(name_file, delimiter=',')
#если файл котировок пуст, в соответствие с исключением типа EmptyDataError
#его также удаляем
try:
#здесь будем рассматривать цены закрытия (CLOSE);
#остальные столбцы можем просто удалить
quotes_data = temp_quotes_data.drop(['', '', '', ''], axis=1)
#Определяем - какое количество строк в файле котировок
how_string_in_file = len(quotes_data.index)
#если файл котировок имеет количество строк менее чем 1 100,
#удаляем его; причина отсев неликвидных инструментов
if how_string_in_file>1100:
#формируем построчные записи для файла days_data.csv, в котором
#определяется количество периодов в течение которых торговался
#данный инструмент
temp_string_in_file = temp_string_in_file + (str(incrim) + "," + str(how_string_in_file)+"\n")
incrim+=1
quotes_data['DATE_str']=quotes_data[''].astype(basestring)
quotes_data['TIME_str']=quotes_data[' 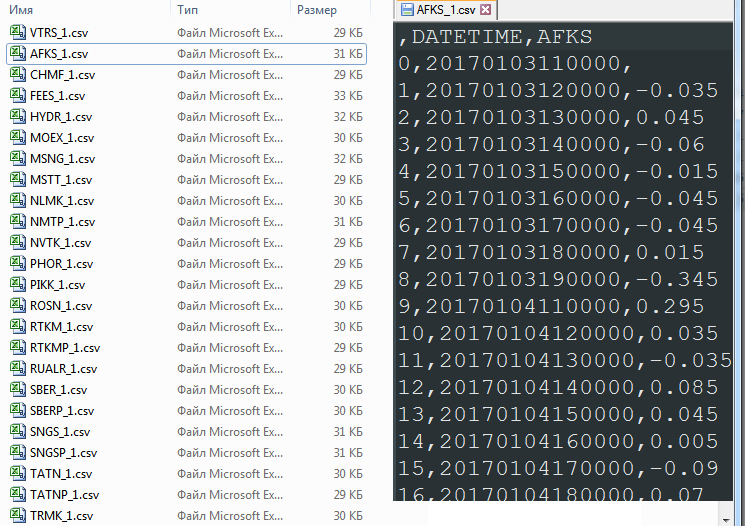
import glob
allFiles = glob.glob("*_1.csv")
frame = pd.DataFrame()
list_ = []
for file_ in allFiles:
df = pd.read_csv(file_,index_col=None, header=0)
list_.append(df)
dfff = reduce(lambda df1,df2: pd.merge(df1,df2,on='DATETIME'), list_)
quotes_data = dfff.drop(['Unnamed: 0_x', 'Unnamed: 0_y', 'Unnamed: 0'], axis=1)
quotes_data.to_csv("securities.csv", sep=',', encoding='utf-8')
quotes_data = quotes_data.drop(['DATETIME'], axis=1)
number_columns=len(quotes_data.columns)
columns_name_0 = quotes_data.columns
columns_name_1 = quotes_data.columns
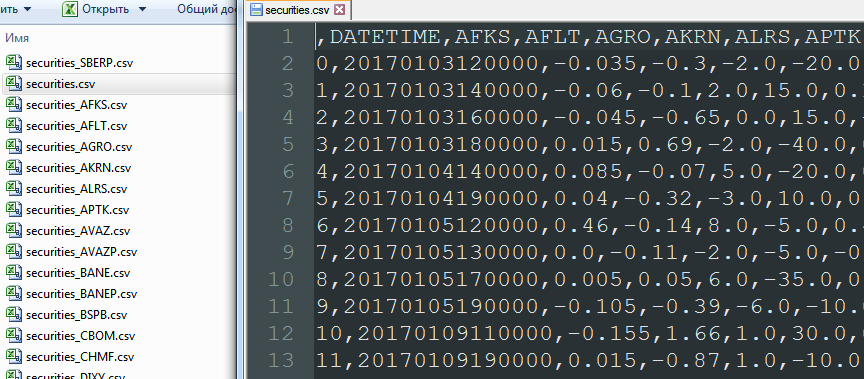
incrim=0
quotes_data_w=quotes_data.shift(1)
for column in columns_name_0:
quotes_data_w[column]=quotes_data_w[column].shift(-1)
quotes_data_w.to_csv("securities_"+column+".csv", sep=',', encoding='utf-8')
#Вернем на место сдвинутые строки
quotes_data_w[column]=quotes_data_w[column].shift(1)
incrim+=1




import pandas as pd
import matplotlib.pyplot as plt
import plotly.plotly as py
import plotly.graph_objs as go
from plotly.tools import FigureFactory as FF
import numpy as np
from scipy import stats, optimize, interpolate
def Normality_Test(L):
x = L
shapiro_results = scipy.stats.shapiro(x)
matrix_sw = [
['', 'DF', 'Test Statistic', 'p-value'],
['Sample Data', len(x) - 1, shapiro_results[0], shapiro_results[1]]
]
shapiro_table = FF.create_table(matrix_sw, index=True)
py.iplot(shapiro_table, filename='pareto_file')
#py.iplot(shapiro_table, filename='normal_file')
#L =np.random.normal(115.0, 10, 860)
L =np.random.pareto(3,50)
Normality_Test(L)




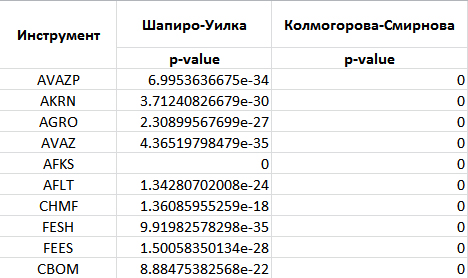
allFiles = glob.glob("*_1.csv")
def Shapiro(df,temp_header):
df=df.drop(df.index[0])
x = df[temp_header].tolist()
shapiro_results = scipy.stats.shapiro(x)
matrix_sw = [
['', 'DF', 'Test Statistic', 'p-value'],
['Sample Data', len(x) - 1, shapiro_results[0], shapiro_results[1]]
]
shapiro_table = FF.create_table(matrix_sw, index=True)
py.iplot(shapiro_table, filename='shapiro-table_'+temp_header)
def Kolmogorov_Smirnov(df,temp_header):
df=df.drop(df.index[0])
x = df[temp_header].tolist()
ks_results = scipy.stats.kstest(x, cdf='norm')
matrix_ks = [
['', 'DF', 'Test Statistic', 'p-value'],
['Sample Data', len(x) - 1, ks_results[0], ks_results[1]]
]
ks_table = FF.create_table(matrix_ks, index=True)
py.iplot(ks_table, filename='ks-table_'+temp_header)
frame = pd.DataFrame()
list_ = []
for file_ in allFiles:
df = pd.read_csv(file_,index_col=None, header=0)
print(file_)
columns = df.columns
temp_header = columns[2]
Shapiro(df,temp_header)
time.sleep(3)
Kolmogorov_Smirnov(df,temp_header)
time.sleep(3)
incrim=0
for column0 in columns_name_1:
df000 = pd.read_csv('securities_'+column0+".csv",index_col=None, header=0)
#Удаляем первую строку с пустотами
df000=df000.drop(df000.index[0])
df000 = df000.drop(['Unnamed: 0'], axis=1)
#Поочередно рассчитываем корреляцию Спирмена для каждого
#инструмента по отношению к прошлым периодам других ценных бумаг
corr_spr=df000.corr('spearman')
#Отсортируем строки в полученном файле корреляций от
#больших значений к меньшим
corr_spr=corr_spr.sort_values([column0], ascending=False)
#Сохраняем как отдельный DataFrame
corr_spr_temp=corr_spr[column0]
corr_spr_temp.to_csv("corr_"+column0+".csv", sep=',', encoding='utf-8')
incrim+=1

incrim=0
all_corr_Files = glob.glob("corr_*.csv")
list_corr = []
quotes_data_end = pd.DataFrame()
for file_corr in all_corr_Files:
df_corr = pd.read_csv(file_corr,index_col=None, header=0)
columns_corr = df_corr.columns
temp_header = columns_corr[0]
quotes_data_end[str(temp_header)]=df_corr.iloc[:,1]
incrim+=1
quotes_data_end.to_csv("_quotes_data_end.csv", sep=',', encoding='utf-8')
plt.figure();
quotes_data_end.plot();



|
Метки: author optimusqp машинное обучение python data mining pandas normality test dataframe |
Метаклассы в C++ |
$class interface {
constexpr
{
compiler.require($interface.variables().empty(),
"Никаких данных-членов в интерфейсах!");
for (auto f : $interface.functions())
{
compiler.require(!f.is_copy() && !f.is_move(),
"Интерфейсы нельзя копировать или перемещать; используйте"
"virtual clone() вместо этого");
if (!f.has_access())
f.make_public(); // сделать все методы публичными!
compiler.require(f.is_public(), // проверить, что удалось
"interface functions must be public");
f.make_pure_virtual(); // сделать метод чисто виртуальным
}
}
// наш интерфейс в терминах С++ будет просто базовым классом,
// а значит ему нужен виртуальный деструктор
virtual ~interface() noexcept { }
};interface Shape
{
int area() const;
void scale_by(double factor);
};class Shape
{
public:
virtual int area() const =0;
virtual void scale_by(double factor) =0;
virtual ~Shape() noexcept { };
};class Point
{
int x = 0;
int y = 0;
public:
Point() = default;
friend bool operator==(const Point& a, const Point& b)
{ return a.x == b.x && a.y == b.y; }
friend bool operator< (const Point& a, const Point& b)
{ return a.x < b.x || (a.x == b.x && a.y < b.y); }
friend bool operator!=(const Point& a, const Point& b) { return !(a == b); }
friend bool operator> (const Point& a, const Point& b) { return b < a; }
friend bool operator>=(const Point& a, const Point& b) { return !(a < b); }
friend bool operator<=(const Point& a, const Point& b) { return !(b < a); }
};$class ordered {
constexpr {
if (! requires(ordered a) { a == a; }) ->
{
friend bool operator == (const ordered& a, const ordered& b)
{
constexpr
{
for (auto o : ordered.variables()) // for each member
-> { if (!(a.o.name$ == b.(o.name)$)) return false; }
}
return true;
}
}
if (! requires(ordered a) { a < a; }) ->
{
friend bool operator < (const ordered& a, const ordered& b)
{
for (auto o : ordered.variables()) ->
{
if (a.o.name$ < b.(o.name)$) return true;
if (b.(o.name$) < a.o.name$) return false; )
}
return false;
}
}
if (! requires(ordered a) { a != a; })
-> { friend bool operator != (const ordered& a, const ordered& b) { return !(a == b); } }
if (! requires(ordered a) { a > a; })
-> { friend bool operator > (const ordered& a, const ordered& b) { return b < a ; } }
if (! requires(ordered a) { a <= a; })
-> { friend bool operator <= (const ordered& a, const ordered& b) { return !(b < a); } }
if (! requires(ordered a) { a >= a; })
-> { friend bool operator >= (const ordered& a, const ordered& b) { return !(a < b); } }
}
};ordered Point
{
int x;
int y;
};template
literal_value pair
{
T1 first;
T2 second;
}; |
Метки: author tangro совершенный код программирование компиляторы c++ блог компании инфопульс украина метаклассы |
Что делают химики и биологи в ЕРАМ? |


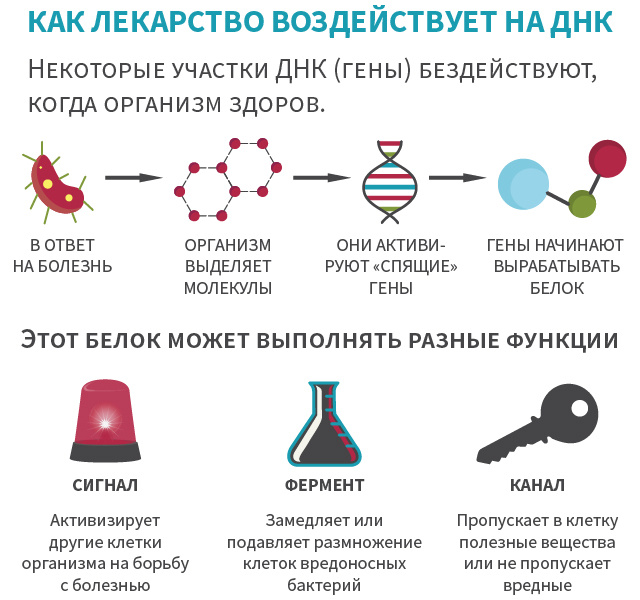
|
Метки: author AliceMir блог компании epam epam systems life sciences химия биология фармацевтика днк |
[Из песочницы] Криптовалюта с точки зрения гражданского права |
|
Метки: author sunnydog финансы в it исследования и прогнозы в it блокчейн право биткоин криптовалюта ico |
Немного о SSL-сертификатах: Какой выбрать и как получить |
 / Flickr / montillon.a / CC
/ Flickr / montillon.a / CC



|
Метки: author 1cloud разработка веб-сайтов блог компании 1cloud.ru 1cloud ssl сертификаты |
[Перевод] Если нет разницы между двумя вариантами кода, выбирай тот, который проще отладить |
as, который пытается преобразовать объект и в случае успеха возвращает результат, в случае неудачи null; или использовать оператор преобразования.
// вариант 1
var thing = GetCurrentItem();
var foo = thing as Foo;
foo.DoSomething();
// вариант 2
var thing = GetCurrentItem();
var foo = (Foo)thing;
foo.DoSomething();
thing не является типом Foo. Оба варианта отработают некорректно, однако сделают они это по-разному.NullReferenceException в методе foo.DoSomething(), и дамп сбоя подтвердит, что переменная foo является null. Однако этого может и не быть в дампе сбоя. Возможно, дамп сбоя захватывает лишь параметры, которые участвовали в выражении, которое в свою очередь привело к исключению. Или может быть переменная thing попадёт в сборщик мусора. Вы не можете определить где проблема когда GetCurrentItem возвращает null или GetCurrentItem возвращает объект другого типа, отлично от типа Foo. И что это если не Foo? thing является null, при вызове метода foo.DoSomething() ты получишь исключение NullReferenceException. Однако, если объект thing имеет другой тип, сбой произойдет в точке преобразования типов и выдаст исключение InvalidCastException. Если повезёт, отладчик покажет что именно нельзя преобразовать. Если не сильно повезёт, можно будет определить где произошел сбой по типу выданного исключения. Задание: Оба варианта ниже функционально эквивалентны. Какой будет проще отладить?
// вариант 1 collection.FirstOrDefault().DoSomething();
// вариант 2 collection.First().DoSomething();
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Schvepsss c# блог компании microsoft microsoft |
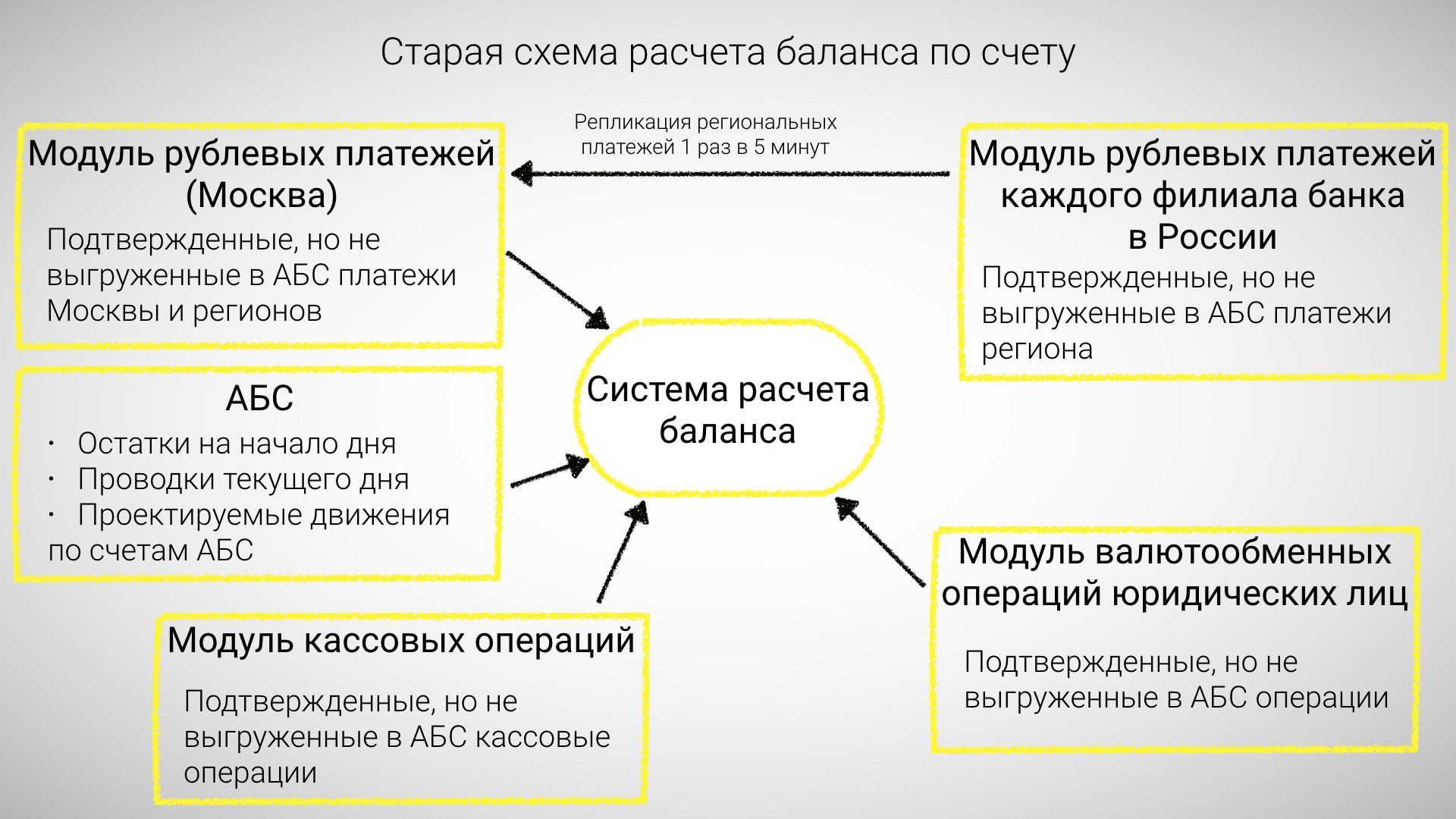
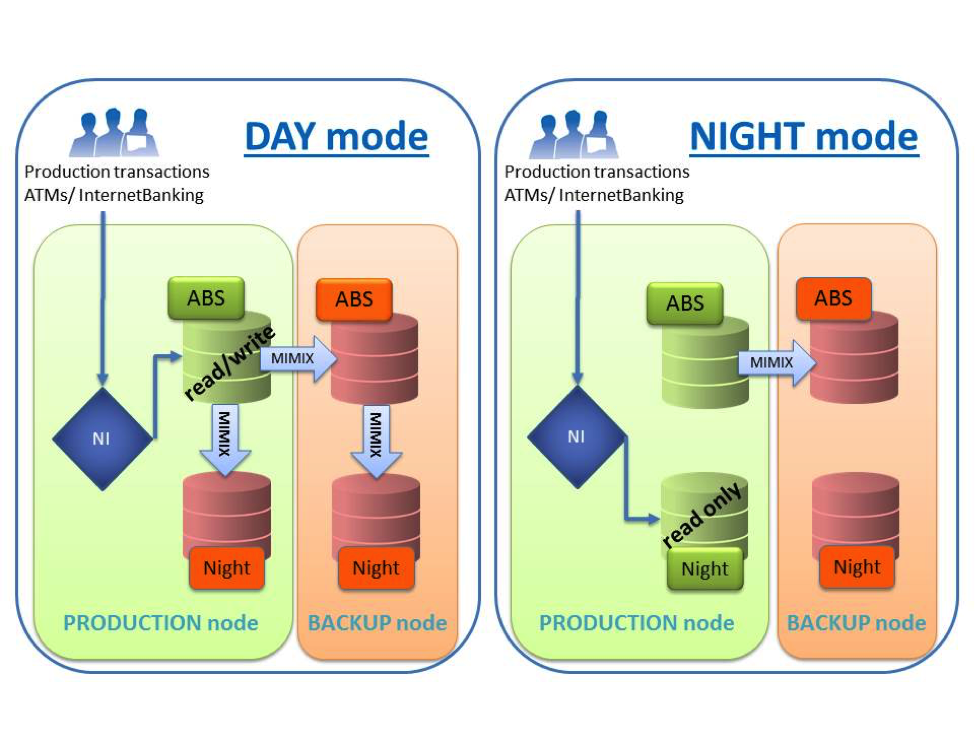
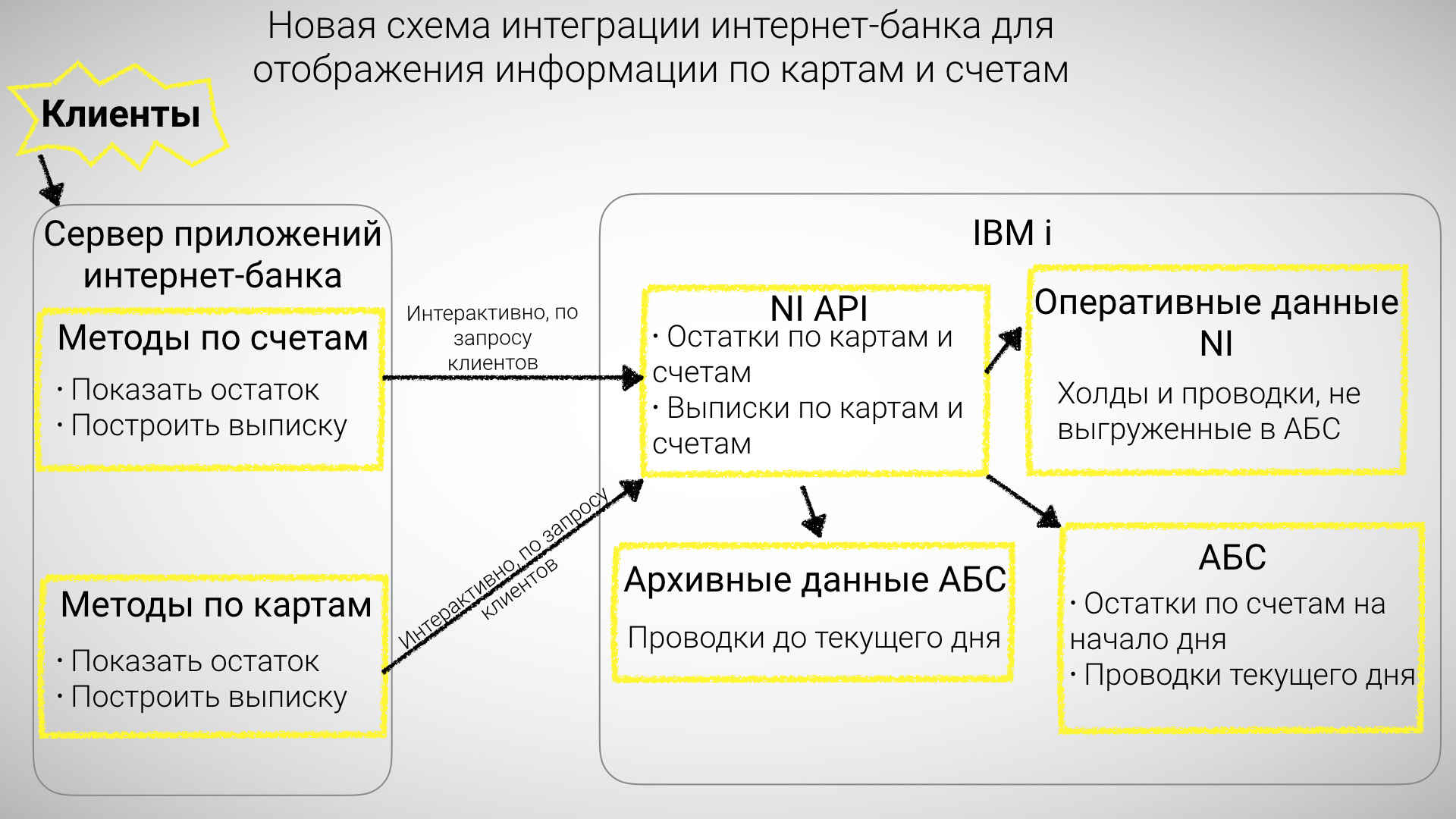
Карты, счета, 2 баланса |


|
Метки: author aBozhiev читальный зал финансы в it блог компании райффайзенбанк карты финансы архитектура приложений банки финансы и банковская сфера финансы в ит архитектура |
[Перевод] Разбираемся с копированием и клонированием |

Я наткнулся на статью Нареша Джоши о копировании и клонировании и был удивлён ситуацией с производительностью. У клонирования есть проблемы с финальными полями. А учитывая тот факт, что интерфейс Cloneable не предоставляет метод clone, то для вызова clone вам необходимо будет знать конкретный тип класса.
Вы можете написать такой код:
((Cloneable)o).clone(); // не работаетЕсли интерфейс Cloneable сломан, то у механизма клонирования могут быть некоторые преимущества. При копировании памяти он может оказаться эффективнее, чем копирование поля за полем. Это подчёркивает Джош Блох, автор Effective Java:
Даг Ли пошёл ещё дальше. Он сказал мне, что теперь клонирует только при копировании массивов. Вам следует использовать клонирование копирования массивов, потому что в целом это самый быстрый способ. Но у Дага типы больше не реализуют Cloneable. Он с ним завязал. И я не считаю это необоснованным.Но это было в 2002-м, разве ситуация не изменилась? Со времён Java 6 у нас есть Arrays.copyOf, что насчёт него? Какова производительность копирования объекта?
Есть только один способ выяснить: прогнать бенчмарки.

Давайте быстро рассмотрим clone и Arrays.copyOf применительно к массивам.
Бенчмарк int array выглядит так:
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public int[] testCopy() {
return Arrays.copyOf(original, size);
}
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public int[] testClone() {
return original.clone();
}Мы создали массив из случайных числовых значений, затем выполнили clone или Arrays.copyOf. Обратите внимание: мы вернули результат копирования, чтобы гарантировать, что код будет выполнен. В главе про escape analysis мы увидим, как невозвращение массива может радикально повлиять на бенчмарк.
Наряду с int array есть версия для byte array, long array и Object array. Я использую флаг DONT_INLINE, чтобы при необходимости легче было анализировать сгенерированный asm.
mvn clean install
java -jar target/benchmark.jar -bm avgt -tu ns -rf csvЭто даёт нам следующие значения средней продолжительности в наносекундах.
На графиках я отобразил одновременно total time/array size. Чем меньше, тем лучше.




Как видите, clone по сравнению с Arrays.copyOf обходится примерно на 10 % дешевле при маленьких массивах, так что это всё ещё хороший вариант. Несколько удивительно, что оба они используют один и тот же механизм копирования.
Давайте рассмотрим сгенерированный asm.
Для testClone есть код выделения памяти, идущий за копированием массива со строки 41 по 47.
0x0000000116972e4c: mov 0x10(%rsi),%r9d ;*getfield original
; - com.github.arnaudroger.ArrayByteCopyVsCloneBenchmark::testClone@1 (line 68)
0x0000000116972e50: mov 0xc(%r12,%r9,8),%r8d ;*invokevirtual clone
; - com.github.arnaudroger.ArrayByteCopyVsCloneBenchmark::testClone@4 (line 68)
; implicit exception: dispatches to 0x0000000116972f0e
0x0000000116972e55: lea (%r12,%r9,8),%rbp ;*getfield original
; - com.github.arnaudroger.ArrayByteCopyVsCloneBenchmark::testClone@1 (line 68)
0x0000000116972e59: movslq %r8d,%rdx
0x0000000116972e5c: add $0x17,%rdx
0x0000000116972e60: and $0xfffffffffffffff8,%rdx
0x0000000116972e64: cmp $0x100000,%r8d
0x0000000116972e6b: ja L0001
0x0000000116972e6d: mov 0x60(%r15),%rbx
0x0000000116972e71: mov %rbx,%r10
0x0000000116972e74: add %rdx,%r10
0x0000000116972e77: cmp 0x70(%r15),%r10
0x0000000116972e7b: jae L0001
0x0000000116972e7d: mov %r10,0x60(%r15)
0x0000000116972e81: prefetchnta 0xc0(%r10)
0x0000000116972e89: movq $0x1,(%rbx)
0x0000000116972e90: prefetchnta 0x100(%r10)
0x0000000116972e98: movl $0xf80000f5,0x8(%rbx) ; {metadata({type array byte})}
0x0000000116972e9f: mov %r8d,0xc(%rbx)
0x0000000116972ea3: prefetchnta 0x140(%r10)
0x0000000116972eab: prefetchnta 0x180(%r10)
L0000: lea 0x10(%r12,%r9,8),%rdi
0x0000000116972eb8: mov %rbx,%rsi
0x0000000116972ebb: add $0x10,%rsi
0x0000000116972ebf: add $0xfffffffffffffff0,%rdx
0x0000000116972ec3: shr $0x3,%rdx
0x0000000116972ec7: movabs $0x1167e5780,%r10
0x0000000116972ed1: callq *%r10 ;*invokevirtual clone
; - com.github.arnaudroger.ArrayByteCopyVsCloneBenchmark::testClone@4 (line 68)
0x0000000116972ed4: mov %rbx,%rax
0x0000000116972ed7: add $0x20,%rsp
0x0000000116972edb: pop %rbp
0x0000000116972edc: test %eax,-0xdf73ee2(%rip) # 0x00000001089ff000
; {poll_return} *** SAFEPOINT POLL ***
0x0000000116972ee2: retqВ testCopy есть код выделения памяти, но со строки 47 идёт гораздо больше кода для работы с длиной копии. Реальное копирование выполняется в строках 79—80.
0x000000010b1639cc: mov 0xc(%rsi),%r10d ;*getfield size
; - com.github.arnaudroger.ArrayByteCopyVsCloneBenchmark::testCopy@5 (line 62)
0x000000010b1639d0: cmp $0x100000,%r10d
0x000000010b1639d7: ja L0005
0x000000010b1639dd: movslq %r10d,%r8 ;*newarray
; - java.util.Arrays::copyOf@1 (line 3236)
; - com.github.arnaudroger.ArrayByteCopyVsCloneBenchmark::testCopy@8 (line 62)
L0000: mov 0x10(%rsi),%r9d ;*getfield original
; - com.github.arnaudroger.ArrayByteCopyVsCloneBenchmark::testCopy@1 (line 62)
0x000000010b1639e4: mov %r9d,0x10(%rsp)
0x000000010b1639e9: add $0x17,%r8
0x000000010b1639ed: mov %r8,%rdx
0x000000010b1639f0: and $0xfffffffffffffff8,%rdx
0x000000010b1639f4: cmp $0x100000,%r10d
0x000000010b1639fb: ja L0004
0x000000010b163a01: mov 0x60(%r15),%rbp
0x000000010b163a05: mov %rbp,%r11
0x000000010b163a08: add %rdx,%r11
0x000000010b163a0b: cmp 0x70(%r15),%r11
0x000000010b163a0f: jae L0004
0x000000010b163a15: mov %r11,0x60(%r15)
0x000000010b163a19: prefetchnta 0xc0(%r11)
0x000000010b163a21: movq $0x1,0x0(%rbp)
0x000000010b163a29: prefetchnta 0x100(%r11)
0x000000010b163a31: movl $0xf80000f5,0x8(%rbp) ; {metadata({type array byte})}
0x000000010b163a38: mov %r10d,0xc(%rbp)
0x000000010b163a3c: prefetchnta 0x140(%r11)
0x000000010b163a44: prefetchnta 0x180(%r11) ;*newarray
; - java.util.Arrays::copyOf@1 (line 3236)
; - com.github.arnaudroger.ArrayByteCopyVsCloneBenchmark::testCopy@8 (line 62)
L0001: mov 0x10(%rsp),%r11d
0x000000010b163a51: mov 0xc(%r12,%r11,8),%r11d ;*arraylength
; - java.util.Arrays::copyOf@9 (line 3237)
; - com.github.arnaudroger.ArrayByteCopyVsCloneBenchmark::testCopy@8 (line 62)
; implicit exception: dispatches to 0x000000010b163b77
0x000000010b163a56: cmp %r10d,%r11d
0x000000010b163a59: mov %r10d,%r9d
0x000000010b163a5c: cmovl %r11d,%r9d ;*invokestatic min
; - java.util.Arrays::copyOf@11 (line 3238)
; - com.github.arnaudroger.ArrayByteCopyVsCloneBenchmark::testCopy@8 (line 62)
0x000000010b163a60: mov %rbp,%rbx
0x000000010b163a63: add $0x10,%rbx
0x000000010b163a67: shr $0x3,%r8 ;*invokestatic arraycopy
; - java.util.Arrays::copyOf@14 (line 3237)
; - com.github.arnaudroger.ArrayByteCopyVsCloneBenchmark::testCopy@8 (line 62)
0x000000010b163a6b: mov 0x10(%rsp),%edi
0x000000010b163a6f: lea (%r12,%rdi,8),%rsi ;*getfield original
; - com.github.arnaudroger.ArrayByteCopyVsCloneBenchmark::testCopy@1 (line 62)
0x000000010b163a73: mov %r8,%rcx
0x000000010b163a76: add $0xfffffffffffffffe,%rcx
0x000000010b163a7a: cmp %r9d,%r11d
0x000000010b163a7d: jb L0006
0x000000010b163a83: cmp %r9d,%r10d
0x000000010b163a86: jb L0006
0x000000010b163a8c: test %r9d,%r9d
0x000000010b163a8f: jle L0007
0x000000010b163a95: lea 0x10(%r12,%rdi,8),%r11
0x000000010b163a9a: cmp %r10d,%r9d
0x000000010b163a9d: jl L0003
0x000000010b163a9f: add $0xfffffffffffffff0,%rdx
0x000000010b163aa3: shr $0x3,%rdx
0x000000010b163aa7: mov %r11,%rdi
0x000000010b163aaa: mov %rbx,%rsi
0x000000010b163aad: movabs $0x10afd5780,%r10
0x000000010b163ab7: callq *%r10
L0002: mov %rbp,%rax
0x000000010b163abd: add $0x30,%rsp
0x000000010b163ac1: pop %rbp
0x000000010b163ac2: test %eax,-0x5b6aac8(%rip) # 0x00000001055f9000
; {poll_return} *** SAFEPOINT POLL ***
0x000000010b163ac8: retqclone сделает копию точно такой же длины, но Arrays.copyOf позволяет нам копировать массив в массив другой длины, что усложняет обработку разных ситуаций и увеличивает стоимость, особенно на маленьких массивах. Похоже, jit никак не смирится с тем фактом, что мы передаём original.length как newLength. Будь это не так, он мог бы упростить код и производительность стала бы на уровне.
Теперь разберёмся с клонированием объектов с 4, 8, 16 и 32 полями. Бенчмарки ищут объекты с 4 полями:
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public Object4 testCopy4() {
return new Object4(original);
}
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public Object4 testClone4() {
return original.clone();
}Нормализованные результаты:

Как видите, для маленьких/средних объектов — меньше 8 полей — клонирование не столь эффективно, как копирование, но его преимущества раскрываются на более крупных объектах.
Это неудивительно и следует из комментария к коду JVM:
// TODO: вместо этого сгенерировать копии полей для маленьких объектов.Кто-то должен был отработать этот комментарий, но так и не сделал этого.
Давайте внимательнее проанализируем asm применительно к копированию и клонированию объектов с 4 полями.
java -jar target/benchmarks.jar -jvmArgs "-XX:+UnlockDiagnosticVMOptions -XX:+TraceClassLoading -XX:+LogCompilation -XX:+PrintAssembly " -f 1 "Object4"В testCopy asm с 17-й по 32-ю строки мы видим код выделения памяти.
Я добавил в asm кое-какую аннотацию, начинающуюся с **.
0x000000010593d28f: mov 0x60(%r15),%rax
0x000000010593d293: mov %rax,%r10
0x000000010593d296: add $0x20,%r10 ;** allocation size
0x000000010593d29a: cmp 0x70(%r15),%r10
0x000000010593d29e: jae L0001
0x000000010593d2a0: mov %r10,0x60(%r15)
0x000000010593d2a4: prefetchnta 0xc0(%r10)
0x000000010593d2ac: mov $0xf8015eab,%r11d ; {metadata('com/github/arnaudroger/beans/Object4')}
0x000000010593d2b2: movabs $0x0,%r10
0x000000010593d2bc: lea (%r10,%r11,8),%r10
0x000000010593d2c0: mov 0xa8(%r10),%r10
0x000000010593d2c7: mov %r10,(%rax)
0x000000010593d2ca: movl $0xf8015eab,0x8(%rax) ; {metadata('com/github/arnaudroger/beans/Object4')}
0x000000010593d2d1: mov %r12d,0xc(%rax)
0x000000010593d2d5: mov %r12,0x10(%rax)
0x000000010593d2d9: mov %r12,0x18(%rax) ;*new ; - com.github.arnaudroger.Object4CopyVsCloneBenchmark::testCopy4@0 (line 60)Строка 19 — это размер выделяемой памяти, 32 байта. Из них 16 байтов для свойств, 12 — для заголовков, 4 — для выравнивания (alignment). Проверить это можно с помощью jol.
com.github.arnaudroger.beans.Object4 object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 4 int Object4.f1 N/A
16 4 int Object4.f2 N/A
20 4 int Object4.f3 N/A
24 4 int Object4.f4 N/A
28 4 (loss due to the next object alignment)
Instance size: 32 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes totalКопирование поля за полем выполняется в строках с 33-й по 48-ю.
L0000: mov 0xc(%rbp),%r11d ;*getfield original4
; - com.github.arnaudroger.Object4CopyVsCloneBenchmark::testCopy4@5 (line 60)
0x000000010593d2e1: mov 0xc(%r12,%r11,8),%r10d ; implicit exception: dispatches to 0x000000010593d322
0x000000010593d2e6: mov %r10d,0xc(%rax) ;*putfield f1
; - com.github.arnaudroger.beans.Object4::@9 (line 12)
; - com.github.arnaudroger.Object4CopyVsCloneBenchmark::testCopy4@8 (line 60)
0x000000010593d2ea: mov 0x10(%r12,%r11,8),%r8d
0x000000010593d2ef: mov %r8d,0x10(%rax) ;*putfield f2
; - com.github.arnaudroger.beans.Object4::@17 (line 13)
; - com.github.arnaudroger.Object4CopyVsCloneBenchmark::testCopy4@8 (line 60)
0x000000010593d2f3: mov 0x14(%r12,%r11,8),%r10d
0x000000010593d2f8: mov %r10d,0x14(%rax) ;*putfield f3
; - com.github.arnaudroger.beans.Object4::@25 (line 14)
; - com.github.arnaudroger.Object4CopyVsCloneBenchmark::testCopy4@8 (line 60)
0x000000010593d2fc: mov 0x18(%r12,%r11,8),%r11d
0x000000010593d301: mov %r11d,0x18(%rax) Для testClone asm можно также посмотреть код выделения памяти с 24-й по 37-ю строку.
0x000000010b17da9d: mov 0x60(%r15),%rbx
0x000000010b17daa1: mov %rbx,%r10
0x000000010b17daa4: add $0x20,%r10 ;** allocation size
0x000000010b17daa8: cmp 0x70(%r15),%r10
0x000000010b17daac: jae L0001
0x000000010b17daae: mov %r10,0x60(%r15)
0x000000010b17dab2: prefetchnta 0xc0(%r10)
0x000000010b17daba: mov $0xf8015eab,%r11d ; {metadata('com/github/arnaudroger/beans/Object4')}
0x000000010b17dac0: movabs $0x0,%r10
0x000000010b17daca: lea (%r10,%r11,8),%r10
0x000000010b17dace: mov 0xa8(%r10),%r10
0x000000010b17dad5: mov %r10,(%rbx)
0x000000010b17dad8: movl $0xf8015eab,0x8(%rbx) ; {metadata('com/github/arnaudroger/beans/Object4')}Это несколько удивляет, потому что в логе компилирования

Применительно к Object.clone указан сбой инлайнинга, потому что это «нативный метод».
clone является внутренним (intrinsic), он инлайнится с помощью inline_native_clone и copy_to_clone.
copy_to_clone генерирует выделение памяти (allocation), а затем копирование long array. Оно возможно, потому что объекты выравнены в памяти по 8 байтов.
L0000: lea 0x8(%r12,%r8,8),%rdi ;** src
0x000000010b17dae4: mov %rbx,%rsi ;** dst
0x000000010b17dae7: add $0x8,%rsi ;** add offset
0x000000010b17daeb: mov $0x3,%edx ;** length
0x000000010b17daf0: movabs $0x10aff4780,%r10
0x000000010b17dafa: callq *%r10 ;*invokespecial clone
; - com.github.arnaudroger.beans.Object4::clone@1 (line 28)
; - com.github.arnaudroger.Object4CopyVsCloneBenchmark::testClone4@4 (line 66)Так что, несмотря на пометку о сбое, инлайнинг полностью выполнен. Выполняется копирование со смещением (offset) в 8 байтов, а также копируется три long или 24 байта, включая 4 байта метаданных класса, 16 байтов на 4 целочисленных значения, а остальное — на выравнивание.
Но поскольку клонирование использует копию памяти, экземпляр не пройдёт escape analysis, что приведёт к отключению некоторых оптимизаций. В следующем бенчмарке мы создадим копию и вернём только одно поле из свежесозданного Object32.
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public int testCopy() {
return new Object32(original).f29;
}
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public int testClone() {
return original.clone().f29;
}Результаты таковы, что, даже хотя clone более эффективно для объектов с 32 полями...

… бенчмарк клонирования работает более чем вчетверо медленнее! Что произошло?
Посмотрим, что находится под капотом asm.
В asm для testClone всё аналогично варианту для Object4CopyVsCloneBenchmark.testClone. В строке 26 выделяется 144 байта — 90 в шестнадцатеричном виде, — из которых 12 байтов на заголовок, 32 x 4 = 128 байтов на поля, 4 байта потеряно на выравнивание.
0x000000010ceebe8c: mov 0xc(%rsi),%r9d ;*getfield original
; - com.github.arnaudroger.Object32CopyVsCloneEABenchmark::testClone@1 (line 69)
0x000000010ceebe90: test %r9d,%r9d
0x000000010ceebe93: je L0002 ;*invokespecial clone
; - com.github.arnaudroger.beans.Object32::clone@1 (line 111)
; - com.github.arnaudroger.Object32CopyVsCloneEABenchmark::testClone@4 (line 69)
0x000000010ceebe99: lea (%r12,%r9,8),%rbp ;*getfield original
; - com.github.arnaudroger.Object32CopyVsCloneEABenchmark::testClone@1 (line 69)
0x000000010ceebe9d: mov 0x60(%r15),%rbx
0x000000010ceebea1: mov %rbx,%r10
0x000000010ceebea4: add $0x90,%r10 ;** object length
0x000000010ceebeab: cmp 0x70(%r15),%r10
0x000000010ceebeaf: jae L0001
0x000000010ceebeb1: mov %r10,0x60(%r15)
0x000000010ceebeb5: prefetchnta 0xc0(%r10)
0x000000010ceebebd: mov $0xf8015eab,%r11d ; {metadata('com/github/arnaudroger/beans/Object32')}
0x000000010ceebec3: movabs $0x0,%r10
0x000000010ceebecd: lea (%r10,%r11,8),%r10
0x000000010ceebed1: mov 0xa8(%r10),%r10
0x000000010ceebed8: mov %r10,(%rbx)
0x000000010ceebedb: movl $0xf8015eab,0x8(%rbx) ; {metadata('com/github/arnaudroger/beans/Object32')}
L0000: lea 0x8(%r12,%r9,8),%rdi ;** src
0x000000010ceebee7: mov %rbx,%rsi ;** dest
0x000000010ceebeea: add $0x8,%rsi ;** add offset of 8
0x000000010ceebeee: mov $0x11,%edx ;** length to copy 0x11 * 8 = 136 bytes
0x000000010ceebef3: movabs $0x10cd5d780,%r10
0x000000010ceebefd: callq *%r10 ;*invokespecial clone
; - com.github.arnaudroger.beans.Object32::clone@1 (line 111)
; - com.github.arnaudroger.Object32CopyVsCloneEABenchmark::testClone@4 (line 69)
0x000000010ceebf00: mov 0x7c(%rbx),%eax ;*getfield f29 ** 7c is 124 bytes, minus the headers 112 that offset 28 ints
; - com.github.arnaudroger.Object32CopyVsCloneEABenchmark::testClone@7 (line 69)
0x000000010ceebf03: add $0x20,%rsp
0x000000010ceebf07: pop %rbp
0x000000010ceebf08: test %eax,-0xb154f0e(%rip) # 0x0000000101d97000
; {poll_return} *** SAFEPOINT POLL ***
0x000000010ceebf0e: retqВ копии один даже не копируется объект, просто возвращается поле f29 из оригинального объекта. Поскольку копирование не эскейпится и создание копии не приводит к побочным эффектам, то можно безопасно полностью удалить код создания нового объекта.
0x0000000109c7b1cc: mov 0xc(%rsi),%r11d ;*getfield original
; - com.github.arnaudroger.Object32CopyVsCloneEABenchmark::testCopy@5 (line 63)
0x0000000109c7b1d0: mov 0x7c(%r12,%r11,8),%eax ;*getfield f29 ** 7c is 124 bytes, minus the headers 112 that offset 28 ints
; - com.github.arnaudroger.beans.Object32::@230 (line 67)
; - com.github.arnaudroger.Object32CopyVsCloneEABenchmark::testCopy@8 (line 63)
; implicit exception: dispatches to 0x0000000109c7b1e1
0x0000000109c7b1d5: add $0x10,%rsp
0x0000000109c7b1d9: pop %rbp
0x0000000109c7b1da: test %eax,-0x47b81e0(%rip) # 0x00000001054c3000
; {poll_return} *** SAFEPOINT POLL ***
0x0000000109c7b1e0: retq Метод clone работает быстрее при копировании массивов и больших объектов. Но удостоверьтесь, что ваш код не использует преимущества escape-анализа. В любом случае это может незначительно повлиять на весь ваш код, так что совет Дага Ли всё ещё актуален: избегайте копирования, за исключением копирования массивов.
|
Метки: author AloneCoder отладка высокая производительность анализ и проектирование систем java блог компании mail.ru group clone copy никто не читает теги |
Использование устройства на базе STM32 в системе полива для открытого грунта |








|
Метки: author Greeds74 программирование микроконтроллеров stm32 chibios lad fbd fx2n mitsubishi |
[Перевод] Методология и руководство по стилю кода компании Ronimo |
|
Метки: author PatientZero разработка игр программирование c++ методология разработки agile руководство по стилю |
Разбор задач финала Яндекс.Алгоритма 2017 |
На днях завершился Яндекс.Алгоритм 2017 — наш чемпионат по спортивному программированию. В финальном раунде 25 финалистам нужно было за два с половиной часа решить шесть задач. Первое место вновь завоевал Геннадий Короткевич из питерского ИТМО — это уже четвёртая его победа после состязаний 2013, 2014 и 2015 года. Никола Йокич из Швейцарской высшей технической школы Цюриха и выпускник Университета Токио Макото Соэдзима стали вторым и третьим, повторив свои прошлогодние результаты. Вот как распределились денежные призы: победа — 300 тысяч рублей, второе место — 150 тысяч, третье — 90 тысяч.

Заявки на участие в Алгоритме 2017 подали 4840 человек. Более 60% из них — россияне. На втором месте по количеству заявок — Беларусь, далее следуют Украина, Индия и Китай. В общей сложности на чемпионат зарегистрировались жители нескольких десятков стран, включая Сингапур, Камерун, Венесуэлу и Перу.
Мы по традиции публикуем формулировки и разобранные решения задач финала.
Автор задачи: Глеб Евстропов (Яндекс, НИУ ВШЭ).
| Имя входного файла: | Имя выходного файла: | Ограничение по времени: | Ограничение по памяти: |
|---|---|---|---|
| стандартный ввод | стандартный вывод | 5 секунд (13 для Java) | 512 мегабайт |
Порядком устав от соревнований по программированию и решения алгоритмических задач, Аркадий решил взять небольшую паузу и кардинально сменить род деятельности. Нашего героя всегда тянуло в горы, поэтому, используя заработанные на различных соревнованиях призовые деньги, он прикупил себе небольшой горнолыжный курорт и занялся его подготовкой к зимнему сезону.
Единственная имеющаяся трасса состоит из контрольных пунктов, пронумерованных от до . Контрольный пункт находится на высоте , причём никакие два пункта не находятся на одной высоте. Поскольку на трассе только один подъёмник, то спуск всегда начинается в контрольном пункте номер и заканчивается в контрольном пункте номер . Некоторые пар контрольных пунктов соединены участками трассы, которые ведут от более высокого контрольного пункта к более низкому.
Привлекательность участка трассы, непосредственно соединяющего контрольный пункт с контрольным пунктом , равна разности высот пунктов, то есть . При этом привлекательностью маршрута, последовательно посещающего контрольные пункты , называется минимальная из привлекательностей его участков, то есть минимум среди величин .
Туристов, посещающих курорт Аркадия, с одной стороны волнует привлекательность маршрута, а с другой — его длина, которая определяется как количество участков трассы в маршруте. Поскольку Аркадий уже не силён в решении подобного рода задач, то именно вам придётся вычислить для каждой возможной длины маршрута от до максимально возможную привлекательность маршрута из в , имеющего длину не менее .
В первой строке входных данных записаны четыре целых числа , , и (, , , ) — количество контрольных пунктов на трассе, количество участков трассы, номер стартового контрольного пункта и номер финишного контрольного пункта соответственно.
Во второй строке записаны различных целых чисел () — высоты, на которых расположены контрольные пункты.
Далее следуют строк, описывающих участки трассы. В -й из них записаны два числа и (, ), означающих, что -й участок трассы идёт от контрольного пункта к контрольному пункту . Гарантируется, что никакие два участка трассы не соединяют напрямую одну и ту же пару контрольных пунктов, что высота контрольного пункта больше высоты контрольного пункта , и что существует хотя бы один маршрут от контрольного пункта до контрольного пункта .
Выведите чисел по одному в строке, -е из которых должно равняться максимально возможной привлекательности маршрута из в , имеющего длину не меньше . Если для некоторого не существует маршрута длиной не меньше , то выведите в соответствующей строке .
| стандартный ввод | стандартный вывод |
| 4 4 2 4 3 4 2 1 2 4 2 1 1 3 3 4 |
3 1 1 |
| 3 2 1 3 3 2 1 1 2 1 3 |
2 -1 |
| 5 10 1 5 8 6 4 3 1 1 2 1 3 1 4 1 5 2 3 2 4 2 5 3 4 3 5 4 5 |
7 3 2 1 |
В первом примере существует прямой участок трассы из стартового контрольного пункта в конечный. Привлекательность такого маршрута равна , а длина . Также существует путь длины , проходящий через контрольные пункты , , и , c привлекательностью равной . Для ответом будет являться данный путь длины , поскольку это самый привлекательный путь длиной не менее .
Заметим, что поскольку все контрольные пункты расположены на различных высотах и все участки трассы идут от более высоких пунктов к более низким, то граф ацикличен. Найдём его топологическую сортировку (например, просто отсортировав вершины по высоте) и будем далее работать с ней.
Опишем два способа решить задачу за квадратичное время. Способ первый: перебрать все возможные значения увлекательности маршрута, после чего оставить в графе только рёбра , такие что и найти самый длинный путь из в , использующий только такие рёбра. Время работы такого решения — , где . Второй способ: динамическое программирование — максимально возможная увлекательность маршрута длины из в . Чтобы вычислить значение рассмотрим все выходящие рёбра и используем релаксацию . Время работы такого решения — .
Заметим, что первое из описанных квадратичных решений быстро найдёт ответ для путей с маленькой увлекательностью, а второе решение лучше подойдёт для коротких путей, и попробуем скомбинировать эти два подхода. Действительно, для пути длины верно, что его увлекательность не превосходит , и наоборот, путь увлекательностью не может иметь длину, больше чем . Введём параметр . Для любого пути из в справедливо, что либо его длина, либо его увлекательность не превосходят . Применим оба решения из второго абзаца, запуская первое только для , а во втором используя только значения . Итоговая сложность полученного решения: . Отметим, что при желаниии такое решение можно реализовать с использованием дополнительной памяти.
Автор задачи: Максим Ахмедов (Яндекс, МГУ, НИУ ВШЭ).
| Имя входного файла: | Имя выходного файла: | Ограничение по времени: | Ограничение по памяти: |
|---|---|---|---|
| стандартный ввод | стандартный вывод | 4 секунды | 512 мегабайт |
Дисклеймер: ситуация, описываемая в задаче, имеет мало отношения к реальному проекту беспилотного автомобиля и является исключительно плодом фантазии авторов соревнования.
Как известно, компания Яндекс с недавних пор занимается разработкой беспилотного автомобиля, в чём некоторые из участников финала соревнования, присутствующие в Москве, имеют шанс убедиться лично. Производство беспилотного автомобиля невозможно без тщательного тестирования на специально оборудованном полигоне. В рамках данной задачи вам будет предложено проверить возможности для перемещения беспилотного автомобиля по полигону, имеющему вид дерева.
Полигон состоит из площадок, соединённых дорогами. Площадки пронумерованы числами от до , а беспилотный автомобиль исходно находится на -й площадке. Цель тестирования состоит в том, чтобы провести за минимальное время автомобиль по маршруту, проходящему по каждой из площадок хотя бы раз, если известно, что автомобиль проезжает одну дорогу за одну минуту, а временем на повороты и развороты можно пренебречь.
Задача осложняется тем, что в рамках данного эксперимента навигация может осуществляться только по специальным радиомаякам. На каждой площадке находится радиомаяк, причём заряда включённого радиомаяка, расположенного на площадке , хватает ровно на минут. Будучи выключенным, радиомаяк не тратит заряд. Изначально все радиомаяки выключены.
Процесс перемещения устроен следующим образом. В один момент времени может быть включён только один радиомаяк. Если в начале минуты автомобиль находится на площадке , а радиомаяк расположен на площадке и включён в течение минут, то автомобиль перемещается по дорогам в сторону уменьшения расстояния до площадки . Если автомобиль уже находится на одной площадке с радиомаяком, то ничего не происходит. Каждый радиомаяк можно включать на целое количество минут произвольное количество раз.
Определите, можно ли составить план включения-выключения радиомаяков таким образом, чтобы автомобиль посетил все площадки хотя бы по одному разу, и если да, то найдите минимальное необходимое количество минут для этого. Возвращаться на исходную площадку не требуется.
В первой строке находится целое число () — количество площадок.
Во второй строке находятся целые числа (), где — количество минут, на которое хватает заряда в радиомаяке на площадке .
В последующих строках находятся описания дорог, каждое из которых состоит из двух целых чисел и (, ) — номеров соединяемых площадок.
Если требуемое возможно, выведите единственное целое число — минимальное время, необходимое для посещения всех площадок. В противном случае выведите число .
| стандартный ввод | стандартный вывод |
| 7 0 3 0 2 4 3 3 1 2 1 3 3 4 1 5 5 6 6 7 |
9 |
| 4 0 1 1 2 1 2 2 3 1 4 |
-1 |
В первом тесте из условия подходит, например, следующий маршрут:
Таким образом за 9 минут можно посетить все площадки.
Данная задача предлагает разобраться с тем, как можно перемещаться по дереву с использованием необычных правил перемещения. Вместо используемого в легенде задачи автомобиля будем считать, что на дереве расположена фишка, а в вершинах дерева расположены кнопки, причём нажатие одной кнопки эквивалентно включению радиомаяка на 1 секунду.
Таким образом, у нас имеется дерево, в вершине 1 которого находится фишка, в котором также имеется набор кнопок: в вершине находится кнопок, нажимая на которые, надо провести автомобиль по всему дереву.
Полезным приёмом при решении задачи часто оказывается рассмотрение более простой задачи, отличающейся на какую-то незначительную деталь. В данном случае полезно рассмотреть постановку, в которой фишка в конце должна обязательно вернуться в стартовую вершину. Отличительной деталью данной постановки является то, что в такой постановке по каждому ребру фишка будет обязана пройти минимум два раза (в одну и в другую сторону), что неверно для исходной задачи. По ряду причин такая задача проще исходной.
Заметим, что после выбора маршрута для корректного его прохождения необходимо сопоставить каждому перемещению по ребру свою кнопку в части дерева, находящейся за концом проходимого ребра. Легко видеть, что оптимальный искомый маршрут будет проходить по каждому ребру не просто минимум два раза, а, на самом деле, ровно два раза, так как в противном случае нам понадобится сопоставлять кнопки большему числу рёбер, что заведомо сложнее.
Обратно, если мы смогли сопоставить каждому ориентированному ребру свою кнопку, то тогда можно рассмотреть произвольный т.н. эйлеров обход дерева, а дальше, используя имеющееся сопоставление, успешно совершить этот обход.
Значит, ответ на нашу задачу (в упрощённой постановке) всегда (такова длина любого эйлерова обхода дерева), и единственное, что надо проверить — что существует сопоставление кнопок рёбрам, удовлетворяющее условию, что ребру соответствует кнопка в поддереве, на которое указывает данное ребро. Данная задача является, на самом деле, задачей о паросочетании в двудольном графе (одной долей которого является множество ориентированных рёбер, а другой — множество кнопок), насыщающего одну из долей. На вопрос о наличии подобного паросочетания даёт ответ классический факт теории паросочетаний, известный как лемма Холла.
Введём обозначения — пусть это множество ориентированных рёбер дерева, — множество кнопок, а для это множество кнопок, которые находятся в поддереве, на которое указывает ребро (формально говоря, кнопка тогда и только тогда, когда конец ребра лежит между началом ребра и кнопкой ). Тогда лемма Холла гласит, что искомое нами паросочетание существует тогда и только тогда, когда для любого набора ориентированных рёбер в объединении поддеревьев всех рёбер в присутствует не меньше кнопок, чем рёбер в множестве :
В противном случае, поступим похожим образом. Если , то аналогичным образом можно добавить в все рёбра, которые лежат в поддереве и смотрят в ту же сторону, что и (то есть, добавление которых не приводит к случаю, описанному выше). Действительно, добавление таких рёбер не изменяет множества покрываемых поддеревьями кнопок, а значит, это только усиливает проверяемое нами условие.
Теперь понятно, какую структуру имеет множество и соответствующее ему множество кнопок . Множество состоит из набора непересекающихся поддеревьев, в каждом из которых взяты все рёбра, смотрящие в направлении от корня поддерева, а является объединением кнопок по всем этим поддеревьям. Заметим, что если всё множество не удовлетворено (то есть, ), то тогда хотя бы в одно из поддеревьев в составе тоже не удовлетворено, иначе можно суммированием соответствующих неравенств для всех поддеревьев показать, что множество тоже должно быть удовлетворено.
Значит, мы окончательно поняли, для каких подмножеств достаточно проверять критерий из леммы Холла: достаточно рассмотреть подмножества, каждое из которых задаётся "корневым" ориентированным ребром , и содержит все рёбра, смотрящие в направлении в поддереве . Опять же, у неравенства для данного подмножества есть понятный физический смысл — необходимо, чтобы для любого поддерева кнопок в нём было не меньше, чем неориентированных рёбер в нём плюс один (здесь плюс один берётся от самого корневого ребра). Обозначим это условие для ориентированного ребра за .
Условие очевидно можно проверить за линейное время. Условий самих по себе линейное количество, но несложным предподсчётом размеров поддеревьев дерева и количеств кнопок в них все условия можно проверить за линейное время в совокупности.
Таким образом, мы научились решать упрощённую версию задачи. Вернёмся к исходной — её отличает от нашей то, что теперь не по каждому ребру мы пройдём в обоих направлениях. Легко видеть, что наш путь теперь характеризуется финальной вершиной , которая обязательно будет листовой, и тогда из множества посещаемых нами ореинтированных рёбер исчезнут рёбра, лежащие на пути от до стартовой вершины . Подвесим дерево за вершину , тогда по-другому можно сказать, что исчезнут все восходящие рёбра от до .
Аналогичным образом применим критерий Холла и посмотрим, что изменится. Рассуждение про рёбра, смотрящие друг на друга, по-прежнему верно, и оно даёт нам условие : ориентированных рёбер, которые мы пройдём, должно быть не больше, чем кнопок всего. Отметим здесь, что мы пройдём ровно рёбер, таким образом, это условие задаёт нижнюю границу на глубину искомой терминальной вершины : (заметим, что это условие может быть выполнено автоматически, если ).
Рассуждение про независимую проверку критерия для подномжеств, задаваемых ориентированным ребром и всеми, которые лежат в его поддереве, по-прежнему верно, но теперь чуть-чуть изменится форма этих подмножеств. А именно, если — ребро, смотрящее вниз, то для него ничего не поменяется (потому как у нас по сравнению с упрощённой задачей исчезли только рёбра, смотрящие вверх). Если же — ребро, смотрящее вверх, то в зависимости от выборе вершины ребро может либо исчезнуть из двудольного графа (тогда соответствующее ему условие просто проверять не надо), либо же, левая часть соответствующего ему условия уменьшится на количество выпавших рёбер, которые лежат в поддереве и смотрят в ту же сторону, что и . Нетрудно понять, что величина уменьшения левой части составляет , где — наименьший общий предок ребра и терминальной вершины в подвешенном дереве с корнем в .
Таким образом, мы имеем набор условий следующего вида:
Для рёбер, смотрящих вниз:
Для рёбер, смотрящих вверх:
Условия проверим за линейное время сразу, так как они не зависят от выбора . Оставшиеся два вида условий переформулируем в виде условия на положение вершины . , как уже было отмечено, эквивалентно тому, что вершина достаточно низко, то есть, находится на глубине минимум . Условие , оказывается, эквивалентно принадлежности некоторому поддереву нашего дерева: действительно, перенеся в левую часть неравенства слагаемое , получим ограничение снизу на глубину вершины, в которой путь до ответвляется от пути до . Это означает, что должно быть ниже ()-й вершины на пути от до , что тоже является условием принадллежности некоторому поддереву.
Заметим, что набор условий вида " принадлежит заданному поддереву" можно проверить за линейное время — достаточно обойти дерево, поддерживая количество удовлетворённых условий, и следить за вершинами, к которых это количество совпадает с количеством условий вообще.
Наконец, надо из всех подходящих вершин выбрать самую глубокую, проверить в ней выполнение условия , и она и будет искомым ответом. Данное решение можно реализовать за линейное время от входных данных.
Автор задачи: Максим Ахмедов (Яндекс, МГУ, НИУ ВШЭ).
| Имя входного файла: | Имя выходного файла: | Ограничение по времени: | Ограничение по памяти: |
|---|---|---|---|
| стандартный ввод | стандартный вывод | 3 секунда | 512 мегабайт |
Плотность неориентированного графа — естественная величина, полагаемая равной отношению количества рёбер к количеству вершин. Важной задачей при изучении различных графов, берущихся, в том числе, из реальной жизни (таких, как граф отношения дружбы в социальной сети, граф соавторства в научной среде или сеть белок-белковых взаимодействий в биоинформатике), является нахождение плотных подграфов — то есть, таких наборов вершин, что сужение графа на этот набор имеет высокую плотность. Нахождение подграфов высокой плотности является хорошо изученной, но довольно сложной задачей, а мы предложим вам необычный взгляд на этот сюжет — мы предложим найти подграф не менее чем заданной плотности.
Рассмотрим неориентированный граф, состоящий из вершин, пронумерованных целыми числами от до , и рёбер . Пусть задан набор из неотрицательных вещественных чисел , удовлетворяющий условию . Положим:
Требуется найти подграф данного графа, имеющий плотность по меньшей мере . Формально, требуется найти такое непустое множество вершин , что , где .
В первой строке находятся два целых числа и (, ), количество вершин и рёбер в графе.
Во второй строке находятся вещественных чисел (, ), заданных с не более чем шестью знаками после десятичной точки.
В -й из последующих строк находятся два целых числа (, ), задающих вершины, соединённые -м ребром графа. Гарантируется, что в графе отсутствуют кратные рёбра и петли.
Гарантируется, что в графе существует подграф, удовлетворяющий требованию задачи.
В первой строке выведите целое число () — количество вершин в искомом множестве .
Во второй строке выведите целых чисел — номера вершин, образующих подграф плотности хотя бы .
Ваш ответ будет признан корректным, если плотность выведенного вами подграфа не меньше, чем . Вершины разрешается выводить в любом порядке. Если возможных ответов несколько, разрешается вывести любой правильный.
| стандартный ввод | стандартный вывод |
| 4 4 0.2 0.1 0 0.7 1 2 2 3 3 1 3 4 |
3 1 2 4 |
| 5 6 0.25 0 0.25 0.25 0.25 2 1 1 3 3 5 5 4 4 1 1 5 |
4 1 5 3 4 |
В первом тесте из условия:
В подграфе, состоящем из вершин , и , присутствует единственное ребро , поэтому его плотность равна .
Во втором тесте из условия:
В подграфе, состоящем из вершин , присутствует 5 рёбер , поэтому его плотность равна .
Отметим очевидный факт: если бы мы могли эффективно найти подграф максимальной плотности в данном нам графе, он бы точно подходил в качестве ответа вне зависимости от набора значений (так как нам гарантируется, что ответ существует). Однако, раз задача нахождения подграфа наибольшей плотности является довольно трудной, о чём нам явно сказано в условии задачи, значит, надо каким-то образом использовать данные нам значения в качестве подсказки.
Верен следующий факт. Положим . Утверждается, что ответ всегда можно найти среди всевозможных , то есть, среди подграфов, образованных каким-то суффиксом вершин в порядке сортировки по всегда есть хотя бы один подграф плотности не меньше . Покажем этот факт.
Положим, аналогично, . Рассмотрим функцию . Будем рассуждать от противного — предположим, что она строго меньше нуля в каждой точке полуинтервала (что как раз значит, что для любого плотность подграфа , равная строго меньше ).
Обозначим за максимальное из чисел . Тогда . Однако верна следующая цепочка равенств:
Таким образом, мы получаем противоречие, значит, хотя бы в одной точке полуинтвервала верно неравенство , что доказывает наше утверждение.
Таким образом, решение принимает следующий вид: упорядочиваем вершины по убыванию , добавляем вершины одну за одной и поддерживаем количество вершин в текущем подграфе. Если плотность стала не меньше , выводим ответ. Сложность получившегося решения — .
Автор задачи: Михаил Тихомиров (МФТИ)
| Имя входного файла: | Имя выходного файла: | Ограничение по времени: | Ограничение по памяти: |
|---|---|---|---|
| стандартный ввод | стандартный вывод | 2 секунды | 512 мегабайт |
На витрине магазина выложено шляп, пронумерованных слева направо от до . Шляпы бывают трёх видов: мужские, женские и универсальные. В магазин по очереди заходят покупатели, причём каждый следующий покупатель может оказаться как мужчиной, так и женщиной.
Каждый покупатель идет вдоль витрины слева направо и выбирает первую подходящую ему шляпу. Так, покупатель-мужчина выберет самую левую среди мужских и универсальных шляп, а покупатель-женщина выберет самую левую среди женских и универсальных шляп. Если ни одной подходящей шляпы на витрине нет, покупатель уходит без покупки. Каждый раз, когда кто-то покупает одну из шляп, продавец записывает номер купленной шляпы.
К концу дня
|
Метки: author Zlobober спортивное программирование программирование ненормальное программирование алгоритмы блог компании яндекс яндекс.алгоритм контест занимательные задачки математика |
Outdoor Wi-Fi: уличные Wi-Fi сети и мосты на оборудовании TP-Link |
|
|
«Рынок становится агрессивнее и хайповее» — Александр Зимин о тенденциях iOS-разработки |

|
Метки: author phillennium разработка под ios разработка мобильных приложений блог компании jug.ru group александр зимин wwdc ios 11 ios development конференция mobius |
[Перевод] JavaScript без this |
this в JavaScript можно назвать одной из наиболее обсуждаемых и неоднозначных особенностей языка. Всё дело в том, что то, на что оно указывает, выглядит по-разному в зависимости от того, где обращаются к this. Дело усугубляется тем, что на this влияет и то, включён или нет строгий режим.
this, стараются вовсе не пользоваться этой конструкцией языка. Не вижу тут ничего плохого. На почве неприятия this было создано много полезного. Например — стрелочные функции и привязка this. Как результат, при разработке можно практически полностью обойтись без this.this» окончена? Нет конечно. Если поразмыслить, можно обнаружить, что задачи, которые традиционно решают с привлечением функций-конструкторов и this, можно решить и другим способом. Этот материал посвящён описанию именно такого подхода к программированию: никаких new и никаких this на пути к более простому, понятному и предсказуемому коду.this. Мы не будем рассматривать здесь основы JS, наша главная цель — описание особого подхода к программированию, исключающего использование this, и, благодаря этому, способствующего устранению потенциальных неприятностей, с this связанных. Если вы хотите освежить свои знания о this, вот и вот материалы, которые вам в этом помогут.function makeAdder(base) {
let current = base;
return function(addition) {
current += addition;
return current;
}
}makeAdder() принимает параметр base и возвращает другую функцию. Эта функция принимает числовой параметр. Кроме того, у неё есть доступ к переменной current. Когда её вызывают, она прибавляет переданное ей число к current и возвращает результат. Между вызовами значение переменной current сохраняется.let counter = (function() {
let privateCounter = 0;
function changeBy(val) {
privateCounter += val;
}
return {
increment: function() {
changeBy(1);
},
decrement: function() {
changeBy(-1);
},
value: function() {
return privateCounter;
}
};
})();
counter.increment();
counter.increment();
console.log(counter.value()); // выводит в лог 2privateCounter — это данные, с которыми нам надо работать, скрытые в замыкании и недоступные напрямую извне. Общедоступные методы increment(), decrement() и value() описывают операции, которые можно выполнять с privateCounter.this. Рассмотрим пример.this. Это — реализация известной структуры данных, которая называется двухсторонняя очередь (deque, double-ended queue ). Это — абстрактный тип данных, который работает как очередь, однако, расти и уменьшаться наша очередь может в двух направлениях.data, которая будет хранить данные каждого элемента очереди. Кроме того, нам нужны указатели на первый и последний элементы, на голову и хвост очереди. Назовём их, соответственно, head и tail. Так как очередь мы создаём на основе связного списка, нам нужен способ связи элементов, поэтому для каждого элемента требуются указатели на следующий и предыдущий элементы. Назовём эти указатели next и prev. И, наконец, требуется отслеживать количество элементов в очереди. Воспользуемся для этого переменной length.data, а также указатели на следующий и предыдущий узлы — next и prev. Исходя из этих соображений создадим объект Node, представляющий собой элемент очереди:let Node = {
next: null,
prev: null,
data: null
};head и tail), а также сведения о собственной длине (переменная length). Исходя из этого, определим объект Deque следующим образом:let Deque = {
head: null,
tail: null,
length: 0
};Node, представляющий собой отдельный узел очереди, и объект Deque, представляющий саму двухстороннюю очередь. Их нужно хранить в замыкании:module.exports = LinkedListDeque = (function() {
let Node = {
next: null,
prev: null,
data: null
};
let Deque = {
head: null,
tail: null,
length: 0
};
// тут нужно вернуть общедоступное API
})();create(). Он устроен довольно просто:function create() {
return Object.create(Deque);
}isEmpty():function isEmpty(deque) {
return deque.length === 0
}deque, и проверяем равняется ли его свойство length нулю.pushFront(). Для того, чтобы его реализовать, надо выполнить следующие операции:Node.Node.head и установить его указатель prev на новый элемент, а указатель next нового элемента установить на тот элемент, который записан в переменную head. В результате первым элементом очереди станет новый объект Node, за которым будет следовать тот элемент, который был первым до выполнения операции. Кроме того, надо не забыть обновить указатель очереди head таким образом, чтобы он ссылался на её новый элемент.length.pushFront():function pushFront(deque, item) {
// Создадим новый объект Node
const newNode = Object.create(Node);
newNode.data = item;
// Сохраним текущий элемент head
let oldHead = deque.head;
deque.head = newNode;
if (oldHead) {
// В этом случае в очереди есть хотя бы один элемент, поэтому присоединим новый элемент к началу очереди
oldHead.prev = newNode;
newNode.next = oldHead;
} else {// Если попадаем сюда — очередь пуста, поэтому просто запишем новый элемент в tail.
deque.tail = newNode;
}
// Обновим переменную length
deque.length += 1;
return deque;
}pushBack(), позволяющий добавлять элементы в конец очереди, очень похож на тот, что мы только что рассмотрели:function pushBack(deque, item) {
// Создадим новый объект Node
const newNode = Object.create(Node);
newNode.data = item;
// Сохраним текущий элемент tail
let oldTail = deque.tail;
deque.tail = newNode;
if (oldTail) {
// В этом случае в очереди есть хотя бы один элемент, поэтому присоединим новый элемент к концу очереди
oldTail.next = newNode;
newNode.prev = oldTail;
} else {// Если попадаем сюда — очередь пуста, поэтому просто запишем новый элемент в head.
deque.head = newNode;
}
// Обновим переменную length
deque.length += 1;
return deque;
}return {
create: create,
isEmpty: isEmpty,
pushFront: pushFront,
pushBack: pushBack,
popFront: popFront,
popBack: popBack
}const LinkedListDeque = require('./lib/deque');
d = LinkedListDeque.create();
LinkedListDeque.pushFront(d, '1'); // [1]
LinkedListDeque.popFront(d); // []
LinkedListDeque.pushFront(d, '2'); // [2]
LinkedListDeque.pushFront(d, '3'); // [3]<=>[2]
LinkedListDeque.pushBack(d, '4'); // [3]<=>[2]<=>[4]
LinkedListDeque.isEmpty(d); // falseLinkedListDeque, до тех пор, пока есть работающая ссылка на неё.popBack() и popFront(), которые, соответственно, удаляют и возвращают первый и последний элементы очереди.ArrayDeque. И помните — никаких this и new.MixedQueue. При таком подходе сначала создают массив фиксированного размера. Назовём его block. Пусть его размер будет 64 элемента. В нём будут храниться элементы очереди. При попытке добавить в очередь больше 64-х элементов создают новый блок данных, который соединяют с предыдущим с помощью связного списка по модели FIFO. Реализуйте методы двухсторонней очереди, используя этот подход. Каковы преимущества и недостатки такой структуры? Запишите свои выводы.join, который позволяет соединять две двухсторонних очереди. Например, вызов LinkedListDeque.join(first, second) присоединит вторую очередь к концу первой и вернёт новую двухстороннюю очередь.for. Для этого упражнения можете использовать итераторы ES6.this, и о том, как хорошо вы во всём этом разбираетесь. Ну и про меня упомянуть не забудьте.an * x^n + an-1*x^n-1 + ... + a1x^1 + a0. Здесь an..a0 — это коэффициенты полинома, а n…1 — показатели степени. Создайте реализацию структуры данных для работы с полиномами, разработайте методы для сложения, вычитания, умножения и деления полиномов. Ограничьтесь только упрощёнными полиномами. Добавьте тесты для проверки правильности решения. Обеспечьте, чтобы все методы, возвращающие результат, возвращали бы его в виде двухсторонней очереди.this стоят усилий по переходу на новую модель программирования, взгляните на eslint-plugin-fp. С помощью этого плагина можно автоматизировать проверки кода. И, если вы работаете в команде, прежде чем отказываться от this, договоритесь с коллегами, иначе, при встрече с ними, не удивляйтесь их угрюмым лицам. Хорошего вам кода!this в JavaScript?
|
Метки: author ru_vds разработка веб-сайтов javascript блог компании ruvds.com разработка |






