Открытый протокол для децентрализованной коммуникации [matrix] ищет спонсоров для продолжения разработки |
|
Метки: author Murz децентрализованные сети matrix.org riot.im matrix мессенджеры мессенджеры для командной работы slack |
Нематериальная мотивация — что туда включено |
|
Метки: author Scif_yar читальный зал собеседование собеседования условия труда условия работы мотивация мотивация персонала мотивация сотрудников |
Универсальная рекламная кампания для всех видов бизнеса |



|
Метки: author Tenqz интернет-маркетинг таргетированная реклама таргетинг маркетинг реклама вконтакте таргетинговая реклама |
[Перевод] Почему я ненавижу Spring |
|
Метки: author s-kozlov java spring framework spring sucks holywar |
Процесс создания синематика вживую. Стрим завтра, 27 июля в 15.00 |
|
|
Высокотехнологичный шопинг: инновации, меняющие облик ритейла и торговых центров |





|
Метки: author MEGA_Accelerator управление проектами управление e-commerce развитие стартапа бизнес-модели блог компании мега accelerator мега акселератор ритейл инновации |
Что нового в nginx? |

Дисклеймер: речь пойдёт о нововведениях в 2016 году. Можно подумать, что это давно, но информация об изменениях в changelog от автора этих самых изменений полезна всегда!








Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.






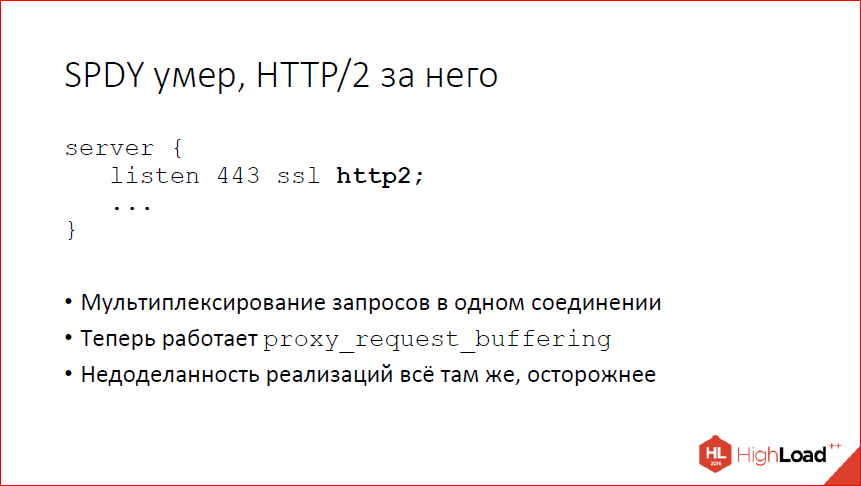
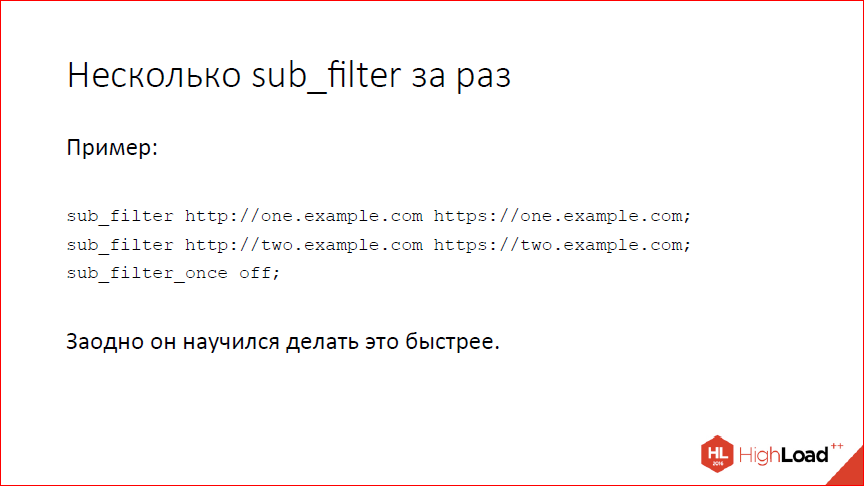
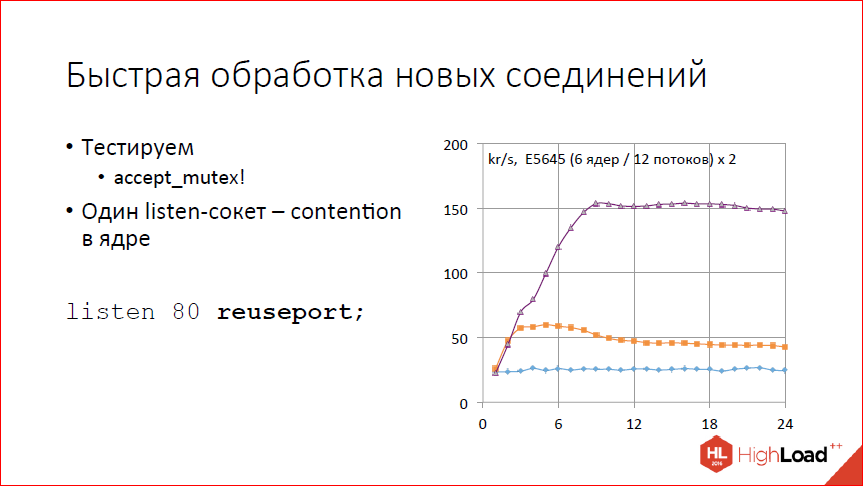




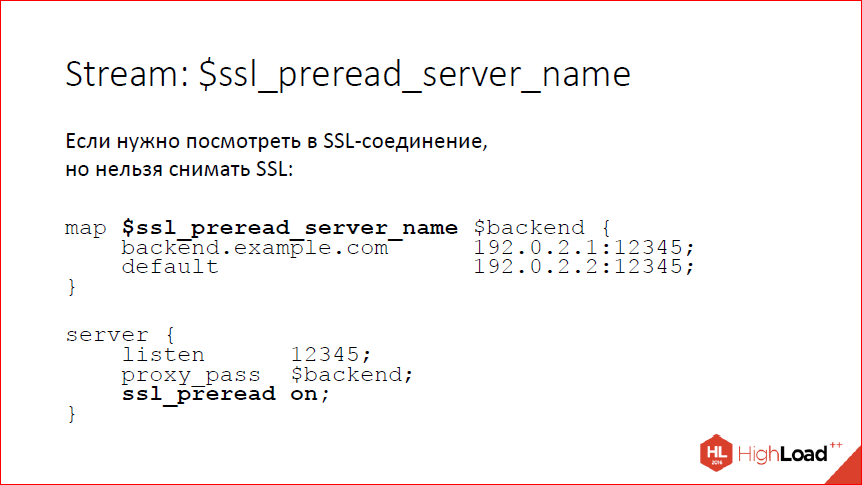





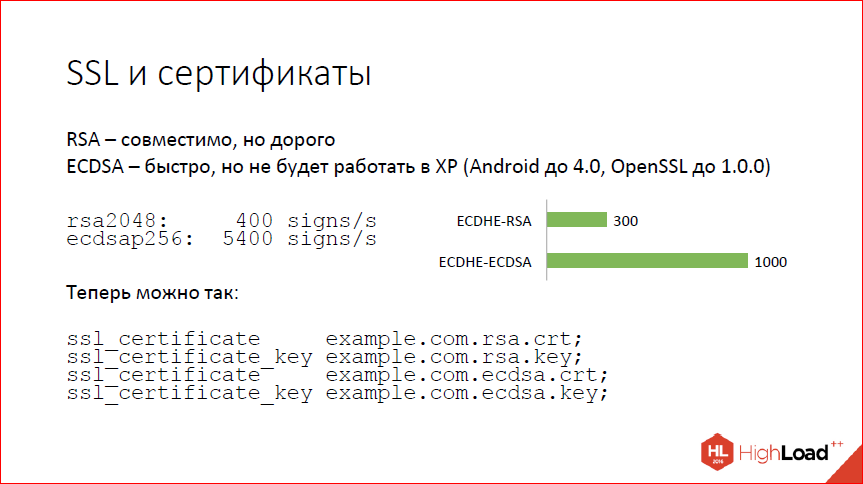
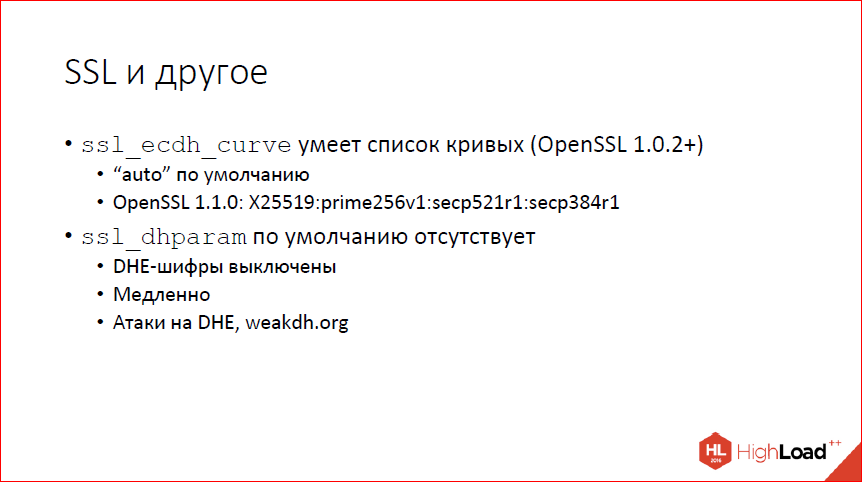



Этот доклад — расшифровка одного из лучших выступлений на профессиональной конференции разработчиков высоконагруженных систем HighLoad++.
Сейчас мы уже вовсю готовим конференцию 2017-года — самый большой HighLoad++
в истории. Если вам интересно и важна стоимость билетов — покупайте сейчас, пока цена ещё не высока!
|
Метки: author olegbunin блог компании конференции олега бунина (онтико) максим дунин highload++ nginx |
«Data mining сейчас — это преимущество на рынке»: о конференции SmartData и больших данных |

 Виталий: На самом деле, технологически всё меняется не так быстро. Важнее то, что сейчас большинство компаний — это такие «догоняющие».
Виталий: На самом деле, технологически всё меняется не так быстро. Важнее то, что сейчас большинство компаний — это такие «догоняющие».  Роман: Мне хочется сказать не конкретно про нейросети, а про «большие и умные данные» в целом: вообще велико расслоение по тому, насколько уже принята на вооружение та или иная технология. Какие-то вещи в одних местах с 2008 года используются, допустим, а где-то их только сейчас узнают, как ни странно. Несмотря на то, что вроде как все следят за статьями, но вижу, что реальное расслоение в индустрии очень большое.
Роман: Мне хочется сказать не конкретно про нейросети, а про «большие и умные данные» в целом: вообще велико расслоение по тому, насколько уже принята на вооружение та или иная технология. Какие-то вещи в одних местах с 2008 года используются, допустим, а где-то их только сейчас узнают, как ни странно. Несмотря на то, что вроде как все следят за статьями, но вижу, что реальное расслоение в индустрии очень большое.|
Метки: author phillennium открытые данные big data блог компании jug.ru group smart data data science smartdataconf конференция виталий худобахшов роман поборчий |
[Перевод] Пиратство и четыре валюты |
|
Метки: author PatientZero разработка игр пиратство drm защита от копирования торренты |
Откуда появился День Сисадмина и почему важно его отмечать |

|
Метки: author ArtX системное администрирование серверное администрирование dps driverpack solution drp сисадмин день сисадмина |
Есть ли альтернатива MS Windows, IE и CSP при доступе в личные кабинеты порталов Госзакупок, ФНС России и Госуслуг |

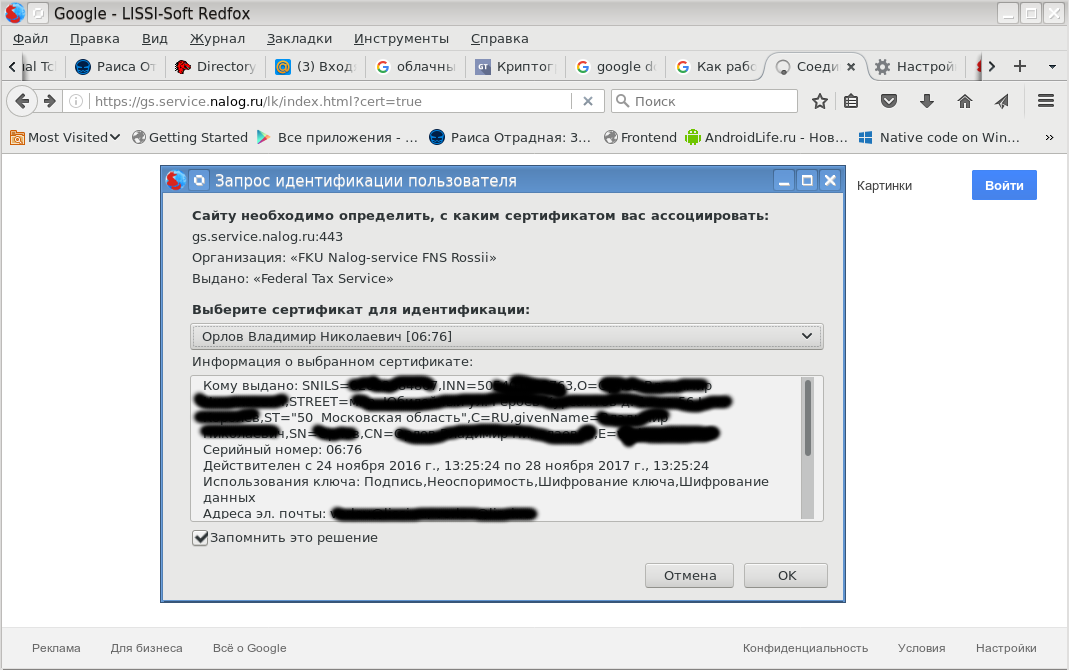
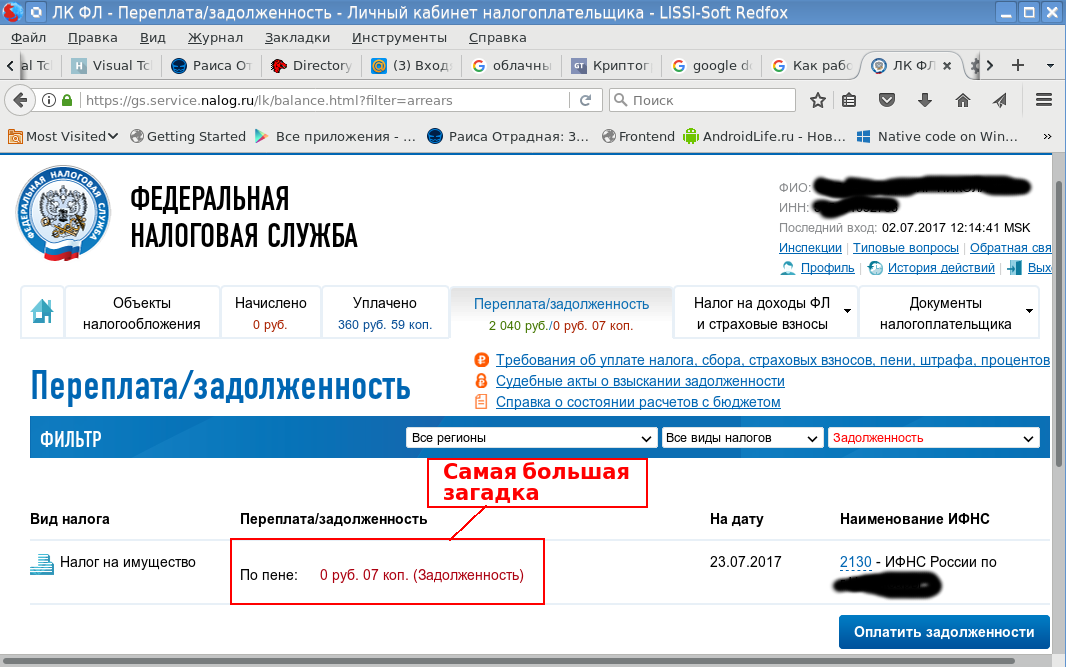
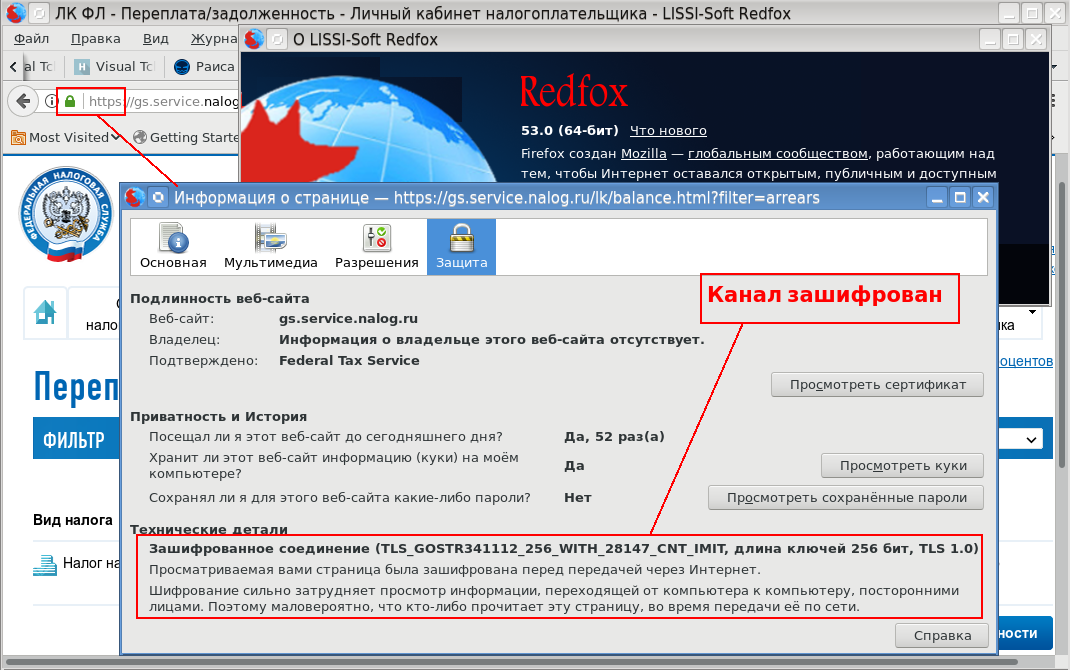
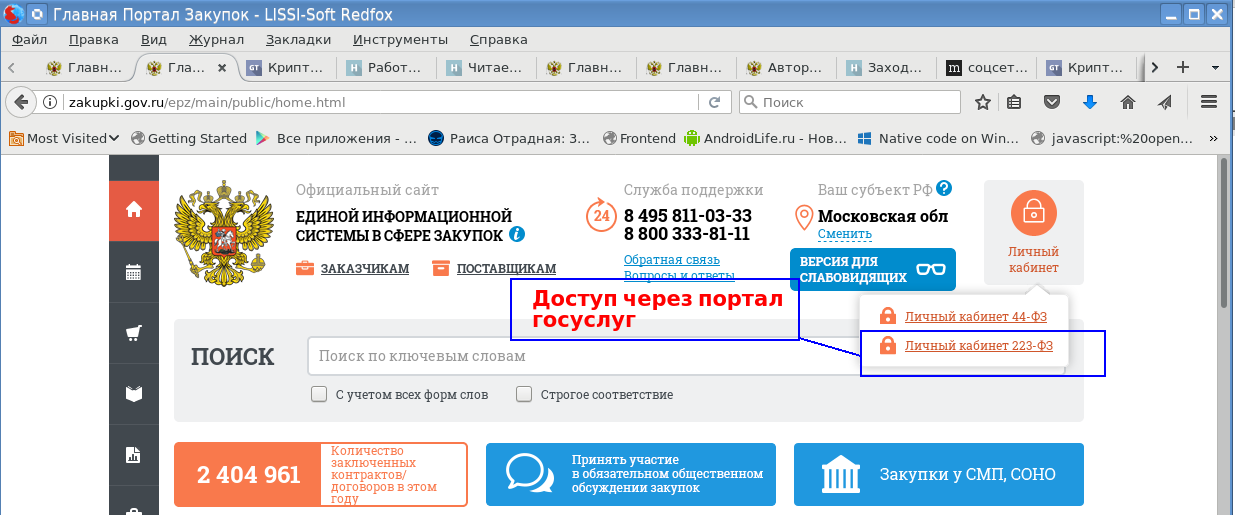
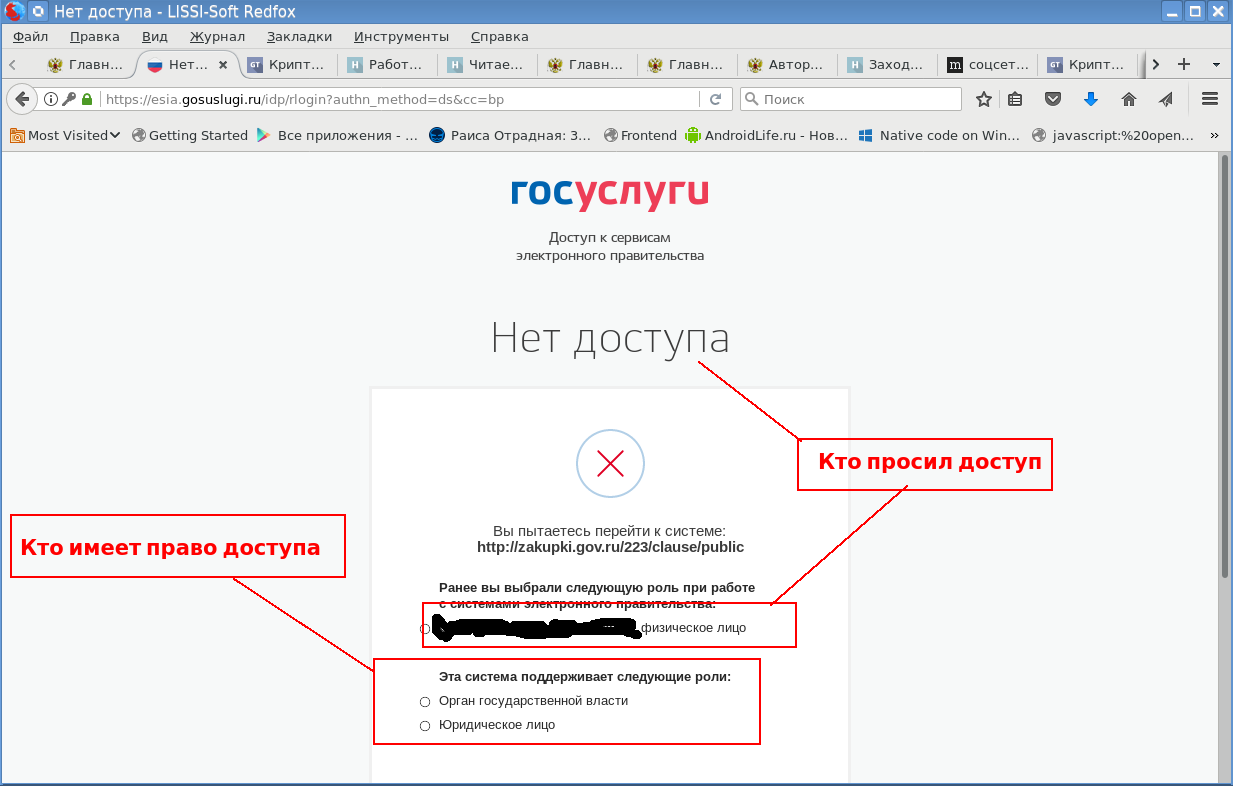
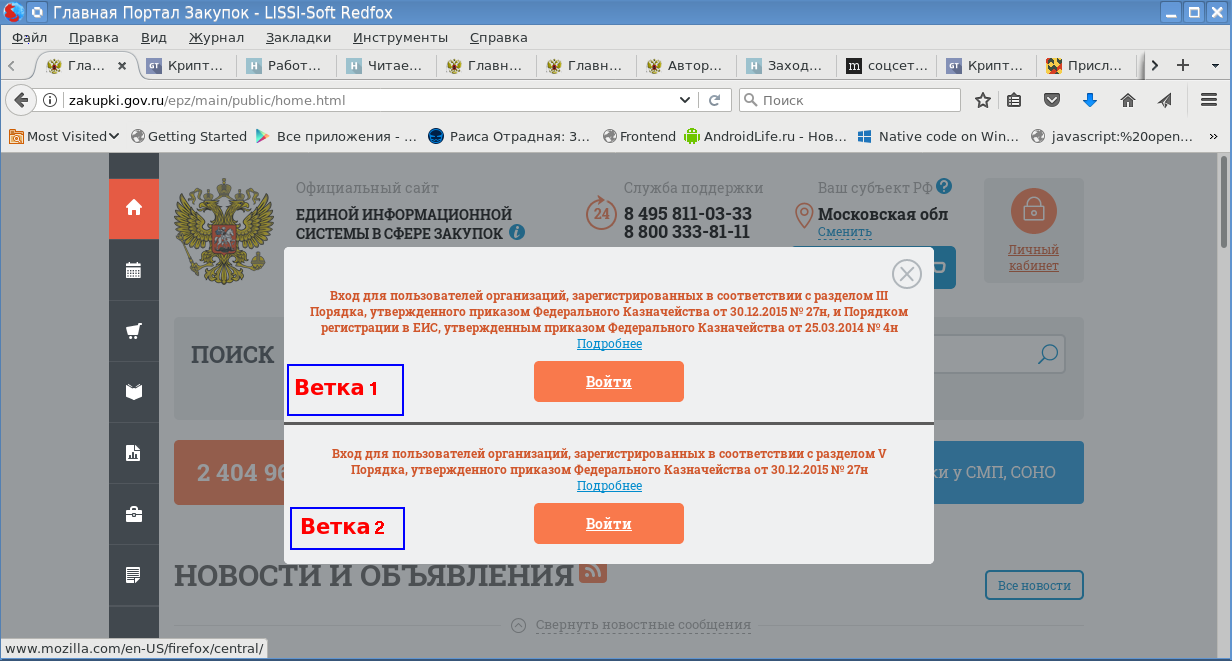
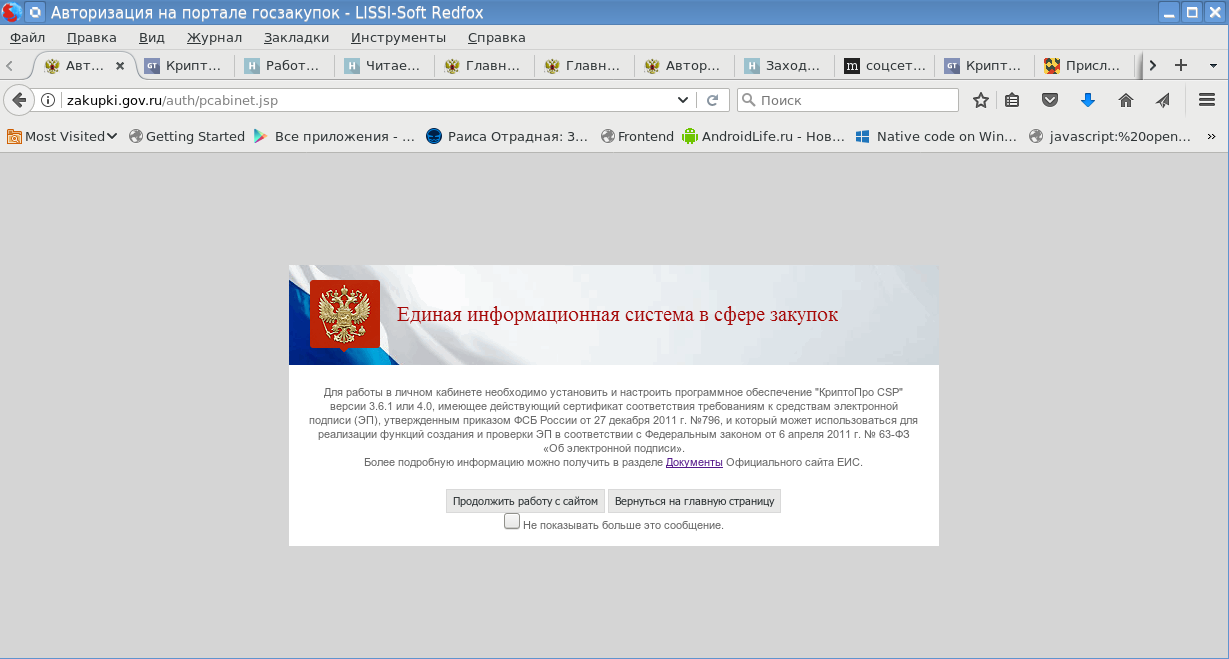
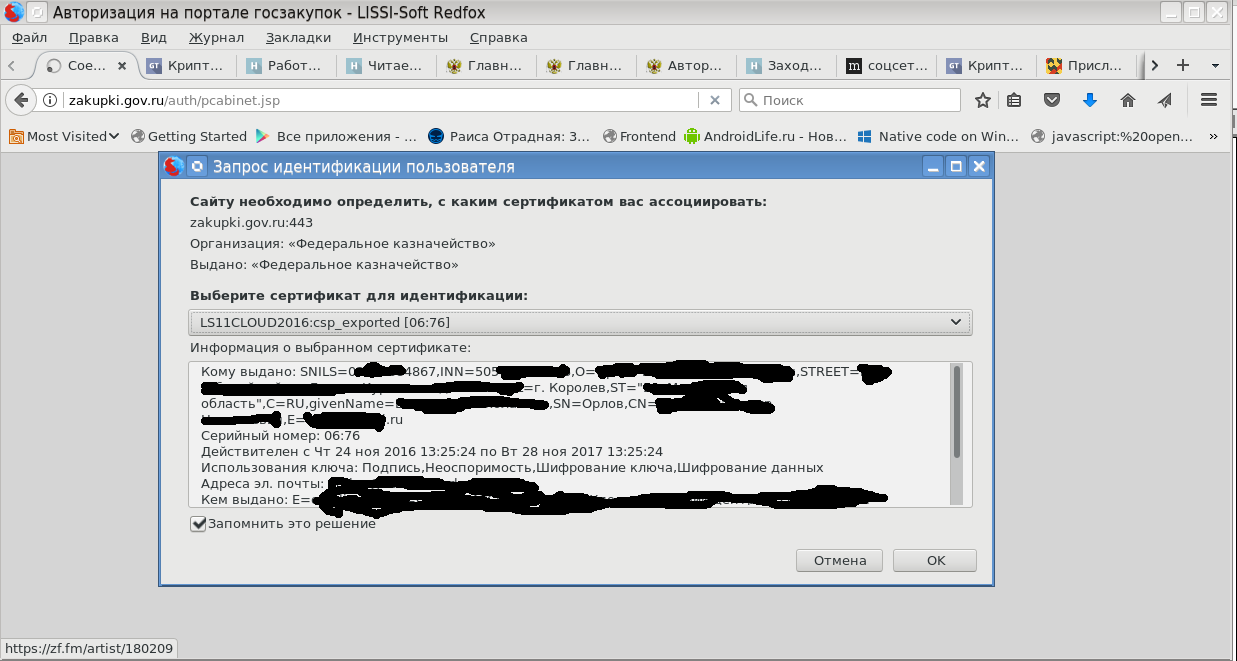

|
|
Приглашаем на Tarantool Meetup 10 августа |

|
Метки: author dedokOne анализ и проектирование систем open source nosql блог компании mail.ru group tarantool dbms in-memory database in-memory-data-grid microservices |
Конкурс по программированию: JSDash (промежуточные результаты 2) |
|
|
[Из песочницы] Покойся с миром, REST. Долгих лет жизни GraphQL |
Rest API превратился в REST-in-Peace API. Долгих лет жизни GraphQL
Примечание переводчика – Rest In Peace, RIP – распространенная эпитафия "Покойся с миром". Первое слово в ней пишется так же, как акроним REST.
Тогда это была попытка рассмешить, но сейчас я убеждаюсь в справедливости шутливого прогноза.
Поймите правильно. Я не собираюсь обвинять GraphQL в убийстве REST или чём-то таком. REST не умрет никогда, также как XML будет жить вечно. Но кто в здравом уме станет использовать XML поверх JSON? На мой взгляд, GraphQL сделает для REST то же самое, что JSON сделал для XML.
Эта статья не стопроцентная агитация в пользу GraphQL. За его гибкость приходится платить. Этому посвящен отдельный раздел.
Я поклонник подхода Начните с вопроса ЗАЧЕМ, поэтому так и поступим.
Вот три наиболее важные проблемы, которые решает GraphQL:
Необходимость несколько раз обращаться за данными для рендеринга компонента. GraphQL позволяет получить все необходимые данные за один запрос к серверу.
Зависимость клиента от сервера. С помощью GraphQL клиент общается на универсальном языке запросов, который: 1) отменяет необходимость для сервера жестко задавать структуру или состав возвращаемых данных и 2) не привязывает клиента к конкретному серверу.
Статья подробно рассказывает, как GraphQL решает эти проблемы.
Начнем с простого описания для тех, кто еще не знаком с GraphQL.
GraphQL это язык. Если научить ему приложение, оно сможет декларативно сообщать о необходимых данных бекенду, который также понимает GraphQL.
Как ребенок познает язык в детстве, а взрослея вынужден прикладывать больше усилий для изучения, – так и GraphQL намного легче внедрить во вновь создаваемое приложение, чем интегрировать в отлаженный сервис.
Чтобы сервис понимал GraphQL, нужно создать отдельный уровень в стеке обработки запросов и открыть к нему доступ клиентам, которым требуется взаимодействие с сервисом. Этот уровень можно считать транслятором языка GraphQL, или GraphQL-понимающим посредником. GraphQL не является платформой хранения данных. Поэтому нам не достаточно просто понимать синтаксис GraphQL, нужно еще транслировать запросы в данные.
Уровень GraphQL, написанный на любом языке программирования, содержит схему (schema) на подобии графа или диаграммы связей, из которой клиенты узнают о возможностях сервиса. Клиентские приложения, знакомые с GraphQL, могут делать запросы по этой схеме в соответствии со своими собственными возможностями. Такой подход отделяет клиентов от сервера и позволяет им развиваться и масштабироваться независимо.
Запросы на языке GraphQL могут быть либо запросами данных – query (операция чтения), либо мутациями – mutation (операции записи). В обоих случаях запрос это обычная строка, которую GraphQL-сервис разбирает, выполняет и сопоставляет с данными в определенном формате. Распространенный формат ответа для мобильных и веб-приложений – JSON.
GraphQL не выходит за рамки обмена данными. Существует клиент и сервер, которым надо взаимодействовать. Клиент должен сообщить серверу, какие данные нужны, а сервер – закрыть эту потребность актуальными данными. GraphQL находится в середине взаимодействия.
Скриншот из моего обучающего курса на Pluralsight – Building Scalable APIs with GraphQL
Вы спросите, почему клиент не может общаться с сервером напрямую? Конечно, может.
Есть несколько причин использовать уровень GraphQL между клиентами и серверами. Возможно, самая популярная причина, – эффективность. Обычно клиент получает на сервере множество ресурсов, но сервер отдает один ресурс за раз. Поэтому клиент вынужден многократно обращаться к серверу, чтобы получить все необходимые данные.
GraphQL перекладывает сложность многократных запросов на плечи сервера, пусть этим занимается уровень GraphQL. Клиент отправляет единственный запрос к уровню GraphQL и получает единственный ответ, в котором содержится все, что клиенту нужно.
Есть много других достоинств GraphQL. Например, важное преимущество при взаимодействии с несколькими сервисами. Когда много клиентов запрашивают данные из многих сервисов, уровень GraphQL посередине упрощает и стандартизирует обмен данными.

Скриншот из моего обучающего курса на Pluralsight – Building Scalable APIs with GraphQL
Вместо того чтобы напрямую обращаться к двум сервисам (на предыдущем слайде), клиент взаимодействует с уровнем GraphQL, и уже тот получает данные у сервисов. Таким образом, GraphQL избавляет клиента от необходимости поддерживать разные API, преобразуя единственный запрос клиента в запросы к нескольким поставщикам данных на понятном им языке.
Представим трех человек, говорящих на трех разных языках, и у каждого есть некая информация. Если нужно задать вопрос, требующий объединить знания всех персон, то помощь переводчика, говорящего на всех трех языках, существенно упростит получение ответа. Именно этим занимается GraphQL.
Но компьютеры пока не столь умны, чтобы самостоятельно отвечать на произвольные вопросы, и где-то должны существовать алгоритмы. Вот почему на уровне GraphQL необходимо задать схему (schema), которую смогут использовать клиенты.
Схема в основе своей – это документ о возможностях, перечисляющий все вопросы, которые клиент может адресовать уровню GraphQL. Использовать схему можно довольно гибко, поскольку речь идет о графе (graph) узлов. В сущности, схема ограничивает то, что можно запросить на уровне GraphQL.
Не совсем понятно? Давайте взглянем на GraphQL, как на замену REST API, чем он в действительности является. Позвольте ответить на вопрос, который вы, наверняка, сейчас задаете.
Большая проблема REST API в многочисленности точек назначения (endpoints). Это вынуждает клиентов делать много запросов, чтобы получить нужные данные.
REST API представляет собой набор точек назначения, каждая из которых соответствует ресурсу. Если клиенту нужны разные ресурсы, приходится делать несколько запросов, чтобы собрать все необходимые данные.
REST API не предлагает клиенту язык запросов. Клиент не влияет на то, какие данные возвращает сервер. Просто нет языка, на котором клиент мог бы указать это. Точнее говоря, доступные клиенту средства влиять на сервер очень ограничены.
Например, точка назначения для операции READ позволяет сделать одно из двух:
/ResouceName – получить список записей;/ResourceName/ResourceID – получить запись по ID. Клиент не может указать, например, какие поля записи хочет взять у данного ресурса. Эта информация зашита в самом REST-сервисе, и он всегда вернет все предусмотренные поля независимо от того, какие из них нужны клиенту. В GraphQL эта проблема называется перевыгрузкой (over-fetching) информации, которая не требуется. Перевыгрузка напрасно нагружает сеть и расходует память на стороне клиента и сервера.
Еще одна значимая проблема REST API – версионирование. Необходимость поддерживать несколько версий означает новые точки назначения. Это влечет дополнительные трудности в использовании и поддержке API и может стать причиной дублирования кода на сервере.
GraphQL призван решить указанные задачи. Конечно, это не все проблемы REST API, но я не хочу углубляться в то, чем REST API является или не является. Скорее, говорю об общепринятом ресурсо-ориентированном подходе к API на основе точек назначения HTTP. Со временем каждый такой API превращается в мешанину обычных точек назначения, как предписывает REST, и специальных, добавленных по соображениям производительности. И тут альтернатива в виде GraphQL выглядит намного лучше.
GraphQL основан на разных идеях и архитектурных решений, но, пожалуй, наиболее важными являются следующие:
GraphQL-схема является строго типизированной. Чтобы создать схему, задают поля (fields) определенных типов (types). Эти типы могут быть примитивами или пользовательскими типами, но все в схеме типизировано. Развитая система типов открывает такие возможности, как интроспекция API, и позволяет создавать мощные инструменты для клиентской и серверной части.
GraphQL описывает данные в виде графа, или диаграммы связей, что очень естественно для данных. Вспомните, когда нужно визуализировать данные, диаграмма наиболее подходящее средство. Во время выполнения GraphQL сохраняет это естественное представление благодаря API, ориентированному на описание связей.
Благодаря последнему пункту я лично верю в превосходство GraphQL.
Все это высокоуровневые концепции. Рассмотрим чуть подробнее.
Для решения проблемы множественных запросов, GraphQL превращает сервер в единственную точку назначения. По сути, GraphQL абсолютизирует идею о настраиваемой точке назначения и делает весь сервер такой точкой, которая может ответить на любой запрос.
Другая важная идея – наличие развитого языка запросов, благодаря которому клиент может работать с единственной точкой назначения. Без такого языка не было бы смысла ограничивать количество точек назначения. Нужен язык для описания настраиваемых запросов и возврата данных.
С помощью языка запросов взаимодействием управляют клиенты. Они запрашивают, что им нужно, а сервер возвращает именно то, что запрошено. Это решает проблему перевыгрузки данных.
К версионированию GraphQL относится интересно. От версионирования можно полностью отказаться. По сути, можно добавлять поля, не удаляя существующие, ведь данные представляют собой граф, и можно как угодно наращивать на нем узлы. Поэтому можно оставить пути для старых API и ввести новые, не помечая их номерами версий. Просто API подрос.
Это особенно актуально для мобильных клиентов, поскольку невозможно прямо указать им, какую версию API использовать. Установленное мобильное приложение может использовать старую версию API на протяжении многих лет. Для веб этой проблемы нет, поскольку можно просто заменить код веб-приложения на сервере. Но это намного сложнее для мобильных приложений.
Все еще не убедил? Что если сравнить GraphQL и REST на конкретном примере?
Допустим, разрабатывается интерфейс на тему фильма «Звездные войны» и его персонажей.
Первое, что нужно создать, – простой визуальный компонент для показа информации о каком-то одном персонаже Звездных войн. Возьмем Дарта Вейдера, который регулярно появляется на протяжении всего фильма. Компонент будет показывать имя, дату рождения, название планеты и названия всех фильмов, в которых участвует персонаж.
Звучит легко, но мы имеем дело с тремя различными ресурсами: Person, Planet и Film. Они достаточно просто взаимосвязаны, так что любой угадает структуру данных. Объект Person принадлежит планете и сам владеет от одного до нескольких объектов Film.
Данные для первого компонента выглядят так:
{
"data": {
"person": {
"name": "Darth Vader",
"birthYear": "41.9BBY",
"planet": {
"name": "Tatooine"
},
"films": [
{ "title": "A New Hope" },
{ "title": "The Empire Strikes Back" },
{ "title": "Return of the Jedi" },
{ "title": "Revenge of the Sith" }
]
}
}
}Пусть с сервера приходит именно такая структура. Тогда можно визуализировать данные в React таким образом:
// The Container Component:
Это простой пример, и поскольку нам, наверное, помогает знание Звездных войн, то связь между UI и данными очевидна. UI использует все придуманные нами ключи из JSON.
Посмотрим, как получить эти данные через RESTful API.
Сначала получим информацию о персонаже по ID. Ожидается, что RESTful API предоставляет ее так:
GET - /people/{id}Такой запрос вернет имя, дату рождения и прочую информацию о персонаже. Хороший RESTful API также сообщит ID планеты персонажа и ID всех фильмов с его участием.
Ответ JSON может выглядеть так:
{
"name": "Darth Vader",
"birthYear": "41.9BBY",
"planetId": 1
"filmIds": [1, 2, 3, 6],
*** other information we do not need ***
}Затем получаем название планеты:
GET - /planets/1И затем получаем названия фильмов:
GET - /films/1
GET - /films/2
GET - /films/3
GET - /films/6И только после шести запросов мы можем собрать ответы и обеспечить компонент необходимыми данными.
Кроме шесть запросов для визуализации довольно простого компонента, это решение было императивным. Мы указали, как получить и обработать данные, чтобы их можно было передать компоненту.
Вы можете сами попробовать и увидеть, что я имею в виду. У Звездных войн есть RESTful API по адресу http://swapi.co/. Сконструируйте объект данных персонажа. Ключи могут называться чуть иначе, но урлы ресурсов будут те же. Вам потребуется ровно шесть запросов. Более того, вы получите избыточную информацию, не нужную для компонента.
Конечно, это одна из возможных реализаций RESTful API для этих данных. Можно представить реализацию лучше, которая упрощает задачу. Например, если в API доступны вложенные ресурсы и сервер знает о взаимосвязи персонажа и фильмов, можно получить фильмы так:
GET - /people/{id}/filmsНо простой RESTful API наверняка не имеет такой возможности, и придется просить бекенд-разработчиков создать для нас дополнительные точки назначения. Такова практика масштабирования RESTful API – приходится добавлять все новые точки назначения, чтобы соответствовать потребностям клиентов. Поддерживать эти точки довольно трудоемко.
Теперь взглянем на подход GraphQL. Сервер GraphQL по максимуму воплощает идею настраиваемой точки назначения, доводя идею до абсолюта. На сервере есть только одна точка назначения, и способ связи с ней не важен. Если обратиться по HTTP, то метод HTTP-запроса будет проигнорирован. Предположим, имеется точка назначения GraphQL, доступная на /graphql по HTTP.
Поскольку ставится задача получить все данные за раз, нужен способ указать серверу состав данных. Для этого служит запрос GraphQL:
GET or POST - /graphql?query={...}Запрос GraphQL – это просто строка, в которой указаны все необходимые данные. И здесь становится видна сила декларативности.
По-русски, потребность в данных выражается так: для указанного персонажа нужны имя, дата рождения, название планеты и названия всех его фильмов. В GraphQL это выглядит так:
{
person(ID: ...) {
name,
birthYear,
planet {
name
},
films {
title
}
}
}Сравните, как описана потребность в данных на человеческом языке и на GraphQL. Описания настолько близки, насколько возможно. Также сравните запрос GraphQL и тот JSON, с которого мы начали. Запрос в точности повторяет структуру ожидаемого JSON, не включая значения. Если провести параллель между запросом и ответом, то запрос является ответом без данных.
Если ответ выглядит так:
Ближайшая к солнцу планета – Меркурий.То вопрос можно представить тем же самым выражением, но без конкретного значения:
(Какая) ближайшая к солнцу планета?Таким же сходство обладает запрос GraphQL. Если взять результирующий JSON, убрать все «ответы» (значения), то получим запрос GraphQL, подходящий на роль вопроса о данном JSON.
Теперь сравним запрос GraphQL c декларативным кодом React UI, в котором описаны данные. Все, что указано в запросе GraphQL, используется в UI, и все используемое в UI присутствует в запросе.
Это отличный способ представлять модель данных GraphQL. Интерфейс знает, какие данные нужны, и получить их не составляет труда. Оформление запроса GraphQL – это простая задача по выявлению того, что используется в качестве переменных непосредственно в UI.
Если поменять местами части этой модели, она будет так же полезна. По запросу GraphQL легко представить, как используется ответ в UI, поскольку ответ имеет такую же «структуру», как запрос. Не нужно специально изучать ответ чтобы понять, как его использовать, и даже не нужна документация по API. Все внутри запроса.
У Звездных войн имеется GraphQL API по адресу. Попробуйте с его помощью получить данные о персонаже. Есть незначительные отличия, но в целом запрос для получения необходимых данных в этом API выглядит так (с Дартом Вейдером в качестве примера):
{
person(personID: 4) {
name,
birthYear,
homeworld {
name
},
filmConnection {
films {
title
}
}
}
}Запрос вернет структуру очень близкую к потребностям визуального компонента. Но главное, все данные получены за один раз.
Идеальное решение – миф. Вместе с гибкостью GraphQL приходят некоторые проблемы и заботы.
Одна из угроз, которой открыт GraphQL, это сетевые атаки на исчерпание ресурсов (типа Denial of Service). Сервер GraphQL может быть атакован избыточно сложными запросами, потребляющими все ресурсы. Легко запросить данные с глубокой вложенностью (пользователь –> друзья –> друзья друзей … ) или применить синонимы полей, чтобы принудить сервер получать одни и те же данные много раз. Хотя подобные атаки происходят не только на GraphQL, при работе с GraphQL нужно иметь их в виду.
Существует несколько противодействий. Можно анализировать стоимость каждого запроса перед выполнением и вводить ограничения на количество данных, которые может потреблять запрос. Можно ввести таймаут на прерывание слишком долгого запроса. Также, поскольку GraphQL лишь уровень, связывающий запрос с хранилищами данных, можно задавать ограничения на более глубоких уровнях под GraphQL.
Если GraphQL API не публичный и предназначен для внутренних клиентов (мобильных или веб), можно использовать списки доступа и предварительно одобренные запросы. Клиенты требуют сервер выполнить такие запросы, указывая вместо запроса его идентификатор. Кажется, Facebook применяет такой подход.
Еще один вопрос при работе с GraphQL – идентификация и авторизация пользователей. Когда выполнять ее – перед, во время или после обработки запроса на GraphQL?
Чтобы ответить на этот вопрос, будем считать, что GraphQL это DSL (domain specific language – язык предметной области) поверх обычной логики получения данных на бекенде. Действительно, это просто дополнительный уровень между клиентом и сервисом данных (или несколькими сервисами).
Другим уровнем будем считать идентификацию и авторизацию. GraphQL не оказывает содействия в реализации этих задач. Он не для того. Но если поместить этот уровень за GraphQL, можно использовать GraphQL для передачи токенов доступа между клиентами и той логикой, которая с ними работает. Примерно так же выполняется идентификация и авторизация в RESTful API.
В GraphQL сложнее кешировать данные на клиенте. С RESTful API это проще, поскольку он подобен словарю. Конкретный адрес возвращает конкретные данные. Можно непосредственно использовать адрес как ключ кеширования.
В GraphQL тоже можно использовать текст запроса в качестве ключа. Но этот подход не очень эффективен и может нарушить целостность данных. Результаты разных запросов могут пересекаться, и такое примитивное кеширование не подходит в этом случае.
Однако существует блестящее решение этой проблемы. Graph Query равно Graph Cache. Если нормализовать данные, которые сформировал GraphQL: превратить иерархическую структуру в плоский список записей и присвоить каждой записи уникальный идентификатор, – то можно легко кешировать записи по отдельности, вместо целого ответа.
Это не так просто реализовать. Существуют взаимозависимые записи, и приходится работать с зацикленными графами. Чтобы записать в кеш или прочитать из него, необходимо полностью разобрать запрос. Требуется дополнительный уровень логики для работы с кешем. Но этот метод намного превосходит кеширование на основе текста запроса. Фреймворк Relay.js реализует эту стратегию кеширования «из коробки».
Возможно, самая большая проблема при использовании GraphQL – так называемые N+1 SQL-запросы. В GraphQL поля запроса реализованы как обычные функции, отправляющие запросы к базе данных. Чтобы заполнить все поля данными, может потребоваться новый SQL-запрос на каждое поле.
В обычном RESTful API легко проанализировать, выявить и решить проблему N+1, просто улучшая сконструированные SQL-запросы. Но в GraphQL, который обрабатывает поля динамически, это сложнее. К счастью, Facebook одним из первых предложил решение этой проблемы – DataLoader.
Название намекает, что утилита DataLoader читает данные из базы и предоставляет функциям, обрабатывающим поля запроса GraphQL. Можно использовать DataLoader вместо прямого чтения данных из базы. Он действует как посредник, уменьшая фактически производимые нами SQL-запросы к базе.
Для этого DataLoader применяет кеширование и пакетное выполнение запросов. Если один клиентский запрос получает из базы ответы на несколько разных вопросов, DataLoader может объединить все эти вопросы и одним пакетом получить ответы. Он также кеширует ответы для ускорения обработки последующих запросов к тем же ресурсам.
Спасибо за внимание. Я также разработал онлайн-курсы на Pluralsight и Lynda. Самые последние курсы – Advanced React.js, Advanced Node.js и Learning Full-stack JavaScript.
Я провожу онлайн- и офлайн-тренинги для групп по JavaScript, Node.js, React.js и GraphQL от начального до продвинутого уровня. Напишите мне, если ищете преподавателя (англ.). Если возникли вопросы по данной статье или другим моим статьям, меня можно найти в этом аккаунте слак (принимаются приглашения самому себе) и задать вопрос в комнате #questions.
Автор оригинала Samer Buna
Оригинал статьи
|
Метки: author teux разработка веб-сайтов api graphql |
IP unnumbered в Debian или раздаем адреса экономно |
# Base interface for IP Unnumbered
auto eth1.3000
iface eth1.3000 inet static
address 99.111.222.129
netmask 255.255.255.128ifup eth1.3000# Клиент 1
auto eth1.3111
iface eth1.3111 inet static
address 10.31.11.1
netmask 255.255.255.0
up ip ro add 99.111.222.130 dev eth1.3111 src 99.111.222.129
down ip ro del 99.111.222.130 dev eth1.3111 src 99.111.222.129
# Клиент 2
auto eth1.3112
iface eth1.3112 inet static
address 10.31.12.1
netmask 255.255.255.0
up ip ro add 99.111.222.131 dev eth1.3112 src 99.111.222.129
up ip ro add 99.111.222.132 dev eth1.3112 src 99.111.222.129
down ip ro del 99.111.222.131 dev eth1.3112 src 99.111.222.129
down ip ro del 99.111.222.132 dev eth1.3112 src 99.111.222.129
# Клиент 3
auto eth1.3113
iface eth1.3113 inet static
address 10.31.13.1
netmask 255.255.255.0
up ip ro add 99.111.222.133 dev eth1.3113 src 99.111.222.129
up ip ro add 99.111.222.134 dev eth1.3113 src 99.111.222.129
up ip ro add 99.111.222.135 dev eth1.3113 src 99.111.222.129
down ip ro del 99.111.222.133 dev eth1.3113 src 99.111.222.129
down ip ro del 99.111.222.134 dev eth1.3113 src 99.111.222.129
down ip ro del 99.111.222.135 dev eth1.3113 src 99.111.222.129
ifup eth1.3111
ifup eth1.3112
ifup eth1.3113subnet 10.31.11.0 netmask 255.255.255.0 {}
subnet 10.31.12.0 netmask 255.255.255.0 {}
subnet 10.31.13.0 netmask 255.255.255.0 {}#INTERFACES=...net.ipv4.conf.all.proxy_arp=1sysctl -w net.ipv4.conf.all.proxy_arp=1set vlans vlan3111 vlan-id 3111
set vlans vlan3112 vlan-id 3112
set vlans vlan3113 vlan-id 3113
set interfaces xe-0/1/0 unit 0 family ethernet-switching port-mode trunk
set interfaces xe-0/1/0 unit 0 family ethernet-switching vlan members 3111-3113
set interfaces ge-0/0/0 unit 0 family ethernet-switching port-mode access
set interfaces ge-0/0/1 unit 0 family ethernet-switching port-mode access
set interfaces ge-0/0/2 unit 0 family ethernet-switching port-mode access
set interfaces ge-0/0/0 unit 0 family ethernet-switching vlan members 3111
set interfaces ge-0/0/1 unit 0 family ethernet-switching vlan members 3112
set interfaces ge-0/0/2 unit 0 family ethernet-switching vlan members 3113
vlan 3111
name vlan3111
vlan 3112
name vlan3112
vlan 3113
name vlan3113
interface GigabitEthernet0/48
switchport mode trunk
switchport trunk allowed vlan add 3111-3113
interface GigabitEthernet0/1
switchport mode access
switchport access vlan 3111
interface GigabitEthernet0/2
switchport mode access
switchport access vlan 3112
interface GigabitEthernet0/3
switchport mode access
switchport access vlan 3113auto eth0
iface eth0 inet static
address 99.111.222.130
netmask 255.255.255.128
gateway 99.111.222.129
|
Метки: author jaredhared системное администрирование сетевые технологии debian linux маршрутизация |
[Перевод] Синглтоны и общие экземпляры |

Каждый раз при обсуждении программного обеспечения с другими разработчиками всплывает тема синглтонов, особенно в контексте развития WordPress’а. Я часто пытаюсь объяснить, почему их надо избегать, даже если они считаются стандартным шаблоном.
В данной статье я попытаюсь раскрыть тему того, почему синглтоны никогда не должны использоваться в коде и какие есть альтернативы для решения похожих проблем.
Синглтон — это шаблон проектирования в разработке программного обеспечения, описанный в книге Design Patterns: Elements of Reusable Object-Oriented Software (авторы — Банда четырёх), благодаря которой о шаблонах проектирования заговорили как об инструменте разработки ПО.
Идея в том, что вам может потребоваться, чтобы существовал лишь один экземпляр класса и чтобы вы предоставляли глобальную единую точку доступа к нему.
Это на самом деле достаточно просто объяснить и понять, и для многих людей синглтон — это лёгкий вход в мир шаблонов проектирования, что делает его самым популярным шаблоном.
Синглтон популярен, он был одним из первых шаблонов, описанных и стандартизированных в книге. Как же так получается, что некоторые разработчики считают его антишаблоном? Неужели он может быть настолько плохим?
Да.
Да, может.
Я заметил, что многие люди путают два смежных понятия. Когда они говорят, что им нужен синглтон, им на самом деле нужно использовать один экземпляр объекта в разных операциях инстанцирования. В общем, когда вы создаёте инстанс, вы создаёте новый экземпляр этого класса. Но для некоторых объектов нужно всегда использовать один и тот же общий экземпляр (shared instance) объекта, вне зависимости от того, где он используется.
Но синглтон не является верным решением для этого.
Путаница вызвана тем, что синглтон объединяет две функции (responsibilities) в одном объекте. Допустим, есть синглтон для подключения к базе данных. Давайте назовём его (очень изобретательно) DatabaseConnection. У синглтона теперь две главных функции:
DatabaseConnection.Именно из-за второй функции люди выбирают синглтон, но эту задачу должен решать другой объект.
Нет ничего плохого в общем экземпляре. Но объект, который вы хотите для этого использовать, — не место для такого ограничения.
Ниже я покажу несколько альтернатив. Но сначала хочу рассказать, какие проблемы может вызвать синглтон.
Прежде всего, и это может показаться скорее теоретической проблемой, синглтон нарушает многие принципы SOLID.
Шаблон синглтон нарушает четыре из пяти принципов SOLID. Он, возможно, хотел бы нарушить и пятый, если бы только мог иметь интерфейсы на первом месте…
Легко сказать, что ваш код не работает только из-за каких-то теоретических принципов. И хотя, согласно моему собственному опыту, эти принципы — самое ценное и надёжное руководство, на которое можно опираться при разработке программного обеспечения, я понимаю, что просто слова «это факт» для многих звучат неубедительно. Мы должны проследить влияние синглтона на вашу повседневную практику.
Здесь перечислены недостатки, с которыми можно столкнуться, если иметь дело с синглтоном:
DatabaseConnection неожиданно понадобилось подключение ко второй, отличной от первой базе данных, значит, вы в беде. Придётся заново пересмотреть саму архитектуру и, возможно, полностью переписать значительную часть кода.Я не хочу быть тем человеком, который во всём видит плохое, но не может предложить решение проблемы. Хотя я считаю, что вы должны оценивать всю архитектуру приложения, чтобы решить, как первым делом избежать использования синглтона, я предлагаю несколько самых распространённых способов в WordPress, когда синглтон можно легко заменить механизмом, который удовлетворяет всем требованиям и лишён большинства недостатков. Но прежде чем рассказать об этом, я хочу отметить, почему все мои предложения — только компромисс.
Существует «идеальная структура» для разработки приложений. Теоретически лучший вариант — единственный инстанцирующий вызов в загрузочном коде, создающий дерево зависимости приложения целиком, сверху донизу. Это будет работать так:
App (нужны Config, Database, Controller).Config для внедрения в App.Database для внедрения в App.Controller для внедрения в App (нужны Router, Views).Router для внедрения в Controller (нужен HTTPMiddleware).С помощью одного вызова выстроится сверху донизу весь стек приложения с внедрением зависимостей по мере необходимости. Цели такого подхода:
Однако, как бы хорошо это ни звучало, в WordPress’е так сделать невозможно, так как он не предоставляет централизованный контейнер или механизм внедрения, все плагины/темы загружаются изолированно.
Держите это в уме, пока мы будем обсуждать подходы. Идеальное решение, при котором весь стек WordPress’а инстанцируется через централизованный механизм внедрения, нам недоступно, поскольку оно требует поддержки WordPress Core. Всем описываемым далее подходам свойственны те или иные общие недостатки вроде сокрытия зависимостей посредством обращения к ним напрямую из логики вместо их внедрения.
Пример кода с использованием синглтон-подхода, который мы будем сравнивать с другими:
// Синглтон.
final class DatabaseConnection {
private static $instance;
private function __construct() {}
// Вызов для получения одного настоящего экземпляра.
public static function get_instance() {
if ( ! isset( self::$instance ) ) {
self::$instance = new self();
}
return self::$instance;
}
// Код логики смешан с кодом механизма инстанцирования.
public function query( ...$args ) {
// Исполняется запрос и возвращается результат.
}
}
// Потребляющий код.
$database = DatabaseConnection::get_instance();
$result = $database->query( $query );Я не включил сюда все подробности реализации, с которыми часто загружаются синглтоны, потому что они неважны для теоретической дискуссии.
В большинстве случаев лучший способ уйти от проблем, связанных с синглтоном, — использовать шаблон проектирования «фабричный метод». Фабрика — это объект, чья единственная обязанность — инстанцировать другие объекты. Вместо DatabaseConnectionManager, который делает собственный экземпляр с помощью метода get_instance(), у вас есть DatabaseConnectionFactory, создающий экземпляры объекта DatabaseConnection. В общем, фабрика всегда будет производить новые экземпляры нужного объекта. Но на основании запрошенного объекта и контекста фабрика может сама решать, создавать ли новый экземпляр или всегда расшаривать какой-то один.
Учитывая название шаблона, вы можете подумать, что он больше похож на код Java, чем PHP-код, так что не стесняйтесь отклоняться от слишком строгого (и ленивого) соглашения об именовании и называйте фабрику более изобретательно.
Пример фабричного метода:
// Фабрика.
final class Database {
public function get_connection(): DatabaseConnection {
static $connection = null;
if ( null === $connection ) {
// Здесь может быть произвольная логика, решающая, какую реализацию использовать.
$connection = new MySQLDatabaseConnection();
}
return $connection;
}
}
// Здесь у нас интерфейс, так что вы можете работать с несколькими реализациями и корректно имитировать (mock) ради тестирования.
interface DatabaseConnection {
public function query( ...$args );
}
// Используемая в данный момент реализация.
final class MySQLDatabaseConnection implements DatabaseConnection {
public function query( ...$args ) {
// Исполняет запрос и возвращает результат.
}
}
// Потребляющий код.
$database = ( new Database )->get_connection();
$result = $database->query( $query );Как видите, потребляющий код не так объёмен и несложен, только есть один нюанс. Мы решили называть фабрику Database вместо DatabaseConnection, так как это часть предоставляемого нами API, и мы всегда должны стремиться к балансу между логической точностью и элегантной краткостью.
Приведённая версия фабрики избавлена почти от всех ранее описанных недостатков, за одним исключением.
DatabaseConnection, но вместо этого создали новую, с фабрикой. Это не проблематично, потому что фабрика — чистая абстракция, вероятность того, что в какой-то момент понадобится отойти от концепции «инстанцирования», очень мала. Если это произойдёт, то, возможно, придётся пересмотреть всю парадигму ООП.Вы, наверное, начинаете удивляться, что мы больше не можем принудительно ограничиваться единственным инстанцированием. Хотя мы всегда отдаём общий экземпляр реализации DatabaseConnection, кто угодно всё ещё может выполнить new MySOLDatabaseConnection и получить доступ к дополнительному экземпляру. Да, это так, и это одна из причин отказа от синглтона. Но это не всегда даёт преимущества в реальных задачах, поскольку делает невозможным соблюдение базовых требований вроде модульного тестирования.
Статичный заместитель (Static Proxy) — другой шаблон проектирования, на который можно поменять синглтон. Он подразумевает ещё более тесную связь, чем фабрика, но это хотя бы связь с абстракцией, а не с конкретной реализацией. Идея в том, что у вас есть статичное сопоставление (static mapping) интерфейса, и эти статичные вызовы прозрачно перенаправляются конкретной реализации. Таким образом, прямой связи с фактической реализацией нет, и статичный заместитель сам решает, как выбирать реализацию для использования.
// Статичный заместитель.
final class Database {
public static function get_connection(): DatabaseConnection {
static $connection = null;
if ( null === $connection ) {
// You can have arbitrary logic in here to decide what
// implementation to use.
$connection = new MySQLDatabaseConnection();
}
return $connection;
}
public static function query( ...$args ) {
// Forward call to actual implementation.
self::get_connection()->query( ...$args );
}
}
// Здесь у нас интерфейс, так что мы можем работать с несколькими реализациями и корректно имитировать (mock) ради тестирования.
interface DatabaseConnection {
public function query( ...$args );
}
// Используемая в данный момент реализация.
final class MySQLDatabaseConnection implements DatabaseConnection {
public function query( ...$args ) {
// Исполняется запрос и возвращается результат.
}
}
// Потребляющий код.
$result = Database::query( $query );Как видите, статичный заместитель создаёт очень короткий и чистый API. К недостаткам можно отнести то, что возникает тесная связь кода с сигнатурой класса. При использовании в правильном месте особых проблем это не вызывает, так как это связь с абстракцией, которую можно контролировать напрямую, а не с конкретной реализацией. Вы всё ещё можете заменить код одной базы данных на код другой, который вы считаете нужным, а реализация всё ещё является совершенно нормальным объектом, который может быть протестирован.
API WordPress Plugin может заменить синглтоны, когда те используются ради возможности обеспечения глобального доступа через плагины. Это самое чистое решение с учётом ограничений WordPress’а, с оговоркой, что вся инфраструктура и архитектура вашего кода привязывается к API WordPress Plugin. Не применяйте этот способ, если вы собираетесь заново использовать ваш код в разных фреймворках.
// Здесь у нас интерфейс, так что мы можем работать с несколькими реализациями и корректно имитировать (mock) ради тестирования.
interface DatabaseConnection {
const FILTER = 'get_database_connection';
public function query( ...$args );
}
// Используемая в данный момент реализация.
class MySQLDatabaseConnection implements DatabaseConnection {
public function query( ...$args ) {
// Исполняется запрос и возвращается результат.
}
}
// Инициализирующий код.
$database = new MySQLDatabaseConnection();
add_filter( DatabaseConnection::FILTER, function () use ( $database ) {
return $database;
} );
// Потребляющий код.
$database = apply_filters( DatabaseConnection::FILTER );
$result = $database->query( $query );Один из основных компромиссов состоит в том, что ваша архитектура напрямую привязана к API WordPress Plugin. Если вы планируете когда-либо предоставлять функциональность плагина для Drupal-сайтов, то код придётся полностью переписать.
Другая возможная проблема — теперь вы зависите от тайминга WordPress-перехватчиков (hooks). Это может привести к багам, связанным с таймингом, их зачастую трудно воспроизвести и исправить.
Локатор служб — это одна из форм контейнера инверсии управления (Inversion of Control Container). Некоторые сайты описывают метод как антишаблон. С одной стороны, это правда, но с другой, как мы уже обсуждали выше, все предложенные здесь рекомендации можно считать лишь компромиссами.
Локатор служб — это контейнер, который предоставляет доступ к службам, реализованным в других местах. Контейнер по большей части — это коллекция экземпляров, сопоставленных с идентификаторами. Более сложные реализации локатора служб могут привносить такие возможности, как ленивое инстанцирование или генерирование заместителей.
// Здесь у нас интерфейс контейнера, так что мы можем менять реализации локатора служб.
interface Container {
public function has( string $key ): bool;
public function get( string $key );
}
// Базовая реализация локатора служб.
class ServiceLocator implements Container {
protected $services = [];
public function has( string $key ): bool {
return array_key_exists( $key, $this->services );
}
public function get( string $key ) {
$service = $this->services[ $key ];
if ( is_callable( $service ) ) {
$service = $service();
}
return $service;
}
public function add( string $key, callable $service ) {
$this->services[ $key ] = $service;
}
}
// Здесь у нас интерфейс, так что мы можем работать с несколькими реализациями и корректно имитировать (mock) ради тестирования.
interface DatabaseConnection {
public function query( ...$args );
}
// Используемая в данный момент реализация.
class MySQLDatabaseConnection implements DatabaseConnection {
public function query( ...$args ) {
// Исполняется запрос и возвращается результат.
}
}
// Инициализирующий код.
$services = new ServiceLocator();
$services->add( 'Database', function () {
return new MySQLDatabaseConnection();
} );
// Потребляющий код.
$result = $services->get( 'Database' )->query( $query );Как вы уже могли догадаться, проблема получения ссылки на экземпляр $services не пропала. Её можно решить, объединив этот метод с любым из предыдущих трёх.
$result = ( new ServiceLocator() )->get( 'Database' )->query( $query );$result = Services::get( 'Database' )->query( $query );$services = apply_filters( 'get_service_locator' );
$result = $services->get( 'Database' )->query( $query );Однако всё ещё нет ответа на вопрос, нужно ли пользоваться антишаблоном локатор служб вместо антишаблона синглтон… С локатором служб связана проблема: он «прячет» зависимости. Представим кодовую базу, которая использует правильное внедрение конструктора. В таком случае достаточно взглянуть на конструктор конкретного объекта, и можно сразу понять, от какого объекта он зависит. Если объект имеет доступ к ссылке на локатор служб, то вы можете обойти это явное разрешение зависимостей и извлечь ссылку (а следовательно, начать зависеть) на любой объект из реальной логики. Вот что имеют в виду, когда говорят, что локатор служб «прячет» зависимости.
Но, учитывая контекст WordPress, мы должны принять тот факт, что с самого начала нам недоступно идеальное решение. Нет технических возможностей реализовать правильное внедрение зависимостей по всей кодовой базе. Это значит, что нам в любом случае придётся искать компромисс. Локатор служб — не идеальное решение, однако этот шаблон хорошо укладывается в легаси-контекст и как минимум позволяет вам собрать все «компромиссы» в одном месте, а не раскидывать их по кодовой базе.
Если вы работаете только в собственном плагине и вам не надо предоставлять доступ к своим объектам другим плагинам, то вам повезло: вы можете использовать настоящее внедрение зависимостей, чтобы избежать глобального доступа к зависимостям.
// Здесь у нас интерфейс, так что мы можем работать с несколькими реализациями и корректно имитировать (mock) ради тестирования.
interface DatabaseConnection {
public function query( ...$args );
}
// Используемая в данный момент реализация.
class MySQLDatabaseConnection implements DatabaseConnection {
public function query( ...$args ) {
// Исполняется запрос и возвращается результат.
}
}
// Для демонстрации идеи мы вынуждены смоделировать весь плагин.
class Plugin {
private $database;
public function __construct( DatabaseConnection $database ) {
$this->database = $database;
}
public function run() {
$consumer = new Consumer( $this->database );
return $consumer->do_query();
}
}
// Потребляющий код.
// Для демонстрации внедрения конструктора также смоделирован как целый класс.
class Consumer {
private $database;
public function __construct( DatabaseConnection $database ) {
$this->database = $database;
}
public function do_query() {
// А вот настоящий потребляющий код.
// В этом месте у нас внедрено произвольное подключение к базе данных.
return $this->database->query( $query );
}
}
// Внедрение зависимости из загрузочного кода по всему дереву.
$database = new MySQLDatabaseConnection();
$plugin = new Plugin( $database );
$result = $plugin->run();Выглядит немного сложнее, но имейте в виду, что мы должны были написать базовую версию всего плагина, чтобы продемонстрировать внедрение зависимостей.
Хотя у нас не может быть полного внедрения зависимостей во всём приложении, но мы, по крайней мере, можем получить его с ограничениями в плагине.
Это пример того, как всё соединить (wiring) вручную с помощью явного инстанцирования самих зависимостей. В более сложной кодовой базе вам захочется использовать автосоединяющееся внедрение зависимостей (Dependency Injector) (специализированный контейнер), которое принимает предварительную информацию о конфигурации и может рекурсивно инстанцировать целое дерево за один вызов.
Вот пример того, как можно сделать это соединение с помощью такого внедрения зависимостей (даны те же классы/интерфейсы, как и в предыдущем примере):
// Позволяет внедрению узнать, какую реализацию использовать для разрешения (resolving) интерфейса DatabaseConnection.
$injector->alias( DatabaseConnection::class, MySQLDatabaseConnection::class );
// Позволяет внедрению узнать, что на запросы DatabaseConnection оно всегда должно возвращать один и тот же общий экземпляр.
$injector->share( DatabaseConnection::class );
// Позволяет внедрению инстанцировать класс Plugin, который заставит его рекурсивно обойти все конструкторы и инстанцировать объекты, чтобы решить зависимости.
$plugin = $injector->make( Plugin::class );Для более сложных потребностей, которые разбросаны по нескольким пользовательским и сторонним плагинам, рассмотрите способы комбинирования рассмотренных подходов, которые не будут противоречить вашим условиям.
Например, в более сложных проектах я использовал следующий подход, чтобы приблизиться к идеальному решению, который описано выше:
На странице Bright Nucleus Architecture вы можете почитать об этом подходе и посмотреть записи.
Несколько возможных подходов позволяют избавиться от синглтонов. Хотя ни один из них не идеален в контексте WordPress’а, они все без исключения предпочтительней синглтона.
Помните, что связанные с синглтонами проблемы заключаются не в том, что те расшарены, а в том, что синглтоны заставляют инстанцировать их самих.
Если вы знаете ситуации, когда синглтон — единственное подходящее решение, пишите в комментариях!
|
|
Developer Preview 4 уже доступна. Официальный запуск платформы Android O совсем скоро |
|
Метки: author Developers_Relations блог компании google андроид android developer preview |
Советы для тех, кто планирует заняться локализацией своего проекта |

|
|
Dotty – будущее языка Scala |
|
Метки: author alextokarev программирование scala java блог компании гк ланит ланит dotty |
Кубок конфедераций: что стоит за беспроблемной связью на стадионе |





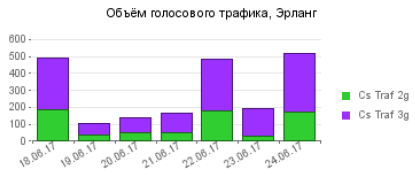
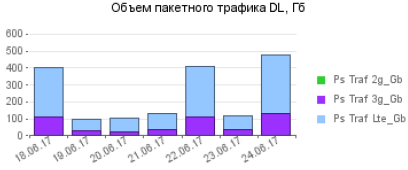



|
Метки: author MegaFon стандарты связи беспроводные технологии блог компании «мегафон» мегафон кубок связь интернет |






