От b2b-приложений к массовому сервису по всему миру |

Привет, Хабр! Меня зовут Евгений Лисовский, я руковожу проектом MAPS.ME — это международный проект, интересный и очень амбициозный. Наша задача — конкурировать с Google, Apple и несколькими компаниями второго эшелона. Сегодня я кратко расскажу о своём трудовом пути, чтобы затем подробнее остановиться на самых интересных этапах.
До института я подрабатывал, собирал компьютеры на заказ. А свой компьютер у меня появился в 1995 году, в 13 лет — спасибо родителям, это было реально очень круто. В институте я начал сам изучать PHP, MySQL, соорудил собственный движок для интернет-магазина. Сделал три сайта, брал по 300 долларов за каждый. С 2004 года я работал в международной компании Radmin.com, которая создаёт b2b-продукт для удалённого управления компьютерами, там я провёл шесть лет. Потом ломанулся в стартапы: KupiBonus, детские товары BabyBoom. Там было интересно! Важны не только успешные проекты, но и фейлы: надо хорошо анализировать, почему они происходили. Потом был Litres. Очень интересный бизнес — продавать электронные книги при уровне пиратства 96 %. В 2015 году мы заработали 15 млн долларов, с 2011 года выручка выросла в 18 раз. Затем я вместе с партнерами запустил собственный проект MoikaMoika.ru. Не то чтобы основатели сразу стали миллионерами, но это интересный опыт. Проект жив и развивается. А дальше про всё это — более подробно.
Я писал на С++ программную часть дипломной работы, а мой партнёр делал аппаратную часть. По сути, печатную плату. Прибор был очень простой: снимал ЭКГ с трёх отведений — правой руки, левой руки, левой ноги — и формировал электрокардиограмму. Она снималась простым аналого-цифровым преобразователем, плюс частотный модулятор на звуковой частоте, и передавалась через звуковую плату компьютера. Поскольку звуковая карта есть во всех компьютерах, то это самый простой способ ввести данные в цифровом виде. Потом я программно снимал огибающую, которая и представляет собой ЭКГ. По высоте зубцов и расстоянию между ними можно определить разные типы заболеваний, отметить определённые паттерны, сравнить их с базой и сделать вывод о диагнозе.

Это было ещё в 2004 году. Тогда я понимал, что наш прибор может стать массовым продуктом, но был я слишком зелен и юн. Главная моя проблема в прошлом — неуверенность в своих силах. Мне казалось, что мир такой большой, вокруг такие взрослые дяди, они зарабатывают деньги, а я ещё такой глупый, маленький и ничего не умею. Это ключевая сложность. Крайне важно перебороть страх. Когда вы делаете что-то новое, вам всегда кажется, что задача неподъёмна. А потом проходит месяц-два, вы оборачиваетесь и понимаете: блин, чего я вообще боялся? Всё нормально, в этом нет ничего сложного. На протяжении всей своей карьеры я боролся со страхом. А ещё очень важно уметь признавать свои ошибки и исправлять их.
После института я начал искать работу веб-программистом, программистом на PHP, MySQL или сисадмином. Для последней должности навыков не хватало, я даже собеседовался в Лабораторию Касперского, но это оказалось очень сложно. Да и с PHP-программированием было не особо. Я пришёл, а мне говорят: вот блокнот, напиши нам плагинатор. И ты думаешь: зачем блокнот, когда есть DreamWeaver, в котором все теги подсвечиваются.
Потом меня пригласили в софтверную международную компанию Radmin интернет-маркетологом. У меня был свободный английский. Погоняли всякие IQ-тесты, позадавали вопросы, я на всё ответил, и мой будущий руководитель говорит: «Я вижу, что ты нормальный парень, но слишком молодой. Если сразу во всё быстро вникнешь и за шесть дней вольёшься в работу, то мы тебя берём. Ты маркетингом занимался?» Я думаю: сайты делал, SEO делал — ну конечно, маркетинг — это моё вообще, любимое. Он: «Google Adwords знаешь?» А я в контекстной рекламе — вообще ни в зуб ногой. Но мне деньги были очень нужны, у меня только сын родился. Говорю: «Ну конечно!»
Так я и устроился на работу. Мне повезло. Этот опыт дал мне, инженеру, огромный профит. Мне стало очень легко общаться с разработчиками. Знаете, есть классическое противостояние между разработчиками и маркетологами. Приходит маркетолог, говорит: сделай мне такую красивую красную кнопку, чтобы всё хорошо работало. А инженеры отвечают: да иди ты куда подальше… И всё, начинается обособление. А когда ты приходишь и говоришь: чувак, всё нормально, я тоже кодил на С++, то IT-директор сразу выдыхает с облегчением. И становится гораздо проще общаться. Ведь практически все современные IT-проекты — это симбиоз разработки и маркетинга продукта, они неотделимы друг от друга. И когда их искусственно разделяют, то получается не очень хорошая ситуация.
В этой компании я работал с контекстной рекламой ещё в 2004 году, когда в России было очень мало интернет-маркетологов. Очень интересный опыт. Я ездил по разным международным конференциям, где уже тогда обсуждалось тестирование лендинговых страниц. В США и Европе А/В-тестирование, оптимизация конверсий и прочие методики были отработаны на высшем уровне. До нас это докатывалось с задержкой примерно в пять лет.
Я не могу сказать, что сделал много за время работы в Radmin. Уйдя в стартап KupiBonus — купонный проект, — я за полгода сделал больше, чем за шесть лет в предыдущей компании. Возможно, динамика жизни в интернете была немного ниже или я боролся с собой: мне казалось, что пора уходить, но я оставался, потому что это хорошая надёжная компания. Я думал: приду на позицию интернет-маркетолога, дорасту до маркетинг-директора — и вот оно, счастье. На самом деле счастье — это достижение целей в создании каких-либо продуктов.
В кризисный 2009 год мне удалось перепозиционировать продукт. Я объездил всю Россию, все федеральные округи, провёл большую работу с продажниками, которые потом распространили нашу систему оптимизации бизнес-процессов по всей стране. И в итоге в кризисный год получилось поднять выручку в России на 30 %.
Какие выводы я сделал для себя, поработав в софтверной компании? Я хотел поменять команду. Я понял, что когда веб-мастер сидит и при мне в буквальном смысле спит, то это беда. Я пытался искать какие-то системы управления проектами, проанализировал кучу разных вариантов. Думал, что если внедрю нормальную систему, то всё сразу заиграет яркими красками. Но на самом деле проблема была в людях. Надо изначально нанимать правильных людей.
Мне захотелось создать свою команду с нуля. Уйдя в стартап, я пришёл в готовую команду. Это тоже оказалось проблемой, потому что людей нанимал не я. У нас не было взаимного доверия, приходилось налаживать отношения, а это достаточно сложно. В купонном бизнесе мой рабочий день начинался с шоколадки и чашки кофе в восемь утра, а заканчивался в одиннадцать вечера. Был даже период (конец 2010 года), когда мы работали по 15 часов в сутки. Это очень динамичный бизнес. Топ-менеджмент у нас была сильный, а ребята в моей команде — слабоваты. В итоге многое приходилось делать самому.
Мне говорили: Женя, ты хреновый менеджер, взял всё на себя, ты должен делегировать. И я понимал, что это так. Я не пытался обмануть себя, работал над собой, но всё равно продолжал делать сам, потому что не мог зафакапить проект.
Было очень приятно, когда президент компании, француз, бывший (до 1998 года) владелец OZON.ru подходил и говорил: Евгений, маркетинг — это ключевое. Это так. Я не мог заснуть ночью, пока не придумывал, как бы выполнить план. А план у нас был конский. Я пришёл из компании с бюджетом в 100 тыс. долларов в год в купонный бизнес с бюджетом 200 тыс. евро в месяц. И нам крайне не хватало лидов.
Затем был проект BabyBoom — классический ретейл. Мой совет: не работайте с неподходящими людьми, увольняйте слабых, нанимайте сильных. Например, в BabyBoom и Litres я собирал команды с нуля и зачастую делал выбор в пользу, может, не самого опытного человека, но готового быстро обучаться. В маркетинге нет ничего суперсложного, всё можно освоить за месяц, если нормально подойти к процессу. В итоге гораздо проще выучить людей, чем нанять очень опытных и дорогих. Также у меня был пунктик, чтобы это была именно моя команда.
Но тут есть одна проблема. Boss Cap — Friend Cap. Это то, чему я научился в BabyBoom, стартапе по продаже детских товаров. Сначала мы подняли 1 млн долларов инвестиций, начали увеличивать оборот, выросли в пять раз. Но логистика в детских товарах очень сложная: часто встречаются крупногабаритные товары. Хотя средний чек достаточно большой, маржинальность доходила до 30 %, однако крупногабаритные товары просто убивали бизнес-модель. Логистика сжирала всю маржу. Добавьте сюда далеко не полную информацию об остатках на складе. К сожалению, у нас не получилось закрыть второй раунд инвестиций из-за слишком большого количества рисков. В итоге проект развалился, и я пошёл в Litres.
На протяжении всей своей карьеры я пытался искать хаки, нестандартные решения, которые позволяют превзойти конкурентов. Результат — это команда, хороший продукт, хороший маркетинг, хороший менеджмент, но без предпринимательских навыков ничего не получится. Нужно работать на опережение.
Что может привести к успеху? Интеллект, эрудиция, социальная адаптация, помноженные на предпринимательские способности. Человек может быть интеллектуалом, но не особо эрудитом, но при этом иметь высокие способности в предпринимательстве и социальной адаптации. Социальная адаптация — это умение общаться, договариваться, строить взаимоотношения с людьми. Очень полезный навык. Постарайтесь развивать его в себе.
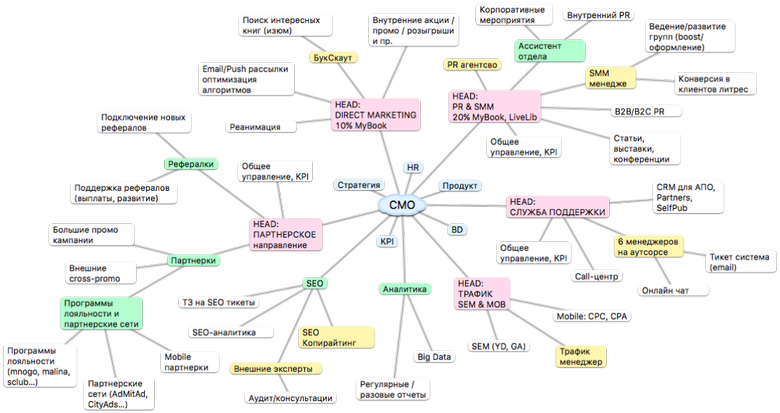
Команда — это основа успешности проекта. Ключевая компетенция руководителя — подбор сотрудников. Я сам искал людей, не прибегая к услугам кадровиков. Я тратил много времени, но оно того стоит. Как обычно я выбирал работников? Я смотрел в их добрые глаза и рассказывал о проекте. Представьте: 2011 год, электронные книги — кто их покупает? Это как продавать мороженое эскимосам. Я рассказывал, что в США электронные книги занимают уже 20 % всего книжного рынка, и сейчас мы будем круто расти. Если у собеседника расширяются глаза, он наливается румянцем — значит, правильный человек, ему это интересно.
Если ты будешь заниматься тем, что тебе нравится, то добьёшься большого результата, и это увидят все: руководство, акционеры. Работайте как собственник. Это очень интересная концепция. Я всегда действовал так, будто это мои деньги, и я их трачу. Я не останусь в проекте, который мне не нравится, но я всегда работаю так, будто это мой собственный проект. Это заметят, поверьте. Но не следуйте принципу «я наёмный работник и выше головы прыгать не буду, потому что больше мне не заплатят». Это неправильный подход, обязательно нужна самоотдача.
Представьте себе, например, строителя по найму. Он строит дома тяп-ляп и мечтает о собственном доме, когда будут деньги. И если он 20 лет работал по найму и строил как придётся, как вы думаете, сможет ли он собственный дом построить хорошо? Конечно же, нет. Невозможно стать предпринимателем, не работая по найму как предприниматель.
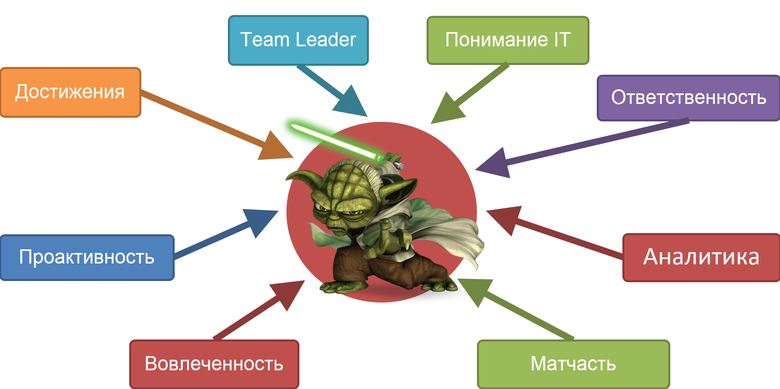
Будьте как Йода. Это прописные истины правильного руководителя в IT. Конечно, должны быть достижения. Если ты приходишь руководить командой, то очень тяжело завоевать авторитет. Нужна открытость. Если ребята понимают, что ты делал, знают о твоих достижениях, то у них не будет вопросов. Если есть достижения, тогда легко вольёшься. Также надо быть лидером и разбираться в IT. Тут мне очень хорошо помогает технический бэкграунд.
Во время работы приходится очень много анализировать. Если человек не умеет пользоваться Excel — скорее всего, у него несистемное мышление, а это значит, что мы не сработаемся. Я не требовал от людей технического образования, главное, чтобы кандидаты понимали базовые принципы. Один пример. В BabyBoom я нанял парня на партнёрские программы, заниматься женскими форумами. Я ему говорю: есть сотни сайтов, давай выберем самые крупные, отранжируем. Сделай мне табличку — и посмотрим, как будем дальше работать. Он пошёл думать, с утра приносит табличку. А в ячейках с рейтингом записаны не цифры 4/5, а «четыре из пяти баллов». Я говорю: а как ты автофильтр включишь? Это же просто символы, а не цифры. Но он меня даже не понял.
Моя ошибка: я недостаточно подробно его расспрашивал на собеседовании. После этого я всем кандидатам давал такое задание: «Представьте, что вы — менеджер партнерской программы в Litres. Существует 10 000 сайтов о книгах. Ваша задача — запартнёриться со всеми этими сайтами. Как вы будете действовать?» Мне важно оценить, как человек понимает бизнес-процессы. Мыслит ли он структурно: «Занесу в табличку, отсортирую по убыванию трафика, возьму топ-20, которые, скорее всего, будут генерировать 80 % трафика, и начну в первую очередь с ними работать». По сути, Excel и Google Docs Spreadsheets — это своеобразные CRM. У меня всё на них сделано и отработано на куче стартапов, никакая система управления проектами не нужна.
Создавая у себя в голове структуру команды и нанимая людей, я всегда давал им понять, где они могут оказаться. Например, кандидату, который пришёл на партнёрские программы, я сказал: «У меня есть план структуры компании на два года вперёд, и здесь есть позиция — руководитель партнёрских программ. Я ничего не гарантирую, но если ты будешь активно расти и развиваться, ты сможешь быть там». В итоге он действительно занял эту должность. И мне это очень приятно. Я люблю, когда сотрудники растут. Также я открыто объясняю, что карьера — это не безоблачный полёт, когда всё ровно и гладко, каждый может забуксовать. Но либо человек движется вперёд, либо мы расстаемся. Есть два состояния: падение и рост. Без вариантов.
В 2011 году в Litres мы сделали мобильное приложение. Так себе, просто читалка. Ни закладок, ни заметок, ни синхронизации позиций — ничего, примитивная читалка с каталогом за деньги.
Понадобилось это как-то продвигать. У меня не было опыта в мобильном маркетинге, и я договорился о взаимном консалтинге с компанией Alawar Entertainment, с подразделением мобильных игр. Я консультировал их по классическому вебу, а они меня — по мобильному сегменту. Так я набрался знаний, и мы начали продвигать свою читалку. В 2012 году выручка выросла на 120 %. Тогда в России мало кто занимался мобильным маркетингом так же активно. Мы просто скупали кучу трафика. Как только в AdMob, впоследствии Facebook, появилась реклама, мы были одними из первых в России, кто начал её активно скупать.
Если бы мы в 2011 году решили сначала сделать суперклассный продукт с кучей возможностей и запустили бы его на год позже, то мы бы прозевали решающий 2012 год. Когда я пришёл в Litres, то один из моих знакомых вёл сделку с Dream Industries. Проект Bookmate. И в конце 2011 года эти ребята подняли 30 млн долларов. А у меня бюджет на маркетинг в 2012 году был 9 млн рублей. Как вы думаете, какие у меня появились мысли? А я проработал в Litres только месяц. Прибегаю к генеральному директору: «Серега, что делать?» — «Ну, работать».
Как мы работали? Как лошадям закрывают глаза шорами, чтобы они не видели, что происходит вокруг, так и мы просто понеслись вперёд. Прошёл год, оборачиваемся — а что-то и не видать никого сзади. Time to Market — вовремя сделанный продукт и хороший маркетинг решили судьбу проекта.
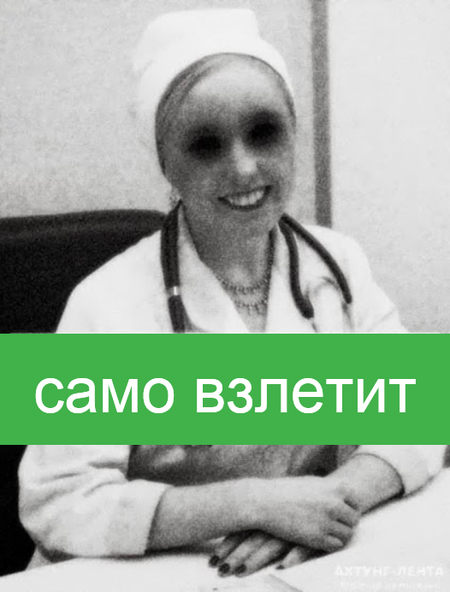
Само ничего не взлетит. Многие думают, что достаточно сделать превосходный продукт, выложить в App Store или Google Play, и оно попрёт как на дрожжах. Это уже давно не работает. Сейчас необходим системный отлаженный маркетинг, привлечение трафика с кучи разных каналов, анализ конверсий и когорт, внутренняя аналитика. Не надейтесь, что кнопочка «Рассказать друзьям» даст вам мощнейший виральный эффект.
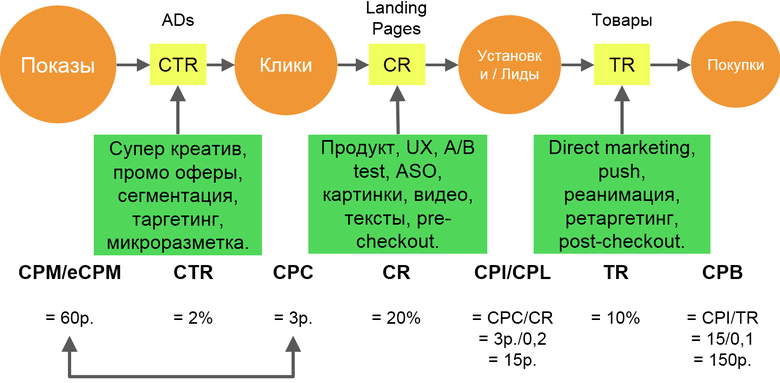
Здесь отображён базовый подход к маркетингу. Есть показы, клики, установки и т. д. Допустим, вы покупаете трафик на Facebook. Думаете, что если поставить CPI 50 центов, то Facebook принесёт вам кучу установок. Такого не будет, потому что Facebook берёт на себя все риски за плохой креатив, за плохой лендинг, за плохие описания, низкий рейтинг и т. д. Естественно, что при этом он будет завышать планку. Покажу на примере контекстной рекламы. Проводя собеседования на должности в маркетинге, я задавал простой вопрос: «Объясни, как работает контекстная реклама?» Кандидат говорит: «Вот, есть система ранжирования…» — «А зачем она нужна?» — «Чтобы рекламодатели нормально друг с другом, чтобы была честная сортировка…» Всё не так.
Представьте, что я — коммерческий директор Яндекс.Директа. Моя задача — увеличить выручку на тысячу показов с контекста. Каким KPI можно это выразить? И CPM, выручка на тысячу показов. Как его максимизировать? Алгоритм ранжирования в Яндекс.Директе — это формула, максимизирующая выручку на тысячу показов, и ничего более. Это не система, которая позволяет уравнять в правах рекламодателей. Это система, максимизирующая выручку. Там есть несколько факторов: CTR, CPC. Если у тебя высокий CTR, то на сторону рекламодателя идёт больше трафика, а значит, больше денег.
Есть ещё один — качество лендинговой страницы. Зачем он нужен? Здесь кандидаты вообще терялись и отвечали: «Чтобы людям было хорошо». На самом деле — для увеличения выручки lifetime value. Надо понимать, что тому, кто продаёт вам трафик, нужны деньги. И этот фактор позволяет контролировать уровень доверия к контекстной рекламе. Если пользователь по объявлению перейдёт на лендинг, где окажется совершенно другая информация, то он потеряет доверие к контекстной рекламе и в долгосрочной перспективе будет реже на неё кликать.
Напоследок приведу пример того, что мы делали в купонных системах. Это из разряда growth hacks, как можно хакнуть систему. Тогда на рынке была компания Darberry, потом её купил «Групон». У них было размещение на Mail.Ru Group за 300 тыс. рублей в день. Очень дорого, как мне тогда казалось. Такими бюджетами я управлял впервые. CTR был достаточно низкий, а стоимость за лид получалась 86 рублей, хотя по модели она была около 50. Дороговато, ещё и женская аудитория. Что делать? У меня был сотрудник, который отвечал за макеты баннеров. Он в шесть вечера часов заявляет, что ему пора бежать на учёбу. А мне до одиннадцати надо отправить макет. Я говорю: «У меня кампания стартует, а ты уходишь». — «Ну, сорян». Потом я его уволил, но в тот вечер пришлось сесть и подумать, как быть.
Я просто открыл Paint и нарисовал баннер, написал на белом фоне «–90 %», максимально растянув на весь экран, без окантовки. Не знаю, как тогда это пропустили. Позже, кстати, запретили делать баннеры без окантовки и сделали заливку градиентом. Но тогда это прокатило. Я отправил. Есть книга Стива Круга «Don’t make me think». Надо всё упрощать — чем проще, тем лучше. Благодаря этому примитивному баннеру CTR вырос более чем в восемь раз. Естественно, конверсия в регистрацию упала, но на выходе я всё равно получил стоимость за лид в 34 рубля.
Правда, потом к нам пришла юридическая служба Mail.Ru Group и сказала, что у вас тут написано «–90 %», а на сайте такой акции нет. Действительно, не было. Потом мы начали подбирать акции под такие большие размещения.
В 2014 году мы с партнёрами решили запустить стартап MoikaMoika. Это запись на мойку без очереди. И звучит неплохо, и рынок приличный. Действительно, есть такая проблема — очереди на мойку. Здесь существует определённая сезонность, но мы рассчитали бизнес-модель, всё прикинули. В 2014 году начали разработку, в феврале 2015-го выпустили на iOS и Android и взялись за маркетинг. Я придумывал всевозможные креативы. Потом, кстати, их блокировали, но какое-то время они работали.
Вот пример того, что если поработать над креативом, над CTR, эффективностью, если сделать биндинг по CPI, то результат будет гораздо хуже.
Начальный капитал стартапа — примерно по 300 тыс. с каждого из основателей. Пример расчёта бизнес-модели MoikaMoika с когортами, конверсиями, примерным подходом:
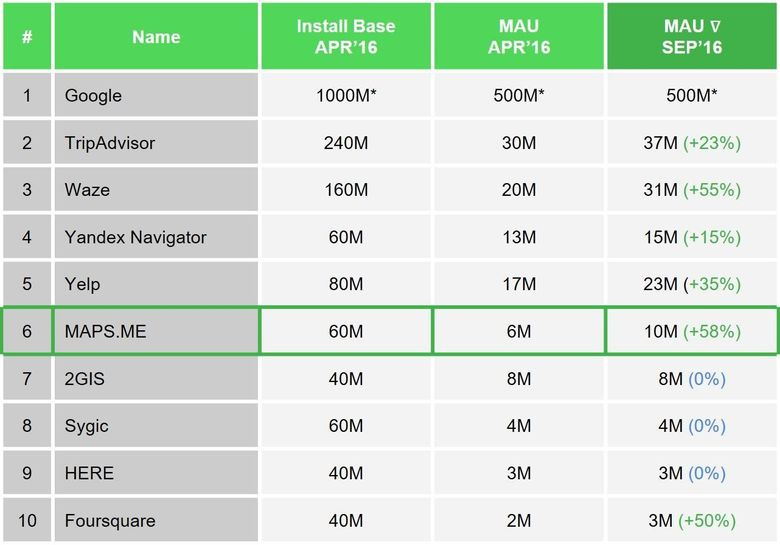
Что касается MAPS.ME, то сегодня проект где-то на шестом месте в мире по размеру аудитории, при этом мы не пытаемся быть Google Maps, у нас своя ниша и свои пользователи. Сейчас мы — карты для путешественников: лёгкие, быстрые и надёжные, созданные для работы без интернета. В этом сегменте мы лидеры, поскольку основная масса навигаторов «старой гвардии» вообще не рассчитана на пешеходную навигацию, а туристов, передвигающихся без автомобиля, — около 70 %. По оценкам Google, 40 % путешественников предпочитают использовать офлайн-карты.
Именно за этот сегмент рынка мы боремся. В год в мире порядка 1,3 млрд путешественников, нам их вполне достаточно :) Однако перед нами стоит задача бороться также за ежедневное использование MAPS.ME, для чего мы активно работаем над функционалом, который позволит лучше удерживать аудиторию. К примеру, в декабре 2016 года мы запустили пробки по 38 странам мира, что позволило поднять уровень дневной аудитории среди автомобилистов и конвертировать пользователей из туристического сценария использования в ежедневный. При этом мы внедряем в весь добавляемый функционал простоту и надёжность: пробки эффективно сжимаются и потребляют в четыре раза меньше мобильного трафика, чем приложения конкурентов, что позволяет использовать нашу навигацию с пробками даже в роуминге. Также весь функционал — поиск, авто-, вело- и пешая навигация, закладки, заметки — работает без интернета. Это не значит, что наши пользователи вообще обходятся без него: по нашей статистике, более 80 % подключаются к интернету в течение дня, что позволяет нам зарабатывать на партнёрских программах с туристическими гигантами вроде Booking.com, с которыми мы за полгода вошли в топ-10 партнёров по объёму бронирований. Интеграция Booking.com для нас — это не только возможность заработать, но и востребованный функционал поиска отелей на карте. Он весьма удобен, если вам важно видеть, где находится отель и как далеко он расположен от транспортных узлов и основных достопримечательностей.
У нас много планов по развитию, сформированных на базе опросов пользователей и бэклогов от нашей службы клиентской поддержки, но все задачи приоритезируются по простому принципу: по вкладу в удержание аудитории, в монетизацию, в привлечение аудитории и по сложности разработки. Это позволяет достигать быстрых побед и двигаться в развитии поступательно, однако немалое внимание мы уделяем и долгосрочному (на три года) стратегическому функционалу.
Если коротко говорить о нашей долгосрочной стратегии, то в рамках туристического сегмента стоит задача расширить применение MAPS.ME, превратить его из инструмента «добраться из точки А в точку В» в полноценный помощник путешественника. Поэтому мы планируем добавлять функционал, востребованный среди туристов: UGC (user-generated content) — рейтинги, отзывы, чтобы туристу было легче выбрать ресторан или любое другое заведение; поиск интересных мест; покупку билетов в музеи и на различные местные активности. Мы убеждены, что карта — это инструмент базовой регулярной потребности, вокруг которого можно надстраивать дополнительный комплементарный функционал, расширяющий сценарии туристического использования. При этом востребованность офлайн-карт будет только расти, особенно в развивающихся странах, где мобильный интернет стоит дорого и имеет плохое покрытие.
В плане монетизации мы также верим в гиперлокальную рекламу, которая в последнее время набирает обороты, ведь малый и средний бизнес значительно ограничен в рекламных инструментах.
У нас сильная команда разработчиков и маркетологов и отлаженная система планирования бизнес-процессов и управления ими. Наш девиз: хорошему продукту — хороший маркетинг. Это позволяет достигать максимальной синергии для проактивного развития проекта и добиваться высоких результатов.

Я выложил все свои наработки в открытый доступ бесплатно для любого использования (некоммерческого/коммерческого): www.lisovskiy.ru/edu. Там есть шаблоны примеров расчёта бизнес-моделей в табличках, презентации. Есть подробный обучающий курс: в 2016 году я постарался собрать воедино весь свой практический опыт. Надеюсь, кому-то это пригодится и поможет в запуске новых проектов и развитии существующих.
|
Метки: author eugene-lisovskiy управление продуктом развитие стартапа карьера в it-индустрии блог компании mail.ru group mail.ru maps.me стартапы |
[Перевод - recovery mode ] Сперва сторифреймы, потом вайрфреймы |


«Я написал бы короче, но у меня не было времени». — Марк Твен

|
Метки: author elder_cat прототипирование веб-дизайн блог компании everyday tools дизайн сайтов дизайн лендингов вайрфреймы мокапы |
11 вопросов к администраторам баз данных PostgreSQL |
 Александр Чистяков: Администратор баз данных – это человек, который умеет читать план запросов. В основном, этим он и отличается от других айтишников. На самом деле, человек, который умеет читать план запроса, немного печален, потому что он хотел бы, чтобы другие айтишники тоже так могли, но они такого не могут. Он пытается их сподвигнуть на это, но они не хотят. Возникает некий конфликт. Человек, который не хочет быть тем, кем он является, но вынужден.
Александр Чистяков: Администратор баз данных – это человек, который умеет читать план запросов. В основном, этим он и отличается от других айтишников. На самом деле, человек, который умеет читать план запроса, немного печален, потому что он хотел бы, чтобы другие айтишники тоже так могли, но они такого не могут. Он пытается их сподвигнуть на это, но они не хотят. Возникает некий конфликт. Человек, который не хочет быть тем, кем он является, но вынужден. Антон Бушмелев: Администратор баз данных – эксперт в своем деле. Это должен быть человек с опытом. Желательно, с background в разработке, чтобы с ходу замечать косяки при “накате” релиза. Администратор должен быть самым квалифицированным человеком в команде. За ним большая ответственность, он один отвечает сразу за много баз. Чем отличается от остальных “айтишников”? Он должен быть фанатом своего дела, любить свою работу!
Антон Бушмелев: Администратор баз данных – эксперт в своем деле. Это должен быть человек с опытом. Желательно, с background в разработке, чтобы с ходу замечать косяки при “накате” релиза. Администратор должен быть самым квалифицированным человеком в команде. За ним большая ответственность, он один отвечает сразу за много баз. Чем отличается от остальных “айтишников”? Он должен быть фанатом своего дела, любить свою работу! Дмитрий Васильев: На инженере базы данных лежит максимальная ответственность не только за текущую работу приложений, но и за сохранность данных, в том числе исторических. Подчас, сердцем и кровеносной системой любого типового проекта является база данных. Нет ничего важнее сохранности данных, это очень большая нагрузка на человека.
Дмитрий Васильев: На инженере базы данных лежит максимальная ответственность не только за текущую работу приложений, но и за сохранность данных, в том числе исторических. Подчас, сердцем и кровеносной системой любого типового проекта является база данных. Нет ничего важнее сохранности данных, это очень большая нагрузка на человека.
 Брюс Момжан: Администратор работает с запросами, которые пишут разработчики приложений, и настраивает БД таким образом, чтобы производительность не падала, работа была надежной, вовремя происходили обновления. Он также устанавливает дополнительные пакеты, делает резервные копии и т.д. – есть множество задач на бэкенде, которые выполняет администратор баз данных, чтобы помочь разработчикам приложений. Этот человек отвечает за то, чтобы все таблицы были созданы, управляет правами пользователей, контролирует, как всё работает и следит за производительностью.
Брюс Момжан: Администратор работает с запросами, которые пишут разработчики приложений, и настраивает БД таким образом, чтобы производительность не падала, работа была надежной, вовремя происходили обновления. Он также устанавливает дополнительные пакеты, делает резервные копии и т.д. – есть множество задач на бэкенде, которые выполняет администратор баз данных, чтобы помочь разработчикам приложений. Этот человек отвечает за то, чтобы все таблицы были созданы, управляет правами пользователей, контролирует, как всё работает и следит за производительностью.|
Метки: author rdruzyagin блог компании pg day'17 russia postgresql dba интервью interview |
Для ИТ-ишников. Если у вас устают глаза, покраснения, раздражение. Возможно эта статья для вас |
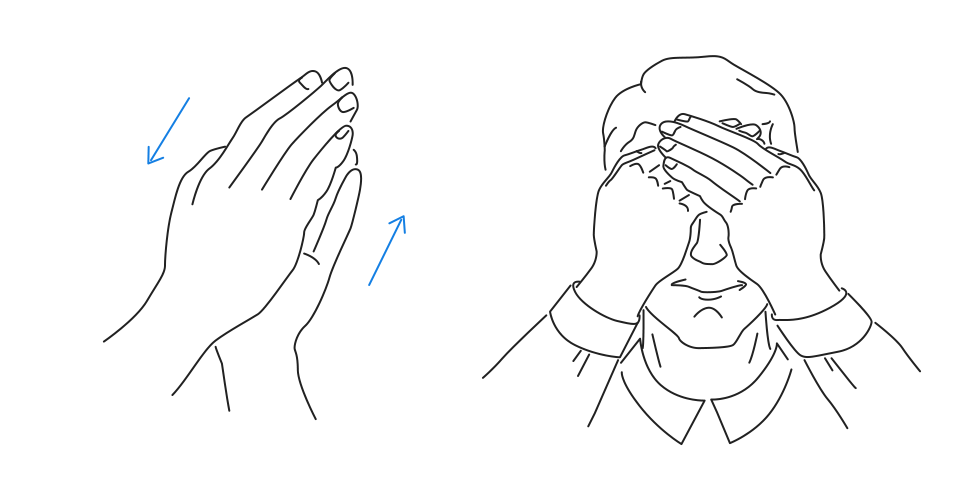




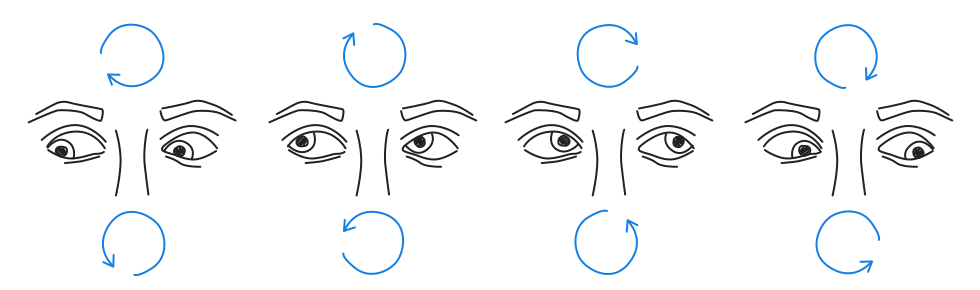
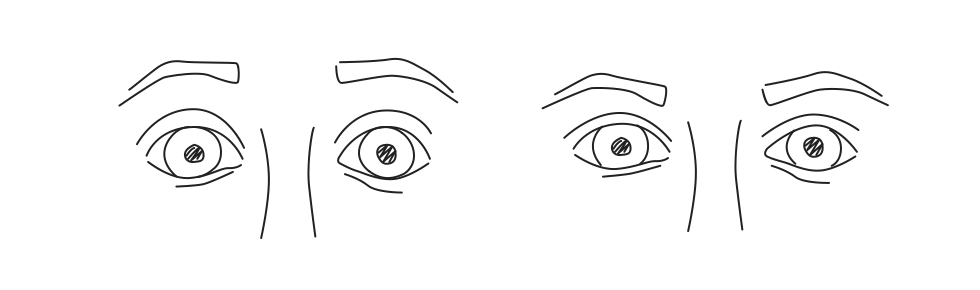
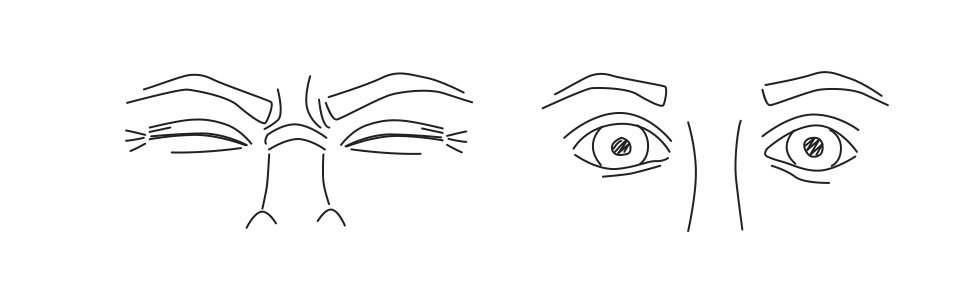
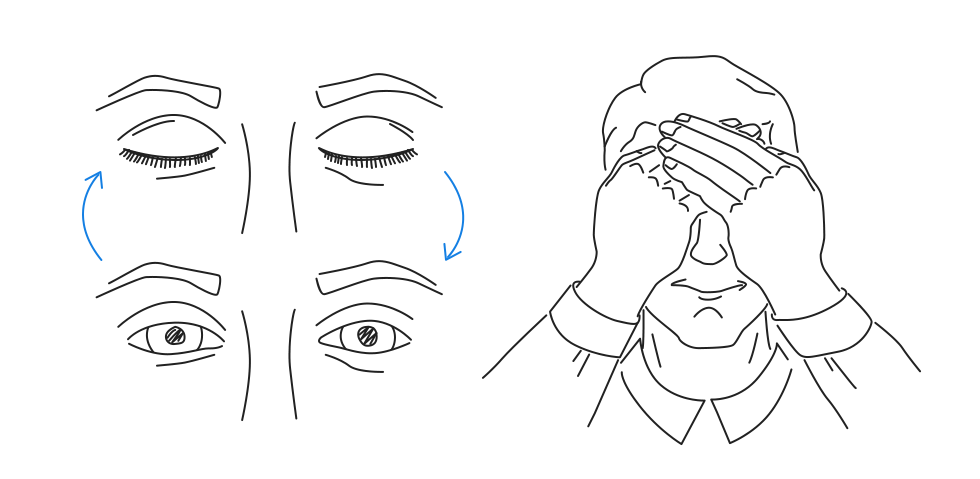

|
Метки: author abz_dn_ua читальный зал исследования и прогнозы в it зрение красные глаза для итшников как правильно сидеть как сохранить зрение |
Технологии платных скоростных дорог: настоящее и недалекое будущее |

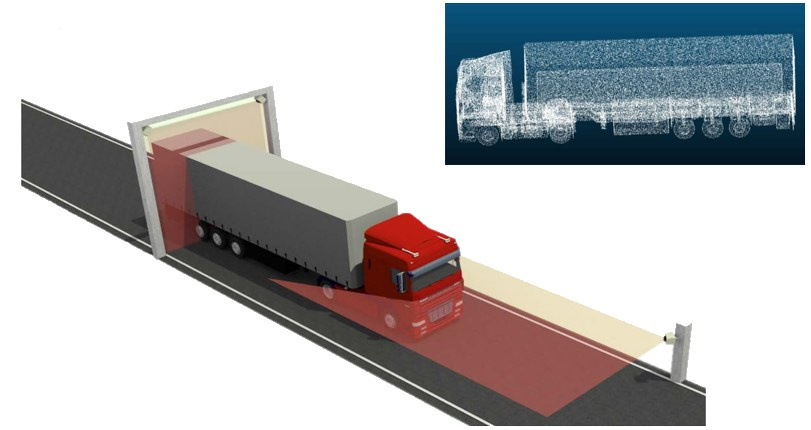

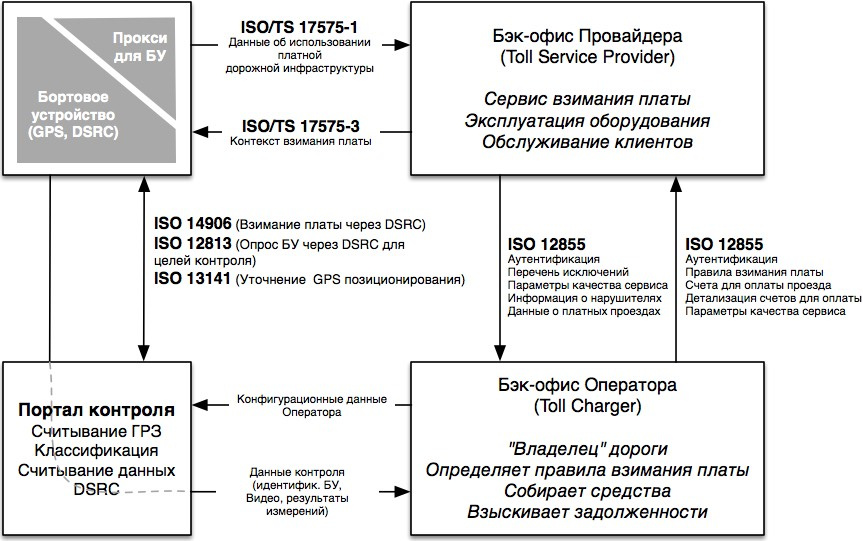

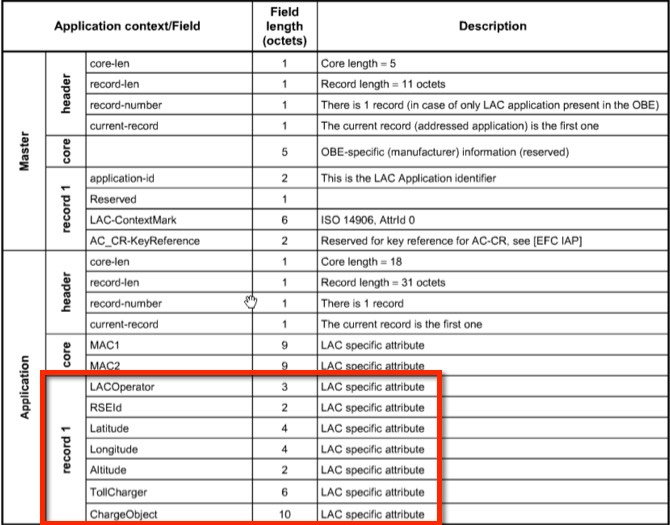
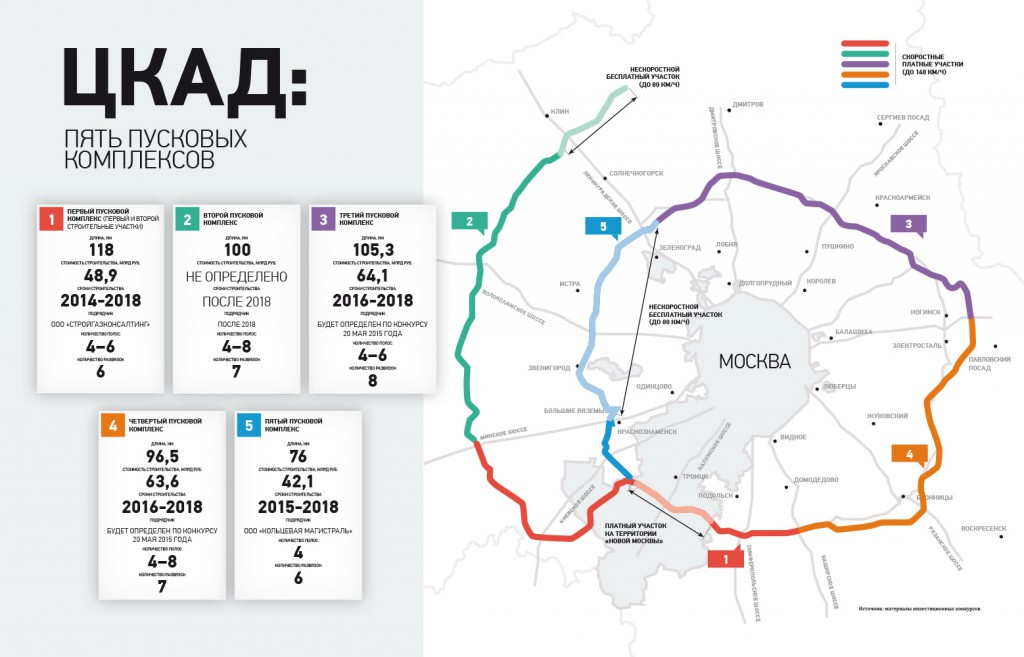
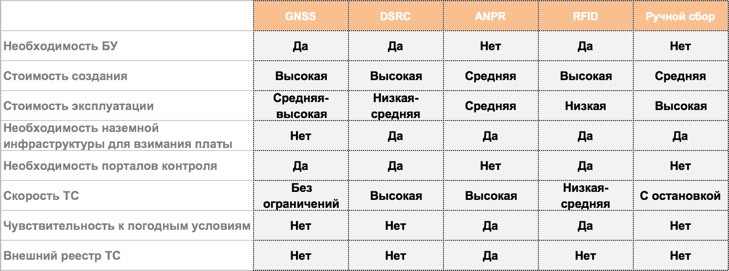
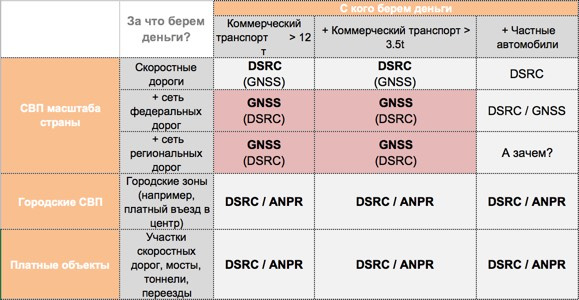
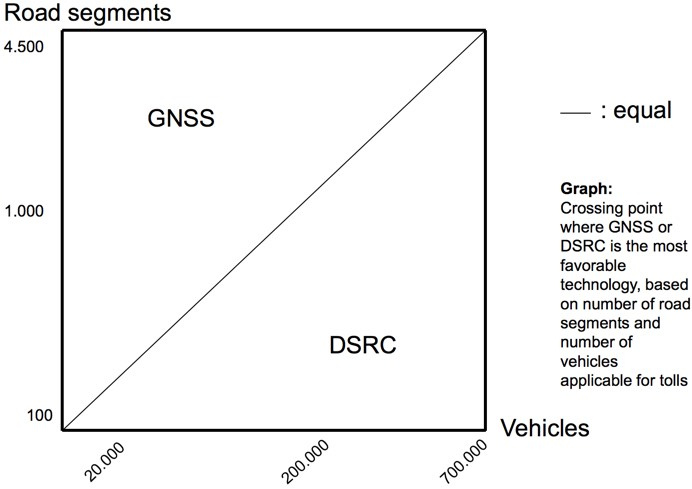
|
Метки: author drosselmayer анализ и проектирование систем итс dsrc свп автоматизация на транспорте умные дороги |
[Перевод - recovery mode ] Самое простое руководство по иконографике |


Главное в дизайне логотипов или иконок — это ничего не усложнять.












|
Метки: author blognetology интерфейсы дизайн мобильных приложений графический дизайн веб-дизайн блог компании нетология иконографика дизайн перевод нетология |
Data Science meetup в офисе Avito 24 июня |



|
Метки: author Oldtuna машинное обучение data mining big data блог компании avito рекомендательные системы рекомендации рекомендательный сервис авито дзен ozon.ru |
[Из песочницы] Страх и ненависть в MiddleWare |




http://some.server/csv/some_tablepgcopy_server db_pub "host=127.0.0.1 dbname=testdb user=testuser password=123";
location ~/csv/(?<table>[0-9A-Za-z_]+) {
pgcopy_query PUT db_pub "COPY $table FROM STDIN WITH DELIMITER as ';' null as '';";
pgcopy_query GET db_pub "COPY $table TO STDOUT WITH DELIMITER ';';";
}

client_body_in_file_only on;
client_body_temp_path /var/lib/postgresql/9.6/main/import;
location ~/json/(?<table>[0-9A-Za-z_]+) {
pgcopy_query PUT db_pub
"COPY (SELECT * FROM import_json_to_simple_data('$request_body_file'))
TO STDOUT;";
pgcopy_query GET db_pub
"COPY (SELECT '['||array_to_string(array_agg(row_to_json(simple_data)),
',')||']' FROM simple_data) TO STDOUT;";
}
location ~/xml/(?<table>[0-9A-Za-z_]+) {
pgcopy_query PUT db_pub
"COPY (SELECT import_xml_to_simple_data('$request_body_file') TO STDOUT;";
pgcopy_query GET db_pub
"COPY (SELECT table_to_xml('$table', false, false, '')) TO STDOUT;";
}
CREATE OR REPLACE FUNCTION import_json_to_simple_data(filename TEXT)
RETURNS void AS $$
BEGIN
INSERT INTO simple_data
SELECT * FROM
json_populate_recordset(null::simple_data,
convert_from(pg_read_binary_file(filename), 'UTF-8')::json);
END;
$$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION import_xml_to_simple_data(filename TEXT)
RETURNS void AS $$
BEGIN
INSERT INTO simple_data
SELECT (xpath('//s_id/text()', myTempTable.myXmlColumn))[1]::text::integer AS s_id,
(xpath('//data0/text()', myTempTable.myXmlColumn))[1]::text AS data0
FROM unnest(xpath('/*/*',
XMLPARSE(DOCUMENT convert_from(pg_read_binary_file(filename), 'UTF-8'))))
AS myTempTable(myXmlColumn);
END;
$$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION import_vt_json(filename TEXT, target_table TEXT)
RETURNS void AS $$
BEGIN
EXECUTE format(
'INSERT INTO %I SELECT * FROM
json_populate_recordset(null::%I,
convert_from(pg_read_binary_file(%L), ''UTF-8'')::json)',
target_table, target_table, filename);
END;
$$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION import_vt_xml(filename TEXT, target_table TEXT)
RETURNS void AS $$
DECLARE
columns_name TEXT;
BEGIN
columns_name := (
WITH
xml_file AS (
SELECT * FROM unnest(xpath(
'/*/*',
XMLPARSE(DOCUMENT
convert_from(pg_read_binary_file(filename), 'UTF-8'))))
--read tags from file
), columns_name AS (
SELECT DISTINCT (
xpath('name()',
unnest(xpath('//*/*', myTempTable.myXmlColumn))))[1]::text AS cn
FROM xml_file AS myTempTable(myXmlColumn)
--get target table cols name and type
), target_table_cols AS ( --
SELECT a.attname, t.typname, a.attnum, cn.cn
FROM pg_attribute a
LEFT JOIN pg_class c ON c.oid = a.attrelid
LEFT JOIN pg_type t ON t.oid = a.atttypid
LEFT JOIN columns_name AS cn ON cn.cn=a.attname
WHERE a.attnum > 0
AND c.relname = target_table --'log_data'
ORDER BY a.attnum
--prepare cols to output from xpath
), xpath_type_str AS (
SELECT CASE WHEN ttca.cn IS NULL THEN 'NULL AS '||ttca.attname
ELSE '((xpath(''/*/'||attname||'/text()'',
myTempTable.myXmlColumn))[1]::text)::'
||typname||' AS '||attname
END
AS xsc
FROM target_table_cols AS ttca
)
SELECT array_to_string(array_agg(xsc), ',') FROM xpath_type_str
);
EXECUTE format('INSERT INTO %s SELECT %s FROM unnest(xpath( ''/*/*'',
XMLPARSE(DOCUMENT convert_from(pg_read_binary_file(%L), ''UTF-8''))))
AS myTempTable(myXmlColumn)', target_table, columns_name, filename);
END;
$$ LANGUAGE plpgsql;
CREATE TABLE simple_data (
s_id SERIAL,
data0 TEXT
);
0;zero
1;one
[ {"s_id": 5, "data0": "five"},
{"s_id": 6, "data0": "six"} ]
<simple_data xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<row>
<s_id>3</s_id>
<data0>three</data0>
</row>
<row>
<s_id>4</s_id>
<data0>four</data0>
</row>
</simple_data>

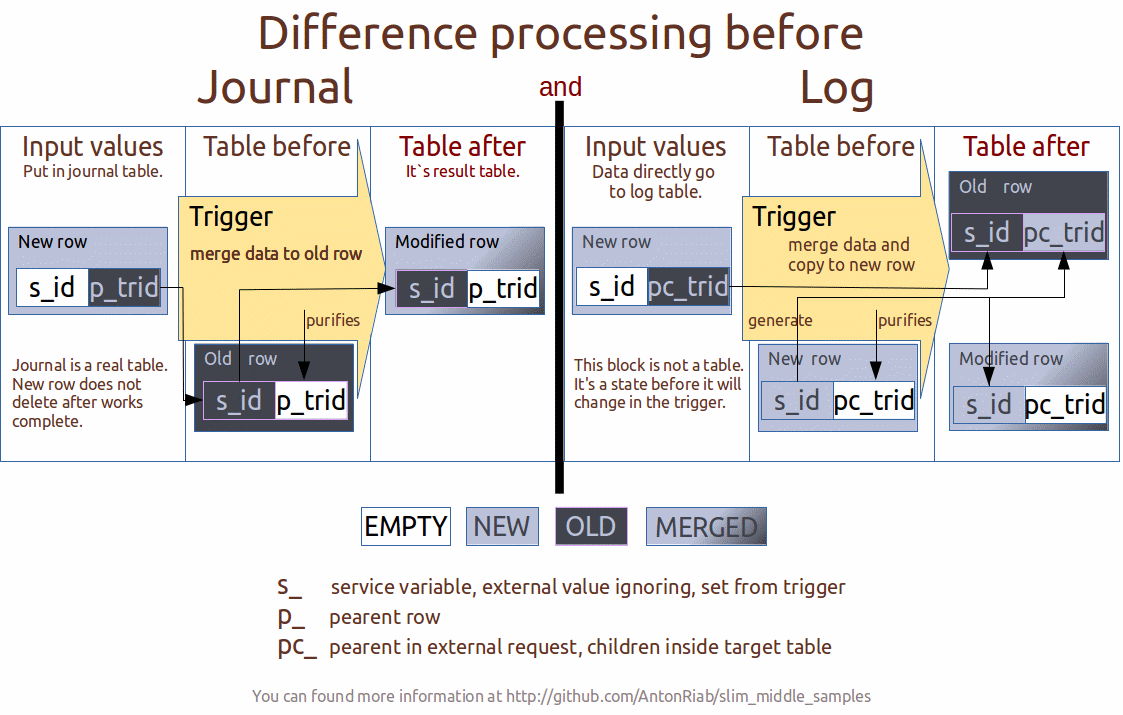
CREATE TABLE rst_data ( --Output/result table 1/2
s_id SERIAL,
data0 TEXT, --Operating Data
data1 TEXT, --Operating Data
);
--Service variable with prefix s_, ingoring input value, it will be setting from trigers
CREATE TABLE jrl_data ( --Input/journal table 2/2
s_id SERIAL, --Service variable, Current ID of record
s_cusr TEXT, --Service variable, User name who created the record
s_tmc TEXT, --Service variable, Time when the record was created
p_trid INTEGER, --Service variable, Target ID/Parent in RST_(result) table,
-- if exists for modification
data0 TEXT,
data1 TEXT,
);
CREATE TABLE log_data ( --Input/output log table 1/1
s_id SERIAL,
s_cusr TEXT,
s_tmc TEXT,
pc_trid INTEGER, --Service variable, Target ID(ParentIN/ChilrdenSAVE)
-- in CURRENT table, if exists for modification
data0 TEXT,
data1 TEXT,
);
CREATE OR REPLACE FUNCTION trg_4_jrl() RETURNS trigger AS $$
DECLARE
update_result INTEGER := NULL;
target_tb TEXT :='rst_'||substring(TG_TABLE_NAME from 5);
BEGIN
--key::text,value::text
DROP TABLE IF EXISTS not_null_values;
CREATE TEMP TABLE not_null_values AS
SELECT key,value from each(hstore(NEW)) AS tmp0
INNER JOIN
information_schema.columns
ON information_schema.columns.column_name=tmp0.key
WHERE tmp0.key NOT LIKE 's_%'
AND tmp0.key <> 'p_trid'
AND tmp0.value IS NOT NULL
AND information_schema.columns.table_schema = TG_TABLE_SCHEMA
AND information_schema.columns.table_name = TG_TABLE_NAME;
IF NEW.p_trid IS NOT NULL THEN
EXECUTE (WITH keys AS (
SELECT (
string_agg((select key||'=$1.'||key from not_null_values), ','))
AS key)
SELECT format('UPDATE %s SET %s WHERE %s.s_id=$1.p_trid', target_tb, keys.key, target_tb)
FROM keys)
USING NEW;
END IF;
GET DIAGNOSTICS update_result = ROW_COUNT;
IF NEW.p_trid IS NULL OR update_result=0 THEN
IF NEW.p_trid IS NOT NULL AND update_result=0 THEN
NEW.p_trid=NULL;
END IF;
EXECUTE format('INSERT INTO %s (%s) VALUES (%s) RETURNING s_id',
target_tb,
(SELECT string_agg(key, ',') from not_null_values),
(SELECT string_agg('$1.'||key, ',') from not_null_values))
USING NEW;
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION trg_4_log() RETURNS trigger AS $$
BEGIN
IF NEW.pc_trid IS NOT NULL THEN
EXECUTE (
WITH
str_arg AS (
SELECT key AS key,
CASE WHEN value IS NOT NULL OR key LIKE 's_%' THEN key
ELSE NULL
END AS ekey,
CASE WHEN value IS NOT NULL OR key LIKE 's_%' THEN 't.'||key
ELSE TG_TABLE_NAME||'.'||key
END AS tkey,
CASE WHEN value IS NOT NULL OR key LIKE 's_%' THEN '$1.'||key
ELSE NULL
END AS value,
isc.ordinal_position
FROM each(hstore(NEW)) AS tmp0
INNER JOIN information_schema.columns AS isc
ON isc.column_name=tmp0.key
WHERE isc.table_schema = TG_TABLE_SCHEMA
AND isc.table_name = TG_TABLE_NAME
ORDER BY isc.ordinal_position)
SELECT format('WITH upd AS (UPDATE %s SET pc_trid=%L WHERE s_id=%L)
SELECT %s FROM (VALUES(%s)) AS t(%s)
LEFT JOIN %s ON t.pc_trid=%s.s_id',
TG_TABLE_NAME, NEW.s_id, NEW.pc_trid,
string_agg(tkey, ','),
string_agg(value, ','),
string_agg(ekey, ','),
TG_TABLE_NAME, TG_TABLE_NAME)
FROM str_arg
) INTO NEW USING NEW;
NEW.pc_trid=NULL;
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;

http://some.server/csv/table_name/*?col1=value&col2=value&col3=value&col4=value#Составляем фильтр SQL
map $args $fst0 {
default "";
"~*(?<tmp00>[a-zA-Z0-9_]+=)(?<tmp01>[a-zA-Z0-9_+-.,:]+)(:?&(?<tmp10>[a-zA-Z0-9_]+=)(?<tmp11>[a-zA-Z0-9_+-.,:]+))?(:?&(?<tmp20>[a-zA-Z0-9_]+=)(?<tmp21>[a-zA-Z0-9_+-.,:]+))?(:?&(?<tmp30>[a-zA-Z0-9_]+=)(?<tmp31>[a-zA-Z0-9_+-.,:]+))?(:?&(?<tmp40>[a-zA-Z0-9_]+=)(?<tmp41>[a-zA-Z0-9_+-.,:]+))?" "$tmp00'$tmp01' AND $tmp10'$tmp11' AND $tmp20'$tmp21' AND $tmp30'$tmp31' AND $tmp40'$tmp41'";
}
#Проверяем на корректность
map $fst0 $fst1 {
default "";
"~(?<tmp0>(:?[a-zA-Z0-9_]+='[a-zA-Z0-9_+-.,:]+'(?: AND )?)+)(:?( AND '')++)?" "$tmp0";
}
map $fst1 $fst2 {
default "";
"~(?<tmp0>[a-zA-Z0-9_+-=,.'' ]+)(?= AND *$)" "$tmp0";
}
#Если контроль корректности пройден, дописываем WHERE
map $fst2 $fst3 {
default "";
"~(?<tmp>.+)" "WHERE $tmp";
}
server {
location ~/csv/(?<table>result_[a-z0-9]*)/(?<columns>\*|[a-zA-Z0-9,_]+) {
pgcopy_query GET db_pub
"COPY (select $columns FROM $table $fst3) TO STDOUT WITH DELIMITER ';';";
}
}

CREATE OR REPLACE FUNCTION foo(filename TEXT) RETURNS TEXT AS $$
return `/bin/echo -n "hello world!"`;
$$ LANGUAGE plperlu;
|
Метки: author AntonRiab разработка веб-сайтов postgresql nginx ngx_pgcopy pgsql web- разработка highload |
[Перевод] Go без глобальных переменных |
Перевод статьи Дейва Чини — ответа на предыдущий пост Питера Бургона "Теория современного Go" — с попыткой провести мысленный эксперимент, как бы выглядел Go без переменных в глобальной области видимости вообще. Хотя в некоторых абзацах можно сломать язык, но пост достаточно интересный.
Давайте проведём мысленный эксперимент, как бы выглядел Go, если бы мы избавились от переменных в глобальной области видимости пакетов. Какие бы были последствия и что мы можем узнать о дизайне Go программ из этого эксперимента?
Я буду говорить только о вычёркивании var, остальные пять определений верхнего уровня остаются разрешены в нашем эксперименте, так как они, по сути, являются константами на этапе компиляции. И, конечно же, вы можете продолжать определять переменные в функциях и любых блоках.
Но сначала, давайте ответим на вопрос почему глобальные переменные в пакетах это плохо? Оставив в стороне очевидную проблему глобального видимого состояния в языке со встроенной конкурентностью (concurrency), глобальные переменные в пакетах, по сути, являются синглтонами, использующимися для неявного изменения состояний между слабо не очень связанными вещами, создавая прочную зависимость и делая код сложным для тестирования.
Как недавно написал Питер Бургон:
tl;dr магия это плохо; глобальные состояние это магия -> глобальные переменные в пакетах это плохо; функция init() не нужна.
Чтобы проверить эту идею, я подробно изучил самую популярную кодовую базу на Go — стандартную библиотеку, чтобы посмотреть как в ней используются глобальные переменные в пакетах, и постарался оценить эффект от нашего эксперимента.
Одно из самых частых использований глобальных var в публичных пакетах это ошибки — io.EOF, sql.ErrNoRows, crypto/x509.ErrUnsupportedAlgorithm и т.д. Без этих переменных мы не сможем сравнить ошибки с заранее предопределёнными значениями. Но можем ли мы их чем-то заменить?
Я писал ранее, что вы должны стараться смотреть на поведение, а не на тип при анализе ошибок. Если же это невозможно, то определение констант для ошибок избавляет от возможной модификации ошибок и сохраняет их семантику.
Оставшиеся переменные для ошибок будут приватными и просто дают символическое имя сообщению об ошибке. Эти переменные не экспортируемые, поэтому их нельзя будет использовать для сравнения извне пакета. Определение их на верхнем уровне пакета, а не в том месте, где они происходит, лишает нас возможности добавлять какой-то дополнительный контекст к ошибке. Вместо этого я рекомендую использовать что-то вроде pkg/errors чтобы сохранять стектрейс в ошибку в момент её происхождения.
Паттерн регистрации используется в нескольких пакетах стандартной библиотеки, таких как net/http, database/sql, flag и немного также в log. Обычно он заключается в глобальной переменной типа map или структуре, которая изменяется некой публичной функцией — классический синглтон.
Невозможность создавать такую переменную-пустышку, которая должна инициализироваться извне лишает возможности пакеты image, database/sql и crypto регистрировать декодеры, драйверы баз данных и криптографические схемы. Но это как раз та самая магия, о которой говорит Питер в своей статье — импортирование пакета, для того, чтобы тот неявно изменил глобальное состояние другого пакета и это действительно зловеще выглядит со стороны.
Регистрация также поощряет повторение бизнес-логики. К примеру, пакет net/http/pprof регистрирует себя и, как побочный эффект, net/http.DefaultServeMux, что не совсем безопасно — другой код теперь не может использовать мультиплексор по умолчанию без того, чтобы не светить наружу информацию, которую выдает pprof — и зарегистрировать его на другой мультиплексор не так уж тривиально.
Если бы глобальных переменных в пакетах не было, такие пакеты как net/http/pprof могли бы предоставлять функцию, которая регистрировала бы пути URL для заданного http.ServeMux, и не зависеть от неявного изменения глобального состояния другого пакета.
Избавление от возможности использовать паттерн регистрации также могло бы помочь решить проблему с множественными копиями одного и того же пакета, которые, будучи импортированными, пытаются все дружно себя зарегистрировать во время старта.
Есть такая идиома для проверки на принадлежность типа интерфейсу:
var _ SomeInterface = new(SomeType)Она встречается по крайней мере 19 раз в стандартной библиотеке. По моему убеждению, такие проверки это, по сути, тесты. Они не должны вообще компилироваться, чтобы потом быть убранными при сборке пакета. Их нужно вынести в соответствующие _test.go файлы. Но если мы запрещаем глобальные переменные в пакетах, это относится также и к тестам, так как же мы можем сохранить эту проверку?
Одним из решений было бы вынести это определение переменной из глобальной области видимости в область видимости функции, которая по-прежнему перестанет компилироваться, если SomeType вдруг перестанет удовлетворять интерфейсу SomeInterface
func TestSomeTypeImplementsSomeInterface(t *testing.T) {
// won't compile if SomeType does not implement SomeInterface
var _ SomeInterface = new(SomeType)
}Но, так как это, по сути, просто тест, то мы можем переписать эту идиому в виде обычного теста:
func TestSomeTypeImplementsSomeInterface(t *testing.T) {
var i interface{} = new(SomeType)
if _, ok := i.(SomeInterface); !ok {
t.Fatalf("expected %t to implement SomeInterface", i)
}
}Как замечание, поскольку спецификация Go говорит, что присвоение пустому идентификатору (_) означает полное вычисление выражения с правой стороны знака присваивания, тут вероятно скрыты пару подозрительных инициализаций в глобальной области видимости.
В предыдущей секции пока всё шло гладко и эксперимент с избавлением от глобальных переменных вроде как удался, но есть в стандартной библиотеке несколько мест, где всё не так просто.
Хоть я и считаю, что паттерн синглтона в целом часто используется там где не нужно, особенно в качестве регистрации, всегда найдется реальный синглтон в каждой программе. Хороший пример этого это os.Stdout и компания.
package os
var (
Stdin = NewFile(uintptr(syscall.Stdin), "/dev/stdin")
Stdout = NewFile(uintptr(syscall.Stdout), "/dev/stdout")
Stderr = NewFile(uintptr(syscall.Stderr), "/dev/stderr")
)С этим определением есть несколько проблем. Во-первых, Stdin, Stdout и Stderr это переменные типа *os.File, а не io.Reader или io.Writer интерфейсы. Это делает их замену альтернативами достаточно проблематичной. Но даже сама идея их замены это как раз та магия, от которой наш эксперимент пытается избавиться.
Как показал предыдущий пример с константными ошибками, мы можем оставить сущность синглтона для стандартных IO дескрипторов, так чтобы пакеты вроде log и fmt могли использовать их напрямую, но не объявлять их как изменяемые глобальные переменные. Что-то вроде такого:
package main
import (
"fmt"
"syscall"
)
type readfd int
func (r readfd) Read(buf []byte) (int, error) {
return syscall.Read(int(r), buf)
}
type writefd int
func (w writefd) Write(buf []byte) (int, error) {
return syscall.Write(int(w), buf)
}
const (
Stdin = readfd(0)
Stdout = writefd(1)
Stderr = writefd(2)
)
func main() {
fmt.Fprintf(Stdout, "Hello world")
}Второй самый популярный способ использования неэкспортируемых глобальных переменных в пакетах это кеши. Они бывают двух типов — реальные кеши, состоящие из объектов типа map (смотри паттерн регистрации выше) или sync.Pool, и квазиконстантные переменные, которые улучшают стоимость компиляции (прим. переводчика — "шта?")
В пример можно привести пакет crypto/ecsda, в котором есть тип zr, чей метод Read() обнуляет любой буфер, который ему передаётся на вход. Пакет содержит единственную переменную типа zr, потому что она встроена в другие структуры вроде io.Reader, потенциально убегая в кучу каждый раз, когда она объявляется.
package ecdsa
type zr struct {
io.Reader
}
// Read replaces the contents of dst with zeros.
func (z *zr) Read(dst []byte) (n int, err error) {
for i := range dst {
dst[i] = 0
}
return len(dst), nil
}
var zeroReader = &zr{}Но при этом тип zr не содержит встроенный io.Reader — он сам имплементирует io.Reader — поэтому мы можем убрать неиспользуемое поле zr.Reader, сделав тем самым zr пустой структурой. В моих тестах этот модифицированный тип можно инициализировать явно без потерь в производительности:\
csprng := cipher.StreamReader{
R: zr{},
S: cipher.NewCTR(block, []byte(aesIV)),
}Возможно, есть смысл пересмотреть некоторые решения для кешей, поскольку инлайнинг (inlining) и escape-анализ очень заметно улучшились с тех времен написания стандартной библиотеки.
И последнее самое частое использование приватных глобальных переменных в пакетах это таблицы — например, в пакетах unicode, crypto/* и math. Эти таблицы обычно кодируют константные данные в виде целочисленных массивов или, чуть реже, простых структур или объектов типа map.
Замена глобальных переменных на константы потребует изменений в языке, что-то подобное описанному тут. Так что, если считать, что нет способа изменить эти таблицы во время работы программы, они могут быть исключением для этого предложения (proposal).
Несмотря на то, что этот пост был всего лишь мысленным экспериментом, уже ясно, что запрет всех глобальных переменных в пакетах это слишком драконовская мера, чтобы быть реальной в языке. Обход возникших с запретом проблем может быть очень непрактичным с точки зрения производительности, и это будет всё равно что повесить плакат "ударь меня" на спины и пригласить всех Go хейтеров повеселиться.
Но при этом, мне кажется есть несколько очень конкретных советов, которые можно извлечь из этого мысленного эксперимента без того, чтобы ударяться в крайности и менять спецификацию языка:
var определений лучше отказаться. Это не какая-то спорная тема, и она точно не уникальна для Go. Синглтон паттерн лучше не использовать, и мутная публичная переменная, которая может быть изменена в любой момент любым, кто знает её имя — это автоматически сигнал "стоп".Приватные определения глобальных переменных более спецефичны, но некоторые паттерны можно извлечь:
string([]byte) там где они не выходят за рамки функции.unicode — это неизбежное следствие отсутствия типа константного массива в Go. До тех пор пока они приватные, и не дают никакого способа их менять, их можно считать фактически константами в рамках этого обсуждения.Резюмируя, подумайте дважды и трижды, прежде чем добавлять в пакет глобальные переменные, которые могут менять значение во время работы программы. Это может быть признаком того, что вы добавили магическое глобальное состояние.
|
Метки: author divan0 go global variables |
У вас есть право на анонимность. Часть 3. Правоприменительная борьба с инструментами анонимности |

“Анонимайзер — изначально средство для скрытия информации о компьютере или пользователе в сети от удалённого сервера. Это веб-сайты и специальные вредоносные программы, позволяющие открывать ранее заблокированные интернет-ресурсы, в том числе, содержащие информацию о пропаганде коррупции, нацизма, детской проституции и порнографии, насилия, жестокости, технологии производства и изготовления взрывчатых веществ и взрывных устройств и иную информацию, наносящую ущерб интересам государства и общества”.
«В судебных решениях четко написано, что подобные ресурсы (анонимайзеры) запрещаются, так как с их помощью можно получить доступ к заблокированному (запрещенному) сайту. Это судебная практика, сложившаяся в России. Поэтому, если анонимайзер прекращает доступ пользователей к заблокированным сайтам, Роскомнадзор считает, что он выполняет судебное решение, и его разблокирует. Анонимайзеры действительно часто начинают взаимодействовать с Роскомнадзором: подключаются к единому реестру и ограничивают доступ к запрещенным сайтам, фактически исполняя российское законодательство»
Пресс-секретарь Роскомнадзора Вадим Ампелонский.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
|
Android Excellence на Google Play |
|
Метки: author Developers_Relations блог компании google приложения android google play |
[Из песочницы] Лайфхаки редактора Unity 3D. Часть 1: Атрибуты |


[MenuItem("Tools/Initialization Project")]string path //полный путь в меню
bool valudate //является ли данный метода валидатором функции (делает пункт меню неактивным)
int order //порядок расположения элемента в рамках одной иерархии[MenuItem("Tools/Initialization Project", true)]
public static bool Initialization()
{
//просто проверка на то, что выделен любой объект
return Selection.gameObjects.Length > 0;
}[MenuItem("Tools/Initialization Project")]
public static void Initialization()
{
//do something...
}
[Range(float min, float max)][Header(string title)][Space][Tooltip(string tip)][SerializeField][NonSerialized][HiddenInInspector][ExecuteInEditMode][RequireComponent(System.Type type)][AddComponentMenu(string path)]public class IntAttribute : PropertyAttribute
{
private string path = “”;
public IntAttribute(string path)
{
this.path = path;
}
}[CustomPropertyDrawer(typeof(IntAttribute ))]
public class IntAttributeDrawer : PropertyDrawer
{
}public interface IResource
{
int ID
{
get;
}
string Name
{
get;
}
}
[System.Serializable]
public class Effect : IResource
{
[SerializeField]
private string name = “”;
[SerializeField]
private int id = 0;
public int ID
{
get
{
return id;
}
}
public string Name
{
get
{
return name;
}
}
}public interface IContainer
{
IResource[] Resources
{
get;
}
}
public abstract class ResourcesContainer : MonoBehavior, IContainer
{
public virtual IResource[] Resources
{
get
{
return null;
}
}
}
public class EffectsContainer : ResourcesContainer
{
[SerializeField]
private Effect[] effects = null;
public override IResource[] Resources
{
get
{
return effects;
}
}
}
[CustomPropertyDrawer(typeof(IntAttribute ))]
public class IntAttributeDrawer : PropertyDrawer
{
protected string[] values = null;
protected List idents = null;
protected virtual void Init(SerializedProperty property)
{
if (attribute != null)
{
IntAttribute intAttribute = (IntAttribute)attribute;
//можно ввести проверки на null, но, я думаю, вы сами справитесь
IResource[] resources = Resources.Load(intAttribute.Path).Resources;
values = new string[resources.Length + 1];
idents = new List(resources.Length + 1);
//добавляем нулевой элемент для назначения -1 значения
values[0] = “-1: None”;
idents.Add(-1);
for (int i = 0; i < resources.Length; i++)
{
values[i+1] = resources[i].ID + “: ” + resources[i].Path;
idents.Add(resources[i].ID);
}
}
}
public override void OnGUI(Rect position, SerializedProperty property, GUIContent label)
{
if (property == null)
{
return;
}
Init(property);
EditorGUI.BeginProperty(position, label, property);
// Draw label
position = EditorGUI.PrefixLabel(position, GUIUtility.GetControlID(FocusType.Passive), label);
// Don't make child fields be indented
int indent = EditorGUI.indentLevel;
EditorGUI.indentLevel = 0;
// Calculate rects
Rect pathRect = new Rect(position.x, position.y, position.width - 6, position.height);
int intValue = property.intValue;
intValue = idents[EditorGUI.Popup(pathRect, Mathf.Max(0, idents.IndexOf(intValue)), Values)];
property.intValue = intValue;
EditorGUI.indentLevel = indent;
EditorGUI.EndProperty();
}
}
Располагаем префаб или ScriptableObject по нужному нам пути (я расположил в Resources/Effects/Container).
Теперь в любом классе объявляем целочисленную переменную и атрибут к ней с путем до префаба.
public class Bullet : MonoBehavior
{
[SerializeField]
[IntAttribute(“Effects/Container”)]
private int effectId = -1;
} 
|
Метки: author BoobenDancer разработка игр unity3d c# unity 3d editor attribute редактор unity лайфхак |
Использование SpreadsheetCloudAPI для написание приложений и облегчения жизни |
Всем привет! Есть у нашей команды хобби — мы любим 3Д печать. И не просто любим, а активно печатаем все и вся — от простых игрушек на стол до деталек, которые даже в Китае не продаются. Каждый у нас в комнате хоть раз что-нибудь да напечатал.

В этой статье хотелось бы поделиться нашим опытом решения проблемы закупки пластика для принтера и как нам в этом помог сервис SpreadsheetCloudAPI. Подробности под катом.
Так же, как простому принтеру нужны чернила, 3Д принтеру нужен пластик. Изначально мы печатали пластиком, который шел в комплекте с принтером. Потом скинулись в равных долях и купили кучу разноцветных катушек. Однако, все печатают в разных объемах, и скидываться поровну в будущем было бы нечестно. Поэтому мы просто завели Excel файлик, где каждый писал сколько он потратил пластика на каждую печать, а при закупке мы пропорционально высчитывали долю каждого.
И все бы хорошо, но со временем количество людей, которые начали пользоваться принтером возросло, особенно после настройки удаленного запуска печати. В итоге пользоваться этим Excel файлом стало жутко неудобно. Так родилась идея написания какой-нибудь программки, которая позволяла бы достаточно просто всем записывать свои сеансы печати, а перед закупкой говорила кто сколько должен скинуться.
В процессе обдумывания идеи приложения, нам под руки попался сервис, который бы написан нашими клиентами, с использованием нашего же Spreadsheet Document Server: SpreadsheetCloudAPI. Он по сути позволит использовать наш текущий Excel файл, как базовую часть приложения, и вообще не думать над хранением данных и логикой вычислений. К тому же он бесплатный.
Итак, что нам надо получить от приложения:
В итоге UI, который нам хочется получить должен выглядеть примерно так:

Да, он не отличается изяществом, но и продавать его мы не собираемся. А для наших нужд он подходит вполне.
Самой главной проблемой в расчете стоимости было то, что пластик продается по килограммам, а расходуется по метрам. Сначала мы даже думали использовать весы, для измерения веса каждой фигурки, но мы же программисты, надо придумать что-то поизящнее, и мы вспомнили школьный курс физики. Пластик имеет плотность, пруток имеет диаметр, мы знаем потраченную длину, и, как результат, мы можем вычислить массу каждой фигурки.
Таким образом, действия пользователя должны сводиться к минимуму: записать сеанс печати, какой пластик использовался и какая его длина ушла. Все! Если знать характеристики пластика, то без проблем вес можно вычислить самостоятельно. И да, все это можно сделать в том же Excel файле, и не писать ни строчки кода! Мы храним данные о доступных материалах на отдельном листе, а формула вычисления веса берет их от туда.
По сути наш бэкэнд не будет делать ничего, кроме общения со SpreadsheetcloudAPI сервисом: он передает введенные данные в него, и принимает пересчитанные части документа обратно. Для реализации серверной части был выбран php.
Для общения с сервисом нам необходимо всего три параметра:
Для удобства работы мы собрали их все в один класс:
class PrivateConst {
const Base_Url = 'http://spreadsheetcloudapi.azurewebsites.net/api/spreadsheet';
const API_KEY = 'API_KEY';
const File_Name = '3D.xlsx';
}Общение с сервисом будет происходить по Web API. В принципе API там достаточно простое и нормально документировано. Например, для добавления ячеек в таблицу (что нам надо при создании новой записи о печати) надо просто послать JSON вида:
{
"id": "some_id",
"filename": "test",
"extension": "xls",
"sheetindex": 0,
"sheetname": "Sheet1",
"startrowindex": 0,
"startcolumnindex": 0,
"endrowindex": 3,
"endcolumnindex": 5,
"mode": "ShiftCellsDown",
"formatmode": "FormatAsPrevious"
}на /api/spreadsheet/insertcells через PUT запрос.
При получении данных нам удалось даже схалявить, так как сервис умеет сам отдавать нам требуемые ячейки в HTML формате (Export to HTML). В результате нам даже не приходится задумываться о том, как отображать данные из документа. Получение этого HTML тоже трудностей не составляет:
function getSessionHtml($id, $sheetName, $rowLimit, $columnLimit){
$params = array(
'id' => $id,
'sheetname' => $sheetName,
);
if($rowLimit > -1){
$params['endrowindex'] = $rowLimit;
}
if($columnLimit > -1){
$params['endcolumnindex'] = $columnLimit;
}
$request = get($params, '/exporttohtml');
return $request;
}где get, это наш метод, отправляющий GET запрос с переданными параметрами на переданный адрес.
Среди параметров этих методов присутствует $id — ID сессия загруженного файла. Она нам позволяет не тратить каждый раз ресурсы на открытие файла, и появляется возможность поочередно выполнять команды и запросы — экономя время и реквесты.
Как я уже писал, данные со SpreadsheetCloudAPI сервиса мы получаем в виде готового HTML. При экспорте данные представляют из себя таблицу, и для редактирования этих данных нам достаточно будет обрабатывать клик на ячейке таблицы и вешать на неё нужный нам эдитор. Для редактирования значений мы используем «Input», для выбора значений из уже имеющихся «Select».
При создании нового сеанса печати нам понадобится выбрать имя пользователя, название материала и ввести значение длины:

Конечно же данные можно редактировать:

Колонка «Cost» редактироваться не будет, она будет вычисляться непосредственно на сервисе и заполняться при экспорте.
На вкладке «Materials» никаких вычислений не производится, мы только задаем значения:


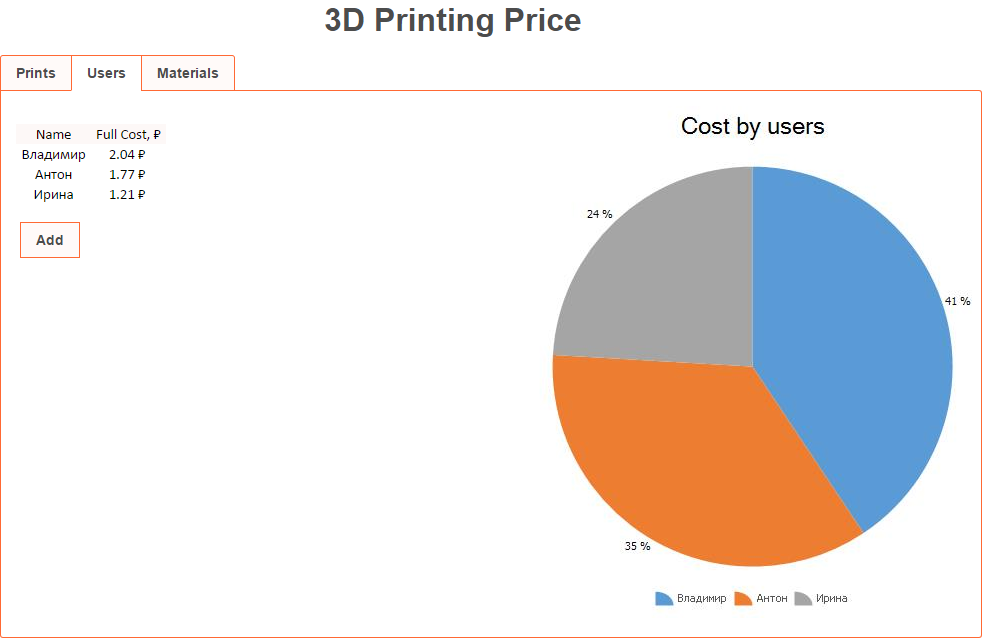
На вкладке «Users» единственный параметр который мы будем создавать и изменять — это имя пользователя. Колонка “Full Cost” будет вычисляться и не предназначена для редактирования. Вишенкой на торт мы решили показать чарт, который наглядно отображает, кто же у нас самый печатающий. Чарт тоже рисуется Excel-ем, а мы его грузим просто картинкой с сервиса.
Вот и все. Достаточно быстро и легко мы создали приложение, в основании которого лежал наш ранее созданный Excel файлик, и это позволило нам не писать ни единой строчки кода для реализации логики приложения и хранения данных, от нас потребовалось сделать только UI.
|
Метки: author Mirimon разработка веб-сайтов блог компании devexpress web- разработка php spreadsheet 3-d печать |
Чем отличается Ubuntu от Debian |
|
Метки: author Grinzzly разработка под linux перевод linux debian ubuntu |
[Перевод] Метрика загруженности процессора (CPU utiliztion) — это не то что вы думаете |
Всем привет. Предлагаю вашему вниманию свой перевод поста "CPU Utilization is Wrong" из блога Брендана Грегга.
Метрика загруженности процессора (CPU utiliztion), которую все мы привыкли использовать, обычно понимается неправильно. Что такое загруженность процессора? То насколько процессор сейчас занят работой? Нет, это не так, и да, я говорю о метрике %CPU, которая используется всегда и везде, в каждой утилите мониторинга производительности, например в top(1).
Как вы думаете, что значит нагрузка на процессор 90% на картинке ниже?

Вот что это значит на самом деле:

Stalled, то есть "приостановлено" значит, что в данный момент процессор не обрабатывает инструкции, обычно это означает, что он ожидает завершения операций ввода/вывода связанных с памятью (здесь и далее речь о RAM, а не дисковом вводе/выводе). Соотношение между "занято" и "приостановлено" (busy/stalled), которое я привел выше, это то что я обычно вижу в продакшене. Вероятно, что ваш процессор тоже большую часть времени находится в stalled состоянии, но вы об этом и не догадываетесь.
Что это значит для вас? Понимание того насколько много ваш процессор находится в приостановленном состоянии может помочь вам понять куда направить усилия по оптимизации производительности приложения: на ускорение кода или уменьшение числа операций ввода/вывода связанных с памятью. Всем кто заинтересован в оптимизации нагрузки на процессор, в особенности в облаках с настроенным автомасштабированием на основе нагрузки на CPU, будет полезно знать насколько долго процессор находится в приостановленном состоянии.
Метрика, которую мы называем нагрузкой на процессор (CPU utilization) на самом деле это "не-idle время", то есть время, которое процессор не выполняет idle-тред. Ядро вашей операционной системы (какую бы ОС вы не использовали) обычно следит за этим во время переключения контекста. Если не-idle тред запустился, а затем спустя 100 милисекунд остановился, то ядро посчитает, что процессор был использован в течение всего этого времени.
Эта метрика так же стара как и системы совместного использования времени (time sharing systems). В бортовом компьютере лунного модуля Apollo (это пионер среди систем совместного использования времени) idle-тред назывался "DUMMY JOB" и инженеры мониторили циклы выполняющие его в сравнении с реальными задачами, это было важной метрикой измерения нагрузки. (Я писал об этом ранее).
Что же с этой метрикой не так?
В наши дни процессоры работают значительно быстрее памяти, поэтому время ожидания памяти доминирует в метрике "нагрузка на процессор". Когда вы видите большие значение %CPU в top(1), вы, должно быть, думаете, что процессор является бутылочным горлышком, когда на самом деле проблема в DRAM.
Со временем все становится только хуже. Долгое время производители процессоров увеличивали тактовые частоты своих процессоров быстрее чем производители памяти уменьшали задержки доступа к памяти (CPU DRAM gap). Примерно в 2005 году процессоры достигли частот в 3 GHz и с тех пор мощность процессоров растет не за счет увеличения тактовой частоты, а за счет большего числа ядер, гипертрединга и многопроцессорных конфигураций. Все это предъявляет еще больше требований к памяти. Производители процессоров пытались снизить задержки связанные с памятью за счет больших по размеру и более умных CPU-кешей, более быстрых шин и соединений. Но проблема со stalled-состоянием все еще не решена.
Сделать это можно используя Performance Monitoring Counters (PMC-счетчики): хардверные счетчики, которые могут быть прочитаны с помощью Linux pref (пакет linux-tools-generic в Линуксе) и других утилит. Для примера понаблюдаем за всей системой в течение 10 секунд:
# perf stat -a -- sleep 10
Performance counter stats for 'system wide':
641398.723351 task-clock (msec) # 64.116 CPUs utilized (100.00%)
379,651 context-switches # 0.592 K/sec (100.00%)
51,546 cpu-migrations # 0.080 K/sec (100.00%)
13,423,039 page-faults # 0.021 M/sec
1,433,972,173,374 cycles # 2.236 GHz (75.02%)
stalled-cycles-frontend
stalled-cycles-backend
1,118,336,816,068 instructions # 0.78 insns per cycle (75.01%)
249,644,142,804 branches # 389.218 M/sec (75.01%)
7,791,449,769 branch-misses # 3.12% of all branches (75.01%)
10.003794539 seconds time elapsed Ключевая метрика здесь instructions per cycle (insns per cycle: IPC, число инструкций за один цикл), которая показывает сколько в среднем инструкций было выполнено за каждый такт. Чем больше, тем лучше. В примере выше значение 0.78 кажется очень неплохим (нагрузка 78%?) до тех пор пока вы не узнаете, что максимальная скорость процессора это IPC 4.0. Такие процессоры называют 4-wide, это название пошло от особенностей пути извлечения/декодирования инструкций в процессоре (подробнее об этом в Википедии).
Это означает, что процессор может выполнить 4 операции за каждый такт, поэтому значение 0.78 для 4-wide системы означает, что процессор работает на 19,5% от своих возможностей. Новый процессор Skylake от Intel — это 5-wide процессор.
Существуют сотни PMC-счетчиков, которые позволяют детальнее разобраться с производительностью системы, например, посчитать число приостановленных циклов по типам.
Если вы работаете в виртуальном окружении, то вероятно у вас нет доступа к PMC-счетчикам, это зависит от поддержки этой фичи гипервизором. Я недавно писал о том, что PMC-счетчики теперь доступны в AWS EC2 в виртуальных машинах базирующихся на Xen.
Если ваш IPC < 1.0, то вероятнее всего, процессор приостановлен из-за медленной памяти, поэтому нужно оптимизировать софт так, чтобы он требовал меньше операций с памятью, совершенствовать кеширование в процессоре и локальность памяти, особенно в NUMA системах. Оптимизация железа в таком случае подразумевает использование процессоров с большим объемом кешей, более быстрой памятью, шинами и соединениями.
Если ваш IPC > 1.0, то вероятно, вы ограничены числом инструкций, которые может выполнять процессор. Попробуйте найти способ уменьшить число выполняемых инструкций: уменьшить число ненужной работы, кешировать операции и т.п. CPU flame графы — отличная утилита для этих целей. С точки зрения тюнинга железа, попробуйте использовать процессор с большей тактовой частотой и большим числом ядер и гипертредов.
Для моих правил выше я выбрал значение IPC 1.0, почему именно его? Я пришел к нему из своего опыта работы с PMC-счетчиками. Вы можете выбрать для себя другое значение. Сделайте два тестовых приложения, одно упирающееся по производительности в процессор, другое — в память. Посчитайте IPC для них и возьмите среднее значение.
Каждая такая утилита должны показывать IPC вместе с нагрузкой на процессор. Или разделять нагрузку на процессор на instruction-retired и циклы stalled циклы, то есть, %INS и %STL.
Кроме утилиты top(1) для Линукса есть утилита tiptop(1), которая показывает IPC для каждого процесса:
tiptop - [root]
Tasks: 96 total, 3 displayed screen 0: default
PID [ %CPU] %SYS P Mcycle Minstr IPC %MISS %BMIS %BUS COMMAND
3897 35.3 28.5 4 274.06 178.23 0.65 0.06 0.00 0.0 java
1319+ 5.5 2.6 6 87.32 125.55 1.44 0.34 0.26 0.0 nm-applet
900 0.9 0.0 6 25.91 55.55 2.14 0.12 0.21 0.0 dbus-daemoПроблема со stalled-циклами может быть не только в задержках связанных с памятью:
Нагрузка на процессор (CPU utilization) это обычно неправильно интерпретируемая метрика, так как она включает циклы, потраченные на ожидание ответа от основной памяти, которые могут доминировать в современных нагрузках. Вы можете понять что на самом деле стоит за %CPU используя дополнительные метрики, включая число инструкций за цикл (IPC). Если IPC < 1.0, то вероятно вы упираетесь в память, если IPC > 1.0, то в скорость процессора. Я писал про IPC в своем предыдущем посте, в том числе написал и о использовании PMC-счетчиках, необходимых для измерения IPC.
Инструменты мониторинга производительности, которые показывают %CPU должны показывать PMC-счетчики, чтобы не вводить пользователей в заблуждение. Например, они могут показывать %CPU с IPC и/или число instruction-retired и stalled циклов. Вооруженные этими метриками разработчики и админы могут решить как правильнее тюнинговать их приложения и системы.
|
Метки: author rrromka системное администрирование настройка linux devops *nix linux top tiptop ipc pmc производительность оптимизация производительности perf |
История разработки и жизни одной маленькой игры. Начало |



дорога ложка к обедуНа конец 2013 года данная игра была востребована, а вот на конец 2014 – уже мало, тк летом 2014 вышел «Hill Climb Racing» и другие игры.
|
Метки: author dampirik разработка под windows phone разработка мобильных приложений разработка игр с# gamedev windows phone разработка игр под windows phone первая игра |
О потребителях и типах Threat Intelligence |
Раз в два-три года в «информационно-безопасном» мире появляется панацея от всех бед, которая защитит и от киберпреступников, и от киберактивистов, от промышленного шпионажа и APT-атак. Все установленные ИБ-системы объявляются морально устаревшими и никуда не годными, их предлагается срочно заменить. Естественно, не бесплатно. За чудо-лекарством выстраиваются очереди, лицензий на всех не хватает. А потом продавец просыпается.
Очень похожая ситуация сейчас складывается с Threat Intelligence. Это очень модно, драйвово, молодёжно, но провайдеры, пользователи и покупатели зачастую понимают под TI совсем разные вещи.

Давайте попробуем разобраться, что же это за загадочный зверь, откуда он так внезапно «выскочил», зачем нужна и кому интересна такая разведка, и можно ли заниматься разведкой за бокалом любимого пива.
Threat Intelligence — это регулярно и системно собирать информацию об угрозах, улучшать и обогащать её, применять эти знания для защиты и делиться ими с теми, кому они могут быть полезны. TI — это не только базы сигнатур для IDS или наборы правил для SIEM. TI — это процессы, у которых есть владельцы, цели, требования и понятный и измеримый (насколько это возможно) результат. TI я буду понимать именно в этом смысле.
Стоит сказать, что до 2014 года никакой threat intelligence не было. Ну, то есть была, конечно, но такое впечатление складывается, когда смотришь на темы выступлений более ранних RSA Conference.
А потом начался настоящий TI-бум! В моём списке компаний и организаций, которые предлагают приобрести или обменяться информацией об угрозах, злоумышленниках и вредоносном коде, 126 строк. И это далеко не все. Три года назад аналитики международных исследовательских компаний на вопрос о размере рынка TI отвечали: «Отстаньте! Нет такого рынка. Считать нечего». Теперь они же (451 Research, MarketsandMarkets, IT-Harvest, IDC и Gartner) оценивают этот рынок в полтора миллиарда долларов в 2018 году.
| Прогноз | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | Годовой рост, % |
|---|---|---|---|---|---|---|---|---|---|
| 451 Research | 1,0 | 3,3 | 34,0 | ||||||
| MarketsandMarkets | 3,0 | 5,86 | 14,3 | ||||||
| IT-Harvest | 0,25 | 0,46 | 1,5 | 80,0 | |||||
| IDC | 0,9 | 1,4 | 11,6 | ||||||
| Gartner | 0,25 | 1,5 | 43,1 |
Благодаря пониманию киберпреступников и их инструментов, тактик и процедур (TTP) можно быстро предлагать и проверять гипотезы. Например, если сотрудник группы реагирования знает, что определённые образцы вредоносного ПО (которое только что нашёл антивирус) нацелены на компрометацию административных учётных записей, это очень сильный довод в пользу того, чтобы проверить логи и попытаться найти подозрительные авторизации.
Например, вероятность эксплуатации конкретной обнаруженной уязвимости в конкретной информационной системе может быть низкой, а CVSS-оценка — высокой (в CVSS v.3 проблему пофиксили и ввели оценку вероятности). Поэтому важно учитывать принятую модель угроз, состояние инфраструктуры и внешние факторы.
В 2015 году SANS Institute провёл исследование потребителей TI из различных отраслей, в котором участвовали 329 респондентов из Северной, Центральной и Южной Америки, Европы, Ближнего Востока и Австралии. Согласно этому исследованию, потребители TI фиксируют положительные изменения в нескольких направлениях обеспечения ИБ после внедрения процессов TI.
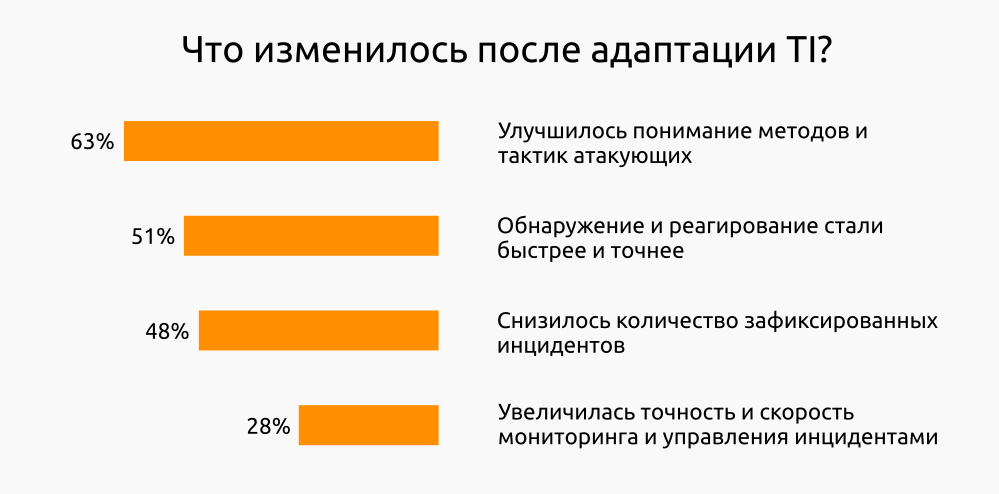
Согласно этому же исследованию очень сильно отличаются формы адаптации.
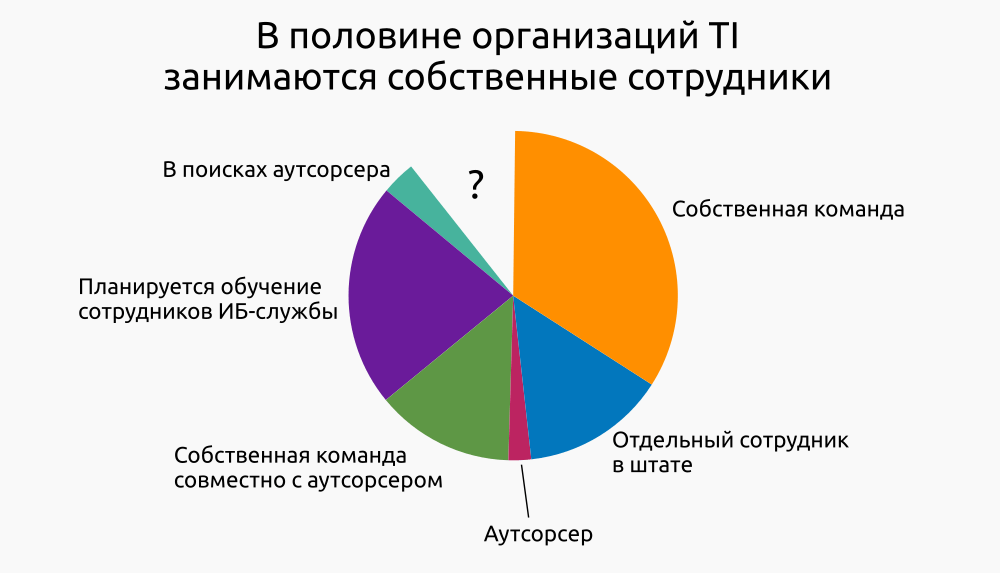
Только в 10% случаев в организациях нет планов развивать разведку киберугроз внутри компании или о таких планах не известно.
Глобально существует два типа TI — стратегическая и тактическая (или «техническая» — кому как нравится). Они сильно отличаются и по результатам, и по способам использования этих результатов.
| Признак | Стратегическая TI | Техническая TI |
|---|---|---|
| Форма | Отчёты, публикации, документы | Наборы правил, параметры настройки |
| Создаётся | Людьми | Машинами или людьми совместно с машинами |
| Потребляют | Люди | Машины и люди |
| Сроки доставки до потребителя | Дни — месяцы | Секунды — часы |
| Период полезности | Долгий (год и более) | Короткий (до появления новой уязвимости или нового метода эксплуатации) |
| Допущения | Гипотезы возможны, однако они должны основываться на каких-то данных | Неприемлемы, поскольку машины не понимают нечётких инструкций |
| Фокус | Планирование, принятие решений | Обнаружение, приоритизация, реагирование |
Чтобы не писать стену скучного текста, я собрал всех потребителей в одной таблице. В каждой ячейке указаны группы потребителей и то, какие результаты могут быть им наиболее интересны.
Один и тот же набор результатов TI может быть интересен различным целевым группам. Например, «Инструменты, ПО и „железки“ атакующих» в таблице находятся в поле «Техники», но, конечно, были бы интересны и «Тактикам».
| Уровень управления |
Операционный уровень |
|
|---|---|---|
| В долгосрочной перспективе |
СТРАТЕГИ Высшее руководство (Совет директоров) Высокоуровневая информация об изменяющихся рисках
|
ТЕХНИКИ Архитекторы и сисадмины Тактики, техники, процедуры (TTP)
|
| В краткосрочной и долгосрочной перспективе |
ТАКТИКИ Руководители служб ИБ Детали конкретных готовящихся и проводимых атак
|
ОПЕРАТОРЫ Сотрудники ИБ, персонал SOC (Центра мониторинга), группа реагирования на инциденты, forensics-персонал Индикаторы атак и компрометации
|
Однако, есть ещё одна сторона, которая заинтересована в получении информации от организации — её партнёры. Часто злоумышленники атакуют подрядчиков или партнёров своей настоящей цели в надежде, что их защиту будет проще преодолеть и получить доступ к информационным ресурсам цели уже оттуда. Поэтому представляется логичным организовать обмен информацией об атаках и угрозах между партнёрами.
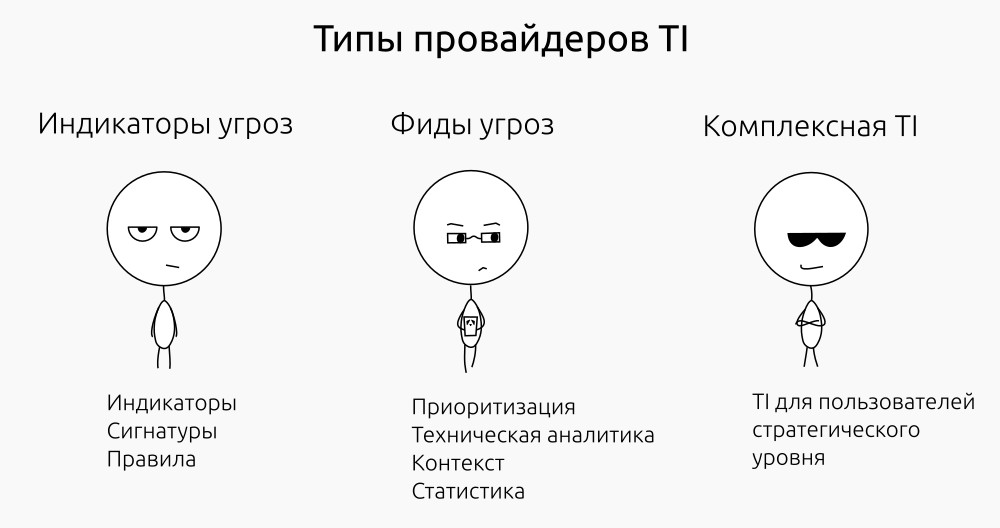
Большое количество СЗИ-вендоров и мейнтейнеров open-source проектов поставляют на регулярной основе индикаторы, сигнатуры и правила обнаружения атак для межсетевых экранов, антивирусов, IPS/IDS, UTM. В некоторых случаях это сырые данные, в других — дополненные оценкой риска или репутации. Индикаторы угроз критичны для технического уровня TI, но часто не предоставляют контекста для реагирования на инцидент.
Технологические вендоры и ИБ-компании предоставляют свои фиды угроз. Они включают в себя проверенные и приоритизированные индикаторы угроз и технический анализ образцов вредоносного кода, информацию о ботнетах, DDoS-атаках и других инструментах и видах вредоносной активности. Часто такие фиды дополняются статистикой и прогнозами: например, «ТОП-10 шифровальщиков» или «Список крупнейших ботнетов» и т.п.
К основным недостаткам таких фидов относят отсутствие отраслевой или региональной специфики и малую ценность для пользователей TI стратегического уровня.
Небольшое число компаний предоставляют по-настоящему комплексную TI: проверенные, актуальные для потребителя индикаторы угроз, фиды угроз и TI стратегического уровня. Сюда обычно входят:
Так сказал Аристотель. А для безопасников общение — способ объединить усилия, чтобы противостоять злоумышленникам. Есть даже более-менее устоявшийся англоязычный термин — «beer intelligence». Это когда безопасники собираются и делятся своими находками и подозрениями друг с другом в неформальной обстановке. Так что да, можно заниматься разведкой и за бокалом пива тоже.
Четвёртый принцип из определения TI — «и делиться ими с теми, кому они могут быть полезны» — как раз про обмен информацией. И организовать его можно не только по схеме Б2Б (безопасник-безопаснику), но и с помощью доверенной третьей стороны (организации), которая собирает, верифицирует, обезличивает и рассылает информацию об угрозах всем участникам сообщества. Такие сообщества поддерживаются государственными или общественными организациями (например, CiSP), волонтёрами (Vulners) и коммерческими компаниями (AlienVault Open Threat Exchange).
Так стоит ли внедрять в своей организации процессы threat intelligence? Стоит, но только если вы знаете: 1) где применять и как оценивать результаты TI; 2) как TI помогает процессам обеспечения ИБ; 3) кто будет отвечать на вопросы, поставленные перед «разведчиками», и можете сформулировать требования к TI.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
|
Apache Spark как ядро проекта. Часть 2. Streaming, и на что мы напоролись |
|
Метки: author 2ANikulin big data apache spark kafka hadoop архитектура системы |
Законы и проекты, которые изменят лицо российского IT. Часть I |

- соблюдение требований законодательства РФ, регулирующих порядок распространения массовой информации;
- недопущение использования сайта в целях совершения уголовно наказуемых деяний, разглашения охраняемой законом тайны, распространения экстремистских материалов, материалов, содержащих нецензурную брань и пр.;
- недопущение распространения телеканалов или телепрограмм, не зарегистрированных в соответствии с законом о СМИ;
- установка специального ПО для определения количества пользователей информационным ресурсом.
|
Метки: author Menaskop фриланс терминология it патентование локализация продуктов законодательство и it-бизнес регулирование интернета законы it it- юрист |
[Перевод] Разработчики, которые используют пробелы, зарабатывают больше, чем те, которые используют табы |


|
Метки: author zarytskiy исследования и прогнозы в it пробелы табуляция статистика stackoverflow |






