[Из песочницы] DI для полностью переиспользуемых JSX-компонентов |

Привет, меня зовут Сергей и мне интересна проблема переиспользования компонент в вебе. Глядя на то, как пытаются применить SOLID к реакту, я решил продолжить эту тему и показать, как можно достичь хорошей переиспользуемости, развивая идею внедрения зависимостей или DI.
DI как основа для построения фреймворка, применительно к вебу, довольно молодой подход. Что бы тут было понятней о чем идет речь, начну c привычных для react-разработчиков вещей.
Уверен, что многие использовали контексты при работе с react. Если не напрямую, то наверняка через connect в redux или inject в mobx-react. Суть в том, что в одном компоненте (MessageList) мы объявляем нечто в контексте, а в другом (Button) — говорим, что хотим получить это нечто из контекста.
const PropTypes = require('prop-types');
const Button = ({children}, context) =>
;
Button.contextTypes = {color: PropTypes.string};
class MessageList extends React.Component {
getChildContext() {
return {color: "purple"};
}
render() {
return ;
}
}Т.е. один раз в родительском компоненте задается context.color, а далее он автоматически пробрасывается любым нижележащим компонентам, в которых через contextTypes объявлена зависимость от color. Таким образом Button можно кастомизировать без прокидывания свойств по иерархии. Причем на любом уровне иерархии можно через getChildContext() ... переопределить color для всех дочерних компонент.
Такой подход лучше изолирует компоненты друг от друга, упрощая их настройку и переиспользование. В примере выше, достаточно в родительском компоненте определить color и все кнопки поменяют цвет. Причем компонент Button может быть в другой библиотеке, которую при этом не надо рефакторить.
Однако, для реакта, в виду недостаточной продуманности, этот подход пока развит слабо. Напрямую его использовать разработчики не рекомендуют:
It is an experimental API and it is likely to break in future releases of React
написано в документации. Оно experimental в текущем виде уже достаточно давно и ощущение, что разработка зашла в тупик. Контексты в компонентах сцеплены с инфраструктурой (getChildContext), псевдотипизацией через PropTypes и больше похожи на service locator, который некоторые считают антипаттерном. Роль контекстов, на мой взгляд, недооценена и в реакте второстепенная: локализация и темизация, а также биндинги к библиотекам вроде redux и mobx.
В других фреймворках подобные инструменты развиты лучше. Например, в vue: provide/inject, а в angular, его angular di это уже полноценный навороченный DI с поддержкой типов typescript. По-сути, начиная с Angular второй версии, разработчики попытались переосмыслить опыт бэкенда (где DI уже давно существует) применительно к фронтенду. А что если попытаться развить аналогичную идею для реакта и его клонов, какие проблемы бы решились?
В полноценном реакт/redux-приложении не всё делают через redux-экшены. Состояние какой-нибудь малозначительной галочки удобнее реализовать через setState. Получается — через redux громоздко, а через setState не универсально, но проще, т.к. он всегда под рукой. Статья You Might Not Need Redux известного автора, как бы говорит "если вам не нужно масштабирование — не используйте redux", подтверждая эту двойственность. Проблема в том, что это сейчас не нужно, а завтра может быть понадобится прикрутить логирование состояния галочки.
В другой статье того же автора, Presentational and Container Components, говорится примерно, что "Все компоненты равны (Presentational), но некоторые равнее (Container)" и при этом высечены в граните (прибиты к redux, mobx, relay, setState). Кастомизация Container компонента усложняется — не предполагается его переиспользовать, он уже прибит к реализации состояния и контексту.
Что бы как-то упростить создание Container-компонент, придумали HOC, но по-сути мало что поменялось. Просто чистый компонент стали комбинировать через connect/inject с чем-то вроде redux, mobx, relay. А полученный монолитный Container использовать в коде.
Иными словами, говорим Presentational и Container, а подразумеваем — переиспользуемый и непереиспользуемый. Первый удобно кастомизировать т.к. все точки расширения в свойствах, а второй — рефакторить, т.к свойств меньше, за счет его прибитости к стейту и некоторой логике. Это — некий компромисс по решению двух противоположных проблем, плата за который — разделение компонент на два типа и жертвование принципом открытости/закрытости.
Например, как в статье Заменяй и властвуй — подход SOLID, где предлагается делать большинство компонент максимально простыми, ухудшая их целостность. Но, сложные компоненты из простых все-равно надо будет где-то собирать и при этом остается вопрос как их кастомизировать. Т.е. проблема переносится на другой уровень.
> this.setState({ dialogOpen: false })} />
> this.setState({ dialogOpen: false })} />
Dialog header
Some content
Если все же условиться, что эти оконечные компоненты мы не кастомизируем, то в реальности получается большое кол-во шаблонного кода, когда ради замены одной Button, весь компонент строится заново. Полноценный SOLID при таком подходе невозможен. Всегда будут компоненты-биндинги к стейту, которые нельзя расширить без модификации и компоненты-шаблоны без логики внутри и этим сложные в использовании.
Развивая идею внедрения зависимостей, можно решить некоторые из этих проблем. Разберем решение на основе вот такого примера:
// @flow
// @jsx lom_h
// setup...
class HelloService {
@mem name = ''
}
function HelloView(props: {greet: string}, service: HelloService) {
return
{props.greet}, {service.name}
> { service.name = e.target.value }} />
}
// HelloView.deps = [HelloService]
ReactDOM.render(Здесь есть одна универсальная форма компонента в виде функции, независимо от того, работает он с состоянием или нет. Контексты используют типы. Из них автоматически генерируются описания зависимостей с помощью babel-plugin-transform-metadata. Аналогично typescript, который это делает, правда, только для классов. Хотя можно описывать аргументы и вручную: HelloView.deps = [HelloService]
А как же быть с жизненным циклом компонента? А так ли нужна низкоуровневая работа с ним в коде? Посредством HOC как раз пытаются убрать эти lifecycle methods из основного кода, например, как в relay/graphql.
Идея в том, что актуализация данных — это не ответственность компонента. Если у вас загрузка данных происходит по факту доступа к этим данным (например, используется lazyObservable из mobx-utils), то componentDidMount в этом случае не нужен. Если надо прикрутить jquery-плагин, то есть свойство refs в элементе и т.д.
Предположим, что универсальный компонент, свободный от vendor lock-in реакта, теперь есть. Пусть, мы даже выделили его в отдельную библиотеку. Осталось решить, как расширять и настраивать то, что приходит в контекст. Ведь HelloService — это некая реализация по-умолчанию.
Что если компоненты, в силу частых изменений требований, та часть приложения, где инкапсуляция начинает мешать. Не сама по себе конечно, а в том виде, как она сегодня реализована практически во всех фреймворках: в виде шаблона, композиции функций или JSX.
Представим на секунду, что в случае любого компонента нельзя заранее сказать, что у него будет кастомизироваться. И нужен способ менять любую внутреннюю часть компонента без рефакторинга (принцип открытости/закрытости), при этом не ухудшая его читабельности, не усложняя его исходную реализацию и не вкладываясь в переиспользуемость изначально (нельзя все предвидеть).
Например, без DI можно проектировать, подразумевая кастомизацию через наследование. Т.е. дробить содержимое на мелкие методы, теряя при этом в наглядности и иерархии. О минусах этого подхода пишет автор в статье Идеальный UI фреймворк:
class MyPanel extends React.Component {
header() { return {this.props.head} }
bodier() { return {this.props.body} }
childs() { return [ this.header() , this.bodier() ] }
render() { return {this.childs()}
}class MyPanelExt extends MyPanel {
footer() { return {this.props.foot} }
childs() { return [ this.header() , this.bodier() , this.footer() ] }
}Надо сказать, что этот автор (@vintage), придумал формат tree, который позволяет описать вышеприведенный пример с сохранением иерархии. Несмотря на то, что многие критикуют этот формат, у него есть преимущество как раз в виде переопределяемости даже самых мелких деталей без специального разбиения на части и рефакторинга. Иными словами, это бесплатная (почти, кроме постижения новой необычной концепции) буковка O в SOLID.
Полностью перенести этот принцип на JSX невозможно, однако частично реализовать его через DI можно попытаться. Смысл в том, что любой компонент в иерархии — это еще и точка расширения, слот, если рассуждать в терминах vue. И мы в родительском компоненте можем поменять его реализацию, зная его идентификатор (исходная реализация или интерфейс). Примерно так работают многие контейнеры зависимостей, позволяя ассоциировать реализации с интерфейсами.
В js/ts, в runtime, без усложнений или внедрения строковых ключей, ухудшающих безопасность кода, нельзя ссылаться на интерфейс. Поэтому следующий пример не заработает в flow или typescript (но аналогичный заработает в C# или Dart):
interface ISome {}
class MySome implements ISome {}
const map = new Map()
map.set(ISome, MySome)Однако, можно ссылаться на абстрактный класс или функцию.
class AbstractSome {}
class MySome extends AbstractSome {}
const map = new Map()
map.set(AbstractSome, MySome)Т.к. создание объектов и компонент происходит внутри DI-контейнера, а там внутри может быть подобный map, то любую реализацию можно переопределить. А т.к. компоненты, кроме самых примитивных — функции, то их можно подменять на функции с таким же интерфейсом, но с другой реализацией.
Например, TodoResetButtonView является частью TodoView. Требуется переопределить TodoResetButtonView на кастомную реализацию.
function TodoResetButtonView({onClick}) {
return
}
function TodoView({todo, desc, reset}) {
return
> todo.finished = !todo.finished}
/>{todo.title} #{todo.id} ({desc.title})
reset
}Предположим у нас нет возможности править TodoView (он в другой библиотеке и мы не хотим его трогать, нарушая open/close принцип и заново тестировать 11 других проектов, которые его использовали со старой кнопкой).
Поэтому создаем новую кнопку и клонируем существующий TodoView, заменяя ее в клоне. Это наследование, только наглядность не нарушается — остается иерархия и не нужно специально заранее проектировать TodoView так, что бы можно было заменить кнопку.
function ClonedTodoResetButtonView({onClick}) {
return
}
const ClonedTodoView = cloneComponent(TodoView, [
[TodoResetButtonView, ClonedTodoResetButtonView]
], 'ClonedTodoView')
const ClonedTodoListView = cloneComponent(TodoListView, [
[TodoView, ClonedTodoView]
], 'ClonedTodoListView')
ReactDOM.render(Переопределять иногда надо не только компоненты, но и их зависимости:
class AbstractHelloService {
name: string
}
function HelloView(props: {greet: string}, service: AbstractHelloService) {
return
{props.greet}, {service.name}
> { service.name = e.target.value }} />
}
class AppHelloService {
@mem name = 'Jonny'
}
function AppView() {
return HelloView получит экземпляр класса AppHelloService. Т.к. AppView.aliases для всех дочерних компонент переопределяет AbstractHelloService.
Есть конечно и минус подхода "все кастомизируется" через наследование. Т.к. фреймворк предоставляет больше точек расширения, то, больше ответственности по кастомизации перекладывается на того, кто использует компонент, а не проектирует его. Переопределяя части компонента "таблица", без осознания смысла, можно ненароком превратить его в "список", а это плохой признак, т.к. является искажением исходного смысла (нарушается LSP принцип).
По-умолчанию, состояние в зависимостях компонента будет выделено под каждый компонент. Однако действует общий принцип: все определяемое в компонентах выше — имеет приоритет над нижележащими зависимостями. Т.е. если зависимость впервые используется в родительском компоненте, то она будет жить вместе с ним и все нижележащие компоненты, ее запросившие, получат именно родительский экземпляр.
class HelloService {
@mem name = 'John'
}
function HelloView(props: {greet: string}, service: HelloService) {
return
{props.greet}, {service.name}
> { service.name = e.target.value }} />
}
class AppHelloService {
@mem name = 'Jonny'
}
function AppView(_, service: HelloService) {
return
В такой конфигурации, оба HelloView разделяют общий экземпляр HelloService. Однако, без HelloService в AppView, на каждый дочерний компонент будет свой экземпляр.
function AppView() {
return
Подобный принцип, когда можно управлять, какому компоненту принадлежит объект, используется в иерархическом DI ангулара.
Я не утверждаю, что подход css-in-js единственно правильный для использования в веб. Но и тут можно применить идею внедрения зависимостей. Проблема аналогична вышеописанной с redux/mobx и контекстами. Например, как и во многих подобных библиотеках, стили jss прибиваются к компоненту через обертку injectSheet и компонент связывается с конкретной реализацией стилей, с react-jss:
import React from 'react'
import injectSheet from 'react-jss'
const styles = {
button: {
background: props => props.color
},
label: {
fontWeight: 'bold'
}
}
const Button = ({classes, children}) => (
)
export default injectSheet(styles)(Button)Однако, эту прямую зависимость от jss и ему подобных можно убрать, перенеся эту ответственность на DI. В коде приложения достаточно определить функцию со стилями, как зависимость компонента и пометить ее соответственно.
// ... setup
import {action, props, mem} from 'lom_atom'
import type {NamesOf} from 'lom_atom'
class Store {
@mem red = 140
}
function HelloTheme(store: Store) {
return {
wrapper: {
background: `rgb(${store.red}, 0, 0)`
}
}
}
HelloTheme.theme = true
function HelloView(
_,
{store, theme}: {
store: Store,
theme: NameOf
}
) {
return
color via css {store.red}: > { store.red = Number(target.value) }}
/>
} Такой подход для стилей обладает всеми преимуществами DI, таким образом обеспечивается темизация и реактивность. В отличие от переменных в css, здесь работают типы в flow/ts. Из минусов — накладные расходы на генерацию и обновление css.
В попытке адаптировать идею внедрения зависимостей для компонентов, получилась библиотека reactive-di. Простые примеры в статье постронены на ее основе, но есть и более сложные, с загрузкой, обработкой статусов загрузки, ошибок и т.д. Есть todomvc бенчмарк для react, preact, inferno. В котором можно оценить оверхед от использования reactive-di. Правда, на 100 todos, погрешность измерений у меня была больше, чем этот оверхед.
Получился упрощенный Angular. Однако есть ряд особенностей, reactive-di
Почему до сих пор идею контекстов не развивали в этом ключе? Скорее всего непопулярность DI на фронтенде объясняется не повсеместным господством flow/ts и отсутствием стандартной поддержки интерфейсов на уровне метаданных. Попытками скопировать сложные реализации с других backend-ориентированных языков (как InversifyJS клон Ninject из C#) без глубокого переосмысления. А также пока недостаточным акцентом: например, некоторое подобие DI есть в react и vue, но там эти реализации являются неотделимой частью фреймворка и роль их второстепенная.
Хороший DI — это еще половина решения. В примерах выше часто мелькал декоратор @mem, который необходим для управления состоянием, построенном на идее ОРП. С помощью mem можно писать код в псевдосинхронном стиле, с простой, по-сравнению с mobx, обработкой ошибок и статусов загрузки. Про него я расскажу в следующей статье.
|
Метки: author redyuf программирование reactjs javascript react.js dependency injection |
[Перевод] Реактивные приложения с Model-View-Intent. Часть 2: View и Intent |
public interface SearchViewState {
final class SearchNotStartedYet implements SearchViewState {}
final class Loading implements SearchViewState {}
final class EmptyResult implements SearchViewState {
private final String searchQueryText;
public EmptyResult(String searchQueryText) {
this.searchQueryText = searchQueryText;
}
public String getSearchQueryText() {
return searchQueryText;
}
}
final class SearchResult implements SearchViewState {
private final String searchQueryText;
private final List result;
public SearchResult(String searchQueryText, List result) {
this.searchQueryText = searchQueryText;
this.result = result;
}
public String getSearchQueryText() {
return searchQueryText;
}
public List getResult() {
return result;
}
}
final class Error implements SearchViewState {
private final String searchQueryText;
private final Throwable error;
public Error(String searchQueryText, Throwable error) {
this.searchQueryText = searchQueryText;
this.error = error;
}
public String getSearchQueryText() {
return searchQueryText;
}
public Throwable getError() {
return error;
}
}
public class SearchInteractor {
final SearchEngine searchEngine;
public Observable search(String searchString) {
if (searchString.isEmpty()) {
return Observable.just(new SearchViewState.SearchNotStartedYet());
}
return searchEngine.searchFor(searchString)
.map(products -> {
if (products.isEmpty()) {
return new SearchViewState.EmptyResult(searchString);
} else {
return new SearchViewState.SearchResult(searchString, products);
}
})
.startWith(new SearchViewState.Loading())
.onErrorReturn(error -> new SearchViewState.Error(searchString, error));
}
}
public interface SearchView {
Observable searchIntent();
void render(SearchViewState viewState);
}
public class SearchFragment extends Fragment implements SearchView {
@BindView(R.id.searchView) android.widget.SearchView searchView;
@BindView(R.id.container) ViewGroup container;
@BindView(R.id.loadingView) View loadingView;
@BindView(R.id.errorView) TextView errorView;
@BindView(R.id.recyclerView) RecyclerView recyclerView;
@BindView(R.id.emptyView) View emptyView;
private SearchAdapter adapter;
@Override
public Observable searchIntent() {
return RxSearchView.queryTextChanges(searchView)
.filter(queryString -> queryString.length() > 3 || queryString.length() == 0)
.debounce(500, TimeUnit.MILLISECONDS);
}
@Override
public void render(SearchViewState viewState) {
if (viewState instanceof SearchViewState.SearchNotStartedYet) {
renderSearchNotStarted();
} else if (viewState instanceof SearchViewState.Loading) {
renderLoading();
} else if (viewState instanceof SearchViewState.SearchResult) {
renderResult(((SearchViewState.SearchResult) viewState).getResult());
} else if (viewState instanceof SearchViewState.EmptyResult) {
renderEmptyResult();
} else if (viewState instanceof SearchViewState.Error) {
renderError();
} else {
throw new IllegalArgumentException("Don't know how to render viewState " + viewState);
}
}
private void renderResult(List result) {
TransitionManager.beginDelayedTransition(container);
recyclerView.setVisibility(View.VISIBLE);
loadingView.setVisibility(View.GONE);
emptyView.setVisibility(View.GONE);
errorView.setVisibility(View.GONE);
adapter.setProducts(result);
adapter.notifyDataSetChanged();
}
private void renderSearchNotStarted() {
recyclerView.setVisibility(View.GONE);
loadingView.setVisibility(View.GONE);
errorView.setVisibility(View.GONE);
emptyView.setVisibility(View.GONE);
}
private void renderLoading() {
recyclerView.setVisibility(View.GONE);
loadingView.setVisibility(View.VISIBLE);
errorView.setVisibility(View.GONE);
emptyView.setVisibility(View.GONE);
}
private void renderError() {
recyclerView.setVisibility(View.GONE);
loadingView.setVisibility(View.GONE);
errorView.setVisibility(View.VISIBLE);
emptyView.setVisibility(View.GONE);
}
private void renderEmptyResult() {
recyclerView.setVisibility(View.GONE);
loadingView.setVisibility(View.GONE);
errorView.setVisibility(View.GONE);
emptyView.setVisibility(View.VISIBLE);
}
}
public class SearchPresenter extends MviBasePresenter {
private final SearchInteractor searchInteractor;
@Override protected void bindIntents() {
Observable search =
intent(SearchView::searchIntent)
.switchMap(searchInteractor::search) // на видео я использовал flatMap(), но здесь имеет смысл использовать switchMap()
.observeOn(AndroidSchedulers.mainThread());
subscribeViewState(search, SearchView::render);
}
}

|
Метки: author valpostnov разработка под android разработка мобильных приложений блог компании tinkoff.ru android mvi mosby mvp mvvm |
Визуализация результатов выборов в Москве на карте в Jupyter Notebook |
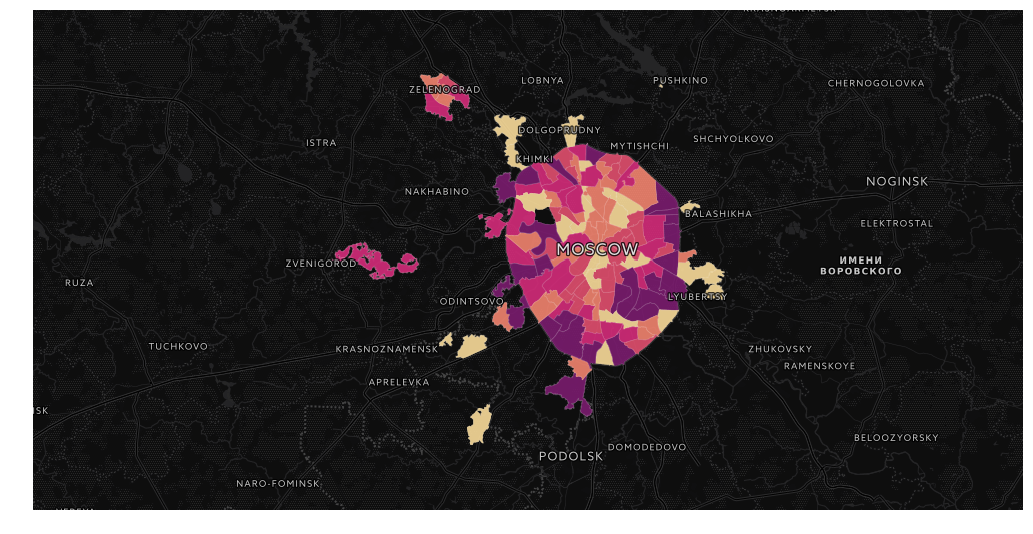
Всем привет!
Сегодня мы поговорим о визуализации геоданных. Имея на руках статистику, явно имеющую пространственную привязку, всегда хочется сделать красивую карту. Желательно, с навигацией да инфоокнами В тетрадках. И, конечно же, чтоб потом можно было показать всему интернету свои успехи в визуализации!
В качестве примера возьмем недавно отгремевшие муниципальные выборы в Москве. Сами данные можно взять с сайта мосгоризбиркома, в можно просто забрать датасеты с https://gudkov.ru/. Там даже есть какая-никакая визуализация, но мы пойдем глубже. Итак, что же у нас в итоге должно получиться?
Потратив некоторое время на написание парсера сайта Избиркома, я получил нужные мне данные. Итак, начнем с импортов.
import pandas as pd
import numpy as np
import os
import pickleЯ работаю в jupyter notebook на Linux-машине. Если вы захотите использовать мой код на Windows машине, то обращайте внимание на написание путей, а также на важные отступления в тексте.
Обычно я использую отдельную папку для проекта, поэтому для простоты задаю текущую директорию:
os.chdir('/data01/jupyter/notebooks/habr/ods_votes/')Дальше нам трубуется забрать данные с самого сайта Избиркома. Для разбора данных я написал отдельный парсер. Весь процесс занимает 10-15 минут. Забрать его можно из репозитория.
Я решил создать большой словарь с датафреймами внутри. Для превращения html-страниц в датафреймы я использовал read_html, эмпирически подбирал нужные датафрейс, а после этого делал небольшую обработку, выкидывая лишнее и добавляя недостающее. Предварительно я уже обработал данные по партиям. Изначально они были не особо читаемы. К тому же, встречается разное написание одних и тех же партий (забавно, но в некоторых случаях это не разное написание, а реально разные партии).
Непосредственно сборка справочника. Что здесь происходит:
В репозитории этой статьи лежат уже готовые данные. Их мы и будем использовать.
import glob
# забираем справочник сокращений для партий
with open('tmp/party_aliases.pkl', 'rb') as f:
party_aliases = pickle.load(f)
votes = {}
# забираем список округов и мунициальных образований
votes['atd'] = pd.read_csv('tmp/atd.csv', index_col=0, sep=';')
votes['data'] = {}
# идем по мунициальным образованиям и собираем статистику ТИК
for v in votes['atd']['municipal'].values:
votes['data']
# забираем статистику по кандидатам
candidates = glob.glob('tmp/data_{}_candidates.csv'.format(v))[0]
votes['data'][v]['candidates'] = pd.read_csv(candidates, index_col=0, sep=';')
votes['data'][v]['votes'] = {}
# теперь по каждому ОИК собираем его статистику
# статистика по УИК
okrug_stats_list = glob.glob('tmp/data_{}*_okrug_stats.csv'.format(v))
for okrug_stats in okrug_stats_list:
okrug = int(okrug_stats.split('_')[2])
try:
votes['data'][v]['votes'][okrug]
except:
votes['data'][v]['votes'][okrug] = {}
votes['data'][v]['votes'][okrug]['okrug_stats'] = pd.read_csv(okrug_stats, index_col=0, sep=';')
# статистика по кандидатам
candidates_stats_list = glob.glob('tmp/data_{}*_candidates_stats.csv'.format(v))
for candidates_stats in candidates_stats_list:
okrug = int(candidates_stats.split('_')[2])
votes['data'][v]['votes'][okrug]['candidates_stats'] = pd.read_csv(candidates_stats, index_col=0, sep=';')
# теперь собираем статистику в удобной нам форме
data = []
# пройдемся по муниципальным округам
for okrug in list(votes['data'].keys()):
#чистим данные
candidates = votes['data'][okrug]['candidates'].replace(to_replace={'party':party_aliases})
group_parties = candidates[['party','elected']].groupby('party').count()
# создаем общую статистику по избирателям
stats = np.zeros(shape=(12))
for oik in votes['data'][okrug]['votes'].keys():
stat = votes['data'][okrug]['votes'][oik]['okrug_stats'].iloc[:,1]
stats += stat
# создаем статистику по партиям
# количество мест
sum_parties = group_parties.sum().values[0]
# количество полученных мест
data_parties = candidates[['party','elected']].groupby('party').count().reset_index()
# процент полученных мест
data_parties['percent'] = data_parties['elected']/sum_parties*100
# собираем итоговую таблицу по округу
tops = data_parties.sort_values('elected', ascending=False)
c = pd.DataFrame({'okrug':okrug}, index=[0])
c['top1'], c['top1_elected'], c['top1_percent'] = tops.iloc[0,:3]
c['top2'], c['top2_elected'], c['top2_percent'] = tops.iloc[1,:3]
c['top3'], c['top3_elected'], c['top3_percent'] = tops.iloc[2,:3]
c['voters_oa'], c['state_rec'], c['state_given'], c['state_anticip'], c['state_out'], c['state_fired'], c['state_box'], c['state_move'], c['state_error'], c['state_right'], c['state_lost'] , c['state_unacc'] = stats
c['voters_percent'] = (c['state_rec'] - c['state_fired'])/c['voters_oa']*100
c['total'] = sum_parties
c['full'] = (c['top1_elected']== sum_parties)
# добавляем полученный датафрейм в список
data.append(c)
# создаем итоговый датафрейм
winners = pd.concat(data,axis=0)Мы получили датафрейм со статистикой явки, бюллютеней (от количества выданных до количества испорченных), распределением мест между партиями.
Можно приступать к визуализации!
Для работы с геоданными мы будем использовать библиотеку geopandas. Что такое geopandas? Это расширение функциональности pandas географическими абстракциями (унаследованными из Shapely), которые позволяют нам проводит аналитические географические операции с геоданными: выборки, оверлей, аггрегация (как, например, в PostGIS для Postgresql).
Напомню, что существует три базовых типа геометрии — точка, линия (а точнее, полилиния, так как состоит из соединенных отрезков) и полигон. У всех у них бывает вариант мульти-(Multi), где геометрия представляет собой объединение отдельных географических образований в один. Например, выход метро может быть точкой, но несколько выходов, объединенных в сущность "станция", уже являются мультиточкой.
Следует обратить внимание, что geopandas неохотно ставится через pip в стандартной установке Python в среде Windows. Проблема, как обычно, в зависимостях. Geopandas опирается на абстракции библиотеки fiona, у которой нет официальных сборок под Windows. Идеально использовать среду Linux, например, в docker-контейнере. Кроме того, в Windows можно использовать менеджер conda, он все зависимости подтягивает из своих репозиториев.
C геометрией муниципальных образований все достаточно просто. Их можно легко забрать из OpenStreetMap (подробнее тут) или, например, из выгрузок NextGIS. Я использую уже готовые шейпы.
Итак, начнем! Выполняем нужные импорты, активируем графики matplotlib...
import geopandas as gpd
%matplotlib inline
mo_gdf = gpd.read_file('atd/mo.shp')
mo_gdf.head()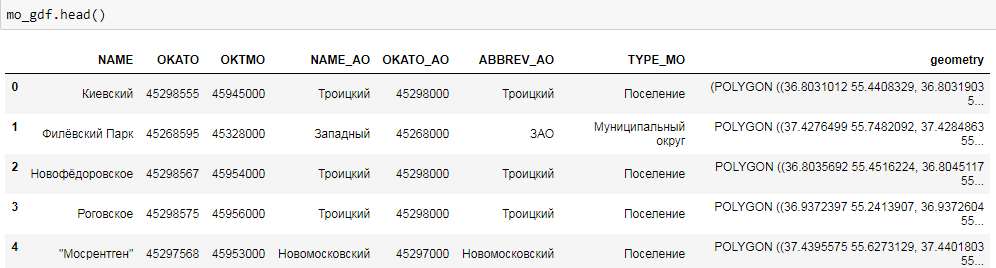
Как видите, это привычный DataFrame. Поле geometry — представление географических объектов (в данном случае — полигонов) в виде WKT, well known text (подробнее — https://en.wikipedia.org/wiki/Well-known_text). Можно довольно просто построить карту наших объектов.
mo_gdf.plot()
Угадывается Москва! Правда, не совсем привычно выглядит. Причина в проекции карты. На Хабре уже есть отличный ликбез по ним.
Итак, представим наши данные в более привычной проекции Web Mercator (исходную проекцию можно легко получить по параметру crs). Окрасим полигоны по названию Административного округа. Ширину линий выставим 0,5. Метод окраски cmap использует стандартные значения matplotlib (если вы, как и я, не помните их наизусть, то вот шпаргалка). Чтобы увидеть легенду карты, задаем параметр legend. Ну а figsize отвечает за размер нашей карты.
mo_gdf_wm = mo_gdf.to_crs({'init' :'epsg:3857'}) #непосредственно преобразование проекции
mo_gdf_wm.plot(column = 'ABBREV_AO', linewidth=0.5, cmap='plasma', legend=True, figsize=[15,15])
Можно построить карту и по типу муниципального образования:
mo_gdf_wm.plot(column = 'TYPE_MO', linewidth=0.5, cmap='plasma', legend=True, figsize=[15,15])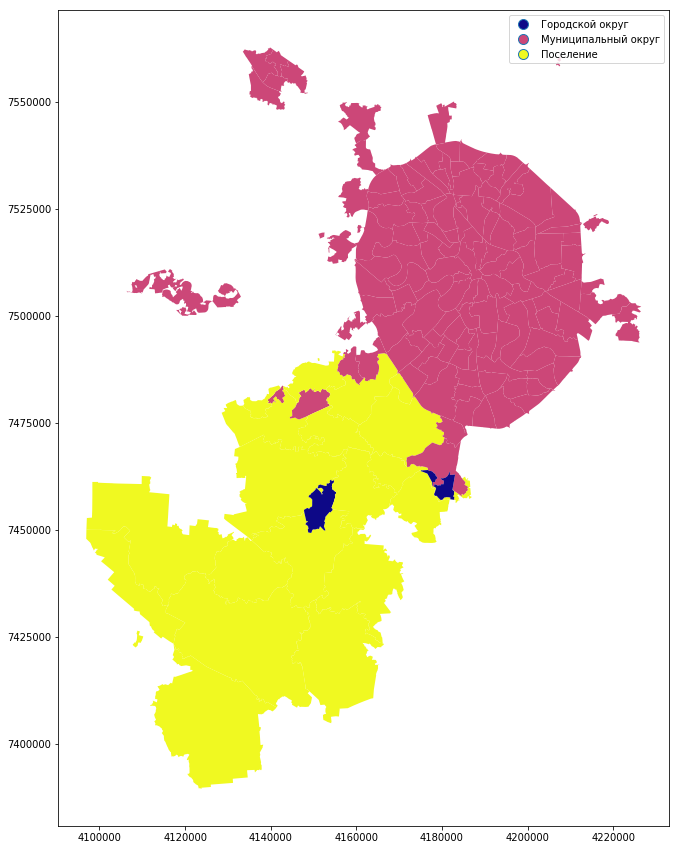
Итак, построим карту статистики по муниципальным округам. Ранее мы уже создали датафрейм winners.
Нам необходимо соединить наш датафрейм с геодатафреймом для создания карты. Немного причешем названия мунициальных округов, чтобы соединение произошло без сюрпризов.
winners['municipal_low'] = winners['okrug'].str.lower()
winners['municipal_low'] = winners['municipal_low'].str.replace('ё', 'е')
mo_gdf_wm['name_low'] = mo_gdf_wm['NAME'].str.lower()
mo_gdf_wm['name_low'] = mo_gdf_wm['name_low'].str.replace('ё', 'е')
full_gdf = winners.merge(mo_gdf_wm[['geometry', 'name_low']], left_on='municipal_low', right_on='name_low', how='left')
full_gdf = gpd.GeoDataFrame(full_gdf)Построим простую категориальная карту, где от зеленого к синему распределены партии-победители. В районе Щукино в этом году и правда не было выборов.
full_gdf.plot(column = 'top1', linewidth=0, cmap='GnBu', legend=True, figsize=[15,15])
Явка:
full_gdf.plot(column = 'voters_percent', linewidth=0, cmap='BuPu', legend=True, figsize=[15,15])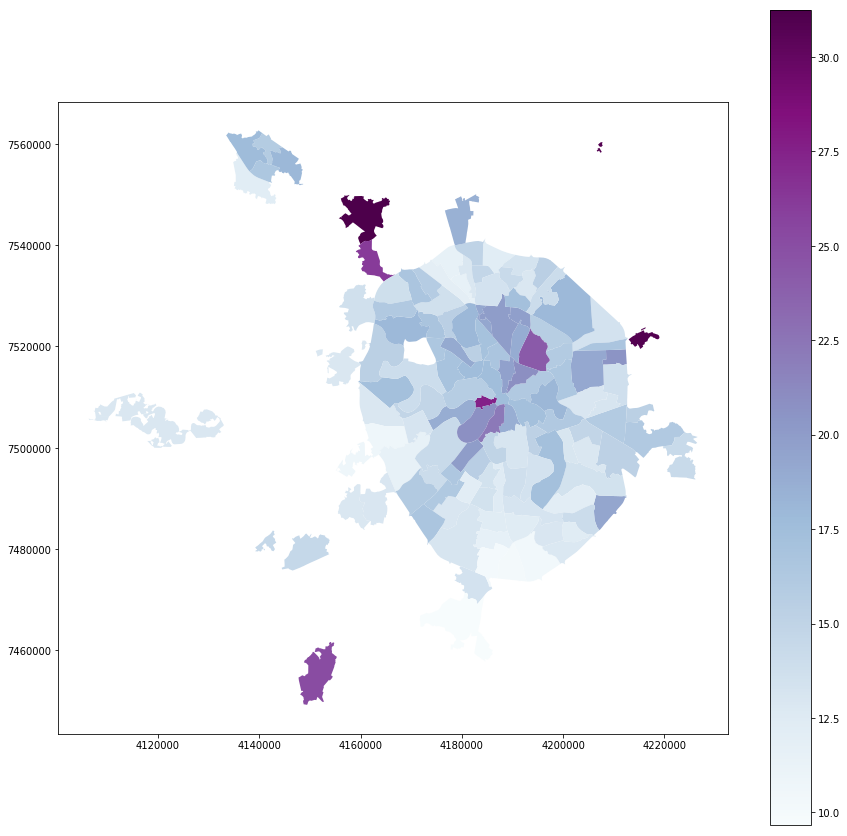
Жители:
full_gdf.plot(column = 'voters_oa', linewidth=0, cmap='YlOrRd', legend=True, figsize=[15,15])
Отлично! У нас получилась симпатичная визуализация. Но хочется и базовую карту, и навигацию! На помощь нам придет библиотека cartoframes.
Одним из самых удобных инструментов для визуализации геоданных является Carto. Для работы с этим сервисом существуюет библиотеке cartoframes, которая позволяет работать с функциями сервиса прямо из тетрадок Jupyter.
Библиотека cartoframes требует внимательного обращения под Windows в силу особенностей разработки (например, при заливке датасета библиотека пытается использовать стиль папок linux, что приводит к печальным последствиям). С кириллическими данными можно легко отстрелить себе ногу (кодировка cp1251 может быть превращена в кракозябры). Лучше ее использовать или в docker-контейнере, или на полноценном Linux. Ставится библиотека только через pip. В windows ее можно успешно установить, предварительно поставив geopandas через conda (или поставив все зависимости руками).
Cartoframes работает с проекцией WGS84. В нее и перепроецируем наш датасет. После соединения двух датафреймов может теряться информация о проекции. Зададим ее заново и перепроецируем.
full_gdf.crs = ({'init' :'epsg:3857'})
full_gdf = full_gdf.to_crs({'init' :'epsg:4326'})Делаем нужные импорты...
import cartoframes
import json
import warnings
warnings.filterwarnings("ignore")Добавляем данные от аккаунта Carto:
USERNAME = 'ваш пользователь Carto'
APIKEY = 'ваш ключ API'И, наконец, подключаемся к Carto и заливаем наш датасет:
cc = cartoframes.CartoContext(api_key=APIKEY, base_url='https://{}.carto.com/'.format(USERNAME))
cc.write(full_gdf, encode_geom=True, table_name='mo_votes', overwrite=True)Датасет можно выгрузить с Carto обратно. Но полноценный геодатафрейм пока только в проекте. Правда, можно с помощью gdal и shapely сконвертировать бинарное представление геометрии PostGIS снова в WKT.
Особенностью работы плагина является приведением типов. Увы, в текущей версии датафрейм заливается в таблицу с назначением типа str для каждого столбца. Об этом надо помнить при работе с картами.
Наконец, карта! Разукрасим данные, положим на базовую карту и включим навигацию. Подсмотреть схемы окрашивания можно здесь.
Для нормальной работы с разбиением классов напишем запрос с приведением типов. Синтаксис PostgreSQL
query_layer = 'select cartodb_id, the_geom, the_geom_webmercator, voters_oa::integer, voters_percent::float, state_out::float from mo_votes'Итак, явка:
from cartoframes import Layer, BaseMap, styling, QueryLayer
l = QueryLayer(query_layer, color={'column': 'voters_percent', 'scheme': styling.darkMint(bins=7)})
map = cc.map(layers=[BaseMap(source='light', labels='front'), l], size=(990, 500), interactive=False)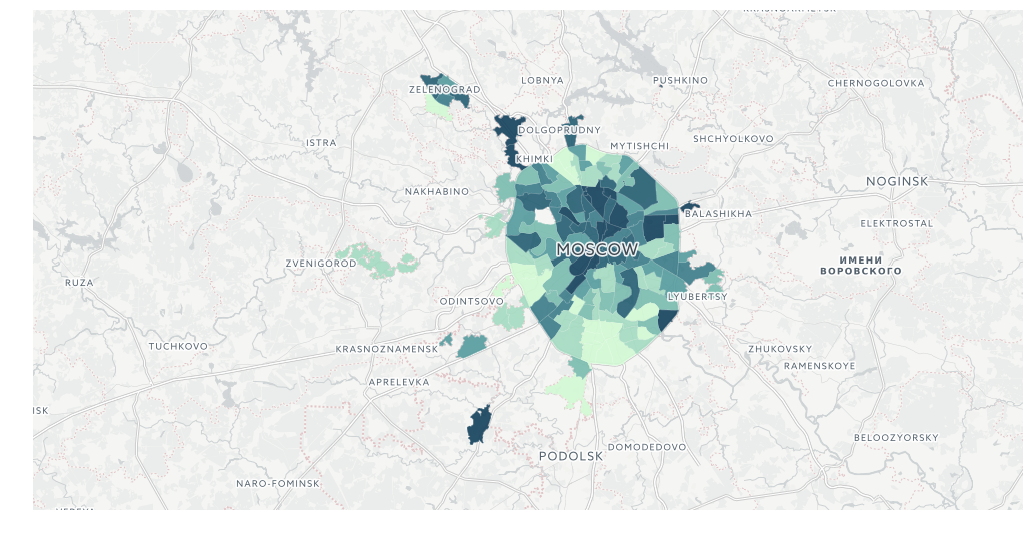
Количество жителей
l = QueryLayer(query_layer, color={'column': 'voters_oa', 'scheme': styling.burg(bins=7)})
map = cc.map(layers=[BaseMap(source='light', labels='front'), l], size=(990, 500), interactive=False)
И, например, надомное голосование
l = QueryLayer(query_layer, color={'column': 'state_out', 'scheme': styling.sunsetDark(bins=5)})
map = cc.map(layers=[BaseMap(source='light', labels='front'), l], size=(990, 500), interactive=False)
Следует заметить, что в данный момент cartoframes не позволяет встроить инфоокна прямо в окно тетрадки, показывать легенду, а также публиковать карты на Carto. Но эти опции в процессе имплементации.
А теперь попробуем более сложный, но весьма гибкий способ встраивания карт в Jupyter Notebook...
Итак, нам хотелось бы получить не только навигацию, но и инфоокна на карте. А еще получить возможность публикации визуализации на своем сервере или на github. Нам поможет folium.
Библиотека folium — довольно специфичная штука. Она представляет собой python-обертку вокруг JS-библиотеки Leaflet, которая как раз и отвечает за картографическую визуализацию. Следующие манипуляции выглядят не очень pythonic, но не пугайтесь, я все поясню.
import foliumПростая визуализация наподобие Carto делается достаточно просто.
Что происходит?
Цветовая шкала основывается на библиотеке Color Brewer. Я крайне рекомендую при работе с картами пользоваться ей.
m = folium.Map(location=[55.764414, 37.647859])
m.choropleth(
geo_data=full_gdf[['okrug', 'geometry']].to_json(),
name='choropleth',
data=full_gdf[['okrug', 'voters_oa']],
key_on='feature.properties.okrug',
columns=['okrug', 'voters_oa'],
fill_color='YlGnBu',
line_weight=1,
fill_opacity=0.7,
line_opacity=0.2,
legend_name='type',
highlight = True
)
m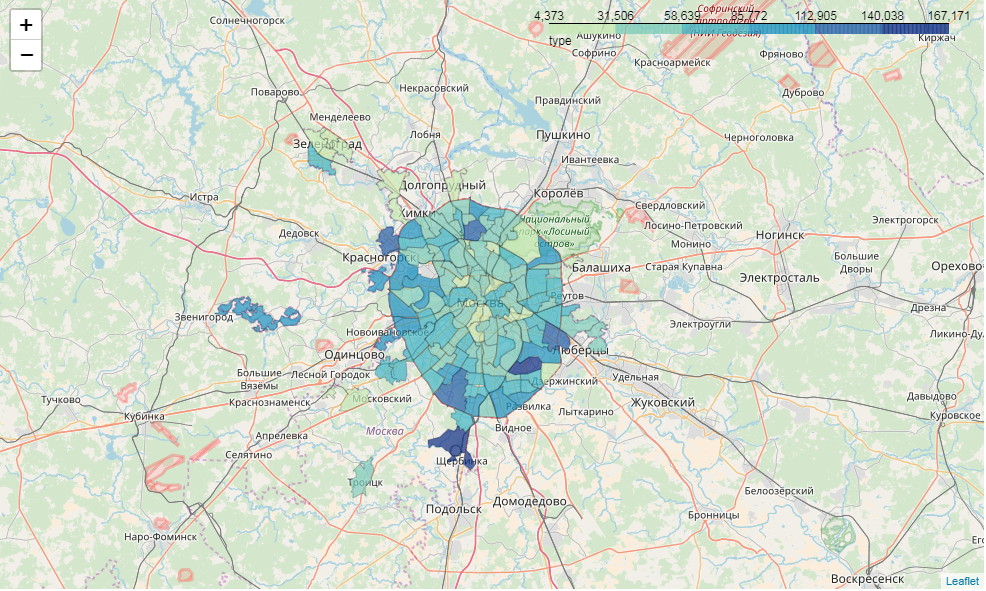
Итак, у нас получилась интерактивная картограмма. Но хотелось бы и инфоокон...
Здесь нам придется немного хакнуть библиотеку. У нас есть партии-победители в каждом ТИК. Для каждой из них мы определим базовый цвет. Но не в каждом округе победа партии означает 100% голосов. К каждому базовому цвету мы определим 3 градации: абсолютная власть (100%), контрольный пакет (>50%) и кооперация (<50%). Напишем функцию определения цвета:
def party_color(feature):
party = feature['properties']['top1']
percent = feature['properties']['top1_percent']
if party == 'Единая Россия':
if percent == 100:
color = '#969696'
elif 50 < percent < 100:
color = '#bdbdbd'
else:
color = '#d9d9d9'
elif party == 'Яблоко':
if percent == 100:
color = '#78c679'
elif 50 < percent < 100:
color = '#addd8e'
else:
color = '#d9f0a3'
elif party == 'КПРФ':
if percent == 100:
color = '#ef3b2c'
elif 50 < percent < 100:
color = '#fb6a4a'
else:
color = '#fc9272'
elif party == 'Справедливая Россия':
if percent == 100:
color = '#2171b5'
elif 50 < percent < 100:
color = '#4292c6'
else:
color = '#6baed6'
elif party == 'Самовыдвижение':
if percent == 100:
color = '#ec7014'
elif 50 < percent < 100:
color = '#fe9929'
else:
color = '#fec44f'
return {"fillColor":color, "fillOpacity":0.8,"opacity":0}Теперь напишем функцию формирования html для инфоокна:
def popup_html(feature):
html = ' Распределение мест в ТИК {}
'.format(feature['properties']['okrug'])
for p in ['top1', 'top2', 'top3']:
if feature['properties'][p + '_elected'] > 0:
html += '
{}: {} мест'.format(feature['properties'][p], feature['properties'][p + '_elected'])
return htmlНаконец, мы конвертируем каждый объект датафрейма в geojson и добавляем его к карте, привязывая к каждому стиль, поведение при наведении и инфоокно
m = folium.Map(location=[55.764414, 37.647859], zoom_start=9)
for mo in json.loads(full_gdf.to_json())['features']:
gj = folium.GeoJson(data=mo, style_function = party_color, control=False, highlight_function=lambda x:{"fillOpacity":1, "opacity":1}, smooth_factor=0)
folium.Popup(popup_html(mo)).add_to(gj)
gj.add_to(m)
m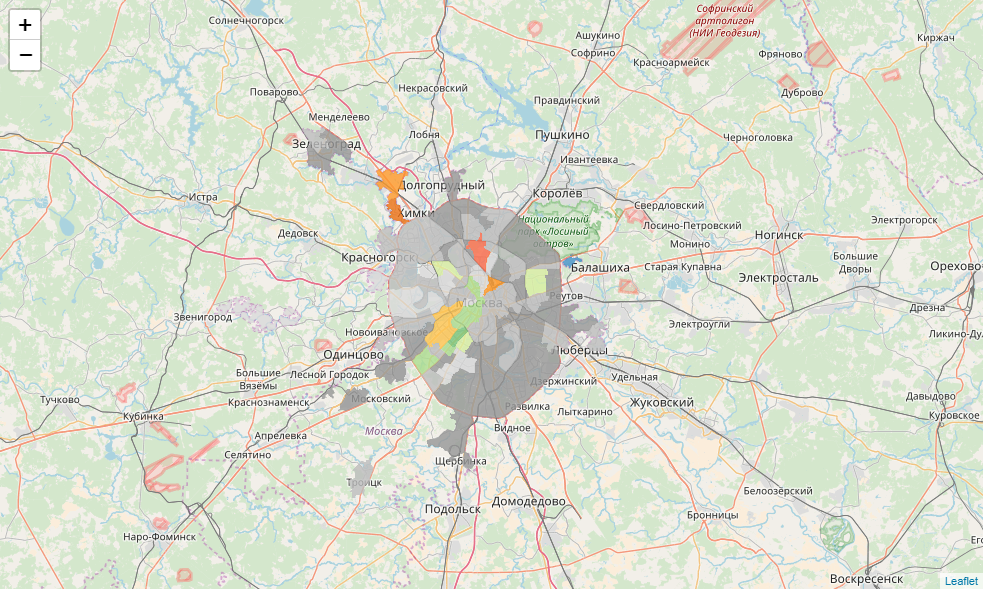
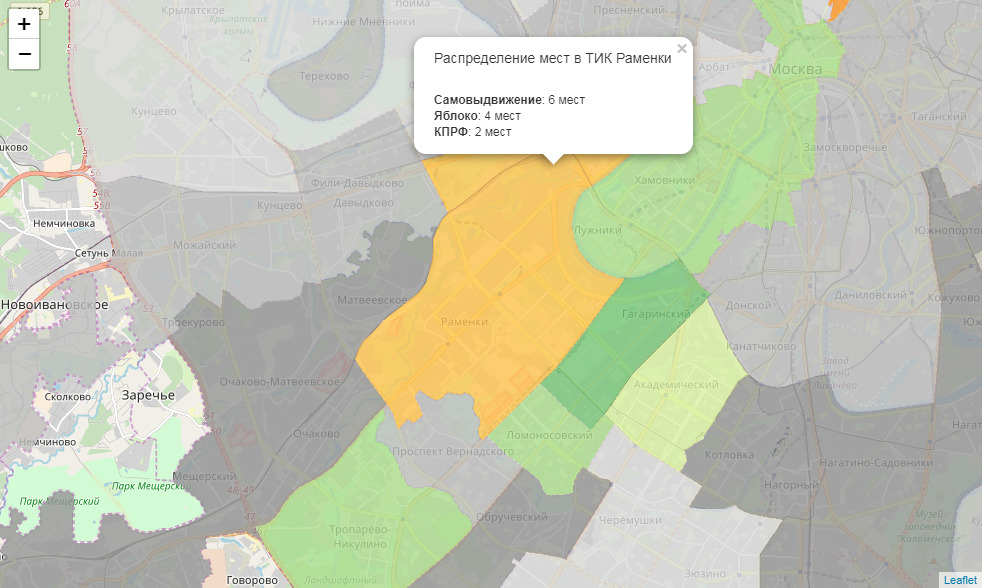
Наконец, мы сохраняем нашу карту. Ее можно опубликовать, например, на Github:
m.save('tmp/map.html')С помощью простых инструментов визуализации геоданных можно найти бесконечный простор для инсайтов. А немного поработав над данными и визуализацией, можно успешно опубликовать ваши инсайты на Carto или на github. Репозиторий этот статьи: https://github.com/fall-out-bug/izbirkom_viz.
Поздравляю, теперь вы политолог!

Вы научились анализировать результаты выборов. Поделитесь инсайтами в коментах!
|
Метки: author fall_out_bug геоинформационные сервисы визуализация данных python data mining блог компании open data science jupyter notebook картография картограмма visualization |
[Из песочницы] Как сделать карьеру в digital: первый год жизни интернет-маркетолога |




|
Метки: author Mlle_booo интернет-маркетинг карьера junior |
HR-робот обзванивает тысячи людей одновременно: рассказываем, как |
 Хабр, привет. Период отпусков закончился, так что вливаемся в работу. Мы работаем и пишем, вы — читаете и тоже работаете (надеемся, и с нашей помощью тоже). Сегодня хотим поделиться еще одним кейсом – расскажем о нашем сотрудничестве с Роботом Верой. Эта компания помогает подбирать персонал для тех, кому нужны новые кадры. Частичная (и эффективная) автоматизация процесса рекрутинга не отменяет того, что нужно много звонить. Здесь на помощь Вере приходим мы – на Voximplant компания автоматизирует телефонный дозвон кандидатам.
Хабр, привет. Период отпусков закончился, так что вливаемся в работу. Мы работаем и пишем, вы — читаете и тоже работаете (надеемся, и с нашей помощью тоже). Сегодня хотим поделиться еще одним кейсом – расскажем о нашем сотрудничестве с Роботом Верой. Эта компания помогает подбирать персонал для тех, кому нужны новые кадры. Частичная (и эффективная) автоматизация процесса рекрутинга не отменяет того, что нужно много звонить. Здесь на помощь Вере приходим мы – на Voximplant компания автоматизирует телефонный дозвон кандидатам.|
Метки: author glagoleva разработка мобильных приложений разработка веб-сайтов программирование javascript блог компании voximplant робозвонок |
«Человек» искусства: способен ли искусственный интеллект творить? |
 / Flickr / franck injapan / PD
/ Flickr / franck injapan / PD|
Метки: author IgorLevin блог компании neurodata lab neurodata lab нейросети |
Ближайшие сто лет в ста словах + конкурс с розыгрышем приглашения на Хабрахабр |
|
Метки: author Cloud4Y читальный зал учебный процесс в it исследования и прогнозы в it блог компании cloud4y будущее конкурс приглашение на хабр прогнозы |
Как чат-боты помогают выстраивать омниканальный опыт |
|
Метки: author LiveTex повышение конверсии монетизация веб-сервисов интернет-маркетинг чат-боты омниканальность клиентский опыт |
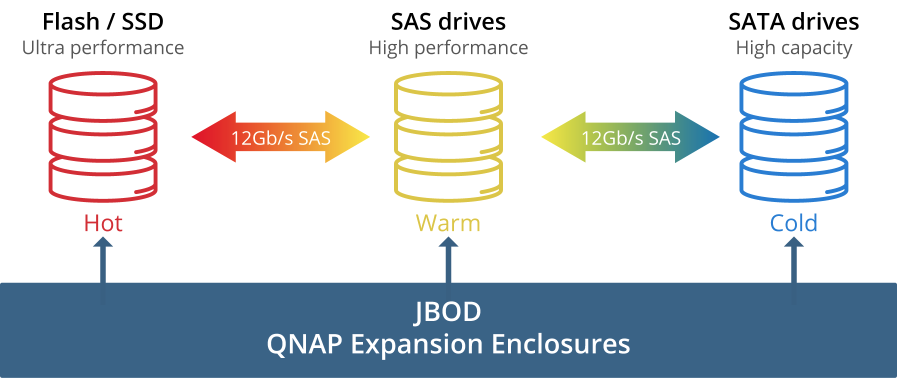
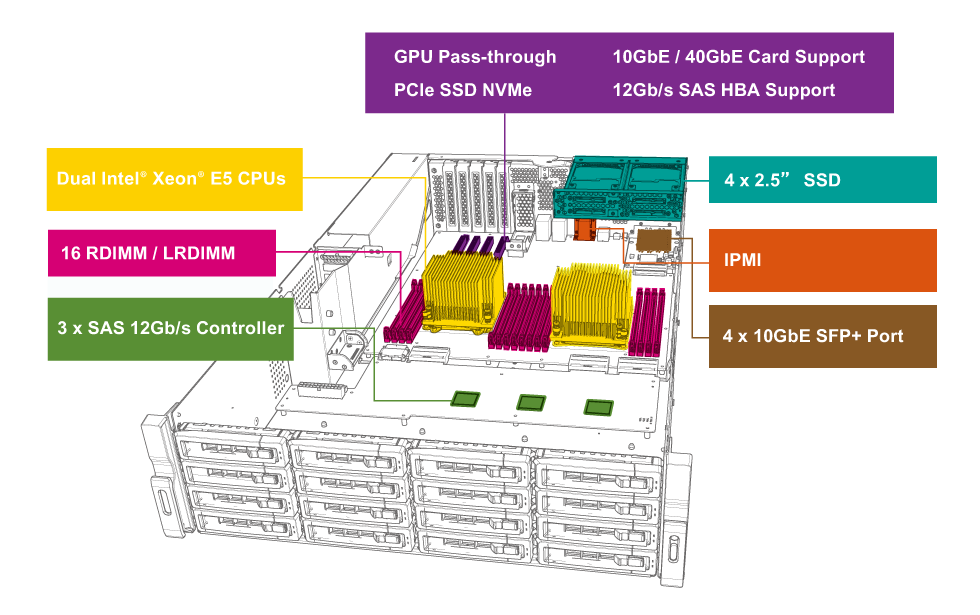
Обзор NAS для малого и среднего бизнеса QNAP TDS-16489U |



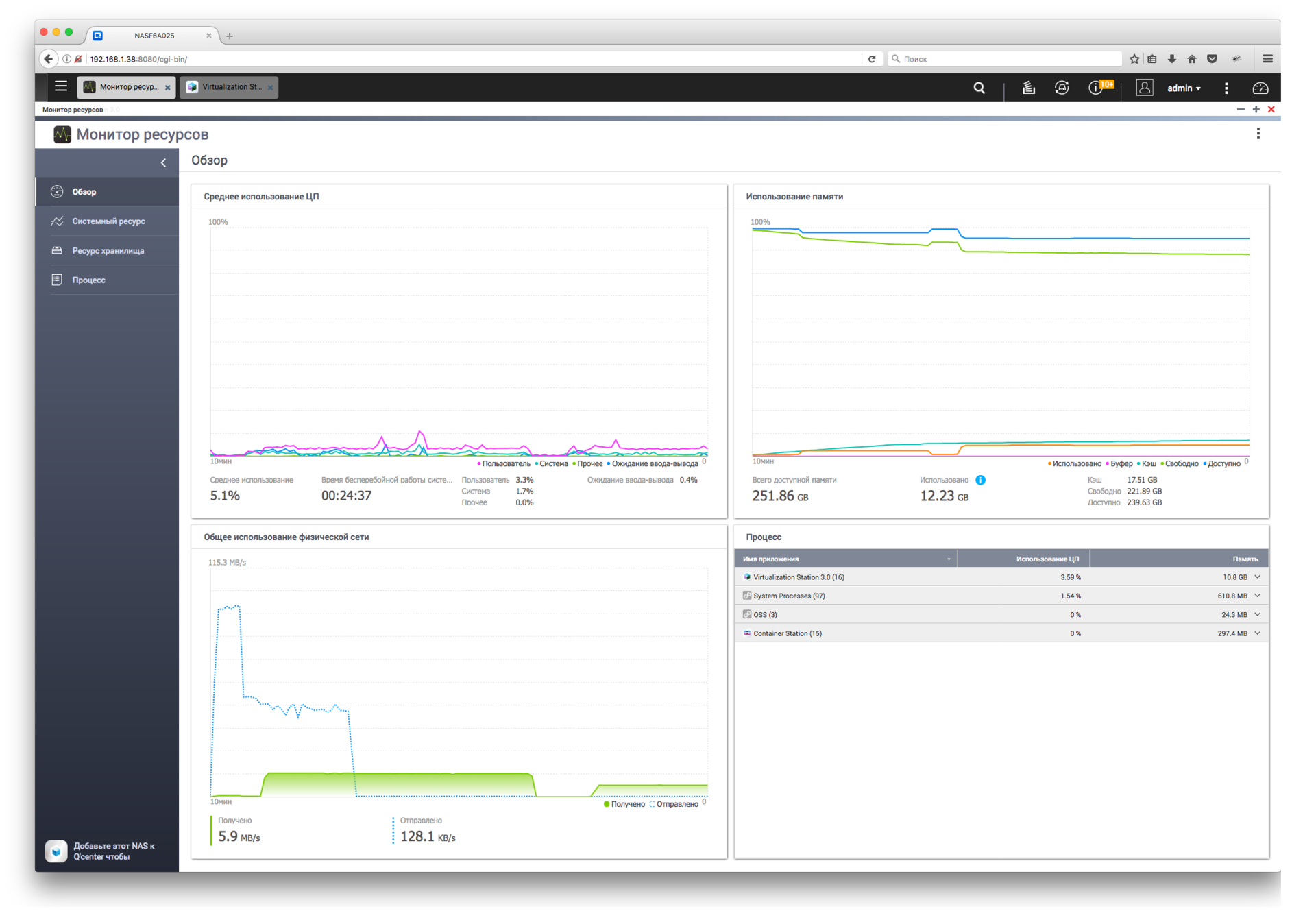

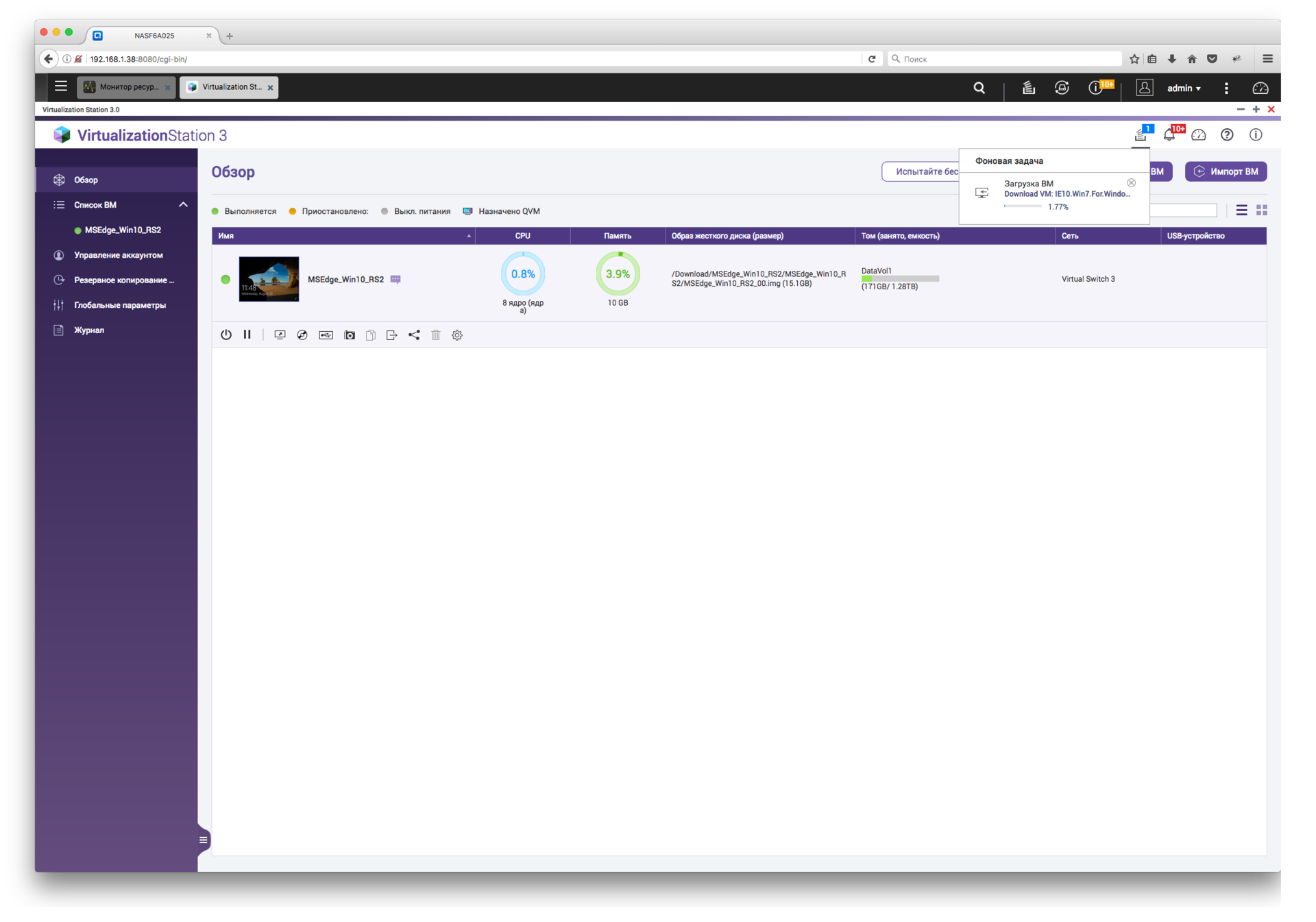
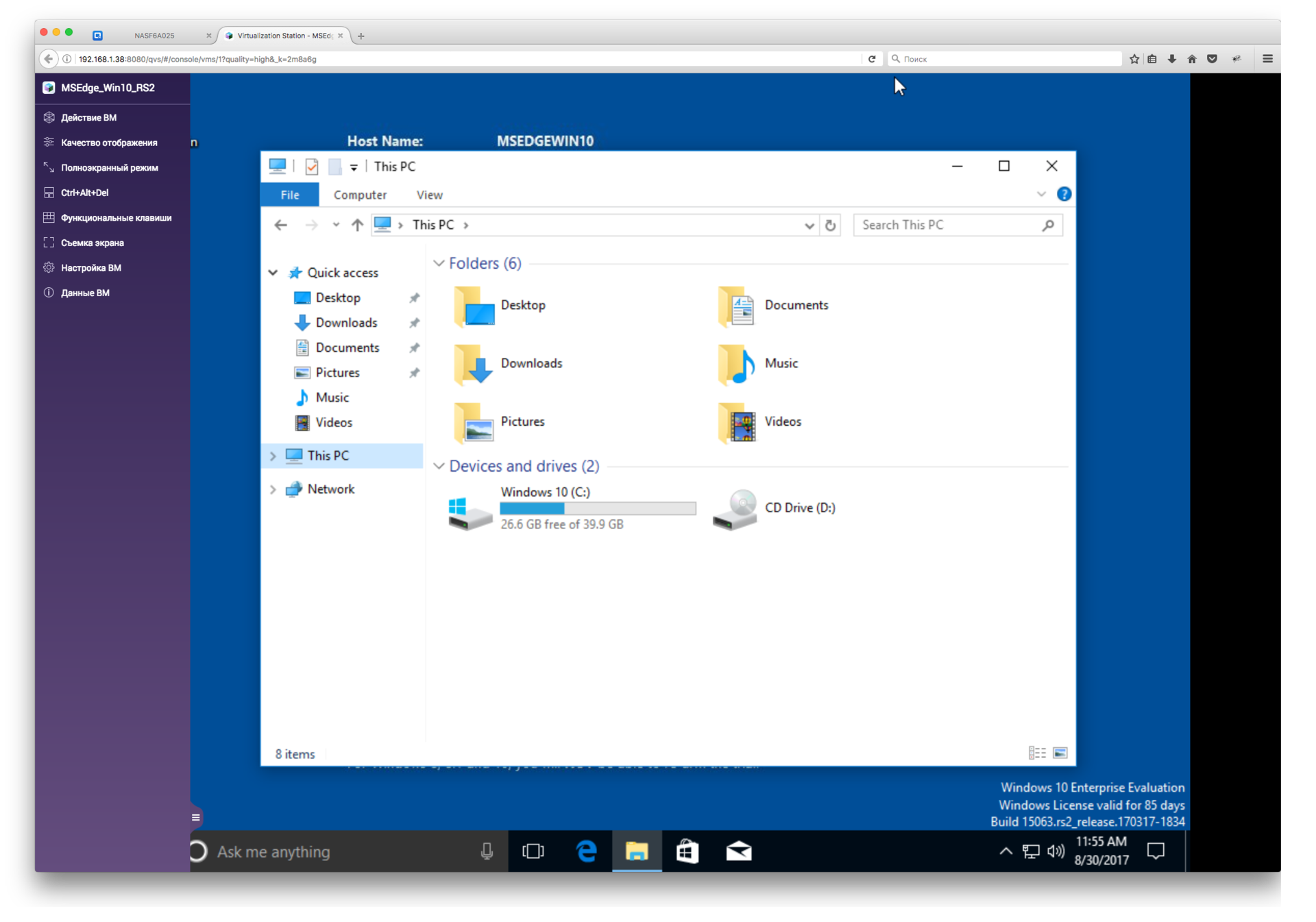

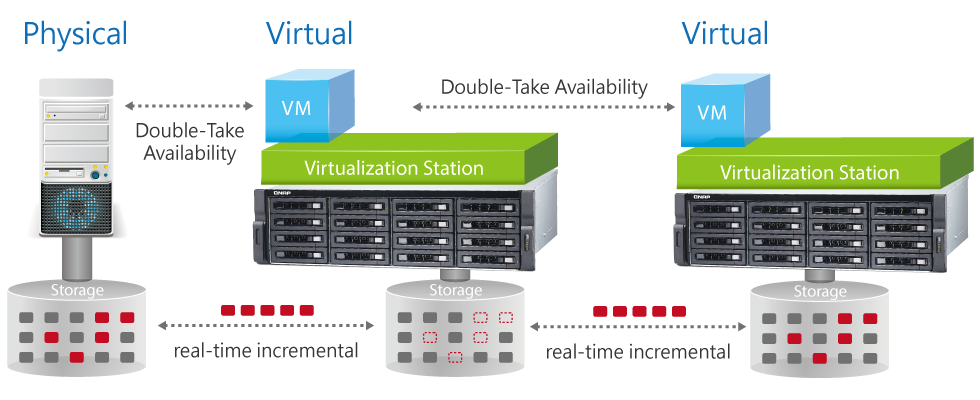
|
Метки: author KorP я пиарюсь nas qnap хранение данных виртуализация контейнеры |
Comodo Group сообщают о четырехкратном увеличении числа киберугроз |


|
Метки: author VASExperts машинное обучение информационная безопасность блог компании vas experts vas experts киберугрозы |
Почта России: страшно ли жить после Страшнова? |

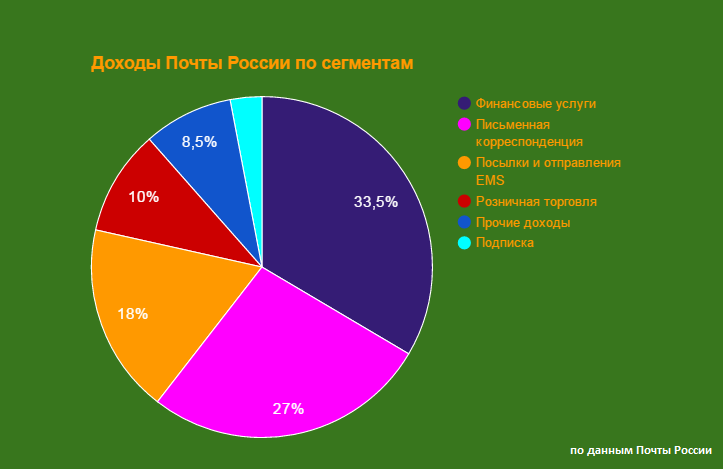

|
|
Переход с ASP.NET к ASP.NET Core 2.0 |
Эта статья является переводом справочного руководства по переносу приложений из ASP.NET в ASP.NET Core 2.0. Ссылка на оригинал
В силу некоторых причин, у нас возникла необходимость перейти с ASP.NET в ASP.NET Core 1.1., о том, как это у нас получилось, читайте тут.
• .NET Core 2.0.0 SDK или более поздняя версия.
Для работы с ASP.NET Core 2.0 проектом, разработчику предстоит сделать выбор – использовать .NET Core, .NET Framework или использовать сразу оба варианта. В качестве дополнительной информации можно использовать руководство Choosing between .NET Core and .NET Framework for server apps (вкратце можно сказать что .NET core является кроссплатформенной библиотекой, в отличие от .NET Framework) для того чтобы понять, какой Фреймворк для вас окажется наиболее предпочтительным.
После выбора нужного Фреймворка в проекте необходимо указать ссылки на пакеты NuGet.
Использование .NET Core позволяет устранить многочисленные явные ссылки на пакеты, благодаря объединенному пакету (мета пакету) ASP.NET Core 2.0. Так выглядит установка мета пакета Microsoft.AspNetCore.All в проект:
Структура файла проекта .csproj была упрощена в ASP.NET Core. Вот некоторые значительные изменения:
• Явное указание файлов является необязательным для добавления их в проект. Таким образом, уменьшается риск конфликтов в процессе слияния XML, если над проектом работает большая команда
• Больше нет GUID ссылок на другие проекты, что улучшает читаемость
• Файл можно редактировать без его выгрузки из Visual Studio:
Точкой входа для ASP.NET приложений является Global.asax файл. Такие задачи, как конфигурация маршрута и регистрация фильтров и областей, обрабатываются в файле Global.asax
public class MvcApplication : System.Web.HttpApplication
{
protected void Application_Start()
{
AreaRegistration.RegisterAllAreas();
FilterConfig.RegisterGlobalFilters(GlobalFilters.Filters);
RouteConfig.RegisterRoutes(RouteTable.Routes);
BundleConfig.RegisterBundles(BundleTable.Bundles);
}
}Этот подход тесно связывает приложение и сервер, на котором развернуто приложение. Для уменьшения связности был представлен OWIN как средство, обеспечивающее более правильный путь совместного использования нескольких фреймворков вместе.
OWIN позволяет добавить в конвейер запроса только необходимые модули. Среда выполнения использует Startup для конфигурации сервисов и конвейера запросов.
Startupрегистрирует набор промежуточных сервисов (middleware) вместе с приложением. Для каждого запроса приложение вызывает поочередно каждый из набора промежуточных сервисов, имеющих указатель на первый элемент связанного списка обработчиков.
Каждый компонент промежуточного сервиса может добавить один или несколько обработчиков в конвейер обработки запросов. Это происходит с помощью возврата ссылки на обработчик, который находится в начале списка.
И обработчик, закончив свою работу, вызывает следующий обработчик из очереди.
В ASP.NET Core, точкой входа в приложении является класс Startup, с помощью которого мы нивелируем зависимость от Global.asax.
Если изначально был выбран .NET Framework то при помощи OWIN мы можем сконфигурировать конвейер запросов как в следующем примере:
using Owin;
using System.Web.Http;
namespace WebApi
{
// Заметка: По умолчанию все запросы проходят через этот конвейер OWIN. В качестве альтернативы вы можете отключить это, добавив appSetting owin: AutomaticAppStartup со значением «false».
// При отключении вы все равно можете использовать приложения OWIN для прослушивания определенных маршрутов, добавив маршруты в файл global.asax с помощью MapOwinPath или расширений MapOwinRoute на RouteTable.Routes
public class Startup
{
// Вызывается один раз при запуске для настройки вашего приложения.
public void Configuration(IAppBuilder builder)
{
HttpConfiguration config = new HttpConfiguration();
//Здесь настраиваем маршруты по умолчанию,
config.Routes.MapHttpRoute("Default", "{controller}/{customerID}", new { controller = "Customer", customerID = RouteParameter.Optional });
//Указываем на то что в качестве файла конфигурации мы будем использовать xml вместо json
config.Formatters.XmlFormatter.UseXmlSerializer = true;
config.Formatters.Remove(config.Formatters.JsonFormatter);
// config.Formatters.JsonFormatter.UseDataContractJsonSerializer = true;
builder.UseWebApi(config);
}
}
}Также при необходимости здесь мы можем добавить другие промежуточные сервисы в этот конвейер (загрузка сервисов, настройки конфигурации, статические файлы и т.д.).
Что касается версии фреймворка .NET Core, то здесь используется подобный подход, но не без использования OWIN для определения точки входа. В качестве альтернативы используется метод Main в Program.cs (по аналогии с консольными приложениям), где и происходит загрузка Startup:
using Microsoft.AspNetCore;
using Microsoft.AspNetCore.Hosting;
namespace WebApplication2
{
public class Program
{
public static void Main(string[] args)
{
BuildWebHost(args).Run();
}
public static IWebHost BuildWebHost(string[] args) =>
WebHost.CreateDefaultBuilder(args)
.UseStartup()
.Build();
}
} Startup должен включать метод Configure. В Configure определяется, какие сервисы будут использоваться в конвейере запроса. В следующем примере (взятом из стандартного шаблона web-сайта), несколько методов расширения используются для настройки конвейера с поддержкой:
• BrowserLink
• Error pages
• Static files
• ASP.NET Core MVC
• Identity
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory)
{
loggerFactory.AddConsole(Configuration.GetSection("Logging"));
loggerFactory.AddDebug();
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
app.UseDatabaseErrorPage();
app.UseBrowserLink();
}
else
{
app.UseExceptionHandler("/Home/Error");
}
app.UseStaticFiles();
app.UseIdentity();
app.UseMvc(routes =>
{
routes.MapRoute(
name: "default",
template: "{controller=Home}/{action=Index}/{id?}");
});
}В итоге мы имеем разделение среды выполнения и приложения, что дает нам возможность осуществить переход на другую платформу в будущем.
Заметка: Для более глубокого понимания ASP.NET Core Startup и Middleware, можно изучить Startup in ASP.NET Core
ASP.NET поддерживает сохранение настроек. Например, это настройки, которые используются средой выполнения, где было развернуто приложение. Сам подход заключался в том, что для хранение пользовательских key-value пар использовалась секция
Приложение получало доступ к этим настройкам с помощью коллекции ConfigurationManager.AppSettings из пространства имен System.Configuration :
string userName = System.Web.Configuration.ConfigurationManager.AppSettings["UserName"];
string password = System.Web.Configuration.ConfigurationManager.AppSettings["Password"];В ASP.NET Core мы можем хранить конфигурационные данные для приложения в любом файле и загружать их с помощью сервисов на начальном этапе загрузки.
Файл, используемый по умолчанию в новом шаблонном проекте appsettings.json:
{
"Logging": {
"IncludeScopes": false,
"LogLevel": {
"Default": "Debug",
"System": "Information",
"Microsoft": "Information"
}
},
// Здесь можно указать настраиваемые параметры конфигурации. Поскольку это JSON, все представлено в виде пар символов: значение
// Как назвать раздел, определяет сам разработчик
"AppConfiguration": {
"UserName": "UserName",
"Password": "Password"
}
}Загрузка этого файла в экземпляр IConfiguration для приложения происходит в Startup.cs:
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }А вот так приложение использует Configuration для получения этих настроек:
string userName = Configuration.GetSection("AppConfiguration")["UserName"];
string password = Configuration.GetSection("AppConfiguration")["Password"];Есть другие способы, основанные на данном подходе, которые позволяют сделать процесс более надежным, например Dependency Injection (DI).
Подход DI обеспечивает доступ к строго типизированному набору объектов конфигурации.
// Предположим, AppConfiguration - это класс, который представляет строго типизированную версию раздела AppConfiguration
services.Configure(Configuration.GetSection("AppConfiguration")); Заметка: Для более глубокого понимания конфигураций ASP.NET Core, можно ознакомится с Configuration in ASP.NET Core.
Важной целью при создании больших масштабируемых приложений является ослабление связи между компонентами и сервисами. Dependency Injection – распространенная техника для решения данной проблемы и ее реализация является встроенным в ASP.NET Core компонентом.
В приложениях ASP.NET разработчики использовали сторонние библиотеки для внедрения Injection Dependency. Примером такой библиотеки является Unity .
Пример настройки Dependency Injection с Unity — это реализация UnityContainer, обернутая в IDependencyResolver:
using Microsoft.Practices.Unity;
using System;
using System.Collections.Generic;
using System.Web.Http.Dependencies;
public class UnityResolver : IDependencyResolver
{
protected IUnityContainer container;
public UnityResolver(IUnityContainer container)
{
if (container == null)
{
throw new ArgumentNullException("container");
}
this.container = container;
}
public object GetService(Type serviceType)
{
try
{
return container.Resolve(serviceType);
}
catch (ResolutionFailedException)
{
return null;
}
}
public IEnumerable GetServices(Type serviceType)
{
try
{
return container.ResolveAll(serviceType);
}
catch (ResolutionFailedException)
{
return new List();
}
}
public IDependencyScope BeginScope()
{
var child = container.CreateChildContainer();
return new UnityResolver(child);
}
public void Dispose()
{
Dispose(true);
}
protected virtual void Dispose(bool disposing)
{
container.Dispose();
}
}Создаем экземпляр своего UnityContainer, регистрируем свою службу и устанавливаем разрешение зависимости для HttpConfiguration в новый экземпляр UnityResolver для нашего контейнера:
public static void Register(HttpConfiguration config)
{
var container = new UnityContainer();
container.RegisterType(new HierarchicalLifetimeManager());
config.DependencyResolver = new UnityResolver(container);
// Опустим остальную часть реализации
}Далее производим инъекцию IProductRepository там, где это необходимо:
public class ProductsController : ApiController
{
private IProductRepository _repository;
public ProductsController(IProductRepository repository)
{
_repository = repository;
}
}Поскольку Dependency Injection является частью ядра ASP.NET Core, мы можем добавить свой сервис в метод ConfigureServices внутри Startup.cs:
public void ConfigureServices(IServiceCollection services)
{
//Добавляем сервис приложения
services.AddTransient();
}И далее инъекцию репозитория можно осуществить в любом месте, как и в случае с Unity.
Заметка: Подробности можно посмотреть в Dependency Injection in ASP.NET Core
Важной частью веб-разработки является возможность обслуживания статики. Самые распространенные примеры статики — это HTML, CSS, JavaScript и картинки.
Эти файлы нужно сохранять в общей папке приложения (или например в CDN) чтобы в дальнейшем они были доступны по ссылке. В ASP.NET Core был изменен подход для работы с статикой.
В ASP.NET статика хранится в разных каталогах.
А в ASP.NET Core статические файлы по умолчанию хранятся в «web root» (/ wwwroot). И доступ к этим файлам осуществляется с помощью метода расширения UseStaticFiles из Startup.Configure:
public void Configure(IApplicationBuilder app)
{
app.UseStaticFiles();
}К примеру, изображения находящееся в папке wwwroot/images будет доступно из браузера по адресу http:///images/.
Заметка: Если был выбран .NET Framework, то дополнительно нужно будет установить NuGet пакет Microsoft.AspNetCore.StaticFiles.
Заметка: Для более подробной ссылки на обслуживание статических файлов в ядре ASP.NET см. Introduction to working with static files in ASP.NET Core.
|
Метки: author Wellsoft c# asp .net asp.net .net core |
[Перевод] Развертывание кода ES2015+ в продакшн сегодня |

script type="module".script type="module" как о способе загрузки модулей ES (и, конечно же, это так), но script type="module" также имеет более быстрый и практичный вариант использования — загружает обычные файлы JavaScript с функциями ES2015+, зная, что браузер может справиться с ними!script type="module" также поддерживает большинство функций ES2015+, которые вы знаете и любите. Например:script type="module", также поддерживает async/awaitscript type="module", также поддерживает классы.script type="module", также поддерживает стрелочные функции.script type="module", также поддерживает fetch, Promises, Map, Set, и многое другое!script type="module". К счастью, если вы в настоящее время генерируете ES5-версию своего кода, вы уже сделали эту работу. Все, что вам теперь нужно — создать версию ES2015+!babel-preset-env (что должны), то второй шаг будет очень прост. Все, что вам нужно сделать, это изменить список браузеров только на те, которые поддерживают script type="module", и Babel автоматически не будет делать ненужные преобразования../path/to/main.js, тогда конфигурация вашей текущей версии ES5 может иметь следующий вид (обратите внимание, так как это ES5, я называю набор (bundle) main-legacy):module.exports = {
entry: {
'main-legacy': './path/to/main.js',
},
output: {
filename: '[name].js',
path: path.resolve(__dirname, 'public'),
},
module: {
rules: [{
test: /\.js$/,
use: {
loader: 'babel-loader',
options: {
presets: [
['env', {
modules: false,
useBuiltIns: true,
targets: {
browsers: [
'> 1%',
'last 2 versions',
'Firefox ESR',
],
},
}],
],
},
},
}],
},
};
script type="module". Вот как это может выглядеть:module.exports = {
entry: {
'main': './path/to/main.js',
},
output: {
filename: '[name].js',
path: path.resolve(__dirname, 'public'),
},
module: {
rules: [{
test: /\.js$/,
use: {
loader: 'babel-loader',
options: {
presets: [
['env', {
modules: false,
useBuiltIns: true,
targets: {
browsers: [
'Chrome >= 60',
'Safari >= 10.1',
'iOS >= 10.3',
'Firefox >= 54',
'Edge >= 15',
],
},
}],
],
},
},
}],
},
};
main.js (ES2015+ синтаксис)main-legacy.js (ES5 синтаксис)script type="module" и script nomodule:
nomodule, но вы можете решить это, встроив JavaScript-сниппет в ваш HTML до использования любых тегов script nomodule. (Примечание: это было исправлено в Safari 11).script defer. Это означает, что они не выполняются до тех пор, пока документ не будет распарсен. Если какую-то часть вашего кода нужно запустить раньше, лучше разбить этот код и загрузить его отдельно.var) и функций (function) отлично от обычных сценариев. Например, к var foo = 'bar' и function foo() {…} в скрипте можно получить доступ через window.foo, но в модуле это не будет работать. Убедитесь, что в своем коде вы не зависите от такого поведения.| Версия | Размер (minified) | Размер (minified + gzipped) |
|---|---|---|
| ES2015+ (main.js) | 80K | 21K |
| ES5 (main-legacy.js) | 175K | 43K |
| Версия | Parse/eval time (по отдельности) | Parse/eval time (среднее) |
|---|---|---|
| ES2015+ (main.js) | 184ms, 164ms, 166ms | 172ms |
| ES5 (main-legacy.js) | 389ms, 351ms, 360ms | 367ms |
node_modules не транспилировался. Однако, если модули опубликованы с исходным кодом ES2015+, возникает проблема. К счастью, она легко исправима. Вам просто нужно удалить исключение node_modules из конфигурации сборки:rules: [
{
test: /\.js$/,
exclude: /node_modules/, // удалите эту строку
use: {
loader: 'babel-loader',
options: {
presets: ['env']
}
}
}
]
node_modules, в дополнение к локальным зависимостям, это замедлит скорость сборки. К счастью, эту проблему можно отчасти решить на уровне инструментария с постоянным локальным кэшированием.script type="module" предназначен для загрузки модулей ES (и их зависимостей) в браузере, его не нужно использовать только для этой цели.script type="module" будет успешно загружать единственный файл Javascript, и это даст разработчикам столь необходимое средство для условной загрузки современного функционала в тех браузерах, которые могут его поддерживать.nomodule, дает нам возможность использовать код ES2015+ в продакшн, и наконец-то мы можем прекратить отправку транспилированного кода в браузеры, которые в нем не нуждаются.|
Метки: author ollazarev разработка веб-сайтов высокая производительность javascript production perfomance optimization es6 webpack |
Вебинар «Fujitsu World Tour 2017 – Строим цифровое будущее вместе» |
 Привет Хабр! 19 сентября в Москве прошла конференция Fujitsu World Tour 2017. На вебинаре*, посвящённом конференции, который состоится 28 сентября в 12:00 (МСК) мы:
Привет Хабр! 19 сентября в Москве прошла конференция Fujitsu World Tour 2017. На вебинаре*, посвящённом конференции, который состоится 28 сентября в 12:00 (МСК) мы:|
Метки: author FeeAR системное администрирование серверное администрирование it- инфраструктура блог компании fujitsu fujitsu вебинар конференция сервер mission critical |
[recovery mode] Быстрый пул для php+websocket без прослойки nodejs на основе lua+nginx |

lua_package_path "/home/username/lib/lua/lib/?.lua;;";
server {
# магия, которая держит вебсокет открытым столько, сколько нам надо внутри nginx
location ~ ^/ws/?(.*)$ {
default_type 'plain/text';
# всё что надо здесь для веб сокета - это включить луа, который будет его хендлить
content_by_lua_file /home/username/www/wsexample.local/ws.lua;
}
# а это магия, которая отдаёт ответы от php
# я шлю только POST запросы, чтобы нормально передать json payload
location ~ ^/lua_fastcgi_connection(/?.*)$ {
internal; # видно только подзапросам внутри nginx
fastcgi_pass_request_body on;
fastcgi_pass_request_headers off;
# never never use it for lua handler
#include snippets/fastcgi-php.conf;
fastcgi_param QUERY_STRING $query_string;
fastcgi_param REQUEST_METHOD "POST"; # $request_method;
fastcgi_param CONTENT_TYPE "application/x-www-form-urlencoded"; #вместо $content_type;
fastcgi_param CONTENT_LENGTH $content_length;
fastcgi_param DOCUMENT_URI "$1"; # вместо $document_uri
fastcgi_param DOCUMENT_ROOT $document_root;
fastcgi_param SERVER_PROTOCOL $server_protocol;
fastcgi_param REQUEST_SCHEME $scheme;
fastcgi_param HTTPS $https if_not_empty;
fastcgi_param GATEWAY_INTERFACE CGI/1.1;
fastcgi_param SERVER_SOFTWARE nginx/$nginx_version;
fastcgi_param REMOTE_ADDR $remote_addr;
fastcgi_param REMOTE_PORT $remote_port;
fastcgi_param SERVER_ADDR $server_addr;
fastcgi_param SERVER_PORT $server_port;
fastcgi_param SERVER_NAME $server_name;
fastcgi_param SCRIPT_FILENAME "$document_root/mywebsockethandler.php";
fastcgi_param SCRIPT_NAME "/mywebsockethandler.php";
fastcgi_param REQUEST_URI "$1"; # здесь вообще может быть что угодно. А можно передать параметр из lua чтобы сделать какой-нибудь роутинг внутри php обработчика.
fastcgi_pass unix:/var/run/php/php7.1-fpm.sock;
fastcgi_keep_conn on;
}
local server = require "resty.websocket.server"
local wb, err = server:new{
-- timeout = 5000, -- in milliseconds -- не надо нам таймаут
max_payload_len = 65535,
}
if not wb then
ngx.log(ngx.ERR, "failed to new websocket: ", err)
return ngx.exit(444)
end
while true do
local data, typ, err = wb:recv_frame()
if wb.fatal then return
elseif not data then
ngx.log(ngx.DEBUG, "Sending Websocket ping")
wb:send_ping()
elseif typ == "close" then
-- send a close frame back:
local bytes, err = wb:send_close(1000, "enough, enough!")
if not bytes then
ngx.log(ngx.ERR, "failed to send the close frame: ", err)
return
end
local code = err
ngx.log(ngx.INFO, "closing with status code ", code, " and message ", data)
break;
elseif typ == "ping" then
-- send a pong frame back:
local bytes, err = wb:send_pong(data)
if not bytes then
ngx.log(ngx.ERR, "failed to send frame: ", err)
return
end
elseif typ == "pong" then
-- just discard the incoming pong frame
elseif data then
-- здесь в пути передаётся реальный uri, а json payload уходит в body
local res = ngx.location.capture("/lua-fastcgi-forward"..ngx.var.request_uri,{method=ngx.HTTP_POST,body=data})
if wb == nil then
ngx.log(ngx.ERR, "WebSocket instaince is NIL");
return ngx.exit(444)
end
wb:send_text(res.body)
else
ngx.log(ngx.INFO, "received a frame of type ", typ, " and payload ", data)
end
end
|
Метки: author romy4 высокая производительность php lua fastcgi websockets nginx highload nodejs lua-nginx-module |
Квантовый компьютер IBM научили моделировать сложные химические элементы |


|
Метки: author it_man высокая производительность блог компании ит-град ит-град ibm квантовый компьютер |
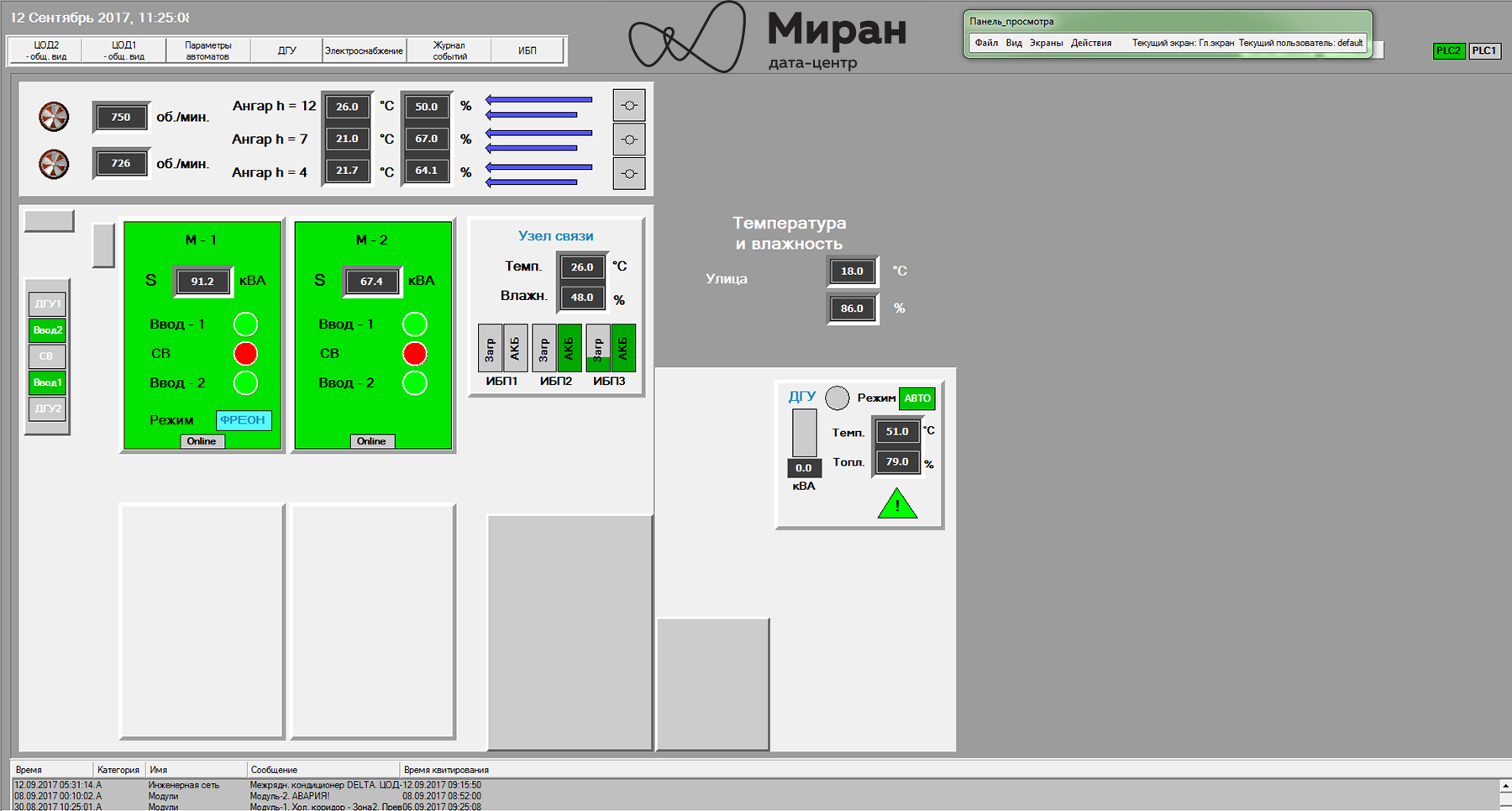
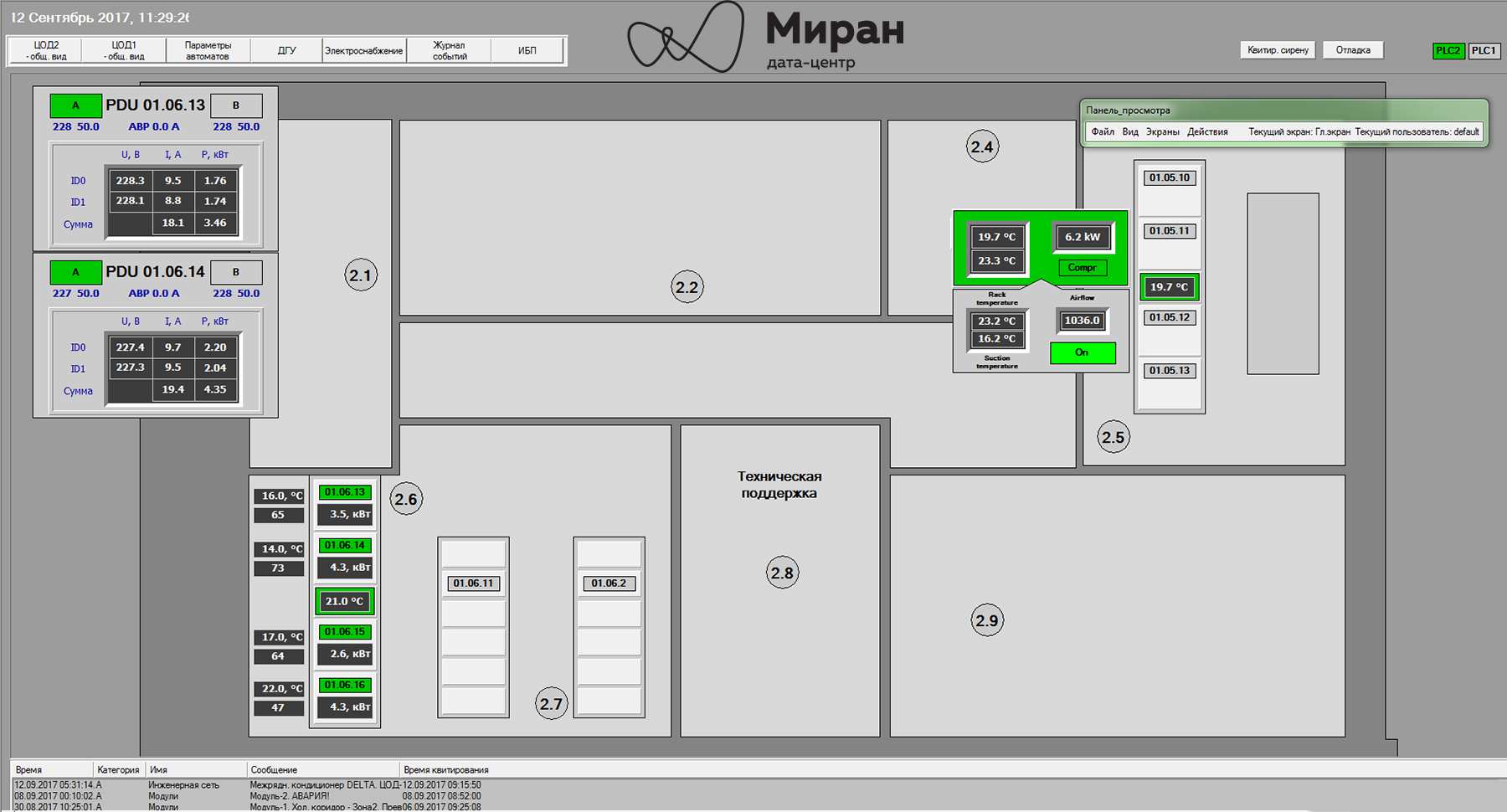
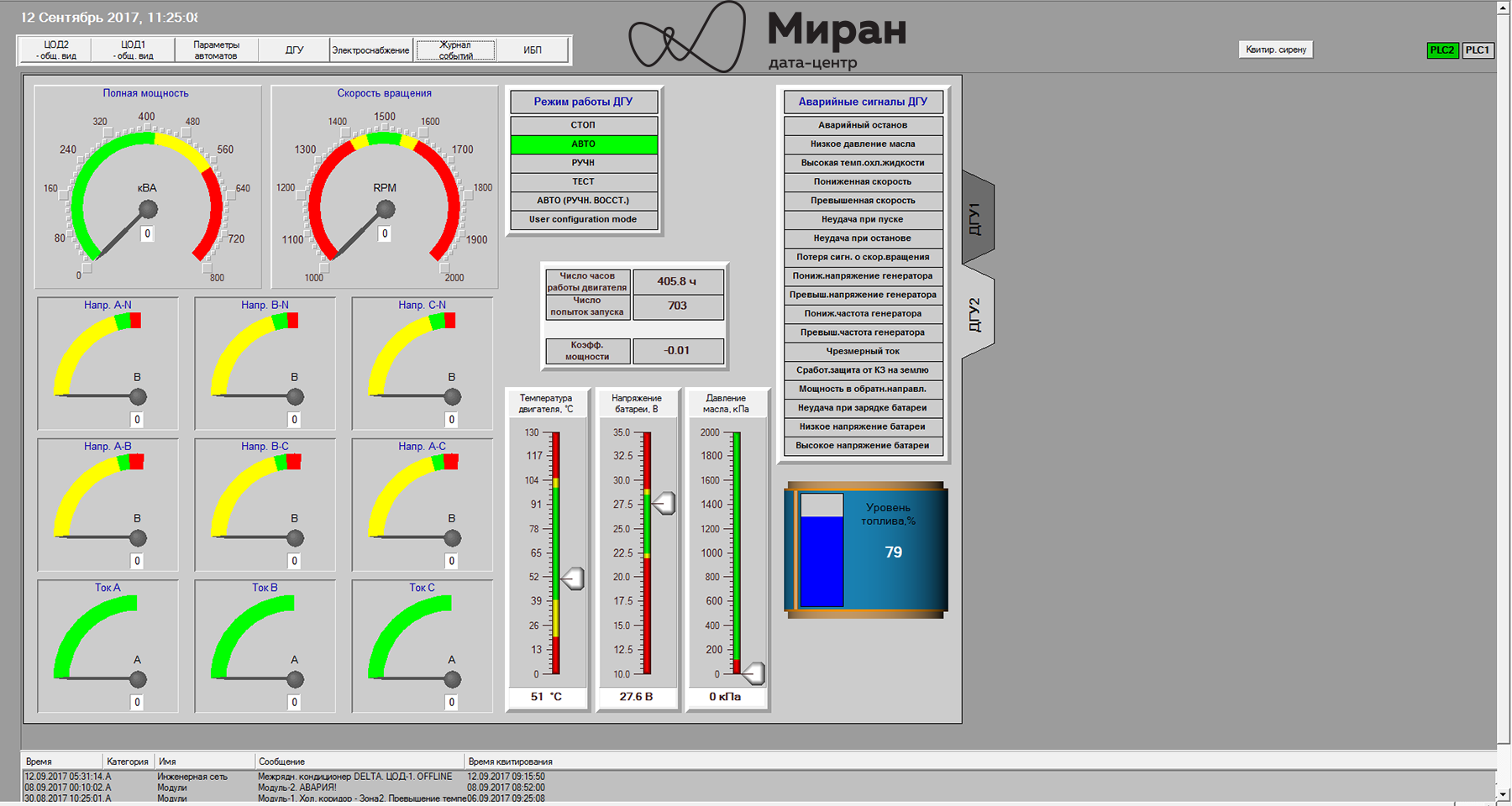
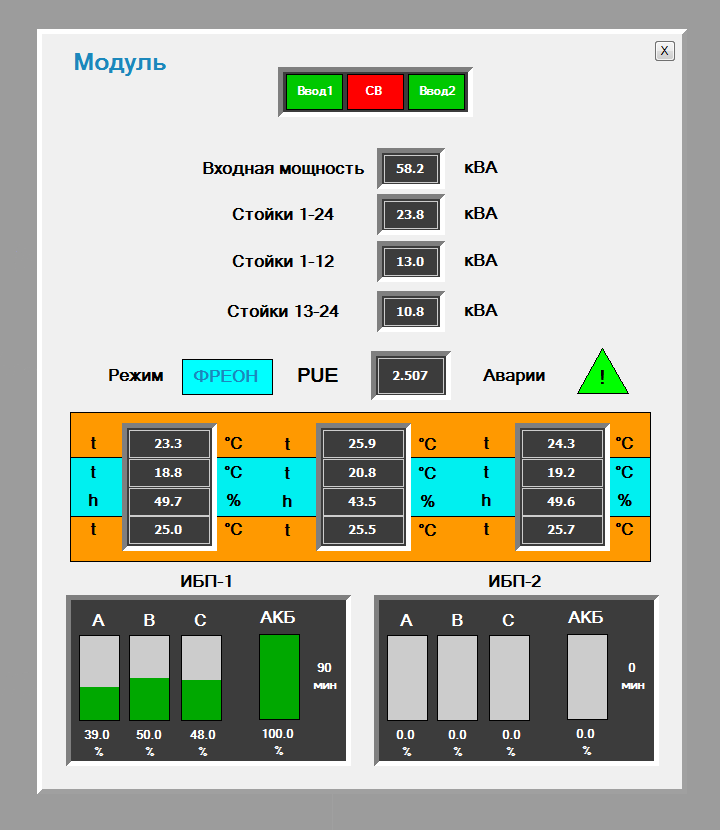
Инженерные системы наших дата-центров и их мониторинг, часть вторая |





На заметку.
Все продукты в семействе Trace Mode защищены HASP-ключами. Для работы в IDE требуется свой ключ, лимитирующий в проекте количество источников данных (e.g. лицензия на 128, 256, 512… N устройств). Для работы МРВ требуется свой ключ. Он лимитирует максимальное количество «каналов» в скомпилированном проекте; в подмножество каналов, помимо самих каналов, входят и вызовы программ, шаблонов экранов. Также ключ определяет доступность некоторых технологий, у нас, в частности, возможность запуска OPC-сервера Trace Mode. Для клиент-консолей, которые используются в АРМах, ключ лимитирует число экранов (в проекте дюжина мнемосхем, а ключ на десять? Два экрана перестанут вызываться). «Тонкие» клиенты? Ну вы поняли, ограничения на кол-во одновременных подключений, шаблонов документов...

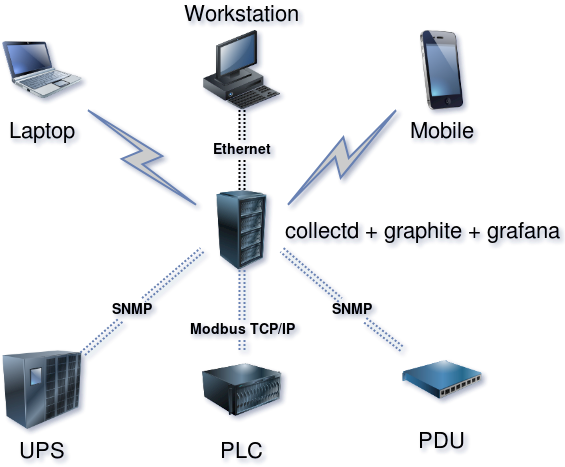
# Config file for collectd(1).
#
# Some plugins need additional configuration and are disabled by default.
# Please read collectd.conf(5) for details.
#
# You should also read /usr/share/doc/collectd-core/README.Debian.plugins
# before enabling any more plugins.
Hostname "graphite"
FQDNLookup true
#BaseDir "/var/lib/collectd"
#PluginDir "/usr/lib/collectd"
TypesDB "/usr/share/collectd/types.db" "/etc/collectd/my_types.db"
Interval 10
#Interval 60
#Timeout 2
#ReadThreads 5
LoadPlugin logfile
LoadPlugin cpu
LoadPlugin disk
LoadPlugin memory
LoadPlugin modbus //тот самый плагин
LoadPlugin snmp
LoadPlugin write_graphite
#LoadPlugin email
#LoadPlugin sensors
#LoadPlugin serial
LogLevel "info"
File STDOUT
Timestamp true
PrintSeverity true
#DC2 VRU Data -------------------------------------------------
RegisterBase 380
RegisterType int16
Type word
Instance "VRU-QF1-Status"
RegisterBase 381
RegisterType int16
Type word
Instance "VRU-QF2-Status"
…
RegisterBase 300
RegisterType int16
Type voltage
Instance "VRU1-U-AN"
RegisterBase 301
RegisterType int16
Type voltage
Instance "VRU1-U-BN"
RegisterBase 302
RegisterType int16
Type voltage
Instance "VRU1-U-CN"
Address "XXX.XXX.XXX.XXX"
Port "502"
Interval 5
Instance "Vars"
Collect "VRU-QF1-Status"
Collect "VRU-QF2-Status"
...
Collect "VRU1-U-AN"
Collect "VRU1-U-BN"
Collect "VRU1-U-CN"
...
# DC2_Module1_UPS1 -------------------------------------------------
Type "percent"
Table false
Instance "Load_A"
Values ".1.3.6.1.2.1.33.1.4.4.1.5.1"
Type "percent"
Table false
Instance "Load_B"
Values ".1.3.6.1.2.1.33.1.4.4.1.5.2"
Type "percent"
Table false
Instance "Load_C"
Values ".1.3.6.1.2.1.33.1.4.4.1.5.3"
...
Address "XXX.XXX.XXX.XXX"
Version 1
Community "public"
Collect "UPS1_load_A"
Collect "UPS1_load_B"
Collect "UPS1_load_C"
...
Interval 5
Host "localhost"
# Port "2003"
Prefix "collectd."
Protocol "tcp"
# Postfix "collectd"
# StoreRates false
# AlwaysAppendDS false
# EscapeCharacter "_"
Include "/etc/collectd/collectd.conf.d/*.conf"




|
Метки: author NobleD5 it- инфраструктура блог компании дата-центр «миран» миран цод инженерная инфраструктура мониторинг scada trace mode grafana |
iOS+Kotlin. Что можно сделать сейчас |

@ExportObjCClass
class KotlinViewController : UIViewController {
constructor(aDecoder: NSCoder) : super(aDecoder)
override fun initWithCoder(aDecoder: NSCoder) = initBy(KotlinViewController(aDecoder))
@ObjCOutlet
lateinit var label: UILabel
@ObjCOutlet
lateinit var textField: UITextField
@ObjCOutlet
lateinit var button: UIButton
@ObjCAction
fun buttonPressed() {
label.text = "Konan says: 'Hello, ${textField.text}!'"
}
}|
Метки: author adev_one разработка под ios разработка под android kotlin android development ios development android ios |
[Перевод] Overview of Cryptoeconomics. Перевод статьи |
|
Метки: author NikMelnikov криптография информационная безопасность криптоэкономика блокчейн |
Библиотека быстрого поиска путей на графе |
Привет, Друзья!
Я написал библиотеку поисков путей на произвольных графах, и хотел бы поделиться ей с вами: http://github.com/anvaka/ngraph.path
Пример использования на огромном графе:
Поиграться с демо можно здесь: https://anvaka.github.io/ngraph.path.demo/
В библиотеке используется мало-известный вариант A* поиска, который называется NBA*. Это двунаправленный поиск, с расслабленными требованиями к функции-эвристике, и очень агрессивным критерием завершения. Не смотря на свою малоизвестность у алгоритма отличная скорость сходимости к оптимальному решению.
Описание разных вариантов A* уже не раз встречалось на хабре. Мне очень понравилось вот это, потому повторяться в этой статье я не буду. Под катом расскажу подробнее почему библиотека работает быстро и о том, как было сделано демо.
"Как-то не верится что так быстро. Ты точно ниче не считаешь предварительно?"
Реакция друга, который первый раз увидел библиотеку.
Сразу должен признаться, я не верю что моя реализация — самая быстрая из возможных. Она работает достаточно быстро учитывая окружение в котором находится (браузер, javascript). Ее скорость сильно будет зависеть от размера графа. И, конечно же, то, что сейчас есть в репозитории можно ускорить и улучшить.
Для замера производительности я взял граф дорог из Нью-Йорка ( ~730 000 ребер, 260 000 узлов). Таблица ниже показывает статистику времени, необходимого для решения одной задачи поиска пути из 250 случайно выбранных:
| Среднее | Медиана | Min | Max | p90 | p99 | |
|---|---|---|---|---|---|---|
| A* ленивый (локальный) | 32ms | 24ms | 0ms | 179ms | 73ms | 136ms |
| NBA* | 44ms | 34ms | 0ms | 222ms | 107ms | 172ms |
| A*, однонаправленный | 55ms | 38ms | 0ms | 356ms | 123ms | 287ms |
| Дейкстра | 264ms | 258ms | 0ms | 782ms | 483ms | 631ms |
Каждый алгоритм решал одну и ту же задачу. A* ленивый самый быстрый, но его решение не всегда оптимально. По-сути, это двунаправленный A* который сразу же выходит как только оба поиска встретились. NBA* двунаправленный, сходится к оптимальному решению. В 99% ему понадобилось меньше чем 172 миллисекунды, чтобы найти кратчайший путь (p99).
Библиотека работает относительно быстро по нескольким причинам.
Во-первых, я изменил структуру данных в приоритетной очереди таким образом, что обновление приоритета любого элемента очереди занимает O(lg n) времени. Это достигается тем, что каждый элемент отслеживает свою позицию в куче во время перестройки очереди.
Во-вторых, во время нагрузочных тестов я заметил, что уборка мусора занимает значительное время. Это не удивительно, поскольку алгоритм создает много маленьких объектов когда он ходит по графу. Решается проблема со сборщиком мусора при помощи пула объектов. Это структура данных которая позволяет повторно использовать объекты, когда они уже не нужны.
Ну и наконец, алгоритм поиска NBA* имеет очень красивый и жесткий критерий посещения узлов.
Признаться, я думаю что это не предел совершенства. Вполне вероятно, если использовать иерархический подход, описанный Борисом удастся ускорить время для еще больших графов.
Создание библиотеки это, конечно, очень интересно. Но мне кажется демо-проект заслуживает отдельного описания. Я усвоил несколько уроков, и хотел бы поделиться с вами, в надежде, что это окажется полезным.
Прежде чем начнем. Кто-то меня спросил: "Но ведь это же граф? Как можно карту представить в виде графа?". Легче всего представить каждый перекресток узлом графа. У каждого перекрестка есть позиция (x, y). Каждый прямой участок дороги сделаем ребром графа. Изгибы дороги можно моделировать как частный случай перекрестков.
Конечно, я слышал об https://www.openstreetmap.org, но их внешний вид меня не сильно привлекал. Когда же я обнаружил API и инструменты типа http://overpass-turbo.eu/ — это как новый мир открылся перед глазами :). Данные они отдают под лицензией ODbL, которая требует чтобы их упомянули (чем больше людей знают о сервисе — тем лучше становится сервис).
API позволяет делать очень сложные запросы, и дает потрясающие объемы информации.
Например, такой запрос даст все велодороги в Москве:
[out:json];
// Сохранить область в переменную `a`
(area["name"="Москва"])->.a;
// Скачать все дороги внутри a у которых аттрибут `highway == cycleway`
way["highway"="cycleway"](area.a);
// и объединить дороги с узлами графа (узлы содержат геопозицию)
node(w);
// Наконец, вернуть результаты
out meta;API очень хорошо описано здесь: http://wiki.openstreetmap.org/wiki/Overpass_API
Я написал три маленьких скрипта, чтобы автоматизировать получение дорог для городов, и сохранять их в мой формат графа.
Данные OSM отдает в виде XML или JSON. К сожалению оба форматы слишком объемные — карта Москвы со всеми дорогами занимает около 47MB. Моя же задача была сделать загрузку сайта как можно быстрее (даже на мобильном соединении).
Можно было бы попробовать сжать gzip'ом — карта Москвы из 47МБ превращается в 7.1МБ. Но при таком подходе у меня не было бы контроля над скоростью распаковки данных — их бы пришлось парсить javascript'ом на клиенте, что тоже повлияло бы на скорость инициализации.
Я решил написать свой формат для графа. Граф разбивается на два бинарных файла. Один с координатами всех вершин, а второй с описанием всех ребер.
Файл с координатами — это просто последовательность из x, y пар (int32, 4 байта на координату). Смещение по которому находится пара координат я рассматриваю как иденификатор вершины (nodeId).

Ребра графа превращаются в обычную последовательность пар fromNodeId, toNodeId.

Последовательность на картинке означает, что первый узел ссылается на второй, а второй ссылается на третий, и так далее.
Общий размер для графа с V узлами и E ребрами можно подсчитать как:
storage_size = V * 4 * 2 + # 4 байта на пару координат на узел
E * 4 * 2 = # 4 байта на пару идентификаторов вершин
(V + E) * 8 # суммарно, в байтахЭто не самый эффективный способ сжатия, но его очень легко реализовать и можно очень быстро восстановить начальный граф на клиенте. Типизированные массивы в javascript'e работают быстрее, чем парсинг JSON'a.
Сначала я хотел добавить также вес ребер, но остановил себя, ибо загрузка на слабом мобильном соединении даже для маленьких графах станет еще медленнее.
Когда я писал демо, я думал, что напишу о нем в Твиттер. Твиттер большинство людей читают с мобилок, а потому и демо должно быть в первую очередь рассчитано на мобильные телефоны. Если оно не будет загружаться быстро, или не будет поддерживать touch — пиши пропало.
Спустя пару дней после анонса, можно признать логику выше оправданной. Твит с анонсом демо стал самым популярным твитом в жизни моего твиттера.
Я тестировал демо в первую очередь на платформах iPhone и Андроид. Для тестов на Андроиде я нашел самый дешевый телефон и использовал его. Это очень сильно помогло с отладкой производительности и удобства использования на маленьком экране.
Самая медленная часть в демо была начальная загрузка сайта. Код, который инициализировал граф выглядел как-то так:
for (let i = 0; i < points.length; i += 2) {
let nodeId = Math.floor(i / 2);
let x = points[i + 0];
let y = points[i + 1];
// graph это https://github.com/anvaka/ngraph.graph
graph.addNode(nodeId, { x, y })
}На первый взгляд — ничего плохого. Но если запустить это на слабеньком процессоре и на большом графе — страничка становится мертвой, пока основной поток занят итерацией.
Выход? Я знаю, некоторые используют Web Workers. Это прекрасное решение, учитывая что все сейчас многоядерное. Но в моем случае, использование web workers значительно бы продлило время, необходимое для создания демо. Нужно было бы продумать как передавать данные между потоками, как синхронизировать, как сохранить жизнь батарее, как быть когда web workers не доступны и т.д.
Поскольку мне не хотелось тратить больше времени, нужно было более ленивое решение. Я решил просто разбить цикл. Просто запускаем его на некоторое время, смотрим сколько времени прошло, и потом вызываем setTimeout() чтобы продолжить на следующей итерации цикла событий. Все это сделано в библиотеке rafor.
С таким решением у браузера появляется возможность постоянно информировать пользователя о том, что происходит внутри:

Теперь, когда у нас загружен граф, нужно показать его на экране. Конечно, использовать SVG для отрисовки миллиона элементов не годится — скорость начнет проседать после первого десятка тысяч. Можно было бы нарезать граф на тайлы, и использовать Leaflet или OpenSeadragon чтоб нарисовать большую картинку.
Мне же хотелось иметь больше контроля на кодом (и подучить WebGL), поэтому я написал свой WebGL отрисовщик с нуля. Там я использую подход "scene graph". В таком подходе мы строим сцену из иерархии элементов, которые можно нарисовать. Во время отрисовки кадра, мы проходим по графу, и даем возможность каждому узлу накопить трансформации или вывести себя на экран. Если вы знакомы с three.js или даже обычным DOM'ом — подход будет не в новинку.
Отрисовщик доступен здесь, но я намеренно не документировал его сильно. Это проект для моего собственного обучения, и я не хочу создавать впечатление, что им можно пользоваться :)

Изначально, я перерисовывал сцену на каждом кадре. Очень быстро я понял, что это сильно греет телефон и батарея уходит в ноль с примечательной скоростью.
Писать код при таких условиях было так же неудобно. Для работы над проектом, я обычно заседал в кофейне в свободное время, где не всегда были розетки. Поэтому мне нужно было либо научиться думать быстрее, либо найти способ не сажать ноутбук так быстро.
Я до сих пор не нашел способ как думать быстрее, потому я выбрал второй вариант. Решение оказалось по-наивному простым:
Не рисуй сцену на каждом кадре. Рисуй только когда попросили, или когда знаешь, что она поменялась.
Может, это покажется слишком очевидным сейчас, но это было вовсе не так сначала. Ведь в основном все примеры использования WebGL описывают простой цикл:
function frame() {
requestAnimationFrame(frame); // Планируем следующий кадр
renderScene(); // рисуем текущий кадр.
// Ничего плохого в этом нет, но батарею мы можем так быстро посадить
}С "консервативным" подходом, мне нужно было вынести requestAnimationFrame() наружу из функции frame():
let frameToken = 0;
function renderFrame() {
if (!frameToken) frameToken = requestAnimationFrame(frame);
}
function frame() {
frameToken = 0;
renderScene();
}Такой подход позволяет кому угодно затребовать нарисовать следующий кадр. Например, когда пользователь перетащил карту и изменил матрицу преобразования, мы вызываем renderFrame().
Переменная frameToken помогает избежать повторного вызова requestAnimationFrame между кадрами.
Да, код становится немного сложнее писать, но жизнь батарее для меня была важнее.
WebGL не самый простой в мире API. Особенно сложно в нем работать с текстом и толстыми линиями (у которых ширина больше одного пикселя).
Учитывая что я совсем новичок в этом деле, я быстро понял, что добавить поддержку текста/линий займет у меня очень много времени.
С другой стороны, из текста мне нужно было нарисовать только пару меток A и B. А из толстых линий — только путь который соединяет две вершины. Задача вполне по силам для DOM'a.
Как вы помните, наш отрисовщик использует граф сцены. Почему бы не добавить в сцену еще один элемент, задачей которого будет применять текущую трансформацию к… SVG элементу? Этот SVG элемент сделаем прозрачным, и положим его сверху на canvas. Чтобы убрать все события от мышки — ставим ему pointer-events: none;.

Получилось очень быстро и сердито.
Мне хотелось сделать так, чтобы навигация была похожа на типичное поведение карты (как в Google Maps, например).
У меня уже была написана библиотека навигации для SVG: anvaka/panzoom. Она поддерживала touch и кинетическое затухание (когда карта продолжает двигаться по инерции). Для того чтобы поддерживать WebGL мне пришлось чуть-чуть подправить библиотеку.
panzoom слушает события от пользователя (mousedown, touchstart, и т.п.), применяет плавные трансформации к матрице преобразования, и потом, вместо того чтобы напрямую работать с SVG, она отдает матрицу "контроллеру". Задача контроллера — применить трансформацию. Контролер может быть для SVG, для DOM или даже мой собственный контроллер, который применяет трансформацию к WebGL сцене.
Мы обсудили как загрузить граф, как его нарисовать, и как двигаться по нему. Но как же понять что было нажато, когда пользователь касается графа? Откуда прокладывать путь и куда?
Когда пользователь кликнул на карту, мы могли бы самым простым способом обойти все точки в графе, посмотреть на их позиции и найти ближайшую. На самом деле, это отличный способ для пары тысяч точек. Если же число точек превышает десятки/сотни тысяч — производительность будет не приемлема.
Я использовал квад дерево чтобы проиндексировать точки. После того как дерево создано — скорость поиска ближайшего соседа становится логарифмической.
Кстати, если термин "квад дерево" звучит устрашающе — не стоит огорчаться! На самом деле квад-деревья, очень-очень похожи на обычные двоичные деревья. Их легко усвоить, легко реализовать и легко применять.
В частности, я использовал собственную реализацию, библиотека yaqt, потому что она неприхотлива по памяти для моего формата данных. Существуют лучшие альтернативы, с хорошей документацией и сообществом (например, d3-quadtree).
Теперь все части на своих местах. У нас есть граф, мы знаем как его нарисовать, знаем что было на нем нажато. Осталось только найти кратчайший путь:
// pathfinder это объект https://github.com/anvaka/ngraph.path
let path = pathFinder.find(fromId, toId);Теперь у нас есть и массив вершин, которые лежат на найденном пути.
Надеюсь, вам понравилось это маленькое путешествие в мир графов и коротких путей. Пожалуйста, дайте знать если библиотека пригодилась, или если есть советы как сделать ее лучше.
Искренне желаю вам добра!
Андрей.
|
Метки: author anvaka разработка игр разработка веб-сайтов программирование алгоритмы javascript a* pathfinding graph webgl |






