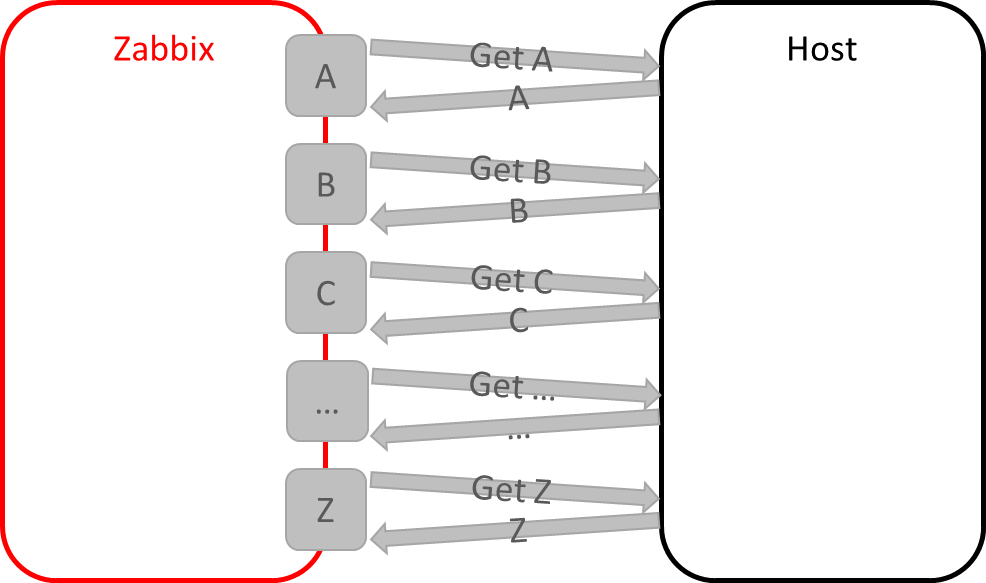
Всем привет. В этой статье мы рассмотрим основные приемы по публикации смарт-контрактов и взаимодействию с ними с использованием Ethereum RPC API. Обсуждаемые методы API позволяют решать такие задачи:
- Создание счёта.
- Создание корректного смарт-контракта.
- Получение информации со смарт-контракта.
- Изменение состояния смарт-контракта.
Содержание:
- Некоторые общие замечания
- Упаковка параметров и возвращаемых данных Создание счёта и работа с ним
- Создание смарт-контракта
- Компиляция исходного кода смарт-контракта
- Извлечение кода из транзакции
- Рассчёт стоимости опубликования контракта
- Выполнение транзакции на публикацию контракта
- Взаимодействие со смарт-контрактом
- Создание контракта с параметрами
- Идентификация методов контракта
- Вызов методов запроса информации
- Вызов методов, изменяющих состояние контракта
Описание используемого API:
Некоторые общие замечания
- Все предлагаемые действия иллюстрируются реальными данными из тестовой сети Rinkeby (на момент написания статьи).
- Состояние транзакций, счетов и смарт-контрактов в Rinkeby можно отслеживать по сайту https://rinkeby.etherscan.io/ (для подсети Ropsten будет, соответственно, https://ropsten.etherscan.io/).
Упаковка параметров и возвращаемых данных
Эта часть также носит общий характер и поэтому вынесена в отдельную главку, но её изучение можно отложить до момента, когда непосредственно понадобится использовать параметры или разобрать ответ смарт-контракта.
Входящий (параметры) или исходящий пакет данных для контракта формируется по следующему принципу:
- Фиксированные по длине типы данных (address, uint32, bytes32) передаются с выравниванием до 32-байтного слова (64 hex-цифры).
- Переменные по длине типы данных (строковые, массивы) передаются по следующей схеме:
- В позиции объекта в списке передается смещение блока с его данными относительно начала пакета (с выравниванием до 32-байтного слова).
- В первом 32-байтном слове блока передается число единиц данных.
- В последующих 32-байтных словах передаются сами данные.
Рассмотрим, например, блок, в котором передается следующий набор данных:
address,
string,
uint32,
address[] (в начале каждой 32-байтовой строки для удобства дан ее шестнадцатеричный адрес относительно начала блока).
000:000000000000000000000000570f5d143ee469d12dc29bf8b3345fa5536476d9
020:0000000000000000000000000000000000000000000000000000000000000080
040:0000000000000000000000000000000000000000000000000000000000001234
060:00000000000000000000000000000000000000000000000000000000000000c0
080:0000000000000000000000000000000000000000000000000000000000000003
0a0:4e65770000000000000000000000000000000000000000000000000000000000
0c0:0000000000000000000000000000000000000000000000000000000000000002
0e0:000000000000000000000000aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa 100:000000000000000000000000bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
В строке 000 передается адрес
0х570f5d143ee469d12dc29bf8b3345fa5536476d9.
В строке 020 передается ссылка на блок, описывающий переменную типа
string —
0x80 байт от начала блока.
В строке 040 передается целое число
0х1234.
В строке 060 передается ссылка на блок, описывающий массив
address[] —
0xc0 байт от начала блока.
В строке 080 передается счетчик символов переменной типа
string —
3.
В строке 0a0 передаются сами символы переменной типа
string — слово
New.
В строке 0c0 передается счетчик элементов массива
address[] —
2.
В строке 0e0 передается первый элемент массива
address[] —
0хaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa.
В строке 100 передается второй элемент массива
address[] —
0хbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb.
Внимание! Весь блок передается одним слитным массивом:
Создание счёта и работа с ним
Для создания нового счёта используется метод
personal_newAccount, в качестве параметра которому передаётся пароль, который в дальнейшем будет использоваться для разблокировки счёта:
{"jsonrpc":"2.0","method":"personal_newAccount","params":["PASSWORD"],"id":1}
В ответ приходит идентификатор счёта, в данном случае —
0xfbeda9914b78b58a0f0e810298f9d545f8379f8d.
{"jsonrpc":"2.0","id":1,"result":"0xfbeda9914b78b58a0f0e810298f9d545f8379f8d"}
Все дальнейшие манипуляции мы будем производить с этого счета —
0xfbeda9914b78b58a0f0e810298f9d545f8379f8d.
Теперь нам необходимо положить на него некоторую сумму для оплаты исполнения транзакций. Так как в тестовой сети Rinkeby поучаствовать в майнинге человеку со стороны невозможно, то для пополнения счетов предусмотрен специальный «кран», процедура использования которого описана здесь —
https://faucet.rinkeby.io/.
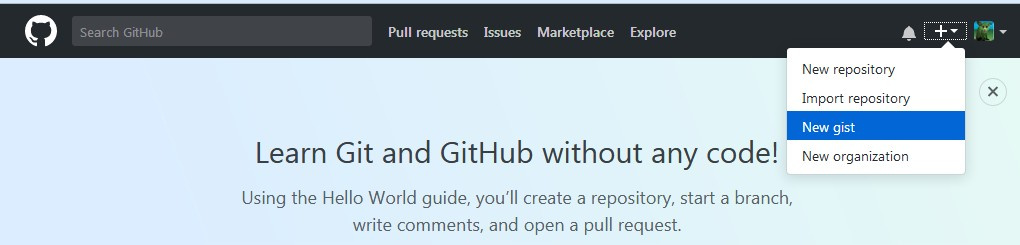
Для пополнения счета необходимо:
- Зарегистрироваться на github.com и создать новый gist:
- Вписать в него идентификатор счета:
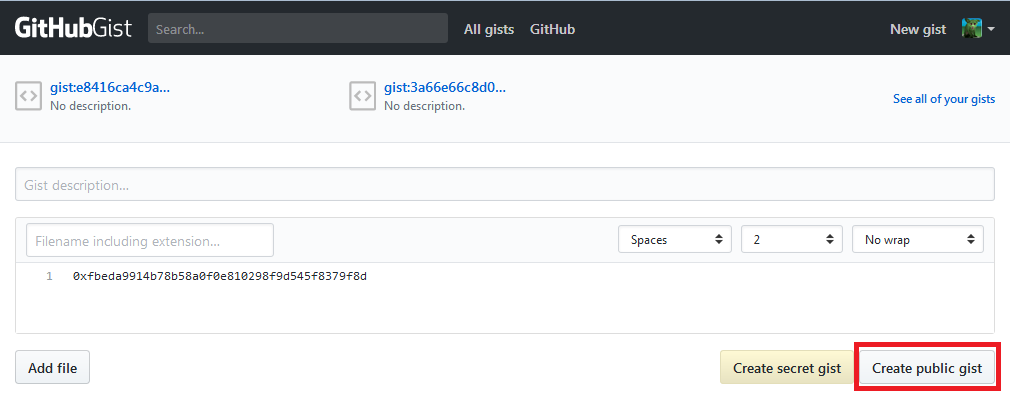
и создать публичный gist («Create public gist»)
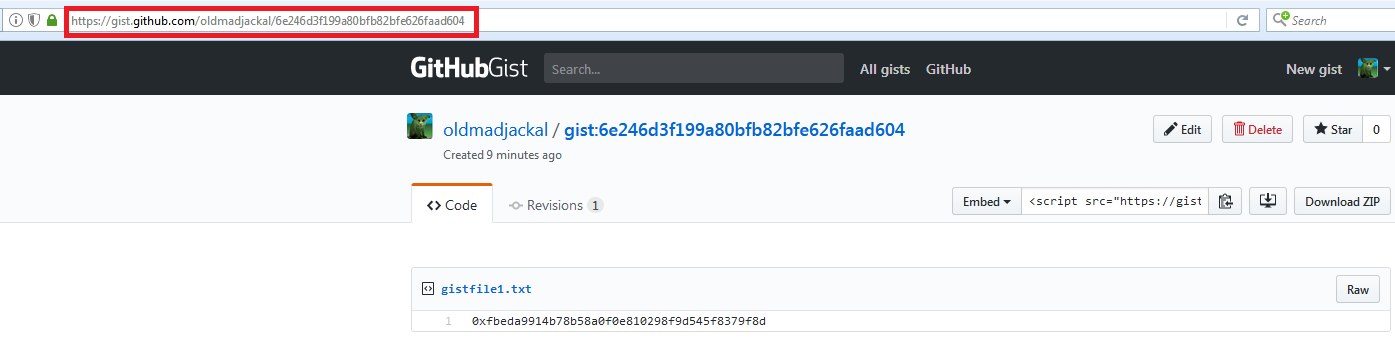
- Далее нам понадобится URL gist-а, в нашем случае — https://gist.github.com/oldmadjackal/6e246d3f199a80bfb82bfe626faad604:
- Переходим на https://faucet.rinkeby.io/, вводим URL gist-а в поле и выбираем сумму пополнения счёта:
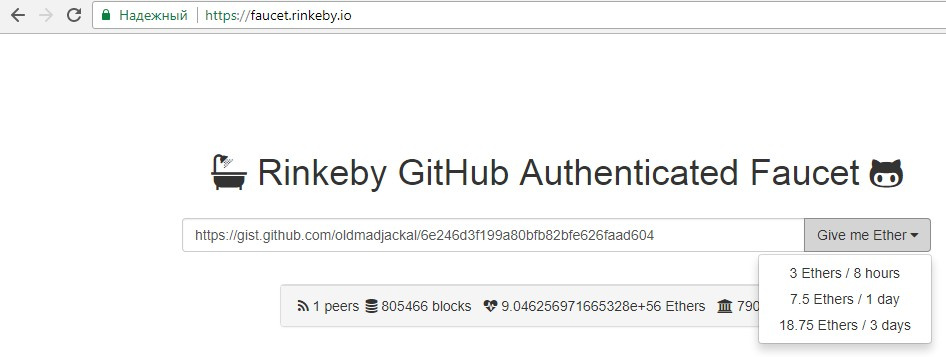
Если всё хорошо, то появится зелёное сообщение с подтверждением. Транзакция может пройти не очень быстро — за 5-10 минут.
- Смотрим счёт на EtherScan:
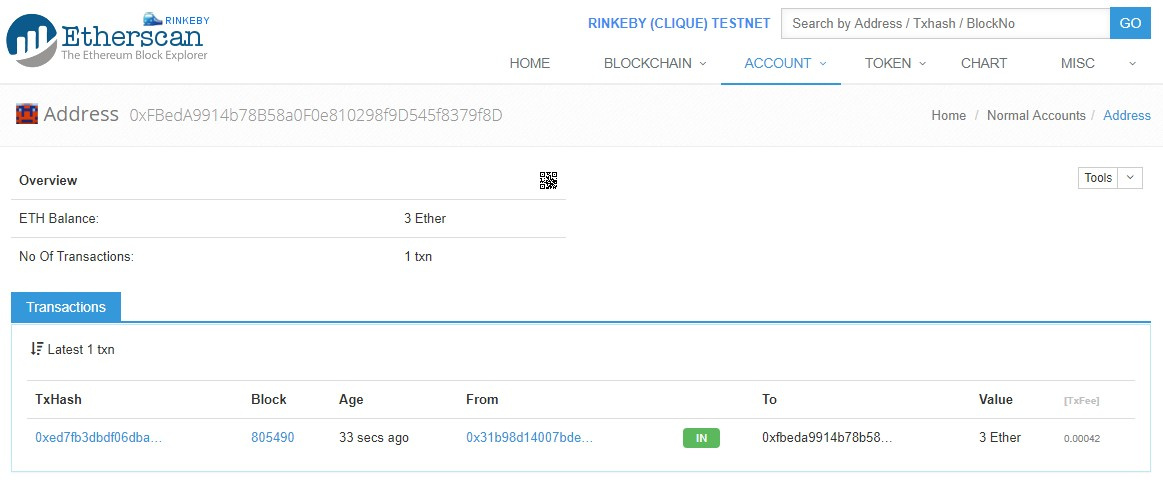
- Для повторных пополнений можно использовать тот же gist.
Для того, чтобы использовать средства со счета — выполнять транзакции любого вида —
счёт необходимо разблокировать. Для разблокировки счёта используется метод personal_unlockAccount. В качестве параметров указываются идентификатор счёта, пароль и продолжительность разблокировки в секундах:
{"jsonrpc":"2.0","method":"personal_unlockAccount","params":["0xfbeda9914b78b58a0f0e810298f9d 545f8379f8d", "PASSWORD", 600],"id":1}
{"jsonrpc":"2.0","id":1,"result":true}
Создание смарт-контракта
Технически смарт-контракт создаётся транзакцией, содержащей в поле данных байт-код контракта и блок параметров инициализации, если такие предусмотрены смарт-контрактом.
Байт-код контракта для формирования транзакции создания может быть получен следующими способами:
- Компиляцией из исходного текста смарт-контракта.
- Извлечением из другой транзакции создания такого же смарт-контракта.
Второй способ можно использовать, чтобы хранить шаблон создания контракта непосредственно в блокчейне — тогда достаточно знать идентификатор транзакции, чтобы его извлечь и «клонировать».
Технически можно извлечь код транзакции непосредственно по идентификатору уже существующего смарт-контракта (метод eth_getCode), но этого делать
НЕЛЬЗЯ, так как он выдаёт байт-код, подвергшийся специальной обработке при создании смарт-контракта (в частности, из него удаляются блоки инициализации).
Компиляция исходного кода смарт-контракта
Для компиляции исходного кода на Solidity я использую Remix —
https://remix.ethereum.org/.

Вводим текст контракта, если ошибок нет — в поле Bytecode будет находиться собственно байткод, в нашем случае:
6060604052341561000f57600080fd5b5b6040805190810160405280600381526020017f4e657700000
000000000000000000000000000000000000000000000000000008152506000908051906020019061
005b929190610062565b505b610107565b82805460018160011615610100020316600290049060005
2602060002090601f016020900481019282601f106100a357805160ff19168380011785556100d1565b
828001600101855582156100d1579182015b828111156100d05782518255916020019190600101906
100b5565b5b5090506100de91906100e2565b5090565b61010491905b8082111561010057600081600
09055506001016100e8565b5090565b90565b6101b6806101166000396000f30060606040526000357 c0100000000000000000000000000000000000000000000000000000000900463ffffffff168063abd95b 951461003e575b600080fd5b341561004957600080fd5b6100516100cd565b604051808060200182810
3825283818151815260200191508051906020019080838360005b8381101561009257808201518184
01525b602081019050610076565b50505050905090810190601f1680156100bf578082038051600183
6020036101000a031916815260200191505b509250505060405180910390f35b6100d5610176565b60
008054600181600116156101000203166002900480601f016020809104026020016040519081016040
52809291908181526020018280546001816001161561010002031660029004801561016b5780601f10
6101405761010080835404028352916020019161016b565b820191906000526020600020905b81548
152906001019060200180831161014e57829003601f168201915b505050505090505b90565b6020604
051908101604052806000815250905600a165627a7a723058208ce8782af87268eb0fb543832301a980
e57bdb35f0a3cdbfe8f2ece20d9a3eaa0029
Извлечение кода из транзакции
Для извлечения кода из транзакции используется метод
eth_getTransactionByHash. В нашем примере «клонируемый» смарт-контракт был создан транзакцией
0xc4d20bb8f9eede45968fc6bc850397e92b9f263eeb11200615cc08562d46c2e7.
{"jsonrpc":"2.0","method":"eth_getTransactionByHash","params":["0xc4d20bb8f9eede45968fc6bc850 397e92b9f263eeb11200615cc08562d46c2e7"],"id":1}
В тэге
input ответа содержится байткод контракта.
{"jsonrpc":"2.0","id":1,"result":{"blockHash":"0x731f202b0232de8c474c71677b29868f65802c068d0d e31b17bec09f3e31144c", "blockNumber":"0xbad3f", "from":"0x17eafa57fd812968d90aecc5a51e330e2e1c11a3", "gas":"0x31b2e", "gasPrice":"0x9c7652400", "hash":"0xc4d20bb8f9eede45968fc6bc850397e92b9f263eeb11200615cc08562d46c2e7", "input":"0x6060604052341561000f57600080fd5b5b6040805190810160405280600381526020017f4e 657700000000000000000000000000000000000000000000000000000000008152506000908051906
020019061005b929190610062565b505b610107565b82805460018160011615610100020316600290
0490600052602060002090601f016020900481019282601f106100a357805160ff19168380011785556
100d1565b828001600101855582156100d1579182015b828111156100d05782518255916020019190
600101906100b5565b5b5090506100de91906100e2565b5090565b61010491905b8082111561010057
60008160009055506001016100e8565b5090565b90565b6101b6806101166000396000f30060606040
526000357c0100000000000000000000000000000000000000000000000000000000900463ffffffff168
063abd95b951461003e575b600080fd5b341561004957600080fd5b6100516100cd565b604051808060
2001828103825283818151815260200191508051906020019080838360005b8381101561009257808
20151818401525b602081019050610076565b50505050905090810190601f1680156100bf578082038
0516001836020036101000a031916815260200191505b509250505060405180910390f35b6100d5610
176565b60008054600181600116156101000203166002900480601f016020809104026020016040519
08101604052809291908181526020018280546001816001161561010002031660029004801561016b
5780601f106101405761010080835404028352916020019161016b565b820191906000526020600020
905b81548152906001019060200180831161014e57829003601f168201915b505050505090505b9056
5b6020604051908101604052806000815250905600a165627a7a723058208ce8782af87268eb0fb5438
32301a980e57bdb35f0a3cdbfe8f2ece20d9a3eaa0029", "nonce":"0x30", "to":null, "transactionIndex":"0x2", "value":"0x0", "v":"0x2c", "r":"0x577865931aac644a3eefb83b59344caeab9e2970cfeb1bef02837b1bb4bccca0", "s":"0x48013e0c5ca3bff66fa7e19ebbcd9eaed63bc0a45004041c310f9fc4dfc5e5e8"}}
Обратите внимание, что если конструктор смарт-контракта предусматривает использование параметров, то кроме байт-кода в тэге input будут указаны значения параметров, следующих сразу следом за байт-кодом. При создании шаблона смарт-контракта для последующего клонирования можно использовать нулевые значения параметров.
Расчет стоимости опубликования контракта
Для расчета стоимости опубликования контракта используется метод
eth_estimateGas, в параметрах которого следует указать номер счета (тэг
from), с которого будет создан контракт, а также байт-код контракта (тэг
data). В ответе будет указано необходимое количество Gas.
Если конструктор смарт-контракта предполагает использование параметров, то они должны быть включены в запрос в тэге
data сразу после байт-кода. В противном случае расчет Gas будет некорректным.
{"jsonrpc":"2.0","method":"eth_estimateGas","params":[{ "from":"0xfbeda9914b78b58a0f0e810298f9d545f8379f8d", "data":"0x6060604052341561000f57600080fd5b5b6040805190810160405280600381526020017f4e6 577000000000000000000000000000000000000000000000000000000000081525060009080519060
20019061005b929190610062565b505b610107565b828054600181600116156101000203166002900
490600052602060002090601f016020900481019282601f106100a357805160ff191683800117855561
00d1565b828001600101855582156100d1579182015b828111156100d057825182559160200191906
00101906100b5565b5b5090506100de91906100e2565b5090565b61010491905b80821115610100576
0008160009055506001016100e8565b5090565b90565b6101b6806101166000396000f300606060405
26000357c0100000000000000000000000000000000000000000000000000000000900463ffffffff1680
63abd95b951461003e575b600080fd5b341561004957600080fd5b6100516100cd565b6040518080602
001828103825283818151815260200191508051906020019080838360005b83811015610092578082
0151818401525b602081019050610076565b50505050905090810190601f1680156100bf5780820380
516001836020036101000a031916815260200191505b509250505060405180910390f35b6100d56101
76565b60008054600181600116156101000203166002900480601f0160208091040260200160405190
8101604052809291908181526020018280546001816001161561010002031660029004801561016b5
780601f106101405761010080835404028352916020019161016b565b8201919060005260206000209
05b81548152906001019060200180831161014e57829003601f168201915b505050505090505b90565 b6020604051908101604052806000815250905600a165627a7a723058208ce8782af87268eb0fb54383
2301a980e57bdb35f0a3cdbfe8f2ece20d9a3eaa0029" }], "id":1}
{"jsonrpc":"2.0","id":1,"result":"0x31b2e"}
Обратите внимание, что в некоторых случаях смарт-контракты содержат семантические (не синтаксические) ошибки, которые пропускаются компилятором, но приводят к неработоспособности контракта. Одним из признаков появления такой ошибки будет резкое — в разы, возрастание стоимости создания контракта.
Выполнение транзакции на публикацию контракта
Для публикации контракта используется метод
eth_sendTransaction. В качестве параметров методу передаются:
- номер счета, с которого создаётся контракт (тэг
from);
- стоимость публикации в Gas (тэг
gas, берется из предыдущего пункта);
- байт-код контракта с пристыкованным блоком параметров конструктора (тэг
data, должен полностью совпадать с использованным в предыдущем пункте).
{"jsonrpc":"2.0","method":"eth_sendTransaction","params":[{ "from":"0xfbeda9914b78b58a0f0e810298f9d545f8379f8d", "gas":"0x31b2e", "data":"0x6060604052341561000f57600080fd5b5b6040805190810160405280600381526020017f4e6 577000000000000000000000000000000000000000000000000000000000081525060009080519060
20019061005b929190610062565b505b610107565b828054600181600116156101000203166002900
490600052602060002090601f016020900481019282601f106100a357805160ff191683800117855561
00d1565b828001600101855582156100d1579182015b828111156100d057825182559160200191906
00101906100b5565b5b5090506100de91906100e2565b5090565b61010491905b80821115610100576
0008160009055506001016100e8565b5090565b90565b6101b6806101166000396000f300606060405
26000357c0100000000000000000000000000000000000000000000000000000000900463ffffffff1680
63abd95b951461003e575b600080fd5b341561004957600080fd5b6100516100cd565b6040518080602
001828103825283818151815260200191508051906020019080838360005b83811015610092578082
0151818401525b602081019050610076565b50505050905090810190601f1680156100bf5780820380
516001836020036101000a031916815260200191505b509250505060405180910390f35b6100d56101
76565b60008054600181600116156101000203166002900480601f0160208091040260200160405190
8101604052809291908181526020018280546001816001161561010002031660029004801561016b5
780601f106101405761010080835404028352916020019161016b565b8201919060005260206000209
05b81548152906001019060200180831161014e57829003601f168201915b505050505090505b90565 b6020604051908101604052806000815250905600a165627a7a723058208ce8782af87268eb0fb54383
2301a980e57bdb35f0a3cdbfe8f2ece20d9a3eaa0029" }], "id":1}
В ответ мы получим номер транзакции:
{"jsonrpc":"2.0","id":1,"result":"0x26cd429a43bc2f706f206fa6a536374cc7bf0e5090f0ed9b8f30ded71 73529f5"}
или сообщение об ошибке:
{"jsonrpc":"2.0","id":1,"error":{"code":-32000,"message":"authentication needed: password or unlock"}}
Теперь необходимо дождаться завершения транзакции и получить результат её исполнения — создан контракт или нет. Для этого используется метод
eth_getTransactionReceipt:
{"jsonrpc":"2.0","method":"eth_getTransactionReceipt","params":["0x26cd429a43bc2f706f206fa6a53 6374cc7bf0e5090f0ed9b8f30ded7173529f5"],"id":1}
Пока транзакция находится в «листе ожидания» (Pending Txn), будет выдаваться следующий ответ:
{"jsonrpc":"2.0","id":1,"result":null}
После исполнения транзакции мы получим полную «квитанцию», в теге
contractAddress которой будет содержаться адрес созданного смарт-контракта:
{"jsonrpc":"2.0", "id":1, "result":{"blockHash":"0x3afdc600435caebebb91497f01372c3ad6ac712c37fe9b1028445d8b41a58fca"
, "blockNumber":"0xc4b16", "contractAddress":"0x2af49c8a413ea4b66ca8fd872befa9d1c8d22562", "cumulativeGasUsed":"0x31b2d", "from":"0xfbeda9914b78b58a0f0e810298f9d545f8379f8d", "gasUsed":"0x31b2d","logs":[], "logsBloom":"0x00000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000",
"root":"0x47b6297fef6ba21c45ea845a6fba19ddb144d957f600cfe7230e05f0f711ac12", "to":null, "transactionHash":"0x26cd429a43bc2f706f206fa6a536374cc7bf0e5090f0ed9b8f30ded7173529f5", "transactionIndex":"0x0"}}
Если в течении 5 минут квитанция не получена, то либо в сети проблемы, либо ваш узел не разослал проводку по сети. Чтобы понять истинную причину, следует просмотреть очередь Pending Txn на etherscan.io (
https://rinkeby.etherscan.io/txsPending). Если транзакции там нет — значит, надо перезапустить клиент Ethereum и повторить публикацию заново.
Теперь следует проверить, корректно ли создался смарт-контракт. Для этого можно использовать метод
eth_getCode — получение кода контракта по его адресу:
{"jsonrpc":"2.0","method":"eth_getCode","params":["0x2af49c8a413ea4b66ca8fd872befa9d1c8d2256 2", "latest" ],"id":1}
Если контракт создался некорректно, то будет получен ответ:
{"jsonrpc":"2.0","id":1,"result":"0x"}
Если в тэге result выдаются некоторые данные, отличные от
0x, то контракт создан успешно.
Взаимодействие со смарт-контрактом
Для демонстрации взаимодействия со смарт-контрактом будем использовать следующий образцовый смарт-контракт:
pragma solidity ^0.4.9;
contract Test
{
address Owner ;
address Seller ;
address Bank ;
address BankCert ;
string Status ;
function Test(address seller_, address bank_)
{
Owner=msg.sender ;
Seller=seller_ ;
Bank=bank_ ;
Status="New" ;
}
// 0xabd95b95
function GetStatus() constant returns (address, address, string retVal)
{
return(Seller, Bank, Status) ;
}
// 0x1bb71149
function SetBankCert(address cert)
{
if(msg.sender!=Bank) return ; BankCert=cert ;
Status="Confirmed" ;
}
}
При создании контракта (конструктор — функция
Test) ему передаются адрес Продавца (
seller_) и адрес Банка (
bank_). Метод
GetStatus возвращает адресa Продавца, Банка и текущий статус контракта. Метод
SetBankCert предназначен для сохранения в контракте некоторого цифрового идентификатора с переводом в статус «Confirmed».
Байт-код контракта:
6060604052341561000f57600080fd5b60405160408061064383398101604052808051906020019091
9080519060200190919050505b336000806101000a81548173ffffffffffffffffffffffffffffffffffffffff021916908 373ffffffffffffffffffffffffffffffffffffffff16021790555081600160006101000a81548173fffffffffffffffffffffffffffffffff fffffff021916908373ffffffffffffffffffffffffffffffffffffffff16021790555080600260006101000a81548173ffffffffff ffffffffffffffffffffffffffffff021916908373ffffffffffffffffffffffffffffffffffffffff160217905550604080519081016040 5280600381526020017f4e657700000000000000000000000000000000000000000000000000000000
008152506004908051906020019061014292919061014b565b505b50506101f0565b82805460018160
0116156101000203166002900490600052602060002090601f016020900481019282601f1061018c57
805160ff19168380011785556101ba565b828001600101855582156101ba579182015b828111156101 b957825182559160200191906001019061019e565b5b5090506101c791906101cb565b5090565b6101 ed91905b808211156101e95760008160009055506001016101d1565b5090565b90565b610444806101 ff6000396000f30060606040526000357c0100000000000000000000000000000000000000000000000 000000000900463ffffffff1680631bb7114914610049578063abd95b9514610082575b600080fd5b34156
1005457600080fd5b610080600480803573ffffffffffffffffffffffffffffffffffffffff1690602001909190505061017 7565b005b341561008d57600080fd5b610095610264565b604051808473ffffffffffffffffffffffffffffffffffffffff1 673ffffffffffffffffffffffffffffffffffffffff1681526020018373ffffffffffffffffffffffffffffffffffffffff1673fffffffffffffffffffffffff fffffffffffffff1681526020018060200182810382528381815181526020019150805190602001908083836 0005b8381101561013a5780820151818401525b60208101905061011e565b505050509050908101906
01f1680156101675780820380516001836020036101000a031916815260200191505b5094505050505
060405180910390f35b600260009054906101000a900473ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffff ffffffffffffffffffffffff163373ffffffffffffffffffffffffffffffffffffffff161415156101d357610261565b80600360006101 000a81548173ffffffffffffffffffffffffffffffffffffffff021916908373ffffffffffffffffffffffffffffffffffffffff1602179055506 040805190810160405280600981526020017f436f6e6669726d6564000000000000000000000000000
00000000000000000008152506004908051906020019061025f92919061035f565b505b50565b60008
061026f6103df565b600160009054906101000a900473ffffffffffffffffffffffffffffffffffffffff166002600090549 06101000a900473ffffffffffffffffffffffffffffffffffffffff16600480805460018160011615610100020316600290 0480601f01602080910402602001604051908101604052809291908181526020018280546001816001
161561010002031660029004801561034c5780601f1061032157610100808354040283529160200191
61034c565b820191906000526020600020905b81548152906001019060200180831161032f57829003
601f168201915b505050505090509250925092505b909192565b828054600181600116156101000203
166002900490600052602060002090601f016020900481019282601f106103a057805160ff191683800
11785556103ce565b828001600101855582156103ce579182015b828111156103cd578251825591602
0019190600101906103b2565b5b5090506103db91906103f3565b5090565b602060405190810160405
280600081525090565b61041591905b808211156104115760008160009055506001016103f9565b509
0565b905600a165627a7a72305820554a2d34ed0a4ad399f7464c8b29ba8c619e7f5de89746021f5aded 9516dd1860029
Создание контракта с параметрами
Если конструктор смарт-контракта использует параметры (как в нашем демонстрационном примере), то они должны быть «упакованы» в соответствии с описанием «Упаковка параметров и возвращаемых данных» и присоединены в хвост к байт-коду контракта.
В нашем случае, передача адреса Продавца
0x794ce6de39fa2d274438cc1692db04dfb5bea836 и адреса Банка
0xfbeda9914 b78b58a0f0e810298f9d545f8379f8d при создании смарт-контракта будет выглядеть следующим образом (байт-код контракта кончается на
0029):
60606040...94000029000000000000000000000000794ce6de39fa2d274438cc1692db04dfb5bea8360
00000000000000000000000fbeda9914b78b58a0f0e810298f9d545f8379f8d
Еще раз обращаю внимание, что расчет Gas должен выполняться для всего блока Байт-код + Параметры, иначе контракт или не будет создан, или будет неработоспособен.
Наш тестовый демо-контракт был создан по адресу
0x3d20e579f5befdc7d3f589adb6155f684d9a751c.
Идентификация методов контракта
Для идентификации метода смарт-контракта, к которому мы обращаемся, используются первые 4 байта (8 шестнадцатеричных цифр) от хэша описания метода.
Например, для метода
GetStatus демо-контракта описанием будет
GetStatus(), а для метода
SetBankCert —
SetBankCert(address). Особое внимание следует обратить на отсутствие
пробелов в описании — были печальные прецеденты :(.
Для определения хэша используется метод
web3_sha3, при этом строчное значение следует давать в шестнадцатеричном представлении (для
GetStatus() это будет
0x4765745374617475732829):
{"jsonrpc":"2.0","method":"web3_sha3","params":["0x4765745374617475732829"],"id":1}
{"jsonrpc":"2.0","id":1,"result":"0xabd95b950242a279866243fa2b8fec5adddf6560d4e1b4f8745cfe7b5 7786865"}
Соответственно, идентификатором метода
GetStatus будет
0xabd95b95, для метода
SetBankCert идентификатор —
0x1bb71149.
Вызов методов запроса информации
Для вызова методов, не связанных с изменением состояния контракта (например, для получения информации о его текущем статусе), может быть использован метод API
eth_call.
Запрос метода имеет такую структуру:
{"jsonrpc":"2.0","method":"eth_call","params":[{"to":<Адрес контракта>, "data":<Данные запроса>},"latest"],"id":1}
Блок
<Данные запроса> формируется следующим образом:
<Идентификатор метода><Данные параметров>
где
<Данные параметров> формируются, как указано в пункте «Упаковка параметров и возвращаемых данных».
Если метод не предполагает наличия параметров, то блок
<Данные запроса> состоит только из идентификатора метода.
Например, для вызова метода
GetStatus демо-контракта
Test используется запрос:
{"jsonrpc":"2.0", "method":"eth_call", "params":[{"to":"0x3d20e579f5befdc7d3f589adb6155f684d9a751c", "data":"0xabd95b95"}, "latest"],"id":1}
на который будет дан ответ:
{"jsonrpc":"2.0", "id":1, "result":"0x000000000000000000000000794ce6de39fa2d274438cc1692db04dfb5bea8360000000000 00000000000000fbeda9914b78b58a0f0e810298f9d545f8379f8d000000000000000000000000000000
000000000000000000000000000000006000000000000000000000000000000000000000000000000
000000000000000034e65770000000000000000000000000000000000000000000000000000000000"
}
Разберем полученный ответ в соответствии с правилами пункта «Упаковка параметров и возвращаемых данных» и с учетом описания метода
GetStatus — function GetStatus() constant returns (address, address, string retVal).
Для удобства анализа разложим ответ на 32-байтные слова:
000:000000000000000000000000794ce6de39fa2d274438cc1692db04dfb5bea836
020:000000000000000000000000fbeda9914b78b58a0f0e810298f9d545f8379f8d
040:0000000000000000000000000000000000000000000000000000000000000060
060:0000000000000000000000000000000000000000000000000000000000000003
080:4e65770000000000000000000000000000000000000000000000000000000000
Исходя из описания мы ожидаем получение следующего набора переменных: address, string. Таким образом:
- в строке 000 находится адрес Продавца (тип
address) — 0x794ce6de39fa2d274438cc1692db04dfb5bea836
- в строке 020 находится адрес Продавца (тип
address) — 0xfbeda9914b78b58a0f0e810298f9d545f8379f8d
- в строке 040 находится ссылка на блок описания статуса контракта (тип
string) — блок начинается с адреса 060
- в строке 060 находится счетчик символов в строке статуса контракта — 3 символа
- в строке 080 находятся собственно символы статуса контракта в шестнадцатеричной кодировке —
New
Вызов методов, изменяющих состояние контракта
Для вызова методов, изменяющих состояние контракта, должен быть использован метод API
eth_sendTransaction.
Запрос метода имеет такую структуру:
{"jsonrpc":"2.0","method":"eth_sendTransaction","params":[{ "from":<Адрес инициатора>, "to":<Адрес контракта>, "gas":<Стоимость исполнения>, "data":<Данные запроса> }], "id":1}
<Адрес инициатора> должен иметь баланс, достаточный для выплаты
<Стоимости исполнения>. Кроме того, следуют учитывать, что контракт может содержать внутренние условия по контролю
<Адреса инициатора>, как, например, в методе
SetBankCert нашего демо-контракта.
Блок
<Данные запроса> формируется следующим образом:
<Идентификатор метода><Данные параметров>
где
<Данные параметров> формируются, как указано в параграфе «Упаковка параметров и возвращаемых данных».
Если метод не предполагает наличия параметров, то блок
<Данные запроса> состоит только из идентификатора метода.
Например, для вызова метода
SetBankCert("0хf7b0f8870a5596a7b57dd3e035550aeb5af16607") демо-контракта,
<Данные запроса> будут иметь следующий вид:
0x1bb71149000000000000000000000000f7b0f8870a5596a7b57dd3e035550aeb5af16607.
Для определения стоимости исполнения, как и при создании смарт-контракта, используется метод
eth_estimateGas, в который передаются всё те же параметры, которые затем будут переданы в методе
eth_sendTransaction.
{"jsonrpc":"2.0","method":"eth_estimateGas","params":[{ "from":"0xfbeda9914b78b58a0f0e810298f9d545f8379f8d", "to":"0x3d20e579f5befdc7d3f589adb6155f684d9a751c", "data":"0x1bb71149000000000000000000000000f7b0f8870a5596a7b57dd3e035550aeb5af16607"
}],"id":1}
{"jsonrpc":"2.0","id":1,"result":"0xd312"}
Как показывает опыт, если в вызываемом методе содержится транзакционный вызов других смарт-контрактов, то сумма Gas может быть рассчитана неверно и транзакция не исполнится. Поэтому рекомендую указывать заведомо большее количество Gas, так как, по идее, излишек использован не будет. В таких случаях я указываю количество Gas, близкое к максимальному —
0х200000.
Далее вызываем метод
eth_sendTransaction:
{"jsonrpc":"2.0", "method":"eth_sendTransaction", "params":[{ "from":"0xfbeda9914b78b58a0f0e810298f9d545f8379f8d", "to":"0x3d20e579f5befdc7d3f589adb6155f684d9a751c", "gas":"0xd312", "data":"0x1bb71149000000000000000000000000f7b0f8870a5596a7b57dd3e035550aeb5af16607"
}],"id":1}
и получаем в ответ идентификатор транзакции:
{"jsonrpc":"2.0","id":1,"result":"0xe55c9fe8f816f5730053fc491ea27acfd83c615b6623d06f25fb281fea 750f3c"}
Как и в случае с созданием смарт-контракта, ожидаем исполнения транзакции, запрашивая квитанцию (метод eth_getTran sactionReceipt):
{"jsonrpc":"2.0","method":"eth_getTransactionReceipt","params":["0xe55c9fe8f816f5730053fc491ea2 7acfd83c615b6623d06f25fb281fea750f3c"],"id":1}
Как только квитанция пришла — транзакция исполнилась:
{"jsonrpc":"2.0", "id":1, "result":{"blockHash":"0xd8bb4a0b0ca3a598a69786f2f40876d547a672044fc8d961ec22da60606fa2fb"
, "blockNumber":"0xc4b6f", "contractAddress":null, "cumulativeGasUsed":"0x459e5", "from":"0xfbeda9914b78b58a0f0e810298f9d545f8379f8d", "gasUsed":"0xd311", "logs":[], "logsBloom":"0x00000000000000000000000000000000000000000000000000000000000000000000 000000000000000000000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000000000000000000000000000000000000000000000
000000000000000000000000000000000000000",
"root":"0x75f6823221a4f0e4f80dfa6c7ccfc961c7522833aac959d6a398537730a62041", "to":"0x3d20e579f5befdc7d3f589adb6155f684d9a751c", "transactionHash":"0xe55c9fe8f816f5730053fc491ea27acfd83c615b6623d06f25fb281fea750f3c", "transactionIndex":"0x1"}}
Однако, само по себе исполнение транзакции вовсе не означает, что смарт-контракт переключился в нужное состояние, кроме того, могут не исполнится внутренние транзакционные вызовы других смарт-контрактов.
На мой взгляд, самый надежный способ проверить, что всё отработало — снова запросить состояние смарт-контракта и убедится, что всё изменилось «как надо».
000:000000000000000000000000794ce6de39fa2d274438cc1692db04dfb5bea836
020:000000000000000000000000fbeda9914b78b58a0f0e810298f9d545f8379f8d
040:0000000000000000000000000000000000000000000000000000000000000060
050:0000000000000000000000000000000000000000000000000000000000000009
060:436f6e6669726d65640000000000000000000000000000000000000000000000
Разобрав ответ, мы увидим, что статус изменился на «Confirmed».
Резюме
В этом руководстве мы рассмотрели выполнение ряда задач, связанных с публикацией смарт-контрактов и взаимодействием с ними с помощью RPC API блокчейн-платформы Ethereum. Разобрались, как создавать счёт, как создавать корректный смарт-контракт, получать по нему информацию и изменять его состояние, а также выяснили, как с этим смарт-контрактом взаимодействовать.
Если у вас возникнут дополнительные вопросы, рад буду ответить/подсказать.


























 Привет хабр!
Привет хабр!






 С того времени, как Google сделал Koltin новой любимой женой уже прошло достаточно времени. И сразу же после этого объявления наша команда начала новый проект полностью на Котлине. Проясню: не тестовый или просто внутренний проект, а новый модуль для живого приложения с 600+ тысячами активных пользователей в месяц. Какой опыт мы из этого извлекли? Что мы выиграли и что потеряли?
С того времени, как Google сделал Koltin новой любимой женой уже прошло достаточно времени. И сразу же после этого объявления наша команда начала новый проект полностью на Котлине. Проясню: не тестовый или просто внутренний проект, а новый модуль для живого приложения с 600+ тысячами активных пользователей в месяц. Какой опыт мы из этого извлекли? Что мы выиграли и что потеряли?








 Дэниэл (@dwhitena) — доктор наук, опытный исследователь данных, он работает в компании Pachyderm (@pachydermIO). Он занимается разработкой современных распределенных конвейеров данных, включающих предсказательные модели, визуализацию данных, статистический анализ и другие возможности. Он выступал на конференциях в разных странах мира (ODSC, Spark Summit, Datapalooza, DevFest Siberia, GopherCon b lheubt), преподает исследование и анализ данных в компании Ardan Labs (@ardanlabs), поддерживает ядро Go для Jupyter и активно участвует в развитии различных проектов по интеллектуальному исследованию данных с открытым исходным кодом.
Дэниэл (@dwhitena) — доктор наук, опытный исследователь данных, он работает в компании Pachyderm (@pachydermIO). Он занимается разработкой современных распределенных конвейеров данных, включающих предсказательные модели, визуализацию данных, статистический анализ и другие возможности. Он выступал на конференциях в разных странах мира (ODSC, Spark Summit, Datapalooza, DevFest Siberia, GopherCon b lheubt), преподает исследование и анализ данных в компании Ardan Labs (@ardanlabs), поддерживает ядро Go для Jupyter и активно участвует в развитии различных проектов по интеллектуальному исследованию данных с открытым исходным кодом.