Фьючерсы, индексы и IPO: как на самом деле устроены биржи и зачем они нужны |

Ликвидность – это возможность быстро и без существенных накладных расходов продать или купить ценную бумагу.
Маркетмейкер – это участник торгов, который по соглашению с биржей обязан поддерживать разницу цен покупки-продажи в определенных пределах. За это он получает от биржи определенные льготы – например возможность совершать операции с ценными бумагами, которые поддерживает маркетмейкер с уменьшенными комиссиями или вовсе без них.
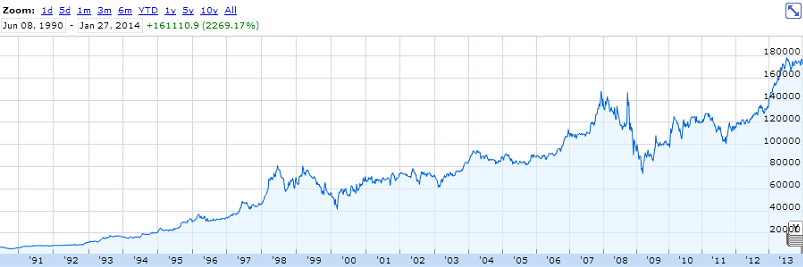
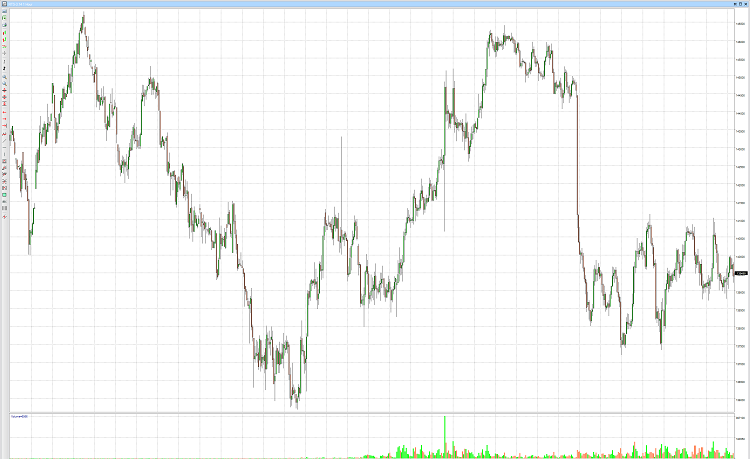
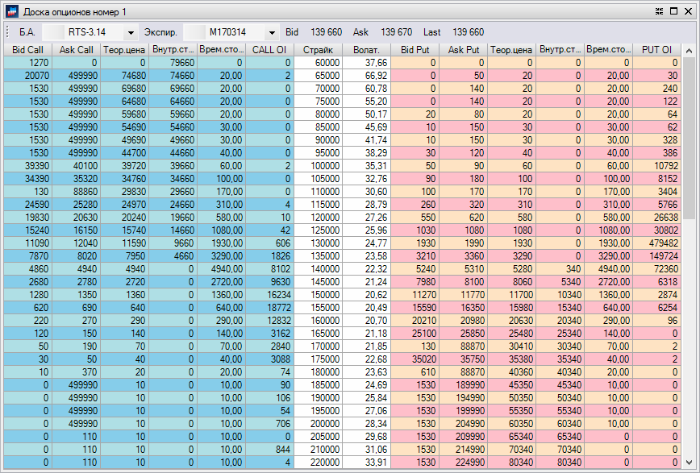
|
Метки: author itinvest финансы в it блог компании itinvest биржи фондовый рынок опционы |
Safari 11 и WebRTC: подводные камни видеозвонков |
 Итак, это свершилось. Кроме iPhone 8, который устарел ровно через полчаса после анонса iPhone 10, Apple обновила свой десктопный и мобильный браузер Safari. Среди прочих улучшений — реализация WebRTC (ходят слухи, что частично позаимствованная у Chromium. «Plan B» на это тоже намекает). Что это значит для разработчиков? Можно звонить через браузер как на десктопе, так и на айфонах. Голосом и видео. Я уже писал про обновленные инструменты разработчика в браузере, а сейчас хочу поделиться, как это все работает в релизе. Мы уже обновили SDK Voximplant, проверили, как Safari звонит в Microsoft Edge, и вот что я хочу рассказать…
Итак, это свершилось. Кроме iPhone 8, который устарел ровно через полчаса после анонса iPhone 10, Apple обновила свой десктопный и мобильный браузер Safari. Среди прочих улучшений — реализация WebRTC (ходят слухи, что частично позаимствованная у Chromium. «Plan B» на это тоже намекает). Что это значит для разработчиков? Можно звонить через браузер как на десктопе, так и на айфонах. Голосом и видео. Я уже писал про обновленные инструменты разработчика в браузере, а сейчас хочу поделиться, как это все работает в релизе. Мы уже обновили SDK Voximplant, проверили, как Safari звонит в Microsoft Edge, и вот что я хочу рассказать…|
Метки: author eyeofhell разработка веб-сайтов программирование safari javascript блог компании voximplant voximplant webrtc |
Мифы об SMS-рассылках |

|
|
Хакеры атаковали министерство обороны Швейцарии |

21 сентября в 14:00 директор по методологии и стандартизации Positive Technologies Дмитрий Кузнецов проведет бесплатный вебинар, посвященный вопросам регулирования безопасности критической информационной инфраструктуры в нашей стране.
В частности, речь пойдет о том, как организована система ГосСОПКА и что потребуется от владельцев информационных систем, попадающих под госрегулирование. Приглашаем специалистов по информационной безопасности, руководителей IT-подразделений организаций, работающих в сфере промышленности, связи, транспорта и здравоохранения.
Для участия в вебинаре нужно зарегистрироваться.
|
Метки: author ptsecurity информационная безопасность блог компании positive technologies взломы хакеры критическая инфраструктура вебинар |
Как сделать хороший ролик для App Store и Google Play |
| Превью приложения (App Previews в iOS App Store) |
Промо-видео (Promo videos в Google Play Store) |
|
| Формат |
Зависит от устройства. Полный список разрешений здесь (в разделе «App Preview Resolutions»). iOS 11: может быть до 3 превью. |
YouTube video. Рекомендуется разрешение 1920x1080. |
| Рекомендации |
Необходимо утверждение, в соответствии с довольно строгими/ограничивающими рекомендациями. Рекомендации App Store стоит изучить как можно внимательнее. Модерационная политика App Store довольно строгая: если модераторы не примут ролик, вам придется его переделывать. |
Утверждение не требуется, рекомендации в виде коротких советов. |
| Размещение и показ |
Версии iOS до 11: кнопка воспроизведения видео наложена на кадр постера, выступающий в качестве первого скриншота. iOS 11 и последующие: автовоспроизведение, отключение звука, зацикливание. Первое превью воспроизводится автоматически и в результатах поиска, и в листинге App Store. |
Кнопка воспроизведения видео наложена на графический объект (feature graphic), открывающий YouTube-видео. Не отображается в результатах поиска. |
| Продолжительность |
До 30 секунд |
Не ограничена |
| Обновление |
Требуется обновление приложения |
Может быть изменено в любое время |
| Тестирование |
Нет способа выполнить A/B тестирование без сторонних инструментов |
Может быть протестировано с помощью инструмента для экспериментов Google Play Store |
| Видео-статистика |
Статистика недоступна |
YouTube Analytics |




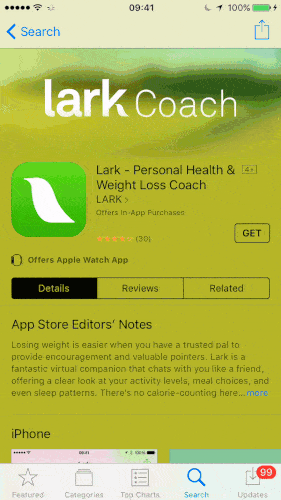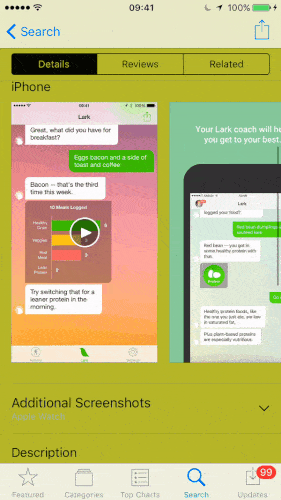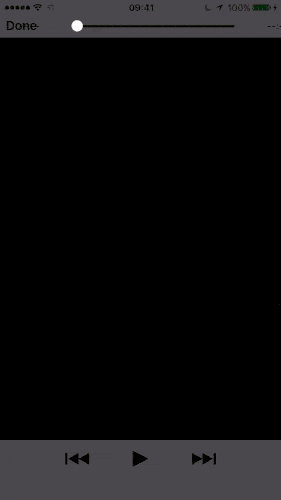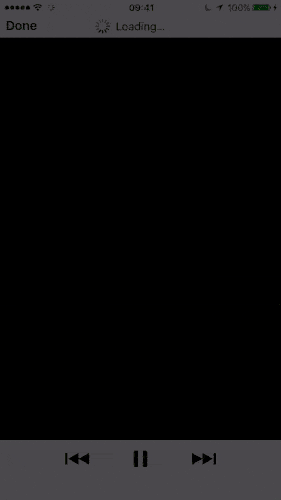

|
|
Дизайн-система Acronis. Часть первая. Единая библиотека компонентов |

Меня зовут Сергей, я работаю старшим дизайнером в компании Acronis. В отделе дизайна продуктов для бизнеса я отвечаю за разработку и внедрение единой библиотеки компонентов.
Так как у нас много продуктов и сервисов, а дизайн в этих продуктах и сервисах сильно отличается, мы решили его унифицировать и привести к единому UI. Зачем? Все просто: такой подход дает возможность оптимизировать работу отдела, сосредоточить дизайнеров на UX, ускорить процесс разработки и запуск новых продуктов, снизить нагрузку на отделы тестирования и значительно сократить количество багов на стороне front-end. В этой статье я расскажу о нашем опыте, остановлюсь на инструментах и покажу, как устроена библиотека изнутри.
Долгое время роль библиотеки играл собранный в Иллюстраторе PDF файл с палитрой цветов, скудным набором элементов и большими планами на будущее в виде 70-ти пустых страниц. Для того, чтобы найти какой-нибудь уже существующий элемент, приходилось постоянно дергать других дизайнеров или лопатить чужие исходники, а потом сверять актуальность с реализованным элементом на одном из тестовых стендов. Пик отчаяния наступал в тот момент, когда на тестовом стенде искомый элемент выглядел несколько иначе и вел себя не совсем так, как было запланировано в макетах. Получалась достаточно стандартная ситуация: дизайнеры тянули одеяло в свою сторону, мотивируя свои решения авторитетным «Хочу, чтобы так!», а разработчики пытались прикрываться мало значимым «Но ведь технические ограничения?!». Такой подход, закономерно, приводил к не самым лучшим результатам по обе стороны баррикад и его нужно было менять. Забегая вперед, скажу, что сейчас большинство сложных UI решений мы принимаем коллегиально и стараемся искать компромисс между красотой и технологичностью. Итак:
Первое, что предстояло сделать, это найти инструменты, которые закроют большую часть потребностей отдела. После длительного изучения различных подходов к формированию библиотек и дизайн-систем, после вороха статей на Medium и тестирования огромного количества приложений и сервисов, мы выстроили следующую схему:

Abstract отвечает за контроль версий и историю изменений мастер-файла библиотеки. Craft используется как библиотека для палитры цветов и замена нативному color инспектору. Lingo отвечает за хранение, подключение и обновление компонентов библиотеки в Sketch файлах.
Такая схема уже сейчас позволяет легко поддерживать библиотеку в актуальном состоянии, контролировать изменения и, что наиболее важно, быстро доставлять обновления дизайнерам. При этом, доступ к мастер-файлу библиотеки имеет только Owner, а остальные участники процесса получают элементы в виде символов и составных компонентов из Lingo. Для доступа к Angular компонентам мы подняли на каждой машине песочницу, чтобы дизайнеры с помощью «npm start» в консоли могли быстро запустить node server и работать с кодом.
Еще раз забегая вперед скажу, что одна из наших основных, долгосрочных и амбициозных задач — перенести большую часть работы над дизайном из графического редактора в браузер.

Десктопное приложение позволяющее контролировать историю изменений, откатываться к прошлым версиям и держать один, всегда актуальный, мастер-файл, доступ к которому есть у каждого члена команды. Для начала работы с Abstract достаточно добавить в приложение уже существующий проект или создать новый. Изменения идут в одной или нескольких параллельных ветках с последующим добавлением утвержденных кусков в мастер-файл.

Так как Abstract не дает создать новую ветку или слить ветку с мастер-файлом без комментария, история изменений появляется сама собой. Благодаря таким комментариям, значительно снижается вероятность случайных или неконтролируемых изменений. К тому же, удобно через какое-то время открыть проект и прочитать историю, посмотреть, как и зачем менялись элементы.

Если говорить о недостатках, то ключевым для некоторых команд может стать отсутствие возможности решать конфликты на уровне слоев в одном артборде, из-за чего параллельная работа над одним экраном невозможна, всегда будет конфликт версий и предложение выбрать один из двух вариантов. В нашей команде такой проблемы нет, так как мы одновременно не работаем над одним артбордом. Остальные мелкие неровности и шероховатости нивелируются полным контролем над происходящим; больше никаких папок по датам, никаких md. файлов с описанием изменений и кучи исходников на внутреннем хранилище.
На данный момент мы используем Craft как библиотеку для цветовой палитры и замену нативному color инспектору. Под рукой не только все цвета, но и названия переменных. Благодаря такому подходу удалось решить еще одну важную проблему. Дизайнеры перестали “пипетить”, а разработчики перестали резонно негодовать, почему в двух макетах у одного и того же элемента отличаются значения цвета. Кто работает в Sketch и использует несколько мониторов знает, что на каждом подключенном мониторе один и тот же цвет взятый пипеткой, в большинстве случаев, будет иметь разный HEX.
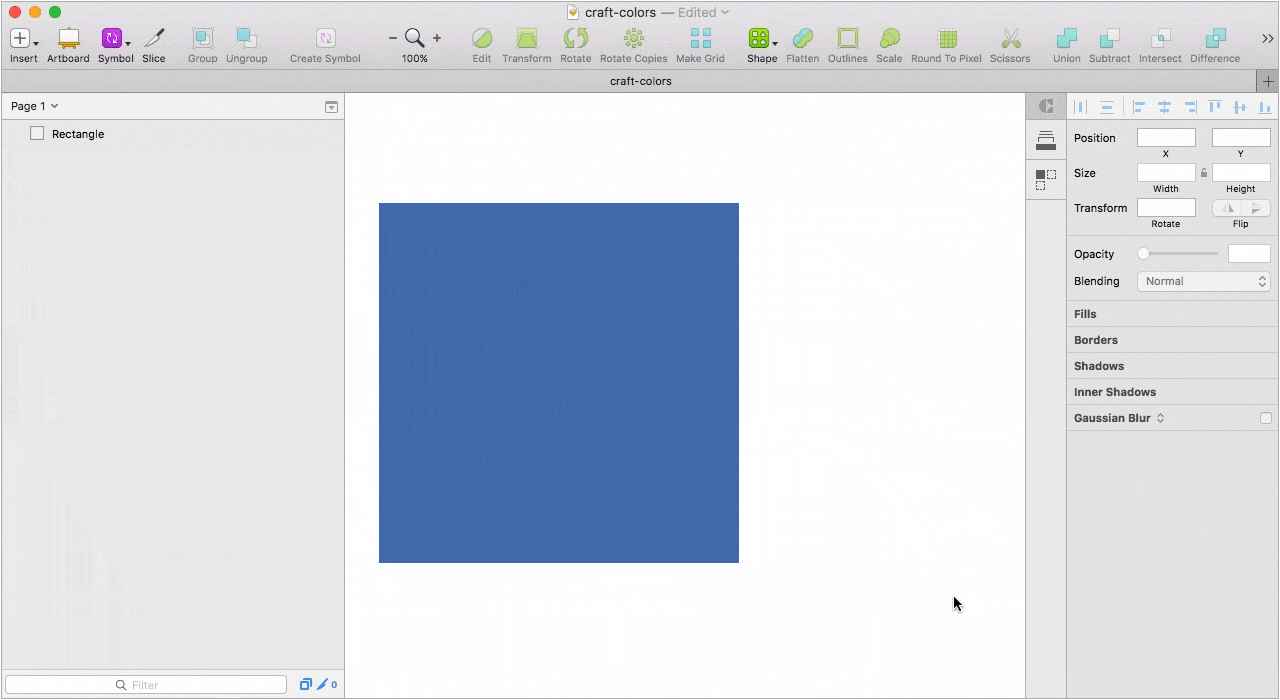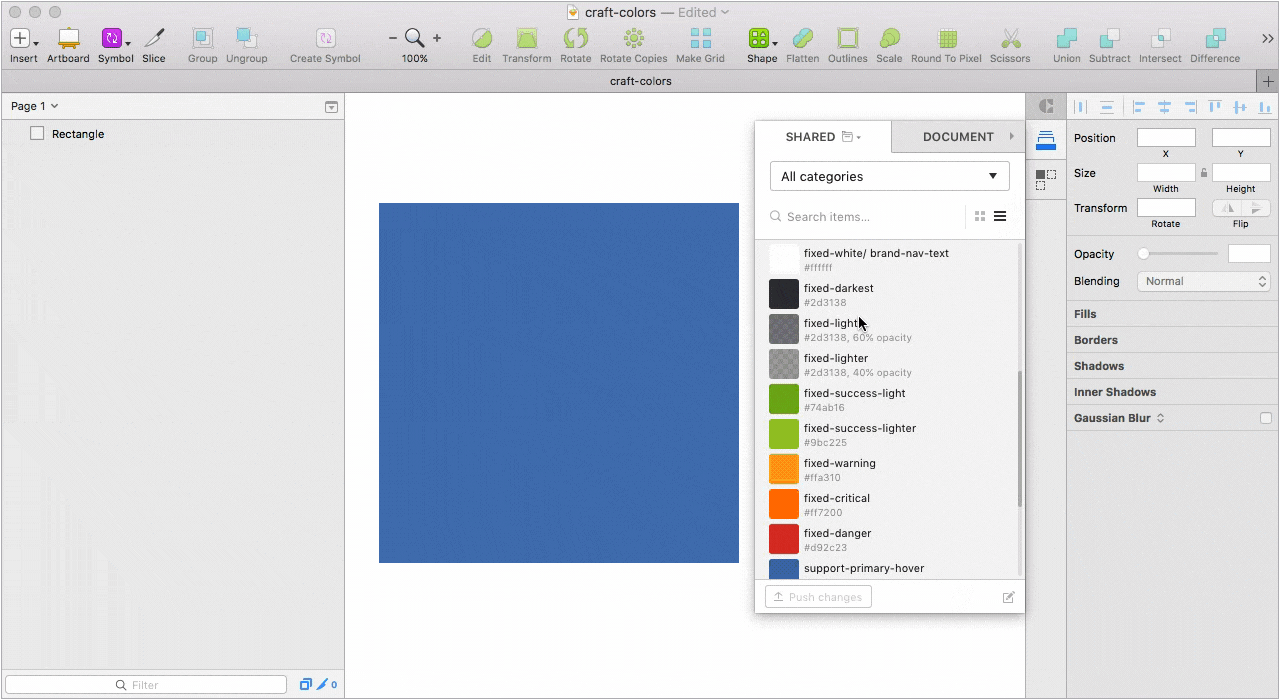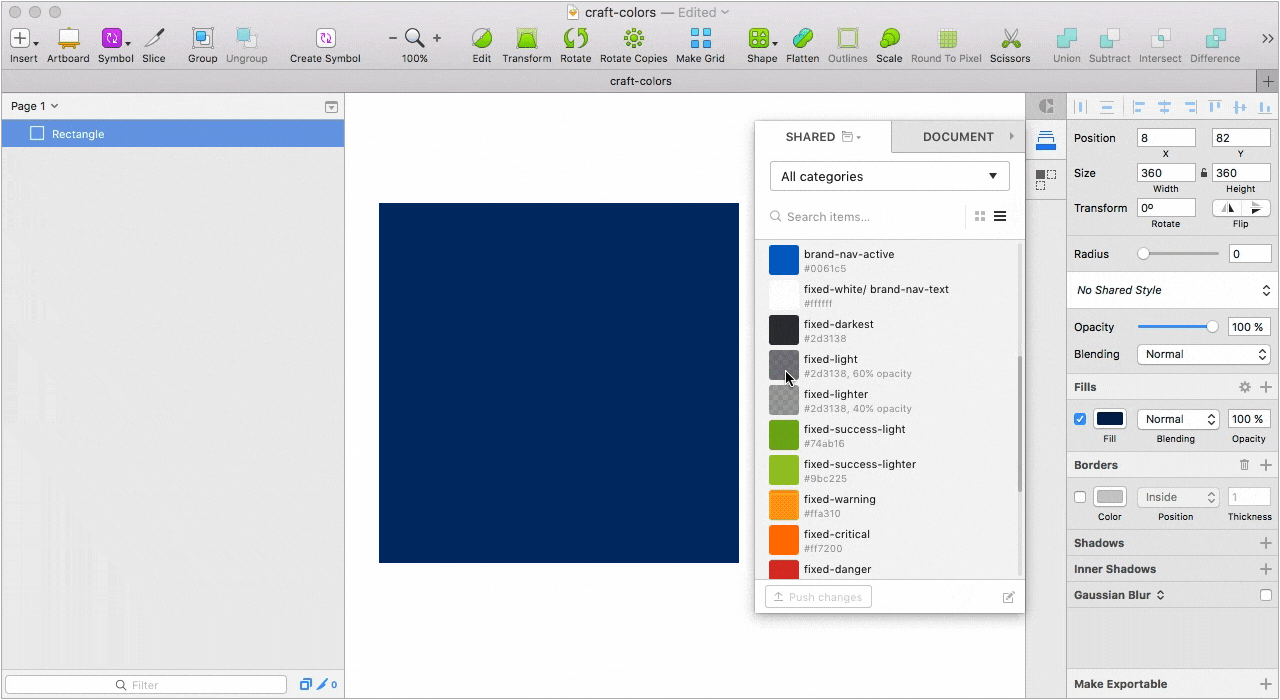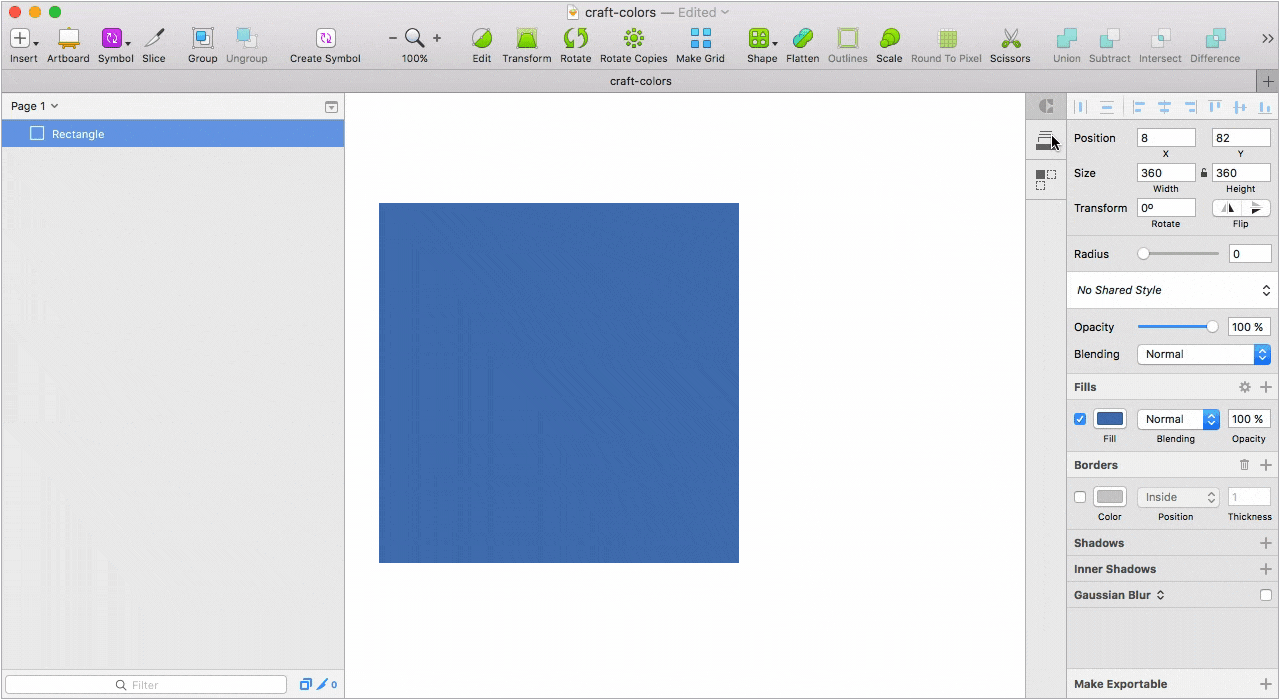
Десктопное приложение, с помощью которого мы решили все проблемы связанные с подключением актуальной библиотеки к новым файлам и обновлением компонентов в уже подключенных проектах.
Можно создать несколько библиотек, разбить библиотеку на категории, проставить теги для каждого элемента, а при импорте элементов выбрать какой элемент добавить, а какой нет. При обновлении существующего компонента в библиотеке, Lingo предложит его заменить, сделать дубликат или отказаться от изменений.
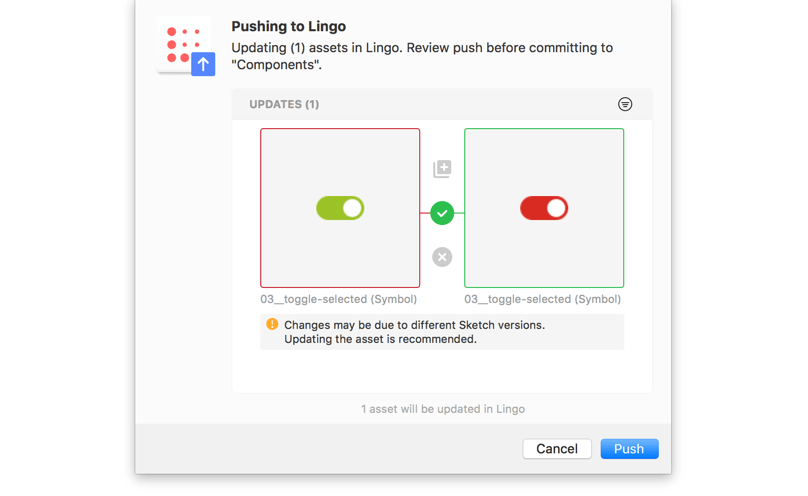
Так же, в Lingo можно хранить составные компоненты в виде папок со слоями или артборды целиком. Для нас эта возможность особенно актуальна, так как мы сознательно не делаем компоненты с большим количеством оверрайдов из-за сложностей в поддержке и кастомизации.
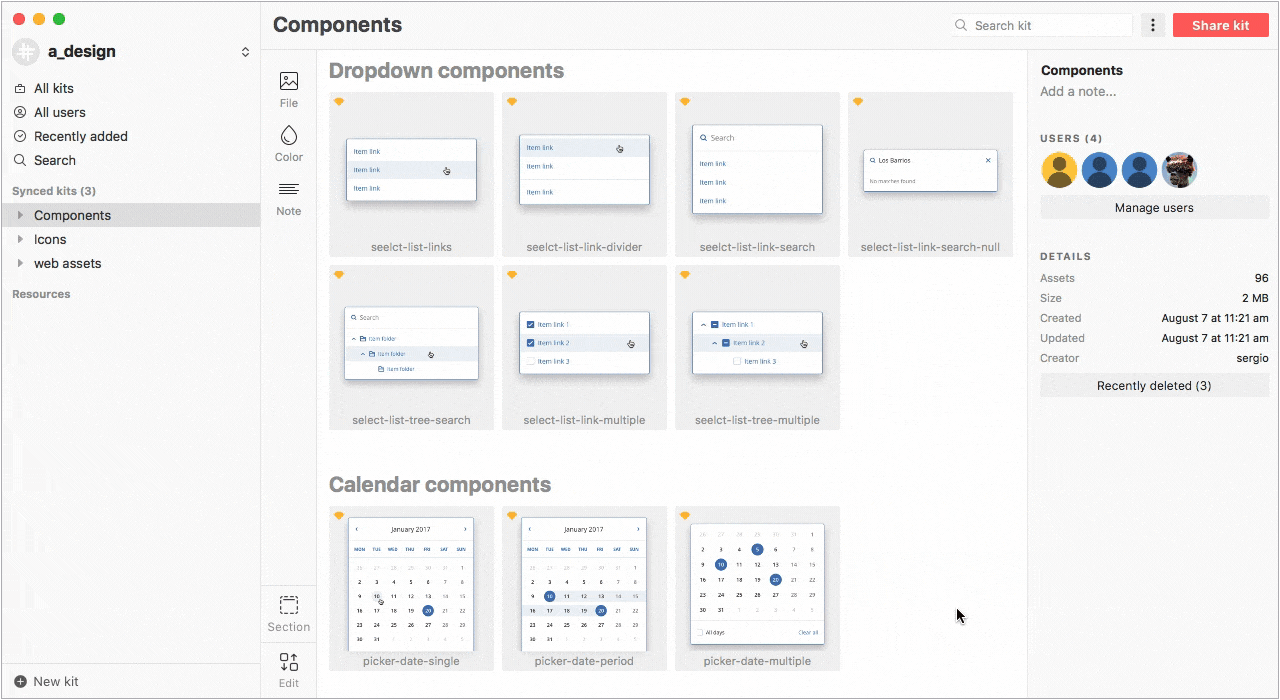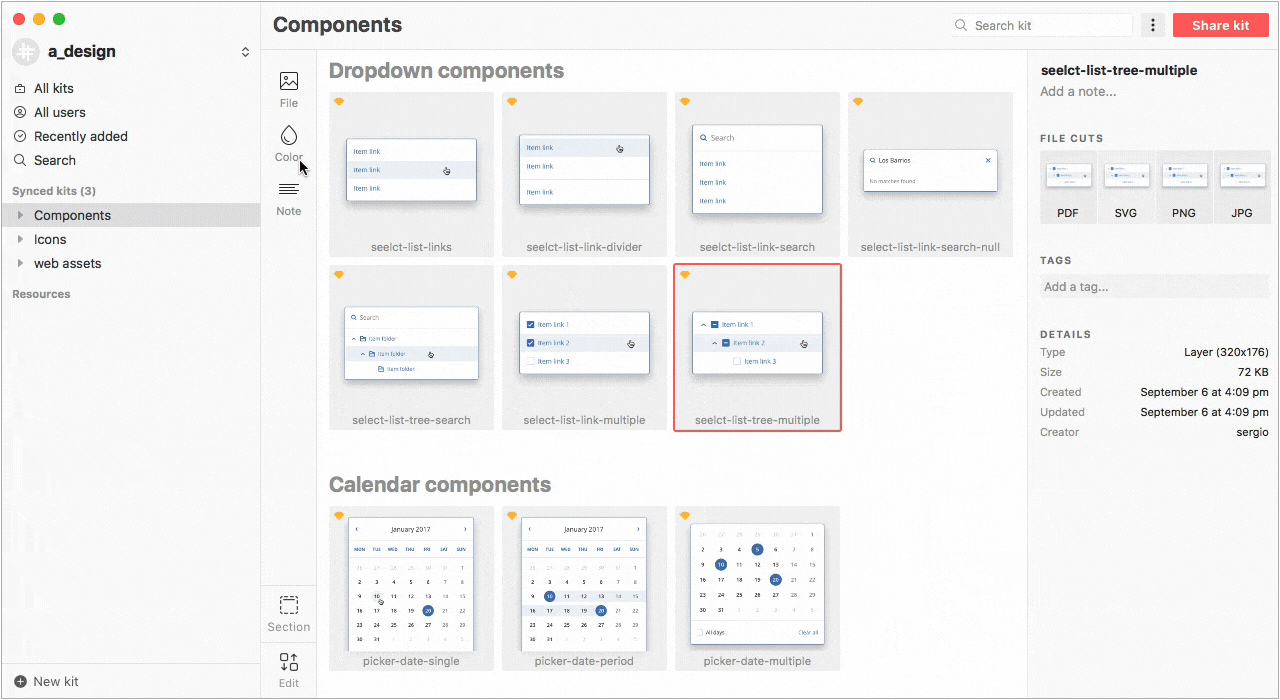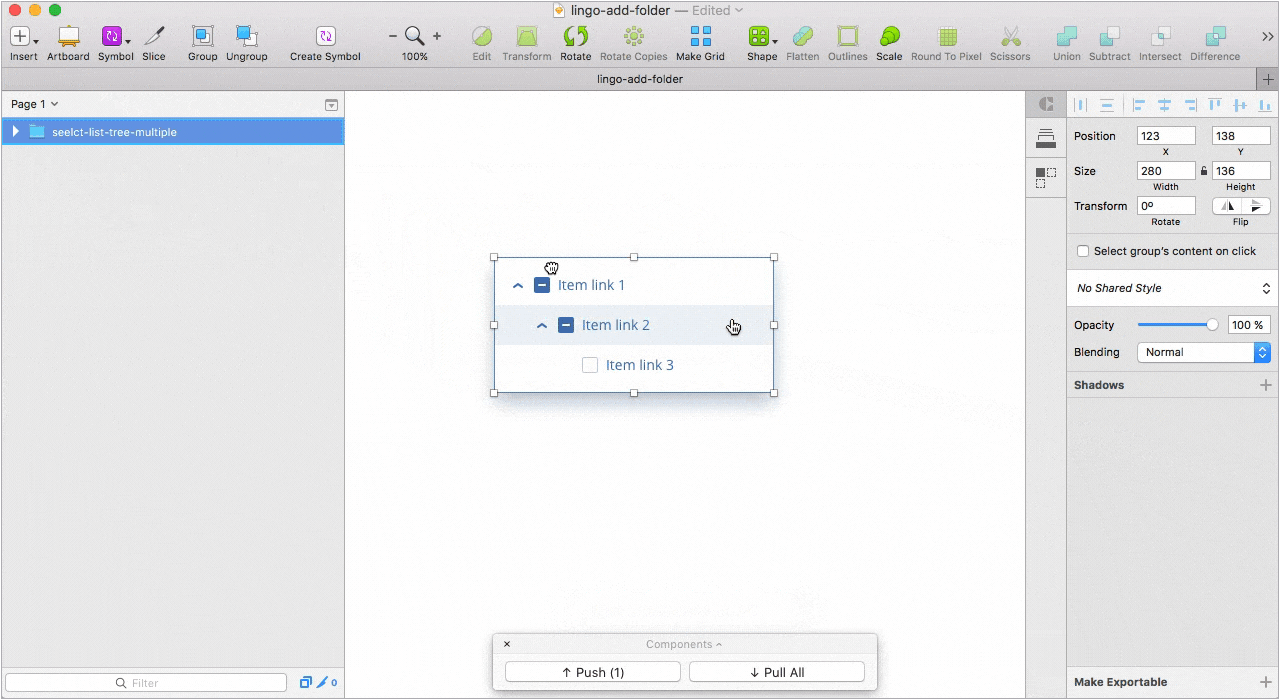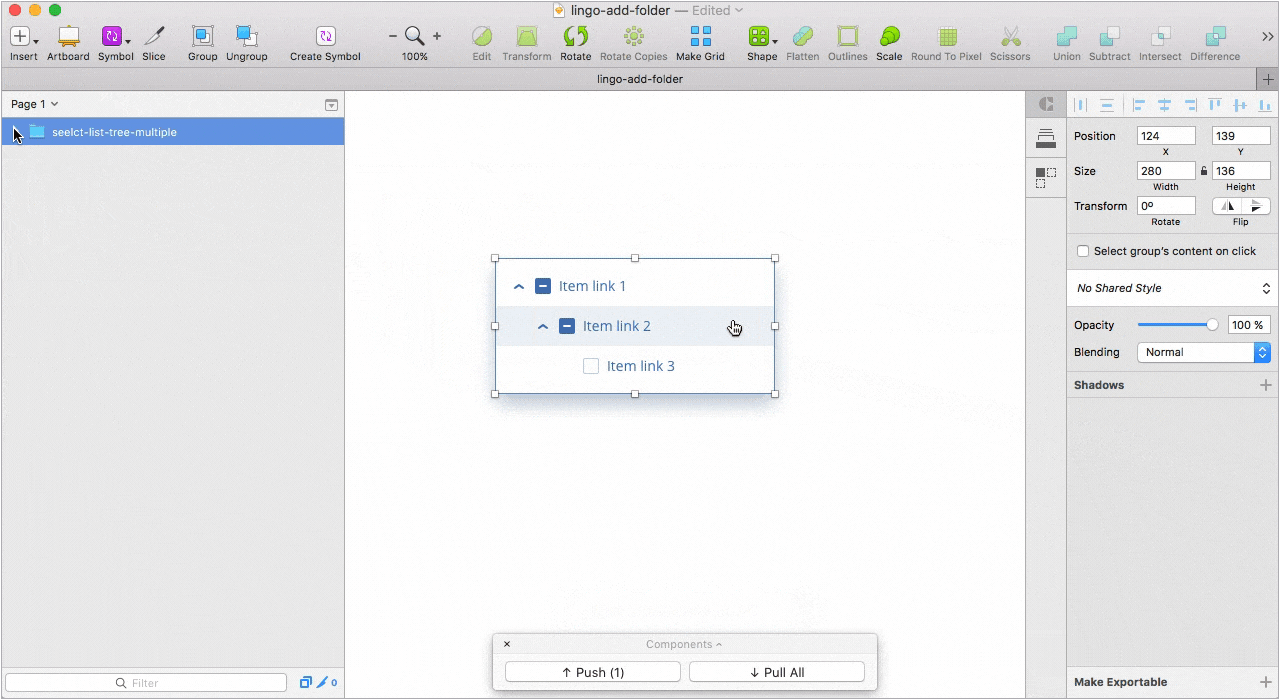
Несмотря на то, что в Sketch 47 будут библиотеки символов которые уже доступны в бета-версии (работают, кстати, круто), мы не спешим уходить с Lingo из-за его возможностей и большей гибкости в работе.
Централизованно мы используем три плагина:
Первый — Shared Text Styles для работы с текстовыми стилями. Позволяет экспортить текстовые стили в JSON, добавлять стили в новый Sketch документ и апдейтить уже подгруженные.
Второй — Relabel button для работы с кнопками. Одна из лучших реализаций плагинов такого рода, на мой взгляд. Достаточно правильно настроить привязки элементов внутри символа.
Третий — Acronis data. Так как мы достаточно много работаем с таблицами и большими массивами данных, я собрал плагин, который генерирует специализированные значения для этих таблиц (offering items, agents name, schedule options, machines и т.д.). Плагин работает на основе dummy data и подтягивает значения из JSON. Перед тем, как собирать кастомное решение, была неудачная попытка подружить единый JSON с Craft, но увы. Как оказалось, Craft не умеет в исходную разметку документа и показывает поля не по порядку.
Рано или поздно перед каждым дизайнером, работающим в Sketch, встает проблема повторного использования символа иконки с другим цветом. В частных случаях можно отвязать иконку от символа или держать несколько символов с разными цветами, что не очень актуально, когда иконок много. Я решил проблему следующим образом: прямоугольники с необходимыми цветами собрал в отдельные символы, а потом эти символы в виде масок добавил к иконкам, у которых может быть несколько цветов. Таким образом изменение цвета становится доступно через overrides.
Несмотря на удобство, у этого способа есть существенный минус. При экспорте SVG в коде будет присутствовать маска. Если на стороне разработки нет способа автоматизировать процесс удаления масок, придется держать отдельную библиотеку чистых иконок.
Неважно, насколько прокачана и удобна библиотека пока она существует исключительно в виде Sketch файла. Если в браузере компонент выглядит не так, как в макетах, библиотека уже неактуальна, а исходники устарели и не соответствуют действительности. Благодаря Сергею Сабурову, Кириллу Севёлову и всей команде мониторинга, наши компоненты плавно перетекают в код и работают именно так, как запланировано. Несмотря на то, что часть новых продуктов и сервисов мы уже начали собирать с помощью текущих компонентов, еще не все front-end команды готовы внедрять и использовать эти компоненты у себя. Где-то фронт написан на Ext JS, где-то используется Vue и быстрый переход с одного фреймворка или библиотеки на другой технически невозможен по ряду причин. О том, почему в компании выбрали именно Angular, подробно поговорим в следующей статье. А пока давайте вернемся к библиотеке и посмотрим, как устроены компоненты.
У каждого компонента есть набор свойств. Свойства позволяют управлять состоянием компонента, его внешним видом и функциональностью. Так выглядит стандартный инпут в Sketch библиотеке:

А вот так в коде:

Чтобы изменить размер и внешний вид инпута достаточно в свойствах указать
[size] = "'sm'"Теперь давайте посмотрим на более сложный пример:

Два типа дропдаунов. В первом случае — это список из значений, во втором к списку значений добавляется строка поиска. Переключимся на код:

С помощью #selectChild получаем вложенный компонент для активного значения поля, через (select) подписываемся на событие текущего компонента, а с помощью директивы *ngFor проходим по массиву из значений и выводим их в выпадающем списке. Чтобы включить строку поиска и возможность искать по списку, во втором примере включаем свойство [search]. Как я говорил выше, более подробно об Angular и работе компонентов на front-end стороне мы расскажем в следующей статье. Stay tuned!
Одна из наших амбициозных и долгосрочных задач — перенести дизайн из Sketch в браузер, чтобы дизайнер мог передавать в разработку не статичные исходники или прототипы, собранные в сторонних приложениях, а готовый код. До того момента, как появились Angular компоненты, для сложных прототипов я продвигал Framer, каждую неделю готовил лекции, рассказывал о принципах и тонкостях работы с Coffee Script. Несмотря на потраченные усилия Framer не прижился по нескольким причинам:
От Framer мы полностью не отказались и изредка собираем в нем шоты для Dribbble. Забиваем гвозди микроскопом, да.
Сейчас, в отделе, мы только начинаем делать первые шаги к коду и не заставляем дизайнеров верстать или учить JS, но даем такую возможность. Возможность расти и развиваться, лучше понимать разработчиков и говорить с ними на одном языке.
Конечно мы только в начале пути, но первые результаты не заставили себя долго ждать. Помимо внедрения новых инструментов, оптимизации процессов и ускорения работы удалось оздоровить коммуникацию не только внутри отдела, но и между командами. Мы стали чаще договариваться, обсуждать и принимать совместные решения, получили прозрачный и понятный workflow который легко масштабировать и добавили еще один вектор развития для дизайнеров в виде работы с кодом. Несмотря на первые успехи и маленькие победы, задач и проблем которые нужно решить еще очень много. Мы ежедневно тестируем заложенные решения, описываем правила и закладываем базовые принципы, чтобы сделать процесс работы еще более прозрачным и комфортным.
Кстати, мы всегда рады опытным дизайнерам. Если вы такой, напишите мне на почту: sergey.nikishkin@acronis.com
|
Метки: author Nikishkin интерфейсы веб-дизайн блог компании acronis inc acronis ui ux product design design system components angular 4 library |
Тест новинки: Crucial BX300 SSD |














|
Метки: author Dmytro_Kikot хранилища данных хранение данных хостинг блог компании ua-hosting.company ssd hdd iops mbs тесты |
kubernetes, playground, микросервисы и немного магии |

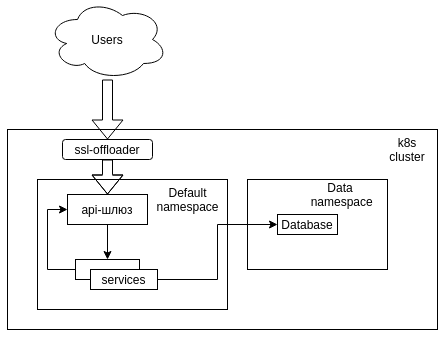
search .svc.cluster.local svc.cluster.local cluster.local
nameserver 192.168.0.2
options ndots:5search .svc.cluster.local svc.cluster.local cluster.local search .svc.cluster.local svc.cluster.local cluster.local default.svc.cluster.local
search default.svc.cluster.local server_name ~^(?.+)\.cluster\.local;
location / {
resolver 192.168.0.2;
proxy_pass http://api-gw.$namespace.svc.cluster.local;
} def BranchName() {
def Name = "${env.BRANCH_NAME}" =~ "play[/]?(.*)"
Name ? Name[0][1] : null
} def K8S_NAMESPACE = BranchName()
build job: 'Create NS', parameters: [[$class: 'StringParameterValue', name: 'K8S_NAMESPACE', value: "${K8S_NAMESPACE}"]]
build job: 'Create api-gw', parameters: [[$class: 'StringParameterValue', name: 'K8S_NAMESPACE', value: "${K8S_NAMESPACE}"]]
|
Метки: author demonight devops kubernetes playground |
Vivaldi 1.12 — Погружение в детали |




|
Метки: author Shpankov браузеры блог компании vivaldi technologies as vivaldi финал |
RailsClub 2017. Ответ на три главных вопроса от Piotr Solnica |


|
Метки: author vorona_karabuta функциональное программирование разработка веб-сайтов ruby on rails ruby блог компании «railsclub» конференция rails dry rom dry-rb |
Директор Linux Foundation использует Mac OS X, анонсируя «год Linux на десктопах» |

|
Метки: author shurup настройка linux linux foundation linux |
[Перевод] Взбираясь на непокорённую гору: сложности создания игры в одиночку |














|
Метки: author PatientZero разработка игр игры инди-разработка создание игр в одиночку |
Как управлять обращениями в ИТ-отдел |

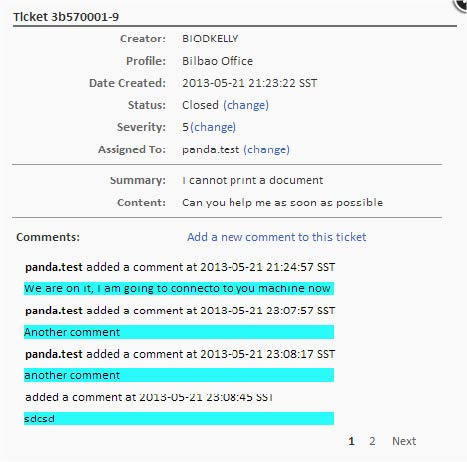








|
|
Из эскулапов в сисадмины: есть ли жизнь в IT после Клятвы Гиппократа? |
|
Метки: author Shaltay учебный процесс в it медицина смена работы врачи |
Резервное копирование для Zimbra Collaboration Suite |

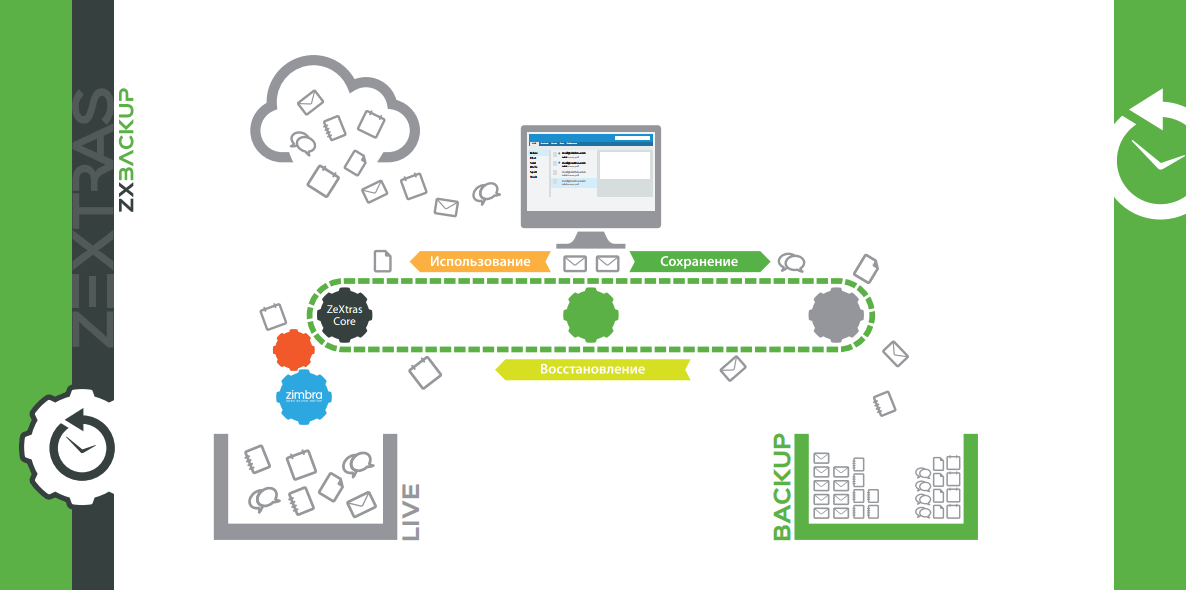

|
|
Go быстрее Rust, Mail.Ru Group сделала замеры |
Эти тесты показывают, как ведут себя голые серверы, без «прочих нюансов» которые зависят от рук программистов.
При тестировании выяснилось, что все претенденты работают примерно с одинаковой производительностью в такой постановке — все упиралось в производительность V8. Однако реализация задания не была лишней — разработка на каждом из языков позволила составить значительную часть субъективных оценок, которые так или иначе могли бы повлиять на окончательный выбор.
GET / HTTP/1.1
Host: service.host
HTTP/1.1 200 OK
Hello World!GET /greeting/user HTTP/1.1
Host: service.host
HTTP/1.1 200 OK
Hello, uservar cluster = require('cluster');
var numCPUs = require('os').cpus().length;
var http = require("http");
var debug = require("debug")("lite");
var workers = [];
var server;
cluster.on('fork', function(worker) {
workers.push(worker);
worker.on('online', function() {
debug("worker %d is online!", worker.process.pid);
});
worker.on('exit', function(code, signal) {
debug("worker %d died", worker.process.pid);
});
worker.on('error', function(err) {
debug("worker %d error: %s", worker.process.pid, err);
});
worker.on('disconnect', function() {
workers.splice(workers.indexOf(worker), 1);
debug("worker %d disconnected", worker.process.pid);
});
});
if (cluster.isMaster) {
debug("Starting pure node.js cluster");
['SIGINT', 'SIGTERM'].forEach(function(signal) {
process.on(signal, function() {
debug("master got signal %s", signal);
process.exit(1);
});
});
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
} else {
server = http.createServer();
server.on('listening', function() {
debug("Listening %o", server._connectionKey);
});
var greetingRe = new RegExp("^\/greeting\/([a-z]+)$", "i");
server.on('request', function(req, res) {
var match;
switch (req.url) {
case "/": {
res.statusCode = 200;
res.statusMessage = 'OK';
res.write("Hello World!");
break;
}
default: {
match = greetingRe.exec(req.url);
res.statusCode = 200;
res.statusMessage = 'OK';
res.write("Hello, " + match[1]);
}
}
res.end();
});
server.listen(8080, "127.0.0.1");
}package main
import (
"fmt"
"net/http"
"regexp"
)
func main() {
reg := regexp.MustCompile("^/greeting/([a-z]+)$")
http.ListenAndServe(":8080", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
switch r.URL.Path {
case "/":
fmt.Fprint(w, "Hello World!")
default:
fmt.Fprintf(w, "Hello, %s", reg.FindStringSubmatch(r.URL.Path)[1])
}
}))
}extern crate hyper;
extern crate regex;
use std::io::Write;
use regex::{Regex, Captures};
use hyper::Server;
use hyper::server::{Request, Response};
use hyper::net::Fresh;
use hyper::uri::RequestUri::{AbsolutePath};
fn handler(req: Request, res: Response) {
let greeting_re = Regex::new(r"^/greeting/([a-z]+)$").unwrap();
match req.uri {
AbsolutePath(ref path) => match (&req.method, &path[..]) {
(&hyper::Get, "/") => {
hello(&req, res);
},
_ => {
greet(&req, res, greeting_re.captures(path).unwrap());
}
},
_ => {
not_found(&req, res);
}
};
}
fn hello(_: &Request, res: Response) {
let mut r = res.start().unwrap();
r.write_all(b"Hello World!").unwrap();
r.end().unwrap();
}
fn greet(_: &Request, res: Response, cap: Captures) {
let mut r = res.start().unwrap();
r.write_all(format!("Hello, {}", cap.at(1).unwrap()).as_bytes()).unwrap();
r.end().unwrap();
}
fn not_found(_: &Request, mut res: Response) {
*res.status_mut() = hyper::NotFound;
let mut r = res.start().unwrap();
r.write_all(b"Not Found\n").unwrap();
}
fn main() {
let _ = Server::http("127.0.0.1:8080").unwrap().handle(handler);
} package lite
import akka.actor.{ActorSystem, Props}
import akka.io.IO
import spray.can.Http
import akka.pattern.ask
import akka.util.Timeout
import scala.concurrent.duration._
import akka.actor.Actor
import spray.routing._
import spray.http._
import MediaTypes._
import org.json4s.JsonAST._
object Boot extends App {
implicit val system = ActorSystem("on-spray-can")
val service = system.actorOf(Props[LiteActor], "demo-service")
implicit val timeout = Timeout(5.seconds)
IO(Http) ? Http.Bind(service, interface = "localhost", port = 8080)
}
class LiteActor extends Actor with LiteService {
def actorRefFactory = context
def receive = runRoute(route)
}
trait LiteService extends HttpService {
val route =
path("greeting" / Segment) { user =>
get {
respondWithMediaType(`text/html`) {
complete("Hello, " + user)
}
}
} ~
path("") {
get {
respondWithMediaType(`text/html`) {
complete("Hello World!")
}
}
}
}Example: Avoid compiling the same regex in a loop
It is an anti-pattern to compile the same regular expression in a loop since compilation is typically expensive. (It takes anywhere from a few microseconds to a few milliseconds depending on the size of the regex.) Not only is compilation itself expensive, but this also prevents optimizations that reuse allocations internally to the matching engines.
In Rust, it can sometimes be a pain to pass regular expressions around if they're used from inside a helper function. Instead, we recommend using the lazy_static crate to ensure that regular expressions are compiled exactly once.
For example:
#[macro_use] extern crate lazy_static; extern crate regex; use regex::Regex; fn some_helper_function(text: &str) -> bool { lazy_static! { static ref RE: Regex = Regex::new("...").unwrap(); } RE.is_match(text) } fn main() {}
Specifically, in this example, the regex will be compiled when it is used for the first time. On subsequent uses, it will reuse the previous compilation.
But you should avoid the repeated compilation of a regular expression in a loop for performance reasons.
Спасибо! Я тоже думал было переписать на split во всех примерах, но потом показалось, что с regexp будет более жизненно. При оказии попробую прогнать wrk со split.
extern crate hyper;
extern crate regex;
#[macro_use] extern crate lazy_static;
use std::io::Write;
use regex::{Regex, Captures};
use hyper::Server;
use hyper::server::{Request, Response};
use hyper::net::Fresh;
use hyper::uri::RequestUri::{AbsolutePath};
fn handler(req: Request, res: Response) {
lazy_static! {
static ref GREETING_RE: Regex = Regex::new(r"^/greeting/([a-z]+)$").unwrap();
}
match req.uri {
AbsolutePath(ref path) => match (&req.method, &path[..]) {
(&hyper::Get, "/") => {
hello(&req, res);
},
_ => {
greet(&req, res, GREETING_RE.captures(path).unwrap());
}
},
_ => {
not_found(&req, res);
}
};
}
fn hello(_: &Request, res: Response) {
let mut r = res.start().unwrap();
r.write_all(b"Hello World!").unwrap();
r.end().unwrap();
}
fn greet(_: &Request, res: Response, cap: Captures) {
let mut r = res.start().unwrap();
r.write_all(format!("Hello, {}", cap.at(1).unwrap()).as_bytes()).unwrap();
r.end().unwrap();
}
fn not_found(_: &Request, mut res: Response) {
*res.status_mut() = hyper::NotFound;
let mut r = res.start().unwrap();
r.write_all(b"Not Found\n").unwrap();
}
fn main() {
let _ = Server::http("127.0.0.1:3000").unwrap().handle(handler);
}
ab -n50000 -c256 -t10 "http://127.0.0.1:3000/| Label | Time per request, ms | Request, #/sec |
|---|---|---|
| Rust | 11.729 | 21825.65 |
| Go | 13.992 | 18296.71 |
ab -n50000 -c256 -t10 "http://127.0.0.1:3000/greeting/hello"| Label | Time per request, ms | Request, #/sec |
|---|---|---|
| Rust | 11.982 | 21365.36 |
| Go | 14.589 | 17547.04 |
ab -n50000 -c256 -t10 "http://127.0.0.1:3000/"| Label | Time per request, ms | Request, #/sec |
|---|---|---|
| Rust | 8.987 | 28485.53 |
| Go | 9.839 | 26020.16 |
ab -n50000 -c256 -t10 "http://127.0.0.1:3000/greeting/hello"| Label | Time per request, ms | Request, #/sec |
|---|---|---|
| Rust | 9.148 | 27984.13 |
| Go | 9.689 | 26420.82 |
ab -n50000 -c256 -t10 "http://127.0.0.1:3000/"| Label | Time per request, ms | Request, #/sec |
|---|---|---|
| Rust | 5.601 | 45708.98 |
| Go | 6.770 | 37815.62 |
ab -n50000 -c256 -t10 "http://127.0.0.1:3000/greeting/hello"| Label | Time per request, ms | Request, #/sec |
|---|---|---|
| Rust | 5.736 | 44627.28 |
| Go | 6.451 | 39682.85 |

|
Метки: author humbug тестирование веб-сервисов программирование высокая производительность rust go benchmark rust is faster than go |
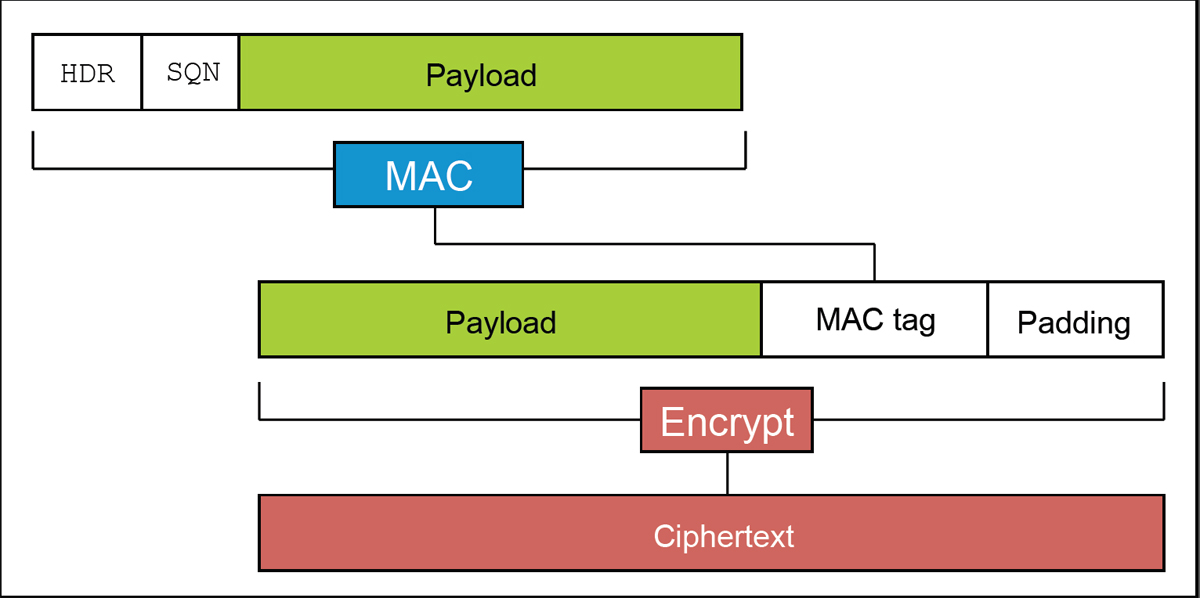
[Перевод] Padding Oracle Attack: криптография по-прежнему пугает |

(0) или (1,1) или (2,2,2) или т.п.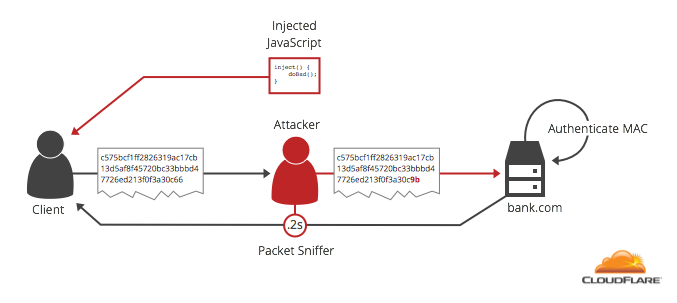


Своё название эта атака получила из-за того, что размер заголовка, хешируемого перед «полезной нагрузкой», ограничил перебор вариантов набивки двухбайтными последовательностями. Будь этот заголовок 14-байтным или длинее, скачок во времени отклика сервера пришёлся бы на более короткие куски открытого текста, и перебирать бы приходилось в сотни раз больше вариантов набивки. С другой стороны, будь этот заголовок 11-байтным, скачок бы пришёлся на переход между 8 и 9 блоками открытого текста, и атака была бы совершенно невозможна. Ну а самое счастливое число — конечно же, 12: с такой длиной заголовка для атаки было бы достаточно перебирать значения последнего байта самого по себе, как и в атаке Воденэ.
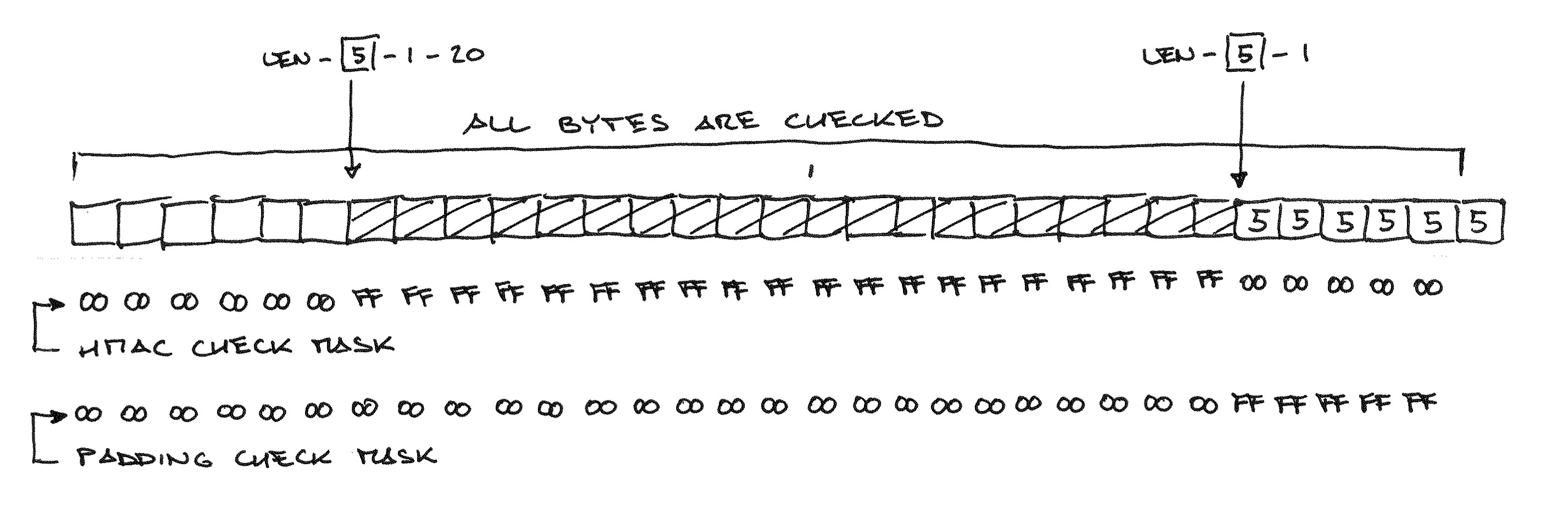


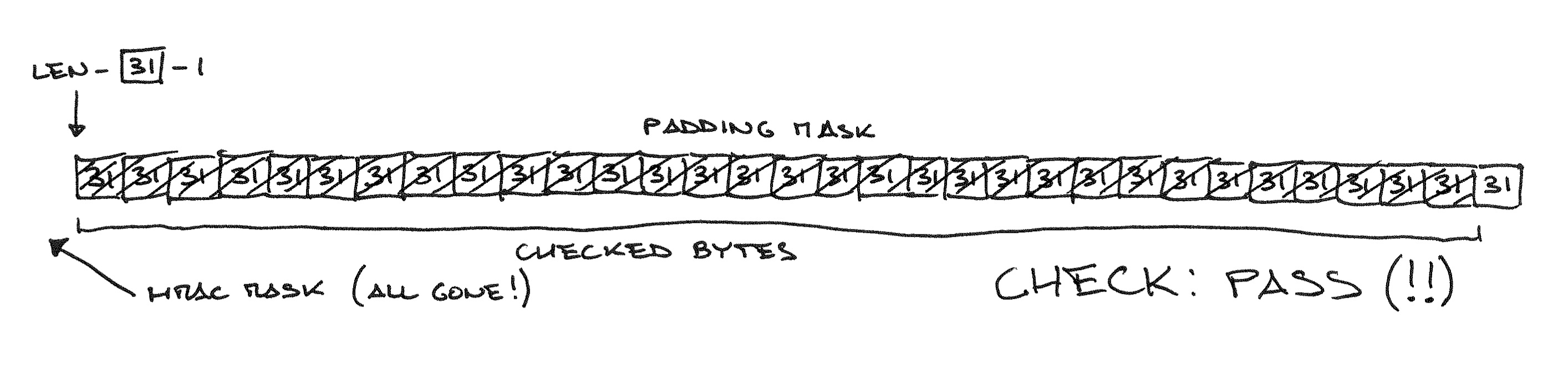

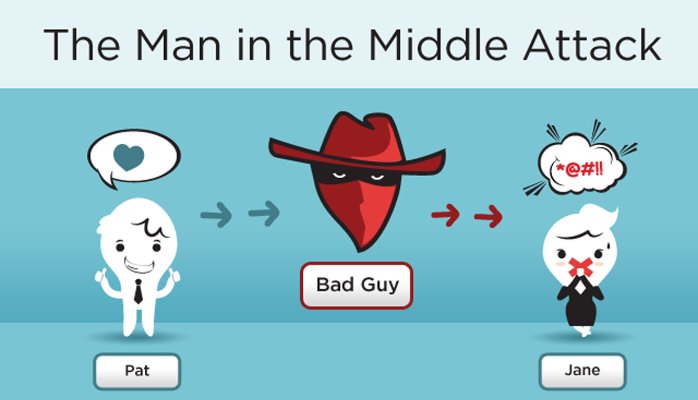
Техническое замечание: даже если POST-запрос оканчивается на последовательность из байтов 31, перед CBC-шифрованием он будет дополнен MAC и набивкой, так что в описанном виде атака не сработает. Подготовительный этап атаки — варьируя запрашиваемый путь, подобрать такую длину POST-запроса, чтобы MAC и настоящая набивка заняли последние два CBC-блока целиком; затем в ходе атаки эти последние два блока будут отбрасываться, а использоваться будут блоки от пятого до третьего с конца. Наладив такую координацию действий между скриптом, генерирующим HTTPS-запросы, и MitM-сервером, злоумышленник может обеспечить, что результат CBC-расшифровки будет оканчиваться на 31 байт со значением 31.
|
|
Глобальные тренды геймдева: о чем расскажут на «4C: Санкт-Петербург»? |
|
Метки: author megapost тестирование игр монетизация игр продвижение игр разработка игр wargaming |
Инфографика: все 42 космических аппарата, похороненные за пределами Земли |


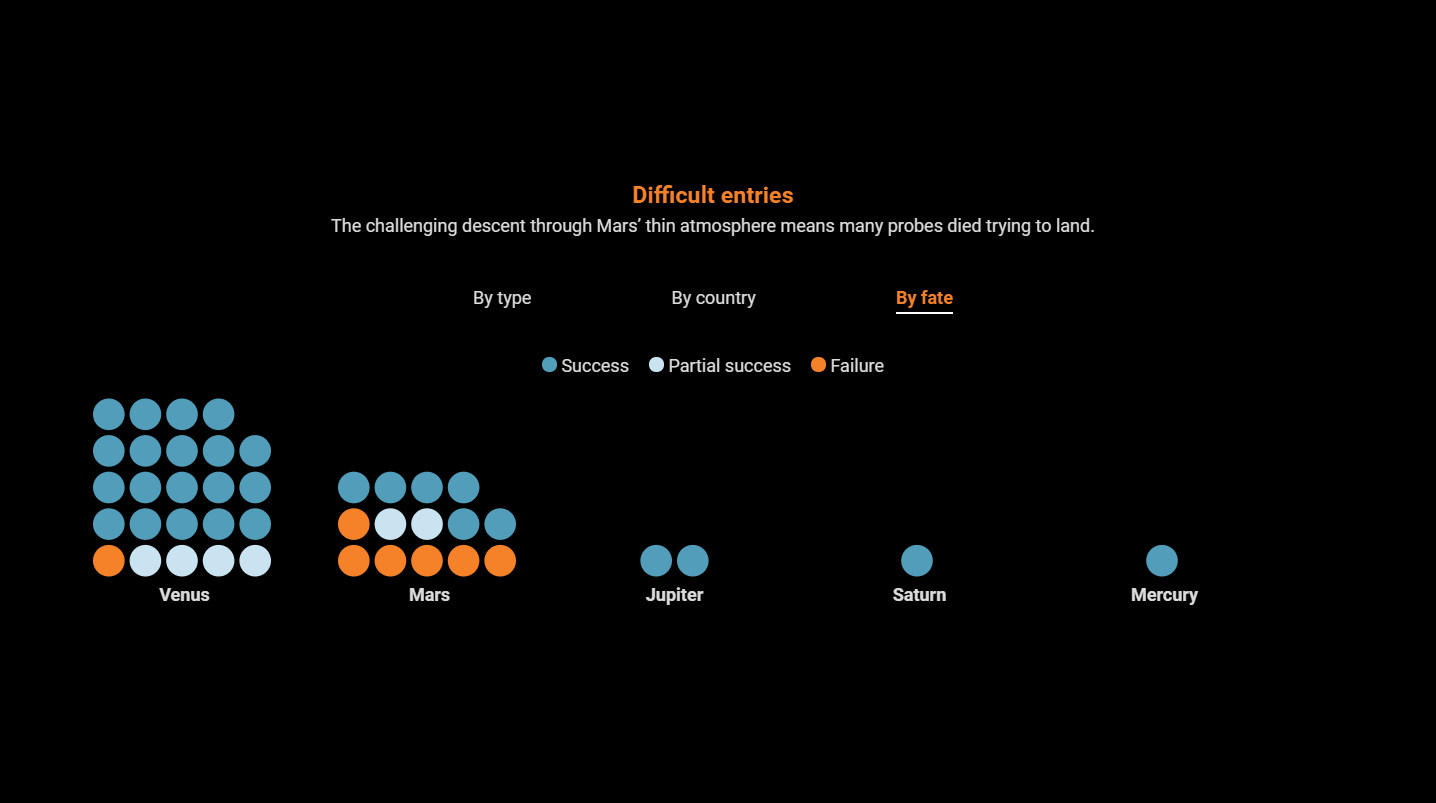
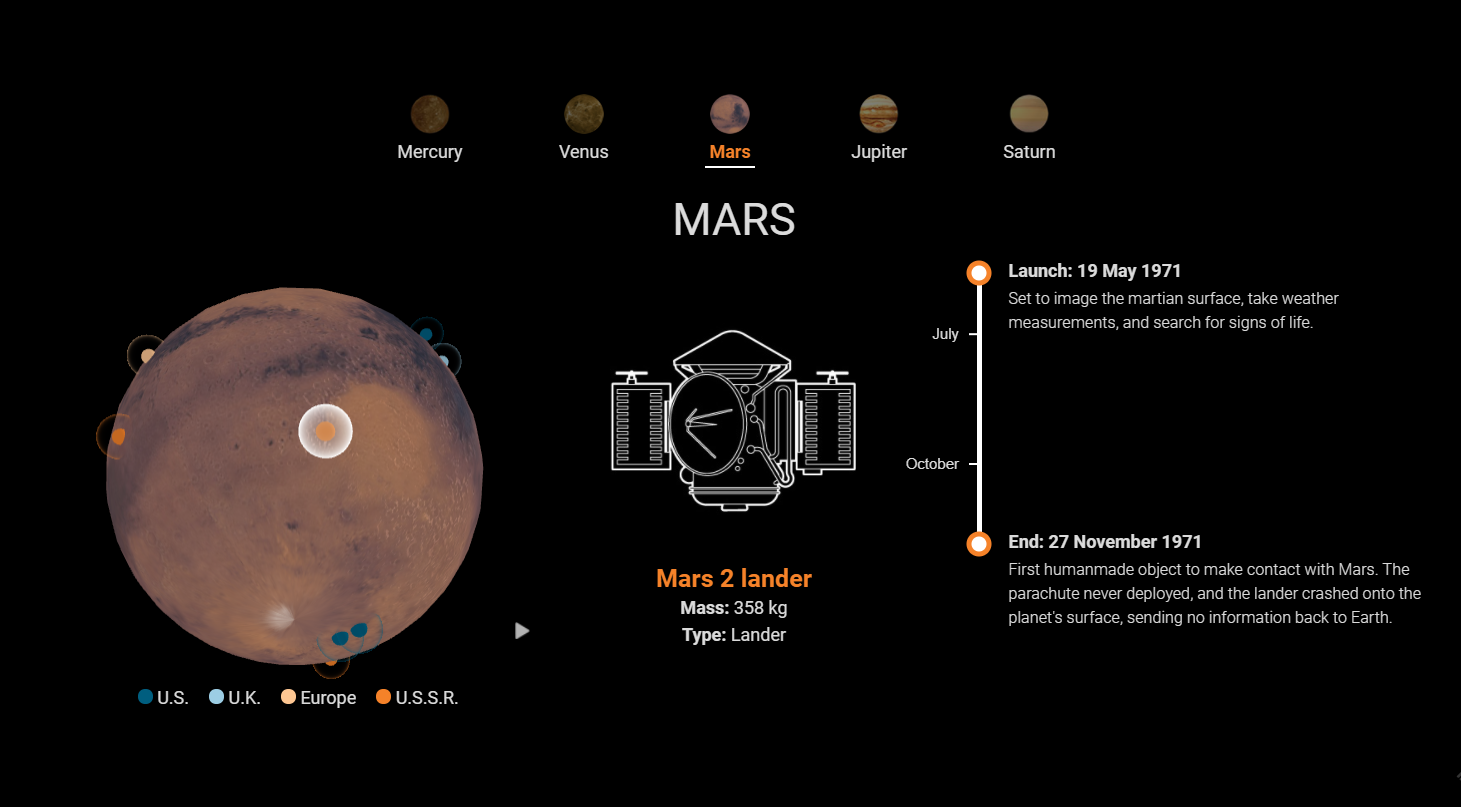
|
Метки: author Tiberius обработка изображений визуализация данных наса nasa кассини космос планеты 42 |
4 распространенные ошибки в дизайне, которые легко исправить |


















|
Метки: author Logomachine работа с векторной графикой графический дизайн блог компании логомашина бизнес логотип фирменный стиль помощь советы |






