Когда размер имеет значение: создаем приложение-линейку с помощью ARKit |

sceneView.debugOptions = ARSCNDebugOptions.showFeaturePoints /
/
private var points: (start: SCNVector3?, end: SCNVector3?)
private var line = SCNNode()
private var isDrawing = false
private var canPlacePoint = false func renderer(_ renderer: SCNSceneRenderer, updateAtTime time: TimeInterval) func renderer(_ renderer: SCNSceneRenderer, updateAtTime time: TimeInterval) {
DispatchQueue.main.async {
self.measure()
}
}
private func measure() {
let hitResults = sceneView.hitTest(view.center, types: [.featurePoint])
if let hit = hitResults.first {
canPlacePoint = true
focus.image = UIImage(named: "focus")
} else {
canPlacePoint = false
focus.image = UIImage(named: "focus_off")
}
}
@objc private func tapped() {
if canPlacePoint {
isDrawing = !isDrawing
if isDrawing {
points.start = nil
points.end = nil
}
}
}
if isDrawing {
let hitTransform = SCNMatrix4(hit.worldTransform)
let hitPoint = SCNVector3Make(hitTransform.m41, hitTransform.m42, hitTransform.m43)
if points.start == nil {
points.start = hitPoint
} else {
points.end = hitPoint
}
}func lineFrom(vector vector1: SCNVector3, toVector vector2: SCNVector3) -> SCNGeometry {
let indices: [Int32] = [0, 1]
let source = SCNGeometrySource(vertices: [vector1, vector2])
let element = SCNGeometryElement(indices: indices, primitiveType: .line)
return SCNGeometry(sources: [source], elements: [element])
}if points.start == nil {
points.start = hitPoint
} else {
points.end = hitPoint
line.geometry = lineFrom(vector: points.start!, toVector: points.end!)
if line.parent == nil {
line.geometry?.firstMaterial?.diffuse.contents = UIColor.white
line.geometry?.firstMaterial?.isDoubleSided = true
sceneView.scene.rootNode.addChildNode(line)
}
}

func distance(from startPoint: SCNVector3, to endPoint: SCNVector3) -> Float {
let vector = SCNVector3Make(startPoint.x - endPoint.x, startPoint.y - endPoint.y, startPoint.z - endPoint.z)
let distance = sqrtf(vector.x * vector.x + vector.y * vector.y + vector.z * vector.z)
return distance
}
|
Метки: author EverydayTools разработка под ios разработка под ar и vr xcode swift блог компании everyday tools arkit ios 11 xcode 9 sdk линейка apple ar |
[Из песочницы] Программирование с использованием PCAP |
Данный текст является переводом статьи Тима Карстенса Programming with pcap 2002 года. В русскоязычном интернете не так много информации по PCAP. Перевод сделан в первую очередь для людей, которым интересна тема захвата трафика, но при этом они плохо владеют английским языком. Под катом, собственно, сам перевод.
Давайте начнем с того, что определим, для кого написана эта статья. Очевидно, что некоторое базовое знание C необходимо (если, конечно, вы не хотите просто понять теорию), для понимания кода приведенного в статье, но вам не нужно быть ниндзя программирования: в тех моментах, которые могут быть понятны только более опытными программистам я постараюсь подробно объяснить все концепции. Так же, пониманию может помочь некоторое базовое знание работы сетей, учитывая что PCAP — это библиотека для реализации сниффинга (Прим. переводчика: Сниффинг — процесс захвата сетевого трафика, своего, или чужого). Все представленные здесь примеры кода были протестированы на FreeBSD 4.3 с ядром по умолчанию.
Первая вещь которую необходимо понять — общая структура PCAP сниффера. Она может выглядеть следующим образом:
eth0, в BSD это может быть xl1, и тому подобное. Мы можем либо указать этот идентификатор в строке, либо попросить PCAP предоставить его нам.pcap_loop, PCAP будет работать до тех пор, пока не получит столько пакетов, сколько мы ему указали. Каждый раз, когда он получает новый пакет, он вызывает определенную нами функцию. Эта функция может делать все что мы хотим. Она может прочитать пакет, и передать информацию пользователю, она может сохранить его в файл, или вовсе не делать ничего. Это ужасно просто. Есть два способа определить устройство, которое мы хотим прослушивать.
Первый — просто позволить пользователю сказать программе имя того устройства с которого он хочет захватывать трафик. Рассмотрим этот код:
#include
#include
int main(int argc, char *argv[])
{
char *dev = argv[1];
printf("Device: %s\n", dev);
return(0);
}Пользователь определяет устройство указывая его имя в качестве первого аргумента программы. Теперь, строка dev содержит имя интерфейса который мы будем прослушивать в формате понятном PCAP (конечно, при условии, что пользователь дал нам реальное имя интерфейса)
Второй способ также очень прост. Давайте взглянем на программу:
#include
#include
int main(int argc, char *argv[])
{
char *dev, errbuf[PCAP_ERRBUF_SIZE];
dev = pcap_lookupdev(errbuf);
if (dev == NULL)
{
fprintf(stderr, "Couldn't find default device: %s\n", errbuf);
return(2);
}
printf("Device: %s\n", dev);
return(0);
}В этом случае, PCAP просто установит имя устройства самостоятельно. "Но подожди, Тим", вы скажете. "Что делать со строкой errbuf?". Большинство PCAP команд позволяют нам передать им строку в качестве одного из аргументов. С какой целью? В том случае, если выполнение команды не удастся, PCAP запишет описание ошибки в переданную строку. В этом случае, если выполнение pcap_lookupdev() провалится, сообщение об ошибке будет помещено в errbuf. Круто, не правда ли? Вот так вот и устанавливается имя устройства для захвата трафика.
Задача создания сессии захвата трафика так же очень проста. Для этого мы будем использовать функцию pcap_open_live(). Прототип этой функции:
pcap_t *pcap_open_live(char *device, int snaplen, int promisc, int to_ms, char *ebuf)Первый аргумент — это имя устройства которое мы определили в предыдущем разделе. snaplen это целое число, которое определяет максимальное число байтов, которое может захватить PCAP. promisc, когда установлен в true, устанавливает устройство в неразборчивый режим (так или иначе, даже если он установлен в false, в определенных случаях интерфейс может находится в неразборчивом режиме). to_ms это время чтения в миллисекундах (значение 0 означает отсутствие таймаута; по крайней мере на некоторых платформах, это означает что вы можете дождаться появления достаточного количества пакетов для прекращения сниффинга до того, как закончите анализ этих пакетов. Поэтому вы должны использовать ненулевое время). Наконец, ebuf это строка в которой мы можем хранить сообщения об ошибках (так же, как мы делали до этого с errbuf). Функция возвращает дескриптор сеанса.
Для демонстрации, рассмотрим этот фрагмент кода:
#include
...
pcap_t *handle;
handle = pcap_open_live(dev, BUFSIZ, 1, 1000, errbuf);
if (handle == NULL)
{
fprintf(stderr, "Couldn't open device %s: %s\n", dev, errbuf);
return(2);
}Этот код открывает устройство помещенное в переменную dev, говорит читать столько байтов, сколько указано в BUFSIZ (константа, которая определена в pcap.h). Мы говорим переключить устройство в неразборчивый режим, что бы захватывать трафик до момента возникновения какой либо ошибки, и в случает ошибки, поместить ее описание в строку errbuf; и после, в случае ошибки, используем эту строку что бы вывести сообщение о том, что пошло не так.
Замечания по поводу разборчивого/неразборчивого режимов сниффинга: два способа очень различны по стилю. Обычно, интерфейс находится в разборчивом режиме, захватывая только тот трафик, который отправлен именно ему. Только трафик направленный от него, к нему, или маршрутизированный через него будет захвачен сниффером. Неразборчивый режим, наоборот, захватывает весь трафик который проходит через кабель. В среде без коммутации это может быть весь сетевой трафик. Очевидным преимуществом этого способа является то, возможно захватить большее количество пакетов, что может быть полезным, или нет, в зависимости от цели захвата трафика. Однако существуют и недостатки. Неразборчивый режим легко детектируется, один узел может четко определить, находится ли другой в неразборчивом режиме или нет. Так же, он работает только в не коммутируемой среде (например хаб, или маршрутизатор использующий APR). Еще одним недостатком является то, что в сетях с большим количеством трафика может не хватить системных ресурсов для захвата и анализа всех пакетов.
Не все устройства предоставляют одни и те же заголовки канального уровня в прочитанных вами пакетах. Ethernet устройства, и некоторые не-Ethernet устройства, могут предоставить Ethernet заголовки, но другие типы устройств, например такие как замыкающие устройства в BSD и OS X, PPP-интерфейсы, и Wi-Fi-интерфейсы в режиме мониторинга — нет.
Вам нужно определить тип заголовков канального уровня, которые предоставляет устройство, и использовать для анализа содержимого пакетов. pcap_datalink() возвращает тип заголовков канального уровня. (Cм. список значений заголовков канального уровня. Возвращаемые значения — значения DHT_ в этом списке)
Если ваша программа не поддерживает заголовки канального уровня предоставляемые устройством, то она должна будет прекратить работу, с помощью подобного кода:
if (pcap_datalink(handle) != DLT_EN10MB)
{
fprintf(stderr, "Device %s doesn't provide Ethernet headers -not supported\n", dev);
return(2);
}который сработает если устройство не поддерживает Ethernet — заголовки. Это может сработать для кода приведенного ниже, который использует заголовки Ethernet.
Часто мы заинтересованы в захвате только определенного типа трафика. Для примера — бывает такое, что единственное что мы хотим — это захватить трафик с порта 23(telnet) для поиска паролей. Или возможно мы хотим перехватить файл который был отправлен через порт 21(FTP). Может быть мы хотим захватить только DNS трафик (порт 53 UDP). Однако, бывают редкие случаи, когда мы просто хотим слепо захватывать весь интернет трафик. Давайте рассмотрим функции pcap_compile() и pcap_setfilter().
Процесс очень простой. После того, как мы вызвали pcap_open_live() и имеем работающую сессию сниффинга, мы можем применить наш фильтр. Вы спросите, почему просто не использовать обычные if/else if выражения? Две причины: первая — фильтр PCAP эффективнее, потому что он фильтрует непосредственно через BPF; соответственно нам нужно куда меньшее количество ресурсов, ведь драйвер BPF делает это напрямую. Вторая — это то, что фильтры PCAP просто проще.
Перед тем, как применить фильтр, мы должны скомпилировать его. Условие фильтра содержится в обычной строке (или массиве char). Синтаксис достаточно хорошо документирован на главной странице tcpdump.org; Я оставлю это вам на самостоятельное рассмотрение. Однако, мы будем использовать простые тестовые выражения, и, возможно, вы достаточно догадливы что бы самостоятельно вывести правила синтаксиса этих условий из приведенных примеров.
Что бы скомпилировать фильтр мы вызываем функцию pcap_compile(). Прототип определяет эту функцию как:
int pcap_compile(pcap_t *p, struct bpf_program *fp, char *str, int optimize, bpf_u_int32 netmask)Первый аргумент — это наш дескриптор сессии (pcap_t* handle в нашем предыдущем примере). Следующий — это указатель на место, где мы будем хранить скомпилированную версию фильтра. Далее идет само выражение, в обычном строковом формате. После идет целое число, которое определяет, нужно ли оптимизировать выражения фильтра, или нет (0 — нет, 1 — да). Наконец, мы должны определить сетевую маску той сети, к которой мы применяем фильтр. Функция возвращает -1 при ошибке; все остальные значения означают успех.
После компиляции фильтра, время применить его. Вызовем pcap_setfilter(). Следуя нашему формату объяснения PCAP, мы должны рассмотреть прототип этой функции:
int pcap_setfilter(pcap_t *p, struct bpf_program *fp)Это очень прямолинейно и просто. Первый аргумент — наш дескриптор сессии, второй — указатель на скомпилированную версию нашего фильтра (это должна быть та же переменная, что и в предыдущей функции pcap_compile()).
Возможно этот пример поможет вам понять лучше:
#include
...
pcap_t *handle; /* Дескриптор сесси */
char dev[] = "rl0"; /* Устройство для сниффинга */
char errbuf[PCAP_ERRBUF_SIZE]; /* Строка для хранения ошибок */
struct bpf_program fp; /* Скомпилированный фильтр */
char filter_exp[] = "port 23"; /* Выражение фильтра */
bpf_u_int32 mask; /* Сетевая маска устройства */
bpf_u_int32 net; /* IP устройства */
if (pcap_lookupnet(dev, &net, &mask, errbuf) == -1) {
fprintf(stderr, "Can't get netmask for device %s\n", dev);
net = 0;
mask = 0;
}
handle = pcap_open_live(dev, BUFSIZ, 1, 1000, errbuf);
if (handle == NULL) {
fprintf(stderr, "Couldn't open device %s: %s\n", dev, errbuf);
return(2);
}
if (pcap_compile(handle, &fp, filter_exp, 0, net) == -1) {
fprintf(stderr, "Couldn't parse filter %s: %s\n", filter_exp, pcap_geterr(handle));
return(2);
}
if (pcap_setfilter(handle, &fp) == -1) {
fprintf(stderr, "Couldn't install filter %s: %s\n", filter_exp, pcap_geterr(handle));
return(2);
}Эта программа настроена на сниффинг трафика который проходит через порт 23, в неразборчивом режиме, на устройстве rl0.
Мы можете заметить, что предыдущий пример содержит функцию, о которой мы еще не говорили. pcap_lookupnet() — это функция которая, получая имя устройства возвращает IPv4 сетевой номер и соответствующую сетевую маску (сетевой номер — это адрес IPv4 ANDed с сетевой маской, поэтому он содержит только сетевую часть адреса). Это существенно, потому что нам нужно знать сетевую маску для применения фильтра.
По моему опыту, этот фильтр не работает в некоторых ОС. В моей тестовой среде я обнаружил, что OpenBSD 2.9 c ядром по умолчанию поддерживает этот тип фильтра, но FreeBSD 4.3 с ядром по умолчанию — нет. Ваш опыт может отличаться.
На текущем этапе мы узнали как определить устройство, приготовить его для захвата трафика, и применить фильтры. Теперь время захватить несколько пакетов. Есть два основных способа захватывать пакеты. Мы можем просто захватить один пакет, или мы можем войти в цикл, который выполняется пока не будет захвачено n пакетов. Мы начнем с того, что покажем, как можно захватить один пакет, и после рассмотрим методы использования циклов. Взглянем на прототип pcap_next():
u_char *pcap_next(pcap_t *p, struct pcap_pkthdr *h)Первый аргумент — дескриптор сессии. Второй — указатель на структуру которая содержит общую информацию о пакете, конкретно — время в которое он был захвачен, длина пакета, и длина его определенной части (например, если он фрагментированный). pcap_next() возвращает u_char указатель на пакет, который описан в структуре. Мы поговорим о чтении пакетов позже.
Это демонстрация использования pcap_next() для захвата пакетов:
#include
#include
int main(int argc, char *argv[])
{
pcap_t *handle; /* Дескриптор сессии */
char *dev; /* Устройсто для сниффинга */
char errbuf[PCAP_ERRBUF_SIZE]; /* Строка для хранения ошибки */
struct bpf_program fp; /* Скомпилированный фильтр */
char filter_exp[] = "port 23"; /* Выражение фильтра */
bpf_u_int32 mask; /* Сетевая маска */
bpf_u_int32 net; /* IP */
struct pcap_pkthdr header; /* Заголовок который нам дает PCAP */
const u_char *packet; /* Пакет */
/* Определение устройства */
dev = pcap_lookupdev(errbuf);
if (dev == NULL)
{
fprintf(stderr, "Couldn't find default device: %s\n", errbuf);
return(2);
}
/* Определение свойств устройства */
if (pcap_lookupnet(dev, &net, &mask, errbuf) == -1)
{
fprintf(stderr, "Couldn't get netmask for device %s: %s\n", dev, errbuf);
net = 0;
mask = 0;
}
/* Создание сессии в неразборчивом режиме */
handle = pcap_open_live(dev, BUFSIZ, 1, 1000, errbuf);
if (handle == NULL)
{
fprintf(stderr, "Couldn't open device %s: %s\n", dev, errbuf);
return(2);
}
/* Компиляция и применения фильтра */
if (pcap_compile(handle, &fp, filter_exp, 0, net) == -1)
{
fprintf(stderr, "Couldn't parse filter %s: %s\n", filter_exp, pcap_geterr(handle));
return(2);
}
if (pcap_setfilter(handle, &fp) == -1)
{
fprintf(stderr, "Couldn't install filter %s: %s\n", filter_exp, pcap_geterr(handle));
return(2);
}
/* Захват пакета */
packet = pcap_next(handle, &header);
/* Вывод его длины */
printf("Jacked a packet with length of [%d]\n", header.len);
/* Закрытие сессии */
pcap_close(handle);
return(0);
}Приложение захватывает трафик любого устройства, полученное через pcap_loockupdev(), помещая его в неразборчивый режим. Оно обнаруживает что пакет попадает в порт 23 (telnet) и сообщает пользователю размер пакета (в байтах). Опять же, программа включает в себя вызов pcap_close(), который мы обсудим позже (хотя он вполне понятен).
Второй способ захвата трафика — использование pcap_loop() или pcap_dispatch() (который в свою очередь сам использует pcap_loop()). Что бы понять использование этих двух функций, нам нужно понять идею функции обратного вызова.
Функция обратного вызова (callback function) не является чем то новым, это обычная вещь в большом количестве API. Концепция, которая стоит за функцией обратного вызова очень проста. Предположим, что у есть программа которая ждет события определенного рода. Просто для примера, предположим что программа ждет нажатие клавиши. Каждый раз, когда пользователь нажимает клавишу, моя программа вызовет функцию, что бы обработать это нажатие клавиши. Это и есть функция обратного вызова. Эти функции используются в PCAP, но вместо вызова их в момент нажатия клавиши, они вызываются тогда, когда PCAP захватывает пакет. Использовать функции обратного вызова можно только в pcap_loop() и pcap_dispatch() которые очень похожи в этом плане. Каждая из них вызывает функцию обратного вызова каждый раз, когда попадется пакет который проходит сквозь фильтр (если конечно фильтр есть. Если нет, то все пакеты, которые были захвачены вызовут функцию обратного вызова).
Прототип pcap_loop() приведен ниже:
int pcap_loop(pcap_t *p, int cnt, pcap_handler callback, u_char *user)Первый аргумент — дескриптор сессии. Дальше идет целое число, которое сообщает pcap_loop() количество пакетов, которые нужно захватить (отрицательное значение говорит о том, что цикл должен выполняться до возникновения ошибки). Третий аргумент — имя функции обратного вызова (только идентификатор, без параметров). Последний аргумент полезен в некоторых приложениях, но в большинстве случаев он просто устанавливается NULL. Предположим, что у нас есть аргументы, которые мы хотим передать функции обратного вызова, в дополнение к тем, которые передает ей pcap_loop(). Последний аргумент как раз то место, где мы это сделаем. Очевидно, вы должны привести их к u_char * типу, что бы убедится что вы получите верные результаты. Как мы увидим позже, PCAP использует некоторые интересные способы передачи информации в виде u_char *. После того, как мы покажем пример того, как PCAP делает это, будет очевидно как сделать это и в этом моменте. Если нет — обратитесь к справочному тексту по С, так как объяснения указателей находятся за рамками темы этого документа. pcap_dispatch() почти идентична в использовании. Единственное различие между pcap_dispatch() и pcap_loop() это то, что pcap_dispatch() будет обрабатывать только первую серию пакетов полученных из системы, тогда как pcap_loop() будет продолжать обработку пакетов или партий пакетов до тех пор пока счетчик не закончится. Для более глубокого обсуждения различий, смотрите официальную документацию PCAP.
Прежде чем мы приведем пример использования pcap_loop(), мы должны проверить формат нашей функции обратного вызова. Мы не можем самостоятельно определить прототип функции обратного вызова, иначе pcap_loop() не будет знать, как использовать ее. Так что мы должны использовать этот формат в качестве прототипа нашей функции обратного вызова:
void got_packet(u_char *args, const struct pcap_pkthdr *header, const u_char *packet);Давайте разберем его более детально. Первое — функция должна иметь void тип. Это логично, потому что pcap_loop() в любом случае не знал бы, что делать с возвращаемым значением. Первый аргумент соответствует последнему аргументу pcap_loop(). Независимо от того, какое значение передается последним аргументом pcap_loop(), оно передается первому аргументу нашей функции обратного вызова. Второй аргумент — это PCAP заголовок, который содержит информацию о том, когда пакет был захвачен, насколько он большой, и так далее. Структура pcap_pkthdr определена в файле pcap.h как:
struct pcap_pkthdr {
struct timeval ts; /* Время захвата */
bpf_u_int32 caplen; /* Длина заголовка */
bpf_u_int32 len; /* Длина пакета */
};Эти значения должны быть достаточно понятными. Последний аргумент — самый интересный из всех, и самый сложный для понимания начинающему программисту. Это другой указатель на u_char, и он указывает на первый байт раздела данных содержащихся в пакете, который был захвачен pcap_loop().
Но как можно использовать эту переменную (названную packet) в прототипе? Пакет содержит много атрибутов, так что, как можно предположить, это не строка, а набор структур (для примера, пакет TCP/IP содержит в себе Ethernet заголовок, IP заголовок, TCP заголовок, и наконец, данные). Этот u_char указатель указывает на сериализованную версию этих структур. Что бы начать использовать какую нибудь из них необходимо произвести некоторые интересные преобразования типов.
Первое, мы должны определить сами структуры, прежде чем мы сможем привести данные к ним. Следующая структура используется мной для чтения TCP/IP пакета из Ethernet.
/* Ethernet адреса состоят из 6 байт */
#define ETHER_ADDR_LEN 6
/* Заголовок Ethernet */
struct sniff_ethernet {
u_char ether_dhost[ETHER_ADDR_LEN]; /* Адрес назначения */
u_char ether_shost[ETHER_ADDR_LEN]; /* Адрес источника */
u_short ether_type; /* IP? ARP? RARP? и т.д. */
};
/* IP header */
struct sniff_ip {
u_char ip_vhl; /* версия << 4 | длина заголовка >> 2 */
u_char ip_tos; /* тип службы */
u_short ip_len; /* общая длина */
u_short ip_id; /* идентефикатор */
u_short ip_off; /* поле фрагмента смещения */
#define IP_RF 0x8000 /* reserved флаг фрагмента */
#define IP_DF 0x4000 /* dont флаг фрагмента */
#define IP_MF 0x2000 /* more флаг фрагмента */
#define IP_OFFMASK 0x1fff /* маска для битов фрагмента */
u_char ip_ttl; /* время жизни */
u_char ip_p; /* протокол */
u_short ip_sum; /* контрольная сумма */
struct in_addr ip_src,ip_dst; /* адрес источника и адрес назначения */
};
#define IP_HL(ip) (((ip)->ip_vhl) & 0x0f)
#define IP_V(ip) (((ip)->ip_vhl) >> 4)
/* TCP header */
typedef u_int tcp_seq;
struct sniff_tcp {
u_short th_sport; /* порт источника */
u_short th_dport; /* порт назначения */
tcp_seq th_seq; /* номер последовательности */
tcp_seq th_ack; /* номер подтверждения */
u_char th_offx2; /* смещение данных, rsvd */
#define TH_OFF(th) (((th)->th_offx2 & 0xf0) >> 4)
u_char th_flags;
#define TH_FIN 0x01
#define TH_SYN 0x02
#define TH_RST 0x04
#define TH_PUSH 0x08
#define TH_ACK 0x10
#define TH_URG 0x20
#define TH_ECE 0x40
#define TH_CWR 0x80
#define TH_FLAGS (TH_FIN|TH_SYN|TH_RST|TH_ACK|TH_URG|TH_ECE|TH_CWR)
u_short th_win; /* окно */
u_short th_sum; /* контрольная сумма */
u_short th_urp; /* экстренный указатель */
};Так как в итоге это все относится к PCAP и нашему загадочному u_char указателю? Эти структуры определяют заголовки, которые предшествуют данным пакета. И как мы в итоге можем разбить пакет? Приготовьтесь увидеть одно из самых практичных использований указателей (для всех новичков в С которые думают что указатели бесполезны говорю: это не так).
Опять же, мы будем предполагать, что мы имеем дело с TCP/IP пакетом Ethernet. Этот же метод применяется к любому пакету. Единственное различие — это тип структуры, которые вы фактически используете. Итак, давайте начнем с определения переменных и определения времени компиляции. Нам нужно будет деконструировать данные пакета.
/* Заголовки Ethernet всегда состоят из 14 байтов */
#define SIZE_ETHERNET 14
const struct sniff_ethernet *ethernet; /* Заголовок Ethernet */
const struct sniff_ip *ip; /* Заголовок IP */
const struct sniff_tcp *tcp; /* Заголовок TCP */
const char *payload; /* Данные пакета */
u_int size_ip;
u_int size_tcp;И теперь мы делаем наше магическое преобразование типов:
ethernet = (struct sniff_ethernet*)(packet);
ip = (struct sniff_ip*)(packet + SIZE_ETHERNET);
size_ip = IP_HL(ip)*4;
if (size_ip < 20) {
printf(" * Invalid IP header length: %u bytes\n", size_ip);
return;
}
tcp = (struct sniff_tcp*)(packet + SIZE_ETHERNET + size_ip);
size_tcp = TH_OFF(tcp)*4;
if (size_tcp < 20) {
printf(" * Invalid TCP header length: %u bytes\n", size_tcp);
return;
}
payload = (u_char *)(packet + SIZE_ETHERNET + size_ip + size_tcp);Как это работает? Рассмотрим структуру пакета в памяти. u_char указатель — просто переменная содержащая адрес в памяти.
Ради простоты, давайте скажем, что адрес на который указывает этот указатель это Х. Тогда, если наши структуры просто находятся в линии, то первая из них — sniff_ethernet, будет расположена в памяти по адресу Х, так же мы можем легко найти адрес структуры после нее. Этот адрес — это Х плюс длина Ethernet заголовка, которая равна 14, или SIZE_ETHERNET.
Аналогично, если у нас есть адрес этого заголовка, то адрес структуры после него — это сам адрес плюс длина этого заголовка. Заголовок IP, в отличие от заголовка Ethernet, не имеет фиксированной длины. Его длина указывается как количество 4-байтовых слов по полю заголовка IP. Поскольку это количество 4-байтных слов, оно должно быть умножено на 4, что бы указать размер в байтах. Минимальная длина этого заголовка составляет 20 байтов.
TCP заголовок так же имеет вариативную длину, эта длина указывается как число 4-байтных слов, в поле "смещения данных" заголовка TCP, и его минимальная длина так же равна 20 байтам.
Итак, давайте сделаем диаграмму:
| VARIABLE | LOCATION(in bytes) |
|---|---|
| sniff_ethernet | X |
| sniff_ip | X + SIZE_ETHERNET |
| sniff_tcp | X + SIZE_ETHERNET + {IP header length} |
| payload | X + SIZE_ETHERNET + {IP header length} + {TCP header length} |
sniff_ethernet структура, находясь в первой линии, просто находится по адресу Х. sniff_ip, которая следует прямо за sniff_ethernet, это адрес Х плюс такое количество байтов, которое занимает структура sniff_ethernet (14 байтов или SIZE_ETHERNET). sniff_tcp находится прямо после двух предыдущих структур, так что его локация это — X плюс размер Ethernet, и IP заголовок. (14 байтов, и 4 раза длина заголовка IP). Наконец, данные (для которых не существует определенной структуры) расположены после них всех.
Итак, на данном этапе мы знаем, как использовать функцию обратного вызова, вызвать ее и получить данные из полученного пакета. Здесь я приложу исходный код готового сниффера. Просто скачайте sniffer.c и попробуйте сами.
На данном этапе вы должны быть способны написать сниффер используя PCAP. Вы изучили базовые концепты которые стоят за открытием PCAP сессии, узнали главные детали о сниффиге пакетов, применении фильтров, и использования функций обратного вызова. Теперь пришло время выйти и самостоятельно захватить трафик.
Тим Карстенс 2002. Все права защищены. Распространение и использование, с модификацией и без нее разрешены при соблюдении следующих условий:
Копия должна содержать вышеупомянутое уведомление об авторских правах и этот список условий:
Имя Тима Карстенса не может использоваться для одобрения или продвижения продуктов, полученных из этого документа, без специального предварительного письменного разрешения.
This document is Copyright 2002 Tim Carstens. All rights reserved. Redistribution and use, with or without modification, are permitted provided that the following conditions are met:
Redistribution must retain the above copyright notice and this list of conditions.
The name of Tim Carstens may not be used to endorse or promote products derived from this document without specific prior written permission.
/ Insert 'wh00t' for the BSD license here /
|
Метки: author Lupus_Anay программирование перевод pcap сниффер захват трафика |
Создание и нормализация словарей. Выбираем лучшее, убираем лишнее |

crunch 4 5 1234567890 -o all_numbers_from_4_to_5.txt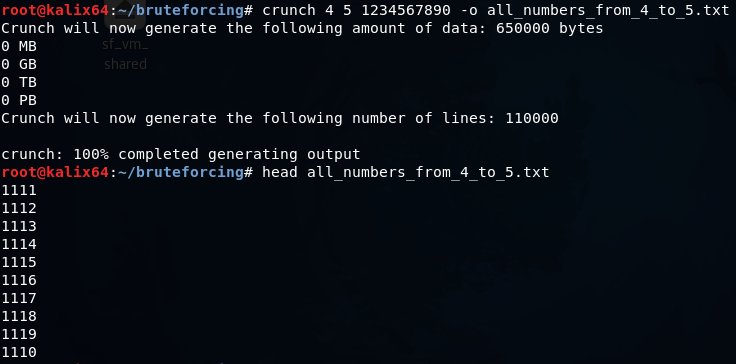
crunch 10 10 qwe RTY 123 \#\@ -t P^@@,ord%% -o Password_template.txt

crunch 1 1 -p Alex Company Position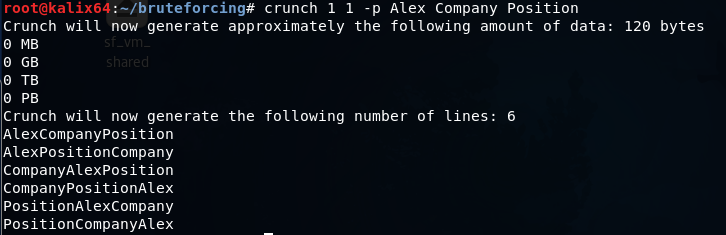
?l = abcdefghijklmnopqrstuvwxyz
?u = ABCDEFGHIJKLMNOPQRSTUVWXYZ
?d = 0123456789
?s = !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
?a = ?l?u?d?s
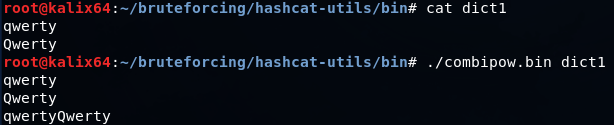
?b = 0x00 - 0xffmp64.bin -1 Pp -2 \@\#\$ ?1assw?2r?d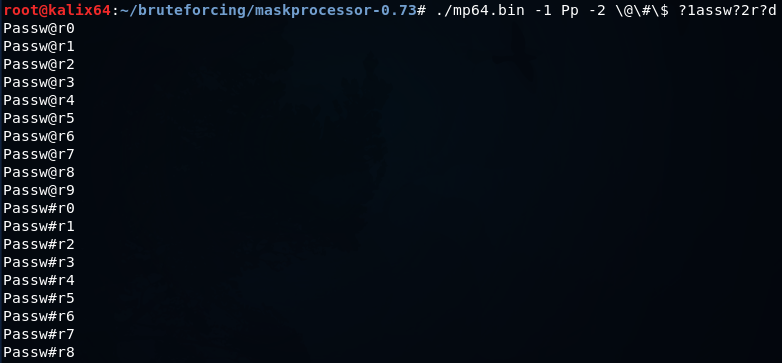
mp64.bin -1 Qq -2 ?d\@\#\$ ?1werty_12?2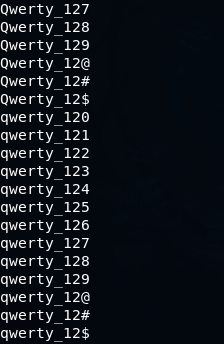
[List.Rules:NT]
:
-c T0Q
-c T1QT[z0]
-c T2QT[z0]T[z1]
-c T3QT[z0]T[z1]T[z2]
-c T4QT[z0]T[z1]T[z2]T[z3]
-c T5QT[z0]T[z1]T[z2]T[z3]T[z4]
-c T6QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]
-c T7QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]
-c T8QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]
-c T9QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]
-c TAQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]
-c TBQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]T[zA]
-c TCQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]T[zA]T[zB]
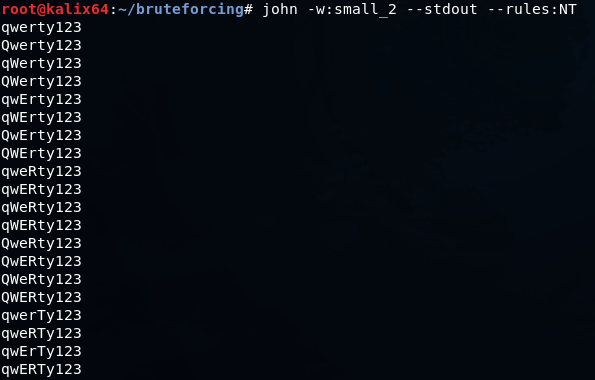
-c TDQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]T[zA]T[zB]T[zC]john -w:QWERTY123.dict --stdout --rules:NT

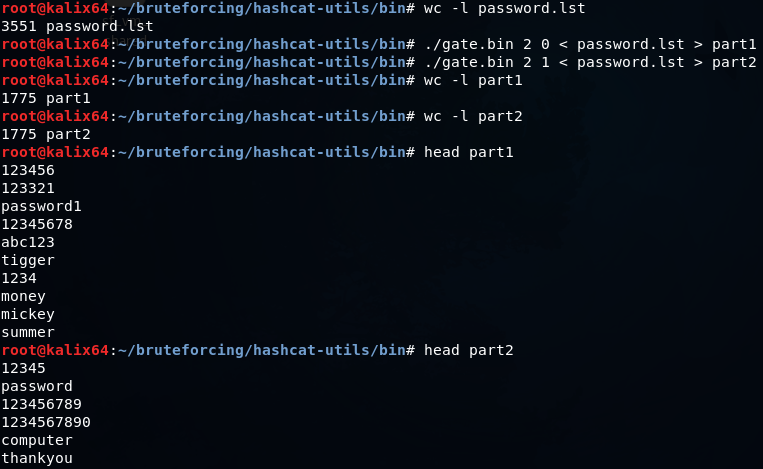
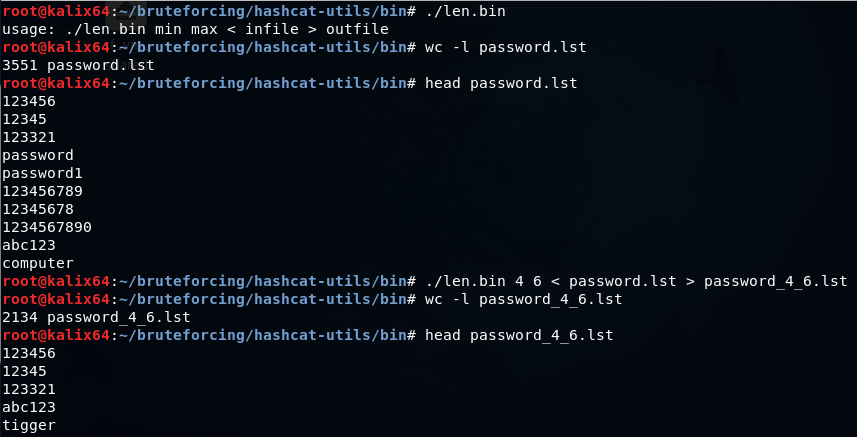



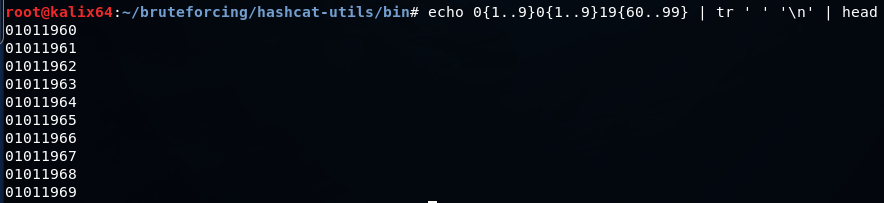
echo 0{1..9}0{1..9}19{60..99} | tr ' ' '\n' >> dates
split -d -l 1000 password.lst splitted_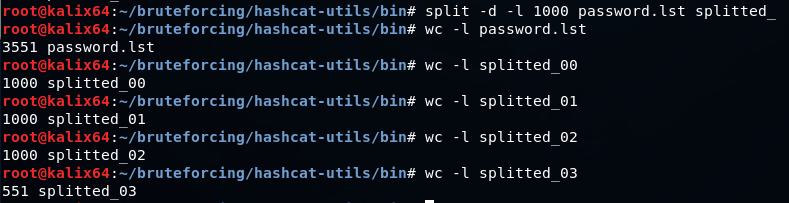
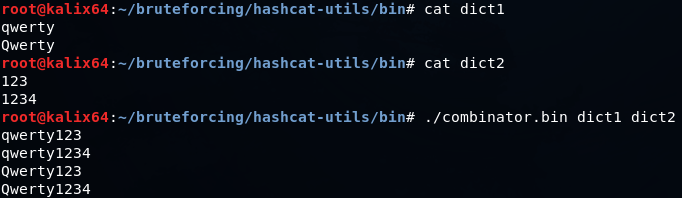
cat dict1 dict2 > combined_dict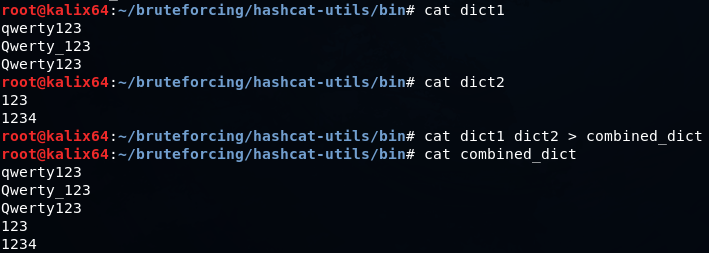
sed 's/^./\u&/' dict_file
sed 's/.$/\u&/' dict_filesed 's/^./word/' dict_filesed 's/.$/word/' dict_file
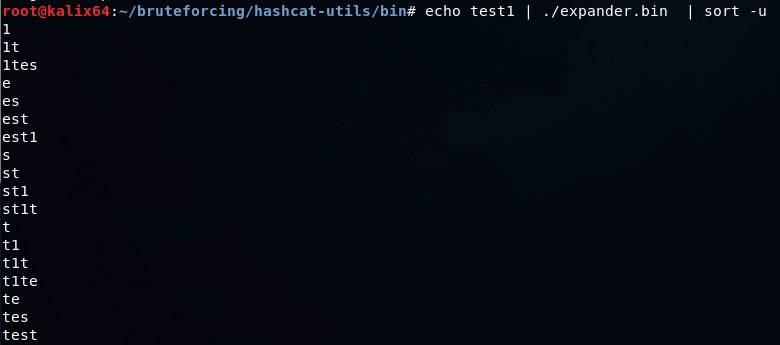
for i in $(cat dict_file) ; do seq -f %02.0f$i 0 99 ; done > numbers_dict_file
nawk 'gsub("[0-9]","&",$0)==2' password.lst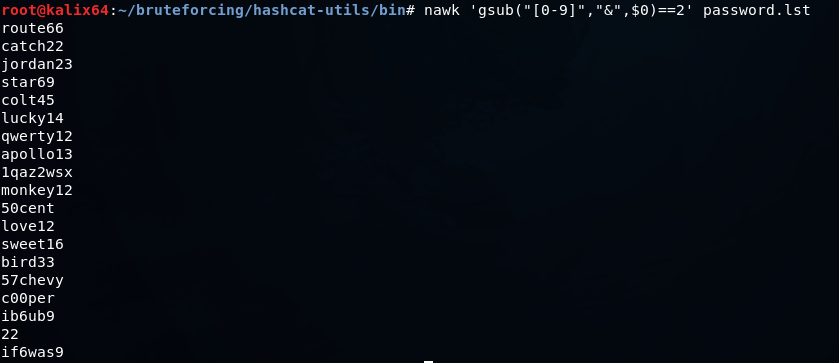
|
Метки: author antgorka информационная безопасность блог компании pentestit wordlist pentest создание словарей maskprocessor crunch john the ripper |
Отчет по пентесту: краткое руководство и шаблон |
В прошлой статье мы подробно разобрали методологию комплексного тестирования защищенности и соответствующий инструментарий этичного хакера. Даже если мы с вами в совершенстве овладеем методикой взлома и проведем тестирование на самом высоком уровне, но не сможем грамотно представить результаты заказчику, то проект будет «так себе». Как написать грамотный отчет по тестированию защищенности – об этом мы и поговорим сегодня.

Прежде чем браться за написание любого отчета нам нужно самим себе задать следующие два важных вопроса:
В случае отчета по тестированию защищенности в качестве читателей выступают:
Генеральный директор оплачивает наши услуги по тестированию защищенности и ожидает увидеть в отчете основные результаты: можно ли проникнуть в сеть его компании и какую информацию можно таким образом получить.
Руководителю департамента информационной безопасности интересны все аспекты проведенного тестирования защищенности:
Руководителю департамента информационных технологий интересно, что его людям придется сделать для закрытия обнаруженных уязвимостей и не повлияет ли это на работоспособность информационных систем.
Разобравшись с потребностями читателей нашего отчета, давайте подумаем и о наших собственных.
Специалистам по тестированию защищенности в отчете необходимо продемонстрировать что:
Теперь мы можем разработать соответствующую структуру отчета.
Для вашего удобства выкладываем шаблон отчета, который мы используем уже несколько лет на наших курсах по этичному хакингу и структура которого соответствует описываемой ниже.
Разберем ключевые элементы отчета по тестированию защищенности.
Раздел «Резюме для руководства»
Раздел на одну, максимум, две страницы в котором пишем, что и зачем мы делали, описываем основные результаты и выводы, приводим ключевые рекомендации. Технические термины стараемся не использовать, так как читатели – высшее руководство, которое не всегда обладает хорошими познаниями в области ИТ/ИБ.
Раздел «Границы проекта»
В данном разделе мы описываем, какие виды тестирования проводились и относительно каких информационных ресурсов. Детализация должна быть такая, чтобы читатели понимали, что вошло в проект, а что осталось за его рамками. При необходимости можем указывать адреса офисов и даже имена людей, задействованных в проекте со стороны заказчика.
Раздел «Наш подход»
Некоторые специалисты по этичному хакингу не любят описывать свой подход, ссылаясь на свои ноу-хау. Мы же рекомендуем придерживаться прозрачности в отношениях с заказчиками и описать хотя бы основные шаги тестирования в соответствии с принятой методологией тестирования защищенности.
Полезным будет и сопоставление этапов тестирования защищенности с выявленными уязвимостями.
Одним из важных моментов в ходе проведения тестирования защищенности является оценка рисков, связанных с возможной эксплуатацией уязвимостей. Если мы не руководствуемся методикой заказчика, а используем некую свою схему оценки, то ее лучше также здесь описать.
Описание выявленных уязвимостей
Основной объем отчета о тестировании защищенности составят описания обнаруженных уязвимостей. Для аудиторских отчетов, а отчет о тестировании защищенности без сомнения относится к данной категории, классической является следующая структура представления информации: наблюдение(finding) – риск – рекомендация.
В подразделе «наблюдение» описывается, какая уязвимость была обнаружена, в какой системе, приводится демонстрация возможности ее эксплуатации с соответствующими скриншотами. Иногда заказчики настаивают на передаче им логов проведенных тестов, в этом случае целесообразно указать использованный инструментарий и дать ссылку на соответствующий файл (как правило, передается заказчику только в электронном виде).
В подразделе «риск» дается описание ситуации, которая может произойти в случае использования потенциальными злоумышленниками данной уязвимости. Для правильной оценки специалистам по тестированию необходимо выяснить критичность скомпрометированного ресурса.
В подразделе «рекомендации» эксперты по тестированию защищенности дают советы, как исправить ситуацию. При этом совет, как правило, состоит из двух частей: необходимой коррекции и необходимого корректирующего действия. Коррекция – это то, что нужно сделать прямо сейчас (например, изменить пароль), корректирующее действие – это то, что нужно сделать в принципе для устранения причины выявленной проблемы (например, внедрить парольную политику, обучить пользователей и т.п.).
Мы кратко рассмотрели структуру отчета, которая, конечно, помогает разрабатывать документ, но любому составителю отчетов нужно еще освоить навык структурирования информации.
Одним из самых лучших учебников по этой теме является книга Барбары Минто «Принцип пирамиды Минто. Золотые правила мышления, делового письма и устных выступлений», которую с удовольствием рекомендуем к прочтению.
|
Метки: author alexdorofeeff информационная безопасность блог компании эшелон тестирование на проникновение анализ защищенности разработка отчетов |
Миграция схемы данных без головной боли: идемпотентность и конвергентность для DDL-скриптов |

alter class drop method foo;
alter class add method bar(…) {
…
}
CONVERGE TABLE OrderHeader(
id VARCHAR(30) NOT NULL,
date DATETIME DEFAULT GETDATE(),
customer_id VARCHAR(30),
customer_name VARCHAR(100),
CONSTRAINT Pk_OrderHeader PRIMARY KEY (id)
);
|
Метки: author IvanPonomarev программирование анализ и проектирование систем sql celesta liquibase реляционные базы данных |
Настройка двухфакторной аутентификации в домене Astra Linux Directory |

[ kdc_cert ]
basicConstraints=CA:FALSE
# Here are some examples of the usage of nsCertType. If it is omitted
keyUsage = nonRepudiation, digitalSignature, keyEncipherment, keyAgreement
#Pkinit EKU
extendedKeyUsage = 1.3.6.1.5.2.3.5
subjectKeyIdentifier=hash
authorityKeyIdentifier=keyid,issuer
# Copy subject details
issuerAltName=issuer:copy
# Add id-pkinit-san (pkinit subjectAlternativeName)
subjectAltName=otherName:1.3.6.1.5.2.2;SEQUENCE:kdc_princ_name
[kdc_princ_name]
realm = EXP:0, GeneralString:${ENV::REALM}
principal_name = EXP:1, SEQUENCE:kdc_principal_seq
[kdc_principal_seq]
name_type = EXP:0, INTEGER:1
name_string = EXP:1, SEQUENCE:kdc_principals
[kdc_principals]
princ1 = GeneralString:krbtgt
princ2 = GeneralString:${ENV::REALM}
[ client_cert ]
# These extensions are added when 'ca' signs a request.
basicConstraints=CA:FALSE
keyUsage = digitalSignature, keyEncipherment, keyAgreement
extendedKeyUsage = 1.3.6.1.5.2.3.4
subjectKeyIdentifier=hash
authorityKeyIdentifier=keyid,issuer
subjectAltName=otherName:1.3.6.1.5.2.2;SEQUENCE:princ_name
# Copy subject details
issuerAltName=issuer:copy
[princ_name]
realm = EXP:0, GeneralString:${ENV::REALM}
principal_name = EXP:1, SEQUENCE:principal_seq
[principal_seq]
name_type = EXP:0, INTEGER:1
name_string = EXP:1, SEQUENCE:principals
[principals]
princ1 = GeneralString:${ENV::CLIENT} #openssl
OpenSSL> engine dynamic -pre SO_PATH:/usr/lib/ssl/engines/engine_pkcs11.so -pre ID:pkcs11 -pre LIST_ADD:1 -pre LOAD -pre MODULE_PATH:/lib64/libASEP11.so
OpenSSL> req -engine pkcs11 -new -key 0:42 -keyform engine -out client.req -subj "/C=RU/ST=Moscow/L=Moscow/O=Aladdin/OU=dev/CN=test1 (!Ваш_Пользователь!)/emailAddress=test1@mail.com"
OpenSSL>quit. [libdefaults]
default_realm = EXAMPLE.RU
pkinit_anchors = FILE:/etc/krb5/cacert.pem
# для аутентификации по токену
pkinit_identities = PKCS11:/lib64/libASEP11.so
|
|
Найм тестировщиков — по обе стороны баррикад |




|
Метки: author DarinaCharisma управление персоналом карьера в it-индустрии блог компании агентство agima собеседование собеседование на работу зарплата в it тестировщики |
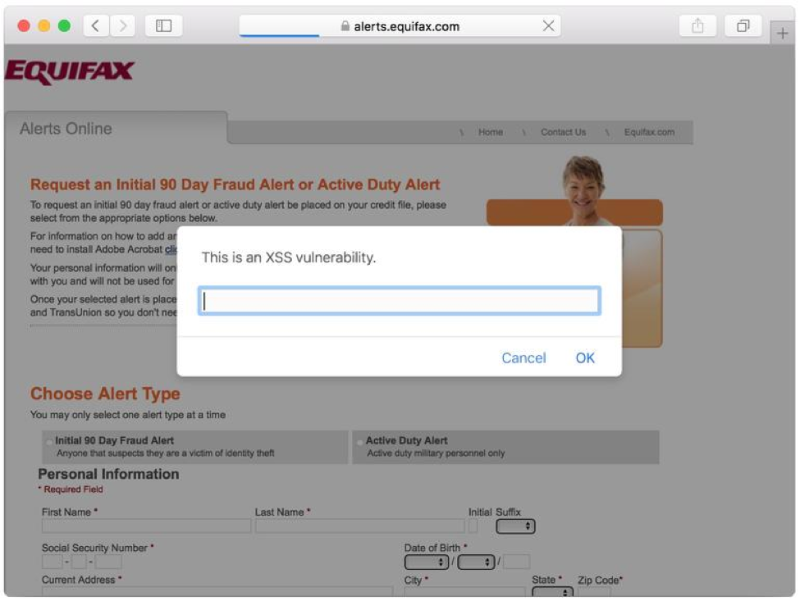
Новая уязвимость веб-сервера Apache Struts позволяет удаленно исполнять код |

|
Метки: author ptsecurity информационная безопасность блог компании positive technologies apache apache struts cisco уязвимости |
[Перевод] «Инновации вокруг»: почему описания на сайтах компаний такие непонятные, и чем это плохо |
|
Метки: author lol_wat контент-маркетинг интернет-маркетинг брендинг стартапы бизнес контент зато звучит круто |
Файловый сервер SAMBA на базе Linux CentOS 7 |

cp /etc/somefile.conf /etc/somefile.conf.bakdhclientifconfigecho proxy=http://your.proxy:8888 >> /etc/yum.confproxy_username=yum-user
proxy_password=qwerty
yum install open-vm-toolsyum install hyperv-daemonsyum updateyum install mc
nmcli device statusnmcli connection modify “ens192” ipv4.addresses “192.168.1.100/24 192.168.1.1”hostnamectl set-hostname ls01.fqdn.comsystemctl restart systemd-hostnamedhostnamectl status
hostname
hostname -s
hostname -fecho net.ipv6.conf.all.disable_ipv6 = 1 >> /etc/sysctl.conf
echo net.ipv6.conf.default.disable_ipv6 = 1 >> /etc/sysctl.confservice network restartsestatusrebootyum install sambachkconfig smb onservice smb start
smbstatusfirewall-cmd --statefirewall-cmd --list-all
firewall-cmd --list-services
firewall-cmd –permanent –remove-service=dhcpv6-clientfirewall-cmd --permanent --add-service=samba
firewall-cmd --reloadmkdir /samba
mkdir /samba/guestchown nobody:nobody /samba/guest
chmod 777 /samba/guestmcedit /etc/samba/smb.conf[global]
workgroup = WORKGROUP
security = user
map to guest = bad user
min protocol = NT1
[guest]
path = /samba/guest
guest ok = Yes
writable = Yes
testparm
service smb restart[global]
log level = 2
[global]
load printers = no
show add printer wizard = no
printcap name = /dev/null
disable spoolss = yes
mkdir /samba/smbconf
mkdir /samba/smblogsmcedit /etc/fstab/etc/samba /samba/smbconf none bind 0 0
/var/log/samba /samba/smblogs none bind 0 0
mount -alsblkparted /dev/sdb mklabel msdosparted /dev/sdb mklabel gptparted /dev/sdb mkpart primary ext4 1MiB 100%mkfs.ext4 /dev/sdb1mcedit /etc/fstab/dev/sdb1 /samba/guest ext4 defaults 0 0
mount –adf -hchmod 777 /samba/guestmkdir /samba/smbimg dd if=/dev/zero of=/samba/smbimg/100M.img bs=100 count=1Mmkfs.ext4 /samba/smbimg/100M.imgmcedit /etc/fstab/samba/smbimg/100M.img /samba/guest ext4 defaults 0 0
mount -adf -hchmod 777 /samba/guestmcedit /etc/fstabnone /samba/guest tmpfs defaults,size=100M 0 0
mount -adf -hcrontab –lcrontab –e SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=“”
HOME=/
#удалять файлы и каталоги каждый час
* 0-23 * * * rm –R /samba/guest/*
#Удалить только файлы старше 1 дня, запуск команды каждые 10 минут
0-59/10 * * * * find /samba/guest/* -type f -mtime +1 -exec rm –f {} \;
#удалить файлы старше 50 минут, запуск команды каждые 10 минут
0-59/10 * * * * find /samba/guest/* -type f -mmin +50 -exec rm -f {} \;
:wq [global]
hosts allow = 192.168.1.100, 192.168.1.101
hosts deny = ALL
[guest]
hosts allow = 192.168.0.0/255.255.0.0
hosts deny = 10. except 10.1.1.1
adduser user1smbpasswd -a user1[global]
passdb backend=tdbsam:/etc/samba/smbpassdb.tdb
[guest]
path = /samba/guest
writable = no
read list = user1, @group2
write list = user2, user3
yum install ntpmcedit /etc/ntp.confserver 192.168.1.10
server 192.168.1.20
server someserver.contoso.com
chkconfig ntpd onservice ntpd startntpq –pyum install samba-winbindchkconfig winbind onservice winbind start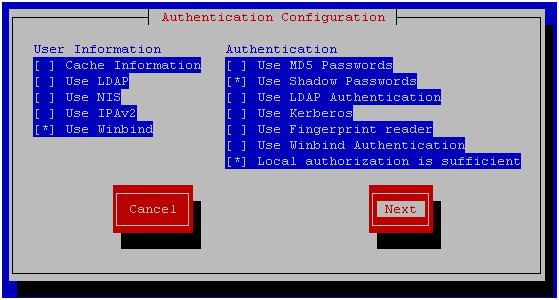
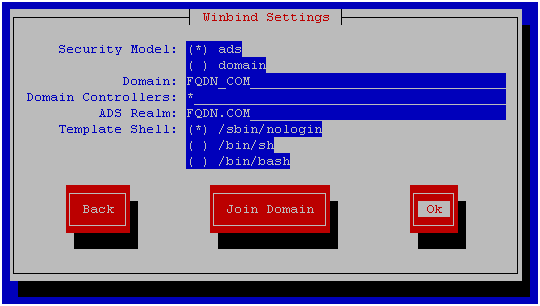
net ads join –U youruser
[libdefaults]
Default_realm = FQDN.COM
[realms]
FQDN.COM = {
kdc = *
}
passwd: files sss winbind
shadow: files sss winbind
group: files sss winbind
[global]
workgroup = FQDN_COM
password server = *
realm = FQDN.COM
security = ads
idmap config *: range = 16777216-33554431
template shell = /sbin/nologin
kerberos method = secrets only
winbind use default domain = false
winbind pffline logon = false
[global]
domain master = no
local master = no
preferred master = no
os level = 0
domain logons = no
[domain users read only]
path = /samba/guest
read list = "@fqdn_com\domain users"
force create mode = 777
directory mask = 777
[domain users writable]
path = /samba/guest
read list = "@fqdn_com\domain users"
write list = "@fqdn_com\domain users"
force create mode = 777
directory mask = 777
service smb restartsmbstatus
setsebool -P samba_export_all_ro=1
setsebool -P samba_export_all_rw=1|
Метки: author dklm системное администрирование серверное администрирование настройка linux linux samba centos centos 7 smb nas |
Компания Oracle передаст проект Java EE в руки сообщества Eclipse Foundation |

Недавно мы объявили, что Oracle начинает изучать возможность перевода технологий Java EE в OpenSource, чтобы сделать процесс разработки этих стандартов более гибким и открытым. С середины августа у нас было много дискуссий с другими поставщиками, членами сообщества и фондами OpenSource, чтобы продвинуть процесс вперед. Вот обновленная информация о достигнутом прогрессе.
Во-первых, мы обратились к IBM и Red Hat, другим крупнейшим вкладчикам платформы Java EE, чтобы запросить поддержку этого нового направления. Oracle, IBM и Red Hat сотрудничают на постоянной основе, чтобы усовершенствовать подход, который мы можем коллективно поддерживать. Мы достигли хорошего прогресса на этом фронте и ожидаем продолжения совместной работы, чтобы сделать этот переход успешным для всех сторон. Спасибо, IBM и Red Hat!
Во-вторых, мы уточнили наше предложение. В соответствии с обычными оговорками о планах, которые могут быть изменены в будущем, мы намерены:
Озвучены намерения перелицензировать принадлежащие Oracle технологии Java EE и наработки, связанные с проектом GlassFish, включая эталонные реализации, наборы для оценки совместимости (TCK) и всю документацию. Независимый проект планируется распространять под новым брендом, т.е. вместо Java EE будет выбрано другое имя, но пакеты javax и определённые в спецификации компоненты сохранят свои прежние названия. Дополнительно будет продемонстрирована возможность сборки совместимых сторонних реализаций Java EE на основе предоставленных исходных текстов, соответствующих требованиям Java EE 8 TCK.
В-третьих, мы встретились с несколькими фондами для обсуждения нашего предложения. Мы ценим время, которое они вложили в нас, и отзывы и предложения, которые они предложили. После тщательного анализа мы выбрали Eclipse Foundation для передачи всех имущественных прав. Eclipse Foundation имеет большой опыт и участие в Java EE и связанных с ним технологиях. Это поможет нам быстро перейти на Java EE, создать благоприятные для сообщества процессы для развития платформы и использовать дополнительные проекты, такие как MicroProfile. Мы с нетерпением ждем этого сотрудничества.
Обратите внимание, что в дополнение ко всему вышесказанному, Oracle продолжит поддерживать существующие лицензии Java EE, включая лицензии, перемещающиеся в Java EE 8. Oracle также намерена продолжать поддерживать существующие версии WebLogic Server и поддерживать Java EE 8 в будущих версиях WebLogic Server. Мы считаем, что этот план позволит нам продолжать поддерживать существующие стандарты Java EE, обеспечивая тем самым эволюцию в более открытой среде. Нам предстоит еще большая работа, но мы уверены, что мы на верном пути. Мы надеемся получить дополнительные обновления в ближайшее время!
Источник
|
Метки: author Crandel oracle java java ee 8 |
Подборка: 10 полезных инструментов для интернет- маркетолога |




|
|
«Восточный» — наш космодром |

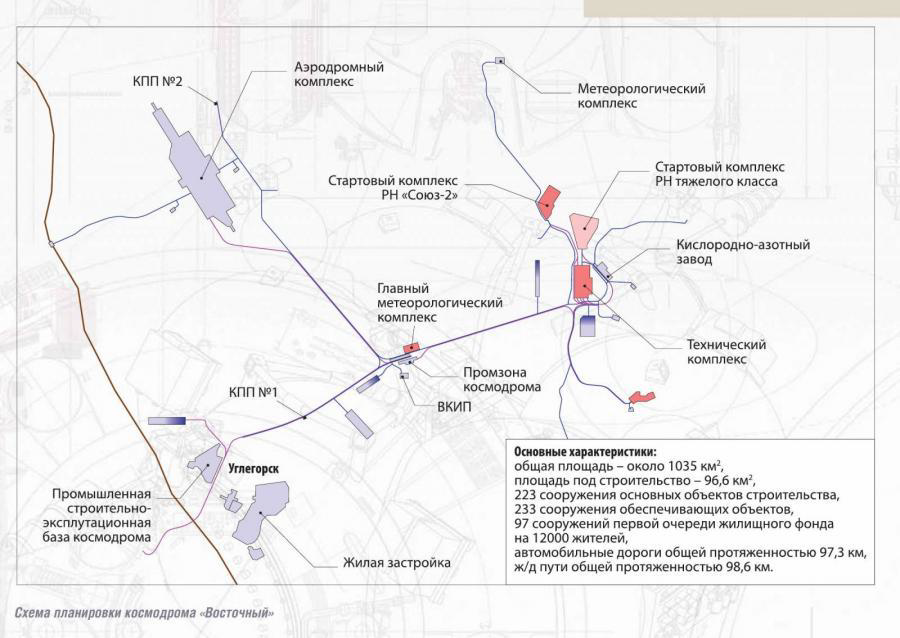
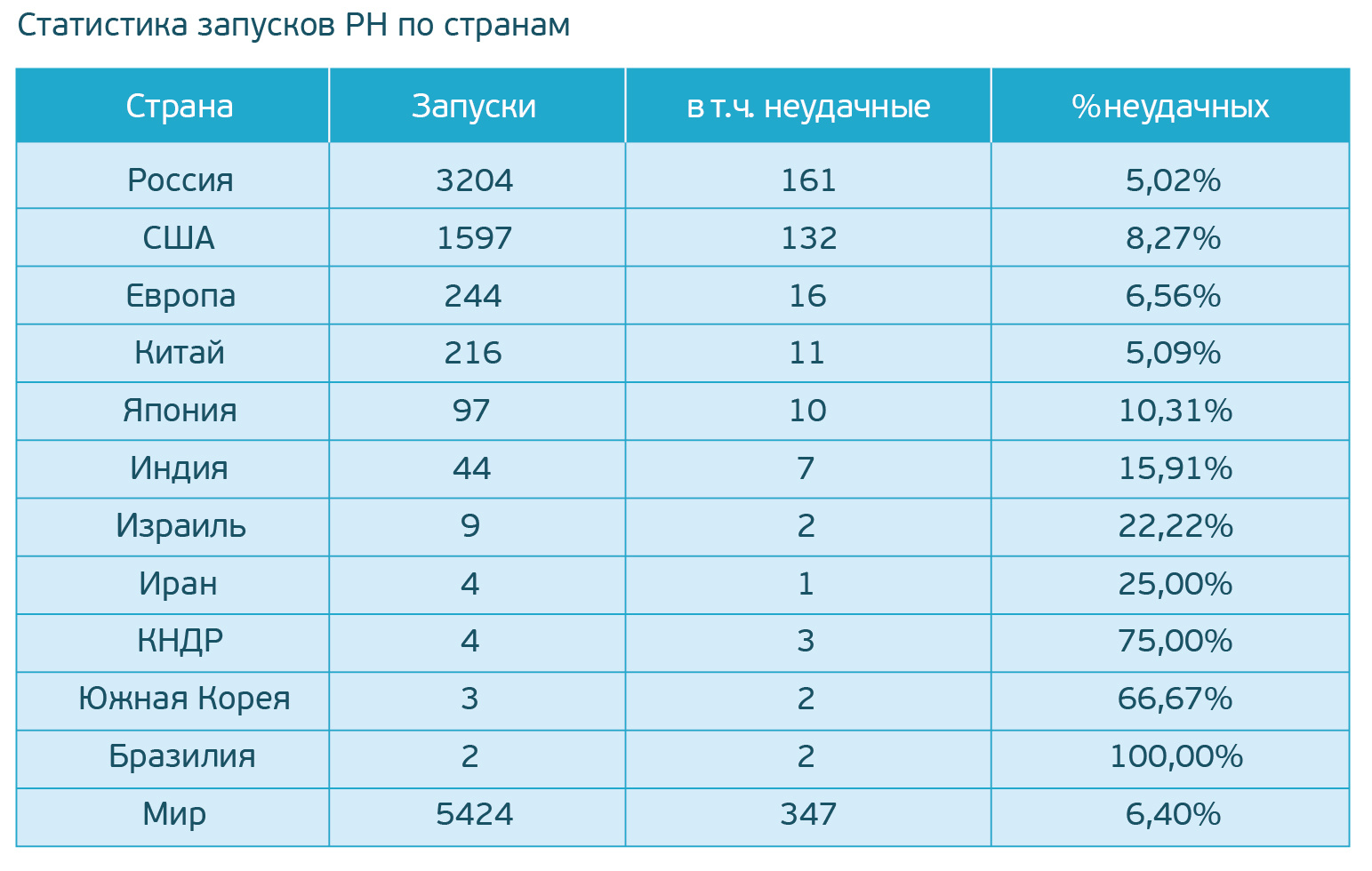








































|
Метки: author virtser управление проектами управление персоналом карьера в it-индустрии блог компании гк ланит космодром инфраструктура инженерные системы |
Конференция VMworld 2017 Europe. День 0 |















|
Метки: author omnimod хранилища данных хранение данных виртуализация it- инфраструктура блог компании инфосистемы джет vmworld виртуализация серверов |
7 причин, почему СМБ не нужны программы лояльности в том виде, в каком они представлены на рынке |

Привет, Хабр! Меня зовут Максим Мелешко, я более 10 лет работаю с программами лояльности, сейчас возглавляю центр компетенций по программам лояльности в «Техносерв Консалтинг». Именно наша команда из «Техносерв Консалтинг» внедряла такие проекты как «Аэрофлот Бонус», Газпромнефть «Нам по пути», «Мвидео-бонус» и многие другие решения. С вашего позволения, буду здесь периодически писать свои мысли о программах лояльности, проблематике внедрения платформ, и как эти платформы помогут заработать бизнесу. Сегодня же начну с того, почему, на мой взгляд, СМБ не нужны программы лояльности в том виде, в каком они представлены на рынке, почему при этом они нужны крупным компаниям и разберем красивый пример.
Сперва хочу высказать свою точку зрения о том, что же такое программа лояльности и для чего она нужна. Если убрать «воду», то программа лояльности — это маркетинговый инструмент для увеличения прибыли компании. Данный инструмент повышает прибыль за счет увеличения базы постоянных клиентов, частоты покупок и среднего чека.
Если вы владелец малого или среднего бизнеса и решили внедрить программу лояльности, вы должны четко понимать, как и за счет чего эта программа будет влиять на перечисленные показатели.
Сейчас на рынке очень много различных систем, позиционирующих себя как платформы лояльности. Их можно встретить даже внутри кассового ПО. Как правило, данные системы умеют выполнять следующие функции:
Итак, сразу перейдем к нашим 7-м причинам, почему СМБ не нужны программы лояльности. На деле, запустив такую систему, СМБ получает примерно следующее:

Что владелец бизнеса получит взамен? Чаще всего — лозунги об эмоциональной привязанности клиентов к бренду и прочие вещи, которые, к сожалению, слабо влияют на прибыль.
Тут возникает вопрос: почему программы лояльности так популярны в крупных бизнесах, ведь на внедрение, содержание и развитие таких программ крупные игроки тратят десятки миллионов долларов. Там же не дураки сидят…
На самом деле программа лояльности зарабатывает деньги, когда выполняются следующие три условия, и в крупных бизнесах они, как правило, действительно выполняются:
Давайте рассмотрим возможности программы лояльности на примере бизнес-кейса в сети АЗС. Один из самых высоко маржинальных товаров в сети АЗС – кофе. В свою очередь, топливо – это низко маржинальный товар, и увеличить его пролив – задача не простая, бак не резиновый. Поэтому будем зарабатывать на кофе.

Благодаря аналитическому модулю программы лояльности, выявляем, что среди клиентов АЗС есть клиенты, которые во время заправки покупают кофе и вишневую слойку. Клиенты данного сегмента делают так не всегда, а в 40% случаях приезда на заправку. Но если они покупают вишневую слойку, то в 100% случаев к ней покупают кофе. Выделим этот сегмент и назовем его «любители вишневых слоек».
Запускаем акцию: в момент посещения заправки «любителю вишневых слоек» сообщается, что отныне он персонально будет получать скидку 20% на его любимый продукт и что мы будем счастливы, если он будет покупать свой любимый продукт еще чаще.
Ниже в таблице приведены результаты такой акции.
| До запуска акции |
После запуска акции |
|||
| Кофе |
Слойка |
Кофе |
Слойка |
|
| Себестоимость 1 шт. |
20 |
40 |
20 |
40 |
| Цена 1 шт. |
80 |
60 |
80 |
48 |
| Продано штук в день |
20 000 |
20 000 |
40 000 |
40 000 |
| Выручка итого по продукту |
1600000 |
1200000 |
3200000 |
1920000 |
| Себестоимость итого по продукту |
400000 |
800000 |
800000 |
1600000 |
| Маржа итого по продукту |
1200000 |
400000 |
2400000 |
320000 |
| Итого маржа |
1600000 |
2720000 |
||
Данная акция стала приносить только по одному сегменту клиентов более миллиона рублей чистой прибыли в день. В программе лояльности таких акций может запускаться десятки и даже сотни в неделю. Впечатляет, правда?
Для достижения максимального результата аналитику пришлось немного попотеть. Было проведено множество различных тестов. Сегмент клиентов был разделен на множество подсегментов. Одному подсегменту, например, направилось сообщение по СМС с одним текстом и скидкой 10%, другому – пуш-уведомление с немного измененным текстом и размером скидки и т.д.
Каждый параметр влияет на отклик: и текст сообщения, и канал, и время доставки, и, конечно же, размер скидки или бонуса. Порой, приходится провести десятки тестов для выявления максимальной прибыли. Система лояльности должна давать такие возможности маркетологу и отображать результаты в онлайне, иначе эффект будет гораздо ниже, либо его не будет вовсе.
На этом пока все. Если какие-то другие темы по лояльности и CRM интересны – пишите. Напишу отдельный материал, а пока у меня в планах рассказать Вам как программы лояльности могут заработать в сегменте среднего и малого бизнеса.
Буду рад ответить на Ваши вопросы по теме. Велком!
|
|
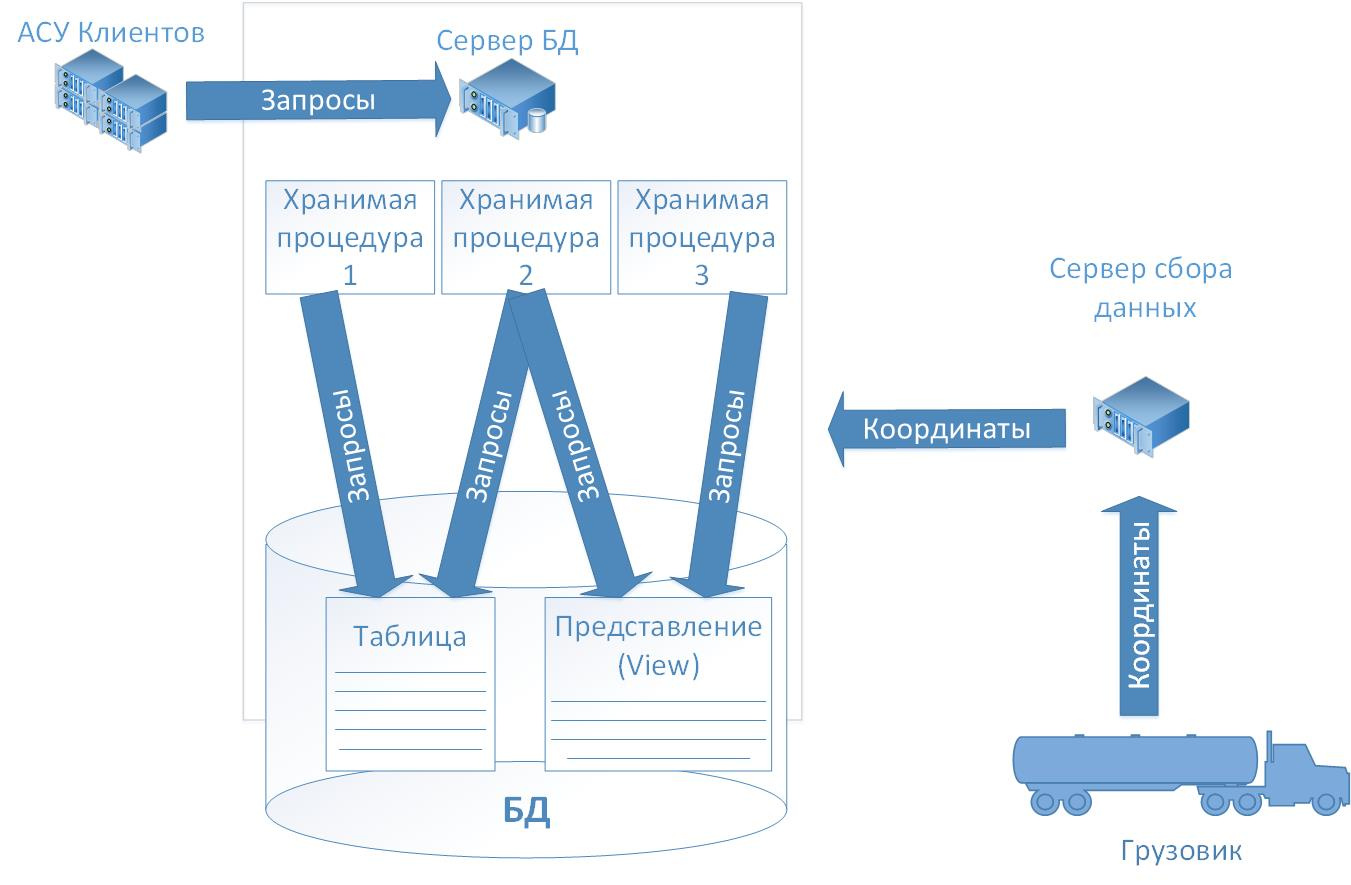
Расследование утечек информации из корпоративной базы данных перевозчика |

|
|
Двухфакторная авторизация для VPN-соединений |




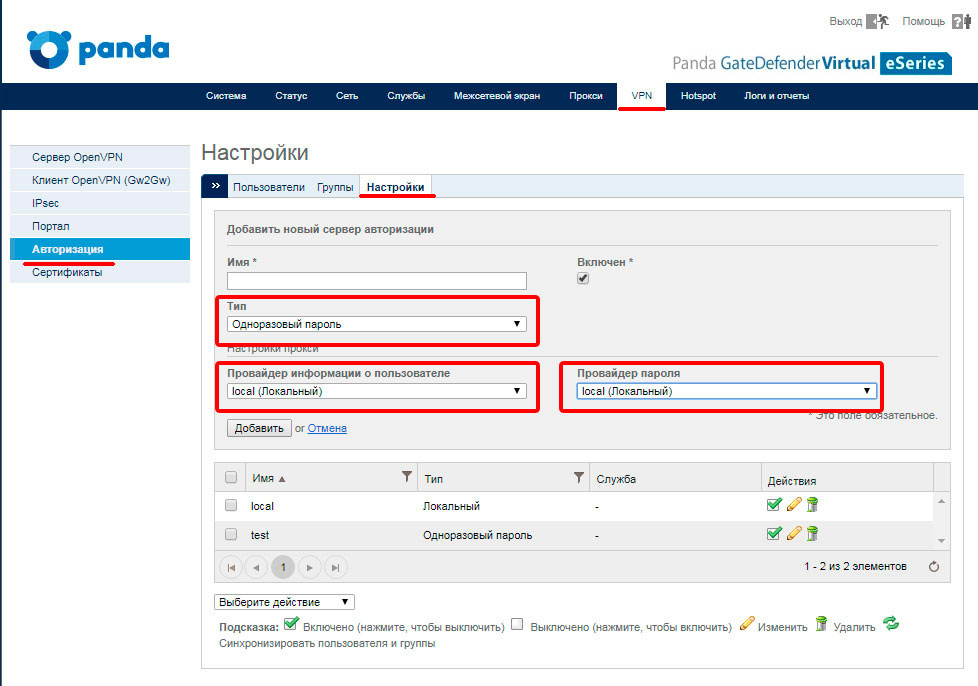
 , соответствующую тому типу VPN, который Вы хотите настроить.
, соответствующую тому типу VPN, который Вы хотите настроить.
 для добавления нового мэппинга к серверу авторизации. Новый сервер появится в правой панели. Чтобы удалить мэппинг, нажмите иконку
для добавления нового мэппинга к серверу авторизации. Новый сервер появится в правой панели. Чтобы удалить мэппинг, нажмите иконку  . Чтобы добавить или удалить все мэппинги, нажмите ссылки Добавить все и Удалить все, соответственно.
. Чтобы добавить или удалить все мэппинги, нажмите ссылки Добавить все и Удалить все, соответственно.





|
|
Детский сад, штаны на лямках: откуда берутся программисты |

















|
|
Чтоб root стоял и фичи были |
 Картинка взята тут, подпись наша
Картинка взята тут, подпись наша

|
Метки: author RegionSoft программирование блог компании regionsoft developer studio день программиста 256 день 13 сентября жизнь программистов |
[Из песочницы] Имплементация OpenId Connect в ASP.NET Core при помощи IdentityServer4 и oidc-client |
Недавно мне потребовалось разобраться, как делается аутентификация на OpenId Connect на ASP.NET Core. Начал с примеров, быстро стало понятно, что чтения спецификации не избежать, затем пришлось уже перейти к чтению исходников и статей разработчиков. В результате возникло желание собрать в одном месте всё, что необходимо для того, чтобы понять, как сделать рабочую реализацию OpenId Connect Implicit Flow на платформе ASP.NET Core, при этом понимая, что Вы делаете.
Статья про специфику имплементации, поэтому рекомендую воспроизводить решение по предложенному в статье коду, иначе будет трудно уловить контекст. Большинство значимых замечаний в комментариях и в тексте статьи содержат ссылки на источники. Некоторые термины не имеют общепринятых переводов на русский язык, я оставил их на английском.
Если Вы понимаете OpenId Connect, можете начинать читать со следующей части.
OpenId Connect (не путать с OpenId) — протокол аутентификации, построенный на базе протокола авторизации OAuth2.0. Дело в том, что задачу OAuth2 входят вопросы только авторизации пользователей, но не их аутентификации. OpenID Connect также задаёт стандартный способ получения и представления профилей пользователей в качестве набора значений, называемых claims. OpenId Connect описывает UserInfo endpoint, который возвращает эти информацию. Также он позволяет клиентским приложениям получать информацию о пользователе в форме подписанного JSON Web Token (JWT), что позволяет слать меньше запросов на сервер.
Начать знакомство с протоколом имеет смысл с официального сайта, затем полезно почитать сайты коммерческих поставщиков облачных решений по аутентификации вроде Connect2id, Auth0 и Stormpath. Описание всех нужных терминов не привожу, во-первых это была бы стена текста, а во вторых всё необходимое есть по этим ссылкам.
Если Identity Server Вам не знаком, рекомендую начать с чтения его прекрасной документации, а также отличных примеров вроде этого.
Мы реализуем OpenId Connect Implicit Flow, который рекомендован для JavaScript-приложений, в браузере, в том числе для SPA. В процессе мы чуть глубже, чем это обычно делается в пошаговых руководствах, обсудим разные значимые настройки. Затем мы посмотрим, как работает наша реализация с точки зрения протокола OpenId Connect, а также изучим, как имплементация соотносится с протоколом.
Основные авторы обеих библиотек — Брок Аллен и Доминик Брайер.
У нас будет 3 проекта:
Сценарий взаимодействия таков: клиентское приложение Client авторизуется при помощи сервера аутентификации IdentityServer и получает access_token (JWT), который затем использует в качестве Bearer-токена для вызова веб-сервиса на сервере Api.
Стандарт OpenId Connect описывает разные варианты порядка прохождения аутентификации. Эти варианты на языке стандарта называются Flow.
Implicit Flow, который мы рассматриваем в этой статье, включает такие шаги:

Для того, чтобы сильно сэкономить на написании станиц, связанных с логином и логаутом, будем использовать официальный код Quickstart.
Запускать Api и IdentityServer в процессе выполнения этого упражнения рекомендую через dotnet run — IdentityServer пишет массу полезной диагностической информации в процессе своей работы, данная информация сразу будет видна в консоли.
Для простоты предполагается, что все проекты запущены на том же компьютере, на котором работает браузер пользователя.
Давайте приступим к реализации. Для определённости будем предполагать, что Вы используете Visual Studio 2017 (15.3). Готовый код решения можно посмотреть здесь
Создайте пустой solution OpenIdConnectSample.
Большая часть кода основана на примерах из документации IdentityServer, однако код в данной статье дополнен тем, чего, на мой взгляд, не хватает в официальной документации, и аннотирован.
Рекомендую ознакомиться со всеми официальными примерами, мы же поглубже рассмотрим именно Implicit Flow.
Создайте solution с пустым проектом, в качестве платформы выберите ASP.NET Core 1.1.
Установите такие NuGet-пакеты
Install-Package Microsoft.AspNetCore.Mvc -Version 1.1.3
Install-Package Microsoft.AspNetCore.StaticFiles -Version 1.1.2
Install-Package IdentityServer4 -Version 1.5.2Версии пакеты здесь значимы, т.к. Install-Package по умолчанию устанавливает последние версии. Хотя авторы уже сделали порт IdentityServer на Asp.NET Core 2.0 в dev-ветке, на момент написания статьи, они ещё не портировали Quickstart UI. Различия в коде нашего примера для .NET Core 1.1 и 2.0 невелики.
Измените метод Main Program.cs так, чтобы он выглядел следующим образом
public static void Main(string[] args)
{
Console.Title = "IdentityServer";
// https://docs.microsoft.com/en-us/aspnet/core/fundamentals/servers/kestrel?tabs=aspnetcore2x
var host = new WebHostBuilder()
.UseKestrel()
// задаём порт, и адрес на котором Kestrel будет слушать
.UseUrls("http://localhost:5000")
// имеет значения для UI логина-логаута
.UseContentRoot(Directory.GetCurrentDirectory())
.UseIISIntegration()
.UseStartup()
.Build();
host.Run();
} Затем в Startup.cs
using System.Security.Claims;
using IdentityServer4;
using IdentityServer4.Configuration;
using IdentityServer4.Models;
using IdentityServer4.Test;ConfigureServices. Рекомендую читать текст методов перед их добавлением в проект — с одной стороны это позволит сразу иметь целостную картину происходящего, с другой стороны лишнего там мало. Настройки информации для клиентских приложений
public static IEnumerable GetIdentityResources()
{
// определяет, какие scopes будут доступны IdentityServer
return new List
{
// "sub" claim
new IdentityResources.OpenId(),
// стандартные claims в соответствии с profile scope
// http://openid.net/specs/openid-connect-core-1_0.html#ScopeClaims
new IdentityResources.Profile(),
};
} Эти настройки добавляют поддержку claim sub, это минимальное требование для соответствия нашего токена OpenId Connect, а также claim scope profile, включающего описанные стандартом OpenId Connect поля профиля типа имени, пола, даты рождения и подобных.
Это аналогичные предыдущим настройки, но информация предназначается для API
public static IEnumerable GetApiResources()
{
// claims этих scopes будут включены в access_token
return new List
{
// определяем scope "api1" для IdentityServer
new ApiResource("api1", "API 1",
// эти claims войдут в scope api1
new[] {"name", "role" })
};
} Сами клиентские приложения, нужно чтобы сервер знал о них
public static IEnumerable GetClients()
{
return new List
{
new Client
{
// обязательный параметр, при помощи client_id сервер различает клиентские приложения
ClientId = "js",
ClientName = "JavaScript Client",
AllowedGrantTypes = GrantTypes.Implicit,
AllowAccessTokensViaBrowser = true,
// от этой настройки зависит размер токена,
// при false можно получить недостающую информацию через UserInfo endpoint
AlwaysIncludeUserClaimsInIdToken = true,
// белый список адресов на который клиентское приложение может попросить
// перенаправить User Agent, важно для безопасности
RedirectUris = {
// адрес перенаправления после логина
"http://localhost:5003/callback.html",
// адрес перенаправления при автоматическом обновлении access_token через iframe
"http://localhost:5003/callback-silent.html"
},
PostLogoutRedirectUris = { "http://localhost:5003/index.html" },
// адрес клиентского приложения, просим сервер возвращать нужные CORS-заголовки
AllowedCorsOrigins = { "http://localhost:5003" },
// список scopes, разрешённых именно для данного клиентского приложения
AllowedScopes =
{
IdentityServerConstants.StandardScopes.OpenId,
IdentityServerConstants.StandardScopes.Profile,
"api1"
},
AccessTokenLifetime = 300, // секунд, это значение по умолчанию
IdentityTokenLifetime = 3600, // секунд, это значение по умолчанию
// разрешено ли получение refresh-токенов через указание scope offline_access
AllowOfflineAccess = false,
}
};
} Тестовые пользователи, обратите внимание, что bob у нас админ
public static List GetUsers()
{
return new List
{
new TestUser
{
SubjectId = "1",
Username = "alice",
Password = "password",
Claims = new List
{
new Claim("name", "Alice"),
new Claim("website", "https://alice.com"),
new Claim("role", "user"),
}
},
new TestUser
{
SubjectId = "2",
Username = "bob",
Password = "password",
Claims = new List
{
new Claim("name", "Bob"),
new Claim("website", "https://bob.com"),
new Claim("role", "admin"),
}
}
};
} ConfigureServices такpublic void ConfigureServices(IServiceCollection services)
{
services.AddMvc();
services.AddIdentityServer(options =>
{
// http://docs.identityserver.io/en/release/reference/options.html#refoptions
options.Endpoints = new EndpointsOptions
{
// в Implicit Flow используется для получения токенов
EnableAuthorizeEndpoint = true,
// для получения статуса сессии
EnableCheckSessionEndpoint = true,
// для логаута по инициативе пользователя
EnableEndSessionEndpoint = true,
// для получения claims аутентифицированного пользователя
// http://openid.net/specs/openid-connect-core-1_0.html#UserInfo
EnableUserInfoEndpoint = true,
// используется OpenId Connect для получения метаданных
EnableDiscoveryEndpoint = true,
// для получения информации о токенах, мы не используем
EnableIntrospectionEndpoint = false,
// нам не нужен т.к. в Implicit Flow access_token получают через authorization_endpoint
EnableTokenEndpoint = false,
// мы не используем refresh и reference tokens
// http://docs.identityserver.io/en/release/topics/reference_tokens.html
EnableTokenRevocationEndpoint = false
};
// IdentitySever использует cookie для хранения своей сессии
options.Authentication = new IdentityServer4.Configuration.AuthenticationOptions
{
CookieLifetime = TimeSpan.FromDays(1)
};
})
// тестовый x509-сертификат, IdentityServer использует RS256 для подписи JWT
.AddDeveloperSigningCredential()
// что включать в id_token
.AddInMemoryIdentityResources(GetIdentityResources())
// что включать в access_token
.AddInMemoryApiResources(GetApiResources())
// настройки клиентских приложений
.AddInMemoryClients(GetClients())
// тестовые пользователи
.AddTestUsers(GetUsers());
}В этом методе мы указываем настройки IdentityServer, в частности сертификаты, используемые для подписывания токенов, настройки scope в смысле OpenId Connect и OAuth2.0, настройки приложений-клиентов, а также настройки пользователей.
Теперь чуть подробнее. AddIdentityServer регистрирует сервис IdentityServer в механизме разрешения зависимостей ASP.NET Core, это нужно сделать, чтобы была возможность добавить его как middleware в Configure.
AddDeveloperSigningCredential добавляет тестовые ключи для подписи JWT-токенов, а именно id_token, access_token в нашем случае. В продакшне нужно заменить эти ключи, сделать это можно, например сгенерировав самоподписной сертификат. AddInMemoryIdentityResources. Почитать о том, что понимается под ресурсами можно тут, а зачем они нужны — тут. Метод Configure должен выглядеть так
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory)
{
loggerFactory.AddConsole(LogLevel.Debug);
app.UseDeveloperExceptionPage();
// подключаем middleware IdentityServer
app.UseIdentityServer();
// эти 2 строчки нужны, чтобы нормально обрабатывались страницы логина
app.UseStaticFiles();
app.UseMvcWithDefaultRoute();
}
Скачайте из официального репозитория Starter UI для IdentityServer, затем скопируйте файлы в папку проекта, так чтобы папки совпали по структуре, например wwwroot с wwwroot.
Проверьте, что проект компилируется.
Данный проект — игрушечный сервер API с ограниченным доступом.
Добавьте в solution ещё один пустой проект Api, в качестве платформы выберите ASP.NET Core 1.1. Т.к. мы не собираемся создавать полноценное веб-приложение в данном проекте, а лишь легковесный веб-сервис, отдающий JSON, ограничимся лишь MvcCore middleware вместо полного Mvc.
Добавьте нужные пакеты, выполнив эти команды в Package Manager Console
Install-Package Microsoft.AspNetCore.Mvc.Core -Version 1.1.3
Install-Package Microsoft.AspNetCore.Mvc.Formatters.Json -Version 1.1.3
Install-Package Microsoft.AspNetCore.Cors -Version 1.1.2
Install-Package IdentityServer4.AccessTokenValidation -Version 1.2.1Начнём с того, что добавим нужные настройки Kestrel в Program.cs
public static void Main(string[] args)
{
Console.Title = "API";
var host = new WebHostBuilder()
.UseKestrel()
.UseUrls("http://localhost:5001")
.UseContentRoot(Directory.GetCurrentDirectory())
.UseIISIntegration()
.UseStartup()
.Build();
host.Run();
} В Startup.cs потребуется несколько меньше изменений.
Для ConfigureServices
public void ConfigureServices(IServiceCollection services)
{
services.AddCors(options=>
{
// задаём политику CORS, чтобы наше клиентское приложение могло отправить запрос на сервер API
options.AddPolicy("default", policy =>
{
policy.WithOrigins("http://localhost:5003")
.AllowAnyHeader()
.AllowAnyMethod();
});
});
// облегчённая версия MVC Core без движка Razor, DataAnnotations и подобного, сопоставима с Asp.NET 4.5 WebApi
services.AddMvcCore()
// добавляем авторизацию, благодаря этому будут работать атрибуты Authorize
.AddAuthorization(options =>
// политики позволяют не работать с Roles magic strings, содержащими перечисления ролей через запятую
options.AddPolicy("AdminsOnly", policyUser =>
{
policyUser.RequireClaim("role", "admin");
})
)
// добавляется AddMVC, не добавляется AddMvcCore, мы же хотим получать результат в JSON
.AddJsonFormatters();
}А вот так должен выглядеть Configure
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory)
{
loggerFactory.AddConsole(LogLevel.Debug);
// добавляем middleware для CORS
app.UseCors("default");
// добавляем middleware для заполнения объекта пользователя из OpenId Connect JWT-токенов
app.UseIdentityServerAuthentication(new IdentityServerAuthenticationOptions
{
// наш IdentityServer
Authority = "http://localhost:5000",
// говорим, что нам не требуется HTTPS при общении с IdentityServer, должно быть true на продуктиве
// https://docs.microsoft.com/en-us/aspnet/core/api/microsoft.aspnetcore.builder.openidconnectoptions
RequireHttpsMetadata = false,
// это значение будет сравниваться со значением поля aud внутри access_token JWT
ApiName = "api1",
// можно так написать, если мы хотим разделить наш api на отдельные scopes и всё же сохранить валидацию scope
// AllowedScopes = { "api1.read", "api1.write" }
// читать JWT-токен и добавлять claims оттуда в HttpContext.User даже если не используется атрибут Authorize со схемоЙ, соответствующей токену
AutomaticAuthenticate = true,
// назначаем этот middleware как используемый для формирования authentication challenge
AutomaticChallenge = true,
// требуется для [Authorize], для IdentityServerAuthenticationOptions - значение по умолчанию
RoleClaimType = "role",
});
app.UseMvc();
}Осталось добавить наш контроллер, он возвращает текущие Claims пользователя, что удобно для того, чтобы понимать, как middleware аутентификации IdentityServer расшифровал access_token.
Добавьте в проект единственный контроллер IdentityController.
Cодержимое файла должно быть таким.
using System.Linq;
using Microsoft.AspNetCore.Mvc;
using Microsoft.AspNetCore.Authorization;
namespace Api.Controllers
{
[Authorize]
public class IdentityController : ControllerBase
{
[HttpGet]
[Route("identity")]
public IActionResult Get()
{
return new JsonResult(from c in User.Claims select new { c.Type, c.Value });
}
[HttpGet]
[Route("superpowers")]
[Authorize(Policy = "AdminsOnly")]
public IActionResult Superpowers()
{
return new JsonResult("Superpowers!");
}
}
}Убедитесь, что проект компилируется.
Этот проект фактически не содержит значимой серверной части. Весь серверный код — это просто настройки веб-сервер Kestrel, с тем чтобы он отдавал статические файлы клиента.
Так же, как и прошлых 2 раза добавьте в решение пустой проект, назовите его Client.
Установите пакет для работы со статическими файлами.
Install-Package Microsoft.AspNetCore.StaticFiles -Version 1.1.2Измените файл Program.cs
public static void Main(string[] args)
{
var host = new WebHostBuilder()
.UseKestrel()
.UseUrls("http://localhost:5003")
.UseContentRoot(Directory.GetCurrentDirectory())
.UseIISIntegration()
.UseStartup()
.Build();
host.Run();
} Класс Startup должен содержать такой код.
public void ConfigureServices(IServiceCollection services)
{
}
public void Configure(IApplicationBuilder app)
{
app.UseDefaultFiles();
app.UseStaticFiles();
}Клиентский код на JavaScript, с другой стороны, и содержит всю логику аутентификации и вызовов Api.
Мы по одному добавим в папку wwwroot проекта следующие файлы.
index.html — простой HTML-файл с кнопками различных действий и ссылкой на JavaScript-файл приложения app.js и oidc-client.js. oidc-client.js — клиентская библиотека, реализующая OpenId Connectapp.js — настройки oidc-client и обработчики событий кнопокcallback.html — страница, на которую сервер аутентификации перенаправляет клиентское приложение, передавая параметры, необходимые для завершения процедуры входа. callback-silent.html — страница, аналогичная callback.html, однако именно для случая, когда происходит "фоновый" повторный логин через iframe. Это нужно чтобы продлевать доступ пользователя к ресурсам без использования refresh_token. index.html
Добавьте новый HTML-файл с таким названием в папку wwwroot проекта.
oidc-client.js
Скачайте этот файл отсюда (1.3.0) и добавьте в проект.
app.js
Добавьте новый JavaScript-файл с таким названием в папку wwwroot проекта.
Добавьте
/// в начале файла для поддержки IntelliSense.
Вставьте этот код к началу app.js
Oidc.Log.logger = console;
Oidc.Log.level = 4;Первой строкой, пользуясь совместимостью по вызываемым методам, устанавливаем стандартную консоль браузера в качестве стандартного логгера для oidc-client. Второй строкой просим выводить все сообщения. Это позволит увидеть больше подробностей, когда мы перейдём ко второй части статьи, и будем смотреть, как же наша имплементация работает.
Теперь давайте по частям добавим остальной код в этот файл.
Эта часть кода самая длинная, и, пожалуй, самая интересная. Она содержит настройки библиотеки основного объекта UserManager библиотеки oidc-client, а также его создание. Рекомендую ознакомиться с самими настройками и комментариями к ним.
var config = {
authority: "http://localhost:5000", // Адрес нашего IdentityServer
client_id: "js", // должен совпадать с указанным на IdentityServer
// Адрес страницы, на которую будет перенаправлен браузер после прохождения пользователем аутентификации
// и получения от пользователя подтверждений - в соответствии с требованиями OpenId Connect
redirect_uri: "http://localhost:5003/callback.html",
// Response Type определяет набор токенов, получаемых от Authorization Endpoint
// Данное сочетание означает, что мы используем Implicit Flow
// http://openid.net/specs/openid-connect-core-1_0.html#Authentication
response_type: "id_token token",
// Получить subject id пользователя, а также поля профиля в id_token, а также получить access_token для доступа к api1 (см. наcтройки IdentityServer)
scope: "openid profile api1",
// Страница, на которую нужно перенаправить пользователя в случае инициированного им логаута
post_logout_redirect_uri: "http://localhost:5003/index.html",
// следить за состоянием сессии на IdentityServer, по умолчанию true
monitorSession: true,
// интервал в миллисекундах, раз в который нужно проверять сессию пользователя, по умолчанию 2000
checkSessionInterval: 30000,
// отзывает access_token в соответствии со стандартом https://tools.ietf.org/html/rfc7009
revokeAccessTokenOnSignout: true,
// допустимая погрешность часов на клиенте и серверах, нужна для валидации токенов, по умолчанию 300
// https://github.com/IdentityModel/oidc-client-js/blob/1.3.0/src/JoseUtil.js#L95
clockSkew: 300,
// делать ли запрос к UserInfo endpoint для того, чтоб добавить данные в профиль пользователя
loadUserInfo: true,
};
var mgr = new Oidc.UserManager(config);Давайте теперь добавим обработчики для кнопок и подписку на них.
function login() {
// Инициировать логин
mgr.signinRedirect();
}
function displayUser() {
mgr.getUser().then(function (user) {
if (user) {
log("User logged in", user.profile);
}
else {
log("User not logged in");
}
});
}
function api() {
// возвращает все claims пользователя
requestUrl(mgr, "http://localhost:5001/identity");
}
function getSuperpowers() {
// этот endpoint доступен только админам
requestUrl(mgr, "http://localhost:5001/superpowers");
}
function logout() {
// Инициировать логаут
mgr.signoutRedirect();
}
document.getElementById("login").addEventListener("click", login, false);
document.getElementById("api").addEventListener("click", api, false);
document.getElementById("getSuperpowers").addEventListener("click", getSuperpowers, false);
document.getElementById("logout").addEventListener("click", logout, false);
document.getElementById("getUser").addEventListener("click", displayUser, false);
// отобразить данные о пользователе после загрузки
displayUser();Осталось добавить пару утилит
function requestUrl(mgr, url) {
mgr.getUser().then(function (user) {
var xhr = new XMLHttpRequest();
xhr.open("GET", url);
xhr.onload = function () {
log(xhr.status, 200 == xhr.status ? JSON.parse(xhr.responseText) : "An error has occured.");
}
// добавляем заголовок Authorization с access_token в качестве Bearer - токена.
xhr.setRequestHeader("Authorization", "Bearer " + user.access_token);
xhr.send();
});
}
function log() {
document.getElementById('results').innerText = '';
Array.prototype.forEach.call(arguments, function (msg) {
if (msg instanceof Error) {
msg = "Error: " + msg.message;
}
else if (typeof msg !== 'string') {
msg = JSON.stringify(msg, null, 2);
}
document.getElementById('results').innerHTML += msg + '\r\n';
});
}В принципе, на этом можно было бы и заканчивать, но требуется добавить ещё две страницы, которые нужны для завершения процедуры входа. Добавьте страницы с таким кодом в wwwroot.
callback.html
callback-silent.html
Готово!
Запускать проекты рекомендую так: запускаете консоль, переходите в папку проекта, выполняете команду dotnet run. Это позволит видеть что IdentityServer и другие приложения логируют в консоль.
Запустите вначале IdentityServer и Api, а затем и Client.
Откройте страницу http://localhost:5003/index.html Client.
На этом этапе Вы можете захотеть очистить консоль при помощи clear().
Теперь давайте настроим консоль, чтобы на самом деле видеть всю интересную информацию.
Например, для Chrome 60 настройки консоли должны выглядеть так.
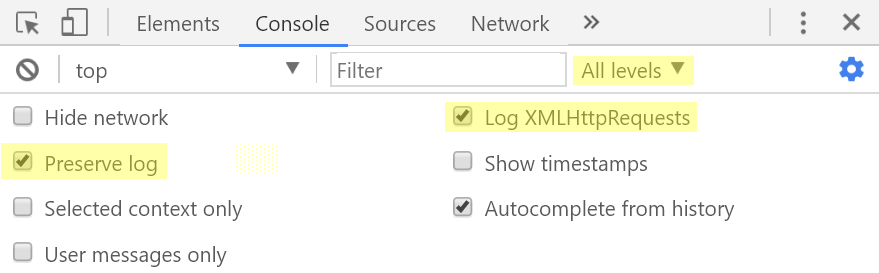
Во вкладке Network инструментов разработчика Вы можете захотеть поставить галочку напротив Preserve log чтобы редиректы не мешали в дальнейшем проверять значения различных параметров.
Обновите страницу при помощи CTRL+F5.
Посмотрим, какие действия соответствуют первым двум шагам спецификации.
1. Клиент готовит запрос на аутентификацию, содержащий нужные параметры запроса.
2. Клиент шлёт запрос на аутентификацию на сервер авторизации.
Кликните на кнопку Login.
Взаимодействие с сервером авторизации начинается с GET-запроса на адрес
http://localhost:5000/.well-known/openid-configuration
Этим запросом oidc-client получает метаданные нашего провайдера OpenId Connect (рекомендую открыть этот адрес в другой вкладке), в том числе authorization_endpoint
http://localhost:5000/connect/authorize
Обратите внимание, что для хранения данных о пользователе используется WebStorage. oidc-client позволяет указать, какой именно объект будет использоваться, по умолчанию это sessionStorage.
В этот момент будет послан запрос на аутентификацию на authorization_endpoint с такими параметрами строки запроса
| Имя | Значение |
|---|---|
| client_id | js |
| redirect_uri | http://localhost:5003/callback.html |
| response_type | id_token token |
| scope | openid profile api1 |
| state | некоторое труднопредсказуемое значение |
| nonce | некоторое труднопредсказуемое значение |
Обратите внимание, что redirect_uri соответствует адресу, который мы указали для нашего клиента с client_id js в настройках IdentityServer.
Т.к. пользователь ещё не аутентифицирован, IdentityServer вышлет в качестве ответа редирект на форму логина.
Затем браузер перенаправлен на http://localhost:5000/account/login.
3. Сервер авторизации аутентифицирует конечного пользователя.
4. Сервер авторизации получает подтверждение от конечного пользователя.
5. Сервер авторизации посылает конечного пользователя обратно на клиент с id token'ом и, если требуется, access token'ом.
Вводим bob в качестве логина и password в качестве пароля, отправляем форму.
Нас вначале вновь перенаправляют на authorization_endpoint, а оттуда на страницу подтверждения в соответствии с OpenId Connect разрешения получения relying party (в данном случае нашим js-клиентом) доступа к различным scopes.
Со всем соглашаемся, отправляем форму. Аналогично форме аутентификации, в ответ на отправку формы нас перенаправляют на authorization_endpoint, данные на authorization_endpoint передаются при помощи cookie.
Оттуда браузер перенаправлен уже на адрес, который был указан в качестве redirect_uri в изначальном запросе на аутентификацию.
При использовании Implicit Flow параметры передаются после #. Это нужно для того, чтобы эти значения были доступны нашему приложению на JavaScript, но при этом не отправлялись на веб-сервер.
| Имя | Значение |
|---|---|
| id_token | Токен с данными о пользователе для клиента |
| access_token | Токен с нужными данными для доступа к API |
| token_type | Тип access_token, в нашем случае Bearer |
| expires_in | Время действия access_token |
| scope | scopes на которые пользователь дал разрешение через пробел |
6. Клиент валидирует id token и получает Subject Identifier конечного пользователя.
oidc-client проверяет вначале наличие сохранённого на клиенте state, затем сверяет nonce с полученным из id_token. Если всё сходится, происходит проверка самих токенов на валидность (например, проверяется подпись и наличие sub claim в id_token). На этом этапе происходит чтение чтение содержимого id_token о объект профиля пользователя библиотеки oidc-client на стороне клиента.
Если Вы захотите расшифровать id_token (проще всего его скопировать из вкладки Network инструментов разработчика), то увидите, что payload содержит что-то подобное
{
"nbf": 1505143180,
"exp": 1505146780,
"iss": "http://localhost:5000",
"aud": "js",
"nonce": "2bd3ed0b260e407e8edd0d03a32f150c",
"iat": 1505143180,
"at_hash": "UAeZEg7xr23ToH2R2aUGOA",
"sid": "053b5d83fd8d3ce3b13d3b175d5317f2",
"sub": "2",
"auth_time": 1505143180,
"idp": "local",
"name": "Bob",
"website": "https://bob.com",
"amr": [
"pwd"
]
}at_hash, который затем используется для валидации в соответствии со стандартом.
Для access_token в нашем случае payload будет выглядеть, в том числе в соответствии с настройками, чуть иначе.
{
"nbf": 1505143180,
"exp": 1505143480,
"iss": "http://localhost:5000",
"aud": [
"http://localhost:5000/resources",
"api1"
],
"client_id": "js",
"sub": "2",
"auth_time": 1505143180,
"idp": "local",
"name": "Bob",
"role": "admin",
"scope": [
"openid",
"profile",
"api1"
],
"amr": [
"pwd"
]
}Если Вы не умеете для себя объяснять все их отличия, сейчас — прекрасный момент устранить этот пробел. Начать можно отсюда, или с повторного прочтения кода настроек IdentityServer.
В случае когда проверка завершается успехом, происходит чтение claims из id_token в объект профиля на стороне клиента.
Затем, но только если указана настройка loadUserInfo, происходит обращение к UserInfo Endpoint. При этом при обращении UserInfo Endpoint для получения claims профиля пользователя в заголовке Authorization в качестве Bearer-токена используется access_token, а полученные claims будут добавлены в JavaScript-объект профиля на стороне клиента.
loadUserInfo имеет смысл использовать если Вы хотите уменьшить размер access_token, если Вы хотите избежать дополнительного HTTP-запроса, может иметь смысл от этой опции отказаться.
Нажмите кнопку "Call API".
Произойдёт ajax-запрос на адрес http://localhost:5001/identity.
А именно, вначале будет OPTIONS-запрос согласно требованиями CORS т.к. мы осуществляем запрос ресурса с другого домена и используем заголовки, не входящие в список "безопасных" (Authorization, например).
Затем будет отправлен, собственно, сам GET-запрос. Обратите внимание, что в заголовке запроса Authorization будет указано значение Bearer <значение access_token>.
IdentityServer middleware на стороне сервера проверит токен. Внутри кода IdentityServer middleware проверка токенов фактически осуществляется стандартным Asp.Net Core JwtBearerMiddleware.
Пользователь будет считаться авторизованным, поэтому сервер вернёт нам ответ с кодом 200.
Отправляется GET-запрос на end_session_endpoint
| Имя | Значение |
|---|---|
| id_token_hint | Содержит значение id_token |
| post_logout_redirect_uri | URI, на который клиент хочет, чтобы провайдер аутентификации |
В ответ нас перенаправляют на страницу, содержащую данные о логауте для пользователя.
На самом деле политики позволяют задавать любые условия предоставления доступа, но я остановился на примере реализации безопасности через роли. Ролевую модель же реализуем через политики и токены, потому что это во-первых просто и наглядно, а во-вторых это наиболее часто используемый способ задания разрешений.
Попробуйте зайти вначале под пользователем alice и нажать кнопку Get Superpowers!, затем зайдите под пользователем bob и проделайте то же самое.
Нажмите Logout и залогиньтесь ещё раз, на этот раз используйте данные
Username: alice
Password: password
На странице подтверждения http://localhost:5000/consent нажмите No, Do Not Allow.
Вы попадёте на страницу завершения логина клиентского приложения http://localhost:5003/callback.html.
По причине того, что страница подтверждения пользователем передаёт фрагмент URL #error=access_denied, выполнение signinRedirectCallback пойдёт по другому пути, и промис в результате будет иметь статус rejected.
На странице callback.html будет для промиса выполнен catch-обработчик, он выведет текст ошибки в консоль.
Скопируйте закодированный id_token из одноимённого параметра URL ответа и убедитесь, что теперь в него не входят claims, которые входят в стандартный scope profile.
Claims, которые входят в стандартный scope profile можно посмотреть тут.
При этом вызвать API получится.
В токене теперь нет claim api1
"scope": [
"openid",
"profile"
],При попытке вызвать Api нам теперь возвращают 401 (Unathorized).
Дождитесь устаревания access_token, нажмите кнопку Call API.
API будет вызван! Это вызвано тем, что IdentityServer использует middleware Asp.Net Core, который использует понятие ClockSkew. Это нужно для того, чтобы всё в целом работало в случае если часы на клиенте и разных серверах несколько неточны, например, не возникали ситуации вроде токена, который был выпущен на период целиком в будущем. Значение ClockSkew по умолчанию 5 минут.
Теперь подождите 5 минут и убедитесь, что вызов API теперь возвращает 401 (Unathorized).
Замечание В клиентском приложении может быть полезно явно обрабатывать ответы с кодом 401, например пытаться обновить access_token.
Давайте теперь добавим в app.js в объект config код, так чтобы получилось
var config = {
// ...
// если true, клиент попытается обновить access_token перед его истечением, по умолчанию false
automaticSilentRenew: true,
// эта страница используется для "фонового" обновления токена пользователя через iframe
silent_redirect_uri: 'http://localhost:5003/callback-silent.html',
// за столько секунд до истечения oidc-client постарается обновить access_token
accessTokenExpiringNotificationTime: 60,
// ...
} При помощи консоли браузера убедитесь что теперь происходит автоматическое обновление access_token. Нажмите кнопку Call API чтобы убедиться, что всё работает.
Если access_token предназначается для ресурса API и ресурс обязан проверить его валидность, в том числе не устарел ли токен, при обращении к нему, то id_token предназначен именно для самого клиентского приложения. Поэтому и проверка должна проводиться на клиенте js-клиенте. Хорошо описано тут.
Если Вы следовали инструкциям, на данный момент Вы:
id_token и access_token вместо одного. |
Метки: author NickT информационная безопасность javascript c# .net .net core authentication authorization tutorial openid connect json web token |






