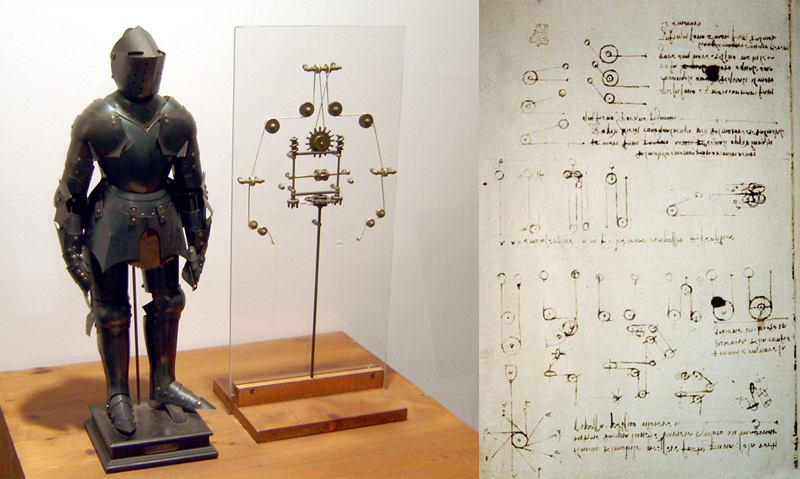
Роботы в человеческом обществе |











|
Метки: author mrKron исследования и прогнозы в it блог компании unet robots iot unet |
Правильный выбор СрЗИ: от рекламных листовок к use case |
|
Метки: author alukatsky информационная безопасность блог компании cisco use case cisco проектирование систем сетевая инфраструктура сетевая безопасность выбор |
Играючи BASH'им дальше |
|
Метки: author vaniacer кодобред bash game scroller |
Просто о сложном: что нужно знать о биоинформатике |



|
Метки: author AliceMir блог компании epam epam биоинформатика life sciences геном секвенирование днк |
Серверы HPE ProLiant Gen8 и Gen9 vs. Gen10 |
 .
.










|
Метки: author Orest_ua хранение данных серверное администрирование серверная оптимизация it- инфраструктура блог компании мук hpe proliant сервера |
Параллельный Hystrix. Повышаем производительность распределенных приложений |
public class CommandHelloWorld extends HystrixCommand {
@Override
protected String run() throws InterruptedException {
// вот тут происходит очень важное обращение во внешнюю систему
// все это работает в пуле потоков хистрикса
Thread.sleep(random.nextInt(500));
return "Hello " + name + "!";
}
}
// клиентский код
String executeCommand(String str) {
// вызов зависает на время, не большее чем установленный таймаут.
return new CommandHelloWorld(str).execute();
}
static List toList(Observable observable) {
return observable.timeout(1, TimeUnit.SECONDS).toList().toBlocking().single();
}
/**
* создает горячую хистриксную команду-источник
*/
static Observable executeCommand(String str) {
LOG.info("Hot Hystrix command created: {}", str);
return new CommandHelloWorld(str).observe();
}
/**
* создает холодную хистриксную команду-источник
*/
static Observable executeCommandDelayed(String str) {
LOG.info("Cold Hystrix command created: {}", str);
return new CommandHelloWorld(str).toObservable();
}
public void testNaive() {
List source = IntStream.range(1, 7).boxed().collect(Collectors.toList());
Observable observable = Observable.from(source)
.flatMap(elem -> executeCommand(elem.toString()));
toList(observable).forEach(el ->LOG.info("List element: {}", el));
}
public void testStupid() {
List source = IntStream.range(1, 50).boxed().collect(Collectors.toList());
Observable observable = Observable.from(source)
.flatMap(elem -> executeCommand(elem.toString()));
toList(observable).forEach(el ->LOG.info("List element: {}", el));
}
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 1
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 2
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 3
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 4
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 5
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 6
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 7
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 8
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 9
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 10
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 11
[hystrix-ExampleGroup-5] INFO org.silentpom.CommandHelloWorld - Command start: 5
[hystrix-ExampleGroup-2] INFO org.silentpom.CommandHelloWorld - Command start: 2
[hystrix-ExampleGroup-9] INFO org.silentpom.CommandHelloWorld - Command start: 9
[hystrix-ExampleGroup-8] INFO org.silentpom.CommandHelloWorld - Command start: 8
[hystrix-ExampleGroup-4] INFO org.silentpom.CommandHelloWorld - Command start: 4
[hystrix-ExampleGroup-1] INFO org.silentpom.CommandHelloWorld - Command start: 1
[hystrix-ExampleGroup-6] INFO org.silentpom.CommandHelloWorld - Command start: 6
[hystrix-ExampleGroup-10] INFO org.silentpom.CommandHelloWorld - Command start: 10
[hystrix-ExampleGroup-3] INFO org.silentpom.CommandHelloWorld - Command start: 3
[main] ERROR org.silentpom.RxHystrixTest - Ooops
com.netflix.hystrix.exception.HystrixRuntimeException: CommandHelloWorld could not be queued for execution and no fallback available.
public void testWindow() {
List source = IntStream.range(1, 50).boxed().collect(Collectors.toList());
Observable observable = Observable.from(source)
.map(elem -> executeCommandDelayed(elem.toString()))
.window(7)
.concatMap(window -> window.flatMap(x -> x));
toList(observable).forEach(el ->LOG.info("List element: {}", el));
}
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 20
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 21
[hystrix-ExampleGroup-3] INFO org.silentpom.CommandHelloWorld - Command start: 3
[hystrix-ExampleGroup-7] INFO org.silentpom.CommandHelloWorld - Command start: 7
[hystrix-ExampleGroup-5] INFO org.silentpom.CommandHelloWorld - Command start: 5
[hystrix-ExampleGroup-4] INFO org.silentpom.CommandHelloWorld - Command start: 4
[hystrix-ExampleGroup-2] INFO org.silentpom.CommandHelloWorld - Command start: 2
[hystrix-ExampleGroup-6] INFO org.silentpom.CommandHelloWorld - Command start: 6
[hystrix-ExampleGroup-1] INFO org.silentpom.CommandHelloWorld - Command start: 1
[hystrix-ExampleGroup-3] INFO org.silentpom.CommandHelloWorld - Command calculation finished: 3
[hystrix-ExampleGroup-6] INFO org.silentpom.CommandHelloWorld - Command calculation finished: 6
[hystrix-ExampleGroup-2] INFO org.silentpom.CommandHelloWorld - Command calculation finished: 2
[hystrix-ExampleGroup-7] INFO org.silentpom.CommandHelloWorld - Command calculation finished: 7
[hystrix-ExampleGroup-1] INFO org.silentpom.CommandHelloWorld - Command calculation finished: 1
[hystrix-ExampleGroup-5] INFO org.silentpom.CommandHelloWorld - Command calculation finished: 5
[hystrix-ExampleGroup-4] INFO org.silentpom.CommandHelloWorld - Command calculation finished: 4
[hystrix-ExampleGroup-8] INFO org.silentpom.CommandHelloWorld - Command start: 8
[hystrix-ExampleGroup-5] INFO org.silentpom.CommandHelloWorld - Command start: 11
[hystrix-ExampleGroup-1] INFO org.silentpom.CommandHelloWorld - Command start: 12
// просим хистрикс запустить команду и вернуть фьючу
static Future executeCommandDelayed(String str) {
LOG.info("Direct Hystrix command created: {}", str);
return new CommandHelloWorld(str).queue();
}
// по старинке синхронно вызываем хистрикс, все в ручную
static String executeCommand(String str) {
LOG.info("Direct Hystrix command created: {}", str);
return new CommandHelloWorld(str).execute();
}
public void testStupid() {
IntStream.range(1, 50).boxed().map(
value -> executeCommandDelayed(value.toString())
).collect(Collectors.toList())
.forEach(el -> LOG.info("List element (FUTURE): {}", el.toString()));
}
[main] INFO org.silentpom.stream.ParallelAsyncServiceTest - Direct Hystrix command created: 2
[main] INFO org.silentpom.stream.ParallelAsyncServiceTest - Direct Hystrix command created: 3
[main] INFO org.silentpom.stream.ParallelAsyncServiceTest - Direct Hystrix command created: 4
[main] INFO org.silentpom.stream.ParallelAsyncServiceTest - Direct Hystrix command created: 5
[main] INFO org.silentpom.stream.ParallelAsyncServiceTest - Direct Hystrix command created: 6
[main] INFO org.silentpom.stream.ParallelAsyncServiceTest - Direct Hystrix command created: 7
[main] INFO org.silentpom.stream.ParallelAsyncServiceTest - Direct Hystrix command created: 8
[main] INFO org.silentpom.stream.ParallelAsyncServiceTest - Direct Hystrix command created: 9
[main] INFO org.silentpom.stream.ParallelAsyncServiceTest - Direct Hystrix command created: 10
[main] INFO org.silentpom.stream.ParallelAsyncServiceTest - Direct Hystrix command created: 11
[main] ERROR org.silentpom.stream.ParallelAsyncServiceTest - Ooops
com.netflix.hystrix.exception.HystrixRuntimeException: CommandHelloWorld could not be queued for execution and no fallback available.
public void testSmart() {
service.waitStream(
IntStream.range(1, 50).boxed().map(
service.parallelWarp(
value -> executeCommand(value.toString())
)
)
).collect(Collectors.toList())
.forEach(el -> LOG.info("List element: {}", el));
}// по традиции threadSize = 7
public ParallelAsyncService(int threadSize) {
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder()
.setNameFormat("parallel-async-thread-%d").build();
// создаем промежуточный экзекутор, который будет создавать команды хистрикса
executorService = Executors.newFixedThreadPool(threadSize, namedThreadFactory);
}
/**
* Maps user function T -> Ret to function T -> Future. Adds task to executor service
* @param mapper user function
* @param user function argument
* @param user function result
* @return function to future
*/
public Function> parallelWarp(Function mapper) {
return (T t) -> {
LOG.info("Submitting task to inner executor");
Future future = executorService.submit(() -> {
LOG.info("Sending task to hystrix");
return mapper.apply(t);
});
return future;
};
}
/**
* waits all futures in stream and rethrow exception if occured
* @param futureStream stream of futures
* @param type
* @return stream of results
*/
public Stream waitStream(Stream> futureStream) {
List> futures = futureStream.collect(Collectors.toList());
// wait all futures one by one.
for (Future future : futures) {
try {
future.get();
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (ExecutionException e) {
Throwable cause = e.getCause();
if (cause instanceof RuntimeException) {
throw (RuntimeException) cause;
}
throw new RuntimeException(e);
}
}
// all futures have completed, it is safe to call get
return futures.stream().map(
future -> {
try {
return future.get();
} catch (Exception e) {
e.printStackTrace();
return null; // не должен вызываться вообще
}
}
);
main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 18
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 19
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 20
[main] INFO org.silentpom.RxHystrix - Cold Hystrix command created: 21
[hystrix-ExampleGroup-4] INFO org.silentpom.CommandHelloWorld - Command start: 4
[hystrix-ExampleGroup-1] INFO org.silentpom.CommandHelloWorld - Command start: 1
[hystrix-ExampleGroup-2] INFO org.silentpom.CommandHelloWorld - Command start: 2
[hystrix-ExampleGroup-3] INFO org.silentpom.CommandHelloWorld - Command start: 3
[hystrix-ExampleGroup-5] INFO org.silentpom.CommandHelloWorld - Command start: 5
[hystrix-ExampleGroup-6] INFO org.silentpom.CommandHelloWorld - Command start: 6
[hystrix-ExampleGroup-7] INFO org.silentpom.CommandHelloWorld - Command start: 7
[hystrix-ExampleGroup-2] INFO org.silentpom.CommandHelloWorld - Command calculation finished: 2
[hystrix-ExampleGroup-5] INFO org.silentpom.CommandHelloWorld - Command calculation finished: 5
[hystrix-ExampleGroup-3] INFO org.silentpom.CommandHelloWorld - Command calculation finished: 3
[hystrix-ExampleGroup-7] INFO org.silentpom.CommandHelloWorld - Command calculation finished: 7
[hystrix-ExampleGroup-6] INFO org.silentpom.CommandHelloWorld - Command calculation finished: 6
[hystrix-ExampleGroup-4] INFO org.silentpom.CommandHelloWorld - Command calculation finished: 4
[hystrix-ExampleGroup-1] INFO org.silentpom.CommandHelloWorld - Command calculation finished: 1
[hystrix-ExampleGroup-4] INFO org.silentpom.CommandHelloWorld - Command start: 11
[hystrix-ExampleGroup-6] INFO org.silentpom.CommandHelloWorld - Command start: 12
[hystrix-ExampleGroup-8] INFO org.silentpom.CommandHelloWorld - Command start: 8
[hystrix-ExampleGroup-7] INFO org.silentpom.CommandHelloWorld - Command start: 13
[hystrix-ExampleGroup-9] INFO org.silentpom.CommandHelloWorld - Command start: 9
|
Метки: author blaze79 параллельное программирование ооп java java hystrix rx stream |
Конкурс Fintech-стартапов FINOPOLIS-2017 |
|
Метки: author FintechLab финансы в it финтех конкурс финополис finopolis fintech competition стартап startup финансы технологии банки форум finopolis 2017 |
[Перевод] О-о-очень долгожданный релиз Sublime Text 3.0 |
Спустя долгие годы ожидания в beta и alpha релизах (а это около 3.5 лет) наконец-то вышел Sublime Text 3.0!
Предисловие: Sublime Text — является комерческим (хотя никто и не заставляет покупать лицензию) графическим текстовым редактором под 3 основные десктопные платформы.
В сравнении с последней бетой, версия 3.0 привносит обновленную тему пользовательского интерфейса, новые цветовые схемы и новую иконку. Помимо этого улучшена подсветка синтаксиса, поддержка тачпада на Windows, поддержка тачбара на macOS и репозитории apt/yum/pacman для Linux.
Я хочу отметить некоторые отличия от Sublime Text 2, хотя это на удивление сложно: практически каждый аспект редактора так или иначе был улучшен, так что даже список основных изменений будет очень большим. Если хотите увидеть полный список изменений, команда подготовила отдельную страницу для этого.
Определенно, в 3 версии добавили огромные фичи, например: прыжок на определение (F12), новый движок для подсветки синтаксиса, новый UI и расширенное API. Однако различия повсюду ощущаются в мелочах, которые сложно выделить самодостаточные: проверка орфографии работает лучше, автоматический отступ стал делать правильные вещи чаще, перенос слов лучше обрабатывает исходный код, правильно поддерживаются мониторы с высоким DPI, а также переход к файлам (Goto Anything ctrl+p) стал умнее. Перечислять все нудно и долго, но отличия разительны.
Одна из особенностей, за которую я особенно горд, — это производительность редактора: он значительно быстрее предшественника во всех областях. Запуск быстре, быстрее открытие файлов, более эффективная прокрутка. Несмотря на то, что 3 версия гораздо больше, она, наоборот, кажется более компактной.
|
Метки: author l4l системное программирование программирование python sublime text 3 редактор кода |
Причуды Stream API |
|
Метки: author ARG89 java блог компании jug.ru group stream |
[Из песочницы] Streaming API. Небольшой пример на PHP |
//все понятно и стандартно
var socket = new WebSocket("wss://streaming.vk.com/stream?key=" + window.key);
var close_connect = ge("close_connect");
/*
* Здесь еще очень много кода
*/
socket.onmessage = function(event) {
var incomingMessage = event.data;
var loading = document.getElementById("loading_text");
var preview = document.getElementById("preview_text");
var serf = document.getElementById("serf");
loading.classList.add("none");
preview.classList.add("none");
serf.classList.remove("none");
parser(event.data); //вот здесь начинается вся логика
console.log(event.data);
};
socket.onclose = function(event) {
if (event.wasClean) {
console.warn('Соединение закрыто чисто');
} else {
console.warn('Обрыв соединения');
}
console.info('Код: ' + event.code + ' причина: ' + event.reason);
var loading = ge("loading_text");
if (event.code == 1006) {
loading.innerHTML = "На этой планете уже есть человек, который сидит на этом сайте.
К сожалению - это не Вы. Повторите попытку позже.
Код ошибки - " + event.code;
} else {
loading.innerHTML = "Что-то или кто-то здесь не так...
Код ошибки - " + event.code;
}
};
socket.onerror = function(error) {};
//close connect
close_connect.addEventListener("click", function() {
socket.close();
close_connect.innerHTML = "Соединение закрыто клиентом.";
ge("analiz_block").classList.remove("none");
}, false);
var parser = function(json) {
var response = JSON.parse(json);
console.log(response);
var code = response.code;
console.log(code);
if (code != 100) return;
var tpl_block = document.getElementById("tpl");
var tpl = tpl_block.innerHTML;
var main_tpl = tpl_block.innerHTML;
var content = document.getElementById("main").innerHTML;
var main = document.getElementById("main");
var time = response.event['creation_time'];
var date = new Date(time);
var type;
var cnt = ge("cnt");
var cnt_value = +cnt.innerHTML;
cnt.innerHTML = cnt_value + 1;
var creation_time = timestampToDate(response.event['creation_time'] * 1000);
if (response.event['event_type'] == "post") {
type = "Публикация";
count['post'] = ++count['post'];
} else if (response.event['event_type'] == "comment") {
type = "Комментарий";
count['comment'] = ++count['comment'];
} else if (response.event['event_type'] == "share") {
type = "Репост";
count['share'] = ++count['share'];
}
var photo_context;
if (response.event.attachments) {
//image
if (response.event.attachments[0].type == "photo") {
photo_context = ' ';
} else {
photo_context = "";
}
} else {
photo_context = "";
}
tpl = tpl.split("{event_type}").join(type);
tpl = tpl.split("{text}").join(response.event['text']);
tpl = tpl.split("{url}").join(response.event['event_url']);
tpl = tpl.split("{date}").join(creation_time);
tpl = tpl.split("{photo}").join(photo_context);
tpl = tpl.split("{type}").join(response.event['event_type']);
tpl = tpl.split("{cnt}").join(cnt_value+1);
tpl = tpl.split("\"").join("'");
if (filter.top) main.innerHTML = tpl + "" + content;
else main.innerHTML = content + "" + tpl;
//post_id
if (response.event['event_type'] != "comment") {
var post_owner_id = response.event.event_id['post_owner_id'];
var post_id = response.event.event_id['post_id'];
var wall_id = post_owner_id + "_" + post_id;
array_post_id.push(wall_id);
}
//limit
if (cnt_value + 1 >= +filter.limit) {
socket.close();
close_connect.innerHTML = "Достигнут лимит публикаций.";
ge("analiz_block").classList.remove("none");
}
}
';
} else {
photo_context = "";
}
} else {
photo_context = "";
}
tpl = tpl.split("{event_type}").join(type);
tpl = tpl.split("{text}").join(response.event['text']);
tpl = tpl.split("{url}").join(response.event['event_url']);
tpl = tpl.split("{date}").join(creation_time);
tpl = tpl.split("{photo}").join(photo_context);
tpl = tpl.split("{type}").join(response.event['event_type']);
tpl = tpl.split("{cnt}").join(cnt_value+1);
tpl = tpl.split("\"").join("'");
if (filter.top) main.innerHTML = tpl + "" + content;
else main.innerHTML = content + "" + tpl;
//post_id
if (response.event['event_type'] != "comment") {
var post_owner_id = response.event.event_id['post_owner_id'];
var post_id = response.event.event_id['post_id'];
var wall_id = post_owner_id + "_" + post_id;
array_post_id.push(wall_id);
}
//limit
if (cnt_value + 1 >= +filter.limit) {
socket.close();
close_connect.innerHTML = "Достигнут лимит публикаций.";
ge("analiz_block").classList.remove("none");
}
}
var analiz = {
start: function() {
//
if (count['post'] == 0 && count['comment'] == 0 && count['share'] == 0) {
alert("Невозможно запустить анализ. Причина - публикации не найдены.");
return;
}
var url = "/vk-competition/VKanaliz.php";
var loading = ge("loading_sp");
var button = ge("btn_analiz");
var analiz_stats = ge("analiz_stats");
loading.classList.remove("none");
button.classList.add("none");
ajax.post({
url: url,
data: "post_id=" + array_post_id.join(","),
callback: function(data) {
var resp = JSON.parse(data);
if (resp.error) {
alert(resp.error);
return;
} else {
var count_likes_all_ = resp.response.count_likes_all;
var count_share_all_ = resp.response.count_share_all;
var count_views_all_ = resp.response.count_views_all;
var analiz_posts = ge("analiz_post");
var analiz_share = ge("analiz_share");
var analiz_comments = ge("analiz_comments");
var analiz_likes = ge("analiz_likes");
var analiz_views = ge("analiz_views");
var analiz_reposts = ge("analiz_reposts");
var analiz_years = ge("analiz_years_");
var analiz_sex = ge("analiz_sex");
var percent_sex_m, percent_sex_w;
if (resp.response.percent_sex_w == "-")
percent_sex_w = 0;
else
percent_sex_w = resp.response.percent_sex_w;
if (resp.response.percent_sex_w == "-")
percent_sex_m = 0;
else
percent_sex_m = 100 - +percent_sex_w;
console.log("spam " + resp.response.spam + "%");
//insert data
analiz_posts.innerHTML = count['post'];
analiz_share.innerHTML = count['share'];
analiz_comments.innerHTML = count['comment'];
analiz_likes.innerHTML = count_likes_all_;
analiz_views.innerHTML = "H" + count_views_all_;
analiz_reposts.innerHTML = count_share_all_;
analiz_sex.innerHTML = percent_sex_w + "%, " + percent_sex_m + "%";
analiz_years.innerHTML = resp.response.middle_years;
//show stats
loading.classList.add("none");
analiz_stats.classList.remove("none");
}
}
});
}
}
|
Метки: author svirepui вконтакте api php |
RailsClub 2017. Интервью с Luca Guidi, автором Hanami: смешиваем FP и OOP в Ruby |

Генеральный партнер: Toptal
Золотой партнер: Лига Цифровой Экономики
Бронзовые партнеры: Mkdev, VoltMobi, Рево, InSales
|
Метки: author vorona_karabuta функциональное программирование ооп ruby on rails ruby блог компании «railsclub» hanami конференция |
Нейросети: как искусственный интеллект помогает в бизнесе и жизни |

“Мы перестаём брать на работу юристов, которые не знают, что делать с нейронной сетью. <...> Вы — студенты вчерашнего дня. Товарищи юристы, забудьте свою профессию. В прошлом году 450 юристов, которые у нас готовят иски, ушли в прошлое, были сокращены. У нас нейронная сетка готовит исковые заявления лучше, чем юристы, подготовленные Балтийским федеральным университетом. Их мы на работу точно не возьмем.”





|
Метки: author onbillion машинное обучение алгоритмы data mining искусственный интеллект нейронные сети нейросети |
[Из песочницы] Как написать хорошее решение для Highload Cup, но недостаточно хорошее чтобы выйти в топ |
На прошлой недели закончилось соревнование HighLoad Cup, идея которого заключалась в реализации HTTP сервера для сайта путешественников. О том как за 5 дней написать решение на Go, которое принесет 52 место в абсолютном зачете из 295, читайте под катом.
Пользователь Afinogen в своей статье уже описывал условия конкурса, но для удобства я сжато повторюсь. Сервер должен реализовывать API для работы сайта путешественников и поддерживать сущности трех видов: путешественник (User), достопримечательность (Location) и посещение (Visit). API должно предоставлять возможность добавлять любые новые сущности в базу, получать их и обновлять, а также делать 2 операции над ними — получение средней оценки достопримечательности (avg) и получение мест, посещенных путешественником (visits). У каждой из этих операций так же есть набор фильтров, которые необходимо учитывать при формировании ответа. Так, например, API позволяет получить среднюю оценку оценку достопримечательности среди мужчин от 18 до 25 лет начиная с 1 апреля 2010 года. Это накладывает дополнительные сложности при реализации.
На всякий случай приведу краткое формальное описание API:
Самый первый вопрос который возникает у всех кто ознакомился с условием задачи — как хранить данные. Многие (как например я) сначала пытались использовать какую-нибудь базу с расчетом на большое количество данных, которые не поместятся в память и не городить костыли. Однако этот подход не давал высокое место в рейтинге. Дело в том что организаторы конкурса очень демократично подошли к размеру данных, поэтому даже без каких либо оптимизаций структуры хранения все данные без труда помещались в памяти. Всего в рейтинговом обстреле было около 1 млн путешественников, 100 тысяч достопримечательностей и 10 миллионов посещений, идентификаторы каждой сущности шли по порядку от 1. На первый взгляд объем может показаться большим, но если посмотреть на размер структур, которые можно использовать для хранения данных, а так же на размер строк в структурах, то можно увидеть что в среднем размеры не слишком большие. Сами структуры и размеры их полей я привел ниже:
type Visit struct { // overall 40 bytes
Id int // 8 bytes
Location int // 8 bytes
User int // 8 bytes
VisitedAt int // 8 bytes
Mark int // 8 bytes
}
type User struct { //overall 133 bytes
Id int // 8 bytes
Email string // 22 bytes + 16 bytes
FirstName string // 12 bytes + 16 bytes
LastName string // 18 bytes + 16 bytes
Gender string // 1 byte + 16 bytes
Birthdate int // 8 bytes
}
type Location struct { // overall 105 bytes
Id int // 8 bytes
Place string // 11 bytes + 16 bytes
Country string // 14 bytes + 16 bytes
City string // 16 bytes + 16 bytes
Distance int // 8 bytes
}Размеры string в структуре я указал в формате "средняя длинна строки" + "размер объекта string". Умножив средний размер каждой структуры на количество объектов получаем, что чисто для хранения данных нам нужно всего лишь примерно 518 МБ. Не там уж не много, при условии того что мы можем разгуляться аж на 4 ГБ.
Самое большое потребление памяти, как это не было бы странно на первый взгляд, происходит не при самом обстреле, а на этапе загрузки данных. Дело в том, что изначально все данные запакованы в .zip архив и в первые 10 минут серверу необходимо загрузить эти данные из архива для дальнейшей работы с ними. Нераспакованный архив весит 200 МБ, + 1.5 ГБ весят файлы после распаковки. Без аккуратной работы с данными и без более агрессивной настройки сборщика мусора загрузить все данные не получалось.
Второй момент, который был очень важен, но не все сразу его заметили — обстрелы сервера проходили так, что состояние гонки не могло получиться в принципе. Тестирование сервера проходило в 3 этапа: на первом этапе шли GET запросы, которые получали объекты и вызывали методы avg (получения средней оценки) и visits (получения посещений пользователем), вторым этапом данные обновлялись (на этом этапе были исключительно POST запросы на создание и обновление данных) и на последнем этапе опять шли GET запросы, только уже на новых данных и с большей нагрузкой. Из-за того что GET и POST запросы были жестко разделены, не было нужды использовать какие-либо примитивы синхронизации потоков.
Таким образом, если принять во внимание два эти момента, а так же вспомнить что id объектов каждой сущности шли по порядку начиная с 1, то в результате все данные можно хранить так:
type Database struct {
usersArray []*User
locationsArray []*Location
visitsArray []*Visit
usersMap map[int]*User
locationsMap map[int]*Location
visitsMap map[int]*Visit
}Все объекты, если хватает размера массива, помещаются в соответствующий типу массив. В случае, если id объекта был бы больше чем размер массива, он помещался бы в соответствующий словарь. Сейчас, зная что в финале данные абсолютно не поменялись, я понимаю что словари лишние, но тогда никаких гарантий этого не было.
Довольно скоро стало понятно, что для быстрой реализации методов avg и visits необходимо хранить не только сами структуры User и Location, но и id посещений пользователя и достопримечательностей вместе с самими структурами соответственно. В результате я добавил поле Visits, представляющее собой обычный массив в эти две структуры, и таким образом смог быстро находит все структуры Visit, ассоциированные с этим пользователем/достопримечательностью.
В процессе тестирования я так же думал об использовании "container/list" из стандартной библиотеки, но знание устройства этого контейнера подсказывало мне что он всегда будет проигрывать и по скорости доступа к элементам, и по памяти. Его единственный плюс — возможность быстрого удаления/добавления в любую точку не сильно важен для этой задачи, так как соотношение количества посещений к пользователям примерно 10 к 1, то мы можем сделать предположение что контейнеры Visit в структурах Location и User будут примерно размером 10. А удалить элемент из начала массива размером 10 единиц не так уж и затратно на общем фоне и не является частой операцией. Что касается памяти, то ее потребление можно проиллюстрировать следующим кодом:
package main
import (
"fmt"
"runtime"
"runtime/debug"
"container/list"
)
func main() {
debug.SetGCPercent(-1)
runtime.GC()
m := &runtime.MemStats{}
runtime.ReadMemStats(m)
before := m.Alloc
for i:=0;i<1000;i++ {
s := make([]int, 0)
for j:=0;j<10;j++ {
s = append(s, 0)
}
}
runtime.ReadMemStats(m)
fmt.Printf("Alloced for slices %0.2f KB\n", float64(m.Alloc - before)/1024.0)
runtime.GC()
runtime.ReadMemStats(m)
before = m.Alloc
for i:=0;i<1000;i++ {
s := list.New()
for j:=0;j<10;j++ {
s.PushBack(1);
}
}
runtime.ReadMemStats(m)
fmt.Printf("Alloced for lists %0.2f KB\n", float64(m.Alloc - before)/1024.0)
}Этот код дает следующий вывод:
Alloced for slices 117.19 KB
Alloced for lists 343.75 KB
Этот код создает 1000 массивов и 1000 списков и заполняет их 10 элементами, так как это среднее число посещений. Число 10 является плохим для массива, так как при добавлении элементов, на 8 элементе он расширится до 16 элементов и тем самым памяти будет затрачено больше чем необходимо. По результатам все равно видно что на решение со слайсами было затрачено в 3 раза меньше памяти, что сходится с теорией, так как каждый элемент списка хранит указатель на следующий, предыдущий элемент и на сам список.
Другие пользователи прошедшие в финал делали еще несколько индексов — например индекс по странам для метода visits. Эти индексы, скорее всего ускорили бы решение, однако не так сильно, как хранение посещений пользователя и хранение посещений достопримечательности вместе с информацией об этом объекте.
Стандартная библиотека для реализации http сервера достаточно удобная в использовании и хорошо распространена, однако когда речь заходит о скорости, все рекомендуют fasthttp. Поэтому первым делом после реализации логики я выкинул стандартный http сервер и заменил его на fasthttp. Замена прошла абсолютно безболезненно, хоть данные две библиотеки имеют разный API.
Далее под замену ушла стандартная библиотека кодирования/декодирования json. Я выбрал easyjson, так как он показывал отличные данные по скорости/памяти + имел схожий с "encoding/json" API. Easyjson генерирует свой собственный парсер для каждой структуры данных, что и позволяет показывать такие впечатляющие результаты. Его единственный минус — небольшое число настроек. Например, в задаче были запросы, в которых одно из полей отсутствовало, что должно приводить в ошибке, однако easyjson тихо пропускал такие поля, из-за чего пришлось лезть в исходных код парсеров.
Так как все методы API за исключением POST методов были реализованы без использования дополнительной памяти, было решено отключить сборщик мусора — все равно если памяти хватает, то зачем гонять его?
Так же был переписан роутинг запросов. Каждый запрос определялся по одному символу, что позволило сэкономить на сравнении строк. Школьная оптимизация.
За 5 последних дней конкурса я, без какого либо опыта участия в подобных конкурсах, написал решение на Go, которое принесло мне 52 место из 295 участников. К сожалению мне не хватило совсем чуть чуть до прохождения в финал, но с другой стороны в финале собрались достойные соперники, поэтому из-за того что данные и условия задачи никак не менялись то маловероятно что я смог бы подняться выше.
|
Метки: author rus_phantom высокая производительность go golang highloadcup |
Привет, Программист |

 Скотт Хансельман, Principal Program Manager в команде Visual Studio Tools . Один из самых известных авторов-программистов из Microsoft — Скотт Хансельман. Известный евангелист Open Source как вне, так и внутри компании (например, именно Скотт выступил за то, чтобы заопенсорсить Windows Live Writer, и в процессе принимал активное участие в рефакторинге). Скотт много кода пишет сам, и знает, что Тебе нужно.
Скотт Хансельман, Principal Program Manager в команде Visual Studio Tools . Один из самых известных авторов-программистов из Microsoft — Скотт Хансельман. Известный евангелист Open Source как вне, так и внутри компании (например, именно Скотт выступил за то, чтобы заопенсорсить Windows Live Writer, и в процессе принимал активное участие в рефакторинге). Скотт много кода пишет сам, и знает, что Тебе нужно.  Мадс Кристенсен — Senior Program Manager в соседней со Скоттом группе Visual Studio. Возможно, вы знакомы с Web Extension Pack, а ныне Web Essentials? Если вы веб-разработчик, то обязательно познакомьтесь. Если нет, то опыт Мадса в написании экстеншенов, о котором он иногда рассказывает в интервью и своем блоге, плюс разные типсы и триксы, будут однозначно полезны для общего развития.
Мадс Кристенсен — Senior Program Manager в соседней со Скоттом группе Visual Studio. Возможно, вы знакомы с Web Extension Pack, а ныне Web Essentials? Если вы веб-разработчик, то обязательно познакомьтесь. Если нет, то опыт Мадса в написании экстеншенов, о котором он иногда рассказывает в интервью и своем блоге, плюс разные типсы и триксы, будут однозначно полезны для общего развития. Phil Haack — программист-блогер с 13-летним стажем. Пишет в основном про веб.
Phil Haack — программист-блогер с 13-летним стажем. Пишет в основном про веб.  Андрей Игнат, технический директор в Electronic Arts. Любитель формата небольших заметок и дайджестов, состоящих из сборной солянки.
Андрей Игнат, технический директор в Electronic Arts. Любитель формата небольших заметок и дайджестов, состоящих из сборной солянки.  Андрей Веселов, Microsoft MVP из Сибири. Много лет ведёт блог, многие наверняка знакомы с его циклами статей. От взгляда Андрея обычно не уходят важные новости. Один из немногих блогеров, кто, спустя 37 страниц постов продолжает держать профессиональную марку. Также публикует дайджесты.
Андрей Веселов, Microsoft MVP из Сибири. Много лет ведёт блог, многие наверняка знакомы с его циклами статей. От взгляда Андрея обычно не уходят важные новости. Один из немногих блогеров, кто, спустя 37 страниц постов продолжает держать профессиональную марку. Также публикует дайджесты. Гуннар Пайпман, еще один MVP. Пишет про всё на свете в разработке (правда, фокусируется на ASP.NET, включая Core), любит фановые проекты.
Гуннар Пайпман, еще один MVP. Пишет про всё на свете в разработке (правда, фокусируется на ASP.NET, включая Core), любит фановые проекты.  Channel 9 — флагманский канал доставки материалов Microsoft во внешний мир. Автор статьи после каждого большого мероприятия обязательно смотрит, нет ли в очередной раз видео про фичи в Visual Studio.
Channel 9 — флагманский канал доставки материалов Microsoft во внешний мир. Автор статьи после каждого большого мероприятия обязательно смотрит, нет ли в очередной раз видео про фичи в Visual Studio.  Microsoft Virtual Academy — флагманский канал доставки обучающих курсов Microsoft во внешний мир. Можно выбрать интересующие темы и составить план обучения по ним.
Microsoft Virtual Academy — флагманский канал доставки обучающих курсов Microsoft во внешний мир. Можно выбрать интересующие темы и составить план обучения по ним. |
Метки: author Schvepsss visual studio блог компании microsoft microsoft день программиста |
[recovery mode] Как ускорить загрузку сайта |

add_header Cache-Control "max-age=31536000, immutable";|
|
Финал Imagine Cup 2017 глазами команды МФТИ |




Я знал текст, который следовало говорить, я долго и упорно репетировал, я подбадривал себя и всё равно ничего не мог с собой поделать: руки и ноги тряслись так, как будто вместо них у меня отбойные молотки. Я думал, что выроню микрофон, и молился, чтобы текст не вылетал из головы. Он, конечно же, вылетал.

Соревнование в этом году проводилось в рекордно сжатые сроки (2 дня вместо 4 дней в прошлом году и недели в более ранние года). Тем не менее даже этого времени было достаточно, чтобы почувствовать, что ты приехал не просто на соревнование, а еще и в некое подобие летнего студенческого лагеря, лагеря амбициозных творческих ребят-сверстников-единомышленников. Общение с ними — это не только отличная практика английского и других иностранных языков, но и прекрасная возможность узнать много нового о других странах и культурах, весело провести время и, самое главное, найти друзей по всему миру.


|
Метки: author shwars блог компании microsoft imagine cup imagine cup 2017 конкурс проектов студенты сиэтл |
Хакатон HackCV, 7-8 октября |
|
Метки: author Evgenia_s5 c++ блог компании luxoft computer vision c/c++ emdedded luxoft automotive engineering |
Аудиоплеер с плейлистом на javascript |

controlslet file = new Audio('track1.mp3');
file.play(); .play().pause().duration currentTimeconst FILES = [
'track1',
'track2',
'track3',
'track4'
] class Player {
constructor(files) {
this.current = null;
this.status = 'pause';
this.progress = 0;
this.progressTimeout = null;
this.files = FILES.map(name => {
return {
name: name
}
});
}
init() {
let playlist = getByQuery('.playlist');
this.files.forEach((f, i) => {
let playlistFileContainer = createElem({
type: 'div',
appendTo: playlist,
textContent: f.name,
class: 'fileEntity',
handlers: {
click: this.play.bind(this, null, i)
}
});
createElem({
type: 'div',
appendTo: playlistFileContainer,
textContent: '--:--',
class: 'fileEntity_duration',
})
});
}
loadFile(i) {
let f = this.files[i];
f.file = new Audio(prepareFilePath(f.name));
f.file.addEventListener('loadedmetadata', () => {
getByQuery('.playlist').children[i].children[0].textContent = prettifyTime(f.file.duration);
});
f.file.addEventListener('ended', this.playNext.bind(this, null, i));
}
play(e, i = this.current || 0) {
if (!this.files[i].file) {
this.loadFile(i);
}
let action = 'play';
if (this.current == i) {
action = this.status === 'pause' ? 'play' : 'pause';
this.toggleStyles(action, i);
} else if (typeof this.current !== 'object') {
this.files[this.current].file.pause();
this.files[this.current].file.currentTime = 0;
this.toggleStyles(action, this.current, i);
} else {
this.toggleStyles(action, i);
}
this.current = i;
this.status = action;
this.files[i].file[action]();
if (action == 'play') {
this.setTitle(this.files[i].name);
this.stopProgress();
this.runProgress();
} else {
this.stopProgress();
}
}
playNext(e, currentIndex) {
let nextIndex = (currentIndex ? currentIndex : this.current) + 1;
if (!this.files[nextIndex]) {
nextIndex = 0;
}
this.play(null, nextIndex);
}
playPrev(e, currentIndex) {
let prevIndex = (currentIndex ? currentIndex : this.current) - 1;
if (!this.files[prevIndex]) {
prevIndex = this.files.length - 1;
}
this.play(null, prevIndex);
}
setTitle(title) {
getByQuery('.progress_bar_title').textContent = title;
}
setProgress(percent = 0, cb) {
getByQuery('.progress_bar_container_percentage').style.width = `${percent}%`;
cb && cb();
}
countProgress() {
let file = this.files[this.current].file;
return (file.currentTime * 100 / file.duration) || 0;
}
runProgress(percent = 0) {
let percentage = percent || this.countProgress();
let cb = percent ? () => {
this.files[this.current].file.currentTime = percentage * this.files[this.current].file.duration / 100;
} : null;
this.setProgress(percentage, cb);
this.progressTimeout = setTimeout(this.runProgress.bind(this), 1000)
}
stopProgress() {
clearTimeout(this.progressTimeout);
this.progressTimeout = null;
}
pickNewProgress(e) {
if (this.status != 'play') {
this.play();
}
let coords = e.target.getBoundingClientRect().left;
let progressBar = getByQuery('.progress_bar_stripe');
let newPercent = (e.clientX - coords) / progressBar.offsetWidth * 100;
this.stopProgress();
this.runProgress(newPercent);
}
toggleStyles(action, prev, next) {
let prevNode = getByQuery('.playlist').children[prev];
let nextNode = getByQuery('.playlist').children[next];
let playPause = getByQuery('.play_pause .play_pause_icon');
if (!next && next !== 0) {
if (!prevNode.classList.contains('fileEntity-active')) {
prevNode.classList.add('fileEntity-active');
}
playPause.classList.toggle('play_pause-play');
playPause.classList.toggle('play_pause-pause');
} else {
prevNode.classList.toggle('fileEntity-active');
nextNode.classList.toggle('fileEntity-active');
}
if (playPause.classList.contains('play_pause-play') && action == 'play' && prev != next) {
playPause.classList.toggle('play_pause-play');
playPause.classList.toggle('play_pause-pause');
}
}
}
DOMContentLoadedwindow.addEventListener('DOMContentLoaded', initHandlers);
function initHandlers() {
let player = new Player(FILES);
player.init();
getByQuery('.player .controls .play_pause').addEventListener('click', player.play.bind(player));
getByQuery('.player .controls .navigation_prev').addEventListener('click', player.playPrev.bind(player));
getByQuery('.player .controls .navigation_next').addEventListener('click', player.playNext.bind(player));
getByQuery('.player .controls .progress_bar_stripe').addEventListener('click', player.pickNewProgress.bind(player));
}
getByQuery()document.querySelector()function getByQuery(elem) {
return typeof elem === 'string' ? document.querySelector(elem) : elem;
}thisplayloadFile|
Метки: author greebn9k разработка веб-сайтов javascript html html5 audio player |
Сеть магазинов «М.Видео» проведёт хакатон по искусственному интеллекту |
|
Метки: author sviridius программирование машинное обучение алгоритмы блог компании м.видео хакатон искусственный интеллект |
Positive Technologies на GitHub |
Поздравляю программистов с их профессиональным днем! В связи с этим праздником наша компания Positive Technologies решила рассказать о своей деятельности, напрямую связанной с разработкой, а именно с открытым исходным кодом и GitHub.

В последнее время все больше и больше компаний, таких как Google, Microsoft, Facebook, JetBrains, выкладывают в открытый доступ исходный код как небольших, так и крупных проектов. Positive Technologies славится не только высококлассными специалистами по информационной безопасности, но и большим количеством профессиональных разработчиков. Это позволяет ей также вносить свой посильный вклад в развитие движения Open Source.
У PT есть следующие GitHub-организации, поддерживающие открытые проекты компании:
Мы подробно описали первую организацию с ее проектами и кратко — все остальные.
Основное сообщество, в котором ведется разработка как изначально открытых проектов, так и тех, которые раньше разрабатывались исключительно внутри компании. Также здесь размещаются учебные и демонстрационные проекты.

Цель сообщества — сформировать открытые готовые решения для управления полным циклом процесса разработки, тестирования и смежных процессов, а также доставки, развёртывания и лицензирования продуктов.
На данный момент сообщество находится в начальной стадии развития, но уже сейчас в нем можно найти некоторые полезные инструменты, написанные на Python. Да, мы его любим.
Активные проекты:
Каждый инструмент имеет автоматическую сборку в Travis CI с выкладкой в PyPI-репозиторий, где их можно найти и установить через стандартный pip install.
Готовятся к публикации еще несколько инструментов:
В качестве контрибьюторов любого инструмента приглашаются все желающие. У нас есть типовой проект ExampleProject, в котором содержатся общая структура и подробная инструкция по созданию собственного проекта в сообществе. Фактически достаточно его скопировать и сделать свой проект по аналогии. Если у вас есть идеи или инструменты для автоматизации чего-либо, давайте делиться ими с сообществом под MIT-лицензией! Это модно, почётно, престижно :)
Группа исследователей, содержащая репозиторий AttackDetection, в который команда обнаружения атак выкладывает правила для определения эксплуатации уязвимостей с помощью систем обнаружения вторжений Snort и Suricata IDS. Основная цель проекта — создание правил для уязвимостей, имеющих широкое распространение и высокий уровень опасности (high impact). Репозиторий содержит файлы для интеграции с oinkmaster — скриптом для обновления и развертывания правил в указанных IDS. А для теста самих правил прилагаются pcap-файлы с трафиком. Стоит отметить, что репозиторий уже набрал свыше 100 добавлений в избранное, а за год добавилось около 40 новых уязвимостей, среди которых BadTunnel, ETERNALBLUE, ImageTragick, EPICBANANA, SambaCry. Все анонсы о новых угрозах публикуются в Twitter.
Сообщество по разработке инструментария (преимущественно веб), используемого в продуктах PT.

PT Pattern Matching Engine — универсальный сигнатурный анализатор кода, который принимает на вход пользовательские шаблоны, описанные на специальном языке. Данный движок испольуется в бесплатном инструменте для проверки веб-приложений на наличие уязвимых компонентов Approof, а также в анализаторе исходного кода PT Application Inspector.
Процесс анализа состоит из нескольких этапов:
Реализованный в проекте подход дает возможность унифицировать задачу разработки шаблонов под различные языки.
В PT.PM внедрена непрерывная интеграция, поддерживаются сборка и тестирование модулей проекта как под Windows, так и под Linux (Mono). Процесс разработки организуется с помощью размеченных метками задач (Issues) и пул-реквестов. Наряду с разработкой ведется документация проекта, а результаты всех значимых сборок публикуются в формате как пакетов NuGet, так и «сырых» артефактов. Организацию PT.PM, вероятно, можно считать образцовой, к которой хотелось бы стремиться во всех остальных проектах.
Для первого этапа, а именно парсинга исходного кода, используются парсеры на базе ANTLR. Этот инструмент генерирует их для различных языков (рантаймов) на основе формальных грамматик, для которых существует репозиторий. Наша компания его активно развивает. В настоящее время поддерживается генерация под Java, C#, Python 2 и 3, JavaScript, C++, Go и Swift, причём поддержка последних трех была добавлена совсем недавно.
Стоит отметить, что ANTLR используется не только в проектах PT направления Application Security, но и в Max Patrol SIEM: там он используется для обработки собственного языка DSL (Domain Specific Language), который применяется для описания динамических групп активов. Обмен опытом в этой сфере позволил не тратить время на задачи, которые уже были решены ранее.
При участии Positive Technologies были разработаны и улучшены грамматики для языков PL/SQL, T-SQL, MySQL, PHP, Java 8 и C#.
Грамматики SQL имеют обширный синтаксис с большим количеством ключевых слов. К счастью, грамматика PL/SQL существовала под ANTLR 3 и портировать её под ANTLR 4 было не очень сложно.
Для T-SQL не было найдено достойных парсеров, не говоря уже об открытых, и мы долго и кропотливо восстанавливали грамматику из документации MSDN. Однако результат получился достойным: она уже охватывает много распространённых синтаксических конструкций, опрятно выглядит, независима от рантайма и покрыта тестами (примерами SQL-запросов из той же MSDN). С 2015 в нее внесли свой вклад более 15 сторонних пользователей. Более того, эта грамматика сейчас уже используется и в DBFW, прототипе межсетевого экрана уровня систем управления базами данных, подпроекте PT Application Firewall. Денис Колегов с Арсением Реутовым рассказывали о нем на PHDays VII: «Как разработать DBFW с нуля».
Грамматика, разработанная вышеупомянутой командой, в первую очередь Иваном Худяшовым и Денисом Колеговым, на основе T-SQL. Она также используется в DBFW.
Данная грамматика транслировалась из грамматики Bison в ANTLR. Она интересна тем, что поддерживает парсинг сразу PHP, JavaScript и HTML. Точнее, участки кода JavaScript и HTML парсятся в текст, который позже обрабатывается парсерами конкретно под эти языки.
Эта грамматика была разработана совсем недавно. За основу была взята грамматика предыдущей версии Java 7. Доработка была относительно быстрой, так как отличий между версиями немного.
Это по большей части экспериментальная грамматика, созданная для сравнения скоростей парсеров на основе ANTLR и парсера Roslyn.

О деталях разработки грамматик можно почитать в нашей прошлогодней статье «Теория и практика парсинга исходников с помощью ANTLR и Roslyn».
Как видно по истории изменений, эти грамматики дорабатываются не только усилиями Positive Technologies, но и большим количеством сторонних разработчиков. За время этой кооперации репозиторий вырос не только количественно, но и качественно.
Позволяет собирать статистику для проектов на различных языках программирования и используется в бесплатном продукте Approof.
В рамках данного проекта разрабатывается парсер страниц ASPX, который используется не только в открытом движке PT.PM, но и во внутреннем анализаторе .NET-приложений (AI.Net), основанном на абстрактной интерпретации кода.

В репозитории идет разработка наборов правил в формате YARA, которые используются в модуле сигнатурного анализа проектов в Approof. В августе прошлого года в рамках PDUG (юзер-группы по безопасной разработке) Алексей Гончаров делал доклад о модуле FingerPrint, используемом в PT AI и Approof.
Движок FingerPrint запускается на наборе исходных кодов сайта (бэкенда, фронтенда) и в соответствии с описанными правилами YARA ищет известные версии сторонних компонентов (например, библиотеку bla-bla версии 3). Правила составляются так, что содержат сигнатуры уязвимых версии библиотек с текстовым описанием проблемы.
Правило представляет собой нескольких условий для проверки файла. Например, условие наличия в файле определенных строк. Если файл им удовлетворяет, то Approof в итоговом отчете выдает информацию об обнаруженных уязвимостях в определенном компоненте с версией N, а также описания относящихся к ним CVE.
Подробнее об этом можно почитать в статье Дениса Ефремова (ИСП РАН) «Разработка правил для Approof». Также см. его доклад «Автоматизация построения правил для Approof» на PDUG секции PHDays.
На PHDays VII в рамках PDUG прошел мастер-класс «Appsec Outback». Для него были разработаны учебно-демонстрационные версии статического анализатора кода Mantaray и межсетевого экрана Schockfish. Данные проекты имеют все основные механизмы, которые используются в реальных средствах защиты. Но, в отличие от последних, их основная цель продемонстрировать алгоритмы и методы защиты, помочь понять процесс анализа и защиты приложений, а также проиллюстрировать фундаментальные теоретические возможности и ограничения технологий.
Также в репозитории имеются примеры реализации механизмов защиты:
В наших проектах используются как разрешительные лицензии (MIT, Apache), так и собственная, которая подразумевает бесплатное использование исключительно в некоммерческих целях.
Процесс переезда на GitHub оказался полезным и дал нам опыт в различных областях — в настройке DevOps под Windows и Linux, написании документации, в разработке.
Positive Technologies развивает Open Source проекты и планирует расширять эту активность.
При конвертации Markdown из формата GitHub в формат Habrahabr использовался HabraMark.
|
Метки: author KvanTTT open source github блог компании positive technologies ptsecurity |






