Обзор инструментария для нагрузочного и перформанс-тестирования |

 Да, старый добрый JMeter. Он вот уже без малого двадцать лет (!) является частым выбором для многих вариантов и типов нагрузочного тестирования: удобный GUI, независимость от платформы (спасибо Java!), поддержка многопоточности, расширяемость, отличные возможности по созданию отчётов, поддержка многих протоколов для запросов. Благодаря модульной архитектуре JMeter можно расширить в нужную пользователю сторону, реализуя даже весьма экзотические сценарии тестирования — причем, если ни один из написанных сообществом за прошедшее время плагинов нас не устроит, можно взять API и написать собственный. При необходимости с JMeter можно выстроить, хоть и ограниченное, но распределённое тестирование, когда нагрузка будет создаваться сразу несколькими машинами.
Да, старый добрый JMeter. Он вот уже без малого двадцать лет (!) является частым выбором для многих вариантов и типов нагрузочного тестирования: удобный GUI, независимость от платформы (спасибо Java!), поддержка многопоточности, расширяемость, отличные возможности по созданию отчётов, поддержка многих протоколов для запросов. Благодаря модульной архитектуре JMeter можно расширить в нужную пользователю сторону, реализуя даже весьма экзотические сценарии тестирования — причем, если ни один из написанных сообществом за прошедшее время плагинов нас не устроит, можно взять API и написать собственный. При необходимости с JMeter можно выстроить, хоть и ограниченное, но распределённое тестирование, когда нагрузка будет создаваться сразу несколькими машинами.  Ещё один давно существующий на рынке и в определенных кругах очень известный продукт, большему распространению которого помешала принятая компанией-производителем политика лицензирования (кстати, сегодня, после слияния подразделения ПО компании Hewlett Packard Enterprise с Micro Focus International, привычное название HPE LoadRunner сменилось на Micro Focus LoadRunner). Интерес представляет логика создания теста, где несколько (наверное, правильно сказать — «много») виртуальных пользователей параллельно что-то делают с тестируемым приложением. Это даёт возможность не только оценить способность приложения обработать поток одновременных запросов, но и понять, как влияет работа одних пользователей, активно что-то делающих с сервисом, на работу других. При этом речь идёт о широком выборе протоколов взаимодействия с тестируемым приложением.
Ещё один давно существующий на рынке и в определенных кругах очень известный продукт, большему распространению которого помешала принятая компанией-производителем политика лицензирования (кстати, сегодня, после слияния подразделения ПО компании Hewlett Packard Enterprise с Micro Focus International, привычное название HPE LoadRunner сменилось на Micro Focus LoadRunner). Интерес представляет логика создания теста, где несколько (наверное, правильно сказать — «много») виртуальных пользователей параллельно что-то делают с тестируемым приложением. Это даёт возможность не только оценить способность приложения обработать поток одновременных запросов, но и понять, как влияет работа одних пользователей, активно что-то делающих с сервисом, на работу других. При этом речь идёт о широком выборе протоколов взаимодействия с тестируемым приложением. Весьма мощный и серьёзный инструмент (не зря названный в честь скорострельного пулемета) — в первую очередь, по причине производительности и широты поддержки протоколов «из коробки». Например, там, где нагрузочное тестирование с JMeter будет медленным и мучительным (увы, плагин поддержки работы с веб-сокетами не особо быстр, что идейно конфликтует со скоростью работы самих веб-сокетов), Galting почти наверняка создаст нужную нагрузку без особых сложностей.
Весьма мощный и серьёзный инструмент (не зря названный в честь скорострельного пулемета) — в первую очередь, по причине производительности и широты поддержки протоколов «из коробки». Например, там, где нагрузочное тестирование с JMeter будет медленным и мучительным (увы, плагин поддержки работы с веб-сокетами не особо быстр, что идейно конфликтует со скоростью работы самих веб-сокетов), Galting почти наверняка создаст нужную нагрузку без особых сложностей. Если коротко, Yandex Tank — это враппер над несколькими утилитами нагрузочного тестирования (включая JMeter), предоставляющий унифицированный интерфейс для их конфигурации, запуска и построения отчётов вне зависимости от того, какая утилита используется «под капотом».
Если коротко, Yandex Tank — это враппер над несколькими утилитами нагрузочного тестирования (включая JMeter), предоставляющий унифицированный интерфейс для их конфигурации, запуска и построения отчётов вне зависимости от того, какая утилита используется «под капотом». Taurus — ещё один фреймворк над несколькими утилитами нагрузочного тестирования. Возможно, вам понравится этот продукт, использующий похожий на Яндекс.Танк подход, но имеющий несколько другой набор «фич», и, пожалуй, более адекватный формат конфигурационных файлов.
Taurus — ещё один фреймворк над несколькими утилитами нагрузочного тестирования. Возможно, вам понравится этот продукт, использующий похожий на Яндекс.Танк подход, но имеющий несколько другой набор «фич», и, пожалуй, более адекватный формат конфигурационных файлов. BenchmarkDotNet берёт на себя рутинные действия при составлении бенчмарков для .NET-проектов и обеспечивает широкие возможности форматирования результатов ценой минимальных усилий. Как говорят авторы, фиче-реквестов хватает, поэтому BenchmarkDotNet есть куда развиваться.
BenchmarkDotNet берёт на себя рутинные действия при составлении бенчмарков для .NET-проектов и обеспечивает широкие возможности форматирования результатов ценой минимальных усилий. Как говорят авторы, фиче-реквестов хватает, поэтому BenchmarkDotNet есть куда развиваться. Замеры производительности фронтенда всегда стояли несколько особняком: с одной стороны, часто задержки связаны со скоростью реакции бэкенда, с другой — именно по поведению фронтенда (точнее, по скорости его реакции) пользователи часто судят о всём приложении, особенно, если речь идёт про веб.
Замеры производительности фронтенда всегда стояли несколько особняком: с одной стороны, часто задержки связаны со скоростью реакции бэкенда, с другой — именно по поведению фронтенда (точнее, по скорости его реакции) пользователи часто судят о всём приложении, особенно, если речь идёт про веб.|
Метки: author ValeriaKhokha тестирование веб-сервисов тестирование it-систем блог компании jug.ru group тестирование гейзенбаг |
4 причины стать Data Engineer |

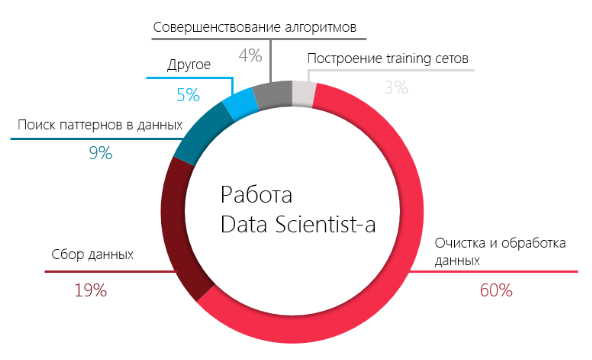
|
Метки: author elena_newprolab машинное обучение data mining big data блог компании new professions lab data engineering data science |
Корпоративные лаборатории: выявление инцидентов информационной безопасности |
|
Метки: author LukaSafonov информационная безопасность блог компании pentestit корпоративные лаборатории pentestit |
[Из песочницы] Начальник, хочу работать из дома |
|
Метки: author digore управление разработкой управление персоналом удаленная работа процесс разработки |
Как платформа чат-ботов наделяет разумом ИТ-проекты Сбербанка |

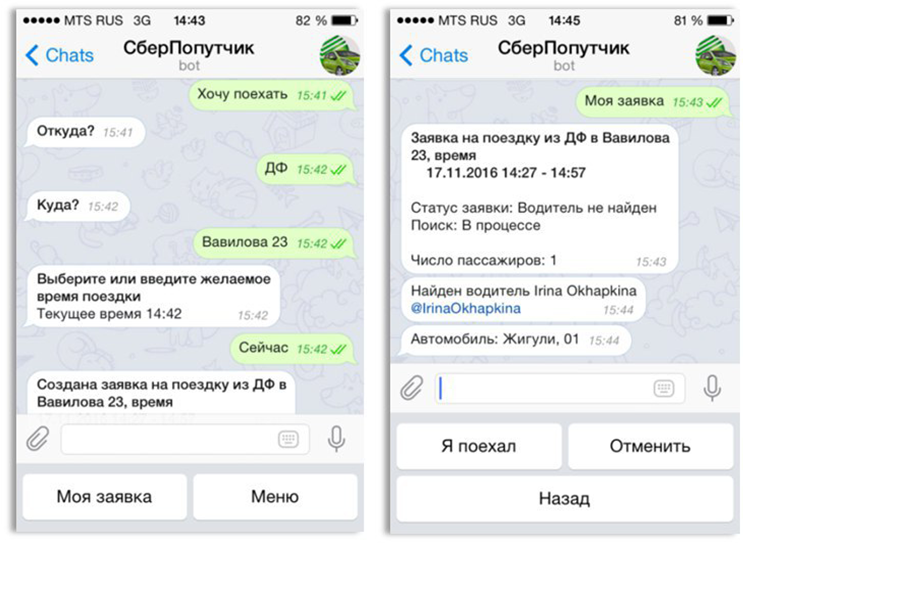
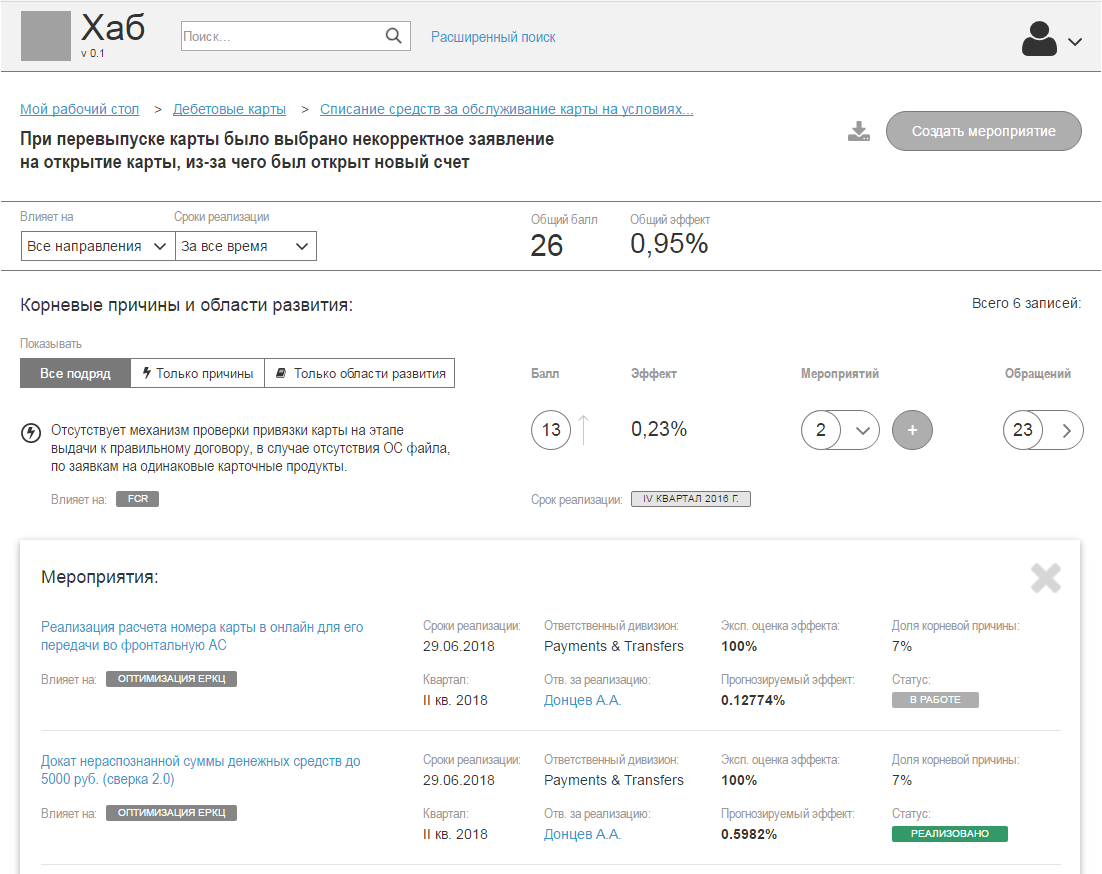
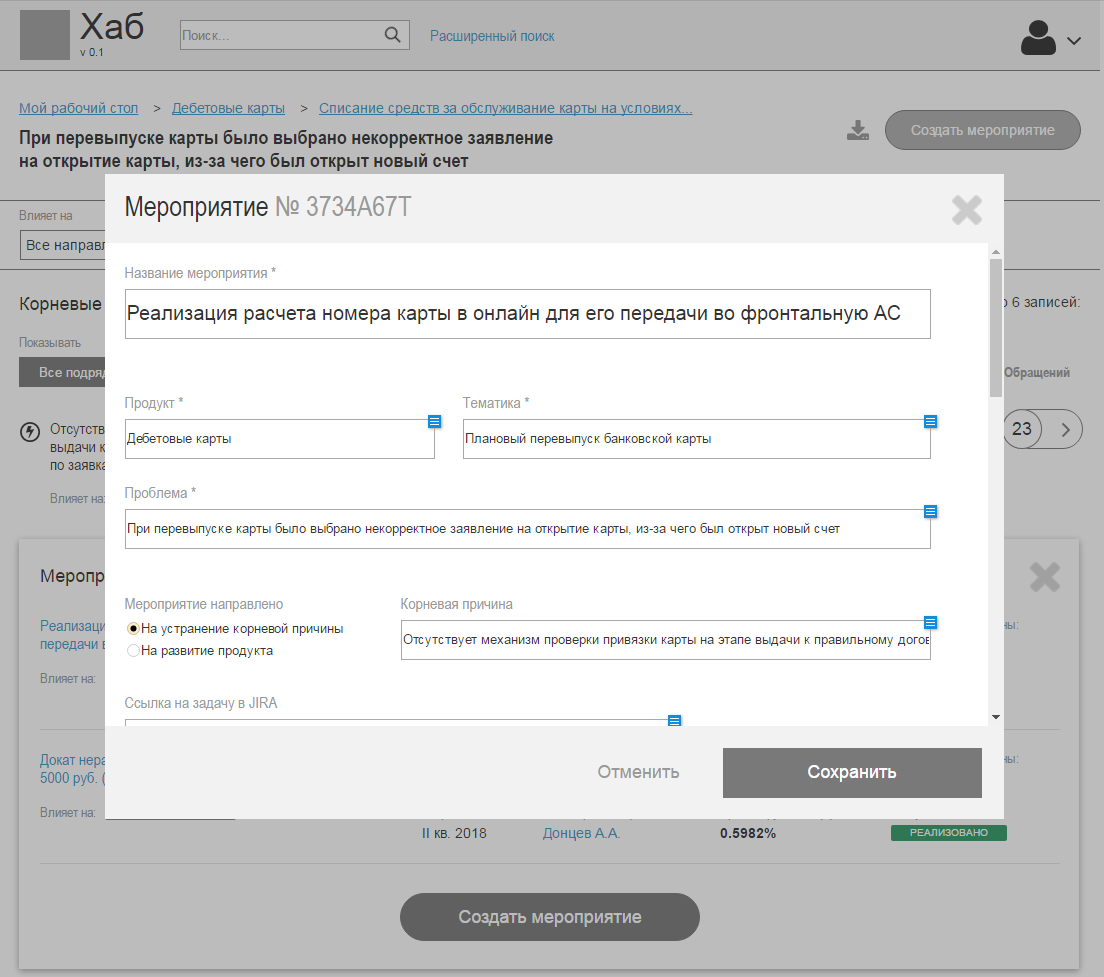
|
Метки: author Sberbank платежные системы машинное обучение биллинговые системы блог компании сбербанк боты сбербанк machine learning |
9 Советов как победить Баннерную Слепоту |



|
|
Конференция VMworld 2017 Europe. День 1 |

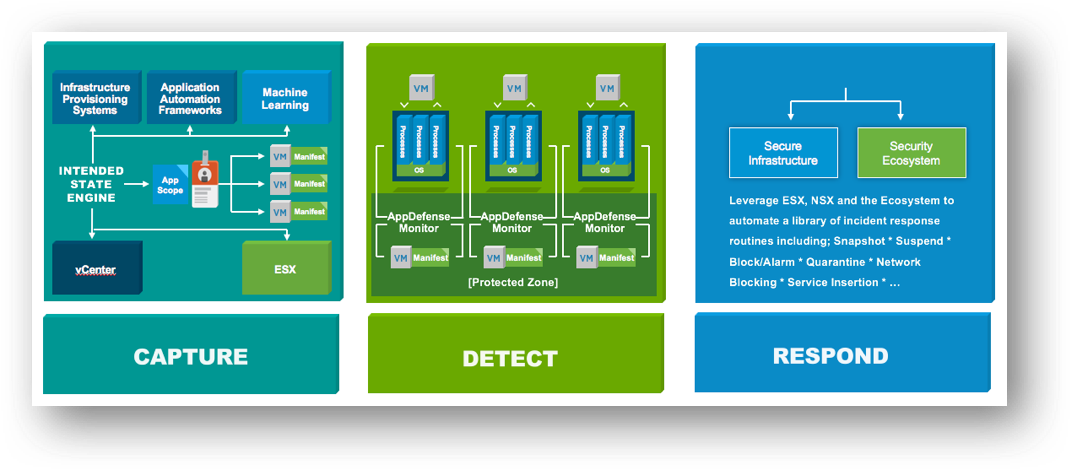








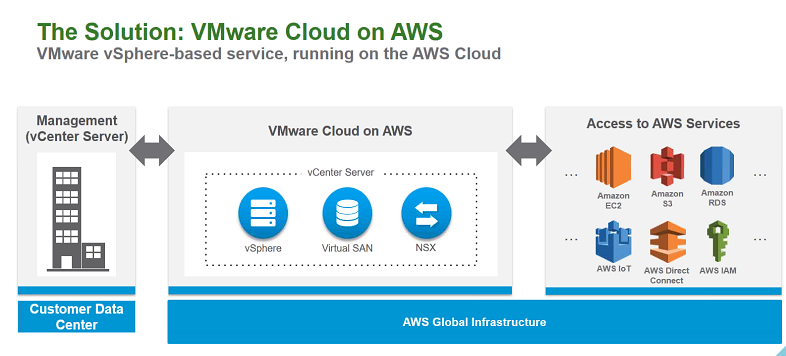













|
Метки: author omnimod хранилища данных хранение данных виртуализация it- инфраструктура блог компании инфосистемы джет vmworld виртуализация серверов vmware |
Проблемы React UI Kit-а и единой дизайн-системы, о которых вы не знали |

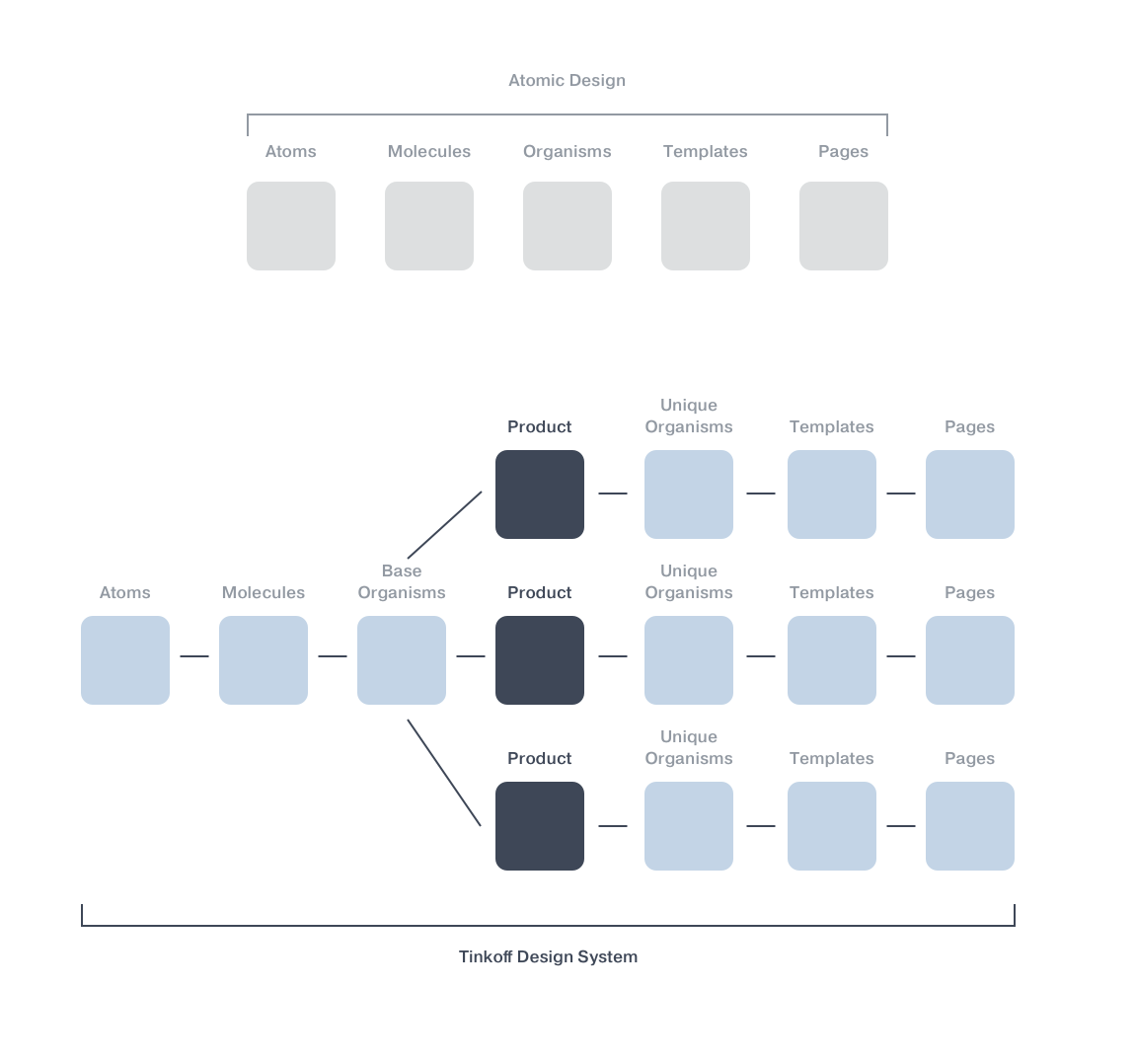
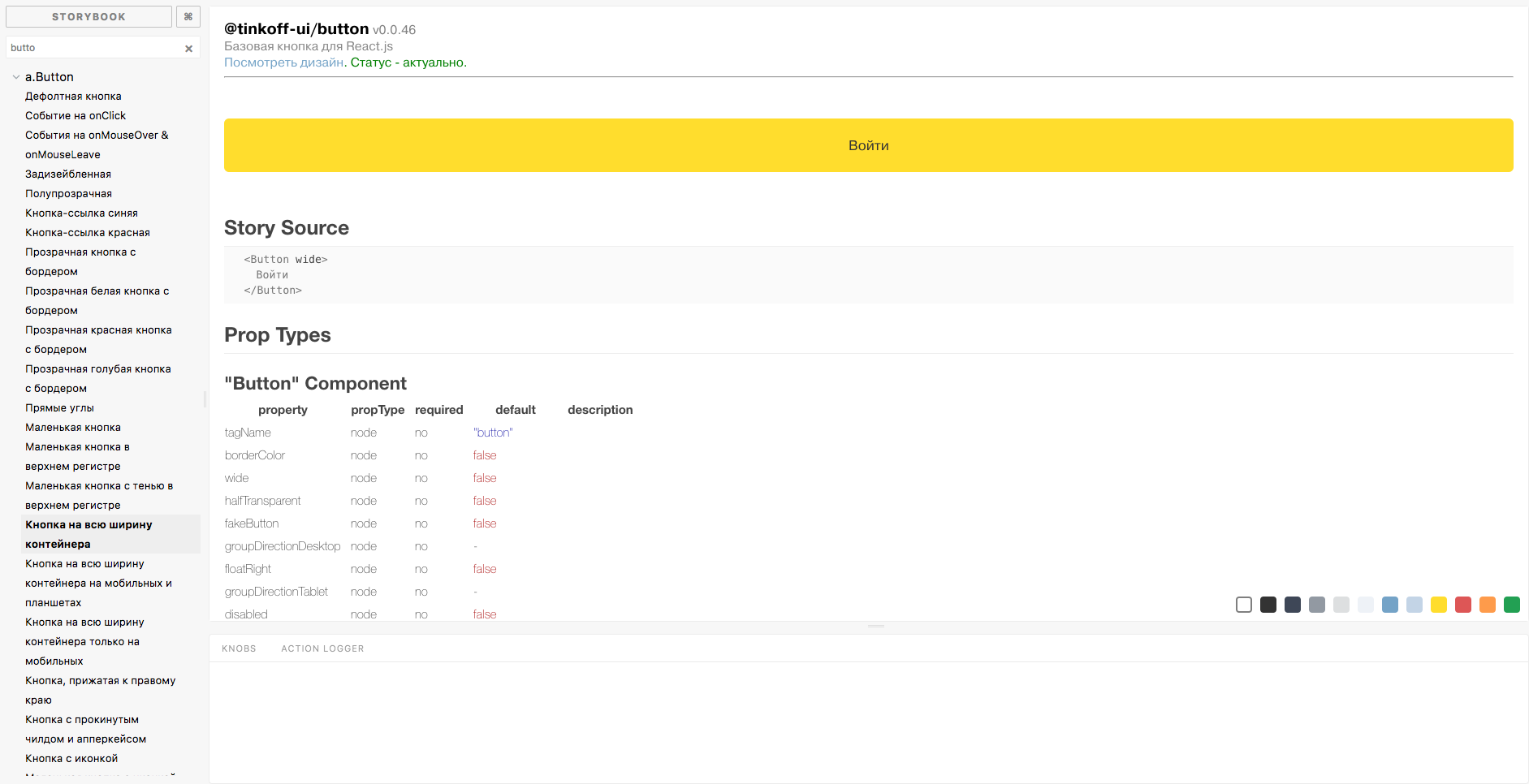
Как показал опрос зала, не все присутствующие на профильной конференции по frontend знают, что такое UI Kit. Если говорить простым языком, UI Kit – это набор элементов пользовательского интерфейса в едином стиле. Еще проще: кнопки, поля для ввода текста, выпадающее меню и прочее в одном цвете.
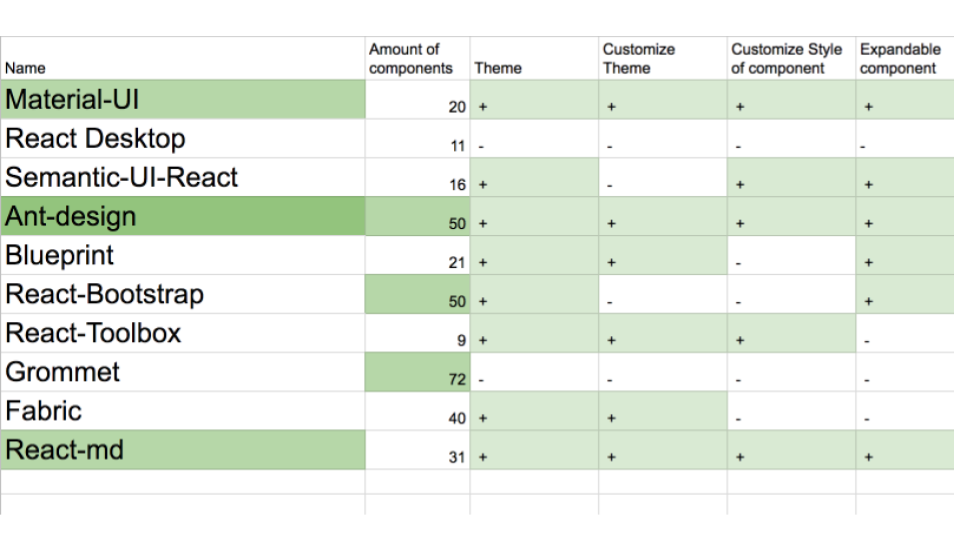


|
Метки: author 6thSence reactjs блог компании tinkoff.ru react react.js uikit ui ux ux/ui design development |
DBaaS: базы данных в облаке |

Друзья, всех с прошедшим вчера Днем программиста! Жизни без багов и красивейшего кода!)
Мы продолжаем разбор облачных сервисов Техносерв Cloud и сегодня детально разложим, из чего состоит наша облачная база данных. Если заглянуть в результаты исследования, проведенного IDG Connect по заказу Oracle, увидим, что DBaaS скоро будет самым востребованным сервисом частного облака. Растет и число публичных сервисов DBaaS.
Снижение затрат за счет консолидации ресурсов, масштабирование по мере необходимости, контроль расходов, доступ к данным из любого места – всё это факторы, влияющие на выбор в пользу облачной базы данных. На рынке облачных услуг свои базы данных предлагают его ведущие игроки – Amazon Web Services, IBM, Microsoft и Oracle. Но есть одна проблема — все они разворачивают БД за пределами России, более того, далеко не все из них предлагают сервис – администрирование, управление производительностью, круглосуточную техническую поддержку (желательно на русском языке), – а только платформу.
Чтобы ответить на этот запрос рынка, мы запустили свой сервис и стали единственным российским облачный провайдером, работающим с четырьмя основными базами данных под ФЗ-152 и ФЗ-242.
Вначале коротко о рынке. Если вы уже знакомы с этой информацией, переходите сразу к блоку "Четыре в одном", но нам показалось, эти данные довольно интересны.
По прогнозу Technavio, в ближайшие годы мировой рынок DBaaS будет демонстрировать экспоненциальный рост — более чем на 65% ежегодно. Вместо того, чтобы вкладывать большие средства в аппаратные платформы, многие компании склонны инвестировать средства в услуги с еженедельной, ежеквартальной или ежегодной оплатой по подписке.
Объем работ по поддержке собственных многочисленных баз данных и серверов может быть весьма серьезным. Стандартизация, когда все в одной среде, переводит процесс на уровень выше и упрощает работу с БД. Тут ключевое слово – «упрощает», отмечают аналитики IDC.

Судя по результатам опросов, реляционные облачные СУБД – в числе самых популярных сервисов публичных облаков. Их используют 35% респондентов, экспериментируют -14%, планируют внедрение – 12% (источник – RightScale).
Более того, переход на облачные вычисления снижает затраты за счет консолидации ресурсов, повышая эффективность ИТ-инфраструктуры. Благодаря консолидации ресурсов можно также предоставить заказчикам дополнительную производительность и повысить управляемость.
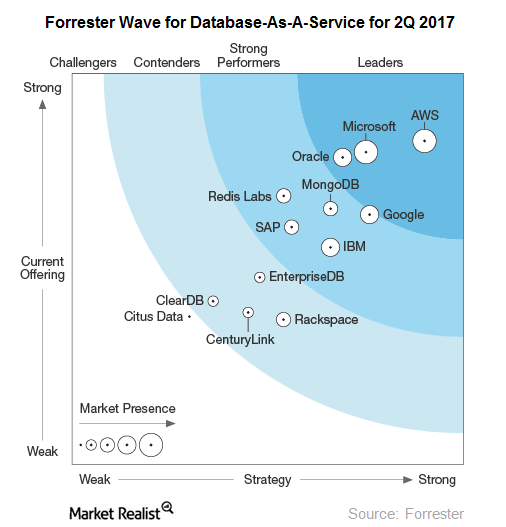
По данным Forrester, AWS – лидер рынка DBaaS. Amazon Relational Database Service позволяет работать с БД Oracle, Microsoft SQL Server, MySQL, MariaDB и PostgreSQL в среде EC2. Из 100 тыс. исследованных 2ndWatch экземпляров БД 67% представляли Amazon RDS.
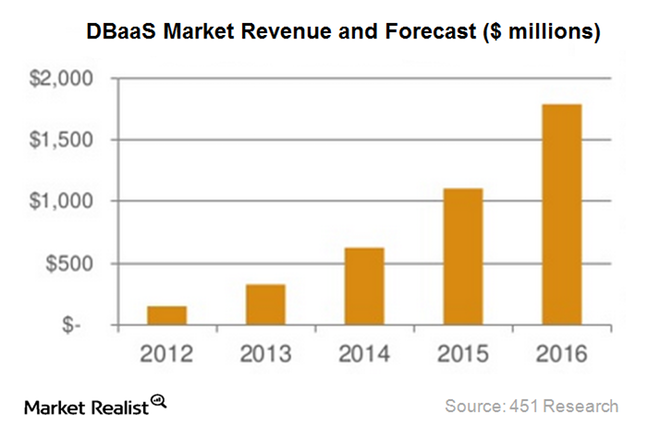
Рост оборота мирового рынка DBaaS в млн. долларов (по данным 451 Research).
Облачные вычисления не только позволяют компаниям масштабироваться по мере необходимости, но также помогают им управлять расходами на обслуживание. Растущая популярность мобильных приложений также побуждает компании использовать DBaaS: доступ к данным можно получить из любого места. Все эти факторы способствуют росту рынка DBaaS.
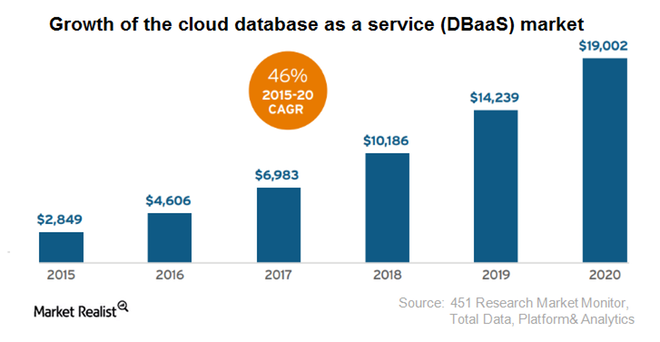
Рост сервиса Oracle DBaaS в мире.
Аналитики Markets&Markets прогнозируют, что рынок облачных СУБД/DBaaS вырастет с 1,07 млрд. долларов в 2014 году до 14,05 млрд. долларов к 2019 году при ежегодных темпах роста (CAGR) в 46%.
Облачная база данных или DBaaS (Database as a Service) – это любая СУБД, предоставляемая по подписке как облачный сервис в рамках платформенной модели обслуживания. То есть DBaaS – один из сервисов PaaS. В случае PaaS, «платформы как сервис», заказчик получает уже установленное и настроенное программное обеспечение для разработки и тестирования или развертывания приложений. Для заказчика создается БД нужной конфигурации в одном из следующих вариантов:
• БД без виртуализации (на физической машине)
• БД на виртуальной машине
• БД в виде контейнера в многоарендной базе данных
Например, развертывание баз данных в отдельных виртуальных машинах на общей серверной платформе упрощает миграцию в облако, но приводит к дополнительным издержкам, усложняет поддержку версий СУБД и т.д. Если СУБД работают на пуле физических серверов с единой ОС, то можно унифицировать версии, упростить управление, эффективнее использовать оборудование, считают в Oracle.
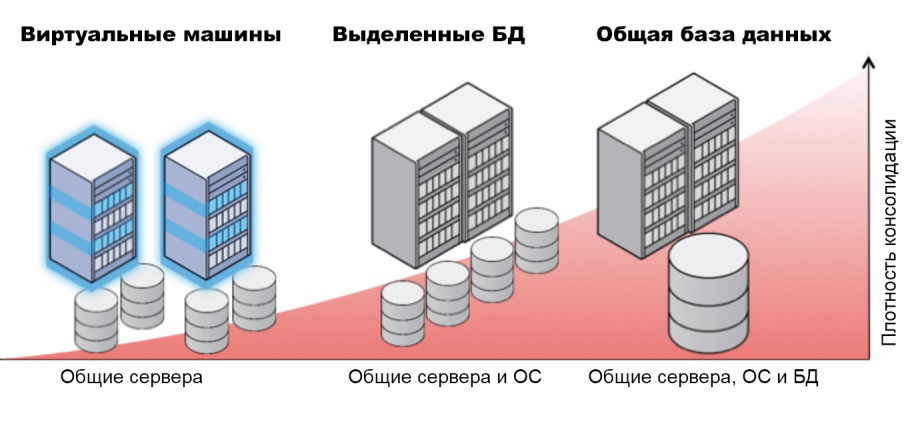
Отдельные базы данных консолидируются на физических серверах и группируются в облачных пулах. Любой сервер из пула может размещать один или несколько экземпляров баз данных (источник – Oracle).
Используя DBaaS, заказчик может получить доступ к базе данных того или иного типа по запросу, быстро развернуть БД на требуемой аппаратной и программной платформе (операционной системе). В данной модели оплата может взиматься в зависимости от емкости и других потребляемых ИТ-ресурсов, а также от функций и средств администрирования базы данных. Отметим, что все функции баз данных, доступные локально, реализованы и в облаке.
DBaaS позволяет, например, оперативно развертывать базы данных или серверы приложений, использовать быстрое клонирование БД большого объема для разработки или тестирования. Базы данных клонируются буквально за секунды с помощью моментальных снимков. После входа в панель технической поддержки дальше все происходит автоматически.
Консолидация ресурсов в ЦОД поставщика услуг повышает эффективность ИТ, а применение стандартных, протестированных конфигураций увеличивает надежность. Можно также заказать конфигурации высокой доступности или катастрофоустойчивые, задействовать гибридную модель при эпизодическом увеличении нагрузки. DBaaS снимает с заказчика проблему развертывания и сопровождения СУБД. Кроме того, с облачной БД можно работать в любое время, из любой точки мира и из любого приложения.
Создание конфигураций баз данных на основе стандартных шаблонов дает возможность применить модель самообслуживания. Это освобождает администраторов от ручной настройки баз данных в ответ на каждый индивидуальный запрос. Когда среда DBaaS готова к использованию, заказчики смогут простыми операциями подготовить базы без привлечения администраторов БД по параметрам выделения ресурсов, установки ограничений доступа и выполнения других обычных задач.
Как показывает практика, многие заказчики DBaaS отмечают:
• Снижение общих расходов.
• Большую независимость бизнес-пользователей от ИТ-подразделений.
• Снижение рисков в сценариях ИТ-планирования.
• Большую предсказуемость и гибкость.
• Разработчики приложений достаточную степень свободы для творчества и инноваций.
• DBaaS улучшает работу администраторов БД. Они больше концентрируются на задачах бизнеса и меньше — на рутинных операциях.
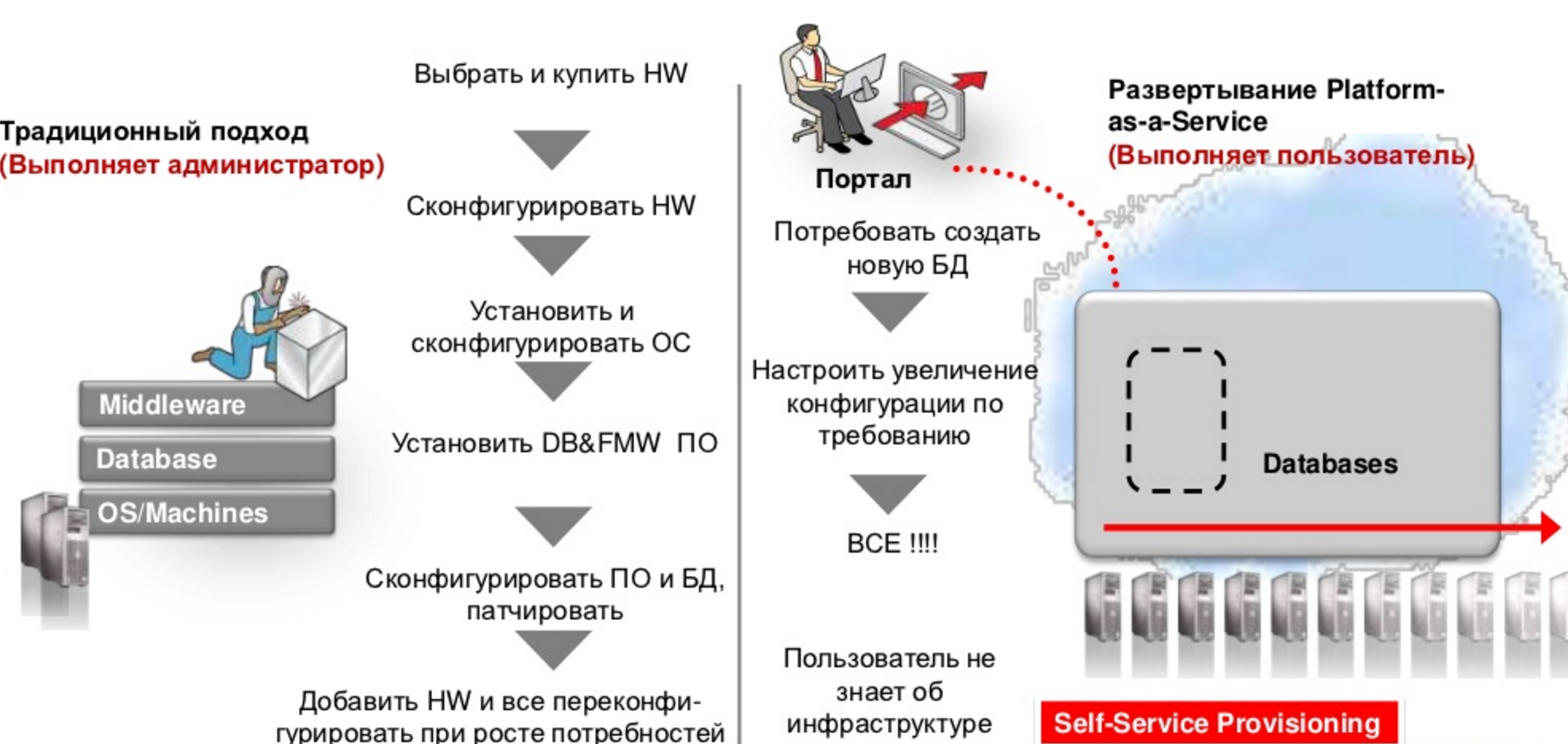
Отличия DBaaS от традиционного подхода (источник – Oracle).
Основные преимущества облачной БД
Начнем с того, что не каждая компания может выделить отдельного сотрудника для мониторинга и управления своей СУБД. Результат — высокие риски остановки бизнес-процессов, прерывание производственных процессов, потеря данных и прочие неприятности. С сервисом «Облачная база данных» все эти заботы мы берем на себя. Преимущества DBaaS:
• высокая масштабируемость,
• снижение затрат,
• быстрое предоставление услуг,
• повышение надежности и безопасности.
Переходим к описанию нашего сервиса «Облачная база данных». Как мы уже сказали, эта услуга может работать с четырьмя основными базами данных: мы предоставляем готовые к работе базы данных Microsoft SQL (лицензии MS по модели SPLA), PostgreSQL и MySQL, а также хостинг Oracle.

Тарифный план предусматривает более 80 вариантов оказания услуги под различные классы экземпляров баз данных.
Клиентам доступны следующие версии и редакции СУБД:
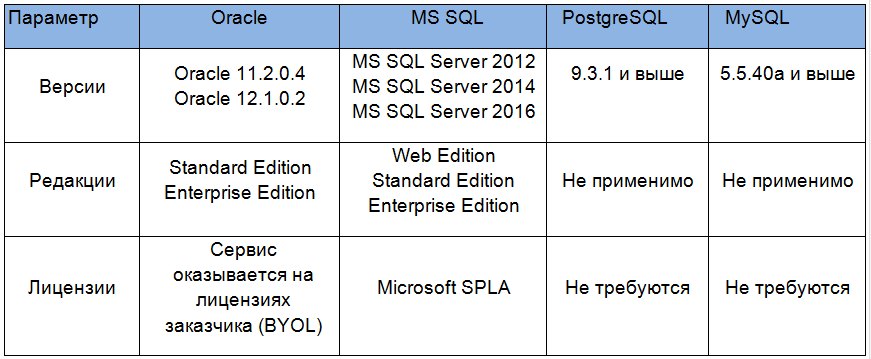
Особенности услуги «Облачная база данных»
• Высокая производительность.
• Оптимизированные в соответствии с рекомендациями разработчиков и лучшими практиками конфигурации ОС и СУБД.
• Профессиональная техническая поддержка, в которой работают специалисты интегратора по базам данных.
• Услуга создавалась с учетом ФЗ-149, ФЗ-152 и ФЗ-242.
• Ценовое предложение в среднем на 35-40% выгоднее западных облачных платформ (с учетом затрат на работы по администрированию баз данных и операционных систем которые по умолчанию включены в состав услуги).
Согласно законодательству РФ, основными документами, определяющими требования к защите информации, являются:
• Закон ФЗ-149 «Об информации, информационных технологиях и о защите информации».
• Закон ФЗ-152 «О персональных данных».
• Приказы ФСТЭК России №17 и №21.
• Закон ФЗ-242, который уточняет ФЗ-152 и обязывает операторов персональных данных обрабатывать и хранить персональные данные россиян с использованием баз данных, размещенных на территории РФ.
По умолчанию наш сервис предоставляется клиентам в соответствии с 3-й и 4-й категориями защищенности ПДн (о безопасности данных), а по запросу – в аттестованном сегменте* платформы, согласно всем требованиям защиты информации, установленным ФСТЭК России.
*Аттестат соответствия требованиям по безопасности информации
Данный аттестат подтверждает безопасность использования нашего облака для размещения ИС государственных и коммерческих организаций, предъявляющих жесткие требования в части защиты информации. Речь идет о российских заказчиках, специализирующихся на обработке ПДн: операторы ГИС, систем ПДн с высоким уровнем защищенности, например, медицинские и страховые компании.
Этот аттестат также исключает этап аттестации ИТ-инфраструктуры заказчика, тем самым до 50% снижает объем требуемых временных трудозатрат, значительно снижает размер инвестиций и существенно облегчает процесс аттестации ИС. Это позволяет оптимизировать финансовые и временные затраты организации, сократив издержки на создание и обслуживание своей ИТ-инфраструктуры, построение и поддержку внутренней системы защиты информации.
Санкции также подталкивают наших потенциальных заказчиков на поиск альтернативных решений на российском рынке. На фоне высокого курса валют и сложной политической ситуации они ищут возможные пути минимизации рисков, и «Облачная база данных», как российский сервис, предлагаемый на территории России по рублевым ценам, заслуживает пристального внимания. Облачные сервисы могут выступить в качестве альтернативы покупке ИТ-оборудования западных вендоров, а открытое ПО, на основе которого сервис функционирует, отвечает курсу на импортозамещение. Open Source платформы, такие как OpenStack, — одна из ключевых альтернатив проприетарным решениям.
Наш сервис включает все опции, обеспечивающие доступность базы данных:
• динамически расширяемые вычислительные ресурсы;
• администрирование ОС и СУБД силами провайдера;
• мониторинг СУБД;
• резервное копирование данных.
И предлагает следующие варианты подключения к БД:
• сети общего пользования (публичный интернет).
• защищенное VPN-подключение поверх интернета (IPSec VPN).
• защищенный L2 VPN-канал связи.
• сеть IP VPN.
• через внутреннюю сеть, при условии размещения серверов приложений в облачной платформе Техносерв Cloud (скорость 10 Гбит/с).
Администрирование БД включает в себя выполнение следующих операций:
• решение инцидентов в работе БД;
• установка и настройка клиента и ПО БД;
• управление доступом к БД;
• резервное копирование БД;
• обновление ПО БД;
• мониторинг доступности БД;
• мониторинг состояния БД и резервных копий, периодическое тестирование резервных копий (1 раз в месяц);
• управление пространством;
• анализ журналов и файлов трассировки;
• восстановление БД из резервных копий в случае сбоя*.
*Если необходимость восстановления базы данных из резервной копии была вызвана некорректными действиями пользователя, то такие работы считаются дополнительными и тарифицируются отдельно.
Администрирование операционных систем включает в себя выполнение следующих операций:
• инсталляция и базовая настройка серверной операционной системы;
• профилактическое обслуживание серверной операционной системы;
• настройка операционной системы (во время эксплуатации);
• решение инцидентов, возникающих в работе систем, в т. ч. восстановление; работоспособности после сбоя;
• обновление системы;
• резервное копирование системных данных;
• мониторинг доступности.
Для реализации сервиса мы используем в своей облачной платформе сегмент OpenStack со следующими возможностями:
• среда виртуализации OpenStack/KVM;
• обмен данными между ВМ — до 10 Гбит\с;
• система управления OpenStack (основана на релизе Mitaka);
• использование модуля виртуализации сети Neutron позволяет реализовывать функции NAT, VPNaaS, FWaaS, LBaaS, маршрутизации;
• программно-определяемое хранилище (SDS) — тройное резервирование обеспечивает не только сохранность данных при выходе из строя любого диска, узла или группы узлов, но и автоматизированное восстановление копий на других узлах.
Ресурсы у сегмента OpenStack (с учетом резервирования):
• vCPU – 1000 ядер.
• vRam – 1400 Гбайт.
• vHDD – 24000 Гбайт.
Наша услуга сокращает эксплуатационные затраты, в которые среди прочего входят зарплаты администраторов БД (например, в Московском регионе зарплата Oracle DBA в месяц может доходить до 200 т.р.), а также снижает риски, связанные с инфраструктурой, на которой развернуты БД. Ее можно использовать для запуска новых или обновления существующих бизнес-приложений, таких как корпоративная система электронной почты, системы CRM и HRM, бухгалтерское, складское, финансовое и аналитическое ПО.
Она сводит к минимуму риск недоступности бизнес-приложений из-за ошибок в работе баз данных, снижает вероятность потери данных из-за несвоевременного резервного копирования, дает возможность обеспечить высокую доступность БД в условиях отсутствия или недостаточности собственных ресурсов/экспертизы. Кроме того, можно повысить отказоустойчивость критичных бизнес-систем за счет использования технологии кластеризации баз данных, получить достаточную производительность при нехватке вычислительных ресурсов и пропускной способности собственного оборудования или реализовать план аварийного восстановления (DRP). Сервис удобно также применять для резервного копирования и проверки консистентности резервных копий данных.
Для разных приложений у нас типовые конфигурации:
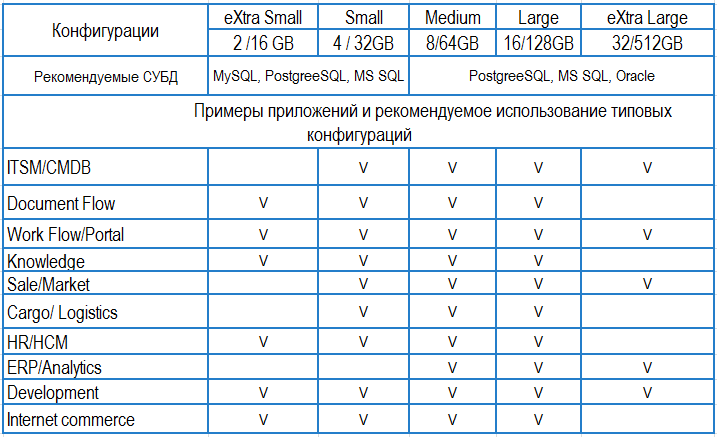
Распространенные варианты использования DBaaS — создание тестовых сред для функционального и нагрузочного тестирования, разовые проекты со сжатыми сроками, решение проблемы эпизодических «пиковых нагрузок», например, формирование аналитической или финансовой отчетности.
Это базовый вариант сервиса для БД Oracle, MS SQL Server (2012/2014/2016 Standard Edition), MySQL и PostgreSQL, при котором заказчику предоставляется система с необходимыми характеристиками. Экземпляр базы данных располагается на виртуальной машине.
Системой резервного копирования Commvault резервируются файлы базы данных и журналы транзакций. Они хранятся семь дней. В течение этого периода можно восстановить БД по состоянию на момент последнего резервирования журнальных файлов (с интервалом в час).
По умолчанию резервное копирование выполняется по следующему сценарию:
• Один раз в неделю — полное резервирование.
• Каждый день сохраняется дифференциальная резервная копия.
• Каждый час сохраняется журнал транзакций.
Целевой срок восстановления (RTO) – до нескольких часов (в зависимости от объёма базы данных), целевая точка восстановления (RPO) – до 1 часа. Время восстановления сервиса в случае потери базы данных зависит от объема БД и интенсивности ее использования. В случае аппаратного сбоя система автоматически заменяется в течение нескольких минут.
Архитектура: Одиночная база данных
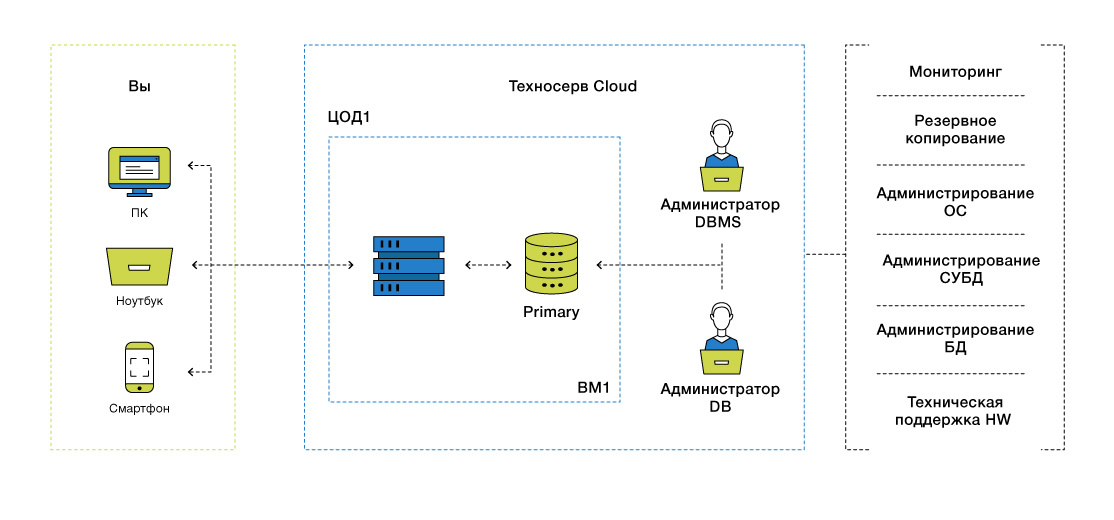
Одиночная база данных — время восстановления и потенциальная потеря данных:
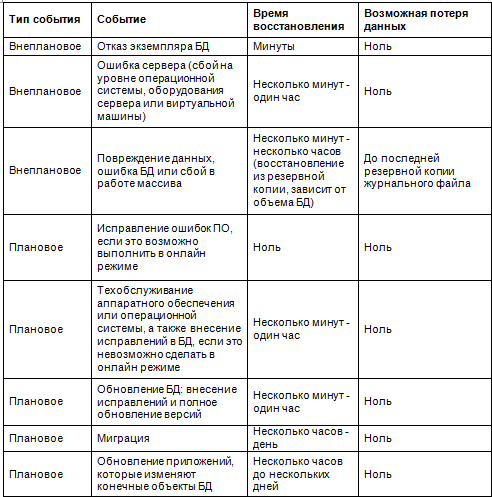
БД повышенной защищенности
Конфигурация зависит от типа БД:
SQL Server 2012/2014/2016 Standard Edition
Database Mirroring: предоставляются две системы с необходимыми характеристиками. На одной из машин располагается основной экземпляр, на второй — резервный. Используется зеркальное отображение базы данных (Database Mirroring), которое обладает следующими преимуществами:
PostgreSQL и MySQL
База данных повышенной защищённости: предоставляется две системы с необходимыми характеристиками. На одной из виртуальных машин располагается основной экземпляр, на второй — резервный. В случае выхода из строя основной базы данных происходит переключение на резервную. Время восстановления сервиса в случае потери базы данных не превышает 15 минут. Резервное копирование выполняется системой Commvault.
Архитектура: База данных повышенной защищенности

Доступность сервиса — 99,95%. RTO – от нескольких минут до 1 часа, RPO – близко или равна нулю.
БД высокой доступности и защищенности
SQL Server 2012/2014/2016 Enterprise Edition
Используются группы высокой доступности (Always On Availability Groups), которые предоставляют широкий набор параметров, позволяющих повысить уровень доступности баз данных и улучшить использование ресурсов, а также обладают следующими преимуществами:
В случае выхода из строя основной базы данных происходит переключение на резервную базу данных, при этом время простоя обычно составляет меньше минуты.
Каждая реплика группы доступности размещается на отдельном узле отказоустойчивого кластера Windows Server (WSFC). Развертывание WSFC требует, чтобы серверы, участвующие в WSFC (также называются узлами), были присоединены к одному и тому же домену.
В качестве последней линии защиты данных используется резервное копирование, которое выполняется системой Commvault.
Архитектура: База данных высокой доступности и защищенности (1)
БД высокой доступности и защищенности. RTO – от нескольких секунд до 1 часа, RPO – близка или равна нулю.
(1) — Данная опция в разработке. Плановый срок ноябрь 2017г.
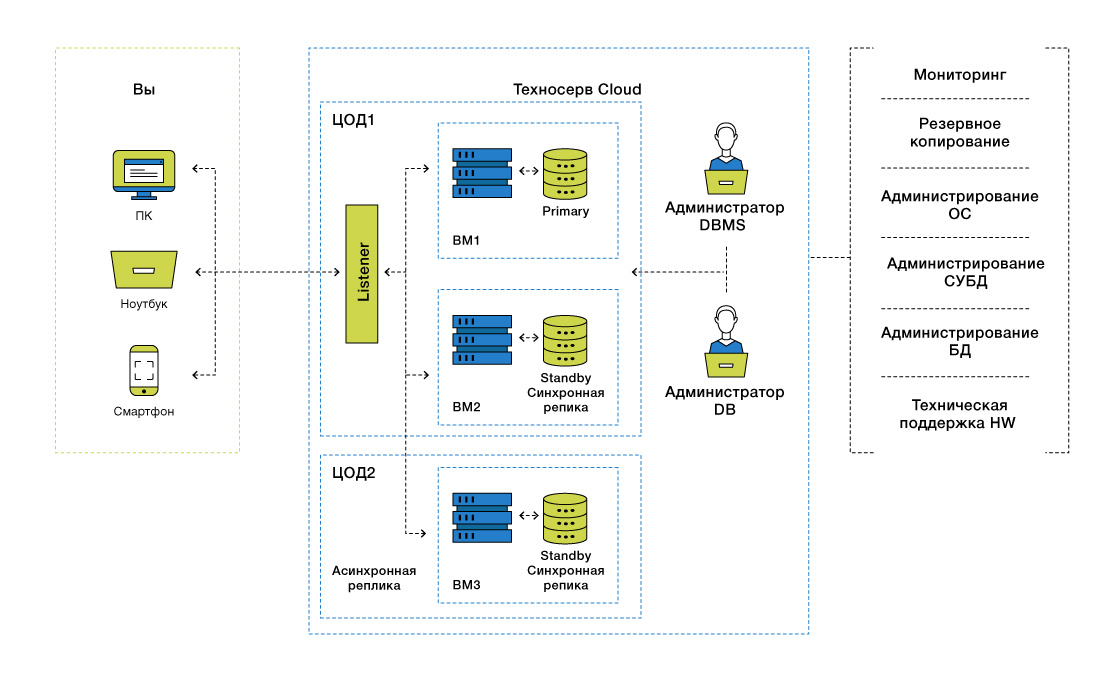
«Облачная база данных» (TS-Cloud.DBaaS) включает в себя:
• Подсистему оркестрации, обеспечивающую управление сервисом и инфраструктурой. Она взаимодействует с порталом самообслуживания и использует ресурсы облака TS-Cloud для размещения ВМ.
• Портал самообслуживания.
• Подсистему резервного копирования на базе сервиса TS-Cloud.BaaS CommVault Simpana.
• Облачную платформу TS-Cloud (OpenStack).
• Подсистему мониторинга на базе Zabbix.
• Cистему доменных имен (DNS)
Модуль оркестрации Heat, являющийся частью платформы OpenStack, дает дополнительный уровень абстракции при работе с облаком и избавляет обслуживающий персонал от множества рутинных действий. Он выделяет и конфигурирует вычислительные ресурсы для сервиса DBaaS при запросе клиентом услуги через портал самообслуживания.
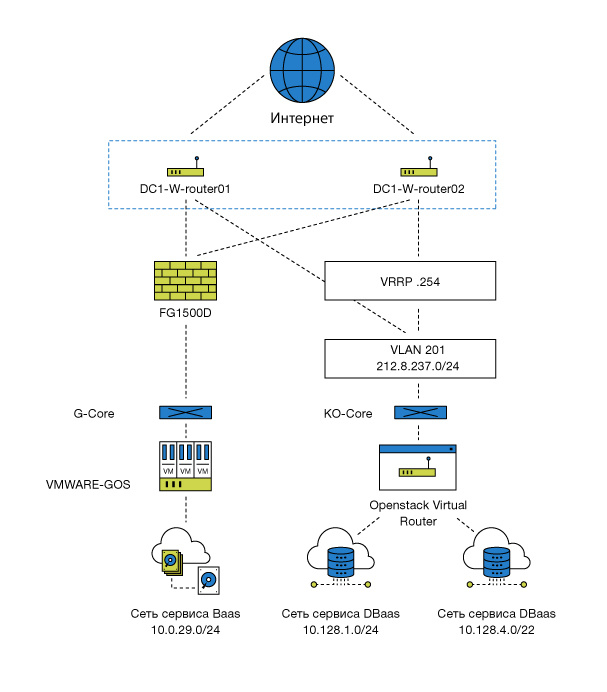
Схема TS-Cloud.DBaaS.
После запроса услуги клиентом портал запускает шаблон стека, соответствующий выбранной клиентом СУБД, и передает в Heat необходимые параметры сервиса (имя узла, размер дисков для размещения БД и транзакционных логов и т.д.). Heat запрашивает ресурсы для сервиса у компонентов платформы виртуализации, создает ВМ из образа, подключает к ней необходимые дополнительные диски и сети, запускает ВМ. Далее ВМ инициализируется при помощи Cloud-init. Метаданные ВМ сервиса (внутренний и внешний сетевые адреса, id стека и т.д.) передаются в портал. Портал самообслуживания взаимодействует с Heat через программный интерфейс Heat-API.
Подсистема оркестрации Ansible и обеспечивает настройку и управление сервиса DBaaS и инфраструктуры, необходимой для работы сервиса. Она управляется порталом самообслуживания и использует ресурсы облака TS-Cloud для размещения ВМ.
Портал самообслуживания взаимодействует с подсистемой оркестрации на базе Ansible через REST API, реализованный при помощи открытого продукта Flansible. Данный интерфейс позволяет исполнять сценарии Ansible (скрипты), отслеживать статус и результат их исполнения.
После запуска ВМ и получения порталом самообслуживания сетевых реквизитов сервиса запускается Ansible-скрипт конфигурирования сервиса — портал через REST-API передает необходимые параметры (внешний и внутренний адрес ВМ сервиса, имя БД, кодировка, имя пользователя БД, пароли и т.д.) и запускает скрипт. В процессе работы скрипта портал отслеживает статус выполнения.
Портал самообслуживания Техносерв Cloud — это интерфейс управления пользователем доступными услугами. В рамках сервиса DBaaS пользователю также предоставляется возможность создания, удаления и открытия заявок по услуге.
Портал взаимодействует с подсистемами автоматизации Heat и Ansible для создания экземпляров БД по запросу пользователя. В разделе «Каталог Услуг» пользователь может выбрать параметры конфигурацию и заказать одну или несколько услуг DBaaS.
После получения параметров заказа портал вызывает API Heat для выделения ресурсов OpenStack, получает от Heat IP-адреса созданных виртуальных машин и передает их по в Ansible для установки выбранной пользователем СУБД.
Процедуры в Heat и Ansible выполняются асинхронно, портал производит мониторинг выполнения этих процедур и сохраняет логи. Система мониторинга Zabbix призвана отслеживать состояние разнообразных сервисов сети, серверов и сетевого оборудования, а также оповещать персонал в случае внештатных и аварийных ситуаций.
Часто возникает вопрос, как перенести БД в облако. Мы разработали сценарии миграции данных на облачную инфраструктуру с использованием технологий Microsoft Mirroring и Always On Availability Groups, Oracle Data Guard, Oracle Golden Gate, Oracle Dbvision. Миграция включает в себя:
• Анализ с выбором методов решения задачи.
• Исследование на готовность системы.
• Рекомендации по подготовки системы.
• Составление детального плана.
• Тестирование процедуры миграции.
• Актуализацию результатов.
• Тестирование перед запуском в эксплуатацию.
• Финальную миграцию.
• Сопровождение постмиграционного периода.
• Решение проблемных вопросов.
• Контроль качества на всех этапах работ.
• Учет всех требований по простою системы, методик и оформления миграционных процедур.
Сколько это стоит?
Закономерный вопрос. Давайте посчитаем. Ежемесячная стоимость сервиса формируется, исходя из конфигурации сервера и размера размещенных на нем баз данных. Активно развивая пул облачных услуг, сегодня мы предлагаем сервисы дешевле, чем зарубежные игроки, а стабильные рублевые цены гарантируют независимость от колебания курса валют. Вот примеры конфигураций сервиса.
Вариант 1. Функциональное тестирование на СУБД PostgreSQL для разработчиков конфигурации «1С: Зарплата и кадры», эксплуатируемой в сети автосервисов.
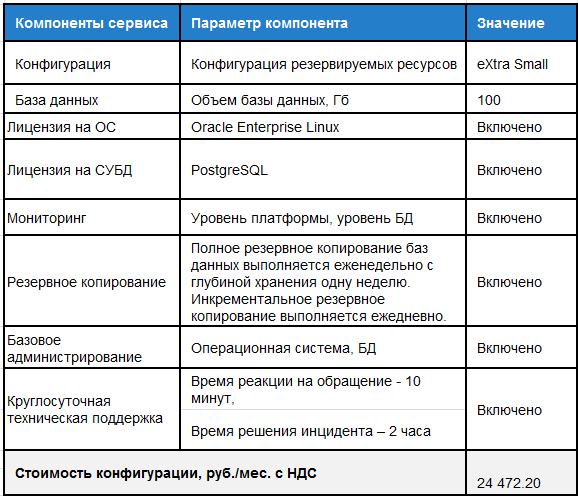
Вариант 2. Пример расчета стоимости сервиса БД MS SQL для ERP MS Axapta эксплуатируемой в сети магазинов детских игрушек.
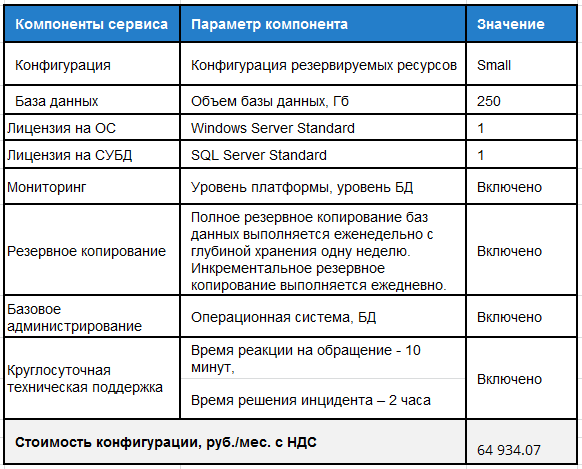
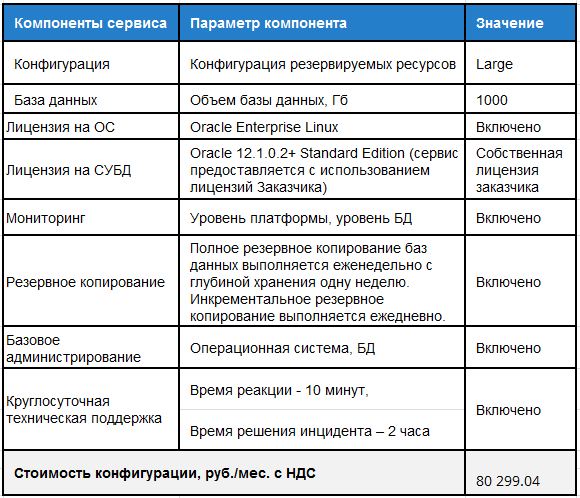
Вариант 3. Пример расчета стоимости сервиса БД Oracle для системы поддержки туристического бизнеса используемой туристическим оператором и его агентствами.
У нас на сайте можно рассчитать стоимость услуги с помощью онлайн-калькулятора.
Поскольку услуга новая, то будет много акций и прочих промо. А пока для первых 10 заказчиков, заявивших, что они пришли с Хабра, мы проводим миграцию данных бесплатно.
|
|
Доклады с Frontend Mix: оптимизация загрузки сайтов и дизайн-система на БЭМ и React |

Предлагаю всем близким к фронтенду посмотреть доклады с прошедшего в августе митапа Frontend MIX. Приглашенные спикеры из Альфа-Лаборатории, Яндекс.Денег и Epam делятся нюансами мобильной оптимизации и выбора между Npm v5, Yarn или pnpm, а также секретами построения дизайн-системы на БЭМ и React.
Под катом вы найдете три видео.
Андрей Мелихов, ведущий разработчик Яндекс.Денег, рассказывает о способах повысить скорость загрузки сайтов на смартфонах.
В докладе упоминаются современные способы передачи контента (HTTP/2: preload, server push), профилирование загрузки в Chrome Dev Tools и оптимизация JavaScript.
В своем докладе Виталий Галахов делится опытом использования методологии БЭМ в Альфа-Лаборатории. Сначала они попробовали БЭМ, потом отказались от нее, а позже все же нашли, где методология оказалась полезной.
Виталий рассказывает, как сделать дизайн-систему унифицированной и масштабируемой на множество команд, при этом не потерять в гибкости, расширяемости и общей элегантности решения.
Закрывал митап разработчик Epam Майкл Башуров, который поделился своим мнением по поводу выбора менеджера пакетов. Обсуждались как сакральные вопросы вроде «нужен ли Yarn» и «когда вышел Npm v5», так и плюсы использования менее популярных продуктов вроде pnpm.
Предлагаю вместе со спикером оценить преимущества и недостатки каждого решения, сравнить форматы и особенности Lock-файлов и решить для себя, что лучше.
Напомню, что за всеми нашими мероприятиями вы можете следить на Я.Встречах – записывайтесь и приходите в гости!
И, как всегда, если хочется уточнить наболевшее или непонятное – пишите в комментариях.
|
Метки: author dimskiy разработка под e-commerce программирование reactjs javascript блог компании яндекс.деньги бэм react yarn pnpm |
Переход от обычной сети ЦОД к SDN |
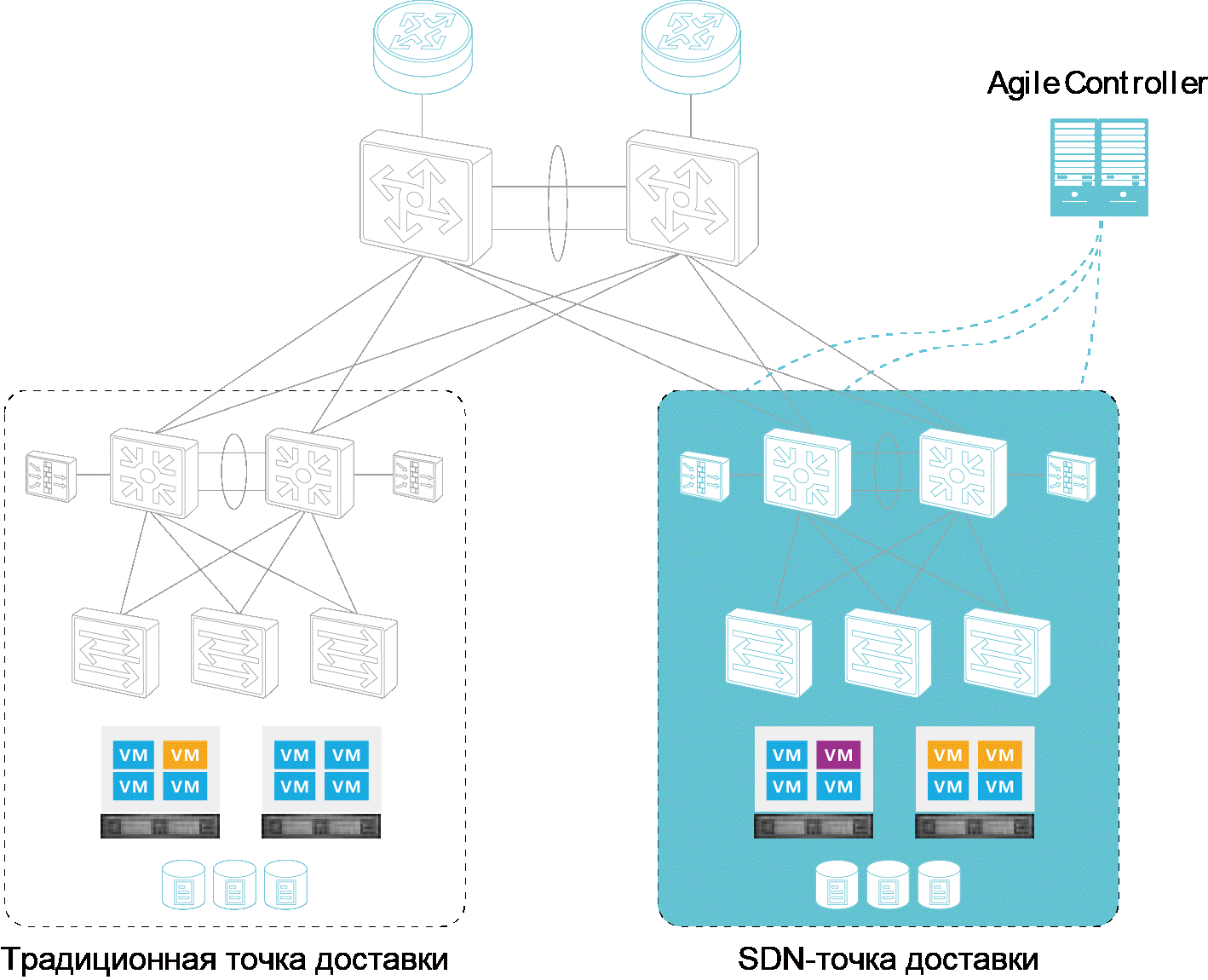
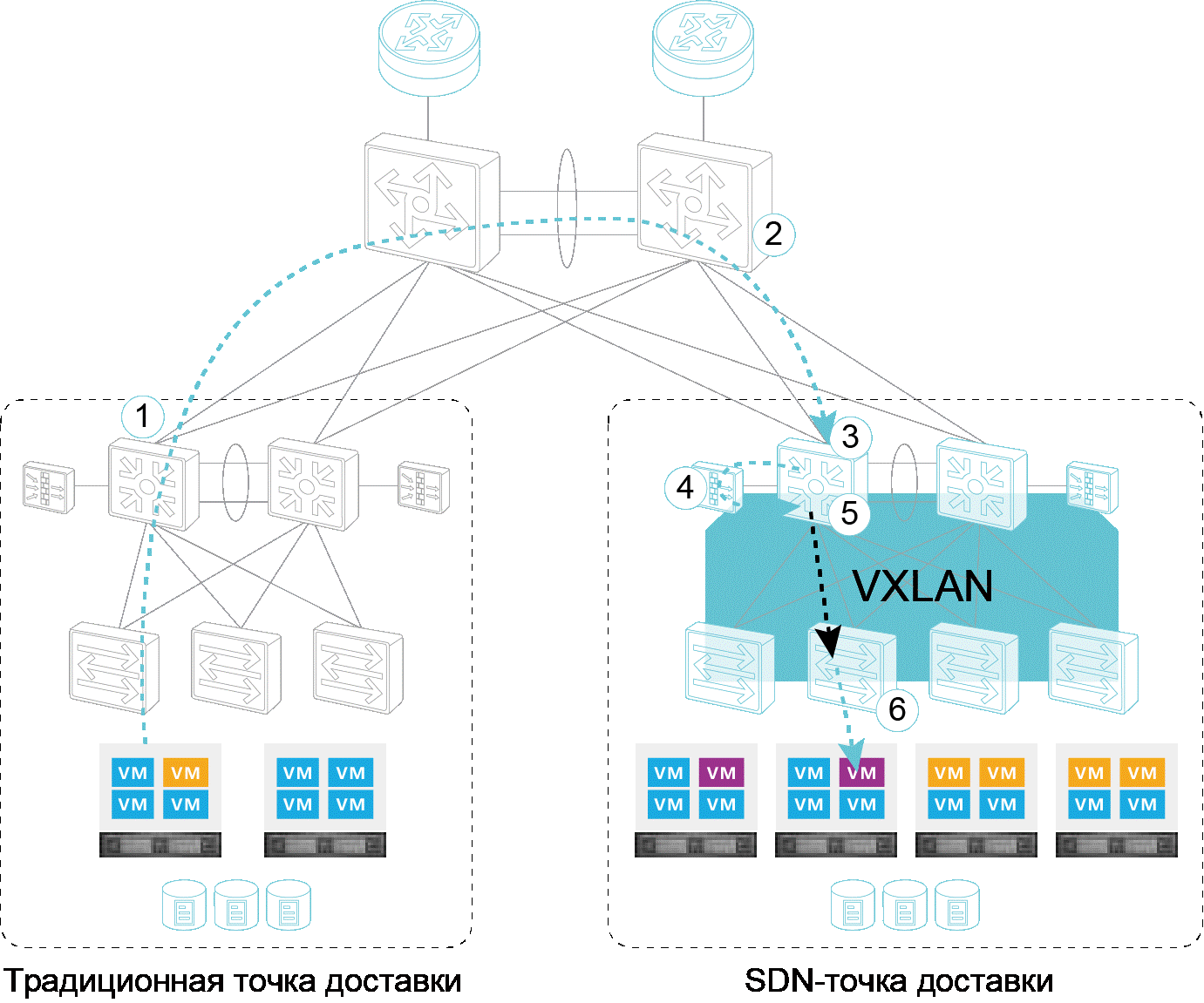

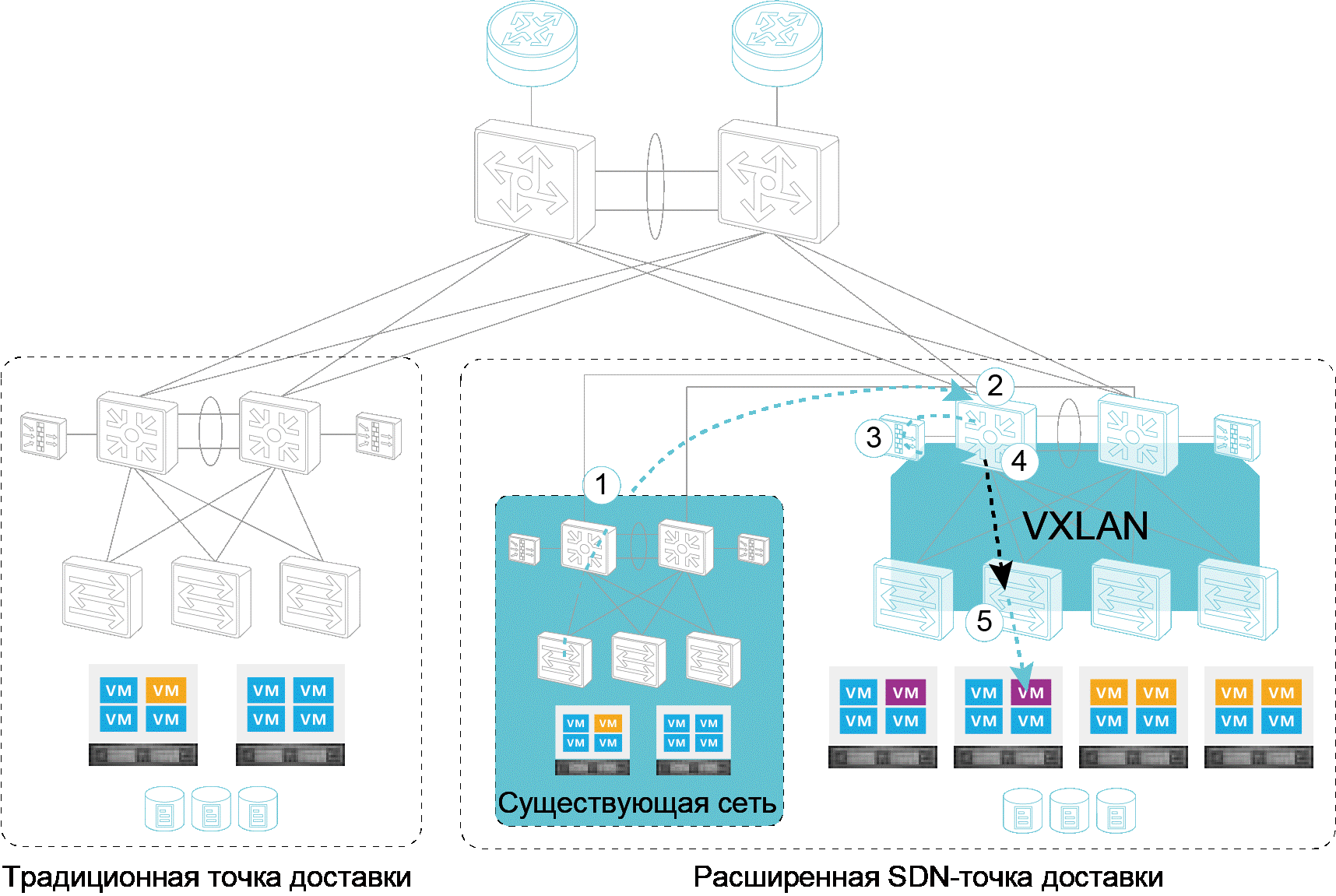
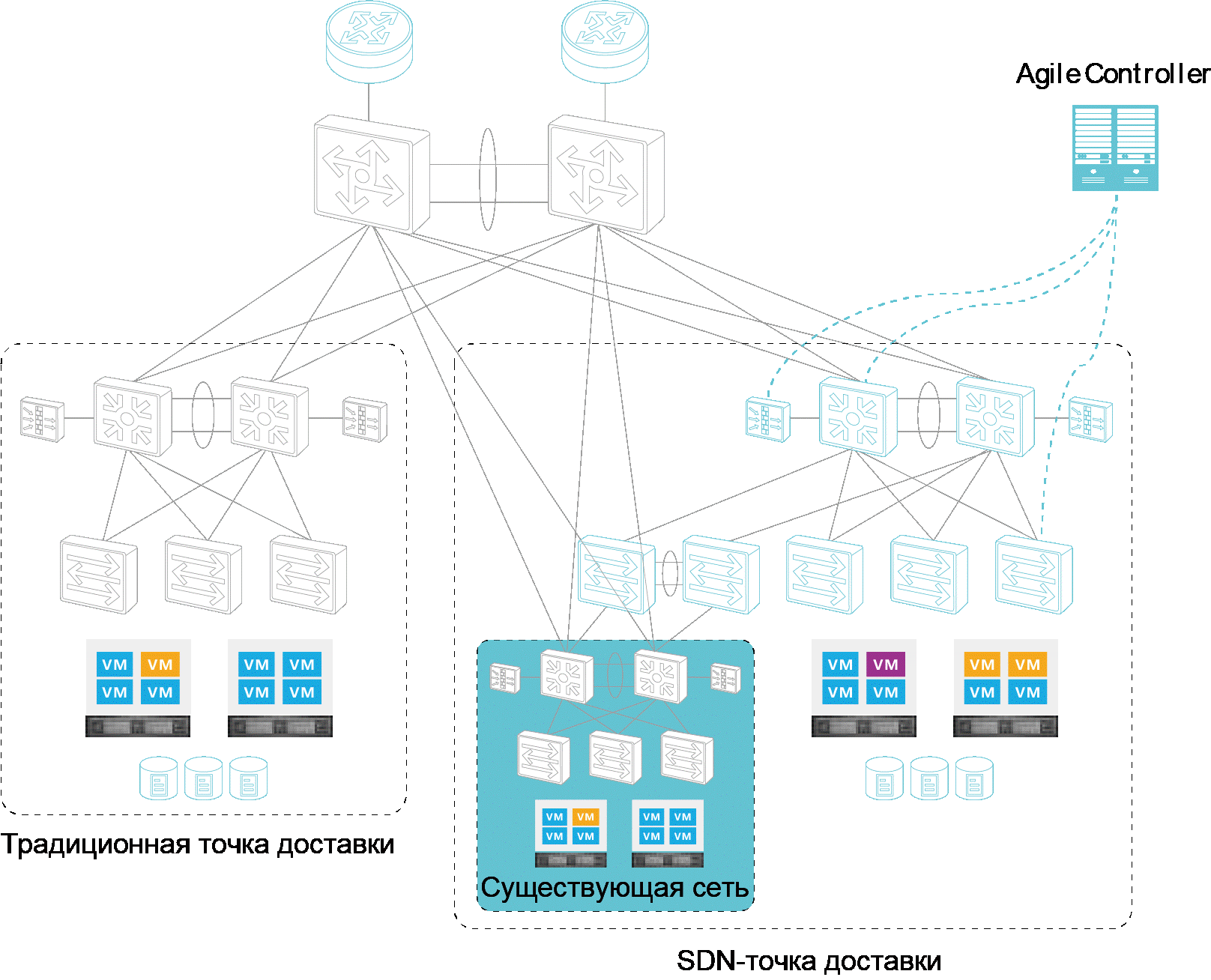

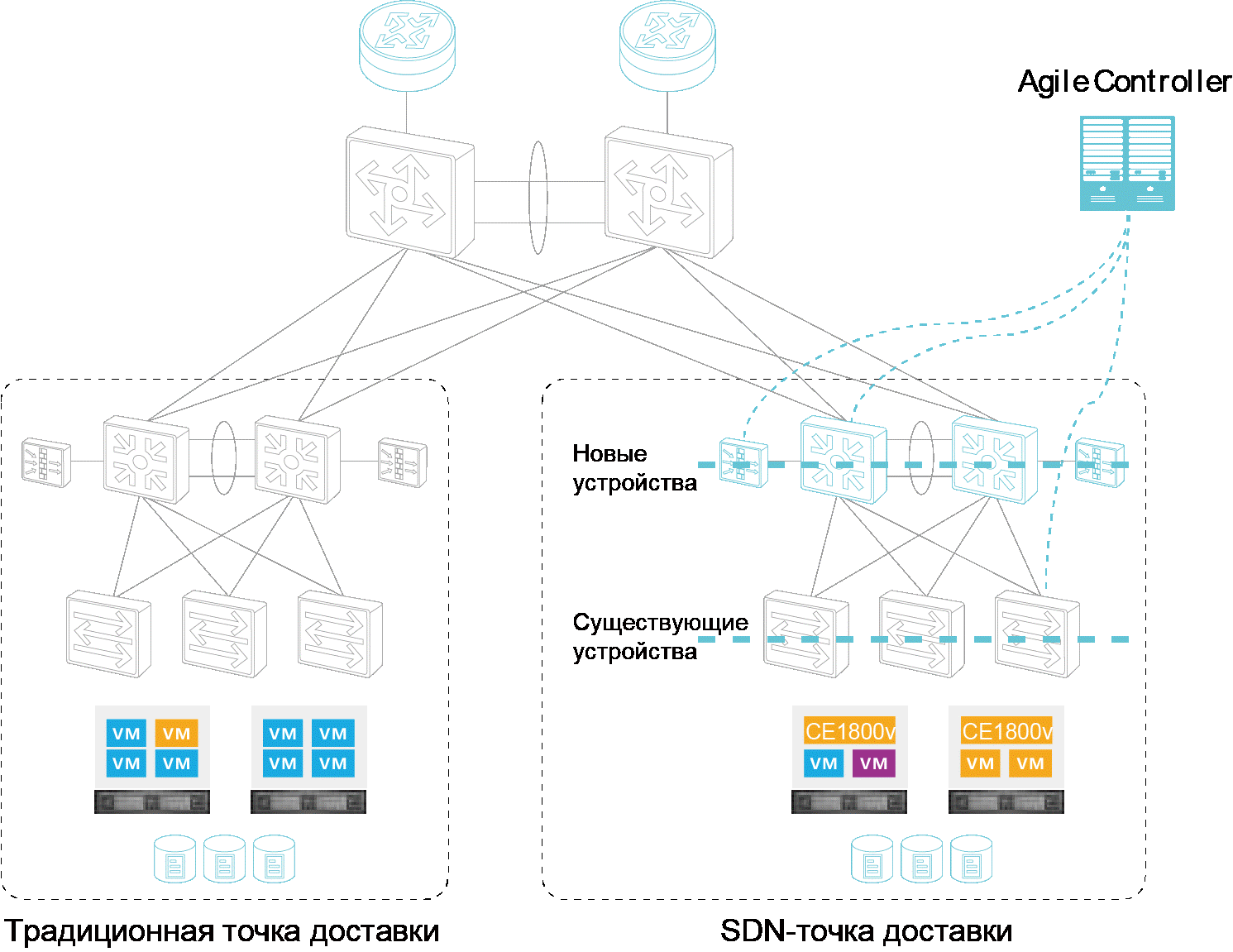

 "
" |
Метки: author Huawei_Russia сетевые технологии блог компании huawei huawei sdn dcn vxlan цод |
Технологические компании-единороги переоценены в среднем на 48%: исследование ученых из Стэнфорда |
|
Метки: author itinvest финансы в it исследования и прогнозы в it блог компании itinvest стартапы единороги кремниевая долина акции финансы оценки стартапов деньги |
Китай сделал новый ход в гонке суперкомпьютеров |


|
Метки: author 1cloud высокая производительность блог компании 1cloud.ru 1cloud суперкомпьютер китай |
Cloud Fabric: как SDN помогает IT более гибко реагировать на изменения |
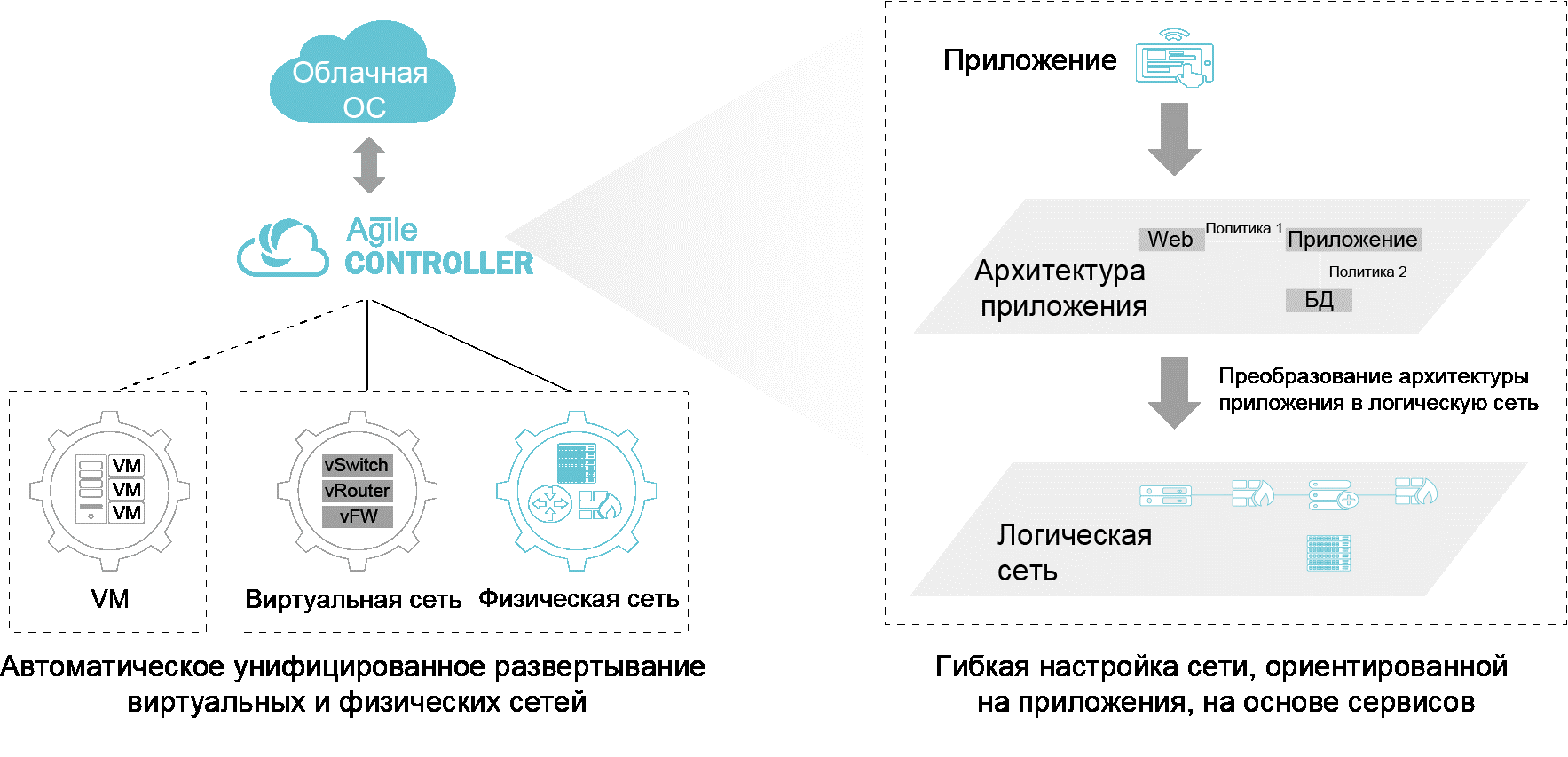
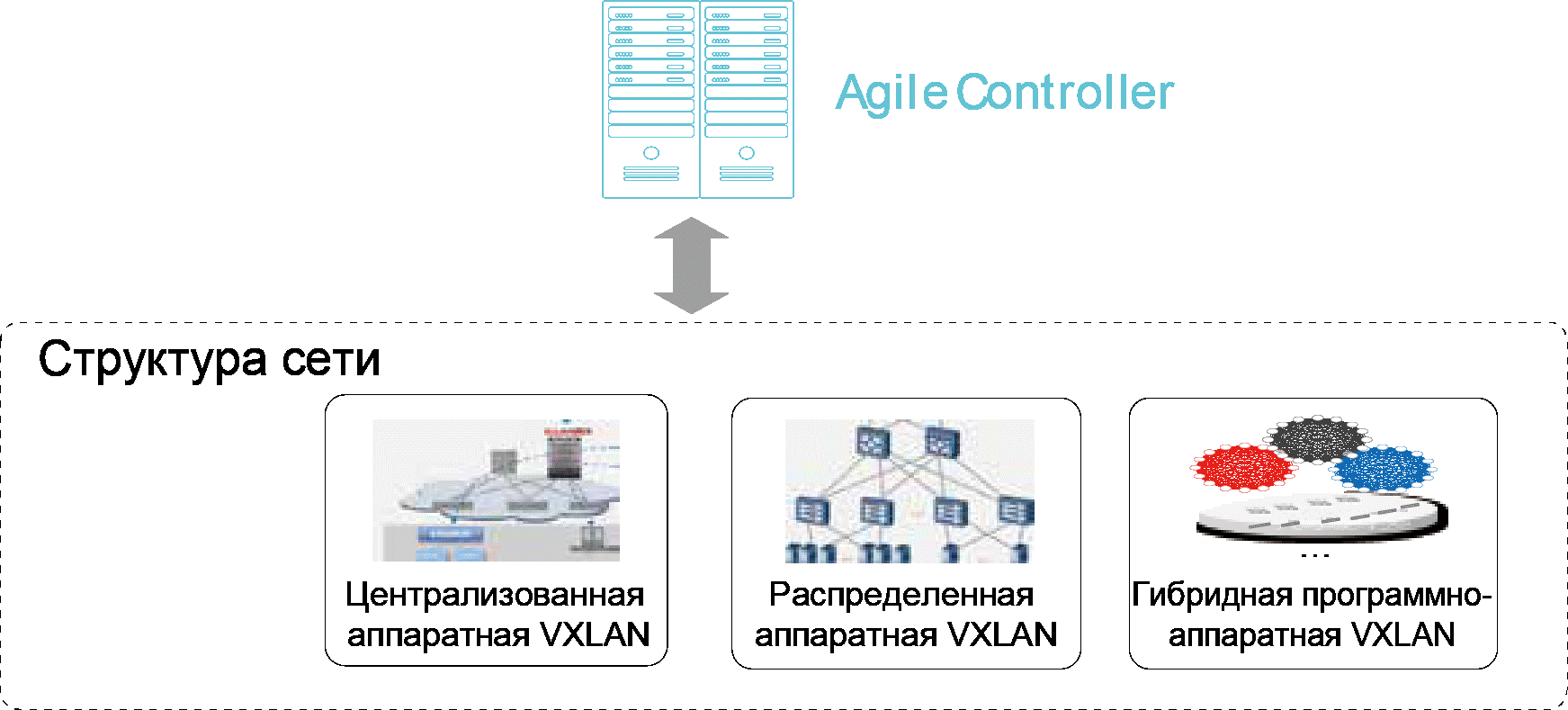
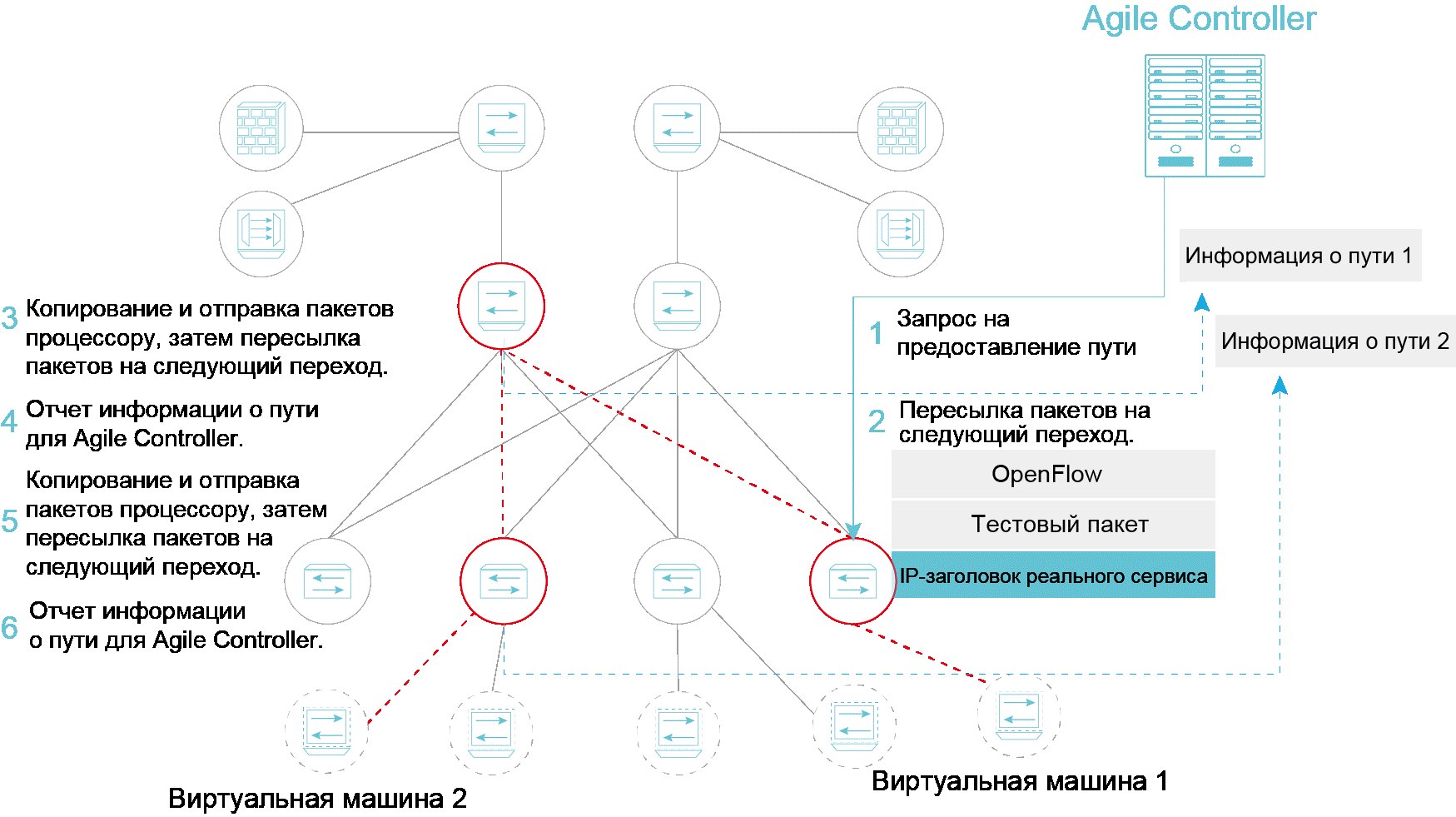
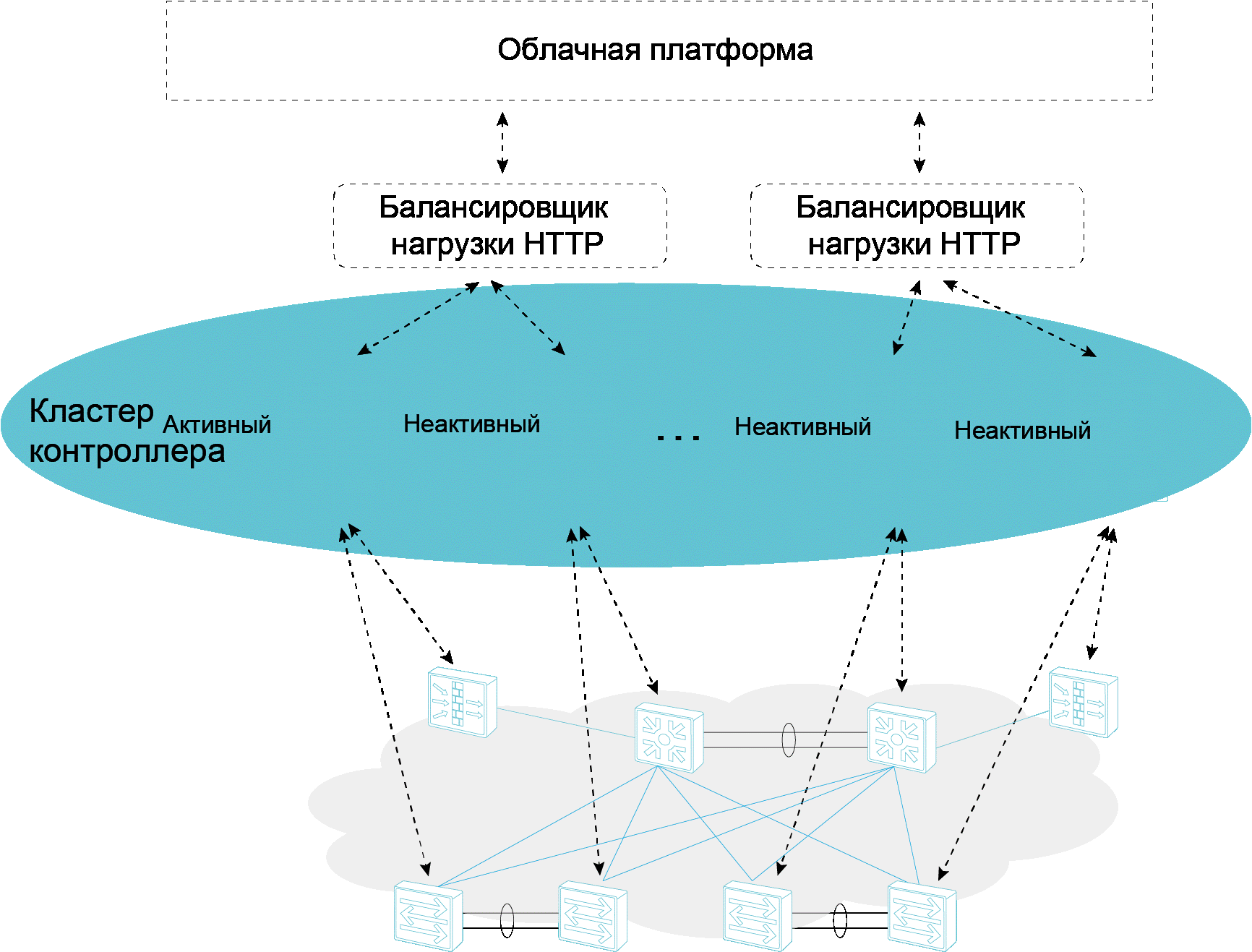
|
Метки: author Huawei_Russia хранение данных системное администрирование облачные вычисления devops блог компании huawei huawei cloud fabric sdn |
Внедрение элементов гибких методологий в Банке |
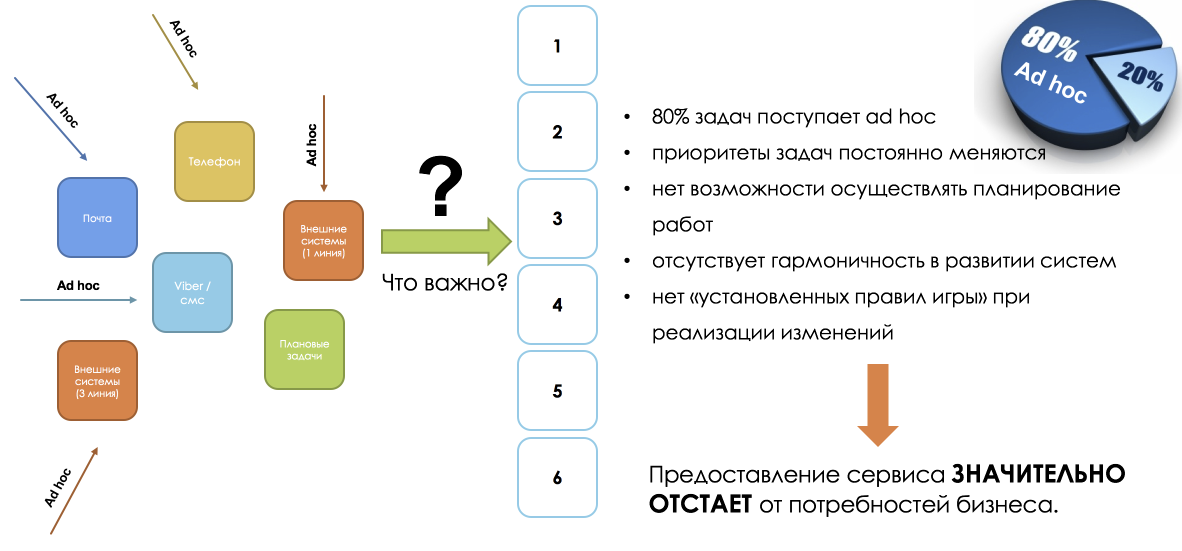





|
Метки: author Balynsky управление разработкой agile управление изменениями банки |
[Перевод] Эволюция разработчика |

Впитывать знания тех, кто много лет учился на собственных ошибках, — бесценно.

Умение найти среди всей шумихи что-то и правда полезное — важное качество хорошего разработчика. Новые технологии рождаются каждый день, и никто не заставляет их использовать.
|
|
Приглашаем на конференцию Azov Developers Meetup — 23 сентября в Таганроге |

 Как проходить интервью с заказчиком
Как проходить интервью с заказчиком Vue.js: новый фреймворк для front end
Vue.js: новый фреймворк для front end Из Тестировщика erectus в QA sapiens
Из Тестировщика erectus в QA sapiens Принцип CQRS в событийной веб архитектуре
Принцип CQRS в событийной веб архитектуре Дизайн-вопросы
Дизайн-вопросы Чистый код в коммерческой разработке. Есть ли предел совершенству?
Чистый код в коммерческой разработке. Есть ли предел совершенству?
 SQL или NoSQL?
SQL или NoSQL? Что? Где? Когда? как модель командной работы
Что? Где? Когда? как модель командной работы|
Метки: author akholyavkin конференции блог компании аркадия разработка тестирование управление проектами таганрог |
Практика формирования требований в ИТ проектах от А до Я. Часть 7. Передача требований в производство. Заключение |
Требование — всего лишь временный посредник для решения проблемы реального мира.
«Фабрики разработки программ» [8]


Дилемма изменений: с момента внесения изменений в требования и их утверждения, программный продукт, разработанный на их предыдущей версии, перестает быть актуальным, становится «недействительным» и входит в конфликт с требованиями.

|
|
Межсерверное WebRTC |
Где может понадобиться межсерверное WebRTC? На ум сразу приходит паттерн Origin-Edge, который используется для масштабирования трансляции на большую аудиторию.





session.createStream({name:'steram1',display:document.getElementById('myVideoDiv')}).publish();/rest-api/pull/startup
{
uri: wss://wcs1-origin.com:8443
remoteStreamName: stream1,
localStreamName: stream1_edge,
}/rest-api/pull/find_all/rest-api/pull/terminate



|
|
SDAccel — проверяем передачу данных |

В предыдущей статье «SDAccel – первое знакомство» я попытался описать основы применения OpenCL на ПЛИС Xilinx. Теперь настало время поделиться результатами экспериментов по передаче данных на модуле ADP-PCIe-KU3. Проверяется передача данных в обоих направлениях. Исходный код программ размещён на GitHub: https://github.com/dsmv/sdaccel
Все эксперименты выполнены на модуле ADM-PCIe_KU3 компании Alpha-Data

Центральным элементом является ПЛИС Xilinx Kintex UltraScale KU060
К ПЛИС подключены два модуля SODIMM DDR3-1600; Ширина памяти 72 бита, это даёт возможность использовать контроллер памяти с коррекцией ошибок.
Существует возможность подключения двух QSFP модулей. Каждый QSFP модуль это четыре двунаправленные линии со скоростью передачи до 10 Гбит/с. Это даёт возможность использовать 1G, 10G, 40G Ethernet, в том числе реализовать Low-Latency Network Card. Также есть интересное свойство – ввод секундной метки от GPS приёмника. Но в данной работе всё это не используется.
Сервер NIMBIX предоставляет разные вычислительные услуги, в том числе среду разработки SDAccel и что более важно – выполнение программы на выбранном аппаратном модуле.
Хочу напомнить, что из себя представляет система OpenCL.
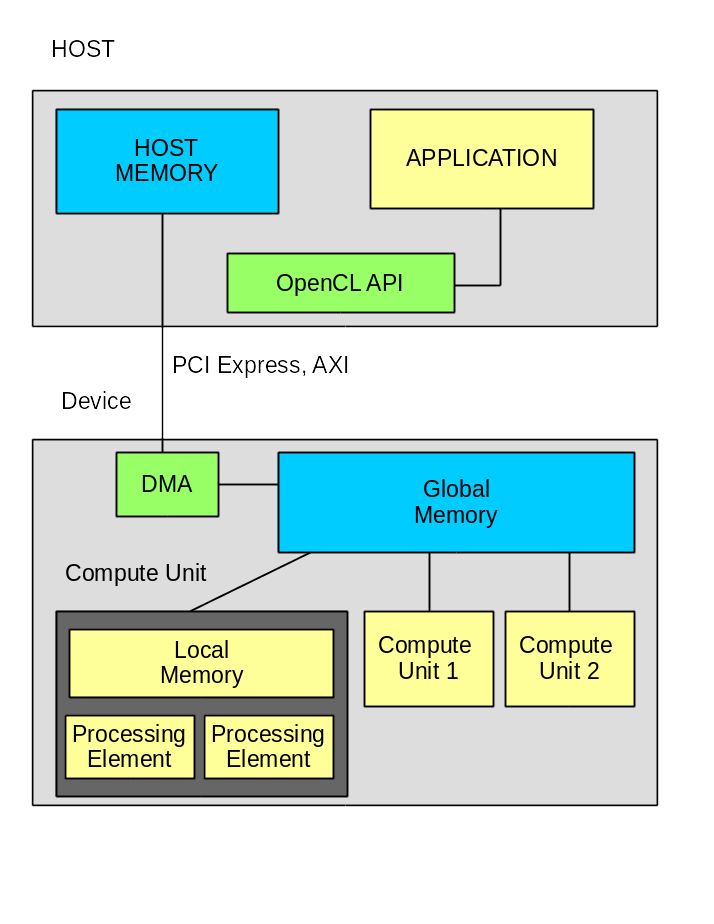
Система состоит из HOST компьютера и вычислителя, которые связаны между собой по шине. В данном случае это PCI Express v3.0 x8;
Прикладное программное обеспечение состоит из двух частей:
Обмен данными идёт только через глобальную память, в данном случае это два модуля SODIMM.
Для работы прикладного ПО требуется инфраструктура, которую должен кто-то предоставить. В данном случае — компания Xilinx. В состав инфраструктуры входят:
Пакет DSA содержит базовую прошивку, в состав которой входят контроллеры для PCI Express, динамической памяти и возможно для других узлов. В составе базовой прошивки есть элемент, который называется OpenCL Region. Вот внутри именно этого элемента и будут реализованы все функции OpenCL kernels. Загрузка прошивки внутрь OpenCL Regions производится через PCI Express с использованием технологии частичной перезагрузки (Partial Reconfiguration). Надо отметить, что Xilinx сильно продвинулся в скорости загрузки. Если в предыдущих версиях загрузка занимала несколько минут, что сейчас около 5 секунд. А в версии 2017.2 объявлено что можно вообще не проводить повторную загрузку прошивки.
На данный момент для модуля ADM-PCIe-KU3 в составе пакета SDAccel доступно два пакета:
Оба пакета имеют поддержку двух контроллеров памяти и PCI Express v3.0 x8; Обратите внимание на суффикс -xpr. Это достаточно важное различие. Вариант без xpr фиксирует положение DDR контроллеров и PCI Express. Вариант с xpr фиксирует только положение PCI Express, а контроллеры DDR участвуют в трассировке прикладных функций OpenCL. Это различие приводит и к различиям в результатах. Вариант без xpr разводится быстрее, а вариант с xpr может получить более оптимальную трассировку. Для данного проекта получилось 1 час 11 минут для варианта без xpr и 1 час 32 минуты для варианта xpr. Логи здесь.
Кстати, в состав каждого DSA пакета входит свой драйвер.
Программа предназначена для проверки непрерывной передачи данных в трёх режимах:
На мой взгляд проверка скорости работы без проверки данных особого смысла не имеет. Поэтому я с помощью OpenCL реализовал на ПЛИС узел генератора тестовой последовательности и узел проверки тестовой последовательности.
Стандарт OpenCL предусматривает обмен между устройством и компьютером только через глобальную память устройства. Обычно это динамическая память на SODIMM. И здесь возникает очень интересный вопрос о возможности передачи данных с предельными скоростями. На модуле ADM-PCIe-KU3 применены два SODIM DDR3-1600. Скорость обмена для одного SODIMM около 10 Гбайт/с. Скорость обмена по шине PCI Express v3.0 x8 – около 5 Гбайт/с (пока получилось намного меньше). Т.е. существует возможность записывать в память один блок поступающий от PCI Express и одновременно считывать второй блок для обработки внутри ПЛИС. А что делать если надо ещё возвращать результат? PCI Express обеспечивает двунаправленный поток на высокой скорости. Но у памяти шина одна, и скорость будет делиться между чтением и записью. Вот здесь и нужен второй SODIMM. У нас существует возможность указать в каком именно модуле будет размещён буфер для обработки.
SDAccel может работать только под некоторыми системами Linux. В списке доступных систем CentOS 6.8, CentOS 7.3, Ubuntu 16.04, RedHat 6.8, RedHat 7.3; Первые эксперименты я начинал на CentOs 6.7; Далее попробовал использовать Ubuntu 16.04, но там не всё заработало. На данный момент я использую CentOS 7.3 и очень доволен этой системой. Однако при настройке SDAccel есть ряд тонкостей. Главная проблема – по умолчанию сетевой интерфейс имеет имя “enp6s0”. Такое имя не понимает сервер лицензий Xilinx. Ему требуется обычный “eth0”.
Настройка здесь: https://github.com/dsmv/sdaccel/wiki/note_04---Install-CentOS-7-and-SDAccel-2017.1
Qt 5.9.1 устанавливается но не работает. Для него требуется более новый компилятор gcc и git. Это тоже решается, подробности здесь: https://github.com/dsmv/sdaccel/wiki/note_05---Install-Qt-5.9.1-and-Git-2.9.3
Для разработки я использую две системы:
Репозитарий dsmv/sdaccel предназначен для разработки примеров для SDAccel. В данный момент там есть только одна программа check_transfer. Для проекта используются ряд возможностей GitHub:
В данном проекте исходные тексты для Qt и SDAссel одни и те же, хотя и находятся в разных каталогах. Однако предполагается, что на Qt будут разрабатываться намного более сложные программы.

(Нажмите на картинку для увеличения)
На рисунке показан внешний вид терминала во время работы программы. Обратите внимание на таблицу. Это таблица с выводом текущего состояния теста. Во время работы очень интересно узнать, а что собственно происходит. Тем более что предусмотрен режим без ограничения по времени. Таблица очень помогает. К сожалению, есть проблемы. SDAccel сделан на основе Eclipse. Мне не удалось научиться запускать программу из среды во внешнем терминале. А во встроенном терминале таблица не работает. Пришлось сделать режим запуска без таблицы. Кстати система Nsight Eclipse Edition для программирования устройств NVIDIA тоже не умеет запускать программы во внешнем терминале. Или может я что-то не знаю?
Я отношусь к тем людям, которые точно знают что 1 килобайт это 1024 байта (а также предполагают что в 1 километре 1024 метра). Но это уже незаконно. Что бы избежать путаницы программа может измерять в обоих режимах и текущий режим отображается в логе.
Давайте рассмотрим некоторые фрагменты кода программы.
Код ядра gen_cnt() очень простой. Функция заполняет массив заданного размера тестовым блоком данных.
__kernel
__attribute__ ((reqd_work_group_size(1,1,1)))
void gen_cnt(
__global ulong8 *pOut,
__global ulong8 *pStatus,
const uint size
)
{
uint blockWr;
ulong8 temp1;
ulong8 checkStatus;
ulong8 addConst;
checkStatus = pStatus[0];
temp1 = pStatus[1];
addConst = pStatus[2];
blockWr = checkStatus.s0 >> 32;
__attribute__((xcl_pipeline_loop))
for ( int ii=0; iicode>Переменная temp1 имеет тип ulong8. Это стандартный тип OpenCL который представляет собой вектор из восьми 64-х разрядных чисел. Обращаться к элементам вектора можно по именам s0..s7 или так temp1.s[ii]. Это достаточно удобно. Ширина вектора 512 бит. Это соответствует ширине внутренней шины для контроллера SODIMM. Одним из элементов оптимизации как раз и заключается в обмене с памятью только 512 битными данными. По указателю pStatus находится блок со статусной информацией, из него считывается текущее значение и константы. Для каждого 64-х битного поля используется своя константа. Это позволяет сделать не только простой счётчик но и что то более сложное. Хотя пока что программа делает только простой счётчик. В конце функции производится запись текущего значения данных и число заполненных блоков.
Для реализации проверки я написал две функции, одна check_read_input — читает данные из динамической памяти и записывает их в pipe. Вторая – check_cnt_m2a – читает данные из pipe и проверяет их. Наверное в данном случае разделение на два kernel и их связь через pipe является избыточным. Но мне было интересно проверить эту технологию.
Код здесь
Программа основана применении виртуальных классов TF_Test и TF_TestThread; На основе этих классов разработаны два класса тестирования
Базовый класс TF_Test содержит функции:
| Название | Назначение |
|---|---|
| Prepare() | Подготовка |
| Start() | Запуск |
| Stop() | Останов |
| StepTable() | Шаг отображения таблицы |
| isComplete() | Работа теста завершена |
| GetResult() | Вывод результата |
Функция main() создаёт по одному экземпляру каждого класса и начинает выполнение.
Каждый класс тестирования создаёт свой поток выполнения, в котором происходит обмен с модулем. Функция main вызывает Prepare() для каждого класса. Внутри этой функции как раз и создаётся поток, выделяется память и проводится вся подготовка. После того как оба класса готовы вызывается старт, что приводит к запуску главного цикла тестирования. При нажатии Ctrl-C или при окончании заданного времени тестирования вызывается Stop(). Классы останавливают работу и с помощью функции isComplete() информируют об этом main(). После остановки вызывается GetResult() для получения результата. В процессе выполнения теста функция main() вызывает StepTable каждые 100 мс для обновления таблицы. Это позволяет обновлять статусную информацию без вмешательства в обмен данными.
Такой подход оказался очень удобным для построения тестовых программ. Здесь все тесты строятся по одинаковому шаблону. В результате их можно запускать параллельно, а можно и поодиночке. В данной программе легко организуется режим как одиночного запуска одного из тестов, так и одновременный запуск.
Система SDAccel предоставляет три режима выполнения программы:
Более подробно — в предыдущей статье.
Интересно сравнить скорости работы в трёх средах. Сравнение очень показательное:
| Emulation-CPU | Emulation-HW | System |
|---|---|---|
| 200 МБ/с | 0.1 МБ/с | 2000 МБ/с |
Числа я округлил что бы лучше видеть порядок. Собственно разница в скорости между Emulation-CPU и Emulation-HW показывает что в разработке прошивок ПЛИС надо переходить на C/C++ или что-то аналогичное. Выигрыш на четыре порядка это очень много, это перекрывает все недостатки С++. При этом надо отметить, что разработка на VHDL/Verilog не исчезнет, и эти языки скорее всего придётся применять для достижения предельных характеристик. Очень перспективным выглядит возможность создания OpenCL kernel на VHDL/Verilog, это позволит сочетать высокую скорость разработки и предельные характеристики ПЛИС. Но это уже тема отдельного исследования и отдельной статьи.
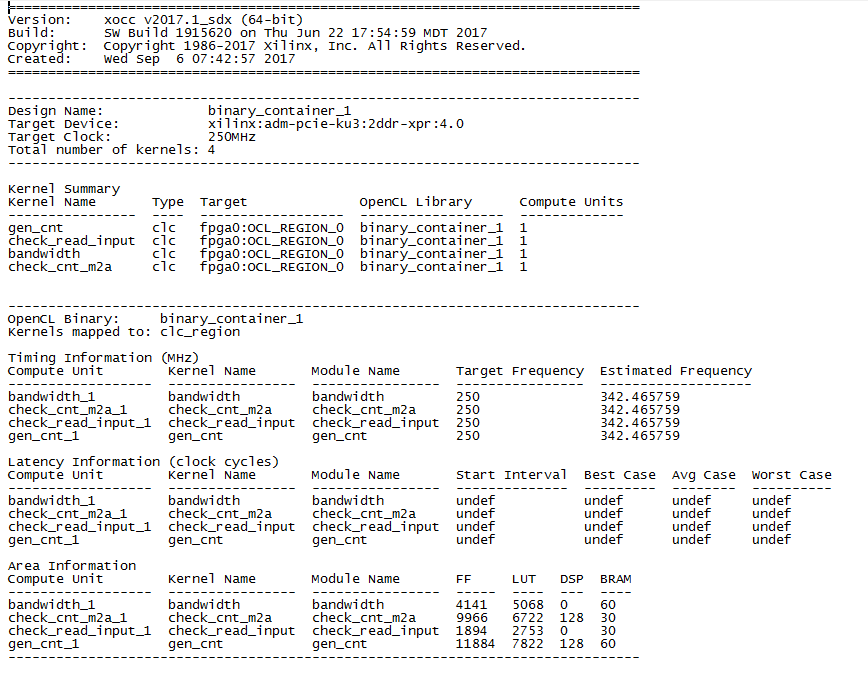
Вот что получилось. Обратите внимание на количество DSP для gen_cnt. Для реализации восьми 64-х разрядных счётчиков потребовалось 128 DSP блоков. Это по 16 блоков на счётчик. Скорее всего это результат работы оптимизатора по раскрытию цикла.
Для достижения предельных результатов должны применяться разные методы оптимизации. GPU имеет фиксированную структуру. Если условно говоря один процессорный элемент GPU может выполнять одну операцию, то что бы параллельно выполнить 100 операций надо задействовать 100 процессорных элементов. А вот в ПЛИС это не является единственным вариантом. Да, мы можем написать один kernel и разместить несколько экземпляров в ПЛИС. Но это приводит к большим накладным расходам. Xilinx рекомендует использовать не более 16 kernel, а точнее портов памяти. Зато внутри одного элемента нет ограничений на распараллеливание. Собственно пример gen_cnt это и показывает. Там сразу в коде записаны восемь 64-х разрядных сумматоров. Кроме того сработал оптимизатор и развернул цикл. Для GPU этот пример надо написать по другому, например сделать один kernel для получения 64-х разрядного отсчёта и запустить сразу восемь экземпляров.
Этот режим может показать что происходит на шинах доступа к памяти. На картинке показан процесс чтения данных из памяти функцией check_read_input().

(Нажмите что бы увеличить)
Во первых здесь видно с какой большой задержкой приходят данные. Задержка от первого запроса до появления первых данных 512 нс. Во вторых видно что чтение идёт блоками по 16 слов (размером 512 бит). При разработке на VHDL я бы использовал больший размер блока. Но видимо контроллер умеет объединять блоки и это не приводит к замедлению. В третьих видно что есть разрывы в получении данных. Они тоже объяснимы. Частота работы OpenCL 250 МГц, частота шины памяти для SODIMM DDR3-1600 составляет 200 МГц. Разрывы точно соответствуют переходу от шины 200 МГц к шине 250 МГц.
Результаты интересные, но я ожидал достичь более высоких скоростей.
| Компьютер | Ввод [MiB/s] | Вывод [MiB/s] |
|---|---|---|
| Intel Core-i5, PCIe v2.0 x8 | 2048 | 1837 |
| Intel Core-i7, PCIe v3.0 x8 | 2889 | 2953 |
| Компьютер | Ввод [MiB/s] | Вывод [MiB/s] |
|---|---|---|
| Intel Core-i5, PCIe v2.0 x8 | 1609 | 1307 |
| Intel Core-i7, PCIe v3.0 x8 | 2048 | 2057 |
Для сравнения, на нашем модуле с аналогичной ПЛИС рекордная скорость ввода составила 5500 MiB/s, хотя по ряду причин пришлось её снизить до 5000. Так что возможности для увеличения скорости обмена есть.
Работа будет продолжаться.
P.S. Хочу выразить благодарность Владимиру Каракозову за помощь в разработке шаблона программы тестирования.
|
Метки: author dsmv2014 параллельное программирование высокая производительность gpgpu fpga opencl xilinx sdaccel |






