Руководство по взаимопониманию между заказчиком и подрядчиком |

Складывается ощущение, что о клиентоориентированности и стремлении к модели «Win-Win» не заявляет только ленивый. Но притом «негласная война» продолжается: исполнители хают «наглых» клиентов, осуждая их в своих уютных бложиках, а заказчики собираются в пятницу вечером в баре, чтобы выдавить слезу разочарования и пожаловаться друзьям на «непрофессионализм» очередных горе-разработчиков / -маркетологов. Каждый тянет одеяло на себя, пытаясь сделать «Win-Lose» в свою пользу. А в итоге получается «Lose-Lose». Хотя очевидно, что 95% рынка с каждой стороны вполне адекватны, у всех есть сильные стороны, достойные уважения.
Как перестать вести эту бессмысленную «борьбу»? Разберем конкретные тезисы без воды и нудной философии.
P. S.: это не категоричные установки, претендующие на истину в последней инстанции, а скорее обращение к рынку. Буду искренне рад, если оно поможет хотя бы нескольким «дуэтам» (это и есть правильная форма сотрудничества). А если еще и случится такое, что однажды кто-то скинет кому-то ссылку на эту статью для избежания конфликта, то буду безгранично счастлив.
Несмотря на громкие заявления об «индивидуальном подходе», скорее всего вы сейчас работаете в режиме «взаимоотнимания» (да, это выдуманный термин, даже не пытайтесь искать).
Даже старик Google знает, что нужно не отнимать, а понимать.
Пример:
Клиент: «Попрошу-ка я у них скидку».
Подрядчик: «Попробуем раздуть смету».
Классическая ситуация, демонстрирующая попытки взаимопрогиба по цене. Даже если потенциальный заказчик не уйдет, этот прогиб даст знать о себе через месяц-другой работы. Истинные намерения так или иначе проявляются.
Почему так происходит?
Это как принцип маятника: качаешь его в одну сторону — сразу приходит ответка. Так и перекидывается ответственность. Люди создают никому не нужные границы, стараясь отстаивать свой «лагерь» (разумеется, никто не отменял жестокой реальности: рынок определяет условия, невозможно постоянно «уступать», во всем нужна умеренность).
Если в вашей картине мира не было бизнесов / команд, которые думали о другой стороне, — это печально. Уверяю, основываясь на своем опыте: они есть. Я видел многих клиентов, которые были в восторге от опережения графика работы и предлагали «не торопиться», даже несмотря на приближение дедлайна. Видел и исполнителей, которые отговаривали клиента от услуги, за которую он уже был готов заплатить. Почему? Потому что у них другое мышление.
Типичная позиция «эгоистов»:
Очевидно ведь, что нужно как минимум одной ногой быть всегда в «лагере» / «шкуре» другой стороны. Не буду объяснять банальные вещи, идем дальше.
Относительно недавно озвучивал данный принцип — то есть он уже не нов, я не открываю Америку в рамках данного материала. Если вы не знаете, как мыслят ваши «оппоненты», и о чем у них болят головы, эта игра всегда будет заканчиваться «Lose-Lose».
Проверьте себя.
Цитаты:
Подрядчик 4 года не интересовался состоянием дел на стороне клиента. 4 года без обратной связи, не задумываясь о том, какая может быть зона риска и последствия. Ваши аккаунты тоже выходят на связь только ближе к дате выставления счета?
Клиент хочет прозрачности: если какая-то задача не выполняется в срок (пусть даже с учетом вашей производственной загруженности), он имеет право на уведомление и объяснение. Когда вы «извиняетесь» на площадке-отзовике в комментариях под негативом — это неплохо, но уже слишком поздно. Не забывайте, что кто-то кому-то уже мог надавать по шапке, запретив в бухгалтерии оплачивать следующий счет.
Ребята может и не обидятся, но осадочек с двух сторон остался. Не выяснили / не зафиксировали «мечты» или пообещали «золотые горы». Классика.
На лицо внутренние организационные проблемы, в которых и признаться побоялись, и «замаскировать» не смогли. Но беда не только в этом. Тут очевидно и одностороннее мышление: ребята закопались в свои процессы. Возможно, на выходе получился [бы] крутой продукт. Но сезонность, Карл, сезонность! Клиент ждал этого раньше.
Видите, некоторые не ругаются. Исполнитель может быть даже не в курсе негатива.
Ради справедливости приведем пример и другой точки зрения:
Дорогие клиенты! Призываю не пользоваться добрым отношением подрядчиков. Вам ведь было бы как минимум «неприятно» (а как максимум — невыгодно), если бы ваших сотрудников загоняли до смерти неоплачиваемыми просьбами? Поймите их: digital-бизнес строится на продаже времени сотрудников. Их «воровство» не преследуется по закону, но это из серии «Win-Lose» — «моя хата с краю». Не обижайтесь, если потом «маятник» ударит в вашу сторону.
А еще есть и другие стороны — партнеры, подрядчики, сотрудники:
Без комментариев. Это либо очень разъяренный сотрудник, либо история намного масштабнее психологических установок, и вряд ли здесь есть один виновник.
И еще много-много других историй (часть из которых могут быть вымышленными / с высоким содержанием субъективности, но все равно заставляющими задуматься), полных ужасов в стиле «меня интересовать не должно», «работай, пока жив», «верните мне мои кровные» и пр.
Это будет самый короткий абзац: создавайте общую понятийную базу, не скупясь на детали.
Есть лексика — это всего лишь набор букв. А есть смысл — он может быть гораздо шире и сложнее букв. И его не всегда выносят «на блюдечке». Учитесь читать между строк. Иногда оппоненты неосознанно подталкивают нас к очень важным выводам:
Но всегда учитывайте, что кто-то извлекает из слов неправильные смыслы. Либо правильные, но такие, которые вы не хотели бы «палить».
Как этого избежать? Думайте, перед тем как что-то озвучивать, на 3 шага вперед.
Разберем на примере конкретного диалога:
Явно нужно обращаться к ЛОР’у — проблемы со слухом, стороны не слышат друг друга.
Оценивая, мы часто неправильно расставляем приоритеты.
У исполнителя может быть отвратительный собственный сайт, мало отзывов, задержки с ответами. Но притом они делают очень крутой продукт (соответственно: большой спрос -> постоянная перегруженность -> нет времени на свой маркетинг).
Будучи на месте клиента, я бы обратил внимание на следующее:
Ну и лично пообщаться с теми, кто уже работал с данным кандидатом, никогда не помешает. И это не заменит обычный мониторинг отзывов.
А исполнителям нужно учиться смотреть «глубже». Не каждый, кто приходит, скажем, за продвижением в органическом поиске, хочет просто ежемесячно покупать отчеты с красивыми цифрами. Кому-то нужно просто «сделать конкурентов» по определенным показателям. А кому-то — провести эксперимент для сравнения с другими источниками трафика (да-да, у низкого LTV могут расти ноги отсюда).
Учитесь отличать их от ошибок. Даже при автоматизированном измерении показателей на фабричном производстве иногда допускаются отклонения в ± 2%. Что уж говорить о человеческом факторе у нас. Просрочка на 5 минут, лишний пиксель, недостаток 0,5 часов в отчете — при больших масштабах работ подобные цифры практически не имеют значения. Если обе стороны будут заострять внимание на мелочах, то потеряют в действительно важных факторах.
Сразу объясню на примере. Статьи и книги учат исполнителей откладывать озвучивание цены на максимально поздний этап. Это преподносится как универсальное правило, хотя по факту оно полезно далеко не всегда. И подрядчик ведет диалог с клиентом следующим образом:
— «А сколько у вас стоит эта услуга?»
— «Ну это зависит от ваших требований»
— «Нам как всем, хотя бы примерную стоимость назовите»
— «Вы хотите на шаблоне или индивидуальный дизайн?»
— [ Мысленно про себя: «Откуда мне знать, я же не профессионал. Сколько меня еще будут здесь мучить?» ] «Не знаю, пусть будет индивидуальный»
— «А с корзиной + онлайн-оплатой будем делать или просто каталог + форма для обратной связи?»
— «Уф, все понятно. Мы вам перезвоним»
Нет повести печальнее на свете, чем повесть о расстроенном клиенте.
Исполнитель, обращаюсь к тебе: ты бы сам выдержал эту пытку, будь на его месте? В договорах ведь пишите «сторона Заказчика» с большой буквы (а кто-то даже игнорирует правила русского языка, когда, общаясь в электронном виде, пишет «Вы»), тогда к чему это неуважение? Разумеется, продукт сложный, это B2B, здесь неприменимо сравнение с выставлением напоказ ценников в ритейле. Но от судьбы не уйдешь: если боишься «испугать ценой», то сделаешь это после презентации решения.
Поэтому call-to-action следующий: не слушайте шаблонные советы (даже вышеозвученные мной :) ). В продажах, управлении проектами и пр. на общие вопросы аля «Как?» можно ответить, только перечислив 100 500 подпунктов «Если / В случае…». В этом-то и прелесть нашей сферы — здесь всегда много альтернативных подходов.
|
Метки: author zarutskiy_k управление проектами управление продажами управление персоналом веб-студии digital- агентства |
[Из песочницы] Как понять, что ваша предсказательная модель бесполезна |
При создании продуктов на основе машинного обучения возникают ситуации, которых хотелось бы избежать. В этом тексте я разбираю восемь проблем, с которыми сталкивался в своей работе.
Мой опыт связан с моделями кредитного скоринга и предсказательными системами для промышленных компаний. Текст поможет разработчиками и дата-сайнтистам строить полезные модели, а менеджерам не допускать грубых ошибок в проекте.
Этот текст не призван прорекламировать какую-нибудь компанию. Он основан на практике анализа данных в компании ООО "Ромашка", которая никогда не существовала и не будет существовать. Под "мы" я подразумеваю команду из себя и моих воображаемых друзей. Все сервисы, которые мы создавали, делались для конкретного клиента и не могут быть проданы или переданы иным лицам.
Пусть предсказательная модель — это алгоритм, который строит прогнозы и позволяет автоматически принимать полезное для бизнеса решение на основе исторических данных.
Я не рассматриваю:
Я буду говорить об алгоритмах обучения с учителем, т.е. таких, которые "увидели" много примеров пар (X,Y), и теперь могут для любого X сделать оценку Y. X — это информация, известная на момент прогноза (например, заполненная клиентом заявка на кредит). Y — это заранее неизвестная информация, необходимая для принятия решения (например, будет ли клиент своевременно платить по кредиту). Само решение может приниматься каким-то простым алгоритмом вне модели (например, одобрять кредит, если предсказанная вероятность неплатежа не выше 15%).
Аналитик, создающий модель, как правило, опирается на метрики качества прогноза, например, среднюю ошибку (MAE) или долю верных ответов (accuracy). Такие метрики позволяют быстро понять, какая из двух моделей предсказывает точнее (и нужно ли, скажем, заменять логистическую регрессию на нейросеть). Но на главный вопрос, а насколько модель полезна, они дают ответ далеко не всегда. Например, модель для кредитного скоринга очень легко может достигнуть точности 98% на данных, в которых 98% клиентов "хорошие", называя "хорошими" всех подряд.
С точки зрения предпринимателя или менеджера очевидно, какая модель полезная: которая приносит деньги. Если за счёт внедрения новой скоринговой модели за следующий год удастся отказать 3000 клиентам, которые бы принесли суммарный убыток 50 миллионов рублей, и одобрить 5000 новых клиентов, которые принесут суммарную прибыль 10 миллионов рублей, то модель явно хороша. На этапе разработки модели, конечно, вряд ли вы точно знаете эти суммы (да и потом — далеко не факт). Но чем скорее, точнее и честнее вы оцените экономическую пользу от проекта, тем лучше.
Достаточно часто построение вроде бы хорошей предсказательной модели не приводит к ожидаемому успеху: она не внедряется, или внедряется с большой задержкой, или начинает нормально работать только после десятков релизов, или перестаёт нормально работать через несколько месяцев после внедрения, или не работает вообще никак… При этом вроде бы все потрудились на славу: аналитик выжал из данных максимальную предсказательную силу, разработчик создал среду, в которой модель работает молниеносно и никогда не падает, а менеджер приложил все усилия, чтобы первые двое смогли завершить работу вовремя. Так почему же они попали в неприятность?
Мы как-то строили модель, предсказывающую крепость пива после дображивания (на самом деле, это было не пиво и вообще не алкоголь, но суть похожа). Задача ставилась так: понять, как параметры, задаваемые в начале брожения, влияют на крепость финального пива, и научиться лучше управлять ей. Задача казалась весёлой и перспективной, и мы потратили не одну сотню человеко-часов на неё, прежде чем выяснили, что на самом-то деле финальная крепость не так уж и важна заказчику. Например, когда пиво получается 7.6% вместо требуемых 8%, он просто смешивает его с более крепким, чтобы добиться нужного градуса. То есть, даже если бы мы построили идеальную модель, это принесло бы прибыли примерно нисколько.
Эта ситуация звучит довольно глупо, но на самом деле случается сплошь и рядом. Руководители инициируют machine learning проекты, "потому что интересно", или просто чтобы быть в тренде. Осознание, что это не очень-то и нужно, может прийти далеко не сразу, а потом долго отвергаться. Мало кому приятно признаваться, что время было потрачено впустую. К счастью, есть относительно простой способ избегать таких провалов: перед началом любого проекта оценивать эффект от идеальной предсказательной модели. Если бы вам предложили оракула, который в точности знает будущее наперёд, сколько бы были бы готовы за него заплатить? Если потери от брака и так составляют небольшую сумму, то, возможно, строить сложную систему для минимизации доли брака нет необходимости.
Как-то раз команде по кредитному скорингу предложили новый источник данных: чеки крупной сети продуктовых магазинов. Это выглядело очень заманчиво: "скажи мне, что ты покупаешь, и я скажу, кто ты". Но вскоре оказалось, что идентифицировать личность покупателя было возможно, только если он использовал карту лояльности. Доля таких покупателей оказалась невелика, а в пересечении с клиентами банка они составляли меньше 5% от входящих заявок на кредиты. Более того, это были лучшие 5%: почти все заявки одобрялись, и доля "дефолтных" среди них была близка к нулю. Даже если бы мы смогли отказывать все "плохие" заявки среди них, это сократило бы кредитные потери на совсем небольшую сумму. Она бы вряд ли окупила затраты на построение модели, её внедрение, и интеграцию с базой данных магазинов в реальном времени. Поэтому с чеками поигрались недельку, и передали их в отдел вторичных продаж: там от таких данных будет больше пользы.
Зато пивную модель мы всё-таки достроили и внедрили. Оказалось, что она не даёт экономии на сокращении брака, но зато позволяет снизить трудозатраты за счёт автоматизации части процесса. Но поняли мы это только после долгих дискуссий с заказчиком. И, если честно, нам просто повезло.
Даже если идеальная модель способна принести большую пользу, не факт, что вам удастся к ней приблизиться. В X может просто не быть информации, релевантной для предсказания Y. Конечно, вы редко можете быть до конца уверены, что вытащили из X все полезные признаки. Наибольшее улучшение прогноза обычно приносит feature engineering, который может длиться месяцами. Но можно работать итеративно: брейншторм — создание признаков — обучение прототипа модели — тестирование прототипа.
В самом начале проекта можно собраться большой компанией и провести мозговой штурм, придумывая разнообразные признаков. По моему опыту, самый сильный признак часто давал половину той точности, которая в итоге получалась у полной модели. Для скоринга это оказалась текущая кредитная нагрузка клиента, для пива — крепость предыдущей партии того же сорта. Если после пары циклов найти хорошие признаки не удалось, и качество модели близко к нулю, возможно, проект лучше свернуть, либо срочно отправиться искать дополнительные данные.
Важно, что тестировать нужно не только точность прогноза, но и качество решений, принимаемых на его основе. Не всегда возможно измерить пользу от модели "оффлайн" (в тестовой среде). Но вы можете придумывать метрики, которые хоть как-то приближают вас к оценке денежного эффекта. Например, если менеджеру по кредитным рискам нужно одобрение не менее 50% заявок (иначе сорвётся план продаж), то вы можете оценивать долю "плохих" клиентов среди 50% лучших с точки зрения модели. Она будет примерно пропорциональна тем убыткам, которые несёт банк из-за невозврата кредитов. Такую метрику можно посчитать сразу же после создания первого прототипа модели. Если грубая оценка выгоды от его внедрения не покрывает даже ваши собственные трудозатраты, то стоит задуматься: а можем ли мы вообще получить хороший прогноз?
Бывает, что созданная аналитиками модель демонстрирует хорошие меры как точности прогноза, так и экономического эффекта. Но когда начинается её внедрение в продакшн, оказывается, что необходимые для прогноза данные недоступны в реальном времени. Иногда бывает, что это настоящие данные "из будущего". Например, при прогнозе крепости пива важным фактором является измерение его плотности после первого этапа брожения, но применять прогноз мы хотим в начале этого этапа. Если бы мы не обсудили с заказчиком точную природу этого признака, мы бы построили бесполезную модель.
Ещё более неприятно может быть, если на момент прогноза данные доступны, но по техническим причинам подгрузить их в модель не получается. В прошлом году мы работали над моделью, рекомендующей оптимальный канал взаимодействия с клиентом, вовремя не внёсшим очередной платёж по кредиту. Должнику может звонить живой оператор (но это не очень дёшево) или робот (дёшево, но не так эффективно, и бесит клиентов), или можно не звонить вообще и надеяться, что клиент и так заплатит сегодня-завтра. Одним из сильных факторов оказались результаты звонков за вчерашний день. Но оказалось, что их использовать нельзя: логи звонков перекладываются в базу данных раз в сутки, ночью, а план звонков на завтра формируется сегодня, когда известны данные за вчера. То есть данные о звонках доступны с лагом в два дня до применения прогноза.
На моей практике несколько раз случалось, что модели с хорошей точностью откладывались в долгий ящик или сразу выкидывались из-за недоступности данных в реальном времени. Иногда приходилось переделывать их с нуля, пытаясь заменить признаки "из будущего" какими-то другими. Чтобы такого не происходило, первый же небесполезный прототип модели стоит тестировать на потоке данных, максимально приближенном к реальному. Может показаться, что это приведёт к дополнительным затратам на разработку тестовой среды. Но, скорее всего, перед запуском модели "в бою" её придётся создавать в любом случае. Начинайте строить инфраструктуру для тестирования модели как можно раньше, и, возможно, вы вовремя узнаете много интересных деталей.
Если модель основана на данных "из будущего", с этим вряд ли что-то можно поделать. Но часто бывает так, что даже с доступными данными внедрение модели даётся нелегко. Настолько нелегко, что внедрение затягивается на неопределённый срок из-за нехватки трудовых ресурсов на это. Что же так долго делают разработчики, если модель уже создана?
Скорее всего, они переписывают весь код с нуля. Причины на это могут быть совершенно разные. Возможно, вся их система написана на java, и они не готовы пользоваться моделью на python, ибо интеграция двух разных сред доставит им даже больше головной боли, чем переписывание кода. Или требования к производительности так высоки, что весь код для продакшна может быть написан только на C++, иначе модель будет работать слишком медленно. Или предобработку признаков для обучения модели вы сделали с использованием SQL, выгружая их из базы данных, но в бою никакой базы данных нет, а данные будут приходить в виде json-запроса.
Если модель создавалась в одном языке (скорее всего, в python), а применяться будет в другом, возникает болезненная проблема её переноса. Есть готовые решения, например, формат PMML, но их применимость оставляет желать лучшего. Если это линейная модель, достаточно сохранить в текстовом файле вектор коэффициентов. В случае нейросети или решающих деревьев коэффициентов потребуется больше, и в их записи и чтении будет проще ошибиться. Ещё сложнее сериализовать полностью непараметрические модели, в частности, сложные байесовские. Но даже это может быть просто по сравнению с созданием признаков, код для которого может быть совсем уж произвольным. Даже безобидная функция log() в разных языках программирования может означать разные вещи, что уж говорить о коде для работы с картинками или текстами!
Даже если с языком программирования всё в порядке, вопросы производительности и различия в формате данных в учении и в бою остаются. Ещё один возможный источник проблем: аналитик при создании модели активно пользовался инструментарием для работы с большими таблицами данных, но в бою прогноз необходимо делать для каждого наблюдения по отдельности. Многие действия, совершаемые с матрицей n*m, с матрицей 1*m проделывать неэффективно или вообще бессмысленно. Поэтому аналитику полезно с самого начала проекта готовиться принимать данные в нужном формате и уметь работать с наблюдениями поштучно. Мораль та же, что и в предыдущем разделе: начинайте тестировать весь пайплайн как можно раньше!
Разработчикам и админам продуктивной системы полезно с начала проекта задуматься о том, в какой среде будет работать модель. В их силах сделать так, чтобы код data scientist'a мог выполняться в ней с минимумом изменений. Если вы внедряете предсказательные модели регулярно, стоит один раз создать (или поискать у внешних провайдеров) платформу, обеспечивающую управление нагрузкой, отказоустойчивость, и передачу данных. На ней любую новую модель можно запустить в виде сервиса. Если же сделать так невозможно или нерентабельно, полезно будет заранее обсудить с разработчиком модели имеющиеся ограничения. Быть может, вы избавите его и себя от долгих часов ненужной работы.
За пару недель до моего прихода в банк там запустили в бой модель кредитного риска от стороннего поставщика. На ретроспективной выборке, которую прислал поставщик, модель показала себя хорошо, выделив очень плохих клиентов среди одобренных. Поэтому, когда прогнозы начали поступать к нам в реальном времени, мы немедленно стали применять их. Через несколько дней кто-то заметил, что отказываем мы больше заявок, чем ожидалось. Потом — что распределение приходящих прогнозов непохоже на то, что было в тестовой выборке. Начали разбираться, и поняли, что прогнозы приходят с противоположным знаком. Мы получали не вероятность того, что заёмщик плохой, а вероятность того, что он хороший. Несколько дней мы отказывали в кредите не худшим, а лучшим клиентам!
Такие нарушения бизнес-логики чаще всего происходят не в самой модели, а или при подготовке признаков, или, чаще всего, при применении прогноза. Если они менее очевидны, чем ошибка в знаке, то их можно не находить очень долго. Всё это время модель будет работать хуже, чем ожидалось, без видимых причин. Стандартный способ предупредить это — делать юнит-тесты для любого кусочка стратегии принятия решений. Кроме этого, нужно тестировать всю систему принятия решений (модель + её окружение) целиком (да-да, я повторяю это уже три раздела подряд). Но это не спасёт от всех бед: проблема может быть не в коде, а в данных. Чтобы смягчить такие риски, серьёзные нововведения можно запускать не на всём потоке данных (в нашем случае, заявок на кредиты), а на небольшой, но репрезентативной его доле (например, на случайно выбранных 10% заявок). A/B тесты— это вообще полезно. А если ваши модели отвечают за действительно важные решения, такие тесты могут идти в большом количестве и подолгу.
Бывает, что модель прошла все тесты, и была внедрена без единой ошибки. Вы смотрите на первые решения, которые она приняла, и они кажутся вам осмысленными. Они не идеальны — 17 партия пива получилась слабоватой, а 14 и 23 — очень крепкими, но в целом всё неплохо. Проходит неделя-другая, вы продолжаете смотреть на результаты A/B теста, и понимаете, что слишком крепких партий чересчур много. Обсуждаете это с заказчиком, и он объясняет, что недавно заменил резервуары для кипячения сусла, и это могло повысить уровень растворения хмеля. Ваш внутренний математик возмущается "Да как же так! Вы мне дали обучающую выборку, не репрезентативную генеральной совокупности! Это обман!". Но вы берёте себя в руки, и замечаете, что в обучающей выборке (последние три года) средняя концентрация растворенного хмеля не была стабильной. Да, сейчас она выше, чем когда-либо, но резкие скачки и падения были и раньше. Но вашу модель они ничему не научили.
Другой пример: доверие сообщества финансистов к статистическим методам было сильно подорвано после кризиса 2007 года. Тогда обвалился американский ипотечный рынок, потянув за собой всю мировую экономику. Модели, которые тогда использовались для оценки кредитных рисков, не предполагали, что все заёмщики могут одновременно перестать платить, потому что в их обучающей выборке не было таких событий. Но разбирающийся в предмете человек мог бы мысленно продолжить имеющиеся тренды и предугадать такой исход.
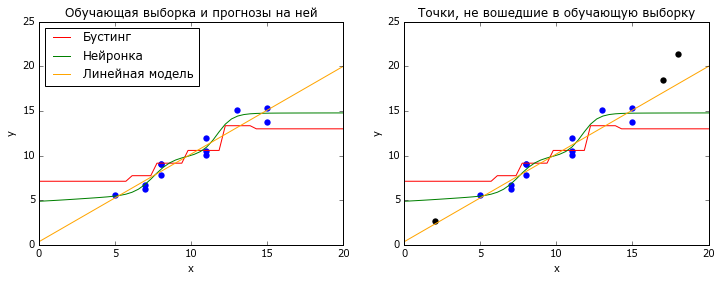
Бывает, что поток данных, к которым вы применяете модель, стационарен, т.е. не меняет своих статистических свойств со временем. Тогда самые популярные методы машинного обучения, нейросетки и градиентный бустинг над решающими деревьями, работают хорошо. Оба этих метода основаны на интерполяции обучающих данных: нейронки — логистическими кривыми, бустинг — кусочно-постоянными функциями. И те, и другие очень плохо справляются с задачей экстраполяции — предсказания для X, лежащих за пределами обучающей выборки (точнее, её выпуклой оболочки).
# coding: utf-8
# настраиваем всё, что нужно настроить
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rc
rc('font', family='Verdana')
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.linear_model import LinearRegression
# генерируем данные
np.random.seed(2)
n = 15
x_all = np.random.randint(20,size=(n,1))
y_all = x_all.ravel() + 10 * 0.1 + np.random.normal(size=n)
fltr = ((x_all<=15)&(x_all>=5))
x_train = x_all[fltr.ravel(),:]
y_train = y_all[fltr.ravel()]
x_new = x_all[~fltr.ravel(),:]
y_new = y_all[~fltr.ravel()]
x_plot = np.linspace(0, 20)
# обучаем модели
m1 = GradientBoostingRegressor(
n_estimators=10,
max_depth = 3,
random_state=42
).fit(x_train, y_train)
m2 = MLPRegressor(
hidden_layer_sizes=(10),
activation = 'logistic',
random_state = 42,
learning_rate_init = 1e-1,
solver = 'lbfgs',
alpha = 0.1
).fit(x_train, y_train)
m3 = LinearRegression().fit(x_train, y_train)
# Отрисовываем графики
plt.figure(figsize=(12,4))
title = {1:'Обучающая выборка и прогнозы на ней',
2:'Точки, не вошедшие в обучающую выборку'}
for i in [1,2]:
plt.subplot(1,2,i)
plt.scatter(x_train.ravel(), y_train, lw=0, s=40)
plt.xlim([0, 20])
plt.ylim([0, 25])
plt.plot(x_plot, m1.predict(x_plot[:,np.newaxis]), color = 'red')
plt.plot(x_plot, m2.predict(x_plot[:,np.newaxis]), color = 'green')
plt.plot(x_plot, m3.predict(x_plot[:,np.newaxis]), color = 'orange')
plt.xlabel('x')
plt.ylabel('y')
plt.title(title[i])
if i == 1:
plt.legend(['Бустинг', 'Нейронка', 'Линейная модель'],
loc = 'upper left')
if i == 2:
plt.scatter(x_new.ravel(), y_new, lw=0, s=40, color = 'black')
plt.show()Некоторые более простые модели (в том числе линейные) экстраполируют лучше. Но как понять, что они вам нужны? На помощь приходит кросс-валидация (перекрёстная проверка), но не классическая, в которой все данные перемешаны случайным образом, а что-нибудь типа TimeSeriesSplit из sklearn. В ней модель обучается на всех данных до момента t, а тестируется на данных после этого момента, и так для нескольких разных t. Хорошее качество на таких тестах даёт надежду, что модель может прогнозировать будущее, даже если оно несколько отличается от прошлого.
Иногда внедрения в модель сильных зависимостей, типа линейных, оказывается достаточно, чтобы она хорошо адаптировалась к изменениям в процессе. Если это нежелательно или этого недостаточно, можно подумать о более универсальных способах придания адаптивности. Проще всего калибровать модель на константу: вычитать из прогноза его среднюю ошибку за предыдущие n наблюдений. Если же дело не только в аддитивной константе, при обучении модели можно перевзвесить наблюдения (например, по принципу экспоненциального сглаживания). Это поможет модели сосредоточить внимание на самом недавнем прошлом.
Даже если вам кажется, что модель просто обязана быть стабильной, полезно будет завести автоматический мониторинг. Он мог бы описывать динамику предсказываемого значения, самого прогноза, основных факторов модели, и всевозможных метрик качества. Если модель действительно хороша, то она с вами надолго. Поэтому лучше один раз потрудиться над шаблоном, чем каждый месяц проверять перформанс модели вручную.
Бывает, что источником нерепрезентативности выборки являются не изменения во времени, а особенности процесса, породившего данные. У банка, где я работал, раньше существовала политика: нельзя выдавать кредиты людям, у которых платежи по текущим долгам превышают 40% дохода. С одной стороны, это разумно, ибо высокая кредитная нагрузка часто приводит к банкротству, особенно в кризисные времена. С другой стороны, и доход, и платежи по кредитам мы можем оценивать лишь приближённо. Возможно, у части наших несложившихся клиентов дела на самом деле были куда лучше. Да и в любом случае, специалист, который зарабатывает 200 тысяч в месяц, и 100 из них отдаёт в счёт ипотеки, может быть перспективным клиентом. Отказать такому в кредитной карте — потеря прибыли. Можно было бы надеяться, что модель будет хорошо ранжировать клиентов даже с очень высокой кредитной нагрузкой… Но это не точно, ведь в обучающей выборке нет ни одного такого!
Мне повезло, что за три года до моего прихода коллеги ввели простое, хотя и страшноватое правило: примерно 1% случайно отобранных заявок на кредитки одобрять в обход почти всех политик. Этот 1% приносил банку убытки, но позволял получать репрезентативные данные, на которых можно обучать и тестировать любые модели. Поэтому я смог доказать, что даже среди вроде бы очень закредитованных людей можно найти хороших клиентов. В результате мы начали выдавать кредитки людям с оценкой кредитной нагрузки от 40% до 90%, но более с жёстким порогом отсечения по предсказанной вероятности дефолта.
Если бы подобного потока чистых данных не было, то убедить менеджмент, что модель нормально ранжирует людей с нагрузкой больше 40%, было бы сложно. Наверное, я бы обучил её на выборке с нагрузкой 0-20%, и показал бы, что на тестовых данных с нагрузкой 20-40% модель способна принять адекватные решения. Но узенькая струйка нефильтрованных данных всё-таки очень полезна, и, если цена ошибки не очень высока, лучше её иметь. Подобный совет даёт и Мартин Цинкевич, ML-разработчик из Гугла, в своём руководстве по машинному обучению. Например, при фильтрации электронной почты 0.1% писем, отмеченных алгоритмом как спам, можно всё-таки показывать пользователю. Это позволит отследить и исправить ошибки алгоритма.
Как правило, решение, принимаемое на основе прогноза модели, является лишь небольшой частью какого-то бизнес-процесса, и может взаимодействовать с ним причудливым образом. Например, большая часть заявок на кредитки, одобренных автоматическим алгоритмом, должна также получить одобрение живого андеррайтера, прежде чем карта будет выдана. Когда мы начали одобрять заявки с высокой кредитной нагрузкой, андеррайтеры продолжили их отказывать. Возможно, они не сразу узнали об изменениях, или просто решили не брать на себя ответственность за непривычных клиентов. Нам пришлось передавать кредитным специалистам метки типа "не отказывать данному клиенту по причине высокой нагрузки", чтобы они начали одобрять такие заявки. Но пока мы выявили эту проблему, придумали решение и внедрили его, прошло много времени, в течение которого банк недополучал прибыль. Мораль: с другими участниками бизнес-процесса нужно договариваться заранее.
Иногда, чтобы зарезать пользу от внедрения или обновления модели, другое подразделение не нужно. Достаточно плохо договориться о границах допустимого с собственным менеджером. Возможно, он готов начать одобрять клиентов, выбранных моделью, но только если у них не более одного активного кредита, никогда не было просрочек, несколько успешно закрытых кредитов, и есть двойное подтверждение дохода. Если почти весь описанный сегмент мы и так уже одобряем, то модель мало что изменит.
Впрочем, при грамотном использовании модели человеческий фактор может быть полезен. Допустим, мы разработали модель, подсказывающую сотруднику магазина одежды, что ещё можно предложить клиенту, на основе уже имеющегося заказа. Такая модель может очень эффективно пользоваться большими данными (особенно если магазинов — целая сеть). Но частью релевантной информации, например, о внешнем виде клиентов, модель не обладает. Поэтому точность угадывания ровно-того-наряда-что-хочет-клиент остаётся невысокой. Однако можно очень просто объединить искусственный интеллект с человеческим: модель подсказывает продавцу три предмета, а он выбирает из них самое подходящее. Если правильно объяснить задачу всем продавцам, можно прийти к успеху.
Я прошёлся по некоторым из основных провалов, с которыми сталкивался при создании и встраивании в бизнес предсказательных моделей. Чаще всего это проблемы не математического, а организационного характера: модель вообще не нужна, или построена по кривой выборке, или есть сложности со встраиванием её в имеющиеся процессы и системы. Снизить риск таких провалов можно, если придерживаться простых принципов:
Высоких вам ROC-AUC и Эр-квадратов!
|
Метки: author cointegrated машинное обучение создание сервисов тестирование |
10 лет Computer Science клубу |

В этом году Computer Science клубу в Санкт-Петербурге исполняется 10 лет. С 2007 года в клубе проходят открытые лекции и курсы, где любой желающий может познакомиться с классическими результатами, современным положением дел и открытыми задачами в различных областях computer science. Вход на все лекции свободный, регистрация не требуется. Слайды и видеозаписи всех прошедших лекций доступны с сайта клуба.
Поздравить клуб с юбилеем приедут сотрудники следующих организаций: Академический университет, Математический институт Стеклова в Санкт-Петербурге, Санкт-Петербургский государственный университет, Яндекс, JetBrains, Montpellier University, Northwestern University, Toyota Technological Institute at Chicago, University of Bergen, University of California at San Diego, Yahoo Research. Они прочитают мини-курсы по следующим темам.
Теоретические:
Прикладные:
|
Метки: author avsmal математика алгоритмы kotlin c++ блог компании спбау computer science графы коды теория сложности искуственный интеллект вычислительная геометрия |
Книга «Аудит безопасности информационных систем» |
|
Метки: author ph_piter профессиональная литература информационная безопасность блог компании издательский дом «питер» книга |
Как перейти на gRPC, сохранив REST |
Многие знакомы с gRPC — открытым RPC-фреймворком от Google, который поддерживает 10 языков и активно используется внутри Google, Netflix, Kubernetes, Docker и многими другими. Если вы пишете микросервисы, gRPC предоставляет массу преимуществ перед традиционным подходом REST+JSON, но на существующих проектах часто переход не так просто осуществить из-за наличия уже использующихся REST-клиентов, которые невозможно обновить за раз. Нередко общаясь на тему gRPC можно услышать "да, мы у нас в компании тоже смотрим на gRPC, но всё никак не попробуем".
Что ж, этой проблеме есть хорошее решение под названием grpc-rest-gateway, которое занимается именно этим — автогенерацией REST-gRPC прокси с поддержкой всех основных преимуществ gRPC плюс поддержка Swagger. В этой статье я покажу на примере как это выглядит и работает, и, надеюсь, это поможет и вам перейти на gRPC, не теряя существующие REST-клиенты.
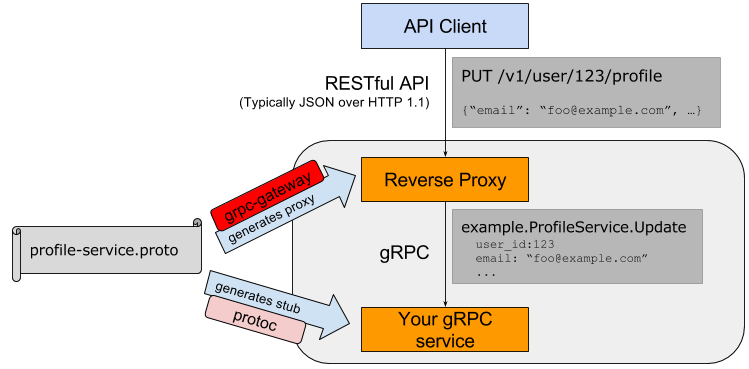
Но, для начала, давайте определимся о каких вообще ситуациях речь. Два самых частых варианта:
Для маленьких проектов это абсолютно нормальный выбор, но по мере того, как проекты и количество людей на нём растут, проблемы REST API начинают очень явно давать о себе знать и отнимать львиную долю времени разработчиков.
Безусловно, REST используется везде и повсюду в виду его простоты и даже размытого понимания, что такое REST. Вообще, REST начался как диссертация одного из создателей HTTP Роя Филдинга под названием "Архитектурные стили и дизайн сетевых программных архитектур". Собственно, REST это и есть лишь архитектурный стиль, а не какая-то чётко описанная спецификация.
Но это и является корнем некоторых весомых проблем. Нет единого соглашения, когда какой метод HTTP использовать, когда какой код возвращать, что передавать в URI, а что в теле запроса и т.д. Есть попытки прийти к общей договорённости, но они, к сожалению, не очень успешны.
Далее, при REST подходе, у вас есть чересчур много сущностей, которые несут смысл — метод HTTP (GET/POST/PUT/DELETE), URI запроса (/users, /user/1), тело запроса ({id: 1}) плюс заголовки (X-User-ID: 1). Всё это добавляет излишнюю сложность и возможность неверной интерпретации, что превращается в большую проблему по мере того, как API начинает использоваться между различными сервисами, которые пишут различные команды и синхронизация всех этих сущностей начинает занимать значительную часть времени команд.
Это приводит нас к следующей проблеме — сложности декларативного описания интерфейсов API и описания типов данных. OpenAPI Specification (известное как Swagger), RAML и API Blueprint частично решают эту проблему, но делают это ценой добавления другой сложности. Кто-то пишет YAML файлы ручками для каждого нового запроса, кто-то использует web-фрейморки с автогенерацией, раздувая код описаниями параметров и типов запроса, и поддержка swagger-спецификации в синхронизации с реальной реализацией API всё равно лежит на плечах ответственных разработчиков, что отнимает время от решения, собственно, задач, которые эти API должны решать.
Отдельная сложность заключается в API, которое развивается и меняется, и синхронизация клиентов и серверов может отнимать довольно много времени и ресурсов.
gRPC решает эти проблемы кодогенерацией и декларативным языком описания типов и RPC-методов. По-умолчанию используется Google Protobuf 3 в качестве IDL, и HTTP/2 для транспорта. Кодогенераторы есть по 10 языков — Go, Java, C++, Python, Ruby, Node.js, C#, PHP, Android.Java, Objective-C. Есть также пока неофициальные реализации для Rust, Swift и прочих.
В gRPC у вас есть только одно место, где вы определяете, как будут именоваться поля, как называться запросы, что принимать и что возвращать. Это описывается в .proto файле. Например:
syntax = "proto3";
package library;
service LibraryService {
rpc AddBook(AddBookRequest) returns (AddBookResponse)
}
message AddBookRequest {
message Author {
string name = 1;
string surname = 2;
}
string isbn = 1;
repeated Author authors = 2;
}
message AddBookResponse {
int64 id = 1;
}Из этого proto-файла, с помощью protoc-компилятора генерируются код клиентов и серверов на всех поддерживаемых языках (ну, на тех, которые вы укажете компилятору). Дальше, если вы что-то изменили в типах или методах — перезапускаете генерацию кода и получаете обновлённый код и клиента, и сервера.
Если вы когда-либо разруливали конфликты в названиях полей вроде UserID vs user_id, вам понравится работать с gRPC.
Но я не буду сильно подробно останавливаться на принципах работы с gRPC, и перейду к вопросу, что же делать, если вы хотите использовать gRPC, но у вас есть клиенты, которые всё ещё должны работать через REST API, и их не просто будет перевести/переписать на gRPC. Это особенно актуально, учитывая, что официальной поддержки gRPC в браузере пока нет (JS только Node.js официально), и реализация для Swift также пока не в списке официальных.
Проект grpc-gateway, как и почти всё в grpc-экосистеме, реализован в виде плагина для protoc-компилятора. Он позволяет добавить аннотации к rpc-определениям в protobuf-файле, который будут описывать REST-аналог этого метода. Например:
import "google/api/annotations.proto";
...
service LibraryService {
rpc AddBook(AddBookRequest) returns (AddBookResponse) {
option (google.api.http) = {
post: "/v1/book"
body: "*"
};
}
}После запуска protoc с указанным плагином, вы получите автосгенерированный код, который будет прозрачно перенаправлять POST HTTP запросы на указанный URI на реальный grpc-сервер и также прозрачно конвертировать и отправлять ответ.
Тоесть формально, это API Proxy, который запущен, как отдельный сервис и делает прозрачную конвертацию REST HTTP запросов в gRPC коммуникацию между сервисами.
Давайте, продолжим пример выше — скажем, наш сервис работы с книгами, должен уметь работать со старым iOS-фронтендом, который пока умеет работать только по REST HTTP. Другие сервисы вы уже перевели на gRPC и наслаждаетесь меньшим количеством головной боли при росте или изменениях ваших API. Добавив выше указанные аннотации, создаём новый сервис — например rest_proxy и в нём автогенерируем код обратного прокси:
protoc -I/usr/local/include -I. \
-I$GOPATH/src \
-I$GOPATH/src/github.com/grpc-ecosystem/grpc-gateway/third_party/googleapis \
--grpc-gateway_out=logtostderr=true:. \
library.protoКод самого сервиса может выглядеть вот как-нибудь так:
import (
"github.com/myuser/rest-proxy/library"
)
var main() {
gw := runtime.NewServeMux(muxOpt)
opts := []grpc.DialOption{grpc.WithInsecure()}
err := library.RegisterLibraryServiceHandlerFromEndpoint(ctx, gw, "library-service.dns.name", opts)
if err != nil {
log.Fatal(err)
}
mux := http.NewServeMux()
mux.Handle("/", gw)
log.Fatal(http.ListenAndServe(":80", mux))
}Этот код запустит наш прокси на 80-м порту, и будет направлять все запросы на gRPC сервер, доступный по library-service.dns.name. RegisterLibraryServiceHandlerFromEndpoint это автоматически сгенерированный метод, который делает всю магию.
Очевидно, что этот прокси может служить входной точкой для всех остальных ваших сервисов на gRPC, которым нужен fallback в виде REST API — просто подключаете остальные автосгенерированные пакаджи и регистрируете их на тот же gw-объект:
err = users.RegisterUsersServiceHandlerFromEndpoint(ctx, gw, "users-service.dns.name", opts)
if err != nil {
log.Fatal(err)
}и так далее.
Автосгенерированный прокси поддерживает автоматический реконнект к сервису, с экспоненциальной backoff-задержкой, как и в обычных grpc-сервисах. Аналогично, поддержка TLS есть из коробки, таймаутов и всё, что доступно в grpc-сервисах, доступно и в прокси.
Отдельно хочется написать про возможность использования т.н. middlewares — обработчиков запросов, которые автоматически должны срабатывать до или после запроса. Типичный пример — ваши HTTP запросы содержат специальный заголовок, который вы хотите передать дальше в grpc-сервисы.
Для примера, я возьму пример со стандартным JWT токеном, которые вы хотите расшифровывать и передавать значение поля UserID grpc-сервисам. Делается это также просто, как и обычные http-middlewares:
func checkJWT(h http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
bearer := r.Header.Get("Authorization")
...
// parse and extract value from token
...
ctx = context.WithValue(ctx, "UserID", claims.UserID)
h.ServeHTTP(w, r.WithContext(ctx))
})
}и заворачиваем наш mux-объект в эту middleware-функцию:
mux.Handle("/", checkJWT(gw))Теперь на стороне сервисов (все gRPC-методы в Go реализации принимают первым параметром context), вы просто достаёте это значение из контекста:
func (s *LIbrary) AddBook(ctx context.Context, req *library.AddBookRequest) (*library.AddBookResponse, error) {
userID := ctx.Value("UserID").(int64)
...
}Разумеется, ничего не ограничивает ваш rest-proxy от реализации дополнительного функционала. Это обычный http-сервер, в конце-концов. Вы можете пробросить какие-то HTTP запросы на другой legacy REST сервис:
legacyProxy := httputil.NewSingleHostReverseProxy(legacyUrl)
mux.Handle("/v0/old_endpoint", legacyProxy)
Отдельной вишенкой в подходе с grpc-gateway есть автоматическая генерация swagger.json файла. Его можно затем использовать с онлайн UI, а можно и отдавать напрямую из нашего же сервиса.
С помощью небольших манипуляций со SwaggerUI и go-bindata, можно добавить ещё один endpoint
к нашему сервису, который будет отдавать красивый и, что самое важное, актуальный и автосгенерированный UI для REST API.
Генерируем swagger.json
protoc -I/usr/local/include -I$GOPATH/src -I$GOPATH/src/github.com/grpc-ecosystem/grpc-gateway/third_party/googleapis --swagger_out=logtostderr=true:swagger-ui/ path/to/library.protoСоздаем handler-ы, которые будут отдавать статику и генерировать index.html (в примере статика добавляется прямо в код с помощью go-bindata):
mux.HandleFunc("/swagger/index.html", SwaggerHandler)
mux.Handle("/swagger/", http.StripPrefix("/swagger/", http.FileServer(assetFS())))
...
// init indexTemplate at start
func SwaggerHandler(w http.ResponseWriter, r *http.Request) {
indexTemplate.Execute(w, nil)
}и вы получаете Swagger UI, подобный этому, с актуальной информацией и возможностью тут же тестировать:

В целом мой опыт работы с grpc-gateway можно пока-что охарактеризовать одной фразой — "оно просто работает из коробки". Из проблем, с которыми приходилось сталкиваться, например могу отметить следующее.
В Go для сериализации в JSON используются так называемые "тэги структур" — мета информация для полей. В encoding/json есть такой тэг omitempty — он означает, что если значение равно нулю (нулевому значению для этого типа), то его не нужно добавлять в результирующий JSON. Плагин grpc-gateway для Go именно этот тег и добавляет к структурам, что приводит иногда к неверному поведению.
Например, у вас есть переменная типа bool в структуре, и вы отдаёте эту структуру в ответе — оба значения true и false одинаково важны в ответе, и фронтенд ожидает это поле получить. Ответ же, сгенерированный grpc-gateway будет содержать это поле, только если значение равно true, в противном случае оно просто будет пропущено (omitempty).
К счастью, это легко решается с помощью опций конфигурации:
customMarshaller := &runtime.JSONPb{
OrigName: true,
EmitDefaults: true, // disable 'omitempty'
}
muxOpt := runtime.WithMarshalerOption(runtime.MIMEWildcard, customMarshaller)
gw := runtime.NewServeMux(muxOpt)Ещё одним моментом, которым хотелось бы поделиться, можно назвать неочевидная семантика работы с самим protoc-компилятором. Команды вызова очень длинные, трудночитаемые, и, что самое важное, логика того, откуда берется protobuf и куда генерируется вывод (+какие директории создаются) — очень неочевидна. Например, вы хотите использовать proto-файл из другого проекта и сгенерировать каким-нибудь плагином код, положив его в текущий проект в папку swagger-ui/. Мне пришлось минут 15 перепробовать массу вариантов вызова protoc, прежде чем стало понятно, как заставить генератор работать именно так. Но, снова же, ничего нерешаемого.
gRPC может ускорить продуктивность и эффективность работы с микросервис архитектурой в разы, но часто помехой становится требование обратной совместимости и поддержки REST API. grpc-gateway предоставляет простой и эффективный способ решения этой проблемы, автоматически генерируя обратный прокси сервер, транслирующий REST/JSON запросы в gRPC вызовы. Проект очень активно развивается и используется в продакшене во многих компаниях.
|
Метки: author divan0 разработка систем связи программирование go api rest swagger grpc |
Платформа для сбора донатов за две недели – итоги антихакатона |

В нашем антихакатоне победила команда студентов Высшей школы экономики – с решением для приема донатов за стриминг. Но лучше всех о проекте расскажет Максим Дьяков, основатель сервиса «ЯСтрим» – передаю микрофон автору.
Под катом немного метаний между ChromeApps и Electron, впечатления от пробы Yandex SpeechKit и вообще о разработке в формате антихакатона.
Одним дождливым летним вечером мы с товарищами решили поучаствовать в антихакатоне Яндекс.Денег. И повод был подходящий, ведь уже давно хотелось создать приложение, связанное со стрим-сервисами и процессом отправки донатов. Наша команда состояла из четырех человек: дизайнера Наумова Александра, ответственного за мобильное приложение Джавида Халилова, главного по ПК-клиентам Александра Кобрина и меня, в качестве бэкенд-разработчика и идейного вдохновителя.
Получилось бодро – через две недели появился минимально жизнеспособный продукт «ЯСтрим».
Для общего понимания немного расскажу о том, как происходит отправка доната и, главное, зачем это вообще нужно.
Под стримингом в этой статье понимается именно игровой стриминг. То есть когда некто транслирует в сеть свой игровой процесс и заодно все это комментирует. У популярных стримеров есть своя аудитория зрителей, которые следят за выходом новых «эпизодов» и порой присылают комментарии, послания или деньги. Разумеется, всё на добровольной основе и без какой-либо практической цели для зрителей – сугубо just for fun.
Раз стриминг для зрителя – это просто способ весело провести время, то нет и явных причин платить кому-то даже 50 рублей (это не кино, и билетов при подключении не спрашивают). Однако индустрия онлайн-стриминга набирает обороты едва ли не быстрее блогинга, а значит, без хорошего денежного потока там не обходится. Вообще, четкого ответа как такового нет. Кидая монетку молодым музыкантам в метро, мы не получаем какую-то услугу или товар, а лишь благодарим исполнителя за творчество – так же и тут.
Что касается технической стороны организации стрима, то уже давно есть известные продукты для захвата и трансляции видео с экрана, но нет толковой системы сбора донатов. Толковой – это такой, которая:
позволяет пользователю с минимумом усилий перевести некую сумму стримеру;
поддерживает передачу сообщения (текстового или голосового) от пользователя стримеру в процессе перевода денег;
показывает стримеру сообщение и оповещения о получении денег от конкретных пользователей;
умеет читать пользовательские сообщения вслух в прямом эфире и содержит настройки по «запикиванию» мата и других не подходящих стримеру слов;
По крайней мере, нет продукта, который бы удовлетворял этим требованиям и не брал собственной комиссии. Кроме того, за перевод денег в большинстве продуктов отвечает их собственная разработка, что добавляет сомнений потребителю. А раз толкового продукта нет – значит, есть повод для стартапа.
Строить только один продукт для передачи донатов бессмысленно – это ограничит его возможности и сведет потенциал разработки практически к нулю. Поэтому решили делать комплексное решение «ЯСтрим», альфа-версию которого вы можете посмотреть на видео:
Так стример видит интерфейс ЯСтрима.
Главное преимущество нашего проекта над конкурентами в том, что ЯСтрим не требует какой-то интеграции с привычным стримеру приложением для захвата экрана и трансляции. Вместо этого оно просто накладывает необходимый интерфейс и пользовательские сообщения на экран, который и захватывается стриминговым приложением.
Так как хотелось охватить рынок побольше, а заодно изучить что-то новое на антихакатоне, решение должно было стать кроссплатформенным – с поддержкой всех стриминговых платформ и сопутствующего ПО. В качестве основы изначально выбрали Chrome Apps, который казался почти идеальным инструментом для отладки и разработки API (особенно понравилась отладка приложений в Postman, который тоже написан под Chrome). Тогда десктопных клиентов можно было бы написать на Chrome Apps сразу под множество платформ.
Вдохновившись лучшим, на мой взгляд, инструментом для разработки Web API – Postman в версии для Chrome – я решил использовать в качестве основы Google Chrome Apps. Написанные под эту платформу приложения работают в Google Chrome и в других браузерах на движке chromium, что позволило бы сделать легкое кроссплатформенное решение.
Вот несколько мотивирующих факторов:
Google Chrome и другие браузеры на движке Chromium составляют большую часть рынка, поэтому решение стало бы «всеядным»;
Что касается бэкенда, то выбор для меня однозначен – ASP.NET. После некоторого опыта конфигурирования сервера на Ubuntu стоит один раз познакомиться с приятным UI Azure, и пути назад не останется. Последний гвоздь в наши сомнения вбила бесплатная подписка Azure на месяц, что в условиях антихакатона – самое оно.

Конечно, во всем этом царстве удобства и бесплатности не обошлось без бесячих моментов.
Хочется поделиться тем фактом, что все это время я находится под впечатлением от книги «Психбольница в руках пациентов» Алана Купера. Книга посвящена теории проектирования взаимодействия, поэтому, когда дело дошло до второй составляющей – зрителей, – очень хотелось опробовать в бою приемы вроде составления персонажей.
Когда мы определились с основными компонентами продукта (приложение для десктопа, веб-форма и мобильное приложение), наш фронт-разработчик внезапно выяснил, что Google прекращает поддержку Chrome Apps на Windows, Mac и Linux. Неловкая пауза, разочарование, негодование, принятие.
В качестве альтернативы отлично подошел фреймворк Electron с открытым кодом. Конечно, насторожила новизна платформы, но растущая популярность компенсировала опасения. Что касается мобильного приложения, то скажем так: у меня в команде по мобильной части был только Android-разработчик. Архитектура для ЯСтрима выбрана клиент-серверная, с Microsoft SQL в качестве бэкенд-базы.
Думаю, нет смысла подробно разбирать архитектуру, рисовать блок-схемы и т.п. – это скучно и специфично для конкретного проекта. Лучше поделюсь советами по собственному опыту проб и ошибок:
В качестве идентификатора лучше выбирать нечто глобально-уникальное, для задела на будущее. Например, для ID онлайн-трансляций я выбрал URL, что позволило решить миллион проблем одним махом (уникальность, быстрый доступ, возможность в дальнейшем работать с API стриминговых платформ).
Детально прорабатывайте платформу вашего будущего сервиса – это сэкономит массу времени на более высоких уровнях реализации. Лучше потратить еще пару дней на платформу, чем на финальных этапах обнаружить, что все надо наполовину переписывать.
Далее наступил этап разработки WEB API нашего сервиса, где основной задачей стало обеспечение безопасности стримеров: что если кто-то изменит настройки донатов, поменяет логотип или затеет еще что-то недоброе.
Так в платформе появились следующие инструменты защиты:
При каждом переводе в поле label вносится специальная метка, а идентификатор операции (если его удается получить) попадает в данные о донате. Это было необходимо для удобной работы с API Яндекс.Денег на стороне стримера и проверки существования перевода в платежной системе.
Когда ЯСтрим получает данные о произведенном донате, пользовательский клиент запрашивает у Яндекс.Денег операцию с таким же ID либо все операции с совпадением по полю label. Донат покажется в стриме, только если транзакция будет найдена.
Все общение пользовательского клиента и стриминговой платформы происходит с использованием специального токена ЯСтрима, который выдается на этапе авторизации в платежной системе.
Результат всех этих изысканий можно было охарактеризовать как «бэкенд работает», что, на мой взгляд, отлично характеризует ранний прототип. Далее еще предстоял рефакторинг, рефакторинг и еще раз увлекательный рефакторинг.
Когда пришло время создавать рабочий билд, у нас никак не выходило подключить React – в результате приложение при запуске выдавало дикие ошибки.

Пример того, что мы ловили при попытках сборки.
Наша команда перекопала вдоль и поперек Stackoverflow и GitHub Issues, так что осталось только открывать новый топик и искать знающих людей. Так мы познакомились с разработчиком Electron и @akashnimare, который имеет подходящий опыт и был готов им поделиться. Кроме того, открыли для себя российское комьюнити Electron, куда стоит зайти любому, кто собирается использовать эту платформу.
С хранением файлов тоже вышла заминка, из которой и родился совет уделять больше внимания фундаментам приложения. Нужно было и нам не лениться, а с самого начала подключать библиотеку electron-storage или electron-storage-json, чтобы не переписывать код, когда выяснится, что local-storage из main недоступен.
Лучиком света в темном царстве незнакомых фреймворков стал Yandex SpeechKit, который не только выдавал отличный результат, но и потребовал минимум времени на изучение документации. Фактически нужная опция озвучки сообщения из пользовательского доната получилась после трех строк кода:
const tts = new ya.speechkit.Tts({
apikey: 'ffffffff-2222-4444-0000-1111111111',
emotion: 'good',
speed: 1.2
})
...
tts.speak(donate.text_data, { speaker: 'zahar' })Достаточно указать персональный ключ API, выбрать голос (zahar), скорость, эмоциональный окрас (good) – и готово.
Подводя итог, хочется сказать, что как стартап мы еще даже не на первой ступени. Но с точки зрения первоначальной цели мы добились главного: успели реализовать практически все фичи (кроме голосовых сообщений, с которыми пока есть шероховатости), что не часто удается молодым разработчикам на реальном проекте. При этом никто не переругался, все четверо в лодке и продолжают верить в успех. Поэтому achievement unlocked, но впереди еще долгий путь.
Если наш опыт показался вам интересным – с удовольствием отвечу на вопросы в комментариях.
|
|
[Из песочницы] История 13 места на Highload Cup 2017 |

11 августа компания Mail.Ru Объявила об очередном конкурсе HighloadCup для системных программистов backend-разработчиков.
Вкратце задача стояла следующим образом: докер, 4 ядра, 4Гб памяти, 10Гб HDD, набор api, и нужно ответить на запросы за наименьшее количество времени. Язык и стек технологий неограничен. В качестве тестирующей системы выступал яндекс-танк с движком phantom.
О том, как в таких условиях добраться до 13 места в финале, и будет эта статья.
Подробно с описанием задачи можно ознакомиться в публикации одного из участников на хабре, или на официальной странице конкурса. О том, как происходило тестирование, написано здесь.
Api представляло из себя 3 get-запроса на просто вернуть записи из базы, 2 get-запроса на агрегирование данных, 3 post-запроса на модификацию данных, и 3 post-запроса на добавление данных.
Сразу были оговорены следующие условия, которые существенно облегчили жизнь:
Запросы были поделены на 3 части: сначала get-запросы по исходным данным, потом серия post-запросов на добавление/изменение данных, и последняя самая мощная серия get-запросов по модифицированным данным. Вторая фаза была очень важна, т.к. неправильно добавив или поменяв данные, можно было получить много ошибок в третьей фазе, и как результат — большой штраф. На данном этапе последняя стадия содержала линейное увеличение числа запросов от 100 до 2000rps.
Еще одним условием было то, что один запрос — одно соединение, т.е. никаких keep-alive, но в какой-то момент от этого отказались, и все get-запросы шли с keep-alive, post-запросы были каждый на новое соединение.
Моей мечтой всегда были и есть Linux, C++ и системное программирование (хотя реальность ужасна), и я решил ни в чем себе не отказывать и нырнуть в это удовольствие с головой.
Т.к. о highload'e я знал чуть менее, чем ничего, и я до последнего надеялся, что писать свой web-сервер не придется, то первым шагом к решению задачи стал поиск подходящего web-сервера. Мой взгляд ухватился за proxygen. В целом, сервер должен был быть хорошим — кто еще знает о хайлоаде столько, сколько facebook?
Исходный код содержит несколько примеров, как использовать этот сервер.
HTTPServerOptions options;
options.threads = static_cast(FLAGS_threads);
options.idleTimeout = std::chrono::milliseconds(60000);
options.shutdownOn = {SIGINT, SIGTERM};
options.enableContentCompression = false;
options.handlerFactories = RequestHandlerChain()
.addThen()
.build();
HTTPServer server(std::move(options));
server.bind(IPs);
// Start HTTPServer mainloop in a separate thread
std::thread t([&] () {
server.start();
}); И на каждое принятое соединение вызывается метод фабрики
class EchoHandlerFactory : public RequestHandlerFactory {
public:
// ...
RequestHandler* onRequest(RequestHandler*, HTTPMessage*) noexcept override {
return new EchoHandler(stats_.get());
}
// ...
private:
folly::ThreadLocalPtr stats_;
}; От new EchoHandler() на каждый запрос у меня по спине вдруг пробежал холодок, но я не придал этому значения.
Сам EchoHandler должен реализовать интерфейс proxygen::RequestHandler:
class EchoHandler : public proxygen::RequestHandler {
public:
void onRequest(std::unique_ptr headers)
noexcept override;
void onBody(std::unique_ptr body) noexcept override;
void onEOM() noexcept override;
void onUpgrade(proxygen::UpgradeProtocol proto) noexcept override;
void requestComplete() noexcept override;
void onError(proxygen::ProxygenError err) noexcept override;
};Все выглядит хорошо и красиво, только успевай обрабатывать приходящие данные.
Роутинг я реализовал с помощью std::regex, благо набор апи простой и небольшой. Ответы формировал на лету с помощью std::stringstream. В данный момент я не заморачивался с производительностью, целью было получить работающий прототип.
Так как данные помещаются в память, то значит и хранить их нужно в памяти!
Структуры данных выглядели так:
struct Location {
std::string place;
std::string country;
std::string city;
uint32_t distance = 0;
std::string Serialize(uint32_t id) const {
std::stringstream data;
data <<
"{" <<
"\"id\":" << id << "," <<
"\"place\":\"" << place << "\"," <<
"\"country\":\"" << country << "\"," <<
"\"city\":\"" << city << "\"," <<
"\"distance\":" << distance <<
"}";
return std::move(data.str());
}
};Первоначальный вариант "базы данных" был такой:
template
class InMemoryStorage {
public:
typedef std::unordered_map Map;
InMemoryStorage();
bool Add(uint32_t id, T&& data, T** pointer);
T* Get(uint32_t id);
private:
std::vector> buckets_;
std::vector Идея была следущей: индексы, по условию, целое 32-битное число, а значит никто не мешает добавлять данные с произвольными индексами внутри этого диапазона (о, как же я ошибался!). Поэтому у меня было BUCKETS_COUNT (=10) хранилищ, чтобы уменьшить время ожидания на мутексе для потоков.
Т.к. были запросы на выборку данных, и нужно было быстро искать все места, в которых бывал пользователь, и все отзывы, оставленные для мест, то нужны были индексы users -> visits и locations -> visits.
Для индекса был написан следующий код, с той же идеологией:
template
class MultiIndex {
public:
MultiIndex() : buckets_(BUCKETS_COUNT), bucket_mutexes_(BUCKETS_COUNT) {
}
void Add(uint32_t id, T* pointer) {
int bucket_id = id % BUCKETS_COUNT;
std::lock_guard lock(bucket_mutexes_[bucket_id]);
buckets_[bucket_id].insert(std::make_pair(id, pointer));
}
void Replace(uint32_t old_id, uint32_t new_id, T* val) {
int bucket_id = old_id % BUCKETS_COUNT;
{
std::lock_guard lock(bucket_mutexes_[bucket_id]);
auto range = buckets_[bucket_id].equal_range(old_id);
auto it = range.first;
while (it != range.second) {
if (it->second == val) {
buckets_[bucket_id].erase(it);
break;
}
++it;
}
}
bucket_id = new_id % BUCKETS_COUNT;
std::lock_guard lock(bucket_mutexes_[bucket_id]);
buckets_[bucket_id].insert(std::make_pair(new_id, val));
}
std::vector GetValues(uint32_t id) {
int bucket_id = id % BUCKETS_COUNT;
std::lock_guard lock(bucket_mutexes_[bucket_id]);
auto range = buckets_[bucket_id].equal_range(id);
auto it = range.first;
std::vector result;
while (it != range.second) {
result.push_back(it->second);
++it;
}
return std::move(result);
}
private:
std::vector> buckets_;
std::vector bucket_mutexes_;
}; Первоначально организаторами были выложены только тестовые данные, которыми инициализировалась база данных, а примеров запросов не было, поэтому я начинал тестировать свой код с помощью Insomnia, которая позволяла легко отправлять и модифицировать запросы и смотреть ответ.
Чуть позже организаторы сжалилсь над участниками и выложили патроны от танка и полные данные рейтинговых и тестовых обстрелов, и я написал простенький скрипт, который позволял тестировать локально корректность моего решения и очень помог в дальнейшем.
И вот наконец-то прототип был закончен, локально тестировщик говорил, что все ОК, и настало время отправлять свое решение. Первый запуск был очень волнительным, и он показал, что что-то не так...
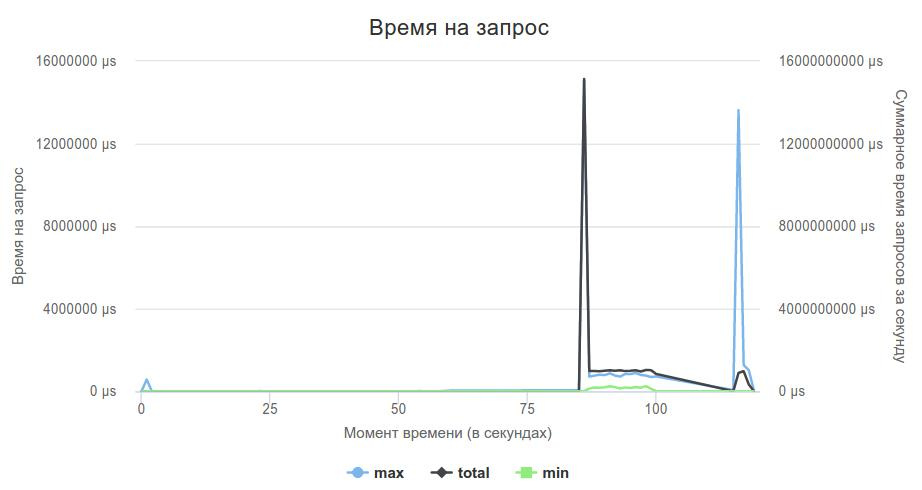
Мой сервер не держал нагрузку в 2000rps. У лидеров в этот момент, насколько я помню, времена были порядка сотен секунд.
Дальше я решил проверить, справляется ли вообще сервер с нагрузкой, или это проблемы с моей реализацией. Написал код, который на все запросы просто отдавал пустой json, запустил рейтинговый обстрел, и увидел, что сам proxygen не справляется с нагрузкой.
void onEOM() noexcept override {
proxygen::ResponseBuilder(downstream_)
.status(200, "OK")
.header("Content-Type", "application/json")
.body("{}")
.sendWithEOM();
}Вот так выглядел график 3-ей фазы.
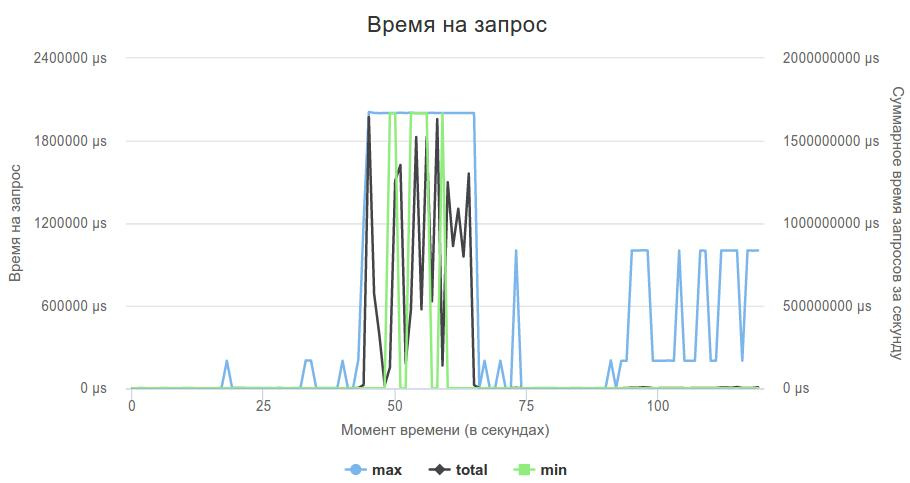
С одной стороны было приятно, что это пока еще проблема не в моем коде, с другой встал вопрос: что делать с сервером? Я все еще надеялся избежать написания своего, и решил попробовать что-нибудь другое.
Следующим подопытным стал Crow. Сразу скажу, мне он очень понравился, и если вдруг в будущем мне потребуется плюсовый http-сервер, то это будет именно он. header-based сервер, я его просто добавил в свой проект вместо proxygen, и немного переписал обработчики запросов, чтобы они начали работать с новым сервером.
Использовать его очень просто:
crow::SimpleApp app;
CROW_ROUTE(app, "/users/").methods("GET"_method, "POST"_method) (
[](const crow::request& req, crow::response& res, uint32_t id) {
if (req.method == crow::HTTPMethod::GET) {
get_handlers::GetUsers(req, res, id);
} else {
post_handlers::UpdateUsers(req, res, id);
}
});
app.bindaddr("0.0.0.0").port(80).multithreaded().run(); В случае, если нет подходящего описания для api, сервер сам отправляет 404, если же есть нужный обработчик, то в данном случае он достает из запроса uint-параметр и передает его как параметр в обработчик.
Но перед тем, как использовать новый сервер, наученный горьким опытом, я решил проверить, справляется ли он с нагрузкой. Также как и в предыдущем случае, написал обработчик, который возвращал пустой json на любой запрос, и отправил его на рейтинговый обстрел.
Crow справился, он держал нагрузку, и теперь нужно было добавить мою логику.
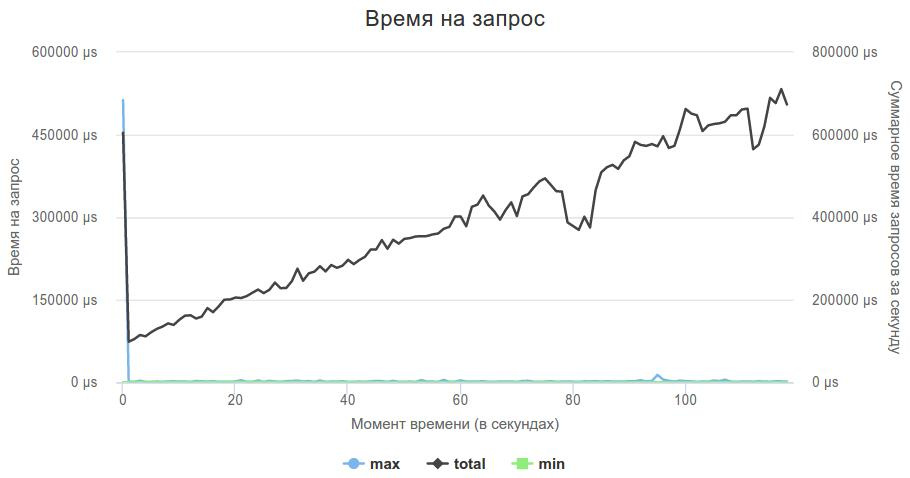
Т.к. логика была уже написана, то адаптировать код к новому серверу было достаточно просто. Все получилось!

100 секунд — уже что-то, и можно начинать заниматься оптимизацией логики, а не поисками сервера.
Т.к. мой сервер все еще формировал ответы с помощью std::stringstream, я решил избавиться от этого в первую очередь. В момент добавления записи в базу данных тут же формировалась строка, содержащая полный ответ с хедером, и в момент запроса отдавал ее.
На данном этапе я решил добавить хедер полностью в ответ по двум причинам:
write()Еще одной проблемой, о которую было сломано много копий в чатике в телеграмме и мной лично, это фильтр пользователей по возрасту. По условию задачи, возраст пользователей хранился в unix timestamp, а в запросах он приходил в виде полных лет: fromAge=30&toAge=70. Как года привести к секундам? Учитывать високосный год или нет? А если пользователь родился 29 февраля?
Итогом стал код, который решал все эти проблемы одним махом:
static time_t t = g_generate_time; // get time now
static struct tm now = (*localtime(&t));
if (search_flags & QueryFlags::FROM_AGE) {
tm from_age_tm = now;
from_age_tm.tm_year -= from_age;
time_t from_age_t = mktime(&from_age_tm);
if (user->birth_date > from_age_t) {
continue;
}
}Результатом стало двухкратное увеличение производительности, со 100 до 50 секунд.
Неплохо на первый взгляд, но в этот момент у лидеров было уже меньше 20 секунд, а я был где-то на 20-40 месте со своим результатом.
В этот момент были сделаны еще два наблюдения:
Стало понятно, что хэши, мутексы и бакеты для хранения данных не нужны, и данные можно прекрасно хранить по индексу в векторе, что и было сделано. Финальную версию можно увидеть здесь (к финалу дополнительно была добавлена часть кода для обработки индексов, если вдруг они превысят лимит).
Каких-то очевидных моментов, которые бы сильно влияли на производительность в моей логике, казалось, не было. Скорей всего с помощью оптимизаций можно было бы скинуть еще несколько секунд, но нужно было скидывать половину.
Я опять начал упираться в работу с сетью/сервером. Пробежавшись по исходникам сервера, я пришел к неутешительному выводу — при отправке происходило 2 ненужных копирования данных: сначала во внутренний буфер сервера, а потом еще раз в буфер для отправки.
В мире нет ничего более беспомощного, безответственного и безнравственного, чем начинать писать свой web-сервер. И я знал, что довольно скоро я в это окунусь.
И вот этот момент настал.
При написании своего сервера было сделано несколько допущений:
Вообще, можно было по-честному поддержать read() и write() в несколько кусков, но текущий вариант работал, поэтому это осталось "на потом".
После серии экспериментов я остановился на следующей архитектуре: блокирующий аccept() в главном потоке, добавление нового сокета в epoll, и std::thread::hardware_concurrency() потоков слушают один epollfd и обрабатывают данные.
unsigned int thread_nums = std::thread::hardware_concurrency();
for (unsigned int i = 0; i < thread_nums; ++i) {
threads.push_back(std::thread([epollfd, max_events]() {
epoll_event events[max_events];
int nfds = 0;
while (true) {
nfds = epoll_wait(epollfd, events, max_events, 0);
// ...
for (int n = 0; n < nfds; ++n) {
// ...
}
}
}));
}
while (true) {
int sock = accept(listener, NULL, NULL);
// ...
struct epoll_event ev;
ev.events = EPOLLIN | EPOLLET | EPOLLONESHOT;
ev.data.fd = sock;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, sock, &ev) == -1) {
perror("epoll_ctl: conn_sock");
exit(EXIT_FAILURE);
}
}EPOLLET гарантирует, что будет разбужен только какой-то один поток, а также что если в сокете останутся недочитанные данные, то epoll на сокет не сработает до тех пор, пока они все не будут вычитаны до EAGAIN. Поэтому следующей рекомендацией по использованию этого флага является делать сокет неблокирующим и читать, пока не вернется ошибка. Но как было обозначено в допущениях, запросы маленькие и читаются за один вызов read(), данных в сокете не остается, и epoll нормально срабатывал на приход новых данных.
Тут я сделал одну ошибку: я использовал std::thread::hardware_concurrency() для определения количества доступных потоков, но это было плохой идеей, потому что этот вызов возвращал 10 (количество ядер на сервере), а в докере было доступно только 4 ядра. Впрочем, на результат это мало повлияло.
Для парсинга http я использовал http-parser (Crow также использует его), для разбора урла — libyuarel, и для декодирования параметров в query-запросе — qs_parse. qs_parse также используется в Crow, он умеет разбирать урл, но так получилось, что я его использовал только для декодирования параметров.
Переписав таким образом свою реализацию, я сумел скинуть еще 10 секунд, и теперь мой результат составлял 40 секунд.
До конца соревнования оставалось полторы недели, и организаторы решили, что 200Мб данных и 2000rps — это мало, и увеличили размер данных и нагрузки в 5 раз: данные стали занимать 1Гб в распакованном виде, а интенсивность обстрела выросла до 10000rps на 3-ей фазе.
Моя реализация, которая хранила ответы целиком, перестала влезать по памяти, делать много вызовов write(), чтобы писать ответ по частям, тоже казалось плохой идеей, и я переписал свое решение на использование writev(): не нужно было дублировать данные при хранении и запись происходила с помощью одного системного вызова (тут тоже добавлено улучшение для финала: writev может записать за раз 1024 элемента массива iovec, а моя реализация для /users/ была очень iovec-затратной, и я добавил возможность разбить запись данных на 2 куска).
Отправив свою реализацю на запуск, я получил фантастические (в хорошем смысле) 245 секунды времени, что позволило мне оказаться на 2 месте в таблице результатов на тот момент.
Так как тестовая система подвержена большому рандому, и одно и то же решение может показывать различающееся в несколько раз время, а рейтинговые обстрелы можно было запускать лишь 2 раза в сутки, то непонятно, какие из следующих улучшений привели к конечному результату, а какие нет.
За оставшуюся неделю я сделал следующие оптимизации:
Заменил цепочки вызовов вида
DBInstance::GetDbInstance()->GetLocations()на указатель
g_location_storageПотом я подумал, что честный http-парсер для get-запросов не нужен, и для get-запроса можно сразу брать урл и больше ни о чем не заботиться. Благо, фиксированные запросы танка это позволяли. Также тут примечателен момент, что можно портить буфер (записывать \0 в конец урла, например). Таким же образом работает libyuarel.
HttpData http_data;
if (buf[0] == 'G') {
char* url_start = buf + 4;
http_data.url = url_start;
char* it = url_start;
int url_len = 0;
while (*it++ != ' ') {
++url_len;
}
http_data.url_length = url_len;
http_data.method = HTTP_GET;
} else {
http_parser_init(parser.get(), HTTP_REQUEST);
parser->data = &http_data;
int nparsed = http_parser_execute(
parser.get(), &settings, buf, readed);
if (nparsed != readed) {
close(sock);
continue;
}
http_data.method = parser->method;
}
Route(http_data);Также в чатике в телеграмме поднялся вопрос о том, что на сервере проверяется только количество полей в хедере, а не их содержимое, и хедеры были безжалостно порезаны:
const char* header = "HTTP/1.1 200 OK\r\n"
"S: b\r\n"
"C: k\r\n"
"B: a\r\n"
"Content-Length: ";Кажется, странное улучшение, но на многих запросах размер ответа существенно сокращался. К сожалению, неизвестно, дало ли это хоть какой-то прирост.
Все эти изменения привели к тому, что лучшее время в песочнице до 197 секунд, и это было 16 место на момент закрытия, а в финале — 188 секунд, и 13 место.
Код решения полностью расположен здесь: https://github.com/evgsid/highload_solution
Код решения на момент финала: https://github.com/evgsid/highload_solution/tree/final
А теперь давайте немного поговорим о магии.
В песочнице особенно выделялись первые 6 мест в рейтинге: у них время было ~140 сек, а у следующих ~ 190 и дальше время плавно увеличивалось.
Было очевидно, что первые 6 человек нашли какую-то волшебную пилюлю.
Я попробовал в качестве эксперимента sendfile и mmap, чтобы исключить копирование из userspace -> kernelspace, но тесты не показали никакого прироста в производительности.
И вот последние минуты перед финалом, прием решений закрывается, и лидеры делятся волшебной пилюлей: BUSY WAIT.
При прочих равных, решение, которое давало 180 секунд с epoll(x, y, z, -1) при использовании epoll(x, y, z, 0) давало сразу же 150 секунд и меньше. Конечно, это не продакшн-решение, но очень сильно уменьшало задержки.
Хорошую статью по этому поводу можно найти тут: How to achieve low latency with 10Gbps Ethernet.
Мое решение, лучший результат которого был 188 в финале, при использовании busy wait сразу же показало 136 секунд, что было бы 4-м временем в финале, и 8-ое место в песочнице на момент написания этой статьи.
Вот так выглядит график лучшего решения:
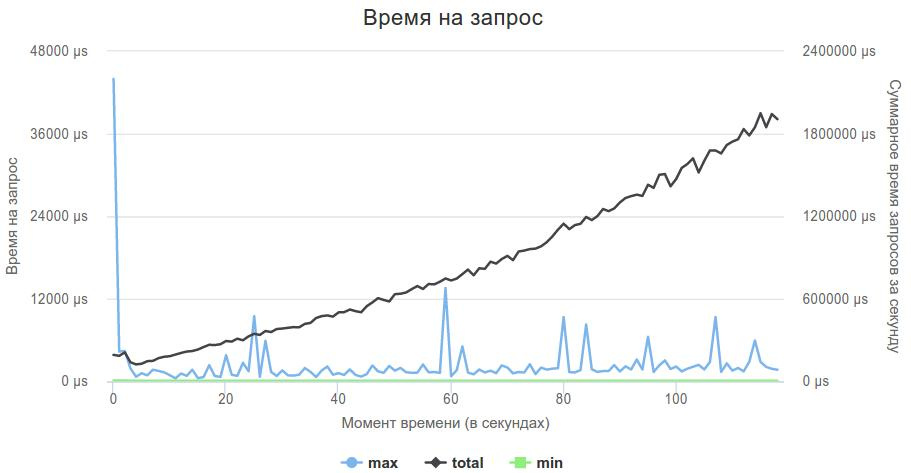
На самом деле, busy wait нужно использовать очень осторожно. Мое решение, когда главный поток принимает соединения, а 4 потока только обрабатывают данные из сокетов, при использовании busy wait стало сильно проседать на post-фазе, потому что accept'у не хватало процессорного времени, и мое решение сильно тормозило. Уменьшение количества обрабатыающих потоков до 3 полностью решило эту проблему.
Тамада хороший, и конкурсы интересные.
Это было очень круто! Это были незабываемые 3 недели системного прогрммирования. Спасибо моей жене и детям, что они были в отпуске, а иначе семья была близка к разводу. Спасибо организаторам, которые не спали ночами, помогали участниками и боролись с танком. Спасибо участникам, которые дали много новых идей и подталкивали к поиску новых решений.
С нетерпением жду следующего конкурса!
|
Метки: author reatfly ненормальное программирование высокая производительность c++ highload конкурс epoll busy wait |
Блиц. Как попасть в Яндекс, минуя первое собеседование |
Редко когда кандидат проходит только одно техническое собеседование — обычно их несколько. Среди причин, почему человеку они могут даваться непросто, можно назвать и ту, что каждый раз приходится общаться с новыми людьми, думать о том, как они восприняли твой ответ, пытаться интерпретировать их реакцию. Мы решили попробовать использовать формат контеста, чтобы сократить количество итераций для всех участников процесса.

Для Блица мы выбрали исключительно алгоритмические задачи. Хотя для оценки раундов и применяется система ACM, в отличие от спортивного программирования все задания максимально приближены к тем, которые постоянно решают в продакшене Поиска. Те, кто решит успешно хотя бы четыре задачи из шести, могут считать, что прошли первый этап отбора в Яндекс. Почему алгоритмы? В процессе работы часто меняются задачи, проекты, языки программирования, платформы — те, кто владеет алгоритмами, всегда смогут перестроиться и быстро научиться новому. Типичная задача на собеседовании — составить алгоритм, доказать его корректность, предложить пути оптимизации.
Квалификацию можно пройти с 18 по 24 сентября включительно. В этом раунде вам нужно будет написать программы для решения шести задач. Можете использовать Java, C++, C# или Python. На всё про всё у вас будет четыре часа. В решающем раунде будут соревноваться те, кто справится как минимум с четырьмя квалификационными задачами. Финал пройдёт одновременно для всех участников — 30 сентября, с 12:00 до 16:00 по московскому времени. Итоги будут подведены 4 октября. Чтобы всем желающим было понятно, с чем они столкнутся на Блице, мы решили разобрать пару похожих задач на Хабре.
Первая задача связана с одной из систем обработки данных, разработанной в Яндексе, — Robust Execution Manager, REM. Он позволяет строить сложные процессы, включающие множество разных операций, и устанавливать зависимости между ними. Так, решение многих задач связано с обработкой пользовательских логов, содержащих информацию о заданных запросах, показанных документах, совершённых кликах и так далее. Поэтому вычисление поискового фактора CTR (click through rate, отношение числа кликов по документу к количеству его показов) зависит от задач обработки пользовательских логов, а от решения задачи вычисления CTR зависит задача доставки значений этого фактора в поисковый runtime. Таким образом, REM позволяет выстраивать цепочки обработки данных, в которых поставщик данных не обязан знать о том, кто эти данные в дальнейшем будет использовать.
В процесс исполнения цепочек обработки могут быть внесены коррективы. Например, уже после построения поисковых логов может выясниться, что значительный объем данных был доставлен с существенной задержкой, и поисковые логи необходимо перестроить. Естественно, после перестроения логов необходимо также перезапустить все процессы, которые от них зависели. Другой пример того же рода — попадание в пользовательские логи запросов, выполненных нашим поисковым роботом. Эти запросы не являются запросами пользователей, а поэтому вносят шум в вычисление поисковых факторов, расчёты экспериментов и так далее. Поэтому в этом случае логи также нужно обновить, после чего перезапустить все процессы их обработки. Поэтому REM поддерживает операцию обновления данных с последующим перезапуском всех задач, зависящих от этих данных.
Задача заключается в реализации именно этой операции. Входными данными будет ациклический ориентированный граф с выделенной вершиной. Граф описывает некоторый процесс обработки данных, при этом вершины представляют этапы этого процесса, а рёбра — зависимости между ними. Выделенная вершина соответствует одной из подзадач, которую необходимо перезапустить из-за изменений в данных. После перезапуска необходимо будет также перезапустить и все подзадачи, зависящие от неё по данным. Необходимо написать программу, которая выводит список этих подзадач, причём в порядке, в котором их необходимо будет перезапустить.
Рассмотрим для начала решение задачи в случае, когда вершины из ответа не нужно упорядочивать. Тогда задача решается достаточно просто: запустим из выделенной вершины любой алгоритм обхода графа (например, обход в глубину), и запишем в ответ все посещённые вершины. Действительно, если задачи с номерами , , ..., зависят по данным от задачи , то после перезапуска задачи необходимо перезапустить все эти задачи, а также те задачи, что зависят уже от них. Кроме того, каждую вершину нужно вывести ровно один раз. Оба этих условия обеспечиваются стандартными методами обхода графов.
#include
#include
using Graph = std::vector>;
void DFS(const Graph& graph,
const int vertice,
std::vector& used,
std::vector& result)
{
used[vertice] = true;
result.push_back(vertice);
for (size_t idx = 0; idx < graph[vertice].size(); ++idx) {
const int adjacent_vertice = graph[vertice][idx];
if (!used[adjacent_vertice]) {
DFS(graph, adjacent_vertice, used, result);
}
}
}
void Solve(const Graph& graph,
const int from,
std::vector& result)
{
std::vector used(graph.size(), false);
DFS(graph, from, used, result);
}
int main() {
int vertices, edges;
std::cin >> vertices >> edges;
Graph graph(vertices + 1);
for (int edge = 0; edge < edges; ++edge) {
int from, to;
std::cin >> from >> to;
graph[from].push_back(to);
}
int reset_vertice;
std::cin >> reset_vertice;
std::vector result;
Solve(graph, reset_vertice, result);
for (std::vector::const_iterator it = result.begin();
it != result.end();
++it)
{
std::cout << *it << " ";
}
std::cout << std::endl;
return 0;
} Теперь мы знаем, как сформировать множество вершин, составляющих ответ, но не знаем, как его упорядочить. Рассмотрим пример: пусть от подзадачи зависят подзадачи и . В таком случае нам неважно, в каком порядке запускать подзадачи и . Но что, если между ними существует явная или неявная (через другие подзадачи) зависимость?

В ситуации, изображённой на картинке, сначала нужно исполнять задачу , а уже потом . Но стандартные методы обхода не позволяют этого добиться. Нам нужен другой алгоритм!
Используем для решения возникшей проблемы топологическую сортировку вершин, входящих в ответ, то есть, введём некоторый порядок на этом множестве вершин, например: , ,...,, и при этом будет верно, что, если , то не зависит прямо или косвенно от . Известно, что такое упорядочение возможно, если граф не содержит циклов. Топологическая сортировка вершин достигается при помощи обхода в глубину: когда для некоторой вершины посещены все её потомки, она добавляется в начало списка. Итоговый список будет искомой сортировкой вершин графа.
Таким образом, поставленная задача решается при помощи обхода в глубину, в процессе которого мы одновременно строим множество вершин, представляющих ответ, и осуществляем топологическую сортировку этих вершин. Топологическая сортировка гарантирует, что соответствующие вершинам графа подзадачи перечислены в правильном порядке.
#include
#include
using Graph = std::vector>;
void DFS(const Graph& graph,
const int vertice,
std::vector& used,
std::vector& result)
{
used[vertice] = true;
for (size_t idx = 0; idx < graph[vertice].size(); ++idx) {
const int adjacent_vertice = graph[vertice][idx];
if (!used[adjacent_vertice]) {
DFS(graph, adjacent_vertice, used, result);
}
}
result.push_back(vertice);
}
void Solve(const Graph& graph,
const int from,
std::vector& result)
{
std::vector used(graph.size(), false);
DFS(graph, from, used, result);
}
int main() {
int vertices, edges;
std::cin >> vertices >> edges;
Graph graph(vertices + 1);
for (int edge = 0; edge < edges; ++edge) {
int from, to;
std::cin >> from >> to;
graph[from].push_back(to);
}
int reset_vertice;
std::cin >> reset_vertice;
std::vector result;
Solve(graph, reset_vertice, result);
for (std::vector::const_reverse_iterator it = result.rbegin();
it != result.rend();
++it)
{
std::cout << *it << " ";
}
std::cout << std::endl;
return 0;
} Эта задача не имеет непосредственного отношения к библиотекам и программам, разрабатываемым в Яндексе, зато она очень интересная и поэтому часто становится темой для обсуждений на кофепоинтах в свободную минуту. Она является несколько упрощённой версией задачи 9D с codeforces.
Необходимо вычислить, каково количество различных бинарных деревьев поиска, в вершинах которых записаны числа от 1 до . Например, если , существует ровно пять различных деревьев, изображённых на картинке ниже:

Если , то количество деревьев равняется 42. Именно поэтому задача очень нравится нашим разработчикам, среди которых немало ценителей творчества Дугласа Адамса.
Эта задача является достаточно простой для тех, кто знаком с методами динамического программирования. Обозначим за количество различных бинарных деревьев поиска, образованных числами , , ..., . Предположим, что мы знаем , , , ..., и хотим вычислить .
Ясно, что в корне любого дерева будет находиться некоторое число из множества Обозначим это число за . Тогда в силу свойств дерева поиска левое поддерево содержит числа , а правое — . Количество различных возможных способов сформировать левое поддерево тогда равняется , а правое — . Поэтому общее количество деревьев, составленных из чисел , , ..., и имеющих в корне значение , равняется произведению . Для того, чтобы найти общее количество деревьев, необходимо просуммировать это произведение для всех возможных значений :
N = int(raw_input())
result = [1, 1]
for count in xrange(2, N + 1):
result.append(0)
for root in xrange(1, count + 1):
result[-1] += result[root - 1] * result[count - root]
print result[N]Задачу можно решить с использованием полученной формулы. Однако те, кому хорошо знакома комбинаторика, могли бы узнать в этом выражении формулу для вычисления чисел Каталана. Поэтому можно для получения ответа использовать формулу с использованием биномиальных коэффициентов:
В процессе решения задачи про бинарные деревья мы получили рекуррентную формулу, полностью аналогичную рекуррентной формуле, возникающей при решении задачи про количество правильных скобочных последовательностей длины , которая, как правило, и используется для введения чисел Каталана в курсах по комбинаторике.
Яндекс.Блиц будет проходить на платформе Контест, где мы обычно проводим Алгоритм. Для участия нужно зарегистрироваться. Мы обязательно пришлём вам напоминание о старте раундов.
|
Метки: author nkmakarov python java c++ c# блог компании яндекс собеседование алгоритмы занимательные задачи задачи для собеседований задачи для программистов математика |
VMware объявила о «конце» vCenter Server для Windows |

|
Метки: author 1cloud виртуализация блог компании 1cloud.ru 1cloud vmware vcsa vcenter |
Анатомия аналитики от Google |
Всем привет!
Мы — разработчики (гордо звучит, не правда ли?), и мы активно пилим новые фичи, правим баги и стараемся сделать наш продукт лучше. Но чтобы понять, а как именно пользователь использует наш продукт, какие фишки продукта ему по душе, а какие — не очень, мы используем аналитику. Есть много разных средств, но в этой статье я бы хотел поговорить именно об аналитике от Google, которая активно развивается и меняется. Старого часового по имени Google Analytics сменяет новый боец — Google Analytics for Firebase (в девичестве — Firebase Analytics).
Уже даже в названиях вы можете уловить этот ветер перемен. А ветер перемен всегда порождает некоторый информационный вакуум, в который попадают разного рода слухи, далеко не всегда достоверные при этом.
Поэтому давайте попробуем разобраться подробно, а что сейчас с этой аналитикой, чем пользоваться-то в итоге. И как вообще дальше жить.
Если про Google Analytics информации довольно много, и она систематизирована (чего только стоит этот ресурс, идеальная справка), то у Google Analytics for Firebase типичная болезнь молодого и активно развивающегося продукта — информации мало, она разрознена и иногда даже противоречива. И я в свое время потратил немало сил и времени, чтобы разобраться, что к чему.
Собственно главная цель данной статьи — это систематизация знаний и нынешнего состояния Google Analytics for Firebase. Некоторая «дорожная карта» Google Analytics for Firebase.
Уверен, данная «карта» сэкономит вам прилично времени и нервов =)
Начну все-таки с самого горячего.
Мне кажется, что данный слух идет с самого появления Firebase Analytics. И с одной стороны, это логично, зачем «Гуглу» два средства аналитики. Но Google Analytics (будем именовать GA) и Google Analytics for Firebase (по старинке назовем FA) — это две аналитики с разными концепциями и подходами, про которые мы поговорим чуть ниже.
GA никуда не денется и не пропадет (по крайней мере сейчас), а также не будет кем-то поглощен. Это как информация от представителей москвовского офиса Гугла, так и инсайды от самих разработчиков.
Фанаты GA могут спать спокойно… пока что. Но кто знает, что будет дальше. Поэтому я настоятельно рекомендую продолжить чтение =)
FA — это аналитика с совершенно другой концепцией и философией. Она является event based и предназначена исключительно для мобилки. Тогда как GA — screen-based и сначала была для веба, а уж потом ее допилили для мобилки.
GA структурирована вокруг иерархичных событий с одним значением, FA — больше о записи одного события с большим количеством параметров (пар «ключ-значение»).
Эти аналитики очень разные. И поэтому они не могут быть взаимозаменяемыми.
Миграции с одной на другую не предусматривается. Но «Гугл» работает над определенной совместимостью этих аналитик, о чем мы тоже поговорим чуть позже.
Коль уж мы затронули тему событий. В плане осмысления «события» GA и FA действительно очень разные. И это особенно заметно на примере.
Допустим, ваше приложение — это игра. По окончании игры вы хотите послать статистику, как в итоге сыграл пользователь. И вы хотите узнать у пользователя общий счет, количество убитых врагов и количество пройденных раундов.
В GA все это будет выглядеть примерно вот так:
// total score
mTracker = googleAnalytics.newTracker(R.xml.tracker_global_config);
HitBuilders.EventBuilder builder = new HitBuilders.EventBuilder()
.setCategory("gameOver")
.setAction("totalScore")
.setLabel("")
.setValue(gameStats.getTotalScore());
mTracker.send(builder.build());
// enemies beaten
mTracker = googleAnalytics.newTracker(R.xml.tracker_global_config);
HitBuilders.EventBuilder builder = new HitBuilders.EventBuilder()
.setCategory("gameOver")
.setAction("enemiesBeaten")
.setLabel("")
.setValue(gameStats.getEnemiesBeaten());
mTracker.send(builder.build());
// roundsSurvived
mTracker = googleAnalytics.newTracker(R.xml.tracker_global_config);
HitBuilders.EventBuilder builder = new HitBuilders.EventBuilder()
.setCategory("gameOver")
.setAction("roundsSurvived")
.setLabel("")
.setValue(gameStats.getRoundsSurvived());
mTracker.send(builder.build());В GA каждое событие по сути представляет собой иерархию параметров:
category -> action -> label -> value
И в самой консоли вы могли наблюдать данную иерархию параметров. Собственно при придумывании событий, которые вы бы хотели отслеживать, вы должны были руководствоваться данной парадигмой. Также в консоли можно строить различные фильтры по данным параметрам.
Но в GA в плане событий есть небольшой минус. Если вы хотите навешать событию дополнительные параметры, помимо вышеназванных, вот тут приходится танцевать вокруг "category" -> "action" -> "label" -> "value", придумывать новые формулировки и прочее. Неудобно. По крайней мере так было раньше.
А теперь посмотрим, как можно данную статистику обыграть с FA:
Bundle params = new Bundle();
params.putLong("totalScore", gameStats.getTotalScore());
params.putLong("enemiesBeaten", gameStats.getEnemiesBeaten());
params.putLong("roundsSurvived", gameStats.getRoundSurvived());
mFirebaseAnalytics.logEvent("game_over", params);Как видите, вместо трех событий мы отправляем одно, что более логично и удобно. Про «события» в FA мы поговорим подробнее чуть ниже.
Второе, чем сильно отличаются аналитики, это — консоль.
Вот как выглядит консоль в GA (картинка кликабельна):

«События» спрятаны глубоко во вкладке «Поведение» слева. Но в стандартном отчете сразу идет разбивка на Category, Action, Label (рисунок кликабельный):

Вот так выглядит консоль FA (рисунок кликабельный):

Первое, что вы видите, это — «Сводка». И я бы сразу обратил внимание на карточку User engagement (рисунок кликабельный):

Наконец-то в FA-консоль добавили нормальный просмотр экранов. До мая мы жили без этого. То есть событие «user engagement» отсылалось, но в консоли его никак нельзя было посмотреть. Это было ужасно. И это, возможно, одна из причин, почему никто не хотел переходить на FA.
Как еще можно заметить, вкладка Events идет сразу за Dashboard, что еще раз подтверждает — FA заточена на работу с событиями. К консоли мы также вернемся чуть позже, а сейчас я предлагаю погрузиться в эту обширную тему «Событий» в FA.
Давайте сразу взглянем на код:
Bundle bundle = new Bundle();
bundle.putString(FirebaseAnalytics.Param.ITEM_ID, id);
bundle.putString(FirebaseAnalytics.Param.ITEM_NAME, name);
bundle.putString(FirebaseAnalytics.Param.CONTENT_TYPE, "image");
mFirebaseAnalytics.logEvent(FirebaseAnalytics.Event.SELECT_CONTENT, bundle);Вы можете отправлять до 500 различных типов событий в своем приложении, включая предустановленные (FirebaseAnalytics.Event.SELECT_CONTENT — это предустановленное, но вы можете задавать и свои типы). Общее количество отправляемых событий не лимитировано (источник).
К каждому событию можно прикреплять до 25 параметров (то, что идет в Bundle). Параметры также есть предопределенные, но никто не запрещает вам задавать кастомные параметры. Описано здесь.
Типы событий и параметров — это обычные String.
Названия событий и параметров чувствительны к регистру. Одинаковые события должны совпадать по типу и параметрам.
Кроме того, есть события, которые отправляются по умолчанию. Весь список автоматически отправляемых событий с описанием приведен по данной ссылке. Как вы можете заметить, там много действительно интересных событий, которые раньше нам не представлялось возможным получить. Круто!
Также по приведенной выше ссылке вы можете прочитать, какие предопределенные события и параметры можно выбрать для определенных событий.
Вы обратили внимание, что как-то подозрительно много говорится про предопределенные названия событий и параметров. И в показательных примерах обычно посылаются именно такие события с параметрами. А это ведь неспроста. Допустим, вы посылаете событие с десятью кастомными параметрами. И тогда в консоли по вашему событию вы увидите следующее (рисунок кликабельный):

«Но где же все мои параметры?» — спросите вы. А нет их на консоли, вот так вот.
Дело в том, что все красивые графики и прочее строятся, только если вы используете предопределенные названия. Используете свое, «кастомное», ничегошеньки не увидите. Только «количество событий» да «количество пользователей».
И до I/O 17 это было прям страшной болью. Графики можно было строить, играя, например, с параметром Value, как в этой статье. Но это, конечно, все не то.
И тут, конечно же, пора бы вспомнить про GA, где все для людей, строй всякие там фильтры по чему угодно и сколько душе угодно.
Но и тут маленькая засада. Стандартные отчеты — да, стройте без проблем. Но в большинстве случаев нам нужны и кастомные отчеты. Например, добавить Secondary dimension, чтобы отсортировать события по моделям устройств. И вот тут всплывает страшное слово «Sampling».
В зависимости от отчета алгоритм сэмплирования в GA различается. То, как конкретно считается семпл для каждого отчёта, «Гугл» не раскрывает, но в целом все практики уже известны. Обычно это hi-based-сэмплирование или cookie-based-сэмплирование. В первом случае берется рандомная выборка из всех записей (событий, просмотров и т.д.), во втором — рандомная выборка по всем пользователям (размеченным кукам или gaid/idfa, если это мобильное приложение).
Поэтому нельзя достоверно говорить об ошибке по каждому полю.
По практике говорят, что при выборке больше 5% ошибка в абсолютных числах в отчетах по событиям составляла меньше 2,5%.
За предоставление информации о сэмплировании хочу выразить благодарность Александру Сергееву из «Яндекса».
Да уж. Все непросто с этими «Событиями». И на самом деле FA идет навстречу пожеланиям простого люда.
Во-первых, никакого сэмплинга в FA нет. Там доступны все данные.
И это очень круто, так как стоимость Google Analytics 360 (платной версии GA без сэмплинга) весьма немаленькая. А в FA вы можете ваши данные выгрузить в BigQuery и там делать с ними все что угодно.
Во-вторых, после I/O 17 появилась возможность строить отчеты и по кастомным параметрам.
Вам прямо на экране конкретного события предлагается зарегистрировать кастомные параметры (рисунок кликабельный):

Но учтите, что всего для данного приложения вы можете зарегистрировать до 50 таких параметров (10 текстовых и 40 числовых). Пробовал лайфхак для обхода данного ограничения: регистрировал для разных событий кастомные параметры с одинаковыми именами. Не помогло, все равно делается «плюс один».
Кроме того, если вы ожидаете увидеть сразу готовые отчеты, спешу вас разочаровать. Отчеты строятся накопительным образом. Допустим, есть у вас «event_1» с кастомным параметром «custom_1», для которого вы хотите построить отчет. В консоли вы настроили, чтобы строился данный отчет в момент времени X. Так вот в отчет попадут все события «event_1», которые придут после момента времени X. А все «event_1» до момента X, увы, не будут обработаны. Так что будьте внимательны.
То есть вроде бы лучше стало, но не сильно. Что еще обидно, вы не можете эти отчеты как-то совмещать друг с другом. Но, пожалуй, мы слишком многого хотим от консоли. Если уж вы хотите делать с данными все что угодно, то добро пожаловать в удивительный мир BigQuery. Давайте немного приоткроем эту завесу таинства данных.
BigQuery — это вообще немного другая галактика.
С BigQuery можно было работать и через GA, но только если у вас premium-режим. В FA же вам прямо во вкладке Events предлагается установить связь (рисунок кликабельный):

Google говорит: «Мы дарим вам машину, но за бензин платите вы». С тарифными планами можно ознакомиться здесь, а еще лучше здесь. Но поверьте, чтобы просто попробовать, вам вполне достаточно будет бесплатных лимитов тарифа Blaze. Да и даже при работе с боевыми продуктами, судя по отзывам товарищей, плата весьма условной получается.
Итак, начнем знакомство. Вот так выглядит консоль BigQuery (рисунок кликабельный):

В левом меню представлен список доступных данных. Например, TestStep — это мой тестовый проект с одним приложением в составе. А bigquery-public-data и Public Datasets — это, как можно догадаться, публичные данные, с которыми вы можете поэкспериментировать и на которых можете потренироваться в написании запросов.
Справа же вы видите список запросов, как успешных, так и не очень.
Теперь взглянем на данные тестового приложения за 14 марта 2017 года (таблица app_events_20170314, рисунок кликабельный):

В таблицу я перебросил все данные за сутки (52 события). Общий состав таблицы представлен перед вами. Как видно, тут каждое событие описывается максимально полно, включая все properties, о которых речь будет чуть ниже.
Давайте посмотрим на превью данных (вкладка Preview, рисунок кликабельный):

Табличный вид с ходу малоинформативен. Намного более понятная форма — это JSON (рисунок кликабельный):

И тогда наше событие представляется в полном виде. В UI почему-то нельзя расширить окно показа json, поэтому приведу полный json последних пяти событий отдельно:
[
{
"user_dim": {
"user_id": null,
"first_open_timestamp_micros": "1488878151620000",
"user_properties": [
{
"key": "first_open_time",
"value": {
"value": {
"string_value": null,
"int_value": "1488880800000",
"float_value": null,
"double_value": null
},
"set_timestamp_usec": "1488878151620000",
"index": null
}
}
],
"device_info": {
"device_category": "mobile",
"mobile_brand_name": null,
"mobile_model_name": null,
"mobile_marketing_name": null,
"device_model": "507SH",
"platform_version": "6.0.1",
"device_id": null,
"resettable_device_id": null,
"user_default_language": "ru-ru",
"device_time_zone_offset_seconds": "10800",
"limited_ad_tracking": "false"
},
"geo_info": {
"continent": "Europe",
"country": "Russia",
"region": "Moscow",
"city": "Moscow"
},
"app_info": {
"app_version": "1.0",
"app_instance_id": "d0c587de4d5804ddc1d34f8d54b981f9",
"app_store": "manual_install",
"app_platform": "ANDROID",
"app_id": "com.example.matsyuk.testfirebase"
},
"traffic_source": null,
"bundle_info": {
"bundle_sequence_id": "65",
"server_timestamp_offset_micros": "-496748"
},
"ltv_info": null
},
"event_dim": [
{
"date": "20170314",
"name": "user_engagement",
"params": [
{
"key": "firebase_screen_class",
"value": {
"string_value": "SecondActivity",
"int_value": null,
"float_value": null,
"double_value": null
}
},
{
"key": "firebase_event_origin",
"value": {
"string_value": "auto",
"int_value": null,
"float_value": null,
"double_value": null
}
},
{
"key": "firebase_screen_id",
"value": {
"string_value": null,
"int_value": "1109587836504693342",
"float_value": null,
"double_value": null
}
},
{
"key": "engagement_time_msec",
"value": {
"string_value": null,
"int_value": "4424",
"float_value": null,
"double_value": null
}
}
],
"timestamp_micros": "1489478210462000",
"previous_timestamp_micros": "1489478205970000",
"value_in_usd": null
}
]
},
{
"user_dim": {
"user_id": null,
"first_open_timestamp_micros": "1488878151620000",
"user_properties": [
{
"key": "first_open_time",
"value": {
"value": {
"string_value": null,
"int_value": "1488880800000",
"float_value": null,
"double_value": null
},
"set_timestamp_usec": "1488878151620000",
"index": null
}
}
],
"device_info": {
"device_category": "mobile",
"mobile_brand_name": null,
"mobile_model_name": null,
"mobile_marketing_name": null,
"device_model": "507SH",
"platform_version": "6.0.1",
"device_id": null,
"resettable_device_id": null,
"user_default_language": "ru-ru",
"device_time_zone_offset_seconds": "10800",
"limited_ad_tracking": "false"
},
"geo_info": {
"continent": "Europe",
"country": "Russia",
"region": "Moscow",
"city": "Moscow"
},
"app_info": {
"app_version": "1.0",
"app_instance_id": "d0c587de4d5804ddc1d34f8d54b981f9",
"app_store": "manual_install",
"app_platform": "ANDROID",
"app_id": "com.example.matsyuk.testfirebase"
},
"traffic_source": null,
"bundle_info": {
"bundle_sequence_id": "64",
"server_timestamp_offset_micros": "-515257"
},
"ltv_info": null
},
"event_dim": [
{
"date": "20170314",
"name": "user_engagement",
"params": [
{
"key": "firebase_screen_class",
"value": {
"string_value": "MainActivity",
"int_value": null,
"float_value": null,
"double_value": null
}
},
{
"key": "firebase_event_origin",
"value": {
"string_value": "auto",
"int_value": null,
"float_value": null,
"double_value": null
}
},
{
"key": "firebase_screen_id",
"value": {
"string_value": null,
"int_value": "1109587836504693341",
"float_value": null,
"double_value": null
}
},
{
"key": "engagement_time_msec",
"value": {
"string_value": null,
"int_value": "17278",
"float_value": null,
"double_value": null
}
}
],
"timestamp_micros": "1489478205970000",
"previous_timestamp_micros": "1489153178047000",
"value_in_usd": null
}
]
},
{
"user_dim": {
"user_id": null,
"first_open_timestamp_micros": "1488878151620000",
"user_properties": [
{
"key": "first_open_time",
"value": {
"value": {
"string_value": null,
"int_value": "1488880800000",
"float_value": null,
"double_value": null
},
"set_timestamp_usec": "1488878151620000",
"index": null
}
}
],
"device_info": {
"device_category": "mobile",
"mobile_brand_name": null,
"mobile_model_name": null,
"mobile_marketing_name": null,
"device_model": "507SH",
"platform_version": "6.0.1",
"device_id": null,
"resettable_device_id": null,
"user_default_language": "ru-ru",
"device_time_zone_offset_seconds": "10800",
"limited_ad_tracking": "false"
},
"geo_info": {
"continent": "Europe",
"country": "Russia",
"region": "Moscow",
"city": "Moscow"
},
"app_info": {
"app_version": "1.0",
"app_instance_id": "d0c587de4d5804ddc1d34f8d54b981f9",
"app_store": "manual_install",
"app_platform": "ANDROID",
"app_id": "com.example.matsyuk.testfirebase"
},
"traffic_source": null,
"bundle_info": {
"bundle_sequence_id": "63",
"server_timestamp_offset_micros": "-500210"
},
"ltv_info": null
},
"event_dim": [
{
"date": "20170314",
"name": "ga_event",
"params": [
{
"key": "label",
"value": {
"string_value": "label1",
"int_value": null,
"float_value": null,
"double_value": null
}
},
{
"key": "firebase_screen_class",
"value": {
"string_value": "MainActivity",
"int_value": null,
"float_value": null,
"double_value": null
}
},
{
"key": "action",
"value": {
"string_value": "action1",
"int_value": null,
"float_value": null,
"double_value": null
}
},
{
"key": "firebase_event_origin",
"value": {
"string_value": "app",
"int_value": null,
"float_value": null,
"double_value": null
}
},
{
"key": "value",
"value": {
"string_value": null,
"int_value": "1",
"float_value": null,
"double_value": null
}
},
{
"key": "category",
"value": {
"string_value": "category1",
"int_value": null,
"float_value": null,
"double_value": null
}
},
{
"key": "firebase_screen_id",
"value": {
"string_value": null,
"int_value": "1109587836504693341",
"float_value": null,
"double_value": null
}
}
],
"timestamp_micros": "1489478204880000",
"previous_timestamp_micros": "1489137436229000",
"value_in_usd": null
}
]
},
{
"user_dim": {
"user_id": null,
"first_open_timestamp_micros": "1488878151620000",
"user_properties": [
{
"key": "first_open_time",
"value": {
"value": {
"string_value": null,
"int_value": "1488880800000",
"float_value": null,
"double_value": null
},
"set_timestamp_usec": "1488878151620000",
"index": null
}
}
],
"device_info": {
"device_category": "mobile",
"mobile_brand_name": null,
"mobile_model_name": null,
"mobile_marketing_name": null,
"device_model": "507SH",
"platform_version": "6.0.1",
"device_id": null,
"resettable_device_id": null,
"user_default_language": "ru-ru",
"device_time_zone_offset_seconds": "10800",
"limited_ad_tracking": "false"
},
"geo_info": {
"continent": "Europe",
"country": "Russia",
"region": "Moscow",
"city": "Moscow"
},
"app_info": {
"app_version": "1.0",
"app_instance_id": "d0c587de4d5804ddc1d34f8d54b981f9",
"app_store": "manual_install",
"app_platform": "ANDROID",
"app_id": "com.example.matsyuk.testfirebase"
},
"traffic_source": null,
"bundle_info": {
"bundle_sequence_id": "62",
"server_timestamp_offset_micros": "-499813"
},
"ltv_info": null
},
"event_dim": [
{
"date": "20170314",
"name": "select_content",
"params": [
{
"key": "firebase_screen_class",
"value": {
"string_value": "MainActivity",
"int_value": null,
"float_value": null,
"double_value": null
}
},
{
"key": "content_type",
"value": {
"string_value": "image",
"int_value": null,
"float_value": null,
"double_value": null
}
},
{
"key": "item_name",
"value": {
"string_value": "name1",
"int_value": null,
"float_value": null,
"double_value": null
}
},
{
"key": "firebase_event_origin",
"value": {
"string_value": "app",
"int_value": null,
"float_value": null,
"double_value": null
}
},
{
"key": "firebase_screen_id",
"value": {
"string_value": null,
"int_value": "1109587836504693341",
"float_value": null,
"double_value": null
}
},
{
"key": "item_id",
"value": {
"string_value": "1",
"int_value": null,
"float_value": null,
"double_value": null
}
}
],
"timestamp_micros": "1489478204208000",
"previous_timestamp_micros": "1489137435605000",
"value_in_usd": null
}
]
},
{
"user_dim": {
"user_id": null,
"first_open_timestamp_micros": "1488878151620000",
"user_properties": [
{
"key": "first_open_time",
"value": {
"value": {
"string_value": null,
"int_value": "1488880800000",
"float_value": null,
"double_value": null
},
"set_timestamp_usec": "1488878151620000",
"index": null
}
}
],
"device_info": {
"device_category": "mobile",
"mobile_brand_name": null,
"mobile_model_name": null,
"mobile_marketing_name": null,
"device_model": "507SH",
"platform_version": "6.0.1",
"device_id": null,
"resettable_device_id": null,
"user_default_language": "ru-ru",
"device_time_zone_offset_seconds": "10800",
"limited_ad_tracking": "false"
},
"geo_info": {
"continent": "Europe",
"country": "Russia",
"region": "Moscow",
"city": "Moscow"
},
"app_info": {
"app_version": "1.0",
"app_instance_id": "d0c587de4d5804ddc1d34f8d54b981f9",
"app_store": "manual_install",
"app_platform": "ANDROID",
"app_id": "com.example.matsyuk.testfirebase"
},
"traffic_source": null,
"bundle_info": {
"bundle_sequence_id": "61",
"server_timestamp_offset_micros": "-537470"
},
"ltv_info": null
},
"event_dim": [
{
"date": "20170314",
"name": "session_start",
"params": [
{
"key": "firebase_screen_class",
"value": {
"string_value": "MainActivity",
"int_value": null,
"float_value": null,
"double_value": null
}
},
{
"key": "firebase_event_origin",
"value": {
"string_value": "auto",
"int_value": null,
"float_value": null,
"double_value": null
}
},
{
"key": "firebase_screen_id",
"value": {
"string_value": null,
"int_value": "1109587836504693341",
"float_value": null,
"double_value": null
}
}
],
"timestamp_micros": "1489478198696000",
"previous_timestamp_micros": "1489137330069000",
"value_in_usd": null
}
]
}
]Красота, да и только!
Теперь более подробно рассмотрим Queries. Выберем первый (рисунок кликабельный):

И перед нами откроется следующий экран (рисунок кликабельный):

Запрос наш довольно произвольный. Обратите внимание на вкладку Results. Собственно, в ней вы и увидите результаты вашего запроса.
Если открыть вкладку Explanation, то вы увидите более подробный процесс прохождения запроса (рисунок кликабельный):

Ну и самая интересная вкладка — Job information (рисунок кликабельный):

Обратите внимание на Bytes Processed, Bytes Billed и Bites Tier. В ходе запроса было обработано 26,4 KB, но платите вы по нижней границе для Bites Tier = 1, то есть платите как за 10 MB. Однако, судя по документации, 1 TB в месяц для вас будет бесплатным, а каждый последующий будет стоить $5. Вполне вам хватит наиграться и напробоваться. Ну и важное дополнение — платите вы только за успешные запросы!
Даже очень краткий обзор по BigQuery получается немаленьким. Это очень мощный и функциональный инструмент, с помощью которого вы можете анализировать данные как угодно. Но за 5 минут в BigQuery вы точно не разберетесь, в отличие от обычной консоли в GA или FA. Поэтому очень круто, если в вашей команде или компании есть человек, который в этом разбирается, и который может получить какие угодно результаты.
Если этим человеком хотите стать вы, то начать можете со вступительного видео от «Гугла», где, кстати, рассказывается и про расчет стоимости. Также есть неплохие статьи — раз и два. Далее советую вам копать в сторону официальной доки и книги по BigQuery (целая книга, Карл!).
Будет здорово, если кто-то уже хорошо покопал в эту сторону и может поделиться советами и опытом =)
Отмечу также, что существуют UI-обертки над BigQuery типа Data Studio, позволяющие загружать туда данные и удобно их визуализировать. Data Studio пока в бете, но в будущем обещает стать очень удобным инструментом.
Мы, по сути, продолжаем тему событий, так как user properties — ее неотъемлемая часть.
User properties (по-русски «Свойства пользователя») — это признаки, с помощью которых вы можете описывать различные сегменты вашей пользовательской базы, такие как язык, географическая локация и т.д. Их еще называют sticky params, так как они прикрепляются к каждому событию.
Изначально к каждому событию прикрепляются только properties по-умолчанию. А если в коде вы вызываете подобный код:
mFirebaseAnalytics.setUserProperty("license_property", mLicenseType);то к каждому последующему вашему событию будет прикрепляться property «license_property» с заданным заранее значением (значение «mLicenseType»). И даже после перезапуска приложения, телефона и прочее данное property будет прикрепляться. То есть property является еще и persistence.
При этом вы должны предварительно зарегистрировать ваше property в консоли (рисунок кликабельный):

Все подробно расписано здесь и в api.
Отмечу, что для конкретного приложения вы можете отправлять до 25 properties (без учета properties, которые отправляются по умолчанию). Список properties, отправляемых по умолчанию, здесь.
Собственно в консоли вы можете фильтровать все, что угодно, по properies и «аудитории» (про «аудиторию» скажем чуть ниже). Например, события (рисунки кликабельные):


Аналогом setUserProperty(...) в GA являются методы setCustomDimension(...) и setCustomMetric(...). Единственное, данные dimension и metric не являются sticky и persistence, и вам будет необходимо к каждому событию каждую сессию вручную прикреплять их.
Думаю, в каждом приложении есть как минимум два аналитических инструмента. Обычно их гораздо больше. Аналитики тоже прогрессивные люди и не стоят на месте. Но нам все это поддерживать. Да и плюс трафик. Так что же лучше сделать?
Есть очень хорошая гугловская статья, которая уже была упомянута мною, где описываются различные варианты.
Кратко представлю их, чтобы вы имели представление:
Чтобы настроить на своем проекте аналитику, вам нужно четко следовать данной документации. Есть уже встроенный в Android Studio плагин, который делает за вас половину работы. Если у вас все в первый раз, то процесс займет не более 15 минут. Хотите API? А вот и оно, довольно короткое и вроде понятное.
После настойки FA через Android Studio Assistant у себя в проекте вы заметите появление нового файла google-services.json. Это специальный файл, в котором прописаны все идентификаторы и пути, которые необходимы для работы в вашем приложении различных гугловских сервисов, в данном случае — для работы FA.
Также в ваш корневой build.gradle добавилась такая строчка:
dependencies {
classpath 'com.google.gms:google-services:3.0.0'
// ...
}Собственно google-services — это специальный плагин, который распарсивает google-services.json, преобразуя его в обычные строчки, используемые FA. А также google-services добавляет все необходимые зависимости для используемых гугловских сервисов (в нашем случае только для FA). Правда, для этого нужно в app/build.gradle в самом конце добавить:
apply plugin: 'com.google.gms.google-services'В google-services.json находится вся необходимая информация для подключения вашего проекта к Firebase, причем не только к аналитике, но и ко всем инстументам.
{
"project_info": {
"project_number": "887654601522",
"firebase_url": "https://fir-test3-4bab3.firebaseio.com",
"project_id": "fir-test3-4bab3",
"storage_bucket": "fir-test3-4bab3.appspot.com"
},
"client": [
{
"client_info": {
"mobilesdk_app_id": "1:887654601522:android:9c6c1c11f784b956",
"android_client_info": {
"package_name": "com.example.matsyuk.firebasetest3"
}
},
"oauth_client": [
{
"client_id": "887654601522-o8rolth1g5mq5qq650844chk07mib2un.apps.googleusercontent.com",
"client_type": 1,
"android_info": {
"package_name": "com.example.matsyuk.firebasetest3",
"certificate_hash": "82f13b732dec32c5ebd4498c3a7acf4bda23a846"
}
},
{
"client_id": "887654601522-4riqkg424gb236q6mqehksn03u4hoqqg.apps.googleusercontent.com",
"client_type": 3
}
],
"api_key": [
{
"current_key": "AIzaSyAYRPNTcgxWP7qUzI__kx9gSwxnIgc3iBo"
}
],
"services": {
"analytics_service": {
"status": 1
},
"appinvite_service": {
"status": 2,
"other_platform_oauth_client": [
{
"client_id": "887654601522-4riqkg424gb236q6mqehksn03u4hoqqg.apps.googleusercontent.com",
"client_type": 3
}
]
},
"ads_service": {
"status": 2
}
}
}
],
"configuration_version": "1"
}С помощью плагина google-services данный json преобразуется в набор строчек, сгенерированныч в файл your_project\app\build\generated\res\google-services\debug\values\values.xml:
887654601522-4riqkg424gb236q6mqehksn03u4hoqqg.apps.googleusercontent.com
https://fir-test3-4bab3.firebaseio.com
887654601522
AIzaSyAYRPNTcgxWP7qUzI__kx9gSwxnIgc3iBo
1:887654601522:android:9c6c1c11f784b956
AIzaSyAYRPNTcgxWP7qUzI__kx9gSwxnIgc3iBo
fir-test3-4bab3.appspot.com
Обратите внимание на такие строчки, как firebase_database_url, google_storage_bucket и т.д. Захотите подключить еще один инструмент от Firebase, в проекте у вас уже все будет готово для этого.
Подробнее про плагин и устройство google-services.json написано здесь.
А теперь рассмотрим жизненный пример. Есть у нас приложение Example с applicationId, равное, допустим, com.fa.example. И есть у нас в продукте flavors:
productFlavors {
dev {
applicationId "com.fa.example.dev"
}
qa {
applicationId "com.fa.example.qa"
}
prod {
// applicationId "com.fa.example"
}
}Далее мы хотим зарегистрировать проект в FA через Android Studio Assistant. Делаем все по инструкции и получаем в консоли проект Example, в котором три приложения:
И если вы посмотрите в проекте app/google-services.json, то в нем будет информация о ваших трех приложениях (трех flavors с разными applicationId). То есть для каждого flavor аналитика будет собираться отдельно.
Также отмечу, что вы можете самостоятельно скачать google-services.json с любого приложения вашего проекта. Но все google-services.json вашего проекта будут одинаковы и будут содержать информацию о всех приложениях в проекте.
Далее такая ситуация. Ваш проект Example настроен с FA. Но вам вдруг понадобилось добавить в проект еще один flavor с другим именем пакета. И для этого flavor вы также хотите собирать аналитику отдельно. Тогда вам необходимо сделать следующее:
Зарегистрировать новое приложение в проекте в консоли:

Скачать новый google-services.json (в котором будет информация о четырех приложениях в проекте) и подставить его вместо старого.
Теперь такой пример. Допустим, есть у вас в проекте buildTypes, и выглядят они в build.gradle-файле следующим образом:
buildTypes {
release {
}
ultra_debug {
applicationIdSuffix ".ultra_debug"
}
debug {
applicationIdSuffix ".debug"
}
}То есть для сборок ultra_debug и debug вы добавляете суффикс к имени пакета. Таким образом, у вас в проекте три вышеназванных buildTypes и три flavors:
productFlavors {
dev {
applicationId "com.fa.example.dev"
}
qa {
applicationId "com.fa.example.qa"
}
prod {
// applicationId "com.fa.example"
}
}Вы запускаете Android Studio Assistant для подключения к проекту FA. Как вы думаете, сколько будет зарегистрировано в консоли приложений и с какими именами пакетов?
Не догадаетесь =) Появятся в консоли такие приложения:
com.fa.example.debug
com.fa.example.dev.debug
com.fa.example.qa.debugПочему именно только с суффиксом «debug», осталось для меня загадкой. Так что имейте в виду данный баг.
Ну и заключительный пример.
У вас в проекте все также те самые три flavors. И вы хотите добавить в проекте еще один flavor (например, custom), но для него нет необходимости в другом applicationId, и при этом данный flavor тоже желательно отдельно от всех остальных просматривать с точки зрения аналитики:
productFlavors {
dev {
applicationId "com.fa.example.dev"
}
qa {
applicationId "com.fa.example.qa"
}
prod {
// applicationId "com.fa.example"
}
custom {
// applicationId "com.fa.example"
}
}Ситуация усложняется еще тем, что в консоли в проект вы не можете добавлять приложения с одинаковым applicationId. Как тогда быть? Делаем следующее:
com.fa.example.google-services.json.google-services.json следующим образом (выделено красным).
То есть в вашем андроидовском проекте будут лежать уже два google-services.json. При сборке google-services plugin сначала смотрит в папку конкретного flavor. Если в этой папке есть google-services.json, то плагин берет его. Если нет, то тогда берется google-services.json с app папки. Довольно удобно и гибко получается в итоге.
Вроде бы жизнь разработчика стала проще. Зарегистрировал проект в консоли, скачал google-services.json, закинул в app/ (ну это все в случае без flavors и прочего), и все, больше ни о чем не думаешь. Но иногда бывает необходимость на лету переключить канал аналитики. И если в GA вы могли задавать в коде id, то в FA пока что такая возможность отсутствует. И были у меня надежды сначала на такую конструкцию (взято с SO):
FirebaseOptions options = new FirebaseOptions.Builder()
.setApplicationId("bla-bla") // Required for Analytics.
.setApiKey("bla-bla") // Required for Auth.
.setDatabaseUrl("bla-bla") // Required for RTDB.
.build();
FirebaseApp.initializeApp(this /* Context */, options, "secondary");Но выдается ошибка «Missing google_app_id. Firebase Analytics disabled». Команда Firebase знает про это и постепенно работает над данной проблемой.
Более подробно про все описанные примеры вы можете прочитать в вышеназванной статье про google-services-плагин и здесь.
В GA есть метод setLocalDispatcher(...). С помощью него мы можем задавать интервал периодической отправки данных. Хорошо, что FA заботится о нас и нашем трафике и не дает нам возможность самим регулировать данный параметр. Но в GA с помощью метода setLocalDispatcher(-1) мы можем отменить автоматическую отправку событий, а с методом dispatchLocalHits() вручную отправлять накопившиеся события. Это очень удобно, когда, например, мы не хотим отправлять события до принятия соглашения и т.д.
У FA подобной возможности накопления и отправки событий нет, придется все руками делать.
Зато хотя бы есть метод setAnalyticsCollectionEnabled(boolean enabled), с помощью которого мы можем включать и отключать аналитику. Например, если мы не хотим отправлять аналитику до принятия пользователем нужного соглашения, то в манифесте прописываем:
А потом, когда нужно, в коде вызовем:
setAnalyticsCollectionEnabled(true);Также можно отключить аналитику на постоянной основе. То есть даже вызов setAnalyticsCollectionEnabled(true) не поможет. Для этого в манифесте прописываем:
Информация взята из данной статьи.
В FA события с реальных устройств приходят в консоль лишь спустя сутки. И в начале не было возможности просмотреть действия пользователя в реальном времени. Чтобы увидеть первые данные, приходилось ждать целые сутки. Сейчас же вы можете воспользоваться вкладкой StreamView/DebugView (рисунок кликабельный):

На картинке выше представлен StreamView, на котором вы можете наблюдать, как себя ведут пользователи в данный момент времени. Также вы можете выбрать режим Snapshot (кнопка User snapshot справа снизу), и вам покажутся действия случайно выбранного пользователя (рисунок кликабельный):

Подобным образом выглядит и DebugView. Наконец-то отлаживаться можно в режиме реального времени. Вы будете видеть все events и properties, которые посылаются вашим приложением, включая и events c properties по умолчанию. Как можно представить, до DebugView процесс отладки был воистину ужасным.
О StreamView и DebugView хорошо расписано здесь.
Что в GA, что в FA, все мы видим такие слова, как «сессия», «количество событий за сессию» и т.д. И, наверное, может сложиться впечатление, что сессия = время жизни процесса. Но это не так. Сессия — это просто временной промежуток, в течение которого ваше приложение активно (находится в foreground). В API FA есть такие методы:
setMinimumSessionDuration (long milliseconds); // default 10 sec
setSessionTimeoutDuration (long milliseconds); // default 30 minТо есть если вы запустили приложение и убили его менее чем за minimumSessionDuration, то сессия даже не начнется. Если же запущенное приложение находится в foreground более minimumSessionDuration, то сессия стартует.
Если ваше приложение было выгружено системой, но оно успело подняться до истечения sessionTimeoutDuration, то это все будет одна сессия. Если вы запустили приложение, что-то поделали там, потом вышли из него (то есть приложение не в foreground), и только через sessionTimeoutDuration+ зашли обратно (при этом приложение не было убито, к примеру), то первая сессия завершится и стартует вторая.
Вы можете формировать разные аудитории, по которым в дальнейшем можно выставлять фильтры, организовывать компании и т.д. Как это выглядит (рисунок кликабельный):

Создание новой «аудитории» (рисунок кликабельный):

Допустим, вам нужна аудитория «Мужчины из России, которые прошли регистрацию». Тогда при создании «аудитории» вы выбираете properties «country» = «Russia» и «sex» = «male» и event «reg_comleted» (это уже ваш кастомный event) = «true».
На этой вкладке у вас есть возможность строить разные воронки (рисунок кликабельный):

Очень нравится маркетологам это делать =)
Отмечу, что подобный функционал есть и у GA.
Есть еще вкладки Attribution и Cohorts. Но, честно говоря, я ими вообще не пользовался. Для чего они нужны, лучше распишут аналитики.
Полное описание консоли можно прочитать здесь.
Немаленькая у нас в итоге получилась статья. Давайте попробуем подвести итоги.
Плюсы:
Минусы:
Меня часто спрашивают, так стоит ли использовать FA или нет. Может, вполне достаточно GA? Или сразу обе аналитики не достойны места в вашем продукте?
Однозначного ответа нет. Все очень зависит от потребностей ваших аналитиков и маркетологов. А также зависит от способностей ваших аналитиков осилить BigQuery. Все-таки мы, разработчики, — это «пехотинцы продукта», особенно в части аналитики. Что нам скажут, то мы и будем делать. Но лично я бы смотрел в сторону связки FA + BigQuery. Уж очень она крутая, и вы никак не ограничены возможностями консоли.
Большое спасибо, что дочитали до конца! Пишите комментарии, дополняйте и поправляйте! Сделаем нашу разработческую жизнь лучше!
P.S. Большое спасибо хочу сказать Тимуру Ахметгарееву за помощь и за то, никогда не бросал в беде =)
P.P.S. И еще добавлю. 16 сентября 2017 совместно с независимым сообществом разработчиков MOSDROID мы организовываем вечернюю встречу для всех, кто заинтересован в разработке под Android. По традиции, мы подготовили для вас несколько докладов. Ждём всех желающих. Зарегистрироваться на встречу можно здесь.
|
|
[Перевод] Пишем оператора для Kubernetes на Golang |

Namespace представляет окружение-песочницу какой-то команды, и мы хотели ограничить доступ к ним так, чтобы команды могли играть только в своих песочницах.RoleBinding к конкретным Namespace и ClusterRole с правом на редактирование. YAML-представление будет выглядеть так:---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: kubernetes-team-1
namespace: team-1
subjects:
- kind: Group
name: kubernetes-team-1
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: edit
apiGroup: rbac.authorization.k8s.ioRoleBinding можно и вручную, но после преодоления отметки в сотню пространств имён это становится утомительным занятием. Как раз здесь помогают операторы Kubernetes — они позволяют автоматизировать создание ресурсов Kubernetes, основываясь на изменениях в ресурсах. В нашем случае мы хотим создавать RoleBinding при создании Namespace.main, которая выполняет требуемую настройку для запуска оператора и затем вызывает действие оператора:func main() {
// Устанавливаем вывод логов в консольный STDOUT
log.SetOutput(os.Stdout)
sigs := make(chan os.Signal, 1) // Создаем канал для получения сигналов ОС
stop := make(chan struct{}) // Создаем канал для получения стоп-сигнала
// Регистрируем получение SIGTERM в канале sigs
signal.Notify(sigs, os.Interrupt, syscall.SIGTERM, syscall.SIGINT)
// Goroutines могут сами добавлять себя в WaitGroup,
// чтобы завершения их выполнения дожидались
wg := &sync.WaitGroup{}
runOutsideCluster := flag.Bool("run-outside-cluster", false, "Set this flag when running outside of the cluster.")
flag.Parse()
// Создаем clientset для взаимодействия с кластером Kubernetes
clientset, err := newClientSet(*runOutsideCluster)
if err != nil {
panic(err.Error())
}
controller.NewNamespaceController(clientset).Run(stop, wg)
<-sigs // Ждем сигналов (до получения сигнала более ничего не происходит)
log.Printf("Shutting down...")
close(stop) // Говорим goroutines остановиться
wg.Wait() // Ожидаем, что все остановлено
}WaitGroup, чтобы корректно остановить все функции Go перед завершением работы приложения.clientset.NamespaceController, в котором будет расположена вся наша логика.NamespaceController:// NamespaceController следит через Kubernetes API за изменениями
// в пространствах имен и создает RoleBinding для конкретного namespace.
type NamespaceController struct {
namespaceInformer cache.SharedIndexInformer
kclient *kubernetes.Clientset
}
// NewNamespaceController создает новый NewNamespaceController
func NewNamespaceController(kclient *kubernetes.Clientset) *NamespaceController {
namespaceWatcher := &NamespaceController{}
// Создаем информер для слежения за Namespaces
namespaceInformer := cache.NewSharedIndexInformer(
&cache.ListWatch{
ListFunc: func(options metav1.ListOptions) (runtime.Object, error) {
return kclient.Core().Namespaces().List(options)
},
WatchFunc: func(options metav1.ListOptions) (watch.Interface, error) {
return kclient.Core().Namespaces().Watch(options)
},
},
&v1.Namespace{},
3*time.Minute,
cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc},
)
namespaceInformer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: namespaceWatcher.createRoleBinding,
})
namespaceWatcher.kclient = kclient
namespaceWatcher.namespaceInformer = namespaceInformer
return namespaceWatcher
}SharedIndexInformer, который будет эффективно (используя кэш) ожидать изменений в пространствах имён (подробнее об informers читайте в статье «Как на самом деле работает планировщик Kubernetes?» — прим. перев.). После этого мы подключаем EventHandler к информеру, благодаря чему при добавлении пространства имён (Namespace) вызывается функция createRoleBinding.createRoleBinding:func (c *NamespaceController) createRoleBinding(obj interface{}) {
namespaceObj := obj.(*v1.Namespace)
namespaceName := namespaceObj.Name
roleBinding := &v1beta1.RoleBinding{
TypeMeta: metav1.TypeMeta{
Kind: "RoleBinding",
APIVersion: "rbac.authorization.k8s.io/v1beta1",
},
ObjectMeta: metav1.ObjectMeta{
Name: fmt.Sprintf("ad-kubernetes-%s", namespaceName),
Namespace: namespaceName,
},
Subjects: []v1beta1.Subject{
v1beta1.Subject{
Kind: "Group",
Name: fmt.Sprintf("ad-kubernetes-%s", namespaceName),
},
},
RoleRef: v1beta1.RoleRef{
APIGroup: "rbac.authorization.k8s.io",
Kind: "ClusterRole",
Name: "edit",
},
}
_, err := c.kclient.Rbac().RoleBindings(namespaceName).Create(roleBinding)
if err != nil {
log.Println(fmt.Sprintf("Failed to create Role Binding: %s", err.Error()))
} else {
log.Println(fmt.Sprintf("Created AD RoleBinding for Namespace: %s", roleBinding.Name))
}
}obj и преобразуем его в объект Namespace. Затем определяем RoleBinding, основываясь на упомянутом в начале YAML-файле, используя предоставленный объект Namespace и создавая RoleBinding. Наконец, логируем, успешно ли прошло создание.Run:// Run запускает процесс ожидания изменений в пространствах имён
// и действия в соответствии с этими изменениями.
func (c *NamespaceController) Run(stopCh <-chan struct{}, wg *sync.WaitGroup) {
// Когда эта функция завершена, пометим функцию go как выполненную
defer wg.Done()
// Инкрементируем wait group, т.к. собираемся вызвать функцию go
wg.Add(1)
// Вызываем функцию go
go c.namespaceInformer.Run(stopCh)
// Ожидаем получения стоп-сигнала
<-stopCh
}WaitGroup, что запустим функцию go и затем вызываем namespaceInformer, который был предварительно определён. Когда поступит сигнал остановки, он завершит функцию go, сообщит WaitGroup, что больше не выполняется, и эта функция завершит свою работу.RoleBinding при появлении Namespace в кластере Kubernetes, готов.|
Метки: author shurup open source go блог компании флант kubernetes devops |
Нам нечего скрывать – все честно в HPE 3PAR Data Reduction Guarantee |

| Рабочая нагрузка | Коэффициент экономии емкости |
|---|---|
| VDI | 2,5 – 6,0 |
| Виртуализация серверов | 1,5 – 2,5 |
| СУБД | 2,0 – 3,5 |
|
Метки: author vlad_msk_ru хранение данных сжатие данных блог компании hewlett packard enterprise hpe 3par 3par data reduction thin provisioning ssd |
[Перевод] Moving Java forward faster |
Недавно в мире Java случилось пара важных событий: Марк Рейнхольд опубликовал письмо, в котором предложил перейти на полугодовой график релизов Java, а за этим последовало сообщение от Oracle, где они предлагают ряд серьезных измненеий в работе над OpenJDK:
Несмотря на то, что коммерческая версия Oracle JDK останется, целью компании станет сделать ее полностью совместимой и взаимозаменяемой с OpenJDK (до конца 2018).
Как мне кажется, это очень важный и нужный шаг для Java как платформы. Ниже я предлагаю перевод письма Марка, которые поясняет как будет работать новый график релизов.
На протяжении более чем 20 лет, платформа Java SE и JDK двигались вперед большими, нерегулярными и непредсказуемыми шагами. Каждый feature-release определялся какой-то основной фичей и график релиза менялся — иногда и не один раз! — чтобы подстроится под график разработки этой фичи.
Этот подход сделал возможным включение нового функционала в релиз с высочайшим качеством, после тщательного ревью и тестирования. Недостатком этого подхода, однако, является то, что более мелкие фичи API, языка и платформы могут быть включены только в финальный релиз, когда главная фича готова.
Это был разумный компромисс десятилетиям до и после начала века, когда конкурентами Java были всего несколько платформ, которые развивались такими же медленными темпами. В наши дни, однако, конкуренты Java развиваются гораздо быстрее.
Чтобы Java могла оставаться конкурентоспособной, мы должны не просто двигаться вперед — мы должны двигаться быстро.
Пять лет назад я размышлял в этом блоге о разнице между разработчиками, которые предпочитают быстрые инновации, и энтерпрайзом, который предпочитает стабильность, а так же фактом, что все, в сущности, предпочитают регулярные и предсказуемые релизы.
Чтобы решить проблемы и тех, и других, я тогда предолжил что мы должны перейти с исторической модели релизов, где релиз определяется набором фич, к модели "поезда", когда релиз выходит строго по расписанию, раз в два года. С таким подходом, разработка может не подстраиваться под релиз и заниматься инновациями, а релиз, независимо от разработки, имеет постоянный график. Любая фича, большая или маленькая, включается в релиз только когда (почти) полностью готова. Если разработка фичи не успевает на текущий релизный "поезд" — это неприятно, но не конец света, т.к. следующий "поезд" отправиться строго по расписанию.
Модель "поезда" с двухгодичным графиком выглядела неплохо в теории, но доказала свою неработоспособность на практике. Нам потребовалось дополнительные 8 месяцев для Java 8 чтобы закрыть критические проблемы безопасности и закончить проект "Лямбда", и это было предпочтительнее, чем откладывать лямбды на два года. Изначально мы даже планировали Java 9 как 2.5 годичный релиз, чтобы включить туда Project Jigsaw, чтобы не задерживать его на 18 месяцев до следующего "поезда". Но в конец-концов нам потребовался еще один год на доработку, и Java 9 выйдет только в этом месяце, через 3.5 года после Java 8.
Оглядываясь назад можно сказать, что двухгодичный цикл релизов просто слишком медленный. Чтобы добиться регулярного графика мы должны выпускать релизы гораздо чаще. Перенос фичи на следующий релиз должен представлять собой тактическое решение с минимумом неудобств, вместо глобального решения с серьезными последствиями.
Итак, мое предложение: давайте выпускать релизы каждые шесть месяцев.
Это достаточно быстро, чтобы избежать проблем от ожидания следующего релиза, но достаточно медленно, чтобы релизы могли оставаться высокого качества.
Воодушевившись примером релизного графика других платформ и операционных систем, я предлагаю, после релиза Java 9, перейти на строгий, регулярный график релизов с новым feature-релизом каждые шесть месяцев, update-релизом каждый квартал и LTS (long term support) релизом каждые три года.
При такой модели общая скорость изменений должна быть такой же, как сегодня. Однако ключевое отличие, что у разработчиков JDK будет гораздо больше возможностей выпускать новые фичи. Полугодовой feature-релиз будет меньше, чем многолетний релиз с кучей новых фич в прошлом, и поэтому на него будет проще переходить. Полугодовой релиз так же уменьшит сложности с портированием кода в старые релизы (backport), т.к. разница между ними не будет превышать 6 месяцев.
Разработчики, которые предпочитают инновации и новые фичи смогут использовать новые feature-релизы или последние доступные update-релизы. Они смогут упаковывать приложения в Докер контейнеры, или любые другие типы контейнеров, указывая точную версию Java, которая им необходима. С таким подходом, т.к. новый релиз Java и приложение могут быть легко протестированы на совместимость с помощью современных CI/CD pipeline-ов, переход на новый релиз будет простым.
Энтерпрайзные разработчики, которые предпочитают стабильность, чтобы они могли запускать несколько больших приложений на одном, общем Java-релизе, смогут использовать LTS вместо feature-релизов. Так же они смогут планировать обновление на следующий LTS строго по расписанию, каждые три года.
Чтобы ориентироваться в новых релизах со строгим графиком и чтобы легко понять, когда был выпущен тот или иной релиз, версия релиза будет выглядеть как $YEAR.$MONTH. То есть, следующий мартовский релиз будет 18.3, а сентябрьский LTS будет 18.9.
Это предложение, если будет принято, потребует серьезных изменений в том, как контрибьюторы в OpenJDK Community производят непосредственно JDK. Я изложил ряд мыслей на этот счет. Этот процесс будет гораздо проще, если мы сможем уменьшить накладные расходы, создаваемые Java Community Process, которые курирует развитие платформы Java SE; мои коллеги Брайн Гетз и Джордж Саб уже подняли этот вопрос на обсуждения с JCP Executive Committee.
Это предложение в конце-концов, затронет каждого разработчика, пользователя и компанию, которые полагаются на Java. Оно так же, если будет успешно внедрено, поможет Java оставаться конкурентоспособной, однако по прежнему опираться на набор таких ценностей, как обратная совместимость, надежность и продуманное развитие на многие годы вперед.
|
Метки: author alek_sys java openjdk oracle java 9 |
[Перевод] PostgreSQL: материализованные представления и FWD |
Вы наверняка знаете, что в Postgres есть материализованные представления (materialized views) и обертки сторонних данных (foreign data wrappers, FWD). Материализованные представления позволяют материализовывать запросы и обновлять их по требованию. Обертки сторонних данных предоставляют функциональность загрузки данных из внешних источников, таких как, например, NoSQL-хранилища или другие серверы Postgres.
Вероятно, что вариант использования материализованных представлений совместно с обертками сторонних данных вы еще не рассматривали. Материализованные представления ускоряют доступ к данным: результаты запросов сохраняются и отпадает необходимость выполнять их еще раз. Доступ к сторонним данным через FWD может быть довольно медленным, поскольку они находятся в других системах. Объединив эти функции, можно в итоге получить быстрый доступ к сторонним данным.
Давайте подтвердим это практикой! Для начала создадим стороннюю таблицу (foreign table):
CREATE DATABASE fdw_test;
\connect fdw_test;
CREATE TABLE world (greeting TEXT);
\connect test
CREATE EXTENSION postgres_fdw;
CREATE SERVER postgres_fdw_test FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host 'localhost', dbname 'fdw_test');
CREATE USER MAPPING FOR PUBLIC SERVER postgres_fdw_test
OPTIONS (password '');
CREATE FOREIGN TABLE other_world (greeting TEXT)
SERVER postgres_fdw_test
OPTIONS (table_name 'world');
\det
List of foreign tables
Schema | Table | Server
--------+-------------+-------------------
public | other_world | postgres_fdw_test
заполним ее данными:
INSERT INTO other_world
SELECT *
FROM generate_series(1, 100000);и создадим материализованное представление на основе сторонней таблицы:
CREATE MATERIALIZED VIEW mat_view (first_letter, count) AS
SELECT left(greeting, 1), COUNT(*)
FROM other_world
GROUP BY left(greeting, 1);Теперь мы можем сравнить время выборки из сторонних таблиц и материализованных представлений:
\timing
SELECT left(greeting, 1) AS first_letter, COUNT(*)
FROM other_world
GROUP BY left(greeting, 1);
first_letter | count
--------------+-------
1 | 11112
2 | 11111
3 | 11111
4 | 11111
5 | 11111
6 | 11111
7 | 11111
8 | 11111
9 | 11111
Time: 354.571 ms
SELECT * FROM mat_view;
first_letter | count
--------------+-------
1 | 11112
2 | 11111
3 | 11111
4 | 11111
5 | 11111
6 | 11111
7 | 11111
8 | 11111
9 | 11111
Time: 0.783 msМатериализованное представление оказалось намного быстрее, однако не все так радужно, поскольку его обновление (refresh) занимает практически столько же времени, сколько и выборка из сторонней таблицы:
REFRESH MATERIALIZED VIEW mat_view;
Time: 364.889 msВышеприведенные команды выполнялись в Postgres 9.6. Однако уже в десятой версии появилось вот такое улучшение:
Выполнение агрегатных функций на серверах FWD, когда это возможно (Jeevan Chalke, Ashutosh Bapat).
Благодаря ему удается уменьшить объем передаваемых от FWD-сервера данных, а также снять с запрашивающего сервера нагрузку по агрегированию. Эта оптимизация реализована в обертке сторонних данных postgres_fdw, которая также умеет выполнять соединения (join) на сторонних серверах (используя расширения).
В Postgres 10 агрегаты сторонних таблиц выполняются быстрее, чем в 9.6, но все же пока медленнее, чем выборки из материализованных представлений:
SELECT left(greeting, 1) AS first_letter, COUNT(*)
FROM other_world
GROUP BY left(greeting, 1);
first_letter | count
--------------+-------
1 | 11112
2 | 11111
3 | 11111
4 | 11111
5 | 11111
6 | 11111
7 | 11111
8 | 11111
9 | 11111
Time: 55.052 msИспользовать агрегаты в материализованных представлениях совсем не обязательно — можно просто скопировать стороннюю таблицу целиком и обновлять соответствующую вьюшку по необходимости (но логическая репликация в Postgres 10 подходит для этого еще лучше):
CREATE MATERIALIZED VIEW mat_view2 AS
SELECT *
FROM other_world;Теперь мы можем сравнить скорость выполнения запроса к сторонней таблице и ее локальной копии:
\o /dev/null
SELECT *
FROM other_world;
Time: 317.428 ms
SELECT * FROM mat_view2;
Time: 34.861 msВ заключение отмечу, что материализованные представления и обертки сторонних данных отлично работают вместе. С помощью материализованных представлений можно создавать локальные копии (кэши) внешних таблиц целиком или агрегированных данных (выборок) из этих таблиц. Обновить такой кэш очень просто: refresh materialized view. При этом в Postgres 10 появились улучшения, которые ускоряют запросы с агрегатными функциями к сторонним таблицам.
Ссылки:
|
Метки: author olemskoi sql postgresql блог компании southbridge postgres fdw materialized view |
От Торонто до Томска: подведение итогов и планирование будущих семинаров по микроэлектронике в России |









|
|
Как, а точнее где мы будем работать через 10 лет |



|
|
Практика формирования требований в ИТ проектах от А до Я. Часть 6. Поведение системы. Совершенстваоние требований |
В очень многих случаях поведение … только потому кажется смешным, что причины его, вполне разумные и основательные, скрыты от окружающих.
Франсуа де Ларошфуко

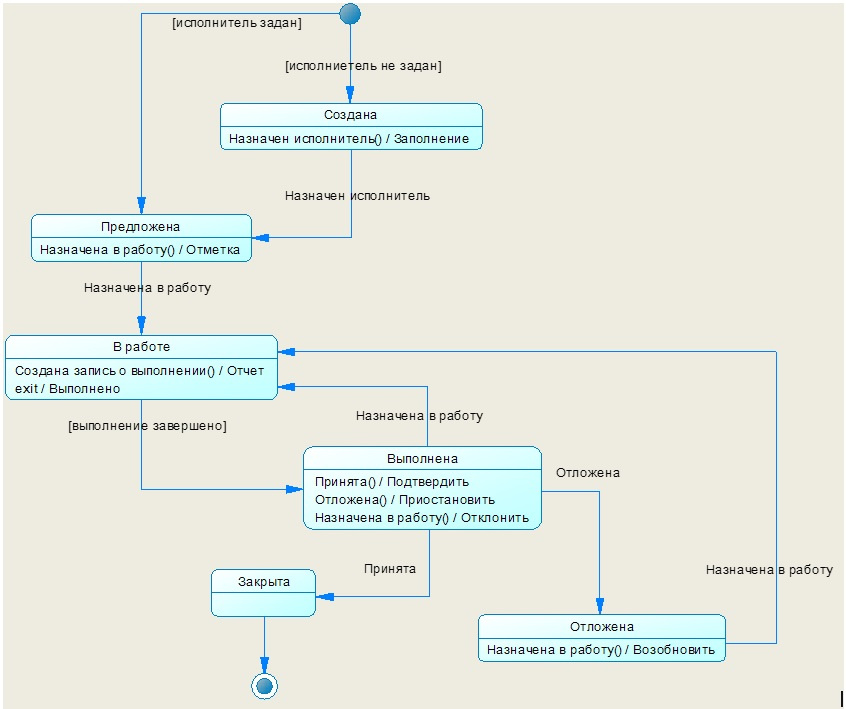
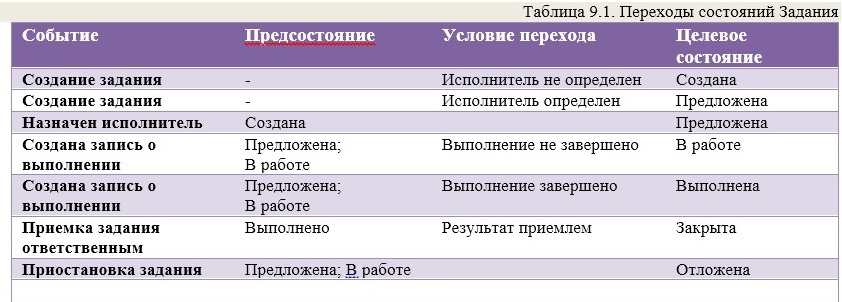

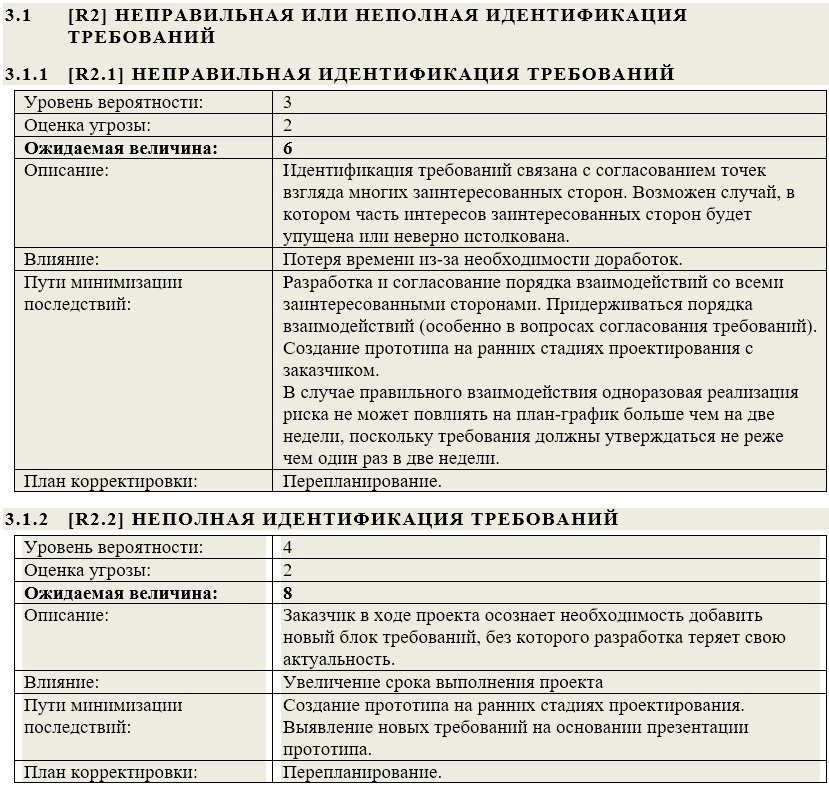
|
|
[Перевод] Это не статья — просто пища для размышлений о том, как её писать |

Статья про «отличную идею» |
«У меня просто была эта замечательная идея! Не знаю была ли у кого-нибудь еще такая же, потому что я не проверял, к тому же я новичок в этой области. В любом случае, моя идея блестящая, поэтому я действительно хотел бы поделиться ею со всеми вами». |
| Статья про «идеи других людей» | «Я только что прочитал эту замечательную книгу, которая мне очень нравится. Я просто резюмирую для вас интересные моменты из неё». |
| Статья «ИТ хакера» | «Я только что разработал эту замечательную программу. Она не основана на каких-либо предыдущих теориях или эмпирических выводах. Да, и сам я не особо теоретик, но в системе много фантастических функций, и интерфейс по-настоящему прекрасен». |
| Статья «хакера-теоретика» | «Я придумал эту теорию, концептуальный инструментарий, модель. Они не связаны с другими теориям, концептуальными инструментариями, моделями или с какими-либо эмпирическими данными. Большинство понятий были определены иначе светилами в данной области, но мне не нравятся их категории, поэтому я придумал свои собственные.» |
| Статья «со множеством идей» | «Я только что завершил крупную исследовательскую работу, где я сделал много интересного. Я думаю, что вы могли бы многому научиться, прочитав эту статью, описывающую все аспекты моей работы.» |
«Трассировка лучей зарекомендовала себя в последние годы как самый общий алгоритм синтеза изображений [10]. Исследователи изучили расчеты пересечения лучей с поверхностями для ряда поверхностных примитивов. К ним относятся шахматные доски [Whitted 80]; хромированные шары [Whitted 80]; манипуляторы [Barr 82]; синие абстрактные вещи [Hanrahan 82]; больше стеклянных шаров [Watterberg 83]; мандрилы [Watterberg 83]; больше мандрилов [Sweeney 83]; зеленые фрактальные холмы [Kajiya 83]; больше стеклянных шаров [SEDIC 83]; водные бесформенные вещи [Kaw 83]; больше хромированных шаров [Heckbert 83]; бильярдные шары [Porter 84]; больше стеклянных шаров [Kajiya 86].
К сожалению, никто не делал трассировку лучей для продуктов питания. До настоящего времени наиболее реалистичными продуктами были классические изображения апельсина и клубники Блинна, но они были созданы с помощью алгоритма построчного сканирования [2]. Проект „Dessert Realism Project“ в Pixar затрагивает эту проблему. В этой статье представлена новая технология трассировки лучей для ограниченного класса десертов, в частности, желатина марки Jell-O. Мы полагаем, что этот метод может применяться к другим маркам желатина и, возможно, к пудингу.
Данная статья делится на три части: метод моделирования статического Jell-O, моделирование движения Jell-O с использованием впечатляющей математики и вычисления пересечения лучей с Jell-O.»
«Трассировка лучей зарекомендовала себя в последние годы как самый общий алгоритм синтеза изображений [10]. Исследователи изучили расчеты пересечения лучей с поверхностями для ряда поверхностных примитивов.»
«К сожалению, никто не делал трассировку лучей для продуктов питания. До настоящего времени наиболее реалистичными продуктами были классические изображения апельсина и клубники Блинна, но они были созданы с помощью алгоритма построчного сканирования [2]. Проект „Dessert Realism Project“ в Pixar затрагивает эту проблему.»
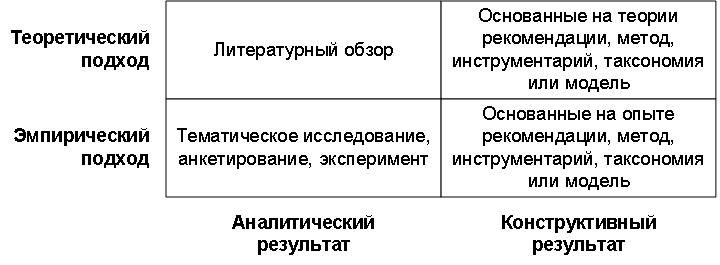
| Серебряной пули нет — сущность и акциденция в программной инженерии (Brooks Jr., 1987) |
Будущее вычислений (Dahlbom and Mathiassen, 1994) |
| 1. Введение. Из всех монстров, которые наполняют кошмары нашего фольклора, ничто не пугает больше, чем оборотни, потому что они неожиданно превращаются из чего-то хорошо знакомого в нечто ужасное. Для них ищут пули из серебра, которые могут волшебным образом уложить их. Хорошо знакомый программный проект, по крайней мере, как кажется менеджеру-не технарю, обладает схожим характером; он обычно безопасен и прост, но способен стать монстром сорванных сроков, раздутых бюджетов и глючных продуктов. И мы слышим отчаянные крики о серебряной пуле — о чем-то, что снижает затраты на программное обеспечение так же быстро, как снижаются затраты на компьютерное оборудование. Но на горизонте предстоящего десятилетия мы не видим никакой серебряной пули. Нет единственной разработки ни в технологиях, ни в методах управления, которая сама по себе обещает хотя бы на один порядок повысить производительность, надежность и простоту. В данной статье я попытаюсь показать, почему это так, исследуя природу проблемы программного обеспечения и свойства предлагаемых пуль. Однако скептицизм — это не пессимизм. Хотя мы не видим поразительных прорывов — и, действительно, я считаю их несовместимыми с природой программного обеспечения — многие обнадеживающие инновации идут полным ходом. Дисциплинированные и последовательные усилия по разработке, распространению и использованию этих нововведений действительно должны привести к улучшению на порядок. Нет царской дороги, но все же дорога есть. |
1. От часов к нашему времени. В четырнадцатом веке в городах Европы стало очень модно инвестировать в технологию часовых механизмов. Часы обычно устанавливались в церковных башнях, чтобы их было видно по всему городу. Они изготавливались на месте часовыми мастерами, которые обычно там же и останавливались, чтобы управлять обслуживанием часового механизма и в процессе обучать этому мастерству своих сыновей. [...] Будучи успешной технологией, часы распространяются по всей Европе, превращая часовщиков в мощную и уважаемую профессию. Но успех технологии способствовал ее развитию, и постепенно технология меняла свой характер. Появились и стали успешными домашние и персональные часы. Огромный объем производства сделал ремесленников устаревшими, заменив их промышленным производственным процессом. Децентрализованное и широкое использование часов превратило городские часы больше в символический, чем функциональный артефакт. Часы теперь более важны, чем когда-либо, но специалисты по часовым механизмам исчезли. Параллели между развитием часовых и компьютерных технологий очевидны. Что они говорят нам о будущем нашей профессии? Специалисты часового дела играли ведущую роль в разработке технологии, которая резко изменила жизнь европейцев и косвенно изменила весь мир. Но как профессионалы, они в действительности не участвовали в этих изменениях или не оценили их. Когда процесс, который они спровоцировали, шел полным ходом, он вывел их из бизнеса. Пойдем ли мы по пути профессионалов часового дела? Или мы сможем активно влиять на будущее нашей профессии? |
«Настоящая статья представляет собой тематическое исследование качественной оценки программы. Автор отслеживал все изменения, внесенные в TeX, в течение десяти лет, включая изменения, внесенные, когда программа была впервые отлажена в 1978 году. Журнал этих ошибок, насчитывающий более 850 элементов, приведен в приложении к данной статье. Ошибки были отнесены к пятнадцати категориям для целей анализа, и некоторые из примечательных ошибок рассматриваются детально. История проекта TeX может дать ценные уроки о подготовке хорошо портируемого программного обеспечения и сопровождении программ, стремящихся к высоким стандартам надежности.»
|
Метки: author Ares_ekb учебный процесс в it исследования и прогнозы в it блог компании ооо «цит». наука аспирантура диссертация |
Искусственный интеллект для ритейла: продажники уровня Скайнет, отзывы уровня Бог |
|
Метки: author LeJay читальный зал хакатоны исследования и прогнозы в it искусственный интеллект продажник уровня скайнет |
Как оптимально рассчитать объем «железа»: сайзинг-модель ЕФС |

| Внутренняя сеть |
|
| Наименование |
Комментарий |
| Пиковое количество бизнес-операций за час |
Берется из бизнес-требований либо рассчитывается: операций за сутки/10 |
| Среднее количество бизнес-операций за сутки |
Берется из бизнес-требований либо рассчитывается: операций за час*10 |
| Пиковое количество запросов через MQ в секунду (прямая интеграция с внешними системами) |
Сумма по взаимодействиям точка-точка через MQ |
| Внешняя сеть |
|
| Наименование |
Комментарий |
| Пиковое количество бизнес-операций за час |
Берется из бизнес-требований либо рассчитывается: операций за сутки/10 |
| Среднее количество бизнес-операций за сутки |
Берется из бизнес-требований либо рассчитывается: операций за час*10 |
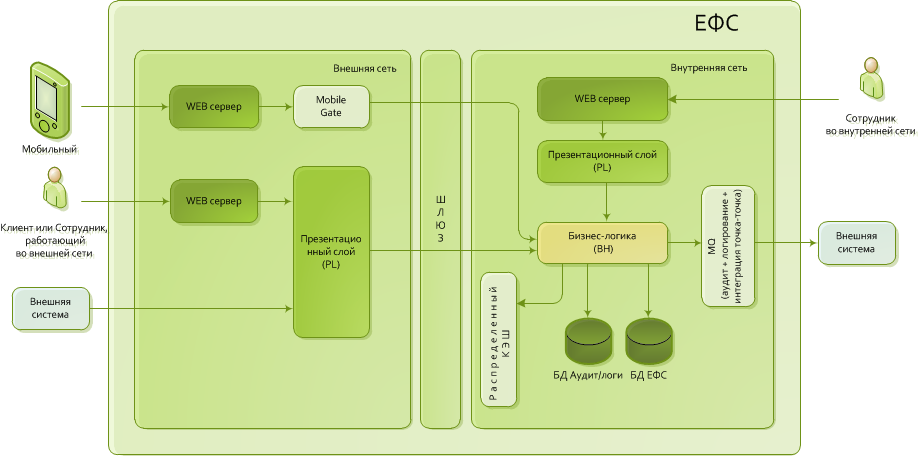
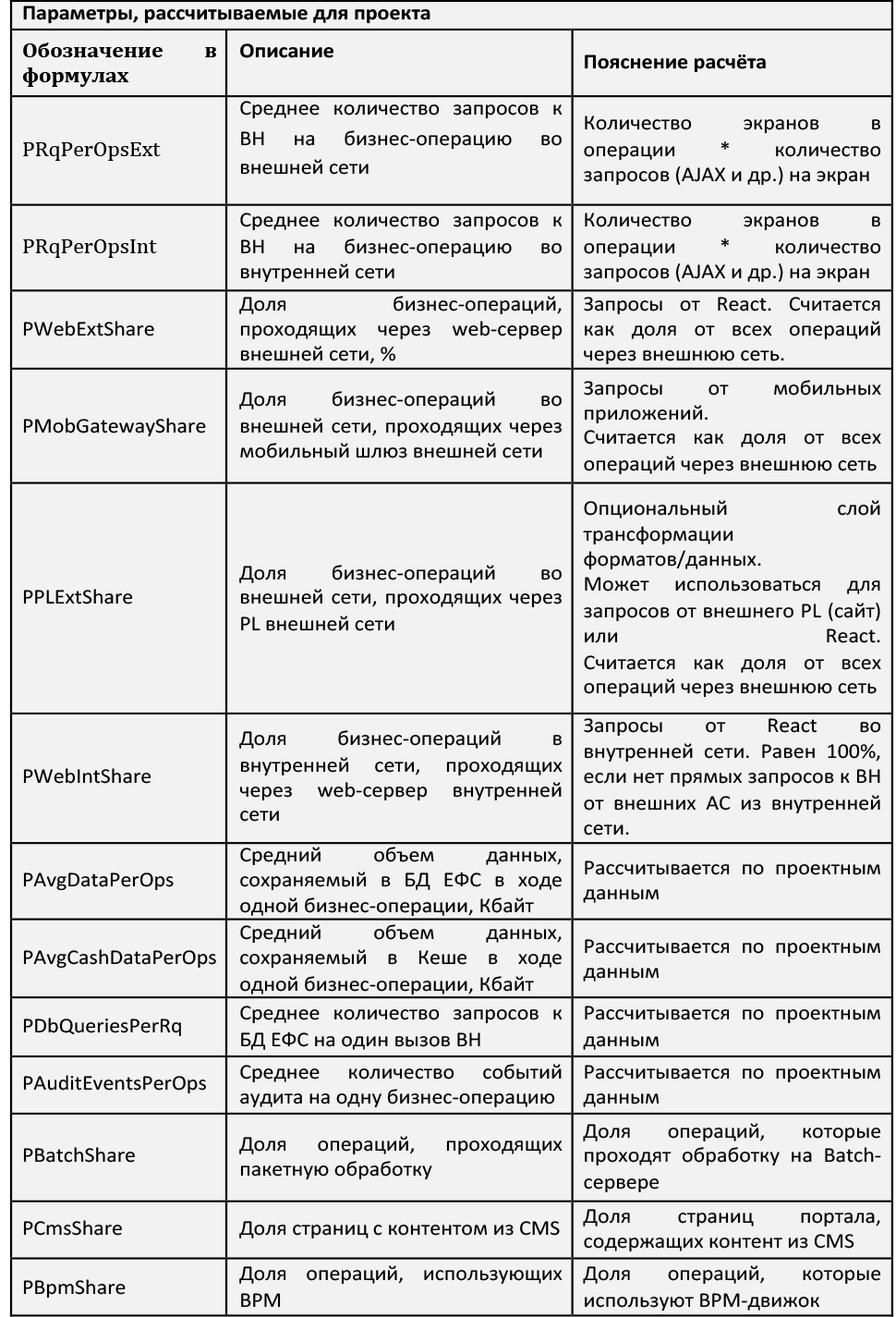
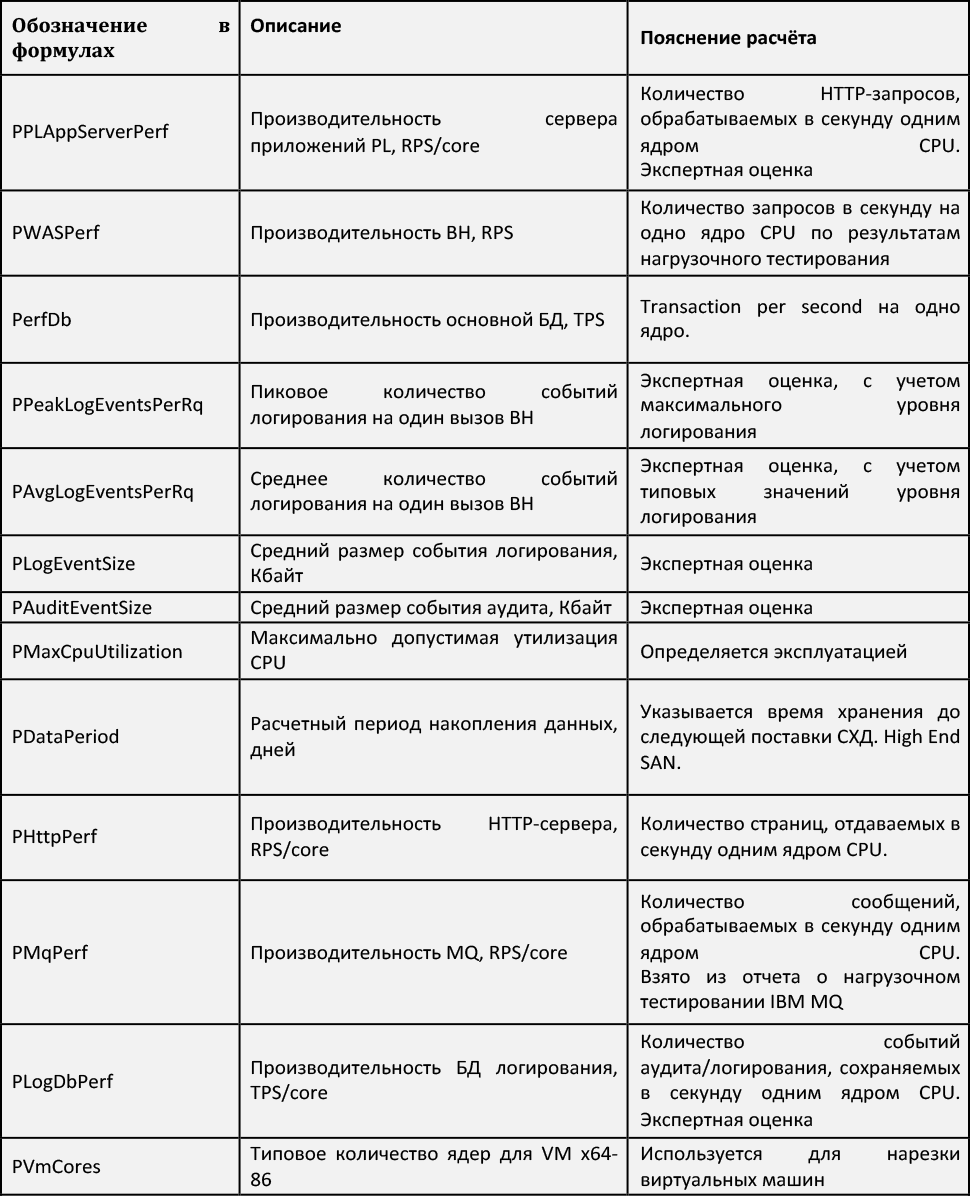
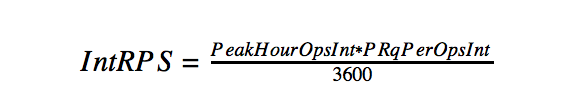
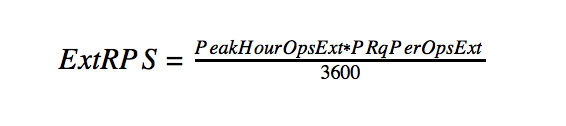

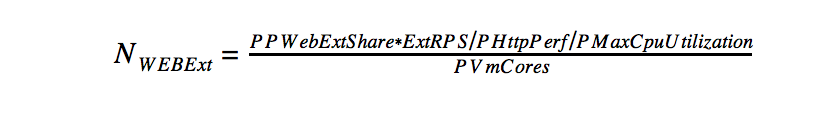


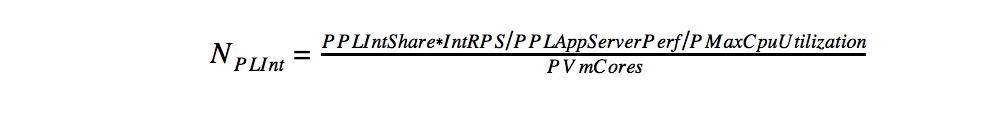

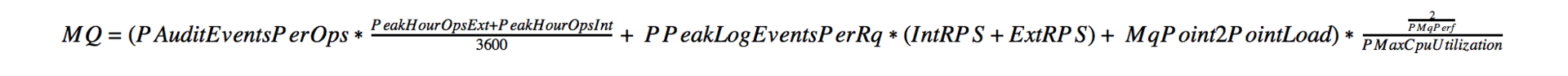


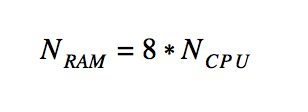

|
Метки: author EFS_programm серверное администрирование it- инфраструктура железо сайзинг |






