Продвинутое конфигурирование Docker Compose (перевод) |
version: '2'
services:
web:
build: .
ports:
- "80:8000"
depends_on:
- db
entrypoint: "./wait-for-it.sh db:5432"
db:
image: postgres$ TAG="latest"
$ echo $TAG
latest
$ DB="postgres"
$ echo $DB
postgresdb:
image: "${DB}:$TAG"web:
environment:
- PRODUCTION=1$ PRODUCTION=1
$ echo $PRODUCTION
1COMPOSE_API_VERSION
COMPOSE_FILE
COMPOSE_HTTP_TIMEOUT
COMPOSE_PROJECT_NAME
DOCKER_CERT_PATH
DOCKER_HOST
DOCKER_TLS_VERIFY# ./.env
# для нашей промежуточной среды
COMPOSE_API_VERSION=2
COMPOSE_HTTP_TIMEOUT=45
DOCKER_CERT_PATH=/mycerts/docker.crt
EXTERNAL_PORT=5000$ docker-compose up -f my-override-1.yml my-overide-2.yml# оригинальный сервис
command: python my_app.py
# новый сервис
command: python my_new_app.py
При использовании опции с несколькими значениями (ports, expose, external_links, dns, dns_search и tmpfs), Docker Compose объединяет значения (в примере ниже Compose открывает порты 5000 и 8000):
# оригинальный сервис
expose:
- 5000
# новый сервис
expose:
- 8000# оригинальный сервис
environment:
- FOO=Hello
- BAR=World
# новый сервис
environment:
- BAR="Python Dev!"
Различные среды
Начнём с базового Docker Compose файла для приложения (docker-compose.yml):
web:
image: "my_dockpy/my_django_app:latest"
links:
- db
- cache
db:
image: "postgres:latest"
cache:
image: "redis:latest"
web:
build: .
volumes:
- ".:/code"
ports:
- "8883:80"
environment:
DEBUG: "true"
db:
command: "-d"
ports:
- "5432:5432"
cache:
ports:
- "6379:6379"web:
ports:
- "80:80"
environment:
PRODUCTION: "true"
cache:
environment:
TTL: "500"
$ docker-compose -f docker-compose.yml -f docker-compose.production.yml up -ddbadmin:
build: database_admin/
links:
- db$ docker-compose -f docker-compose.yml -f docker-compose.admin.yml run dbadmin db-backupwebapp:
build: .
ports:
- "8000:8000"
volumes:
- "/data"web:
extends:
file: common-services.yml
service: webappweb:
extends:
file: common-services.yml
service: webapp
environment:
- DEBUG=1
cpu_shares: 5
links:
- db
important_web:
extends: web
cpu_shares: 10
db:
image: postgres
COMPOSE_API_VERSION= # должно быть 2
COMPOSE_HTTP_TIMEOUT= # мы используем 30 на продакшне и 120 в разработке
DOCKER_CERT_PATH= # храните путь сертификации здесь
EXTERNAL_PORT= # установите внешний порт здесь (запомните, 5000 для Flask и 8000 для Django)|
Метки: author Tully серверное администрирование виртуализация devops *nix блог компании отус otus docker-compose |
Oracle фактически ликвидирует Sun |
Избегайте этой ловушки, не следует придавать антропоморфные черты Ларри Эллисону.
Брайэн Кантрилл
Похоже, что в Oracle приняли решение окончательно избавиться от трудовых ресурсов, составляющих костяк Sun Microsystems. Массовые увольнения затронули около 2500 сотрудников, работающих над операционной системой Solaris, платформой SPARC и системами хранения данных ZFS Storage Appliance.

Это не рядовая трансформация — оптимизация, а настоящая бойня. По мнению создателя системы динамической отладки Dtrace Брайэна Кантрилла (Bryan Cantrill) на сей раз нанесен непоправимый ущерб, в результате потери 90% производственных кадров подразделения Solaris, включая все руководство.
В 2009 г. Oracle приобрел испытывающую серьезнейшие трудности на рынке Sun Microsystems за 5.6 млрд. долларов США. Компания теряла позиции на рынке вследствие лавинообразного распространения Linux в качестве серверной ОС, успеха платформы amd64 и невнятной стратегии по взаимоотношениям с сообществом открытого ПО. Solaris стал открытым слишком поздно — лишь в 2005 г., причем открытым не полностью, отдельные элементы ОС, такие как локализация и некоторые драйвера, оставались проприетарными. Затем появился OpenSolaris, однако точкой сбора сообщества он не сумел стать. То ли дело была в лицензии CDDL, то ли проблема была в том, что Sun пыталась манипулировать проектом. Трудно сказать почему именно, но не взлетел.
Kicked butt, had fun, didn't cheat, loved our customers, changed computing forever. Scott McNealy
Эпитафия Скота МакНили как нельзя лучше отражает жизненный путь компании — отлично развлекались, не дурили головы своим заказчикам и навсегда изменили ИТ. Довольно быстро стало очевидно, что Solaris Ораклу попросту не нужен, и развивать его он не намерен. Затем 13 августе 2010 г. случилось одно из самых позорных событий в истории открытого ПО — компания втихую закрыла исходный код OS Solaris. Никаких официальных заявлений на сей счет не последовало.
We will distribute updates to approved CDDL or other open source-licensed code following full releases of our enterprise Solaris operating system. In this manner, new technology innovations will show up in our releases before anywhere else. We will no longer distribute source code for the entirety of the Solaris operating system in real-time while it is developed, on a nightly basis.
Это всего лишь отрывок из внутреннего циркуляра для сотрудников компании, который естественно сразу же просочился в прессу. Тут речь идет о том, что исходный код будут выкладывать только во время релиза новой версии ОС, а обновления будут только бинарными. Но это оказалось неправдой, после выхода Solaris 11 исходный код не выложили.
Для тех, кто владеет английским очень рекомендую посмотреть выступление Брайэна Кантрилла на конференции Usenix. Эпиграф к статье — одна из его цитат, вот еще несколько.

О принципах руководства компании. Оставшись без мудрого руководства манагеров инженеры выдали гору инноваций: ZFS, DTrace, Zones и много других.
Sun управлялась со стороны враждующих группировок во главе с атаманами, как Сомали.
О закрытии исходного кода OpenSolaris.
Это ОТВРАТИТЕЛЬНАЯ выходка со стороны корпорации. Вот из-за такого поведения мы становимся циничными и подозрительными.
О последствиях закрытия исходников OpenSolaris для нового проекта ОС illumos — полностью открытого форка OpenSolaris.
Мы готовимся к моменту Судного Дня в лицензиях открытого исходного кода, у нас есть такие сценарии, они работают и это здорово.
Вскоре после этого из Oracle ушли все разработчики DTrace, создатели ZFS, команда zones и сетевики. Вся разработка и инновация на этих направлениях далее происходила операционной системе illumos, где осела диаспора программистов из Sun Solaris. Благодаря особенностям открытых лицензий, в том числе CDDL, в рамках которой шла разработка OpenSolaris, Oracle не может претендовать на все последующие улучшения в коде illumos. То есть может, но только в рамках своего же проекта с открытым кодом. Сценарии Судного Дня работают как надо.
Для полноты картины стоит добавить, что Oracle активно участвует в разработке ядра Linux, где традиционно входит в десятку наиболее активных компаний.
NetBeans Apache Foundation, верное решение.Sun Microsystems еще недавно — живая легенда и лучшее, что когда-либо было в Unix. Вот лишь небольшая часть их наследия.
Компания Oracle имела все возможности для того, чтобы развивать и поддерживать OpenSolaris, но вместо этого закрыла исходники и с тех пор Solaris уже не имел будущего. Когда тяжба с компанией Google за использования Java в мобильной ОС Андроид закончилась пшиком в Oracle потеряли к активам Sun Microsystems всякий интерес. Вместо этого компания будет продавать ПО на основе собственной операционной системы — Unbreakable Linux.
|
Метки: author temujin управление сообществом управление разработкой управление проектами oracle sun microsystems solaris opensolaris illumos |
Микросервисы — MIF на C++ |
 Около трех лет назад у меня была идея создания небольшого каркаса для разработки небольших сервисов, которые могли бы как-то взаимодействовать между собой, предоставлять API во вне, работать с базами данных и кое-что по мелочи еще. Во время решения некоторых рабочих задач, окончательно сформировалась идея своего проекта, близкого к решению рабочих задач. Примерно год назад все это сформировалось в проект MIF (MetaInfo Framework). Предполагалось, что с его помощью можно будет решать такие задачи, как:
Около трех лет назад у меня была идея создания небольшого каркаса для разработки небольших сервисов, которые могли бы как-то взаимодействовать между собой, предоставлять API во вне, работать с базами данных и кое-что по мелочи еще. Во время решения некоторых рабочих задач, окончательно сформировалась идея своего проекта, близкого к решению рабочих задач. Примерно год назад все это сформировалось в проект MIF (MetaInfo Framework). Предполагалось, что с его помощью можно будет решать такие задачи, как:struct Data
{
int field1 = 0;
std::string field2;
};
int main()
{
Data data;
data.field1 = 100500;
data.field2 = "Text";
using Meta = Mif::Reflection::Reflect;
std::cout << "Struct name: " << Meta::Name::GetString() << std::endl;
std::cout << "Field count: " << Meta::Fields::Count << std::endl;
std::cout << "Field1 value: " << data.field1 << std::endl;
std::cout << "Field2 value: " << data.field2 << std::endl;
std::cout << "Modify fields." << std::endl;
data.*Meta::Fields::Field<0>::Access() = 500100;
data.*Meta::Fields::Field<1>::Access() = "New Text.";
std::cout << "Field1 value: " << data.field1 << std::endl;
std::cout << "Field2 value: " << data.field2 << std::endl;
return 0;
}
MIF_REFLECT_BEGIN(Data)
MIF_REFLECT_FIELD(field1)
MIF_REFLECT_FIELD(field2)
MIF_REFLECT_END()
MIF_REGISTER_REFLECTED_TYPE(Data)
// STD
#include
#include
// MIF
#include // STD
#include
#include Struct name: Base1
field1 = 1
field2 = true
Struct name: Base2
field3 = Text
Struct name: Data
field4 = 100
field5 = String
field6 = key1
Struct name: Nested
field = 100
key2
Struct name: Nested
field = 200
#include {
"Base1" :
{
"field1" : 1,
"field2" : true
},
"Base2" :
{
"field3" : "Text"
},
"field4" : 100,
"field5" : "String",
"field6" :
[
{
"id" : "key1",
"val" :
{
"field" : 100
}
},
{
"id" : "key2",
"val" :
{
"field" : 200
}
}
]
}
// BOOST
#include
1
1
Text
100
String
2
0
-
key1
100
-
key2
200
// data.h
namespace Service
{
namespace Data
{
using ID = std::string;
struct Human
{
std::string name;
std::string lastName;
std::uint32_t age = 0;
};
enum class Position
{
Unknown,
Developer,
Manager
};
struct Employee
: public Human
{
Position position = Position::Unknown;
};
using Employees = std::map;
} // namespace Data
} // namespace Service
// meta/data.h
namespace Service
{
namespace Data
{
namespace Meta
{
using namespace ::Service::Data;
MIF_REFLECT_BEGIN(Human)
MIF_REFLECT_FIELD(name)
MIF_REFLECT_FIELD(lastName)
MIF_REFLECT_FIELD(age)
MIF_REFLECT_END()
MIF_REFLECT_BEGIN(Position)
MIF_REFLECT_FIELD(Unknown)
MIF_REFLECT_FIELD(Developer)
MIF_REFLECT_FIELD(Manager)
MIF_REFLECT_END()
MIF_REFLECT_BEGIN(Employee, Human)
MIF_REFLECT_FIELD(position)
MIF_REFLECT_END()
} // namespace Meta
} // namespace Data
} // namespace Service
MIF_REGISTER_REFLECTED_TYPE(::Service::Data::Meta::Human)
MIF_REGISTER_REFLECTED_TYPE(::Service::Data::Meta::Position)
MIF_REGISTER_REFLECTED_TYPE(::Service::Data::Meta::Employee)
// imy_company.h
namespace Service
{
struct IMyCompany
: public Mif::Service::Inherit
{
virtual Data::ID AddEmployee(Data::Employee const &employee) = 0;
virtual void RemoveAccount(Data::ID const &id) = 0;
virtual Data::Employees GetEmployees() const = 0;
};
} // namespace Service
// ps/imy_company.h
namespace Service
{
namespace Meta
{
using namespace ::Service;
MIF_REMOTE_PS_BEGIN(IMyCompany)
MIF_REMOTE_METHOD(AddEmployee)
MIF_REMOTE_METHOD(RemoveAccount)
MIF_REMOTE_METHOD(GetEmployees)
MIF_REMOTE_PS_END()
} // namespace Meta
} // namespace Service
MIF_REMOTE_REGISTER_PS(Service::Meta::IMyCompany)
// id/service.h
namespace Service
{
namespace Id
{
enum
{
MyCompany = Mif::Common::Crc32("MyCompany")
};
} // namespace Id
} // namespace Service
// service.cpp
// MIF
#include
{
public:
// …
private:
// …
// IMyCompany
virtual Data::ID AddEmployee(Data::Employee const &employee) override final
{
// ...
}
virtual void RemoveAccount(Data::ID const &id) override final
{
// ... }
}
virtual Data::Employees GetEmployees() const override final
{
// ...
}
};
} // namespace
} // namespace Detail
} // namespace Service
MIF_SERVICE_CREATOR
(
::Service::Id::MyCompany,
::Service::Detail::MyCompany
)
// MIF
#include (argc, argv);
}
// MIF
#include (argc, argv);
}
2017-08-09T14:01:23.404663 [INFO]: Starting network application on 0.0.0.0:55555
2017-08-09T14:01:23.404713 [INFO]: Starting server on 0.0.0.0:55555
2017-08-09T14:01:23.405442 [INFO]: Server is successfully started.
2017-08-09T14:01:23.405463 [INFO]: Network application is successfully started.
Press 'Enter' for quit.
2017-08-09T14:01:29.032171 [INFO]: MyCompany
2017-08-09T14:01:29.041704 [INFO]: AddEmployee. Name: Ivan LastName: Ivanov Age: 25 Position: Manager
2017-08-09T14:01:29.042948 [INFO]: AddEmployee. Name: Petr LastName: Petrov Age: 30 Position: Developer
2017-08-09T14:01:29.043616 [INFO]: GetEmployees.
2017-08-09T14:01:29.043640 [INFO]: Id: 0 Name: Ivan LastName: Ivanov Age: 25 Position: Manager
2017-08-09T14:01:29.043656 [INFO]: Id: 1 Name: Petr LastName: Petrov Age: 30 Position: Developer
2017-08-09T14:01:29.044481 [INFO]: Removed employee account for Id: 0 Name: Ivan LastName: Ivanov Age: 25 Position: Manager
2017-08-09T14:01:29.045121 [INFO]: GetEmployees.
2017-08-09T14:01:29.045147 [INFO]: Id: 1 Name: Petr LastName: Petrov Age: 30 Position: Developer
2017-08-09T14:01:29.045845 [WARNING]: RemoveAccount. Employee with id 0 not found.
2017-08-09T14:01:29.046652 [INFO]: ~MyCompany
2017-08-09T14:02:05.766072 [INFO]: Stopping network application ...
2017-08-09T14:02:05.766169 [INFO]: Stopping server ...
2017-08-09T14:02:05.767180 [INFO]: Server is successfully stopped.
2017-08-09T14:02:05.767238 [INFO]: Network application is successfully stopped.
2017-08-09T14:01:29.028821 [INFO]: Starting network application on 0.0.0.0:55555
2017-08-09T14:01:29.028885 [INFO]: Starting client on 0.0.0.0:55555
2017-08-09T14:01:29.042510 [INFO]: Employee Id: 0
2017-08-09T14:01:29.043296 [INFO]: Employee Id: 1
2017-08-09T14:01:29.044082 [INFO]: Employee. Id: 0 Name: Ivan LastName: Ivanov Age: 25 Position: Manager
2017-08-09T14:01:29.044111 [INFO]: Employee. Id: 1 Name: Petr LastName: Petrov Age: 30 Position: Developer
2017-08-09T14:01:29.044818 [INFO]: Removed account 0
2017-08-09T14:01:29.045517 [INFO]: Employee. Id: 1 Name: Petr LastName: Petrov Age: 30 Position: Developer
2017-08-09T14:01:29.045544 [INFO]: Removed again account 0
2017-08-09T14:01:29.046357 [WARNING]: Error: [Mif::Remote::Proxy::RemoteCall] Failed to call remote method "IMyCompany::RemoveAccount" for instance with id "411bdde0-f186-402e-a170-4f899311a33d". Error: RemoveAccount. Employee with id 0 not found.
2017-08-09T14:01:29.046949 [INFO]: Client is successfully started.
2017-08-09T14:01:29.047311 [INFO]: Network application is successfully started.
Press 'Enter' for quit.
2017-08-09T14:02:02.901773 [INFO]: Stopping network application ...
2017-08-09T14:02:02.901864 [INFO]: Stopping client ...
2017-08-09T14:02:02.901913 [INFO]: Client is successfully stopped.
2017-08-09T14:02:02.901959 [INFO]: Network application is successfully stopped.
[WARNING]: Error: [Mif::Remote::Proxy::RemoteCall] Failed to call remote method "IMyCompany::RemoveAccount" for instance with id "411bdde0-f186-402e-a170-4f899311a33d". Error: RemoveAccount. Employee with id 0 not found.
// MIF
#include (argc, argv);
}
curl -iv -X POST "http://localhost:55555/" -d 'Test data'
// STD
#include
#include
#include
#include
// MIF
#include namespace Service
{
struct IAdmin
: public Mif::Service::Inherit
{
virtual void SetTitle(std::string const &title) = 0;
virtual void SetBody(std::string const &body) = 0;
virtual std::string GetPage() const = 0;
};
} // namespace Service
class Application
: public Mif::Application::HttpServer
{
//...
private:
// Mif.Application.HttpService
virtual void Init(Mif::Net::Http::ServerHandlers &handlers) override final
{
std::string const adminLocation = "/admin";
std::string const viewLocation = "/view";
auto service = Mif::Service::Create(viewLocation);
auto webService = Mif::Service::Cast(service);
auto factory = Mif::Service::Make();
factory->AddInstance(Service::Id::Service, service);
std::chrono::microseconds const timeout{10000000};
auto clientFactory = Service::Ipc::MakeClientFactory(timeout, factory);
handlers.emplace(adminLocation, Mif::Net::Http::MakeServlet(clientFactory));
handlers.emplace(viewLocation, Mif::Net::Http::MakeWebService(webService));
}
};
namespace Service
{
namespace Detail
{
namespace
{
class WebService
: public Mif::Service::Inherit
<
IAdmin,
Mif::Net::Http::WebService
>
{
public:
WebService(std::string const &pathPrefix)
{
AddHandler(pathPrefix + "/stat", this, &WebService::Stat);
AddHandler(pathPrefix + "/main-page", this, &WebService::MainPage);
}
private:
// …
// IAdmin
virtual void SetTitle(std::string const &title) override final
{
// ...
}
// …
// Web hadlers
Result Stat()
{
// ...
std::map resp;
// Fill resp
return resp;
}
Result
MainPage(Prm const &format)
{
// ...
}
};
} // namespace
} // namespace Detail
} // namespace Service
MIF_SERVICE_CREATOR
(
::Service::Id::Service,
::Service::Detail::WebService,
std::string
)
curl "http://localhost:55555/view/main-page?format=text"
curl "http://localhost:55555/view/main-page?format=html"
curl "http://localhost:55555/view/main-page?format=json"
|
Метки: author NYM программирование c++ web-services c++11 microservices reflection rpc web-backend |
[Из песочницы] Простой WebScraping на R через API hh.ru |
Не так давно преподаватель дал задание: cкачать данные с некоторого сайта на выбор. Не знаю почему, но первое, что пришло мне в голову — это hh.ru.
Далее встал вопрос: "А что же собственно будем выкачивать?", ведь на сайте порядка 5 млн. резюме и 100.000 вакансий.
Решив посмотреть, какими навыками мне придется овладеть в будущем, я набрал в поисковой строке "data science" и призадумался. Может быть по синонимичному запросу найдется больше вакансий и резюме? Нужно узнать, какие формулировки популярны в данный момент. Для этого удобно использовать сервис GoogleTrends.
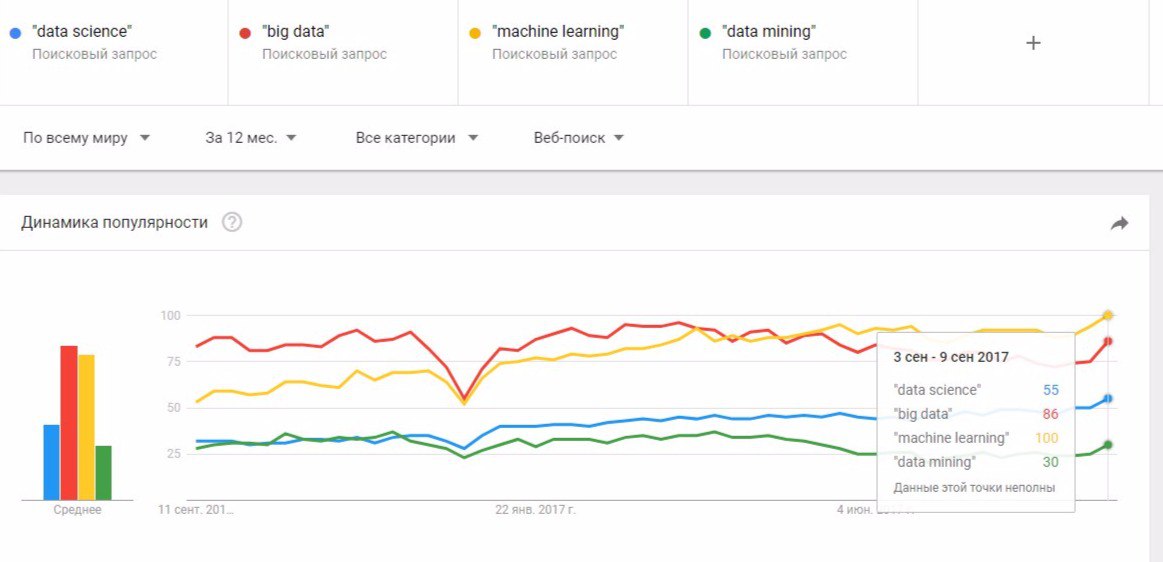
Отсюда видно, что выгоднее всего искать по запросу "machine learning". Кстати, это действительно так.
Соберем вначале вакансии. Их довольно мало, всего 411. API hh.ru поддерживает поиск по вакансиям, поэтому задача становится тривиальной. Единственное, нам необходимо работать с JSON. Для этой цели я использовал пакет jsonlite и его метод fromJSON() принимающий на вход URL и возвращающий разобранную структуру данных.
data <- fromJSON(paste0("https://api.hh.ru/vacancies?text=\"machine+learning\"&page=", pageNum) # Здесь pageNum - номер страницы. На странице отображается 20 вакансий.# Scrap vacancies
vacanciesdf <- data.frame(
Name = character(), # Название компании
Currency = character(), # Валюта
From = character(), # Минимальная оплата
Area = character(), # Город
Requerement = character(), stringsAsFactors = T) # Требуемые навыки
for (pageNum in 0:20) { # Всего страниц
data <- fromJSON(paste0("https://api.hh.ru/vacancies?text=\"machine+learning\"&page=", pageNum))
vacanciesdf <- rbind(vacanciesdf, data.frame(
data$items$area$name, # Город
data$items$salary$currency, # Валюта
data$items$salary$from, # Минимальная оплата
data$items$employer$name, # Название компании
data$items$snippet$requirement)) # Требуемые навыки
print(paste0("Upload pages:", pageNum + 1))
Sys.sleep(3)
}Записав все данные в DataFrame, давайте немного его почистим. Переведем все зарплаты в рубли и избавимся от столбца Currency, так же заменим NA значения в Salary на нулевые.
# Сделаем приличные названия столбцов
names(vacanciesdf) <- c("Area", "Currency", "Salary", "Name", "Skills")
# Вместо зарплаты NA будет нулевая
vacanciesdf[is.na(vacanciesdf$Salary),]$Salary <- 0
# Переведем зарплаты в рубли
vacanciesdf[!is.na(vacanciesdf$Currency) & vacanciesdf$Currency == 'USD',]$Salary <- vacanciesdf[!is.na(vacanciesdf$Currency) & vacanciesdf$Currency == 'USD',]$Salary * 57
vacanciesdf[!is.na(vacanciesdf$Currency) & vacanciesdf$Currency == 'UAH',]$Salary <- vacanciesdf[!is.na(vacanciesdf$Currency) & vacanciesdf$Currency == 'UAH',]$Salary * 2.2
vacanciesdf <- vacanciesdf[, -2] # Currency нам больше не нужна
vacanciesdf$Area <- as.character(vacanciesdf$Area)После этого имеем DataFrame вида:

Пользуясь случаем, посмотрим сколько вакансий в городах и какая у них средняя зарплата.
vacanciesdf %>% group_by(Area) %>% filter(Salary != 0) %>%
summarise(Count = n(), Median = median(Salary), Mean = mean(Salary)) %>%
arrange(desc(Count))
Для scraping`a в R обычно используется пакет rvest, имеющий два ключевых метода read_html() и html_nodes(). Первый позволяет скачивать страницы из интернета, а второй обращаться к элементам страницы с помощью xPath и CSS-селектора. API не поддерживает возможность поиска по резюме, но дает возможность получить информацию о нем по id. Будем выгружать все id, а затем уже через API получать данные из резюме. Всего резюме на сайте по данному запросу — 1049.
hhResumeSearchURL <- 'https://hh.ru/search/resume?exp_period=all_time&order_by=relevance&text=machine+learning&pos=full_text&logic=phrase&clusters=true&page=';
# Загрузим очередную страницу с номером pageNum
hDoc <- read_html(paste0(hhResumeSearchURL, as.character(pageNum)))
# Выделим все аттрибуты ссылок на странице
ids <- html_nodes(hDoc, css = 'a') %>% as.character()
# Выделим из ссылок необходимые id ( последовательности букв и цифр длины 38 )
ids <- as.vector(ids) %>% `[`(str_detect(ids, fixed('/resume/'))) %>%
str_extract(pattern = '/resume/.{38}') %>% str_sub(str_count('/resume/') + 1)
ids <- ids[4:length(ids)] # В первых 3х мусорПосле этого уже известным нам методом fromJSON получим информацию, содержащуюся в резюме.
resumes <- fromJSON(paste0("https://api.hh.ru/resumes/", id))hhResumeSearchURL <- 'https://hh.ru/search/resume?exp_period=all_time&order_by=relevance&text=machine+learning&pos=full_text&logic=phrase&clusters=true&page=';
for (pageNum in 0:51) { # Всего 51 страница
#Вытащим id резюме
hDoc <- read_html(paste0(hhResumeSearchURL, as.character(pageNum)))
ids <- html_nodes(hDoc, css = 'a') %>% as.character()
# Выделим все аттрибуты ссылок на странице
ids <- as.vector(ids) %>% `[`(str_detect(ids, fixed('/resume/'))) %>%
str_extract(pattern = '/resume/.{38}') %>% str_sub(str_count('/resume/') + 1)
ids <- ids[4:length(ids)] # В первых 3х мусор
Sys.sleep(1) # Подождем на всякий случай
for (id in ids) {
resumes <- fromJSON(paste0("https://api.hh.ru/resumes/", id))
skills <- if (is.null(resumes$skill_set)) "" else resumes$skill_set
buffer <- data.frame(
Age = if(is.null(resumes$age)) 0 else resumes$age, # Возраст
if (is.null(resumes$area$name)) "NoCity" else resumes$area$name,# Город
if (is.null(resumes$gender$id)) "NoGender" else resumes$gender$id, # Пол
if (is.null(resumes$salary$amount)) 0 else resumes$salary$amount, # Зарплата
if (is.null(resumes$salary$currency)) "NA" else resumes$salary$currency, # Валюта
# Список навыков одной строкой через ,
str_c(if (!length(skills)) "" else skills, collapse = ","))
write.table(buffer, 'resumes.csv', append = T, fileEncoding = "UTF-8",col.names = F)
Sys.sleep(1) # Подождем на всякий случай
}
print(paste("Скачал страниц:", pageNum))
}Также почистим получившийся DataFrame, конвертируя валюты в рубли и удалив NA из столбцов.

SkillNameDF <- data.frame(SkillName = str_split(str_c(
resumes$Skills, collapse = ','), ','), stringsAsFactors = F)
names(SkillNameDF) <- 'SkillName'
mostSkills <- head(SkillNameDF %>% group_by(SkillName) %>%
summarise(Count = n()) %>% arrange(desc(Count)), 15 )
resumes %>% group_by(Gender) %>% filter(Salary != 0) %>%
summarise(Count = n(), Median = median(Salary), Mean = mean(Salary)
resumes %>% filter(Age!=0) %>% group_by(Age) %>%
summarise(Count = n()) %>% arrange(desc(Count))
|
Метки: author pdepdepde программирование data mining api scraping data science |
Blockchain Life 2017: от золотой пиццы к криптовалютной лихорадке |
|
Метки: author megapost финансы в it биткоины |
Архитектурная пирамида приложения |

большинство систем работают лучше всего, если они остаются простыми, а не усложняютсяА YAGNI не проектировать наперед сверх меры:
Вам это не понадобитсяОба они очень абстрактны и годятся для любого приложения, что делает их основополагающими.
Каждая часть знания должна иметь единственное, непротиворечивое и авторитетное представление в рамках системыА принцип SRP:
каждый объект должен иметь одну ответственность
Клиенты не должны зависеть от методов, которые они не используют.Неожиданно, с этим принципом у меня возникли самые большие проблемы. Он чем-то похож на YAGNI — «клиенту могут и не понадобятся эти методы интерфейса». С другой стороны у него очень много и от SRP — «один интерфейс для одной задачи». Его можно было бы отнести к обобщению «Сложность» и поставить на один уровень с YAGNI и KISS, но эти два принципа более абстрактны.
Модули верхних уровней не должны зависеть от модулей нижних уровней. Оба типа модулей должны зависеть от абстракций. Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.Слабая связность (loose coupling) — это не принцип, а метрика, показывающая, насколько компоненты системы независимы друг от друга. Слабо связанные компоненты не зависят от внешних изменений и легко могут быть использованы повторно. IoC и DIP являются средствами для достижения слабой связности компонентов в системе.
программные сущности (классы, модули, функции и т. п.) должны быть открыты для расширения, но закрыты для измененияА LSP:
Функции, которые используют базовый тип, должны иметь возможность использовать подтипы базового типа, не зная об этом.Грамотная реализация этих принципов позволит в будущем изменять (расширять) функционал приложения не изменяя уже написанный код, а создавая новый.
|
|
[Из песочницы] Plugin for HANA Database project in Visual Studio |
|
Метки: author Peiman visual studio .net hana tfs |
Как на Java c помощью КриптоПро подписать документ PDF |

#
# List of providers and their preference orders (see above):
#
security.provider.1=ru.CryptoPro.JCSP.JCSPgrant {
// There is no restriction to any algorithms.
permission javax.crypto.CryptoAllPermission;
};

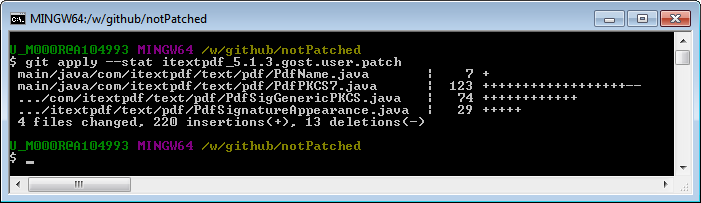
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:2.3.2:compile (default-compile) on project itextpdf: Compilation failure: Compilation failure:
[ERROR] \github\iTextpdf_5.1.3_patched_cryptopro_bc1.50\src\main\java\com\itextpdf\text\pdf\PdfPKCS7.java:[138,23] error: package ru.CryptoPro.JCP does not exist
[ERROR] \github\iTextpdf_5.1.3_patched_cryptopro_bc1.50\src\main\java\com\itextpdf\text\pdf\PdfPKCS7.java:[139,31] error: package ru.CryptoPro.reprov.x509 does not exist
org.bouncycastle
bctsp-jdk15
1.46
jar
compile
true
Exception in thread "main" java.lang.NoClassDefFoundError: org/bouncycastle/asn1/DEREncodable
at com.itextpdf.text.pdf.PdfSigGenericPKCS.setSignInfo(PdfSigGenericPKCS.java:97)
at com.itextpdf.text.pdf.PdfSignatureAppearance.preClose(PdfSignatureAppearance.java:1003)
at com.itextpdf.text.pdf.PdfSignatureAppearance.preClose(PdfSignatureAppearance.java:904)
at com.itextpdf.text.pdf.PdfStamper.close(PdfStamper.java:194)
at ru.alfabank.ccjava.trustcore.logic.SignatureProcessor.pdfSignature(SignatureProcessor.java:965)
at ru.alfabank.ccjava.trustcore.logic.SignatureProcessor.main(SignatureProcessor.java:1363)
Caused by: java.lang.ClassNotFoundException: org.bouncycastle.asn1.DEREncodable
at java.net.URLClassLoader.findClass(Unknown Source)
at java.lang.ClassLoader.loadClass(Unknown Source)
at sun.misc.Launcher$AppClassLoader.loadClass(Unknown Source)
at java.lang.ClassLoader.loadClass(Unknown Source)
... 6 more
org.bouncycastle
bcprov-ext-jdk15on
1.50
org.bouncycastle
bcprov-jdk15on
1.50
org.bouncycastle
bcmail-jdk15on
1.50
/**
*
* @param aliases
* - имена контейнеров с ключами ЭП
* @param data
* - массив байтов с документом PDF
* @param pdfVersion
* - номер версии формата PDF
* @return
* @throws SignatureProcessorException
*/
public static byte[] samplePDFSignature(String[] aliases, byte[] data, char pdfVersion) throws SignatureProcessorException {
ByteArrayOutputStream bais = new ByteArrayOutputStream();
HashMap currSignAttrMap = new HashMap();
for (String alias : aliases) {
X509Certificate certificate = (X509Certificate) signAttributesMap1.get(alias)[0];
PrivateKey privateKey = (PrivateKey) signAttributesMap1.get(alias)[1];
currSignAttrMap.put(certificate, privateKey);
if (certificate == null) {
throw new SignatureProcessorException(PDF_SIGNATURE_ERROR + CERTIFICATE_NOT_FOUND_BY_ALIAS);
}
if (privateKey == null) {
throw new SignatureProcessorException(PDF_SIGNATURE_ERROR + PRIVATE_KEY_NOT_FOUND_BY_ALIAS);
}
}
try {
FileInputStream fis = new FileInputStream(new File(FILE_PATH));
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buf = new byte[1024];
int n = 0;
while ((n = fis.read(buf, 0, buf.length)) != -1) {
baos.write(buf, 0, n);
}
fis.close();
byte[] im = baos.toByteArray();
X509Certificate innerCA = obtainCertFromTrustStoreJKS(false, INNER_CA);
PdfStamper stp = null;
PdfReader reader = null;
int pageNumber = 1;
for (Entry entry : currSignAttrMap.entrySet()) {
if (bais.toByteArray().length == 0) {
reader = new PdfReader(data);
} else {
reader = new PdfReader(bais.toByteArray());
bais = new ByteArrayOutputStream();
}
stp = PdfStamper.createSignature(reader, bais, pdfVersion); //'\0'
Certificate[] certPath = new Certificate[] {entry.getKey(), innerCA};
PdfSignatureAppearance sap = stp.getSignatureAppearance();
sap.setProvider("JCSP"); //JCP
sap.setCrypto(entry.getValue(), certPath, null,
PdfSignatureAppearance.CRYPTOPRO_SIGNED);
Image image = Image.getInstance(im);
sap.setImage(image);
sap.setVisibleSignature(new Rectangle(150, 150), pageNumber, null);
pageNumber++;
stp.close();
bais.close();
reader.close();
}
} catch (RuntimeException e) {
throw new SignatureProcessorException(PDF_SIGNATURE_ERROR + ExceptionUtils.getFullStackTrace(e));
} catch (IOException e) {
throw new SignatureProcessorException(PDF_SIGNATURE_ERROR + ExceptionUtils.getFullStackTrace(e));
} catch (DocumentException e) {
throw new SignatureProcessorException(PDF_SIGNATURE_ERROR + ExceptionUtils.getFullStackTrace(e));
} catch (CertificateEncodingException e) {
throw new SignatureProcessorException(PDF_SIGNATURE_ERROR + ExceptionUtils.getFullStackTrace(e));
} catch (Exception e) {
throw new SignatureProcessorException(PDF_SIGNATURE_ERROR + ExceptionUtils.getFullStackTrace(e));
}
return bais.toByteArray();
}


|
|
Apache Ignite 2.1 — теперь со вкусом Persistence |
|
Метки: author artemshitov программирование java big data блог компании gridgain apache ignite data grid compute grid highload gridgain |
[Из песочницы] Получение текста запросов из SoapHttpClientProtocol |
public class SoapHttpClientProtocolSpy: SoapHttpClientProtocol
{
private XmlWriterSpy writer;
private XmlReaderSpy reader;
public SoapHttpClientProtocolSpy() : base(){}
protected override XmlWriter GetWriterForMessage(SoapClientMessage message, int bufferSize)
{
writer = new XmlWriterSpy(base.GetWriterForMessage(message, bufferSize));
return writer;
}
protected override XmlReader GetReaderForMessage(SoapClientMessage message, int bufferSize)
{
reader = new XmlReaderSpy(base.GetReaderForMessage(message, bufferSize));
return reader;
}
public string XmlRequest => reader?.Xml;
public string XmlResponce => writer?.Xml;
} public class XmlWriterSpy : XmlWriter
{
//это же декоратор, поэтому просто пользуемся той реализацией, которая придет
private XmlWriter _me;
private XmlTextWriter _bu;
private StringWriter _sw;
public XmlWriterSpy(XmlWriter implementation)
{
_me = implementation;
_sw = new StringWriter();
_bu = new XmlTextWriter(_sw);
_bu.Formatting = Formatting.Indented;
}
public override void Flush()
{
_me.Flush();
_bu.Flush();
_sw.Flush();
}
public string Xml => _sw?.ToString();
public override void Close() { _me.Close(); _bu.Close(); }
public override string LookupPrefix(string ns) { return _me.LookupPrefix(ns); }
public override void WriteBase64(byte[] buffer, int index, int count) { _me.WriteBase64(buffer, index, count); _bu.WriteBase64(buffer, index, count); }
public override void WriteCData(string text) { _me.WriteCData(text); _bu.WriteCData(text); }
//И так далее, в том же духе
} public class XmlReaderSpy : XmlReader
{
//это же декоратор, поэтому просто пользуемся той реализацией, которая придет
private XmlReader _baseXmlReader;
StringWriter _sw;
public string Xml => _sw?.ToString();
public XmlReaderSpy(XmlReader xmlReader)
{
_sw = new StringWriter();
_baseXmlReader = xmlReader;
}
public override bool Read()
{
//получаем прочитанную ноду
var res = _baseXmlReader.Read();
//каждый тип ноды придется обрабатывать немного по-разному
switch (_baseXmlReader.NodeType)
{
case XmlNodeType.Element:
_sw.Write("<" + _baseXmlReader.Name);
while (_baseXmlReader.MoveToNextAttribute())
_sw.Write(" " + _baseXmlReader.Name + "='" + _baseXmlReader.Value + "'");
_sw.Write(_baseXmlReader.HasValue || _baseXmlReader.IsEmptyElement ? "/>" : ">");
//поскольку мы перемещались по элементу, надо вернуться на исходную
_baseXmlReader.MoveToElement();
break;
case XmlNodeType.Text:
_sw.Write(_baseXmlReader.Value);
break;
case XmlNodeType.CDATA:
_sw.Write(_baseXmlReader.Value);
break;
case XmlNodeType.ProcessingInstruction:
_sw.Write("");
break;
case XmlNodeType.Comment:
_sw.Write("");
break;
case XmlNodeType.Document:
_sw.Write("");
break;
case XmlNodeType.Whitespace:
_sw.Write(_baseXmlReader.Value);
break;
case XmlNodeType.SignificantWhitespace:
_sw.Write(_baseXmlReader.Value);
break;
case XmlNodeType.EndElement:
_sw.Write("");
break;
}
return res;
}
}
using (var worker = new Service())
{
try
{
res = worker.Metod(....);
Log.Info((worker?.XmlRequest ?? "")+(worker?.XmlResponce ?? ""));
}
catch (System.Exception ex)
{
Log.Error((worker?.XmlRequest ?? "")+(worker?.XmlResponce ?? ""));
throw ex;
}
}
|
Метки: author XelMed программирование c# .net soap webservice webclient |
Эзотерический язык, транслирующийся в шаблоны C++ |
, на шаблонах C++ (посередине) и на описываемом в статье языке (снизу)") Шаблоны C++ — полный по Тьюрингу язык, на котором можно писать compile-time программы. Только вот синтаксис рассчитан на описание параметризованных типов и слабо приспособлен к ясному выражению чего-то более сложного. В этой статье рассмотрим, как типы и шаблоны становятся значениями и функциями, а также узнаем, к чему привела попытка автора создать свой функциональный язык, транслирующийся в шаблоны C++. Для прочтения текста знания в области функционального программирования почти не требуются.
Шаблоны C++ — полный по Тьюрингу язык, на котором можно писать compile-time программы. Только вот синтаксис рассчитан на описание параметризованных типов и слабо приспособлен к ясному выражению чего-то более сложного. В этой статье рассмотрим, как типы и шаблоны становятся значениями и функциями, а также узнаем, к чему привела попытка автора создать свой функциональный язык, транслирующийся в шаблоны C++. Для прочтения текста знания в области функционального программирования почти не требуются.constexpr, а мне хотелось остаться в области извращённых развлечений и использовать минимум возможностей языка. Замечательные статьи Жизнь во время компиляции от HurrTheDurr и Интерпретация во время компиляции, или Альтернативное понимание лямбд в C++11 от ilammy (вторая — более хардкорная и без using template с constexpr) описывали практически всё, что извращённому уму нужно было знать. В итоге я оставил статью в черновиках, но не оставил желания метапрограммировать. И сегодня я возвращаюсь с заново написанным текстом и новыми идеями.std::vector принимает метазначение T и возвращает метазначение std::vector. Важно, что у метазначения есть набор метаполей (с точки зрения C++ — вложенные классы, псевдонимы типов, статические константные поля), с помощью которых можно сделать самое интересное.value, и понимать его как значение, которое возвращает метафункция. Метафункции над целыми числами запишутся довольно просто:template
struct square {
static const int value = x * x;
};
square<5>::value.struct One;
struct Zero;
one и zero только объявлены и практически бесполезны. Достаточно ли этого? Да. Чему же тогда они равны и как их использовать? Равны они, что важно, только самим себе. Это своего рода абстрактные символы, которые можно задействовать в символьных вычислениях (почти как в Mathematica и др.). Метапрограмма будет вычислять значения метавыражений различной сложности. Рассмотрим сначала эти выражения, а несколько позже займёмся интерпретацией символов и выводом результатов на экран.template
struct Not {
typedef Zero value;
};
template <>
struct Not {
typedef One value;
};
Not принимает некоторое значение и возвращает единицу, если это значение — ноль. Во всех остальных случаях она возвратит ноль. Таким образом, за счёт специализации шаблонов, мы имеем паттерн-матчинг (сравнение с образцом) в зачаточной стадии: можем описывать отдельно поведение функции для одного или нескольких аргументов, имеющих конкретные значения, а компилятор C++, отметив соответствие параметров шаблона одному из образцов, подставит нужную специализацию. Пользуясь этим, мы могли бы уже написать что-то рекурсивное (например факториал, разделив описание на fac<0> и fac<всё остальное>).value, можно представить себе, как выглядят многозначные функции. Запишем конструктор списка Cons и пустой список Nil, хорошо знакомые знатокам функционального программирования:template
struct Cons {
typedef h head;
typedef t tail;
};
struct Nil;
Cons в ФП — функция, конструирующая список из первого элемента (головы) и списка остальных элементов (хвост). Обычному списку будет соответствовать Cons>>. Поскольку для работы со списком нужно уметь получать его составные части, мы сделаем Cons многозначной функцией, возвращающей голову (Cons<...,...>::head), и хвост (Cons<...,...>::tail). Любители ООП могут представить, что Cons — это конструктор, а head и tail — геттеры. В ФП все присваивания заменяются на // отрицание непустого списка
template
struct negate {
private: // инкапсулируем промежуточные вычисления
typedef typename list::head h; // голова
typedef typename Not::value not_head; // отрицание головы
typedef typename list::tail t; // хвост
typedef typename negate::value not_tail; // отрицание хвоста
public:
// список из отрицаний элементов - это отрицание головы,
// соединённое с хвостом отрицаний
typedef Cons value;
};
// отрицание пустого списка
template <>
struct negate {
// пустой список - сам себе отрицание
typedef Nil value;
};
f (x+y) (g y) z.-- список - либо слитые голова и хвост (причём хвост - сам список),
-- либо пустота
data List a = Cons a List | Nil
-- хелперы для получения головы и хвоста
head (Cons x _) = x -- возвращает голову
tail (Cons _ xs) = xs -- возвращает хвост
-- отрицание списка
negate (Cons x xs) = Cons (Not x) (negate xs)
negate Nil = Nil
negate::value , конечно, не сработает, но если One будет иметь метаполя head и tail, он вполне подойдёт. Впрочем, пока negate не «разыменовали» с помощью ::value, программа продолжает -- Преобразованная голова соединяется с преобразованным хвостом
map f (Cons x xs) = Cons (f x) (map f xs)
-- Пустой список преобразовывать не нужно
map f Nil = Nil
std::transform. В нашем же языке метафункция map объявляется с помощью параметризации шаблона шаблоном:// преобразование непустого списка
// f - шаблон с одним аргументом - унарная метафункция
template class f, typename list>
struct map {
private:
typedef typename list::head h; // голова
typedef typename f::value new_head; // преобразованная голова
typedef typename list::tail t; // хвост
typedef typename map::value new_tail; // преобразованный хвост
public:
// Преобразованная голова соединяется с преобразованным хвостом
typedef Cons value;
};
// преобразование пустого списка
template class f>
struct map {
// пустой список преобразовывать не нужно
typedef Nil value;
};
f сюда можем подставить описанную ранее функцию Not и посчитать список отрицаний:typedef map>>>::value list;
// list эквивалентно Cons>>
typedef — это некий эквивалент оператора присваивания. Или, что звучит более корректно для функциональных языков, — операция задания соответствии имени и выражения.using x = Not::value;
template
using g = Cons;
value, когда метафункция возвращает одно метазначение. Это может быть более удобным, если программисту лень явно указывать ::value, а также накладывать требование вычислимости.negate компилируется, а negate::value — нет. Пользуясь громоздкими метаполями можно написать метафункцию ветвления, которая вычисляет ::value только для одной своей ветки в зависимости от условия и возвращает это значение. Получится, что одно из выражений никогда не вычислится: все операции выполняются только при получении ::value, а его никто не трогал:// рассмотрим только одну из специализаций
template
struct If {
// expr1, expr2 вычислены, а expr1::value и expr2::value - нет
typedef typename expr1::value value;
}
// If, destroy>::value не разрушит мир
g имеет смысл уже вычисленного f::value . И если ветвиться между двумя рекурсивными вариантами, вычисления будут бесконечными — аналог переполнения стека на этапе компиляции.template
struct If {
// expr1, expr2 вычислены
typedef expr1 value;
};
// If::value>::value разрушит мир
f x возвращает унарную функцию g, неявно использующую аргумент x функции f.f x = g
where g xs = Cons x xs
-- использование: (f x) xs или, что полезнее, map (f x) list
Cons, но g как унарную можно передать в уже написанную функцию map, а как бинарную — Cons нет!this которого содержит весь нужный контекст, а operator () принимает требуемые интерфейсом аргументы. Красивая концепция из ФП заменяется эквивалентной по мощности концепцией ООП. Даже стандартный шаблон std::function предусмотрен!// до C++11: функциональный объект, захвативший переменную
struct f {
f(something& x) : x(x) {}
something_else operator () (something_else& xs) { // xs - явный аргумент
return Cons(x, xs);
}
private:
something x; // неявный аргумент
};
// C++11 и выше: лямбда-функция, захватившая переменную
something x;
auto f = [x](something_else& xs) { return Cons(x, xs); };
int(int)) на функциональные объекты (например, std::function) программист C++ получает полноценный аналог замыканий.template
struct f {
template
struct g {
typedef Cons value;
};
};
// использование: f::g::value или map::g, list>
f «вылезает» символ g, но в остальном — честное замыкание. Выражение f::g может быть использовано вместо обычной унарной функции (например, Not).Cons и Nil. Кроме того, это может оказаться даже более простым ходом. Чтобы передать в метафункцию два списка, достаточно… передать два списка: f, для вариадических же шаблонов требуется задавать обёртку, захватывающую все списки, кроме последнего: f, y1, y2, y3>, так как список аргументов произвольной длины должен быть один, и несколько списков, записанные подряд, просто «слипнутся». По завершении вычислений приходится возвращать обёртку, т.к. в C++ нельзя затайпдефить список из нескольких типов. А чтобы «выковырить» список из обёртки и передать в метафункцию (скажем, f), придётся использовать метаколлбеки: реализовать у обёртки метаметод принимающий эту метафункцию f и передающий ей содержимое списка:typename
struct list_wrapper {
// передаём в list_wrapper<...>::call функцию,
// которой передадут наши аргументы xs
struct call class f> {
typedef typename f::value value;
};
};
negate нужно сконструировать вспомогательную унарную метафункцию f, которая принимает результат рекурсивного применения negate к хвосту списка, вычисляет отрицание головы и возвращает обёртку для собранного вместе списка:typename
struct negate {
template
struct f {
typedef list_wrapper::value, ys> value;
};
typedef typename negate::template call::value;
};
typename <>
struct negate<> {
typedef list_wrapper<> value;
};
negate выглядит более громоздко даже по сравнению с версией для Cons/Nil. Здесь требуются и более серьёзные измышления, когда как для написания «обычной» версии достаточно основ ФП и механической замены Haskell -> C++. Поэтому с помощью вариадических шаблонов лучше написать обёртку для преобразования последовательности параметров в список Cons/Nil, а затем при реализации программы пользоваться уже им. Так мы сможем и задавать списки приятным перечислением через запятую, и мыслить более простыми категориями.void One::print();), либо — внутри метафункции, если возможностей паттерн-матчинга хватает для рассмотрения всех вариантов. Вот, например, метафункция print, распечатывающая свой аргумент (единицу, ноль или список) на этапе конструирования экземпляра print<...>:template
struct print {
print () {
std::cout << "unknown number" << std::endl;
}
};
template <>
struct print {
print () {
std::cout << "1" << std::endl;
}
};
template <>
struct print {
print () {
std::cout << "0" << std::endl;
}
};
// print::value>() выведет "1"
One и Zero и построить сложение, умножение,…decltype никак нельзя было провести чисто функциональные вычисления над типами, создать переменные и объекты C++ соответствующих типов, провести вычисления над ними, а потом снова вернуться к вычислениям над типами.sum, three> // тип - корректно
sum, three>() // значение - компилируется
do_something(sum(), three()) // значения - компилируется
sum(), three()> // нельзя посчитать,
// т.к. нет перехода от значений к типам
sum()), decltype(three())> // C++11; компилируется
decltype типы были аналогией чистоты, а значения — сущностями императивного мира: параметром шаблона мог быть только тип, а тип мог быть получен только преобразованиями типа; один раз создав значение, нельзя было вернуться обратно к типам.decltype. Впрочем, decltype свой аргумент не исполняет, а лишь отвечает на вопрос «какой бы был тип выражения, если бы мы его начали считать», отчего не нарушает функциональной чистоты. Поэтому, пока выражение над переменными не покидает скобки decltype, чистота сохраняется. С точки зрения языка шаблонов, decltype выгодно использовать вместе с перегрузкой операторов. В следующем примере выражения эквивалентны, но нижнее выглядит менее громоздко:typedef sum, three> x;
typedef decltype(one() + two() + three()) x;
auto v = one() + two() + three(); // v выполнится как императивная конструкция
typedef decltype(v) x;
::value, скобочки и typename сильно выматывают программиста и растягивают код программы. Конечно, логика говорит, что решивший программировать в таком стиле должен страдать, но… это одно из тех извращённых развлечений, к которым зачастую склоняется мозг айтишника. Хочется попробовать сделать так, чтобы извращённость сохранилась, но в той степени, когда страдания ещё можно терпеть.
One;
Zero;
Not (val x) = Zero; // общий случай
Not (Zero) = One; // частный случай
And(val x, val y); // для x,y != One,Zero And не определена
And(val x, One) = x; // One - константа, val x - аргумент
And(val x, Zero) = Zero;
// использование: Not(One) или And(One, Zero)
typename), другой шаблон (template class ) и т.д., и это следует указывать. А значит, создавая метаФВП, одним typename не обойтись и требование указания типа переходит также в мой язык. По умолчанию задан тип val, соответствующий обычному метазначению (структура или обычный тип в C++). Для описания функций можно комбенировать типы с помощью стрелки (->). Например, val -> val — унарная функция (шаблон, принимающий один параметр), (val, val) -> val — бинарная функция (шаблон, принимающий два параметра) и так далее.#type можно задавать синонимы, чтобы ещё чуть-чуть сократить запись и прояснить смысл за счёт уместного именования:#type number = val;
#type list = val;
#type unary = number -> number;
#type map_t = (unary, list) -> list;
// map_t раскроется в template class, typename> class
#type как аналог #define в C, задающий текстовые преобразования, которые нехитрым способом можно провести и вручную.Nil;
Cons(val x, val y) {
head = x;
tail = y;
}
::value. То есть f(x) эквивалентно f::value . Но у Cons сгенерируется только два метаполя head и tail. Предотвращать раскрытие ::value требуется явно с помощью апострофа: Cons(x, xs)'.::value как одна из частых конструкций должна была раскрываться автоматически, но должна была быть возможность (а) передать нераскрытое значение (см. проблему функции ветвления и бесконечной рекурсии выше под спойлером) и (б) использовать другие метаполя, кроме value. В итоге я остановился на «экранировании», записи метаполей через точку и ввёл обратный для экранирования оператор "!", раскрывающий ::value:Cons(x, xs)'.head; // x
Cons(x, xs)'.tail; // xs
Not(Zero); // One
Not(Zero)'!; // One
::value может вполне сосуществовать со множественным возвратом. Реализуя отрицание списка negate на C++, мы создавали локальные метапеременные, которые вполне можно было возвратить. Здесь — аналогично, только все значения публичны:// отрицание непустого списка:
// список из отрицаний элементов - это отрицание головы,
// соединённое с хвостом отрицаний
negate (list list) = Cons(not_head, not_tail)' {
h = list.head; // голова
not_head = Not(h); // отрицание головы
t = list.tail; // хвост
not_tail = negate(t); // отрицание хвоста
} // точку с запятой можно опустить!
// пустой список - сам себе отрицание
negate (Nil) = Nil;
// преобразование непустого списка
map (unary f, list list) = Cons(new_head, new_tail)' {
h = list.head; // голова
new_head = f(h); // преобразованная голова
t = list.tail; // хвост
new_tail = map(f, t); // преобразованный хвост
}
// преобразование пустого списка
map (unary f, Nil) = Nil;
unary и list можно было сразу указать val -> val и val соответственно, но запись оказалась бы более длинной и менее наглядной.f(val x) = {
g(val xs) = Cons(x, xs)';
}
// использование: f(x)'.g(list) или map(f(x)'.g, list)
value и возвращать value. Одноимённый с классом член в C++ уже отдан конструктору, из-за чего задание ему нового смысла через typedef приводит к ошибке компиляции:template
struct f {
template
struct value { // value!
typedef Cons value; // value!
};
};
f (val x) = g(Not(x)) {
g (val x) = x; // будет заменено на g (x1) = x1
// т.к. x станет параметром template f и не допустит x как параметр template g
}
::value, нигде не сказано, что f(x) — это f::value , а не call::result. Это знание хранилось внутри транслятора, и его использование в программе прорывало бы абстракцию:f(val x) = One;
f(Zero) = Zero;
main {
print::value>(); // почему так?
}
impure { код } может появляться вместо объявления значения/функции, а также справа после знака "=" при объявлении функции. В этих случаях код на C++ вставляется в соответствующее место программы. Для экспортирования выражения перед ним ставится ключевое слово impure. С точки зрения C++ это эквивалентно конструированию объекта типа, описываемого выражением.impure приготовим «распечатыватель» списка:print(val list) {
head = list.head;
tail = list.tail;
impure {
// после typedef-ов head, tail расположится следующий блок кода:
print() {
impure print(head); // преобразуется в "print();"
std::cout << ", ";
impure print(tail);
}
}
}
print(Zero) = impure { // аналогично print(Zero) { impure { ..., но короче
print() {
std::cout << "0";
}
}
print(One) = impure {
print() {
std::cout << "1";
}
}
print(Nil) = impure {
print() {
std::cout << std::endl;
}
}
namespace и using namespace:namespace ns1 {
namespace ns2 {
f(val x) = x;
}
}
namespace ns3 {
using namespace ns1.ns2;
g(val x) = f(x);
}
using namespace также является вынужденной мерой. В С++ в некоторых случаях недостаточно записи вида f::y . Если f, x или z — не конкретные типы/шаблоны, а параметры шаблона, то ::y становится выходом чёрного ящика. Нужно указывать, что мы получаем при вычислении ::y — тип или шаблон (например, typename f::y или f::template y ). Я не автоматизировал эти указания и не реализовал синтаксический сахар для более простого описания вручную, поэтому каждое использование точки вызывает появление «typename». Т.е. f::y оттранслируется во что-то некорректное вида typename typename f::value::typename y::value . В случае пространства имён это излишне, using namespace позволяет обойтись без вставки «typename».f (val x) = y(x) { y(x) = g(x); } // было
f = lambda (val x) -> y(x) { y(x) = g(x); } // стало
template struct f {}; // пусть была метафункция f
using g = f; // нельзя описать эквивалентность шаблона шаблону
// нужно описать эквивалентность выражений, соответствующих типам
template using g = f; // g - тип, f - тип
map(lambda(val x) -> y, xs) придётся модифицировать язык и генерировать шаблоны с временными именами.value::value — это конструктор, поэтому не получается напрямую реализовать лямбду, которая возвращает лямбду. Для возврата функций из лямбд и разрешения записей вида g = f нужно использовать другие концепции и почти полностью переписать транслятор.impure { private: } в код или элементарной модификацией языка.fMap(fCurry(fCons).fApply(vXs), vObj.vYs) — при доступе к метаполю подставится template, typename или ничего, если первым символом имени будет «f», «v» или «n» соответственно).// объявляем значение x
struct x {
typedef internal::value type; // тип значения x
};
// объявляем функцию f(x) = x
struct f {
typedef internal::function type; // тип функции f
template
struct value {
typedef typename x::type type; // тип результата функции f
struct result { // обёртка для того, чтобы избежать value::value
typedef x value;
};
};
};
internal со списком типов и метафункциями для работы с ними; за счёт дополнительной обёртки struct result можно будет избавиться от value::value и возвращать безымянные функции из функций. Также из-за того, что любое значение или функция будет выражаться в виде структуры (то есть просто типа, а не типа или шаблона), можно будет задавать синонимы функций (с помощью typedef), отменить обязательное описание типов аргументов функции, устранить ограничения на лямбды и возврат функций из ФВП.value использовать два значения так, чтобы при увеличении глубины вложенности использовалось другое значение. Получится, что вместо value::value будет value1::value2 и никаких попыток переопределения конструктора не будет:template
struct f {
typedef internal::True uses_value1; // использует value1
template
struct value1 {
typedef internal::False uses_value1; // использует value2
typedef Cons value2;
};
};
uses_value1 будет выбирать, доступаться до value1 или до value2.val дополнительных типов для чисел (int, uint, ...) и массивов ([val], [int], [uint], ...). При использовании метаполей придётся решить описанную выше проблему с указанием template и typename, т.к. для чисел ничего не требуется указывать, а для типов и шаблонов — требуется.main:// строим списки:
my_list = Cons(One, Cons(One, Cons(Zero, Nil)')')';
negated_list = negate(my_list);
negated_list2 = map(Not, my_list);
impure {
int main() {
// печатаем списки:
std::cout << "my list is ";
impure print(my_list);
std::cout << "negated list is ";
impure print(negated_list);
std::cout << "negated list is also ";
impure print(negated_list2);
}
}
my list is 1, 1, 0,
negated list is 0, 0, 1,
negated list is also 0, 0, 1,
impure {
#include
}
One;
Zero;
Not (val x) = Zero; // общий случай
Not (Zero) = One; // частный случай
And(val x, val y); // для x,y != One,Zero And не определена
And(val x, One) = x; // One - константа, val x - аргумент
And(val x, Zero) = Zero;
#type number = val;
#type list = val;
#type unary = number -> number;
#type map_t = (unary, list) -> list;
Nil;
Cons(val x, val y) {
head = x;
tail = y;
}
// отрицание непустого списка:
negate (list list) = Cons(not_head, not_tail)' {
h = list.head;
not_head = Not(h);
t = list.tail;
not_tail = negate(t);
}
// пустой список - сам себе отрицание
negate (Nil) = Nil;
// преобразование непустого списка
map (unary f, list list) = Cons(new_head, new_tail)' {
h = list.head;
new_head = f(h);
t = list.tail;
new_tail = map(f, t);
}
// преобразование пустого списка
map (unary f, Nil) = Nil;
print(val list) {
head = list.head;
tail = list.tail;
impure {
print() {
impure print(head);
std::cout << ", ";
impure print(tail);
}
}
}
print(Zero) = impure {
print() {
std::cout << "0";
}
}
print(One) = impure {
print() {
std::cout << "1";
}
}
print(Nil) = impure {
print() {
std::cout << std::endl;
}
}
my_list = Cons(One, Cons(One, Cons(Zero, Nil)')')';
negated_list = negate(my_list);
negated_list2 = map(Not, my_list);
impure {
int main() {
std::cout << "my list is ";
impure print(my_list);
std::cout << "negated list is ";
impure print(negated_list);
std::cout << "negated list is also ";
impure print(negated_list2);
}
}
#include
struct One;
struct Zero;
template
struct Not {
typedef Zero _value;
};
template <>
struct Not {
typedef One _value;
};
template
struct And;
template
struct And {
typedef x _value;
};
template
struct And {
typedef Zero _value;
};
struct Nil;
template
struct Cons {
typedef x head;
typedef y tail;
};
template
struct negate {
typedef typename list::head h;
typedef typename Not ::_value not_head;
typedef typename list::tail t;
typedef typename negate ::_value not_tail;
typedef Cons _value;
};
template <>
struct negate {
typedef Nil _value;
};
template class f, typename list>
struct map {
typedef typename list::head h;
typedef typename f ::_value new_head;
typedef typename list::tail t;
typedef typename map ::_value new_tail;
typedef Cons _value;
};
template class f>
struct map {
typedef Nil _value;
};
template
struct print {
typedef typename list::head head;
typedef typename list::tail tail;
print() {
print ();
std::cout << ", ";
print ();
}
};
template <>
struct print {
print() {
std::cout << "0";
}
};
template <>
struct print {
print() {
std::cout << "1";
}
};
template <>
struct print {
print() {
std::cout << std::endl;
}
};
typedef Cons > > my_list;
typedef typename negate ::_value negated_list;
typedef typename map ::_value negated_list2;
int main() {
std::cout << "my list is ";
print ();
std::cout << "negated list is ";
print ();
std::cout << "negated list is also ";
print ();
}
node src/compile <исходник> # запуск|
|
[Перевод] JavaScript: методы асинхронного программирования |

console.log('1')
console.log('2')
console.log('3')console.log('1')
setTimeout(function afterTwoSeconds() {
console.log('2')
}, 2000)
console.log('3')setTimeout. Коллбэк будет вызвана, в данном примере, через 2 секунды. Приложение при этом не остановится, ожидая, пока истекут эти две секунды. Вместо этого его исполнение продолжится, а когда сработает таймер, будет вызвана функция afterTwoSeconds.
XMLHttpRequest (XHR), но вы вполне можете использовать тут jQuery ($.ajax), или более современный стандартный подход, основанный на использовании функции fetch. И то и другое сводится к использованию промисов. Код, в зависимости от похода, будет меняться, но вот, для начала, такой пример:// аргумент url может быть чем-то вроде 'https://api.github.com/users/daspinola/repos'
function request(url) {
const xhr = new XMLHttpRequest();
xhr.timeout = 2000;
xhr.onreadystatechange = function(e) {
if (xhr.readyState === 4) {
if (xhr.status === 200) {
// Код обработки успешного завершения запроса
} else {
// Обрабатываем ответ с сообщением об ошибке
}
}
}
xhr.ontimeout = function () {
// Ожидание ответа заняло слишком много времени, тут будет код, который обрабатывает подобную ситуацию
}
xhr.open('get', url, true)
xhr.send();
}// Вызовем функцию "doThis" с другой функцией в качестве параметра, в данном случае - это функция "andThenThis". Функция "doThis" исполнит код, находящийся в ней, после чего, в нужный момент, вызовет функцию "andThenThis".
doThis(andThenThis)
// Внутри "doThis" обращение к переданной ей функции осуществляется через параметр "callback" , фактически, это просто переменная, которая хранит ссылку на функцию
function andThenThis() {
console.log('and then this')
}
// Назвать параметр, в котором окажется функция обратного вызова, можно как угодно, "callback" - это просто распространённый вариант
function doThis(callback) {
console.log('this first')
// Для того, чтобы функция, ссылка на которую хранится в переменной, была вызвана, нужно поместить после имени переменной скобки, '()', иначе ничего не получится
callback()
}request:function request(url, callback) {
const xhr = new XMLHttpRequest();
xhr.timeout = 2000;
xhr.onreadystatechange = function(e) {
if (xhr.readyState === 4) {
if (xhr.status === 200) {
callback(null, xhr.response)
} else {
callback(xhr.status, null)
}
}
}
xhr.ontimeout = function () {
console.log('Timeout')
}
xhr.open('get', url, true)
xhr.send();
}callback, поэтому, после выполнения запроса и получения ответа сервера, коллбэк будет вызван и в случае ошибки, и в случае успешного завершения операции.const userGet = `https://api.github.com/search/users?page=1&q=daspinola&type=Users`
request(userGet, function handleUsersList(error, users) {
if (error) throw error
const list = JSON.parse(users).items
list.forEach(function(user) {
request(user.repos_url, function handleReposList(err, repos) {
if (err) throw err
//Здесь обработаем список репозиториев
})
})
})handleUsersList;SON.parse, преобразовываем его, для удобства, в объект;repos_url — это URL для наших следующих запросов, и получили мы его из первого запроса.handleReposList. Здесь, так же как и при загрузке списка пользователей, можно обработать ошибки или полезные данные, в которых содержится список репозиториев пользователя.try {
request(userGet, handleUsersList)
} catch (e) {
console.error('Request boom! ', e)
}
function handleUsersList(error, users) {
if (error) throw error
const list = JSON.parse(users).items
list.forEach(function(user) {
request(user.repos_url, handleReposList)
})
}
function handleReposList(err, repos) {
if (err) throw err
// Здесь обрабатываем список репозиториев
console.log('My very few repos', repos)
}forEach, здесь три, заключается в том, что такой код тяжело читать и поддерживать. Подобная проблема существует, пожалуй, со дня появления функций обратного вызова, она широко известна как ад коллбэков.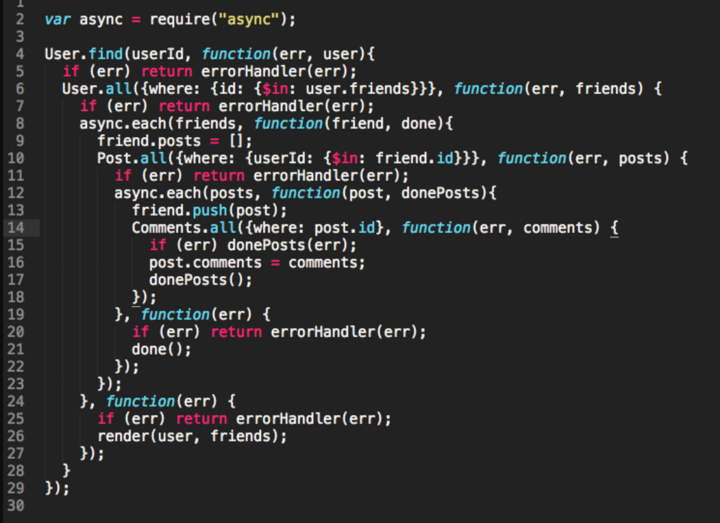
const myPromise = new Promise(function(resolve, reject) {
// Здесь будет код
if (codeIsFine) {
resolve('fine')
} else {
reject('error')
}
})
myPromise
.then(function whenOk(response) {
console.log(response)
return response
})
.catch(function notOk(err) {
console.error(err)
})resolve и reject;Promise. Если код будет выполнен успешно, вызывают метод resolve, если нет — reject;resolve, будет исполнен метод .then для объекта Promise, аналогично, если будет вызван reject, будет исполнен метод .catch.resolve и reject принимают только один параметр, в результате, например, при выполнении команды вида resolve('yey', 'works'), коллбэку .then будет передано лишь 'yey';.then, в конце соответствующих коллбэков следует всегда использовать return, иначе все они будут выполнены одновременно, а это, очевидно, не то, чего вы хотите достичь;reject, если следующим в цепочке идёт .then, он будет выполнен (вы можете считать .then выражением, которое выполняется в любом случае);.then в каком-то из них возникнет ошибка, следующие за ним будут пропущены до тех пор, пока не будет найдено выражение .catch;resolve или reject, а также состояния «resolved» и «rejected», которые соответствуют успешному, с вызовом resolve, и неуспешному, с вызовом reject, завершению работы промиса. Когда промис оказывается в состоянии «resolved» или «rejected», оно уже не может быть изменено.function request(url) {
return new Promise(function (resolve, reject) {
const xhr = new XMLHttpRequest();
xhr.timeout = 2000;
xhr.onreadystatechange = function(e) {
if (xhr.readyState === 4) {
if (xhr.status === 200) {
resolve(xhr.response)
} else {
reject(xhr.status)
}
}
}
xhr.ontimeout = function () {
reject('timeout')
}
xhr.open('get', url, true)
xhr.send();
})
}request, возвращено будет примерно следующее.
request, перепишем остальной код.const userGet = `https://api.github.com/search/users?page=1&q=daspinola&type=Users`
const myPromise = request(userGet)
console.log('will be pending when logged', myPromise)
myPromise
.then(function handleUsersList(users) {
console.log('when resolve is found it comes here with the response, in this case users ', users)
const list = JSON.parse(users).items
return Promise.all(list.map(function(user) {
return request(user.repos_url)
}))
})
.then(function handleReposList(repos) {
console.log('All users repos in an array', repos)
})
.catch(function handleErrors(error) {
console.log('when a reject is executed it will come here ignoring the then statement ', error)
}).then при успешном разрешении промиса. У нас имеется список пользователей. Во второе выражение .then мы передаём массив с репозиториями. Если что-то пошло не так, мы окажемся в выражении .catch.const userGet = `https://api.github.com/search/users?page=1&q=daspinola&type=Users`
const userRequest = request(userGet)
// Если просто прочитать эту часть программы вслух, можно сразу понять что именно делает код
userRequest
.then(handleUsersList)
.then(repoRequest)
.then(handleReposList)
.catch(handleErrors)
function handleUsersList(users) {
return JSON.parse(users).items
}
function repoRequest(users) {
return Promise.all(users.map(function(user) {
return request(user.repos_url)
}))
}
function handleReposList(repos) {
console.log('All users repos in an array', repos)
}
function handleErrors(error) {
console.error('Something went wrong ', error)
}.then раскрывает смысл вызова userRequest. С кодом легко работать, его легко читать.function. С помощью генераторов асинхронный код можно сделать очень похожим на синхронный. Например, выглядеть это может так:function* foo() {
yield 1
const args = yield 2
console.log(args)
}
var fooIterator = foo()
console.log(fooIterator.next().value) // выведет 1
console.log(fooIterator.next().value) // выведет 2
fooIterator.next('aParam') // приведёт к вызову console.log внутри генератора и к выводу 'aParam'return, используют выражение yield, которое останавливает выполнение функции до следующего вызова .next итератора. Это похоже на выражение .then в промисах, которое выполняется при разрешении промиса.request:function request(url) {
return function(callback) {
const xhr = new XMLHttpRequest();
xhr.onreadystatechange = function(e) {
if (xhr.readyState === 4) {
if (xhr.status === 200) {
callback(null, xhr.response)
} else {
callback(xhr.status, null)
}
}
}
xhr.ontimeout = function () {
console.log('timeout')
}
xhr.open('get', url, true)
xhr.send()
}
}url, но вместо того, чтобы сразу выполнить запрос, мы хотим его выполнить только тогда, когда у нас будет функция обратного вызова для обработки ответа.function* list() {
const userGet = `https://api.github.com/search/users?page=1&q=daspinola&type=Users`
const users = yield request(userGet)
yield
for (let i = 0; i<=users.length; i++) {
yield request(users[i].repos_url)
}
}request, которая она принимает url и возвращает функцию, которая ожидает коллбэк);users, для отправки в следующий .next;users и ожидаем, для каждого из них, .next, возвращая, для каждого, соответствующий коллбэк.try {
const iterator = list()
iterator.next().value(function handleUsersList(err, users) {
if (err) throw err
const list = JSON.parse(users).items
// Отправляем список пользователей итератору
iterator.next(list)
list.forEach(function(user) {
iterator.next().value(function userRepos(error, repos) {
if (error) throw repos
// Здесь обрабатываем информацию о репозиториях каждого пользователя
console.log(user, JSON.parse(repos))
})
})
})
} catch (e) {
console.error(e)
}async, какую функцию предполагается выполнять асинхронно, и, используя await, сообщить системе о том, какая часть кода должна ждать разрешения соответствующего промиса.sumTwentyAfterTwoSeconds(10)
.then(result => console.log('after 2 seconds', result))
async function sumTwentyAfterTwoSeconds(value) {
const remainder = afterTwoSeconds(20)
return value + await remainder
}
function afterTwoSeconds(value) {
return new Promise(resolve => {
setTimeout(() => { resolve(value) }, 2000);
});
}sumTwentyAfterTwoSeconds;afterTwoSeconds, который может завершиться вызовом resolve или reject;.then, где завершается операция, отмеченная ключевым словом await, в данном случае — это всего одна операция.request к использовании в конструкции async/await:function request(url) {
return new Promise(function(resolve, reject) {
const xhr = new XMLHttpRequest();
xhr.onreadystatechange = function(e) {
if (xhr.readyState === 4) {
if (xhr.status === 200) {
resolve(xhr.response)
} else {
reject(xhr.status)
}
}
}
xhr.ontimeout = function () {
reject('timeout')
}
xhr.open('get', url, true)
xhr.send()
})
}async, в которой используем ключевое слово await:async function list() {
const userGet = `https://api.github.com/search/users?page=1&q=daspinola&type=Users`
const users = await request(userGet)
const usersList = JSON.parse(users).items
usersList.forEach(async function (user) {
const repos = await request(user.repos_url)
handleRepoList(user, repos)
})
}
function handleRepoList(user, repos) {
const userRepos = JSON.parse(repos)
// Обрабатываем тут репозитории для каждого пользователя
console.log(user, userRepos)
}list, которая обработает запрос. Ещё конструкция async/await нам понадобится в цикле forEach, чтобы сформировать список репозиториев. Вызвать всё это очень просто:list()
.catch(e => console.error(e))async/await можно почитать здесь.async/await, как и минус генераторов, заключается в том, что эту конструкцию не поддерживают старые браузеры, а для её использования в серверной разработке нужно пользоваться Node 8. В подобной ситуации, опять же, поможет транспилятор, например — babel.async/await. Если вы хотите как следует разобраться с тем, о чём мы говорили — поэкспериментируйте с этим кодом и со всеми рассмотренными технологиями.$.ajax и fetch. Если у вас есть идеи о том, как улучшить качество кода при использовании вышеописанных методик — буду благодарен, если расскажете об этом мне.|
Метки: author ru_vds разработка веб-сайтов javascript блог компании ruvds.com разработка callback async await promise generator асинхронный код |
6 сентября на Дизайн-заводе Flacon прошел неформальный митап для back-end разработчиков |

|
Метки: author Prosfera блог компании qiwi kubernetes qiwi docker big data meetup |
Метавычисления и глубокие свёрточные сети: интервью с профессором ИТМО |

 Алексей Потапов
Алексей ПотаповВот, например, несколько неплохих курсов:
Introduction into Deep Learning
Neural Networks and Deep Learning
Convolutional Neural Networks for Visual Recognition
|
Метки: author ARG89 машинное обучение big data блог компании jug.ru group deep learning |
AMD готовится потеснить Intel на рынке серверных решений |
 / Фото / twin-loc.fr / CC BY-SA
/ Фото / twin-loc.fr / CC BY-SA

|
Метки: author it_man высокая производительность блог компании ит-град ит-град intel amd ит-инфраструктура |
Технокубок 2017-2018 |
Каждый год Министерство образования и науки РФ публикует перечень школьных олимпиад, дающих льготы при поступлении в вузы. С 2015 года в этот список входит и Технокубок — олимпиада по программированию под эгидой Mail.Ru Group.

Поучаствовать в Технокубке могут ученики 8—11-х классов. Олимпиада позволяет ребятам оценить свои силы и пообщаться с профессионалами IT-отрасли, а главное — дает шанс поступить в ведущие профильные вузы России.
В 2017/18 учебном году Технокубок стал олимпиадой II уровня. Каждый вуз определяет льготу самостоятельно — это может быть максимальный балл по информатике или зачисление без вступительных испытаний. Судить о льготах на текущий год можно исходя из прошлогодних привилегий: как правило, эти сведения доступны на сайтах вузов. Также информация есть здесь.
Зарегистрироваться на Технокубок можно до 12 ноября. Заочные отборочные раунды пройдут 17 сентября, 15 октября и 12 ноября. Для того чтобы попасть в финал, достаточно победить в одном из трех отборочных раундов. Для интересующихся — примеры и разборы задач прошлых лет:
Технокубок 2015/16
1-й и 2-й отборочный раунд
Финал
Технокубок 2016/17
1-й отборочный раунд
2-й отборочный раунд
3-й отборочный раунд
Финал

В преддверии каждого отборочного тура проводятся ознакомительные онлайн-раунды. Они нужны для того, чтобы школьники разобрались в платформе Codeforces, на базе которой проводятся основные этапы. Во время ознакомительных раундов можно потренироваться на двух простых задачах, их результаты никак не повлияют на итоговый рейтинг.
Очный финал состоится в марте 2018-го на двух московских площадках: в МГТУ им. Н. Э. Баумана и в МФТИ. Награждение победителей пройдет в офисе Mail.Ru Group.

Каждый год в Технокубке участвует около 3 тысяч школьников из России и стран СНГ. Всего за время существования олимпиады в ней приняли участие более 7 тысяч человек.
Участникам, занявшим первые три места, помимо льгот при поступлении достанутся ценные призы. Кроме того, финалисты, которые попадут в МГТУ им. Н. Э. Баумана и в МФТИ, получат привилегии при поступлении в Технопарк и Технотрек — бесплатные практико-ориентированные образовательные проекты Mail.Ru Group.

В составе оргкомитета олимпиады — председатель совета директоров и сооснователь Mail.Ru Group Дмитрий Гришин. Сопредседатели оргкомитета — ректор МФТИ Н. Н. Кудрявцев и ректор МГТУ им. Н. Э. Баумана А. А. Александров. Председатель жюри — Михаил Мирзаянов, старший преподаватель кафедры математических основ информатики и олимпиадного программирования Саратовского государственного университета, основатель и генеральный директор Codeforces, дважды серебряный призер чемпионата мира по программированию ACM-ICPC.

Зарегистрироваться, узнать подробности и задать вопросы можно на сайте олимпиады и в группе в ВКонтакте. Технокубок-2018 ждет новых героев!
|
Метки: author sat2707 спортивное программирование программирование блог компании mail.ru group технокубок олимпиада школьников поступление |
Почему для 99% малого бизнеса бесполезен аудит сайта? |
|
Метки: author wilelf интернет-маркетинг веб-аналитика аудит сайтов seo юзабилити контент-маркетинг |
[recovery mode] Считывание ввода пользователя (цифр) в приложении 3CX Call Flow Designer |

LESS_THAN(callflow$.Index,LEN(callflow$.Digits)).CONCATENATE(MID(callflow$.Digits,callflow$.Index,1),".wav").
callflow$.Index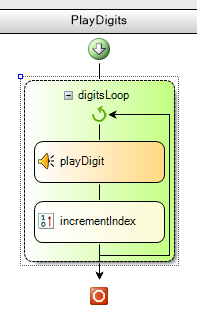
requestInput.Buffer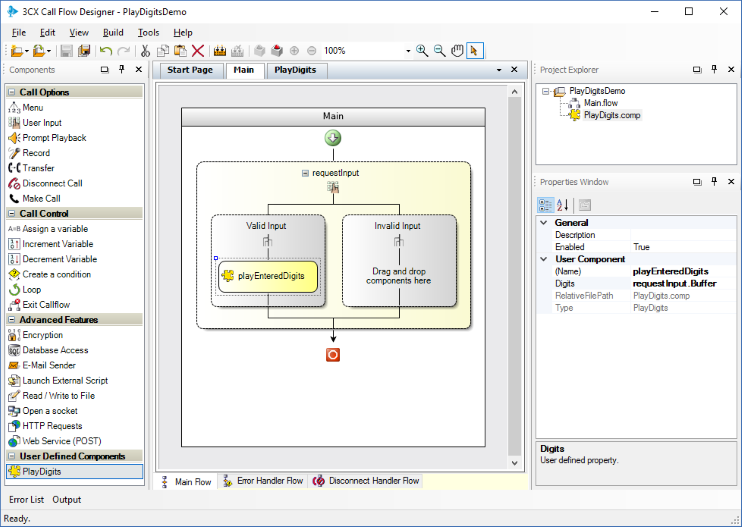
|
|
Машинное обучение руками «не программиста»: классификация клиентских заявок в тех.поддержку |
Привет! Меня зовут Кирилл и я алкоголик более 10 лет был менеджером в сфере ИТ. Я не всегда был таким: во время учебы в МФТИ писал код, иногда за вознаграждение. Но столкнувшись с суровой реальностью (в которой необходимо зарабатывать деньги, желательно побольше) пошел по наклонной — в менеджеры.

Но не все так плохо! С недавнего времени мы с партнерами целиком и полностью ушли в развитие своего стартапа: системы учета клиентов и клиентских заявок Okdesk. С одной стороны — больше свободы в выборе направления движения. Но с другой — нельзя просто так взять и заложить в бюджет "3-х разработчиков на 6 месяцев для проведение исследований и разработки прототипа для…". Много приходится делать самим. В том числе — непрофильные эксперименты, связанные с разработкой (т.е. те эксперименты, что не относятся к основной функциональности продукта).
Одним из таких экспериментов стала разработка алгоритма классификации клиентских заявок по текстам для дальнейшей маршрутизации на группу исполнителей. В этой статье я хочу рассказать, как "не программист" может за 1,5 месяца в фоновом режиме освоить python и написать незамысловатый ML-алгоритм, имеющий прикладную пользу.
В моём случае — дистанционное обучение на Coursera. Там довольно много курсов по машинному обучению и другим дисциплинам, связанным с искусственным интеллектом. Классикой считается курс основателя Coursera Эндрю Ына (Andrew Ng). Но минус этого курса (помимо того, что курс на английском языке: это не всем по силам) — редкостный инструментарий Octave (бесплатный аналог MATLAB-а). Для понимания алгоритмов это не главное, но лучше учиться на более популярных инструментах.
Я выбрал специализацию "Машинное обучение и анализ данных" от МФТИ и Яндекса (в ней 6 курсов; для того что написано в статье, достаточно первых 2-х). Главное преимущество специализации
— это живое сообщество студентов и менторов в Slack-е, где почти в любое время суток есть кто-то, к кому можно обратиться с вопросом.
В рамках статьи не будем погружаться в терминологические споры, поэтому желающих придраться к недостаточной математической точности прошу воздержаться (обещаю, что не буду выходить за рамки приличия :).
Итак, что же такое машинное обучение? Это набор методов для решения задач, требующих каких-либо интеллектуальных затрат человека, но при помощи вычислительных машин. Характерной чертой методов машинного обучения является то, что они "обучаются" на прецедентах (т.е. на примерах с заранее известными правильными ответами).
Более математизированное определение выглядит так:
Вот пример из жизни. Банк выдает кредиты. У банка накопилось множество анкет заёмщиков, для которых уже известен исход: вернули кредит, не вернули, вернули с просрочкой и т.д. Объектом в этом примере является заемщик с заполненной анкетой. Данные из анкеты — параметры объекта. Факт возврата или невозврата кредита — это "ответ" на объекте (анкете заёмщика). Совокупность анкет с известными исходами является обучающей выборкой.
Возникает естественное желание уметь предсказывать возврат или невозврат кредита потенциальным заемщиком по его анкете. Поиск алгоритма предсказания — задача машинного обучения.
Примеров задач машинного обучения множество. В этой статье подробнее поговорим о задаче классификации текстов.
Напомним о том, что мы разрабатываем Okdesk — облачный сервис для обслуживания клиентов. Компании, которые используют Okdesk в своей работе, принимают клиентские заявки по разным каналам: клиентский портал, электронная почта, web-формы с сайта, мессенджеры и так далее. Заявка может относиться к той или иной категории. В зависимости от категории у заявки может быть тот или иной исполнитель. Например, заявки по 1С должны отправляться на решение к специалистам 1С, а заявки связанные с работой офисной сети — группе системных администраторов.
Для классификации потока заявок можно выделить диспетчера. Но, во-первых, это стоит денег (зарплата, налоги, аренда офиса). А во-вторых, на классификацию и маршрутизацию заявки будет потрачено время и заявка будет решена позже. Если бы можно было классифицировать заявку по её содержанию автоматически — было бы здорово! Попробуем решить эту задачу силами машинного обучения (и одного ИТ-менеджера).
Для проведения эксперимента была взята выборка из 1200 заявок с проставленными категориями. В выборке заявки распределены по 14-ти категориям. Цель эксперимента: разработать механизм автоматической классификации заявок по их содержанию, который даст в разы лучшее качество, по сравнению с random-ом. По результатам эксперимента необходимо принять решение о развитии алгоритма и разработке на его базе промышленного сервиса для классификации заявок.
Для проведение эксперимента использовался ноутбук Lenovo (core i7, 8гб RAM), язык программирования Python 2.7 с библиотеками NumPy, Pandas, Scikit-learn, re и оболочкой IPython. Подробнее напишу об используемых библиотеках:
Из библиотеки Scikit-learn нам понадобятся некоторые модули, о предназначение которых я напишу по ходу изложения материала. Итак, импортируем все необходимые библиотеки и модули:
import pandas as pd
import numpy as np
import re
from sklearn import neighbors, model_selection, ensemble
from sklearn.grid_search import GridSearchCV
from sklearn.metrics import accuracy_scoreИ переходим к подготовке данных.
(конструкция import xxx as yy означает, что мы подключаем библиотеку xxx, но в коде будем обращаться к ней через yy)
При решении первых реальных (а не лабораторных) задач, связанных с машинным обучением, вы откроете для себя, что основная часть времени уходит не на обучение алгоритма (выбор алгоритма, подбор параметров, сравнение качества разных алгоритмов и т.д.). Львиная доля ресурсов уйдет на сбор, анализ и подготовку данных.
Есть различные приемы, методы и рекомендации по подготовке данных для разных классов задач машинного обучения. Но большинство экспертов называют подготовку данных скорее искусством, чем наукой. Есть даже такое выражение — feature engineering (т.е. конструирование параметров, описывающих объекты).
В задаче классификации текстов "фича" у объекта одна — текст. Скормить его алгоритму машинного обучения нельзя (допускаю, что мне не все известно :). Текст необходимо как-то оцифровать и формализовать.
В рамках эксперимента использовались примитивные методы формализации текстов (но даже они показали неплохой результат). Об этом поговорим далее.
Напомним, что в качестве исходных данных у нас есть выгрузка 1200 заявок (распределенных неравномерно по 14 категориям). Для каждой заявки есть поле "Тема", поле "Описание" и поле "Категория". Поле "Тема" — сокращенное содержание заявки и оно обязательно, поле "Описание" — расширенное описание и оно может быть пустым.
Данные загружаем из .xlsx файла в DataFrame. В .xlsx файле много столбцов (параметров реальных заявок), но нам нужны только "Тема", "Описание" и "Категория".
После загрузки данных объединяем поля "Тема" и "Описание" в одно поле для удобства дальнейшей обработки. Для этого предварительно необходимо заполнить чем-нибудь все пустые поля "Описание" (пустой строкой, например).
# Объявляем переменную issues типа DataFrame
issues = pd.DataFrame()
# Добавляем в issues столбцы Theme, Description и Cat, присваивая им значения полей Тема, Описание и Категория из .xlsx файла. u’...’ — потому что ‘…’ есть utf
issues[['Theme', 'Description','Cat']] = pd.read_excel('issues.xlsx')[[u'Тема', u'Описание', u'Категория']]
# Заполняем пустые ячейки столбца Description пустой строкой
issues.Description.fillna('', inplace = True)
# Объединяем столбцы Theme и Description (пробел используем в качестве разделителя) в столбец Content
issues['Content'] = issues.Theme + ' ' + issues.DescriptionИтак, у нас есть переменная issues типа DataFrame, в которой мы будем работать со столбцами Content (объединенное поле для полей "Тема" и "Описание") и Cat (категория заявки). Перейдем к формализации содержания заявки (т.е. столбца Content).
Как было сказано выше, первым делом необходимо формализовать текст заявки. Формализацию будем проводить следующим образом:
Матрица из п.4 есть формализованное описание содержания заявок. Говоря математизированным языком, каждая строка матрицы — координаты вектора соответствующей заявки в пространстве словаря. Для обучения алгоритма будем использовать полученную матрицу.
Важный момент: п.3 осуществляем после того, как выделим из обучающей выборки случайную подвыборку для контроля качества алгоритма (тестовую выборку). Это необходимо для того, чтобы лучше понимать, какое качество алгоритм покажет "в бою" на новых данных (например, не сложно реализовать алгоритм, который на обучающей выборке будет давать идеально верные ответы, но на любых новых данных будет работать не лучше random-а: такая ситуация называется переобучением). Отделение тестовой выборки именно до составления словаря важно потому, что если бы мы составляли словарь в том числе и на тестовых данных, то обученный на выборке алгоритм получился бы уже знакомым с неизвестными объектами. Выводы о его качестве на неизвестных данных будут некорректными.
Теперь покажем, как п.п. 1-4 выглядят в коде.
Первым делом приведем все тексты к нижнему регистру (“принтер” и “Принтер” — одинаковые слова только для человека, но не для машины):
#объявляем функцию приведения строки к нижнему регистру
def lower(str):
return str.lower()
#применяем функцию к каждой ячейке столбца Content
issues['Content'] = issues.Content.apply(lower)Далее определим вспомогательный словарь “слов-паразитов” (его наполнение производилось опытным итерационным путем для конкретной выборки заявок):
garbagelist = [u'спасибо', u'пожалуйста', u'добрый', u'день', u'вечер',u'заявка', u'прошу', u'доброе', u'утро']Объявим функцию, которая разбивает текст каждой заявки на слова длиной 2 и более символов, а затем включает полученные слова, за исключением “слов-паразитов”, в массив:
def splitstring(str):
words = []
#разбиваем строку по символам из []
for i in re.split('[;,.,\n,\s,:,-,+,(,),=,/,«,»,@,\d,!,?,"]',str):
#берём только "слова" длиной 2 и более символов
if len(i) > 1:
#не берем слова-паразиты
if i in garbagelist:
None
else:
words.append(i)
return wordsДля разбиения текста на слова по символам-разделителям используется библиотека регулярных выражений re и её метод split. В метод split передается массив символов-разделителей (набор символов-разделителей пополнялся итерационно-опытным путем) и строка, подлежащая разбиению.
Применяем объявленную функцию к каждой заявке. На выходе получаем исходный DataFrame, в котором появился новый столбец Words с массивом слов (за исключением “слов-паразитов”), из которых состоит каждая заявка.
issues['Words'] = issues.Content.apply(splitstring)Теперь приступим к составлению словаря входящих в содержание всех заявок слов. Но перед этим, как писали выше, разделим обучающую выборку на контрольную (так же известную как "тестовая", "отложенная") и ту, на которой будем обучать алгоритм.
Разделение выборки осуществляем методом train_test_split модуля model_selection библиотеки Scikit-learn. В метод передаем массив с данными (тексты заявок), массив с метками (категории заявок) и размер тестовой выборки (обычно выбирают 30% от всей). На выходе получаем 4 объекта: данные для обучения, метки для обучения, данные для контроля и метки для контроля:
issues_train, issues_test, labels_train, labels_test = model_selection.train_test_split(issues.Words, issues.Cat, test_size = 0.3)Теперь объявим функцию, которая составит словарь по данным, оставленным на обучение (issues_train), и применим функцию в этим данным:
def WordsDic(dataset):
WD = []
for i in dataset.index:
for j in xrange(len(dataset[i])):
if dataset[i][j] in WD:
None
else:
WD.append(dataset[i][j])
return WD
#применяем функцию к данным
words = WordsDic(issues_train)Итак, мы составили словарь из слов, составляющих тексты всех заявок из обучающей выборки (за исключением заявок, оставленных на контроль). Словарь записали в переменную words. Размер массива words получился равным 12015-м элементов (т.е. слов).
Перейдем к заключительному шагу подготовки данных для обучения. А именно: составим матрицу размера (количество заявок в выборке) x (количество слов в словаре), где в i-й строке j-го столбца находится количество вхождений j-го слова из словаря в i-ю заявку из выборки.
#объявляем матрицу размером len(issues_train) на len(words), заполняем её нулями
train_matrix = np.zeros((len(issues_train),len(words)))
#заполняем матрицу, проставляя в [i][j] количество вхождений j-го слова из words в i-й объект обучающей выборки
for i in xrange(train_matrix.shape[0]):
for j in issues_train[issues_train.index[i]]:
if j in words:
train_matrix[i][words.index(j)]+=1Теперь у нас есть всё необходимое для обучения: матрица train_matrix (формализованное содержание заявок в виде координат векторов, соответствующих заявкам, в пространстве словаря, составленного по всем заявкам) и метки labels_train (категории заявок из оставленной на обучение выборки).
Перейдем к обучению алгоритмов на размеченных данных (т.е. таких данных, для которых известны правильные ответы: матрица train_matrix с метками labels_train). В этом разделе будет мало кода, так как большинство методов машинного обучения реализовано в библиотеке Scikit-learn. Разработка своих методов может быть полезной для усвоения материала, но с практической точки зрения в этом нет потребности.
Ниже постараюсь простым языком изложить принципы конкретных методов машинного обучения.
Никогда не знаешь, какой алгоритм машинного обучения будет давать лучший результат на конкретных данных. Но, понимая задачу, можно определить набор наиболее подходящих алгоритмов, чтобы не перебирать все существующие. Выбор алгоритма машинного обучения, который будет использоваться для решения задачи, осуществляется через сравнение качества работы алгоритмов на обучающей выборке.
Что считать качеством алгоритма, зависит от задачи, которую вы решаете. Выбор метрики качества — отдельная большая тема. В рамках классификации заявок была выбрана простая метрика: точность (accuracy). Точность определяется как доля объектов в выборке, для которых алгоритм дал верный ответ (поставил верную категорию заявки). Таким образом, мы выберем тот алгоритм, который будет давать бОльшую точность в предсказании категорий заявок.
Важно сказать о таком понятии, как гиперпараметр алгоритма. Алгоритмы машинного обучения имеют внешние (т.е. такие, которые не могут быть выведены аналитически из обучающей выборки) параметры, определяющие качество их работы. Например в алгоритмах, где требуется рассчитать расстояние между объектами, под расстоянием можно понимать разные вещи: манхэттенское расстояние, классическую евклидову метрику и т.д.
У каждого алгоритма машинного обучения свой набор гиперпараметров. Выбор лучших значений гиперпараметров осуществляется, как ни странно, перебором: для каждой комбинации значений параметров вычисляется качество алгоритма и далее для данного алгоритма используется лучшая комбинация значений. Процесс затратный с точки зрения вычислений, но куда деваться.
Для определения качества алгоритма на каждой комбинации гиперпараметров используется кросс-валидация. Поясню, что это такое. Обучающая выборка разбивается на N равных частей. Алгоритм последовательно обучается на подвыборке из N-1 частей, а качество считается на одной отложенной. В итоге каждая из N частей 1 раз используется для подсчета качества и N-1 раз для обучения алгоритма. Качество алгоритма на комбинации параметров считается как среднее между значениями качества, полученными при кросс-валидации. Кросс-валидация необходима для того, чтобы мы могли больше доверять полученному значению качества (при усреднении мы нивелируем возможные “перекосы” конкретного разбиения выборки). Чуть подробнее сами знаете где.
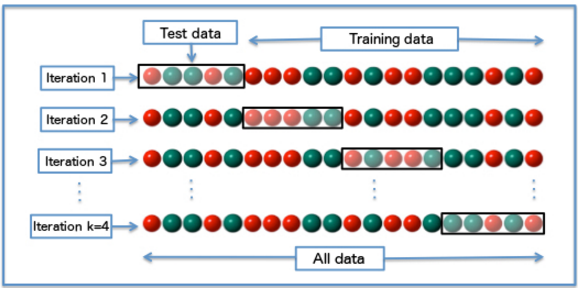
Итак, для выбора наилучшего алгоритма для каждого алгоритма:
С точки зрения программирования описанного выше алгоритма нет ничего сложного. Но и в этом нет потребности. В библиотеке Scikit-learn есть готовый метод подбора параметров по сетке (метод GridSearchCV модуля grid_search). Все что нужно — передать в метод алгоритм, сетку параметров и число N (количество частей, на которые разбиваем выборку для кросс-валидации; их ещё называют "folds").
В рамках решения задачи было выбрано 2 алгоритма: k ближайших соседей и композиция случайных деревьев. О каждом из них рассказ далее.
Метод k ближайших соседей наиболее прост в понимании. Заключается он в следующем.
Есть обучающая выборка, данные в которой уже формализованы (подготовлены к обучению). Т.е объекты представлены в виде векторов какого-либо пространства. В нашем случае заявки представлены в виде векторов пространства словаря. Для каждого вектора обучающей выборки известен правильный ответ.
Для каждого нового объекта вычисляются попарные расстояния между этим объектом и объектами обучающей выборки. Затем берутся k ближайших объектов из обучающей выборки и для нового объекта возвращается ответ, который преобладает в подвыборке из k ближайших объектов (для задач, где нужно предсказать число, можно брать среднее значение из k ближайших).
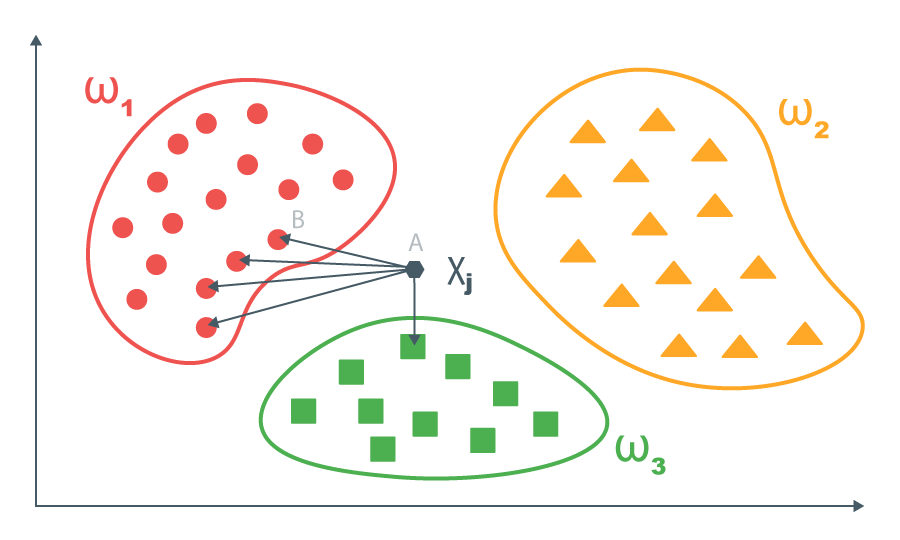
Алгоритм можно развить: давать бОльший вес значению метки на более близком объекте. Но для задачи классификации заявок делать этого не будем.
Гиперпараметрами алгоритма в рамках нашей задачи являются число k (по скольки ближайшим соседям будем делать вывод) и определение расстояния. Количество соседей перебираем в диапазоне от 1 до 7, определение расстояния выбираем из манхэттенского расстояния (сумма модулей разности координат) и евклидовой метрики (корень из суммы квадратов разности координат).
Выполняем незамысловатый код:
%%time
#задаем сетку для подбора гиперпараметров
param_grid = {'n_neighbors': np.arange(1,8), 'p': [1,2]}
#задаем количество fold-ов для кросс-валидации
cv = 3
#объявляем классификатор
estimator_kNN = neighbors.KNeighborsClassifier()
#передаем сетку, классификатор и количество fold-ов в метод подбора параметров по сетке
optimazer_kNN = GridSearchCV(estimator_kNN, param_grid, cv = cv)
#запускаем подбор параметров по сетке на обучающей выборке
optimazer_kNN.fit(train_matrix, labels_train)
#смотрим лучшие параметры и качество алгоритма на лучших параметрах
print optimazer_kNN.best_score_
print optimazer_kNN.best_params_Через 2 минуты 40 секунд узнаем, что лучшее качество в 53,23% показывает алгоритм на 3 ближайших соседях, определенных по манхэттенскому расстоянию.
Решающие деревья — ещё один алгоритм машинного обучения. Обучение алгоритма представляет собой пошаговое разбиение обучающей выборки на части (чаще всего на две, но в общем случае это не обязательно) по какому-либо признаку. Вот простой пример, иллюстрирующий работу решающего дерева:

У решающего дерева есть внутренние вершины (в которых принимаются решения о дальнейшем разбиении выборки) и финальные вершины (листы), по которым дается прогноз попавшим туда объектам.
В решающей вершине проверяется простое условие: соответствие какого-то (об этом далее) j-го признака объекта условию xj больше или равно какому-то t. Объекты, удовлетворяющие условию, отправляются в одну ветку, а не удовлетворяющие — в другую.
При обучении алгоритма можно было бы разбивать обучающую выборку до тех пор, пока во всех вершинах не останется по одному объекту. Такой подход даст отличный результат на обучающей выборке, но на неизвестных данных получится "шляпа". Поэтому важно определить так называемый "критерий останова" — условие, при котором вершина становится листом и дальнейшее ветвление этой вершины приостанавливается. Критерий останова зависит от задачи, вот некоторые типы критериев: минимальное количество объектов в вершине и ограничение на глубину дерева. В решении поставленной задачи использовался критерий минимального количества объектов в вершине. Число, равное минимальному количеству объектов, является гиперпараметром алгоритма.
Новые (требующие предсказания) объекты прогоняются по обученному дереву и попадают в соответствующий им лист. Для объектов, попавших в лист, даем следующий ответ:
Осталось поговорить о том, как выбирать для каждой вершины признак j (по какому признаку разбиваем выборку в конкретной вершине дерева) и соответствующий этому признаку порог t. Для этого вводят так называемый критерий ошибки Q(Xm,j,t). Как видно, критерий ошибки зависит от выборки Xm (та часть обучающей выборки, что дошла до рассматриваемой вершины), параметра j, по которому будет разбиваться выборка Xm в рассматриваемой вершине и порогового значения t. Необходимо подобрать такое j и такое t, при котором критерий ошибки будет минимальным. Так как возможный набор значений j и t для каждой обучающей выборки ограничен, задача решается перебором.
Что такое критерий ошибки? В черновой версии статьи на этом месте было много формул и сопровождающих объяснений, рассказ про критерий информативности и его частные случаи (критерий Джинни и энтропийный критерий). Но статья получилась и так раздутой. Желающие разобраться в формальностях и математике смогут почитать обо всем в интернете (например, здесь). Ограничусь "физическим смыслом" на пальцах. Критерий ошибки показывает уровень "разнообразия" объектов в получающихся после разбиения подвыборках. Под "разнообразием" в задачах классификации подразумевается разнообразие классов, а в задачах регрессии (где предсказываем числа) — дисперсия. Таким образом, при разбиении выборки мы хотим максимальным образом уменьшить "разнообразие" в получающихся подвыборках.
С деревьями разобрались. Перейдем к композиции деревьев.
Решающие деревья могут выявить очень сложные закономерности в обучающей выборке. Но чем лучший результат обучающие деревья показывают на обучении, тем худший результат они покажут на новых данных — деревья переобучаются. Для устранения этой проблемы придуман механизм объединения обучающих деревьев в композиции (леса).
Для построения композиции деревьев берется N обученных деревьев и их результат “усредняется”. Для задач регрессии (там, где предсказываем число) берется среднее значение предсказанных чисел, а для задач классификации — самый популярный (из N предсказаний) предсказанный класс.
Таким образом, для построения леса необходимо сначала обучить N решающих деревьев. Но делать это на одной и той же обучающей выборке бессмысленно: мы получим N одинаковых алгоритмов и результат усреднения будет равен результату любого из них. Поэтому для обучения базовых деревьев используется рандомизация: обучение каждого базового дерева производится по случайной подвыборке объектов исходной обучающей выборки и/или по случайному набору параметров (т.е. для обучения каждого базового алгоритма берутся не все параметры объектов, а только случайный набор определенного размера). Но и этого бывает недостаточно для построения независимых алгоритмов — применяют рандомизацию признаков для разбиения на каждой вершине (т.е. на каждой вершине каждого дерева признак выбирают не из всего набора, а из случайной подвыборки признаков определенного размера; важно, что для каждой вершины каждого дерева случайная подвыборка — своя). Поэтому алгоритм и называется композицией случайных деревьев.
Перейдем наконец-то к практике! При обучении алгоритма будем искать лучшие значения для 2-х гиперпараметров: минимального количества объектов в узле (гиперпараметр для дерева) и количества базовых алгоритмов (гиперпараметр для леса).
Запускаем код:
%%time
#задаем сетку для подбора гиперпараметров
param_grid = {'n_estimators': np.arange(20,101,10), 'min_samples_split': np.arange(4,11, 1)}
#задаем количество fold-ов для кросс-валидации
cv = 3
#объявляем классификатор
estimator_tree = ensemble.RandomForestClassifier()
#передаем сетку, классификатор и количество fold-ов в метод подбора параметров по сетке
optimazer_tree = GridSearchCV(estimator_tree, param_grid, cv = cv)
#запускаем подбор параметров по сетке на обучающей выборке
optimazer_tree.fit(train_matrix, labels_train)
#смотрим лучшие параметры и качество алгоритма на лучших параметрах
print optimazer_tree.best_score_
print optimazer_tree.best_params_Через 3 минуты 30 секунд узнаем, что лучшее качество в 65,82% показывает алгоритм из 60 деревьев, для которых минимальное количество объектов в узле равно 4.
Теперь проверим работу двух обученных алгоритмов на отложенной (тестовой, контрольной — как её только не называют) выборке.
Для этого составим матрицу test_matrix, являющуюся проекцией объектов отложенной выборки на пространство словаря, составленного по обучающей выборке (т.е. составляем такую же матрицу, что и train_matrix, только для отложенной выборки).
#Создаем матрицу размером len(issues_test) на len(words)
test_matrix = np.zeros((len(issues_test),len(words)))
#заполняем матрицу, проставляя в [i][j] количество вхождений j-го слова из words в i-й объект тестовой выборки
for i in xrange(test_matrix.shape[0]):
for j in issues_test[issues_test.index[i]]:
if j in words:
test_matrix[i][words.index(j)]+=1Для получения качества алгоритмов используем метод accuracy_score модуля metrics библиотеки Scikit-learn. Передаем в него предсказания на отложенной выборке каждого из алгоритмов и известные для отложенной выборки значения меток:
print u'Случайный лес:', accuracy_score(optimazer_tree.best_estimator_.predict(test_matrix), labels_test)
print u'kNN:', accuracy_score(optimazer_kNN.best_estimator_.predict(test_matrix), labels_test)Получаем 51,39% на алгоритме k ближайших соседей и 73,46% на композиции случайных деревьев.
Целью эксперимента было получение результата, “в разы” лучшего, чем random. На самом деле речь шла о “глупых” алгоритмах, частным случаем которых является random. В общем случае, “глупые” алгоритмы это такие алгоритмы, построить которые можно без сколь-нибудь серьезного анализа обучающей выборки.
Сравним полученное качество с 3-мя видами “глупых” алгоритмов:
Равномерный random на 14 классах дает примерно 100/14 * 100% = 7,14% качество. Алгоритм, который всегда выдает самый популярный класс даст качество в 14,5% (такая доля у самого популярного класса в обучающей выборке). Для получения качества на пропорциональном random-е напишем простой код. Каждому объекту отложенной выборки алгоритм будет присваивать класс объекта из обучающей выборки, выбранный равномерным random-ом:
#импортируем библиотеку random
import random
#объявляем массив, куда будем складывать random-ные предсказания
rand_ans = []
#предсказываем
for i in xrange(test_matrix.shape[0]):
rand_ans.append(labels_train[labels_train.index[random.randint(0,len(labels_train))]])
#смотрим качество
print u'Пропорциональный random:', accuracy_score(rand_ans, labels_test)Получаем 14,52%.
Итак, используя не самые сложные методы мы получили качество классификации в разы выше, чем дают “глупые” алгоритмы. Ура!
Для промышленного применения машинного обучения при классификации заявок, необходимо получить качество не ниже 90% — такой ориентир дают потенциальные потребители. Результаты эксперимента показывают, что такое качество может быть достигнуто. Ведь даже при подготовке данных к обучению мы не использовали такие “классические” методы подготовки текстов как стемминг и ранжирование слов при попадании в словарь (если слово встречается пару раз в выборке, оно скорее всего мусорное и его можно исключить). К тому-же, в словаре для одного и того же слова было несколько написаний (например: "печать", "пичать", "печять" и т.д.) — с этим тоже можно бороться (желательно в школе) и повышать качество алгоритма.
Кроме того, в эксперименте использовался только один параметр: текст. Если весь текст заявки это фраза "Не работает" или "Проблема", у нас не так много вариантов определить что случилось. У всех возможных категорий заявок одинаковая вероятность быть верным ответом. Но если мы знаем, что заявка пришла из бухгалтерии, а дата регистрации совпадает с датой квартального отчета, количество возможных вариантов резко сокращается.
В общем, можно инвестировать в разработку промышленного модуля классификации заявок для Okdesk.
"Отлично! Работаем дальше!" (с)
|
Метки: author krubinshteyn машинное обучение алгоритмы saas / s+s python блог компании okdesk machine learning ai okesk coursera образование онлайн |
Сегментация лица на селфи без нейросетей |
 Приветствую вас, коллеги. Оказывается, не все компьютерное зрение сегодня делается с использованием нейронных сетей. Хотя многие стартапы и заявляют, что у них дип лернинг везде, спешу вас разочаровать, они просто хотят хайпануть немножечко. Рассмотрим, например, задачу сегментации. В нашем слаке развернулась целая драма. Одна богатая и высокотехнологичная селфи-компания собрала датасет для сегментации селфи с помощью нейросетей (а это непростое и недешевое занятие). А другая, более бедная и не очень развитая решила, что можно подкупить людей, размечающих фотки, и
Приветствую вас, коллеги. Оказывается, не все компьютерное зрение сегодня делается с использованием нейронных сетей. Хотя многие стартапы и заявляют, что у них дип лернинг везде, спешу вас разочаровать, они просто хотят хайпануть немножечко. Рассмотрим, например, задачу сегментации. В нашем слаке развернулась целая драма. Одна богатая и высокотехнологичная селфи-компания собрала датасет для сегментации селфи с помощью нейросетей (а это непростое и недешевое занятие). А другая, более бедная и не очень развитая решила, что можно подкупить людей, размечающих фотки, и спполучить базу. В общем, страсти в этих ваших Интернетах еще те. Недавно я наткнулся на статью, где без всяких нейросетей на устройстве делают очень даже хорошую сегментацию. Для сегментации от пользователя требуется дать алгоритму несколько подсказок, но с помощью dlib и opencv такие подсказки легко автоматизируются. В качестве бонуса мы так же сгладим вырезанное лицо и перенесем на какого-нибудь рандомного человека, тем самым поймем, как работают маски во всех этих снапчятах и маскарадах. В общем, классика еще жива, и если вы хотите немного окунуться в классическое компьютерное зрение на питоне, то добро пожаловать под кат.
Кратко опишем алгоритм, а затем перейдем к его реализации по шагам. Допустим, у нас есть некоторое изображение, мы просим пользователя нарисовать на изображении две кривых. Первая (синий цвет) должна полностью принадлежать объекту интереса. Вторая (зеленый цвет) должна касаться только фона изображения.

Далее делаем следующие шаги:
Дальнейший материал будет разбавляться вставками кода на питоне, если вы планируете выполнять его по мере чтения поста, то вам понадобятся следующие импорты:
%matplotlib inline
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style("dark")
plt.rcParams['figure.figsize'] = 16, 12
import pandas as pd
from PIL import Image
from tqdm import tqdm_notebook
from skimage import transform
import itertools as it
from sklearn.neighbors.kde import KernelDensity
import matplotlib.cm as cm
import queue
from skimage import morphology
import dlib
import cv2
from imutils import face_utils
from scipy.spatial import Delaunay
 Идея того, как автоматизировать штрихи была навеяна приложением FaceApp, которое якобы использует нейросети для трансформации. Как мне кажется, они если и используют сети где то, то только в детектировании особых точек на лице. Взгляните на скриншот справа, они предлагают выровнять свое лицо по контуру. Вероятно, алгоритм детекции обучен примерно на таком масштабе. Как только лицо попадает в контур, сама рамка контура исчезает, значит особые точки вычислились. Позвольте вам представить сегодняшнего подопытного, а так-же напомнить, что из себя представляют эти самые особые точки на лице.
Идея того, как автоматизировать штрихи была навеяна приложением FaceApp, которое якобы использует нейросети для трансформации. Как мне кажется, они если и используют сети где то, то только в детектировании особых точек на лице. Взгляните на скриншот справа, они предлагают выровнять свое лицо по контуру. Вероятно, алгоритм детекции обучен примерно на таком масштабе. Как только лицо попадает в контур, сама рамка контура исчезает, значит особые точки вычислились. Позвольте вам представить сегодняшнего подопытного, а так-же напомнить, что из себя представляют эти самые особые точки на лице.
img_input = np.array(Image.open('./../data/input2.jpg'))[:500, 400:, :]
print(img_input.shape)
plt.imshow(img_input)
Теперь воспользуемся возможностями бесплатного программного обеспечения с открытым исходным кодом и найдем рамку вокруг лица и особые точки на лице, всего их 62.
# инстанцируем класс для детекции лиц (рамка)
detector = dlib.get_frontal_face_detector()
# инстанцируем класс для детекции ключевых точек
predictor = dlib.shape_predictor('./../data/shape_predictor_68_face_landmarks.dat')
# конвертируем изображение в много оттенков серого
img_gray = cv2.cvtColor(img_input, cv2.COLOR_BGR2GRAY)
# вычисляем список рамок на каждое найденное лицо
rects = detector(img_gray, 0)
# вычисляем ключевые точки
shape = predictor(img_gray, rects[0])
shape = face_utils.shape_to_np(shape)img_tmp = img_input.copy()
for x, y in shape:
cv2.circle(img_tmp, (x, y), 1, (0, 0, 255), -1)
plt.imshow(img_tmp)
Оригинальная рамка на лице слишком мелкая (зеленый цвет), нам понадобится рамка, которая полностью содержит в себе лицо с некоторым зазором (красный цвет). Коэффициенты расширения рамки получены эмпирическим путем с помощью анализа нескольких десятков селфи разного масштаба и разных людей.
# оригинальная рамка
face_origin = sorted([(t.width()*t.height(),
(t.left(), t.top(), t.width(), t.height()))
for t in rects],
key=lambda t: t[0], reverse=True)[0][1]
# коэффициенты расширения рамки
rescale = (1.3, 2.2, 1.3, 1.3)
# расширение рамки, так чтобы она не вылезла за края
(x, y, w, h) = face_origin
cx = x + w/2
cy = y + h/2
w = min(img_input.shape[1] - x, int(w/2 + rescale[2]*w/2))
h = min(img_input.shape[0] - y, int(h/2 + rescale[3]*h/2))
fx = max(0, int(x + w/2*(1 - rescale[0])))
fy = max(0, int(y + h/2*(1 - rescale[1])))
fw = min(img_input.shape[1] - fx, int(w - w/2*(1 - rescale[0])))
fh = min(img_input.shape[0] - fy, int(h - h/2*(1 - rescale[1])))
face = (fx, fy, fw, fh)img_tmp = cv2.rectangle(img_input.copy(), (face[0], face[1]),
(face[0] + face[2], face[1] + face[3]),
(255, 0, 0), thickness=3, lineType=8, shift=0)
img_tmp = cv2.rectangle(img_tmp, (face_origin[0], face_origin[1]),
(face_origin[0] + face_origin[2], face_origin[1] + face_origin[3]),
(0, 255, 0), thickness=3, lineType=8, shift=0)
plt.imshow(img_tmp)

Теперь у нас имеется область, которая точно не относится к лицу — всё, что вне красной рамки. Выберем оттуда некоторое количество случайных точек и будем считать их штрихами фона. Также у нас имеются 62 точки, которые точно расположены на лице. Для упрощения задачи я выберу 5 из них: по одной на уровне глаз на краю лица, по одной на уровне рта на краю лица и одну внизу посередине подбородка. Все точки внутри этого пятиугольника будут принадлежать только лицу. Опять же для простоты будем считать, что лицо вертикально расположено на изображении и потому мы можем отразить полученный пятиугольник по оси , тем самым получив восьмиугольник. Все, что внутри восьмиугольника будем считать штрихом объекта.
# выбираем вышеописанные пять точек
points = [shape[0].tolist(), shape[16].tolist()]
for ix in [4, 12, 8]:
x, y = shape[ix].tolist()
points.append((x, y))
points.append((x, points[0][1] + points[0][1] - y))
# я не особо в прототипе запариваюсь над производительностью
# так что вызываю триангуляцию Делоне,
# чтобы использовать ее как тест на то, что точка внутри полигона
# все это можно делать быстрее, т.к. точный тест не нужен
# для прототипа :good-enough:
hull = Delaunay(points)
xy_fg = []
for x, y in it.product(range(img_input.shape[0]), range(img_input.shape[1])):
if hull.find_simplex([y, x]) >= 0:
xy_fg.append((x, y))
print('xy_fg%:', len(xy_fg)/np.prod(img_input.shape))
# вычисляем количество точек для фона
# примерно равно что бы было тому, что на лице
r = face[1]*face[3]/np.prod(img_input.shape[:2])
print(r)
k = 0.1
xy_bg_n = int(k*np.prod(img_input.shape[:2]))
print(xy_bg_n)
# накидываем случайные точки
xy_bg = zip(np.random.uniform(0, img_input.shape[0], size=xy_bg_n).astype(np.int),
np.random.uniform(0, img_input.shape[1], size=xy_bg_n).astype(np.int))
xy_bg = list(xy_bg)
xy_bg = [(x, y) for (x, y) in xy_bg
if y < face[0] or y > face[0] + face[2] or x < face[1] or x > face[1] + face[3]]
print(len(xy_bg)/np.prod(img_input.shape[:2]))img_tmp = img_input/255
for x, y in xy_fg:
img_tmp[x, y, :] = img_tmp[x, y, :]*0.5 + np.array([1, 0, 0]) * 0.5
for x, y in xy_bg:
img_tmp[x, y, :] = img_tmp[x, y, :]*0.5 + np.array([0, 0, 1]) * 0.5
plt.imshow(img_tmp)
Теперь у нас есть два набора данных: точки объекта и точки фона .
points_fg = np.array([img_input[x, y, :] for (x, y) in xy_fg])
points_bg = np.array([img_input[x, y, :] for (x, y) in xy_bg])Посмотрим на распределение цветов по RGB каналам в каждом из множеств. Первая гистограмма — для объекта, вторая — для фона.
fig, axes = plt.subplots(nrows=2, ncols=1)
sns.distplot(points_fg[:, 0], ax=axes[0], color='r')
sns.distplot(points_fg[:, 1], ax=axes[0], color='g')
sns.distplot(points_fg[:, 2], ax=axes[0], color='b')
sns.distplot(points_bg[:, 0], ax=axes[1], color='r')
sns.distplot(points_bg[:, 1], ax=axes[1], color='g')
sns.distplot(points_bg[:, 2], ax=axes[1], color='b')
Радует, что распределения отличаются. Это значит, что если мы сможем получить функции, оценивающие вероятность принадлежности точки к нужному распределению, то мы получим нечеткие маски. И оказывается такой способ есть — kernel density estimation. Для заданного набора точек, можно построить функцию оценки плотности для новой точки следующим образом (для простоты пример для одномерного распределения):
где:
Мы для простоты будем использовать Гауссово ядро:
Хотя для скорости Гауссово ядро не лучший выбор и если взять ядро Епанечникова, то все будет считаться быстрее. Так же я буду использовать KernelDensity из sklearn, что в итоге выльется в 5 минут скоринга. Авторы этой статьи утверждают, что замена KDE на оптимальную реализацию сокращает расчеты на устройстве до одной секунды.
# инстанцируем классы KDE для объекта и фона
kde_fg = KernelDensity(kernel='gaussian',
bandwidth=1,
algorithm='kd_tree',
leaf_size=100).fit(points_fg)
kde_bg = KernelDensity(kernel='gaussian',
bandwidth=1,
algorithm='kd_tree',
leaf_size=100).fit(points_bg)
# инициализируем и вычисляем маски
score_kde_fg = np.zeros(img_input.shape[:2])
score_kde_bg = np.zeros(img_input.shape[:2])
likelihood_fg = np.zeros(img_input.shape[:2])
coodinates = it.product(range(score_kde_fg.shape[0]),
range(score_kde_fg.shape[1]))
for x, y in tqdm_notebook(coodinates,
total=np.prod(score_kde_fg.shape)):
score_kde_fg[x, y] = np.exp(kde_fg.score(img_input[x, y, :].reshape(1, -1)))
score_kde_bg[x, y] = np.exp(kde_bg.score(img_input[x, y, :].reshape(1, -1)))
n = score_kde_fg[x, y] + score_kde_bg[x, y]
if n == 0:
n = 1
likelihood_fg[x, y] = score_kde_fg[x, y]/nВ итоге у нас есть несколько масок:
score_kde_fg — оценка вероятности быть точкой объекта score_kde_bg — оценка вероятности быть точкой объекта likelihood_fg — нормализированная вероятность быть точкой объекта 1 - likelihood_fg нормализированная вероятность быть точкой фона Посмотрим на следующие распределения.
sns.distplot(score_kde_fg.flatten())
plt.show()
sns.distplot(score_kde_bg.flatten())
plt.show()
Распределение значений likelihood_fg:
sns.distplot(likelihood_fg.flatten())
plt.show()
Вселяет надежду то, что на есть два пика, и количество точек, принадлежащих лицу, явно не меньше, чем фоновых точек. Нарисуем полученные маски.
plt.matshow(score_kde_fg, cmap=cm.bwr)
plt.show()
plt.matshow(score_kde_bg, cmap=cm.bwr)
plt.show()
plt.matshow(likelihood_fg, cmap=cm.bwr)
plt.show()
plt.matshow(1 - likelihood_fg, cmap=cm.bwr)
plt.show()
К сожалению, часть косяка двери получилась частью лица. Хорошо, что косяк далеко от лица. Этим-то свойством мы и воспользуемся в следущей части.
Представим изображение как граф, узлами которого являются пиксели, а ребрами соединены точки сверху и снизу от текущей точки, а так же справа и слева от неё. Весами ребер будем считать абсолютное значение разницы вероятностей принадлежности точек к объекту или к фону:
Соответственно, чем вероятности ближе к друг другу, тем меньше вес ребра между точками. Воспользуемся алгоритмом Дейкстры для поиска наикратчайших путей и их расстояний от точки до всех остальных. Алгоритм мы вызовем два раза, подав на вход все вероятности принадлежности в объекту и затем вероятности принадлежности точек к фону. Понятие расстояния зашьем сразу в алгоритм, а расстояние между точками, принадлежащими одной группе (объекту или фону), будет равно нулю. В рамках алгоритма Дейкстры мы можем поместить все эти точки в группу посещенных вершин.
def dijkstra(start_points, w):
d = np.zeros(w.shape) + np.infty
v = np.zeros(w.shape, dtype=np.bool)
q = queue.PriorityQueue()
for x, y in start_points:
d[x, y] = 0
q.put((d[x, y], (x, y)))
for x, y in it.product(range(w.shape[0]), range(w.shape[1])):
if np.isinf(d[x, y]):
q.put((d[x, y], (x, y)))
while not q.empty():
_, p = q.get()
if v[p]:
continue
neighbourhood = []
if p[0] - 1 >= 0:
neighbourhood.append((p[0] - 1, p[1]))
if p[0] + 1 <= w.shape[0] - 1:
neighbourhood.append((p[0] + 1, p[1]))
if p[1] - 1 >= 0:
neighbourhood.append((p[0], p[1] - 1))
if p[1] + 1 < w.shape[1]:
neighbourhood.append((p[0], p[1] + 1))
for x, y in neighbourhood:
# тут вычисляется расстояние
d_tmp = d[p] + np.abs(w[x, y] - w[p])
if d[x, y] > d_tmp:
d[x, y] = d_tmp
q.put((d[x, y], (x, y)))
v[p] = True
return d
# вызываем алгоритм для двух масок
d_fg = dijkstra(xy_fg, likelihood_fg)
d_bg = dijkstra(xy_bg, 1 - likelihood_fg)plt.matshow(d_fg, cmap=cm.bwr)
plt.show()
plt.matshow(d_bg, cmap=cm.bwr)
plt.show()
А теперь относим к объекту все те точки, от которых расстояние до объекта меньше чем расстояния до фона (можно добавить некоторый зазор).
margin = 0.0
mask = (d_fg < (d_bg + margin)).astype(np.uint8)
plt.matshow(mask)
plt.show()
Можно отправить себя в космос.
img_fg = img_input/255.0
img_bg = (np.array(Image.open('./../data/background.jpg'))/255.0)[:800, :800, :]
x = int(img_bg.shape[0] - img_fg.shape[0])
y = int(img_bg.shape[1]/2 - img_fg.shape[1]/2)
img_bg_fg = img_bg[x:(x + img_fg.shape[0]), y:(y + img_fg.shape[1]), :]
mask_3d = np.dstack([mask, mask, mask])
img_bg[x:(x + img_fg.shape[0]), y:(y + img_fg.shape[1]), :] = mask_3d*img_fg + (1 - mask_3d)*img_bg_fg
plt.imshow(img_bg)
Вы наверняка заметили, что маска слегка рваная на краях. Но это легко исправить методами математической морфологии.

Допустим, у нас есть структурный элемент (СЭ) типа "диск" — бинарная маска диска.
Мы воспользуемся размыканием, что сначала удалит "волосатость" по краям, а потом вернет первоначальный размер (объект "похудеет" после эрозии).
mask = morphology.opening(mask, morphology.disk(11))
plt.imshow(mask)
После применения такой маски результат станет поприятнее:
img_fg = img_input/255.0
img_bg = (np.array(Image.open('./../data/background.jpg'))/255.0)[:800, :800, :]
x = int(img_bg.shape[0] - img_fg.shape[0])
y = int(img_bg.shape[1]/2 - img_fg.shape[1]/2)
img_bg_fg = img_bg[x:(x + img_fg.shape[0]), y:(y + img_fg.shape[1]), :]
mask_3d = np.dstack([mask, mask, mask])
img_bg[x:(x + img_fg.shape[0]), y:(y + img_fg.shape[1]), :] = \
mask_3d*img_fg + (1 - mask_3d)*img_bg_fg
plt.imshow(img_bg)
Возьмем случайную фотку из интернетов для эксперимента по переносу лица.
img_target = np.array(Image.open('./../data/target.jpg'))
img_target = (transform.rescale(img_target, scale=0.5, mode='constant')*255).astype(np.uint8)
print(img_target.shape)
plt.imshow(img_target)
Найдем на подопытном все 62 колючевые точки лица, напомню, что они будут в том же порядке как и на любом другом лице.
img_gray = cv2.cvtColor(img_target, cv2.COLOR_BGR2GRAY)
rects_target = detector(img_gray, 0)
shape_target = predictor(img_gray, rects_target[0])
shape_target = face_utils.shape_to_np(shape_target)Чтобы перенести одно лицо на другое, нужно первое лицо отмасштабировать под новое, повернуть и передвинуть, т.е. применить некоторое аффинное преобразование к первому лицу. Оказывается, что и аффинное преобразование не некоторое, а вполне конкретное. Оно должно быть таким, которое переводит 62 точки первого лица в 62 точки второго лица. Получается, что для получения оператора аффинного преобразования нам необходимо решить задачу линейной регрессии.
Данное уравнение легко решается с помощью псевдообратной матрицы:
Так и сделаем:
# добавим справа к матрицам колонку единиц,
# иначе будет только масштабирование и поворот, без переноса
X = np.hstack((shape, np.ones(shape.shape[0])[:, np.newaxis]))
Y = np.hstack((shape_target, np.ones(shape_target.shape[0])[:, np.newaxis]))
# учим оператор
A = np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), Y)
# выбираем точки лица по искомой маске
X = np.array([(y, x, 1) for (x, y) in
it.product(range(mask.shape[0]),
range(mask.shape[1])) if mask[x, y] == 1.0])
# вычисляем новые координаты маски на целевом изображении
Y = np.dot(X, A).astype(np.int)img_tmp = img_target.copy()
for y, x, _ in Y:
if x < 0 or x >= img_target.shape[0] or y < 0 or y >= img_target.shape[1]:
continue
img_tmp[x, y, :] = np.array([0, 0, 0])
plt.imshow(img_tmp)
img_trans = img_target.copy().astype(np.uint8)
points_face = {}
for ix in range(X.shape[0]):
y1, x1, _ = X[ix, :]
y2, x2, _ = Y[ix, :]
if x2 < 0 or x2 >= img_target.shape[0] or
y2 < 0 or y2 >= img_target.shape[1]:
continue
points_face[(x2, y2)] = img_input[x1, y1, :]
for (x, y), c in points_face.items():
img_trans[x, y, :] = c
plt.imshow(img_trans)
В качестве домашней работы вы можоте самостоятельно сделать следующие улучшения:
Ноутбук с исходниками находится тут. Приятного времяпрепровождения.
Как обычно спс bauchgefuehl за редактуру.
|
|






