Выходим в интернет за пределами РФ: (MikroTik<->Ubuntu) * GRE / IPsec |
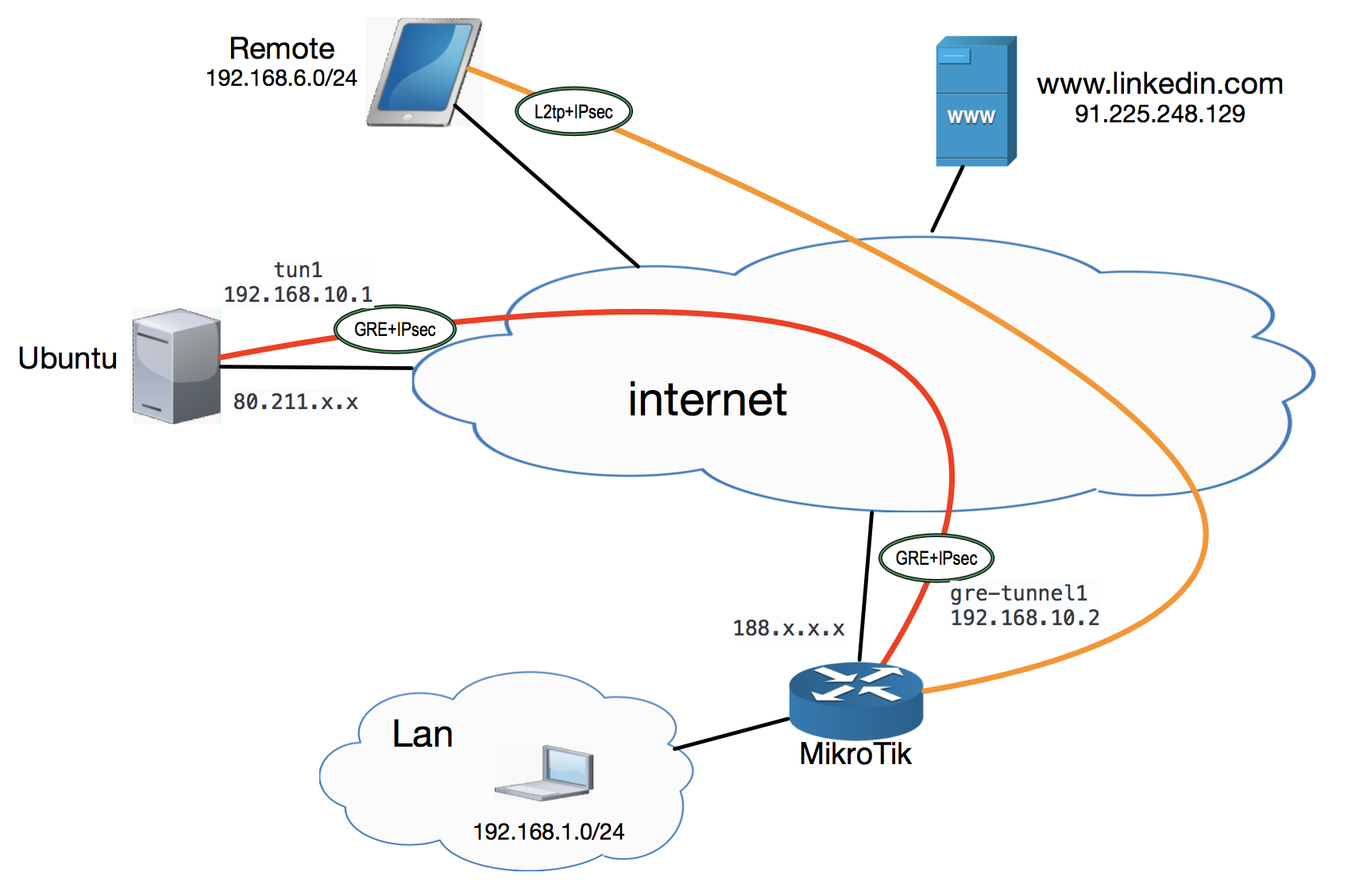

$ sudo apt install traceroute$ sudo cat << EOF >> /etc/network/interfaces
iface tun1 inet static
address 192.168.10.1
netmask 255.255.255.0
pre-up iptunnel add tun1 mode gre local 80.211.x.x remote 188.x.x.x ttl 255
up ifconfig tun1 multicast
pointopoint 192.168.10.2
post-down iptunnel del tun1
EOF
$ sudo service networking restart$ ifconfig tun1
tun1 Link encap:UNSPEC HWaddr 10-D3-29-B2-00-00-B0-8A-00-00-00-00-00-00-00-00
inet addr:192.168.10.1 P-t-P:192.168.10.2 Mask:255.255.255.255
inet6 addr: fe80::200:5ffa:50d3:c9c2/64 Scope:Link
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1476 Metric:1
RX packets:379 errors:0 dropped:0 overruns:0 frame:0
TX packets:322 errors:4 dropped:7 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:103387 (103.3 KB) TX bytes:159422 (159.4 KB)

$ ping 192.168.10.2
PING 192.168.10.2 (192.168.10.2) 56(84) bytes of data.
64 bytes from 192.168.10.2: icmp_seq=1 ttl=64 time=56.0 ms
64 bytes from 192.168.10.2: icmp_seq=2 ttl=64 time=59.9 ms
64 bytes from 192.168.10.2: icmp_seq=3 ttl=64 time=56.3 ms
64 bytes from 192.168.10.2: icmp_seq=4 ttl=64 time=56.1 ms
--- 192.168.10.2 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3004ms
rtt min/avg/max/mdev = 56.091/57.137/59.936/1.618 ms
user@vps:~$ $ sudo cat << EOF >> /etc/network/interfaces
#static route"
up ip ro add 192.168.1.0/24 via 192.168.10.2
up ip ro add 192.168.6.0/24 via 192.168.10.2
EOF
$ sudo service networking restart$ sudo echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
$ sudo sysctl -p$ sudo iptables -t nat -A POSTROUTING -j SNAT --to-source 80.211.x.x -o eth0/ip route
add comment=linkedin distance=1 dst-address=91.225.248.0/22 gateway=gre-tunnel1
add comment=linkedin distance=1 dst-address=108.174.0.0/20 gateway=gre-tunnel1
add comment=linkedin distance=1 dst-address=185.63.144.0/22 gateway=gre-tunnel1
$ apt install strongswan$ cat << EOF > /etc/ipsec.conf
# ipsec.conf - strongSwan IPsec configuration file
config setup
charondebug="ike 2, knl 2, cfg 2, net 2, esp 2, dmn 2, mgr 2"
conn %default
# keyexchange=ikev2
conn mikrotik
# Try connect on daemon start
auto=start
# Authentication by PSK (see ipsec.secret)
authby=secret
# Disable compression
compress=no
# Re-dial setings
closeaction=clear
dpddelay=30s
dpdtimeout=150s
dpdaction=restart
# ESP Authentication settings (Phase 2)
esp=aes128-sha1
# UDP redirects
forceencaps=no
# IKE Authentication and keyring settings (Phase 1)
ike=aes128-sha1-modp2048,aes256-sha1-modp2048
ikelifetime=86400s
keyingtries=%forever
lifetime=3600s
# Internet Key Exchange (IKE) version
# Default: Charon - ikev2, Pluto: ikev1
keyexchange=ikev1
# connection type
type=transport
# Peers
left=188.x.x.x
right=80.211.x.x
# Protocol type. May not work in numeric then need set 'gre'
leftprotoport=47
rightprotoport=47
EOF
$ echo "80.211.x.x 188.x.x.x : PSK VeryBigSecret" >> /etc/ipsec.secrets$ ipsec restart


$ ipsec status
Security Associations (1 up, 0 connecting):
mikrotik[2]: ESTABLISHED 60 minutes ago, 80.211.x.x[80.211.x.x]...188.x.x.x[188.x.x.x]
mikrotik{2}: INSTALLED, TRANSPORT, reqid 1, ESP SPIs: cc075de3_i 07620dfa_o
mikrotik{2}: 80.211.x.x/32[gre] === 188.x.x.x/32[gre]


auto tun1
iface tun1 inet static
address 192.168.10.1
netmask 255.255.255.0
pre-up iptunnel add tun1 mode gre local 80.211.x.x remote 188.x.x.x ttl 255
up ifconfig tun1 multicast
pointopoint 192.168.10.2
mtu 1435
post-down iptunnel del tun1
|
Метки: author eov системное администрирование сетевые технологии серверное администрирование настройка linux ubuntu linux gre ipsec strongswan vps mikrotik |
Специфика использования Redux в Polymer и Vue |

redux с polymer и vue, а так же описание азов самого redux, дабы не эту тему хочу раскрыть в статье.The only way to change the state is to emit an action, an object describing what happened.

polymer при связке с redux дак это односторонний биндинг.changeInput: function(e) {
this.dispatch("setText", e.currentTarget.value);
}change диспатчим action и после чего измененное значение попадает в propFromReduxStore и контрол перерендерится уже с новым значением.vue немного другая ситуация, в нем нет как такагого одностороннего биндинга, как в polymer. Но подобную функциональность можно достигнуть через модификатор syncchangeInput: function(e) {
this.actionsRedux("setText", e.currentTarget.value);
}polymer.html-элементов в виде шаблона.
redux описанному выше. И что бы избежать неконсистентной ситуации, когда контрол уже перерендерился в виду своего внутреннего состояния, а прибинденная модель еще не поменялась через action и не соответствует данному представлению необходимо производить дополнительные действия для блокировки прямого изменения state.changeCheck: function(e) { //Здесь ловим клик по компоненту
//Предотвращаем bubbling события, что бы компонент сразу не перерендерил компонент
e.stopPropagation();
this.dispatch("setChecked", !this.propFromReduxStore);
}
changeCheck: function() {
this.actionsRedux("setChecked", !this.propFromReduxStore);
}click, а если и есть, то узнаем мы об его наступлении уже постфактум, не говоря уже об его подалении, но зато есть модификатор native, который позволяет получить доступ ко всем возможным нативным событиям. Так же есть модификатор stop, который даже позволит нам не писать e.stopPropagation(), как это было с polymer. Малость, а приятно.React не рассмотрел, так как на практике его не использовал, если не считать jsx-темплейтов в vue, но это совершенно не то. Но все-таки, насколько я наслышен от коллег по цеху, там таких проблем нет, в виду внутренней архитектуры обработки событий.|
Метки: author kolesoffac разработка веб-сайтов программирование javascript redux polymer.js vue.js state events |
Считаем до трёх: четыре |





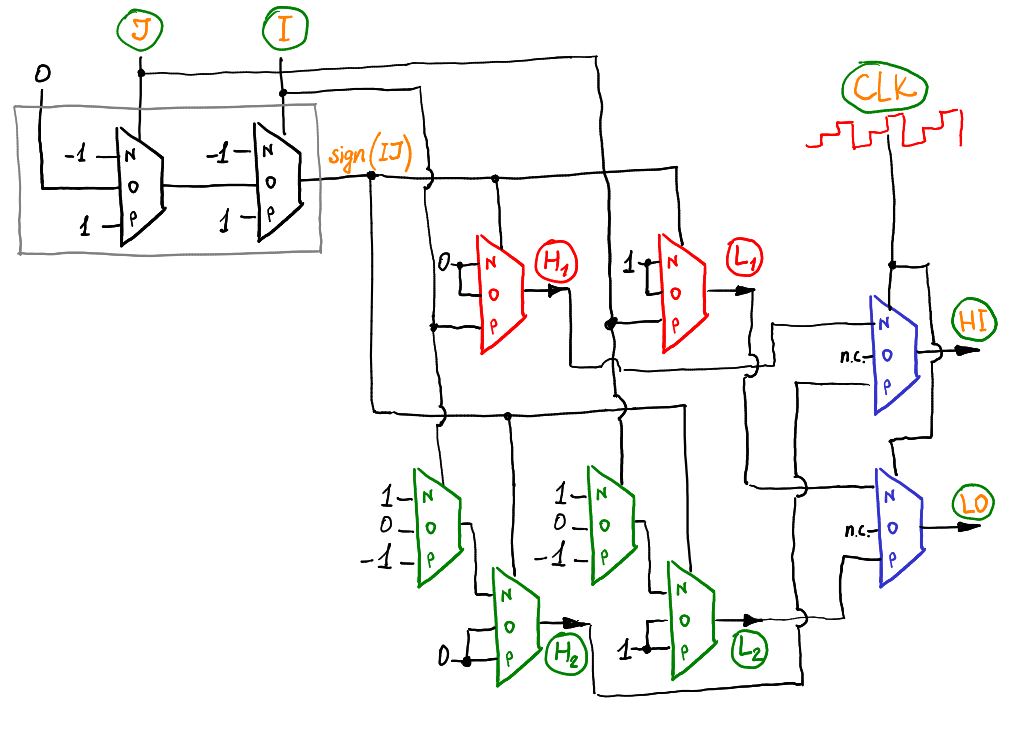
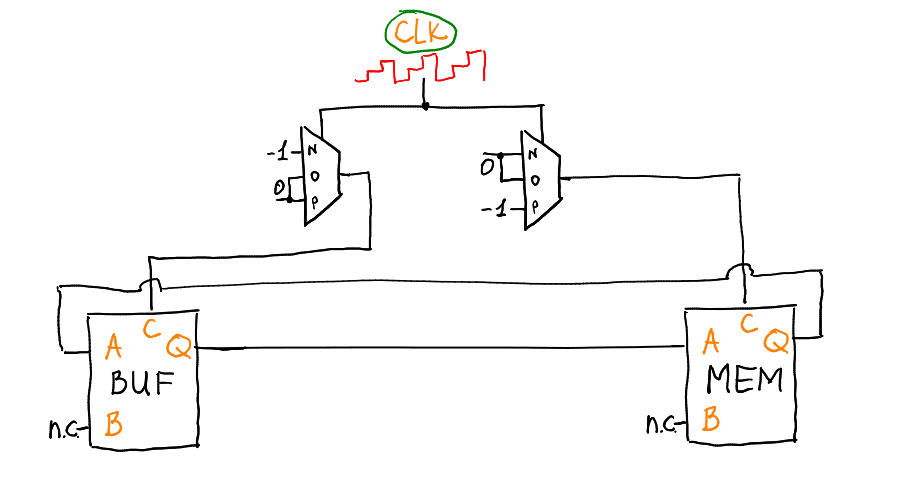
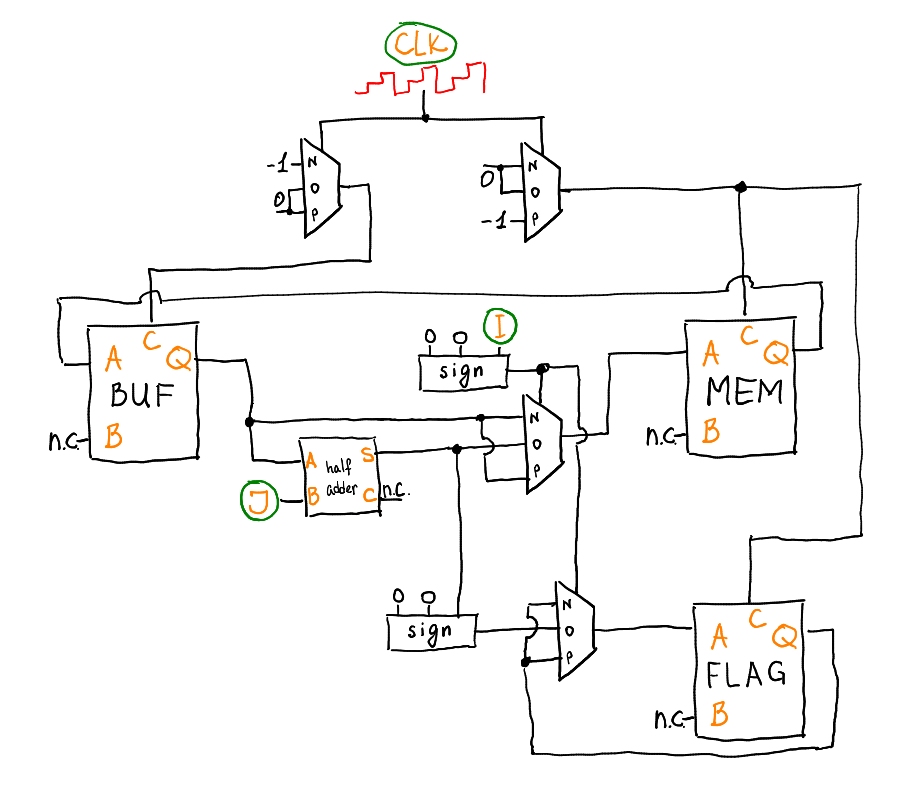


|
Метки: author haqreu программирование микроконтроллеров ненормальное программирование математика занимательные задачки алгоритмы троичные вычисления железки |
Intel научит дроны самостоятельности |

|
Метки: author 1cloud разработка для интернета вещей блог компании 1cloud.ru 1cloud myriad x intel movidius |
[Перевод] Spring: ваш следующий Java микрофреймворк |
В этой статье мы поговорим о новой концепции в готовящемся к выходу Spring Framework 5 которая называется функциональный веб-фреймворк и посмотрим, как она может помочь при разработке легковесных приложений и микросервисов.
Вы, возможно, удивлены видеть Spring и микрофреймворк в одном предложении. Но все верно, Spring вполне может стать вашим следующим Java микрофреймворком. Чтобы избежать недоразумений, давайте определим, что им имеем в виду под микро:
Несмотря на то, что некоторые из этих пунктов актуальны при использовании Spring Boot, он сам по себе добавляет дополнительную магию поверх самого Spring Framework. Даже такие базовые аннотации, как @Controller не совсем прямолинейны, что уж говорить про авто-конфигурации и сканирование компонентов. В общем-то, для крупномасштабных приложений, просто незаменимо то, что Spring берет на себя заботу о DI, роутинге, конфигурации и т.п. Однако, в мире микросервисов, где приложения это просто шестеренки в одной больной машине, вся мощь Spring Boot может быть немного лишней.
Для решения этой проблемы, команда Spring представила новую фичу, которая называется функциональный веб-фреймворк — и именно о ней мы и будем говорить. В целом, это часть большего под-проекта Spring WebFlux, который раньше назывался Spring Reactive Web.
Для начала, давайте вернемся к основам и посмотрим, что такое веб-приложение и какие компоненты мы ожидаем иметь в нем. Несомненно, есть базовая вещь — веб-сервер. Чтобы избежать ручной обработки запросов и вызова методов приложения, нам пригодится роутер. И, наконец, нам нужен обработчик — кусок кода, который принимает запрос и отдает ответ. По сути, это все, что нужно! И именно эти компоненты предоставляет функциональный веб-фреймворк Spring, убирая всю магию и фокусируясь на фундаментальном минимуме. Отмечу, что это вовсе не значит, что Spring резко меняет направление и уходит от Spring MVC, функциональный веб просто дает еще одну возможность создавать приложения на Spring.
Давайте рассмотрим пример. Для начала, пойдем на Spring Initializr и создадим новый проект используя Spring Boot 2.0 и Reactive Web как единственную зависимость. Теперь мы можем написать наш первый обработчик — функцию которая принимает запрос и отдает ответ.
HandlerFunction hello = new HandlerFunction() {
@Override
public Mono handle(ServerRequest request) {
return ServerResponse.ok().body(fromObject("Hello"));
}
};Итак, наш обработчик это просто реализация интерфейса HandlerFunction который принимает параметр request (типа ServerRequest) и возвращает объект типа ServerResponse с текстом "Hello". Spring так же предоставляет удобные билдеры чтобы создать ответ от сервера. В нашем случае, мы используем ok() которые автоматически возвращают HTTP код ответа 200. Чтобы вернуть ответ, нам потребуется еще один хелпер — fromObject, чтобы сформировать ответ из предоставленного объекта.
Мы так же можем сделать код немного более лаконичным и использовать лямбды из Java 8 и т.к. HandlerFunction это интерфейс одного метода (single abstract method interface, SAM), мы можем записать нашу функцию как:
HandlerFunction hello = request -> ServerResponse.ok().body(fromObject("Hello"));Теперь, когда у нас есть хендлер, пора определить роутер. Например, мы хотим вызвать наш обработчик когда URL "/" был вызван с помощью HTTP метода GET. Чтобы этого добиться, определим объект типа RouterFunction который мапит функцию-обработчик, на маршрут:
RouterFunction router = route(GET("/"), hello);route и GET это статические методы из классов RequestPredicates и RouterFunctions, они позволяют создать так называемую RouterFunction. Такая функция принимает запрос, проверяет, соответствует ли он все предикатам (URL, метод, content type, etc) и вызывает нужную функцию-обработчик. В данном случае, предикат это http метод GET и URL '/', а функция обработчик это hello, которая определена выше.
А сейчас пришло время собрать все вместе в единое приложение. Мы используем легковесный и простой сервер Reactive Netty. Чтобы интегрировать наш роутер с веб-сервером, необходимо превратить его в HttpHandler. После этого можно запустить сервер:
HttpServer
.create("localhost", 8080)
.newHandler(new ReactorHttpHandlerAdapter(httpHandler))
.block();ReactorHttpHandlerAdapter это класс предоставленный Netty, который принимает HttpHandler, остальной код, думаю, не требует пояснений. Мы создаем новые веб-сервер привязанный к хосту localhost и на порту 8080 и предоставляем httpHandler созданный из нашего роутера.
И это все, приложение готово! И его полный код:
public static void main(String[] args)
throws IOException, LifecycleException, InterruptedException {
HandlerFunction hello = request -> ServerResponse.ok().body(fromObject("Hello"));
RouterFunction router = route(GET("/"), hello);
HttpHandler httpHandler = RouterFunctions.toHttpHandler(router);
HttpServer
.create("localhost", 8080)
.newHandler(new ReactorHttpHandlerAdapter(httpHandler))
.block();
Thread.currentThread().join();
}Последняя строчка нужна только чтобы держать JVM процесс живым, т.к. сам HttpServer его не блокирует. Вы возможно сразу обратите внимание, что приложение стартует мгновенно — там нет ни сканирования компонентов, ни авто-конфигурации.
Мы так же может запустить это приложение как обычное Java приложение, не требуется никаких контейнеров приложений и прочего.
Чтобы запаковать приложение для деплоймента, мы можем воспользоваться преимуществами Maven плагина Spring и просто вызвать
./mvnw package
Эта команда создаст так называемый fat JAR со всеми зависимостями, включенными в JAR. Это файл может быть задеплоен и запущен не имея ничего, кроме установленной JRE
java -jar target/functional-web-0.0.1-SNAPSHOT.jar
Так же, если мы проверим использование памяти приложением, то увидим, что оно держится примерно в районе 32 Мб — 22 Мб использовано на metaspace (классы) и около 10 Мб занято непосредственно в куче. Разумеется, наше приложение ничего и не делает — но тем не менее, это просто показатель, что фреймворк и рантайм сами по себе требуют минимум системных ресурсов.
В нашем примере, мы возвращали строку, но вернуть JSON ответ так же просто. Давайте расширим наше приложение новым endpoint-ом, который вернет JSON. Наша модель будет очень простой — всего одно строковое поле под названием name. Чтобы избежать ненужного boilerplate кода, мы воспользуемся фичей из проекта Lombok, аннотацией @Data. Наличие этой аннотации автоматически создаст геттеры, сеттеры, методы equals и hashCode, так что нам не придется релизовывать их вручную.
@Data
class Hello {
private final String name;
}Теперь, нам нужно расширить наш роутер чтобы вернуть JSON ответ при обращении к URL /json. Это можно сделать вызвав andRoute(...) метод на существующем роуте. Также, давайте вынесем код роутер в отдельную функцию, чтобы отделить его от кода приложения и позволить использовать позже в тестах.
static RouterFunction getRouter() {
HandlerFunction hello = request -> ok().body(fromObject("Hello"));
return
route(
GET("/"), hello)
.andRoute(
GET("/json"), req ->
ok()
.contentType(APPLICATION_JSON)
.body(fromObject(new Hello("world")));
}После перезапуска, приложение вернет { "name": "world" } при обращении к URL /json при запросе контента с типом application/json.
Вы, возможно, заметили, что мы не определили контекст приложения — он нам просто не нужен! Несмотря на то, что мы можем объявить RouterFunction как бин (bean) в контексте Spring WebFlux приложения, и он точно так же будет обрабатывать запросы на определенные URL, роутер можно запустить просто поверх Netty Server чтобы создавать простые и легковесные JSON сервисы.
Для тестирования реактивных приложений, Spring предоставляет новый клиент под названием WebTestClient (подобно MockMvc). Его можно создать для существующего контекста приложения, но так же можно определить его и для RouterFunction.
public class FunctionalWebApplicationTests {
private final WebTestClient webTestClient =
WebTestClient
.bindToRouterFunction(
FunctionalWebApplication.getRouter())
.build();
@Test
public void indexPage_WhenRequested_SaysHello() {
webTestClient.get().uri("/").exchange()
.expectStatus().is2xxSuccessful()
.expectBody(String.class)
.isEqualTo("Hello");
}
@Test
public void jsonPage_WhenRequested_SaysHello() {
webTestClient.get().uri("/json").exchange()
.expectStatus().is2xxSuccessful()
.expectHeader().contentType(APPLICATION_JSON)
.expectBody(Hello.class)
.isEqualTo(new Hello("world"));
}
}WebTestClient включает ряд assert-ов, которые можно применить к полученному ответу, чтобы провалидировать HTTP код, содержимое ответа, тип ответа и т.п.
Spring 5 представляет новую парадигму для разработки маленьких и легковесных microservice-style веб-приложений. Такие приложения могут работать без контекста приложений, автоконфигурации и в целом использовать подход микрофреймворков, когда роутер и функции-обработчики и веб-сервер опеределены явно в теле приложения.
Доступен на GitHub
Я так же являюсь и автором оригинальной статьи, так что вопросы можно задавать в комментариях.
|
Метки: author alek_sys java spring spring 5 |
[Из песочницы] Stateless аутентификация при помощи Spring Security и JWT |
@RequestMapping(value = "/login", produces = "application/json", method = RequestMethod.GET)
@ResponseStatus(value = HttpStatus.NO_CONTENT)
public void login(HttpServletResponse response) {
SessionUser user = (SessionUser) SecurityContextHolder.getContext().getAuthentication().getPrincipal();
tokenAuthenticationService.addAuthentication(response, user);
SecurityContextHolder.getContext().setAuthentication(null);
} public void addAuthentication(HttpServletResponse response, SessionUser user) {
Cookie access = new Cookie("access_token", tokenHandler.createAccessToken(user));
access.setPath("/");
access.setHttpOnly(true);
response.addCookie(access);
Cookie refresh = new Cookie("refresh_token", tokenHandler.createRefreshToken(user));
refresh.setPath("/");
refresh.setHttpOnly(true);
response.addCookie(refresh);
}public String createRefreshToken(SessionUser user) {
//возвращает токен, в котором хранится только username
}
public SessionUser parseRefreshToken(String token) {
//парсит username из токена и получает данные пользователя из реализации UserDetailsService
}
public String createAccessToken(SessionUser user) {
//возвращает токен, в котором хранятся все данные для воссоздания SessionUser
}
public SessionUser parseAccessToken(String token) {
//использует данные из токена для создания нового SessionUser
} @Bean
public TokenAuthenticationService tokenAuthenticationService() {
return new TokenAuthenticationService();
}
@Bean
public TokenHandler tokenHandler() {
return new TokenHandler();
}@Override
protected void configure(HttpSecurity http) throws Exception {
http.authorizeRequests()
//Ресурсы доступные анонимным пользователям
.antMatchers("/", "/login").permitAll()
//Все остальные доступны только после аутентификации
.anyRequest().authenticated()
.and()
.sessionManagement().sessionCreationPolicy(SessionCreationPolicy.STATELESS)
.and()
.addFilterBefore(new StatelessAuthenticationFilter(tokenAuthenticationService()), UsernamePasswordAuthenticationFilter.class)
}public class StatelessAuthenticationFilter extends GenericFilterBean {
private final TokenAuthenticationService tokenAuthenticationService;
public StatelessAuthenticationFilter(TokenAuthenticationService tokenAuthenticationService) {
this.tokenAuthenticationService= tokenAuthenticationService;
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain)
throws IOException, ServletException {
HttpServletRequest httpRequest = (HttpServletRequest) request;
HttpServletResponse httpResponse = (HttpServletResponse) response;
Authentication authentication = tokenAuthenticationService.getAuthentication(httpRequest, httpResponse);
SecurityContextHolder.getContext().setAuthentication(authentication);
filterChain.doFilter(request, response);
SecurityContextHolder.getContext().setAuthentication(null);
}
}— Присутствует access токен?За это отвечает еще один метод из уже известного вам TokenAuthenticationService:
— Нет? Отклонить запрос.
— Да?
— — Действительный и не истек?
— — Да? Разрешить запрос.
— — Нет? Попробовать получить новый access токен при помощи refresh токена.
— — — Получилось?
— — — Да? Разрешить запрос, и добавить новый access токен к ответу.
— — — Нет? Отклонить запрос.
public Authentication getAuthentication(HttpServletRequest request, HttpServletResponse response) {
Cookie[] cookies = request.getCookies();
String accessToken = null;
String refreshToken = null;
if (cookies != null) {
for (Cookie cookie : cookies) {
if (("access_token").equals(cookie.getName())) {
accessToken = cookie.getValue();
}
if (("refresh_token").equals(cookie.getName())) {
refreshToken = cookie.getValue();
}
}
}
if (accessToken != null && !accessToken.isEmpty()) {
try {
SessionUser user = tokenHandler.parseAccessToken(accessToken);
return new UserAuthentication(user);
} catch (ExpiredJwtException ex) {
if (refreshToken != null && !refreshToken.isEmpty()) {
try {
SessionUser user = tokenHandler.parseRefreshToken(refreshToken);
Cookie access = new Cookie("access_token", tokenHandler.createAccessToken(user));
access.setPath("/");
access.setHttpOnly(true);
response.addCookie(access);
return new UserAuthentication(user);
} catch (JwtException e) {
return null;
}
}
return null;
} catch (JwtException ex) {
return null;
}
}
return null;
} 1. id (BIGINT)И создал класс RefreshTokenDao с двумя методами использующими JdbcTemplate для общения с этой таблицей:
2. username (VARCHAR)
3. token (VARCHAR)
4. expires (TIMESTAMP)
public void insert(String username, String token, long expires) {
String sql = "INSERT INTO refresh_token "
+ "(username, token, expires) VALUES (?, ?, ?)";
jdbcTemplate.update(sql, username, token, new Timestamp(expires));
}
public int updateIfNotExpired(String username, String token, long expiration) {
String sql = "UPDATE refresh_token "
+ "SET expires = ? "
+ "WHERE username = ? "
+ "AND token = ? "
+ "AND expires > ?";
Timestamp now = new Timestamp(System.currentTimeMillis());
Timestamp newExpirationTime = new Timestamp(now.getTime() + expiration);
return jdbcTemplate.update(sql, newExpirationTime, username, token, now);
}|
Метки: author AnarSultanov java spring security jwt |
[Перевод] ggplot2: как легко совместить несколько графиков в одном, часть 2 |
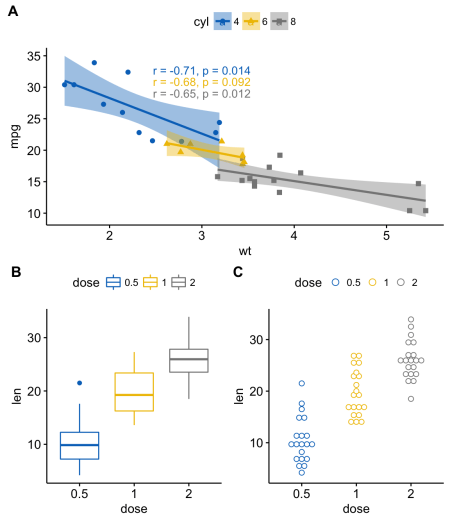
ggarrange() для изменения расположения графиков по строкам или столбцам.ggarrange(sp, # Первая строка с диаграммой разброса
ggarrange(bxp, dp, ncol = 2, labels = c("B", "C")), # Вторая строка с диаграммой рассеивания и точечной диаграммой
nrow = 2,
labels = "A" # Метки диаграммы разброса
) 
ggdraw() + draw_plot() + draw_plot_label().ggdraw()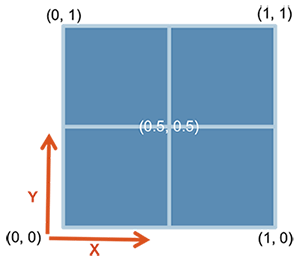
draw_plot(plot, x = 0, y = 0, width = 1, height = 1)plot: график для размещения (ggplot2 или gtable)x, y: координаты x/y левого нижнего угла графикаwidth, height: ширина и высота графикаdraw_plot_label(label, x = 0, y = 1, size = 16, ...)label: вектор метокx, y: вектор с х/у координатами каждой метки соответственноsize: размер шрифта меткиlibrary("cowplot")
ggdraw() +
draw_plot(bxp, x = 0, y = .5, width = .5, height = .5) +
draw_plot(dp, x = .5, y = .5, width = .5, height = .5) +
draw_plot(bp, x = 0, y = 0, width = 1, height = 0.5) +
draw_plot_label(label = c("A", "B", "C"), size = 15,
x = c(0, 0.5, 0), y = c(1, 1, 0.5))
arrangeGrop() [в gridExtra] помогает изменить расположение графиков по строкам или столбцам.library("gridExtra")
grid.arrange(sp, # Первая строка с одним графиком на две колонки
arrangeGrob(bxp, dp, ncol = 2),# Вторая строка с двумя графиками в двух колонках
nrow = 2) # Количество строк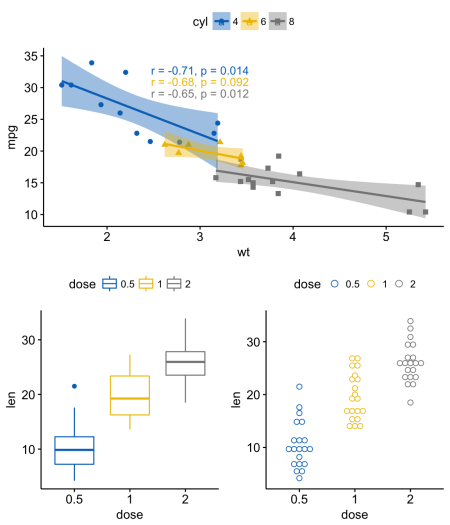
grid.arrange() можно также использовать аргумент layout_matrix для создания сложного взаимного расположения графиков.layout_matrix — матрица 2х2 (2 строки и 2 столбца). Первая строка — все единицы, там, где первый график, занимающий две колонки; вторая строка содержит графики 2 и 3, каждый из которых занимает свою колонку.grid.arrange(bp, # столбчатая диаграмма на две колонки
bxp, sp, # диаграммы рассеивания и разброса
ncol = 2, nrow = 2,
layout_matrix = rbind(c(1,1), c(2,3)))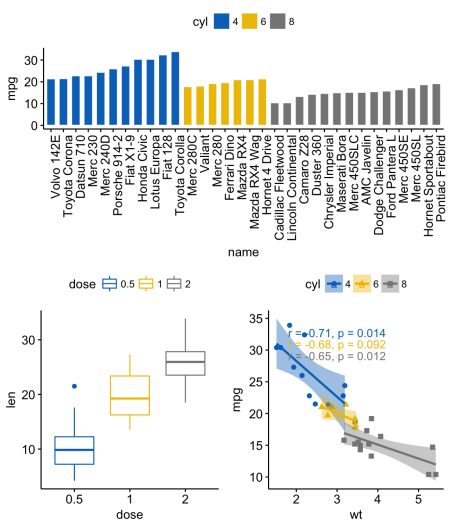
grid.arrange(), используя вспомогательную функцию draw_plot_label() [в cowplot].grid.arrange() или arrangeGrob() (тип gtable), сначала нужно преобразовать их в тип ggplot с помощью функции as_ggplot() [в ggpubr]. После можно применять к ним фунцию draw_plot_label() [в cowplot].library("gridExtra")
library("cowplot")
# Упорядочиваем графики с arrangeGrob
# возвращает тип gtable (gt)
gt <- arrangeGrob(bp, # столбчатая диаграмма на две колонки
bxp, sp, # диаграммы рассеивания и разброса
ncol = 2, nrow = 2,
layout_matrix = rbind(c(1,1), c(2,3)))
# Добавляем метки к упорядоченным графикам
p <- as_ggplot(gt) + # преобразуем в ggplot
draw_plot_label(label = c("A", "B", "C"), size = 15,
x = c(0, 0, 0.5), y = c(1, 0.5, 0.5)) # Добавляем метки
p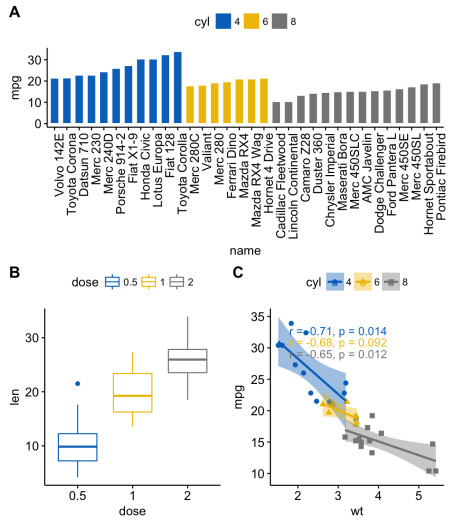
arrangeGrob() вместо grid.arrange(). Основное отличие этих двух функций состоит в том, что grid.arrange() автоматически выводит упорядоченные графики. Поскольку мы хотели добавить аннотацию к графикам до того, как их нарисовать, предпочтительно в таком случае использовать функцию arrangeGrob().grid.layout(). Он также предоставляет вспомогательную функцию viewport()для задания региона, или области видимости. Функция print() применяется для размещения графиков в заданном регионе.grid.newpage()library(grid)
# Перейти на новую страницу
grid.newpage()
# Создать расположение: nrow = 3, ncol = 2
pushViewport(viewport(layout = grid.layout(nrow = 3, ncol = 2)))
# Вспомогательная функция для задания области в расположении
define_region <- function(row, col){
viewport(layout.pos.row = row, layout.pos.col = col)
}
# Упорядочить графики
print(sp, vp = define_region(row = 1, col = 1:2)) # Расположить в двух колонках
print(bxp, vp = define_region(row = 2, col = 1))
print(dp, vp = define_region(row = 2, col = 2))
print(bp + rremove("x.text"), vp = define_region(row = 3, col = 1:2))
ggarrange() [в ggpubr] с такими аргументами:common.legend = TRUE: сделать общую легендуlegend: задать положение легенды. Разрешенное значение — одно из c(“top”, “bottom”, “left”, “right”)ggarrange(bxp, dp, labels = c("A", "B"),
common.legend = TRUE, legend = "bottom")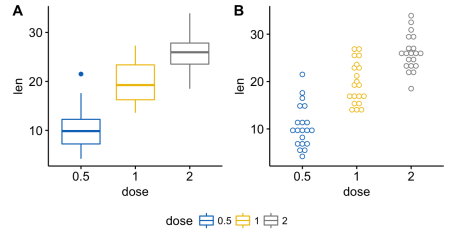
# Диаграмма разброса, цвет по группе ("Species")
sp <- ggscatter(iris, x = "Sepal.Length", y = "Sepal.Width",
color = "Species", palette = "jco",
size = 3, alpha = 0.6)+
border()
# График плотности безусловного распределения по x (панель сверху) и по y (панель справа)
xplot <- ggdensity(iris, "Sepal.Length", fill = "Species",
palette = "jco")
yplot <- ggdensity(iris, "Sepal.Width", fill = "Species",
palette = "jco")+
rotate()
# Почистить графики
yplot <- yplot + clean_theme()
xplot <- xplot + clean_theme()
# Упорядочить графики
ggarrange(xplot, NULL, sp, yplot,
ncol = 2, nrow = 2, align = "hv",
widths = c(2, 1), heights = c(1, 2),
common.legend = TRUE)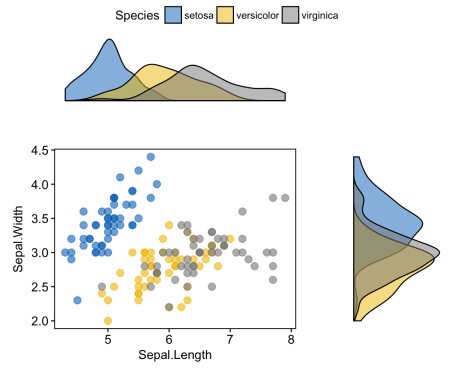
|
Метки: author qc-enior визуализация данных визуализация ggplot2 |
Открытые проблемы в области распознавания речи. Лекция в Яндексе |

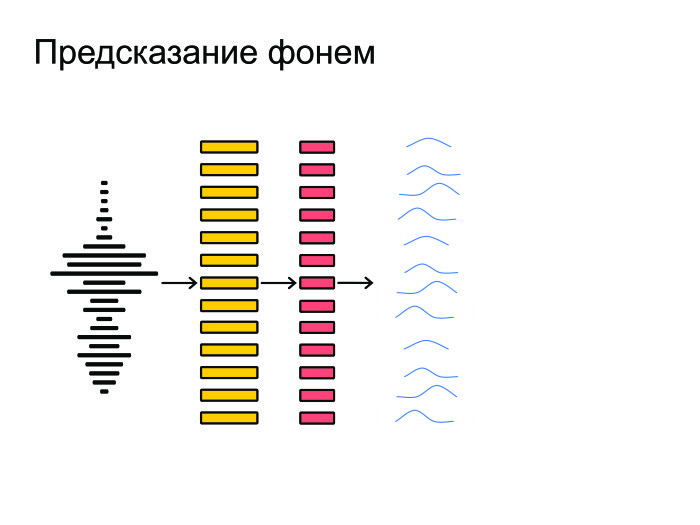
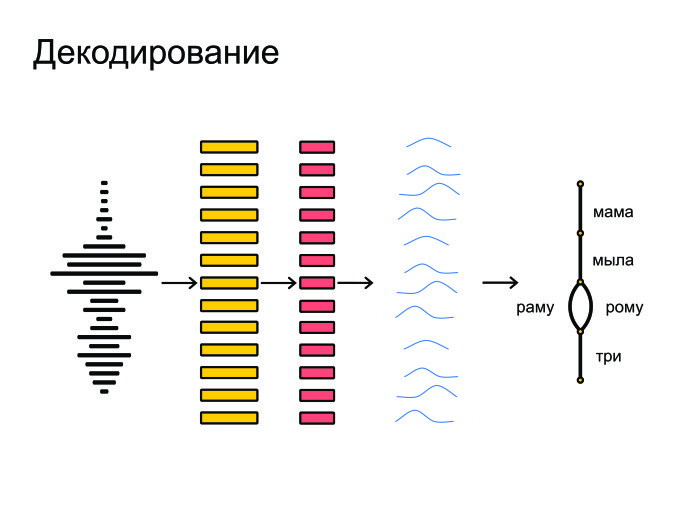
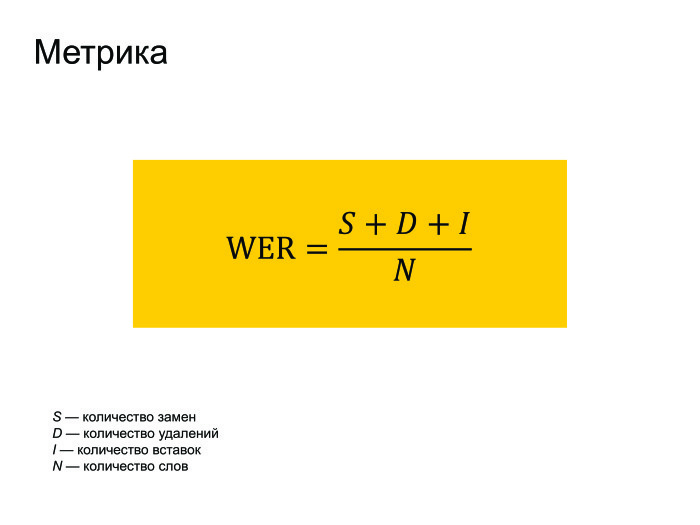

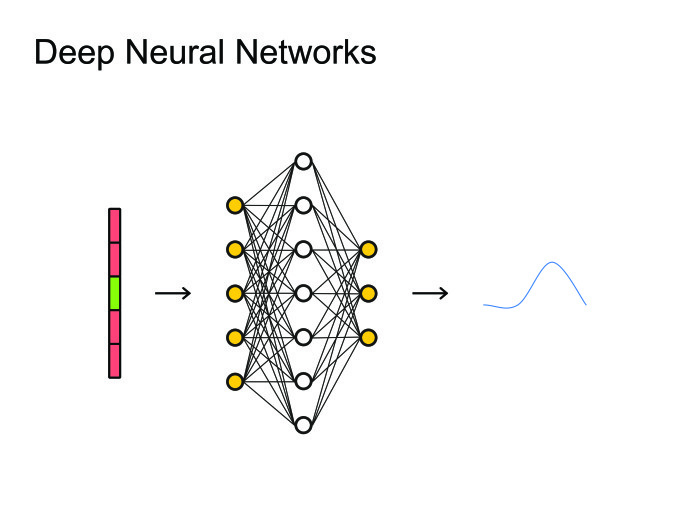
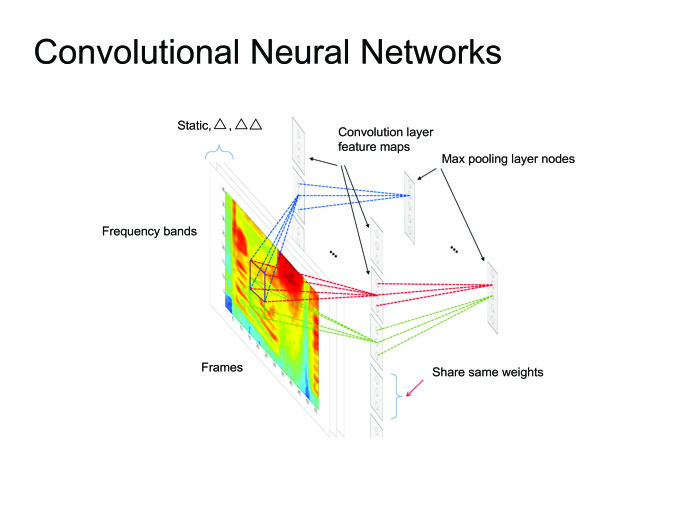
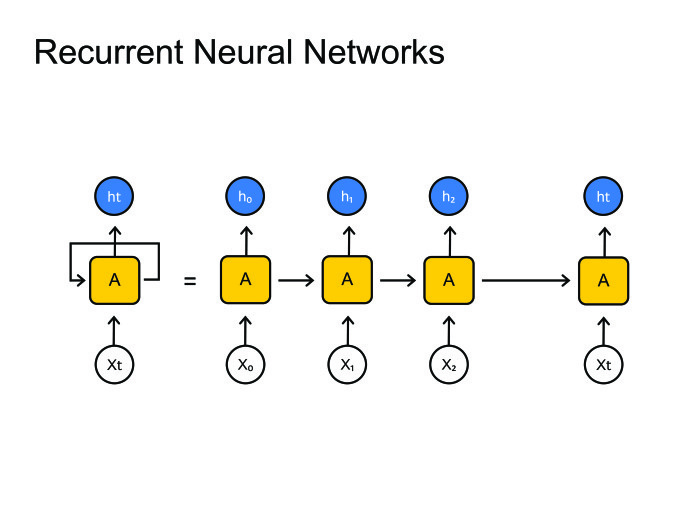
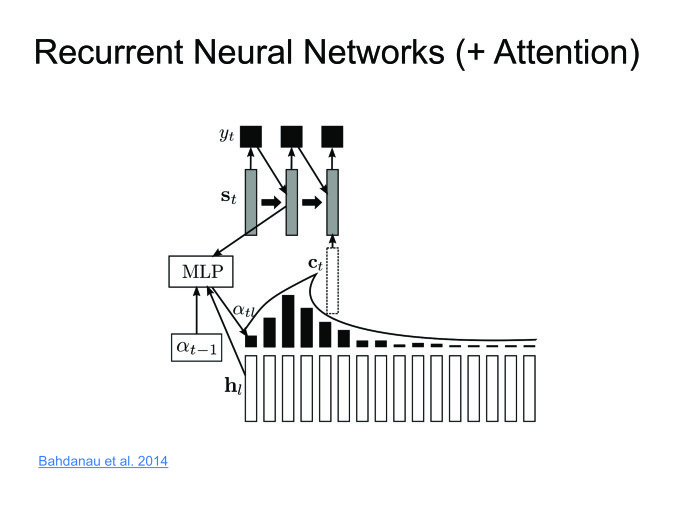
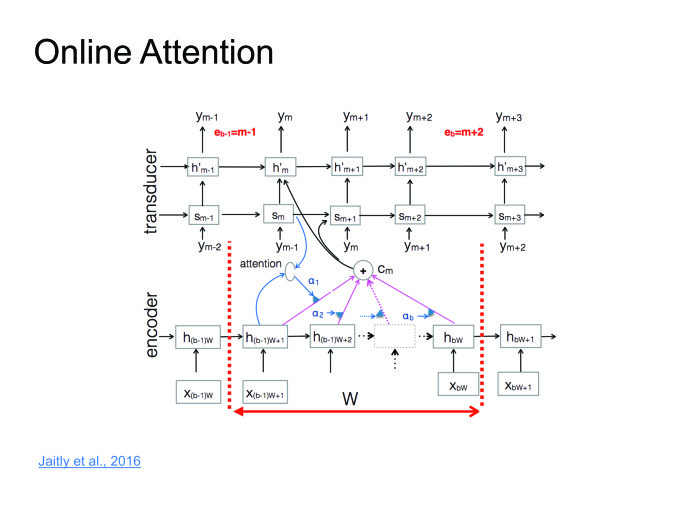



|
|
Java 8 и Android или Повесть о земле и небе |

|
Метки: author vlad2711 разработка под android java java 7 java 8 android android studio |
[Из песочницы] Сбалансированное дерево поиска B-tree (t=2) |
const int t=2;
struct BNode {
int keys[2*t];
BNode *children[2*t+1];
BNode *parent;
int count; //количество ключей
int countSons; //количество сыновей
bool leaf;
bool is_leaf() {
if (this->children[0]==NULL) return true;
else return false;
}
};class Tree {
private:
BNode *root;
void insert_to_node(int key, BNode *node);
void sort(BNode *node);
void restruct(BNode *node);
void print(BNode *node, ofstream& fout);
void deletenode(BNode *node);
bool searchKey(int key, BNode *node);
void remove(int key, BNode *node);
void removeFromNode(int key, BNode *node);
void removeLeaf(int key, BNode *node);
void lconnect(BNode *node, BNode *othernode);
void rconnect(BNode *node, BNode *othernode);
void repair(BNode *node);
public:
Tree();
~Tree();
void insert(int key);
bool search(int key);
void remove(int key);
void print();
};Tree::Tree() { root=NULL; }
Tree::~Tree(){ if(root!=NULL) deletenode(root); }
void Tree::deletenode(BNode *node){
if (node!=NULL){
for (int i=0; i<=(2*t-1); i++){
if (node->children[i]!=NULL) deletenode(node->children[i]);
else {
delete(node);
break;
}
}
}
}void Tree::insert_to_node(int key, BNode *node){
node->keys[node->count]=key;
node->count=node->count+1;
sort(node);
}void Tree::sort(BNode *node) {
int m;
for (int i=0; i<(2*t-1); i++){
for (int j=i+1; j<=(2*t-1); j++){
if ((node->keys[i]!=0) && (node->keys[j]!=0)){
if ((node->keys[i]) > (node->keys[j])){
m=node->keys[i];
node->keys[i]=node->keys[j];
node->keys[j]=m;
}
} else break;
}
}
}void Tree::insert(int key){
if (root==NULL) {
BNode *newRoot = new BNode;
newRoot->keys[0]=key;
for(int j=1; j<=(2*t-1); j++) newRoot->keys[j]=0;
for (int i=0; i<=(2*t); i++) newRoot->children[i]=NULL;
newRoot->count=1;
newRoot->countSons=0;
newRoot->leaf=true;
newRoot->parent=NULL;
root=newRoot;
} else {
BNode *ptr=root;
while (ptr->leaf==false){ //выбор ребенка до тех пор, пока узел не будет являться листом
for (int i=0; i<=(2*t-1); i++){ //перебираем все ключи
if (ptr->keys[i]!=0) {
if (keykeys[i]) {
ptr=ptr->children[i];
break;
}
if ((ptr->keys[i+1]==0)&&(key>ptr->keys[i])) {
ptr=ptr->children[i+1]; //перенаправляем к самому последнему ребенку, если цикл не "сломался"
break;
}
} else break;
}
}
insert_to_node(key, ptr);
while (ptr->count==2*t){
if (ptr==root){
restruct(ptr);
break;
} else {
restruct(ptr);
ptr=ptr->parent;
}
}
}
}void Tree::restruct(BNode *node){
if (node->count<(2*t-1)) return;
//первый сын
BNode *child1 = new BNode;
int j;
for (j=0; j<=t-2; j++) child1->keys[j]=node->keys[j];
for (j=t-1; j<=(2*t-1); j++) child1->keys[j]=0;
child1->count=t-1; //количество ключей в узле
if(node->countSons!=0){
for (int i=0; i<=(t-1); i++){
child1->children[i]=node->children[i];
child1->children[i]->parent=child1;
}
for (int i=t; i<=(2*t); i++) child1->children[i]=NULL;
child1->leaf=false;
child1->countSons=t-1; //количество сыновей
} else {
child1->leaf=true;
child1->countSons=0;
for (int i=0; i<=(2*t); i++) child1->children[i]=NULL;
}
//второй сын
BNode *child2 = new BNode;
for (int j=0; j<=(t-1); j++) child2->keys[j]=node->keys[j+t];
for (j=t; j<=(2*t-1); j++) child2->keys[j]=0;
child2->count=t; //количество ключей в узле
if(node->countSons!=0) {
for (int i=0; i<=(t); i++){
child2->children[i]=node->children[i+t];
child2->children[i]->parent=child2;
}
for (int i=t+1; i<=(2*t); i++) child2->children[i]=NULL;
child2->leaf=false;
child2->countSons=t; //количество сыновей
} else {
child2->leaf=true;
child2->countSons=0;
for (int i=0; i<=(2*t); i++) child2->children[i]=NULL;
}
//родитель
if (node->parent==NULL){ //если родителя нет, то это корень
node->keys[0]=node->keys[t-1];
for(int j=1; j<=(2*t-1); j++) node->keys[j]=0;
node->children[0]=child1;
node->children[1]=child2;
for(int i=2; i<=(2*t); i++) node->children[i]=NULL;
node->parent=NULL;
node->leaf=false;
node->count=1;
node->countSons=2;
child1->parent=node;
child2->parent=node;
} else {
insert_to_node(node->keys[t-1], node->parent);
for (int i=0; i<=(2*t); i++){
if (node->parent->children[i]==node) node->parent->children[i]=NULL;
}
for (int i=0; i<=(2*t); i++){
if (node->parent->children[i]==NULL) {
for (int j=(2*t); j>(i+1); j--) node->parent->children[j]=node->parent->children[j-1];
node->parent->children[i+1]=child2;
node->parent->children[i]=child1;
break;
}
}
child1->parent=node->parent;
child2->parent=node->parent;
node->parent->leaf=false;
delete node;
}
}bool Tree::search(int key){
return searchKey(key, this->root);
}
bool Tree::searchKey(int key, BNode *node){
if (node!=NULL){
if (node->leaf==false){
int i;
for (i=0; i<=(2*t-1); i++){
if (node->keys[i]!=0) {
if(key==node->keys[i]) return true;
if ((keykeys[i])){
return searchKey(key, node->children[i]);
break;
}
} else break;
}
return searchKey(key, node->children[i]);
} else {
for(int j=0; j<=(2*t-1); j++)
if (key==node->keys[j]) return true;
return false;
}
} else return false;
}void Tree::removeFromNode(int key, BNode *node){
int i;
for (i=0; i<=(node->count-1); i++){
if (node->keys[i]==key){
if (i==0) {
node->keys[0]=node->keys[1];
node->keys[1]=node->keys[2];
node->keys[2]=0;
node->children[0]=node->children[1];
node->children[1]=node->children[2];
node->children[2]=node->children[3];
node->children[3]=NULL;
break;
}
if (i==1) {
node->keys[1]=node->keys[2];
node->keys[2]=0;
node->children[1]=node->children[2];
node->children[2]=node->children[3];
node->children[3]=NULL;
break;
}
if (i==2) {
node->keys[2]=0;
node->children[2]=node->children[3];
node->children[3]=NULL;
break;
}
}
}
node->count=node->count-1;
}void Tree::lconnect(BNode *node, BNode *othernode){
if (node==NULL) return;
for (int i=0; i<=(othernode->count-1); i++){
node->keys[node->count]=othernode->keys[i];
node->children[node->count]=othernode->children[i];
node->count=node->count+1;
}
node->children[node->count]=othernode->children[othernode->count];
for (int j=0; j<=node->count; j++){
if (node->children[j]==NULL) break;
node->children[j]->parent=node;
}
delete othernode;
}
void Tree::rconnect(BNode *node, BNode *othernode){
if (node==NULL) return;
for (int i=0; i<=(othernode->count-1); i++){
node->keys[node->count]=othernode->keys[i];
node->children[node->count+1]=othernode->children[i+1];
node->count=node->count+1;
}
for (int j=0; j<=node->count; j++){
if (node->children[j]==NULL) break;
node->children[j]->parent=node;
}
delete othernode;
}void Tree::repair(BNode *node){
if ((node==root)&&(node->count==0)){
if (root->children[0]!=NULL){
root->children[0]->parent=NULL;
root=root->children[0];
} else {
delete root;
}
return;
}
BNode *ptr=node;
int k1;
int k2;
int positionSon;
BNode *parent=ptr->parent;
for (int j=0; j<=parent->count; j++){
if (parent->children[j]==ptr){
positionSon=j; //позиция узла по отношению к родителю
break;
}
}
//если ptr-первый ребенок (самый левый)
if (positionSon==0){
insert_to_node(parent->keys[positionSon], ptr);
lconnect(ptr, parent->children[positionSon+1]);
parent->children[positionSon+1]=ptr;
parent->children[positionSon]=NULL;
removeFromNode(parent->keys[positionSon], parent);
if(ptr->count==2*t){
while (ptr->count==2*t){
if (ptr==root){
restruct(ptr);
break;
} else {
restruct(ptr);
ptr=ptr->parent;
}
}
} else
if (parent->count<=(t-2)) repair(parent);
} else {
//если ptr-последний ребенок (самый правый)
if (positionSon==parent->count){
insert_to_node(parent->keys[positionSon-1], parent->children[positionSon-1]);
lconnect(parent->children[positionSon-1], ptr);
parent->children[positionSon]=parent->children[positionSon-1];
parent->children[positionSon-1]=NULL;
removeFromNode(parent->keys[positionSon-1], parent);
BNode *temp=parent->children[positionSon];
if(ptr->count==2*t){
while (temp->count==2*t){
if (temp==root){
restruct(temp);
break;
} else {
restruct(temp);
temp=temp->parent;
}
}
} else
if (parent->count<=(t-2)) repair(parent);
} else { //если ptr имеет братьев справа и слева
insert_to_node(parent->keys[positionSon], ptr);
lconnect(ptr, parent->children[positionSon+1]);
parent->children[positionSon+1]=ptr;
parent->children[positionSon]=NULL;
removeFromNode(parent->keys[positionSon], parent);
if(ptr->count==2*t){
while (ptr->count==2*t){
if (ptr==root){
restruct(ptr);
break;
} else {
restruct(ptr);
ptr=ptr->parent;
}
}
} else
if (parent->count<=(t-2)) repair(parent);
}
}
}void Tree::removeLeaf(int key, BNode *node){
if ((node==root)&&(node->count==1)){
removeFromNode(key, node);
root->children[0]=NULL;
delete root;
root=NULL;
return;
}
if (node==root) {
removeFromNode(key, node);
return;
}
if (node->count>(t-1)) {
removeFromNode(key, node);
return;
}
BNode *ptr=node;
int k1;
int k2;
int position;
int positionSon;
int i;
for (int i=0; i<=node->count-1; i++){
if (key==node->keys[i]) {
position=i; //позиция ключа в узле
break;
}
}
BNode *parent=ptr->parent;
for (int j=0; j<=parent->count; j++){
if (parent->children[j]==ptr){
positionSon=j; //позиция узла по отношению к родителю
break;
}
}
//если ptr-первый ребенок (самый левый)
if (positionSon==0){
if (parent->children[positionSon+1]->count>(t-1)){ //если у правого брата больше, чем t-1 ключей
k1=parent->children[positionSon+1]->keys[0]; //k1 - минимальный ключ правого брата
k2=parent->keys[positionSon]; //k2 - ключ родителя, больше, чем удаляемый, и меньше, чем k1
insert_to_node(k2, ptr);
removeFromNode(key, ptr);
parent->keys[positionSon]=k1; //меняем местами k1 и k2
removeFromNode(k1, parent->children[positionSon+1]); //удаляем k1 из правого брата
} else { //если у правого единственного брата не больше t-1 ключей
removeFromNode(key, ptr);
if (ptr->count<=(t-2)) repair(ptr);
}
} else {
//если ptr-последний ребенок (самый правый)
if (positionSon==parent->count){
//если у левого брата больше, чем t-1 ключей
if (parent->children[positionSon-1]->count>(t-1)){
BNode *temp=parent->children[positionSon-1];
k1=temp->keys[temp->count-1]; //k1 - максимальный ключ левого брата
k2=parent->keys[positionSon-1]; //k2 - ключ родителя, меньше, чем удаляемый и больше, чем k1
insert_to_node(k2, ptr);
removeFromNode(key, ptr);
parent->keys[positionSon-1]=k1;
removeFromNode(k1, temp);
} else { //если у единственного левого брата не больше t-1 ключей
removeFromNode(key, ptr);
if (ptr->count<=(t-2)) repair(ptr);
}
} else { //если ptr имеет братьев справа и слева
//если у правого брата больше, чем t-1 ключей
if (parent->children[positionSon+1]->count>(t-1)){
k1=parent->children[positionSon+1]->keys[0]; //k1 - минимальный ключ правого брата
k2=parent->keys[positionSon]; //k2 - ключ родителя, больше, чем удаляемый и меньше, чем k1
insert_to_node(k2, ptr);
removeFromNode(key, ptr);
parent->keys[positionSon]=k1; //меняем местами k1 и k2
removeFromNode(k1, parent->children[positionSon+1]); //удаляем k1 из правого брата
} else {
//если у левого брата больше, чем t-1 ключей
if (parent->children[positionSon-1]->count>(t-1)){
BNode *temp=parent->children[positionSon-1];
k1=temp->keys[temp->count-1]; //k1 - максимальный ключ левого брата
k2=parent->keys[positionSon-1]; //k2 - ключ родителя, меньше, чем удаляемый и больше, чем k1
insert_to_node(k2, ptr);
removeFromNode(key, ptr);
parent->keys[positionSon-1]=k1;
removeFromNode(k1, temp);
} else { //если у обоих братьев не больше t-1 ключей
removeFromNode(key, ptr);
if (ptr->count<=(t-2)) repair(ptr);
}
}
}
}
}void Tree::remove(int key, BNode *node){
BNode *ptr=node;
int position; //номер ключа
int i;
for (int i=0; i<=node->count-1; i++){
if (key==node->keys[i]) {
position=i;
break;
}
}
int positionSon; //номер сына по отношению к родителю
if (ptr->parent!=NULL){
for(int i=0; i<=ptr->parent->count; i++){
if (ptr->children[i]==ptr){
positionSon==i;
break;
}
}
}
//находим наименьший ключ правого поддерева
ptr=ptr->children[position+1];
int newkey=ptr->keys[0];
while (ptr->is_leaf()==false) ptr=ptr->children[0];
//если ключей в найденном листе не больше 1 - ищем наибольший ключ в левом поддереве
//иначе - просто заменяем key на новый ключ, удаляем новый ключ из листа
if (ptr->count>(t-1)) {
newkey=ptr->keys[0];
removeFromNode(newkey, ptr);
node->keys[position]=newkey;
} else {
ptr=node;
//ищем наибольший ключ в левом поддереве
ptr=ptr->children[position];
newkey=ptr->keys[ptr->count-1];
while (ptr->is_leaf()==false) ptr=ptr->children[ptr->count];
newkey=ptr->keys[ptr->count-1];
node->keys[position]=newkey;
if (ptr->count>(t-1)) removeFromNode(newkey, ptr);
else {
//если ключей не больше, чем t-1 - перестраиваем
removeLeaf(newkey, ptr);
}
}
}void Tree::remove(int key){
BNode *ptr=this->root;
int position;
int positionSon;
int i;
if (searchKey(key, ptr)==false) {
return;
} else {
//ищем узел, в котором находится ключ для удаления
for (i=0; i<=ptr->count-1; i++){
if (ptr->keys[i]!=0) {
if(key==ptr->keys[i]) {
position=i;
break;
} else {
if ((keykeys[i])){
ptr=ptr->children[i];
positionSon=i;
i=-1;
} else {
if (i==(ptr->count-1)) {
ptr=ptr->children[i+1];
positionSon=i+1;
i=-1;
}
}
}
} else break;
}
}
if (ptr->is_leaf()==true) {
if (ptr->count>(t-1)) removeFromNode(key,ptr);
else removeLeaf(key, ptr);
} else remove(key, ptr);
}|
Метки: author AnitaChess алгоритмы c++ структуры данных b-tree б-дерево алгоритмы обработки данных |
Управление сертификатами с помощью протокола ACME |
Возникла передо мной такая задача: автоматический выпуск сертификатов для Web приложения. И требования:
Наверное многие уже слышали про бесплатные сертификаты от LetsEncrypt и certbot. А можно ли certbot заменить Java?

Многие, конечно, любят LetsEncrypt за бесплатные сертификаты, которые, фактически, позволят перевести весь вэб на https. Но не многие
знают, что для этого они придумали специальный протокол — ACME. И для меня он по значимости чуть ли не выше самих бесплатных сертификатов.
Основные особенности протокола:
Для тех, кому интересны детали и все возможные варианты взаимодействия, можно почитать официальную документацию. Она действительно простая и легко читается в отличии от наших гостов. Здесь же я приведу диаграмму последовательности при выдаче сертификата, которую нужно представлять, если Вы решили интегрироваться.

На официальном сайте LetsEncrypt есть множество клиентов работающих по протоколу ACME. Я взял acme4j. Эта библиотека достаточно компактная и работает в compact1 profile!
У неё есть вполне рабочий пример использования, с помощью которого я смог выпустить себе сертификат. Для того, чтобы интегрировать библиотеку достаточно с минимальными изменениями скопировать этот код.
Для продления сертификата необходимо авторизоваться, взять уже готовый CSR и отправить его в CA. После чего скачать новый сертификат.
Единственная проблема, которая у меня возникла — это подкладывание сертификата в nginx. Поясню на примере:
И вот тут проблема: для того чтобы включить 443 порт с новым сертификатом, nginx должен перезачитать конфигурацию. Но чтобы это сделать нужен root. Запускать приложение из под root — плохая идея. Запускать nginx из под пользователя тоже — нельзя будет слушать 80/443 порты.
Я добавил правило для пользователя в sudoers, чтобы можно было делать sudo nginx -s reload. Но это выглядит как костыль. Может кто-нибудь знает как это сделать красивее?
Получение сертификата в автоматическом режиме оказалось достаточно простой процедурой. А если использовать ACME сервер boulder, то можно даже развернуть такую схему у себя в большой организации! Если у вас есть собственный CA для внутренних сервисов, то ACME должен сильно упростить работу с сертификатами.
|
Метки: author dernasherbrezon java it- стандарты acme letsencrypt embedded |
Дайджест интересных материалов для мобильного разработчика #220 (4 сентября — 10 сентября) |
 |
Последний отсчёт — Гугл развлекается |
 |
VK by design |
 |
Цвет в дизайне интерфейсов: инструкция по применению |
 iOS
iOS Как сделать измерение в реальном времени с ARKit и Pusher Умное распознавание жестов в iOS 11 с Core ML и TensorFlow DIY Prisma на CoreML Делаем будильник для iOS Unit-тестирование MVC
Как сделать измерение в реальном времени с ARKit и Pusher Умное распознавание жестов в iOS 11 с Core ML и TensorFlow DIY Prisma на CoreML Делаем будильник для iOS Unit-тестирование MVC Android Почему ARCore лучше, чем ARKit? Продвинутая Android-анимация ObjectBox 1.0: объектно-ориентированная БД Android 8.0 Oreo: тщательный анализ Эффективное тестирование для Android-разработчиков Материальный дизайн: документация по разработке Введение в Flutter для Android-разработчиков RxJava против корутинов Kotlin Android Oreo: режим “картинка в картинке” Работа с каналами уведомлений Оптимизация приложений для Chromebook Android NDK. Как интегрировать готовые библиотеки в случае FFmpeg.
Android Почему ARCore лучше, чем ARKit? Продвинутая Android-анимация ObjectBox 1.0: объектно-ориентированная БД Android 8.0 Oreo: тщательный анализ Эффективное тестирование для Android-разработчиков Материальный дизайн: документация по разработке Введение в Flutter для Android-разработчиков RxJava против корутинов Kotlin Android Oreo: режим “картинка в картинке” Работа с каналами уведомлений Оптимизация приложений для Chromebook Android NDK. Как интегрировать готовые библиотеки в случае FFmpeg. Введение в ARCore Ник Бутчер про адаптивные иконки
Введение в ARCore Ник Бутчер про адаптивные иконки Reveal Animations: разные анимации
Reveal Animations: разные анимации Разработка Почему вам надо «читать» продукты как книгу История успеха Blackbox 500 бесплатных онлайн-курсов на сентябрь 10 факторов, влияющих на стоимость разработки приложения Используя силу ничего Запуск моделей TensorFlow на iOS и Android Как сделать приложение вроде Uber: руководство на миллион долларов 5 шаблонов UX-дизайна для мобильных приложений
Разработка Почему вам надо «читать» продукты как книгу История успеха Blackbox 500 бесплатных онлайн-курсов на сентябрь 10 факторов, влияющих на стоимость разработки приложения Используя силу ничего Запуск моделей TensorFlow на iOS и Android Как сделать приложение вроде Uber: руководство на миллион долларов 5 шаблонов UX-дизайна для мобильных приложений Аналитика, маркетинг и монетизация Советы по локализации ASO
Аналитика, маркетинг и монетизация Советы по локализации ASO Устройства, IoT, AI
Устройства, IoT, AI|
|
Валидация React компонентов с помощью Livr.js |
import React from 'react';
import Validation, {DisabledOnErrors, ValidationInput} from 'react-livr-validation';
const schema = {
login: ['required', 'not_empty'],
password: ['required', 'not_empty']
};
const data = {
login: '',
password: ''
};
export default function() {
return (
);
}
const customRules = {
alpha_chars: function() {
return function(value) {
if (typeof value === 'string') {
if (!/[a-z,A-Z]+/.test(value)) {
return 'WRONG_FORMAT';
}
}
};
}
};
const aliasedRules = [
{
name: 'strong_password',
rules: { min_length: 6 },
error: 'TOO_SHORT'
}
];
// ... form
// @flow
import React, {Component} from 'react'
import {ValidationComponent} from 'react-livr-validation'
import get from 'lodash/get'
import noop from 'lodash/noop'
import compose from 'ramda/src/compose'
import styled from 'styled-components'
type DataChunk = {
name: string,
value: any
}
type State = {
touched: boolean
}
type Props = {
// will be passed by HOC
setData: (data: DataChunk) => void,
getError: (name: string) => ?string,
getErrors: () => Object,
className: string, // for the error block
style: Object // for the error block
errorCodes: Object,
name: string,
field: string
}
class NestedError extends Component {
props: Props;
isTouched() {
const {children} = this.props;
return get(children, 'props.value')
}
state: State = {
touched: this.isTouched()
}
setTouched() {
this.setState({
touched: true
})
}
cloneElement() {
const {children} = this.props;
const onBlur = get(children, 'props.onBlur', noop);
return React.cloneElement(
children,
{
onBlur: compose(this.setTouched, onBlur)
}
)
}
render() {
const {touched} = this.state;
const {
children,
field,
name,
getError,
errorCodes,
style,
className
} = this.props;
const errors = getErrors();
const error = get(errors, `${field}`.${name});
return (
{touched ? children : this.cloneElement()}
{error &&
{errorCodes[error] || error}
}
);
}
}
const Error = styled.div`
color: red;
`;
export default ValidationComponent(NestedError)
|
Метки: author one_more reactjs javascript react.js livr.js validation |
Задача о премировании: почувствуй себя менеджером |
Если вы менеджер в этой компании, то станете ли премировать вторую команду и почему?
|
Метки: author Bonart управление разработкой управление проектами управление продуктом управление персоналом культура разработки командный дух качество разработки мотивация |
Как воскресить Ягуара за тысячу часов? |
 Бывает меня спрашивают — как я пишу эмуляторы? Попробую ответить на примере одной провалившейся консоли.
Бывает меня спрашивают — как я пишу эмуляторы? Попробую ответить на примере одной провалившейся консоли.|
Метки: author MaxAkaAltmer реверс-инжиниринг программирование анализ и проектирование систем эмуляция atari jaguar |
[Из песочницы] Как я перестал любить Angular |
Много лет я работал с AngularJS и по сей день использую его в продакшене. Несмотря на то, что идеальным, в силу своей исторически сложившейся архитектуры, его назвать нельзя — никто не станет спорить с тем, что он стал просто вехой в процессе эволюции не только JS фреймворков, но и веба в целом.
На дворе 2017ый год и для каждого нового продукта/проекта встает вопрос выбора фреймворка для разработки. Долгое время я был уверен, что новый Angular 2/4 (далее просто Angular) станет главным трендом enterprise разработки еще на несколько лет вперед и даже не сомневался что буду работать только с ним.
Сегодня я сам отказываюсь использовать его в своем следующем проекте.
Дисклеймер: данная статья строго субъективна, но таков мой личный взгляд на происходящее и касается разработки enterprise-level приложений.

За годы эволюции большинство недостатков фреймворка были устранены, библиотеки доведены до весьма стабильного состояния, а размеры комьюнити стремятся к бесконечности. Пожалуй, можно сказать, что в первом ангуляре мало что можно сильно улучшить не сломав при этом сотни существующих приложений.
Несмотря на колоссальные труды и общее ускорение фреймворка (особенно после 1.5),
основным его недостатком я бы все же назвал скорость работы. Конечно это простительно, учитывая что спустя столько лет, худо-бедно до сих пор поддерживается обратная совместимость.

И вот наконец Angular был переписан с нуля дабы стать основной для многих будущих веб-приложений.
Конечно путь к этому был долог и полон Breaking Changes,
но на сегодняшний день Angular 4 стабилен и позиционируется как полностью production-ready.
Одна из наиболее крутых вещей, которую дал нам новый Angular — популяризация TypeScript.
Лично я был с ним знаком и работал еще до того, как он стал основным для моего любимого фреймворка,
но многие узнали о нем именно благодаря Angular.

Не буду подробно останавливаться на TypeScript, т.к. это тема для отдельной статьи,
да и написано о нем уже больше чем нужно. Но для enterprise разработки TypeScript дает огромное количество преимуществ. Начиная с самой статической типизации и областями видимости и заканчивая поддержкой ES7/8 даже для IE9.
Главное преимущество работы с TypeScript — богатый инструментарий и прекрасная поддержка IDE. По нашему опыту, юнит тестов с TS приходится писать существенно меньше.

Если вы читаете данную статью, то с вероятностью 95% вы уже знаете что это такое.
Но для тех 5% кто еще не знает — Vue.js это крайне легковесный (но очень богатый по функционалу) фреймворк, вобравший в себя многое хорошее, как из AngularJS, так и из React.
Фактически больше он похож все же на React, но шаблоны практически идентичны AngularJS (HTML + Mustache).
В реальности от AngularJS, он отличается очень даже разительно, но в поверхносном смысле,
понять как он работает, если у вас уже был опыт работы с React или AngularJS, будет несложно.
Последний мой проект, который совсем недавно вышел в production, мы писали на AngularJS 1.5-1.6.
Вопреки наличию стабильной версии Angular уже долгое время, мы приняли решение не мигрировать на него по ряду причин (не столько технических, сколько политических).
Но одной из фич современного веба мы пользовались с самого начала — это TypeScript.
Вот пример нашего компонента из данного проекта:
import {Component} from "shared-front/app/decorators";
import FileService, {ContentType, IFile} from "../file.service";
import AlertService from "shared/alert.service";
@Component({
template: require("./file.component.html"),
bindings: {
item: "<",
},
})
export default class FileComponent {
public static $inject = ["fileService"];
public item: IFile;
constructor(private fileService: FileService, private alertService: AlertService) {
}
public isVideo() {
return this.item.contentKeyType === ContentType.VIDEO;
}
public downloadFile() {
this.fileService.download(this.getFileDownloadUrl()).then(() => {
this.alertService.success();
});
}
private getFileDownloadUrl() {
return `url-for-download${this.item.text}`;
}
}На мой взгляд выглядит очень даже приятно, не слишком многословно, даже если вы не фанат TS.
К тому же все это замечательно тестируется как Unit-тестами, так и Е2Е.
Продолжай AngularJS развиваться, как тот же React, и будь он побыстрее, можно было бы и по сей день продолжать писать крупные проекты на нем.
В принципе это по прежнему вполне разумно, если ваша команда очень хорошо знакома с AngularJS. Но думаю, что большинство все же предпочитает двигаться в ногу со временем и захочет выбрать нечто более современное.
Так мы и поступили, рационально выбрав Angular 2 (позже 4) для нашего нового проекта несколько месяцев назад.
Выбор казался довольно очевидным, учитывая, что вся наша команда имеет большой опыт работы с первой версией. К тому же, лично я ранее работал с alpha-RC версиями и тогда проблемы фреймворка списывались на 0.х номер версии.
К сожалению, как теперь стало понятно, многие из этих проблем заложены в архитектуру и не изменятся в ближайшее время.
А вот пример компонента из проекта на Angular:
import {Component} from '@angular/core';
import FileService, {ContentType, IFile} from "../file.service";
import AlertService from "shared/alert.service";
@Component({
selector: 'app-file',
templateUrl: './file.component.html',
styleUrls: ['./file.component.scss']
})
export class FileComponent {
Input() item: IFile;
constructor(private fileService: FileService, private alertService: AlertService) {
}
public isVideo() {
return this.item.contentKeyType === ContentType.VIDEO;
}
public downloadFile() {
this.fileService.download(this.getFileDownloadUrl()).subscribe(() => {
this.alertService.success();
});
}
private getFileDownloadUrl() {
return `url-for-download${this.item.text}`;
}
}
Возможно чуть чуть более многословно, но гораздо чище.
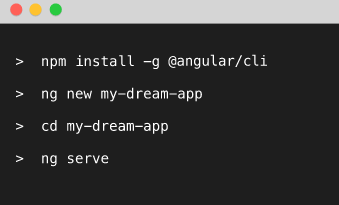
Первое, что вы установите при разработке нового Angular 4 приложения это Angular CLI
Нужен он CLI для того, чтобы упростить создание новых компонентов/модулей/тестов итд.
На мой взгляд это едва ли не лучшее, что есть в новом Angular. Тула действительно очень удобная в использовании и сильно ускоряет процесс разработки.
Это то, чего так сильно не хватало в AngularJS, и все решали проблему отсутствия данной тулзы по-своему. Множество различных сидов (стартеров), сотни разных подходов к одному и тому же, в общем анархия. Теперь с этим покончено.
Конечно CLI тоже имеет ряд недостатков в части настроек и конфигурации "под себя", но все же он на голову выше аналогичных утилит для React (create-react-app) или Vue (vue-cli). Хотя второй, благодаря своей гибкости, становится лучше с каждым днем.
Изначально я не хотел писать очередную хейтерскую статью вроде
Angular 2 is terrible (нашелся даже перевод).
Однако, несмотря на то, что статья выше была написана для уже весьма устаревшей версии,
по большинству пунктов она совершенно в точку.
Я бы даже сказал, что местами автор был слишком мягок.
В целом не совсем разделяю взгяд автора на RxJS, т.к. библиотека невероятно мощная.
An Ajax request is singular, and running methods like Observable.prototype.map when there will only ever be one value in the pipe makes no semantic sense. Promises on the other hand represent a value that has yet to be fulfilled, which is exactly what a HTTP request gives you. I spent hours forcing Observables to behave before giving up using Observable.prototype.toPromise to transform the Observable back to a Promise and simply using Promise.all, which works much better than anything Rx.js offers.
В реальности, благодаря RxJS, со временем становится очень приятно воспринимать любые данные,
пусть даже не совсем подходящие для Observable, как единую шину.
Но суровая правда в том, что Object.observe нативно мы все же не увидим:
After much discussion with the parties involved, I plan to withdraw the Object.observe proposal from TC39 (where it currently sits at stage 2 in the ES spec process), and hope to remove support from V8 by the end of the year (the feature is used on 0.0169% of Chrome pageviews, according to chromestatus.com).
И несмотря на огромное количество фич, которые Rx позволяет делать — делать его ядром фреймворка не самый правильный подход. Думаю желающие, вроде меня, могли бы подключить его и отдельно без особых проблем.
Также не соглашусь в целом по поводу TypeScript'а, так как это все же замечательный язык, но об этом ниже.
Статья крайне рекомендуется к ознакомлению, если вы уже используете или планируете использовать Angular
Однако все же изложу несколько собственных мыслей (к сожалению, все больше негативных), не упомянутых в статье выше.
Пожалуй самое болезненное разочарование для меня — это то, во что превратили работу с TypeScript'ом в Angular.
Ниже несколько примеров наиболее неудачных решений.
Одной из основных проблем использования TypeScript в Angular я считаю крайне спорные API.
Сам по себе TypeScript идеально подходит для написания максимально строгого кода, без возможностей случайно сделать шаг не в ту сторону. Фактически он просто создан для того, чтобы писать публичный API, но команда Angular сделала все, чтобы данное преимущество превратилось в недостаток.
Примеры:
По какой-то причине команда Angular решила сделать класс HttpParams иммутабельным.
Иммутабельность это здорово, но если вы думаете, что большинство классов в Angular являются таковыми, то это вовсе не так.
Например код вида:
let params = new HttpParams();
params.set('param', param);
params.set('anotherParam', anotherParam);
...
this.http.get('test', {params: params});Не будет добавлять параметры к запросу. Казалось бы почему?
Ведь никаких ошибок, ни TypeScript ни сам Angular не отображает.
Только открыв сам класс в TypeScript можно найти комментарий
This class is immuatable — all mutation operations return a new instance.
Конечно, это совершенно неочевидно.
В вот и вся документация про них:
http
.post('/api/items/add', body, {
params: new HttpParams().set('id', '3'),
})
.subscribe();Начнем с того, что документация по Angular вообще не имеет толкового разбора и описания Observable и того, как с ними работать.
Нет даже толковых ссылок на документацию по RxJS. И это при том, что Rx является ключевой частью фреймворка, а само создание Observable уже отличается:
// rx.js
Rx.Observable.create();
vs
// Angular
new Observable()Ну да и черт с ним, здесь я хотел рассказать о Rx + TypeScript + Angular.
Допустим вы хотите использовать некий RxJS оператор, вроде do:
observable.do(event => {...})В коде никакой ошибки не произойдет, это сработает и замечательно запустится.
Вот только, во время выполнения возникнет такая ошибка:
ERROR TypeError: observable.do is not a function
Потому что вы очевидно (потратили кучу времени на поиск проблемы) забыли заимпортировать сам оператор:
import 'rxjs/add/operator/do';Почему это ломается в рантайме, если у нас есть TypeScript? Не знаю. Но это так.
Претензий к новому ангуляровскому роутеру у меня накопилось уже великое множество, но его API — одна из основных.
Теперь для работы с параметрами предлагается подписываться на события роутера.
Ок, пускай, но приходят всегда все события, независимо от того, какие нам нужны.
А проверять предлагается через instanceof (снова новый подход, отличный от большинства других мест):
this.router.events.subscribe(event => {
if(event instanceof NavigationStart) {
...
}
}В очередной раз странным решением было сделать всю работу с роутами командами — причем массивом из них. Простые и наиболее распространенные переходы будут выглядеть как-то так:
this.router.navigate(['/some']);
...
this.router.navigate(['/other']);
Почему это плохо?
Потому что команды в данном случае имеют сигнатуру any[].
Для незнакомых с TypeScript — это фактически отключение его фич.
Это при том, что роутинг — наиболее слабо связанная часть в Angular.
Например мы в нашем AngularJS приложении наоборот старались типизировать роуты,
чтобы вместо простых строк они были хотя бы enum.
Это позволяет находить те или иные места, где используется данный роут без глобального поиска по строке 'some'.
Но нет, в Angular это преимущество TypeScript не используется никак.
Этот раздел также мог бы пойти на отдельную статью, но скажу лишь, что в данном случае
игнорируются любые фичи TypeScript и название модуля пишется как строка, в конце через #
{
path: 'admin',
loadChildren: 'app/admin/admin.module#AdminModule',
},Для начала — в Angular есть два типа форм: обычные
и реактивные.
Само собой, работать с ними нужно по-разному.
Однако лично меня раздражает именно API reactive forms:
// Зачем нужен первый пустой параметр?
// Почему name это массив c валидатором??
this.heroForm = this.fb.group({
name: ['', Validators.required ],
});или из документации
// Почему пустое поле это имя??
this.heroForm = this.fb.group({
name: '', // <--- the FormControl called "name"
});и так далее
this.complexForm = fb.group({
// Почему понадобился compose ?
// Неужели нельзя без null ??
'lastName': [null, Validators.compose([Validators.required, Validators.minLength(5), Validators.maxLength(10)])],
'gender' : [null, Validators.required],
})А еще — нельзя просто использовать атрибуты типа [disabled] с реактивными формами...
Это далеко не все примеры подобных откровенно спорных решений, но думаю, что для раздела про API этого хватит
К сожалению использование горячо любимого мною TypeScript'а в Angular слишком сильно завязано на декораторы.
Декораторы — прекрасная вещь, но к сожалению в рантайме нет самой нужной их части, а именно __metadata.
__metadata просто напросто содержит информацию о классе/типе/методе/параметрах, помеченном тем или иным декоратором,
для того чтобы позже эту информацию можно было получить в рантайме.
Без метаданных декораторы тоже можно использовать — во время компиляции, но толку в таком случае от них не очень много.
Впрочем, мы в нашем AngularJS приложении использовали такие декораторы, например @Component:
export const Component = (options: ng.IComponentOptions = {}) => controller => angular.extend(options, {controller});Он фактически просто оборачивает наши TypeScript классы в компоненты AngularJS и делает их контроллерами.
Но в Angular, несмотря на экспериментальность фичи, это стало частью ядра фреймворка,
что делает необходимым использование полифила reflect-metadata в совершенно любом случае. Очень спорное решение.
Обилие внутренних классов и абстракций, а также всякие хитрости завязанные на TypeScript,
также не идут на пользу его принятию комьюнити. Да еще и портят впечатление о TS в целом.
Самый яркий пример подобных проблем — это Dependency Injection в Angular.
Сама по себе концепция замечательная, особенно для unit тестирования.
Но практика показывает, что большой нужды делать из фронтенда нечто Java-подобное нет.
Да, в нашем AngularJS приложении мы очень активно это использовали, но поработав с тестированием Vue компонентов, я серьезно начал сомневаться в пользе DI.
В Angular для большинства обычных зависимостей, вроде сервисов, DI будет выглядеть очень просто, с получением через конструктор:
constructor(heroService: HeroService) {
this.heroes = heroService.getHeroes();
}Но так работает только для TypeScript классов, и если вы хотите добавить константу, необходимо будет использовать @Inject:
constructor(@Inject(APP_CONFIG) config: AppConfig) {
this.title = config.title;
}Ах да, сервисы которые вы будете инжектить должны быть проанотированы как @Injectable().
Но не все, а только те, у которых есть свои зависимости, если их нет — можно этот декоратор не указывать.
Consider adding @Injectable() to every service class, even those that don't have dependencies and, therefore, do not technically require it.
Here's why:
Future proofing: No need to remember @Injectable() when you add a dependency later.
Consistency: All services follow the same rules, and you don't have to wonder why a decorator is missing.
Почему бы не сделать это обязательным сразу, если потом это рекомендуется делать всегда?
Еще прекрасная цитата из официальной документации по поводу скобочек:
Always write@Injectable(), not just@Injectable. The application will fail mysteriously if you forget the parentheses.
Короче говоря, создается впечатление, что TypeScript в Angular явно используется не по назначению.
Хотя еще раз подчеркну, что сам по себе язык обычно очень помогает в разработке.
Синтаксис шаблонов — основная претензия к Angular. И по вполне объективным причинам.
Пример не только множества разных директив, но еще и разных вариантов их использования:
style using ngStyle
Hello Wordl!
CSS class using property syntax, this text is blue
object of classes
array of classes
string of classesИзначально разработчики позиционировали новый синтакисис шаблонов, как спасение от множества директив.
Обещали, что будет достаточно только [] и ().
| Binding | Example |
|---|---|
| Properties | |
| Events | |
| Two-way |
К сожалению в реальности директив едва ли не больше чем в AngularJS.
И да, простое правило запоминания синтаксиса two-way binding про банан в коробке
из официальной документации:
Visualize a banana in a box to remember that the parentheses go inside the brackets.
Вообще писать про документацию Angular даже нет смысла, она настолько неудачная,
что достаточно просто попытаться ее почитать, чтобы все стало понятно.
Контрпример — доки Vue.
Мало того, что написаны подробно и доходчиво, так еще и на 6 языках,
в т.ч. русском.
Angular позволяет использовать так называемый View encapsulation.
Суть сводится к эмуляции Shadow DOM или использовании нативной его поддержки.
Сам по себе Shadow DOM — прекрасная вещь и действительно потенциально позволяет использовать даже разные CSS фреймворки для разных копмонентов без проблем.
Однако нативная поддержка на сегодняшний день совершенно печальна.
По умолчанию включена эмуляция Shadow DOM.
Вот пример простого CSS для компонента:
.first {
background-color: red;
}
.first .second {
background-color: green;
}
.first .second .third {
background-color: blue;
}Angular преобразует это в:
.first[_ngcontent-c1] {
background-color: red;
}
.first[_ngcontent-c1] .second[_ngcontent-c1] {
background-color: green;
}
.first[_ngcontent-c1] .second[_ngcontent-c1] .third[_ngcontent-c1] {
background-color: blue;
}Совершенно не ясно зачем делать именно так.
Например Vue делает то же самое, но гораздо чище:
.first[data-v-50646cd8] {
background-color: red;
}
.first .second[data-v-50646cd8] {
background-color: green;
}
.first .second .third[data-v-50646cd8] {
background-color: blue;
}Не говоря уже о том, что в Vue это не дефолтное поведение и включается добавлением простого scoped к стилю.
Так же хотелось бы отметить, что Vue (vue-cli webpack) подобным же образом позволяет указывать SASS/SCSS, тогда как для Angular CLI нужны команды типа ng set defaults.styleExt scss.
Не очень понятно зачем все это, если внутри такой же webpack.
Но это все ерунда, реальные проблемы у нас начались, когда нам потребовалось использовать сторонние компоненты.
В частности мы использовали один из наиболее популярных UI фреймворков — PrimeNG,
а он иногда использует подобные селекторы:
body .ui-tree .ui-treenode .ui-treenode-content .ui-tree-toggler {
font-size: 1.1em;
}Они по определению имеют больший приоритет нежели стили компонента, который использует в себе тот или иной сторонний элемент.
Что в итоге приводит к необходимости писать нечто подобное:
body :host >>> .ui-tree .ui-treenode .ui-treenode-content .ui-tree-toggler {
font-size: 2em;
}Иногда и вовсе приходилось вспомнить великий и ужасный !important.
Безусловно все это связано конкретно с PrimeNG и не является как таковой проблемой фреймворка, но это именно та проблема, которая скорее всего возникнет и у вас при реальной работе с Angular.
В примере выше мы использовали >>> — как и /deep/ это алиас для так называемого shadow-piercing селектора.
Он позволяет как бы "игнорировать" Shadow DOM и для некоторых сторонних компонентов порой просто незаменим.
В одном из относительно свежих релизов Angular создатели фреймворка решили,
в соответствии со стандартом, задепрекейтить /deep/ и >>>.
Никаких ошибок или ворнингов их использование не принесло, они просто перестали работать.
Как выяснилось позже, теперь работает только ::ng-deep — аналог shadow-piercing селектора в Angular вселенной.
Обновление это было отнюдь не мажорной версии (4.2.6 -> 4.3.0), просто в один прекрасный момент наша верстка во многих местах поползла (спасибо и NPM за версии с шапочкой ^).
Конечно, не все наши разработчики ежедневно читают ChangeLog Angular 4, да и за трендами веб разработки не всегда можно уследить. Само собой сначала грешили на собственные стили — пришлось потратить немало времени и нервов для обнаружения столь неприятной особенности.
К тому же скоро и ::ng-deep перестанет работать.
Как в таком случае править стили кривых сторонних компонентов, вроде тех же PrimeNG, ума не приложу.
Наш личный вывод: дефолтная настройка — эмуляция Shadow DOM порождает больше проблем чем решает.
Это вполне потянет на отдельную статью, но вкратце суть в том, что команда Angular действительно написала свой HTML парсер. По большей части это было необходимо для обеспечения регистрозависимости.
Нет смысла холиварить на тему ухода Angular от стандартов, но по мнению многих это довольно странная идея, ведь в том же AngularJS обычного HTML (регистронезависимого) вполне хватало.
С AngularJS нередко бывало такое: добавили вы некий а тест не написали.
Прошло некоторое время и модуль который содержит логику данного компонента был удален/отрефакторен/итд.
Так или иначе — теперь ваш компонент не отображается.
Теперь он сразу определяет неизвестные теги и выдает ошибку если их не знает.
Правда теперь любой сторонний компонент требует либо полного отключения этой проверки,
либо включения CUSTOM_ELEMENTS_SCHEMA которая пропускает любые тэги с -
Сорцы можете оценить самостоятельно
...
const TAG_DEFINITIONS: {[key: string]: HtmlTagDefinition} = {
'base': new HtmlTagDefinition({isVoid: true}),
'meta': new HtmlTagDefinition({isVoid: true}),
'area': new HtmlTagDefinition({isVoid: true}),
'embed': new HtmlTagDefinition({isVoid: true}),
'link': new HtmlTagDefinition({isVoid: true}),
'img': new HtmlTagDefinition({isVoid: true}),
'input': new HtmlTagDefinition({isVoid: true}),
'param': new HtmlTagDefinition({isVoid: true}),
'hr': new HtmlTagDefinition({isVoid: true}),
'br': new HtmlTagDefinition({isVoid: true}),
'source': new HtmlTagDefinition({isVoid: true}),
'track': new HtmlTagDefinition({isVoid: true}),
'wbr': new HtmlTagDefinition({isVoid: true}),
'p': new HtmlTagDefinition({
closedByChildren: [
'address', 'article', 'aside', 'blockquote', 'div', 'dl', 'fieldset', 'footer', 'form',
'h1', 'h2', 'h3', 'h4', 'h5', 'h6', 'header', 'hgroup', 'hr',
'main', 'nav', 'ol', 'p', 'pre', 'section', 'table', 'ul'
],
closedByParent: true
}),
...
'td': new HtmlTagDefinition({closedByChildren: ['td', 'th'], closedByParent: true}),
'th': new HtmlTagDefinition({closedByChildren: ['td', 'th'], closedByParent: true}),
'col': new HtmlTagDefinition({requiredParents: ['colgroup'], isVoid: true}),
'svg': new HtmlTagDefinition({implicitNamespacePrefix: 'svg'}),
'math': new HtmlTagDefinition({implicitNamespacePrefix: 'math'}),
'li': new HtmlTagDefinition({closedByChildren: ['li'], closedByParent: true}),
'dt': new HtmlTagDefinition({closedByChildren: ['dt', 'dd']}),
'dd': new HtmlTagDefinition({closedByChildren: ['dt', 'dd'], closedByParent: true}),
'rb': new HtmlTagDefinition({closedByChildren: ['rb', 'rt', 'rtc'
...А теперь ключевой момент — все эти ошибки происходят в консоли браузера в рантайме,
нет, ваш webpack билд не упадет, но и увидеть что либо кроме белого экрана не получится.
Потому что по умлочанию используется JIT компилятор.
Однако это решается прекомпиляцией шаблонов благодаря другому, AOT компилятору.
Нужно всего лишь собирать с флагом --aot, но и здесь не без ложки дегтя, это плохо работает с ng serve
и еще больше тормозит и без того небыструю сборку. Видимо поэтому он и не включен по умолчанию (а стоило бы).
Наличие двух различно работающих компиляторов само по себе довольно опасно звучит,
и на деле постоянно приводит к проблемам.
У нас с AOT было множество разнообразных ошибок, в том числе весьма неприятные и до сих пор открытые, например нельзя использовать экспорты по умолчанию
Обратите внимание на элегантные предлагаемые решения проблемы:
don't use default exports :)
Just place both export types and it works
Или нечто подобное описанному здесь (AOT не всегда разбирает замыкания)
Код подобного вида вызывает очень странные ошибки компилятора AOT:
@NgModule({
providers: [
{provide: SomeSymbol, useFactor: (i) => i.get('someSymbol'), deps: ['$injector']}
]
})
export class MyModule {}Приходится подстраиваться под компилятор и переписывать код в более примитивном виде:
export factoryForSomeSymbol = (i) => i.get('someSymbol');
@NgModule({
providers: [
{provide: SomeSymbol, useFactor: factoryForSomeSymbol, deps: ['$injector']}
]
})
export class MyModule {}Также хотелось бы отметить, что текст ошибок в шаблонах зачастую совершенно неинформативен.
Одна из концептуально очень крутых вещей которые появились в Angular это Zone.js.
Он позволяет отслеживать контекст выполнения для асинхронных задач, но новичков отпугивают огромной длины стактрейсы. Например:
core.es5.js:1020 ERROR Error: Uncaught (in promise): Error: No clusteredNodeId supplied to updateClusteredNode.
Error: No clusteredNodeId supplied to updateClusteredNode.
at ClusterEngine.updateClusteredNode (vis.js:47364)
at VisGraphDataService.webpackJsonp.../../../../../src/app/services/vis-graph-data.service.ts.VisGraphDataService.updateNetwork (vis-graph-data.service.ts:84)
at vis-graph-display.service.ts:63
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invoke (zone.js:391)
at Object.onInvoke (core.es5.js:3890)
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invoke (zone.js:390)
at Zone.webpackJsonp.../../../../zone.js/dist/zone.js.Zone.run (zone.js:141)
at zone.js:818
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invokeTask (zone.js:424)
at Object.onInvokeTask (core.es5.js:3881)
at ClusterEngine.updateClusteredNode (vis.js:47364)
at VisGraphDataService.webpackJsonp.../../../../../src/app/services/vis-graph-data.service.ts.VisGraphDataService.updateNetwork (vis-graph-data.service.ts:84)
at vis-graph-display.service.ts:63
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invoke (zone.js:391)
at Object.onInvoke (core.es5.js:3890)
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invoke (zone.js:390)
at Zone.webpackJsonp.../../../../zone.js/dist/zone.js.Zone.run (zone.js:141)
at zone.js:818
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invokeTask (zone.js:424)
at Object.onInvokeTask (core.es5.js:3881)
at resolvePromise (zone.js:770)
at zone.js:696
at zone.js:712
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invoke (zone.js:391)
at Object.onInvoke (core.es5.js:3890)
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invoke (zone.js:390)
at Zone.webpackJsonp.../../../../zone.js/dist/zone.js.Zone.run (zone.js:141)
at zone.js:818
at ZoneDelegate.webpackJsonp.../../../../zone.js/dist/zone.js.ZoneDelegate.invokeTask (zone.js:424)
at Object.onInvokeTask (core.es5.js:3881)Некоторым Zone.js нравится и
наверняка в продакшене нам это еще не раз поможет, но в нашем проекте большой пользы мы пока не извлекли.
А ошибок в консоли зачастую больше одной и поиск сути проблемы постоянно осложняется анализом таких стактрейсов.
Не говоря уж о том, что нередко длины консоли хрома часто просто не хватает чтобы вместить все сразу.
И сама суть проблемы остается где-то далеко наверху, если ошибка происходит слишком много раз.

Еще один пункт, который формально не относится к самому фреймворку — это довольно скудное количество готовых наборов UI компонентов. Думаю, что написание большинства компонентов с нуля — непозволительная роскошь для многих веб-разработчиков. Зачастую проще, быстрее и разумнее взять готовый UI framework вместо написания собственных гридов и деревьев.
Да, я понимаю, что выбирать фреймворк по наличиую UI компонентов в корне неверно,
но при реальной разработке это необходимо.
Вот список основных UI фреймворков для Angular: https://angular.io/resources (раздел UI components).
Рассмотрим наиболее популярные бесплатные варианты.

Безусловно, наибольшие надежды я возлагал на Angular Material 2 ввиду того, что разрабатывается он командой Angular и наверняка будет соответствовать всем гайдлайнам.
К сожалению, несмотря на его возраст, набор компонентов крайне мал.
На момент начала написания данной статьи, и уж тем более, когда мы выбирали фреймворк для проекта — гридов не было.
И вот совсем недавно он-таки появился. Но функционал все же пока довольно базовый.
Я считаю, что Angular Material 2 подойдет лишь небольшим или, в лучшем случае, средним проектам, т.к. до сих пор нет, например, деревьев. Часто очень нужны компоненты вроде multiple-select, коих тоже нет.
Отдельно стоит сказать про очень скупую документацию и малое количество примеров.
Перспективы развития тоже довольно печальные.
| Feature | Status |
|---|---|
| tree | In-progress |
| stepper | In-progress, planned Q3 2017 |
| sticky-header | In-progress, planned Q3 2017 |
| virtual-repeat | Not started, planned Q4 2017 |
| fab speed-dial | Not started, not planned |
| fab toolbar | Not started, not planned |
| bottom-sheet | Not started, not planned |
| bottom-nav | Not started, not planned |

По тем же причинам, что и выше не буду останавливаться на Bootstrap фреймворках типа
ng2-bootstrap (получше) и ngx-bootstrap.
Они очень даже неплохи, но простейшие вещи можно сделать и обычным CSS, а сложных компонентов тут нет (хотя наверняка многим будет достаточно modal, datepicker и typeahead).
Это на сегодняшний день наиболее популярый фреймворк содержащий множество сложных компонентов. В том числе гриды и деревья (и даже Tree Table!).
Изначально я вообще довольно скептически относился к PrimeFaces т.к. у меня был давний опыт работы с JSF, и много неприятных воспоминаний. Да и выглядят PrimeNG визуально так же (не очень современно). Но на момент начала нашего проекта достойных альтернатив не было, и все же хочется сказать спасибо разработчикам за то, что в короткие сроки был написан дейтсивтельно широчайший инструментарий.
Однако проблем с этим набором компонентов у нас возникало очень много.
Часто документация совершенно не помогает.
Забыли добавить некий модуль — что-то просто молча не работает и никаких ошибок не возникает.
Приходится дебажить и выясняется, что сорцы совершенно без комментариев.
В общем, несмотря на наличие большого количества готовых компонентов,
по возможности, я бы не рекомендовал выбирать PrimeNG в качестве базы.
Луч света в темном царстве — это относительно молодая (меньше года от роду) библиотека Clarity от vmware.
Набор компонентов впечатляет,
документация крайне приятная, да и выглядят здорово.
Фреймворк не просто предоставляет набор UI компонентов, но и CSS гайдлайны.
Эдакий свой bootstrap. Благодаря этому достигается консистентный и крайне приятный/минималистичный вид компонентов.
Гриды очень функциональные и стабильные, а сорцы говорят сами за себя
(о боже, комментарии и юнит тесты, а так можно было?).
Однако пока что очень слабые формы,
нет datepicker'а и select2-подобного компонента.
Работа над ними идет в данный момент:
DatePicker,
Select 2.0
(как всегда дизайн на высоте, и хотя с разработкой не торопятся я могу быть уверен, что делают на совесть).
Пожалуй, "Clarity Design System" — единственная причина почему я еще верю в жизнь Angular
(и вообще единственный фреймворк который не стыдно использовать для enterprise разработки).
Как никак VMware серьезнейший мейнтейнер и есть надежда на светлое будущее.
Мы только начали его использовать и наверняка еще столкнемся с проблемами,
но на сегодняшний день он нас полностью устраивает и просто прекрасно работает.
Да, я считаю что для Angular на сегодняшний день есть лишь один достойный UI фреймворк.
О чем это говорит?
Полноценно разрабатывать такие фреймворки для Angular могут лишь серьезнейшие компании вроде той же VMware. Нужен ли вам такой суровый enterprise? Каждый решает сам.
А теперь давайте посмотрим, что происходит с одним из свежих конкурентов.

Для сравнения мощные уже существующие фреймворки для Vue.js с теми же гридами:
Element (~15k stars), Vue Material
(существенно младше Angular Material 2 но уже содержит в разы больше),
Vuetify (снова Material и снова множество компонентов),
Quasar,
также надо отметить популярные чисто китайские фреймворки типа
iView и Muse-UI
(iView выглядит очень приятно, но документация хромает).
Вот и простой, но очевидный, пример того, что писать компоненты на Vue гораздо проще.
Это позволяет даже выбирать наиболее приглянувшийся из множества наборов компонентов,
нежели надяться на один, который поддерживает огромная команда.
Благодаря Clarity есть надежда на то, что наш Angular проект в дальнейшем будет становится только лучше.
Однако для нас стало очевидно, что количество всевозможных проблем с Angular,
а также многочисленные его усложнения совершенно не приносят пользы даже для больших проектов.
В реальности все это лишь увеличивает время разработки, не снижая стоимость поддержки и рефакторинга.
Поэтому для нашего нового проекта мы выбрали Vue.js.
Достаточно просто развернуть базовый webpack шаблон для vue-cli и оценить скорость работы библиотеки.
Несмотря на то, что лично я всегда был сторонником фреймворков all-in-one,
Vue без особых проблем делает почти все то же, что и Angular.
Ну и конечно, множество тех же UI framework'ов также играет свою роль.
Единственное чего немного не хватает — чуть более полноценной поддержки TypeScript,
уж очень много головной боли он нам сэкономил за эти годы.
Но ребята из Microsoft уже вот вот вмержает ее.
А потом она появится и в webpack шаблоне.
Почему мы не выбрали React? После AngularJS наша команда гораздо проще вошла в Vue,
ведь все эти v-if, v-model и v-for уже были очень знакомы.
Лично мне во многом, но не во всем, нравится Aurelia но уж больно она малопопулярна,
а в сравнении с взрывным ростом популярности Vue она кажется совсем неизвестной.
Надеюсь, что через год-два Angular под давлением community все-таки избавится от всего лишнего,
исправит основные проблемы и станет наконец тем enterprise framework'ом, которым должен был.
Но сегодня я рекомендую вам посмотреть в сторону других, более легковесных и элегантных решений.
И поверьте, спустя 4 года работы с Angular, вот так бросить его было очень нелегко.
Но достаточно один раз попробовать Vue...
|
Метки: author MooooM разработка веб-сайтов javascript html css angularjs angular angular 4 vue vue.js typescript |
ICO для моей игры: ошибки и инсайты |

Мы делаем игру, в которой каждый сможет построить свой успешный бизнес на базе реальной криптовалюты, а заработанные в игре деньги тратить в реальной жизни. И все это — в пиратской атмосфере 17 века.
|
Метки: author Alienter финансы в it gamedev indiedev ico финансирование стартапов |
[Из песочницы] Что «под капотом» у LinkedList? |

LinkedList numbers = new LinkedList<>(); // модификатор transient указывает на то, что данное свойство класса нельзя
// сериализировать
transient int size = 0;
transient Node first;
transient Node last; 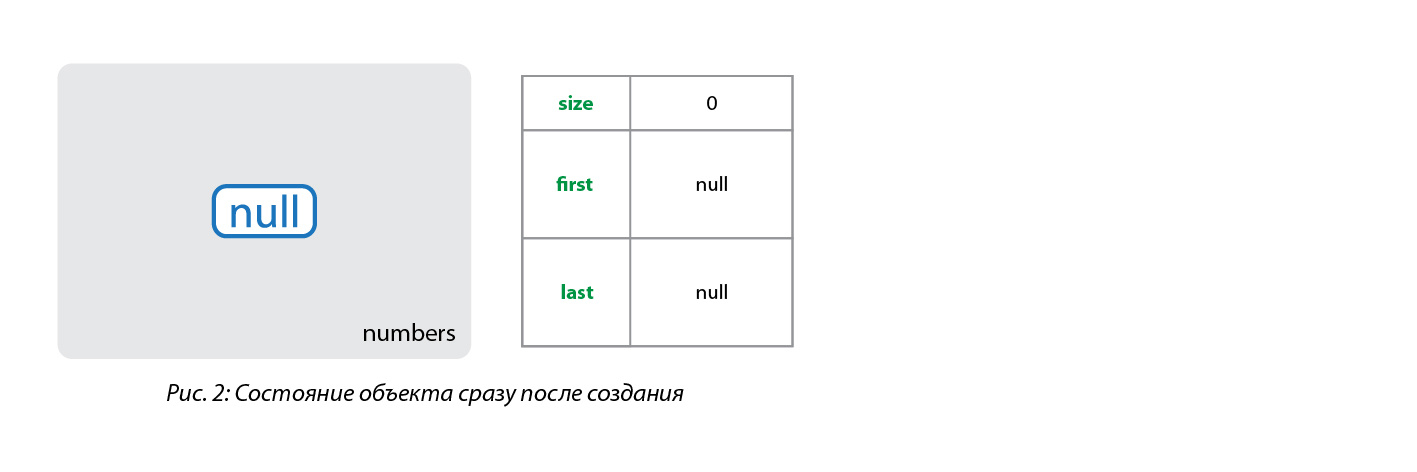
numbers.add(8);private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} 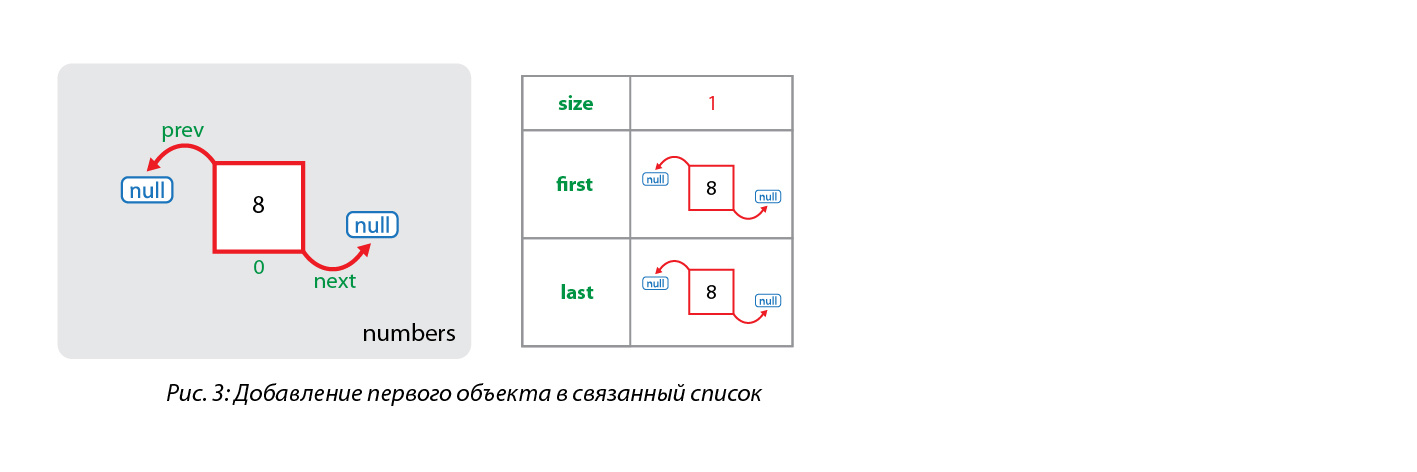
numbers.add(5);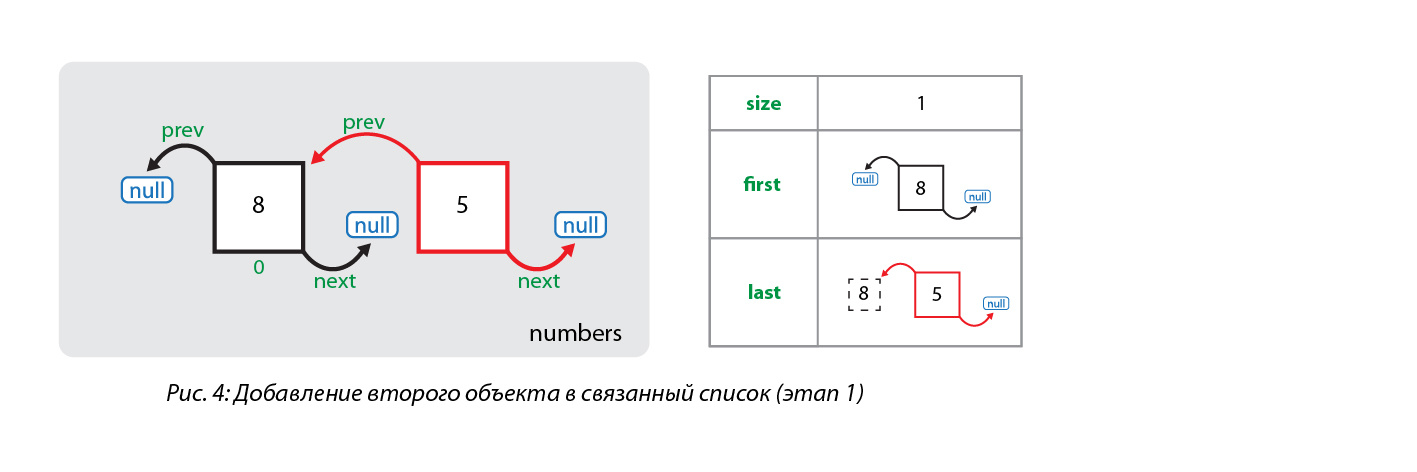

numbers.add(1, 13);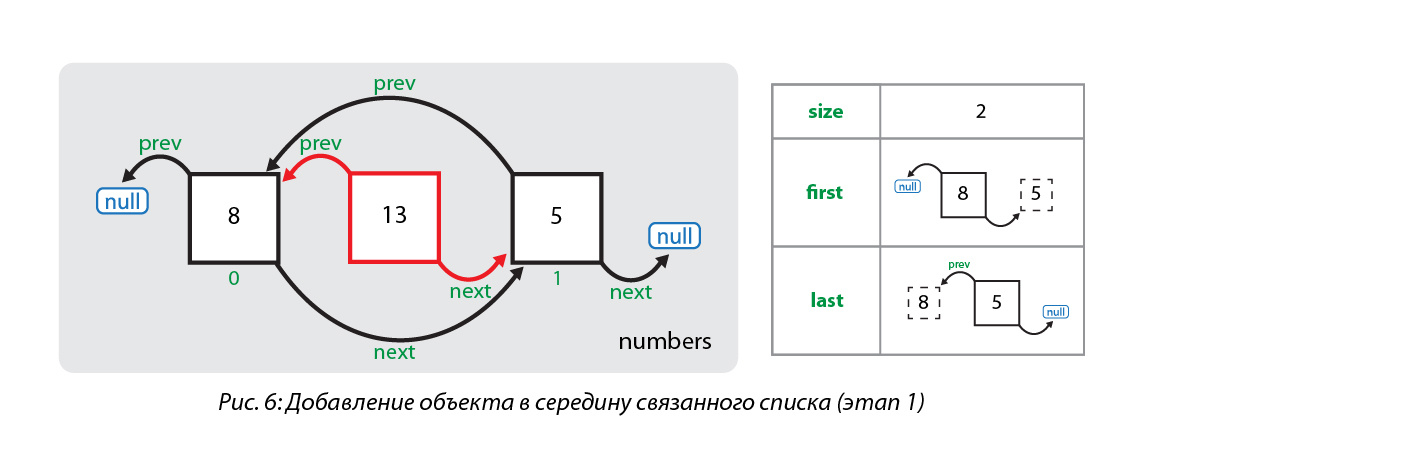
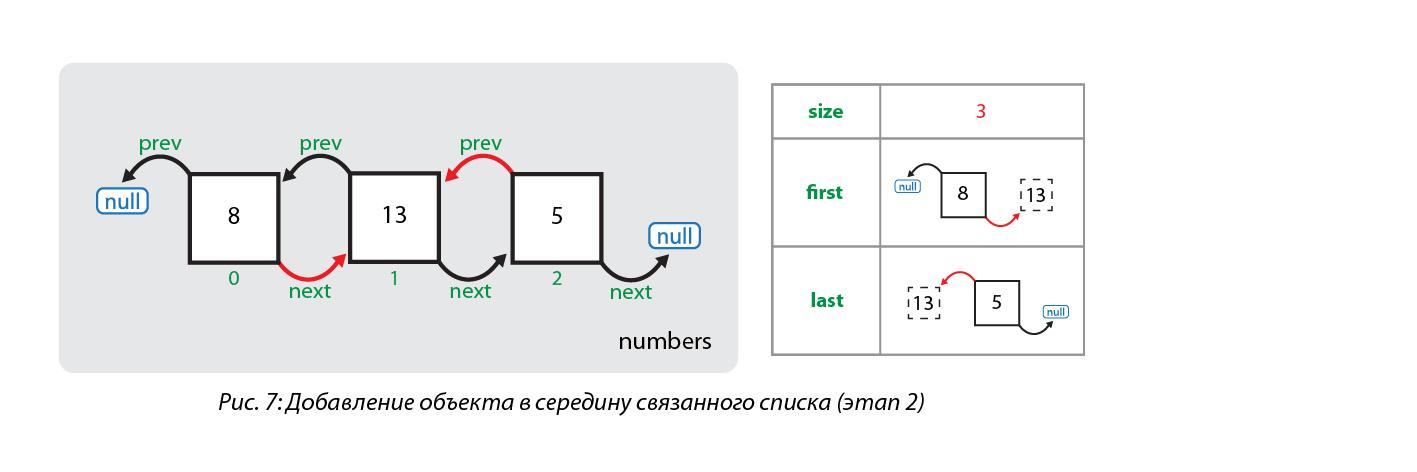
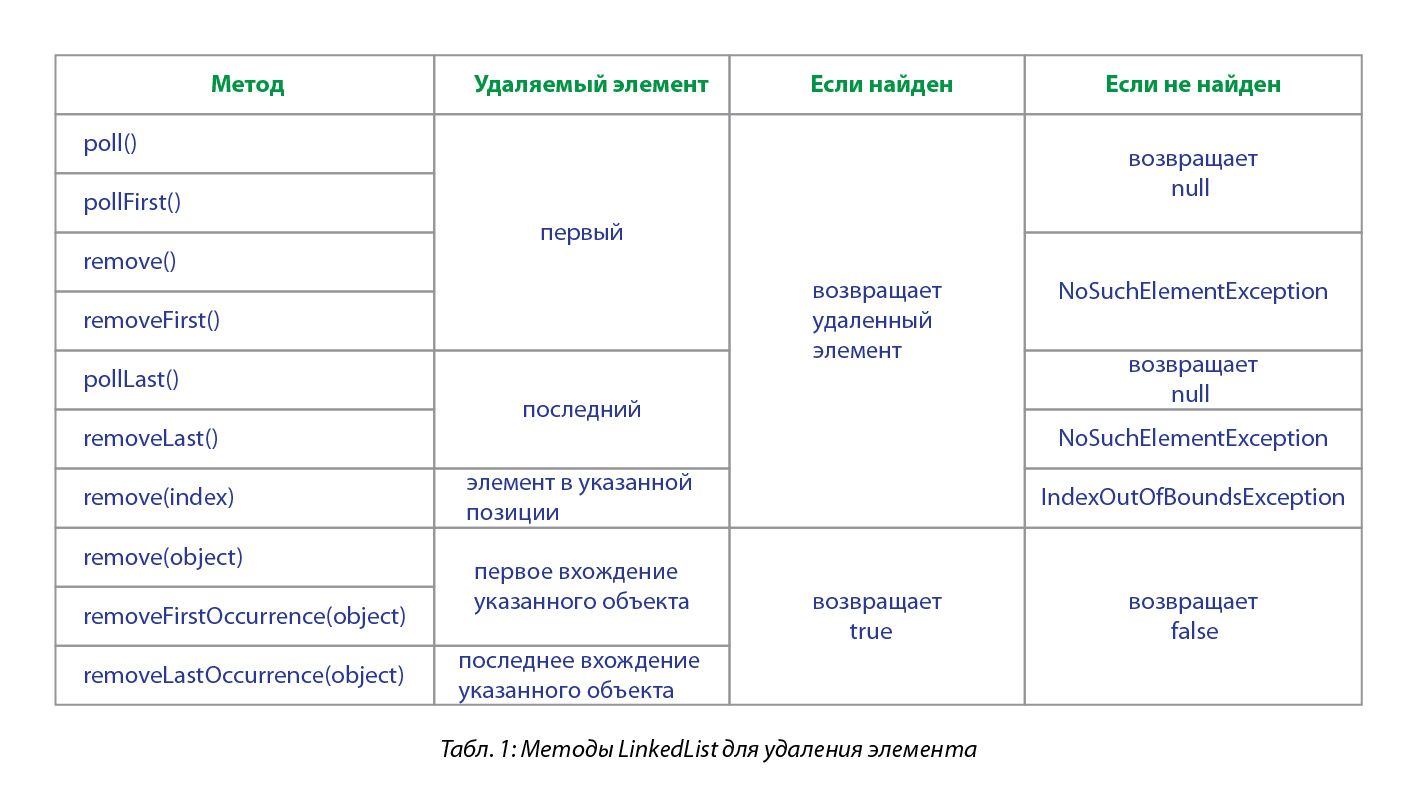
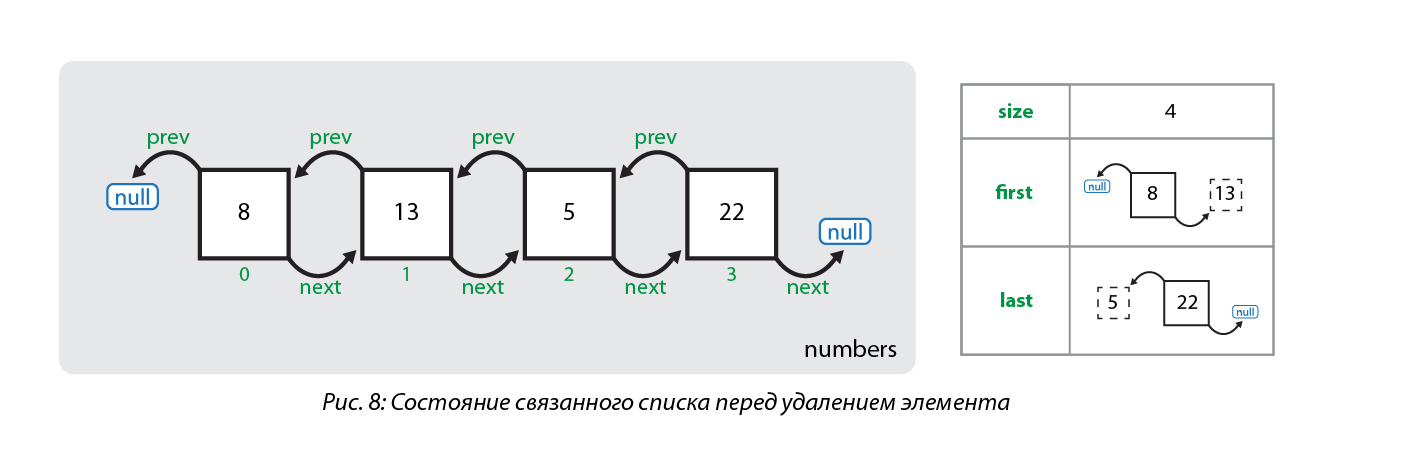
numbers.remove(Integer.valueOf(5));numbers.remove(5);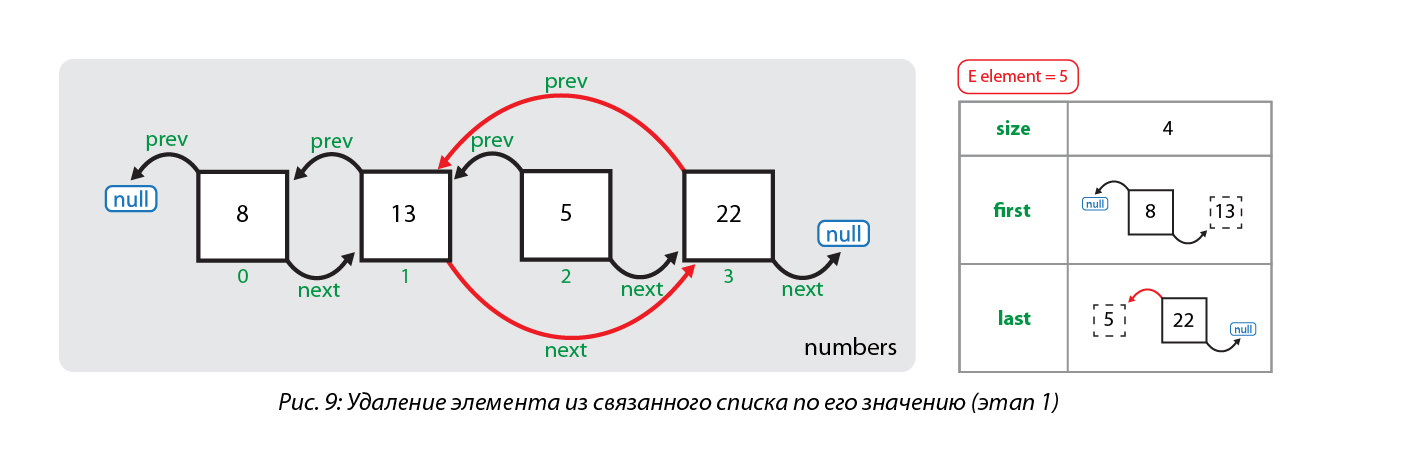
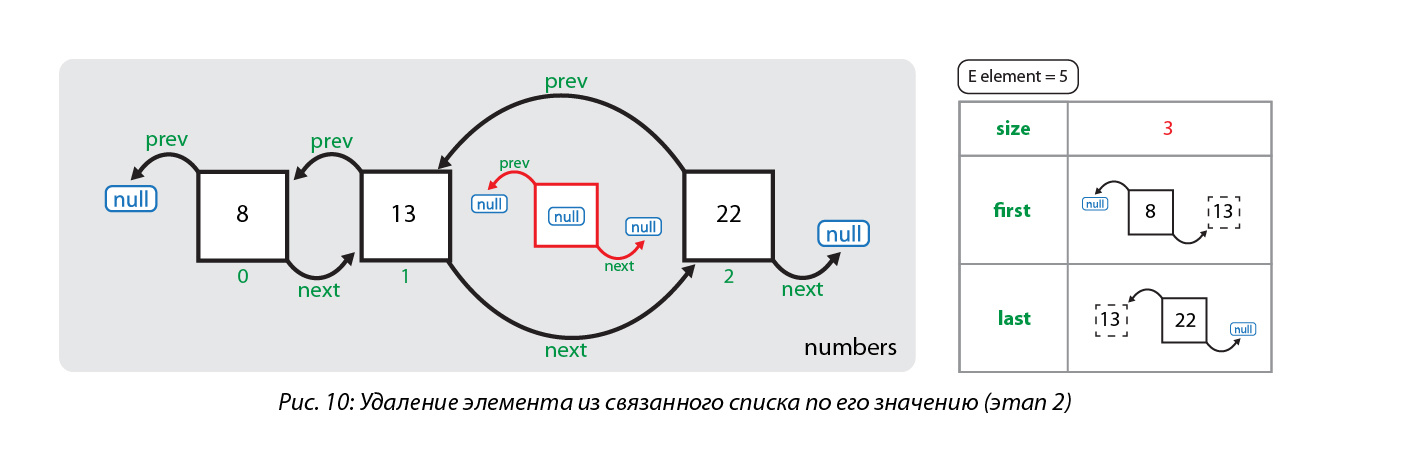
|
Метки: author AsteriskIT программирование java linkedlist |
[Из песочницы] Путь джедая. От мелкого юзера до сотрудника IT-компании |
|
Метки: author FaMon учебный процесс в it qa html css selenium история |
Learnopengl. Урок 2.4 — Текстурные карты |

Ранее мы обсуждали возможность каждого объекта иметь уникальный материал, чтобы по-разному реагировать на свет. Это отлично подходит для того, чтобы придать каждому объекту уникальный вид относительно других объектов на сцене. Но этого все еще не дает нам большой гибкости в настройке внешнего вида объекта.
В предыдущем уроке мы определили материал для целого объекта, но в реальном мире объекты обычно состоят не из одного, а из нескольких материалов. Представьте себе машину: ее внешний корпус блестящий; окна частично отражают окружающую среду; у машины также есть матовые покрышки, а еще есть сверкающие обода (сверкающие, если вы хорошо моете свою машину). Так вот, каждый объект имеет разные свойства материала для каждой своей части.
Итак, наша система материалов из предыдущего урока не подходит для более или менее сложных объектов, по этому нам нужно расширить ее, введя диффузную и бликовую карты. Это даст нам возможность влиять на диффузный (и, косвенным образом, на фоновый, так как это почти всегда одно и то же) и бликовый компоненты объекта с большей точностью.
Все, что нам нужно — это способ установить диффузный цвет для каждого фрагмента объекта. Что может повлиять на значение цвета, основываясь на позиции фрагмента?
Припоминаете? Это — текстуры, которые мы интенсивно обсуждали в одном из предыдущих уроков. Карты освещения – всего лишь другое название того же принципа: используя изображение, нанесенное на поверхность объекта, мы можем делать выборки цвета для каждого фрагмента. В сценах с освещением это обычно называется диффузной картой (как правило ее так называют 3D художники), так как текстурное изображение представляет все диффузные цвета объекта.
Для демонстрации диффузных карт мы будем использовать изображение деревянного контейнера с железной рамкой:

Использование диффузных карт в шейдерах очень похоже на использование текстур в одном из предыдущих уроков. Однако теперь мы заменим ранее определенный вектор vec3 диффузного цвета диффузной картой sampler2D.
Имейте в виду, что
sampler2Dэто, так называемый, непрозрачный тип данных. Это значит, что мы не можем создать экземпляр такого типа, мы можем только определить его как uniform. Если мы попытаемся использовать этот тип не как uniform (например как параметр функции), то GLSL выведет странные ошибки. Это правило также распространяется и на любую структуру, которая содержит непрозрачный тип.
Мы также удалили вектор ambient, так как он в большинстве случаев совпадает с диффузным цветом, так что нам не нужно хранить его отдельно:
struct Material {
sampler2D diffuse;
vec3 specular;
float shininess;
};
...
in vec2 TexCoords;
Если вы такой упрямый и все еще хотите установить фоновый цвет отличным от диффузного, то можете оставить вектор
ambient. Но фоновый цвет будет один для всего объекта. Чтобы получить различные значения фонового цвета для каждого фрагмента объекта, вам нужно использовать отдельную текстуру для значений фонового цвета.
Обратите внимание, что нам снова нужны текстурные координаты во фрагментном шейдере, по этому мы объявляем дополнительную входящую переменную. Затем мы просто делаем выборку из текстуры, чтобы извлечь значение диффузного цвета фрагмента:
vec3 diffuse = light.diffuse * diff * vec3(texture(material.diffuse, TexCoords));
Также не забудьте установить фоновый цвет материала таким же, как и диффузный:
vec3 ambient = light.ambient * vec3(texture(material.diffuse, TexCoords));
Это все, что нам нужно для использования диффузной карты. Как вы могли заметить, в этом нет ничего нового, но это дает впечатляющий рост визуального качества. Чтобы это заработало, нам нужно добавить текстурные координаты к данным вершин и передать их в качестве вершинного атрибута во фрагментный шейдер, загрузить текстуру и связать ее с соответствующим текстурным блоком.
Обновленные вершинные данные можно найти здесь. Теперь они включают в себя позиции вершин, векторы нормалей и текстурные координаты для каждой вершины куба. Давайте обновим вершинный шейдер, чтобы он мог принимать текстурные координаты, как вершинный атрибут и передавать их во фрагментный шейдер:
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec3 aNormal;
layout (location = 2) in vec2 aTexCoords;
...
out vec2 TexCoords;
void main()
{
...
TexCoords = aTexCoords;
}
Удостоверьтесь, что обновили вершинные атрибуты обоих VAO (прим. переводчика: имеются ввиду VAO текстурированного куба и VAO куба-лампы), так чтобы они совпадали с новыми вершинными данными, и загрузили изображение контейнера в текстуру. Перед тем, как нарисовать контейнер нам нужно присвоить переменной material.diffuse предпочтительный текстурный блок и связать с ним текстуру контейнера:
lightingShader.setInt("material.diffuse", 0);
...
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, diffuseMap);
Используя диффузную карту, мы снова получили огромный прирост детализации и теперь, с добавленным освещением, наш контейнер действительно начал блистать (в буквальном смысле). Вероятно, теперь он выглядит вот так:

Вы можете найти полный исходный код приложения здесь.
Вероятно, вы заметили, что блик выглядит немного странно, ведь наш объект — это контейнер, который большей частью состоит из дерева. А, как мы знаем, дерево не дает такого зеркального блеска. Мы можем исправить это, установив вектор specular в структуре Material равным vec3(0.0), но это значит, что железная рамка контейнера тоже перестанет давать блики, а мы знаем, что металл должен, хотя бы немного блестеть. И снова мы хотели бы контролировать, какие части объекта должны блестеть и с какой силой. Эта проблема очень похожа на обсуждение диффузных карт. Совпадение? Не думаю.
Мы снова можем воспользоваться текстурной картой, только теперь для зеркальных бликов. Это значит, что нам нужно создать черно-белую (или цветную, если хотите) текстуру, которая определит силу блеска каждой части объекта. Вот пример бликовой карты:

Интенсивность блеска определяется яркостью каждого пикселя изображения. Каждый пиксель такой карты может быть представлен как цветовой вектор, где черный цвет — это vec3(0.0), а серый — vec3(0.5), например. Затем, во фрагментном шейдере мы отбираем соответствующее цветовое значение и умножаем его на интенсивность бликового цвета. Соответственно, чем "белее" пиксель, тем больше получается результат умножения, а, следовательно, и яркость блика на фрагменте объекта.
Так как контейнер большей частью состоит из дерева, а дерево — это материал, который не дает бликов, то вся "деревянная" часть текстуры закрашена черным. Черные части вообще не блестят. Поверхность стальной рамки контейнера имеет переменную силу зеркального блеска: сама сталь дает довольно интенсивные блики, в то время как трещины и потертости – нет.
Технически, дерево тоже имеет зеркальные отражения, хотя и с намного более низкой силой блеска (свет сильнее рассеивается), но в образовательных целях, мы сделаем вид, что дерево никак не реагирует на зеркальный свет.
Используя инструменты, такие как Photoshop или Gimp, довольно просто превратить диффузную текстуру в бликовую. Достаточно просто вырезать некоторые части, сделать изображение черно-белым и увеличить яркость/контрастность.
Карта зеркальных отражений — это самая обычная текстура, по этому код ее загрузки очень похож на загрузку диффузной карты. Удостоверьтесь, что вы правильно загрузили изображение и сгенерировали текстурный объект. Так как мы используем новую текстуру в том же фрагментом шейдере, нам нужно использовать другой текстурный блок для карты бликов. Давайте свяжем эту текстуру с соответствующим текстурным блоком перед визуализацией:
lightingShader.setInt("material.specular", 1);
...
glActiveTexture(GL_TEXTURE1);
glBindTexture(GL_TEXTURE_2D, specularMap);
Затем обновим свойства материала во фрагментном шейдере, чтобы отражающий компонент принимался в качестве sampler2D, а не vec3:
struct Material {
sampler2D diffuse;
sampler2D specular;
float shininess;
};
И, наконец, нам нужно провести выборку карты бликов, чтобы получить соответствующую интенсивность блика для каждого фрагмента объекта:
vec3 ambient = light.ambient * vec3(texture(material.diffuse, TexCoords));
vec3 diffuse = light.diffuse * diff * vec3(texture(material.diffuse, TexCoords));
vec3 specular = light.specular * spec * vec3(texture(material.specular, TexCoords));
FragColor = vec4(ambient + diffuse + specular, 1.0);
Используя карту бликов, мы можем с чрезвычайной точностью определить, какие части объекта дают зеркальные блики, и установить соответствующую их интенсивность. Таким образом, карта бликов дает нам дополнительный уровень контроля поверх диффузной карты.
Вы также можете использовать в бликовой карте цвета, которые определяют не только интенсивность блика, но и его цвет. Однако в реальности, цвет блика в значительной степени (а в большинстве случаев и полностью) зависит от источника света, поэтому использование цветных карт бликов не даст реалистичных результатов (вот почему эти изображения обычно черно-белые — нас интересует только интенсивность блика).
Если вы запустите приложение, то увидите, что материал контейнера очень похож, на деревянный контейнер с железной рамкой:
Вы можете найти полный исходный код приложения здесь.
Используя диффузные и бликовые карты, мы можем добавить огромное количество деталей в относительно простые объекты. Мы можем добавить еще больше деталей, используя другие текстурные карты, такие как карты нормалей/рельефа и/или карты отражений, но их мы прибережем для следующих уроков. Покажите ваш контейнер друзьям и семье и помните, что однажды наш контейнер может стать еще более привлекательным, чем сейчас!
|
Метки: author eanmos разработка игр программирование c++ opengl 3 glsl перевод |






