Прорыв на рынке автоматизации процессов управления бизнесом |

|
Метки: author Flexbby блог компании flexbby flexbby parametric автоматизация бизнеса bpm crm time management масштабирование приложений инновации в it инновационные решения |
[Перевод] Надёжность Go в инфраструктуре Dropbox |
«Go — эффективный, масштабируемый и производительный язык. Некоторые программисты получают удовольствие от работы с ним; другие находят его прозаическим, даже скучным. В этой статье мы расскажем, почему все эти позиции не противоречат друг другу. Go спроектирован для решения проблем, возникающих в софтверной разработке в Google, что привело к созданию языка, который не является прорывным с исследовательской точки зрения, тем не менее это прекрасный инструмент для разработки крупных софтверных проектов». — Роб Пайк, 2012
|
Метки: author m1rko разработка веб-сайтов высокая производительность go dropbox bazel rust состояние гонки |
NeoDelphi`низм |
Тип чтоооо будет, если челик коснётся провода, по которому 220В + 880А идёт?
Евгений Гусев
Кстати
Я не основатель
Я бог
А ты тип библию написал
Моисей короч ты
TDelphi Act 0
И ш
Ты написал то библию уже?
TDelphi Act 1








|
Метки: author sbasyrov читальный зал delphi |
[Из песочницы] Ruby on Rails для разработки маркетплейса |
Мысли и выводы, опубликованные в данной статье, сформировались на основе опыта моей компании, которая не первый год занимается разработкой онлайн маркетплейсов разного типа. Мы имеем достаточно большое количество проектов, которые создавались с использованием Ruby on Rails. Сейчас же я хочу рассказать, почему мы отдали наше предпочтение именно этому фреймворку и ни разу об этом не пожалели.
Макретплейс – это электронная торговая площадка, оформленная в виде веб- или мобильного приложения, где покупатели и продавцы могут общаться и заключать сделки. Это своего рода механизм, который помогает установить связь между провайдерами. От обычного интернет-магазина маркетплейс отличается тем, что в нем представлено не один (обычно, он же и владелец), а много различных брендов поставщиков услуг.
Для общего понимания, вот основные отличия маркетплейса от интернет-магазина:
И это лишь основные моменты. Таким образом, покупатель получает удобную площадку, где есть буквально всё; продавец получает больше покупателей без лишних затрат на промо (чем не дополнительный канал продаж?); владелец маркетплейса получает доход без лишних "телодвижений" (ведь, все, что ему необходимо делать – не изготовлять товары и доставлять их, а создать и поддерживать маркетплейс).
В качестве примера маркетплейса можно рассмотреть Amazon, Airbnb, Uber, Spotify или OLX. Эти гиганты давно себя зарекомндовали на рынке. Кроме того, не следует забывать и про App Store с Google Play, ведь это тоже маркетплейсы. И мы практически каждый день ими пользуемся.
Важный для понимания темы нюанс – маркетплейсы разделяются на различные типы на основе принципов взаимодействия покупателей и продавцов. Всего их насчитывается 8 на сегодняшний день:
B2B (англ. "business to business"),
mCommerce (сокращение от "мобильная коммерция"),
Crowdfunding (от англ. "crowdfund" – "финансирование посредством сбора денег у сообщества"),
C2C (англ. "customer to customer" – "потребитель для потребителя"),
eCommerce (сокращение от "электронная коммерция"),
B2C (англ. "business to customer"),
peer-to-peer (от англ. "равные для равных")
auction platforms (от англ. "аукцион")
Но давайте ближе к теме. Прежде, чем начать восхваление Ruby on Rails (далее в статье RoR), в контексте разработки маркетплейсов, наверное, нужно также упомянуть и альтернативы, которые присутствуют на рынке. Дабы материал не показался предвзятым.
Вы должны понимать, что в свое время мы использовали и другие технологии создания маркетплейсов помимо RoR. Поэтому нам есть с чем сравнить.
Это самое интересное. На самом деле, способов предостаточно. Порой более чем, поскольку каждая компания, предоставляющая платформу для разработки, твердит, что только эта платформа идеально подходит для вашего маркетплейса. Остальные "непременно будут плохо работать или иметь ограниченный функционал". Однознаности нет, и каждый вибирает сам.
Функционал, кстати, вполне отдельная тема. Ведь чтобы пользователь остался с маркетплейсом, нужно продумать кучу вещей, начиная от удобной авторизации, заканчивая интеграцией с платежной системой. О функционале можно долго говорить, но вот основные моменты:
Но вернемся к способам разработки. Поскольку их достаточно много, то удобнее всего будет отсортировать их на 3 категории:
Покупка готового решения
Здесь я имею в виду покупку решения от Shopify, Magento или Woocommerce (на самом деле, примеров больше). Просто, быстро, удобно. Но есть и минусы. Основным минусом такого способа является невозможность кастомизировать ваш маркетплейс, настроить так, как вам удобно. Он будет шаблонным, и внести в него требующиеся вам изменения будет если не невозможно, то очень дорого в итоге. И если таких потребностей у вас нет, то решение идеально подойдет.
Использование открытой платформы
Такая открытая платформа, как, например, Sharetribe, WordPress или Spree – это что-то среднее между кастомной разработкой и готовым решением. С одной стороны, здесь вы получите большую свободу для настроек и изменений. По сути, разработкой будет заниматься ваша команда. Но в то же время, создать здесь нечто более, что выходит за рамки возможностей платформы, не получится.
Для разработки с нуля используются различные фреймфорки (англ. "web application framework").
Несмотря на то, что для каждой платформы находится много любителей и противников (маркетплейсы также часто создаются на платформах Laravel, Django, Meteor), мы предпочитаем именно Ruby on Rails.
И вот почему:
Во-первых, это простота разработки. Для RoR существует огромное множество библиотек, где есть все, о чем можно только мечтать. Даже если вопрос или проблема еще не появились, для них уже есть решение.
Это очень удобно, ведь ничего не нужно изобретать.
Эта же простота разработки приводит к следующему преимуществу – значительному сокращению времени на разработку. Что может быть лучше, если проект можно запустить в два раза быстрее, чем планировалось ранее? К тому же, именно из-за простоты, команда разработчиков сравнительно невелика. А это – очевидная экономия.
RoR рассчитан на сайты с большим количеством информации. Другими словами, если нужно предусмотреть наполнение сайта контентом, то нет ничего лучше, чем Ruby on Rails. Это очень важно для CRM и CMS систем.
Сообщество разработчиков может прийти на выручку и тогда, когда необходимо заменить или нанять еще одного разработчика в команду. С поиском кандидата не будет проблем.
Существует огромное количество маркетплейсов, возданных на Ruby on Rails. Тот же Shopify (о котором шла речь ранее) или всемирно известный Couchserfing.
Можно долго говорить о том, как хорошо и легко работать на RoR. Однако, основная цель моей статьи – рассказать, что этот фреймворк прекрасно подходит для создания онлайн маркетплейсов. Надеюсь, что мне это удалось, и информация как про маркетплейсы, так и про Ruby on Rails была для вас полезной.
|
Метки: author IrynaKorkishko интернет-маркетинг маркетплейс маркетинг реклама в интернете фрейморк e-commerce |
[Перевод] 10 основ брендинга для начинающих предпринимателей |

|
Метки: author Logomachine брендинг блог компании логомашина дизайн логотип бизнес совет перевод |
[Перевод] Невидимые сообщения в именах свойств JavaScript |
|
Метки: author ru_vds разработка веб-сайтов javascript блог компании ruvds.com unicode разработка |
[Из песочницы] 5G Глазами Huawei |
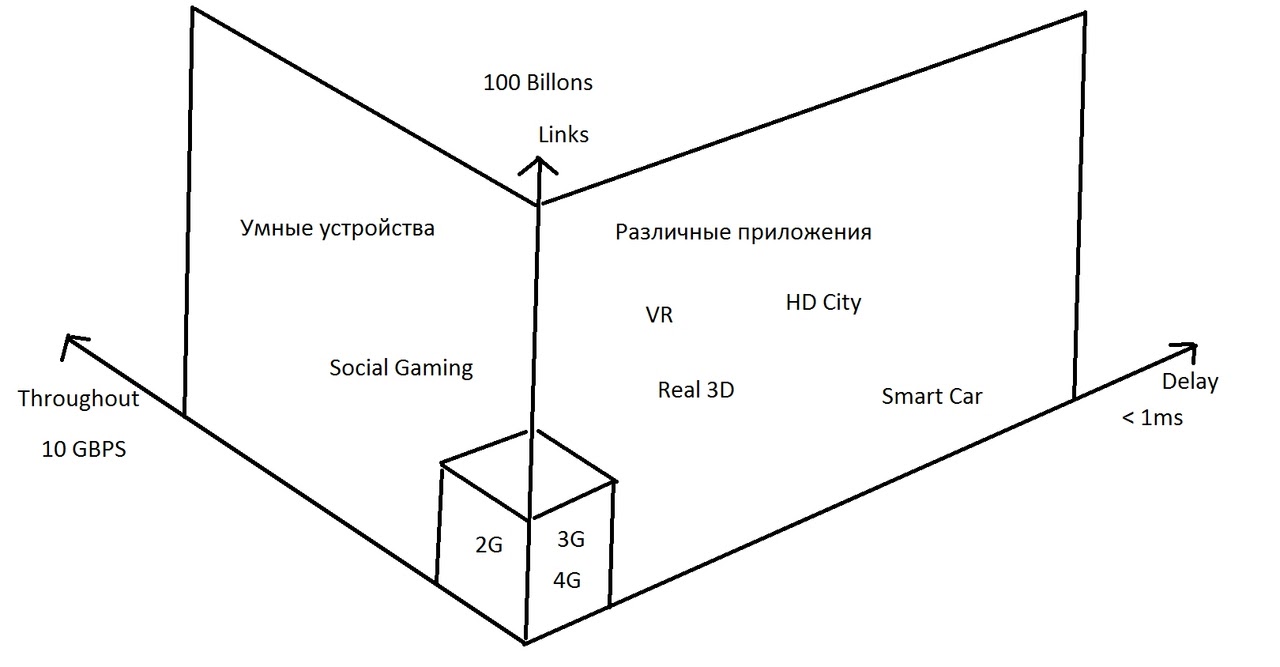
Статья о будущей сети 5G, о которой рассказывали на Honor Cup 2016.

Основные различия между этими технологиями: скорость, объём передачи данных и кол-во соединений. Как заявили на конференции, что если сама концепция будет успешно реализована, то поколения 6G не будет.
|
Метки: author sbasyrov исследования и прогнозы в it 5g huawei |
Использование Hotspot Helper Extension |
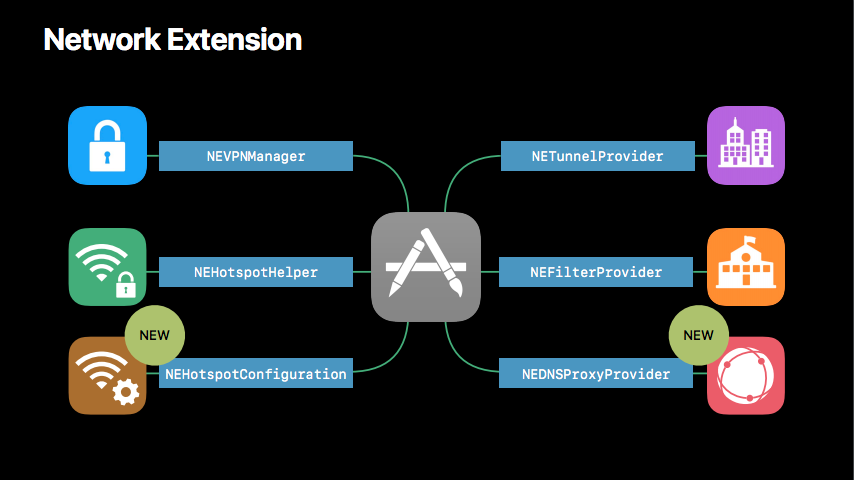
 |
 |
|---|
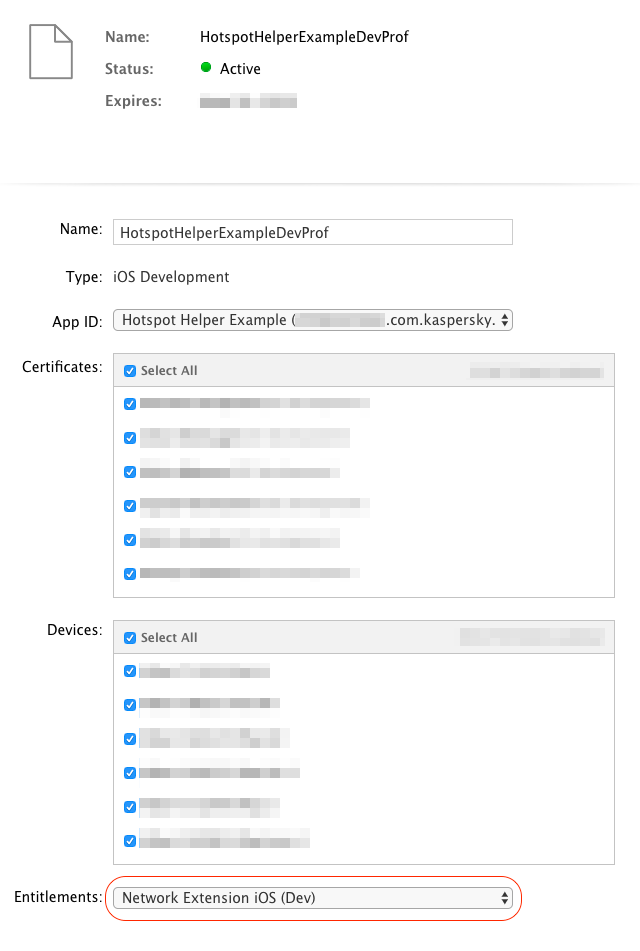
class NEHotspotHelper
class func register(options: [String : NSObject]? = nil, queue: DispatchQueue,
handler: @escaping NetworkExtension.NEHotspotHelperHandler) -> Bool
typealias NEHotspotHelperHandler = (NEHotspotHelperCommand) -> Void
func createResponse(_ result: NEHotspotHelperResult) -> NEHotspotHelperResponse func createTCPConnection(_ endpoint: NWEndpoint) -> NWTCPConnection
func createUDPSession(_ endpoint: NWEndpoint) -> NWUDPSession func bind(to command: NEHotspotHelperCommand)var networkList: [NEHotspotNetwork]? { get }let network =
network.setPassword("PASSWORD")
let response = command.createResponse(.success)
response.setNetworkList([network])
response.deliver() |
 |
|---|
var network: NEHotspotNetwork? { get }// Идентифицируют сеть
var ssid: String { get }
var bssid: String { get }
// Отражают силу сигнала по шкале от 0.0 до 1.0 (дБ, увы, не предоставляются)
var signalStrength: Double { get }
// Признак необходимости ввода пароля для подключения к сети
var isSecure: Bool { get }
// Признак, показывающий, было ли подключение выполнено автоматически
// или пользователь явно выбрал эту сеть в настройках
var didAutoJoin: Bool { get }
// Helper уверен, что не обрабатывает эту сеть.
case none
// Helper предполагает, что сможет обработать подключение к этой сети, но не уверен полностью*.
case low
// Helper уверен, что может полноценно обработать подключение к этой сети.
case highlet network = command.network
// Оценить сеть и определить уровень confidence...
network.setConfidence()
let response = command.createResponse(.success)
response.setNetwork(network)
response.deliver() var network: NEHotspotNetwork? { get }let network = command.network
// Авторизовать пользователя необходимым образом и сформировать результат обработки команды
// Вывести UILocalNotification в случае необходимости дополнительного взаимодействия (.uiRequired)
command.createResponse().deliver() let network = command.network
// Произвести любые необходимые действия для авторизации пользователя любыми средствами
// за неограниченные период времени и сформировать результат выполнения команды
command.createResponse().deliver() let network = command.network
if network.didJustJoin {
// Новое подключение к сети, для обработки которой выбран данный Helper
}
else {
// Поддержка сессии в сети, в которой была произведена авторизация (раз в 300 сек.)
}
// Обеспечить авторизацию пользователя в сети любым способом
// и сформировать результат обработки команды
command.createResponse().deliver() class func logoff(_ network: NEHotspotNetwork) -> Boollet network = NEHotspotHelper.supportedNetworkInterfaces().first let network = command.network
// Произвести logoff и сбросить внутренние данные сессии авторизации
let response = command.createResponse(.success).deliver()let network = NEHotspotHelper.supportedNetworkInterfaces().first
let network = NEHotspotHelper.supportedNetworkInterfaces().first
if !network.isChosenHelper {
// Hotspot Helper не обрабатывает активную сеть
}func createTCPConnection(_ endpoint: NWEndpoint) -> NWTCPConnection
func createUDPSession(_ endpoint: NWEndpoint) -> NWUDPSessionfunc bind(to command: NEHotspotHelperCommand)|
Метки: author AndreyGusev разработка под ios блог компании «лаборатория касперского» ios development wi-fi |
[Из песочницы] Оптимизация шаблонов представления в Codeigniter Framework при помощи AST трансформаций |
В последнее время, я работал с порталом, посещаемостью около 100 тысяч человек в месяц написанном на Codeigniter. Все бы ничего, но любая страница этого портала отдавалась сервером не меньше 3 секунд. При этом, железо уже не было куда расширять а об архитектуре приложения говорить не будем. Мне нужно было найти решение которое помогло бы сократить время ответа приложения с наименьшими изменениями кода.
Codeigniter — прекрасный фреймворк для веб-приложений, спору нет.
Он легок, гибок, и очень прост в обучении.
Но есть несколько проблем. Одной из которых является отсутствие обработчика для представлений. В качестве шаблонизатора используется чистый php (с мелкими вставками Codeigniter).
Многие скажут, что это не проблема, а преимущество — отсутствие предварительной обработки перед выводом на страницу может значительно уменьшить время ответа от приложения, особенно если шаблонизатор тоже написан на php а не в виде с-расширения.
На самом деле большой плюс шаблонизаторов в том — что они могут компилировать шаблоны и кэшировать их на диске для последующего минования процесса их обработки. То есть, если шаблоны меняются не часто, при использовании шаблонизатора мы получаем как минимум один плюс — удобство. Если шаблонов много — тогда сюда добавиться еще кэширование. Не знаю как другие разработчики, но я предпочитаю использовать шаблонизатор когда это возможно.
Когда вы используете Codeigniter для небольшого проекта то, скорее всего никаких проблем с шаблонами не будет заметно. Но когда ваш проект разрастается до сотен шаблонов — вы будете страдать от медленной компоновки шаблонов.
Так было и в моем случае — количество файлов шаблонов подключаемых при загрузке страницы достигало 50 (информация от встроенной функции get_included_files).
Страница, которую я выбрал для опыта имеет следующий вид и является наиболее загруженой на сайте:

На странице выводиться список из 30 элементов — ресторанов и разного рода информации о них, каждый из которых, в свою очередь, компонируется из +- 35 шаблонов. Так как в качестве шаблонизатора используется php и больше ничего то никакого кеширования там нет. В итоге, нам нужно скомпонировать около 900 шаблонов.
Перед работой с шаблонами, я смог, при помощи минимальных оптимизаций кода, сократить время вывода страницы на 1 секунду (30%) до +-2 секунд:
Loading Time: Base Classes 0.0274
Controller Execution Time 1.9403
Total Execution Time 1.9687Это было все еще слишком много
Понятное дело, что компоновка около 900 шаблонов дело затратное, тем более на php.
Поэтому, нужно было "склеить" все эти шаблоны в один, чтобы не делать это каждый раз когда запрашивается страница.
Использование готового шаблонизатора типа twig или smarty отпали сразу, так как пришлось бы переписывать все контроллеры, и шаблоны а их очень много.
В то время я уже был немного знаком с AST деревьями.
Шаблоны представляли что-то в следующем виде:
...
...Конструкция
$this->load->view(string $templatePath,array $params)делает "include" с передачей дополнительных параметров $params
Суть задачи была в том, чтобы заменить все такие вызовы на содержимое самих шаблонов и передачу в них параметров inline. Рекурсивно.
Интересно, подумал я и взялся за инструменты которых нашлось аж один: Nikic PHP-Parser. Это очень мощный инструмент который позволяет делать разного рода манипуляции над абстрактным синтаксическим деревом вашего кода и потом сохранять измененное дерево обратно в php код. И все это можно делать в самом же php — парсер не имеет каких-либо зависимостей от с-расширений и может работать на php 5.2+.
PHP-Parser предоставляет удобные инструменты для работой с AST: интерфейсы NodeVisitor и NodeTraverser при помощи которых мы и будем сооружать наш оптимизатор.
Главное — это найти все вызовы метода view на свойстве класса load и понять, что за шаблон должен быть загружен. Это можно проделать с помощью NodeVisitor. Нас интересует его метод leaveNode(Node $node) который будет вызван когда NodeTraverser будет "уходить" с узла дерева AST:
class MyNodeVisitor extends NodeVisitorAbstract {
public function leaveNode(Node $node) {
// если тип узла - вызов метода то обрабатываем его
if ($node instanceof Node\Expr\MethodCall) {
// проверяем, вызов ли это нужного нам метода
if ($node->name == 'view') {
// тут также нужно проверить на чем этот метод вызывается
// возможно это не функционал Codeigniter'a, тогда у нас будет ошибка
// я это проигнорировал :)
// мы должны проверить, сможем ли мы узнать какой шаблон подключается.
// если параметр - скалярная строка, тогда без проблем
// можно достать информацию и с других типов, но это сложнее и мы это пропустим
if ($node->args[0]->value instanceof \PhpParser\Node\Scalar\String_) {
// дадим методу уникальное имя, чтобы потом можно было правильно обработать
$code = md5(mt_rand(0, 7219832) . microtime(true));
$node->name = 'to_be_changed_' . $code;
$params = null;
// сохраним параметры, которые нам нужно будет передать `inline`
if (count($node->args) > 1) {
if ($node->args[1]->value instanceof Node\Expr\Array_) {
$params = new Node\Expr\Array_($node->args[1]->value->items, [
'kind' => Node\Expr\Array_::KIND_SHORT,
]);
} else {
if ($node->args[1]->value->name != 'this') {
$params = $node->args[1]->value;
}
}
}
// сохраним место, где мы должны будем заменить шаблон
// замена происходит в другом прогоне по коду
$this->nodesToSubstitute[] = new TemplateReference($this->nodeIndex, $node->args[0]->value->value, $params, $code);
}
}
...Таким образом мы сможем выделить все элементы которые должны заменить. Также можно сделать замену и любых других элементов: явных require, include и т.д.
Не забываем что замену нужно делать рекурсивно вглубь. Для этого, нужно сделать обертку над PHP-Parser где именно и будет происходить замена на внутренности шаблона:
class CodeigniterTemplateOptimizer {
private $optimizedFiles = [];
private $parser;
private $traverser;
private $prettyPrinter;
private $factory;
private $myVisitor;
private $templatesFolder = '';
public function __construct(string $templatesFolder) {
$this->parser = (new ParserFactory)->create(ParserFactory::PREFER_PHP5);
$this->traverser = new MyNodeTraverser();
$this->prettyPrinter = new PrettyPrinter\Standard();
$this->factory = new BuilderFactory();
$this->templatesFolder = $templatesFolder;
$this->myVisitor = new MyNodeVisitor();
$this->traverser->addVisitor($this->myVisitor);
}
public function optimizeTemplate(string $relativePath, $depth = 0, $keepOptimizing = true) {
if (substr($relativePath, -4, 4) !== '.php') {
$relativePath .= '.php';
}
if (!isset($this->optimizedFiles[$relativePath])) {
$templatePath = $this->templatesFolder . $relativePath;
if (file_exists($templatePath)) {
$templateOffset = 0;
$notOptimized = file_get_contents($templatePath);
// читаем код в AST
$stmts = $this->parser->parse($notOptimized);
if ($keepOptimizing) {
$this->myVisitor->clean();
$this->traverser->setCurrentWorkingFile($relativePath);
// здесь мы обходим наше AST
$stmts = $this->traverser->traverse($stmts);
// Получаем список элементов к замене от MyNodeVisitor
$inlineTemplateReference = $this->myVisitor->getNodesToSubstitute();
++$depth;
$stmsBefore = count($stmts);
foreach ($inlineTemplateReference as $ref) {
// погружаемся глубже - рекурсивно обрабатываем шаблоны вглубь
$nestedTemplateStatements = $this->optimizeTemplate($ref->relativePath, $depth);
$subtempalteLength = count($nestedTemplateStatements);
$insertOffset = $ref->nodeIndex + $templateOffset;
$pp = new PrettyPrinter\Standard();
// вставляем параметры для шаблона `inline`: при помощи конструкции `extract`
if ($ref->paramsNodes) {
array_unshift($nestedTemplateStatements, new Node\Expr\FuncCall(new Node\Name('extract'), [$ref->paramsNodes]));
}
// мы нашли то место, где должны вставить содержание шаблона
if (get_class($stmts[$insertOffset]) === 'PhpParser\Node\Expr\MethodCall' && ($stmts[$insertOffset]->name === "to_be_changed_" . $ref->code)) {
// чтобы не "ламать" набор стейтментов родительского AST
// вставляем шаблон в if(1), чтобы он выглядел как один элемент
$stmts[$insertOffset] = new Node\Stmt\If_(new Node\Scalar\LNumber(1), [
'stmts' => $nestedTemplateStatements
]);
} else {
// этот кусок кода намеренно вырезан, здесь вложенная обработка ast
}
}
}
// записываем в кеш "оптимизированных" шаблонов.
// В этот момент уже все вложенные шаблоны оптимизированы
$this->optimizedFiles[$relativePath] = $stmts;
} else {
throw new Exception("File not exists `" . $templatePath . "` when optimizing templates");
}
}
// возвращаем оптимизированный шаблон
return $this->optimizedFiles[$relativePath];
}
public function writeToFile(string $filePath, $nodes) {
$code = $this->prettyPrinter->prettyPrintFile($nodes);
// create directories in a path if they not exists
if (!is_dir(dirname($filePath))) {
mkdir(dirname($filePath), 0755, true);
}
// write to file
file_put_contents($filePath, $code);
}
} Вот и все, запускаем оптимизатор:
// создаем объект оптимизатора с параметром - путем к шаблонам
$optimizer = new CodeigniterTemplateOptimizer('./views/');
// сохраняем оптимизированный шаблон куда нужно
$optimizer->writeToFile($to, $optimizer->optimizeTemplate($from));При помощи DirectoryIterator можно за две минуты соорудить скрипт который будет оптимизировать всю папку шаблонов.
После замены шаблонов на оптимизированные, мне удалось сократить более чем 1с времени на выполнение, результаты профайлера Codeigniter:
Loading Time: Base Classes 0.0229
Controller Execution Time 0.7975
Total Execution Time 0.8215При помощи оптимизации шаблонов мне удалось сократить больше времени чем при оптимизации php-кода. Затраты на оптимизацию шаблонов несопоставимы с изменением многих строк кода. Также оптимизация шаблонов никаким образом не изменяет поведение приложения (это ж ведь просто "склеивание") что есть очень положительным фактом.
Фрагменты кода приведенные в статье были адаптированы для наведения общих моментов которые помогут вам разобраться и не претендуют на работоспособность.
|
Метки: author dot5enko компиляторы php codeigniter шаблонизатор ast парсер |
Сначала они воруют, а когда ты побеждаешь, то тебя убивают |
Люди обращают внимание на проблемы образования лишь в конце, когда их решать уже невозможно.



|
Метки: author InkOut разработка мобильных приложений дит емп коррупция |
[Из песочницы] Пишем и собираем приложения для Android в linux консоли |

В данной статье я покажу как можно собрать apk файл в Ubuntu используя лишь
утилиты командной строки.
Обычно для создания приложений для Adroid используется Android Studio.
Но для сборки небольших программ можно обойтись командной строкой.
Например, когда ресурсы компьютера ограничены и ваше приложение очень простое.
В качестве постоянной среды разработки это, возможно, не очень удобно, но если вам нужно
иногда собирать какие-нибудь мелкие утилиты — это в самый раз.
Разработка под Android не является основным направлением моей деятельности,
я иногда делаю какие-то небольшие приложения для своих нужд.
Раньше я использовал QPython, но он достаточно тяжел и неудобен в работе.
Поэтому я перешел к разработке нативных программ. Даже при поверхностном знании Java
это не составляет больших трудностей.
Данное руководство в большой степени базируется на этом документе. Кому интересны подробности, обращайтесь к первоисточнику.
Похожая статья уже встречалась на этом ресурсе, но в ней было рассмотрена разработка в Windows.
Здесь же я рассмотрю, как можно собрать приложение в linux.
Тестирование проводилось на стареньком нетбуке с процессором Атом, 1Гб ОЗУ
и 8Гб SSD диска.
Я тестировал приложение на Ubuntu 17.04.
Начиная с Ubunu 16.04 android-sdk можно установить через пакетный менеджер.
В принципе, тот же SDK можно
скачать с сайта.
Качать файл из раздела 'Get just the command line tools'
По сути это не сильно меняет процесс, но через пакетный менеджер все гораздо проще.
Разница будет лишь в путях и установке дополнительных пакетов "android-platform".
Итак, приступим к установке.
sudo apt install android-sdkБудет установлено большое количество пакетов, включая Java.
Далее, в зависимости от требуемой версии Android, необходимо установить нужную
версию пакетов. Для lolipop 5.1 необходимо ставить:
sudo apt install google-android-platform-22-installer
sudo apt install google-android-build-tools-22-installerТак же необходимо установить дополнительный пакет.
sudo apt install apksignerЕсли вы планируете устанавливать apk-пакет через adb, то необходимо немного дополнительных настроек.
С помощью lsusb найти подключенное устройство
# lsusb
....
Bus 001 Device 004: ID 1782:75b0 MyDevice
....И создать файл с правилом:
sudo vi /etc/udev/rules.d/51-android.rulesВ файл добавить одну строку:
SUBSYSTEM=="usb", ATTR{idVendor}=="1782", MODE="0666", GROUP="plugdev"Здесь "1782" взято из вывода lsusb.
Перезапускаем сервис
sudo systemctl restart udevПосле подключения через adb, на устройстве необходимо подтвердить соединение.
Теперь все готово к работе.
Приложение, которое будем собирать немного сложнее, чем 'Hello world'.
В общем-то все просто.
Я подготовил пример который возьмем за основу.
Сначала создадим ключ для подписи файла:
keytool -genkeypair -keystore keystore.jks -alias androidkey \
-validity 10000 -keyalg RSA -keysize 2048 \
-storepass android -keypass androidЭто нам пригодится позже.
Здесь указываем имя приложения в атрибуте "android:label".
Так же приложение будет использоваться свою иконку, она указана в атрибуте "android:icon"
Сама иконка лежит в каталоге "res/drawable-mdpi" файл "icon.png". В качестве иконки можно взять любой небольшой png файл.
Файл с расположением элементов находится в каталоге "/res/layout/".
В него можно добавлять виджеты, если вы захотите расширить функционал.
Исходный код приложения находится здесь "java/ru/kx13/extractvidid"
package ru.kx13.extractvidid;
import android.app.Activity;
import android.os.Bundle;
import android.widget.TextView;
import android.widget.Button;
import android.widget.Toast;
import android.view.View;
import android.content.ClipboardManager;
import android.content.ClipData;
public class MainActivity extends Activity {
private static String extract(String s) {
int start = s.indexOf("%3D");
int end = s.indexOf("%26");
if(start == -1 || end == -1) {
return "error";
}
return s.substring(start + 3, end);
}
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
TextView text = (TextView)findViewById(R.id.my_text);
text.setText("Извлечь youtube video id");
Button button = (Button) findViewById(R.id.button_id);
button.setOnClickListener(new View.OnClickListener() {
public void onClick(View v) {
ClipboardManager myClipboard = (ClipboardManager) getSystemService(CLIPBOARD_SERVICE);
ClipData abc = myClipboard.getPrimaryClip();
ClipData.Item item = abc.getItemAt(0);
String text = item.getText().toString();
String video_id = MainActivity.extract(text);
ClipData myClip = ClipData.newPlainText("text", video_id);
myClipboard.setPrimaryClip(myClip);
Toast toast = Toast.makeText(getApplicationContext(),
video_id, Toast.LENGTH_SHORT);
toast.show();
}
});
}
}Код весьма прост и примитивен, но этот шаблон можно использовать в других приложениях.
Я не стал использовать утилит сборки типа make или ant, т.к. весь код
находится в одном файле и особых преимуществ это не даст.
Поэтому это обычный shell скрипт:
#!/bin/sh
SOURCE=ru/kx13/extractvidid
BASE=/usr/lib
SDK="${BASE}/android-sdk"
BUILD_TOOLS="${SDK}/build-tools/22.0.1"
PLATFORM="${SDK}/platforms/android-22"
mkdir -p build/gen build/obj build/apk
"${BUILD_TOOLS}/aapt" package -f -m -J build/gen/ -S res -M AndroidManifest.xml -I "${PLATFORM}/android.jar"
javac -source 1.7 -target 1.7 -bootclasspath "${JAVA_HOME}/jre/lib/rt.jar" \
-classpath "${PLATFORM}/android.jar" -d build/obj \
build/gen/${SOURCE}/R.java java/${SOURCE}/MainActivity.java
"${BUILD_TOOLS}/dx" --dex --output=build/apk/classes.dex build/obj/
"${BUILD_TOOLS}/aapt" package -f -M AndroidManifest.xml -S res/ -I "${PLATFORM}/android.jar" \
-F build/Extractor.unsigned.apk build/apk/
"${BUILD_TOOLS}/zipalign" -f 4 build/Extractor.unsigned.apk build/Extractor.aligned.apk
apksigner sign --ks keystore.jks \
--ks-key-alias androidkey --ks-pass pass:android \
--key-pass pass:android --out build/Extractor.apk \
build/Extractor.aligned.apkНекоторые замечания по поводу путей.
Для сборки просто запустите
./build.shЕсли все настроено правильно никаких сообщений не будет выведено, а в каталоге "build" появится файл "Extractor.apk"
Теперь надо установить наше приложение
adb install -r build/Extractor.apkЕсли все прошло нормально, на устройстве появится новое приложение.
Можно запускать и пользоваться.
В общем случае можно перекинуть файл apk на устройство любым удобным способом.
Как видно из статьи начать разработку в консоли совсем несложно.
Консольные утилиты позволяют разрабатывать программы при весьма небольших ресурсах.
Приятной разработки!
|
Метки: author kx13 разработка под android android sdk linux command line |
PGHACK. Соревнование в офисе Avito 2 сентября |

|
Метки: author pkorobeinikov администрирование баз данных блог компании avito pghack postgres postgresql соревнование avito |
Предупреждён — значит, интеллектуальный обзвон |
 Клиент что-то заказал и ждёт, когда ему это привезут? День доставки заранее согласован? Значит, курьер может выезжать? Увы, нет. Рейд курьера может быть бессмыслен и бесполезен, потому что клиент… только что вышел в магазин, застрял в пробке, сидит на совещании, заснул, ушел с ребенком на детскую площадку – и ещё 1000 и одна причина, почему не сейчас. Как плохой футболист, которому внезапно дали пас. И, чтобы передача состоялась, надо как-то проверить, удобно ли клиенту, и не будет ли курьер мотаться почём зря. В компания СДЭК задумались, как это сделать, и при помощи Voximplant нашли для себя оптимальное решение, о котором – под катом.
Клиент что-то заказал и ждёт, когда ему это привезут? День доставки заранее согласован? Значит, курьер может выезжать? Увы, нет. Рейд курьера может быть бессмыслен и бесполезен, потому что клиент… только что вышел в магазин, застрял в пробке, сидит на совещании, заснул, ушел с ребенком на детскую площадку – и ещё 1000 и одна причина, почему не сейчас. Как плохой футболист, которому внезапно дали пас. И, чтобы передача состоялась, надо как-то проверить, удобно ли клиенту, и не будет ли курьер мотаться почём зря. В компания СДЭК задумались, как это сделать, и при помощи Voximplant нашли для себя оптимальное решение, о котором – под катом.|
Метки: author southpole разработка мобильных приложений разработка веб-сайтов программирование javascript блог компании voximplant automatization |
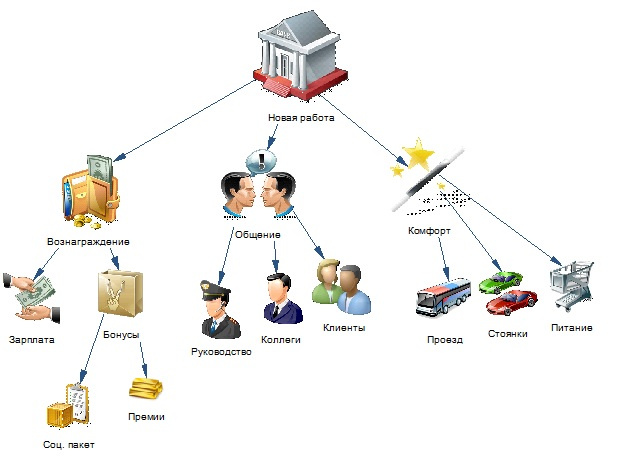
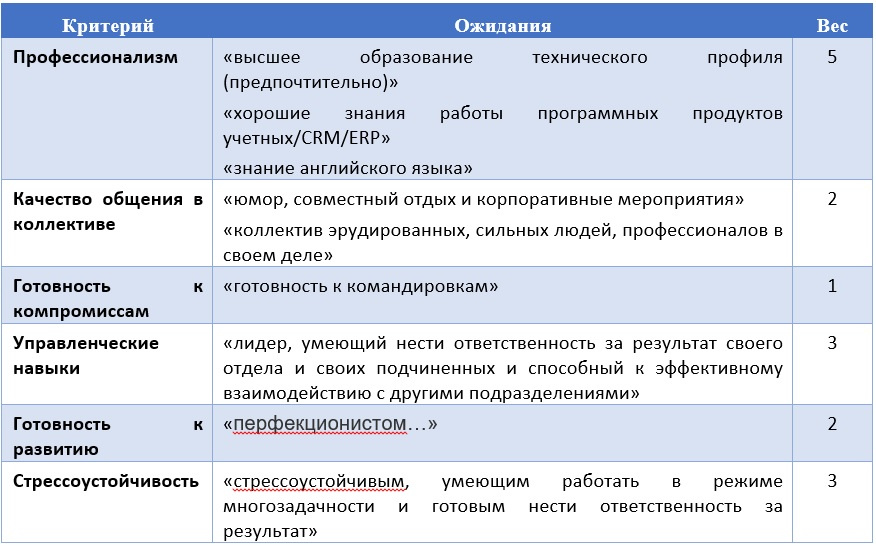
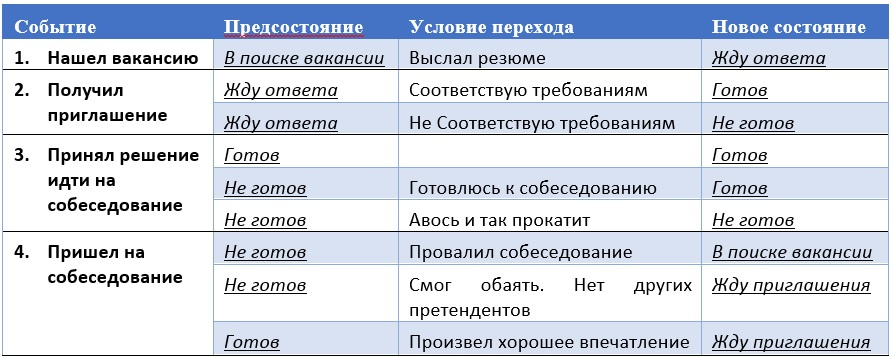
ГДЕ ЛОГИКА? Учимся мыслить системно. Часть 3 |


|
Метки: author ARadzishevskiy читальный зал учебный процесс в it системный анализ управление требованиями формализация проблем |
Хакатон «Budget-Pro»: первый шаг к победе в конкурсе |

|
|
[Перевод] Вышел GitLab 9.4: Связанные задачи и веб-мониторинг приложений |

В GitLab 9.4 мы представляем связанные задачи, веб-мониторинг приложений, обновленную навигацию, групповые майлстоуны и многое другое!
Сложно кого-то удивить, когда работаешь открыто. Но такой подход позволяет нам рассказать о причинах наших нововведений, а также объяснить, как они позволят в будущем сделать GitLab еще лучше.
В GitLab 9.4 помимо добавления новой функциональности также закладываются основы многих будущих нововведений. Теперь вы официально можете связывать задачи друг с другом, серьезно расширена функциональность переменных в CI, а система мониторинга без дополнительных настроек анализирует гораздо больше метрик.
Более того, мы даем вам возможность заглянуть в будущее с помощью опциональной бета-версии новой системы навигации. Мы надеемся, что совместная работа с пользователями поможет нам сделать улучшения, которые понравятся всем.
Вдобавок к этому, мы добавляем простую и понятную интеграцию с Trello при помощи GitLab PowerUp для Trello.
Также, продолжая разговор об интеграции, в версию 9.4 входит новое приложение Slack для GitLab.
А если одного беглого взгляда недостаточно, мы проводим работу по внедрению полной автоматизации настройки инструментария DevOps при помощи Auto DevOps. Данная функциональность проводит полный анализ вашего приложения и автоматически настраивает его сборку, тестирование и развертывание в Kubernetes. Посмотреть за ходом работ можно на обзорной странице Auto DevOps.

Matt добавил поддержку учетных данных профиля EC2 при использовании кластеров elasticsearch AWS; ранее можно было использовать только статические данные IAM. Это сложная работа, которая значительно улучшает интеграцию GitLab с elasticsearch. Благодаря этим нововведениям, некоторые аспекты нашего Улучшенного глобального поиска настраиваются автоматически, когда GitLab запущен на AWS.
Matt также работал над изначальной имплементацией AWS. Спасибо, Matt!
При добавлении ссылки на одну задачу из другой GitLab автоматически сокращает ее и создает перекрестную ссылку. Но, по мере того, как задачи разрастаются, а проекты становятся все более сложными, становится сложнее отслеживать ссылки и быстро находить нужные задачи.
Для решения этой проблемы мы вводим функциональность связанных задач. Теперь вы можете объявить задачи связанными между собой, после чего в описании каждой задачи будут отображаться ссылка на другую, а также ее статус и название.
Для создания такой связи просто добавьте ссылку на задачу, которую вы хотите связать с текущей или найдите ее в поиске, введя # (так можно было сделать и раньше). В дальнейшем мы планируем добавлять и другие типы взаимоотношений между задачами с использованием этого механизма.

Больше информации о связанных задачах в нашей документации
Мы стремимся сделать работу с GitLab как можно проще и быстрее, поэтому мы работаем над обновлениями навигации. Поскольку изменения в навигации поначалу могут сбивать с толку, мы выпускаем первый этап обновлений как опциональную конфигурацию GitLab 9.4.
Для ее включения нажмите на иконку вашего профиля в правом верхнем углу экрана и выберите вариант Turn on new navigation.
Мы внесли изменения в глобальную навигацию в верхней части экрана, а также ввели контекстную навигацию в левом меню — его содержимое зависит от того, на какой странице вы находитесь. По прежнему продолжаются работы над новым интерфейсом; он окончательно заменит текущий вариант навигации в ближайшие несколько месяцев. Информация о процессе его разработки, а также о том, что еще предстоит сделать, находится в этом посте.
Будем рады обратной связи.
Больше информации об обновлениях навигации в [нашей документации]

В GitLab 9.0 мы выпустили систему мониторинга производительности, интегрированную с развертыванием CI/CD, занимающуюся сбором статистики (использование процессора и памяти) развернутых на Kubernetes приложений. Это был успешный первый шаг, и теперь мы запускаем веб-мониторинг приложений, поддерживающий уже не только Kubernetes.
Теперь GitLab автоматически отслеживает ключевые индикаторы, влияющие на опыт работы с системой, такие как пропускная способность, частота ошибок и задержка. Просто подключите Prometheus к одному из поддерживаемых распределителей нагрузки или HTTP серверов, и отслеживание статистики начнется автоматически.
Очень важно, чтобы работа с системой была простой и интуитивной. Теперь GitLab стал еще ближе к этому, благодаря включению обратной связи о производительности в инструмент, которым разработчики пользуются каждый день.
Больше информации о веб-мониторинге приложений в нашей документации

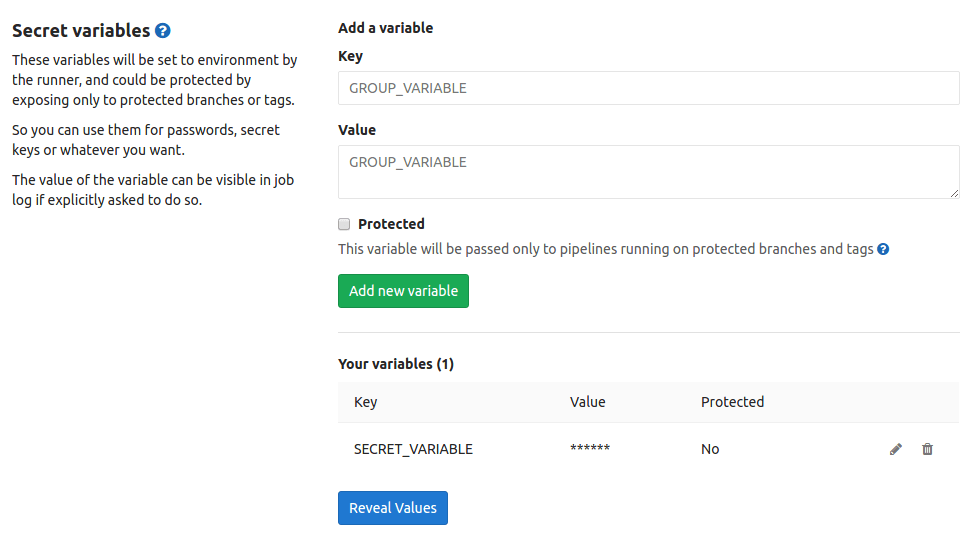
Секретные переменные очень полезны в ситуациях, когда вам требуется место для безопасного хранения важной информации. До сих пор секретные переменные хранились на уровне проекта. Однако, мы знаем, что различные проекты в одной группе часто хранят общую информацию о развертывании, а также учетные данные для доступа к внешним сервисам.
Благодаря введению секретных переменных группового уровня исчезает необходимость дублирования переменных между проектами: теперь достаточно ввести данные один раз, и у каждого проекта или подгруппы в группе автоматически откроется доступ к ним. Также эти данные легко обновлять: просто измените их в одном месте, и они автоматически обновятся для всех проектов.
Больше информации о секретных переменных группового уровня в нашей документации
В GitLab 9.2 мы добавили расписания конвейеров, благодаря которым можно настроить автоматический запуск конвейеров через определенные временные интервалы. Вдобавок к этому множество команд хотят иметь возможность задавать значения определенным переменным при выполнении расписания.
В GitLab 9.4 мы добавляем возможность определять переменные при создании или изменении расписания конвейеров: эти значения будут добавлены ко всем уже определенным переменным. При помощи этой функциональности вы также можете переопределять уже существующие переменные для какого-либо определенного запуска, например, можно изменить на один день выполнение тестов определенным конвейером.
Больше информации о переменных в расписаниях конвейеров в нашей документации
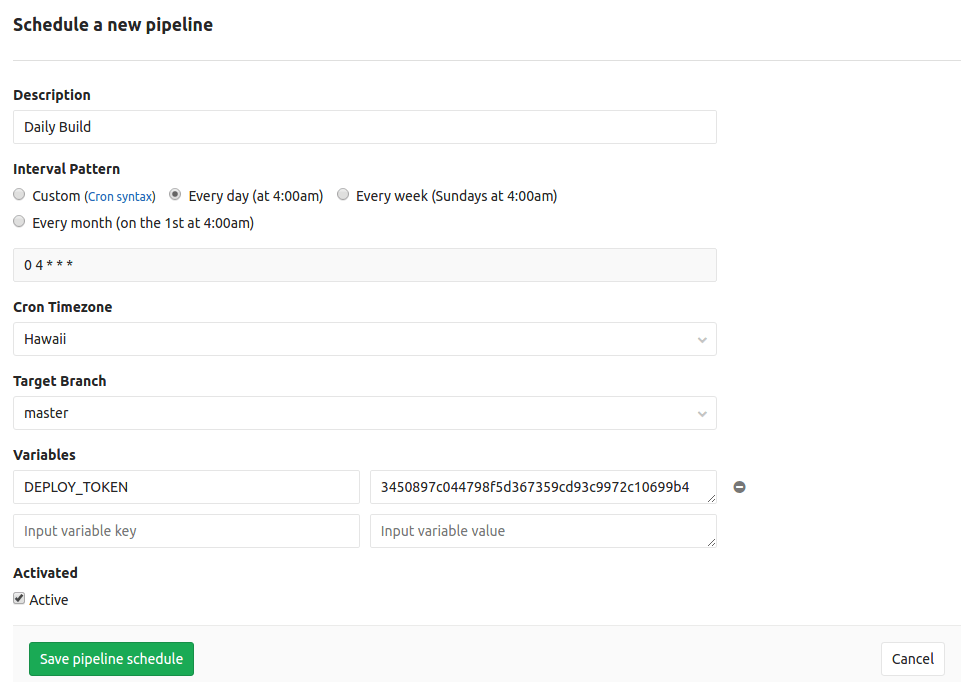
Использование переменных для определения значений, используемых при развертывании на определенные конкретные среды зачастую является правильным решением. Поскольку для разных сред (например, staging и production) могут потребоваться различные значения переменных для выполнения одного и того же задания (например, название приложения), важно создать прямую связь между некоторыми переменными и соответствующей средой.
В GitLab 9.4 для решения этой задачи добавлены секретные переменные для сред; теперь разработчики могут уточнять, какие среды получат определенную переменную. Можно даже включать динамические среды, к примеру, review/. Так что теперь можно с легкостью проводить развертывание на различные среды.
Больше информации о секретных переменных для сред в нашей документации

Пользуетесь одновременно Trello и GitLab? Теперь это стало еще проще благодаря новому GitLab Power-Up! Для его подключения в Trello перейдите в раздел Power-Ups и найдите Power-Up GitLab. После настройки вы сможете прикреплять мерж-реквесты GitLab прямо к карточкам Trello.
В Trello вам понадобится настроить ваш домен, например gitlab.com/api/v4 для GitLab.com, а также добавить ваш персональный токен.
Больше информации о GitLab Power-Up для Trello в нашей документации

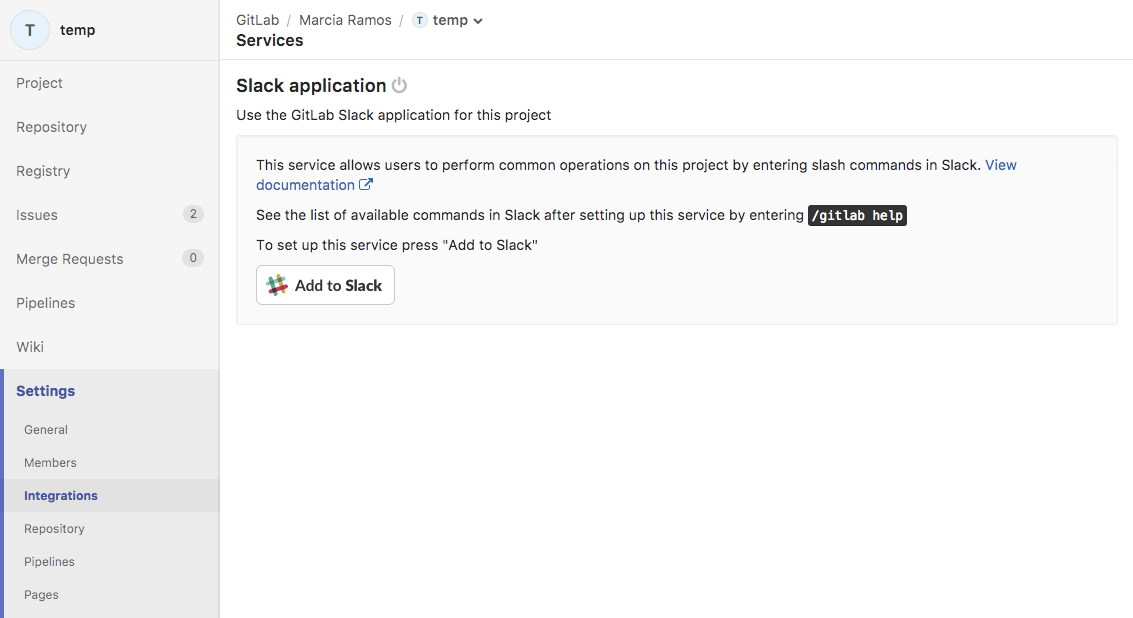
GitLab уже глубоко связан с Slack (и Mattermost, Microsoft Teams и HipChat), но у нас до сих пор не было приложения в директории приложения Slack. Теперь оно у нас есть! Интегрировать Slack в ваши проекты на GitLab.com стало гораздо проще.
Вы можете настроить интеграцию с приложением из настроек проекта в GitLab (Settings > Integrations). Скоро это также будет доступно из директории самого Slack. Вместе с Slack мы работаем над тем, чтобы убедиться, что приватные инстансы будут способны использовать одно и то же приложение Slack в ближайшем будущем. И, конечно, приватные инстансы можно интегрировать с Slack вручную по шагам, описанным в документации.
Подробнее в документации о приложении GitLab Slack для GitLab.com
Мы постепенно ускоряемся с локализацией GitLab. Большое спасибо участникам нашего комьюнити, которые посодействовали в добавлении дополнительных языков — китайского, французского, японского и бразильского португальского. Огромное спасибо Huang Tao за постоянный вклад в это дело!
В GitLab 9.4 мы добавили локализацию поддержки для страницы коммитов.
Подробнее о локализации в нашем гайде
Майлстоуны — одна из основных частей отслеживания задач. Их часто используют, чтобы отмечать спринты (35 неделя), релизы (версия 9.4) или категорию (бэклог) задач и мерж-реквестов. Часто майлстоуны охватывают несколько проектов: у вас есть возможность быстро создавать майлстоуны для нескольких проектов сразу. Теперь еще лучше: мы добавили возможность создавать групповые майлстоуны.
Групповые майлстоуны ведут себя точно так же, как и их двойники — проектные майлстоуны, но создаются в группе и оттуда доступны для всех проектов, прямо принадлежащих этому (родительскому) проекту.
Чтобы создать групповой майлстоун, перейдите в вашу группу, нажмите Issues, а потомMilestones.
Читайте подробнее в документации о групповых майлстоунах
Важные изменения:
Компании продолжают внедрять CI/CD по всей организации, и их хранилища артефактов тоже растут. В GitLab 9.4 вы сможете перемещать существующие артефакты CI в Amazon S3, чтобы освободить дополнительное локальное пространство и эффективно и надежно сохранять сколько угодно артефактов. Сейчас эту операцию нужно проводить каждый раз, когда вы захотите переместить ваши локальные артефакты в S3, но в следующей итерации это будет происходить автоматически, и все новые артефакты будут сохраняться в хранилище объектов сразу после их создания — никаких миграций вручную.
Подробности в документации об артефактах CI
В GitLab 9.4 появились новые улучшенные опции настройки для .gitlab-ci.yml. Они дают более гибко настраивать образы Docker, которые вы хотите использовать для ваших конвейеров. Чтобы воспользоваться этими возможностями, вам потребуется версия GitLab Runner 9.4 или выше.
Теперь вы сможете определить для вашего образа Docker специальную точку входа (entrypoint), чтобы переопределить ту, которая используется по умолчанию. Ниже приведен пример настройки точки входа для /bin/sh — это сделает образ подходящим для работ GitLab CI без дополнительных модификаций:
image:
name: super/sql:experimental
entrypoint: ["/bin/sh"]Также вы можете определять алиасы для сервисов, чтобы запускать несколько параллельных инстансов одного и того же образа Docker, и определять команды прямо в конфигурационном файле.
services:
- name: super/sql:latest
command: ["/usr/bin/super-sql", "run"]
alias: super-sql-1
- name: super/sql:latest
alias: super-sql-2Подробности об изменении в документации о расширенной настройке Docker
Мы добавили поддержку верификации сертификата LDAP через SSL. По умолчанию эта опция будет отключена, чтобы обеспечить обратную совместимость до выхода GitLab 9.5. Кроме того, чтобы упростить настройку безопасного соединения, вы теперь можете определить файл сертификата CA и версию SSL. Названия способов шифрования ssl и tls превратились в simple_tls и start_tls соответственно.
Читайте документацию по LDAP
GitLab определяет настройки CI/CD в YAML файле .gitlab-ci.yml, расположенном в корне репозитория. Бывают случаи, когда вам нужно определить другую локацию для определения ваших конвейеров — например, когда вы зеркалируете SVN репозиторий и не можете хранить файлы в корне проекта.
Начиная с версии GitLab 9.4, вы сможете определять специальный путь в Settings > Pipelines, по которому будут считываться настройки CI/CD — вместо .gitlab-ci.yml по умолчанию. Переменная под названием $CI_CONFIG_PATH доступна для работ, которым нужен доступ к текущей локации настроек.
Читайте подробности в документации о GitLab CI/CD
По умолчанию процесс кэширования заключается в скачивании файлов, их выполнении и повторной загрузки в конце. Любые изменения в рамках этого процесса будут сохраняться для следующих запусков. Это называется политикой кэширования pull-push.
Шаг кэширования по умолчанию состоит из восстановления и архивации зависимостей ваших работ, что позволяет ускорить последующий запуск. Если в кэшированный контент внесут какое-то изменение, оно по умолчанию запишется на сервер кэширования — это тоже политика кэширования pull-push.
Если вам не нужно обновлять кэшированные файлы в определенной работе, вы можете пропустить шаг загрузки, выставив policy: pull в настройках работы. А если у вас есть работа, которая всегда воссоздает кэш без обращения к предыдущему содержанию, вы можете использовать policy: push, чтобы избежать излишней нагрузки на сервер кэширования. Для этой функциональности потребуется GitLab Runner версии 9.4 или выше.
Читайте документацию о GitLab CI/CD
Начиная со следующего релиза 22 августа мы будем подписывать все новые пакеты. Наряду с подписанным пакетом 9.5.0 мы также будем предоставлять подписанные версии двух последних релизов (9.4 и 9.3).
Подписание пакетов добавляет уверенности в том, что файлы .deb и .rpm, необходимые для установки GitLab, не были кем-либо изменены.
Также в этом релизе мы выпустили GitLab Runner 9.4.
.gitlab-ci.yml (мерж-реквест).gitlab-ci.yml (мерж-реквест)unregister добавилась опция --all (мерж-реквест)Полный список изменений смотрите в CHANGELOG GitLab Runner .
Полная документация по GitLab Runner
Подробные release notes и инструкции по обновлению/установке можно прочитать в оригинальном англоязычном посте: https://about.gitlab.com/2017/07/22/gitlab-9-4-released/
Перевод с английского выполнен переводческой артелью «Надмозг и партнеры», http://nadmosq.ru. Над переводом работали rishavant и sgnl_05 .
|
|
Как встать на плечи гиганта. Пособие для финтех-стартапов |




|
Метки: author Sterhel хакатоны финансы в it блог компании «альфа-банк» альфа альфа-банк финансы стартапы банк |
Игра-головоломка Neo Angle. Продолжение истории разработки и релиз в Appstore |










|
Метки: author ian_phobos разработка мобильных приложений разработка игр unity3d gamedev puzzle mobile development neo angle appstore |
Базовая фортификация Linux: выбираем ежи и учимся рыть траншеи |
Несмотря на то, что Linux по праву считается более защищенной системой, чем MS Windows, самого по себе этого факта мало.
Поэтому я хочу рассказать про базовую настройку безопасности в семействе Linux. Статья ориентирована на начинающих Linux-администраторов, но возможно и матерые специалисты почерпнут для себя что-нибудь интересное. В тексте не будет пошаговых инструкций – лишь базовое описание технологий и методов, а также несколько личных рекомендаций.
Первая и самая главная рекомендация - аккуратнее относиться к инструкциям в интернете. К сожалению, часто эти инструкции содержат неактуальную, а то и вредную информацию и не объясняют, почему делается так, а не иначе. Всегда надо понимать, что именно вы делаете. Копировать же команды в консоль и вовсе опасно.
Как правило, большинство продуктов достаточно хорошо документированы, и информацию лучше черпать из официальных источников.
В сети часто встречаются рекомендации не работать под пользователем root - суперпользователем, обладающим полными правами на все. Отчасти рекомендация верная: работать под root небезопасно с точки зрения фатальности возможных ошибок и опасности перехвата пароля.
Так как реально на сервере вы работаете пару раз за год, и при этом занимаетесь в основном обновлением или небольшой правкой конфигов, работа с рут-правами напоминает как раз временное повышение привилегий с помощью sudo. Но ряд разумных мер предосторожности все равно не помешает:
в идеале настроить вход на сервер по ключам;
не вводить пароль от суперпользователя на ненадежных машинах;
Установка обновлений безусловно нужна и полезна. Только вот не один раз именно обновление как отдельных пакетов, так и операционной системы приводило к краху. Поэтому всегда перед обновлениями стоит проверить их установку на копии рабочего сервера.
Если на сервере работает более чем один пользователь или пара сервисов, запущенных под разными аккаунтами, то хорошим тоном будет разделить права доступа к файловой системе и сузить область поражения в случае чего.
В каждом дистрибутиве используется так называемая избирательная система доступа. Например, возможность пользователя открыть файл проверяется по списку управления доступом (Access Control List, ACL) - какие «галочки» для этого пользователя включены.
Хороший принцип в обеспечении безопасности – предоставлять только те права, которые действительно необходимы для работы.
В частности, в системах Linux для файлов используется следующий механизм предоставления доступа:
у каждого объекта есть три параметра доступа - для владельца, для группы пользователей, куда входит владелец и для всех остальных;
Право доступа удобно представить в числовом виде. Число будет трехзначным, вычисляемым по простой схеме:
| Тип доступа | Владалец | Группа | Все |
| Право читать | 400 | 40 | 4 |
| Право изменять | 200 | 20 | 2 |
| Право запускать | 100 | 10 | 1 |
Таким образом, право на полные права для всех на объект будут выглядеть как: (400+200+100) + (40+20+10)+(4+2+1) = 777. Такие права, как правило, не нужны никогда и никому, допустимо их выставлять лишь в процессе отладки.
Подобный механизм доступа иногда называется UGO (User-Group-Others).
Подробнее о правах доступа и работе с ними можно почитать в соответствующих материалах.
Конечно, не всегда такой механизм доступа удобен. Например, при необходимости дать права пользователю на конкретный объект придётся добавлять его в группу, а то и создавать новую. Поэтому в системах UNIX добавлен чуть усложненный механизм доступа, называемый ACL. Он поддерживает уже более гибкие и сложные списки доступа.
По умолчанию эта система отключена. Для ее включения необходимо монтировать жесткий диск с опцией acl. Для примера включим acl для корневого раздела, добавив опцию монтирования в /etc/fstab:
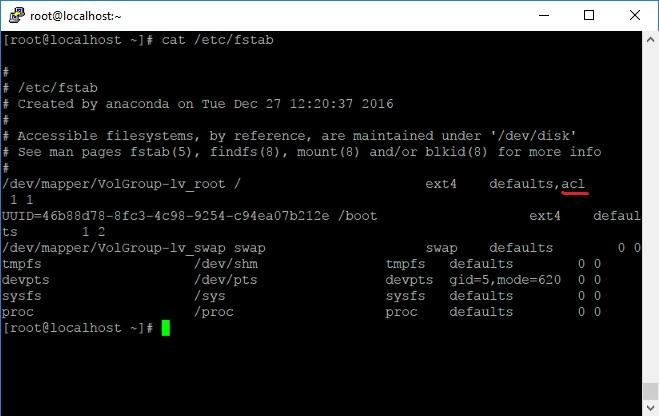
Теперь система загрузится с поддержкой расширенных ACL.
Теперь можно управлять списками доступа с помощью команды setfacl. Просмотр текущих разрешений - getfacl.
Подробнее ознакомиться можно в документации, я же для примера дам полные права доступа пользователю user на файл test.txt:
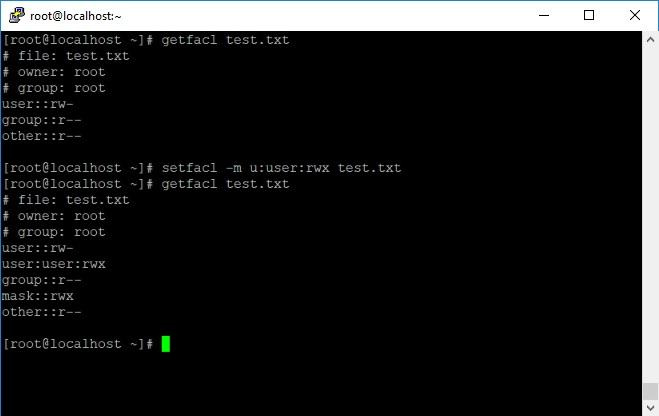
Предоставление полных прав пользователю user.
Механизм защиты довольно прост, эффективен… и напоминает ACL в файловой системе NTFS.
Основной механизм для защиты доступа к серверу - традиционно фаерволл. В системах GNU\Linux для этого используется встроенный в ядро netfilter.
В системе netfilter трафик проходит через так называемые цепочки. Цепочка - это упорядоченный список правил. В каждом правиле есть критерии для фильтрации пакета и действие, которое нужно совершить с пакетом, попавшим под эти критерии. Критериев существует довольно много, действия по умолчанию:
ACCEPT. Пропускаем пакет;
DROP. Удаляем пакет;
QUEUE. Передаем пакет на анализ внешней программе;
Цепочки по умолчанию выглядят так:
PREROUTING. Изначальная обработка входящих пакетов;
INPUT. Обработка входящих пакетов, адресованных непосредственно локальному процессу;
FORWARD. Обработка входящих пакетов, перенаправленных на выход. Нужно отметить, что перенаправляемые пакеты проходят сначала цепочку PREROUTING, затем FORWARD и POSTROUTING;
OUTPUT. Обработка пакетов, генерируемых локальными процессами;
Разумеется, цепочки можно создавать и свои. В свою очередь цепочки для удобства работы объединены в следующие таблицы:
raw. Эта таблица просматривается до передачи пакета системе определения состояний. Используется довольно редко, содержит цепочки PREROUTING и OUTPUT;
mangle. Содержит правила модификации IP-пакетов. Как правило, модифицируется заголовок пакета. Содержит все пять стандартных цепочек;
nat. Работает только с пакетами, создающими новое соединение. Помимо стандартных, поддерживает действия DNAT, SNAT, MASQUERADE, REDIRECT. В современных операционных системах содержит цепочки PREROUTING, INPUT, OUTPUT, и POSTROUTING;
Цепочки с одинаковым названием, но в разных таблицах независимы друг от друга. Например, raw PREROUTING и mangle PREROUTING обычно содержат разный набор правил: пакеты сначала проходят через цепочку raw PREROUTING, а потом через mangle PREROUTING.
Также в фаерволе есть специальный модуль определения состояний пакетов -conntrack. Состояния могут быть следующих видов:
NEW. Новое подключение, соединение получает это состояние, если обнаружен первый пакет в соединении;
ESTABLISHED. Уже состоявшееся подключение. Соединение получает это состояние, если пакет уже не первый. Очень удобно использовать для разрешения ответного трафика;
RELATED. Самое «хитрое» состояние соединения. Соединение получает его, только если само было инициировано из другого соединения. Типичный пример - работа FTP-сервера, в котором канал передачи данных поднимается отдельно от канала приема команд;

Путь проверки пакета в системе netfilter.
Для управления фаерволом чаще всего используется утилита iptables. Материала по ней достаточно, поэтому ограничусь общей рекомендацией - блокируем все, что не разрешено. А что разрешено - максимально ограничиваем.
Например, если доступ по SSH к серверу необходим только с определенных внешних адресов - разрешите доступ только с них.
Но с iptables работать не всегда удобно, потому что требуется глубокое понимание пути прохождения пакетов. В качестве альтернативы часто используются другие утилиты, вроде ufw в системах Ubuntu.
Например, для предоставления доступа по ssh с помощью ufw достаточно выполнить команду:
ufw allow from 1.2.3.4 to any port 22
Тоже самое с помощью iptables выглядело бы более громоздко. Разрешим входящий трафик:
iptables -A INPUT -p tcp -s 1.2.3.4 --dport 22 -j ACCEPT
Затем разрешим ответный трафик:
iptables -A OUTPUT -p tcp --sport 22 -d 1.2.3.4 -j ACCEPT
Надо сказать, что чаще вместо того чтобы делать два явных правила для входящего и ответного трафика, просто разрешают трафик установленных соединений (ESTABLISHED) и связанных с установленными (RELATED). Для этого достаточно разрешить все подключения ESTABLISHED и RELATED следующими командами:
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -A OUTPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
В современных RPM-дистрибутивах вроде CentOS, Fedora и Red Hat в качестве замены iptables используют демона firewalld. От привычного механизма он отличен тем, что может применять правила на ходу без перезагрузки списка, а также работой с зонами - уровнями доверия к сетевым подключениям. Немного напоминает встроенный фаервол Windows. Правда, использовать его после iptables немного непривычно, и часто системные администраторы предпочитают вернуть сложный, но привычный iptables.
В связке с фаерволом тесно работает и такой механизм как fail2ban, который делает следующее:
мониторит лог какого-либо сервиса, например ssh или ftp;
Подробнее с настройкой fail2ban можно ознакомиться в официальной Wiki.
SELinux - дополнительный механизм принудительной системы контроля доступа. В отличие от классической избирательной, доступ основан на специальных политиках, а не ACL.
Минусы системы доступа на базе ACL:
пользователь сервера может предоставить доступ к своим файлам - например, к закрытым ключам;
Устранить эти недостатки может SELinux, созданный АНБ (Агентство Национальной Безопасности США) и Red Hat еще в 1998 году. В ядре Linux-систем эта технология присутствует уже давно. Тем не менее в некоторых инструкциях до сих пор часто встречается рекомендация ее отключить, что не всегда справедливо. Подробнее про SELinux можно почитать в профильной статье на Хабре, поэтому ограничусь небольшим ликбезом.
У SELinux есть три режима работы:
enforcing. Режим работы по-умолчанию, все неразрешенные действия блокируются;
permissive. Все неразрешенные действия выполняются, но записываются в журнал;
Узнать текущий режим работы можно командой getenforce, переключиться между режимами enforcing и permissive можно командой setenforce. Выключение же SELinux требует перезагрузки системы.
Механизм защиты применяется после классического, и базируется на специальной маркировке объектов. Посмотреть текущую маркировку можно командой:
ls -Z

Смотрим маркировку свежесозданного файла.
В качестве примера настройки я разберу ситуацию, когда мы хотим разместить сайт в папке не по умолчанию и «повесить» веб-сервер на другой порт. Одной смены значений в конфигурационном файле httpd.conf будет недостаточно, необходимо сказать SELinux, что веб-серверу следует предоставить доступ к папке и к порту. Для этого необходимо:
установить пакет администрирования policycoreutils-python;
сказать системе о маркировке папки командами:
semanage fcontext -a -t httpd_sys_content_t "/path/to/www(/.*)?"
semanage fcontext -a -t httpd_sys_rw_content_t "/path/to/www(/.*)?"восстановить маркировки командой:
restorecon -R /path/to/wwwsemanage port -a -t http_port_t -p tcp 81Разумеется перед тем, как проделывать все это, рекомендую детально ознакомиться с работой SELinux.
SELinux как решение не уникален. Второй по популярности механизм защиты - это AppArmor. Его разработку изначально курировала Novell, но после инструмент забросили как бесперспективный. Однако теперь над AppArmor работает Canonical, и продукт тесно связан с системой Ubuntu. Что касается отличий, то AppArmor удобнее SELinux благодаря множеству готовых политик.
Есть и механизм обучения, при котором действия пользователей записываются в журнал, но не блокируются - так можно запустить новую защиту в качестве «пилота» и сразу устранить огрехи. Если в SELinux этот режим включается для всей системы, то с AppArmor его можно активировать для конкретного приложения. Пример такого назначения:
aa-complain /path/to/bin
Ключевое отличие AppArmor от SELinux заключается в том, что AppArmor привязывает политику к пути, а SELinux опирается на дескриптор файла. Если заблокировать исполнение файла и потом переместить его, то AppArmor позволит файлу запуститься, а SELinux - нет.
Если же файл перезапишут по исходному пути, то уже AppArmor заблокирует его, а SELinux разрешит выполнение. Избежать этих недоразумений можно включением политики «блокировать все, кроме явно разрешенного».
Если описать отличия коротко, то разработчики SELinux делали упор не на простоту использования, а именно на безопасность. С AppArmor все обстоит с точностью до наоборот. Почитать об AppArmor подробнее можно в документации от производителя, либо в библиотеке Ubuntu.
Увы, не могу дать однозначный совет, что вам выбрать, потому что это вопрос приоритетов и предпочтений по дистрибутиву ОС. Поклонники Centos и Red Hat чаще выбирают SELinux, а любители Ubuntu - AppArmor.
Кстати, напишете в комментариях, какой механизм предпочитаете вы?
В этом разделе я расскажу про несколько полезных, но не must-have механизмов для защиты сервера.
В системах GNU\Linux можно ограничить список терминалов, куда может подключаться пользователь root. Сделать это можно путем модификации файла /etc/securetty. Если файл пустой, то root не сможет напрямую подключаться вовсе, и для получения полных прав понадобится su или sudo.
Также может быть полезно задать срок действия пароля следующей командой:
chage -M 20 username
Где 20 - это срок действия пароля в днях. Другим вариантом будет изменение общей политики паролей в файле /etc/login.defs. Допустим, мы хотим, чтобы пароль нужно было менять каждые 20 дней, и чтобы пользователь за 5 дней получал напоминание об этом. Тогда содержимое файла будет следующим:
PASS_MAX_DAYS 20
PASS_MIN_DAYS 0
PASS_WARN_AGE 5
Другой полезной возможностью является политика сложности паролей. Для этого используется модуль pam_cracklib. Например, если мы хотим, чтобы в пароле содержались как минимум одна большая буква, как минимум одна маленькая, как минимум одна цифра и сам пароль был не менее 8 символов в длину, поможет добавление строки:
password required pam_cracklib.so minlen=8 lcredit=1 ucredit=1 dcredit=1
в файл /etc/pam.d/system-auth.
Еще одна нужная опция - уведомление о каждом вводе sudo для контроля доступа к правам суперпользователя. Для этого достаточно добавить в файл /etc/sudoers следующие строки:
mailto [admin@domain.com](mailto:admin@domain.com)
mail_always on
Разумеется, в системе должен быть настроен агент отправки почты. Неплохим вариантом замены стандартного sendmail является ssmtp, который легко сдружится с отправкой писем даже через бесплатные почтовые сервисы.
Во избежание компиляции и запуска зловредного ПО не лишним будет отключить компиляторы на сервере для использования пользователями.
Для начала посмотрим список исполняемых файлов командой:
rpm -q --filesbypkg gcc | grep 'bin'
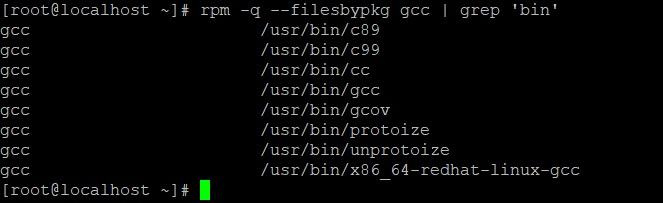
Исполняемые файлы gcc.
Теперь будет удобно создать отдельную группу командой:
groupadd compilerGroup
Затем сменить группу-владельца для нужных файлов:
chown root:compilerGroup /usr/bin/gcc
И задать права доступа, запрещающие доступ к файлам всем прочим:
chmod 0750 /usr/bin/gcc
Хороший способ защитить системные файлы и конфигурации даже от суперпользователя - это атрибут иммуности. Для его применения используется команда chattr +i filename.
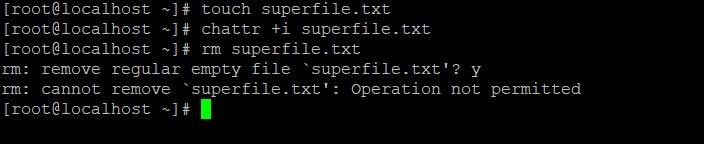
Даже root не может удалить иммунный файл.
Для снятия этого атрибута достаточно выполнить команду chattr -i filename.
Я думаю у каждого администратора есть еще свои best-practices по безопасности серверов. Предлагаю поделиться ими с коллегами в комментариях.
|
Метки: author Tri-Edge системное администрирование серверное администрирование настройка linux блог компании сервер молл linux для всех безопасность linux selinux |
[Из песочницы] Истинная реализация нейросети с нуля на языке программирования C# |

Здравствуй, Хабр! Данная статья предназначена для тех, кто приблизительно шарит в математических принципах работы нейронных сетей и в их сути вообще, поэтому советую ознакомиться с этим перед прочтением. Хоть как-то понять, что происходит можно сначала здесь, потом тут.
Недавно мне пришлось сделать нейросеть для распознавания рукописных цифр(сегодня будет не совсем её код) в рамках школьного проекта, и, естественно, я начал разбираться в этой белиберде теме. Посмотрев приблизительно достаточно об этом в интернете, я понял чуть более, чем ничего. Но неожиданно(как это обычно бывает) получилось наткнуться на книгу Саймона Хайкина(не знаю почему раньше не загуглил). И тогда началось потное вкуривание матчасти нейросетей, состоящее из одного матана.
На самом деле, несмотря на обилие математики, она не такая уж и запредельно сложная. Понять сатанистские каракули и письмена этого пособия сможет среднестатистический 11-классник товарищ-физмат или 1~2-курсник технарьской шараги. Помимо этого, пусть книга достаточно объёмная и трудная для восприятия, но вещи, написанные в ней, реально объясняют, что "твориться у тачки под капотом". Как вы поняли я крайне рекомендую(ни в коем случае не рекламирую) "Нейронные сети. Полный курс" Саймона Хайкина к прочтению в том случае, если вам придётся столкнуться с применением/написанием/разработкой нейросетей и прочего подобного stuff'а. Хотя в ней нет материала про новомодные свёрточные сети, никто не мешает загуглить лекции от какого-нибудь харизматичного работника Yandex/Mail.ru/etc. никто не мешает.
Конечно, осознав устройство сеток, я не мог просто остановиться, так как впереди предстояло написание кода. В связи со своим параллельным занятием, заключающемся в создани игр на Unity, языком реализации оказался ламповый и няшный шарпей 7 версии(ибо она последняя актуальная). Именно в этот момент, оказавшись на просторах интернета, я понял, что число внятных туториалов по написанию нейросетей с нуля(без ваших фреймворков) на шарпе бесконечно мало. Ладно. Я мог использовать, всякие Theano и Tensor Flow, НО под капотом моей смерть-машины в моём ноутбуке стоит "красная" видеокарта без особой поддержки API, через которые обращаются к мощи GPU(ведь именно их и используют Theano/Tensor Flow/etc.).
Моя видеокарта называется ATI Radeon HD Mobility 4570. И если кто знает, как обратиться к её мощностям для параллелизации нейросетевых вычислений, пожалуйста, напишите в комментарии. Тогда вы поможете мне, и возможно у этой статьи появится продолжение. Не осуждается предложение других ЯП.
Просто, как я понял, она настолько старая, что нифига не поддерживает. Может быть я не прав.
То, что я увидел(третье вообще какая-то эзотерика с некрасивым кодом), несомненно может повергнуть в шок и вас, так как выдаваемое за нейросети связано с ними так же, как и Yanix с качественным рэпом. Вскоре я понял, что могу рассчитывать только на себя, и решил написать данную статью, чтобы всякие юзеры не вводили других в заблуждение.
Здесь я не буду рассматривать код сети для распознования цифр(как упоминалось ранее), ибо я оставил его на флэшке, удалив с ноута, а искать сей носитель информации мне лень, и в связи с этим я помогу вам сконструировать многослойный полносвязный персептрон для решения задачи XOR и XAND(XNOR, хз как ещё).
Прежде чем начать программировать это, можнонужно нарисовать на бумаге, дабы облегчить представление структуры и работы нейронки. Моё воображение вылилось в следующую картинку. И да, кстати, это консольное приложение в Visual Studio 2017, с .NET Framework версии 4.7.
Многослойный полносвязный персептрон.
Один скрытый слой.
4 нейрона в скрытом слое(на этом количестве персептрон сошёлся).
Алгоритм обучения — backpropagation.
Критерий останова — преодоление порогового значения среднеквадратичной ошибки по эпохе.(0.001)
Скорость обучения — 0.1.
Функция активации — логистическая сигмоидальная.

Потом надо осознать, что нам нужно куда-то записывать веса, проводить вычисления, немного дебажить, ну и кортежи поюзать(но для них юзинг мне не нужен). Соответственно, using'и у нас такие.
В папке release||debug этого прожекта располагаются файлы(на каждый слой по одному) по имени типа (fieldname)_memory.xml сами знаете для чего. Они создаются заранее с учётом общего количества весов каждого слоя. Знаю, что XML — это не лучший выбор для парсинга, просто времени было немного на это дело.
using System.Xml;
using static System.Math;
using static System.Console;Также вычислительные нейроны у нас двух типов: скрытые и выходные. А веса могут считываться или записываться в память. Реализуем сию концепцию двумя перечислениями.
enum MemoryMode { GET, SET }
enum NeuronType { Hidden, Output }Всё остальное будет происходить внутри пространства имён, которое я назову просто: Neural Network.
namespace NeuralNetwork
{
//всё, что будет описано ниже, располагается здесь
}Прежде всего, важно понимать, почему нейроны входного слоя я изобразил квадратами. Ответ прост. Они ничего не вычисляют, а лишь улавливают информацию из внешнего мира, то есть получают сигнал, который будет пропущен через сеть. Вследствие этого, входной слой имеет мало общего с остальными слоями. Вот почему стоит вопрос: делать для него отдельный класс или нет? На самом деле, при обработке изображений, видео, звука стоит его сделать, лишь для размещения логики по преобразованию и нормализации этих данных к виду, подаваемому на вход сети. Вот почему я всё-таки напишу класс InputLayer. В нём находиться обучающая выборка организованная необычной структурой. Первый массив в кортеже — это сигналы-комбинации 1 и 0, а второй массив — это пара результатов этих сигналов после проведения операций XOR и XAND(сначала XOR, потом XAND).
class InputLayer
{
private (double[], double[])[] _trainset = new(double[], double[])[]//да-да, массив кортежей из 2 массивов
{
(new double[]{ 0, 0 }, new double[]{ 0, 1 }),
(new double[]{ 0, 1 }, new double[]{ 1, 0 }),
(new double[]{ 1, 0 }, new double[]{ 1, 0 }),
(new double[]{ 1, 1 }, new double[]{ 0, 1 })
};
//инкапсуляция едрид-мадрид
public (double[], double[])[] Trainset { get => _trainset; }//такие няшные свойства нынче в C# 7
}Теперь реализуем самое важное, то без чего ни одна нейронная сеть не станет терминатором, а именно — нейрон. Я не буду использовать смещения, потому что просто не хочу. Нейрон будет напоминать модель МакКаллока-Питтса, но иметь другую функцию активации(не пороговую), методы для вычисления градиентов и производных, свой тип и совмещенные линейные и нелинейные преобразователи. Естественно без конструктора уже не обойтись.
class Neuron
{
public Neuron(double[] inputs, double[] weights, NeuronType type)
{
_type = type;
_weights = weights;
_inputs = inputs;
}
private NeuronType _type;
private double[] _weights;
private double[] _inputs;
public double[] Weights { get => _weights; set => _weights = value; }
public double[] Inputs { get => _inputs; set => _inputs = value; }
public double Output { get => Activator(_inputs, _weights); }
private double Activator(double[] i, double[] w)//преобразования
{
double sum = 0;
for (int l = 0; l < i.Length; ++l)
sum += i[l] * w[l];//линейные
return Pow(1 + Exp(-sum), -1);//нелинейные
}
public double Derivativator(double outsignal) => outsignal * (1 - outsignal);//формула производной для текущей функции активации уже выведена в ранее упомянутой книге
public double Gradientor(double error, double dif, double g_sum) => (_type == NeuronType.Output) ? error * dif : g_sum * dif;//g_sum - это сумма градиентов следующего слоя
}Ладно у нас есть нейроны, но их необходимо объединить в слои для вычислений. Возвращаясь к моей схеме выше, хочу объяснить наличие чёрного пунктира. Он разделяет слои так, чтобы показать, что они содержат. То есть один вычислительный слой содержит нейроны и веса для связи с нейронами предыдущего слоя. Нейроны объединяются массивом, а не списком, так как это менее ресурсоёмко. Веса организованы матрицей(двумерным массивом) размера(нетрудно догадаться) [число нейронов текущего слоя X число нейронов предыдущего слоя]. Естественно, слой инициализирует нейроны, иначе словим null reference. При этом эти слои очень похожи друг на друга, но имеют различия в логике, поэтому скрытые и выходной слои должны быть реализованы наследниками одного базового класса, который кстати оказывается абстрактным.
abstract class Layer//модификаторы protected стоят для внутрииерархического использования членов класса
{//type используется для связи с одноимённым полю слоя файлом памяти
protected Layer(int non, int nopn, NeuronType nt, string type)
{//увидите это в WeightInitialize
numofneurons = non;
numofprevneurons = nopn;
Neurons = new Neuron[non];
double[,] Weights = WeightInitialize(MemoryMode.GET, type);
for (int i = 0; i < non; ++i)
{
double[] temp_weights = new double[nopn];
for (int j = 0; j < nopn; ++j)
temp_weights[j] = Weights[i, j];
Neurons[i] = new Neuron(null, temp_weights, nt);//про подачу null на входы ниже
}
}
protected int numofneurons;//число нейронов текущего слоя
protected int numofprevneurons;//число нейронов предыдущего слоя
protected const double learningrate = 0.1d;//скорость обучения
Neuron[] _neurons;
public Neuron[] Neurons { get => _neurons; set => _neurons = value; }
public double[] Data//я подал null на входы нейронов, так как
{//сначала нужно будет преобразовать информацию
set//(видео, изображения, etc.)
{//а загружать input'ы нейронов слоя надо не сразу,
for (int i = 0; i < Neurons.Length; ++i)
Neurons[i].Inputs = value;
}//а только после вычисления выходов предыдущего слоя
}
public double[,] WeightInitialize(MemoryMode mm, string type)
{
double[,] _weights = new double[numofneurons, numofprevneurons];
WriteLine($"{type} weights are being initialized...");
XmlDocument memory_doc = new XmlDocument();
memory_doc.Load($"{type}_memory.xml");
XmlElement memory_el = memory_doc.DocumentElement;
switch (mm)
{
case MemoryMode.GET:
for (int l = 0; l < _weights.GetLength(0); ++l)
for (int k = 0; k < _weights.GetLength(1); ++k)
_weights[l, k] = double.Parse(memory_el.ChildNodes.Item(k + _weights.GetLength(1) * l).InnerText.Replace(',', '.'), System.Globalization.CultureInfo.InvariantCulture);//parsing stuff
break;
case MemoryMode.SET:
for (int l = 0; l < Neurons.Length; ++l)
for (int k = 0; k < numofprevneurons; ++k)
memory_el.ChildNodes.Item(k + numofprevneurons * l).InnerText = Neurons[l].Weights[k].ToString();
break;
}
memory_doc.Save($"{type}_memory.xml");
WriteLine($"{type} weights have been initialized...");
return _weights;
}
abstract public void Recognize(Network net, Layer nextLayer);//для прямых проходов
abstract public double[] BackwardPass(double[] stuff);//и обратных
}Класс Layer — это абстрактный класс, поэтому нельзя создавать его экземпляры. Это значит, что наше желание сохранить свойства "слоя" выполняется путём наследования родительского конструктора через ключевое слово base и пустой конструктор наследника в одну строчку(ибо вся логика конструктора определена в базовом классе, и её не надо переписывать).
Теперь непосредственно классы-наследники: Hidden и Output. Сразу два класса в цельном куске кода.
class HiddenLayer : Layer
{
public HiddenLayer(int non, int nopn, NeuronType nt, string type) : base(non, nopn, nt, type){}
public override void Recognize(Network net, Layer nextLayer)
{
double[] hidden_out = new double[Neurons.Length];
for (int i = 0; i < Neurons.Length; ++i)
hidden_out[i] = Neurons[i].Output;
nextLayer.Data = hidden_out;
}
public override double[] BackwardPass(double[] gr_sums)
{
double[] gr_sum = null;
//сюда можно всунуть вычисление градиентных сумм для других скрытых слоёв
//но градиенты будут вычисляться по-другому, то есть
//через градиентные суммы следующего слоя и производные
for (int i = 0; i < numofneurons; ++i)
for (int n = 0; n < numofprevneurons; ++n)
Neurons[i].Weights[n] += learningrate * Neurons[i].Inputs[n] * Neurons[i].Gradientor(0, Neurons[i].Derivativator(Neurons[i].Output), gr_sums[i]);//коррекция весов
return gr_sum;
}
}
class OutputLayer : Layer
{
public OutputLayer(int non, int nopn, NeuronType nt, string type) : base(non, nopn, nt, type){}
public override void Recognize(Network net, Layer nextLayer)
{
for (int i = 0; i < Neurons.Length; ++i)
net.fact[i] = Neurons[i].Output;
}
public override double[] BackwardPass(double[] errors)
{
double[] gr_sum = new double[numofprevneurons];
for (int j = 0; j < gr_sum.Length; ++j)//вычисление градиентных сумм выходного слоя
{
double sum = 0;
for (int k = 0; k < Neurons.Length; ++k)
sum += Neurons[k].Weights[j] * Neurons[k].Gradientor(errors[k], Neurons[k].Derivativator(Neurons[k].Output), 0);//через ошибку и производную
gr_sum[j] = sum;
}
for (int i = 0; i < numofneurons; ++i)
for (int n = 0; n < numofprevneurons; ++n)
Neurons[i].Weights[n] += learningrate * Neurons[i].Inputs[n] * Neurons[i].Gradientor(errors[i], Neurons[i].Derivativator(Neurons[i].Output), 0);//коррекция весов
return gr_sum;
}
}В принципе, всё самое важное я описал в комментариях. У нас есть все компоненты: обучающие и тестовые данные, вычислительные элементы, их "конгламераты". Теперь настало время всё связать обучением. Алгоритм обучения — backpropagation, следовательно критерий останова выбираю я, и выбор мой — есть преодоление порогового значения среднеквадратичной ошибки по эпохе, которое я выбрал равным 0.001. Для поставленной цели я написал класс Network, описывающий состояние сети, которое принимается в качестве параметра многих методов, как вы могли заметить.
class Network
{
//все слои сети
InputLayer input_layer = new InputLayer();
public HiddenLayer hidden_layer = new HiddenLayer(4, 2, NeuronType.Hidden, nameof(hidden_layer));
public OutputLayer output_layer = new OutputLayer(2, 4, NeuronType.Output, nameof(output_layer));
//массив для хранения выхода сети
public double[] fact = new double[2];//не ругайте за 2 пожалуйста
//ошибка одной итерации обучения
double GetMSE(double[] errors)
{
double sum = 0;
for (int i = 0; i < errors.Length; ++i)
sum += Pow(errors[i], 2);
return 0.5d * sum;
}
//ошибка эпохи
double GetCost(double[] mses)
{
double sum = 0;
for (int i = 0; i < mses.Length; ++i)
sum += mses[i];
return (sum / mses.Length);
}
//непосредственно обучение
static void Train(Network net)//backpropagation method
{
const double threshold = 0.001d;//порог ошибки
double[] temp_mses = new double[4];//массив для хранения ошибок итераций
double temp_cost = 0;//текущее значение ошибки по эпохе
do
{
for (int i = 0; i < net.input_layer.Trainset.Length; ++i)
{
//прямой проход
net.hidden_layer.Data = net.input_layer.Trainset[i].Item1;
net.hidden_layer.Recognize(null, net.output_layer);
net.output_layer.Recognize(net, null);
//вычисление ошибки по итерации
double[] errors = new double[net.input_layer.Trainset[i].Item2.Length];
for (int x = 0; x < errors.Length; ++x)
errors[x] = net.input_layer.Trainset[i].Item2[x] - net.fact[x];
temp_mses[i] = net.GetMSE(errors);
//обратный проход и коррекция весов
double[] temp_gsums = net.output_layer.BackwardPass(errors);
net.hidden_layer.BackwardPass(temp_gsums);
}
temp_cost = net.GetCost(temp_mses);//вычисление ошибки по эпохе
//debugging
WriteLine($"{temp_cost}");
} while (temp_cost > threshold);
//загрузка скорректированных весов в "память"
net.hidden_layer.WeightInitialize(MemoryMode.SET, nameof(hidden_layer));
net.output_layer.WeightInitialize(MemoryMode.SET, nameof(output_layer));
}
//тестирование сети
static void Test(Network net)
{
for (int i = 0; i < net.input_layer.Trainset.Length; ++i)
{
net.hidden_layer.Data = net.input_layer.Trainset[i].Item1;
net.hidden_layer.Recognize(null, net.output_layer);
net.output_layer.Recognize(net, null);
for (int j = 0; j < net.fact.Length; ++j)
WriteLine($"{net.fact[j]}");
WriteLine();
}
}
//запуск сети
static void Main(string[] args)
{
Network net = new Network();
Train(net);
Test(net);
ReadKey();//чтоб консоль не закрывалась :)
}
}Результат обучения.

Итого, путём насилования мозга несложных манипуляций, мы получили основу работающей нейронной сети. Для того, чтобы заставить её делать что-либо другое, достаточно поменять класс InputLayer и подобрать параметры сети для новой задачи. Через время(какое конкретно не знаю) напишу продолжение этой статьи с руководством по созданию с нуля свёрточной нейронной сети на C# и здесь сделаю апдейт этой с ссылками на MLP-рекогнитор картинок MNIST(но это не точно) и код статьи на Python(точно, но дольше ждать).
За сим всё, буду рад ответить на вопросы в комментариях, а пока извольте, новые дела ждут.
P.S.: Для желающих помацать код клацать.
P.P.S.: Сеть по ссылке выше — потненькая необученная няша-стесняша.
|
Метки: author Stefanio ооп машинное обучение c# нейронные сети neural networks tutorial обучалка шарпеи шарп дотнет .net c# 7 |






