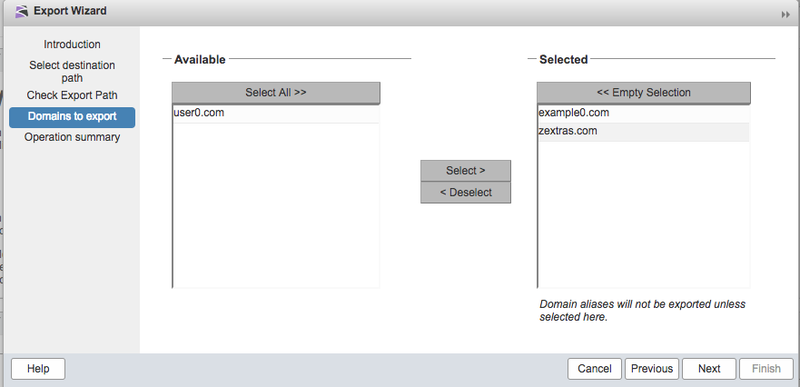
[Перевод] 37 причин, почему ваша нейросеть не работает |
0. Как использовать это руководство?
I. Проблемы с набором данных
II. Нормализация данных/Проблемы аугментации
III. Проблемы реализации
IV. Проблемы обучения

При тестировании новой сетевой архитектуры или написании нового кода сначала используйте стандартные наборы данных вместо своих. Потому что для них уже есть много результатов и они гарантированно «разрешимые». Там не будет проблем с шумом в метках, разницей в распределении обучение/тестирование, слишком большой сложностью набора данных и т.д.

«… любую статистику предобработки (например, среднее данных) нужно вычислять на данных для обучения, а потом применять на данных валидации/тестирования. Например, будет ошибкой вычисление среднего и вычитание его из каждого изображения во всём наборе данных, а затем разделение данных на фрагменты для обучения/валидации/тестирования».


«Для весов эти гистограммы должны иметь примерно гауссово (нормальное) распределение, спустя какое-то время. Гистограммы сдвигов обычно начинаются с нуля и обычно заканчиваются на уровне примерно гауссова распределения (единственное исключение — LSTM). Следите за параметрами, которые отклоняются на плюс/минус бесконечность. Следите за сдвигами, которые становятся слишком большими. Иногда такое случается в выходном слое для классификации, если распределение классов слишком несбалансировано».
|
|
Android Architecture Components. Часть 4. ViewModel |

public class MyViewModel extends ViewModel {
private MutableLiveData showProgress = new MutableLiveData<>();
//new thread
public void doSomeThing(){
showProgress.postValue(true);
...
showProgress.postValue(false);
}
public MutableLiveData getProgressState(){
return showProgress;
}
} @Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
final MyViewModel viewModel = ViewModelProviders.of(this).get(MyViewModel.class);
viewModel.getProgressState().observe(this, new Observer() {
@Override
public void onChanged(@Nullable Boolean aBoolean) {
if (aBoolean) {
showProgress();
} else {
hideProgress();
}
}
});
viewModel.doSomeThing();
} 
public class LocationLiveData extends LiveData implements
GoogleApiClient.ConnectionCallbacks,
GoogleApiClient.OnConnectionFailedListener,
LocationListener {
private final static int UPDATE_INTERVAL = 1000;
private GoogleApiClient googleApiClient;
public LocationLiveData(Context context) {
googleApiClient =
new GoogleApiClient.Builder(context, this, this)
.addApi(LocationServices.API)
.build();
}
@Override
protected void onActive() {
googleApiClient.connect();
}
@Override
protected void onInactive() {
if (googleApiClient.isConnected()) {
LocationServices.FusedLocationApi.removeLocationUpdates(
googleApiClient, this);
}
googleApiClient.disconnect();
}
@Override
public void onConnected(Bundle connectionHint) {
LocationRequest locationRequest = new LocationRequest().setInterval(UPDATE_INTERVAL).setPriority(LocationRequest.PRIORITY_HIGH_ACCURACY);
LocationServices.FusedLocationApi.requestLocationUpdates(
googleApiClient, locationRequest, this);
}
@Override
public void onLocationChanged(Location location) {
setValue(location);
}
@Override
public void onConnectionSuspended(int cause) {
setValue(null);
}
@Override
public void onConnectionFailed(ConnectionResult connectionResult) {
setValue(null);
}
}
public class NetworkLiveData extends LiveData {
private Context context;
private BroadcastReceiver broadcastReceiver;
public NetworkLiveData(Context context) {
this.context = context;
}
private void prepareReceiver(Context context) {
IntentFilter filter = new IntentFilter();
filter.addAction("android.net.wifi.supplicant.CONNECTION_CHANGE");
filter.addAction("android.net.wifi.STATE_CHANGE");
broadcastReceiver = new BroadcastReceiver() {
@Override
public void onReceive(Context context, Intent intent) {
WifiManager wifiMgr = (WifiManager) context.getSystemService(Context.WIFI_SERVICE);
WifiInfo wifiInfo = wifiMgr.getConnectionInfo();
String name = wifiInfo.getSSID();
if (name.isEmpty()) {
setValue(null);
} else {
setValue(name);
}
}
};
context.registerReceiver(broadcastReceiver, filter);
}
@Override
protected void onActive() {
super.onActive();
prepareReceiver(context);
}
@Override
protected void onInactive() {
super.onInactive();
context.unregisterReceiver(broadcastReceiver);
broadcastReceiver = null;
}
}
public class DetectorViewModel extends AndroidViewModel {
//для хранения вводимых данных, решил создать Repository, листинг его можно посмотреть на GitHub по линке в конце материала
private IRepository repository;
private LatLng point;
private int radius;
private LocationLiveData locationLiveData;
private NetworkLiveData networkLiveData;
private MediatorLiveData statusMediatorLiveData = new MediatorLiveData<>();
private MutableLiveData statusLiveData = new MutableLiveData<>();
private String networkName;
private float[] distance = new float[1];
private Observer locationObserver = new Observer() {
@Override
public void onChanged(@Nullable Location location) {
checkZone();
}
};
private Observer networkObserver = new Observer() {
@Override
public void onChanged(@Nullable String s) {
checkZone();
}
};
private Observer mediatorStatusObserver = new Observer() {
@Override
public void onChanged(@Nullable Status status) {
statusLiveData.setValue(status.toString());
}
};
public DetectorViewModel(final Application application) {
super(application);
repository = Repository.getInstance(application.getApplicationContext());
initVariables();
locationLiveData = new LocationLiveData(application.getApplicationContext());
networkLiveData = new NetworkLiveData(application.getApplicationContext());
statusMediatorLiveData.addSource(locationLiveData, locationObserver);
statusMediatorLiveData.addSource(networkLiveData, networkObserver);
statusMediatorLiveData.observeForever(mediatorStatusObserver);
}
//Для того чтобы зря не держать LocationService в работе, мы от него отписываемся если WiFi network подходит.
private void updateLocationService() {
if (isRequestedWiFi()) {
statusMediatorLiveData.removeSource(locationLiveData);
} else if (!isRequestedWiFi() && !locationLiveData.hasActiveObservers()) {
statusMediatorLiveData.addSource(locationLiveData, locationObserver);
}
}
//считываем данные с репозитория
private void initVariables() {
point = repository.getPoint();
if (point.latitude == 0 && point.longitude == 0)
point = null;
radius = repository.getRadius();
networkName = repository.getNetworkName();
}
//метод, который отвечает за проверку того находимся мы в нужной зоне или нет
private void checkZone() {
updateLocationService();
if (isRequestedWiFi() || isInRadius()) {
statusMediatorLiveData.setValue(Status.INSIDE);
} else {
statusMediatorLiveData.setValue(Status.OUTSIDE);
}
}
public LiveData getStatus() {
return statusLiveData;
}
// методы которые отвечают за запись данных в репозиторий
public void savePoint(LatLng latLng) {
repository.savePoint(latLng);
point = latLng;
checkZone();
}
public void saveRadius(int radius) {
this.radius = radius;
repository.saveRadius(radius);
checkZone();
}
public void saveNetworkName(String networkName) {
this.networkName = networkName;
repository.saveNetworkName(networkName);
checkZone();
}
public int getRadius() {
return radius;
}
public LatLng getPoint() {
return point;
}
public String getNetworkName() {
return networkName;
}
public boolean isInRadius() {
if (locationLiveData.getValue() != null && point != null) {
Location.distanceBetween(locationLiveData.getValue().getLatitude(), locationLiveData.getValue().getLongitude(), point.latitude, point.longitude, distance);
if (distance[0] <= radius)
return true;
}
return false;
}
public boolean isRequestedWiFi() {
if (networkLiveData.getValue() == null)
return false;
if (networkName.isEmpty())
return false;
String network = networkName.replace("\"", "").toLowerCase();
String currentNetwork = networkLiveData.getValue().replace("\"", "").toLowerCase();
return network.equals(currentNetwork);
}
@Override
protected void onCleared() {
super.onCleared();
statusMediatorLiveData.removeSource(locationLiveData);
statusMediatorLiveData.removeSource(networkLiveData);
statusMediatorLiveData.removeObserver(mediatorStatusObserver);
}
} public class MainActivity extends LifecycleActivity {
private static final int PERMISSION_LOCATION_REQUEST = 0001;
private static final int PLACE_PICKER_REQUEST = 1;
private static final int GPS_ENABLE_REQUEST = 2;
@BindView(R.id.status)
TextView statusView;
@BindView(R.id.radius)
EditText radiusEditText;
@BindView(R.id.point)
EditText pointEditText;
@BindView(R.id.network_name)
EditText networkEditText;
@BindView(R.id.warning_container)
ViewGroup warningContainer;
@BindView(R.id.main_content)
ViewGroup contentContainer;
@BindView(R.id.permission)
Button permissionButton;
@BindView(R.id.gps)
Button gpsButton;
private DetectorViewModel viewModel;
private LatLng latLng;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
ButterKnife.bind(this);
checkPermission();
}
@Override
public void onRequestPermissionsResult(int requestCode, @NonNull String[] permissions, @NonNull int[] grantResults) {
super.onRequestPermissionsResult(requestCode, permissions, grantResults);
if (grantResults[0] == PackageManager.PERMISSION_GRANTED) {
init();
} else {
showWarningPage(Warning.PERMISSION);
}
}
private void checkPermission() {
if (PackageManager.PERMISSION_GRANTED == checkSelfPermission(
Manifest.permission.ACCESS_FINE_LOCATION)) {
init();
} else {
requestPermissions(new String[]{Manifest.permission.ACCESS_FINE_LOCATION}, PERMISSION_LOCATION_REQUEST);
}
}
private void init() {
viewModel = ViewModelProviders.of(this).get(DetectorViewModel.class);
if (Utils.isGpsEnabled(this)) {
hideWarningPage();
checkingPosition();
initInput();
} else {
showWarningPage(Warning.GPS_DISABLED);
}
}
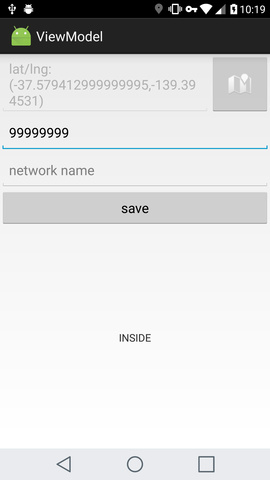
private void initInput() {
radiusEditText.setText(String.valueOf(viewModel.getRadius()));
latLng = viewModel.getPoint();
if (latLng == null) {
pointEditText.setText(getString(R.string.chose_point));
} else {
pointEditText.setText(latLng.toString());
}
networkEditText.setText(viewModel.getNetworkName());
}
@OnClick(R.id.get_point)
void getPointClick(View view) {
PlacePicker.IntentBuilder builder = new PlacePicker.IntentBuilder();
try {
startActivityForResult(builder.build(MainActivity.this), PLACE_PICKER_REQUEST);
} catch (GooglePlayServicesRepairableException e) {
e.printStackTrace();
} catch (GooglePlayServicesNotAvailableException e) {
e.printStackTrace();
}
}
@OnClick(R.id.save)
void saveOnClick(View view) {
if (!TextUtils.isEmpty(radiusEditText.getText())) {
viewModel.saveRadius(Integer.parseInt(radiusEditText.getText().toString()));
}
viewModel.saveNetworkName(networkEditText.getText().toString());
}
@OnClick(R.id.permission)
void permissionOnClick(View view) {
checkPermission();
}
@OnClick(R.id.gps)
void gpsOnClick(View view) {
startActivityForResult(new Intent(android.provider.Settings.ACTION_LOCATION_SOURCE_SETTINGS), GPS_ENABLE_REQUEST);
}
private void checkingPosition() {
viewModel.getStatus().observe(this, new Observer() {
@Override
public void onChanged(@Nullable String status) {
updateUI(status);
}
});
}
private void updateUI(String status) {
statusView.setText(status);
}
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
if (requestCode == PLACE_PICKER_REQUEST) {
if (resultCode == RESULT_OK) {
Place place = PlacePicker.getPlace(data, this);
updatePlace(place.getLatLng());
}
}
if (requestCode == GPS_ENABLE_REQUEST) {
init();
}
}
private void updatePlace(LatLng latLng) {
viewModel.savePoint(latLng);
pointEditText.setText(latLng.toString());
}
private void showWarningPage(Warning warning) {
warningContainer.setVisibility(View.VISIBLE);
contentContainer.setVisibility(View.INVISIBLE);
switch (warning) {
case PERMISSION:
gpsButton.setVisibility(View.INVISIBLE);
permissionButton.setVisibility(View.VISIBLE);
break;
case GPS_DISABLED:
gpsButton.setVisibility(View.VISIBLE);
permissionButton.setVisibility(View.INVISIBLE);
break;
}
}
private void hideWarningPage() {
warningContainer.setVisibility(View.GONE);
contentContainer.setVisibility(View.VISIBLE);
}
} compile 'com.jakewharton:butterknife:8.6.0'
compile 'com.google.android.gms:play-services-maps:11.0.2'
compile 'com.google.android.gms:play-services-location:11.0.2'
compile 'com.google.android.gms:play-services-places:11.0.2'
annotationProcessor 'com.jakewharton:butterknife-compiler:8.6.0'|
|
Колебания цен на нефть: виноват ли алгоритмический трейдинг? |


|
Метки: author itinvest финансы в it блог компании itinvest нефть колебания цен биржа |
Охота на рыжего демона или пеленгатор помех спутниковой навигации |










|
|
Security Week 31: Борец с WannaCry арестован в США, Svpeng получил новую фишку, Cisco патчит 15 дыр |
 Что мы знаем о Маркусе Хатчинсе? На удивление мало. До истории с WannaCry о нем вообще ничего не было слышно, но тут его прославил блестящий ход со стоп-доменом. Парень порылся в коде троянца, нашел механизм самоуничтожения при получении ответа с захардкоденного домена, зарегал домен (затраты составили $10) и сумел существенно затормозить эпидемию Воннакрая.
Что мы знаем о Маркусе Хатчинсе? На удивление мало. До истории с WannaCry о нем вообще ничего не было слышно, но тут его прославил блестящий ход со стоп-доменом. Парень порылся в коде троянца, нашел механизм самоуничтожения при получении ответа с захардкоденного домена, зарегал домен (затраты составили $10) и сумел существенно затормозить эпидемию Воннакрая. Кроноса заметили в даркнете в 2014 году, когда его авторы открыли предзаказ за $7000. Цена, видимо, оказалась завышена, так как после релиза его начали продавать по $3000, а уже в 2015 году он шел по $2000. На Youtube, кстати, есть ролик, рекламирующий Кроноса, предположительно снятый подельником Хатчинса.
Кроноса заметили в даркнете в 2014 году, когда его авторы открыли предзаказ за $7000. Цена, видимо, оказалась завышена, так как после релиза его начали продавать по $3000, а уже в 2015 году он шел по $2000. На Youtube, кстати, есть ролик, рекламирующий Кроноса, предположительно снятый подельником Хатчинса. Что интересно, для перехвата клавиатурного ввода используются так называемые специальные возможности Android – функции облегчения работы со смартфоном для инвалидов. При этом Svpeng отказывается работать, если в списке клавиатурных раскладок обнаруживается русская. Роман Унучек, который у нас тут собаку съел на андроидной малвари, утверждает, что это обычная тактика для российских киберпреступников, чтобы избежать уголовного преследования. Мол, если в России ничего плохого их детище не делает, то и преступления как бы нет.
Что интересно, для перехвата клавиатурного ввода используются так называемые специальные возможности Android – функции облегчения работы со смартфоном для инвалидов. При этом Svpeng отказывается работать, если в списке клавиатурных раскладок обнаруживается русская. Роман Унучек, который у нас тут собаку съел на андроидной малвари, утверждает, что это обычная тактика для российских киберпреступников, чтобы избежать уголовного преследования. Мол, если в России ничего плохого их детище не делает, то и преступления как бы нет.
|
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» klsw malwaretech wannacry kronos svpeng cisco ospf |
Второй Hackfest в истории ReactOS |

|
Метки: author Jeditobe блог компании фонд reactos хакфест хакатон hackfest hackathon reactos |
[Перевод] XBRL: просто о сложном - Глава 6. Погружение в XBRL - Часть 1. Приступаем |
В предыдущих главах мы потрогали пальцем воду, выясняя, что представляет из себя XBRL, и что с его помощью можно сделать. С этим багажом знаний мы готовы к полному погружению в настоящий XBRL в нашей заключительной главе. Мы рассмотрим основные шаги по созданию таксономии и отчета и покажем, как XBRL выглядит в реальной жизни.
В этой главе мы покажем процесс формирования таксономии и связанного с ней отчета на уже знакомом вам примере про демографию компании. Как и в реальной жизни, мы не сможем сделать все правильно с первой же попытки, поэтому процесс их формирования у нас будет разбит на несколько разных версий. Разработка большинства реальных таксономий занимает от нескольких недель до нескольких месяцев (и даже лет).
Примечание: Мы не будем создавать базы ссылок определений (definition linkbase) и базы ссылок на реcурсы (reference linkbase). В реальной жизни вы могли бы создать по крайней мере одну из них, чтобы более подробно описать свои концепты, но для целей данной главы они не нужны. После того, как вы освоите базы ссылок ярлыков (label linkbase) и презентаций (presentation linkbase), с пониманием баз ссылок определений и ресурсов не должно возникнуть никаких проблем.
Начнем с простой таксономии для нашего примера.
Прежде всего нам нужен документ, содержащий схему таксономии.
Хорошей практикой является использование в имени документа даты создания таксономии, чтобы легко различать созданные в разное время версии таксономии.
Давайте считать, что мы начинаем наш маленький проект в первый день года, сразу после боя курантов, тогда назовем документ с таксономией следующим образом – ‘sample-2017-01-01.xsd’. Будем обсуждать наш документ небольшими частями, создавая таксономию шаг за шагом.
Как и в любой XML-схеме, мы начинаем с корневого элемента schema:
...
Обратите внимание на атрибуты внутри корневого элемента:
targetNameSpaceОстальные атрибуты определяют префиксы элементов схемы. Префикс указывает, каким пространством имен определяется элемент:
xmlnsxmlns:xbrlixmlns:linkxmlns:xlinkxmlns:samplesample.Все приведенные ниже документы имеют одинаковые атрибуты определения пространств имен в корневом элементе. Мы не будем описывать их отдельно для каждого нового типа элемента.
Спецификация XBRL включает в себя ряд схем:
- XBRL Instance
Содержит определения (типы, атрибуты, элементы), необходимые для объявления фактов и концептов;- XBRL Linkbase
Содержит определения, необходимые для объявления ссылок от одной части таксономии (или базы ссылок) к другой;- XBRL XLink
Используется для объявления самих баз ссылок, это пространство имен понадобится вам при создании собственного расширения спецификации XBRL;- W3C XLink
Пространство имен для XML Link; обратите внимание, что схема для этой части спецификации находится на сайте xbrl.org, поскольку W3C не предоставляет эту схему, а для спецификации XBRL она необходима.
Наш следующий шаг – импортировать схему отчета XBRL, чтобы мы могли использовать конструкции из нее в своих определениях элементов.
Элементimportдолжен точно определить схему, идентифицированную пространством имен. Документ схемы, на который указывает URI в атрибутеschemaLocation, должен реально существовать.
Схема отчета XBRL импортирует схему XBRL Linkbase, а она, в свою очередь, импортирует схемы XBRL XLink и W3C XLink. Это означает, что нам не нужно самостоятельно импортировать эти схемы.
Пространство имен W3C XML Schema стандартизировано и автоматически распознается поддерживающим нашу схему программным обеспечением.
Концепты в нашей таксономии определяются как элементы схемы. Из нашего примера мы ранее получили следующие концепты:
| Имя | Тип |
|---|---|
| nr_employees_total | non-negative integer item |
| nr_employees_male | non-negative integer item |
| nr_employees_female | non-negative integer item |
| nr_employees_age_up_to_20 | non-negative integer item |
| nr_employees_age_21_to_40 | non-negative integer item |
| nr_employees_age_41_and_up | non-negative integer item |
Концепт, отражающий общее количество сотрудников, определяется следующим образом:
Разберем атрибуты концепта:
idnamexbrli:periodTypeinstant.typenonNegativeIntegerItemType, определенный в схеме отчета XBRL.substitutionGroupitem, определенное в схеме отчета XBRL.nillablenillable, это позволяет передавать по ним пустые факты.Остальные концепты определяются аналогично, но каждый со своими значениями атрибутов id и name.
Нам также понадобится абстрактный концепт, который будет служить корнем иерархии представления нашего отчета. Ему (произвольно) присвоим тип xbrli:stringItemType. Для передачи фактов абстрактные концепты не используются, поэтому можно указать любой тип для удовлетворения требований спецификации XBRL по его наличию.
Абстрактный концепт должен иметь атрибут abstract со значением true.
Если мы хотим представить полноценную таксономию или отчет, нам надо предоставить дополнительную информацию о концептах в виде баз ссылок. Начнем с двух из них – базы ярлыков и базы презентаций.
Связь с базами ссылок указывается в элементе appinfo, который размещается внутри элемента annotation:
У связи с базой ссылок есть следующие атрибуты:
xlink:typesimple.xlink:hrefxlink:rolelabelLinkbaseRef и presentationLinkbaseRef, определенные схемой XBRL Linking.xlink:arcrolelinkbase.База ярлыков содержит три типа элементов:
Эти элементы размещаются внутри элемента labelLink:
...
У элемента labelLink есть следующие атрибуты:
xlink:typeextended.xlink:rolelink.Локаторы размещаются в элементы loc. Они указывают на концепты связанной с ними таксономии.
xlink:typeloc всегда указывается locator, означающий, что он используется как локатор (концептов).xlink:hrefid.xlink:labelДля определения ярлыков используется элемент label.
xlink:typexlink:labellabel обеспечивает возможность обращаться к ярлыку внутри базы ссылок. Обратите внимание, что каждая из приведенных меток связана с одним и тем же концептом, и во всех из них используется одно и то же значение атрибута. Это позволяет использовать связь один-ко-многим от концепта к его ярлыкам. В нашем примере это три разных вида ярлыков для концепта ‘nr_employees_total’.xlink:rolexml:langНаконец, после определения локаторов к концептам и ресурсов ярлыков, мы можем связать их с помощью дуг ярлыков.
xlink:typexlink:arcrolexlink:fromlabel локатора в качестве значения этого атрибута.xlink:tolabel ресурса. Поскольку мы использовали один и тот же label для трех разных ярлыков, наша дуга образует связь один-ко-многим между концептом и его ярлыками.
Презентации содержат два типа элементов:
Все они располагаются внутри элемента presentationLink:
...
Здесь все аналогично базе ссылок ярлыков, не будем повторяться.
Дуги презентаций связывают концепты в parent-child иерархию (дерево):
xlink:typexlink:arcrolexlink:fromxlink:toorderpriorityuseoptional, мы обозначаем, что концепт может быть частью сети презентаций. Общепринятой практикой является указание этого значения, хотя оно же используется по умолчанию в случае отсутствия атрибута.preferredLabelПримечание: Поскольку атрибут preferredLabel может указываться только для дочерних концептов, корневой элемент иерархии презентации предпочтительного вида ярлыка иметь не может.
Создав таксономию, мы можем использовать ее для создания отчета.
Документ с отчетом XBRL содержит следующие виды элементов:
Все эти элементы размещаются внутри элемента xbrl:
...
Ссылка на схему указывается в элементе schemaRef:
xlink:typexlink:hrefhref-атрибут. Он указывает расположение схемы таксономии на сайте ее создателя.У нас в примере есть два контекста – начало отчетного периода и конец отчетного периода:
12-34567
2016-01-01
12-34567
2016-12-31
identityidentifierscheme) для определения того, по какой организации составляется отчет. В нашем примере мы используем несуществующую схему на вымышленном сайте.periodinstantСсылка, указанная в элементе identifier, ссылается на несуществующую статистическую организацию, которая публикует идентификаторы подотчетных организаций. Наша воображаемая компания имеет идентификатор ‘12-34567’. В реальном мире мы бы использовали, к примеру, тикер фондовой биржи или идентификатор организации в национальном налоговом органе.Для всех числовых фактов должны быть указаны единицы измерения:
Person
idmeasureТеперь мы наконец достигли финальной цели всего нашего упражнения – передачи фактов:
35
41
23
27
12
15
5
9
23
21
7
11Каждый факт – это отдельный связанный с концептом элемент. Значение элемента является значением факта.
contextRefid контекста. Наш пример содержит факты для каждого концепта в каждом из контекстов.unitRefdecimalsdecimals (десятичные знаки) или precision (точность). В нашем примере все факты целочисленные, поэтому указываем decimals со значением ‘0’.После всей проделанной работы нам хотелось бы увидеть, как формируется наш отчет в привязке к таксономии и, в частности, к базам ссылок презентаций и ярлыков.
Для этого воспользуемся простым инструментом, который создает веб-страничку для нашего отчета с отображением фактов в табличном виде. Он располагает контексты в столбцах таблицы, а ярлыки концептов из базы ссылок ярлыков – слева от нее. Иерархия концептов, определенная в базе ссылок презентаций, задает порядок следования и отступы для фактов.
Полученный нами результат выглядит примерно следующим образом:
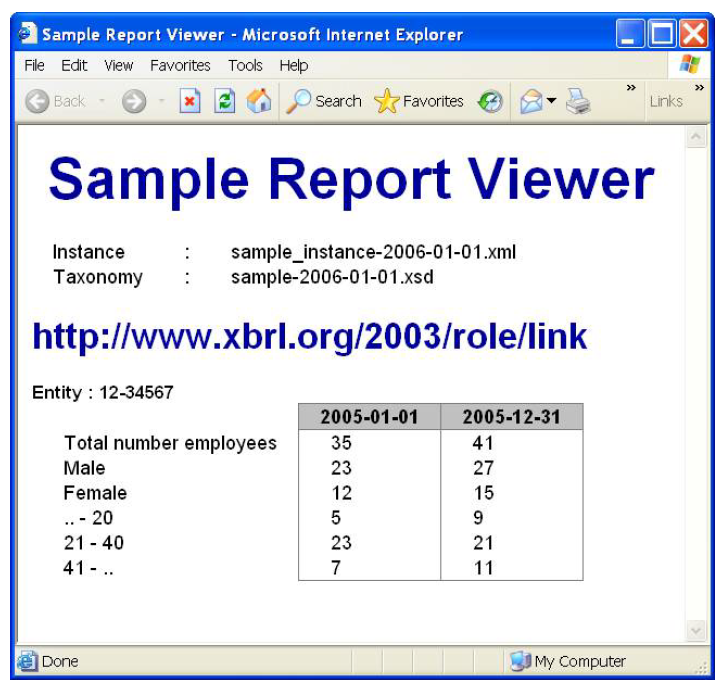
В общем, мы неплохо потрудились!
|
Метки: author r_udaltsov анализ и проектирование систем it- стандарты xbrl финансы отчетность цб рф |
Подготовка к проекту внедрения SAP HCM |
|
Метки: author virvit управление проектами управление персоналом erp- системы hcm sap hcm erp подготовка к проекту |
Как перенести сервер Zimbra на другой сервер |

$ tar xfz Zextras_migration_tool-X.X.X.tgz
$ ls
Zextras_migration_tool-X.X.X.tgz Zextras_migration_tool-X.X.X/$ cd Zextras_migration_tool-X.X.X
$ ./install.sh -h
./install.sh -h | ./install.sh [ -u ] all|zimlet|core
-h This very message
-u Uninstall the target
The targets available for (un)installation are:
core -- Zextras Migration Tool Core
zimlet -- Zextras Migration Tool Zimlet
all -- Zextras Migration Tool Core followed by Zextras Migration Tool Zimlet
* In order to use Zextras Migration Tool both
* core and zimlet need to be installed.$ su -
# ./install.sh all$ sudo ./install.sh all

Wget http://www.Zextras.com/download/Zextras_suite-latest.tgz$ tar xfz Zextras_suite-X.X.X.tgz
$ ls
Zextras_suite-X.X.X.tgz Zextras_suite-X.X.X/./install.sh all



|
|
[Перевод - recovery mode ] 10 типов структур данных, которые нужно знать + видео и упражнения |
|
|
[Из песочницы] Как мы оптимизировали Ragdoll анимацию смерти в Unity |

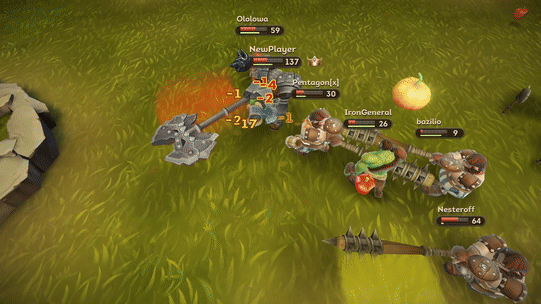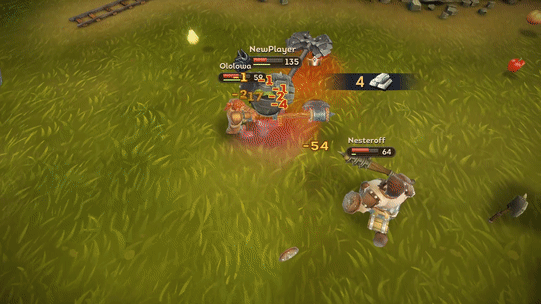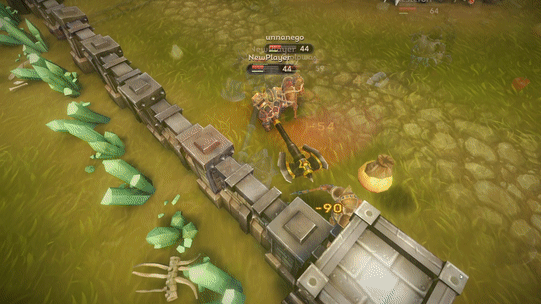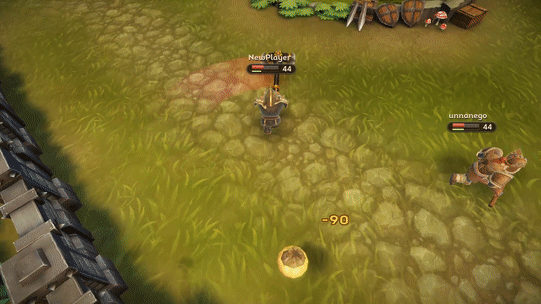
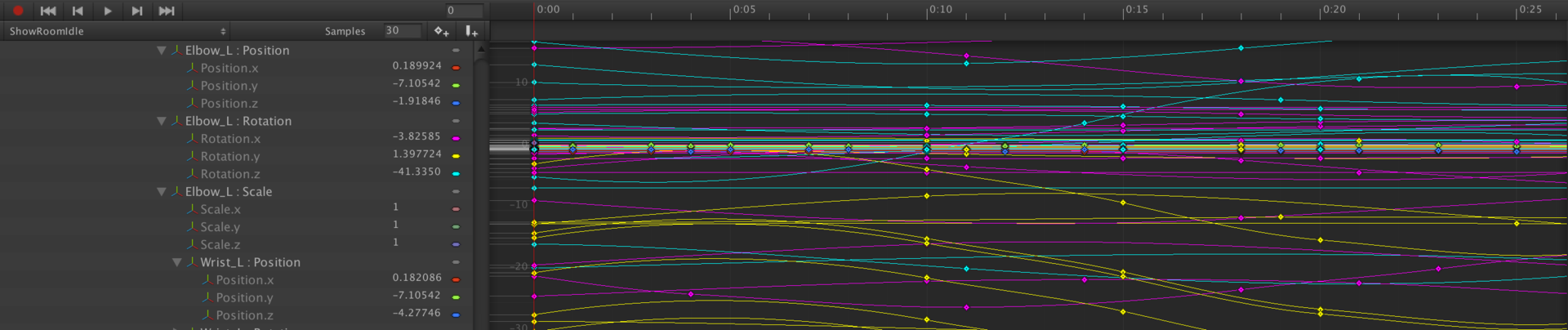
Properties = new Dictionary ();
Properties.Add ( "localPosition.x", new AnimationCurve () );
Properties.Add ( "localPosition.y", new AnimationCurve () );
Properties.Add ( "localPosition.z", new AnimationCurve () );
Properties.Add ( "localRotation.x", new AnimationCurve () );
Properties.Add ( "localRotation.y", new AnimationCurve () );
Properties.Add ( "localRotation.z", new AnimationCurve () );
Properties.Add ( "localRotation.w", new AnimationCurve () );
Properties.Add ( "localScale.x", new AnimationCurve () );
Properties.Add ( "localScale.y", new AnimationCurve () );
Properties.Add ( "localScale.z", new AnimationCurve () );
Properties["localPosition.x"].AddKey (new Keyframe (time, _animObj.localPosition.x, 0.0f, 0.0f));
Properties["localPosition.y"].AddKey (new Keyframe (time, _animObj.localPosition.y, 0.0f, 0.0f));
Properties["localPosition.z"].AddKey (new Keyframe (time, _animObj.localPosition.z, 0.0f, 0.0f));
Properties["localRotation.x"].AddKey (new Keyframe (time, _animObj.localRotation.x, 0.0f, 0.0f));
Properties["localRotation.y"].AddKey (new Keyframe (time, _animObj.localRotation.y, 0.0f, 0.0f));
Properties["localRotation.z"].AddKey (new Keyframe (time, _animObj.localRotation.z, 0.0f, 0.0f));
Properties["localRotation.w"].AddKey (new Keyframe (time, _animObj.localRotation.w, 0.0f, 0.0f));
Properties["localScale.x"].AddKey (new Keyframe (time, _animObj.localScale.x, 0.0f, 0.0f));
Properties["localScale.y"].AddKey (new Keyframe (time, _animObj.localScale.y, 0.0f, 0.0f));
Properties["localScale.z"].AddKey (new Keyframe (time, _animObj.localScale.z, 0.0f, 0.0f));
Path to the game object this curve applies to. The relativePath is formatted similar to a pathname, e.g. «root/spine/leftArm». If relativePath is empty it refers to the game object the animation clip is attached to.
private List _recorders;
void Start ()
{
Configurate ();
}
void Configurate ()
{
_recorders = new List ();
var allTransforms = gameObject.GetComponentsInChildren< Transform > ();
for ( int i = 0; i < allTransforms.Length; ++i )
{
string path = CreateRelativePathForObject ( transform, allTransforms [ i ] );
_recorders.Add( new AnimationRecorderItem ( path, allTransforms [ i ] ) );
}
}
private string CreateRelativePathForObject ( Transform root, Transform target )
{
if ( target == root )
{
return string.Empty;
}
string name = target.name;
Transform bufferTransform = target;
while ( bufferTransform.parent != root )
{
name = string.Format ( "{0}/{1}", bufferTransform.parent.name, name );
bufferTransform = bufferTransform.parent;
}
return name;
}
private float _recordingTimer;
private bool _recording = false;
void Update ()
{
if ( _recording )
{
for ( int i = 0; i < _recorders.Count; ++i )
{
_recorders [ i ].AddFrame ( _recordingTimer );
}
_recordingTimer += Time.deltaTime;
}
}
private const float CAPTURING_INTERVAL = 1.0f / 30.0f;
private float _lastCapturedTime;
private float _recordingTimer;
private bool _recording = false;
void Update ()
{
if ( Input.GetKeyDown ( KeyCode.Space ) && !_recording )
{
StartRecording ();
return;
}
if ( _recording )
{
if (_recordingTimer==0.0f||_recordingTimer-_lastCapturedTime>=CAPTURING_INTERVAL)
{
for ( int i = 0; i < _recorders.Count; ++i )
{
_recorders [ i ].AddFrame ( _recordingTimer );
}
_lastCapturedTime = _recordingTimer;
}
_recordingTimer += Time.deltaTime;
}
}
public void StartRecording ()
{
Debug.Log ( "AnimationRecorder recording started" );
_recording = true;
}
private void ExportAnimationClip ()
{
AnimationClip clip = new AnimationClip ();
for ( int i = 0; i < _recorders.Count; ++i )
{
Dictionary propertiles = _recorders [ i ].Properties;
for ( int j = 0; j < propertiles.Count; ++j )
{
string name = _recorders [ i ].PropertyName;
string propery = propertiles.ElementAt ( j ).Key;
var curve = propertiles.ElementAt ( j ).Value;
clip.SetCurve ( name, typeof(Transform), propery, curve );
}
}
clip.EnsureQuaternionContinuity ();
string path = "Assets/" + gameObject.name + ".anim";
AssetDatabase.CreateAsset ( clip, path );
Debug.Log ( "AnimationRecorder saved to = " + path );
}

|
Метки: author blackfxx разработка игр unity3d анимация ragdoll оптимизация gamedev steam android ios |
[Перевод] Laracon 2017 — краткий обзор и куча полезных ссылок |

Я побывал первый раз на конференции Laracon лично и, должен сказать, я получил там весьма приятный опыт — возможно, даже более приятный, чем я ожидал. Конференция была хорошо организована и доклады были разнообразными, информативными и действенными. Первый день был посвящен техническим вопросам и в основном вращался вокруг Laravel. Второй день был разбавлен выступлениями на самые разные темы, довольно занимательными и заставляющими задуматься.
Лично мне больше всего понравилась возможность встретиться с целой кучей людей, с которыми я общаюсь Твиттере.
Другой интересный момент — это возможность совершить небольшое ”пищевое паломничество” в Нью-Йорке. На Лараконе также было много бесплатной еды, и я даже немного ее попробовал, но я не собирался упускать эту возможность.
В этой статье будет краткий обзор того, что я узнал на презентациях. К сожалению, мне не удалось прослушать блок докладов от Science Fair. Я не делал заметок и не смогу представить детальный отчет по каждому выступлений. По некоторым выступлениям материала много, по другим — мало.
Тема: Создаем панель управления с помощью Laravel, Vue.js и Pusher
Мне уже был знаком материал, который Фрик осветил в своем выступлении, поскольку я уже читал запись в его блоге на эту тему. И всё же я узнал много нового, поскольку он кодил в прямом эфире, чтобы показать, как сделаны компоненты времени/погоды, статистики packagist и лента Твиттера.
Он также представил впечатляющие в статистику по опенсорс-пакетам Spatie.
Ссылки:
Тема: Как строить многопользовательские приложения
Презентация попала в точку, поскольку половина аудитории мечтала построить свое крутое SaaS-приложение. Том говорил о различных стратегиях баз данных: Он сравнивал, как можно использовать одну базу и как несколько, говорил об их достоинствах и недостатках. Также он говорил о других своих соображениях: например, о том, что надо сегментировать разные компоненты своего приложения (очереди, консольные команды, миграции, хранилище файлов, кэш и т.д.) и стратегии назначения доменов. Я поделюсь деталями ниже, так как его презентация уже есть в открытом доступе.
Том упоминал у себя в Твиттере, что он будет выступать впервые, так что для первого раза вышло вполне неплохо.
Ссылки:
Тема: CRUDово по дизайну
Адам в своем выступлении сфокусировался на том, что контроллеры надо делать как можно более RESTful. Вначале он показал скриншот Basecamp 3, который упоминал в своем твите David Heinemeier Hansson (DHH):

https://twitter.com/dhh/status/647163196839739392
Здесь надо обратить внимание на следующие показатели: количество контроллеров, маленькое количество методов на каждый контроллер и среднее число строк кода в каждом методе.
Адам писал код прямо на сцене для демо-приложения — Casthacker. В его файле маршрутов было два контроллера — PodcastsController с 13-ю методами и EpisodesController с 5-ю.
Он переработал их в дополнительные контроллеры при помощи следующих принципов:
Главная мысль демо была в том, что никогда не надо писать кастомные действия. Ограничьте методы контролера до 7 CRUD-действий: index, create, store, show, edit, update и destroy.
// Примеры:
// До
PodcastsController@publish
PodcastsController@unpublish
// После
PublishedPodcastsController@store
PublishedPodcastsController@destroy
// До
PodcastsController@subscribe
// После
SubscriptionsController@storeЕго презентацию и демо-приложение еще нельзя посмотреть онлайн, но он написал в Твиттере, что скоро всё выложит. Но если вы уже подписаны на его курс Test-Driven Laravel, то вы найдете эту тему в секции “Publishing Concert Drafts”.
Ссылки:
Тема: Laravel Scout + Algolia + Vue
Меня впечатлила презентация Максима, где он в прямом эфире показывал, как легко можно построить поисковый интерфейс для своего существующего проекта. Примерно за 15-20 минут он построил функционирующий поисковый интерфейс для списка выступающих на конференции. Для этого сделал следующее:
scout:import.Если вы не знали, у Algolia Есть опция поиска в документации Laravel.
Ссылки:
Тема: Состояние Vue на 2017 год
Презентация Vue показалось мне немного сдержанной, и на то есть причины, поскольку Vue 2.x сейчас находится в стабильном состоянии и в ближайшее время не планируется никаких релизов с новыми крутыми функциями.
Первая конференция VueConf проходила в Польше в июне.
Эван в основном говорил о росте Vue: показывал впечатляющую статистику из Github (61.2k+ звезд), NPM (622k+ загрузок в месяц) и Chrome Devtools (228k+ активных пользователей в неделю). Он также приводил примеры роста экосистемы Vue. Самое примечательное из — Weex, мобильный UI-фреймворк.
Также я отметил ряд моментов:
Ссылки:
Тема: Управление зависимостями
Я пропустил довольно большой кусок этого выступления. Похоже, там предлагали Private Packagist (или Satis) в качестве решения задачи по мирроингу пакетов и управлению рисками зависимостей софта.
Во второй половине доклада дали хорошие подсказки для композера:
composer update [--dry-run] вместо полного composer update. Метка dry-run позволяет просматривать изменения без какого-либо влияния на файлы.composer.lock в систему контроля версий. Используйте git checkout composer.lock , чтобы разрешать конфликты слияния в lock-файле.Важное уточнение к последнему пункту: если вы работаете в команде, у вас будут возникать проблемы с composer.lock, только если все одновременно запустят composer update в своих ветках без какой-либо цели. Если следовать этим двум правилам, то проблемы будут возникать редко:
composer.lock для обновления пакетов.composer update , если надо проапгрейдить конкретную зависимость при работе над какой-то функцией или при исправлении баги. Этот момент также надо обговаривать со всей командой, чтобы несколько человек ненароком не обновили один и тот же пакет, пока они работают над чем-то еще.Ссылки:
Тема: Laravel Horizon (возможно, там было что-то другое, но именно эта тема была у всех в голове)
Наконец, пришло время главного доклада. Тейлор прошелся по всему списку новых функций Laravel 5.5. Я включил в список ссылки на Laravel News и Laracasts, где можно изучить в деталях все функции. Меня особенно порадовали классы кастомных правил валидации. Я писал о них раньше в другой статье.
Но все взоры были прикованы к Horizon. Когда его наконец показали публике, я очень обрадовался, потому что это именно то, что мне нужно для моей текущей работы. Horizon — это пакет Laravel, который помогает управлять очередями через конфигурационный файл. И у него отличный интерфейс. Если вы часто страдаете от того, что приходится управлять несколькими проваленными задачами одновременно через командную строку, то Horizon вам понравится. Одно предостережение: он поддерживает только драйвер Redis, но это опенсорс, так что в сообществе, возможно, скоро добавят поддержку и других драйверов.
Сайт Horizon запустили на 2ой день конференции: https://horizon.laravel.com
Тейлор также намекнул, что скоро будет больше обновлений. Почти наверняка они будут связаны с файлом cloud.yml, который был у него в корневой папке демо-приложения, и командой cloud deploy, при помощи которой он вносил изменения в конфигурацию.
Ссылки:
Тема: Настройка Laravel
Мэтт так тараторил, что шутка про повторный просмотр его выступления на Youtube на скорости 0.5 и шуткой-то не является.
Он рассказал о многих базовых и продвинутых техниках кастомизации Laravel, чтобы настроить его под особые нужды вашего приложения. Его презентация доступна в списке ссылок ниже, так что я не буду повторять материал.
Что меня особенно зацепило в его выступлении, так это его мысли о читабельности кода:
Мне вспомнилась иллюстрация, которую я видел в книге “Чистый код” за авторством Роберта Мартина (Дядя Боб):

Источник:
http://www.osnews.com/story/19266/WTFs_m
Полагаю, плохая читабельность кода будет означать, что показатель “что это за хрень?!” в минуту будет довольно высоким.
Ссылки:
Тема: webpack — основные идеи и не только
Шон очень круто объяснил, чем является webpack для backend-разработчиков, которые в основном используют его вместе с Laravel Mix.
webpack — это компоновщик модулей. Он объединяет модули JavaScript (ES6, CommonJS и AMD) для запуска в браузере. У енго модульная архитектура, основанная на плагинах. 80% webpack-а построено на плагинах.
В остальной части доклада обсуждали компоненты плагинов и “tapable” элементы.
Материалы, возможно, будут полезны, если вы разрабатываете плагины или если вы пытаетесь отлаживать модуль, но в большинстве случаев от всех этих проблем прикроет Laravel Mix.
Вы можете помочь разработчикам webpack, если вы поддержите их на сайте Open Collective.
Ссылки:
Тема: Запуск и масштабирование стороннего проекта
Эту презентацию подготовили основатели Geocod.io, которые по особому стечению обстоятельств оказались мужем и женой. В своем докладе они рассказали о своем опыте по запуску и масштабированию стороннего проекта.
Многие идеи, которые они озвучили, вполне очевидны. Например, решай свою собственную проблему, создай MVP, ратифицируй свой продукт, знай свой рынок, не масштабируйся слишком рано и т.д. Впрочем, помимо таких идей они делились своим собственным опытом, поэтому слушать их было интересно. Также они дали пару практических советов по поводу переноса компании в США, страховки и SaaS-приложений для обслуживания клиентов и аналитики, которыми они пользовались сами.
Ссылки:
Тема: Отладка дизайна
Выступление Лауры содержало правильное сообщение для правильной целевой аудитории. Она подвела всех к мысли о том, что к редизайну сайта надо подходить с точки зрения разработчика — решать проблемы по шагам. Такой подход облегчает работу для того, у кого нет природной склонности к дизайну.
Она показала, как подобрать основной цвет, общую палитру, типографику (шрифты, иерархия, размеры), отступы, планировку и как навести блеск в конце. Все материалы были очень практичны. Для меня бонусом стал список инструментов, которые она использовала. Я перечислил их ниже.
Ссылки:
Тема: Как создавать приложения, которые люди будут покупать
Доклад Джастина был весьма занимательным. Возможно, он немного пересекался с предыдущим докладом о стороннем проекте, но подход был другой.
Ключевые мысли его доклада:
Он также порекомендовал пару книг. Ссылки на них вы увидите ниже.
Ссылки:
Тема: Убить чудовище
Большинству людей, возможно, было бы интересно послушать выступление Джеффри “Глубинный анализ цветовой темы, которую я использую”. Если судить по комментариям к его видеозаписям на Laracasts, людям интересны IDE-темы так же, как и сам код.
Джеффри озвучил 9 причин, почему нужно “Убить чудовище”. В этот момент я перестал делать записи, и поэтому у меня нет детального изложения его материала. Основная мысль, которую я запомнил (потому что он возвращался к ней много раз) — это то, что все переделки кода должны быть грубыми. Это значит, что если какая-то часть кода перестала вас устраивать, то переделайте ее самым простым из возможных способов. Если после этого ваш код не стал лучше, не бойтесь вернуться к предыдущей версии.
В основном он затрагивал те темы, которые в той или иной степени освещались на Laracasts: очистка внутреннего api, использование одиночных traits, уменьшение количества условий в views, событий/слушателей и объектов запросов.
Под конец он выдал пару интересных цитат. Мне особенно понравилась цитата про убийство кода. Я нашел ее источник и добавил к ссылкам ниже.
Если вам нужно доказательство будущего, то вам не нужен Терминатор T-1000. Вам нужен Кенни из Южного Парка. Нам нужен код, который можно убить легко и весело.
Ссылки:
Тема: Глубокое влияние
Тема, о которой говорил Джек, была довольно мрачная (по крайней мере, первая половина), но он всё же преподносил ее довольно легко и смог донести свою точку зрения. Ключевая мысль была в том что в определенный период нужно позволить себе глубоко сфокусироваться на своей работе, отказавшись от постоянных развлечений современной жизни. Мы постоянно ходим по краю и не углубляемся в реальную работу, и при этом мы очень заняты, но так не должно быть.
В зависимости от того, с какой точки зрения на это посмотреть, его высказывание было либо полностью неуместным, либо как раз-таки попало в точку, поскольку зал был полон людей, которые сидели, уткнувшись в свои ноутбуки или телефоны. Он также говорил о модели обучения, которую он назвал “Заплати вперед”. При такой модели вы обучаете троих людей, и каждый из них в свою очередь обучает еще троих, и так далее. Доклад прозвучал вполне уместно для конца конференции: он не освещал никаких технических вопросов, и всё же заставляла задуматься о некоторых вещах.
Ссылки:
|
Метки: author r-moiseev программирование php laravel javascript api vue.js pusher algolia composer packagist webpack geocod.io |
[recovery mode] ГДЕ ЛОГИКА? Учимся мыслить системно. Часть 2 |
Для успеха в жизни — умение общаться с людьми гораздо важнее обладания талантом
Джон Лаббок
|
Метки: author ARadzishevskiy читальный зал учебный процесс в it системный анализ управление требованиями формализация проблем |
«Советы инженерам»: обзор Huawei S5720-52X-PWR-SI V2R9SPC500 |


48GE PoE+, 4*10GE портов.
SI версия поддерживает L3 маршрутизацию, включая RIP и OSPF.
Версия ПО V200R009C00SPC500.
Мощность блока питания 500Вт, для PoE доступно 370.
Стекирование возможно через 1/10GE Uplinks.
Интерфейсы 10GE поддерживают практически любые трансиверы, в том числе SNR.
Поддерживается управление через web интерфейс и CLI (telnet, ssh v2), SNMP v2c/v3, централизованное через eSight.
router id 192.168.30.4
#
ospf 1
area 0.0.0.0
network 10.0.50.0 0.0.0.255
#
interface Vlanif50
mtu 9198
ospf timer hello 1
ospf timer dead 3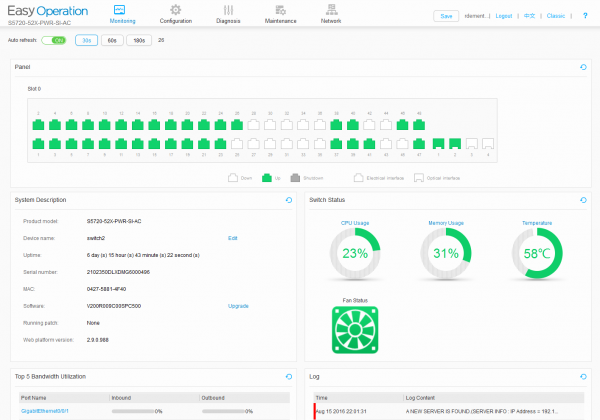
dhcp enable
#
dhcp snooping enable
dhcp snooping alarm dhcp-rate enable
dhcp snooping user-bind autosave flash:/dhcp-bind.tbl write-delay 6000
arp dhcp-snooping-detect enable
dhcp server detect
vlan 2
name office
dhcp snooping enable
dhcp snooping check dhcp-request enable
dhcp snooping check dhcp-rate enable
arp anti-attack check user-bind enable
ip source check user-bind enable
vlan 3
name guest
dhcp snooping enable
dhcp snooping check dhcp-request enable
dhcp snooping check dhcp-rate enable
arp anti-attack check user-bind enable
ip source check user-bind enable
vlan 4
name voice
dhcp snooping enable
dhcp snooping check dhcp-request enable
dhcp snooping check dhcp-rate enable
arp anti-attack check user-bind enable
ip source check user-bind enable
interface GigabitEthernet0/0/1
port link-type hybrid
voice-vlan 4 enable
port hybrid pvid vlan 2
port hybrid tagged vlan 4
port hybrid untagged vlan 2
stp root-protection
stp bpdu-filter enable
stp edged-port enable
trust dscp
stp instance 0 root primary
stp bpdu-protectionuser-interface maximum-vty 15
user-interface con 0
authentication-mode aaa
history-command max-size 20
screen-length 40
user-interface vty 0 14
authentication-mode aaa
history-command max-size 20
idle-timeout 30 0
screen-length 40stelnet server enable
[HUAWEI] aaa
[HUAWEI-aaa] local-user admin123 password irreversible-cipher Huawei@123
[HUAWEI-aaa] local-user admin123 service-type ssh
[HUAWEI-aaa] local-user admin123 privilege level 15
[HUAWEI-aaa] quit
[HUAWEI] ssh user admin123 authentication-type passworddomain default_admin
authentication-scheme default
accounting-scheme Radius
service-scheme Admin
radius-server Radius|
Метки: author Huawei_Russia системное администрирование сетевые технологии советы обзор опыт |
«Ржавая» IP-камера: прошивка на Rust |
# free
total used free shared buffers cached
Mem: 60128 17376 42752 0 2708 4416
-/+ buffers/cache: 10252 49876
Swap: 0 0 0
# cat /proc/cpuinfo
Processor : ARM926EJ-S rev 5 (v5l)
BogoMIPS : 218.72
Features : swp half thumb fastmult edsp java
CPU implementer : 0x41
CPU architecture: 5TEJ
CPU variant : 0x0
CPU part : 0x926
CPU revision : 5
Hardware : hi3518
Revision : 0000
Serial : 0000000000000000
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author erlyvideo rust блог компании эрливидео ip camera hardware embedded |
Пятничная дискуссия |
На днях натолкнулся на Хабре на статью, в которой автор пытается навалять по морде одному очень популярному на сегодня языку программирования, да именно навалять по морде, а не взвешенно раскритиковать. И не было бы этой статьи, если бы не два но: первое но — отвратительно низкое качество: статья по стилю оформления, аргументации и всему содержанию похожа на кликбейт, второе но — вокруг нее развернулась серьезная дискуссия, а сама статья вышла в топ, (видимо те кто ставил плюсы, хотят видеть больше наполненных болью и отчаянием статей). Но, давайте отсечем все лишнее: как и десяток лет назад, и десяток лет до того, мы вновь видим статью критикующую Инструмент с точки зрения абстракной правильности.
И так, вечер, пятница, какие языки вам сегодня кажутся наиболее совершенными, если бы вы разрабатывали язык программирования, то чем бы он отличался от конкурентов, какие задачи решал лучше других, за счет чего победил бы в битве языков?
|
Метки: author rumkin совершенный код программирование ненормальное программирование языки программирования |
RADIUS аутентификация пользователей доверенного домена |
Причина = Не удается установить подключение из-за отказа в разрешении на удаленный доступ для учетной записи пользователя. Чтобы разрешить удаленный доступ, включите такое разрешение для учетной записи пользователя или, если в ней указано, что управление доступом осуществляется с помощью соответствующей политики удаленного доступа, включите разрешение на удаленный доступ для этой политики.
Set objOU = GetObject("LDAP://dc=DOM3,dc=local")
objOU.Filter = Array("user")
For Each objUser In objOU
objUser.PutEx 1,"msNPAllowDialin", vbnull
objUser.SetInfo
Next|
Метки: author v0rdych системное администрирование серверное администрирование radius windows domain mixed-mode dial-in policy |
Может ли дрон купить пиво? (Вопрос к размышлению) |

Наверно сейчас вы задумались над вопросом, который указан в заголовке статьи, так же как и мы с kichik. В итоге мы пришли к выводу, что всё же дрон не может купить пиво, потому что становится невозможным идентифицировать хозяина, а значит и законность продажи алкоголя.
UPD Так как этот вопрос вызвал спор, присоединяйтесь к голосованию во ВК и делитесь своим мнением в комментариях. Давайте докопаемся до истины вместе.






Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Schvepsss блог компании microsoft microsost день пива iot интернет вещей домашняя пивоварня |
Что отставной генерал НАТО преподаёт студентам Университета Иннополис |


|
Метки: author T-Fazullin учебный процесс в it блог компании innopolis university университет иннополис нато гибкая разработка программное обеспечение образование |
Как пережить хардфорк и не слечь в больницу |

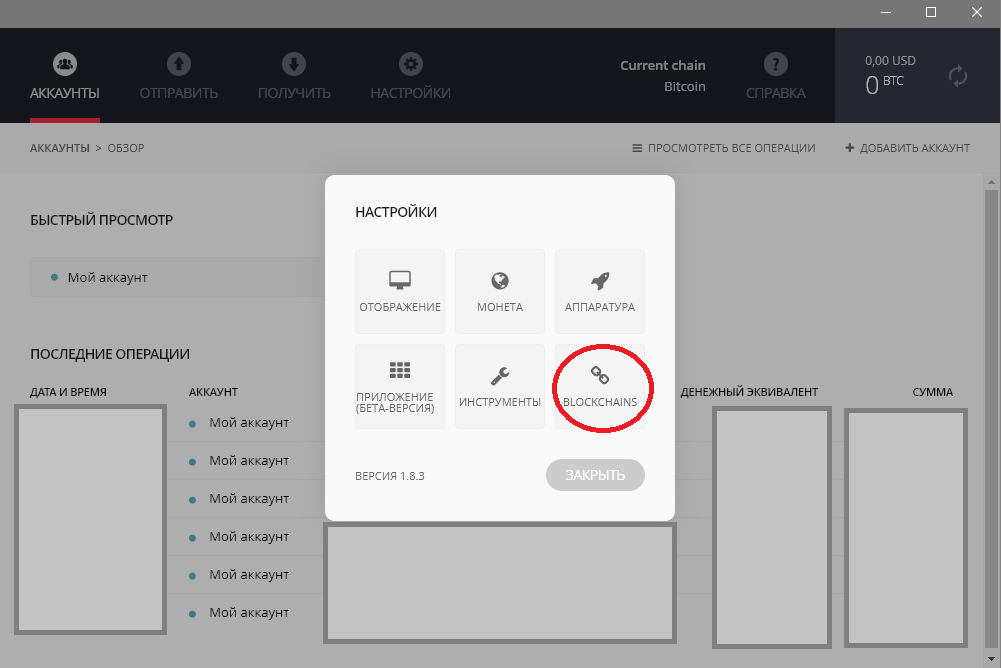
Согласно идее форка, дублируется весь блокчейн — соответственно, и все кошельки. Ledger предоставляет доступ к дублированному кошельку в блокчейне Bitcoin Cash, он называется Main-кошельком. Однако в целях безопасности рекомендуется перевести все средства на новый кошелек — Split. Дмитрий зашел в кошелек Ledger и увидел ноль на балансе BTC и BCH-Split. Ноль на балансе BTC был вызван багом приложения, а ноль на BCH-Split нормален, потому что коины на него еще нужно перевести с кошелька BCH-Main.
Восстановление кошелька было пунктом не обязательным. Многие люди в обсуждении на Reddit писали, что кошелек показывает нулевой баланс и пустую историю транзакций после смены блокчейна. Эта проблема исправляется вторым пунктом.







|
Метки: author onbillion финансы в it биткоин туториал устройства кошелек криптовалюта |






