Как не дать отвлекать себя от работы. Советы и слэк-бот |
 Отвлекаться плохо, очень плохо! Все это знают, но не все знают, что с этим делать и каков реальный масштаб проблемы. Поэтому я решил собрать вместе несколько техник по снижению числа отвлечений и даже написал небольшого бота, помогающего мне в этом.
Отвлекаться плохо, очень плохо! Все это знают, но не все знают, что с этим делать и каков реальный масштаб проблемы. Поэтому я решил собрать вместе несколько техник по снижению числа отвлечений и даже написал небольшого бота, помогающего мне в этом.
 Если вы уже отправили одного коллегу ждать, но уже пишет другой со своей задачей? Ваше сердце принадлежит тому, кто написал первым. Второго ставим в очередь. При этом сообщаем, что можно и нужно написать про задачу подробнее, но читать вы будете, только когда разберетесь с первой.
Если вы уже отправили одного коллегу ждать, но уже пишет другой со своей задачей? Ваше сердце принадлежит тому, кто написал первым. Второго ставим в очередь. При этом сообщаем, что можно и нужно написать про задачу подробнее, но читать вы будете, только когда разберетесь с первой.|
Метки: author fo2rist gtd отвлечение внимания продуктивность slack |
[Перевод] Размышления о токенах |


5Kb8kLf9zgWQnogidDA76MzPL6TsZZY36hWXMssSzNydYXYB9KF3a1076bf45ab87712ad64ccb3b10217737f7faacbf2872e88fdd9a537d8fe266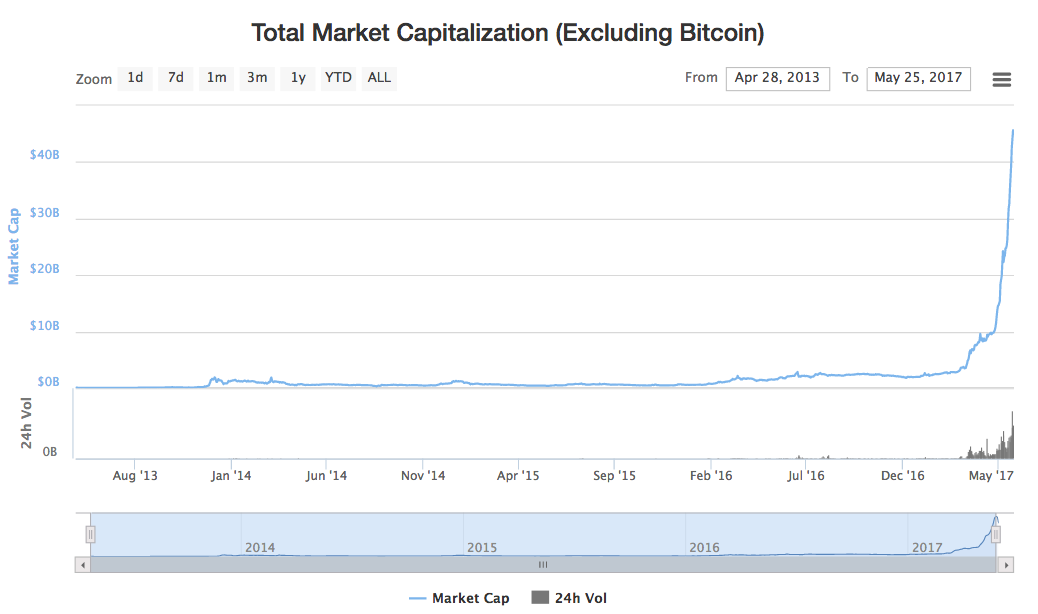

|
|
Повторяющиеся задачи в Redmine |

У вас есть регулярные задачи? Скажем, провести планерку по понедельникам в 10:30, сформировать отчет клиенту по четвергам в 18:00? Или клиент по вторникам накатывает обновления, и админ должен с 10:00 быть на постоянной связи? Нужно начинать рабочий день с чек-листа? 20 числа оплатить аренду?
Если вы работаете в Redmine, вы не можете штатными средствами поставить регулярную задачу. Придется каждый раз ставить ее вручную. Это лишнее время, лишнее внимание и риск ошибки.
Чтобы исключить человеческий фактор, мы разработали бесплатный плагин redmine_recurring_tasks, который автоматически ставит задачу ежедневно, еженедельно или ежемесячно.
Плагин совместим с другими популярными плагинами, в частности с redmine_tags и redmine_checklists. Есть возможность настроить вручную копирование атрибутов из других плагинов. Если есть вопросы по совместимости, уточняйте в комментариях.
Пользуйтесь на здоровье!
|
Метки: author olemskoi управление проектами управление персоналом блог компании southbridge redmine redmine-plugin redmine_recurring_tasks |
Истории успеха Kubernetes в production. Часть 2: Concur и SAP |








|
Метки: author shurup it- инфраструктура devops блог компании флант kubernetes docker openstack sap concur истории успеха |
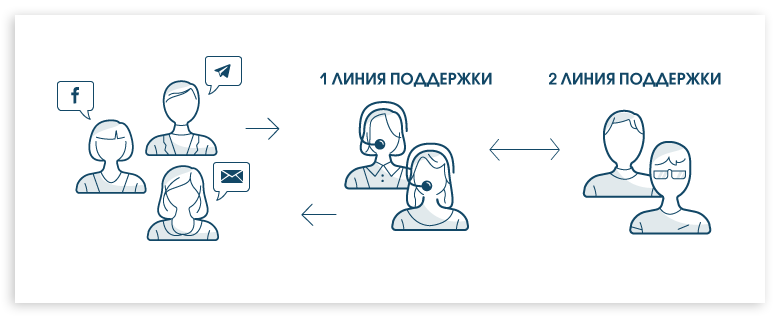
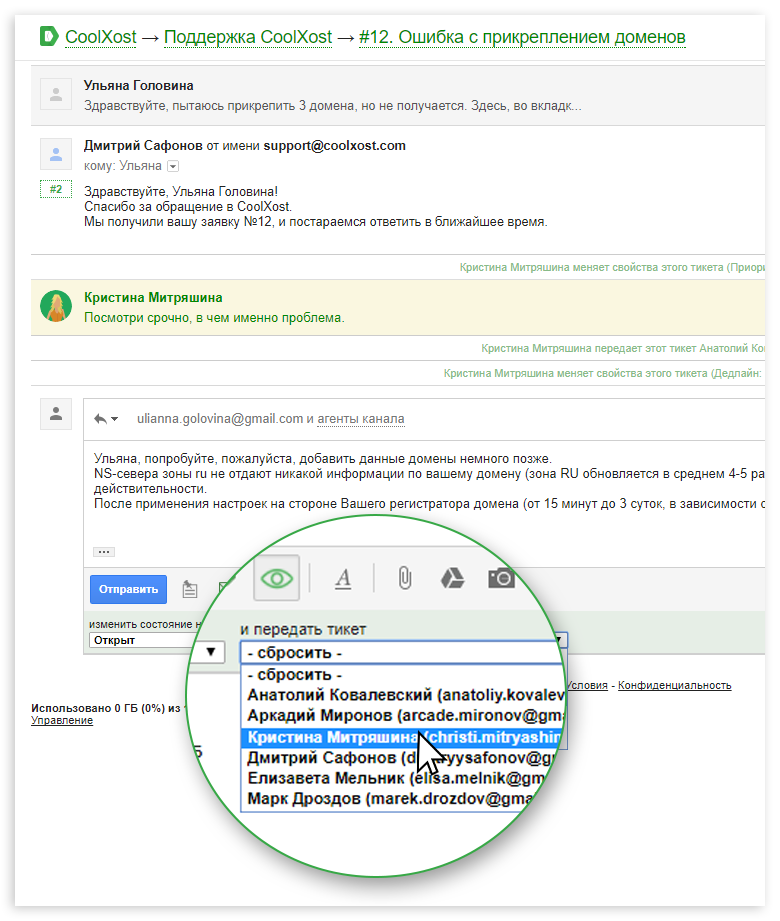
Кейс: как организовать мультиканальную поддержку клиентов на примере одного хостинг провайдера |

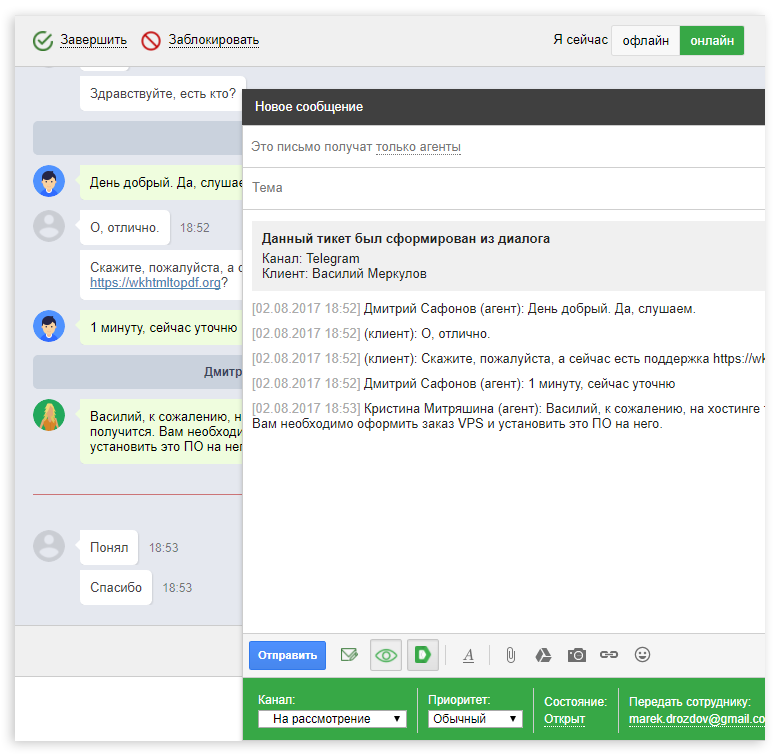
|
Метки: author ChiPer управление проектами управление персоналом блог компании deskun help desk service desk поддержка клиентов saas мультиканальность хелпдеск хостинг gmail |
JavaScript как праздник |

typeof myVar
myVar.constructor
const a = 5
const a = 4
VM1825:1 Uncaught SyntaxError: Identifier 'a' has already been declared
at :1:1
|
Метки: author rboots node.js javascript |
Конец CSRF близок? |

Пер. Под катом вас ждет перевод смешноватой и несложной статьи о CSRF и новомодном способе защиты от него.
Уязвимость CSRF или XSRF (это синонимы), кажется, существовала всегда. Её корнем является всем известная возможность делать запрос от одного сайта к другому. Допустим, я создам такую форму на своем сайте.
Ваш браузер загрузит мой сайт и, соответственно, мою форму. Её я могу незамедлительно отправить, используя простой javascript.
document.getElementById("stealMoney").submit(); Поэтому подобная атака буквально расшифровывается, как межсайтовая подделка запроса. Я подделываю запрос, который отправляется между моим сайтом и вашим банком. В действительности, проблема состоит не в том, что я отправлю запрос, а в том, что ваш браузер отправит вместе с запросом и ваши куки. Это означает, что запрос будет обладать всеми вашими правами, так что, если вы залогинены в текущий момент на сайте вашего банка, то только что вы пожертвовали мне тысячу долларов. Данке шон! Если же вы не были залогинены, то деньги всё еще на месте. Существуют несколько способов защиты от подобных злостных посягательств.
Не буду вдаваться в детали о способах защиты, так как в интернете полным-полно информации о них, но давайте быстро пробежимся по основным реализациям.
Принимая запрос в нашем приложении, потенциально мы можем узнать о том, откуда он пришел, посмотрев на два заголовка. Они называются origin и referer. Так что мы можем проверить один или оба значения, чтобы узнать, пришёл ли запрос с нашего приложения или откуда-то ещё. Если источник запроса не ваш сайт, то можно просто на него ответить ошибкой. Проверка этих заголовков может нас защитить, но проблема в том, что они не всегда могут присутствовать.
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
accept-encoding: gzip, deflate, br
cache-control: max-age=0
content-length: 166
content-type: application/x-www-form-urlencoded
dnt: 1
origin: https://example.com
referer: https://example.com /login
upgrade-insecure-requests: 1
user-agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36Существуют два способа использования уникальных защитных токенов, но принцип их использования един. Когда пользователь посещает страницу, скажем, страницу банка, то в форму перечисления денег вставляется скрытое поле с уникальным токеном. Если пользователь действительно находится на сайте банка, то вместе с запросом он отправит этот токен, так что можно будет проверить, совпадает ли он с тем, что вы вставили в форму. При попытке CSRF атаки атакующий никогда не сможет получить это значение. Даже в случае запроса к странице Same Origin Policy (SOP) не позволит ему прочитать страницу, где есть данный токен. Такой метод хорошо себя зарекомендовал, однако он требует от приложения логики по внедрению токенов в формы и проверки их подлинности при входящих запросах. Еще один похожий метод заключается во внедрении такого же токена в форму и передачи куки, содержащего то же значение. Когда настоящий пользователь отправляет форму, то происходит сверка значения токена в куки со значением в форме. Если они не совпадают, то такой запрос не будет принят сервером.
Вышеописанные методы защиты давали нам достаточно надежную защиту против CSRF на протяжении довольно долгого времени. Конечно, проверка заголовков origin и referer не на 100% надежна, так что большинство сайтов полагается на тактику с уникальными токенами. Сложность состоит в том, что оба метода защиты требуют от сайта внедрения и поддержки решения. Вы скажете, что это совсем несложно. Согласен! Никогда не возникало проблем. Но это некрасиво. По сути мы обороняемся от поведения браузера хитрым способом. А можем ли мы просто сказать браузеру перестать делать вещи, которые мы не хотим, чтобы он делал?.. Теперь можем!
По сути Same-Site куки могут свести на нет любую CSRF атаку. Насмерть. Чуть более, чем полностью. Адьёс, CSRF! Они действенно и быстро помогают решить проблему безопасности. К тому же применить их чрезвычайно просто. Возьмем для примера какую-то куку.
Set-Cookie: sess=smth123; path=/ А теперь просто добавьте атрибут SameSite
Set-Cookie: sess=smth123; path=/; SameSiteВсё, вы закончили. Нет, правда! Используя данный атрибут, вы как-бы говорите браузеру предоставить куки определенную защиту. Существую два режима такой защиты: Strict или Lax, в зависимости от того, насколько серьезно вы настроены. Атрибут Same-Site без указания режима будет работать в стандартном варианте т.е. Strict. Вы можете выставить режим так:
SameSite=Strict
SameSite=Lax Такой режим предпочтительней и безопасней, но может не подойти для вашего приложения. Этот режим означает, что c ваше приложение не будет отправлять куки ни на один запрос с другого ресурса. Само собой в таком случае CSRF не будет возможен в корне. Однако здесь можно столкнуться с проблемой, что куки не будут пересылаться также при навигации высокого уровня (т.е. даже при переходе по ссылке). Например, если бы я сейчас разместил ссылку на Вконтакте, а Фейсбук использовал куки Вконтакте, то при переходе по ссылке вы бы оказались разлогинены, вне зависимости от того, были ли вы залогинены до этого. Такое поведение, конечно, может не порадовать пользователя, но можно быть уверенным в безопасности.
Что можно сделать с этим? Можно поступить, как Амазон. У них реализована как-бы двойная аутентификация с помощью двух куки. Первый куки позволяет амазону просто знать, кто вы и показывать вам ваше имя. Для него не используется SameSite. Второй куки позволяет делать покупки, менять что-то в аккаунте. Для него резонно используется SameSite. Такое решение позволяет одновременно предоставлять пользователям удобство и оставаться приложению безопасным.
Режим Lax решает проблемы с разлогированием описанную выше, но при этом сохраняет хороший уровень защиты. В сущности он добавляет исключение, когда куки передаются при навигации высокого уровня, которая использует “безопасные” HTTP методы. Согласно https://tools.ietf.org/html/rfc7231#section-4.2.1 безопасными методами считаются GET, HEAD, OPTIONS и TRACE.
Вернемся к нашему примеру атаки в начале.
Такая атака уже не сработает в режиме Lax, так как мы обезопасили себя от POST-запросов. Конечно, злоумышленник может использовать метод GET.
Поэтому режим Lax можно назвать компромиссом между безопасностью и удобством пользователей.
SameSite куки защищают нас от CSRF атак, но нельзя забывать про другие виды уязвимостей. К примеру XSS или браузерные атаки по времени.
От автора перевода: К сожалению, пока SameSite куки поддерживают только Chrome и Opera, а также браузер для андроида. Пруф: https://caniuse.com/#feat=same-site-cookie-attribute
Оригинал: https://www.kuoll.com/the-end-of-csrf/
До этого появлялась здесь: https://scotthelme.co.uk/csrf-is-dead/
|
Метки: author Kirylka информационная безопасность перевод csrf |
Когда нужна локализация: почему так трудно найти хорошего переводчика |

Regards,
Ivan IvanovС уважением,
Иван ИвановС уважением Иван Иванов|
|
Геометрия в компьютерных играх |

canvas.drawRect(x1, y1, x2, y2, paint);public boolean isTouched(float x, float y){
return (x>x1)&&(xy1)&&(ycode>Path path = new Path();
paint.setStyle(Paint.Style.FILL);
path.moveTo(x1, y1);
path.lineTo(x2, y2);
path.lineTo(x3, y3);
.....
path.lineTo(x1, y1); //замыкаем фигуру
path.close();
canvas.drawPath(path, paint);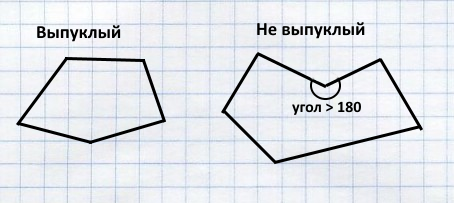
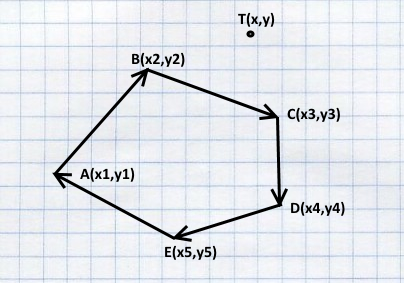
private boolean isLeftHandSituated(float dotX, float dotY, float x1, float y1, float x2, float y2){
float d = (dotX - x1) * (y2 - y1) - (dotY - y1) * (x2 - x1);
return d>0;
}float dx = dotX - smileX;
float dy = dotY - smileY;
double distance = Math.sqrt((dx * dx + dy * dy));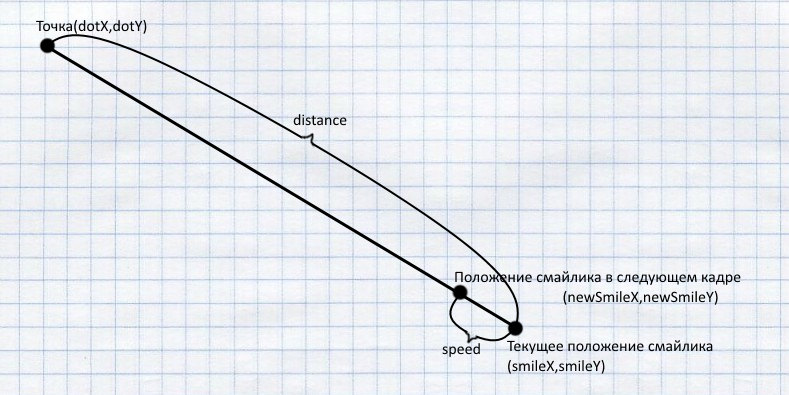
private float speed=5;
double rate = speed / distance;
newSmileX = smileX + (float) (dx * rate);
newSmileY = smileY + (float) (dy * rate);float dx = dotX - cannonX;
float dy = dotY - cannonY;
double theta = Math.atan2(dx, dy); //получаем угол в радианах
angle = Math.toDegrees(theta); //переводим его в градусы.|
|
[Перевод] Лицензирование музыки для инди-разработчиков |



|
Метки: author PatientZero разработка игр лицензирование музыки copyright лицензионный контент |
[Перевод] Как за 6 шагов узнать хороший дизайн |







|
Метки: author Logomachine брендинг блог компании логомашина дизайн логотип бизнес советы |
[Из песочницы] Аналитические системы для мобильных приложений: тест и критерии выбора |




|
Метки: author OxanaFomina аналитика мобильных приложений аналитические платформы |
[Из песочницы] ERP: с чего начать внедрение. Альтернативный взгляд со стороны клиента |
|
Метки: author pebble erp- системы erp |
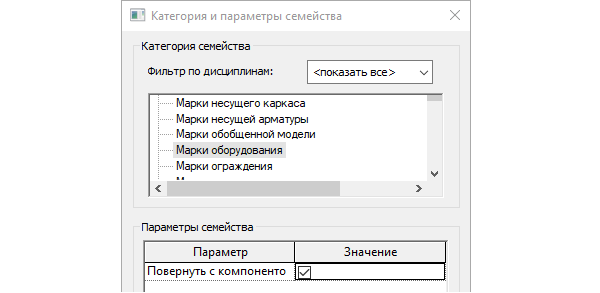
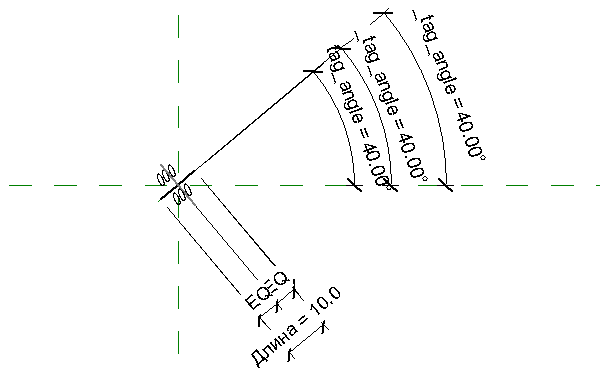
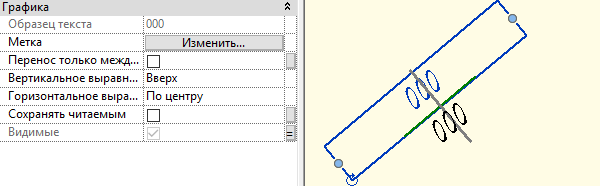
Семейство марки с поворотом (Tag) для загружаемых семейств Autodesk Revit |



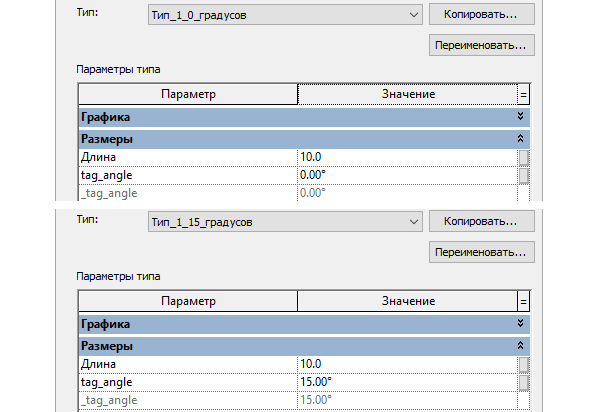

|
Метки: author Akunets cad/cam сапр revit revitfamily |
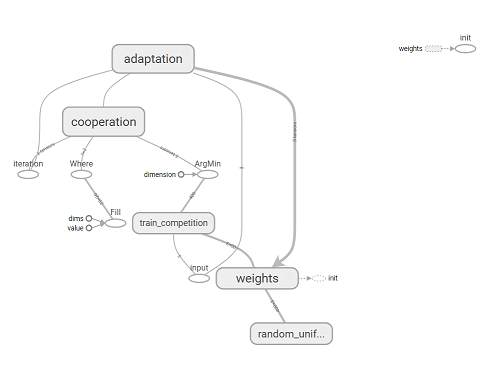
[Из песочницы] Карта самоорганизации (Self-orginizing map) на TensorFlow |


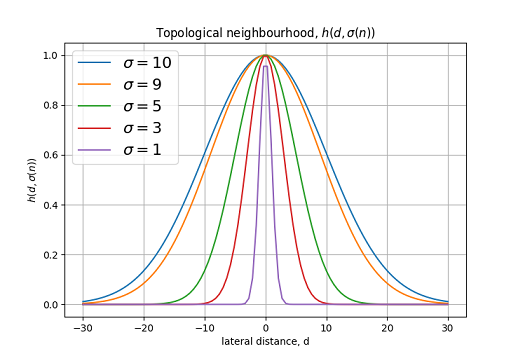

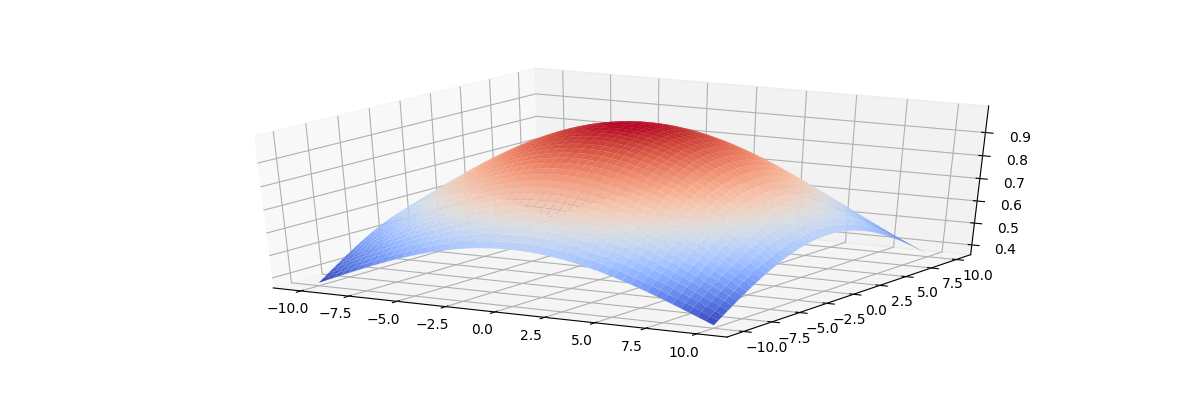


import numpy as np
import tensorflow as tf
class SOMNetwork():
def __init__(self, input_dim, dim=10, sigma=None, learning_rate=0.1, tay2=1000, dtype=tf.float32):
#если сигма на определена устанавливаем ее равной половине размера решетки
if not sigma:
sigma = dim / 2
self.dtype = dtype
#определяем константы использующиеся при обучении
self.dim = tf.constant(dim, dtype=tf.int64)
self.learning_rate = tf.constant(learning_rate, dtype=dtype, name='learning_rate')
self.sigma = tf.constant(sigma, dtype=dtype, name='sigma')
#тау 1 (формула 6)
self.tay1 = tf.constant(1000/np.log(sigma), dtype=dtype, name='tay1')
#минимальное значение сигма на шаге 1000 (определяем по формуле 3)
self.minsigma = tf.constant(sigma * np.exp(-1000/(1000/np.log(sigma))), dtype=dtype, name='min_sigma')
self.tay2 = tf.constant(tay2, dtype=dtype, name='tay2')
#input vector
self.x = tf.placeholder(shape=[input_dim], dtype=dtype, name='input')
#iteration number
self.n = tf.placeholder(dtype=dtype, name='iteration')
#матрица синаптических весов
self.w = tf.Variable(tf.random_uniform([dim*dim, input_dim], minval=-1, maxval=1, dtype=dtype),
dtype=dtype, name='weights')
#матрица позиций всех нейронов, для определения латерального расстояния
self.positions = tf.where(tf.fill([dim, dim], True))
def __competition(self, info=''):
with tf.name_scope(info+'competition') as scope:
#вычисляем минимум евклидова расстояния для всей сетки нейронов
distance = tf.sqrt(tf.reduce_sum(tf.square(self.x - self.w), axis=1))
#возвращаем индекс победившего нейрона (формула 1)
return tf.argmin(distance, axis=0)
def training_op(self):
#определяем индекс победившего нейрона
win_index = self.__competition('train_')
with tf.name_scope('cooperation') as scope:
#вычисляем латеральное расстояние d
#для этого переводим инедкс победившего нейрона из 1d координаты в 2d координату
coop_dist = tf.sqrt(tf.reduce_sum(tf.square(tf.cast(self.positions -
[win_index//self.dim, win_index-win_index//self.dim*self.dim],
dtype=self.dtype)), axis=1))
#корректируем сигма (используя формулу 3)
sigma = tf.cond(self.n > 1000, lambda: self.minsigma, lambda: self.sigma * tf.exp(-self.n/self.tay1))
#вычисляем топологическую окрестность (формула 2)
tnh = tf.exp(-tf.square(coop_dist) / (2 * tf.square(sigma)))
with tf.name_scope('adaptation') as scope:
#обновляем параметр скорости обучения (формула 5)
lr = self.learning_rate * tf.exp(-self.n/self.tay2)
minlr = tf.constant(0.01, dtype=self.dtype, name='min_learning_rate')
lr = tf.cond(lr <= minlr, lambda: minlr, lambda: lr)
#вычисляем дельта весов и обновляем всю матрицу весов (формула 4)
delta = tf.transpose(lr * tnh * tf.transpose(self.x - self.w))
training_op = tf.assign(self.w, self.w + delta)
return training_op
#сеть размером 20х20 нейронов
som = SOMNetwork(input_dim=3, dim=20, dtype=tf.float64, sigma=3)
test_data = np.random.uniform(0, 1, (250000, 3))
training_op = som.training_op()
init = tf.global_variables_initializer()
with tf.Session() as sess:
init.run()
for i, color_data in enumerate(test_data):
if i % 1000 == 0:
print('iter:', i)
sess.run(training_op, feed_dict={som.x: color_data, som.n:i})


|
Метки: author M00nL1ght машинное обучение python machine learning tensorflow neural networks |
[Перевод] Новый V8 и скорость Node.js: техники оптимизации сегодня и завтра |

try/catch.try/catch, расположенном в ней (sum with trу catch).try/catch (sum without try catch).try (sum wrapped).try/catch (sum function).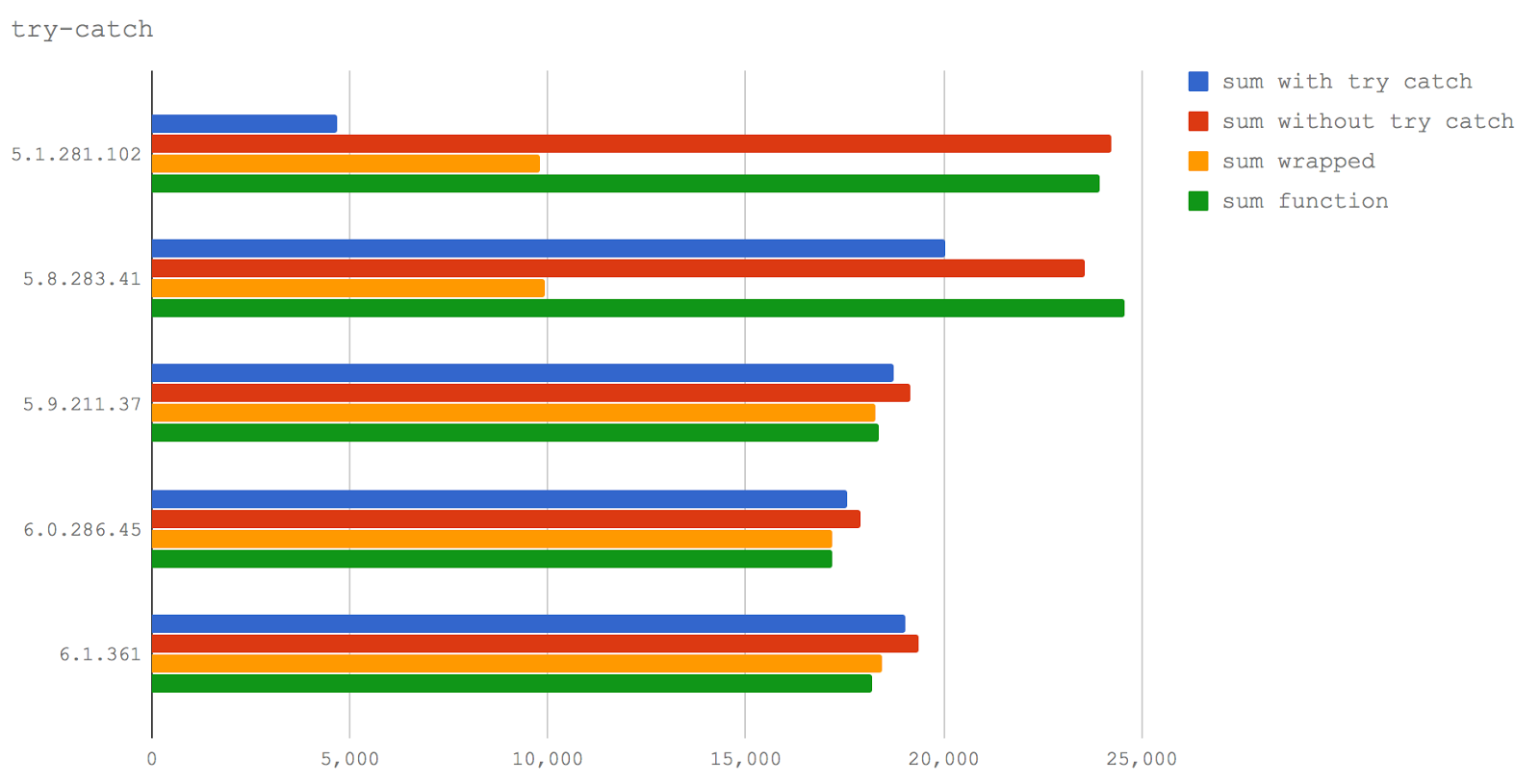
try/catch на производительность, подтверждается в Node 6 (V8 5.1), а в Node 8.0-8.2 (V8 5.8) try/catch оказывает гораздо меньшее влияние на производительность.try оказывается гораздо более медленным, чем вызов её за пределами try — это справедливо и для Node 6 (V8 5.1), и для Node 8.0-8.2 (V8 5.8).try на производительность практически не влияет.delete избегал любой, кто хотел писать высокопроизводительный код на JS (ну, по крайней мере, в случаях, когда надо было написать оптимальный код для самых нагруженных частей программ).delete сводится к тому, как V8 обходится с динамической природой объектов JavaScript, и с цепочками прототипов (также потенциально динамическими), которые усложняют поиск свойств на низком уровне реализации движка.delete ключ из объекта, последующие операции доступа к свойствам будут выполняться методом поиска в хэш-таблице. Именно поэтому программисты команду delete стараются не использовать, вместо этого устанавливая свойства в undefined, что, в плане уничтожения значения, ведёт к тому же результату, но добавляет сложностей при проверке существования свойства. Однако, обычно такой подход достаточно хорош, например, при подготовке объектов к сериализации, так как JSON.stringify не включает значения undefined в свой вывод (undefined, в соответствии со спецификацией JSON, не относится к допустимым значениям).undefined (setting to undefined).delete (delete).delete была использована для удаления свойства, которое было добавлено позже всего (delete last property).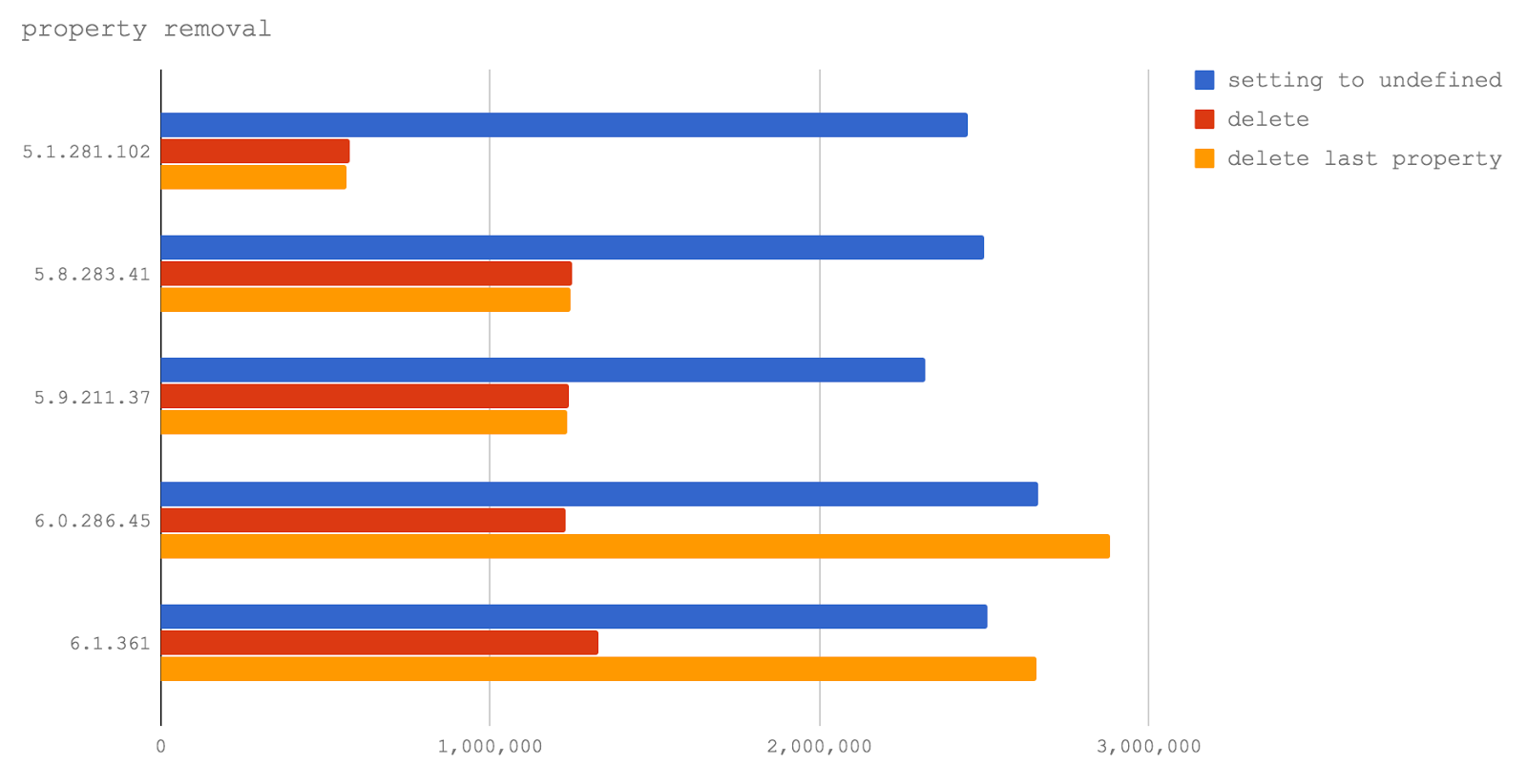
undefined. Это очень хорошо, так как говорит о том, что команда разработчиков V8 работает над улучшением производительности команды delete.delete можно и нужно использовать в коде, написанном для будущих релизов Node, мы вынуждены рекомендовать этого не делать. Команда delete продолжает негативно влиять на производительность.arguments, доступным в обычных функциях (в противовес им, стрелочные функции объекта arguments не имеют), заключается в том, что он похож на массив, но массивом не является.arguments необходимо скопировать в массив. В прошлом у JS-разработчиков была склонность ставить знак равенства между более коротким и более быстрым кодом. Хотя такой подход, в случае клиентского кода, позволяет достичь снижения объёма данных, которые должен загрузить браузер, то же самое может повлечь проблемы с серверным кодом, где размер программ гораздо менее важен, нежели скорость их выполнения. В результате, соблазнительно короткий способ преобразовать объект arguments в массив стал весьма популярным:Array.prototype.slice.call(arguments). Такая команда вызывает метод slice объекта Array, передавая объект arguments как контекст this для этого метода. Метод slice видит объект, который похож на массив, после чего делает своё дело. В результате мы получаем массив, собранный из содержимого объекта arguments, похожего на массив.arguments передаётся чему-либо, находящемуся вне контекста функции (например, если его возвращают из функции или передают другой функции, как при вызове Array.prototype.slice.call(arguments)), обычно это вызывает падение производительности. Исследуем это утверждение.arguments и цена копирования arguments в массив, который потом передаётся за пределы функции вместо объекта arguments.arguments другой функции без преобразования arguments в массив (leaky arguments).arguments с использованием конструкции Array.prototype.slice (Array.prototype.slice arguments).for и копирование каждого свойства (for-loop copy arguments)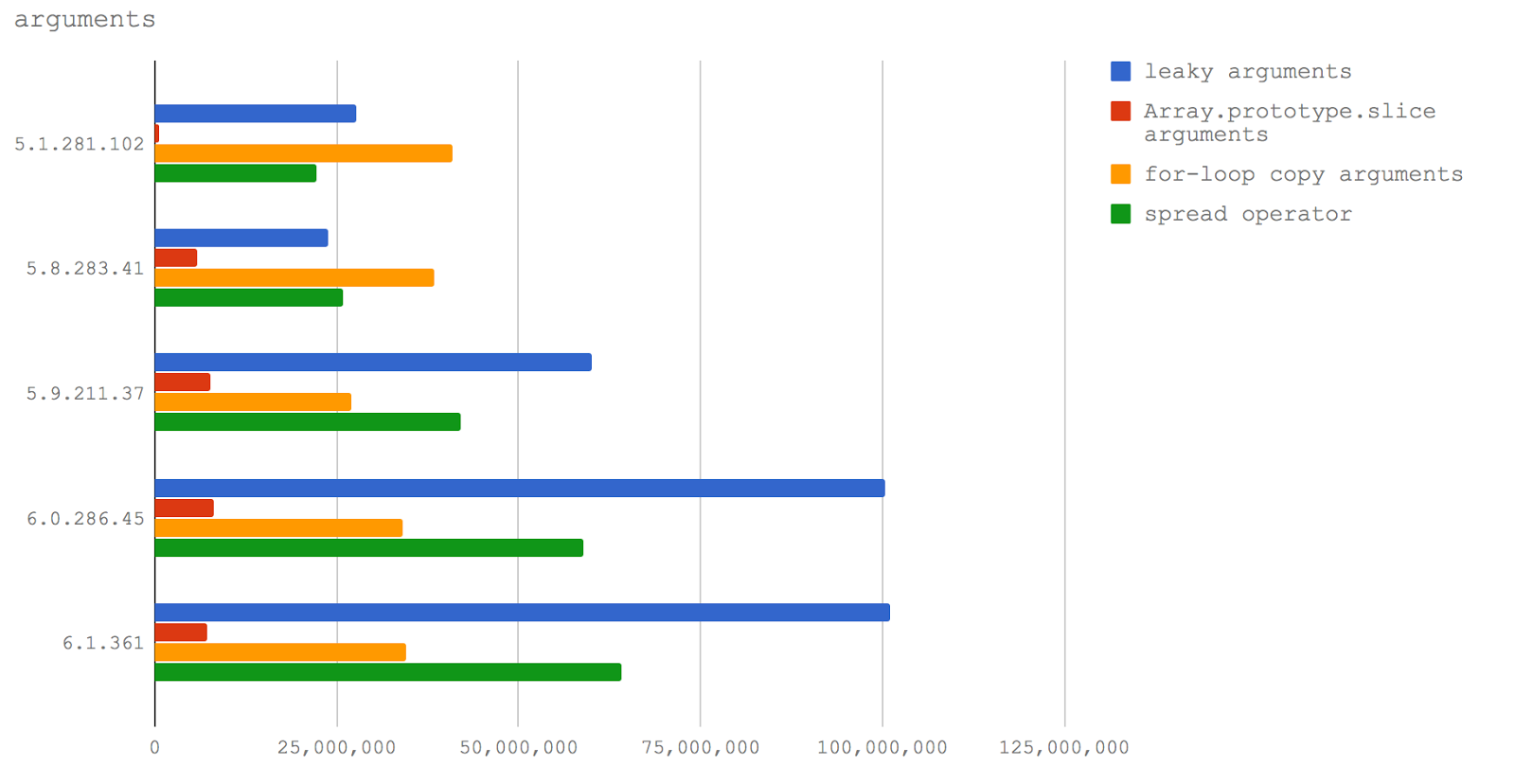
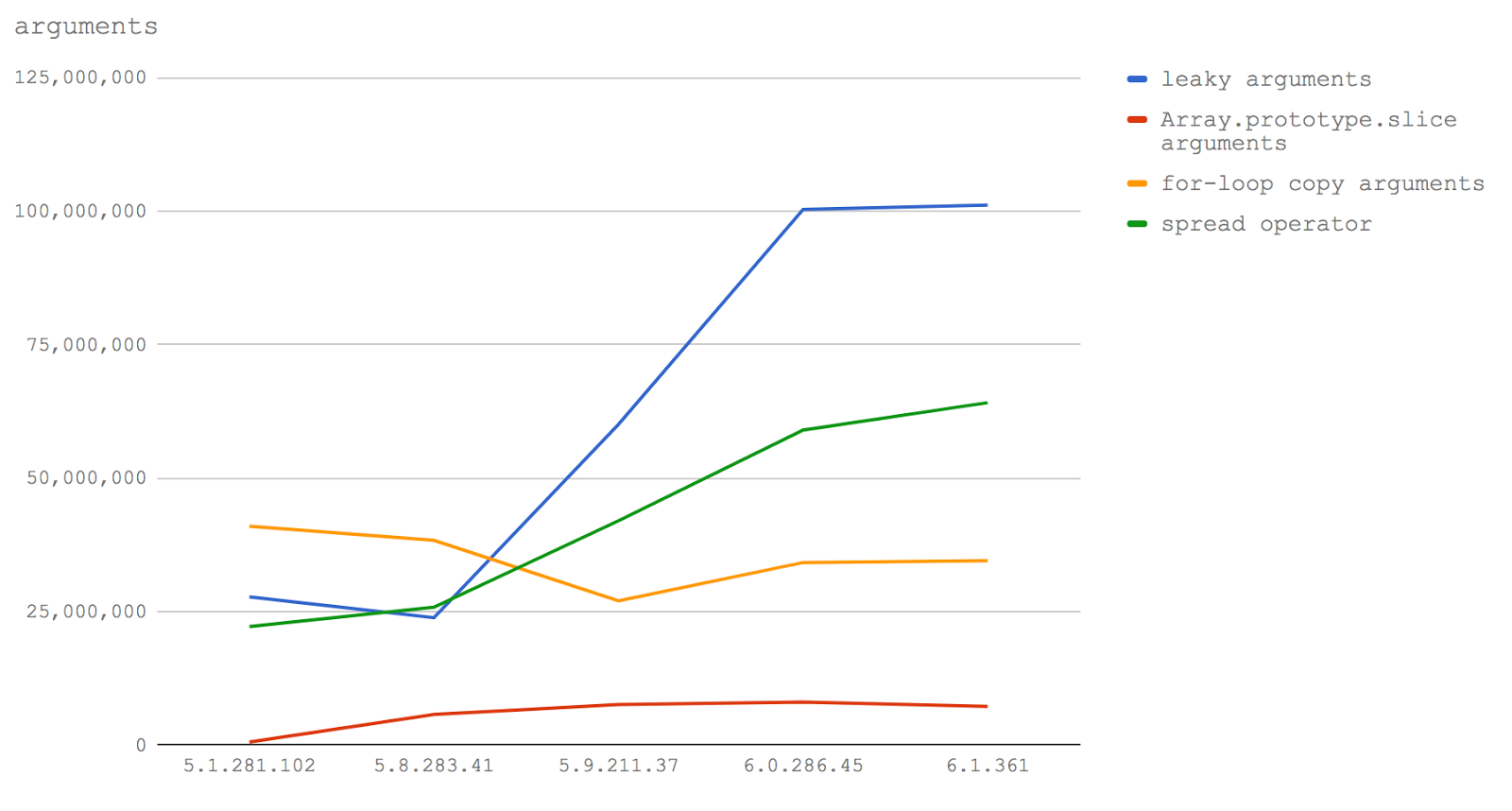
for для копирования ключей из arguments в новый (заранее созданный) массив (подробности вы можете увидеть в коде тестов).arguments в другие функции не происходит, поэтому тут могут быть другие преимущества в плане производительности, если нам не нужен полный массив и можно работать со структурой, похожей на массив, но массивом не являющейся.function add (a, b) {
return a + b
}
const add10 = function (n) {
return add(10, n)
}
console.log(add10(20))a функции add частично применён как число 10 в функции add10.bind:function add (a, b) {
return a + b
}
const add10 = add.bind(null, 10)
console.log(add10(20))bind не используют, так как он ощутимо медленнее, чем вышеописанный способ с замыканием.bind и замыкания в различных версиях V8. Для сравнения здесь же используется непосредственный вызов исходной функции.bind, который частично применяет первый аргумент другой функции (bind).
bind очень медленный, и выглядит очевидным, что использование стрелочных функций для этих целей позволяет достичь самой высокой скорости. Однако, производительность при использовании bind, начиная с V8 версии 5.9 (Node 8.3+) значительно растёт. Такой подход оказывается самым быстрым (хотя, разница в производительности тут практически неразличима) в V8 6.1 (Node будущих версий).bind несущественна, в текущих же условиях это быстрее, чем использование обычных функций. Однако, мы не можем говорить о том, что полученные результаты справедливы в любых ситуациях, так как нам, вероятно, надо исследовать больше типов частичного применения функций со структурами данных различных размеров для того, чтобы получить более полную картину.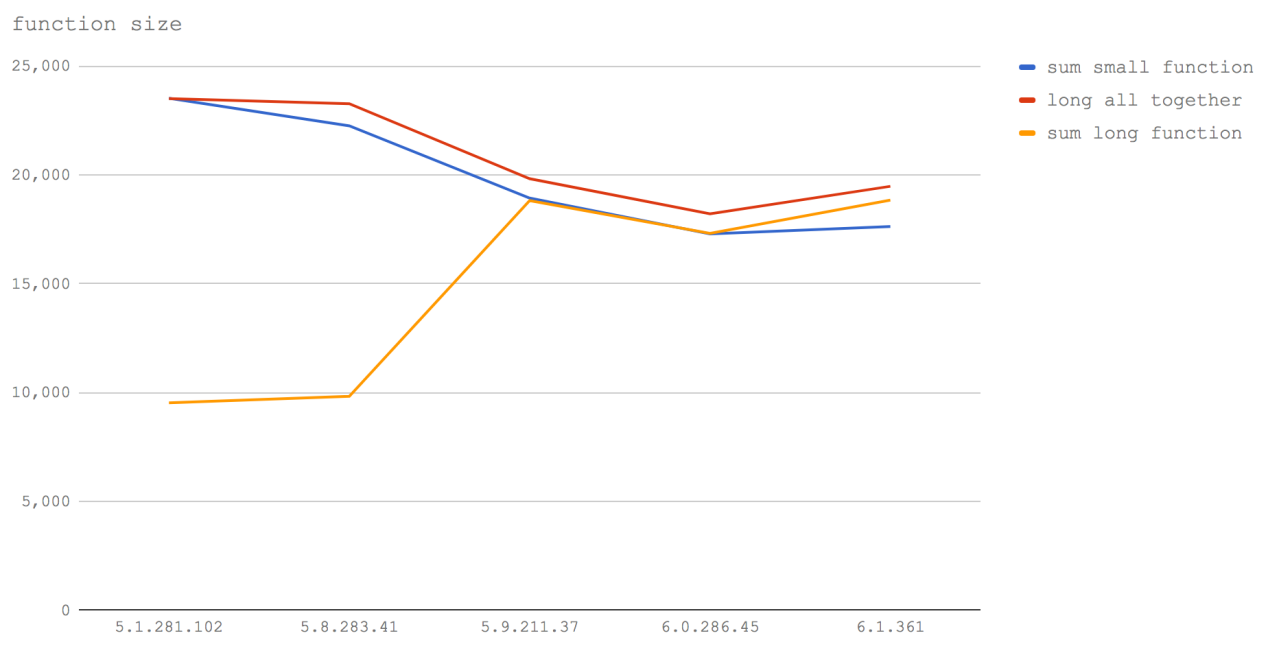
Number.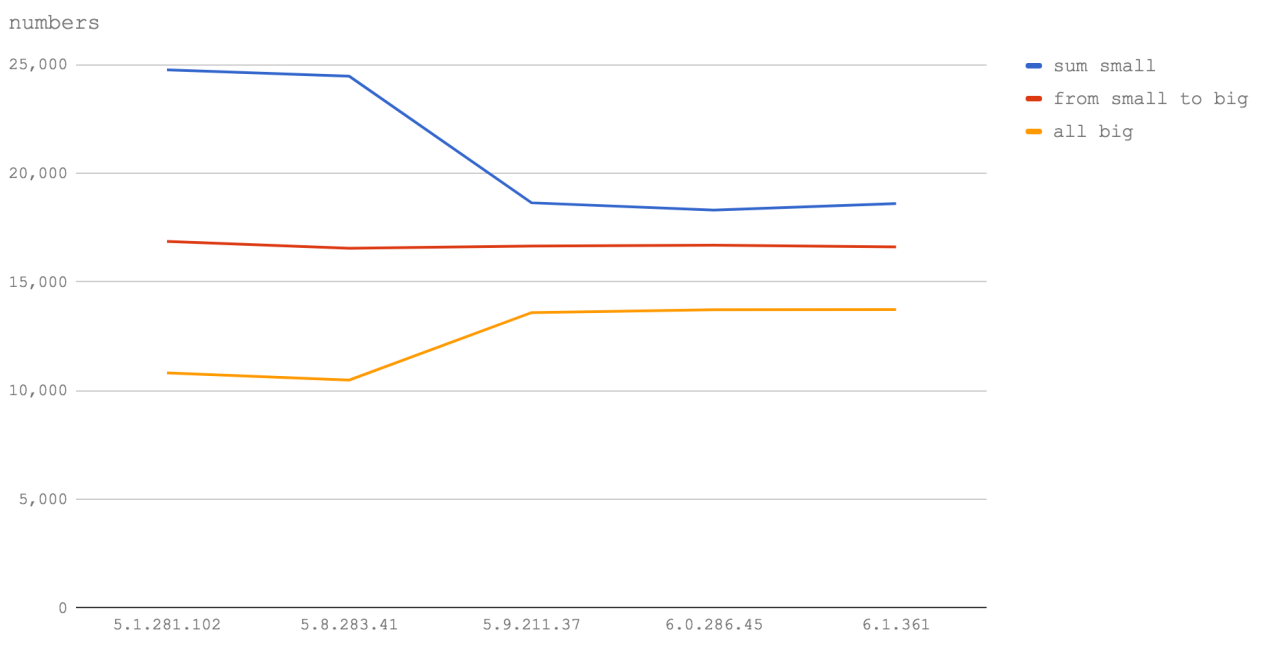
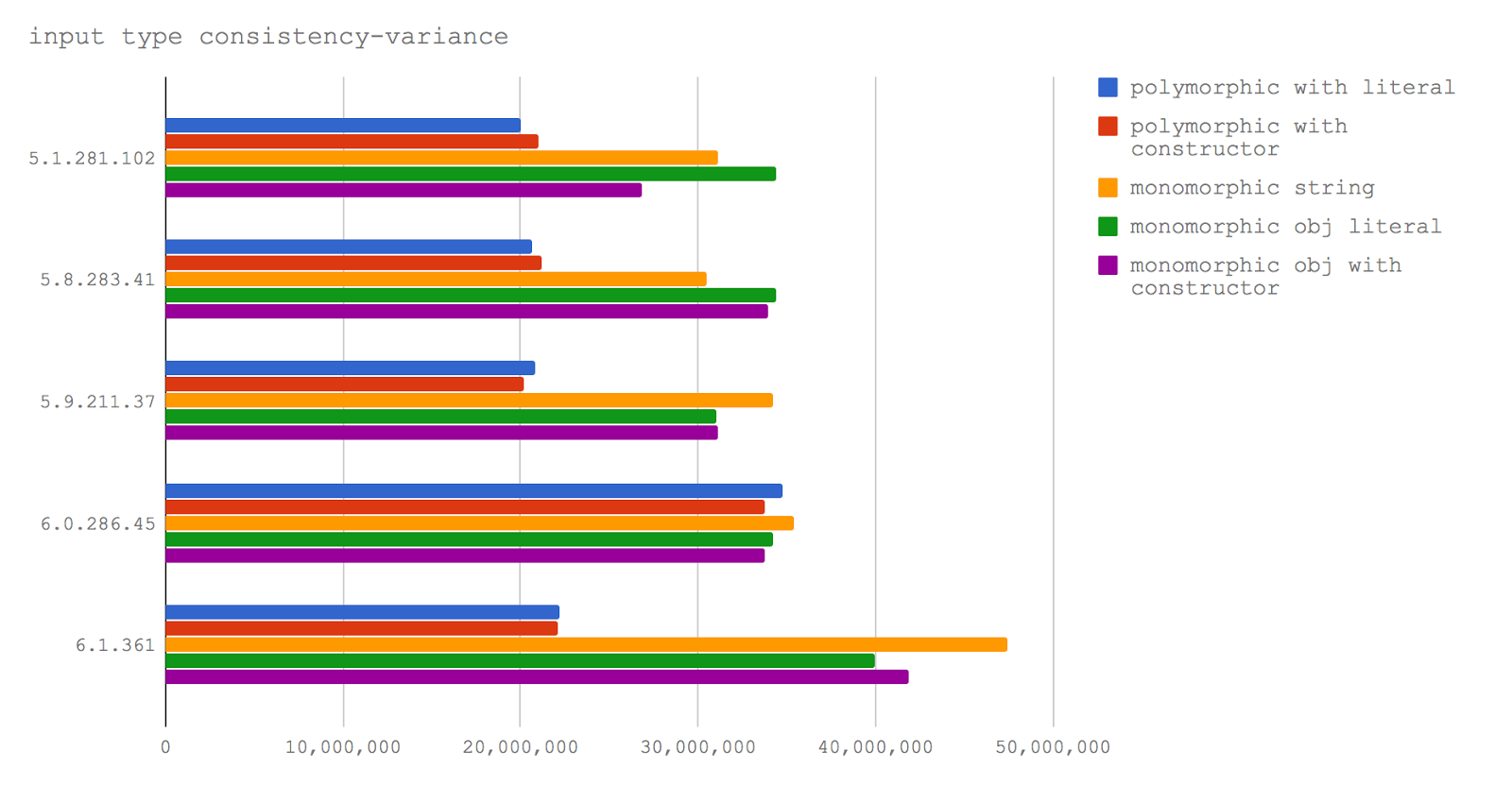
for, которые используются в коде тестов.for-in с применением hasOwnProperty для определения того, является ли свойство свойством объекта (for-in).Object.keys и перебор ключей с использованием метода reduce объекта Array. Доступ к значениям свойств осуществляется внутри функции-итератора, переданной reduce (Object.keys functional).Object.keys и перебор ключей с использованием метода reduce объекта Array. Доступ к значениям свойств осуществляется внутри стрелочной функции-итератора, переданной reduce (Object.keys functional with arrow).Object.keys, в цикле for. Доступ к значениям свойств объекта осуществляется в том же цикле (Object.keys with for loop).Object.values и перебор значений свойств объекта с использованием метода reduce объекта Array (Object.values functional).Object.values и перебор значений с использованием метода reduce объекта Array, при этом функция-итератор, переданная методу reduce, была стрелочной функцией (Object.values functional with arrow).Object.values, в цикле for (Object.values with for loop).Object.values.
for-in, без сомнения, является самым быстрым способом перебора ключей объекта, и затем — доступа к значениям его свойств. Этот способ даёт примерно 40 миллионов операций в секунду, что в 5 раз быстрее, чем при использовании ближайшего по производительности подхода, предусматривающего использование Object.keys, и дающего примерно 8 миллионов операций в секунду.for-in что-то случилось и производительность упала до всего четвёртой части скорости, достижимой в предыдущих версиях. Однако, это подход остался самым производительным.Object.keys, растёт, этот метод оказывается быстрее метода с циклом for-in, однако, скорость пока даже не приближается к тем результатам, которые были характерны для for-in в V8 5.1 и 5.8 (Node 6, Node 8.0-8.2).Object.values для прямого получения значений свойств медленнее, чем использование Object.keys и доступ к значениям объектов по ключам. Кроме того, процедурные циклы оказываются быстрее, чем функциональный подход. Таким образом, при таком подходе может понадобиться больше работы, когда дело доходит до перебора свойств объектов.for-in из-за его высокой производительности, текущее состояние дел может оказаться весьма неприятным. Значительная часть скорости теряется, а никакой доступной альтернативы нам не предлагают.

d8. Однако, эти тесты удаётся воспроизвести на Node. Результаты теста следует рассматривать, исходя из предположения, что ситуация может измениться в обновлениях Node (основываясь на том, как Node интегрируется с V8). Этот вопрос требует дополнительного анализа. Благодарим Якоба Куммертова за то, что обратил на это наше внимание.debugger.debugger (with debugger).debugger (without debugger).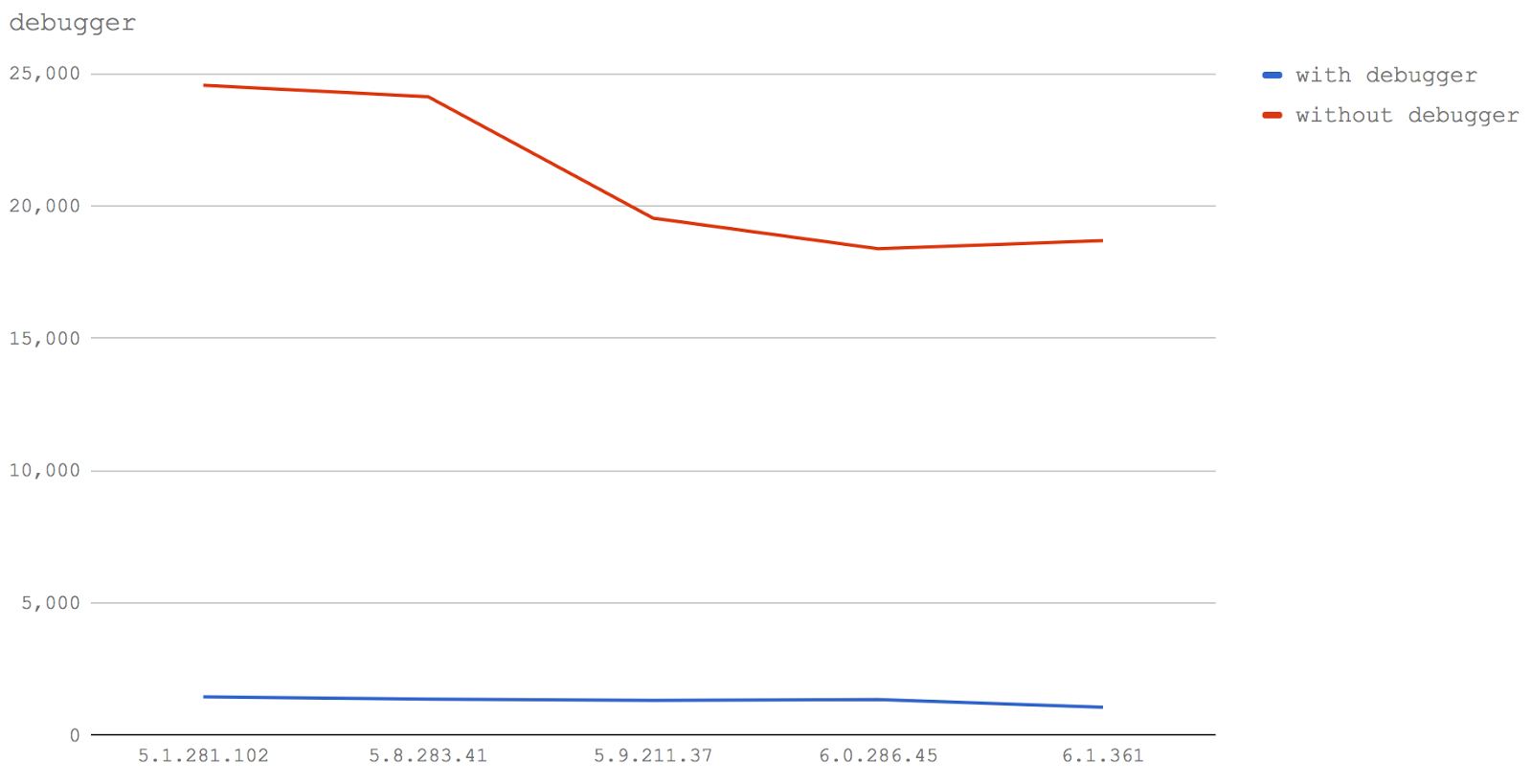
debugger.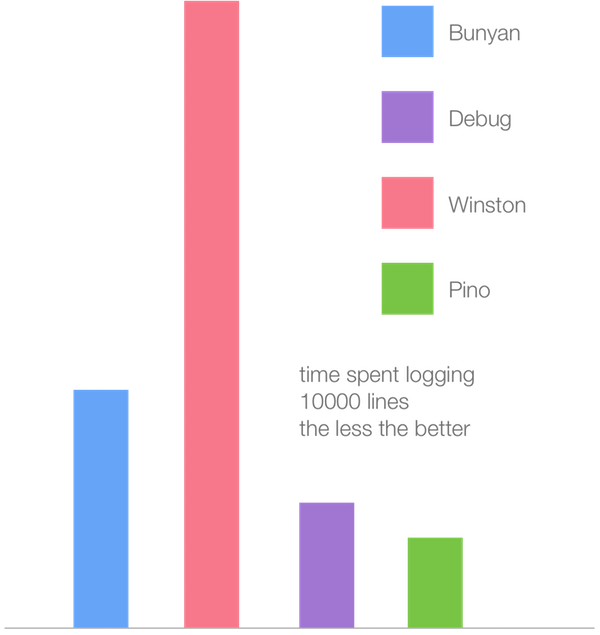
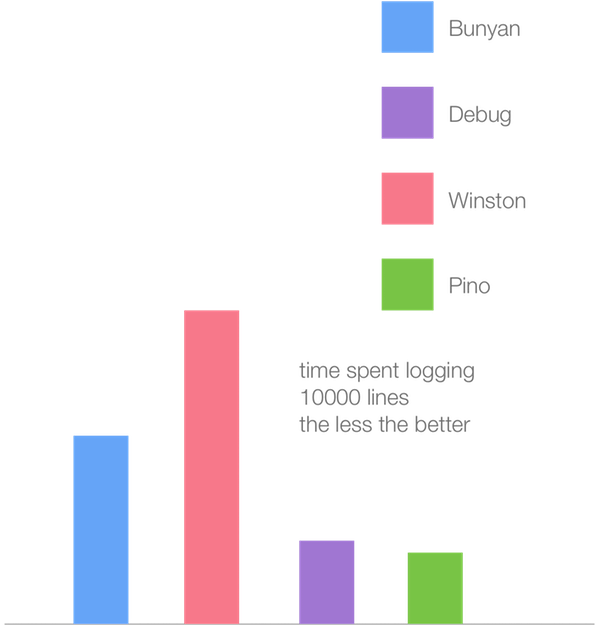
|
Метки: author ru_vds разработка веб-сайтов node.js javascript блог компании ruvds.com v8 turbofan производительность оптимизация разработка |
Dagger 2. Subcomponents. Best practice |

Adapter adapter = new Adapter(this, getContext(), list);
recyclerView.setAdapter(adapter);
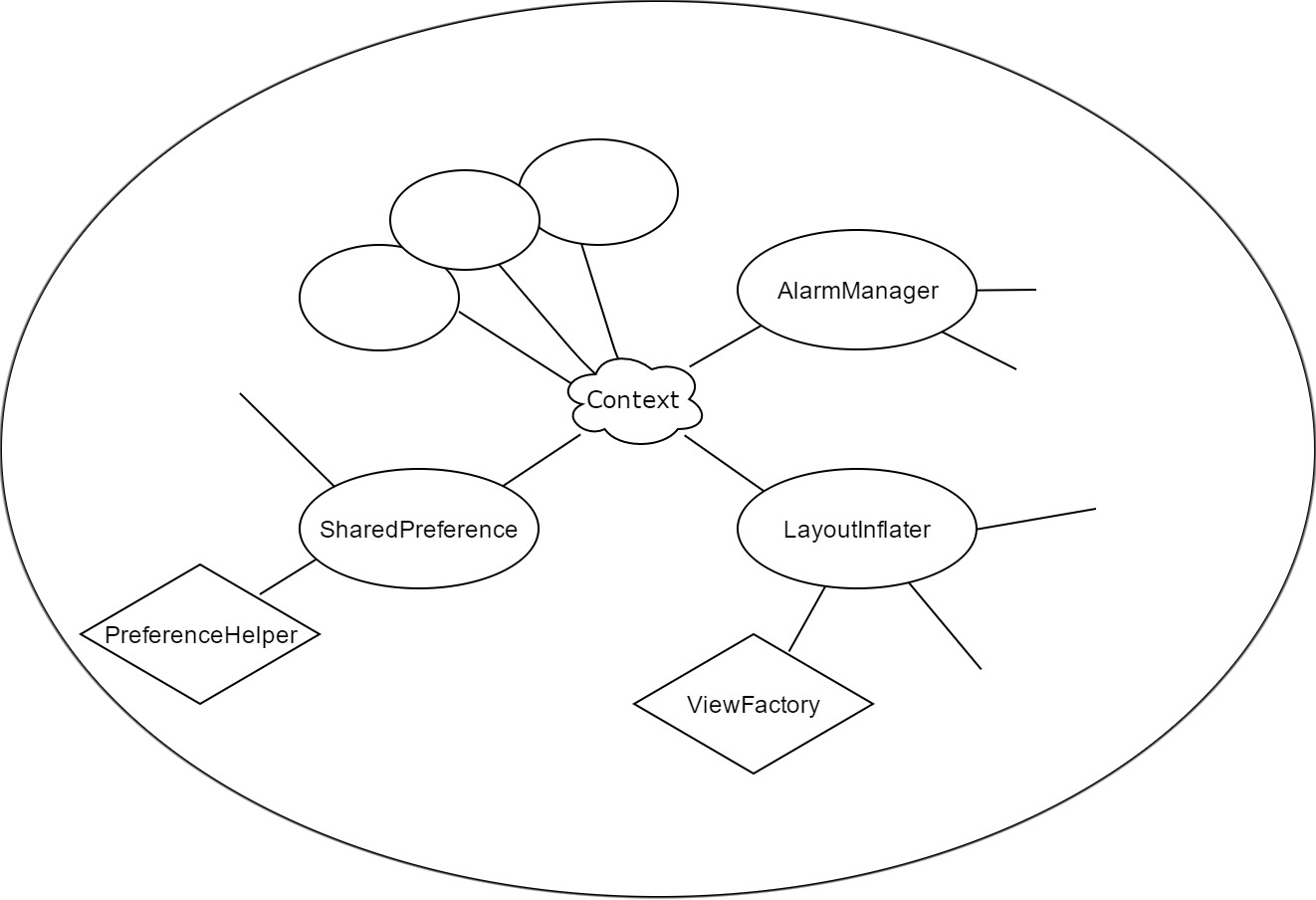
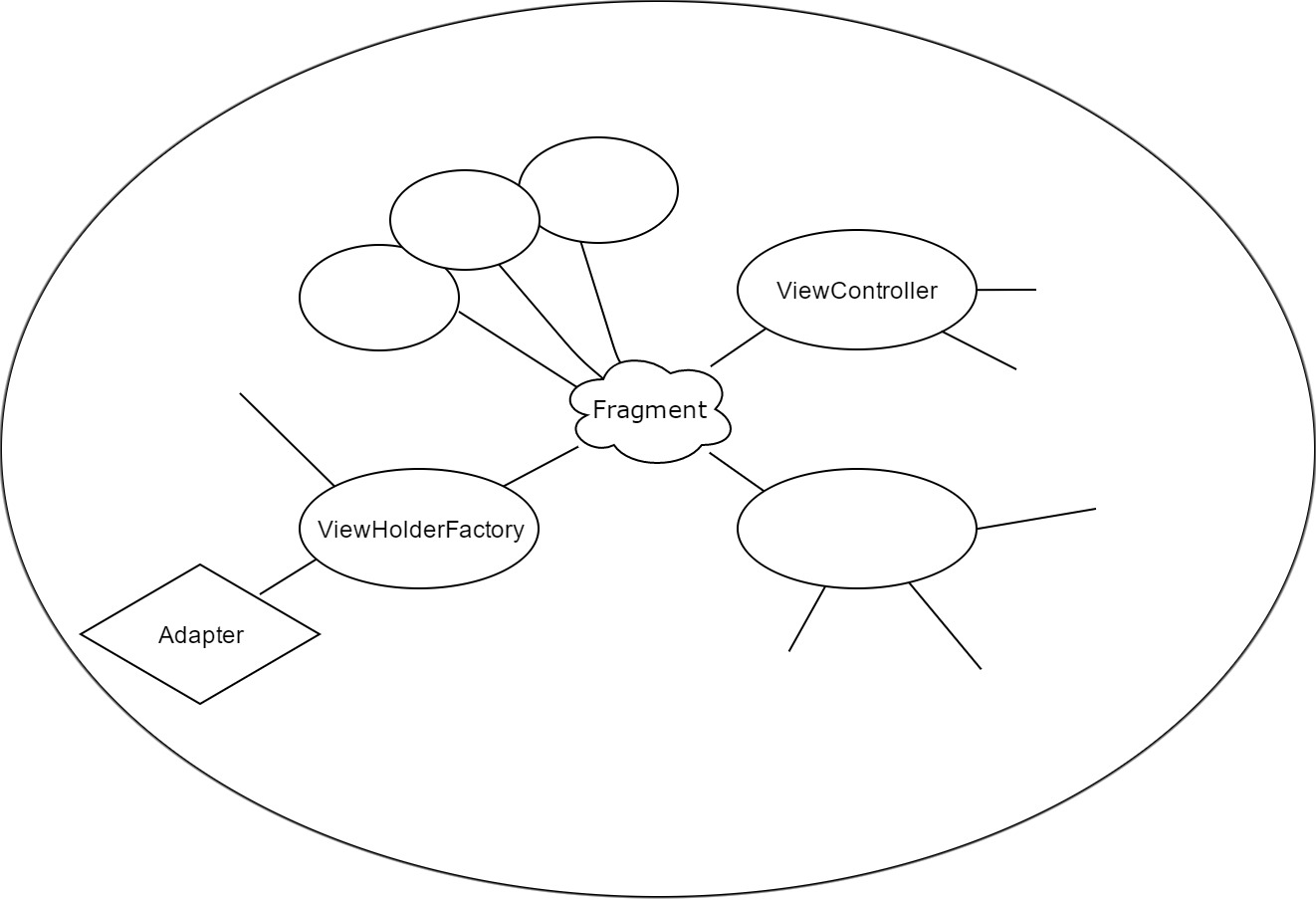
@Module
public class ListModule {
}
@Module
public class ListModule {
private final ListFragment fragment;
public ListModule(ListFragment fragment) {
this.fragment = fragment;
}
}
@Provides
public Adapter provideAdapter(Context context) {
return new Adapter(fragment, context, fragment.initList());
}
@Provides
public List provideListOfModels() {
return fragment.initList();
}
@Provides
public Adapter provideAdapter(Context context, List list) {
return new Adapter(fragment, context, list);
}
@Scope
@Retention(RetentionPolicy.Runtime)
public @interface Singleton {}
@Scope
@Retention(RetentionPolicy.Runtime)
public @interface ListScope {}
ВАЖНО: В одном Component’е, подписанном определенным Scope’ом могут находиться только модули, provide-методы которых подписаны тем же самым Scope’ом. Т.о. мы не пересекаем два разных графа зависимостей.
@Module
public class ListModule {
private final ListFragment fragment;
public ListModule(ListFragment fragment) {
this.fragment = fragment;
}
@ListScope
@Provides
public List provideListOfModels() {
return fragment.initList();
}
@ListScope
@Provides
public Adapter provideAdapter(Context contex, List list) {
return new Adapter(fragment, context, list);
}
}
@ListScope
@Subcomponent(modules = ListModule.class)
public interface ListComponent {
void inject(ListFragment fragment);
}
@Singleton
@Component(modules = AppModule.class)
public interface AppComponent {
ListComponent listComponent(ListModule listModule);
}
public class App extends Application {
private ListComponent listComponent;
public ListComponent initListComponent(ListFragment fragment) {
listComponent = appComponent.listComponent(new ListModule(fragment));
return listComponent
}
public ListComponent getListComponent() {
return listComponent;
}
public void destroyListComponent() {
listComponent = null;
}
}
public class ListFragment extends Fragment {
@Inject
Adapter adapter;
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
App.getInstance().initListComponent(this).inject(this);
init();
}
private void init() {
recyclerView.setAdapter(adapter);
}
@Override
public void onDestroy() {
super.onDestroy();
App.getInstance.destroyListComponent();
}
}


public class ListItemViewHolderFactory {
private final Listener listener;
private final LayoutInflater layoutInflater;
public ListItemViewHolderFactory(LayoutInflater layoutInflater, Listener listener) {
this.layoutInflater = layoutInflater;
this.listener = listener;
}
public ListItemViewHolder createViewHolder(ViewGroup parent) {
View view = layoutInflater.inflate(R.layout.item, parent, false);
return new ListItemViewHolder(view, listener);
}
}
@Module
public class ListModule {
private final ListFragment fragment;
public ListModule(ListFragment fragment) {
this.fragment = fragment;
}
@ListScope
@Provides
public List provideListOfModels() {
return fragment.initList();
}
@ListScope
@Provides
public Adapter provideAdapter(ListItemViewHolderFactory factory,
Context context,
List list) {
return new Adapter(factory, context, list);
}
@ListScope
@Provides
public ListItemViewHolderFactory provideVhFactory(LayoutInflater layoutInflater) {
return new ListItemViewHolderFactory (layoutInflater, fragment);
}
}

|
Метки: author htc-cs разработка под android разработка мобильных приложений dagger 2 |
Как контролировать состояние корпоративной беспроводной сети при помощи Extreme NSight |
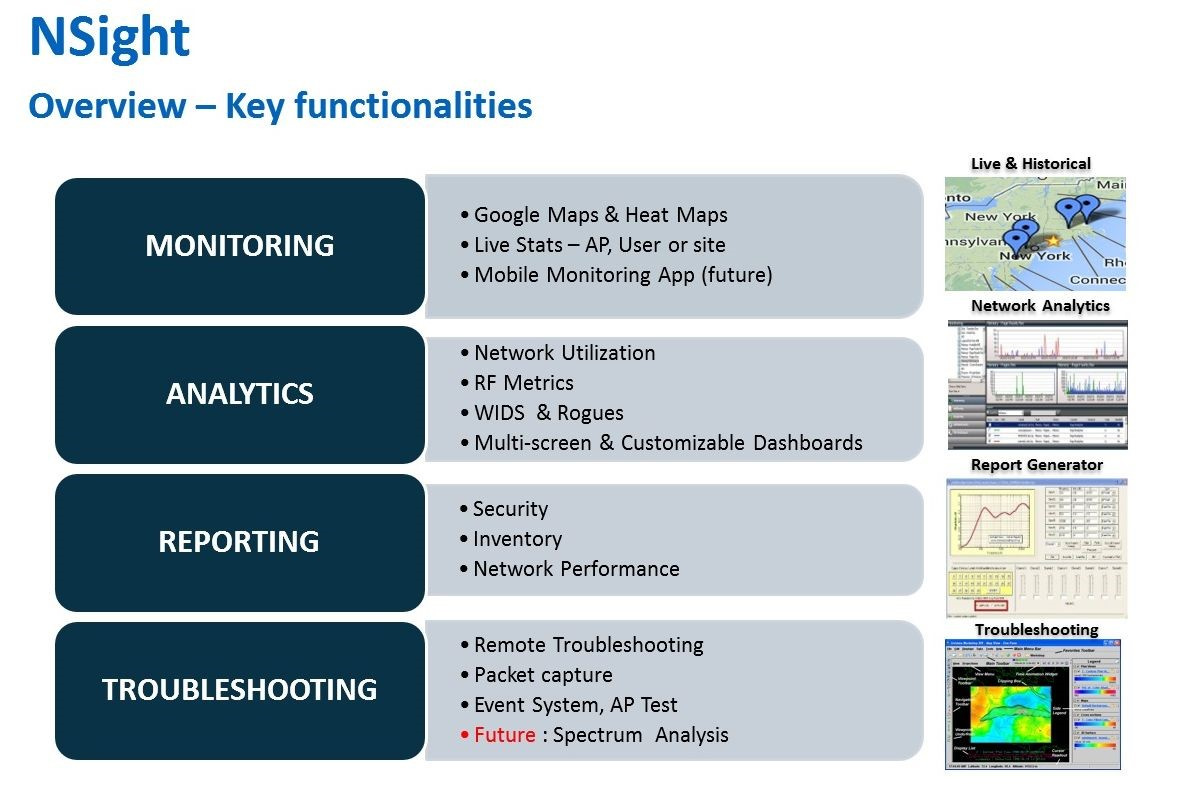



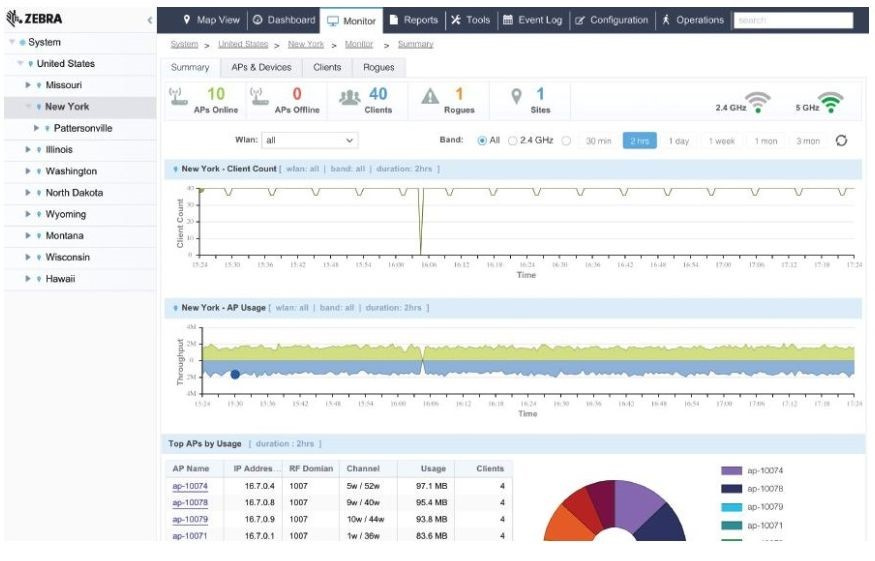

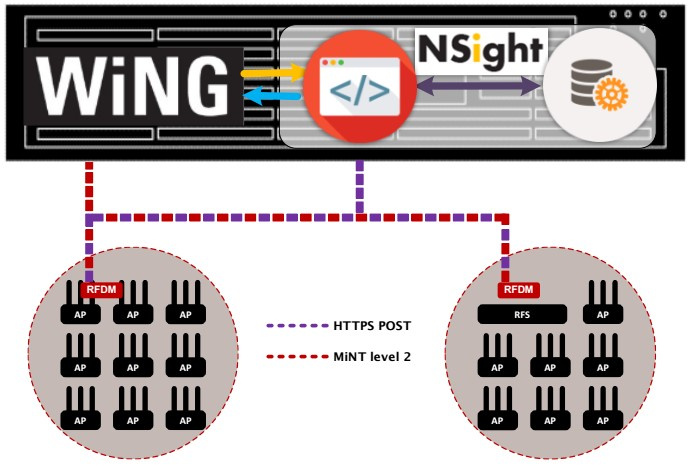
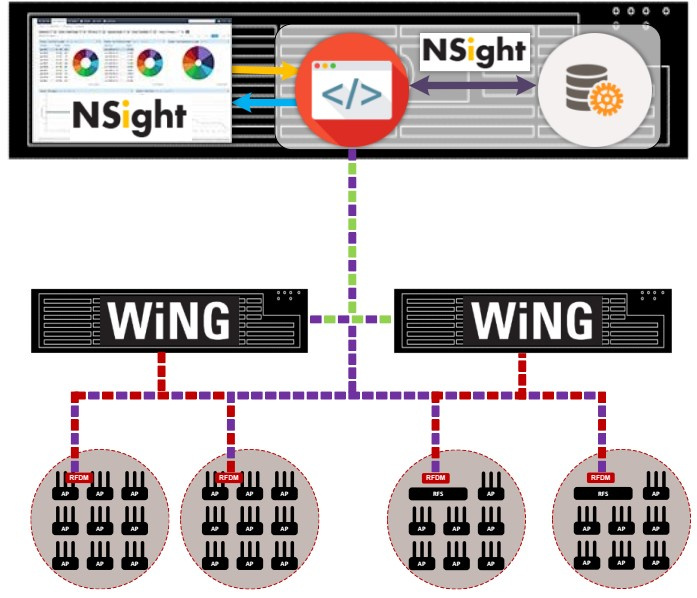
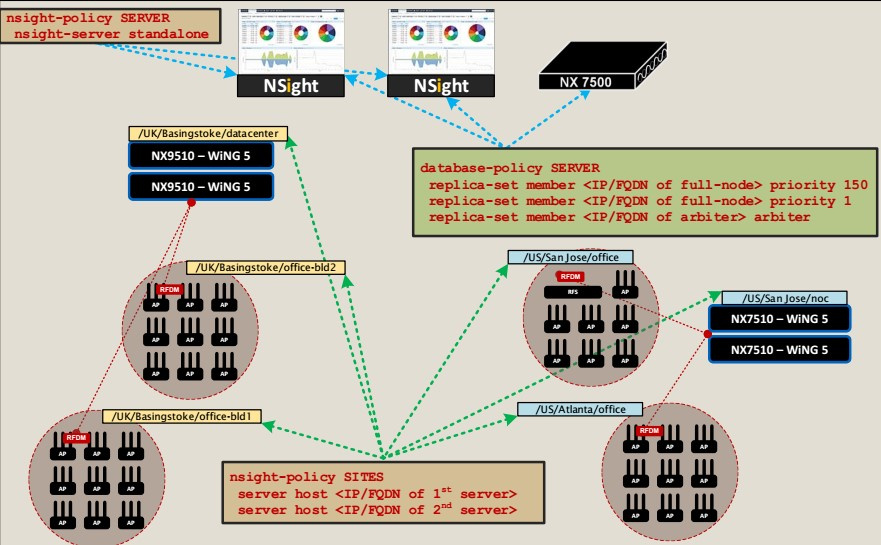
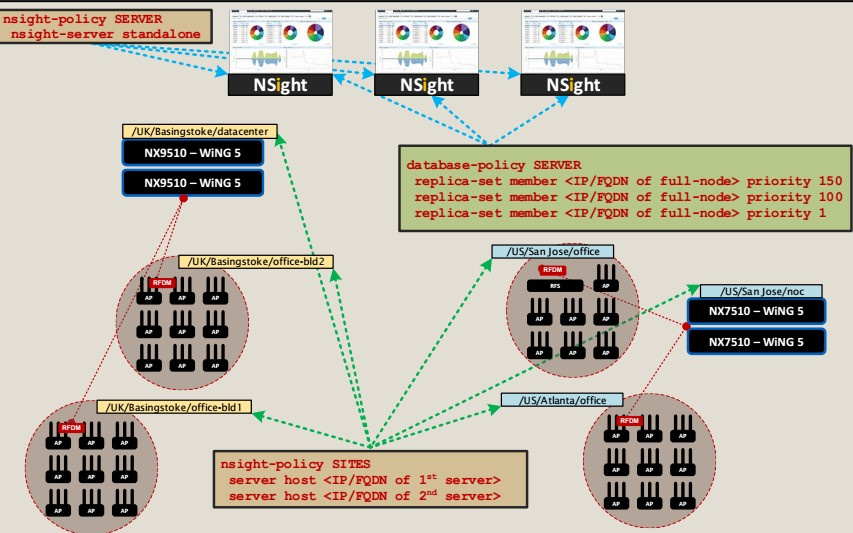
|
Метки: author pilot-retail беспроводные технологии блог компании пилот extreme networks гк quot; пилот extreme nsight wi-fi беспроводные сети |
[Перевод] Microsoft не изолировала Windows Defender в песочнице, так что это сделал я |

SimpleDacl, Profile и WinFFI.SimpleDacl работает и с файлами, и с директориями, у него есть несколько недостатков. Во-первых, он полностью переписывает существующую ACL и преобразует унаследованные элементы ACE в «нормальные». Кроме того, он пренебрегает теми элементами ACE, которые не может парсить (например, всё, кроме AccessAllowedAce и AccessDeniedAce. Примечание: мы не поддерживаем обязательные и проверочные записи контроля доступа).HANDLE и указатель в объекты Rust для управления временем их работы.
HANDLEs для сканируемого файла, и коммуникацией между процессами. Родительский процесс устанавливает два этих значения HANDLEs перед созданием дочернего процесса AppContainer. Теперь изолированный дочерний процесс загружает библиотеку антивирусного движка и сканирует входящий файл на предмет вирусов.HANDLEs сокетам под Windows. Во-вторых, эти сокеты не наследовались дочерним процессом AppContainer. Из-за этого приходится представить ещё одну «опору» для поддержки appjaillauncher-rs: TcpServer.TcpServer отвечает за асинхронный TCP-сервер и клиентский сокет, совместимый с перенаправлением STDIN/STDOUT/STDERR. Созданные вызовом socket сокеты не могут перенаправлять стандартные потоки ввода-вывода. Для правильного стандартного перенаправления ввода-вывода нужны «нативные» сокеты (как те, которые создаются через WSASocket). Чтобы разрешить перенаправление, TcpServer создаёт эти «нативные» сокеты и не запрещает явно для них наследование.std::vector может выставить свой поддерживающий буфер другому коду. Оригинальный вектор остаётся валидным, даже если поддерживающий буфер изменили. В случае Vec в Rust это не так. Здесь Vec требует создания нового объекта из «заготовок» старого Vec.unwrap, но это приведёт к сбою рантайма, когда неизбежно вылезет Error (или None).String/str, PathBuf/Path) нужно немного привыкнуть. Они идут парами с похожими именами, но ведут себя по-разному. В Rust принадлежащий тип представляет расширяемый, изменчивый объект (обычно строку). Слайс — это вид неизменяемого буфера символов (тоже обычно строка).|
Метки: author m1rko разработка под windows информационная безопасность rust c++ windows defender appjaillauncher |
DataGrip 2017.2 |

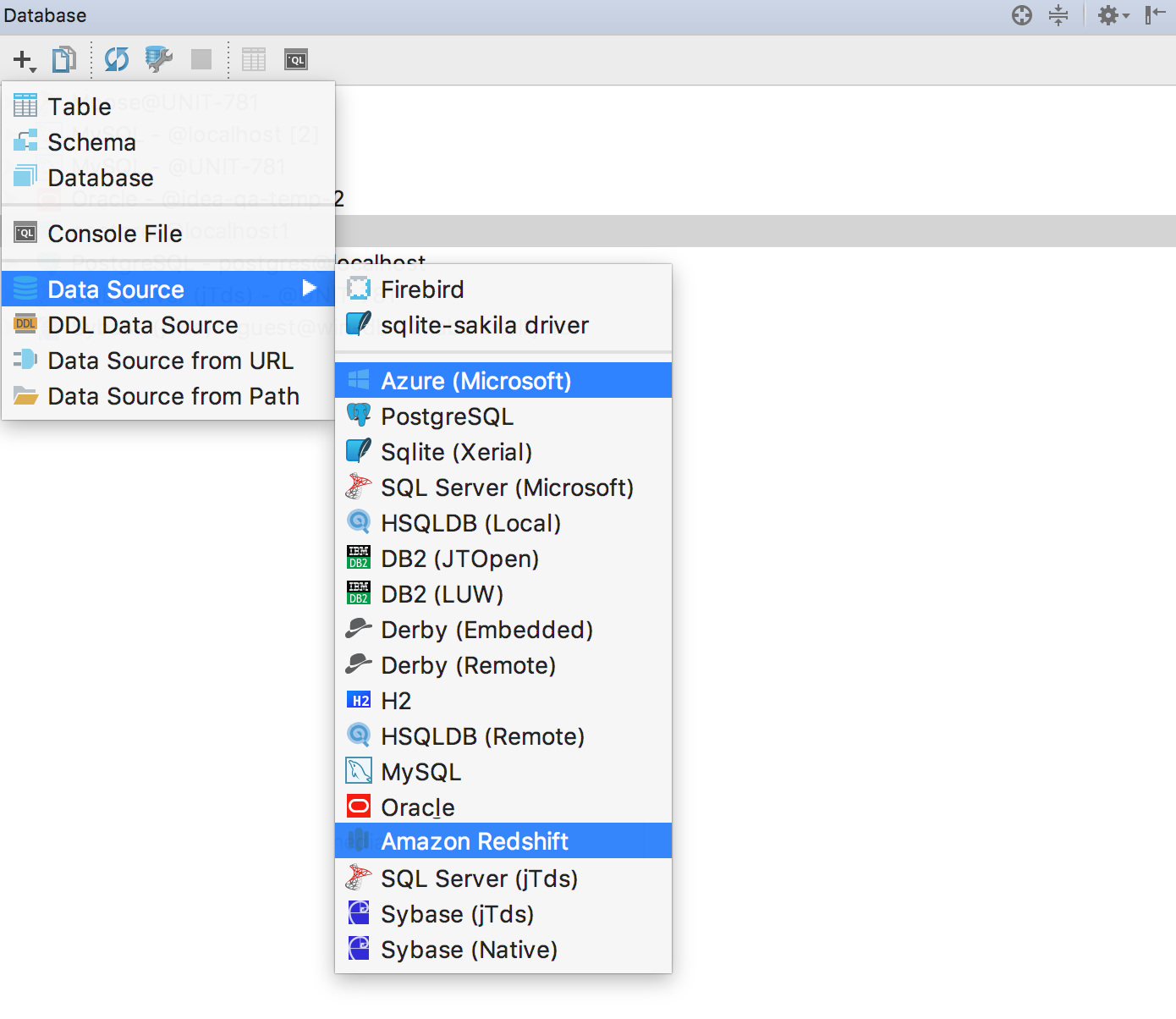
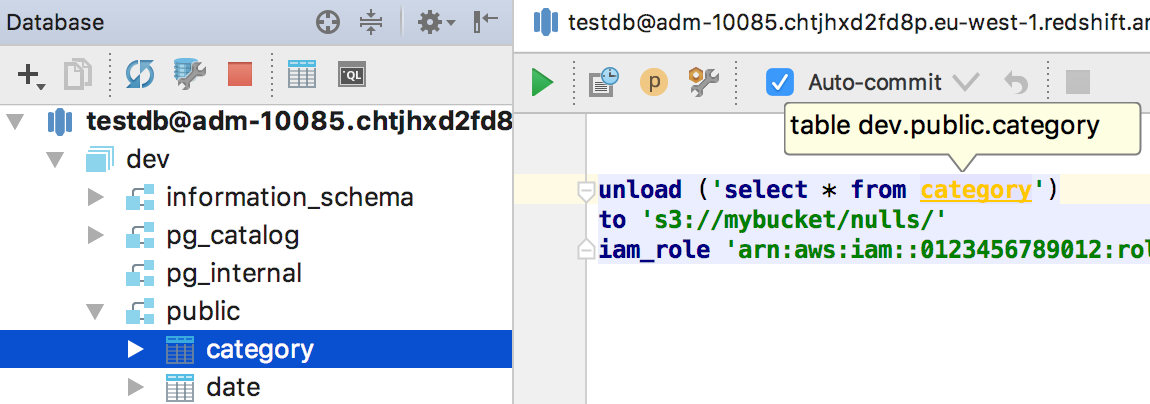

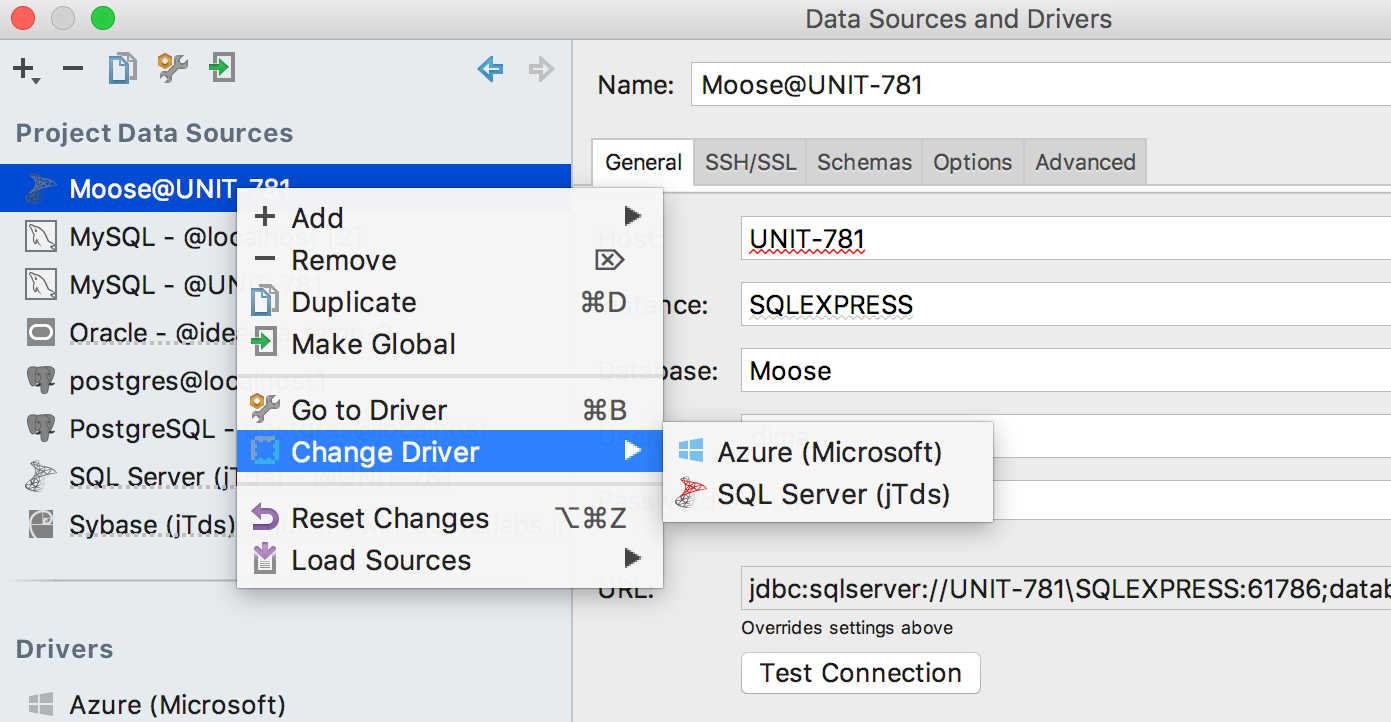

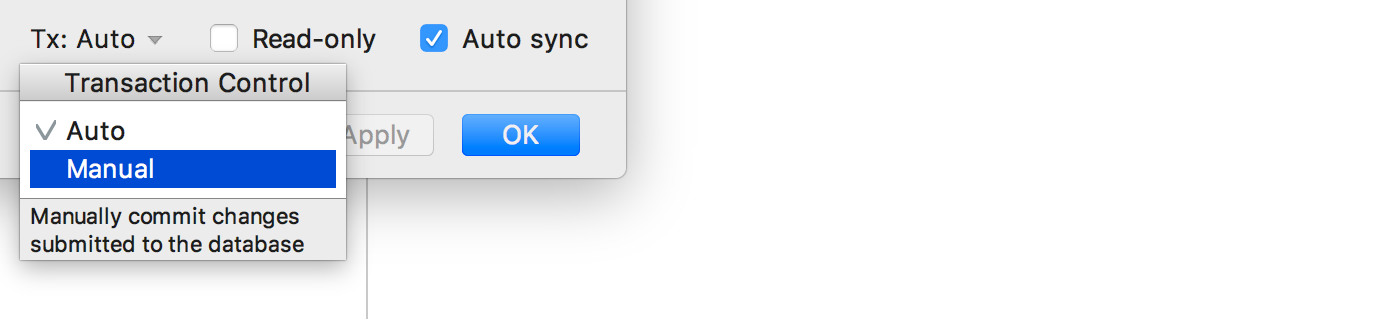
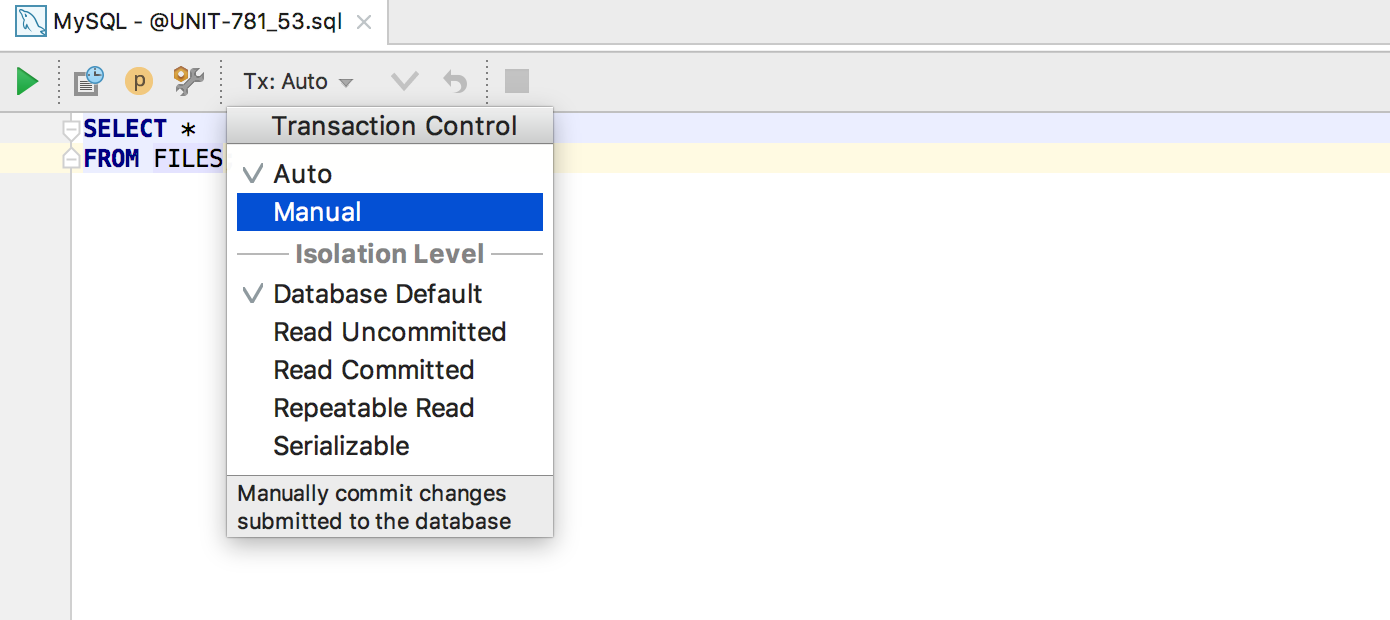
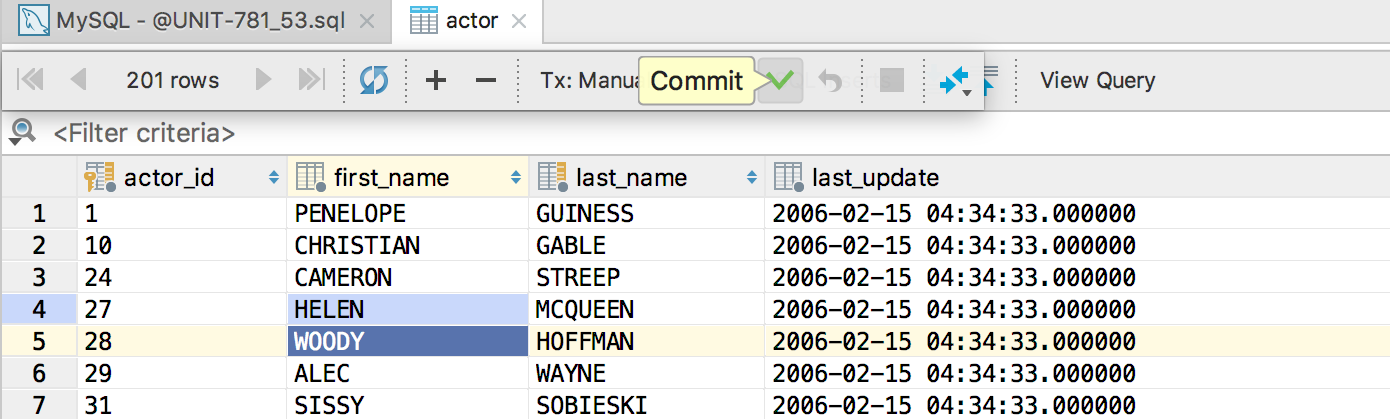
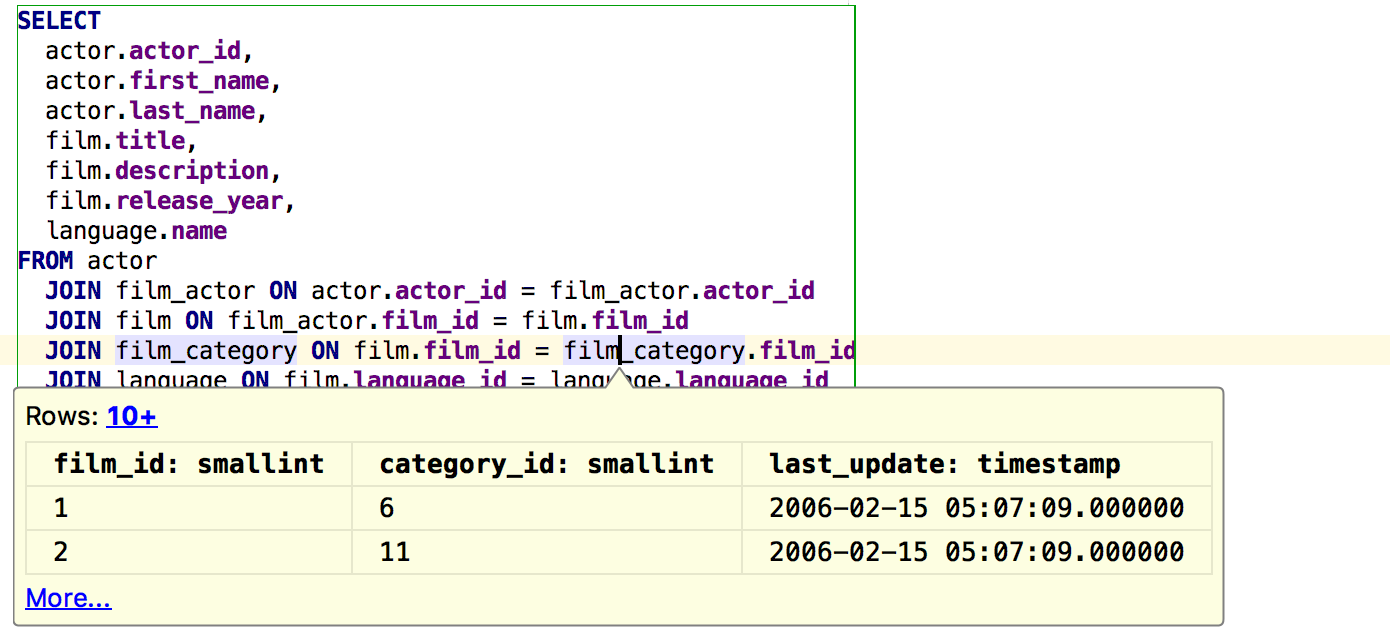
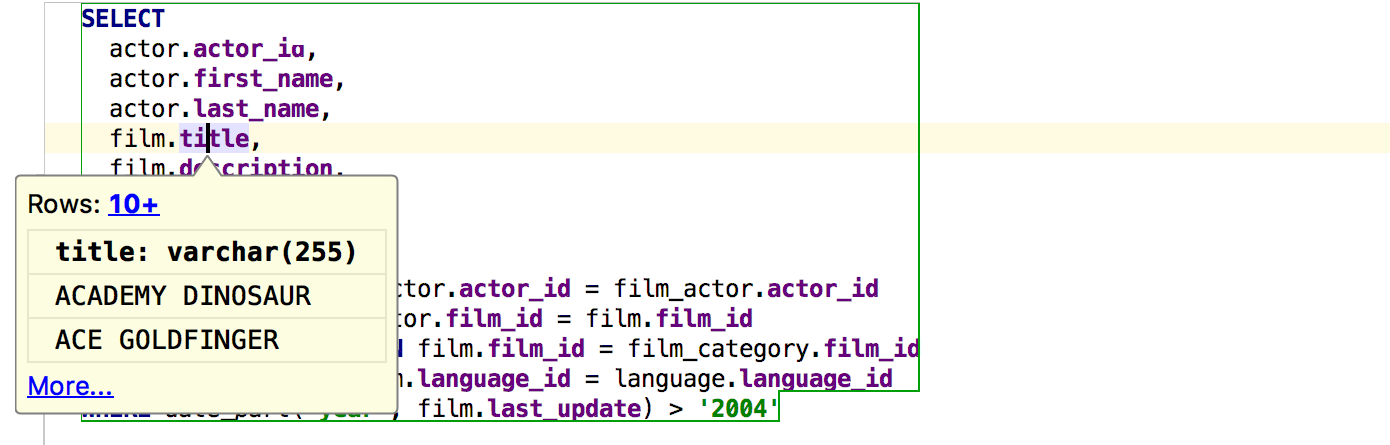
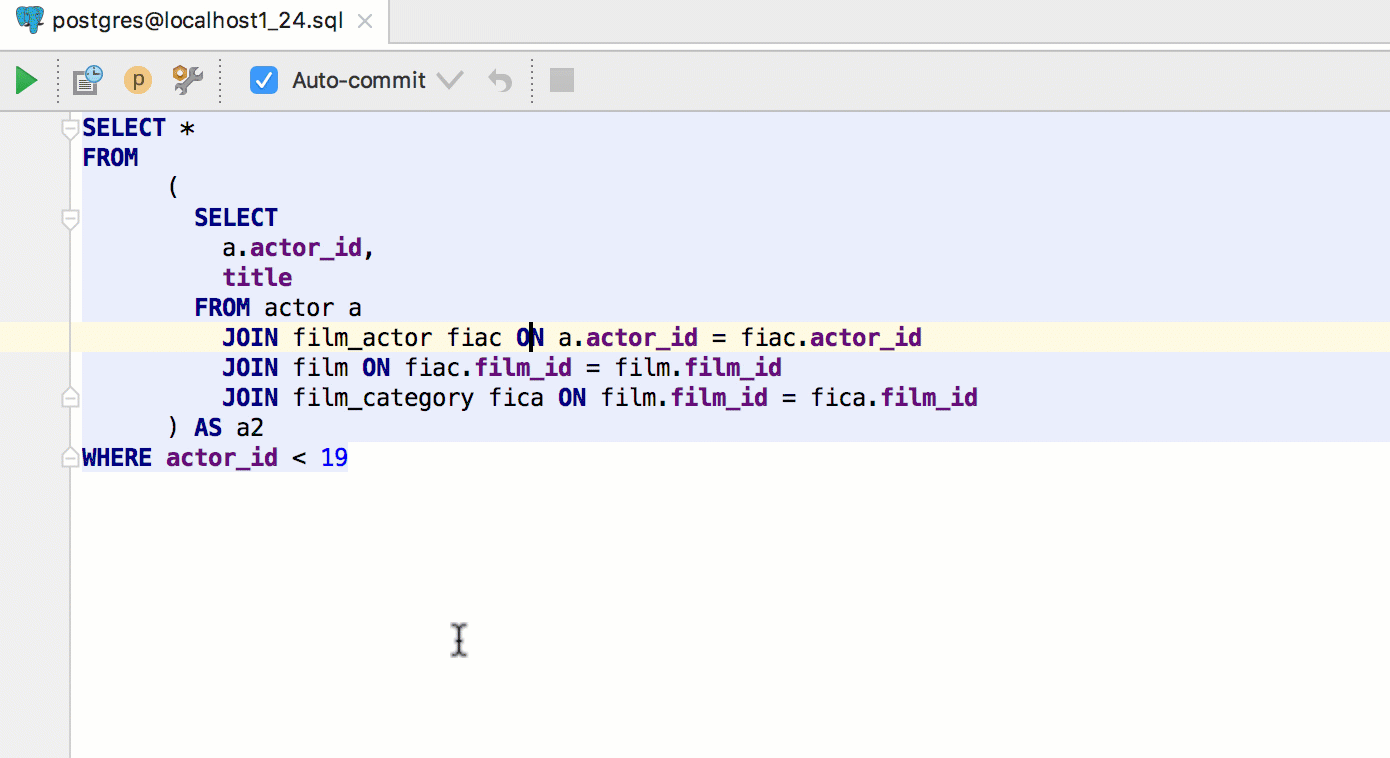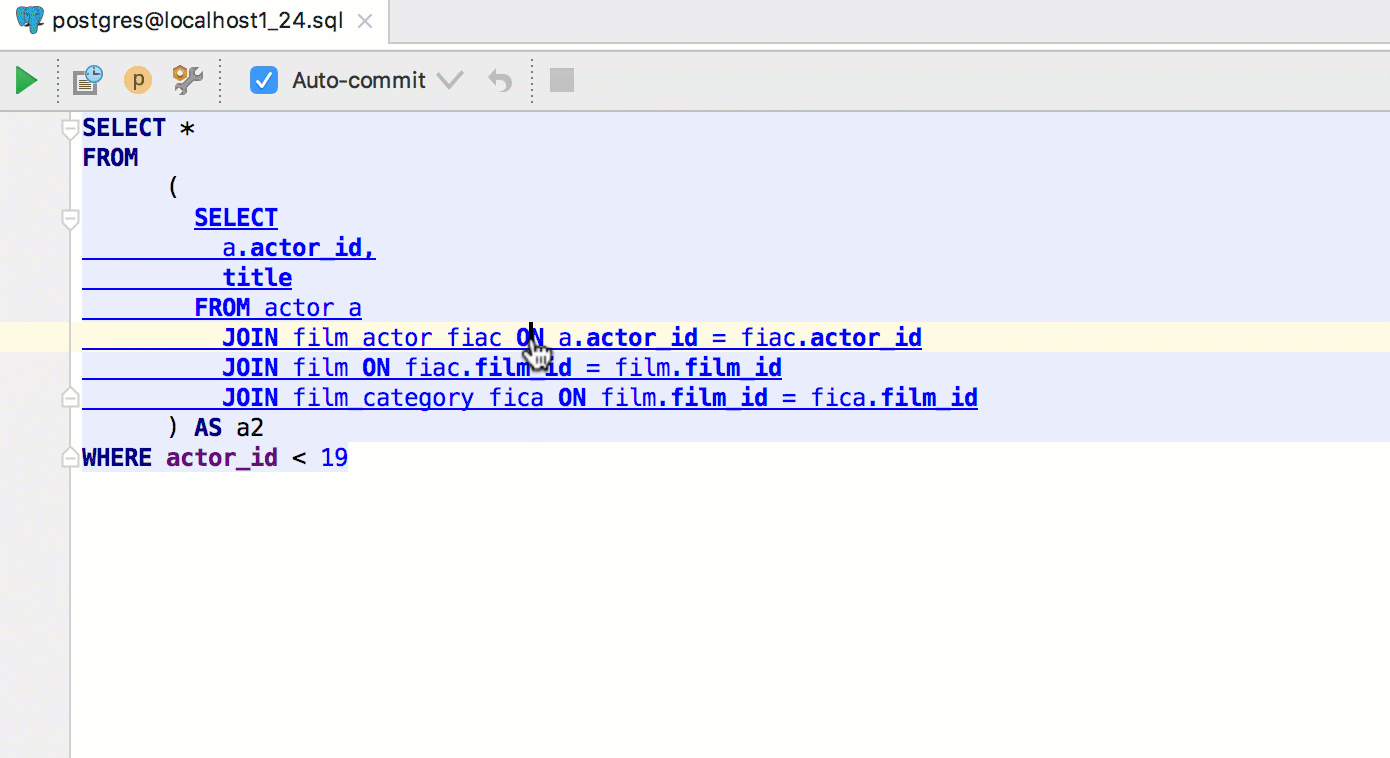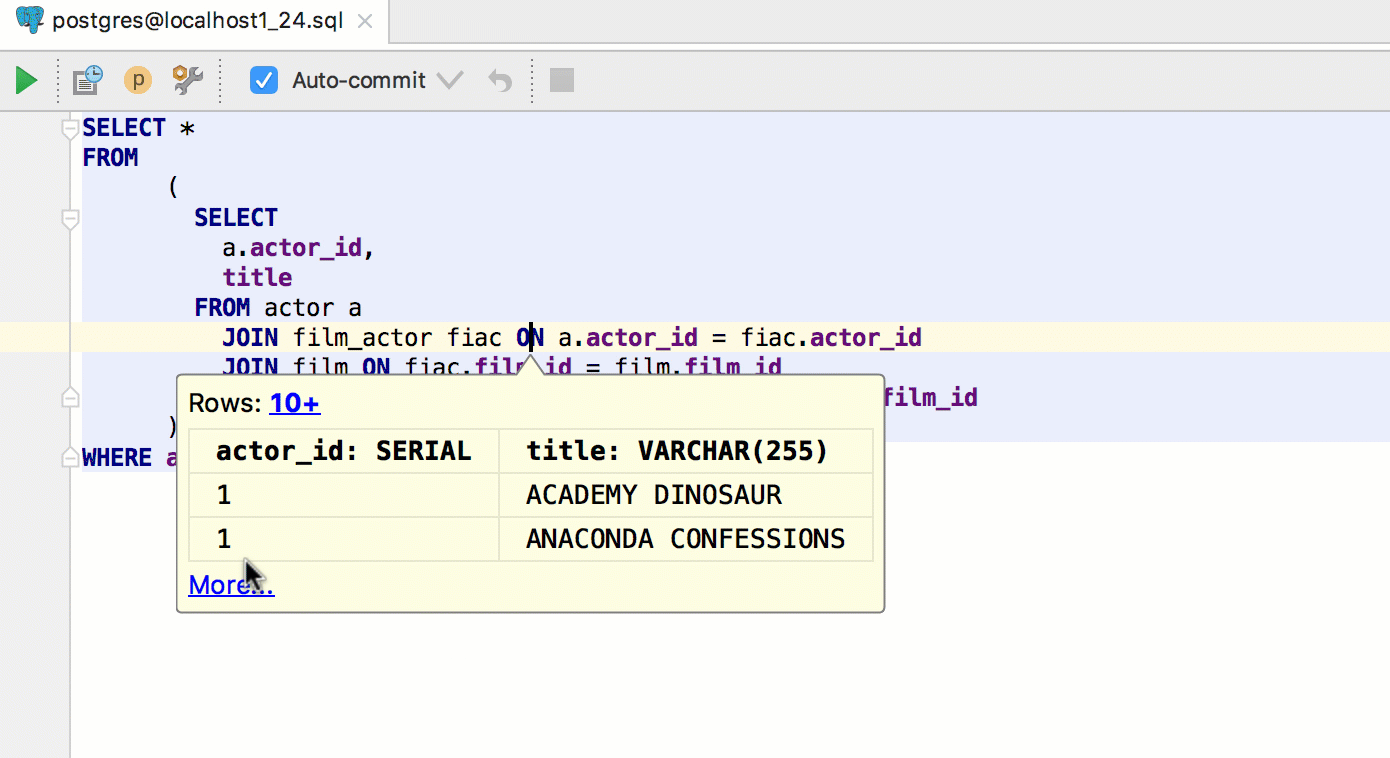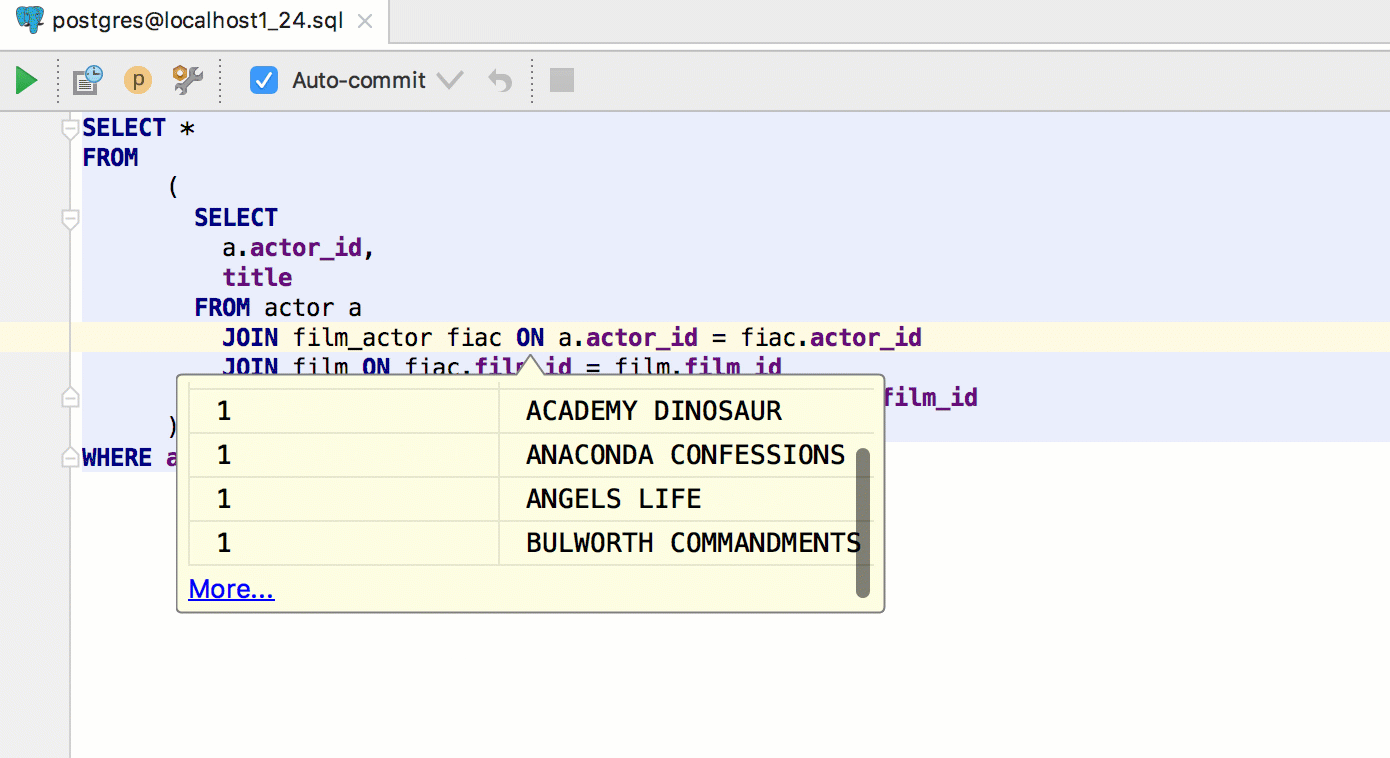
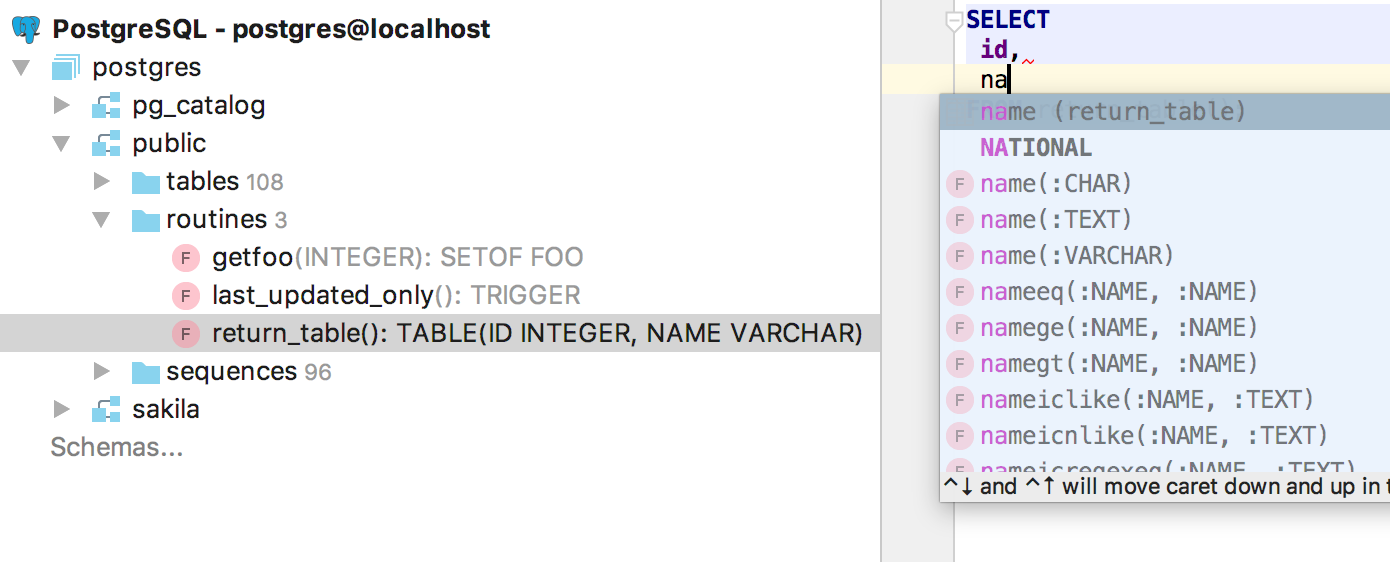
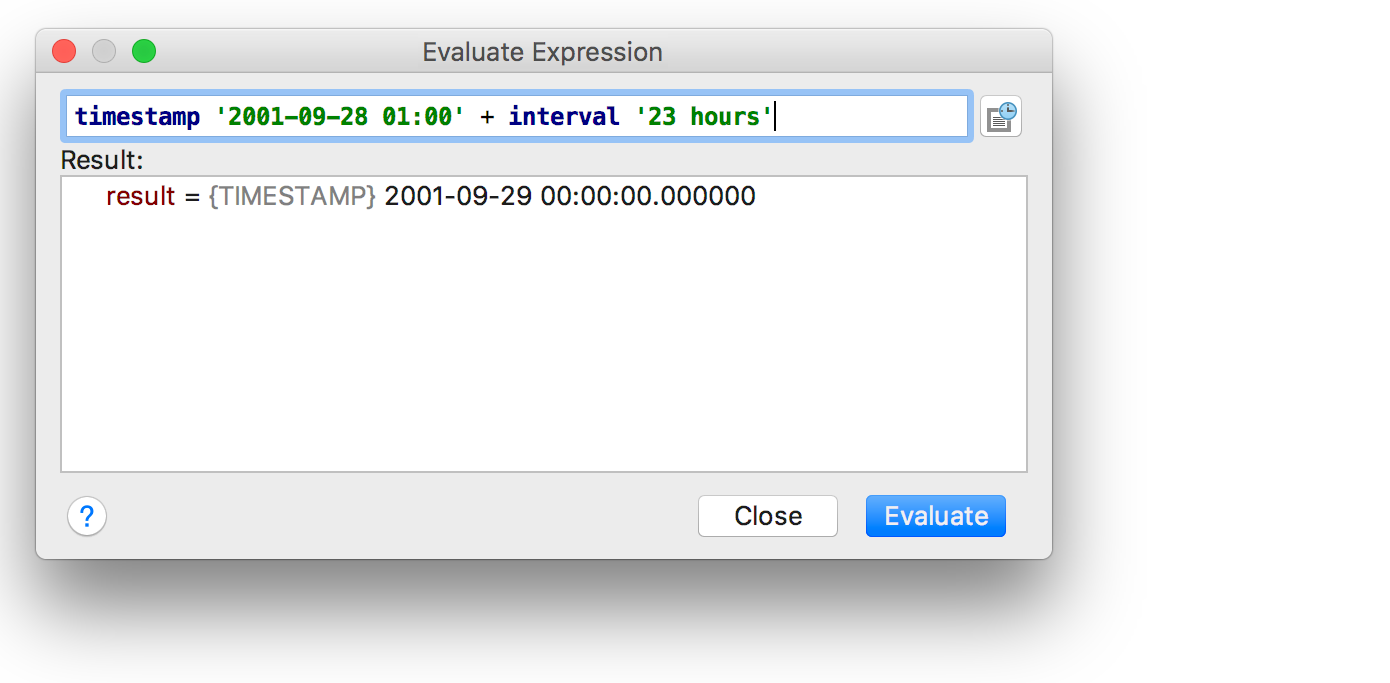
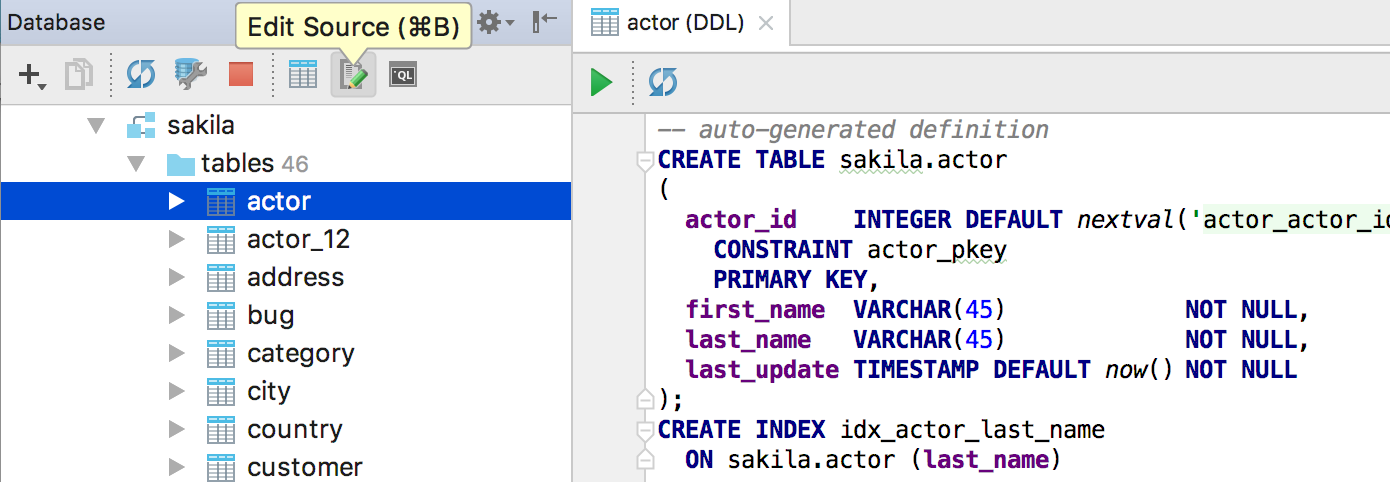
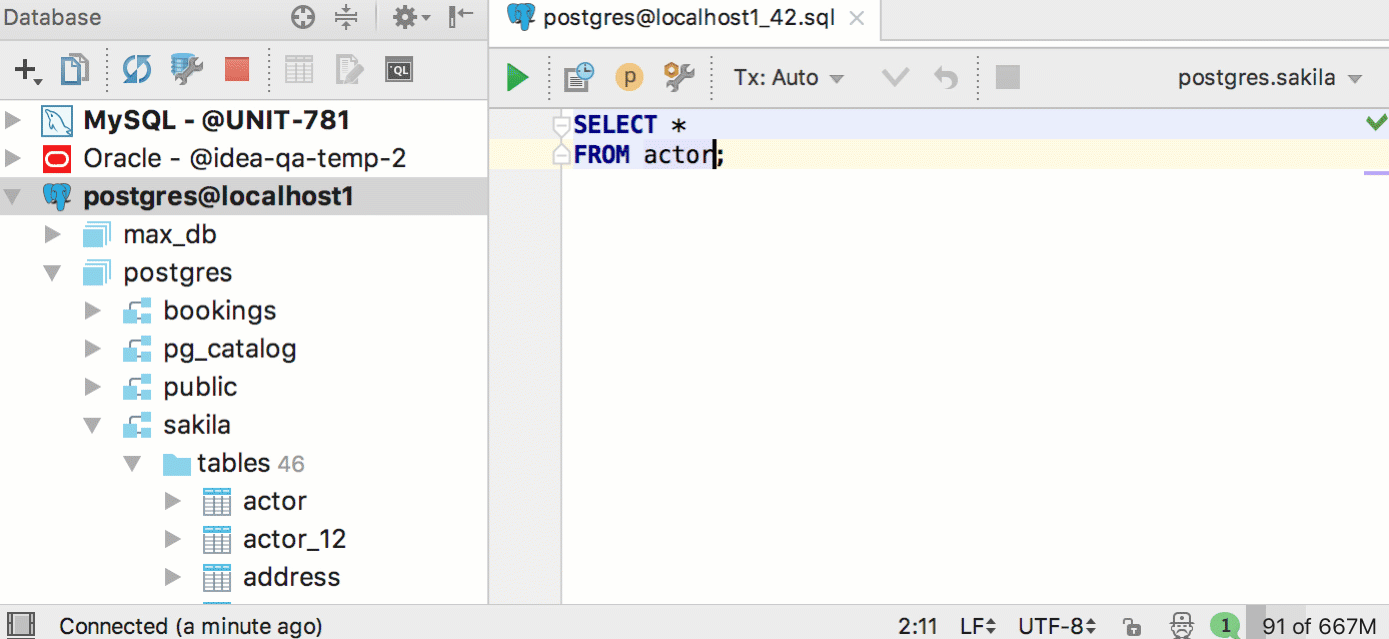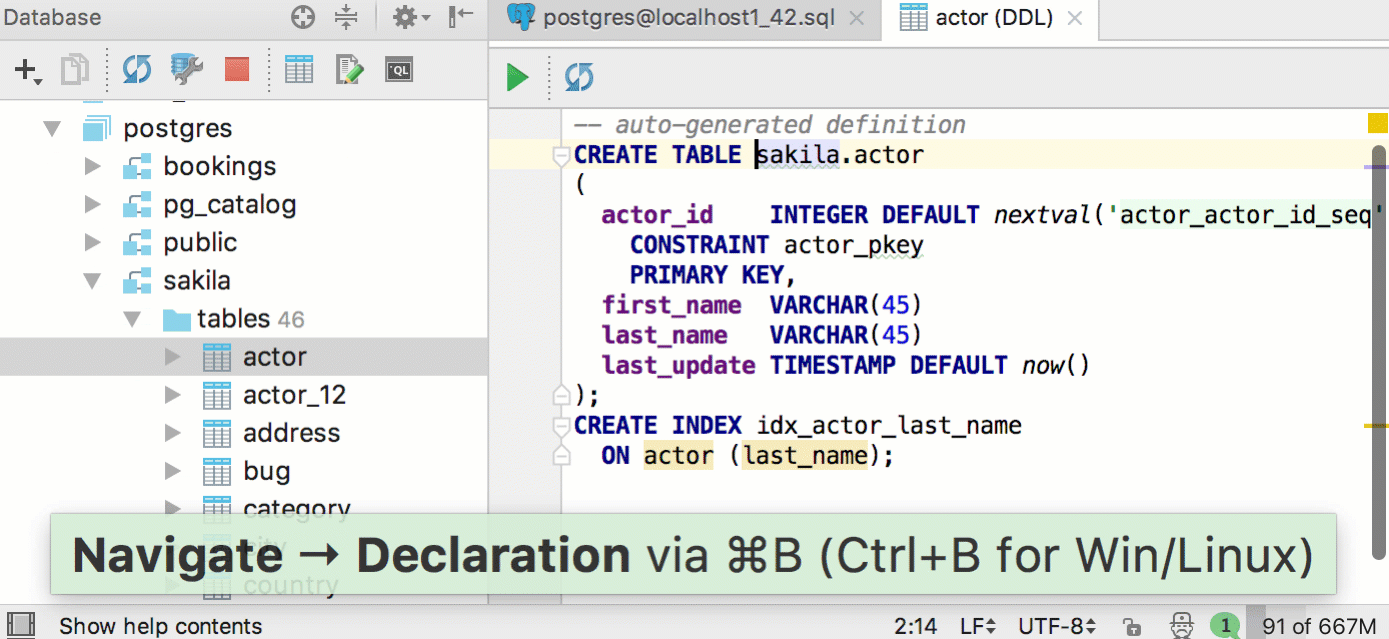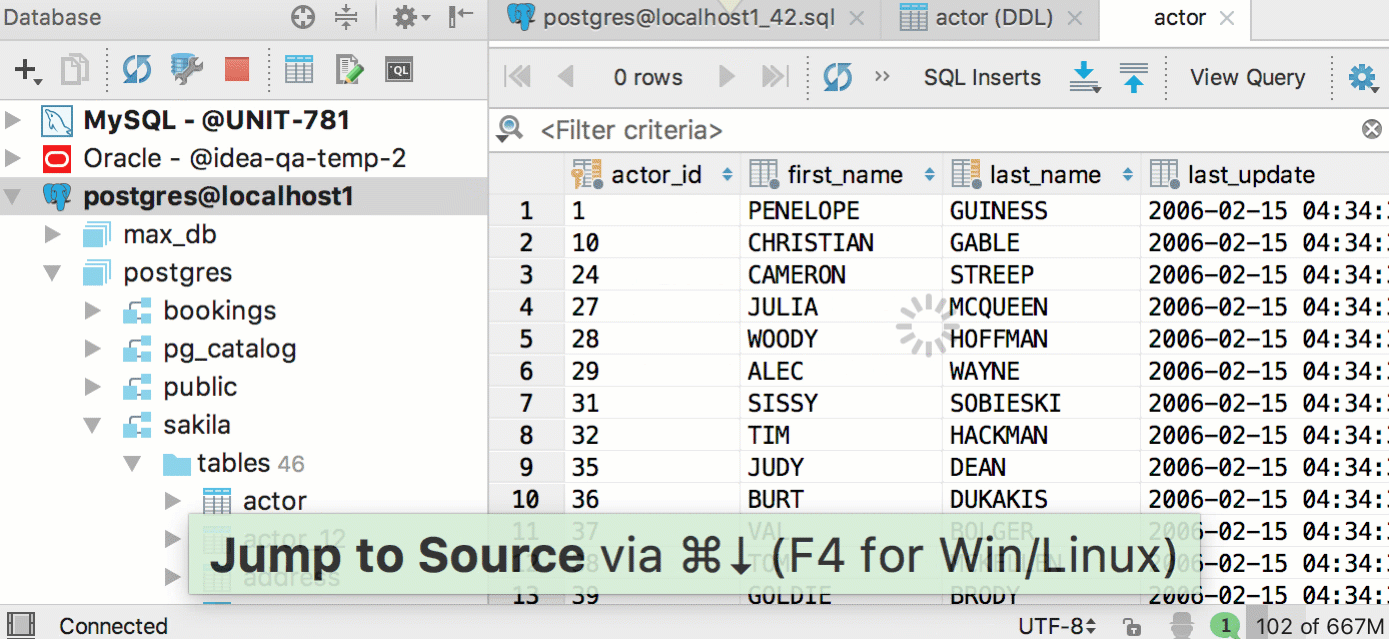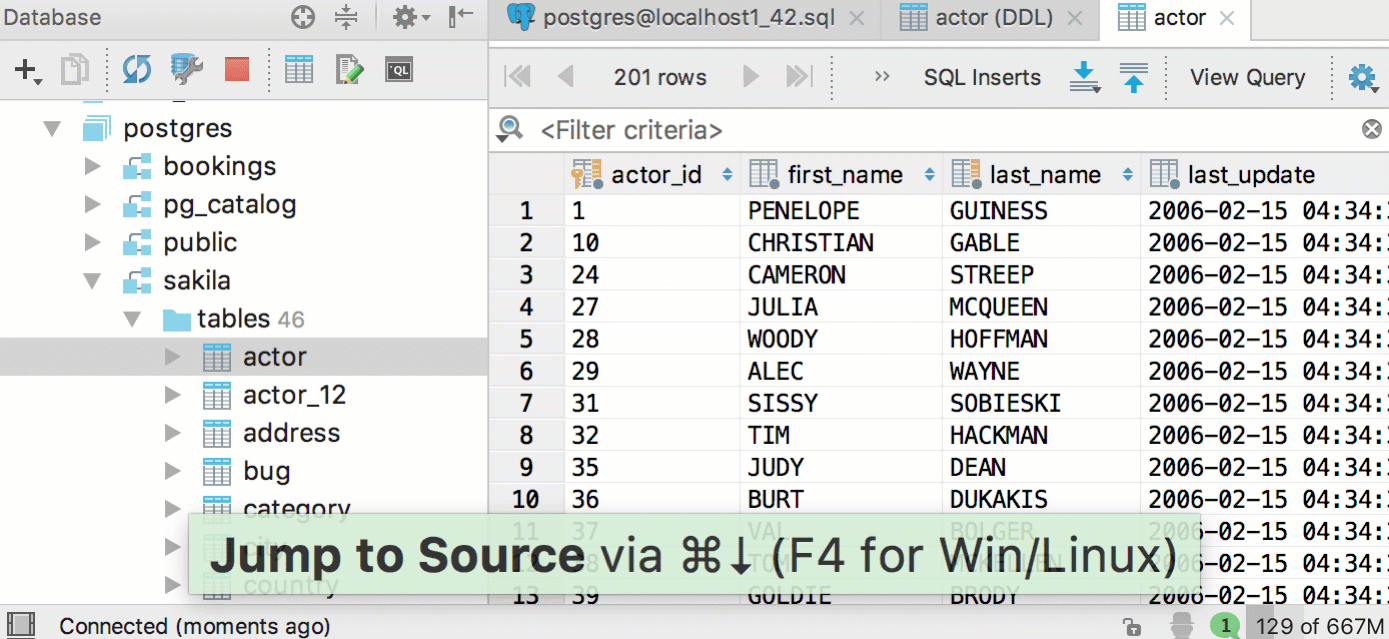
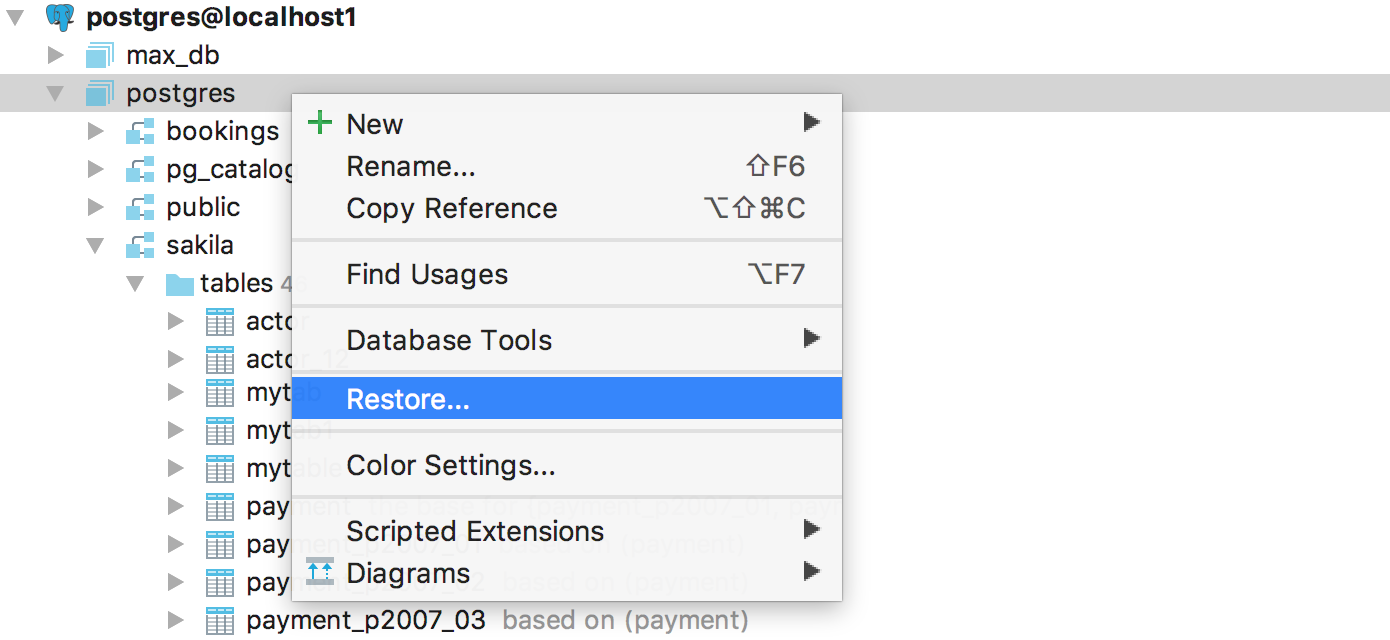
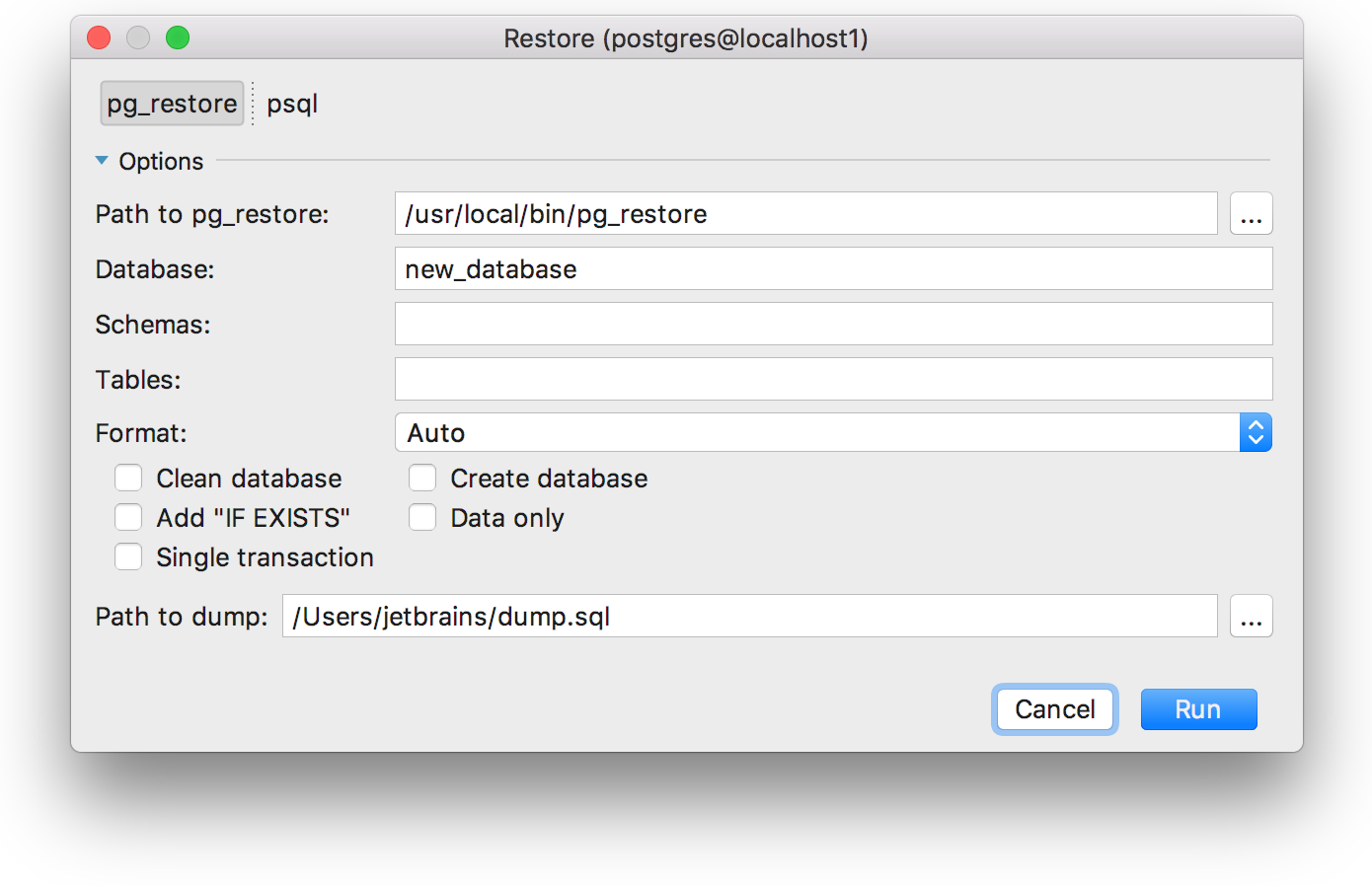
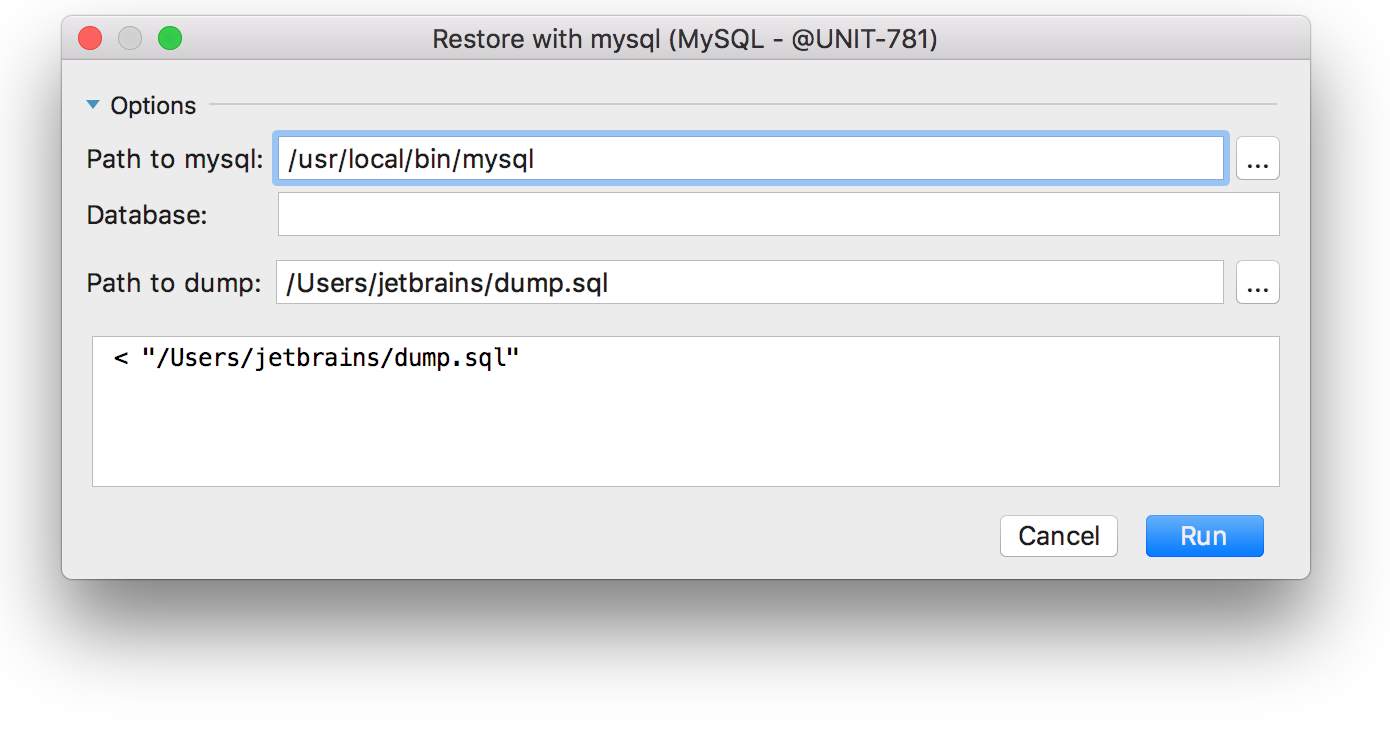
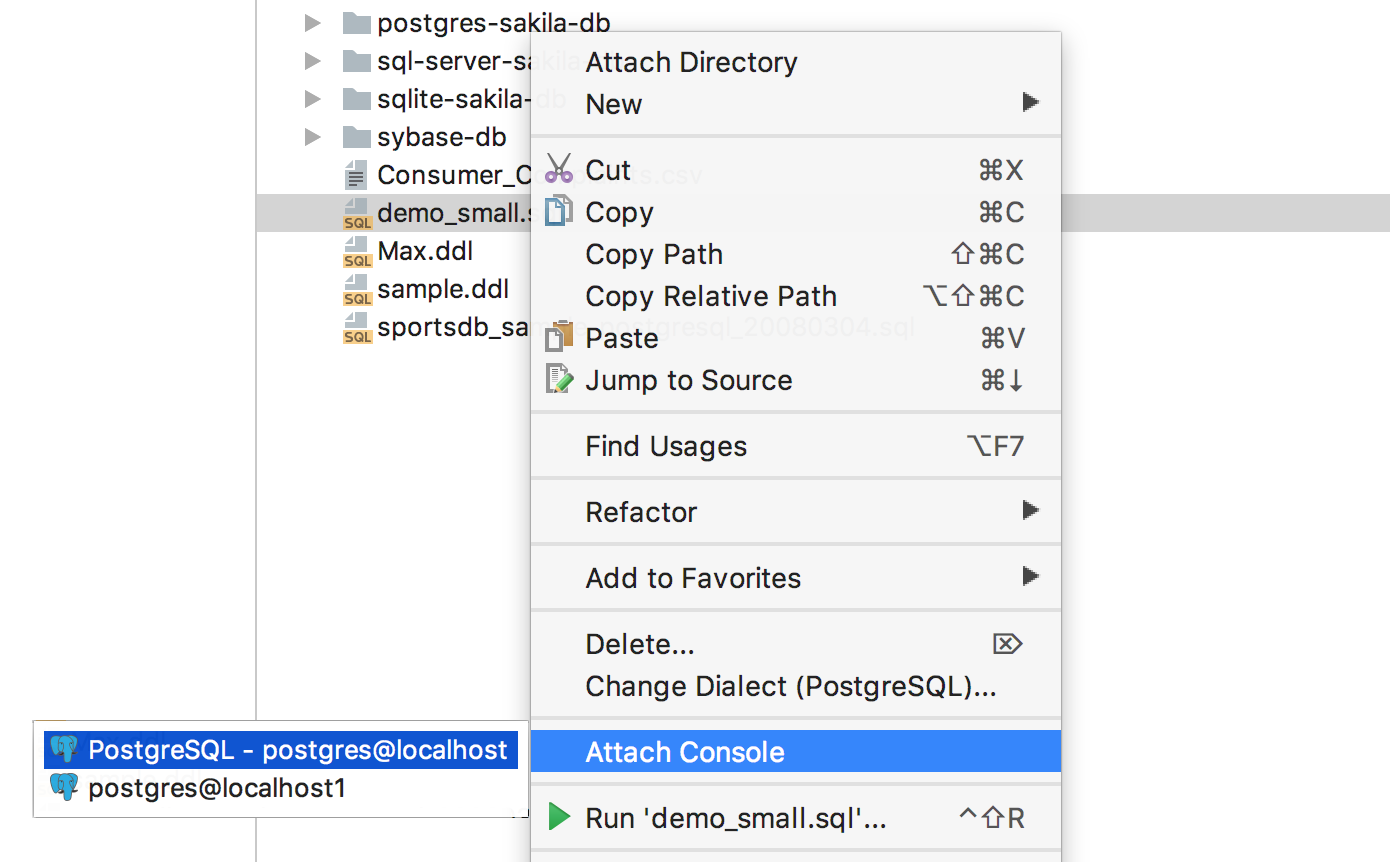
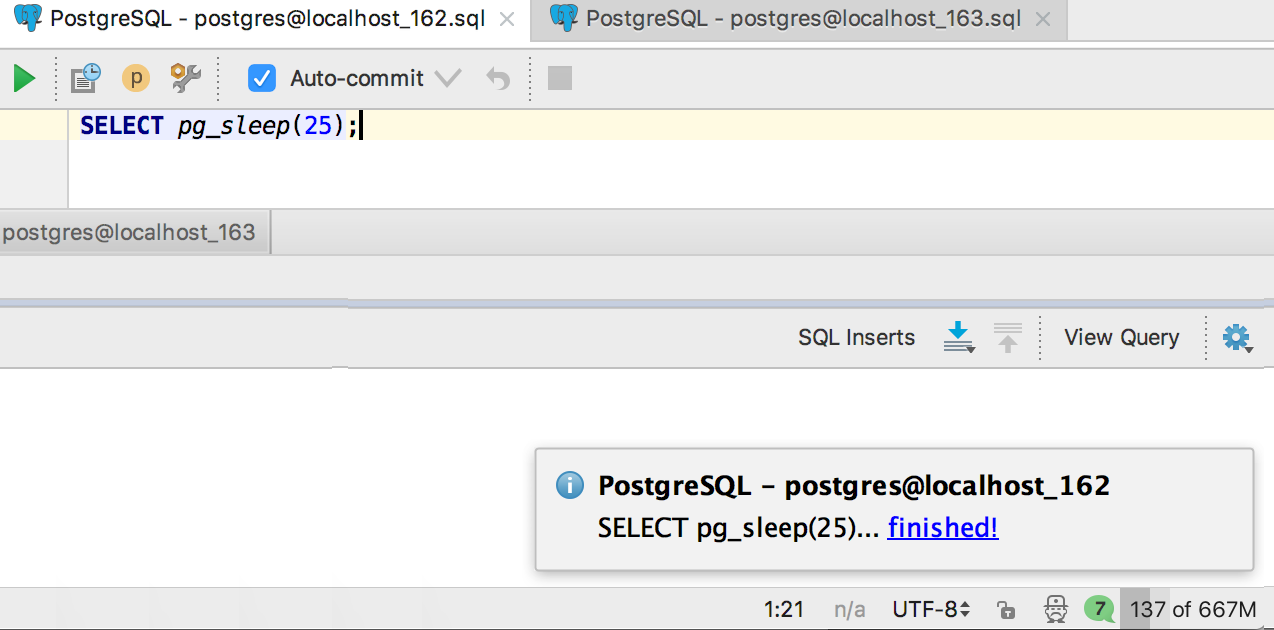


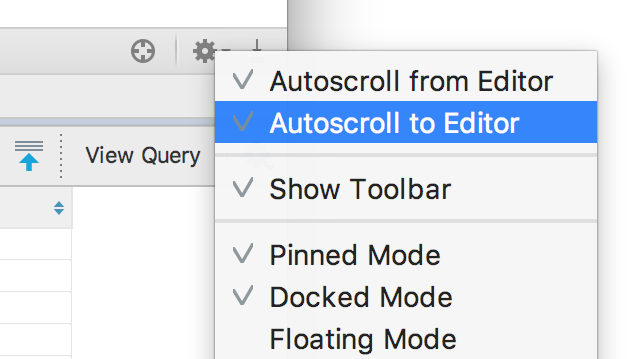
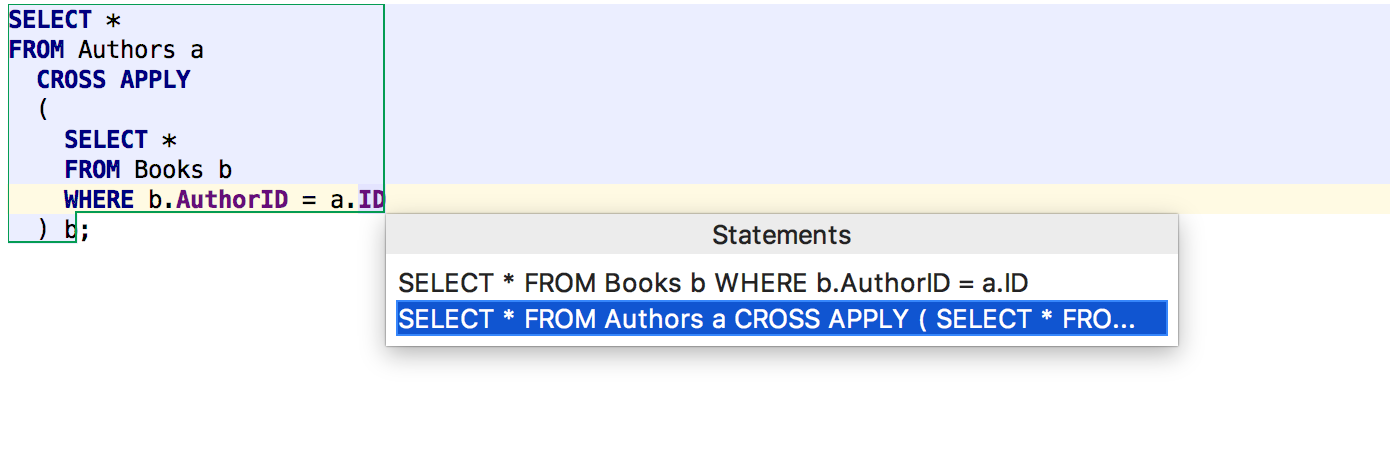
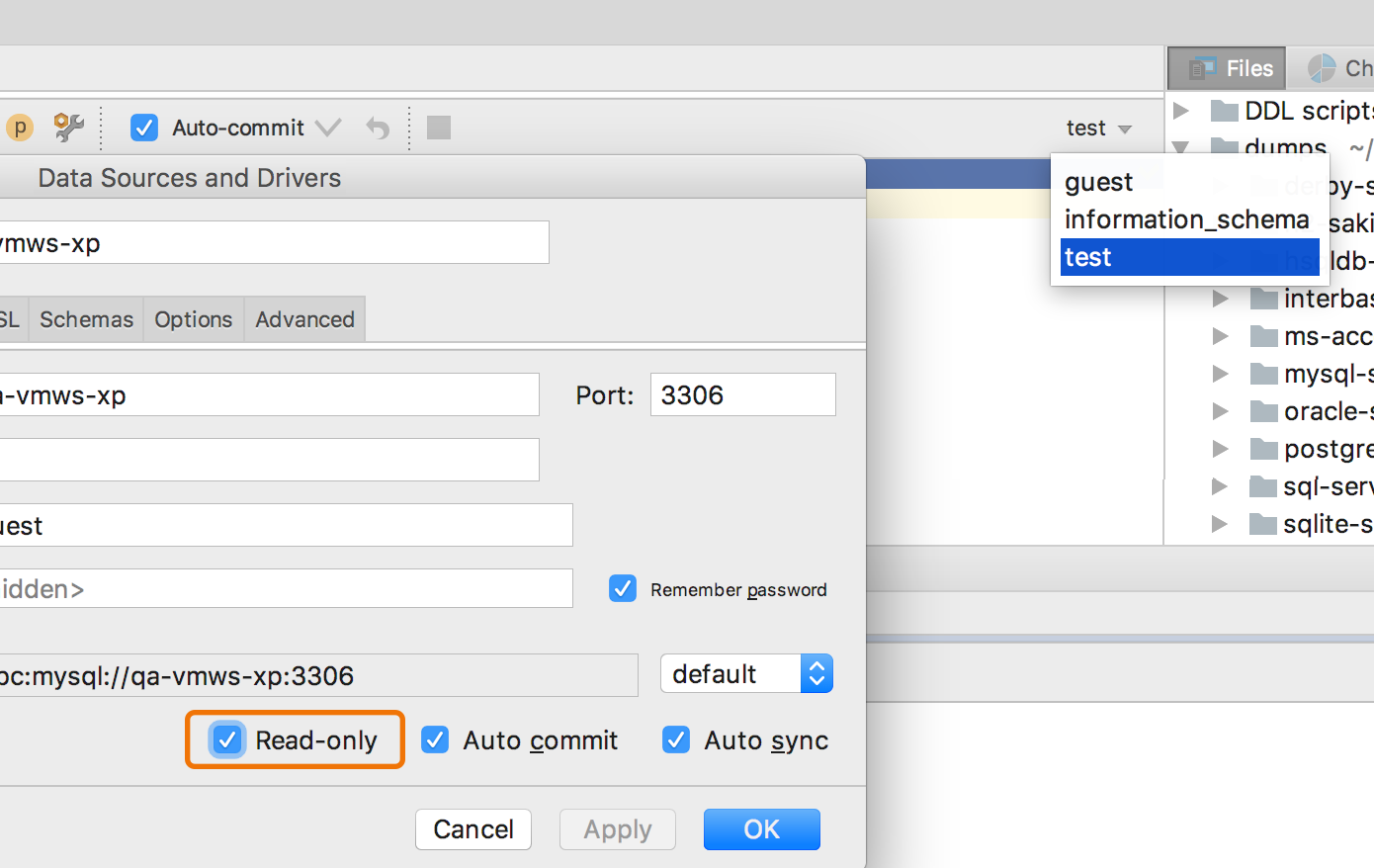
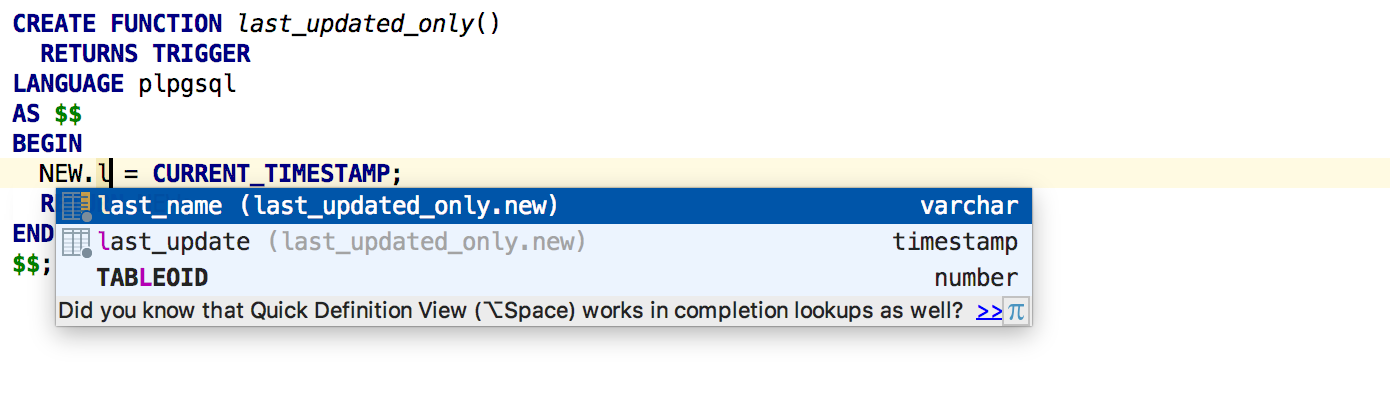

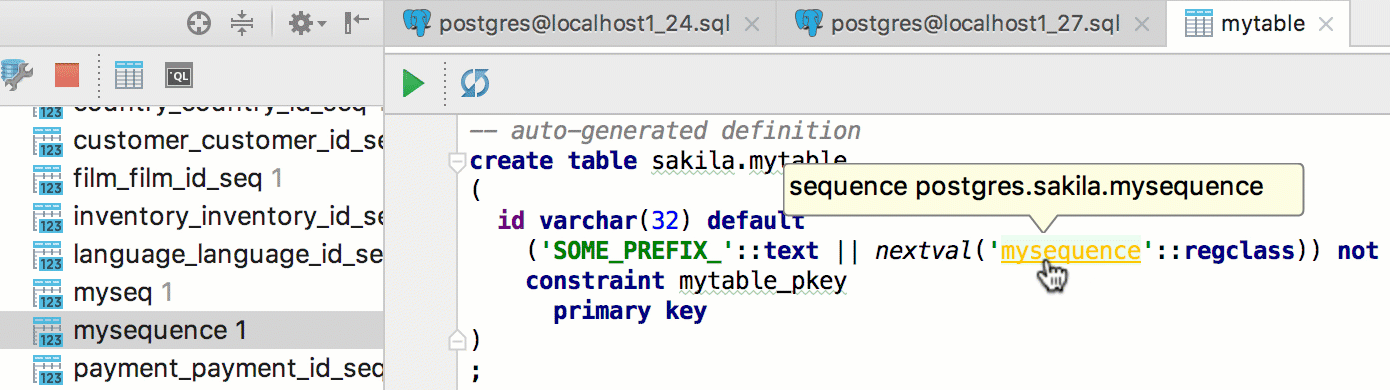
|
Метки: author moscas sql postgresql mysql amazon web services блог компании jetbrains jetbrains datagrip redshift aws sql server |






