[Из песочницы] Поиск пакетов Go на PowerShell |


Set-ExecutionPolicy RemoteSigned
New-Item -Path 'C:\work\goPS.ps1' -Type File -Force
function Find-GoPackage {
}
# Нетипизированная
$no_type
# Типизированная, строка
[string]$have_type
[CmdletBinding()]
Param (
[string]$Name = ""
)
$uri = "http://go-search.org/api?action=search&q=" + $Name
$hits = $($(Invoke-WebRequest -Uri $uri).Content | ConvertFrom-Json).hits
return $hits
function Find-GoPackage {
[CmdletBinding()]
Param (
[string]$Name = ""
)
$uri = "http://go-search.org/api?action=search&q=" + $Name
$hits = $($(Invoke-WebRequest -Uri $uri).Content | ConvertFrom-Json).hits
return $hits
}
PS C:\ >. “C:\work\goPS.ps1”
Find-GoPackage json | Format-Table -Wrap -AutoSize
Test-Path $PROFILE
New-Item -Path $PROFILE -Type File -Force
notepad $PROFILE
|
Метки: author pavelgeme2 системное администрирование powershell package management go golang |
[Перевод] Создание оффлайнового распознавания лиц с точностью 99,38% на Python и Node.js |








|
Метки: author Raiffeisenbank исследования и прогнозы в it блог компании райффайзенбанк распознавание лиц оффлайн |
Разработка под Sailfish OS глазами iOS-разработчика |





Label {
text: "Hello habrahabr!"
color: Theme.highlightColor
x: Theme.horizontalPageMargin
width: parent.width - x*2
font.pixelSize: Theme.fontSizeSmall
wrapMode: Text.Wrap
}

function requestUrl(source) {
var url = "http://newsapi.org/v1/articles?"
url += "source=" + source
url += "&apiKey=" + apiKey
return url
}
if (status === XMLHttpRequest.DONE) {
var objectArray = JSON.parse(req.responseText);
if (objectArray.errors !== undefined) {
console.log("Error fetching tweets: " + objectArray.errors[0].message)
} else {
for (var key in objectArray.statuses) {
var jsonObject = objectArray.statuses[key];
news.append(jsonObject);
}
}
if (wasLoading == true) {
newsObject.isLoaded()
}
}


|
|
Модульное тестирование Pega-приложений: меняем жизнь к лучшему с Ninja |




final String myClass = "MyOrg-MyApp-Work-MyCase";
// prepare a Top-level page
preparePage("MyTopLevelPage").create(myClass)
.prop("pyLabel", "This is my top level page for a case")
.prop("MyProp", "My value");
// prepare parameter
prepareParameter("myParam").value("My param value");// mock nested activity invocation
expect().activity().className("MyOrg-MyApp-Work-MyCase").name("NestedActivity").andMock(new MockBehaviour() {
@Override
public void process(MockActivityContext context) throws Exception {
// assert parameters
context.assertParameter("myParam").value("My value");
// assert Primary page
context.assertPrimaryPage().prop("MyProp", "My value");
// assert Top-level page
context.assertPage("TopLevelPage").exists().prop("pyLabel", "This is my TLP");
// set properties in Primary
context.preparePrimaryPage().prop("pyNote", "My note for this page");
// set parameters on Top-level page
context.preparePage("TopLevelPage").prop("pyLabel", "This is MODIFIED TLP");
// set parameters
context.prepareParameter("myResult").value("Success");
}
}); //mock Obj-Browse method invocation
final String opClass = "Data-Admin-Operator-ID";
expect().objBrowse().page("OperatorList").className(opClass).andMock(new MockBehaviour() {
@Override
public void process(MockObjBrowseContext context) throws Exception {
// prepare result set
final PreparePageList pxResults = context.preparePage("OperatorList").prop("pxResultCount", "2").pageList("pxResults");
pxResults.append(opClass).prop("pyUserIdentifier", "info@pegadevops.com").prop("pyLabel", "Operator ID record");
pxResults.append(opClass).prop("pyUserIdentifier", "alexander.lutay@pegadevops.com").prop("pyLabel", "Operator ID record");
}
}); // what about covering a Function with a unit test?
invoke().function().ruleSet("MyRuleset").library("MyLibrary").name("Func").args().string("My string").longO(123).date(new Date());
// would you like to unit test a When rule?
invoke().when().primaryPage("pyWorkPage").name("ToBeOrNotToBe");// assert activity status
assertActivityStatus().good();
// assert Clipboard state
assertPage("MyTestPage").exists().propAbsent("ErrorCode")
.prop("ResultCode", "0").propPresent("ResultDescription");
// assert Params
assertParameter("MyParam").value("Some value");Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author lutalex тестирование веб-сервисов тестирование it-систем блог компании гк ланит pega тестирование корпоративные приложения |
Red Team: командное взаимодействие при проведении тестирования на проникновение |
|
Метки: author LukaSafonov информационная безопасность блог компании pentestit корпоративные лаборатории pentestit red team |
[recovery mode] Тестирование прототипов при разработке программного продукта |

Тестирование прототипа поможет обмануть время и устранить глобальные проблемы в самом начале разработки.
В интерактивных прототипах не должно быть Lorem Ipsum, стандартных картинок с горами Axure и перечеркнутых прямоугольников.
Если очень нужно проверить сложную дорогую функциональность, которую разрабатывать минимум год, то сделайте быстрое решение и проверяйте его.
|
|
[Перевод] Flash мертв: кто следующий? |



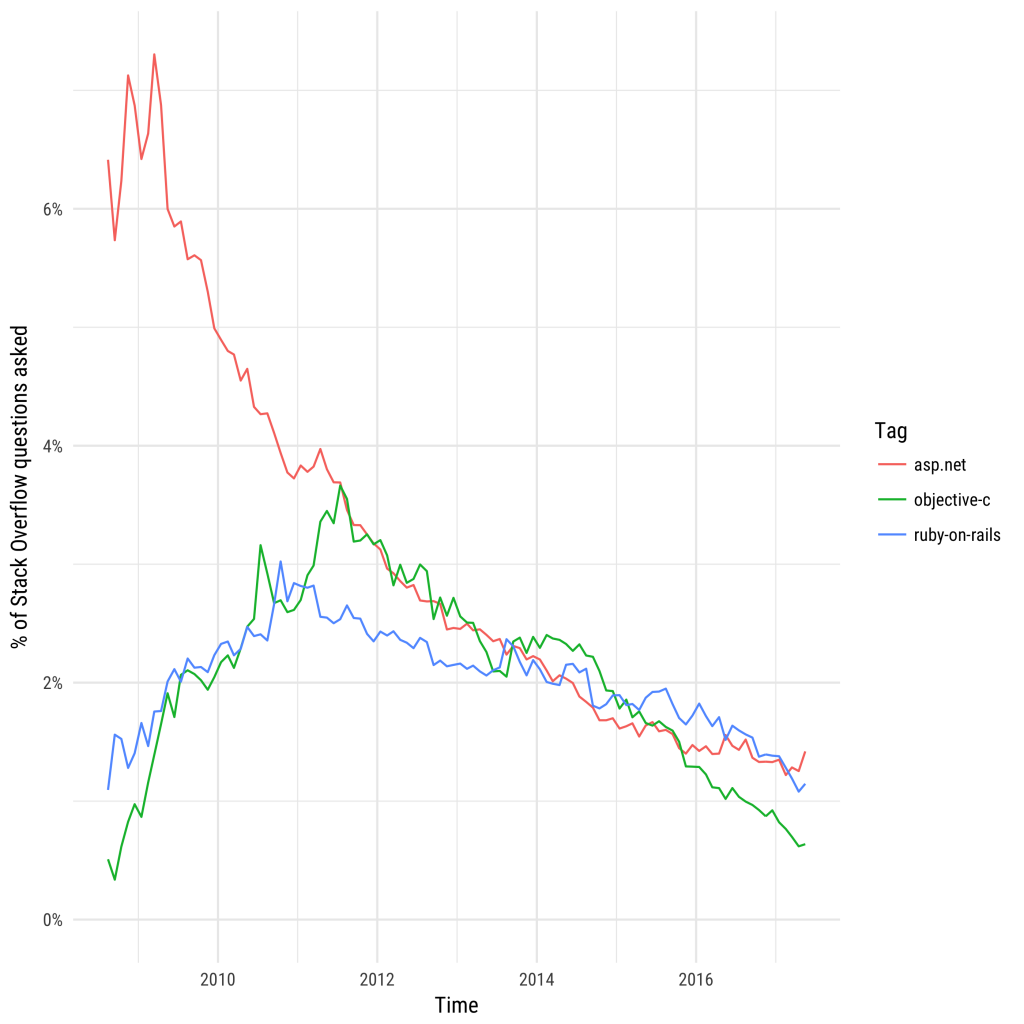
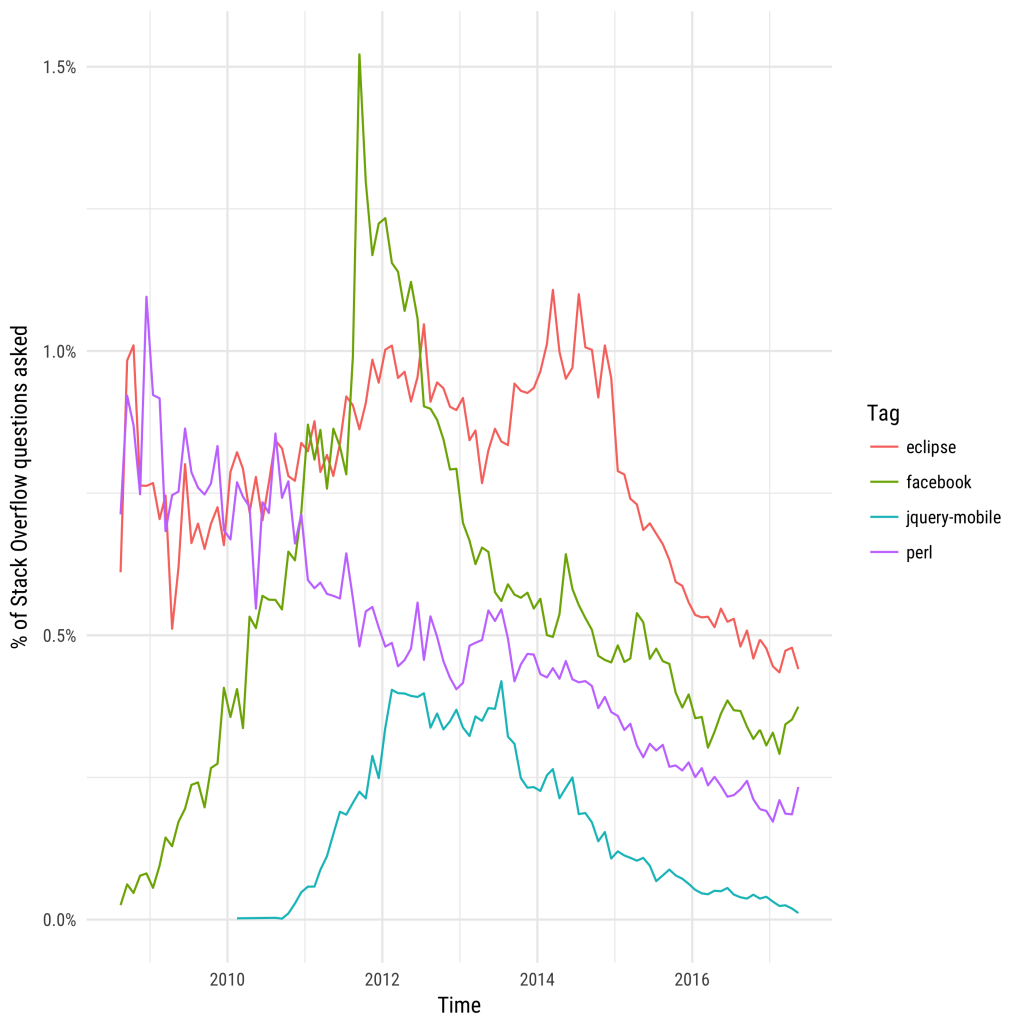
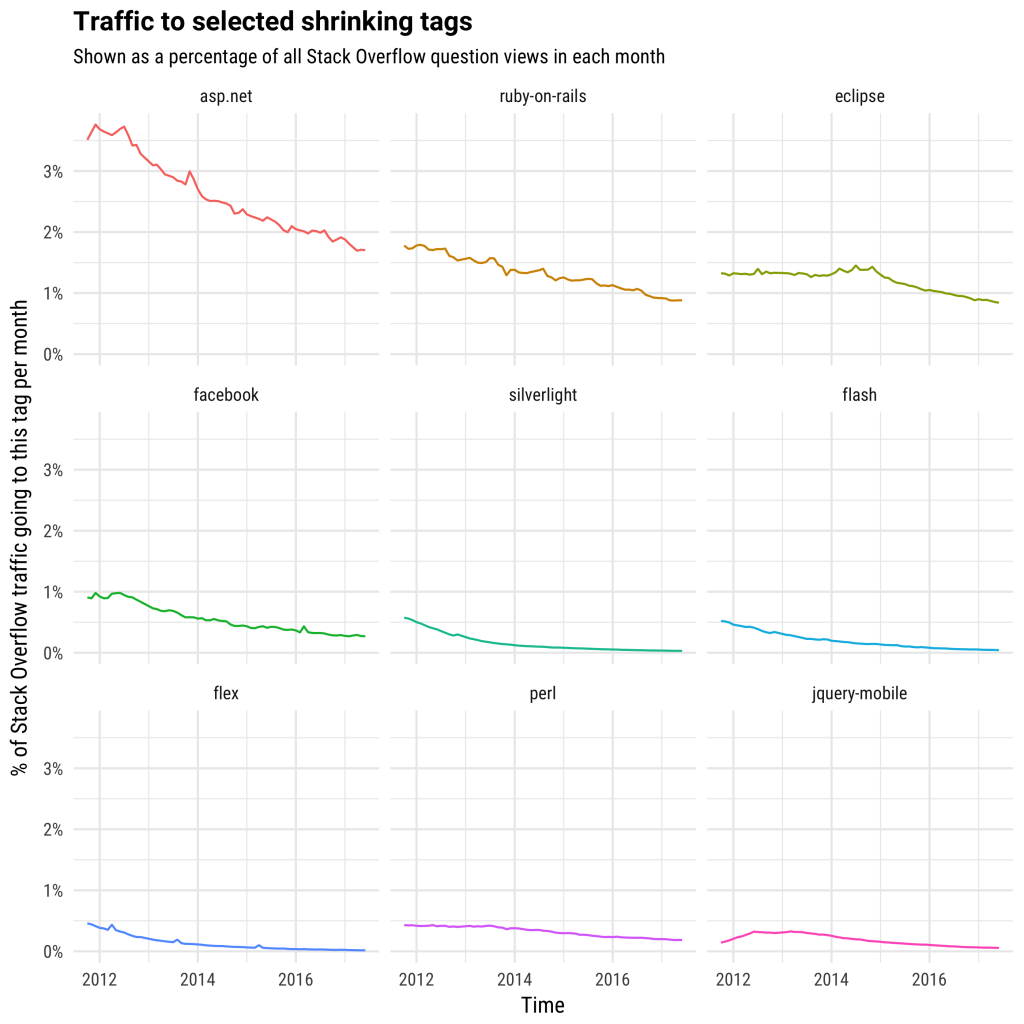
|
Метки: author nanton adobe flash блог компании everyday tools stack overflow прогнозы silverlight flex ruby on rails eclipse |
[Из песочницы] Машинное обучение в горнолыжном спорте |

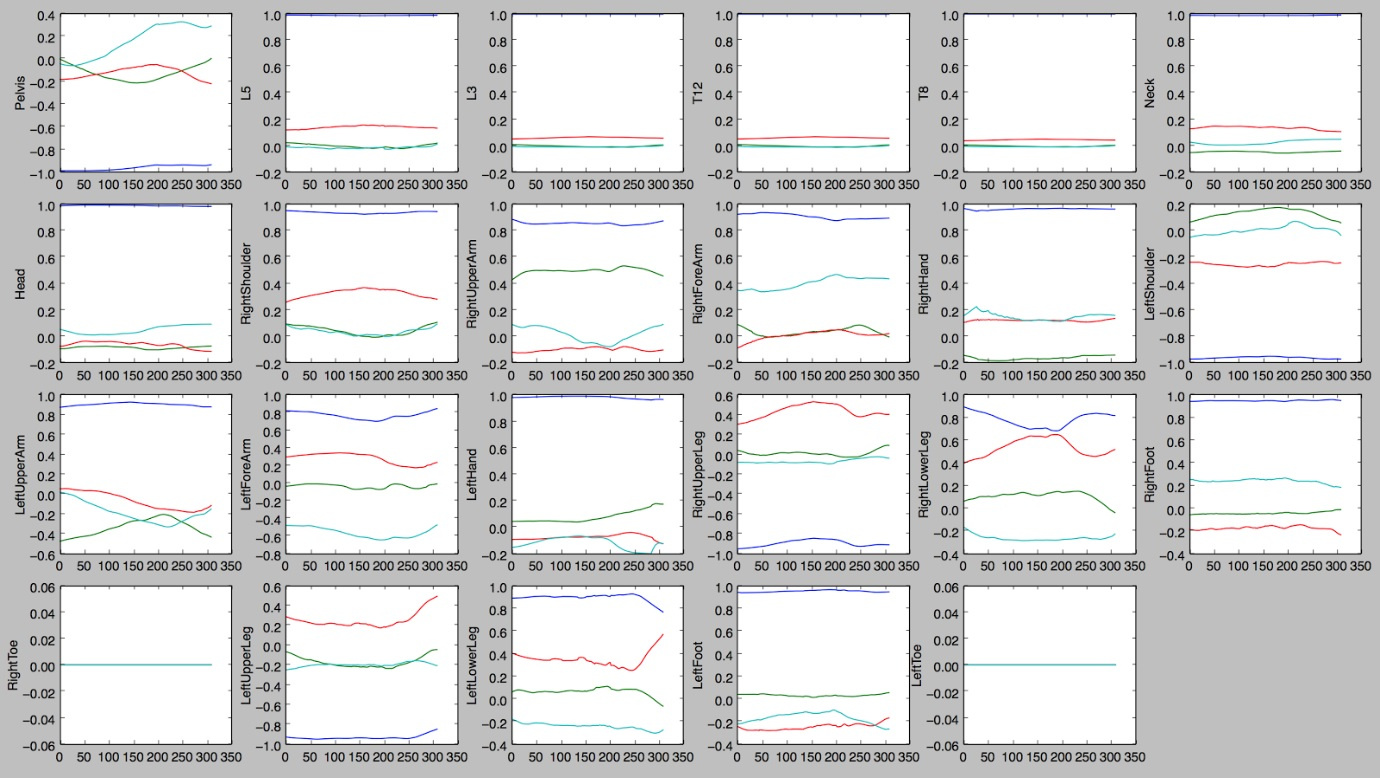
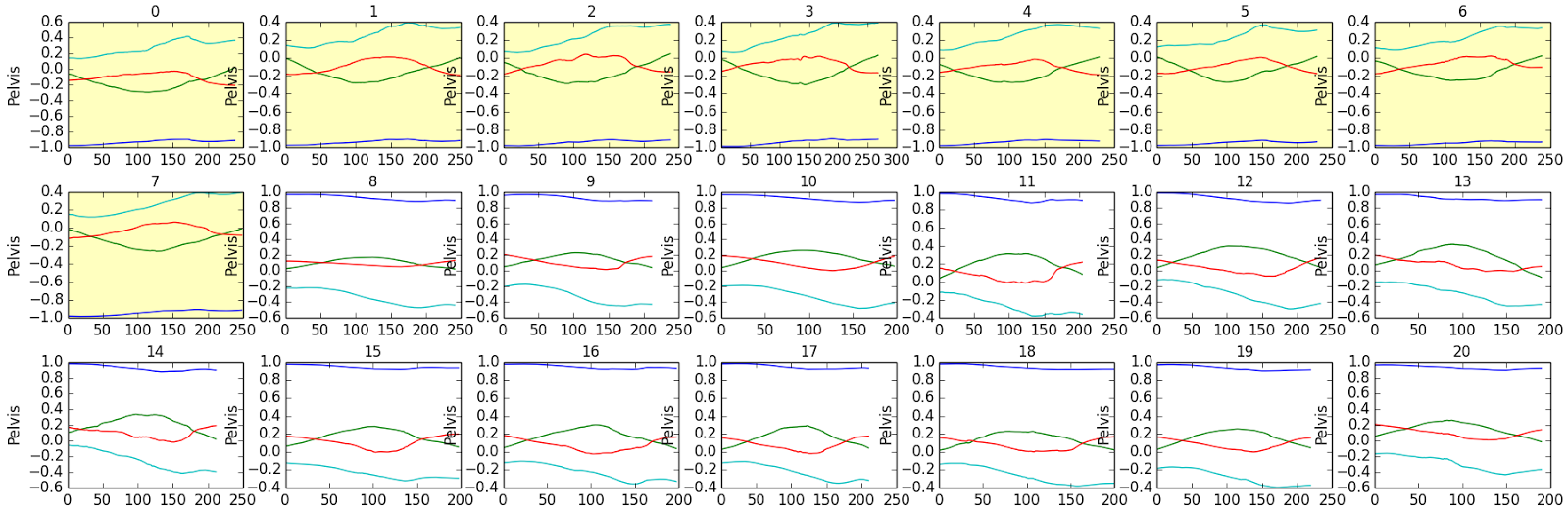

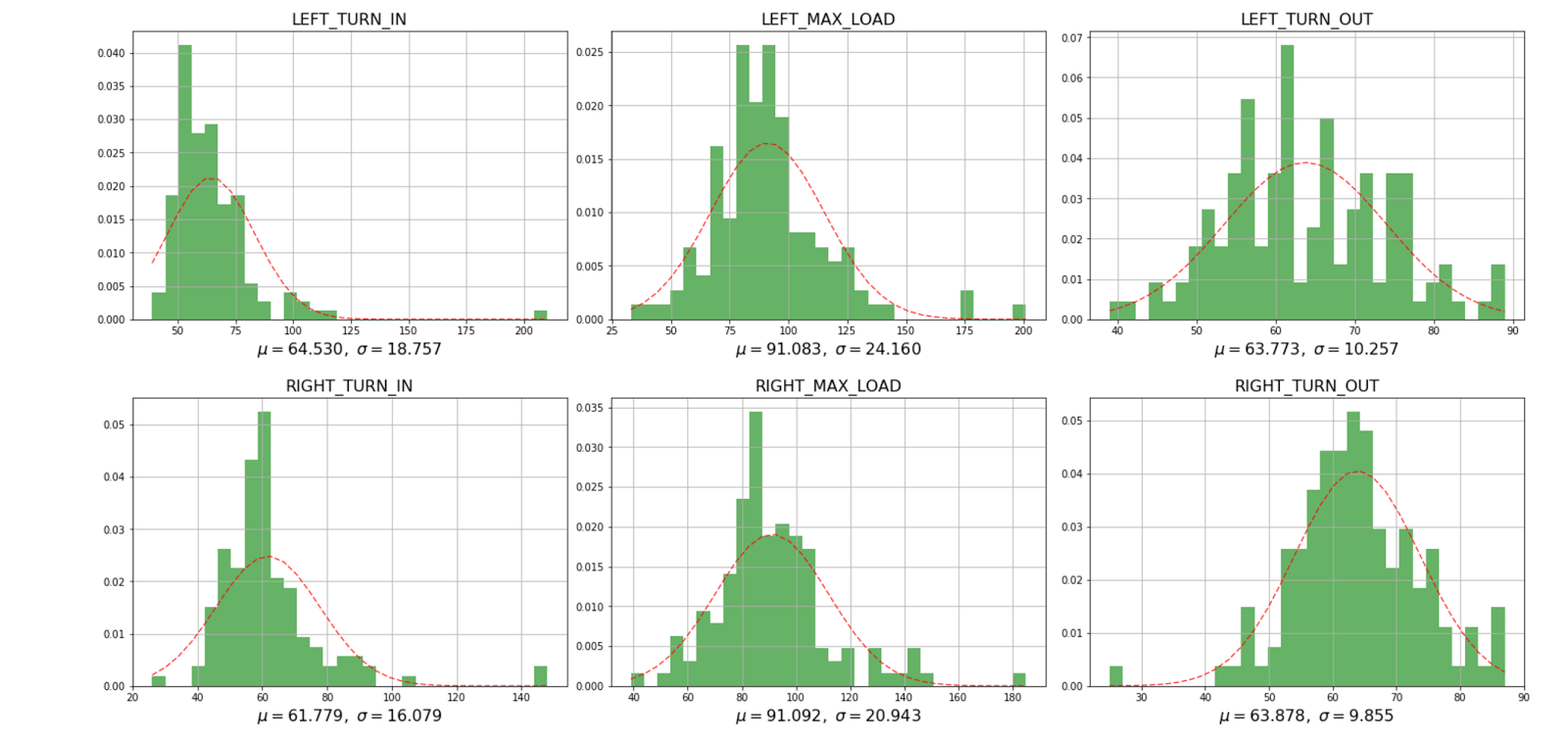

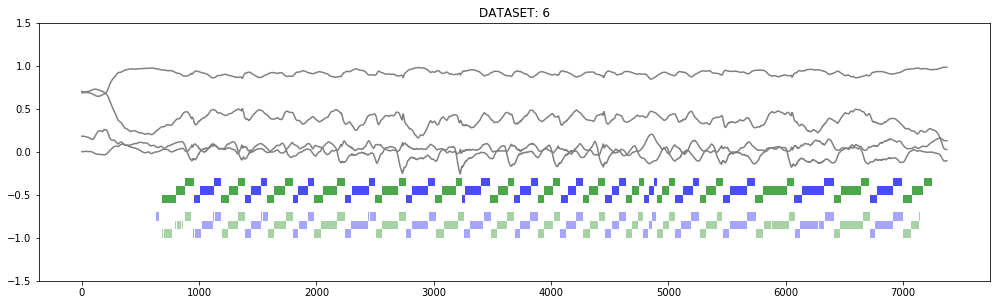
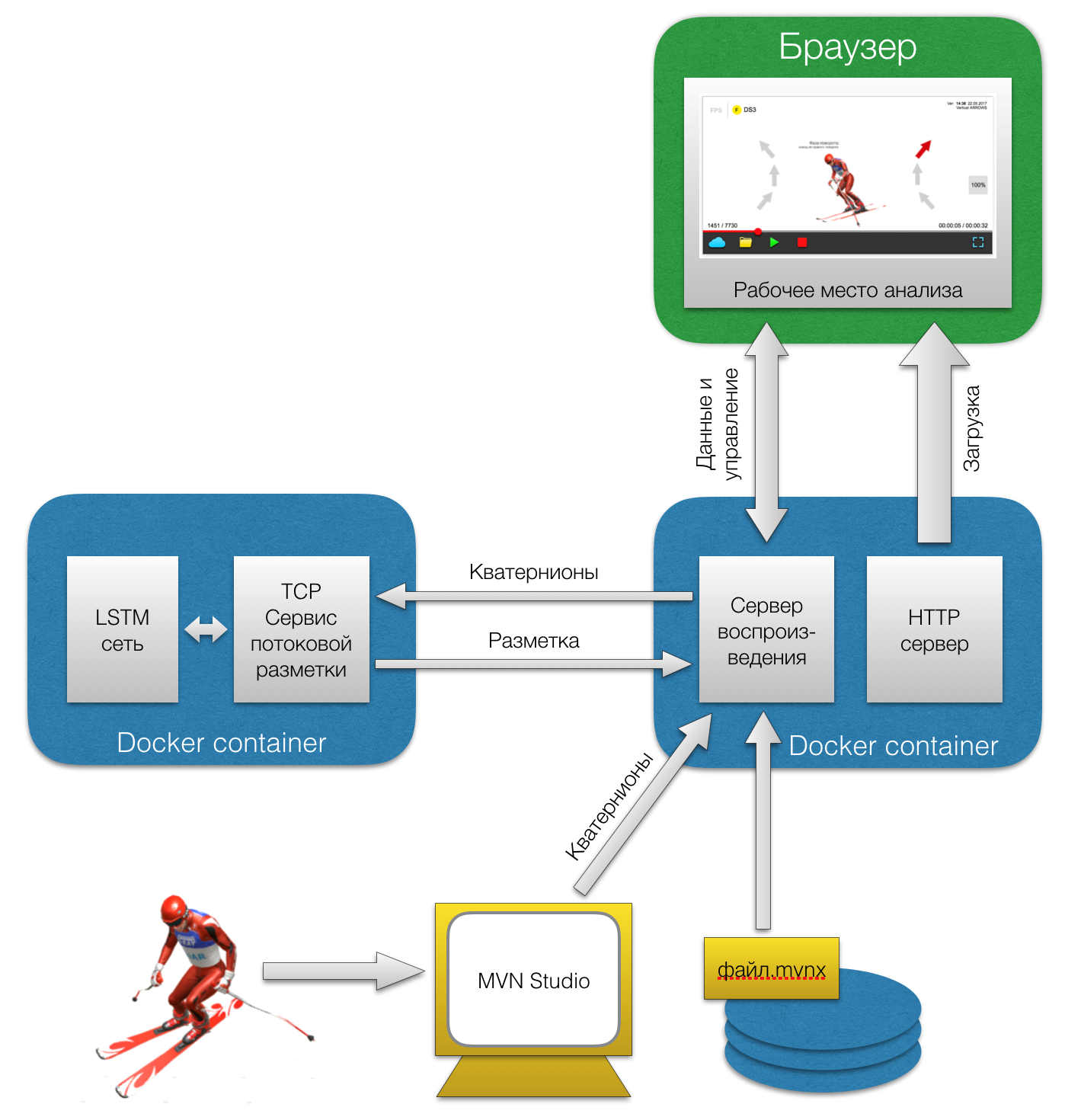
|
Метки: author ROING машинное обучение data mining machine learning ski |
Контейнеры быстрого развёртывания |

az container create -g aci_grp --name nginx --image library/nginx --ip-address public
az container create -g aci_grp --name nginx --image library/nginx --ip-address public –cpu 2 --memory 5


|
|
Внедряем безопасность в процесс разработки крупного проекта |
В данной статье нам хотелось бы поделиться своим опытом внедрения нашей команды пентестеров в цикл разработки большого проекта «Мой Офис». Найти материал подобной тематики с реальными кейсами на русском языке практически невозможно. Всем, кого интересует модные направления пентестов, теория, практика, методики, тулзы и реально найденные уязвимости в контексте безопасной разработки, — добро пожаловать под кат. Статья изобилует полезными ссылками на теоретические и практические материалы. Но давайте по порядку.
Дисклеймер:
Статья состоит из двух частей. Первая часть — организационная, которая определяет проблему, рассказывает в целом о подходах к тестам на проникновение и о наших путях решения поставленных задач (наверняка содержит информацию, которая многим известна). Вторая — более техническая, с описанием используемых тулзов и найденных уязвимостей.
Если ты, %username%, любишь технические детали, можешь переходить ко второй части.
И, конечно же, не забудь свой чай с печеньками.
Начать стоит с небольшого вступления, описывающего подходы к пентестам и их особенности. Основываясь на нашем опыте, охватывающем различные компании разнообразного профиля, оптимальным видится следующее деление.
Классический вариант, при котором какая-либо организация (включая банки и компании государственного сектора) приходит к компании, занимающейся предоставлением услуг тестов на проникновение, и выдает скоуп адресов пентестерам. После проведения работ команда-исполнитель дает рекомендации по исправлению уязвимостей.
Виды работ:
В безопасности, как и в любом сложном процессе, нет “серебряной пули” — никакое средство само по себе не даст полной уверенности в защищенности системы, будь то антивирусное ПО, системы обнаружения вторжений и т.п. То же можно сказать и о тестах на проникновение, в которых нет универсальных подходов, поскольку у каждого из них есть свои минусы и плюсы.
Разовый тест на проникновение эффективен для оценки общего состояния безопасности — пентестеры проводят моделирование ситуации, в которой злоумышленник с ограниченными финансами и в сжатые сроки пытается проникнуть в систему, и какой ущерб он может нанести компании заказчика.
Подход повторяет “единоразовый пентест”, либо его отдельные части. В данном случае аудит защищенности производиться несколько раз в год. Виды работ такие же, как и в первом подходе.
После первого аудита с оценкой общих проблем в безопасности данный подход дает возможность держать себя в курсе применимых исправлений к найденным уязвимостям при прошлых аудитах, появившихся проблем при применении исправлений (да, и такое бывает) и по результатам следующих проверок.
Данный вариант позволяет проводить более тщательное изучение периметра компании аудиторами за счет их повышенной осведомленности о сервисах по результатам прошлых тестов на проникновение.
Суть данного подхода — в создании своей багбаунти-программы на открытой/закрытой основе, ведение которой осуществляется силами сторонней организации. Такая команда привлекает к своей работе пентестеров на постоянных условиях и производит выплаты за каждую уязвимость в отдельности. Это хорошая возможность дополнительного дохода для исследователей. Примером использования такого подхода является американская компания SYNACK.
Возникает резонный вопрос: “Чем это отличается от HackerOne?” Основное отличие — в количестве исследователей и их скиллах. Для попадания в программу нужно пройти собеседование и тестовое задание, как при устройстве на работу в оффенсив-компанию. Следовательно, получается меньше участников, но выше общий уровень скиллов (и отсутствие всем известных нам персонажей, которые любят кидать отчеты сканеров).
Виды работ (в рамках данного подхода):
Подход предполагает постоянное штудирование своих сервисов десятками человеческих "сканеров", мотивированных вознаграждениями за уязвимости. Он позволяет обеспечить большее покрытие при проведении работ.
Несмотря вышеозначенные преимущества, у подхода есть и свои недостатки:
Именно этот подход рассматривается подробно в нашей статье. Суть его — в постоянном исследовании разрабатываемых продуктов от релиза к релизу.
Список видов работ в данном случае несколько шире по сравнению с описанными выше подходами. Он включает в себя:
Что касается таких пунктов, как Десктопные приложения и Hardering, то задача не в поиске бинарных уязвимостей (если говорить о десктопах) и не в тотальном закручивании гаек (в случае с Hardering). Главное — это взгляд на систему с пентестерской стороны.
Особенность подхода состоит в том, что он максимально близок к работе безопасников на местах в компаниях, которые создают защиту изнутри, а именно:
В итоге получается, что работы проводятся уже не черным, а всеми нами любимом белым ящиком.

Важно отметить, что данный подход помогает решать и такую проблему, как нехватка собственных ресурсов (секьюрити-специалистов) компании для анализа безопасности приложений. Многие исследователи предпочитают оффенсив-компании для работы из-за наличия постоянного опыта в разных направлениях ИБ, привлечение их на аутсорсе позволяет компенсировать нехватку ресурсов.
Начнем с определений. SDLC — это основа разработки, которая определяет процесс, используемый организациями для создания приложения с момента зарождения идеи до выхода в эксплуатацию.
На данный момент существует большое количество моделей SDLC, самые известные из них — Waterfall, Iterative, Agile (подробнее о них можно почитать тут). Все они имеют свои достоинства и недостатки, каждая из них весьма вариативна в использовании; все зависит от размера проекта, бюджета, объема человеческих ресурсов и других особенностей. Их всех объединяет наличие шести ключевых этапов:

SecureSDLC — тот же SDLC, но с приставкой Secure. Просто добавляешь приставку, и все становится безопасным (нет). Суть всего этого весьма проста: как видно на прекрасной картинке из Интернета, к каждому из этапов разработки добавляются действия, связанные с безопасностью (расчеты рисков, статический\динамический анализ кода, фаззинг, обучение и т.п.).
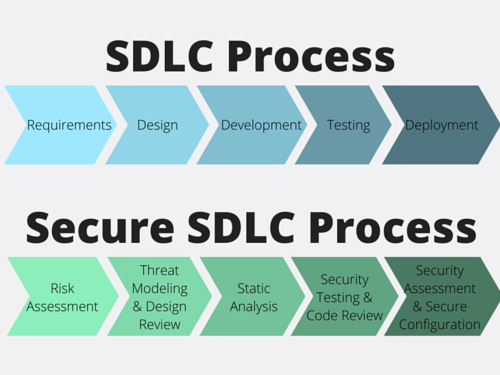
В классической реализаций SDLC проверка безопасности ограничивалась стадией тестирования, если вообще проводились.
Расширенная реализация нацелена на:
В настоящее время имеется большое количество компаний, практикующих безопасную разработку. Например, такие крупные и известные, как Microsoft, Cisco, Dell. Сегодня любой уважающий себя вендор следит за безопасностью своих решений (но не всегда это получается). Абсолютно у каждого производителя есть свой подход, который формируется, исходя из внутренних особенностей разработки.
В качестве скелета при построении своей безопасной разработки многие используют общепринятые в мире практики:
На очередной картинке из Интернета можно увидеть соответствие бизнес-функций и практик безопасности.

В настоящее время мы ведем большой проект (подробности и особенности — далее), работая по двум большим направлениям: “пентест” разрабатываемых продуктов и бинарные исследования. В данной статье мы сосредоточимся на пентестерской части.
Изначально наш процесс поиска уязвимостей в данном проекте прошел этапы от разового пентеста до пентестов с повторением несколько раз в год — как сервисов внешнего периметра, так и разрабатываемых продуктов. Данные подходы, по нашему мнению, показали себя не так эффективно, в отличие от проектов по анализу защищенности на постоянной основе.
Что же не устроило нас в классических подходах? У разового пентеста есть некоторые недостатки:
По причине низкой осведомленности аудиторов о внутренних особенностях разрабатываемых продуктов и отсутствия какого-либо разделения по компонентам (для пентестера продукты имеют вид определенного скоупа адресов, пакетов мобильных приложений или бинарей десктопных приложений), список продуктов выглядит как книжная полка с большим количеством книг, на корешках которых отсутствуют названия — глаза разбегаются от обилия сервисов.

Из-за этого появляется проблема выделения времени — оно выделяется на весь проект в целом, и какому-то компоненту может быть уделено меньше внимания. Ресурсы распределяются неэффективно, и это не подходит для глубокого изучения продуктов. Поэтому было принято решение разделять продукты на условные компоненты.
В нашем случаем мы работаем с компанией «Новые облачные технологии» над их продуктом «МойОфис», который представляет собой платформу совместного редактирования документов, хранения файлов, почтовую систему, мессенджер. Для всего этого существуют как мобильные, так и десктопные версии.
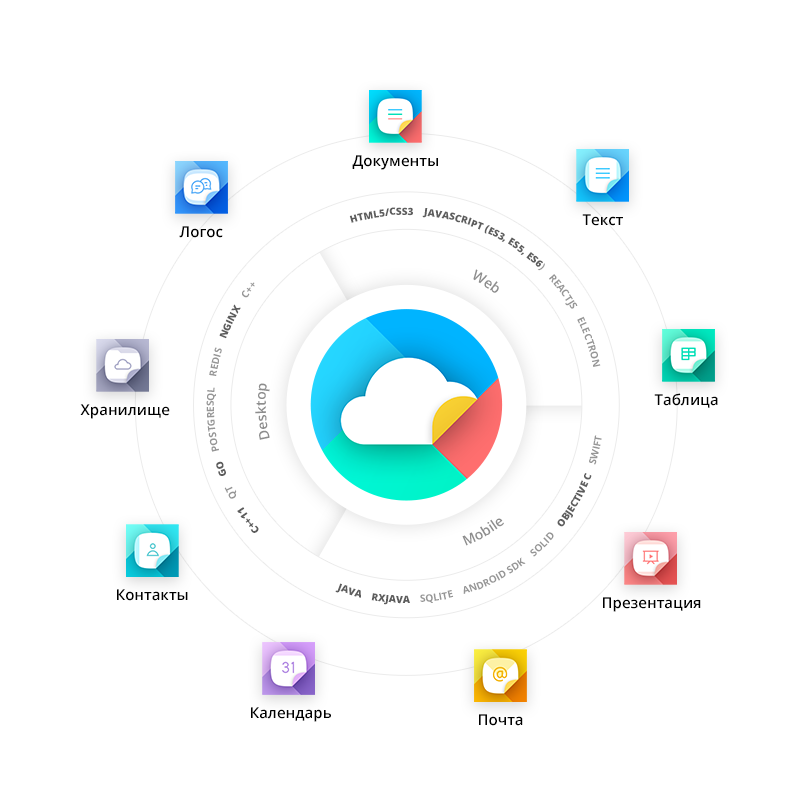
Перед началом работ над таким обширным продуктом, как «МойОфис», необходимо выделить основные его модули и части (даже с виду неделимые), чтобы не получилось той самой книжной полки. Это необходимо и для лучшего понимания внутренних процессов приложений и распределения ресурсов команды.
У нас это получилось таким образом:
Все это вместе предоставляет большой интерес для исследователя: как возможность изучить какие-то доселе невиданные технологии, так и прокачаться больше в уже изученной теме.
Чтобы “бесшовно” встроиться в процесс разработки такого продукта, нам необходимо адаптироваться к его глобальным циклам планирования, в нашем случае — релизным циклам. Релиз новых версий «МойОфис» происходит каждые три месяца. Поэтому мы живем спринтами как раз по три месяца. Что же такое спринт в нашем понимании?
Спринт для нас — это ячейка времени, в рамках которой мы стараемся максимально распланировать наши работы. Внутри большого спринта у нас есть более мелкая единица измерения — слот, который равен одной неделе. Мы берем продукты, доступные нам, смотрим циклы и сроки изменений в них, и в необходимой последовательности ставим аудиты этих продуктов в график нашего спринта, разбивая по слотам.
Естественно, мы понимаем, что планирование сроков в разработке, мягко говоря, получается очень плохо, потому ожидаем законного вопроса: “А если сроки едут, что делаете?”

Тут на помощь приходит старая игра детства — “пятнашки”. Помните, там была пустая ячейка, через которую можно было двигать другие фишки, и тем самым менять порядок, не выходя за рамки коробки? В нашем случае, коробка — это и есть такой “спринт”.
Количество пустых слотов решено было увеличить, поскольку есть разные “внеплановые” работы, ресерчи сторонних решений, используемых в разрабатываемых продуктах, а также иные работы, которые могут относиться к проекту. Тем самым, мы мобильны в планировании, а пустые слоты заполнить всегда можно.
Пример одного из спринтов (первое число — номер недели спринта):
Misc — это как раз те свободные слоты, их наличие очень важно. Как можно заметить, на некоторые, довольно большие части (как Веб, где проверяется и API-часть), мы закладываем больше времени (10 рабочих дней). Также в Misc попадают дополнительные исследования и совместная проработка security-ориентированной архитектуры совместно со специалистами заказчика.
Для такого проекта с нашей стороны было очень важным подобрать команду, которая обладает экспертизой сразу во всех интересующих направлениях (все, безусловно, универсалы, но каждый в чем-то разбирается больше, например, в анализе мобильных приложений). В итоге, получилось три человека, работающих фуллтайм над проектом и находящихся в постоянном контакте с заказчиком.
Исходя из наличия экспертизы у каждого в каком-либо направлении, внутри команды происходит шаринг опыта между аудиторами. Даже при условии ротации аудиторов с другими командами опыт остается внутри, ведь в случае необходимости заменяется только один человек. “Новичок” в течении недели узнает организационные особенности работы и по истечении первого спринта приобретает полную картину и понимание взаимодействия большого количества компонентов друг с другом.
В своих тестах мы используем полную копию того, что поставляется клиентам, со всеми свежайшими обновлениями. Забегая вперед, скажем, что мы посчитали довольно важным развернуть полностью весь «Мой Офис» с нуля и понять каждый шаг, где, что и как деплоится и настраивается, попутно пытаясь сравнить это с документацией. Учитывая, что наша специализация — далеко не системное администрирование, это была сложная задача для “падавана юного”.
Поскольку мы — большие любители багбаунти и такие же не любители писать отчеты и генерировать официальные тексты, было решено отойти от отчетности, присущей классическим тестам на проникновение, и перенять опыт у багбаунти-программ.
В своем подходе мы используем JIRA для создания тикетов (разработчики и тестировщики пользуются этим, почему бы нам тоже не начать это делать), где есть абсолютно стандартные поля, как на HackerOne:
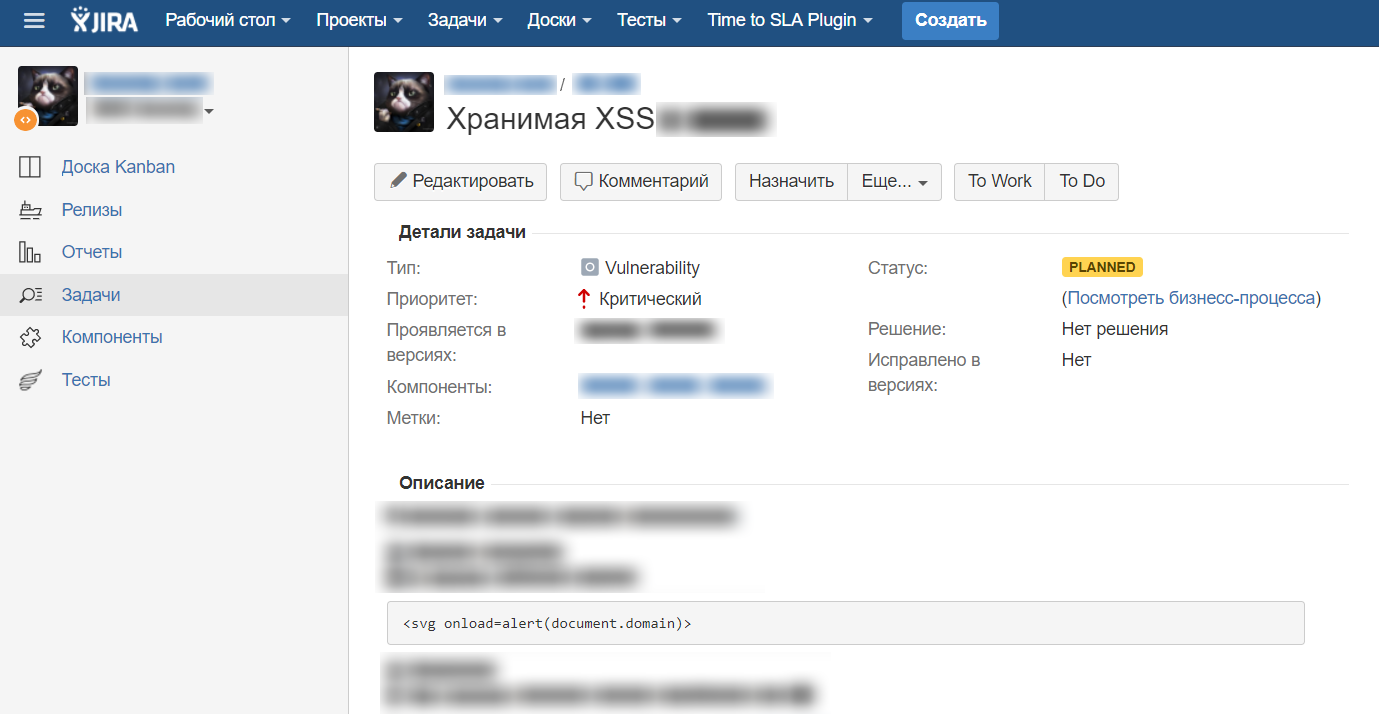
При таком донесении информации абсолютно любой человек поймет, насколько эта уязвимость критична, даже без какой-либо квалификации в безопасности или вообще в IT.
Дисклеймер: мы стараемся делать статьи так, чтобы из статьи каждый смог вынести для себя что-то новое и интересное. Так, из первой части менеджер или тимлид команды может наверняка почерпнуть тактику ведения проектов, тогда как из второй кое-что может пригодится исследователям ИБ и разработчикам.
Выглядит так, что вводная часть раскрыта. Давайте перейдем непосредственно к самому анализу защищенности (ура-ура, технические подробности).
Одна из интересных составляющих работы для опытного пентестера — это использование модных и современных технологий. Давайте посмотрим на них. Прежде чем начать, мы, конечно же, посмотрели Веб, попутно регистрируясь с именами ‘“>{{7*7}}, позаливали файлы, поотправляли почту, поставили мобильные приложения и в целом осмотрелись вокруг, как все работает.
После мы пошли к тимлидам разработки и вместе засели над схемой серверной архитектуры на большом листе А1, который с трудом умещается на стене кабинета. Сюда мы ее не вставим, но в целом все довольно стандартно и круто:
Клиентская часть — это AngularJS и полноценное SPA (Single Page Application) без явных костылей со стороны серверного API (таких как “а вот тут отдадим формочку с бекенда!”).
Серверная часть — по-разному, в качестве фронта используется nginx, за ним множество java/golang сервисов, которые обрабатывают клиентские запросы.
Анализировать SPA-приложения очень круто и довольно удобно, с точки зрения запросов-ответов все логично и складно. Поиск уязвимостей в самом SPA, конечно же, довольно сложная задача.
Да, тут нет секрета, мы, как и многие, используем Burp (никакого Larry Lau, только лицензия) и его модули для поиска разного рода уязвимостей (инъекции, IDOR, SSTI и другие). Без этого инструмента вообще никак.
Также его могут применять разработчики, чтобы проверить результат после исправления уязвимости, вместо того, чтобы просить нас и растягивать весь этот процесс. Для этого будет достаточно бесплатной версии и двух вкладок Proxy и Repeater.
Также мы используем пучок кастомных скриптов, рассмотрим один из них.
Как вы уже знаете, среди продуктов, исследуемых нами, есть почта. Одной из мощнейших атак здесь может быть XSS в письмах. Причем все еще осложняется тем, что в письмах можно использовать HTML для создания красивых писем в фирменных стилях, а не просто plaintext. Перед разработчиком стоит задача сделать возможность использования HTML так, чтобы отправитель не мог внедрить свой JavaScript.
В security-мире есть исследователь Mario Heiderich @0x6D6172696F (.mario), который много времени посвятил поиску XSS в разных крупных сервисах вроде Google, участвовал в создании библиотеки DOMPurify для безопасной подстановки unsafe html сразу в DOM (подробнее о ней будет рассказано ниже). А главное — он опубликовал для нее автотесты, которые используют различные хитрости и тонкости работы браузеров и HTML5. Идеальное решение для тестирования почтового сервиса на возможность внедрения JS.
Ссылка на демо и тесты.
И не забудьте о специальных векторах для HTML5.
Что мы сделали? Мы взяли эти тесты (+ дописали некоторые свои из секретных закромов) и отослали на IMAP-сервер своим скриптом на Python в десять строчек, ибо обычно HTML нельзя отправлять из Веб-клиента, а только напрямую на почтовый сервер, попутно открывая письма в браузере. Исполнился JS? Заводим тикет.
Наверняка все знают, что можно обнаружить открытие письма пользователем с помощью картинки (тег img) в письме, но и другие теги могут позволить нам это сделать. Тут нам опять поможет репозиторий Cure53. С его помощью можно обнаружить теги, которые сливают информацию о пользователях.
Ограничение схем для некоторых тегов, например, почему нельзя использовать file:/// для тех же "img src" (подробно по ссылке от ValdikSS), были сразу учтены при разработке.
Следующая проблема — это вложения. Обязательно нужно тестировать вложения разных форматов с XSS-нагрузкой, их можно взять тут. Этим мы проверим, как сервер хранит и отдает вложенные файлы в письмах.
Все приложения под каждую из платформ являются классическими нативными приложениями.
Для исследования iOS и Android используются оба подхода: автоматизированный и ручной. Для Tizen — только ручной. Про автоматизированный — в снятии “низко висящих фруктов” здесь очень помогает MobSF.
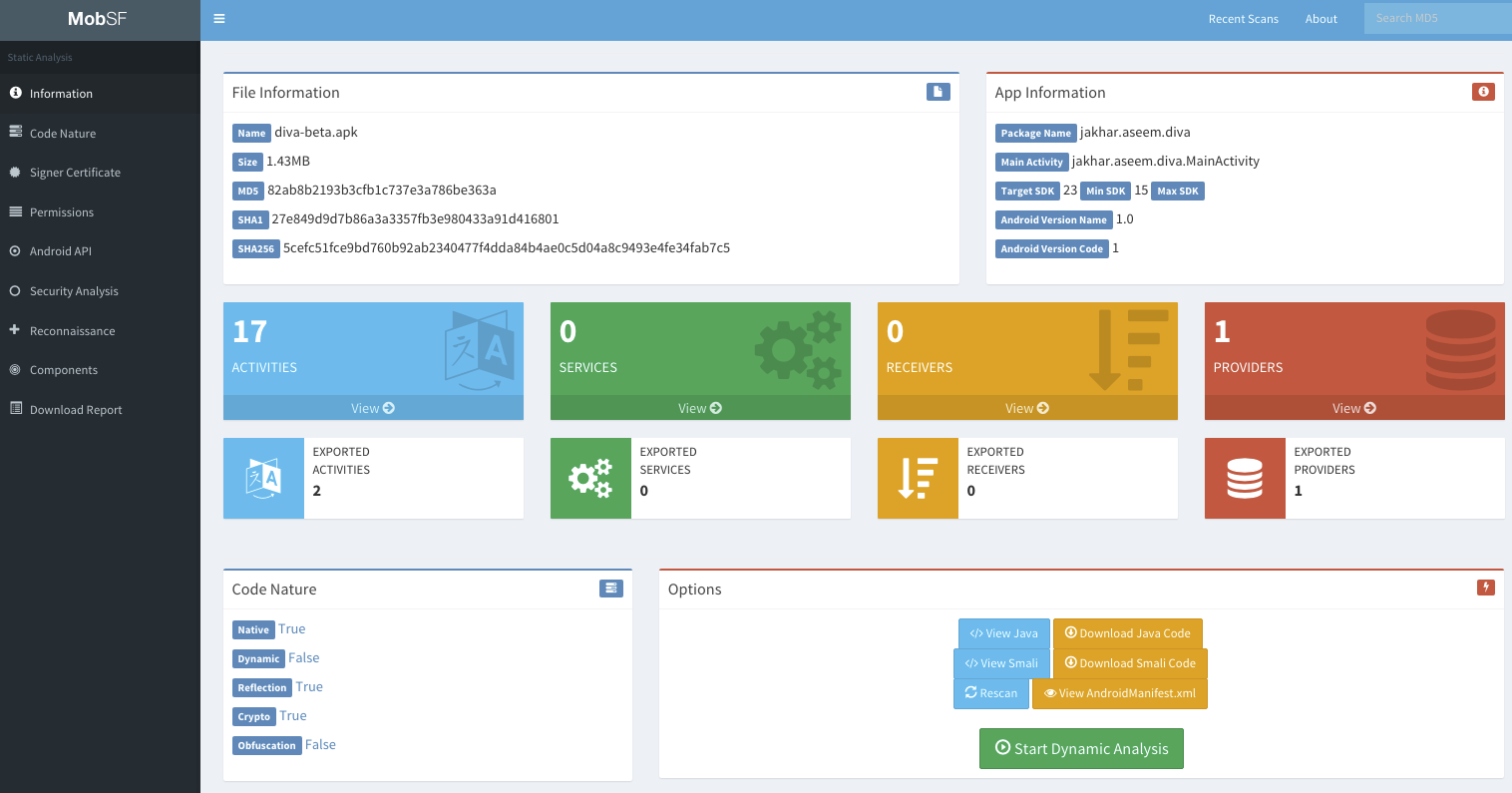
Он позволяет автоматически собрать типичные проблемы, сделать ревью ресиверов, сервисов и т.п. вещей в Android и даже осуществляет некоторое подобие анализа исходного кода (после декомпиляции). Также проверяет флаги (Stack smashing protection, PIE ...) при компиляции.
Ручной анализ — Android (+root), iOS + jailbreak (на данный момент мы используем последний доступный джейл для iOS 9.3.3).
А вот с Tizen не все так просто. Сам он очень странный и непривычный. Система является одним большим браузером с поддержкой HTML5, давно находится в разработке и тоже представляет интерес для исследователей безопасности, как что-то новое и неизученное.
Для начала вопрос — сколько вы вообще держали телефонов c TizenOS? Вот столько же статей и security-тулз для этой платформы. Мы пошли по developer way — скачали Tizen SDK, подключились к телефону и дебажили приложение. В этом режиме можно просмотреть файловую систему, получить debug console и делать другие вещи, позволяющие найти проблемы в безопасности. К сожалению, функционал достаточно ограничен, и нет прямого консольного доступа к OS.
Инструмент находится на официальном сайте Tizen. Можно использовать эмулятор, если есть желание познакомиться с этой операционной системой.
Сама платформа Tizen на данный момент имеет большое количество недостатков со стороны безопасности. Можно вспомнить недавнюю новость о сорока зеродеях в платформе и вот эту публикацию . Также о некоторых уязвимостях в SmartTV, где был затронут и TizenOS, рассказывал BeLove — презентация.
Про десктопные приложения «Мой Офис» будет отдельная статья, посвященная бинарному фаззингу. В рамках же данных работ (именно в пентестах) смотрятся такие области, как взаимодействие с файловой системой (временные папки, права на них и т.п.), DLL hijacking, работа с сетью (передача данных по защищенным каналам — TLS), хранение токенов и подобное.
Многие десктопные приложения написаны на основе Electron, на котором созданы решения GitHub, Slack, Discord и многие другие. Сам Electron является открытым проектом и представляет собой webview, то есть небольшой браузер, который визуально не отличить от нативного приложения.
Зачастую при исследовании безопасности какого-либо продукта возникает проблема, связанная с тем, что не всегда прозрачно и понятно, где же в итоге была найдена уязвимость: в кастомном написанном коде заказчика или в стороннем продукте, библиотеках, фреймворках, которые используются при разработке. У нас также был такой случай.
При исследовании одного из компонентов нами была найдена довольно критичная уязвимость клиентской части — внедрение JS-кода, ну или просто XSS. Изначально было непонятно, почему так произошло, ведь данный компонент использовал ту самую JS библиотеку DOM Purify для защиты от XSS.
DOM Purify — это средство только для DOM-а, сверхбыстрое, убер-толерантное XSS-дезинфицирующее решение для HTML, MathML и SVG (немножко описания с Гита). MathML — это язык разметки на основе XML для представления математических символов и формул. Все это, конечно, работает и в контексте HTML5 фишек. То есть в этом продукте собрано все самое новое и современное.
Он написан на JavaScript и работает во всех популярных браузерах:
Разрабатывает инструмент компания Cure53, в частности, Mario Heiderich @0x6D6172696F (.mario), а контрибьютят туда такие известные ребята, как @filedescriptor, @shafigullin и другие. Выходит, такая сборная самых крутых исследователей веб-безопасности трудится над открытым программным средством для защиты от уязвимостей клиентской стороны.
Ссылочка на Гит.
Немного пораскинув мозгами, мы пришли к выводу, что уязвимость действительно не в разработанном приложении, а в подключенной JS-библиотеке.
Далее, мы проверили уязвимость на последней версии DOM Purify и были весьма удивлены, что такой простой пейлоад без всяких хитростей сработал, но только под Safari.
Payload: 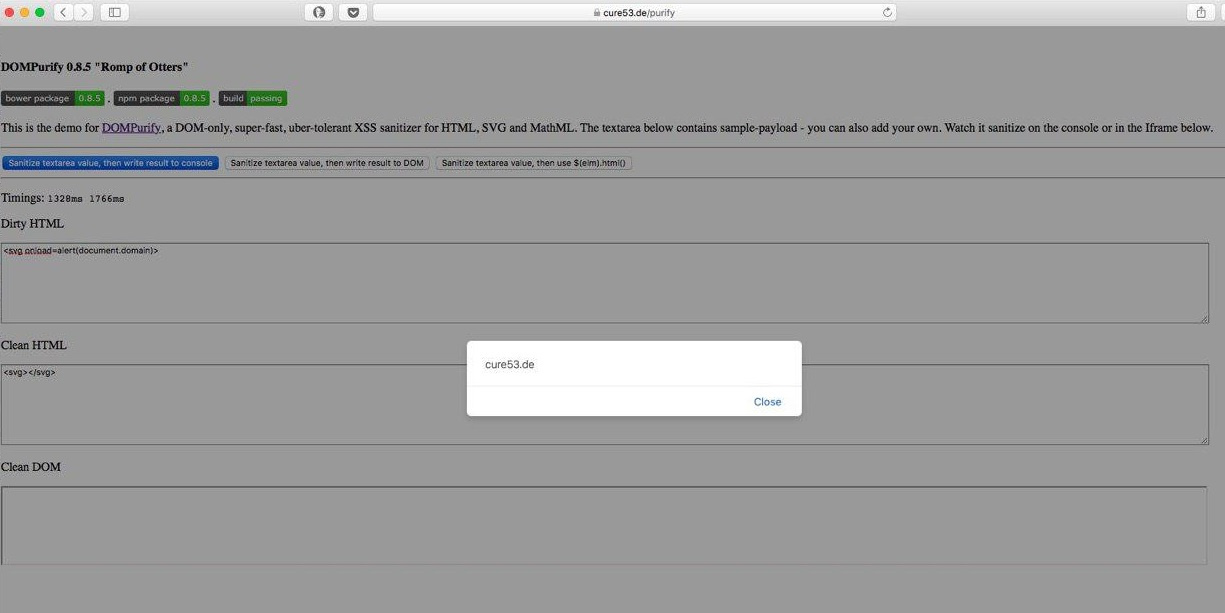
Ребята быстро исправили уязвимость, а компания FastMail, которая взяла DOM Purify под крыло своей багбаунти-программы, выплатила нам немножко денег “на пиво”.
Но на этом все не закончилось, поскольку дыра работала только для Safari, мы немного копнули в его сторону и получилось, что функция DOMParser работает некорректно, и при парсинге html страницы исполняет JS, что никакой браузер из популярных не делает (да-да, даже IE), о чем мы сообщили в Apple.
Payload: new DOMParser().parseFromString('
И буквально на днях Apple выдало CVE-2017-7038 — что-то очень похожее на UXSS-уязвимость, но без обхода SOP. Подробнее обо всех возможных уязвимых функциях, возможно, мы когда-нибудь опишем в отдельной статье.
В итоге, получилась такая нетривиальная схема: XSS в приложении «Мой Офис» была возможна из-за подключения DOM Purify-библиотеки, которая не обрабатывала SVG теги (хотя должна была), а отдавала напрямую стандартной браузерной функции DOMParser, которая была реализована с ошибкой.
Вот таким длинным путем мы исправили уязвимость не только у нашего клиента, но и сделали мир немного безопаснее.
Невозможно написать что-то большое и не допустить ни одной баги, нет такой методологии. Поэтому разберем парочку реальных уязвимостей с высоким уровнем критичности.
Поскольку у нас есть хранение и редактирование документов, мы каким-то образом должны отрисовывать пользователю документ и вносить изменения в них, если это нужно. Как вы можете знать, современные офисные документы — это набор XML-файлов, упакованных в архив. А какое редактирование документов без парсера XML?
Каждый Веб-ресерчер сразу же подумает про XXE. Как же посмотреть эту уязвимость в действии в данном случае?
Вот как раз шаг номер три является опасным, осуществляется он с помощью опенсорсной библиотеки, в которой можно было подключать внешние сущности. Что мы сделали:
]>
…
&xxe; И после обработки увидели содержимое /etc/passwd. Но с помощью этой уязвимости можно не только читать файлы на сервере.
Так или иначе, нам не удалось ничего важного прочитать, поскольку весь парсинг происходит в изолированном контейнере (docker). Уязвимость была оперативно закрыта.
Кстати, для генерации подобных файлов и проверки XXE можно использовать тулзу. С её помощью некоторые исследователи находили XXE и в багбаунти-программах тоже.
Расскажем и про честное RCE — удаленное выполнение команд OS на сервере. Некоторая часть микросервисов написана на Java, в том числе, с применением Spring. Уязвимости такого рода для Spring (и не только) очень хорошо поддаются фаззингу, если вы отправите на сервер {{7*7}}, то в ответе на странице получите выполнение математической функции равное 49.
Далее, можно уже пробовать выполнять функции языка и даже запустить команду с помощью:
${T(java.lang.Runtime).getRuntime().exec("ls")}Подробнее про похожую уязвимость в Spring Boot Oauth модуле можно прочитать тут. А тут тикет на гите, описывающий проблему, которая повлекла выполнение кода в нашем случае.
Но в нашей конкретной ситуации такая простая отправка пейлоада не работала, поскольку при отправке запроса на Веб-сервер наши кавычки проходили URL-encode и не воспринимались Spring-ом как спецсимволы. Что же делать в такой ситуации? Все достаточно просто: можно, используя стандартные средства языка, провести кодировку из числовых значений в символы с помощью функции java.lang.Character.toString() и конкатенировать все символы. Про данный трюк можно прочитать тут.
В итоге, у нас получился большой и страшный пейлоад (чтение /etc/passwd/):
${T(org.apache.commons.io.IOUtils).toString(T(java.lang.Runtime).getRuntime().exec(T(java.lang.Character).toString(99).concat(T(java.lang.Character).toString(97)).concat(T(java.lang.Character).toString(116)).concat(T(java.lang.Character).toString(32)).concat(T(java.lang.Character).toString(47)).concat(T(java.lang.Character).toString(101)).concat(T(java.lang.Character).toString(116)).concat(T(java.lang.Character).toString(99)).concat(T(java.lang.Character).toString(47)).concat(T(java.lang.Character).toString(112)).concat(T(java.lang.Character).toString(97)).concat(T(java.lang.Character).toString(115)).concat(T(java.lang.Character).toString(115)).concat(T(java.lang.Character).toString(119)).concat(T(java.lang.Character).toString(100))).getInputStream())}Стоит отметить, что RCE было также внутри docker-контейнера, и хоть он создан не для защиты, но все же дает некую изоляцию.
Уф, вот и подошла к концу статья. Давайте теперь суммируем, чем отличается наш подход от классических тестов на проникновение:
Каждый подход следует улучшать и для полноты картины можно расширять команду узконаправленными специалистами, добавлять больше активных действий с разработчиками и заниматься их обучением в области безопасности.
Конечно же, такой подход также не дает стопроцентной уверенности в безопасности продуктов, но он более методичный и обширный, чем классические тесты на проникновение. Он максимально направлен на оперативное реагирование, на выпуск нового кода и ликвидацию уязвимостей на как можно более раннем этапе.
Надеемся, что вы смогли вынести для себя что-то новое и приобрели понимание того, как происходит работа по поиску уязвимостей в крупных проектах.
P.S. Выражаю благодарность за помощь в подготовке материала BeLove.
|
|
Галерный хакатон |


|
Метки: author spmbt управление разработкой управление проектами управление персоналом хакатон лайфхак быстрая разработка оптимизация рабочего времени |
Juniper Node Slicing и Universal Chassis |
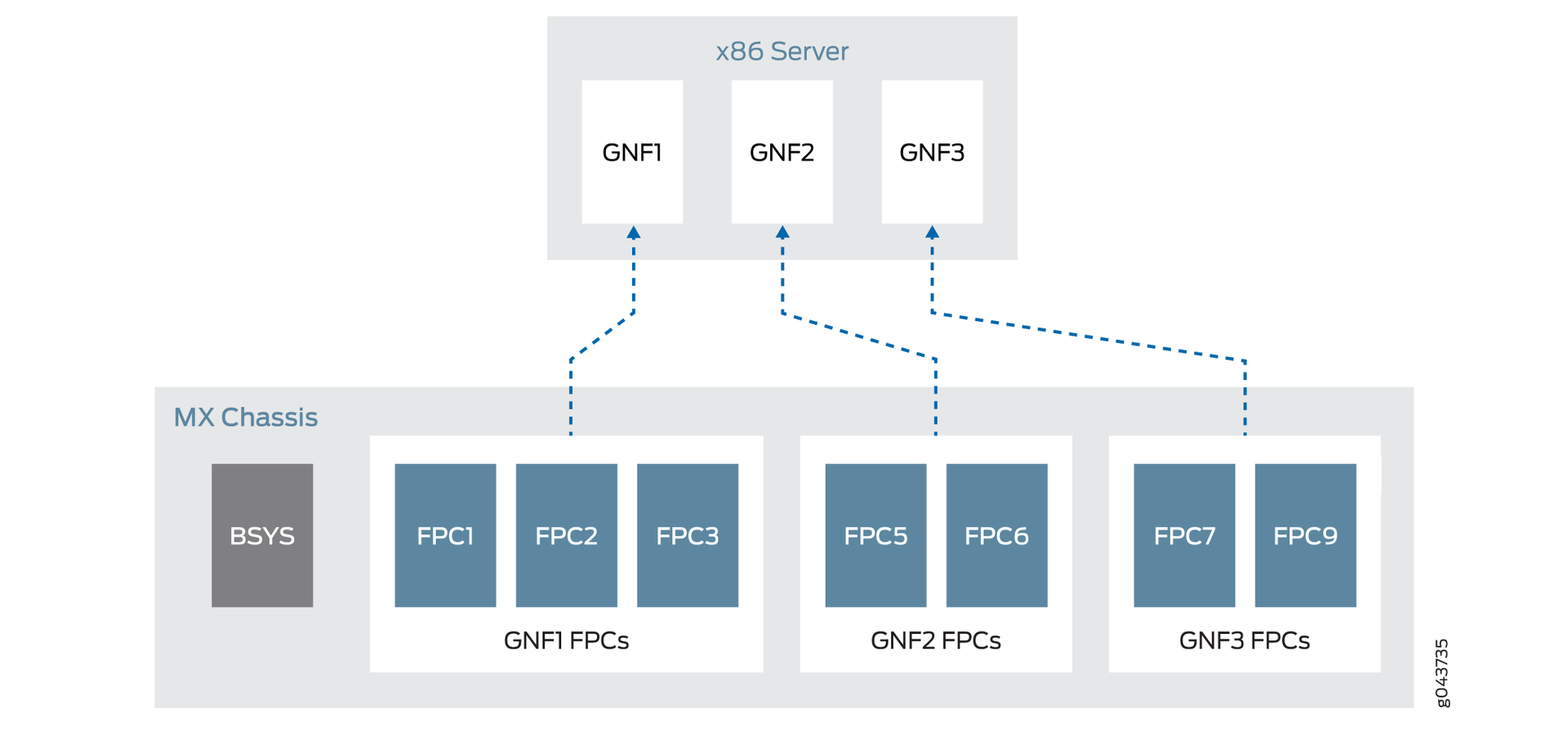
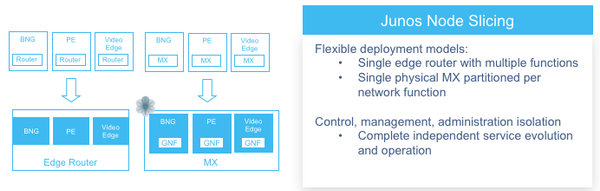
|
Метки: author a_andreev системное администрирование сетевые технологии децентрализованные сети виртуализация it- инфраструктура juniper disaggregation virtualization |
Обзор возможностей библиотеки Apache Curator для Apache Zookeeper |

По долгу работы мне приходится сталкиваться с проектированием и разработкой распределенных приложений. Такие приложения часто используют различные средства межпроцессного взаимодействия для организации взаимодействия компонентов. Особые сложности возникают в процессе реализации алгоритмов, обрабатывающих связанные данные распределенно. Для поддержки таких задач используются специализированные системы распределенной координации. Самым популярным и широко используемым продуктом является Apache Zookeeper.
Zookeeper — продукт сложный. Несмотря на солидный возраст, периодически в нем обнаруживаются те или иные ошибки. Однако, это лишь следствие его возможностей, которые помогают сделать жизнь легче многим разработчикам распределенных систем. Далее, я рассмотрю некоторые особенности Zookeeper, которые помогут понять лучше его возможности, а затем перейдем к библиотеке Apache Curator (Netflix), которая делает жизнь разработчиков распределенного ПО приятной и предлагает множество готовых рецептов для реализации распределенных объектов координации.
Как уже ранее было отмечено, Zookeeper — жизненно важный компонент распределенных систем. Базу данных Zookeeper проще всего представить в виде дерева, похожего на файловую систему, при этом каждый элемент дерева идентифицируется путем (/a/path/to/node) и хранит в себе произвольные данные. Таким образом, с помощью Zookeper вполне можно организовать иерархическое распределенное хранилище данных, а также другие интересные конструкции. Полезность и широкая распространенность Zookeeper-а обеспечивается рядом важнейших свойств, которые перечислены далее.
Консенсус обеспечивается с помощью алгоритма ZAB, данный алгоритм обеспечивает свойства C(consistency) и P(partition tolerance) CAP-теоремы, что означает целостность и устойчивость к разделению, жертвуя доступностью. На практике это приводит к следующим эффектам:
Консенсус — способность распределенной системы каким-то образом прийти к соглашению о ее текущем состоянии. Zookeeper использует алгоритм ZAB, часто применяются и другие алгоритмы — Raft,
Raft.
Клиент, устанавливая соединение с кластером Zookeeper, создает сессию. В рамках сессии существует возможность создавать узлы, которые будут видны другим клиентам, но, время существования которых равно времени жизни сессии. При завершении сессии данные узлы будут удалены. Такие узлы имеют ограничения — они могут быть только терминальными и не могут иметь потомков, то есть, нельзя иметь эфемерные поддеревья. Эфемерные узлы часто применяются с целью
реализации систем обнаружения сервисов.
Представим, что у нас есть несколько экземпляров сервиса, между которыми производится балансировка нагрузки. Если какой-то из экземпляров появляется, то для него создается эфемерный узел, в котором находится адрес сервиса, а при аварии сервиса этот узел удаляется и более не может использоваться для балансировки. Эфемерные узлы применяются очень часто.
Клиент может подписаться (watch) на события узлов и получать обновления при возникновении каких-либо событий, связанных с данными узлами. Однако, тут тоже есть ограничение — после возникновения события на узле, подписка снимается и ее необходимо восстанавливать заново, при этом, очевидно, существует возможность пропуска других событий, которые возникают на данном узле. В связи с данным фактом, возможность использования данной функции достаточно ограничена.
Например, в рамках сервисов обнаружения ее применять можно, для реакции на изменение конфигурации, но необходимо помнить, что после установки подписки необходимо выполнить операцию "вручную", чтобы убедиться, что пропуска изменения состояния не произошло.
Zookeeper позволяет создавать узлы, имена которых формируются с добавлением последовательно возрастающих чисел, при этом данные узлы могут быть эфемерными. Эта возможность широко применяется как для решения прикладных задач (например, все однотипные сервисы, регистрируют себя как эфемерные узлы), так и для реализации "рецептов" Zookeeper, к примеру, справедливой распределенной блокировки.
Версии узлов позволяют определить было ли изменение узла между чтением и записью, то есть при операции set можно указать ожидаемую версию узла, в том случае, если она не совпадет, значит, что изменение узла было произведено другим клиентом и требуется заново вычитать состояние. Данный механизм позволяет реализовать упорядоченное изменение состояния данных, например, при реализации "рецепта" распределенный счетчик.
Существует возможность задавать для узлов ограничения доступа, определяемые ACL, что предназначено для защиты данных от недоверенных приложений. Стоит отметить, что, конечно, ACL не защищают от перегрузок, которые может создать вредоносный клиент, предоставляя только механизм ограничения доступа к содержимому.
Zookeeper позволяет устанавливать узлам TTL, по истечении которого (если нет обновлений) узел будет удален. Данная функциональность появилась сравнительно недавно.
Существует возможность подключения к кластеру серверов в режиме наблюдатель (observer), которые могут использоваться для выполнения операций чтения, что очень полезно в тех случаях, когда нагрузка на кластер, генерируемая операциями записи является высокой. С использованием серверов-наблюдателей проблема может быть решена. Может возникнуть вопрос, почему бы просто в кластер не добавлять обычные узлы? Ответ кроется в алгоритме консенсуса — чем больше узлов, позволяющих писать данные, тем дольше будет тратиться времени на достижение консенсуса и тем меньше будет производительность
кластера на запись. Серверы-наблюдатели не участвуют в консенсусе, а поэтому не влияют на производительность операций записи.
Zookeeper не использует внешнее время для синхронизации узлов. Это достаточно полезное свойство, системы, которые ориентируются на точное время более подвержены ошибкам, связанным с его рассогласованием.
Конечно, в бочке меда должен быть деготь и он действительно есть — Zookeeper имеет свойств, которые могут ограничивать его применение. Есть даже выражение, которое достаточно иронично описывает сложности работы с Zookeeper — Single Cluster of Failure © Pinterest, что саркастически демонстрирует тот факт, что, стремясь избавиться от единой точки отказа с помощью распределенной системы, используя Zookeeper, можно столкнуться с ситуацией, когда он станет той самой точкой отказа.
Zookeeper загружает базу в память и держит ее там. Если база данных не помещается в RAM, то она будет помещена в Swap, что приведет к существенной деградации производительности. Если БД большая, требуется сервер с достаточно большим объемом RAM (что, впрочем, не является проблемой в настоящее время, когда 1TB RAM на сервере — далеко не предел).
Если при настройке клиента выбрать неверно время таймаута сессии, то это может вести к непредсказуемым последствиям, которые будут обостряться при увеличении нагрузки на кластер и выходе из строя части узлов кластера. Пользователи стремятся уменьшить время сессии (по умолчанию 30 секунд), чтобы увеличить сходимость системы, поскольку эфемерные узлы будут удаляться быстрее, но это ведет к меньшей стабильности системы под нагрузкой.
Обычно, в кластере используют 3 узла, которые участвуют в достижении консенсуса, желание добавить дополнительные узлы существенно снизит производительность операций записи. Количество узлов должно быть нечетным (требование алгоритма ZAB), соответственно, расширение кластера до 5, 7, 9 узлов будет негативно влиять на производительность. Если проблема именно в операциях чтения — используйте узлы-наблюдатели.
Максимальный размер данных в узле ограничен 1MB. В случае, если требуется хранить большие объемы данных, Zookeeper не подойдет.
Zookepeer не накладывает на то, сколько у узла может быть потомков, однако, максимальный размер пакета данных, который сервер может отправить клиенту составляет 4МБ (jute.maxbuffer). Если у узла такое количество потомков, что их перечень не помещается в один пакет, то, к сожалению, не существует способа получить сведения о них. Данное ограничение обходится с помощью организации иерархических "псевдоплоских" списков таким же образом, каким строятся кэши в файловой системе, имена или дайджесты объектов разбиваются на части и организуются в иерархическую структуру.
Несмотря на недостатки, достоинства их перевешивают, что делает Zookeeper важнейшим компонентом многих распределенных экосистем, например, Cloudera CDH5, или DC/OS, Apache Kafka и других.
Поскольку Zookeeper реализован с использованием языка Java, то в средах JVM его использование является органичным, к примеру, достаточно легко запустить сервер или даже кластер серверов из Java и использовать его для реализации интеграционных или smoke-тестов приложения без необходимости развертывания стороннего сервера. Однако, API клиента Zookeeper достаточно низкоуровневый, что, хотя и позволяет выполнять операции, но напоминает заплыв против течения реки. Кроме того, требуется глубокое понимание основ Zookeeper, чтобы правильно реализовать обработку исключительных ситуаций. К примеру, когда я использовал для работы с Zookeeper базовый интерфейс, отладка и поиск ошибок в коде распределенной координации и обнаружения доставляли достаточно большие проблемы и требовали существенное время.
Однако, решение существует и оно было подарено сообществу разработчиком Netflix Джорданом Циммерманом. Знакомьтесь, Apache Curator.
На главной странице проекта расположена цитата:

Это утверждение на 100% отражает суть Curator. Начав использовать данную библиотеку, я обнаружил, что код работы с Zookeeper стал простым и понятным, а количество ошибок и время на их устранение снизилось кратно. Если, как ранее было сказано — стандартный клиент напоминает заплыв против течения, то с куратором ситуация меняется на 180 градусов. Кроме того, в рамках Curator-а реализовано большое количество готовых рецептов, которые я обзорно рассмотрю далее.
API выполнен в форме исключительно удобного текучего интерфейса, что позволяет просто и лаконично определять требуемые действия. К примеру (далее, примеры приводятся на языке Scala):
client
.create()
.orSetData()
.forPath("/object/path", byteArray)что может быть переведено как "создай узел или, если существует, просто установи данные для пути "/object/path" и запиши в него byteArray".
Или, к примеру:
client
.create()
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath("/head/child", byteArray)"создай узел типа последовательный и эфемерный для пути "/head/child000000XXXX" и запиши в него byteArray". Еще несколько примеров могут быть найдены на этой странице руководства.
Curator поддерживает как синхронный, так и асинхронный режим выполнения операций. В случае асинхронного использования клиент имеет тип AsyncCuratorFramework, в отличие от синхронного CuratorFramework. А каждая цепочка вызовов принимает метод thenAccept, в котором указывается Callback, который вызывается при завершении операции. Более подробно об асинхронном интерфейсе можно узнать на посвященной ему странице руководства.
val async = AsyncCuratorFramework.wrap(client);
async.checkExists().forPath(somePath).thenAccept(stat -> mySuccessOperation(stat))При использовании Scala использование асинхронного интерфейса не кажется оправданным, поскольку функциональность может быть легко реализована с использованием Scala Future, что позволяет коду сохранить особенности scala-way разработки. Однако, в случае Java и других JVM языков, данный интерфейс может быть полезным.
Zookeeper не поддерживает семантику хранимых данных. Это означает, что разработчики самостоятельно несут ответственность за то, в каких форматах хранятся данные и по каким путям они расположены. Это может стать неудобным во многих случаях, например, когда в проект приходят новые разработчики. Для решения данных проблем Curator поддерживает схемы данных, которые позволяют задавать ограничения на пути и типы узлов, в рамках данных путей. Схема, создаваемая из конфигурации, может быть представлена в формате Json:
[
{
"name": "test",
"path": "/a/b/c",
"ephemeral": "must",
"sequential": "cannot",
"metadata": {
"origin": "outside",
"type": "large"
}
}
]Миграции Curator чем-то напоминают Liquibase, только для Zookeeper. С их помощью возможно отражать эволюцию базы данных в новых версиях продукта. Миграция состоит из набора последовательно выполняемых операций. Каждая операция представлена некоторыми преобразованиями над БД Zookeeper. Curator самостоятельно отслеживает примененность миграций с помощью Zookeeper. Данная функция может быть использована в процессе развертывания новой версии приложения. Подробно миграции описаны на
соответствующей странице руководства.
Для упрощения тестирования, Curator позволяет встроить сервер или даже кластер серверов Zookeeper в приложение. Данную задачу можно достаточно просто решить и без использования Curator, только с Zookeeper, но Curator предоставляет более лаконичный интерфейс. К примеру, в случае Zookeeper без Curator:
class ZookeeperTestServer(zookeperPort: Int, tmp: String) {
val properties = new Properties()
properties.setProperty("tickTime", "2000")
properties.setProperty("initLimit", "10")
properties.setProperty("syncLimit", "5")
properties.setProperty("dataDir", s"$tmp")
properties.setProperty("clientPort", s"$zookeperPort")
val zooKeeperServer = new ZooKeeperServerMain
val quorumConfiguration = new QuorumPeerConfig()
quorumConfiguration.parseProperties(properties)
val configuration = new ServerConfig()
configuration.readFrom(quorumConfiguration)
private val thread = new Thread() {
override def run() = {
zooKeeperServer.runFromConfig(configuration)
}
}
def start = {
thread.start()
}
def stop = {
thread.interrupt()
}
}
...
val s = new ZookeeperTestServer(port, tmp)
s.start
...
s.stop
В случае Curator:
val s = new TestingServer(port)
s.start()
...
s.stop()
Рецепты Curator — основной мотив использования данной библиотеки для реализации распределенных механизмов взаимодействия процессов. Далее, перечислим основные рецепты, которые поддерживаются Curator и как они могут применяться. Некоторые рецепты я не применял на практике, поэтому для них дан максимально приближенный к руководству перевод.
Данные рецепты предназначены для реализации отказоустойчивой модели выполнения процессов, в рамках которой существует текущий лидер и несколько процессов находится в горячем резерве. Как только лидер перестает выполнять свои функции, другой процесс становится лидером. Существует два подходящих рецепта:
Блокировки — один из важнейших механизмов распределенной межпроцессной синхронизации. Curator предоставляет широкий набор объектов блокировок:
Хочу заметить, что Zookeeper — не лучший кандидат для организации интенсивных распределенных очередей, если требуется обеспечить пропуск большого количества сообщений, то рекомендую воспользоваться специально предназначенным решением, например, Apache Kafka, RabbitMQ или другими. Тем не менее, Curator предоставляет набор рецептов для поддержки очередей:
Apache Curator безусловно стоит того, чтобы рассмотреть ее к применению, библиотека является выдающимся образцом инженерного труда и позволяет значительно упростить взаимодействие с Apache Zookeeper. К недостаткам библиотеки можно отнести малый объем документации, что повышает входной барьер для начинающих разработчиков. В своей практике мне не раз требовалось изучать исходные коды библиотеки, чтобы понять как именно работает тот или иной рецепт. Однако, это дает и положительный эффект — глубокое понимание реализации позволяет совершать меньше логических ошибок, основанных на предположениях.
Необходимо отметить, что разработчики Curator рекомендуют изучить документацию Zookeeper до того, как начать использовать библиотеку. Это очень разумный совет, поскольку Zookeeper является продуктом, для эффективного использования которого необходимо понимать как именно он функционирует, а не только знать его API. Эти затраты безусловно окупятся, а в руках опытного инженера возможности Zookeeper позволяет создавать надежные и производительные распределенные системы.
|
|
Разбор задач викторины Postgres Pro на PGDay'17 |
Хорошей традицией на постгресовых конференциях стало устраивать викторины с розыгрышем билетов на следующие конференции. Наша компания Postgres Professional на недавнем PgDay’17 разыгрывала билеты на PgConf.Russia 2018, которая пройдет в феврале 2018 года в Москве. В этой статье представлен обещанный разбор вопросов викторины.
Участникам конференции были предложены следующие вопросы:
Варианты ответа: WAL, Hint bits, Vacuum, Russian Hackers, Еноты.
Еноты и пылесос тоже могли работать с системой и писать на диск. Суть вопроса, конечно, именно в записи, произошедшей в результате чтения, а не случайно совпавшей с ним по времени.
Правильный ответ — Hint bits, в русской документации это “вспомогательные биты”. К сожалению, в документации мало о них говорится, но это восполнено в Wiki. Эти биты находятся в заголовке кортежа, и предназначены для ускорения вычисления его видимости. Они содержат информацию о том:
Значения этих битов могут быть проставлены и при операции чтения, если при определении видимости было определено значение какого-либо из них.
CREATE TABLE t (id serial primary key, code text unique);Поиск правильного ответа начнем с того факта, что в системной таблице pg_class хранятся не только таблицы, но и индексы, последовательности, представления и некоторые другие объекты.
Поскольку мы создаем таблицу, то одна запись в pg_class точно добавится. Итак, одна запись в pg_class есть.
Следующий факт, который нам понадобится, заключается в том, что для реализации ограничений PRIMARY KEY и UNIQUE в PostgreSQL используются уникальные индексы.
В создаваемой таблице есть и первичный ключ (id), и уникальный (code). Значит на каждое из этих ограничений будет создано по индексу. Промежуточный итог — 3 записи.
Теперь посмотрим на тип данных serial, который используется для столбца id. В действительности, такого типа данных нет, столбец id будет создан с типом integer, а указание serial означает, что нужно создать последовательность и указать её в качестве значения по умолчанию для id. Таким образом, будет создана последовательность, а количество записей в pg_class увеличивается до 4.
Столбец code объявлен с типом text, а этот тип может содержать очень большие значения, значительно превышающие размер страницы (обычно 8KB). Как их хранить? В PostgreSQL используется специальная технология для хранения значений большого размера — TOAST. Суть её в том, что если строка таблицы не помещается на страницу, то создается еще одна специальная toast-таблица, в которую будут записываться значения «длинных» столбцов. Для пользователя вся эта внутренняя кухня не видна, мы работаем с основной таблицей и можем даже не догадываться как там всё внутри устроено. А PostgreSQL для того чтобы быстро «склеивать» строки из двух таблиц создает еще и индекс на toast-таблицу. В итоге, наличие столбца code с типом text приводит к тому, что в pg_class создаются еще две записи: для toast-таблицы и для индекса на неё.
Общий итог и правильный ответ: 6 записей (сама таблица, два уникальных индекса, последовательность, toast-таблица и индекс на неё).
CREATE TABLE t1(x int, y int);
CREATE TABLE t2(x int not null, y int not null);В обе добавили 1 млн записей. Какая таблица займет больше места на диске и почему?
Варианты ответа были такими: Первая, вторая, займут поровну, первая займет меньше или столько же, сколько вторая, зависит от версии PostgreSQL.
Если в первую таблицу добавили значения, не являющиеся NULL, то она будет занимать столько же места, сколько и вторая. Если же в нее добавили NULL’ы, она будет занимать меньше места.
Это так вследствие особенностей хранения NULL-ов (вернее, не-хранения: они не хранятся, вместо них в заголовке записи проставляются специальные биты, указывающие на то, что значение соответствующего поля — NULL). Подробнее об этом можно узнать из из документации и доклада Николая Шаплова Что у него внутри.
Кстати, если в таблице t1 только одно из двух полей будет NULL, t1 займет столько же места, сколько и t2. Хотя NULL не занимает места, действует выравнивание, и поэтому в целом на занимаемый записями объем это не влияет. Выравнивание еще встретится нам в задаче №4.
Дотошный читатель возразит: «ну хорошо, сами NULL’ы не хранятся, но где-то же должна храниться та самая битовая строка t_bits, где по биту отводится на каждое поле, способное принимать значение NULL! Она не нужна для таблицы t2, но нужна для t1. Поэтому t1 может занять и больше места, чем t2».
Но дотошный читатель забыл про выравнивание. Заголовок записи без t_bits занимает ровно 23 байта. А под t_bits будет в t1 выделен один байт заголовка записи; а в случае t2 он будет съеден выравниванием.
Если у Вас установлено расширение pageinspect, можно заглянуть в заголовок записи, и, справляясь с документацией, увидеть разницу:
SELECT * FROM heap_page_items(get_raw_page('t1', 0)) limit 1;
SELECT * FROM heap_page_items(get_raw_page('t2', 0)) limit 1;
CREATE TABLE test(i1 int, b1 bigint, i2 int);Можно ли переписать определение так, чтобы ее записи занимали меньше места на диске и если да, то как? Предложите Ваш вариант.
Тут все просто, дело в выравнивании. Если у вас 64-разрядная архитектура, то поля в записи, имеющие длину 8 байт и более, будут выровнены по 8 байт. Так процессор умеет быстрее читать их из памяти. Поэтому 4-байтные int нужно складывать рядом, тогда они будут занимать вместе 8 байт.
На 32-разрядной архитектуре разницы нет. О внутреннем устройстве записей можно узнать из документации и уже упоминавшегося доклада Николая Шаплова Что у него внутри.
Результат неожиданный: timetz занимает больше места (12 байт), чем timestamptz (8 байт),
почему же так? Это историческое наследие. И никто не собирается от него избавиться? См. ответ Тома Лэйна. Кстати, если кому нибудь действительно понадобилось timetz (time with time zone) на практике, напишите нам об этом.
Ответ простой: в PostgreSQL пока такого средства нет. Чексуммы есть во многих местах, но защищают не всё. Поэтому ответы типа “задампить и сравнить” мы вынуждены были считать правильными. В Postgres Pro ведется работа над улучшением самоконтроля целостности.
(10,20)>(20,10)
array[20,20]>array[20,10]
Сравнение строк производится слева направо, поэтому первое выражение ложно.
Сравнение массивов производится также, поэтому второе — истино.
Варианты ответа: Statistics Collector, Checkpointer, WAL archiving, Autovacuum, Bgwriter, Ни одна из перечисленных
В документации сказано, что track_counts включает сбор статистики доступа к таблицам и индексам, которая нужна, в том числе, для автовакуума. С помощью этой статистики автоваккум решает, за какие таблицы ему браться. Подробности можно почитать в комментариях к исходникам автовакуума.
Конечно, архивирование WAL, Bgwriter и checkpointer с этим параметром не связаны.
select NULL IS NULL IS NULL ?Это, наверное, самый простой вопрос. Ответ False, т.к. NULL — это NULL, и всё это истина.
CLUSTER [VERBOSE] table_name [ USING index_name ] Команда CLUSTER упорядочивает таблицу в соответствие с некоторым индексом. Некоторые индексы могут задавать порядок, а некоторые — нет.
Ответ можно узнать с помощью команды
select amname from pg_am where amclusterable ;Эта команда выдаст два ответа — ожидаемый btree и не очень ожидаемый GiST. Казалось бы, какой порядок задает GIST-индекс? Раскроем страшную тайну — CLUSTER просто перестраивает таблицу, обходя ее в порядке обхода индекса. Для GiST порядок не столь определен, как для B-Tree, и зависит от порядка, в котором записи помещались в таблицу. Тем не менее, этот порядок есть, и есть сообщения, что кластеризация по GIST в отдельных случаях помогает.
При использовании пространственных индексов, например, она означает, что геометрически близкие объекты будут находится, скорее всего, ближе друг другу и в таблице.
При каком значении этой же опции на реплике задержка при выполнении COMMIT на мастере будет меньше, и почему?
synchronous_commit = on на мастере означает, что мастер будет считать COMMIT завершенным только после получения сообщения от реплики об успешной записи соответствующей части WAL’a на диск (ну, или о её застревании в буфере ОС, если у вас стоит fsync = off, но так делать не стоит, если данные представляют хоть какую-то ценность). Хитрость же в том, что момент, когда WAL сбрасывается на диск, определяется локальным значением synchronous_commit, то есть его значением на реплике.
Если на реплике synchronous_commit = off, запись произойдет не сразу, а когда WAL writer процесс сочтёт нужным ее выполнить; если точнее, он занимается этим раз в wal_writer_delay миллисекунд, но при большой нагрузке на систему сбрасываются только целиком сформированные страницы, так что в итоге максимальный промежуток времени между формированием WAL записи и ее записью на диск при асинхронном коммите получается 3 * wal_writer_delay. Все это время мастер будет терпеливо ждать, он не может объявить транзакцию завершенной до окончания записи.
Если же на реплике synchronous_commit имеет более высокое значение (хотя бы local), она сразу попытается записать WAL на диск, и поэтому задержка всего COMMIT потенциально будет меньше. Впрочем, и запись синхронного коммита можно отложить с помощью commit_delay, но это уже совсем другая история. Из этого всего следует неочевидный сходу вывод: выключенный synchronous_commit, который, казалось бы, должен уменьшать задержку COMMIT, в описанной схеме с репликацией ее увеличивает.
Подробнее об этом можно почитать в архиве списков рассылки и в документации:
Надёжность и журнал упреждающей записи, synchronous_commit.
select #array[1,2,3] - #array[2,3]Чтобы ответить на этот вопрос, надо знать, как PostgreSQL работает с массивами. Унарный оператор “#”, определенный в расширении intarray
вычисляет длину массива. При этом напрашивается ответ: в первом массиве три элемента, во втором — два. Казалось бы — ответом будет число 1! Но нет, если выполнить этот запрос, ответом будет ДВА. Откуда?
Важно учитывать также приоритет операторов (он намертво пришит к синтаксису и для пользовательских операторов это ведет часто к неочевидной семантике). У унарного # приоритет ниже, чем у оператора вычитания. Поэтому правильно запрос читается так:
select #( array[1,2,3] - #(array[2,3]))Ближе к концу викторины надо активизировать чувство юмора.
CREATE TABLE t (id serial primary key, code text unique);Этот вопрос “случайно” повторяет вопрос №2. См. также следующий вопрос.
Надо заметить, что ответ на 13-й вопрос, тем не менее, не должен повторять ответа на 2-й вопрос :) Это заметил всего лишь один из участников. Ведь таблица t уже создана в вопросе №2. Повторная команда не создаст ни одной записи в БД. (см также Задачи, расположенные по цепочке, Квант №10, 1987 )
История этого вопроса такова. Случайно, в процессе подготовки викторины, в ней два раза был напечатан один и тот же вопрос. Увидев это, Иван Фролков пошутил “надо было использовать UNION, а не UNION ALL”. Шутка понравилась “товарищу полковнику” ( www.anekdot.ru/id/-10077921 ), и викторина была пополнена 14-м вопросом.
В составлении викторины участвовали:
Алексей Шишкин, Алексей Игнатов, Арсений Шер, Анастасия Лубенникова, Александр Алексеев, Иван Панченко, Иван Фролков.
За 12-й вопрос мы благодарны Николаю Шуляковскому из mail.ru.
Победители викторины получили промокоды, которые они могут ввести вместо оплаты участия в PgConf.Russia 2018
.|
Метки: author x-wao postgresql блог компании postgres professional pgconf |
Олег Ненашев, Кирилл Толкачёв и Александр Тарасов про Groovy DSL и Pipeline в Jenkins на jug.msk.ru |



script {
— Tarasov Aleksandr (@aatarasoff) July 27, 2017
Главное - результат!)
}


|
Метки: author dbelob java groovy grails блог компании jug.ru group jug jug.msk.ru jenkins pipeline |
JetBrains MPS для интересующихся #3 |
У меня на дачке не было света 2 дня, я практически иссох и впал в спячку, но я снова здесь!
В этом посте мы начнем писать предсказания погоды и немного напишем кода, а не потыкаем мышкой! Ура! Наконец-то!
Очень простые! Пока прогнозировать будем только следующий день, а правила придумаем сами; а точнее, правил не будет. Мы просто будем выводить температуру на следующий день, абсолютно такую же, как и сегодня.
Сделаем один прикольчик, демонстрирующий возможности projectional editor.
В данном случае мы прибегнем к крутой фиче — мы создадим концепт, который будет содержать только ссылку на исходные данные, а данные мы будем выводить как график на своем Swing компоненте. О как умеем, хотя swing я жуть как не люблю.
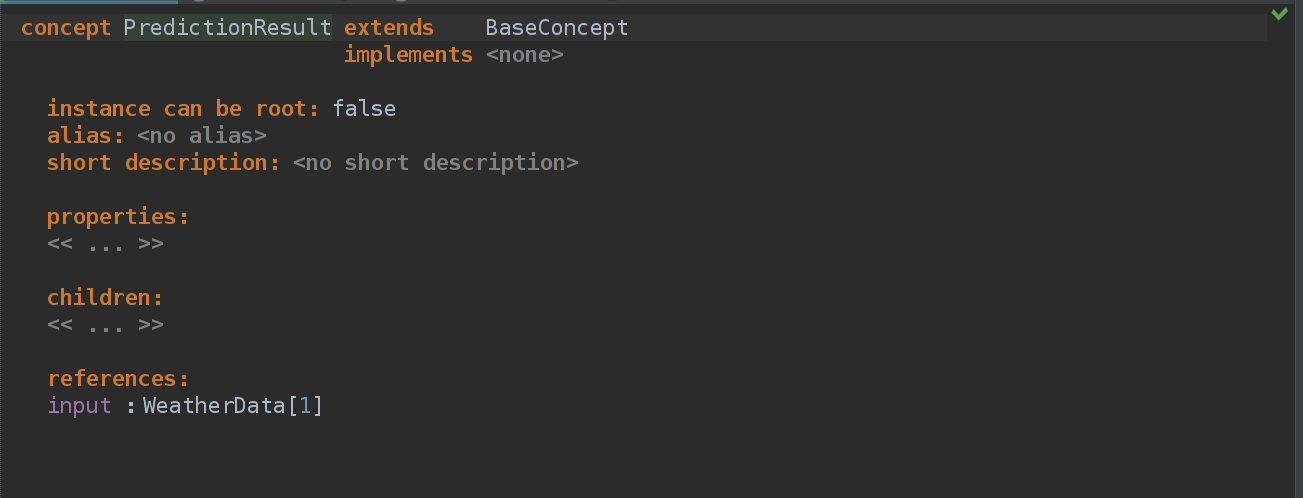
Создаем концепт PredictionResult, добавляем в него reference "input", которая является ссылкой на реализацию концепта в текущем scope AST! Но поскольку нам не нужны области видимости, или scope, то для нас сойдет поиск всех элементов данного типа.(Кстати, Scopes это не самая легкая тема в MPS + по ней довольно сложная документация, местами непонятная, так что я накатаю статейку про Scope тоже. Когда нибудь.) Но теперь нужно добавить идентификацию для WeatherData, изменим немного структуру и Editor аспект.
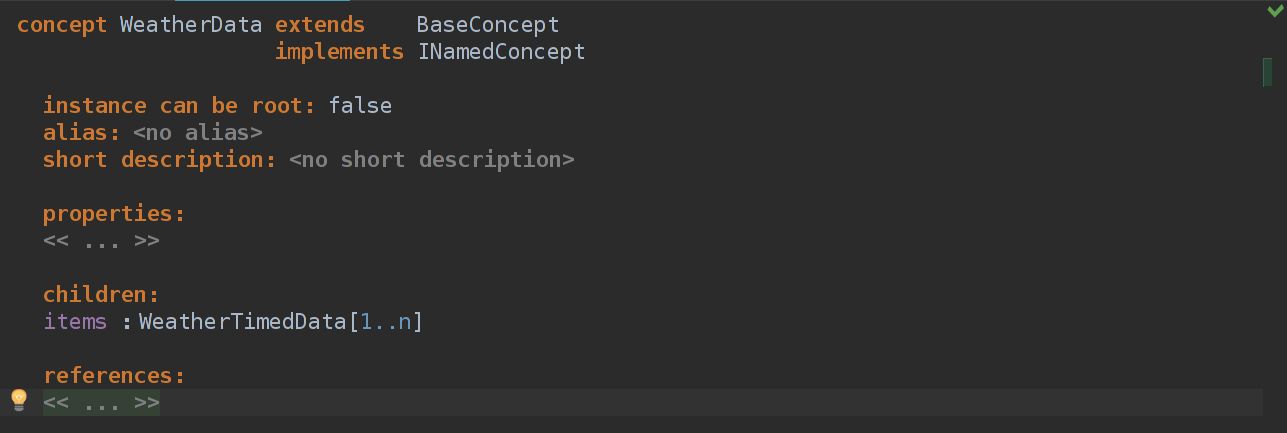
Я добавил INamedConcept после implements, и теперь у нашего концепта WeatherData есть имя, но мы его никак не присваеваем, поэтому изменим Editor.
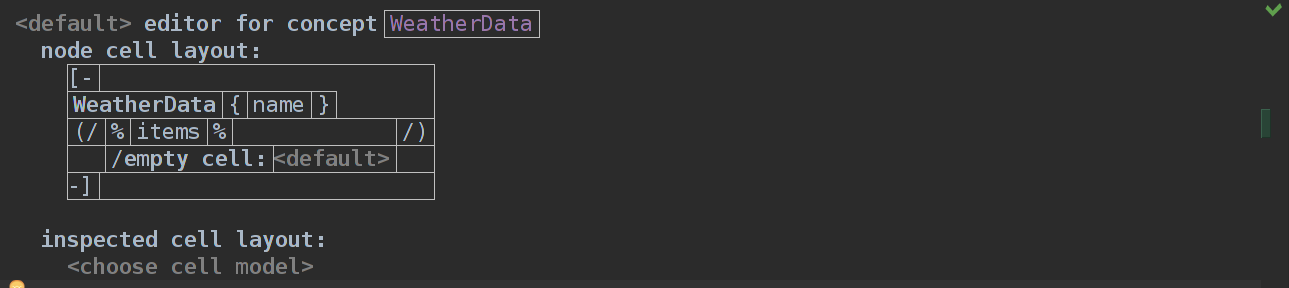
Здесь мы просто добавили 1 строчку, которая будет содержать имя. Пересоберем язык и посмотрим, че получилось.

Ура, теперь называем эту WeatherData именем "today" и возвращаемся к концепту PredictionResult и меняем его Editor аспект.
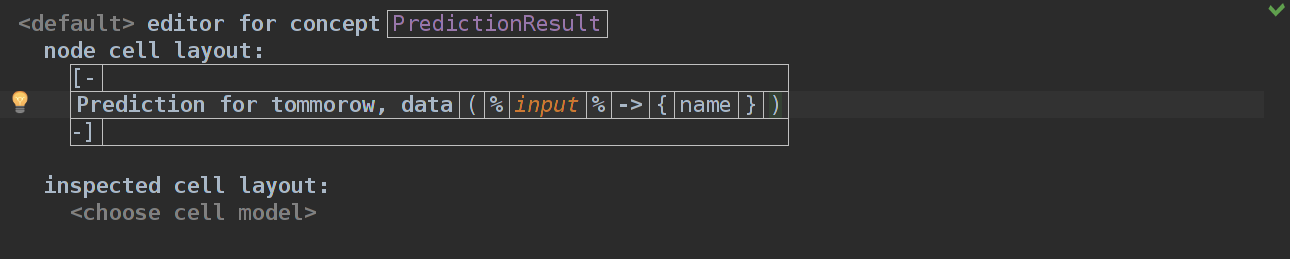
Пока так. У нас будет отображаться Prediction for tommorow, data %name_of_weather_data%
Добавим концепт в PredictionList — наш рутовый концепт, где пока находятся только входные данные.
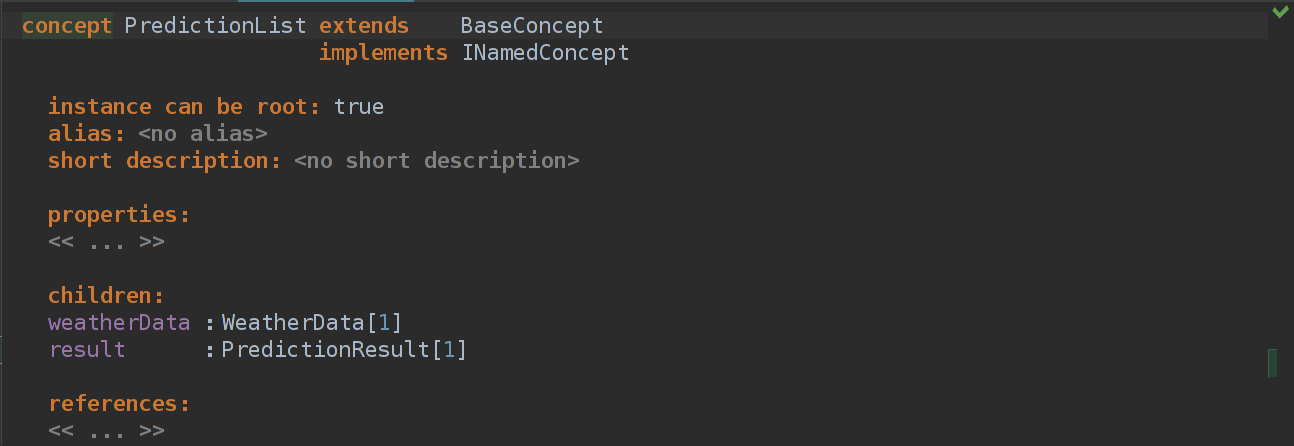
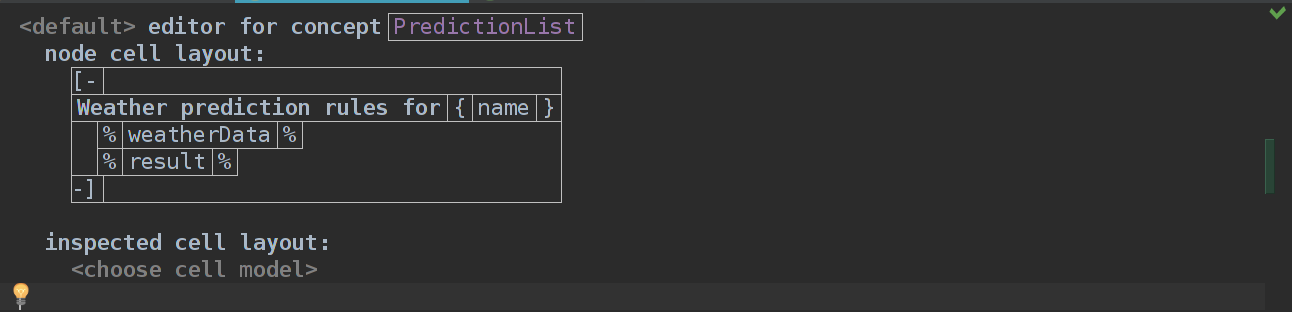
Если собрать, то получится
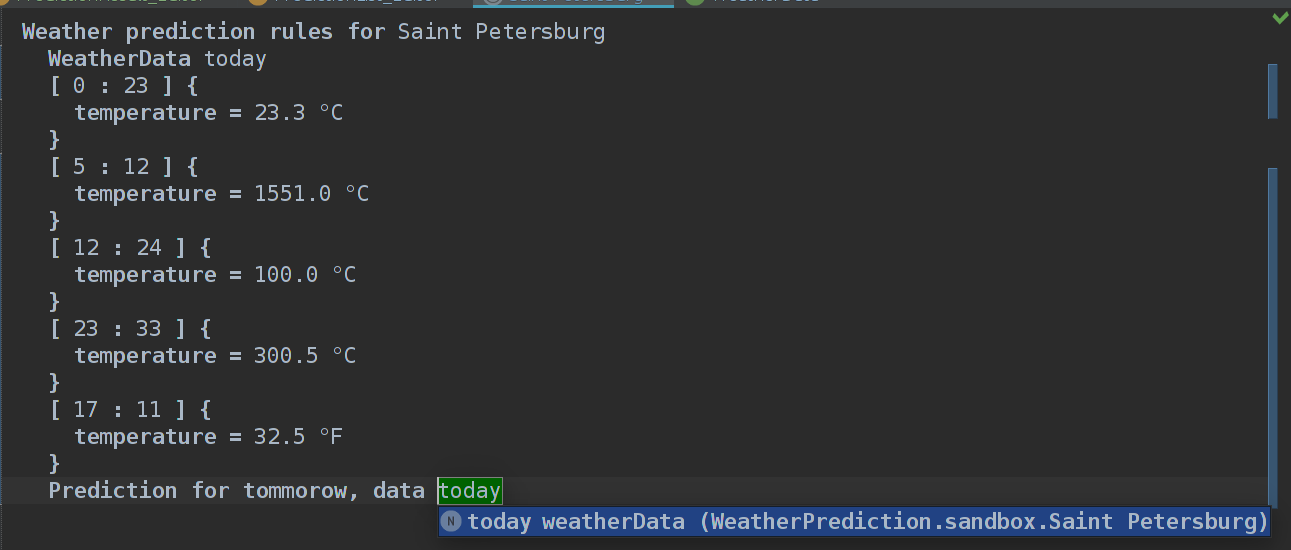
… как раз то, чего мы и хотели. Мы можем выбирать из списка WeatherData(ничего страшного, что у нас только 1 WeatherData, зато расширяемо).
Здорово, теперь нужно как-то круто выводить наши прогнозы. Я уже написал, что выводить мы их будем на swing компоненте, если кто не знает — javax.swing. — пакет для разработки нативных графических интерфейсов на Java. На нем построена IntelliJ. Swing компоненты можно юзать в editor. Уря.
Перед тем, как рисовать все это дело, распишем по пунктам, как мы будем действовать.
а y
P.S. формулы это ужас
Рисуем!
Чтобы Вас не мучать поэтапным написанием строчек, скину весь и пройдусь по более-менее сложным местам.
{
final int chartWidth = 400;
final int chartHeight = 200;
final JPanel panel = new JPanel() {
@Override
protected void paintComponent(final Graphics graphics) {
super.paintComponent(graphics);
editorContext.getRepository().getModelAccess().runReadAction(new Runnable() {
public void run() {
string unit = node.unit;
final list labels = node.input.items.where({~it => !it.temperature.concept.isAbstract(); }).select({~it =>
message debug "Woaw!" + it.temperature.concept.isAbstract(), , ;
double x = it.time.hours * 60 + it.time.minutes;
double y = it.temperature.getValueFromUnit(unit.toString());
new Point2D.Double(x, y);
}).sortBy({~it => it.x; }, asc).toList;
final double minTemp = labels.sortBy({~it => it.y; }, asc).first.y;
final double maxTemp = labels.sortBy({~it => it.y; }, asc).last.y;
final double yKoef = chartHeight / (maxTemp - minTemp);
final double xKoef = chartWidth / (60.0 * 24.0);
int prevY = chartHeight;
int prevX = -1;
Graphics2D g2 = ((Graphics2D) graphics);
labels.forEach({~it =>
message debug unit + "/" + it.y, , ;
int xTranslated = (int) (it.x * xKoef);
int yTranslated = chartHeight - (int) ((it.y - minTemp) * yKoef);
g2.setStroke(new BasicStroke(1));
if (prevX > 0) {
// It is first element, no need to draw trailing line
g2.drawLine(prevX, prevY, xTranslated, yTranslated);
}
g2.drawString(String.format("%.2f", it.y) + unit, xTranslated + 3, chartHeight - Math.abs(chartHeight - (yTranslated + 20)));
g2.setStroke(new BasicStroke(5));
g2.drawLine(xTranslated, yTranslated, xTranslated, yTranslated);
prevX = xTranslated;
prevY = yTranslated;
});
}
});
}
};
panel.setPreferredSize(new Dimension(chartWidth, chartHeight));
return panel;
} Первое, что бросается в глаза — editorContext.getRepository().getModelAccess().runReadAction...
Это такая фишка редактора MPS: чтобы получить доступ к модели/узлу откуда угодно, нам нужно запросить выполнение этого кода. Это похоже на runOnUIThread в андроиде, смысл примерно тот же. Короче, если нужно получить что-то из главного потока, то нужно делать это именно так. Еще есть runWriteAction, он нужен для внесения изменений и он нам еще потребуется.
Что происходит внутри:
1) Мы определяем единицы измерения
1) Определяем ширину и высоту графика
2) Трансформируем массив типа WeatherTimedData в список типа java.awt.geom.Point2D.Double, где
а y = температура в выбранном измерении, например, в цельсиях.
Мы используем синтаксис baseLanguage, который облегчает работу с коллекциями и позволяет нормально использовать различные паттерны, например map, filter, flatMap. Естественно,
вместо привычных названий используются select, where, selectMany соотвественно.
Внимание! Кусок кода, отвечающий за фильтрацию WeatherTimedData, а именно where({~it => !it.temperature.concept.isAbstract(); }) — когда мы инициализируем новый WeatherTimedData, то у нас не иницилизирована температура. То есть у нас нет дефолта в цельсиях или фаренгейтах, поэтому у нас абстрактная температура, и если бы мы не добавили этой фильтрации, то у нас зависал бы редактор. Вот он, опыт!
3) Получаем верхнюю и нижнюю границы температур, затем получаем те самые "коэффициенты" для проекций на оси
4) Рисование на компоненте — очень простая часть. Если рисуем первую точку — рисуем только точку и подпись о температуре, если рисуем НЕ первую — рисуем линию между предыдущей и текущей точками. Ну и плюс всякие визуальные прикольчики, аля отступы от краев, чтобы видно было текст.
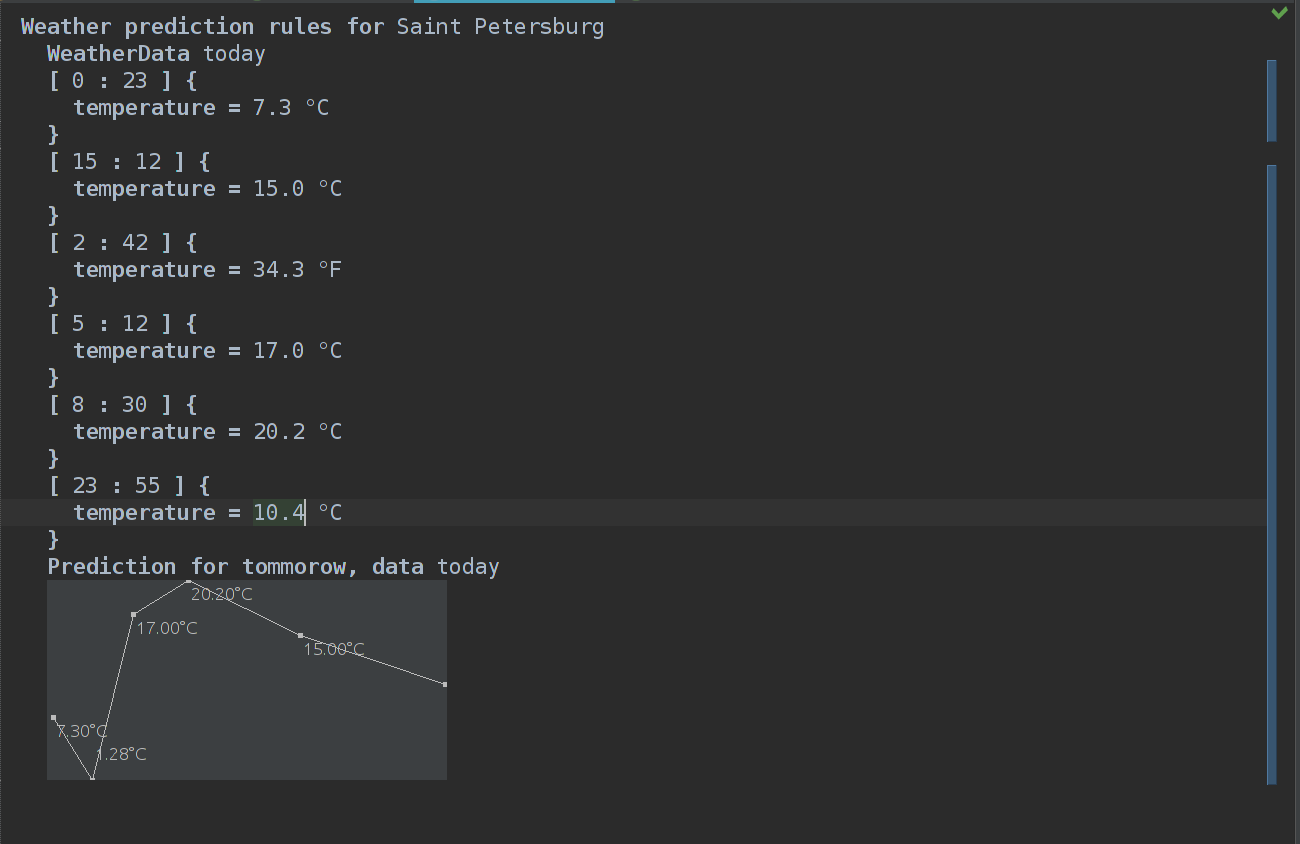
Вау! Это что такое — реально график? Прямо в редакторе кода? Который реактивно обновляется если поменять температуру или время? Вау!
Тем не менее, сейчас у нас захардкожены ширина и высота графика, а так же мы не можем выбрать единицы измерения.
Самое время сейчас заменить везде наши захардкоженные "°C", "°F" на enumeration datatype. Думаю, объяснять суть enumeration не стоит, только в контексте MPS.
enumeration datatype — это простой enum class, который может быть использован в property.
Если раньше мы использовали только string, integer и _FPNumber_String, то теперь мы можем создать enum для единиц измерения температур, в котором будет 2 элемента: цельсий и фаренгейт.
ПКМ на WeatherPrediction.structure -> New -> Enum Data Type -> TemperatureUnit.
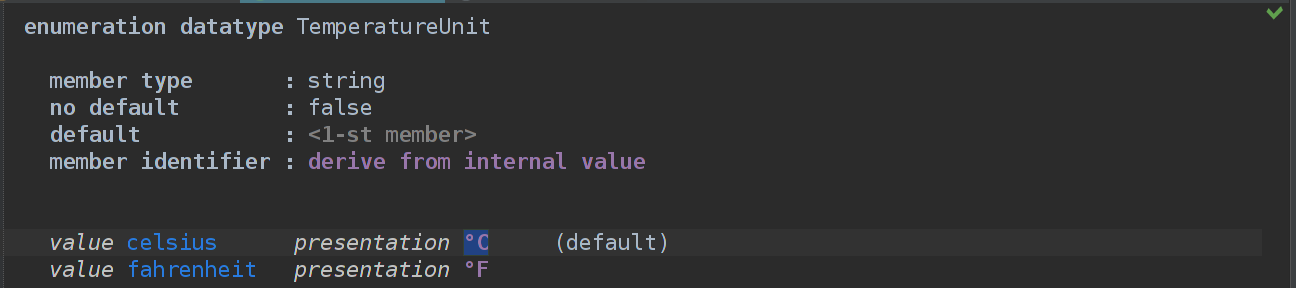
Выбираем тип, в данном случае string
Нам нужно дефолтное значение, так что оставляем false в no default
default = first member(celsius)
member identifier — отвечает за определение элемента по входным данным. Чтобы изменить значение TemperatureUnit, нужно подать на вход строку, которая сравнивается с каждым внутренним или внешним значением, смотря какое выбрать.
Поясняю: то, что слева и синенькое — внутренее значением элемента enum. Оно скрыто. Справа — внешнее, оно используется для отображения в редакторе.
То есть если мы в member identifier выберем derive from internal value, то задавать значение нам придется либо celsius, либо fahrenheit. А если мы выберем derive from presentation, то задавать значение придется строками °C или °F. Еще можно добавить кастомную идентификацию, например, чтобы можно было задавать значение по внутреннему и внешнему значению, но это уже сами, нам не нужно.
Выбираем derive from presentation и добавляем 2 элемента.
Четко!
Добавляем свойство unit в PredictionResult.
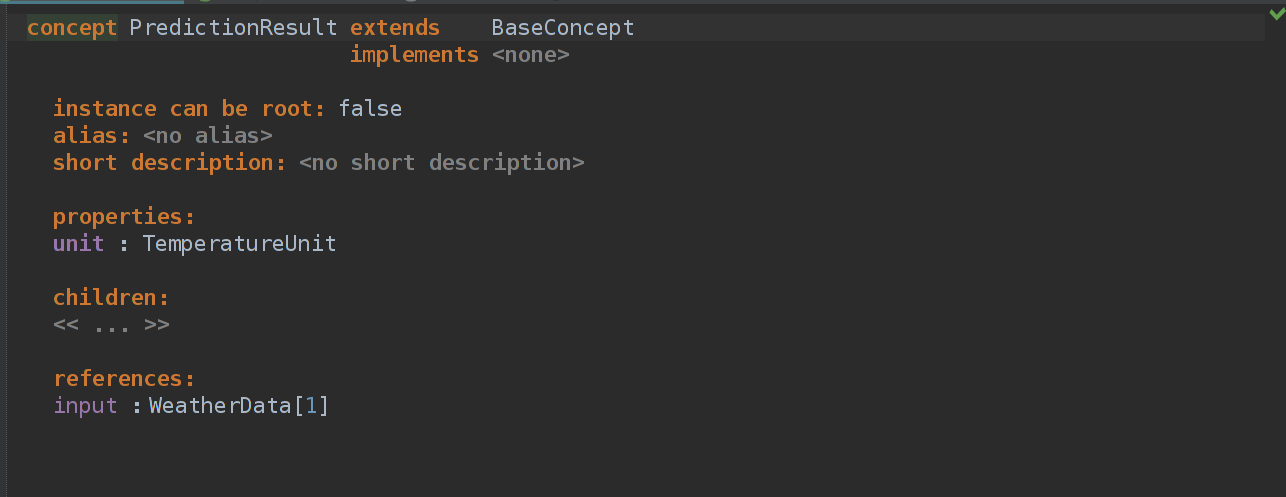
Теперь нужно добавить выпадающий список, в котором мы будем выбирать единицу измерения.
string[] units = enum/TemperatureUnit/.members.select({~it => it.externalValue; }).toArray;
final ModelAccess modelAccess = editorContext.getRepository().getModelAccess();
final JComboBox box = new JComboBox(units);
box.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent p0) {
modelAccess.executeCommand(new EditorCommand(editorContext) {
protected void doExecute() {
Object selectedItem = box.getSelectedItem();
node.unit = selectedItem.toString();
}
});
}
});
box.setSelectedIndex(0);
box; Это код для другого $swing component$ в коде редактора PredictionResult. Мы получаем список возможных единиц измерения температуры, создаем выпадающий список, вешаем обработчик события. Здесь тоже используется "прикол MPS", вместо readAction или writeAction можно просто executeCommand. Видимо, 2 предыдущих существуют для читаемости.
При изменении выбранного элемента из JComboBox меняется node.unit, который задается строковым значением, как я объяснял выше.
Собираем язык, смотрим.

Можете мне поверить, там действитетельно выпадает еще и фаренгейт. Осталось только связать JComboBox и график, и на этом можно будет закончить, а сделать это будет легко.
Привожу оригинальный код отрисовки графика.
{
public void run() {
string unit = "°C";
final list labels = node.input.items.select({~it =>
double x = it.time.hours * 60 + it.time.minutes;
double y = it.temperature.getValueFromUnit(unit.toString());
new Point2D.Double(x, y);
}).sortBy({~it => it.x; }, asc).toList;
final double minTemp = labels.sortBy({~it => it.y; }, asc).first.y;
final double maxTemp = labels.sortBy({~it => it.y; }, asc).last.y;
final double yKoef = chartHeight / (maxTemp - minTemp);
final double xKoef = chartWidth / (60.0 * 24.0);
int prevY = chartHeight;
int prevX = -1;
Graphics2D g2 = ((Graphics2D) graphics);
labels.forEach({~it =>
message debug unit + "/" + it.y, , ;
int xTranslated = (int) (it.x * xKoef);
int yTranslated = chartHeight - (int) ((it.y - minTemp) * yKoef);
g2.setStroke(new BasicStroke(1));
if (prevX > 0) {
// It is first element, no need to draw trailing line
g2.drawLine(prevX, prevY, xTranslated, yTranslated);
}
g2.drawString(String.format("%.2f", it.y) + unit, xTranslated + 3, chartHeight - Math.abs(chartHeight - (yTranslated + 20)));
g2.setStroke(new BasicStroke(5));
g2.drawLine(xTranslated, yTranslated, xTranslated, yTranslated);
prevX = xTranslated;
prevY = yTranslated;
});
}
} Да, смекаете? Нам нужно только заменить string unit = "°C"; на string unit = node.unit; и мы гучи!
А теперь итог: график в цельсиях и фаренгейтах, уаа!
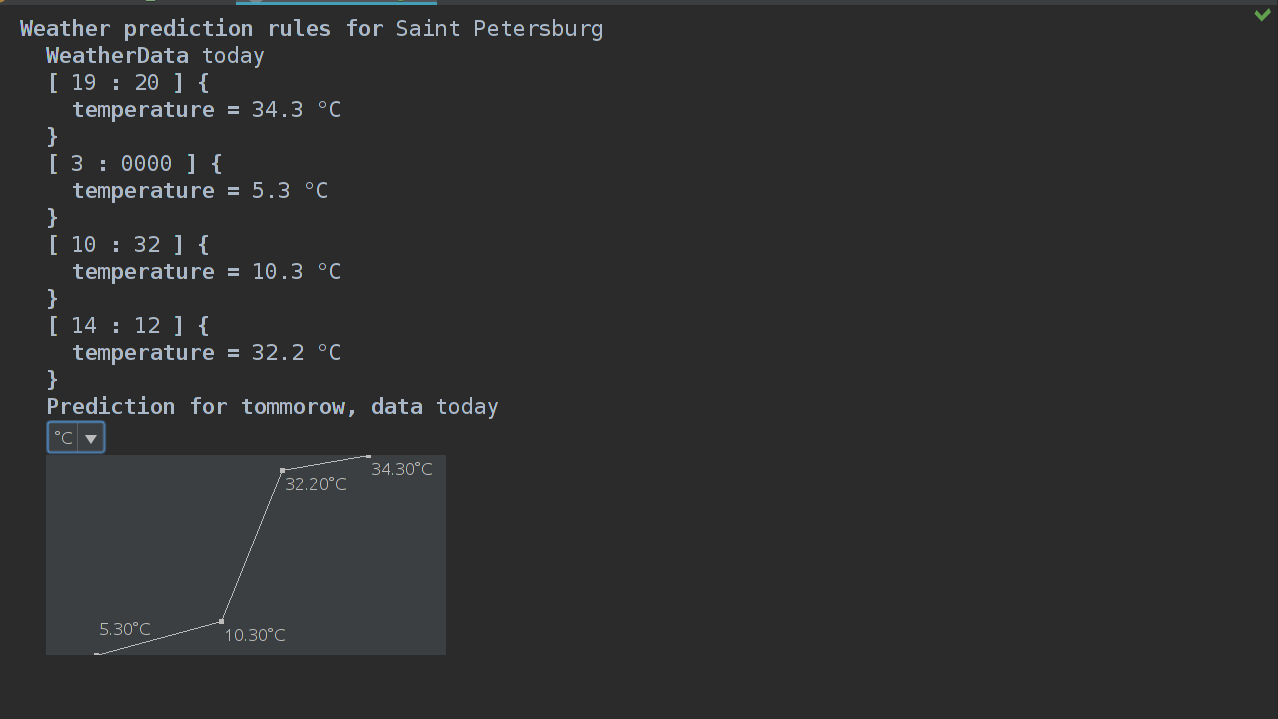
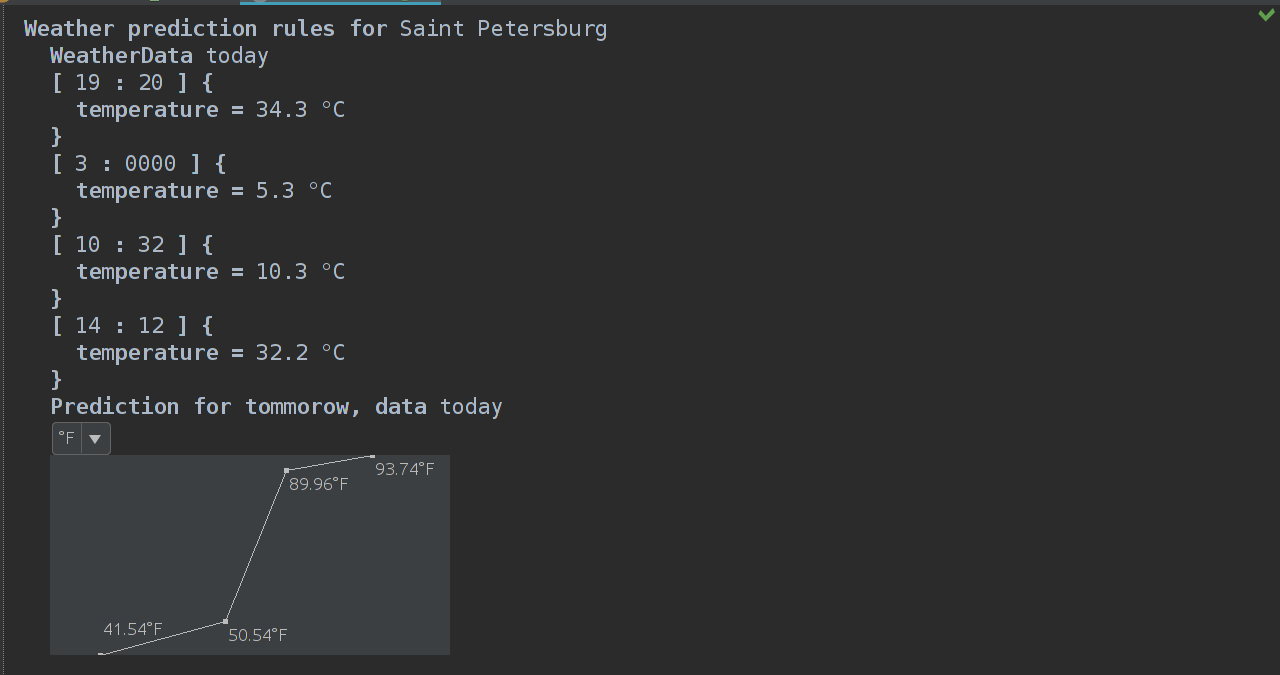
P.S.
Я думаю именно в этой статье очень много опечаток, расхождений, потому что я много отвлекался, как минимум на то, чтобы реализовать то, что хотел поведать в этой статье. Что ни день, то открытие, поэтому, пожалуйста, пишите в комментах все моменты, которые вам кажутся странными, скорее всего это я выпал из контекста повествования и написал какую-то ересь.
В следующей статье мы рассмотрим такой аспект, как TextGen. Будем генерировать прогноз погоды в текстовую форму!
|
Метки: author enchantinggg программирование java jetbrains mps programming language design |
Математический пакет для Android — «Микро-Математика» — теперь с открытым исходным кодом |
Некоторое время назад я писал здесь о «Микро-Математике» — математическом пакете для Android, который я разработал в качестве хобби-поделки. Этим летом исполняется три года с тех пор, как «Микро-Математика» была выложена в Google Play на всеобщее обозрение. С тех пор программа развивалась дальше, и вот настал момент, когда доход от Google Play окупил разработку. В связи с этим я не вижу смысла дальше утаивать исходный код от общественности и перевожу проект в разряд Open Source. Тех, кому интересно познакомиться с репозиторием «Микро-Математики» на github, и, быть может, поучаствовать в дальнейшем развитии проекта, прошу под кат.
Я не буду повторять здесь содержание предыдущей статьи — идеология, ядро и базовый функционал приложения с тех пор не изменились. Естественно, за три года добавилось много новых возможностей. Выделю наиболее важные, на мой взгляд:
Реализован функциональный файловый менеджер, который поддерживает не только SD-карту, но и доступ к ресурсам приложения. За основу взято ядро достаточно известного файлового менеджера «Ghost Commander»
В ресурсах приложения теперь содержится большая библиотека примеров.
Если у тех, кто пользуется этим приложением, есть интересные примеры вычислений, и вы не против поделиться ими с общественностью, высылайте их мне по почте, я с удовольствием включу их в эту библиотеку.
Теперь приложение может работать с комплексными числами:

Кроме этого, добавлена поддержка массивов, использование которых позволяет значительно ускорить расчёт
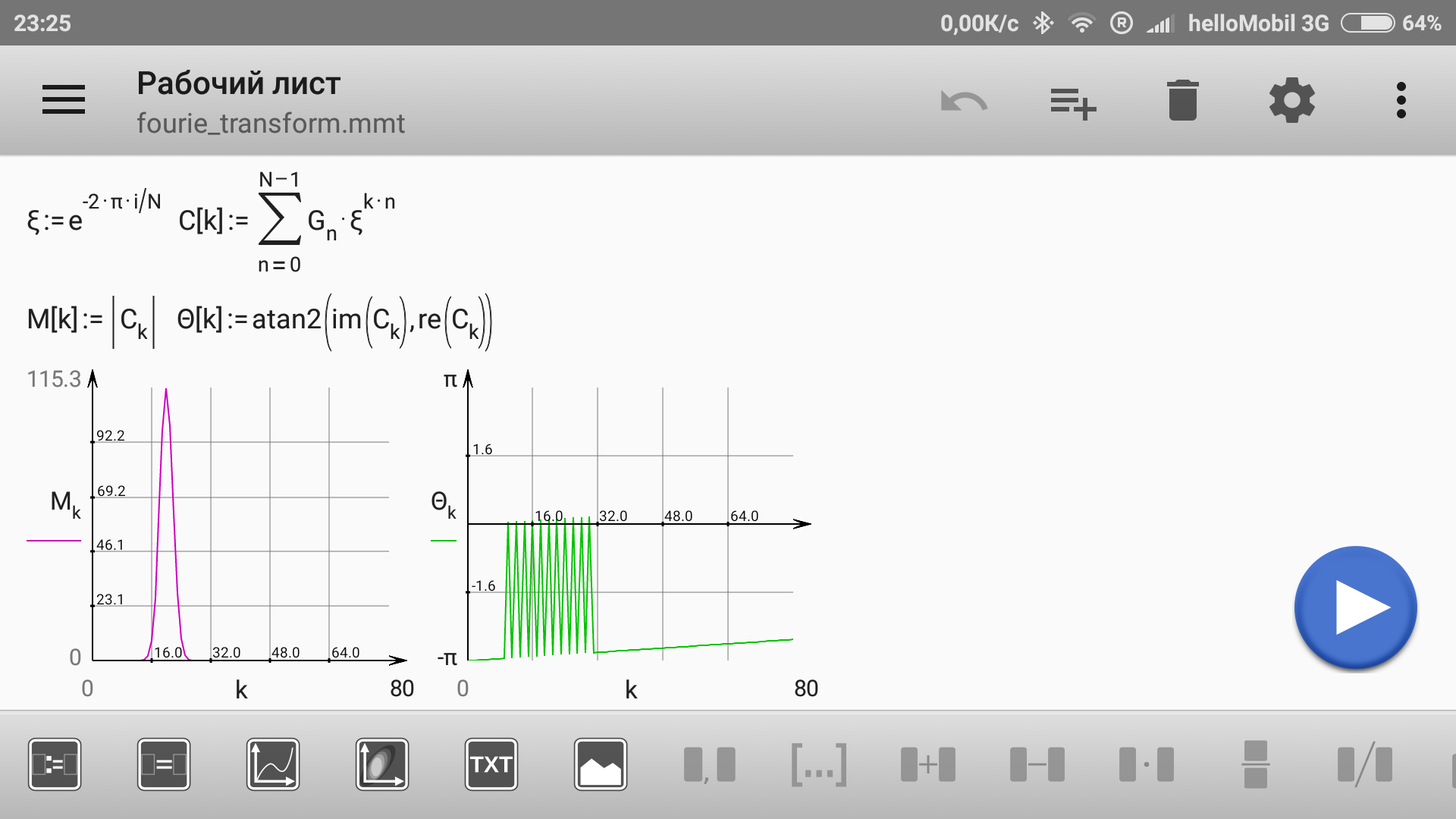
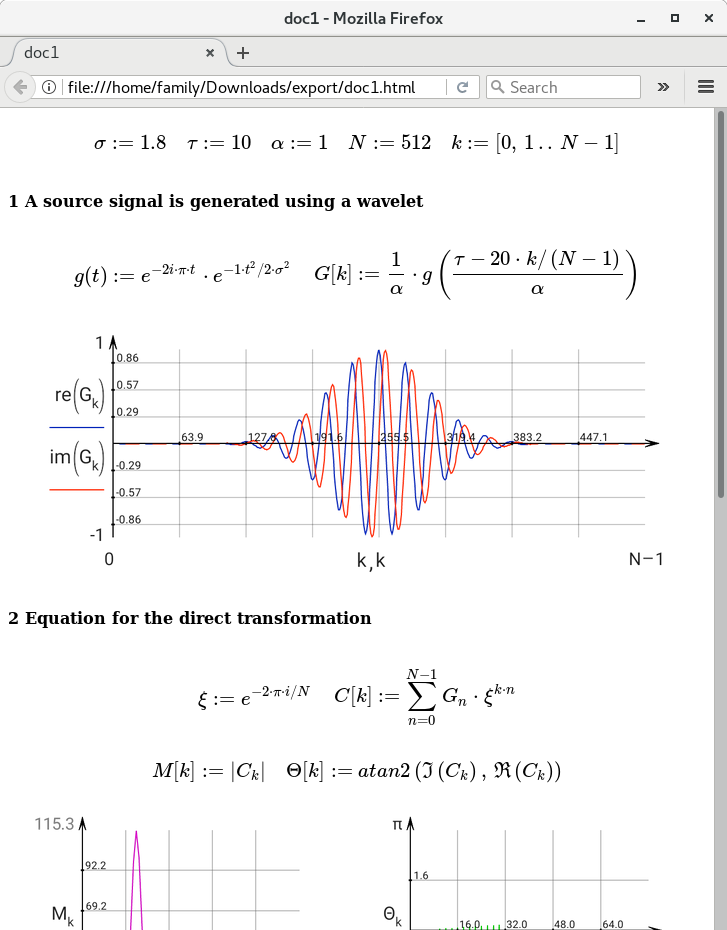
Появился экспорт документа в формате HTML, после чего его можно открыть в браузере, например, на ПК:
Github репозиторий находится тут. Лицензия — GNU General Public License v3.0.
Так уж исторически сложилось, что вся разработка у меня происходит под Linux, и, стыдно сказать, до сих пор в Eclipse. Но я открыт к альтернативным рабочим окружениям, так что если кто-то захочет запуллить конвертацию служебных скриптов под Windows, или проектные файлы для Android Studio — буду только рад.
На текущий момент в репозитории содержится как весь исходный код и SVG-исходники всех иконок приложения, так и некоторые вспомогательные вещи:
За последнее время я получил много пожеланий по дальнейшему развитию приложения. Среди них могу выделить такие, как:
Для одного человека работы многовато, поэтому приглашаю к сотрудничеству всех энтузиастов, кто интересуется математикой, алгоритмами, численными методами и т.д. Спасибо за внимание!
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author mkulesh разработка под android разработка мобильных приложений математика open source разработка приложений андроид |
Как сделать простое «главное меню» для игры в Unreal Engine 4 |
|
Метки: author norlin разработка игр unreal engine unreal engine 4 главное меню blueprints umg longread |
Работа с сервлетами для чайников. GET / POST |

package ru.javawebinar.topjava.model;
/**
* Класс Bot.
*
* Created by promoscow on 26.07.17.
*/
public class Bot {
private Integer id;
private String name;
private String serial;
public Bot(String name, String serial, Integer id) {
this.name = name;
this.serial = serial;
this.id = id;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSerial() {
return serial;
}
public void setSerial(String serial) {
this.serial = serial;
}
@Override
public String toString() {
return "Bot{" +
"id=" + id +
", name='" + name + ''' +
", serial=" + serial +
'}';
}
}
botServlet
web.BotServlet
0
botServlet
/bot
Bot info
ID: ${bot.id} | Name: ${bot.name} | Serial number: ${bot.serial}
Update
Имя атрибута формы: «id» (name=«id»), значение, которое мы передадим — поле id объекта bot (${bot.id}), также, мы вносим в поле имеющееся значение, полученное в атрибуте «bot» (placeholder="${bot.id}).
import model.Bot;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/**
* Bot Servlet class.
*
* Created by promoscow on 26.07.17.
*/
public class BotServlet extends HttpServlet {
Bot bot;
@Override
public void init(ServletConfig config) throws ServletException {
super.init();
bot = new Bot("Amigo", "228274635", 1);
}
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.out.println("Enter doGet");
String action = request.getParameter("action");
request.setAttribute("bot", bot);
switch (action == null ? "info" : action) {
case "update":
request.getRequestDispatcher("/update.jsp").forward(request, response);
break;
case "info":
default:
request.getRequestDispatcher("/bot.jsp").forward(request, response);
break;
}
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.out.println("Enter doPost");
request.setCharacterEncoding("UTF-8");
String action = request.getParameter("action");
if ("submit".equals(action)) {
bot.setId(Integer.parseInt(request.getParameter("id")));
bot.setName(request.getParameter("name"));
bot.setSerial(request.getParameter("serial"));
}
request.setAttribute("bot", bot);
request.getRequestDispatcher("/bot.jsp").forward(request, response);
}
}|
Метки: author xpendence java servlets get post javaee |
Тематическое моделирование средствами BigARTM |
# In[1]:
#!/usr/bin/env python
# coding: utf-8
# In[2]:
text=u' На практике очень часто возникают задачи для решения\
которых используются методы оптимизации в обычной жизни при \
множественном выборе например подарков к новому году мы интуитивно \
решаем задачу минимальных затрат при заданном качестве покупок '
# In[3]:
import time
start = time.time()
import pymystem3
mystem = pymystem3 . Mystem ( )
z=text.split()
lem=""
for i in range(0,len(z)):
lem =lem + " "+ mystem. lemmatize (z[i])[0]
stop = time.time()
print u"Время, затраченное lemmatize- %f на обработку %i слов "%(stop - start,len(z))
#In [4]:
start = time.time()
import nltk
from nltk.stem import SnowballStemmer
stemmer = SnowballStemmer('russian')
stem=[stemmer.stem(w) for w in text.split()]
stem= ' '.join(stem)
stop = time.time()
print u"Время, затраченное stemmer NLTK- %f на обработку %i слов "%(stop - start,len(z))
#In [5]:
start = time.time()
from Stemmer import Stemmer
stemmer = Stemmer('russian')
text = ' '.join( stemmer.stemWords( text.split() ) )
stop = time.time()
print u"Время, затраченное Stemmer- %f на обработку %i слов"%(stop - start,len(z))
#In [6]:
import nltk
from nltk.corpus import brown
stop_words= nltk.corpus.stopwords.words('russian')
stop_word=" "
for i in stop_words:
stop_word= stop_word+" "+i
print stop_word
#In [6]:
#!/usr/bin/env python
# -*- coding: utf-8 -*
from __future__ import unicode_literals
import nltk
from nltk import word_tokenize
from nltk.util import ngrams
from collections import Counter
text = "На практике очень часто возникают задачи для решения которых используются методы\ оптимизации в обычной жизни при множественном выборе например подарков к новому\
году мы интуитивно решаем задачу минимальных затрат при заданном качестве покупок"
#In [7]:
token = nltk.word_tokenize(text)
bigrams = ngrams(token,2)
trigrams = ngrams(token,3)
fourgrams = ngrams(token,4)
fivegrams = ngrams(token,5)
#In [8]:
for k1, k2 in Counter(bigrams):
print (k1+"_"+k2)
#In [9]:
for k1, k2,k3 in Counter(trigrams):
print (k1+"_"+k2+"_"+k3)
#In [10]:
for k1, k2,k3,k4 in Counter(fourgrams):
print (k1+"_"+k2+"_"+k3+"_"+k4)
#In [11]:
for k1, k2,k3,k4,k5 in Counter(fivegrams):
print (k1+"_"+k2+"_"+k3+"_"+k4+"_"+k5)
#In [12]:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import codecs
import os
import nltk
import numpy as np
from nltk.corpus import brown
stop_words= nltk.corpus.stopwords.words('russian')
import pymystem3
mystem = pymystem3.Mystem()
path='Texts_habrahabr'
f=open('habrahabr.txt','a')
x=[];y=[]; s=[]
for i in range(1,len(os.listdir(path))+1): #перебор файлов с документами по номерам i
filename=path+'/'+str(i)+".txt"
text=" "
with codecs.open(filename, encoding = 'UTF-8') as file_object:# сбор текста из файла i-го документа
for line in file_object:
if len(line)!=0:
text=text+" "+line
word=nltk.word_tokenize(text)# токинезация текста i-го документа
word_ws=[w.lower() for w in word if w.isalpha() ]#исключение слов и символов
word_w=[w for w in word_ws if w not in stop_words ]#нижний регистр
lem = mystem . lemmatize ((" ").join(word_w))# лемматизация i -го документа
lema=[w for w in lem if w.isalpha() and len(w)>1]
freq=nltk.FreqDist(lema)# распределение слов в i -м документе по частоте
z=[]# обновление списка для нового документа
z=[(key+":"+str(val)) for key,val in freq.items() if val>1] # частота упоминания через : от слова
f.write("|text" +" "+(" ").join(z).encode('utf-8')+'\n')# запись в мешок слов с меткой |text
c=[];d=[]
for key,val in freq.items():#подготовка к сортировке слов по убыванию частоты в i -м документе
if val>1:
c.append(val); d.append(key)
a=[];b=[]
for k in np.arange(0,len(c),1):#сортировка слов по убыванию частоты в i -м документе
ind=c.index(max(c)); a.append(c[ind])
b.append(d[ind]); del c[ind]; del d[ind]
x.append(i)#список номеров документов
y.append(len(a))#список количества слов в документах
a=a[0:10];b=b[0:10]# TOP-10 для частот a и слов b в i -м документе
y_pos = np.arange(1,len(a)+1,1)#построение TOP-10 диаграмм
performance =a
plt.barh(y_pos, a)
plt.yticks(y_pos, b)
plt.xlabel(u'Количество слов')
plt.title(u'Частоты слов в документе № %i'%i, size=12)
plt.grid(True)
plt.show()
plt.title(u'Количество слов в документах', size=12)
plt.xlabel(u'Номера документов', size=12)
plt.ylabel(u'Количество слов', size=12)
plt.bar(x,y, 1)
plt.grid(True)
plt.show()
f.close()

#In [1]:
#!/usr/bin/env python
# -*- coding: utf-8 -*
import artm
# создание частотной матрицы из batch
batch_vectorizer = artm.BatchVectorizer(data_path='habrahabr.txt',# путь к "мешку слов"
data_format='vowpal_wabbit',# формат данных
target_folder='habrahabr', #папка с частотной матрицей из batch
batch_size=10)# количество документов в одном batch#In [2]:
batch_vectorizer = artm.BatchVectorizer(data_path='habrahabr',data_format='batches')
dictionary = artm.Dictionary(data_path='habrahabr')# загрузка данных в словарь
model = artm.ARTM(num_topics=10,
num_document_passes=10,#10 проходов по документу
dictionary=dictionary,
scores=[artm.TopTokensScore(name='top_tokens_score')])
model.fit_offline(batch_vectorizer=batch_vectorizer, num_collection_passes=10)#10 проходов по коллекции
top_tokens = model.score_tracker['top_tokens_score']
#In [3]:
for topic_name in model.topic_names:
print (topic_name)
for (token, weight) in zip(top_tokens.last_tokens[topic_name],
top_tokens.last_weights[topic_name]):
print token, '-', round(weight,3)
|
Метки: author Scorobey математика python тематическое моделирование лемматизация стемминг python 2.7 nltk ngram |






