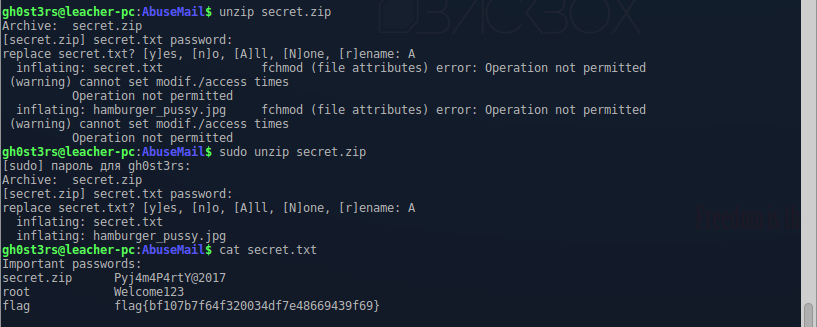
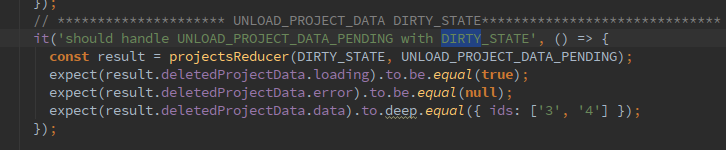
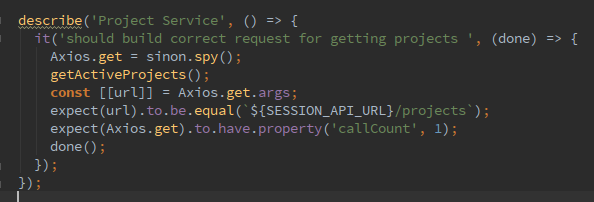
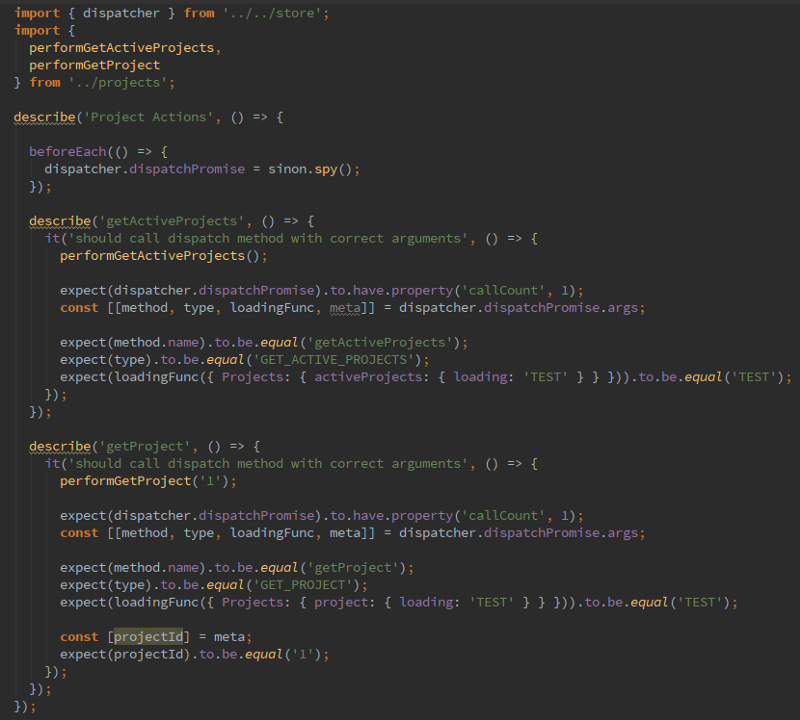
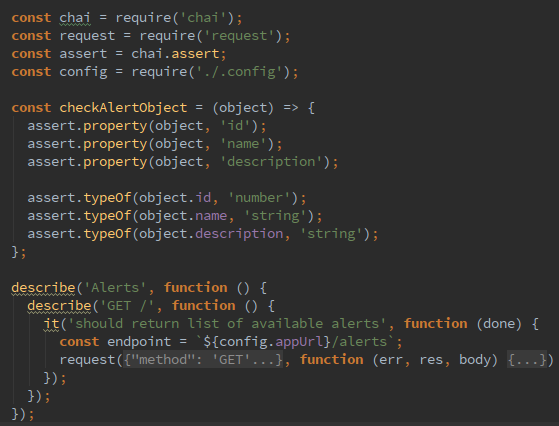
Любимые игры через Dolphin на мощном компьютере работают достаточно неплохо. Игра выполняется с полной скоростью, нет графических глитчей и можно использовать любой контроллер. Однако при попадании в новую область или загрузке нового эффекта присутствует совсем небольшое, но заметное «подвисание». Если отключить для проверки ограничитель количества кадров, то видно, что игра может работать гораздо быстрее, чем на полной скорости. Что же происходит?
Замедление при загрузке новых областей, эффектов, моделей и остального обычно называется пользователями и разработчиками «подвисанием при компиляции шейдеров». Эта проблема присутствовала в Dolphin с самого начала, но привлекла внимание только недавно.
Когда игры едва работали, лёгкие подвисания конечно были, но не вызывали больших проблем. Однако, эмуляция во многих играх постепенно улучшилась до почти идеального состояния, а подвисания оставались неизменными в течение многих лет. С момента выпуска Dolphin 4.0 пользователи начали ещё сильнее жаловаться на подвисание при компиляции шейдеров. Частично это было вызвано повышением требований к видеопроцессору из-за целочисленной математики, но в основном подвисание стало заметно потому, что других серьёзных проблем в эмуляторе не осталось.
Разработчики испытывали к подвисанию при компиляции шейдеров неприязнь и даже антипатию. Проблема казалась неразрешимой, в сообществе она вызывала боль и раздражение. Иронично то, что мы ненавидели подвисание, как никто другой, но сама безумная сложность задачи отпугивала большинство разработчиков. Несмотря на это, некоторые из них продолжали в одиночестве хранить надежду. Решение родилось как теория, которая имела
вероятность сработать. Теория, которая бы потребовала сотен, если не тысяч человеко-часов
только для проверки возможности её реализации.
Именно эта надежда подтолкнула нас к сложному путешествию почти без шансов на успех. Путешествию, потребовавшему два года работы нескольких специалистов по видеопроцессорам. И всё это для того, чтобы эмулировать весь путь первичного программируемого конвейера GameCube/Wii
без этого раздражающего подвисания.
Это был рассвет эры убершейдеров.
Проблема
Современные видеопроцессоры невероятно универсальны, но универсальность имеет свою цену — они
безумно сложны. Для использования всей их мощи разработчики используют шейдеры — программы, которые видеопроцессор выполняет так же, как центральный процессор выполняет приложения. Они программируют видеопроцессор на реализацию эффектов и сложных техник рендеринга. Разработчики пишут код на языке шейдеров в API (например, в OpenGL), а компилятор шейдеров в видеодрайвере транслирует код в двоичные команды, которые может выполнять видеопроцессор. Для такого компилирования требуются вычислительные ресурсы и время, поэтому в современных играх для PC эту проблему решают компилированием в моменты, когда частота кадров не важна, например, во время загрузки. Из-за большого количества различных компьютерных видеопроцессоров игры для PC не могут заранее компилировать шейдеры под определённый видеопроцессор. Поэтому единственный способ выполнения шейдеров на конкретном оборудовании — компилирование их видеодрайвером в определённый момент игры.
 Видеопроцессор GameCube Flipper, самый большой чип на материнской плате. Источник: Anandtech
Видеопроцессор GameCube Flipper, самый большой чип на материнской плате. Источник: Anandtech
В консолях всё совершенно по-другому. Если вы точно знаете, на каком оборудовании будет выполняться игра, и знаете, что это оборудование никогда не будет меняться, то можете просто предварительно откомпилировать программы для видеопроцессора и записать их на диск, ускорив загрузку игры и обеспечив постоянную скорость работы. Это особенно важно на старых консолях, у которых не хватает памяти, а может и вообще нет возможности хранить шейдеры в памяти. Видеопроцессор GameCube под названием Flipper как раз является таким случаем.
У Flipper есть элементы с постоянными функциями, поэтому в нём использовался программируемый модуль TEV (Texture EnVironment, текстурная среда), который можно сконфигурировать для выполнения огромного множества эффектов и техник рендеринга — почти так же, как это делают пискельные шейдеры. Фактически возможности модуля TEV очень похожи на функции пиксельных шейдеров DirectX 8 в Xbox! Он был настолько универсальным и мощным, что Flipper с некоторыми модификациями использовали в качестве видеопроцессора Wii (уже под названием Hollywood). К сожалению для нас, модуль TEV предназначен для выполнения конфигураций TEV в играх непосредственно в момент, когда требуется эффект. Нет никакой предварительной загрузки конфигураций TEV, потому что в модуле TEV нет для этого памяти.
Эта мгновенная загрузка стала источником всех наших проблем. Dolphin должен быть транслировать каждую используемую игрой конфигурацию Flipper/Hollywood в специализированный шейдер, который мог выполнить видеопроцессор компьютера. Шейдеры нужно компилировать, а это занимает время. Но модуль TEV не имеет возможности сохранять конфигурации, поэтому игры GC/Wii настраивают его таким образом, чтобы он рендерил эффект
сразу же, как только он потребуется, без всяких задержек и уведомлений. Чтобы справиться с этим несоответствием, Dolphin может только отложить поток видеопроцессора, пока поток видеопроцессора и видеодрайвер выполняют компиляцию, то есть, фактически, приостанавливая работу эмулируемой консоли GC/Wii. Обычно компиляция выполняется между кадрами и пользователи этого не замечают, но если она длится дольше кадра, то игра ощутимо приостанавливается до завершения компиляции. Это и есть
подвисание при компиляции шейдеров. Обычно подвисание длится всего пару кадров, но в очень нагруженных сценах с несколькими компилирующимися шейдерами возможны подвисания
больше чем на секунду.
Пока не создастся кеш шейдеров, игровой процесс Metroid Prime 3 довольно мучителен (
GIF).
Dolphin был первым эмулятором, эмулирующим на полной скорости систему с программируемым видеопроцессором, поэтому нам пришлось решать эту проблему самостоятельно. Мы реализовали кеширование шейдеров, то есть при включении любой конфигурации во второй раз она уже не подвисала. Но для создания надёжного кеша нужно было бы играть в игру несколько часов, а замена видеопроцессора компьютера, обновление видеодрайвера или даже переход на новую версию Dolphin могли привести к устареванию кеша и новым подвисаниям. В течение нескольких лет нам казалось, что с проблемами при компиляции шейдеров сделать ничего не удастся, и многие задавались вопросом, возможно ли это вообще…
Решение неразрешимой проблемы
Из всех оставшихся проблем Dolphin на подвисание при компиляции шейдеров пользователи жаловались больше всего. При обсуждениях в баг-трекерах, на форумах, в соцсетях и IRC постоянно всплывал этот вопрос. Через несколько лет мы уже стали реагировать на него иначе. Сначала подвисание даже не считали багом. Какое значение имеют небольшие торможения, если игры вообще едва работают? Всё изменилось в январе 2015 года, когда подвисание формально признали проблемой в баг-трекере Dolphin и информация о ней начала распространяться.
За последние годы пользователи задали кучу вопросов о подвисании, требовали решения проблемы, объявляли эмулятор бесполезным, а не которые даже ругали разработчиков на чём свет стоит за недостаток внимания к компиляции шейдеров. Правда заключается в том, что мы ненавидим эти подвисания как никто другой, и мы думали об этой проблеме много лет. Придумывалось множество решений, некоторые из них даже тестировались. Но казалось, что задачу не решить без серьёзных побочных эффектов.
Возможные решения
Генерировать все шейдеры заранее!
 Для справки: на Земле около 7,5 x 1015 песчинок.
Для справки: на Земле около 7,5 x 1015 песчинок.
Dolphin умеет довольно быстро генерировать нужные ему шейдеры, но проблема заключается в компиляции. Но если бы нам удалось каким-то образом сгенерировать и скомпилировать шейдеры для каждой возможной конфигурации, это бы решило проблему, так ведь? К сожалению, это попросту невозможно.
Существует примерно 5,64 x 10
511 возможных конфигураций только одного модуля TEV, и нам бы пришлось создавать уникальный шейдер для каждой из конфигураций. Кроме того, в системе используются вершинные шейдеры для эмуляции полупрограммируемого модуля аппаратных преобразований и освещения (Hardware Transform and Lighting unit), и они ещё больше увеличивают количество комбинаций.
Даже если бы мы могли скомпилировать их, эти шейдеры можно было бы использовать только в версии Dolphin, для которой они сгенерированы. При обновлении до новой сборки потребовался бы новый комплект шейдеров. В других случаях, например, при замене видеокарты или обновлении видеодрайверов
тоже потребовалась бы рекомпиляция. И всё это возможно было бы при наличии у драйвера низкоуровневого кеша, который есть не у всех драйверов.
Предугадывать шейдеры, которые потребуются игре!

Если бы нам удалось генерировать и компилировать шейдеры только на экранах загрузки и в других подобных случаях, то подвисания были бы незаметны. Но реализовать прогнозирование так, чтобы оно решало проблему, просто невозможно. Влияние на скорость и сложности с реализацией «предсказаний» быстрой перемоткой вперёд и прогнозированием вводимых данных слишком затратны для ситуаций, которых они могли помочь.
Предсказания вслепую тоже не работают — игра может выбирать запускаемые конфигурации и никак не предупреждает об этом, а предыдущие конфигурации ничего не говорят нам о следующих. Единственный способ узнать, какие шейдеры потребуются игре — пройти игру и найти каждую конфигурацию, которая ей может понадобиться.
… Что привело нас к ещё одному предложенному решению.
Общие шейдеры

Для описания конфигурации эмулируемого видеопроцессора Dolphin использует объект «Unique ID» («UID»). Эти UID превращаются в код шейдера и передаются видеодрайверу для компиляции. Поскольку UID присваиваются до компиляции и не подгоняются под какой-то конкретный компьютерный видеопроцессор, то они совместимы с любым компьютером и теоретически их можно делать общими. Теоретически, если пользователи будут делиться файлами UID, то они смогут компилировать шейдеры заранее и у них не возникнет подвисание. В настоящее время в API Vulkan
уже есть такая возможность, которая необходима, чтобы избежать проблемы с кешированием шейдеров у некоторых драйверов.
Так почему же это решение так и не было реализовано?
- Dolphin продолжает совершенствоваться. При внесении графических улучшений все эти UID пришлось бы выбросить.
- Не все игры можно так обработать. У популярных игр была бы почти полная коллекция UID, но людям, играющим в малоизвестные шедевры, мы ничем не смогли бы помочь.
- При тестировании оказалось, что разные игры имеют очень мало общих UID. У The Legend of Zelda: The Wind Waker и The Legend of Zelda: Twilight Princess есть небольшая часть общих конфигураций (15%), но они работают на одинаковом базовом движке. Большинство игр будут иметь гораздо меньше общего, поэтому обмен информацией о популярных играх точно ничем не помогло бы менее известным.
- У пользователей могут отсутствовать разные UID. Существует почти бесконечное количество конфигураций. Даже стопроцентное прохождение игры не гарантирует того, что вы задействуете их все.
Разработчики какое-то время взвешивали это решение, но обсуждение инфраструктуры обмена UID и поиска хорошего способа их распространения создавали больше разногласий, чем решений. Эту систему можно было бы использовать для
улучшения уже работающего решения, но само оно им стать не могло.
Асинхронная компиляция шейдеров
 Асинхронная компиляция шейдеров
Асинхронная компиляция шейдеров, получившая популярность благодаря форку — это нестандартное решение дилеммы компиляции шейдеров.
Tino посмотрел на проблему почти так же, как некоторые современные игры решают задачу динамической компиляции новых шейдеров. Когда игрок появляется в новой области, новые объекты иногда просто возникают из ничего, то есть загружаются динамически. Он задумался, не удастся ли получить похожий результат в эмуляторе, и в своём форке начал переписывать способ обработки шейдеров.
Концепция асинхронной компиляции шейдеров меняла поведение Dolphin, когда он не находил кешированного шейдера для обнаруженной конфигурации Flipper/Hollywood. Вместо приостановки игры и ожидания компиляции шейдера он просто пропускал рендеринг объекта. Это значило, что никаких пауз и подвисаний не стало, но некоторые объекты могли отсутствовать в кадре, пока их шейдер не был
готов.
Для некоторых игр этот способ сработал неплохо. В части игр движок отсекал объекты при отрисовке таким образом, что объекты вне области видимости камеры или закрывавшие всего несколько пикселей экрана всё равно рендерились. В таком случае пропуск рендеринга таких объектов был едва заметен. Однако в других играх это приводило к описанному выше эффекту «появления ниоткуда».
При пропуске компиляции шейдеров объекты могли возникать из воздуха, а графика выглядела поломанной (
GIF). Зато игровой процесс оставался плавным!
Пользователи задавали вопрос: почему в Dolphin не включили асинхронные шейдеры Tino хотя бы в виде опции для решения проблемы подвисаний при компиляции шейдеров. Всё свелось к тому, что люди, которые
могли реализовать эту функцию вместе с другими основными разработчиками, были против такого решения. Они видели в нём только хак, который привёл бы к куче ложноположительных отчётов в баг-трекере и возникновению в будущем ещё больших проблем. В чём-то они были правы: стало ясно, что некоторым играм
нужно рендерить объекты в том кадре, в котором они ожидаются. В этом случае головы аватаров Mii рендерились только один раз во встроенный буфер кадра (Embedded Framebuffer, EFB). Если копия EFB отсутствовала из-за асинхронной компиляции шейдеров, то головы Mii не отображались до конца игры или до их регенерации.
 Безголовые Mii
Безголовые Mii
Несмотря на все изъяны, пользователи форка Tino уверовали в асинхронную компиляцию шейдеров. Пусть асинхронные шейдеры вызывают проблемы, главное — они
решили проблему
подвисания при компиляции шейдеров. Из-за очевидных недостатков его нельзя было объединить с мастер-веткой Dolphin, но такое решение определённо подчеркнуло серьёзность проблемы с компиляцией генерируемых шейдеров. Работа Tino над асинхронной компиляцией шейдеров наглядно показала нам, насколько эта проблема волнует пользователей, и ещё больше мотивировала команду на поиск более совершенного решения.
Решение
Написать интерпретатор конвейера рендеринга GameCube/Wii внутри шейдеров и запустить его в видеокарте компьютера
Иногда лучший способ решить неразрешимую проблему — посмотреть на неё под другим углом. Что бы мы не пытались сделать, не было никакой возможности компилировать специализированные шейдеры с такой же скоростью, с которой игра меняет конфигурации.
Но что если мы не будем полагаться на специализированные шейдеры? У нас родилась безумная идея — эмулировать
сам конвейер рендеринга с помощью интерпретатора, который выполняется непосредственно в видеопроцессоре как множество огромных универсальных шейдеров. Если мы будем компилировать эти огромные шейдеры при запуске игры, то когда игра будет менять конфигурацию Flipper/Hollywood для рендеринга эффектов, такие «убершейдеры» будут
конфигурировать себя сами и выполнять рендеринг без необходимости новых шейдеров. Теоретически, это решит проблему с подвисанием при компиляции шейдеров благодаря
полному отказу от компиляции.
Эта мысль выглядела безумной, но она была первой, имевшей потенциал решения этой неразрешимой проблемы. Сложность этого решения заключалась в абсурдном объёме работы и знаний для достижения хотя бы этапа проверки его возможности. Чтобы вы понимали: даже среди всех разработчиков Dolphin только два-три человека
в лучшем случае имели знания не только о «железе» GameCube/Wii, но и о современных видеопроцессорах, GPU, API
и драйверах, необходимые для написания и оптимизации шейдеров. Это ещё не говоря о том, что выполнение интерпретатора как огромных шейдеров — не слишком простая задача для видеопроцессора. Многие опасались, что результаты всей этой работы не смогут выполняться с полной скоростью даже на современных видеокартах.
Чтобы гарантировать выигрыш, потребовались бы сотни, если не тысячи, часов отупляющей, монотонной, но сложной работы.
Первая попытка была сделана в 2015 году, когда разработчику
phire настолько надоели подвисания на его новом мощном компьютере, что он внёс предложение и разработал фреймворк для
убершейдера. Хотя он был в курсе всех сложностей, но, казалось, он решительно намеревался доказать, что убершейдеры — решение нашей древней проблемы. phire
в одиночку попытался заново научить Dolphin рендерингу.
 Это не графический фильтр.
Это не графический фильтр.
 Кажется, тут есть пара глитчей...
Кажется, тут есть пара глитчей...
 Благодаря своей простоте SM64 стала одной из первых игр, в которой что-то рендерилось через убершейдеры.
Благодаря своей простоте SM64 стала одной из первых игр, в которой что-то рендерилось через убершейдеры.
После дошлифовки этой функции в течение месяца ему удалось довести пиксельные убершейдеры до того этапа, на котором некоторые игры выглядели почти так же, как их версии на быстрых шейдерах. Удивительно было не то, что они работают, а то, что прототипы убершейдеров позволяют выполнять игры на полной скорости. Сам phire вспоминает, что его первой реакцией было:
нифига себе, они действительно работают на полной скорости. Он признавался, что
видеопроцессоры и не должны были справиться с работой на играбельной скорости, но им это удалось. Против всех ожиданий, прототипы доказали, что убершейдеры могут стать решением проблемы с подвисаниями при компиляции шейдеров. Поэтому при дальнейшем усовершенствовании мы повысили точность убершейдеров, исправили многие ошибки и реализовали недостающие возможности.
 В самом начале убершейдеры превращали игры в картинку искажённой реальности.
В самом начале убершейдеры превращали игры в картинку искажённой реальности.
 Но ситуация быстро улучшалась.
Но ситуация быстро улучшалась.
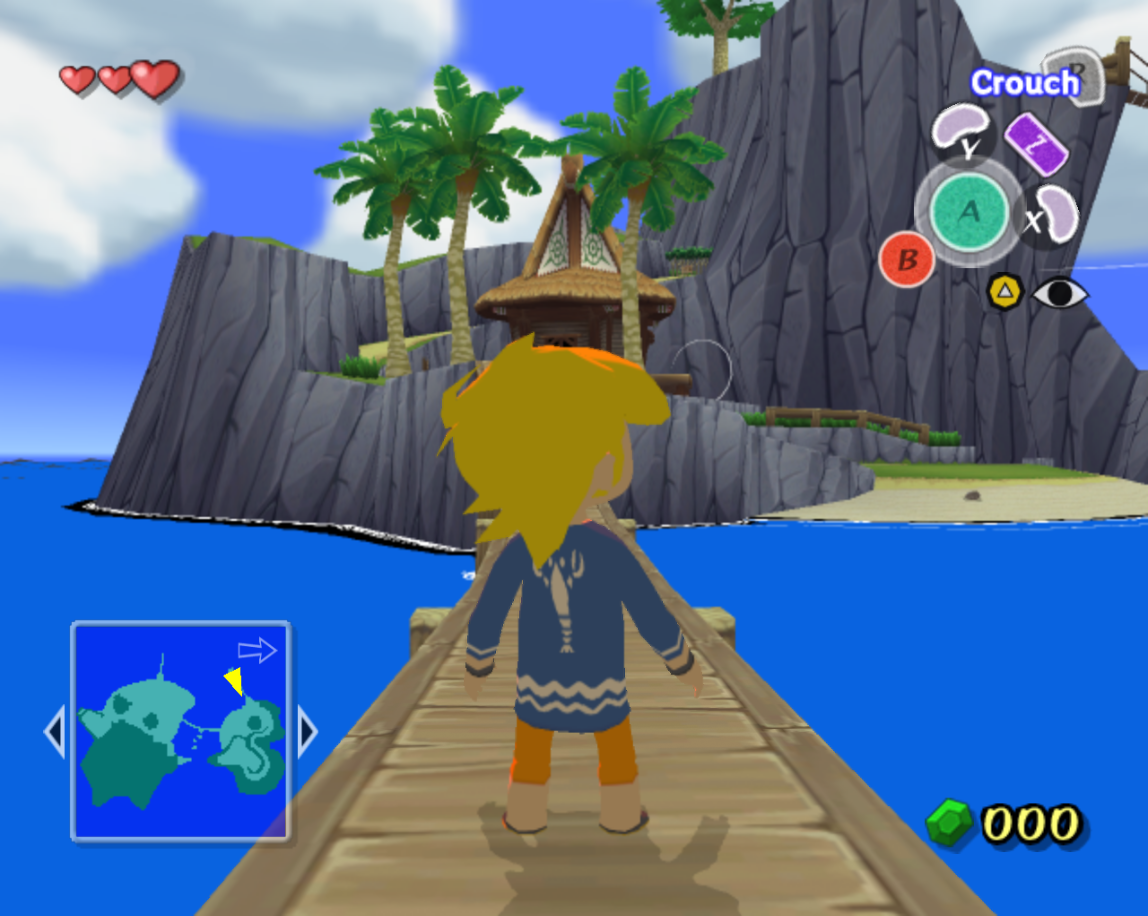 Мы глазом не успели моргнуть, а Wind Waker уже стала рендериться всего лишь с небольшими ошибками.
Мы глазом не успели моргнуть, а Wind Waker уже стала рендериться всего лишь с небольшими ошибками.
 phire довольно быстро удалось добиться идеального рендеринга Wind Waker. К сожалению, другие игры с более широким списком возможностей требовали гораздо больше работы.
phire довольно быстро удалось добиться идеального рендеринга Wind Waker. К сожалению, другие игры с более широким списком возможностей требовали гораздо больше работы.
Доведя проект убершейдеров до этого этапа, phire совершенно выбился из сил. Более того, ему ещё предстояла куча работы по отладке других проектов к выпуску Dolphin 5.0. Оказалось, что задержки имеют свою цену — из-за выгорания и волнений по поводу ограничений драйверов и API phire потерял весь свой запал. Несмотря на то, примерно 90% было готово, оставались ещё 90%, в том числе несколько важных функций.
- Завершение вершинных убершейдеров
- Инфраструктурные/соединительные пиксельные и вершинные убершейдеры
- Решение проблем с производительностью OpenGL и (после rebase) с Vulkan
- Очистка кода, исправление ошибок и получение таких же результатов рендеринга, как на специализированных шейдерах
- Опции графического интерфейса пользователя
- Дополнительно — гибридный режим для встроенных и слабых видеопроцессоров
Мучительно было видеть, что такой объём работы завис в неопределённости. Но не удавалось найти разработчиков, способных и желающих взяться за столь огромный проект. Даже те, кто решил работать над ним, не готовы были к подчистке кода, исправлению ошибок и работе над инфраструктурой. Больше года развитие убершейдеров простаивало, список так и не завершённых функций постоянно разрастался, а надежда постепенно угасала…
Убершейдеры 2.0
Подвисания при компиляции шейдеров Dolphin были одной из самых заметных ошибок, поэтому после завершения разработки убершейдеров пользователи о них не забыли. Давно заброшенный пул-реквест продолжал пополняться комментариями, о проблеме писали на форумах и даже заявляли о ней в разных формах в баг-трекере.
Убершейдеры оставались первой настоящей надеждой на устранение подвисаний, и они ежемесячно всплывали в обсуждениях. Полученный прогресс только подстегнул интерес сообщества к решению. После множества просьб, жалоб и даже
шантажа требований
Stenzek с неохотой начал работать над убершейдерами.
Ещё даже до того, как Stenzek занялся убершейдерами, команда приняла решения относительно поддержки графических API. Одно из решений, а именно отказ от API D3D12, получило смешанные, если не отрицательные отзывы. В отличие от решения с D3D9, мы не хотели проходить процесс постепенного отказа и избавились от него сразу же, как стало очевидно, что никто не хочет поддерживать этот API.
Но это оказалось удачным решением, потому что избавление от API позволило возродить проект убершейдеров, когда Stenzek оказался к этому готов. Он был архитектором бекэнда Vulkan в Dolphin, поэтому хотел проделать лишний труд, чтобы заставить убершейдеры работать с Vulkan.
Когда пиксельные и вершинные убершейдеры наконец были объединены вместе и готовы и запуску, тестеры незамедлительно использовали их в самых сложных играх. Учитывая то, что ни одно из предыдущих решений не работало нормальнов Metroid Prime 3, эта игра стала первым кандидатом.
Metroid Prime 3 была одной из немногих игр, в которой подвисания шейдеров снижали рейтинг до неиграбельного. До недавнего времени (
GIF)!
Первый тест убершейдеров увенчался огромным успехом: подвисания полностью исчезли в D3D, а в OpenGL и Vulkan на ранних этапах возникали только некоторые странные торможения. Продолжив работу над убершейдерами, мы намного улучшили их работу во всех API, за несколькими исключениями, о которых я расскажу позже. Но просто запускать игру на убершейдерах был недостаточно: они сами отъедали большое количество ресурсов видеокарты компьютера. Конечно, требования разных игр отличаются, но обычно на видеокарту сильно влияло разрешение, в котором запускалась игра. С «родным» разрешением 1x (480p) справлялось большинство видеокарт, а более мощные карты могли даже работать с разрешениями от 1080p или выше, при этом используя только убершейдеры. К сожалению, у многих наших пользователей не было оборудования, необходимого для запуска убершейдеров в разрешении, к которому они привыкли. Поэтому им приходилось выбирать между разрешением и плавностью работы.
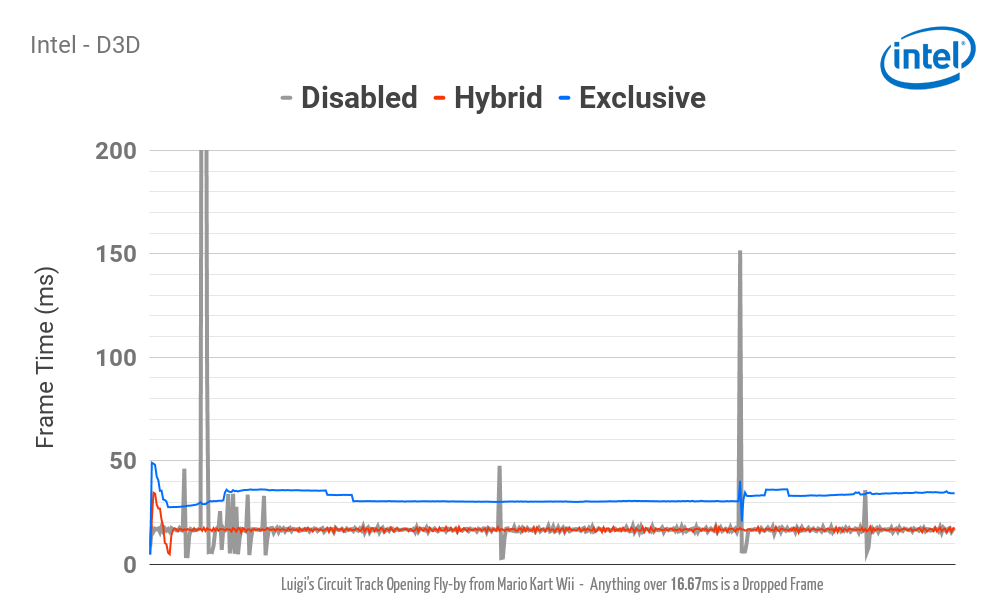
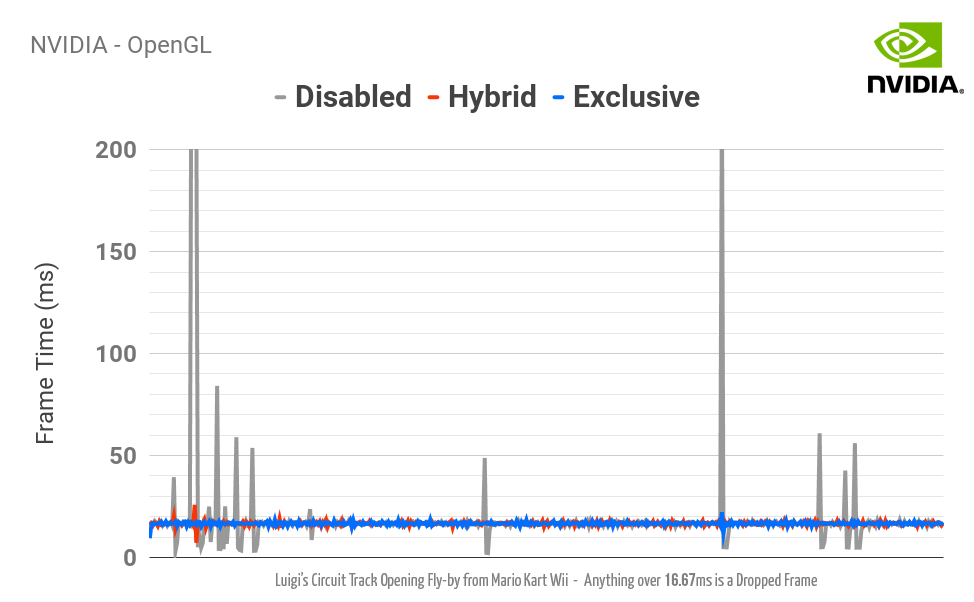
 Встроенные видеопроцессоры Intel едва справляются с специализированными шейдерами Dolphin на высоких разрешениях, не говоря уж об убершейдерах. (Нажмите на изображение для просмотра статистики.)
Встроенные видеопроцессоры Intel едва справляются с специализированными шейдерами Dolphin на высоких разрешениях, не говоря уж об убершейдерах. (Нажмите на изображение для просмотра статистики.)
У
очень большой части пользователей Dolphin в компьютерах стоят встроенные видеопроцессоры. При тестировании встроенных видеопроцессоров они
в лучшем случае давали в 3D-играх с убершейдерами в разрешении 1x всего около
50% скорости! Разработчики понимали, что ошибкой будет игнорировать огромную часть пользователей Dolphin и сделали убершейдеры опциональными. Продолжилась работа над поиском более надёжного решения, способного раз и навсегда решить проблемы с производительностью.
Гибридный режим убершейдеров
Гибридный режим убершейдеров — это соединение убершейдеров и асинхронной генерации шейдеров в одном красивом решении, взявшем лучшее от каждого подхода, но избавившемся от их недостатков. Поскольку гибридный режим сильно снижал потребление ресурсов убершейдерами, мы ожидали, что это будет самый популярный режим убершейдеров.
В гибридном режиме при появлении новой конфигурации конвейера Dolphin использует уже скомпилированные убершейдеры для мгновенного рендеринга эффекта без подвисаний, продолжая компилировать специализированный шейдер в фоновом режиме. После создания специализированных шейдеров Dolphin передаёт рендеринг объектов из убершейдера в эти сгенерированные специализированные шейдеры.
Если предположить, что драйверы и API будут вести себя нужным нам образом, то это станет отличным решением. Поскольку убершейдеры выполняются только для части объектов в сцене и не для всех кадров, влияние на производительность почти незаметно, а подвисания полностью устраняются. К сожалению, драйвера и API неидеальны, что ограничивает эффективность гибридного режима на некоторых машинах. И это приводит нас к…
Доске позора API и драйверов для убершейдеров
Перед разработчиками драйверов видеопроцессоров стоит сложная задача: им нужно выжать как можно больше мощности из оборудования, но в то же время обеспечить стабильность работы. Мы не хотим оскорбить никого из создателей драйверов, но одним из самых серьёзных препятствий в этом проекте стало огромное количество странностей в поведении драйверов и API. Из-за них приходилось придумывать обходные пути и вносить другие изменения в функционал.
Мы хотим привлечь к этому вопросу внимание. Возможно, кто-нибудь вне проекта сможет придумать обходной путь или хотя бы будет следить за обновлениями драйверов/API, в которых перечисленные ошибки, возможно, исправят.
Генерация вариантов шейдеров
Драйверы могут выполнять операции неожиданным и неконтролируемым для нас образом. Когда нам нужно сгенерировать новый конвейер для других состояний смешения или глубины, некоторые драйверы недостаточно умны, чтобы использовать в разных конвейерах одинаковые шейдеры. Это приводит к незначительным подвисаниям при первом использовании режима смешения. В большинстве случаев используемые игрой варианты генерируются за несколько первых минут игрового процесса, но когда стремишься к совершенству, это всё равно может раздражать.
К счастью, некоторые драйверы умны (например, драйвер Mesa) и делятся шейдерами с разными конвейерами, поэтому дополнительное подвисание не возникает. Все другие драйверы в различной мере страдают от подвисаний при генерации вариантов. Пока мы ничего не можем с этим сделать, но надеемся, что со временем драйверы Vulkan позаимствуют у Mesa нужное нам поведение.
Блокировка шейдеров NVIDIA в OpenGL и Vulkan
Некоторые пользователи сообщают о том, что в OpenGL и Vulkan (в гибридном режиме) присутствуют незначительные подвисания при компиляции шейдеров. Мы не совсем понимаем, что происходит, потому что такого не бывает D3D, но мы почти уверены, что это странность драйвера NVIDIA, а не ошибка обработки Dolphin. Согласно нашим тестам эта проблема не связана с генерацией вариантов.
Скомпилированные шейдеры NVIDIA в OpenGL и Vulkan намного медленнее, чем в D3D
Это особенно раздражает, потому что у нас нет хорошей возможности избавиться от этого бага. Мы передаём одинаковые шейдеры видеопроцессорам с OpenGL, Vulkan и D3D, но оказывается, что D3D
гораздо быстрее обрабатывает шейдеры. Это значит, что на GTX 760 с OpenGL или Vulkan вы можете получить разрешение 1x, но с D3D его можно спокойно удвоить или даже утроить без заметного подтормаживания.
NVIDIA запрещает дизассемблировать шейдеры, несмотря на то, что
все другие производители видеопроцессоров предоставляют открытые дизассемблированные шейдеры. Поэтому мы никак не можем исправить эту ошибку или разобраться, почему скомпилированный код настолько эффективнее в D3D. Задумайтесь, насколько это забавно: мы хотим, чтобы Dolphin быстрее работал с картами NVIDIA, но компания не даёт нам для этого инструментов. Надеюсь, в будущем компания откажется от этого препятствия. Без предоставленных другими производителями инструментов для дизассемблирования исправление ошибок было бы гораздо сложнее.
Печально то, что нужные нам инструменты доступны — если вы достаточно большая игровая компания. Исправление: компания NVIDIA сообщила нам, что она предоставляет инструменты дизассемблирования шейдеров только для Direct3D 12 (с подписанием договора о неразглашении), а для других API такие инструменты недоступны. Надеемся, инструменты для других API появятся в будущем.
В драйвере AMD для Vulkan по-прежнему нет поддержки кеша шейдеров
Пока мы писали эту статью, наши мечты исполнились! Драйвер AMD для Vulkan теперь поддерживает кеш шейдеров! Это сильно облегчает отчаянную ситуацию с убершейдерами, потому что иначе бы нам приходилось рекомпилировать убершейдеры при каждом запуске. Кроме того, это шаг к решению упомянутой выше проблемы с подвисанием при генерации вариантов.
Видеодрайверы для macOS по-прежнему ужасны
Как и в случае с многими другими восхитительными функциями, пользователи macOS, скорее всего, ждут неизбежной фразы «но на macOS...». Вот и она. Устаревшие, неэффективные драйверы OpenGL 4.1 для macOS никак не могут справиться с задачей обработки убершейдеров на сколько-нибудь приемлемом уровне. Гибридный режим
снижает торможение, но режим убершейдеров в одиночку слишком медленный. И ещё один недостаток: macOS по-прежнему не поддерживает ни в одном из драйверов кеширование шейдеров.
Рекомендуемые настройки убершейдеров
Учитывая все перечисленные проблемы с драйверами, неудивительно, что некоторые видеокарты лучше работают с определёнными API и настройками. Мы выбрали
общие рекомендуемые настройки для разных видеокарт. Можно придерживаться этих рекомендаций с зависимости от предпочтений и модели видеокарты. Не забывайте, что при изменении некоторых настроек во время игры, например, попиксельного освещения или уровня сглаживания (anti-aliasing) потребуется компилирование новых шейдеров, при котором может возникнуть существенная пауза. Также учтите, что для убершейдеров требуется бОльшая мощность видеопроцессора, то есть при таких же настройках необходима более мощная видеокарта.
- Intel в Windows
- В режиме Hybrid используйте D3D. Режим Exclusive Mode (в котором применяются только убершейдеры) работает, но встроенные видеокарты Intel пока недостаточно мощны, чтобы работать на полной скорости даже с «родным» разрешением 1x.
- При генерировании драйвером вариантов для OpenGL возникает подвисание.
- Драйвер Vulkan поддерживает процессоры только от Skylake и мощнее, к тому же в нём слишком много багов и пока его не стоит использовать.
- Intel в Linux
- В режиме Hybrid используйте Vulkan. Exclusive Mode работает, но не на полной скорости.
- Потрясающий драйвер Anv скорее всего может использовать все преимущества убершейдеров.
- Видеодрайвер Intel i965 не передаёт шейдеры OpenGL между потоками. Это значит, что поток рендеринга всегда будет рекомпилировать шейдер, что приводит к подвисаниям. Exclusive Mode работает правильно, хоть он и медленный, но в Hybrid Mode возникают подвисания.
 Нажмите на изображение, чтобы посмотреть подробности
Нажмите на изображение, чтобы посмотреть подробности
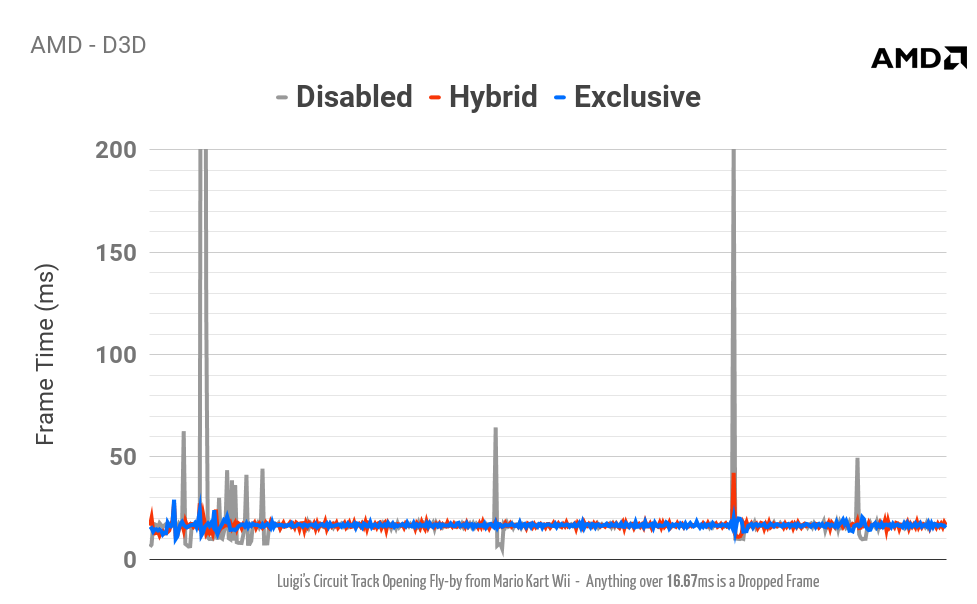
- AMD в Windows
- В режиме Hybrid используйте D3D.
- В Exclusive Mode используйте D3D или Vulkan.
- В целом драйвер OpenGL AMD довольно медленный.
- AMD в Linux
- В режимах Exclusive и Hybrid используйте Vulkan.
- radv ведёт себя похоже на anv и работает довольно неплохо.
 Нажмите на изображение, чтобы посмотреть подробности
Нажмите на изображение, чтобы посмотреть подробности
- NVIDIA в Windows
- В режиме Hybrid используйте D3D или OpenGL.
- В режиме Exclusive используйте D3D, OpenGL или Vulkan. Убершейдеры D3D обычно более эффективны, чем у OpenGL и Vulkan, что приводит к более высокой производительности со слабыми видеопроцессорами.
- NVIDIA в Linux
- В режиме Hybrid используйте OpenGL.
- В режиме Exclusive используйте OpenGL или Vulkan. Скорость может зависеть от того, какой API в игре быстрее. Учтите, что в Vulkan возникают подвисания при генерировании вариантов конвейера, что может вызвать пару незначительных подвисаний в самом начале игры.
- NVIDIA в Android
- В режиме Hybrid используйте OpenGL.
- В режиме Exclusive используйте OpenGL или Vulkan. В режиме Exclusive даже можно получить полную скорость на NVIDIA Shield TV в очень простых играх.
 Нажмите на изображение, чтобы посмотреть подробности
PowerVR
Нажмите на изображение, чтобы посмотреть подробности
PowerVR в
Android
- Не рекомендуется. При выполнении убершейдеров возникают графические повреждения из-за ошибок компиляции шейдеров, но они самостоятельно исправляются в режиме Hybrid Mode в процессе компиляции специализированных шейдеров. Слишком медленно и бесполезно на современном оборудовании.
Adreno в
Android
- Не рекомендуется. Hybrid Mode приводит к сбою, а Exclusive Mode демонстрирует серьёзные графические повреждения. Тоже слишком медленно и бесполезно на современном оборудовании.
Mali в
Android
- Не тестировался. Но мы можем с уверенностью сказать, что ничего хорошего не выйдет.
В заключение
Сейчас очень странно говорить о проекте убершейдеров в прошлом времени. Он завершён, объединён с основной веткой и его можно использовать прямо сейчас в последних тестовых сборках. Хотя местами возникают сложности, мы наконец нашли решение проблемы подвисаний при компиляции шейдеров. Со временем, когда видеокарты станут мощнее, а Exclusive Mode получит большее распространение, убершейдеры улучшатся. Когда драйверы Vulkan повзрослеют, а у других драйвером исправят странное поведение, режим Hybrid Mode тоже должен стать лучше. И мы, со своей стороны, конечно же, продолжим улучшать эмуляцию
Хоть проблема с подвисаниями в сущности решена, эмулятору Dolphin
всё равно нужен достаточно быстрый компьютер. Кроме того, есть небольшие недостатки в JIT, которые могут вызывать подвисания. Сейчас JIT с поддержкой ветвления в Dolphin испытывает большие проблемы в играх, использующих JIT (например, в играх N64 VC). Они приводят к подвисаниям, которые
похожи на подвисания при компиляции шейдеров, но на самом деле не имеют с ними ничего общего. Хоть мы и надеемся решить эту проблему, но, скорее всего, добавим опцию отключения поддержки ветвления, если не удастся решить её полностью, чтобы пользователи могли отключать ветвление в проблематичных играх.
Из-за этой огромной статьи июльского отчёта о прогрессе не будет. Мы
объединим потрясающие июльские изменения с августовским отчётом о прогрессе. Он будет большим, так что ждите!

https://habrahabr.ru/post/334868/

































 Медиа
Медиа

 Веб Разработка
Веб Разработка



 CSS
CSS JavaScript
JavaScript VueJS:
VueJS: React:
React: Angular:
Angular: Браузеры
Браузеры

 Занимательное
Занимательное

 H2O – библиотека машинного обучения, предназначенная как для локальных вычислений, так и с использованием кластеров, создаваемых непосредственно средствами H2O или же работая на кластере Spark. Интеграция H2O в кластеры Spark, создаваемые в Azure HDInsight, была добавлена недавно и в этой публикации (являющейся дополнением моей прошлой статьи:
H2O – библиотека машинного обучения, предназначенная как для локальных вычислений, так и с использованием кластеров, создаваемых непосредственно средствами H2O или же работая на кластере Spark. Интеграция H2O в кластеры Spark, создаваемые в Azure HDInsight, была добавлена недавно и в этой публикации (являющейся дополнением моей прошлой статьи: 
 Эта статья представляет собой адаптацию разделов 2 и 3 из главы 9 моей книги «
Эта статья представляет собой адаптацию разделов 2 и 3 из главы 9 моей книги «