[Из песочницы] Автоматическое развертывание приложения с Maven и Wildfly |
org.wildfly.plugins
wildfly-maven-plugin
${wildfly-hostname}
${wildfly-port}
${wildfly-username}
${wildfly-password}
${wildfly-name}
localhost
localhost
9990
admin
admin
core.war
dev
Prod_Server
9990
admin
admin
core-prod_vers.war
|
Метки: author SicYar системное администрирование it- инфраструктура devops wildfly maven администрирование |
Автоэнкодеры в Keras, Часть 6: VAE + GAN |

 из скрытых (latent) переменных
из скрытых (latent) переменных  . значительно ниже, чем размерность объектов (в части про VAE эти размерности были 2 и 784), а также всегда присутствует некоторая случайность, то одному и тому же может соответствовать многомерное распределение , то есть
. значительно ниже, чем размерность объектов (в части про VAE эти размерности были 2 и 784), а также всегда присутствует некоторая случайность, то одному и тому же может соответствовать многомерное распределение , то есть  . Это распределение можно представить как:
. Это распределение можно представить как:
 некоторый средний наиболее вероятный объект при заданном , а
некоторый средний наиболее вероятный объект при заданном , а  — шум какой-то сложной природы.
— шум какой-то сложной природы. и выход автоэнкодера
и выход автоэнкодера  с помощью некоторого функционала ошибки
с помощью некоторого функционала ошибки  ,
,
 — энкодер и декодер., мы определяем шум
— энкодер и декодер., мы определяем шум  , которым приближаем настоящий шум ., мы учим автоэнкодер подстраиваться под шум , убирая его, то есть находить среднее значение в заданной метрике (во второй части это показывалось наглядно на простом искусственном примере)., который мы определяем функционалом , не соответствует реальному шуму , то
, которым приближаем настоящий шум ., мы учим автоэнкодер подстраиваться под шум , убирая его, то есть находить среднее значение в заданной метрике (во второй части это показывалось наглядно на простом искусственном примере)., который мы определяем функционалом , не соответствует реальному шуму , то  окажется сильно смещенным от реального (пример: если в регрессии реальный шум лаплассовский, а минимизируется разность квадратов, то предсказанное значение будет смещено в сторону выбросов).
окажется сильно смещенным от реального (пример: если в регрессии реальный шум лаплассовский, а минимизируется разность квадратов, то предсказанное значение будет смещено в сторону выбросов). :
: и переводят его в
и переводят его в  . Однако роли у них разные: декодер восстанавливает объект, закодированный энкодером, при обучении опираясь на некоторую метрику сравнения; генератор же генерирует случайный объект, который ни с чем не сравнивается, лишь бы дискриминатор не мог отличить, какому из распределений
. Однако роли у них разные: декодер восстанавливает объект, закодированный энкодером, при обучении опираясь на некоторую метрику сравнения; генератор же генерирует случайный объект, который ни с чем не сравнивается, лишь бы дискриминатор не мог отличить, какому из распределений  или
или  он принадлежит.
он принадлежит. был похож на оригинал, а не просто какой-то случайный из
был похож на оригинал, а не просто какой-то случайный из  , как в чистом GAN.
, как в чистом GAN.
 — активации на
— активации на  -ом слое дискриминатора, а — энкодер и декодер.
-ом слое дискриминатора, а — энкодер и декодер. будет лучше.
будет лучше.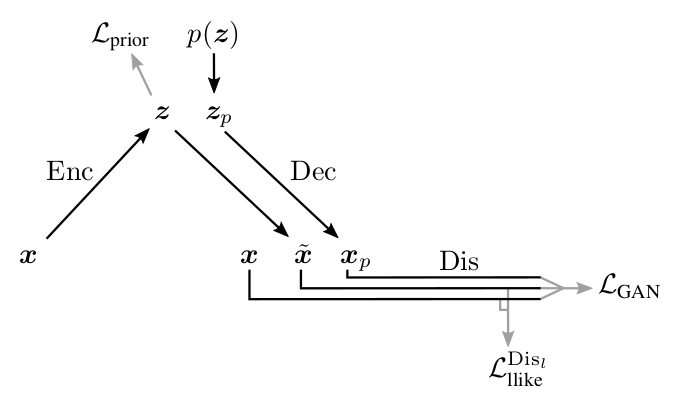 — входной объект из ,
— входной объект из , — сэмплированный из ,
— сэмплированный из , — объект сгенерированный декодером из , — объект восстановленный из ,
— объект сгенерированный декодером из , — объект восстановленный из ,![\mathcal L_{prior} = KL \left[ Q(Z|X)||P(Z) \right]](https://habrastorage.org/getpro/habr/post_images/9e5/0fe/123/9e50fe123a7a8f84e366f8a93cc6856c.svg) — лосс, заставляющий энкодер переводить в нужное нам (точно как в части 3 про VAE),
— лосс, заставляющий энкодер переводить в нужное нам (точно как в части 3 про VAE), — метрика между активациями -ого слоя дискриминатора
— метрика между активациями -ого слоя дискриминатора  на реальном и восстановленным
на реальном и восстановленным  ,
, — кросс-энтропия между реальным распределением лейблов настоящих/сгенерированных объектов, и распределением вероятности предсказываемым дискриминатором.
— кросс-энтропия между реальным распределением лейблов настоящих/сгенерированных объектов, и распределением вероятности предсказываемым дискриминатором. , так как это схлопнет разницу активаций в 0. Поэтому обучение всех сетей надо ограничить только на релевантные им лоссы.
, так как это схлопнет разницу активаций в 0. Поэтому обучение всех сетей надо ограничить только на релевантные им лоссы. ), а с другой, пытается обмануть дискриминатор (увеличивая
), а с другой, пытается обмануть дискриминатор (увеличивая  ). В статье авторы утверждают, что, меняя коэффициент
). В статье авторы утверждают, что, меняя коэффициент  , можно влиять на то, что важнее для сети: контент () или стиль (). Не могу, однако, сказать, что наблюдал этот эффект.
, можно влиять на то, что важнее для сети: контент () или стиль (). Не могу, однако, сказать, что наблюдал этот эффект.from IPython.display import clear_output
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from keras.layers import Dropout, BatchNormalization, Reshape, Flatten, RepeatVector
from keras.layers import Lambda, Dense, Input, Conv2D, MaxPool2D, UpSampling2D, concatenate
from keras.layers.advanced_activations import LeakyReLU
from keras.layers import Activation
from keras.models import Model, load_model
# Регистрация сессии в keras
from keras import backend as K
import tensorflow as tf
sess = tf.Session()
K.set_session(sess)
# Импорт датасета
from keras.datasets import mnist
from keras.utils import to_categorical
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test .astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
y_train_cat = to_categorical(y_train).astype(np.float32)
y_test_cat = to_categorical(y_test).astype(np.float32)
# Глобальные константы
batch_size = 64
batch_shape = (batch_size, 28, 28, 1)
latent_dim = 8
num_classes = 10
dropout_rate = 0.3
gamma = 1 # Коэффициент гамма
# Итераторы тренировочных и тестовых батчей
def gen_batch(x, y):
n_batches = x.shape[0] // batch_size
while(True):
idxs = np.random.permutation(y.shape[0])
x = x[idxs]
y = y[idxs]
for i in range(n_batches):
yield x[batch_size*i: batch_size*(i+1)], y[batch_size*i: batch_size*(i+1)]
train_batches_it = gen_batch(x_train, y_train_cat)
test_batches_it = gen_batch(x_test, y_test_cat)
# Входные плейсхолдеры
x_ = tf.placeholder(tf.float32, shape=(None, 28, 28, 1), name='image')
y_ = tf.placeholder(tf.float32, shape=(None, 10), name='labels')
z_ = tf.placeholder(tf.float32, shape=(None, latent_dim), name='z')
img = Input(tensor=x_)
lbl = Input(tensor=y_)
z = Input(tensor=z_)
def add_units_to_conv2d(conv2, units):
dim1 = int(conv2.shape[1])
dim2 = int(conv2.shape[2])
dimc = int(units.shape[1])
repeat_n = dim1*dim2
units_repeat = RepeatVector(repeat_n)(lbl)
units_repeat = Reshape((dim1, dim2, dimc))(units_repeat)
return concatenate([conv2, units_repeat])
# у меня получалось, что батч-нормализация очень сильно тормозит обучение на начальных этапах (подозреваю, что из-за того, что P и P_g почти не ра)
def apply_bn_relu_and_dropout(x, bn=False, relu=True, dropout=True):
if bn:
x = BatchNormalization(momentum=0.99, scale=False)(x)
if relu:
x = LeakyReLU()(x)
if dropout:
x = Dropout(dropout_rate)(x)
return x
with tf.variable_scope('encoder'):
x = Conv2D(32, kernel_size=(3, 3), strides=(2, 2), padding='same')(img)
x = apply_bn_relu_and_dropout(x)
x = MaxPool2D((2, 2), padding='same')(x)
x = Conv2D(64, kernel_size=(3, 3), padding='same')(x)
x = apply_bn_relu_and_dropout(x)
x = Flatten()(x)
x = concatenate([x, lbl])
h = Dense(64)(x)
h = apply_bn_relu_and_dropout(h)
z_mean = Dense(latent_dim)(h)
z_log_var = Dense(latent_dim)(h)
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(batch_size, latent_dim), mean=0., stddev=1.0)
return z_mean + K.exp(K.clip(z_log_var/2, -2, 2)) * epsilon
l = Lambda(sampling, output_shape=(latent_dim,))([z_mean, z_log_var])
encoder = Model([img, lbl], [z_mean, z_log_var, l], name='Encoder')
with tf.variable_scope('decoder'):
x = concatenate([z, lbl])
x = Dense(7*7*128)(x)
x = apply_bn_relu_and_dropout(x)
x = Reshape((7, 7, 128))(x)
x = UpSampling2D(size=(2, 2))(x)
x = Conv2D(64, kernel_size=(5, 5), padding='same')(x)
x = apply_bn_relu_and_dropout(x)
x = Conv2D(32, kernel_size=(3, 3), padding='same')(x)
x = UpSampling2D(size=(2, 2))(x)
x = apply_bn_relu_and_dropout(x)
decoded = Conv2D(1, kernel_size=(5, 5), activation='sigmoid', padding='same')(x)
decoder = Model([z, lbl], decoded, name='Decoder')
with tf.variable_scope('discrim'):
x = Conv2D(128, kernel_size=(7, 7), strides=(2, 2), padding='same')(img)
x = MaxPool2D((2, 2), padding='same')(x)
x = apply_bn_relu_and_dropout(x)
x = add_units_to_conv2d(x, lbl)
x = Conv2D(64, kernel_size=(3, 3), padding='same')(x)
x = MaxPool2D((2, 2), padding='same')(x)
x = apply_bn_relu_and_dropout(x)
# l-слой на котором будем сравнивать активации
l = Conv2D(16, kernel_size=(3, 3), padding='same')(x)
x = apply_bn_relu_and_dropout(x)
h = Flatten()(x)
d = Dense(1, activation='sigmoid')(h)
discrim = Model([img, lbl], [d, l], name='Discriminator')
z_mean, z_log_var, encoded_img = encoder([img, lbl])
decoded_img = decoder([encoded_img, lbl])
decoded_z = decoder([z, lbl])
discr_img, discr_l_img = discrim([img, lbl])
discr_dec_img, discr_l_dec_img = discrim([decoded_img, lbl])
discr_dec_z, discr_l_dec_z = discrim([decoded_z, lbl])
cvae_model = Model([img, lbl], decoder([encoded_img, lbl]), name='cvae')
cvae = cvae_model([img, lbl])
# Базовые лоссы
L_prior = -0.5*tf.reduce_sum(1. + tf.clip_by_value(z_log_var, -2, 2) - tf.square(z_mean) - tf.exp(tf.clip_by_value(z_log_var, -2, 2)))/28/28
log_dis_img = tf.log(discr_img + 1e-10)
log_dis_dec_z = tf.log(1. - discr_dec_z + 1e-10)
log_dis_dec_img = tf.log(1. - discr_dec_img + 1e-10)
L_GAN = -1/4*tf.reduce_sum(log_dis_img + 2*log_dis_dec_z + log_dis_dec_img)/28/28
# L_dis_llike = tf.reduce_sum(tf.square(discr_l_img - discr_l_dec_img))/28/28
L_dis_llike = tf.reduce_sum(tf.nn.sigmoid_cross_entropy_with_logits(labels=tf.sigmoid(discr_l_img),
logits=discr_l_dec_img))/28/28
# Лоссы энкодера, декодера, дискриминатора
L_enc = L_dis_llike + L_prior
L_dec = gamma * L_dis_llike - L_GAN
L_dis = L_GAN
# Определение шагов оптимизатора
optimizer_enc = tf.train.RMSPropOptimizer(0.001)
optimizer_dec = tf.train.RMSPropOptimizer(0.0003)
optimizer_dis = tf.train.RMSPropOptimizer(0.001)
encoder_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, "encoder")
decoder_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, "decoder")
discrim_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, "discrim")
step_enc = optimizer_enc.minimize(L_enc, var_list=encoder_vars)
step_dec = optimizer_dec.minimize(L_dec, var_list=decoder_vars)
step_dis = optimizer_dis.minimize(L_dis, var_list=discrim_vars)
def step(image, label, zp):
l_prior, dec_image, l_dis_llike, l_gan, _, _ = sess.run([L_prior, decoded_z, L_dis_llike, L_GAN, step_enc, step_dec],
feed_dict={z:zp, img:image, lbl:label, K.learning_phase():1})
return l_prior, dec_image, l_dis_llike, l_gan
def step_d(image, label, zp):
l_gan, _ = sess.run([L_GAN, step_dis], feed_dict={z:zp, img:image, lbl:label, K.learning_phase():1})
return l_gan
digit_size = 28
def plot_digits(*args, invert_colors=False):
args = [x.squeeze() for x in args]
n = min([x.shape[0] for x in args])
figure = np.zeros((digit_size * len(args), digit_size * n))
for i in range(n):
for j in range(len(args)):
figure[j * digit_size: (j + 1) * digit_size,
i * digit_size: (i + 1) * digit_size] = args[j][i].squeeze()
if invert_colors:
figure = 1-figure
plt.figure(figsize=(2*n, 2*len(args)))
plt.imshow(figure, cmap='Greys_r')
plt.grid(False)
ax = plt.gca()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
# Массивы, в которые будем сохранять результаты, для последующей визуализации
figs = [[] for x in range(num_classes)]
periods = []
save_periods = list(range(100)) + list(range(100, 1000, 10))
n = 15 # Картинка с 15x15 цифр
from scipy.stats import norm
# Так как сэмплируем из N(0, I), то сетку узлов, в которых генерируем цифры берем из обратной функции распределения
grid_x = norm.ppf(np.linspace(0.05, 0.95, n))
grid_y = norm.ppf(np.linspace(0.05, 0.95, n))
grid_y = norm.ppf(np.linspace(0.05, 0.95, n))
def draw_manifold(label, show=True):
# Рисование цифр из многообразия
figure = np.zeros((digit_size * n, digit_size * n))
input_lbl = np.zeros((1, 10))
input_lbl[0, label] = 1
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z_sample = np.zeros((1, latent_dim))
z_sample[:, :2] = np.array([[xi, yi]])
x_decoded = sess.run(decoded_z, feed_dict={z:z_sample, lbl:input_lbl, K.learning_phase():0})
digit = x_decoded[0].squeeze()
figure[i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit
if show:
# Визуализация
plt.figure(figsize=(15, 15))
plt.imshow(figure, cmap='Greys')
plt.grid(False)
ax = plt.gca()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
return figure
# Рисование распределения z
def draw_z_distr(z_predicted):
im = plt.scatter(z_predicted[:, 0], z_predicted[:, 1])
im.axes.set_xlim(-5, 5)
im.axes.set_ylim(-5, 5)
plt.show()
def on_n_period(period):
n_compare = 10
clear_output() # Не захламляем output
# Сравнение реальных и декодированных цифр
b = next(test_batches_it)
decoded = sess.run(cvae, feed_dict={img:b[0], lbl:b[1], K.learning_phase():0})
plot_digits(b[0][:n_compare], decoded[:n_compare])
# Рисование многообразия для рандомного y
draw_lbl = np.random.randint(0, num_classes)
print(draw_lbl)
for label in range(num_classes):
figs[label].append(draw_manifold(label, show=label==draw_lbl))
xs = x_test[y_test == draw_lbl]
ys = y_test_cat[y_test == draw_lbl]
z_predicted = sess.run(z_mean, feed_dict={img:xs, lbl:ys, K.learning_phase():0})
draw_z_distr(z_predicted)
periods.append(period)
sess.run(tf.global_variables_initializer())
nb_step = 3 # Количество шагов во внутреннем цикле
batches_per_period = 3
for i in range(48000):
print('.', end='')
# Шаги обучения дискриминатора
for j in range(nb_step):
b0, b1 = next(train_batches_it)
zp = np.random.randn(batch_size, latent_dim)
l_g = step_d(b0, b1, zp)
if l_g < 1.0:
break
# Шаг обучения декодера и энкодера
for j in range(nb_step):
l_p, zx, l_d, l_g = step(b0, b1, zp)
if l_g > 0.4:
break
b0, b1 = next(train_batches_it)
zp = np.random.randn(batch_size, latent_dim)
# Периодическая визуализация результата
if not i % batches_per_period:
period = i // batches_per_period
if period in save_periods:
on_n_period(period)
print(i, l_p, l_d, l_g)
from matplotlib.animation import FuncAnimation
from matplotlib import cm
import matplotlib
def make_2d_figs_gif(figs, periods, c, fname, fig, batches_per_period):
norm = matplotlib.colors.Normalize(vmin=0, vmax=1, clip=False)
im = plt.imshow(np.zeros((28,28)), cmap='Greys', norm=norm)
plt.grid(None)
plt.title("Label: {}\nBatch: {}".format(c, 0))
def update(i):
im.set_array(figs[i])
im.axes.set_title("Label: {}\nBatch: {}".format(c, periods[i]*batches_per_period))
im.axes.get_xaxis().set_visible(False)
im.axes.get_yaxis().set_visible(False)
return im
anim = FuncAnimation(fig, update, frames=range(len(figs)), interval=100)
anim.save(fname, dpi=80, writer='ffmpeg')
for label in range(num_classes):
make_2d_figs_gif(figs[label], periods, label, "./figs6/manifold_{}.mp4".format(label), plt.figure(figsize=(10,10)), batches_per_period)
# Трансфер стиля
def style_transfer(X, lbl_in, lbl_out):
rows = X.shape[0]
if isinstance(lbl_in, int):
label = lbl_in
lbl_in = np.zeros((rows, 10))
lbl_in[:, label] = 1
if isinstance(lbl_out, int):
label = lbl_out
lbl_out = np.zeros((rows, 10))
lbl_out[:, label] = 1
# Кодирем стиль входящего изображения
zp = sess.run(z_mean, feed_dict={img:X, lbl:lbl_in, K.learning_phase():0})
# Восстанавливаем из этого стиля, заменяя лейбл
created = sess.run(decoded_z, feed_dict={z:zp, lbl:lbl_out, K.learning_phase():0})
return created
# Картинка трансфера стиля
def draw_random_style_transfer(label):
n = 10
generated = []
idxs = np.random.permutation(y_test.shape[0])
x_test_permut = x_test[idxs]
y_test_permut = y_test[idxs]
prot = x_test_permut[y_test_permut == label][:batch_size]
for i in range(num_classes):
generated.append(style_transfer(prot, label, i)[:n])
generated[label] = prot
plot_digits(*generated, invert_colors=True)
draw_random_style_transfer(7)


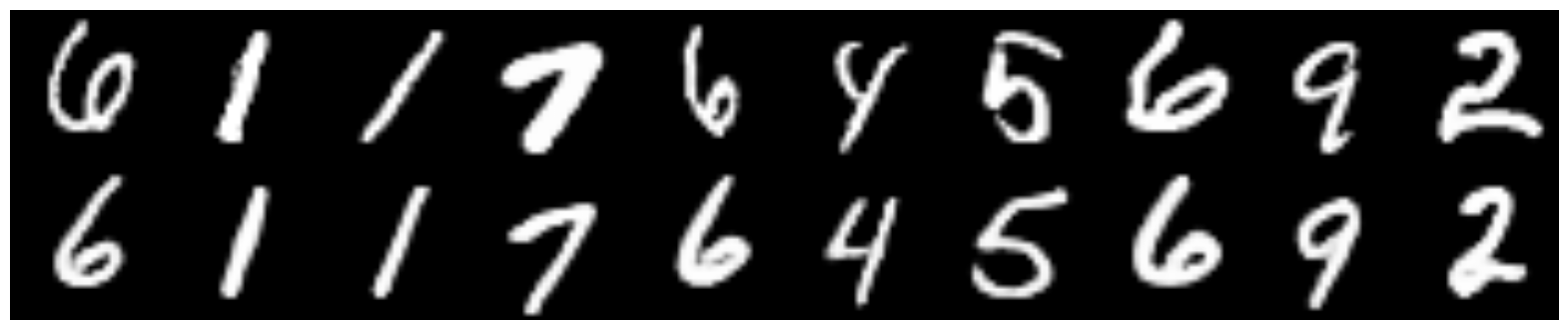
 :
:



















 ).
).

|
Метки: author iphysic обработка изображений машинное обучение математика алгоритмы python gan keras mnist deep learning machine learning autoencoder |
[Из песочницы] Работа с гетерогенными контейнерами с C++17 |
struct Circle
{
void Print() { cout << "Circle. " << "Radius: " << radius << endl; }
double Area() { return 3.14 * radius * radius; }
double radius;
};
struct Square
{
void Print() { cout << "Square. Side: " << side << endl; }
double Area() { return side * side * side * side; }
double side;
};
struct EquilateralTriangle
{
void Print() { cout << "EquilateralTriangle. Side: " << side << endl; }
double Area() { return (sqrt(3) / 4) * (side * side); }
double side;
};
using Shape = variant;
struct Shape
{
virtual void Print() = 0;
virtual double Area() = 0;
virtual ~Shape() {};
};
struct Circle : Shape
{
Circle(double val) : radius(val) {}
void Print() override { cout << "Circle. " << "Radius: " << radius << endl; }
double Area() override { return 3.14 * radius * radius; }
double radius;
};
struct Square : Shape
{
Square(double val) : side(val) {}
void Print() override { cout << "Square. Side: " << side << endl; }
double Area() override { return side * side * side * side; }
double side;
};
struct EquilateralTriangle : Shape
{
EquilateralTriangle(double val) : side(val) {}
void Print() override { cout << "EquilateralTriangle. Side: " << side << endl; }
double Area() override { return (sqrt(3) / 4) * (side * side); }
double side;
};
vector shapes;
shapes.emplace_back(new Square(8.2));
shapes.emplace_back(new Circle(3.1));
shapes.emplace_back(new Square(1.8));
shapes.emplace_back(new EquilateralTriangle(10.4));
shapes.emplace_back(new Circle(5.7));
shapes.emplace_back(new Square(2.9));
vector> shapes;
shapes.emplace_back(make_shared(8.2));
shapes.emplace_back(make_shared(3.1));
shapes.emplace_back(make_shared(1.8));
shapes.emplace_back(make_shared(10.4));
shapes.emplace_back(make_shared(5.7));
shapes.emplace_back(make_shared(2.9));
for (shared_ptr shape: shapes)
{
shape->Print();
}
// Вывод:
// Square. Side: 8.2
// Circle. Radius: 3.1
// Square. Side: 1.8
// EquilateralTriangle. Side: 10.4
// Circle. Radius: 5.7
// Square. Side: 2.9
vector operations;
operations.emplace_back(EquilateralTriangle { 5.6 });
operations.emplace_back(Square { 8.2 });
operations.emplace_back(Circle { 3.1 });
operations.emplace_back(Square { 1.8 });
operations.emplace_back(EquilateralTriangle { 10.4 });
operations.emplace_back(Circle { 5.7 });
operations.emplace_back(Square { 2.9 });
struct Visitor
{
void operator()(Circle& c) { c.Print(); }
void operator()(Square& c) { c.Print(); }
void operator()(EquilateralTriangle& c) { c.Print(); }
};
...
...
...
for (Shape& shape: shapes)
{
visit(Visitor{}, shape);
}
template < typename... Func >
class Visitor : Func... { using Func::operator()...; }
template < class... Func > make_visitor(Func...) -> Visitor < Func... >;
for (Shape& shape: shapes)
{
visit(make_visitor(
[]](Circle& c) { c.Print(); },
[]](Square& c) { c.Print(); },
[]](EquilateralTriangle& c) { c.Print(); }
), shape);
}
for (Shape& shape: shapes)
{
visit(make_visitor([]](auto& c) { c.Print(); }), shape);
}
template <
typename InputIter,
typename InputSentinelIter,
typename... Callable
>
void apply(InputIter beg,
InputSentinelIter end,
Callable... funcs)
{
for (auto _it = beg; _it != end; ++_it)
visit(make_visitor(funcs...), *_it);
};
apply(shapes.begin(), shapes.end(), [](auto& shape) { shape.Print(); });
apply(shapes.begin(), shapes.end(),
[] (Circle& shape) { shape.Print(); },
[] (Square& shape) { shape.Print(); },
[] (EquilateralTriangle& shape) { shape.Print(); });
template <
typename InputIter,
typename InputSentinelIter,
typename... Callable
>
void apply(InputIter beg,
InputSentinelIter end,
Callable... funcs)
{
for (auto _it = beg; _it != end; ++_it)
visit(make_visitor(funcs..., [](...){}), *_it);
};
// Выводит информацию только для типов Circle
apply(shapes.begin(), shapes.end(), [] (Circle& shape) { shape.Print(); });
// Выводит информацию только для типов Circle
for_each(shapes.begin(), shapes.end(),
[] (shared_ptr shape) {
if (dynamic_pointer_cast(shape))
shape->Print();
});
template <
typename InputIter,
typename InputSentinelIter,
typename OutputIter,
typename... Callable
>
void filter(InputIter beg,
InputSentinelIter end,
OutputIter out,
Callable... funcs)
{
for (auto _it = beg; _it != end; ++_it)
{
if (visit(make_visitor(funcs..., [] (...) { return false; }),
*_it))
*out++ = *_it;
}
};
vector filtered;
filter(shapes.begin(), shapes.end(),
back_inserter(filtered),
[] (Circle& c) { return c.radius > 4.; },
[] (Square& s) { return s.side < 5.; });
apply(filtered.begin(), filtered.end(), [](auto& shape) { shape.Print(); });
// Вывод:
// Square. Side: 1.8
// Circle. Radius: 5.7
// Square. Side: 2.9
vector> filtered;
copy_if(shapes.begin(), shapes.end(),
back_inserter(filtered),
[] (shared_ptr shape)
{
if (auto circle = dynamic_pointer_cast(shape))
{
return circle->radius > 4.;
}
else if (auto square = dynamic_pointer_cast(shape))
{
return square->side < 5.;
}
else return false;
});
for_each(filtered.begin(), filtered.end(), [](shared_ptr shape) { shape->Print(); });
// Вывод:
// Square. Side: 1.8
// Circle. Radius: 5.7
// Square. Side: 2.9
template <
typename InputIter,
typename InputSentinelIter,
typename AccType,
typename... Callable
>
struct reduce < InputIter, InputSentinelIter, AccType, false, Callable... >
{
constexpr auto operator()(InputIter beg, InputSentinelIter end,
AccType initial_acc, Callable... funcs)
{
for (auto _it = beg; _it != end; ++_it)
{
initial_acc = visit(utility::make_overloaded_from_tup(
tup_funcs(initial_acc, funcs...),
make_index_sequence{},
[&initial_acc] (...) { return initial_acc; } ),
*_it);
}
return initial_acc;
}
};
template < typename... Types, typename Func, size_t... I >
constexpr auto tuple_transform_impl(tuple t, Func func, index_sequence)
{
return make_tuple(func(get(t)...));
}
template < typename... Types, typename Func >
constexpr auto tuple_transform(tuple t, Func f)
{
return tuple_transform_impl(t, f make_index_sequence{});
}
template < typename Func, typename Ret, typename _, typename A, typename... Rest >
A _sec_arg_hlpr(Ret (Func::*)(_, A, Rest...));
template < typename Func >
using second_argument = decltype(_sec_arg_hlpr(&Func::operator()));
template < typename AccType, typename... Callable >
constexpr auto tup_funcs(AccType initial_acc, Callable... funcs)
{
return tuple_transform(tuple{ funcs... },
[&initial_acc](auto func) {
return [&initial_acc, &func] (second_argument arg) {
return func(initial_acc, arg); };
});
}
using ShapeCountT = tuple;
auto result = reduce(shapes.begin(), shapes.end(),
ShapeCountT{},
[] (ShapeCountT acc, Circle& item)
{
auto [cir, sq, tr] = acc;
return make_tuple(++cir, sq, tr);
},
[] (ShapeCountT acc, Square& item)
{
auto [cir, sq, tr] = acc;
return make_tuple(cir, ++sq, tr);
},
[] (ShapeCountT acc, EquilateralTriangle& item)
{
auto [cir, sq, tr] = acc;
return make_tuple(cir, sq, ++tr);
});
auto [cir, sq, tr] = result;
cout << "Circle count: " << cir
<< "\tSquare count: " << sq
<< "\tTriangle count: " << tr << endl;
// Вывод:
// Circle count: 2 Square count: 3 Triangle count: 2

|
Метки: author JegernOUTT ненормальное программирование c++ c++17 map apply reduce filter modern c++ |
[Из песочницы] Интеграция 1С с DLL с помощью Python |
import ctypes
def callback_recv(*args):
print(args)
lib = ctypes.cdll.LoadLibrary('test.dll')
Callback = ctypes.CFUNCTYPE(None, ctypes.c_int, ctypes.c_char_p)
my_func = getattr(lib, '_ZN7GtTools4testEPKcPFviS1_E')
cb_func = Callback(callback_recv)
my_func(ctypes.c_char_p('some data'), cb_func)
class GtAlgoWrapper():
# com spec
_public_methods_ = ['solve','resultCallback', 'progressCallback',] # методы объекта
_public_attrs_ = ['version',] # атрибуты объекта
_readonly_attr_ = []
_reg_clsid_ = '{2234314F-F3F1-2341-5BA9-5FD1E58F1526}' # uuid объекта
_reg_progid_= 'GtAlgoWrapper' # id объекта
_reg_desc_ = 'COM Wrapper For GTAlgo' # описание объекта
def __init__(self):
self.version = '0.0.1'
self.progressOuterCb = None
# ...
def solve(self, data):
# ...
return ''
def resultCallback(self, obj):
# ...
return obj
def progressCallback(self, obj):
# в колбэк необходимо передавать 1С объект, в котором идет подключение
# например ЭтотОбъект или ЭтаФорма
if str(type(obj)) == "":
com_obj = win32com.client.Dispatch(obj)
try:
# сохраним функцию из 1С (progressCallback) в отдельную переменную
self.progressOuterCb = com_obj.progressCallback1C;
except AttributeError:
raise Exception('"progressCallback" не найден в переданном объекте')
return obj
def main():
import win32com.server.register
win32com.server.register.UseCommandLine(GtAlgoWrapper)
print('registred')
if __name__ == '__main__':
main()
Функция progressCallback1C(знач, тип) Экспорт
Сообщить("значение = " + знач);
Сообщить("тип = " + тип);
КонецФункции
//...
Процедура Кнопка1Нажатие(Элемент)
//Создадим объект
ГТАлго = Новый COMОбъект("GtAlgoWrapper");
//Установим колбэки
ГТАлго.progressCalback(ЭтотОбъект);
//...
Данные = ...; // JSON строка
ГТАлго.solve(Данные);
КонецПроцедуры
_dependencies = ['libwinpthread-1.dll',
'libgcc_s_dw2-1.dll',
# ...,
'GtRouting0-0-1.dll']
def solve(self, data):
prefix_path = 'C:/release'
# должны быть подключены все зависимые библиотеки
try:
for dep in self._dependencies:
ctypes.cdll.LoadLibrary(os.path.join(prefix_path, dep))
# запоминаем библиотеку с нужной нам точкой входа
lib = ctypes.cdll.LoadLibrary(os.path.join(prefix_path, 'GtAlgo0-0-1.dll'))
except WindowsError:
raise Exception('cant load' + dep)
solve_func = getattr(lib, '_ZN6GtAlgo5solveEPKcPFviS1_ES3_')
# создаем колбэки
StatusCallback = ctypes.CFUNCTYPE(None, ctypes.c_int, ctypes.c_char_p)
ResultCallback = ctypes.CFUNCTYPE(None, ctypes.c_int, ctypes.c_char_p)
scb_func = StatusCallback(self.progressOuterCb)
rcb_func = ResultCallback(self.resultOuterCb)
# колбэки 1C превратились в функции которые мы передадим в DLL. Magic!
if self.resultOuterCb is None:
raise Exception('resultCallback function is not Set')
if self.progressOuterCb is None:
raise Exception('progressCallback function is not Set')
# запустим алгоритм
solve_func(ctypes.c_char_p(data), scb_func, rcb_func)
|
Метки: author atnes python c++ com dll |
«Ты, гроза, грозись, а мы друг за друга держись!» — сказ о том, как я ADSL-модем спасал |



...
...
...
sudo xinit ./home/eas/eas.boot & ## Инициируем загрузку иксов#!/bin/sh
xset -dpms
xset s off
xset s noblank
matchbox-window-manager -use_titlebar no & ## Запускаем оконный менеджер
unclutter -idle 0.01 -root & ## Скрываем курсор мыши
WEBKIT_DISABLE_TBS=1 epiphany-browser -a http://podivilov.local/ --profile /home/eas/.config ## Запускаем браузер в kiosk-режиме на весь экран$code_default = file_get_contents('https://***.podivilov.ru/api/method/weather.getCode/?token=********************');
$code_extra = file_get_contents('https://***.podivilov.ru/api/method/weather.getCode.extra/?token=********************');$json = file_get_contents('http://api.openweathermap.org/data/2.5/weather?lat=**.******&lon=**.******&APPID=********************************'); // lat & lon - широта и долгота, а APPID - api-код, который можно получить опосля регистрации на сайте
$data = json_decode($json,true);
$result = substr($data['weather'][0]['icon'], 0, -1);
dim xHttp: Set xHttp = createobject("MSXML2.ServerXMLHTTP")
xHttp.Open "GET", "https://***.podivilov.ru/api/method/weather.getCode/?token=********************", False
xHttp.setOption 2, 13056
xHttp.Send
If xHttp.responseText = "1" Then
Set objShell = CreateObject("WScript.Shell")
objShell.Run """C:\путь_к_программе\EAS.exe"""
Set objShell = Nothing
Else
WScript.Quit
End If|
Метки: author Mihip облачные вычисления настройка linux беспроводные технологии nginx *nix безопасность adsl гроза raspberry pi |
Хакеры и биржи: как атакуют сферу финансов |



|
Метки: author itinvest информационная безопасность блог компании itinvest биржи банки сфера финансов |
[Перевод] Используем IoC-контейнер Laravel на полную мощность |
Laravel имеет мощный IoC-контейнер, но, к сожалению, официальная документация Laravel не описывает все его возможности. Я решил изучить его и задокументировать для собственного использования.
Примеры в данной статье основаны на Laravel 5.4.26, другие версии могут отличаться.
Я не буду объяснять, что такое DI и IoC в этой статье — если вы не знакомы с этими принципами, вы можете прочитать статью "What is Dependency Injection?" от Fabien Potencier (создателя фреймворка Symfony).
В Laravel существует несколько способов получения сущности контейнера * и самый простой из них это вызов хелпера app():
$container = app();Я не буду описывать другие способы, вместо этого я сфокусирую свое внимание на самом контейнере.
* В Laravel есть класс Application, который наследуется от Container (именно поэтому хелпер называется app()), но в этой статье я буду описывать только методы класса Container.
Для использования контейнера Laravel вне фреймворка необходимо установить его с помощью Composer, после чего мы можем получить контейнер так:
use Illuminate\Container\Container;
$container = Container::getInstance();Самый простой способ использования контейнера — указать в конструкторе классы, которые необходимы вашему классу используя type hinting:
class MyClass
{
private $dependency;
public function __construct(AnotherClass $dependency)
{
$this->dependency = $dependency;
}
}Затем, вместо создание объекта с помощью new MyClass, нужно вызвать метод контейнера make():
$instance = $container->make(MyClass::class);Контейнер автоматически создаст и внедрит зависимости, что будет эквивалентно следующему коду:
$instance = new MyClass(new AnotherClass());(За исключением того случая, когда у AnotherClass есть свои зависимости. В таком случае контейнер автоматически создаст и внедрит его зависимости, зависимости его зависимостей и т.д.)
Ниже показан более реальный пример, который взят из документации PHP-DI. В нем логика отправки сообщения отделена от логики регистрации пользователя:
class Mailer
{
public function mail($recipient, $content)
{
// Send an email to the recipient
// ...
}
}class UserManager
{
private $mailer;
public function __construct(Mailer $mailer)
{
$this->mailer = $mailer;
}
public function register($email, $password)
{
// Create the user account
// ...
// Send the user an email to say hello!
$this->mailer->mail($email, 'Hello and welcome!');
}
}use Illuminate\Container\Container;
$container = Container::getInstance();
$userManager = $container->make(UserManager::class);
$userManager->register('dave@davejamesmiller.com', 'MySuperSecurePassword!');Для начала определим интерфейсы:
interface MyInterface { /* ... */ }
interface AnotherInterface { /* ... */ }Затем создадим классы, реализующие эти интерфейсы. Они могут зависеть от других интерфейсов (или других классов, как это было ранее):
class MyClass implements MyInterface
{
private $dependency;
public function __construct(AnotherInterface $dependency)
{
$this->dependency = $dependency;
}
}Теперь свяжем интерфейсы с реализацией с помощью метода bind():
$container->bind(MyInterface::class, MyClass::class);
$container->bind(AnotherInterface::class, AnotherClass::class);И передадим название интерфейса вместо названия класса в метод make():
$instance = $container->make(MyInterface::class);Примечание: Если вы забудете привязать интерфейс к реализации, вы получите немного странную ошибку:
Fatal error: Uncaught ReflectionException: Class MyInterface does not existЭто происходит потому, что контейнер пытается создать экземпляр интерфейса (new MyInterface), который не является классом.
Ниже представлен реальный пример связывания интерфейса с конкретной реализацией — изменяемый драйвер кеша:
interface Cache
{
public function get($key);
public function put($key, $value);
}class RedisCache implements Cache
{
public function get($key) { /* ... */ }
public function put($key, $value) { /* ... */ }
}class Worker
{
private $cache;
public function __construct(Cache $cache)
{
$this->cache = $cache;
}
public function result()
{
// Use the cache for something...
$result = $this->cache->get('worker');
if ($result === null) {
$result = do_something_slow();
$this->cache->put('worker', $result);
}
return $result;
}
}use Illuminate\Container\Container;
$container = Container::getInstance();
$container->bind(Cache::class, RedisCache::class);
$result = $container->make(Worker::class)->result();Связывание может быть использовано и с абстрактным классом:
$container->bind(MyAbstract::class, MyConcreteClass::class);Или для замены класса его потомком (классом, который наследуется от него):
$container->bind(MySQLDatabase::class, CustomMySQLDatabase::class);Если объект при создании требует дополнительной настройки, вы можете передать замыкание вторым параметром в метод bind() вместо названия класса:
$container->bind(Database::class, function (Container $container) {
return new MySQLDatabase(MYSQL_HOST, MYSQL_PORT, MYSQL_USER, MYSQL_PASS);
});Каждый раз, когда будет запрашиваться класс Database, будет создан новый экземпляр MySQLDatabase с указанной конфигурацией (если нужно иметь только один экземпляр класса, используйте Singleton, о котором говорится ниже).
Замыкание получает в качестве первого параметра экземпляр класса Container, который может быть использован для создания других классов, если это необходимо:
$container->bind(Logger::class, function (Container $container) {
$filesystem = $container->make(Filesystem::class);
return new FileLogger($filesystem, 'logs/error.log');
});Замыкание также можно использовать для настройки класса после создания:
$container->bind(GitHub\Client::class, function (Container $container) {
$client = new GitHub\Client;
$client->setEnterpriseUrl(GITHUB_HOST);
return $client;
});Вместо того, чтобы полностью перезаписывать биндинг, мы может использовать метод resolving() для регистрации коллбеков, которые будут вызваны после создания требуемого объекта:
$container->resolving(GitHub\Client::class, function ($client, Container $container) {
$client->setEnterpriseUrl(GITHUB_HOST);
});Если было зарегистрировано несколько коллбеков, все они будут вызваны. Это также работает для интерфейсов и абстрактных классов:
$container->resolving(Logger::class, function (Logger $logger) {
$logger->setLevel('debug');
});
$container->resolving(FileLogger::class, function (FileLogger $logger) {
$logger->setFilename('logs/debug.log');
});
$container->bind(Logger::class, FileLogger::class);
$logger = $container->make(Logger::class);Также есть возможность регистрации коллбека, который будет вызываться при создании любого класса (это может быть полезно для логгирования или при отладке):
$container->resolving(function ($object, Container $container) {
// ...
});Вы также можете использовать метод extend() для того, чтобы обернуть оригинальный класс и вернуть другой объект:
$container->extend(APIClient::class, function ($client, Container $container) {
return new APIClientDecorator($client);
});Класс возвращаемого объекта должен реализовывать тот же интерфейс, что и класс оборачиваемого объекта, иначе вы получите ошибку.
Каждый раз, когда возникает необходимость в каком либо классе (если указано имя класса или биндинга, созданного с помощью метода bind()), создается новый экземпляр требуемого класса (или вызывается замыкание). Для того, чтобы иметь только один экземпляр класса необходимо вызвать метод singleton() вместо метода bind():
$container->singleton(Cache::class, RedisCache::class);Пример с замыканием:
$container->singleton(Database::class, function (Container $container) {
return new MySQLDatabase('localhost', 'testdb', 'user', 'pass');
});Для того, чтобы получить синглтон из класса, необходимо передать его, опустив второй параметр:
$container->singleton(MySQLDatabase::class);Экземпляр синглтона будет создан только один раз, в дальнейшем будет использоваться тот же самый объект.
Если у вас уже есть сущность, которую вы хотите переиспользовать, то используйте метод instance(). Например, Laravel использует это для того, чтобы у класса Container был только один экземпляр:
$container->instance(Container::class, $container);При биндинге вы можете использовать произвольную строку вместо названия класса или интерфейса, однако вы уже не сможете использовать type hinting и должны будете использовать метод make():
$container->bind('database', MySQLDatabase::class);
$db = $container->make('database');Для того, чтобы одновременно иметь название класса и короткое имя, вы можете использовать метод alias():
$container->singleton(Cache::class, RedisCache::class);
$container->alias(Cache::class, 'cache');
$cache1 = $container->make(Cache::class);
$cache2 = $container->make('cache');
assert($cache1 === $cache2);Контейнер позволяет хранить и произвольные значения (например, данные конфигурации):
$container->instance('database.name', 'testdb');
$db_name = $container->make('database.name');Также поддерживается array-access синтаксис, который выглядит более привычно:
$container['database.name'] = 'testdb';
$db_name = $container['database.name'];Это может быть полезно при использовании его с биндингом-замыканием:
$container->singleton('database', function (Container $container) {
return new MySQLDatabase(
$container['database.host'],
$container['database.name'],
$container['database.user'],
$container['database.pass']
);
});(Сам Laravel не использует контейнер для хранения конфигурации, для этого существует отдельный класс — Config, а вот PHP-DI так делает).
Совет: array-access синтаксис можно использовать для создания объектов вместо метода make():
$db = $container['database'];До сих пор мы использовали DI только для конструкторов, но Laravel также поддерживает DI для произвольных функций:
function do_something(Cache $cache) { /* ... */ }
$result = $container->call('do_something');Дополнительные параметры могут быть переданы как простой или ассоциативный массив:
function show_product(Cache $cache, $id, $tab = 'details') { /* ... */ }
// show_product($cache, 1)
$container->call('show_product', [1]);
$container->call('show_product', ['id' => 1]);
// show_product($cache, 1, 'spec')
$container->call('show_product', [1, 'spec']);
$container->call('show_product', ['id' => 1, 'tab' => 'spec']);DI может использован для любых вызываемых методов:
$closure = function (Cache $cache) { /* ... */ };
$container->call($closure);class SomeClass
{
public static function staticMethod(Cache $cache) { /* ... */ }
}$container->call(['SomeClass', 'staticMethod']);
// or:
$container->call('SomeClass::staticMethod');class PostController
{
public function index(Cache $cache) { /* ... */ }
public function show(Cache $cache, $id) { /* ... */ }
}$controller = $container->make(PostController::class);
$container->call([$controller, 'index']);
$container->call([$controller, 'show'], ['id' => 1]);Container позволяет использовать сокращение вида ClassName@methodName для создания объекта и вызова его метода. Пример:
$container->call('PostController@index');
$container->call('PostController@show', ['id' => 4]);Контейнер используется для создания экземпляра класса, т.е.:
Пример ниже будет работать:
class PostController
{
public function __construct(Request $request) { /* ... */ }
public function index(Cache $cache) { /* ... */ }
}$container->singleton('post', PostController::class);
$container->call('post@index');Наконец, вы можете передать название "метода по умолчанию" в качестве третьего параметра. Если первым параметром передано название класса и не указано название метода, будет вызвать метод по умолчанию. Laravel использует это в обработчиках событий:
$container->call(MyEventHandler::class, $parameters, 'handle');
// Equivalent to:
$container->call('MyEventHandler@handle', $parameters);Метод bindMethod() позволяет переопределить вызов метода, например, для передачи параметров:
$container->bindMethod('PostController@index', function ($controller, $container) {
$posts = get_posts(...);
return $controller->index($posts);
});Все примеры ниже будут работать, при этом будет вызвано замыкание вместо настоящего метода:
$container->call('PostController@index');
$container->call('PostController', [], 'index');
$container->call([new PostController, 'index']);Однако любы дополнительные параметры, переданные в метод call(), не будут переданы в замыкание и они не могут быть использованы:
$container->call('PostController@index', ['Not used :-(']);Примечания: метод wrap() не является частью интерфейса Container, он есть только в классе Container. См. [Pull Request(https://github.com/laravel/framework/pull/16800), в котором объясняется, почему параметры не передаются при переопределении.
Может случиться так, что вы захотите иметь разные реализации одного интерфейса в зависимости от места, где он необходим. Ниже показан немного измененный пример из документации Laravel:
$container
->when(PhotoController::class)
->needs(Filesystem::class)
->give(LocalFilesystem::class);
$container
->when(VideoController::class)
->needs(Filesystem::class)
->give(S3Filesystem::class);Теперь контроллеры PhotoController и VideoController могут зависеть от интерфейса Filesystem, но каждый из низ получит свою реализацию этого интерфейса.
Также можно передать замыкание в метод give(), как вы делаете это в методе bind():
$container
->when(VideoController::class)
->needs(Filesystem::class)
->give(function () {
return Storage::disk('s3');
});Или можно использовать именованную зависимость:
$container->instance('s3', $s3Filesystem);
$container
->when(VideoController::class)
->needs(Filesystem::class)
->give('s3');Помимо объектов, контейнер позволяет производить биндинг примитивных типов (строк, чисел и т.д.). Для этого нужно передать название переменной (вместо названия интерфейса) в метод needs(), а в метод give() передать значение, которое будет подставлено контейнером при вызове метода:
$container
->when(MySQLDatabase::class)
->needs('$username')
->give(DB_USER);Также мы можем передать замыкание в метод give(), для того, чтобы отложить вычисление значения до тех пор, пока оно не понадобится:
$container
->when(MySQLDatabase::class)
->needs('$username')
->give(function () {
return config('database.user');
});Мы не можем передать в метод give() название класса или именованную зависимость (например, give('database.user')), потому, что оно будет возвращено как есть. Зато мы можем использовать замыкание:
$container
->when(MySQLDatabase::class)
->needs('$username')
->give(function (Container $container) {
return $container['database.user'];
});Вы можете использовать контейнер для добавления тегов к связанным (по назначению) биндингам:
$container->tag(MyPlugin::class, 'plugin');
$container->tag(AnotherPlugin::class, 'plugin');И затем получить массив сущностей с указанным тегом:
foreach ($container->tagged('plugin') as $plugin) {
$plugin->init();
}Оба параметра метода tag() так же принимают и массив:
$container->tag([MyPlugin::class, AnotherPlugin::class], 'plugin');
$container->tag(MyPlugin::class, ['plugin', 'plugin.admin']);Примечание: эта возможность контейнера используется довольно редко, поэтому вы можете смело пропустить ее описание.
Коллбэк, зарегистрированный с помощью метода rebinding(), вызывается при изменении биндинга. В примере ниже сессия была заменена уже после того, как она была использована классом Auth, поэтому класс Auth должен быть проинформирован об изменении :
$container->singleton(Auth::class, function (Container $container) {
$auth = new Auth;
$auth->setSession($container->make(Session::class));
$container->rebinding(Session::class, function ($container, $session) use ($auth) {
$auth->setSession($session);
});
return $auth;
});
$container->instance(Session::class, new Session(['username' => 'dave']));
$auth = $container->make(Auth::class);
echo $auth->username(); // dave
$container->instance(Session::class, new Session(['username' => 'danny']));
echo $auth->username(); // dannyБольше информации на эту тему можно найти здесь и здесь.
Существует также сокращение, которое может пригодиться в некоторых случаях — метод refresh():
$container->singleton(Auth::class, function (Container $container) {
$auth = new Auth;
$auth->setSession($container->make(Session::class));
$container->refresh(Session::class, $auth, 'setSession');
return $auth;
});Оно так же возвращает существующий экземпляр класса или биндинг (если он существует), поэтому вы можете сделать так:
// это сработает, только если вы вызовете методы `singleton()` или `bind()` с названием класса
$container->singleton(Session::class);
$container->singleton(Auth::class, function (Container $container) {
$auth = new Auth;
$auth->setSession($container->refresh(Session::class, $auth, 'setSession'));
return $auth;
});Лично мне такой синтаксис кажется немного запутанным, поэтому я предпочитаю более подробную версию, которая описана выше.
Примечание: эти методы не являются частью интерфейса Container, они есть только в классе Container.
Метод makeWith() позволяет вам передать дополнительные параметры в конструктор. При этом игнорируются существующие экземпляры или синглтоны (т.е. создается новый объект). Это может быть полезно при создании объектов с разными параметрами и у которых есть какие-либо зависимости:
class Post
{
public function __construct(Database $db, int $id) { /* ... */ }
}$post1 = $container->makeWith(Post::class, ['id' => 1]);
$post2 = $container->makeWith(Post::class, ['id' => 2]);Note: In Laravel 5.3 and below it was simply make($class, $parameters). It was removed in Laravel 5.4, but then re-added as makeWith() in 5.4.16. In Laravel 5.5 it looks like it will be reverted back to the Laravel 5.3 syntax.
Примечание: В Laravel >=5.3 этот метод называется просто make($class, $parameters). Он был удален в Laravel 5.4, но потом возвращен обратно под названием makeWith в версии 5.4.16. Похоже, что в Laravel 5.5 его название будет снова изменено на make().
Я описал все методы, которые показались мне полезными, но для полноты картины я опишу оставшиеся доступные методы.
Метод bound() проверяет, существует класс или алиас, связанный с помощью методов bind(), singleton(), instance() или alias():
if (! $container->bound('database.user')) {
// ...
}Также можно использовать метод isset и array-access синтаксис:
if (! isset($container['database.user'])) {
// ...
}Значение, указано в методах binding(), instance(), alias() Может быть удалено с помощью unset():
unset($container['database.user']);
var_dump($container->bound('database.user')); // falseМетод bindIf() делает то же самое, что и метод bind(), за тем исключением, что он создает биндинг только если он не существует (см. описание метода bound() выше). Теоретически его можно использовать в пакете для регистрации биндинга по умолчанию, позволяя пользователю переопределить его.
$container->bindIf(Loader::class, FallbackLoader::class);Не существует метода singletonIf(), вместо этого вы можете использовать bindIf($abstract, $concrete, true):
$container->bindIf(Loader::class, FallbackLoader::class, true);Или написать код проверки самостоятельно:
if (! $container->bound(Loader::class)) {
$container->singleton(Loader::class, FallbackLoader::class);
}Метод resolved() возвращает true, если экземпляр класса до этого был создан.
var_dump($container->resolved(Database::class)); // false
$container->make(Database::class);
var_dump($container->resolved(Database::class)); // trueОно сбрасывается при вызове метода unset() (см. описание метода bound() выше).
unset($container[Database::class]);
var_dump($container->resolved(Database::class)); // falseМетод factory() возвращает замыкание, которое не принимает параметров и при вызове вызывает метод make().
$dbFactory = $container->factory(Database::class);
$db = $dbFactory();Метод wrap() оборачивает замыкание в еще одно замыкание, которое внедрит зависимости в оборачиваемое при вызове. Метод принимает массив параметров, которые будут переданы в оборачиваемое замыкание; возвращаемое замыкание не принимает никаких параметров:
$cacheGetter = function (Cache $cache, $key) {
return $cache->get($key);
};
$usernameGetter = $container->wrap($cacheGetter, ['username']);
$username = $usernameGetter();Примечание: метод wrap() не является частью интерфейса Container, он есть только в классе Container.
Метод afterResolving() работает точно так же, как и метод resolving(), за тем исключением, что коллбэки, зарегистрированные с его помощью вызываются после коллбэков, зарегистрированных методом resolving().
isShared() – Проверяет, существует ли синглтон/экземпляр для указанного типа
isAlias() – Проверяет, существует ли алиас с указанным названием
hasMethodBinding() – Проверяет, есть ли в контейнере биндинг для указанного метода
getBindings() – Возвращает массив всех зарегистрированных биндингов
getAlias($abstract) – Возращает алиас для указанного класса/биндинга
forgetInstance($abstract) – Удаляет указанный экземпляр класса из контейнера
forgetInstances() – Удаляет все экземпляры классов
flush() – Удаляет все биндинги и созданные экземпляры классов, полностью очищая контейнер
setInstance() – Заменяет объект, возвращаемый getInstance() (подсказка: используйте setInstance(null)для очистки, в последующем будет создан новый экземпляр контейнера)
Примечание: ни один из этих методов не является частью интерфейса Container.
|
Метки: author muhammad_97 php laravel ioc dependency injection |
Как стать тимлидом и не взорваться |

Два года назад я начал негласно исполнять роль iOS-lead в компании и формированием стабильной работы iOS отдела. Спустя полгода это трансформировалось в официальную должность. Из-за отсутствия опыта у меня возникало огромное количество проблем, которые вызывали жжение в области нижней части кресла. Это происходило из-за ряда факторов:
Если вы стали лидом и первоначальная эйфория сменилась небольшим горением и унынием, то пара советов не будет лишней.
Исторически сложилось, что существует две классические структурные модели управления компанией.
Первая — вертикальная система управления. Её практикуют реже, к примеру basecamp или 37 signals. Смысл заключается в том, что у вас есть ряд сильных специалистов, способных самостоятельно регулировать свою деятельность.

Вторая — иерархическая система управления.

Есть разработчик, за ним стоит platform lead, за ним CTO, далее CEO. Каждый участник курирует определенный вектор развития. Чем ниже располагается в иерархии человек, тем за более узкоспециализированный вектор он отвечает. Разработчик отвечает лишь за код, который он производит. Lead отвечает целиком за платформу и за её развитие. Технический директор отвечает за техническую составляющую в компании. А генеральный директор — за развитие компании.
Чем больше становится компания, чем больше появляется процессов и участников, тем сложнее становится иерархия. Появляются дополнительные роли, такие как Mobile Lead. У него в подчинении находятся лиды мобильных платформ, которых может быть больше одного на платформе. Это зависит от количества подчиненных на конкретном уровне в компании.
Оптимальное количество людей, которых может контролировать один человек, сильно варьируется от сферы деятельности и от модели управления. В IT в классической литературе это число колеблется от 5 до 9 человек.

Меньшее количество людей ведет к тому, что дополнительная иерархическая роль избыточна и просто усложняет процессы.

Большее ведет к тому, что контроль, обучение и другие функции становится сложнее выполнять. Необходимо добавлять новые роли.

Рассмотрим классическую ситуацию карьерного роста в IT-компании. Когда человек достигает определенного уровня квалификации, он может либо перейти на следующий уровень иерархии при наличии определенных личностных качеств, либо сменить род деятельности/область деятельности/компанию и расти горизонтально дальше. На картинке ниже представлена классическая краткая форма развития. Следующая ступень развития разработчика — team lead либо tech lead. Первая предполагает уход в сторону менеджмента, вторая — глубокий горизонтальный рост специалиста. Team lead дальше уходит в platform lead либо CTO. Из tech lead получаются архитекторы разного калибра.
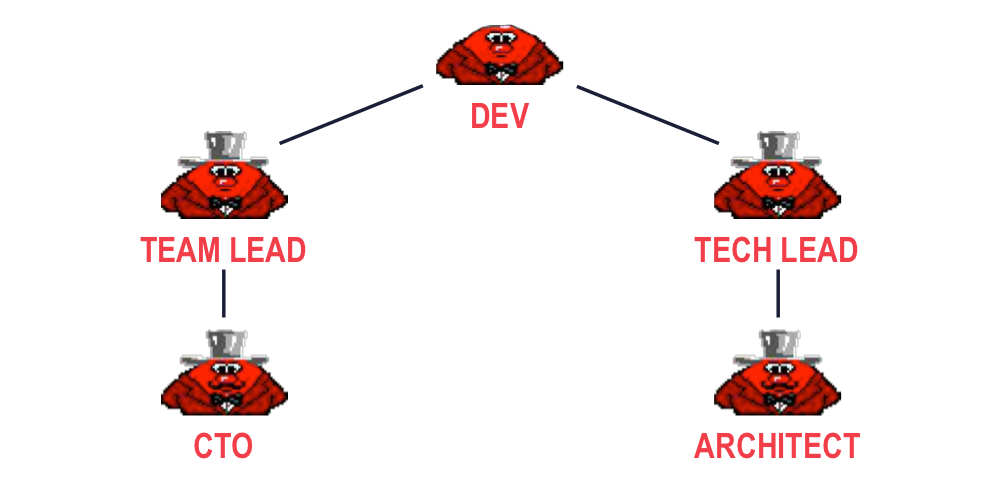
Для начала определимся, что ждет руководство от лида. В зависимости от размера компании его роль может сводиться как к управлению конкретной командой, так и развитию направления целиком. При этом необходимо быть готовым к тому, что разработчики будут требовать от вас высоких технических навыков, а управленцы более высокого звена — выполнения менеджерских задач. Чаще всего team lead это в некоторой степени программист, и в некоторой степени менеджер.
Говорят, что со временем team lead начинает терять навыки программиста с течением времени. В реальности же большинство основ программирования были сформулированы более 40 лет назад. Порой эти знания более ценные, чем знание конкретного sdk. Но чаще всего наставничество помимо помощи в самых простых программных вопросах сводится к следующему:
Построение экосистемы. Сейчас в IT бизнесе выигрывает та компания, которая предоставляет не просто продукт, а старается построить экосистему. Которая может решать множество задач бизнеса и позволяет пользоваться различными функциями, которые предоставляет компания. Это касается и Apple, и Google, и Facebook. Со временем любой бизнес начинает превращаться в платформу. Похожая ситуация наблюдается и в разработке. Вам необходимо построить для разработчика экосистему целиком, чтобы вопросов возникало как много меньше. Это касается и процессных вещей, и архитектуры. Нужно сформировать документированную систему гайдов, которые позволят новым разработчикам быстро влиться в процесс, а участникам команды не забывать принятые нормы.
Построение системы обучения. Адекватный лид должен грамотно выстраивать процесс обучения всех членов команды, правильно соотнося их собственные интересы с бизнес-задачами компании. Если человек хочет изучить сложный кастомный UI, то задача лида придумать, как это можно использовать во благо. Это касается и других направлений, будь то технические знания или менеджерский бэкграунд. Важно следить за выполнением этих задач, обычно разработчики в своей голове ставят более низкий приоритет данным таскам. Старайтесь помочь в развитии даже в тех областях, в которых у вас меньше знаний. Сводите с нужным специалистом или дайте время разобраться самому, а потом пусть расскажет другим. Так человек укрепит свои знания. Ситуация, когда у разработчика или у вас отсутствуют знания в какой-то области, нормальна. Осознание и принятие этого способствует обучению.

Привитие принципов отношения к коду. Очень важно донести до разработчика мысль, что сам код не стоит ни гроша. Лишь функциональность, которая выполняется этим кодом, имеют смысл. Отсюда и растёт вся экосистема, которую необходимо построить. Важно понимать, что бизнес диктует правила для написания кода, а не наоборот. Если у вас банковская система с крайне высокой надежностью, то TDD вам необходим. Если же вы пишете MVP-приложения, то смысла строить сложную систему и архитектуру на первом этапе попросту нет.
Бытует мнение, что большинство разработчиков являются интровертами. В действительности, это очень близко к истине. Благодаря этому знанию появляется несколько методик, которые можно применять в работе.
Организуйте ежемесячные встречи с разработчиками. Сценарий таких встреч каждый месяц повторяется. Поначалу разработчик говорит, что всё ок, всё хорошо, проблем нет. Но основная сила психолога в вопросах. В беседе узнается, что и систему оценки на проекте в прошлом месяце можно улучшить, и взаимоотношения между отделами подтянуть, а ещё было придумано оригинальное решение, которое можно вынести как базовое и написать по нему гайд. Ведь на другом проекте возникли такие же проблемы и решали их дольше, чем нужно. Беседу обязательно надо конспектировать, потому что в ней могут быть отличные мысли. Их можно и нужно претворять в жизнь. После таких бесед часть проблем нивелируется. Так как процесс итеративный, он помогает устранять проблемы и не занимает много времени. Такие встречи не нужно превращать в совещания отделов. Это должны быть именно тет-а-тет беседы в спокойной обстановке. Так вы сможете решить даже сложные личностные проблемы.

Станьте «большим братом». Lead несет ответственность за работу своего подразделения. Он должен быть в курсе задач, сроков исполнения и качества функциональности на выходе для каждого разработчика. Однако, в процессе работы не стоит впадать в крайности. Пословица «Всё хорошо в меру» работает здесь отлично. Старайтесь не вмешиваться, если всё идёт хорошо. При этом всегда держите руку на пульсе и предотвращайте кризисные ситуации. Сотрудник комфортнее всего работает, когда на него не давят сверху, но при этом он чувствует влияние невидимого «большого брата», который является не контроллером, а советчиком.

Внедряйте «безликий код». Самый долгий и трудный процесс — привести код вашего отдела к «безликому коду», когда нельзя по стилю определить, кто писал. Это направление правильное и трудное. Если возможна вариативность решения, вы встретите несколько лагерей. Чтобы в случае кризисной ситуации в ваш адрес не посыпалось «вот решили тогда так, а это оказалось плохо, и сейчас все минусы всплыли», необходимо дипломатично решать каждый вопрос. Помните, что с базовыми решениями, которые вы разрабатываете и согласовываете, будут работать другие люди. Делайте удобно для них.

Классика — когда самый продуктивный разработчик становится лидом. Руководство часто думает, что раз вы делаете фичи быстрее, то можете делать столько же, сколько и средний разработчик, плюс взять обязанности лида. Можете попросить прописать прямо в контракте, какой процент рабочего времени вы будете программировать. Зона ответственности становится совсем другой, ваши обязанности меняются. Есть два варианта развития событий.
На этапе согласования новой роли заранее продумайте список вопросов, ожиданий от новой роли. Спросите, чего ожидают от вас. Поймите, что вам конкретно нужно сделать и сформулируйте это. Только тогда приступайте к работе. Иначе так и будете не укладываться в сроки разработки, не наладите процессы, систему обучения и все остальные задачи. Отношения с менеджерами, разработчиками и остальными людьми в компании так или иначе ухудшатся. Вы будете думать, что вы герой, который горбатится на выходных ради блага компании. А на самом деле стали человеком, на которого нельзя положиться. Ведь неизвестно, будет ли сделана задача и как качественно.
Именно поэтому нужно четко регламентировать, зачем вам программировать, сколько времени и что это даст отделу и в целом компании. Если речь идет о 30% времени, в течение которых вы будете проектировать архитектуру общих решений в компании, библиотек или стандартов — одно дело. Это поможет не заниматься рутинными задачами, не забыть код и смотреть на него более глобально. Но если вам говорят о 70% или 90% времени, то люди просто не понимают, зачем им нужен team lead. Или заранее планируют, что вы будете работать больше 40 часов. Можете либо аргументированно объяснить, как сделать лучше, либо просто ответить отказом. Лучше всего поговорить об ожиданиях.
Составьте план развития. Необходимо сделать четкий план развития себя и отдела хотя бы на ближайший год. Это может быть наработка общих процессов, создание базовых общих решений, ведение курса лекций или создание школы. Всё исходя из потребностей, которые есть у компании сейчас. Если цель — научиться писать код, то уход в сторону архитектуры и мета-принципов. Если заявить о себе на рынке — участие в конференциях и публикации. Если такого плана нет, то начинается ряд проблем:

Найдите наставника. Очень здорово, когда есть человек, который уже проходил этот путь. Если он может откровенно ответить на ваши вопросы — это огромнейший плюс и не пользоваться этим большая ошибка. Идеально, если это лид вашей платформы, которого вы лично знаете и уважаете как специалиста.

Не надумывайте. Возьмите себе за привычку вести прямой диалог в случае возникновения непонимания. Решится огромная куча проблем, при этом они не будут перерастать во что-то большее, включая личностные конфликты.
Делегируйте и отслеживайте выполнение. Необходимо сразу начинать направлять и контролировать процесс выполнения. Что это нам дает? То, что мы перестаем делать кажущиеся важными рутинные задачи путем простого делегирования и можем выполнять задачи, которые и входят в наш план. Плюс различного рода оптимизации в виде CI/CD/статических анализаторов, кодогенераторов, базовых либ и так далее. Всё это экономит нам время в будущем.
Кто-то из разработчиков уходит в программный запой на неделю и возвращается с готовой фичей, а кому-то требуется ежедневный контроль. Наблюдение, анализ и логическое мышление помогут вам разобраться, кто есть кто.
Делегируйте. Главное — это понимание того, что большинство задач можно и нужно делегировать. На первом этапе может показаться, что дел стало больше. Особенно, если вы были разработчиком с ключевыми обязанностями вроде написания архитектурных решений. Вполне может оказаться, что рядом не будет человека с нужными компетенциями. Значит, компетенции надо выращивать. Возможно это будет трудно принять на первом этапе, но это единственно правильный путь в вашем положении.

Контролируйте время. Следите за временем, отведенным на задачу. Речь о тактических и стратегических задачах. Говорю не о ежедневной работе, хотя она и будет являться основным фактором успеха. Под тактическими задачами подразумевается выполнение конкретных больших задачах в виде создания базовых библиотек, задокументированных процессов или процесса обучения. Под стратегическими — определения вектора развития. В какой момент уйти с objective-C? Как сформировать экосистему, чтобы она работала эффективнее? Какие задачи необходимо решить, чтобы эффективность решения задач бизнеса возросла? Это и есть примеры стратегических вопросов. Они наиболее сложные и наиболее длительные, но именно от них зависит ваше завтра.

Важным моментом будет являться то, насколько вы понимаете, что интересно людям. Это можно использовать как дополнительный фактор и роста разработчика и проработки какого-то отдельного компонента вашей экосистемы. Разработчики, как правило, любят заниматься интересными вещами и в свободное время. Вы можете им помочь и в этом. Важно лишь понять, что действительно интересно человеку.
Можно долго и красиво рассуждать о том, какой вы замечательный человек и специалист. Но факт остается фактом — не ошибается лишь тот, кто ничего не делает. И чем больше человек начинает отходить от своей зоны комфорта, тем выше вероятность ошибки. Конкретный отход от фул-тайм разработчика к более менеджерской роли предполагает сильное взаимодействие с командой и другими отделами в компании. Вполне логично, что появляются новые нестандартные для человека ситуации. И он не всегда знает, как их решать.
При встрече с неприятной ситуацией первое, что нужно сделать — понять, что только вы можете ее исправить и никто другой. И чем дольше вы с ней затягиваете, тем сильнее в конце выстрелит пушка времени. А теперь перейдём от абстракций к конкретным примерам.
Принятие решений. Бывает, что людей в команду спускают сверху. Вам необходимо сразу четко обозначить здесь правила: либо у вас есть право вето на абсолютно все решения по построению команды, либо необходимо объяснить руководству, почему будет работать именно так. В идеале и самое часто встречающееся на практике — когда team lead сам формирует себе команду. Повышается моральная ответственность так как решения принимал сам lead.
Личностные качества. В команде есть человек, который по каким-то причинам вас не устраивает. При этом абсолютно не важно, наняли его вы, или он уже был или дали со стороны. Все люди ошибаются и вы не исключение. Особенно на первом этапе, когда всё ваше собеседование строится не на том, чтобы понять насколько человек вообще впишется в команду, а знает ли он, как решить алгоритмическую задачу по поиску элемента в бинарном дереве. Вы должны понимать, что любой алгоритм можно выучить за один день, любой framework при должном усердии от начального применения в первый же день до глубокого погружения в течение месяца. А личностные качества, некое «абстрактное чувство кода» за день-неделю-месяц или год не исправишь. В этом вопросе тем более не нужно ориентироваться на hr и считать, что это их работа. Потому что в итоге человек будет работать большую часть своего времени именно с вами в период работы в компании, а не с hr.
К минусам можно также отнести то, что со временем ваши технические навыки будут падать. Это и миф, и правда одновременно. Роль лида позволяет более широко взглянуть на некоторые технические аспекты, на мета-принципы программирования. А то, что вы не будете знать как запрограммировать в iOS 10 новый фреймворк CallKit и какие интерфейсные методы в нём есть — это пережить будет тяжело, но в целом можно.
Я долгое время испытывал чувство гордости за то, что никто из членов моей команды не уволился, а уж тем более его не уволили за низкую производительность/крупные косяки в работе. Считал неким долгом помочь человеку, даже если это занимало некоторое количество моего свободного времени на выходных. Но необходимо раз и навсегда понять, что всё, что должен делать менеджер любого уровня — это направлять и помогать человеку, а не делать за него. Проведите несколько личных бесед для того, чтобы обозначить проблему. Чтобы не было конфликта ожиданий и что вы оба понимаете, проблема нужно решать. Постройте стратегию решения проблемы и жестко её контролируйте. Это может не сработать. Чтобы удостовериться, что проблема не в вас, то попросите другого разработчика в команде выступить неким независимым экспертом по оценке производительности/квалификации или просто моральной работы в команде. Если ваши мнения сошлись, то расставайтесь без тени сомнения. Так вы убережете и свои нервы, и нервы членов команды. И даже сам человек будет благодарен спустя какое-то время, что именно так всё закончилось. Чем больше времени проходит и больше опыта я получаю, тем меньше нужно времени, чтобы понять, совершил я ошибку или нет.
Вам необходимо заранее понимать, что бывают и конфликтные ситуации. Но чаще всего это решается через личную беседу. Просто говорите прямо, хотя это бывает крайне сложно.
Одна из самых частых негативных историй, которые я слышу от разработчиков про lead'ов — все интересные куски лид забирает себе. От лидов же получаю другой фидбэк, что самая частая проблема — есть задача и её ВООБЩЕ НИКАК!!!111 нельзя делегировать.Отсюда вытекает ряд проблем.
Весь ваш ориентир или хайповое слово KPI заключается только в вашей команде. Если есть крутая команда, которая сплоченно, быстро делает продукт и соблюдает процессы — вы хороший лид. Старайтесь постепенно повышать различного рода компетенции в других людях. Крайне важно, чтобы это было осознанным выбором самого человека, а не навязанной сверху практикой.
Раз у вас уже возник вопрос «а что дальше?» в бытность разработчиком, то он у вас возникнет и на этапе team lead. А здесь всё также можно следовать разобранной ранее схеме. Вопрос лишь в том, стоит ли развиваться как менеджер или всё-таки уйти еще глубже в сторону разработки как архитектор. Попробуйте, и вы сможете четко ответить на этот вопрос. Но как я говорил ранее, не задавайте его себе в первые несколько месяцев. Потому что находясь вне привычной зоны комфорта человек по умолчанию склонен негативно реагировать на любые стимулы. Разберитесь хотя бы в базовых вещах, потом принимайте решение.
Роль team lead, как и роль менеджера, имеет ряд специфических особенностей, зависящих от внешних и внутренних факторов бизнеса, времени, технологий и видения самой компании. Если стали лидом, первым делом:
Что сработало в моем случае может сработать и в вашем. Главная же доктрина заключается в том, что всё приходит с опытом. Если вы работаете в этом направлении, конечно. Проблемы со временем не исчезнут, вы просто научитесь их решать.
Помните, что учиться можно не только на своём опыте, но и учась на чужих ошибках. Teamleadство — это круто.
С. Макконнелл. Сколько стоит программный проект
Дж. Ханк Рейнвотер Как пасти котов
Давид Хейнемейер Ханссон и Джейсон Фрид. Rework
|
Метки: author niklnd тестирование мобильных приложений разработка под ios xcode swift блог компании touch instinct ios management |
[Перевод] Делаем data science-портфолио: история через данные |
Перевод внезапно удачно попал в струю других датасайенсных туториалов на хабре. :)
Этот написан Виком Паручури, основателем Dataquest.io, где как раз и занимаются подобного рода интерактивным обучением data science и подготовкой к реальной работе в этой области. Каких-то эксклюзивных ноу-хау здесь нет, но очень подробно рассказан процесс от сбора данных до первичных выводов о них, что может быть интересно не только желающим составить резюме на data science, но и тем, кто просто хочет попробовать себя в практическом анализе, но не знает, с чего начать.
Data science-компании всё чаще смотрят портфолио, когда принимают решение о приёме на работу. Это, в частности, из-за того, что лучший способ судить о практических навыках — именно портфолио. И хорошая новость в том, что оно полностью в вашем распоряжении: если постараетесь – сможете собрать отличное портфолио, которым будут впечатлены многие компании.
Первый шаг в высококачественному портфолио – это понимание, какие умения в нём надо продемонстрировать.
Основные навыки, которые компании хотят видеть в data scientist-ах, и, соответственно, продемонстрированными в их портфолио, это:
Всякое хорошее портфолио содержит несколько проектов, каждый из которых может демонстрировать 1-2 данных пункта. Это первый пост из цикла, который будет рассматривать получение гармоничного data science-портфолио. Мы рассмотрим, как сделать первый проект для портфолио, и как рассказать хорошую историю через данные. В конце будет проект, который поможет раскрыть вашу способность общаться и способность делать заключения на основе данных.
Я точно не буду переводить весь цикл, но планирую коснуться интересного туториала о машинном обучении оттуда же.
В принципе, Data science вся состоит из общения. Вы видите в данных какую-то закономерность, потом ищете эффективный способ объяснить эту закономерность другим, потом убеждаете их предпринять те действия, которые вы считаете нужными. Одно из важнейших умений в data science — наглядно рассказать историю через данные. Удачная история может лучше преподнести ваши догадки и помочь другим понять ваши идеи.
История в контексте data science — это изложение всего того, что вы нашли и того, что это значит. Примером может служить открытие того, что прибыль вашей компании снизилась на 20% за последний год. Просто указать на этот факт недостаточно: надо объяснить, почему прибыль упала и что с этим делать.
Основные компоненты историй в данных это:
Лучшее средство доходчиво рассказать историю через данные — это Jupyter notebook. Если вы с ним незнакомы — тут хороший туториал. Jupyter notebook позволяет интерактивно исследовать данные и публиковать их на различных сайтах, включая гитхаб. Публикация результатов полезна для сотрудничества — ваш анализ смогут расширить другие люди.
Мы в этом посте будем использовать Jupyter notebook вместе с питоновскими библиотеками типа Pandas и matplotlib.
Первый шаг к созданию проекта — это определиться с темой. Стоит выбрать что-то, что вам интересно и что есть желание поисследовать. Всегда видно, когда люди сделали проект просто чтобы было, а когда потому, что им действительно интересно было покопаться в данных. На этом шаге имеет смысл потратить время, чтобы точно найти что-то увлекающее.
Хороший способ найти тему — полазить по разным датасетам и посмотреть, что есть интересного. Вот хорошие места для начала:
В реальной data science часто не получается найти полностью подготовленный для ваших изысканий датасет. Возможно, придётся агрегировать различные источники данных или серьёзно их чистить. Если тема вам очень интересна — имеет смысл сделать то же и здесь: лучше покажете себя в итоге.
Мы для поста будем использовать данные о Нью-Йоркских общеобразовательных школах, отсюда.
На всякий случай, приведу пример более близких к нам (россиянам) аналогичных датасетов:
Важно сделать весь проект от начала до конца. Для этого полезно ограничить область изучения так, чтобы точно знать, что вы закончите. Проще добавить что-то к уже завершённому проекту, чем пытаться закончить то, что уже попросту надоело доводить до конца.
В нашем случае, мы будем изучать оценки ЕГЭ старшеклассников вместе с различной демографической и прочей информацией о них. ЕГЭ или Единый Государственный экзамен — это тест, который старшеклассники сдают перед поступлением в колледж. Колледжи учитывают оценки, когда принимают решение о зачислении, так что хорошо сдать его — весьма важно. Экзамен состоит из трёх частей, каждая из которых оценивается в 800 баллов. Общий балл в итоге 2400 (хотя иногда это плавало туда-сюда - в датасете всё по 2400). Старшие школы часто оцениваются по среднему баллу ЕГЭ и высокий средний балл обычно является показателем того, насколько хорош школьный округ.
Были определённые жалобы на несправедливость оценок некоторым нацменьшинствам в США, поэтому анализ по Нью-Йорку поможет пролить свет на справедливость ЕГЭ.
Датасет с оценками ЕГЭ — здесь, а датасет с информацией по каждой школе — здесь. Это будет основой нашего проекта, но нам понадобится ещё информация, чтобы сделать полноценный анализ.
В оригинале экзамен называется SAT — Scholastic Aptitude Test. Но поскольку он практически по смыслу идентичен нашему ЕГЭ — решил так его и переводить.
Как только есть хорошая тема — полезно просмотреть другие датасеты, которые могут расширить тему или помочь углубить исследование. Лучше делать это в начале, чтобы было как можно больше данных для исследования по мере создания проекта. Если данных будет мало — есть шанс, что вы сдадитесь слишком рано.
В нашем случае, есть ещё несколько датасетов по этой теме на том же сайте, которые освещают демографическую информацию и результаты экзаменов.
Вот ссылки на все датасеты, что будем использовать:
Все эти данные связаны между собой, и мы сможем их объединить прежде, чем начнём анализ.
Прежде, чем погружаться в анализ данных, полезно выяснить общую информацию о предмете. В нашем случае, мы знаем кое-что, что может оказаться полезным:
То, что я перевёл как "Районы" на самом деле называется в NYC "боро", и столбцы, соответственно, называются Borough.
Чтобы действительно понять контекст данных, нужно потратить время и об этих данных почитать. В нашем случае, каждая вышеприведённая ссылка содержит описание данных для каждой колонки. Похоже, у нас есть данные по оценкам ЕГЭ старшеклассников, вместе с другими датасетами, которые содержат демографическую и прочую информацию.
Запустим кое-какой код, чтобы прочесть данные. Используем Jupyter notebook для наших исследований. Нижеприведённый код:
import pandas
import numpy as np
files = ["ap_2010.csv", "class_size.csv", "demographics.csv", "graduation.csv", "hs_directory.csv", "math_test_results.csv", "sat_results.csv"]
data = {}
for f in files:
d = pandas.read_csv("schools/{0}".format(f))
data[f.replace(".csv", "")] = d
Как только мы всё прочитали, можно использовать на датафреймах метод head, чтобы вывести первые 5 строк каждого:
for k,v in data.items():
print("\n" + k + "\n")
print(v.head())Уже можно видеть в датасетах определённые особенности:
math_test_results
| DBN | Grade | Year | Category | Number Tested | Mean Scale Score | Level 1 # | \ | |
|---|---|---|---|---|---|---|---|---|
| 0 | 01M015 | 3 | 2006 | All Students | 39 | 667 | 2 | |
| 1 | 01M015 | 3 | 2007 | All Students | 31 | 672 | 2 | |
| 2 | 01M015 | 3 | 2008 | All Students | 37 | 668 | 0 | |
| 3 | 01M015 | 3 | 2009 | All Students | 33 | 668 | 0 | |
| 4 | 01M015 | 3 | 2010 | All Students | 26 | 677 | 6 |
| Level 1 % | Level 2 # | Level 2 % | Level 3 # | Level 3 % | Level 4 # | Level 4 % | \ | |
|---|---|---|---|---|---|---|---|---|
| 0 | 5.1% | 11 | 28.2% | 20 | 51.3% | 6 | 15.4% | |
| 1 | 6.5% | 3 | 9.7% | 22 | 71% | 4 | 12.9% | |
| 2 | 0% | 6 | 16.2% | 29 | 78.4% | 2 | 5.4% | |
| 3 | 0% | 4 | 12.1% | 28 | 84.8% | 1 | 3% | |
| 4 | 23.1% | 12 | 46.2% | 6 | 23.1% | 2 | 7.7% |
| Level 3+4 # | Level 3+4 % | |
|---|---|---|
| 0 | 26 | 66.7% |
| 1 | 26 | 83.9% |
| 2 | 31 | 83.8% |
| 3 | 29 | 87.9% |
| 4 | 8 | 30.8% |
ap_2010
| DBN | SchoolName | AP Test Takers | Total Exams Taken | Number of Exams with scores 3 4 or 5 | |
|---|---|---|---|---|---|
| 0 | 01M448 | UNIVERSITY NEIGHBORHOOD H.S. | 39 | 49 | 10 |
| 1 | 01M450 | EAST SIDE COMMUNITY HS | 19 | 21 | s |
| 2 | 01M515 | LOWER EASTSIDE PREP | 24 | 26 | 24 |
| 3 | 01M539 | NEW EXPLORATIONS SCI,TECH,MATH | 255 | 377 | 191 |
| 4 | 02M296 | High School of Hospitality Management | s | s | s |
sat_results
| DBN | SCHOOL NAME | Num of SAT Test Takers | SAT Critical Reading Avg. Score | SAT Math Avg. Score | SAT Writing Avg. Score | |
|---|---|---|---|---|---|---|
| 0 | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL STUDIES | 29 | 355 | 404 | 363 |
| 1 | 01M448 | UNIVERSITY NEIGHBORHOOD HIGH SCHOOL | 91 | 383 | 423 | 366 |
| 2 | 01M450 | EAST SIDE COMMUNITY SCHOOL | 70 | 377 | 402 | 370 |
| 3 | 01M458 | FORSYTH SATELLITE ACADEMY | 7 | 414 | 401 | 359 |
| 4 | 01M509 | MARTA VALLE HIGH SCHOOL | 44 | 390 | 433 | 384 |
class_size
| CSD | BOROUGH | SCHOOL CODE | SCHOOL NAME | GRADE | PROGRAM TYPE | CORE SUBJECT (MS CORE and 9-12 ONLY) | CORE COURSE (MS CORE and 9-12 ONLY) | \ | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | GEN ED | - | - | |
| 1 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | CTT | - | - | |
| 2 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | GEN ED | - | - | |
| 3 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | CTT | - | - | |
| 4 | 1 | M | M015 | P.S. 015 Roberto Clemente | 02 | GEN E | - | - |
| SERVICE CATEGORY(K-9* ONLY) | NUMBER OF STUDENTS / SEATS FILLED | NUMBER OF SECTIONS | AVERAGE CLASS SIZE | SIZE OF SMALLEST CLASS | \ | |
|---|---|---|---|---|---|---|
| 0 | - | 19.0 | 1.0 | 19.0 | 19.0 | |
| 1 | - | 21.0 | 1.0 | 21.0 | 21.0 | |
| 2 | - | 17.0 | 1.0 | 17.0 | 17.0 | |
| 3 | - | 17.0 | 1.0 | 17.0 | 17.0 | |
| 4 | - | 15.0 | 1.0 | 15.0 | 15.0 |
| SIZE OF LARGEST CLASS | DATA SOURCE | SCHOOLWIDE PUPIL-TEACHER RATIO | |
|---|---|---|---|
| 0 | 19.0 | ATS | NaN |
| 1 | 21.0 | ATS | NaN |
| 2 | 17.0 | ATS | NaN |
| 3 | 17.0 | ATS | NaN |
| 4 | 15.0 | ATS | NaN |
demographics
| DBN | Name | schoolyear | fl_percent | frl_percent | \ | |
|---|---|---|---|---|---|---|
| 0 | 01M015 | P.S. 015 ROBERTO CLEMENTE | 20052006 | 89.4 | NaN | |
| 1 | 01M015 | P.S. 015 ROBERTO CLEMENTE | 20062007 | 89.4 | NaN | |
| 2 | 01M015 | P.S. 015 ROBERTO CLEMENTE | 20072008 | 89.4 | NaN | |
| 3 | 01M015 | P.S. 015 ROBERTO CLEMENTE | 20082009 | 89.4 | NaN | |
| 4 | 01M015 | P.S. 015 ROBERTO CLEMENTE | 20092010 | 96.5 |
| total_enrollment | prek | k | grade1 | grade2 | ... | black_num | black_per | \ | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 281 | 15 | 36 | 40 | 33 | ... | 74 | 26.3 | |
| 1 | 243 | 15 | 29 | 39 | 38 | ... | 68 | 28.0 | |
| 2 | 261 | 18 | 43 | 39 | 36 | ... | 77 | 29.5 | |
| 3 | 252 | 17 | 37 | 44 | 32 | ... | 75 | 29.8 | |
| 4 | 208 | 16 | 40 | 28 | 32 | ... | 67 | 32.2 |
| hispanic_num | hispanic_per | white_num | white_per | male_num | male_per | female_num | female_per | \ | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 189 | 67.3 | 5 | 1.8 | 158.0 | 56.2 | 123.0 | 43.8 | |
| 1 | 153 | 63.0 | 4 | 1.6 | 140.0 | 57.6 | 103.0 | 42.4 | |
| 2 | 157 | 60.2 | 7 | 2.7 | 143.0 | 54.8 | 118.0 | 45.2 | |
| 3 | 149 | 59.1 | 7 | 2.8 | 149.0 | 59.1 | 103.0 | 40.9 | |
| 4 | 118 | 56.7 | 6 | 2.9 | 124.0 | 59.6 | 84.0 | 40.4 |
graduation
| Demographic | DBN | School Name | Cohort | \ | |
|---|---|---|---|---|---|
| 0 | Total Cohort | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL | 2003 | |
| 1 | Total Cohort | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL | 2004 | |
| 2 | Total Cohort | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL | 2005 | |
| 3 | Total Cohort | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL | 2006 | |
| 4 | Total Cohort | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL | 2006 Aug |
| Total Cohort | Total Grads — n | Total Grads — % of cohort | Total Regents — n | \ | |
|---|---|---|---|---|---|
| 0 | 5 | s | s | s | |
| 1 | 55 | 37 | 67.3% | 17 | |
| 2 | 64 | 43 | 67.2% | 27 | |
| 3 | 78 | 43 | 55.1% | 36 | |
| 4 | 78 | 44 | 56.4% | 37 |
| Total Regents — % of cohort | Total Regents — % of grads | ... | Regents w/o Advanced — n | \ | |
|---|---|---|---|---|---|
| 0 | s | s | ... | s | |
| 1 | 30.9% | 45.9% | ... | 17 | |
| 2 | 42.2% | 62.8% | ... | 27 | |
| 3 | 46.2% | 83.7% | ... | 36 | |
| 4 | 47.4% | 84.1% | ... | 37 |
| Regents w/o Advanced — % of cohort | Regents w/o Advanced — % of grads | \ | |
|---|---|---|---|
| 0 | s | s | |
| 1 | 30.9% | 45.9% | |
| 2 | 42.2% | 62.8% | |
| 3 | 46.2% | 83.7% | |
| 4 | 47.4% | 84.1% |
| Local — n | Local — % of cohort | Local — % of grad | s Still Enrolled — n | \ | |
|---|---|---|---|---|---|
| 0 | s | s | s | s | |
| 1 | 20 | 36.4% | 54.1% | 15 | |
| 2 | 16 | 25% | 37.200000000000003% | 9 | |
| 3 | 7 | 9% | 16.3% | 16 | |
| 4 | 7 | 9% | 15.9% | 15 |
| Still Enrolled — % of cohort | Dropped Out — n | Dropped Out — % of cohort | |
|---|---|---|---|
| 0 | s | s | s |
| 1 | 27.3% | 3 | 5.5% |
| 2 | 14.1% | 9 | 14.1% |
| 3 | 20.5% | 11 | 14.1% |
| 4 | 19.2% | 11 | 14.1% |
hs_directory
| dbn | school_name | boro | \ | |
|---|---|---|---|---|
| 0 | 17K548 | Brooklyn School for Music & Theatre | Brooklyn | |
| 1 | 09X543 | High School for Violin and Dance | Bronx | |
| 2 | 09X327 | Comprehensive Model School Project M.S. 327 | Bronx | |
| 3 | 02M280 | Manhattan Early College School for Advertising | Manhattan | |
| 4 | 28Q680 | Queens Gateway to Health Sciences Secondary Sc... | Queens |
| building_code | phone_number | fax_number | grade_span_min | grade_span_max | \ | |
|---|---|---|---|---|---|---|
| 0 | K440 | 718-230-6250 | 718-230-6262 | 9 | 12 | |
| 1 | X400 | 718-842-0687 | 718-589-9849 | 9 | 12 | |
| 2 | X240 | 718-294-8111 | 718-294-8109 | 6 | 12 | |
| 3 | M520 | 718-935-3477 | NaN | 9 | 10 | |
| 4 | Q695 | 718-969-3155 | 718-969-3552 | 6 | 12 |
| expgrade_span_min | expgrade_span_max | ... | priority02 | \ | |
|---|---|---|---|---|---|
| 0 | NaN | NaN | ... | Then to New York City residents | |
| 1 | NaN | NaN | ... | Then to New York City residents who attend an ... | |
| 2 | NaN | NaN | ... | Then to Bronx students or residents who attend... | |
| 3 | 9 | 14.0 | ... | Then to New York City residents who attend an ... | |
| 4 | NaN | NaN | ... | Then to Districts 28 and 29 students or residents |
| priority03 | priority04 | priority05 | \ | |
|---|---|---|---|---|
| 0 | NaN | NaN | NaN | |
| 1 | Then to Bronx students or residents | Then to New York City residents | NaN | |
| 2 | Then to New York City residents who attend an ... | Then to Bronx students or residents | Then to New York City residents | |
| 3 | Then to Manhattan students or residents | Then to New York City residents | NaN | |
| 4 | Then to Queens students or residents | Then to New York City residents | NaN |
| priority06 | priority07 | priority08 | priority09 | priority10 | Location 1 | |
|---|---|---|---|---|---|---|
| 0 | NaN | NaN | NaN | NaN | NaN | 883 Classon Avenue\nBrooklyn, NY 11225\n(40.67... |
| 1 | NaN | NaN | NaN | NaN | NaN | 1110 Boston Road\nBronx, NY 10456\n(40.8276026... |
| 2 | NaN | NaN | NaN | NaN | NaN | 1501 Jerome Avenue\nBronx, NY 10452\n(40.84241... |
| 3 | NaN | NaN | NaN | NaN | NaN | 411 Pearl Street\nNew York, NY 10038\n(40.7106... |
| 4 | NaN | NaN | NaN | NaN | NaN | 160-20 Goethals Avenue\nJamaica, NY 11432\n(40... |
Чтобы с данными работать было легче, нам надо объединить все датасеты в один — это позволит нам быстро сравнивать колонки в датасетах. Для этого, прежде всего, надо найти общую колонку для объединения. Глядя на то, что нам ранее вывелось, можно предположить, что такой колонкой может быть DBN, поскольку она повторяется в нескольких датасетах.
Если мы загуглим "DBN New York City Schools", то придём сюда, где объясняется, что DBN — это уникальный код для каждой школы. При исследовании датасетов, особенно правительственных, приходится частенько проделать детективную работу, чтобы понять, что значит каждый столбец, даже каждый датасет иногда.
Теперь проблема в том, что два датасета, class_size и hs_directory — не содержат DBN. В hs_directory он называется dbn, поэтому просто переименуем или скопируем его в DBN. Для class_size нужен будет другой подход.
Столбец DBN выглядит так:
In [5]: data["demographics"]["DBN"].head()
Out[5]:
0 01M015
1 01M015
2 01M015
3 01M015
4 01M015
Name: DBN, dtype: objectЕсли посмотрим на class_size - вот то, что мы увидим в первых 5 строках:
In [4]:
data["class_size"].head()
Out[4]:| CSD | BOROUGH | SCHOOL CODE | SCHOOL NAME | GRADE | PROGRAM TYPE | CORE SUBJECT (MS CORE and 9-12 ONLY) | / | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | GEN ED | - | |
| 1 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | CTT | - | |
| 2 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | GEN ED | - | |
| 3 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | CTT | - | |
| 4 | 1 | M | M015 | P.S. 015 Roberto Clemente | 02 | GEN ED | - |
| CORE COURSE (MS CORE and 9-12 ONLY) | SERVICE CATEGORY(K-9* ONLY) | NUMBER OF STUDENTS / SEATS FILLED | / | |
|---|---|---|---|---|
| 0 | - | - | 19.0 | |
| 1 | - | - | 21.0 | |
| 2 | - | - | 17.0 | |
| 3 | - | - | 17.0 | |
| 4 | - | - | 15.0 |
| NUMBER OF SECTIONS | AVERAGE CLASS SIZE | SIZE OF SMALLEST CLASS | SIZE OF LARGEST CLASS | DATA SOURCE | SCHOOLWIDE PUPIL-TEACHER RATIO | |
|---|---|---|---|---|---|---|
| 0 | 1.0 | 19.0 | 19.0 | 19.0 | ATS | NaN |
| 1 | 1.0 | 21.0 | 21.0 | 21.0 | ATS | NaN |
| 2 | 1.0 | 17.0 | 17.0 | 17.0 | ATS | NaN |
| 3 | 1.0 | 17.0 | 17.0 | 17.0 | ATS | NaN |
| 4 | 1.0 | 15.0 | 15.0 | 15.0 | ATS | NaN |
Как можно заметить, DBN — это просто комбинация CSD,BOROUGH и SCHOOL_ CODE. Для незнакомых с Нью-Йорком: он состоит из 5 районов. Каждый район — это организационная единица, приблизительно равная по размеру достаточно большому городу США. DBN расшифровывается как районно-окружной номер. Похоже, что CSD — это округ, BOROUGH — район и в сочетании со SCHOOL_CODE получается DBN.
Теперь, когда мы знаем, как составить DBN, мы можем добавить его в class_size и hs_directory.
In
data["class_size"]["DBN"] = data["class_size"].apply(lambda x: "{0:02d}{1}".format(x["CSD"], x["SCHOOL CODE"]), axis=1)
data["hs_directory"]["DBN"] = data["hs_directory"]["dbn"]Один из самых потенциально интересных датасетов — это датасет опросов учеников, родителей и учителей по поводу качества школ. Эти опросы включают информацию о субъективном восприятии безопасности каждой школы, учебных стандартах и прочем. Перед тем, как объединять наши датасеты, давайте добавим данные по опросам. В реальных data science-проектах вы часто будете натыкаться на интересные данные по ходу анализа и, возможно, захотите так же их подключить. Гибкий инструмент, типа Jupyter notebook, позволяет быстро добавить дополнительный код и переделать анализ.
В нашем случае, добавим дополнительные данные по опросам в наш словарь data, после чего объединим все датасеты. Данные по опросам состоят из двух файлов, один на все школы, и один на школьный округ 75. Чтобы их объединить, потребуется написать немного кода. В нём мы сделаем что:
In [66]:
survey1 = pandas.read_csv("schools/survey_all.txt", delimiter="\t", encoding='windows-1252')
survey2 = pandas.read_csv("schools/survey_d75.txt", delimiter="\t", encoding='windows-1252')
survey1["d75"] = False
survey2["d75"] = True
survey = pandas.concat([survey1, survey2], axis=0)Как только мы объединим все опросы, появится дополнительная трудность. Мы хотим минимизировать количество столбцов в нашем объединённом датасете, чтобы можно было легко сравнивать колонки и выявлять зависимости. К несчастью, данные по опросам содержат много ненужных нам колонок:
In [16]:
survey.head()
Out[16]:| N_p | N_s | N_t | aca_p_11 | aca_s_11 | aca_t_11 | aca_tot_11 | / | |
|---|---|---|---|---|---|---|---|---|
| 0 | 90.0 | NaN | 22.0 | 7.8 | NaN | 7.9 | 7.9 | |
| 1 | 161.0 | NaN | 34.0 | 7.8 | NaN | 9.1 | 8.4 | |
| 2 | 367.0 | NaN | 42.0 | 8.6 | NaN | 7.5 | 8.0 | |
| 3 | 151.0 | 145.0 | 29.0 | 8.5 | 7.4 | 7.8 | 7.9 | |
| 4 | 90.0 | NaN | 23.0 | 7.9 | NaN | 8.1 | 8.0 |
| bn | com_p_11 | com_s_11 | ... | t_q8c_1 | t_q8c_2 | t_q8c_3 | t_q8c_4 | / | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | M015 | 7.6 | NaN | ... | 29.0 | 67.0 | 5.0 | 0.0 | |
| 1 | M019 | 7.6 | NaN | ... | 74.0 | 21.0 | 6.0 | 0.0 | |
| 2 | M020 | 8.3 | NaN | ... | 33.0 | 35.0 | 20.0 | 13.0 | |
| 3 | M034 | 8.2 | 5.9 | ... | 21.0 | 45.0 | 28.0 | 7.0 | |
| 4 | M063 | 7.9 | NaN | ... | 59.0 | 36.0 | 5.0 | 0.0 |
| t_q9 | t_q9_1 | t_q9_2 | t_q9_3 | t_q9_4 | t_q9_5 | |
|---|---|---|---|---|---|---|
| 0 | NaN | 5.0 | 14.0 | 52.0 | 24.0 | 5.0 |
| 1 | NaN | 3.0 | 6.0 | 3.0 | 78.0 | 9.0 |
| 2 | NaN | 3.0 | 5.0 | 16.0 | 70.0 | 5.0 |
| 3 | NaN | 0.0 | 18.0 | 32.0 | 39.0 | 11.0 |
| 4 | NaN | 10.0 | 5.0 | 10.0 | 60.0 | 15.0 |
Мы справимся с этим, заглянув в файл со словарём данных, который мы скачали вместе с данными по опросам. Он расскажет нам про важные поля:
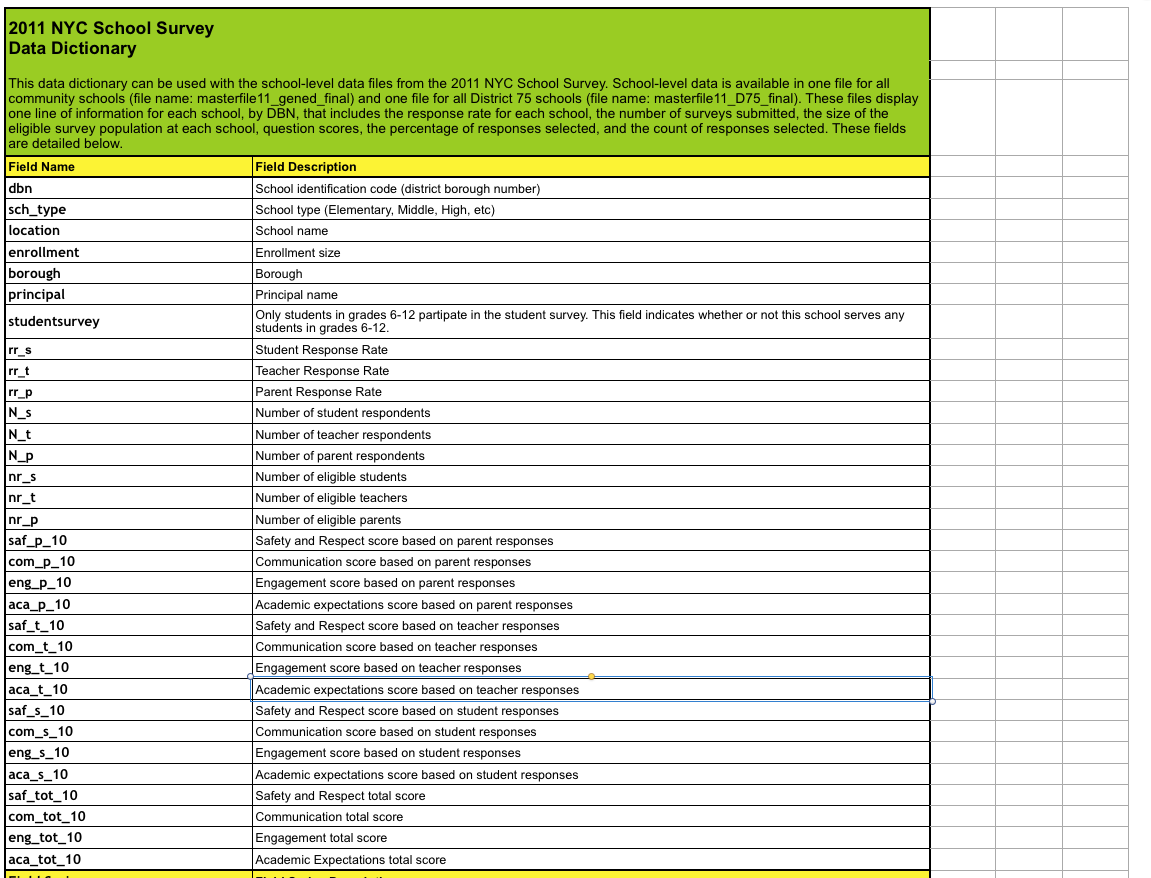
А потом мы удалим все не относящиеся к нам столбцы в survey:
In [17]:
survey["DBN"] = survey["dbn"]
survey_fields = ["DBN", "rr_s", "rr_t", "rr_p", "N_s", "N_t", "N_p", "saf_p_11", "com_p_11", "eng_p_11", "aca_p_11", "saf_t_11", "com_t_11", "eng_t_10", "aca_t_11", "saf_s_11", "com_s_11", "eng_s_11", "aca_s_11", "saf_tot_11", "com_tot_11", "eng_tot_11", "aca_tot_11",]
survey = survey.loc[:,survey_fields]
data["survey"] = survey
survey.shape
Out[17]:
(1702, 23)Понимание того, что именно содержит каждый датасет и какие столбцы из него важны, может сэкономить кучу времени и усилий в дальнейшем.
Если мы взглянем на некоторые датасеты, включая class_size, мы сразу увидим проблему:
In [18]: data["class_size"].head()
Out[18]:| CSD | BOROUGH | SCHOOL CODE | SCHOOL NAME | GRADE | PROGRAM TYPE | CORE SUBJECT (MS CORE and 9-12 ONLY) | / | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | GEN ED | - | |
| 1 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | CTT | - | |
| 2 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | GEN ED | - | |
| 3 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | CTT | - | |
| 4 | 1 | M | M015 | P.S. 015 Roberto Clemente | 02 | GEN ED | - |
| CORE COURSE (MS CORE and 9-12 ONLY) | SERVICE CATEGORY(K-9* ONLY) | NUMBER OF STUDENTS / SEATS FILLED | NUMBER OF SECTIONS | AVERAGE CLASS SIZE | / | |
|---|---|---|---|---|---|---|
| 0 | - | - | 19.0 | 1.0 | 19.0 | |
| 1 | - | - | 21.0 | 1.0 | 21.0 | |
| 2 | - | - | 17.0 | 1.0 | 17.0 | |
| 3 | - | - | 17.0 | 1.0 | 17.0 | |
| 4 | - | - | 15.0 | 1.0 | 15.0 |
| SIZE OF SMALLEST CLASS | SIZE OF LARGEST CLASS | DATA SOURCE | SCHOOLWIDE PUPIL-TEACHER RATIO | DBN | |
|---|---|---|---|---|---|
| 0 | 19.0 | 19.0 | ATS | NaN | 01M015 |
| 1 | 21.0 | 21.0 | ATS | NaN | 01M015 |
| 2 | 17.0 | 17.0 | ATS | NaN | 01M015 |
| 3 | 17.0 | 17.0 | ATS | NaN | 01M015 |
| 4 | 15.0 | 15.0 | ATS | NaN | 01M015 |
Для каждой школы есть несколько строк (что можно понять по повторяющимся полям DBN и SCHOOL NAME). Хотя, если мы взглянем на sat_results - в нём только по одной строке на школу:
In [21]:
data["sat_results"].head()
Out[21]:| DBN | SCHOOL NAME | Num of SAT Test Takers | SAT Critical Reading Avg. Score | SAT Math Avg. Score | SAT Writing Avg. Score | |
|---|---|---|---|---|---|---|
| 0 | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL STUDIES | 29 | 355 | 404 | 363 |
| 1 | 01M448 | UNIVERSITY NEIGHBORHOOD HIGH SCHOOL | 91 | 383 | 423 | 366 |
| 2 | 01M450 | EAST SIDE COMMUNITY SCHOOL | 70 | 377 | 402 | 370 |
| 3 | 01M458 | FORSYTH SATELLITE ACADEMY | 7 | 414 | 401 | 359 |
| 4 | 01M509 | MARTA VALLE HIGH SCHOOL | 44 | 390 | 433 | 384 |
Чтобы объединить эти датасеты, нужен способ уплотнить датасеты типа class_size так, чтобы в них было по одной строке на каждую старшую школу. Если не получится — то не получится и сравнить оценки ЕГЭ с размерами класса. Мы сможем этого достичь, получше разобравшись в данных, а потом сделав некоторые агрегации.
По датасету class_size - похоже, что GRADE и PROGRAM TYPE содержат разные оценки по каждой школе. Ограничив каждое поле единственным значением, мы сможем отбросить все строчки-дубликаты. В коде ниже мы:
In [68]:
class_size = data["class_size"]
class_size = class_size[class_size["GRADE "] == "09-12"]
class_size = class_size[class_size["PROGRAM TYPE"] == "GEN ED"]
class_size = class_size.groupby("DBN").agg(np.mean)
class_size.reset_index(inplace=True)
data["class_size"] = class_sizeДальше нам надо ужать датасет demographics. Данные собраны за несколько лет по одним и тем же школам. Мы выберем только те строки, где поле schoolyear свежее всего.
In [69]:
demographics = data["demographics"]
demographics = demographics[demographics["schoolyear"] == 20112012]
data["demographics"] = demographicsТеперь нам нужно сжать датасет math_test_results. Он делится по значениям Grade и Year. Мы можем выбрать единственный класс за единственный год:
In [70]:
data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Year"] == 2011]
data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Grade"] == Наконец, graduation тоже надо уплотнить:
In [71]:
data["graduation"] = data["graduation"][data["graduation"]["Cohort"] == "2006"]
data["graduation"] = data["graduation"][data["graduation"]["Demographic"] == "Total Cohort"]Очистка и исследование данных критичны перед работой над сутью проекта. Хороший, годныйцелостный датасет поможет быстрее сделать анализ.
Вычисление переменных может ускорить наш анализ возможностью делать сравнивание быстрее и в принципе давая возможность делать некоторые, невозможные без них, сравнения. Первое, что мы можем сделать — посчитать общий балл ЕГЭ из отдельных колонок SAT Math Avg. Score, SAT Critical Reading Avg. Score, и SAT Writing Avg. Score. В коде ниже мы:
In [72]:
cols = ['SAT Math Avg. Score', 'SAT Critical Reading Avg. Score', 'SAT Writing Avg. Score']
for c in cols:
data["sat_results"][c] = data["sat_results"][c].convert_objects(convert_numeric=True)
data['sat_results']['sat_score'] = data['sat_results'][cols[0]] + data['sat_results'][cols[1]]Далее нам надо распарсить координаты каждой школы, чтобы делать карты. Они позволят нам отметить положение каждой школы. В коде мы:
Выведем наши датасеты, посмотрим, что получилось:
In [74]:
for k,v in data.items():
print(k)
print(v.head())math_test_results
| DBN | Grade | Year | Category | Number Tested | Mean Scale Score | \ | |
|---|---|---|---|---|---|---|---|
| 111 | 01M034 | 8 | 2011 | All Students | 48 | 646 | |
| 280 | 01M140 | 8 | 2011 | All Students | 61 | 665 | |
| 346 | 01M184 | 8 | 2011 | All Students | 49 | 727 | |
| 388 | 01M188 | 8 | 2011 | All Students | 49 | 658 | |
| 411 | 01M292 | 8 | 2011 | All Students | 49 | 650 |
| Level 1 # | Level 1 % | Level 2 # | Level 2 % | Level 3 # | Level 3 % | Level 4 # | \ | |
|---|---|---|---|---|---|---|---|---|
| 111 | 15 | 31.3% | 22 | 45.8% | 11 | 22.9% | 0 | |
| 280 | 1 | 1.6% | 43 | 70.5% | 17 | 27.9% | 0 | |
| 346 | 0 | 0% | 0 | 0% | 5 | 10.2% | 44 | |
| 388 | 10 | 20.4% | 26 | 53.1% | 10 | 20.4% | 3 | |
| 411 | 15 | 30.6% | 25 | 51% | 7 | 14.3% | 2 |
| Level 4 % | Level 3+4 # | Level 3+4 % | |
|---|---|---|---|
| 111 | 0% | 11 | 22.9% |
| 280 | 0% | 17 | 27.9% |
| 346 | 89.8% | 49 | 100% |
| 388 | 6.1% | 13 | 26.5% |
| 411 | 4.1% | 9 | 18.4% |
survey
| DBN | rr_s | rr_t | rr_p | N_s | N_t | N_p | saf_p_11 | com_p_11 | eng_p_11 | \ | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 01M015 | NaN | 88 | 60 | NaN | 22.0 | 90.0 | 8.5 | 7.6 | 7.5 | |
| 1 | 01M019 | NaN | 100 | 60 | NaN | 34.0 | 161.0 | 8.4 | 7.6 | 7.6 | |
| 2 | 01M020 | NaN | 88 | 73 | NaN | 42.0 | 367.0 | 8.9 | 8.3 | 8.3 | |
| 3 | 01M034 | 89.0 | 73 | 50 | 145.0 | 29.0 | 151.0 | 8.8 | 8.2 | 8.0 | |
| 4 | 01M063 | NaN | 100 | 60 | NaN | 23.0 | 90.0 | 8.7 | 7.9 | 8.1 |
| ... | eng_t_10 | aca_t_11 | saf_s_11 | com_s_11 | eng_s_11 | aca_s_11 | \ | |
|---|---|---|---|---|---|---|---|---|
| 0 | ... | NaN | 7.9 | NaN | NaN | NaN | NaN | |
| 1 | ... | NaN | 9.1 | NaN | NaN | NaN | NaN | |
| 2 | ... | NaN | 7.5 | NaN | NaN | NaN | NaN | |
| 3 | ... | NaN | 7.8 | 6.2 | 5.9 | 6.5 | 7.4 | |
| 4 | ... | NaN | 8.1 | NaN | NaN | NaN | NaN |
| saf_tot_11 | com_tot_11 | eng_tot_11 | aca_tot_11 | |
|---|---|---|---|---|
| 0 | 8.0 | 7.7 | 7.5 | 7.9 |
| 1 | 8.5 | 8.1 | 8.2 | 8.4 |
| 2 | 8.2 | 7.3 | 7.5 | 8.0 |
| 3 | 7.3 | 6.7 | 7.1 | 7.9 |
| 4 | 8.5 | 7.6 | 7.9 | 8.0 |
ap_2010
| DBN | SchoolName | AP Test Takers | Total Exams Taken | Number of Exams with scores 3 4 or 5 | |
|---|---|---|---|---|---|
| 0 | 01M448 | UNIVERSITY NEIGHBORHOOD H.S. | 39 | 49 | 10 |
| 1 | 01M450 | EAST SIDE COMMUNITY HS | 19 | 21 | s |
| 2 | 01M515 | LOWER EASTSIDE PREP | 24 | 26 | 24 |
| 3 | 01M539 | NEW EXPLORATIONS SCI,TECH,MATH | 255 | 377 | 191 |
| 4 | 02M296 | High School of Hospitality Management | s | s | s |
sat_results
| DBN | SCHOOL NAME | Num of SAT Test Takers | SAT Critical Reading Avg. Score | \ | |
|---|---|---|---|---|---|
| 0 | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL STUDIES | 29 | 355.0 | |
| 1 | 01M448 | UNIVERSITY NEIGHBORHOOD HIGH SCHOOL | 91 | 383.0 | |
| 2 | 01M450 | EAST SIDE COMMUNITY SCHOOL | 70 | 377.0 | |
| 3 | 01M458 | FORSYTH SATELLITE ACADEMY | 7 | 414.0 | |
| 4 | 01M509 | MARTA VALLE HIGH SCHOOL | 44 | 390.0 |
| SAT Math Avg. Score | SAT Writing Avg. Score | sat_score | |
|---|---|---|---|
| 0 | 404.0 | 363.0 | 1122.0 |
| 1 | 423.0 | 366.0 | 1172.0 |
| 2 | 402.0 | 370.0 | 1149.0 |
| 3 | 401.0 | 359.0 | 1174.0 |
| 4 | 433.0 | 384.0 | 1207.0 |
class_size
| DBN | CSD | NUMBER OF STUDENTS / SEATS FILLED | NUMBER OF SECTIONS | \ | |
|---|---|---|---|---|---|
| 0 | 01M292 | 1 | 88.0000 | 4.000000 | |
| 1 | 01M332 | 1 | 46.0000 | 2.000000 | |
| 2 | 01M378 | 1 | 33.0000 | 1.000000 | |
| 3 | 01M448 | 1 | 105.6875 | 4.750000 | |
| 4 | 01M450 | 1 | 57.6000 | 2.733333 |
| AVERAGE CLASS SIZE | SIZE OF SMALLEST CLASS | SIZE OF LARGEST CLASS | SCHOOLWIDE PUPIL-TEACHER RATIO | |
|---|---|---|---|---|
| 0 | 22.564286 | 18.50 | 26.571429 | NaN |
| 1 | 22.000000 | 21.00 | 23.500000 | NaN |
| 2 | 33.000000 | 33.00 | 33.000000 | NaN |
| 3 | 22.231250 | 18.25 | 27.062500 | NaN |
| 4 | 21.200000 | 19.40 | 22.866667 | NaN |
demographics
| DBN | Name | schoolyear | \ | |
|---|---|---|---|---|
| 6 | 01M015 | P.S. 015 ROBERTO CLEMENTE | 20112012 | |
| 13 | 01M019 | P.S. 019 ASHER LEVY | 20112012 | |
| 20 | 01M020 | PS 020 ANNA SILVER | 20112012 | |
| 27 | 01M034 | PS 034 FRANKLIN D ROOSEVELT | 20112012 | |
| 35 | 01M063 | PS 063 WILLIAM MCKINLEY | 20112012 |
| fl_percent | frl_percent | total_enrollment | prek | k | grade1 | grade2 | \ | |
|---|---|---|---|---|---|---|---|---|
| 6 | NaN | 89.4 | 189 | 13 | 31 | 35 | 28 | |
| 13 | NaN | 61.5 | 328 | 32 | 46 | 52 | 54 | |
| 20 | NaN | 92.5 | 626 | 52 | 102 | 121 | 87 | |
| 27 | NaN | 99.7 | 401 | 14 | 34 | 38 | 36 | |
| 35 | NaN | 78.9 | 176 | 18 | 20 | 30 | 21 |
| ... | black_num | black_per | hispanic_num | hispanic_per | white_num | \ | |
|---|---|---|---|---|---|---|---|
| 6 | ... | 63 | 33.3 | 109 | 57.7 | 4 | |
| 13 | ... | 81 | 24.7 | 158 | 48.2 | 28 | |
| 20 | ... | 55 | 8.8 | 357 | 57.0 | 16 | |
| 27 | ... | 90 | 22.4 | 275 | 68.6 | 8 | |
| 35 | ... | 41 | 23.3 | 110 | 62.5 | 15 |
| white_per | male_num | male_per | female_num | female_per | |
|---|---|---|---|---|---|
| 6 | 2.1 | 97.0 | 51.3 | 92.0 | 48.7 |
| 13 | 8.5 | 147.0 | 44.8 | 181.0 | 55.2 |
| 20 | 2.6 | 330.0 | 52.7 | 296.0 | 47.3 |
| 27 | 2.0 | 204.0 | 50.9 | 197.0 | 49.1 |
| 35 | 8.5 | 97.0 | 55.1 | 79.0 | 44.9 |
graduation
| Demographic | DBN | School Name | Cohort | \ | |
|---|---|---|---|---|---|
| 3 | Total Cohort | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL | 2006 | |
| 10 | Total Cohort | 01M448 | UNIVERSITY NEIGHBORHOOD HIGH SCHOOL | 2006 | |
| 17 | Total Cohort | 01M450 | EAST SIDE COMMUNITY SCHOOL | 2006 | |
| 24 | Total Cohort | 01M509 | MARTA VALLE HIGH SCHOOL | 2006 | |
| 31 | Total Cohort | 01M515 | LOWER EAST SIDE PREPARATORY HIGH SCHO | 2006 |
| Total Cohort | Total Grads — n | Total Grads — % of cohort | Total Regents — n | \ | |
|---|---|---|---|---|---|
| 3 | 78 | 43 | 55.1% | 36 | |
| 10 | 124 | 53 | 42.7% | 42 | |
| 17 | 90 | 70 | 77.8% | 67 | |
| 24 | 84 | 47 | 56% | 40 | |
| 31 | 193 | 105 | 54.4% | 91 |
| Total Regents — % of cohort | Total Regents — % of grads | ... | Regents w/o Advanced — n | \ | |
|---|---|---|---|---|---|
| 3 | 46.2% | 83.7% | ... | 36 | |
| 10 | 33.9% | 79.2% | ... | 34 | |
| 17 | 74.400000000000006% | 95.7% | ... | 67 | |
| 24 | 47.6% | 85.1% | ... | 23 | |
| 31 | 47.2% | 86.7% | ... | 22 |
| Regents w/o Advanced — % of cohort | Regents w/o Advanced — % of grads | \ | |
|---|---|---|---|
| 3 | 46.2% | 83.7% | |
| 10 | 27.4% | 64.2% | |
| 17 | 74.400000000000006% | 95.7% | |
| 24 | 27.4% | 48.9% | |
| 31 | 11.4% | 21% |
| Local — n | Local — % of cohort | Local — % of grads | Still Enrolled — n | \ | |
|---|---|---|---|---|---|
| 3 | 7 | 9% | 16.3% | 16 | |
| 10 | 11 | 8.9% | 20.8% | 46 | |
| 17 | 3 | 3.3% | 4.3% | 15 | |
| 24 | 7 | 8.300000000000001% | 14.9% | 25 | |
| 31 | 14 | 7.3% | 13.3% | 53 |
| Still Enrolled — % of cohort | Dropped Out — n | Dropped Out — % of cohort | |
|---|---|---|---|
| 3 | 20.5% | 11 | 14.1% |
| 10 | 37.1% | 20 | 16.100000000000001% |
| 17 | 16.7% | 5 | 5.6% |
| 24 | 29.8% | 5 | 6% |
| 31 | 27.5% | 35 | 18.100000000000001% |
hs_directory
| dbn | school_name | boro | \ | |
|---|---|---|---|---|
| 0 | 17K548 | Brooklyn School for Music & Theatre | Brooklyn | |
| 1 | 09X543 | High School for Violin and Dance | Bronx | |
| 2 | 09X327 | Comprehensive Model School Project M.S. 327 | Bronx | |
| 3 | 02M280 | Manhattan Early College School for Advertising | Manhattan | |
| 4 | 28Q680 | Queens Gateway to Health Sciences Secondary Sc... | Queens |
| building_code | phone_number | fax_number | grade_span_min | grade_span_max | \ | |
|---|---|---|---|---|---|---|
| 0 | K440 | 718-230-6250 | 718-230-6262 | 9 | 12 | |
| 1 | X400 | 718-842-0687 | 718-589-9849 | 9 | 12 | |
| 2 | X240 | 718-294-8111 | 718-294-8109 | 6 | 12 | |
| 3 | M520 | 718-935-3477 | NaN | 9 | 10 | |
| 4 | Q695 | 718-969-3155 | 718-969-3552 | 6 | 12 |
| expgrade_span_min | expgrade_span_max | ... | priority05 | priority06 | priority07 | priority08 | \ | |
|---|---|---|---|---|---|---|---|---|
| 0 | NaN | NaN | ... | NaN | NaN | NaN | NaN | |
| 1 | NaN | NaN | ... | NaN | NaN | NaN | NaN | |
| 2 | NaN | NaN | ... | Then to New York City residents | NaN | NaN | NaN | |
| 3 | 9 | 14.0 | ... | NaN | NaN | NaN | NaN | |
| 4 | NaN | NaN | ... | NaN | NaN | NaN | NaN |
| priority09 | priority10 | Location 1 | \ | |
|---|---|---|---|---|
| 0 | NaN | NaN | 883 Classon Avenue\nBrooklyn, NY 11225\n(40.67... | |
| 1 | NaN | NaN | 1110 Boston Road\nBronx, NY 10456\n(40.8276026... | |
| 2 | NaN | NaN | 1501 Jerome Avenue\nBronx, NY 10452\n(40.84241... | |
| 3 | NaN | NaN | 411 Pearl Street\nNew York, NY 10038\n(40.7106... | |
| 4 | NaN | NaN | 160-20 Goethals Avenue\nJamaica, NY 11432\n(40... |
| DBN | lat | lon | |
|---|---|---|---|
| 0 | 17K548 | 40.670299 | -73.961648 |
| 1 | 09X543 | 40.827603 | -73.904475 |
| 2 | 09X327 | 40.842414 | -73.916162 |
| 3 | 02M280 | 40.710679 | -74.000807 |
| 4 | 28Q680 | 40.718810 | -73.806500 |
После всей подготовки наконец, мы можем объединить все датасеты по столбцу DBN. В итоге у нас получится датасет с сотнями столбцов, из всех исходных. При объединении важно отметить, что в некоторых датасетах нет тех школ, что есть в датасете sat_results. Чтобы это обойти, нам надо объединять датасеты через outer join, тогда мы не потеряем данные. В реальном анализе отсутствие данных — обычное дело. Продемонстрировать возможность исследовать и справляться с таким отсутствием — важная часть портфолио.
Про разные типы джоинов можно почитать здесь.
В коде ниже мы:
In [75]:
flat_data_names = [k for k,v in data.items()]
flat_data = [data[k] for k in flat_data_names]
full = flat_data[0]
for i, f in enumerate(flat_data[1:]):
name = flat_data_names[i+1]
print(name)
print(len(f["DBN"]) - len(f["DBN"].unique()))
join_type =|
Метки: author kayan математика визуализация данных python data mining data science |
VK Streaming API Contest |

|
Метки: author apiwoman программирование открытые данные вконтакте api блог компании вконтакте конкурс |
Отвечаем на вопросы читателей: что такое когнитивная система IBM Watson, и как она работает? |






|
Метки: author ibm машинное обучение высокая производительность блог компании ibm ibm watson когнитивные системы облачные сервисы будущее |
Автоматизация блокирования Petya/NonPetya |
# Get the ID and security principal of the current user account
$myWindowsID=[System.Security.Principal.WindowsIdentity]::GetCurrent()
$myWindowsPrincipal=new-object System.Security.Principal.WindowsPrincipal($myWindowsID)
# Get the security principal for the Administrator role
$adminRole=[System.Security.Principal.WindowsBuiltInRole]::Administrator
# Check to see if we are currently running "as Administrator"
if ($myWindowsPrincipal.IsInRole($adminRole))
{
# We are running "as Administrator" - so change the title and background color to indicate this
$Host.UI.RawUI.WindowTitle = $myInvocation.MyCommand.Definition + "(Elevated)"
$Host.UI.RawUI.BackgroundColor = "DarkBlue"
clear-host
}
else
{
# We are not running "as Administrator" - so relaunch as administrator
# Create a new process object that starts PowerShell
$newProcess = new-object System.Diagnostics.ProcessStartInfo "PowerShell";
# Specify the current script path and name as a parameter
$newProcess.Arguments = $myInvocation.MyCommand.Definition;
# Indicate that the process should be elevated
$newProcess.Verb = "runas";
# Start the new process
[System.Diagnostics.Process]::Start($newProcess);
# Exit from the current, unelevated, process
exit
}
$Compname = Get-WmiObject -Class win32_computersystem | select -expa name
$Cred = $Compname+"\admin"
Write-Verbose -Message "Start process" -Verbose
Write-Verbose -Message "Adding firewall rule" -Verbose
try{New-NetFirewallRule -Action Block -Description Peta.A -Direction Inbound -DisplayName Peta.A_Block -Profile Any -Protocol TCP -LocalPort 135,139,445,1024-1035}
catch{netsh advfirewall firewall add rule name="Petya.A_Block" protocol=TCP dir=in localport=135,139,445,1024-1035 action=block}
if((Test-Path -Path C:\Windows\perfc) -eq $true)
{
try
{
Remove-Item -Path C:\Windows\perfc -Force -ea Stop
Write-Verbose -Message "File perfc was already exist" -Verbose
}
catch {Write-Verbose -Message "File perfc already fixed" -Verbose}
}
if((Test-Path -Path C:\Windows\perfc.dll) -eq $true)
{
try
{
Remove-Item -Path C:\Windows\perfc.dll -Force -ea Stop
Write-Verbose -Message "File perfc.dll was already exist" -Verbose
}
catch {Write-Verbose -Message "File perfc.dll already fixed" -Verbose}
}
if((Test-Path -Path C:\Windows\perfc.dat) -eq $true)
{
try
{
Remove-Item -Path C:\Windows\perfc.dat -Force -ea stop
Write-Verbose -Message "File perfc.dat was already exist" -Verbose
}
catch {Write-Verbose -Message "File perfc.dat already fixed" -Verbose}
}
try{
New-item -Path C:\Windows -ItemType File -Name Perfc -Force -ea Stop
New-item -Path C:\Windows -ItemType File -Name Perfc.dll -Force -ea Stop
New-item -Path C:\Windows -ItemType File -Name Perfc.dat -Force -ea stop
}catch{Write-Verbose -Message "Dont need to create new files"}
Write-Verbose -Message "Successfully created" -Verbose
$acl1 = Get-acl C:\Windows\Perfc
$acl2 = Get-acl C:\Windows\Perfc.dll
$acl3 = Get-acl C:\Windows\Perfc.dat
$acl1.SetAccessRuleProtection($true,$true)
$acl2.SetAccessRuleProtection($true,$true)
$acl3.SetAccessRuleProtection($true,$true)
$accrule1 = New-Object System.Security.AccessControl.FileSystemAccessRule("NT AUTHORITY\SYSTEM","FullControl","Deny")
$accrule2 = New-Object System.Security.AccessControl.FileSystemAccessRule("BUILTIN\Администраторы","FullControl","Deny")
$accrule3 = New-Object System.Security.AccessControl.FileSystemAccessRule("BUILTIN\Администраторы","ReadAndExecute","Allow")
$accrule4 = New-Object System.Security.AccessControl.FileSystemAccessRule("BUILTIN\Администраторы","ReadAndExecute","Allow")
$acl1.SetAccessRule($accrule1)
$acl1.SetAccessRule($accrule2)
$acl1.SetAccessRule($accrule3)
$acl1.SetAccessRule($accrule4)
$acl2.SetAccessRule($accrule1)
$acl2.SetAccessRule($accrule2)
$acl2.SetAccessRule($accrule3)
$acl2.SetAccessRule($accrule4)
$acl3.SetAccessRule($accrule1)
$acl3.SetAccessRule($accrule2)
$acl3.SetAccessRule($accrule3)
$acl3.SetAccessRule($accrule4)
Set-Acl -AclObject $acl1 -Path C:\Windows\Perfc -ea SilentlyContinue
Set-Acl -AclObject $acl2 -Path C:\Windows\Perfc.dll -ea SilentlyContinue
Set-Acl -AclObject $acl2 -Path C:\Windows\Perfc.dat -ea SilentlyContinue
Write-Verbose -Message "Searching for exe files in temp" -Verbose
$Prof= Get-ChildItem -Path "C:\Users" -Force |where {!($_.Name -like "Все пользователи")-or!($_.Name -like "Public")}| select -expa fullname
[array]$TempFiles = $null
[array]$TempPath = $nell
Foreach ($P in $Prof)
{
$TempPath = $P+"\AppData\Local"
Get-ChildItem -Path "$TempPath" -Force -Recurse -ErrorAction SilentlyContinue | where {$_.name -like "*.exe"} | select name,fullname | Format-Table -HideTableHeaders
}
if ($TempFiles -eq $null){Write-Verbose -Message "None exe file was found" -Verbose}
else{Write-Warning -Message "$TempFiles" -Verbose}
Write-Host "Press any key to continue ..."
$x = $host.UI.RawUI.ReadKey("NoEcho,IncludeKeyDown")
|
Метки: author djipa powershell petya.c |
Как запутать аналитика. Часть вторая: что такое моделирование предметной области? |
|
Метки: author maxstroy семантика проектирование и рефакторинг ооп анализ и проектирование систем it- стандарты аналитика owl атрибут тип моделирование предметной области |
Как мы хомяка яблоками кормили или эффективный backend на Go для iOS |

Как и обещал, рассказываю о том, как мы мигрировали свой бэкенд на Go и смогли уменьшить объем бизнес логики на клиенте более, чем на треть.
Для кого: небольшим компаниям, Go и мобильным разработчикам, а также всем, кто в тренде или просто интересуется данной тематикой.
О чем: причины перехода на Go, с какими сложностями столкнулись, а также инструкции и советы по улучшению архитектуры мобильного приложения и его бэкенда.
Уровень: junior и middle.
Долгое время наша команда мобильной аутсорс разработки работала над сторонними проектами, у которых были свои бэкенд разработчики, а мы выступали в роли подрядчика для конкретного продукта. Несмотря на то, что в договоренностях всегда было четко оговорено, что именно мы, как мобильные девелоперы, диктуем музыку и API, далеко не всегда это помогало.

Настолько не всегда, что недавно я сделал небольшой сборник травмирующих душу ситуаций, который выложил в одной из своих прошлых статей.
Так получилось, что у нас тогда в команде был довольно сильный Java(Spring) разработчик, и мы решили каждому новому заказчику твердо объявлять: мы сами пишем бэкенд, либо ищите кого-нибудь другого. Поначалу боялись, что такая принципиальная позиция будет отпугивать, а мы в итоге останемся голыми на хлебе и воде. Но как оказалось, что если мы уже понравились кому-то на этапе переговоров и с нами хотят работать, то практически обо всем можно договориться. Даже когда у клиента в команде уже есть свои люди, которых он изначально планировал задействовать. Тогда-то мы узнали такое умное слово как микросервисы, и что можно делать отдельный сервак с бизнес логикой, выполняющий задачи строго для мобильного приложения. Не буду спорить, что такой подход не везде уместен, но речь дальше пойдет не об этом.
После нескольких успешных проектов Java оказалась слишком тяжелой для нас. Много времени уходило на рутину, чтобы сделать все максимально удобно для приложения.
Не хочу сказать ничего плохого о Spring и Java в целом, это удивительный инструмент под серьезные задачи, как огромный толстопузый испанский галеон. А мы искали что-то больше похожее на легковесный пиратский клипер.
Нам надо было быстро внедрять фичи, легко их менять и не греть голову в поисках самого оптимального решения в каждой ситуации. Знаете, как это бывает, когда долго гуглишь на предмет типового решения твоей задачи, чтобы оно было наиболее подходящим, потом оказывается, что из 10 из них 5 уже устарели. А потом еще тратишь полчаса на выбор названия для переменной.
У Go такой проблемы нет. От слова совсем. Иногда даже через слишком: сидишь, ищешь идеальное решение, а StackOverflow тебе на это отвечает: 'Ну да, просто циклом for, а ты чего ждал?'
Со временем к этому привыкаешь и перестаешь гуглить всякие мелочи по пустякам, а начинаешь включать голову и просто писать код.
Начнем с того, что там нет наследования. Поначалу это просто выносило мозг. Приходится ломать все свое представление об ООП и привыкать к [утиной типизации].(https://ru.wikipedia.org/wiki/%D0%A3%D1%82%D0%B8%D0%BD%D0%B0%D1%8F_%D1%82%D0%B8%D0%BF%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F) Формулируя простыми словами: если это выглядит как утка, плавает как утка и крякает как утка, то это, возможно, и есть утка.
По сути, есть только интерфейсное наследование.
А во-вторых, из существенных минусов, — малое количество готовых инструментов, но зато много багов. Многие вещи нельзя сделать привычным способом, а кое-что вообще отсутствует как класс. Например, нет нормального фреймворка для IoC (инверсия зависимостей). Опытные гоферы скажут, что есть либа от Facebook. Но может я просто не умею ее готовить, либо все-таки ее удобство на самом деле оставляет желать лучшего. Оно просто не может сравниться со Spring и потому приходится много работать руками.
Еще из небольших ограничений Go в целом, например, нельзя сделать API вида:
/cards/:id
/cards/somethingТак как для существующего http роутера — это взаимоисключающие запросы. Он путается между wildcard переменной и конкретным адресом something. Глупое ограничение, но приходится с этим жить. Если же кто-то знает решение, то буду рад услышать.
Также отсутствует hibernate или более менее адекватные аналоги. Да, есть множество ORM, но все они пока довольно слабые. Лучшее, что я встретил за время разработки на Go — это gorm. Ее главное преимущество — это удобнейший маппинг ответа от базы в структуру. А запросы придется писать на голом sql, если не хотите провести долгие часы за отладкой сомнительного поведения.
P.S. Хочу отдельно поделиться workaround-ом, который возник в процессе работы с этой либой. Если вам нужно записать id после insert в какую-то переменную с помощью gorm, а не в структуру как обычно, то поможет следующий костыль. На уровне запроса переименовываем результат returning на любой другой, отличный от id:
... returning id as valueС последующим сканом в переменную:
... Row().Scan(&variable)Оказывается, дело в том, что поле 'id' воспринимается gorm-ом как конкретное поле объекта. И чтобы развязаться, нужно на уровне запроса ее переименовать во что-нибудь другое.
Хочется начать с порога вхождения: он минимален. Вспоминая какой скрежет вызывал в освоении тот же Spring, то Go, по сравнению с ним, можно преподавать в младших классах, настолько он прост.
И эта простота заключается не только в языке, но и в окружении, которое он за собой несет.
Вам не нужно читать долгие маны по gradle и maven, не потребуется писать длиннющие конфиги, чтобы все хотя бы просто один раз запустилось. Здесь все обходится парой команд, а достойный сборщик и профилировщик уже является частью языка и не требует глубокого исследования для старта.
Как говорится: easy to learn, hard to master. Это то, чего мне всегда лично не хватало в современных технологиях: их как будто делают не для людей.
Из этого же следует скорость разработки. Язык был сделан для одной цели:

По сути, это backend язык для бизнеса. Он быстр, он прост и позволяет решать сложные задачи понятными способами. Насчет сложных задач и понятности — это отдельная тема для разговора, потому что в Go есть такая классная вещь как горутинки и каналы. Это удобнейшая многопоточность с минимальной возможностью для выстрела себе в ногу.
В качестве web framework остановили свой выбор на Gin. Есть еще Revel, но нам он показался слишком узким и непоколебимо диктующим свою парадигму. Мы же предпочитаем чуть больше развязанные руки, чтобы можно было быть гибкими.
Gin соблазнил удобным API и отсутствием лишних сложностей. Порог вхождения у него просто приторно низкий. Настолько, что стажеры разбирались в нем буквально за день. Там просто негде запутаться. Весь нужный функционал как на ладони.
Конечно, и он не без проблем. Некоторые решения, например, кэш, сделаны третьей стороной. И происходит конфликт импортов, если вы у себя привыкли использовать import через github, а у них сделано через gopkg и наоборот. В итоге два плагина могут быть просто взаимоисключающими.
Если кто-то знает решение этой проблемы, то напишите, пожалуйста, в комментариях.
Долго писать не буду, а сразу скажу, что это без сомнений Glide. Если вы работали с gradle или maven, то вам наверняка знакома парадигма объявлений зависимостей в неком файле с последующим их задействованием по необходимости. Так вот Glide — это хомячий Gradle, с решением конфликтов и прочими плюшками.
Кстати, если у вас возникнут проблемы при тестировании, когда go test лезет в папку vendor, жадно тестируя каждую либу, то проблема решается элементарно:
go test $(glide novendor)Этот параметр исключает папку vendor из тестирования.
В сам репозиторий достаточно положить glide.yaml и glide.lock файлы.
Мобильной разработке это все никак не поможет, но просто, чтобы вы знали)
Это будет объемный раздел о передаче и хранении данных с бэкенда на клиент. Начнем с Go, плавно переходя на мобильную платформу.
Если вы никогда не сталкивались с Realm и не понимаете о чем речь, то правильно раскрыли спойлер.
Realm — это мобильная база, которая облегчает работу с синхронизацией данных на протяжении всего приложения. В ней нет таких проблем как в CoreData, где постоянно приходится работать в контекстах, даже когда объект еще никуда не сохранен. Легче соблюдать консистентность.
Достаточно просто создать сущность и работать с ней как с обычным объектом, передавая между потоками и жонглируя ею как душе угодно.
Множество операций она делает за вас, но, конечно, и у нее есть косяки: отсутствует не привязанный к регистру поиск, в целом поиск не доделан нормально, потребляет памяти как не в себя (особенно на android), отсутствует группировка как в FRC, и так далее.
Мы посчитали, что стоит мириться с этими проблемами и оно того стоит.
Чтобы не повторяться, коротко скажу, что мы в качестве orm используем Gorm и дам пару рекомендаций:
Наверное, это все применимо к любой технологии, тут я немного скапитанил, но все же. Лишний раз напомнить не повредит, это важно.
Теперь, что касается мобильного приложения. Ваша основная задача — сделать так, чтобы поля, возвращаемые в запросах, имели одинаковые названия с соответствующими им на клиенте. Этого можно легко добиться с помощью так называемых тегов:

Убедитесь, что тег json имеет правильное название. И желательно, чтобы у него был установлен флаг omitempty, как в примере. Это позволяет избежать захламления ответа пустующими полями.
У вас может справедливо возникнуть вопрос: при чем тут вообще Go, если одинаковые названия можно сделать в любом языке? И будете правы, но одним из преимуществ Go является легчайшее форматирование чего угодно через рефлексию и структуры. Пусть рефлексия есть во многих языках, но в Go с ней работать проще всего.
Кстати, если вам нужно спрятать из ответа пустую структуру, то наилучший способ — это перегрузить метод MarshalJSON у структуры:
// Допустим, надо скрыть пустое поле Pharmacy у объекта Object
func (r Object) MarshalJSON() ([]byte, error) {
type Alias Object
var pharmacy *Pharmacy = nil
// Если id != 0, то используем значение. Если нет - ставим nil
if r.Pharmacy.ID != 0 {
pharmacy = &r.Pharmacy
}
return json.Marshal(&struct {
Pharmacy *Pharmacy `json:"pharmacy,omitempty"`
Alias
}{
Pharmacy: pharmacy,
Alias: (Alias)(r),
})
}Многие не заморачиваются и сразу пишут в структурах указатель вместо значения, но это не Go way. Go вообще не любит указатели там, где они не нужны. Это лишает его возможности оптимизировать ваш код и использовать весь свой потенциал.
Кроме названий полей еще обратите внимание на их типы. Числа должны быть числами, а строки строками (спасибо, кэп). В том, что касается дат, то удобнее всего использовать RFC3339. На сервере дату можно отформатировать также через перегрузку:
func (c *Comment) MarshalJSON() ([]byte, error) {
type Alias Comment
return json.Marshal(&struct {
CreatedAt string `json:"createdAt"`
*Alias
}{
CreatedAt: c.CreatedAt.Format(time.RFC3339),
Alias: (*Alias)(c),
})
}А на клиенте это делается через форматирование даты по следующему шаблону:
"yyyy-MM-dd'T'HH:mm:ssZ"Еще одним преимуществом RFC3339 является то, что он выступает форматом даты по умолчанию для Swagger. И сама по себе отформатированная таким образом дата, довольно читаема для человека, особенно по сравнению с posix time.
На клиенте же (пример для iOS, но на Android аналогично), при идеальном совпадении названий всех полей и отношений класса, сохранение можно сделать одним генерик методом:
func save(dictionary: [String : AnyObject]) -> Promise{
return Promise {fulfill, reject in
let realm = Realm.instance
// Если у вас есть дата в словаре, то здесь надо ее отформатировать перед записью.
// Так как реалм не умеет сохранять дату в виде строго.
try! realm.write {
realm.create(T.self, value: dictionary, update: true)
}
fulfill()
}
} Для массивов ситуация аналогичная, но сохранение придется гонять уже в цикле. Часто неопытные разработчики допускают ошибку и заворачивают в цикл целиком блок записи:
array.forEach { object in
try! realm.write {
realm.create(T.self, value: object, update: true)
}
}Что просто в корне неверно, потому что так вы открываете новую транзакцию на каждый объект, вместо того, чтобы сохранить все скопом. А если у вас подключены еще уведомления для обновлений, то все становится еще 'веселее'. Правильнее сделать следующим образом, вынося транзакцию на уровень выше:
try! realm.write {
array.forEach { object in
realm.create(T.self, value: object, update: true)
}
}Как вы могли заметить, у нас полностью отвалился промежуточный слой, отвечающий за маппинг. Когда данные достаточно подготовлены, их можно сразу лупить в базу без дополнительной обработки. И чем лучше у вас бэкенд, тем меньше этой дополнительной обработки потребуется. В идеале только дату сконвертировать в объект. Все остальное должно быть сделано заранее.
Кстати, немного отходя от темы. Если вам не нужно иметь персистентную базу данных на клиенте, то это не повод отказываться от Realm. Он позволяет работать с собой строго в оперативной памяти, сбрасывая свое наполнение по первому требованию.
Ссылки для iOS и Android.
Такой подход позволяет использовать все преимущества реактивной базы данных и вышеописанный маппинг.
Еще хочу добавить для особо внимательных к мелочам: здесь нет утверждения, что Go — это единственно верное решение и панацея для мобильной разработки. Каждый может решать эту задачу по-своему. Мы выбрали этот путь.
Сейчас пойдет много кода для Go разработчиков. Если вы мобильный девелопер, то можете свободно пролистать к следующему разделу.
Теперь мы подошли к самому интересному, если вы Go разработчик. Допустим, вы пишите бэкенд для некоего типового приложения: у вас есть слой с REST API, некая бизнес логика, модель, логика работы с базой данных, утилиты, скрипты миграции и конфиг с ресурсами. Вам как-то все это надо увязать у себя в проекте по классам и папочкам, соблюсти принципы SOLID и, желательно, не сойти с ума при этом.
Пока накидаем абстрактно, не погружаясь слишком глубоко, но так, чтобы была понятна общая структура. Если будет интересно, то посвящу этому полноценный отдельный материал. Все-таки сейчас речь идет о мобильном приложении в связке с Go.
Сразу оговорюсь, что не претендую на догматичность своих высказываний, каждый волен работать в своем проекте как считает нужным.
Начнем со скриншота нашей структуры:
(До чего милые в Intellij Idea хомячки, не правда ли? Каждый раз умиляюсь)
В неразвернутых директориях содержатся сразу Go файлы, либо файлы ресурсов. Проще говоря, все раскрыто так, чтобы видеть максимальное погружение.
В этой статьей расскажу только о том, что отвечает за бизнес логику: api, сервисы, работа с базой и как все это зависит друг от друга. Если вы, уважаемая публика, проявите интерес к этой теме, то потом распишу и остальное, потому как информации там слишком много для одной статьи.
Итак, по порядку:
Web
В вебе хранится все, что отвечает за обработку запросов: байндеры, фильтры и контроллеры — а вся их спайка происходит в api.go. Пример такого склеивания:
regions := r.Group("/regions")
regions.GET("/list", Cache.Gin, rc.List)
regions.GET("/list/active", Cache.Gin, regionController.ListActive)
regions.GET("", binders.Coordinates, regionController.RegionByCoord)Там же происходит инициализация контроллеров и инъекция зависимостей. По сути весь api.go файл состоит из метода Run, где формируется и стартуется роутер, и кучи вспомогательных методов по созданию контроллеров со всеми зависимостями и их групп.
Web.Binders
В папке binders располагаются биндеры, которые парсят параметры из запросов, конвертируют в удобный формат и закидывают в контекст для дальнейшей работы.
Пример метода из этого пакета. Он берет параметр из query, конвертирует в bool и кладет в контекст:
func OpenNow(c *gin.Context) {
openNow, _ := strconv.ParseBool(c.Query(BindingOpenNow))
c.Set(BindingOpenNow, openNow)
}Самый простой вариант без обработки ошибок. Просто для наглядности.
Web.Controllers
Обычно на уровне контроллеров делают больше всего ошибок: напихают лишней логики, забудут про интерфейсы и изоляцию, а потом вообще скатятся к функциональному программированию. Вообще в Go контроллеры страдают от той же болезни, что и в iOS: их постоянно перенагружают. Поэтому сразу определим, какие задачи они должны выполнять:
c.IndentedJSON(http.StatusCreated, gin.H { "identifier": m.ID })Возьмем какой-нибудь пример типового контроллера.
Класс, если опускать импорты, начинается с интерфейса контроллера. Да-да, соблюдаем букву 'D' в слове SOLID, даже если у вас всегда будет только одна реализация. Это значительно облегчает тестирование, давая возможность подменять сам контроллер на его mock:
type Order interface {
PlaceOrder(c *gin.Context)
AroundWithPrices(c *gin.Context)
}Далее у нас идет сама структура контроллера и его конструктор, принимающий в себя зависимости, который мы будем вызывать при создании контроллера в api.go:
// С маленькой буквы, чтобы наружу ничего не вываливалось
type order struct {
service services.Order
}
func NewOrder(service services.Order) Order {
return &order {
service: service,
}
}И, наконец, метод, обрабатывающий запрос. Так как мы успешно прошли слой с биндингом, то можем быть уверены, что все параметры у нас гарантировано есть и мы можем получить их с помощью MustGet, не боясь панических атак:
func (o order)PlaceOrder(c *gin.Context) {
m := c.MustGet(BindingOrder).(*model.Order)
o.service.PlaceOrder(m)
c.IndentedJSON(http.StatusCreated, gin.H {
"identifier": m.ID,
})
}С опциональными параметрами та же история, но только на уровне биндера стоит заложить некое нулевое значение, которое вы будете проверять в контроллере, подставляя в него дефолтное при отсутствии, или просто игнорируя.
Services
Ситуация с сервисами во многом идентична, они так же начинаются с интерфейса, структуры и конструктора с последующим набором методов. Акцент хочется сделать на одной детали — это принцип работы с базой.
Конструктор сервиса должен принимать в себя набор репозиториев, с которыми он будет работать, и фабрику транзакций:
func NewOrder(repo repositories.Order, txFactory TransactionFactory) Order {
return &order { repo: repo, txFactory: txFactory }
}Фабрика транзакций — это просто класс, генерирующий транзакции, здесь ничего сложного:
type TransactionFactory interface {
BeginNewTransaction() Transaction
}type TransactionFactory interface {
BeginNewTransaction() Transaction
}
type transactionFactory struct {
db *gorm.DB
}
func NewTransactionFactory(db *gorm.DB) TransactionFactory {
return &transactionFactory{db: db}
}
func (t transactionFactory)BeginNewTransaction() Transaction {
tx := new(transaction)
tx.db = t.db
tx.Begin()
return tx
}А вот на самих транзакциях остановиться стоит. Начнем с того, что это вообще такое. Транзакция представляет из себя тот же интерфейс с реализацией, который содержит методы для старта транзакции, завершения, отката и доступа к реализации движка уровнем ниже:
type Transaction interface {
Begin()
Commit()
Rollback()
DataSource() interface{}
}type Transaction interface {
Begin()
Commit()
Rollback()
DataSource() interface{}
}
type transaction struct {
Transaction
db *gorm.DB
tx *gorm.DB
}
func (t *transaction)Begin() {
t.tx = t.db.Begin()
}
func (t *transaction)Commit() {
t.tx.Commit()
}
func (t *transaction)Rollback() {
t.tx.Rollback()
}
func (t *transaction)DataSource() interface{} {
return t.tx
}Если с begin, commit, rollback все должно быть понятно, то Datasource — это просто костыль для доступа к низкоуровневой реализации, потому что работа с любой БД в Go устроена так, что транзакция является просто копией акссессора к базе со своими измененными настройками. Он нам понадобится позже при работе в репозиториях.
Собственно, вот и пример работы с транзакциями в методе сервиса:
func (o order)PlaceOrder(m *model.Order) {
tx := o.txFactory.BeginNewTransaction()
defer tx.Commit()
o.repo.Insert(tx, m)
}Начали транзакцию, выполнили доступ к базе, закоммитили или откатили, как больше нравится.
Конечно, все преимущество транзакций особенно раскрывается при нескольких операциях, но и даже если у вас всего одна, как в примере, хуже от этого не будет.
Знаю, что нет управления уровнями изоляции.
Если нашли еще какие косяки — пишите в комментах.
В качестве дополнительного совета юниорам, хочу сказать, что транзакция должна быть открыта минимально возможное время. Постарайтесь подготовить все данные так, чтобы на период между begin и commit приходилось минимальное количество логики и вычислений.
Бывает, что транзакцию открывают и идут курить, отправляя, например запрос в гугл. А потом удивляются, почему это с дедлоком зафакапилось все.
Интересный факт
Во многих современных базах данных, deadlock определяется максимально просто: по таймауту. При большой нагрузке сканировать ресурсы на предмет определения блокировки — дорого. Поэтому часто вместо этого используется обычный таймаут. Например, в mysql. Если не знать эту особенность, то можно подарить себе чудеснейшие часы веселой отладки.
Repositories
Тоже самое: интерфейс, структура, конструктор, который, как правило, уже без параметров.
Просто приведу пример операции Insert, которую мы вызывали в коде сервиса:
func (order)Insert(tx Transaction, m *model.Order) {
db := tx.DataSource().(*gorm.DB)
query := "insert into orders (shop_id) values (?) returning id"
db.Raw(query, m.Shop.ID).Scan(m)
}Получили из транзакции низкоуровневый модификатор доступа, составили запрос, выполнили его. Готово.
Всего этого вполне должно хватить, чтобы не угробить архитектуру. По крайней мере слишком быстро. Если возникли вопросы или возражения, то пишите в комментариях, буду рад обсудить.
Ладно, хомяки это мило, но как теперь с этим работать на клиенте?
Начнем, как и в случае с Go, с нашего стека. Вообще, мы активно используем реактив практически везде, но сейчас расскажу про более щадящий вариант архитектуры, чтобы так сразу не травмировать ничью психику.
Сетевой слой:
Alamofire для Swift проектов и AFNetworking для Objective-C.
Кстати, а вы знали, что Alamofire — это и есть AFNetworking? Префикс AF значит Alamofire, в чем можно убедиться, заглянув в лицензию AFNetworking:
Замыкания:
Многие в качестве callback-ов для бизнес логики передают в параметры запросов блоки для успеха/провала или лепят один на все. В итоге в параметрах каждого метода бизнес логики висит толстенное замыкание или даже не одно, что не сказывается положительно на читаемости проекта.
Иногда блок отдают в качестве возвращаемого значения, что тоже неудобно.
Есть такая замечательная вещь как промисы. Реализация iOS: PromiseKit. Простыми словами — вместо кучи блоков, передаваемых в метод, вы возвращаете объект, который потом можно развернуть не только в success/failure замыкания, но еще и некий always, вызывающийся всегда, независимо от успеха/провала метода.
Их также можно чередовать, объединять и делать множество приятных вещей.
Как по мне, так ключевое преимущество — это именно последовательное применение. Можно разделить flow бизнес логики на маленькие операции, вызываемые друг за другом. В итоге, например, метод получения детализации для некого товара, будет выглядеть так:
func details(id: Int) -> Promise {
return getDetails(id)
.then(execute: parse)
.then(execute: save)
} А так внутренний метод getDetails, просто делающий запрос на конкретный адрес:
func getDetails(id: Int) -> Promise> {
return Promise { fulfill, reject in
Alamofire.request(NetworkRouter.drugDetails(id: id)).responseJSON { fulfill($0) }
}
}Не самый чистый код, но для копипасты подойдет. Прячу под кат, потому что код реально трэш. Постараюсь обновить, когда руки дойдут. Уже даже стыдно за легаси, кочующий из проекта в проект.
func parseAsDictionary(response: DataResponse) -> Promise<[String:AnyObject]> {
return Promise {fulfill, reject in
switch response.result {
case .success(let value):
let json = value as! [String : AnyObject]
guard response.response!.statusCode < 400 else {
let error = Error(dictionary: json)
reject(error)
return
}
fulfill(json)
break
case .failure(let nserror):
let error = Error(error: nserror as NSError)
reject(error)
break
}
}
}
// Выше этот метод уже был, но продублриюу
func save(items: [[String : AnyObject]]) -> Promise {
return Promise {fulfill, reject in
let realm = Realm.instance
try! realm.write {
items.forEach { item in
// Замените на свой класс или сделайте generic
realm.create(Item.self, value: item, update: true)
}
}
fulfill(items.count)
}
} А в самом контроллере, если вы используете MVC, все максимально просто:
_ = service.details().then {[weak self] array -> Void in
// Success. Do w/e you like.
}База данных
Вопрос про хранение данных описывал выше, когда говорил про работу с ORM на Go-side, поэтому повторяться не буду, только добавлю ссылку на то как получать уведомления об обновлениях базы в том же контроллере. По сути если в БД что-то добавилось, то контроллер асинхронно об этом узнает. Это гораздо удобнее, чем каждый раз мучиться с подсчетом datasource при каждом малейшем движении. А если еще и эти изменения могут произойти не только из одного места, то вообще швах.
Сюда перетаскивать кусок кода из гайда по fine-grained notifications не буду, дабы не плодить копипасту.
class ViewController: UITableViewController {
var notificationToken: NotificationToken? = nil
override func viewDidLoad() {
super.viewDidLoad()
let realm = try! Realm()
let results = realm.objects(Person.self).filter("age > 5")
// Observe Results Notifications
notificationToken = results.addNotificationBlock { [weak self] (changes: RealmCollectionChange) in
guard let tableView = self?.tableView else { return }
switch changes {
case .initial:
// Results are now populated and can be accessed without blocking the UI
tableView.reloadData()
break
case .update(_, let deletions, let insertions, let modifications):
// Query results have changed, so apply them to the UITableView
tableView.beginUpdates()
tableView.insertRows(at: insertions.map({ IndexPath(row: $0, section: 0) }),
with: .automatic)
tableView.deleteRows(at: deletions.map({ IndexPath(row: $0, section: 0)}),
with: .automatic)
tableView.reloadRows(at: modifications.map({ IndexPath(row: $0, section: 0) }),
with: .automatic)
tableView.endUpdates()
break
case .error(let error):
// An error occurred while opening the Realm file on the background worker thread
fatalError("\(error)")
break
}
}
}
deinit {
notificationToken?.stop()
}
}Многие разработчики болеют гигантоманией, которая вызывает у них желание запихнуть всю бизнес логику в один файл с названием ApiManager.swift. Или есть более латентные формы, когда этот файл делят на много других, где каждый — это extension от ApiManager, что на самом деле совсем не лучше.
Получается перегруженный божественный класс и к тому же singleton, отвечающий просто за все. Я сам раньше так работал, когда занимался мелкими приложениями, но на крупном проекте это здорово аукнулось.
Лечится это с помощью SOA (service oriented architecture). Есть отличное видео от Rambler, где подробнейшим образом разбирается, что это такое и с чем его едят, но я постараюсь на пальцах дать инструкцию по внедрению в проект.
Вместо одного менеджера делаем несколько сервисов. Каждый сервис — это отдельный класс без состояния с набором методов по вышеописанному принципу. Сервисы также могут вызывать друг друга, это нормально. А чтобы использовать сервис в контроллере, то просто передаете ему нужный объект в конструкторе или создаете во viewDidLoad. Конечно, второй вариант хуже, но для начала сойдет. Иногда бывает, что прямо здесь и сейчас надо срочно подключить еще один сервис в контроллер, а разгребать всю эту цепочку зависимостей, проверять каждое место, где контроллер используется, нет никакого желания.
Пример таких сервисов в одном из проектов:

Где в каждом сервисе находится ограниченный набор методов, за которые он отвечает и с которыми работает. Желательно, чтобы сервис не превышал 200-300 строк. Если он перевалил за этот объем, то значит бедняга выполняет совсем не одну задачу, которая ему предназначена.
В итоге, вся ваша логика на клиенте сводится к следующему: запрос на сервер, парсинг в контейнер и сохранение в базу. Все, никаких промежуточных действий.
Подытожу. Хорошо подготовленные данные на бэкенде в связке с Realm-ом на mobile-side дают возможность практически целиком отказаться от дополнительной бизнес логики на клиенте, сводя все к работе с интерфейсом. Можно не согласиться, но по-моему, так и должно быть. Ведь любой клиент, пусть даже и такой классный как iOS или Android, — это в первую очередь вью вашего продукта!
А перед тем как закончить, хотелось бы поделиться наболевшим. Многие в комментариях к моим статьям выказывают недовольство, что я рассказываю очевидные вещи и вообще капитаню, а кое-кто даже не стесняется минус в карму зарядить за это.
Но вот что я хочу сказать. Своей работой я стараюсь подтянуть общий уровень разработчиков в сообществе.
Вы можете сказать, что это чересчур смело. Но знаете, как становится грустно, когда на собеседование приходит человек, считающий себя классным специалистом или, по крайней мере, сильным мидлом, но при этом даже не знающий простейших вещей? Который путается между MVP и MVVM и похоже, что вообще разрабатывает интуитивно.
Из серии, когда заглядываешь человеку в код, видишь там несуразную лютую жесть и спрашиваешь его: “Вася, почему ты так сделал?” А он отвечает: “Хз, иначе не работало.”
Про архитектуру даже не заикаюсь.
Что ж, надеюсь, было полезно. И как всегда, буду рад услышать любые вопросы, критику и предложения.
P.S. Прикладываю опрос. Стоит ли делать в будущих статьях титульную информацию с кратким сюжетом и целевой аудиторией? Нигде такого не видел, но мне кажется, могло бы быть полезно. Да, есть тэги, но они, на мой взгляд, недостаточно заметны и не раскрывают сути.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Mehdzor разработка под ios разработка мобильных приложений go api golang ios backend |
Вероятностный и информационный анализ результатов измерений на Python |
|
Метки: author Scorobey разработка под windows математика python информационная теория измерений энтропия диаграмма распределения |
Petya и другие. ESET раскрывает детали кибератак на корпоративные сети |





script2exe, был сильно обфусцирован, но его функциональность осталась такой же, как в прежних атаках.
severalwdadwajunior, который работал в сети Tor.
.xcryptedopenssl. Шифрование осуществляется с помощью алгоритмов RSA-2048 и AES-256.



medoc_online.php в одной из директорий на сервере FTP M.E.Doc. Доступ к бэкдору можно было получить через HTTP, хотя он был зашифрован, и атакующему нужен был пароль для его использования. 
Win32/TeleBot trojan
VBS/Agent.BB trojan
VBS/Agent.BD trojan
VBS/Agent.BE trojan
Win32/PSW.Agent.ODE trojan
Win64/PSW.Agent.K trojan
Python/Filecoder.R trojan
Win32/Filecoder.AESNI.C trojan
Win32/Filecoder.NKH trojan
Win32/Diskcoder.C trojan
Win64/Riskware.Mimikatz application
Win32/RiskWare.Mimikatz applicationtransfinance.com[.]ua (IP: 130.185.250.171)
bankstat.kiev[.]ua (IP: 82.221.128.27)
www.capital-investing.com[.]ua (IP: 82.221.131.52)api.telegram.org (IP: 149.154.167.200, 149.154.167.197, 149.154.167.198, 149.154.167.199)1557E59985FAAB8EE3630641378D232541A8F6F9
31098779CE95235FED873FF32BB547FFF02AC2F5
CF7B558726527551CDD94D71F7F21E2757ECD10991D955D6AC6264FBD4324DB2202F68D097DEB241
DCF47141069AECF6291746D4CDF10A6482F2EE2B
4CEA7E552C82FA986A8D99F9DF0EA04802C5AB5D
4134AE8F447659B465B294C131842009173A786B
698474A332580464D04162E6A75B89DE030AA768
00141A5F0B269CE182B7C4AC06C10DEA93C91664
271023936A084F52FEC50130755A41CD17D6B3B1
D7FB7927E19E483CD0F58A8AD4277686B2669831
56C03D8E43F50568741704AEE482704A4F5005AD
38E2855E11E353CEDF9A8A4F2F2747F1C5C07FCF
4EAAC7CFBAADE00BB526E6B52C43A45AA13FD82B
F4068E3528D7232CCC016975C89937B3C54AD0D1A4F2FF043693828A46321CCB11C5513F73444E34
5251EDD77D46511100FEF7EBAE10F633C1C5FC53759DCDDDA26CF2CC61628611CF14CFABE4C27423
77C1C31AD4B9EBF5DB77CC8B9FE9782350294D70
EAEDC201D83328AF6A77AF3B1E7C4CAC65C05A88
EE275908790F63AFCD58E6963DC255A54FD7512A
EE9DC32621F52EDC857394E4F509C7D2559DA26B
FC68089D1A7DFB2EB4644576810068F7F451D5AA1C69F2F7DEE471B1369BF2036B94FDC8E4EDA03E
AF07AB5950D35424B1ECCC3DD0EEBC05AE7DDB5EBDD2ECF290406B8A09EB01016C7658A283C407C3
9C694094BCBEB6E87CD8DD03B80B48AC1041ADC9
D2C8D76B1B97AE4CB57D0D8BE739586F82043DBD34F917AABA5684FBE56D3C57D48EF2A1AA7CF06DD297281C2BF03CE2DE2359F0CE68F16317BF0A86
|
Метки: author esetnod32 антивирусная защита блог компании eset nod32 malware petya diskcoder.c telebots |
Symfony: Webpack Encore — плагин для управления ресурсами |
yarn add @symfony/webpack-encore --dev
yarn add sass-loader node-sass --dev
+-assets/
---+ dist/
------+ fontawesome/
------+ jquery/
------+ bootstrap/
/* подключим плагин */
var Encore = require('@symfony/webpack-encore');
Encore
/* Установим путь куда будет осуществляться сборка */
.setOutputPath('web/build/')
/* Укажем web путь до каталога web/build */
.setPublicPath('/build')
/* Каждый раз перед сборкой будем очищать каталог /build */
.cleanupOutputBeforeBuild()
/* Добавим наш главный файл ресурсов в сборку */
.addStyleEntry('styles', './assets/app.scss')
/* Включим поддержку sass/scss файлов */
.enableSassLoader()
/* В режиме разработки будем генерировать карту ресурсов */
.enableSourceMaps(!Encore.isProduction());
/* Экспортируем финальную конфигурацию */
module.exports = Encore.getWebpackConfig();
@import "dist/fontawesome/css/font-awesome";
@import "dist/bootstrap/css/bootstrap";
/* Тут можно определить свои стили или подключить собственные библиотеки */
./node_modules/.bin/encore dev
var $ = require('./dist/jquery/jquery-3.2.1');
require('./dist/bootstrap/js/bootstrap');
/* подключим плагин */
var Encore = require('@symfony/webpack-encore');
Encore
/* Установим путь куда будет осуществляться сборка */
.setOutputPath('web/build/')
/* Укажем web путь до каталога web/build */
.setPublicPath('/build')
/* Каждый раз перед сборкой будем очищать каталог /build */
.cleanupOutputBeforeBuild()
/* --- Добавим основной JavaScript в сборку --- */
.addEntry('scripts', './assets/app.js')
/* Добавим наш главный файл ресурсов в сборку */
.addStyleEntry('styles', './assets/app.scss')
/* Включим поддержку sass/scss файлов */
.enableSassLoader()
/* В режиме разработки будем генерировать карту ресурсов */
.enableSourceMaps(!Encore.isProduction());
/* Экспортируем финальную конфигурацию */
module.exports = Encore.getWebpackConfig();
./node_modules/.bin/encore dev
/* подключим плагин */
var Encore = require('@symfony/webpack-encore');
Encore
/* Установим путь куда будет осуществляться сборка */
.setOutputPath('web/build/')
/* ... */
.autoProvidejQuery()
/* В режиме разработки будем генерировать карту ресурсов */
.enableSourceMaps(!Encore.isProduction());
/* Экспортируем финальную конфигурацию */
module.exports = Encore.getWebpackConfig();
var $ = require('./dist/jquery/jquery-3.2.1');
global.$ = global.jQuery = $;
require('./dist/bootstrap/js/bootstrap');
/* webpack.config.js */
// ...
.enableVersioning()
// ...
# app/config/config.yml
framework:
# ...
assets:
# Функционал доступен начиная с Symfony 3.3
json_manifest_path: '%kernel.project_dir%/web/build/manifest.json'
require('./app.scss');
var $ = require('./dist/jquery/jquery-3.2.1');
global.$ = global.jQuery = $;
require('./dist/bootstrap/js/bootstrap');
./node_modules/.bin/encore production
|
Метки: author shude symfony php node.js symfony webpack encore |
Экономия на спичках или восстановление данных из скрежещущего HDD Seagate ST3000NC002-1DY166 |








|
|
Who is Mr. Hacker? |

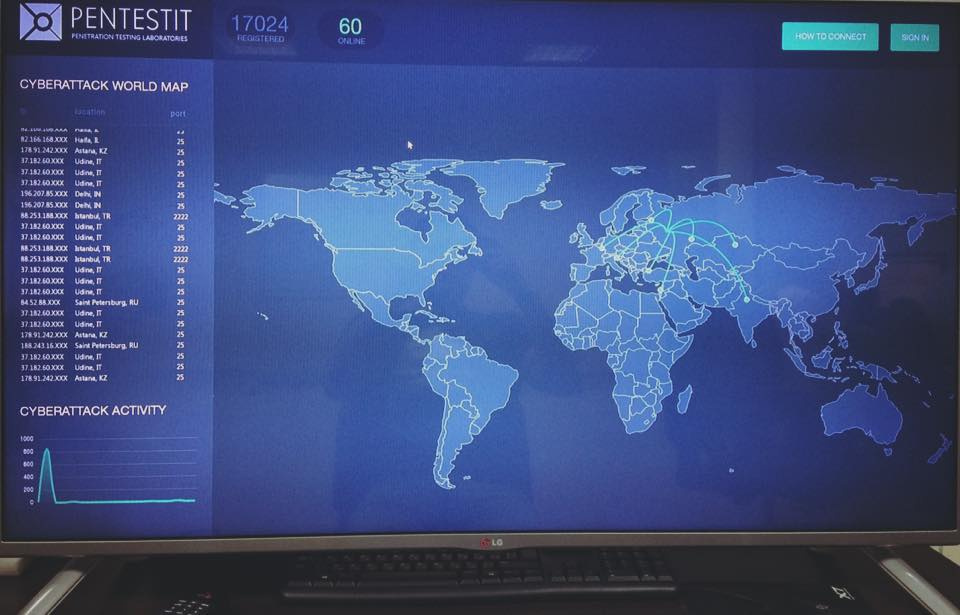
|
Метки: author LukaSafonov информационная безопасность penetration testing lab |
Security Week 26: ExPetr – не вымогатель, Intel PT позволяет обойти PatchGuard, в Malware Protection Engine снова RCE |
 Мимикрия чрезвычайно распространена в животном мире. Чтобы было проще прятаться от хищников, или наоборот, легче подкрадываться к добыче незамеченными, звери, рептилии, птицы и насекомые приобретают окраску, схожую с окружающей местностью. Встречается мимикрия и под предметы, и, наконец, под животных других видов – более опасных, или менее вкусных.
Мимикрия чрезвычайно распространена в животном мире. Чтобы было проще прятаться от хищников, или наоборот, легче подкрадываться к добыче незамеченными, звери, рептилии, птицы и насекомые приобретают окраску, схожую с окружающей местностью. Встречается мимикрия и под предметы, и, наконец, под животных других видов – более опасных, или менее вкусных.
 Проблема кроется в замечательной технологии Intel PT (Processor Trace), которая позволяет секьюрити-продуктам отслеживать поток команд, исполняемый процессором, чтобы моментально определять возможную атаку. Задумка отличная, но CyberArk смогли использовать PT для запуска своего кода в пространстве ядра. Они, конечно, отрепортили все это в Microsoft, но получили ответ, что все это ерунда, так как для использования уязвимости нужны админские права. А раз так, то это уже и не уязвимость, ибо админу и так позволено на машине все, и если таковым стал злоумышленник – туши свет, сливай воду.
Проблема кроется в замечательной технологии Intel PT (Processor Trace), которая позволяет секьюрити-продуктам отслеживать поток команд, исполняемый процессором, чтобы моментально определять возможную атаку. Задумка отличная, но CyberArk смогли использовать PT для запуска своего кода в пространстве ядра. Они, конечно, отрепортили все это в Microsoft, но получили ответ, что все это ерунда, так как для использования уязвимости нужны админские права. А раз так, то это уже и не уязвимость, ибо админу и так позволено на машине все, и если таковым стал злоумышленник – туши свет, сливай воду.
|
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» klsw petya expetr msmpeng patchguard intelpt eternalblue |






