[Перевод] О-о-очень долгожданный релиз Sublime Text 3.0 |
Спустя долгие годы ожидания в beta и alpha релизах (а это около 3.5 лет) наконец-то вышел Sublime Text 3.0!
Предисловие: Sublime Text — является комерческим (хотя никто и не заставляет покупать лицензию) графическим текстовым редактором под 3 основные десктопные платформы.
В сравнении с последней бетой, версия 3.0 привносит обновленную тему пользовательского интерфейса, новые цветовые схемы и новую иконку. Помимо этого улучшена подсветка синтаксиса, поддержка тачпада на Windows, поддержка тачбара на macOS и репозитории apt/yum/pacman для Linux.
Я хочу отметить некоторые отличия от Sublime Text 2, хотя это на удивление сложно: практически каждый аспект редактора так или иначе был улучшен, так что даже список основных изменений будет очень большим. Если хотите увидеть полный список изменений, команда подготовила отдельную страницу для этого.
Определенно, в 3 версии добавили огромные фичи, например: прыжок на определение (F12), новый движок для подсветки синтаксиса, новый UI и расширенное API. Однако различия повсюду ощущаются в мелочах, которые сложно выделить самодостаточные: проверка орфографии работает лучше, автоматический отступ стал делать правильные вещи чаще, перенос слов лучше обрабатывает исходный код, правильно поддерживаются мониторы с высоким DPI, а также переход к файлам (Goto Anything ctrl+p) стал умнее. Перечислять все нудно и долго, но отличия разительны.
Одна из особенностей, за которую я особенно горд, — это производительность редактора: он значительно быстрее предшественника во всех областях. Запуск быстре, быстрее открытие файлов, более эффективная прокрутка. Несмотря на то, что 3 версия гораздо больше, она, наоборот, кажется более компактной.
|
Метки: author l4l системное программирование программирование python sublime text 3 редактор кода |
Причуды Stream API |
|
Метки: author ARG89 java блог компании jug.ru group stream |
[Из песочницы] Как написать хорошее решение для Highload Cup, но недостаточно хорошее чтобы выйти в топ |
На прошлой недели закончилось соревнование HighLoad Cup, идея которого заключалась в реализации HTTP сервера для сайта путешественников. О том как за 5 дней написать решение на Go, которое принесет 52 место в абсолютном зачете из 295, читайте под катом.
Пользователь Afinogen в своей статье уже описывал условия конкурса, но для удобства я сжато повторюсь. Сервер должен реализовывать API для работы сайта путешественников и поддерживать сущности трех видов: путешественник (User), достопримечательность (Location) и посещение (Visit). API должно предоставлять возможность добавлять любые новые сущности в базу, получать их и обновлять, а также делать 2 операции над ними — получение средней оценки достопримечательности (avg) и получение мест, посещенных путешественником (visits). У каждой из этих операций так же есть набор фильтров, которые необходимо учитывать при формировании ответа. Так, например, API позволяет получить среднюю оценку оценку достопримечательности среди мужчин от 18 до 25 лет начиная с 1 апреля 2010 года. Это накладывает дополнительные сложности при реализации.
На всякий случай приведу краткое формальное описание API:
Самый первый вопрос который возникает у всех кто ознакомился с условием задачи — как хранить данные. Многие (как например я) сначала пытались использовать какую-нибудь базу с расчетом на большое количество данных, которые не поместятся в память и не городить костыли. Однако этот подход не давал высокое место в рейтинге. Дело в том что организаторы конкурса очень демократично подошли к размеру данных, поэтому даже без каких либо оптимизаций структуры хранения все данные без труда помещались в памяти. Всего в рейтинговом обстреле было около 1 млн путешественников, 100 тысяч достопримечательностей и 10 миллионов посещений, идентификаторы каждой сущности шли по порядку от 1. На первый взгляд объем может показаться большим, но если посмотреть на размер структур, которые можно использовать для хранения данных, а так же на размер строк в структурах, то можно увидеть что в среднем размеры не слишком большие. Сами структуры и размеры их полей я привел ниже:
type Visit struct { // overall 40 bytes
Id int // 8 bytes
Location int // 8 bytes
User int // 8 bytes
VisitedAt int // 8 bytes
Mark int // 8 bytes
}
type User struct { //overall 133 bytes
Id int // 8 bytes
Email string // 22 bytes + 16 bytes
FirstName string // 12 bytes + 16 bytes
LastName string // 18 bytes + 16 bytes
Gender string // 1 byte + 16 bytes
Birthdate int // 8 bytes
}
type Location struct { // overall 105 bytes
Id int // 8 bytes
Place string // 11 bytes + 16 bytes
Country string // 14 bytes + 16 bytes
City string // 16 bytes + 16 bytes
Distance int // 8 bytes
}Размеры string в структуре я указал в формате "средняя длинна строки" + "размер объекта string". Умножив средний размер каждой структуры на количество объектов получаем, что чисто для хранения данных нам нужно всего лишь примерно 518 МБ. Не там уж не много, при условии того что мы можем разгуляться аж на 4 ГБ.
Самое большое потребление памяти, как это не было бы странно на первый взгляд, происходит не при самом обстреле, а на этапе загрузки данных. Дело в том, что изначально все данные запакованы в .zip архив и в первые 10 минут серверу необходимо загрузить эти данные из архива для дальнейшей работы с ними. Нераспакованный архив весит 200 МБ, + 1.5 ГБ весят файлы после распаковки. Без аккуратной работы с данными и без более агрессивной настройки сборщика мусора загрузить все данные не получалось.
Второй момент, который был очень важен, но не все сразу его заметили — обстрелы сервера проходили так, что состояние гонки не могло получиться в принципе. Тестирование сервера проходило в 3 этапа: на первом этапе шли GET запросы, которые получали объекты и вызывали методы avg (получения средней оценки) и visits (получения посещений пользователем), вторым этапом данные обновлялись (на этом этапе были исключительно POST запросы на создание и обновление данных) и на последнем этапе опять шли GET запросы, только уже на новых данных и с большей нагрузкой. Из-за того что GET и POST запросы были жестко разделены, не было нужды использовать какие-либо примитивы синхронизации потоков.
Таким образом, если принять во внимание два эти момента, а так же вспомнить что id объектов каждой сущности шли по порядку начиная с 1, то в результате все данные можно хранить так:
type Database struct {
usersArray []*User
locationsArray []*Location
visitsArray []*Visit
usersMap map[int]*User
locationsMap map[int]*Location
visitsMap map[int]*Visit
}Все объекты, если хватает размера массива, помещаются в соответствующий типу массив. В случае, если id объекта был бы больше чем размер массива, он помещался бы в соответствующий словарь. Сейчас, зная что в финале данные абсолютно не поменялись, я понимаю что словари лишние, но тогда никаких гарантий этого не было.
Довольно скоро стало понятно, что для быстрой реализации методов avg и visits необходимо хранить не только сами структуры User и Location, но и id посещений пользователя и достопримечательностей вместе с самими структурами соответственно. В результате я добавил поле Visits, представляющее собой обычный массив в эти две структуры, и таким образом смог быстро находит все структуры Visit, ассоциированные с этим пользователем/достопримечательностью.
В процессе тестирования я так же думал об использовании "container/list" из стандартной библиотеки, но знание устройства этого контейнера подсказывало мне что он всегда будет проигрывать и по скорости доступа к элементам, и по памяти. Его единственный плюс — возможность быстрого удаления/добавления в любую точку не сильно важен для этой задачи, так как соотношение количества посещений к пользователям примерно 10 к 1, то мы можем сделать предположение что контейнеры Visit в структурах Location и User будут примерно размером 10. А удалить элемент из начала массива размером 10 единиц не так уж и затратно на общем фоне и не является частой операцией. Что касается памяти, то ее потребление можно проиллюстрировать следующим кодом:
package main
import (
"fmt"
"runtime"
"runtime/debug"
"container/list"
)
func main() {
debug.SetGCPercent(-1)
runtime.GC()
m := &runtime.MemStats{}
runtime.ReadMemStats(m)
before := m.Alloc
for i:=0;i<1000;i++ {
s := make([]int, 0)
for j:=0;j<10;j++ {
s = append(s, 0)
}
}
runtime.ReadMemStats(m)
fmt.Printf("Alloced for slices %0.2f KB\n", float64(m.Alloc - before)/1024.0)
runtime.GC()
runtime.ReadMemStats(m)
before = m.Alloc
for i:=0;i<1000;i++ {
s := list.New()
for j:=0;j<10;j++ {
s.PushBack(1);
}
}
runtime.ReadMemStats(m)
fmt.Printf("Alloced for lists %0.2f KB\n", float64(m.Alloc - before)/1024.0)
}Этот код дает следующий вывод:
Alloced for slices 117.19 KB
Alloced for lists 343.75 KB
Этот код создает 1000 массивов и 1000 списков и заполняет их 10 элементами, так как это среднее число посещений. Число 10 является плохим для массива, так как при добавлении элементов, на 8 элементе он расширится до 16 элементов и тем самым памяти будет затрачено больше чем необходимо. По результатам все равно видно что на решение со слайсами было затрачено в 3 раза меньше памяти, что сходится с теорией, так как каждый элемент списка хранит указатель на следующий, предыдущий элемент и на сам список.
Другие пользователи прошедшие в финал делали еще несколько индексов — например индекс по странам для метода visits. Эти индексы, скорее всего ускорили бы решение, однако не так сильно, как хранение посещений пользователя и хранение посещений достопримечательности вместе с информацией об этом объекте.
Стандартная библиотека для реализации http сервера достаточно удобная в использовании и хорошо распространена, однако когда речь заходит о скорости, все рекомендуют fasthttp. Поэтому первым делом после реализации логики я выкинул стандартный http сервер и заменил его на fasthttp. Замена прошла абсолютно безболезненно, хоть данные две библиотеки имеют разный API.
Далее под замену ушла стандартная библиотека кодирования/декодирования json. Я выбрал easyjson, так как он показывал отличные данные по скорости/памяти + имел схожий с "encoding/json" API. Easyjson генерирует свой собственный парсер для каждой структуры данных, что и позволяет показывать такие впечатляющие результаты. Его единственный минус — небольшое число настроек. Например, в задаче были запросы, в которых одно из полей отсутствовало, что должно приводить в ошибке, однако easyjson тихо пропускал такие поля, из-за чего пришлось лезть в исходных код парсеров.
Так как все методы API за исключением POST методов были реализованы без использования дополнительной памяти, было решено отключить сборщик мусора — все равно если памяти хватает, то зачем гонять его?
Так же был переписан роутинг запросов. Каждый запрос определялся по одному символу, что позволило сэкономить на сравнении строк. Школьная оптимизация.
За 5 последних дней конкурса я, без какого либо опыта участия в подобных конкурсах, написал решение на Go, которое принесло мне 52 место из 295 участников. К сожалению мне не хватило совсем чуть чуть до прохождения в финал, но с другой стороны в финале собрались достойные соперники, поэтому из-за того что данные и условия задачи никак не менялись то маловероятно что я смог бы подняться выше.
|
Метки: author rus_phantom высокая производительность go golang highloadcup |
Финал Imagine Cup 2017 глазами команды МФТИ |




Я знал текст, который следовало говорить, я долго и упорно репетировал, я подбадривал себя и всё равно ничего не мог с собой поделать: руки и ноги тряслись так, как будто вместо них у меня отбойные молотки. Я думал, что выроню микрофон, и молился, чтобы текст не вылетал из головы. Он, конечно же, вылетал.

Соревнование в этом году проводилось в рекордно сжатые сроки (2 дня вместо 4 дней в прошлом году и недели в более ранние года). Тем не менее даже этого времени было достаточно, чтобы почувствовать, что ты приехал не просто на соревнование, а еще и в некое подобие летнего студенческого лагеря, лагеря амбициозных творческих ребят-сверстников-единомышленников. Общение с ними — это не только отличная практика английского и других иностранных языков, но и прекрасная возможность узнать много нового о других странах и культурах, весело провести время и, самое главное, найти друзей по всему миру.


|
Метки: author shwars блог компании microsoft imagine cup imagine cup 2017 конкурс проектов студенты сиэтл |
Сеть магазинов «М.Видео» проведёт хакатон по искусственному интеллекту |
|
Метки: author sviridius программирование машинное обучение алгоритмы блог компании м.видео хакатон искусственный интеллект |
Positive Technologies на GitHub |
Поздравляю программистов с их профессиональным днем! В связи с этим праздником наша компания Positive Technologies решила рассказать о своей деятельности, напрямую связанной с разработкой, а именно с открытым исходным кодом и GitHub.

В последнее время все больше и больше компаний, таких как Google, Microsoft, Facebook, JetBrains, выкладывают в открытый доступ исходный код как небольших, так и крупных проектов. Positive Technologies славится не только высококлассными специалистами по информационной безопасности, но и большим количеством профессиональных разработчиков. Это позволяет ей также вносить свой посильный вклад в развитие движения Open Source.
У PT есть следующие GitHub-организации, поддерживающие открытые проекты компании:
Мы подробно описали первую организацию с ее проектами и кратко — все остальные.
Основное сообщество, в котором ведется разработка как изначально открытых проектов, так и тех, которые раньше разрабатывались исключительно внутри компании. Также здесь размещаются учебные и демонстрационные проекты.

Цель сообщества — сформировать открытые готовые решения для управления полным циклом процесса разработки, тестирования и смежных процессов, а также доставки, развёртывания и лицензирования продуктов.
На данный момент сообщество находится в начальной стадии развития, но уже сейчас в нем можно найти некоторые полезные инструменты, написанные на Python. Да, мы его любим.
Активные проекты:
Каждый инструмент имеет автоматическую сборку в Travis CI с выкладкой в PyPI-репозиторий, где их можно найти и установить через стандартный pip install.
Готовятся к публикации еще несколько инструментов:
В качестве контрибьюторов любого инструмента приглашаются все желающие. У нас есть типовой проект ExampleProject, в котором содержатся общая структура и подробная инструкция по созданию собственного проекта в сообществе. Фактически достаточно его скопировать и сделать свой проект по аналогии. Если у вас есть идеи или инструменты для автоматизации чего-либо, давайте делиться ими с сообществом под MIT-лицензией! Это модно, почётно, престижно :)
Группа исследователей, содержащая репозиторий AttackDetection, в который команда обнаружения атак выкладывает правила для определения эксплуатации уязвимостей с помощью систем обнаружения вторжений Snort и Suricata IDS. Основная цель проекта — создание правил для уязвимостей, имеющих широкое распространение и высокий уровень опасности (high impact). Репозиторий содержит файлы для интеграции с oinkmaster — скриптом для обновления и развертывания правил в указанных IDS. А для теста самих правил прилагаются pcap-файлы с трафиком. Стоит отметить, что репозиторий уже набрал свыше 100 добавлений в избранное, а за год добавилось около 40 новых уязвимостей, среди которых BadTunnel, ETERNALBLUE, ImageTragick, EPICBANANA, SambaCry. Все анонсы о новых угрозах публикуются в Twitter.
Сообщество по разработке инструментария (преимущественно веб), используемого в продуктах PT.

PT Pattern Matching Engine — универсальный сигнатурный анализатор кода, который принимает на вход пользовательские шаблоны, описанные на специальном языке. Данный движок испольуется в бесплатном инструменте для проверки веб-приложений на наличие уязвимых компонентов Approof, а также в анализаторе исходного кода PT Application Inspector.
Процесс анализа состоит из нескольких этапов:
Реализованный в проекте подход дает возможность унифицировать задачу разработки шаблонов под различные языки.
В PT.PM внедрена непрерывная интеграция, поддерживаются сборка и тестирование модулей проекта как под Windows, так и под Linux (Mono). Процесс разработки организуется с помощью размеченных метками задач (Issues) и пул-реквестов. Наряду с разработкой ведется документация проекта, а результаты всех значимых сборок публикуются в формате как пакетов NuGet, так и «сырых» артефактов. Организацию PT.PM, вероятно, можно считать образцовой, к которой хотелось бы стремиться во всех остальных проектах.
Для первого этапа, а именно парсинга исходного кода, используются парсеры на базе ANTLR. Этот инструмент генерирует их для различных языков (рантаймов) на основе формальных грамматик, для которых существует репозиторий. Наша компания его активно развивает. В настоящее время поддерживается генерация под Java, C#, Python 2 и 3, JavaScript, C++, Go и Swift, причём поддержка последних трех была добавлена совсем недавно.
Стоит отметить, что ANTLR используется не только в проектах PT направления Application Security, но и в Max Patrol SIEM: там он используется для обработки собственного языка DSL (Domain Specific Language), который применяется для описания динамических групп активов. Обмен опытом в этой сфере позволил не тратить время на задачи, которые уже были решены ранее.
При участии Positive Technologies были разработаны и улучшены грамматики для языков PL/SQL, T-SQL, MySQL, PHP, Java 8 и C#.
Грамматики SQL имеют обширный синтаксис с большим количеством ключевых слов. К счастью, грамматика PL/SQL существовала под ANTLR 3 и портировать её под ANTLR 4 было не очень сложно.
Для T-SQL не было найдено достойных парсеров, не говоря уже об открытых, и мы долго и кропотливо восстанавливали грамматику из документации MSDN. Однако результат получился достойным: она уже охватывает много распространённых синтаксических конструкций, опрятно выглядит, независима от рантайма и покрыта тестами (примерами SQL-запросов из той же MSDN). С 2015 в нее внесли свой вклад более 15 сторонних пользователей. Более того, эта грамматика сейчас уже используется и в DBFW, прототипе межсетевого экрана уровня систем управления базами данных, подпроекте PT Application Firewall. Денис Колегов с Арсением Реутовым рассказывали о нем на PHDays VII: «Как разработать DBFW с нуля».
Грамматика, разработанная вышеупомянутой командой, в первую очередь Иваном Худяшовым и Денисом Колеговым, на основе T-SQL. Она также используется в DBFW.
Данная грамматика транслировалась из грамматики Bison в ANTLR. Она интересна тем, что поддерживает парсинг сразу PHP, JavaScript и HTML. Точнее, участки кода JavaScript и HTML парсятся в текст, который позже обрабатывается парсерами конкретно под эти языки.
Эта грамматика была разработана совсем недавно. За основу была взята грамматика предыдущей версии Java 7. Доработка была относительно быстрой, так как отличий между версиями немного.
Это по большей части экспериментальная грамматика, созданная для сравнения скоростей парсеров на основе ANTLR и парсера Roslyn.

О деталях разработки грамматик можно почитать в нашей прошлогодней статье «Теория и практика парсинга исходников с помощью ANTLR и Roslyn».
Как видно по истории изменений, эти грамматики дорабатываются не только усилиями Positive Technologies, но и большим количеством сторонних разработчиков. За время этой кооперации репозиторий вырос не только количественно, но и качественно.
Позволяет собирать статистику для проектов на различных языках программирования и используется в бесплатном продукте Approof.
В рамках данного проекта разрабатывается парсер страниц ASPX, который используется не только в открытом движке PT.PM, но и во внутреннем анализаторе .NET-приложений (AI.Net), основанном на абстрактной интерпретации кода.

В репозитории идет разработка наборов правил в формате YARA, которые используются в модуле сигнатурного анализа проектов в Approof. В августе прошлого года в рамках PDUG (юзер-группы по безопасной разработке) Алексей Гончаров делал доклад о модуле FingerPrint, используемом в PT AI и Approof.
Движок FingerPrint запускается на наборе исходных кодов сайта (бэкенда, фронтенда) и в соответствии с описанными правилами YARA ищет известные версии сторонних компонентов (например, библиотеку bla-bla версии 3). Правила составляются так, что содержат сигнатуры уязвимых версии библиотек с текстовым описанием проблемы.
Правило представляет собой нескольких условий для проверки файла. Например, условие наличия в файле определенных строк. Если файл им удовлетворяет, то Approof в итоговом отчете выдает информацию об обнаруженных уязвимостях в определенном компоненте с версией N, а также описания относящихся к ним CVE.
Подробнее об этом можно почитать в статье Дениса Ефремова (ИСП РАН) «Разработка правил для Approof». Также см. его доклад «Автоматизация построения правил для Approof» на PDUG секции PHDays.
На PHDays VII в рамках PDUG прошел мастер-класс «Appsec Outback». Для него были разработаны учебно-демонстрационные версии статического анализатора кода Mantaray и межсетевого экрана Schockfish. Данные проекты имеют все основные механизмы, которые используются в реальных средствах защиты. Но, в отличие от последних, их основная цель продемонстрировать алгоритмы и методы защиты, помочь понять процесс анализа и защиты приложений, а также проиллюстрировать фундаментальные теоретические возможности и ограничения технологий.
Также в репозитории имеются примеры реализации механизмов защиты:
В наших проектах используются как разрешительные лицензии (MIT, Apache), так и собственная, которая подразумевает бесплатное использование исключительно в некоммерческих целях.
Процесс переезда на GitHub оказался полезным и дал нам опыт в различных областях — в настройке DevOps под Windows и Linux, написании документации, в разработке.
Positive Technologies развивает Open Source проекты и планирует расширять эту активность.
При конвертации Markdown из формата GitHub в формат Habrahabr использовался HabraMark.
|
Метки: author KvanTTT open source github блог компании positive technologies ptsecurity |
[Из песочницы] Программирование с использованием PCAP |
Данный текст является переводом статьи Тима Карстенса Programming with pcap 2002 года. В русскоязычном интернете не так много информации по PCAP. Перевод сделан в первую очередь для людей, которым интересна тема захвата трафика, но при этом они плохо владеют английским языком. Под катом, собственно, сам перевод.
Давайте начнем с того, что определим, для кого написана эта статья. Очевидно, что некоторое базовое знание C необходимо (если, конечно, вы не хотите просто понять теорию), для понимания кода приведенного в статье, но вам не нужно быть ниндзя программирования: в тех моментах, которые могут быть понятны только более опытными программистам я постараюсь подробно объяснить все концепции. Так же, пониманию может помочь некоторое базовое знание работы сетей, учитывая что PCAP — это библиотека для реализации сниффинга (Прим. переводчика: Сниффинг — процесс захвата сетевого трафика, своего, или чужого). Все представленные здесь примеры кода были протестированы на FreeBSD 4.3 с ядром по умолчанию.
Первая вещь которую необходимо понять — общая структура PCAP сниффера. Она может выглядеть следующим образом:
eth0, в BSD это может быть xl1, и тому подобное. Мы можем либо указать этот идентификатор в строке, либо попросить PCAP предоставить его нам.pcap_loop, PCAP будет работать до тех пор, пока не получит столько пакетов, сколько мы ему указали. Каждый раз, когда он получает новый пакет, он вызывает определенную нами функцию. Эта функция может делать все что мы хотим. Она может прочитать пакет, и передать информацию пользователю, она может сохранить его в файл, или вовсе не делать ничего. Это ужасно просто. Есть два способа определить устройство, которое мы хотим прослушивать.
Первый — просто позволить пользователю сказать программе имя того устройства с которого он хочет захватывать трафик. Рассмотрим этот код:
#include
#include
int main(int argc, char *argv[])
{
char *dev = argv[1];
printf("Device: %s\n", dev);
return(0);
}Пользователь определяет устройство указывая его имя в качестве первого аргумента программы. Теперь, строка dev содержит имя интерфейса который мы будем прослушивать в формате понятном PCAP (конечно, при условии, что пользователь дал нам реальное имя интерфейса)
Второй способ также очень прост. Давайте взглянем на программу:
#include
#include
int main(int argc, char *argv[])
{
char *dev, errbuf[PCAP_ERRBUF_SIZE];
dev = pcap_lookupdev(errbuf);
if (dev == NULL)
{
fprintf(stderr, "Couldn't find default device: %s\n", errbuf);
return(2);
}
printf("Device: %s\n", dev);
return(0);
}В этом случае, PCAP просто установит имя устройства самостоятельно. "Но подожди, Тим", вы скажете. "Что делать со строкой errbuf?". Большинство PCAP команд позволяют нам передать им строку в качестве одного из аргументов. С какой целью? В том случае, если выполнение команды не удастся, PCAP запишет описание ошибки в переданную строку. В этом случае, если выполнение pcap_lookupdev() провалится, сообщение об ошибке будет помещено в errbuf. Круто, не правда ли? Вот так вот и устанавливается имя устройства для захвата трафика.
Задача создания сессии захвата трафика так же очень проста. Для этого мы будем использовать функцию pcap_open_live(). Прототип этой функции:
pcap_t *pcap_open_live(char *device, int snaplen, int promisc, int to_ms, char *ebuf)Первый аргумент — это имя устройства которое мы определили в предыдущем разделе. snaplen это целое число, которое определяет максимальное число байтов, которое может захватить PCAP. promisc, когда установлен в true, устанавливает устройство в неразборчивый режим (так или иначе, даже если он установлен в false, в определенных случаях интерфейс может находится в неразборчивом режиме). to_ms это время чтения в миллисекундах (значение 0 означает отсутствие таймаута; по крайней мере на некоторых платформах, это означает что вы можете дождаться появления достаточного количества пакетов для прекращения сниффинга до того, как закончите анализ этих пакетов. Поэтому вы должны использовать ненулевое время). Наконец, ebuf это строка в которой мы можем хранить сообщения об ошибках (так же, как мы делали до этого с errbuf). Функция возвращает дескриптор сеанса.
Для демонстрации, рассмотрим этот фрагмент кода:
#include
...
pcap_t *handle;
handle = pcap_open_live(dev, BUFSIZ, 1, 1000, errbuf);
if (handle == NULL)
{
fprintf(stderr, "Couldn't open device %s: %s\n", dev, errbuf);
return(2);
}Этот код открывает устройство помещенное в переменную dev, говорит читать столько байтов, сколько указано в BUFSIZ (константа, которая определена в pcap.h). Мы говорим переключить устройство в неразборчивый режим, что бы захватывать трафик до момента возникновения какой либо ошибки, и в случает ошибки, поместить ее описание в строку errbuf; и после, в случае ошибки, используем эту строку что бы вывести сообщение о том, что пошло не так.
Замечания по поводу разборчивого/неразборчивого режимов сниффинга: два способа очень различны по стилю. Обычно, интерфейс находится в разборчивом режиме, захватывая только тот трафик, который отправлен именно ему. Только трафик направленный от него, к нему, или маршрутизированный через него будет захвачен сниффером. Неразборчивый режим, наоборот, захватывает весь трафик который проходит через кабель. В среде без коммутации это может быть весь сетевой трафик. Очевидным преимуществом этого способа является то, возможно захватить большее количество пакетов, что может быть полезным, или нет, в зависимости от цели захвата трафика. Однако существуют и недостатки. Неразборчивый режим легко детектируется, один узел может четко определить, находится ли другой в неразборчивом режиме или нет. Так же, он работает только в не коммутируемой среде (например хаб, или маршрутизатор использующий APR). Еще одним недостатком является то, что в сетях с большим количеством трафика может не хватить системных ресурсов для захвата и анализа всех пакетов.
Не все устройства предоставляют одни и те же заголовки канального уровня в прочитанных вами пакетах. Ethernet устройства, и некоторые не-Ethernet устройства, могут предоставить Ethernet заголовки, но другие типы устройств, например такие как замыкающие устройства в BSD и OS X, PPP-интерфейсы, и Wi-Fi-интерфейсы в режиме мониторинга — нет.
Вам нужно определить тип заголовков канального уровня, которые предоставляет устройство, и использовать для анализа содержимого пакетов. pcap_datalink() возвращает тип заголовков канального уровня. (Cм. список значений заголовков канального уровня. Возвращаемые значения — значения DHT_ в этом списке)
Если ваша программа не поддерживает заголовки канального уровня предоставляемые устройством, то она должна будет прекратить работу, с помощью подобного кода:
if (pcap_datalink(handle) != DLT_EN10MB)
{
fprintf(stderr, "Device %s doesn't provide Ethernet headers -not supported\n", dev);
return(2);
}который сработает если устройство не поддерживает Ethernet — заголовки. Это может сработать для кода приведенного ниже, который использует заголовки Ethernet.
Часто мы заинтересованы в захвате только определенного типа трафика. Для примера — бывает такое, что единственное что мы хотим — это захватить трафик с порта 23(telnet) для поиска паролей. Или возможно мы хотим перехватить файл который был отправлен через порт 21(FTP). Может быть мы хотим захватить только DNS трафик (порт 53 UDP). Однако, бывают редкие случаи, когда мы просто хотим слепо захватывать весь интернет трафик. Давайте рассмотрим функции pcap_compile() и pcap_setfilter().
Процесс очень простой. После того, как мы вызвали pcap_open_live() и имеем работающую сессию сниффинга, мы можем применить наш фильтр. Вы спросите, почему просто не использовать обычные if/else if выражения? Две причины: первая — фильтр PCAP эффективнее, потому что он фильтрует непосредственно через BPF; соответственно нам нужно куда меньшее количество ресурсов, ведь драйвер BPF делает это напрямую. Вторая — это то, что фильтры PCAP просто проще.
Перед тем, как применить фильтр, мы должны скомпилировать его. Условие фильтра содержится в обычной строке (или массиве char). Синтаксис достаточно хорошо документирован на главной странице tcpdump.org; Я оставлю это вам на самостоятельное рассмотрение. Однако, мы будем использовать простые тестовые выражения, и, возможно, вы достаточно догадливы что бы самостоятельно вывести правила синтаксиса этих условий из приведенных примеров.
Что бы скомпилировать фильтр мы вызываем функцию pcap_compile(). Прототип определяет эту функцию как:
int pcap_compile(pcap_t *p, struct bpf_program *fp, char *str, int optimize, bpf_u_int32 netmask)Первый аргумент — это наш дескриптор сессии (pcap_t* handle в нашем предыдущем примере). Следующий — это указатель на место, где мы будем хранить скомпилированную версию фильтра. Далее идет само выражение, в обычном строковом формате. После идет целое число, которое определяет, нужно ли оптимизировать выражения фильтра, или нет (0 — нет, 1 — да). Наконец, мы должны определить сетевую маску той сети, к которой мы применяем фильтр. Функция возвращает -1 при ошибке; все остальные значения означают успех.
После компиляции фильтра, время применить его. Вызовем pcap_setfilter(). Следуя нашему формату объяснения PCAP, мы должны рассмотреть прототип этой функции:
int pcap_setfilter(pcap_t *p, struct bpf_program *fp)Это очень прямолинейно и просто. Первый аргумент — наш дескриптор сессии, второй — указатель на скомпилированную версию нашего фильтра (это должна быть та же переменная, что и в предыдущей функции pcap_compile()).
Возможно этот пример поможет вам понять лучше:
#include
...
pcap_t *handle; /* Дескриптор сесси */
char dev[] = "rl0"; /* Устройство для сниффинга */
char errbuf[PCAP_ERRBUF_SIZE]; /* Строка для хранения ошибок */
struct bpf_program fp; /* Скомпилированный фильтр */
char filter_exp[] = "port 23"; /* Выражение фильтра */
bpf_u_int32 mask; /* Сетевая маска устройства */
bpf_u_int32 net; /* IP устройства */
if (pcap_lookupnet(dev, &net, &mask, errbuf) == -1) {
fprintf(stderr, "Can't get netmask for device %s\n", dev);
net = 0;
mask = 0;
}
handle = pcap_open_live(dev, BUFSIZ, 1, 1000, errbuf);
if (handle == NULL) {
fprintf(stderr, "Couldn't open device %s: %s\n", dev, errbuf);
return(2);
}
if (pcap_compile(handle, &fp, filter_exp, 0, net) == -1) {
fprintf(stderr, "Couldn't parse filter %s: %s\n", filter_exp, pcap_geterr(handle));
return(2);
}
if (pcap_setfilter(handle, &fp) == -1) {
fprintf(stderr, "Couldn't install filter %s: %s\n", filter_exp, pcap_geterr(handle));
return(2);
}Эта программа настроена на сниффинг трафика который проходит через порт 23, в неразборчивом режиме, на устройстве rl0.
Мы можете заметить, что предыдущий пример содержит функцию, о которой мы еще не говорили. pcap_lookupnet() — это функция которая, получая имя устройства возвращает IPv4 сетевой номер и соответствующую сетевую маску (сетевой номер — это адрес IPv4 ANDed с сетевой маской, поэтому он содержит только сетевую часть адреса). Это существенно, потому что нам нужно знать сетевую маску для применения фильтра.
По моему опыту, этот фильтр не работает в некоторых ОС. В моей тестовой среде я обнаружил, что OpenBSD 2.9 c ядром по умолчанию поддерживает этот тип фильтра, но FreeBSD 4.3 с ядром по умолчанию — нет. Ваш опыт может отличаться.
На текущем этапе мы узнали как определить устройство, приготовить его для захвата трафика, и применить фильтры. Теперь время захватить несколько пакетов. Есть два основных способа захватывать пакеты. Мы можем просто захватить один пакет, или мы можем войти в цикл, который выполняется пока не будет захвачено n пакетов. Мы начнем с того, что покажем, как можно захватить один пакет, и после рассмотрим методы использования циклов. Взглянем на прототип pcap_next():
u_char *pcap_next(pcap_t *p, struct pcap_pkthdr *h)Первый аргумент — дескриптор сессии. Второй — указатель на структуру которая содержит общую информацию о пакете, конкретно — время в которое он был захвачен, длина пакета, и длина его определенной части (например, если он фрагментированный). pcap_next() возвращает u_char указатель на пакет, который описан в структуре. Мы поговорим о чтении пакетов позже.
Это демонстрация использования pcap_next() для захвата пакетов:
#include
#include
int main(int argc, char *argv[])
{
pcap_t *handle; /* Дескриптор сессии */
char *dev; /* Устройсто для сниффинга */
char errbuf[PCAP_ERRBUF_SIZE]; /* Строка для хранения ошибки */
struct bpf_program fp; /* Скомпилированный фильтр */
char filter_exp[] = "port 23"; /* Выражение фильтра */
bpf_u_int32 mask; /* Сетевая маска */
bpf_u_int32 net; /* IP */
struct pcap_pkthdr header; /* Заголовок который нам дает PCAP */
const u_char *packet; /* Пакет */
/* Определение устройства */
dev = pcap_lookupdev(errbuf);
if (dev == NULL)
{
fprintf(stderr, "Couldn't find default device: %s\n", errbuf);
return(2);
}
/* Определение свойств устройства */
if (pcap_lookupnet(dev, &net, &mask, errbuf) == -1)
{
fprintf(stderr, "Couldn't get netmask for device %s: %s\n", dev, errbuf);
net = 0;
mask = 0;
}
/* Создание сессии в неразборчивом режиме */
handle = pcap_open_live(dev, BUFSIZ, 1, 1000, errbuf);
if (handle == NULL)
{
fprintf(stderr, "Couldn't open device %s: %s\n", dev, errbuf);
return(2);
}
/* Компиляция и применения фильтра */
if (pcap_compile(handle, &fp, filter_exp, 0, net) == -1)
{
fprintf(stderr, "Couldn't parse filter %s: %s\n", filter_exp, pcap_geterr(handle));
return(2);
}
if (pcap_setfilter(handle, &fp) == -1)
{
fprintf(stderr, "Couldn't install filter %s: %s\n", filter_exp, pcap_geterr(handle));
return(2);
}
/* Захват пакета */
packet = pcap_next(handle, &header);
/* Вывод его длины */
printf("Jacked a packet with length of [%d]\n", header.len);
/* Закрытие сессии */
pcap_close(handle);
return(0);
}Приложение захватывает трафик любого устройства, полученное через pcap_loockupdev(), помещая его в неразборчивый режим. Оно обнаруживает что пакет попадает в порт 23 (telnet) и сообщает пользователю размер пакета (в байтах). Опять же, программа включает в себя вызов pcap_close(), который мы обсудим позже (хотя он вполне понятен).
Второй способ захвата трафика — использование pcap_loop() или pcap_dispatch() (который в свою очередь сам использует pcap_loop()). Что бы понять использование этих двух функций, нам нужно понять идею функции обратного вызова.
Функция обратного вызова (callback function) не является чем то новым, это обычная вещь в большом количестве API. Концепция, которая стоит за функцией обратного вызова очень проста. Предположим, что у есть программа которая ждет события определенного рода. Просто для примера, предположим что программа ждет нажатие клавиши. Каждый раз, когда пользователь нажимает клавишу, моя программа вызовет функцию, что бы обработать это нажатие клавиши. Это и есть функция обратного вызова. Эти функции используются в PCAP, но вместо вызова их в момент нажатия клавиши, они вызываются тогда, когда PCAP захватывает пакет. Использовать функции обратного вызова можно только в pcap_loop() и pcap_dispatch() которые очень похожи в этом плане. Каждая из них вызывает функцию обратного вызова каждый раз, когда попадется пакет который проходит сквозь фильтр (если конечно фильтр есть. Если нет, то все пакеты, которые были захвачены вызовут функцию обратного вызова).
Прототип pcap_loop() приведен ниже:
int pcap_loop(pcap_t *p, int cnt, pcap_handler callback, u_char *user)Первый аргумент — дескриптор сессии. Дальше идет целое число, которое сообщает pcap_loop() количество пакетов, которые нужно захватить (отрицательное значение говорит о том, что цикл должен выполняться до возникновения ошибки). Третий аргумент — имя функции обратного вызова (только идентификатор, без параметров). Последний аргумент полезен в некоторых приложениях, но в большинстве случаев он просто устанавливается NULL. Предположим, что у нас есть аргументы, которые мы хотим передать функции обратного вызова, в дополнение к тем, которые передает ей pcap_loop(). Последний аргумент как раз то место, где мы это сделаем. Очевидно, вы должны привести их к u_char * типу, что бы убедится что вы получите верные результаты. Как мы увидим позже, PCAP использует некоторые интересные способы передачи информации в виде u_char *. После того, как мы покажем пример того, как PCAP делает это, будет очевидно как сделать это и в этом моменте. Если нет — обратитесь к справочному тексту по С, так как объяснения указателей находятся за рамками темы этого документа. pcap_dispatch() почти идентична в использовании. Единственное различие между pcap_dispatch() и pcap_loop() это то, что pcap_dispatch() будет обрабатывать только первую серию пакетов полученных из системы, тогда как pcap_loop() будет продолжать обработку пакетов или партий пакетов до тех пор пока счетчик не закончится. Для более глубокого обсуждения различий, смотрите официальную документацию PCAP.
Прежде чем мы приведем пример использования pcap_loop(), мы должны проверить формат нашей функции обратного вызова. Мы не можем самостоятельно определить прототип функции обратного вызова, иначе pcap_loop() не будет знать, как использовать ее. Так что мы должны использовать этот формат в качестве прототипа нашей функции обратного вызова:
void got_packet(u_char *args, const struct pcap_pkthdr *header, const u_char *packet);Давайте разберем его более детально. Первое — функция должна иметь void тип. Это логично, потому что pcap_loop() в любом случае не знал бы, что делать с возвращаемым значением. Первый аргумент соответствует последнему аргументу pcap_loop(). Независимо от того, какое значение передается последним аргументом pcap_loop(), оно передается первому аргументу нашей функции обратного вызова. Второй аргумент — это PCAP заголовок, который содержит информацию о том, когда пакет был захвачен, насколько он большой, и так далее. Структура pcap_pkthdr определена в файле pcap.h как:
struct pcap_pkthdr {
struct timeval ts; /* Время захвата */
bpf_u_int32 caplen; /* Длина заголовка */
bpf_u_int32 len; /* Длина пакета */
};Эти значения должны быть достаточно понятными. Последний аргумент — самый интересный из всех, и самый сложный для понимания начинающему программисту. Это другой указатель на u_char, и он указывает на первый байт раздела данных содержащихся в пакете, который был захвачен pcap_loop().
Но как можно использовать эту переменную (названную packet) в прототипе? Пакет содержит много атрибутов, так что, как можно предположить, это не строка, а набор структур (для примера, пакет TCP/IP содержит в себе Ethernet заголовок, IP заголовок, TCP заголовок, и наконец, данные). Этот u_char указатель указывает на сериализованную версию этих структур. Что бы начать использовать какую нибудь из них необходимо произвести некоторые интересные преобразования типов.
Первое, мы должны определить сами структуры, прежде чем мы сможем привести данные к ним. Следующая структура используется мной для чтения TCP/IP пакета из Ethernet.
/* Ethernet адреса состоят из 6 байт */
#define ETHER_ADDR_LEN 6
/* Заголовок Ethernet */
struct sniff_ethernet {
u_char ether_dhost[ETHER_ADDR_LEN]; /* Адрес назначения */
u_char ether_shost[ETHER_ADDR_LEN]; /* Адрес источника */
u_short ether_type; /* IP? ARP? RARP? и т.д. */
};
/* IP header */
struct sniff_ip {
u_char ip_vhl; /* версия << 4 | длина заголовка >> 2 */
u_char ip_tos; /* тип службы */
u_short ip_len; /* общая длина */
u_short ip_id; /* идентефикатор */
u_short ip_off; /* поле фрагмента смещения */
#define IP_RF 0x8000 /* reserved флаг фрагмента */
#define IP_DF 0x4000 /* dont флаг фрагмента */
#define IP_MF 0x2000 /* more флаг фрагмента */
#define IP_OFFMASK 0x1fff /* маска для битов фрагмента */
u_char ip_ttl; /* время жизни */
u_char ip_p; /* протокол */
u_short ip_sum; /* контрольная сумма */
struct in_addr ip_src,ip_dst; /* адрес источника и адрес назначения */
};
#define IP_HL(ip) (((ip)->ip_vhl) & 0x0f)
#define IP_V(ip) (((ip)->ip_vhl) >> 4)
/* TCP header */
typedef u_int tcp_seq;
struct sniff_tcp {
u_short th_sport; /* порт источника */
u_short th_dport; /* порт назначения */
tcp_seq th_seq; /* номер последовательности */
tcp_seq th_ack; /* номер подтверждения */
u_char th_offx2; /* смещение данных, rsvd */
#define TH_OFF(th) (((th)->th_offx2 & 0xf0) >> 4)
u_char th_flags;
#define TH_FIN 0x01
#define TH_SYN 0x02
#define TH_RST 0x04
#define TH_PUSH 0x08
#define TH_ACK 0x10
#define TH_URG 0x20
#define TH_ECE 0x40
#define TH_CWR 0x80
#define TH_FLAGS (TH_FIN|TH_SYN|TH_RST|TH_ACK|TH_URG|TH_ECE|TH_CWR)
u_short th_win; /* окно */
u_short th_sum; /* контрольная сумма */
u_short th_urp; /* экстренный указатель */
};Так как в итоге это все относится к PCAP и нашему загадочному u_char указателю? Эти структуры определяют заголовки, которые предшествуют данным пакета. И как мы в итоге можем разбить пакет? Приготовьтесь увидеть одно из самых практичных использований указателей (для всех новичков в С которые думают что указатели бесполезны говорю: это не так).
Опять же, мы будем предполагать, что мы имеем дело с TCP/IP пакетом Ethernet. Этот же метод применяется к любому пакету. Единственное различие — это тип структуры, которые вы фактически используете. Итак, давайте начнем с определения переменных и определения времени компиляции. Нам нужно будет деконструировать данные пакета.
/* Заголовки Ethernet всегда состоят из 14 байтов */
#define SIZE_ETHERNET 14
const struct sniff_ethernet *ethernet; /* Заголовок Ethernet */
const struct sniff_ip *ip; /* Заголовок IP */
const struct sniff_tcp *tcp; /* Заголовок TCP */
const char *payload; /* Данные пакета */
u_int size_ip;
u_int size_tcp;И теперь мы делаем наше магическое преобразование типов:
ethernet = (struct sniff_ethernet*)(packet);
ip = (struct sniff_ip*)(packet + SIZE_ETHERNET);
size_ip = IP_HL(ip)*4;
if (size_ip < 20) {
printf(" * Invalid IP header length: %u bytes\n", size_ip);
return;
}
tcp = (struct sniff_tcp*)(packet + SIZE_ETHERNET + size_ip);
size_tcp = TH_OFF(tcp)*4;
if (size_tcp < 20) {
printf(" * Invalid TCP header length: %u bytes\n", size_tcp);
return;
}
payload = (u_char *)(packet + SIZE_ETHERNET + size_ip + size_tcp);Как это работает? Рассмотрим структуру пакета в памяти. u_char указатель — просто переменная содержащая адрес в памяти.
Ради простоты, давайте скажем, что адрес на который указывает этот указатель это Х. Тогда, если наши структуры просто находятся в линии, то первая из них — sniff_ethernet, будет расположена в памяти по адресу Х, так же мы можем легко найти адрес структуры после нее. Этот адрес — это Х плюс длина Ethernet заголовка, которая равна 14, или SIZE_ETHERNET.
Аналогично, если у нас есть адрес этого заголовка, то адрес структуры после него — это сам адрес плюс длина этого заголовка. Заголовок IP, в отличие от заголовка Ethernet, не имеет фиксированной длины. Его длина указывается как количество 4-байтовых слов по полю заголовка IP. Поскольку это количество 4-байтных слов, оно должно быть умножено на 4, что бы указать размер в байтах. Минимальная длина этого заголовка составляет 20 байтов.
TCP заголовок так же имеет вариативную длину, эта длина указывается как число 4-байтных слов, в поле "смещения данных" заголовка TCP, и его минимальная длина так же равна 20 байтам.
Итак, давайте сделаем диаграмму:
| VARIABLE | LOCATION(in bytes) |
|---|---|
| sniff_ethernet | X |
| sniff_ip | X + SIZE_ETHERNET |
| sniff_tcp | X + SIZE_ETHERNET + {IP header length} |
| payload | X + SIZE_ETHERNET + {IP header length} + {TCP header length} |
sniff_ethernet структура, находясь в первой линии, просто находится по адресу Х. sniff_ip, которая следует прямо за sniff_ethernet, это адрес Х плюс такое количество байтов, которое занимает структура sniff_ethernet (14 байтов или SIZE_ETHERNET). sniff_tcp находится прямо после двух предыдущих структур, так что его локация это — X плюс размер Ethernet, и IP заголовок. (14 байтов, и 4 раза длина заголовка IP). Наконец, данные (для которых не существует определенной структуры) расположены после них всех.
Итак, на данном этапе мы знаем, как использовать функцию обратного вызова, вызвать ее и получить данные из полученного пакета. Здесь я приложу исходный код готового сниффера. Просто скачайте sniffer.c и попробуйте сами.
На данном этапе вы должны быть способны написать сниффер используя PCAP. Вы изучили базовые концепты которые стоят за открытием PCAP сессии, узнали главные детали о сниффиге пакетов, применении фильтров, и использования функций обратного вызова. Теперь пришло время выйти и самостоятельно захватить трафик.
Тим Карстенс 2002. Все права защищены. Распространение и использование, с модификацией и без нее разрешены при соблюдении следующих условий:
Копия должна содержать вышеупомянутое уведомление об авторских правах и этот список условий:
Имя Тима Карстенса не может использоваться для одобрения или продвижения продуктов, полученных из этого документа, без специального предварительного письменного разрешения.
This document is Copyright 2002 Tim Carstens. All rights reserved. Redistribution and use, with or without modification, are permitted provided that the following conditions are met:
Redistribution must retain the above copyright notice and this list of conditions.
The name of Tim Carstens may not be used to endorse or promote products derived from this document without specific prior written permission.
/ Insert 'wh00t' for the BSD license here /
|
Метки: author Lupus_Anay программирование перевод pcap сниффер захват трафика |
Создание и нормализация словарей. Выбираем лучшее, убираем лишнее |

crunch 4 5 1234567890 -o all_numbers_from_4_to_5.txt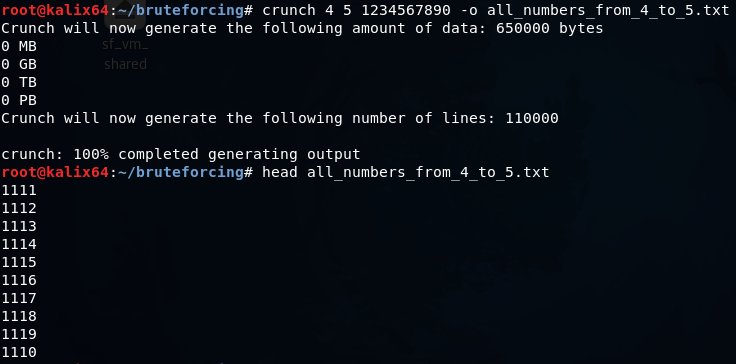
crunch 10 10 qwe RTY 123 \#\@ -t P^@@,ord%% -o Password_template.txt

crunch 1 1 -p Alex Company Position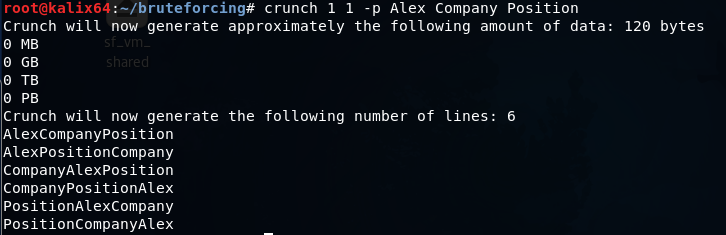
?l = abcdefghijklmnopqrstuvwxyz
?u = ABCDEFGHIJKLMNOPQRSTUVWXYZ
?d = 0123456789
?s = !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
?a = ?l?u?d?s
?b = 0x00 - 0xffmp64.bin -1 Pp -2 \@\#\$ ?1assw?2r?d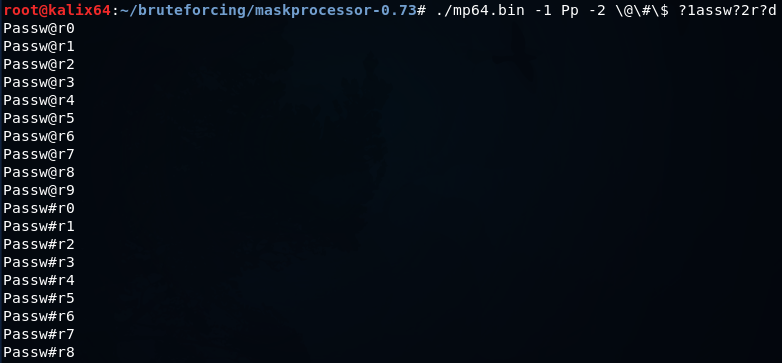
mp64.bin -1 Qq -2 ?d\@\#\$ ?1werty_12?2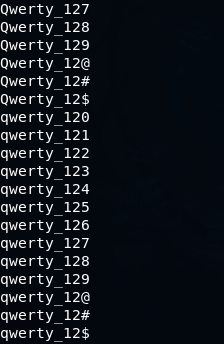
[List.Rules:NT]
:
-c T0Q
-c T1QT[z0]
-c T2QT[z0]T[z1]
-c T3QT[z0]T[z1]T[z2]
-c T4QT[z0]T[z1]T[z2]T[z3]
-c T5QT[z0]T[z1]T[z2]T[z3]T[z4]
-c T6QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]
-c T7QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]
-c T8QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]
-c T9QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]
-c TAQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]
-c TBQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]T[zA]
-c TCQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]T[zA]T[zB]
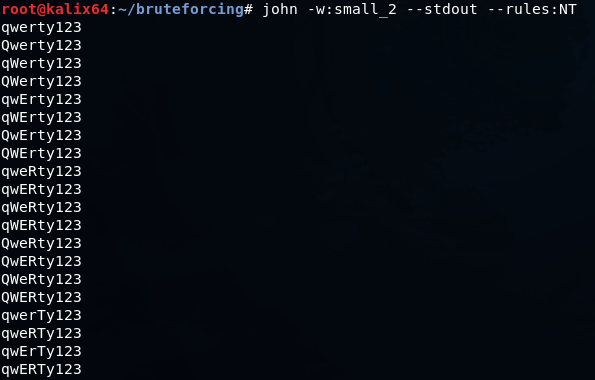
-c TDQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]T[zA]T[zB]T[zC]john -w:QWERTY123.dict --stdout --rules:NT

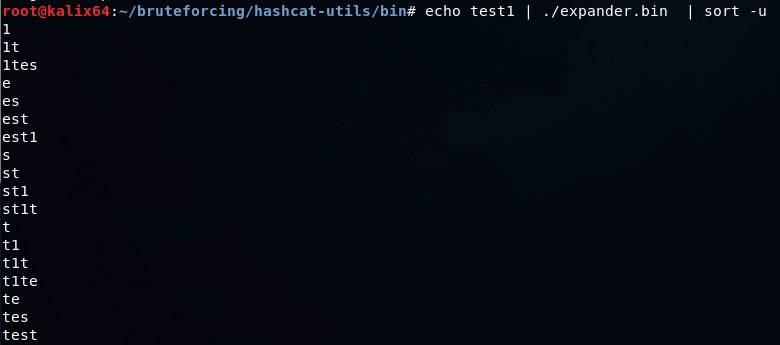



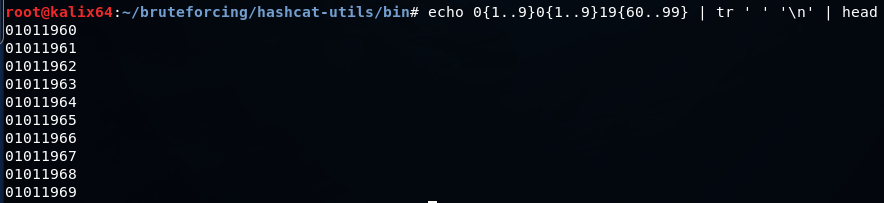
echo 0{1..9}0{1..9}19{60..99} | tr ' ' '\n' >> dates
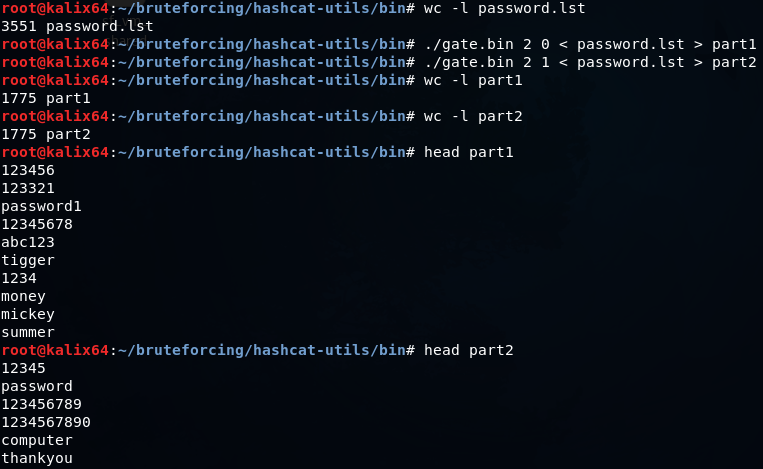
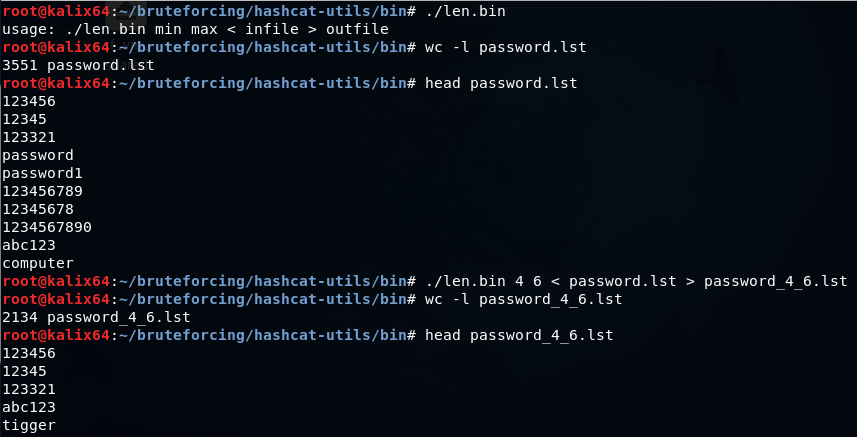
split -d -l 1000 password.lst splitted_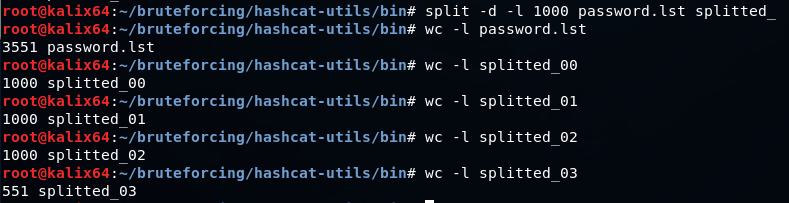
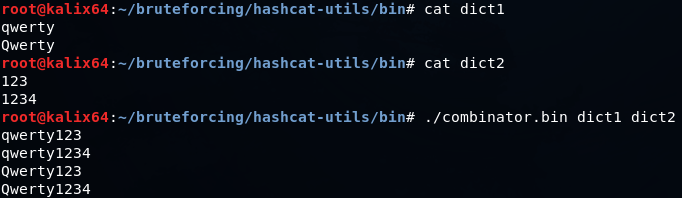
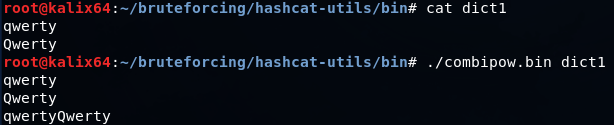
cat dict1 dict2 > combined_dict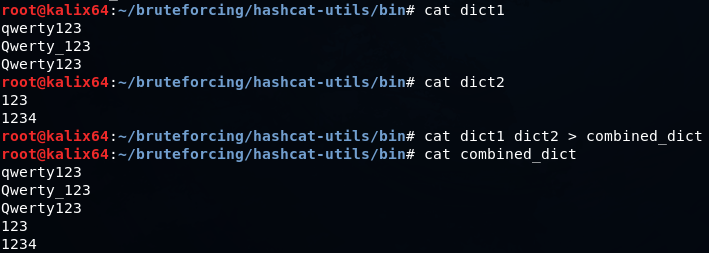
sed 's/^./\u&/' dict_file
sed 's/.$/\u&/' dict_filesed 's/^./word/' dict_filesed 's/.$/word/' dict_file
for i in $(cat dict_file) ; do seq -f %02.0f$i 0 99 ; done > numbers_dict_file
nawk 'gsub("[0-9]","&",$0)==2' password.lst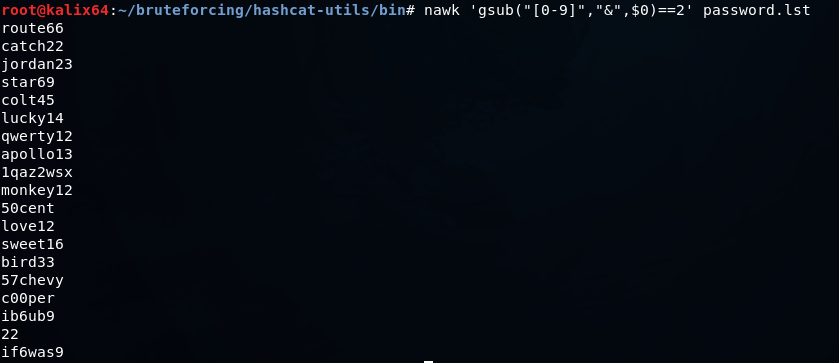
|
Метки: author antgorka информационная безопасность блог компании pentestit wordlist pentest создание словарей maskprocessor crunch john the ripper |
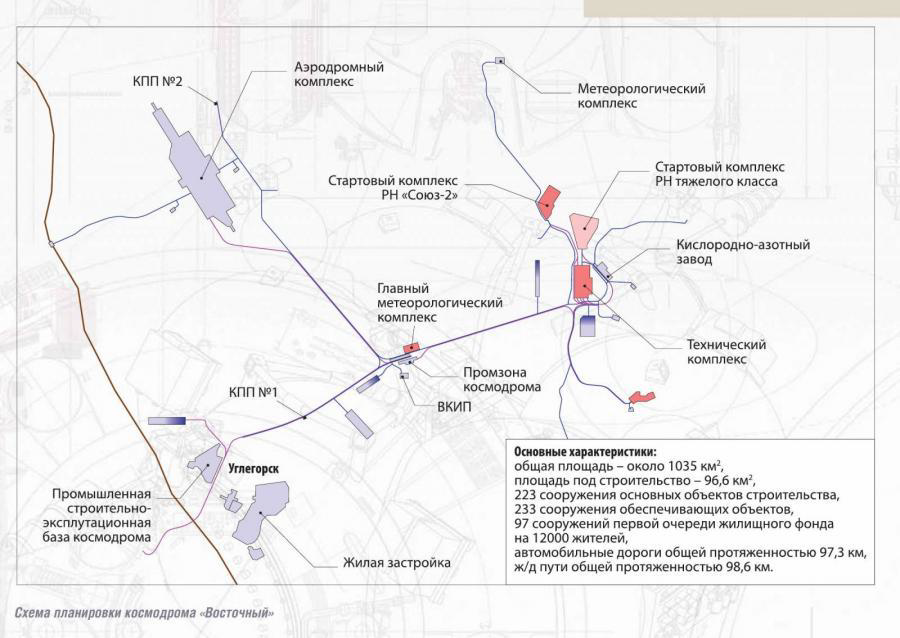
«Восточный» — наш космодром |

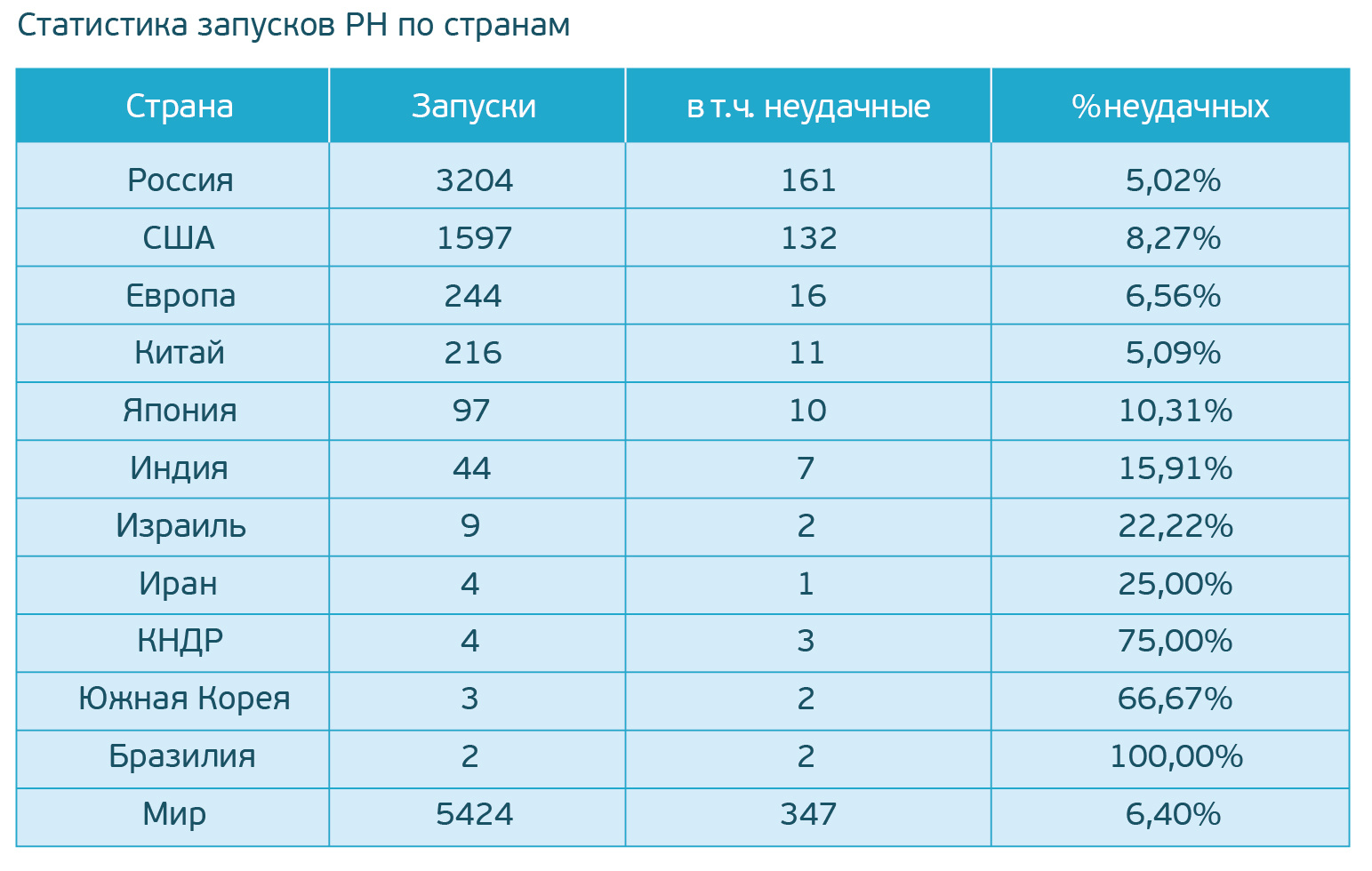








































|
Метки: author virtser управление проектами управление персоналом карьера в it-индустрии блог компании гк ланит космодром инфраструктура инженерные системы |
«Восточный» — наш космодром |
|
Метки: author virtser управление проектами управление персоналом карьера в it-индустрии блог компании гк ланит космодром инфраструктура инженерные системы |
«Восточный» — наш космодром |
|
Метки: author virtser управление проектами управление персоналом карьера в it-индустрии блог компании гк ланит космодром инфраструктура инженерные системы |
Расследование утечек информации из корпоративной базы данных перевозчика |

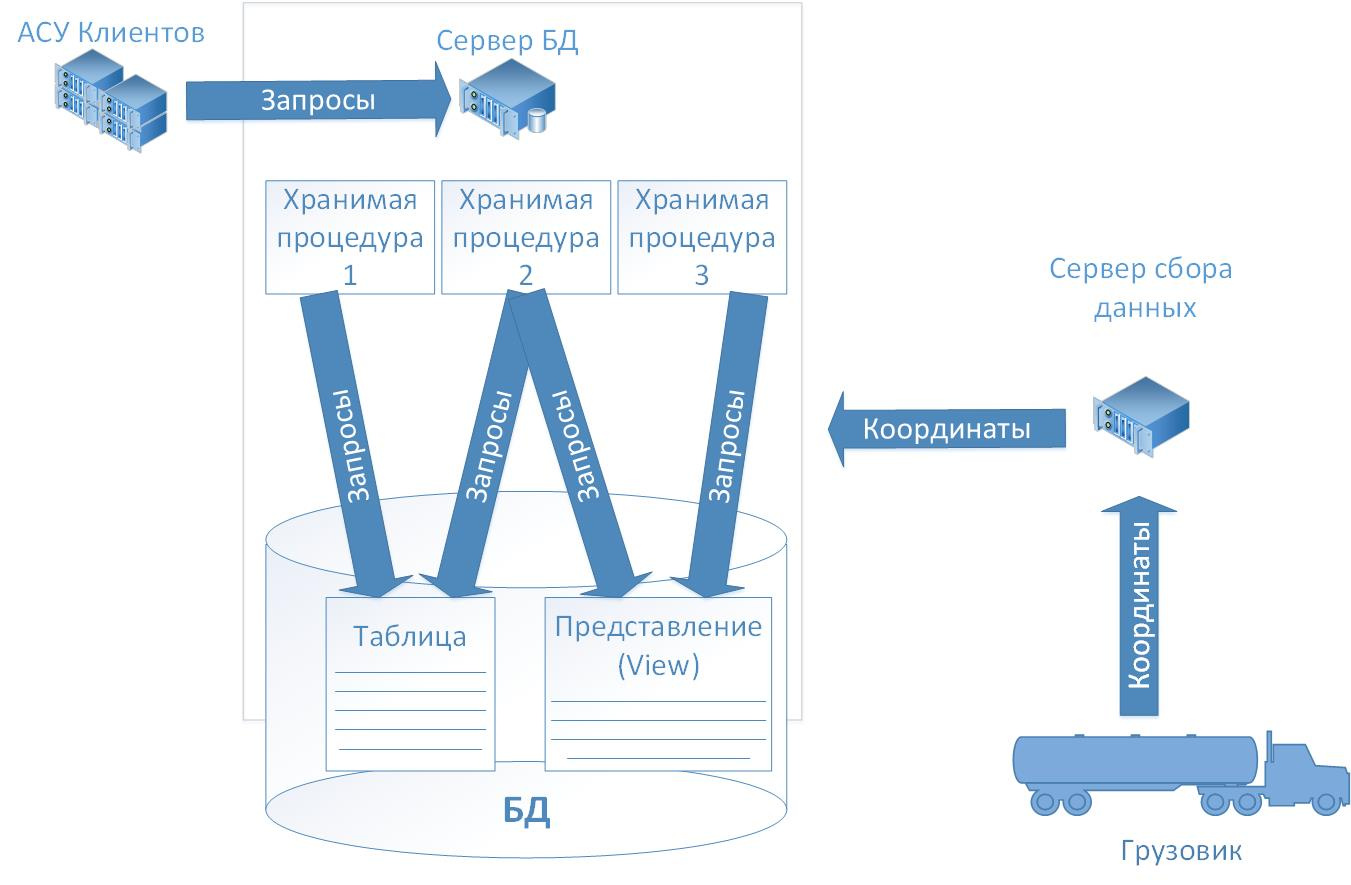
|
|
Расследование утечек информации из корпоративной базы данных перевозчика |
|
|
Расследование утечек информации из корпоративной базы данных перевозчика |
|
|
Детский сад, штаны на лямках: откуда берутся программисты |

















|
|
Детский сад, штаны на лямках: откуда берутся программисты |
|
|
Детский сад, штаны на лямках: откуда берутся программисты |
|
|
Чтоб root стоял и фичи были |
 Картинка взята тут, подпись наша
Картинка взята тут, подпись наша

|
Метки: author RegionSoft программирование блог компании regionsoft developer studio день программиста 256 день 13 сентября жизнь программистов |
Уязвимость BlueBorne в протоколе Bluetooth затрагивает миллиарды устройств |

|
Метки: author LukaSafonov информационная безопасность блог компании pentestit blueborne bluetooth |
ReactOS 0.4.6 доступен для загрузки |

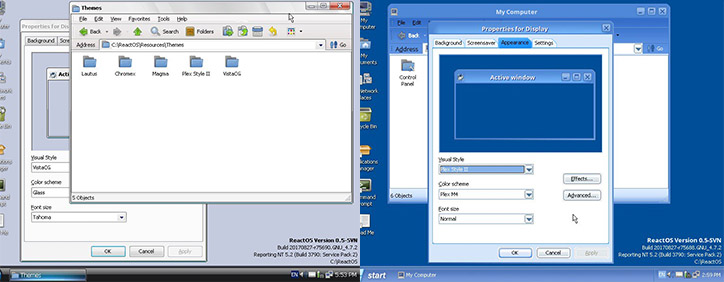
|
Метки: author Jeditobe реверс-инжиниринг разработка под windows open source блог компании фонд reactos reactos udf nfs usb twin peaks совсем не то чем кажется |






