[Перевод] 67 полезных инструментов, библиотек и ресурсов для экономии времени веб-разработчиков |


|
Метки: author Arturo01 разработка веб-сайтов программирование библиотеки фреймворки инструменты ресурсы |
Автоматизируй это: десять применений пользовательского API для QIWI Кошелька |

|
Метки: author d_garmashev хакатоны блог компании qiwi qiwi qiwi api contest конкурс по тысяче рублей за идею конкурс идей |
Экспресс Купертино — Москва. Новые фичи iOS 11, обсуждение Apple Special Event и конкурс от Avito |
Мы все знаем, что почти каждый iOS-разработчик хотел бы оказаться вечером 12 сентября в театре Стива Джобса в Купертино. Вместо фокусов с телепортацией и материализацией приглашений на это событие мы устроили Avito Special iOS Event.
Сначала послушаем короткие тематические доклады от iOS-разработчиков из ведущих российских компаний, а затем будет совместный просмотр конференции Apple. Специально для Хабра будем вести здесь прямую видеотрансляцию той части, что с докладами, у нас в Avito, а затем — текстовую трансляцию из Калифорнии. Чтобы было ещё веселее, мы подготовили конкурс для тех, кто способен предвидеть будущее.

Итак, под катом:
Все большие события Apple окружены атмосферой тайны. Все пытаются угадать, что именно расскажут и покажут на конференции. Предлагаем вам сделать свои ставки в этой форме. Каждый ответ имеет свой вес в баллах. Тому (или тем), у кого наиболее развита интуиция/дар предвидения/etc, мы подарим сувенир от Avito. Ответы закончим принимать с началом трансляции конференции Apple. Теперь — к докладам.
Итак, максимально быстро окунаемся в дивный новый мир iOS 11. Мы позвали на митап специалистов из Rabler&Co, Avito и App in the Air. Сегодняшние рассказы — о практическом опыте реализации новых фич iOS 11. Даже если вы сильно не следили за обновлениями, после этого поста вы будете чётко знать, чего не хватает вашим приложениям, чтобы стать полностью iOS 11-совместимыми.
(UPD 18:28: Мы впервые решили вставить прямую трансляцию с YouTube в пост на Хабре, поэтому ниже уже есть запасная ссылка. Просто на всякий случай).
Разработчики приложения Афиша Рестораны, Самвел Меджлумян и Дмитрий Антышев, рассказывают о том, как они смогли прикрутить ARKit к своему проекту. Помимо тонны хайпа, видеодемок и кривой Гаттнера много внимания уделено вопросам алгоритмов расчета положения точек в пространстве и построения маршрутов. Если вы до сих пор сомневаетесь, что ARKit можно с пользой встроить в ваше приложение — опыт ребят может помочь вам изменить свое решение.
В Avito сильно развита традиция внутренних хакатонов, о чем мы уже писали в нашем блоге. На одном из них команда мобильных разработчиков решила известную боль пользователей — при подаче объявления они всеми возможными способами пытаются скрывать лица и номера машин. Кто-то одевает пакеты, кто-то прикрывается руками, наиболее продвинутые делают это в графическом редакторе, но суть остается — для обеспечения конфиденциальности люди тратят слишком много усилий.
Тимофей Хомутников рассказывает о том, как при помощи нового фреймворка Vision и набора костылей эта проблема была решена. И чтобы доклад не сводился к простому использованию системного SDK, Тимофей проводит ликбез по существующим способам и алгоритмам определения автомобильных номеров.
Разработчики App in the Air известны тем, что каждый год одними из первых реализуют все новые плюшки из обновления iOS – и неважно, насколько они на первый взгляд релевантны приложению, получается стабильно круто. Этот год тоже не стал исключением. Сергей Пронин, CTO компании, рассказывает про ключевую функциональность, реализованную командой до релиза iOS 11. В нее вошли Drag and Drop, iMessage Live Messages, ARKit, SiriKit и Notifications Privacy.
Особое внимание в докладе Сергей уделяет Drag and Drop. И на примере кейса из своего приложения показывает, что встроить его и кастомизировать для своих нужд достаточно просто.
Текстовая трансляция из телеграм-канала Tolstoy Live будет обновляться и здесь:
• 1:50:03 PM
Всем привет! Смело отписывайтесь от канала — сегодня по мере возможности буду вести трансляцию Apple Special Event для тех, кому лень или некогда смотреть самому. Ну и вообще, началась осень, куча ивентов и все такое.
И напоследок бонус: свежие картинки с Тимом Куком. Сделано с любовью.

Пишите в комментариях, что думаете о сегодняшней конференции, докладах и практическом применении iOS 11!
|
|
[Перевод] DevOps с Kubernetes и VSTS. Часть 1: Локальная история |

c:
cd \
minikube start --vm-driver hyperv --hyperv-virtual-switch minikube
kubectl config set-cluster minikube --server=https://kubernetes:8443 --certificate-authority=c:/users//.minikube/ca.crt PS:\> kubectl get nodes
NAME STATUS AGE VERSION
minikube Ready 11m v1.6.4

minikube docker-env | Invoke-Expressionversion: '2'
services:
api:
image: api
build:
context: ./API
dockerfile: Dockerfile
frontend:
image: frontend
build:
context: ./frontend
dockerfile: DockerfileFROM microsoft/aspnetcore:1.1
ARG source
WORKDIR /app
EXPOSE 80
COPY ${source:-obj/Docker/publish} .
ENTRYPOINT ["dotnet", "API.dll"]cd API
dotnet restore
dotnet build
dotnet publish -o obj/Docker/publish
cd ../frontend
dotnet restore
dotnet build
dotnet publish -o obj/Docker/publish
cd ..
docker-compose -f docker-compose.yml build
apiVersion: v1
kind: Service
metadata:
name: demo-backend-service
labels:
app: demo
spec:
selector:
app: demo
tier: backend
ports:
- protocol: TCP
port: 80
nodePort: 30081
type: NodePort
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: demo-backend-deployment
spec:
replicas: 2
template:
metadata:
labels:
app: demo
tier: backend
spec:
containers:
- name: backend
image: api
ports:
- containerPort: 80
imagePullPolicy: Neverspec:
containers:
- name: frontend
image: frontend
ports:
- containerPort: 80
env:
- name: "ASPNETCORE_ENVIRONMENT"
value: "Production"
volumeMounts:
- name: config-volume
mountPath: /app/wwwroot/config/
imagePullPolicy: Never
volumes:
- name: config-volume
configMap:
name: demo-app-frontend-configapiVersion: v1
kind: ConfigMap
metadata:
name: demo-app-frontend-config
labels:
app: demo
tier: frontend
data:
config.json: |
{
"api": {
"baseUri": "http://kubernetes:30081/api"
}
}PS:\> cd k8s
PS:\> kubectl apply -f .\app-demo-frontend-config.yml
configmap "demo-app-frontend-config" created
PS:\> kubectl apply -f .\app-demo-backend-minikube.yml
service "demo-backend-service" created
deployment "demo-backend-deployment" created
PS:\> kubectl apply -f .\app-demo-frontend-minikube.yml
service "demo-frontend-service" created
deployment "demo-frontend-deployment" created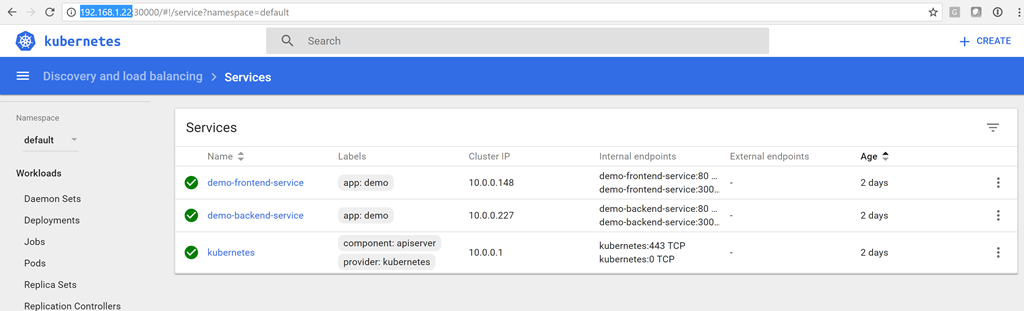
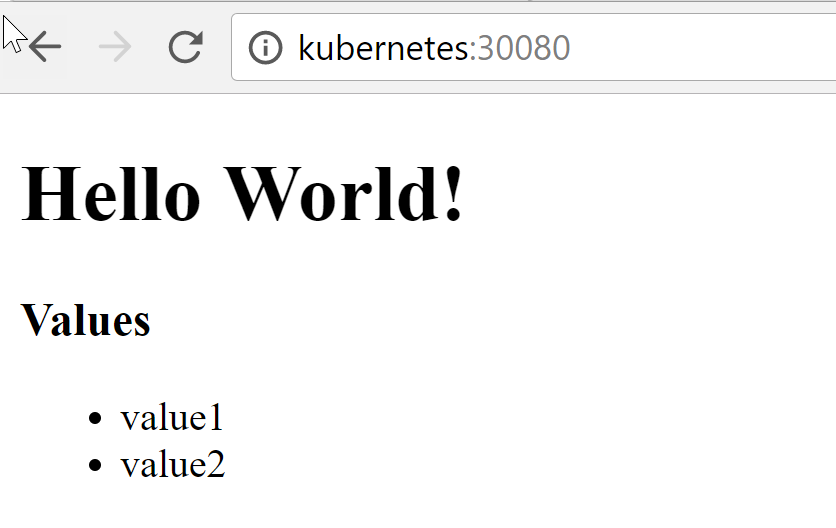
PS:> kubectl get pods
NAME READY STATUS RESTARTS AGE
demo-backend-deployment-951716883-fhf90 1/1 Running 0 28m
demo-backend-deployment-951716883-pw1r2 1/1 Running 0 28m
demo-frontend-deployment-477968527-bfzhv 1/1 Running 0 14s
demo-frontend-deployment-477968527-q4f9l 1/1 Running 0 24s
PS:> kubectl delete pods demo-backend-deployment-951716883-fhf90 demo
-backend-deployment-951716883-pw1r2 demo-frontend-deployment-477968527-bfzhv demo-frontend-deployment-477968527-q4f9l
pod "demo-backend-deployment-951716883-fhf90" deleted
pod "demo-backend-deployment-951716883-pw1r2" deleted
pod "demo-frontend-deployment-477968527-bfzhv" deleted
pod "demo-frontend-deployment-477968527-q4f9l" deleted
PS:> kubectl get pods
NAME READY STATUS RESTARTS AGE
demo-backend-deployment-951716883-4dsl4 1/1 Running 0 3m
demo-backend-deployment-951716883-n6z4f 1/1 Running 0 3m
demo-frontend-deployment-477968527-j2scj 1/1 Running 0 3m
demo-frontend-deployment-477968527-wh8x0 1/1 Running 0 3m|
Метки: author stasus программирование visual studio microsoft azure блог компании microsoft microsoft kubernetes k8s vsts devops minikube kubectl |
Конкурс идей от ABBYY – куда бежать и что делать |
 Всем привет. Меня зовут Игорь Акимов, я руководитель направления мобильных продуктов ABBYY. Наверное, многие знают ABBYY по лучшим словарям Lingvo и помощнику любого студента FineReader, но кроме этого мы занимаемся ещё много чем интересным в сфере интеллектуальной обработки информации и лингвистики. За 28 лет накопили огромный багаж в сфере машинного обучения и нейросетей, а новых проектов и идей так много, что кажется, нам нужна помощь :) Поэтому мы приглашаем вас принять участие в конкурсе. Мы ищем идеи по применению новых технологий в мобильной разработке, которые будут близки большому числу людей. И назвали конкурс мы смело – mABBYYlity (тут и ABBYY, и мобильность, и ability – способность). Короче, всё основное тут – mobility.abbyy.com. А в статью за подробностями.
Всем привет. Меня зовут Игорь Акимов, я руководитель направления мобильных продуктов ABBYY. Наверное, многие знают ABBYY по лучшим словарям Lingvo и помощнику любого студента FineReader, но кроме этого мы занимаемся ещё много чем интересным в сфере интеллектуальной обработки информации и лингвистики. За 28 лет накопили огромный багаж в сфере машинного обучения и нейросетей, а новых проектов и идей так много, что кажется, нам нужна помощь :) Поэтому мы приглашаем вас принять участие в конкурсе. Мы ищем идеи по применению новых технологий в мобильной разработке, которые будут близки большому числу людей. И назвали конкурс мы смело – mABBYYlity (тут и ABBYY, и мобильность, и ability – способность). Короче, всё основное тут – mobility.abbyy.com. А в статью за подробностями.|
|
Охота на кремлевского демона |

Нельзя сказать, что я не искал с этим демоном встречи. Я дождался пока он вылезет и выследил его логово. Поиграл с ним немного. Потом демон исчез, как обычно, по расписанию — в 9.00. Я успокоился и занялся своими бытовыми делами.
Дело было в том, что у нас в Питере не найти в книжных магазинах рабочую тетрадь по английскому языку "Планета знаний" 3 класс. Ну как в Союзе было, дефицит. И мне жена дала задание — зайти в книжные в Москве. Дескать, в столице все есть, тетки на форуме оттуда заказывают, платят 500 рублей за доставку, а ты, пользуясь случаем, купишь сам и сэкономишь для семьи. Хоть какой-то толк от неудачника будет. Я включаю Гугль-карту, задаю фразу "книжные магазины" и не понимаю. Ни Красной площади, ни реки, какие-то непонятные улицы.
Черт! Он вылез опять! Я ведь еще успел только до Варварки дойти.
И, повинуясь зову природы, я расчехлил опять свое оружье.
Каждый охотник желает знать где сидит фазан.
Народная запоминалка по физике
Нам кажется, даже приятно оказаться испуганными. Не потому, что страх предупреждает нас о реальной опасности или побуждает предпринять какое-то действие против нее, но потому, что он делает наш опыт необычайно интенсивным.
Кори Робин. "Страх. История политической идеи"
Пока расчехляю — думаю так.
Он ведь, собака, мешает мне жить, выполнять простые бытовые надобности. И всем этим туристам, которые поднимаются из Китай-города на площадь тоже мешает. И тем парням, которые на Кремлевской набережной попали в ДТП тоже мешает. И бегунам, и таксистам, и их пассажирам. И еще многим людям, о которых я не вспомнил. А кто это у нас в России отвечает за радио частоты? Чтобы чисто все было, без помех. Кажется ГРЧЦ называется, Главный Радичастотный Центр. И сайт у него имеется — http://www.grfc.ru/grfc/. И он ведь может по массовой жалобе, например, людей в интернете проверить наличие демона и найти его, но не делает. А ну как президент спросит на следующей прямой линии, кто это кошмарит его население. Но я эти Радичастотные Центры могу понять. У них на носу мероприятие мощное в месте хорошем, на природе — Спектр-Форум. Бархатный сезон, курортный роман и все такое. Обсудят там чистоту спектра и с новыми силами за работу. Эх, где мои шестнадцать лет...
Но я их не буду ждать и все равно расчехляю, так как адреналин уже зашкаливает.
Где я еще смогу половить живого демона, как не на Родине? Вот возьмем Европу — скучно живут, бедолаги. Довольствуются, можно сказать, резиновыми демонами, благо стоят недорого. Настоящие-то у них вот так не гуляют по улицам. А если и прошмыгнут, то быстро и прячась, чтобы не дай бог не заметили.
Оружье мое выглядит так:

Про его внутреннее устройство можно прочитать в моей предыдущей статье.
Сейчас мне осталось рассказать только про кабель. Он кажется неказистым с виду, но по нему ходит целых 5 ГГц.

Пеленгатор подключается к планшету по USB3, а у него требования к качеству кабеля довольно серьезные. Благо кабель у меня должен быть не очень длинный, я беру кусочки простой витой пары UTP и соединяю разъем типа A с разъемом типа C. На пеленгаторе стоит тип C, так как нельзя толщину сильно увеличивать, будет некрасиво. Получается вот такая скрутка всех цветов радуги. И самое главное — надо добавить еще отдельных земляных проводов в эту скрутку. С одним, например, даже на такой длине USB-интерфейс выдает ошибки и связи с платой нет.
На стороне A все очень просто.

А на стороне C нужен еще резистор (согласно стандарта на type C), который я в формате SMD не нашел, поэтому поставил большой советский. Вот как спасают иногда старые запасы наших отцов!

Вернемся же к нашему подопечному, пока вы совсем не заскучали. Разные мобильные устройства реагируют на демона сильно по разному. У меня на руках был Samsung Duos и Lenovo Phab 2 Pro (звезда будущих статей про AR-пеленгаторы). Samsung даже в непосредственной близости от демона редко улетал во Внуково. Он просто не мог найти навигационное решение. Экран его GPSTest выглядел так:
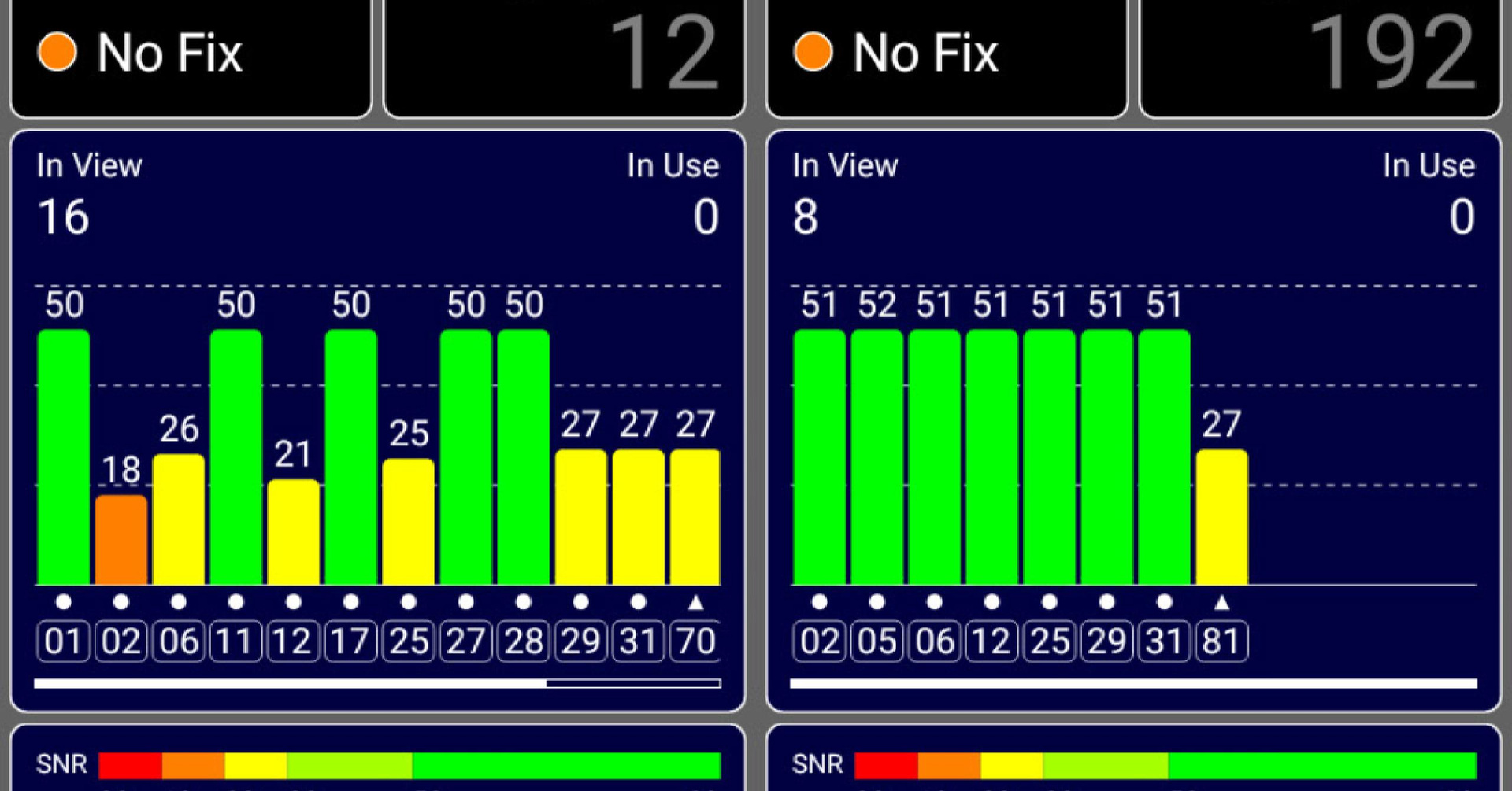
Здесь особо примечательно то, что значение ОСШ (SNR) около 50 дБ на этом смартфоне не бывает в принципе. Потери в антенне этого устройства приводят к довольно большому системному коэффициенту шума (System Noise Floor). Я при открытом небе видел всего 40 дБ с небольшим. И это является одним из признаков пришествия демона, наблюдаемым на обычных мобильных устройствах.
Еще необходимо заметить, что, наряду с поддельными спутниками, принимаются и настоящие. У них ОСШ (SNR) значительно меньше. Правый скриншот снят под Москворецким мостом, поэтому там есть только один настоящий спутник, но остальные (поддельные) принимаются так, как будто они все у меня в кармане.
А вот более новый гаджет — Lenovo Phab 2 Pro тупо показывает Внуково:
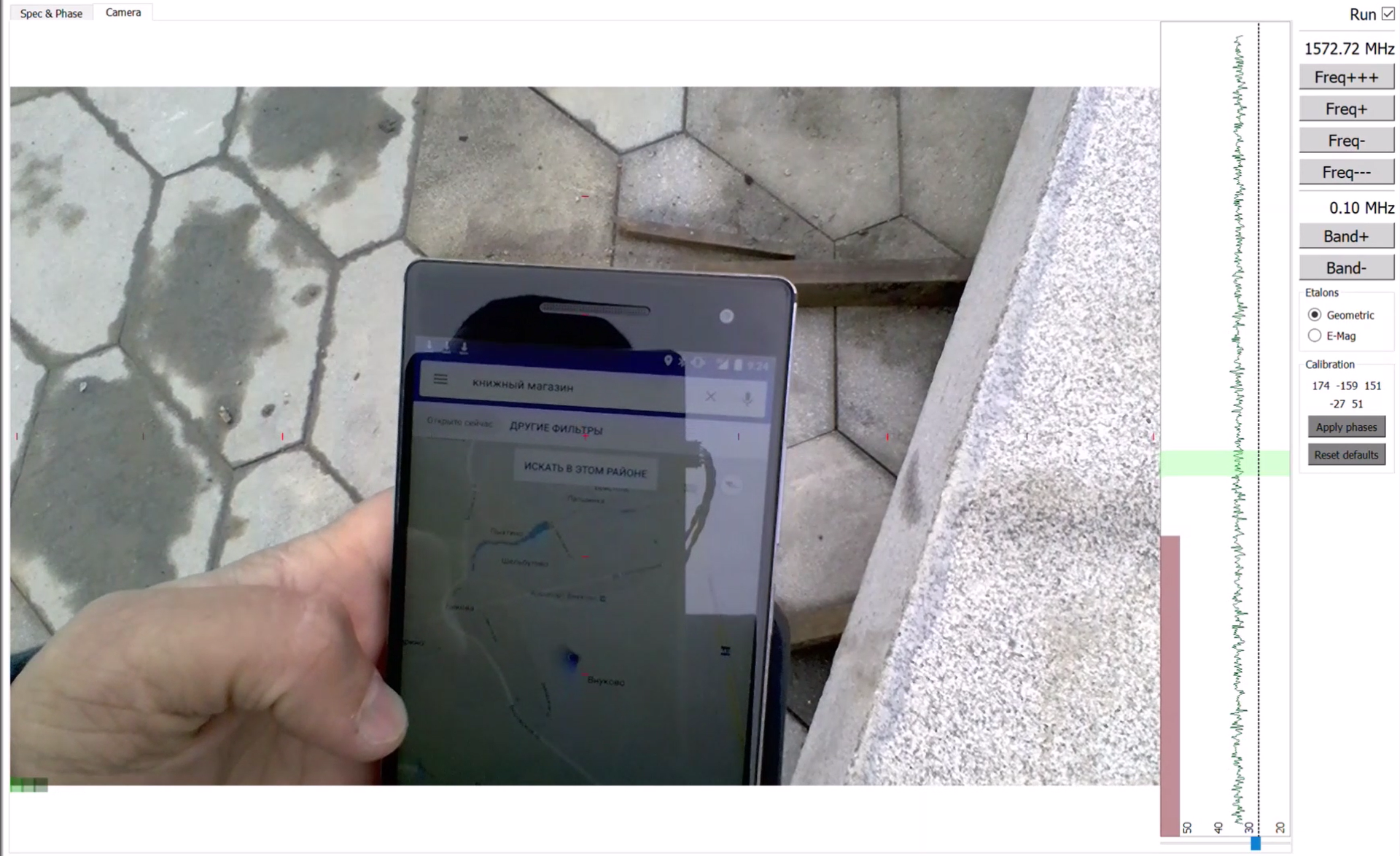
Вот в этот гаджет я и вставил московскую СИМку и планировал нормально ориентироваться в Москве. Но ...
Давайте рассмотрим спектр демона. Ниже на видео вы увидите его справа вертикально. Я развернул картинку, чтобы было нагляднее.

Во-первых, есть рог демона центральный гармонический сигнал, который, видимо, должен забивать приемники, чтобы они хуже принимали настоящие спутники. Ниже на 20 дБ идет уже тело демона широкий сигнал, который имитирует спутниковый.
Чувствую, что вы уже достаточно разогрелись, приступим в основному блюду. Так как пеленгатор построен на дополненной реальности, я предлагаю просто посмотреть пару видео с поля боя.
На первом я спускаюсь по парку Зарядье, который отмывают от строительной грязи. Это поэтому у меня ботинки такие грязные.
На втором я прогуливаюсь по Кремлевской набережной.
Я внимательно читал статью на Медузе и не вижу смысла не верить авторам. Раз коллеги нашли демона там, значит он там и был.
Просто он переехал.
P.S.
Может мой Phab 2 Pro так завис, но я увидел, что демон пропал только в 10.30, ровно. И было это аж возле хакспейса Нейрон на Хохловском. Меня удивляет и возмущает, как же далеко он бьет. Зачем? Также я подозреваю демона в формализме. Почему он включается и выключается в моменты времени, кратные часу или получасу? Нехорошо все это. Демон, надо бы поберечь население.
|
|
Робоотчет о GDD Europe 2017 |








|
Метки: author redmadrobot разработка под android блог компании redmadrobot redmadrobot мобильная разработка |
[Перевод] JavaScript: загадочное дело выражения null >= 0 |
|
Метки: author ru_vds разработка веб-сайтов javascript блог компании ruvds.com разработка стандарты |
[Перевод] JavaScript: загадочное дело выражения null >= 0 |
|
Метки: author ru_vds разработка веб-сайтов javascript блог компании ruvds.com разработка стандарты |
Импортозамещение в нефтегазовом секторе: как добывающие компании на «Эльбрус» собрались |

|
|
Импортозамещение в нефтегазовом секторе: как добывающие компании на «Эльбрус» собрались |
|
|
[Из песочницы] Как понять, что ваша предсказательная модель бесполезна |
При создании продуктов на основе машинного обучения возникают ситуации, которых хотелось бы избежать. В этом тексте я разбираю восемь проблем, с которыми сталкивался в своей работе.
Мой опыт связан с моделями кредитного скоринга и предсказательными системами для промышленных компаний. Текст поможет разработчиками и дата-сайнтистам строить полезные модели, а менеджерам не допускать грубых ошибок в проекте.
Этот текст не призван прорекламировать какую-нибудь компанию. Он основан на практике анализа данных в компании ООО "Ромашка", которая никогда не существовала и не будет существовать. Под "мы" я подразумеваю команду из себя и моих воображаемых друзей. Все сервисы, которые мы создавали, делались для конкретного клиента и не могут быть проданы или переданы иным лицам.
Пусть предсказательная модель — это алгоритм, который строит прогнозы и позволяет автоматически принимать полезное для бизнеса решение на основе исторических данных.
Я не рассматриваю:
Я буду говорить об алгоритмах обучения с учителем, т.е. таких, которые "увидели" много примеров пар (X,Y), и теперь могут для любого X сделать оценку Y. X — это информация, известная на момент прогноза (например, заполненная клиентом заявка на кредит). Y — это заранее неизвестная информация, необходимая для принятия решения (например, будет ли клиент своевременно платить по кредиту). Само решение может приниматься каким-то простым алгоритмом вне модели (например, одобрять кредит, если предсказанная вероятность неплатежа не выше 15%).
Аналитик, создающий модель, как правило, опирается на метрики качества прогноза, например, среднюю ошибку (MAE) или долю верных ответов (accuracy). Такие метрики позволяют быстро понять, какая из двух моделей предсказывает точнее (и нужно ли, скажем, заменять логистическую регрессию на нейросеть). Но на главный вопрос, а насколько модель полезна, они дают ответ далеко не всегда. Например, модель для кредитного скоринга очень легко может достигнуть точности 98% на данных, в которых 98% клиентов "хорошие", называя "хорошими" всех подряд.
С точки зрения предпринимателя или менеджера очевидно, какая модель полезная: которая приносит деньги. Если за счёт внедрения новой скоринговой модели за следующий год удастся отказать 3000 клиентам, которые бы принесли суммарный убыток 50 миллионов рублей, и одобрить 5000 новых клиентов, которые принесут суммарную прибыль 10 миллионов рублей, то модель явно хороша. На этапе разработки модели, конечно, вряд ли вы точно знаете эти суммы (да и потом — далеко не факт). Но чем скорее, точнее и честнее вы оцените экономическую пользу от проекта, тем лучше.
Достаточно часто построение вроде бы хорошей предсказательной модели не приводит к ожидаемому успеху: она не внедряется, или внедряется с большой задержкой, или начинает нормально работать только после десятков релизов, или перестаёт нормально работать через несколько месяцев после внедрения, или не работает вообще никак… При этом вроде бы все потрудились на славу: аналитик выжал из данных максимальную предсказательную силу, разработчик создал среду, в которой модель работает молниеносно и никогда не падает, а менеджер приложил все усилия, чтобы первые двое смогли завершить работу вовремя. Так почему же они попали в неприятность?
Мы как-то строили модель, предсказывающую крепость пива после дображивания (на самом деле, это было не пиво и вообще не алкоголь, но суть похожа). Задача ставилась так: понять, как параметры, задаваемые в начале брожения, влияют на крепость финального пива, и научиться лучше управлять ей. Задача казалась весёлой и перспективной, и мы потратили не одну сотню человеко-часов на неё, прежде чем выяснили, что на самом-то деле финальная крепость не так уж и важна заказчику. Например, когда пиво получается 7.6% вместо требуемых 8%, он просто смешивает его с более крепким, чтобы добиться нужного градуса. То есть, даже если бы мы построили идеальную модель, это принесло бы прибыли примерно нисколько.
Эта ситуация звучит довольно глупо, но на самом деле случается сплошь и рядом. Руководители инициируют machine learning проекты, "потому что интересно", или просто чтобы быть в тренде. Осознание, что это не очень-то и нужно, может прийти далеко не сразу, а потом долго отвергаться. Мало кому приятно признаваться, что время было потрачено впустую. К счастью, есть относительно простой способ избегать таких провалов: перед началом любого проекта оценивать эффект от идеальной предсказательной модели. Если бы вам предложили оракула, который в точности знает будущее наперёд, сколько бы были бы готовы за него заплатить? Если потери от брака и так составляют небольшую сумму, то, возможно, строить сложную систему для минимизации доли брака нет необходимости.
Как-то раз команде по кредитному скорингу предложили новый источник данных: чеки крупной сети продуктовых магазинов. Это выглядело очень заманчиво: "скажи мне, что ты покупаешь, и я скажу, кто ты". Но вскоре оказалось, что идентифицировать личность покупателя было возможно, только если он использовал карту лояльности. Доля таких покупателей оказалась невелика, а в пересечении с клиентами банка они составляли меньше 5% от входящих заявок на кредиты. Более того, это были лучшие 5%: почти все заявки одобрялись, и доля "дефолтных" среди них была близка к нулю. Даже если бы мы смогли отказывать все "плохие" заявки среди них, это сократило бы кредитные потери на совсем небольшую сумму. Она бы вряд ли окупила затраты на построение модели, её внедрение, и интеграцию с базой данных магазинов в реальном времени. Поэтому с чеками поигрались недельку, и передали их в отдел вторичных продаж: там от таких данных будет больше пользы.
Зато пивную модель мы всё-таки достроили и внедрили. Оказалось, что она не даёт экономии на сокращении брака, но зато позволяет снизить трудозатраты за счёт автоматизации части процесса. Но поняли мы это только после долгих дискуссий с заказчиком. И, если честно, нам просто повезло.
Даже если идеальная модель способна принести большую пользу, не факт, что вам удастся к ней приблизиться. В X может просто не быть информации, релевантной для предсказания Y. Конечно, вы редко можете быть до конца уверены, что вытащили из X все полезные признаки. Наибольшее улучшение прогноза обычно приносит feature engineering, который может длиться месяцами. Но можно работать итеративно: брейншторм — создание признаков — обучение прототипа модели — тестирование прототипа.
В самом начале проекта можно собраться большой компанией и провести мозговой штурм, придумывая разнообразные признаков. По моему опыту, самый сильный признак часто давал половину той точности, которая в итоге получалась у полной модели. Для скоринга это оказалась текущая кредитная нагрузка клиента, для пива — крепость предыдущей партии того же сорта. Если после пары циклов найти хорошие признаки не удалось, и качество модели близко к нулю, возможно, проект лучше свернуть, либо срочно отправиться искать дополнительные данные.
Важно, что тестировать нужно не только точность прогноза, но и качество решений, принимаемых на его основе. Не всегда возможно измерить пользу от модели "оффлайн" (в тестовой среде). Но вы можете придумывать метрики, которые хоть как-то приближают вас к оценке денежного эффекта. Например, если менеджеру по кредитным рискам нужно одобрение не менее 50% заявок (иначе сорвётся план продаж), то вы можете оценивать долю "плохих" клиентов среди 50% лучших с точки зрения модели. Она будет примерно пропорциональна тем убыткам, которые несёт банк из-за невозврата кредитов. Такую метрику можно посчитать сразу же после создания первого прототипа модели. Если грубая оценка выгоды от его внедрения не покрывает даже ваши собственные трудозатраты, то стоит задуматься: а можем ли мы вообще получить хороший прогноз?
Бывает, что созданная аналитиками модель демонстрирует хорошие меры как точности прогноза, так и экономического эффекта. Но когда начинается её внедрение в продакшн, оказывается, что необходимые для прогноза данные недоступны в реальном времени. Иногда бывает, что это настоящие данные "из будущего". Например, при прогнозе крепости пива важным фактором является измерение его плотности после первого этапа брожения, но применять прогноз мы хотим в начале этого этапа. Если бы мы не обсудили с заказчиком точную природу этого признака, мы бы построили бесполезную модель.
Ещё более неприятно может быть, если на момент прогноза данные доступны, но по техническим причинам подгрузить их в модель не получается. В прошлом году мы работали над моделью, рекомендующей оптимальный канал взаимодействия с клиентом, вовремя не внёсшим очередной платёж по кредиту. Должнику может звонить живой оператор (но это не очень дёшево) или робот (дёшево, но не так эффективно, и бесит клиентов), или можно не звонить вообще и надеяться, что клиент и так заплатит сегодня-завтра. Одним из сильных факторов оказались результаты звонков за вчерашний день. Но оказалось, что их использовать нельзя: логи звонков перекладываются в базу данных раз в сутки, ночью, а план звонков на завтра формируется сегодня, когда известны данные за вчера. То есть данные о звонках доступны с лагом в два дня до применения прогноза.
На моей практике несколько раз случалось, что модели с хорошей точностью откладывались в долгий ящик или сразу выкидывались из-за недоступности данных в реальном времени. Иногда приходилось переделывать их с нуля, пытаясь заменить признаки "из будущего" какими-то другими. Чтобы такого не происходило, первый же небесполезный прототип модели стоит тестировать на потоке данных, максимально приближенном к реальному. Может показаться, что это приведёт к дополнительным затратам на разработку тестовой среды. Но, скорее всего, перед запуском модели "в бою" её придётся создавать в любом случае. Начинайте строить инфраструктуру для тестирования модели как можно раньше, и, возможно, вы вовремя узнаете много интересных деталей.
Если модель основана на данных "из будущего", с этим вряд ли что-то можно поделать. Но часто бывает так, что даже с доступными данными внедрение модели даётся нелегко. Настолько нелегко, что внедрение затягивается на неопределённый срок из-за нехватки трудовых ресурсов на это. Что же так долго делают разработчики, если модель уже создана?
Скорее всего, они переписывают весь код с нуля. Причины на это могут быть совершенно разные. Возможно, вся их система написана на java, и они не готовы пользоваться моделью на python, ибо интеграция двух разных сред доставит им даже больше головной боли, чем переписывание кода. Или требования к производительности так высоки, что весь код для продакшна может быть написан только на C++, иначе модель будет работать слишком медленно. Или предобработку признаков для обучения модели вы сделали с использованием SQL, выгружая их из базы данных, но в бою никакой базы данных нет, а данные будут приходить в виде json-запроса.
Если модель создавалась в одном языке (скорее всего, в python), а применяться будет в другом, возникает болезненная проблема её переноса. Есть готовые решения, например, формат PMML, но их применимость оставляет желать лучшего. Если это линейная модель, достаточно сохранить в текстовом файле вектор коэффициентов. В случае нейросети или решающих деревьев коэффициентов потребуется больше, и в их записи и чтении будет проще ошибиться. Ещё сложнее сериализовать полностью непараметрические модели, в частности, сложные байесовские. Но даже это может быть просто по сравнению с созданием признаков, код для которого может быть совсем уж произвольным. Даже безобидная функция log() в разных языках программирования может означать разные вещи, что уж говорить о коде для работы с картинками или текстами!
Даже если с языком программирования всё в порядке, вопросы производительности и различия в формате данных в учении и в бою остаются. Ещё один возможный источник проблем: аналитик при создании модели активно пользовался инструментарием для работы с большими таблицами данных, но в бою прогноз необходимо делать для каждого наблюдения по отдельности. Многие действия, совершаемые с матрицей n*m, с матрицей 1*m проделывать неэффективно или вообще бессмысленно. Поэтому аналитику полезно с самого начала проекта готовиться принимать данные в нужном формате и уметь работать с наблюдениями поштучно. Мораль та же, что и в предыдущем разделе: начинайте тестировать весь пайплайн как можно раньше!
Разработчикам и админам продуктивной системы полезно с начала проекта задуматься о том, в какой среде будет работать модель. В их силах сделать так, чтобы код data scientist'a мог выполняться в ней с минимумом изменений. Если вы внедряете предсказательные модели регулярно, стоит один раз создать (или поискать у внешних провайдеров) платформу, обеспечивающую управление нагрузкой, отказоустойчивость, и передачу данных. На ней любую новую модель можно запустить в виде сервиса. Если же сделать так невозможно или нерентабельно, полезно будет заранее обсудить с разработчиком модели имеющиеся ограничения. Быть может, вы избавите его и себя от долгих часов ненужной работы.
За пару недель до моего прихода в банк там запустили в бой модель кредитного риска от стороннего поставщика. На ретроспективной выборке, которую прислал поставщик, модель показала себя хорошо, выделив очень плохих клиентов среди одобренных. Поэтому, когда прогнозы начали поступать к нам в реальном времени, мы немедленно стали применять их. Через несколько дней кто-то заметил, что отказываем мы больше заявок, чем ожидалось. Потом — что распределение приходящих прогнозов непохоже на то, что было в тестовой выборке. Начали разбираться, и поняли, что прогнозы приходят с противоположным знаком. Мы получали не вероятность того, что заёмщик плохой, а вероятность того, что он хороший. Несколько дней мы отказывали в кредите не худшим, а лучшим клиентам!
Такие нарушения бизнес-логики чаще всего происходят не в самой модели, а или при подготовке признаков, или, чаще всего, при применении прогноза. Если они менее очевидны, чем ошибка в знаке, то их можно не находить очень долго. Всё это время модель будет работать хуже, чем ожидалось, без видимых причин. Стандартный способ предупредить это — делать юнит-тесты для любого кусочка стратегии принятия решений. Кроме этого, нужно тестировать всю систему принятия решений (модель + её окружение) целиком (да-да, я повторяю это уже три раздела подряд). Но это не спасёт от всех бед: проблема может быть не в коде, а в данных. Чтобы смягчить такие риски, серьёзные нововведения можно запускать не на всём потоке данных (в нашем случае, заявок на кредиты), а на небольшой, но репрезентативной его доле (например, на случайно выбранных 10% заявок). A/B тесты— это вообще полезно. А если ваши модели отвечают за действительно важные решения, такие тесты могут идти в большом количестве и подолгу.
Бывает, что модель прошла все тесты, и была внедрена без единой ошибки. Вы смотрите на первые решения, которые она приняла, и они кажутся вам осмысленными. Они не идеальны — 17 партия пива получилась слабоватой, а 14 и 23 — очень крепкими, но в целом всё неплохо. Проходит неделя-другая, вы продолжаете смотреть на результаты A/B теста, и понимаете, что слишком крепких партий чересчур много. Обсуждаете это с заказчиком, и он объясняет, что недавно заменил резервуары для кипячения сусла, и это могло повысить уровень растворения хмеля. Ваш внутренний математик возмущается "Да как же так! Вы мне дали обучающую выборку, не репрезентативную генеральной совокупности! Это обман!". Но вы берёте себя в руки, и замечаете, что в обучающей выборке (последние три года) средняя концентрация растворенного хмеля не была стабильной. Да, сейчас она выше, чем когда-либо, но резкие скачки и падения были и раньше. Но вашу модель они ничему не научили.
Другой пример: доверие сообщества финансистов к статистическим методам было сильно подорвано после кризиса 2007 года. Тогда обвалился американский ипотечный рынок, потянув за собой всю мировую экономику. Модели, которые тогда использовались для оценки кредитных рисков, не предполагали, что все заёмщики могут одновременно перестать платить, потому что в их обучающей выборке не было таких событий. Но разбирающийся в предмете человек мог бы мысленно продолжить имеющиеся тренды и предугадать такой исход.
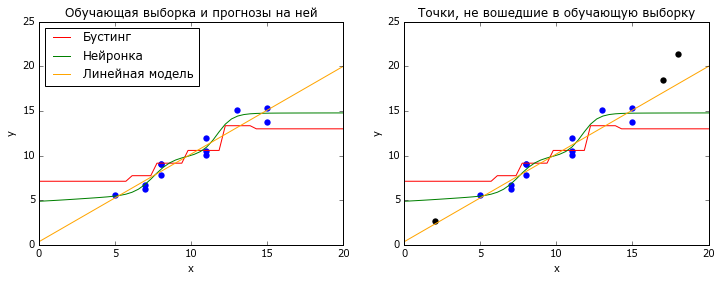
Бывает, что поток данных, к которым вы применяете модель, стационарен, т.е. не меняет своих статистических свойств со временем. Тогда самые популярные методы машинного обучения, нейросетки и градиентный бустинг над решающими деревьями, работают хорошо. Оба этих метода основаны на интерполяции обучающих данных: нейронки — логистическими кривыми, бустинг — кусочно-постоянными функциями. И те, и другие очень плохо справляются с задачей экстраполяции — предсказания для X, лежащих за пределами обучающей выборки (точнее, её выпуклой оболочки).
# coding: utf-8
# настраиваем всё, что нужно настроить
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rc
rc('font', family='Verdana')
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.linear_model import LinearRegression
# генерируем данные
np.random.seed(2)
n = 15
x_all = np.random.randint(20,size=(n,1))
y_all = x_all.ravel() + 10 * 0.1 + np.random.normal(size=n)
fltr = ((x_all<=15)&(x_all>=5))
x_train = x_all[fltr.ravel(),:]
y_train = y_all[fltr.ravel()]
x_new = x_all[~fltr.ravel(),:]
y_new = y_all[~fltr.ravel()]
x_plot = np.linspace(0, 20)
# обучаем модели
m1 = GradientBoostingRegressor(
n_estimators=10,
max_depth = 3,
random_state=42
).fit(x_train, y_train)
m2 = MLPRegressor(
hidden_layer_sizes=(10),
activation = 'logistic',
random_state = 42,
learning_rate_init = 1e-1,
solver = 'lbfgs',
alpha = 0.1
).fit(x_train, y_train)
m3 = LinearRegression().fit(x_train, y_train)
# Отрисовываем графики
plt.figure(figsize=(12,4))
title = {1:'Обучающая выборка и прогнозы на ней',
2:'Точки, не вошедшие в обучающую выборку'}
for i in [1,2]:
plt.subplot(1,2,i)
plt.scatter(x_train.ravel(), y_train, lw=0, s=40)
plt.xlim([0, 20])
plt.ylim([0, 25])
plt.plot(x_plot, m1.predict(x_plot[:,np.newaxis]), color = 'red')
plt.plot(x_plot, m2.predict(x_plot[:,np.newaxis]), color = 'green')
plt.plot(x_plot, m3.predict(x_plot[:,np.newaxis]), color = 'orange')
plt.xlabel('x')
plt.ylabel('y')
plt.title(title[i])
if i == 1:
plt.legend(['Бустинг', 'Нейронка', 'Линейная модель'],
loc = 'upper left')
if i == 2:
plt.scatter(x_new.ravel(), y_new, lw=0, s=40, color = 'black')
plt.show()Некоторые более простые модели (в том числе линейные) экстраполируют лучше. Но как понять, что они вам нужны? На помощь приходит кросс-валидация (перекрёстная проверка), но не классическая, в которой все данные перемешаны случайным образом, а что-нибудь типа TimeSeriesSplit из sklearn. В ней модель обучается на всех данных до момента t, а тестируется на данных после этого момента, и так для нескольких разных t. Хорошее качество на таких тестах даёт надежду, что модель может прогнозировать будущее, даже если оно несколько отличается от прошлого.
Иногда внедрения в модель сильных зависимостей, типа линейных, оказывается достаточно, чтобы она хорошо адаптировалась к изменениям в процессе. Если это нежелательно или этого недостаточно, можно подумать о более универсальных способах придания адаптивности. Проще всего калибровать модель на константу: вычитать из прогноза его среднюю ошибку за предыдущие n наблюдений. Если же дело не только в аддитивной константе, при обучении модели можно перевзвесить наблюдения (например, по принципу экспоненциального сглаживания). Это поможет модели сосредоточить внимание на самом недавнем прошлом.
Даже если вам кажется, что модель просто обязана быть стабильной, полезно будет завести автоматический мониторинг. Он мог бы описывать динамику предсказываемого значения, самого прогноза, основных факторов модели, и всевозможных метрик качества. Если модель действительно хороша, то она с вами надолго. Поэтому лучше один раз потрудиться над шаблоном, чем каждый месяц проверять перформанс модели вручную.
Бывает, что источником нерепрезентативности выборки являются не изменения во времени, а особенности процесса, породившего данные. У банка, где я работал, раньше существовала политика: нельзя выдавать кредиты людям, у которых платежи по текущим долгам превышают 40% дохода. С одной стороны, это разумно, ибо высокая кредитная нагрузка часто приводит к банкротству, особенно в кризисные времена. С другой стороны, и доход, и платежи по кредитам мы можем оценивать лишь приближённо. Возможно, у части наших несложившихся клиентов дела на самом деле были куда лучше. Да и в любом случае, специалист, который зарабатывает 200 тысяч в месяц, и 100 из них отдаёт в счёт ипотеки, может быть перспективным клиентом. Отказать такому в кредитной карте — потеря прибыли. Можно было бы надеяться, что модель будет хорошо ранжировать клиентов даже с очень высокой кредитной нагрузкой… Но это не точно, ведь в обучающей выборке нет ни одного такого!
Мне повезло, что за три года до моего прихода коллеги ввели простое, хотя и страшноватое правило: примерно 1% случайно отобранных заявок на кредитки одобрять в обход почти всех политик. Этот 1% приносил банку убытки, но позволял получать репрезентативные данные, на которых можно обучать и тестировать любые модели. Поэтому я смог доказать, что даже среди вроде бы очень закредитованных людей можно найти хороших клиентов. В результате мы начали выдавать кредитки людям с оценкой кредитной нагрузки от 40% до 90%, но более с жёстким порогом отсечения по предсказанной вероятности дефолта.
Если бы подобного потока чистых данных не было, то убедить менеджмент, что модель нормально ранжирует людей с нагрузкой больше 40%, было бы сложно. Наверное, я бы обучил её на выборке с нагрузкой 0-20%, и показал бы, что на тестовых данных с нагрузкой 20-40% модель способна принять адекватные решения. Но узенькая струйка нефильтрованных данных всё-таки очень полезна, и, если цена ошибки не очень высока, лучше её иметь. Подобный совет даёт и Мартин Цинкевич, ML-разработчик из Гугла, в своём руководстве по машинному обучению. Например, при фильтрации электронной почты 0.1% писем, отмеченных алгоритмом как спам, можно всё-таки показывать пользователю. Это позволит отследить и исправить ошибки алгоритма.
Как правило, решение, принимаемое на основе прогноза модели, является лишь небольшой частью какого-то бизнес-процесса, и может взаимодействовать с ним причудливым образом. Например, большая часть заявок на кредитки, одобренных автоматическим алгоритмом, должна также получить одобрение живого андеррайтера, прежде чем карта будет выдана. Когда мы начали одобрять заявки с высокой кредитной нагрузкой, андеррайтеры продолжили их отказывать. Возможно, они не сразу узнали об изменениях, или просто решили не брать на себя ответственность за непривычных клиентов. Нам пришлось передавать кредитным специалистам метки типа "не отказывать данному клиенту по причине высокой нагрузки", чтобы они начали одобрять такие заявки. Но пока мы выявили эту проблему, придумали решение и внедрили его, прошло много времени, в течение которого банк недополучал прибыль. Мораль: с другими участниками бизнес-процесса нужно договариваться заранее.
Иногда, чтобы зарезать пользу от внедрения или обновления модели, другое подразделение не нужно. Достаточно плохо договориться о границах допустимого с собственным менеджером. Возможно, он готов начать одобрять клиентов, выбранных моделью, но только если у них не более одного активного кредита, никогда не было просрочек, несколько успешно закрытых кредитов, и есть двойное подтверждение дохода. Если почти весь описанный сегмент мы и так уже одобряем, то модель мало что изменит.
Впрочем, при грамотном использовании модели человеческий фактор может быть полезен. Допустим, мы разработали модель, подсказывающую сотруднику магазина одежды, что ещё можно предложить клиенту, на основе уже имеющегося заказа. Такая модель может очень эффективно пользоваться большими данными (особенно если магазинов — целая сеть). Но частью релевантной информации, например, о внешнем виде клиентов, модель не обладает. Поэтому точность угадывания ровно-того-наряда-что-хочет-клиент остаётся невысокой. Однако можно очень просто объединить искусственный интеллект с человеческим: модель подсказывает продавцу три предмета, а он выбирает из них самое подходящее. Если правильно объяснить задачу всем продавцам, можно прийти к успеху.
Я прошёлся по некоторым из основных провалов, с которыми сталкивался при создании и встраивании в бизнес предсказательных моделей. Чаще всего это проблемы не математического, а организационного характера: модель вообще не нужна, или построена по кривой выборке, или есть сложности со встраиванием её в имеющиеся процессы и системы. Снизить риск таких провалов можно, если придерживаться простых принципов:
Высоких вам ROC-AUC и Эр-квадратов!
|
Метки: author cointegrated машинное обучение создание сервисов тестирование |
[Из песочницы] Как понять, что ваша предсказательная модель бесполезна |
При создании продуктов на основе машинного обучения возникают ситуации, которых хотелось бы избежать. В этом тексте я разбираю восемь проблем, с которыми сталкивался в своей работе.
Мой опыт связан с моделями кредитного скоринга и предсказательными системами для промышленных компаний. Текст поможет разработчиками и дата-сайнтистам строить полезные модели, а менеджерам не допускать грубых ошибок в проекте.
Этот текст не призван прорекламировать какую-нибудь компанию. Он основан на практике анализа данных в компании ООО "Ромашка", которая никогда не существовала и не будет существовать. Под "мы" я подразумеваю команду из себя и моих воображаемых друзей. Все сервисы, которые мы создавали, делались для конкретного клиента и не могут быть проданы или переданы иным лицам.
Пусть предсказательная модель — это алгоритм, который строит прогнозы и позволяет автоматически принимать полезное для бизнеса решение на основе исторических данных.
Я не рассматриваю:
Я буду говорить об алгоритмах обучения с учителем, т.е. таких, которые "увидели" много примеров пар (X,Y), и теперь могут для любого X сделать оценку Y. X — это информация, известная на момент прогноза (например, заполненная клиентом заявка на кредит). Y — это заранее неизвестная информация, необходимая для принятия решения (например, будет ли клиент своевременно платить по кредиту). Само решение может приниматься каким-то простым алгоритмом вне модели (например, одобрять кредит, если предсказанная вероятность неплатежа не выше 15%).
Аналитик, создающий модель, как правило, опирается на метрики качества прогноза, например, среднюю ошибку (MAE) или долю верных ответов (accuracy). Такие метрики позволяют быстро понять, какая из двух моделей предсказывает точнее (и нужно ли, скажем, заменять логистическую регрессию на нейросеть). Но на главный вопрос, а насколько модель полезна, они дают ответ далеко не всегда. Например, модель для кредитного скоринга очень легко может достигнуть точности 98% на данных, в которых 98% клиентов "хорошие", называя "хорошими" всех подряд.
С точки зрения предпринимателя или менеджера очевидно, какая модель полезная: которая приносит деньги. Если за счёт внедрения новой скоринговой модели за следующий год удастся отказать 3000 клиентам, которые бы принесли суммарный убыток 50 миллионов рублей, и одобрить 5000 новых клиентов, которые принесут суммарную прибыль 10 миллионов рублей, то модель явно хороша. На этапе разработки модели, конечно, вряд ли вы точно знаете эти суммы (да и потом — далеко не факт). Но чем скорее, точнее и честнее вы оцените экономическую пользу от проекта, тем лучше.
Достаточно часто построение вроде бы хорошей предсказательной модели не приводит к ожидаемому успеху: она не внедряется, или внедряется с большой задержкой, или начинает нормально работать только после десятков релизов, или перестаёт нормально работать через несколько месяцев после внедрения, или не работает вообще никак… При этом вроде бы все потрудились на славу: аналитик выжал из данных максимальную предсказательную силу, разработчик создал среду, в которой модель работает молниеносно и никогда не падает, а менеджер приложил все усилия, чтобы первые двое смогли завершить работу вовремя. Так почему же они попали в неприятность?
Мы как-то строили модель, предсказывающую крепость пива после дображивания (на самом деле, это было не пиво и вообще не алкоголь, но суть похожа). Задача ставилась так: понять, как параметры, задаваемые в начале брожения, влияют на крепость финального пива, и научиться лучше управлять ей. Задача казалась весёлой и перспективной, и мы потратили не одну сотню человеко-часов на неё, прежде чем выяснили, что на самом-то деле финальная крепость не так уж и важна заказчику. Например, когда пиво получается 7.6% вместо требуемых 8%, он просто смешивает его с более крепким, чтобы добиться нужного градуса. То есть, даже если бы мы построили идеальную модель, это принесло бы прибыли примерно нисколько.
Эта ситуация звучит довольно глупо, но на самом деле случается сплошь и рядом. Руководители инициируют machine learning проекты, "потому что интересно", или просто чтобы быть в тренде. Осознание, что это не очень-то и нужно, может прийти далеко не сразу, а потом долго отвергаться. Мало кому приятно признаваться, что время было потрачено впустую. К счастью, есть относительно простой способ избегать таких провалов: перед началом любого проекта оценивать эффект от идеальной предсказательной модели. Если бы вам предложили оракула, который в точности знает будущее наперёд, сколько бы были бы готовы за него заплатить? Если потери от брака и так составляют небольшую сумму, то, возможно, строить сложную систему для минимизации доли брака нет необходимости.
Как-то раз команде по кредитному скорингу предложили новый источник данных: чеки крупной сети продуктовых магазинов. Это выглядело очень заманчиво: "скажи мне, что ты покупаешь, и я скажу, кто ты". Но вскоре оказалось, что идентифицировать личность покупателя было возможно, только если он использовал карту лояльности. Доля таких покупателей оказалась невелика, а в пересечении с клиентами банка они составляли меньше 5% от входящих заявок на кредиты. Более того, это были лучшие 5%: почти все заявки одобрялись, и доля "дефолтных" среди них была близка к нулю. Даже если бы мы смогли отказывать все "плохие" заявки среди них, это сократило бы кредитные потери на совсем небольшую сумму. Она бы вряд ли окупила затраты на построение модели, её внедрение, и интеграцию с базой данных магазинов в реальном времени. Поэтому с чеками поигрались недельку, и передали их в отдел вторичных продаж: там от таких данных будет больше пользы.
Зато пивную модель мы всё-таки достроили и внедрили. Оказалось, что она не даёт экономии на сокращении брака, но зато позволяет снизить трудозатраты за счёт автоматизации части процесса. Но поняли мы это только после долгих дискуссий с заказчиком. И, если честно, нам просто повезло.
Даже если идеальная модель способна принести большую пользу, не факт, что вам удастся к ней приблизиться. В X может просто не быть информации, релевантной для предсказания Y. Конечно, вы редко можете быть до конца уверены, что вытащили из X все полезные признаки. Наибольшее улучшение прогноза обычно приносит feature engineering, который может длиться месяцами. Но можно работать итеративно: брейншторм — создание признаков — обучение прототипа модели — тестирование прототипа.
В самом начале проекта можно собраться большой компанией и провести мозговой штурм, придумывая разнообразные признаков. По моему опыту, самый сильный признак часто давал половину той точности, которая в итоге получалась у полной модели. Для скоринга это оказалась текущая кредитная нагрузка клиента, для пива — крепость предыдущей партии того же сорта. Если после пары циклов найти хорошие признаки не удалось, и качество модели близко к нулю, возможно, проект лучше свернуть, либо срочно отправиться искать дополнительные данные.
Важно, что тестировать нужно не только точность прогноза, но и качество решений, принимаемых на его основе. Не всегда возможно измерить пользу от модели "оффлайн" (в тестовой среде). Но вы можете придумывать метрики, которые хоть как-то приближают вас к оценке денежного эффекта. Например, если менеджеру по кредитным рискам нужно одобрение не менее 50% заявок (иначе сорвётся план продаж), то вы можете оценивать долю "плохих" клиентов среди 50% лучших с точки зрения модели. Она будет примерно пропорциональна тем убыткам, которые несёт банк из-за невозврата кредитов. Такую метрику можно посчитать сразу же после создания первого прототипа модели. Если грубая оценка выгоды от его внедрения не покрывает даже ваши собственные трудозатраты, то стоит задуматься: а можем ли мы вообще получить хороший прогноз?
Бывает, что созданная аналитиками модель демонстрирует хорошие меры как точности прогноза, так и экономического эффекта. Но когда начинается её внедрение в продакшн, оказывается, что необходимые для прогноза данные недоступны в реальном времени. Иногда бывает, что это настоящие данные "из будущего". Например, при прогнозе крепости пива важным фактором является измерение его плотности после первого этапа брожения, но применять прогноз мы хотим в начале этого этапа. Если бы мы не обсудили с заказчиком точную природу этого признака, мы бы построили бесполезную модель.
Ещё более неприятно может быть, если на момент прогноза данные доступны, но по техническим причинам подгрузить их в модель не получается. В прошлом году мы работали над моделью, рекомендующей оптимальный канал взаимодействия с клиентом, вовремя не внёсшим очередной платёж по кредиту. Должнику может звонить живой оператор (но это не очень дёшево) или робот (дёшево, но не так эффективно, и бесит клиентов), или можно не звонить вообще и надеяться, что клиент и так заплатит сегодня-завтра. Одним из сильных факторов оказались результаты звонков за вчерашний день. Но оказалось, что их использовать нельзя: логи звонков перекладываются в базу данных раз в сутки, ночью, а план звонков на завтра формируется сегодня, когда известны данные за вчера. То есть данные о звонках доступны с лагом в два дня до применения прогноза.
На моей практике несколько раз случалось, что модели с хорошей точностью откладывались в долгий ящик или сразу выкидывались из-за недоступности данных в реальном времени. Иногда приходилось переделывать их с нуля, пытаясь заменить признаки "из будущего" какими-то другими. Чтобы такого не происходило, первый же небесполезный прототип модели стоит тестировать на потоке данных, максимально приближенном к реальному. Может показаться, что это приведёт к дополнительным затратам на разработку тестовой среды. Но, скорее всего, перед запуском модели "в бою" её придётся создавать в любом случае. Начинайте строить инфраструктуру для тестирования модели как можно раньше, и, возможно, вы вовремя узнаете много интересных деталей.
Если модель основана на данных "из будущего", с этим вряд ли что-то можно поделать. Но часто бывает так, что даже с доступными данными внедрение модели даётся нелегко. Настолько нелегко, что внедрение затягивается на неопределённый срок из-за нехватки трудовых ресурсов на это. Что же так долго делают разработчики, если модель уже создана?
Скорее всего, они переписывают весь код с нуля. Причины на это могут быть совершенно разные. Возможно, вся их система написана на java, и они не готовы пользоваться моделью на python, ибо интеграция двух разных сред доставит им даже больше головной боли, чем переписывание кода. Или требования к производительности так высоки, что весь код для продакшна может быть написан только на C++, иначе модель будет работать слишком медленно. Или предобработку признаков для обучения модели вы сделали с использованием SQL, выгружая их из базы данных, но в бою никакой базы данных нет, а данные будут приходить в виде json-запроса.
Если модель создавалась в одном языке (скорее всего, в python), а применяться будет в другом, возникает болезненная проблема её переноса. Есть готовые решения, например, формат PMML, но их применимость оставляет желать лучшего. Если это линейная модель, достаточно сохранить в текстовом файле вектор коэффициентов. В случае нейросети или решающих деревьев коэффициентов потребуется больше, и в их записи и чтении будет проще ошибиться. Ещё сложнее сериализовать полностью непараметрические модели, в частности, сложные байесовские. Но даже это может быть просто по сравнению с созданием признаков, код для которого может быть совсем уж произвольным. Даже безобидная функция log() в разных языках программирования может означать разные вещи, что уж говорить о коде для работы с картинками или текстами!
Даже если с языком программирования всё в порядке, вопросы производительности и различия в формате данных в учении и в бою остаются. Ещё один возможный источник проблем: аналитик при создании модели активно пользовался инструментарием для работы с большими таблицами данных, но в бою прогноз необходимо делать для каждого наблюдения по отдельности. Многие действия, совершаемые с матрицей n*m, с матрицей 1*m проделывать неэффективно или вообще бессмысленно. Поэтому аналитику полезно с самого начала проекта готовиться принимать данные в нужном формате и уметь работать с наблюдениями поштучно. Мораль та же, что и в предыдущем разделе: начинайте тестировать весь пайплайн как можно раньше!
Разработчикам и админам продуктивной системы полезно с начала проекта задуматься о том, в какой среде будет работать модель. В их силах сделать так, чтобы код data scientist'a мог выполняться в ней с минимумом изменений. Если вы внедряете предсказательные модели регулярно, стоит один раз создать (или поискать у внешних провайдеров) платформу, обеспечивающую управление нагрузкой, отказоустойчивость, и передачу данных. На ней любую новую модель можно запустить в виде сервиса. Если же сделать так невозможно или нерентабельно, полезно будет заранее обсудить с разработчиком модели имеющиеся ограничения. Быть может, вы избавите его и себя от долгих часов ненужной работы.
За пару недель до моего прихода в банк там запустили в бой модель кредитного риска от стороннего поставщика. На ретроспективной выборке, которую прислал поставщик, модель показала себя хорошо, выделив очень плохих клиентов среди одобренных. Поэтому, когда прогнозы начали поступать к нам в реальном времени, мы немедленно стали применять их. Через несколько дней кто-то заметил, что отказываем мы больше заявок, чем ожидалось. Потом — что распределение приходящих прогнозов непохоже на то, что было в тестовой выборке. Начали разбираться, и поняли, что прогнозы приходят с противоположным знаком. Мы получали не вероятность того, что заёмщик плохой, а вероятность того, что он хороший. Несколько дней мы отказывали в кредите не худшим, а лучшим клиентам!
Такие нарушения бизнес-логики чаще всего происходят не в самой модели, а или при подготовке признаков, или, чаще всего, при применении прогноза. Если они менее очевидны, чем ошибка в знаке, то их можно не находить очень долго. Всё это время модель будет работать хуже, чем ожидалось, без видимых причин. Стандартный способ предупредить это — делать юнит-тесты для любого кусочка стратегии принятия решений. Кроме этого, нужно тестировать всю систему принятия решений (модель + её окружение) целиком (да-да, я повторяю это уже три раздела подряд). Но это не спасёт от всех бед: проблема может быть не в коде, а в данных. Чтобы смягчить такие риски, серьёзные нововведения можно запускать не на всём потоке данных (в нашем случае, заявок на кредиты), а на небольшой, но репрезентативной его доле (например, на случайно выбранных 10% заявок). A/B тесты— это вообще полезно. А если ваши модели отвечают за действительно важные решения, такие тесты могут идти в большом количестве и подолгу.
Бывает, что модель прошла все тесты, и была внедрена без единой ошибки. Вы смотрите на первые решения, которые она приняла, и они кажутся вам осмысленными. Они не идеальны — 17 партия пива получилась слабоватой, а 14 и 23 — очень крепкими, но в целом всё неплохо. Проходит неделя-другая, вы продолжаете смотреть на результаты A/B теста, и понимаете, что слишком крепких партий чересчур много. Обсуждаете это с заказчиком, и он объясняет, что недавно заменил резервуары для кипячения сусла, и это могло повысить уровень растворения хмеля. Ваш внутренний математик возмущается "Да как же так! Вы мне дали обучающую выборку, не репрезентативную генеральной совокупности! Это обман!". Но вы берёте себя в руки, и замечаете, что в обучающей выборке (последние три года) средняя концентрация растворенного хмеля не была стабильной. Да, сейчас она выше, чем когда-либо, но резкие скачки и падения были и раньше. Но вашу модель они ничему не научили.
Другой пример: доверие сообщества финансистов к статистическим методам было сильно подорвано после кризиса 2007 года. Тогда обвалился американский ипотечный рынок, потянув за собой всю мировую экономику. Модели, которые тогда использовались для оценки кредитных рисков, не предполагали, что все заёмщики могут одновременно перестать платить, потому что в их обучающей выборке не было таких событий. Но разбирающийся в предмете человек мог бы мысленно продолжить имеющиеся тренды и предугадать такой исход.
Бывает, что поток данных, к которым вы применяете модель, стационарен, т.е. не меняет своих статистических свойств со временем. Тогда самые популярные методы машинного обучения, нейросетки и градиентный бустинг над решающими деревьями, работают хорошо. Оба этих метода основаны на интерполяции обучающих данных: нейронки — логистическими кривыми, бустинг — кусочно-постоянными функциями. И те, и другие очень плохо справляются с задачей экстраполяции — предсказания для X, лежащих за пределами обучающей выборки (точнее, её выпуклой оболочки).
# coding: utf-8
# настраиваем всё, что нужно настроить
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rc
rc('font', family='Verdana')
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.linear_model import LinearRegression
# генерируем данные
np.random.seed(2)
n = 15
x_all = np.random.randint(20,size=(n,1))
y_all = x_all.ravel() + 10 * 0.1 + np.random.normal(size=n)
fltr = ((x_all<=15)&(x_all>=5))
x_train = x_all[fltr.ravel(),:]
y_train = y_all[fltr.ravel()]
x_new = x_all[~fltr.ravel(),:]
y_new = y_all[~fltr.ravel()]
x_plot = np.linspace(0, 20)
# обучаем модели
m1 = GradientBoostingRegressor(
n_estimators=10,
max_depth = 3,
random_state=42
).fit(x_train, y_train)
m2 = MLPRegressor(
hidden_layer_sizes=(10),
activation = 'logistic',
random_state = 42,
learning_rate_init = 1e-1,
solver = 'lbfgs',
alpha = 0.1
).fit(x_train, y_train)
m3 = LinearRegression().fit(x_train, y_train)
# Отрисовываем графики
plt.figure(figsize=(12,4))
title = {1:'Обучающая выборка и прогнозы на ней',
2:'Точки, не вошедшие в обучающую выборку'}
for i in [1,2]:
plt.subplot(1,2,i)
plt.scatter(x_train.ravel(), y_train, lw=0, s=40)
plt.xlim([0, 20])
plt.ylim([0, 25])
plt.plot(x_plot, m1.predict(x_plot[:,np.newaxis]), color = 'red')
plt.plot(x_plot, m2.predict(x_plot[:,np.newaxis]), color = 'green')
plt.plot(x_plot, m3.predict(x_plot[:,np.newaxis]), color = 'orange')
plt.xlabel('x')
plt.ylabel('y')
plt.title(title[i])
if i == 1:
plt.legend(['Бустинг', 'Нейронка', 'Линейная модель'],
loc = 'upper left')
if i == 2:
plt.scatter(x_new.ravel(), y_new, lw=0, s=40, color = 'black')
plt.show()Некоторые более простые модели (в том числе линейные) экстраполируют лучше. Но как понять, что они вам нужны? На помощь приходит кросс-валидация (перекрёстная проверка), но не классическая, в которой все данные перемешаны случайным образом, а что-нибудь типа TimeSeriesSplit из sklearn. В ней модель обучается на всех данных до момента t, а тестируется на данных после этого момента, и так для нескольких разных t. Хорошее качество на таких тестах даёт надежду, что модель может прогнозировать будущее, даже если оно несколько отличается от прошлого.
Иногда внедрения в модель сильных зависимостей, типа линейных, оказывается достаточно, чтобы она хорошо адаптировалась к изменениям в процессе. Если это нежелательно или этого недостаточно, можно подумать о более универсальных способах придания адаптивности. Проще всего калибровать модель на константу: вычитать из прогноза его среднюю ошибку за предыдущие n наблюдений. Если же дело не только в аддитивной константе, при обучении модели можно перевзвесить наблюдения (например, по принципу экспоненциального сглаживания). Это поможет модели сосредоточить внимание на самом недавнем прошлом.
Даже если вам кажется, что модель просто обязана быть стабильной, полезно будет завести автоматический мониторинг. Он мог бы описывать динамику предсказываемого значения, самого прогноза, основных факторов модели, и всевозможных метрик качества. Если модель действительно хороша, то она с вами надолго. Поэтому лучше один раз потрудиться над шаблоном, чем каждый месяц проверять перформанс модели вручную.
Бывает, что источником нерепрезентативности выборки являются не изменения во времени, а особенности процесса, породившего данные. У банка, где я работал, раньше существовала политика: нельзя выдавать кредиты людям, у которых платежи по текущим долгам превышают 40% дохода. С одной стороны, это разумно, ибо высокая кредитная нагрузка часто приводит к банкротству, особенно в кризисные времена. С другой стороны, и доход, и платежи по кредитам мы можем оценивать лишь приближённо. Возможно, у части наших несложившихся клиентов дела на самом деле были куда лучше. Да и в любом случае, специалист, который зарабатывает 200 тысяч в месяц, и 100 из них отдаёт в счёт ипотеки, может быть перспективным клиентом. Отказать такому в кредитной карте — потеря прибыли. Можно было бы надеяться, что модель будет хорошо ранжировать клиентов даже с очень высокой кредитной нагрузкой… Но это не точно, ведь в обучающей выборке нет ни одного такого!
Мне повезло, что за три года до моего прихода коллеги ввели простое, хотя и страшноватое правило: примерно 1% случайно отобранных заявок на кредитки одобрять в обход почти всех политик. Этот 1% приносил банку убытки, но позволял получать репрезентативные данные, на которых можно обучать и тестировать любые модели. Поэтому я смог доказать, что даже среди вроде бы очень закредитованных людей можно найти хороших клиентов. В результате мы начали выдавать кредитки людям с оценкой кредитной нагрузки от 40% до 90%, но более с жёстким порогом отсечения по предсказанной вероятности дефолта.
Если бы подобного потока чистых данных не было, то убедить менеджмент, что модель нормально ранжирует людей с нагрузкой больше 40%, было бы сложно. Наверное, я бы обучил её на выборке с нагрузкой 0-20%, и показал бы, что на тестовых данных с нагрузкой 20-40% модель способна принять адекватные решения. Но узенькая струйка нефильтрованных данных всё-таки очень полезна, и, если цена ошибки не очень высока, лучше её иметь. Подобный совет даёт и Мартин Цинкевич, ML-разработчик из Гугла, в своём руководстве по машинному обучению. Например, при фильтрации электронной почты 0.1% писем, отмеченных алгоритмом как спам, можно всё-таки показывать пользователю. Это позволит отследить и исправить ошибки алгоритма.
Как правило, решение, принимаемое на основе прогноза модели, является лишь небольшой частью какого-то бизнес-процесса, и может взаимодействовать с ним причудливым образом. Например, большая часть заявок на кредитки, одобренных автоматическим алгоритмом, должна также получить одобрение живого андеррайтера, прежде чем карта будет выдана. Когда мы начали одобрять заявки с высокой кредитной нагрузкой, андеррайтеры продолжили их отказывать. Возможно, они не сразу узнали об изменениях, или просто решили не брать на себя ответственность за непривычных клиентов. Нам пришлось передавать кредитным специалистам метки типа "не отказывать данному клиенту по причине высокой нагрузки", чтобы они начали одобрять такие заявки. Но пока мы выявили эту проблему, придумали решение и внедрили его, прошло много времени, в течение которого банк недополучал прибыль. Мораль: с другими участниками бизнес-процесса нужно договариваться заранее.
Иногда, чтобы зарезать пользу от внедрения или обновления модели, другое подразделение не нужно. Достаточно плохо договориться о границах допустимого с собственным менеджером. Возможно, он готов начать одобрять клиентов, выбранных моделью, но только если у них не более одного активного кредита, никогда не было просрочек, несколько успешно закрытых кредитов, и есть двойное подтверждение дохода. Если почти весь описанный сегмент мы и так уже одобряем, то модель мало что изменит.
Впрочем, при грамотном использовании модели человеческий фактор может быть полезен. Допустим, мы разработали модель, подсказывающую сотруднику магазина одежды, что ещё можно предложить клиенту, на основе уже имеющегося заказа. Такая модель может очень эффективно пользоваться большими данными (особенно если магазинов — целая сеть). Но частью релевантной информации, например, о внешнем виде клиентов, модель не обладает. Поэтому точность угадывания ровно-того-наряда-что-хочет-клиент остаётся невысокой. Однако можно очень просто объединить искусственный интеллект с человеческим: модель подсказывает продавцу три предмета, а он выбирает из них самое подходящее. Если правильно объяснить задачу всем продавцам, можно прийти к успеху.
Я прошёлся по некоторым из основных провалов, с которыми сталкивался при создании и встраивании в бизнес предсказательных моделей. Чаще всего это проблемы не математического, а организационного характера: модель вообще не нужна, или построена по кривой выборке, или есть сложности со встраиванием её в имеющиеся процессы и системы. Снизить риск таких провалов можно, если придерживаться простых принципов:
Высоких вам ROC-AUC и Эр-квадратов!
|
Метки: author cointegrated машинное обучение создание сервисов тестирование |
[Из песочницы] История 13 места на Highload Cup 2017 |

11 августа компания Mail.Ru Объявила об очередном конкурсе HighloadCup для системных программистов backend-разработчиков.
Вкратце задача стояла следующим образом: докер, 4 ядра, 4Гб памяти, 10Гб HDD, набор api, и нужно ответить на запросы за наименьшее количество времени. Язык и стек технологий неограничен. В качестве тестирующей системы выступал яндекс-танк с движком phantom.
О том, как в таких условиях добраться до 13 места в финале, и будет эта статья.
Подробно с описанием задачи можно ознакомиться в публикации одного из участников на хабре, или на официальной странице конкурса. О том, как происходило тестирование, написано здесь.
Api представляло из себя 3 get-запроса на просто вернуть записи из базы, 2 get-запроса на агрегирование данных, 3 post-запроса на модификацию данных, и 3 post-запроса на добавление данных.
Сразу были оговорены следующие условия, которые существенно облегчили жизнь:
Запросы были поделены на 3 части: сначала get-запросы по исходным данным, потом серия post-запросов на добавление/изменение данных, и последняя самая мощная серия get-запросов по модифицированным данным. Вторая фаза была очень важна, т.к. неправильно добавив или поменяв данные, можно было получить много ошибок в третьей фазе, и как результат — большой штраф. На данном этапе последняя стадия содержала линейное увеличение числа запросов от 100 до 2000rps.
Еще одним условием было то, что один запрос — одно соединение, т.е. никаких keep-alive, но в какой-то момент от этого отказались, и все get-запросы шли с keep-alive, post-запросы были каждый на новое соединение.
Моей мечтой всегда были и есть Linux, C++ и системное программирование (хотя реальность ужасна), и я решил ни в чем себе не отказывать и нырнуть в это удовольствие с головой.
Т.к. о highload'e я знал чуть менее, чем ничего, и я до последнего надеялся, что писать свой web-сервер не придется, то первым шагом к решению задачи стал поиск подходящего web-сервера. Мой взгляд ухватился за proxygen. В целом, сервер должен был быть хорошим — кто еще знает о хайлоаде столько, сколько facebook?
Исходный код содержит несколько примеров, как использовать этот сервер.
HTTPServerOptions options;
options.threads = static_cast(FLAGS_threads);
options.idleTimeout = std::chrono::milliseconds(60000);
options.shutdownOn = {SIGINT, SIGTERM};
options.enableContentCompression = false;
options.handlerFactories = RequestHandlerChain()
.addThen()
.build();
HTTPServer server(std::move(options));
server.bind(IPs);
// Start HTTPServer mainloop in a separate thread
std::thread t([&] () {
server.start();
}); И на каждое принятое соединение вызывается метод фабрики
class EchoHandlerFactory : public RequestHandlerFactory {
public:
// ...
RequestHandler* onRequest(RequestHandler*, HTTPMessage*) noexcept override {
return new EchoHandler(stats_.get());
}
// ...
private:
folly::ThreadLocalPtr stats_;
}; От new EchoHandler() на каждый запрос у меня по спине вдруг пробежал холодок, но я не придал этому значения.
Сам EchoHandler должен реализовать интерфейс proxygen::RequestHandler:
class EchoHandler : public proxygen::RequestHandler {
public:
void onRequest(std::unique_ptr headers)
noexcept override;
void onBody(std::unique_ptr body) noexcept override;
void onEOM() noexcept override;
void onUpgrade(proxygen::UpgradeProtocol proto) noexcept override;
void requestComplete() noexcept override;
void onError(proxygen::ProxygenError err) noexcept override;
};Все выглядит хорошо и красиво, только успевай обрабатывать приходящие данные.
Роутинг я реализовал с помощью std::regex, благо набор апи простой и небольшой. Ответы формировал на лету с помощью std::stringstream. В данный момент я не заморачивался с производительностью, целью было получить работающий прототип.
Так как данные помещаются в память, то значит и хранить их нужно в памяти!
Структуры данных выглядели так:
struct Location {
std::string place;
std::string country;
std::string city;
uint32_t distance = 0;
std::string Serialize(uint32_t id) const {
std::stringstream data;
data <<
"{" <<
"\"id\":" << id << "," <<
"\"place\":\"" << place << "\"," <<
"\"country\":\"" << country << "\"," <<
"\"city\":\"" << city << "\"," <<
"\"distance\":" << distance <<
"}";
return std::move(data.str());
}
};Первоначальный вариант "базы данных" был такой:
template
class InMemoryStorage {
public:
typedef std::unordered_map Map;
InMemoryStorage();
bool Add(uint32_t id, T&& data, T** pointer);
T* Get(uint32_t id);
private:
std::vector> buckets_;
std::vector Идея была следущей: индексы, по условию, целое 32-битное число, а значит никто не мешает добавлять данные с произвольными индексами внутри этого диапазона (о, как же я ошибался!). Поэтому у меня было BUCKETS_COUNT (=10) хранилищ, чтобы уменьшить время ожидания на мутексе для потоков.
Т.к. были запросы на выборку данных, и нужно было быстро искать все места, в которых бывал пользователь, и все отзывы, оставленные для мест, то нужны были индексы users -> visits и locations -> visits.
Для индекса был написан следующий код, с той же идеологией:
template
class MultiIndex {
public:
MultiIndex() : buckets_(BUCKETS_COUNT), bucket_mutexes_(BUCKETS_COUNT) {
}
void Add(uint32_t id, T* pointer) {
int bucket_id = id % BUCKETS_COUNT;
std::lock_guard lock(bucket_mutexes_[bucket_id]);
buckets_[bucket_id].insert(std::make_pair(id, pointer));
}
void Replace(uint32_t old_id, uint32_t new_id, T* val) {
int bucket_id = old_id % BUCKETS_COUNT;
{
std::lock_guard lock(bucket_mutexes_[bucket_id]);
auto range = buckets_[bucket_id].equal_range(old_id);
auto it = range.first;
while (it != range.second) {
if (it->second == val) {
buckets_[bucket_id].erase(it);
break;
}
++it;
}
}
bucket_id = new_id % BUCKETS_COUNT;
std::lock_guard lock(bucket_mutexes_[bucket_id]);
buckets_[bucket_id].insert(std::make_pair(new_id, val));
}
std::vector GetValues(uint32_t id) {
int bucket_id = id % BUCKETS_COUNT;
std::lock_guard lock(bucket_mutexes_[bucket_id]);
auto range = buckets_[bucket_id].equal_range(id);
auto it = range.first;
std::vector result;
while (it != range.second) {
result.push_back(it->second);
++it;
}
return std::move(result);
}
private:
std::vector> buckets_;
std::vector bucket_mutexes_;
}; Первоначально организаторами были выложены только тестовые данные, которыми инициализировалась база данных, а примеров запросов не было, поэтому я начинал тестировать свой код с помощью Insomnia, которая позволяла легко отправлять и модифицировать запросы и смотреть ответ.
Чуть позже организаторы сжалилсь над участниками и выложили патроны от танка и полные данные рейтинговых и тестовых обстрелов, и я написал простенький скрипт, который позволял тестировать локально корректность моего решения и очень помог в дальнейшем.
И вот наконец-то прототип был закончен, локально тестировщик говорил, что все ОК, и настало время отправлять свое решение. Первый запуск был очень волнительным, и он показал, что что-то не так...
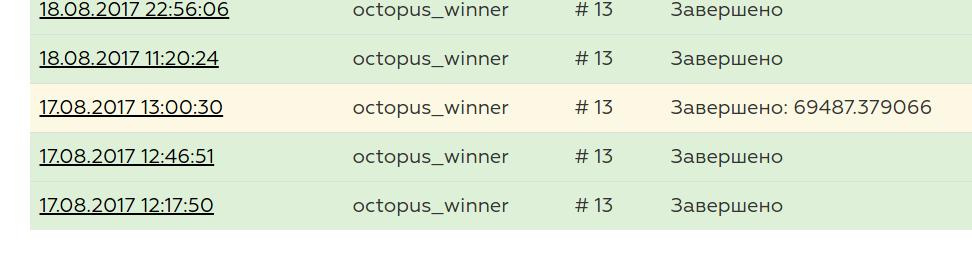
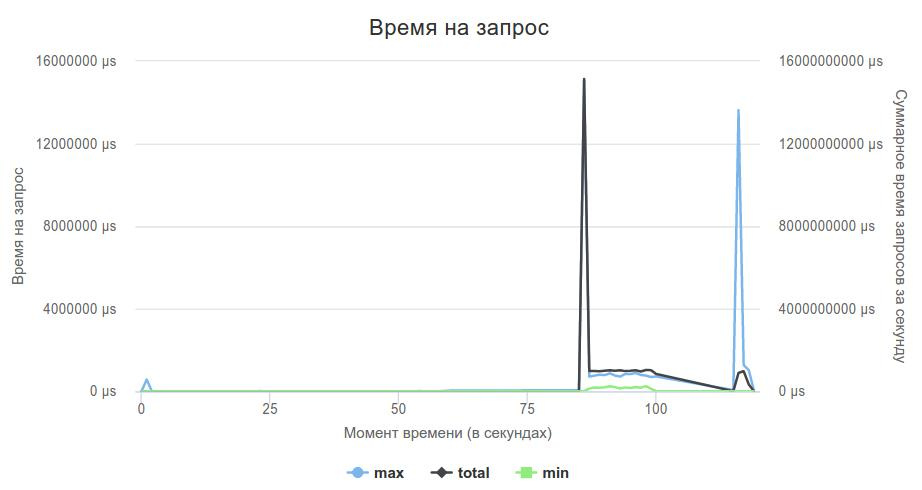
Мой сервер не держал нагрузку в 2000rps. У лидеров в этот момент, насколько я помню, времена были порядка сотен секунд.
Дальше я решил проверить, справляется ли вообще сервер с нагрузкой, или это проблемы с моей реализацией. Написал код, который на все запросы просто отдавал пустой json, запустил рейтинговый обстрел, и увидел, что сам proxygen не справляется с нагрузкой.
void onEOM() noexcept override {
proxygen::ResponseBuilder(downstream_)
.status(200, "OK")
.header("Content-Type", "application/json")
.body("{}")
.sendWithEOM();
}Вот так выглядел график 3-ей фазы.
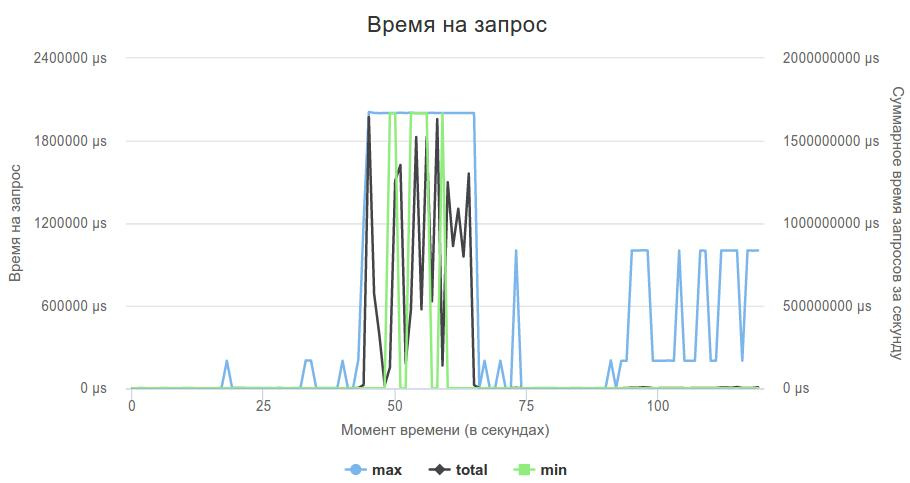
С одной стороны было приятно, что это пока еще проблема не в моем коде, с другой встал вопрос: что делать с сервером? Я все еще надеялся избежать написания своего, и решил попробовать что-нибудь другое.
Следующим подопытным стал Crow. Сразу скажу, мне он очень понравился, и если вдруг в будущем мне потребуется плюсовый http-сервер, то это будет именно он. header-based сервер, я его просто добавил в свой проект вместо proxygen, и немного переписал обработчики запросов, чтобы они начали работать с новым сервером.
Использовать его очень просто:
crow::SimpleApp app;
CROW_ROUTE(app, "/users/").methods("GET"_method, "POST"_method) (
[](const crow::request& req, crow::response& res, uint32_t id) {
if (req.method == crow::HTTPMethod::GET) {
get_handlers::GetUsers(req, res, id);
} else {
post_handlers::UpdateUsers(req, res, id);
}
});
app.bindaddr("0.0.0.0").port(80).multithreaded().run(); В случае, если нет подходящего описания для api, сервер сам отправляет 404, если же есть нужный обработчик, то в данном случае он достает из запроса uint-параметр и передает его как параметр в обработчик.
Но перед тем, как использовать новый сервер, наученный горьким опытом, я решил проверить, справляется ли он с нагрузкой. Также как и в предыдущем случае, написал обработчик, который возвращал пустой json на любой запрос, и отправил его на рейтинговый обстрел.
Crow справился, он держал нагрузку, и теперь нужно было добавить мою логику.
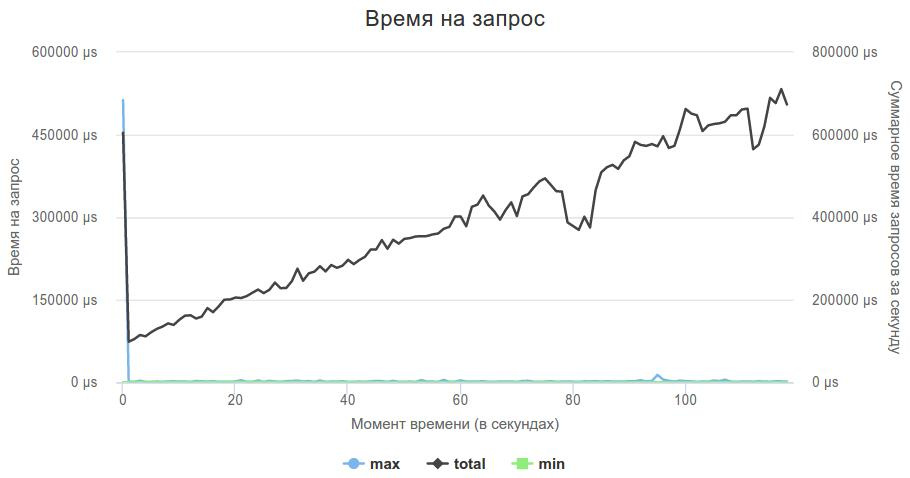
Т.к. логика была уже написана, то адаптировать код к новому серверу было достаточно просто. Все получилось!

100 секунд — уже что-то, и можно начинать заниматься оптимизацией логики, а не поисками сервера.
Т.к. мой сервер все еще формировал ответы с помощью std::stringstream, я решил избавиться от этого в первую очередь. В момент добавления записи в базу данных тут же формировалась строка, содержащая полный ответ с хедером, и в момент запроса отдавал ее.
На данном этапе я решил добавить хедер полностью в ответ по двум причинам:
write()Еще одной проблемой, о которую было сломано много копий в чатике в телеграмме и мной лично, это фильтр пользователей по возрасту. По условию задачи, возраст пользователей хранился в unix timestamp, а в запросах он приходил в виде полных лет: fromAge=30&toAge=70. Как года привести к секундам? Учитывать високосный год или нет? А если пользователь родился 29 февраля?
Итогом стал код, который решал все эти проблемы одним махом:
static time_t t = g_generate_time; // get time now
static struct tm now = (*localtime(&t));
if (search_flags & QueryFlags::FROM_AGE) {
tm from_age_tm = now;
from_age_tm.tm_year -= from_age;
time_t from_age_t = mktime(&from_age_tm);
if (user->birth_date > from_age_t) {
continue;
}
}Результатом стало двухкратное увеличение производительности, со 100 до 50 секунд.
Неплохо на первый взгляд, но в этот момент у лидеров было уже меньше 20 секунд, а я был где-то на 20-40 месте со своим результатом.
В этот момент были сделаны еще два наблюдения:
Стало понятно, что хэши, мутексы и бакеты для хранения данных не нужны, и данные можно прекрасно хранить по индексу в векторе, что и было сделано. Финальную версию можно увидеть здесь (к финалу дополнительно была добавлена часть кода для обработки индексов, если вдруг они превысят лимит).
Каких-то очевидных моментов, которые бы сильно влияли на производительность в моей логике, казалось, не было. Скорей всего с помощью оптимизаций можно было бы скинуть еще несколько секунд, но нужно было скидывать половину.
Я опять начал упираться в работу с сетью/сервером. Пробежавшись по исходникам сервера, я пришел к неутешительному выводу — при отправке происходило 2 ненужных копирования данных: сначала во внутренний буфер сервера, а потом еще раз в буфер для отправки.
В мире нет ничего более беспомощного, безответственного и безнравственного, чем начинать писать свой web-сервер. И я знал, что довольно скоро я в это окунусь.
И вот этот момент настал.
При написании своего сервера было сделано несколько допущений:
Вообще, можно было по-честному поддержать read() и write() в несколько кусков, но текущий вариант работал, поэтому это осталось "на потом".
После серии экспериментов я остановился на следующей архитектуре: блокирующий аccept() в главном потоке, добавление нового сокета в epoll, и std::thread::hardware_concurrency() потоков слушают один epollfd и обрабатывают данные.
unsigned int thread_nums = std::thread::hardware_concurrency();
for (unsigned int i = 0; i < thread_nums; ++i) {
threads.push_back(std::thread([epollfd, max_events]() {
epoll_event events[max_events];
int nfds = 0;
while (true) {
nfds = epoll_wait(epollfd, events, max_events, 0);
// ...
for (int n = 0; n < nfds; ++n) {
// ...
}
}
}));
}
while (true) {
int sock = accept(listener, NULL, NULL);
// ...
struct epoll_event ev;
ev.events = EPOLLIN | EPOLLET | EPOLLONESHOT;
ev.data.fd = sock;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, sock, &ev) == -1) {
perror("epoll_ctl: conn_sock");
exit(EXIT_FAILURE);
}
}EPOLLET гарантирует, что будет разбужен только какой-то один поток, а также что если в сокете останутся недочитанные данные, то epoll на сокет не сработает до тех пор, пока они все не будут вычитаны до EAGAIN. Поэтому следующей рекомендацией по использованию этого флага является делать сокет неблокирующим и читать, пока не вернется ошибка. Но как было обозначено в допущениях, запросы маленькие и читаются за один вызов read(), данных в сокете не остается, и epoll нормально срабатывал на приход новых данных.
Тут я сделал одну ошибку: я использовал std::thread::hardware_concurrency() для определения количества доступных потоков, но это было плохой идеей, потому что этот вызов возвращал 10 (количество ядер на сервере), а в докере было доступно только 4 ядра. Впрочем, на результат это мало повлияло.
Для парсинга http я использовал http-parser (Crow также использует его), для разбора урла — libyuarel, и для декодирования параметров в query-запросе — qs_parse. qs_parse также используется в Crow, он умеет разбирать урл, но так получилось, что я его использовал только для декодирования параметров.
Переписав таким образом свою реализацию, я сумел скинуть еще 10 секунд, и теперь мой результат составлял 40 секунд.
До конца соревнования оставалось полторы недели, и организаторы решили, что 200Мб данных и 2000rps — это мало, и увеличили размер данных и нагрузки в 5 раз: данные стали занимать 1Гб в распакованном виде, а интенсивность обстрела выросла до 10000rps на 3-ей фазе.
Моя реализация, которая хранила ответы целиком, перестала влезать по памяти, делать много вызовов write(), чтобы писать ответ по частям, тоже казалось плохой идеей, и я переписал свое решение на использование writev(): не нужно было дублировать данные при хранении и запись происходила с помощью одного системного вызова (тут тоже добавлено улучшение для финала: writev может записать за раз 1024 элемента массива iovec, а моя реализация для /users/ была очень iovec-затратной, и я добавил возможность разбить запись данных на 2 куска).
Отправив свою реализацю на запуск, я получил фантастические (в хорошем смысле) 245 секунды времени, что позволило мне оказаться на 2 месте в таблице результатов на тот момент.
Так как тестовая система подвержена большому рандому, и одно и то же решение может показывать различающееся в несколько раз время, а рейтинговые обстрелы можно было запускать лишь 2 раза в сутки, то непонятно, какие из следующих улучшений привели к конечному результату, а какие нет.
За оставшуюся неделю я сделал следующие оптимизации:
Заменил цепочки вызовов вида
DBInstance::GetDbInstance()->GetLocations()на указатель
g_location_storageПотом я подумал, что честный http-парсер для get-запросов не нужен, и для get-запроса можно сразу брать урл и больше ни о чем не заботиться. Благо, фиксированные запросы танка это позволяли. Также тут примечателен момент, что можно портить буфер (записывать \0 в конец урла, например). Таким же образом работает libyuarel.
HttpData http_data;
if (buf[0] == 'G') {
char* url_start = buf + 4;
http_data.url = url_start;
char* it = url_start;
int url_len = 0;
while (*it++ != ' ') {
++url_len;
}
http_data.url_length = url_len;
http_data.method = HTTP_GET;
} else {
http_parser_init(parser.get(), HTTP_REQUEST);
parser->data = &http_data;
int nparsed = http_parser_execute(
parser.get(), &settings, buf, readed);
if (nparsed != readed) {
close(sock);
continue;
}
http_data.method = parser->method;
}
Route(http_data);Также в чатике в телеграмме поднялся вопрос о том, что на сервере проверяется только количество полей в хедере, а не их содержимое, и хедеры были безжалостно порезаны:
const char* header = "HTTP/1.1 200 OK\r\n"
"S: b\r\n"
"C: k\r\n"
"B: a\r\n"
"Content-Length: ";Кажется, странное улучшение, но на многих запросах размер ответа существенно сокращался. К сожалению, неизвестно, дало ли это хоть какой-то прирост.
Все эти изменения привели к тому, что лучшее время в песочнице до 197 секунд, и это было 16 место на момент закрытия, а в финале — 188 секунд, и 13 место.
Код решения полностью расположен здесь: https://github.com/evgsid/highload_solution
Код решения на момент финала: https://github.com/evgsid/highload_solution/tree/final
А теперь давайте немного поговорим о магии.
В песочнице особенно выделялись первые 6 мест в рейтинге: у них время было ~140 сек, а у следующих ~ 190 и дальше время плавно увеличивалось.
Было очевидно, что первые 6 человек нашли какую-то волшебную пилюлю.
Я попробовал в качестве эксперимента sendfile и mmap, чтобы исключить копирование из userspace -> kernelspace, но тесты не показали никакого прироста в производительности.
И вот последние минуты перед финалом, прием решений закрывается, и лидеры делятся волшебной пилюлей: BUSY WAIT.
При прочих равных, решение, которое давало 180 секунд с epoll(x, y, z, -1) при использовании epoll(x, y, z, 0) давало сразу же 150 секунд и меньше. Конечно, это не продакшн-решение, но очень сильно уменьшало задержки.
Хорошую статью по этому поводу можно найти тут: How to achieve low latency with 10Gbps Ethernet.
Мое решение, лучший результат которого был 188 в финале, при использовании busy wait сразу же показало 136 секунд, что было бы 4-м временем в финале, и 8-ое место в песочнице на момент написания этой статьи.
Вот так выглядит график лучшего решения:
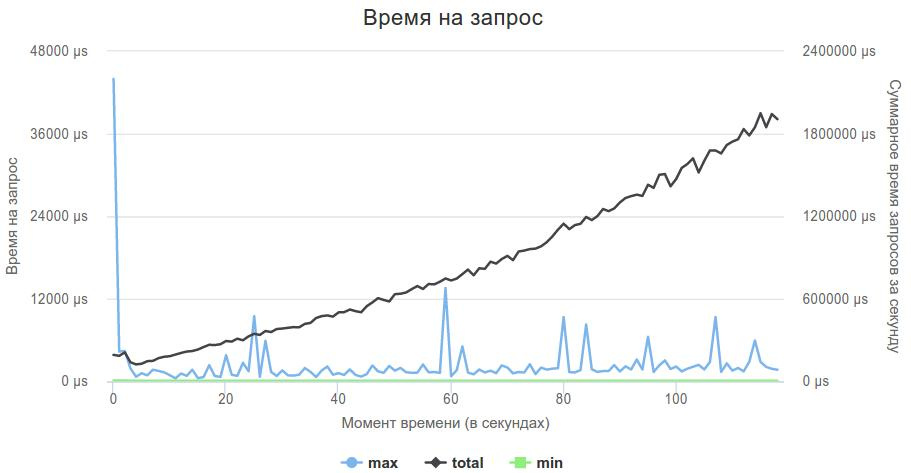
На самом деле, busy wait нужно использовать очень осторожно. Мое решение, когда главный поток принимает соединения, а 4 потока только обрабатывают данные из сокетов, при использовании busy wait стало сильно проседать на post-фазе, потому что accept'у не хватало процессорного времени, и мое решение сильно тормозило. Уменьшение количества обрабатыающих потоков до 3 полностью решило эту проблему.
Тамада хороший, и конкурсы интересные.
Это было очень круто! Это были незабываемые 3 недели системного прогрммирования. Спасибо моей жене и детям, что они были в отпуске, а иначе семья была близка к разводу. Спасибо организаторам, которые не спали ночами, помогали участниками и боролись с танком. Спасибо участникам, которые дали много новых идей и подталкивали к поиску новых решений.
С нетерпением жду следующего конкурса!
|
Метки: author reatfly ненормальное программирование высокая производительность c++ highload конкурс epoll busy wait |
[Из песочницы] История 13 места на Highload Cup 2017 |
11 августа компания Mail.Ru Объявила об очередном конкурсе HighloadCup для системных программистов backend-разработчиков.
Вкратце задача стояла следующим образом: докер, 4 ядра, 4Гб памяти, 10Гб HDD, набор api, и нужно ответить на запросы за наименьшее количество времени. Язык и стек технологий неограничен. В качестве тестирующей системы выступал яндекс-танк с движком phantom.
О том, как в таких условиях добраться до 13 места в финале, и будет эта статья.
Подробно с описанием задачи можно ознакомиться в публикации одного из участников на хабре, или на официальной странице конкурса. О том, как происходило тестирование, написано здесь.
Api представляло из себя 3 get-запроса на просто вернуть записи из базы, 2 get-запроса на агрегирование данных, 3 post-запроса на модификацию данных, и 3 post-запроса на добавление данных.
Сразу были оговорены следующие условия, которые существенно облегчили жизнь:
Запросы были поделены на 3 части: сначала get-запросы по исходным данным, потом серия post-запросов на добавление/изменение данных, и последняя самая мощная серия get-запросов по модифицированным данным. Вторая фаза была очень важна, т.к. неправильно добавив или поменяв данные, можно было получить много ошибок в третьей фазе, и как результат — большой штраф. На данном этапе последняя стадия содержала линейное увеличение числа запросов от 100 до 2000rps.
Еще одним условием было то, что один запрос — одно соединение, т.е. никаких keep-alive, но в какой-то момент от этого отказались, и все get-запросы шли с keep-alive, post-запросы были каждый на новое соединение.
Моей мечтой всегда были и есть Linux, C++ и системное программирование (хотя реальность ужасна), и я решил ни в чем себе не отказывать и нырнуть в это удовольствие с головой.
Т.к. о highload'e я знал чуть менее, чем ничего, и я до последнего надеялся, что писать свой web-сервер не придется, то первым шагом к решению задачи стал поиск подходящего web-сервера. Мой взгляд ухватился за proxygen. В целом, сервер должен был быть хорошим — кто еще знает о хайлоаде столько, сколько facebook?
Исходный код содержит несколько примеров, как использовать этот сервер.
HTTPServerOptions options;
options.threads = static_cast(FLAGS_threads);
options.idleTimeout = std::chrono::milliseconds(60000);
options.shutdownOn = {SIGINT, SIGTERM};
options.enableContentCompression = false;
options.handlerFactories = RequestHandlerChain()
.addThen()
.build();
HTTPServer server(std::move(options));
server.bind(IPs);
// Start HTTPServer mainloop in a separate thread
std::thread t([&] () {
server.start();
}); И на каждое принятое соединение вызывается метод фабрики
class EchoHandlerFactory : public RequestHandlerFactory {
public:
// ...
RequestHandler* onRequest(RequestHandler*, HTTPMessage*) noexcept override {
return new EchoHandler(stats_.get());
}
// ...
private:
folly::ThreadLocalPtr stats_;
}; От new EchoHandler() на каждый запрос у меня по спине вдруг пробежал холодок, но я не придал этому значения.
Сам EchoHandler должен реализовать интерфейс proxygen::RequestHandler:
class EchoHandler : public proxygen::RequestHandler {
public:
void onRequest(std::unique_ptr headers)
noexcept override;
void onBody(std::unique_ptr body) noexcept override;
void onEOM() noexcept override;
void onUpgrade(proxygen::UpgradeProtocol proto) noexcept override;
void requestComplete() noexcept override;
void onError(proxygen::ProxygenError err) noexcept override;
};Все выглядит хорошо и красиво, только успевай обрабатывать приходящие данные.
Роутинг я реализовал с помощью std::regex, благо набор апи простой и небольшой. Ответы формировал на лету с помощью std::stringstream. В данный момент я не заморачивался с производительностью, целью было получить работающий прототип.
Так как данные помещаются в память, то значит и хранить их нужно в памяти!
Структуры данных выглядели так:
struct Location {
std::string place;
std::string country;
std::string city;
uint32_t distance = 0;
std::string Serialize(uint32_t id) const {
std::stringstream data;
data <<
"{" <<
"\"id\":" << id << "," <<
"\"place\":\"" << place << "\"," <<
"\"country\":\"" << country << "\"," <<
"\"city\":\"" << city << "\"," <<
"\"distance\":" << distance <<
"}";
return std::move(data.str());
}
};Первоначальный вариант "базы данных" был такой:
template
class InMemoryStorage {
public:
typedef std::unordered_map Map;
InMemoryStorage();
bool Add(uint32_t id, T&& data, T** pointer);
T* Get(uint32_t id);
private:
std::vector> buckets_;
std::vector Идея была следущей: индексы, по условию, целое 32-битное число, а значит никто не мешает добавлять данные с произвольными индексами внутри этого диапазона (о, как же я ошибался!). Поэтому у меня было BUCKETS_COUNT (=10) хранилищ, чтобы уменьшить время ожидания на мутексе для потоков.
Т.к. были запросы на выборку данных, и нужно было быстро искать все места, в которых бывал пользователь, и все отзывы, оставленные для мест, то нужны были индексы users -> visits и locations -> visits.
Для индекса был написан следующий код, с той же идеологией:
template
class MultiIndex {
public:
MultiIndex() : buckets_(BUCKETS_COUNT), bucket_mutexes_(BUCKETS_COUNT) {
}
void Add(uint32_t id, T* pointer) {
int bucket_id = id % BUCKETS_COUNT;
std::lock_guard lock(bucket_mutexes_[bucket_id]);
buckets_[bucket_id].insert(std::make_pair(id, pointer));
}
void Replace(uint32_t old_id, uint32_t new_id, T* val) {
int bucket_id = old_id % BUCKETS_COUNT;
{
std::lock_guard lock(bucket_mutexes_[bucket_id]);
auto range = buckets_[bucket_id].equal_range(old_id);
auto it = range.first;
while (it != range.second) {
if (it->second == val) {
buckets_[bucket_id].erase(it);
break;
}
++it;
}
}
bucket_id = new_id % BUCKETS_COUNT;
std::lock_guard lock(bucket_mutexes_[bucket_id]);
buckets_[bucket_id].insert(std::make_pair(new_id, val));
}
std::vector GetValues(uint32_t id) {
int bucket_id = id % BUCKETS_COUNT;
std::lock_guard lock(bucket_mutexes_[bucket_id]);
auto range = buckets_[bucket_id].equal_range(id);
auto it = range.first;
std::vector result;
while (it != range.second) {
result.push_back(it->second);
++it;
}
return std::move(result);
}
private:
std::vector> buckets_;
std::vector bucket_mutexes_;
}; Первоначально организаторами были выложены только тестовые данные, которыми инициализировалась база данных, а примеров запросов не было, поэтому я начинал тестировать свой код с помощью Insomnia, которая позволяла легко отправлять и модифицировать запросы и смотреть ответ.
Чуть позже организаторы сжалилсь над участниками и выложили патроны от танка и полные данные рейтинговых и тестовых обстрелов, и я написал простенький скрипт, который позволял тестировать локально корректность моего решения и очень помог в дальнейшем.
И вот наконец-то прототип был закончен, локально тестировщик говорил, что все ОК, и настало время отправлять свое решение. Первый запуск был очень волнительным, и он показал, что что-то не так...
Мой сервер не держал нагрузку в 2000rps. У лидеров в этот момент, насколько я помню, времена были порядка сотен секунд.
Дальше я решил проверить, справляется ли вообще сервер с нагрузкой, или это проблемы с моей реализацией. Написал код, который на все запросы просто отдавал пустой json, запустил рейтинговый обстрел, и увидел, что сам proxygen не справляется с нагрузкой.
void onEOM() noexcept override {
proxygen::ResponseBuilder(downstream_)
.status(200, "OK")
.header("Content-Type", "application/json")
.body("{}")
.sendWithEOM();
}Вот так выглядел график 3-ей фазы.
С одной стороны было приятно, что это пока еще проблема не в моем коде, с другой встал вопрос: что делать с сервером? Я все еще надеялся избежать написания своего, и решил попробовать что-нибудь другое.
Следующим подопытным стал Crow. Сразу скажу, мне он очень понравился, и если вдруг в будущем мне потребуется плюсовый http-сервер, то это будет именно он. header-based сервер, я его просто добавил в свой проект вместо proxygen, и немного переписал обработчики запросов, чтобы они начали работать с новым сервером.
Использовать его очень просто:
crow::SimpleApp app;
CROW_ROUTE(app, "/users/").methods("GET"_method, "POST"_method) (
[](const crow::request& req, crow::response& res, uint32_t id) {
if (req.method == crow::HTTPMethod::GET) {
get_handlers::GetUsers(req, res, id);
} else {
post_handlers::UpdateUsers(req, res, id);
}
});
app.bindaddr("0.0.0.0").port(80).multithreaded().run(); В случае, если нет подходящего описания для api, сервер сам отправляет 404, если же есть нужный обработчик, то в данном случае он достает из запроса uint-параметр и передает его как параметр в обработчик.
Но перед тем, как использовать новый сервер, наученный горьким опытом, я решил проверить, справляется ли он с нагрузкой. Также как и в предыдущем случае, написал обработчик, который возвращал пустой json на любой запрос, и отправил его на рейтинговый обстрел.
Crow справился, он держал нагрузку, и теперь нужно было добавить мою логику.
Т.к. логика была уже написана, то адаптировать код к новому серверу было достаточно просто. Все получилось!
100 секунд — уже что-то, и можно начинать заниматься оптимизацией логики, а не поисками сервера.
Т.к. мой сервер все еще формировал ответы с помощью std::stringstream, я решил избавиться от этого в первую очередь. В момент добавления записи в базу данных тут же формировалась строка, содержащая полный ответ с хедером, и в момент запроса отдавал ее.
На данном этапе я решил добавить хедер полностью в ответ по двум причинам:
write()Еще одной проблемой, о которую было сломано много копий в чатике в телеграмме и мной лично, это фильтр пользователей по возрасту. По условию задачи, возраст пользователей хранился в unix timestamp, а в запросах он приходил в виде полных лет: fromAge=30&toAge=70. Как года привести к секундам? Учитывать високосный год или нет? А если пользователь родился 29 февраля?
Итогом стал код, который решал все эти проблемы одним махом:
static time_t t = g_generate_time; // get time now
static struct tm now = (*localtime(&t));
if (search_flags & QueryFlags::FROM_AGE) {
tm from_age_tm = now;
from_age_tm.tm_year -= from_age;
time_t from_age_t = mktime(&from_age_tm);
if (user->birth_date > from_age_t) {
continue;
}
}Результатом стало двухкратное увеличение производительности, со 100 до 50 секунд.
Неплохо на первый взгляд, но в этот момент у лидеров было уже меньше 20 секунд, а я был где-то на 20-40 месте со своим результатом.
В этот момент были сделаны еще два наблюдения:
Стало понятно, что хэши, мутексы и бакеты для хранения данных не нужны, и данные можно прекрасно хранить по индексу в векторе, что и было сделано. Финальную версию можно увидеть здесь (к финалу дополнительно была добавлена часть кода для обработки индексов, если вдруг они превысят лимит).
Каких-то очевидных моментов, которые бы сильно влияли на производительность в моей логике, казалось, не было. Скорей всего с помощью оптимизаций можно было бы скинуть еще несколько секунд, но нужно было скидывать половину.
Я опять начал упираться в работу с сетью/сервером. Пробежавшись по исходникам сервера, я пришел к неутешительному выводу — при отправке происходило 2 ненужных копирования данных: сначала во внутренний буфер сервера, а потом еще раз в буфер для отправки.
В мире нет ничего более беспомощного, безответственного и безнравственного, чем начинать писать свой web-сервер. И я знал, что довольно скоро я в это окунусь.
И вот этот момент настал.
При написании своего сервера было сделано несколько допущений:
Вообще, можно было по-честному поддержать read() и write() в несколько кусков, но текущий вариант работал, поэтому это осталось "на потом".
После серии экспериментов я остановился на следующей архитектуре: блокирующий аccept() в главном потоке, добавление нового сокета в epoll, и std::thread::hardware_concurrency() потоков слушают один epollfd и обрабатывают данные.
unsigned int thread_nums = std::thread::hardware_concurrency();
for (unsigned int i = 0; i < thread_nums; ++i) {
threads.push_back(std::thread([epollfd, max_events]() {
epoll_event events[max_events];
int nfds = 0;
while (true) {
nfds = epoll_wait(epollfd, events, max_events, 0);
// ...
for (int n = 0; n < nfds; ++n) {
// ...
}
}
}));
}
while (true) {
int sock = accept(listener, NULL, NULL);
// ...
struct epoll_event ev;
ev.events = EPOLLIN | EPOLLET | EPOLLONESHOT;
ev.data.fd = sock;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, sock, &ev) == -1) {
perror("epoll_ctl: conn_sock");
exit(EXIT_FAILURE);
}
}EPOLLET гарантирует, что будет разбужен только какой-то один поток, а также что если в сокете останутся недочитанные данные, то epoll на сокет не сработает до тех пор, пока они все не будут вычитаны до EAGAIN. Поэтому следующей рекомендацией по использованию этого флага является делать сокет неблокирующим и читать, пока не вернется ошибка. Но как было обозначено в допущениях, запросы маленькие и читаются за один вызов read(), данных в сокете не остается, и epoll нормально срабатывал на приход новых данных.
Тут я сделал одну ошибку: я использовал std::thread::hardware_concurrency() для определения количества доступных потоков, но это было плохой идеей, потому что этот вызов возвращал 10 (количество ядер на сервере), а в докере было доступно только 4 ядра. Впрочем, на результат это мало повлияло.
Для парсинга http я использовал http-parser (Crow также использует его), для разбора урла — libyuarel, и для декодирования параметров в query-запросе — qs_parse. qs_parse также используется в Crow, он умеет разбирать урл, но так получилось, что я его использовал только для декодирования параметров.
Переписав таким образом свою реализацию, я сумел скинуть еще 10 секунд, и теперь мой результат составлял 40 секунд.
До конца соревнования оставалось полторы недели, и организаторы решили, что 200Мб данных и 2000rps — это мало, и увеличили размер данных и нагрузки в 5 раз: данные стали занимать 1Гб в распакованном виде, а интенсивность обстрела выросла до 10000rps на 3-ей фазе.
Моя реализация, которая хранила ответы целиком, перестала влезать по памяти, делать много вызовов write(), чтобы писать ответ по частям, тоже казалось плохой идеей, и я переписал свое решение на использование writev(): не нужно было дублировать данные при хранении и запись происходила с помощью одного системного вызова (тут тоже добавлено улучшение для финала: writev может записать за раз 1024 элемента массива iovec, а моя реализация для /users/ была очень iovec-затратной, и я добавил возможность разбить запись данных на 2 куска).
Отправив свою реализацю на запуск, я получил фантастические (в хорошем смысле) 245 секунды времени, что позволило мне оказаться на 2 месте в таблице результатов на тот момент.
Так как тестовая система подвержена большому рандому, и одно и то же решение может показывать различающееся в несколько раз время, а рейтинговые обстрелы можно было запускать лишь 2 раза в сутки, то непонятно, какие из следующих улучшений привели к конечному результату, а какие нет.
За оставшуюся неделю я сделал следующие оптимизации:
Заменил цепочки вызовов вида
DBInstance::GetDbInstance()->GetLocations()на указатель
g_location_storageПотом я подумал, что честный http-парсер для get-запросов не нужен, и для get-запроса можно сразу брать урл и больше ни о чем не заботиться. Благо, фиксированные запросы танка это позволяли. Также тут примечателен момент, что можно портить буфер (записывать \0 в конец урла, например). Таким же образом работает libyuarel.
HttpData http_data;
if (buf[0] == 'G') {
char* url_start = buf + 4;
http_data.url = url_start;
char* it = url_start;
int url_len = 0;
while (*it++ != ' ') {
++url_len;
}
http_data.url_length = url_len;
http_data.method = HTTP_GET;
} else {
http_parser_init(parser.get(), HTTP_REQUEST);
parser->data = &http_data;
int nparsed = http_parser_execute(
parser.get(), &settings, buf, readed);
if (nparsed != readed) {
close(sock);
continue;
}
http_data.method = parser->method;
}
Route(http_data);Также в чатике в телеграмме поднялся вопрос о том, что на сервере проверяется только количество полей в хедере, а не их содержимое, и хедеры были безжалостно порезаны:
const char* header = "HTTP/1.1 200 OK\r\n"
"S: b\r\n"
"C: k\r\n"
"B: a\r\n"
"Content-Length: ";Кажется, странное улучшение, но на многих запросах размер ответа существенно сокращался. К сожалению, неизвестно, дало ли это хоть какой-то прирост.
Все эти изменения привели к тому, что лучшее время в песочнице до 197 секунд, и это было 16 место на момент закрытия, а в финале — 188 секунд, и 13 место.
Код решения полностью расположен здесь: https://github.com/evgsid/highload_solution
Код решения на момент финала: https://github.com/evgsid/highload_solution/tree/final
А теперь давайте немного поговорим о магии.
В песочнице особенно выделялись первые 6 мест в рейтинге: у них время было ~140 сек, а у следующих ~ 190 и дальше время плавно увеличивалось.
Было очевидно, что первые 6 человек нашли какую-то волшебную пилюлю.
Я попробовал в качестве эксперимента sendfile и mmap, чтобы исключить копирование из userspace -> kernelspace, но тесты не показали никакого прироста в производительности.
И вот последние минуты перед финалом, прием решений закрывается, и лидеры делятся волшебной пилюлей: BUSY WAIT.
При прочих равных, решение, которое давало 180 секунд с epoll(x, y, z, -1) при использовании epoll(x, y, z, 0) давало сразу же 150 секунд и меньше. Конечно, это не продакшн-решение, но очень сильно уменьшало задержки.
Хорошую статью по этому поводу можно найти тут: How to achieve low latency with 10Gbps Ethernet.
Мое решение, лучший результат которого был 188 в финале, при использовании busy wait сразу же показало 136 секунд, что было бы 4-м временем в финале, и 8-ое место в песочнице на момент написания этой статьи.
Вот так выглядит график лучшего решения:
На самом деле, busy wait нужно использовать очень осторожно. Мое решение, когда главный поток принимает соединения, а 4 потока только обрабатывают данные из сокетов, при использовании busy wait стало сильно проседать на post-фазе, потому что accept'у не хватало процессорного времени, и мое решение сильно тормозило. Уменьшение количества обрабатыающих потоков до 3 полностью решило эту проблему.
Тамада хороший, и конкурсы интересные.
Это было очень круто! Это были незабываемые 3 недели системного прогрммирования. Спасибо моей жене и детям, что они были в отпуске, а иначе семья была близка к разводу. Спасибо организаторам, которые не спали ночами, помогали участниками и боролись с танком. Спасибо участникам, которые дали много новых идей и подталкивали к поиску новых решений.
С нетерпением жду следующего конкурса!
|
Метки: author reatfly ненормальное программирование высокая производительность c++ highload конкурс epoll busy wait |
Блиц. Как попасть в Яндекс, минуя первое собеседование |
Редко когда кандидат проходит только одно техническое собеседование — обычно их несколько. Среди причин, почему человеку они могут даваться непросто, можно назвать и ту, что каждый раз приходится общаться с новыми людьми, думать о том, как они восприняли твой ответ, пытаться интерпретировать их реакцию. Мы решили попробовать использовать формат контеста, чтобы сократить количество итераций для всех участников процесса.

Для Блица мы выбрали исключительно алгоритмические задачи. Хотя для оценки раундов и применяется система ACM, в отличие от спортивного программирования все задания максимально приближены к тем, которые постоянно решают в продакшене Поиска. Те, кто решит успешно хотя бы четыре задачи из шести, могут считать, что прошли первый этап отбора в Яндекс. Почему алгоритмы? В процессе работы часто меняются задачи, проекты, языки программирования, платформы — те, кто владеет алгоритмами, всегда смогут перестроиться и быстро научиться новому. Типичная задача на собеседовании — составить алгоритм, доказать его корректность, предложить пути оптимизации.
Квалификацию можно пройти с 18 по 24 сентября включительно. В этом раунде вам нужно будет написать программы для решения шести задач. Можете использовать Java, C++, C# или Python. На всё про всё у вас будет четыре часа. В решающем раунде будут соревноваться те, кто справится как минимум с четырьмя квалификационными задачами. Финал пройдёт одновременно для всех участников — 30 сентября, с 12:00 до 16:00 по московскому времени. Итоги будут подведены 4 октября. Чтобы всем желающим было понятно, с чем они столкнутся на Блице, мы решили разобрать пару похожих задач на Хабре.
Первая задача связана с одной из систем обработки данных, разработанной в Яндексе, — Robust Execution Manager, REM. Он позволяет строить сложные процессы, включающие множество разных операций, и устанавливать зависимости между ними. Так, решение многих задач связано с обработкой пользовательских логов, содержащих информацию о заданных запросах, показанных документах, совершённых кликах и так далее. Поэтому вычисление поискового фактора CTR (click through rate, отношение числа кликов по документу к количеству его показов) зависит от задач обработки пользовательских логов, а от решения задачи вычисления CTR зависит задача доставки значений этого фактора в поисковый runtime. Таким образом, REM позволяет выстраивать цепочки обработки данных, в которых поставщик данных не обязан знать о том, кто эти данные в дальнейшем будет использовать.
В процесс исполнения цепочек обработки могут быть внесены коррективы. Например, уже после построения поисковых логов может выясниться, что значительный объем данных был доставлен с существенной задержкой, и поисковые логи необходимо перестроить. Естественно, после перестроения логов необходимо также перезапустить все процессы, которые от них зависели. Другой пример того же рода — попадание в пользовательские логи запросов, выполненных нашим поисковым роботом. Эти запросы не являются запросами пользователей, а поэтому вносят шум в вычисление поисковых факторов, расчёты экспериментов и так далее. Поэтому в этом случае логи также нужно обновить, после чего перезапустить все процессы их обработки. Поэтому REM поддерживает операцию обновления данных с последующим перезапуском всех задач, зависящих от этих данных.
Задача заключается в реализации именно этой операции. Входными данными будет ациклический ориентированный граф с выделенной вершиной. Граф описывает некоторый процесс обработки данных, при этом вершины представляют этапы этого процесса, а рёбра — зависимости между ними. Выделенная вершина соответствует одной из подзадач, которую необходимо перезапустить из-за изменений в данных. После перезапуска необходимо будет также перезапустить и все подзадачи, зависящие от неё по данным. Необходимо написать программу, которая выводит список этих подзадач, причём в порядке, в котором их необходимо будет перезапустить.
Рассмотрим для начала решение задачи в случае, когда вершины из ответа не нужно упорядочивать. Тогда задача решается достаточно просто: запустим из выделенной вершины любой алгоритм обхода графа (например, обход в глубину), и запишем в ответ все посещённые вершины. Действительно, если задачи с номерами , , ..., зависят по данным от задачи , то после перезапуска задачи необходимо перезапустить все эти задачи, а также те задачи, что зависят уже от них. Кроме того, каждую вершину нужно вывести ровно один раз. Оба этих условия обеспечиваются стандартными методами обхода графов.
#include
#include
using Graph = std::vector>;
void DFS(const Graph& graph,
const int vertice,
std::vector& used,
std::vector& result)
{
used[vertice] = true;
result.push_back(vertice);
for (size_t idx = 0; idx < graph[vertice].size(); ++idx) {
const int adjacent_vertice = graph[vertice][idx];
if (!used[adjacent_vertice]) {
DFS(graph, adjacent_vertice, used, result);
}
}
}
void Solve(const Graph& graph,
const int from,
std::vector& result)
{
std::vector used(graph.size(), false);
DFS(graph, from, used, result);
}
int main() {
int vertices, edges;
std::cin >> vertices >> edges;
Graph graph(vertices + 1);
for (int edge = 0; edge < edges; ++edge) {
int from, to;
std::cin >> from >> to;
graph[from].push_back(to);
}
int reset_vertice;
std::cin >> reset_vertice;
std::vector result;
Solve(graph, reset_vertice, result);
for (std::vector::const_iterator it = result.begin();
it != result.end();
++it)
{
std::cout << *it << " ";
}
std::cout << std::endl;
return 0;
} Теперь мы знаем, как сформировать множество вершин, составляющих ответ, но не знаем, как его упорядочить. Рассмотрим пример: пусть от подзадачи зависят подзадачи и . В таком случае нам неважно, в каком порядке запускать подзадачи и . Но что, если между ними существует явная или неявная (через другие подзадачи) зависимость?

В ситуации, изображённой на картинке, сначала нужно исполнять задачу , а уже потом . Но стандартные методы обхода не позволяют этого добиться. Нам нужен другой алгоритм!
Используем для решения возникшей проблемы топологическую сортировку вершин, входящих в ответ, то есть, введём некоторый порядок на этом множестве вершин, например: , ,...,, и при этом будет верно, что, если , то не зависит прямо или косвенно от . Известно, что такое упорядочение возможно, если граф не содержит циклов. Топологическая сортировка вершин достигается при помощи обхода в глубину: когда для некоторой вершины посещены все её потомки, она добавляется в начало списка. Итоговый список будет искомой сортировкой вершин графа.
Таким образом, поставленная задача решается при помощи обхода в глубину, в процессе которого мы одновременно строим множество вершин, представляющих ответ, и осуществляем топологическую сортировку этих вершин. Топологическая сортировка гарантирует, что соответствующие вершинам графа подзадачи перечислены в правильном порядке.
#include
#include
using Graph = std::vector>;
void DFS(const Graph& graph,
const int vertice,
std::vector& used,
std::vector& result)
{
used[vertice] = true;
for (size_t idx = 0; idx < graph[vertice].size(); ++idx) {
const int adjacent_vertice = graph[vertice][idx];
if (!used[adjacent_vertice]) {
DFS(graph, adjacent_vertice, used, result);
}
}
result.push_back(vertice);
}
void Solve(const Graph& graph,
const int from,
std::vector& result)
{
std::vector used(graph.size(), false);
DFS(graph, from, used, result);
}
int main() {
int vertices, edges;
std::cin >> vertices >> edges;
Graph graph(vertices + 1);
for (int edge = 0; edge < edges; ++edge) {
int from, to;
std::cin >> from >> to;
graph[from].push_back(to);
}
int reset_vertice;
std::cin >> reset_vertice;
std::vector result;
Solve(graph, reset_vertice, result);
for (std::vector::const_reverse_iterator it = result.rbegin();
it != result.rend();
++it)
{
std::cout << *it << " ";
}
std::cout << std::endl;
return 0;
} Эта задача не имеет непосредственного отношения к библиотекам и программам, разрабатываемым в Яндексе, зато она очень интересная и поэтому часто становится темой для обсуждений на кофепоинтах в свободную минуту. Она является несколько упрощённой версией задачи 9D с codeforces.
Необходимо вычислить, каково количество различных бинарных деревьев поиска, в вершинах которых записаны числа от 1 до . Например, если , существует ровно пять различных деревьев, изображённых на картинке ниже:

Если , то количество деревьев равняется 42. Именно поэтому задача очень нравится нашим разработчикам, среди которых немало ценителей творчества Дугласа Адамса.
Эта задача является достаточно простой для тех, кто знаком с методами динамического программирования. Обозначим за количество различных бинарных деревьев поиска, образованных числами , , ..., . Предположим, что мы знаем , , , ..., и хотим вычислить .
Ясно, что в корне любого дерева будет находиться некоторое число из множества Обозначим это число за . Тогда в силу свойств дерева поиска левое поддерево содержит числа , а правое — . Количество различных возможных способов сформировать левое поддерево тогда равняется , а правое — . Поэтому общее количество деревьев, составленных из чисел , , ..., и имеющих в корне значение , равняется произведению . Для того, чтобы найти общее количество деревьев, необходимо просуммировать это произведение для всех возможных значений :
N = int(raw_input())
result = [1, 1]
for count in xrange(2, N + 1):
result.append(0)
for root in xrange(1, count + 1):
result[-1] += result[root - 1] * result[count - root]
print result[N]Задачу можно решить с использованием полученной формулы. Однако те, кому хорошо знакома комбинаторика, могли бы узнать в этом выражении формулу для вычисления чисел Каталана. Поэтому можно для получения ответа использовать формулу с использованием биномиальных коэффициентов:
В процессе решения задачи про бинарные деревья мы получили рекуррентную формулу, полностью аналогичную рекуррентной формуле, возникающей при решении задачи про количество правильных скобочных последовательностей длины , которая, как правило, и используется для введения чисел Каталана в курсах по комбинаторике.
Яндекс.Блиц будет проходить на платформе Контест, где мы обычно проводим Алгоритм. Для участия нужно зарегистрироваться. Мы обязательно пришлём вам напоминание о старте раундов.
|
Метки: author nkmakarov python java c++ c# блог компании яндекс собеседование алгоритмы занимательные задачи задачи для собеседований задачи для программистов математика |
Искусственный интеллект для ритейла: продажники уровня Скайнет, отзывы уровня Бог |
|
Метки: author LeJay читальный зал хакатоны исследования и прогнозы в it искусственный интеллект продажник уровня скайнет |
Продвинутое конфигурирование Docker Compose (перевод) |
version: '2'
services:
web:
build: .
ports:
- "80:8000"
depends_on:
- db
entrypoint: "./wait-for-it.sh db:5432"
db:
image: postgres$ TAG="latest"
$ echo $TAG
latest
$ DB="postgres"
$ echo $DB
postgresdb:
image: "${DB}:$TAG"web:
environment:
- PRODUCTION=1$ PRODUCTION=1
$ echo $PRODUCTION
1COMPOSE_API_VERSION
COMPOSE_FILE
COMPOSE_HTTP_TIMEOUT
COMPOSE_PROJECT_NAME
DOCKER_CERT_PATH
DOCKER_HOST
DOCKER_TLS_VERIFY# ./.env
# для нашей промежуточной среды
COMPOSE_API_VERSION=2
COMPOSE_HTTP_TIMEOUT=45
DOCKER_CERT_PATH=/mycerts/docker.crt
EXTERNAL_PORT=5000$ docker-compose up -f my-override-1.yml my-overide-2.yml# оригинальный сервис
command: python my_app.py
# новый сервис
command: python my_new_app.py
При использовании опции с несколькими значениями (ports, expose, external_links, dns, dns_search и tmpfs), Docker Compose объединяет значения (в примере ниже Compose открывает порты 5000 и 8000):
# оригинальный сервис
expose:
- 5000
# новый сервис
expose:
- 8000# оригинальный сервис
environment:
- FOO=Hello
- BAR=World
# новый сервис
environment:
- BAR="Python Dev!"
Различные среды
Начнём с базового Docker Compose файла для приложения (docker-compose.yml):
web:
image: "my_dockpy/my_django_app:latest"
links:
- db
- cache
db:
image: "postgres:latest"
cache:
image: "redis:latest"
web:
build: .
volumes:
- ".:/code"
ports:
- "8883:80"
environment:
DEBUG: "true"
db:
command: "-d"
ports:
- "5432:5432"
cache:
ports:
- "6379:6379"web:
ports:
- "80:80"
environment:
PRODUCTION: "true"
cache:
environment:
TTL: "500"
$ docker-compose -f docker-compose.yml -f docker-compose.production.yml up -ddbadmin:
build: database_admin/
links:
- db$ docker-compose -f docker-compose.yml -f docker-compose.admin.yml run dbadmin db-backupwebapp:
build: .
ports:
- "8000:8000"
volumes:
- "/data"web:
extends:
file: common-services.yml
service: webappweb:
extends:
file: common-services.yml
service: webapp
environment:
- DEBUG=1
cpu_shares: 5
links:
- db
important_web:
extends: web
cpu_shares: 10
db:
image: postgres
COMPOSE_API_VERSION= # должно быть 2
COMPOSE_HTTP_TIMEOUT= # мы используем 30 на продакшне и 120 в разработке
DOCKER_CERT_PATH= # храните путь сертификации здесь
EXTERNAL_PORT= # установите внешний порт здесь (запомните, 5000 для Flask и 8000 для Django)|
Метки: author Tully серверное администрирование виртуализация devops *nix блог компании отус otus docker-compose |
Oracle фактически ликвидирует Sun |
Избегайте этой ловушки, не следует придавать антропоморфные черты Ларри Эллисону.
Брайэн Кантрилл
Похоже, что в Oracle приняли решение окончательно избавиться от трудовых ресурсов, составляющих костяк Sun Microsystems. Массовые увольнения затронули около 2500 сотрудников, работающих над операционной системой Solaris, платформой SPARC и системами хранения данных ZFS Storage Appliance.

Это не рядовая трансформация — оптимизация, а настоящая бойня. По мнению создателя системы динамической отладки Dtrace Брайэна Кантрилла (Bryan Cantrill) на сей раз нанесен непоправимый ущерб, в результате потери 90% производственных кадров подразделения Solaris, включая все руководство.
В 2009 г. Oracle приобрел испытывающую серьезнейшие трудности на рынке Sun Microsystems за 5.6 млрд. долларов США. Компания теряла позиции на рынке вследствие лавинообразного распространения Linux в качестве серверной ОС, успеха платформы amd64 и невнятной стратегии по взаимоотношениям с сообществом открытого ПО. Solaris стал открытым слишком поздно — лишь в 2005 г., причем открытым не полностью, отдельные элементы ОС, такие как локализация и некоторые драйвера, оставались проприетарными. Затем появился OpenSolaris, однако точкой сбора сообщества он не сумел стать. То ли дело была в лицензии CDDL, то ли проблема была в том, что Sun пыталась манипулировать проектом. Трудно сказать почему именно, но не взлетел.
Kicked butt, had fun, didn't cheat, loved our customers, changed computing forever. Scott McNealy
Эпитафия Скота МакНили как нельзя лучше отражает жизненный путь компании — отлично развлекались, не дурили головы своим заказчикам и навсегда изменили ИТ. Довольно быстро стало очевидно, что Solaris Ораклу попросту не нужен, и развивать его он не намерен. Затем 13 августе 2010 г. случилось одно из самых позорных событий в истории открытого ПО — компания втихую закрыла исходный код OS Solaris. Никаких официальных заявлений на сей счет не последовало.
We will distribute updates to approved CDDL or other open source-licensed code following full releases of our enterprise Solaris operating system. In this manner, new technology innovations will show up in our releases before anywhere else. We will no longer distribute source code for the entirety of the Solaris operating system in real-time while it is developed, on a nightly basis.
Это всего лишь отрывок из внутреннего циркуляра для сотрудников компании, который естественно сразу же просочился в прессу. Тут речь идет о том, что исходный код будут выкладывать только во время релиза новой версии ОС, а обновления будут только бинарными. Но это оказалось неправдой, после выхода Solaris 11 исходный код не выложили.
Для тех, кто владеет английским очень рекомендую посмотреть выступление Брайэна Кантрилла на конференции Usenix. Эпиграф к статье — одна из его цитат, вот еще несколько.

О принципах руководства компании. Оставшись без мудрого руководства манагеров инженеры выдали гору инноваций: ZFS, DTrace, Zones и много других.
Sun управлялась со стороны враждующих группировок во главе с атаманами, как Сомали.
О закрытии исходного кода OpenSolaris.
Это ОТВРАТИТЕЛЬНАЯ выходка со стороны корпорации. Вот из-за такого поведения мы становимся циничными и подозрительными.
О последствиях закрытия исходников OpenSolaris для нового проекта ОС illumos — полностью открытого форка OpenSolaris.
Мы готовимся к моменту Судного Дня в лицензиях открытого исходного кода, у нас есть такие сценарии, они работают и это здорово.
Вскоре после этого из Oracle ушли все разработчики DTrace, создатели ZFS, команда zones и сетевики. Вся разработка и инновация на этих направлениях далее происходила операционной системе illumos, где осела диаспора программистов из Sun Solaris. Благодаря особенностям открытых лицензий, в том числе CDDL, в рамках которой шла разработка OpenSolaris, Oracle не может претендовать на все последующие улучшения в коде illumos. То есть может, но только в рамках своего же проекта с открытым кодом. Сценарии Судного Дня работают как надо.
Для полноты картины стоит добавить, что Oracle активно участвует в разработке ядра Linux, где традиционно входит в десятку наиболее активных компаний.
NetBeans Apache Foundation, верное решение.Sun Microsystems еще недавно — живая легенда и лучшее, что когда-либо было в Unix. Вот лишь небольшая часть их наследия.
Компания Oracle имела все возможности для того, чтобы развивать и поддерживать OpenSolaris, но вместо этого закрыла исходники и с тех пор Solaris уже не имел будущего. Когда тяжба с компанией Google за использования Java в мобильной ОС Андроид закончилась пшиком в Oracle потеряли к активам Sun Microsystems всякий интерес. Вместо этого компания будет продавать ПО на основе собственной операционной системы — Unbreakable Linux.
|
Метки: author temujin управление сообществом управление разработкой управление проектами oracle sun microsystems solaris opensolaris illumos |
Oracle фактически ликвидирует Sun |
Избегайте этой ловушки, не следует придавать антропоморфные черты Ларри Эллисону.
Брайэн Кантрилл
Похоже, что в Oracle приняли решение окончательно избавиться от трудовых ресурсов, составляющих костяк Sun Microsystems. Массовые увольнения затронули около 2500 сотрудников, работающих над операционной системой Solaris, платформой SPARC и системами хранения данных ZFS Storage Appliance.
Это не рядовая трансформация — оптимизация, а настоящая бойня. По мнению создателя системы динамической отладки Dtrace Брайэна Кантрилла (Bryan Cantrill) на сей раз нанесен непоправимый ущерб, в результате потери 90% производственных кадров подразделения Solaris, включая все руководство.
В 2009 г. Oracle приобрел испытывающую серьезнейшие трудности на рынке Sun Microsystems за 5.6 млрд. долларов США. Компания теряла позиции на рынке вследствие лавинообразного распространения Linux в качестве серверной ОС, успеха платформы amd64 и невнятной стратегии по взаимоотношениям с сообществом открытого ПО. Solaris стал открытым слишком поздно — лишь в 2005 г., причем открытым не полностью, отдельные элементы ОС, такие как локализация и некоторые драйвера, оставались проприетарными. Затем появился OpenSolaris, однако точкой сбора сообщества он не сумел стать. То ли дело была в лицензии CDDL, то ли проблема была в том, что Sun пыталась манипулировать проектом. Трудно сказать почему именно, но не взлетел.
Kicked butt, had fun, didn't cheat, loved our customers, changed computing forever. Scott McNealy
Эпитафия Скота МакНили как нельзя лучше отражает жизненный путь компании — отлично развлекались, не дурили головы своим заказчикам и навсегда изменили ИТ. Довольно быстро стало очевидно, что Solaris Ораклу попросту не нужен, и развивать его он не намерен. Затем 13 августе 2010 г. случилось одно из самых позорных событий в истории открытого ПО — компания втихую закрыла исходный код OS Solaris. Никаких официальных заявлений на сей счет не последовало.
We will distribute updates to approved CDDL or other open source-licensed code following full releases of our enterprise Solaris operating system. In this manner, new technology innovations will show up in our releases before anywhere else. We will no longer distribute source code for the entirety of the Solaris operating system in real-time while it is developed, on a nightly basis.
Это всего лишь отрывок из внутреннего циркуляра для сотрудников компании, который естественно сразу же просочился в прессу. Тут речь идет о том, что исходный код будут выкладывать только во время релиза новой версии ОС, а обновления будут только бинарными. Но это оказалось неправдой, после выхода Solaris 11 исходный код не выложили.
Для тех, кто владеет английским очень рекомендую посмотреть выступление Брайэна Кантрилла на конференции Usenix. Эпиграф к статье — одна из его цитат, вот еще несколько.
О принципах руководства компании. Оставшись без мудрого руководства манагеров инженеры выдали гору инноваций: ZFS, DTrace, Zones и много других.
Sun управлялась со стороны враждующих группировок во главе с атаманами, как Сомали.
О закрытии исходного кода OpenSolaris.
Это ОТВРАТИТЕЛЬНАЯ выходка со стороны корпорации. Вот из-за такого поведения мы становимся циничными и подозрительными.
О последствиях закрытия исходников OpenSolaris для нового проекта ОС illumos — полностью открытого форка OpenSolaris.
Мы готовимся к моменту Судного Дня в лицензиях открытого исходного кода, у нас есть такие сценарии, они работают и это здорово.
Вскоре после этого из Oracle ушли все разработчики DTrace, создатели ZFS, команда zones и сетевики. Вся разработка и инновация на этих направлениях далее происходила операционной системе illumos, где осела диаспора программистов из Sun Solaris. Благодаря особенностям открытых лицензий, в том числе CDDL, в рамках которой шла разработка OpenSolaris, Oracle не может претендовать на все последующие улучшения в коде illumos. То есть может, но только в рамках своего же проекта с открытым кодом. Сценарии Судного Дня работают как надо.
Для полноты картины стоит добавить, что Oracle активно участвует в разработке ядра Linux, где традиционно входит в десятку наиболее активных компаний.
NetBeans Apache Foundation, верное решение.Sun Microsystems еще недавно — живая легенда и лучшее, что когда-либо было в Unix. Вот лишь небольшая часть их наследия.
Компания Oracle имела все возможности для того, чтобы развивать и поддерживать OpenSolaris, но вместо этого закрыла исходники и с тех пор Solaris уже не имел будущего. Когда тяжба с компанией Google за использования Java в мобильной ОС Андроид закончилась пшиком в Oracle потеряли к активам Sun Microsystems всякий интерес. Вместо этого компания будет продавать ПО на основе собственной операционной системы — Unbreakable Linux.
|
Метки: author temujin управление сообществом управление разработкой управление проектами oracle sun microsystems solaris opensolaris illumos |






