Zyxel Nebula: обзор ключевых возможностей облачной сетевой экосистемы |


|
Метки: author Orest_ua сетевые технологии облачные вычисления беспроводные технологии it- инфраструктура блог компании мук zyxel nebula точки доступа облака |
[Из песочницы] Необразованная молодёжь |



Конечно, какие-то полезные знания они дали, но по эффективности знания/время — в глубоком дне.— понравившийся комментарий.
|
Метки: author aleshqqa1337 учебный процесс в it обучение обучение программистов молодые специалисты вуз колледжи |
[Перевод] Как создавали систему чувств ИИ в Thief: The Dark Project |
|
Метки: author PatientZero разработка игр система чувств искусственный интеллект конечные автоматы thief half-life |
Security Week 39: Вечер восхитительных историй о том, как бизнесу наплевать на безопасность |
 В этот раз новости из нашего дайджеста содержат самоочевидную мораль: многим компаниям плевать на безопасность их клиентов, пока это не наносит прямой финансовый ущерб. К счастью, это касается не всех компаний, но эта неделя выдалась особенно богатой на подобные постыдные истории.
В этот раз новости из нашего дайджеста содержат самоочевидную мораль: многим компаниям плевать на безопасность их клиентов, пока это не наносит прямой финансовый ущерб. К счастью, это касается не всех компаний, но эта неделя выдалась особенно богатой на подобные постыдные истории. Соответственно, мобильных приложений для трейдинга выпущено очень много. Понятно, что их вендоры должны тщательно выстраивать систему безопасности, даже в ущерб удобству – деньги на кону большие. Но вот на поверку все оказалось не так. Исследователи из IOActive взяли 21 приложение из топа (как для iOS, так и для Android) и нашли там много веселых дыр. Очень много. Вплоть до хранения паролей открытым текстом и передачи данных по HTTP.
Соответственно, мобильных приложений для трейдинга выпущено очень много. Понятно, что их вендоры должны тщательно выстраивать систему безопасности, даже в ущерб удобству – деньги на кону большие. Но вот на поверку все оказалось не так. Исследователи из IOActive взяли 21 приложение из топа (как для iOS, так и для Android) и нашли там много веселых дыр. Очень много. Вплоть до хранения паролей открытым текстом и передачи данных по HTTP. По данным Guardian, контору взломали еще осенью 2016 года, а обнаружили это только в марте. Скорее всего, атака шла через учетные данные админа почтового сервера. Никакой двухфакторной аутентификации не было – пароль то ли отбрутфорсили, то ли выманили из админа каким-либо методом социальной инженерии.
По данным Guardian, контору взломали еще осенью 2016 года, а обнаружили это только в марте. Скорее всего, атака шла через учетные данные админа почтового сервера. Никакой двухфакторной аутентификации не было – пароль то ли отбрутфорсили, то ли выманили из админа каким-либо методом социальной инженерии. 
|
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» klsw deloitte macos high sierra keychain |
[Перевод] «Тюльпаномания»: биржевой пузырь, которого не было |

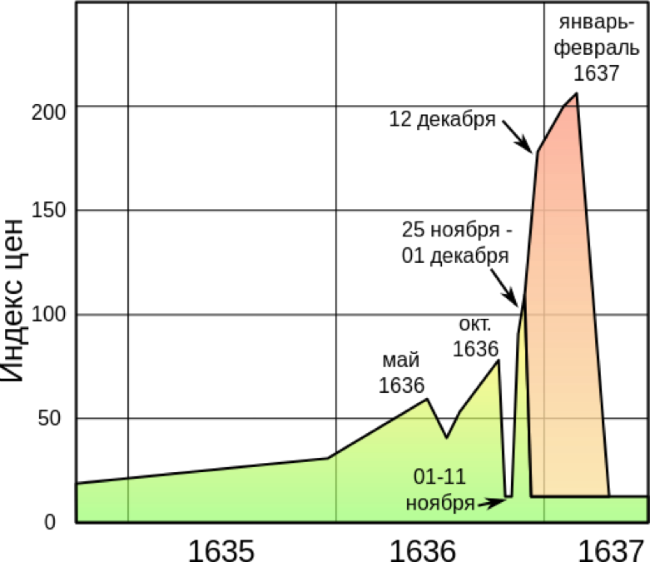

|
Метки: author itinvest блог компании itinvest тюльпаномания финансы история биржа фондовый рынок спекуляции |
Пять вещей, которые нужно знать о Spring Framework 5 |
На этой неделе, сразу за релизом Java 9 вышла новая мажорная версия одного из самых популярных фреймворков для разработки приложения на Java — Spring Framework версии 5. Под катом подробности и краткое описание, что же поменялось.
Читать дальше ->|
Метки: author alek_sys программирование java spring framework |
Интернет там, где его нет, или Стационарная связь на базе 3G-LTE |

Задумал я сделать интернет у себя на даче, в глуши. И наконец возможность срослась с желанием! Проблем в моей глуши две: дураки частые перебои с электроэнергией (в зависимости от погоды может ещё отключиться АТС) и плохая мобильная связь. Сигнал ловится не везде, а где ловится, там нестабилен. Добавляет сложности и оцинкованная крыша дома, экранирующая радиоволны. Возможности современного оборудования и корректировка запросов сужали и улучшали подходящие свойства, что привело меня к мысли создать максимально работоспособный узел сети. Я расскажу о том, как пытался поймать LTE-сигнал, с описанием оборудования и возможными проблемами.
В моей глуши нормально ловится только МТС, в связи с чем был выбран именно этот оператор. Качество покрытия я определял с помощью https://4g-faq.ru/karty-pokrytiya/. На этой карте удобно выбирать режимы сети, а также хорошо видно ориентировочное расположение вышек стандартов 3G и LTE.
Направление установки антенн выбиралось примерно так:

Коэффициент усиления антенны я выбирал в зависимости от расстояния до населённых пунктов. Подходящее направление сигнала — с помощью мобильного приложения Netmonitor. Для этого пришлось поездить к ближайшим вышкам. Netmonitor — приложение бесплатное, самое удобное и простое в управлении, аналоги меня не впечатлили. Также в нём сохраняются истории замеров, поэтому, когда я вернулся на «площадку», было удобно выбирать направление.

Для начала необходимо понять, какой режим сети вас интересует. Диапазон частот у 3G и LTE разный, и, чтобы принимать их сигналы, необходимо выбрать антенны или облучатели, в зависимости от конфигурации, с соответствующей частотностью. Конечно, можно взять антенны с частотным диапазоном, который захватывает оба стандарта, но в таком случае выходной сигнал будет немного хуже (опять же, в зависимости от количества переходников, длины кабелей и их свойств; эти характеристики влияют на все конфигурации данной системы, в том числе это касается и затухания сигнала).
Необходимо заранее проверить на площадке уровни сигналов мобильных сетей. Как уже говорил, я выбрал МТС, потому что здесь он ловится всегда и у МТС довольно много вышек (по сравнению с другими операторами) с разными режимами сетей, в том числе и LTE, который, надеюсь, в будущем проапгрейдят до 5G. Так что своё оборудование я подобрал «на вырост».
Лишний раз переплачивать мне не хотелось. И система с легко заменяемыми компонентами выходила дешевле, чем спутниковый интернет и предложения от фирм, которые делают готовые наборы. Вариант со «свистком» отпал на первый день подбора оборудования: такая система крайне нестабильна. Ещё я планировал поставить систему на долгосрочную работу, но этот вариант тоже не подходил, поскольку компоненты корпуса при длительной работе перегревались и выводили «свисток» из строя до его остывания. В большинстве случаев данная проблема решалась пришаманенным кулером, но нестабильность подключения и потери пакетов не склонили меня к этому варианту. По той же причине я отказался от мысли о тандеме «свисток» + роутер (с поддержкой «свистка»).
Изначально я планировал использовать «восьмёрку», она же антенна Харченко, но, учитывая зону покрытия и расстояние до ближайших населённых пунктов, есть возможность успешно ловить 3G-LTE на дистанциях, превышающих возможности «восьмёрки». Такой диапазон частот соответствует этим сетям и взят на случай непогоды, когда осадки существенно ухудшают качество сигнала. Меня удивил тот факт, что 4G-LTE работают в трёх диапазонах: около 800, около 1600 и около 2500.
Частотные диапазоны LTE-сетей у различных провайдеров:
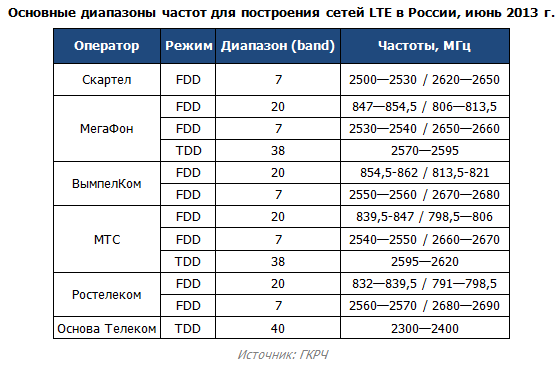
Здесь разобраны частотные диапазоны 3G-сетей:
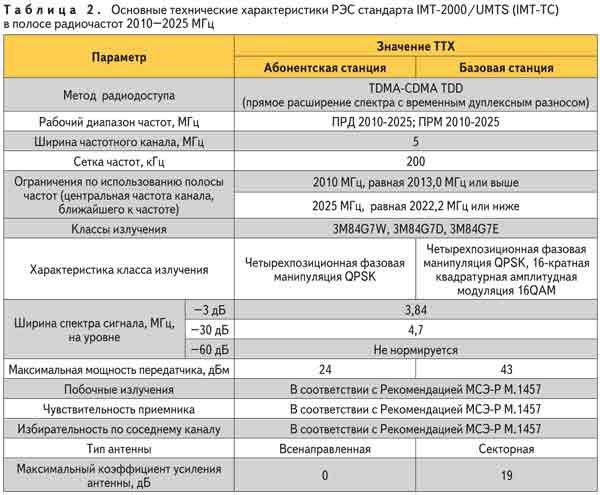
Офсет, как мне кажется, гораздо лучше, так что я сделал неправильный выбор, особенно учитывая свои возможности: но LTE я ловил на «волнушку», и проблема заключается в высоте. Для начала я долго и усердно выбирал оборудование и возможные связки, в том числе и различные типы антенн. В итоге мне понравились два варианта:
Коэффициент усиления у обоих наборов — от 24 до 28 dbi. Остановился я на втором: у него гораздо меньше проблем с ловлей сигнала от телефонных вышек. Кабель взял с пониженными потерями и затуханиями, чтобы сигнал на приём был стабильнее.
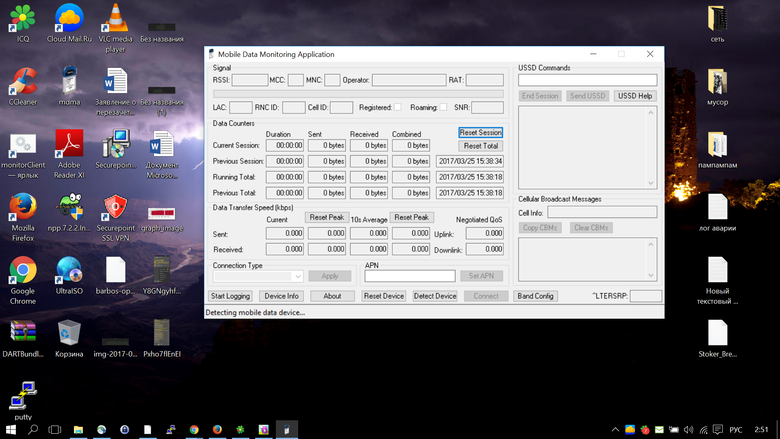
На месте я выставлял антенну с помощью Google Maps и программы MDMA. Настольная версия MDMA позволяет проверить уровень сигнала на принимающем устройстве (модуль модема в роутере). С этой программой обращаться не так просто, но если вы разобрались с Netmonitor, то у вас она вряд ли вызовет затруднения. В конце концов, есть очень неплохие рекомендации и понятные инструкции. Обратите внимание, что нужно подключение через USB «папа-папа».
Для проверки направления антенны достаточно собрать всю систему, то есть подключить антенну к роутеру, а роутер — к компьютеру, но только через USB-переходник. После чего запускаем MDMA и выбираем направление антенны.
MDMA:
Выбор конкретной модели роутера был обусловлен вышеперечисленными требованиями, но список был ограничен этими моделями:
Разброс цен — от 4 до 9 тысяч рублей за единицу. Я выбрал Huawei B315S из-за дешевизны и возможности создания IP-телефонии и подключения до 32 устройств. А ещё он может ловить LTE.
Роутер B315s-22:




Huawei B315S изначально был привязан к Yota, но я выполнил отвязку
Поскольку, кроме МТС, у меня ничего не ловилось, то и смысла усиливать то, что не ловится, не было. Но ситуация сложилась так, что мне пришлось купить роутер Yota, привязанный к сим-картам одноименного оператора (другие не подходили, проверял). Для отвязки каждого роутера свой способ, информацию легко найти в интернете, в том числе и на 4pda.ru. Полное название модели по классификации — Huawei LTE CPE B315s-22, так что, если вам необходимы технические характеристики, ищите по названию в интернете.
Оборудование подключается почти так же, как и обычный роутер. Разница в том, что необходимо подключить внешние антенны, которые будут ловить сигнал. Чтобы у вас появился интернет, не требуется никакого стороннего ПО, но, как я уже указывал, оно необходимо для определения направления антенны. На рынке тысячи вариантов разъёмов и коннекторов, и вам нужны те, которые подходят непосредственно для вашего оборудования. В моем случае это коннекторы на кабелях SMA со стороны роутера и TS9 со стороны антенн. К счастью, оборудование я подобрал таким образом, что можно прямо из коробки провести первичную настройку и начать пользоваться интернетом. Никаких танцев с бубнами не потребовалось, только в настройках через веб-интерфейс поменял пароли и режим рабочего сигнала.
Две антенны работают в тандеме по технологии MIMO, волновой канал с 24—28 dbi. Два кабеля с пониженными потерями длиной 10 метров, стандарт 5D-FB. Соответственно, придётся либо заказать переходники, либо заменить разъёмы подходящими, с одной стороны — для антенн, с другой — для подключения роутера.
Результат трудов:

Сразу хочу дать рекомендации на основании своего опыта:
Считаю, что я молодец: всё работает, скорости хватает на комфортный онлайн-просмотр фильмов. Ещё есть куда расти: на основе этой системы я планирую создать зачатки умного дома. Сейчас интернет ловится только на 3G, поэтому нужно кое-что доделать: увеличить высоту мачты, перепрошить модуль модема для возможности подключения безлимитного интернета, купить тариф для планшетов типа «Безлимитище» или аналог.
Тем, кто пойдёт по моим стопам, рекомендую сразу брать безлимитный тариф, потому что у меня всего 30 Гб трафика. Сети 4G хоть и ловятся оборудованием, но очень плохо. Гипотез две: либо я не принял в расчёт рельеф, либо нашёл антенны, которые не подходят по диапазону рабочих частот. Полагаю, что виноваты антенны: продавец заявляет, что на них написан ошибочный частотный диапазон, но, скорее всего, это ложь, потому что сети 3G ловятся идеально, а именно их диапазон указан на антеннах.
|
Метки: author asterrios стандарты связи беспроводные технологии блог компании mail.ru group мобильный интернет lte |
[Из песочницы] Нагрузочное тестирование PostgreSQL, используя JMeter, Yandex.Tank и Overload |
Итак, данный мануал подойдет для тех, кто ищет универсальный инструментарий для тестинга большого пула систем и решения большинства задач по нагрузочному тестированию. Статья рассчитана на новичков в этом деле, поэтому постараюсь максимально детализировать и упрощать процесс. Коротко обсудим каждый из элементов в нашей связке и перейдем к их первичной установке и настройке:
Залогом успеха для правильной установки JMeter является правильная установка java. На данном этапе стоит сказать о том, что все манипуляции дальше будут происходить под ОС Linux. На официальном сайте хорошие мануалы со всеми нюансами:
С Java разобрались для контрольной проверки сделайте java -version в консоле, ответ должен быть примерно таким:

wget https://archive.apache.org/dist/jmeter/binaries/apache-jmeter-2.13.tgz
Распаковываем:
tar -zxvf apache-jmeter-2.13.tgz
JMeter установлен и уже будет работать. Для первичной настройки достаточно будет внести только одно изменение. Идем по пути apache-jmeter-2.13/bin открываем для правки файл jmeter без расширения:
cd apache-jmeter-2.13/bin nano jmeter
Находим строку, как на скриншоте ниже. Выставляем значения heap size в соответствии с характеристиками используемого сервера. Первое значение HEAP Xms — объем оперативной памяти выделяемый процессу при его старте, а второе Xmx — максимальное значение оперативной памяти, которое будет доступно процессу.

sudo apt-get install python-pip build-essential python-dev libffi-dev gfortran libssl-dev sudo -H pip install --upgrade pip sudo -H pip install --upgrade setuptools sudo -H pip install https://api.github.com/repos/yandex/yandex-tank/tarball/master
Дальше следует рассказать нашему орудию куда стрелять и чем. Для этого создадим рабочую директорию на машине с танком с конфигурационным файлом load.ini:
mkdir test cd test nano load.ini
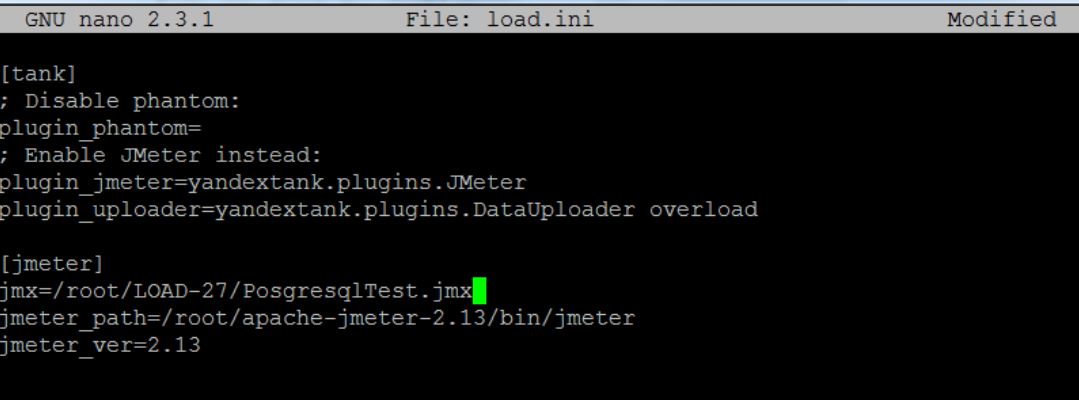
Содержимое конфигурационного файла является руководством к действиям танка, в нем необходимо отразить все ключевые моменты теста. Вот пример load.ini для теста с использованием JMeter:
Пришло время написать первый тест. Для этого открываем клиент JMeter - большинство Windows систем требуют запуск от имени администратора. Про то как начать осваивать JMeter, а заодно разобраться в его GUI хорошо написано в этой статье. У нас же пример с базой данных, что немного отличается от обычных http запросов. Первое отличие в том, что PostgreSQL не поддерживается в JMeter из коробки, поэтому нужно скачать драйвер нужной версии. После чего нужно подложить скаченный .jar в директорию /lib в папке с JMeter. Этот же .jar нужно подложить по аналогичному пути на машине с танком. С драйвером разобрались переходим к скрипту.
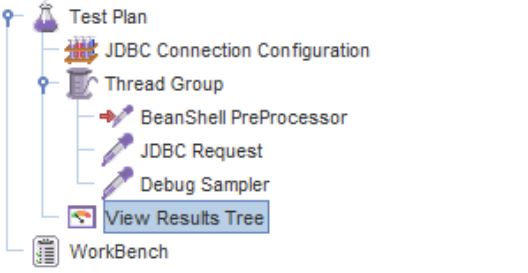
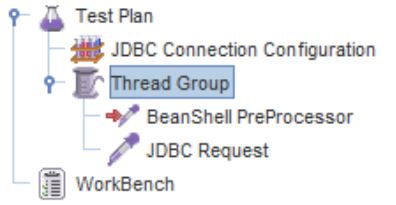
Первое, что нужно сделать это настроить подключение к БД, для этого правой кнопкой жмем на Test Plan -> Add -> Config Element -> JDBC Connection Configuration. Дерево теста пополнится конфигурационным элементом, как на скриншоте: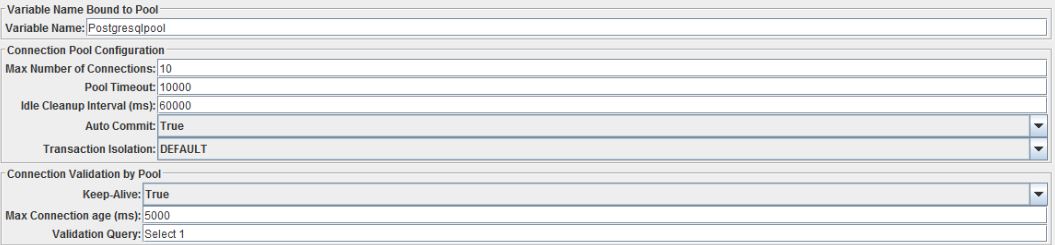

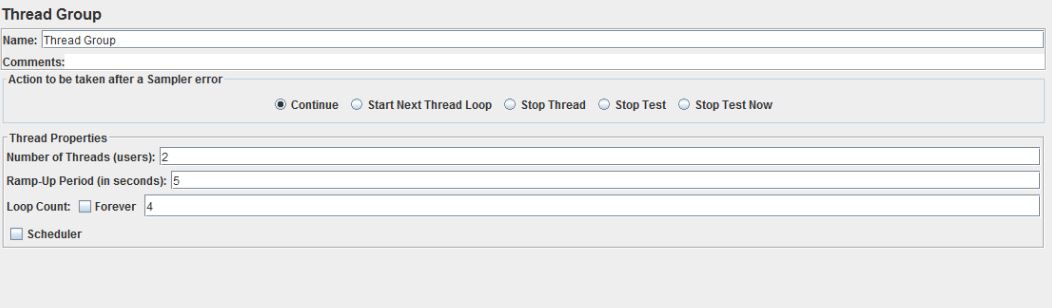
Приступаем к дальнейшему наполнению дерева теста. Опять нажимаем Test Plan -> Add -> Threads (Users) -> Thread Group.
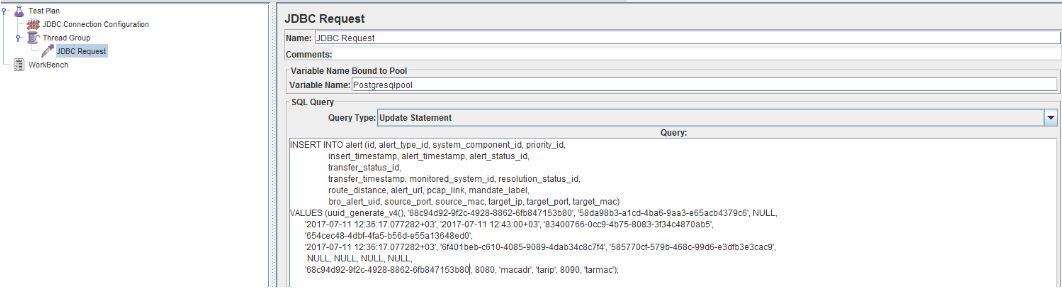
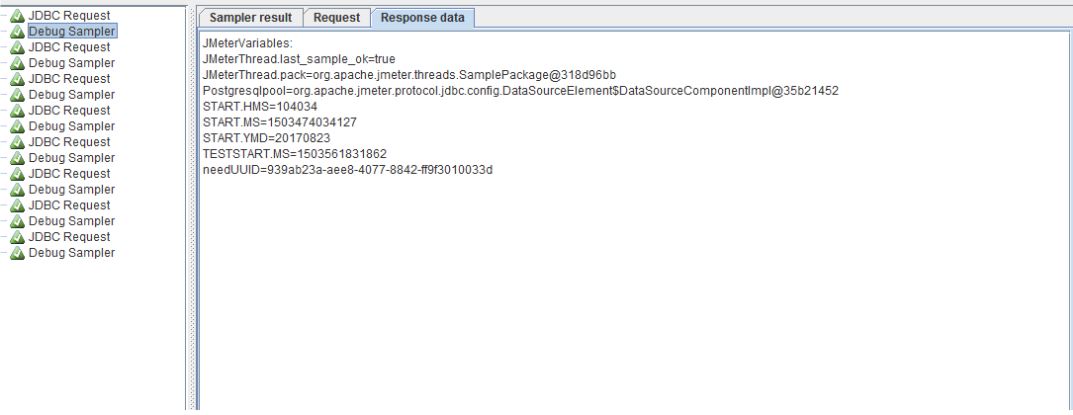
В целом скрипт готов, но нам необходимо его отладить, делается это так:
Пришло время тестового запуска пока из самого JMeter — для этого достаточно нажать

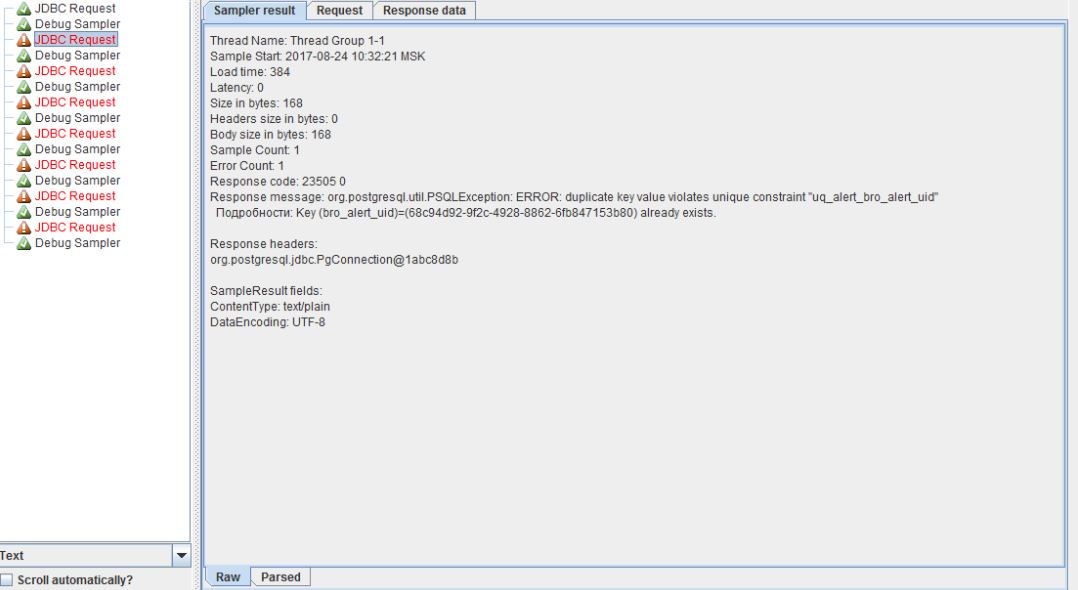
Видим, что первый отработал успешно и смотрим на поле Response message, оно говорит о том, что поле должно быть уникальным. Значит переходим к параметризации. Есть много способов как это сделать, наиболее уникальным из них является параметризация с помощью BeanShell PreProcessor. Для этого нам нужно вставить перед нашим JDBC Request указанный выше препроцессор - Thread Group -> Add -> Pre Processors -> BeanShell PreProcessor. О препроцессорах можно почитать тут или на сайте JMeter. BeanShell PreProcessor не рекомендуется использовать при больших нагрузках, как стабильный и быстрый вариант используйте JSR223 PreProcessor + Groovy. 
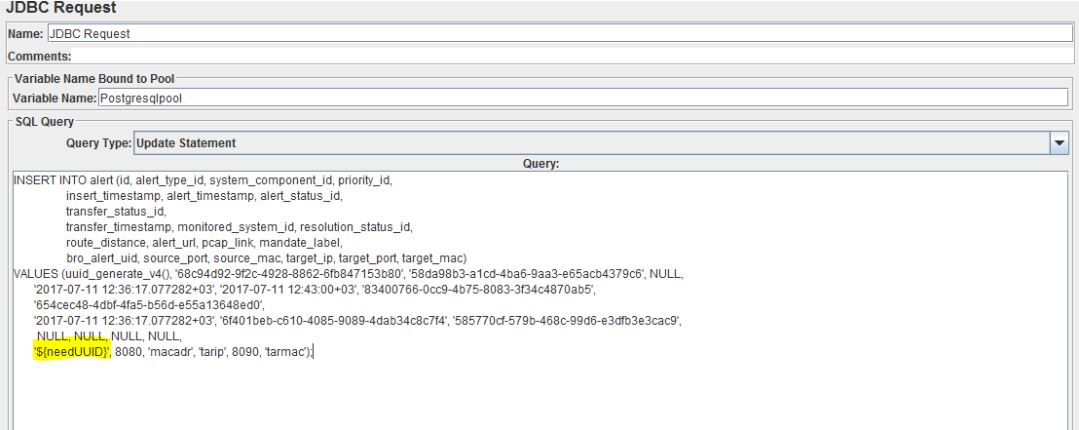
psql -h IpAddress -d dbName -U UserName
Сам count делаем так:
select count(*) from alert;
Возвращаемся на машину с танком, переходим в директорию где находится load.ini и вводим команду для запуска танка:
yandex-tank
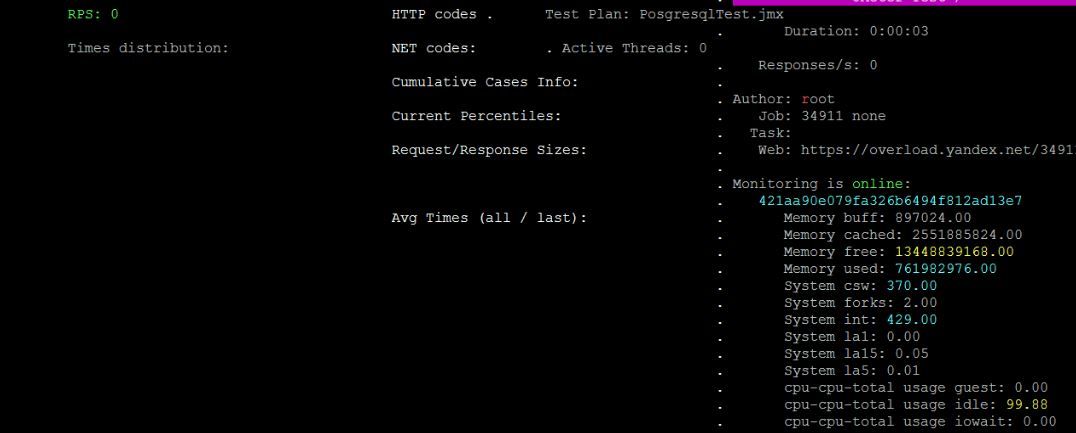
Спустя несколько секунд после запуска появится окно с текущими параметрами теста. Учитывайте, что при коротких тестах танк может не успеть получить данные о текущих параметрах.
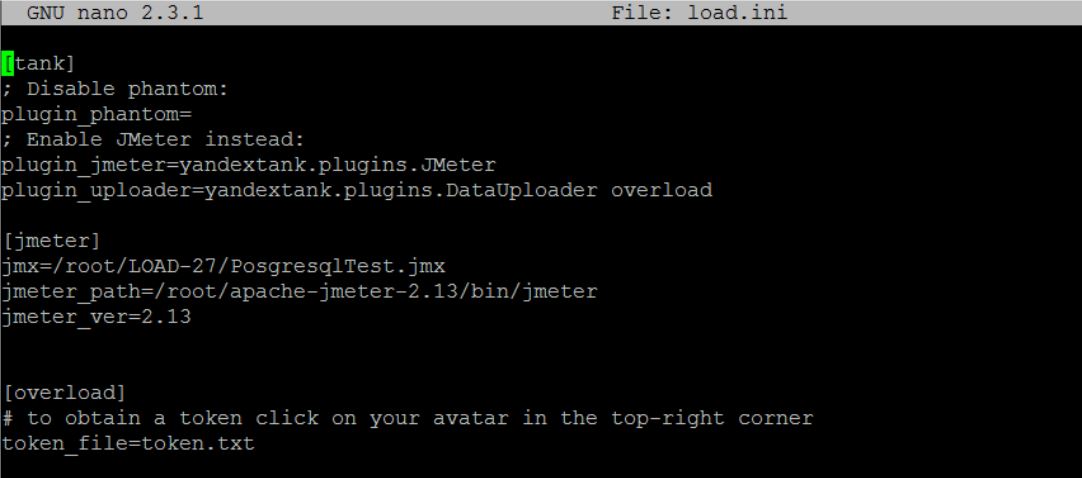
Проверив выполнение и отработку теста перейдем к настройке мониторингов. Благо для настройки мониторинга средствами Overload, потребуется минимальные усилия. Достаточно следующих действий:Получаем примерно следующее содержимое load.ini:
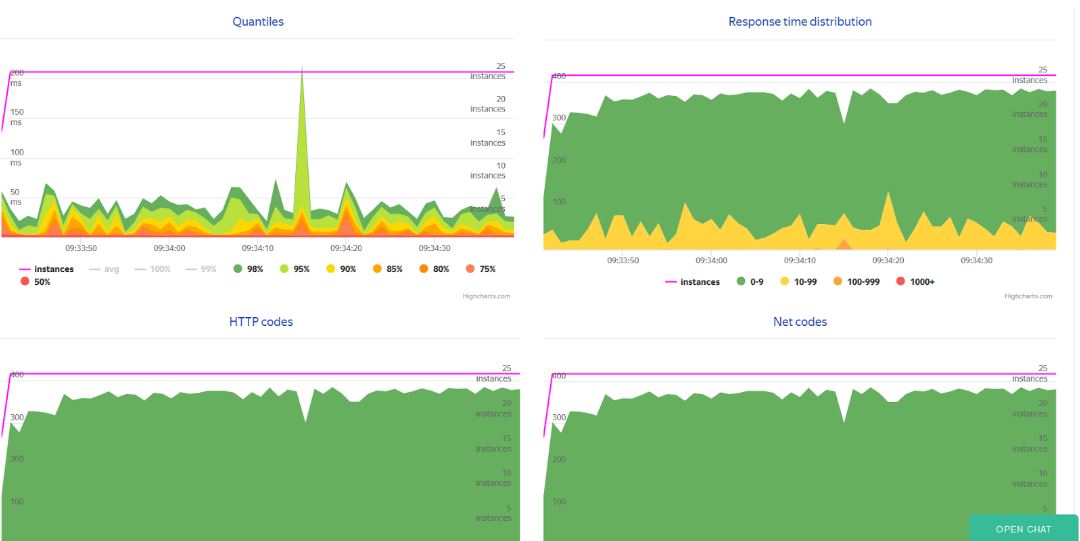
Напоследок хорошо было бы сказать о том, что с недавних пор, а именно, начиная с версии 3.2 у JMeter появились встроенное решение на базе infux для мониторинга, но там, в отличие от Overload, придется все настраивать самостоятельно.
На этом все. Всем хороших стрельб!
|
Метки: author login40k тестирование веб-сервисов postgresql jmeter yandex.tank yandex.overload нагрузочное тестирование |
Зачем нужны заголовки |

Зачем нужны заголовки и какие теги для них использовать?
Этот вопрос нам задают чаще всего.
Когда много лет назад придумали HTML, мир был совсем другим. Авторы спецификации вдохновлялись текстовыми документами, где в одном потоке подряд шли абзацы, списки, таблицы, картинки и, конечно, заголовки. Прямо как в ваших рефератах и курсовых: самый большой заголовок — название, заголовки поменьше — части или главы.
В HTML с тех пор шесть уровней заголовков: от
Еда
Фрукты
Классные
Яблоки
Вообще
Но секции лучше задавать явно с помощью элемента , помните третий выпуск? Эти два фрагмента идентичны, с точки зрения семантики, но этот гораздо понятнее, хоть и многословнее.
Еда
Фрукты
Классные
Яблоки
Вообще
Из-за такой системы неявных секций, спецификация настойчиво рекомендует не использовать элементы для подписей под заголовками. Это обычный параграф, а заголовок должен обозначать отдельную часть содержимого. В спецификации есть глава с примерами разметки сложных элементов: подписи, крошки, диалоги — почитайте.
Ладно! Раз у нас есть явные секции, то по вложенности легко определить отношение частей. Так может браузеры сами догадаются какого уровня заголовки нужны? А то считать:
Такая же идея пришла в голову авторам HTML5 и они описали в спецификации алгоритм аутлайна. Он разрешает использовать на странице только
Еда
Фрукты
Яблоки
Разработчикам идея очень понравилась, многие даже бросились её внедрять. Но вот беда: алгоритм аутлайна до сих не внедрил ни один браузер, читалка или поисковик. На таких страницах все заголовки кричат, что они №1 и самые важные. Но если важно всё, то уже ничего не важно.
Не надо так делать, об этом теперь пишет сама спецификация. За уровнем заголовков нужно следить самим. На самом деле, это не так сложно: на типичной странице вряд ли наберётся структурных частей больше, чем на 3 уровня. Так что не ленитесь.
Нет, погоди. Я ставлю класс на
Фрукты бесплатно
Только за деньги
Вы конечно правы, стили создают визуальную модель важности: крупный чёрный текст важнее, меленький серенький вообще не важен. Но только если вы смотрите на такую страницу.
Есть две важные группы пользователей, которые читают вашу страницу по тегам разметки. Они не смотрят насколько крупный и чёрный ваш
Читалками или скринридерами пользуются люди, которые плохо или совсем не видят ваши интерфейсы, или не могут управлять браузером привычным образом. VoiceOver, NVDA, JAWS читают содержимое вслух и ориентируются только по значимым тегам. Элементы div и span не значат ни-че-го, какие бы классы и стили вы не накрутили. Такой сайт — как газета без заголовков, просто месиво текста.
Да какая газета! Очнись, 2017 на дворе, я изоморфное одностраничное приложение делаю, а не стенгазету. У меня тут стейты компонентов — нафига семантика там, где нет текста? Очень хороший вопрос.
Все читалки идут по странице тег за тегом, от первого к последнему. И читают подряд всё, что внутри. Крайне неэффективно: каждая страница начинается с шапки и пока её пройдёшь, забудешь за чем шёл. Поэтому у читалок есть специальные режимы, показывающие только важные части страницы. Структурные элементы header, nav, main и другие, все ссылки, все заголовки.
Если вывести все заголовки и прочитать их, можно составить ментальную, а не визуальную модель страницы. А потом взять и сразу перейти к нужной секции, выбрав её заголовок. Меню, поиск, каталог, настройки, логин — все эти части вашего приложения можно озаглавить, чтобы упростить доступ к ним.
- Инстаграм
- Лента
- Закат
- Латте
- Настройки
- ПрофильНо бывает, что в дизайне нет заголовков для важных частей. Дизайнер рисует, ему всё ясно: меню с котлетой, поиск с полем и так далее. Но это не должно мешает вам делать доступные интерфейсы. Расставьте нужные заголовки, а потом доступно их спрячьте. Как? Только не display: none, его читалки игнорируют. Есть такой паттерн visually hidden, подробнее в описании к видео.
Думайте не только о том, как выглядит ваша вёрстка, но и о том, насколько логично организована разметка. Не забывайте о заголовках: пусть стили показывают, а заголовки рассказывают о ваших страницах или приложениях.
Вопросы можно задавать здесь.
|
|
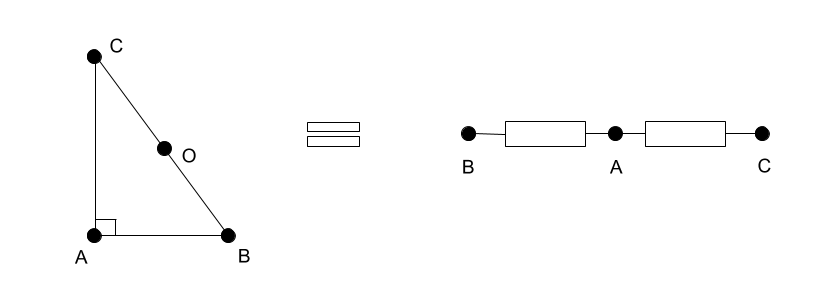
Геометрия данных 1. Симплексы и графы |

|
Метки: author dmagin математика дистанционная матрица лапласиан метрический тензор граф симплекс |
[Из песочницы] Простая Scada на Python |
import modbus_tk
import modbus_tk.defines as cst
import modbus_tk.modbus_tcp as modbus_tcpmaster = modbus_tcp.TcpMaster(host=slaveIP, port=int(slavePort))
master.set_timeout(1.0)getDI=master.execute(1, cst.READ_DISCRETE_INPUTS, 0, 10)
master.execute(1,сst.READ_COILS, 0, 10)
master.execute(1,cst.READ_INPUT_REGISTERS, 100, 3)
master.execute(1,cst.READ_HOLDING_REGISTERS, 100, 12)
print getDi(0,1,0,1,0,0,0,0,0)from Tkinter import *root = Tk()im = PhotoImage(file=backGroundPath) canv = Canvas(root,width=1900,height=950,bg="black",bd=0, highlightthickness=0, relief='ridge')canv.place(x=0, y=25)canv.create_image(1, 1,anchor=NW, image=im)root.mainloop()def jobModbusTCP():
getDI=master.execute(1, cst.READ_DISCRETE_INPUTS, 0, 10)
if(int(getDI[0]) == 1):
canv.itemconfig(diFig1,fill='red')
if(int(getDI[0]) == 0):
canv.itemconfig(diFig1,fill='green')
if(int(getDI[1]) == 1):
canv.itemconfig(diFig2,fill='red')
if(int(getDI[1]) == 0):
canv.itemconfig(diFig2,fill='green')
root.after(1000, jobModbusTCP)
from Tkinter import *
import modbus_tk
import modbus_tk.defines as cst
import modbus_tk.modbus_tcp as modbus_tcp
import math
def jobModbusTCP():
getDI=master.execute(1, cst.READ_DISCRETE_INPUTS, 0, 10)
if(int(getDI[0]) == 1):
canv.itemconfig(diFig1,fill='red')
if(int(getDI[0]) == 0):
canv.itemconfig(diFig1,fill='green')
if(int(getDI[1]) == 1):
canv.itemconfig(diFig2,fill='red')
if(int(getDI[1]) == 0):
canv.itemconfig(diFig2,fill='green')
root.after(1000, jobModbusTCP)
master = modbus_tcp.TcpMaster(host='192.168.0.1', port=502)
master.set_timeout(1.0)
root = Tk()
im = PhotoImage(file='bg.gif')
canv = Canvas(root,width=1900,height=950,bg="black",bd=0, highlightthickness=0, relief='ridge')
canv.place(x=0, y=25)
canv.create_image(1, 1,anchor=NW, image=im)
diFig1=canv.create_rectangle(10,10,30,30,fill='gray', outline='black')
diFig2=canv.create_oval(50,50,80,80,fill='gray', outline='black')
root.after(1, jobModbusTCP)
root.mainloop()
|
Метки: author jackmas python python 2.7 |
Полезные лайфхаки: отвечаем на самые популярные вопросы (Часть 2) |

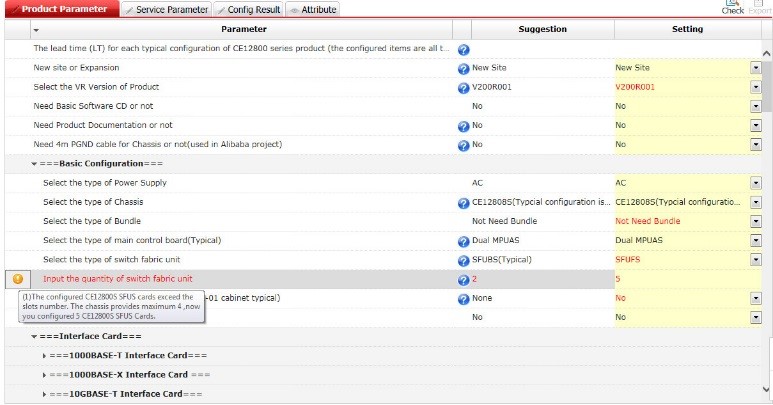
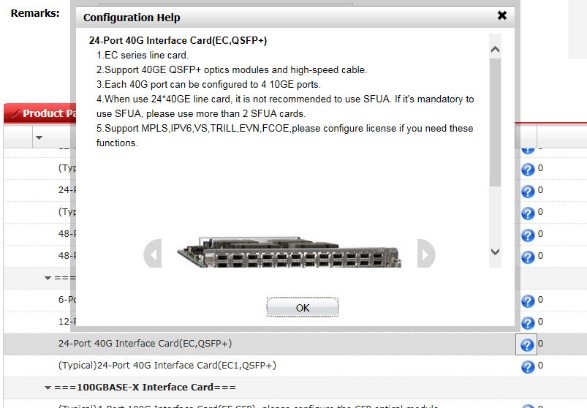
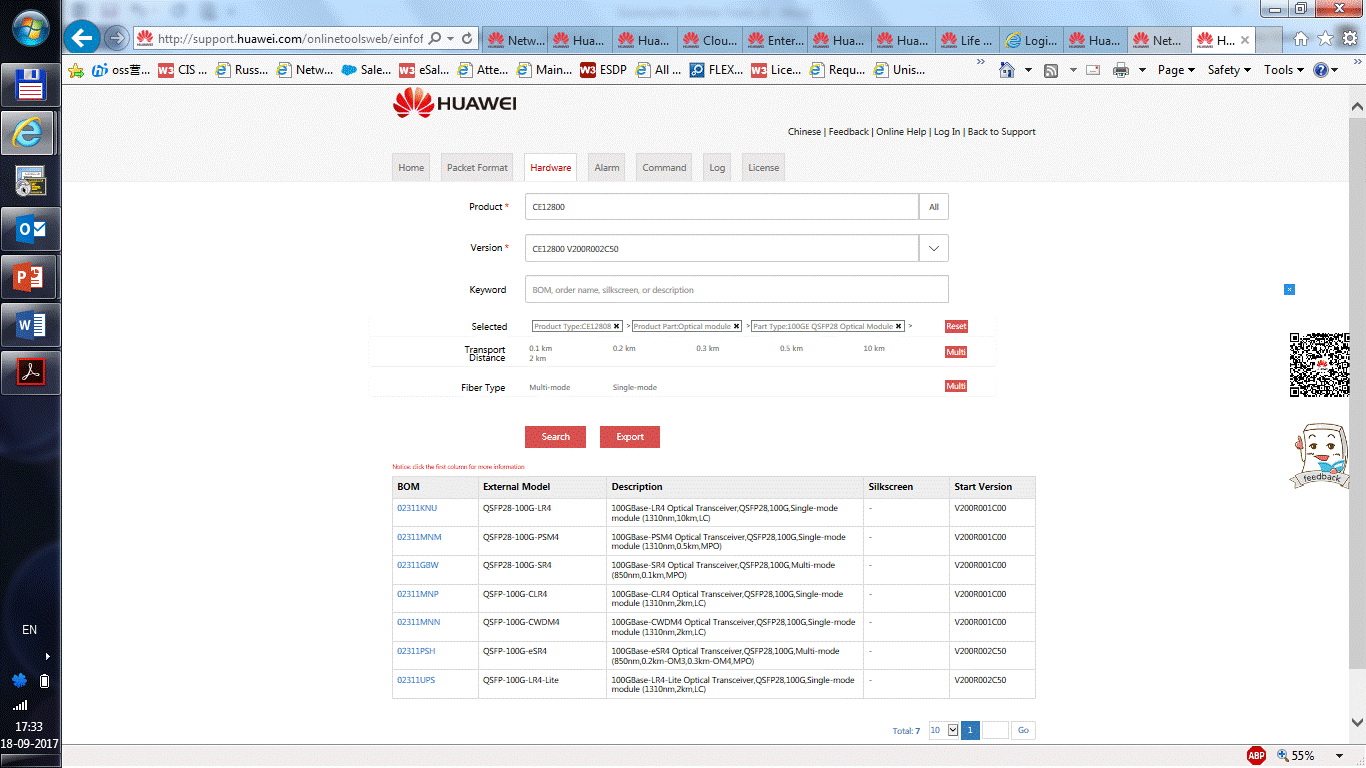
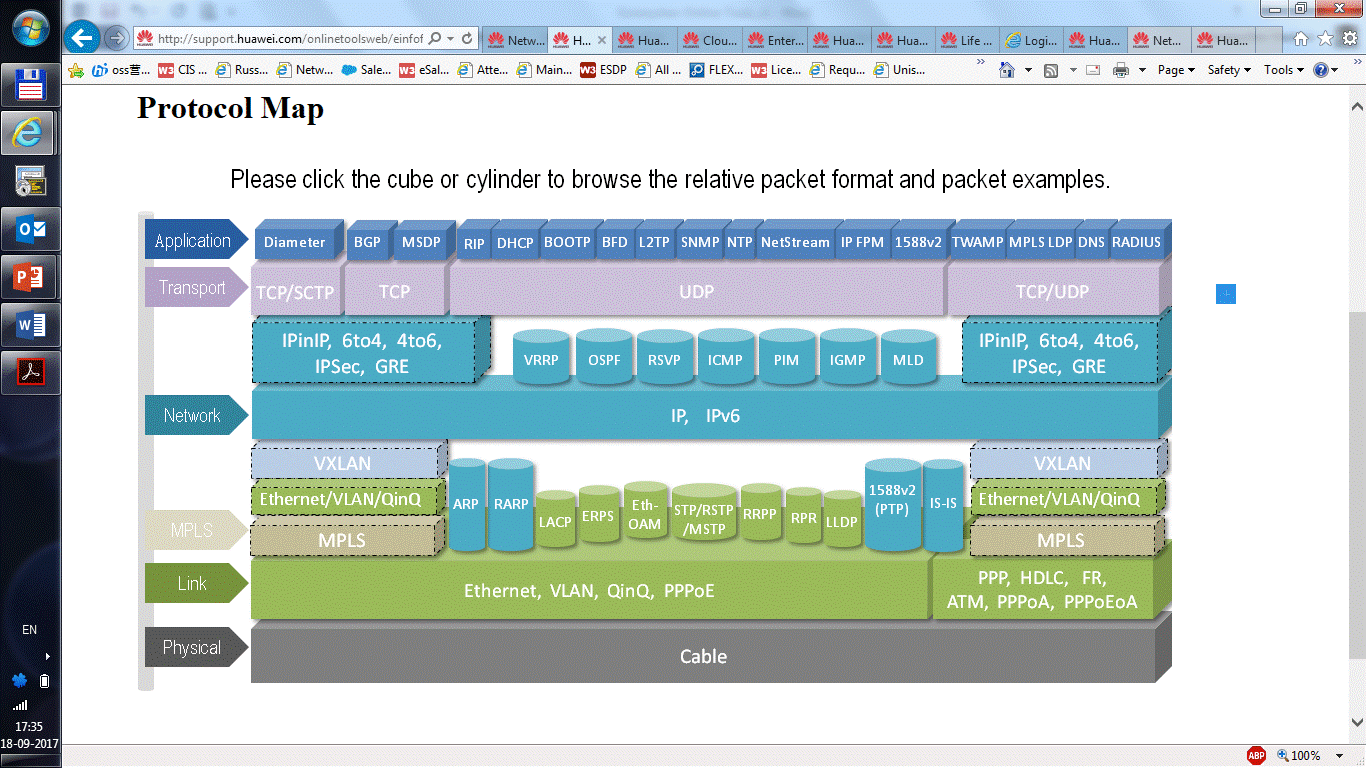
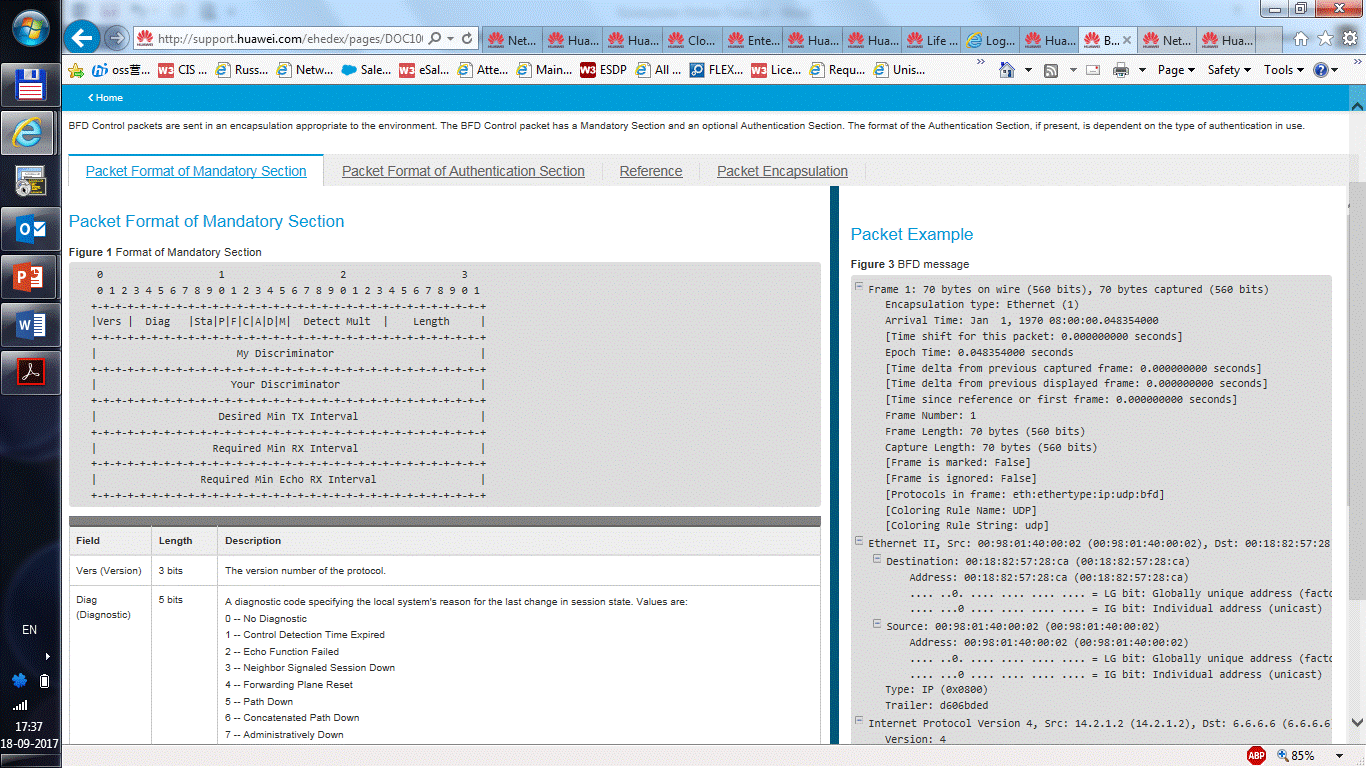
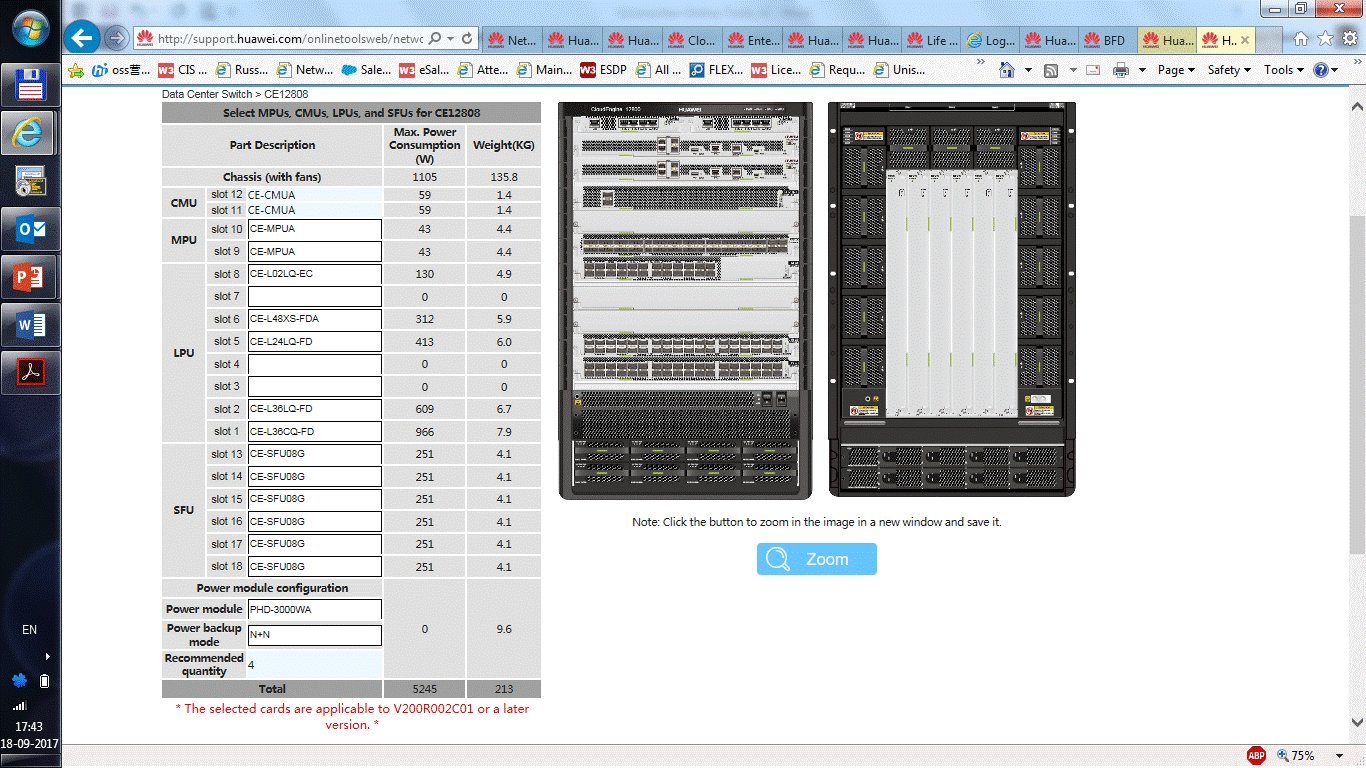
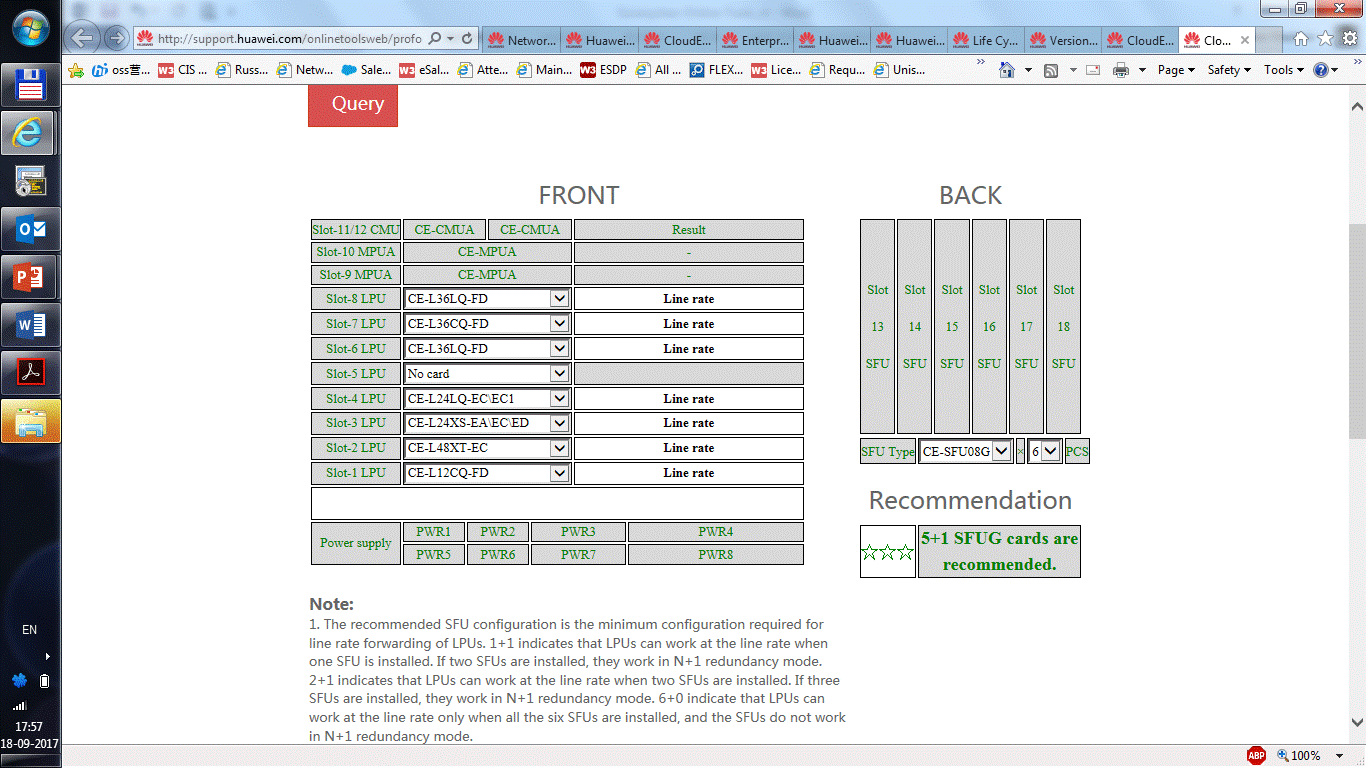
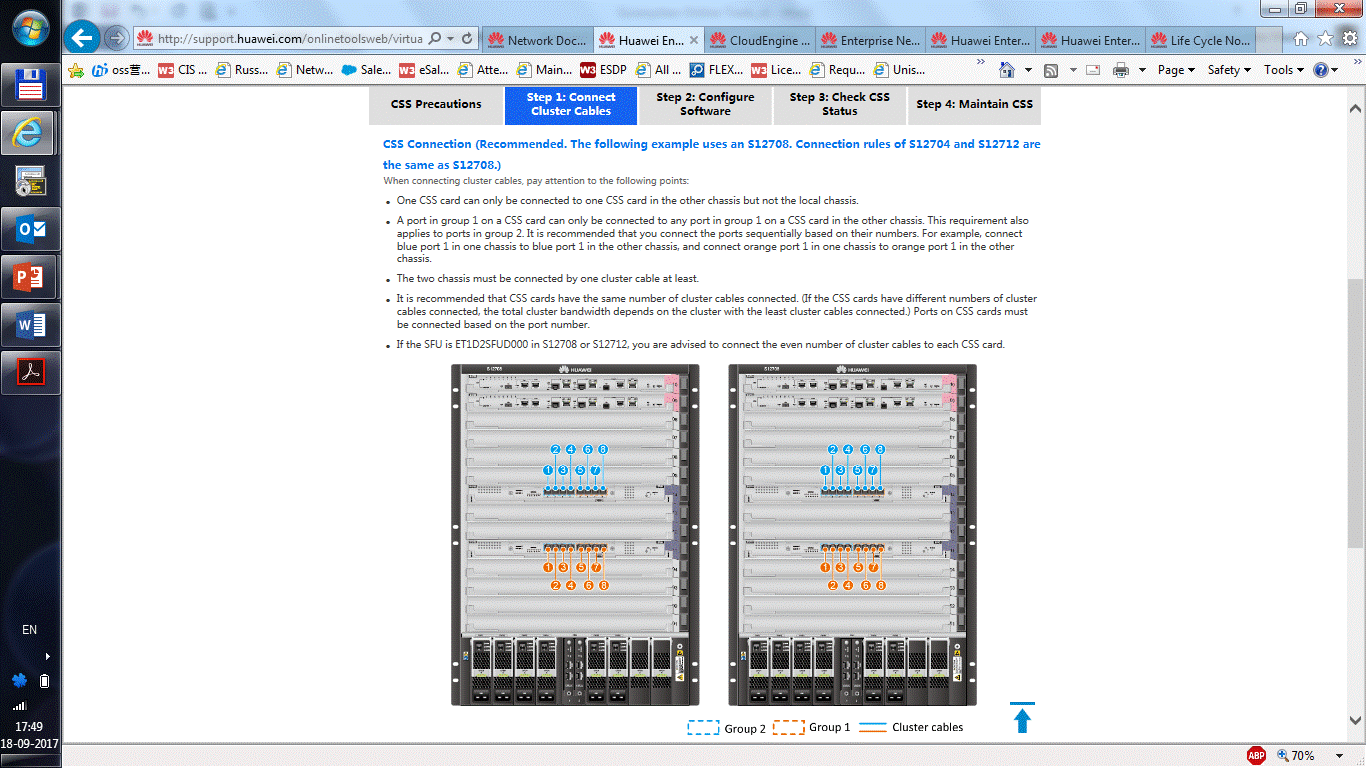
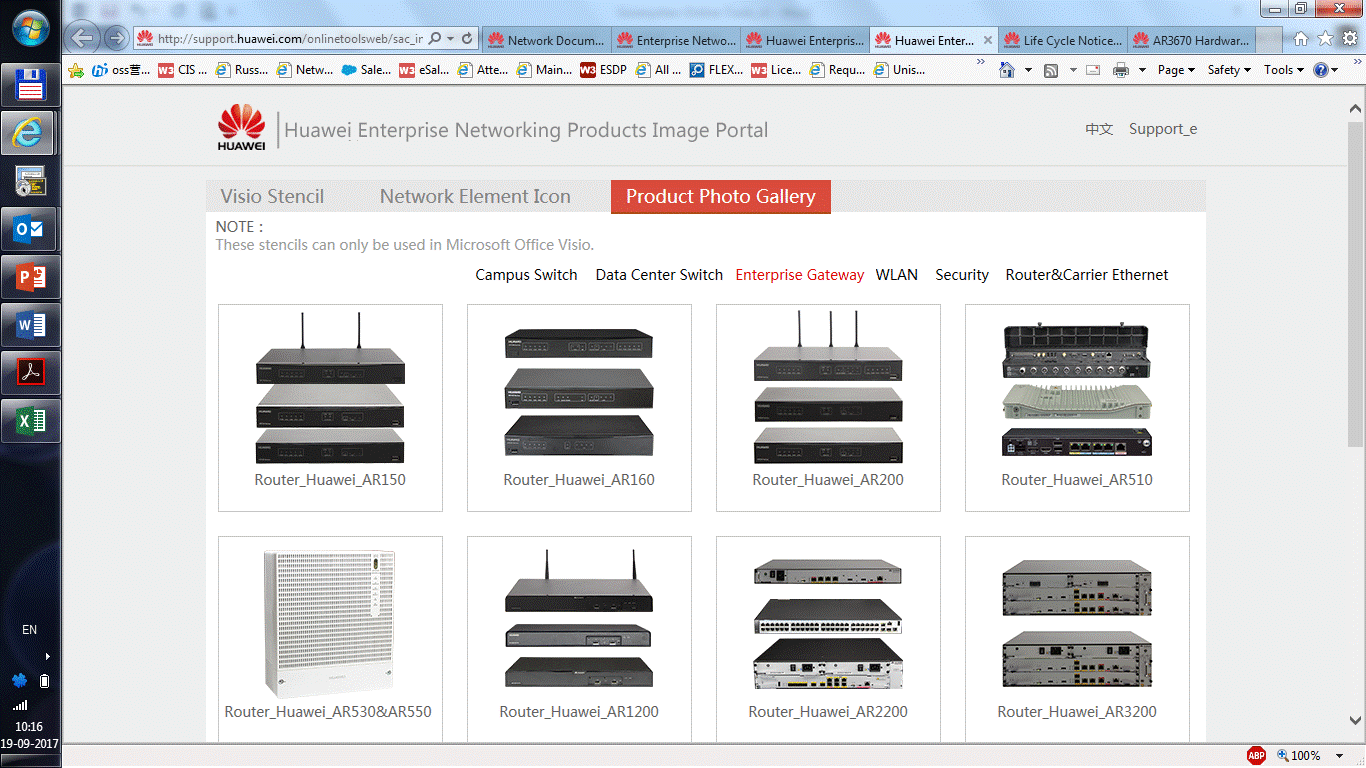

|
Метки: author Huawei_Russia сетевые технологии серверное администрирование блог компании huawei лайфхак huawei |
ПРОSTOR 2017. Снимаем маркетинговые обертки, или в поисках технологического прорыва |








|
|
К вопросу о странностях и систематическом подходе |
|
Метки: author GarryC программирование микроконтроллеров схемотехника |
[Перевод] Learnopengl. Урок 3.3 — Класс 3D-модели |

class Model
{
public:
/* Методы */
Model(char *path)
{
loadModel(path);
}
void Draw(Shader shader);
private:
/* Данные модели */
vector meshes;
string directory;
/* Методы */
void loadModel(string path);
void processNode(aiNode *node, const aiScene *scene);
Mesh processMesh(aiMesh *mesh, const aiScene *scene);
vector loadMaterialTextures(aiMaterial *mat, aiTextureType type, string typeName);
}; void Draw(Shader shader)
{
for(unsigned int i = 0; i < meshes.size(); i++)
meshes[i].Draw(shader);
}#include Assimp::Importer importer;
const aiScene *scene = importer.ReadFile(path, aiProcess_Triangulate | aiProcess_FlipUVs); void loadModel(string path)
{
Assimp::Importer import;
const aiScene *scene = import.ReadFile(path, aiProcess_Triangulate | aiProcess_FlipUVs);
if(!scene || scene->mFlags & AI_SCENE_FLAGS_INCOMPLETE || !scene->mRootNode)
{
cout << "ERROR::ASSIMP::" << import.GetErrorString() << endl;
return;
}
directory = path.substr(0, path.find_last_of('/'));
processNode(scene->mRootNode, scene);
} void processNode(aiNode *node, const aiScene *scene)
{
// обработать все полигональные сетки в узле(если есть)
for(unsigned int i = 0; i < node->mNumMeshes; i++)
{
aiMesh *mesh = scene->mMeshes[node->mMeshes[i]];
meshes.push_back(processMesh(mesh, scene));
}
// выполнить ту же обработку и для каждого потомка узла
for(unsigned int i = 0; i < node->mNumChildren; i++)
{
processNode(node->mChildren[i], scene);
}
} Внимательный читатель мог заметить, что список сеток можно было бы получить и просто пройдясь по их массиву, хранимому в объекте сцены, без всей этой кутерьмы с индексами в узле. Однако, более сложный метод, что был использован оправдан возможностью установления отношений родитель-потомок между полигональными сетками. Рекурсивный проход позволяет устанавливать подобные отношения между определенными объектами.
Пример использования: любая многокомпонентная движущаяся модель, например, автомобиль. При его перемещении вам бы хотелось, чтобы все зависимые детали (двигатель, рулевое колесо, покрышки и прочее) также перемещались. Подобная система объектов легко создается как иерархия родитель-потомок.
В данный момент такая система нами не используется, однако, рекомендуется придерживаться такого подхода, если в будущем вам захочется добавить больше возможностей управления полигональными сетками. В конечном итоге, эти отношения устанавливаются художниками-моделлерами, создавшими данную модель.
Mesh processMesh(aiMesh *mesh, const aiScene *scene)
{
vector vertices;
vector indices;
vector textures;
for(unsigned int i = 0; i < mesh->mNumVertices; i++)
{
Vertex vertex;
// обработка координат, нормалей и текстурных координат вершин
...
vertices.push_back(vertex);
}
// орбаботка индексов
...
// обработка материала
if(mesh->mMaterialIndex >= 0)
{
...
}
return Mesh(vertices, indices, textures);
} glm::vec3 vector;
vector.x = mesh->mVertices[i].x;
vector.y = mesh->mVertices[i].y;
vector.z = mesh->mVertices[i].z;
vertex.Position = vector;Массив положений вершин в Assimp назван просто mVertices, что несколько неинтуитивно.
vector.x = mesh->mNormals[i].x;
vector.y = mesh->mNormals[i].y;
vector.z = mesh->mNormals[i].z;
vertex.Normal = vector; if(mesh->mTextureCoords[0]) // сетка обладает набором текстурных координат?
{
glm::vec2 vec;
vec.x = mesh->mTextureCoords[0][i].x;
vec.y = mesh->mTextureCoords[0][i].y;
vertex.TexCoords = vec;
}
else
vertex.TexCoords = glm::vec2(0.0f, 0.0f); for(unsigned int i = 0; i < mesh->mNumFaces; i++)
{
aiFace face = mesh->mFaces[i];
for(unsigned int j = 0; j < face.mNumIndices; j++)
indices.push_back(face.mIndices[j]);
} if(mesh->mMaterialIndex >= 0)
{
aiMaterial *material = scene->mMaterials[mesh->mMaterialIndex];
vector diffuseMaps = loadMaterialTextures(material,
aiTextureType_DIFFUSE, "texture_diffuse");
textures.insert(textures.end(), diffuseMaps.begin(), diffuseMaps.end());
vector specularMaps = loadMaterialTextures(material,
aiTextureType_SPECULAR, "texture_specular");
textures.insert(textures.end(), specularMaps.begin(), specularMaps.end());
} vector loadMaterialTextures(aiMaterial *mat, aiTextureType type, string typeName)
{
vector textures;
for(unsigned int i = 0; i < mat->GetTextureCount(type); i++)
{
aiString str;
mat->GetTexture(type, i, &str);
Texture texture;
texture.id = TextureFromFile(str.C_Str(), directory);
texture.type = typeName;
texture.path = str;
textures.push_back(texture);
}
return textures;
} Заметьте, что в нашем коде действует предположение о характере хранимых в файле модели путей к файлам текстуры. Мы считаем, что эти пути относительны папки, содержащей файл модели. В этом случае полный путь к файлу текстуры можно получить слиянием ранее сохраненного пути к папке с моделью (сделано в методе loadModel) и пути к текстуре (поэтому в GetTexture также передается и путь к папке).
Некоторые модели, доступные к скачиванию в сети, хранят текстурные пути в абсолютном виде, что, очевидно, вызовет проблемы на вашей машине. Вероятно, вам потребуется воспользоваться редактором, чтобы привести пути к текстурам в порядок.
struct Texture {
unsigned int id;
string type;
aiString path; // храним путь к текстуре для нужд сравнения объектов текстур
};vector textures_loaded; vector loadMaterialTextures(aiMaterial *mat, aiTextureType type, string typeName)
{
vector textures;
for(unsigned int i = 0; i < mat->GetTextureCount(type); i++)
{
aiString str;
mat->GetTexture(type, i, &str);
bool skip = false;
for(unsigned int j = 0; j < textures_loaded.size(); j++)
{
if(std::strcmp(textures_loaded[j].path.C_Str(), str.C_Str()) == 0)
{
textures.push_back(textures_loaded[j]);
skip = true;
break;
}
}
if(!skip)
{ // если текстура не была загружена – сделаем это
Texture texture;
texture.id = TextureFromFile(str.C_Str(), directory);
texture.type = typeName;
texture.path = str;
textures.push_back(texture);
// занесем текстуру в список уже загруженных
textures_loaded.push_back(texture);
}
}
return textures;
} Некоторые версии Assimp становятся заметно медлительными, будучи собранными как отладочная версия или использованные в отладочной сборке вашего проекта. Если столкнетесь с подобным поведением – стоит попробовать работу с релизными сборками.
Модификация файла модели заключается в изменении путей к текстурам на относительный, вместо абсолютного, который сохранен в оригинальном файле.


|
Метки: author UberSchlag разработка игр программирование c++ перевод opengl opengl 3 model loading assimp learnopengl.com |
[Из песочницы] «Нормальный у нас такой UX. UX? Не до этого нам, у нас тут сроки поджимают!» Снимаем мантию — моя интерпретация |


- Почему же UX вбирает в себя столько ресурсов, времени и внимания?
- Как и откуда появилось данное направление, что оно привносит в жизнь, какова его польза?
- И все-таки, какова причина того, что данный термин зазвучал лишь 5-7 лет назад, а то и меньше, получив популярность с появлением и разработкой именно цифровых технологий и продуктов?

Задача UXer-ов состоит в том, чтобы подготовить и создать сцену, а герой как бы сливался с ней воедино, чтобы все сочеталось друг с другом и он чувствовал себя частью всецелостной картины, легко и непринужденно вливаясь в нее и обеспечивая так называемый бесшовный процесс работы и взаимодействия со всеми имеющимися в ней элементами.
А UX-er — это своего рода режиссер, который учитывает все нюансы, проникнувшись эмпатией ко всем героям.
Именно он снимает столько дублей, сколько необходимо для обеспечения дальнейшего выбора оптимального варианта.
Выборка и нарезка лучших дублей (результат тщательного исследования и анализа) дает толчок к созданию эффективного и удобного продукта.

Представьте, что аккумулятор Вашего автомобиля за ночь разрядился, только потому, что вечером после работы, во время парковки, Ваш ребенок на заднем сиденье отвлек внимание и сказал, что на следующий день занятия в школе отменены по определенной причине. Так как Вы опоздали в школу из-за ситуации в метро (недоразумения, о котором расскажу ниже), данная новость стала известна только сейчас и от ребенка, а не от преподавателя. Ну а причина вообще осталась скрыта “за семью замками”, так как ребенок не был внимательным и главное, что он уловил — это то, что завтра не надо в школу. Ура! Вы, понимая, что с ребенком кто-то должен завтра посидеть, незамедлительно набираете бабушку, чтобы поскорей с ней договориться. Ребенок в это время теряет свой телефон в машине и включает свет в салоне. Вы не обращаете внимание, заняты разговором. Ребенок находит телефон и забывает отключить свет. А освещение в салоне не предусмотрено к автоматическому отключению через определенный промежуток времени, также нет звука, дающего Вам понять, что что-то не до конца выключено. После удачной парковки, Вы выходите из машины, тут же звонит Ваша жена и просит купить молока и хлеба. Ребенок отвлекает и балуется рядом. Перед тем, как выйти, Вы выключаете ближний свет и поворачиваете ключи, вытаскиваете их из зажигания, но как оказалось, не доворачиваете до конца механический элемент отвечающий за свет фар, так как переключатель не предусмотрен таким образом, чтобы понять, что Вы действительно повернули в положение off (выключено). Вы же довернули до состояния, когда светят габаритные огни. Из-за яркого света на парковке свет габаритов уже не заметен явным образом. Вы закрываете машину и бежите скорее в магазин, все еще общаясь по телефону. Внутренний свет остался включенным. За ночь батарея села.

Перед тем как забрать ребенка из школы и сесть в автомобиль, Вы были вынуждены проехать несколько станций на метро.
Вы привыкли оставлять машину на другой станции, так как оттуда легче добраться домой и до школы без пробок.
Есть еще один важный момент, 2 дня назад Вы прилетели из важной командировки и сразу же поехали в офис на встречу, оставили багаж в офисе, сейчас пришло время его забрать домой.
На станции метро есть специальный широкий турникет. Обычно рядом также присутствует дежурный. Там проходят люди с колясками и большими сумками. Ваш случай. Вы знаете что на Вашей проездной карте достаточно средств, пополнили ее относительно недавно. Но подносите карту, а двери не открываются и при этом издают сигнал, что что-то не срабатывает. Вы пробуете еще раз, смотрите на проходящих в обычный турникет людей и не можете понять, что идет не так.
Как обычно, дежурного рядом не оказывается в нужный момент, и Вам приходится возвращаться к месту, где все покупают билеты, чтобы убедится, что баланс положительный и с картой все в порядке. Вы теряете время, ждете в очереди, психуете. Ведь Вы опаздываете за ребенком в школу. И вот дождавшись Вашей очереди, Вы убеждаетесь, что все так как и предполагалось, карта рабочая, бюджет достаточный. Вы возвращаетесь, пробуете и опять. Уже переходите в стадию отчаяния и тут видите дежурного, который тоже замечает Ваше недовольство по выражению лица. Он объясняет что Вы делаете не так и находит решение проблемы очень быстро, оказывается Вам нужно держать карту немного дольше, чем у обыкновенного турникета — более 5 секунд. К сожалению, эта информация нигде не фигурирует за неимением продуманного UX. И это факт.

На работе, с самого утра у Вас все расписано, встреча за встречей. Очень важный день. Планинг на следующий месяц. Вы опоздали и не позавтракали дома. Между встречами очень короткие перерывы, а тем временем Вы грезите о чашечке горячего и пробуждающего кофе. Буквально мчитесь к кофе-машине после первого совещания. Нажимаете на кнопку, выбираете желанный напиток из списка кофейной карты (надеясь, что наполненная чашечка будет Вас ждать) и убегаете в туалет.
После, в коридоре Вас встречает директор и ему интересно узнать Ваше мнение по определенному вопросу. Вы общаетесь, а внутри себя думаете о чашечке кофе, которая ждет Вас. Разговор заканчивается, Вы рады и бежите к желанному. Но расстраиваетесь, так как все остановилось на месте, на котором Вы все это начали. Тут к автомату подходит еще один человек, и Вы уже смотрите на него как на конкурента, а он пытается объяснить, что Вы не дожали кнопку до конца и по этой причине остались без долгожданного напитка. Нет ни сигнала, ни световых индикаторов, свидетельствующих, что машина начала работу.
Отсутствие грамотного UX.

И вот мы пришли к самому начальному звену во всей цепочке событий. Вы проспали. Будильник не сработал вовремя. Вы на время сна отключаете свой смартфон и убираете его подальше от себя на ночь, считаете это более безвредным. Вы используете обыкновенные электронные часы — будильник. В этот раз он не сработал, так как сбилось время. А время сбилось по вине Вашего домашнего любимца, который успел пройтись по этим часам во время Вашего сна и сбросить таймер. Часы Вы оставили на полу, рядом с Вашей кроватью. Если бы интерфейс у этих часов был бы проработан немного иначе, расположение кнопок имело другую конфигурацию, возможно, этого бы не произошло.
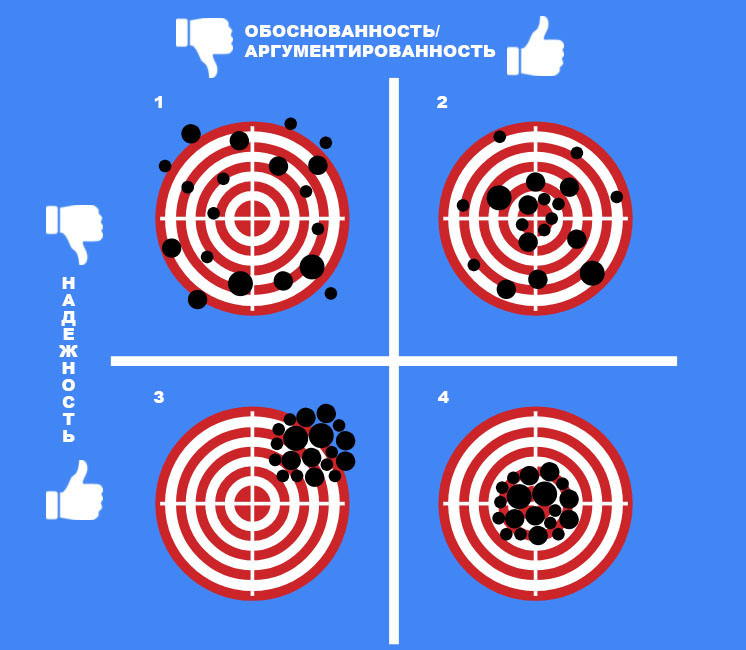
Пример 1:
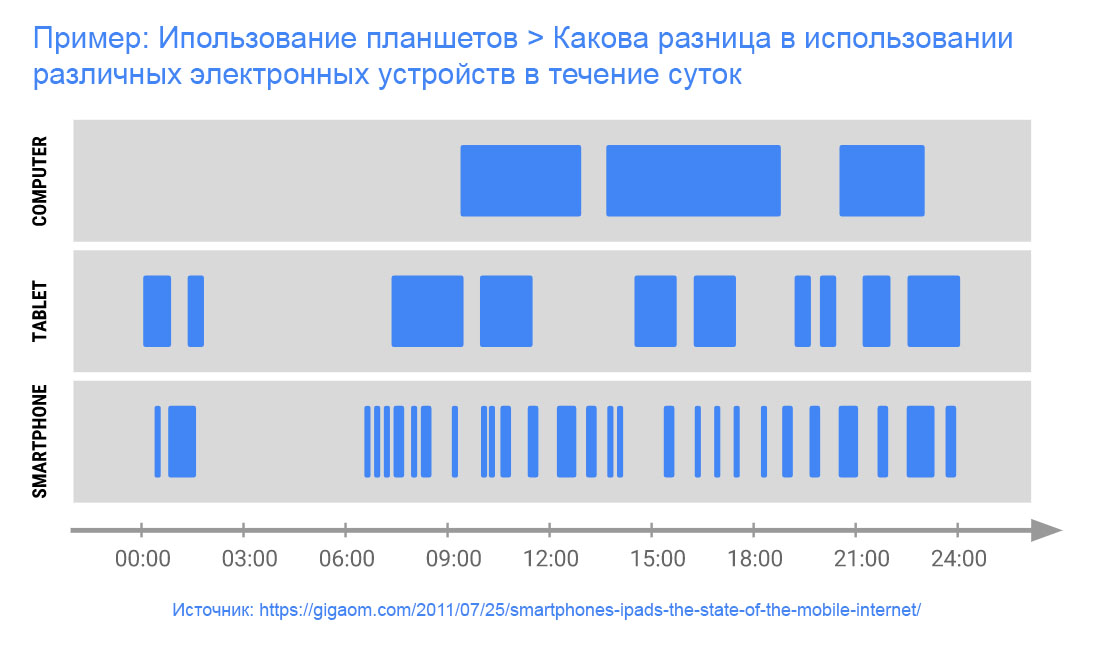
Цель — Определить как люди используют их электронные планшеты в настоящее время?

- Какие действия выполняются на планшетных компьютерах?
- В каких местах чаще всего используются планшеты?
- С какими приложениями предпочитают работать на планшетах, в каком контексте?
Пример 2:
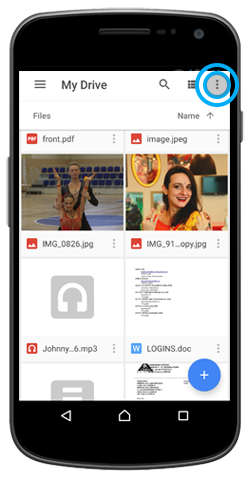
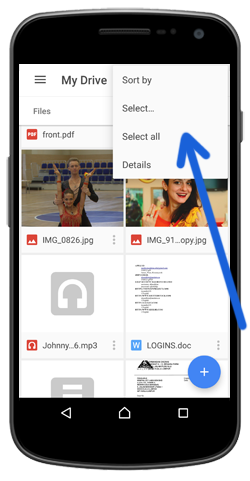
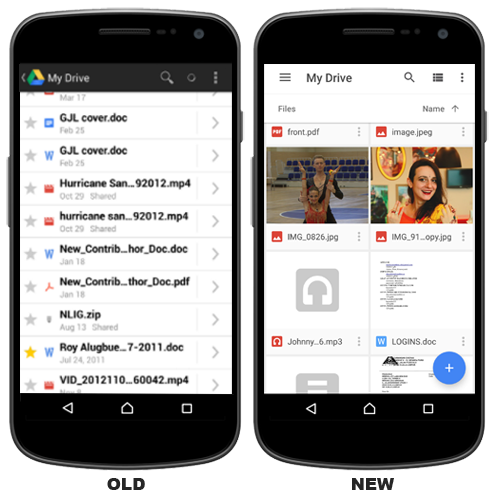
Цель — Определить насколько удобен в использовании файловый менеджер в Google Drive?

- Насколько понятен формат вывода информации на экран, удобно ли ее воспринимать и работать с ней?
- Может ли пользователь переключаться между разными режимами просмотра/вывода информации?
- Может ли пользователь воспользоваться поиском?
- Может ли пользователь перемещаться по папкам и просматривать их содержимое?
- Может ли пользователь открыть файл и просмотреть его, не скачивая его на компьютер?
- Они вообще понимают как это работает? [Восприятие и понимание продукта/услуги/окружения]
- Могут ли они найти это, какова вероятность? [Осведомленность, очевидность того или иного элемента продукта]
- Будут ли они оперировать с этим (элемент, функция), насколько очевидно, как могут воспользоваться? [Выполнение поставленной задачи]
- Как им это нравится, довольны ли, удовлетворены ли все мотивы? [Удовлетворенность пользователя, чувства после взаимодействия с продуктом]
- Насколько это полезно, лояльность пользователей? [Полезность, практичность, потребность и необходимость в использовании]
Пример 2:
Цель — Определить способы передвижения людей в окрестностях города Красноярска и установить какие устройства/инструменты/приложения чаще всего используются при этом?

- Какие сложности люди испытывают во время передвижения по городу?
- Что работает или не работает (какая функция действительно выручает, а какая не представляет надобности, не является востребованной) в тех или иных цифровых продуктах/приложениях/услугах, чаще всего используемых в качестве вспомогательных средств при ориентировании в городе?
- Какие преграды могут встречаться на пути? Как такие факторы, как общедоступность, надежность, экономия времени, цена, многолюдность и другие влияют на результат перемещения?
Приведу краткий пример:
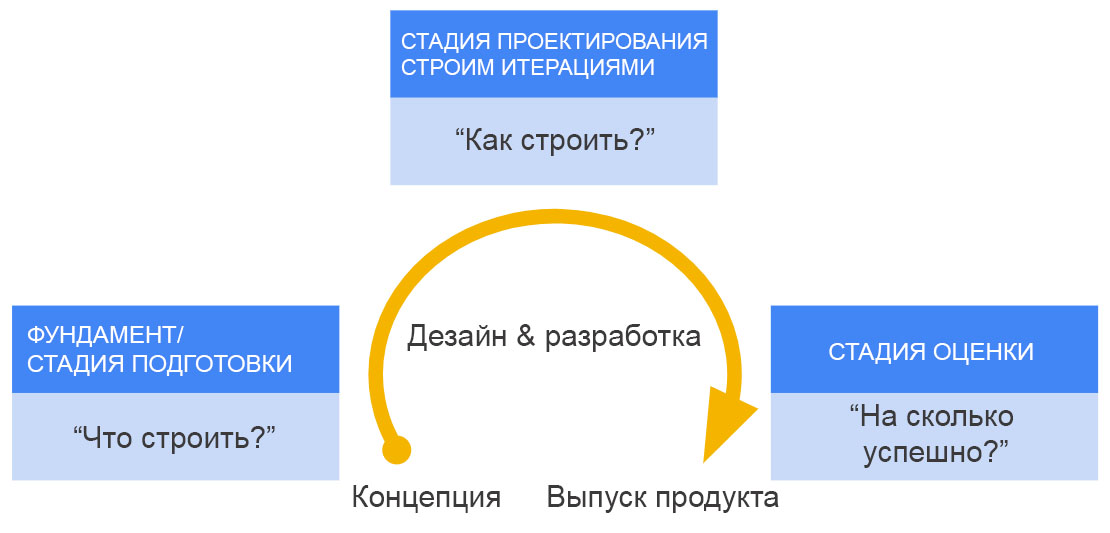
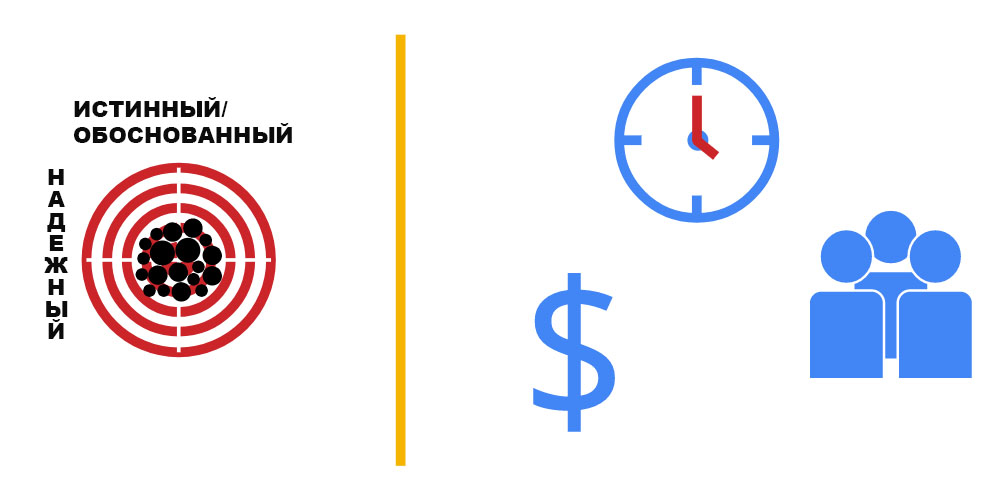
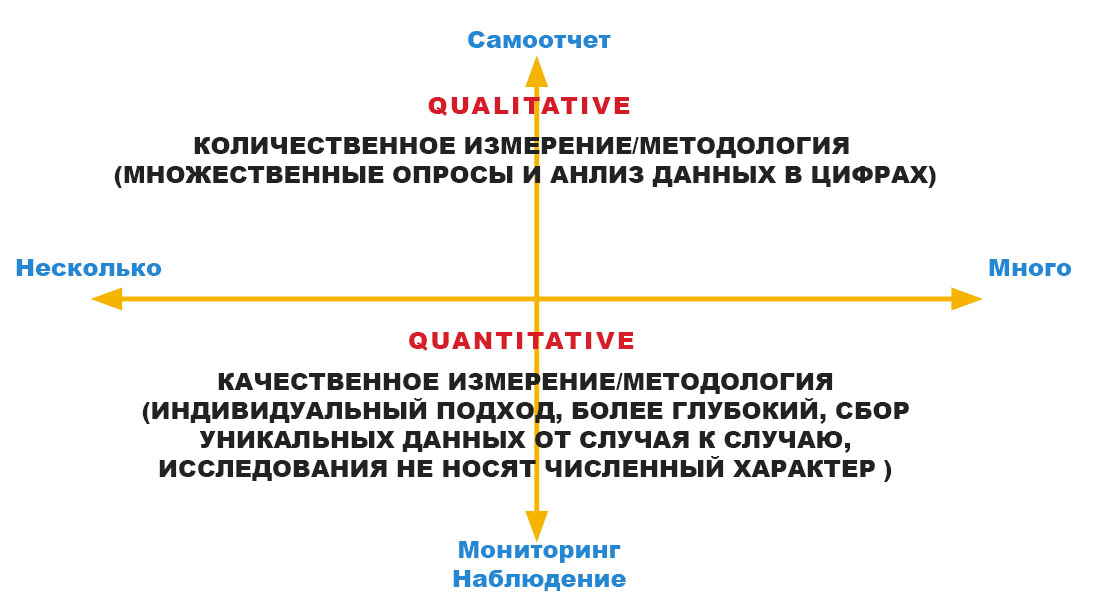
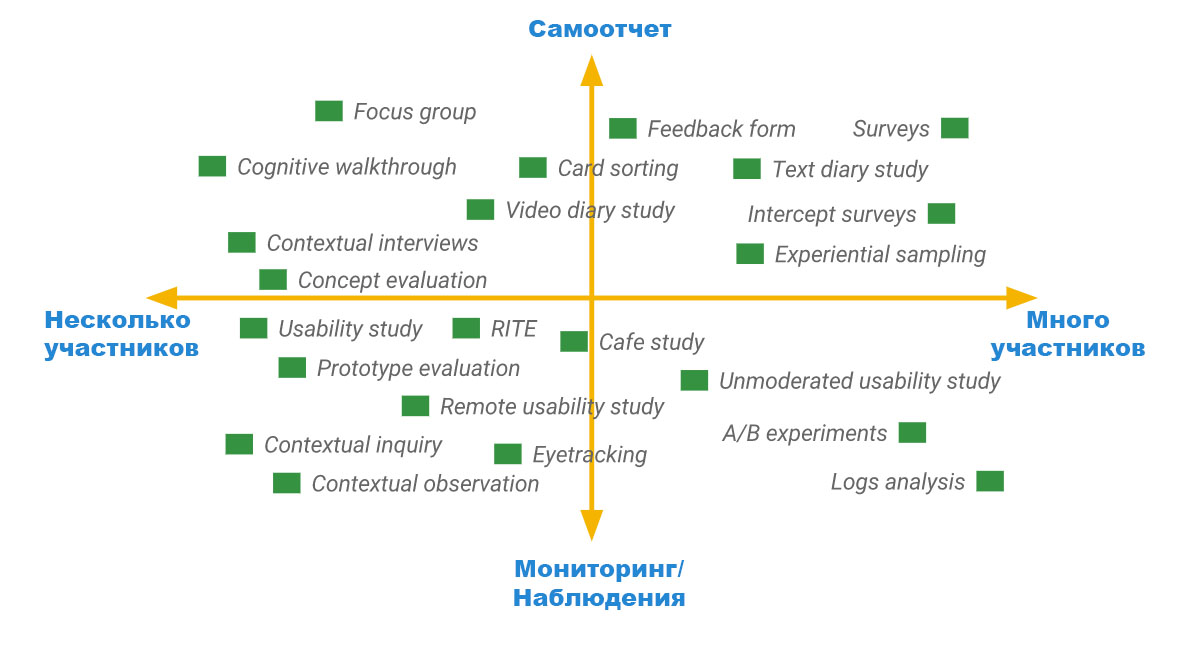
Мужчина в возрасте 65+, зарабатывающий меньше чем $13 000 в год (около $1000 в месяц) имеет меньшую вероятность быть собственником iphone 7, чем человек в возрасте 45+, зарабатывающий $20 000 годовых. Этой информации конечно же недостаточно, чтобы утверждать об этом, однако кое-какие данные уже позволяют выстраивать те или иные предположения, что уже не мало.


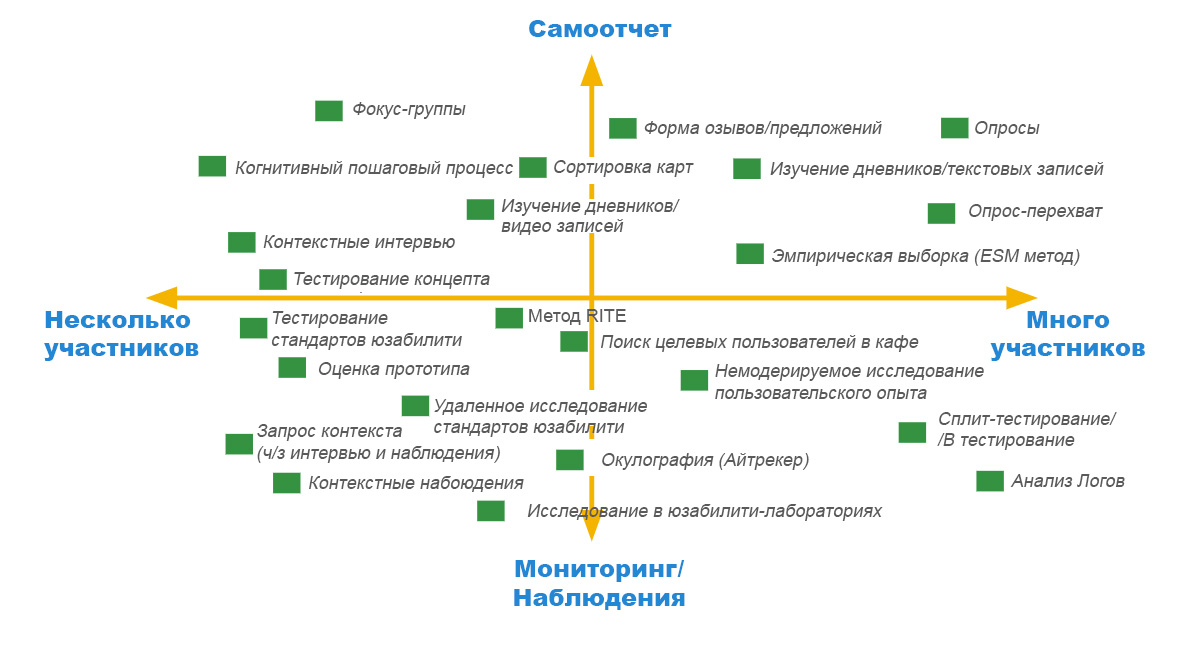




















|
Метки: author kasandra555 прототипирование интерфейсы дизайн мобильных приложений usability ux/ui |
Страницы 404 |




































|
Метки: author MagisterLudi интерфейсы графический дизайн веб-дизайн usability блог компании edison 404 error |
Sonata Import Bundle |

$application = new Application();
// ... register commands
$application->run();$command = '/usr/bin/php ';
$command .= $this->get('kernel')->getRootDir() . '/console ';
$command .= 'promoatlas:sonata:import ';
$command .= $fileEntity->getId() . ' ';
$command .= '"' . $this->admin->getCode() . '" ';
$command .= '"' . ($fileEntity->getEncode() ? $fileEntity->getEncode() : 'utf8') . '" ';
$command .= ' > /dev/null 2>&1 &';function setOwner(Owner $owner);
$owner = $em->findOwner(); // не найдено, вернет null
$entity->setOwner($owner);$validator = $this->getContainer()->get('validator');
$errors = $validator->validate($entity);if (!$this->em->isOpen()) {
$this->em = $this->em->create(
$this->em->getConnection(),
$this->em->getConfiguration()
);
}doctrs_sonata_import:
mappings:
- { name: center_point, class: promaotlas.form_format.point}
- { name: city_autocomplete, class: promoatlas.form_format.city_pa}
upload_dir: %kernel.root_dir%/../web/uploads
class_loader: Doctrs\SonataImportBundle\Loaders\CsvFileLoader
encode:
default: utf8
list:
- cp1251
- utf8
- koir8public function __toString(){
retrun $this->x . ', ' . $this->y;
}class Point implements ImportAbstract {
public function getFormatValue($value){
$value = explode(',', $value);
$point = new \PHPOpenGIS\MainBundle\Geometry\Point($value[0], $value[1] ?? 0);
return $point;
}
}class CityPa implements ImportAbstract, ContainerAwareInterface {
private $container;
public function setContainer(ContainerInterface $container = null) {
$this->container = $container;
}
public function getFormatValue($value){
/** @var ContainerInterface $container */
$container = $this->container;
$city = $container->get('promoatlas.city_autocomplete')->byName($value);
return $city;
}
}|
Метки: author DOC_tr symfony php symfony. sonata symfony2 bundle |
Чеклист: как выбрать модель системы управления правами доступа и не прогадать |
|
Метки: author SolarSecurity информационная безопасность блог компании solar security idm iga itsm права доступа |
[Перевод] Selenium и Node.js: пишем надёжные браузерные тесты |

driver.sleep — худший враг разработчика тестов. Однако, несмотря на это, его используют повсюду. Возможно, это так из-за краткости документации для Node-версии Selenium, и из-за того, что она покрывает лишь синтаксис API. Ей недостаёт примеров из реальной жизни.driver.sleep, рассмотрим пример. Предположим, у нас есть анимированная панель, которая, в ходе появления на экране, меняет размеры и положение. Взглянем на неё.
Close меняется вместе с панелью: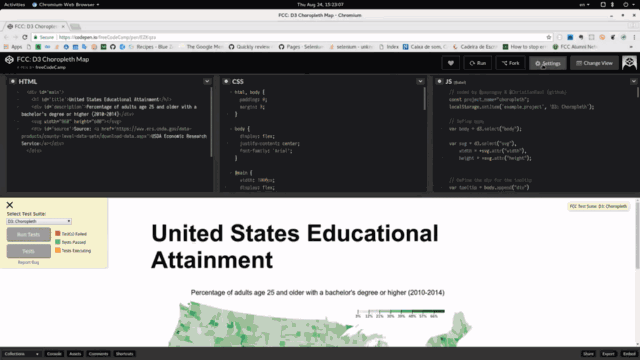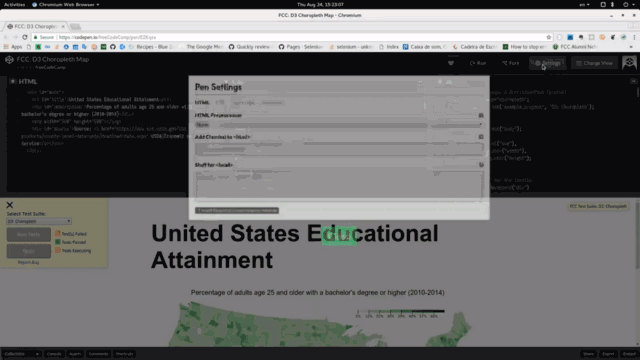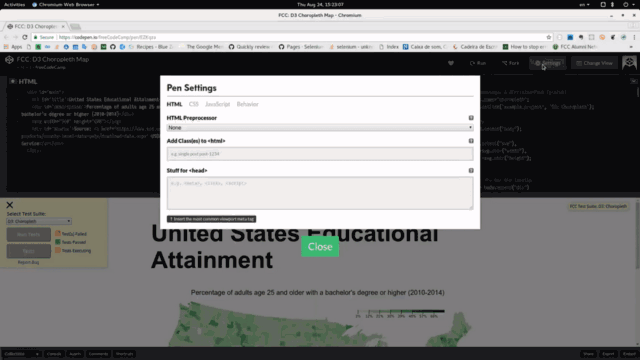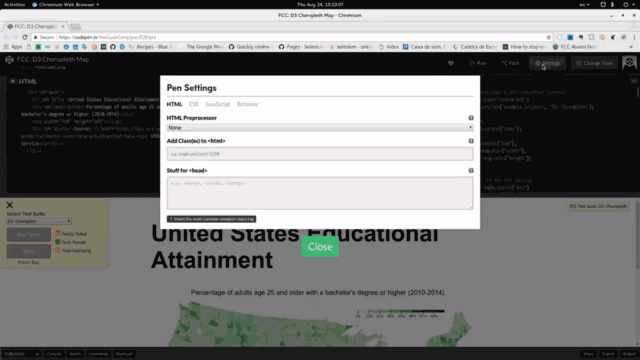
Close в процессе анимации, вы, вполне возможно, просто по ней не попадёте.System.InvalidOperationException : Element is not clickable at point (326, 792.5)driver.sleep(1000) для того, чтобы панель пришла в нормальное состояние». Похоже, задача решена? Однако, не всё так просто.driver.sleep(1000) выполняет именно то, чего от неё можно ожидать. Она останавливает выполнение теста на 1000 миллисекунд и позволяет браузеру продолжать работать: загружать страницы, размещать на них фрагменты документов, анимировать или плавно выводить на экран элементы, или делать что угодно другое.driver.sleep(1000) обычно помогает достичь того, ради чего её вызывают. Итак, почему бы ей не воспользоваться?driver.sleep не всегда работоспособны? Другими словами, почему это недетерминированный механизм?driver.sleep(1000) даст сбой.driver.sleep. Затем, полагаясь на удачу, программист будет надеяться, что это улучшение сработает во всех возможных сценариях тестирования, что оно поможет справиться с различными нагрузками на систему, сгладит отличия в системах визуализации различных браузеров, и так далее. Но перед нами всё ещё недетерминированный подход. Поэтому так поступать нельзя.driver.sleep — это, во многих ситуациях, вредная команда, подумайте вот о чём. Без driver.sleep тесты будут работать гораздо быстрее. Например, мы надеемся, что анимация из нашего примера займёт всего 800 миллисекунд. В реальном тестовом наборе подобное предположение приведёт к использованию чего-то вроде driver.sleep(2000), опять же, в надежде на то, что 2-х секунд хватит на то, чтобы анимация успешно завершилась, какими бы ни были дополнительные факторы, влияющие на браузер и страницу.driver.sleep, теперь выполняется меньше пятнадцати секунд.driver.sleep и преобразования тестов в надёжные, полностью детерминированные конструкции.my-button был добавлен в DOM после загрузки страницы:// Код инициализации Selenium опущен для ясности
// Загрузка страницы.
driver.get('https:/foobar.baz');
// Найти элемент.
const button = driver.findElement(By.id('my-button'));
button.click();driver.findElement ожидает, что элемент уже присутствует в DOM. Он выдаст ошибку, если элемент невозможно немедленно найти. В данном случае «немедленно», из-за вызова driver.get, означает: «после того, как завершится загрузка страницы».driver.findElement может быть удобен, если вы уверены, что элемент уже имеется в DOM.driver.get('https:/foobar.baz');
// Страница загружается, засыпаем на несколько секунд
driver.sleep(3000);
// Надеемся, что три секунды достаточно для того, чтобы по прошествии этого времени элемент можно было бы найти на странице.
const button = driver.findElement(By.id('my-button'));
button.click();driver.wait для того, чтобы ожидать того момента, когда элемент появится в DOM, не более двадцати секунд.const button = driver.wait(
until.elementLocated(By.id('my-button')),
20000
);
button.click();driver.wait завершит работу за одну секунду. Он не будет ждать все двадцать секунд, которые ему отведены.driver.sleep, который всегда будет ждать всё заданное время.const button = driver.wait(
until.elementLocated(By.id('my-button')),
20000
)
.then(element => {
return driver.wait(
until.elementIsVisible(element),
20000
);
});
button.click();driver.sleep. Рассмотрим ещё несколько примеров, которые помогут обойтись без driver.sleep в более сложных обстоятельствах.until JavaScript API для Selenium уже имеет некоторое количество вспомогательных методов, которые можно использовать с driver.wait. Кроме того, можно организовать ожидание до тех пор, пока элемент не будет больше существовать, ожидать появления элемента, содержащего конкретный текст, ожидать показа уведомления, или использовать много других условий.driver.wait можно предоставить функцию, которая возвращает true или false.opacity некоего элемента стало бы равным единице:// Получить элемент.
const element = driver.wait(
until.elementLocated(By.id('some-id')),
20000
);
// driver.wait всего лишь нужна функция, которая возвращает true или false.
driver.wait(() => {
return element.getCssValue('opacity')
.then(opacity => opacity === '1');
});const waitForOpacity = function(element) {
return driver.wait(element => element.getCssValue('opacity')
.then(opacity => opacity === '1');
);
};driver.wait(
until.elementLocated(By.id('some-id')),
20000
)
.then(waitForOpacity);const element = driver.wait(
until.elementLocated(By.id('some-id')),
20000
)
.then(waitForOpacity);
// Вот незадача. Переменная element может быть true или false, это не элемент, у которого есть метод click().
element.click();const element = driver.wait(
until.elementLocated(By.id('some-id')),
20000
)
.then(waitForOpacity)
.then(element => {
// Так тоже не пойдёт, element и здесь является логическим значением.
element.click();
}); const waitForOpacity = function(element) {
return driver.wait(element => element.getCssValue('opacity')
.then(opacity => {
if (opacity === '1') {
return element;
} else {
return false;
});
);
};false. Такой шаблон подходит для повторного использования, его можно задействовать при написании собственных условий.driver.wait(
until.elementLocated(By.id('some-id')),
20000
)
.then(waitForOpacity)
.then(element => element.click());const element = driver.wait(
until.elementLocated(By.id('some-id')),
20000
)
.then(waitForOpacity);
element.click();until, вы могли заметить методы вроде elementIsNotVisible или elementIsDisabled или на не столь очевидный метод stalenessOf.// Элемент уже добавлен в DOM, отсюда сразу же произойдёт возврат.
const desiredElement = driver.wait(
until.elementLocated(By.id('some-id')),
20000
);
// Но с элементом нельзя взаимодействовать до тех пор, пока панель с индикатором загрузки
// не исчезнет.
driver.wait(
until.elementIsNotVisible(By.id('loading-panel')),
20000
);
// Панель с информацией о загрузке больше не видна, с элементом теперь можно взаимодействовать, не опасаясь ошибок.
desiredElement.click();stalenessOf особенно полезен. Он ожидает, пока элемент не будет удалён из DOM, что, кроме прочих причин, может произойти из-за обновления страницы.iframe для продолжения работы:let iframeElem = driver.wait(
until.elementLocated(By.className('result-iframe')),
20000
);
// Выполняем некое действие, которое приводит к обновлению iframe.
someElement.click();
// Ожидаем пока предыдущий iframe перестанет существовать:
driver.wait(
until.stalenessOf(iframeElem),
20000
);
// Переключаемся на новый iframe.
driver.wait(
until.ableToSwitchToFrame(By.className('result-iframe')),
20000
);
// Всё, что будет написано здесь, относится уже к новому iframe.sleep. Полагаться на метод sleep — значит основываться на произвольных предположениях. А это, рано или поздно, приводит к сбоям.|
Метки: author ru_vds node.js javascript блог компании ruvds.com selenium тестирование |