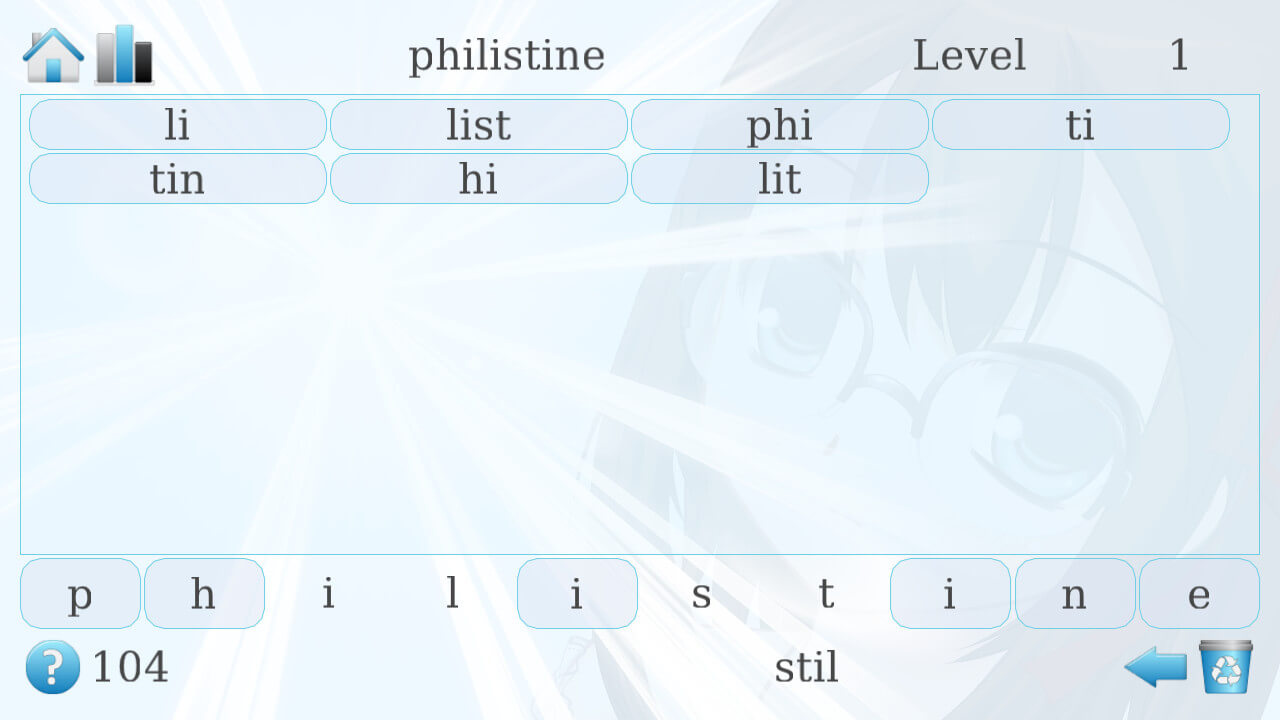
Эксперимент: действительно ли все разбираются в дизайне? |



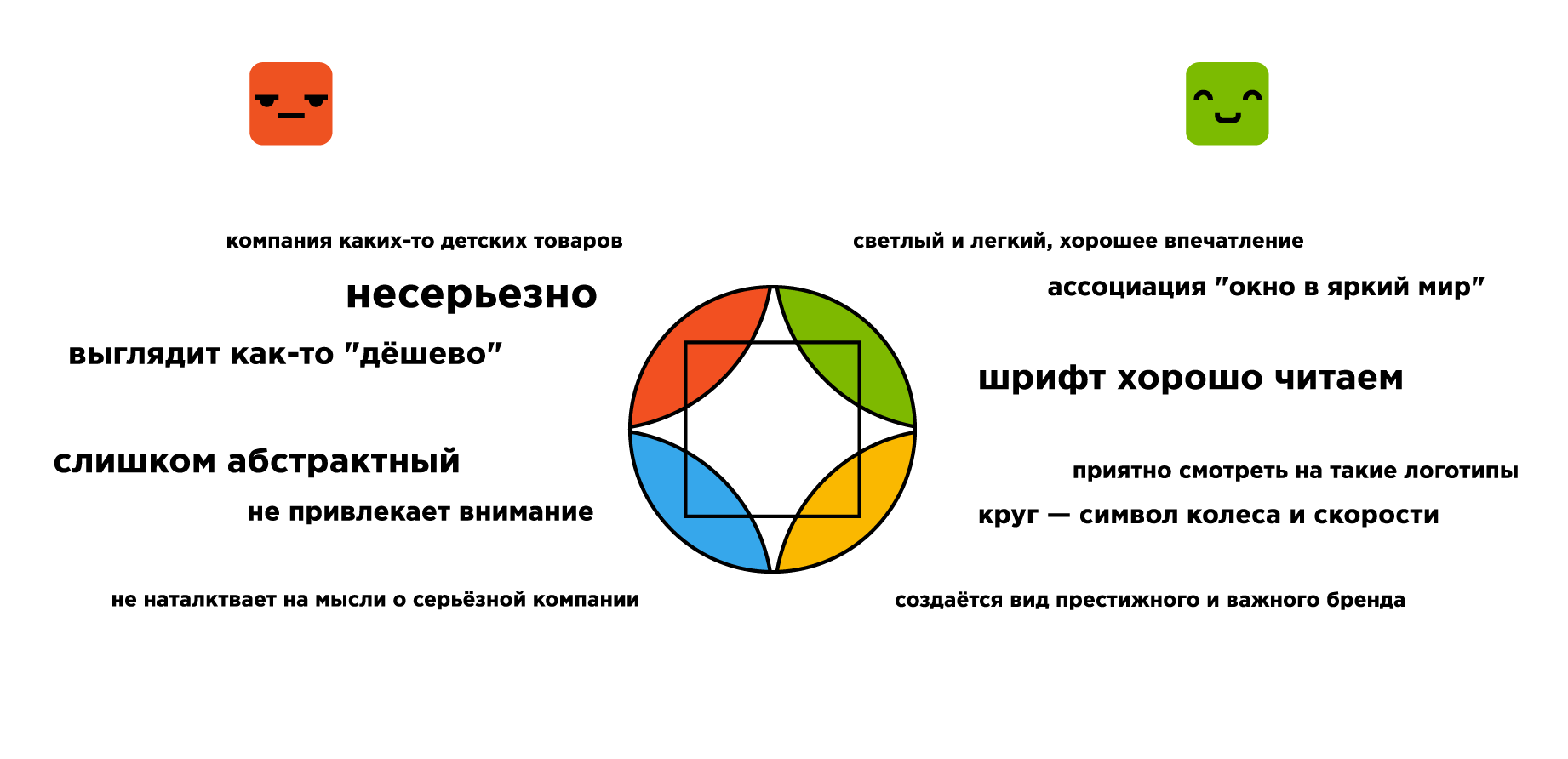
«Яркие цвета и простые формы обеспечили легкость восприятия и просмотра логотипа, округлость притянула взгляд и внимание своей совершенной, без изъянов и излишеств формой. Просто, увлекательно и с намеком на совершенство». [М, 17, маркетолог-программист]Это очень приятно, особенно если учесть, что этот логотип сделал лично я за пару минут. А ведь я даже не дизайнер! Тем не менее 57% опрошенных связали успех моей вымышленной фирмы «Polska Moto» именно с логотипом. Они искали причины в сочетании цветов, похожести на Майкрософт, простоте и нестандартности:
«Возможно, повлияла идея гармоничного сочетания разных элементов — четырех основных цветов, круга и квадрата, при этом логотип остался мягким и скругленным, глаз ни за что не цепляется». [Ж, 23, интернет-маркетинг]


Логотип не отражает сущности компании, он безлик и похож на сотни других. Первая ассоциация с ним — Microsoft, а не мотоиндустрия. [Ж, 26, фрилансер]
Цвета логотипа слишком заезжены. Вызывают сильную ассоциацию с Microsoft или Google. [М, 18 лет, —]… или все-таки хорошо?
Минималистичность, геометрия, цветовая гамма соответствует корпорации Майкрософт, что изначально внушает уверенность. [Ж, 17, маркетолог]
Ассоциация с Windows / Google (цвета и геометрия) [Ж, 22, юрист ]Группы по-разному восприняли факт «несоответствия сфере»:
Скучный лого, никак не намекают на связь с мотопроизводством. Цвета не соответствуют специализации (слишком ярко).
Не понятно чем занимается компания. Это скорее похоже на сферу развлечений. [Ж, 23, графический дизайнер]
Яркий логотип, не построенный на стереотипных идеях о мотоциклах. При этом внешне создаётся вид престижного и важного бренда. [М, 24, дизайнер-фрилансер]
… логотип не заезженный и не похож на другие логотипы производителей авто-механики или авто. [Ж, 16, программист]Мнения разошлись и насчет цветовой гаммы логотипа:
Слишком несерьёзно выглядит сочетание цветов [М, 22, —]
Я считаю, что все детали помешали успеху компании. Форма и цвета больше подходят логотипу цирка [Ж, 30, дизайн]
Логотип напоминает калейдоскоп и вызывает этим приятные воспоминая из детства. Этим располагает к себе. [Ж, 30, техник строитель / домохозяйка]
Простота логотипа и его броскость (яркость) легко запоминались пользователями и угадывались [М, 25, инженер-программист]
… Меня крайне смущает квадрат в центре. [Ж, 24, дизайн]
Мне кажется, этот контур квадрата здесь абсолютно лишний… [Ж, 19, студент издательского дела]Однако группа с «успешной компанией» нашла в квадрате глубинный смысл:
Из-за квадрата [Ж, 32, дизайн]
В интернете ходит картинка с тремя кругами: дорого, долго, качественно. И на пересечении их результат. Я думаю в квадрате они тоже выделили что у них все и сразу :) [М, 21, разработчик]
…4 стихии мира (кружок — сам логотип) и многогранность этого мира, так как внутри квадрат. Для мототехники это важно. [Ж, 21, логист и переводчик]Опрашиваемые даже не смогли определиться, простой это логотип или сложный:
… он визуально сложный [М, 24, Веб]
Перегруженность деталями и цветами [М, 20, студент-программист]
Лого создан на основе простых форм и цветов [Ж, 25, дизайнер полиграфии]
Простой, яркий, запоминающийся логотип [Ж, 23, педагог]


|
Метки: author Danya_Baranov работа с векторной графикой графический дизайн блог компании логомашина бизнес эксперимент интересное полезно |
[Из песочницы] Генерация родословного дерева на основе данных Wikipedia |
@BeforeClass
public static void Start() {
driver = DriverHelper.getDriver();
}
@Test
public void testGetDriver() {
driver.navigate().to("https://ru.wikipedia.org/wiki/%D0%A0%D1%8E%D1%80%D0%B8%D0%BA");
assertTrue(driver.getTitle().equals("Рюрик — Википедия"));
}
@AfterClass
public static void Stop() {
driver.quit();
}
public final class DriverHelper{
private static final int TIMEOUT = 30;
public static WebDriver getDriver() {
WebDriver driver = new ChromeDriver();
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(TIMEOUT, TimeUnit.SECONDS);
return driver;
}
}
@Test
public void testGetPerson() throws Exception {
PersonPage page = new PersonPage(driver);
Person person = page.getPerson("https://ru.wikipedia.org/wiki/Владимир_Александрович");
assertTrue(person.getName().equals("Владимир Александрович"));
assertTrue(person.getUrl().equals(
"https://ru.wikipedia.org/wiki/
%D0%92%D0%BB%D0%B0%D0%B4%D0%B8%D0%BC%D0%B8%D1%80_
%D0%90%D0%BB%D0%B5%D0%BA%D1%81%D0%B0%D0%BD%D0%B4%D1%80%D0%BE%D0%B2%D0%B8%D1%87"));
}
public Person getPerson(String url) throws MalformedURLException {
driver.navigate().to(url);
String name = getName();
Person person = new Person(driver.getCurrentUrl());
person.setName(name);
return person;
}
private String getName() throws MalformedURLException {
String namePage = driver.findElement(By.cssSelector("#firstHeading")).getText();
return namePage;
}
@Test
public void testGetChildrenUrl() throws Exception {
driver.navigate().to("https://ru.wikipedia.org/wiki/Рюрик");
PersonPage page = new PersonPage(driver);
List children = page.getChildrenUrl();
assertTrue(children.size() == 1);
Person person = children.get(0);
assertTrue(person.getUrl().equals("https://ru.wikipedia.org/wiki/
%D0%98%D0%B3%D0%BE%D1%80%D1%8C_
%D0%A0%D1%8E%D1%80%D0%B8%D0%BA%D0%BE%D0%B2%D0%B8%D1%87"));
}
public List getChildrenUrl() throws MalformedURLException {
List childrenLinks = driver.findElements(
By.xpath("//table[contains(@class, 'infobox')]//tr[th[.='Дети:']]//a"));
List children = new ArrayList();
for (WebElement link : childrenLinks) {
Person person = new Person(link.getAttribute("href"));
children.add(person);
}
return children;
}
@Test
public void testChildrenSize() throws Exception {
driver.navigate().to("https://ru.wikipedia.org/wiki/Рюрик");
PersonPage page = new PersonPage(driver);
List children = page.getChildrenUrl();
assertTrue(children.size() == 1);
driver.navigate().to("https://ru.wikipedia.org/wiki/Владимир_Святославич");
children = page.getChildrenUrl();
assertTrue(children.size() == 16);
driver.navigate().to("https://ru.wikipedia.org/wiki/Владимир_Ярославич_(князь_галицкий)");
children = page.getChildrenUrl();
assertTrue(children.size() == 0);
driver.navigate().to("https://ru.wikipedia.org/wiki/Мария_Добронега");
children = page.getChildrenUrl();
assertTrue(children.size() == 0);
}
public void setChild(int childId) {
if (!children.contains(childId)) {
children.add(childId);
}
}
public final class GenerateGenealogicalTree {
public static void main(String[] args) throws Exception {
String url = getUrl(args);
GenealogicalTree tree = getGenealogicalTreeByUrl(url);
saveResultAndQuit(tree);
}
public static GenealogicalTree getGenealogicalTreeByUrl(String url) throws MalformedURLException {
WebDriver driver = DriverHelper.getDriver();
Person person = new Person(url);
GenealogicalTree tree = new GenealogicalTree(person);
PersonPage page = new PersonPage(driver);
while (tree.hasUnvisitingPerson()) {
String currentUrl = tree.getCurrentUrl();
Person currentPerson = page.getPerson(currentUrl);
tree.setCurrentPerson(currentPerson);
if (!tree.isCurrentPersonDeleted()) {
List children = page.getChildrenUrl();
tree.setChildren(children);
}
tree.updatingCurrentPerson();
}
driver.quit();
return tree;
}
}
public final class GenealogicalTree {
private List allPersons;
private int indexCurrentUnvisitedPerson;
private boolean isCurrentPersonDeleted;
}
public GenealogicalTree(Person person) {
if (person == null) {
throw new IllegalArgumentException("Укажите непустого основателя династии");
}
allPersons = new ArrayList();
allPersons.add(person);
indexCurrentUnvisitedPerson = 0;
isCurrentPersonDeleted = false;
}
public boolean hasUnvisitingPerson() {
return indexCurrentUnvisitedPerson < allPersons.size();
}
public String getCurrentUrl() {
return allPersons.get(indexCurrentUnvisitedPerson).getUrl();
}
public void setCurrentPerson(Person currentPerson) {
int indexDuplicate = allPersons.indexOf(currentPerson);
if ((0 <= indexDuplicate) && (indexDuplicate < indexCurrentUnvisitedPerson)) {
removePerson(indexDuplicate);
} else {
allPersons.get(indexCurrentUnvisitedPerson).copyMainData(currentPerson);
isCurrentPersonDeleted = false;
}
}
@Override
public boolean equals(Object object) {
if ((object == null) || (!(object instanceof Person))) {
return false;
}
Person person = (Person) object;
return this.url.equals(person.url);
}
@Override
public int hashCode() {
return this.url.hashCode();
}
private void removePerson(int indexDuplicate) {
int idRemovedPerson = allPersons.get(indexCurrentUnvisitedPerson).getId();
int idDuplicate = allPersons.get(indexDuplicate).getId();
for (int i = 0; i < indexCurrentUnvisitedPerson; i++) {
Person person = allPersons.get(i);
person.replaceChild(idRemovedPerson, idDuplicate);
}
allPersons.remove(indexCurrentUnvisitedPerson);
isCurrentPersonDeleted = true;
}
public void replaceChild(int oldId, int newId) {
if (oldId == newId) {
return;
}
if (!children.contains(oldId)) {
return;
}
children.remove((Object) oldId);
setChild(newId);
}
public void setChildren(List children) {
if (isCurrentPersonDeleted) {
throw new IllegalArgumentException(
"Нельзя установить детей удаленной персоне. Текущая персона уже другая");
}
for (Person person : children) {
int index = allPersons.indexOf(person);
int id;
if (index >= 0) {
id = allPersons.get(index).getId();
} else {
allPersons.add(person);
id = person.getId();
}
allPersons.get(indexCurrentUnvisitedPerson).setChild(id);
}
}
public void updatingCurrentPerson() {
if (isCurrentPersonDeleted) {
isCurrentPersonDeleted = false;
} else {
indexCurrentUnvisitedPerson++;
}
}
public class MySqlHelper {
private static final String url = "jdbc:mysql://localhost:3306/genealogicaltree"
+ "?serverTimezone=UTC&useUnicode=yes&characterEncoding=UTF-8";
private static final String user = "root";
private static final String password = "";
private static Connection connection;
private static Statement statement;
private static ResultSet resultSet;
public static void saveTree(String tableName, List tree) throws MalformedURLException {
try {
connection = DriverManager.getConnection(url, user, password);
statement = connection.createStatement();
String table = createTable(tableName);
statement.executeUpdate(table);
for (Person person : tree) {
String insert = insertPerson(tableName, person);
statement.executeUpdate(insert);
}
} catch (SQLException sqlEx) {
sqlEx.printStackTrace();
} finally {
try {
connection.close();
} catch (SQLException se) {
}
try {
statement.close();
} catch (SQLException se) {
}
}
}
private static String createTable(String tableName) {
StringBuilder sql = new StringBuilder();
sql.append("CREATE TABLE " + tableName + " (");
sql.append("id INTEGER not NULL, ");
sql.append("name VARCHAR(255), ");
sql.append("url VARCHAR(2048), ");
sql.append("children VARCHAR(255), ");
sql.append("PRIMARY KEY ( id ))");
return sql.toString();
}
private static String insertPerson(String tableName, Person person) {
StringBuilder sql = new StringBuilder();
sql.append("INSERT INTO genealogicaltree." + tableName);
sql.append("(id, name, url, nameUrl, children, parents, numberGeneration) \n VALUES (");
sql.append(person.getId() + ",");
sql.append("'" + person.getName() + "',");
sql.append("'" + person.getUrl() + "',");
sql.append("'" + person.getChildren() + "',");
sql.append(");");
return sql.toString();
}
}
private static void saveResultAndQuit(GenealogicalTree tree) throws Exception {
Timestamp timestamp = new Timestamp(System.currentTimeMillis());
String tableName = "generate" + timestamp.getTime();
MySqlHelper.saveTree(tableName, tree.getGenealogicalTree());
}
driver.navigate().to("https://ru.wikipedia.org/wiki/Ярослав_Святославич");
children = page.getChildrenUrl();
assertTrue(children.size() == 3);
driver.navigate().to("https://ru.wikipedia.org/wiki/Людовик_VII");
children = page.getChildrenUrl();
assertTrue(children.size() == 5);
driver.navigate().to("https://ru.wikipedia.org/wiki/Галеран_IV_де_Бомон,_граф_де_Мёлан");
children = page.getChildrenUrl();
assertTrue(children.size() == 0);
driver.navigate().to("https://ru.wikipedia.org/wiki/Юрий_Ярославич_(князь_туровский)");
children = page.getChildrenUrl();
assertTrue(children.size() == 5);
public List getChildrenUrl() throws MalformedURLException {
waitLoadPage();
List childrenLinks = getChildrenLinks();
List children = new ArrayList();
for (WebElement link : childrenLinks) {
if (DriverHelper.isSup(link)) {
continue;
}
Person person = new Person(link.getAttribute("href"));
person.setNameUrl(link.getText());
if (person.isCorrectNameUrl()) {
children.add(person);
}
}
return children;
}
private List getChildrenLinks() {
List childrenLinks = DriverHelper.getElements(driver,
By.xpath("//table[contains(@class, 'infobox')]//tr[th[.='Дети:']]" +
"//a[not(@class='new' or @class='extiw')]"));
return childrenLinks;
}
private void waitLoadPage() {
this.driver.findElement(By.cssSelector("#firstHeading"));
}
public final class DriverHelper {
/**
* Возвращает список элементов без ожидания их появления.
* По умолчанию установлено неявное ожидание - это значит, что если на
* странице нет заданных элементов, то пустой результат будет выведен не
* сразу, а через таймаут, что приведет к потере времени. Чтобы не терять
* время создан этот метод, где неявное ожидание обнуляется, а после поиска
* восстанавливается.
*/
public static List getElements(WebDriver driver, By by) {
driver.manage().timeouts().implicitlyWait(0, TimeUnit.SECONDS);
List result = driver.findElements(by);
driver.manage().timeouts().implicitlyWait(DriverHelper.TIMEOUT, TimeUnit.SECONDS);
return result;
}
public static boolean isSup(WebElement element) {
String parentTagName = element.findElement(By.xpath(".//..")).getTagName();
return parentTagName.equals("sup");
}
}
public class Person {
private String nameUrl;
public boolean isCorrectNameUrl() {
Pattern p = Pattern.compile("^[\\D]+.+");
Matcher m = p.matcher(nameUrl);
return m.matches();
}
}
public List getChildrenUrl() {
waitLoadPage();
if (DriverHelper.hasAnchor(driver)) {
return new ArrayList();
}
...
}
public final class DriverHelper {
...
public static boolean hasAnchor(WebDriver driver) throws MalformedURLException {
URL url = new URL(driver.getCurrentUrl());
return url.getRef() != null;
}
...
}
@Test
public void testEmptyChildrenInPersonWithAnchor() throws Exception {
driver.navigate().to("https://ru.wikipedia.org/wiki/Владимир_Александрович");
PersonPage page = new PersonPage(driver);
List children = page.getChildrenUrl();
assertTrue(children.size() == 5);
driver.navigate().to(
"https://ru.wikipedia.org/wiki/Владимир_Александрович#.D0.A1.D0.B5.D0.BC.D1.8C.D1.8F");
children = page.getChildrenUrl();
assertTrue(children.size() == 0);
}
private String getName() throws MalformedURLException {
waitLoadPage();
String namePage = driver.findElement(By.cssSelector("#firstHeading")).getText();
if (!DriverHelper.hasAnchor(driver)) {
return namePage;
}
String anchor = DriverHelper.getAnchor(driver);
List list = DriverHelper.getElements(driver, By.id(anchor));
if (list.size() == 0) {
return namePage;
}
String name = list.get(0).getText().trim();
return name.isEmpty() ? namePage : name;
}
public final class DriverHelper {
...
public static String getAnchor(WebDriver driver) throws MalformedURLException {
URL url = new URL(driver.getCurrentUrl());
return url.getRef();
}
...
}
| id | name | children | url | urlName |
|---|---|---|---|---|
| 8 | Пелагея | [] | ссылка | Пелагея |
| 9 | Марфа | [] | ссылка | Марфа |
| 10 | Софья | [] | ссылка | Софья |
| 15 | Анна | [] | ссылка | Анна |
| 23 | Евдокия (младшая) | [] | ссылка | Евдокия |
| 26 | Феодора | [] | ссылка | Феодора |
| 28 | Мария | [] | ссылка | Мария |
| 29 | Феодосия | [] | ссылка | Феодосия |
| 36 | Дети Петра I | [] | ссылка | Наталья |
| 133 | Семья | [] | ссылка | Александр |
| 360 | Брак и дети | [] | ссылка | Луана Оранско-Нассауская |
private List parents = new ArrayList();
private int numberGeneration = 0;
public void setParent(int parent) {
parents.add(parent);
}
public void setNumberGeneration(int numberGeneration) {
if (this.numberGeneration == 0) {
this.numberGeneration = numberGeneration;
}
}
public void setChildren(List children) {
if (isCurrentPersonDeleted) {
throw new IllegalArgumentException(
"Нельзя установить детей удаленной персоне. Текущая персона уже другая");
}
Person currentPerson = allPersons.get(indexCurrentUnvisitedPerson);
int numberGeneration = currentPerson.getNumberGeneration();
numberGeneration++;
int idParent = currentPerson.getId();
for (Person person : children) {
int index = allPersons.indexOf(person);
int id;
if (index >= 0) { // Непервый родитель, номер поколения не трогаем
allPersons.get(index).setParent(idParent);
id = allPersons.get(index).getId();
} else { // Первый родитель
person.setNumberGeneration(numberGeneration);
person.setParent(idParent);
allPersons.add(person);
id = person.getId();
}
currentPerson.setChild(id);
}
}
|
Метки: author fonkost тестирование веб-сервисов открытые данные алгоритмы selenium seleniumwebdriver java wikipedia.org |
Контроль опасных кассовых операций: интеграция видеонаблюдения с 1С |
|
Метки: author randall управление продажами erp- системы ecm/ сэд блог компании ivideon с:предприятие интеграция видеонаблюдение касса ivideon |
Социнжиниринг в военной пропаганде |

— Мы обращаемся к вам, командир подводной лодки «U-507» капитан-лейтенант Блюм. С вашей стороны было очень опрометчиво оставить свою жену в Бремене, где в настоящее время проводит свой отпуск ваш друг капитан-лейтенант Гроссберг. Их уже, минимум, трижды видели вместе в ресторане, а ваша соседка фрау Моглер утверждает: ваши дети отправлены к матери в Мекленбург…
Цитата из «Операция «Гроза» — И. Бунич
«Военные власти проверили 20000 женщин. Свыше 80 процентов из них оказались больными венерическими заболеваниями. Среди проверенных женщин только 21 процент – проститутки. Остальные 79 процентов распределяются так: 61 процент – замужние женщины, вступившие в случайную связь, 18 процентов – девушки, знакомые военнослужащих (при этом 17 процентов в возрасте до 20 лет). Обе группы женщин оказались в большинстве своем членами быстрорастущего общества женщин „V“ (»Победа"), которые заявили о своем патриотическом стремлении утешать войска. А твоя девушка тоже среди них?".
Цитата из книги Крысько В. Г. — Секреты психологической войны (цели, задачи, методы, формы, опыт). Советую, там прямо весь опыт в методологии.
«Ежедневное меню объединенных сил:
Завтрак: яйцо, хлеб с маслом, 2 фрукта, фруктовый сок, молоко, кофе, чай. Обед: мясо, фасоль или картошка, бутерброд с сыром, сладости, фруктовый сок. Ужин: мясо, хлеб с маслом, зелень (овощи), яйцо, молоко, фрукты и фруктовый сок, кофе, чай. Пленные питаются так же, как солдаты объединенных сил».


«К лету 1940 г. германские передачи велись уже более чем на 30 языках. Один из руководителей нацистского иновещания сравнивал немецкие коротковолновые станции с дальнобойными орудиями, стреляющими через все границы. Чтобы пресечь влияние зарубежного иновещания на германское население, нацисты с 1 сентября 1939 г. запретили прослушивание иностранных радиопередач на территории Германии, была введена смертная казнь за распространение почерпнутых из них сведений.
После вступления Великобритании в войну в сентябре 1939 г. в структуре Би-Би-Си была создана Европейская служба, на которую возлагались задачи информационно-пропагандистской поддержки военных действий стран антигитлеровской коалиции на европейском театре военных действий. Передачи на европейскую аудиторию велись как на английском, так и на немецком, французском, португальском, испанском и других языках народов Европы. Стартовавшее еще в феврале 1938 г. немецкоязычное вещание Би-Би-Си быстро наращивало объем передач, совершенствовалось их содержание. Стремясь нейтрализовать воздействие британского вещания, государства нацистского блока организовали глушение радиопередач Би-Би-Си. В свою очередь, британские власти, убедившиеся в малой эффективности гитлеровской радиопропаганды, отказались от ответного глушения передач германского радио на Англию».
Беспалова А.Г., Корнилов Е.А., Короченский А.П.,
Лучинский Ю.В., Станько А.И.
ИСТОРИЯ МИРОВОЙ ЖУРНАЛИСТИКИ.
«Радиослушатели начали повторять эти звуки всеми возможными способами в знак поддержки движения сопротивления, — пишет Уэлч. — По всей оккупированной территории Европы люди чертили букву V и выстукивали ее „морзянкой“, демонстрируя свою солидарность… .19 июля 1941 года Уинстон Черчилль одобрительно отозвался о ней в своей речи и с тех пор стал изображать знак V пальцами».
Психологические приемы, которые помогли победить во Второй мировой войне
Фиона Макдоналд
BBC Culture

«One Saturday a big football match was to be played between Celtic and Rangers. At the same time we believed the Germans were to launch a bombing raid on Clydeside. The game was to be broadcast on the radio ,the commentator was R.E, Kingsley (REX). In the late morning however, a blanket of fog descended upon Clydeside so the match had to be abandoned. But, of course the Germans couldn't be allowed to find out about the fog as they would cancel their raid. So, REX Kingsley actually did a complete broadcast of a non existent game ,with all the goals and sound effects such as cheering and chanting. He even announced that it was a gloriously sunny day without a cloud in the sky. It was so life like it actually fooled the German Luftwaffe.»
|
Метки: author Milfgard информационная безопасность блог компании мосигра пропаганда реклама контент-маркетинг история социнжиниринг |
[recovery mode] QuadBraces III |
class QuadBracesTagConstant extends QuadBracesTagPrototype {
protected $_name = 'constant';
protected $_start = '\{\*';
protected $_rstart = '\/';
protected $_finish = '\*\}';
protected $_order = 5;
public function main(array $m,$key='') {
$v = '';
if (empty($key) || !defined($key)) {
$this->_error = 'not found';
} else { $v = constant($key); }
return $v;
}
}{{news-item? &title=`Мухи съели мера города` &date=`15-09-17` &url=`/news/150917.html`}}
[+title+]
[+date+]
Читать далее
Мухи съели мера города
15-09-17
Читать далее
array(
array('url' => '/','title' => 'Глагне'),
array('url' => '/about.html','title' => 'О сайте'),
array(
'url' => '/news/','title' => 'Новости','children' => array(
array('url' => '/news/10-09-17.html','title' => 'Мухи прилетели в город'),
array('url' => '/news/15-09-17.html','title' => 'Мухи съели мера города')
)
),
array('url' => '/contacts.html','title' => 'Контакты'),
);[:menu@top-menu:]$parser->paths = 'D:/projects/mysite/content,D:/repo/templates/default';
$fn = $parser->search('snippet','basis.snipcon');D:/projects/mysite/content/snippets/basis/snipcon.php
D:/repo/templates/default/snippets/basis/snipcon.phpD:/projects/mysite/content/snippets/basis/snipcon.php
D:/projects/mysite/content/snippets/basis/ru/snipcon.php
D:/repo/templates/default/snippets/basis/snipcon.php
D:/repo/templates/default/snippets/basis/ru/snipcon.phpdefine("QUADBRACES_LOCALIZED",true);$parser->paths = 'D:/projects/mysite/content,D:/repo/templates/default';
$parser->language = 'ru';D:/projects/mysite/content/lang/ru/
D:/repo/templates/default/lang/ru/D:/projects/foo/content/template/templates/news/single.html
D:/projects/foo/content/template/templates/news/ru/single.html|
Метки: author XanderBass php quadbraces modx шаблонизация |
[Из песочницы] Бэкап файлов Windows-сервера своими руками |
pdate v1.1 build 2007.12.06Ссылка из встроенного мануала pdate ведет туда же, а именно — в никуда.
© 2005-2007 Pavel Malakhov 24pm@mail.ru
pm4u.opennet.ru/mysoft/pdate.htmК счастью, на том же ресурсе есть краткая статья по этой программе, там же ее можно скачать.
:Main
REM Здесь описаны условия, в каком случае будет выполняться полный \ дифференциальный бэкап, либо обновление базового бэкапа.
REM Базовое условие - создание полного бэкапа если он не существует
IF NOT EXIST %baseArch% GOTO BaseArchive
REM полный бэкап раз месяц + дифференциальныt бэкапы к нему
IF %dm% EQU 1 GOTO BaseArchive ELSE GOTO UpdateArchive
REM обновляем базовый архив в 1 день месяца
REM IF %dm% EQU 1 GOTO UpdateBase ELSE GOTO UpdateArchive
REM Ежеквартальный полный бэкап (2, 19, 36 неделя года)
REM IF NOT %wn%.%dw% EQU 02.5 GOTO UpdateArchive
REM IF NOT %wn%.%dw% EQU 19.5 GOTO UpdateArchive
REM IF NOT %wn%.%dw% EQU 36.5 GOTO UpdateArchive
REM Обновляем базовый архив, каждую субботу
REM IF %dw% EQU 6 (GOTO UpdateBase) ELSE (GOTO UpdateArchive)
REM А здесь можно разместить действие, которое выполнится если предыдущие условия не отработают.
REM Я стараюсь избегать подобного поведения
ECHO Warning! No one condition matching, check :Main block of script >> %Log%
GOTO End
@ ECHO OFF
REM Sources were found on http://sysadminwiki.ru/wiki/Резервное_копирование_в_Windows
CD %~dp0
TITLE winfsbackup
MODE CON: COLS=120 LINES=55
ECHO Setting vars...
REM --- Definition block ---
SET verboseLevel=1
SET tmpDir=D:\winfsbackup\tmp
SET run_7z=D:\winfsbackup\7z\7za.exe
SET run_pdate=D:\winfsbackup\pdate\pdate.exe
FOR /F "usebackq" %%a IN (`%run_pdate% e`) DO (SET dm=%%a)
FOR /F "usebackq" %%a IN (`%run_pdate% u`) DO (SET dw=%%a)
FOR /F "usebackq" %%a IN (`%run_pdate% V`) DO (SET wn=%%a)
SET LogDir=D:\winfsbackup\log
SET Log=%LogDir%\general.log
SET dDir=D:\winfsbackup\backup
SET dlmDir=D:\winfsbackup\backup\old
SET baseArch=%dDir%\general.7z
SET IncludeList=lists\include_general.txt
SET ExcludeList=lists\exclude_general.txt
SET ExcludeRegexp=lists\exclude_regexp.txt
SET updArch_dw=%dDir%\day_general_%dw%.7z
SET updArch_wn=%dDir%\week_general_%wn%.7z
IF %verboseLevel%==0 GOTO Main
ECHO Verbose mode ON!
ECHO Today is %wn% week of year, %dw% day of week.
ECHO Full quarter backup will execute (if enabled) on 2, 19 and 36 week, friday.
ECHO Temporary directory is %tmpDir%
ECHO Now logging into %Log%
ECHO Current backup directory is %dDir%, older backups stored into %dlmDir%
:Main
REM Here discribed conditions - in which case script will make new backup, update older one, etc
REM You are free to change these conditions
REM Make sure you envisaged all possible cases
REM Actions here are not disigned to be active more than 1 at same time, excluding base condition
REM If you want multiple conditions, you should edit it
REM Base condition - full backup will be created if it is not exist
IF NOT EXIST %baseArch% GOTO BaseArchive
REM Command below turns on making full backup at 1'st day of every month, in other days - increments
REM IF %dm% EQU 1 GOTO BaseArchive ELSE GOTO UpdateArchive
REM This option enables updating full backup every month
IF %dm% EQU 1 GOTO UpdateBase ELSE GOTO UpdateArchive
REM Uncomment these 3 commands if you want to run full backup ~every quarter (2, 19, 36 week of year)
REM IF NOT %wn%.%dw% EQU 02.5 GOTO UpdateArchive
REM IF NOT %wn%.%dw% EQU 19.5 GOTO UpdateArchive
REM IF NOT %wn%.%dw% EQU 36.5 GOTO UpdateArchive
REM This option enables rewriting base archive every saturday with new files in order to decrease size of increments
REM IF %dw% EQU 6 (GOTO UpdateBase) ELSE (GOTO UpdateArchive)
REM Here you can place default action if conditions of previous ones were not executed.
%run_pdate% "Z --- \A\c\t\i\o\n \w\a\s\ \n\o\t \s\e\l\e\c\t\e\d\! >> %Log%
ECHO Warning! No one condition matching, check :Main block of script
GOTO End
:BaseArchive
ECHO Clear %dlmDir% and move data of previous month to that dir...
IF NOT EXIST %dlmDir%\nul MKDIR %dlmDir%
DEL /Q %dlmDir%\*
MOVE /Y %dDir%\* %dlmDir% 2> nul
%run_pdate% "====== Y B =======" > %Log%
%run_pdate% "Z --- \S\t\a\r\t \t\o \c\r\e\a\t\e \n\e\w \a\r\c\h\i\v\e" >> %Log%
ECHO Creating new backup %baseArch%
%run_7z% a %baseArch% -w%tmpDir% -i@%IncludeList% -x@%ExcludeList% -xr@%ExcludeRegexp% -bsp2 -ssw -slp -scsWIN -mmt=on -mx3 -ms=off >> %Log%
IF %ERRORLEVEL%==0 (
%run_pdate% "Z --- \E\x\i\t \c\o\d\e \0 \- \a\r\c\h\i\v\e \s\u\c\c\e\s\s\f\u\l\l\y \c\r\e\a\t\e\d!" >> %Log%
) ELSE (
IF %ERRORLEVEL%==1 (
%run_pdate% "Z --- \W\a\r\n\i\n\g\! \R\e\c\i\e\v\e\d\ \e\x\i\t \c\o\d\e \1" >> %Log%
) ELSE (
IF %ERRORLEVEL%==2 (
%run_pdate% "Z --- \E\x\i\t \c\o\d\e \2 \- \F\A\T\A\L \E\R\R\O\R\!" >> %Log%
) ELSE (
IF %ERRORLEVEL%==7 (
%run_pdate% "Z --- \E\x\i\t \c\o\d\e \7 \- \C\o\m\m\a\n\d \p\r\o\m\p\t \e\r\r\o\r!" >> %Log%
) ELSE (
IF %ERRORLEVEL%==8 (
%run_pdate% "Z --- \E\x\i\t \c\o\d\e \8 \- \N\o\t \e\n\o\u\g\h \m\e\m\o\r\y" >> %Log%
) ELSE (
ECHO Recieved error 255 - user stopped running process or exit code unknown! >> %Log%
)
)
)
)
)
)
)
GOTO End
:UpdateBase
ECHO Refreshing base archive
ECHO ******* ******* ******* >> %Log%
%run_pdate% "Z --- \S\t\a\r\t \t\o \u\p\d\a\t\e \a\r\c\h\i\v\e" >> %Log%
%run_7z% u %baseArch% -up0q1r2x1y2z1w0 -w%tmpDir% -i@%IncludeList% -x@%ExcludeList% -xr@%ExcludeRegexp% -bsp2 -ssw -slp -scsWIN -mmt=on -mx5 -ms=off >> %Log%
IF %ERRORLEVEL%==0 (
%run_pdate% "Z --- \E\x\i\t \c\o\d\e \0 \- \u\p\d\a\t\e \s\u\c\c\e\s\s\f\u\l\l\y \f\i\n\i\s\h\e\d" >> %Log%
) ELSE (
IF %ERRORLEVEL%==1 (
%run_pdate% "Z --- \W\a\r\n\i\n\g\! \R\e\c\i\e\v\e\d\ \e\x\i\t \c\o\d\e \1" >> %Log%
) ELSE (
IF %ERRORLEVEL%==2 (
%run_pdate% "Z --- \E\x\i\t \c\o\d\e \2 \- \F\A\T\A\L \E\R\R\O\R\!" >> %Log%
) ELSE (
IF %ERRORLEVEL%==7 (
%run_pdate% "Z --- \E\x\i\t \c\o\d\e \7 \- \C\o\m\m\a\n\d \p\r\o\m\p\t \e\r\r\o\r!" >> %Log%
) ELSE (
IF %ERRORLEVEL%==8 (
%run_pdate% "Z --- \E\x\i\t \c\o\d\e \8 \- \N\o\t \e\n\o\u\g\h \m\e\m\o\r\y" >> %Log%
) ELSE (
ECHO Recieved error 255 - user stopped running process or exit code unknown! >> %Log%
)
)
)
)
)
)
)
GOTO End
:UpdateArchive
ECHO Updtaing existing full backup
ECHO ******* ******* ******* >> %Log%
%run_pdate% "Z --- \S\t\a\r\t \t\o \u\p\d\a\t\e \a\r\c\h\i\v\e" >> %Log%
IF %dw%==7 (SET updArch=%updArch_wn%) ELSE SET updArch=%updArch_dw%
REM --- Check files existence ---
IF EXIST %updArch% DEL /Q %updArch%
REM --- Create incremental archive ---
|
Метки: author urfinejuse системное администрирование резервное копирование 7zip backup windows server 2003 r2 sp2 |
Первый в России OpenHack от Microsoft (то есть от нас) |

|
|
[Перевод] Применение PowerShell для ИТ-безопасности. Часть III: бюджетная классификация |

1. $cur = Get-Date
2. $Global:Count=0
3. $Global:baseline = @{"Monday" = @(3,8,5); "Tuesday" = @(4,10,7);"Wednesday" = @(4,4,4);"Thursday" = @(7,12,4); "Friday" = @(5,4,6); "Saturday"=@(2,1,1); "Sunday"= @(2,4,2)}
4. $Global:cnts = @(0,0,0)
5. $Global:burst = $false
6. $Global:evarray = New-Object System.Collections.ArrayList
7.
8. $action = {
9. $Global:Count++
10. $d=(Get-Date).DayofWeek
11. $i= [math]::floor((Get-Date).Hour/8)
12.
13. $Global:cnts[$i]++
14.
15. #event auditing!
16.
17. $rawtime = $EventArgs.NewEvent.TargetInstance.LastAccessed.Substring(0,12)
18. $filename = $EventArgs.NewEvent.TargetInstance.Name
19. $etime= [datetime]::ParseExact($rawtime,"yyyyMMddHHmm",$null)
20.
21. $msg="$($etime)): Access of file $($filename)"
22. $msg|Out-File C:\Users\bob\Documents\events.log -Append
23.
24.
25. $Global:evarray.Add(@($filename,$etime))
26. if(!$Global:burst) {
27. $Global:start=$etime
28. $Global:burst=$true
29. }
30. else {
31. if($Global:start.AddMinutes(15) -gt $etime ) {
32. $Global:Count++
33. #File behavior analytics
34. $sfactor=2*[math]::sqrt( $Global:baseline["$($d)"][$i])
35.
36. if ($Global:Count -gt $Global:baseline["$($d)"][$i] + 2*$sfactor) {
37.
38.
39. "$($etime): Burst of $($Global:Count) accesses"| Out-File C:\Users\bob\Documents\events.log -Append
40. $Global:Count=0
41. $Global:burst =$false
42. New-Event -SourceIdentifier Bursts -MessageData "We're in Trouble" -EventArguments $Global:evarray
43. $Global:evarray= [System.Collections.ArrayList] @();
44. }
45. }
46. else { $Global:burst =$false; $Global:Count=0; $Global:evarray= [System.Collections.ArrayList] @();}
47. }
48. }
49.
50. Register-WmiEvent -Query "SELECT * FROM __InstanceModificationEvent WITHIN 5 WHERE TargetInstance ISA 'CIM_DataFile' and TargetInstance.Path = '\\Users\\bob\' and targetInstance.Drive = 'C:' and (targetInstance.Extension = 'txt' or targetInstance.Extension = 'doc' or targetInstance.Extension = 'rtf') and targetInstance.LastAccessed > '$($cur)' " -sourceIdentifier "Accessor" -Action $action
51.
52.
53. #Dashboard
54. While ($true) {
55. $args=Wait-Event -SourceIdentifier Bursts # wait on Burst event
56. Remove-Event -SourceIdentifier Bursts #remove event
57.
58. $outarray=@()
59. foreach ($result in $args.SourceArgs) {
60. $obj = New-Object System.Object
61. $obj | Add-Member -type NoteProperty -Name File -Value $result[0]
62. $obj | Add-Member -type NoteProperty -Name Time -Value $result[1]
63. $outarray += $obj
64. }
65.
66.
67. $outarray|Out-GridView -Title "FAA Dashboard: Burst Data"
68. }1. $Get-WmiObject -Query "SELECT * From CIM_DataFile where Path = '\\Users\\bob\' and Drive = 'C:' and (Extension = 'txt' or Extension = 'doc' or Extension = 'rtf')"1. $Action = {
2.
3. Param (
4.
5. [string] $Name
6.
7. )
8.
9. $classify =@{"Top Secret"=[regex]'[tT]op [sS]ecret'; "Sensitive"=[regex]'([Cc]onfidential)|([sS]nowflake)'; "Numbers"=[regex]'[0-9]{3}-[0-9]{2}-[0-9]{3}' }
10.
11.
12. $data = Get-Content $Name
13.
14. $cnts= @()
15.
16. foreach ($key in $classify.Keys) {
17.
18. $m=$classify[$key].matches($data)
19.
20. if($m.Count -gt 0) {
21.
22. $cnts+= @($key,$m.Count)
23. }
24. }
25.
26. $cnts
27. }1. $RunspacePool = [RunspaceFactory]::CreateRunspacePool(1, 5)
2.
3. $RunspacePool.Open()
4.
5. $Tasks = @()
6.
7.
8. foreach ($item in $list) {
9.
10. $Task = [powershell]::Create().AddScript($Action).AddArgument($item.Name)
11.
12. $Task.RunspacePool = $RunspacePool
13.
14. $status= $Task.BeginInvoke()
15.
16. $Tasks += @($status,$Task,$item.Name)
17. }
|
|
[recovery mode] Техподдержка 3CX отвечает: как заменить или обновить SSL сертификат на сервере |





|
|
[Из песочницы] Очередное решение HighLoadCup на Go |
type User struct {
id uint
email string
first_name string
last_name string
gender bool
birth_date int64
age int
visits Visits
json []byte
}
type Location struct {
id uint
place string
country string
city string
distance int64
visits Visits
json []byte
}
type Visit struct {
id uint
location *Location
user *User
visited_at int64
mark int64
json []byte
}
func countAge(timestamp *int64) int {
now := time.Now()
t := time.Unix(*timestamp, 0)
years := now.Year() - t.Year()
if now.Month() > t.Month() || now.Month() == t.Month() && now.Day() >= t.Day() {
years += 1
}
return years
}
|
Метки: author WebProd высокая производительность go highloadcup |
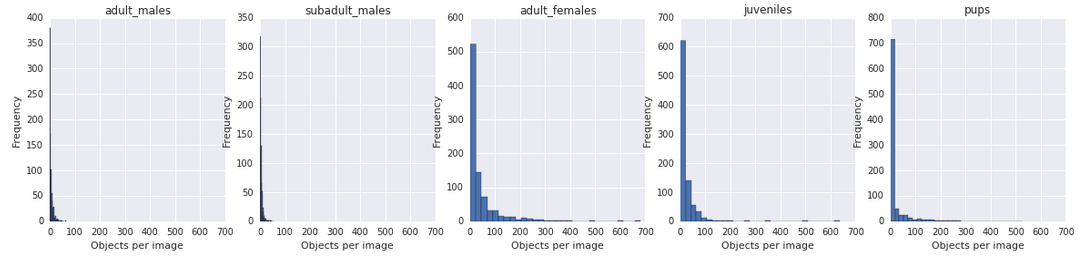
Kaggle: как наши сеточки считали морских львов на Алеутских островах |

Привет, Коллеги!
27 июня закончилось соревнование на Kaggle по подсчёту морских львов (сивучей) на аэрофотоснимках NOAA Fisheries Steller Sea Lions Population Count. В нем состязались 385 команд. Хочу поделиться с вами историей нашего участия в челлендже и (почти) победой в нём.
Как многие уже знают, Kaggle – это платформа для проведения онлайн соревнований по Data Science. И в последнее время там стало появляться всё больше и больше задач из области компьютерного зрения. Для меня этот тип задач наиболее увлекателен. И соревнование Steller Sea Lions Population Count — одно из них. Я буду повествовать с расчётом на читателя, который знает основы глубокого обучения применительно к картинкам, поэтому многие вещи я не буду детально объяснять.
Пару слов о себе. Я учусь в аспирантуре в университете города Хайдельберг в Германии. Занимаюсь исследованиями в области глубокого обучения и компьютерного зрения. Страничка нашей группы CompVis.
Захотелось поучаствовать в рейтинговом соревновании на Kaggle с призами. На это дело мной был также подбит Дмитрий Котовенко , который в это время проходил учебную практику в нашей научной группе. Было решено участвовать в соревновании по компьютерному зрению.
На тот момент у меня был некий опыт участия в соревнованиях на Kaggle, но только в нерейтинговых, за которые не дают ни медалей, ни очков опыта (Ranking Points). Но у меня был довольно обширный опыт работы с изображениями с помощью глубокого обучения. У Димы же был опыт на Kaggle в рейтинговых соревнованиях, и была 1 бронзовая медаль, но работать с компьютерным зрением он только начинал.
Перед нами встал нелёгкий выбор из 3 соревнований: предсказание рака матки на медицинских изображениях, классификация спутниковых изображений из лесов Амазонии и подсчёт сивучей на аэрофотоснимках. Первое было отброшено из-за визуально не очень приятных картинок, а между вторым и третьим было выбрано третье из-за более раннего дедлайна.
В связи со значительным уменьшением популяции сивучей на западных Алеутских островах (принадлежащих США) за последние 30 лет ученые из NOAA Fisheries Alaska Fisheries Science Center ведут постоянный учет количества особей с помощью аэрофотоснимков с дронов. До этого времени подсчет особей производился на фотоснимках вручную. Биологам требовалось до 4 месяцев, чтобы посчитать количество сивучей на тысячах фотографий, получаемых NOAA Fisheries каждый год. Задача этого соревнования — разработать алгоритм для автоматического подсчета сивучей на аэрофотоснимках.
Все сивучи разделены на 5 классов:
 ),
), ),
), ),
), ),
), ).
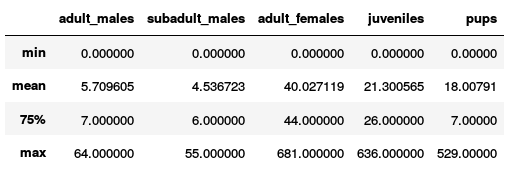
).Дано 948 тренировочных картинок, для каждой из которых известно Ground Truth число особей каждого класса. Требуется предсказать число особей по классам на каждой из 18641 тестовых картинок. Вот пример некоторых частей из датасета.

Картинки разных разрешений: 4608x3456 до 5760x3840. Качество и масштаб очень разнообразный, как видно из примера выше.
Положение на лидерборде определяется ошибкой RMSE, усредненной по всем тестовым изображениям и по классам.
Как бонус организаторы предоставили копии тренировочных изображений с сивучами, помеченными точками разного цвета. Каждый цвет соответствовал определенному классу. Все эти точки были кем-то размечены вручную (я надеюсь, биологами), и они не всегда находились чётко в центре животного. То есть, по факту, мы имеем грубую позицию каждой особи, заданную одной точкой. Выглядит это так.

(image credits to bestfitting)
Самые частые классы сивучей — это самки (), подростки () и детеныши ().
Здесь я кратко перечислю, какие были проблемы с данными, да и с задачей в целом.
В Германии, как и в России, в этом году выпали большие выходные на 1 Мая. Свободные дни с субботы по понедельник оказались как никогда кстати для того, чтобы начать погружаться в задачу. Соревнование длилось уже больше месяца. Всё началось с того, что мы с Димой Котовенко в субботу прочитали условие.
Первое впечатление было противоречивым. Много данных, нету устоявшегося способа, как решать такие задачи. Но это подогревало интерес. Не всё ж "стакать xgboost-ы”. Цель я поставил себе довольно скромную — просто попасть в топ-100 и получить бронзовую медальку. Хотя потом цели поменялись.
Первых 3 дня ушло на обработку данных и написание первой версии пайплайна. Один добрый человек, Radu Stoicescu, выложил кернел, который преобразовывал точки на тренировочных изображениях в координаты и класс сивуча. Здорово, что на это не пришлось тратить своё время. Первый сабмит я сделал только через неделю после начала.
Очевидно, решать эту задачу в лоб с помощью semantic segmentation нельзя, так как нет Ground Truth масок. Нужно либо генерить грубые маски самому либо обучать в духе weak supervision. Хотелось начать с чего-то попроще.
Задача подсчёта числа объектов/людей не является новой, и мы начали искать похожие статьи. Было найдено несколько релевантных работ, но все про подсчёт людей CrowdNet, Fully Convolutional Crowd Counting, Cross-scene Crowd Counting via Deep Convolutional Neural Networks. Все они имели одну общую идею, основанную на Fully Convolutional Networks и регрессии. Я начал с чего-то похожего.
Хотим научиться предсказывать хитмапы (2D матрицы) для каждого класса, да такие, что бы можно было просуммировать значения в каждом из них и получить число объектов класса.
Для этого генерируем Grount Truth хитмапы следующим образом: в центре каждого объекта рисуем гауссиану. Это удобно, потому что интеграл гауссианы равен 1. Получаем 5 хитмапов (по одному на каждый из 5 классов) для каждой картинки из тренировочной выборки. Выглядит это так.

Увеличить
Среднеквадратичное отклонение гауссиан для разных классов выставил на глазок. Для самцов – побольше, для детенышей – поменьше. Нейронная сеть (тут и далее по тексту я имею в виду сверточную нейронную сеть) принимает на вход изображения, нарезанные на куски (тайлы) по 256x256 пикселей, и выплёвывает 5 хитмапов для каждого тайла. Функция потерь – норма Фробениуса разности предсказанных хитмапов и Ground Truth хитмапов, что эквивалентно L2 норме вектора, полученного векторизацией разности хитмапов. Такой подход иногда называют Density Map Regression. Чтобы получить итоговое число особей в каждом классе, мы суммируем значения в каждом хитмапе на выходе.
| Метод | Public Leaderboard RMSE |
|---|---|
| Baseline 1: предсказать везде 0 | 29.08704 |
| Baseline 2: предсказать везде среднее по train | 26.83658 |
| Мой Density Map Regression | 25.51889 |
Моё решение, основанное на Density Map Regression, было немного лучше бейзлайна и давало 25.5. Вышло как-то не очень.

В задачах на зрение, бывает очень полезно посмотреть глазами на то, что породила ваша сеть, случаются откровения. Я так и сделал. Посмотрел на предсказания сети — они вырождаются в нуль по всем классам, кроме одного. Общее число животных предсказывалось ещё куда ни шло, но все сивучи относились сетью к одному классу.
Оригинальная задача, которая решалась в статьях — это подсчет количества людей в толпе, т. е. был только один класс объектов. Вероятно, Density Map Regression не очень хороший выбор для задачи с несколькими классами. Да и всё усугубляет огромная вариация плотности и масштаба объектов. Пробовал менять L2 на L1 функцию потерь и взвешивать классы, всё это не сильно влияло на результат.
Было ощущение, что L2 и L1 функции потерь делают что-то не так в случае взаимоисключающих классов, и что попиксельная cross-entropy функция потерь может работать лучше. Это натолкнуло меня на идею натренировать сеть сегментировать особей с попиксельной cross-entropy функцией потерь. В качестве Ground Truth масок я нарисовал квадратики с центром в ранее полученных координатах объектов.
Но тут появилась новая проблема. Как получить количество особей из сегментации? В чатике ODS Константин Лопухин признался, что использует xgboost для регрессии числа сивучей по набору фич, посчитанных по маскам. Мы же хотели придумать как сделать всё end-to-end с помощью нейронных сетей.
Тем временем, пока я занимался crowd counting и сегментацией, у Димы заработал простой как апельсин подход. Он взял VGG-19, натренированную на классификации Imagenet, и зафайнтьюнил ее предсказывать количество сивучей по тайлу. Он использовал обычную L2 функцию потерь. Получилось как всегда — чем проще метод, тем лучше результат.
Итак, стало понятно, что обычная регрессия делает свое дело и делает хорошо. Идея с сегментацией была радостно отложена до лучших времен. Я решил обучить VGG-16 на регрессию. Присобачил в конце выходной слой для регрессии на 5 классов сивучей. Каждый выходной нейрон предсказывал количество особей соответствующего класса.
Я резко вышел в топ-20 c RMSE 20.5 на паблик лидерборде.

К этому моменту целеполагание претерпело небольшие изменения. Стало понятно, что целиться имеет смысл не в топ-100, а как минимум в топ-10. Это уже не казалось чем-то недостижимым.
Выяснилось, что на test выборке многие снимки были другого масштаба, сивучи на них выглядели крупнее, чем на train. Костя Лопухин (отдельное ему за это спасибо) написал в слаке ODS, что уменьшение тестовых картинок по каждой размерности в 2 раза давало существенный прирост на паблик лидерборде.
Но Дима тоже не лыком шит, он подкрутил что-то в своей VGG-19, уменьшил картинки и вышел на 2-e место со скором ~16.

(image credits to Konstantin Lopuhin)
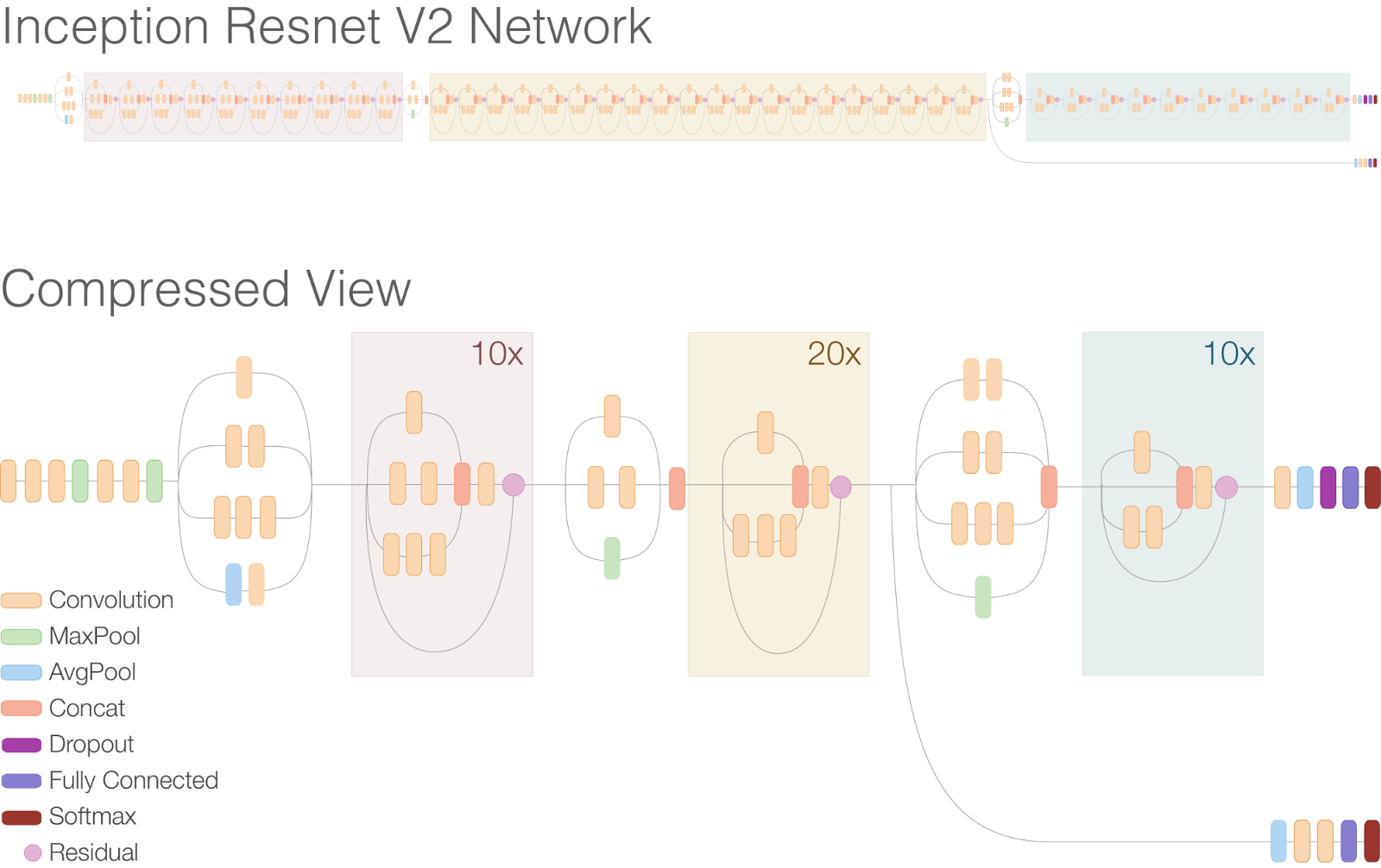
С функцией потерь у нас всё понятно. Время начинать экспериментировать с более глубокими сетями. В ход пошли VGG-19, ResnetV2-101, ResnetV2-121, ResnetV2-152 и тяжелая артиллерия — Inception-Resnet-V2.
Inception-Resnet-V2 — это архитектура придуманная Google, которая представляет собой комбинацию трюков от Inception архитектур (inception блоки) и от ResNet архитектур (residual соединения). Эта сеть изрядно глубже предыдущих и выглядит этот монстр вот так.
(image from research.googleblog.com)
В статье "Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning" ребята из Google показывают, что эта архитектура давала на тот момент state of the art на Imagenet без использования ансамблей.
Кроме самих архитектур мне пришлось перебрать:
Лучшей комбинацией оказались: Inception-Resnet-V2-BASE + average-pooling + FC-слой на 256 нейронов + Dropout + финальный FC-слой на 5 нейронов. Inception-Resnet-V2-BASE обозначает часть оригинальной сети от первого до последнего сверточного слоя.
Лучшим размером входного тайла оказался 299x299 пикселей.
Для тренировочных картинок мы делали типичный набор аугментаций для задач из CV.
К каждому тайлу применялись:
Test time augmentation мы не делали. Потому что предсказание на всех тестовых картинках и так занимало полдня.
В какой-то момент, пока я перебирал гиперпараметры и архитектуры сетей, мы объединились в команду с Димой Котовенко. Я в тот момент был 2-м месте, Дима на 3-м. Для отвода китайцев в ложном направлении команду назвали "DL Sucks".

Объединились, потому что было бы нечестно у кого-то забирать медальку, ведь с Димой мы активно обсуждали наши решения и обменивались идеями. Этому событию очень порадовался Костя, мы освободили ему призовое место. С 4-го он попал на 3-е.
Последние 3-4 недели соревнования мы плотно держались на 2-м месте на паблик лидерборде, по одной десятой, по одной тысячной улучшая скор перебором гиперпараметров и стакая модели.
Нам казалось, что уменьшение в 2 раза всех тестовых изображений — это пошло и грубо. Хотелось сделать всё красиво, чтобы сеть предсказала как нужно отмасштабировать каждое из изображений. Дима инвестировал в эту идею довольно много времени. Если вкратце, то он пытался по картинке предсказать масштаб сивучей, что равносильно предсказанию высоты полета дрона во время съемки. К сожалению, из-за недостатка времени и ряда проблем, с которыми мы столкнулись, это не было доведено до конца. Например, многие картинки содержат только одного сивуча и большая часть пространства — это море и камни. Поэтому, не всегда, глядя только на скалы или море, возможно понять с какой высоты был сделан снимок.
За пару дней до дедлайна мы собрали все лучшие модели и сделали ансамбль из 24 нейронных сетей. Все модели имели лучшую архитектуру Inception-Resnet-V2, которую я описал ранее. Отличались модели только тем, насколько агрессивно мы аугментировали картинки, на каком масштабе тестовых изображений делались предсказания. Выходы с разных сетей усреднялись.
Команда "DL Sucks" закончила соревнование на 2-м месте на паблик лидерборде, что не могло не радовать, так как мы были "в деньгах". Мы понимали, что на прайвэт лидерборде всё может поменяться и нас вообще может выкинуть из первой десятки. У нас был приличный разрыв с 4-м и 5-м местом, и это добавляло нам уверенности. Вот так выглядело положение на лидерборде:
1-е место 10.98445 outrunner (Китаец 1)
2-е место 13.29065 Мы (DL Sucks)
3-е место 13.36938 Костя Лопухин
4-е место 14.03458 bestfitting (Китаец 2)
5-е место 14.47301 LeiLei-WeiWei (Команда из двух китайцев)
Оставалось дождаться финальных результатов…
И что бы вы думали? Китаец нас обошел! Мы были сдвинуты со 2-го на 4-ое место. Ну ничего, зато получили по золотой медали ;)
Первое место, как оказалось, занял другой китаец, альфа-гусь outrunner. И решение у него было почти как у нас. Обучил VGG-16 c дополнительным полносвязным слоем на 1024 нейрона предсказывать количество особей по классам. Что вывело его на первое место, так это ad-hoc увеличение количества подростков на 50% и уменьшение количества самок на такое же число, умножение количества детёнышей на 1.2. Такой трюк поднял бы нас на несколько позиций выше.
Финальное положение мест:
1-е место 10.85644 outrunner (Китаец 1)
2-е место 12.50888 Костя Лопухин
3-е место 13.03257 (Китаец 2)
4-е место 13.18968 Мы (DL Sucks)
5-е место 14.47301 Дмитро Поплавский (тоже в слаке ODS) в команде с 2 другими
Резонный вопрос — а нельзя ли натренировать детектор и посчитать потом баундинг боксы каждого класса? Ответ — можно. Некоторые парни так и сделали. Александр Буслаев (13-ое место) натренировал SSD, а Владимир Игловиков (49-ое место) — Faster RCNN.
Пример предсказания Владимира:

(image credits to Vladimir Iglovikov)
Минус такого подхода состоит в том, что он сильно ошибается, когда сивучи на фотографии очень плотно лежат друг к другу. А наличие нескольких различных классов еще и усугубляет ситуацию.
Решение, основанное на сегментации с помощью UNet, тоже имеет место быть и вывело Константина на 2 место. Он предсказывал маленькие квадратики, которые он нарисовал внутри каждого сивуча. Далее — танцы с бубном. По предсказанным хитмапам Костя вычислял различные фичи (площади выше заданных порогов, количество и вероятности блобов) и скармливал их в xgboost для предсказания числа особей.

(image credits to Konstantin Lopuhin)
Подробнее про его решение можно посмотреть на youtube.
У 3-го места (bestfitting) тоже решение основано на UNet. Опишу его в двух словах. Парень разметил вручную сегментационные маски для 3 изображений, обучил UNet и предсказал маски на еще 100 изображениях. Поправил маски этих 100 изображений руками и заново обучил на них сеть. С его слов, это дало очень хороший результат. Вот пример его предсказания.

(image credits to bestfitting)
Для получения числа особей по маскам он использовал морфологические операции и детектор блобов.
Итак, начальная цель была попасть хотя бы в топ-100. Цель мы выполнили и даже перевыполнили. Было перепробовано много всяких подходов, архитектур и аугментаций. Оказалось, проще метод – лучше. А для сетей, как ни странно, глубже — лучше. Inception-Resnet-V2 после допиливания, обученная предсказывать количество особей по классам, давала наилучший результат.
В любом случае это был полезный опыт создания хорошего решения новой задачи в сжатые сроки.
В аспирантуре я исследую в основном Unsupervised Learning и Similarity Learning. И мне, хоть я и занимаюсь компьютерным зрением каждый день, было интересно поработать с какой-то новой задачей, не связанной с моим основным направлением. Kaggle дает возможность получше изучить разные Deep Learning фреймворки и попробовать их на практике, а также поимплементировать известные алгоритмы, посмотреть как они работают на других задачах. Мешает ли Kaggle ресерчу? Вряд ли он мешает, скорее помогает, расширяет кругозор. Хотя времени он отнимает достаточно. Могу сказать, что проводил за этим соревнованием по 40 часов в неделю (прямо как вторая работа), занимаясь каждый день по вечерам и на выходных. Но оно того стоило.
Кто дочитал, тому спасибо за внимание и успехов в будущих соревнованиях!
Мой профиль на Kaggle: Artem.Sanakoev
Краткое техническое описание нашего решения на Kaggle: ссылка
Код решения на github: ссылка
|
|
Как в IT-компании запустить патентный процесс |


|
Метки: author daria_iatskina патентование #patents хабрахабр |
[Перевод] Как работает JS: управление памятью, четыре вида утечек памяти и борьба с ними |
|
Метки: author ru_vds разработка веб-сайтов javascript блог компании ruvds.com разработка обучение управление памятью сборка мусора |
Как компании перенести свою инфраструктуру в облако и избежать ошибок |


«Если клиент, разворачивая инфраструктуру, решает установить приложения, не поддерживающие cloud-архитектуру и заточенные только на on-premise-инсталляцию, провал гарантирован, — говорит Екатерина Юдина, руководитель проекта, контент-инженер компании «IT-ГРАД». — Чтобы избежать подобной ситуации, поставщик услуг предлагает возможность бесплатного и заблаговременного тестирования».
|
Метки: author it_man управление разработкой блог компании ит-град ит-град хостинг миграция iaas |
Компьютерное зрение. Задайте вопрос эксперту Intel |
 Далеко не все ответы можно найти в Интернет. Особенно если вопрос ваш относится к достаточно узкой или новой области — тут необходима консультация гуру, Владельца Тайного Знания. В традициях блога Intel — проведение блого-семинаров, построенных на вопросах читателей. На эти вопросы отвечают эксперты Intel, принимавшие непосредственное участие в создании технологий и продуктов — кому, как не им знать все детали?
Далеко не все ответы можно найти в Интернет. Особенно если вопрос ваш относится к достаточно узкой или новой области — тут необходима консультация гуру, Владельца Тайного Знания. В традициях блога Intel — проведение блого-семинаров, построенных на вопросах читателей. На эти вопросы отвечают эксперты Intel, принимавшие непосредственное участие в создании технологий и продуктов — кому, как не им знать все детали? Анатолий Бакшеев, руководитель команды Computer Vision for Retail в Intel. Занимается компьютерным зрением и машинным обучением вот уже более 11 лет, в том числе последние несколько лет Deep Learning’ом. Начал свою карьеру в компании Itseez и проработал там более 10 лет до тех пор, пока компания не была приобретена Intel. За это время в его портфолио накопилось множество выполненных проектов, спроектированных и оптимизированных алгоритмов, большое количество кода, выложенного в библиотеку OpenCV, а также ее оптимизация под NVIDIA GPU.
Анатолий Бакшеев, руководитель команды Computer Vision for Retail в Intel. Занимается компьютерным зрением и машинным обучением вот уже более 11 лет, в том числе последние несколько лет Deep Learning’ом. Начал свою карьеру в компании Itseez и проработал там более 10 лет до тех пор, пока компания не была приобретена Intel. За это время в его портфолио накопилось множество выполненных проектов, спроектированных и оптимизированных алгоритмов, большое количество кода, выложенного в библиотеку OpenCV, а также ее оптимизация под NVIDIA GPU. Вадим Писаревский, бессменный руководитель команды OpenCV, начиная с 2000 года.
Вадим Писаревский, бессменный руководитель команды OpenCV, начиная с 2000 года.|
Метки: author saul разработка робототехники обработка изображений блог компании intel opencv машинное зрение распознавание образов вопросы экспертам |
Nuklear+ — миниатюрный кроссплатформенный GUI |
 Nuklear+ (читается как "Nuklear cross", значит "кроссплатформенный Nuklear") — это надстройка над GUI библиотекой Nuklear, которая позволяет абстрагироваться от драйвера вывода и взаимодействия с операционной системой. Нужно написать один простой код, а он потом уже сможет скомпилироваться под все поддерживаемые платформы.
Nuklear+ (читается как "Nuklear cross", значит "кроссплатформенный Nuklear") — это надстройка над GUI библиотекой Nuklear, которая позволяет абстрагироваться от драйвера вывода и взаимодействия с операционной системой. Нужно написать один простой код, а он потом уже сможет скомпилироваться под все поддерживаемые платформы.
Я уже писал на хабре статью "Nuklear — идеальный GUI для микро-проектов?". Тогда задача была простой — сделать маленькую кроссплатформенную утилиту с GUI, которая будет примерно одинаково выглядеть в Windows и Linux. Но с тех самых пор меня не отпускал вопрос, а можно ли на Nuklear сделать что-то более-менее сложное? Можно ли целиком на нём сделать какой-нибудь реальный проект, которым будут пользоваться?
Именно поэтому следующую свою игру, Wordlase, я делал на чистом Nuklear. И без всякого там OpenGL. Даже фоновые картинки у меня имеют тип nk_image. В конечном итоге это дало возможность выбора драйвера отрисовки, вплоть до чистого X11 или GDI+.
Ещё в прошлой своей статье я заложил основы Nuklear+ — библиотеки, призванной спрятать всю "грязь" от программиста и дать ему сфокусироваться на создании интерфейса. Библиотека умеет загружать шрифты, картинки, создавать окно операционной системы и контекст отрисовки.
Полный пример кода есть в Readme на GitHub. Там можно увидеть, что код получается довольно простой. Также я перенёс на Nuklear+ свои проекты dxBin2h и nuklear-webdemo. И сделать это было очень просто — вся инициализация заменяется на один вызов nkc_init, события обрабатываются nkc_poll_events, отрисовка функцией nkc_render, а в качестве деструктора вызывается nkc_shutdown.
Но вернёмся к Wordlase, на примере которой и построена данная публикация. С недавних пор у игры есть веб-демо. Я не писал какого-то специфичного веб-кода для игры — это чистое С89 приложение, скомпилированное с помощью Emscripten. И если полностью следовать примеру из Readme Nuklear+ (а именно, использовать nkc_set_main_loop), то веб-версия приложения будет получена абсолютно на халяву, без особых лишних затрат.
Самой интересной частью Nuklear+ являются поддерживаемые фронтэнды и бэкэнды. В данном случае под фронтэндом понимается часть, ответственная за взаимодействие с ОС и отрисовку окна. Т.е. непосредственно то, что видит пользователь. Реализации лежат в папке nkc_frontend. Сейчас поддерживаются: SDL, GLFW, X11, GDI+. Они не равносильны. Например, GDI+ использует WinAPI даже для рендера шрифтов и загрузки изображений, т.е. получить ровно такую же картинку в других ОС будет проблематично. Реализация так же не везде одинакова. Например, реализация Х11 пока не умеет изменять разрешение экрана в полноэкранном режиме (буду рад видеть Pull Request)
Выбрать фронтэнд для своего приложения просто — нужно установить переменную препроцессора NKCD=NKC_x, где x это одно из: SDL, GLFW, XLIB, GDIP. Например: gcc -DNKCD=NKC_GLFW main.c
Бэкэнд в данном случае выполняет непосредственно отрисовку. Реализация в папке nuklear_drivers. Отрисовка средствами любой версии OpenGL выдаёт примерно одинаковую картинку на всех ОС и фронтэндах. Ведь для загрузки изображений там всегда используется stb_image, а шрифт рендерится стандартными средствами Nuklear (тоже основано на stb). В то же время чистый Х11 драйвер даже не умеет загружать шрифты. Так что не забывайте тестировать своё приложение для выбранной пары бэкэнд+фронтэнд.
Например: Wordlase, GLFW3, OpenGL 2, Windows

Или: Wordlase, SDL2, OpenGL ES, Linux

В качестве бэкэнда по умолчанию выбран OpenGL2, если доступен. Можно задать NKC_USE_OPENGL=3 для OpenGL 3, и NKC_USE_OPENGL=NGL_ES2 для OpenGL ES 2.0. Для использования чистого Х11 отрисовщика константу NKC_USE_OPENGL указывать не надо. Также OpenGL опции не влияют на GDI+ — там отрисовка всегда идёт своими средствами.
Вот скриншот с GDI+: Wordlase, GDI+, без OpenGL, Windows

Этот бэкэнд полноценно поддерживает полупрозрачные изображения, картинка близка к оригиналу. Разница в шрифте: хинтинг, сглаживание, да даже размер (также буду рад Pull Request'у для автоматической подстройки размера GDI+ шрифта под размер stb_ttf).
И самый ужасный случай — чистый Х11 отрисовщик, который до моего pull request даже не умел загружать картинки. Wordlase, X11, без OpenGL, Linux:

Вот здесь уже довольно много отличий: логотип, солнечные лучи, более острый край девушки, шрифт. Почему? Фон в игре на лету собирается из нескольких полупрозрачных PNG. Но чистый Х11 поддерживает только битовую прозрачность, прямо как GIF. Также отрисовщик Х11 очень медленно работает на больших изображениях с прозрачностью. А если в движке отключить прозрачность, то картинка становится ещё хуже. Wordlase, X11, без OpenGL, без прозрачности:

Так зачем вообще нужны отрисовщики GDI+ и Х11, если они так уродливы? Потому, что они плохи только для больших изображений с прозрачностью. А если делать маленькую утилиту, где картинки используются только как иконки пользовательского интерфейса, то эти отрисовщики становятся вовсе неплохим вариантом, т.к. имеют минимальное количество зависимостей. Также я пользовался чистым Х11 отрисовщиком на слабых системах, где OpenGL только программный. В таком случае Х11 работает быстрее OpenGL. Подсказка: если вместо кучи полупрозрачных PNG использовать один большой JPEG, то Х11 будет работать быстро и корректно.
Пример хорошего использования чистого Х11 бэкэнда — главное игровое окно Wordlase. Больших картинок там почти нет, зато есть несколько интерфейсных иконок, которые вполне корректно отображаются:

Отлично, отрисовщик выбран, окно ОС создаётся. Теперь самое время заняться GUI!
Самым первым в Wordlase показывается экран выбора языка:

Здесь видны сразу 2 интересных техники: несколько картинок на фоне окна и центрирование виджетов.
Поместить картинку на фон окна достаточно просто:
nk_layout_space_push(ctx, nk_rect(x, y, width, height));
nk_image(ctx, img);x и y — позиция на экране, width и height — размеры изображения.
Центрирование является более сложной задачей, т.к. не поддерживается Nuklear напрямую. Нужно вычислять положение самостоятельно:
if ( nk_begin(ctx, WIN_TITLE,
nk_rect(0, 0, winWidth, winHeight), NK_WINDOW_NO_SCROLLBAR)
) {
int i;
/* 0.2 are a space skip on button's left and right, 0.6 - button */
static const float ratio[] = {0.2f, 0.6f, 0.2f}; /* 0.2+0.6+0.2=1 */
/* Just make vertical skip with calculated height of static row */
nk_layout_row_static(ctx,
(winHeight - (BUTTON_HEIGHT+VSPACE_SKIP)*langCount )/2, 15, 1
);
nk_layout_row(ctx, NK_DYNAMIC, BUTTON_HEIGHT, 3, ratio);
for(i=0; i* skip 0.2 left */
if( nk_button_image_label(ctx, image, caption, NK_TEXT_CENTERED)
){
loadLang(nkcHandle, ctx, i);
}
nk_spacing(ctx, 1); /* skip 0.2 right */
}
}
nk_end(ctx);Следующая прикольная штучка — выбор темы оформления в настройках:

Реализуется тоже просто:
if (nk_combo_begin_color(ctx, themeColors[s.curTheme],
nk_vec2(nk_widget_width(ctx), (LINE_HEIGHT+5)*WTHEME_COUNT) )
){
int i;
nk_layout_row_dynamic(ctx, LINE_HEIGHT, 1);
for(i=0; icode>Здесь главное понимать, что всплывающее поле combo — это такое же окно, как и главное. И располагать там можно что угодно.
Самым сложно выглядящим окном является основное игровое окно:
На самом деле, тут тоже нет ничего сложного. На экране всего 4 ряда:
nk_property_int)nk_group_scrolled)Единственный непонятный момент здесь — задание точных размеров элементам. Выполняется это с помощью соотношения ряда:
float ratio[] = {
(float)BUTTON_HEIGHT/winWidth, /* square button */
(float)BUTTON_HEIGHT/winWidth, /* square button */
(float)topWordSpace/winWidth,
(float)WORD_WIDTH/winWidth
};
nk_layout_row(ctx, NK_DYNAMIC, BUTTON_HEIGHT, 4, ratio);BUTTON_HEIGHT и WORD_WIDTH — константы, измеряются в пикселях; topWordSpace вычисляется как ширина экрана минус ширины всех остальных элементов.
И последнее сложно выглядящее окно — статистика:
Расположение элементов регулируется с помощью группировки. Ведь всегда можно сказать Nuklear: "в этом ряду будет 2 виджета". Но группа тоже является виджетом. Т.е. можно просто создать группу с помощью nk_group_begin и nk_group_end, а дальше позиционироваться внутри неё как внутри обычного окна (nk_layout_row и пр.).
Nuklear уже готов даже для коммерческих игр и приложений. А Nuklear+ может сделать их создание более приятным.
|
|
[Перевод] PHP жив. PHP 7 на практике |
Недавно PHP-проекты Avito перешли на версию PHP 7.1. По этому случаю мы решили вспомнить, как происходил переход на PHP 7.0 у нас и наших коллег из OLX. Дела давно минувших дней, но остались красивые графики, которые хочется показать миру.
Первая часть рассказа основана на статье PHP’s not dead! PHP7 in practice, которую написал наш коллега из OLX Lukasz Szyma'nski (Лукаш Шиманьски): переход OLX на PHP 7. Во второй части — опыт перехода Avito на PHP 7.0 и PHP 7.1: процесс, трудности, результаты с графиками.

Компания OLX Europe управляет десятью сайтами, самый большой из которых — OLX.pl. Все наши сайты должны работать максимально эффективно, поэтому миграция на PHP 7 стала для нас основным приоритетом.
В этом посте расскажем, с какими проблемами пришлось столкнуться и чего удалось получить с переходом на PHP 7. Про переход было рассказано на конференции PHPers Summit 2016.
Вопреки нашим опасениям, миграция прошла гладко. За исключением стандартного списка необходимых изменений из официальной документации, пришлось внести лишь некоторые правки, связанные с нашей архитектурой.
Стоит упомянуть, что десять наших сайтов работают в разных странах. И изменения мы выкатываем последовательно: на один сайт за другим. Такой подход особенно важно применять при серьёзных изменениях.
Мы начали обновление версии с самого маленького сайта и переходили ко всё более крупным, поглядывая, чтобы тесты проходили успешно. Это позволило следить за возникновением неожиданных проблем и снизило потенциальный ущерб.
Отказ от поддержки Memcache в PHP 7 подтолкнул нас к переходу на Memcached. Пришлось поддержать две версии сайта: PHP 5 + Memcache и PHP 7 + Memcached.
Для решения задачи использовали простенькую обёртку. Она выбирает подходящий PHP-модуль для соединения с кэшом, исходя из информации о сервере, на котором выполняется код.
|
Метки: author pik4ez разработка веб-сайтов php блог компании avito php7 olx avito |
Набор полезных советов для эффективного использования FreeIPA |

ansible_virtualization_role == "guest" and ansible_virtualization_type == "lxc"get_sudorule_diff() takes exactly 2 arguments (3 given)diff = get_sudorule_diff(client, ipa_sudorule, module_sudorule)diff = get_sudorule_diff(ipa_sudorule, module_sudorule)1. Добавляем репозиторий
wget -qO - http://apt.numeezy.fr/numeezy.asc | apt-key add -
echo -e 'deb http://apt.numeezy.fr jessie main' >> /etc/apt/sources.list
2. Устанавливаем пакеты
apt-get update
apt-get install -y freeipa-client
3. Создаём директории
mkdir -p /etc/pki/nssdb
certutil -N -d /etc/pki/nssdb
mkdir -p /var/run/ipa
4. Убираем дефолтный конфиг
mv /etc/ipa/default.conf ~/
5. Устанавливаем и настраиваем клиент
ipa-client-install
6. Включаем создание директорий
echo 'session required pam_mkhomedir.so' >> /etc/pam.d/common-session
7. Проверяем, чтобы в /etc/nsswitch.conf был указан sss провайдер
passwd: files sss
group: files sss
shadow: files sss
8. Перезагружаем sssd
systemctl restart sssdip addr add $ADDR dev $IFaceip addr del $ADDR|
Метки: author Vrenskiy системное администрирование серверное администрирование *nix блог компании pixonic freeipa ansible |
Ходим за покупками с full-stack redux |
Всем привет! В этой статье я хочу на простом примере рассказать о том, как синхронизировать состояние redux-приложений между несколькими клиентами и сервером, что может оказаться полезным при разработке realtime-приложений.

В качестве примера мы будем разрабатывать список покупок, с возможностью изменять позиции с любого устройства в реальном времени, по следующим требованиям:
Дабы обойтись минимальными трудозатратами, не будем делать UI для доступа ко всем спискам, а просто будем различать их по идентификатору в URL.
Можно заметить, что приложение в таком виде с точки зрения клиентского функционала и UI мало чем будет отличаться от знаменитого todo-списка. Поэтому статья в большей мере будет посвящена клиент-серверному взаимодействию, сохранению и обработке состояния на сервере.
В планах у меня также написание следующей статьи, где на примере этого же приложения мы рассмотрим, как сохранять redux-состояние в DynamoDB и выкатывать упакованное в Docker приложение в AWS.
Для создания среды разработки воспользуемся замечательным инструментом create-react-app. Создавать прототипы с ним довольно легко: он подготовит все необходимое для продуктивной разработки: webpack c hot-reload, начальный набор файлов, jest-тесты. Можно было бы настроить это все самостоятельно для большего контроля над процессом сборки, но в данном приложении это не принципиально.
Придумываем название для нашего приложения и создаем его, передав в качестве аргумента в create-react-app:
create-react-app deal-on-meal
cd deal-on-mealcreate-react-app создал нам некоторую структуру проекта, но на самом деле для его корректной работы необходимо лишь, чтобы файл ./src/index.js являлся точкой входа. Поскольку же наш проект подразумевает использование как клиента, так и сервера, то изменим начальную структуру на следующую:
src
+--client
+--modules
+--components
+--index.js
+--create-store.js
+--socket-client.js
+--action-emitter.js
+--constants
+--socket-endpoint-port.js
+--server
+--modules
+--store
+--utils
+--bootstrap.js
+--connection-handler.js
+--server.js
+--index.js
+-- registerServiceWorker.jsДобавим так же в package.json команду для старта сервера node ./src/server.js
Состояние приложения redux хранит в так называемом store в виде javascript-объекта любого типа. При этом любое изменение состояния должен проводить reducer — чистая функция, на вход которой подается текущее состояние и action (тоже javascript-объект). Возвращает же она новое состояние с изменениями.
Мы можем использовать нашу клиентскую логику для списка покупок, которую реализует reducer, как на стороне браузера, так и в node.js окружении. Таким образом мы сможем хранить состояние списка независимо от клиента и сохранять его в БД.
Для работы с сервером будем использовать давно уже ставшую стандартом для работы с websockets библиотеку socket.io. Для каждого списка заведем свой room и будем посылать каждый action тем пользователям, которые находятся в этой же комнате. Помимо этого, для каждой комнаты на сервере будем хранить свой store с состоянием для этого списка.
Синхронизация клиентов с сервером будет происходить следующим образом:
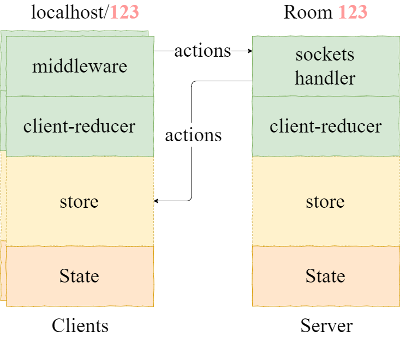
То есть каждый раз когда происходит какой-либо action, то:
В основном в redux-мире взаимодействие с сервером происходит по http, через библиотеки вроде redux-thunk или redux-saga, которые позволяют добавить немного асинхронности и сайд-эффектов в синхронный, чистый мир redux. Хотя нам не требуется такого рода связь с сервером, мы тоже будем использовать redux-saga на клиенте, но только для одной задачи: перенаправления на только что созданный список в случае, если в URL нет идентификатора.
Не буду заострять особого внимания на инициализации, необходимой для работы redux, это хорошо описано в официальной документации redux, скажу лишь, что нам необходимо зарегистрировать два middleware: из упомянутого пакета redux-saga и наш emitterMiddleware. Первый нужен для редиректа, как уже было упомянуто, а последний мы напишем для синхронизации экшенов с сервером через socket.io-client.
Создадим файл ./src/client/action-emitter.js в котором и будет реализация упомянутого emitterMiddleware:
export const syncSocketClientWithStore = (socket, store) =>
{
socket.on('action', action => store.dispatch({ ...action, emitterExternal: true }));
};
export const createEmitterMiddleware = socket => store => next => action =>
{
if(!action.emitterExternal)
{
socket.emit('action', action);
}
return next(action);
};createEmitterMiddleware является фабрикой наших middleware и нужна для того, чтобы хранить в себе ссылку на socket, переданный снаружи. Также здесь есть еще один нюанс: экшены, которые приходят снаружи, не нужно отправлять на сервер. Для этого я предлагаю их помечать (в данном случае полем emitterExternal), и в случае такого экшена middleware ничего не должен делать. Можно было бы использовать экшен-декоратор, но нужды в этом я не вижу.syncSocketClientWithStore совершенно прост: он слушает сокет на сообщение action и просто передает принятое действие в store, помечая его уже упомянутым флагом.Как я уже упоминал, мы будем использовать на клиенте redux-saga, чтобы при первом заходе местоположение клиента менялось на соответствующее списку, который мог быть создан только что. Незамысловатым образом в ./src/client/modules/products-list/saga/index.js опишем сагу, реагирующую на получение списка продуктов и комнаты, в которой находится клиент:
import { call, takeLatest } from 'redux-saga/effects'
import actionTypes from '../action-types';
export function* onSuccessGenerator(action)
{
yield call(window.history.replaceState.bind(window.history), {}, '', `/${action.roomId}`);
}
export default function* ()
{
yield takeLatest(actionTypes.FETCH_PRODUCTS_SUCCESS, onSuccessGenerator);
}Входной точкой для сервера будет добавленный в скрипты в package.json ./src/server.js:
require('babel-register')({
presets: ['env', 'react'],
plugins: ['transform-object-rest-spread', 'transform-regenerator']
});
require('babel-polyfill');
const port = require('./constants/socket-endpoint-port').default;
const clientReducer = require('./client').rootReducer;
require('./server/bootstrap').start({ clientReducer, port });
Стоит обратить внимание, что при старте нашего сервера ему передается клиентский reducer: это необходимо для того, чтобы сервер тоже мог поддерживать актуальное состояние списков, получая только действия, а не все состояние целиком. Заглянем в ./src/server/bootstrap.js:
import createSocketServer from 'socket.io';
import connectionHandler from './connection-handler';
import createStore from './store';
export const start = ({ clientReducer, port }) =>
{
const socketServer = createSocketServer(port);
const store = createStore({ socketNamespace: socketServer.of('/'), clientReducer });
socketServer.on('connection', connectionHandler(store));
console.log('listening on:', port);
}Приступим к специфичной для нашего сервера логике и опишем действия, которые он должен поддерживать:
Все эти действия я предлагаю также описать с помощью redux и для этого сделать модуль ./src/server/modules/room-service, содержащий соответствующие saga и reducer. Там же мы сделаем простейшее хранилище для наших комнатных store ./src/server/modules/room-service/data/in-memory.js:
export default class InMemoryStorage
{
constructor()
{
this.innerStorage = {};
}
getRoom(roomId)
{
return this.innerStorage[roomId];
}
saveRoom(roomId, state)
{
this.innerStorage[roomId] = state;
}
deleteRoom(roomId)
{
delete this.innerStorage[roomId];
}
}При событии socket-сервера будем просто делать dispatch c соответствующим action из модуля room-service на серверном store. Опишем это в ./src/server/connection-handler.js:
import { actions as roomActions } from './modules/room-service';
import templateParseUrl from './utils/template-parse-url';
const getRoomId = socket => templateParseUrl('/list/{roomId}', socket.handshake.headers.referer).roomId.toString() || socket.id.toString().slice(1, 6);
export default store => socket =>
{
const roomId = getRoomId(socket);
store.dispatch(roomActions.userJoin({ roomId, socketId: socket.id }));
socket.on('action', action => store.dispatch(roomActions.dispatchClientAction({ roomId, clientAction: action, socketId: socket.id })));
socket.on('disconnect', () => store.dispatch(roomActions.userLeft({ roomId })));
};Оставим обработку userJoin и userLeft на совести пытливого читателя, не поленившегося заглянуть в репозиторий, а сами посмотрим на то, как обрабатывается dispatchClientAction. Как мы помним, необходимо сделать два действия:
За первое отвечает генератор ./src/server/modules/room-service/saga/dispatch-to-room.js:
import { call, put } from 'redux-saga/effects';
import actions from '../actions';
import storage from '../data';
const getRoom = storage.getRoom.bind(storage);
export default function* ({ socketServer, clientReducer }, action)
{
const storage = yield call(getRoom, action.roomId);
yield call(storage.store.dispatch.bind(storage.store), action.clientAction);
yield put(actions.emitClientAction({ roomId: action.roomId, clientAction: action.clientAction, socketId: action.socketId }));
};Он же кладет следующий action модуля room-service — emitClientAction, на который реагирует ./src/server/modules/room-service/saga/emit-action.js:
import { call, select } from 'redux-saga/effects';
export default function* ({ socketNamespace }, action)
{
const socket = socketNamespace.connected[action.socketId];
const roomEmitter = yield call(socket.to.bind(socket), action.roomId);
yield call(roomEmitter.emit.bind(roomEmitter), 'action', action.clientAction);
};Вот таким незамысловатым образом экшены попадают на остальных клиентов в комнате. В простоте, на мой взгляд, и кроется прелесть full-stack redux, а также мощь переиспользования клиентской логики для воспроизведения состояния на сервере и других клиентах.
Хоть немного сумбурно, но мой рассказ подходит к концу. Я не акцентировал внимание на вещах, о которых уже есть множество статей и уроков (в любом случае, полный код приложения можно посмотреть в репозитории), а остановился на том, о чем информации, на мой взгляд, меньше. Так что если остались какие-то вопросы — прошу в комменты.
|
Метки: author glebsmagliy javascript redux full-stack websockets node.js redux-saga |






